- 投稿日:2020-06-28T22:21:07+09:00
MySQLでINFORMATION_SCHEMA からバッファプールのインデックスのページ数とデータサイズを取得する
タイトルそのまま、
参照は下記です。
行方不明にならないようにメモ書きするデータサイズB表示
SELECT INDEX_NAME, COUNT(*) AS Pages, ROUND(SUM(IF(COMPRESSED_SIZE = 0, @@GLOBAL.innodb_page_size, COMPRESSED_SIZE))) AS 'Total Data (B)' FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE WHERE INDEX_NAME='emp_no' AND TABLE_NAME = '`{スキーマ名}`.`{テーブル名}`';データサイズMB表示
SELECT INDEX_NAME, COUNT(*) AS Pages, ROUND(SUM(IF(COMPRESSED_SIZE = 0, @@GLOBAL.innodb_page_size, COMPRESSED_SIZE))) AS 'Total Data (B)' FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE WHERE INDEX_NAME='emp_no' AND TABLE_NAME = '`{スキーマ名}`.`{テーブル名}`';参照
https://dev.mysql.com/doc/refman/5.6/ja/innodb-information-schema-buffer-pool-tables.htmlINFORMATION_SCHEMA.INNODB_BUFFER_PAGEについて
https://dev.mysql.com/doc/refman/5.6/ja/innodb-buffer-page-table.html
- 投稿日:2020-06-28T18:19:14+09:00
f1-micro mysql-client not install
解決策
apt-get install -y default-mysql-clientgcpのf1-microにmysql-clientが導入できなくて焦った
参考にさせていただきました
https://yourmystar-engineer.hatenablog.jp/entry/2019/07/15/140644
https://kuriya0909.hatenablog.com/entry/2019/12/19/092845
- 投稿日:2020-06-28T18:08:20+09:00
【MySQL】連番挿入を楽にする【AUTO_INCREMENT】の連番状態をリセット(初期化)する方法
ここにズレた連番があるじゃろ?
( ^ω^)
⊃NOT連番⊂mysql> select * from shops; +----------+-----------------------+---------+ | shops_id | shops_name | parking | +----------+-----------------------+---------+ | 001 | pizzeria SERICO | Y | | 002 | JAKSON CURRY & COFFEE | N | | 004 | Le•ciel | Y | +----------+-----------------------+---------+これをこうして…
( ^ω^)
≡⊃⊂≡/* 番号にズレがある箇所のレコードを消去 */ mysql> delete from shops where shops_id = 4; /* AUTO_INCREMENTの状態リセット(初期化) */ mysql> ALTER TABLE shops AUTO_INCREMENT = 2; /* 改めてレコード追加 */ mysql> INSERT INTO shops(shops_name, parking) -> VALUES ('Le•ciel', 'Y');こうじゃ
( ^ω^)
⊃YES連番⊂mysql> select * from shops; +----------+-----------------------+---------+ | shops_id | shops_name | parking | +----------+-----------------------+---------+ | 001 | pizzeria SERICO | Y | | 002 | JAKSON CURRY & COFFEE | N | | 003 | Le•ciel | Y | +----------+-----------------------+---------+連番のズレが発生した経緯
/* shops_id'003'にINSERTするべきデータを間違えた */ mysql> INSERT INTO shops(shops_name, parking) -> VALUES ('Cafe Flore', 'N'); mysql> select * from shops; +----------+-----------------------+---------+ | shops_id | shops_name | parking | +----------+-----------------------+---------+ | 001 | pizzeria SERICO | Y | | 002 | JAKSON CURRY & COFFEE | N | | 003 | Cafe Flore | N | +----------+-----------------------+---------+ /* 削除して */ mysql> delete from shops -> where shops_id = 3; /* 再度正しいデータをINSERT */ mysql> INSERT INTO shops(shops_name, parking) -> VALUES ('Le•ciel', 'Y'); /* 番号がズレてることに気づく */ mysql> select * from shops; +----------+-----------------------+---------+ | shops_id | shops_name | parking | +----------+-----------------------+---------+ | 001 | pizzeria SERICO | Y | | 002 | JAKSON CURRY & COFFEE | N | | 004 | Le•ciel | Y | +----------+-----------------------+---------+補足
今回のように一度挿入したレコードを削除してもAUTO_INCREMENTの値は増えます。
例えエラーでレコードが挿入できなくても、AUTO_INCREMENTの値は挿入しようとしたレコードの分だけ増え続けます。そして、次にレコードを挿入した時には欠番が発生することになります。AUTO_INCREMENTはALTER TABLE文で定義を変えられることを知っていれば問題ないです。
mysql> ALTER TABLE 'TABLE名' AUTO_INCREMENT = 1;・参考
MySQLのAUTO_INCREMENTについて色々と調べてみた。
https://qiita.com/sakuraya/items/0dd0bb4114e56f42556d
- 投稿日:2020-06-28T17:31:16+09:00
Rails のデータを React から参照するアプリケーション作成 ( Rails + React + MySQL )
はじめに
他の方の記事を参考に自分なりに Rails + React + MySQL の環境を作ってみたので、その時のやり方をまとめました。
上からコピペするだけで動くようにまとめてみたので、はじめてだけどやってみたいという方がいらっしゃれば、試していただきたいです。コマンド
こちらの項目で実施することは以下となります。
上から順番にターミナルで実行していただければと思います。
- やること
- rails アプリケーションの作成
- webpacker インストール
- react インストール
- MVC作成
- migration
$ rails _5.2.4.2_ new react_sample_app --webpack=react -d mysql $ cd react_sample_app # Webpackを有効にする $ rails webpacker:install # Reactを有効にする $ rails webpacker:install:react # sample モデルを scaffold にて作成 $ rails g scaffold sample title:string body:string # migrate $ rails db:create $ rails db:migrate※routeなどの細かい設定が面倒だと思ってscaffoldを使いましたが、scaffoldが必須というわけではありません。
View
続いては、Viewの設定をしていきます。
application.html.erb
全体へ反映させたいことをこちらに記載していきます。
- やること
javascript_include_tag→javascript_pack_tagへ変更する- view のファイル毎に読み込む javascript(React) を指定するために、
<%= yield :javascript %>を追記app/views/layouts/application.html.erb<!DOCTYPE html> <html> <head> <title>ReactSampleApp</title> <%= csrf_meta_tags %> <%= csp_meta_tag %> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <!-- javascript_include_tag を下記へ変更する --> <!-- javascript_include_tag 'application', 'data-turbolinks-track': 'reload' --> <%= javascript_pack_tag 'application', 'data-turbolinks-track': 'reload' %> </head> <body> <%= yield %> <!-- view のファイル毎に読み込む javascript(React) を指定するために必要 --> <%= yield :javascript %> </body> </html>個別のerbファイル
ここでは例えとして、
app/views/samples/index.html.erb上に変更を加えますが、他の画面で実装していただいも何も問題ありません。
- やること
- Rails から React へ渡すデータを作成(content_tagにより)
- view のファイル毎に読み込む javascript(React) を指定する
app/views/samples/index.html.erb<!-- 省略 --> <!-- 一番下の行に以下を追記 --> <!-- content_tag の data 属性を React へ渡す --> <%= content_tag :div, id: "resources-container", data: { q: params, resources_path: samples_path, }.to_json do %> <% end %> <!-- view のファイル毎に読み込む javascript(React) を指定することができる --> <% content_for :javascript do %> <%= javascript_pack_tag 'hello_react' %> <% end %>javascript
ここでは、コマンド入力時に作成した
app/javascript/packs/hello_react.jsxを用いますが、個々にファイルを設定していただいて問題ありません。
- やること
- Hello コンポーネントの作成
- props を state に格納する
- state.name を更新する関数を作成する
- レンダリングする HTML要素を作成する
- Rails から読み込みたい & React からレンダリングしたい要素を指定
- 指定した要素(node)から、data を取得する
- Hello コンポーネントを呼び出し
- data を Hello コンポーネントの props として渡す
- node へ React からレンダリングする
app/javascript/packs/hello_react.jsximport React from 'react' import ReactDOM from 'react-dom' import PropTypes from 'prop-types' // Hello コンポーネントの作成 class Hello extends React.Component { constructor(props) { super(props) // props を state に格納する this.state = { q: this.props.q || '', resources_path: this.props.resources_path || '', name: this.props.name || 'David' } } render() { // state.name を更新する関数を作成する const setName = e => { this.setState({ name: e.target.value }) } // レンダリングする HTML要素を作成する return ( <div> <div>Hello {this.state.name}!</div> <input type="text" defaultValue={this.state.name} onChange={setName}/> </div> ) } } document.addEventListener('DOMContentLoaded', () => { // Rails から読み込みたい & React からレンダリングしたい要素を指定する const node = document.getElementById('resources-container') // 指定した要素(node)から、data を取得する const data = JSON.parse(node.getAttribute('data')) ReactDOM.render( // Hello コンポーネントを呼び出し // Rails から取得した data を Hello コンポーネントの props として渡す <Hello {...data}/>, // node へ React からレンダリングする node ) })rails s と webpacker 起動を一括して実行する方法
以下に、
scriptsの部分を追記します。
すると、yarn startをターミナル上で実行するたけで、rails s & bin/webpack-dev-serverを実行してくれます。package.json{ "name": "react_sample_app", "private": true, "dependencies": { "@babel/preset-react": "^7.10.1", "@rails/webpacker": "5.1.1", "babel-plugin-transform-react-remove-prop-types": "^0.4.24", "prop-types": "^15.7.2", "react": "^16.13.1", "react-dom": "^16.13.1" }, "devDependencies": { "webpack-dev-server": "^3.11.0" }, // 以下を追記する "scripts": { "start": "rails s & bin/webpack-dev-server" } }$ yarn startまとめ
いかがでしたか。
間違いなどがあれば、お手数をおかけしますがご指摘いただけると嬉しいです。React を理解しているとスマホアプリを作れる React Native への導線が引けるかなーと思い勉強中です。
まずは、Rails と連携していけているアプリケーションを作れるようになりたいなーと思っています。
- 投稿日:2020-06-28T17:27:12+09:00
【MacOS - Homebrew版】MySQLの設定方法(英語を翻訳してみた)
はじめに
注意点
- 本格的に勉強し出して2ヶ月半ほどの初学者が書いてます
- とりあえず、MySQLを動かしたい初学者向けの記事です
- 書いたことについては動作確認をしています
- 2020年6月28日時点
- 導入環境等は以下のとおり
導入環境
- MacOS X 10.15.5 (Catalina)
- Homebrew を使用
- MySQL Version 8.0.19
結論
身も蓋もないですが、LGTMが多いQiitaの記事を参照するのが確実です!
これを読めば、大体分かります。ただ、出てくる英文メッセージについて逐一解説すれば差別化 + 補足ができるのでは
ないかと思い、この記事を書くこととしました。また、実際に直面したトラブルについてもまとめてみました。
記事が冗長になってしまいましたが、MySQL導入が上手くいかない方の参考になれば幸いです。導入手順
概要
取り扱う内容は以下のとおりです。
あと、ターミナル上に出てくる英語はしっかり読みましょう!
- Homebrewをアップデートし、MySQLをインストールする
- MySQLサーバーを立ち上げて、停止してみる
- MySQLのパスワード設定等を行う
- 設定したパスワードで接続する
- もうよく分からんけど上手くいかないから再設定する(該当の方のみ)
1. Homebrewをアップデートし、MySQLをインストールする
a. Homebrewのアップデートを行う
$ brew updateb. Homebrew で MySQL をインストールする
$ brew install mysqlc. Homebrewインストール後のメッセージについて
実行するであろうコマンドが、一通り解説されます。
ざっと理解した方が、今後の作業が結果としてスムーズにいくような気がします。# パスワードを設定せず、インストールしました。 # セキュリティを高めるためには、以下のコマンドを入力してください。 We've installed your MySQL database without a root password. To secure it run: mysql_secure_installation # MySQLは、デフォルトではローカルからしか接続できない設定となっています。 # (デプロイする際には設定が必要になる、ということだと思われます。。。) MySQL is configured to only allow connections from localhost by default # ログインするには以下のコマンドを実行 To connect run: mysql -uroot # サーバーを立ち上げる(+ Macの再起動後に自動的にMySQLを再起動したい)には以下を実行 To have launchd start mysql now and restart at login: brew services start mysql # サーバーを立ち上げる(+ Macの再起動後に自動的にMySQLを再起動しない)には以下を実行 Or, if you don't want/need a background service you can just run: mysql.server start ==> Summary ? /usr/local/Cellar/mysql/8.0.19_1: 286 files, 288.8MB2. MySQLサーバーを立ち上げて、停止してみる
a. MySQLサーバーの立ち上げ
まずMySQLサーバーが立ち上がるか確認しましょう。
mysql.server startなお、Macの再起動後に自動的にMySQLサーバーを立ち上げたい人は、
以下のコマンドでもよいかと思います。(ここだけ、試せていません。。。)brew services start mysql立ち上がると、以下のとおりになるかと思います。
Starting MySQL SUCCESS!b. MySQLサーバーを停止する
以下を入力します。
mysql.server stopすると、以下のとおり成功するはずです。
Shutting down MySQL .. SUCCESS!c. MySQLサーバーの状態を確認する
以下を入力します。
MySQLサーバーが動いているのか、停止しているのか分かります。mysql.server status動いている場合は、以下のとおり。
# XXXXX に5桁の番号が入る SUCCESS! MySQL running (XXXXX)停止している場合は、以下のとおり。
ERROR! MySQL is not runningd. 停止しているサーバーを停止しようとすると
以下のメッセージが出てきます。
ERROR! MySQL server PID file could not be found!ちなみに、この一文でググると、今回のケースにおいては明後日の方向の情報が出てきます。
(サーバーの立ち上げも停止もできない方向けの情報が主にヒットするかと思います)まず、サーバーの状態を確認して、サーバーの立ち上げがやっぱりできない場合に、
「MySQL server PID file could not be found!」でググってみましょう!3. MySQLのパスワード設定等を行う
a. パスワード等の初期設定
Homebrew経由でインストールをすると、rootパスワードは設定されていません。
よって、パスワード等を設定します。MySQLサーバーが立ち上がった状態で行いましょう。
以下を入力します。mysql_secure_installation続いて、以下のコマンド入力画面を参照してください。
英文をかなり雑に意訳しましたので、参考までにご覧ください。なお、場合によっては、このとおりメッセージが出ないかもしれないです。
ただ、基本的な内容は変わらないかと思います。# SQLサーバーのセキュリティ設定を行います。 Securing the MySQL server deployment. # パスワードなしの状態でログインしています。 Connecting to MySQL using a blank password. # パスワードを強固なものとするため、「VALIDATE PASSWORD component」を設定したいか訊かれます。 VALIDATE PASSWORD COMPONENT can be used to test passwords and improve security. It checks the strength of password and allows the users to set only those passwords which are secure enough. Would you like to setup VALIDATE PASSWORD component? # YESにすると、パスワードのレベルをどれぐらい厳しくするか求められます。 # NOにすると、123のような簡単なパスワードに設定できます(セキュリティ上よろしくないですが)。 # ここでは`y`を選びました。 Press y|Y for Yes, any other key for No: y # 私は、LOWにしたいので、0を入力しました(パスワードは8文字以上にすること) # 厳しくしたい人は、1 や 2 にしてください There are three levels of password validation policy: LOW Length >= 8 MEDIUM Length >= 8, numeric, mixed case, and special characters STRONG Length >= 8, numeric, mixed case, special characters and dictionary file Please enter 0 = LOW, 1 = MEDIUM and 2 = STRONG: 0 Using existing password for root. # パスワードがどれくらい破られにくいか表示してくれています。 # 100点満点中、25点でした 笑 Estimated strength of the password: 25 # 先ほど設定したパスワードに変更してよければ、`y`を入力。 # パスワードがどれくらい強固か示した上で、改めてユーザーに確認させるためにわざわざ聞いているのかと思われます。 Change the password for root ? ((Press y|Y for Yes, any other key for No) : 入力したパスワードが表示されている ... skipping. # アノニマス(匿名)ユーザーというのがあるらしく、それを使うとユーザーアカウントがなくとも、 # 誰でもMySQLにログインできてしまうようです。これは、インストールなどを円滑にするためにある # ユーザーです。デプロイする前には、絶対にアノニマスユーザーを削除してください! By default, a MySQL installation has an anonymous user, allowing anyone to log into MySQL without having to have a user account created for them. This is intended only for testing, and to make the installation go a bit smoother. You should remove them before moving into a production environment. # さて、あなたはアノニマスユーザーを削除しますよね? # 私は、アノニマスユーザーを大人しく消しました 笑 Remove anonymous users? (Press y|Y for Yes, any other key for No) : y Success. # 普通は、ルートユーザーはローカルからしかアクセスできない設定にするものです。 # だって、誰かがルートユーザーにログインして、色々悪さしたら困るでしょ? Normally, root should only be allowed to connect from 'localhost'. This ensures that someone cannot guess at the root password from the network. # ルートユーザーにリモートログインできない設定にしますよね? # 私は、大人しくリモートログインできない設定にしました 笑 Disallow root login remotely? (Press y|Y for Yes, any other key for No) : y Success. # デフォルトの設定では、誰でもアクセスできる「test」というデータベースが生成されています。 # これも、デプロイする前には、絶対に削除してください!!! By default, MySQL comes with a database named 'test' that anyone can access. This is also intended only for testing, and should be removed before moving into a production environment. # ということで「test」のデータベース、削除しといていいですよね? # 大人しく、削除することにしました 笑 Remove test database and access to it? (Press y|Y for Yes, any other key for No) : y - Dropping test database... Success. - Removing privileges on test database... Success. # これまでの設定を即反映しますか? # 「privilege table ~」 と書いてますが、先ほど削除したばっかりなのでリロードはされないかと思います Reloading the privilege tables will ensure that all changes made so far will take effect immediately. # 反映したいので、`y`を選択しました Reload privilege tables now? (Press y|Y for Yes, any other key for No) : y Success. All done!b. その他の設定方法
先ほど書いたとおり、Homebrew経由でインストールした場合、
rootパスワードは設定されていない状態です。なので、
mysql -urootにてとりあえずMySQLにログインしてしまい、
そこからパスワードを設定する方法もあるようです。その場合、おそらく以下のコマンドを入力することになるかと思います。
mysql> USE mysql; mysql> ALTER USER 'root'@'localhost' identified BY '任意のパスワード';ここでは細かく触れませんが、何も知らない状態で2つの方法を見るとどちらが正しいのか
混乱しそうだと思ったので、一応、触れておきました。ちなみに、この方法だとセキュリティ上の設定ができず、アノニマスユーザーが残ってしまうので、
あまりよろしくないのかなと思います。(実際のところはよく分かっていませんが。。。)4. 設定したパスワードで接続する
a. 接続方法
さて、MySQLに接続しましょう!
mysql -uroot -pすると、以下が表示されます。
パスワードを入力しましょう!Enter password:成功すると、以下のとおり表示されるはずです。
おつかれさまでした!!!Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 10 Server version: 8.0.19 Homebrew Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>ちなみに、
exitと入力すると、MySQLを終えることができます。mysql> exit Byeb. パスワードを間違えた場合
以下のとおり表示されるはずです。
なお、これはMySQLサーバーが起動している場合です。ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)c. MySQLサーバーが起動していない場合
以下のとおり表示されます。
パスワードが合っていようとも、以下のとおりエラーになります。ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)ちなみに、安易にこのメッセージでググり始めてしまうと不幸の始まりです笑
mysql.sockファイルがないのか、再作成が必要なのかと考え出してしまうかもしれませんが、
単純にサーバーが停止しているだけではないか、まず疑いましょう。d. パスワードを忘れた残念な方へ
おつかれさまです。
奇遇ですね、友達になりたいです 笑この記事を参照しましょう 笑
5. もうよく分からんけど上手くいかないから再設定する方へ
変な設定をしてしまった場合、作業が上手くいかない可能性があります。
心当たりがある場合、素直に再設定する方が早いかと思います。MySQLをHomebrewでインストールして初期設定まで行ったけど、MySQLがどうしても起動しなかったときの対応 - Qiita
なお、案内のとおり、再起動はしましょう!
再起動しないと、エラーになります!その他で参考にしたもの
その他、参考にさせていただいたものを以下に記します。
- 【公式】 MySQL :: MySQL 8.0 Reference Manual :: 2.10.4 Securing the Initial MySQL Account
- 英語ですが、日本語翻訳するとなんとなく分かることもあるかと
- 「brew services start mysql」と「mysql.server start」の違い - Qiita
- タイトルの通り、違いが分からなかったので参考にさせていただきました
- Mysql 5.7* パスワードをPolicyに合わせるとめんどくさい件について - Qiita
- ゴニョゴニョやっていたら、パスワードレベルがmediumになってしまったため参考にしました
- 投稿日:2020-06-28T17:27:12+09:00
【MacOS - Homebrew版】MySQLの設定方法(インストール→MySQLサーバー立ち上げ→パスワード設定等)
はじめに
注意点
- 本格的に勉強し出して2ヶ月半ほどの初学者が書いてます
- とりあえず、MySQLを動かしたい初学者向けの記事です
- 書いたことについては動作確認をしています
- 2020年6月28日時点
- 導入環境等は以下のとおり
導入環境
- MacOS X 10.15.5 (Catalina)
- Homebrew を使用
- MySQL Version 8.0.19
結論
身も蓋もないですが、LGTMが多いQiitaの記事を参照するのが確実です!
これを読めば、大体分かります。ただ、出てくる英文メッセージについて逐一解説すれば差別化 + 補足ができるのでは
ないかと思い、この記事を書くこととしました。また、実際に直面したトラブルについてもまとめてみました。
記事が冗長になってしまいましたが、MySQL導入が上手くいかない方の参考になれば幸いです。導入手順
概要
取り扱う内容は以下のとおりです。
あと、ターミナル上に出てくる英語はしっかり読みましょう!
- Homebrewをアップデートし、MySQLをインストールする
- MySQLサーバーを立ち上げて、停止してみる
- MySQLのパスワード設定等を行う
- 設定したパスワードで接続する
- もうよく分からんけど上手くいかないから再設定する(該当の方のみ)
1. Homebrewをアップデートし、MySQLをインストールする
a. Homebrewのアップデートを行う
$ brew updateb. Homebrew で MySQL をインストールする
$ brew install mysqlc. Homebrewインストール後のメッセージについて
実行するであろうコマンドが、一通り解説されます。
ざっと理解した方が、今後の作業が結果としてスムーズにいくような気がします。# パスワードを設定せず、インストールしました。 # セキュリティを高めるためには、以下のコマンドを入力してください。 We've installed your MySQL database without a root password. To secure it run: mysql_secure_installation # MySQLは、デフォルトではローカルからしか接続できない設定となっています。 # (デプロイする際には設定が必要になる、ということだと思われます。。。) MySQL is configured to only allow connections from localhost by default # ログインするには以下のコマンドを実行 To connect run: mysql -uroot # サーバーを立ち上げる(+ Macの再起動後に自動的にMySQLを再起動したい)には以下を実行 To have launchd start mysql now and restart at login: brew services start mysql # サーバーを立ち上げる(+ Macの再起動後に自動的にMySQLを再起動しない)には以下を実行 Or, if you don't want/need a background service you can just run: mysql.server start ==> Summary ? /usr/local/Cellar/mysql/8.0.19_1: 286 files, 288.8MB2. MySQLサーバーを立ち上げて、停止してみる
a. MySQLサーバーの立ち上げ
まずMySQLサーバーが立ち上がるか確認しましょう。
mysql.server startなお、Macの再起動後に自動的にMySQLサーバーを立ち上げたい人は、
以下のコマンドでもよいかと思います。(ここだけ、試せていません。。。)brew services start mysql立ち上がると、以下のとおりになるかと思います。
Starting MySQL SUCCESS!b. MySQLサーバーを停止する
以下を入力します。
mysql.server stopすると、以下のとおり成功するはずです。
Shutting down MySQL .. SUCCESS!c. MySQLサーバーの状態を確認する
以下を入力します。
MySQLサーバーが動いているのか、停止しているのか分かります。mysql.server status動いている場合は、以下のとおり。
# XXXXX に5桁の番号が入る SUCCESS! MySQL running (XXXXX)停止している場合は、以下のとおり。
ERROR! MySQL is not runningd. 停止しているサーバーを停止しようとすると
以下のメッセージが出てきます。
ERROR! MySQL server PID file could not be found!ちなみに、この一文でググると、今回のケースにおいては明後日の方向の情報が出てきます。
(サーバーの立ち上げも停止もできない方向けの情報が主にヒットするかと思います)まず、サーバーの状態を確認して、サーバーの立ち上げがやっぱりできない場合に、
「MySQL server PID file could not be found!」でググってみましょう!3. MySQLのパスワード設定等を行う
a. パスワード等の初期設定
Homebrew経由でインストールをすると、rootパスワードは設定されていません。
よって、パスワード等を設定します。MySQLサーバーが立ち上がった状態で行いましょう。
以下を入力します。mysql_secure_installation続いて、以下のコマンド入力画面を参照してください。
英文をかなり雑に意訳しましたので、参考までにご覧ください。なお、場合によっては、このとおりメッセージが出ないかもしれないです。
ただ、基本的な内容は変わらないかと思います。# SQLサーバーのセキュリティ設定を行います。 Securing the MySQL server deployment. # パスワードなしの状態でログインしています。 Connecting to MySQL using a blank password. # パスワードを強固なものとするため、「VALIDATE PASSWORD component」を設定したいか訊かれます。 VALIDATE PASSWORD COMPONENT can be used to test passwords and improve security. It checks the strength of password and allows the users to set only those passwords which are secure enough. Would you like to setup VALIDATE PASSWORD component? # YESにすると、パスワードのレベルをどれぐらい厳しくするか求められます。 # NOにすると、123のような簡単なパスワードに設定できます(セキュリティ上よろしくないですが)。 # ここでは`y`を選びました。 Press y|Y for Yes, any other key for No: y # 私は、LOWにしたいので、0を入力しました(パスワードは8文字以上にすること) # 厳しくしたい人は、1 や 2 にしてください There are three levels of password validation policy: LOW Length >= 8 MEDIUM Length >= 8, numeric, mixed case, and special characters STRONG Length >= 8, numeric, mixed case, special characters and dictionary file Please enter 0 = LOW, 1 = MEDIUM and 2 = STRONG: 0 Using existing password for root. # パスワードがどれくらい破られにくいか表示してくれています。 # 100点満点中、25点でした 笑 Estimated strength of the password: 25 # 先ほど設定したパスワードに変更してよければ、`y`を入力。 # パスワードがどれくらい強固か示した上で、改めてユーザーに確認させるためにわざわざ聞いているのかと思われます。 Change the password for root ? ((Press y|Y for Yes, any other key for No) : 入力したパスワードが表示されている ... skipping. # アノニマス(匿名)ユーザーというのがあるらしく、それを使うとユーザーアカウントがなくとも、 # 誰でもMySQLにログインできてしまうようです。これは、インストールなどを円滑にするためにある # ユーザーです。デプロイする前には、絶対にアノニマスユーザーを削除してください! By default, a MySQL installation has an anonymous user, allowing anyone to log into MySQL without having to have a user account created for them. This is intended only for testing, and to make the installation go a bit smoother. You should remove them before moving into a production environment. # さて、あなたはアノニマスユーザーを削除しますよね? # 私は、アノニマスユーザーを大人しく消しました 笑 Remove anonymous users? (Press y|Y for Yes, any other key for No) : y Success. # 普通は、ルートユーザーはローカルからしかアクセスできない設定にするものです。 # だって、誰かがルートユーザーにログインして、色々悪さしたら困るでしょ? Normally, root should only be allowed to connect from 'localhost'. This ensures that someone cannot guess at the root password from the network. # ルートユーザーにリモートログインできない設定にしますよね? # 私は、大人しくリモートログインできない設定にしました 笑 Disallow root login remotely? (Press y|Y for Yes, any other key for No) : y Success. # デフォルトの設定では、誰でもアクセスできる「test」というデータベースが生成されています。 # これも、デプロイする前には、絶対に削除してください!!! By default, MySQL comes with a database named 'test' that anyone can access. This is also intended only for testing, and should be removed before moving into a production environment. # ということで「test」のデータベース、削除しといていいですよね? # 大人しく、削除することにしました 笑 Remove test database and access to it? (Press y|Y for Yes, any other key for No) : y - Dropping test database... Success. - Removing privileges on test database... Success. # これまでの設定を即反映しますか? # 「privilege table ~」 と書いてますが、先ほど削除したばっかりなのでリロードはされないかと思います Reloading the privilege tables will ensure that all changes made so far will take effect immediately. # 反映したいので、`y`を選択しました Reload privilege tables now? (Press y|Y for Yes, any other key for No) : y Success. All done!b. その他の設定方法
先ほど書いたとおり、Homebrew経由でインストールした場合、
rootパスワードは設定されていない状態です。なので、
mysql -urootにてとりあえずMySQLにログインしてしまい、
そこからパスワードを設定する方法もあるようです。その場合、おそらく以下のコマンドを入力することになるかと思います。
mysql> USE mysql; mysql> ALTER USER 'root'@'localhost' identified BY '任意のパスワード';ここでは細かく触れませんが、何も知らない状態で2つの方法を見るとどちらが正しいのか
混乱しそうだと思ったので、一応、触れておきました。ちなみに、この方法だとセキュリティ上の設定ができず、アノニマスユーザーが残ってしまうので、
あまりよろしくないのかなと思います。(実際のところはよく分かっていませんが。。。)4. 設定したパスワードで接続する
a. 接続方法
さて、MySQLに接続しましょう!
mysql -uroot -pすると、以下が表示されます。
パスワードを入力しましょう!Enter password:成功すると、以下のとおり表示されるはずです。
おつかれさまでした!!!Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 10 Server version: 8.0.19 Homebrew Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>ちなみに、
exitと入力すると、MySQLを終えることができます。mysql> exit Byeb. パスワードを間違えた場合
以下のとおり表示されるはずです。
なお、これはMySQLサーバーが起動している場合です。ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)c. MySQLサーバーが起動していない場合
以下のとおり表示されます。
パスワードが合っていようとも、以下のとおりエラーになります。ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)ちなみに、安易にこのメッセージでググり始めてしまうと不幸の始まりです笑
mysql.sockファイルがないのか、再作成が必要なのかと考え出してしまうかもしれませんが、
単純にサーバーが停止しているだけではないか、まず疑いましょう。d. パスワードを忘れた残念な方へ
おつかれさまです。
奇遇ですね、友達になりたいです 笑この記事を参照しましょう 笑
5. もうよく分からんけど上手くいかないから再設定する方へ
変な設定をしてしまった場合、作業が上手くいかない可能性があります。
心当たりがある場合、素直に再設定する方が早いかと思います。MySQLをHomebrewでインストールして初期設定まで行ったけど、MySQLがどうしても起動しなかったときの対応 - Qiita
なお、案内のとおり、再起動はしましょう!
再起動しないと、エラーになります!その他で参考にしたもの
その他、参考にさせていただいたものを以下に記します。
- 【公式】 MySQL :: MySQL 8.0 Reference Manual :: 2.10.4 Securing the Initial MySQL Account
- 英語ですが、日本語翻訳するとなんとなく分かることもあるかと
- 「brew services start mysql」と「mysql.server start」の違い - Qiita
- タイトルの通り、違いが分からなかったので参考にさせていただきました
- Mysql 5.7* パスワードをPolicyに合わせるとめんどくさい件について - Qiita
- ゴニョゴニョやっていたら、パスワードレベルがmediumになってしまったため参考にしました
- 投稿日:2020-06-28T17:16:45+09:00
令和の Lambda x RDS
はじめに
Lambda x RDSは令和になってから重大ニュースがいくつかあった影響もあり、
VPC Lambdaは遅い、同時接続数がつらい、だからアンチパターンかと思いきや、
VPC Lambdaそんなに悪くない、Proxy使えばいい、とも言われてて
相反する情報が多く混乱してしまったので、平成と令和での状況変化を各記事を参考にまとめる
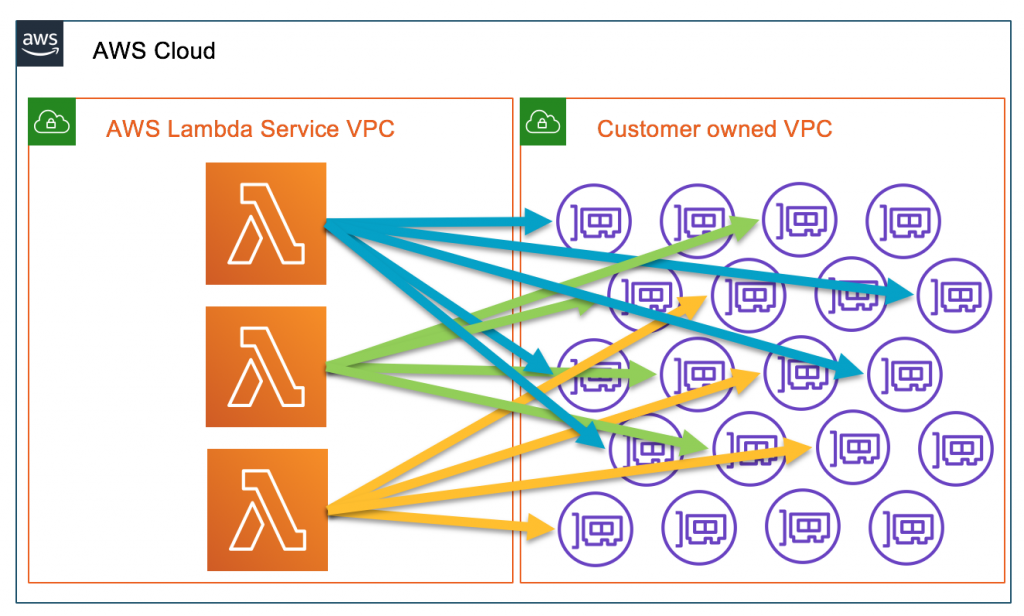
※「VPC Lambda」 = VPC内で実行するオプションを付けたLambda(デフォルトはVPC外で実行される)【平成】 以下5つの点でLambdaとRDSは相性が良くないと言われていた
1. VPC Lambdaでの実行時に、起動コストが高い問題 初回起動時はコールドスタートでENIの作成とアタッチなどに10~20秒ほどかかる 対応方法 定期的にlambdaをkickする 2. VPC Lambdaでの実行時に、サブネットのIPを浪費する問題 アタッチされたENIの数だけサブネット内のIPを消費してしまう サブネットのIPリミットやアカウントのENI作成リミット、APIレートを使い切るリスクがある また、LambdaのスケーリングがENIのリミットに依存する 対応方法 lambda用に別で大きめのサブネットを切る 3. VPC Lambdaでの実行時に、インターネットアクセスするにNat Gatewayが必要な問題 1時間あたり$0.062 1GBあたり$0.062 何もしなくても $44.64/月 かかってしまう 高い。。。 4. VPC外での実行時はRDSにPublicAccessを許可する必要がある問題 VPC内がだめなら、外が良いのかというとそうでもない RDSのポート公開はビジネスではセキュリティリスクになるので取れない方法になる 個人用途ならぎりあり 対応方法 lambdaのIPレンジのみからPublicAccessを許可する https://dev.classmethod.jp/articles/limiting-access-to-just-aws-ip-ranges/ 5. 最大接続数の問題 lambdaは同時実行数を制御することが難しく、東京リージョンだと最大1000まで増やせる性能がある 一方mysqlはコネクション数が多いとその分スペックを要求され、ピークに合わせるとコスパが悪くなる 同時接続数の制御としては、コネクションプールが使われることが多い しかし、lambdaではコンテナ間でデータ共有する仕組みがないため、コネクションプールの実装が難しい なので、スケールアップで対応するしかなく、ピークに合わせてチューニングするとコスパが悪い そのため、LambdaはDynamoDBとの組み合わせが推奨されている 対応方法 これを許容できる規模のサービスで使う 自身でコネクションプールするサービスを作る 参考 なぜAWS LambdaとRDBMSの相性が悪いかを簡単に説明する https://www.keisuke69.net/entry/2017/06/21/121501 AWS LambdaをVPC内に配置する際の注意点 https://devlog.arksystems.co.jp/2018/04/04/4807/ Lambda x RDSはアンチパターンやでって話1 https://qiita.com/teradonburi/items/86400ea82a65699672ad Lambda x RDSはアンチパターンやでって話2 https://www.keisuke69.net/entry/2017/06/21/121501 VPC Lambdaそんなに悪くないでって話 https://dev.classmethod.jp/articles/serverless-meetup-osaka-5-vpclambda-demerit/【令和】 問題の致命的な部分がほぼ改善された
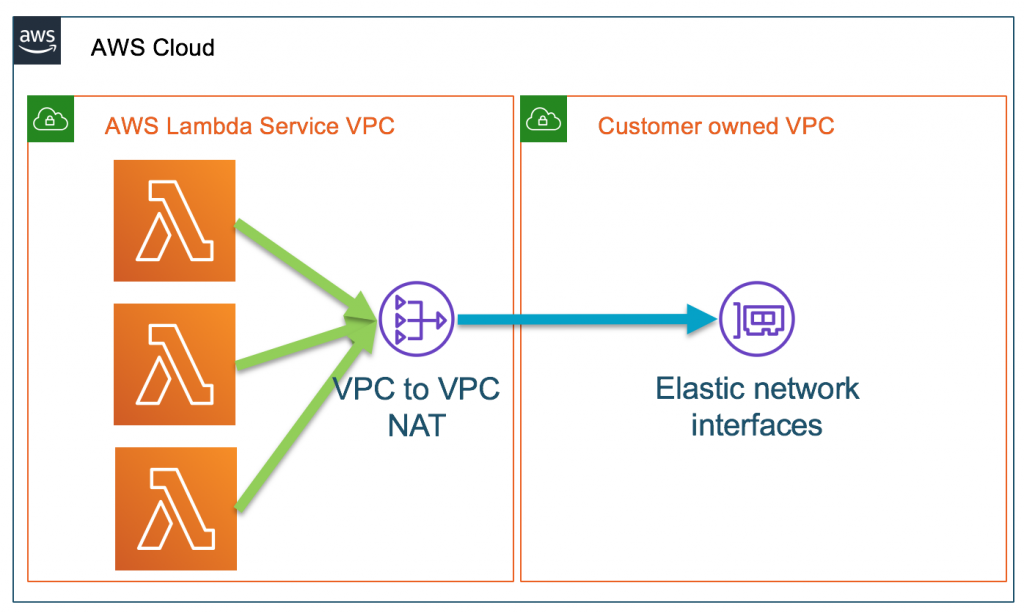
1. 「VPC内での実行時に起動コストが高い問題」の解決 2019年9月頃にコールドスタートの起動速度が改善された Lambda関数が作成された時に「Hyperplane ENI」がマッピングされるようになった そのおかげでENIの作成/アタッチのコストが削減されたみたい ただし、アクセス数が増加すると追加のENIが作成されて、その瞬間は「2~6秒」ほどレイテンシが発生するらしい 追加のENIは使われないと削除されるらしい 完全には改善できていないが、大分マシになったという印象 2. 「VPC内での実行時にサブネットのIPを浪費する問題」の解決 「Hyperplane ENI」によってENIを使い回すので浪費がなくなった ENIの作成リミット依存もなくなった 3. 「VPC Lambdaでの実行時に、インターネットアクセスするにNat Gatewayが必要な問題」 動きなし、引き続き課金が必要 4. 「VPC外での実行時はRDSにPublicAccessを許可する必要がある問題」 動きなし、引き続きRDSをPublicAccess許可にしないといけない ただ、これはIP制限でなんとかなる気がする VPC Lambdaが改善されたので、必要性は薄れたかも 5. 「最大接続数の問題」の解決 2019年12月「RDS Proxy(プレビュー版)」リリース コネクションプーリングやフェイルオーバーを担ってくれるProxyがリリースされた これを使えばピークカットできるので、問題は解決できそう ただし、「RDS Proxy」を使うと追加料金がかかる 基となるデータベースインスタンスの vCPU あたりの料金: 0.018USD/時間 db.r5.large(Aurora)を使用している場合、 db.r5.large 使用料: $252 ($0.35 x 24時間 x 30日) プロキシ使用量: $25.92 ($0.018 x 2vCPU x 24時間 x 30日) 現時点でまだプレビュー版なので本番投入可能な状態はまだ先になりそう いくつかの検証ブログを見るにまだコントロールしづらそうな感じはする 参考 【公式】 Amazon RDS プロキシのご紹介 (プレビュー) https://aws.amazon.com/jp/about-aws/whats-new/2019/12/amazon-rds-proxy-available-in-preview/ 【公式】 PostgreSQL 互換の Amazon RDS Proxy (プレビュー) https://aws.amazon.com/jp/about-aws/whats-new/2020/04/amazon-rds-proxy-with-postgresql-compatibility-preview/ 【公式】Amazon RDS プロキシの料金 https://aws.amazon.com/jp/rds/proxy/pricing/ 【公式】 Announcing improved VPC networking for AWS Lambda functions https://aws.amazon.com/jp/blogs/compute/announcing-improved-vpc-networking-for-aws-lambda-functions/ 【公式】AWS LambdaでAmazon RDS Proxyを使用する https://aws.amazon.com/jp/blogs/news/using-amazon-rds-proxy-with-aws-lambda/ VPC アーキテクチャ変更のまとめ https://dev.classmethod.jp/articles/announced-vpclambda-improved/ RDS Proxy パフォーマンス検証1 https://tech.fusic.co.jp/posts/2019-12-11-aws-lambda-with-rds-proxy-performance-1/ RDS Proxy パフォーマンス検証2 https://blog.mmmcorp.co.jp/blog/2020/04/03/lambda-rds-proxy/Tips: 「Hyperplane ENI」とは
「Hyperplane」というのが、2017年のre:Inventで紹介されていたAWS内部で使われているネットワーク関連技術 もともとは内部的なS3 Load Balancerとして開発されたらしい これらの問題を解決するソリューション トラブル解決が困難 キャパシティ管理が困難 コストが増大 ネットワークロードバランサーやNATゲートウェイなどに使われている そのHyperplaneを使って、ENIをNATできるようにして、VPCの問題を解決したらしい 参考 [レポート] AWS を支えるネットワークインフラと要素技術 #AWSSummit https://dev.classmethod.jp/articles/awssummit-2018-day2-h1-2-10-aws-network-infrastructure/ AWS re:Invent 2017 Keynote - Tuesday Night Live with Peter DeSantis https://www.youtube.com/watch?v=dfEcd3zqPOA&feature=youtu.be&t=4661↓これが
↓こうなった
画像引用: AWS Compute Blogまとめ
2020/06時点で「VPC Lambda」は使い物になるかというと、
VPCの問題は改善されたが、RDS Proxyがまだプレビュー版なので、正式版がくるまでは規模のあるビジネス用途ではまだ厳しそう。
個人用途ならVPCの改善だけでもありだけど、インターネットアクセスするなら
NatGateway課金が必要なのでお財布と相談って感じ。よし、VPC Lambda一択だ!と思いきや、
ステイッステイッ、まだだまだだ、な状況※2020/07/01 追記
https://dev.classmethod.jp/articles/rds-proxy-ga/
RDS Proxy が GA(General Availability:一般利用可能) になりました!
- 投稿日:2020-06-28T13:47:09+09:00
【k8s】mysqlから学ぶConfigMap&Secret
はじめに
kubernetes(以下k8s)でmysqlのdeploymentを作成するしていく中でk8sのConfigMp,Secretについて学べるなと考えました。
そこで本記事では、k8sでmysqlのdeploymentを作成する手順を記載と共にconfigmapやsecretの使用方法についてd記載していきます。この記事で学べること
- k8s deployment
- k8s ConfigMap
- k8s Secret
- kubectlコマンドの基礎
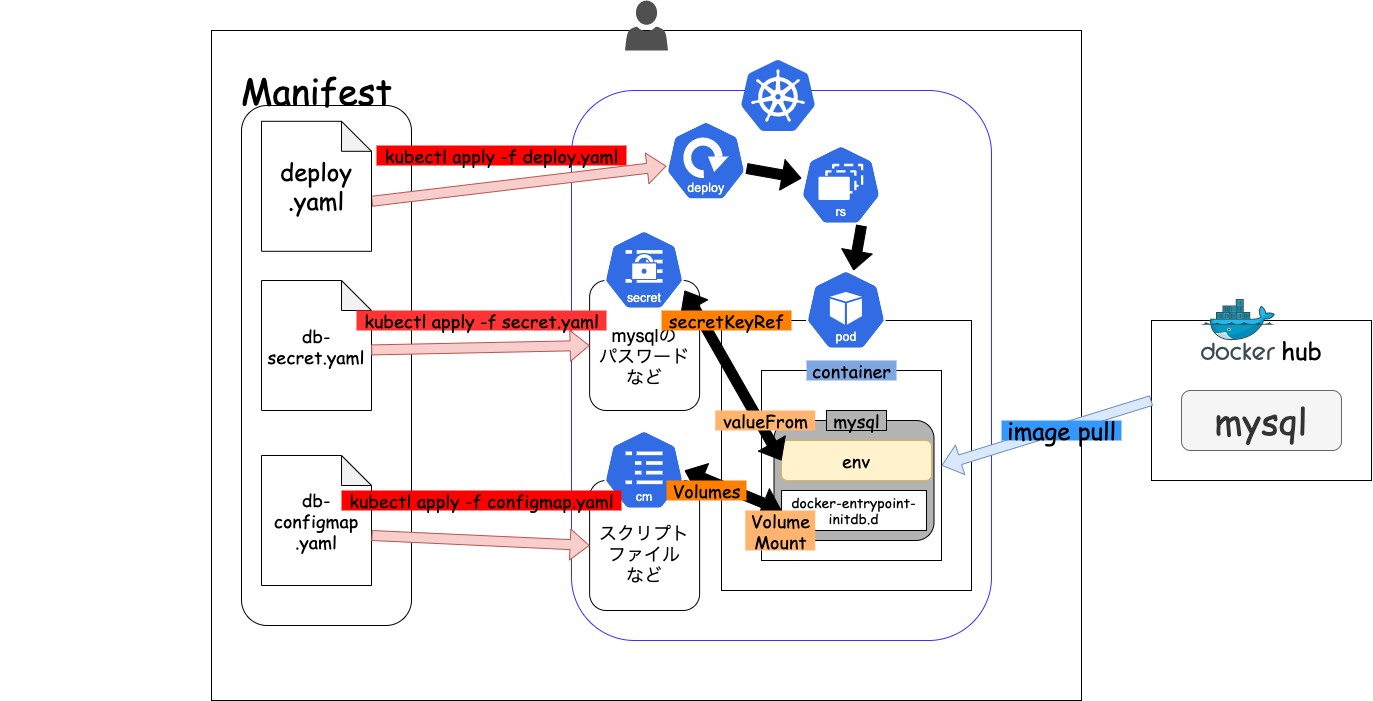
全体図
構築する実行環境は以下の通りになります。
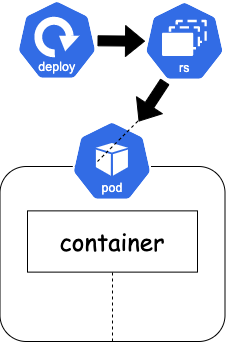
deployment
podの拡張概念。
図の通り、deploymentがrs(replicaset)を生成し、rsがpodを生成してくれます。
podは一つ以上のコンテナからできています。
今回の場合は、mysqlコンテナが一つ入ったpodが生成されます。
configMap
k8s Config&Storageリソースの一つ。
configMapはその名の通り、(configuration mapping)以下のような設定情報をコンテナにマッピングすることができます。
- 環境変数
- ファイル(volume)
configmapとして切り分けておくことで、設定ファイルを複数のコンテナに即座に反映させることができます。
今回はmysqlコンテナに初期化時にdatabaseを生成するための設定ファイルをマッピングします。secret
k8s Config&Storageリソースの一つ。
secretはconfigmapと異なりパスワードなどの以下のような機密情報をコンテナにマッピングするために使用します。
- 環境変数
- ファイル(volume)
今回は、環境変数にmysqlのパスワード情報をマッピングします。
環境構築手順
リソースの作成
deploymentの作成
deploy.yamlapiVersion: apps/v1 kind: Deployment metadata: name: mysql spec: selector: matchLabels: app: mysql template: metadata: labels: app: mysql spec: containers: - name: mysql image: mysql:5.7 # コンテナのどの場所にマッピングするかを記述する。 volumeMounts: - name: sql-init-config # docker-entrypoint-initdb.dディレクトリ下にスクリプトファイルを入れておくと初期化時データベースを作成してくれる。 mountPath: /docker-entrypoint-initdb.d env: - name: MYSQL_ROOT_PASSWORD # secretを使用して環境変数を設定する。 valueFrom: secretKeyRef: name: sql-secret key: password ports: - containerPort: 800 # podに提供するvolumeを指定する。 volumes: # volumeMounts.nameと一致させる必要がある。 - name: sql-init-config # volumeとしてconfigMapを使う。 configMap: name: db-init-configmap items: - key: init.sql path: init.sqlここで、着目すべき部分は以下の通りです。
deploy.yamlapiVersion: apps/v1 # ・・・・・・・・・・・・・・・・・・・・ spec: # =============コンテナについて書く。================ containers: - name: mysql image: mysql:5.7 # コンテナのどの場所にマッピングするかを記述する。 volumeMounts: - name: sql-init-config # docker-entrypoint-initdb.dディレクトリ下にスクリプトファイルを入れておくと初期化時データベースを作成してくれる。 mountPath: /docker-entrypoint-initdb.d env: - name: MYSQL_ROOT_PASSWORD # secretを使用して環境変数を設定する。 valueFrom: secretKeyRef: name: sql-secret key: password ports: - containerPort: 800 # ======================================= # --------podに提供するvolumeを指定する。--------- volumes: # volumeMounts.nameと一致させる必要がある。 - name: sql-init-config # volumeとしてconfigMapを使う。 configMap: name: db-init-configmap items: - key: init.sql path: init.sql # -----------------------------------------
- コンテナのどの場所にマウントするか指定する
spec.containers[*].volumeMountsに記述する- 環境変数として、secretをマッピングする
spec.containers[*].env.valueFrom.secretKeyRefに記述する。- コンテナ(pod)に提供するvolumeを指定する。
spec.volumesに記述する。configmapを作成する。
configmap.yamlapiVersion: v1 kind: ConfigMap metadata: name: db-init-configmap data: # init.sqlファイルをしてコンテナ内にマッピングされる。 init.sql: | CREATE DATABASE IF NOT EXISTS app;secretを作成
secret.yamlapiVersion: v1 kind: Secret metadata: name: sql-secret type: Opaque data: # パスワードをbase64でエンコードした値 password: cGFzc3dvcmQ=エンコードのやり方は
$ encode -n [sqlのパスワード] | base64ファイルを作成が終わったら、kubectlコマンドでそれぞれのリソースを作成します。
$ kubectl apply -f deploy.yaml deployment.apps/mysql created$ kubectl apply -f configmap.yaml configmap/db-init-configmap created$ kubectl apply -f secret.yaml secret/sql-secret createdちゃんと設定できているか確認する
そのためmysqlのコンテナにログインしてみます。
まずは、deploymentから作成されたmysqlのpodを確認します。
$ kubectl get po NAME READY STATUS RESTARTS AGE mysql-b6cff87cf-9dfbx 1/1 Running 0 3m54smysqlのpodが起動していることが確認できます。このpod名を利用してコンテナ内にログインしまう。
コマンドは以下の通りです。
$ kubectl exec -it mysql-b6cff87cf-9dfbx bash環境変数を確認
root@mysql-b6cff87cf-9dfbx:/# env | grep MYSQL_ROOT MYSQL_ROOT_PASSWORD=passwordすると、MYSQL_ROOT_PASSWORDが環境変数として設定されていることがわかります。
configmapの確認
実際にマウント先に指定したdocker-entrypoint-initdb.ディレクトリの中身を見てみます。
root@mysql-b6cff87cf-9dfbx:/# ls docker-entrypoint-initdb.d/ init.sqlちゃんとinit.sqlファイルがマウントされていることがわかります。
また、ファイルの中身を見てみると。。root@mysql-b6cff87cf-9dfbx:/# cat docker-entrypoint-initdb.d/init.sql CREATE DATABASE IF NOT EXISTS app;configmapで指定した中身と一緒になっています。
mysqlにappデータベースが生成されているか確認
まずは、mysqlにログインしてみます。
root@mysql-b6cff87cf-9dfbx:/# mysql -u root -p Enter password: (passwordと入力してください。) /// mysql>これでログインできました。
次にデータベースの一覧をみてみます。
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | app | | mysql | | performance_schema | | sys | +--------------------+ 5 rows in set (0.00 sec)appデータベースが生成されていることが確認できました。
まとめ
configMap
- 設定ファイルなどをコンテナにマッピングすることができる。
- コンテナのどこにマッピングするか(
spec.container[].volumeMounts)などを記載するsecret
- パスワードの機密情報をコンテナにマッピングすることができる。
- 環境変数にマッピングする場合は、
spec.container[].env.valuefromに記述するconfigmapやsecretを使用するときは、コンテナにどの種類のvolumeを使用するか(
spec.volumes)などを記述する必要がある。kubectl
- リソース(deployment,configmapなど)を作成する
kubectl apply -f [リソースのファイルパス]- podの一覧を表示する
kubectl get po- pod内にログインする
kubectl exec -it [pod名] bash
- 投稿日:2020-06-28T10:41:56+09:00
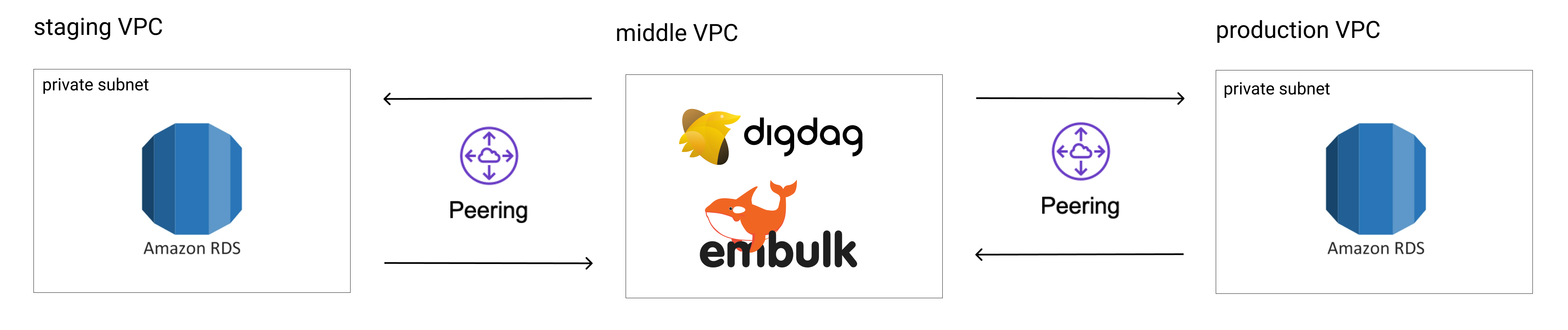
Digdag + Embulk で production から staging へデータ同期する
Digdag と Embulk を使って Staging に Production のデータを同期した話です。
環境構築から同期が完了するまで、たくさんのエラーと格闘したので書き留めておきます。実行時の環境は以下になります。
Embulk v0.9.22 embulk-input-mysql 0.10.1 embulk-output-mysql 0.8.7 MySQL 5.7.21前回、 Digdag + Embulk + Fargateによるデータマスキング をしましたが、同じ Docker image を使って Staging 同期にも利用しています。
構成
管理を絶対にしたかったので Staging と Production は直接繋げず、中間の VPC を置いてそことそれぞれがピアリングする構成にしました。
staging には開発メンバーが動作確認をするために、ある程度量のデータが入った状態です。
Tips
Deplicate Entry 回避
マスクしたデータを UNIQUE KEY が貼られているカラムにコピーする際、単純に embulk-filter-mask で値をマスクするだけでは Deplicate Entry エラーが発生します。 また、Staging 環境にはある程度データが入った状態なので、マスク対象でないカラムでも偶然に値が被ってしまうことがあるでしょう。
そのような場合は、 embulk-filter-ruby_proc がおすすめです。
filters: # before - type: mask columns: - { name: email, type: email } # *****@example.com とマスクされるが、UNIQUE 制約に引っかかる # after - type: ruby_proc columns: - name: email proc: | ->(email) do "#{SecureRandom.hex(15)}@example.com" # c131f413e3d239b937b595224ef6f2@example.com endproc でランダムに文字列を生成すれば、Duplicate Entry エラーを回避できます。
Staging 環境では実際にメールが送信されてしまうので、@example.comの部分は自社のドメインにすると良いでしょう。truncate_insert モードを使う
マスクしたデータに限らず Staging と Production のデータの差分から、一時的にどうしても重複が出てしまう場合がありました。例えば foreign_id に UNIQUE 制約が付いている場合、
# Staging id: 1, foreign_id: 1 id: 2, foreign_id: 2 # Production id: 1, foreign_id: 2 <- id 1 を元に foreign_id = 2 を merge したいが duplicate エラー id: 2, foreign_id: 3 # 期待する結果 id: 1, foreign_id: 2 id: 2, foreign_id: 3この際 merge モードを利用していましたが、truncate_insert モードを利用することで回避できました。
truncate_insert は既存のデータは削除して読み込んだデータに追記するモードです。(テーブルをドロップしない)ステータスをアップデートする
Staging 環境では Production 同等にバッチが走っているのですが、オブジェクトの status が完了状態ではないと更新対象になってしまいエラーが発生するケースがありました。例えば、status が完了状態でないと外部の決済サービスにリクエストが飛ぶが、当然 Production のデータは存在しないためエラーとなります。
after_loadを使えばクエリの実行後に指定の SQL を実行できます。
これにより、status が完了の状態でコピーすることができます。out: ... {% if env.IS_MIDDLE == 'true' %} after_load: "update table set status = [完了ステータス] where status = [未完了ステータス]" {% endif %}分析 DB を作成する際に同じ image を使っていることから、Staging 同期をする時だけ実行する必要があります。環境変数で実行環境を判別するフラグを受け取り、if 文で分岐をします。
外部キー制約のチェックを外す
同期時、外部キー制約に引っかかってしまう場合があります。
MySQL ではGLOBAL、SESSION 共にFOREIGN_KEY_CHECKS変数を書き換えることで外部キー制約を外せるのですが、AWS の RDS では GLOBAL の変数を更新できないことが分かりました。なので、
before_loadを使って SESSION ごとにset FOREIGN_KEY_CHECKS=0にすることで外部キー制約のチェックを外すことができました。out: ... before_load: 'set FOREIGN_KEY_CHECKS=0;'s3 の同期
本番のデータを同期するのであれば、S3にある画像データも移行する必要があります。なので、Digdag のワークフローに s3 sync するタスクも追加します。
一度、Ruby で同期するスクリプトを書いたのですが大量の assets を同期するのは思ったより時間がかかることが分かったので、素直に awscli を使うことにしました。
# Dockerfile RUN apk --update --no-cache add python py-pip groff less mailcap curl jq && \ pip install --upgrade awscli==1.14.5 s3cmd==2.0.1 python-magic && \ apk -v --purge del py-pip && \ RUN if [ "$ENVIRONMENT" == "production" ]; \ then curl -qL -o aws_credentials.json 169.254.170.2$AWS_CONTAINER_CREDENTIALS_RELATIVE_URI && \ aws configure set aws_access_key_id `jq -r '.AccessKeyId' aws_credentials.json` && \ aws configure set aws_secret_access_key `jq -r '.SecretAccessKey' aws_credentials.json` && \ aws configure set aws_session_token `jq -r '.Token' aws_credentials.json`; \ fi# main.dig ... +s3_sync: if>: ${IS_MIDDLE} # 中間 VPC で実行する時のみ S3 sync する _do: sh>: aws s3 sync s3://xxx-assets-production s3://xxx-assets-stagings3 sync コマンドで指定する順番を間違えると、assets が吹き飛ぶので気をつけましょう。
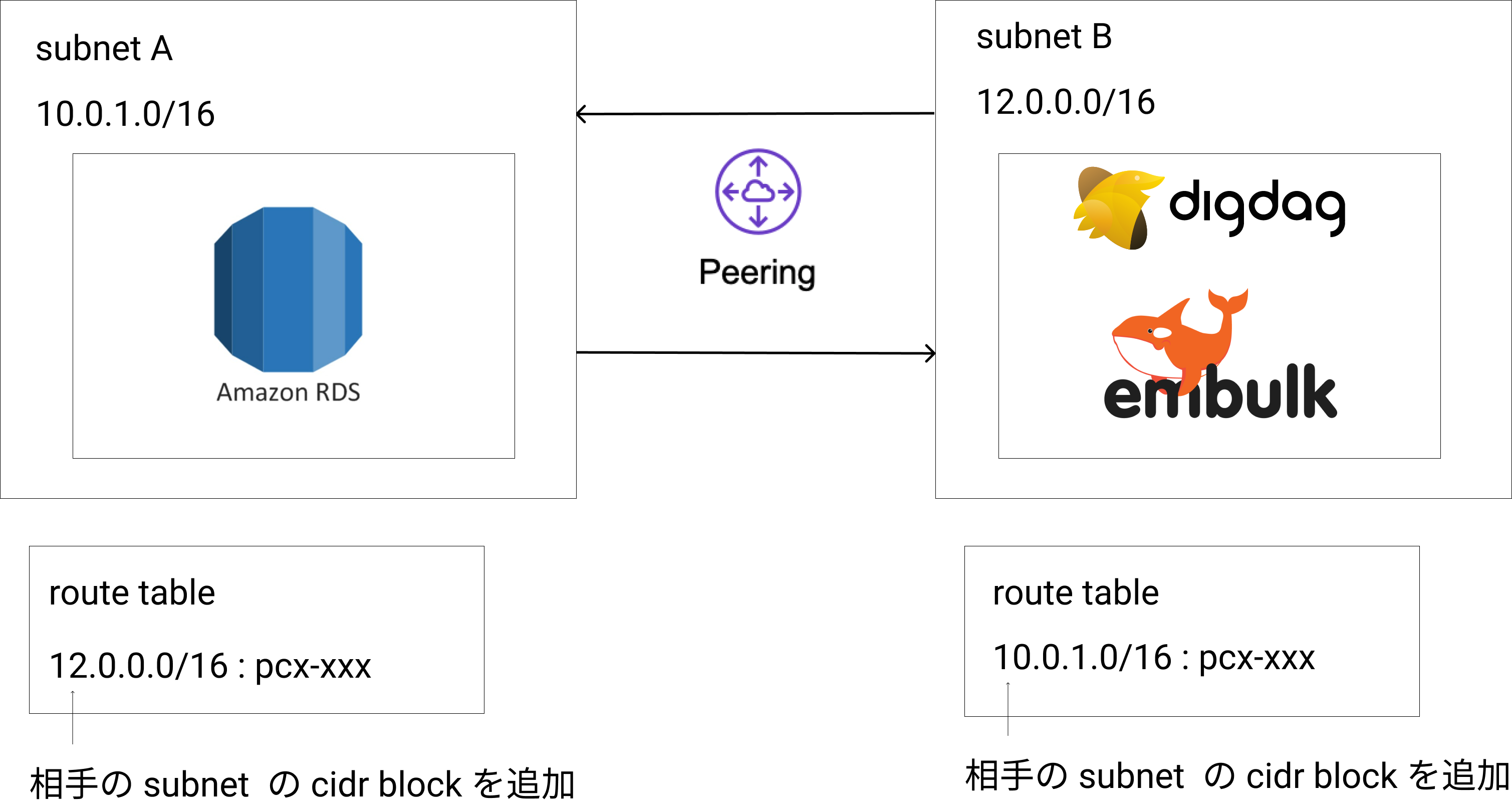
(余談) VPC Peering
タイトルにない VPC Peering についてです。
Peering する際は、通信したい相手の cidr block をサブネットのルートテーブルに追加するということを伝えたいです。
VPC Peering と聞くと VPC のルートテーブルに追加すれば繋がるのかなと思っていたのと、巷の参考記事にはどのルートテーブルのか明記していないことが多かったので少しだけ戸惑いました。
AWS の公式にはちゃんとサブネットに関連づけられたルートテーブルと書いてあります。
今後の課題
設定ファイルの自動生成
Embulk は同期のための設定ファイルを手動で作成する必要があります。
手間なので input のテーブル定義を読み取って設定ファイルを作成するスクリプトを書きます。検索エンジンの reindex をワークフローに組み込む
ElasticSearch や Algolia などを利用している場合、データを同期した後に reindex する必要があります。
なので digdag のワークフローに組み込みます。まとめ
Digdag と Embulk を使って Staging に Production のデータを同期することについて書きました。
同じことをする際は参考になれば幸いです。
- 投稿日:2020-06-28T10:41:56+09:00
Digdag + Embulk で production から staging へデータを同期する
Digdag と Embulk を使って Staging に Production のデータを同期した話です。
環境構築から同期が完了するまで、たくさんのエラーと格闘したので書き留めておきます。実行時の環境は以下になります。
Embulk v0.9.22 embulk-input-mysql 0.10.1 embulk-output-mysql 0.8.7 MySQL 5.7.21前回、 Digdag + Embulk + Fargateによるデータマスキング をしましたが、同じ Docker image を使って Staging 同期にも利用しています。
構成
管理を絶対にしたかったので Staging と Production は直接繋げず、中間の VPC を置いて中間とそれぞれがピアリングする構成にしました。
Staging には既にある程度のデータが入った状態です。
Tips
Deplicate Entry 回避
マスクしたデータを UNIQUE KEY が貼られているカラムにコピーする際、単純に embulk-filter-mask で値をマスクするだけでは Deplicate Entry エラーが発生します。 また、Staging 環境にはある程度データが入った状態なので、マスク対象でないカラムでも偶然に値が被ってしまうことがあるでしょう。
そのような場合は、 embulk-filter-ruby_proc がおすすめです。
filters: # before - type: mask columns: - { name: email, type: email } # *****@example.com とマスクされるが、UNIQUE 制約に引っかかる # after - type: ruby_proc columns: - name: email proc: | ->(email) do "#{SecureRandom.hex(15)}@example.com" # c131f413e3d239b937b595224ef6f2@example.com endproc でランダムに文字列を生成すれば、Duplicate Entry エラーを回避できます。
Staging 環境では実際にメールが送信されてしまうので、@example.comの部分は自社のドメインにすると良いでしょう。truncate_insert モードを使う
マスクしたデータに限らず Staging と Production のデータの差分から、一時的にどうしても重複してしまう場合がありました。例えば foreign_id に UNIQUE 制約が付いている場合、
# Staging id: 1, foreign_id: 1 id: 2, foreign_id: 2 # Production id: 1, foreign_id: 2 <- id 1 を元に foreign_id = 2 を merge したいが duplicate エラー id: 2, foreign_id: 3 # 期待する結果 id: 1, foreign_id: 2 id: 2, foreign_id: 3この際 merge モードを利用していましたが、truncate_insert モードを利用することで回避できました。
truncate_insert は既存のデータは削除して読み込んだデータに追記するモードです。(テーブルをドロップしない)ステータスをアップデートする
Staging では Production 同様にバッチが走っているのですが、オブジェクトの status が完了状態ではないと更新対象になってしまいエラーが発生しました。例えば、status が完了状態でないと外部の決済サービスにリクエストが飛びますが、当然 Production のデータは存在しないためエラーとなります。
after_loadを使えばクエリの実行後に指定の SQL を実行できます。
これにより、status が完了の状態でコピーすることができます。out: ... {% if env.IS_MIDDLE == 'true' %} after_load: "update table set status = [完了ステータス] where status = [未完了ステータス]" {% endif %}分析 DB を作成する際に同じ image を使っていることから、Staging 同期をする時だけ実行します。環境変数で実行環境を判別するフラグを受け取り、if 文で分岐をします。
外部キー制約のチェックを外す
同期時、外部キー制約に引っかかってしまう場合があります。
MySQL ではGLOBAL、SESSION 共にFOREIGN_KEY_CHECKS変数を書き換えることで外部キー制約を外せるのですが、AWS の RDS では GLOBAL の変数を更新できないことが分かりました。なので、
before_loadを使って SESSION ごとにset FOREIGN_KEY_CHECKS=0にすることで外部キー制約のチェックを外します。out: ... before_load: 'set FOREIGN_KEY_CHECKS=0;'s3 の同期
本番のデータを同期するのであれば、S3にある画像データも移行する必要があります。なので、Digdag のワークフローに s3 sync するタスクも追加します。
一度、Ruby で同期するスクリプトを書いたのですが大量の assets を同期するのは思ったより時間がかかることが分かったので、素直に awscli を使うことにしました。
# Dockerfile RUN apk --update --no-cache add python py-pip groff less mailcap curl jq && \ pip install --upgrade awscli==1.14.5 s3cmd==2.0.1 python-magic && \ apk -v --purge del py-pip && \ RUN if [ "$ENVIRONMENT" == "production" ]; \ then curl -qL -o aws_credentials.json 169.254.170.2$AWS_CONTAINER_CREDENTIALS_RELATIVE_URI && \ aws configure set aws_access_key_id `jq -r '.AccessKeyId' aws_credentials.json` && \ aws configure set aws_secret_access_key `jq -r '.SecretAccessKey' aws_credentials.json` && \ aws configure set aws_session_token `jq -r '.Token' aws_credentials.json`; \ fi# main.dig ... +s3_sync: if>: ${IS_MIDDLE} # 中間 VPC で実行する時のみ S3 sync する _do: sh>: aws s3 sync s3://xxx-assets-production s3://xxx-assets-stagings3 sync コマンドで指定する順番を間違えると、assets が吹き飛ぶので気をつけましょう。
(余談) VPC Peering
タイトルにない VPC Peering についてです。
Peering する際は、通信したい相手の cidr block をサブネットのルートテーブルに追加するということを伝えたいです。
VPC Peering と聞くと VPC のルートテーブルに追加すれば繋がるのかなと思っていたのと、巷の参考記事にはどのルートテーブルなのか明記していないことが多かったので少しだけ戸惑いました。
AWS の公式にはちゃんとサブネットに関連づけられたルートテーブルと書いてあります。
今後の課題
設定ファイルの自動生成
Embulk は同期のための設定ファイルを手動で作成する必要があります。
手間なので input のテーブル定義を読み取って、設定ファイルを自動生成するスクリプトを書きます。検索エンジンの reindex をワークフローに組み込む
ElasticSearch や Algolia などの検索エンジンを利用している場合、データを同期した後に reindex する必要があります。なので Digdag のワークフローに組み込む予定です。
まとめ
Digdag と Embulk を使って Staging に Production のデータを同期することについて書きました。
同じことをされる際に参考になれば幸いです。
- 投稿日:2020-06-28T09:44:40+09:00
(自分用)Flask_AWS_1(AWS仮想環境にPHP,MySQL,phpMyAdmin,Pythonのインストール)
項目
- PHPのインストール
- MySQLのインストール
- PHPMyAdminのインストール
- Pythonのインストール
1.PHPのインストール
ターミナル# まずLinux仮想マシンに接続、ここを覚えてないなら1つ前のやつを見て $ ssh -i ~/.ssh/FirstKey.pem ec2-user@(パブリックIP) # 管理者権限に変更 $$ sudo su # PHPをインストール $$ yum install -y php # PHPの設定を変える前にバックアップを取っておく $$ cp /etc/php.ini /etc/php.bak # viでPHPの設定変更 $$ vi /etc/php.ini
:set numberで行番号を表示:520で520行目に移動iにて記述モードにし、error_reporting = E_ALL & ~E_DEPRECATEDという行を、error_reporting = E_ALL & ~E_DEPRECATED & ~E_NOTICEに変更するescでコマンドモードに戻る:537で537行目へiからのdisplay_errors = OffをOnに変更、esc:wqで保存終了ターミナル# Apacheを再起動し適用 $$ service httpd restart # [OK]*2出たら多分大丈夫2.MySQLのインストール
- 前回に引き続き管理者権限でログインしてる前提
ターミナル# MySQLのインストール $$ yum install -y mysql-server # MySQLをPHPがいい感じに動かせるものを入れる $$ yum install -y php-mysqlnd # Pythonでいい感じにね $$ yum install mysql-connector-python # MySQLを起動 $$ service mysqld start # MySQLの設定をあれこれ $$ mysql_secure_installation # 一発目のrootパスワード聞いてくるところはそのままEnter # rootパスワード新しくするか聞かれるので、yes # 好きなパスワードを入力 # anonymousユーザ消すか聞いてくるのでyes # あとは全部yでも良さげ # MySQLでの文字コードを設定 $$ vi /etc/my.cnf # `:set number`で行数を表示し空白の10行目に $$ character-set-server = utf8 # と入力する、繰り返すが`i`で入力モードにし、入力後`esc`でコマンドモード # `:wq`で保存終了 # MySQLを再起動 $$ service mysqld restart #[OK]と出れば`OK`3.PHPMyAdminのインストール
- 前回に続き仮想環境の管理者権限内を前提
ターミナル# phpMyAdminのインストール先を作成 $$ yum-config-manager --enable epel # phpMyAdminをインストール $$ yum install -y phpmyadmin # phpMyAdminの設定を開く $$ vi /etc/httpd/conf.d/phpMyAdmin.conf # ここで127.0.0.1って書いてあるところをグローバルIPに変更すると、自分のローカルなマシンだけが接続変更出来る様になる # やらなくていいと思う # もし変えたい場合は、`:%s/127.0.0.1/自分のグローバルIP/g`で変更 # Apacheの再起動 $$ service httpd restart
http://前に設定したAWSのパブリックIP/phpmyadmin/に接続すると、phpMyAdminのページが出てくる- ユーザ名は
root、パスワードはMySQLインストールで設定したやつを入れる4.Pythonのインストール
- 前に続き仮想環境内(管理者権限ではない)
ターミナル# 一回Linux環境アップデート $$ sudo yum -y update # Pythonインストール $$ sudo yum install python36-devel python36-libs python36-setuptools # もうMySQLをPythonでいい感じにするやつはインストール済み # Apacheを再起動 $$ service httpd restart5.終わりに
- 環境構築がいっっっちばんつまらない最悪
- 投稿日:2020-06-28T00:51:10+09:00
express mysql docker-compose Error: connect ECONNREFUSED
const express = require('express') const app = express() var mysql = require('mysql'); var connection = mysql.createConnection({ host : 'mysql', // localhostは間違い, 0.0.0.0は間違い port : 3306, user : 'root', password : 'password', database : 'testdb' });対象
docker-composeでnodejs(express), mysqlを立ち上げて接続しようとしてエラーが出た人。
自分の場合、hostを修正した場合に成功しました。
user, password, databaseは各自確認してください。
- 投稿日:2020-06-28T00:18:47+09:00
MySQLをインストール、使用する時に困った事(自分用の備忘録)
$brew install mysqlで最新版をインストールし
$mysql.server start
$mysql -uroot
で起動せずエラーが発生
Error: Can't connect to local MySQL server through socket '/tmp/mysql.sock' (38)$mysql --version
でバージョンが見つからない
パスは以前に通してるはずなのにな、と
$ open -e ~/.bash_profileでパスを確認すると
~.bash_profile~
export PATH=$PATH:/usr/local/mysql@5.7/bin前回はmysql5.7で実装してて今インストールしたのは@8.0.19だからそりゃパス通らない訳だ。
@5.7だけ消して保存、
$source ~/.bash_profile
このコマンドで編集内容を反映させる。確か結構前も同じような事ですごく時間割いてしまったので同じ事が起きた時のために残しておきます。
他、mysql関連のファイルも一度全て消してから
再度インストールしなおして
$mysql.server start
$mysql -uroot
で接続出来た。