- 投稿日:2020-06-01T23:34:22+09:00
plt.close() だけではメモリが解放されない。plt.clf() → plt.close() とするべき。
要約
# NG # メモリが解放されない plt.close() # OK # メモリが解放される plt.clf() plt.close() # NG # 順番を逆にするとメモリが解放されない # plt.close() で figure を閉じると、描画内容を clear 出来なくなるからだろう。 plt.close() plt.clf()経緯
一度に数千枚のグラフを描画していた所、out of memory エラーが出てしまいました。 毎回
plt.close()をしていたので何故だろうと思い以下の実験方法で調べました。その結果、plt.close()だけではメモリが解放されない事が分かりました。そして、plt.clf() → plt.close()とすればメモリが解放される事が分かりました。実験方法
メモリサイズが大きいグラフを10回連続でプロットします。
各プロット終了時のメモリ使用量を記録しておき、プロット回数とメモリ使用量の関係を調べます。
この手順を以下の4パターンで行います。
後処理の方法 パターン1 plt.clf() パターン2 plt.clf() → plt.close() パターン3 plt.close() パターン4 plt.close() → plt.clf() ただし、パターンごとに毎回 kernel を restart します。 メモリ使用量のベースラインを揃えるためです。
これを行うコードは以下の通りです。
import matplotlib.pyplot as plt import numpy as np import psutil mem_ary = [] # 10回プロットする for i in range(10): # メモリサイズが大きいグラフを描画 x = np.arange(1e7) y = np.arange(1e7) plt.plot(x, y) # =================================================== # 以下のパターン1からパターン4のいずれか1つを実行する # 残りはコメントアウトする # =================================================== # パターン1 plt.clf() # パターン2 plt.clf() plt.close() # パターン3 plt.close() # パターン4 plt.close() plt.clf # =================================================== # メモリ使用量を記録 mem = psutil.virtual_memory().used / 1e9 mem = round(mem, 1) mem_ary.append(mem)結果と結論
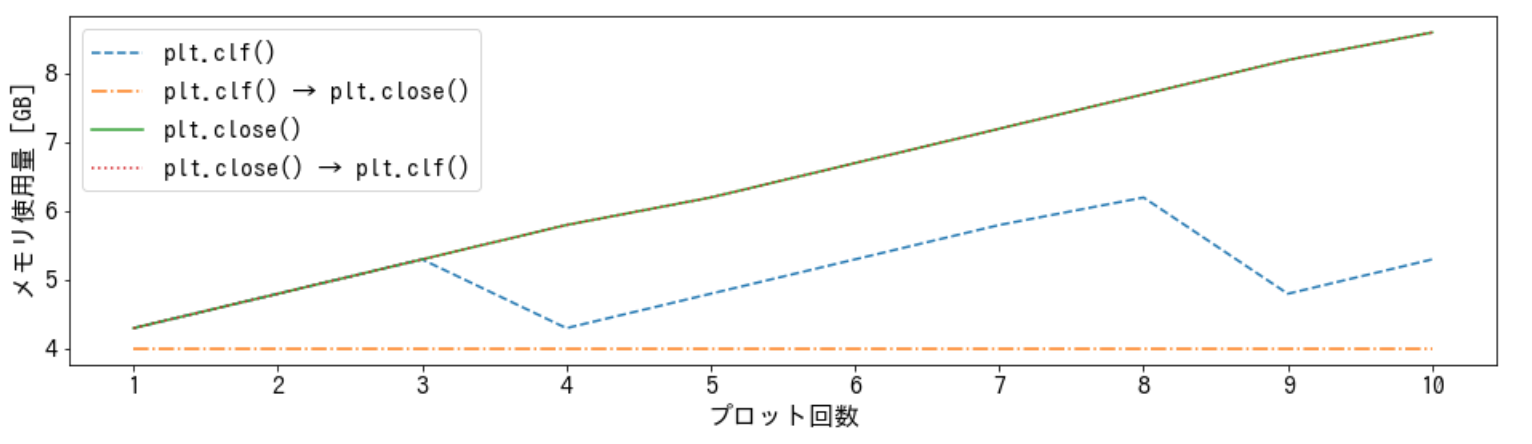
結果をグラフにまとめると次の様になりました。
plt.clf() → plt.close()だけ、メモリ使用量が増加していません。従って、plt.clf() → plt.close()とするべき事が分かります。また、順番を逆にして
plt.close() → plt.clf()とするとメモリが解放されなくなっています。注意した方がいいでしょう。原因は、おそらくplt.close()で figure を閉じると、描画内容を clear 出来なくなるからだと思います。(参考:plt.close()の公式DOC、plt.clf()の公式DOC)バージョン
matplotlib:3.2.1
- 投稿日:2020-06-01T23:22:41+09:00
【Python】Udemyで画像判定AIアプリ開発 Part1
pipでflickrapiをインストールしようとしたらエラーが出力
環境
Windows10
python3.7.6
Anaconda内容
pipでflickrapiをインストールする為,下記コマンドを入力
(tf140) C:\Users\ユーザー名>pip install flickrapiエラーが発生
ERROR: Exception: Traceback (most recent call last): File "C:\python\envs\tf140\lib\site-packages\pip\_vendor\urllib3\response.py", line 425, in _error_catcher yield File "C:\python\envs\tf140\lib\site-packages\pip\_vendor\urllib3\response.py", line 507, in read ~~省略~~ raise ReadTimeoutError(self._pool, None, "Read timed out.") pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host='files.pythonhosted.org', port=443): Read timed out.調べてみたら,「Read timed out」普通に読み込みが長すぎて,エラーが出力されたっぽい。
対応と結果
下記コマンドを投入
pip --default-timeout=100 install flickrapiタイムアウトになるまでの時間(デフォルト値)を100秒に変更みたいな感じかな、、、、?
上手くいきました
- 投稿日:2020-06-01T23:22:41+09:00
【Python】Udemy 画像判定AIアプリ開発 Part1
pipでflickrapiをインストールしようとしたらエラーが出力
環境
Windows10
python3.7.6
Anaconda内容
pipでflickrapiをインストールする為,下記コマンドを入力
(tf140) C:\Users\ユーザー名>pip install flickrapiエラーが発生
ERROR: Exception: Traceback (most recent call last): File "C:\python\envs\tf140\lib\site-packages\pip\_vendor\urllib3\response.py", line 425, in _error_catcher yield File "C:\python\envs\tf140\lib\site-packages\pip\_vendor\urllib3\response.py", line 507, in read ~~省略~~ raise ReadTimeoutError(self._pool, None, "Read timed out.") pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host='files.pythonhosted.org', port=443): Read timed out.調べてみたら,「Read timed out」普通に読み込みが長すぎて,エラーが出力されたっぽい。
対応と結果
下記コマンドを投入
pip --default-timeout=100 install flickrapiタイムアウトになるまでの時間(デフォルト値)を100秒に変更みたいな感じかな、、、、?
上手くいきました
- 投稿日:2020-06-01T23:21:18+09:00
ゼロから始めるLeetCode Day43「5. Longest Palindromic Substring」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
その対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイト。
せっかくだし人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
前回
ゼロから始めるLeetCode Day42「2. Add Two Numbers」今はTop 100 Liked QuestionsのMediumを解いています。
Easyは全て解いたので気になる方は目次の方へどうぞ。Twitterやってます。
問題
5. Longest Palindromic Substring
難易度はMedium。
Top 100 Liked Questionsからの抜粋です。文字列である
sが与えられるのでその文字列の中で最も長い回文(どちらから読んでも同じになる)を探し出すようなアルゴリズムを設計してください。Input: "babad"
Output: "bab"
Note: "aba" is also a valid answer.Input: "cbbd"
Output: "bb"以前解いた、
ゼロから始めるLeetCode Day30「234. Palindrome Linked List」
こちらに似ていますが、前回はあくまで与えられた連結リストが回文であるかをチェックするだけであったのに対し、今回は文字列でその中から最長のものを抽出するというものに変わっており、少し複雑になっています。解法
とはいえ、回文の問題のオーソドックスな考え方は前回のような要素をひっくり返した物を舐めていくものと元々の要素を比較し、仮に一致するのであれば比較を続け、そうでなければそれらの文字列を用意した文字列に保存しておく、というものでしょう。
例えば、例として与えられている
"babad"であれば、
babad
と
dabab
を前から一緒に舐めていき、一致する一つ目のaから二つ目のaまでを元々保存してある文字列の長さと比べ、要素が長い方を残すようにし、最後にその文字列を返せば解けそうです。
問題はその要素の舐め方をどのように設定するかですが、反転はスライスの[::-1]で簡単に実装できます。
なので、O(N^2)にはなりますが、for文を二つ回すという荒技で解いてみましょう。class Solution: def longestPalindrome(self, s: str) -> str: if not s: return "" for i in range(len(s),0,-1): for j in range(len(s)-i+1): if s[j:i+j] == s[j:i+j][::-1]: return s[j:i+j] # Runtime: 4884 ms, faster than 25.37% of Python3 online submissions for Longest Palindromic Substring. # Memory Usage: 13.7 MB, less than 22.69% of Python3 online submissions for Longest Palindromic Substring.流石に遅いですね・・・
めちゃくちゃ速い回答例としては、以下のようなものがありました。
class Solution(object): def longestPalindrome(self, s: str) -> str: if len(s) < 2: return s start = 0 maxLen = 1 i = 0 while i < len(s): l = i r = i while r < len(s) - 1 and s[r] == s[r+1]: r += 1 i = r + 1 while r < len(s)-1 and l > 0 and s[r+1] == s[l-1]: l -= 1 r += 1 if maxLen < r - l + 1: start = l maxLen = r - l + 1 return s[start: start + maxLen] # Runtime: 116 ms, faster than 95.05% of Python3 online submissions for Longest Palindromic Substring. # Memory Usage: 13.8 MB, less than 22.69% of Python3 online submissions for Longest Palindromic Substring.スッゲェ速い!!!!!
勉強すべきことは尽きませんね。とても良いです。では今回はここまで。お疲れ様でした。
- 投稿日:2020-06-01T22:56:38+09:00
RubyとPython間のプロセス間通信を行う(POSIX メッセージキュー)
概要
rubyとpythonのdaemon間でデータの受け渡しをredis(Pub/Sub)1を使って考えていたら、プロセス間通信(POSIX IPC)使ったほうが手軽だよと天の声が聞こえたので試してみました。
なお、今回はraspberry pi上で動かすので、電源問題のためにもプロセス数は可能な限り減らす作戦で検討しています。
POSIX メッセージキューとは
POSIXのシステムコール/ライブラリ関数を通じて利用できる、プロセス間通信の一つ。非同期型通信プロトコルで、誤解を恐れずにいえばRabbitMQなどのメッセージングミドルウェアの超簡易版のようなもの。POSIX準拠なので簡素なAPIでお手軽に利用できます。
詳しくは以下をご参照ください。
https://linuxjm.osdn.jp/html/LDP_man-pages/man7/mq_overview.7.html
システム全体
- OS: Raspbian GNU/Linux 10 (buster)
- ruby: ruby 2.5.7p206 (2019-10-01 revision 67816) [armv7l-linux-eabihf]
- 利用ライブラリ: posix-mqueue
- https://github.com/sirupsen/posix-mqueue
- python: Python 2.7.16
- 利用ライブラリ: posix_ipc
- https://pypi.org/project/posix_ipc/
Ruby側の実装(送信側)
どっちが送信/受信でもよいのですが、今回はRubyを送信側としてみました。
利用ライブラリはposix-mqueueを利用させていただきました。
めっちゃシンプル。require 'posix/mqueue' require 'json' def main m = POSIX::Mqueue.new("/whatever", msgsize: 8192, maxmsg: 10) 10.times do |i| m.send({ messsage: "hello python world #{i}" }.to_json) sleep 1 end m.send ({ message: 'end'}.to_json) ensure m.unlink if m end if __FILE__ == $PROGRAM_NAME main endPython側の実装(受信側)
こちらも恐ろしくシンプルです。
利用ライブラリはposix_ipc# -*- coding: utf-8 -*- import time import posix_ipc import json def main () : mq = posix_ipc.MessageQueue("/whatever", posix_ipc.O_CREAT) while True: data = mq.receive() j = json.loads(data[0]) # -> (message, priority)のタプルで戻ってくる print j if j.get('message') == "end": break if __name__ == "__main__" : main()結果
想定通りPython側で出力されました!
$ python main.py {u'messsage': u'hello python world 0'} {u'messsage': u'hello python world 1'} {u'messsage': u'hello python world 2'} {u'messsage': u'hello python world 3'} {u'messsage': u'hello python world 4'} {u'messsage': u'hello python world 5'} {u'messsage': u'hello python world 6'} {u'messsage': u'hello python world 7'} {u'messsage': u'hello python world 8'} {u'messsage': u'hello python world 9'} {u'message': u'end'}簡単なソースですが一応githubにも上げておきました。
https://github.com/y-amadatsu/posix-mq-with-raspberry-pi-os余談
ちなみにPOSIX メッセージを使うとメッセージQueueが
/dev/mqueue配下に表示されます。マウントしてlsやrmで操作することも可能です。このあたりはすごくUNIX!って感じcat /dev/mqueue/whatever QSIZE:350 NOTIFY:0 SIGNO:0 NOTIFY_PID:0
- 投稿日:2020-06-01T22:36:22+09:00
pythonでHello worldと表示する方法
- 投稿日:2020-06-01T22:20:59+09:00
PythonでCSVファイルの読み込み時、UnicodeDecodeErrorによるエラー【初心者向け】
はじめに
pythonでcsvファイルを読み込んだ際に下記のエラーが出てくる理由をまとめました。
import pandas as pd pd.read_csv("file/to/path")pandasでread_csvした際に下記のコードが出てきてしまった方の参考になればと思います。
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x90 in position 0: invalid start byte1. 解決策
先に結論だけ言うと下記のコードのようにしてください。
pd.read_csv("file/to/path", encoding="shift-jis")encoding="shift-jis"
だけつけたら大体OKなはず!
それでもエラーが出てしまう人は2以降を読んで理由を検討してみてください。2. エラーが出てきてしまう理由
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x90 in position 0: invalid start byteそもそもこのエラーは何を怒っているのかというとざっくりですが
'utf-8'っていう文字コードのままだとデータの読み込みができない的なことを言っています。例えるなら英語読めないから日本語に直してからデータ読み込ませて!
みたいなことです。なので別の文字コードに変換してあげましょう。
その文字コードを変換することをエンコーディングと呼びます。3. では、なんで"shift-jisなのかというと
それを説明する為に、代表的な文字コードの説明をざっとさせてください。
UTF-8
世界的にも最もポピュラーな文字コードで、Unicode用の符号化方式の1つです。ASCIIで定義している文字を、Unicodeでそのまま使用することを目的として制定しています。
ここでは難しい事は置いといて、一番使われてるんだな的な認識で大丈夫です。
JISコード
インターネット上で標準的な文字コードで、特に電子メールでの使用が一般的です。
EUC
Extended Unix Codeを略したもので、日本語UNIXが使用しています。
Shift_JIS
Microsoft社が開発したコードで、ASCIIコードの文字に日本語の文字を加えた物です。Windows、Macでも採用しており、PC上のファイルで広く用いられています。
つまり、日本語が入っているcsvファイルは、UTF-8では読めないからShift_JIS に変更しろってことですね
Shift_JISにエンコードしてデータを読み込めなかった人は、
ファイルが他の文字コードのどれに当てはまるのか考えて試してみてください。
以上メモ書きまでに
※初心者なので間違ってるところがありましたら教えてください!!
- 投稿日:2020-06-01T22:01:28+09:00
Speech Signal Processing Toolkitをpython経由で操作する
Speech Signal Processing Toolkit (SPTK)は、音声分析、音声合成、ベクトル量子化,データ処理などを行うことができるC言語のライブラリです。振動などの信号処理に使えないかと思い、試してみることにしました。
今回、
SPTKを使って実現したい内容は下記の通りです。
- python経由で操作可能であること
- 解析に伴うデータの受け渡しをnumpy.ndarrayで行えること
- できればwindows上で利用可能なこと
pythonのモジュールとして、
librosaという高機能な信号処理ツールや、pysptkという有志の方が公開してくださっているSPTKのラッパーもあるのですが、私が使いたいSPTKのコマンドに対応していないようだったので、止むを得ず取り組んだ次第です。尚、わたくし信号処理の知識が皆無(プログラミングも怪しい)ですので、用語などの間違いがあるかもしれません。悪しからずご了承ください。
1. SPTKの導入
windowsの場合
下記HPを参考にさせて頂きました。
VisualStudio2019 x64 Native Toolsでビルドします。思っていたよりも手軽に導入できたのですが、私の環境では「pitch.exe」のビルドでコケるという問題が発生しました。
なので、bin/Makefile.makファイルの「pitch.exe」関係の記述を全部削除してからビルドするという強引な方法で回避しました・・・。ubuntuの場合
下記HPを参考にさせて頂きました。
aptでも導入できるのですが、aptでインストールできるSPTKは一部のコマンドでオプションの機能に制限があるようでした(これは私の環境の問題かもしれません)。コマンド使用時に余計なことでハマってしまう可能性があるので、素直にソースファイルからビルドした方が良いと思います。$ tar xvzf SPTK-3.11.tar.gz $ cd SPTK-3.11 $ ./configure $ make $ sudo make install1. SPTKの使い方
まずは
SPTKの使い方について勉強しました。参考になる素晴らしいHPがあります。かなり詳細な解説をしてくださっており大変勉強になりました。ありがとうございます。SPTKのコマンド操作
SPTKは基本的にコンソール経由でコマンドを使って操作するツールのようです。ここでは、SPTKのsinというコマンドでsin波のデータを作成し、sin.dataというファイル名で保存してみます。コンソールを開いて下記コマンドを入力してください。周期16で長さが48(3周期分)のsin波のバイト列が、
sin.dataというファイル名で保存されます。$ sin -l 48 -p 16 > sin.dataファイルの中身を確認するには、次のように
SPTKコマンドを入力します。$ x2x +f < sin.data | dmp +f以下のように結果が出力され、ファイルの中身を確認することができます。左側の数字はインデックス番号です。インデックス番号は表示用に自動的に追加されたもので、実際のデータファイルには(右側の)数値のみが格納されていることに留意してください。
0 0 1 0.382683 2 0.707107 3 0.92388 4 1 5 0.92388 …なお、テキストデータも読み込むことができるようです。その場合は、数値をスペースでセパレートした(スペース・セパレート・バリュー?)テキストデータファイル(下記例では
sin.txt)を用意して、次のようなコマンドで読み込んでください。$ x2x +af < sin.txt | dmp +fテキストデータを読み込む場合は、オプションを
+afのようにASCIIに対応したものにしないといけません。(このような基本的な仕様を把握していなたったので、思うような解析結果が出ず、半日ほど時間を無駄にすることになりました・・・)pythonでのデータの読み込み
では、先ほど保存しておいたバイト列のデータ
sin.dataを、pythonで読み込んでみます。import numpy as np with open('sin.data', mode='rb') as f: data = np.frombuffer(f.read(), dtype='float32') print(data)結果
[ 0.0000000e+00 3.8268343e-01 7.0710677e-01 9.2387950e-01 1.0000000e+00 9.2387950e-01 7.0710677e-01 3.8268343e-01 1.2246469e-16 -3.8268343e-01 -7.0710677e-01 -9.2387950e-01 -1.0000000e+00 -9.2387950e-01 -7.0710677e-01 -3.8268343e-01 -2.4492937e-16 3.8268343e-01 7.0710677e-01 9.2387950e-01 1.0000000e+00 9.2387950e-01 7.0710677e-01 3.8268343e-01 3.6739403e-16 -3.8268343e-01 -7.0710677e-01 -9.2387950e-01 -1.0000000e+00 -9.2387950e-01 -7.0710677e-01 -3.8268343e-01 -4.8985874e-16 3.8268343e-01 7.0710677e-01 9.2387950e-01 1.0000000e+00 9.2387950e-01 7.0710677e-01 3.8268343e-01 6.1232340e-16 -3.8268343e-01 -7.0710677e-01 -9.2387950e-01 -1.0000000e+00 -9.2387950e-01 -7.0710677e-01 -3.8268343e-01]pythonでのデータの作成
次に、
SPTKに渡すバイト列データをpythonで作成してみます。型を指定するところが結構大事です。(私はここでもハマりました)arr = np.array(range(0,5)) # 適当に数列を作る with open('test.data', mode='wb') as f: arr = arr.astype(np.float32) # float32型にする barr = bytearray(arr.tobytes()) # bytarrayにする f.write(barr)ファイルを
SPTKで読み込んで確認します。$ x2x +f < test.data | dmp +f0 0 1 1 2 2 3 3 4 4pythonとSPTKの連携
この要領でpythonで作成したnumpy.ndarrayをバイト列でファイルに保存し、そのファイルをコマンドを介して渡してやれば
SPTKでデータ処理できそうです。
試しにsin.dataを使ってちょっとやってみます。import subprocess # データを読み込み、窓関数をかけるコマンド cmd = 'x2x +f < sin.data | window -l 16' p = subprocess.check_output(cmd, shell = True) out = np.frombuffer(p, dtype='float32') print(out)[-0.0000000e+00 3.0001572e-03 2.5496081e-02 8.6776853e-02 1.8433140e-01 2.7229854e-01 2.8093100e-01 1.7583697e-01 5.6270582e-17 -1.5203877e-01 -2.0840828e-01 -1.7030001e-01 -9.3926586e-02 -3.3312235e-02 -5.5435672e-03 2.4845590e-18 1.5901955e-33 3.0001572e-03 2.5496081e-02 8.6776853e-02 1.8433140e-01 2.7229854e-01 2.8093100e-01 1.7583697e-01 1.6881173e-16 -1.5203877e-01 -2.0840828e-01 -1.7030001e-01 -9.3926586e-02 -3.3312235e-02 -5.5435672e-03 2.4845590e-18 3.1803911e-33 3.0001572e-03 2.5496081e-02 8.6776853e-02 1.8433140e-01 2.7229854e-01 2.8093100e-01 1.7583697e-01 2.8135290e-16 -1.5203877e-01 -2.0840828e-01 -1.7030001e-01 -9.3926586e-02 -3.3312235e-02 -5.5435672e-03 2.4845590e-18]より効率的なデータの受け渡し
SPTKにデータを渡すためだけにファイルを作成するなんて、なんとまぁ無駄な行為なんだろうと嘆いていたのですが、io.BytesIOなる便利なものがあるのですね。最終的にはこんなものを用意しました。
import io import shlex, subprocess from typing import List import numpy def sptk_wrap(in_array : numpy.ndarray, sptk_cmd : str) -> numpy.ndarray: ''' 入力 in_array : 波形データ sptk_cmd : sptkのコマンド(例 'window -l 16') 出力 解析後のデータ ''' # numpy.ndarrayをbytearrayに変換 arr = in_array.astype(np.float32) barr = bytearray(arr.tobytes()) bio = io.BytesIO(barr) # sptkのコマンド cmd = shlex.split(sptk_cmd) proc = subprocess.Popen(cmd, stdin=subprocess.PIPE, stdout=subprocess.PIPE) out, err = proc.communicate(input=bio.read()) return np.frombuffer(out, dtype='float32') def sptk_wrap_pipe(in_array : numpy.ndarray, sptk_cmd_pipe : List[str]) -> numpy.ndarray: ''' 入力 in_array : 波形データ sptk_cmd_pipe : sptkのコマンドをパイプしたい順にリストに格納したもの (例) cmd_list = [ 'window -l 512 -L 512 -w 2', 'spec -l 512 -o 0', ] 出力 解析後のデータ ''' out_array = numpy.copy(in_array) for l in sptk_cmd_pipe: out_array = sptk_wrap(out_array, l) return out_array # スペクトルの解析例 def ndarr2sp_ndarr(in_array : numpy.ndarray, length : int, wo : int = 2, oo : int = 0) -> numpy.ndarray: ''' 入力 : 波形データ 出力 : Logパワースペクトル オプション: wo : 窓関数のオプション(0:blackman 1:hammin 2:hanning 3:barlett) oo : 出力するスペクトルの形態(0: 20 × log |Xk| ) sptkコマンド例 window -l 512 -L 512 -w 2 | spec -l 512 -o 0 ''' cmd_list = [ "window -l {0} -L {0} -w {1} ".format(length, wo), "spec -l {0} -o {1}".format(length, oo), ] return sptk_wrap_pipe(in_array, cmd_list)2.使用例
適当な波形データを作成して実際に解析してみます。ここでは、作成するデータの周波数を変えながら、データ長さ512のサンプルを10セット作成しました。
import numpy as np import matplotlib.pyplot as plt N = 2**9 # 解析する波形のサンプル数 512 dt = 0.01 # サンプリング間隔 t = np.arange(0, N*dt, dt) # 時間軸 freq = np.linspace(0, 1.0/dt, N) # 周波数軸 samples = [] for f in range(1,11): # 作成する波形の周波数を1~10に変えながら10セットの波形サンプルを作成 wave = np.sin(2*np.pi*f*t) samples.append(wave) samples = np.asarray(samples) print(samples.shape)出力:(10, 512)
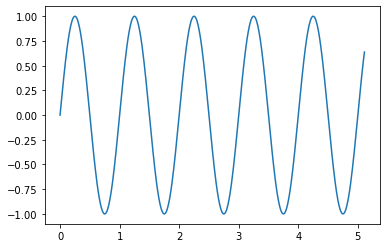
作成したデータをプロットするとこんな感じです。
1個目のデータ(周波数1Hz)
plt.plot(t, samples[0])
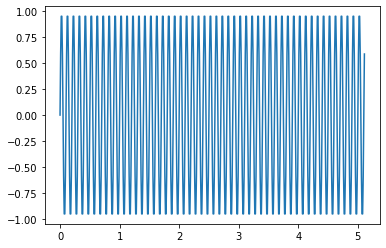
10個目のデータ(周波数10Hz)
plt.plot(t, samples[9])
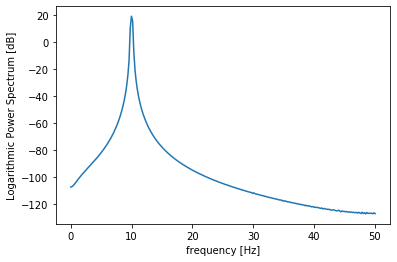
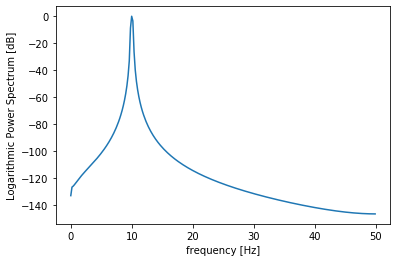
では、10個目のデータのスペクトルを
SPTKを使って解析してみます。ps = ndarr2sp_ndarr(samples[9], N) plt.plot(freq[:N//2+1], ps) plt.xlabel("frequency [Hz]") plt.ylabel("Logarithmic Power Spectrum [dB]")
複数のデータをまとめて解析することもできます。ただし、結果がフラットに連結された状態で出力されるのでリシェイプが必要です。
まずはデータセットの
shapeを確認しておく。samples_shape = samples.shape print(samples_shape)出力:(10, 512)
10個まとめて
SPTKで解析。ps_s = ndarr2sp_ndarr(samples, N) print(ps_s.shape)出力:(2570,)
リシェイプする。
ps_s = ps_s.reshape((samples_shape[0],-1)) print(ps_s.shape)出力:(10, 257)
10個目のデータ(周波数10Hz)
print(np.max(ps_s[9])) plt.plot(freq[:N//2+1], ps_s[9]) plt.xlabel("frequency [Hz]") plt.ylabel("Logarithmic Power Spectrum [dB]")出力:19.078928
3.補足
自分で解析した結果との比較を行ってみました。データ数で正規化したり窓関数の補正値を掛けたりしてみたのですが、
SPTKで解析した結果と比較するとデシベル値が微妙にズレています。理由が分からない・・・。何かアホなことをしている可能性が高いです。(どなたか詳しい方教えてください)
wavedata = samples[9] # ハニング窓をかける hanningWindow = np.hanning(len(wavedata)) wavedata = wavedata * hanningWindow # 補正係数を計算しておく acf = 1/(sum(hanningWindow)/len(wavedata)) # フーリエ変換(周波数信号に変換) F = np.fft.fft(wavedata) # 正規化 + 交流成分2倍 F = 2*(F/N) F[0] = F[0]/2 # 振幅スペクトル Adft = np.abs(F) # 窓関数を掛けた際の補正係数をかける Adft = acf * Adft # パワースペクトル Pdft = Adft ** 2 # 対数パワースペクトル PdftLog = 10 * np.log10(Pdft) # PdftLog = 10 * np.log(Pdft) print(np.max(PdftLog)) start=0 stop=int(N/2) plt.plot(freq[start:stop], PdftLog[start:stop]) plt.xlabel("frequency [Hz]") plt.ylabel("Logarithmic Power Spectrum [dB]") plt.show()出力:-0.2237693

- 投稿日:2020-06-01T21:53:22+09:00
GANで思い出の白黒写真をカラーにしたい
動機
機械学習関連ではありがちなテーマですが、白黒写真をカラー化してみたいと思います。GitHubにコードもあげて置きました。[GitHub]
先日、自分の父の遺品を改めて見返していた際に、ふと昔の白黒写真が出てきて。亡くなった当時のまま放置していたのですが、今ならこれもカラー化できると思ったのがキッカケです。技術ブログというより、個人の趣味ブログ的な感じです。尚、GANの勉強をする際に参考にさせて頂いてる方のブログ、本があります。その方の記事は非常に勉強になることばかりで、今回の記事も内容被る部分がございます。下記にリンク貼っておきますので、是非ご覧ください。
[参考URL]
Shikoan's ML Blog
モザイク除去から学ぶ 最先端のディープラーニングブログの構成
pix2pixの概要
GAN
Generator(生成器)にDiscriminator(分類器)を組み込み、両者を並行して学習していきます。GeneratorのLossにDiscriminatorの予測値を使った動的な損失関数を加えていくイメージです。GANには色々な種類があり、定義によってその分けも様々ですが、以下のような分け方が存在します。
種類 概要 Conditional GAN Genaratorのinputとoutputに関係性がある Non-Conditional GAN Genaratorのinputとoutputに関係性がない 今回のpix2pixは典型的なConditional GAN(CGAN)になります。よくGANのチュートリアルで登場するDCGANはノイズデータからoutputを生成するので、Non-Conditional GANになります。
pix2pixはCGANということもあって、inputの情報が非常に重要になってきます。例えばDCGANでは、Discriminatorとの関係で出てくるAdversarial Lossを使って、学習が進みますが、pix2pixの場合、Adversarial Lossに加え、fake画像とreal画像の差(例えばL1 lossやMSE)も使用して学習が進んでいます。そうすることで、他のGANに比べ学習の進みが早く、結果も安定しやすいという特徴があります。また逆にL1-lossだけを使用して学習する様な手法の場合、どうしても損失を少なくするために全体的にぼんやりしたOutputを出力してしまったり、平均的な画素で全体をベタ塗りしてしまったりといった感じになりやすく、Adversarial Lossを入れることで、L1lossはむしろ大きくなる可能性があってもより本物っぽい画像を出力できる様に学習が進んでいく傾向にあります。知覚品質と歪みにはトレードオフがあるという原理はGANを考えていく上で非常に重要な要素の一つです。参考: The Perception-Distortion Tradeoff (2017) [arXiv]
PatchGAN
下記、pix2pixの元論文になりますが、PatchGANについての詳細はこちらを参照するのが良いかと思います。
Image-to-Image Translation with Conditional Adversarial Networks (2016) [arXiv]
PatchGANでは、Discriminatorが画像の正誤判定を行う際に、いくつかの領域に分け、それぞれの領域で正誤判定を行う形になります。
領域を分割するといっても、実際に画像を分割し各々別個でDiscriminatorに突っ込むわけではありません。理論上はそうなのですが、実装上は1枚の画像をDiscriminatorに突っ込みその出力を2階のテンソルにします。その時、テンソルがもつ各ピクセルの値はinput画像のパッチ領域の情報を元に導き出されているため、結果的にテンソルが持つ、各ピクセルの値と実際のTrue or False(1 or 0)の間のLossをとることで、PatchGANを実現しています。言葉で説明してもよく分からないと思うので、上記のフランス国旗で例を出してみます。
fig, axes = plt.subplots(1,2) # 画像の読み込み img = cv2.imread('france.jpg') img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) img = cv2.resize(img, (600, 300)) # オリジナルサイズ -> (300, 600, 3) axes[0].imshow(img) axes[0].set_xticks([]) axes[0].set_yticks([]) img = ToTensor()(img) # (300, 600, 3) -> (3, 300, 600) img = img.view(1, 3, 300, 600) # (3, 300, 600) -> (1, 3, 300, 600) img = nn.AvgPool2d(100)(img) # (1, 3, 300, 600) -> (1, 3, 3, 6) img = nn.Conv2d(3, 1, kernel_size=1)(img) # (1, 3, 3, 6) -> (1, 1, 3, 6) img = np.squeeze(img.detach().numpy()) axes[1].imshow(img, cmap='gray') axes[1].set_xticks([]) axes[1].set_yticks([])[結果]
上記では、inputされた画像を(3, 6)サイズの特徴マップに落とし込んでいますが、これは元の画像のパッチ領域を全て(1, 1)に圧縮してることに他なりません。上記の例では
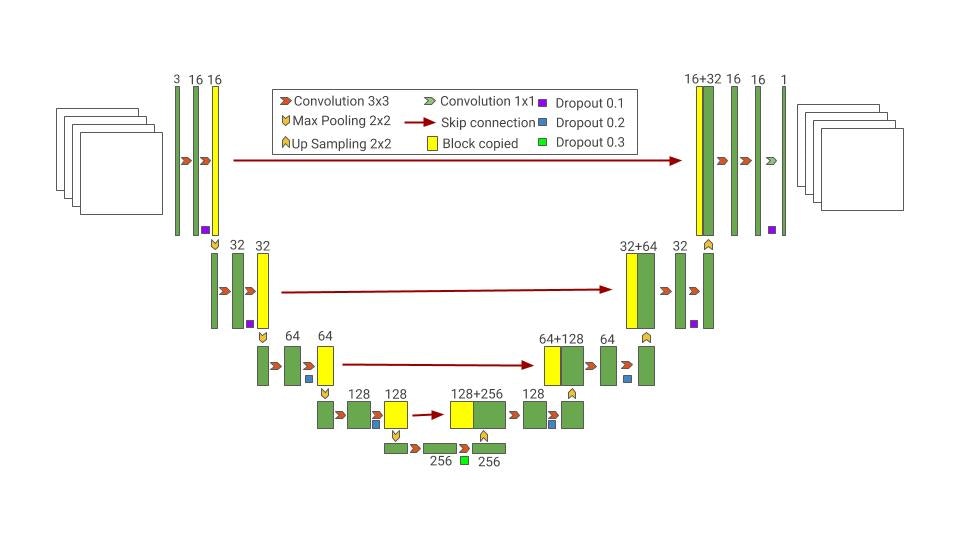
3×6=18個のピクセルに対して真偽判定を行います。Unet
pix2pixではGeneratorにU-netを使用します。Segmentationでも同じみのU-netはEncoder-Decoder構造に加え、Skip-Connectionを張ることで、入力データの情報をなるべく失わないよう工夫しています。下記が実験で使用したGeneratorのforwardメソッドですが、元々の情報を
torch.catで都度連結させていることが分かります。def forward(self, x): x1 = self.enc1(x) x2 = self.enc2(x1) x3 = self.enc3(x2) x4 = self.enc4(x3) out = self.dec1(x4) out = self.dec2(torch.cat([out, x3], dim=1)) out = self.dec3(torch.cat([out, x2], dim=1)) out = self.dec4(torch.cat([out, x1], dim=1)) return outちなみに下記のU-netのイメージは最近twitterで話題に挙がっていたGoogleが無償で公開している機械学習関連のイメージスライドになります。[ML Visuals]
良い感じの絵が沢山あるので是非一度ご覧ください。
今回のデータセットについて
Google PhotoScan
学習データとしてMIT-Adobe FiveK Datasetを使用します。こちらはimage enhance系の論文でよく使用されるもので、加工前画像とプロの編集者による加工後画像のセットになっていますが、今回はこの加工後の画像を使用します。加工後の写真に関していえば、普通のカラー写真よりも鮮やかな色彩の写真が多く、割と今回のタスクにもあってるかなと思いチョイスしました。データサイズが小さいバージョンであれば、データの容量も大きくなくダウンロードもある程度手頃です。
実際の白黒写真ですが、こちらはiPhoneの『Google PhotoScan』というアプリでデータ化しました。このアプリはググれば詳しく出てくるのですが、かなり優秀で写真屋さんに行かずとも結構綺麗にデータ化してくれます(しかも一瞬で)。元々の写真はかなり古く黄ばんでいたのですが、白黒画像に変換したところ通常の白黒画像とあまり見た目も変わらない感じでした。画像サイズ
fivekにある画像も、実際にカラー化したい画像も正方形では無く長方形で、しかも縦横比がバラバラな感じです。そこで、以下の4パターンのいずれかを採用しようと考えました。
- 一律正方形にResize
- 元々のアスペクト比を変えず正方形にReisize、空白の領域は黒く塗りつぶす
- 元々のアスペクト比を変えず正方形にReisize、空白の領域に元々の画像の情報を入れ込む。
- 縦長の画像を回転させ横長に変換後、一律同じ長方形のサイズにリサイズ
- 正方形にCrop
とりあえず今回は3の手法でいくことにしました。1と4に関しては、画像の特徴を大きく変えてしまう可能性があること、2と3に関しては、3の方が情報量が多いかなと考えたことが採用の理由です。勿論素直に行くと5番かもしれませんが、本番用写真まで正方形Cropは少し嫌なので。
尚、出力結果は後処理で元々のアスペクト比にCropします。
学習開始
その1
学習その1です。
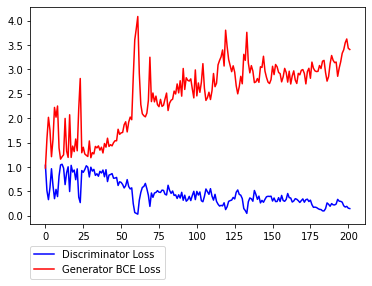
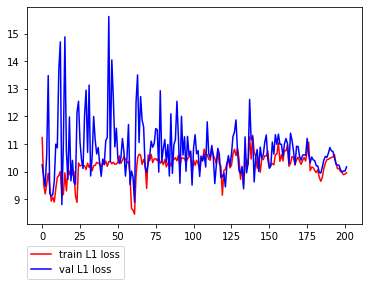
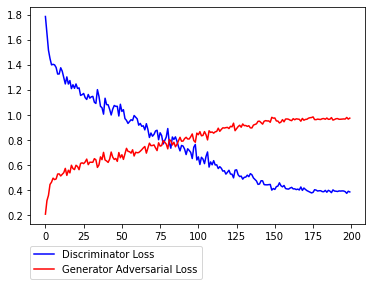
序盤暴れがちなところからスタートして徐々にDiscriminatorが強くなり、Generatorのロスが大きくなっていく様子が見て取れます。L1lossに関しては減少しているかどうかはっきりとは分からない感じです。(
L1lossが小さい=本物に近い色合い≠本物っぽいというとこがGANの評価の難しさではあります。)その2
学習その2です。学習1では、Discriminatorが強くなる傾向があったので、次は以下の点を変えてみて、実験をすることにしました。
- D,及びGのAdversarial LossをBCEからHingeLossに変更 - DのBatchNormalizationをInstanceNormalizationに変更 - Dのweight更新頻度を半減 (Gの半分)Cross entropy loss と Hinge loss
その2ではその1からの変更点として、その1で使用したbinary cross entropy から hinge loss に損失関数を変更します。その狙いはざっくり言うと、
弱いロスにすることで片一方(D or G)のネットワークが強くなりすぎるのを防ぐことにあります。
以下は、鉄板のクロスエントロピー(D version)です。D:loss = -\sum_{i=1}^{n}\bigl(y_ilogt_i - (i-y_i) log(1-t_i) \bigl)要は
target=1の時はその出力をできるだけ高く(最終層にsigmoidかますので、大きければ大きいほど1に近く)。target=0の時はその出力を負の方向に大きくするように訓練すれば、ロスが小さくなる感じです。逆にGについては上式を最大化させる様に訓練することになります。更にGの場合自ら生成した偽画像しか評価されないため、上式の左項が消えて、よりシンプルになります。
G:loss = \sum_{i=1}^{n}log\Bigl(1 - D\bigl(G(z_i))\bigl) \Bigl)\\ = -\sum_{i=1}^{n}log\Bigl(D\bigl(G(z_i))\bigl) \Bigl)一方、ヒンジ損失ですが、このサイトが分かり易いかと思います。[参考]
サイトではSVM以外にはあまり使われないと書いてますが、現在こうして他の手法に活きてくるのが、面白いです。クロスエントロピーではtargetを(0,1)と表現しましたが、ヒンジでは(-1,1)と表現します。t = ±1 \\ Loss = max(0, 1-t*y)式のまんまですが、
target=-1のときはより小さな出力を、逆にtarget=1の時は大きな出力を出せば損失が小さくて済みます。しかしクロスエントロピーと違って、ある程度でロスを0と打ち切ってしまうこともわかります。クロスエントロピーの場合、完全に(0,1)で予測しないといつまでたってもロスが消えませんが、ヒンジではそうではありません。これが弱いロスと言われる所以です。PyTorchの実装は以下の通りです。ヒンジのところはDとGによるパターン分けが面倒なので、まとめてクラス化するのが良いかと思います。# ones: 全ての値が1のpatch # zeros: 全ての値が0のpatch # Gloss(BCE) loss = torch.nn.BCEWithLogitsLoss()(d_out_fake, ones) # Gloss(Hinge) loss = -1 * torch.mean(d_out_fake) # Dloss(BCE) loss_real = torch.nn.BCEWithLogitsLoss()(d_out_real, ones) loss_fake = torch.nn.BCEWithLogitsLoss()(d_out_fake, zeros) loss = loss_reak + loss_fake # Dloss(Hinge) loss_real = -1 * torch.mean(torch.min(d_out_real-1, zeros)) loss_fake = -1 * torch.mean(torch.min(-d_out_fake-1, zeros)) loss = loss_reak + loss_fakeInstance Normalization
Instance Normalization は Batch Normalizationの派生です。Batch Normalizationも含めその内容は下記の記事に良くまとまっています。
【GIF】初心者のためのCNNからバッチノーマライゼーションとその仲間たちまでの解説
BatchNormalizationとは一つのミニバッチに含まれるデータの同チャンネル同士で標準化処理を行いますが、InstanceNormalizationでは、ミニバッチ全体でなくデータ単体で行われます。要はバッチサイズ1のBatchNormalizationです。
例えばpix2pixの派生であるpix2pixHDなどでも使われていますが、その目的は勾配の増加を抑えることで学習を収束させにくくすることにあります。これをDに適用することでDとGのバランスをとることが主たる目的になります。以下、結果になります。先ほどよりDiscriminatorの収束が明らかに遅くなっているのが分かります。また、L1lossの減少も先ほどより大きい様に感じます。
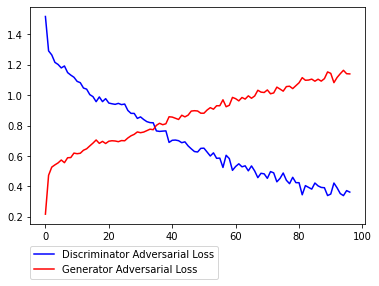
その3
学習その3は、学習1から以下の点を変更しました。
- 基本は学習1を踏襲 - 学習率を元論文に揃える。 (1e-4 -> 2e-4) - Schedulerを使った学習率の調整を削除 - 画像サイズを320から256に変更 (論文を踏襲) - PatchGANの領域数を10x10から4x4に変更 - trainの際のaugmentationにおけるBlurを削除しかしながら、殆ど1と変わらない結果に終わってしまいました。
その4
今までの結果を見るに、
自然の風景は割とカラー化できるものの、人物に関しては全然上手くいかないという傾向が見えてきました。本来の目的上これでは意味が無いので、改めて自分でデータを取得してくることに。尚、データの集め方については、以前のQiita記事でも書いたのですが、BingImageSearchを使用しました。[Qiita記事のリンク]
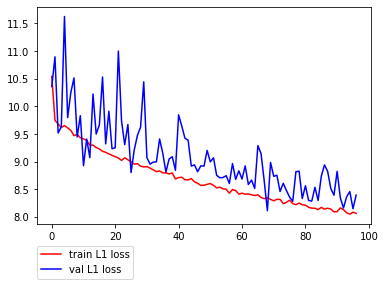
尚、その2をベースにしていますが、若干いじっています。それとデータ数がおよそ3倍(13,000枚超)程度になったため、200epochを100epochに減らしています。# 学習1からの変更点 - 学習データの追加 (fivek -> fivek+人物画像) - epoch数を200 -> 97 - D,及GのAdversarial LossをBCEからHingeLossに変更 (その2と一緒) - DのBatchNormalizationをInstanceNormalizationに変更 (その2と一緒) - Dのweight更新頻度を半減 (その2と一緒) - Schedulerを使った学習率の調整を削除 (その3と一緒) - 学習率を 1e-4->2e-4 に変更 (その3と一緒) # 出力の画素数が少し物足りなかっただけの理由、本当は良くないかも - 画像サイズの変更(320->352) (<-new) - 上記に伴い、PatchGANの領域数を(10,10)->(11,11)に変更 (<-new)以下、結果です。その2と比べ、終盤の上下動が大きいのはschedulerを削除したのが1番の原因だと思われます。
まとめ。そして肝心の写真の結果
色々、試行錯誤しましたが風景画像はかなりの割合で違和感なく着色できるのに対し、人物画像や派手なコントラストの画像(例; 人・服・花・人工物...など)はあまり着色が進まないといった傾向が分かりました。
(左:fake画像 右:real画像)
これはこれで逆に神秘的に感じてくる様な気がします。眺めていると面白い。そしていよいよ本番用のデータです。
しっかりカラー化はしてる様です(笑)一安心。。。(最後に考察)
最後のテスト画像ですが、学習&検証データよりもムラが目立つ結果になってしまいました。おそらくですがこれはそもそもの解像度の問題も多分にあるのでは無いかと、考えています。上の写真はまだ良い方で、他の白黒写真はデータ化しても結局、拡大すると輪郭はわかるものの細かなところで解像度のムラが大きく結果も残念な感じでした。なので、本格的にやろうと思ったら今度は超解像タスクも並行してやる。あるいは学習データを敢えてボカす等の工夫をする必要があるかもしれません。それは次回やる(予定です)。





























- 投稿日:2020-06-01T21:27:41+09:00
背景画像からポーズ登録を行うPGMと登録したポーズ画像とカメラ画像を比較して音楽に合わせてポーズ一致率を図るゲームのようなPGM
背景画像からポーズ登録を行うPGMと登録したポーズ画像とカメラ画像を比較して音楽に合わせてポーズ一致率を図るPGMを作成しました
参考にしたサイト
Pythonのif文による条件分岐の書き方 | note.nkmk.me
opencv - Python で cv2.imshow としても画像が表示されない - スタック・オーバーフロー
Pythonでグローバル変数とか無い、正確にはモジュール内変数。だっけ? - When it’s ready.
Python, splitでカンマ区切り文字列を分割、空白を削除しリスト化 | note.nkmk.me
Python配列のループ処理 - Qiita
Pythonのcloseメソッドの使い方を現役エンジニアが解説【初心者向け】 | TechAcademyマガジン
Pythonでファイルの読み込み、書き込み(作成・追記) | note.nkmk.me
PythonでCSVファイルを読み込み・書き込み(入力・出力) | note.nkmk.me
OpenCV 接続したカメラから動画を取得しよう (Python)
使用した音源取得サイト
音源は以下のサイトのものを使用しました
フリーのBGMとゲーム用音楽素材[Wave,MP3]
githubURL:https://github.com/NanjoMiyako/PoseAndMusicGameサンプルデータはhttps://github.com/NanjoMiyako/PoseAndMusicGameのsampleDataフォルダに置いてあります
ポーズ登録PGM、ポーズ一致度計算PGM両方とも、カメラを使用するため、
実行時にはOS?のpython実行時のカメラ起動をONに設定する必要があります。
背景画像からポーズ登録を行うPGMについて
背景画像からポーズ登録を行うPGMはposeRegist1.pyを実行することで行います。実行時には以下のコマンドライン引数を入力します
引数1:ポーズ画像保存フォルダ
引数2:ポーズエッジ画像保存フォルダポーズ登録はまずポーズ差分取得用の背景画像を登録します。
背景画像はposeRegist1.py実行時に'h'キーを押すことで行います。
得られた背景画像に対して、Diffを行うことで各ポーズの登録を行います。
Diffの実行はposeRegist1.py実行時に'd'キーを押すことで行います。ポーズ登録時には背景にはなるべく白一色のような、物のない場所でかつ、ポーズ登録対象者の服装は背景の画像より十分に差分のとれるような濃い色の服装のほうがよりしっかりとポーズ登録画像が得られるため推奨です...
登録したポーズに合わせて音楽とポーズの一致率を計算していくPGMについて
登録したポーズに合わせて音楽とポーズの一致率を計算していくPGMはPoseAndMusic.pyを実行することで行います。実行時には以下のコマンドライン引数を入力します
引数1:ポーズ画像保存フォルダ
引数2:ポーズエッジ画像保存フォルダ
引数3:ポーズフローファイルパス
引数4:再生する音楽ファイルパスポーズの流れファイルはcsvで以下のように記述します。
ポーズ名1(拡張子除く),経過時間1(秒)
ポーズ名2(拡張子除く),経過時間2(秒)
...
- 投稿日:2020-06-01T21:21:56+09:00
python2.7でmatplotlibがうまくいかない時
概要
Macのpyenv環境にある
python2でmatplotlibを使う貰い物のコードを試していると、うまくいかない。結果からいうと、
pyside2をインストールし、matplotlibのコンフィグmatplotlibrcを編集し、
backend osx
を
backend qt5agg
とすればうまくいった。環境
Mac OSX 10.15.5
Python 2.7.17(pyenvでインストール)エラー内容
python-code.py(仮名)を打つと下記の様なエラーが。Traceback (most recent call last): File "python-code.py", line 60, in <module> import matplotlib.pyplot as plt File "/Users/username/.pyenv/versions/2.7.17/lib/python2.7/site-packages/matplotlib/pyplot.py", line 115, in <module> _backend_mod, new_figure_manager, draw_if_interactive, _show = pylab_setup() File "/Users/username/.pyenv/versions/2.7.17/lib/python2.7/site-packages/matplotlib/backends/__init__.py", line 63, in pylab_setup [backend_name], 0) File "/Users/username/.pyenv/versions/2.7.17/lib/python2.7/site-packages/matplotlib/backends/backend_macosx.py", line 17, in <module> from matplotlib.backends import _macosx RuntimeError: Python is not installed as a framework. The Mac OS X backend will not be able to function correctly if Python is not installed as a framework. See the Python documentation for more information on installing Python as a framework on Mac OS X. Please either reinstall Python as a framework, or try one of the other backends. If you are using (Ana)Conda please install python.app and replace the use of 'python' with 'pythonw'. See 'Working with Matplotlib on OSX' in the Matplotlib FAQ for more information.読むと、
from matplotlib.backends import _macosxあたりが示している様に、GUIのライブラリがダメらしい。
解決策
調べてみると、よくあるエラーの様で、解決策がいくつか出てきた。
Qtを使うqt5aggでうまくいきそうだが、もう一難。
python3ではおなじみPyQt5は、python2ではつかえないらしい。代わりの物はあるらしく
pyside2というらしい。
これを入れる。pip install pyside2そして、
python -c "import matplotlib;print(matplotlib.matplotlib_fname())"で、
matplotlibrc(matplotのコンフィグファイル)のパスを調べて、42行目のbackend : macosxをコメントアウトして、
qt5aggを加える。# backend : macosx backend : qt5aggこれで、無事目的の動作をした。
めでたし。補足
なお、
Tkを使うTkaggを試したが、うまくいかず。参考
https://qiita.com/masatomix/items/03419c7ea10262da18f3
https://stackoverflow.com/questions/57238618/how-do-you-display-a-figure-in-matplotlib-using-pyside2
- 投稿日:2020-06-01T21:20:18+09:00
【あつ森】どうぶつ達の性別を予測するAIを作ったら、製作者の愛を感じた
こんにちわ???
前回記事(機械学習で住宅価格が予測できるなら「あつ森」の家具の価格も予測できるんじゃないか説)に引き続き
あつ森のデータで遊んでいると、面白い結果を発見したので、記事にしました!データ?
データは前回記事と同じ、kaggleのあつ森データセットです。
? https://www.kaggle.com/jessicali9530/animal-crossing-new-horizons-nookplaza-dataset
今回利用したのは「villagers.csv」ファイルです。
どうぶつ達のマスターデータとなっています。
以下のような列構成になっています。
インデックス 列名 タイプ ユニーク数 最頻値 最大値 最小値 平均値 標準偏差 0 Name 文字列 391 Admiral - - - - 1 Species 文字列 35 Cat - - - - 2 Gender 文字列 2 Male - - - - 3 Personality 文字列 8 Lazy - - - - 4 Hobby 文字列 6 Fashion - - - - 5 Birthday 文字列 361 1-Dec - - - - 6 Catchphrase 文字列 388 bloop - - - - 7 Favorite Song 文字列 89 Forest Life - - - - 8 Style 1 文字列 6 Simple - - - - 9 Style 2 文字列 6 Simple - - - - 10 Color 1 文字列 14 Black - - - - 11 Color 2 文字列 14 Red - - - - 12 Wallpaper 文字列 154 backyard-fence wall - - - - 13 Flooring 文字列 128 backyard lawn - - - - 14 Furniture List 文字列 391 10742;10742;~ - - - - 15 Filename 文字列 391 ant00 - - - - 16 Unique Entry ID 文字列 391 25GGGSHzwEnKmepJk - - - - 答え合わせ用に一見性別がどっちかわからなそうな、どうぶつ数体分のデータを抜き取っておきます。
ビジュアライズでデータをみてみよう⭐️
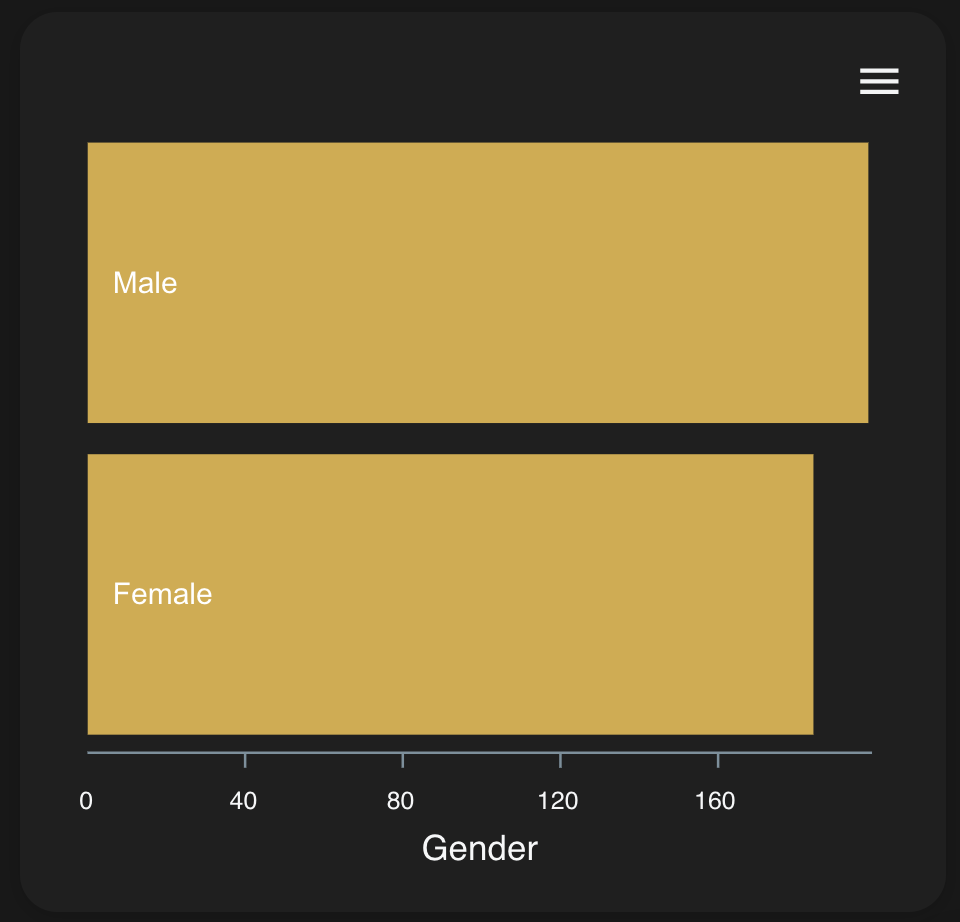
男女比
Male: 199
Female: 185
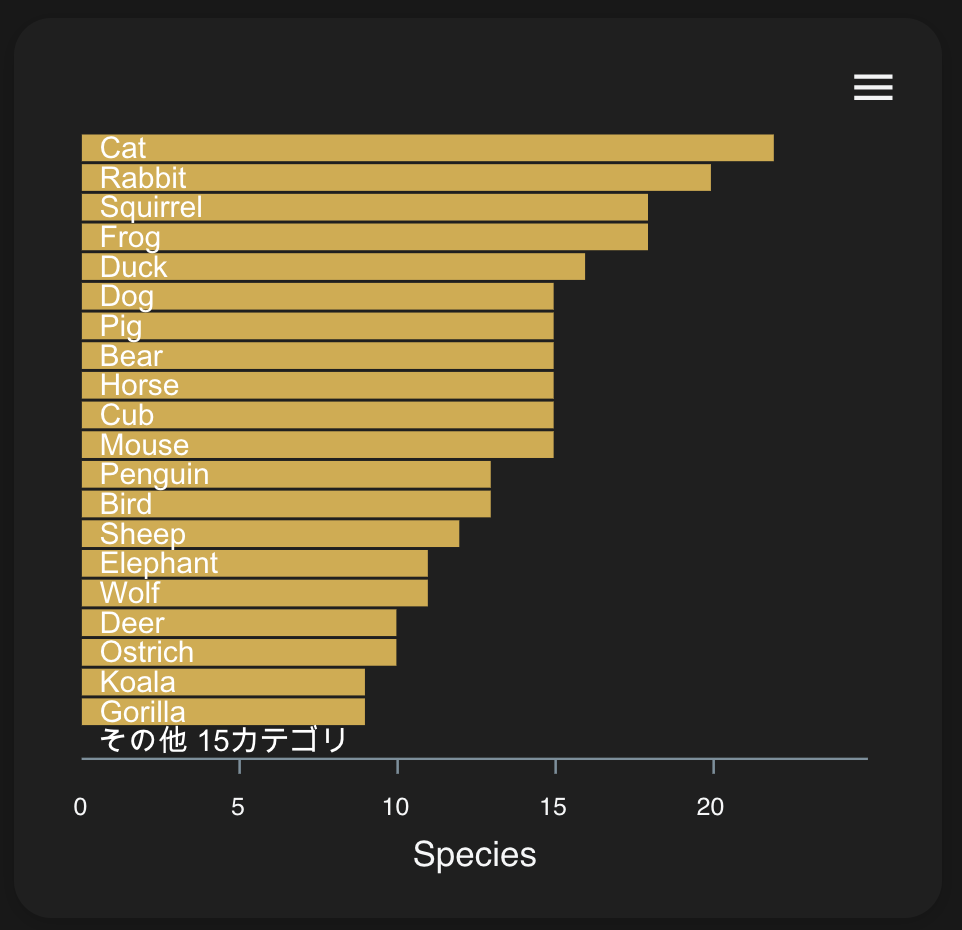
と大体均衡になってます。種族の分布
猫、うさぎ、リスってモロ人気出そうなあざと可愛い系キャラがおおくなっとる?
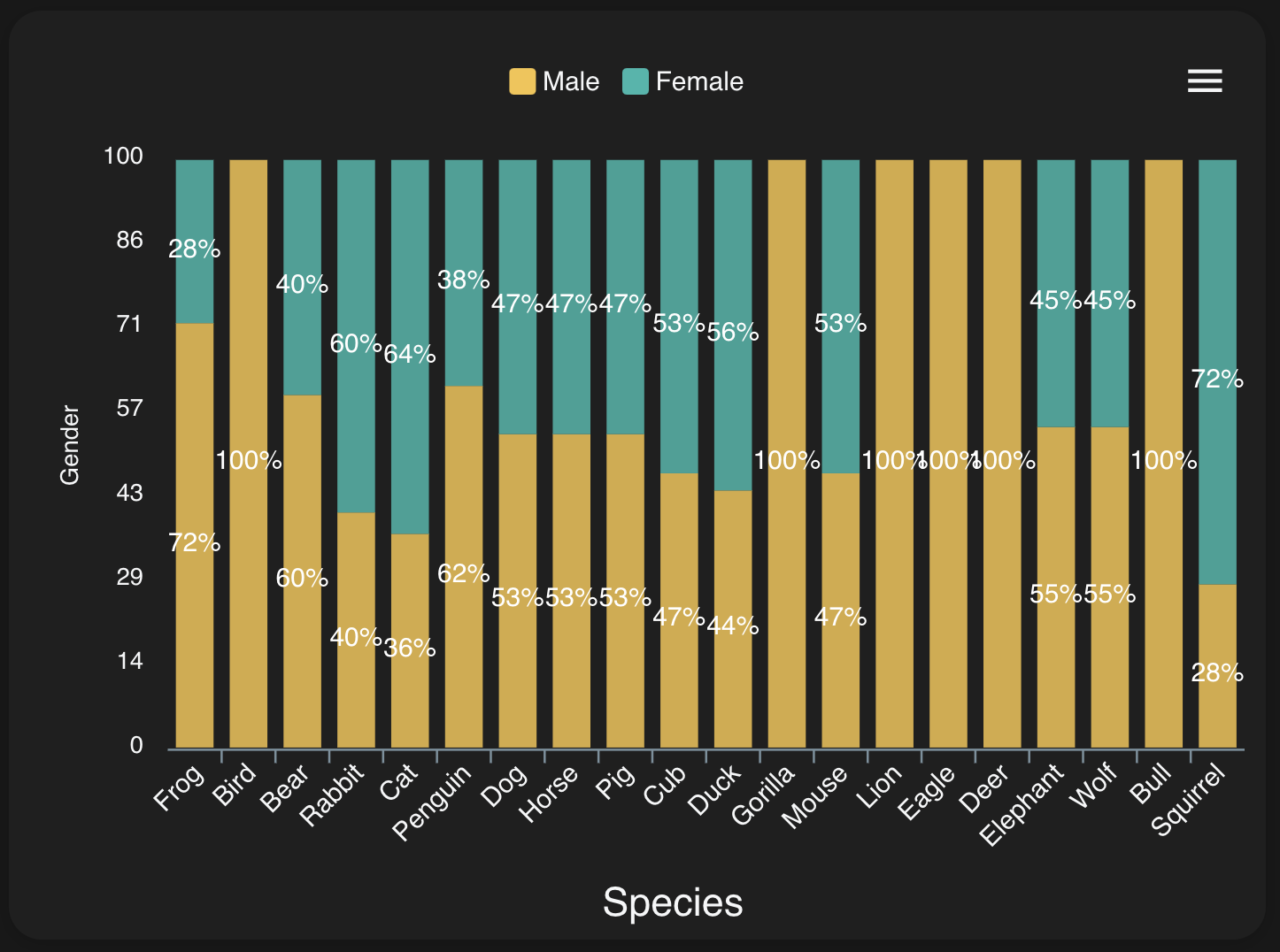
こういうことを平然とやってのけるNintendo、おそるべし。相関関係も見てみましょう!
ゴリラ男しかいないんかいw
結構種族によって男女比はバラバラなんですね。
他の列も結構カテゴリによって男女比はばらつきがある模様。オートで学習?
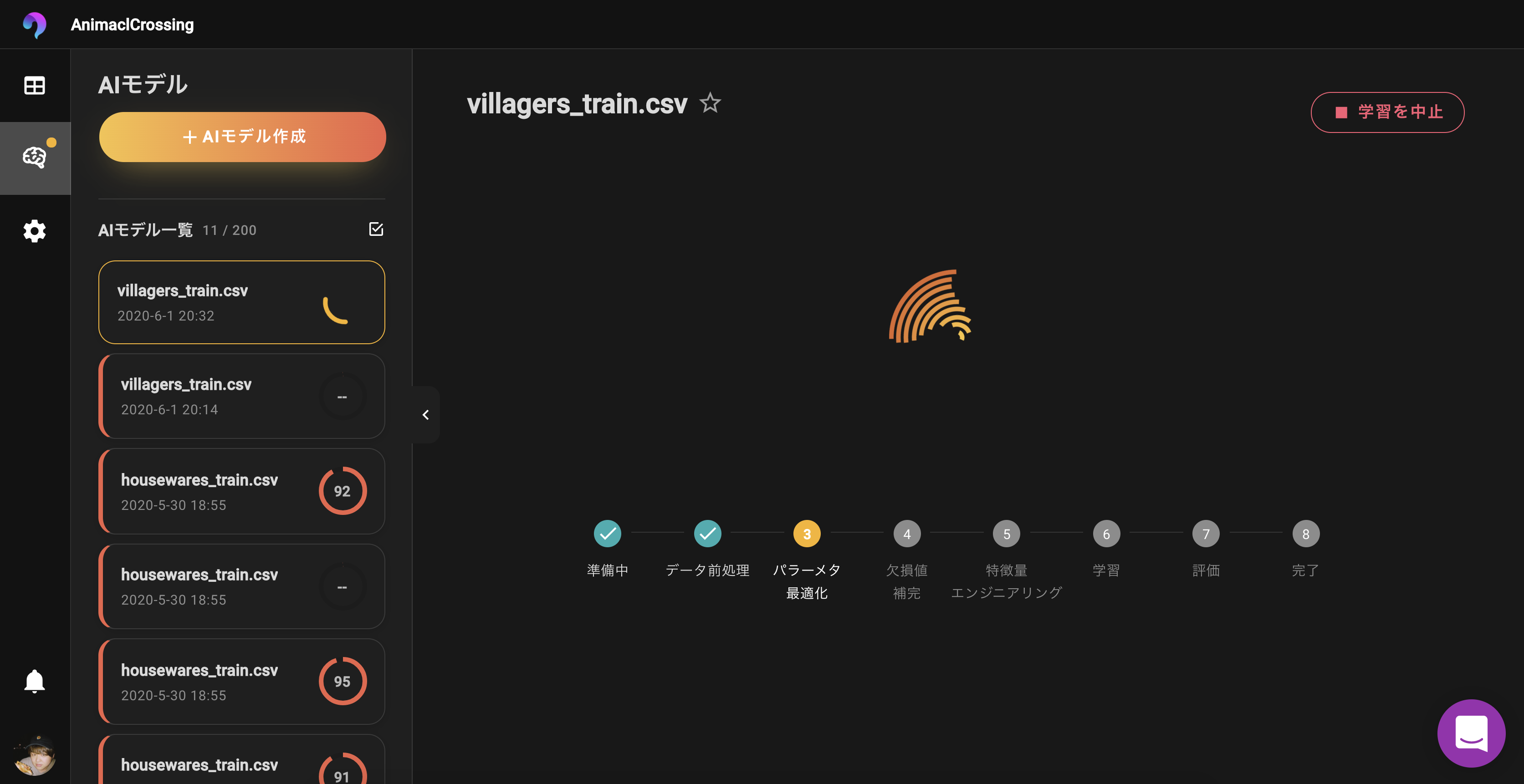
まずは学習に利用しない列を選びます。
Name, Filename, Unique Entry IDなどは固有値になってるので削除!学習スタート?
約2分ほどで学習完了しました。
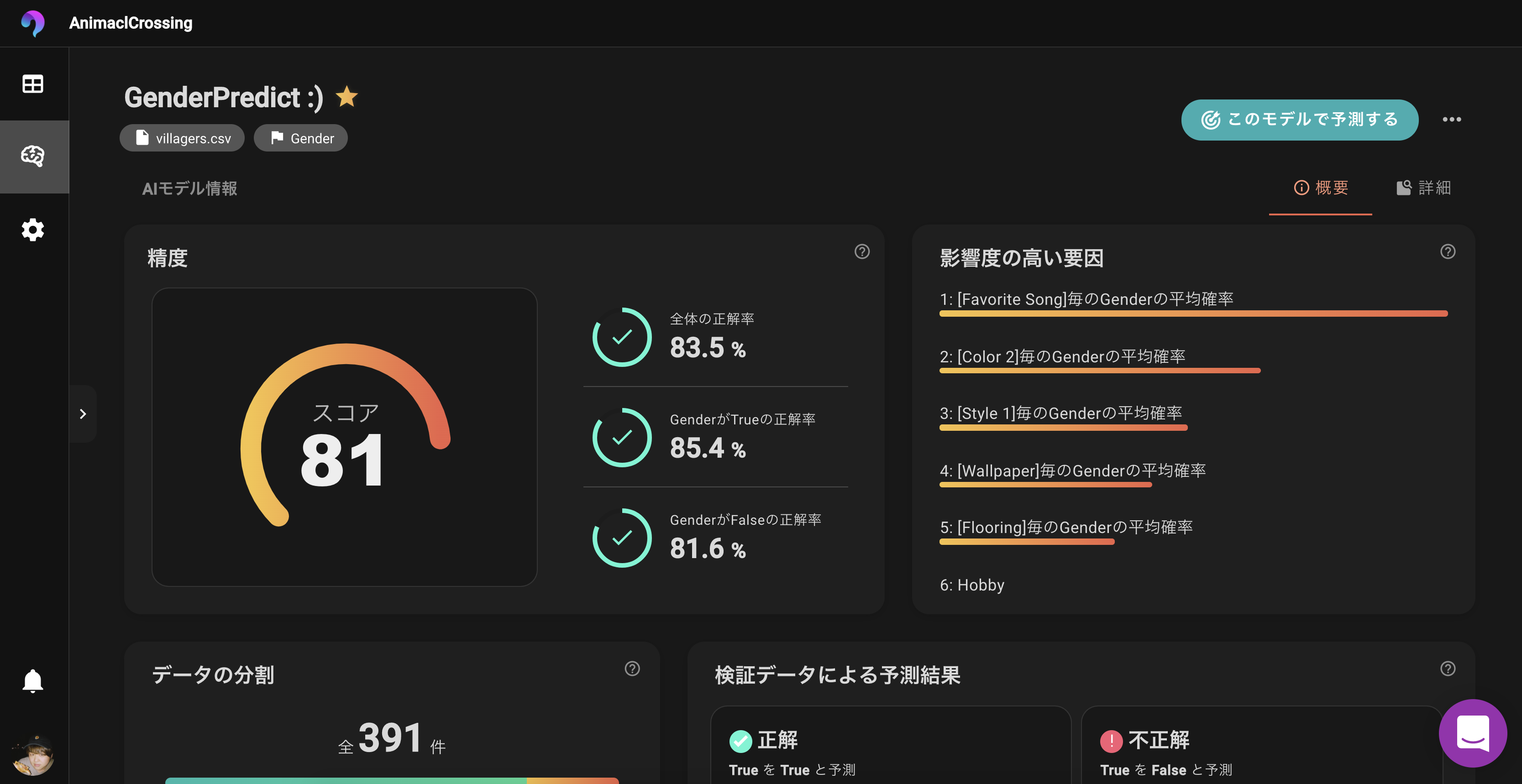
スコアは81となかなかですね!
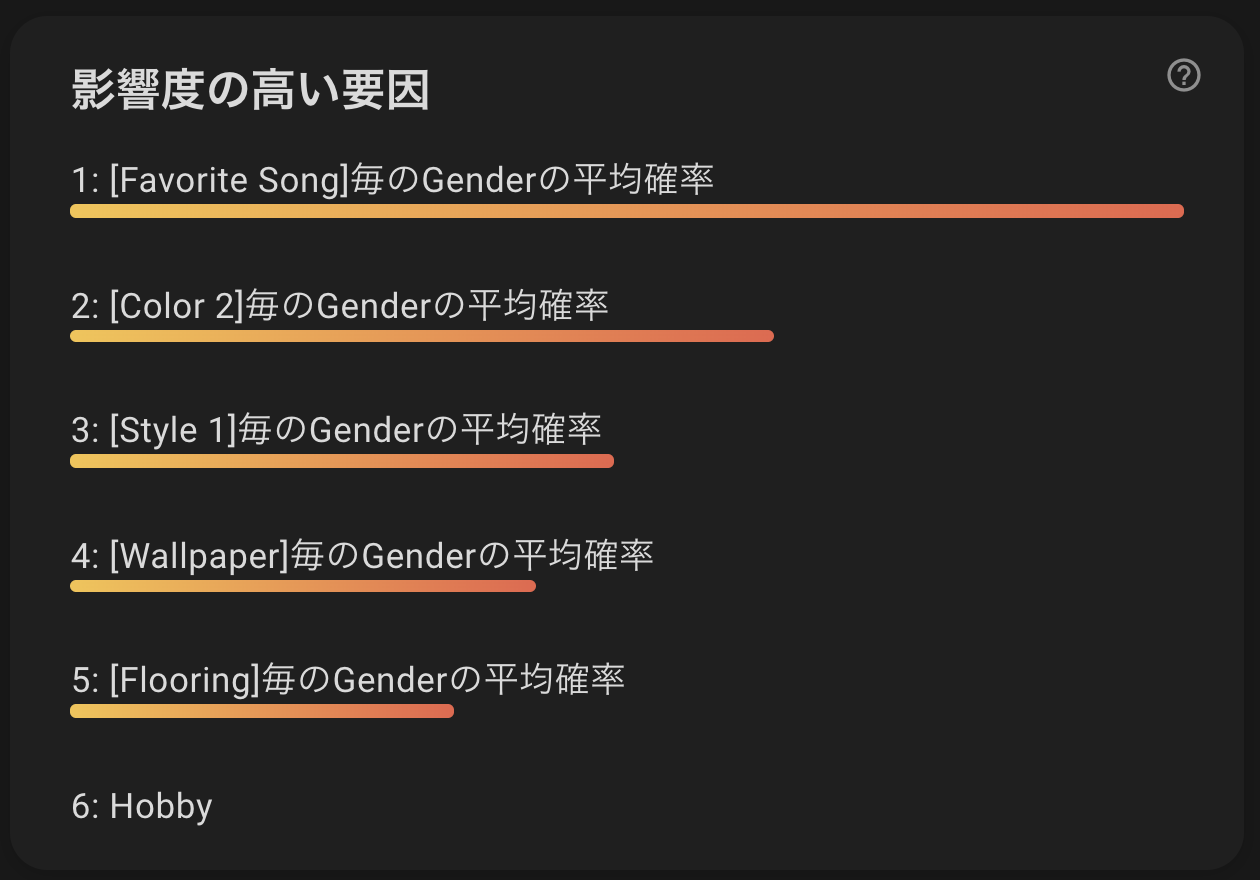
精度も80%超えているため、いい感じの精度のモデルが出来上がりました。影響度の高い要因を確認してみると...?
すげーリアルな趣味趣向で男女が分けられてやがるっ!!!
影響度の高い要因をみてみましょう
影響度ランキング1位はなんと、「好きな曲」!!
そうか、女子は女子らしい曲、男は男らしい曲がみんな好きなわけか!!
村人に、「好きな曲何?」って聞いたらだいたい性別が推測できちゃうわけかーーー
確かに中学の頃とか男はみんなBUMPが好きだし、女はみんな倖田來未が好きだったわ。そして、2位は「2番目の色」
1番目の色じゃねーーの?と思いました。
顔のメインカラーは白で、それに青がポイントであると男の子っぽいし
ピンクが乗ってると女の子っぽいって感じなのでしょうか3位は「スタイル1」
スタイル1とは、好きな家具や服の好みで、シンプル・クール・アクティブ・ゴージャスなどがあります。
これも納得ですね。
人間も趣味趣向で、だいたい男女わかりますもんね。その他の結果
こんな感じでした。
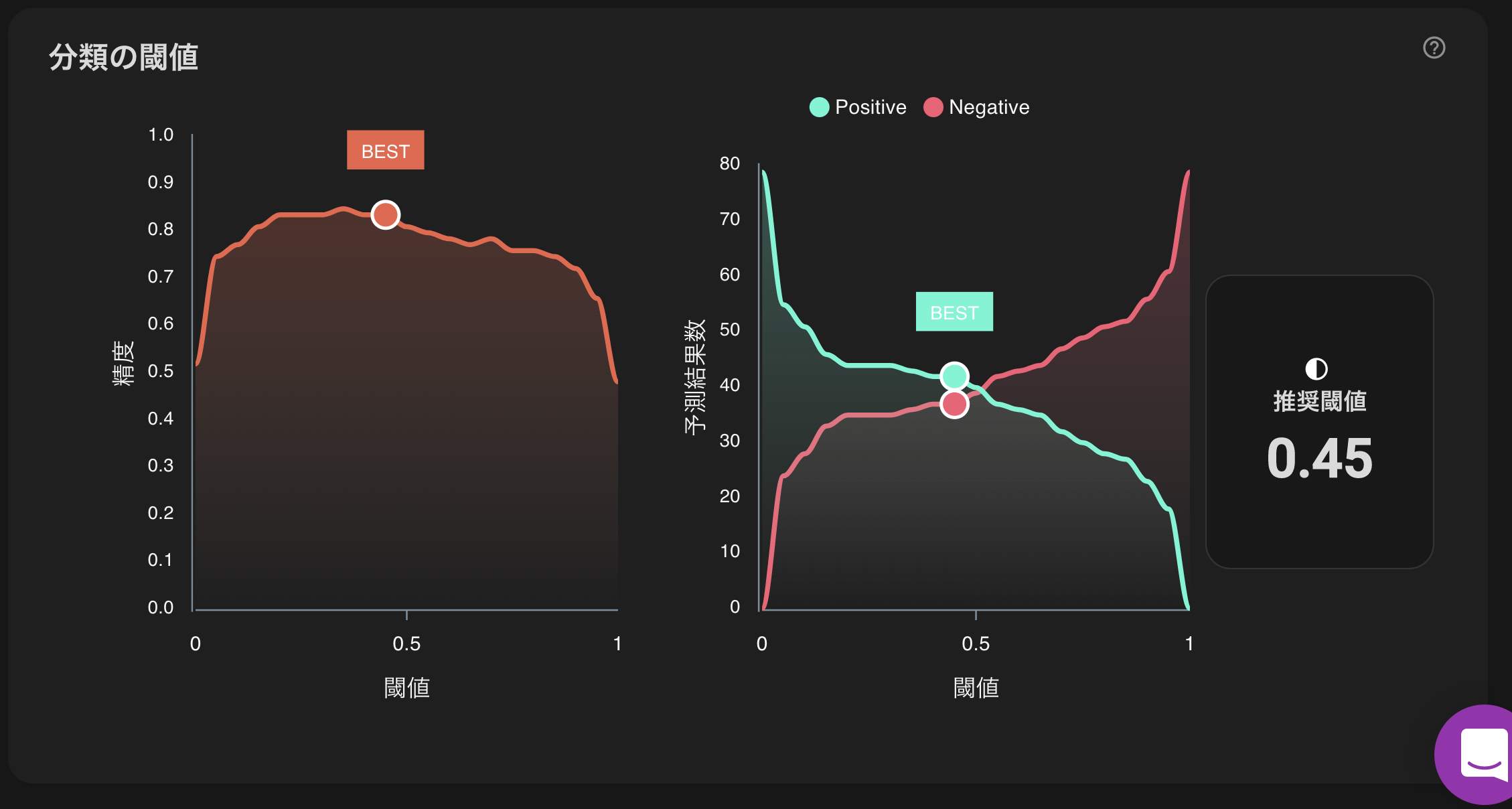
混同行列
閾値
モデルによる予測と答え合わせ?♂️?♂️
男女がわかりづらいこいつらをAIによって、白黒はっきりさせてあげましょう。
エントリーナンバー1「1ごう」
赤レンジャーってことはおそらく男なんだろうが、仮面とタイツのせいでわかりづらい!
ということで予測します!
正解: 「男の子」
予測結果: 87%の確率で「男の子」
⭕️ 正解エントリーナンバー2「ジュペッティ」
一見男の子っぽさもあるが、化粧がハートってのもあり、女の子にも見えます。
正解: 「男の子」
予測結果: 86%の確率で「女の子」
❌ 大はずれ
サブカラーが「赤」、スタイル2が「シンプル」と女の子に多い特性だったのか??エントリーナンバー3「ラッキー」
顔が見えんw
正解: 「男の子」
予測結果: 97%の確率で「男の子」
⭕️ 正解
見た目はあれだが、あからさまな男の子の趣味だったのだろうエントリーナンバー4「マグロ」
うーーーん、実に微妙な容姿。髪型とか見ると男っぽさもあるが、全体はピンクで可愛いし
正解: 「女の子」(女の子でこの名前はちょっと問題あるんじゃねーの?)
予測結果: 97%の確率で「女の子」
⭕️ 正解
趣味が「ファッション」、スタイル1が「シンプル」、スタイル2が「キュート」まあいかにも女の子な中身だったんですね。まとめ
いやーー、あつ森スタッフのキャラへの愛情がよくわかります。
それぞれのキャラに、ちゃんとこの子は女の子でこういう性格だからこの曲が好きで、この壁紙が好きでと
ちゃんとそのどうぶつ目線でマスターデータを作っていると思うと、感動します。
ゲームバランスやバグには関係ないことにここまで時間と労力をかけて世界観を作り出していることは本当に称賛に値します。みなさんも、データで遊んでみては??
? https://www.kaggle.com/jessicali9530/animal-crossing-new-horizons-nookplaza-dataset
? https://www.varista.ai





- 投稿日:2020-06-01T21:13:37+09:00
Pandas練習問題(編集中)
下書き
# -*- coding: utf-8 -*- import pandas as pd import numpy as np # ファイルパス定義 IN_FPATH = "./input/q1_input.csv" OUT_FPATH = "./output/q1_output.csv" # ファイルの読み込み df = pd.read_csv(IN_FPATH) df.date = pd.to_datetime(df.date) # q1-1) # 前回フェーズ列を追加せよ df_pre_phase = df.phase.copy() df_diff_phase = df.phase.diff() df_pre_phase = df_pre_phase - df_diff_phase df_pre_phase[ df_diff_phase == 0 ] = np.nan df_pre_phase = df_pre_phase.fillna(method='ffill') df["pre_phase"] = df_pre_phase # 前々回フェーズ列を追加せよ df_pre_pre_phase = df.pre_phase.copy() df_diff_phase = df.pre_phase.diff() df_pre_pre_phase = df_pre_pre_phase - df_diff_phase df_pre_pre_phase[ df_diff_phase == 0 ] = np.nan df_pre_pre_phase = df_pre_pre_phase.fillna(method='ffill') df["df_pre_pre_phase"] = df_pre_pre_phase # q1-2) # フェーズ4→5へ遷移した日を"1"にした列を追加せよ df_phase4_5 = df.phase.copy() df_diff_phase = df.phase.diff() df_phase4_5[ df.phase!=5 ] = 0 #np.nan df_phase4_5[ (df.phase==5) & (df_pre_phase==4) ] = 1 df_phase4_5[ df_diff_phase != 1 ] = 0 #np.nan df["Phase4_5"] = df_phase4_5 # q1-3) # フェーズ5→6へ遷移した日を"1"にした列を追加せよ df_phase5_6 = df.phase.copy() df_diff_phase = df.phase.diff() df_phase5_6[ df.phase!=6 ] = 0 #np.nan df_phase5_6[ (df.phase==6) & (df_pre_phase==5) ] = 1 df_phase5_6[ df_diff_phase != 1 ] = 0 #np.nan df["Phase5_6"] = df_phase5_6 # q1-4) # フェーズが5→6へ遷移する度にカウントアップする列を追加せよ df_5_6_countup = df_phase5_6.cumsum() df["5_6_countup"] = df_5_6_countup # q1-5) # フェーズが5→6へ遷移する度にカウントアップする列を追加せよ # ただし、フェーズが4→5へ遷移したときにカウントを0クリアせよ df_phase4_5_counter = df_5_6_countup.copy() df_phase4_5_counter[ df_phase4_5==0 ] = np.nan df_phase4_5_counter = df_phase4_5_counter.fillna(method='ffill') df_5_6_counter_phase4_clear = df_5_6_countup - df_phase4_5_counter df["5_6_countup_4clear"] = df_5_6_counter_phase4_clear # q1-6) # フェーズ5の累積時間の列を追加せよ # ただし、前回フェーズが4の場合は累積から除外する df_phase5_erapsed = df.date.copy() df_diff_phase = df.phase.diff() df_phase5_erapsed[ (df.phase!=5)|(df_diff_phase==0) ] = np.nan df_phase5_erapsed = df_phase5_erapsed.fillna(method='ffill') df_phase5_erapsed = df_phase5_erapsed.fillna(method='bfill') df_phase5_erapsed = df.date - df_phase5_erapsed df_phase5_erapsed = df_phase5_erapsed.dt.total_seconds() df_phase5_erapsed[ (df_phase5_6!=1) ] = np.nan df["phase5_erapsed"] = df_phase5_erapsed df["phase5_erapsed_1st"] = df_phase5_erapsed[df_pre_pre_phase==4] df_phase5_erapsed_cumsum = df_phase5_erapsed.copy() df_phase5_erapsed_cumsum = df_phase5_erapsed_cumsum.cumsum() df_phase5_erapsed_cumsum_st = df_phase5_erapsed_cumsum.copy() df_phase5_erapsed_cumsum_st[ (df["Phase5_6"]!=1)|(df["df_pre_pre_phase"]!=4) ] = np.nan df_phase5_erapsed_cumsum_st = df_phase5_erapsed_cumsum_st.fillna(method='ffill') df_phase5_erapsed_cumsum_st = df_phase5_erapsed_cumsum_st.fillna(0) df_phase5_erapsed_cumsum = df_phase5_erapsed_cumsum - df_phase5_erapsed_cumsum_st df["phase5_erapsed_cumsum"] = df_phase5_erapsed_cumsum df["phase5_erapsed_cumsum"] = df["phase5_erapsed_cumsum"].fillna(method="ffill") df["phase5_erapsed_mean"] = df["phase5_erapsed_cumsum"]/(df["5_6_countup_4clear"]-1) df["phase5_erapsed_mean"] = df["phase5_erapsed_mean"].fillna(method="ffill") # q1-7) # フェーズ6の累積時間の列を追加せよ df_phase6_5 = df.phase.copy() df_phase6_5[ df.phase!=5 ] = 0 df_phase6_5[ (df.phase==5) & (df_pre_phase==6) ] = 1 df_phase6_5[ df_diff_phase != -1 ] = 0 #np.nan df_phase6_erapsed = df.date.copy() df_diff_phase = df.phase.diff() df_phase6_erapsed[ (df.phase!=6)|(df_diff_phase==0) ] = np.nan df_phase6_erapsed = df_phase6_erapsed.fillna(method='ffill') df_phase6_erapsed = df_phase6_erapsed.fillna(method='bfill') df_phase6_erapsed = df.date - df_phase6_erapsed df_phase6_erapsed = df_phase6_erapsed.dt.total_seconds() df_phase6_erapsed[ (df_phase6_5!=1) ] = np.nan df_phase6_erapsed_cumsum = df_phase6_erapsed.cumsum() df_phase6_erapsed_cumsum_st = df_phase6_erapsed_cumsum.copy() df_phase6_erapsed_cumsum_st = df_phase6_erapsed_cumsum_st.fillna(method='ffill') df_phase6_erapsed_cumsum_st = df_phase6_erapsed_cumsum_st.fillna(0) df_phase6_erapsed_cumsum_st[ (df["Phase5_6"]!=1)|(df["df_pre_pre_phase"]!=4) ] = np.nan df_phase6_erapsed_cumsum_st = df_phase6_erapsed_cumsum_st.fillna(method='ffill') df_phase6_erapsed_cumsum_st = df_phase6_erapsed_cumsum_st.fillna(0) df["phase6_erapsed_cumsum"] = df_phase6_erapsed_cumsum - df_phase6_erapsed_cumsum_st df["phase6_erapsed_cumsum"] = df["phase6_erapsed_cumsum"].fillna(method="ffill") df["phase6_erapsed_mean"] = ( df_phase6_erapsed_cumsum - df_phase6_erapsed_cumsum_st )/(df["5_6_countup_4clear"]) df["phase6_erapsed_mean"] = df["phase6_erapsed_mean"].fillna(method="ffill") # ファイル出力 df.to_csv(OUT_FPATH, encoding="shift-jis")
- 投稿日:2020-06-01T21:08:06+09:00
Pythonでメール(msgファイル)を読み込む
以前の記事ではOutlookからフォルダとメールの情報を読み込む方法を紹介しました。
PythonでOutlookのメールを読み込む
https://qiita.com/konitech913/items/8a285522b0c118d5f905ここまでしなくても、単独のメールデータ(msgファイル)を読み込んで、メール内の情報を読み込みたいというケースがあると思います。
例えば、「問い合わせのメール」をmsgファイルとして自分のPCのとあるフォルダに保存しておいて、そのファイルから情報を抜き出しExcelに書き写したい場合などです。
msgファイルをPythonで読み込む
outlookを操作するためにはwin32com.clientをimportする必要があります。
私はAnacondaを使っていますが、特に追加でインストールしなくてもimportできました。import win32com.client次にOutlookのオブジェクトを作成します。
outlook = win32com.client.Dispatch("Outlook.Application").GetNamespace("MAPI")そして、
OpenSharedItem("xxx.msg")というメソッドを使って、対象のmsgファイルを読み込みます。
ここでは「これはテストです.msg」というファイルを読み込みます。mail = outlook.OpenSharedItem("これはテストです.msg")このmailがメールを表すインスタンスです。属性の意味は下表の通り。
属性 意味 mail.subject 件名 mail.sendername 差出人名 mail.senderEmailAddress 差出人のメールアドレス mail.receivedtime 受信日時 mail.body 本文 mail.Unread 未読フラグ print("件名: " ,mail.subject) print("差出人: %s [%s]" % (mail.sendername, mail.senderEmailAddress)) print("受信日時: ", mail.receivedtime) print("未読: ", mail.Unread) print("本文: ", mail.body)実行結果件名: これはテストです 差出人: ***[*********@gmail.com] 受信日時: 2020-05-30 07:17:33+00:00 未読: False 本文: ちゃんと受け取れてますか?ちゃんと読み込めていますね。
- 投稿日:2020-06-01T20:46:40+09:00
Pythonを学習するためのWeb教材
Pythonを独学で学習するためのWebの教材をご紹介します。
@IT「Python入門」 Deep Insider編集部 かわさきしんじ
この記事は53回にも及ぶ長編で、Pythonをきっちり学ぶことができる記事だと思います。Python-izm
すでに他の言語でのプログラミング経験がある方が、Pythonの特徴を捉えつつ学ぶように書かれていると思います。実践的な事も記載してあります。
- 投稿日:2020-06-01T20:29:37+09:00
Anaconda環境構築で ll load failed: 指定されたモジュールが見つかりません。(import numpyas np file....) のエラーを解決したのでメモ
前書き
新社会人になり就活前に途中まで行っていた「Pythonではじめる機械学習」を再開しました。
パソコンも変えて久しぶりのAnacondaを動かそうとしたときエラーがでました。
以前勉強していたコードが動かなくなったので解決策を初投稿します。問題
import numpy as np file "c:\programdata\anaconda3\lib\site-packages\numpy_init_.py", line 140, in from . import _distributor_init file "c:\programdata\anaconda3\lib\site-packages\numpy_distributor_init.py", line 34, in from . import _mklinit importerror: dll load failed: 指定されたモジュールが見つかりません。
と表示される。
numpyなどはAnacondaに作った環境で動くはずなのにと勉強再開してすぐに躓きました。原因
新しいPCにしたことでPathが通っていませんでした。
昔の自分はPathを通す作業をしていたんだと感心。てっきり環境構築の手順から忘れ去られていました。解決策
- windowsマークをクリック
- 環境変数を編集
- (ユーザー名)のユーザー環境変数(U)の中にあるPATHをクリック
新規(N)をクリック
C:\Users(ユーザー名)\Anaconda3\
C:\Users(ユーザー名)\Anaconda3\Scripts\
C:\Users(ユーザー名)\Anaconda3\Library\bin
を追加するおわりに
これからは調べて分かったことは自分なりにまとめて投稿しようと思います。
早く会社の仕事が自由にこなせるように頑張ります。
- 投稿日:2020-06-01T20:29:37+09:00
不偏推定量と一致推定量
※細かいことを読むのが面倒な方や時間が惜しい方はここから読んで頂ければなと思います。
Twitterで「不偏推定量難しい...一致推定量っていうのもあるけど何が違うの?」みたいなのを観測し、そういえば自分も統計学を勉強し始めた時に同じような疑問を長らく抱えていたのを思い出しました1。
Google先生に「不偏推定量 一致推定量」と尋ねると、4万件弱ヒットするようです。その中に自分の拙い記事を加えたところで、どれほど価値があるのか、かなり微妙な感じがするのですが、まぁいいかということで書いていきます。
他サイトの解説とはちょっとテイストを変えているので、もしかしたらこの記事で腑に落ちる人もいるかもしれないですしね。
では、さっそく始めていきます。
■ そもそも何で統計量の性質なんて考えるの?
例えば、平均の推定を考えると、標本平均や中央値、刈り込み平均などたくさんの選択肢があります。このように、あるパラメータ(平均とか分散とか)の値を推定したい時には、様々な選択肢があることが一般的です。
では、様々な選択肢がある中でどの方法を用いれば良いのか?つまり、良い推定とは一体何なのかということが問題になってきます。
不偏性や一致性は、そのような問題を考える際にひとつの基準となります。2
■ 一応、定義を見ておく。。。
おそらく、この記事にたどり着くまでに散々一致性と不偏性の定義を見てきていて、定義の話はもういいから腑に落ちる説明をくれという気持ちになっていると思うのですが、一応自分用のメモでもあるので。。。。
◆一致性
一致性にも実は色々あるのですが、ここでは弱一致推定量と強一致推定量を紹介します。とりあえず、違いは分からなくて大丈夫です。「なんかあるわー」ぐらいに思ってください。
・弱一致推定量
推定量の列 $\{T_n\}$ が、全ての $\varepsilon>0$ と全ての $\theta \in \Theta$ で、
\lim_{n→\infty}P\,(\,|\,T_n-\theta\,|\,≧\varepsilon \,)\,=0ならば、$T_n$ を $\theta$ の弱一致推定量と呼びます。
・強一致推定量
推定量の列 $\{T_n\}$ が、全ての $\theta \in \Theta$ で、
P(\,\lim_{n→\infty}T_n=\theta)=1ならば、$T_n$ を $\theta$ の強一致推定量と呼びます。
違いがものすごく気になる方は、『統計学への確率論,その先へ』の4.2 様々な確率的収束の概念とその強弱(P125)を読むといいと思います。
◆不偏性
不偏とは、文字通り偏っていないということなのですが、「偏っていない」とは一体なんなのでしょうか。統計学における偏りは次のようなものです。
・偏り(バイアス)
偏り(バイアス)は推定量の平均が、推定されているパラメータとどのくらい離れているのかを表すものです。数式で書くと次のようになります。
パラメータ $\theta$ の推定量を $T(X)$ とすると、偏りは
E\,[\,T(X)\,]-\thetaと定義されます。
おそらく、バイアスという言葉の方がよく使われると思うのですが、不偏(の「偏」)に合わせて今回は偏りという言葉の方を使うことにします。
・不偏性
上述のように偏りは、$E\,[\,T(X)\,]-\theta$ と定義されます。不偏であるとは、偏っていないということなので、
E\,[\,T(X)\,]-\theta=0であればよいということです。$\theta$ を右辺に移行すれば、
E\,[\,T(X)\,]=\thetaとなります。これを満たす推定量 $T(X)$ をパラメータ $\theta$ の不偏推定量といいます。
■ 時間が惜しい人はここから。
細かい話はいいからという人はここから読んで下さい。
おそらく最も目にした不偏推定量の例は不偏分散であり、しかもちゃんと手計算で標本分散の期待値を確認したと思います。
ここではシミュレーションでどんなもんなのかを確認していきます。
◆標本分散
標本分散は、
\frac{1}{N} \sum_{i=1}^{N} (X_i-\bar{X})^{\,2}で定義されます。よくご存じのように標本分散は、不偏推定量ではありません。つまり、標本分散による分散の推定は、平均を取ると偏ります。
これを体験してみましょう。
★標本分散の偏りを体験する。
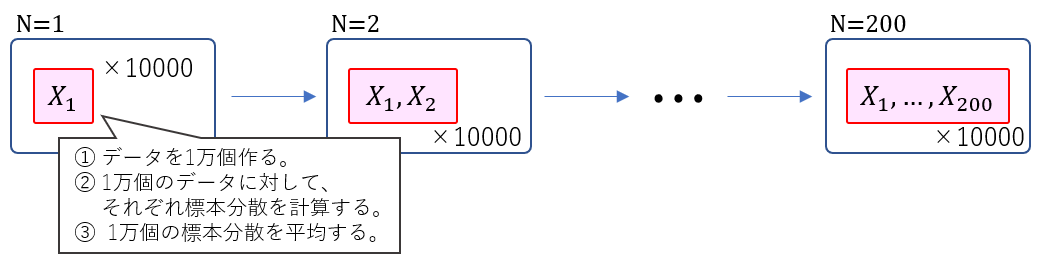
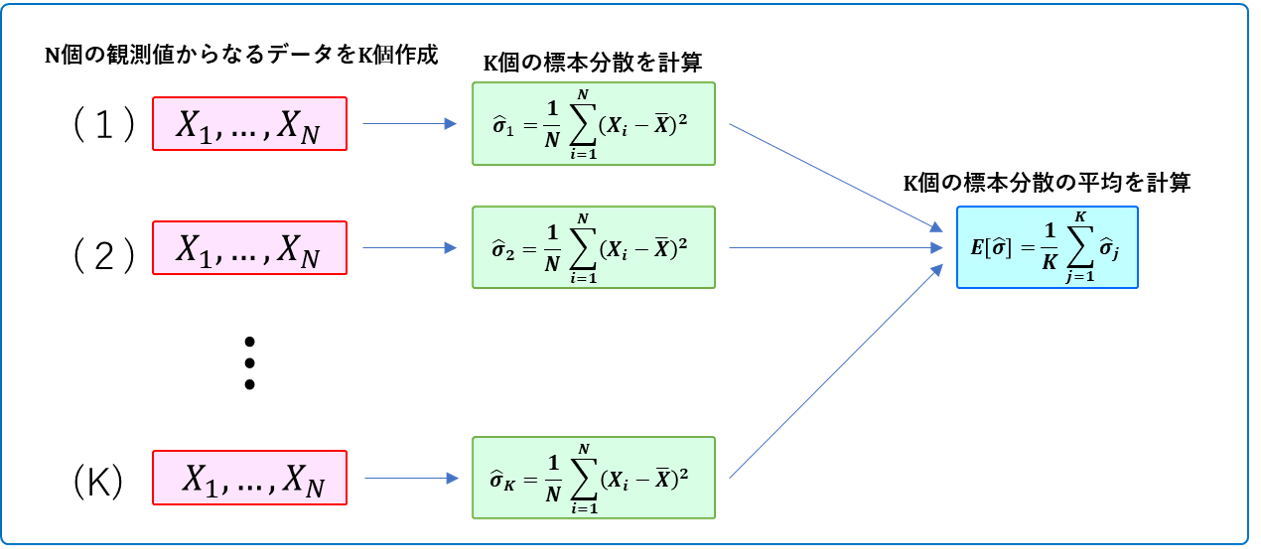
今、真の平均が $10$、真の分散が $25$ である正規分布から独立に $N$ 個の観測値が得られたとします。
X_1,X_2,...,X_N \stackrel{i.i.d}{\sim} N(10,5^2)この$N$ 個の観測値を使って、分散を標本分散で推定します。そして、各 $N$ ごとに、「データを抽出→標本分散を計算」を10000回繰り返します。この10000個の標本分散の平均値を、各 $N$ における標本分散の期待値の推定値とします。
なにごちゃごちゃ言ってんだよ?わかんねぇよ?という方はこの図を。。。
吹き出し内の意味が分からないよという人はこちらを。。。
この図でいうところの $K$ が今回は10000ということです。
※分かりにくかったら図を作り直すのでコメント下さい(><)
(そういえば最近顔文字を使う人を見なくなりましたね)コードに起こすとこんな感じ。「コードなんてどうでもいいぜ」っていう人は、その下のグラフを見て下さい。
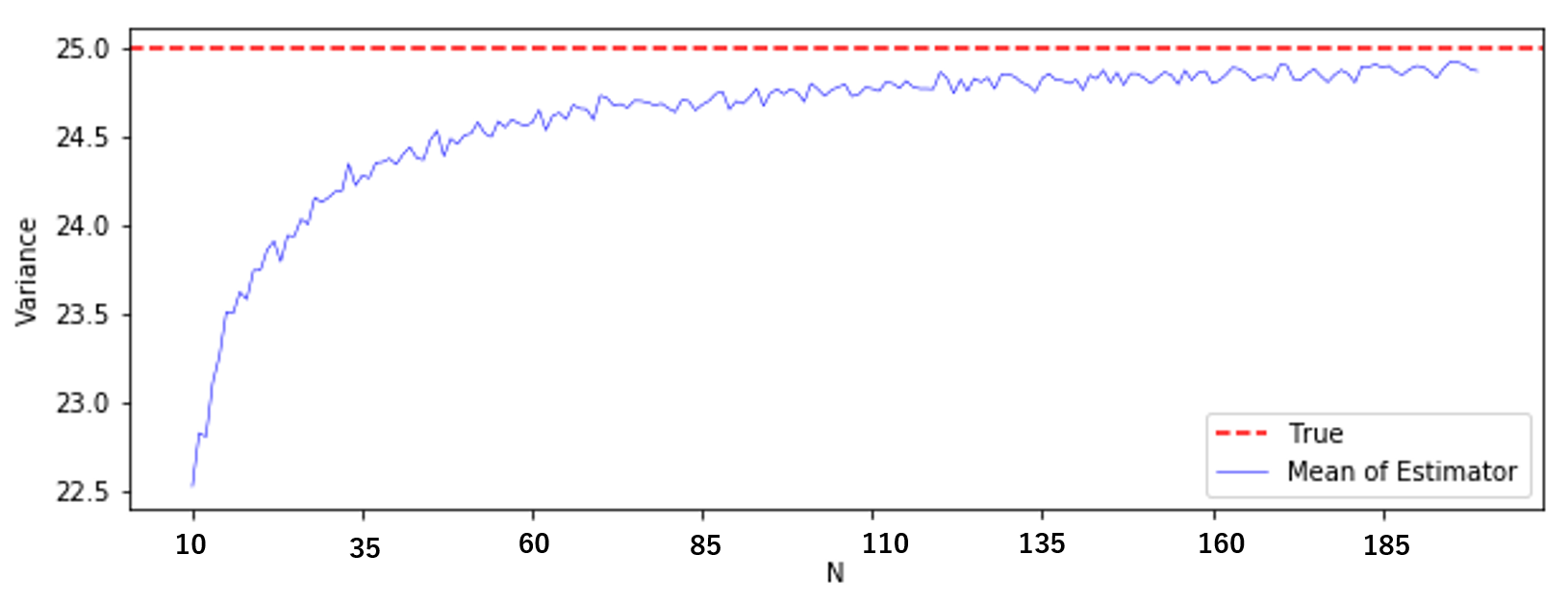
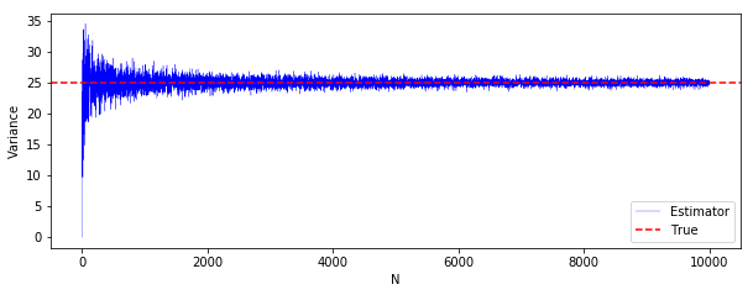
import numpy as np import matplotlib import matplotlib.pyplot as plt np.random.seed(42) M_var0 = 200 K_var0 = 10000 mu_var0 = 10 std_var0 = 5 EV_var0 = [] for N in range(M_var0): V_var0 = [] for i in range(K): X = np.random.normal(mu, std, N) V_var0.append(np.var(X, ddof = 0)) #ddof=0で標本分散 #ddof=1で不偏分散 EV_var0.append(np.mean(V_var0)) EV_var00 = np.array(EV_var0) plt.figure(figsize = (10, 3.5)) plt.axhline(25, ls = "--", color = "red", label = "True") plt.plot(EV_var00, color = 'blue', linewidth = 0.5, label = "Mean ofEstimator") plt.xlabel("N") plt.ylabel("Variance") plt.legend(loc = "lower right") plt.show()
横軸が $N$、縦軸が分散です。
真の分散25(赤線)に対して、標本分散の平均値(青線)は小さいようです。真値付近が見にくいので、もう少し拡大してみましょう。
EV_var00 = np.array(EV_var0) plt.figure(figsize = (10, 3.5)) plt.axhline(25, ls = "--", color = "red", label = "True") plt.plot(EV_var00[10:], color = 'blue', linewidth = 0.5, label = "Mean of Estimator") plt.xlabel("N") plt.ylabel("Variance") plt.legend(loc = "lower right") plt.show()($N=10$ から見ているだけです。横軸の数字はPPTに張り付けてからコメントボックスで書きました。横着してごめんなさい。)
やはり標本分散の平均値は、真の分散よりも小さいですね。
これがいわゆる偏り(バイアス)というやつです。
つまり、同じ観測値の数 $N$ で、何回も何回もデータをとって標本分散を計算し、これを平均しても「真の分散」と等しくなりません(標本分散の方が小さくなります)。これを偏り(バイアス)というのです。
実際、$X$ の真の分散を $\sigma^2$ とし、標本分散の平均を計算してみると、
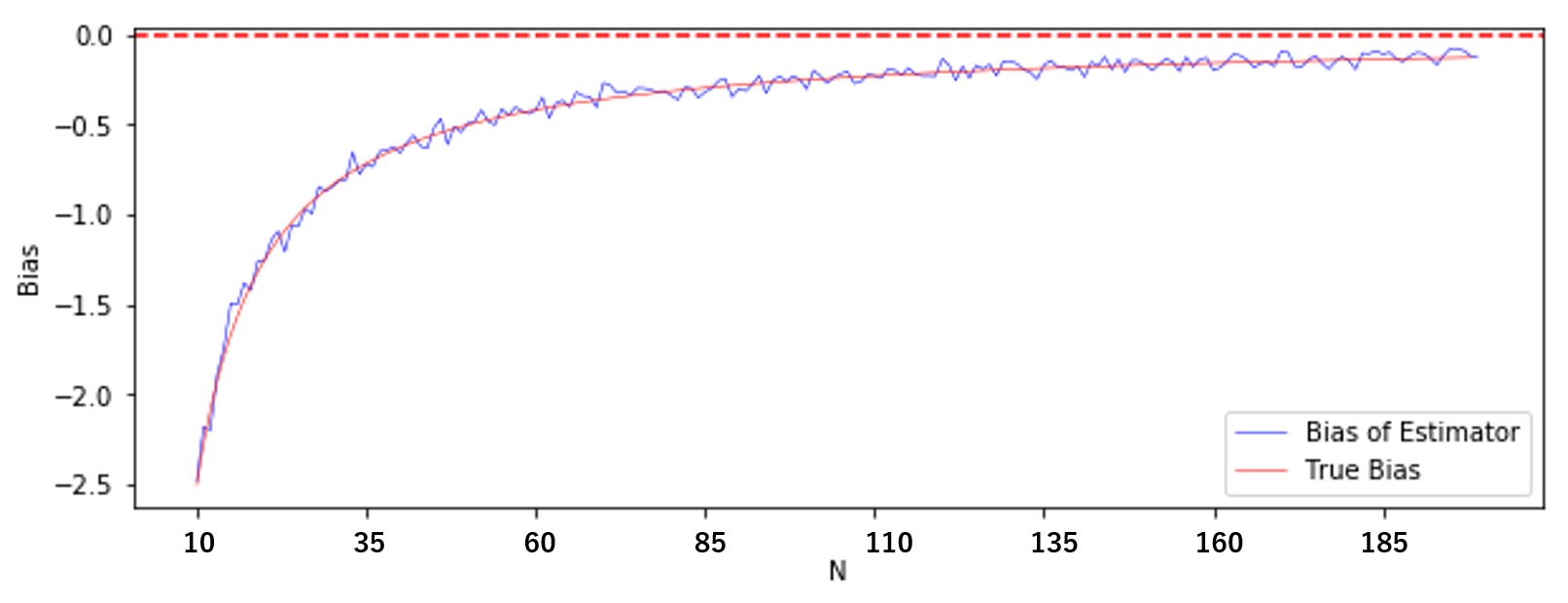
\begin{eqnarray} E\biggl[\frac{1}{N} \sum_{i=1}^{N} (X_i-\bar{X})^{\,2}\biggl] &=& \frac{N-1}{N} \sigma^2\\ \\ &=& \sigma^2-\frac{1}{N}\sigma^2 \end{eqnarray}
となるので、標本分散は、真の分散 $\sigma^2$ よりも $-\frac{1}{N}\sigma^2$ だけ理論上偏っていることがわかります。シミュレーションによって得られた標本分散の偏りと、計算で得られた理論上の偏りを比較してみましょう。
n = np.arange(M_var0-1) True_bias = -1 / n * 25 #理論上の偏り(バイアス) plt.figure(figsize = (10, 3.5)) plt.plot(Bias_var0, color = 'blue', linewidth = 0.5, label = "Bias of Estimator") plt.plot(True_bias, color = 'red', linewidth = 0.5, label = "True Bias") plt.axhline(0, ls = "--", color = "red") plt.xlabel("N") plt.ylabel("Bias") plt.legend(loc = "lower right") plt.show()(やはり見にくかったので $N=10$ から)
青線がシミュレーションによる偏り、赤線の実線が理論上の偏りです。
ほぼ理論通りの偏りが生じていますね。
余談ですが、先の計算結果を見るとわかる通り、標本分散の場合は偏りが $N$ に依存し、$N$ を大きくすれば偏りは $0$ に近付きます。
★不偏分散は偏っていないのか?
さて、ここまで見てきて
「ということは、不偏分散を使ったら推定に偏りは生じないってこと?」
つまり、
「何回も何回もデータをとって、不偏分散を計算し、これを平均したら、真の分散と等しくなるの?」
ということを考えると思います。
実際、その通りです。標本分散でやったのと同じことを不偏分散でも試してみましょう。
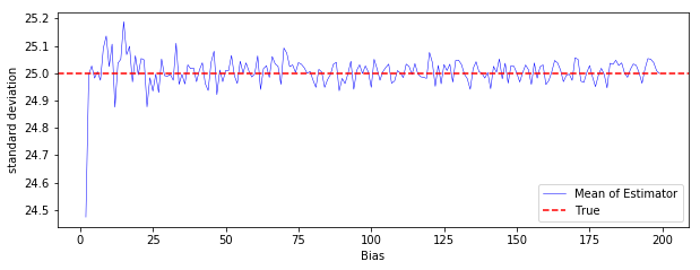
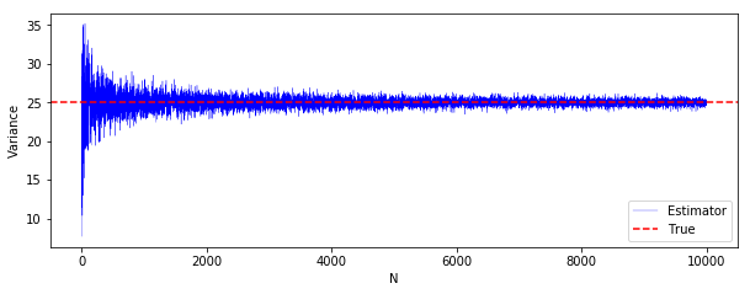
np.random.seed(42) M_var1 = 200 K_var1 = 10000 mu_var1 = 10 std_var1 = 5 EV_var1 = [] for N in range(M_var1): V_var1 = [] for i in range(K): X = np.random.normal(mu, std, N) V_var1.append(np.var(X, ddof = 1)) EV_var1.append(np.mean(V_var1)) plt.figure(figsize = (10, 3.5)) plt.plot(EV_var1, color = 'blue', linewidth = 0.5, label = "Mean of Estimator") plt.axhline(25, ls = "--", color = "red", label = "True") plt.xlabel("Bias") plt.ylabel("standard deviation") plt.legend(loc = "lower right") plt.show()
縦軸の値の幅が小さいので、実感しにくいかもしれませんが、$N$ がどの値の時でも、不偏分散の平均値は真の分散に近い値をとっています。
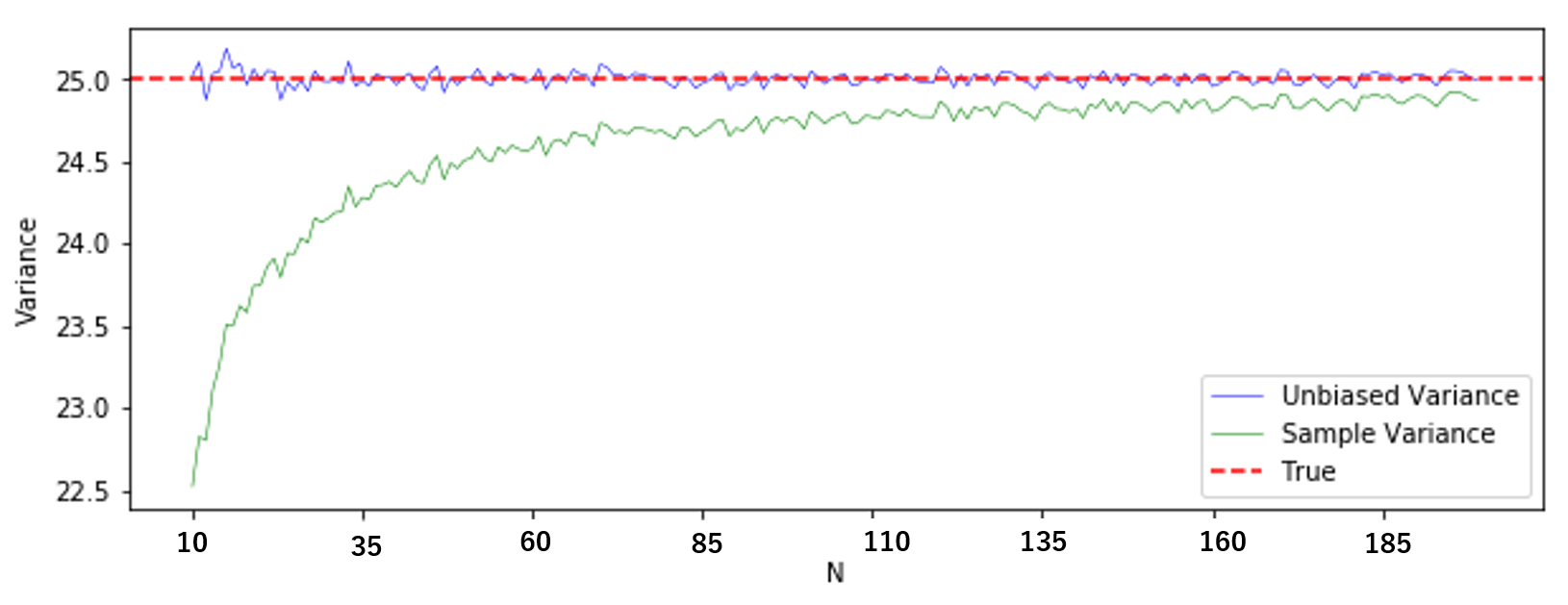
不偏分散が不偏であることを実感するために「標本分散の平均値」と「不偏分散の平均値」を比較してみましょう。
plt.figure(figsize = (10, 3.5)) plt.plot(EV_var1[10:], color = 'blue', linewidth = 0.5, label = "Unbiased Variance") plt.plot(EV_var00[10:], color = 'green', linewidth = 0.5, label = "Sample Variance") plt.axhline(25, ls = "--", color = "red", label = "True") plt.xlabel("Bias") plt.ylabel("standard deviation") plt.legend(loc = "lower right") plt.show()(やはり見にくかったので $N=10$ から)
緑線が標本分散の平均、青線が不偏分散の平均です。不偏分散は標本分散に比べて、偏りが著しく小さいということが分かると思います。
何度も何度もしつこいですが、ある観測値の数 $N$ を固定して分散を繰り返し推定し、それら得られた推定値を平均した値が、真の値と等しいかというのがイメージになります。
★一致性
偏りについては、なんとなくわかったと思います。では一致性との違いは何なのでしょうか?
一致性は、平均的とかそういったものではなく、単純に1回の推定で $N$ を無限大にしたら真値と一致するかというものです。なので、実験は単に $N$ を増やしていくだけで済みます。
結論から言うと、標本分散は一致性を持つのですが、これをシミュレーションで確認します。(証明はこのあたりが参考になると思います。)
一致性の場合は、$N=1$ で推定 $→$ $N=2$ で推定$→$・・・と、どんどんデータを大きくしていった時の挙動を見ます。(各 $N$ ごとに1回しか推定しません。)
np.random.seed(42) M_consistent = 10000 mu_consistent = 10 std_consistent = 5 V_consistent = [] for N in range(M_consistent): X_consistent = np.random.normal(mu_consistent, std_consistent, N) V_consistent.append(np.var(X_consistent, ddof = 0)) plt.figure(figsize = (10, 3.5)) plt.plot(V_consistent, color = 'blue', linewidth = 0.3, label = "Estimator") plt.axhline(25, ls = "--", color = "red", label = "True") plt.xlabel("N") plt.ylabel("Variance") plt.legend(loc = "lower right") plt.show()
$N$ が大きくなるにつれて、真の分散に近付いて行っている様子がわかりますね。
不偏分散もほとんど同じような感じです。
割っている数が$N$ か $N-1$ かの違いなので、ある程度大きくなってしまえば、この違いは無視できそうだということは分かると思います。
np.random.seed(42) M_consistent1 = 10000 mu_consistent1 = 10 std_consistent1 = 5 V_consistent1 = [] for N in range(M_consistent1): X_consistent1 = np.random.normal(mu_consistent1, std_consistent1, N) V_consistent1.append(np.var(X_consistent1, ddof = 1)) plt.figure(figsize = (10, 3.5)) plt.plot(V_consistent1, color = 'blue', linewidth = 0.3, label = "Estimator") plt.axhline(25, ls = "--", color = "red", label = "True") plt.xlabel("N") plt.ylabel("Variance") plt.legend(loc = "lower right") plt.show()
■ まとめ
大した事をやっていないのにすごく疲れました。後半、ちょっと雑な感じがしなくもないですが、簡潔に書いてある方が。。。ね。。。
ざっくりまとめておくと、
不偏性:同じ観測値の数で、何回も何回も繰り返しデータを取って推定し、それらを平均した時に真値と等しくなるか。
一致性:1回の推定で、観測値の数をとてつもなく大きくしたら真値と等しくなるか。
という感じでしょうかね。
★ 参考文献 ★
[1] 野田,宮岡:数理統計学の基礎(1992)
[2] 清水:統計学への確率論,その先へ(2019)
[3] 不偏標本分散の一致性を示してみる(リンク)
[4] 不偏分散の分散(リンク)
[5] 標本分散、不偏分散が一致推定量であること(リンク)

- 投稿日:2020-06-01T20:29:37+09:00
不偏推性と一致
Twitterで「不偏推定量難しい...一致推定量っていうのもあるけど何が違うの?」みたいなのを観測し、そういえば自分も統計学を勉強し始めた時に同じような疑問を長らく抱えていたのを思い出しました1。
Google先生に「不偏推定量 一致推定量」と尋ねると、4万件弱ヒットするようです。その中に自分の拙い記事を加えたところで、どれほど価値があるのか、かなり微妙な感じがするのですが、まぁいいかということで書いていきます。
他サイトの解説とはちょっとテイストを変えているので、もしかしたらこの記事で腑に落ちる人もいるかもしれないですしね。
では、さっそく始めていきます。
※細かいことを読むのが面倒な方や時間が惜しい方はここから読むといいと思います。
■ そもそも何で統計量の性質なんて考えるの?
例えば、平均の推定を考えると、標本平均や中央値、刈り込み平均などたくさんの選択肢があります。このように、あるパラメータ(平均とか分散とか)の値を推定したい時には、様々な選択肢があることが一般的です。
では、様々な選択肢がある中でどの方法を用いれば良いのか?つまり、良い推定とは一体何なのかということが問題になってきます。
不偏性や一致性は、そのような問題を考える際にひとつの基準となります。2
■ 一応、定義を見ておく。。。
おそらく、この記事にたどり着くまでに散々一致性と不偏性の定義を見てきていて、定義の話はもういいから腑に落ちる説明をくれという気持ちになっていると思うのですが、一応自分用のメモでもあるので。。。。
◆一致性
一致性にも実は色々あるのですが、ここでは弱一致推定量と強一致推定量を紹介します。とりあえず、違いは分からなくて大丈夫です。「なんかあるわー」ぐらいに思ってください。
・弱一致推定量
推定量の列 $\{T_n\}$ が、全ての $\varepsilon>0$ と全ての $\theta \in \Theta$ で、
\lim_{n→\infty}P\,(\,|\,T_n-\theta\,|\,≧\varepsilon \,)\,=0ならば、$T_n$ を $\theta$ の弱一致推定量と呼びます。
・強一致推定量
推定量の列 $\{T_n\}$ が、全ての $\theta \in \Theta$ で、
P(\,\lim_{n→\infty}T_n=\theta)=1ならば、$T_n$ を $\theta$ の強一致推定量と呼びます。
違いがものすごく気になる方は、『統計学への確率論,その先へ』の4.2 様々な確率的収束の概念とその強弱(P125)を読むといいと思います。
◆不偏性
不偏とは、文字通り偏っていないということなのですが、「偏っていない」とは一体なんなのでしょうか。統計学における偏りは次のようなものです。
・偏り(バイアス)
偏り(バイアス)は推定量の平均が、推定されているパラメータとどのくらい離れているのかを表すものです。数式で書くと次のようになります。
パラメータ $\theta$ の推定量を $T(X)$ とすると、偏りは
E\,[\,T(X)\,]-\thetaと定義されます。
おそらく、バイアスという言葉の方がよく使われると思うのですが、不偏(の「偏」)に合わせて今回は偏りという言葉の方を使うことにします。
・不偏性
上述のように偏りは、$E\,[\,T(X)\,]-\theta$ と定義されます。不偏であるとは、偏っていないということなので、
E\,[\,T(X)\,]-\theta=0であればよいということです。$\theta$ を右辺に移行すれば、
E\,[\,T(X)\,]=\thetaとなります。これを満たす推定量 $T(X)$ をパラメータ $\theta$ の不偏推定量といいます。
■ 時間が惜しい人はここから。
細かい話はいいからという人はここから読んで下さい。
おそらく最も目にした不偏推定量の例は不偏分散であり、しかもちゃんと手計算で標本分散の期待値を確認したと思います。
ここではシミュレーションでどんなもんなのかを確認していきます。
◆標本分散
標本分散は、
\frac{1}{N} \sum_{i=1}^{N} (X_i-\bar{X})^{\,2}で定義されます。よくご存じのように標本分散は、不偏推定量ではありません。つまり、標本分散による分散の推定は、平均を取ると偏ります。
これを体験してみましょう。
★標本分散の偏りを体験する。
今、真の平均が $10$、真の分散が $25$ である正規分布から独立に $N$ 個の観測値が得られたとします。
X_1,X_2,...,X_N \stackrel{i.i.d}{\sim} N(10,5^2)この$N$ 個の観測値を使って、分散を標本分散で推定します。そして、各 $N$ ごとに、「データを抽出→標本分散を計算」を10000回繰り返します。この10000個の標本分散の平均値を、各 $N$ における標本分散の期待値の推定値とします。
なにごちゃごちゃ言ってんだよ?わかんねぇよ?という方はこの図を。。。
吹き出し内の意味が分からないよという人はこちらを。。。
この図でいうところの $K$ が今回は10000ということです。
※分かりにくかったら図を作り直すのでコメント下さい(><)
(そういえば最近顔文字を使う人を見なくなりましたね)コードに起こすとこんな感じ。「コードなんてどうでもいいぜ」っていう人は、その下のグラフを見て下さい。
import numpy as np import matplotlib import matplotlib.pyplot as plt np.random.seed(42) M_var0 = 200 K_var0 = 10000 mu_var0 = 10 std_var0 = 5 EV_var0 = [] for N in range(M_var0): V_var0 = [] for i in range(K): X = np.random.normal(mu, std, N) V_var0.append(np.var(X, ddof = 0)) #ddof=0で標本分散 #ddof=1で不偏分散 EV_var0.append(np.mean(V_var0)) EV_var00 = np.array(EV_var0) plt.figure(figsize = (10, 3.5)) plt.axhline(25, ls = "--", color = "red", label = "True") plt.plot(EV_var00, color = 'blue', linewidth = 0.5, label = "Mean ofEstimator") plt.xlabel("N") plt.ylabel("Variance") plt.legend(loc = "lower right") plt.show()
横軸が $N$、縦軸が分散です。
真の分散25(赤線)に対して、標本分散の平均値(青線)は小さいようです。真値付近が見にくいので、もう少し拡大してみましょう。
EV_var00 = np.array(EV_var0) plt.figure(figsize = (10, 3.5)) plt.axhline(25, ls = "--", color = "red", label = "True") plt.plot(EV_var00[10:], color = 'blue', linewidth = 0.5, label = "Mean of Estimator") plt.xlabel("N") plt.ylabel("Variance") plt.legend(loc = "lower right") plt.show()($N=10$ から見ているだけです。横軸の数字はPPTに張り付けてからコメントボックスで書きました。横着してごめんなさい。)
やはり標本分散の平均値は、真の分散よりも小さいですね。
これがいわゆる偏り(バイアス)というやつです。
つまり、同じ観測値の数 $N$ で、何回も何回もデータをとって標本分散を計算し、これを平均しても「真の分散」と等しくなりません(標本分散の方が小さくなります)。これを偏り(バイアス)というのです。
実際、$X$ の真の分散を $\sigma^2$ とし、標本分散の平均を計算してみると、
\begin{eqnarray} E\biggl[\frac{1}{N} \sum_{i=1}^{N} (X_i-\bar{X})^{\,2}\biggl] &=& \frac{N-1}{N} \sigma^2\\ \\ &=& \sigma^2-\frac{1}{N}\sigma^2 \end{eqnarray}
となるので、標本分散は、真の分散 $\sigma^2$ よりも $-\frac{1}{N}\sigma^2$ だけ理論上偏っていることがわかります。シミュレーションによって得られた標本分散の偏りと、計算で得られた理論上の偏りを比較してみましょう。
n = np.arange(M_var0-1) True_bias = -1 / n * 25 #理論上の偏り(バイアス) plt.figure(figsize = (10, 3.5)) plt.plot(Bias_var0, color = 'blue', linewidth = 0.5, label = "Bias of Estimator") plt.plot(True_bias, color = 'red', linewidth = 0.5, label = "True Bias") plt.axhline(0, ls = "--", color = "red") plt.xlabel("N") plt.ylabel("Bias") plt.legend(loc = "lower right") plt.show()(やはり見にくかったので $N=10$ から)
青線がシミュレーションによる偏り、赤線の実線が理論上の偏りです。
ほぼ理論通りの偏りが生じていますね。
余談ですが、先の計算結果を見るとわかる通り、標本分散の場合は偏りが $N$ に依存し、$N$ を大きくすれば偏りは $0$ に近付きます。
★不偏分散は偏っていないのか?
さて、ここまで見てきて
「ということは、不偏分散を使ったら推定に偏りは生じないってこと?」
つまり、
「何回も何回もデータをとって、不偏分散を計算し、これを平均したら、真の分散と等しくなるの?」
ということを考えると思います。
実際、その通りです。標本分散でやったのと同じことを不偏分散でも試してみましょう。
np.random.seed(42) M_var1 = 200 K_var1 = 10000 mu_var1 = 10 std_var1 = 5 EV_var1 = [] for N in range(M_var1): V_var1 = [] for i in range(K): X = np.random.normal(mu, std, N) V_var1.append(np.var(X, ddof = 1)) EV_var1.append(np.mean(V_var1)) plt.figure(figsize = (10, 3.5)) plt.plot(EV_var1, color = 'blue', linewidth = 0.5, label = "Mean of Estimator") plt.axhline(25, ls = "--", color = "red", label = "True") plt.xlabel("Bias") plt.ylabel("standard deviation") plt.legend(loc = "lower right") plt.show()
縦軸の値の幅が小さいので、実感しにくいかもしれませんが、$N$ がどの値の時でも、不偏分散の平均値は真の分散に近い値をとっています。
不偏分散が不偏であることを実感するために「標本分散の平均値」と「不偏分散の平均値」を比較してみましょう。
plt.figure(figsize = (10, 3.5)) plt.plot(EV_var1[10:], color = 'blue', linewidth = 0.5, label = "Unbiased Variance") plt.plot(EV_var00[10:], color = 'green', linewidth = 0.5, label = "Sample Variance") plt.axhline(25, ls = "--", color = "red", label = "True") plt.xlabel("Bias") plt.ylabel("standard deviation") plt.legend(loc = "lower right") plt.show()(やはり見にくかったので $N=10$ から)
緑線が標本分散の平均、青線が不偏分散の平均です。不偏分散は標本分散に比べて、偏りが著しく小さいということが分かると思います。
何度も何度もしつこいですが、ある観測値の数 $N$ を固定して分散を繰り返し推定し、それら得られた推定値を平均した値が、真の値と等しいかというのがイメージになります。
★一致性
偏りについては、なんとなくわかったと思います。では一致性との違いは何なのでしょうか?
一致性は、平均的とかそういったものではなく、単純に1回の推定で $N$ を無限大にしたら真値と一致するかというものです。なので、実験は単に $N$ を増やしていくだけで済みます。
結論から言うと、標本分散は一致性を持つのですが、これをシミュレーションで確認します。(証明はこのあたりが参考になると思います。)
一致性の場合は、$N=1$ で推定 $→$ $N=2$ で推定$→$・・・と、どんどんデータを大きくしていった時の挙動を見ます。(各 $N$ ごとに1回しか推定しません。)
np.random.seed(42) M_consistent = 10000 mu_consistent = 10 std_consistent = 5 V_consistent = [] for N in range(M_consistent): X_consistent = np.random.normal(mu_consistent, std_consistent, N) V_consistent.append(np.var(X_consistent, ddof = 0)) plt.figure(figsize = (10, 3.5)) plt.plot(V_consistent, color = 'blue', linewidth = 0.3, label = "Estimator") plt.axhline(25, ls = "--", color = "red", label = "True") plt.xlabel("N") plt.ylabel("Variance") plt.legend(loc = "lower right") plt.show()
$N$ が大きくなるにつれて、真の分散に近付いて行っている様子がわかりますね。
不偏分散もほとんど同じような感じです。
割っている数が$N$ か $N-1$ かの違いなので、ある程度大きくなってしまえば、この違いは無視できそうだということは分かると思います。
np.random.seed(42) M_consistent1 = 10000 mu_consistent1 = 10 std_consistent1 = 5 V_consistent1 = [] for N in range(M_consistent1): X_consistent1 = np.random.normal(mu_consistent1, std_consistent1, N) V_consistent1.append(np.var(X_consistent1, ddof = 1)) plt.figure(figsize = (10, 3.5)) plt.plot(V_consistent1, color = 'blue', linewidth = 0.3, label = "Estimator") plt.axhline(25, ls = "--", color = "red", label = "True") plt.xlabel("N") plt.ylabel("Variance") plt.legend(loc = "lower right") plt.show()
■ まとめ
大した事をやっていないのにすごく疲れました。後半、ちょっと雑な感じがしなくもないですが、簡潔に書いてある方が。。。ね。。。
ざっくりまとめておくと、
不偏性:同じ観測値の数で、何回も何回も繰り返しデータを取って推定し、それらを平均した時に真値と等しくなるか。
一致性:1回の推定で、観測値の数をとてつもなく大きくしたら真値と等しくなるか。
という感じでしょうかね。
★ 参考文献 ★
[1] 野田,宮岡:数理統計学の基礎(1992)
[2] 清水:統計学への確率論,その先へ(2019)
[3] 不偏標本分散の一致性を示してみる(リンク)
[4] 不偏分散の分散(リンク)
[5] 標本分散、不偏分散が一致推定量であること(リンク)
- 投稿日:2020-06-01T20:29:37+09:00
腑に落ちない人のための不偏推定量と一致推定量の解説
※細かいことを読むのが面倒な方や時間が惜しい方はここから読んで頂ければなと思います。
※この記事は「不偏性とか一致性とか色々調べたけど、どれを見てもいまいち腑に落ちないんだよなー」と思っている方向けの解説です。本や他サイトでたくさん迷走してから読んでください。
ではでは、本文です。
Twitterで「不偏推定量難しい...一致推定量っていうのもあるけど何が違うの?」みたいなのを観測し、そういえば自分も統計学を勉強し始めた時に同じような疑問を長らく抱えていたのを思い出しました1。
Google先生に「不偏推定量 一致推定量」と尋ねると、4万件弱ヒットするようです。その中に自分の拙い記事を加えたところで、どれほど価値があるのか、かなり微妙な感じがするのですが、まぁいいかということで書いていきます。
他サイトの解説とはちょっとテイストを変えているので、もしかしたらこの記事で腑に落ちる人もいるかもしれないですしね。
では、さっそく始めていきます。
■ そもそも何で統計量の性質なんて考えるの?
例えば、平均の推定を考えると、標本平均や中央値、刈り込み平均などたくさんの選択肢があります。このように、あるパラメータ(平均とか分散とか)の値を推定したい時には、様々な選択肢があることが一般的です。
では、様々な選択肢がある中でどの方法を用いれば良いのか?つまり、良い推定とは一体何なのかということが問題になってきます。
不偏性や一致性は、そのような問題を考える際にひとつの基準となります。2
■ 一応、定義を見ておく。。。
おそらく、この記事にたどり着くまでに散々一致性と不偏性の定義を見てきていて、定義の話はもういいから腑に落ちる説明をくれという気持ちになっていると思うのですが、一応自分用のメモでもあるので。。。。
◆一致性
一致性にも実は色々あるのですが、ここでは弱一致推定量と強一致推定量を紹介します。とりあえず、違いは分からなくて大丈夫です。「なんかあるわー」ぐらいに思ってください。
・弱一致推定量
推定量の列 $\{T_n\}$ が、全ての $\varepsilon>0$ と全ての $\theta \in \Theta$ で、
\lim_{n→\infty}P\,(\,|\,T_n-\theta\,|\,≧\varepsilon \,)\,=0ならば、$T_n$ を $\theta$ の弱一致推定量と呼びます。
・強一致推定量
推定量の列 $\{T_n\}$ が、全ての $\theta \in \Theta$ で、
P(\,\lim_{n→\infty}T_n=\theta)=1ならば、$T_n$ を $\theta$ の強一致推定量と呼びます。
違いがものすごく気になる方は、『統計学への確率論,その先へ』の4.2 様々な確率的収束の概念とその強弱(P125)を読むといいと思います。
◆不偏性
不偏とは、文字通り偏っていないということなのですが、「偏っていない」とは一体なんなのでしょうか。統計学における偏りは次のようなものです。
・偏り(バイアス)
偏り(バイアス)は推定量の平均が、推定されているパラメータとどのくらい離れているのかを表すものです。数式で書くと次のようになります。
パラメータ $\theta$ の推定量を $T(X)$ とすると、偏りは
E\,[\,T(X)\,]-\thetaと定義されます。
おそらく、バイアスという言葉の方がよく使われると思うのですが、不偏(の「偏」)に合わせて今回は偏りという言葉の方を使うことにします。
・不偏性
上述のように偏りは、$E\,[\,T(X)\,]-\theta$ と定義されます。不偏であるとは、偏っていないということなので、
E\,[\,T(X)\,]-\theta=0であればよいということです。$\theta$ を右辺に移行すれば、
E\,[\,T(X)\,]=\thetaとなります。これを満たす推定量 $T(X)$ をパラメータ $\theta$ の不偏推定量といいます。
■ 時間が惜しい人はここから。
細かい話はいいからという人はここから読んで下さい。
おそらく最も目にした不偏推定量の例は不偏分散であり、しかもちゃんと手計算で標本分散の期待値を確認したと思います。
ここではシミュレーションでどんなもんなのかを確認していきます。
◆標本分散
標本分散は、
\frac{1}{N} \sum_{i=1}^{N} (X_i-\bar{X})^{\,2}で定義されます。よくご存じのように標本分散は、不偏推定量ではありません。つまり、標本分散による分散の推定は、平均を取ると偏ります。
これを体験してみましょう。
★標本分散の偏りを体験する。
今、真の平均が $10$、真の分散が $25$ である正規分布から独立に $N$ 個の観測値が得られたとします。
X_1,X_2,...,X_N \stackrel{i.i.d}{\sim} N(10,5^2)この$N$ 個の観測値を使って、分散を標本分散で推定します。そして、各 $N$ ごとに、「データを抽出→標本分散を計算」を10000回繰り返します。この10000個の標本分散の平均値を、各 $N$ における標本分散の期待値の推定値とします。
なにごちゃごちゃ言ってんだよ?わかんねぇよ?という方はこの図を。。。
吹き出し内の意味が分からないよという人はこちらを。。。
この図でいうところの $K$ が今回は10000ということです。
※分かりにくかったら図を作り直すのでコメント下さい(><)
(そういえば最近顔文字を使う人を見なくなりましたね)コードに起こすとこんな感じ。「コードなんてどうでもいいぜ」っていう人は、その下のグラフを見て下さい。
import numpy as np import matplotlib import matplotlib.pyplot as plt np.random.seed(42) M_var0 = 200 K_var0 = 10000 mu_var0 = 10 std_var0 = 5 EV_var0 = [] for N in range(M_var0): V_var0 = [] for i in range(K): X = np.random.normal(mu, std, N) V_var0.append(np.var(X, ddof = 0)) #ddof=0で標本分散 #ddof=1で不偏分散 EV_var0.append(np.mean(V_var0)) EV_var00 = np.array(EV_var0) plt.figure(figsize = (10, 3.5)) plt.axhline(25, ls = "--", color = "red", label = "True") plt.plot(EV_var00, color = 'blue', linewidth = 0.5, label = "Mean ofEstimator") plt.xlabel("N") plt.ylabel("Variance") plt.legend(loc = "lower right") plt.show()
横軸が $N$、縦軸が分散です。
真の分散25(赤線)に対して、標本分散の平均値(青線)は小さいようです。真値付近が見にくいので、もう少し拡大してみましょう。
EV_var00 = np.array(EV_var0) plt.figure(figsize = (10, 3.5)) plt.axhline(25, ls = "--", color = "red", label = "True") plt.plot(EV_var00[10:], color = 'blue', linewidth = 0.5, label = "Mean of Estimator") plt.xlabel("N") plt.ylabel("Variance") plt.legend(loc = "lower right") plt.show()($N=10$ から見ているだけです。横軸の数字はPPTに張り付けてからコメントボックスで書きました。横着してごめんなさい。)
やはり標本分散の平均値は、真の分散よりも小さいですね。
これがいわゆる偏り(バイアス)というやつです。
つまり、同じ観測値の数 $N$ で、何回も何回もデータをとって標本分散を計算し、これを平均しても「真の分散」と等しくなりません(標本分散の方が小さくなります)。これを偏り(バイアス)というのです。
実際、$X$ の真の分散を $\sigma^2$ とし、標本分散の平均を計算してみると、
\begin{eqnarray} E\biggl[\frac{1}{N} \sum_{i=1}^{N} (X_i-\bar{X})^{\,2}\biggl] &=& \frac{N-1}{N} \sigma^2\\ \\ &=& \sigma^2-\frac{1}{N}\sigma^2 \end{eqnarray}
となるので、標本分散は、真の分散 $\sigma^2$ よりも $-\frac{1}{N}\sigma^2$ だけ理論上偏っていることがわかります。シミュレーションによって得られた標本分散の偏りと、計算で得られた理論上の偏りを比較してみましょう。
n = np.arange(M_var0-1) True_bias = -1 / n * 25 #理論上の偏り(バイアス) plt.figure(figsize = (10, 3.5)) plt.plot(Bias_var0, color = 'blue', linewidth = 0.5, label = "Bias of Estimator") plt.plot(True_bias, color = 'red', linewidth = 0.5, label = "True Bias") plt.axhline(0, ls = "--", color = "red") plt.xlabel("N") plt.ylabel("Bias") plt.legend(loc = "lower right") plt.show()(やはり見にくかったので $N=10$ から)
青線がシミュレーションによる偏り、赤線の実線が理論上の偏りです。
ほぼ理論通りの偏りが生じていますね。
余談ですが、先の計算結果を見るとわかる通り、標本分散の場合は偏りが $N$ に依存し、$N$ を大きくすれば偏りは $0$ に近付きます。
★不偏分散は偏っていないのか?
さて、ここまで見てきて
「ということは、不偏分散を使ったら推定に偏りは生じないってこと?」
つまり、
「何回も何回もデータをとって、不偏分散を計算し、これを平均したら、真の分散と等しくなるの?」
ということを考えると思います。
実際、その通りです。標本分散でやったのと同じことを不偏分散でも試してみましょう。
np.random.seed(42) M_var1 = 200 K_var1 = 10000 mu_var1 = 10 std_var1 = 5 EV_var1 = [] for N in range(M_var1): V_var1 = [] for i in range(K): X = np.random.normal(mu, std, N) V_var1.append(np.var(X, ddof = 1)) EV_var1.append(np.mean(V_var1)) plt.figure(figsize = (10, 3.5)) plt.plot(EV_var1, color = 'blue', linewidth = 0.5, label = "Mean of Estimator") plt.axhline(25, ls = "--", color = "red", label = "True") plt.xlabel("Bias") plt.ylabel("standard deviation") plt.legend(loc = "lower right") plt.show()
縦軸の値の幅が小さいので、実感しにくいかもしれませんが、$N$ がどの値の時でも、不偏分散の平均値は真の分散に近い値をとっています。
不偏分散が不偏であることを実感するために「標本分散の平均値」と「不偏分散の平均値」を比較してみましょう。
plt.figure(figsize = (10, 3.5)) plt.plot(EV_var1[10:], color = 'blue', linewidth = 0.5, label = "Unbiased Variance") plt.plot(EV_var00[10:], color = 'green', linewidth = 0.5, label = "Sample Variance") plt.axhline(25, ls = "--", color = "red", label = "True") plt.xlabel("Bias") plt.ylabel("standard deviation") plt.legend(loc = "lower right") plt.show()(やはり見にくかったので $N=10$ から)
緑線が標本分散の平均、青線が不偏分散の平均です。不偏分散は標本分散に比べて、偏りが著しく小さいということが分かると思います。
何度も何度もしつこいですが、ある観測値の数 $N$ を固定して分散を繰り返し推定し、それら得られた推定値を平均した値が、真の値と等しいかというのがイメージになります。
★一致性
偏りについては、なんとなくわかったと思います。では一致性との違いは何なのでしょうか?
一致性は、平均的とかそういったものではなく、単純に1回の推定で $N$ を無限大にしたら真値と一致するかというものです。なので、実験は単に $N$ を増やしていくだけで済みます。
結論から言うと、標本分散は一致性を持つのですが、これをシミュレーションで確認します。(証明はこのあたりが参考になると思います。)
一致性の場合は、$N=1$ で推定 $→$ $N=2$ で推定$→$・・・と、どんどんデータを大きくしていった時の挙動を見ます。(各 $N$ ごとに1回しか推定しません。)
np.random.seed(42) M_consistent = 10000 mu_consistent = 10 std_consistent = 5 V_consistent = [] for N in range(M_consistent): X_consistent = np.random.normal(mu_consistent, std_consistent, N) V_consistent.append(np.var(X_consistent, ddof = 0)) plt.figure(figsize = (10, 3.5)) plt.plot(V_consistent, color = 'blue', linewidth = 0.3, label = "Estimator") plt.axhline(25, ls = "--", color = "red", label = "True") plt.xlabel("N") plt.ylabel("Variance") plt.legend(loc = "lower right") plt.show()
$N$ が大きくなるにつれて、真の分散に近付いて行っている様子がわかりますね。
不偏分散もほとんど同じような感じです。
割っている数が$N$ か $N-1$ かの違いなので、ある程度大きくなってしまえば、この違いは無視できそうだということは分かると思います。
np.random.seed(42) M_consistent1 = 10000 mu_consistent1 = 10 std_consistent1 = 5 V_consistent1 = [] for N in range(M_consistent1): X_consistent1 = np.random.normal(mu_consistent1, std_consistent1, N) V_consistent1.append(np.var(X_consistent1, ddof = 1)) plt.figure(figsize = (10, 3.5)) plt.plot(V_consistent1, color = 'blue', linewidth = 0.3, label = "Estimator") plt.axhline(25, ls = "--", color = "red", label = "True") plt.xlabel("N") plt.ylabel("Variance") plt.legend(loc = "lower right") plt.show()
■ まとめ
大した事をやっていないのにすごく疲れました。後半、ちょっと雑な感じがしなくもないですが、簡潔に書いてある方が。。。ね。。。
ざっくりまとめておくと、
不偏性:同じ観測値の数で、何回も何回も繰り返しデータを取って推定し、それらを平均した時に真値と等しくなるか。
一致性:1回の推定で、観測値の数をとてつもなく大きくしたら真値と等しくなるか。
という感じでしょうかね。
★ 参考文献 ★
[1] 野田,宮岡:数理統計学の基礎(1992)
[2] 清水:統計学への確率論,その先へ(2019)
[3] 不偏標本分散の一致性を示してみる(リンク)
[4] 不偏分散の分散(リンク)
[5] 標本分散、不偏分散が一致推定量であること(リンク)
- 投稿日:2020-06-01T20:29:37+09:00
腑に落ちない人のための不偏性と一致性の解説
※細かいことを読むのが面倒な方や時間が惜しい方はここから読んで頂ければなと思います。
※この記事は「不偏性とか一致性とか色々調べたけど、どれを見てもいまいち腑に落ちないんだよなー」と思っている方向けの解説です。本や他サイトでたくさん迷走してから読んでください。
ではでは、本文です。
Twitterで「不偏推定量難しい...一致推定量っていうのもあるけど何が違うの?」みたいなのを観測し、そういえば自分も統計学を勉強し始めた時に同じような疑問を長らく抱えていたのを思い出しました1。
Google先生に「不偏推定量 一致推定量」と尋ねると、4万件弱ヒットするようです。その中に自分の拙い記事を加えたところで、どれほど価値があるのか、かなり微妙な感じがするのですが、まぁいいかということで書いていきます。
他サイトの解説とはちょっとテイストを変えているので、もしかしたらこの記事で腑に落ちる人もいるかもしれないですしね。
では、さっそく始めていきます。
■ そもそも何で統計量の性質なんて考えるの?
例えば、平均の推定を考えると、標本平均や中央値、刈り込み平均などたくさんの選択肢があります。このように、あるパラメータ(平均とか分散とか)の値を推定したい時には、様々な選択肢があることが一般的です。
では、様々な選択肢がある中でどの方法を用いれば良いのか?つまり、良い推定とは一体何なのかということが問題になってきます。
不偏性や一致性は、そのような問題を考える際にひとつの基準となります。2
■ 一応、定義を見ておく。。。
おそらく、この記事にたどり着くまでに散々一致性と不偏性の定義を見てきていて、定義の話はもういいから腑に落ちる説明をくれという気持ちになっていると思うのですが、一応自分用のメモでもあるので。。。。
◆一致性
一致性にも実は色々あるのですが、ここでは弱一致推定量と強一致推定量を紹介します。とりあえず、違いは分からなくて大丈夫です。「なんかあるわー」ぐらいに思ってください。
・弱一致推定量
推定量の列 $\{T_n\}$ が、全ての $\varepsilon>0$ と全ての $\theta \in \Theta$ で、
\lim_{n→\infty}P\,(\,|\,T_n-\theta\,|\,≧\varepsilon \,)\,=0ならば、$T_n$ を $\theta$ の弱一致推定量と呼びます。
・強一致推定量
推定量の列 $\{T_n\}$ が、全ての $\theta \in \Theta$ で、
P(\,\lim_{n→\infty}T_n=\theta)=1ならば、$T_n$ を $\theta$ の強一致推定量と呼びます。
違いがものすごく気になる方は、『統計学への確率論,その先へ』の4.2 様々な確率的収束の概念とその強弱(P125)を読むといいと思います。
◆不偏性
不偏とは、文字通り偏っていないということなのですが、「偏っていない」とは一体なんなのでしょうか。統計学における偏りは次のようなものです。
・偏り(バイアス)
偏り(バイアス)は推定量の平均が、推定されているパラメータとどのくらい離れているのかを表すものです。数式で書くと次のようになります。
パラメータ $\theta$ の推定量を $T(X)$ とすると、偏りは
E\,[\,T(X)\,]-\thetaと定義されます。
おそらく、バイアスという言葉の方がよく使われると思うのですが、不偏(の「偏」)に合わせて今回は偏りという言葉の方を使うことにします。
・不偏性
上述のように偏りは、$E\,[\,T(X)\,]-\theta$ と定義されます。不偏であるとは、偏っていないということなので、
E\,[\,T(X)\,]-\theta=0であればよいということです。$\theta$ を右辺に移行すれば、
E\,[\,T(X)\,]=\thetaとなります。これを満たす推定量 $T(X)$ をパラメータ $\theta$ の不偏推定量といいます。
■ 時間が惜しい人はここから。
細かい話はいいからという人はここから読んで下さい。
おそらく最も目にした不偏推定量の例は不偏分散であり、しかもちゃんと手計算で標本分散の期待値を確認したと思います。
ここではシミュレーションでどんなもんなのかを確認していきます。
◆標本分散
標本分散は、
\frac{1}{N} \sum_{i=1}^{N} (X_i-\bar{X})^{\,2}で定義されます。よくご存じのように標本分散は、不偏推定量ではありません。つまり、標本分散による分散の推定は、平均を取ると偏ります。
これを体験してみましょう。
★標本分散の偏りを体験する。
今、真の平均が $10$、真の分散が $25$ である正規分布から独立に $N$ 個の観測値が得られたとします。
X_1,X_2,...,X_N \stackrel{i.i.d}{\sim} N(10,5^2)この$N$ 個の観測値を使って、分散を標本分散で推定します。そして、各 $N$ ごとに、「データを抽出→標本分散を計算」を10000回繰り返します。この10000個の標本分散の平均値を、各 $N$ における標本分散の期待値の推定値とします。
なにごちゃごちゃ言ってんだよ?わかんねぇよ?という方はこの図を。。。
吹き出し内の意味が分からないよという人はこちらを。。。
この図でいうところの $K$ が今回は10000ということです。
※分かりにくかったら図を作り直すのでコメント下さい(><)
(そういえば最近顔文字を使う人を見なくなりましたね)コードに起こすとこんな感じ。「コードなんてどうでもいいぜ」っていう人は、その下のグラフを見て下さい。
import numpy as np import matplotlib import matplotlib.pyplot as plt np.random.seed(42) M_var0 = 200 K_var0 = 10000 mu_var0 = 10 std_var0 = 5 EV_var0 = [] for N in range(M_var0): V_var0 = [] for i in range(K): X = np.random.normal(mu, std, N) V_var0.append(np.var(X, ddof = 0)) #ddof=0で標本分散 #ddof=1で不偏分散 EV_var0.append(np.mean(V_var0)) EV_var00 = np.array(EV_var0) plt.figure(figsize = (10, 3.5)) plt.axhline(25, ls = "--", color = "red", label = "True") plt.plot(EV_var00, color = 'blue', linewidth = 0.5, label = "Mean ofEstimator") plt.xlabel("N") plt.ylabel("Variance") plt.legend(loc = "lower right") plt.show()
横軸が $N$、縦軸が分散です。
真の分散25(赤線)に対して、標本分散の平均値(青線)は小さいようです。真値付近が見にくいので、もう少し拡大してみましょう。
EV_var00 = np.array(EV_var0) plt.figure(figsize = (10, 3.5)) plt.axhline(25, ls = "--", color = "red", label = "True") plt.plot(EV_var00[10:], color = 'blue', linewidth = 0.5, label = "Mean of Estimator") plt.xlabel("N") plt.ylabel("Variance") plt.legend(loc = "lower right") plt.show()($N=10$ から見ているだけです。横軸の数字はPPTに張り付けてからコメントボックスで書きました。横着してごめんなさい。)
やはり標本分散の平均値は、真の分散よりも小さいですね。
これがいわゆる偏り(バイアス)というやつです。
つまり、同じ観測値の数 $N$ で、何回も何回もデータをとって標本分散を計算し、これを平均しても「真の分散」と等しくなりません(標本分散の方が小さくなります)。これを偏り(バイアス)というのです。
実際、$X$ の真の分散を $\sigma^2$ とし、標本分散の平均を計算してみると、
\begin{eqnarray} E\biggl[\frac{1}{N} \sum_{i=1}^{N} (X_i-\bar{X})^{\,2}\biggl] &=& \frac{N-1}{N} \sigma^2\\ \\ &=& \sigma^2-\frac{1}{N}\sigma^2 \end{eqnarray}
となるので、標本分散は、真の分散 $\sigma^2$ よりも $-\frac{1}{N}\sigma^2$ だけ理論上偏っていることがわかります。シミュレーションによって得られた標本分散の偏りと、計算で得られた理論上の偏りを比較してみましょう。
n = np.arange(M_var0-1) True_bias = -1 / n * 25 #理論上の偏り(バイアス) plt.figure(figsize = (10, 3.5)) plt.plot(Bias_var0, color = 'blue', linewidth = 0.5, label = "Bias of Estimator") plt.plot(True_bias, color = 'red', linewidth = 0.5, label = "True Bias") plt.axhline(0, ls = "--", color = "red") plt.xlabel("N") plt.ylabel("Bias") plt.legend(loc = "lower right") plt.show()(やはり見にくかったので $N=10$ から)
青線がシミュレーションによる偏り、赤線の実線が理論上の偏りです。
ほぼ理論通りの偏りが生じていますね。
余談ですが、先の計算結果を見るとわかる通り、標本分散の場合は偏りが $N$ に依存し、$N$ を大きくすれば偏りは $0$ に近付きます。
★不偏分散は偏っていないのか?
さて、ここまで見てきて
「ということは、不偏分散を使ったら推定に偏りは生じないってこと?」
つまり、
「何回も何回もデータをとって、不偏分散を計算し、これを平均したら、真の分散と等しくなるの?」
ということを考えると思います。
実際、その通りです。標本分散でやったのと同じことを不偏分散でも試してみましょう。
np.random.seed(42) M_var1 = 200 K_var1 = 10000 mu_var1 = 10 std_var1 = 5 EV_var1 = [] for N in range(M_var1): V_var1 = [] for i in range(K): X = np.random.normal(mu, std, N) V_var1.append(np.var(X, ddof = 1)) EV_var1.append(np.mean(V_var1)) plt.figure(figsize = (10, 3.5)) plt.plot(EV_var1, color = 'blue', linewidth = 0.5, label = "Mean of Estimator") plt.axhline(25, ls = "--", color = "red", label = "True") plt.xlabel("Bias") plt.ylabel("standard deviation") plt.legend(loc = "lower right") plt.show()
縦軸の値の幅が小さいので、実感しにくいかもしれませんが、$N$ がどの値の時でも、不偏分散の平均値は真の分散に近い値をとっています。
不偏分散が不偏であることを実感するために「標本分散の平均値」と「不偏分散の平均値」を比較してみましょう。
plt.figure(figsize = (10, 3.5)) plt.plot(EV_var1[10:], color = 'blue', linewidth = 0.5, label = "Unbiased Variance") plt.plot(EV_var00[10:], color = 'green', linewidth = 0.5, label = "Sample Variance") plt.axhline(25, ls = "--", color = "red", label = "True") plt.xlabel("Bias") plt.ylabel("standard deviation") plt.legend(loc = "lower right") plt.show()(やはり見にくかったので $N=10$ から)
緑線が標本分散の平均、青線が不偏分散の平均です。不偏分散は標本分散に比べて、偏りが著しく小さいということが分かると思います。
何度も何度もしつこいですが、ある観測値の数 $N$ を固定して分散を繰り返し推定し、それら得られた推定値を平均した値が、真の値と等しいかというのがイメージになります。
★一致性
偏りについては、なんとなくわかったと思います。では一致性との違いは何なのでしょうか?
一致性は、平均的とかそういったものではなく、単純に1回の推定で $N$ を無限大にしたら真値と一致するかというものです。なので、実験は単に $N$ を増やしていくだけで済みます。
結論から言うと、標本分散は一致性を持つのですが、これをシミュレーションで確認します。(証明はこのあたりが参考になると思います。)
一致性の場合は、$N=1$ で推定 $→$ $N=2$ で推定$→$・・・と、どんどんデータを大きくしていった時の挙動を見ます。(各 $N$ ごとに1回しか推定しません。)
np.random.seed(42) M_consistent = 10000 mu_consistent = 10 std_consistent = 5 V_consistent = [] for N in range(M_consistent): X_consistent = np.random.normal(mu_consistent, std_consistent, N) V_consistent.append(np.var(X_consistent, ddof = 0)) plt.figure(figsize = (10, 3.5)) plt.plot(V_consistent, color = 'blue', linewidth = 0.3, label = "Estimator") plt.axhline(25, ls = "--", color = "red", label = "True") plt.xlabel("N") plt.ylabel("Variance") plt.legend(loc = "lower right") plt.show()
$N$ が大きくなるにつれて、真の分散に近付いて行っている様子がわかりますね。
不偏分散もほとんど同じような感じです。
割っている数が$N$ か $N-1$ かの違いなので、ある程度大きくなってしまえば、この違いは無視できそうだということは分かると思います。
np.random.seed(42) M_consistent1 = 10000 mu_consistent1 = 10 std_consistent1 = 5 V_consistent1 = [] for N in range(M_consistent1): X_consistent1 = np.random.normal(mu_consistent1, std_consistent1, N) V_consistent1.append(np.var(X_consistent1, ddof = 1)) plt.figure(figsize = (10, 3.5)) plt.plot(V_consistent1, color = 'blue', linewidth = 0.3, label = "Estimator") plt.axhline(25, ls = "--", color = "red", label = "True") plt.xlabel("N") plt.ylabel("Variance") plt.legend(loc = "lower right") plt.show()
■ まとめ
大した事をやっていないのにすごく疲れました。後半、ちょっと雑な感じがしなくもないですが、簡潔に書いてある方が。。。ね。。。
ざっくりまとめておくと、
不偏性:同じ観測値の数で、何回も何回も繰り返しデータを取って推定し、それらを平均した時に真値と等しくなるか。
一致性:1回の推定で、観測値の数をとてつもなく大きくしたら真値と等しくなるか。
という感じでしょうかね。
★ 参考文献 ★
[1] 野田,宮岡:数理統計学の基礎(1992)
[2] 清水:統計学への確率論,その先へ(2019)
[3] 不偏標本分散の一致性を示してみる(リンク)
[4] 不偏分散の分散(リンク)
[5] 標本分散、不偏分散が一致推定量であること(リンク)
- 投稿日:2020-06-01T19:48:50+09:00
行列の積を文字式で計算?
M5StickCのIMUで遊ぼうと、三次元回転やカルマンフィルタの勉強していたら、
どうしても行列からは逃げられないっぽい、というか行列使ったほうが楽だよ、な匂いが。
行列の積すら記憶の彼方でググってしまった私ですが・・・
式を間違えないようにいじるのが面倒で、勢いでpythonの勉強兼ねて、数式が入った行列式の積を数式のまま出すプログラムを作ってみた(笑)追記:演算子(*(スカラー倍含む),+,-)も対応してみた。電卓のように確定した計算分は表示される
積、スカラーとの積、和・差、だけですが、まずはやってみました。##########\python>matrixmul_str.py Matrix input and operator test a,b,c[Enter](Matrix row 1) d,e,f[Enter]....(Matrix row 2...) to finish matrix,[Enter] or operator '*','+','-' ex.for [a,b] [x] [ 12] [c,d] * [y] + [-34] a,b[Enter] c,d[Enter] *[Enter] x[Enter] y[Enter] + 12[Enter] -34[Enter] [Enter]ここから入力部
$\left(\begin{array}{ccc}a & b\\c & d \end{array}\right)\left(\begin{array}{ccc}x\\y\end{array}\right)+\left(\begin{array}{ccc}12\\-34\end{array}\right)$を入れ、$\left(\begin{array}{ccc}(a*x+b*y)+12\\(c*x+d*y)+(-34)\end{array}\right)$を得ています。input Matrix data. >a,b >c,d >* [ a b ] [ c d ] >x >y >+ [ a*x+b*y ] [ c*x+d*y ] >12 >-34 > [ (a*x+b*y)+12 ] [ (c*x+d*y)+(-34) ]定数*行列もOK.
input Matrix data. >mag >* [ mag ] >a,b >c,d > [ mag*a mag*b ] [ mag*c mag*d ]
matrixmul_str.py 2つの行列を式の文字列として入力したら、式として積を表示する
matrixmul_str.py#!/usr/bin/env python3 # 行列を式の文字列のまま積を計算する import sys def str_brackets(s): if (s.find("+")>=0) or (s.find("-")>=0): # +/-があればカッコで括る 先頭でも return "({})".format(s) else: return s def matrixstr_add(A,B,op): Acol=len(A[0]) Arow=len(A) Bcol=len(B[0]) Brow=len(B) C=A if Acol!=Bcol or Arow!=Brow: print("Matrix add/sub matching error") sys.exit() for r in range(0,Arow): for c in range(0,Acol): C[r][c] = str_brackets(A[r][c]) + op + str_brackets(B[r][c]) return C def matrixstr_mul(A,B): Acol=len(A[0]) Arow=len(A) Bcol=len(B[0]) Brow=len(B) if Acol==1 and Arow==1: R = B for r in range(0,Brow): for c in range(0,Bcol): R[r][c]="{}*{}".format(str_brackets(A[0][0]),str_brackets(B[r][c])) elif Bcol==1 and Brow==1: for r in range(0,Arow): for c in range(0,Acol): R[r][c]="{}*{}".format(str_brackets(B[0][0]),str_brackets(A[r][c])) elif Acol!=Brow: print("Matrix mul. matching error") sys.exit() else: R=[] for r in range(0,Arow): Rrow=[] for c in range(0,Bcol): s="" for i in range(0,Acol): s += "{}*{}+".format(str_brackets(A[r][i]),str_brackets(B[i][c])) Rrow.append(s[:-1]) R.append(Rrow) return R def print_matrix(A): for r in range(0,len(A)): s="[" for c in range(0,len(A[0])): s += " {} ".format(A[r][c]) s += "]" print(s) def make_matrix(s): # s="a11,a12,a13..// a21,a22,a23...// .... an1,an2,an3...ann" style # ex: "a11,a12,a13//a21,a22,a23//a31,a32,a33" # [a11,a12,a13] # [a21,a22,a23] # [a31,a32,a33] Srow=s.split("//") M=[] for r in range(0,len(Srow)): Scol=[x.strip() for x in Srow[r].split(",")] M.append(Scol) cnum_pre=len(M[0]) for r in range(1,len(M)): cnum = len(M[r]) if cnum!=cnum_pre: print("The number of columns is not uniform error") sys.exit() return M def stdin_matrix(): s="" operator="" while True: print(">",end='') s_inp=input() if s_inp=="+" or s_inp=="-" or s_inp=="*": s=s[2:] operator=s_inp break elif len(s_inp)==0 or s_inp=="=": s=s[2:] break else: s += "//{}".format(s_inp) return make_matrix(s),operator print ("\nMatrix input and operator test") print ("a,b,c[Enter](Matrix row 1)") print ("d,e,f[Enter]....(Matrix row 2...)") print ("to finish matrix,[Enter] or operator '*','+','-'") print ("ex.for [a,b] [x] [ 12]") print (" [c,d] * [y] + [-34]") print ("a,b[Enter]") print ("c,d[Enter]") print ("*[Enter]") print ("x[Enter]") print ("y[Enter]") print ("+") print ("12[Enter]") print ("-34[Enter]") print ("[Enter]") print ("input Matrix data.") (A,op2)=stdin_matrix() while True: print_matrix(A) op=op2 if op=="*": (B,op2)=stdin_matrix() A = matrixstr_mul(A,B) elif op=="+" or op=="-": (B,op2)=stdin_matrix() A = matrixstr_add(A,B,op) else: break
- 投稿日:2020-06-01T19:22:33+09:00
ファビコンの配置(Python,Flask,Heroku使用時)
ファビコンが反映されない!
全然ファビコンが表示されなかった。調べてもわからなかった。
ファビコン 配置ファビコン 場所
で調べるとだいたい「ルートディレクトリに」「index.htmlと同じ階層に」って出てくる。
「htmlのheadにlink書けば(imagesファイルとかでも)大丈夫」という話もあった。htmlとcssしかないサイトとは違う!
html,cssだと
project ├ index.html ├ favicon.ico ←--ルート、index.htmlと同じ階層 ├ css │ └ stylesheet.css └ images └ photo.pngjsが加わると
project ├ index.html ├ favicon.ico ←--ルート、index.htmlと同じ階層 ├ css │ └ stylesheet.css ├ js │ └ common.js └ images └ photo.pngってかんじだけど、これがだいたい調べると出てきていた。
Flaskが加わると変えないといけない。
フラスク パイソン ファビコン フォルダ 配置あたりを組み合わせて検索。project ├ static │ ├ css │ │ └ stylesheet.css │ ├ js │ │ └ common.js │ ├ images │ │ └ favicon.ico ←--┐ │ └ favicon.ico ←--staticの中(もしくはさらにimagesの中でも可) ├ templates │ └ index.html ├ app.py └ servise.dbプログラミングスクールでFlask練習用に作ったページでもでこうなってたから、ちゃんと見ればよかった。
あとこのバックエンド系のフォルダ作ったのは別の作業者だったので、配置が違う理由とか全く考えずに使っていた。参考
- 投稿日:2020-06-01T19:20:04+09:00
FlaskのTips
flaskはpythonでウェブアプリケーションを作るためのライブラリである。ここでは、flaskを使ううえでの基本的な方法をまとめる。
インストール
pip install flask導入
まず最初に、最も簡単な"Hello World"を返すAPIを作る。
app.pyfrom flask import Flask app = Flask(__name__) @app.route('/') def root(): return "Hello World!" if __name__ == "__main__": app.run()
- 関数
@app.route(url)でデコレートすると、そのurlにアクセスすると、その関数が実行されるようになる。python app.py上で作成した
app.pyを実行すると、ウェブサーバーが起動する。ブラウザでhttp://localhost:5000/にアクセスすると、画面にHello World!が表示されるようになる。開発時の設定
app.pyfrom flask import Flask app = Flask(__name__) @app.route('/') def root(): return "Hello World!" if __name__ == "__main__": app.run(debug=True,host='localhost',port=5000)
mainを上のように変える。debug=Trueを渡すと(デバッグモード)、サーバーが起動している時に、app.pyや後述するhtmlファイルなどを変更した時に、自動的にロードされる。debugの初期値はFalse。host・portは自由に決めれる。portの初期値は5000。外部からアクセスできるようにする。
app.pyfrom flask import Flask app = Flask(__name__) @app.route('/') def root(): return "Hello World!" if __name__ == "__main__": app.run(debug=False,host='0.0.0.0',port=5000)
mainを上のように変える。host=localhostの時にはローカルからしかアクセスできない。外部からアクセスできるようにするには、host="0.0.0.0"。- セキュリティの理由から
debug=Falseにする。ブラウザも同時に起動する
app.pyimport threading,webbrowser from flask import Flask app = Flask(__name__) @app.route('/') def root(): return "Hello World!" if __name__ == "__main__": threading.Timer(1.0, lambda: webbrowser.open('http://localhost:5000') ).start() app.run(debug=False)
mainでブラウザーを開くコマンドを追加する。app.pyを実行すると同時にブラウザーが立ち上がり、ページが表示される。app.run()にdebug=Trueを渡すと、コードを変更するたびにmainが再実行されるため、その度にブラウザーが追加で開いてしまう。それを防ぐためdebug=Falseを渡している.デバッグモード(
debug=True)でブラウザーを自動で開くようにしたい時には、mainはif __name__ == "__main__": app.run(debug=True)にして、
#!/bin/sh ( sleep 2; open http://localhost:5000/ ) & python app.pyのようなシェルスクリプトを実行するような方法がある。
htmlファイルを返す
app.pyfrom flask import Flask,render_template app = Flask(__name__) @app.route('/') def main(): return render_template('index.html') if __name__ == "__main__": app.run()/templates/index.html<html> <body> Hello World! </body> </html>
- htmlファイルを返す時には
render_template(file)を用いる。- htmlファイル(ここでは
index.html)はapp.pyと同じ場所にtemplatesというディレクトリを作り、その中に配置する。http://localhost:5000/にブラウザからアクセスするとindex.htmlがレンダリングされ、この場合は"Hellow World!"が表示される。CSS・JavaScriptファイル
- CSSファイルやJavaScriptファイルはディレクトリ
./staticに配置する。画像もここに配置する。- htmlファイルからは、それぞれ
<head> <script src="/static/script.js"></script> <link rel="stylesheet" href="/static/style.css"> </head>のように呼び出す。
GETリクエスト
- ここでは
/getのアドレスにGETリクエストを受けて、{"message":"Hello World!"}というjsonオブジェクトを返すapiを考える。app.pyfrom flask import Flask,request,jsonify,render_template app = Flask(__name__) @app.route('/') def index_html(): return render_template('index.html') @app.route('/get',methods=['GET']) def get(): return jsonify({'message':'Hello world!'}) if __name__ == '__main__': app.run()
- デコレータ
@app.route(url,methods)でリクエストを受け入れるurlとmethodsを指定。jsonify()はオブジェクトを文字列になおし、適切なレスポンスを生成する関数である。/templates/index.html<html> <body> <button onclick='get();'>get</button> <script> function get(){ fetch('/get').then( response => response.json() ).then( json => { document.body.innerHTML += JSON.stringify(json); } ).catch( e => console.log(e) ); } </script> </body> </html>
- ボタンを押すと、返ってくるJSONを文字列として表示される。
POSTリクエスト
- ここでは
/postのアドレスにPOSTリクエストを受けて、同じJSONをそのまま返すapiを考える。app.pyfrom flask import Flask,request,jsonify,render_template app = Flask(__name__) @app.route('/') def index_html(): return render_template('index.html') @app.route('/post',methods=['POST']) def post(): #送られてきたjsonをそのまま返す。 req = request.json return jsonify(req) if __name__ == '__main__': app.run()
- POSTリクエストで送られてきたJSONは
request.jsonで得られる。/templates/index.html<html> <body> <button onclick='post();'>post</button> <script> function post(){ fetch('/post', { method: "POST", headers: { "Content-Type": "application/json"}, body: JSON.stringify({"message": "Hello World!!!"}) }).then( response => response.json() ).then( json => { document.body.innerHTML += JSON.stringify(json); } ).catch( e => console.log(e) ); } </script> </body> </html>
- ここでは、ボタンを押すと
{'message':'Hello World!!!'}のJSONをデータとして持つPOSTリクエストを送る。同じJSONが返ってくるのでそれを表示する。画像データを返すAPI
サーバーはデータを受信し、matplotlibでグラフを作成し、その画像データを返すようなAPIを考える。ここでは画像データをdataURLに変換してデータを返す。dataURLは画像データをurlとして表現したものである。
app.pyfrom flask import Flask,render_template,jsonify,request import matplotlib matplotlib.use('agg') from matplotlib import pyplot as plt from matplotlib.backends.backend_agg import FigureCanvasAgg import io,base64 app = Flask(__name__) @app.route('/') def main(): return render_template('index.html') @app.route('/image',methods=['POST']) def image(): data = request.json x = data['x'] y = data['y'] #図を作成 plt.figure(figsize=(3,3),dpi=100) plt.plot(x,y,'k*-',markersize=10) #図をdataURLに変更 canvas = FigureCanvasAgg(plt.gcf()) png_output = io.BytesIO() canvas.print_png(png_output) img_data = base64.b64encode(png_output.getvalue()).decode('utf-8') dataurl = 'data:image/png;base64,'+img_data return jsonify({'img_data':dataurl}) if __name__ == "__main__": app.run()
- まず、サーバー上での図の描画になるので、下のコマンドを
matplotlib関連のライブラリのimportの一番最初に行うことに注意する。import matplotlib matplotlib.use('agg')
image()ではmatplotlibでデータからグラフを作成し、それをdataURLに変換し、それを返している。/templates/index.html<html> <body> <button onclick="image();">img</button> <div id='img'></div> <script> function image(){ fetch('/image', { method: "POST", headers: { "Content-Type": "application/json"}, body: JSON.stringify({"x":[0,1,2,3,4,5], "y":[5,2,4,0,3,8]}) }).then( response => response.json() ).then( json => { document.getElementById('img').innerHTML = `<img src="${json['img_data']}">`; } ).catch( e => console.log(e) ); } </script> </body> </html>
- imgボタンをクリックすると、データ
x=[0,1,2,3,4,5]、y=[5,2,4,0,3,8]をサーバーに送る。- レスポンスが返ってきたら、dataURLをimgタグのsrcに入れれば画像が表示される。
クロスオリジンリクエスト(COR):別のドメインからのアクセス
デフォルトでは別のドメインからのアクセスは制限されている。これを許可するためには
flask-corsのパッケージを使う。pip install flask-corsapp.pyfrom flask import Flask from flask_cors import CORS app = Flask(__name__) CORS(app) @app.route('/') def root(): return "Hello World!" if __name__ == "__main__": app.run()
- 単に
CORSをappに適用するだけでOK。ユーザー認証(ダイジェスト認証)
認証のために
flask-httpauthのパッケージを用いる。pip install flask-httpauthapp.pyfrom flask import Flask from flask_httpauth import HTTPDigestAuth app = Flask(__name__) app.config['SECRET_KEY'] = 'secret key here' auth = HTTPDigestAuth() users = { 'Michael': 'pw_m', 'Smith': 'pw_s' } @auth.get_password def get_pw(username): if username in users: return users.get(username) return None @app.route('/') @auth.login_required def root(): return "Hello World!" if __name__ == "__main__": app.run()
- ユーザー名を与えられた時に、そのユーザーが存在するならば、そのユーザーのパスワードを返し、ユーザーが存在しないならば、
Noneを返す関数を作り(get_pw)、それを@auth.get_passwordでデコレートする。- ここではユーザは'Michael'と'Smith'二人存在し、パスワードはそれぞれ'pw_m'、'pw_s'であるとする。
- 認証が必要な関数を
@auth.login_requiredでデコレートする。- アクセスすると認証画面が最初に表れ、正しいユーザー名・パスワードを入力すると、"Hello World"が表示される。
- 投稿日:2020-06-01T19:20:04+09:00
Flaskの便利な使い方まとめ
flaskはpythonでウェブアプリケーションを作るためのライブラリである。ここでは、flaskを使ううえでの基本的な方法をまとめる。
インストール
pip install flask導入
まず最初に、最も簡単な"Hello World"を返すAPIを作る。
app.pyfrom flask import Flask app = Flask(__name__) @app.route('/') def root(): return "Hello World!" if __name__ == "__main__": app.run()
- 関数
@app.route(url)でデコレートすると、そのurlにアクセスすると、その関数が実行されるようになる。python app.py上で作成した
app.pyを実行すると、ウェブサーバーが起動する。ブラウザでhttp://localhost:5000/にアクセスすると、画面にHello World!が表示されるようになる。開発時の設定
app.pyfrom flask import Flask app = Flask(__name__) @app.route('/') def root(): return "Hello World!" if __name__ == "__main__": app.run(debug=True,host='localhost',port=5000)
mainを上のように変える。debug=Trueを渡すと(デバッグモード)、サーバーが起動している時に、app.pyや後述するhtmlファイルなどを変更した時に、自動的にロードされる。debugの初期値はFalse。host・portは自由に決めれる。portの初期値は5000。外部からアクセスできるようにする。
app.pyfrom flask import Flask app = Flask(__name__) @app.route('/') def root(): return "Hello World!" if __name__ == "__main__": app.run(debug=False,host='0.0.0.0',port=5000)
mainを上のように変える。host=localhostの時にはローカルからしかアクセスできない。外部からアクセスできるようにするには、host="0.0.0.0"。- セキュリティの理由から
debug=Falseにする。ブラウザも同時に起動する
app.pyimport threading,webbrowser from flask import Flask app = Flask(__name__) @app.route('/') def root(): return "Hello World!" if __name__ == "__main__": threading.Timer(1.0, lambda: webbrowser.open('http://localhost:5000') ).start() app.run(debug=False)
mainでブラウザーを開くコマンドを追加する。app.pyを実行すると同時にブラウザーが立ち上がり、ページが表示される。app.run()にdebug=Trueを渡すと、コードを変更するたびにmainが再実行されるため、その度にブラウザーが追加で開いてしまう。それを防ぐためdebug=Falseを渡している.デバッグモード(
debug=True)でブラウザーを自動で開くようにしたい時には、mainはif __name__ == "__main__": app.run(debug=True)にして、
#!/bin/sh ( sleep 2; open http://localhost:5000/ ) & python app.pyのようなシェルスクリプトを実行するような方法がある。
htmlファイルを返す
app.pyfrom flask import Flask,render_template app = Flask(__name__) @app.route('/') def main(): return render_template('index.html') if __name__ == "__main__": app.run()/templates/index.html<html> <body> Hello World! </body> </html>
- htmlファイルを返す時には
render_template(file)を用いる。- htmlファイル(ここでは
index.html)はapp.pyと同じ場所にtemplatesというディレクトリを作り、その中に配置する。http://localhost:5000/にブラウザからアクセスするとindex.htmlがレンダリングされ、この場合は"Hellow World!"が表示される。CSS・JavaScriptファイル
- CSSファイルやJavaScriptファイルはディレクトリ
./staticに配置する。画像もここに配置する。- htmlファイルからは、それぞれ
<head> <script src="/static/script.js"></script> <link rel="stylesheet" href="/static/style.css"> </head>のように呼び出す。
GETリクエスト
- ここでは
/getのアドレスにGETリクエストを受けて、{"message":"Hello World!"}というjsonオブジェクトを返すapiを考える。app.pyfrom flask import Flask,request,jsonify,render_template app = Flask(__name__) @app.route('/') def index_html(): return render_template('index.html') @app.route('/get',methods=['GET']) def get(): return jsonify({'message':'Hello world!'}) if __name__ == '__main__': app.run()
- デコレータ
@app.route(url,methods)でリクエストを受け入れるurlとmethodsを指定。jsonify()はオブジェクトを文字列になおし、適切なレスポンスを生成する関数である。/templates/index.html<html> <body> <button onclick='get();'>get</button> <script> function get(){ fetch('/get').then( response => response.json() ).then( json => { document.body.innerHTML += JSON.stringify(json); } ).catch( e => console.log(e) ); } </script> </body> </html>
- ボタンを押すと、返ってくるJSONを文字列として表示される。
POSTリクエスト
- ここでは
/postのアドレスにPOSTリクエストを受けて、同じJSONをそのまま返すapiを考える。app.pyfrom flask import Flask,request,jsonify,render_template app = Flask(__name__) @app.route('/') def index_html(): return render_template('index.html') @app.route('/post',methods=['POST']) def post(): #送られてきたjsonをそのまま返す。 req = request.json return jsonify(req) if __name__ == '__main__': app.run()
- POSTリクエストで送られてきたJSONは
request.jsonで得られる。/templates/index.html<html> <body> <button onclick='post();'>post</button> <script> function post(){ fetch('/post', { method: "POST", headers: { "Content-Type": "application/json"}, body: JSON.stringify({"message": "Hello World!!!"}) }).then( response => response.json() ).then( json => { document.body.innerHTML += JSON.stringify(json); } ).catch( e => console.log(e) ); } </script> </body> </html>
- ここでは、ボタンを押すと
{'message':'Hello World!!!'}のJSONをデータとして持つPOSTリクエストを送る。同じJSONが返ってくるのでそれを表示する。画像データを返すAPI
サーバーはデータを受信し、matplotlibでグラフを作成し、その画像データを返すようなAPIを考える。ここでは画像データをdataURLに変換してデータを返す。dataURLは画像データをurlとして表現したものである。
app.pyfrom flask import Flask,render_template,jsonify,request import matplotlib matplotlib.use('agg') from matplotlib import pyplot as plt from matplotlib.backends.backend_agg import FigureCanvasAgg import io,base64 app = Flask(__name__) @app.route('/') def main(): return render_template('index.html') @app.route('/image',methods=['POST']) def image(): data = request.json x = data['x'] y = data['y'] #図を作成 plt.figure(figsize=(3,3),dpi=100) plt.plot(x,y,'k*-',markersize=10) #図をdataURLに変更 canvas = FigureCanvasAgg(plt.gcf()) png_output = io.BytesIO() canvas.print_png(png_output) img_data = base64.b64encode(png_output.getvalue()).decode('utf-8') dataurl = 'data:image/png;base64,'+img_data return jsonify({'img_data':dataurl}) if __name__ == "__main__": app.run()
- まず、サーバー上での図の描画になるので、下のコマンドを
matplotlib関連のライブラリのimportの一番最初に行うことに注意する。import matplotlib matplotlib.use('agg')
image()ではmatplotlibでデータからグラフを作成し、それをdataURLに変換し、それを返している。/templates/index.html<html> <body> <button onclick="image();">img</button> <div id='img'></div> <script> function image(){ fetch('/image', { method: "POST", headers: { "Content-Type": "application/json"}, body: JSON.stringify({"x":[0,1,2,3,4,5], "y":[5,2,4,0,3,8]}) }).then( response => response.json() ).then( json => { document.getElementById('img').innerHTML = `<img src="${json['img_data']}">`; } ).catch( e => console.log(e) ); } </script> </body> </html>
- imgボタンをクリックすると、データ
x=[0,1,2,3,4,5]、y=[5,2,4,0,3,8]をサーバーに送る。- レスポンスが返ってきたら、dataURLをimgタグのsrcに入れれば画像が表示される。
クロスオリジンリクエスト(COR):別のドメインからのアクセス
デフォルトでは別のドメインからのアクセスは制限されている。これを許可するためには
flask-corsのパッケージを使う。pip install flask-corsapp.pyfrom flask import Flask from flask_cors import CORS app = Flask(__name__) CORS(app) @app.route('/') def root(): return "Hello World!" if __name__ == "__main__": app.run()
- 単に
CORSをappに適用するだけでOK。ユーザー認証(ダイジェスト認証)
認証のために
flask-httpauthのパッケージを用いる。pip install flask-httpauthapp.pyfrom flask import Flask from flask_httpauth import HTTPDigestAuth app = Flask(__name__) app.config['SECRET_KEY'] = 'secret key here' auth = HTTPDigestAuth() users = { 'Michael': 'pw_m', 'Smith': 'pw_s' } @auth.get_password def get_pw(username): if username in users: return users.get(username) return None @app.route('/') @auth.login_required def root(): return "Hello World!" if __name__ == "__main__": app.run()
- ユーザー名を与えられた時に、そのユーザーが存在するならば、そのユーザーのパスワードを返し、ユーザーが存在しないならば、
Noneを返す関数を作り(get_pw)、それを@auth.get_passwordでデコレートする。- ここではユーザは'Michael'と'Smith'二人存在し、パスワードはそれぞれ'pw_m'、'pw_s'であるとする。
- 認証が必要な関数を
@auth.login_requiredでデコレートする。- アクセスすると認証画面が最初に表れ、正しいユーザー名・パスワードを入力すると、"Hello World"が表示される。
- 投稿日:2020-06-01T18:59:55+09:00
100日後にエンジニアになるキミ - 73日目 - プログラミング - スクレイピングについて4
昨日までのはこちら
100日後にエンジニアになるキミ - 70日目 - プログラミング - スクレイピングについて
100日後にエンジニアになるキミ - 66日目 - プログラミング - 自然言語処理について
100日後にエンジニアになるキミ - 63日目 - プログラミング - 確率について1
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
今回もスクレイピングの続きです。
前回までで、リクエストと構文解析までは終わっています。
今回は取得したデータを保存する方法です。取得した情報の保存
スクレイピングは1つのURLで終わらないことが多いため
リスト型などに取得した情報を格納しておき、適宜ファイルやデータベースに出力することでデータを保存できます。import requests from bs4 import BeautifulSoup url = 'アクセスURL' res = requests.get(url) soup = BeautifulSoup(res.content, "html.parser") # 空のリストを用意 result_list = [] # a タグを全て取得する a_tags = soup.find_all('a') for a in a_tags[0:10]: # aタグのhrefをリストに格納する result_list.append(a.get('href')) print(result_list)['http://www.otupy.com', '/otu/', '/business/', '/global/', '/news/', '/python/', '/visits/', '/recruit/', '/vision/']
リストに格納したものをファイル化するのは次のコードで行えます。
with open('ファイルパス','w') as _w: for row in result_list: _w.write('\t'.join(row))ファイルのダウンロード方法
スクレイピングで取得できるのはテキスト情報だけではありません。
リクエスト先がファイルの場合はファイルを取得することができます。ファイルのダウンロードは次のようなコードで実現できます。
import requests import os url = 'ファイルのURL' # URLからファイル名を抜き出す file_name = os.path.basename(url) print(file_name) # 対象URLにストリーミングアクセスする res = requests.get(url, stream=True) if res.status_code == 200: print('file download start {0}'.format(file_name)) # バイトコードでファイル書き込みを行う with open(file_name, 'wb') as file: # chunk_sizeごとにファイル書き込みを進める for chunk in res.iter_content(chunk_size=1024): file.write(chunk) print('file download end {0}'.format(file_name))ファイルとして保存するには一度アクセスできるかを確かめた後に
レスポンスをファイルとして書き込みします。
res.iter_content(chunk_size=チャンクサイズ)で少しづつ書き込みをしていきます。URLエンコード
URLには日本語などの特殊な文字は使えません。
日本語検索時のURLなどで日本語をURLに使いたい場合は
文字列を特定のコード(記号や英数字の羅列)に変換する必要があります。日本語からURLに使える文字列にすることを
URLエンコードと言います。逆に
URLエンコードされて読めなくなった文字列を、再び読める状態に変換することを
URLデコードと言います。pythonでは
urllibライブラリを用います。URLエンコード
urllib.parse.quote('対象文字列')デコード
urllib.parse.unquote('対象文字列')import urllib.parse # URLエンコード st = '乙py' s_quote = urllib.parse.quote(st) print(s_quote) ## デコード d_quote = urllib.parse.unquote('%E4%B9%99py') print(d_quote)%E4%B9%99py
乙pyまとめ
スクレイピングに関して、補足的な知識を載せています。
少量なのですぐにためせると思います。昨日までの分を復習しておきましょう。
君がエンジニアになるまであと27日
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython
- 投稿日:2020-06-01T18:35:30+09:00
「Project Jupyter」によるWeb上での実行環境
@ITによるPythonの記事
Pythonを勉強するにあたり、その言語の特徴を最初に知っておくことは、「行儀の良い」コードを書くためには重要だと思います。
そこで、Pythonの特徴を調べたところ@ITに記事がありました。
「1行で多くの処理を記述可能」という特徴を読んで、昔Perlで挫折した経験を持つ身としては一抹の不安を感じますが、「シンプルな方が良い」というモットーらしいので、それに期待することにします。
「Project Jupyter」によるWeb上でのPython実行環境
@ITの記事「Pythonってどんな言語なの?」で紹介されていた「Webで利用できるPython環境」である「Project Jupyter」のGUIが少し変更になっていたので操作方法を記載します。
サイト「Project Jupyter」へアクセス
まずは、「Project Jupyter」のページへアクセスします。
https://jupyter.org/index.html
JupyterLabの起動
そして、「JupyterLab 1.0」の「Try it in your browser」をクリックします。
「Try Jupyter」のページに遷移しますので、「Try JupyterLab」をクリックします。
起動中の画面が出ますので、起動するまでしばらく待ちます。
以下のような画面が表示されると起動が完了します。
Python実行用タグの作成
Pythonを実行するには、メニュー[File]-[New]-[Notebook]を選択します。
すると、ダイアログが表示されますので、「Python3」を選択します。
Pythonを実行するための新しいタグが作成されます。
Pythonコードの実行
新しくできたタグにある、テキストエリアにPythonのプログラムを入力します。
タグ内の上側にある「▶︎」ボタンを押します。
すると、入力したPythonコードが実行されます。
注意点
「Project Jupyter」によるWeb上でのPython実行環境は、何も入力せずに一定時間が過ぎると作成した環境自体が失われ、最初からやり直す必要があるのでご注意ください。あくまでもお試し環境ということで、ご注意ください。
最後までご覧いただき、誠にありがとうございました。

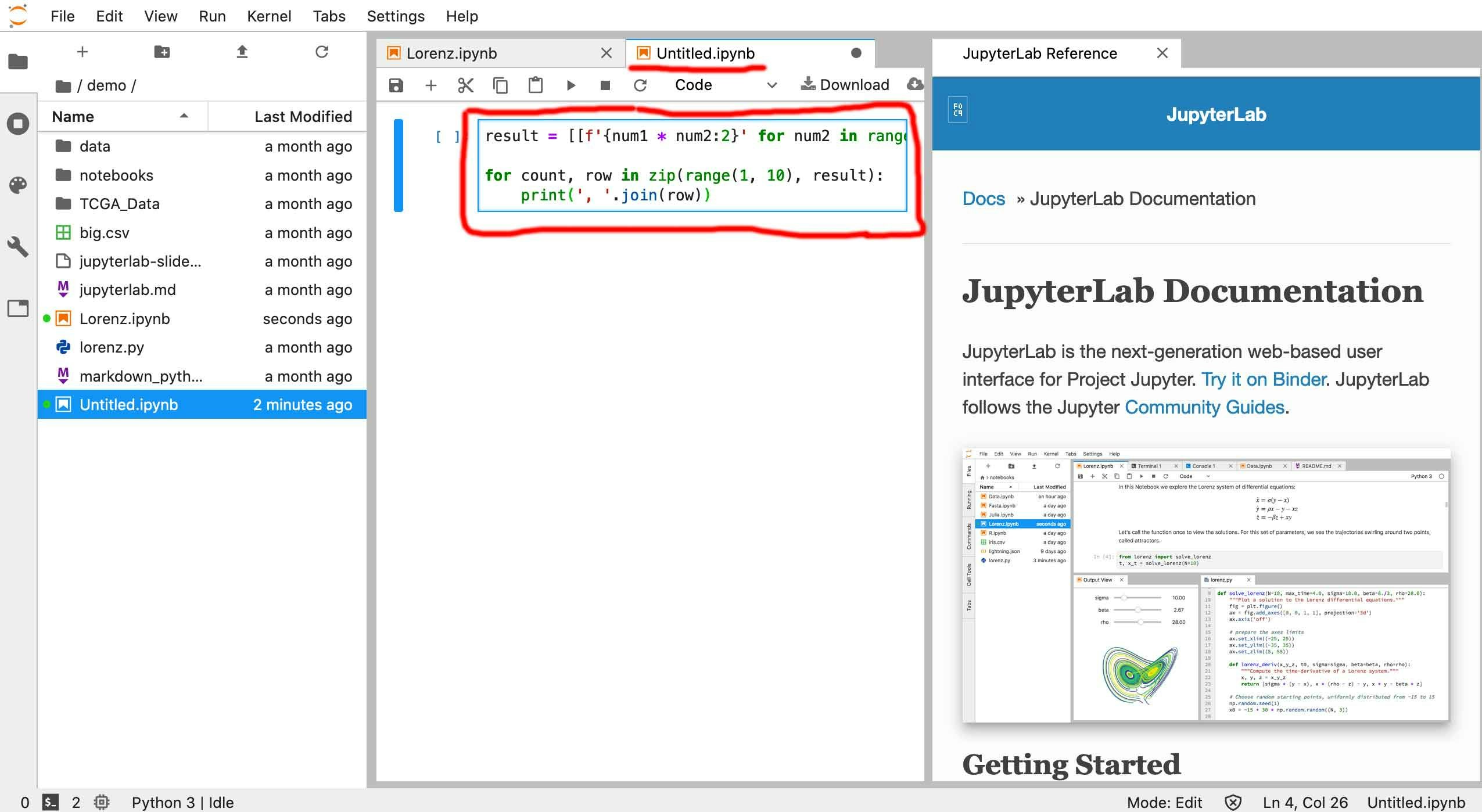

- 投稿日:2020-06-01T17:38:46+09:00
[cx_Oracle入門] cx_Oracle概要
cx_Oracleとは
cx_OracleはPythonからOracle DatabaseにSQLアクセスするためのモジュールです。オラクル社が自ら作成しています。
PEP 249 (Python Database API Specification v2.0)になるべく準拠するように作成されています。
2020/6/1(本記事初期公表)時点のcx_Oracleのバージョンは7.3です。
Python2.7以降、もしくはPython3.5以降で稼働します。
ライセンスはBSD licenseです。
DBアクセス部分はPro*Cではなく、ODPI-C(Oracle Database Programming Interface for C)という、オラクル社提供のOSSのC言語用のOracle Databaseアクセスライブラリを使用しています。
cx_Oracleには大きくは以下のような機能があります。
- 基本的なSQLアクセス(DML / DDL / DCL)
- PL/SQLの実行(無名PL/SQL、ストアドプログラム)
- SODA(Simple Oracle Document Access, JSONドキュメントストアにアクセスするためのAPI)への対応
- XML DB(XMLType)への対応
- オブジェクト機能への対応
- クライアントサイド・コネクションプールの提供
- その他Oracle Database機能への対応(インスタンスの起動/停止等)
cx_Oracleの基本的な情報源
すべて英語ベースです。
- 公式ドキュメンテーション
- GitHubcx_Oracleのインストール
前準備
cx_Oracleを利用するためにはOracle Clientが必要です。Instant Clientでも問題ありません。JavaでいうところのThin Driverに相当するものはありません。
Oracle Clientのバージョンは11.2以上に対応しています。接続先のOracle Database Server側は、利用しているOracle Clientが対応しているバージョンが利用可能となります。cx_Oracleを利用したアプリケーションをテストする前に、SQL*PlusやSQL Developerなどを使用して、cx_Oracleインストール対象マシンからOracle Databaseにアクセスできることを確認しておいてください。インストール
pipやcondaのようなパッケージマネージャーを使用してインストールすることが可能です。以下、pipでのインストール例です。
pip install cx_Oracleサンプルアプリケーション
sample01a.py#!/usr/bin/env python3 # -*- coding: utf-8 -*- import cx_Oracle # (1) USERID = "admin" PASSWORD = "FooBar" DESTINATION = "atp1_low" SQL = "select 12345 from dual" connection = cx_Oracle.connect(USERID, PASSWORD, DESTINATION) # (2) cursor = connection.cursor() # (3) cursor.execute(SQL) # (4) for row in cursor: # (5) print(row[0]) # (6) connection.close() # (7)以下、他の言語でOracle Databaseにアクセスするアプリケーションを作成したことのある方であれば不要なレベルですが、ソース内のコメント番号に対応して、各行を簡単に解説します。
- cx_Oracleをimportする必要があります。
- データベースに接続し、セッションを確立します。
- SQL文をハンドリングするためのカーソルオブジェクトを作成します。
- SQL文を実行します。
- 今回はSELECT文を発行しているので、結果セットの内容を取り出しています。
- レコードはタプルで戻されます。
- セッションを切断します。
- 投稿日:2020-06-01T17:32:34+09:00
AtCoderBeginnerContest169復習&まとめ(後半)
AtCoder ABC169
2020-05-31(日)に行われたAtCoderBeginnerContest169の問題をA問題から順に考察も踏まえてまとめたものとなります.
後半ではDEの問題を扱います.前半はこちら.
問題は引用して記載していますが,詳しくはコンテストページの方で確認してください.
コンテストページはこちら
公式解説PDFD問題 Div Game
問題文
正の整数$N$が与えられます。$N$に対して、以下の操作を繰り返し行うことを考えます。
・はじめに、以下の条件を全て満たす正の整数$z$を選ぶ。
◦ある素数$p$と正の整数$e$を用いて、$z=p^e$と表せる
◦$N$が$z$で割り切れる
◦以前の操作で選んだどの整数とも異なる
・$N$を、$N/z$に置き換える
最大で何回操作を行うことができるか求めてください。とりあえず素因数分解すれば,この問題は簡単に解けることは気づいたので,いつもお世話になっている記事検索して,素因数分解の部分のコードをコピーしました.
Pythonで高速素因数分解〜競プロ用〜
今回の問題は,ある素因数$p_1$を$k$個,持っているとき,何回操作を行うことができるかを考えないといけませんが,操作回数 → 必要な素因数$p_1$の個数は
$1 → 1$
$2 → 3$
$3 → 6$
$4 → 10$
$5 → 15$
と階差数列になっています.
これを計算すると,$m$回操作をするために必要な素因数$p_1$の個数は$\frac{m(m + 1)}{2}$個となることがわかるため,素因数分解した各素因数に対して,操作が何回できるかを計算し,足していくことで答えを得ることができました.abc169d.pydef factorization(n): arr = [] temp = n for i in range(2, int(-(-n**0.5//1))+1): if temp%i==0: cnt=0 while temp%i==0: cnt+=1 temp //= i arr.append([i, cnt]) if temp!=1: arr.append([temp, 1]) if arr==[]: arr.append([n, 1]) return arr n = int(input()) if n == 1: print(0) else: x_list = factorization(n) ans = 0 for x in x_list: n = 2 while True: if x[1] < (n * n + n) // 2: ans += n - 1 break n += 1 print(ans)入力が$1$のときだけ,気を付けないとですね.
E問題 Count Median
問題文
$N$個の整数$X_1,X_2,⋯,X_N$があり、$A_i \leq X_i \leq B_i$であることがわかっています。$X_1,X_2,⋯,X_N$の中央値として考えられる値はいくつあるか求めてください。BとC問題に時間とられ過ぎて,間に合いませんでしたが,$A$と$B$を別々にソートして,その中央値を使えば解けるのは,すぐにわかりました.
データ数が奇数個の場合までコード書いてタイムアップ.問題に関して,まず$A_1,A_2,...,A_N$をソートした結果,得られる数列を$C_1,C_2,...,C_N$とし,$B_1,B_2,...,B_N$をソートした結果,得られる数列を$D_1,D_2,...,D_N$とする.
データ数が奇数個
答えは$D_{(N+1)/2} - C_{(N+1)/2} + 1$個となる.
データ数が偶数個
答えは$D_{N/2} - C_{N/2} + D_{N/2+1} - C_{N/2+1} + 1$個となる.
例えば,$C_{N/2}=5, C_{N/2+1}=7, D_{N/2}=7, D_{N/2+1}=9$とすると,考えられる組み合わせは,
5 6 7 7 6 13/2 7 8 13/2 7 15/2 9 7 15/2 8 と重複しているものが多く,答えは$6,13/2,7,15/2,8$の$5$個である.
この答は,表の行数+列数 - 1であるため,上記の計算式で,同様の答えを得ることができる.abc169e.pyn = int(input()) a_list = [] b_list = [] for i in range(0, n): a, b = map(int, input().split()) a_list.append(a) b_list.append(b) a_list.sort() b_list.sort() if n % 2 == 0: x1 = n // 2 - 1 x2 = n // 2 print(b_list[x2] - a_list[x2] + b_list[x1] - a_list[x1] + 1) else: x = n // 2 print(b_list[x] - a_list[x] + 1)AからCの問題セットがいつも通りの難易度であれば,5完できてたと思うが,勉強不足を感じます.
就職するまでに,少しでもプログラミングの力上がればいいなと思って始めたので,目的に合っている感じはしているので,今後も参加していきたいと思います(BとC問題通せず,rate落ちてたら距離を置くとこだった).
F問題は,今週忙しいので時間ができたときにでも追記できたらいいなと思ってます.後半も最後まで読んでいただきありがとうございました.
- 投稿日:2020-06-01T17:32:15+09:00
RaspberryPi C#でLチカ
マクロソフト製のGPIOライブラリを使う
呼び出し方
using System.Device.Gpio;GitにC#で書かれたLチカサンプルソースがあるので利用します。
RaspberryPiにNetCoreをインストール
LinuxのArmのところをクリックします
クリックした次に画面でパスをコピペできるのでパスを取得します
$ wget パス$ mkdir -p $HOME/dotnet && tar zxf dotnet-sdk-3.1.100-linux-x64.tar.gz -C $HOME/dotnet vim ~/.bashrc #パスを追加する export DOTNET_ROOT=$HOME/dotnet export PATH=$PATH:$HOME/dotnetdotnetをパスを通します
VisualStudioMacでコンソールアプリの開発
.net Coreを選択
NugetからSystem.Device.Gpioを取得
MicroSoft製のGpioライブラリをダウンロードします
using System; using System.Device.Gpio; using System.Threading; namespace led { class Program { static void Main(string[] args) { //GPIOを番号を指定すること int pin = 7; GpioController controller = new GpioController(); controller.OpenPin(pin, PinMode.Output); int lightTimeInMilliseconds = 1000; int dimTimeInMilliseconds = 200; while(true) { Console.WriteLine($"Light for {lightTimeInMilliseconds}ms"); controller.Write(pin, PinValue.High); Thread.Sleep(lightTimeInMilliseconds); Console.WriteLine($"Dim for {dimTimeInMilliseconds}ms"); controller.Write(pin, PinValue.Low); Thread.Sleep(dimTimeInMilliseconds); } } } }ビルド
dllを指定すると実行できます。exeに出力するやり方もあります。
$ dotnet led.dllポイント
controller.OpenPin(pin, PinMode.Output) はGPIOを番号すること
VisualStudioMacで作成したプロジェクトファイルをMonoDevelopで開きデバッグする
MoNoDevelopにSDKのパスを設定する
C#でのLチカ動作確認とれました。



- 投稿日:2020-06-01T17:32:15+09:00
Raspberry Pi C#でLチカ
マイクロソフト製のGPIOライブラリを使う
呼び出し方
using System.Device.Gpio;GitにC#で書かれたLチカサンプルソースがあるので利用します。
RaspberryPiにNetCore 3.1をインストール
LinuxのArmのところをクリックします
クリックした次に画面でパスをコピペできるのでパスを取得します
$ wget パス$ mkdir -p $HOME/dotnet && tar zxf dotnet-sdk-3.1.100-linux-x64.tar.gz -C $HOME/dotnet $ vim ~/.bashrc #パスを追加する export DOTNET_ROOT=$HOME/dotnet export PATH=$PATH:$HOME/dotnetdotnetをパスを通します
VisualStudioMacでコンソールアプリの開発
.net Coreを選択
NugetからSystem.Device.Gpioを取得
MicroSoft製のGpioライブラリをダウンロードします
using System; using System.Device.Gpio; using System.Threading; namespace led { class Program { static void Main(string[] args) { //GPIOを番号を指定すること int pin = 7; GpioController controller = new GpioController(); controller.OpenPin(pin, PinMode.Output); int lightTimeInMilliseconds = 1000; int dimTimeInMilliseconds = 200; while(true) { Console.WriteLine($"Light for {lightTimeInMilliseconds}ms"); controller.Write(pin, PinValue.High); Thread.Sleep(lightTimeInMilliseconds); Console.WriteLine($"Dim for {dimTimeInMilliseconds}ms"); controller.Write(pin, PinValue.Low); Thread.Sleep(dimTimeInMilliseconds); } } } }ビルド
dllを指定すると実行できます。exeに出力するやり方もあります。
$ dotnet led.dllポイント
controller.OpenPin(pin, PinMode.Output) はGPIOを番号すること
課題
VisualStudioMacで作成したプロジェクトファイルをMonoDevelopで開きデバッグする
MoNoDevelopにSDKのパスを設定する
C#でのLチカ動作確認とれました。