- 投稿日:2020-07-03T22:44:08+09:00
【PyTorch】RuntimeError: Expected object of scalar type Float but got scalar type Double for argument #4 'mat1'
PyTorchでのエラー
同じところで詰まった方のために残しておきます。
PyTorchを使っていたら以下のようなエラーが出ました。
RuntimeError: Expected object of scalar type Float but got scalar type Double for argument #4 'mat1'
色々調べた結果、Tensor型に変換するときにテンソルの中の数値がtorch.double型になってしまうことが問題だそうです。(PyTorchのクラス内ではtorch.float型が前提となっているメソッドなどが多くある)
なので、
修正前
X_train = torch.from_numpy(X_train) y_train = torch.from_numpy(y_train) X_test = torch.from_numpy(X_test) y_test = torch.from_numpy(y_test)修正後
X_train = torch.from_numpy(X_train).float() y_train = torch.from_numpy(y_train).long() X_test = torch.from_numpy(X_test).float() y_test = torch.from_numpy(y_test).long()のように.float()あるいは.long()で変換してあげるとよいみたいです。(.long()はラベルに対しての変換)
参考文献 :
第2回 PyTorchのテンソル&データ型のチートシート
- 投稿日:2020-07-03T21:48:08+09:00
ゼロから始めるLeetCode Day75 「15. 3Sum」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
Python3で解いています。
前回
ゼロから始めるLeetCode Day74 「12. Integer to Roman」今はTop 100 Liked QuestionsのMediumを優先的に解いています。
Easyは全て解いたので気になる方は目次の方へどうぞ。Twitterやってます。
技術ブログ始めました!!
技術はLeetCode、Django、Nuxt、あたりについて書くと思います。こちらの方が更新は早いので、よければブクマよろしくお願いいたします!問題
15. 3Sum
難易度はMedium。問題としては、n個の整数の配列
numsがあるとすると、numsにa + b + c = 0となる要素a, b, cがあるかどうかを確認するアルゴリズムを設計し、0の和を与える配列の中のすべてのユニークな三重項を求めよ。Example:
Given array nums = [-1, 0, 1, 2, -1, -4],
A solution set is:
[
[-1, 0, 1],
[-1, -1, 2]
]解法
3つ選び、0になる組み合わせを選べ、というものです。
組み合わせの鉄則とも言えるかもしれませんが、先に固定するものを決めることが良いと思います。今回は以下のように僕は書きました。
class Solution: def threeSum(self, nums: List[int]) -> List[List[int]]: nums.sort() ans = [] for i in range(len(nums)-2): if i > 0 and nums[i] == nums[i-1]: continue left = i+1 right = len(nums)-1 while left < right: sums = nums[i]+nums[left]+nums[right] if sums < 0: left += 1 elif sums > 0: right -= 1 else: ans.append([nums[i],nums[left],nums[right]]) while left < right and nums[left]==nums[left+1]: left += 1 while left > right and nums[right]==nums[right-1]: right -= 1 left += 1 right -= 1 return ans # Runtime: 1092 ms, faster than 45.79% of Python3 online submissions for 3Sum. # Memory Usage: 17.1 MB, less than 76.15% of Python3 online submissions for 3Sum.まず最初にソートすることによって昇順に並べ替えます。
こうすることで前から要素をfor文で回していった時に要素の大小の指定がしやすくなります。具体的な例を上げるならば、これを
[-1,0,1,2,-1,-4]
ソートすると、
[-4,-1,-1,0,1,2]
という風になります。これの要素を最初から舐めていくときに、どういう風に3sumのうちの残りの二つの要素をどうやって選択していくべきかがこの問題の核と言えるでしょう。
コードで書いたように、僕は
i+1をleft,len(nums)-1をrightとし、仮にそれらを足した時にそれらの合計値であるsumsが0より小さければleftの要素を+1、0より大きければrightを-1することで解決しました。
これは上でも述べたソートをしているからできることです。実際には
-4+(-1)+2=-3<0
なので、leftの要素を動かして、
-4+(-1)+2=-3<0
これでも一緒なのでまたleftの要素を動かして
-4+0+2=-2<0
といった風なフローとなっています。そして仮にそれら以外、すなわちsums==0となった場合は用意していた
ansに要素を追加する、というものです。こういった和の組み合わせ系は今回のような形式で解くのが楽な気がするので典型的な問題としてしっかり覚えておきたいですね。
では今回はここまで。お疲れ様でした。
- 投稿日:2020-07-03T21:39:07+09:00
ubuntu で sudo をつけるとデフォルトのpython 呼ばれる。
- 投稿日:2020-07-03T21:09:20+09:00
MacでOpenMVGを動かす
MacでOpenMVGを動かします。
今回は、標準でインストールされるチュートリアルの実行と結果の表示まで行います。実行環境
macOS Mojave(バージョン10.14.5)
pyenv+python 3.7.5
cmake 3.16.4
Xcode 11.3.1手順
OpenMVGのインストール
必要なpythonライブラリをインストール
$ pip install sphinxGithubからソースコードをクローン
$ git clone --recursive https://github.com/openMVG/openMVG.gitopenMVG/src/CMakeLists.txtを編集
編集前:# ============================================================================== # IMAGE IO detection # ============================================================================== find_package(JPEG QUIET) find_package(PNG QUIET) find_package(TIFF QUIET)編集後:
(set〜を追加)# ============================================================================== # IMAGE IO detection # ============================================================================== set(CMAKE_FIND_FRAMEWORK LAST) find_package(JPEG QUIET) find_package(PNG QUIET) find_package(TIFF QUIET)Xcodeを利用してビルドを実施
$ mkdir openMVG_Build $ cd openMVG_Build $ cmake -DCMAKE_BUILD_TYPE=RELEASE -G "Xcode" . ../openMVG/src/ $ xcodebuild -configuration Releaseチュートリアルの実行
チュートリアルを実行
$ cd software/SfM $ python3 tutorial_demo.pyチュートリアルでは、下記のフォルダに格納された10枚の画像から3次元点群を生成します。
openMVG_Build/software/SfM/ImageDataset_SceauxCastle/images
カメラの内部パラメータも格納されています
$ cat K.txt 2905.88 0 1416 0 2905.88 1064 0 0 1MeshLabのインストール
MeshLabのサイトからmac版をダウンロードし、インストール
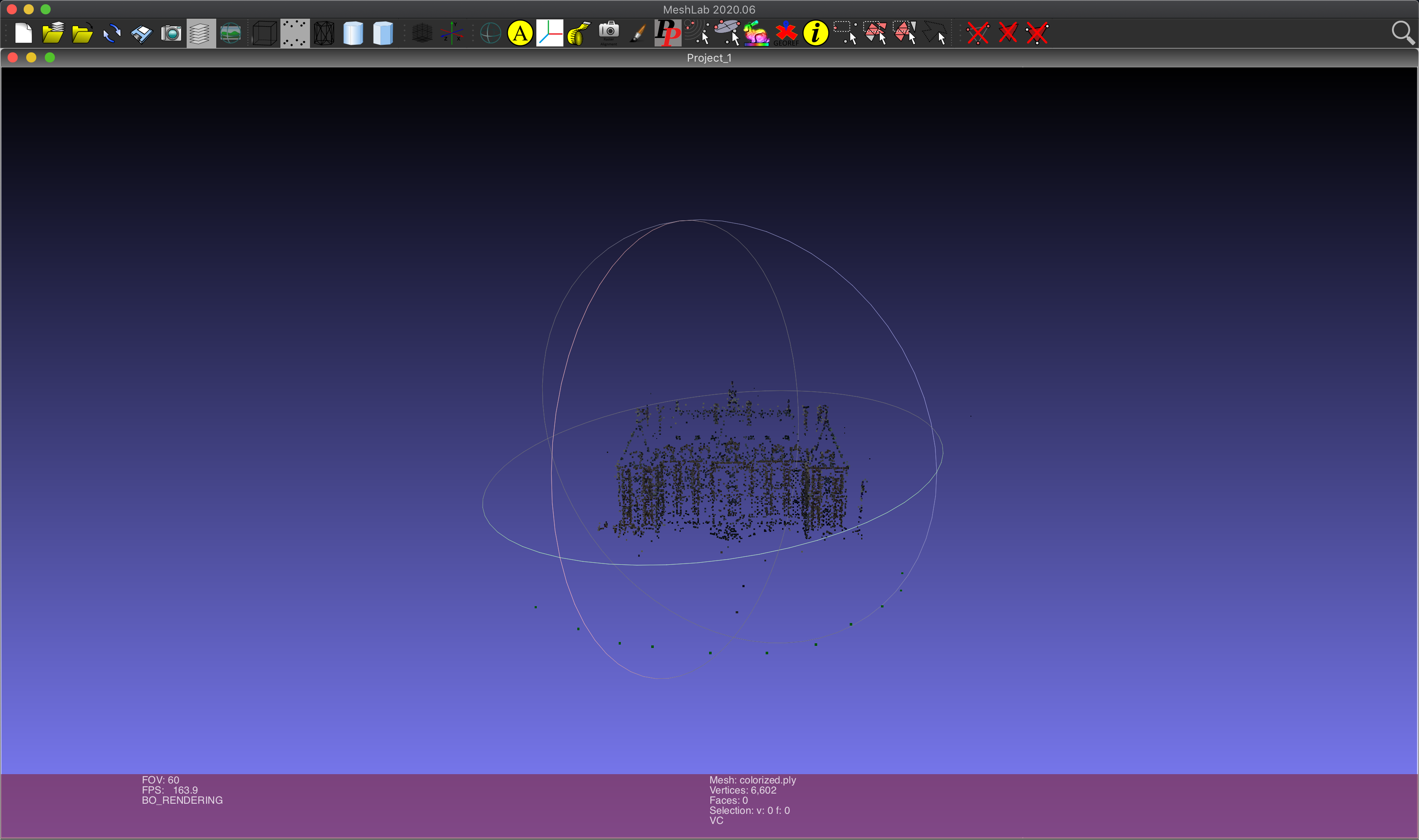
https://www.meshlab.net/[File]>[Import Mesh.]から
openMVG_Build/src/software/SfM/tutorial_out/reconstruction_sequential/colorized.ply
を読み込む下図のように表示されたら成功です。

- 投稿日:2020-07-03T20:09:14+09:00
ffmpeg-python環境を構築して動画の分割を行う
概要
- python-ffmpegを利用して動画を分割する
- python-ffmpegを動かすまでの手順
- 備忘録
前提
- 環境
- python: v.3.7.7
- python-ffmpeg: v.0.2.0
- ffmpeg: v.4.3
ffpmegをインストールする
- ビルド済みのイメージを利用する
- https://www.johnvansickle.com/ffmpeg/ からビルド済みファイルを利用すれば楽チン
- ダウンロードしたファイルを解凍後、
/usr/local/bin配下にコピーすればOK
ffprobeをコピーしないと、ffmpeg.probeを実行した際に、[Errno 2] No such file or directory: 'ffprobe': 'ffprobe'とエラーが出るので注意wget http://johnvansickle.com/ffmpeg/releases/ffmpeg-release-arm64-static.tar.xz tar xvf ffmpeg-release-arm64-static.tar.xz sudo cp ./ffmpeg-4.3-arm64-static/ffmpeg /usr/local/bin sudo cp ./ffmpeg-4.3-arm64-static/ffprobe /usr/local/bin
python-ffmpegをインストールする
- pip installするだけ
pip install ffmpeg-python
動画の切り出しコードを書く
import ffmpeg srcfile_path = 'hoge.mp4' # 動画の格納パス split_num = 5 # 動画の分割数 # ffmpeg.probeを実施して、動画のメタデータを取得 video_info = ffmpeg.probe(srcfile_path) # 動画の全長(秒)を取得 duration = float(video_info['streams'][0]['duration']) stride = duration/split_num # 動画をN個に分割 for i in range(split_num): start = int(i * stride) stream = ffmpeg.input(srcfile_path, ss=start, t=stride) # cオプションは、ffmpegの-vcodecと-acodecをまとめて指定 # c="copy"指定することで、再変換する手間と時間を抑える stream = ffmpeg.output(stream, 'output_{}'.format(i), c="copy") ffmpeg.run(stream)
OpenCV使った方法もあるけど、動画の編集処理だけだったらffmpegは楽チンで便利〜
- 投稿日:2020-07-03T18:56:22+09:00
pandasのデータフレームにgroup_idを付与したい
はじめに
pandasで重複削除したい場合や、集約したいときにはdrop_duplicatesやgroupbyを使えばやりたいことができます。
PandasのDataFrameやSeriesで重複要素を取り除く方法
Python
Pandas の groupby の使い方ただ、groupbyするときと同じような条件で、各groupにgroup_idを付与したい、みたいなこともたまにありますが、やりかたがわからなかったので実装してみました。(bestプラクティスじゃないかもだけど簡単に実装できた)
group_idの付与
# pandasのimport import pandas as pd # データフレームの用意 df = pd.DataFrame({ 'building_name': ['Aビル', 'Aビル', 'Bビル', 'Cビル', 'Bビル', 'Bビル', 'Dビル'], 'property_scale': ['large', 'large', 'small', 'small', 'small', 'small', 'large'], 'city_code': [1, 1, 1, 2, 1, 1, 1] }) df
building_name property_scale city_code Aビル large 1 Aビル large 1 Bビル small 1 Cビル small 2 Bビル small 1 Bビル small 1 Dビル large 1 # グループobject化 group_info = df.groupby(['property_scale', 'city_code'])# 一応中身みておく group_info.groups{('large', 1): Int64Index([0, 1, 6], dtype='int64'),
('small', 1): Int64Index([2, 4, 5], dtype='int64'),
('small', 2): Int64Index([3], dtype='int64')}# こちらも見ておく group_info.get_group(('large', 1))
building_name property_scale city_code Aビル large 1 Aビル large 1 Dビル large 1 # group_idの付与 df = pd.concat([ group_info.get_group(group_name).assign(group_id=group_id) for group_id, group_name in enumerate(group_info.groups.keys())]) df
building_name property_scale city_code group_id Aビル large 1 0 Aビル large 1 0 Dビル large 1 0 Bビル small 1 1 Bビル small 1 1 Bビル small 1 1 Cビル small 2 2 いちおう関数化もしておきます
import pandas as pd from pandas.core.frame import DataFrame def add_group_id(df: DataFrame, by: list) -> DataFrame: """byの値が重複しているレコードにgroup_idを付与する. Args: df (DataFrame): 任意のデータフレーム by (list): グループ化するカラム名 Returns: DataFrame """ # すでにgroup_idカラムが入っている場合はbyにgroup_idも追加する if 'group_id' in df.columns: by += ['group_id'] group_info = df.groupby(by=by) new_df = pd.concat([ group_info.get_group(group_name).assign(group_id=group_id) for group_id, group_name in enumerate(group_info.groups.keys())]) return new_df追記
@r_beginners さんにコメントいただき、そもそもgroupbyにgroup_id算出の機能があるみたいです。
import pandas as pd from pandas.core.frame import DataFrame def add_group_id(df: DataFrame, by: list) -> DataFrame: """byの値が重複しているレコードにgroup_idを付与する. Args: df (DataFrame): 任意のデータフレーム by (list): グループ化するカラム名 Returns: DataFrame """ # すでにgroup_idカラムが入っている場合はbyにgroup_idも追加する if 'group_id' in df.columns: by += ['group_id'] new_df = df.assign(group_id =df.groupby(by).ngroup()) return new_df@nkay さんのコメントにもあるように、pd.factorize()も使えそうですね。
pandasのメソッドもっと勉強しよう。。
- 投稿日:2020-07-03T18:53:27+09:00
tkinterでBMIを測定してみた
はじめに
僕は最近、バイトや教習所に行っているせいで深夜にご飯を食べることがよくあります。なので、太ったのではないかと思い、自分が今どういった体系なのか知りたくなったのでBMIを測定するツールを作ってみました。
手順
1.ウィンドウを表示する
qiita.pyroot=tk.Tk() root.geometry("400x300") root.title("BMI診断ツール")2.ウィンドウに必要なものを表示する
身長、体重のラベルと、身長、体重、BMI、体系のテキストボックス、ボタンををそれぞれ用意する。そして、それらを適切な場所に配置する。
qiita.py#ラベルを作る height_lavel=tk.Label(text="身長(m)") height_lavel.place(x=60,y=50) weight_lavel=tk.Label(text="体重(kg)") weight_lavel.place(x=60,y=80) bmi_lavel=tk.Label(text="BMI") bmi_lavel.place(x=60,y=200) result_lavel=tk.Label(text="あなたの体系は?") result_lavel.place(x=50,y=240) #テキストボックスを作る height_box=tk.Entry(width=20) height_box.place(x=140,y=50) weight_box=tk.Entry(width=20) weight_box.place(x=140,y=80) bmi_box=tk.Entry(width=20) bmi_box.place(x=140,y=200) result_box=tk.Entry(width=20) result_box.place(x=140,y=240) #ボタンを作る buttonl=tk.Button(root,text="診断する",font=("Halvetica",14),command=Buttonclick) buttonl.place(x=140,y=130)3.出力の条件を考える
BMIは体重(kg)/身長(m)x身長(m)なのでこの式に当てはめてBMIを出力させます。また今回はBMIが18.5を下回ると「瘦せ型」、18.5から25の間で「標準体型」、25以上で「肥満」というコメントも出力されるようにしました。
qiita.pyheight=float(height_box.get()) weight=float(weight_box.get()) bmi=weight/(height*height) if bmi<18.5: result = "痩せ型" elif 18.5<=bmi<25: result = "標準体型" elif 25<=bmi: result = "肥満" result_box.delete(0,tk.END) result_box.insert(0,result)4.ボタンを押してプログラムが実行されるようにする
qiita.pydef Buttonclick():結果
無事に出力できました。
ソースコード
qiita.py#codimg:utf-8 import tkinter as tk def Buttonclick(): height=float(height_box.get()) weight=float(weight_box.get()) bmi=weight/(height*height) bmi_box.delete(0,tk.END) bmi_box.insert(0,bmi) if bmi<18.5: result = "痩せ型" elif 18.5<=bmi<25: result = "標準体型" elif 25<=bmi: result = "肥満" result_box.delete(0,tk.END) result_box.insert(0,result) #ウィンドウを作る root=tk.Tk() root.geometry("400x300") root.title("BMI診断ツール") #ラベルを作る height_lavel=tk.Label(text="身長(m)") height_lavel.place(x=60,y=50) weight_lavel=tk.Label(text="体重(kg)") weight_lavel.place(x=60,y=80) bmi_lavel=tk.Label(text="BMI") bmi_lavel.place(x=60,y=200) result_lavel=tk.Label(text="あなたの体系は?") result_lavel.place(x=50,y=240) #テキストボックスを作る height_box=tk.Entry(width=20) height_box.place(x=140,y=50) weight_box=tk.Entry(width=20) weight_box.place(x=140,y=80) bmi_box=tk.Entry(width=20) bmi_box.place(x=140,y=200) result_box=tk.Entry(width=20) result_box.place(x=140,y=240) #ボタンを作る buttonl=tk.Button(root,text="診断する",font=("Halvetica",14),command=Buttonclick) buttonl.place(x=140,y=130) root.mainloop()感想
初めて自分で何か動くものをpythonで作れました。なかなか時間はかかったけど、完成した時はとても嬉しかったです。また夏休みにでもpythonでこのようなものを作ってみようかなと思います。
参考文献
「いちばんやさしいPython入門教室」大澤文孝[著]

- 投稿日:2020-07-03T18:45:25+09:00
Pythonでcsvファイルの最終行を読む方法いろいろ
Linuxではファイルの後ろから
n行取得することのできるtailというコマンドがある. 結構便利なのでPythonでも同じことができるようにしたい.
tail(file_name, n)でファイルの後ろからn行取得する関数を, いくつかのアプローチで作っていきたいと思う.最後のアプローチに関してはit-swarm.devというサイトのテキストファイルの最後の行を効率的に見つけるというページを参考にしている.
使用するファイル
読み込むファイルはテキストファイルでもなんでも良かったのだが, 今回は
csvファイルを使う.
ファイル名はtest.csv. 内容は, ビットコインの価格を一秒ずつ86400行(一日分)まとめたもの.test.csvdate,price,size 1588258800,933239.0,3.91528007 1588258801,933103.0,3.91169431 1588258802,932838.0,2.91 1588258803,933217.0,0.5089811 (中略) 1588345195,955028.0,0.0 1588345196,954959.0,0.05553 1588345197,954984.0,1.85356 1588345198,955389.0,10.91445135 1588345199,955224.0,3.61106本題とは関係ないが, それぞれの項目を一応説明するとdate, price, sizeの単位は, UnixTime, YEN, BTC.
最初の行は, 時刻1588258800, つまり5月1日0時0分0秒に933239.0円で3.91528007枚のビットコインの売買があったという意味である.素直に先頭から読む
まずは組み込み関数
open()を使ってファイルオブジェクトを取得し, 先頭からすべての行を読んで最後のn行だけ出力する方法.
nが0や負の整数だとおかしな結果になるので, 本当は自然数のみに限定する処理を行う必要があるが, 見やすさ重視ということで.def tail(fn, n): # ファイルを開いてすべての行をリストで取得する with open(fn, 'r') as f: # 一行読む. 一行目はヘッダーだから結果は捨てる f.readline() # 全行読む lines = f.readlines() # 後ろからn行だけ返す return lines[-n:] # 結果 file_name = 'test.csv' tail(file_name, 3) # ['1588345197,954984.0,1.85356\n', # '1588345198,955389.0,10.91445135\n', # '1588345199,955224.0,3.61106\n']テキストファイルであればこのままでも良いが, csvファイル用にもう少し使いやすくする.
def tail(fn, n): # ファイルを開いてすべての行をリストで取得する with open(fn, 'r') as f: f.readline() lines = f.readlines() # 文字列を配列にしてから返す. ついでにstr->floatに型変換する return [list(map(float ,line.strip().split(','))) for line in lines[-n:]] # 結果 tail(file_name, 3) # [[1588345197.0, 954984.0, 1.85356], # [1588345198.0, 955389.0, 10.91445135], # [1588345199.0, 955224.0, 3.61106]]変わったのは
returnの行だけだが, 関数が混みあっていてわかりづらいので, 噛み砕いて説明する.
それぞれの行に関して以下の処理を行っている.
strip()で改行コードを削除
'1588345197,954984.0,1.85356\n'->'1588345197,954984.0,1.85356'
split()で文字列をカンマ区切りで配列に変換
'1588345197,954984.0,1.85356'->['1588345197', '954984.0', '1.85356']
map()で配列のそれぞれの要素を文字列からfloat型に変換
['1588345197', '954984.0', '1.85356']->[1588345197.0, 954984.0, 1.85356]csvモジュールを使う
csvモジュールは行ごとに自動で配列に変換してくれるので, 若干処理が遅くはなるが, より簡潔に記述できる.
import csv def tail_csv(fn, n): with open(fn) as f: # ファイルオブジェクトをcsvリーダーに変換 reader = csv.reader(f) # ヘッダーを捨てる next(reader) # 全行読む rows = [row for row in reader] # 最後のn行だけfloatにして返す return [list(map(float, row)) for row in rows[-n:]]pandasモジュールを使う
pandasにはtail関数があるので驚くほど簡単に記述できる.
import pandas as pd def tail_pd(fn, n): df = pd.read_csv(fn) return df.tail(n).values.tolist()pandasはnumpy配列を扱っているので,
tolist()で最後にリストに変換している. numpy配列のままで良いなら必要はない.それぞれのパターンで実行時間を計測
ipythonにはtimeitという便利なコマンドがあるので, ループ回数を100として比較してみる.timeit -n100 tail('test.csv', 3) 18.8 ms ± 175 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) timeit -n100 tail_csv('test.csv', 3) 67 ms ± 822 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) timeit -n100 tail_pd('test.csv', 3) 30.4 ms ± 2.45 ms per loop (mean ± std. dev. of 7 runs, 100 loops each)特に何のモジュールも使わずそのまま読むのが早いことがわかった.
pandasはコードの簡潔さとそこそこのスピードなのでコスパは一番良さそう.
csvモジュールは使わない行までわざわざ文字列から配列に変換しているから, そのせいで成績は断トツで悪くなっている.ファイルを後ろから読めば一瞬
ここまでのアプローチは結局どれもすべての行を読み込んでいる. しかし, 欲しいのは後ろの数行なのだから, 後ろからファイルを読む方法があれば一瞬で読み込みが完了するはずだ.
テキストファイルの最後の行を効率的に見つけるというページを参考にした.
後ろから100バイトくらいずつ順に読んでいき, 改行コードが見つかればそれ以降の文字列が最後の行である. ページの中では最終行のみを見つけているが,tailコマンドを実現するには後ろからn行見つける必要があるので, そこだけ調整する.まず予備知識として, ファイルポインタの操作方法について説明する.
使う関数はf.tell(),f.read(size),f.seek(offset, whence)の3つ.
f.tell()は現在ポインタが指す位置を返す.
f.read(size)は現在の位置からsizeバイト読んだ内容を返す. ポインタは読んだ位置まで移動する. 正の方向にしか進めない.
f.seek(offset, whence)はポインタの位置を移動させる関数である.
引数のwhenceは位置を表す.0, 1, 2のいずれかの値が入る.0はファイルの先頭,1は現在のポインタの位置,2はファイルの末尾を意味する.
offsetには整数を入力する.readと異なり負の値も渡せるので, 例えばf.seek(-15, 1)は現在のポインタの位置を15個先頭側に戻す.これらを踏まえて実装していく.
def tail_b(fn, n=None): # nを与えないときは最後の行だけ単体で返す if n is None: n = 1 is_list = False # nは自然数 elif type(n) != int or n < 1: raise ValueError('n has to be a positive integer') # nを与えたときはn行をリストにまとめて返す else: is_list = True # seek()はバイナリモード以外だと予期せぬ挙動を見せるので'rb'を指定する with open(fn, 'rb') as f: # ヘッダーを除いた左端の位置を探すために最初の一行(ヘッダーの行)を読む f.readline() # 一番最初の改行コードを左端(ファイルの末尾から読んでいったときの終端)とする # -2は'\r\n'の2バイトを意味する left_end = f.tell() - 2 # 128バイトずつ読む chunk_size = 128 # ファイルの末尾(2)から1バイト戻る. read(1)で読むため f.seek(-1, 2) # ファイル末尾には空行や空白などがあることも多いから # それらを除いたファイルの最後の文字の位置(右端)を探す while True: if f.read(1).strip() != b'': # 右端 right_end = f.tell() break # 1歩進んだから2歩下がる f.seek(-2, 1) # 左端までのまだ読んでいない残りのバイト数 unread = right_end - left_end # 読んだ行数. これがn以上になればn行読み取れたことになる num_lines = 0 while True: # 未読のバイト数がchunk_sizeより小さくなったら, 端数をchunk_sizeとする if unread < chunk_size: chunk_size = f.tell() - left_end # 現在地からchunk_sizeだけファイルの先頭側に移動する f.seek(-chunk_size, 1) # 移動した分だけ読む chunk = f.read(chunk_size) # readでまた進んでしまったのでまた先頭側にchunk_size移動する f.seek(-chunk_size, 1) # 未読バイト数を更新する unread -= chunk_size # 改行コードが含まれるなら if b'\r' in chunk: # 改行コードの数だけnum_linesをカウントアップ num_lines += chunk.count(b'\r') # 読んだ行数がn行以上, もしくは未読のバイト数が0になったら終了の合図 if num_lines >= n or not unread: # 今の位置から右端まで読み, # バイト列をデコードしてから改行コード'\r\n'で区切って配列に変換する # 配列の最初の要素は'\r\n'より左側の不完全な行だから削除する lines = f.read(right_end-left_end-unread).decode('utf-8').split('\r\n')[1:] # 最後に後ろからn個取り出し, float型に変換して返す result = [list(map(float, line.split(','))) for line in lines[-n:]] # nを指定しなかったときは最後の一行を単体で返す if not is_list: return result[-1] else: return result解説は注釈で行っている.
ではメインの時間測定を行う.timeit -n100 tail_b(fn, 3) 87.8 µs ± 3.74 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)これまでのベストタイムは最初のアプローチで,
18.8 ms ± 175 µsだった. 実行時間は0.5%ほどになったということだ. つまり200倍であるが, 86400行を最初から全部読むか後ろから数行読むかの違いなのだから大差がつくのは当然である.おわりに
4つのパターンを紹介したが, 他にも
subprocessモジュールを使ってシステムのtailコマンドを実行するという方法もあるようだ. 環境に依存する方法であるため, 今回は省いた.
紹介した中での一番のオススメは, やはりpandasを使った2行で書ける方法だ. Pythonとは, 他人のコードを利用して自分がいかに楽できるかを極める言語である.ファイルの後ろから読んでいく方法に関しては, 早さが必要な場合や行数や文字数がとんでもなく多くて先頭からファイルを読んでいては時間がかかりすぎる場合などに使うと良いだろう.
また,chunk_sizeを128に設定したのは特に意味はない. ファイルの一行の長さよりは大きい方が良いが, 行によって長さが大きく異なるファイルもあるため, 何とも言えない.
短い行は数文字だが, 長い行は1万文字といったようなファイルを扱うならば, chunk_sizeを動的に変更する必要があるだろう.
例えば一度の探索で改行コードが一つも見つからなかったときは次のchunk_sizeを2倍2倍と増やしていくなどである.
他にも, 探索の終わっている行の平均長から次のchunk_sizeを決定する方法なども有効だと思われる.
- 投稿日:2020-07-03T17:56:04+09:00
UWSC を Python で置換しよう(5) Robotを作ってみよう
はじめに
「UWSC を Python で置換しよう」第五回です。今回は実際にロボットを作っていきます。いろいろあって投稿がしばらくできませんでした。
前回同様なにぶん、調べながら書いているため、間違っている点もあるかと思います。
その場合は、ビシバシ編集リクエストをください(汗
何気に、UWSCで検索したら、以下のサイトに補足されていたようなので、フォーラムに書いてあった欲しい機能を実装してみようと思う
CSWU~どうする UWSCなしの互換システム
https://wiki3.jp/CSWU前回は
UWSC を Python で置換しよう(4) チートシート[2]
次回は
未定足りない機能を作ろう
UWSCにあって、今回の環境にない機能のいくつかを作りこみます。作る機能は、
- 1.画像検索(フォーカス)ハイライト
- 2.要素検索(フォーカス)ハイライト
- 3.GETID/CLKITEMの互換機能
なお、機能作成にあたり、以下のサイトには大変お世話になりました。作りたい機能があったら、参考にしてみるといいと思います。
Python Example
https://www.programcreek.com/python/1.画像検索(フォーカス)ハイライト
画像検索をした際に、画面のどこでマッチしたのかを、画面上に矩形を描くことでわかりやすくします
win32guiをインポートして、(left,top,right,bottom)を与えると、検出した場所をハイライトしてくれるようにします。矩形の線種や色を変える場合はwin32ui.CreatePen,win32api.RGB,pyhandle,win32conで設定が必要になりますfunc_dhlight.pyimport win32gui ##デスクトップのハイライト def dhlight(x1, y1, x2, y2): hwnd=win32gui.WindowFromPoint((x1,y1)) hdc=win32gui.GetDC(hwnd) rc=(x1, y1, x2, y2) win32gui.DrawFocusRect(hdc, rc) win32gui.ReleaseDC(hwnd,hdc) if __name__ == '__main__': ##pyautoguiのlocateOnScreenと組み合わせて使う感じですね ##ただし、locateOnScreenはBox(left, top, width, height)を返すので pos_x,pos_y,size_w,size_h = pyautogui.locateOnScreen('target.png') x1 = pos_x y1 = pos_y x2 = pos_x + size_w y2 = pos_y + size_h dhlight(x1, y1, x2, y2) ##と書けば、target.pngが見つかったところに点線で矩形が表示されます。2.要素検索(フォーカス)ハイライト
ブラウザ上の要素を検索した際、どの要素を選択したのか、ハイライト表示します
こちらは、seleniumのcss挿入を利用しますので、cssの書き換えを禁止していたり、動的なUI/UXの場合は反応しないかもしれません(いっそ要素の座標とってwin32guiで描画したほうがいいかも)
css("background: white; border: 1px solid blue;")を差し込んでいるだけなので、好みで変更できます。func_hhlight.pyfrom selenium import webdriver from selenium.common.exceptions import NoSuchElementException ##Html Elementのハイライト def hhlight(element): driver = element._parent def apply_style(s): driver.execute_script("arguments[0].setAttribute('style', arguments[1]);",element, s) original_style = element.get_attribute('style') apply_style("background: white; border: 1px solid blue;") time.sleep(.3) apply_style(original_style) if __name__ == '__main__': driver = webdriver.Chrome() driver.implicitly_wait(10) driver.set_page_load_timeout(5) driver.set_script_timeout(5) driver.get('https://www.google.com/') ## こんな感じに、要素を検索して、作った関数に要素を渡すと指定したCSSが適用されて、 ## どの要素が選択されているのかわかるようになります search_box = driver.find_element_by_name("q") hhlight(search_box)3.GETID/CLKITEMの互換機能
UWSCではGETIDでウインドウIDを取得して操作しましたが、これをPythonでそのまま行うのは難しいので、ウインドウ名からプロセスIDを取得(get_pid)とプロセスIDからウインドウハンドルを取得(get_hwnds)する関数を作って、対応することにした。
func_getid.pyimport os,sys,re,time,subprocess import win32api, win32gui, win32con, win32process def get_pid(title): hwnd = win32gui.FindWindow(None, title) threadid,pid = win32process.GetWindowThreadProcessId(hwnd) return pid def get_hwnds(pid): def callback(hwnd, hwnds): if win32gui.IsWindowVisible(hwnd) and win32gui.IsWindowEnabled(hwnd): _, found_pid = win32process.GetWindowThreadProcessId(hwnd) if found_pid == pid: hwnds.append(hwnd) return True hwnds = [] win32gui.EnumWindows(callback, hwnds) return hwnds def clkitem(win_title,itemid): #ウインドウタイトルで探す hwnd = win32gui.FindWindow(0, win_title) #ウインドウのアイテムをリスト化 inplay_children = [] def is_win_ok(hwnd, *args): s = win32gui.GetWindowText(hwnd) inplay_children.append(hwnd) win32gui.EnumChildWindows(hwnd, is_win_ok, None) #アイテムIDの番号を指定し、アイテム/ボタンのハンドルを取得 button_hwnd = inplay_children[itemid] #ウインドウをアクティブにする win32gui.SetForegroundWindow(hwnd) #指定したボタンをクリック(押下->解除を送信) win32api.PostMessage(button_hwnd, win32con.WM_LBUTTONDOWN, 0, 0) win32api.PostMessage(button_hwnd, win32con.WM_LBUTTONUP, 0, 0) #ウインドウIDからプロセスIDを取得 pid = get_pid(u"電卓") #電卓の1つめのボタンをクリック clkitem(u"電卓",1) #プロセスIDからハンドルを取得して操作[GETCTLHND]と同等 for hwnd in get_hwnds(pid): if hwnd == 0: print(u"ウインドウが見つからない") else: #サイズ指定(リサイズ) win32gui.MoveWindow(hwnd, 100, 100, 500, 500, True) #最大化 win32gui.ShowWindow(hwnd, win32con.SW_MAXIMIZE) time.sleep(1) #閉じる win32gui.SendMessage(hwnd,win32con.WM_CLOSE,0,0)これで、画面内のネイティブアプリのリサイズや移動、フォーカスが可能になりました
ブラウザに限ればseleniumで行った方が簡単ですね。ロボットを作ってみよう
<<動作シナリオ>>
[]で括られた部分は使うモジュール名
- 1.ログイン情報の入ったini(setting.ini)を読み込む : [ConfigParser]
- 2.ブラウザを開いて、最大化した後、iniのlogin_urlに移動 : [Selenium]
- 3.ログイン情報を利用してログイン : [Selenium]
- 4.指定の画面(投稿)に移動 : [Selenium / win32gui]
- 5.記入情報一覧の入ったExcelファイルを開く [xlrd]
- 6.1行ずつ、入力フォームに転記 [Selenium]
- 7.Excelファイルの最終行を検知したら、画面を閉じて終了 [Selenium]
設定ファイル(setting.ini)
setting.ini[Server] login_id = user01 login_pw = password login_url = https://127.0.0.1/wp/wp-login.php [SitePage] write_fourm = 投稿 [WriteFile] excel_file = input_list.xlsxinput_list.xlsx[Sheet1] title,text,tag,format テスト1,初めての投稿1,未分類,標準 テスト2,初めての投稿2,未分類,標準 テスト3,初めての投稿3,未分類,標準 テスト4,初めての投稿4,未分類,標準 テスト5,初めての投稿5,未分類,標準 テスト6,初めての投稿6,未分類,標準ロボットソース
実際に、シナリオに合わせて、ソースを書いていきます。本当はもっと、関数とか作って読みやすく作ればいいのですが、シナリオが追いやすいように、フラットに書いています。なお、UTF-8で書いていますので注意してください
wordpress_auto_post.py# -*- coding: utf-8 -*- #モジュール読み込み import os,sys,re,time,subprocess import pyautogui import win32gui import configparser import xlrd from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.by import By from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.common.alert import Alert from selenium.webdriver.common.desired_capabilities import DesiredCapabilities from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.select import Select ##デスクトップのハイライト def dhlight(x1, y1, x2, y2): hwnd=win32gui.WindowFromPoint((x1,y1)) hdc=win32gui.GetDC(hwnd) rc=(x1, y1, x2, y2) win32gui.DrawFocusRect(hdc, rc) win32gui.ReleaseDC(hwnd,hdc) ##Html Elementのハイライト def hhlight(element): driver = element._parent def apply_style(s): driver.execute_script("arguments[0].setAttribute('style', arguments[1]);",element, s) original_style = element.get_attribute('style') apply_style("background: white; border: 1px solid blue;") time.sleep(.3) apply_style(original_style) # 設定ファイル読み込み CONF_FILEPATH = 'setting.ini' config = configparser.ConfigParser() config.read( CONF_FILEPATH, 'UTF-8') #confファイルで[]で囲った場所を指定 config_server = config['Server'] config_page = config['SitePage'] config_excel = config['WriteFile'] #confで[]の下に変数とデータを入れてる内容を取得 uid = config_server['login_id'] upw = config_server['login_pw'] url = config_server['login_url'] search_button = config_page['write_fourm'] xlsxfile = config_excel['excel_file'] ##Chromeを初期化 options = Options() ##Chromeのパス(通常は指定不要、ポータブル版などを使う場合やstable/beta切り替え時) options.binary_location = 'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe' options.add_argument('--start-maximized') options.add_argument('--disable-gpu') ## ChromeのWebDriverオブジェクトを作成する。 driver = webdriver.Chrome(options=options,executable_path="C:\Python37\chromedriver.exe") #要素が見つかるまでの待ち時間、ドライバ生成直後にのみ指定可能 driver.implicitly_wait(10) #ページが完全にロードされるまで最大で5秒間待つよう指定、ドライバ生成直後にのみ指定可能 driver.set_page_load_timeout(5) #Javascript実行が終了するまで最大5秒間待つように指定 driver.set_script_timeout(5) #URL移動 driver.get(url) #ログイン処理 user_id_elm = driver.find_element_by_id("user_login") #エレメントハイライト hhlight(user_id_elm) user_id_elm.send_keys(uid) user_pw_elm = driver.find_element_by_id("user_pass") hhlight(post_fourm) user_pw_elm.send_keys(upw) login_submit = driver.find_element_by_id("wp-submit") hhlight(post_fourm) login_submit.submit() time.sleep(5) #投稿 menu_post_elm = driver.find_element_by_xpath("/html/body/div[1]/div[1]/div[2]/ul/li[3]/a/div[3]") hhlight(menu_post_elm) menu_post_elm.click() time.sleep(2) #新規追加 new_post_elm = driver.find_element_by_xpath("/html/body/div[1]/div[2]/div[2]/div[1]/div[3]/a") hhlight(new_post_elm) new_post_elm.click() time.sleep(2) #Excelファイルを開く wb = xlrd.open_workbook(xlsxfile) #シート指定 sheet = wb.sheet_by_name('sheet1') #最終行検出 last_row = sheet.nrows #全行2次元配列に読み込み(メモリに余裕がなければ、1行ずつ読んだ方がいい) readcells = [sheet.row_values(row) for row in range(sheet.nrows)] time.sleep(5) #記事タイトル card_title_elm = driver.find_element_by_xpath("//*[@id='post-title-0']") #記事本文 card_body_elm = driver.find_element_by_xpath("/html/body/div[1]/div[2]/div[2]/div[1]/div[3]/div[1]/div/div/div/div[2]/div[3]/div/div[1]/div/div/div[2]/div[1]/div[3]/div/div/div/div/div/div/p") # driverを終了 driver.close()ロボットを動かす
python ./wordpress_auto_post.py問題なけれな動いて投稿されるはず。
最後に
UWSCがなくなったのは本当に痛い、もっと簡単な自動化ツールが出てくるといいですね。
次回は何か思いついたら続編を書くと思います。
- 投稿日:2020-07-03T17:29:12+09:00
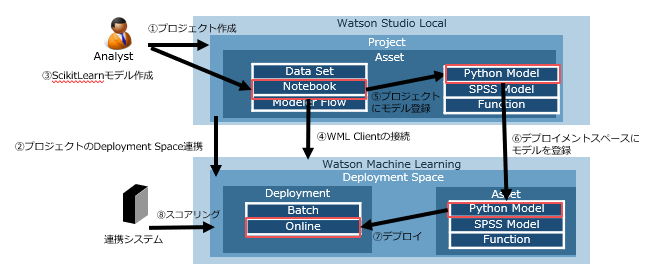
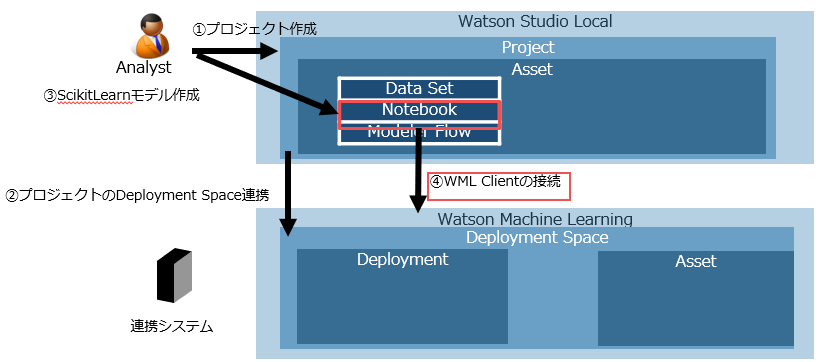
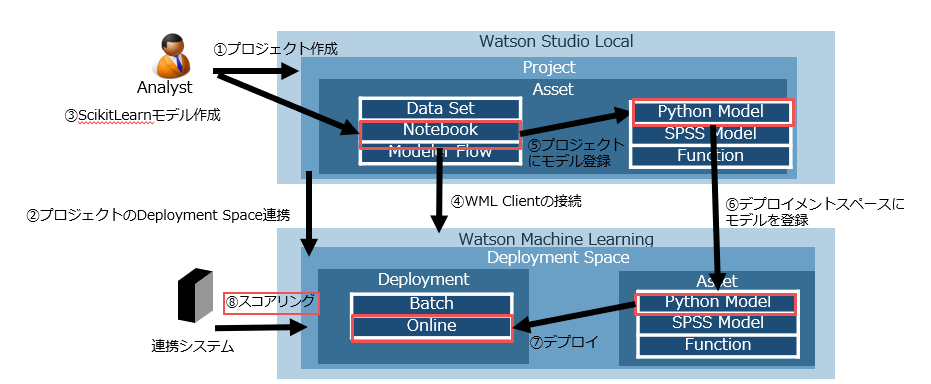
PythonでつくったモデルをWatson Machine LearningでREST API化(CP4D編)
Cloud pak for Data 3.0.1(以下CP4D) でPythonでつくったモデルをREST API化します。
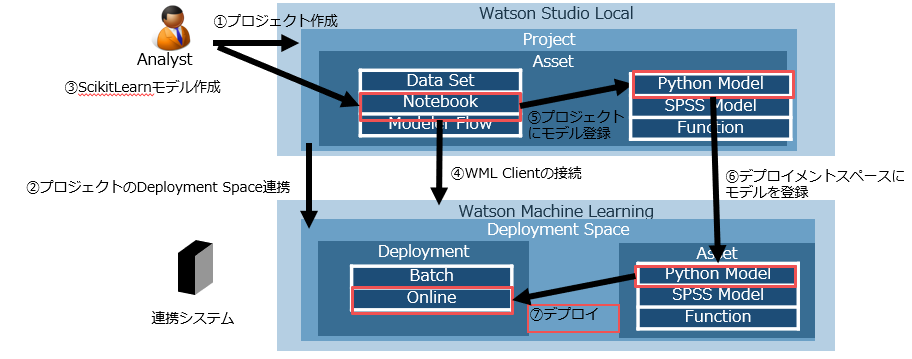
Watson Stuido Localという開発環境でモデルを作成し、Watson Machine Learningという実行環境にデプロイすることでREST API化することができます。
REST API化するとつくったモデルを外部のアプリケーションから呼び出すことが可能になります。例えば、Webの回遊行動から購入を予測するようなモデルを作れば、スマホのアプリにリアルタイムにその広告をだしたりすることができます。また、装置のセンサーデータから故障を予想するようなモデルを作れば、リアルタイムに故障の可能性があることを通知するようなことができます。
サポートされているフレームワークは以下になります。scikitlearnやKeras、xgboostなどがサポートされています。
Framework support details
https://www.ibm.com/support/knowledgecenter/en/SSQNUZ_3.0.1/wos/wos-frameworks-wml-cloud.html■テスト環境
CP4D: 3.0.1
WML Client: 1.0.103
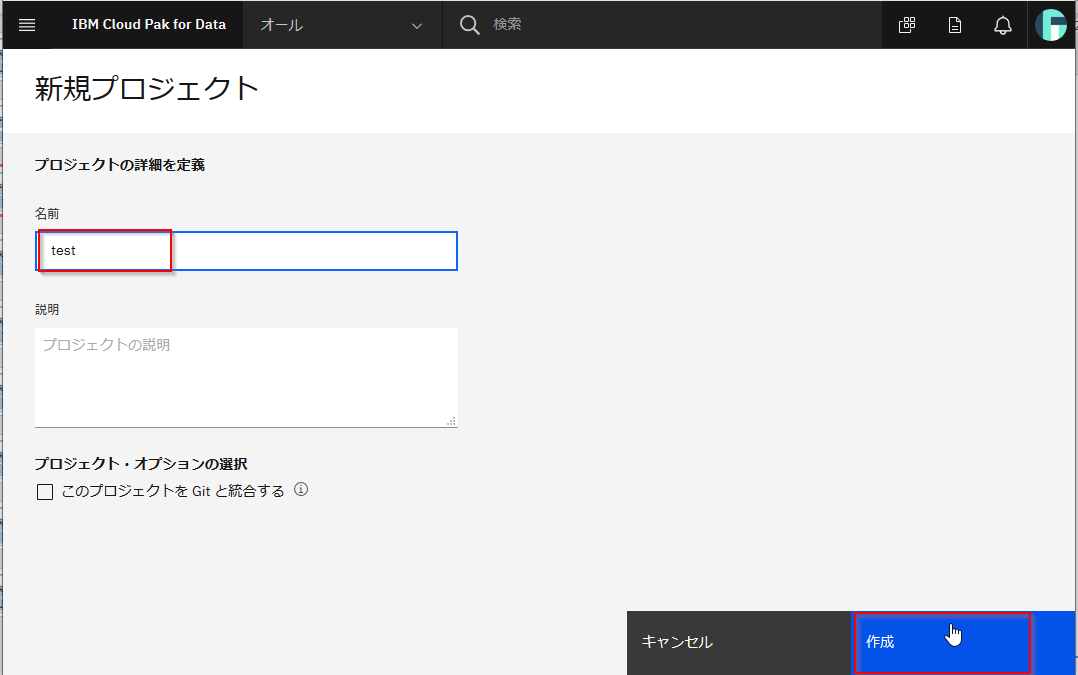
Scikitlearn: 0.22.1①プロジェクト作成
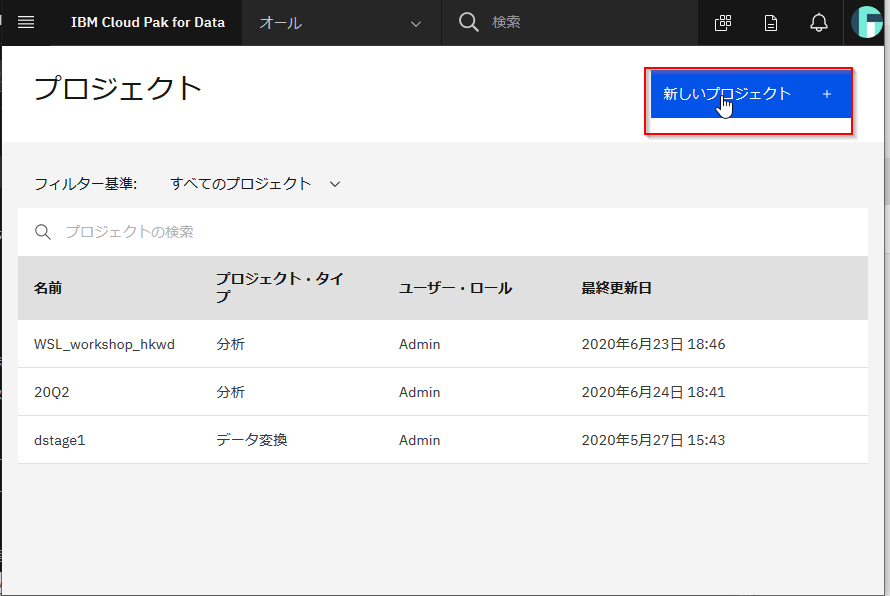
最初にモデルを作成するNotebookを作るためにプロジェクトを作成します。すでにプロジェクトがある場合にはそれをつかっていただいて構いません。その場合は②に進んでください。
CP4Dのメニューからプロジェクトを選択します
新しいプロジェクトを作成します。
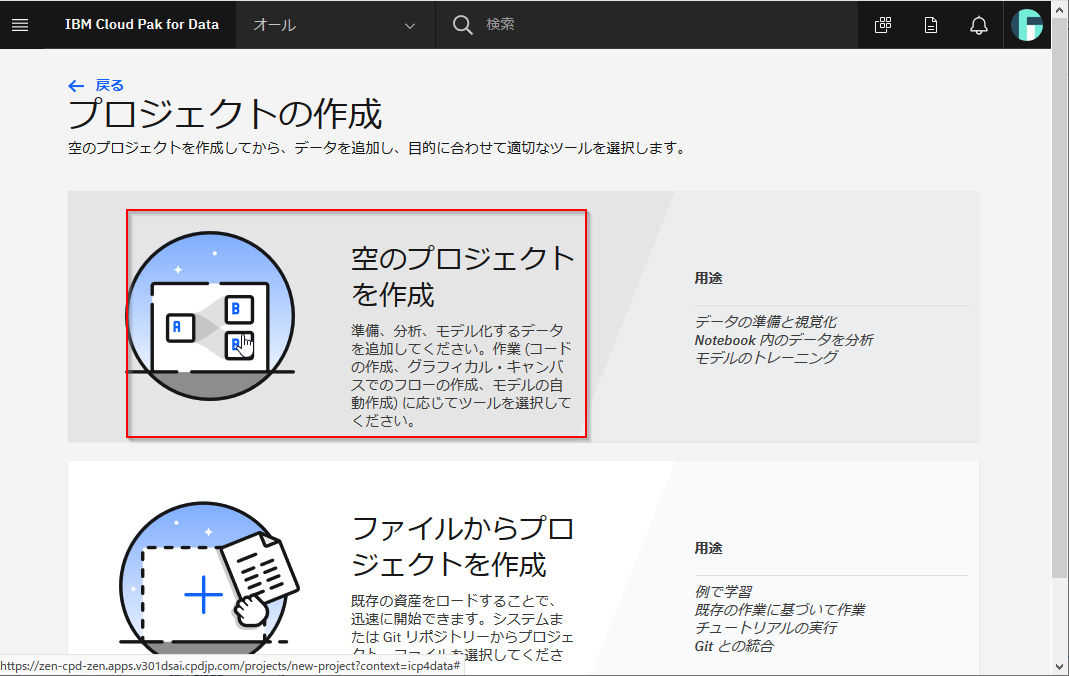
分析プロジェクトを選択し、次へをクリックしてください。
空のプロジェクトを作成します。
名前を設定して、作成します。
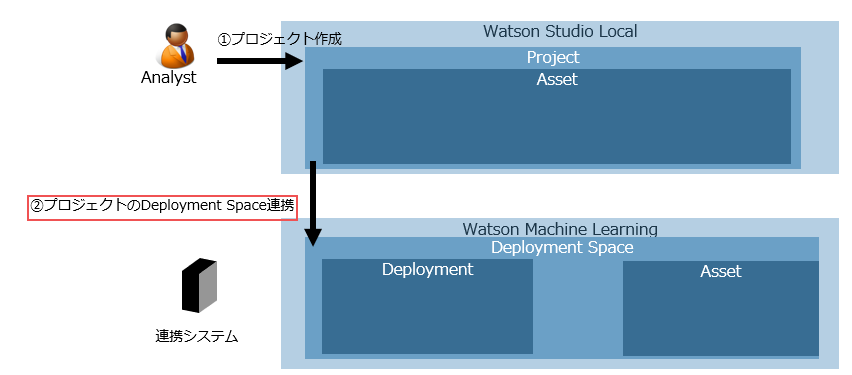
②プロジェクトのDeployment Space連携
Watson Machine LearningでREST API化するためにはWatson Machine Learning内にDeployment Spaceという場所を用意し、そこに作成したモデルを保管する必要があります。ここではWatson Studioのプロジェクトに対応するDeployment Spaceを設定します。
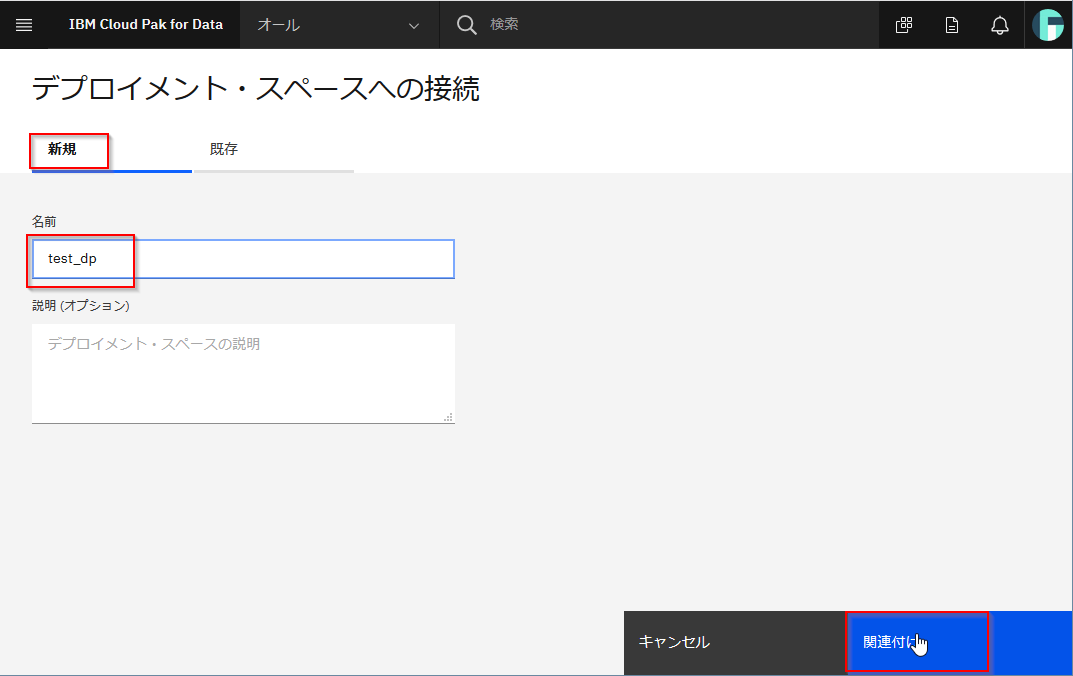
プロジェクトの設定タブに移ります。
デプロイメントスペースの関連付けボタンをクリックしてください。
既存のDeployment Spaceがある場合はそれを選択しても構いませんが、ここでは新規に作成し、関連付けをクリックします。
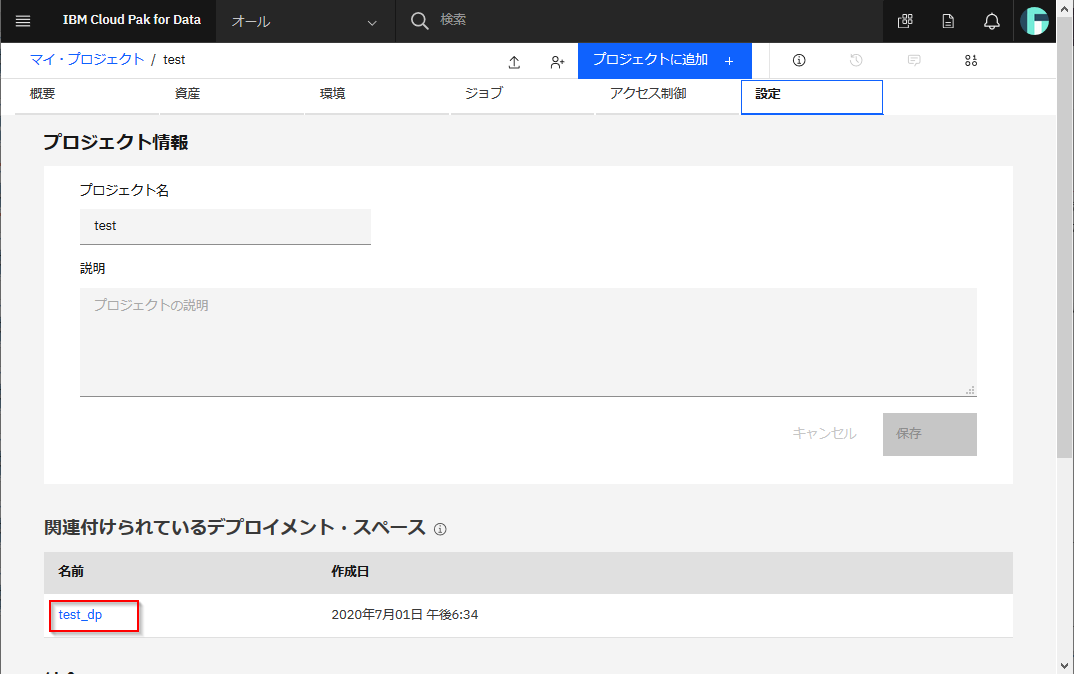
以下のように関連付けができたことを確認します。
注:正確に言えば、デプロイメント・スペースの作成は必須ですが、プロジェクトとデプロイメント・スペースを関連付けること自体は必須ではありません。関連付けられていないデプロイメント・スペースにもモデルを保存することはできます。ただ、関連付けをしておくことでデプロイメント・スペースのuidを見つけやすくすることができ、便利になります。
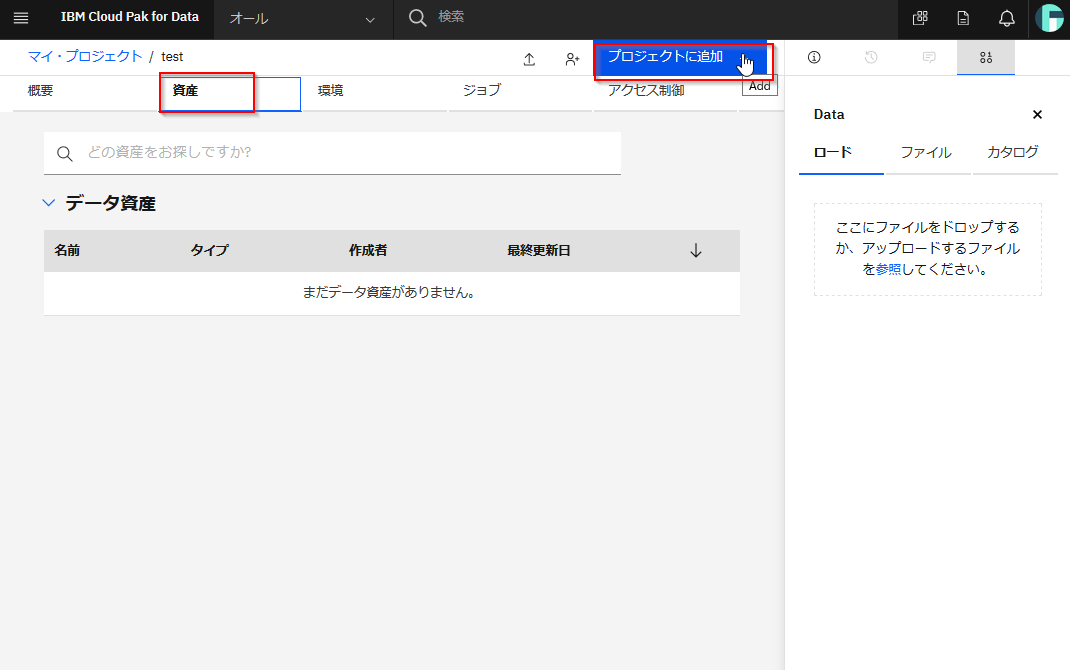
③ScikitLearnモデル作成
Watson StudioのNotebookでScikitLearnの予測モデルを作成します。
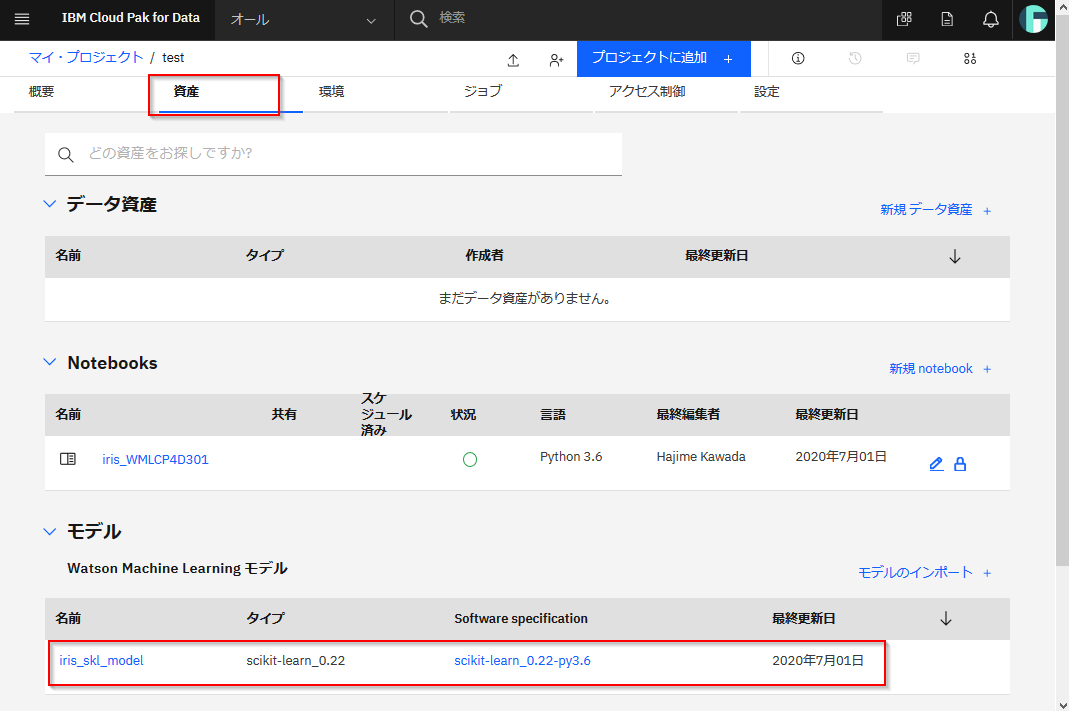
資産タブに移り、プロジェクトに追加ボタンをクリックしてください。
Notebookをクリックしてください。
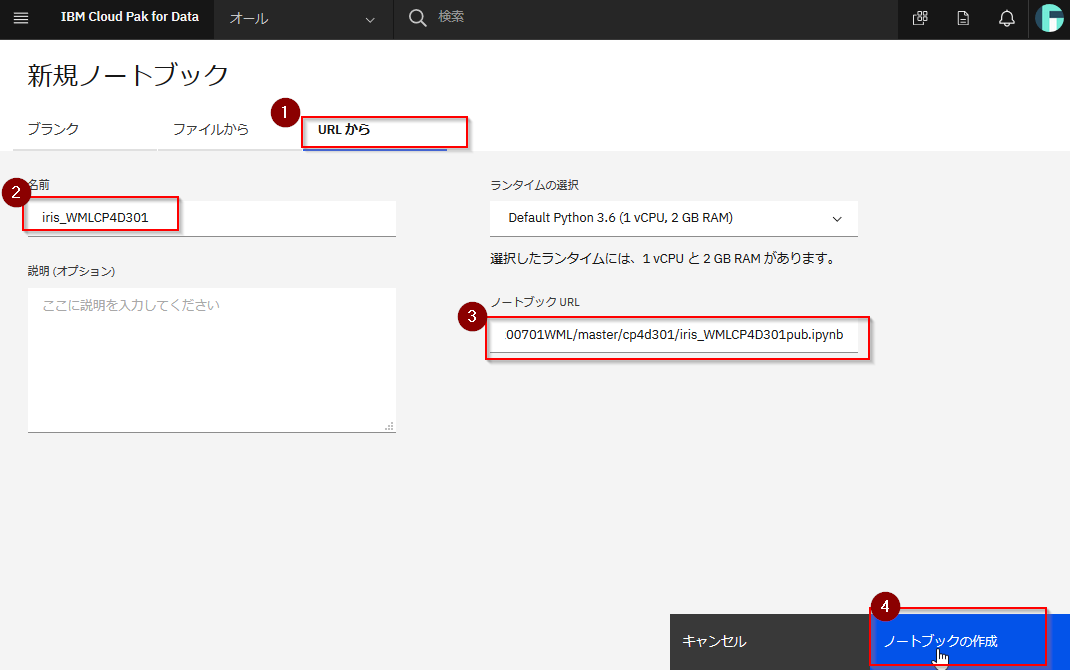
「URLから」を選択し、任意の名前を指定します。
ノートブックURLに以下のURLを指定します。
https://raw.githubusercontent.com/hkwd/200701WML/master/cp4d301/iris_WMLCP4D301pub.ipynb
設定ができたら、ノートブックの作成をクリックしてください。
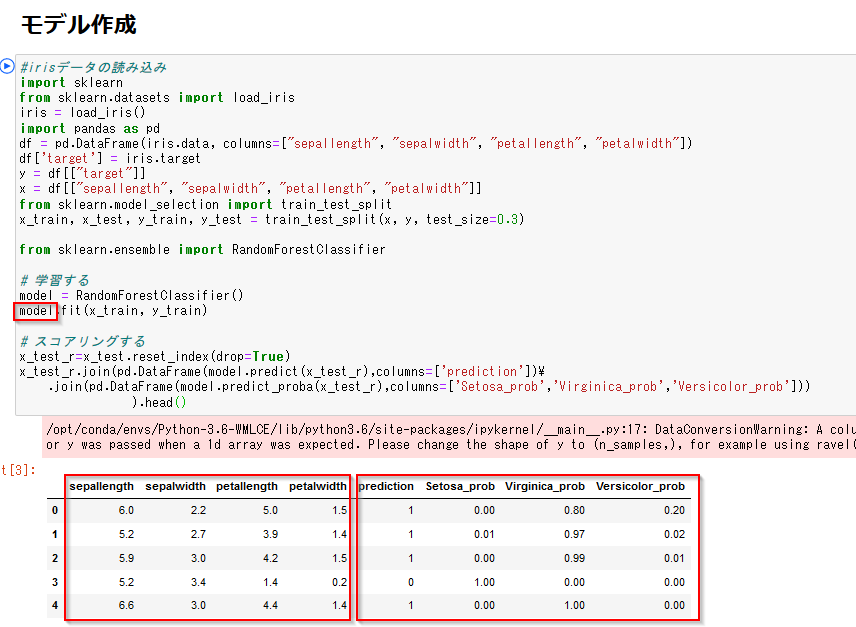
モデル作成のセルを実行してください。
Scikitlearnのライブラリに入っているirisのデータを読み込んでモデルを作っています。modelという変数にモデルが格納されました。"sepallength"(ガクの長さ), "sepalwidth"(ガクの幅), "petallength"(花弁の長さ), "petalwidth"(花弁の幅)をつかって、アヤメの種類であるSetosa、Virginica、Versicolorのいずれかを判別予測するモデルになっています。predictionが判別結果で、0がSetosa、1がVirginica、2がVersicolorを意味しています。Setosa_prob、Virginica_prob、Versicolor_probの各列はそれぞれのアヤメの種類である確率を意味しています。以下の例の0番目のアヤメで言うと80%の確率でVirginica種であると予測したことになります。
④WML Clientの接続
プロジェクトやデプロイメント・スペースにモデルを格納したり、デプロイしたりするために、NotebookからWatson Machine Learningのクライアント・ライブラリを読み込み、Watson Machine Learningのサービスに接続します。
Watson Machine Learningのクライアント・ライブラリ(watson-machine-learning-client-V4)はCP4DのPython環境では読み込まれているのですが、バージョンが1.0.95とやや古くCP4D3.0.1に対応できていないので、まず、pipで更新してください。ここではバージョン1.0.103を使いました。
!pip install --upgrade watson-machine-learning-client-V4以下でWMLクライアントでWatson Machine Learningのサービスに接続します。
clientというオブジェクトでWatson Machine Learningの操作が可能になります。import sys,os,os.path token = os.environ['USER_ACCESS_TOKEN'] from watson_machine_learning_client import WatsonMachineLearningAPIClient wml_credentials = { "token": token, "instance_id" : "wml_local", "url": os.environ['RUNTIME_ENV_APSX_URL'], "version": "3.0.1" } client = WatsonMachineLearningAPIClient(wml_credentials)⑤プロジェクトにモデル登録
先ほどインスタンス化したWMLのクライアントであるclientをつかって、プロジェクトに①でつくったirisの予測モデルであるmodelを保存します。
まず、set.default_projectでWMLクライアントでプロジェクトにつなぎます。
project_id = os.environ['PROJECT_ID'] client.set.default_project(project_id)次にモデルのメタデータを作っていきます。メタデータにどんなものがあるかはclient.repository.ModelMetaNames.show()で調べることができます。
ここではいくつか主要なものを設定します。
以下は説明変数のスキーマを設定しています。この設定がされているとWatson Machine LearningのGUIでテスト実行をするUIが使えるようになります。
説明変数の入ったpandasのDataFrameであるx_trainから列名とデータ型を取得しています。x_fields=[{'name': i, 'type': str(v)} for i,v in x_train.dtypes.items()]
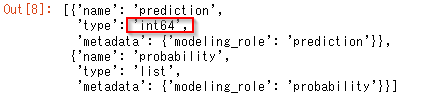
以下は出力結果のスキーマを設定しています。基本的には定型文ですが、目的変数の入ったpandasのDataFrameであるy_trainからデータ型を取得しています。
y_fields=[{'name': 'prediction', 'type': str(y_train.dtypes[0]),'metadata': {'modeling_role': 'prediction'}}] y_fields.append({'name': 'probability', 'type': 'list','metadata': {'modeling_role': 'probability'}})
その他、NAMEやTYPEなどのメタデータも設定し、ディクショナリにまとめます。なお、scikit learnが0.20ではRUNTIME_UIDを指定していましたが、今回モデルを作成したscikit learnが0.22の場合はRUNTIME_UIDではなくSOFTWARE_SPEC_UIDの指定が必要でした。
model_name = 'iris_skl_model' #scikit learnが0.22の場合はRUNTIME_UIDではなくSOFTWARE_SPEC_UIDの指定が必要 sw_spec_uid = client.software_specifications.get_uid_by_name("scikit-learn_0.22-py3.6") #モデルのメタデータを定義 pro_model_meta_props = { client.repository.ModelMetaNames.NAME: model_name, client.repository.ModelMetaNames.SOFTWARE_SPEC_UID: sw_spec_uid, client.repository.ModelMetaNames.TYPE: "scikit-learn_0.22", client.repository.ModelMetaNames.INPUT_DATA_SCHEMA:[{ "id":"input1", "fields":x_fields }], client.repository.ModelMetaNames.OUTPUT_DATA_SCHEMA: { "id":"output", "fields": y_fields} }WMLのクライアントのrepository.store_modelのメソッドでプロジェクトの資産としてmodelを保存します。
戻り値の中にIDが含まれているので取っておきます。#プロジェクトにモデルを保存 stored_pro_model_details = client.repository.store_model(model, meta_props=pro_model_meta_props, training_data=x_train, training_target=y_train) pro_model_uid=stored_pro_model_details['metadata']['guid']この時点でプロジェクトの資産をみてみるとモデルとして保存されているのがわかります。
WMLクライアントのrepository.list_models()メソッドでも同様に確認ができます。
注:正確に言えば、プロジェクトへのモデル保存は、REST API化するという目的のためには必須ではありませんが、デプロイメント・スペースに保存するモデルをプロジェクトにも保存しておくことで、Watson Studio上でもテストをしたり、GUIでデプロイメント・スペースに保存する(プロモート機能)ことができるようになります。
⑥デプロイメントスペースにモデルを登録
いよいよmodelをWatson Machine Learning内のデプロイメント・スペースに登録していきます。
Watson Data APIというREST APIをつかって②で関連付けたデプロイメント・スペースのIDを取得し、set.default_spaceメソッドで接続します。
#関連付けられたデプロイメント・スペースのIDを取得 import json, requests # get project info r = requests.get(os.environ['RUNTIME_ENV_APSX_URL'] + "/v2/projects/" + os.environ['PROJECT_ID'], headers = {"Authorization": "Bearer " + os.environ['USER_ACCESS_TOKEN']}) wmlProjectCompute = [c for c in r.json()["entity"]["compute"] if c["type"] == "machine_learning"][0] space_uid = wmlProjectCompute["properties"]["space_guid"] print(space_uid) #デプロイメントスペースに接続 client.set.default_space(space_uid)
- 参考
- Watson Data API (Beta) - IBM Cloud API Docs https://cloud.ibm.com/apidocs/watson-data-api#get-project
先ほど⑤で作成したモデルのメタデータに加えて、上で取得したデプロイメント・スペースのuidを設定します。
# モデルのメタデータにデプロイメントスペースのIDを追加 ds_model_meta_props=pro_model_meta_props ds_model_meta_props[client.repository.ModelMetaNames.SPACE_UID]= space_uid先ほどの⑤と同様にrepository.store_modelでmodelを保存し、戻り値からモデルのuidを取得します。
#デプロイメントスペースにモデルを保存 stored_ds_model_details = client.repository.store_model(model, meta_props=ds_model_meta_props, training_data=x_train, training_target=y_train) ds_model_uid = stored_ds_model_details["metadata"]["guid"]これでデプロイメント・スペースにもモデルが保存されました。
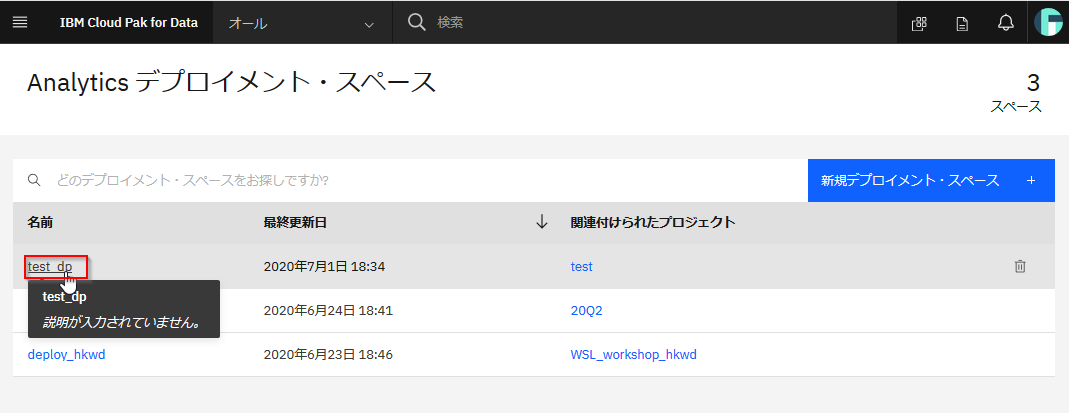
分析デプロイメントを開いてみます。
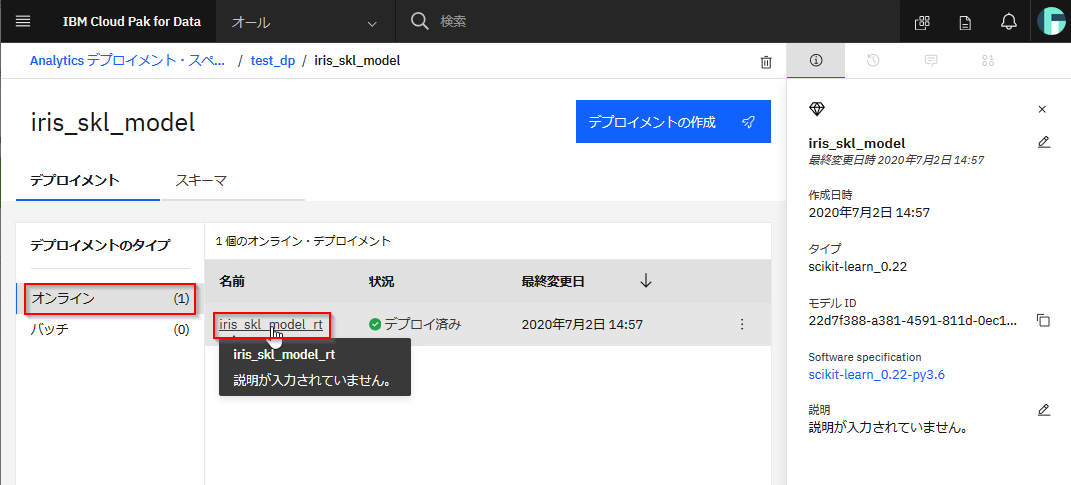
②でプロジェクトと関連付けたデプロイメント・スペースをクリックしてください。
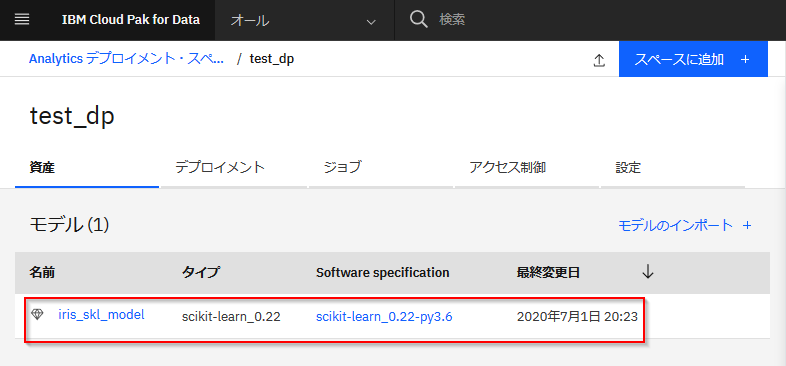
以下のようにモデルが登録されていることがわかります。
⑦モデルをオンラインスコアリングとしてデプロイ
デプロイメント・スペースに保存したモデルをデプロイしてREST API化します。
分析デプロイメントのGUIでもデプロイは可能ですが、ここではWMLクライアントのAPIで行ってみます。
まずデプロイメントのメタデータを定義します。
client.deployments.ConfigurationMetaNames.get()でどんなメタデータがあるかは確認ができます。
ここではNAMEとONLINEを指定します。
ONLINEを指定するとREST APIで説明変数を入力すると、リアルタイムに予測結果の目的変数を返すことができます。
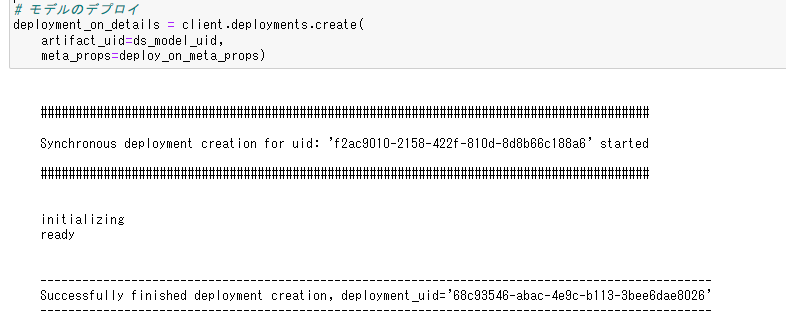
その他にもBATCHなどのデプロイ方法があります。deployment_on_name = 'iris_skl_model_rt' # オンラインスコアリングのメタデータ定義 deploy_on_meta_props = { client.deployments.ConfigurationMetaNames.NAME: deployment_on_name, client.deployments.ConfigurationMetaNames.ONLINE: {} }deployments.createメソッドでモデルをデプロイします。artifact_uidにはデプロイメントスペースに登録したモデルのuidを指定します。プロジェクトに保存したモデルのuidではないことに注意してください。
# モデルのデプロイ deployment_on_details = client.deployments.create( artifact_uid=ds_model_uid, meta_props=deploy_on_meta_props)少し時間がかかり、以下のようなメッセージがでて、モデルがデプロイされます。
戻り値にデプロイメントのuidが含まれるのでそれを取得します。
deployment_on_uid = client.deployments.get_uid(deployment_on_details)分析デプロイメントに移って、デプロイされていることを確認します。
先ほど登録したモデルをクリックします。
以下のようにオンラインタイプとしてデプロイされていることがわかります。
デプロイメントをクリックします。
このデプロイメントのREST APIのエンドポイントURLや様々な言語でのサンプルコードが表示されます。
⑧スコアリング
先ほどのサンプルコードなどを使って、以下の図のように外部のアプリケーションからスコアリングするのが本来の使い方ですが、ここではテストとして、WMLクライアントをつかってNotebookからスコアリングしてみます。
まずインプットデータである説明変数をテストデータのpandasから作ります。ここではx_test[0:2]で先頭から2行分を抜き出しています。
payload = { client.deployments.ScoringMetaNames.INPUT_DATA:[{ "fields": x_test.columns.tolist(), "values": x_test[0:2].values.tolist() }] }以下のようなデータをインプットデータとして作りました。
"sepallength"(ガクの長さ), "sepalwidth"(ガクの幅), "petallength"(花弁の長さ), "petalwidth"(花弁の幅)という説明変数名とその値を[4.5, 2.3, 1.3, 0.3], [6.0, 3.4, 4.5, 1.6]という2件分与えています。
スコアリングはdeployments.scoreのメソッドで行います。デプロイメントのuidとインプットデータを与えます。
predict=client.deployments.score(deployment_on_uid, payload ) }以下の結果が返ってきました。
1件目の結果は[1, [0.0, 0.99, 0.01]]です。まずpredictionとして1が返っていますのでVirginicaと予測しています。次のリスト[0.0, 0.99, 0.01]はSetosa_prob、Virginica_prob、Versicolor_probです。Virginicaが99%の確率だと予測しています。同様に2件目は100%の確率でSentosaだと予測しています。
まとめ
PythonのScikitLearnでつくったモデルがREST APIになり、アプリケーションから利用できるようになりました。
完成したNotebookはこちらです。
https://github.com/hkwd/200701WML/blob/master/cp4d301/iris_WMLCP4D301pub.ipynb参考
PythonでのCloud Pak for Dataのオブジェクト操作例 (WML client, project_lib) - Qiita https://qiita.com/ttsuzuku/items/eac3e4bedc020da93bc1













- 投稿日:2020-07-03T17:23:31+09:00
Deep Learning Specialization (Coursera) 自習記録 (C4W2)
はじめに
Deep Learning Specialization の Course 4, Week 2 (C4W2) の内容です。
(C4W2L01) Why look at case studies?
内容
参考
- 投稿日:2020-07-03T16:55:39+09:00
日本初の英語でのデータサイエンスのブートキャンプがローンチ
データは最新にして最大の資産だ
世界屈指のコーディングブートキャンプ Le Wagonは、高度な機械学習とデータサイエンスの9週間集中Pythonトレーニングを東京にて開講する事を正式に決定いたしました。 このコースは英語にて行われます。
日本に於いて増大するテック教育のニーズにお答えすると共に、現在に至るまでに培ってきた実績ある教育方法を活かして、Le Wagonは新たにデータサイエンスブートキャンプの開講を決定いたしました。長期・短期のコーディングブートキャンプに於いて世界最高峰であるLe Wagonがデータサイエンスの授業を提供するまでに、発足から7年も待ったのには理由があります。「Le Wagonが発足した2013年当時は、データの分野は十分に完成されていなかったのです。今日に於いてはこの職種はより整理され、求められるスキルも標準化されています」と元Googleのエンジニアであり、Le Wagonの3人の共同創業者の1人・最高技術責任者であるSebastien Saunierは述べています。
絶大な需要のあるスキルセット
9週間にも及ぶ濃密な学習の後、参加者は非常に高度な技能を手に入れて卒業します。卒業する頃には、データの収集・保管・精査・探索・変換や、データ予測・高度な機械学習・深層学習モデルを習得している事になります。
プログラムを卒業してすぐに、ジュニアデータサイエンティストや、データアナリスト、データエンジニアとしてデータチームに所属して仕事をすることができるでしょう。
データサイエンティストになる方法
この新しいブートキャンプは、今まで成功したLe Wagonの教育アプローチを踏襲したカリキュラムになっています。9週間のうち、90%の時間は実践的に本物のデータサイエンスプロジェクトに関わり、手を動かして学びます。これにより、データサイエンスのプロジェクトの立ち上げに必要なスキルを得ることができ、卒業直後から即戦力として就職しやすくなります。
このブートキャンプでは、データサイエンス基礎・機械学習・データエンジニアリング・深層学習・(そして、Le Wagonの御家芸である)擬似プロジェクトの5つに分かれたモジュールを、理論的な知識と業界標準のツールを習得しながら学ぶことができます。.
このコースに応募する際には数学とプログラミングの知識は必須です。ブートキャンプの応募者には、事前面接と40時間の予習課題があります。
このカリキュラムはデータアナリティクスとデータサイエンスのプロの教師陣によって行われます。
カリキュラム概要
- データサイエンスツール: Jupyter Notebook, Pandas, データ視覚化
- データサイエンスにおける数学: 統計・確率・線形代数
- 機械学習: 線形回帰, scikit-learn, 過剰適合
- プロダクション環境の機械学習システム: Google Cloud Platform
- ベストプラクティス: GitHub, データプロジェクトマネジメント
- 深層学習: Keras, ニューラル・ネットワーク, コンピュータビジョン, 自然言語処理 (NLP)
- 高度なデータサイエンスプロジェクト

- 投稿日:2020-07-03T16:32:06+09:00
だから僕はpandasを辞めた【データサイエンス100本ノック(構造化データ加工編)篇 #4】
だから僕はpandasを辞めた【データサイエンス100本ノック(構造化データ加工編)篇 #4】
データサイエンス100本ノック(構造化データ加工編)のPythonの問題を解いていきます。この問題群は、模範解答ではpandasを使ってデータ加工を行っていますが、私達は勉強がてらにNumPyを用いて処理していきます。
はじめに
NumPyの勉強として、データサイエンス100本ノック(構造化データ加工編)のPythonの問題を解いていきます。
Pythonでデータサイエンス的なことをする人の多くはpandas大好き人間かもしれませんが、実はpandasを使わなくても、NumPyで同じことができます。そしてNumPyの方がたいてい高速です。
pandas大好き人間だった僕もNumPyの操作には依然として慣れていないので、今回この『データサイエンス100本ノック』をNumPyで操作することでpandasからの卒業を試みて行きたいと思います。今回は23~35問目をやっていきます。GroupByというテーマのようです。
初期データは以下のようにして読み込みました(データ型指定はとりあえず後回し)。import numpy as np import pandas as pd from numpy.lib import recfunctions as rfn # 模範解答用 df_customer = pd.read_csv('data/customer.csv') df_receipt = pd.read_csv('data/receipt.csv') # 僕たちが扱うデータ arr_customer = np.genfromtxt( 'data/customer.csv', delimiter=',', encoding='utf-8', names=True, dtype=None) arr_receipt = np.genfromtxt( 'data/receipt.csv', delimiter=',', encoding='utf-8', names=True, dtype=None)つぎに
今回のテーマまでくるとcsvをそのまま読み込んだだけの構造化配列の効率悪さが目立ってくるので、今回はこれを使うのを辞めました
。NumPy配列を効率よく操作するために重要なのは、その配列が「数値データであること」「メモリレイアウトが最適化されていること」の2点です。そこで以下の関数を導入します。
def array_to_dict(arr): dic = dict() for colname in arr.dtype.names: if np.issubdtype(arr[colname].dtype, np.number): # 数値データの場合はメモリレイアウトを最適化して辞書に格納 dic[colname] = np.ascontiguousarray(arr[colname]) else: # 文字列データの場合は数値データに変換して辞書に格納 unq, inv = np.unique(arr[colname], return_inverse=True) dic[colname] = inv dic['Code_' + colname] = unq # 数値を文字列に戻すときに使う配列 return dic dic_customer = array_to_dict(arr_customer) dic_receipt = array_to_dict(arr_receipt) dic_receiptこの関数ではテーブルが辞書になって帰ってきます。テーブルの各列ごとにndarrayになっています。
{'sales_ymd': array([20181103, 20181118, 20170712, ..., 20170311, 20170331, 20190423]), 'sales_epoch': array([1257206400, 1258502400, 1215820800, ..., 1205193600, 1206921600, 1271980800]), 'store_cd': array([29, 10, 40, ..., 44, 6, 13], dtype=int64), 'Code_store_cd': array(['S12007', 'S12013', 'S12014', ..., 'S14048', 'S14049', 'S14050'], dtype='<U6'), 'receipt_no': array([ 112, 1132, 1102, ..., 1122, 1142, 1102]), 'receipt_sub_no': array([1, 2, 1, ..., 1, 1, 2]), 'customer_id': array([1689, 2112, 5898, ..., 8103, 582, 8306], dtype=int64), 'Code_customer_id': array(['CS001113000004', 'CS001114000005', 'CS001115000010', ..., 'CS052212000002', 'CS052514000001', 'ZZ000000000000'], dtype='<U14'), 'product_cd': array([2119, 3235, 861, ..., 457, 1030, 808], dtype=int64), 'Code_product_cd': array(['P040101001', 'P040101002', 'P040101003', ..., 'P091503003', 'P091503004', 'P091503005'], dtype='<U10'), 'quantity': array([1, 1, 1, ..., 1, 1, 1]), 'amount': array([158, 81, 170, ..., 168, 148, 138])}この作業がいかに重要か、
np.argsort()で試してみます。arr_receipt['sales_ymd'].flags['C_CONTIGUOUS'] # False dic_receipt['sales_ymd'].flags['C_CONTIGUOUS'] # True %timeit np.argsort(arr_receipt['sales_ymd']) # 7.33 ms ± 134 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) %timeit np.argsort(dic_receipt['sales_ymd']) # 5.98 ms ± 58.3 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)これはいい。
なんか構造化配列がどうのとか利便性がどうのとかが無視されて、もはや扱いづらい物になっているような気もしますが、この記事はpandasを捨ててNumPyを勉強しようというのが主題なので問題ありません!ついでに、前回ごちゃついていた、構造化配列を作成するコードも関数化します。
def make_array(size, **kwargs): arr = np.empty(size, dtype=[(colname, subarr.dtype) for colname, subarr in kwargs.items()]) for colname, subarr in kwargs.items(): arr[colname] = subarr return arrP_023
P-023: レシート明細データフレーム(df_receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)と売上数量(quantity)を合計せよ。
np.bincount()を利用して店舗コード列の値ごとに合計を求めます。店舗コード列を文字から数値データに変換したからこそ使える技です。In[023]make_array( dic_receipt['Code_store_cd'].size, store_cd=dic_receipt['Code_store_cd'], amount=np.bincount(dic_receipt['store_cd'], dic_receipt['amount']), quantity=np.bincount(dic_receipt['store_cd'], dic_receipt['quantity']))Out[023]array([('S12007', 638761., 2099.), ('S12013', 787513., 2425.), ('S12014', 725167., 2358.), ('S12029', 794741., 2555.), ('S12030', 684402., 2403.), ('S13001', 811936., 2347.), ('S13002', 727821., 2340.), ('S13003', 764294., 2197.), ('S13004', 779373., 2390.), ('S13005', 629876., 2004.), ('S13008', 809288., 2491.), ('S13009', 808870., 2486.), ('S13015', 780873., 2248.), ('S13016', 793773., 2432.), ('S13017', 748221., 2376.), ('S13018', 790535., 2562.), ('S13019', 827833., 2541.), ('S13020', 796383., 2383.), ('S13031', 705968., 2336.), ('S13032', 790501., 2491.), ('S13035', 715869., 2219.), ('S13037', 693087., 2344.), ('S13038', 708884., 2337.), ('S13039', 611888., 1981.), ('S13041', 728266., 2233.), ('S13043', 587895., 1881.), ('S13044', 520764., 1729.), ('S13051', 107452., 354.), ('S13052', 100314., 250.), ('S14006', 712839., 2284.), ('S14010', 790361., 2290.), ('S14011', 805724., 2434.), ('S14012', 720600., 2412.), ('S14021', 699511., 2231.), ('S14022', 651328., 2047.), ('S14023', 727630., 2258.), ('S14024', 736323., 2417.), ('S14025', 755581., 2394.), ('S14026', 824537., 2503.), ('S14027', 714550., 2303.), ('S14028', 786145., 2458.), ('S14033', 725318., 2282.), ('S14034', 653681., 2024.), ('S14036', 203694., 635.), ('S14040', 701858., 2233.), ('S14042', 534689., 1935.), ('S14045', 458484., 1398.), ('S14046', 412646., 1354.), ('S14047', 338329., 1041.), ('S14048', 234276., 769.), ('S14049', 230808., 788.), ('S14050', 167090., 580.)], dtype=[('store_cd', '<U6'), ('amount', '<f8'), ('quantity', '<f8')])Time[023]# 模範解答 %%timeit df_receipt.groupby('store_cd').agg({'amount':'sum', 'quantity':'sum'}).reset_index() # 9.14 ms ± 234 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) %%timeit make_array( dic_receipt['Code_store_cd'].size, store_cd=dic_receipt['Code_store_cd'], amount=np.bincount(dic_receipt['store_cd'], dic_receipt['amount']), quantity=np.bincount(dic_receipt['store_cd'], dic_receipt['quantity'])) # 473 µs ± 19.6 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)P_024
P-024: レシート明細データフレーム(df_receipt)に対し、顧客ID(customer_id)ごとに最も新しい売上日(sales_ymd)を求め、10件表示せよ。
np.maximum()を利用して売上日の最大値を求めます。
まず顧客ID列に基づいて売上日をソートします。つづいて、顧客IDが変わる行の位置を取得し、np.ufunc.reduceat()を利用して顧客IDごとに同じ処理(np.maximum())を行います。In[024]sorter_index = np.argsort(dic_receipt['customer_id']) sorted_id = dic_receipt['customer_id'][sorter_index] sorted_ymd = dic_receipt['sales_ymd'][sorter_index] cut_index, = np.concatenate( ([True], sorted_id[1:] != sorted_id[:-1])).nonzero() make_array( cut_index.size, customer_id=dic_receipt['Code_customer_id'], sales_ymd=np.maximum.reduceat(sorted_ymd, cut_index))[:10]Out[024]array([('CS001113000004', 20190308), ('CS001114000005', 20190731), ('CS001115000010', 20190405), ('CS001205000004', 20190625), ('CS001205000006', 20190224), ('CS001211000025', 20190322), ('CS001212000027', 20170127), ('CS001212000031', 20180906), ('CS001212000046', 20170811), ('CS001212000070', 20191018)], dtype=[('customer_id', '<U14'), ('sales_ymd', '<i4')])P_025
P-025: レシート明細データフレーム(df_receipt)に対し、顧客ID(customer_id)ごとに最も古い売上日(sales_ymd)を求め、10件表示せよ。
In[025]sorter_index = np.argsort(dic_receipt['customer_id']) sorted_id = dic_receipt['customer_id'][sorter_index] sorted_ymd = dic_receipt['sales_ymd'][sorter_index] cut_index, = np.concatenate( ([True], sorted_id[1:] != sorted_id[:-1])).nonzero() make_array( cut_index.size, customer_id=dic_receipt['Code_customer_id'], sales_ymd=np.minimum.reduceat(sorted_ymd, cut_index))[:10]Out[025]array([('CS001113000004', 20190308), ('CS001114000005', 20180503), ('CS001115000010', 20171228), ('CS001205000004', 20170914), ('CS001205000006', 20180207), ('CS001211000025', 20190322), ('CS001212000027', 20170127), ('CS001212000031', 20180906), ('CS001212000046', 20170811), ('CS001212000070', 20191018)], dtype=[('customer_id', '<U14'), ('sales_ymd', '<i4')])P_026
P-026: レシート明細データフレーム(df_receipt)に対し、顧客ID(customer_id)ごとに最も新しい売上日(sales_ymd)と古い売上日を求め、両者が異なるデータを10件表示せよ。
In[026]sorter_index = np.argsort(dic_receipt['customer_id']) sorted_id = dic_receipt['customer_id'][sorter_index] sorted_ymd = dic_receipt['sales_ymd'][sorter_index] cut_index, = np.concatenate( ([True], sorted_id[1:] != sorted_id[:-1])).nonzero() sales_ymd_max = np.maximum.reduceat(sorted_ymd, cut_index) sales_ymd_min = np.minimum.reduceat(sorted_ymd, cut_index) new_arr = make_array(cut_index.size, customer_id=dic_receipt['Code_customer_id'], sales_ymd_max=sales_ymd_max, sales_ymd_min=sales_ymd_min) new_arr[sales_ymd_max != sales_ymd_min][:10]Out[026]array([('CS001114000005', 20190731, 20180503), ('CS001115000010', 20190405, 20171228), ('CS001205000004', 20190625, 20170914), ('CS001205000006', 20190224, 20180207), ('CS001214000009', 20190902, 20170306), ('CS001214000017', 20191006, 20180828), ('CS001214000048', 20190929, 20171109), ('CS001214000052', 20190617, 20180208), ('CS001215000005', 20181021, 20170206), ('CS001215000040', 20171022, 20170214)], dtype=[('customer_id', '<U14'), ('sales_ymd_max', '<i4'), ('sales_ymd_min', '<i4')])P_027
P-027: レシート明細データフレーム(df_receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の平均を計算し、降順でTOP5を表示せよ。
np.bincount()を用いて店舗コードごとの数と金額総計を計算し、総計÷数で平均を求めます。In[027]mean_amount = (np.bincount(dic_receipt['store_cd'], dic_receipt['amount']) / np.bincount(dic_receipt['store_cd'])) new_arr = make_array(dic_receipt['Code_store_cd'].size, store_cd=dic_receipt['Code_store_cd'], amount=mean_amount) new_arr[np.argsort(mean_amount)[::-1]][:5]Out[027]array([('S13052', 402.86746988), ('S13015', 351.11196043), ('S13003', 350.91551882), ('S14010', 348.79126214), ('S13001', 348.47038627)], dtype=[('store_cd', '<U6'), ('amount', '<f8')])P_028
P-028: レシート明細データフレーム(df_receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の中央値を計算し、降順でTOP5を表示せよ。
最大・最小値を求める場合と同じように操作して、
np.median()を店舗コードごとにforループさせます。In[028]sorter_index = np.argsort(dic_receipt['store_cd']) sorted_cd = dic_receipt['store_cd'][sorter_index] sorted_amount = dic_receipt['amount'][sorter_index] cut_index, = np.concatenate( ([True], sorted_cd[1:] != sorted_cd[:-1], [True])).nonzero() median_amount = np.array([np.median(sorted_amount[s:e]) for s, e in zip(cut_index[:-1], cut_index[1:])]) new_arr = make_array(dic_receipt['Code_store_cd'].size, store_cd=dic_receipt['Code_store_cd'], amount=median_amount) new_arr[np.argsort(median_amount)[::-1]][:5]以下のように、
np.lexsort()を用いて「店舗コード→売上金額」順に並べた配列を作成し、店舗コードごとの数を数えて中央値となるインデックスを求める方法もありますが、np.lexsort()が遅すぎました。# 配列をソート sorter_index = np.lexsort((dic_receipt['amount'], dic_receipt['store_cd'])) sorted_cd = dic_receipt['store_cd'][sorter_index] sorted_amount = dic_receipt['amount'][sorter_index] # 中央値のインデックスを求める counts = np.bincount(sorted_cd) median_index = counts//2 median_index[1:] += counts.cumsum()[:-1] # 中央値を計算 med_a = sorted_amount[median_index] med_b = sorted_amount[median_index - 1] median_amount = np.where(counts % 2, med_a, (med_a+med_b)/2)Out[028]array([('S13052', 190.), ('S14010', 188.), ('S14050', 185.), ('S14040', 180.), ('S13003', 180.)], dtype=[('store_cd', '<U6'), ('amount', '<f8')])P_029
P-029: レシート明細データフレーム(df_receipt)に対し、店舗コード(store_cd)ごとに商品コード(product_cd)の最頻値を求めよ。
店舗コードと商品コードで二次元平面
mappingを作成し、np.add.at()を用いて各行が該当する点に1を加えます。そして、np.argmax()を用いて店舗コードごとに最大値をとる商品コードを取得します。In[029]mapping = np.zeros((dic_receipt['Code_store_cd'].size, dic_receipt['Code_product_cd'].size), dtype=int) np.add.at(mapping, (dic_receipt['store_cd'], dic_receipt['product_cd']), 1) make_array( dic_receipt['Code_store_cd'].size, store_cd=dic_receipt['Code_store_cd'], product_cd=dic_receipt['Code_product_cd'][np.argmax(mapping, axis=1)])Out[029]array([('S12007', 'P060303001'), ('S12013', 'P060303001'), ('S12014', 'P060303001'), ('S12029', 'P060303001'), ('S12030', 'P060303001'), ('S13001', 'P060303001'), ('S13002', 'P060303001'), ('S13003', 'P071401001'), ('S13004', 'P060303001'), ('S13005', 'P040503001'), ('S13008', 'P060303001'), ('S13009', 'P060303001'), ('S13015', 'P071401001'), ('S13016', 'P071102001'), ('S13017', 'P060101002'), ('S13018', 'P071401001'), ('S13019', 'P071401001'), ('S13020', 'P071401001'), ('S13031', 'P060303001'), ('S13032', 'P060303001'), ('S13035', 'P040503001'), ('S13037', 'P060303001'), ('S13038', 'P060303001'), ('S13039', 'P071401001'), ('S13041', 'P071401001'), ('S13043', 'P060303001'), ('S13044', 'P060303001'), ('S13051', 'P050102001'), ('S13052', 'P050101001'), ('S14006', 'P060303001'), ('S14010', 'P060303001'), ('S14011', 'P060101001'), ('S14012', 'P060303001'), ('S14021', 'P060101001'), ('S14022', 'P060303001'), ('S14023', 'P071401001'), ('S14024', 'P060303001'), ('S14025', 'P060303001'), ('S14026', 'P071401001'), ('S14027', 'P060303001'), ('S14028', 'P060303001'), ('S14033', 'P071401001'), ('S14034', 'P060303001'), ('S14036', 'P040503001'), ('S14040', 'P060303001'), ('S14042', 'P050101001'), ('S14045', 'P060303001'), ('S14046', 'P060303001'), ('S14047', 'P060303001'), ('S14048', 'P050101001'), ('S14049', 'P060303001'), ('S14050', 'P060303001')], dtype=[('store_cd', '<U6'), ('product_cd', '<U10')])P_030
P-030: レシート明細データフレーム(df_receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の標本分散を計算し、降順でTOP5を表示せよ。
まず
np.bincount()を用いて店舗コードごとの数と金額総計を計算します。つづいて総計÷数で平均を求めます。つづいて偏差を計算し、np.bincount()を用いて店舗コードごとの合計÷数より分散を求めます。In[030]counts = np.bincount(dic_receipt['store_cd']) mean_amount = (np.bincount(dic_receipt['store_cd'], dic_receipt['amount']) / counts) deviation_array = mean_amount[dic_receipt['store_cd']] - dic_receipt['amount'] var_amount = np.bincount(dic_receipt['store_cd'], deviation_array**2) / counts new_arr = make_array(dic_receipt['Code_store_cd'].size, store_cd=dic_receipt['Code_store_cd'], amount=var_amount) new_arr[np.argsort(var_amount)[::-1]][:5]Out[030]array([('S13052', 440088.70131127), ('S14011', 306314.55816389), ('S14034', 296920.08101128), ('S13001', 295431.99332904), ('S13015', 295294.36111594)], dtype=[('store_cd', '<U6'), ('amount', '<f8')])P_031
P-031: レシート明細データフレーム(df_receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の標本標準偏差を計算し、降順でTOP5を表示せよ。
分散の平方根が標準偏差ですので、前問に
np.sqrt()を適用します。In[031]counts = np.bincount(dic_receipt['store_cd']) mean_amount = (np.bincount(dic_receipt['store_cd'], dic_receipt['amount']) / counts) deviation_array = mean_amount[dic_receipt['store_cd']] - dic_receipt['amount'] var_amount = np.bincount(dic_receipt['store_cd'], deviation_array**2) / counts new_arr = make_array(dic_receipt['Code_store_cd'].size, store_cd=dic_receipt['Code_store_cd'], amount=np.sqrt(var_amount)) new_arr[np.argsort(var_amount)[::-1]][:5]Out[031]array([('S13052', 663.39181583), ('S14011', 553.45691627), ('S14034', 544.90373555), ('S13001', 543.53656117), ('S13015', 543.40993837)], dtype=[('store_cd', '<U6'), ('amount', '<f8')])P_032
P-032: レシート明細データフレーム(df_receipt)の売上金額(amount)について、25%刻みでパーセンタイル値を求めよ。
In[032]np.percentile(dic_receipt['amount'], np.arange(5)/4)Out[032]array([ 10., 102., 170., 288., 10925.])P_033
P-033: レシート明細データフレーム(df_receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の平均を計算し、330以上のものを抽出せよ。
27問目と同じです。
In[033]mean_amount = (np.bincount(dic_receipt['store_cd'], dic_receipt['amount']) / np.bincount(dic_receipt['store_cd'])) new_arr = make_array(dic_receipt['Code_store_cd'].size, store_cd=dic_receipt['Code_store_cd'], amount=mean_amount) new_arr[mean_amount >= 330]Out[033]array([('S12013', 330.19412998), ('S13001', 348.47038627), ('S13003', 350.91551882), ('S13004', 330.94394904), ('S13015', 351.11196043), ('S13019', 330.20861588), ('S13020', 337.87993212), ('S13052', 402.86746988), ('S14010', 348.79126214), ('S14011', 335.71833333), ('S14026', 332.34058847), ('S14045', 330.08207343), ('S14047', 330.07707317)], dtype=[('store_cd', '<U6'), ('amount', '<f8')])P_034
P-034: レシート明細データフレーム(df_receipt)に対し、顧客ID(customer_id)ごとに売上金額(amount)を合計して全顧客の平均を求めよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。
まず「文字列⇔数値」変換用の列に対して
.astype()戦法を用いて非会員を判定し、.nonzero()でその値を抽出します。つづいてnp.in1d()を用いて顧客ID列の各行が会員かどうかを判定する真偽値配列is_memberを作成します。最後に顧客IDごとに合計して、それを平均します。In[034]startswithZ, = (dic_receipt['Code_customer_id'].astype('<U1') == 'Z').nonzero() is_member = np.in1d(dic_receipt['customer_id'], startswithZ, invert=True) sums = np.bincount(dic_receipt['customer_id'][is_member], dic_receipt['amount'][is_member]) np.mean(sums)Out[034]2547.742234529256P_035
P-035: レシート明細データフレーム(df_receipt)に対し、顧客ID(customer_id)ごとに売上金額(amount)を合計して全顧客の平均を求め、平均以上に買い物をしている顧客を抽出せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。なお、データは10件だけ表示させれば良い。
前問に抽出する過程を加えるだけです。
In[035]startswithZ, = (dic_receipt['Code_customer_id'].astype('<U1') == 'Z').nonzero() is_member = np.in1d(dic_receipt['customer_id'], startswithZ, invert=True) sums = np.bincount(dic_receipt['customer_id'][is_member], dic_receipt['amount'][is_member]) mean = np.mean(sums) new_arr = make_array(dic_receipt['Code_customer_id'].size - startswithZ.size, store_cd=dic_receipt['Code_customer_id'][~startswithZ], amount=sums) new_arr[sums > mean][:10]Out[035]array([('CS001113000004', 3044.), ('CS001113000004', 3337.), ('CS001113000004', 4685.), ('CS001113000004', 4132.), ('CS001113000004', 5639.), ('CS001113000004', 3496.), ('CS001113000004', 3726.), ('CS001113000004', 3485.), ('CS001113000004', 4370.), ('CS001113000004', 3300.)], dtype=[('store_cd', '<U14'), ('amount', '<f8')])ちなみに模範解答ではなぜか
df_receipt.groupby('customer_id').amount.sum()を2度行っています。おわりに
NumPyにはgroupbyがないのでなかなか手強い戦いとなりました。
- 投稿日:2020-07-03T16:12:36+09:00
多項式回帰で重回帰分析やってみた
単回帰と重回帰
- 単回帰…一つの入力データを使って、ある値を予測しようとする手法。
ex)身長のデータを使って体重を予測。
y=w₀+w₁X
- 重回帰…二つ以上の入力データを使って、ある値を予測しようとする手法。
ex)身長、ウエスト、体脂肪…を使って、体重を予測。
y=w₀+w₁x₁+w₂x₂+w₃x₃+…多項式回帰による例
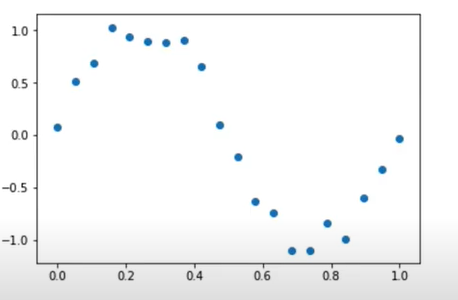
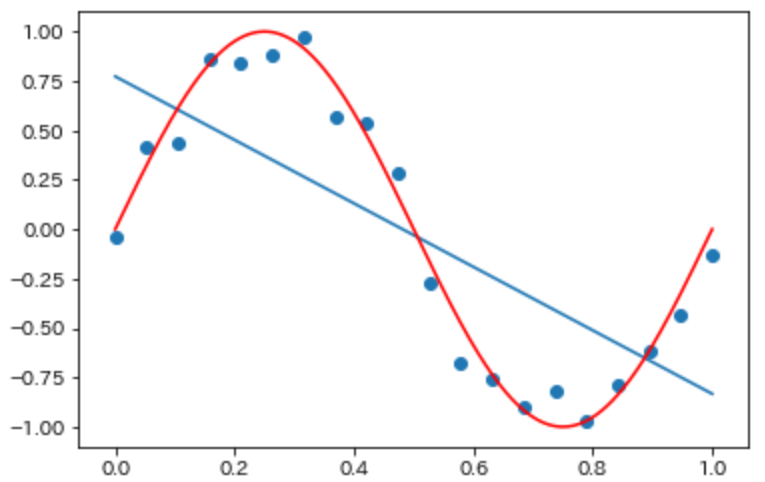
今、下図のようなデータを回帰したい。しかし、明らかに直線では表現できない形だ。
多項式回帰によって回帰を試みる。
多項式回帰…重回帰分析の一種。入力データxに加えてx^2,x^3…を新たな入力データとして加える。
最小二乗法は万能ではない
- 最小二乗法はモデルが複雑化しやすいアルゴリズム。
学習不足・過学習という問題
学習不足…訓練データを十分に表現できていない状況。損失関数が高いまま。
過学習(過剰適合)…訓練データに過度に適合している状況。汎化性能が低くなっている。
正則化というテクニック
正則化…適切な係数を取捨選択したり、係数の大きさを小さくして、過学習を防止する手法。本当に大切な係数を見つけ出す。
変数選択
漸次的選択法…係数を一つずつ足す、もしくは減らしながら当てはまりの良さを最大にしていく。縮小推定
①リッジ回帰…係数の絶対値を縮小する。
②Lasso回帰…いくつかの係数を完全に0にする。実践(多項式回帰)
import numpy as np import matplotlib.pyplot as plt data_size=20 #0~1までを20個区切りで表す。 X=np.linspace(0,1,data_size) #low以上high未満の一様乱数 noise=np.random.uniform(low=-1.0,high=1.0,size=data_size)*0.2 y=np.sin(2.0*np.pi*X)+noise #0~1までを1000個区切りで表す。 X_line=np.linspace(0,1,1000) sin_X=np.sin(2.0*np.pi*X_line) def plot_sin(): plt.scatter(X,y) plt.plot(X_line,sin_X,"red") plot_sin()
from sklearn.linear_model import LinearRegression #線形回帰モデル生成 lin_reg_model=LinearRegression().fit(X.reshape(-1,1),y) #切片,傾き lin_reg_model.intercept_,lin_reg_model.coef_ plt.plot(X_line,lin_reg_model.intercept_+lin_reg_model.coef_*X_line) plot_sin()
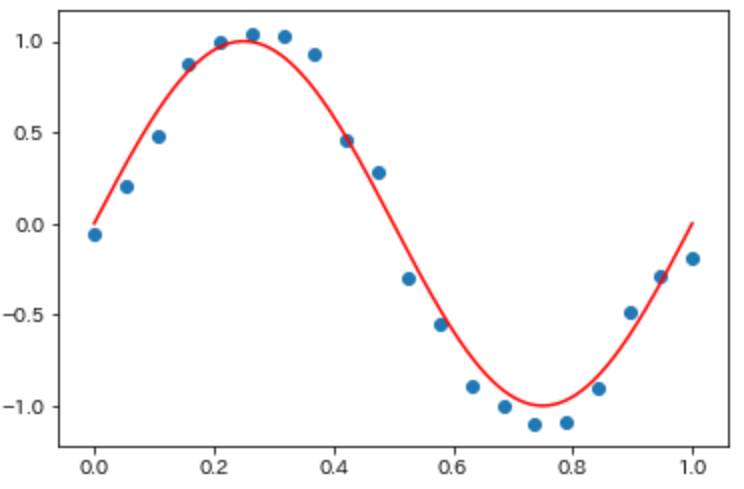
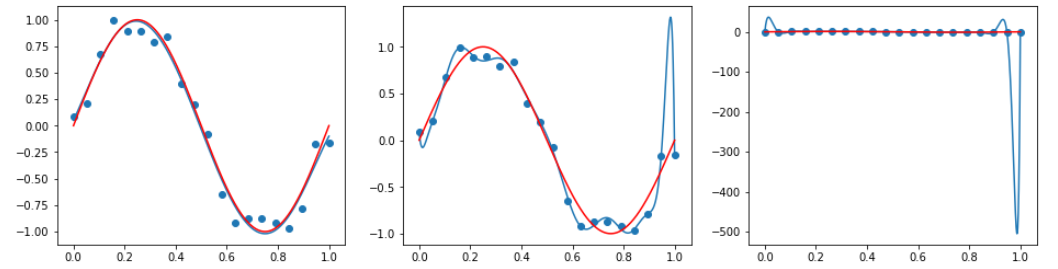
from sklearn.preprocessing import PolynomialFeatures #0乗~3乗までの4つのカラムを生成(20行4列のデータフレーム生成) poly = PolynomialFeatures(degree=3) poly.fit(X.reshape(-1,1)) X_poly_3=poly.transform(X.reshape(-1,1)) lin_reg_3_model=LinearRegression().fit(X_poly_3,y) X_line_poly_3=poly.fit_transform(X_line.reshape(-1,1)) plt.plot(X_line,lin_reg_3_model.predict(X_line_poly_3)) plot_sin()
fig,axes=plt.subplots(1,3,figsize=(16,4)) for degree,ax in zip([5,15,25],axes): poly=PolynomialFeatures(degree=degree) X_poly=poly.fit_transform(X.reshape(-1,1)) lin_reg=LinearRegression().fit(X_poly,y) X_line_poly=poly.fit_transform(X_line.reshape(-1,1)) ax.plot(X_line,lin_reg.predict(X_line_poly)) ax.scatter(X,y) ax.plot(X_line,sin_X,"red")
実践(正規化)
import mglearn import pandas as pd from sklearn.model_selection import train_test_split X,y=mglearn.datasets.load_extended_boston() df_X=pd.DataFrame(X) dy_y=pd.DataFrame(y) X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=0) lin_reg_model=LinearRegression().fit(X_train,y_train) print(round(lin_reg_model.score(X_train,y_train),3))#訓練データ適合率 print(round(lin_reg_model.score(X_test,y_test),3))#テストデータ適合率
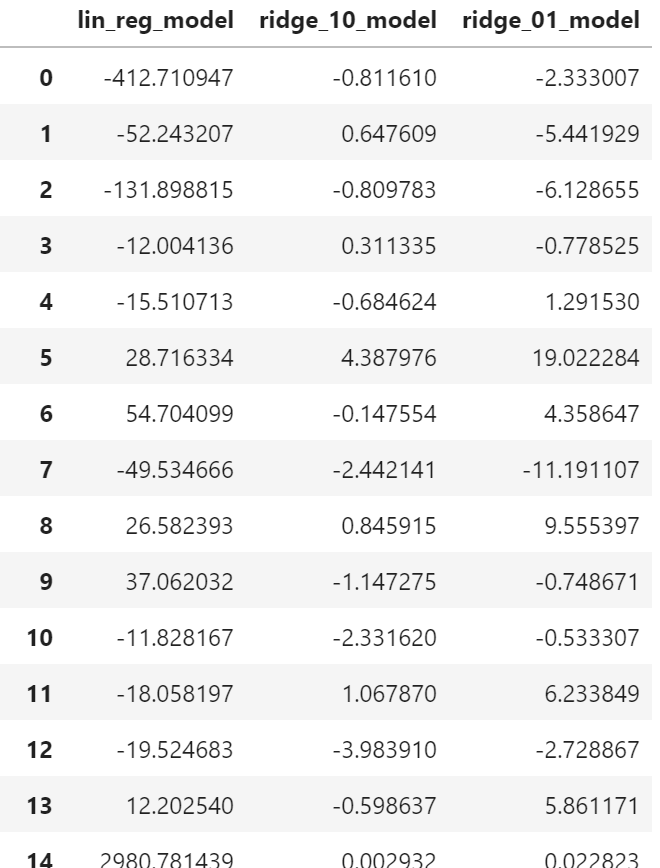
リッジ回帰モデル生成
from sklearn.linear_model import Ridge,Lasso ridge_model=Ridge().fit(X_train,y_train) def print_score(model): print(round(model.score(X_train,y_train),3))#訓練データ適合率 print(round(model.score(X_test,y_test),3))#テストデータ適合率#alphaが大きいほど絶対値を小さく(default=1) ridge_10_model=Ridge(alpha=10).fit(X_train,y_train) print_score(ridge_10_model)
ridge_01_model=Ridge(alpha=0.1).fit(X_train,y_train) print_score(ridge_01_model)
coefficients=pd.DataFrame({"lin_reg":lin_reg.coef_,"ridge_10_model":ridge_10_model.coef_,"ridge_01_model":ridge_01_model.coef_}) coefficients
Lasso回帰モデル生成
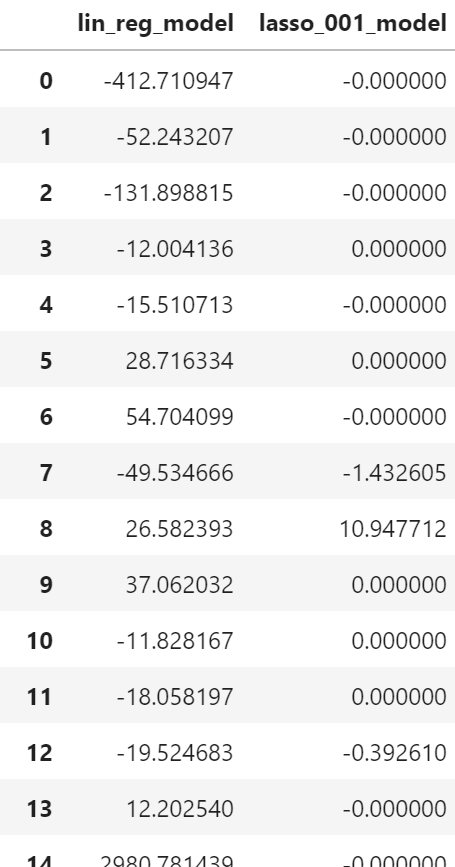
lasso_001_model=Lasso(alpha=0.01,max_iter=10000).fit(X_train,y_train) print_score(lasso_001_model)
coefficients_lasso=pd.DataFrame({"lin_reg":lin_reg.coef_, "lasso_001_model":lasso_001_model.coef_})





- 投稿日:2020-07-03T14:07:56+09:00
【初心者】Pythonの関数
Pythonで関数を使ってみる
引数のデフォルトを指定する
def hello(name="A", age=10): result = "Hello I'm " + name + ", I'm " + str(age) print(result) >>> hello() Hello I'm A, I'm 10 >>> hello("Bob", 20) Hello I'm Bob, I'm 20文字列の引数を逆にする
>>> def reverse(s): cnt = len(s) result="" if cnt < 1: result = s else: i = cnt-1 while i > -1: result = result + s[i] i = i - 1 print(result) >>> reverse("abcde") edcba >>> reverse("a") a3で割り切れるか、5で割り切れるか、両方で割り切れるか
>>> def fb(n): mod3 = n % 3 mod5 = n % 5 result = "" if mod3 == 0: result += "Fizz" if mod5 == 0: result += "Buzz" return result >>> i = 1 >>> while i <= 20: print(i, fb(i)) i = i + 1 1 2 3 Fizz 4 5 Buzz 6 Fizz 7 8 9 Fizz 10 Buzz 11 12 Fizz 13 14 15 FizzBuzz 16 17 18 Fizz 19 20 Buzz
- 投稿日:2020-07-03T13:35:40+09:00
PythonCGIでラズパイのGPIOを操作しよう
前提
python -m http.server 8080 --cgiでCGIが実行可能- Apache2をインストール済み
Apache2の設定
- 過去の記事を参考にして設定してください。
GPIOを使うための設定
sudo usermod -aG gpio www-dataをしておく解説
先ほどのコマンドを入力せずに実行するとエラーは表示されないが、ラズパイに反応が現れない。そこでエラーログを確認してみる。
less /var/log/apache2/error.logとして確認すると、RuntimeError: No access to /dev/mem. Try running as root!とエラーが表示されている。「ルートとして実行してみてください。」と書かれているので先ほどの設定でルート権限を与えた。www-dataというのはApache2のユーザ名である。
- 投稿日:2020-07-03T12:56:26+09:00
PyAutoGuiを使って、いまさらWindows Server 2003 R2上で動くVB6のプログラムのUIテストを自動化してみた(入力コマンドチートシート)
winautoguiでのキーおよびマウス操作
UWSCでがんばってたUIテスト自動化で、どうやってもキー入力を受け付けない要素が出てきたので(おのれグレープシティー)pyAutoGUIで自動化スクリプトを書くときに自分で使うであろうコマンドをPyAutoGui's documentationから抜き出してきました。
ちなみに私ががんばってる環境は以下の通り
OS:Windows Server 2003 R2
アプリの開発言語:Visual Basic 6
今回自動化に使用したPythonのバージョン:2.7.18この記事を書くのに参考にしたサイト
- PyAutoGuiで繰り返し作業をPythonにやらせよう
- UWSC を Python で置換しよう(1)環境構築編
- UWSC を Python で置換しよう(2)関数置き換え
- UWSC を Python で置換しよう(3)チートシート[1]
- UWSC を Python で置換しよう(4)チートシート[2]
- pythonでマウスの現在座標を表示する
- Welcome to PyAutoGUI's documentation!
- Python〜pyautoguiで日本語入力する方法
- Pythonで「UnicodeDecodeError」に遭遇した場合 ←こっちはPython3.X系
- Python スクリプト実行時に UnicodeDecodeError が出る場合の対処方法 ←こっちはPython2.7.X系
偉大なる先人たちに感謝!
……pipでモジュールを導入する方法については偉大なる先人達のページをどうぞマウス編
マウス移動
pyautogui.moveTo(100, 200) # 座標(100,200)にマウスカーソルが移動 pyautogui.moveTo(None,500) # 座標(100,500)にマウスカーソルが移動 pyautogui.moveTo(600,None) # 座標(600,500)にマウスカーソルが移動マウスクリック
pyautogui.click() # マウスカーソルがある場所でクリックイベント発火 pyautogui.click(x=100, y=200) # マウスカーソルを座標(100,200)に移動してクリックイベント発火 pyautogui.click(button='right')# これで右クリックマウスクリック応用編
pyautogui.click(clicks=2) # 左クリックボタンでダブルクリック pyautogui.click(clicks=2, interval=0.25) # 左クリックボタンクリック→0.25秒待機→左クリックボタンクリック pyautogui.click(button='right', clicks=3, interval=0.25) #マウス右ボタントリプルクリック、間隔0.25秒キーボード入力編
文字列送信
pyautogui.write('ハローワールド!') # ただ単に「ハローワールド!」が出力される pyautogui.write('hello world!', interval=0.25) #1文字ずつ0.25秒間隔で"hello world!"が出力されるキー押下(押して離す)
pyautogui.press('enter') # エンターキーが押下される pyautogui.press('f1') # ファンクション1[F1]キーが押下される pyautogui.press('left') # 左矢印[←]キーが押下されるキーダウン(キーを押しっぱなしにする)
pyautogui.keyDown('shift') # [Shift]キーを押しっぱなしにする。keyUpするまでそのまま pyautogui.press('left') # pressなので[←]キーが押して離される pyautogui.press('left') # pressなので[←]キーが押して離される pyautogui.press('left') # pressなので[←]キーが押して離される pyautogui.keyUp('shift') # [Shift]キーが上がる(キーを離す)キー操作ちょっと応用編
配列要素にキーコードを持たせて
write()関数のように使ってやるpyautogui.press(['left', 'left', 'left']) # 配列要素で実現版 pyautogui.press('left',presses=3) # 同じボタンの連打ならpressesオプションで回数が指定できる pyautogui.press('left',presses=3, interval=0.25) # write()と同様にintervalオプションで入力間隔を調整できるキーの同時押し(ホットキー)機能
pyautogui.hotkey('ctrl', 'shift', 'esc') #[Ctrl]+[Shift]+[Esc]でタスクマネージャーを起動もちろんこのように書いても良いけれど……
pyautogui.keyDown('ctrl') pyautogui.keyDonw('shift') pyautogui.keyDown('esc') pyautogui.keyUp('esc') pyautogui.keyUp('shift') pyautogui.keyup('ctrl')ホットキー機能使った方が簡単だよね。
仮想キー一覧
pyAutoGuiで使える仮想キーの一覧だよ。
['\t', '\n', '\r', ' ', '!', '"', '#', '$', '%', '&', "'", '(', ')', '*', '+', ',', '-', '.', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '<', '=', '>', '?', '@', '[', '\\', ']', '^', '_', '`', 'a', 'b', 'c', 'd', 'e','f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '{', '|', '}', '~', 'accept', 'add', 'alt', 'altleft', 'altright', 'apps', 'backspace', 'browserback', 'browserfavorites', 'browserforward', 'browserhome', 'browserrefresh', 'browsersearch', 'browserstop', 'capslock', 'clear', 'convert', 'ctrl', 'ctrlleft', 'ctrlright', 'decimal', 'del', 'delete', 'divide', 'down', 'end', 'enter', 'esc', 'escape', 'execute', 'f1', 'f10', 'f11', 'f12', 'f13', 'f14', 'f15', 'f16', 'f17', 'f18', 'f19', 'f2', 'f20', 'f21', 'f22', 'f23', 'f24', 'f3', 'f4', 'f5', 'f6', 'f7', 'f8', 'f9', 'final', 'fn', 'hanguel', 'hangul', 'hanja', 'help', 'home', 'insert', 'junja', 'kana', 'kanji', 'launchapp1', 'launchapp2', 'launchmail', 'launchmediaselect', 'left', 'modechange', 'multiply', 'nexttrack', 'nonconvert', 'num0', 'num1', 'num2', 'num3', 'num4', 'num5', 'num6', 'num7', 'num8', 'num9', 'numlock', 'pagedown', 'pageup', 'pause', 'pgdn', 'pgup', 'playpause', 'prevtrack', 'print', 'printscreen', 'prntscrn', 'prtsc', 'prtscr', 'return', 'right', 'scrolllock', 'select', 'separator', 'shift', 'shiftleft', 'shiftright', 'sleep', 'space', 'stop', 'subtract', 'tab', 'up', 'volumedown', 'volumemute', 'volumeup', 'win', 'winleft', 'winright', 'yen', 'command', 'option', 'optionleft', 'optionright']意外と使いそうな所だと
['kana', 'kanji','ctrlright','decimal','numlock']とかですかね?
日本語文字列どうする問題
コピペです。はい。ご唱和ください。日本語はコピペです。
がんばりました。私も。Unicodeがいけないのか?はたまたShift-JISじゃないとだめなのか?と
答えは先人が出しておりました。import pyperclip as clipboard clipboard.copy("日本語文字列") pyautogui.hotkey('ctrl','v')これですよ。
あとはunicodedecodeerror 'ascii' codec can't decodeに不幸にも出会ってしまったときには先人達の知恵をお借りしてデフォルトの文字コードをUTF-8にしちゃいましょう。
まとめ
基本的にはWelcome to PyAutoGUI's documentation!の例をそのまままとめただけ+自分のトライアンドエラーの記録ですが、これだけでもあると助かる人が居れば幸いです。
それでは良い自動化ライフを!
- 投稿日:2020-07-03T12:48:49+09:00
【初心者】Phthonで文字列を抽出する
文字列
0以上のインデックスを指定
一番左の文字を指定したいときは[0]。
>>> w = "abcde" >>> w[0] 'a' >>> w[4] 'e'マイナスのインデックスを指定
一番右の文字を指定したいときは[-1]。
>>> w = "abcde" >>> w[-5] 'a' >>> w[-1] 'e'インデックスの範囲外を指定するとエラー
>>> w = "abcde" >>> w[5] Traceback (most recent call last): File "<pyshell#10>", line 1, in <module> word[5] IndexError: string index out of range >>> w[-6] Traceback (most recent call last): File "<pyshell#18>", line 1, in <module> w[-6] IndexError: string index out of rangeコロンを利用して範囲を指定する
>>> w = "abcde" >>> w[1:4] 'bcd' >>> w[0:3] 'abc' >>> w[:3] 'abc' >>> w[3:0] '' >>> w[-1:] 'e' >>> w[:-1] 'abcd' >>> word[-4:-2] 'bc' >>> word[-2:-4] ''
- 投稿日:2020-07-03T12:01:39+09:00
簡単なロボット操作用ウェブアプリケーションを作ってます。「RaspberryPi3B+とDjangoChannels」
イントロ
始めまして。s_rae です。
頑張ってプログラミングの勉強をしています。最近簡単なロボットを作ってみました。
ホイールが2つとBluetoothモジュールをつけてあるロボットです。アプリ開発の練習としてそのロボットを操作できるインタフェースを作ろう!と思いました。
RaspberryPi3B+にDjango+DjangoChannelsでバックエンドを作り、PyBluezでBluetoothのメッセージを送れるようにしました。
まだ未完成のものですが途中までの過程でもよろしければ見て下さい。
また、母国語が日本語ではないので少し不自然かも知れませんがご了承下さい。お試し
必要なもの
RaspberryPi3B+
- Raspberry Pi OS (32-bit) Lite
- Python3.7.3以上
- pip
- git
Bluetoothシリアル通信可能なロボット・IoT機器(まだ繋げられるものはすごく限定されていますがいずれいろんな機器を繋げられるようにすることが目標です。)
ホームサーバーなのでラズパイとクライエント側は同じネットワークに接続して下さい。
(OSの設置方法はRaspberryPiの公式ホームページを参考して下さい。Raspberry Pi Imagerを使ったら手軽に設置できます。)
設置方法
まずはsshでラズパイにアクセスして下さい。私はLinuxのshell(bash)を使ってます。
$ ssh pi@ラズパイのIPアドレスリポジトリーからcloneしてください。
$ cd ~ $ git clone https://github.com/samanthanium/dullahan_local.git $ cd dullahan_localredisをインストールして下さい。
$ wget http://download.redis.io/releases/redis-6.0.5.tar.gz $ tar xzf redis-6.0.5.tar.gz $ cd redis-6.0.5 $ make必要なパッケージをダウンロードしてください。
$ pip install -r requirements.txtプロジェクトのsettings.pyを見つけて下さい。
$ cd dullahan好きなテキストエディターを使ってsettings.pyのALLOWED_HOSTSにラズパイのIPアドレスを入力して下さい。
settings.py... ALLOWED_HOSTS = ['ラズパイのIPアドレス'] ...最後にテストサーバーを起動してみて下さい。
$ cd ../ #~/dullahan_local $ python manage.py migrate $ redis-server & $ python manage.py runserver IPアドレス:8080 & $ python manage.py runworker background-tasks作成過程
目標設定
- ラズパイとロボットをBluetoothで繋げる
- クライエント側にキレイな操作画面を見せる
- なんとかしてリアルタイムでロボットを操作する
ここまで出来れば第一段階成功!と思いました。
また、今Pythonを勉強し始めたところだったのでとにかくPythonで作りたいと決定しました。
調べ段階
私が作ろうとするのはチャットシステム(?)に似てると思いました。
Robotとクライエント側がmessageを送ったり受け取ったりする感じです。
ここで人気のWebSocketプロトコルを使えば出来るかも!と思いました。
WebSocketはTCPの上に行われるfull-duplex(全二重?)通信です。
HTTPのようにメッセージを送るたびに通信を切るのではなく通信を保持します。Django ChannelsはHTTP基盤のDjangoフレームワークにWebSocketの通信手段を加えます。
DjangoとDjango Channelsを使うことでHTTPでクライエントにキレイなインタフェースを転送し、WebSocketでメッセージをリアルタイムで交換できることがわかりました。
クライエント側からWebSocketメッセージをもらったらDjangoChannelsはconsumerクラス(そのメッセージを処理するclass)にメッセージを送ります。
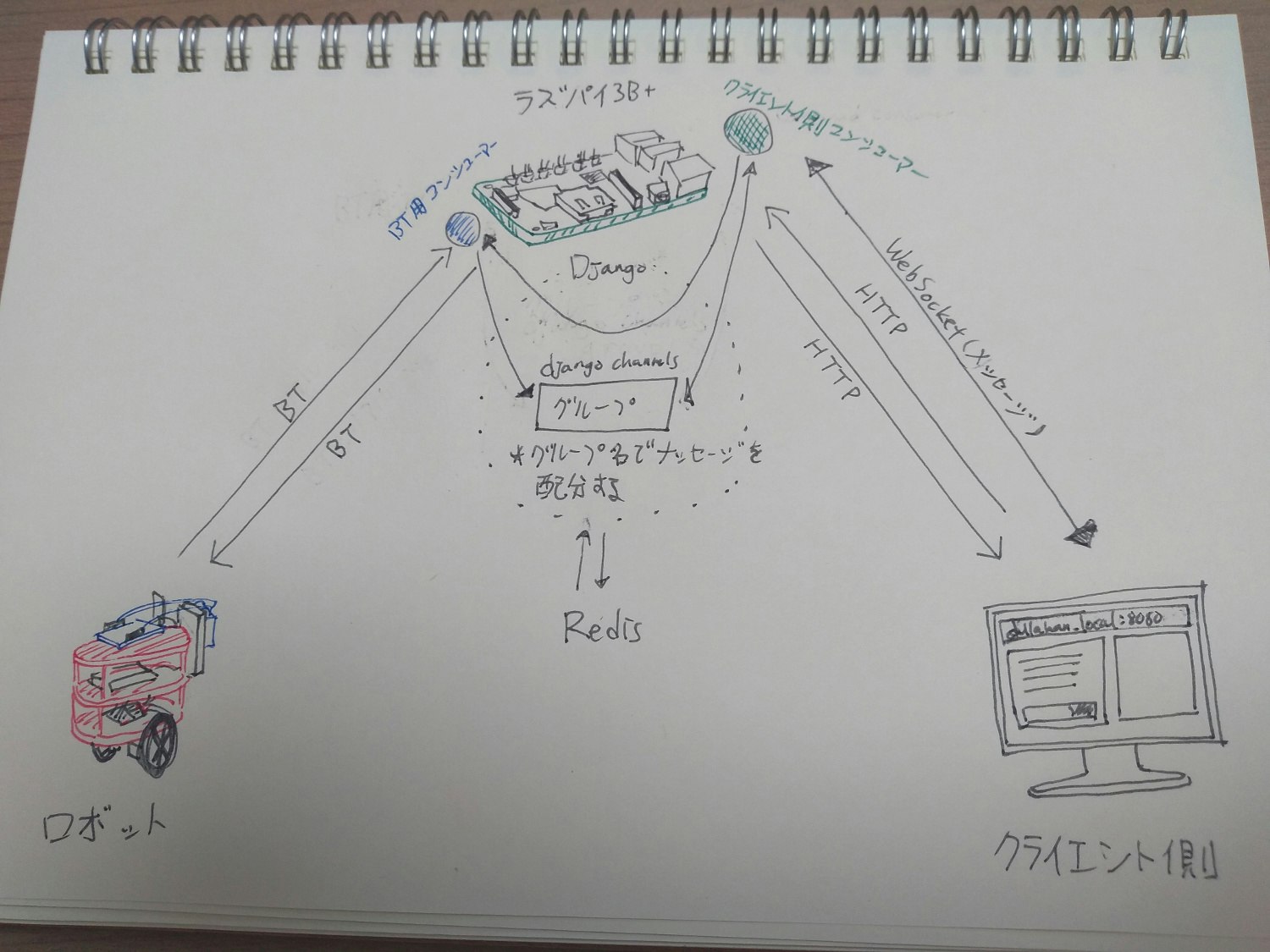
consumer達でgroupを作りそのgroup内でメッセージを共有することも可能です。仕組み
色々調べて読んだ結果こんな仕組みを考えました。
クライエント側のメッセージ処理するconsumerはロボットのconsumerがあるバックグラウンドワーカーにそのメッセージを飛ばします。
ロボットのconsumerはBluetoothでロボットにメッセージをまた送ります。ロボットからメッセージをもらうときはほぼ逆パターンで行われます。
ここで注意したことは:
バックグラウンドワーカーを使うことでロボットのセンサーデーターを持続的にもらうことができます。
ロボットもgroupに追加してしまうと何回も同じメッセージがロボットに送られることがあるのでこのような感じにしました。多くの改善すべき点の一つです。
結果
こんな感じのアプリケーションになりました。
ホーム画面
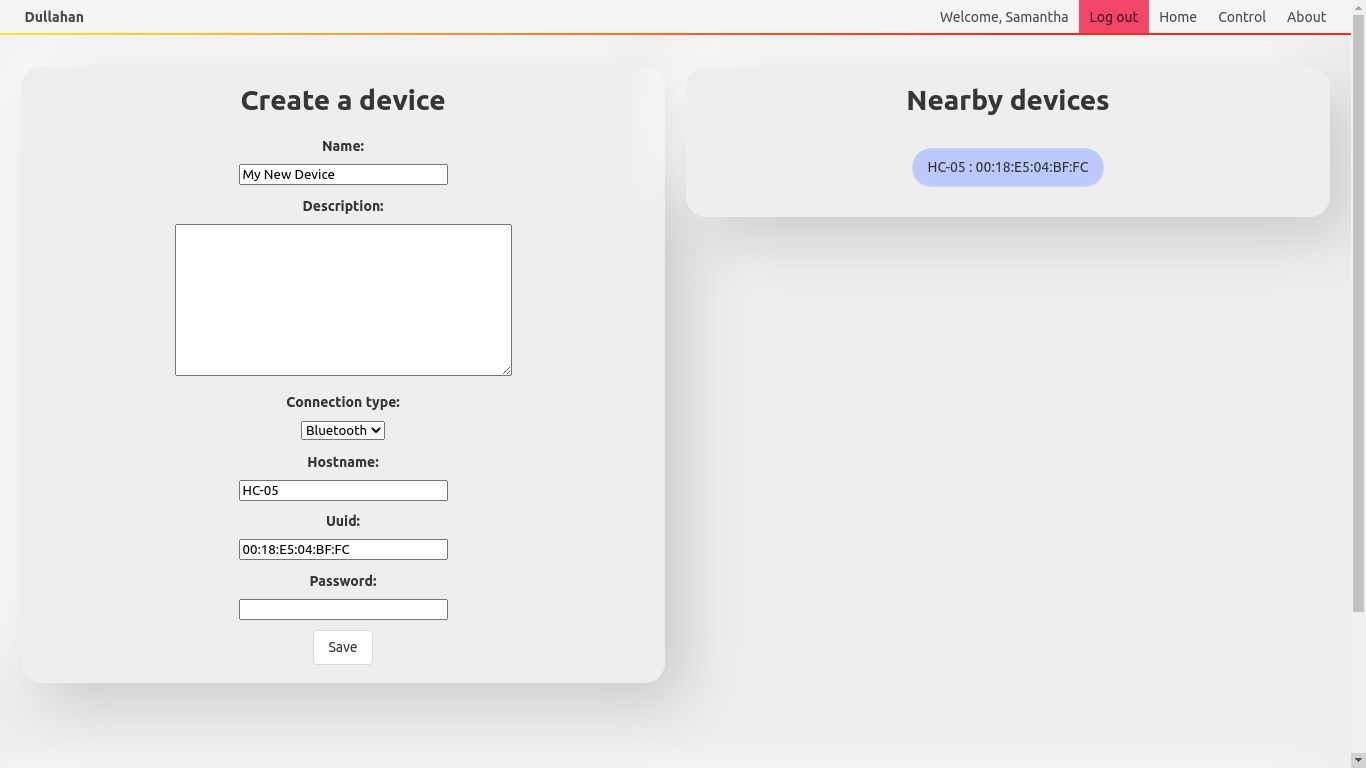
デバイス登録画面
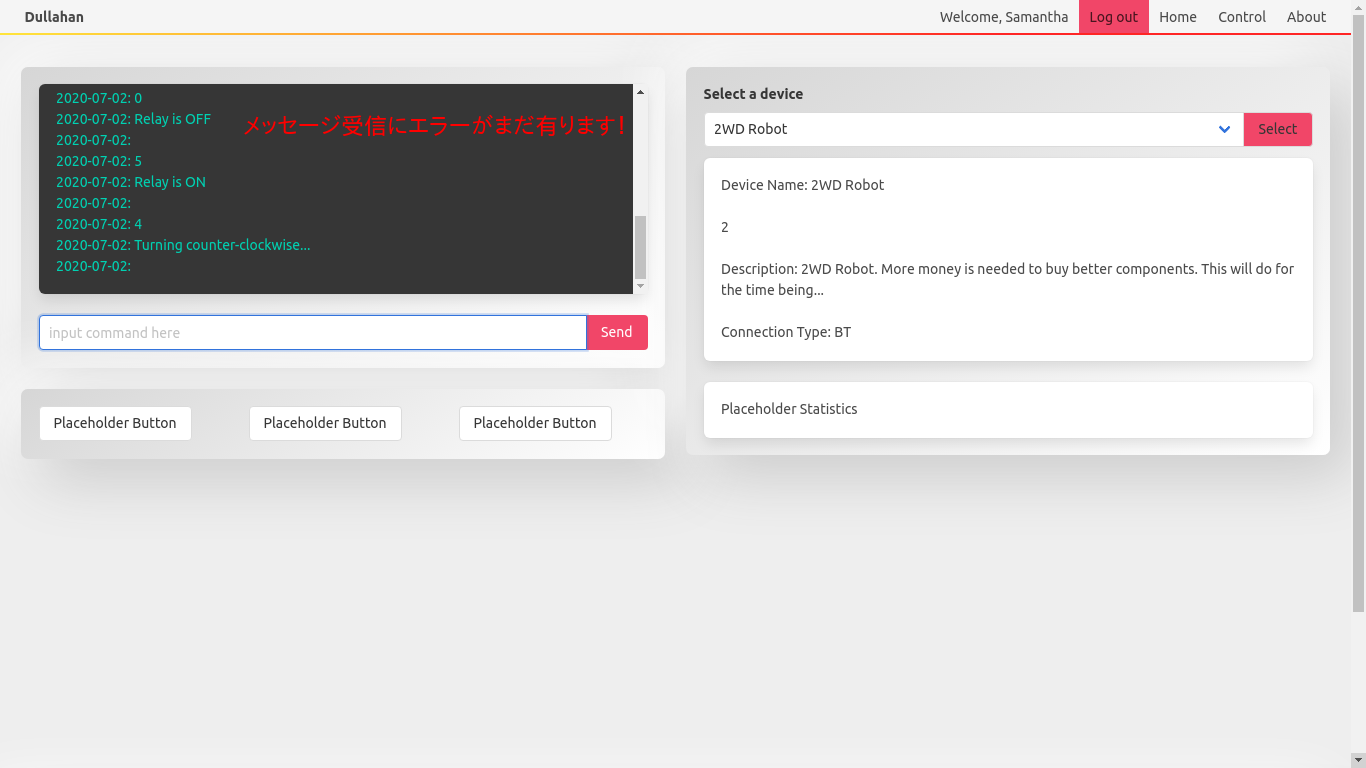
コントロール画面
+ロボット
このリンクで動作が見れます!(画像クオリティー低いです)
https://youtu.be/UL7yFSde5Hw所感
PythonもDjangoも自分にとって新しいものでしたので作るのにジタバタしてしまったのが残念です。
なんとか動けばいいと思って作ったらあとでコードを読み返す時大変でした。
これからも色々直して機能を追加しようと思います。
でもロボットが動いたときはとても嬉しかったです!
ここまで読んでくださりありがとうございます!


- 投稿日:2020-07-03T11:48:28+09:00
Power QueryでPythonに引数を渡して実行する
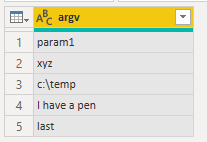
Power QueryでPythonにパラメーターを渡して実行する方法があります。試しにこんなコードを書いてみます。
argv2table.pyimport pandas as pd import csv my_argv = [r'MY_ARGVS'] l = list(csv.reader(my_argv, delimiter=' '))[0] df = pd.DataFrame(l, columns=['argv'])ここで注意したいのは、冒頭の
MY_ARGVSの部分は後々置換対象となるので、コード中に二度と登場させてはいけないということです。Power Queryではこう書きます
(argv) => let Source = Text.FromBinary(File.Contents("c:\temp\argv2table.py")), rep = Text.Replace(Source, "MY_ARGVS", argv), pyexe = Python.Execute(rep), df1 = pyexe{[Name="df"]}[Value] in df1こちらを実行して、適当なパラメーターをスペース区切りで入れてみます。
こんなふうに、各パラメータから構成されるテーブルが返されます。
csv.readerで分割しているので、ダブルクォーテーションによる引用も可能です。Power BIのParameterを渡せば、レポート画面からPythonに渡す引数を変えることもできますね。
ただ、まいどまいどPermissionを尋ねられるので実用性は疑問です。

- 投稿日:2020-07-03T11:02:03+09:00
ESP32をPythonで動かすためにMicroPythonをWindowsで入れる
ESP32はarduinoベースのファームウェアが最初から入っている。これをPythonで書けるようにファームウェアを変更する。
MicroPython参考
https://micropython-docs-ja.readthedocs.io/ja/latest/esp32/tutorial/intro.html#powering-the-boardコマンドプロントからpipを利用してesptool.pyをインストールする。
micropythonを入れるための下準備。
pip install esptoolインストールしたesptoolからespのフラッシュを消去。
参考ページには
esptool.py --port /dev/ttyUSB0 erase_flash
とコマンドが書いてあったがここでエラーが発生。
Windowsの場合はポートの名前が違う。
デバイスマネージャからESP32をつないでいるポートを見るとCOM5とあったので、こちらで通してみたところ通った。
Linux/macとポート番号の指定の仕方が違うので戸惑った。
esptool.py --port COM5 erase_flash次はファームウェアを入れる
これも元のコマンドは
esptool.py --chip esp32 --port /dev/ttyUSB0 write_flash -z 0x1000 esp32-20180511-v1.9.4.bin
と記載があった。
MicropythonのESP32のファームウェアを見に行くといろいろある。
GENERICのunstableでは無い物の中で一番上にある最新版をダウンロードした。
(esp32-idf3-20191220-v1.12.binと書かれているもの)
https://micropython.org/download/esp32/
コマンドプロントでダウンロードフォルダへ移動。
cd Downloadダウンロードしたファームウェアを入れる。
esptool.py --chip esp32 --port COM5 write_flash -z 0x1000 esp32-idf3-20191220-v1.12.bin
(portを現在のポートに、0X1000以降をダウンロードしたファームウェアに書き換える。)
----ばっかり出てコネクティングで止まってしまうときはESP32本体のBOOTボタンを押すとインストールが進む。これでMicroPythonがインストールできた。
Pythonのソースコードの転送はこっちを参考にした。
https://qiita.com/moomooya/items/ea30fe1113b21ebc9329#%E3%82%BD%E3%83%BC%E3%82%B9%E3%82%B3%E3%83%BC%E3%83%89%E3%81%AE%E8%BB%A2%E9%80%81参考記事
ESP32 での MicroPython の始め方
https://micropython-docs-ja.readthedocs.io/ja/latest/esp32/tutorial/intro.html#powering-the-boardギリギリまでお手軽にMicroPythonでIoTやるための手引書
https://qiita.com/moomooya/items/ea30fe1113b21ebc9329

- 投稿日:2020-07-03T09:55:00+09:00
pythonのプロパティのあれこれ n
はじめに
pythonの「property」について理解できていなかったので、
いろいろ調べたことをまとめていきたいと思います。そもそもプロパティってなんだっけ?
簡単Pythonには、
値をしっかり管理したいけど、インスタンス変数のように自然に値にアクセスできるようにもしたい。
この両者のいいとこ取りをしたのが、「プロパティ」。と書かれています。
要は外から簡単に値を変得られない上に、取り出しは簡単にしたい時に役立つものと思ってもらったら良いです。def プロパティ名(self): 処理 'プロパティの値を取り出すメソッドを定義する' @property def プロパティ名(self): return 値 'プロパティの値を設定' @プロパティ名.setter def プロパティ名(瀬lf、値) 値を設定する処理プロパティはこんな感じで定義します。
@propertyを見たら「ハイ!きた!」と思ってください。
インスタンス変数って?
プロパティは、インスタンス変数とつながりがあるので、ここではインスタンス変数について説明していきます。
インスタンス変数とは、クラスを実行する時に生成するインスタンスごとに独立して存在する変数です。
ちょっと難しいですよね。def __init__(self, message): self.message = message #インスタンス変数 messageこの「self.message」がインスタンス変数です。
次に全体の定義と動きを見ていきましょう。#インスタンス変数 class MyClass: def __init__(self, message): # 初期化: インスタンス作成時に自動的に呼ばれる self.message = message # インスタンス変数 message を宣言 def print_message(self): # インスタンス変数 message の値を表示する関数 print(self.message) # インスタンス変数 message にアクセスし表示する instance = MyClass("instance") # インスタンス instance を作成 python = MyClass("python") # インスタンス python を作成 print(instance.message) -> instanceと表示される print(python.message) -> pythonと表示される instance.print_message() -> instanceと表示される python.print_message() -> pythonと表示される instance.message = 'Python' #self.messageの中身を「Python」に変更 print(instance.message) -> Pythonと表示される = 今まで「instance」と表示されていたのが変更されている上のコードでわかるように簡単に値を取り出せますが、変更も簡単にできてしまいますよね。
変更が簡単にできてしまうと、間違えて変更してしまうなどの予期せぬことが起きてしまいます。
先ほども言いましたが、変更などの管理がしっかりできて、簡単に取り出せるものがプロパティです。さっそく活用例を参考に理解を深めていきましょう。
プロパティの活用例
class PropertyClass: def __init__(self, msg): self.message = msg def __str__(self): return self.message @propaty def message(self): return self.__message @message.setter def message(self, value): if value != '': self.__message = value ①pc= PropertyClass('Hello') ②print(pc.messsage) -> Hello ③pc.message = '' -> messageの中身を「Hello」から空文字列に変更 ④print(pc) -> Hello ⑤pc.message = 'Bye!' -> messageの中身を「Hello」から「Bye!」に変更 ⑥print(pc) -> Bye!①で「Hello」を引数として渡し、「self.message」の中身が「Hello」になります。
②messageメソッドを呼び出すと、「Hello」が戻り値として返ってきます。
③「message」の値を空文字列に変更しています。
④③で空文字列に変更したはずですが、再び「Hello」が表示されています。
なぜでしょう?
新たな値を設定する時、まず「@message.setter」のところで手続きが行われます。if value != '': self.__message = value今回はこのように空文字列以外の時変更受け付けますよと言っています。
よって空文字列は拒否されたため「Hello」が表示されたのです。
⑤懲りずに次は「Bye!」に変更しようとします。
⑥今回は空文字列ではないので、変更が許可されました。また、今回は「message」として、外部から直接アクセスされることはありません。
「」のように_が2つついているものは、外部からのアクセスができないので覚えておいてください。このように値を新たに設定する時に、予想外のものが入ってしまわないように制御できるのがポイントです。
この章で大まかな動きは理解できたと思います。
次の章ではもう少し詳しく見ていきましょう。propertyとsetterの動き
propertyとsetterがついている部分がどのように呼び出されているの確認して、理解を深めましょう。
class Myclass: def __init__(self, input_name): self.hidden_name = input_name @property def name(self): print('inside the getter') return self.hidden_name @name.setter def name(self, input_name): print('inseide the setter') self.hidden_name = input_name ①mc = Myclass('Hello') -> 「Hello」を引数として渡す ②print(mc.name) -> 'Hello'と表示 + 'inside the getter'と表示 ③mc.name = 'Python' -> 値を'Python'に変更 + 'inside the setter'と表示 ④print(mc.name) -> 'Python'と表示 + 'inside the getter'と表示②で、'inside the getter'と表示されていことから分かるように、'@prperty'が呼び出されていることがわかります。
一方、③で値を変更させるときは'inside the setter'とあるように、'@name.setter'の方が呼び出されています。
その結果、④では正常に値が変更されています。このことから分かるように値を呼び出す時には'@property'が呼び出され、値を変更する時に'@〇〇.setter'が呼び出されます。
そして、予期せぬ値が入り込まないように、'setter'で値を制限することができます。
気付いた人もいるかもしれないですが、呼び出しの際にも'()'が最後に必要ないので簡単に呼び出すことができます。最後に
今回はプロパティに関して説明してきました。
「簡単に呼び出せて、値の設定はきっちり行うもの」と認識してもらうと理解が早まるのかなとおおいます。
今後も記事はアップデートし行きます。
また、時間があれば他の記事も覗いていってください。
- 投稿日:2020-07-03T09:55:00+09:00
pythonのプロパティのあれこれ
はじめに
pythonの「property」について理解できていなかったので、
いろいろ調べたことをまとめていきたいと思います。そもそもプロパティってなんだっけ?
簡単Pythonには、
値をしっかり管理したいけど、インスタンス変数のように自然に値にアクセスできるようにもしたい。
この両者のいいとこ取りをしたのが、「プロパティ」。と書かれています。
要は外から簡単に値を変得られない上に、取り出しは簡単にしたい時に役立つものと思ってもらったら良いです。def プロパティ名(self): 処理 'プロパティの値を取り出すメソッドを定義する' @property def プロパティ名(self): return 値 'プロパティの値を設定' @プロパティ名.setter def プロパティ名(self、値) 値を設定する処理プロパティはこんな感じで定義します。
@propertyを見たら「ハイ!きた!」と思ってください。
インスタンス変数って?
プロパティは、インスタンス変数とつながりがあるので、ここではインスタンス変数について説明していきます。
インスタンス変数とは、クラスを実行する時に生成するインスタンスごとに独立して存在する変数です。
ちょっと難しいですよね。def __init__(self, message): self.message = message #インスタンス変数 messageこの「self.message」がインスタンス変数です。
次に全体の定義と動きを見ていきましょう。#インスタンス変数 class MyClass: def __init__(self, message): # 初期化: インスタンス作成時に自動的に呼ばれる self.message = message # インスタンス変数 message を宣言 def print_message(self): # インスタンス変数 message の値を表示する関数 print(self.message) # インスタンス変数 message にアクセスし表示する instance = MyClass("instance") # インスタンス instance を作成 python = MyClass("python") # インスタンス python を作成 print(instance.message) #instanceと表示される print(python.message) #pythonと表示される instance.print_message() #instanceと表示される python.print_message() #pythonと表示される instance.message = 'Python' #self.messageの中身を「Python」に変更 print(instance.message) #Pythonと表示される = 今まで「instance」と表示されていたのが変更されている上のコードでわかるように簡単に値を取り出せますが、変更も簡単にできてしまいますよね。
変更が簡単にできてしまうと、間違えて変更してしまうなどの予期せぬことが起きてしまいます。
先ほども言いましたが、変更などの管理がしっかりできて、簡単に取り出せるものがプロパティです。さっそく活用例を参考に理解を深めていきましょう。
プロパティの活用例
class PropertyClass: def __init__(self, msg): self.message = msg def __str__(self): return self.message @propaty def message(self): return self.__message @message.setter def message(self, value): if value != '': self.__message = value pc= PropertyClass('Hello') # ① print(pc.messsage) #Hello ② pc.message = '' #messageの中身を「Hello」から空文字列に変更 ③ print(pc) # Hello ④ pc.message = 'Bye!' #messageの中身を「Hello」から「Bye!」に変更 ⑤ print(pc) #Bye! ⑥①で「Hello」を引数として渡し、「self.message」の中身が「Hello」になります。
②messageメソッドを呼び出すと、「Hello」が戻り値として返ってきます。
③「message」の値を空文字列に変更しています。
④③で空文字列に変更したはずですが、再び「Hello」が表示されています。
なぜでしょう?
新たな値を設定する時、まず「@message.setter」のところで手続きが行われます。if value != '': self.__message = value今回はこのように空文字列以外の時変更受け付けますよと言っています。
よって空文字列は拒否されたため「Hello」が表示されたのです。
⑤懲りずに次は「Bye!」に変更しようとします。
⑥今回は空文字列ではないので、変更が許可されました。また、今回は「message」として、外部から直接アクセスされることはありません。
「」のように_が2つついているものは、外部からのアクセスができないので覚えておいてください。このように値を新たに設定する時に、予想外のものが入ってしまわないように制御できるのがポイントです。
この章で大まかな動きは理解できたと思います。
次の章ではもう少し詳しく見ていきましょう。propertyとsetterの動き
propertyとsetterがついている部分がどのように呼び出されているの確認して、理解を深めましょう。
class Myclass: def __init__(self, input_name): self.hidden_name = input_name @property def name(self): print('inside the getter') return self.hidden_name @name.setter def name(self, input_name): print('inseide the setter') self.hidden_name = input_name mc = Myclass('Hello') #「Hello」を引数として渡す ① print(mc.name) #'Hello'と表示 + 'inside the getter'と表示 ② mc.name = 'Python' #値を'Python'に変更 + 'inside the setter'と表示 ③ print(mc.name) #'Python'と表示 + 'inside the getter'と表示 ④②で、'inside the getter'と表示されていことから分かるように、'@prperty'が呼び出されていることがわかります。
一方、③で値を変更させるときは'inside the setter'とあるように、'@name.setter'の方が呼び出されています。
その結果、④では正常に値が変更されています。このことから分かるように値を呼び出す時には'@property'が呼び出され、値を変更する時に'@〇〇.setter'が呼び出されます。
そして、予期せぬ値が入り込まないように、'setter'で値を制限することができます。
気付いた人もいるかもしれないですが、呼び出しの際にも'()'が最後に必要ないので簡単に呼び出すことができます。最後に
今回はプロパティに関して説明してきました。
「簡単に呼び出せて、値の設定はきっちり行うもの」と認識してもらうと理解が早まるのかなとおおいます。
今後も記事はアップデートし行きます。
また、時間があれば他の記事も覗いていってください。
- 投稿日:2020-07-03T06:26:53+09:00
データサイエンスはじめて1か月以内で参加したコンペで銀メダル(上位3%)とるまで!
はじめに
データサイエンス・機械学習っておもしろそうだけど、どうやって勉強すすめたらいいんだろう?というところから2月に勉強をスタートし、勉強のinputだけではなく実践したいと思って3月にKaggleのコンペに参戦!
その結果がなんと、銀メダル (+上位3%)をとることができました!
この記事では、そんな自分の勉強してきた過程とコンペを進めてきた流れをまとめてみようと思っているので、一例として見てもらえると嬉しいです!
概要
➀コンペの紹介
➁コンペ終了までの流れ
(コンペ参加する前→コンペ参加後)
③コンペ中にしていたその他の勉強今回参加したコンペ
M5 Forecasting - Accuracy コンペ (2020年3月~6月)
今回取り組んだコンペは、この時系列データのテーブルコンペで、内容としては、アメリカの小売大手であるウォルマートの「商品の売り上げ予測」
過去約5年間分のデータが与えられた上で、その後に続く1か月(28日分)の売り上げ予測をするといったものでした。
(感想としては、データ量が多かった......。 メモリの使い方も含めて、効率の良いプログラムを考えさせられたコンペにもなりました)タイムライン
3月から6月末までの4か月間のコンペで、タイムラインとしては、以下のように進んでいきました。
3/3 コンペ開始
↓
3月の中旬 コンペに参戦
↓
6/1 Public Leaderboard の期間の正解データ公開
(Kaggleに予測結果を提出しても、自分の相対的な順位がわからない目隠し状態に! )
↓
6/30 コンペ終了結果
記事の冒頭でもふれましたが、
結果は... 114位(上位3%)!! (純粋にうれしい!)
・エントリー数:88,742
・チーム数:5,558
コンペに取り組むまでの流れ(勉強のしはじめ)
python以外のプログラミング言語の経験はありましたが、この時点では、自分自身pythonを使ったことがなかったので、pandasって何?matplotlibって何?というような基本的なライブラリですら知らない状態から始めました。
この期間は、主に、機械学習やpythonの基礎知識を吸収する期間として考えていました。内容としては、別の記事(機械学習をゼロから学ぶための勉強法)にまとめてあるので、詳しくはこの記事を参照してもらえればと思いますが、ここでは簡単にまとめて話すと、以下の3点をおさえられるような本・サイトを見つけて、勉強をしていったというような流れです。
➀機械学習の基礎知識をつける(単語・用語の理解)
→ 機械学習&ディープラーニングのしくみと技術がこれ1冊でしっかりわかる教科書 (本)
➁ライブラリの使い方を理解 (numpy,pandas,matplotlibなどデータサイエンスで必須なもの)
➂実際にコンペに挑戦(Kaggle)するための入門書
→実践Data Scienceシリーズ PythonではじめるKaggleスタートブック (本)
M5コンペに参加してから
友人と4人で参加したコンペでありましたが、Kaggleのメダル対象コンペは全員はじめてということと、長期間のコンペということもあり、探りさぐりで進めてました。ここでは、他メンバーからの助力もありつつですが、チームのタスク・進捗管理の役割を担当していたので、進めていった大まかな流れや使っていたツールについて以下ではその概観をまとめていこうと思います。
全体として、チームでやっていたこと
・週に一度のミーティング
進捗の共有や、ノートブックなどの情報共有、わからないところの質問、検討等。
これを週1で行えたのは、今回のような長期的なコンペではとても有効だとおもった。ここで、今後の方針やタスク管理の話もできたので、とても進めやすかったです。Slack
週1ミーティングを待たずに、気になったこと等があれば、Slackで情報共有、検討を行った。また、メンバーがSlackをよく使っている人が多かったので、Slackと以下のようなツールを連携させて、通知を集中させることによって、よりKaggleに専念できるようにしてました!
Trello
進捗管理ツールの1つ。
Slack と連携させることで、trelloに進捗を書いたらSlackに通知、Slackからtrelloの更新ができるように。GitHub
コードの共有など。
Slackと連携させることにより、pushしたときに、commitしたメッセージがSlack にも通知させられるようにした(いちいち、pushしたことを報告しなくていいので便利!)
あとは、容量の重いデータなどはDriveで共有。(序盤) EDA・前処理中心(全員)
どのコンペでも基本だと思いますが、まず「データの理解・把握」に努めて進めてました。
コンペ開始後2,3週間後にコンペに参加したので、他の人のノートブックも集まりつつあったので、それらを読みつつ、自分たちで解析しつつといった感じです。(初心者としての戦い方)
個人的に、このころ留意していたこととしては、kaggleを始める前に「勉強してた内容を定着・実践させられるように」という目標を立てて進めてました。
上で紹介したような本やサイトだと、titanicを例にして、基本的な流れや使い方を学ぶことはできるとは思うのですが、やはり実践してみないとつかめないこともあるということで、自分で気になるデータを可視化させたり、処理を行うためにはどうしたらいいかなということを考えながら、前述の本やサイトに戻ったり、他のメンバーに聞いたりして進めていきました。(中盤)EDA・前処理とモデル作りでの分業(2:2)
全員で前処理を進めていって、ある程度データの概観がつかめてきたあたりで、前処理をそのまま続けるメンバーとモデル作りを進めるメンバーとに役割を分担して進めていこうという話になりました。
どのくらい前処理をしたらいいのかといったペース配分がわからず、最終的にはここで考えた特徴量を活かすことができなかったという点もあったので、次回への反省にしたいなと思いつつ、個人的には、役割を分担したことで自分のタスクがわかりやすくなり、集中できたかなと思ってます。(初心者としての戦い方)
まだ、前処理が慣れきっていない部分ともう少し経験を積みたいという想いから、中盤では自分は前処理に専念してました。EDA・前処理と一言でいっても意味は広いと思いますが、主に序盤ではデータの可視化・分析を、中盤からはそれを受けてのデータ加工を中心に勉強・実践していきました。(終盤)前処理しつつも、モデル作り重視(1:3)
終盤に入り、時間的な制約も感じつつあったので、方針を確定させた上で、前処理を中心に行っていた自分も、モデル作りに参戦。
特に、この終盤では、順位の動きが全くわからない目隠し状態に入ってしまっていたので、相対的な位置がわからず試行錯誤したりという感じでした。(初心者としての戦い方)
後述の通り、AtmaCupを通してモデル作りは経験していたものの、時系列データに関しては取り組んだことはなく、わからない点も多かったので、メンバーから教えてもらいながら取り組めたのは大きかった。また、期間的な問題もあり、この部分に関しては、先行して取り組んでいたメンバーに頼る部分が大きかったので、自分でも複数モデルを作ったり、検証期間を複数とるなどができるように今後頑張っていきたいと感じた。まとめ
一人でコンペに参加することと比べて、チームでコンペに参加できるとできることの幅が広がりそうと感じていましたが、実際にそうだと思う反面、チームで進めていく上での難しさという面も感じました。私自身Kaggleで初めてのメダル対象コンペだったので、その中で、チームを組んで良かったという点をあげるとすると、以下の点だと思います。
<チームを組んで良かったこと>
- わからないことを気軽に質問できる。
- 役割分担ができるので、自分の勉強したいことを集中して、順番にこなすことができる+得意分野で役割を分担することもできる (一人で始めるとしたら、前処理、モデル作りの勉強をしながら、それらを実装しなければいけないのでかなり大変だと思う)
- 異なる視点からのアプローチ案がでてくるので、一人だけで考えているときより、より多くのアイデアや手法を考えることができる。
最後に、データサイエンス始めたての自分が一人だけでは、このメダル取るまではたどり着けなかったと思っているので、一緒にKaggleのコンペに参加し、質問に応じてくれた友人達に感謝を伝えたいと思っています! 改めてありがとうございました‼
コンペ中に並行して勉強していたこと
少し本編から外れるので「おまけ」といった形になりますが、最後にこのコンペの期間中に他に取り組んでいた勉強(こと)について紹介します。
また自分のアウトプットの一環として、記事にまとめようかとも考えているので、ここでは、簡単にまとめておきますが、主に取り組んでいたのは以下の3つです。Machine Learning (Coursera) (2020年4月~5月)
ライブラリの使い方も理解してきて、実践で使えるようになってきたものも、どのような仕組みで機械学習を行っているのかがわからない部分もあり、理論的な部分を学ぼうと思って、受けた講座。
理論的な学習をmatlabを使ってできたので、より機械学習を理解する勉強になってよかった。DeepLearing基礎講座 (東大・松尾研) (2020年4月~)
このコンペでは用いなかったが、深層学習/Deep Learningについて理解したいと思っていたので、受けている講座。
機械学習・深層学習の基礎の部分のみならず、CNN,RNN,強化学習,VAEなどを講義を通して学習し、その後の演習で実践しながら理解ができるようになっているので勉強になっている。(現在進行形)AtmaCup#5 (2020年5月29日~6月6日)
EDA・前処理・モデル作りの一連の流れを一人で一度やってみたいと思い、参加したコンペ。
内容としては、時系列なしの、テーブル+信号データのコンペ
分析内容が難しかったということもあったが、参加者の中には日本人Kagglerの上位層も複数いて、コンペ終了後のエッセンスの公開や振り返り会では、勉強になることも多かった。


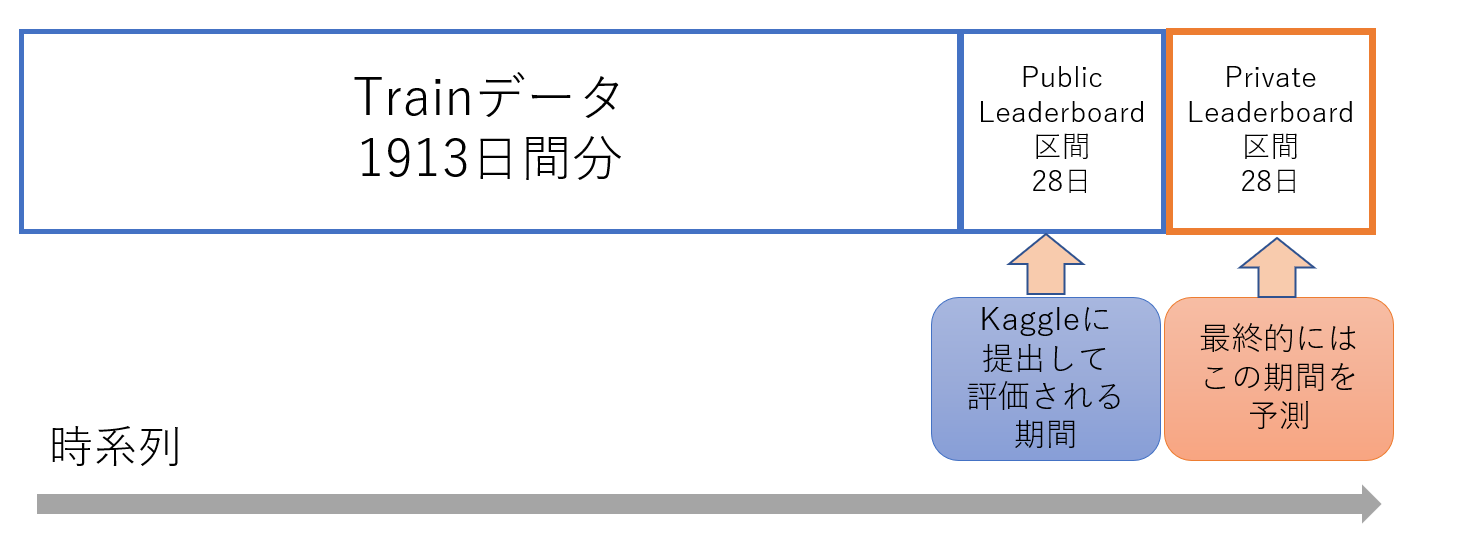
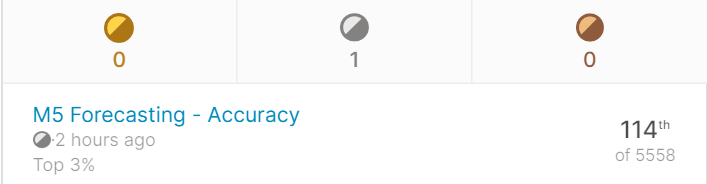
- 投稿日:2020-07-03T05:32:14+09:00
contextlib.suppress
import contextlib import os try: os.remove('somefile.tmp') # 存在しないファイル except FileNotFoundError: pass #上のtry,exceptと同じコードが短く書けます with contextlib.suppress(FileNotFoundError): os.remove('somefile.tmp')
- 投稿日:2020-07-03T05:27:10+09:00
contextlib.ContextDecorator
import contextlib # @contextlib.contextmanager # def tag(name): # print('<{}>'.format(name)) # yield # print('</{}>'.format(name)) class tag(contextlib.ContextDecorator): def __init__(self, name): self.name = name self.start_tag = '<{}>'.format(name) self.end_tag = '</{}>'.format(name) def __enter__(self): print(self.start_tag) def __exit__(self, exc_type, exc_val, exc_tb): print(exc_type) print(exc_val) print(exc_tb) print(self.end_tag) with tag('h2'): raise Exception('error') print('test')実行結果:
h2> <class 'Exception'> error <traceback object at 0x7fa12715e0f0> </h2> Traceback (most recent call last): File "/Users/hamazakiisao/PycharmProjects/python_programming/lesson.py", line 27, in <module> raise Exception('error') Exception: error
- 投稿日:2020-07-03T03:21:48+09:00
辞書引きアルゴリズム入門
はじめに
業務で自然言語処理をしていて何かと高速化を求められる場面が多く、辞書引きアルゴリズムという言葉に行き着いた。
自然言語処理界隈で深層学習が幅を利かせすぎているせいか、辞書引きアルゴリズムと聞いても同じようにピンとこない人の方が多そう。辞書引きアルゴリズムとは
テキスト中の有り得る全ての部分文字列から辞書にある単語を引いてくるアルゴリズムのこと。
形態素解析とかの処理の裏側を支えている。
この道を極めるとMeCabとかJumanとかが作れるらしい。
例えば、abcという文字列が与えられた場合、部分文字列は以下のようになる。
- a
- b
- c
- ab
- bc
- abc
これらの部分文字列が辞書にあるかどうかを調べていく。
要するに文字列の中から辞書内の単語を引っ張ってくるアルゴリズム、といった感じである。この部分文字列の列挙の計算量は$O(N^2)$であるが、この時点でアプリケーションとして実用化には程遠い。($O(N)$が望ましい)
ちなみに、辞書はハッシュと呼ばれることもあるが、文字列のハッシュ値の計算に$O(N)$を要するので、結局$O(N^3)$かかってしまう。
高速化の例
そこで、何とか高速化しないといけない。
例として$共通接頭辞検索$というものがある。これは「公務執行妨害」という文に対して
- 公
- 公務
- 公務執行
- 公務執行妨害
という同じ接頭辞を持つ文のうち、辞書に登録されている単語を引っ張ってくる処理である。
これはトライ木というデータ構造を用いて高速化されている。
(トライ木については、ここを参照)公 |---end 務 |---end 執行 |---end 妨害 | end「公」という文字が出てきたら、こんな感じに部分文字列をたどって検索できるようにしておく。
(endが出てきたらその時点で1単語として登録されている)このトライ木の検索の計算量は$O(K)$である。(K:平均単語長)
共通接頭辞検索を用いることで、「大学辞めたい」という文章に対して、
- 「大」という文字について共通接頭辞検索
- 「学」という文字について共通接頭辞検索
- (省略)
こんな感じで辞書引きができる。
これは$O(NK)$である。豆知識
MeCabの中でもトライ木は使われているらしく、ダブル配列という最速のトライ木の実装方法が使用されているらしい。(リンク先はダブル配列のわかりやすいスライド)
DartsというC++のライブラリが公開されており、簡単にダブル配列が使えるようになっている。次は、辞書を引いた後の処理にも焦点を当てたい。
- 投稿日:2020-07-03T01:40:22+09:00
(自分用)Django_1(基本のき/Hello World/テンプレート)
項目
- Djangoプロジェクトを作る
- サーバアドレスの指定
- Djangoを動かしてみる
- Hello World
- テンプレート(html)呼び出し
- テンプレートへpy側からデータ受け渡し
1.プロジェクトを作る
- プロジェクト = アプリケーションをまとめる単位
- APPの機能ごとにアプリケーションを作り、最後にそれを馬鹿でかいプロジェクトに纏めるとかが良いと思う
- 環境構築に関しては
Django_環境構築みたいなのに後日書くかもしれんし書かないかもしれんターミナル# 一回Djangoのバージョンだけ確認しておく $ python -m django --version # myappってプロジェクトを作る、startprojectって入れる事でプロジェクトの中身もある程度用意してくれる $ django-admin startproject myapp
- これによって、自分が居たディレクトリの中に
myappってディレクトリが出来ているmyappの中身
manage.py:このプロジェクトを動かしたり管理したりする時に使う、名前そのままmyapp(myappの中にもう1つmyappがある)
__init__.py:このディレクトリでPythonを使うと宣言するasgi.py:ASGI互換サーバに接続する際の基点になるらしい、よく分からないsettings.py:ここを編集する事でプロジェクトの設定を弄れるurls.py:ここに接続した時、どのdefを動かすかを決めるwsgi.py:WSGI互換サーバに接続する際の基点、全然分からないstartprojectによって上に書いた馬鹿でかいプロジェクトが作れる2.サーバアドレスの指定
- サーバからどのアドレスに接続すれば良いかを教えてあげる
settings.py# ここを見つけ出して、自分のページのアドレスを入れる # SECURITY WARNING: don't run with debug turned on in production! # DEBUG = True ALLOWED_HOSTS = ["自分のアドレス"]3.Djangoを動かしてみる
ターミナル# myappへ移動 $ cd myapp # Djangoのサーバを動かす $ python manage.py runserver
https://localhost:8000/にアクセスして、ロケットが出てくれば成功- 言うまでも無いが、実行終了は
Ctrl + c4.Hello World
- プロジェクト = アプリケーションが沢山集まったもの
ターミナル# 上で作ったmyapp(馬鹿でかいプロジェクト)に移動 $ cd myapp # myapp内にアプリーション作成、startappでアプリケーションを作るよと宣言 # 例に漏れず作ったアプリケーションの中に有る程度用意がされている $ python manage.py startapp hellomyappmyapp ┣━ hello ┣━ manage.py ┗━ myapp
- こんな感じのディレクトリが出来上がる
helloの中身は取り敢えずviews.pyだけ意識すればOK
views.pyはバックエンドの動きとかを書く場所、Flaskのpyファイルと同じviews.pyfrom django.shortcuts import render from django.http import HttpResponse def index(request): return HttpResponse('Hello World')
index(request)で、この関数が要求された時にHttpResponse()の中に入った値を返すrequestメソッドされたらHttpResponseの中身を返すと覚えればOKmyapp/myapp/urls.pyfrom django.contrib import admin from django.urls import include, path urlpatterns = [ path('hello/', include('hello.urls')), path('admin/', admin.site.urls), ]
- プロジェクトのルーティング
- このパスの時にどのアプリケーションを動かすかを設定する
- ここではリンクの末尾が
/helloの時、helloアプリケーションを動かすよと言っている- Djangoの動く流れ
- プロジェクトのルーティング→アプリのルーティング(動かす関数を指定)→指定された動作が実行される
helloの中にurls.pyというファイルを作るmyapp/hello/urls.pyfrom django.urls import path from . import views urlpatterns = [ path('', views.index, name='index'), ]
- アプリケーションのルーティング
path('', views.index, name='index'),で、どのファイルのどの関数が、どの場合に動作するかを指示している''はアドレスを指定している、今回は何も無いので/helloで動く。
もし何か入れれば/hello/~~って感じのアドレスで動く。<int:question_id>/というものをここに入れる事も有るのだが、ちょい難しいので割愛views.indexでviewsのindexって関数を動かすよと宣言- 一応その動きに
name='index'ってやつで属性付けしておくmyapp/myapp/settings.py# ここを見つけて書き足す! INSTALLED_APPS = [ 'hello.apps.HelloConfig', # これを付け足す! 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ]
- どのクラスを参照するか設定している
- アプリケーション名が
bbsならbbs.apps.BbsConfigみたいな感じで書くターミナル# プロジェクトのディレクトリに戻って... $ cd myapp # Djangoを起動! $ python manage.py runserver
- Flaskと比べると嫌になる程複雑だ...
5.テンプレート(html)呼び出し
- テンプレート(html)を
views.pyから呼び出して使用するmyapp/hello/views.pyfrom django.shortcuts import render from django.http import HttpResponse def index(request): return render(request, 'hello/index.html')
return render()の中にPATHを入れる事でhtmlを指定できる- このPATHは後述する
templatesディレクトリの中に入っていなければならないので、templatesまでは省略し、templateの中のhelloの中に有るindex.htmlと指定するindex.html<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> </head> <body> <p>Hello WoWWoW</p> </body> </html>
index.htmlは取り敢えず普通に書いてもよろしい- 実行結果で
Hello WoWWoWと表示されれば完了6.テンプレートへpy側からデータ受け渡し
views.pyfrom django.shortcuts import render from django.http import HttpResponse def index(request): context = { 'message': 'Hello World', 'players': ['勇者', '戦士', '魔法使い', '忍者'] } enemy = "スライム" return render(request, 'hello/index.html', context ,enemy)
- こんな感じで渡したいものを
return render()の中に入れる- 渡すものを
context ={ ~~ }の様に纏め、context1つのみをreturnの所に入れる裏技がある(templates)/hello/index.html<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> </head> <body> <p>{{ message }}</p> {% for player in players %} <p>{{ player }}はモンスターと戦った</p> {% endfor %} <p>{{ enemy }}</p> </body> </html>
{{ ~~ }}に変数名を入れる事でpy側で書いた内容を渡せる- Flaskでも書いたが、html側でpythonを使いたい時は
{% ~~ %}で書く- For文やif文の場合は
{% endfor %}で締めなければならない- ↑ここの詳しい解説はFlask_2,3あたりのテンプレートの項目が詳しいかも
7.終わりに
- Flaskと比べて面倒くさすぎる!