- 投稿日:2020-06-28T22:10:30+09:00
Spring Cloud FunctionでAmazon API Gatewayのプロキシ統合なLambda関数をサクッと書いてみる
はじめに
Lambda関数をJavaで実装するのは面倒くさい。
Spring Cloud Functionというのを使うと、その辺の煩雑さを良い感じにフレームワークが吸収してくれるらしい。
ということで、本当に良い感じに吸収されてサクッと書けるのかを試してみた。ちなみに、Spring Cloud Functionはプロキシ統合していないサンプルは多くあれど、統合版はなかなか見つからなかったので、その検討の一助にもなれば。
構成
以下のようなMavenプロジェクトを作成する。
SpringCloudFunctionTest ├── pom.xml ├── serverless.yml └── src ├── main │ ├── java │ │ └── com │ │ └── springcloudfunctiontest │ │ ├── AWSLambdaHandler.java │ │ ├── Hello.java │ │ └── SpringCloudFunctionExampleApplication.java │ └── resources │ └── application.properties └── test └── java └── com └── springcloudfunctiontest └── SpringCloudFunctionExampleApplicationTests.javapom.xmlは↓こんな感じにしておく。
pom.xml<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.1.6.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.techprimers.serverless</groupId> <artifactId>spring-cloud-function-test</artifactId> <version>0.0.1-SNAPSHOT</version> <name>spring-cloud-function-test</name> <description>Demo project for Spring Boot with Spring Cloud Function</description> <properties> <java.version>1.8</java.version> <spring-cloud.version>Greenwich.SR2</spring-cloud.version> </properties> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-function-adapter-aws</artifactId> </dependency> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-lambda-java-events</artifactId> <version>2.0.2</version> </dependency> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-lambda-java-core</artifactId> <version>1.1.0</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>Greenwich.SR2</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <dependencies> <dependency> <groupId>org.springframework.boot.experimental</groupId> <artifactId>spring-boot-thin-layout</artifactId> <version>1.0.10.RELEASE</version> </dependency> </dependencies> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <configuration> <createDependencyReducedPom>false</createDependencyReducedPom> <shadedArtifactAttached>true</shadedArtifactAttached> <shadedClassifierName>aws</shadedClassifierName> </configuration> </plugin> </plugins> </build> </project>ハンドラのコード
通常のSpring Bootなアプリ同様、
SpringApplication.runするクラスを作る。SpringCloudFunctionExampleApplication.javapackage com.springcloudfunctiontest; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class SpringCloudFunctionExampleApplication { public static void main(String[] args) { SpringApplication.run(SpringCloudFunctionExampleApplication.class, args); } }で、Lambdaのイベントハンドラを作る。
正直、このクラスが空っぽで良い理由がよく分からない……。
API Gatewayのバックエンドに置くので、InputとOutputにはそれぞれAPIGatewayProxyRequestEventとAPIGatewayProxyResponseEventを設定する。AWSLambdaHandler.javapackage com.springcloudfunctiontest; import com.amazonaws.services.lambda.runtime.events.APIGatewayProxyRequestEvent; import com.amazonaws.services.lambda.runtime.events.APIGatewayProxyResponseEvent; import org.springframework.cloud.function.adapter.aws.SpringBootRequestHandler; public class AWSLambdaHandler extends SpringBootRequestHandler<APIGatewayProxyRequestEvent, APIGatewayProxyResponseEvent> { }最後に、ビジネスロジックのクラスを作成する。
APIGatewayProxyRequestEventとAPIGatewayProxyResponseEvent`の仕様はjavadocを確認しよう。しかし、Spring Cloud Functionはマルチクラウドでの互換性がウリなのに、こんなインタフェースにしたら完全にAWS特化な実装になっちゃうよなぁ……。
最後のsetBodyのJSONの扱いが雑なのは気にしないように。
Hello.javapackage com.springcloudfunctiontest; import com.amazonaws.services.lambda.runtime.events.APIGatewayProxyRequestEvent; import com.amazonaws.services.lambda.runtime.events.APIGatewayProxyResponseEvent; import org.springframework.stereotype.Component; import java.util.function.Function; import java.util.Map; @Component public class Hello implements Function<APIGatewayProxyRequestEvent, APIGatewayProxyResponseEvent> { @Override public APIGatewayProxyResponseEvent apply(APIGatewayProxyRequestEvent input) { Map<String, String> queryStringParameter = input.getQueryStringParameters(); String id = queryStringParameter.get("id"); String name = null; if( id.equals("11111") ) { name = "\"Taro\""; } else { name = "\"Nanashi\""; } APIGatewayProxyResponseEvent responseEvent = new APIGatewayProxyResponseEvent(); responseEvent.setStatusCode(200); responseEvent.setBody("{\"name\":" + name + "}"); return responseEvent; } }テストコード
テストコードも普通に書ける。
SpringCloudFunctionExampleApplicationTests.javapackage com.springcloudfunctiontest; import java.util.HashMap; import java.util.Map; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; import static org.assertj.core.api.Assertions.assertThat; import com.amazonaws.services.lambda.runtime.events.APIGatewayProxyRequestEvent; import com.amazonaws.services.lambda.runtime.events.APIGatewayProxyResponseEvent; @RunWith(SpringRunner.class) @SpringBootTest public class SpringCloudFunctionExampleApplicationTests { @Test public void HelloTest1() { Hello hello = new Hello(); APIGatewayProxyRequestEvent request = new APIGatewayProxyRequestEvent(); Map<String,String> queryStringParameter = new HashMap<>(); queryStringParameter.put("id", "11111"); request.setQueryStringParameters(queryStringParameter); APIGatewayProxyResponseEvent response = hello.apply(request); assertThat(response.getBody()).isEqualTo("{\"name\":\"Taro\"}"); } @Test public void HelloTest2() { Hello hello = new Hello(); APIGatewayProxyRequestEvent request = new APIGatewayProxyRequestEvent(); Map<String,String> queryStringParameter = new HashMap<>(); queryStringParameter.put("id", "22222"); request.setQueryStringParameters(queryStringParameter); APIGatewayProxyResponseEvent response = hello.apply(request); assertThat(response.getBody()).isEqualTo("{\"name\":\"Nanashi\"}"); } }デプロイ
手でいちいちS3にアップロードしたり、パイプラインのビルド待ちしたりするのも面倒臭いので、正式版のアプリでないからServerless Frameworkでテキトーにデプロイしよう。
serverless.ymlservice: test provider: name: aws runtime: java8 timeout: 30 region: ap-northeast-1 package: artifact: target/spring-cloud-function-test-0.0.1-SNAPSHOT-aws.jar functions: hello: handler: org.springframework.cloud.function.adapter.aws.SpringBootStreamHandler events: - http: path: testapi method: get integration: lambda-proxy request: template: application/json: '$input.json("$")'これでデプロイすると、こんな感じでちゃんとRESTAPIが返されるぞ!
$ curl -X GET https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/dev/testapi?id=11111; echo {"name":"Taro"}結論
うーん、Springフレームワークの恩恵を全然預かっていないので、普通のLambdaのイベントハンドラを作った時と手間としては変わらなかった気分。もっとフレームワークの機能をふんだんに使うようになったらありがたみがわかるのだろうか。
今回は、JavaでLambda関数を書くならやっぱりAPIGatewayProxyRequestEventを使うと実装が楽だね、ということと、Serverless Frameworkのデプロイがお手軽だね、と言うことは理解できた。
- 投稿日:2020-06-28T20:58:45+09:00
Amazon Honeycode でノーコードを始めてみた
はじめに
6 月 24 日に発表されたばかりの AWS 謹製のノーコードツール「Amazon Honeycode」に触ってみました。Honeycode アプリケーションを動かすまでの流れをまとめています。一歩踏み込んだ検証はまだ行っていませんので、表面的な内容にとどまっていますが、まずはイメージを掴むことを優先しました。
はじめての Amazon Honeycode
Honeycode にサインアップする
投稿時点では、Oregon リージョンのみサービス提供されています。AWS 管理コンソールにログインし、Oregon リージョンに切り替えて、[Sign up for Honeycode] を選択します。
Honeycode アカウントを作成する
必要な情報を入力し、[Create account] を選択します。
メールアドレスを確認する
確認メールが届きますので、[Confirm now] を選択します。わたしの場合、迷惑メールに振り分けられていました。受信トレイに届かないと思ったら、迷惑メールフォルダを確認してみてください。
- 差出人:Honeycode <no-reply@honeycode.aws>
- メールタイトル:Confirm your email address
Honeycode にサインインする
メールアドレスとパスワードを入力し、[Sign in] を選択します。
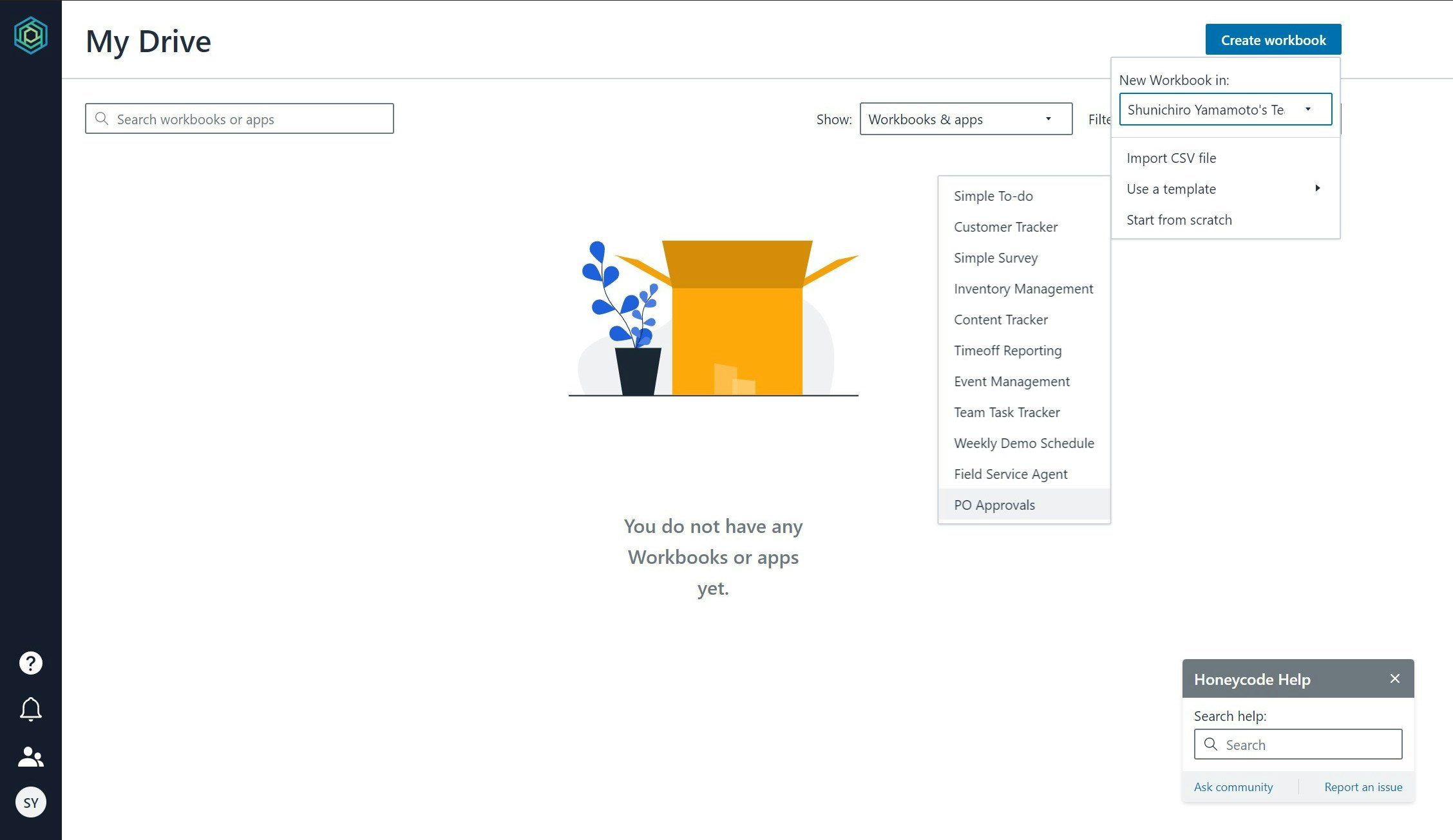
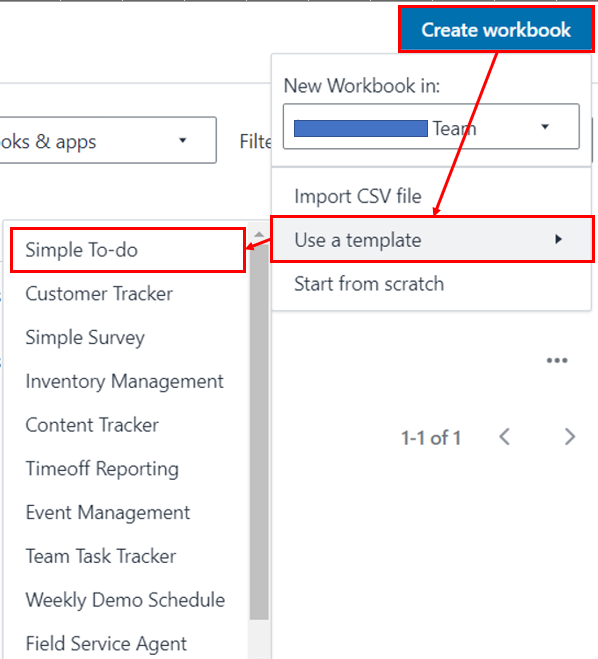
workbook を作成する
[Create workbook] を選択し、workbook を作成します。業務利用を想定し、[Use a template] メニューから [PO Approvals] を選択してみました。
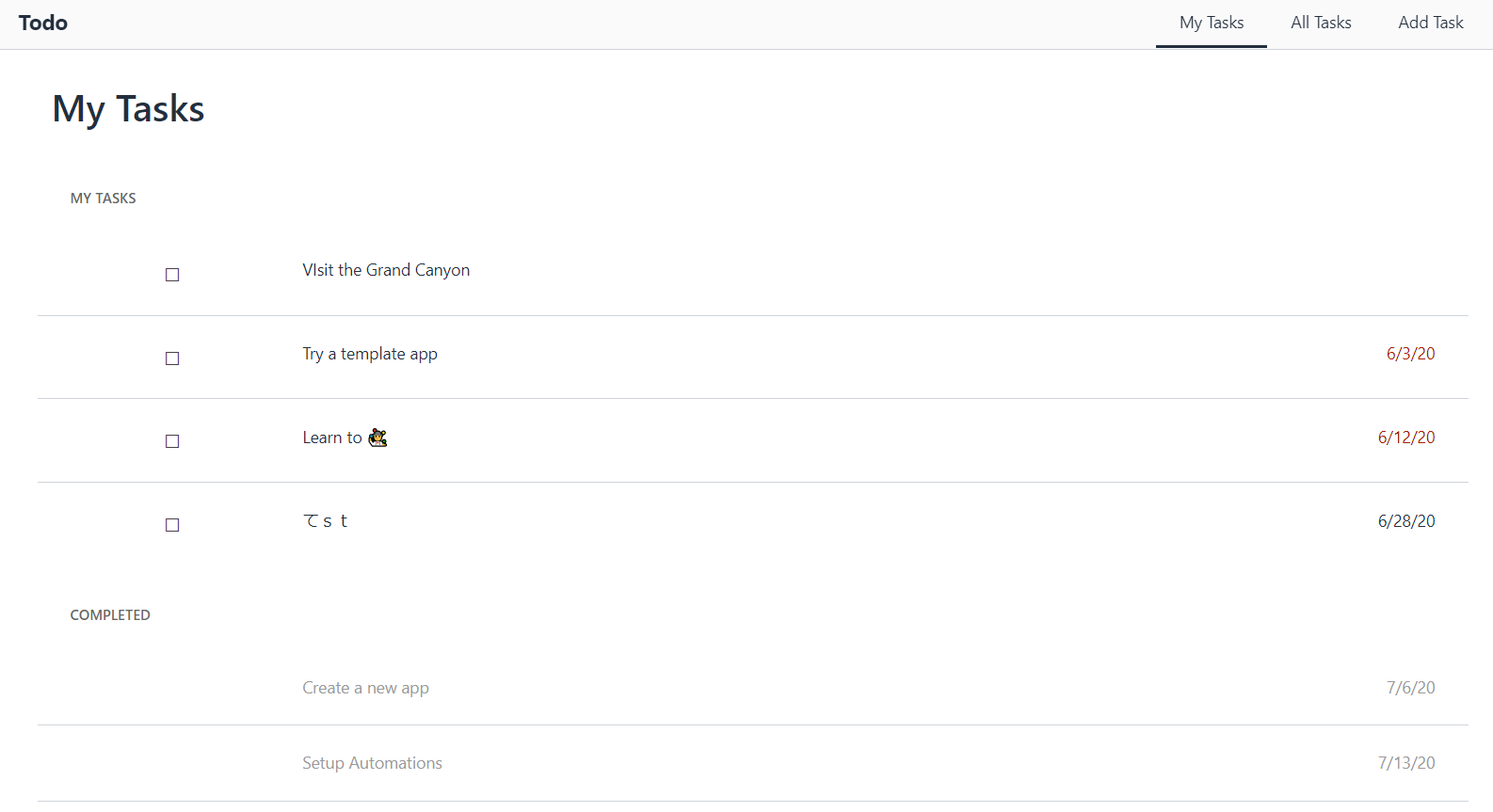
購買発注承認アプリ:テーブル編
最初は、Tables ビューです。購買発注トランザクション、承認者マスタ、プロジェクトマスタなど、6 つのテーブルから構成されています。一般的なスプレッドシートの間隔で、マスタデータをメンテナンスできます。試しに、1 レコード追加してみました。
購買発注承認アプリ:アプリ編
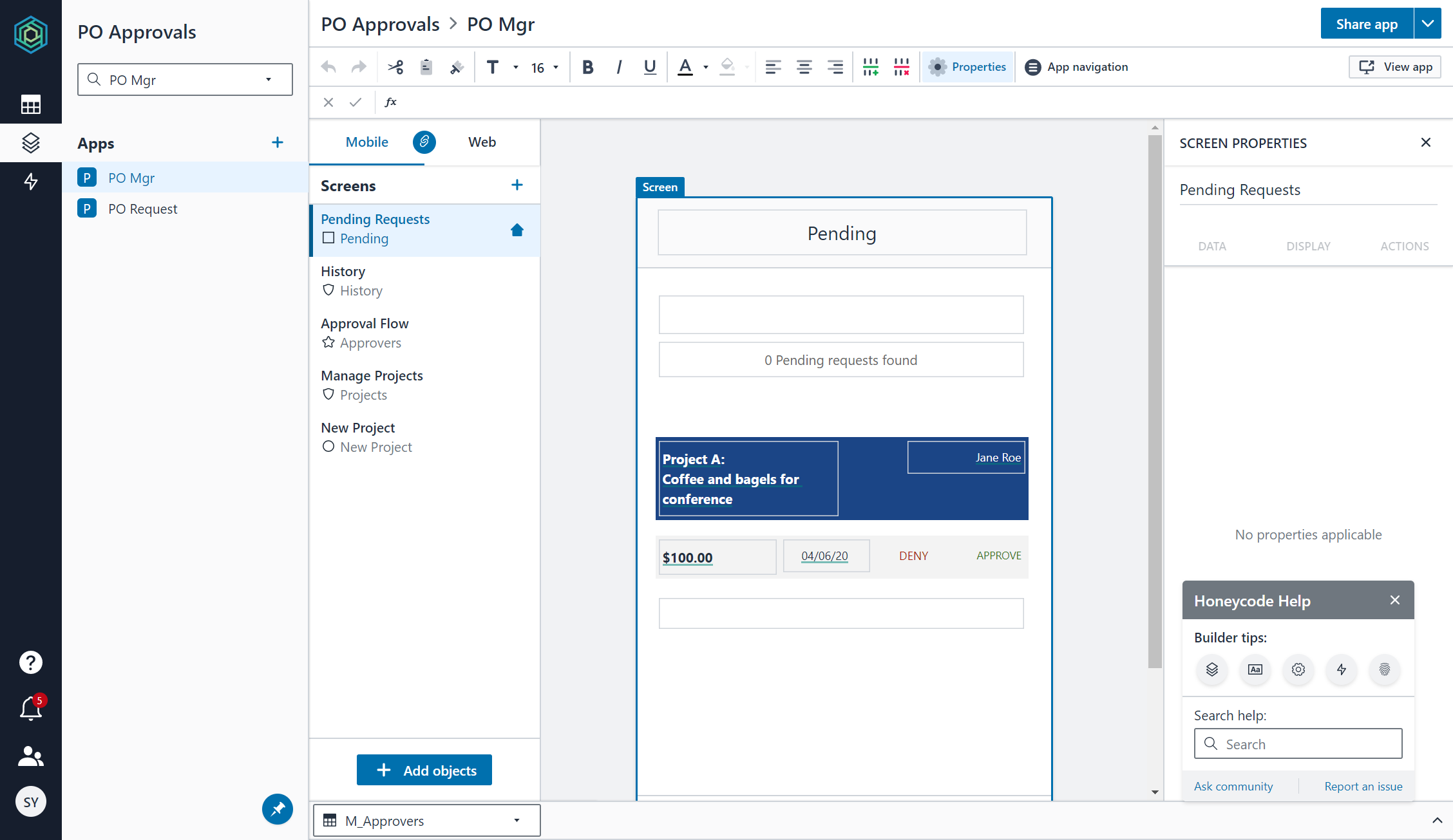
Apps ビューに切り替えます。承認者用の "PO Mgr" アプリと、申請者用の "PO Request" アプリの 2 アプリから構成されています。アプリ名から何となく想像がつきますね。
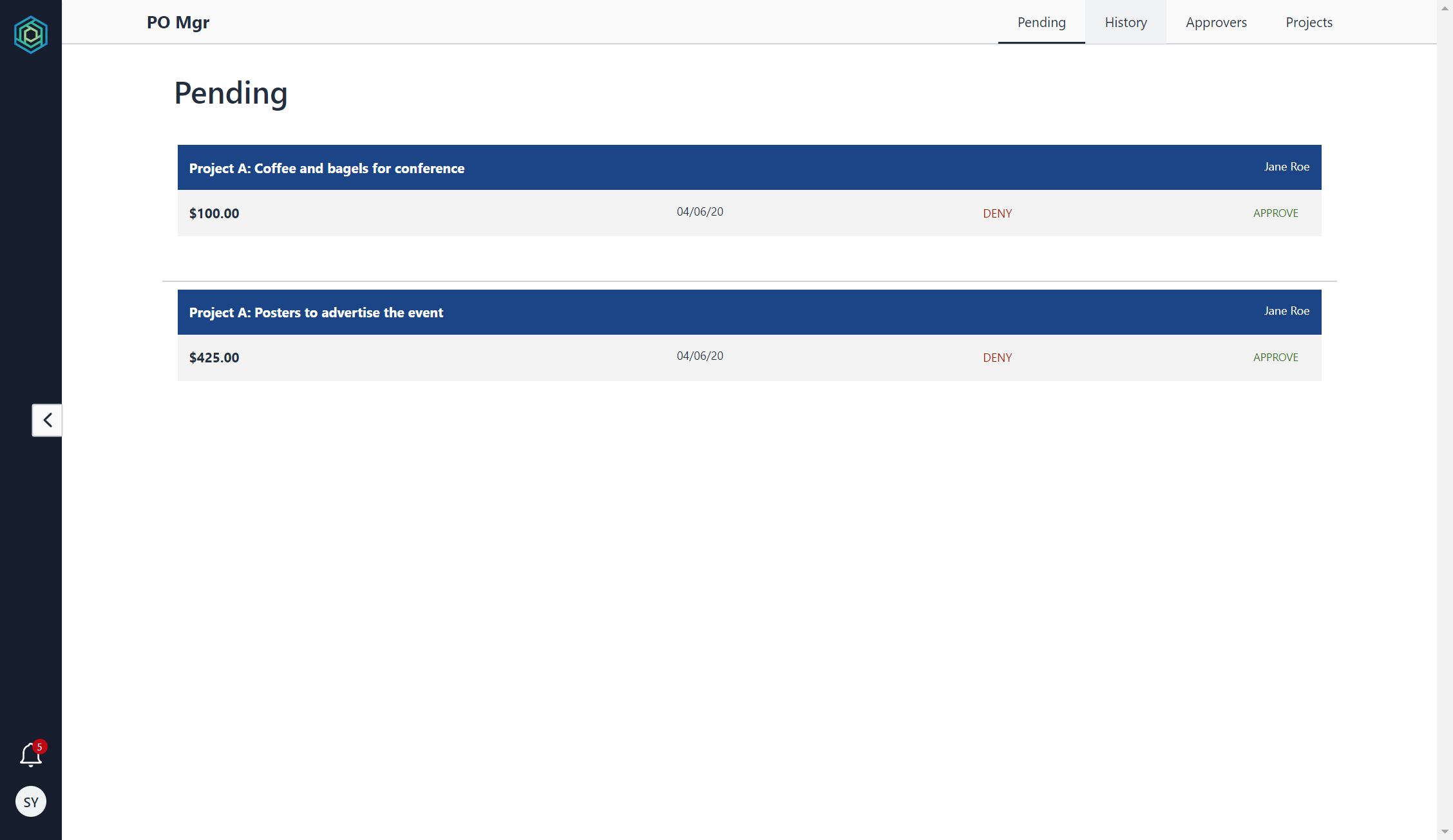
右上の [View app] を選択すると、別タブでアプリが開きます。承認待ち(Pending)、承認履歴(History)、承認者一覧(Approvers)、プロジェクト一覧 (Projects)タブでページを切り替えることが可能です。試しに、数件承認してみましたが、問題なく動作しました。
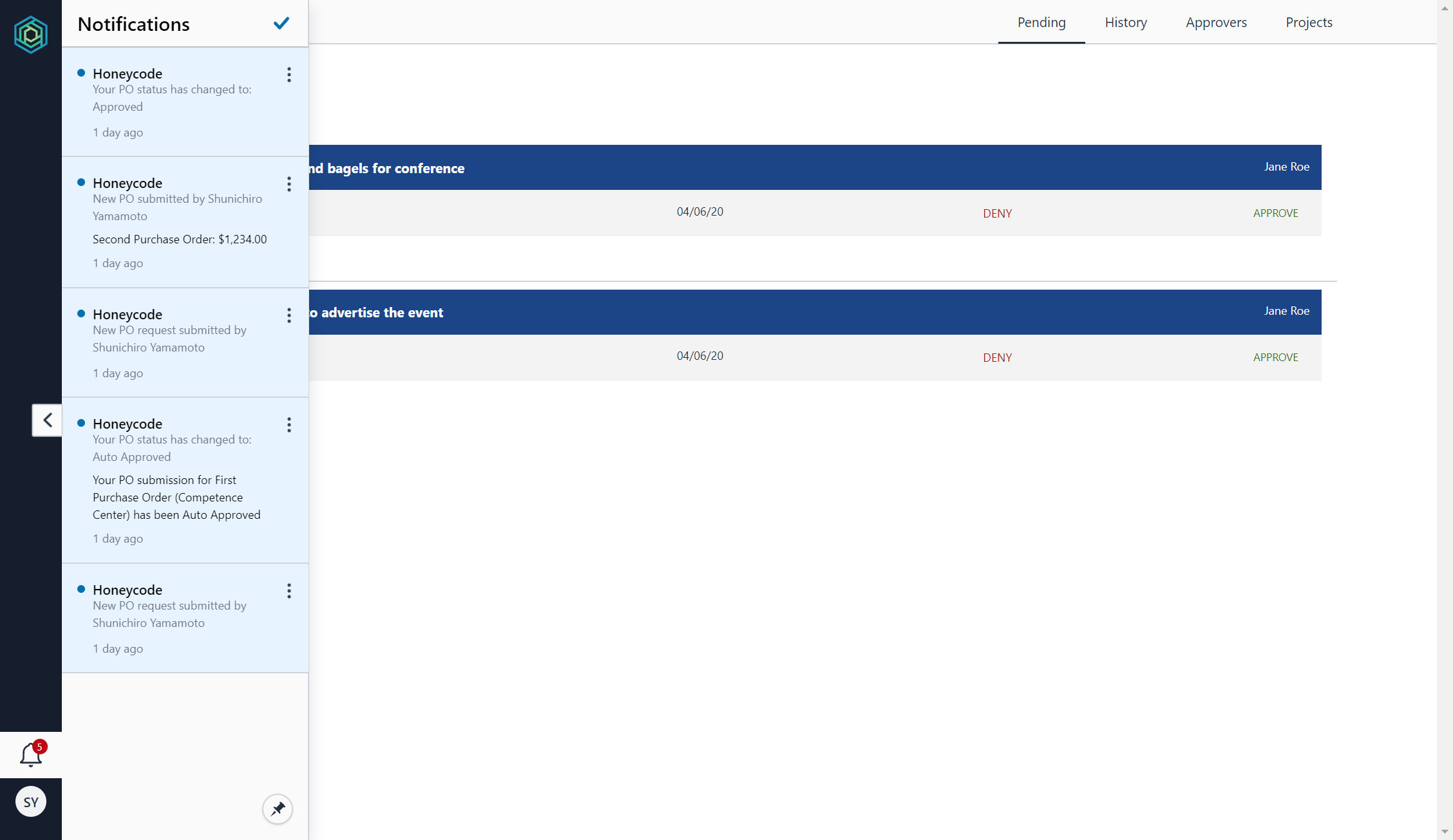
通知アイコンに件数がバッジ表示されています。クリックしてみると、申請された、自動承認された、承認されたなど、各種ステータス変更が通知されていました。なお、画面上での通知だけでなく、メールでも通知されています(差出人メールアドレスは、notifications@honeycode.aws)。このあたりが抜かりないなと思いました。
さいごに
取り急ぎ、リリースされたばかりの Amazon Honeycode に触れてみました。テンプレートアプリのカスタマイズまでは行っていませんが、ノーコードのお手軽さは、十分に伝わってきました。表形式のマスタデータおよびトランザクションデータと、データと I/O するための画面を可能な限り簡単に作成するという目的に特化することで、アプリケーション開発の民主化を強力に推進しようとしている、という印象です。
Microsoft SharePoint でリストをデータストアとして、簡易的なワークフローなどを作成するイメージに近いですが、一般的な企業ユースでは Office 365 に軍配が上がるかも知れませんね。Excel や Outlook に代表されるユーザとの距離感の近さが圧倒的な強みだと思います。
ですが、個人的には参考リンク先にある「コードに逃げ込む」派なので、ノーコードの世界は自分のいる世界ではない、というのが結論です。「簡単なものが簡単に作れる」のはいいことですが、「複雑なものは簡単には作れない」ことには変わりないので、"技術的卓越性" を磨いていきたいと思います。
参考リンク
https://us-west-2.console.aws.amazon.com/honeycode/home?region=us-west-2#/landing
https://jp.techcrunch.com/2020/06/25/2020-06-24-why-aws-built-a-no-code-tool/




- 投稿日:2020-06-28T18:13:31+09:00
AWS メモ1
クラウドとは
AWSのようなクラウドサービスプラットフォームからインターネット経由で仮想サーバーなど、ITリソースをオンデマンド(利用したい時に、利用した分だけ従量課金)で利用できるサービスの総称である。
オンプレミスとは
サーバー、ネットワーク、ソフトウェアなどの設備を自分たちで導入・運用すること。こちらが、クラウドサービスが主流になるまでは従来の方法であった。
AWSとは
Amazon社内のビジネス課題を解決するために生まれたサービスである。webサービスという形態で、ITインフラストラクチャーサービスの提供をしている。
AWSのメリット
1.設備投資費(固定費)が柔軟な変動費になる
2.スケールによる大きなコストメリット
3.キャパシティ予測が不要
4.速度と俊敏性の向上
5.データセンターの運用と保守への投資が不要に
6.わずか数分で世界中にデプロイ*デプロイとは→開発したソフトウェアを実際の運用環境に配置・展開して実用に供することを指す場合が多い。
- 投稿日:2020-06-28T18:06:31+09:00
AWS日記13 (Textract)
はじめに
今回は Amazon Textractを利用してテキスト抽出機能試します。
今回作成したAmazon Textract のテキスト抽出機能を試すページ
準備
[Amazon Textractの資料]
Amazon Textract※ 2020年6月時点で、Textractは 「アジアパシフィック (東京)」 リージョンで利用できないため 「米国西部 (オレゴン)」 リージョンで試しました。
WEBページ・API作成
GO言語のAWS Lambda関数ハンドラー aws-lambda-go を使用してHTMLやJSONを返す処理を作成します。
また、Textract を使用するため aws-sdk-go を利用します。[参考資料]
AWS SDK for Go API Reference
Amazon Textractを試してみた
Amazon Textract(OCR)についてまとめてみたテキストを抽出するには AnalyzeDocument を使う。
main.gofunc analyzeDocument(img string)(string, error) { b64data := img[strings.IndexByte(img, ',')+1:] data, err := base64.StdEncoding.DecodeString(b64data) if err != nil { log.Print(err) return "", err } svc := textract.New(session.New(), &aws.Config{ Region: aws.String("us-west-2"), }) input := &textract.AnalyzeDocumentInput{ Document: &textract.Document{ Bytes: data, }, FeatureTypes: []*string{aws.String("TABLES")}, } res, err2 := svc.AnalyzeDocument(input) if err2 != nil { return "", err2 } if len(res.Blocks) < 1 { return "No Document", nil } var wordList []string for _, v := range res.Blocks { if aws.StringValue(v.BlockType) == "WORD" || aws.StringValue(v.BlockType) == "LINE" { wordList = append(wordList, aws.StringValue(v.Text)) } } results, err3 := json.Marshal(wordList) if err3 != nil { return "", err3 } return string(results), nil }終わりに
今回はAmazon Textractを試しました。
- 投稿日:2020-06-28T17:55:42+09:00
AWS まとめ
AWS
Amazon Web Servicesの略で、Amazonが提供している100以上のクラウドコンピューティングサービスの総称
クラウドサービスとして世界最大規模クラウドコンピューティング
インターネットを介してサーバー・ストレージ・データベース・ソフトウェアといったコンピューターを使った様々なサービスを利用すること
クラウドコンピューティングでは、手元に1台のPCとインターネットに接続できる環境さえあれば、サーバーや大容量のストレージ、高速なデータベースなどを必要な分だけ利用可能サーバー
ホームページを表示するために必要となる情報を格納しておく場所
ストレージ
パソコンのデータを長期間保管しておくための補助記憶装置
データベース
データを1つの場所に集約し、保管・管理だけでなく、参照したいデータを簡単に抽出できるようにする「箱」のようなシステム
ソフトウェア
コンピューターを動かすプログラムとそのプログラムが処理するデータ。
AWSのメリット
【コスト面】
ハードウェア・ソフトウェアの購入費用が不要。
従量制の課金となるため、定額制と比べて無駄なコストが発生しにくい(変動費)。【拡張性】
スペック(CPU・メモリ・ストレージ容量などの拡張)が簡単かつスピーディーに行える。【管理者負担】
ハードウェアの管理やソフトウェアのアップデートといった管理者の負担がかからない。【セキュリティ面面】
常に最新のセキュリティが施され、さまざまな第三者機関認証を取得したセキュアな環境を利用できる。
サービス側で最新化の処理を行ってくれるため、管理者の手間がない。【スピード】
ハードウェアの購入などが不要なため、必要な環境をすぐに利用できる。
スペックの変更にも時間がかからない。【スペース】
サーバーを設置する物理的なスペースを用意する必要がない。AWSのデメリット
【コスト】
従量制の課金となるため、使い方によっては定額制のサービスと比べ高額になりやすい。
毎月の費用が読みにくく予算化しづらい。【ノウハウ】
サービスが100種類以上あり、利用のために相応のノウハウが必要。
AWSではサーバーなどの環境は用意してくれるが、その先の管理はユーザーが行うことが必要であるため、問題が発生した際のトラブルシュートなどの技術も必要。
- 投稿日:2020-06-28T17:16:45+09:00
令和の Lambda x RDS
はじめに
Lambda x RDSは令和になってから重大ニュースがいくつかあった影響もあり、
VPC Lambdaは遅い、同時接続数がつらい、だからアンチパターンかと思いきや、
VCP Lambdaそんなに悪くない、Proxy使えばいい、とも言われてて
相反する情報が多く混乱してしまったので、平成と令和での状況変化を各記事を参考にまとめる【平成】 以下5つの点でLambdaとRDSは相性が良くないと言われていた
1. VPC Lambdaでの実行時に、起動コストが高い問題 初回起動時はコールドスタートでENIの作成とアタッチなどに10~20秒ほどかかる 対応方法 定期的にlambdaをkickする 2. VPC Lambdaでの実行時に、サブネットのIPを浪費する問題 アタッチされたENIの数だけサブネット内のIPを消費してしまう サブネットのIPリミットやアカウントのENI作成リミット、APIレートを使い切るリスクがある また、LambdaのスケーリングがENIのリミットに依存する 対応方法 lambda用に別で大きめのサブネットを切る 3. VPC Lambdaでの実行時に、インターネットアクセスするにNat Gatewayが必要な問題 1時間あたり$0.062 1GBあたり$0.062 何もしなくても $44.64/月 かかってしまう 高い。。。 4. VPC外での実行時はRDSにPublicAccessを許可する必要がある問題 VPC内がだめなら、外が良いのかというとそうでもない RDSのポート公開はビジネスではセキュリティリスクになるので取れない方法になる 個人用途ならぎりあり 対応方法 lambdaのIPレンジのみからPublicAccessを許可する https://dev.classmethod.jp/articles/limiting-access-to-just-aws-ip-ranges/ 5. 最大接続数の問題 lambdaは同時実行数を制御することが難しく、東京リージョンだと最大1000まで増やせる性能がある 一方mysqlはコネクション数が多いとその分スペックを要求され、ピークに合わせるとコスパが悪くなる 同時接続数の制御としては、コネクションプールが使われることが多い しかし、lambdaではコンテナ間でデータ共有する仕組みがないため、コネクションプールの実装が難しい なので、スケールアップで対応するしかなく、ピークに合わせてチューニングするとコスパが悪い そのため、LambdaはDynamoDBとの組み合わせが推奨されている 対応方法 これを許容できる規模のサービスで使う 自身でコネクションプールするサービスを作る 参考 なぜAWS LambdaとRDBMSの相性が悪いかを簡単に説明する https://www.keisuke69.net/entry/2017/06/21/121501 AWS LambdaをVPC内に配置する際の注意点 https://devlog.arksystems.co.jp/2018/04/04/4807/ Lambda x RDSはアンチパターンやでって話1 https://qiita.com/teradonburi/items/86400ea82a65699672ad Lambda x RDSはアンチパターンやでって話2 https://www.keisuke69.net/entry/2017/06/21/121501 VPC Lambdaそんなに悪くないでって話 https://dev.classmethod.jp/articles/serverless-meetup-osaka-5-vpclambda-demerit/【令和】 問題の致命的な部分がほぼ改善された
1. 「VPC内での実行時に起動コストが高い問題」の解決 2019年9月頃にコールドスタートの起動速度が改善された Lambda関数が作成された時に「Hyperplane ENI」がマッピングされるようになった そのおかげでENIの作成/アタッチのコストが削減されたみたい ただし、アクセス数が増加すると追加のENIが作成されて、その瞬間は「2~6秒」ほどレイテンシが発生するらしい 追加のENIは使われないと削除されるらしい 完全には改善できていないが、大分マシになったという印象 2. 「VPC内での実行時にサブネットのIPを浪費する問題」の解決 「Hyperplane ENI」によってENIを使い回すので浪費がなくなった ENIの作成リミット依存もなくなった 3. 「VPC Lambdaでの実行時に、インターネットアクセスするにNat Gatewayが必要な問題」 動きなし、引き続き課金が必要 4. 「VPC外での実行時はRDSにPublicAccessを許可する必要がある問題」 動きなし、引き続きRDSをPublicAccess許可にしないといけない ただ、これはIP制限でなんとかなる気がする VPC Lambdaが改善されたので、必要性は薄れたかも 5. 「最大接続数の問題」の解決 2019年12月「RDS Proxy(プレビュー版)」リリース コネクションプーリングやフェイルオーバーを担ってくれるProxyがリリースされた これを使えばピークカットできるので、問題は解決できそう ただし、「RDS Proxy」を使うと追加料金がかかる 基となるデータベースインスタンスの vCPU あたりの料金: 0.018USD/時間 db.r5.large(Aurora)を使用している場合、 db.r5.large 使用料: $252 ($0.35 x 24時間 x 30日) プロキシ使用量: $25.92 ($0.018 x 2vCPU x 24時間 x 30日) 現時点でまだプレビュー版なので本番投入可能な状態はまだ先になりそう いくつかの検証ブログを見るにまだコントロールしづらそうな感じはする 参考 【公式】 Amazon RDS プロキシのご紹介 (プレビュー) https://aws.amazon.com/jp/about-aws/whats-new/2019/12/amazon-rds-proxy-available-in-preview/ 【公式】 PostgreSQL 互換の Amazon RDS Proxy (プレビュー) https://aws.amazon.com/jp/about-aws/whats-new/2020/04/amazon-rds-proxy-with-postgresql-compatibility-preview/ 【公式】Amazon RDS プロキシの料金 https://aws.amazon.com/jp/rds/proxy/pricing/ 【公式】 Announcing improved VPC networking for AWS Lambda functions https://aws.amazon.com/jp/blogs/compute/announcing-improved-vpc-networking-for-aws-lambda-functions/ 【公式】AWS LambdaでAmazon RDS Proxyを使用する https://aws.amazon.com/jp/blogs/news/using-amazon-rds-proxy-with-aws-lambda/ VPC アーキテクチャ変更のまとめ https://dev.classmethod.jp/articles/announced-vpclambda-improved/ RDS Proxy パフォーマンス検証1 https://tech.fusic.co.jp/posts/2019-12-11-aws-lambda-with-rds-proxy-performance-1/ RDS Proxy パフォーマンス検証2 https://blog.mmmcorp.co.jp/blog/2020/04/03/lambda-rds-proxy/Tips: 「Hyperplane ENI」とは
「Hyperplane」というのが、2017年のre:Inventで紹介されていたAWS内部で使われているネットワーク関連技術 もともとは内部的なS3 Load Balancerとして開発されたらしい これらの問題を解決するソリューション トラブル解決が困難 キャパシティ管理が困難 コストが増大 ネットワークロードバランサーやNATゲートウェイなどに使われている そのHyperplaneを使って、ENIをNATできるようにして、VPCの問題を解決したらしい 参考 [レポート] AWS を支えるネットワークインフラと要素技術 #AWSSummit https://dev.classmethod.jp/articles/awssummit-2018-day2-h1-2-10-aws-network-infrastructure/ AWS re:Invent 2017 Keynote - Tuesday Night Live with Peter DeSantis https://www.youtube.com/watch?v=dfEcd3zqPOA&feature=youtu.be&t=4661↓これが
↓こうなった
画像引用: AWS Compute Blogまとめ
2020/06時点で「VPC Lambda」は使い物になるかというと、
VPCの問題は改善されたが、RDS Proxyがまだプレビュー版なので、正式版がくるまでは規模のあるビジネス用途ではまだ厳しそう。
個人用途ならVPCの改善だけでもありだけど、インターネットアクセスするなら
NatGateway課金が必要なのでお財布と相談って感じ。よし、VPC Lambda一択だ!と思いきや、
ステイッステイッ、まだだまだだ、な状況
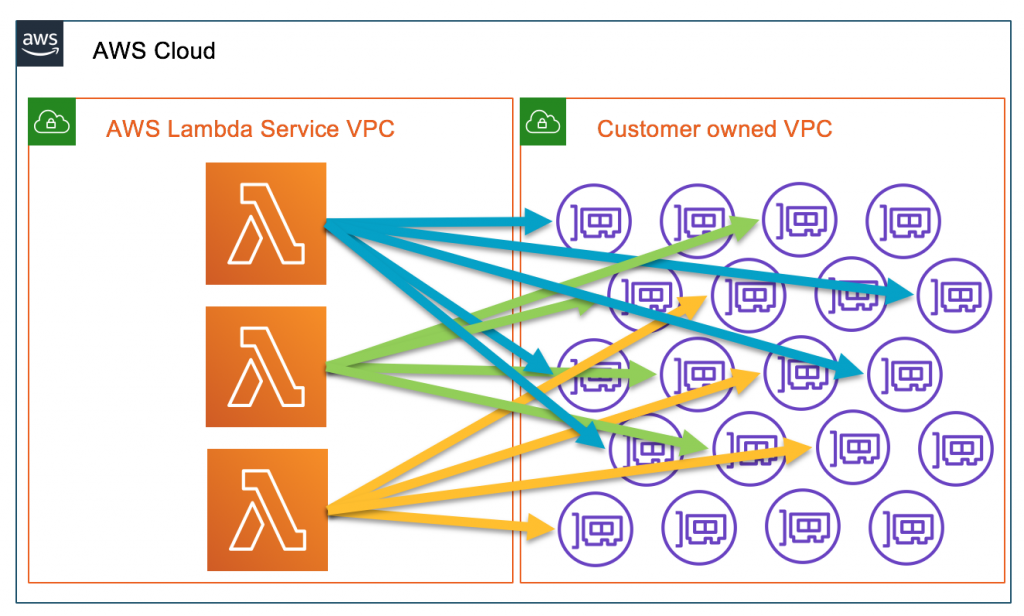
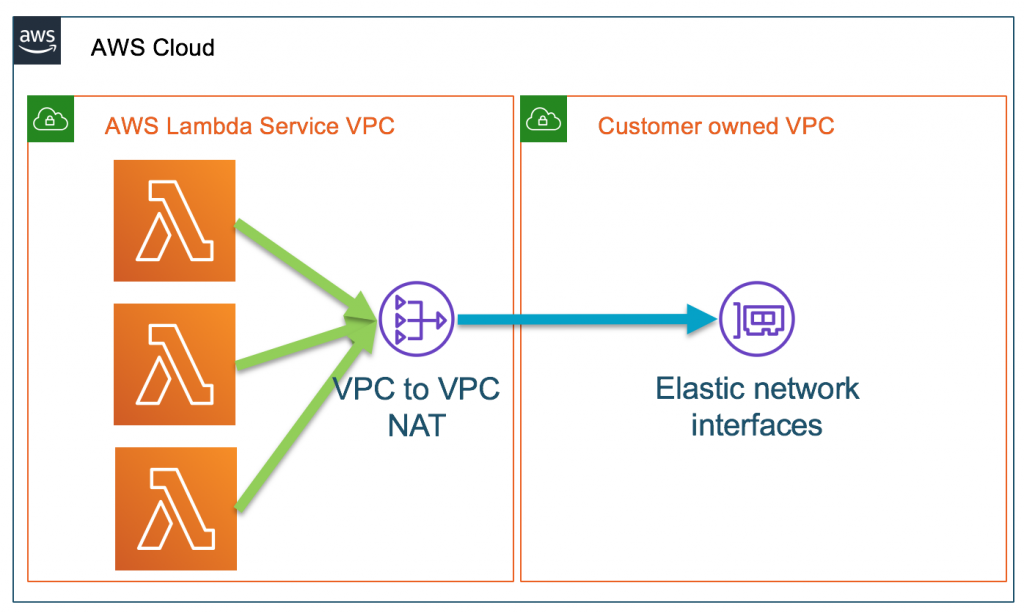
- 投稿日:2020-06-28T17:01:38+09:00
TerraformでAWS VPCを変更する(再作成が発生する場合、しない場合)
TerraformでAWS VPCを変更するコード(コマンド)
CIDRのように一度設定した後は変更できないようなパラメータ(※)を変更しようとした場合、VPCの再作成することになるはず。
再作成が発生してしまう場合、どのような挙動やメッセージとなるのかを確認する。※ だいぶ前からCIDRの拡張は可能になってたんですね。知らなかった。
実行環境
- Windows 10 Home (1919)
- Git Bash (git version 2.25.1.windows.1)
- AWS CLI (aws-cli/2.0.3 Python/3.7.5 Windows/10 botocore/2.0.0dev7)
- Terraform (v0.12.26)
再作成が発生してしまうパターン
実行前の状態確認
$ aws ec2 describe-vpcs --region=us-west-2 { "Vpcs": [ { "CidrBlock": "10.10.0.0/16", "DhcpOptionsId": "dopt-0ebee8b328487036e", "State": "available", "VpcId": "vpc-0aad429d595d7ac0d", "OwnerId": "679788997248", "InstanceTenancy": "default", "CidrBlockAssociationSet": [ { "AssociationId": "vpc-cidr-assoc-0a18a1435cc1d68ab", "CidrBlock": "10.10.0.0/16", "CidrBlockState": { "State": "associated" } } ], "IsDefault": false, "Tags": [ { "Key": "CostGroup", "Value": "prj01" }, { "Key": "Name", "Value": "prj01VPC" } ] } ] }VPC作成時のmain.tfと同じ。こちら。
main.tfを編集して、CIDRを変更
$ diff main.tf main.tf.old 7c7 < cidr_block = "10.20.0.0/16" --- > cidr_block = "10.10.0.0/16"planで変更点を確認
$ ../terraform.exe plan Refreshing Terraform state in-memory prior to plan... The refreshed state will be used to calculate this plan, but will not be persisted to local or remote state storage. aws_vpc.prj01VPC: Refreshing state... [id=vpc-0aad429d595d7ac0d] ------------------------------------------------------------------------ An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: -/+ destroy and then create replacement Terraform will perform the following actions: # aws_vpc.prj01VPC must be replaced -/+ resource "aws_vpc" "prj01VPC" { ~ arn = "arn:aws:ec2:us-west-2:679788997248:vpc/vpc-0aad429d595d7ac0d" -> (known after apply) assign_generated_ipv6_cidr_block = false ~ cidr_block = "10.10.0.0/16" -> "10.20.0.0/16" # forces replacement ~ default_network_acl_id = "acl-01ca95405b2203904" -> (known after apply) ~ default_route_table_id = "rtb-000535d0bee883194" -> (known after apply) ~ default_security_group_id = "sg-00c024ac152dee0af" -> (known after apply) ~ dhcp_options_id = "dopt-0ebee8b328487036e" -> (known after apply) ~ enable_classiclink = false -> (known after apply) ~ enable_classiclink_dns_support = false -> (known after apply) ~ enable_dns_hostnames = false -> (known after apply) enable_dns_support = true ~ id = "vpc-0aad429d595d7ac0d" -> (known after apply) instance_tenancy = "default" + ipv6_association_id = (known after apply) + ipv6_cidr_block = (known after apply) ~ main_route_table_id = "rtb-000535d0bee883194" -> (known after apply) ~ owner_id = "679788997248" -> (known after apply) tags = { "CostGroup" = "prj01" "Name" = "prj01VPC" } } Plan: 1 to add, 0 to change, 1 to destroy. ------------------------------------------------------------------------ Note: You didn't specify an "-out" parameter to save this plan, so Terraform can't guarantee that exactly these actions will be performed if "terraform apply" is subsequently run.
- 「must be replaced」と表示がある
- 変更するCIDRに「forces replacement」と表示がある
- 「1 to add」と「1 to destroy」と表示がある 上記より、設定の変更ではなく、再作成が発生してしまうことがplanからもわかる。
apply
$ ../terraform.exe apply aws_vpc.prj01VPC: Refreshing state... [id=vpc-0aad429d595d7ac0d] An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: -/+ destroy and then create replacement Terraform will perform the following actions: # aws_vpc.prj01VPC must be replaced -/+ resource "aws_vpc" "prj01VPC" { ~ arn = "arn:aws:ec2:us-west-2:679788997248:vpc/vpc-0aad429d595d7ac0d" -> (known after apply) assign_generated_ipv6_cidr_block = false ~ cidr_block = "10.10.0.0/16" -> "10.20.0.0/16" # forces replacement ~ default_network_acl_id = "acl-01ca95405b2203904" -> (known after apply) ~ default_route_table_id = "rtb-000535d0bee883194" -> (known after apply) ~ default_security_group_id = "sg-00c024ac152dee0af" -> (known after apply) ~ dhcp_options_id = "dopt-0ebee8b328487036e" -> (known after apply) ~ enable_classiclink = false -> (known after apply) ~ enable_classiclink_dns_support = false -> (known after apply) ~ enable_dns_hostnames = false -> (known after apply) enable_dns_support = true ~ id = "vpc-0aad429d595d7ac0d" -> (known after apply) instance_tenancy = "default" + ipv6_association_id = (known after apply) + ipv6_cidr_block = (known after apply) ~ main_route_table_id = "rtb-000535d0bee883194" -> (known after apply) ~ owner_id = "679788997248" -> (known after apply) tags = { "CostGroup" = "prj01" "Name" = "prj01VPC" } } Plan: 1 to add, 0 to change, 1 to destroy. Do you want to perform these actions? Terraform will perform the actions described above. Only 'yes' will be accepted to approve. Enter a value: yes aws_vpc.prj01VPC: Destroying... [id=vpc-0aad429d595d7ac0d] aws_vpc.prj01VPC: Destruction complete after 1s aws_vpc.prj01VPC: Creating... aws_vpc.prj01VPC: Creation complete after 9s [id=vpc-06bc5f188ef3b2fe8] Apply complete! Resources: 1 added, 0 changed, 1 destroyed.変更後の確認
$ aws ec2 describe-vpcs --region=us-west-2 { "Vpcs": [ { "CidrBlock": "10.20.0.0/16", "DhcpOptionsId": "dopt-0ebee8b328487036e", "State": "available", "VpcId": "vpc-06bc5f188ef3b2fe8", "OwnerId": "679788997248", "InstanceTenancy": "default", "CidrBlockAssociationSet": [ { "AssociationId": "vpc-cidr-assoc-0373fb92a40bc4aba", "CidrBlock": "10.20.0.0/16", "CidrBlockState": { "State": "associated" } } ], "IsDefault": false, "Tags": [ { "Key": "CostGroup", "Value": "prj01" }, { "Key": "Name", "Value": "prj01VPC" } ] } ] }「"CidrBlock": "10.20.0.0/16"」となっており、また、VpcIdが「vpc-0aad429d595d7ac0d」から「vpc-06bc5f188ef3b2fe8」に代わっており、確かに再作成されていることがわかります。
再作成は発生しないパターン
main.tfを編集して、タグを変更
$ diff main.tf main.tf.old2 10c10 < Name = "prj01VPC version2" --- > Name = "prj01VPC"planで変更点を確認
$ ../terraform.exe plan Refreshing Terraform state in-memory prior to plan... The refreshed state will be used to calculate this plan, but will not be persisted to local or remote state storage. aws_vpc.prj01VPC: Refreshing state... [id=vpc-06bc5f188ef3b2fe8] ------------------------------------------------------------------------ An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: ~ update in-place Terraform will perform the following actions: # aws_vpc.prj01VPC will be updated in-place ~ resource "aws_vpc" "prj01VPC" { arn = "arn:aws:ec2:us-west-2:679788997248:vpc/vpc-06bc5f188ef3b2fe8" assign_generated_ipv6_cidr_block = false cidr_block = "10.20.0.0/16" default_network_acl_id = "acl-0ec7d4e945ff1d7f0" default_route_table_id = "rtb-0d64bb221c3f9d1ff" default_security_group_id = "sg-03b425d2c42c1e984" dhcp_options_id = "dopt-0ebee8b328487036e" enable_classiclink = false enable_classiclink_dns_support = false enable_dns_hostnames = false enable_dns_support = true id = "vpc-06bc5f188ef3b2fe8" instance_tenancy = "default" main_route_table_id = "rtb-0d64bb221c3f9d1ff" owner_id = "679788997248" ~ tags = { "CostGroup" = "prj01" ~ "Name" = "prj01VPC" -> "prj01VPC version2" } } Plan: 0 to add, 1 to change, 0 to destroy. ------------------------------------------------------------------------ Note: You didn't specify an "-out" parameter to save this plan, so Terraform can't guarantee that exactly these actions will be performed if "terraform apply" is subsequently run.さきほどとは異なり、「will be updated in-place」との表記になっていることを確認。
また、「add」と「destroy」は0で、「1 to change」となっていることも確認。applyで変更を適用
$ ../terraform.exe apply aws_vpc.prj01VPC: Refreshing state... [id=vpc-06bc5f188ef3b2fe8] An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: ~ update in-place Terraform will perform the following actions: # aws_vpc.prj01VPC will be updated in-place ~ resource "aws_vpc" "prj01VPC" { arn = "arn:aws:ec2:us-west-2:679788997248:vpc/vpc-06bc5f188ef3b2fe8" assign_generated_ipv6_cidr_block = false cidr_block = "10.20.0.0/16" default_network_acl_id = "acl-0ec7d4e945ff1d7f0" default_route_table_id = "rtb-0d64bb221c3f9d1ff" default_security_group_id = "sg-03b425d2c42c1e984" dhcp_options_id = "dopt-0ebee8b328487036e" enable_classiclink = false enable_classiclink_dns_support = false enable_dns_hostnames = false enable_dns_support = true id = "vpc-06bc5f188ef3b2fe8" instance_tenancy = "default" main_route_table_id = "rtb-0d64bb221c3f9d1ff" owner_id = "679788997248" ~ tags = { "CostGroup" = "prj01" ~ "Name" = "prj01VPC" -> "prj01VPC version2" } } Plan: 0 to add, 1 to change, 0 to destroy. Do you want to perform these actions? Terraform will perform the actions described above. Only 'yes' will be accepted to approve. Enter a value: yes aws_vpc.prj01VPC: Modifying... [id=vpc-06bc5f188ef3b2fe8] aws_vpc.prj01VPC: Still modifying... [id=vpc-06bc5f188ef3b2fe8, 10s elapsed] aws_vpc.prj01VPC: Modifications complete after 17s [id=vpc-06bc5f188ef3b2fe8] Apply complete! Resources: 0 added, 1 changed, 0 destroyed.実行後の確認
$ aws ec2 describe-vpcs --region=us-west-2 { "Vpcs": [ { "CidrBlock": "10.20.0.0/16", "DhcpOptionsId": "dopt-0ebee8b328487036e", "State": "available", "VpcId": "vpc-06bc5f188ef3b2fe8", "OwnerId": "679788997248", "InstanceTenancy": "default", "CidrBlockAssociationSet": [ { "AssociationId": "vpc-cidr-assoc-0373fb92a40bc4aba", "CidrBlock": "10.20.0.0/16", "CidrBlockState": { "State": "associated" } } ], "IsDefault": false, "Tags": [ { "Key": "CostGroup", "Value": "prj01" }, { "Key": "Name", "Value": "prj01VPC version2" } ] } ] }VpcIdも「vpc-06bc5f188ef3b2fe8」のままであり、再作成されていないことがわかる。
メモ
「-out」パラメータ
Note: You didn't specify an "-out" parameter to save this plan, so Terraform can't guarantee that exactly these actions will be performed if "terraform apply" is subsequently run.
コマンドの末尾に上記のメッセージが出力されていた。
「-out」パラメータでプランを保存できる、と。planで確認した際とapplyする際に、環境やTerraformのコードが変更されてしまったことによる想定外の変更を回避するための機能とのこと。
- 投稿日:2020-06-28T15:12:44+09:00
Amazon Honeycodeを触ってみた
Honeycodeをさわってみた
ネットニュースでAWSがHoneyCodeなるもののBeta版をリリースしたとのこと。
コードを記述せずにウェブ & モバイルアプリを構築する
どうやら最近流行りのノンコード・ローコード開発ツールっぽい。
私自身、コードを書くのが好きとはいえこういった最新っぽいものが出てくるととりあえず触ってみたくなる。
ということで触ってみた。準備
準備といったってたいした操作は必要ない
AWSコンソールからHoneyCodeと調べればHitするのでクリックして進めるだけ
アカウント登録だけ必要だったので適当にぽちぽち。ログインするとこんな感じ
テンプレートから作ってみる
いくつか標準的なテンプレートが用意されているみたいだったので、Simple-ToDoを使ってみる
それっぽいのができている
Edit画面
これがEdit画面。Excel、というかMSOfficeっぽいUI。(Googleスプレッドシートとかのほうが近いかもしれない)これは確かに非エンジニアの人でもアレルギーを起こしにくい。
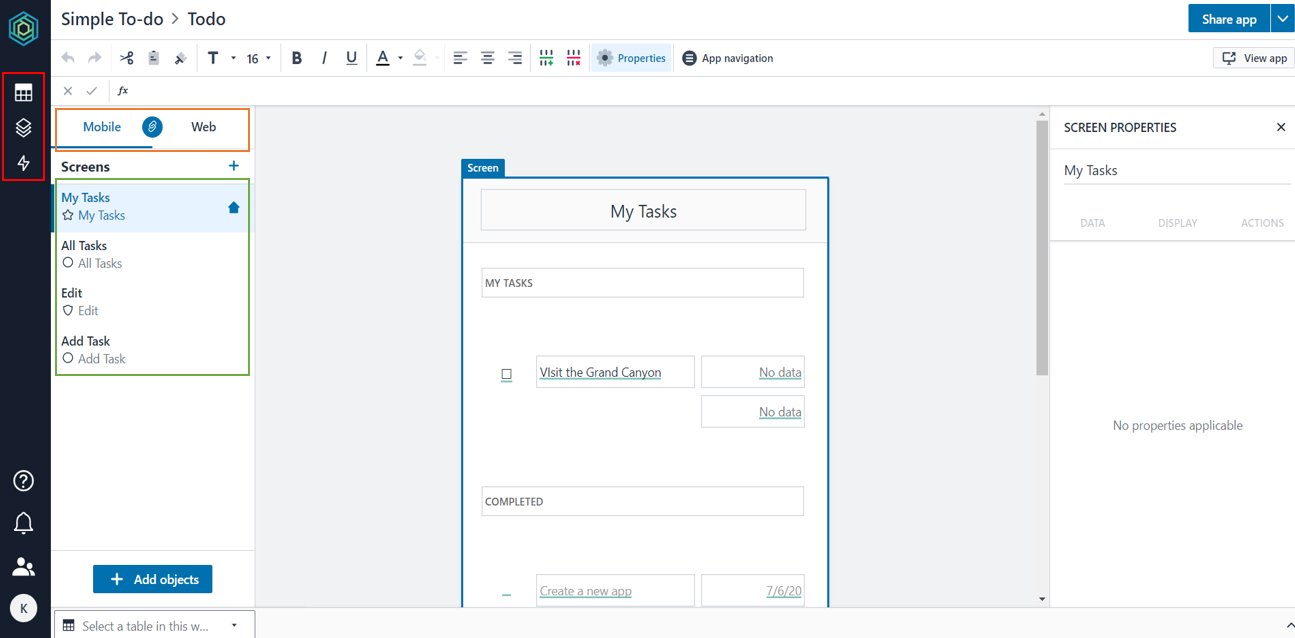
オレンジの枠 -> Mobile版とWeb版のアプリを切り替えられる(同時開発できるってすげー)
緑の枠 -> アプリの画面切り替え
赤い枠 -> UI、ロジック、データの3層を切り替えられる。(これが結構面白いのでさらに解説)
UI・・・いわゆる画面の見た目のところ。上の画像に見えてるのがUIのEdit画面(Builderと呼ばれる)
データ・・・Webアプリで利用するデータを管理する。ややこしいRDBを触る必要がなくて完全にエクセルライクでデータを管理できる(Tablesと呼ばれる)
ロジック・・・アプリの中で必要になる業務ロジックを記載できる(Automationsと呼ばれる)データの管理画面(Tables)。こんな感じでRDBを触らずにWebアプリのデータを管理できる。BuilderではこのTablesから表名、列名を参照する形になる。
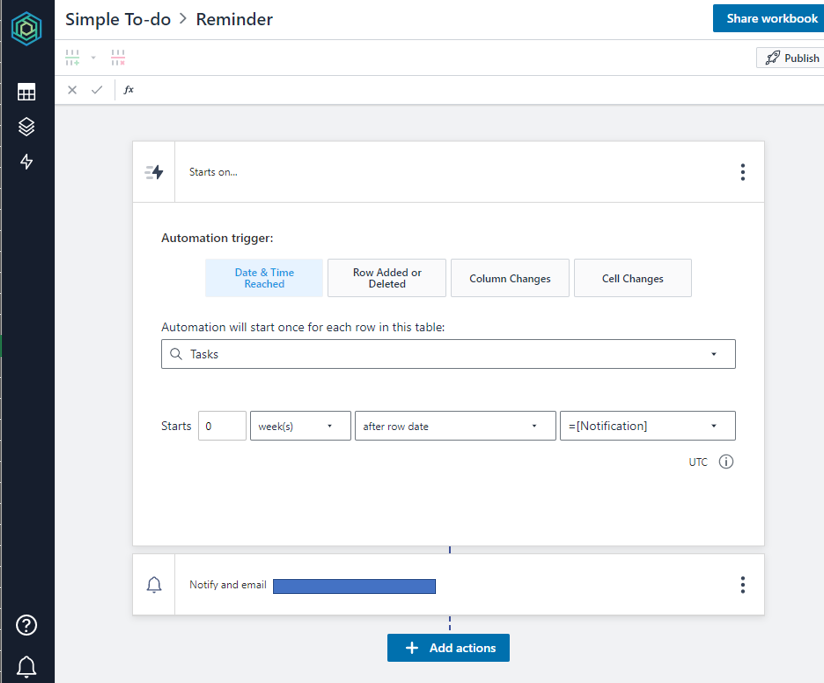
ロジックの管理画面(Automations)。こ、、このUIは・・・P〇werAutomate…!?
PowerAutomateに限らず、例えばZapierなんかとも似ているUIですね。ロジックの管理画面であっても決してコードを意識させない徹底ぶり
さわってみて
これで何か業務アプリをノーコード開発するか?…といわれると閉口するしかないが(案件がないだけで使いどころはあるはず)
ただ、Tables,Builder,Automationという3層でUI、ロジック、データというWebアプリの3要素を見事に、かつ非エンジニアにも直感的に理解できるようにまとめている点には感動した
機会があればぜひ、それなりに使えるアプリを組んでみたい。

- 投稿日:2020-06-28T14:18:05+09:00
SAMでS3にCSVファイルアップロードをトリガーにDynamoDBへの登録処理の作成 Lambdaの関数部分
概要
前回の記事のLambda関数の部分です
Lambda
Lambda関数は以下になります
import json import boto3 import os import csv import codecs import sys import traceback import collections from datetime import datetime s3 = boto3.resource('s3') dynamodb = boto3.resource('dynamodb') bucket = os.environ['bucket'] tableName = os.environ['table'] def lambda_handler(event, context): key=event['Records'][0]['s3']['object']['key'] #get() does not store in memory try: obj = s3.Object(bucket, key).get()['Body'] except: print("S3 Object could not be opened. Check environment variable. ") print(traceback.format_exc()) try: table = dynamodb.Table(tableName) except: print("Error loading DynamoDB table. Check if table was created correctly and environment variable.") print(traceback.format_exc()) batch_size = 100 batch = [] date =datetime.now() dateStr=date.strftime('%Y%m%d') #DictReader is a generator; not stored in memory for row in csv.DictReader(codecs.getreader('utf-8')(obj)): if len(batch) >= batch_size: write_to_dynamo(batch) batch.clear() batch.append(row) if batch: write_to_dynamo(batch) return { 'statusCode': 200, 'body': json.dumps('Uploaded to DynamoDB Table') } def write_to_dynamo(rows): try: table = dynamodb.Table(tableName) except: print("Error loading DynamoDB table. Check if table was created correctly and environment variable.") try: with table.batch_writer() as batch: for i in range(len(rows)): row=rows[i] batch.put_item( Item=row ) except: print(traceback.format_exc()) print("Error executing batch_writer")ソースの説明
- BOTO3の使い方は公式ドキュメント参照。
- コードを見ればなんとなくわかるかと思いますが、使用するリソースを指定して使用します。
- バケット名、テーブル名は環境変数としてLambdaの定義に指定しています
key=event['Records'][0]['s3']['object']['key']の部分でS3にオブジェクトが格納されたときに渡されるキーを取得しています。補足
- BOTO3には他のサービスを使用する機能も色々あるので必要に応じて使うとよさそうです。
- 最初は処理の中で日時をセットしたり、カラムの内容の変換を行っていましたが、Lambda内で下手に処理をやると処理時間が伸びてしまったので事前に加工できるなら加工してしまった方がよさそうです。
- 前回の記事ではDynamoDBのキャパシティーモードをプロビジョニングにしたところ大量にデータを登録するときに失敗してしまったので大量にインサートを行うときはオンデマンドの方がよさそうです。ただしお金がかかるのでお試しでやる場合はしっかりと考えた方が・・・
- DynamoDBにグローバルセカンダリーインデックスがあると余分にキャパシティを消費するのでそのあたりも実際に使う前に考えた方がよさそうです。
- 状況の確認はCloudWatchLogs で確認できるので処理に時間がかかる時はそちらで確認できます。
- 投稿日:2020-06-28T14:01:27+09:00
AWS日記12 (Translate)
はじめに
今回は Amazon Translateを利用して翻訳機能を試します。
今回作成したAmazon Translate の翻訳機能を試すページ
準備
[Amazon Translateの資料]
Amazon TranslateWEBページ・API作成
GO言語のAWS Lambda関数ハンドラー aws-lambda-go を使用してHTMLやJSONを返す処理を作成します。
また、Translate を使用するため aws-sdk-go を利用します。[参考資料]
AWS SDK for Go API Reference
aws translateコマンドをシェルのエイリアスに設定すると便利
Amazon Translateを使ってみた&自動翻訳付きチャットを作ってみた翻訳するには Text を使う。
main.gofunc translateText(message string, sourceLanguageCode string, targetLanguageCode string)(string, error) { svc := translate.New(session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) params := &translate.TextInput{ Text: aws.String(message), SourceLanguageCode: aws.String(sourceLanguageCode), TargetLanguageCode: aws.String(targetLanguageCode), } res, err := svc.Text(params) if err != nil { log.Print(err) return "", err } return aws.StringValue(res.TranslatedText), nil }※ 入力された文字列が日本語か英語か判断するため、今回は簡易的にアルファベットを含むかどうかで判定しました。
main.gofunc sendMessage(message string)(string, error) { if regexp.MustCompile(`[a-zA-Z]`).Match([]byte(message)) { return translateText(message, languageCodeEn, languageCodeJa) } return translateText(message, languageCodeJa, languageCodeEn) }終わりに
今回はAmazon Translateを試しました。
- 投稿日:2020-06-28T13:48:19+09:00
AWS,GCP,Azureの対応用語表とベストプラクティス(階層・ユーザー・定義された権限編)
はじめに
AWS,GCP,Azureを使っているのですが対応している用語が分かりづらかったのでまとめました。
また弊社のように今は小規模な組織で厳密に権限管理をするほどではないけど、スケールする可能性があり将来的な負債にはしたくないという方向けの低工数だけど効果がある最適なベストプラクティスをまとめました。
1年前の自分に読ませてあげたいことが書いてあります。階層
階層 AWS GCP Azure ルート 組織 組織 AzureAD ※2 環境の
グループ ※1OU フォルダ 管理グループ 独立した環境 アカウント プロジェクト サブスクリプション VMなどの
グループリソースグループ VMなど リソース リソース リソース ※1:環境だけでなくグループ化したものもグループ化できる、ファイルとディレクトリをイメージすると分かりやすい
※2:厳密にはAzureADは認可認証サービスなので少し違うベストプラクティス
AWSのアカウントなど「独立した環境」レイヤーで開発、本番環境を分離することをお勧めします。
独立している環境なのでヒューマンエラーが起きにくくなります。
また、組織が大きくなったときに「独立した環境」をそのまま「環境のグループ」に移動するのは比較的簡単ですが、「独立した環境」内を整理するのは大変です。ユーザー
ユーザー AWS GCP Azure 個人 ユーザー
アカウント ※3ユーザー グループ グループ
グループグループ マシンユーザー ※1 ロール ※2 サービス
アカウントサービス
プリンシパル※1:プログラムなど人以外がアクセスするときの認証情報を持った仮想のユーザー
※2:「プログラムによるアクセス」ユーザーという選択肢もある
※3:個人のGoogleアカウントではなくGsuiteもしくはCloudIdentityを用いた方が管理が楽ですベストプラクティス
組織がスケールする可能性があるならば、個人ではなくグループで管理することをお勧めします。入退社や新規開発の度に管理するのは組織が大きくなるとどんどん大変になります。
マシンユーザーはコード管理をお勧めします。環境による差分を生じさせないためです。「独立した環境」の定義された権限
ユーザー AWS GCP Azure 全ての権限 Administrator
Accessオーナー 所有者 権限以外の権限 PowerUser
Access編集者 共同作成者 閲覧者 ※1 読み権限 ReadOnly
Access参照者 閲覧者 ※1:Firestoreのレコード書き換えることができてしまうので注意
ベストプラクティス
各環境で必要な権限をグループに付与しましょう。
開発者グループには
開発環境では「全ての権限」もしくは「権限以外の権限」、
本番環境では「読み権限」と必要ならば特定のリソースのみの権限がお勧めです。
弊社では、開発者・ITインフラ・ITインフラ特権・アドミンにグループ分けをして各環境で必要な最小権限を与えております。最後に
最後までご覧いただきありがとうございます。
最小権限の原則を満たしつつ権限不足で業務に支障が出ないようにすることは大変難しいですが、ITインフラ担当者の腕の見せ所だと思いますので私を含め皆さん頑張りましょう!
間違いなどございましたらコメントいただけますと幸いです。
- 投稿日:2020-06-28T12:18:30+09:00
AWS認定 デベロッパー アソシエイト 受験・合格体験記
オンライン受験
家族の意見によりテストセンターでの受験を見合わせていましたが、自宅でオンライン受験されたトレノケート山下さんのブログを発見!
コードを勉強するために半年前から受験を計画していたり、自宅待機の時間でPython・Translate・Transcribe・Comprehendを使ったサーバーレス環境(API Gateway+Lambda+DynamoDB)などをハンズオンする時間がありましたので、躊躇なく受験を決めました。
既にクラスメソッドすずきさんが詳細な記事を書かれていますので、私は検索しても見つからなかったポイントをメモしておきます。
ポイント
①システムテストでMacがフリーズする
事前にOnVUEを起動させてシステムテストを行ったのですが、最後のテスト項目で練習問題が表示されずMacがフリーズしました。
これは、ESET(ウィルススキャン)設定4箇所を無効にした後に、ESETを停止することで、システムテストは成功しました。以下は設定を無効にした時の画面です。(もちろん受験後は元に戻します)
②モニタが大きいとマウスポインタの移動が大変
受験前はキーボードショートカットでNextボタンを押せばいいかな〜と思っていたのですが、ショートカットキーが見つけられませんでした。
そのため、画面左上のラジオボタンをマウスでクリックすることで回答し、Nextボタン押すために画面右下までポインタを対角線上に移動する繰り返しで結構キツかったのですが、MagicTrackpadに助けられました。勉強方法
BlackBelt、ハンズオン、参考書、Udemy、模擬試験、サンプル問題を利用しました。
脳に定着させるために、以下の例の様に暗記だけにならない、出来るだけ本質を見抜くことに注意しました。
- DynamoDBの可用性(3つのAZにコピーする)や結果整合性(⇄強い整合性)の仕組みはS3が土台だからである
- SAM、CDK、Beanstalk、StepFunctionは、Cloudformationを使っている
- SecretManager(ローテーションされる)とSystemManagerパラメータストアの違い
- S3のサーバサイド暗号化(保存先で暗号化複合化)とクライアントサイド暗号化の違い(通信途中も暗号化される)
楽しく勉強して合格できました。
- 投稿日:2020-06-28T11:40:11+09:00
Amazon Linux2にDockerをインストールする
Docker初心者の私がAmazon Linux2(AMI)イメージから作成したEC2インスタンスに
Dockerをインストールし色々と触ってみたので備忘録として残します。・インスタンスで使用するパッケージを更新する
すでに実施済みのインスタンスであれば不要です
実行コマンド
sudo yum update -y実行結果
・・・ Updated: amazon-linux-extras.noarch 0:1.6.11-1.amzn2 amazon-linux-extras-yum-plugin.noarch 0:1.6.11-1.amzn2 ca-certificates.noarch 0:2019.2.32-76.amzn2.0.2 cloud-init.noarch 0:19.3-3.amzn2 kernel-tools.x86_64 0:4.14.181-140.257.amzn2 python.x86_64 0:2.7.18-1.amzn2 python-devel.x86_64 0:2.7.18-1.amzn2 python-libs.x86_64 0:2.7.18-1.amzn2 selinux-policy.noarch 0:3.13.1-192.amzn2.6.2 selinux-policy-targeted.noarch 0:3.13.1-192.amzn2.6.2 Complete!・Amazon Linux ExtrasからDockerをインストールする
Amazon Linux Extrasとは何ぞやということについてはAWS(公式)-Amazon Linux 2-よくある質問の[Amazon Linux Extras]を確認してください。
実行コマンド
sudo amazon-linux-extras install docker実行結果
・・・ Installed: docker.x86_64 0:19.03.6ce-4.amzn2 Dependency Installed: containerd.x86_64 0:1.3.2-1.amzn2 libcgroup.x86_64 0:0.41-21.amzn2 pigz.x86_64 0:2.3.4-1.amzn2.0.1 runc.x86_64 0:1.0.0-0.1.20200204.gitdc9208a.amzn2 Complete!この時点ではまだインストールしただけなのでDockerホストは起動していません。
試しに稼働中のDockerコンテナを表示するコマンドを実行してみます。sudo docker ps「Dockerデーモンにアクセス出来ません」とエラーになります。
Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?・Dockerデーモンを起動する
実行コマンド
sudo service docker start実行結果
Redirecting to /bin/systemctl start docker.serviceDockerデーモンが起動したのか、再度確認してみます。
sudo docker psまだ一つもコンテナを起動していないので一つも表示されませんが、Dockerデーモンが稼働していることは確認できました。
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES・Dockerコマンドをsudo無しで実行出来るようにする
毎回Dockerコマンド(psなど)を実行するのに"sudo"を付けるのは面倒なので、Dockerグループに
Dockerを利用するユーザーを登録します。
今回はデフォルトで作成される"ec2-user"で行います。実行コマンド
sudo usermod -a -G docker ec2-user実行結果(/etc/groupの登録内容を確認)
dockerグループのサブグループにec2-userが含まれていることが確認できるcat /etc/group | grep docker docker:x:993:ec2-user一度ログアウトしてから先程実行した
docker psを実行すると、エラーとならずに実行できる
ことが確認できる。
※ログアウトしないと上記グループ登録が反映されていないことがある
これで作成したEC2インスタンスでDockerを利用する準備が整いました。
Dockerを利用して色々と試して行こうと思います。
- 投稿日:2020-06-28T10:55:12+09:00
TerraformでECS FargateなコンテナにFireLensを適用する
はじめに
FargateのログはデフォルトだとCloudWatch Logsに収集される。
このままでも良いのだけど、加工したり転送したりと色々やりたいときに手間にならない方法としてFireLensが使えるらしいので、試してみる。以前書いた記事をベースに、以下の記事と同様のことをTerraformで実装する。
【Developers.IO】[アップデート] ECS/Fargateでログ出力先をカスタマイズできる「FireLens」機能がリリースされました
事前準備
上記の記事の構成でFireLensを使うのに必要なのは以下。
まずはこれを用意していく。
- ログの書き込み先となるFirehoseの準備
- ECSのタスクロール(Notタスク実行ロール)へのFirehoseへの書き込み権限のアタッチ
- Firehoseに対する書き込み先のS3の書き込み権限のアタッチ
これまでの記事に書いているように、
localなリソースは名前の定義程度なので、テキトーに良い感じな名前を振ってもらえれば良い。まずは、以下のような感じでログの書き込み先を作成する。
s3_configurationのcloudwatch_logging_optionsは有ってもなくても良い。
エラー時の原因調査にログが必要であればつけておこう(これがないと、本当に何の手掛かりもなくログが出力されないことになる)
エラー時に出力するlog_group_nameは、別のリソースで作っておく。loggroup.tf################################################################################ # CloudWatch Logs # ################################################################################ resource "aws_cloudwatch_log_group" "firelenstest"{ name = "${local.loggroup_name}" }kinesis.tf################################################################################ # Kinesis Firehose # ################################################################################ resource "aws_kinesis_firehose_delivery_stream" "firelenstest" { name = "${local.stream_name}" destination = "s3" s3_configuration { role_arn = "${data.aws_iam_role.firehose.arn}" bucket_arn = "${data.aws_s3_bucket.firelenstest.arn}" cloudwatch_logging_options { enabled = "true" log_group_name = "${data.aws_cloudwatch_log_group.firelenstest.name}" log_stream_name = "kinesis_error" } } }次に、ECSのタスクロールにFirehoseへの書き込み権限をアタッチする。
タスク実行ロールではなくてタスクロールの信頼ポリシーの設定なのに、Principalsがecs-tasks.amazonaws.comなのは不思議だが、どうやらこれでOKらしい。iam.tf################################################################################ # IAM Role for ECS Task # ################################################################################ resource "aws_iam_role" "ecs_task" { name = "${local.ecs_task_role_name}" assume_role_policy = "${data.aws_iam_policy_document.ecs_task_trust.json}" } data "aws_iam_policy_document" "ecs_task_trust" { statement { effect = "Allow" actions = [ "sts:AssumeRole", ] principals { type = "Service" identifiers = [ "ecs-tasks.amazonaws.com", ] } } } resource "aws_iam_role_policy_attachment" "ecs_task" { role = "${aws_iam_role.ecs_task.name}" policy_arn = "${aws_iam_policy.ecs_task_custom.arn}" } resource "aws_iam_policy" "ecs_task_custom" { name = "ecs-task-role-policy" description = "ECS Task Role Policy for Firehose" policy = "${data.aws_iam_policy_document.ecs_task_custom.json}" } data "aws_iam_policy_document" "ecs_task_custom" { version = "2012-10-17" statement { sid = "FirehosePutRecord" effect = "Allow" actions = [ "firehose:PutRecordBatch", ] resources = [ "*", ] } }最後に、Firehoseに対する書き込み先のS3の書き込み権限のアタッチをすれば準備完了だ。
書き込み先のS3もここでリソースを準備してしまおう。
こんかい、エラー時にCloudWatch Logsにも出力するつもりなので、logs:PutLogEventsのアクセス権限をFirehoseにアタッチしている。CloudWatch Logsに出さないという強気戦略であれば、不要だろう。
↑の準備とiam.tfで名前が重複しているので、コンカチするか分けるかはお任せする。やりやすい方で良いと思う。s3.tf################################################################################ # S3 Bucket # ################################################################################ resource "aws_s3_bucket" "firelenstest" { bucket = "${local.bucket_name}" acl = "private" }iam.tf################################################################################ # IAM Role for Kinesis Firehose # ################################################################################ resource "aws_iam_role" "firehose" { name = "${local.firehose_role_name}" assume_role_policy = "${data.aws_iam_policy_document.firehose_trust.json}" } data "aws_iam_policy_document" "firehose_trust" { statement { effect = "Allow" actions = [ "sts:AssumeRole", ] principals { type = "Service" identifiers = [ "firehose.amazonaws.com", ] } } } resource "aws_iam_role_policy_attachment" "firehose" { role = "${aws_iam_role.firehose.name}" policy_arn = "${aws_iam_policy.firehose_custom.arn}" } resource "aws_iam_policy" "firehose_custom" { name = "firehose-role-policy" description = "Firehose Role Policy" policy = "${data.aws_iam_policy_document.firehose_custom.json}" } data "aws_iam_policy_document" "firehose_custom" { version = "2012-10-17" statement { sid = "S3Access" effect = "Allow" actions = [ "s3:AbortMultipartUpload", "s3:GetBucketLocation", "s3:GetObject", "s3:ListBucket", "s3:ListBucketMultipartUploads", "s3:PutObject" ] resources = [ "arn:aws:s3:::${aws_s3_bucket.firelenstest.bucket}", "arn:aws:s3:::${aws_s3_bucket.firelenstest.bucket}/*", ] } statement { sid = "CloudWatchLogsAccess" effect = "Allow" actions = [ "logs:PutLogEvents" ] resources = [ "${aws_cloudwatch_log_group.firelenstest.arn}" ] } }ECSサービスとタスク定義の修正
ECSサービスとタスク定義は以下の通りに修正する。
ポイントは以下の通り。
aws_ecs_task_definitionにFireLensのコンテナ(Fluentbitのコンテナ)を仕込んでいるので、通常のHTTPサーバとは構成が異なる可能性あり- コンテナイメージのパスは公式のAWS Fargate 用ユーザーガイドに書かれている値を設定する。他所のリポジトリから取得することでイメージが未来永劫同じであることの担保がされなくなってしまうため、それを嫌うのであれば、自分のECRリポジトリにコピーを行い、安定板として自分で管理するのが良い。が、その後のメンテ性とは裏返しになるので、注意が必要な部分ではある。
ポイントになるのは以下の部分。
デフォルトではawslogsで定義する部分を以下のように変更する。
optionsで指定できるプロパティは、AWS Fargate用ユーザーガイドによると、Fluentd または Fluent Bit 出力設定の生成に使用されます。
らしい。が、Fluent Bitのドキュメントには言及がない。おそらくこの辺が使えるのだろうが、イマイチよく分からないな……。
"logConfiguration": { "logDriver": "awsfirelens", "options": { "Name": "firehose", "region": "${data.aws_region.current.name}", "delivery_stream": "${aws_kinesis_firehose_delivery_stream.firelenstest.name}" } }また、以下の部分で、Fluent Bitをサイドカーコンテナとして起動している。
imageのパスは、↑のユーザーガイドに書かれているものを設定する。リージョンごとに違うので注意。Fluent Bitそのものが出力するログは、awslogsでCloudWatch Logsに転送する(自分のストリームにはログは出せないというか、出してしまうと障害解析ができない)。{ "name" : "log_router", "image": "906394416424.dkr.ecr.ap-northeast-1.amazonaws.com/aws-for-fluent-bit:latest", "firelensConfiguration": { "type": "fluentbit" }, "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "${data.aws_cloudwatch_log_group.firelenstest.name}", "awslogs-region": "${data.aws_region.current.name}", "awslogs-stream-prefix": "ecs" } } }ECSを定義するHCLの全文は以下。
ecs.tf
ecs.tfresource "aws_ecs_cluster" "firelenstest" { name = "${local.ecs_cluster_name}" } resource "aws_ecs_task_definition" "firelenstest" { family = "${local.ecs_family_name}" task_role_arn = "${data.aws_iam_role.ecs_task.arn}" execution_role_arn = "${data.aws_iam_role.task_execution.arn}" network_mode = "awsvpc" cpu = "256" memory = "1024" requires_compatibilities = [ "FARGATE", ] container_definitions = <<EOF [ { "name" : "${local.ecs_container_name}", "image": "${data.aws_ecr_repository.firelenstest.repository_url}:${local.container_image_tag}", "cpu": 0, "memoryReservation": 512, "portMappings": [ { "containerPort": 9000, "hostPort": 9000, "protocol": "tcp" } ], "logConfiguration": { "logDriver": "awsfirelens", "options": { "Name": "firehose", "region": "${data.aws_region.current.name}", "delivery_stream": "${aws_kinesis_firehose_delivery_stream.firelenstest.name}" } } }, { "name" : "log_router", "image": "906394416424.dkr.ecr.ap-northeast-1.amazonaws.com/aws-for-fluent-bit:latest", "firelensConfiguration": { "type": "fluentbit" }, "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "${data.aws_cloudwatch_log_group.firelenstest.name}", "awslogs-region": "${data.aws_region.current.name}", "awslogs-stream-prefix": "ecs" } } } ] EOF } resource "aws_ecs_service" "firelenstest" { name = "${local.ecs_service_name}" cluster = "${aws_ecs_cluster.firelenstest.id}" launch_type = "FARGATE" task_definition = "${aws_ecs_task_definition.firelenstest.arn}" desired_count = 1 load_balancer { target_group_arn = "${data.aws_alb_target_group.firelenstest.arn}" container_name = "${var.prefix}-Container" container_port = 9000 } deployment_controller { type = "CODE_DEPLOY" } network_configuration { subnets = flatten(["${data.aws_subnet_ids.my_vpc.ids}",]) security_groups = [ "${data.aws_security_group.firelenstest.id}", ] assign_public_ip = "true" } }出力の確認
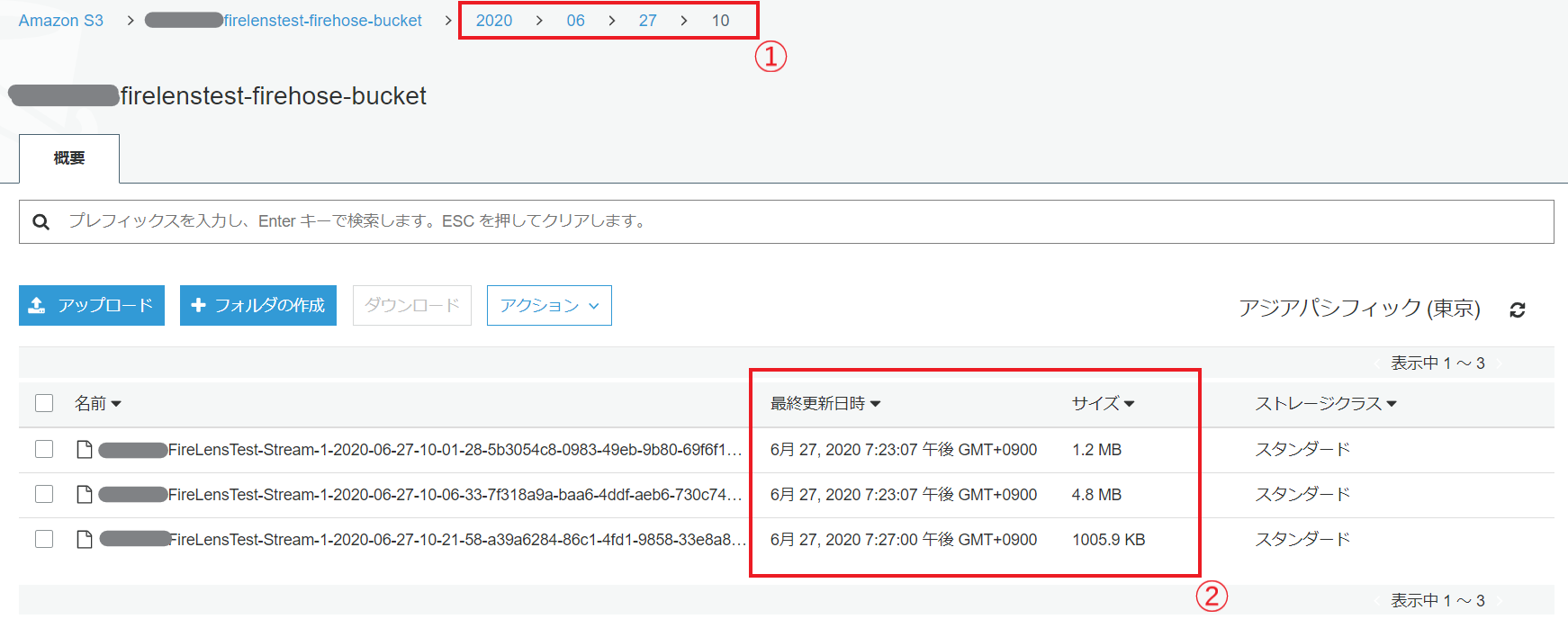
これを動かすと、S3に
こんな感じで出力される。①…時間単位でディレクトリが作られる
②…kinesis.tfでs3_configurationのデフォルト設定を適用すると、5MiBまたは5分単位で出力される。ログ分割に関する時間やバッファリングのチューニングは↑この設定で行える。
ログ出力そのものの設定は、Fluent Bit側の設定になる。詳細はユーザーガイドの『カスタム設定ファイルの指定』を参照。
- 投稿日:2020-06-28T09:44:40+09:00
(自分用)Flask_AWS_1(AWS仮想環境にPHP,MySQL,phpMyAdmin,Pythonのインストール)
項目
- PHPのインストール
- MySQLのインストール
- PHPMyAdminのインストール
- Pythonのインストール
1.PHPのインストール
ターミナル# まずLinux仮想マシンに接続、ここを覚えてないなら1つ前のやつを見て $ ssh -i ~/.ssh/FirstKey.pem ec2-user@(パブリックIP) # 管理者権限に変更 $$ sudo su # PHPをインストール $$ yum install -y php # PHPの設定を変える前にバックアップを取っておく $$ cp /etc/php.ini /etc/php.bak # viでPHPの設定変更 $$ vi /etc/php.ini
:set numberで行番号を表示:520で520行目に移動iにて記述モードにし、error_reporting = E_ALL & ~E_DEPRECATEDという行を、error_reporting = E_ALL & ~E_DEPRECATED & ~E_NOTICEに変更するescでコマンドモードに戻る:537で537行目へiからのdisplay_errors = OffをOnに変更、esc:wqで保存終了ターミナル# Apacheを再起動し適用 $$ service httpd restart # [OK]*2出たら多分大丈夫2.MySQLのインストール
- 前回に引き続き管理者権限でログインしてる前提
ターミナル# MySQLのインストール $$ yum install -y mysql-server # MySQLをPHPがいい感じに動かせるものを入れる $$ yum install -y php-mysqlnd # Pythonでいい感じにね $$ yum install mysql-connector-python # MySQLを起動 $$ service mysqld start # MySQLの設定をあれこれ $$ mysql_secure_installation # 一発目のrootパスワード聞いてくるところはそのままEnter # rootパスワード新しくするか聞かれるので、yes # 好きなパスワードを入力 # anonymousユーザ消すか聞いてくるのでyes # あとは全部yでも良さげ # MySQLでの文字コードを設定 $$ vi /etc/my.cnf # `:set number`で行数を表示し空白の10行目に $$ character-set-server = utf8 # と入力する、繰り返すが`i`で入力モードにし、入力後`esc`でコマンドモード # `:wq`で保存終了 # MySQLを再起動 $$ service mysqld restart #[OK]と出れば`OK`3.PHPMyAdminのインストール
- 前回に続き仮想環境の管理者権限内を前提
ターミナル# phpMyAdminのインストール先を作成 $$ yum-config-manager --enable epel # phpMyAdminをインストール $$ yum install -y phpmyadmin # phpMyAdminの設定を開く $$ vi /etc/httpd/conf.d/phpMyAdmin.conf # ここで127.0.0.1って書いてあるところをグローバルIPに変更すると、自分のローカルなマシンだけが接続変更出来る様になる # やらなくていいと思う # もし変えたい場合は、`:%s/127.0.0.1/自分のグローバルIP/g`で変更 # Apacheの再起動 $$ service httpd restart
http://前に設定したAWSのパブリックIP/phpmyadmin/に接続すると、phpMyAdminのページが出てくる- ユーザ名は
root、パスワードはMySQLインストールで設定したやつを入れる4.Pythonのインストール
- 前に続き仮想環境内(管理者権限ではない)
ターミナル# 一回Linux環境アップデート $$ sudo yum -y update # Pythonインストール $$ sudo yum install python36-devel python36-libs python36-setuptools # もうMySQLをPythonでいい感じにするやつはインストール済み # Apacheを再起動 $$ service httpd restart5.終わりに
- 環境構築がいっっっちばんつまらない最悪
- 投稿日:2020-06-28T01:23:10+09:00
AWS lightsailでディレクトリルートを変更する
AWS lightsail + node.jsでルートディレクトリを変更したい
node.jsをインストールしたlinuxベースのAWS lightsailで、
gitクローンしたディレクトリをディレクトリルートに指定します。laightsailの環境は
・nodejs v12.16.1
・apache v2.4.41(unix)sudo vi /opt/bitnami/apache2/conf/bitnami/bitnami.confで、viエディタを開きます。
escキーを押してから
/DocumentRootでドキュメントルートを指定している行にジャンプします。
(普通にカーソル移動でもokです。)ここで、
DocumentRoot "gitクローンしたファイルパス"IPアドレスやドメインをたたけば、htmlファイルが表示されます。
- 投稿日:2020-06-28T00:41:24+09:00
Route53 で RDS endpoint の短縮名を登録する
Aurora MySQLのtextをEC2 MariaDBレプリカでMroonga全文検索 で言及した件の続編。
レプリカ設定 MASTER_HOSTは60文字以下にする必要がある。Amazon RDSのendpointは長くなりがちで、東京リージョンではcluster名に使えるのはわずか5文字。Route53を使って短い別名を登録しておくのが本来だろう。
上記記事では5文字のクラスタ名にしたが、実際にRoute53を使う手順を示す。
AWSコンソール手順
- Route53
- ホストゾーン
- ホストゾーンの作成
- ドメイン名:
vpc.example.com- コメント:
for devlop1など対象VPCを示すコメント文字列を入れる(強く推奨)- タイプ: Amazon VPCのプライベートホストゾーン
- VPC ID: 対象VPCを選択
- 作成ボタン
- レコードセットの作成
- 名前:
rdsmainなど短縮ホスト名- タイプ:
CNAME- エイリアス: いいえ
- TTL(秒): 60秒とか300秒とか
- 値: RDS endpoint たとえば
rdsmain-develop1.xxxxxxxxxxxx.ap-northeast-1.rds.amazonaws.com- ルーティングポリシー: シンプル
- レコードセットの保存ボタン
太字が要設定項目、それ以外はデフォールトのままなので、想像するより簡単。
「レコードセット」は必要なだけ(RDS instanceの数だけ)繰り返して作る。ドメイン名の決定
参考ドキュメント
example.com や accounting.example.com など、重複する名前空間を持つプライベートホストゾーンとパブリックホストゾーンがある場合、リゾルバー は最も具体的な一致に基づいてトラフィックをルーティングします。
一致するプライベートホストゾーンはあるが、リクエスト内のドメイン名やタイプと一致するレコードがない場合、リゾルバー はリクエストをパブリック DNS リゾルバーに転送しません。つまり
example.comをプライベートホストゾーンのドメインとして使ってしまうと、www-dev.example.comなどパブリックに登録してあっても、そのVPC内部からは引けなくなってしまう。この不都合を避けるために、プライベートホストゾーンと、インターネットパブリックのドメイン空間を分離して使うことが必要である。具体的には上記のように、自己保有ドメインのサブドメインを1つ割り当てる。
例
- パブリック:example.com
- プライベート:vpc.example.com
Route53 private hosted zone の影響範囲は特定のVPCだけなので、同じドメイン名を指定した private hosted zone をVPCの数だけつくれば、全部のVPCのそれぞれのRDS instance、endpointは異なるRDS instanceに共通短縮名、たとえば
rdsmain.vpc.example.comとつけることもできる。並行開発する複数環境、ステージング環境の DB Host名が統一できたりする。アンチパターン
.testや.localなど存在しないであろうTopLevelDomainを使って、プライベートホストゾーンを作成する「存在しないであろう」というところに十分な根拠が無い。
2012年以降ICANNでは募集要項の要件を満たした申請であれば、基本的には誰でもgTLDの登録ができる方針となった。
.dev.foo.appなどをGoogleが所有していて、Chrome の HSTSプレロードリストに追加したことで、private に設置していた.devホストへの接続に https が強制された。
https://www.d-wood.com/blog/2018/10/26_10573.html予約済み TLD の test, example, invalid, localhost にはどれも想定用途があり、本記事の目的で使うと名前が役割と一致しない。
プライベートホストゾーンのドメインはドメイン形式であれば、任意のものが使える。参照するのも特定VPCの内部からだけなので、ランダム生成文字列を含めて、衝突リスクを十分に下げることはできるだろう。
しかし、自己保有ドメインのサブドメインが確実で、人間にも認識しやすい、短い名前にできる。コメントが大事
[ec2-user@ip-10-0-1-10 ~]$ aws route53 list-hosted-zones { "HostedZones": [ { "ResourceRecordSetCount": 5, "CallerReference": "xxxxxxxx-24F7-3C10-xxxxxxxx-xxxxxxxx", "Config": { "Comment": "for develop-1", "PrivateZone": true }, "Id": "/hostedzone/Z03030941IDQ3T8GQLY1", "Name": "vpc.example.com." }, { "ResourceRecordSetCount": 5, "CallerReference": "xxxxxxxx-3CC0-CB66-xxxxxxxx-xxxxxxxx", "Config": { "Comment": "for staging", "PrivateZone": true }, "Id": "/hostedzone/Z0365884OJ124AKJYPA", "Name": "vpc.example.com." } ] }おわかりいただけるだろうか。APIの初手、
list-hosted-zonesでは、privateの場合の関連vpcの情報が出てこないのである。
AWSコンソールのホストゾーン一覧画面は寂しいが、APIの時点で情報が出てきていない。今後もここが改善される見込みは薄い。
対象VPCを示すコメント文字列を入れることを強く推奨するのは、この一覧画面の情報不足をコメントで補うためである。