- 投稿日:2020-06-28T23:53:48+09:00
【Dash】 参考URL
- 投稿日:2020-06-28T23:42:49+09:00
ゼロから始めるLeetCode Day70 「295. Find Median from Data Stream」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
Python3で解いています。
前回
ゼロから始めるLeetCode Day69 「279. Perfect Squares」今はTop 100 Liked QuestionsのMediumを優先的に解いています。
Easyは全て解いたので気になる方は目次の方へどうぞ。Twitterやってます。
技術ブログ始めました!!
技術はLeetCode、Django、Nuxt、あたりについて書くと思います。こちらの方が更新は早いので、よければブクマよろしくお願いいたします!問題
295. Find Median from Data Stream
難易度はHard。
Top 100 Liked Questionsからの抜粋です。問題としては、クラスの実装になります。
中央値は、順序付き整数リストの中間値です。リストのサイズが偶数の場合、中間値はありません。したがって、中央値は2つの中間値の平均値となります。
例えば、
[2,3,4]
中央値は3
[2,3]
中央値は(2 + 3) / 2 = 2.5以下の2つの操作をサポートするデータ構造体を設計します。
void addNum(int num)- データストリームからデータ構造体に整数値を追加します。
double findMedian()- これまでのすべての要素の中央値を返します。Example:
addNum(1)
addNum(2)
findMedian() -> 1.5
addNum(3)
findMedian() -> 2解法
平均値ではなく中央値であることを念頭において、その部分をどう実装するかがかなり重要な部分になりそうですね。
他の部分はこの問題を解こうと思った人にとってはそこまで大変ではなさそうです。
class MedianFinder: def __init__(self): """ initialize your data structure here. """ self.sorted_list = [] self.length = 0 def addNum(self, num: int) -> None: low,high = 0,self.length-1 while high >= low: mid = (high+low)//2 if self.sorted_list[mid] > num: high = mid-1 else: low = mid+1 self.sorted_list.insert(low,num) self.length += 1 def findMedian(self) -> float: if self.length % 2 == 0: median = self.length//2 return (self.sorted_list[median]+self.sorted_list[median-1])/2.0 else: return self.sorted_list[self.length//2] # Your MedianFinder object will be instantiated and called as such: # obj = MedianFinder() # obj.addNum(num) # param_2 = obj.findMedian() # Runtime: 296 ms, faster than 30.86% of Python3 online submissions for Find Median from Data Stream. # Memory Usage: 25.2 MB, less than 18.26% of Python3 online submissions for Find Median from Data Stream.
addNumの部分で二分探索を使い、リストの長さを保存しておくことでfindMedianの中でその長さを使ってスムーズに書くことにしました。
見返してみると基本的なことの集合問題みたいな感じですね。それぞれの断片的な知識をしっかりと覚えていれば書けますが、そこまで速度が出ない、というジレンマに陥るタイプです。ここからどうやって改善していくか、という点についてですが、二分探索の部分が少し重くなってしまっている、というのが以下の解答例で分かります。
from heapq import * class MedianFinder: def __init__(self): self.heaps = [], [] def addNum(self, num): small, large = self.heaps heappush(small, -heappushpop(large, num)) if len(large) < len(small): heappush(large, -heappop(small)) def findMedian(self): small, large = self.heaps if len(large) > len(small): return float(large[0]) return (large[0] - small[0]) / 2.0 # Runtime: 200 ms, faster than 82.39% of Python3 online submissions for Find Median from Data Stream. # Memory Usage: 24.6 MB, less than 98.20% of Python3 online submissions for Find Median from Data Stream.リストを二つ用意し、それぞれをヒープとして扱うことで軽量化していますね。
僕に先の解答からこちらのように変換できる能力があれば良かったのですが、わからなかったために今回はdiscussから引っ張ってきました。
では今回はここまで。お疲れ様でした。
- 投稿日:2020-06-28T23:10:13+09:00
WindowsでPyAudioがPython 3.7, 3.8, 3.9 にインストールできない場合の対処法
2020年6月現在PyAudio公式版はWindowsのPython 3.6.Xまでしか対応していません。
https://pypi.org/project/PyAudio/#files3.7以上でインストールしようとすると
"Microsoft Visual C++ 14.0 is required."
というエラーが出ますが、エラーに従ってMicrosoft C++ Build ToolsをインストールしてもPyAudioの依存関係の設定が上手くいっておらず、インストールできません。3.7以上でPyAudioを使うには非公式版ですが
https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyaudio
からバージョンに対応したwhlファイルをダウンロードしてインストールすれば使えます。例えばPython 3.8 on x86-64なら
py -m pip install PyAudio‑0.2.11‑cp38‑cp38‑win_amd64.whlでインストールできます。動作は問題ありませんでした。
公式版ならWindows版Python3.6.Xを使うのが無難です。
Microsoft C++ Build Toolsをインストールしても結果には関係ありませんのでご注意ください。そのような誤った記事が多くありました。
- 投稿日:2020-06-28T22:54:41+09:00
Sharpe RatioとSortino Ratioについて
1 目的
Sharpe RatioとSortino Ratioの意味を説明します。
2 内容
2-1 Sharpe Ratioについて
株式投資における銘柄選定においては、期待リターンが高く、リスク(日々の変動率,Volatilityのこと)が低い銘柄を選ぶことが一般的によいとされている。リターンとリスクの関係を示したものがSharpe Ratioである。Sharpe Ratioの計算式は下記で定義されます。
Sharpe Ratio = \biggl({\frac{R_{p}-R_{f}}{σ_{p}}} \biggl)$R_{p}:$ 期待リターンを表します。実際の計算方法はこちらをご覧ください。
$R_{f}:$ 無リスクリターンを示します。何もしなくても得られる利益です。(例:配当、利息)
$σ_{p}:$ Volatilityを表します。実際の計算方法はこちらをご覧ください。上記式より、Sharpe Ratioが大きい=高期待リターン & 低リスク(Volatility)となり一般的によい傾向となります。逆にSharpe Ratioが低い場合は、リスク(Volarility)が高いということですので、損をした場合の損金が大きくなることを示しております。一般的に$Sharpe Ratio > 1 $の銘柄を買うことがよいとされております。
- 投稿日:2020-06-28T22:53:45+09:00
【Python】中学生がパーセプトロンを実装してアヤメを分類してみた
はじめに
この記事を書く際に、Python機械学習プログラミング -GitHubを参考にしました。本当にありがとうございました。
ニューロンについて
神経を構成する細胞で、刺激を受けて興奮し、またその刺激を他の細胞に伝達する。神経細胞。
ニューロンは以下のような画像のものです。
あなたの脳の中に、だいたい2000億個のニューロンが入っています。
そして、各ニューロンが下の画像のようにつながります。結合部分がシナプスと呼ばれます。
ニューロンによって情報が伝わる仕組み
- 細胞部が刺激される
- 神経インパルスが「発火」する
- 情報であるスパイク列が軸索を通ってシナプスまで届けられる
- どんどん下流の神経細胞まで進んでいく。
ニューロンを数式化
ニューロンを簡単に図で表すと、下のようになります。
入力値は $x_1 ... x_m$ までいくつもありますが、出力値はいつでも「発火する」か「発火しない」かの二択となります。
今回は「発火する」場合の出力値を1, 「発火しない」場合の出力値を-1とします。(出力値は任意です)
ちなみに $w$ はweightの頭文字で、入力値の重要度を決定しています。
$y$ は出力値を表しています。これを数式化すると、こうなります。
z = x_1w_1 + ... + x_mw_m = \sum_{x=1}^{m} x_iw_iここで新しく登場した $z$ は、総入力と呼ばれ、英語ではnet inputと呼びます。
そして、上の画像で示した $\theta$ は、閾値(しきい値)と呼ばれ、$z \geq \theta$ の時、「発火して」 1が出力されます。
対して、$z < \theta$ の場合は「発火しない」ため、−1が出力されます。f(z) = \left\{ \begin{array}{ll} 1 & (z \geq 0) \\ 0 & (z \lt 0) \end{array} \right.この時、$f(z)$ は、0以上になったときに"1"それ以下では"0"を出力する決定関数となります。
単位ステップ関数
このグラフを見れば分かる通り、zが0以上になった時に発火して1が出力されることがわかります。
このように、あるタイミングで突然発火する関数をヘヴィサイドの階段関数と呼ぶそうです。
単純パーセプトロンについて
さて、ここまでは形式ニューロンと呼ばれる簡単なニューロンについての話題でした。
次に、パーセプトロンというアルゴリズムについて説明します。1958年に登場した単純パーセプトロンは、とても単純なアルゴリズムで動いています。
1. 重みを0または適当な数で初期化 2. 入力値ごとに出力値を計算し、重みを更新するたったこれだけです。
重みが更新される式は以下の通りです。
W_j := W_j + \Delta W_j左の各重み $W_j$ は、$\Delta W_j$で更新されます。
$\Delta W_j$は、
\Delta W_j = \eta\:(\:y^{(i)}-\hat{y}^{(i)}\:)\: x_{j}^{(i)}と表記することができます。
$y^{(i)}$ は、真のクラスラベル(正解の分類)を表し、$\hat{y}^{(i)}$ は出力値(分類結果)を表します。
そして、$\eta$ は学習率を示し、$x_{j}^{(i)}$ は入力値を示します。具体的な数字を当てはめてみよう
ジェネライズした式を理解したので、次は具体的な数で試してみましょう。
例えば、分類を間違ってしまったパターン考えます。
\Delta W_j = \eta\:(\:1-(-1)\:)\: x_{j}^{(i)} = \eta\:(2)\:x_{j}^{(i)}$\eta$ が1, $x_{j}^{(i)}$ が0.5の場合、重みが1に更新されます。
これによって、総入力( $x_{j}^{(i)} W_j$ )の数がより大きな正の数となり、間違う可能性が低くなります。
そして、これをずっと続けて間違いがなくなるまで繰り返すのが、単純パーセプトロンです。
単純パーセプトロンの欠点
単純パーセプトロンは、線形分離不可能な2つのクラスを分離することができません。
また、線形分離が不可能なため、XOR演算ができません。(XOR演算とは?)
入力値 $x_1$, $x_2$ について考えます。
$x_1$ $x_2$ $x_1$ XOR $x_2$ 0 0 0 0 1 1 1 1 0 1 0 1 この時、それぞれをプロットするとこうなります。
見ればわかる通り、これは線形分離不可能です。
XOR演算を解くためには、多層パーセプトロンを実装する必要があります。
パーセプトロンを実装してみよう!!
開発環境:
Chrome 83
Google Colab
Mac OS High Sierra1. パーセプトロンをモジュール化
import numpy as np class Perceptron(object): def __init__(self, eta=0.01, n_iter=50, random_state=1): self.eta = eta self.n_iter = n_iter self.random_state = random_state def fit(self, X, y): rgen = np.random.RandomState(self.random_state) self.w_ = rgen.normal(loc=0.0, scale=0.01, size=1 + X.shape[1]) self.errors_ = [] for _ in range(self.n_iter): errors = 0 for xi, target in zip(X, y): update = self.eta * (target - self.predict(xi)) self.w_[1:] += update * xi self.w_[0] += update errors += int(update != 0.0) self.errors_.append(errors) return self def net_input(self, X): return np.dot(X, self.w_[1:]) + self.w_[0] def predict(self, X): return np.where(self.net_input(X) >= 0.0, 1, -1)元コード: GitHub
2. アイリスデータセットを確認
#データの読み込みと確認, X, yの指定 import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None) df.head() y = df.iloc[0:100, 4].values y = np.where(y == 'Iris-setosa', -1, 1) X = df.iloc[0:100, [0, 2]].values元コード: GitHub
3. プロット用の関数
from matplotlib.colors import ListedColormap def plot_decision_regions(X, y, classifier, resolution=0.02): # setup marker generator and color map markers = ('s', 'x', 'o', '^', 'v') colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan') cmap = ListedColormap(colors[:len(np.unique(y))]) # plot the decision surface x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1 x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1 xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution)) Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T) Z = Z.reshape(xx1.shape) plt.contourf(xx1, xx2, Z, alpha=0.3, cmap=cmap) plt.xlim(xx1.min(), xx1.max()) plt.ylim(xx2.min(), xx2.max()) # plot class samples for idx, cl in enumerate(np.unique(y)): plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1], alpha=0.8, c=colors[idx], marker=markers[idx], label=cl, edgecolor='black')元コード: GitHub
4. プロット
plot_decision_regions(X, y, classifier=ppn) plt.xlabel('sepal length [cm]') plt.ylabel('petal length [cm]') plt.legend(loc='upper left') # plt.savefig('images/02_08.png', dpi=300) plt.show()元コード: GitHub
5. こんな感じ
最後に
次は多層パーセプトロンの実装を試してみたいと思います。







- 投稿日:2020-06-28T22:22:46+09:00
Pythonでピラミッドを表示させる
はじめに
Pythonを学習してみようと思い、参考書をもとに10時間くらい勉強しました。
そのアウトプットとして、Pythonでピラミッドを作成してみました。環境
- Windows10
- PyCharm 2020.1.2
- Python3.8
実行結果
> python pyramid.py Please input number => 6 * *** ***** ******* ********* ***********コード
pyramid.pynum=int(input('Please input number => ')) spc=' '*max(0,num-1) for i in range(1,2*num,2): ast='*'*max(1,i) out=spc+ast print(out) spc=spc.replace(' ','',1)コードの解説
input関数を使用して、num変数にキーボードからの入力した値を代入します。
このとき、取得した値はstr型になるので、このあとのためにint型にしておきます。spc変数には、空白を代入していきます。
for文を使ってピラミッドを表示していきます。
range関数で1から2ずつ加算させていきます。これによって、*が1つ,3つ,5つ…と増えていきます。
ループの最後に空白を1ずつ取り除いてあげます。(try、expectを使って数字以外が入力したときの対処も入れても良いかもしれません。)
まとめ
このプログラムを作成することで
- input関数
- int()
- range関数
- max関数
- for文
- replaceメソッド
- Pythonのお作法
が理解出来ました。
- 投稿日:2020-06-28T22:13:33+09:00
製薬企業研究者がPythonのユニットテストについてまとめてみた
はじめに
ここでは、
unittestを用いたPythonのテストについて解説していきます。テストの基本
テストは、対処となる関数に対応させるように、以下のように書きます。
import unittest def average(num1, num2): return (num1 + num2) / 2 class AverageTests(unittest.TestCase): def test_average(self): actual = average(1, 2) expected = 1.5 self.assertEqual(actual, expected)
averageという関数に対して、AverageTestsというclassが用意され、このクラス内のメソッドとして、test_averageが書かれています。
このように、テスト用の関数はtest_テスト対象の関数名とすることが多いです。
assertメソッド上の例のように、テストの判定時には
assertメソッドが使われます。
よく使われるassertメソッドには、以下のようなものがあります。
- assertEqual(actual, expected):actualとexpectedが等しいかどうか
- assertNotEqual(actual, expected):actualとexpectedが等しくないかどうか
- assertTrue(bool):boolが
Trueであるかどうか- assertFalse(bool):boolが
Falseであるかどうか- assertGreater(num1, num2):num1がnum2より大きいかどうか
- assertGreaterEqual(num1, num2):num1がnum2以上かどうか
- assertLess(num1, num2):num1がnum2より小さいかどうか
- assertLessEqual(num1, num2):num1がnum2以下かどうか
- assertIn(value, values):valueがvaluesに含まれるかどうか
まとめ
ここでは、
unittestを用いたPythonのテストの書き方について解説しました。
テストを味方につけて、開発効率を上げていきたいところです。
- 投稿日:2020-06-28T21:54:30+09:00
[光-Hikari-のPython]08章-03 モジュール(標準ライブラリのインポートと利用)
[Python]08章-03 標準ライブラリのインポートと利用
今までは、自分で作成したモジュールやモジュール群(パッケージ)をインポートしました。
これらはまた、他人が作成したモジュールもインポートできると説明しました。実は、モジュールはほかにもPythonをインストールした際に一緒についてくるモジュール群があり、これを標準ライブラリと言います。
また、Pythonをインストールした際に一緒にインストールされなかったライブラリもあります。これらは別の第三者の組織や研究団体、個人的に作成したモジュール群もあり、これを外部ライブラリと言います。
外部ライブラリについては次節で説明します。※ライブラリはモジュールで構成されているものもありますし、パッケージで構成されているものもあります。
まずは、標準ライブラリについて、この節で説明していきたいと思います。
いろいろな標準ライブラリ
前述の通り、標準ライブラリはPythonが用意したものです。主に以下のものが存在し、インポートして利用します。(ほかにもまだ標準ライブラリは存在します)
モジュール 使用用途 math 数学で用いる計算の関する処理(log, sin, cosなどの関数が利用可能) random 乱数を発生させたいときに利用 csv CSVファイル入出力の際に利用 xml XMLファイル入出力の際に利用 json JSONファイル入出力の際に利用 os ファイルのディレクトリなどを操作したい際に利用 datetime 日時に関する処理をしたい際に利用 urllib Webから情報を取得したい際に利用 すべては説明できませんが、以下で外部ライブラリを使用してプログラムを書いてみましょう。
標準ライブラリ(mathモジュール)
まずは、mathモジュールを用いて、円の円周と面積を求めるプログラムを作成してみましょう。
mathモジュールは以下のリンク先に詳細がありますので、それを参照しながら作成を進め、説明していきたいと思います。
https://docs.python.org/ja/3/library/math.htmlchap08の中に、samp08-03-01.pyというファイル名でファイルを作成し、以下のコードを書いてください。
samp08-03-01.py##mathモジュールのインポート import math ##円周を求める関数 def circumference_func(r): C = r * 2 * math.pi return C ##面積を求める関数 def area_func(r): S = math.pow(r, 2) * math.pi return S r = int(input('円の半径の長さrを入力してください:')) ##円周を求める関数の呼び出し print(f'円周の長さ:{circumference_func(r)}') ##面積を求める関数の呼び出し print(f'面積:{area_func(r)}')【実行結果】
円の半径の長さrを入力してください:5
円周の長さ:31.41592653589793
面積:78.53981633974483円周と円の面積の求め方は問題ないと思いますが、今回は、mathモジュールの中から、math.piとmath.pow()関数を利用しています。
上記のリンク先にもmathモジュールにたくさん関数がありますが、それぞれ見てみましょう。
【数学関数piマニュアルより引用】
math.pi
利用可能なだけの精度の数学定数 π = 3.141592... (円周率)。math.piとすることで、その個所が3.1415...という円周率(定数)となります。
【数学関数powマニュアルより引用】
math.pow(x, y)
x の y 乗を返します。例外的な場合については、 C99 標準の付録 'F' に可能な限り従います。特に、 pow(1.0, x) と pow(x, 0.0) は、たとえ x が零や NaN でも、常に 1.0 を返します。もし x と y の両方が有限の値で、 x が負、 y が整数でない場合、 pow(x, y) は未定義で、 ValueError を送出します。
組み込みの ** 演算子と違って、 math.pow() は両方の引数を float 型に変換します。正確な整数の冪乗を計算するには ** もしくは組み込みの pow() 関数を使ってください。円の面積を求める際に、r2しているので、プログラム中ではmath.pow(r, 2)としています。
なお、インポートの際にあらかじめ何の関数を使用するかをわかっている場合、以下のように記載すれば、math.piやmath.pow(r, 2)においては、piやpow(r, 2)と省略して書くことも可能です。
samp08-03-02.py##mathモジュールのインポート from math import pi, pow ##円周を求める関数 def circumference_func(r): C = r * 2 * pi return C ##面積を求める関数 def area_func(r): S = pow(r, 2) * pi return S r = int(input('円の半径の長さrを入力してください:')) ##円周を求める関数の呼び出し print(f'円周の長さ:{circumference_func(r)}') ##面積を求める関数の呼び出し print(f'面積:{area_func(r)}')標準ライブラリ(randomモジュール)
次は乱数を発生させるrandomモジュールをインポートしてプログラムを作成してみます。
内容は大吉・中吉・小吉・凶・大凶のいずれかを出力させるプログラムです。randomモジュールは以下のリンク先に詳細がありますので、それを参照しながら作成を進め、説明していきたいと思います。
https://docs.python.org/ja/3/library/random.htmlsamp08-03-03.py##randomモジュールのインポート import random omikuji = random.randint(0, 4) if omikuji == 0: print('大吉') elif omikuji == 1: print('中吉') elif omikuji == 2: print('小吉') elif omikuji == 3: print('凶') else: print('大凶')【実行結果】
中吉※実行結果は実行ごとに変化しますので注意してください。
プログラムに関しては問題ないと思いますが、今回は新たにrandom.randint()関数を使用しています。
【randint関数マニュアルより引用】
random.randint(a, b)
a <= N <= b であるようなランダムな整数 N を返します。randrange(a, b+1) のエイリアスです。このrandint関数ではa以上b未満の整数の乱数を返します。上記の実行結果ではたまたま乱数値が1であったため、「中吉」と出力されています。
最後に
標準ライブラリの中で、今回はmathモジュールとrandomモジュールを紹介しました。mathモジュールについては今後AIの分野で使用することも増えますし、randomモジュールは簡単なゲームなどを作成する際にも乱数の要素を取り入れて使用します。
今回紹介できなかったそのほかの標準ライブラリ(csvやdatetimeモジュールなど)については後程触れて生きたいと思います。
【目次リンク】へ戻る
- 投稿日:2020-06-28T21:54:04+09:00
raspberryPiでPIRモーションセンサを使う
概要
RaspberryPi2 と PIRモーションセンサ から動態を検知した/していないをプログラムで取得します。
前提
- raspberryPiのモデルはraspberryPi2 modelB v1.1
- モーションセンサーはPIRモーションセンサ
- 使う言語はpython3
- RaspberryOS
Raspberry Pi OS (32-bit) Lite Minimal image based on Debian Buster Version:May 2020 Release date:2020-05-27 Kernel version:4.19
- raspberryPiが起動する状態である。
常に検知範囲に動体があるので、動体が無いことが異常とする。
常にセンサーが動体を検知していることが前提で、
検知しなくなった(対象物が止まっている)ことを検知するプログラムです。
e.g. 常に動作しているファンの停止を検知する。センサーは動体を検知し続ける事はできない。
センサーの検知タイミングなのか何なのか、
動体があっても検知しないケースがあるようです。
なので一定回数以上動体を検知しないときに何かアクションをすることを想定しています。
e.g. 動体が無いことを20回以上検知する。準備
pip3のインストール
sudo apt install python3-distutils curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py python3 get-pip.pyRPi.GPIOのインストール
sudo apt install python3-dev pip3 install RPi.GPIOセンサーとraspberryPiの接続
以下の 公式から取得したGPIOのPINアサイン を参考にして
ジャンパワイヤで以下のように接続する。
- raspberryPiの2番 5V power と センサーのVCC
- raspberryPiの6番 ground と センサーのGRD
- raspberryPiの12番 GPIO 18 と センサーのout
センサー側
rasqberryPi側
センサーで値を取得する
import RPi.GPIO as GPIO from time import sleep GPIO.setmode(GPIO.BCM) # GPIOの18を指定 GPIO.setup(18, GPIO.IN, pull_up_down=GPIO.PUD_DOWN) count = 0 while True: sleep(1) # センサーが動体を検知すると1が返ってくる。 if GPIO.input(18) == 1: count = 0 print("yes") # 1が返ってこない場合が20回を超えるとyabeeeeeを出力する。 else: count += 1 print("no good") if count > 20: print("yabeeeee") else: pass



- 投稿日:2020-06-28T21:44:04+09:00
Python手遊び(Pandas/DataFrameことはじめ)
この記事、何?
先の記事にも書いたけど、Pandasはじめました。
シャットダウン時の静的保存をcsvと考えて、オンメモリの使いやすい保存場所がDataFrameね。
で、SQLでいうところのSELECTやWHEREの文法を記録しておこうかと。
ついでにPLSやってみた使用例も挙げておこうかと。コード・・・の前の一言
まあ、文法の確認なのでひねりもなくコード・・・とも思ったけど、ちょっとだけ。
「予測が機能している」ということが簡単に確認できる方法としてよく以下のものを使っている。(式)
y = f(x1, x2) = x1 + x2 * 2(データ)
# 7行×3列 csvpath = 'SimplePrediction.csv' # ,y,x1,x2 # 1,5,1,2 # 2,11,3,4 # 3,15,3,6 # 4,16,2,7 # 5,11,1,5 # 6,0,5,2 # 7,0,1,2まあ、「これ、機械学習?」って言われそうだけど、NNとかSVMとかを機能させた実例って、人が手動で追っかけるのめんどいでしょ?これだったら検算が簡単だしね。重宝してます。はい。
コード
1本目はこれ。DataFrameをどうにかしている実例。
import pandas as pd # 7行×3列 csvpath = 'SimplePrediction.csv' # ,y,x1,x2 # 1,5,1,2 # 2,11,3,4 # 3,15,3,6 # 4,16,2,7 # 5,11,1,5 # 6,0,5,2 # 7,0,1,2 def main(): df = pd.read_csv(csvpath) print('-- 元の形 --') print(df) print('-- 先頭5行 --') print(df[:5]) print('-- 末尾2行 --') print(df[-2:]) print('-- 2列目のみ --') print(df.iloc[:, 1:2]) print('-- 末尾2列 --') print(df.iloc[:, -2:]) print('-- 先頭5行の末尾2列を保存 --') print(df.iloc[:5, -2:]) df.iloc[:5, -2:].to_csv('X.csv', index=False) print('-- 先頭5行の2列目のみを保存 --') print(df.iloc[:5, 1:2]) df.iloc[:5, 1:2].to_csv('y.csv', index=False) if __name__ == '__main__': main()2本目はこれ。
上記を使ってモデルを作る。ファイル化する。
それを読み込んで予測をする。import pandas as pd # 5行×2列 Xpath = 'X.csv' # x1,x2 # 1,2 # 3,4 # 3,6 # 2,7 # 1,5 # 5行×1列 ypath = 'y.csv' # y # 5 # 11 # 15 # 16 # 11 def get_xy(): X = pd.read_csv(Xpath) y = pd.read_csv(ypath) return X, y def save_model(): X, y = get_xy() # モデル作成 from sklearn.cross_decomposition import PLSRegression model = PLSRegression(n_components=2) model.fit(X, y) # 保存 from sklearn.externals import joblib joblib.dump(model, 'pls.pickle') def use_model(): X, y = get_xy() # 読み込み pls = joblib.load('pls.pickle') y_pred = pls.predict(X) # y = f(x1, x2) = x1 + x2 * 2 を仕込んであるのでPLSで完全一致を確認 print(y_pred) def main(): # save_model() use_model() if __name__ == '__main__': main()感想
まあ、特に。
- 投稿日:2020-06-28T21:35:38+09:00
Few-shot vid2vidで顔イラストをアニメ風に動かしてみた
はじめに
「Few-shot Video-to-Video Synthesis」(以下、Few-shot vid2vid)は2019年に発表され話題になったGANです。今年になって、公式の実装も公開されました。[paper, github]
今回の記事では、はじめにFew-shot vid2vidについて簡単に紹介した後、実際に学習と動画生成を試した結果を書いていきます。
Few-shot vid2vidとは
一言で言うと、動画→動画の変換を行うGANであるvid2vid [paper]の進化形です。下図は論文からの引用で、左がvid2vid、右がFew-shot vid2vidを示します。
vid2vidは一つのドメインで学習を行い、それについての動画生成しかできません。例えば上の図のように骨格画像から全身画像への変換を行う場合、Aさんの画像を集めて学習を行ったとしたらAさんの動画しか生成できません。Bさんの動画を生成したければ、Bさんの画像を集めて学習させる必要があります。
これに対し、Few-shot vid2vidでは複数のドメインで学習を行い、動画生成する際は学習時になかったドメインにも対応できます。例えば学習データに入れていなかったZさんの動画を生成することも可能です。この時Example imageとしてZさんの画像が必要になりますが、これは1~数枚(few shot)で機能します。このようなFew-shot合成は、ネットワークの一部のモジュールの重みをExample imageから抽出した特徴量によって動的に変更することで可能になっています。
※こちらのページの解説が参考になりました。
「数枚の画像で動きを転移できるFew shot vid2vid(Few shot video to video Synthesis)」また公式の動画では、彫刻を躍らせたり絵画をしゃべらせたりといった応用が紹介されていて面白いです。
Few-Shot Video-to-Video Synthesis (youtube)実験
今回はFew-shot vid2vidを使って、アニメ系の顔イラストを動かす実験をしてみました。
公式の動画では絵画(モナリザ)を動かしていますが、よりデフォルメされたアニメの絵でも上手く動かせるのか気になったからです。
あと、1枚のイラストを元にアニメのように動かせたら、けっこう実用的なのではないかと思ったからです。ここからは、実際に作業した内容を書いていきます。
作業環境
自宅のゲーム用PCにUbuntuとCUDA等を入れて作った環境です。
OS : Ubuntu 18.04.4 LTS
GPU : GeForce RTX 2060 SUPER(8GB) x1データセット作成
Few-shot vid2vidを学習させるには、元画像と対になるラベル画像のセットが大量に必要です。
元画像としては、実験のため個人的に集めた画像からキャラの顔部分だけ切り抜いた物を使用しました。
問題はラベル画像の作成方法ですが、調べたところアニメ顔用のlandmark検出ツールが公開されていたので、こちらをありがたく使わせて頂きました。
Anime face landmark detection by deep cascaded regression流れとしては以下の通りです。
(1) landmark検出により目や口などのパーツの代表点を取得
(2) 各点の位置を元に顔ラベルを描画
ここの処理はOpenCVのrectangle()やfillPoly()などを使って作りました。
(3) 元絵と顔ラベルをセットにして、Few-shot vid2vidで使える形式のデータセットを作成
landmark検出点をそのまま使わずに顔ラベルを描くことにしたのは、その方が各パーツの大きさや位置を制御しやすいと思ったからです。(以前、pix2pixHD等で色々遊んでいた時の結果の傾向から)
ただ、このラベルの描き方が本当に良いかは分かりません。この描き方の違いで生成結果の質はかなり変わると思います。また、(3)のデータセット作成に際しては拡大・縮小・回転等のaugmentationを行っています。
この時、Few-shot vid2vidに適したシーケンスデータ(時系列的に連続して変化)となるよう調整しました。
1シーケンスにつき元画像/顔ラベルをそれぞれ20枚とし、最終的に3000シーケンス程度の学習データを用意しました。学習
作成したデータセットで、Few-shot vid2vidの学習を行いました。
※学習は主に2020年の5月上旬に行ったので、githubのコードはその時点の最新版を使いました。以下、メモ程度ですが書いておきます。
・準備は本家のREADMEにしたがって特に問題なく完了。
推奨通りPyTorch1.2を使用。FlowNet2をコンパイル。
自分の環境だと初回学習時にnumpyのエラーが出たが、numpyのバージョンを下げることで解消。
・1回のiterationで使うシーケンス枚数の最大値(seq_len_max)を変更。
seq_len_maxはdata/base_dataset.py内で指定されている。(デフォルト値は30)
GPUメモリサイズと学習時間の問題のため、これを30->16に変更。
・学習時のオプションで、生成画像の解像度は288x288を指定。
GPUメモリサイズによりこの位が限界だった。本当はもっと大きくしたい。
・かかった学習時間は3~4days。評価
学習後のモデルを使い、動画生成の確認を行いました。
ここでは、学習時に使っていない画像として、前回の記事で確認したStyleGANで生成したイラストをExample imageに使用しました。結果を以下に示します。
静止画: Example image (動かしたいイラスト)
動画: 一番左が顔ラベルの入力、右側がExample imageに対応する生成結果
となります。
以下、もう一例。
全体的に、元絵の特徴をうまくとらえた上で動かせているように思いました。元絵で目を閉じている例が一つありますが、その場合の目の色は推測で(確率的に?)自然な色にしてくれていると思われます。頭の動きにもある程度は追従できているようです。
現状の問題としては、以下のような傾向がみられました。
・表情や頭の動きが大きくなると、目や口の周囲に期待しない線が出たり、髪の部分がぼやけてしまう。
--> 学習用データセットの作り方次第で、もう少し動きに強くすることはできるかも。
・顔や目の縦横比、目の離れ方などが顔ラベルの入力で規定されるため、元キャラの個性がやや失われる。
--> これらをパラメータとして正規化し、Exampleごとに調整して顔ラベルを描くことで改善できる?おわり
Few-shot vid2vidを使い、顔イラストをアニメ風に動かす実験を行いました。
けっこう面白い結果が得られているので、データセットの作り方や学習条件を見直し、もっと質を上げられないか検討してみる予定です。良い結果が出たら改めて書きたいと思います。
もっと強力なGPU環境があれば、更に解像度を上げてきれいに生成したい所ですが。(AWSは高いし...)次回は、また全然別のデータを使ってFew-shot vid2vidの実験をしてみた結果を書こうかと思います。








- 投稿日:2020-06-28T20:55:19+09:00
[競プロ用]素数とか約数とか素因数分解まとめ
素数判定
- 割り切れるかどうかの判定は√Nまでしか見なくていい。
N = a * b (a <= b)とした時に、aで割り切れることが判定できていればbで割れるかを判定する必要がない。- すなわち、最大でも
a = bのケースまで割れるかを判定してあげればいいことになるので、N = a * b = a * a = a ** 2を満たすaまで見ればいい。- O(√N)
# 素数判定 def isPrime(n: int): # validation chech if n < 0: raise("[ERROR] parameter must be not less than 0 (n >= 0)") if n == 0 or n == 1: return False for i in range(2, n + 1): # √N以下まで見ればいい。i*iとして比較するのは小数を扱いたくないため。 if i * i > n: return True if n % i == 0: return False # 素数判定 N = 7 print(isPrime(N)) # True素数列挙 / エラトステネスの篩
- Nまでのリストを用意して、素数に該当するものが見つかったらその倍数を削除していく。
- 上と同じく√NまででOK
- 倍数削除は
i ** 2から行うのは、それまでの処理でi * (i - 1)はふるい落とされているため。eg.)
i = 5のとき、5 * 2、5 * 3、5 * 4はいずれも、2の倍数、3の倍数、2の倍数として落とされている。
# エラトステネスの篩 # 素数列挙 (区間指定可) def getPrimes(last: int, first: int = 1): # validation check if not isinstance(last, int) or \ not isinstance(first, int): raise("[ERROR] parameter must be integer") if last < 0 or first < 0: raise("[ERROR] parameter must be not less than 0 (first >= 0 & last >= 0)") if last < first: last, first = first, last isPrime = [True] * (last + 1) # 素数かどうか # 0と1をFalseに isPrime[0] = isPrime[1] = False for i in range(2, int(last ** 0.5 + 1)): if isPrime[i]: # 篩にかける。iの倍数をすべてFalseにしていく。このとき i^2まではすでにふるい落とされているので見る必要がない for j in range(i ** 2, last + 1, i): isPrime[j] = False return [i for i in range(first, last + 1) if isPrime[i]] # 素数列挙 N = 10 # 末尾の数字を含む print(getPrimes(N)) # [2, 3, 5, 7] # 素数列挙 F = 13 L = 23 # 末尾の数字を含む print(getPrimes(F, L)) # [13, 17, 19, 23] # 素数の個数 N = 10 ** 7 print(len(getPrimes(N))) # 664579 # 2.5sくらい約数列挙
約数を高速で列挙するコード(Python)参考にしました。
ソートされて出てくる。# 約数列挙 def getDivisors(n: int): # validation check if not isinstance(n, int): raise("[ERROR] parameter must be integer") if n < 0: raise("[ERROR] parameter must be not less than 0 (n >= 0)") lowerDivisors, upperDivisors = [], [] i = 1 while i * i <= n: if n % i == 0: lowerDivisors.append(i) if i != n // i: upperDivisors.append(n//i) i += 1 return lowerDivisors + upperDivisors[::-1] # 約数列挙 N = 120 print(getDivisors(N)) # [1, 2, 3, 4, 5, 6, 8, 10, 12, 15, 20, 24, 30, 40, 60, 120]複数の整数に対して約数の個数取得(別の手法)
- 上のコードで約数を取得してリストの長さから算出するというのを、1からNまで繰り返してもいいが、別の手法。
- 約数側をループさせていき、その約数を持つものはカウントさせていく。
- この時にその約数自体をリストに含めてしまえば、複数の整数に対して一発で約数のリストも求められそう。
- O(NlogN)。10^7とかだと列挙は厳しい。
# 約数の個数を一斉取得 def getNumsOfDivisorsOfEachNumbers(n: int): # validation check if not isinstance(n, int): raise("[ERROR] parameter must be integer") if n < 0: raise("[ERROR] parameter must be not less than 0 (n >= 0)") nums = [0] * (n + 1) # 0-indexed for i in range(1, n + 1): for j in range(i, n + 1, i): nums[j] += 1 nums.pop(0) return nums # 約数の個数を一斉取得 N = 10 print(getNumsOfDivisorsOfEachNumbers(N))参考) AtCoderのABC172 D問題
素因数分解
- 冷静に割ってもいってもいいが、上と同じように複数の数に対して素因数を同時に求めたい時に有用な方法。
- エラトステネスの篩において倍数を削除していく時にフラグで管理するのではなく、なんの数で割ったのかを記載しておくことde後から辿ることができるようにしている。
- ダブリングに似た方法で素因数を取得していく。
eg.) 例えば10を素因数分解するとき。
- リストの10を参照する。
- 10を2で割れるので2を素因数リストに加え、
- 10/2=5から保養の5に対応するところを見る。
- 5は5と書かれており素数とわかるので判定を終了する。
import time # 素因数分解 def primeFactrization(n: int): # validation check if not isinstance(n, int): raise("[ERROR] parameter must be integer") if n < 0: raise("[ERROR] parameter must be not less than 0 (n >= 0)") dividableMinimunPrime = [i for i in range(0, n + 1)] # 数iを割りきる最小の素数 for i in range(2, int(n ** 0.5 + 1)): if dividableMinimunPrime[i] == i: for j in range(i ** 2, n + 1, i): if dividableMinimunPrime[j] == j: # 条件を削除して上書きを許可すると得られる素因数が降順になる。 dividableMinimunPrime[j] = i # ダブリングと同じ要領で進めていく primeFactors = [] rest = n while dividableMinimunPrime[rest] != rest: primeFactors.append(dividableMinimunPrime[rest]) rest //= dividableMinimunPrime[rest] primeFactors.append(rest) return primeFactors N = 200000 start = time.time() print(primeFactrization(N)) elapsedTime = time.time() - start print("time: {} [sec]".format(elapsedTime)) # [2, 2, 2, 2, 2, 2, 5, 5, 5, 5, 5] # time: 0.05865812301635742 [sec] # time: 0.07313990592956543 [sec] # time: 0.05380010604858399 [sec]参考) AtCoder ABC152 E問題


- 投稿日:2020-06-28T20:48:23+09:00
平均値で埋めるだけじゃない!少し踏み込んだ欠損値補完
欠損値の種類
実は、欠損値には3種類あります
たくさんの文献を漁ったところ、こちらがわかりやすかったので引用させていただきます。
これら3つの種類に合わせて欠損値を補完していくことが、精度向上のために必要です。Missing Completely At Random (MCAR)
MCAR は完全にランダムで生じる欠損値である。ほとんどの欠損値補完アルゴリズムが有効である。
Missing At Random (MAR)
MAR は、観測データに依存してランダムに生じる欠損値である。例えば、水稲標本を調べたデータで、ある品種(例えば、コシヒカリ)だけに限って特定の特徴量(例えば、乾燥重量)が欠損になっている場合である。MAR の場合は、ほかの特徴量と関係を利用して、ある程度バイアスを抑えて補正することができる。
Missing Not At Random (MNAR)
MNAR は、欠損データに依存して生じる欠損値である。例えば、水稲標本を調べたデータで、ななつ星という品種が、ほとんど栽培実験が行われていないために、そもそもデータとして収集されていないような欠損値のことである。MNAR の場合、そもそもデータが少ない(存在しない)ので、補正が極めて困難である。
前提
本記事では、欠損値「補完」を前提としているので、欠損値をまるごと削除する方法はご紹介しません。
df.dropna(inplace=True)また、本記事は kaggleで勝つデータ分析の技術を参考にしています。
欠損値補完まとめ
- 欠損値のまま取り扱う
- 欠損値を代表値で埋める
- 欠損値を他の変数から予測する
- 欠損値から新たな特徴量を作成する
有効性
施策 MCAR MAR MNAR 1. 欠損値のまま取り扱う O O △ 2. 欠損値を代表値で埋める O △1 X 3. 欠損値を他の変数から予測する O O X 4. 欠損値から新たな特徴量を作成する O △2 X これらを一つずつ噛み砕いて説明していきます。
なお、本記事で掲載するコードは github 上にpush済みです必要ライブラリ
import pandas as pd import numpy as np import xgboost as xgb from IPython.core.display import display from typing import List, Unionデータ準備
記事pandasで欠損値NaNを除外(削除)・置換(穴埋め)・抽出から拝借したこちらのデータを少しだけ編集して使わせていただいています。
df = pd.read_csv('sample_nan.csv') display(df)
name age state point 0 Alice 24.0 NY NaN 1 Charlie NaN CA NaN 2 Dave 68.0 TX 70.0 3 Ellen NaN CA 88.0 4 Frank 30.0 NaN NaN 1. 欠損値のまま取り扱う
GBDTモデルは欠損値を埋めずにそのまま入力することができる
「欠損値は何かしらの理由があって欠損している」という情報を持っているため、安易に埋めるのはかえって精度を下げかねない
2. 欠損値を代表値で埋める
欠損値を「平均値」「中央値」「最頻値」などの代表値で埋める
次の二つの方法がある。
- 全データの統計量で埋める
- カテゴリごとの統計量で埋める
2-1. 全データの統計量で埋める
全てのレコードから算出した代表値で埋める
平均値
df_mean = df.copy() df_mean.fillna(df_mean.mean(), inplace=True) # 平均値 display(df_mean)
name age state point 0 Alice 24.000000 NY 79.0 1 Charlie 40.666667 CA 79.0 2 Dave 68.000000 TX 70.0 3 Ellen 40.666667 CA 88.0 4 Frank 30.000000 NaN 79.0 中央値
df_median = df.copy() df_median.fillna(df_median.median(), inplace=True) # 中央値 display(df_median)
name age state point 0 Alice 24.0 NY 79.0 1 Charlie 30.0 CA 79.0 2 Dave 68.0 TX 70.0 3 Ellen 30.0 CA 88.0 4 Frank 30.0 NaN 79.0 最頻値
df_mode = df.copy() df_mode.fillna(df_mode.mode().iloc[0], inplace=True) # 最頻値 display(df_mode)
name age state point 0 Alice 24.0 NY 70.0 1 Charlie 24.0 CA 70.0 2 Dave 68.0 TX 70.0 3 Ellen 24.0 CA 88.0 4 Frank 30.0 CA 70.0 2-2. カテゴリごとの統計量で埋める
あるカテゴリ変数ごとの統計量で欠損値を補完する
今回は、
stateごとの代表値でageとpointの欠損値を補完するclass BayesianAverage: """ Bayesian Averageを計算する """ def __init__(self, m: Union[float, int], C: int): """ イニシャライザ @param m: あらかじめの値 @param C: 値mの観測回数 """ self.m = m self.C = C def predict(self, xs: List[Union[float, int]]): """ Bayesian Averageを計算する関数 あらかじめ値mのデータをC回観測した経験の上で、実測値の平均を計算する @param xs: 実測値のリスト @return: Bayesian Average """ return (np.sum(xs) + (self.C * self.m)) / (len(xs) + self.C)df_state = df.copy() ba_age, ba_point = BayesianAverage(40, 3), BayesianAverage(80, 3) # <- ハイパーパラメータ # ba_age: 40歳の人を3人追加する設定 (本来であれば、クラスごとに傾向が異なるので、クラスごとに異なるオブジェクトを生成する必要がある) # ba_point: 80点の人を3人追加する設定 (本来であれば、クラスごとに傾向が異なるので、クラスごとに異なるオブジェクトを生成する必要がある) df_state = df_state.groupby('state').agg({'age': ba_age.predict, 'point': ba_point.predict}) display(df_state) # 一つ一つの値はBayesian Average # age point # state # CA 40.0 82.0 # NY 36.0 80.0 # TX 47.0 77.5 # これらを埋める df_bayes_ave = df.copy() for column in ['age', 'point']: for state, data in df_bayes_ave.groupby('state'): bayes_ave = df_state.loc[state, column] df_bayes_ave.loc[df_bayes_ave['state'] == state, column] = data[column].fillna(value=bayes_ave) display(df_bayes_ave)
state age point CA 40.0 82.0 NY 36.0 80.0 TX 47.0 77.5
name age state point 0 Alice 24.0 NY 80.0 1 Charlie 40.0 CA 82.0 2 Dave 68.0 TX 70.0 3 Ellen 40.0 CA 88.0 4 Frank 30.0 NaN NaN 前者のテーブル: 一つ一つの値がBayesian Averageとなっている。
例えば、(1,1)成分はstateがCAの人のageの平均値$\dfrac{0 + 40 \times 3}{0 + 3}=40$
(3,2)成分はstateがTXの人のpointの平均値$\dfrac{70 + 80 \times 3}{1 + 3}=77.5$
後者のテーブル: Bayesian Averageで欠損値を埋めたテーブル
3. 欠損値を他の変数から予測する
今作った
df_bayes_aveのageとpointを説明変数として、stateの最後の行にある欠損値NaNを予測するStep1:
stateが欠損していないレコードの集まりと、stateが欠損しているレコードの集まりで分ける
そして、前者を「訓練データ」、後者を「テストデータ」とするStep2:
訓練データを予測モデルに通して、
stateを予測するように学習するStep3:
テストデータを予測モデルに通して、NaNである
stateを予測する# ====Step1: データ準備============== # [前提] df_bayes_aveを用いて、stateの最後の行NaNを予測する # state -> indexへの変換辞書 state_s2i = {state: i for i, state in enumerate(df_bayes_ave['state'].dropna().unique())} print(f'stateの種類: {state_s2i}') # stateの種類: {'NY': 0, 'CA': 1, 'TX': 2} X_train = df_bayes_ave[['age', 'point']].dropna() # 訓練データ(説明変数)には欠損を含めない y_train = df_bayes_ave['state'].dropna().map(state_s2i) # 訓練データ(目的変数)には欠損を含めない X_test = df_bayes_ave[df_bayes_ave.isnull().any(axis=1)][['age', 'point']] # テストデータは欠損が含まれているレコードのみ抽出 # ================================ # ======Step2: 学習================= # xgboostのオブジェクトに変換する dtrain = xgb.DMatrix(X_train, label=y_train) # ハイパーパラメータ設定 param = {'max_depth': 2, 'eta': 0.1, 'objective': 'multi:softmax', 'num_class': len(state_s2i)} # 学習 bst = xgb.train(param, dtrain, 20) # =============================== # ======Step3: 予測================= # 予測 dtest = xgb.DMatrix(X_test) pred_test = bst.predict(dtest) print(pred_test) # [1.] # ================================ # index -> stateへの変換辞書 state_i2s = {i: state for state, i in state_s2i.items()} # 予測値を欠損値に代入する X_test['state'] = [state_i2s[int(pred)] for pred in pred_test] # 欠損がない訓練データと欠損を埋めたテストデータを結合 train_test = pd.concat([X_train.join(y_train.map(state_i2s)), X_test]) df_bayes_ave2 = pd.concat([df_bayes_ave['name'], train_test], axis=1)[['name', 'age', 'state', 'point']] display(df_bayes_ave2)
name age state point 0 Alice 24.0 NY 80.0 1 Charlie 40.0 CA 82.0 2 Dave 68.0 TX 70.0 3 Ellen 40.0 CA 88.0 4 Frank 30.0 CA NaN
stateの最後の行にある欠損値は「CA」と予測できた4. 欠損値から新たな特徴量を作成する
欠損値から新たな特徴量を作成するアイデアはいくらでも出てきそうですが、ここでは二つ紹介します。
4-1. 欠損しているかどうかを表す二値変数を新たに作る
[メリット] 後に欠損値を埋めたとしても、「欠損していた」という情報が失われない
df_isnull = df.copy() df_isnull['point_isnull'] = df_isnull.isnull()['point'].map({True: 1, False: 0}) df_isnull['point'].fillna(np.mean(df_isnull['point']), inplace=True) # 平均値で埋める display(df_isnull)
name age state point point_isnull 0 Alice 24.0 NY 79.0 1 1 Charlie NaN CA 79.0 1 2 Dave 68.0 TX 70.0 0 3 Ellen NaN CA 88.0 0 4 Frank 30.0 NaN 79.0 1 4-2. レコードごとに欠損している変数の数を数える
df_null_num = df.copy() df_null_num['null_num'] = df_null_num.isnull().sum(axis=1) display(df_null_num)
name age state point null_num 0 Alice 24.0 NY NaN 1 1 Charlie NaN CA NaN 2 2 Dave 68.0 TX 70.0 0 3 Ellen NaN CA 88.0 1 4 Frank 30.0 NaN NaN 2 4-3. 欠損値の組み合わせを新たな変数とする
複数の説明変数で、いくつかの欠損値を保持していた場合、その組み合わせを考える。欠損値を含む各レコードで、どの組み合わせになっているかを新たな変数とする
name age state point 0 Alice 24.0 NY NaN 1 Charlie NaN CA NaN 2 Dave 68.0 TX 70.0 3 Ellen NaN CA 88.0 4 Frank 30.0 NaN NaN ↓
name age state point null_comb 0 Alice 24.0 NY NaN 1 1 Charlie NaN CA NaN 2 2 Dave 68.0 TX 70.0 0 3 Ellen NaN CA 88.0 3 4 Frank 30.0 NaN NaN 4 # null_combの説明 0: 欠損を含まない 1: pointのみ欠損 2: age, pointが欠損 3: ageのみ欠損 4: state, pointが欠損参考文献
- 投稿日:2020-06-28T20:34:09+09:00
Amazon EMR / Cloud Dataproc を Python でお手軽に試す
はじめに
普段使い慣れている Python でお手軽に MapReduce アプリケーションを作成し、 Amazon EMR で実行できないかと思っていたところ、mrjob という Python のフレームワークを知りました。他には PySpark 等の選択肢もありますが、より学習コストが低く、お手軽に実装できる印象のフレームワークです。そこでこの記事では、mrjob で作成したアプリケーションを Amazon EMR 上で実行するまでの方法を記述したいと思います。ついでに GCP の Cloud Dataproc 上でも実行してみます。
mrjob 概要
mrjob は、 Hadoop クラスタで実行するアプリケーションを Python で作成することのできるフレームワークです。Hadoop の専門的な知識がなくても、簡単にローカルやクラウド上などの環境で MapReduce アプリケーションを実行することができます。mrjob は、内部的には Hadoop Streaming での実行を行っています。そもそも Hadoop とは?という場合は、こちらの記事で概要を記述しているので、良ければ参照してください。
MapReduce アプリケーション
通常、MapReduce アプリケーションは、入力のデータセットを分割し、Map 処理、(Shuffle 処理)、Reduce 処理を実行します。また、Map 処理の出力結果を Reduce 処理に渡す前に、Combine 処理という中間集計を行う処理を使用することもできます。
今回実装するアプリケーションは、文書内で単語が出現する回数を数えるプログラムです。次の入力を受け取ることを想定しています。
input.txtWe are the world, we are the children We are the ones who make a brighter dayMap 処理
キーバリューのペアを入力として1行ずつ受け取り、0個以上のキーバリューのペアを返します。
InputInput: (None, "we are the world, we are the children")OutputOutput: "we", 1 "are", 1 "the", 1 "world", 1 "we", 1 "are", 1 "the", 1 "children", 1Combine 処理
1行ごとのキーとそのバリューのリストを入力として受け取り、0個以上のキーバリューのペアを返します。
InputInput: ("we", [1, 1])OutputOutput: "we", 2Reduce 処理
キーとそのバリューのリストを入力として受け取り、0個以上のキーバリューのペアを出力として返します。
InputInput: ("we", [2, 1]) # 1行目の "we" は 2回、2行目の "we" は1回出現OutputOutput: "we", 3環境構築
Python で MapReduce アプリケーションを作成するための環境を構築します。
mrjob のインストール
PyPI からインストールすることができます。今回は、バージョン 0.7.1 を使用しています。
pip install mrjob==0.7.1MapReduce の実装
それでは、上記の処理を mrjob で記述してみます。処理が単純で、一つのステップで記述できる場合は、次のように mrjob.job.MRJob を継承したクラスを作成します。
mr_word_count.pyimport re from mrjob.job import MRJob WORD_RE = re.compile(r"[\w']+") class MRWordCount(MRJob): # 入力を1行ずつ処理し、(単語, 1)のキーバリューを生成する def mapper(self, _, line): for word in WORD_RE.findall(line): yield word.lower(), 1 # 1行ごとのキーとそのバリューのリストを入力として受け取り、合計する def combiner(self, word, counts): yield word, sum(counts) # キーとそのバリューのリストを入力として受け取り、合計する def reducer(self, word, counts): yield word, sum(counts) if __name__ == '__main__': MRWordCount.run()処理がより複雑で、複数のステップでの処理が必要な場合は、次のように mrjob.step.MRStep を MRJob の steps 関数に渡してあげることで処理を定義することができます。
mr_word_count.pyimport re from mrjob.job import MRJob from mrjob.step import MRStep WORD_RE = re.compile(r"[\w']+") class MRWordCount(MRJob): def steps(self): return [ MRStep(mapper=self.mapper_get_words, combiner=self.combiner_count_words, reducer=self.reducer_count_words), MRStep(mapper=..., combiner=..., reducer=...), ... ] def mapper_get_words(self, _, line): for word in WORD_RE.findall(line): yield word.lower(), 1 def combiner_count_words(self, word, counts): yield word, sum(counts) def reducer_count_words(self, word, counts): yield word, sum(counts) if __name__ == '__main__': MRWordCount.run()MapReduce の実行
ローカル、Amazon EMR、Cloud Dataproc の環境でアプリケーションを実行してみます。パッケージ構成はこのようになっています。
パッケージ構成. ├── config.yaml ├── input.txt └── src ├── __init__.py └── mr_word_count.pyアプリケーションの実行にあたり、入力のパスなどのオプションを指定することができます。オプションは、Config ファイルにあらかじめ記述しておく方法と、コンソールから渡す方法があります。指定するオプションが被った場合はコンソールから渡した方の値が優先されます。Config ファイルは yaml か json の形式で定義することができます。
mrjob で作成したアプリケーションを実行するには、コンソールから次のように入力します。
python {アプリケーションのパス} -r {実行環境} -c {Config ファイルのパス} < {入力のパス} > {出力のパス}ローカル
ローカルで実行する場合は、必要なければ実行環境や Config ファイルのパスを指定する必要はありません。また、出力のパスを指定しない場合は標準出力に出力されます。
python src/mr_word_count.py < input.txt # 実行環境や Config ファイルのパスを渡す必要がある場合 python src/mr_word_count.py -r local -c config.yaml < input.txt上記のコマンドを実行すると、アプリケーションが実行され、次のような結果が標準出力に出力されます。
"world" 1 "day" 1 "make" 1 "ones" 1 "the" 3 "we" 3 "who" 1 "brighter" 1 "children" 1 "a" 1 "are" 3Amazon EMR
Amazon EMR 上で実行するには、AWS_ACCESS_KEY_ID と AWS_SECRET_ACCESS_KEY を環境変数に設定するか、Config ファイルに設定する必要があります。また、インスタンスタイプやそのコア数なども設定することができます。アプリケーションとその関連ファイルは、実行される前に S3 にアップロードされます。
config.yamlrunners: emr: aws_access_key_id: <your key ID> aws_secret_access_key: <your secret> instance_type: c1.medium num_core_instances: 4そのほかのオプションはこちらでみることができます。
実行する際には、環境に emr を選択してあげます。
python src/mr_word_count.py -r emr -c config.yaml input.txt --output-dir=s3://emr-test/output/Cloud Dataproc
Cloud Dataproc を利用するために、GCP から Dataproc の API を有効化します。そして、環境変数の GOOGLE_APPLICATION_CREDENTIALS にクレデンシャルファイルのパスを指定します。Config ファイルには、インスタンスのゾーンやタイプ、コア数を設定します。そのほかのオプションはこちらです。
config.yamlrunners: dataproc: zone: us-central1-a instance_type: n1-standard-1 num_core_instances: 2実行する際には、環境に dataproc を選択してあげます。
python src/mr_word_count.py -r dataproc -c config.yaml input.txt --output-dir=gs://dataproc-test/output/まとめ
mrjob を利用することで、Python でも簡単に MapReduce アプリケーションを作成することができ、作成したアプリケーションのクラウド環境での実行も簡単に行うことができました。
また、mrjob はドキュメントも豊富なので、入門がしやすく「Python でお手軽に MapReduce ジョブを実行したい」という場合にとても便利なフレームワークでした。

- 投稿日:2020-06-28T20:17:01+09:00
【2020年度版】税金と手取りの計算を全部Pythonにやらせてみる
概要
税金の計算って難しいですよね。
社会人になると毎年なんとなく税金やら保険料やらが引かれてますが、僕は税金について全然詳しくないのでなにがなんやらという状態です。
さらに聞いた話だと今年から控除やら所得税やらのルールが変わるみたいです。
「退屈なことは全部Pythonにやらせよう」とう格言(?)があるので、今回は勉強を兼ねてPythonで税金計算用のクラスを作ってみようと思います。
ゼロからいろいろ調べながら書いたので知ってる人にとっては当たり前の説明が多いかもしれません。Github
Githubに税金計算用のクラスを作ってあげました。コードを書くにあたって参考にしたサイト
使い方
税金の難しい話をする前に、まずは簡単に使い方を説明しようと思います。
今回作ったTaxクラスはtax.pyの中で実装されています。
例として年収500万の独身男性の場合を考えます。
親のディレクトリにtax.pyがある状態で以下を実行します。# coding: utf-8 import sys, os sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定 from common.tax import Tax gross_salary = 5000000 tax = Tax(gross_salary) print("gross_salary, income = ", tax.gross_salary, tax.income) print("income_tax, inhabitant_tax, insurance_premiun = ", tax.income_tax(), tax.inhabitant_tax(), tax.social_insurance_premium()) print("net_salary = ", tax.net_salary()) print("max_hurusato_donation = ", tax.max_hurusato_donation())出力gross_salary, income = 5000000 3560000.0 income_tax, inhabitant_tax, insurance_premiun = 110575.0 215575.0 619249.9999999999 net_salary = 4054600.0 max_hurusato_donation = 56035.593432760994
- gross_salary : 収入
- income : 給与所得
- inhabitant_tax : 住民税
- income_tax : 所得税
- insurance_premium : 社会保険料
- net_salary : 手取り
- max_hurusato_donation : ふるさと納税で自己負担2000円で全額控除できる上限
です。このケースだと額面が500万円、税金や保険料などでいろいろ引かれて手取りがだいたい400万円くらいってことです。
上の例だとtaxの引数は収入(=gross_salary)しか与えていませんが、扶養家族がいたり障害者である場合は控除されるので、引数を指定することでそういったケースも計算可能です。
では、個々について順番に説明していきます。給与所得
まずは給与所得についてです。僕は税金に関して無知だったので、「なんとなく収入から税金が引かれて手取りが減る」ことまでは理解していたものの、給与所得とはなんぞ?という状態でした。
実は諸々の税金は額面の収入から直接計算されるわけではなく、給与所得控除という控除が行われた後の金額に適用されます。
今回は会社員を前提で話していますが、本来仕事をするときには必要経費が発生するので(収入) - (経費) = (所得)の図式が成り立ちます。雇われの身である会社員の場合はあまりピンとこないかもしれませんが、働いていれば経費にあたる出費があるだろうという前提で、すべての会社員が収入から引かれます。
ちなみにこれは源泉徴収表にも会社からの額面の収入のとなりに給与所得控除後の金額という名前で控除後の金額が記載されています↓
Pythonのコードは以下になります。
2020年以降はルールが変わってこの給与所得控除が10万円減り、のちに出てくる所得税が10万円増えました。
なのでプラマイゼロで引かれる金額は変わらないのですが、年収850万円以上の人は今回の改正で払う金額が多くなっています。
僕は年収850万もないですが、個人的には頑張って年収が増えても所得税でいっぱい引かれると思うとモチベーションがいまいち上がらないのでこの改正は別に嬉しくはないですね。。
こうして計算した給与所得控除後の金額をincomeとして返します。
このincomeの値は他のクラス関数でもよく使うので、コンストラクタの中でself.incomeに代入しています。Tax.income()def income(self): """ 給与所得控除の計算, 収入を引数として控除額を返す 2020年以降は控除が10万減額し、所得税で10万増えたので実質変わらない ただし、850万以上は給与所得控除の額が減ったで実質的には増税 """ employment_income_deduction = 0 if self.gross_salary < 550000: employment_income_deduction = self.gross_salary elif self.gross_salary <1800000: employment_income_deduction = self.gross_salary * 0.4 - 100000 elif self.gross_salary <3600000: employment_income_deduction = self.gross_salary*0.3 + 80000 elif self.gross_salary <6600000: employment_income_deduction = self.gross_salary*0.2 + 440000 elif self.gross_salary <8500000: employment_income_deduction = self.gross_salary*0.1 + 1100000 else: employment_income_deduction = 1950000 income = self.gross_salary - employment_income_deduction return income社会保険料
次に社会保険料について見ていきます。
これは税金とは別枠の厚生年金とか雇用保険とかそのへんです。
計算式は以下に書いていますが、健康保険料率と免除保険料率、雇用保険料率なるものが出てきますね。
これらから計算した保険料率を収入にかけたものが最終的な保険料になります。
健康保険料率は地域によって違いますが、東京の場合は9.87%なので、
self.health_insurance_premium_rateにはデフォルトで0.0987が入っています。
免除保険料率は厚生年金がどれくらい免除されるかを決めるものです。
免除保険料率は年齢と共に上がる傾向がありますが、平均で0.4%くらいなのでself.rebate_contribution_rateはデフォルトで0.04です。
これらの値はコンストラクタで個別に設定可能です。
これらの値が2で割られているのは会社と半分ずつ負担しているためです。
雇用保険料率は一律0.3%なので、それらを足し合わせて保険料率を計算します。Tax.social_insurance_preium()def social_insurance_premium(self): """ 保険料の計算 保険料率 = 健康保険料率/2 + (厚生年金保険料率18.3%-免除保険料率)/2 + 雇用保険料率0.3% """ # 保険料率 insurance_premium_rate = (self.health_insurance_premium_rate)/2 \ + (0.183 - self.rebate_contribution_rate)/2 \ + 0.003 # 社会保険料 = 年収 x 保険料率 social_insurance_premium = self.gross_salary*insurance_premium_rate return social_insurance_premium所得税
次に所得税です。
所得税はincome()で計算した所得からまず基礎控除を引きます。
基礎控除は今までは一律38万円でしたが、2020年からは48万円に引き上げられました。
(上でも述べたようにその分給与所得控除が10万円引き下げられました。)
ただし、今回から新しく加わったルールとして年収2400万を超えると段階的に基礎控除の額が減り、2500万円を越えるとゼロになります。
さらにそこから扶養控除(dependents_deduction)、障害者控除(handicapped_deduction)が引かれます。
コンストラクタで特に指定しない場合はdependents_deductionもhandicapped_deductionもゼロに設定されています。こうして諸々の控除された後の所得を
target_of_income_taxとし、ここから所得税を計算します。
年収が高いほどたくさん取られる仕組みになっています。
なお、ここで出てくる所得税率(self.income_tax_rate)はふるさと納税をする場合の計算にも使います。Tax.income_tax()def income_tax(self): """ 所得税の計算 """ # 所得税における扶養控除 dependents_deduction = self.high_school_student * 480000 + self.college_student * 630000 # 所得税における障害者控除 handicapped_deduction = self.handicapped * 260000 # 基礎控除、2019年までは一律38万円だったが、2020年からは48万円に。ただし2000万を超えると段階的に減る basic_deduction = 0 if self.income < 24000000: basic_deduction = 480000 elif self.income < 24500000: basic_deduction = 320000 elif self.income < 25000000: basic_deduction = 160000 # 所得税の対象となる金額、所得から控除や保険料を引いたもの target_of_income_tax = (self.income \ - self.social_insurance_premium() \ - self.spousal_deduction() \ - dependents_deduction \ - handicapped_deduction \ - basic_deduction) # 年収別の所得税率と控除額 if target_of_income_tax < 1950000: self.income_tax_rate = 0.05 deduction = 0 elif target_of_income_tax < 3300000: self.income_tax_rate = 0.1 deduction = 97500 elif target_of_income_tax < 6950000: self.income_tax_rate = 0.2 deduction = 427500 elif target_of_income_tax < 9000000: self.income_tax_rate = 0.23 deduction = 636000 elif target_of_income_tax < 18000000: self.income_tax_rate = 0.33 deduction = 1536000 elif target_of_income_tax < 40000000: self.income_tax_rate = 0.40 deduction = 2796000 else: self.income_tax_rate = 0.45 deduction = 479.6 # 所得税の計算 income_tax = target_of_income_tax * self.income_tax_rate - deduction # 所得税がマイナスにになった場合はゼロにする if income_tax <= 0: income_tax = 0 return income_tax住民税
住民税の計算は所得税と似ているので、所得税の仕組みがわかればそれほど難しくないと思います。
所得税とは控除の額が違う他、前年度の収入に対して税金がかかる点でも違います。
(プログラム上では前年度、今年度の区別は特にしていません)Tax.inhabitant_tax()def inhabitant_tax(self): """ 住民税の計算, 課税所得を引数に住民税を計算する """ # 住民税における扶養控除 dependents_deduction = self.high_school_student * 330000 + self.college_student * 450000 # 住民税における障害者控除 handicapped_deduction = self.handicapped * 270000 # 基礎控除、所得税と同様2020年から変更 basic_deduction = 0 if self.income < 24000000: basic_deduction = 430000 elif self.income < 24500000: basic_deduction = 190000 elif self.income < 25000000: basic_deduction = 150000 # 所得から各種控除、基礎控除(43万円)を引き、税率10%をかける # さらに均等割5000円を足して、調整控除2500円を引く inhabitant_tax = (self.income - self.social_insurance_premium() - self.spousal_deduction() - dependents_deduction - handicapped_deduction - basic_deduction) * 0.1 + 5000 - 2500 # 計算した住民税がマイナスになった場合はゼロとする if inhabitant_tax <=0: inhabitant_tax = 0 return inhabitant_tax手取り
ここまでくれば手取りを計算することができます。
額面の収入から今まで計算してきた社会保険料、所得税、住民税を引きます。Tax.net_salary()def net_salary(self): """ 手取りの計算、収入から所得税、住民税、社会保険料を引く """ total_tax = self.inhabitant_tax() + self.income_tax() net_salary = self.gross_salary - total_tax - self.social_insurance_premium() return net_salaryふるさと納税
今まで出てきたものとは少し毛色が違いますが、ふるさと納税についても実装しました。
ふるさと納税は地方に寄付することで返礼品を受け取れるというシステムです。
その際に寄付に応じて所得税、住民税を減税することができます。
上限額までは寄付した金額のうち2000円のみが自己負担で、残りの金額すべてを控除にあてることができます。
以下の関数では控除に全額あてることができる寄付の金額の上限を計算しています。
計算式はコメントやコードを参考にしてください。Tax.max_hurusato_donation()def max_hurusato_donation(self): """ ふるさと納税で自己負担2000円で全額控除される上限の計算 言い換えるとreturnの金額から2000円引いたものが所得税および住民税から控除される """ # 住民税所得割額(=住民税)から計算する # ふるさと納税控除額の上限 hurusato_deduction = self.inhabitant_tax() * 0.2 # (控除金額) =(寄附金額-2000)×(90%-所得税の税率×1.021) # (寄付金額) = (控除金額)/(90%-所得税の税率×1.021)+2000 max_hurusato_donation = hurusato_deduction / (0.9 - self.income_tax_rate * 1.021) + 2000 return max_hurusato_donation可視化
これだけだと
Pythonで書く意味ある?と言われてしまいそうなので、matplotlibを使って可視化してみます。
まずは必要なライブラリをimportします。Tax.show_ipynb# coding: utf-8 import sys, os sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定 from common.tax import Tax import numpy as np import pandas as pd from matplotlib import pyplot as plt import seaborn as sns %matplotlib inline pd.options.display.precision = 0 plt.rcParams['font.family'] = 'AppleGothic'年収200-1200万円まで100万円刻みで計算し、
listに突っ込みます。Tax.show_ipynb2# 額面年収、200〜1,200万まで1万刻みで gross_salaries = [i for i in range(2000000,12010000, 1000000)] # 所得 incomes = [] # 税金 total_taxes = [] # 住民税 inhabitant_taxes = [] # 所得税 income_taxes = [] #社会保険料(=社会保険料控除) social_insurance_premiums = [] # 手取り年収 net_salaries = [] # ふるさと納税控除上限とそのときの寄付額 max_hurusato_donation = [] for gross_salary in gross_salaries: tax = Tax(gross_salary) # リストに値を追加 incomes.append(tax.income) total_taxes.append(tax.income_tax() + tax.inhabitant_tax()) inhabitant_taxes.append(tax.inhabitant_tax()) income_taxes.append(tax.income_tax()) social_insurance_premiums.append(tax.social_insurance_premium()) net_salaries.append(tax.net_salary()) max_hurusato_donation.append(tax.max_hurusato_donation() - 2000) #自己負担2000円を引く
dataframeに格納します。df.head()とかで中身を見れます。Tax.show_ipynb3df = pd.DataFrame() df['年収'] = gross_salaries df['手取り'] = net_salaries df['税金'] = total_taxes df['住民税'] = inhabitant_taxes df['所得税'] = income_taxes df['社会保険料'] = social_insurance_premiums df['ふるさと納税控除上限'] = max_hurusato_donation棒グラフで可視化します。
Tax.show_ipynb4df.index = ['200', '300', '400', '500', '600', '700', '800', '900', '1000', '1100', '1200'] plt.figure(figsize=(12,7)) plt.rcParams["font.size"] = 14 plt.grid(axis='y') yticks = [0, 1000000, 2000000, 3000000, 4000000, 5000000, 6000000, 7000000, 8000000, 9000000, 10000000, 11000000, 12000000] plt.ylim(0, 12500000) plt.yticks(yticks) plt.bar(df.index, df['手取り']) plt.bar(df.index, df['税金'], bottom= df['手取り']) plt.bar(df.index, df['ふるさと納税控除上限'], bottom= df['手取り'] + df['税金'] - df['ふるさと納税控除上限']) plt.bar(df.index, df['社会保険料'], bottom= df['手取り'] + df['税金']) plt.xlabel('Salary (yen*10000)') plt.ylabel('Breakdown (yen)') plt.title('') plt.legend(['net-salary', 'tax','hurusato_deduction', 'insurance']) plt.show()
グラフの説明
- 横軸が年収、縦軸のうち青が手取り、(オレンジ+緑)が税金で、緑がそのうちふるさと納税で控除できる上限、赤が社会保険料
グラフを見た僕の感想
- 年収800万円くらいまでは税金よりも社会保険料の方が多いが、それ以上だと税金の方が多くなってくる
- 今の日本が高額納税者(=高収入の人)に支えられていることがわかる
- 年収1000万円でも手取り700万ちょっとしかもらえないのか...
- ふるさと納税はやった方が良い
まとめ
- Pythonを使って税金や手取りを計算するクラスを作り、可視化してみた
- 計算や解釈の誤りがあれば随時直す予定なので、もし見つけた方がいたら教えてもらえると嬉しいです


- 投稿日:2020-06-28T20:12:25+09:00
[cx_Oracle入門](第10回) 更新系DML文とDDL/DCL文
検証環境
- Oracle Cloud利用
- Oracle Linux 7.7 (VM.Standard2.1)
- Python 3.6
- cx_Oracle 8.0.0
- Oracle Database 19.5 (ATP, 1OCPU)
- Oracle Instant Client 18.5
※今回以降、cx_Oracleのバージョンを7.3から8に変更します。7.3だと説明が異なる場合もなるべくフォローします。
更新系DML文とDDL/DCL文の実行
基本SELECT文と同じで、Cursorオブジェクトのexecute()メソッドでSQL文を実行します。以下、サンプルです。
sample10a.pyimport cx_Oracle USERID = "admin" PASSWORD = "FooBar" DESTINATION = "atp1_low" SQL1 = """ create table dept( deptno number(2,0), dname varchar2(14), loc varchar2(13), constraint pk_dept primary key (deptno) ) """ SQL2 = "insert into dept values(10, 'ACCOUNTING', 'NEW YORK')" SQL3 = "commit" SQL4 = "select * from dept" with cx_Oracle.connect(USERID, PASSWORD, DESTINATION) as connection: with connection.cursor() as cursor: cursor.execute(SQL1) cursor.execute(SQL2) cursor.execute(SQL3) print(cursor.execute(SQL4).fetchone())バインド変数
バインド変数の扱いも、基本的には第7回と同様です。以下サンプルです。前述のsample10a.pyの実行が前提となっています。
sample10b.pyimport cx_Oracle USERID = "admin" PASSWORD = "FooBar" DESTINATION = "atp1_low" SQL1 = "insert into dept values(:deptno, :dname, :loc)" SQL2 = "commit" binds = [{"deptno":20, "dname":"RESEARCH", "loc":"DALLAS"}, {"deptno":30, "dname":"SALES", "loc":"CHICAGO"}] with cx_Oracle.connect(USERID, PASSWORD, DESTINATION) as connection: with connection.cursor() as cursor: cursor.prepare(SQL1) cursor.executemany(None, binds) cursor.execute(SQL2)下から2行目のexecutemany()メソッドは、利用方法から想像がつくとは思いますが、2番目のパラメータのリストの要素数の回数のPreparedStatementを実行します。
NULL値のバインド
DBのNULL値は、Python上ではNoneが該当します。NULLを格納したい場合はバインド変数にはNoneを設定します。NULL値をSELECTした場合は、Noneが変数に格納されます。
Output先としてのバインド変数
ここまで、SQLへ値を渡す形のバインド変数の例ばかりでした。実際には、SQLから受ける形のバインド変数も存在します。この場合、Cursorオブジェクトのvarメソッドを利用して、値を受けるバインド変数の役割をするPython変数を作成することで対応が可能です。以下、RETURNING句を受けるバインド変数利用のサンプルです。前述のsample10b.pyの実行が前提となっています。
sample10c.pyimport cx_Oracle USERID = "admin" PASSWORD = "FooBar" DESTINATION = "atp1_low" SQL1 = """ update dept set deptno = deptno + 10 where deptno > 0 returning deptno into :out_deptno """ SQL2 = "rollback" with cx_Oracle.connect(USERID, PASSWORD, DESTINATION) as connection: with connection.cursor() as cursor: bind_deptno = cursor.var(int) cursor.execute(SQL1, out_deptno = bind_deptno) print(f"DEPTNO = {bind_deptno.getvalue()}") print(f"RowCount = {cursor.rowcount}") cursor.execute(SQL2)下から5行目が、SQLからの出力を受けるバインド変数のための、Python変数の定義です。var変数の引数にデータを受ける際のPythonデータ型を指定します。
下から3行目のgetvalue()で、SQL文のRETURNING句のバインド変数内容を受け取っています。引数はデフォルトが0で、バインド変数の位置を指定します。今回はバインド変数が一つしかないので0(一つ目)で問題ありません。この例の場合だと、printされる更新後の列値はintのリストの形で戻ります。更新行数を知る
先のサンプルの下から2行目が該当します。
更新SQL実行後にサンプルにあるCursorオブジェクトのrowcount属性にアクセスすると、更新された行数を取得することが可能です。SELECT文でこの属性値にアクセスした場合は、その時点でfetchされた行数が格納されています。
- 投稿日:2020-06-28T19:36:22+09:00
囚人のジレンマゲームの相手を搾取する戦略
概要
繰り返し囚人のジレンマゲームにおけるZero-determinant戦略(ゼロ行列式戦略)をPythonによるシミュレーションを用いて紹介します.これまで,この繰り返しゲームにおいて,プレイヤーの戦略として,一方的に相手プレイヤーの得点を決めたり,相手よりも常に高い得点を得るという究極的で一方的な戦略はないと思われてきました.しかし,近年の研究で,このような戦略が存在することがわかりました.この戦略がどんな戦略であるかを簡単に紹介していきます.
(Zero-determinant戦略について,詳しくは,https://qiita.com/igenki/items/1f977e842134b3ace7c7 をご覧ください.この記事との差異は,以下のプログラムを使って,自分でこの戦略を試すことで,Zero-determinant戦略を理解することができます.)
この記事は以下の内容を含みます.
- 囚人のジレンマゲームのシミュレーション
- Zero-determinant戦略を使ったシミュレーション実験
囚人のジレンマゲーム
ゲームの内容
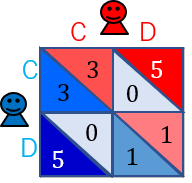
囚人のジレンマゲームとは、ゲーム理論における最も代表的なゲームの1つです.このゲームは,よく以下の得点表で与えられます.
このゲームのルールは,2人いるプレイヤー(プレイヤー$X$と$Y$)がそれぞれ,協力($C$:Cooperate)か裏切り($D$:Defect)かを選びます.各プレイヤーが選んだ行動によって,得点が決まります.
$X$と$Y$がお互い$C$を選べば,両者はそこそこ良い得点である$3$点を得ることができます.$X$と$Y$のどちらかが$C$を選び,もう一方が$D$を選べば,$C$を選んだプレイヤーは最も低い得点である$0$点を得ることになり,$D$を選んだプレイヤーは最も高い得点である$5$点を得ることができます.$X$と$Y$がお互い$D$を選べば,両者は,小さい得点である$1$点を得ることになります.お互い$C$を選べば,両者の得点を合わせると$6(=3+3)$となり,全体にとっては最も良い得点になり,相手に一方的に裏切られると,裏切られたプレイヤーは大損をするといった構造になっています.
このように,各プレイヤーは本当は協力し合いたいと思っているのに,裏切りに誘惑されてしまうというジレンマがあるというゲームです.
シミュレーション
以下のプログラムは,繰り返し囚人のジレンマゲームのシミュレーションプログラムです.
シミュレーションでは,上記の得点表のゲームを繰り返し行います.
プレイヤーの戦略を定義します.
プレイヤーは,記憶1(Memory-One)戦略を使っているとします.この記憶1戦略は,前回のゲームの結果のみを考慮して,今回の行動($C$ or$ D$)を確率的に決定するという戦略です.プレイヤー$X$の戦略を,${\bf p}=(p_{CC},p_{CD},p_{DC},p_{DD}; p_0)$と定義します.
例えば,$p_{CC}$は,前回のゲームで,プレイヤー$X$が$C$を選び,プレイヤー$Y$が$C$を選んだとき,今回のゲームで協力する確率となります.$p_{CD}$は,前回のゲームで,プレイヤー$X$が$C$を選び,プレイヤー$Y$が$D$を選んだとき,今回のゲームで協力する確率となります.その他も同様に考えます.$p_0$は,初回のゲームで協力する確率です.
プレイヤー$Y$の戦略は,同様に,${\bf q}=(q_{CC},q_{CD},q_{DC},q_{DD}; q_0)$とします.
以下の図は,ゲームの状態遷移のイメージです.$CC$(相互協力)から$CC$に移る確率は,各プレイヤーの協力する確率をかけて,$p_{CC} q_{CC}$となります.また,$CD$から$CD$に移る確率は,プレイヤー$X$の協力する確率とプレイヤー$Y$の裏切る確率をかけて,$p_{CD}(1-q_{CD})$となります.
これをPythonで実装します.
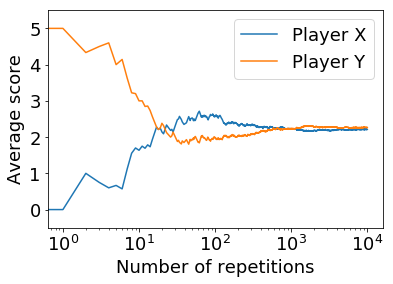
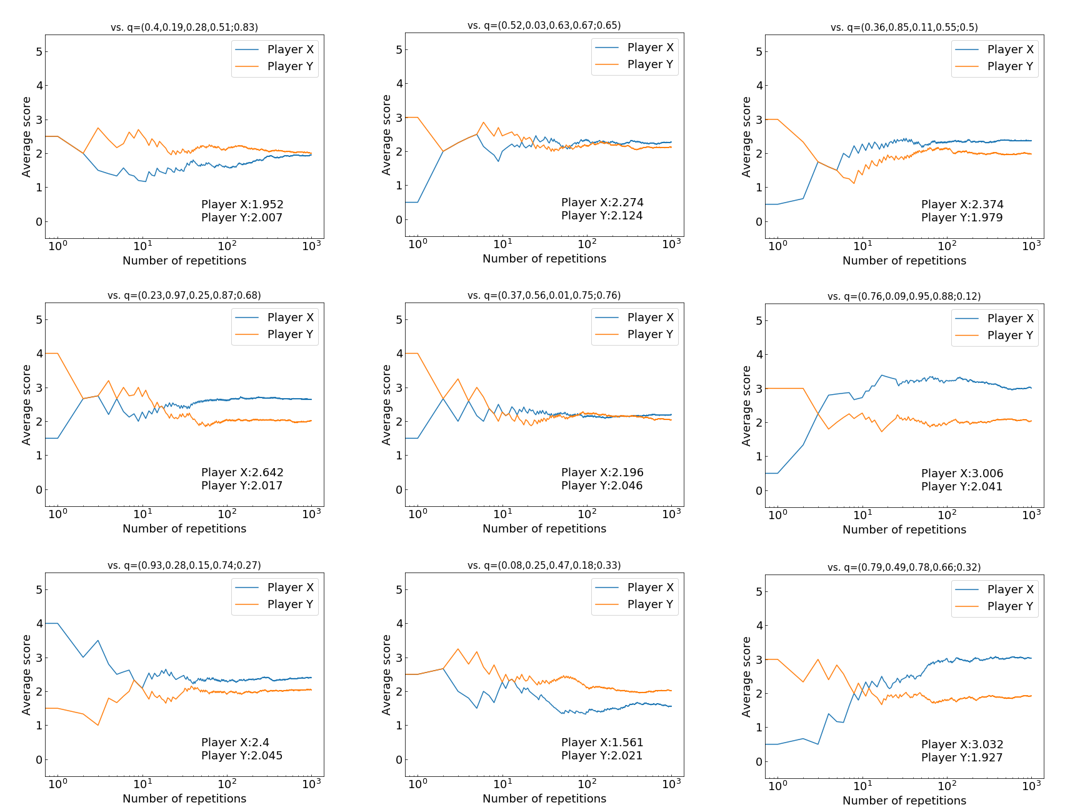
import random if __name__ == '__main__': max_t = 10000 # ゲームの繰り返し回数 point_x = 0; point_y = 0 # 得点を初期化 state = '0' # ゲームの状態を設定 payoff = {'T':5, 'R':3, 'P':1, 'S':0} # ゲームの得点を設定 p = {'CC':1/2, 'CD':1/2, 'DC':1/2, 'DD':1/2, '0' :1/2} # プレイヤーXの戦略 q = {'CC':1/2, 'CD':1/2, 'DC':1/2, 'DD':1/2, '0' :1/2} # プレイヤーYの戦略 # 繰り返しゲーム for t in range(max_t): # 前回のゲームの結果を基に,C or Dを選択する action_x = 'C' if random.random() <= p[state] else 'D' action_y = 'C' if random.random() <= q[state] else 'D' # 決めた行動を基に利得を配分 if action_x == 'C' and action_y == 'C': point_x += payoff['R']; point_y += payoff['R']; state = 'CC' elif action_x == 'C' and action_y == 'D': point_x += payoff['S']; point_y += payoff['T']; state = 'CD' elif action_x == 'D' and action_y == 'C': point_x += payoff['T']; point_y += payoff['S']; state = 'DC' elif action_x == 'D' and action_y == 'D': point_x += payoff['P']; point_y += payoff['P']; state = 'DD' # 各プレイヤーの平均点数を出力 print(f'Player X: {point_x/max_t} Points') print(f'Player Y: {point_y/max_t} Points')このシミュレーションを実行すると,結果は以下のようになります.
Player X: 2.2142 Points Player Y: 2.2647 Pointsほぼ同点の結果となりました.これは,プレイヤー$X$の戦略は,${\bf p}=(1/2,1/2,1/2,1/2; 1/2)$,プレイヤー$Y$の戦略も${\bf q}=(1/2,1/2,1/2,1/2; 1/2)$としているので,当然の結果です.
以下の図は,今回のシミュレーションの平均得点の推移です.
1回目のゲームで,各プレイヤーの得点(y軸上の点)は,プレイヤー$X$が$0$点(青線),プレイヤー$Y$が$5$点(オレンジ線)なので,$X$は$C$を選び,$Y$は$D$を選んでいるということがわかります.このことから,1回目のゲームでは,プレイヤー$Y$の方が得点が高くなっていますが,ゲームを繰り返すと,同じ戦略を採っているということもあり,得点差が小さくなっていくことがわかります.
実験
いろいろな戦略を与えて,実験してみます.
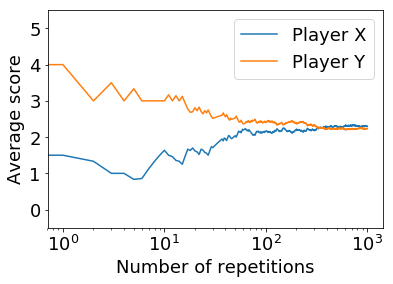
ここでは,プレイヤー$X$の戦略を${\bf p}=(1,0,0,1; 1)$($WSLS$戦略と呼ばれる)と決めます.プレイヤー$Y$は,先ほどと同じ,${\bf q}=(1/2,1/2,1/2,1/2; 1/2)$とします.これで実験を行います.その結果は,以下のようになります.
Player X: 2.295 Points Player Y: 2.235 Pointsこの結果では,プレイヤー$X$が勝っていますが,負けることもあります.得点の推移は以下のようになります.
次に,プレイヤー$Y$の戦略を${\bf q}=(1/2,1/2,1/2,1/2; 1/2)$以外に,いろいろ戦略変えて実験してみます.$\bf q$はランダムに乱数で設定しています.以下の図は,実際に$\bf q$をいろいろ変えて実験してみたものです.各図の$Y$の戦略は図の上に表示されています.各図のプレイヤー$X$の戦略は$WSLS$戦略${\bf p}=(1,0,0,1; 1)$となっています.
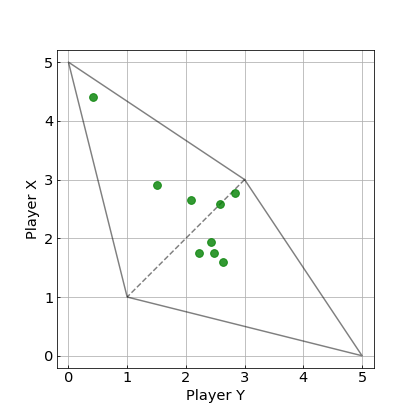
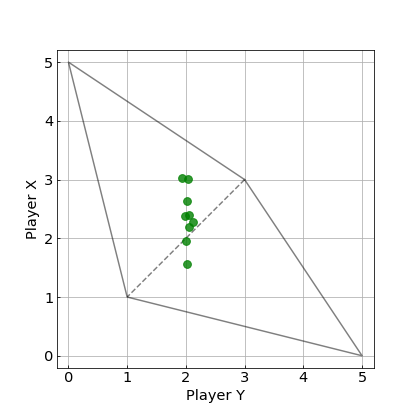
上の実験結果における最終的な平均得点に着目した図を以下に示します.
この図から,$WSLS$戦略が9つの戦略中で,3戦略について,勝つことができています.破線の付近にある2つの戦略に対しては,ほぼ引き分け,その他の4つの戦略については,$WSLS$戦略が負けています.
Zero-determinant戦略
次にZero-determinant(ZD)戦略を使った実験をします.
ZD戦略は,繰り返し囚人のジレンマゲームにおける戦略です.2012年に,米国科学アカデミー紀要(https://www.pnas.org/content/109/26/10409 )で発表されました.この戦略を使うプレイヤーは,相手の利得を一定値に固定することができます(Equalizer戦略).また,相手の戦略に関わらず,相手以上の利得(得点)を得ることができます(Extortion戦略).ここでの利得というのは,ゲームを繰り返したときの期待利得(平均得点)です.この戦略は,導出過程で,行列式(determinant)と呼ばれる数式をゼロ(Zero)にすることことで,導出されます.したがって,Zero-determinantという名前が付きました.
ZD戦略を実験
ZD戦略は,部分戦略のとして,Equalizer戦略やExtortion戦略もち,その他にもありますが,今回は,上のシミュレーションプログラムを用いて,この2つ戦略を紹介していきます.
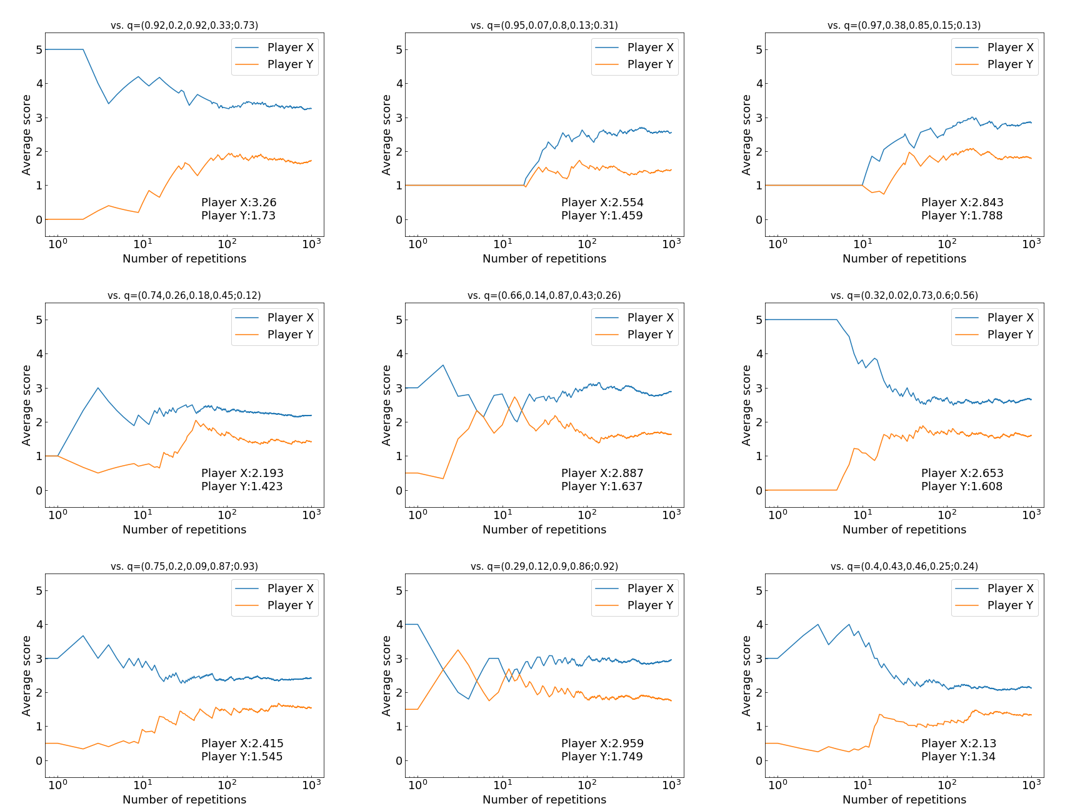
Equalizer戦略
この戦略は,相手の利得を一定値に固定することが可能です.
Equalizer戦略の1つの例として,${\bf p}=(2/3,0,2/3,1/3;1)$があります.この戦略$\bf p$をプレイヤー$X$が使うと,プレイヤー$Y$は,どんな戦略を使っても,平均得点を2点に固定されてしまいます.
これが本当かを実験していきます.上のシミュレーションプログラムで,プレイヤー$X$はEqualizer戦略${\bf p}=(2/3,0,2/3,1/3;1)$と設定し,$Y$の戦略${\bf q}=(1/2,1/2,1/2,1/2; 1/2)$をとします.これで,実験すると以下の結果が得られました.
Player X: 2.3457 Points Player Y: 1.9992 Points結果を見ると,プレイヤ-の点数が,約$2$点($1.9992$点)となっていることがわかると思います.これは,たまたまではなく,何回実験しても同様な結果が得られます.以下の図は,平均得点の推移です.
相手の得点(オレンジ線)が,ゲームの回数を重ねるごとに,$2$点に近づくことがわかります.今回の実験では,プレイヤー$Y$の戦略を${\bf q}=(1/2,1/2,1/2,1/2; 1/2)$としていましたが,他のどんな戦略${\bf q}$であったとしても,Equalizer戦略 ${\bf p}=(2/3,0,2/3,1/3;1)$は,$Y$の平均得点を$2$点にさせます.
プレイヤー$Y$の戦略を${\bf q}=(1/2,1/2,1/2,1/2; 1/2)$以外に,いろいろ戦略変えて実験してみます.$\bf q$はランダムに乱数で設定しています.以下の図は,実際に$\bf q$をいろいろ変えて実験してみたものです.各図の$Y$の戦略は図の上に表示されています.
やはり,プレイヤー$Y$がどんな戦略$\bf q$を採っても,約$2$点に固定されてしまいます.
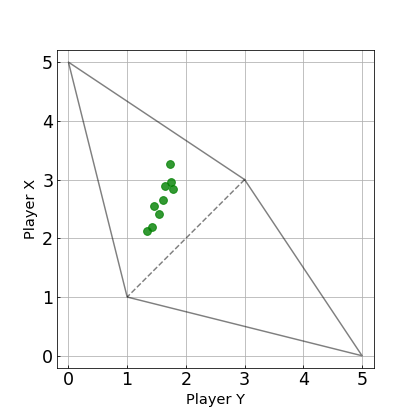
上の実験結果における最終的な平均得点に着目した図を以下に示します.
今回のシミュレーションでは,完全な$2$点とはなっていませんが,ゲームの回数を増やすとより$2$点に近づきます.はじめの$WSLS$戦略の実験の図と比べると,明らかに,$Y$の得点が$2$点付近に集まっていることがわかります.
今回のEqualizer戦略は$Y$の得点を,$2$点に固定していますが,固定できる得点は$2$点以外にも可能です.このゲームの得点表では,固定できる得点の範囲は,$1$点から$3$点の範囲となります.
Extortion戦略
相手の戦略に関わらず,常に相手以上の得点を得ることができます.
Extortion戦略の1つの例として,${\bf p}=(11/13,1/2,7/26,0;0)$があります.この戦略$\bf p$をプレイヤー$X$が使うと,プレイヤー$Y$は,どんな戦略を使っても,プレイヤー$X$に勝つことはできません.
これが本当かを$Y$の戦略$\bf q$をいろいろ変えて,実験していきます.その結果が以下の図です.
この図において,最終結果を見ると,Extortion戦略のプレイヤー$X$(青線)が,$Y$がどんな戦略であろうと,常に高い平均得点を得られているとがわかります.
上の実験結果における最終的な平均得点に着目した図を以下に示します.
このExtortion戦略 ${\bf p}=(11/13,1/2,7/26,0;0)$は,上の図について,プレイヤー$X$の得点を$s_X$,プレイヤー$Y$の得点を$s_Y$とすると,$s_X-1=3(s_Y-1)$の関係を一方的に強いる戦略です.したがって,これはシミュレーションの結果なので,正確には$s_X-1=3(s_Y-1)$の関係にはなっていませんが,この直線の式に沿ったような結果になっています.もっとゲームの回数を増すと,この直線により近づきます.
繰り返し囚人のジレンマゲームでは,裏切りが最も強い戦略ですが,その裏切り戦略(常に裏切り$ALLD$戦略)に対しては,Extortion戦略は裏切りで返すので,引き分けるという結果になります.また,Extortion戦略を相手がとった場合も,裏切り合いとなり,引き分けという結果になります.
したがって,Extortion戦略は,$ALLD$戦略(とExtortion戦略)からの搾取を防ぎ,その他の戦略に対しては,搾取することができる戦略であると今回はまとめます.
(補足)
今回は紹介しませんが,Extortion戦略は,戦略を変えることで自分の得点を改善するプレイヤーに対して,協力を促すことができます.$ALLD$戦略には,この性質はありません.自分が$ALLD$戦略を採った場合,相手は協力的な戦略にするほど,相手は得点が下がってしまいます.しかし,Extortion戦略は,相手が協力的な戦略を採るほど,相手により高い得点を与えることができます.その結果,相手は協力戦略(常に協力する$ALLC$戦略)に導かれます(Extortion戦略に対しての最適反応は$ALLC$戦略を採ることとなる).その結果,相手が$ALLC$戦略を採ってくれると,Extortion戦略にとっても,高得点になります.Extortion戦略は,$ALLD$戦略以外の戦略に対しては搾取する戦略なので,$ALLC$戦略に対しては,大きく得点を搾取することができます.
したがって,戦略を変えることで自分の得点を改善するプレイヤーに対してはとても有効な戦略だと言われています.
まとめ
ZD戦略がどんな戦略であるか,Pythonによるシミュレーションを使いながら紹介しました.特に,部分戦略であるEqualizer戦略やExtortion戦略の2つを紹介しました.Equalizer戦略は,相手の平均得点を操作することができたり,Extortion戦略は,相手以上の得点が得るというどちらの戦略も興味深く,強力な戦略であるということを示してきました.この記事で,ZD戦略について,興味を持ってもらえると嬉しく思います.
参考文献
- (Qiita ゼロ行列式戦略(Zero-determinant strategies)のまとめ) -https://qiita.com/igenki/items/1f977e842134b3ace7c7
- (PNASの論文) https://www.pnas.org/content/109/26/10409



- 投稿日:2020-06-28T19:30:55+09:00
Pythonでログ解析したい
各サーバーやプログラムのログを解析/集計する時に使用する関数の備蓄録です。
「Pythonでログを解析してみたい!」という方は是非参考にしてください!1行を空白で区切る
splitを使用します。
splitの使用法は大きく分けて
str.split()の様に区切り文字を指定せず、文字列strが空白区切りにされたリストを返してもらうstr.split('区切り文字')の様に区切り文字を指定し、文字列strを指定した区切り文字で区切ったリストを返してもらうこの2つの使用法があります。
前者のstr.split()を使用します。
ログはタブや1文字分の空白で区切られていることが多いです。
ログの中で区切り文字が統一されていれば区切り文字を指定するのも良いのですが、残念ながら、タブと1文字分の空白の両方が混同されていることもあります。
str.split()であればタブも1文字分の空白も同じ「空白」として区切ってくれるのです。
もちろん、カンマなどで区切られている時は、str.split('区切り文字')を採用します。カウントする
アクセス数を集計する際、
count.py# カウントする関数 def count( targets): cnt = {} for target in targets: if target in cnt.keys(): cnt[target] += 1 else: cnt[target] = 1 return cnt # このリスト内の文字列の出現回数を調べたい... targets = ['aaa','bbb','ccc','aaa','bbb','aaa'] # カウントする関数を呼び出す result = count( targets) # カウント結果の閲覧 for key in result.keys(): print(key + ':' + result[key])この様な関数を実装し、呼び出しても良いのですが、Python3系の標準パッケージに含まれているCollectionsの中にインスタンスを作成するだけでカウントしてくれる
collections.Counterククラスがあるので、それを使いましょう。上に書いたcount.pyを
collections.Counterクラスを使用して書き換えるとこうなります。count.pyimport collections # このリスト内の文字列の出現回数を調べたい... targets = ['aaa','bbb','ccc','aaa','bbb','aaa'] # カウントする関数を呼び出す result = collections.Counter( targets) # カウント結果の閲覧 for key in result.keys(): print(key + ':' + result[key])カウント結果の閲覧方法はどちらも変わりません。
であれば、カウントするだけでなく他のこともできるcollections.Counterクラスを利用する方がお得ですね!
- 投稿日:2020-06-28T19:28:46+09:00
tracemallocの出力をフィルタする
現在Pythonのプログラム上で、どの変数がどれくらいのメモリを確保しているのかを確認するためのモジュールとして、
tracemallocという標準モジュールがあります。これを使えば例えばこんなコードを書くことで、ある処理のメモリ解放漏れを確認することができます。
tracemallocを直接呼び出すコードimport tracemalloc tracemalloc.start() snap1 = tracemalloc.take_snapshot() size1 = sum([stat.size for stat in snap1.statistics("filename")]) for stat in snap1.statistics('lineno')[:10]: print(stat) # ... ある処理 ... snap2 = tracemalloc.take_snapshot() size2 = sum([stat.size for stat in snap2.statistics("filename")]) for stat in snap2.compare_to(snap1, 'lineno')[:10]: print(stat) diff = abs(size1 - size2) print("処理終了後メモリ量{:,}バイト".format(diff))with構文を使うなら、こんな感じ
with構文を使うべくクラス化したものimport tracemalloc class MemCheck: """ メモリチェックを行うためのクラス。with構文で使用する。 withを抜けたときに自動的にチェックが行われる。 """ def __init__(self): """ 初期化 """ pass def __enter__(self): tracemalloc.start() self.snap = tracemalloc.take_snapshot() self.size = sum([stat.size for stat in self.snap.statistics("filename")]) print("") print("-----TEST START!!!!-----") for stat in self.snap.statistics('lineno')[:10]: print(stat) return self def __exit__(self, ex_type, ex_value, trace): print("-----TEST END!!!!!!-----") snap = tracemalloc.take_snapshot() size = sum([stat.size for stat in snap.statistics("filename")]) for stat in snap.compare_to(self.snap, 'lineno')[:10]: print(stat) diff = abs(self.size - size) print("処理終了後メモリ量{:,}バイト".format(diff)) print("-" * 20) return False def main(): with MemCheck(): # ...ある処理...ただ実際これを動かすと、メモリを使用しているオブジェクトの中に、tracemallocモジュール内部や、デバッガの動作用のオブジェクトも含まれてしまうため、メモリ解放漏れのテストなどに使おうとするとやや厄介です。
そのために、データをフィルタするためのfilter_traces()というメソッドが用意されています。
ですが、ドキュメントを見ると用例が二つしか書かれていないため、「デバッグ用のオブジェクトはまるっと無視したい」とか、逆に「自分が書いたコードだけをテスト対象にしたい」という事態に対応できません。
フォルダ名を指定して「このフォルダ配下のファイルだけをトレースしたい」とかいうときにはどうすればいいのか。
こうする
以下のように書けばいいのです。
with構文を使う例にフィルタを追加したものimport tracemalloc from pathlib import Path class MemCheck: """ メモリチェックを行うためのクラス。with構文で使用する。 withを抜けたときに自動的にチェックが行われる。 """ def __init__(self): """ 初期化 """ pass def __enter__(self): tracemalloc.start() self.snap = tracemalloc.take_snapshot().filter_traces(self.get_filter_traces()) self.size = sum([stat.size for stat in self.snap.statistics("filename")]) print("") print("-----TEST START!!!!-----") for stat in self.snap.statistics('lineno')[:10]: print(stat) return self def __exit__(self, ex_type, ex_value, trace): print("-----TEST END!!!!!!-----") snap = tracemalloc.take_snapshot().filter_traces(self.get_filter_traces()) size = sum([stat.size for stat in snap.statistics("filename")]) for stat in snap.compare_to(self.snap, 'lineno')[:10]: print(stat) diff = abs(self.size - size) print("処理終了後メモリ量{:,}バイト".format(diff)) print("-" * 20) return False # 追加 def get_filter_traces(self): return ( tracemalloc.Filter(True, str(Path(__file__).parent.parent / ".venv" / "lib" / "site-packages" / "*")), tracemalloc.Filter(True, str(Path(__file__).parent.parent / "src" / "*")), ) def main(): with MemCheck(): # ...ある処理...コード内にある
get_filter_traces()メソッドが、filter_traces()メソッド用のフィルタリストを返却するメソッドです。フィルタは全てのスナップショット取得処理に適用させたいので、このようにしています。
filter_traces()メソッドの引数はtracemalloc.Filterオブジェクトのタプルを受け取るようになっており、tracemalloc.Filterオブジェクトは、コンストラクタの第一引数に、そのフィルタに「一致するものを表示する(True)」のか、「一致しないものを表示する(False)」を指定、第二引数(filename_pattern)にフィルタに指定するファイル名を指定します。このファイル名、ドキュメントを見ると「Filename pattern of the filter (str). Read-only property.」と書いてあるので一見正規表現でも突っ込めばいいのか というと、そうではなく、fnmatchというモジュールで処理できるShell形式のワイルドカード文字列を指定します)
正規表現などのパターンマッチを使い慣れてるとパターン=正規表現と思ってしまう人もいるかもしれませんが、正規表現ではないのでご注意ください。であればそれくらい分かるようなコメントを書いて欲しかったところですが・・・。
srcフォルダ配下のファイルだけをtrace対象にすると何も出てこなくなることがある
なお、メモリを確保したのが自分が書いたプログラムそのものではなく自分が書いたプログラムで呼び出したオブジェクトである場合は、
tracemalloc.take_snapshot()で出てくるのは自分で書いたソースファイルの行番号ではなく、呼び出したオブジェクトを定義しているソースファイルの行番号になります(自分のプログラムでPyPDF.PdfFileReaderを呼び出し、そこで読み込んだメモリが解放されていなかった場合、「\lib\site-packages\PyPDF2\配下のファイルでメモリが確保されている」と表示される)。このため、フィルタを作成する場合は「srcフォルダ配下」だけでなく、上記例のように「呼び出しているモジュールのフォルダ」もtrace対象に入れるようにしましょう。仮想環境のフォルダがプロジェクト内に生成されるようになっていれば、上記のように
.venv\lib\site-packages\*あたりが検索対象になっていればOKです。どうやって気付いたのか
C:\PythonNN\Lib\tracemalloc.pyファイルを開いてFilterの処理を追いました(棒)。こういうことしなければ分からない挙動は勘弁して欲しい…。
- 投稿日:2020-06-28T19:17:12+09:00
銘柄のVolatilityの計算方法
1 目的
ある銘柄について、一定期間のVolatilityを計算する。
2 内容
2-1 Volatilityの計算式
ある株式銘柄の価格について、任意の日の銘柄価格を$S_{i}$とするとき、前日との変化率$c_{i}$を下記のとおり定義する。
c_{i} = \biggl({\frac{S_i}{S_{i-1}}} \biggl)このとき開始日からn営業日後までの株式銘柄のVolatilityを下記数式で定義する。
vol_{n} = \sqrt{\sum_{i=1}^{n} {(c_{i}-\bar{c})}^{2}}2-2 Volatilityを計算するソースコード例
test.py#年間volatirity(取引日252日の設定)を計算する関数。 def volatility(DF): df = DF.copy() df["daily_ret"] = DF["Close"].pct_change() vol = df["daily_ret"].std() * np.sqrt(252) return vol
- 投稿日:2020-06-28T19:05:28+09:00
PythonでJOI難易度4を埋める
はじめに
Python(PyPy)を使って、JOI難易度4の問題を解きます。問題と難易度はこのサイトを参照しています。
F - 通学経路
考えたこと
場合の数で習う
みたいな図をlistで実装して解きました。a, b = map(int,input().split()) n = int(input()) c = [list(map(int,input().split())) for _ in range(n)] def solver(s,t,cons): m = [[0] * s for _ in range(t)] #上で説明したlist for i in range(s): #横の端は1で固定 for con in cons: if con[0] == i + 1 and con[1] == 1: #工事中の交差点が端にあった場合の処理 break else: m[0][i] = 1 continue break for i in range(t): #同様に縦も for con in cons: if con[0] == 1 and con[1] == i + 1: break else: m[i][0] = 1 continue break for i in range(1,t): for j in range(1,s): flag = False for con in cons: if con[0] == j + 1 and con[1] == i + 1: #終了地点 flag = True break if flag: continue m[i][j] = m[i][j-1] + m[i-1][j] return m[-1][-1] #ゴールに書いてある数字が答え print(solver(a,b,c))flagの配置がとても汚い
A - 最大の和
考えたこと
毎回sumする時間はないので、累積和を使う。n, k = map(int,input().split()) a = [int(input()) for _ in range(n)] sums = [0] for i in range(n): sums.append(sums[-1]+a[i]) ans = sums[k] for i in range(k,n+1): ans = max(sums[i]-sums[i-k],ans) print(ans)C - カードゲーム
考えたこと
ゲーム系の問題は苦手です。シミュレーションしました。n = int(input()) taro = [int(input()) for _ in range(n)] taro.sort() hana = [] for i in range(1,2*n+1): #重複はないので、taroが持っていないカードはhanaが持っている if i not in taro: hana.append(i) m = taro.pop(0) for _ in range(2*n): for i in range(len(hana)): #出せるカードの最小値を調べる if hana[i] > m: m = hana.pop(i) break else: m = 0 for i in range(len(taro)): #出せるカードの最小値を調べる if taro[i] > m: m = taro.pop(i) break else: m = 0 if len(hana) == 0 or len(taro) == 0: #どちらかが0になったら終了 break print(len(hana)) #最後の枚数 print(len(taro)) #最後の枚数C - パーティー
考えたこと
自分と$n$人の友達の距離(何人の友達を経由するか)をまとめたlistを作り2以下の人数をカウントn = int(input()) m = int(input()) f = [list(map(int,input().split())) for _ in range(m)] d = [0] * n for i in range(m): #友達(距離1)を調べる if f[i][0] == 1: d[f[i][1]-1] = 1 for i in range(m): #友達の友達(距離2)を調べる if d[f[i][0]-1] == 1: if d[f[i][1]-1] == 0: d[f[i][1]-1] = 2 #友達の友達は距離2 elif d[f[i][1]-1] == 1: if d[f[i][0]-1] == 0: d[f[i][0]-1] = 2 #友達の友達は距離2 ans = d.count(1) + d.count(2) - 1 print(max(0,ans))C - タイル (Tile)
考えたこと
左右上下のどの縁からの距離が近いを計算して、それを3で割った余りで処理します。
色は一番近い縁から順に塗られていくので、それぞれのマスで場合分けする必要があります。n = int(input()) k = int(input()) ab = [list(map(int,input().split())) for _ in range(k)] for i in range(k): x1 = ab[i][0]-1 x2 = n - ab[i][0] y1 = ab[i][1]-1 y2 = n - ab[i][1] m = min(x1,x2,y1,y2) % 3 if m == 0: print(1) if m == 1: print(2) if m == 2: print(3)C - 看板 (Signboard)
考えたこと
対象の文字を数えてありえる組み合わせを全パターン調べようとすると面倒なので、先に距離を決めてシミュレーションします。n = int(input()) s = input() plate = [input() for _ in range(n)] ans = 0 for i in range(n): p = plate[i] start =[] check = False for k in range(len(p)): if p[k] == s[0]: #スタート地点を調べる start.append(k) for k in range(1,len(p)+1): #文字間の距離 if check: break for j in start: #前で調べた最初の文字を選ぶ flag = 0 c = 0 #cを増やしていくことによって、距離の等倍を表現 while j + k * c < len(p) and c < len(s): #j(最初の文字)からc文字目までの距離 if p[j+k*c] != s[c]: break else: c += 1 flag += 1 if flag == len(s): #目的の文字が作成可能ならansに+1 ans += 1 check = True break print(ans)flagが汚い
C - 超都観光 (Super Metropolis)
考えたこと
初期値を(1,1)と誤読してました。初期値は(x1,y1)です。北東か南西に進むときだけ斜めに進むルートがあるので場合分けが必要で、それ以外は普通にgridの最短経路です。
鬼の場合分けしました()
- 縦または横移動のみの場合は、どちらかの座標の差は0になるのでmaxを取ります
- 北東に進むとき場合は、計算すると分りますがそれぞれの座標の差のmaxを取ればいいことが分ります。これは南西も同様です
- その他の場合は、斜めの道が使えないのでそれぞれの座標の差の絶対値の和を取ります
w, h, n = map(int,input().split()) spots = [list(map(int,input().split())) for _ in range(n)] def search_route(s,g): if s[0] == g[0] or s[1] == g[1]: #縦または横移動のみ return max(abs(g[1] - s[1]), abs(g[0] - s[0])) elif s[0] < g[0] and s[1] < g[1]: #北東に進む return max(g[0] - s[0], g[1] - s[1]) elif s[0] > g[0] and s[1] > g[1]: #南西に進む return max(s[0] - g[0], s[1] - g[1]) else: #それ以外 return abs(s[0] - g[0]) + abs(s[1] - g[1]) ans = 0 for i in range(n-1): ans += search_route(spots[i],spots[i+1]) print(ans)A - ポスター (Poster)
考えたこと
ポスターを回転する操作を固定してそれぞれの場合を考えます。回転は$0°,90°,180°,270°$のいずれかです。あとは、目的のポスターと色の異なるマスを数えるだけです。気分でinputを変えていますが普通のinputでも大丈夫です
import sys read = sys.stdin.buffer.read readline = sys.stdin.buffer.readline readlines = sys.stdin.buffer.readlines sys.setrecursionlimit(10 ** 7) import numpy as np #回転するという操作はnumpyを使います n = int(readline()) s = np.array([list(readline().rstrip().decode()) for _ in range(n)]) t = [readline().rstrip().decode() for _ in range(n)] ans = float('inf') for i in range(4): check = np.rot90(s,i) #回転 c = min(4-i,i) for j in range(n): for k in range(n): if check[j][k] != t[j][k]: c += 1 ans = min(ans,c) print(ans)まとめ
汚いコードが多いので修正して、最終的にはC++で書く予定です。難易度4くらいが今の自分の適正レベルな気がしますが、さらなるレベルアップを目指して精進していきます。ではまた~

- 投稿日:2020-06-28T19:03:33+09:00
Python手遊び (Pandas DataFrameでCSVはかける。けど、CSVからDBへは全列Insertだけ?)
この記事、何?
Pandas DataFrameでCSVはかけるけど、CSVからDBへは全列Insertだけ?ってことで、DataFrameをDBに更新(UPDATE)する関数を作ったという話。
この前初めて、PandasのDataFrameをまじめに使い始めた。
で、to_csvでDBの値とかをいきなりCSVにできるって知って、「おおっ、すごい!」と。。。じゃ、逆は?って話。
例えば、DBからCSVにExportして、何らかの外部ツールがCSVの値を編集して、それを再反映したい場合は?と。まあ、よく考えてみたらPrimaryKeyとかどう考えているわけ?って話になる。
そう考えると、OSSでライブラリ化してある共通仕様では対応しないよね。っていうあ、素直にSQLかけよという話かも。というわけで、ニッチな処理を作ってみた。
つまり、何作ったの?
PandasのDataFrame、主キー、更新対象の列群 を与えて、更新する処理。
主キーとして、文字列型を一つ、更新対象列群として、文字列を複数持つlist型で。
主キーとして指定された文字列で大勝レコードを指定、それ以外をUPDATEのSETの対象列にするSQLを作ってCommitする感じ。まあ・・・それだけ。
まあ、やっつけ版なのでいろいろと制約事項があるけど。制約事項
・主キーは1列で構成
・各種列は固定(主キーは文字、ほかはfloat)
・DBはPostgreSQL
・その他...できあがり
def get_connection_string(): hostname = localhost port = '5432' database = 'db01' username = 'user01' password = 'manager' return f'postgresql://{username}:{password}@{hostname}:{port}/{database}' def get_cur(): conn = psycopg2.connect(get_connection_string()) cur = conn.cursor() return conn, cur # 更新 # I : 更新対象データ # 主キー列 # 更新対象列群 def update_data(df, column_key, columns): import pandas as pd conn, cur = get_cur() for i in range(len(df)): paras = list() col_sqls = list() for column in columns: paras.append(float(df.at[i, column])) col_sqls.append(f' {column} = %s ') sql = f''' UPDATE RDKIT SET {','.join(col_sqls)} WHERE SampleName = '{df.at[i, 'samplename']}' ''' print(sql) print(paras) cur.execute(sql, paras) conn.commit() # CSVからDBへ書き込み def test05(): import pandas as pd df = pd.read_csv('abc.csv') # df = pd.read_csv('edited.csv') column_key = 'samplename' columns = ['maxestateindex', 'maxabsestateindex', 'heavyatommolwt', 'exactmolwt', 'qed', 'molwt'] update_data(df, column_key, columns) # DBからCSVに書き出す def test06(): import pandas as pd sql = f''' SELECT SampleName , MaxEStateIndex, MaxAbsEStateIndex, HeavyAtomMolWt, ExactMolWt, qed, MolWt FROM RDKIT ''' conn, cur = get_cur() df = pd.read_sql(sql=sql, con=conn) df.to_csv('exported.csv') def main(): test05() # test06() if __name__ == '__main__': main()感想
うーん・・・いまいち。
やっつけ感がある。
後日もうちょっと考えてみよう。。。
- 投稿日:2020-06-28T18:21:32+09:00
拡張フィボナッチ数列(k-ボナッチ数列 : 直前のk項の和)の一般項を線形代数とPythonで求める
(スマホからだと数式が表示できない場合があるようなので、その場合はPCなどからご覧ください。申し訳ありません。)
拡張フィボナッチ数列とは?
フィボナッチ数列は、直前の2つの項を足して次の項を作る数列です。式で表すと、
\begin{cases} \begin{align} a_{n+2} &= a_{n+1} + a_{n}\\ a_0 &= 0\\ a_1 &= 1 \end{align} \end{cases}となります。これを拡張して直前の$k$個の項を足した数を次の項にしたものが拡張フィボナッチ数列です。名前を探しましたが、見つからなかったのでここでは $k$ -ボナッチ数列と呼ぶことにします。式で表すと、
\begin{cases} \begin{align} a_{n+k} &= a_{n+k-1}+a_{n+k-2}+\dots+a_{n}\\ &=\displaystyle \sum_{i=n}^{n+k-1}a_i \\ a_0 &= a_1 = \dots = a_{k-2} = 0\\a_{k-1} &= 1 \end{align} \end{cases}となります。前回の記事(トリボナッチ数列の一般項を線形代数とPythonで求める)で $k=3$ である、トリボナッチ数列を扱いました。今回はそれを拡張していきます。
前準備
(トリボナッチ数列の一般項を線形代数とPythonで求めるとほぼ同じですので、飛ばしていただいて構いません。)
漸化式を満たす実数の数列のなす空間を$V$とします。数列${ a_n }$の最初の$k$項 $a_0,a_1,\dots,a_{k-1}$ が与えられているので、$n\geq k$において数列 ${ a_n }$ は一意に定まります。
\begin{align} \boldsymbol{v_0}&=\{\overbrace{1,0,0,\dots,0}^{k個},1,\dots \}\\ \boldsymbol{v_1}&=\{0,1,0,\dots,0,1,\dots \}\\ & \vdots \\ \boldsymbol{v_{k-1}}&=\{0,0,0,\dots,1,1,\dots\} \end{align}とします。$c_0,c_1,\dots,c_{k-1}\in \mathbb{C}$に対して、$c_0\boldsymbol{v_0}+c_1\boldsymbol{v_1}+\dots+c_{k-1}\boldsymbol{v_{k-1}}=\boldsymbol{0}$が成り立ったとすると、
c_0\{1,0,0,\dots \}+c_1\{0,1,0,\dots \}+\dots+c_{k-1}\{0,\dots,1,\dots \}\\=\{c_0,c_1,\dots,c_{k-1},\dots \}=\{0,0,\dots,0,\dots \}となるので、$c_0=c_1=\dots =c_{k-1}=0$ です。よって、$\boldsymbol{v_0},\boldsymbol{v_1},\dots,\boldsymbol{v_{k-1}}$は一次独立とわかります。
次に、
\boldsymbol{a}= \{ a_0,a_1,\dots,a_{k-1},\dots \}を$V$の勝手な元とすると、
\begin{align} \boldsymbol{a}&=\{ a_0,0,0,\dots \}+\{0,a_1,0,\dots \} +\dots+\{0,\dots,0,a_{k-1},\dots \} \\ &=a_0\{1,0,0,\dots \}+a_1\{0,1,0,\dots \}+\dots+a_{k-1}\{0,\dots,0,1,\dots \} \\ &=a_0\boldsymbol{v_0}+a_1\boldsymbol{v_1}+\dots+a_{k-1}\boldsymbol{v_{k-1}} \end{align}となり、$\boldsymbol{v_0},\boldsymbol{v_1},\dots,\boldsymbol{v_{k-1}}$ の一次結合で表せます。よって、$\boldsymbol{v_0},\boldsymbol{v_1},\dots,\boldsymbol{v_{k-1}}$ は$V$を生成します。
以上より、$\boldsymbol{v_0},\boldsymbol{v_1},\dots,\boldsymbol{v_{k-1}}$ は一次独立かつ$V$を生成するので、$V$の基底となります。
ここで、写像 $f:V\rightarrow V$を
f(\{ a_n\}_{n=0}^{\infty})=\{ a_n\}_{n=1}^{\infty}とします。$\boldsymbol{a}={ a_0,a_1,a_2,\dots } \in V$のとき、$f(\boldsymbol{a})={ a_1,a_2,a_3,\dots }$も漸化式を満たすので、$f(\boldsymbol{a})\in V$です。
\boldsymbol{a}=\{ a_n\}_{n=0}^{\infty}\in V \\ \boldsymbol{b}=\{ b_n\}_{n=0}^{\infty}\in V \\ c\in \mathbb{C}とすると、
f(\boldsymbol{a}+\boldsymbol{b})=f(\{ a_n+b_n\}_{n=0}^{\infty})=\{ a_n+b_n\}_{n=1}^{\infty}=\{ a_n\}_{n=1}^{\infty}+\{ b_n\}_{n=1}^{\infty}=f(\boldsymbol{a})+f(\boldsymbol{b})\\ f(c\boldsymbol{a})=f(c\{ a_n\}_{n=0}^{\infty})=c\{ a_n\}_{n=1}^{\infty}=cf(\boldsymbol{a})が成り立つので、$f$は$V$の線形変換です。
漸化式を行列で表現
$\boldsymbol{v_0},\boldsymbol{v_1},\dots,\boldsymbol{v_{k-1}}$ に関して、
\begin{align} f(\boldsymbol{v_0})&=\{0,0,\dots,0,1,\dots \}=\boldsymbol{v_{k-1}}\\ f(\boldsymbol{v_1})&=\{1,0,\dots,0,1,\dots \}=\boldsymbol{v_0}+\boldsymbol{v_{k-1}}\\ f(\boldsymbol{v_2})&=\{0,1,\dots,0,1,\dots \}=\boldsymbol{v_1}+\boldsymbol{v_{k-1}}\\ \vdots \\ f(\boldsymbol{v_{k-1}})&=\{0,0,\dots,1,1,\dots \}=\boldsymbol{v_{k-2}}+\boldsymbol{v_{k-1}} \end{align}なので、
[f(\boldsymbol{v_0})\quad f(\boldsymbol{v_1})\quad f(\boldsymbol{v_2}) \quad \cdots \quad f(\boldsymbol{v_{k-1}})]= [\boldsymbol{v_0}\ \boldsymbol{v_1}\ \boldsymbol{v_2} \cdots \boldsymbol{v_{k-1}}] \begin{bmatrix} 0 & 1 & 0 & 0 & \cdots & 0\\ 0 & 0 & 1 & 0 & \cdots & 0\\ 0 & 0 & 0 & 1 & \cdots & 0\\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & 0 & \cdots & 1\\ 1 & 1 & 1 & 1 & \cdots & 1 \end{bmatrix}と表せます。よって、$f$の基底 $\boldsymbol{v_0},\boldsymbol{v_1},\dots,\boldsymbol{v_{k-1}}$ に関する表現行列は、
\overbrace{ \begin{bmatrix} 0 & 1 & 0 & 0 & \cdots & 0\\ 0 & 0 & 1 & 0 & \cdots & 0\\ 0 & 0 & 0 & 1 & \cdots & 0\\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & 0 & \cdots & 1\\ 1 & 1 & 1 & 1 & \cdots & 1 \end{bmatrix} }^{k行k列}です。この表現行列を$A$とします。
固有値と公比の関係
(トリボナッチ数列の一般項を線形代数とPythonで求めると同じですので、飛ばしていただいて構いません。)
\boldsymbol{p}=\{ r^{n} \}_{n=0}^{\infty}=\{1,r,r^2,\dots \}が$V$に属したとすると、
f(\boldsymbol{p})=f(\{ r^{n} \}_{n=0}^{\infty})=\{ r^{n} \}_{n=1}^{\infty}=\{ r^{n+1} \}_{n=0}^{\infty}=r\{ r^{n} \}_{n=0}^{\infty}=r\boldsymbol{p}より、$\boldsymbol{p}$は固有値$r$の固有ベクトルになります。逆に、上の式から$f$の固有値 $r$の固有ベクトルは、公比$r$の等比数列になることも分かります。よって、公比と固有値は等しいとわかります。
固有値を求める
$f$の固有値を求めます。$A$の固有多項式は、$I$を単位行列として、
\varphi_k(\lambda)=|A-\lambda I|\\ =\begin{vmatrix} -\lambda & 1 & 0 & 0 & \cdots & 0\\ 0 & -\lambda & 1 & 0 & \cdots & 0\\ 0 & 0 & -\lambda & 1 & \cdots & 0\\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & 0 & \cdots & 1\\ 1 & 1 & 1 & 1 & \cdots & 1-\lambda \end{vmatrix}\\1列目に沿って余因子展開すると、
\begin{align} \varphi_k&=(-1)^{1+1}(-\lambda) \begin{vmatrix} -\lambda & 1 & 0 & \cdots & 0\\ 0 & -\lambda & 1 & \cdots & 0\\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \cdots & 1\\ 1 & 1 & 1 & \cdots & 1-\lambda \end{vmatrix} + (-1)^{k+1}\cdot 1 \begin{vmatrix} 1 & 0 & 0 & \cdots & 0\\ -\lambda & 1 & 0 & \cdots & 0\\ 0 & -\lambda & 1 & \cdots & 0\\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \cdots & 1\\ \end{vmatrix} \\ &=-\lambda \varphi_{k-1} - (-1)^{k} \end{align}と漸化式のように表せます。両辺を$(-1)^k$で割ると、
\begin{align} \frac{\varphi_k}{(-1)^k} &= -\lambda \frac{\varphi_{k-1}}{(-1)^k} - 1\\ &=\lambda \frac{\varphi_{k-1}}{(-1)^{k-1}} - 1 \end{align}$b_k = \displaystyle \frac{\varphi_k}{(-1)^k}$とおくと、
\begin{align} b_k &= \lambda b_{k-1} - 1\\ b_k - \frac{1}{\lambda - 1} &= \lambda \left(b_{k-1} - \frac{1}{\lambda - 1}\right)\\ &=\cdots \\ &= \lambda^{k-2}\left(b_{2} - \frac{1}{\lambda - 1}\right) \end{align}であり、初項は、
\begin{align} b_2- \frac{1}{\lambda - 1} &= \displaystyle \frac{\varphi_2}{(-1)^2} - \frac{1}{\lambda - 1}\\ &=\varphi_2 - \frac{1}{\lambda - 1}\\ &=\begin{vmatrix} -\lambda & 1 \\ 1 & 1-\lambda \end{vmatrix}- \frac{1}{\lambda - 1}\\ &=\lambda^2 - \lambda - 1- \frac{1}{\lambda - 1}\\ &=\frac{\lambda^3-2\lambda^2}{\lambda-1} \end{align}です。よって、
\begin{align} b_k &- \frac{1}{\lambda - 1}= \lambda^{k-2} \frac{\lambda^3-2\lambda^2}{\lambda-1}\\ b_k &= \frac{\lambda^{k+1}-2\lambda^k}{\lambda-1} + \frac{1}{\lambda - 1} \\ &= \frac{\lambda^{k+1}-2\lambda^k+1}{\lambda-1}\\ &=\lambda^k - \lambda^{k-1} - \lambda^{k-2} - \dots - \lambda^2 - \lambda - 1\quad (\because 組み立て除法) \end{align}が導出されました。方程式 $\varphi_k(\lambda) = (-1)^k b_k = 0$ は、$b_k = 0$ と同値であることがわかります。
しかし、$b_k=0$は簡単には解くことはできません。あとの章で計算機を用いて数値的に求めることにします。
$k$ 個の解を $\lambda_0,\lambda_1,\dots,\lambda_{k-1}$とすると、それぞれの解に対応する固有ベクトルである等比数列の
\boldsymbol{u_0}=\{ \lambda_0^{n} \}_{n=0}^{\infty}\\ \boldsymbol{u_1}=\{ \lambda_1^{n} \}_{n=0}^{\infty}\\ \vdots \\ \boldsymbol{u_{k-1}}=\{ \lambda_{k-1}^{n} \}_{n=0}^{\infty}は$V$に属します。これらは $\lambda_0,\lambda_1,\dots,\lambda_{k-1}$ が全て異なるとすると、$f$の相異なる固有値に対応する固有ベクトルなので一次独立です。また、$\dim V=k$ です。よって、$\boldsymbol{u_0},\boldsymbol{u_1},\dots,\boldsymbol{u_{k-1}}$ は$V$の基底となります。
係数の決定
以上より、ある $c_0,c_1,\dots,c_{k-1}$が存在して、
\boldsymbol{a_n}=c_0\boldsymbol{u_0}+c_1\boldsymbol{u_1}+\dots+c_{k-1}\boldsymbol{u_{k-1}}と表せるので、
\begin{align} \boldsymbol{a_n}&=c_0\boldsymbol{u_0}+c_1\boldsymbol{u_1}+\dots+c_{k-1}\boldsymbol{u_{k-1}}\\ \Leftrightarrow \{a_0,a_1,\dots,a_{k-1},\dots \}&=c_0\{ \lambda_0^{n} \}_{n=0}^{\infty}+c_1\{ \lambda_1^{n} \}_{n=0}^{\infty}+\dots+c_{k-1}\{ \lambda_{k-1}^{n} \}_{n=0}^{\infty}\\ \Leftrightarrow \{0,0,\dots,1,\dots \}&=c_0\{ 1,\lambda_0,\dots,\lambda_0^{k-1},\dots \}+c_1\{1,\lambda_1,\dots,\lambda_1^{k-1},\dots \}+\dots+c_{k-1}\{ 1,\lambda_{k-1},\dots,\lambda_{k-1}^{k-1},\dots\} \\ \Leftrightarrow \{0,0,\dots,1,\dots \}&=\{ c_0+c_1+\dots+c_{k-1},\ c_0\lambda_0+c_1\lambda_1+\dots+c_{k-1}\lambda_{k-1},\dots, c_0\lambda_0^{k-1}+c_1\lambda^{k-1}+\dots+c_{k-1}\lambda^{k-1}, \dots\} \end{align}これを行列で表現すると、
\begin{bmatrix} 1 & 1 & 1 & \cdots & 1\\ \lambda_0 & \lambda_1 & \lambda_2 & \cdots & \lambda_{k-1} \\ \lambda_0^2 & \lambda_1^2 & \lambda_2^2 & \cdots & \lambda_{k-1}^2\\ \vdots & \vdots & \vdots & \ddots & \vdots \\ \lambda_0^{k-1} & \lambda_1^{k-1} & \lambda_2^{k-1} & \cdots & \lambda_{k-1}^{k-1} \end{bmatrix} \begin{bmatrix} c_1 \\ c_2 \\ c_3 \\ \vdots \\ c_{k-1} \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \\ 0 \\ \vdots \\ 1 \end{bmatrix}です。左の行列の行列式は、ヴァンデルモンド行列式 $V_k$ であり、
V_k = \begin{vmatrix} 1 & 1 & 1 & \cdots & 1\\ \lambda_0 & \lambda_1 & \lambda_2 & \cdots & \lambda_{k-1} \\ \lambda_0^2 & \lambda_1^2 & \lambda_2^2 & \cdots & \lambda_{k-1}^2\\ \vdots & \vdots & \vdots & \ddots & \vdots \\ \lambda_0^{k-1} & \lambda_1^{k-1} & \lambda_2^{k-1} & \cdots & \lambda_{k-1}^{k-1} \end{vmatrix} =\prod_{0\leq i < j \leq k-1}\big(\lambda_j - \lambda_i\big)と知られています。クラメルの公式を用いると、$0\leq m\leq k-1$ に対して
\begin{align} c_m &= \frac{\begin{vmatrix} 1 & 1 & \cdots & 1 & 0 & 1 & \cdots & 1\\ \lambda_0 & \lambda_1 & \cdots & \lambda_{m-1} & 0 & \lambda_{m+1} & \cdots & \lambda_{k-1} \\ \lambda_0^2 & \lambda_1^2 & \cdots & \lambda_{m-1}^2 & 0 & \lambda_{m+1}^2 & \cdots & \lambda_{k-1}^2\\ \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \ddots & \vdots \\ \lambda_0^{k-1} & \lambda_1^{k-1} & \cdots & \lambda_{m-1}^{k-1} & 1 & \lambda_{m+1}^{k-1} & \cdots & \lambda_{k-1}^{k-1} \end{vmatrix}}{V_k}\\ &=\frac{(-1)^{m}\begin{vmatrix} 0 & 1 & 1 & \cdots & 1 & 1 & \cdots & 1\\ 0 & \lambda_0 & \lambda_1 & \cdots & \lambda_{m-1} & \lambda_{m+1} & \cdots & \lambda_{k-1} \\ 0 & \lambda_0^2 & \lambda_1^2 & \cdots & \lambda_{m-1}^2 & \lambda_{m+1}^2 & \cdots & \lambda_{k-1}^2\\ 0 & \vdots & \vdots & \vdots & \vdots & \vdots & \ddots & \vdots \\ 1 & \lambda_0^{k-1} & \lambda_1^{k-1} & \cdots & \lambda_{m-1}^{k-1} & \lambda_{m+1}^{k-1} & \cdots & \lambda_{k-1}^{k-1} \end{vmatrix}}{V_k}\quad (\because 列をm回交換)\\ &=\frac{(-1)^{m+k-1}\begin{vmatrix} 1 & \lambda_0^{k-1} & \lambda_1^{k-1} & \cdots & \lambda_{m-1}^{k-1} & \lambda_{m+1}^{k-1} & \cdots & \lambda_{k-1}^{k-1}\\ 0 & 1 & 1 & \cdots & 1 & 1 & \cdots & 1\\ 0 & \lambda_0 & \lambda_1 & \cdots & \lambda_{m-1} & \lambda_{m+1} & \cdots & \lambda_{k-1} \\ 0 & \lambda_0^2 & \lambda_1^2 & \cdots & \lambda_{m-1}^2 & \lambda_{m+1}^2 & \cdots & \lambda_{k-1}^2\\ 0 & \vdots & \vdots & \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & \lambda_0^{k-2} & \lambda_1^{k-2} & \cdots & \lambda_{m-1}^{k-2} & \lambda_{m+1}^{k-2} & \cdots & \lambda_{k-1}^{k-2} \end{vmatrix}}{V_k}\quad (\because 行をk-1回交換)\\ &=\frac{(-1)^{m+k-1}\begin{vmatrix} 1 & 1 & \cdots & 1 & 1 & \cdots & 1\\ \lambda_0 & \lambda_1 & \cdots & \lambda_{m-1} & \lambda_{m+1} & \cdots & \lambda_{k-1} \\ \lambda_0^2 & \lambda_1^2 & \cdots & \lambda_{m-1}^2 & \lambda_{m+1}^2 & \cdots & \lambda_{k-1}^2\\ \vdots & \vdots & \vdots & \vdots & \vdots & \ddots & \vdots \\ \lambda_0^{k-2} & \lambda_1^{k-2} & \cdots & \lambda_{m-1}^{k-2} & \lambda_{m+1}^{k-2} & \cdots & \lambda_{k-1}^{k-2} \end{vmatrix}}{V_k}\\ &=\frac{(-1)^{m+k-1}\displaystyle \prod_{0\leq i < j \leq k-1かつi\neq mかつj \neq m}\big(\lambda_j - \lambda_i\big)}{\displaystyle \prod_{0\leq i < j \leq k-1}\big(\lambda_j - \lambda_i\big)}\quad (\because ヴァンデルモンド行列式)\\ &=\frac{(-1)^{m+k-1}}{\displaystyle \prod_{0\leq i < j \leq k-1かつ(i=mまたはj=m)}\big(\lambda_j - \lambda_i\big)}\\ &=\frac{(-1)^{m+k-1}}{\displaystyle \prod_{0\leq i < m}\big(\lambda_m - \lambda_i\big)\prod_{m < j \leq k-1}\big(\lambda_j - \lambda_m\big)}\\ &=\frac{(-1)^{m+k-1}}{\displaystyle \prod_{0\leq i < m}\big(\lambda_m - \lambda_i\big)\prod_{m < j \leq k-1}(-1)\big(\lambda_m - \lambda_j\big)}\\ &=\frac{(-1)^{m+k-1}}{\displaystyle \prod_{0\leq i < m}\big(\lambda_m - \lambda_i\big)(-1)^{k-m-1}\prod_{m < j \leq k-1}\big(\lambda_m - \lambda_j\big)}\\ &=\frac{(-1)^{(m+k-1)-(k-m-1)}}{\displaystyle \prod_{0\leq i < m}\big(\lambda_m - \lambda_i\big)\prod_{m < j \leq k-1}\big(\lambda_m - \lambda_j\big)}\\ &=\frac{(-1)^{2m}}{\displaystyle \prod_{0\leq i < m}\big(\lambda_m - \lambda_i\big)\prod_{m < j \leq k-1}\big(\lambda_m - \lambda_j\big)}\\ &=\frac{1}{\displaystyle \prod_{0\leq i <m,m<i\leq k-1}\big(\lambda_m - \lambda_i\big)} \end{align}が求められます。
以上より、
\begin{align} \boldsymbol{a_n} &= c_0 \boldsymbol{u_0} + c_1 \boldsymbol{u_1} +\dots+ c_{k-1} \boldsymbol{u_{k-1}}\\ &=\left\{ \frac{\lambda_0^n}{\displaystyle \prod_{1\leq i \leq k-1}\big(\lambda_0 - \lambda_i\big)} + \frac{\lambda_1^n}{\displaystyle \prod_{0\leq i <1,1 <j\leq k-1}\big(\lambda_1 - \lambda_i\big)} +\dots+ \frac{\lambda_{k-1}^n}{\displaystyle \prod_{0\leq i \leq k-2}\big(\lambda_{k-1} - \lambda_i\big)}\right\}_{n=0}^{\infty}\\ &=\left\{\sum_{i=0}^{k-1}\frac{\lambda_i^n}{\displaystyle \prod_{0\leq j <i, i< j\leq k-1}\big(\lambda_i - \lambda_j\big)}\right\}_{n=0}^{\infty} \end{align}なので、
a_n = \sum_{i=0}^{k-1}\frac{\lambda_i^n}{\displaystyle \prod_{0\leq j <i, i< j\leq k-1}\big(\lambda_i - \lambda_j\big)}が導けました。
実装例と計算量比較
以上までで、一般項の形はわかりましたが、具体的な $\lambda_0,\lambda_1,\dots,\lambda_{k-1}$ の値はわかっていません。5次以上の方程式には代数的解法は必ずしも存在しないので数値解を求めます。今回もPythonのnumpyライブラリを利用して求めます。以下の問題を考えます。
自然数 $K,N$ が与えられます。$K$ -ボナッチ数列の第 $N$ 項を出力してください。
実装例1 : 定義通りに計算
teigi.pyk, n = map(int, input().split()) a = [0] * max(n+1,k) a[k-1] = 1 for i in range(k,n+1): for j in range(1,k+1): a[i] += a[i-j] print(a[n])定義通りに計算していくと、各 $i (K \leq i \leq N)$ に対して $K$ 回の加算が必要なので、$O(K(N-K)) = O(KN)$ となります。
実装例2 : 一般項を用いる
ippankou.pyimport numpy as np import warnings warnings.filterwarnings('ignore') # 複素数の計算時にWarningが発生するので消しておく k, n = map(int, input().split()) equation = [1] for i in range(k): equation.append(-1) # equation = [1, -1, -1, ... , -1] = lambda^k - lambda^{k-1} - ... - lambda -1 = 0 lam = np.roots(equation) # lambda_i a = 0 for i in range(k): prod = 1 for j in range(k): if j != i: prod *= lam[i] - lam[j] a += np.power(lam[i],n) / prod print(int(round(a)))一般項を用いて計算すると、各 $i (0 \leq i \leq K)$ に対して、各 $j (0 \leq j < i, i < j \leq K)$ の乗算と $N$ 乗計算で $O(\log N)$ が必要なので、$O(K(K+\log N)) = O(K^2+K\log N)$ となります。この方法では、前回の $k=3$ のときと同じように、浮動小数点数による数値の$10^{14}$ 分の1程度の誤差が発生していると思われます。
実装例3 : 以下の漸化式を用いる(k 項の和を保存して最初と最後だけ入れ替え)
\begin{align} a_{n+k} &= \sum_{i=n}^{n+k-1}a_i\\ a_{n+k+1} &= \sum_{i=n+1}^{n+k}a_i \\ &= a_{n+k}+\sum_{i=n}^{n+k-1}a_i-a_n\\ &= a_{n+k}+a_{n+k}-a_n\\ &= 2a_{n+k} - a_n \end{align}zenkashiki.pyk, n = map(int, input().split()) a = [0] * max(n+1,k) a[k-1] = 1 a[k] = 1 for i in range(0,n-k): a[i+k+1] = 2 * a[i+k] - a[i] print(a[n])このように、一般項を求めなくても $k$ 項の和を保存しておく累積和のようなアルゴリズムを考えれば計算量 $O(N)$ で求めることができます。
実行例
2 5 5 3 50 3122171529233 4 25 1055026 10 50 1082392024832 50 30 0 100 150 1125899906842618 1000 1010 1024計算量の比較
実装1 実装2 実装3 定義通り 一般項 漸化式 $O(NK)$ $O(K^2+K\log N)$ $O(N)$ 実装2と実装3の計算量の比較により、$N$ と $K^2+K\log N$ を比較してどちらの方が高速か考えてから計算すると良いと思います。
実行時間の比較
measure_time.pyimport time import numpy as np import warnings warnings.filterwarnings('ignore') # 複素数の計算時にWarningが発生するので消しておく k, n = map(int, input().split()) # 実装1 start = time.time() a = [0] * max(n+1,k) a[k-1] = 1 for i in range(k,n+1): for j in range(1,k+1): a[i] += a[i-j] elapsed_time = time.time() - start print ("実装1 : {0}".format(elapsed_time) + "[sec]") # 実装2 start = time.time() equation = [1] for i in range(k): equation.append(-1) # equation = [1, -1, -1, ... , -1] = lambda^k - lambda^{k-1} - ... - lambda -1 = 0 lam = np.roots(equation) # lambda_i a = 0 for i in range(k): prod = 1 for j in range(k): if j != i: prod *= lam[i] - lam[j] a += np.power(lam[i],n) / prod elapsed_time = time.time() - start print ("実装2 : {0}".format(elapsed_time) + "[sec]") # 実装3 start = time.time() a = [0] * max(n+1,k) a[k-1] = 1 a[k] = 1 for i in range(0,n-k): a[i+k+1] = 2 * a[i+k] - a[i] elapsed_time = time.time() - start print ("実装3 : {0}".format(elapsed_time) + "[sec]")計測結果例
100 100000 実装1 : 33.17268109321594[sec] 実装2 : 0.29273509979248047[sec] 実装3 : 0.9141891002655029[sec] 2000 3000 実装1 : 0.6759321689605713[sec] 実装2 : 18.358761072158813[sec] 実装3 : 0.0006489753723144531[sec] 5 100000 実装1 : 2.0344340801239014[sec] 実装2 : 0.24581313133239746[sec] 実装3 : 1.1652131080627441[sec]計算量比較でも考えていたように、$N > K^2+K\log N$ のときは実装2、$N < K^2+K\log N$ のときは実装3が高速と確かめられます。
- 投稿日:2020-06-28T17:58:01+09:00
Pythonデータ分析試験に合格したので要点をまとめてみた
この記事について
Pythonデータ分析試験に合格したので、要点をまとめてみました。
1. データ分析エンジニアの役割
教師あり学習と教師なし学習
教師あり学習は正解となるラベルが存在する学習方式です。
正解ラベルである目的のデータを目的変数と呼びます。
目的変数以外のデータを説明変数と呼びます。
教師あり学習は説明変数を用いて、目的変数を予測する学習方式ということになります。一方、教師なし学習は正解ラベルを用いない学習方式です。
正解ラベルがないので、目的変数がない学習方式ということです。分類とクラスタリング
教師あり学習の分類は、事前にいくつのグループに分けるのか、明確に定義します。
例えば、イヌとネコに分類したい場合は2グループに分けることになります。一方、クラスタリングは教師なし学習に分類され、グループ数がいくつになるのか明確ではありません。
ひょっとしたら、3グループかもしれないですし、5グループになるかもしれません。機械学習の処理手順
機械学習はこのような手順で処理していきます。
データ入手 -> データ加工 -> データ可視化 -> アルゴリズム選択 -> 学習プロセス -> 精度評価 -> 試験運用 -> 結果利用(サービス運用)機械学習はとにもかくにもデータが必要です。
データ分析のパッケージ
データ分析での主なパッケージは以下の通りです。
- Jupyter Notebook
- NumPy
- pandas
- Matplotlib
- scikit-learn
- SciPy
間違っても
djangoなんてものは使っていないです。
参考書籍ではSciPyは存在感が薄いですが、データ分析で利用されるパッケージです。※djangoに興味がある方はググってみてください。Flaskの親戚です。
2. Pythonと環境
pipコマンド
pipコマンドは
-Uオプションをつけることでインストールするライブラリが最新版に更新されます。
明示的に最新版をインストールするには、このようになります。$ pip install -U numpy pandas空白文字列の削除
左右の空白文字を削除する場合は
stripメソッドを利用します。inbird = ' Condor Penguin Duck ' print("befor strip: {}".format(bird)) print("after strip: {}".format(bird.strip()))outbefor strip: Condor Penguin Duck after strip: Condor Penguin Duckpickleモジュール
pickleモジュールはPythonオブジェクトを直列化して、ファイルで読み書きできるようにします。
pathlibモジュール
Pythonでパスを利用する場合は、pathlibモジュールを使います。
マジックコマンド
Jupyter Notebookにはマジックコマンドというコマンドがあります。
例えば、%%timeitと%timeitがあります。
どちらも、プログラムを複数回実行して、実行時間を計測するコマンドです。
%timeitは1行のプログラムに対して時間を計測します。
一方、%%timeitはセル全体の処理時間を測定します。in%%timeit x = np.arange(10000) fig, ax = plt.subplots() ax.pie(x, shadow=True) ax.axis('equal') plt.show()out# 図形の出力は省略 12 s ± 418 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)3. 数式を読むための基礎知識
数学はQiitaで書くと時間がかかるので、ざっくりと紹介していきます。
どんな傾向があるかグラフ等をよく見ておくと良いと思います。対数関数
以下のような数式で表される関数を対数関数と呼びます。
f\left( x\right) =\log _{2}xユークリッド距離
ベクトルの大きさをスカラーを求める方法、つまりノムルを求める方法として、ユークリッド距離があります。
\left\| x\right\| _{1}=\left| x_{1}\right| +\left| x_{2}\right| +\ldots +\left| x_{n}\right|簡単に言えば、ベクトルの各要素の絶対値を足し合わせています。
行列の掛け算
m × sの行列とs × nの行列をかけると、m × nの行列になります。
m × sの行列とx × nの行列のように、行列の数が合わないとかけることはできません。
また、数学の掛け算と違い行列の掛け算は順番が変わると結果が変わります。自然対数の微分
$f\left( x\right) =e^{x}$は微分しても数値は変わりません。
f'\left( x\right) =e^{x}4.1 NumPy
dtype属性
NumPyの配列ndarrayの要素のデータ型は
dtype属性で確認できます。
ちなみに、Pythonのtypeメソッドは配列自体の型(ndarray)を確認できます。ina = np.array([1, 2, 3]) print("ndarray dtype: {}".format(a.dtype)) print("ndarray type: {}".format(type(a)))outndarray dtype: int32 ndarray type: <class 'numpy.ndarray'>コピーと参照
ndarrayでは
b = aという操作は参照となります。(bの値を変更するとaの値も変更される)
b = a.copy()と操作するとコピーとして扱われます。(bの値を変更してもaの値は変更されない)Python標準のリストをスライスした場合はコピーが渡されますが、Numpyでのスライスの結果は参照が渡されます。
色々な組み合わせを試してみると、より理解が深まると思います。
nan
NumPyで数値ではないことを宣言するには
np.nanを使用します。ina = np.array([1, np.nan, 3]) print(a)out[ 1. nan 3.]行列の分割
vpslit関数では行方向、hsplit関数では列方向に行列を分解します。
ina = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) first1, second1 = np.vsplit(a, [2]) first2, second2 = np.hsplit(second1, [2]) print(second2)out[[9]]平均値
行列の平均値を求めるにはmeanメソッドを用います。
ina = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) a.mean()out5.0論理値
ndarrayは演算子で比較するとTrue / Falseで表示されます。
ina = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) a > 4outarray([[False, False, False], [False, True, True], [ True, True, True]])4.2 Pandas
インデックス / カラム名の指定
DataFrameからインデックスやカラムを指定して、データを抽出するにはlocメソッド / ilocメソッドを使用します。
locメソッドはインデックスとカラム名をインデックス名やカラム名を指定します。
ilocメソッドはインデックスとカラムを位置や範囲で指定します。indf = pd.DataFrame([[1, 2, 3], [5, 7, 11], [13, 17, 19]]) df.index = ["01", "02", "03"] df.columns = ["A", "B", "C"] display(df.loc[["01", "03"], ["A", "C"]]) display(df.iloc[[0, 2], [0, 2]])
データの書き込み / 読み込み
データの書き込みは
to_xxx、読み込みはto_xxxで行います。
excelやcsv、pickle等が対応しています。indf.to_excel("FileName.xlsx") df = pd.read_excel("FineName.xlsx")データの並べ替え
データはsort_valuesメソッドで並べ替えます。
デフォルトでは昇順で並べ替えが行われます。
降順に並べ替えるにはascending=Falseを引数に設定します。indf = pd.DataFrame([[1, 2, 3], [5, 7, 11], [13, 17, 19]]) df.index = ["01", "02", "03"] df.columns = ["A", "B", "C"] df.sort_values(by="C", ascending=False)
One-hotエンコーディング
get_dummiesメソッドを使うとOne-hotエンコーディングに変換できます。
One-hotエンコーディングではカテゴリ変数の種類だけ列を追加します。日付配列
日付配列を取得するには
data_rangeメソッドを使用します。
引数のstartとendに日付を設定することができます。indates = pd.date_range(start="2020-01-01", end="2020-12-31") print(dates)outDatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04', '2020-01-05', '2020-01-06', '2020-01-07', '2020-01-08', '2020-01-09', '2020-01-10', ... '2020-12-22', '2020-12-23', '2020-12-24', '2020-12-25', '2020-12-26', '2020-12-27', '2020-12-28', '2020-12-29', '2020-12-30', '2020-12-31'], dtype='datetime64[ns]', length=366, freq='D')4.3 Matplotlib
サブプロット
subplotsメソッドの引数で配置するサブプロット数を指定します。
数値一つの場合は2行のサブプロット、ncolsを指定すると2列のサブプロットが配置されます。infig, axes = plt.subplots(2) display(plt.show())
infig, axes = plt.subplots(ncols=2) display(plt.show())
散布図
散布図は
scatterメソッドで描画することができます。ヒストグラム
ヒストグラムは
histメソッドで描画することができます。
bins引数でビン数を指定することができます。円グラフ
円グラフは
piメソッドで描画することができます。
デフォルトでは、右から反時計回りに描画されます。スタイル
色はHTMLやX11、CSS4で定義された色名を指定することができます。
フォントスタイルは辞書で定義してまとめて適用した李、個々に適用することもできます。4.4 scikit-learn
分類モデル
分類モデルのデータセットは学習データとテストデータに分割します。
これはモデルの汎化能力を評価する必要がある為です。決定木
決定木はモデルが可視化でき、内容が理解しやすい特徴があります。
パラメータはユーザーが設定する必要があります。
決定木の目的は情報利得の最大化もしくは不純度の最小化です。
(どちらも同じ意味を指します)次元削減
次元削減とは、データをなるべく損ねることなく次元を削減するタスクです。
例えば、XとYの二次元データのうち、重要でないYのデータを削除して、Xのみの一次元データにすることができます。ROC曲線とAUC
ROC曲線は確率の高い順にデータを並べたとき、各データの確率以上のデータはすべて正例であると予測することです。
AUCの値が1に近づくほど確率が相対的に高いサンプルが正例、相対的に低いサンプルが負例となる傾向が高まります。
つまり、AUCはモデル間の良さを比較することが可能です。参考/引用




- 投稿日:2020-06-28T17:53:19+09:00
AtCoderBeginnerContest172復習&まとめ(前半)
AtCoder ABC172
2020-06-27(土)行われたAtCoderBeginnerContest172の問題をA問題から順に考察も踏まえてまとめたものとなります.
前半ではABCDまでの問題を扱います.
問題は引用して記載していますが,詳しくはコンテストページの方で確認してください.
コンテストページはこちら
公式解説PDFA問題 Calc
問題文
整数$a$が入力されます。値$a+a^2+a^3$を出力してください。abc172a.pya = int(input()) print(a + a**2 + a**3)B問題 Minor Change
問題文
文字列$S,T$が与えられます。次の操作を繰り返して$S$を$T$に変更するとき、操作回数の最小値を求めてください。
操作:$S$の$1$文字を選んで別の文字に書き換えるfor文で前から一文字ずつ合っているかどうか確認しました.
abc172b.pys = input() t = input() count = 0 for i in range(len(s)): if s[i] != t[i]: count +=1 print(count)C問題 Tsundoku
問題文
二台の机 A, B があります。机 A には$N$冊の本が、机 B には$M$冊の本が、それぞれ縦に積まれています。
机 A に現在上から$i$番目に積まれている本$(1 \leq i \leq N)$は読むのに$A_i$分を要し、机 B に現在上から$i$番目に積まれている本$(1 \leq i \leq M)$は読むのに$B_i$分を要します。
次の行為を考えます。
・本が残っている机を選び、その机の最も上に積まれた本を読んで机から取り除く。
合計所要時間が$K$分を超えないようにこの行為を繰り返すとき、最大で何冊の本を読むことができるでしょうか。本を読むこと以外に要する時間は無視します。とりあえず,再帰で解こうと思いましたが,実行時間に引っかかるのが明らかだったので,いろいろ工夫を凝らしてコード書きました.
解説にpythonの参考コード載ってて,こんなにシンプルに書けるようになりたいなと思いました.abc172c.pyn, m, k = map(int, input().split()) a_list = list(map(int, input().split())) b_list = list(map(int, input().split())) new_a_list = [[0, 0]] a_sum = 0 for i in range(0, n): a_sum += a_list[i] if a_sum <= k: new_a_list.append([i + 1, a_sum]) else: break best = len(new_a_list) - 1 b_sum = 0 a_sum = new_a_list[-1][1] a_count = new_a_list[-1][0] flag = 1 for i in range(0, m): b_sum += b_list[i] while True: if b_sum <= k - a_sum: if best < i + 1 + a_count: best = i + 1 + a_count break if a_count == 0: flag = 0 break a_count -= 1 a_sum = new_a_list[-(len(new_a_list) - a_count)][1] if flag == 0: break print(best)D問題 Sum of Divisors
問題文
正整数$X$に対し、$X$の正の約数の個数を$f(X)$とします。
正整数$N$が与えられるので、$\sum_{K=1}^{N}K×f(K)$を求めてください。圧倒的数学力不足(汗)
解けなかったので,解説見て書いてあることそのまま実装したら解けました.abc172d.pyn = int(input()) total = 0 for j in range(1, n + 1): x = j y = n // x total += y * (y + 1) * x // 2 print(total)実装はシンプルだけど思いつかなかったし,そもそも実行時間制限: 3 sec 見落としてた.(見落としてなくても解けないと思うけど)
前半はここまでとなります.
前半の最後まで読んでいただきありがとうございました.後半はEF問題の解説となりますが,時間的に記事作成できないと思います(汗).
- 投稿日:2020-06-28T17:36:03+09:00
[cx_Oracle入門](第9回) DBとPythonのデータ型のマッピング(バージョン8以降)
検証環境
- Oracle Cloud利用
- Oracle Linux 7.7 (VM.Standard2.1)
- Python 3.6
- cx_Oracle 8.0.0
- Oracle Database 19.5 (ATP, 1OCPU)
- Oracle Instant Client 18.5
はじめに
Oracle DatabaseとPythonでは当然ながらデータ型が異なります。本記事では、cx_Oracleがどのように両者のデータ型の仲立ちを行うのかを解説します。
データ型のマッピングの概要
Oracle Databaseのどのデータ型が、最終的にどのPythonのデータ型にマッピングされるのかは、cx_Oracleのマニュアルにまとめられています。Oracle DatabaseとPythonの間のデータ型のやり取りは、
Oracle Databaseのデータ型 ⇔ cx_Oracleのデータ型 ⇔ Pythonのデータ型
という流れを経て変換されます。基本、あるOracle Databaseのデータ型に対応する、「DB_TYPE_」で始まる名称のcx_Oracleのデータ型が存在します。なお、cx_Oracle 7.3(8の前)まで使用されていたcx_Oracleデータ型はシノニムとして引き続き利用できますが、将来廃止予定のため、バージョン8で新規のアプリケーションを作成する場合や、cx_Oracleデータ型を利用しなければならない改定が入った場合は、「DB_TYPE_」で始まるcx_Oracleデータ型を使用するようにしましょう。また、DB APIで定義されているデータ型も引き続きサポートされます。■ データ型のマッピング
Oracle Databaseのデータ型 cx_Oracleのデータ型 Pythonのデータ型 CHA cx_Oracle.DB_TYPE_CHAR str VARCHAR2 cx_Oracle.DB_TYPE_VARCHAR str NUMBER cx_Oracle.DB_TYPE_NUMBER float もしくは int DATE cx_Oracle.DB_TYPE_DATE datetime.datetime TIMESTAMP cx_Oracle.DB_TYPE_TIMESTAMP datetime.datetime RAW cx_Oracle.DB_TYPE_RAW bytes ■ DB APIに準拠しているデータ型のマッピング
Oracle Databaseのデータ型 cx_Oracleのデータ型 Pythonのデータ型 CHAR, VARCHAR2 cx_Oracle.STRING str NUMBER cx_Oracle.NUMBER float もしくは int DATE cx_Oracle.DATETIME datetime.datetime TIMESTAMP cx_Oracle.TIMESTAMP datetime.datetime RAW cx_Oracle.BINARY bytes ■マニュアル参照先
DB APIに準拠しているcx_Oracleデータ型
cx_Oracle独自のデータ型ここで注意しないといけないのは、NUMBER型に対応したPythonのデータ型に、floatとintの2種類が存在する点です。これは、NUMBER型の定義や格納されている値に依存します。以下のサンプルアプリケーションの実行結果を確認してください。
sample06a.py(再掲)import cx_Oracle USERID = "admin" PASSWORD = "FooBar" DESTINATION = "atp1_low" SQL1 = """ create table sample06a (col1 number, col2 number, col3 number, col4 number(5, 0), col5 number(5, 0), col6 number(5, 2), col7 number(5, 2), col8 number(5, 2)) """ SQL2 = "insert into sample06a values(7, 7.0, 7.1, 7, 7.0, 7, 7.0, 7.1)" SQL3 = "commit" SQL4 = "select * from sample06a" with cx_Oracle.connect(USERID, PASSWORD, DESTINATION) as connection: with connection.cursor() as cursor: cursor.execute(SQL1) cursor.execute(SQL2) cursor.execute(SQL3) row = cursor.execute(SQL4).fetchone() print(f"NUMBERに「7」 : {type(row[0])}") print(f"NUMBERに「7.0」 : {type(row[1])}") print(f"NUMBERに「7.1」 : {type(row[2])}") print(f"NUMBER(5, 0)に「7」 : {type(row[3])}") print(f"NUMBER(5, 0)に「7.0」 : {type(row[4])}") print(f"NUMBER(5, 2)に「7」 : {type(row[5])}") print(f"NUMBER(5, 2)に「7.0」 : {type(row[6])}") print(f"NUMBER(5, 2)に「7.1」 : {type(row[7])}")実行結果$ python sample06a.py NUMBERに「7」 : <class 'int'> NUMBERに「7.0」 : <class 'int'> NUMBERに「7.1」 : <class 'float'> NUMBER(5, 0)に「7」 : <class 'int'> NUMBER(5, 0)に「7.0」 : <class 'int'> NUMBER(5, 2)に「7」 : <class 'float'> NUMBER(5, 2)に「7.0」 : <class 'float'> NUMBER(5, 2)に「7.1」 : <class 'float'>実行結果から、以下の法則が見受けられます。
- 精度なしのNUMBER型の場合、0以外の小数がある場合はfloat型、そうではない場合はint型
- 小数部が0のNUMBER型の場合、常にint型
- 小数部が0ではないNUMBER型の場合、常にfloat型
int型の場合は特段問題ありませんが、問題はfloat型です。Oracle Databaseがよく利用されるビジネスアプリケーションの場合、特にお金に関する情報で浮動小数だと丸め誤差が発生して問題となる可能性が懸念されます。そのような場合、Pythonではdecimalモジュールを使用して処理しますが、前述の表のとおり、cx_Oracle自身はdecimalへの変換を行いません。ただし、cx_Oracleはこのような場合の備えを用意しています。
outputtypehandler
先述のような理由で、cx_Oracleのデフォルトのデータ型の変換仕様を利用したくない場合、Connectionオブジェクトのoutputtypehandler属性に自作のデータ変換関数を指定すると、オリジナルの変換ルールではなく、その関数を変換に使用するようになります。Python→Oracleの方向の場合はinputtypehandler属性となります。
sample09a.pyimport cx_Oracle import decimal USERID = "admin" PASSWORD = "FooBar" DESTINATION = "atp1_low" SQL = "select * from sample06a" def num2Dec(cursor, name, defaultType, size, precision, scale): if defaultType == cx_Oracle.DB_TYPE_NUMBER: return cursor.var(decimal.Decimal, arraysize=cursor.arraysize) with cx_Oracle.connect(USERID, PASSWORD, DESTINATION) as connection: with connection.cursor() as cursor: row = cursor.execute(SQL).fetchone() print(f"OutputTypeHandlerなし") print(f"NUMBERに「7」をセットして3倍 : {row[0] * 3}") print(f"NUMBERに「7.1」をセットして3倍 : {row[2] * 3}") with connection.cursor() as cursor: cursor.outputtypehandler = num2Dec row = cursor.execute(SQL).fetchone() print(f"OutputTypeHandlerあり") print(f"NUMBERに「7」をセットして3倍 : {row[0] * 3}") print(f"NUMBERに「7.1」をセットして3倍 : {row[2] * 3}")このスクリプトは先のスクリプトで作成したテーブルとデータをSELECTしている点、ご注意ください。
スクリプトの真ん中あたりのnum2Dec関数が実際の新しいデータ変換ルーチンとなります。下から5行目にて、outputtypehandlerとしてnum2Dec関数をセットすることで、この関数が機能するようになります。
outputtypehandlerの関数名や引数名は任意のものを指定できますが、引数の仕様は以下のとおりに定められており、関数内で使用しなくとも、6つとも引数として必要です。
引数の順番 意味 1 操作対象のCursorオブジェクト 2 列名 3 列のcx_Oracleのデータ型 4 列のサイズ 5 列の小数桁数(NUMBER(p,s)のs) 6 列の全体桁数(NUMBER(p,s)のp) サンプル中のCursorオブジェクトのvarメソッドは、該当する列の変数に関して、変数の情報を引数で指定した形に更新するメソッドとなります。1個目の引数には変更先のデータ型を指定します。指定必須です。varメソッド自体はoutputtypehandler以外の用途にも広く使われるメソッドで、メソッドの仕様としては2個目以降の引数は任意指定ですが、outputtypehandler用途の場合、arraysizeというパラメータが必須となり、Cursorオブジェクトのarraysizeを設定する必要があります。
実行結果$ python sample09a.py outputtypehandlerなし NUMBERに「7」をセットして3倍 : 21 NUMBERに「7.1」をセットして3倍 : 21.299999999999997 outputtypehandlerあり NUMBERに「7」をセットして3倍 : 21 NUMBERに「7.1」をセットして3倍 : 21.3実行結果のように、outputtypehandlerを経由させると、より期待する計算結果になっています。outputtypehandlerを使用せず、一旦Pythonのfloat型の変数で受けてからdecimalに変換する形でももちろん構いませんが、対応列数が多い場合などはoutputtypehandlerを使用すると楽にコーディングできます。
- 投稿日:2020-06-28T17:31:14+09:00
wordcloudを使ってアプリレビューを可視化する
アプリをダウンロードするとき、まずそのアプリに投稿されているレビューを参考にする人は多いと思います。
でもレビューって数が多くて全部見るのは難しいですよね。
そこで今回は wordcloud という表現で、アプリのレビューをひとめでわかるように可視化してみたいと思います。wordcloudとは
ある文書中の出現する単語を様々な大きさ、色で表すことで、文書の特徴を一枚の画像に可視化したものです。
レビューデータの収集
App Storeのアプリレビューは下記のURLに該当するアプリのIDを入れると、JSON形式で取得することができます。
https://itunes.apple.com/jp/rss/customerreviews/id=(アプリID)/page=1/json
今回はTwitterアプリを対象とします。IDは333903271です。
page=のあとの数字を変えることで、10ページ分まで取得することができます。下記のスクリプトでアプリのレビューデータを取得します。
import pandas as pd import requests import json rss_url = 'https://itunes.apple.com/jp/rss/customerreviews/id={}/sortBy=mostRecent/page={}/json' app_id = '333903271' def get_reviews(url): """ iOSレビュー取得のAPIレスポンスから[点数、タイトル、文章、名前]のリストを取得する """ response = requests.get(url, timeout=3.5) response_json = json.loads(response.text) reviews = [[int(entry['im:rating']['label']), entry['title']['label'], entry['content']['label'], entry['author']['name']['label']]\ for entry in response_json['feed']['entry']] return reviews review_list = [] # 1~10ページ分のレビューを収集 for i in range(1, 11): page_url = rss_url.format(app_id, i) reviews = get_reviews(page_url) review_list += reviews review_df = pd.DataFrame(review_list, columns=['point', 'title', 'review', 'name'])収集したデータはこんな感じ。
WordCloudの作成
集めたレビューデータを元にwordcloud画像を作成します。
まず、形態素解析のためにいMeCabをインストールします。$ brew install mecab $ brew install mecab-ipadic続いてpythonでwordcloudライブラリをインストールします。
$ pip install wordcloud下記のスクリプトでwordcloudを作成できます。
日本語入力のために、実行環境での日本語フォントファイルのパスを指定してください。# 日本語用のフォントが格納されているパスを指定 FONT_PATH = '/System/Library/Fonts//ヒラギノ角ゴシック W3.ttc' def prepare_word_list(words): """ wodcloudに入力用の文字列を作成する Args: words([str]): 文章のリスト Retruns: str: 全単語から指定した品詞のみを抽出し、スペース区切りで結合した文字列 """ m = MeCab.Tagger('') parsed_words = [] for word in words: items = [x.split('\t') for x in m.parse(word).splitlines()] for item in items: if item[0] == 'EOS' or item[0] == '': pass elif item[1].split(',')[0] in ["名詞", "形容詞", "動詞"]: parsed_words.append(item[0]) return ' '.join(parsed_words) def make_wordcloud(words, file_name): """ 入力した文章から、wordcloud画像ファイルを作成する。 Args: words(str): スペース区切りで単語を結合した文字列 file_name(str): 画像ファイル出力先のパス Returns: なし """ parsed_words = prepare_word_list(words) wordc = wordcloud.WordCloud( font_path = FONT_PATH, background_color='white', contour_width=2, width=800, height=600, ).generate(parsed_words) wordc.to_file(file_name) make_wordcloud(review_df['review'], './image/twitter_wordcloud.png')完成したwordcloud画像がこちら!
Twitter, アカウント、 凍結、 フォロー、 タイムライン、、、などtwitterらしいワードが並んでいますね。
まとめ
iosアプリのレビューを可視化することができました。
大量の文書のイメージをクイックに捉えたい時にwordcloudは良いかもしれませんね。


- 投稿日:2020-06-28T17:25:58+09:00
jupyter で、import module を作る簡単な方法
jupyterで自作モジュールを作成したいなと思ったのですが、どうすればいいのかな?と思い解決した方法を残します。
環境
OS : MacOS Catalina 10.15.5
Machine : 1.2 GHz デュアルコアIntel Core m3
Version : Python 3.7.7実行方法
いろいろ調べた時に出てきた方法が、具体的にjupyter で何をすればいいのかがわかりにくかったので、実際にjupyterで作成して実行するまでの流れをメモしました。
手順
- module化したいコードを作成
- jupyter でtextファイルを作成
- コードをtextファイルにコピーする。
- textファイルの拡張子を
.pyに変更する以上で、モジュールを作成することができました。
自作モジュールのimportについては他の方の文献を参考にしていただければと思います。
参考文献
pythonで自作関数をモジュール化・パッケージ化
Python3 自作モジュールのインポートにハマる参考コード
import sys, os from pathlib import Path # signalfuncなどのある親ディレクトリのパスを取得,これはJupyter系特有の書き方 current_dir = os.path.join(Path().resolve()) # モジュールのあるパスを追加 sys.path.append(str(current_dir) + '/../make_module') ``
- 投稿日:2020-06-28T16:57:56+09:00
Raspberry Pi 4 で 5秒ごとにCPUの温度を表示させる
はじめに
Rasberry Pi 4 を使っていると結構CPUが熱くなります.
どれくらいCPUが熱くなるのか調べたかったので,Python3を使って5秒ごとにCPUの温度を表示させるプログラムを作ってみました.環境
OS : Ubuntu server20.04 + Xubuntu Desktop(gdm3)
プログラム
cpu_temperature.pyimport time import threading import subprocess def schedule(interval, func, wait = True): base_time = time.time() next_time = 0 while True: t = threading.Thread(target = func) t.start() if wait: t.join() next_time = ((base_time - time.time()) % interval) or interval time.sleep(next_time) def get_cpu_temperature(): output = subprocess.check_output("cat /sys/class/thermal/thermal_zone0/temp", shell = True, encording = "UTF-8") return int(output) / 1000 def print_cpu_temperature(): print(get_cpu_temperature()) if __name__ == "__main__": schedule(5, print_cpu_temperature)解説
schedule関数
以下の記事を参考にしました.
Pythonで一定時間ごとに処理を実行する
記事で紹介されているschedule関数のパクリです.
intervalで何秒間隔で実行させたいのか,funcでどの関数を実行させたいのか指定できます.
詳しくはURL先の記事を参照してほしいです.get_cpu_temperature関数
以下の記事を参考にしました.
RaspberryPi(Raspbian)のCPUの温度をcatを使わないで取得してみた
Pythonからコマンドを実行する
vcgencmdを使った方法でもCPU温度を取得できるみたいですが,今回はその方法を使わずに cat を使って取得することにしました.
cat を使う方法だと1000倍の値で出力されるため,そのまま表示するとわかりづらいです.LinuxのコマンドをPython3から呼ぶにはいろいろな方法がありますが,今回は cat を使って取得した文字列をPython内で加工したかったのでcheck_output関数を使用することにしました.
check_output関数で cat を使ってCPU温度を取得します.そのままでは1000倍された値なので文字列をint型に直し,1000で割ってreturnさせるような形にしました.
vcgencmdを使う場合はそのままreturnさせても良いと思います.print_cpu_temperature関数
get_cput_temperature関数で得た値をprintするだけの関数です.
元々schedule関数とget_cpu_temperature関数を使ってグラフを描こうとしたのですが,その前に上2つの関数が正しく動いてくれないと困るので,この関数を作ってみました.if name == "main"内
5秒間隔でprint_cpu_temperature関数を実行せよ,という意味です.
5の部分を10に変えると10秒間隔になります.
- 投稿日:2020-06-28T16:43:08+09:00
pythonのsubprocessでかんたん並列実行
・大量のデータを並列処理したい。
・せっかくCPUがコアがたくさんあるので有効活用したい。
・とりあえずスクリプトは書いてみたけど並列実行向けに書き直す余裕はない。色々調べて、subprocess.Popen()を使う方法が簡単そうだったので実験してみた。
参考記事
https://qiita.com/HidKamiya/items/e192a55371a2961ca8a4実行環境と負荷試験用サンプルコード
Windows 10 (64bit)
Python 3.7.6CPUはRyzen 9 3950Xでこういう環境。
以下のコードで実験します。
(コマンドライン引数で指定したフィボナッチ数列の下2桁を表示するだけ。)fib_sample.pyimport sys def fib(n): a, b = 0, 1 for i in range(n): a, b = b, a + b return a if __name__ == "__main__": num = int(sys.argv[1]) result = fib(num) print("n = {0}, result % 100 = {1}".format(num, result % 100))例えば
python fib_sample.py 10000と実行すれば、n = 10000, result % 100 = 75と表示して終了します。シーケンシャルに実行
まずsubprocess.run()でシーケンシャルに実行してみる。
subprocess.run(['python', r".\fib_sample.py", str(500000 + i)])で引数を与えてpythonを実行する。コマンドライン引数を500000から500063まで変えて、64回実行すると、batch_sequential.pyfrom time import time import subprocess start=time() loop_num = 64 for i in range(loop_num): subprocess.run(['python', r".\fib_sample.py", str(500000 + i)]) end=time() print("%f sec" %(end-start))> python .\batch_sequential.py n = 500000, result % 100 = 25 n = 500001, result % 100 = 26 n = 500002, result % 100 = 51 (中略) n = 500061, result % 100 = 86 n = 500062, result % 100 = 31 n = 500063, result % 100 = 17 130.562213 sec2分強かかった。
当たり前だがCPUコアもぜんぜん使われていない。
並列実行
同じ処理をsubprocess.Popen()で並列実行してみる。subprocess.Popen()はsubprocess.run()と違って生成したプロセスの終了を待たない。
以下のコードは、max_processで指定した数だけプロセス実行→それらがすべて終了するのを待つ→次のプロセス実行→...を繰り返している。batch_parallel.pyfrom time import time import subprocess start=time() #並列プロセス実行数の最大値 max_process = 16 proc_list = [] loop_num = 64 for i in range(loop_num): proc = subprocess.Popen(['python', r".\fib_sample.py", str(500000 + i)]) proc_list.append(proc) if (i + 1) % max_process == 0 or (i + 1) == loop_num: #max_process毎に、全プロセスの終了を待つ for subproc in proc_list: subproc.wait() proc_list = [] end=time() print("%f sec" %(end-start))Ryzen 3950Xの物理コア数に合わせて16並列で実行した結果。
> python .\batch_parallel.py n = 500002, result % 100 = 51 n = 500004, result % 100 = 28 n = 500001, result % 100 = 26 (中略) n = 500049, result % 100 = 74 n = 500063, result % 100 = 17 n = 500062, result % 100 = 31 8.165289 sec並列実行しているので処理が終わる順番がばらばらになっている。
130.562秒→8.165秒でほぼ16倍高速化された。すべてのコアが使われて、正しく並列実行できていることがわかる。
ちなみに物理コア数ではなく論理コア数に合わせて32並列で実行しても早くはならない。むしろ時々遅くなる。
並列実行数を変えて3回ずつ実行したときの、平均実行時間は下のグラフのようになった。
バックグラウンドで色々アプリケーションを走らせていたのであまり正確ではないが、傾向は正しいと思う。まとめ
まあまあお手軽に高速化できた。
上記のコードだと、並列実行を始めたあとその中で一番処理の長いプロセスの終了を待つので、たまたま処理時間の長いプロセスがいるとそいつの終了を待つオーバーヘッドが大きくなってしまう。本来は各プロセスの実行が終わったらすぐに次のプロセスを立ち上げて常時並列数が一定になるようなコードにするべきだと思う。
もっとも、実際は同じ長さの大量のデータファイルを同じ信号処理にかけるというような用途での高速化が目的だったので、実行時間はまあ大体同じだろうという見込みがあり目をつむった。とりあえず手軽に高速化という目的は果たせたので満足。



