- 投稿日:2020-07-03T23:57:51+09:00
転職2日目
はじめに
転職生活2日目は、1日目に依頼を受けていたHPのCloudFrontへの移行作業の準備を行いました。
つまずいた事
- CloudFrontの利用方法
- CloudFrontを利用するにあたり、S3へアップロードをする際のコマンドがわからなかった
- S3のディストリビューションの設定がうまく行かなかった
CloudFront自体初耳だったので、教えてもらった事を端的に書いていくと以下です。
CloudFront
- スピードと安全性の高さが魅力の「高速コンテンツ配信ネットワーク機能」である
- 静的ホームページを配置する事で、今まで払っていたサーバー代等のコストダウンに繋がる
- 静的ホームページの場合、index.htmlを配置しておくことで、フレームワークを利用しなくても簡単にWeb上に反映する事ができる
他にも配信に関する遅延は少なかったり、利用料金は使った分だけ支払う従量課金制で、無料利用枠として毎月50GBのデータ送信等が1年間無料は魅力的だなと感じました。
利用方法は、こちらの記事を参考に勉強させていただきました。
S3へアップロードをする際のコマンド
手順
①AWS CLI のインストール
②追加ファイルを作成
③パスを通す
④S3へアップロードする以上でアップロードができました。
①AWS CLI バージョン2をインストール
こちらを参考にインストールします。
②追加ファイルを作成
格納予定のディレクトリに以下を追加
.sample.sh#!/bin/bash set -e AWS_ACCESS_KEY_ID=[Access key ID] AWS_SECRET_ACCESS_KEY=[Secret access key] aws s3 sync --exclude "*.DS_Store" public/ s3://[該当のドメイン] AWS_ACCESS_KEY_ID= AWS_SECRET_ACCESS_KEY= aws cloudfront create-invalidation --distribution-id [distributionのid] --paths /index.html /index.css #distributionのidは、CloudFront Distributionsから確認できるIDを入力※Git Hub上にAccess keyとSecret access keyをpushしないように、gitignoreで除外処理は必須
.gitignore/.sample.sh③パスを通す
ターミナルls -la #該当ファイルのパス状況を確認 -rw-r--r-- 1 ****** staff 360 7 3 16:46 .sample.sh #パスが通っていないターミナルchmod +x .sample.sh #パスを通すコマンドターミナルls -la #該当ファイルのパス状況を確認 -rwxr-xr-x 1 ****** staff 360 7 3 16:46 .sample.sh #xが追加された事がわかりますターミナルsource ~/.bash_profile #これでパスが通りましたターミナル./.sample.sh上記コマンド入力後、uploadすることができました。
さいごに
自分が学んだ事以外の知識が必要になるため、調べる事は大切だと感じました。
また、パスを通す際にsourceコマンドを利用のは勉強していましたが、いざ実際に仕事として考えると抜けてしまう事が多いので、忘れないよう注意していこうと思います。
- 投稿日:2020-07-03T22:35:05+09:00
AWS SAA対策メモ(ストレージとDB編)
SAA対策の自分用のメモ。
どんどん更新して加筆修正していく予定。インスタンスストア(エフェメラルディスク)
☆ホストコンピュータに物理的にくっついている。インスタンスを再起動すると、別のホストコンピュータでインスタンスが起動されてしまい、データは消えてしまう。
EBS
ブロックストレージ
確保した容量分課金(使っていなくても)
スナップショット機能(S3に保存)
☆EC2インスタンスとは独立しているため、再起動してもデータは残る
複数のEC2インスタンスにアタッチすることはできない
☆同AZ内のEC2インスタンスのみにアタッチ可能。ただし、スナップショットを取得し、任意のAZでボリュームを復元し、EC2インスタンスにアタッチすれば、別のAZでもアタッチ可能。
汎用SSD
中小規模のDBなどで使用プロビジョンドIOPS SSD
ハイパフォーマンス、汎用SSDではできないミッションクリティカルな低レイテンシー高スループット向け
高スループットなアプリや大規模DB(RDSやNoSQL)で使用スループット最適化HDD
高スループット低コスト、ビッグデータやデータウェアハウス、ログ処理向けコールドHDD
アクセス頻度の低い大量のデータ用EBS最適化オプション(デフォルトは無効)
より大きなIOPSが必要なときに設定。EC2インスタンスとEBS間の専用帯域を設ける。
有効になっているインスタンスをEBS最適化インスタンスという。スナップショットによるバックアップは増分のみ,
EBSボリュームを別リージョンでも使いたい時は、スナップショットを作成し、別リージョンで復元、そのEBSボリュームを新しいEC2にアタッチする☆暗号化
新規に作成するときに暗号化のオプションを選択できる
また、既存のEBSボリュームを暗号化したい場合には、一度スナップショットを取得し、それを復元する際に暗号化する事ができる。暗号化されたボリュームからのスナップショットは暗号化されている。S3
インターネット経由のオブジェクトストレージサービス
容量無制限で高耐障害性、高可用性のリージョンサービス
固有のID(オブジェクトキー)を付与し、これでアクセスする。オブジェクトキーは全体で一意である必要あり
オブジェクトを保存するバケット
プレフィックス
☆VPCエンドポイント
インターネットを経由せずにVPC内部からアクセス可能。インターネットアクセスを排除3ヶ所のAZに自動複製して高可用性
☆結果整合性モデル
データを更新後、タイミングによっては古いデータが読み込まれる事がある。しかし、一貫性は担保されているので、ちゃんと時間が経つと、全てのデータは更新される種類
- スタンダード(デフォルト)
標準ー低頻度アクセス(Infrequent-Access)
アクセス頻度は低いが、必要になったらすぐに取り出せる必要があるデータに使う1ゾーン低頻度アクセス
1つのAZにのみ保存のため、可用性は下がるが、コストを約20%カットできる。Intelligent-Tiering
自動的にコスト効率のより良いストレージクラスに移動させるReduced redundancy storage?
2つのAZにのみ保存のため、可用性は下がる。Glacier
アーカイブ用。データの取り出しには手続きが必要。テープアーカイブとか。
取り出しについて
- Expedited 1~5分でデータを取り出し可能。高価
- Standard 3~5時間でデータを取り出し可能
- Bulk 5~12時間でデータを取り出し可能
Glacier Deep Archive
年1回取り出すとかバージョニング
オブジェクトの世代管理。バージョンIDを付与。MFA Deleteを有効にすると、誤った削除などを防げるライフサイクルポリシー
自動で削除や別ストレージへのアーカイブ処理を設定できる静的ウェブホスティング
静的コンテンツであれば、 S3をwebサーバーのように使用できる。ただし、パブリック読み取権限が必要で、HTTPSには対応していない。署名付きURL
クロスリージョンレプリケーションS3のパフォーマンス改善に、ファイル名のプレフィックスに16進数の文字列をつける。インデックス格納先が分散されてハイパフォーマンスになる
パブリックアクセスの項目でアクセス制御が可能
有効期限つき署名付きURLを発行できる。☆暗号化(3つのサーバーサイド暗号化)
- S3管理のキーによるもの
- KMS管理のキーによるもの
- ユーザーのキーによるもの
Storage Gateway
オンプレとAWSストレージをつなぐ
ファイルゲートウェイ
テープゲートウェイ
物理のテープストレージの代替保管型ボリュームゲートウェイ
オンプレのデータのスナップショットをS3へ。データはオンプレにある。キャッシュ型ボリュームゲートウェイ
S3にスナップショットを保管し、よく使われるデータのみをキャッシュとしてオンプレに保存EFS
共有ファイルシステム
複数AZの複数EC2インスタンスからアクセス可能
ビッグデータやコンテンツの共有リポジトリに使う
オートスケール可暗号化
RDSのリードレプリカで読み取り頻度の高いDB用、読み取りスループットを増やし、パフォーマンス向上
RDSの障害発生時
シングルAZの場合、RDSが自動で再起動。ポイントタイムリカバリが復元可能マルチAZの場合、マスターに障害発生したら自動的にスレーブへフェイルオーバー。スレーブが代わりにマスターに昇格。特に対応は不要。
Aurora
オートスケーリングあり
頻繁にデータ更新があるDB用DynamoDB
キーバリュー型のNoSQL
非/半構造化データを扱う
3カ所のAZに自動保存
結果整合性モデル
2カ所のAZへの書き込みが完了したら、正常に書き込みが完了したと見なされるが、そのときに3カ所目のAZで読み取李処理があると、最新のデータが取得できない可能性がある。
セッションデータ
DynamoDBの使い方
利用負荷があらかじめ予測できる場合はプロビジョンドスループット、利用負荷があらかじめ予測できない場合はオンデマンドキャパシティーモードを選択
ユースケースは大量のデータ処理が必要なモバイルゲームやアドテク、IoTのデータ処理など
DAX (DynamoDB Accelerator)DynamoDB用のインメモリキャッシュ。低レイテンシー。読み取りスループット向上
ユースケース
JSONドキュメント保存、IoTデータ格納、セッション保存、S3オブジェクトのメタデータ保存などRedshift
ペタバイトのデータも扱えるマネージド型データウェアハウス
大量のデータの集計と分析が可能
列志向DB↔︎行志向はこれまでのRDBで、データ量が増えるほど遅くなる
ノード、リーダーノード、コンピュータノード、クラスター
自動スナップショットは8時間ごと or ノードあたり5GBの変更時。自動スナップショットの場合、保存期間が過ぎると、自動削除される。
自動削除が嫌なら手動でスナップショットを取る
クロスリージョンスナップショット可能
冗長性を高めるのは、ノード数を増やそう
Redshift spectrumElastiCache
マネージド型インメモリデータベース
高スループットで低レイテンシー
毎回DBにクエリを投げるのは非効率だから使用。RDBのパフォーマンス向上。
ElastiCacheをDBの前におくことで、DBの負荷を軽減&パフォーマンス向上
高速にリアルタイム処理が必要な場合はインメモリキャッシュを利用してデータ処理を高速化する
Memcached
キャッシュ用、シンプルな構造Redis
マスタースレーブ型、複雑な構造、フェイルオーバーあり、
- 投稿日:2020-07-03T19:46:56+09:00
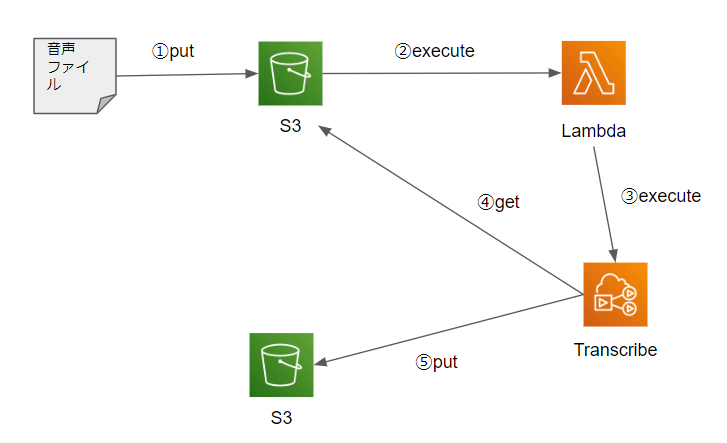
Amazon Transcribeを使って音声ファイルを文字越しする
Amazon Transcribeが日本語に対応していたので使ってみたかった。
Terraformスクリプト全体はこちらにあります。全体概要
音声ファイルをS3のバケットにアップロードすることをトリガーにして、S3がLambdaを実行し、LambdaはS3にアップロードされたファイル名をキーにしてTranscribeを呼び出す。
Terraformのディレクトリ構成
以下のようにディレクトリをきっている。
terraformのディレクトリの切り方はいっつも迷う・・・・root ┣ iam # 権限まわり ┣ lambda ┗ s3 main.tf variable.tf # これは各自作る注意どころ
何も考えないでterraformを記述していくと、以下のエラーが出る。
[ERROR] BadRequestException: An error occurred (BadRequestException) when calling the StartTranscriptionJob operation: The S3 URI that you provided can't be accessed. Make sure that you have read permission and try your request again.TranscribeがS3へアクセスできないということは分かったが、解決するのにてこずった。
一連の流れのトリガーとなるS3へS3へのアクセス権を与えるという、卵と鶏のような権限をアタッチする必要がある。lambda/role.tfresource "aws_iam_role_policy_attachment" "transcribe_access_s3_policy_attachment" { policy_arn = aws_iam_policy.transcribe_access_s3_policy.arn role = aws_iam_role.execute_transcribe_role.name }
- 投稿日:2020-07-03T19:12:17+09:00
【AWS】AWS SDK for PHPを使ってSESでメールを送信する
はじめに
PHPでSESを使ってメールを送信したいが、ちょっとAWSの認証まわりが面倒くさかったり、
検索しても以前の情報とかがヒットしたりするので書いておきます。
認証まわりは色々やり方がありますが、AWS認証情報用のiniファイルを作成して実行する方法です。送信用のポリシーを作成する
SES送信用のポリシーを作成してください。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "ses:SendEmail", "Resource": "*" } ] }SES認証用のユーザーを作成して、iniファイルを作成する
AWSのIAMでSES認証用のユーザーを作成してください。
ポリシーは上で作ったやつ。
作成すると、「Access key ID」、「Secret access key」が表示されるので、それを元に以下のiniファイルを作成してください。aws_credential.ini[default] aws_access_key_id = XXXXXXXXXXXXXXXXXXXXXX aws_secret_access_key = XXXXXXXXXXXXXXXXXXXXXXcomposer
composerでAWS SDKを取得してください。
requireに「"aws/aws-sdk-php": "3.*"」を追加して、composer updateする。PHP
aws_ses.phpinclude_once dirname(__DIR__) . '/vendor/autoload.php'; use Aws\Credentials\CredentialProvider; use Aws\Ses\SesClient; use Aws\Exception\AwsException; // iniファイルで設定した[]のテキストを設定 $profile = 'default'; // ini指定 $path = dirname(__DIR__) . '/aws_credential.ini'; // iniファイルでの認証するための処理 $provider = CredentialProvider::ini($profile, $path); $provider = CredentialProvider::memoize($provider); // SES用オブジェクト生成 $client = new Aws\Ses\SesClient([ 'region' => 'us-east-1', // SESを設定しているリージョン 'version' => '2010-12-01', 'credentials' => $provider ]); // 送信元メールアドレス $from_mail = 'no-reply@test.com'; // SESで設定したメールアドレス // 送信先メールアドレス $to_mail = 'test@gmail.com'; //送信者名 $from_name = mb_encode_mimeheader("テスト送信者",'utf-8'); // 文字コード $char_set = 'UTF-8'; // 件名 $subject = '件名でーす'; // 本文 $body = '本文でーす'; try { // メール送信 $result = $client->sendEmail([ 'Destination' => [ 'ToAddresses' => [$to_mail], ], 'ReplyToAddresses' => [$from_mail], 'Source' => $from_name, 'Message' => [ 'Body' => [ 'Text' => [ 'Charset' => $char_set, 'Data' => $body, ], ], 'Subject' => [ 'Charset' => $char_set, 'Data' => $subject, ], ], ]); // 送信ID $messageId = $result['MessageId']; } catch (AwsException $e) { $this->log("SES送信失敗。" . $e->getAwsErrorMessage()); }以上でございます!
- 投稿日:2020-07-03T17:40:43+09:00
Private subnet内でNAT gatewayを介さずにlambdaからlambdaを呼び出す
はじめに
だいぶ特定領域の話になりますがとあるプロダクト開発にあたってちょっとした知見を得たので後学のために残しておきます。
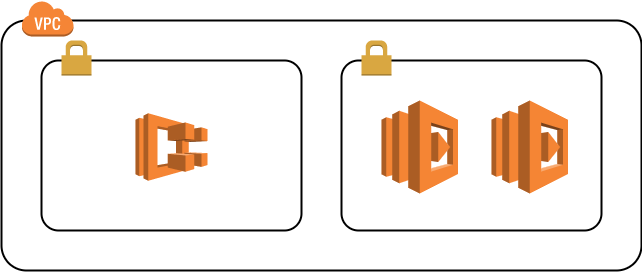
構成
まずは今回の構成を一部分だけピックアップしたものが以下のものになります。
要件としては、プライベートサブネット内で動いているサービス(今回であればECS上で動かしています)からマイクロサービスとして切り出した同じくプライベートサブネット内のlambdaを呼び出し(invoke)、さらにそのlambdaから別のlambdaを呼び出す。
ただし、lambdaからVPC内のリソースにアクセスするためにlambdaをVPC内に置く必要があると言った具合です。
この場合同じVPC内なため、セキュリティグループを適切に設定すればECSからlambdaを呼び出すことはうまくいきますが、lambdaから別のlambdaを呼び出すのはうまくいきませんでした。どうやらlambdaから別のlambdaを呼び出す場合は、同じVPC内にあっても一旦パブリックネットワークを経由する必要があるようです。そのためこのままでは何かしらの手段でパブリックネットワークへアクセスする必要があります。単純にlambdaをパブリックサブネットに置くことも考えられますが、lambdaだけパブリックサブネットに置くのは避けたいところです。また、パブリックサブネットにNAT gatewayを置くことでもこの問題は解決可能です。しかしNAT gatewayを使用すると転送量に応じてそこそこの額が請求されてしまうので、頻繁に呼び出されるlambdaではあまり使いたくありません。
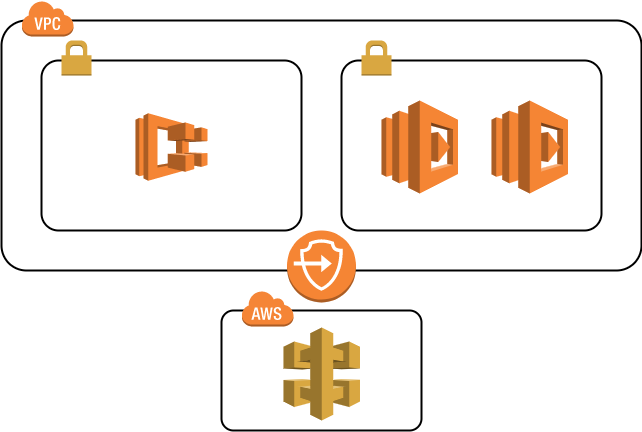
解決策
そこで今回はPrivate API gatewayを作成し、AWS PrivateLink経由でapiをコールしてlambdaを呼び出す方針としました。AWSの構成は以下のようになります。
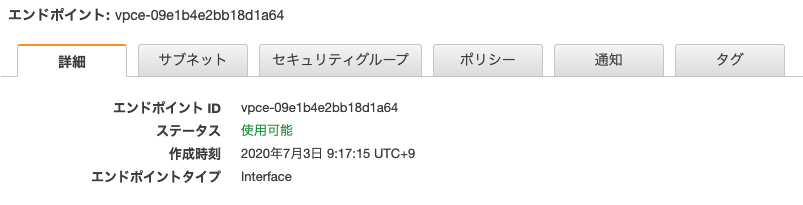
流れとしてはECSからlambdaを呼び出し、lambdaからVPC PrivateLinkによってPrivate API Gatewayを介して別のlambdaを呼び出す。と言ったようになります。VPC Endpoint
VPC PrivateLinkで扱うEndpointを作成します。このエンドポイントを通して他のAWSサービス(API gateway, S3など)にアクセスが可能になります。用途としてはNAT gatewayと被りますが、こちらの方が安く済むようです。
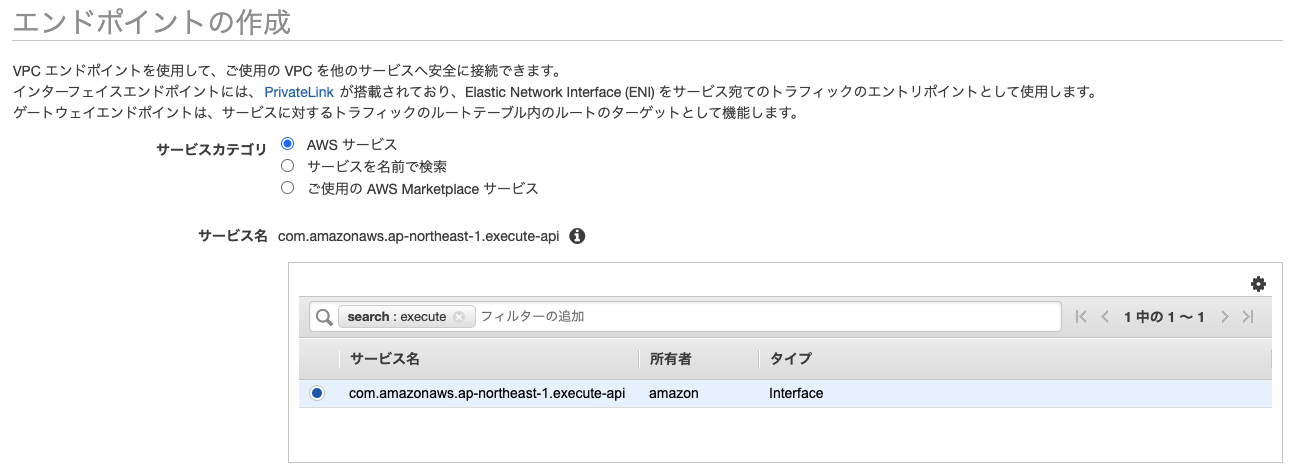
エンドポイントは、VPC Management serviceより左ペインのエンドポイントをクリック、「エンドポイントの作成」ボタンより作成画面を開くことができます。
作成するエンドポイントはexecute-apiです。これがapi gatewayを呼び出すためのエンドポイントになります。VPC及びサブネットは今回使用するlambdaが所属するプライベートサブネットを指定します。セキュリティグループは以下のようにアクセス元(今回であればlambda)からの443ポートでのアクセスを許可しておきます。
これでprivate API gatewayへのエンドポイントを通じたアクセスが可能になります。作成したエンドポイントのIDはあとで使用します。
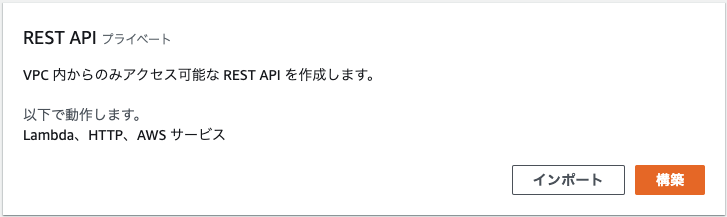
Private API Gateway
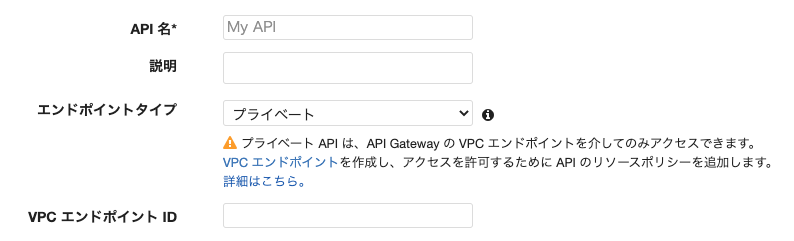
「APIを作成」を押すとAPIの選択画面が開きます。一番下に「REST API プライベート」があるのでこちらを使用すると楽だと思われます。
エンドポイントタイプがプライベートになっていることを確認してください。VPCエンドポイントIDには先ほど取得したエンドポイントIDを入力します。
あとは通常通りAPIを作成すればOKです。適当なURLへのアクセス時にlambdaをinvokeするようにしてください。ここで生成されたURLは先ほどのエンドポイントからのみアクセスが可能です。(このURLを使用するにはVPC内でのプライベートDNS機能がオンになっている必要があります。)Invoke Lambda
これでVPC PrivateLinkを使用したAPI Gatewayへのアクセスが可能になったのでAPI Gatewayごしにlambdaの実行が可能になりました。以下に実際にlambdaにデプロイしたコードの抜粋を示しておきます。Go言語を使用していますがエラー処理は省いてあること、また今回はPOSTリクエストしていることに注意してください。APIGatewayURLは先ほどAPI Gatewayで生成したURLです。
b, _ := json.Marshal(reqBody) req, err := http.NewRequest( "POST", APIGatewayURL, bytes.NewReader(b), ) req.Header.Set("Content-Type", "application/json") client := &http.Client{} resp, _ := client.Do(req) defer resp.Body.Close()うまくいったそのままのテンションで書いてしまったので情報不足あればコメントください。
参考
https://qiita.com/horit0123/items/86c727d8d3ae74b9e52a
https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/apigateway-private-apis.html
https://stackoverflow.com/questions/52761465/invoking-a-lambda-function-from-another-lambda-function-inside-of-a-vpc

- 投稿日:2020-07-03T16:47:57+09:00
ESCにtargetGroupを2つ登録する際にコンソールからだとできないのでメモ
ESCにtargetGroupを2つ登録する際にコンソールからだとできないのでメモ
aws ecs create-service \ --cluster api \ --service-name api \ --launch-type FARGATE \ --load-balancers '[{"targetGroupArn":"arn:aws:elasticloadbalancing:ap-northeast-1:xxx:targetgroup/pro-api/xxx","containerName":"nginx","containerPort":80},{"targetGroupArn":"arn:aws:elasticloadbalancing:ap-northeast-1:xxx:targetgroup/pro-api-internal/xxx","containerName":"nginx","containerPort":80}]' \ --desired-count 2 \ --task-definition pro-api:1 \ --network-configuration "awsvpcConfiguration={subnets=[subnet-xxxxxx],securityGroups=[sg-xxxxxxx],assignPublicIp=ENABLED}" --profile
- 投稿日:2020-07-03T16:09:03+09:00
InfoScale Enterpriseを用いたSAP HANAの可用性向上と災害対策【AWS編】
はじめに
企業がパブリック クラウド上に SAP HANAを導入する過程で、その可用性要件に対処する事が重要です。そのために、HANA データベース フレームワークは、組み込みの高可用性 およびシステム レプリケーション (HSR) 機能を提供します。ほとんどの障害をカバーしますが、幾つかの障害イベントが発生した場合、復旧の際に手動のオペレーションが必要になります。
本記事では、InfoScale Enterprise を使用して AWS クラウドにデプロイされるSAP HANA および SAP NetWeaver/ S/4HANA 環境の可用性を向上させるために必要な技術情報を説明しております。InfoScaleによって、AWS上のSAP HANA の可用性が向上するユースケース
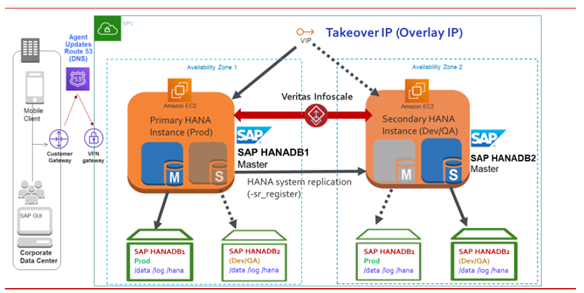
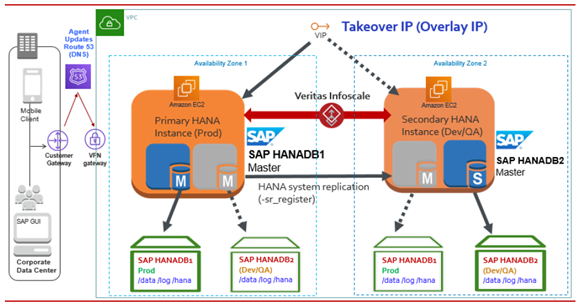
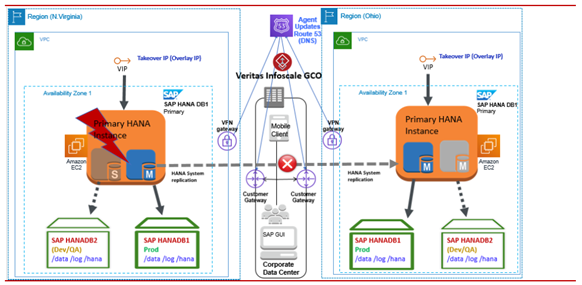
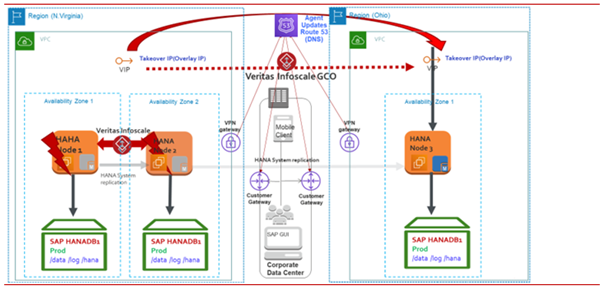
以下の図は、InfoScale for SAP HANA でサポートされる可用性の構成シナリオを表しています。本番環境で SAP HDB インスタンスに障害が発生した場合、InfoScale は障害を検出し、そのインスタンスを開発ノードまたはテストノードに移動します。 InfoScale Enterpriseでは、次のユース ケースで SAP HANA データベース インスタンスを監視および制御できます。
同じ AZ 内の SAP HANA インスタンス
このシナリオでは、マスター インスタンス (レプリケーションのプライマリ) とスタンバイ インスタンス (レプリケーションのセカンダリ) が同じ AZ 内の HANA システム レプリケーションと共に構成されます。 マスター・インスタンスに障害が発生すると、SAPHDB Agentはセカンダリをプライマリに昇格させます。
メモ: フェイルオーバー操作は HANA HA フェイルオーバーのガイドラインに従って実行され、SAPHDB Agentは HANA フェイルオーバー・ルールに従います。同じ AWSリージョン内のAZ全体のSAP HANAインスタンス
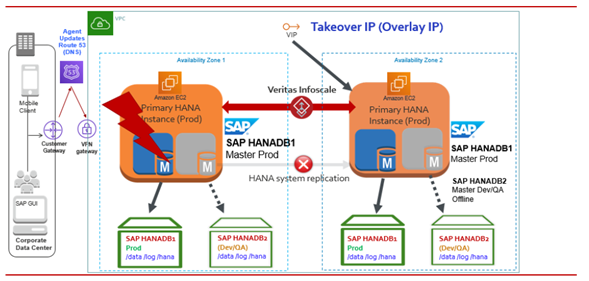
この設定では、SAP HANA のプライマリインスタンスとセカンダリインスタンスが同じ AZ または同じリージョン内の異なる AZ に存在します。HANA システム レプリケーションが 2 つのインスタンス間で有効になっている場合、データとログはセカンダリ インスタンスにレプリケートされます。 この例では、プライマリ (マスター) インスタンスとセカンダリ (ワーカー) インスタンスは、ローカル クラスタリングを使用して異なる AZ で構成されています。
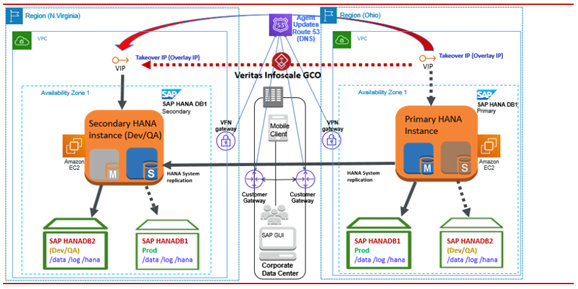
プライマリインスタンスに障害が発生したり、利用できなくなったりすると、SAPHDB Agentは障害を識別し、セカンダリインスタンスでのフェイルオーバーのオペレーションが自動的に起動します。次の図は、その動作の説明です。
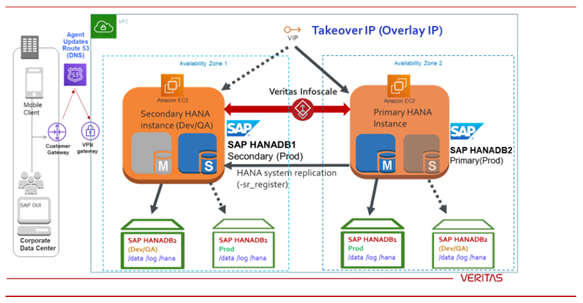
古いプライマリ インスタンスで障害をクリアし、その他の必要なメンテナンスアクティビティを実行することもできます。SAPHDB Agentは、自動再登録機能を使用して、元のプライマリ インスタンスをセカンダリ インスタンスとして自動で指定できます。その後、HANA システム レプリケーションは、データレプリケーションの方向を逆転させます。次の図は、その動作の説明です。
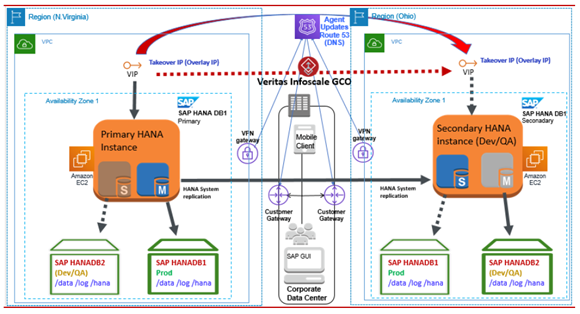
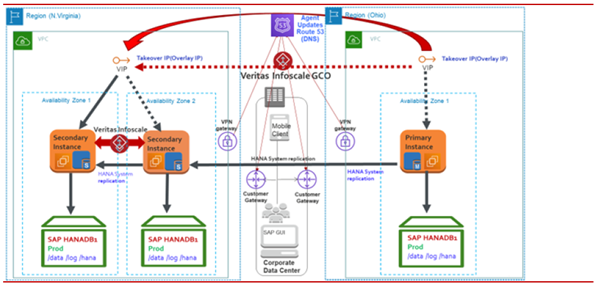
AWS リージョン間の単一インスタンス SAP HANA データベース
AWSリージョン全体で単一のHANAデータベースインスタンスを構成することができ、GCO構成を使用してInfoScale Agentによって制御および監視することができます。次の図は、その動作の説明です。
プライマリインスタンスに障害が発生したり、利用できなくなったりすると、SAPHDB Agentは障害を識別し、他のリージョンのセカンダリインスタンスでのフェイルオーバーのオペレーションを自動的に起動します。次の図は、その動作の説明です。
障害をクリアし、古いプライマリ インスタンスで必要なその他のメンテナンスアクティビティを実行する必要があります。SAPHDB Agentは、自動再登録機能を使用して、元のプライマリ インスタンスをセカンダリ インスタンスとして自動的に指定できます。次の図は、その動作の説明です。
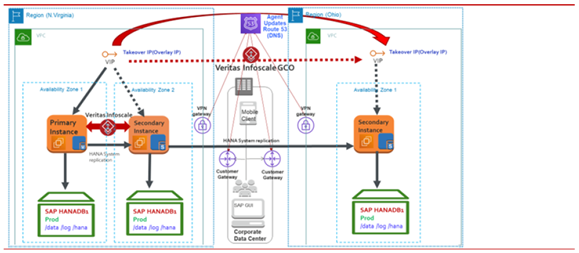
AWS リージョン間の SAP HANA データベースインスタンス (カスケードシナリオ)
このシナリオでは、HANA データベースのプライマリとセカンダリは、それぞれ N.バージニア リージョンのアベイラビリティーゾーン1とアベイラビリティーゾーン2で構成されます。3 番目の HANA データベース インスタンスはオハイオ リージョンにあります。次の図は、そのカスケード構成の説明です。
プライマリ・インスタンスに障害が発生すると、SAPHDB Agentは、同じリージョン内の 1 次インスタンスから 2 次インスタンスに IP リソースをフェイルオーバーすることによって、自動的にフェイルオーバーを起動します。仮想 IP フェイルオーバー操作は、AWSIP および IP Agentによって管理されます。次の図は、セカンダリがプライマリになり、アベイラビリティーゾーン2でアクティブになっている動作の説明です。
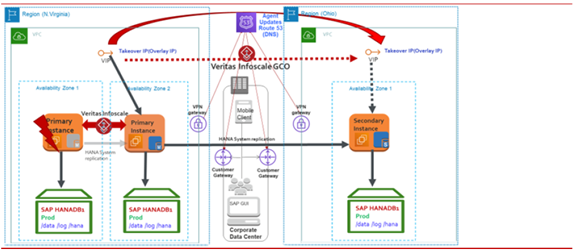
AZ またはリージョン内のすべてのインスタンスに障害が発生した場合、SAPHDB Agentは、プライマリからリモートリージョンのセカンダリ・インスタンスに IP リソースをフェイルオーバーすることによって、フェイルオーバーを自動的に起動します。 次の図は、リモート領域のセカンダリがプライマリになる動作の説明です。
その後、N.Virginia リージョンのインスタンスの障害をクリアし、オハイオ州の現在のプライマリに再登録する必要があります。次の図は、レプリケーションの方向が逆になっている動作の説明です。
詳しい内容については、ベリタスよりホワイトペーパーが公開されています。是非こちらをご覧ください。おわりに
如何でしたでしょうか? 今回の記事と記事中に紹介したホワイトペーパーによって、AWS上のInfoScale Enterpriseを用いたSAP HANAの可用性向上と災害対策をイメージできたのではないでしょうか? 今回の内容は、InfoScale Enterpriseを用いたSAP HANAの可用性向上と災害対策【AWS編】でした。【Microsoft Azure編】、【Google Cloud Platform編】の記事もよろしければ続けてご覧下さい!
商談のご相談はこちら
本稿からのお問合せをご記入の際には「お問合せ内容」に#GWCのタグを必ずご記入ください。ご記入いただきました内容はベリタスのプライバシーポリシーに従って管理されます。
その他のリンク
【まとめ記事】ベリタステクノロジーズ 全記事へのリンク集もよろしくお願いいたします。
- 投稿日:2020-07-03T14:48:29+09:00
CodeCommitにcommit/pushしたらLambda経由でSlackにcommentつき通知を飛ばす
AWS CodeCommit上で管理しているリポジトリに、誰かがcommit/pushしたらSlackで通知を受け取りたいと思って試行錯誤したときのメモになります。Lamda関数はNode.jsで記述しています。
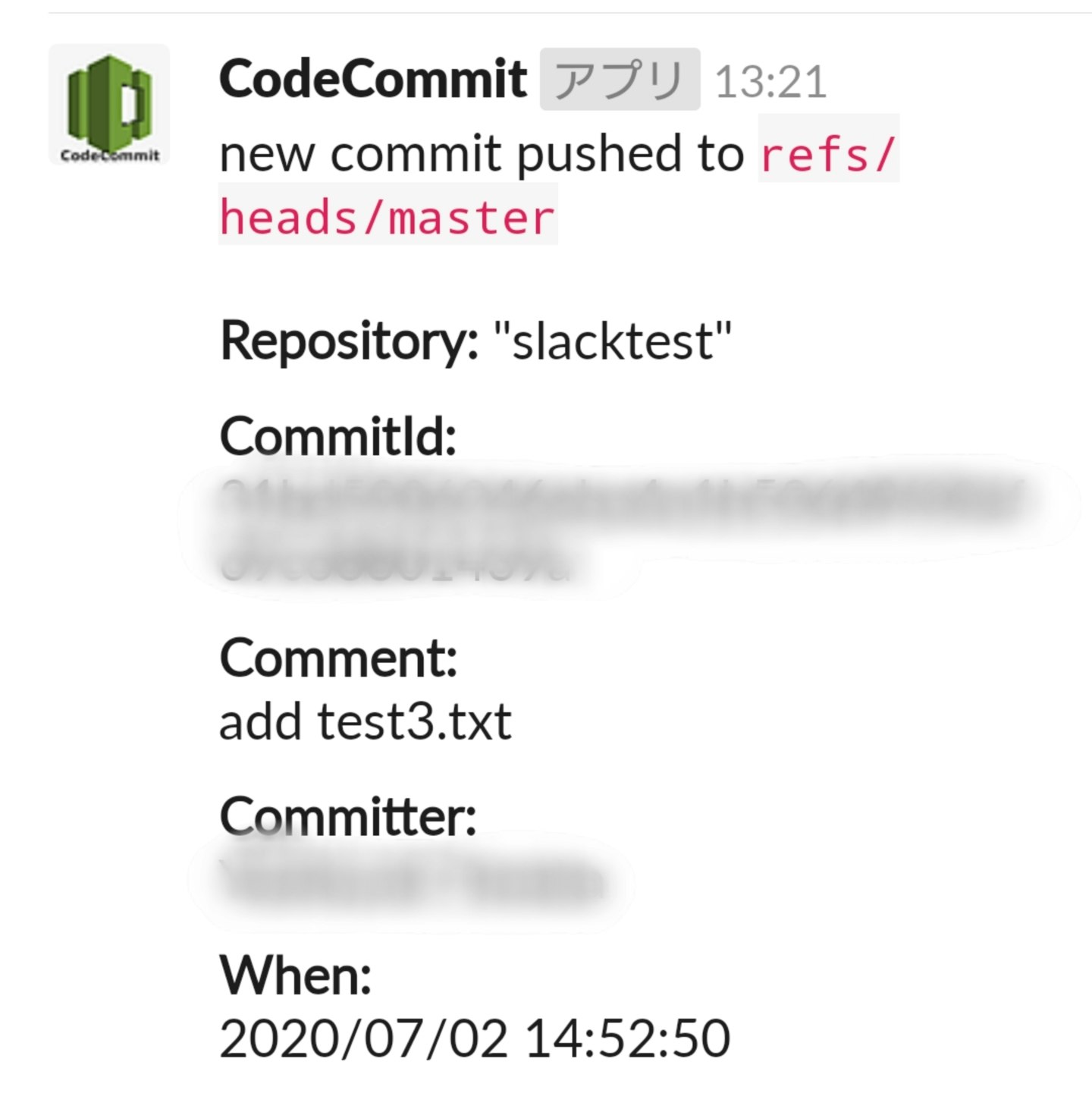
スクリーンショット
※ アイコンとCodeCommitの太字はSlack Incomming Webhookのカスタマイズで変更しています。
前置き
- CodeCommitやLamda、Slackの細かい話は書きません。
- Lamda関数のNode.jsのサンプルコードや注意点だけを書きます。
- 以下はすべてAWS Console上からの操作です。
処理の流れ
CodeCommit → トリガー → Lambda → Slack Incomming WebhookのURLにPOST → Slackからスマホアプリ等に通知が飛ぶ
Lamda関数
適当な名前でLamda関数を作成します。以下のサンプルコードをindex.jsに上書きします。
optionsのIncomming WebhookのURLと、中程にあるSlack上に表示するメッセージのBlock Kitテンプレートはお好みに合わせて修正します。codeCommitToSlackWebhookconst AWS = require('aws-sdk'); const codecommit = new AWS.CodeCommit({ region: 'ap-northeast-1' }); const https = require('https'); //const util = require("util"); const options = { hostname: 'hooks.slack.com', path: '/services/*******/*******/*******', method: 'POST', headers: { "Accept" : "application/json", "Content-Type" : "application/json; charset=UTF-8" } }; exports.handler = function(event, context) { let repository = event.Records[0].eventSourceARN.split(":")[5]; let references = event.Records[0].codecommit.references; let funcArr = references.map((x) => { return new Promise((resolve,reject) => { let params = { commitId: x.commit, repositoryName: repository }; codecommit.getCommit(params, function(err, data) { if (err) reject(err); else resolve({params:params,data:data}); }); }); }); Promise.all(funcArr) .then((values) => { //console.log(util.inspect({ // values:values //},{colors:true, depth: null})); return new Promise((resolve,reject) => { let blocks = []; blocks.push({ type: 'section', text: { type: 'mrkdwn', text: `new commit pushed to \`${references[0].ref}\`\n\n*Repository:* "${repository}"`, } }); let v = values.map((x) => { let tmp = new Date(x.data.commit.committer.date.split(' ')[0]*1000); tmp = `${tmp.getFullYear()}/${('0'+(tmp.getMonth()+1)).slice(-2)}/${('0'+tmp.getDate()).slice(-2)} ${('0'+tmp.getHours()).slice(-2)}:${('0'+tmp.getMinutes()).slice(-2)}:${('0'+tmp.getSeconds()).slice(-2)}`; return { type: 'section', fields: [ { type: 'mrkdwn', text: '*CommitId:*\n'+x.params.commitId }, { type: 'mrkdwn', text: '*Comment:*\n'+x.data.commit.message }, { type: 'mrkdwn', text: '*Committer:*\n'+x.data.commit.committer.name }, { type: 'mrkdwn', text: '*When:*\n'+tmp } ] }; }); values = {blocks:blocks.concat(v)}; resolve(values); }); }).then((value) => { //console.log(util.inspect({ // value:value //},{colors:true, depth: null})); let req = https.request(options, (res) => { let body = ''; //console.log('statusCode: '+res.statusCode); res.setEncoding('utf8'); res.on('data', (chunk) => { body += chunk; }); res.on('end',() => { //console.log({body:body}); context.done(null,body); }); }); req.on('error',(e) => { //console.log({e:e}); context.fail(e); }); req.write(JSON.stringify(value)); req.end(); }).catch((err) => { //console.log({err:err}); context.fail(err); }); };Lambdaのアクセス権限
- Lambda アクセス権 → 実行ロール → IAMロールの設定が別ウィンドウで開く
- 「ポリシーをアタッチします」で
AWSCodeCommitReadOnlyをアタッチLambdaのトリガー
- Lambda 設定 → デザイナー → トリガーの追加
- トリガーの設定 →
CodeCommitを選択- リポジトリ名選択、トリガー名に
slackWebhookTriggerなど入力、ブランチ名をすべてのブランチを選択- 追加
通知のテスト
- CodeCommit リポジトリ選択
- 設定 → トリガー →
slackWebhookTriggerなどトリガー名のリンク- ページ下部 → トリガーのテスト
Lambdaの注意点
環境変数を設定しないと通知内容に含まれる時刻がUTCになってしまいます。以下を設定します。
- Lambda 設定 → 環境変数 → キー:
TZ、値:Asia/Tokyoを追加デバッグ
Lambda関数内のconsole.logのコメントアウトを外し、CloudWatch Logsでどこでエラーが発生しているか確認します。
参考URL
例: AWS Lambda 関数の AWS CodeCommit トリガーを作成する
https://docs.aws.amazon.com/ja_jp/codecommit/latest/userguide/how-to-notify-lambda.html以上です。
- 投稿日:2020-07-03T14:14:42+09:00
プロキシに阻まれながらAWS CLIをEC2インスタンスから動かしたときの話
この記事の概要
プロキシがある環境下でAWS CLIをEC2インスタンスから使う方法を書きます。
その中でハマったポイントがあったのですが、ハマったことにより知見が深まったのでQiitaに投稿します。
主にAWS CLI周りの話とSquidの話となります。使ったツール・プロダクト等は以下です。
- Squid(Windows版)
- AWS CLI
- Direct Connect
- IAM
- EC2
- S3(あまり本題には出てきませんが)
背景
弊社には他の多くの会社さんと同様、インターネットへ接続するためのプロキシ(通称「社内プロキシ」)が存在しています。
そんな弊社に所属する私は業務上の事情でAWS CLIでS3上の操作を行う必要が出てきました。
しかし、先日開発用端末を変えたことにより、その端末にAWS CLIがインストールされていないのです。
セキュリティの観点からアクセスキーは発行したくないし、端末にAWS CLIをインストールする以外の方法を検討しました。
そこで、IAMロールをEC2インスタンスにアタッチすることでアクセスキーを発行することなく認証させる方法を知っていたということもあり、この方法を採用しました。
しかも、AWSにはAWS CLIがプリインストールされたAmazon Linuxのイメージが公式で提供されており、これを使えば準備が楽そう…。
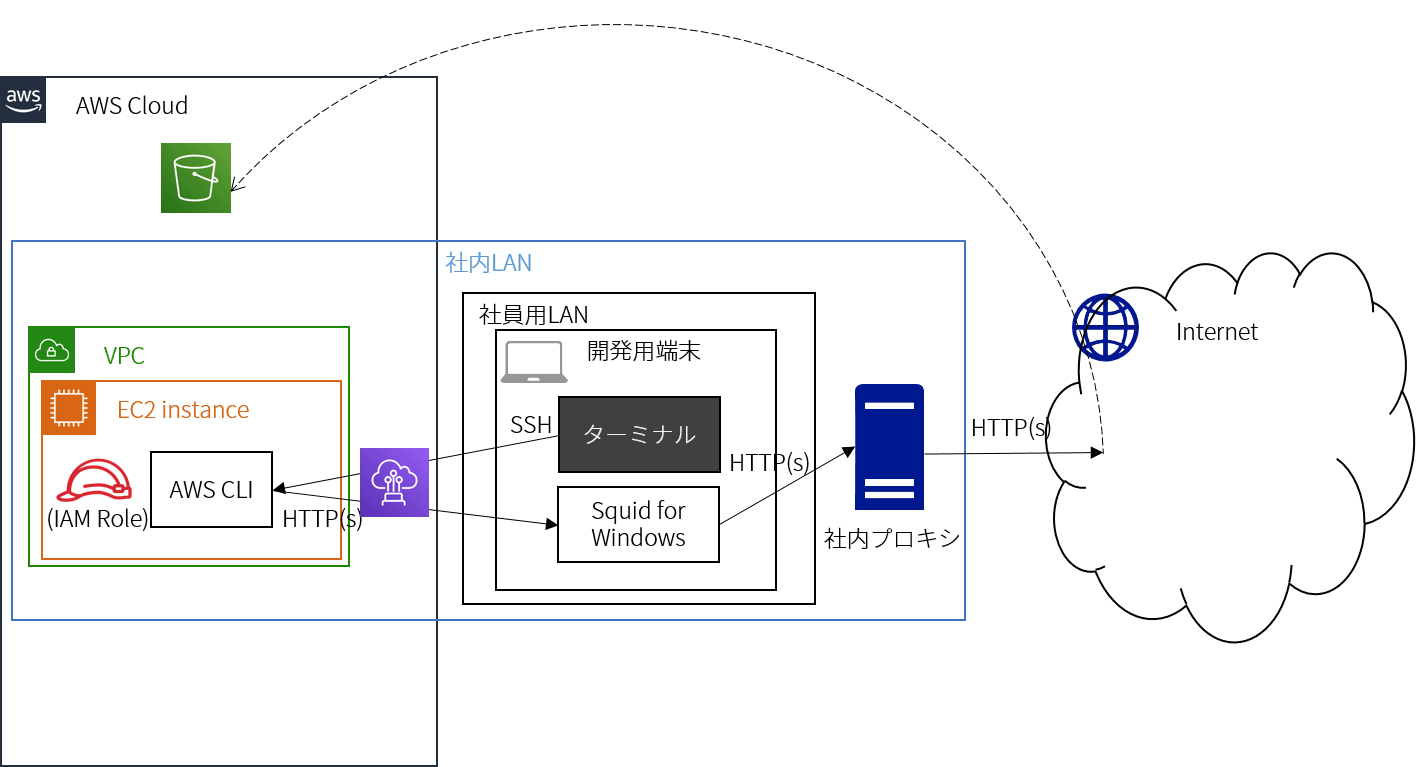
AWS CLIを使うには社内プロキシを突破してインターネットへ出る必要がありますが、まあSquidを活用した多段プロキシ構成で切り抜けれるだろうと思い作業を開始しました。構成・通信の概略を示すと次の通りです。(あくまで概略です。)
AWS CLI自体にはそこそこ慣れているつもりで楽に準備ができるのではと思ったが、その思い上がり故に落とし穴に引っかかる私でありました…。
ハマりポイント その1 AWS CLIを使うには
no_proxy=169.254.169.254が必要AWS CLIがプリインストールされたEC2インスタンスにIAMロールを付与して…。
インスタンスが起動したらプロキシ設定して…。$ export http_proxy=http://(SquidのホストIP):(Squidで開けているport) $ export https_proxy=http://(SquidのホストIP):(Squidで開けているport) $ export no_proxy=localhost,127.0.0.1いざ
aws s3 ls!$ aws s3 ls Unable to locate credentials. You can configure credentials by running "aws configure".ん?ちゃんとIAMロール付けてるんですが…。
$ aws configure list Name Value Type Location ---- ----- ---- -------- profile <not set> None None access_key <not set> None None secret_key <not set> None None region ap-northeast-1 config-file ~/.aws/config一旦ターミナルを落として一呼吸。
もう一度AWS CLIの設定を確認。$ aws configure list Name Value Type Location ---- ----- ---- -------- profile <not set> None None access_key ******************** iam-role secret_key ******************** iam-role region ap-northeast-1 config-file ~/.aws/configターミナルを落とした…、まさか!
exportコマンドで環境変数をいじったことが影響しているのだろうか?$ export hoge=fuga $ aws configure list Name Value Type Location ---- ----- ---- -------- profile <not set> None None access_key ******************** iam-role secret_key ******************** iam-role region ap-northeast-1 config-file ~/.aws/config変わらない…。
ということはプロキシの影響か…、しかしAWS CLIってインターネットへの接続が必要だよな…。調べてみたところ
169.254.169.254へのアクセスをプロキシ経由で行わないように設定する必要があるようです。
唐突に謎のIPアドレスが出てきたぞ!?と思ったのですが、169.254.169.254へはインスタンスメタデータを取得するためにアクセスするらしいです。
インスタンスメタデータというのは、その動いているインスタンスに関するデータで、実行中のインスタンスを設定または管理するために使用されるものとのことでした。
そして、インスタンスメタデータへのアクセスはそのインスタンス内からのみアクセスが許可されているということだそうです。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/ec2-instance-metadata.htmlということで、no_proxy設定を追加。
$ export no_proxy=localhost,127.0.0.1,169.254.169.254ハマりポイント その2 SquidでSSL通信をするには
never_direct allow CONNECTの設定が必要今度こそ
aws s3 ls!
…レスポンスが返ってこない。
curl http://www.google.comはレスポンスが返ってくる。
AWS CLIはhttps通信らしいので、
curl https://www.google.comを実行すると…、あれ?返ってこない。Squidのログを見ると503で弾きましたというログが残っている…。
開けてるポートの問題か?もしかして社内プロキシに弾かれて503になっている?
色々想像しましたが、SquidのデフォルトではSSL通信を直接接続しようとするらしいです。
私のググり力が欠如しておりこの辺りの情報がやや少なく、この情報にたどり着くまで紆余曲折を経たのですが、結局この設定をSquidに入れれば解決でした。squid.confnever_direct allow CONNECT結局どのような手順で設定するか
Windows端末にSquidをインストール
- squid.diladele.comからWindows用インストーラをダウンロード・インストール
※Squid for Windowsはそれなりに実績もあり信頼はできるのですが、squid-cache.orgによる公式の提供はLinux版のみのようなので、あくまで自己責任でのご利用をお願いいたします。
- Squidを起動
- 右下のSquidのアイコンをクリックして
Open Squid Configurationをクリック- 以下の設定を変更
squid.conf(略) # Squid normally listens to port 3128 http_port (競合しない任意のport番号) # ←わざわざ変えなくても結構ですが念の為 (略) dns_nameservers (社内でご利用のDNSサーバのIPアドレス) (略)
- 以下の設定を末尾に追加
squid.confcache_peer (社外へ出るためのプロキシのホスト名もしくはIPアドレス) parent (社外へ出るためのプロキシのport番号) 0 no-query no-netdb-exchange no-digest login=(社外へ出るためのプロキシのID):(社外へ出るためのプロキシのPassword) default cache deny all never_direct allow all never_direct allow CONNECT # ←今回のハマりポイント2
- 設定ファイルを保存
- 右下のSquidのアイコンをクリックして
Stop Squid Service→Start Squid Serviceで再起動IAMロール付きEC2インスタンス作成
(簡易な記述ですみません…。)
- EC2インスタンス用のIAMロールを適切なポリシーを付与して作成
- AWS CLIがプリインストールされているイメージからEC2インスタンスを作成
- EC2インスタンスにIAMロールをアタッチ
EC2インスタンス側での設定
- EC2インスタンスにSSH接続
- プロキシ設定を実施
$ export http_proxy=http://(SquidをインストールしたWindows端末のIP):(Squidで開けているport) $ export https_proxy=http://(SquidをインストールしたWindows端末のIP):(Squidで開けているport) $ export no_proxy=localhost,127.0.0.1,169.254.169.254 # ←今回のハマりポイント1最後に
AWS CLIの話とSquidの話をしましたが、設定にしてみたらこんな少しの設定の話です。
でもそんな少しの設定でも色々な学びがあるんだなあと痛感しました。
あと、Squidは使い終わったらこまめにOFFにするようにしましょう。念の為。
気になったところやうまく行かない点などあれば是非コメント下さい。
- 投稿日:2020-07-03T13:07:28+09:00
【Laravel】No connections available in the pool...の原因と対処法
はじめに
Laravelにて開発中、以下のようなエラーが発生したため、その原因と対処法を簡単に記します。
laravel.logNo connections available in the pool {"exception":"[object] (Predis\\ClientException(code: 0): No connections available in the pool at /var/www/application/vendor/predis/predis/src/Connection/Aggregate/RedisCluster.php:337)...エラーメッセージより
Redisの接続に異常がある
と見当がつく。
原因
Redisへの接続情報に誤りがあった。
具体的には、Redisのホスト名が誤っていた。
根本原因は、AWS Systems Managerのパラメータストアで管理していた、Redisのホスト名に関する変数の値が古いままとなっていた。対処法
- Laravelの.envを確認。
- Redis接続情報とAWSのElastiCacheにて使用しているRedis情報を照合。
- ホスト名に誤り発見。「REDIS_HOST=」の部分。
- Laravelの.env修正。
- しかし直らず。
- Laravelの.envの作成元であるphp-fpmを確認。
- 該当部分の設定も変更。同じく「REDIS_HOST=」の部分。
- php-fpm再起動。
sudo service php-fpm restart- 直った。
蛇足
php-fpm管理の環境変数初期設定にはAWS Systems Managerを利用していた。
当エラー発生前にEC2インスタンスの再起動が発生しており、AWS Systems ManagerのRedisホスト名が古いままであり実際の値と異なっていたため、Redisへの接続に不具合が生じることとなった。
よって根本解決として、AWS Systems ManagerのRedisホストの変数名を新しいものへと変更した。終わりです。
- 投稿日:2020-07-03T13:07:28+09:00
【Laravel × Redis】No connections available in the pool...の原因と対処法
はじめに
Laravelにて開発中、以下のようなエラーが発生したため、その原因と対処法を簡単に記します。
laravel.logNo connections available in the pool {"exception":"[object] (Predis\\ClientException(code: 0): No connections available in the pool at /var/www/application/vendor/predis/predis/src/Connection/Aggregate/RedisCluster.php:337)...エラーメッセージより
Redisの接続に異常がある
と見当がつく。
原因
Redisへの接続情報に誤りがあった。
具体的には、Redisのホスト名が誤っていた。
根本原因は、AWS Systems Managerのパラメータストアで管理していた、Redisのホスト名に関する変数の値が古いままとなっていた。対処法
- Laravelの.envを確認。
- Redis接続情報とAWSのElastiCacheにて使用しているRedis情報を照合。
- ホスト名に誤り発見。「REDIS_HOST=」の部分。
- Laravelの.env修正。
- しかし直らず。
- Laravelの.envの作成元であるphp-fpmを確認。
- 該当部分の設定も変更。同じく「REDIS_HOST=」の部分。
- php-fpm再起動。
sudo service php-fpm restart- 直った。
蛇足
php-fpm管理の環境変数初期設定にはAWS Systems Managerを利用していた。
当エラー発生前にEC2インスタンスの再起動が発生しており、AWS Systems ManagerのRedisホスト名が古いままであり実際の値と異なっていたため、Redisへの接続に不具合が生じることとなった。
よって根本解決として、AWS Systems ManagerのRedisホストの変数名を新しいものへと変更した。終わりです。
- 投稿日:2020-07-03T11:19:01+09:00
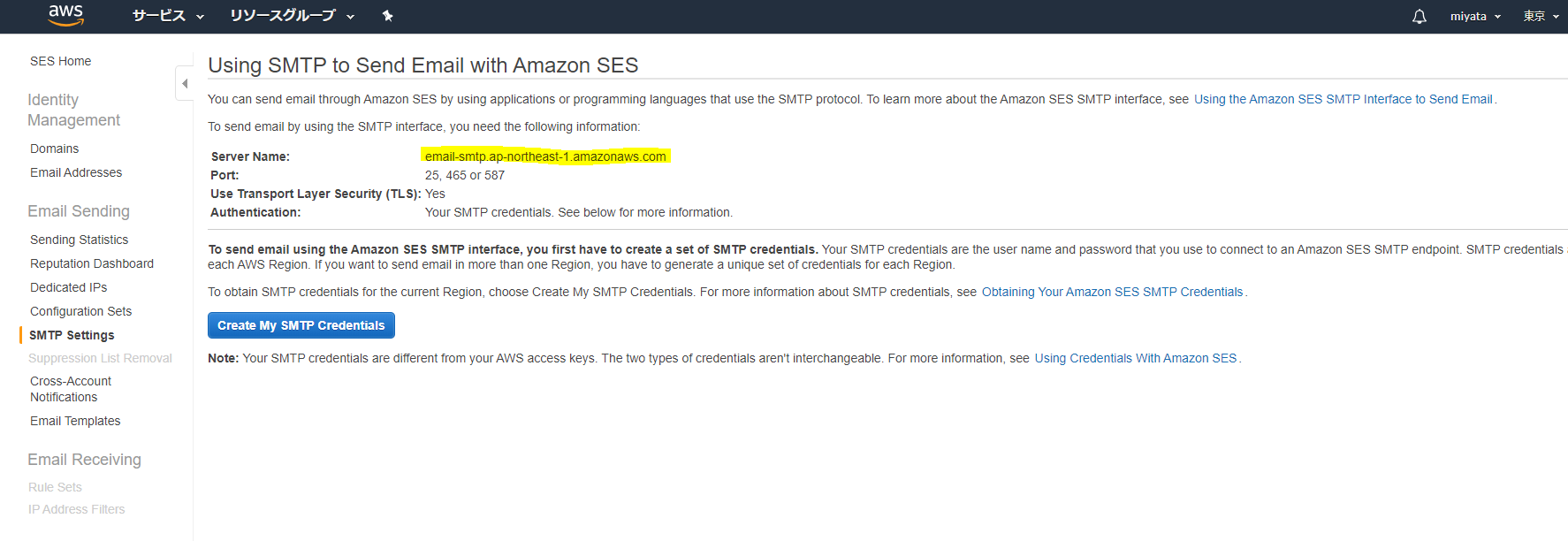
Amazon Simple Email Service が、アジアパシフィック (東京)リージョンで利用可能に!!!!!!
Amazon Simple Email Service が、米国東部 (オハイオ)、アジアパシフィック (シンガポール)、アジアパシフィック (東京)、およびアジアパシフィック (ソウル) リージョンで利用可能に
このリンクだけで話が終わってしまうんですが。
何が凄いって、もうこれで他のサービスは全部東京リージョンなのに、SESだけバージニアとかいう提案書を書かなくてもいい…楽。
たまにother serviceとか書いて、リージョン外に置いてる人見かけるけど顧客がグローバルサービスと勘違いするからやめて欲しいちゃんとap-northeast-1になってる!
ちゃんとap-northeast-1になってる!!!!
最近、AWSが日本リージョンに優しくて嬉しいですね。
Amazon Lexも早くリージョン対応だけじゃなく日本語化対応して欲しい…。おまけ
AWS CLIで東京リージョン指定してSES送っても、ちゃんと届く…!!


- 投稿日:2020-07-03T11:04:10+09:00
aws-lambda-redshift-loaderでS3とRedshiftを連携する
概要
https://github.com/awslabs/aws-lambda-redshift-loader を利用してS3とRedshiftを連携する時の手順についてのメモです。これを用いる事で、S3にCSVファイルを置くだけで、自動的にRedshiftにそのCSVをINSERTしてくれるようになります。基本的に上記のREADMEを読んで、実行していけば良いだけなのですが何点かつまづいたのでそれをメモしておきます。今後同じ事をする際に参考になれば幸いです。
前提
今回の例では既にVPCやサブネットがある状態で構築していきます。またCloud Formationで環境を構築しますが、実行するユーザーは必要な権限が与えられている(具体的にはAdministratorAccessが付与されている)状態で行ってます。利用したaws-lambda-redshift-loaderのバージョンは2.7.3になります。また途中でnode.jsを利用する部分があり、ローカルでnode.jsの最新が動くようにセットアップされており、ローカルからAWS CLIを実行できるように設定済みとします。
事前準備
ReadMeのPre-workの所にあたります。
まずKMSのキーが必要なので作ります。aliasは必ずLambdaRedshiftLoaderKeyという名前である必要があるのでそうします。
あと既存VPC内で作成する場合にはCloudFormationで以下の三つのパラメータを求められます。
- KmsKeyArn
- The KMS Key to use for Encryption of the database password
- SecurityGroups
- Security Groups as CSV list to use for the deployed function (may be required for Redshift security policy)
- SubnetIds
- List of private Subnets in VPC in which the function will egress network connections
KmsKeyArnは作成したキーのARNを入れればOKです。SecurityGroupsは理解があっているか自信がないのですが、Lambdaを実行する際に実行を許可するセキュリティグループという意味合いのはずです。今回はlambda-redshift-loaderという名前で新規作成して、VPCからのみアクセス許可で設定をしています。SubnetIdsはそのまま利用するサブネットIDを記載すればOKです。
環境構築
ここに関しては上記パラメータを登録して、CloudFormationを実行させるだけです。ReadMeの中からap-northeast-1、Launch in VPCの物を実行させます。ここは特に詰まる事なく完了しました。
設定作成
ReadMeのPost Installにあたります。この後設定ファイルを作成するのですが、設定ファイルを作成するためのEC2を作るためのCloudFormationもReadMe中に記載されています。今回ではローカルでできたのでローカルで実行させます。
手順としてはGitからレポジトリをクローンし、node setup.jsを実行すると設定等を色々聞かれ、正常に実行されると設定が反映されます。なおこの方法だと、入力を途中で間違えると全部やり直しになるので入力内容をあらかじめ準備して置く事をお勧めします。なお、今回は試していませんがReadMeによるとnode.jsで直接セットアップの関数を実行させる方法も書かれています。
項目の詳細や必須かどうかはReadMeのConfiguration Referenceに書かれています。
これを読んでおかないと非常にわかりづらいです。以下が入力例です。注意点としてもしACSESS KEYがNULLだったらという記述があるのですが、NULLという文字を入力すると動ず空欄にするのが正しいです。
Enter the Region for the Configuration > ap-northeast-1 Enter the S3 Bucket & Prefix to watch for files > (バケット名)/(設定したいディレクトリ 例:data/analysis1) Enter a Filename Filter Regex > (空欄) Enter the Cluster Endpoint > (redshiftのクラスターエンドポイント 例:example.xxxxxxxxxxxx.ap-northeast-1.redshift.amazonaws.com ) Enter the Cluster Port > (redshiftのポート、変えてないので5439) Does your cluster use SSL (Y/N) > N Enter the Database Name > (redshiftのDB名) Enter the Table to be Loaded > (redshiftのDB名) Enter the comma-delimited column list (optional) > (空欄) Should the Table be Truncated before Load? (Y/N) > (データを入れる際にTruncateするかなので注意、Nで設定) Enter the Database Username > (redshiftのDBユーザ名) Enter the Database Password (will be displayed, but encrypted before storing) > (redshiftのDBパスワード) Enter the Data Format (CSV, JSON, AVRO, Parquet, and ORC) > CSV Enter the CSV Delimiter > , Ignore Header (first line) of the CSV file? (Y/N) > (1行目を含めるか、今回は含めないようにしてCSVを作ったのでYを設定) Enter the S3 Bucket for Redshift COPY Manifests > (COPY ManifestsをおくS3バケット、データと同じバケットにしてディレクトリを分けた) Enter the Prefix for Redshift COPY Manifests > manifest/success Enter the Prefix to use for Failed Load Manifest Storage (must differ from the initial manifest path) > manifest/failed Enter the Access Key used by Redshift to get data from S3. If NULL then Lambda execution role credentials will be used > (空欄) Enter the Secret Key used by Redshift to get data from S3. If NULL then Lambda execution role credentials will be used > (空欄) Enter the SNS Topic ARN for Successful Loads > (空欄) Enter the SNS Topic ARN for Failed Loads > (空欄) How many files should be buffered before loading? > (処理スピードに関わるのだろうが、一旦1に設定) Batches can be buffered up to a specified size. How large should a batch be before processing (bytes)? > (空欄) How old should we allow a Batch to be before loading (seconds)? > (空欄) Additional Copy Options to be added > (空欄) If Encrypted Files are used, Enter the Symmetric Master Key Value > (空欄)以上が正常に実行されれば動くはずです。動かない場合はDynamoDBにエラーが蓄積されているので原因はそこで確認できます(あまりわかりやすいエラーではなく、nodeのエラーを読み解く必要があります)。
設定に関してはディレクトごとに保存されているようで、ディレクトリ名を同じにすれば間違った設定をしても上書きすることができるようです。設定に関してもDynamoDBに入っているので、そこから変更できそうなのですが変更したらうまく動かなくなったりしたのでsetup.jsからやる方が良さそうです。まとめ
以上、十分手軽ですが色々と設定を変えようとしたりしたりとか、あまりAWSの知見がない状態だとそこそこ手がかかる部分もあるかと思います。ただ、仕組みが出来上がった後は非常に楽なので、是非試していただければと思います。この記事が参考になれば幸いです。
参考
- aws-lambda-redshift-loader
- Amazon Redshiftとデータ連携を行う各種サービスについて整理してみた
- 様々なRedshiftとの連携方法がまとめられています。
- 管理不要なAmazon Redshift Database Loader
- ReadMEが日本語訳されています。
- 投稿日:2020-07-03T10:58:38+09:00
EC2、RDSを利用してRailsアプリをデプロイする [NGINX + puma + PostgreSQL + Rails 6]
目標:AWSのEC2、RDSを利用してRailsアプリをデプロイする
- Railsチュートリアルをより実践的な環境、Ultimate Hard Modeで挑みたい
- NGINX, puma, PostgreSQL, Rails 6で開発〜デプロイ
- ローカル開発環境へ移行 はじめてのDockerでRails開発環境構築 [NGINX + Rails 5 (puma) + PostgreSQL] - Qiita
- 脱Herokuで模擬CI/CD環境を取り入れたい(この後自動デプロイまでいきたい)
- AWSを利用した、より実践的な本番環境構築のウォームアップ
このような目的のため、とりあえずAWS上でアプリが動くことを目標にしています
そのためセキュリティ面で本来必要そうな手順(環境変数定義や、SSL対応)を排除して進行しております備忘録的に記録を残しておりますので、
思い出したことや、不備あれば随時訂正いたします気づき
環境構築は学習コスト(時間)高い、けど仮想環境なら壊しても怒られないし、やってみようでなんとかなる
作ったアプリが最終的にどのような環境で動くのか、開発にトップダウンの視点が加わる
AWSの無料範囲内で学べる、学習コスト(マネー)低すぎる
環境
AWS EC2 (amazon linux2)
AWS RDS (PostgreSQL 11.6)
NGINX: 1.12.2
puma: 3.12.1
Rails: 6.0.0
Ruby: 2.6.3
備忘録
前提
- EC2インスタンスが稼働している
- VPCはインターネット接続が可能(セキュリティグループ、サブネット、ルートテーブルの設定が適切)
- EC2インスタンスとローカル環境はSSH接続が可能(鍵認証)
- root権限をもつユーザーを作成しログインしていること
- RDSでデータベースインスタンスを作成している(今回はPostgreSQL 11.6, 初期データベースsample_app_production)
- EC2はGitHubと接続しており、
/var/www/railsディレクトリにgit cloneでアプリを設置済み- master.keyを設定済み
参考:上記については以下のサイトを参考に進めました、感謝。
(DBの選定、設定の部分が異なっております)
【画像付きで丁寧に解説】AWS(EC2)にRailsアプリをイチから上げる方法【その1〜ネットワーク,RDS環境設定編〜】 - Qiita
パッケージのアップデート
まずは
sudo yum updateNGINXインストール
amazon-linux-extrasからインストール可能sudo amazon-linux-extras install nginx1.12 -y起動と自動起動設定
sudo systemctl start nginx && sudo systemctl enable nginx && systemctl status nginxこの時点でブラウザからEC2のElastic IPにアクセスすると
"Welcome to nginx on Amazon Linux!"というページが表示される(NGINXがポート: 80ポートで待ち受けている)参考: NGINX関連コマンド
起動終了
$ sudo systemctl start nginx $ systemctl status nginx ● nginx.service - The nginx HTTP and reverse proxy server . . . [sample_app@ip-10-0-0-44 rails]$ sudo systemctl stop nginx自動起動
sudo systemctl enable nginxPostgreSQL(クライアント)をインストール
sudo amazon-linux-extras install postgresql11参考:クライアント以外もインストールする
sudo yum install postgresql-server postgresql-devel postgresql-contrib参考:
amazon-linux-extrasを使わない方法やアンインストールなどEC2(Amazon Linux2)にPostgreSQLをインストールする | my opinion is my own
PostgreSQL install Amazon linux2
Amazon linux2にpostgresqlをインストールする手順 | 瀬戸内の雲のようにPostgreSQL install
PostgreSQL: Linux downloads (Red Hat family)PostgreSQL uninstall
How To Completely Uninstall PostgreSQL | ObjectRocketPostgreSQLに接続
PostgreSQLクライアントであるpsqlからRDSに作成したDBインスタンスに接続
psql --host=<DBインスタンスのエンドポイント> --port=5432 --dbname=sample_app_production --username=sample_app --port=5432 --dbname=sample_app_production --username=sample_app ユーザ sample_app のパスワード: psql (11.5、サーバ 11.6) SSL 接続 (プロトコル: TLSv1.2、暗号化方式: ECDHE-RSA-AES256-GCM-SHA384、ビット長: 256、圧縮: オフ) "help" でヘルプを表示します。 sample_app_production=>RDSに接続可能なこと、初期データベースが存在することが確認できれば問題ないです
参考:AWS RDS公式
PostgreSQL データベースエンジンを実行する DB インスタンスへの接続 - Amazon Relational Database Service
psql を使用した PostgreSQL DB インスタンスへの接続
psql コマンドラインユーティリティのローカルインスタンスを使用して、PostgreSQL DB インスタンスに接続できます。PostgreSQL またはクライアントコンピュータにインストールされた psql クライアントのいずれかが必要です。psql を使用して PostgreSQL DB インスタンスに接続するには、ホスト情報とアクセス認証情報を指定する必要があります。
以下の形式のいずれかを使用して、Amazon RDS 上の PostgreSQL DB インスタンスに接続します。接続時にパスワードを求められます。バッチジョブまたはスクリプトには、
--no-passwordオプションを使用します。この DB インスタンスに初めて接続する場合、デフォルトのデータベース名 *postgres** を
--dbnameオプションに使用してみてください。*Unix の場合、次の形式を使用します。
psql \ --host=<DB instance endpoint> \ --port=<port> \ --username=<master user name> \ --password \ --dbname=<database name>(中略)
たとえば、次のコマンドは、架空の認証情報を使用して、
mypgdbという PostgreSQL DB インスタンス上のmypostgresqlというデータベースに接続します。psql --host=mypostgresql.c6c8mwvfdgv0.us-west-2.rds.amazonaws.com --port=5432 --username=awsuser --password --dbname=mypgdb参考:psql認証のtrust, ident, md5
RDSでDBインスタンスを作成したときの情報を使用します
接続認証にOSのユーザー名とDBのユーザー名の一致を求める仕組みがあるようですが
RDSとのhost-client接続ではユーザー名が違ってもパスワード認証で問題なかったですPostgreSQL 認証に失敗しないための Ident、MD5、Trust 比較 - eTuts+ Server Tutorial
うまくいかない時は
タイムアウトしてしまい、認証に至らない(超重要)
セキュリティグループの設定を確認する
私はアウトバウンドの設定が必要でした(控えめに言って半日悩んだ)
EC2からRDS(MySQL)に接続できない。セキュリティグループの設定について・・・ - Qiitaクライアント(EC2)とホスト(RDS)のPostgreSQLバージョンが異なる
amazon-linux-extrasを使用せずにインストールすると
クライアント側が古いバージョンになってしまうことがありました
(RDS側は初期設定のPostgreSQL 11.6)
古いバージョンのアンインストールをして、新しいものをインストールしてください警告: psql のメジャーバージョンは 9 ですが、サーバーのメジャーバージョンは 11 です。 psql の機能の中で、動作しないものがあるかもしれません。参考(メモ):以下はクライアントとしてpsqlを利用するだけなら関係ないかも
設定ファイルの場所
postgresql.conf
sudo vi /var/lib/pgsql/data/postgresql.confpg_hba.conf(認証関係)
sudo vi /var/lib/pgsql/data/pg_hba.confユーザーpostgresのパスワードがわからない
途中自動生成されたユーザーpostgresのpasswordがわからず再設定しました
Postgresでパスワードを忘れた場合の対策 - Qiitalocal(EC2)にDBを設置する場合のコマンドメモ
$ sudo postgresql-setup initdb $ sudo systemctl enable postgresql.service $ sudo systemctl start postgresql.servicePostgreSQLの設定をする
config/database.ymlを編集default: &default adapter: postgresql encoding: unicode username: postgres password: password pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> timeout: 5000 development: <<: *default host: db database: myapp_development test: <<: *default host: db database: myapp_test production: <<: *default database: sample_app_production username: postgres # RDS DBインスタンスのユーザー名 password: password # RDS DBインスタンスのパスワード host: xxxx.xxxx.ap-northeast-1.rds.amazonaws.com # RDS DBインスタンスのエンドポイント本来ここに平文でユーザー名やパスワードを記録しないほうがよい
productionの
<<: *defaultが抜けていてadapterが指定されていないよと半日怒られ続けました...
"adapterActiveRecord::AdapterNotSpecified: database configuration does not specify adapter"hostを指定していればportの指定は不要でした
参考:database.ymlのPostgreSQL向け設定情報 ActiveRecord::ConnectionAdapters::PostgreSQLAdapter
NGINXの設定をする
dockerで環境構築したものが引き継がれたらいいのに...
pumaとsocket接続するようにしています
/etc/nginx/conf.d/sample_app.confを作成、編集
vi /etc/nginx/conf.d/sample_app.conferror_log /var/www/rails/sample_app/log/nginx.error.log; access_log /var/www/rails/sample_app/log/nginx.access.log; ##ココ upstream sample_app { server unix:///var/www/rails/sample_app/tmp/sockets/puma.sock; } server { listen 80; client_max_body_size 4G; server_name 54.238.15.249; keepalive_timeout 5; # Location of our static files root /var/www/rails/sample_app/public; location ~ ^/assets/ { root /var/www/rails/sample_app/public; } location / { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; if (!-f $request_filename) { proxy_pass http://sample_app; break; } } error_page 500 502 503 504 /500.html; location = /500.html { root /var/www/rails/sample_app/public; } }NGINX再起動
sudo systemctl restart nginx参考:NGINXコマンドほか
自動起動設定
sudo chkconfig nginx onpumaの設定をする
アプリケーションサーバーとしてunicornは使用しません
Railsに組み込まれているpumaを利用してみますNGINXとpumaはソケット接続するため
config/puma.rbに以下を2点編集
(私はDockerで開発環境をNGINX + pumaに設定をした時点で設定済みでした)# ポート: 3000をlistenしない #port ENV.fetch("PORT") { 3000 } # socketの設定 bind "unix://#{Rails.root}/tmp/sockets/puma.sock"参考:puma.rbの設定 puma/dsl.rb at master · puma/puma
参考:puma関連コマンド
production環境でpuma起動
bundle exec rails s -e productionpuma, pumactlコマンドは私の環境では使えませんでした
bundle exec pumactl startPumaの起動におけるpumaコマンドとpumactlコマンドの違い - Qiita
pumaコマンドとpumactlコマンドの違い
このあたりちゃんと説明した日本語の情報がとても少なくて、リポジトリのREADMEを読んだり「what is deference between puma command and pumactl command」みたいなキーワードでがんばって調べたらRuby Journalになんかそれっぽいことが書いてあった。英語ができないととてもつらい。
As we can see that above operations can be tedious and error prone and definitely not fun to work with a big deployment scale. Introducing pumactl, this utility automates all of above tasks.
Digesting Pumactl要するに、pumaコマンドで起動したりしてるといちいちオプション付けないといけないから大規模開発だとめっちゃつらいしやばいくらい闇だし、pumaコマンドでやってることはpumactlコマンドで自動化しような。ということを言っている。
なるほど、確かに。pumactlコマンドだと問答無用で設定ファイルが読まれるようになっているから、スレッドの数はどうするんだだの、ポート番号はどうするんだだの、ちゃんとコードで管理できる。
停止や再起動においてもpumactlコマンドで安全にできるらしい。
Available commands: halt, restart, phased-restart, start, stats, status, stop, reload-worker-directory
YarnとNodeをインストール、アップデート
Rails 6以降で必要
以降の過程でYarnが必要、nodeが古いと言われますYarn
# wgetインストール済みなら省略可能 $ yum -y install wget $ wget https://dl.yarnpkg.com/rpm/yarn.repo -O /etc/yum.repos.d/yarn.repo $ curl --silent --location https://rpm.nodesource.com/setup_6.x | bash - $ sudo yum install yarn $ yarn --version 1.22.4Node
$ sudo npm install n -g $ sudo n stable $ node -v v12.18.2参考:capistrano・EC2・postgresql・rails6で自動デプロイ設定した際のエラー例 - Qiita
アプリを起動させる
マイグレーション、アセットプリコンパイル
# マイグレーション bundle exec rake db:migrate RAILS_ENV=production # プリコンパイル bundle exec rake assets:precompile RAILS_ENV=productionWebサーバー、アプリケーションサーバー起動
# NGINX再起動 sudo service nginx restart # puma起動 bundle exec rails s -e production問題なければブラウザからElastic IPにアクセスすることで、
アプリのインターフェイスが表示されるはずです"We're sorry, but something went wrong."
もうね、怒られるのなれましたよ
ブラウザにに上記メッセージが表示される場合ログを確認しましょう
cd log # アプリルート直下 tail -n 30 production.log tail -n 30 nginx.error.log私の場合
production.logは空っぽで
nginx.error.logで以下のエラーが記録されていました"connect() to unix:/home/var/www/rails/sample_app/tmp/sockets/puma.sock failed (2: No such file or directory) while connecting to upstream"
/etc/nginx/conf.d/sample_app.confのsocketパス指定が間違っておりました
その他既知の問題点
SSL非対応
config/environments/production.rbのconfig.force_ssl = trueをconfig.force_ssl = falseに新規ユーザー登録のところでメール認証がうまく行かない
今後対応
- 投稿日:2020-07-03T09:33:49+09:00
最短でAWS初心者(未経験含む)がソリューションアーキテクトアソシエイト(SAA)を取得するためにやること2選
こんにちは、みきおです。
タイトルの通り、初心者(未経験)だけどとにかく効率的にソリューションアーキテクトアソシエイト(SAA)を取得したい人の養分になればと思います。対象
- 初心者(未経験)だけどSAAを取得したい人
- とにかく効率重視でSAAを取得したい人
- SAAを取得したい人
- Black Belt?なにそれ?だけどSAAを取得したい人
- 他の人がどんな勉強をしたか参考にしたい人
はじめに
SAAを取得するためにやるべきことは大きく3つのステップに分けられます。
- AWSサービス群の全体の把握
- 各サービスの詳細の把握
- 試験対策
上記のうち、各サービスの詳細の把握と試験対策についてだいぶ被るので一つにまとめます。
1. AWSサービス群の全体の把握
AWS認定アソシエイト3資格対策
をおすすめします。
3資格対策と銘打たれていますが、デベロッパーアソシエイトでは不十分でした。SAAについても1下記書籍オンリーでは未経験者にはきついと思いますので、下記に続きます。2. 各サービスの詳細の把握と試験対策
Udemyのソリューションアーキテクトアソシエイトの試験対策にて模擬試験を周回します。
全65問を回答後に各設問に対する答えと詳細な解説がついてきます。解説で理解できない部分をググるなりすると理解が深まってくるかと思います。
1周以上がマストで2周以上80~90%の正解率が出せればベストです。
心配性な方はUdemyのハンズオンもやってみてもいいかもしれませんが、動画が待ってられなかったのと聞き取りづらい箇所があったので私はあまりお勧めしませんしやってません。さいごに
勉強時間などを書いておきます。
平日:約1時間(だいたい週4ほど)
休日:約2~6時間
32~68時間くらいなので間をとって50時間くらいかなと思います。配分は書籍(全体の把握)と模擬試験で半々くらいだったと思います。全体を把握するのに時間がかかりましたが、覚えがはやい方はもう少し短時間で済むかもしれません。
2020年4月ごろから勉強を始め、試験2週間前くらいから焦って本腰を入れて勉強し6月6日に取得しましたが計画的にやれば1か月では取得できるかと思います。
ちなみに1問1答形式でWEBに無料で公開してくれているサイトがあり、当初はできるだけお金をかけたくないとそれもやりこみましたが、必要経費とみなしてさっさとUdemyの模擬試験をやり込んでおけばよかったと思ってます。多数の方が書かれていますが、Udemyはセールをやっているタイミング2で購入するのがベストです。
デベロッパーアソシエイトの取得はオンライン試験を受けたので、その際の様子も今後記事にしたいと思います。
ちなみにSAA取得後にlambdaとdynamodbをバックにしたWEBアプリを作りました。その後デベロッパーアソシエイトを受験しています。
WEBアプリの構成について簡易的ですが記事にしていますので、興味があればこちらもどうぞ。
これから個人開発をはじめてみようと思っている人へおすすめしたいアレコレ2020
- 投稿日:2020-07-03T09:33:31+09:00
Forward Security Hub Findings to Slack featuring Cross Account Cross Region
AWS Security Hub という便利なサービスがあります
今回はこのサービス自体の解説は省きます。簡単に言えばセキュリティが専門外の人間にもフレンドリーな心強い味方というところでしょうか※1。
想定読者の方が 複数アカウント、複数リージョンに同サービスを有効化 できていること、またはかかる前提知識があるものとして、そこから先のことをやります動機
こいつはいちリージョン毎にセッティングしていく必要があります。それがまあ頑張ってできたとしましょう。
マネジメントコンソール はたしかによくできています。
しかしだからといってそのままでは、複数アカウント、複数リージョンのマネジメントコンソールを人が温かく毎日毎日一つ一つ開いて見張ってないといけないのか、ということになってきます。 そんなことはやってられません。
折角 Findings が挙がってきていてもどれがどれだか手に負えず、めんどくさくなって結局見なくなったり中途半端になるようでは無意味だし、課金に見合いません。そこでまず対応を優先すべき深刻度の高い Findings を何らかの方法で一箇所に抽出、集約し、見やすくしたくなるのです。
今日の目標はそれです解決策の概要
具体的には、Slack の特定 Channel に配信させるのがいいのではと思いつきました。都合の良いことにもう中の人が作ってくれてます。
これと これ を入れていくことにしましょう
後者だけで OK です ※ 2020/07/03訂正Enabling AWS Security Hub integration with AWS Chatbot
https://aws.amazon.com/blogs/security/enabling-aws-security-hub-integration-with-aws-chatbot/
- Configure AWS Chatbot and Security Hub
- Configure a Slack client
- AWS Chatbot と Slack の関連付け
- Tie it all together
- CloudFormation stack の作成
- ここまでではまだ 手動で転送はできるが自動化まではされていない
- Bonus: Send all critical findings to Slack
- CRITICAL findings を slack に自動転送させる
CLI で全 region にやる
さて、詳しくはそれぞれのリンク先の説明に沿ってしっかり進めていただければと思います※2。
しかしですね、それをそのまま手でチマチマと全リージョンやっていくのは嫌ですよ。ですのでスクリプトにしますCLI で一気にやって いきます
- 但し複数リージョンに展開しようとした時、 本家のテンプレート ではうまくいかない場合があります
- そこでこのスクリプトでは次に示す課題を 解決したテンプレート を使っています
課題: 2つめ以降 の region で SecurityHub_to_AWSChatBot.yml が失敗する
SlackChannelConfigが以前に実施した他リージョンで設定済みのためとおもわれます。このオリジナルテンプレートのままでは進めません。仕方がないので このように します課題: Stack 削除時に AddCustomActionSHResource1 DELETE_FAILED になってしまう
LambdaCreateCustomActionのバグとみられる。修正していますマスターアカウントに展開していく
マスターアカウント でこれをやりましょう
そしてこのようになります
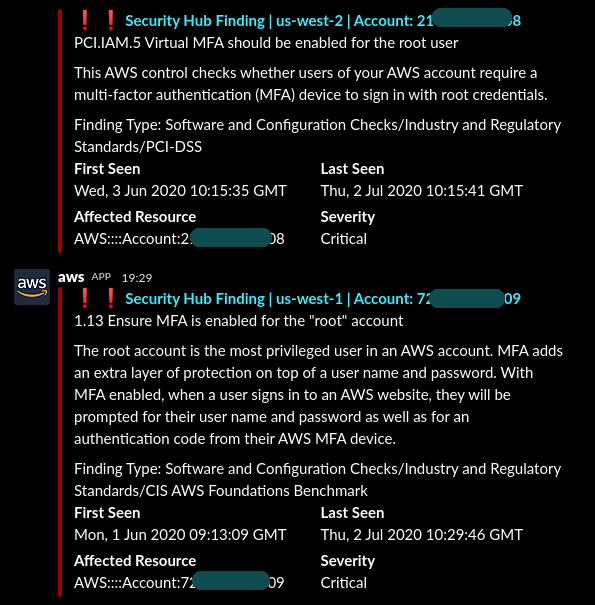
- 複数アカウント、 複数 region の CRITICAL な Findings が配信されてきているのがお分かりいただけるでしょうか。(深刻なアラートが出てしまってますが検証専用アカウントです)
- クロスアカウント: 今回紹介した手順はマスターアカウントだけでOK。マスターアカウントで既にメンバーアカウント群の Findings を集約できているから
- クロスリージョン: どの region も通知先として指定した Slack channel は同じなので、最終的にはみんなその channel に来るというわけ。
これでセキュリティチームが Security Hub について平時に注目しておけばよいポイントは、たった一箇所で済むことになりました※4。
抽出対象の深刻度の種類や下限は状況に応じて適宜調整しましょう
その先もどんどん効率よくしていき、安心安全な aws にしてゆきましょうnote
※1 攻撃を検知したり遮断してくれるのとはまた別です。あくまでも「セキュリティ標準に照らしてAWSの環境に芳しくない状態(Finding)があるからこうしたほうがいいよ」という示唆をしてくれるものです。いくら危ないからといってこのサービス自身が勝手にリソースに変更を加えたりすることは しません (Custom Action 等で任意のイベントドリブンは可能)。示唆から先の行動はユーザに委ねられます
※2 指定した Slack channel が private のときは /invite @AWS してください。これをしないと届きません
※3 ここでいうマスターアカウントは Organizations のそれ ではありません。ご注意ください
※4 但しこれだけではまたちょっと別の課題が残ります。 グローバルサービスを対象とした同じ内容の Findings が、リージョンの数だけ重複して送られてきてしまう、という点です。たとえば IAM 関係とか Root MFA 有効化しろ、みたいなのがですね。これについては素直にさっさと remediation に沿って解決させるか、重複しないようなんらかの修正を考えたほうがよいでしょう
※ 2020/07/03訂正 前者は Lambda function で WebHook を叩く仕様。これはこれで自由度は高いが、よりシンプルに SNS, Chatbot で実現できる方法+αとして後者が紹介されています

- 投稿日:2020-07-03T09:33:31+09:00
Forward Security Hub Findings to Slack featuring Cross-Account Cross-Region
AWS Security Hub という便利なサービスがあります
今回はこのサービス自体の解説は省きます。簡単に言えばセキュリティが専門外の人間にもフレンドリーな心強い味方というところでしょうか※1。
想定読者の方が 複数アカウント、複数リージョンに同サービスを有効化 できていること、またはかかる前提知識があるものとして、そこから先のことをやります動機
こいつはいちリージョン毎にセッティングしていく必要があります。それがまあ頑張ってできたとしましょう。
マネジメントコンソール はたしかによくできています。
しかしだからといってそのままでは、複数アカウント、複数リージョンのマネジメントコンソールを人が温かく毎日毎日一つ一つ開いて見張ってないといけないのか、ということになってきます。 そんなことはやってられません。
折角 Findings が挙がってきていてもどれがどれだか手に負えず、めんどくさくなって結局見なくなったり中途半端になるようでは無意味だし、課金に見合いません。そこでまず対応を優先すべき深刻度の高い Findings を何らかの方法で一箇所に抽出、集約し、見やすくしたくなるのです。
今日の目標はそれです解決策の概要
具体的には、Slack の特定 Channel に配信させるのがいいのではと思いつきました。都合の良いことにもう中の人が作ってくれてます。
これと これ を入れていくことにしましょう
後者だけで OK です ※ 2020/07/03訂正Enabling AWS Security Hub integration with AWS Chatbot
https://aws.amazon.com/blogs/security/enabling-aws-security-hub-integration-with-aws-chatbot/
- Configure AWS Chatbot and Security Hub
- Configure a Slack client
- AWS Chatbot と Slack の関連付け
- Tie it all together
- CloudFormation stack の作成
- ここまでではまだ 手動で転送はできるが自動化まではされていない
- Bonus: Send all critical findings to Slack
- CRITICAL findings を slack に自動転送させる
CLI で全 region にやる
さて、詳しくは
それぞれの上記の リンク先の説明に沿ってしっかり進めていただければと思います※2。
しかしですね、それをそのまま手でチマチマと全リージョンやっていくのは嫌ですよ。ですのでスクリプトにしますCLI で一気にやって いきます
- 但し複数リージョンに展開しようとした時、 本家のテンプレート ではうまくいかない場合があります
- そこでこのスクリプトでは次に示す課題を 解決したテンプレート を使っています
課題: 2つめ以降 の region で SecurityHub_to_AWSChatBot.yml が失敗する
SlackChannelConfigが以前に実施した他リージョンで設定済みのためとおもわれます。このオリジナルテンプレートのままでは進めません。仕方がないので このように します課題: Stack 削除時に AddCustomActionSHResource1 DELETE_FAILED になってしまう
LambdaCreateCustomActionのバグとみられる。修正していますマスターアカウントに展開していく
マスターアカウント でこれをやりましょう
そしてこのようになります
- 複数アカウント、 複数 region の CRITICAL な Findings が配信されてきているのがお分かりいただけるでしょうか。(深刻なアラートが出てしまってますが検証専用アカウントです)
- クロスアカウント: 今回紹介した手順はマスターアカウントだけでOK。マスターアカウントで既にメンバーアカウント群の Findings を集約できているから
- クロスリージョン: どの region も通知先として指定した Slack channel は同じなので、最終的にはみんなその channel に来るというわけ。
これでセキュリティチームが Security Hub について平時に注目しておけばよいポイントは、たった一箇所で済むことになりました※4。
抽出対象の深刻度の種類や下限は状況に応じて適宜調整しましょう
その先もどんどん効率よくしていき、安心安全な aws にしてゆきましょうnote
※1 攻撃を検知したり遮断してくれるのとはまた別です。あくまでも「セキュリティ標準に照らしてAWSの環境に芳しくない状態(Finding)があるからこうしたほうがいいよ」という示唆をしてくれるものです。いくら危ないからといってこのサービス自身が勝手にリソースに変更を加えたりすることは しません (Custom Action 等で任意のイベントドリブンは可能)。示唆から先の行動はユーザに委ねられます
※2 指定した Slack channel が private のときは /invite @AWS してください。これをしないと届きません
※3 ここでいうマスターアカウントは Organizations のそれ ではありません。ご注意ください
※4 但しこれだけではまたちょっと別の課題が残ります。 グローバルサービスを対象とした同じ内容の Findings が、リージョンの数だけ重複して送られてきてしまう、という点です。たとえば IAM 関係とか Root MFA 有効化しろ、みたいなのがですね。これについては素直にさっさと remediation に沿って解決させるか、重複しないようなんらかの修正を考えたほうがよいでしょう
※ 2020/07/03訂正 前者は Lambda function で WebHook を叩く仕様。これはこれで自由度は高いが、よりシンプルに SNS, Chatbot で実現できる方法+αとして後者が紹介されています
- 投稿日:2020-07-03T09:33:31+09:00
Foward Security Hub Findings to Slack featuring Cross Account Cross Region
AWS Security Hub という便利なサービスがあります
今回はこのサービス自体の解説は省きます。簡単に言えばセキュリティが専門外の人間にもフレンドリーな心強い味方というところでしょうか。 ※1
想定読者の方が 複数アカウント、複数リージョンに同サービスを有効化 できていること、またはかかる前提知識があるものとして、そこから先のことをやります動機
こいつはいちリージョン毎にセッティングしていく必要があります。それがまあ頑張ってできたとしましょう。
マネジメントコンソール はたしかによくできています。
しかしだからといってそのままでは、複数アカウント、複数リージョンのマネジメントコンソールを人が温かく毎日毎日一つ一つ開いて見張ってないといけないのか、ということになってきます。 そんなことはやってられません。
折角 Findings が挙がってきていてもどれがどれだか手に負えず、めんどくさくなって結局見なくなったり中途半端になるようでは無意味だし、課金に見合いません。そこでまず対応を優先すべき深刻度の高い Findings を何らかの方法で一箇所に抽出、集約し、見やすくしたくなるのです。
今日の目標はそれです解決策の概要
具体的には、Slack の特定 Channel に配信させるのがいいのではと思いつきました。都合の良いことにもう中の人が作ってくれてます。これ と これ を入れていくことにしましょう
How to Enable Custom Actions in AWS Security Hub
https://aws.amazon.com/blogs/apn/how-to-enable-custom-actions-in-aws-security-hub/
Step 1: Send to Email Custom Actionこれはメールの話なので省略- Step 2: Send to Slack Custom Action
- Step 3: Testing Custom Actions in AWS Security Hub
Enabling AWS Security Hub integration with AWS Chatbot
https://aws.amazon.com/blogs/security/enabling-aws-security-hub-integration-with-aws-chatbot/
- Configure AWS Chatbot and Security Hub
- Configure a Slack client
- AWS Chatbot と Slack の関連付け
- Tie it all together
- CloudFormation stack の作成
- Note: ここまでではまだ、 手動で転送はできるが自動化まではされていない
- Bonus: Send all critical findings to Slack
- CRITICAL findings を slack に自動転送させる
CLI で全 region にやる
さて、詳しくはそれぞれのリンク先の説明に沿ってしっかり進めていただければと思います。 ※2
しかしですね、それをそのまま手でチマチマと全リージョンやっていくのは嫌ですよ。ですのでスクリプトにしますCLI で一気にやって いきます
- 但し複数リージョンに展開しようとした時、 本家のテンプレート ではうまくいかない場合があります
- そこでこのスクリプトでは次に示す課題を 解決したテンプレート を使っています
課題: 2つめ以降 の region で SecurityHub_to_AWSChatBot.yml が失敗する
SlackChannelConfigが以前に実施した他リージョンで設定済みのためとおもわれます。このオリジナルテンプレートのままでは進めません。仕方がないので このように します課題: Stack 削除時に AddCustomActionSHResource1 DELETE_FAILED になってしまう
LambdaCreateCustomActionのバグとみられる。修正していますマスターアカウントに展開していく
マスターアカウント でこれをやりましょう
- これは冒頭で述べたとおり既に Security Hub のマスター・メンバー間の関係構築に成功しているマルチアカウント環境での話になります
- その有効化工程も ツールが公開 されていますが割愛
- ここでいうマスターアカウントは Organizations のそれ ではありません。ご注意ください
そしてこのようになります
- 複数アカウント、 複数 region の CRITICAL な Findings が配信されてきているのがお分かりいただけるでしょうか。(深刻なアラートが出てしまってますが検証専用アカウントです)
- クロスアカウント: 今回紹介した手順はマスターアカウントだけでOK。マスターアカウントで既にメンバーアカウント群の Findings を集約できているから
- クロスリージョン: どの region も通知先として指定した Slack channel は同じなので、最終的にはみんなその channel に来るというわけ。
これでセキュリティチームが Security Hub について平時に注目しておけばよいポイントは、たった一箇所で済むことになりました。 ※3
抽出対象の深刻度の種類や下限は状況に応じて適宜調整しましょう
その先もどんどん効率よくやっていき、安心安全な aws にしてゆきましょうnote
※1 攻撃を検知したり遮断してくれるのとはまた別です。あくまでも「セキュリティ標準に照らしてAWSの環境に芳しくない状態(Finding)があるからこうしたほうがいいよ」という示唆をしてくれるものです。いくら危ないからといってこのサービス自身が勝手にリソースに変更を加えたりすることはしません(Custom Action 等で任意のイベントドリブンは可能)。示唆から先の行動はユーザに委ねられます
※2 指定した Slack channel が private のときは /invite @AWS してください。これをしないと届きません
※3 但しこれだけではまたちょっと別の課題が残ります。 グローバルサービスを対象とした同じ内容の Findings が、リージョンの数だけ重複して送られてきてしまう、という点です。たとえば IAM 関係とか Root MFA 有効化しろ、みたいなのがですね。これについては素直にさっさと remediation に沿って解決させるか、重複しないようなんらかの修正を考えたほうがよいでしょう
- 投稿日:2020-07-03T06:01:36+09:00
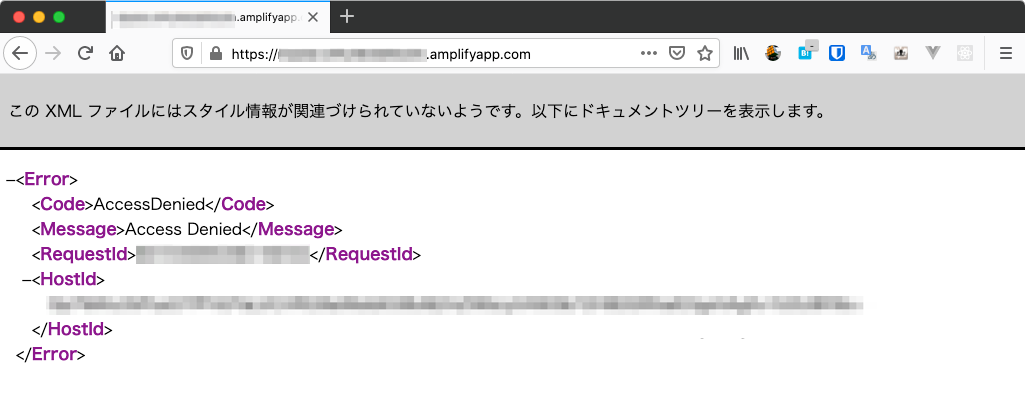
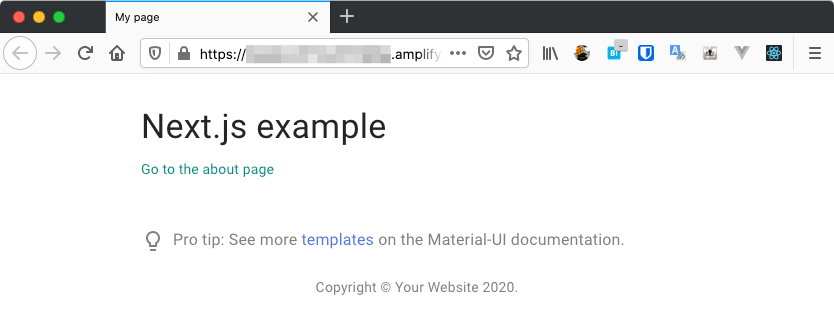
AWS AmplifyでhostingしたNext.jsのSPAが「403 Access Denied」となったときの対処法
Next.jsでSPAを作成してAWS Amplifyでhostingを試みたところ「403 Access Denied」が表示されました。
原因と対処法をまとめます。再現手順
Next.jsのアプリケーションは予め作成されており、Githubにpush済みであることを前提とします。
以下コマンドを実行して、プロジェクトを初期化します。
$ amplify init Note: It is recommended to run this command from the root of your app directory ? Enter a name for the project next-app ? Enter a name for the environment production ? Choose your default editor: Visual Studio Code ? Choose the type of app that you\'re building javascript Please tell us about your project ? What javascript framework are you using react ? Source Directory Path: src ? Distribution Directory Path: build ? Build Command: npm run-script build ? Start Command: npm run-script start以下コマンドを実行して、hostingを追加します。
$ amplify add hosting ? Select the plugin module to execute Hosting with Amplify Console (Managed hosting with custom domains, Continuous deployment) ? Choose a type Continuous deployment (Git-based deployments) ? Continuous deployment is configured in the Amplify Console. Please hit enter once you connect your repositoryAmplify Consoleの画面がブラウザで開くので、Github認証をしてデプロイ対象を選択します。
リポジトリとブランチの選択以外はデフォルトのままです。デプロイが完了して、デプロイ先のURLにアクセスすると「403 Access Denied」が表示されます。
なにがいけなかったのか?
Next.jsを静的HTMLにエクスポートできていないことと、エクスポート先のディレクトリを指定できていないことが原因です。
ハマリポイントは3点あります。
1. package.json に記載されているbuildコマンドに静的HTMLへのエクスポートコマンドが含まれていない
create-next-appで自動生成されたpackage.jsonをそのまま使用していたのですが、buildのコマンドがnext buildのみとなっています。
next buildコマンドは.nextディレクトリにハイブリッドページの起動を前提としたファイルをビルドするだけなので、静的HTMLは出力してくれません。
buildのコマンドにnext exportを追加することで、outディレクトリに静的HTMLを出力するようになります。package.json{ // 省略 "scripts": { "dev": "next", "build": "next build && next export", // 修正 "start": "next start", "post-update": "echo \"codesandbox preview only, need an update\" && yarn upgrade --latest" } }加えて
.gitignoreにoutを追記しておきましょう。echo "out\n" >> .gitignore2. amplify initしたときのDistribution Directory Pathが誤っている
amplify initしたときの選択肢「Distribution Directory Path」にデフォルトであるbuildをそのまま入力していました。
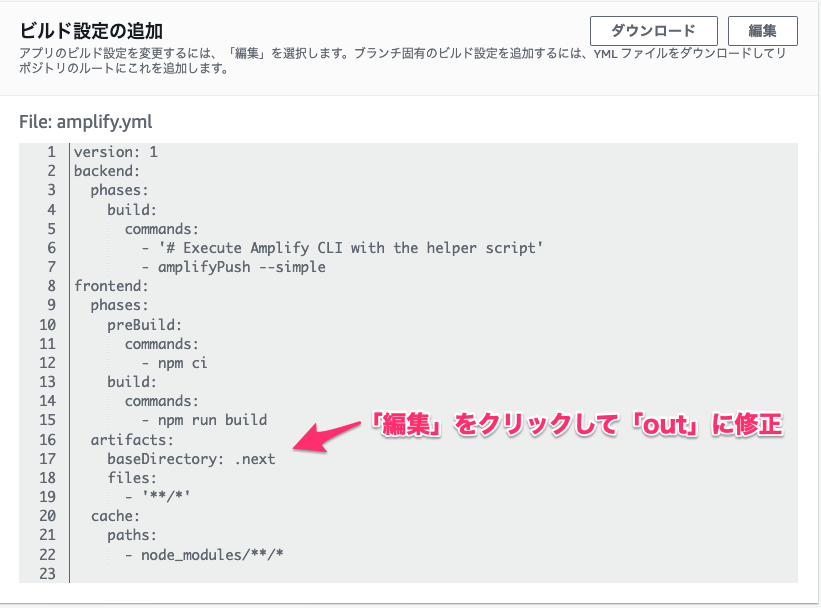
next exportコマンドはoutディレクトリに静的HTMLを出力するのでこのディレクトリを指定する必要があります。$ amplify init Note: It is recommended to run this command from the root of your app directory ? Enter a name for the project next-app ? Enter a name for the environment production ? Choose your default editor: Visual Studio Code ? Choose the type of app that you\'re building javascript Please tell us about your project ? What javascript framework are you using react ? Source Directory Path: src ? Distribution Directory Path: out # 修正 ? Build Command: npm run-script build ? Start Command: npm run-script start3. amplify hostingしたときのビルドの設定が誤っている(Continuous deployment を選択したときのみ該当)
Amplify ConsoleでContinuous deploymentの設定をするときに、アプリのビルド設定が自動検出されるのですが、ここのディレクトリ指定も
buildとなっています。
静的HTMLの出力先であるoutに修正しましょう。
動作確認
以上3点を修正して、再度デプロイしたところ無事にSPAが表示されました

- 投稿日:2020-07-03T00:49:08+09:00
ステートバケットでtfstateを管理しているときに更新競合したらどうなるか確認した
はじめに
Terraformをチームで開発する際に、リポジトリ管理+ステートバケットを使って管理するのが良いとされているが、何も考えずにtfstateを競合させた場合に何が起きるかを確認した。
構成
もともと以下の構成をしているTerraformのリポジトリがあるとする。
. ├── 00_main.tf └── 01_resource1.tf00_main.tfterraform { backend "s3" { bucket = "terraform-test" key = "test/terraform.tfstate" region = "ap-northeast-1" }01_resource1.tfresource "aws_s3_bucket" "terraform_test_1" { bucket = "terraform-test-1" acl = "private" }このリポジトリで、メンバAとBが上記状態をチェックアウトした後に
- メンバAが以下のリソースをapply
02_resource2.tfresource "aws_s3_bucket" "terraform_test_2" { bucket = "terraform-test-2" acl = "private" }
- その後、メンバBがリポジトリを更新しないで以下のリソースをapply
03_resource2.tfresource "aws_s3_bucket" "terraform_test_3" { bucket = "terraform-test-3" acl = "private" }としたらどうなるか。
実験結果
もしかしたらTerraformが良い感じにtfstateの更新日時とかで管理してくれるかと思ったがそんなことはなかった。
メンバAのterraform planでは当然、
terraform_test_2のバケットのaddだけができた。Terraform will perform the following actions: # aws_s3_bucket.terraform_test_2 will be created + resource "aws_s3_bucket" "terraform_test_2" { + acceleration_status = (known after apply) + acl = "private" + arn = (known after apply) + bucket = "terraform-test-2" + bucket_domain_name = (known after apply) + bucket_regional_domain_name = (known after apply) + force_destroy = false + hosted_zone_id = (known after apply) + id = (known after apply) + region = (known after apply) + request_payer = (known after apply) + website_domain = (known after apply) + website_endpoint = (known after apply) + versioning { + enabled = (known after apply) + mfa_delete = (known after apply) } } Plan: 1 to add, 0 to change, 0 to destroy.しかし、メンバBのterraform planでは、以下のようになってしまった。
Terraform will perform the following actions: # aws_s3_bucket.terraform_test_2 will be destroyed - resource "aws_s3_bucket" "terraform_test_2" { - acl = "private" -> null - arn = "arn:aws:s3:::terraform-test-2" -> null - bucket = "terraform-test-2" -> null - bucket_domain_name = "terraform-test-2.s3.amazonaws.com" -> null - bucket_regional_domain_name = "terraform-test-2.s3.ap-northeast-1.amazonaws.com" -> null - force_destroy = false -> null - hosted_zone_id = "Z2M4EHUR26P7ZW" -> null - id = "terraform-test-2" -> null - region = "ap-northeast-1" -> null - request_payer = "BucketOwner" -> null - versioning { - enabled = false -> null - mfa_delete = false -> null } } # aws_s3_bucket.terraform_test_3 will be created + resource "aws_s3_bucket" "terraform_test_3" { + acceleration_status = (known after apply) + acl = "private" + arn = (known after apply) + bucket = "terraform-test-3" + bucket_domain_name = (known after apply) + bucket_regional_domain_name = (known after apply) + force_destroy = false + hosted_zone_id = (known after apply) + id = (known after apply) + region = (known after apply) + request_payer = (known after apply) + website_domain = (known after apply) + website_endpoint = (known after apply) + versioning { + enabled = (known after apply) + mfa_delete = (known after apply) } } Plan: 1 to add, 0 to change, 1 to destroy.うーむ、これは危険。ちゃんとterraform planの内容を確認しないと、他人の作ったリソースをあっさり消してしまう可能性があるということか……。
しかも、リソースに
prevent_destroy = trueすれば消えないかと思いきや、あくまでも「prevent_destroy = trueが書かれたファイルを明示的にdestroyで消せない」だけであり、そもそも.tfファイルが存在しない場合は容赦なくdestoryの対象になってしまうようだ。もちろん、メンバAが正しく
git pushをして、メンバBが適宜git pullしてくれればこの悲劇は回避されるが、結局、人依存の運用にしてしまうのはイケてないなぁ……。エンタープライズ版にすると、この問題は回避されるのだろうか。結論
そうか、そもそも人力で
terraform applyするということ自体がナンセンスということか。複数人でリポジトリ管理するのであれば、しっかりとブランチ戦略を作り、検証の済んだIaCをmasterブランチにプルリクして、然るべきメンバがレビュー承認をすることで初めて商用環境向けのIaCのデプロイパイプラインが起動して、その中で間違いがないかを確認するフローを作り上げるべきなんだ。
実践Terraform AWSにおけるシステム設計とベストプラクティスがすべてを物語っていた。
ということで、中途半端に人力でterraform applyをする環境を作ってはいけない。
せいぜい検証環境や開発環境までにしておけ、ということだ。