- 投稿日:2020-06-01T21:54:59+09:00
JAWS-UG CLI専門支部 #155R EC2入門参加まとめ #jawsug_cli
JAWS-UG CLI専門支部 #155R EC2入門に参加してみて
155回目のハンズオン!もうすぐ6年!
オンラインハンズオンは4/27からスタートして1ヵ月が経ちました。
CLI覚えて転職したメンバーが多いのが支部の特徴!
CLIなれるとマネコン操作がめんどくさくなるらしい→そう言えるようになりたい!
オンラインになって今のところ毎回参加できているので、オンラインっていいなーとしみじみおもう。
シェルは冪等性を担保し易い。マイクロサービスとシェルは考え方が近い。
※冪等性とは何回やっても同じ結果が得られること。EC2は現在402コマンドあるとのこと!
マネジメントコンソールだと
VPCメニュー、EC2メニュー(AutoScaling、ELBが含まれている)、、
APIだとそれぞれわかれている。
EC2、AutoScaling、ELB(CLB)、ELBv2(ALB)、ebs、ec2-instance-connect
生い立ちが違うのかなぁできるようになったこと
1.デフォルトVPCの作成(すでにあった)
2.キーペアの作成
3.ユーザデータの設定
4.セキュリティグループの設定(インバウンドルール追加)
5.インスタンス作成
6.インスタンスメタデータの取得
7.インスタンスの破棄
8.セキュリティグループの設定(インバウンドルール削除)
9.キーペアの削除
10.デフォルトVPCの削除1.デフォルトVPCの作成
作るときは1コマンドで済むが削除するときは1個1個削除する必要がある。
デフォルトVPCは決めることが少ないので検証環境を作る場合に最適。
本番環境には適さない。
VPCは1アカウント5個の上限がある。上限緩和はできる。
デフォルトVPCだと--group-nameが使える。カスタムVPCは--group-idが必要。VPCの作成.aws ec2 create-default-vpc確認.aws ec2 describe-vpcs \ --filters "Name=isDefault,Values=true" \ --query "Vpcs[].CidrBlock" \ --output text2.キーペアの作成
OSにログオンするときのsshキー。
事前にキーファイルを置くディレクトリを作成して権限修正。
mkdir -p ${HOME}/.ssh && chmod 700 ${HOME}/.sshキーペアの作成.aws ec2 create-key-pair \ --key-name ${EC2_KEY_PAIR_NAME} \ --query 'KeyMaterial' --output text \ > ${FILE_SSH_KEY_SECRET} \ && cat ${FILE_SSH_KEY_SECRET} \ && chmod 400 ${FILE_SSH_KEY_SECRET}--key-name \${EC2_KEY_PAIR_NAME} → キーの名前を指定(任意)。
--query 'Key Material' --output text → queryとoutputを併用することで秘密鍵を出力。
> ${FILE_SSH_KEY_SECRET} → リダイレクトで秘密鍵をファイルに出力。作成後の確認.aws ec2 describe-key-pairs \ --query "KeyPairs[?KeyName == \`${EC2_KEY_PAIR_NAME}\`].KeyName" \ --output text3.ユーザデータの作成
ユーザデータとはインスタンス作成時に変更内容をスクリプトで記述しておくと、OS内部の設定を変更してくれる。
たとえばホスト名やyumアップデートなど。
インスタンス作成時に毎回実施する操作はユーザデータに残しておくとよい。
ヒアドキュメントの中にさらにヒアドキュメントで書くというテクニック!(知らなかった)UserDataを出力するファイルを指定.FILE_USER_DATA="${DIR_USER_DATA}/${USER_DATA_NAME}.bash" \ && echo ${FILE_USER_DATA}UserDataの処理を記述.cat << EOF1 > ${FILE_USER_DATA} #!/bin/bash # configure sshd cat << EOF >> /etc/ssh/sshd_config Port ${PORT_SSHD} EOF systemctl restart sshd.service # yum yum update -y EOF1 cat ${FILE_USER_DATA}※SSHが使用するポートを変更して、yumアップデートをかける。
4.セキュリティグループの設定
セキュリティグループはAWS版ファイアウォール。通信のインバウンド、アウトバンドはだいたいここで制御。
サブネット単位での通信制限はNetworkACL(NACL)。
セキュリティグループはステートフルなので、インバウンドを許可するとアウトバンドも許可される。
NACLはステートレス。インバウンド、アウトバンドそれぞれ設定が必要。インバウンドルール許可.aws ec2 authorize-security-group-ingress \ --group-name ${EC2_SECURITY_GROUP_NAME} \ --protocol ${EC2_SECURITY_GROUP_PROTOCOL} \ --port ${EC2_SECURITY_GROUP_PORT} \ --cidr ${EC2_SECURITY_GROUP_CIDR}authorize-security-group-ingress → 指定したプロトコル、ポート、通信元からのインバウンドルールを許可。
--group-name \${EC2_SECURITY_GROUP_NAME} → セキュリグループ名。
--protocol \${EC2_SECURITY_GROUP_PROTOCOL} → セキュリグループのプロトコル(tcp | udp | ICMP)を指定。
--port \${EC2_SECURITY_GROUP_PORT} → 許可するポート番号を指定。
--cidr \${EC2_SECURITY_GROUP_CIDR} → 許可するIPを指定。VPCIDの取得.EC2_VPC_ID=$( \ aws ec2 describe-vpcs \ --filters Name=isDefault,Values=true \ --query 'Vpcs[].VpcId' \ --output text \ ) \ && echo ${EC2_VPC_ID}インバウンドルールの確認.aws ec2 describe-security-groups \ --filter Name=vpc-id,Values=${EC2_VPC_ID} \ Name=group-name,Values=${EC2_SECURITY_GROUP_NAME} \ Name=ip-permission.protocol,Values=${EC2_SECURITY_GROUP_PROTOCOL} \ Name=ip-permission.to-port,Values=${EC2_SECURITY_GROUP_PORT} \ Name=ip-permission.cidr,Values=${EC2_SECURITY_GROUP_CIDR} \ --query "SecurityGroups[].IpPermissions[?IpProtocol == \`${EC2_SECURITY_GROUP_PROTOCOL}\` \ && ToPort == \`${EC2_SECURITY_GROUP_PORT}\` \ && IpRanges[?CidrIp == \`${EC2_SECURITY_GROUP_CIDR}\`]].IpRanges[][].CidrIp" \ --output text--filterの内容
デフォルトVPC、指定したセキュリティグループ名、指定したプロトコル、指定したポート、指定したソース元IPに合致するセキュリティグループを検索
--queryの内容
指定したポートと指定したソース元IPに合致するIPを抽出5.インスタンス作成
インスタンス作成.aws ec2 run-instances \ --image-id ${EC2_IMAGE_ID} \ --instance-type ${EC2_INSTANCE_TYPE} \ --tag-specifications ${STRING_TAG_CONF} \ --user-data file://${FILE_USER_DATA} \ --key-name ${EC2_KEY_PAIR_NAME} \ --associate-public-ip-address--image-id \${EC2_IMAGE_ID} = AMIのIDを指定する。GUIから使いたいAMIのIDを取得しておく。
※AmazonLinux2無料利用枠の対象AMIはami-0a1c2ec61571737d
--instance-type \${EC2_INSTANCE_TYPE} = インスタンスタイプを指定する。無料利用枠だとt2.micro。
--tag-specifications \${STRING_TAG_CONF} = タグを指定。複数指定する場合は、カンマでつなげる。
※"ResourceType=instance,Tags=[{Key=Name,Value=handson-cli-ec2-getting_started-instance},{Key=instancetype,Value=t2.micro}]"--user-data file://\${FILE_USER_DATA} = 作成したUserdataのファイルを指定する。
--key-name ${EC2_KEY_PAIR_NAME} = 作成したキーペア名を指定する。
--associate-public-ip-address = パブリックIPのアサイン。作成後の確認.aws ec2 describe-instances \ --filters Name=tag-key,Values=Name \ Name=tag-value,Values=${EC2_INSTANCE_TAG_NAME} \ Name=instance-state-name,Values=running \ --query Reservations[].Instances[].Tags[].Value \ --output textSSHログイン.ssh ${EC2_PUBLIC_IP} \ -i ${FILE_SSH_KEY_SECRET} \ -l ec2-user \ -p ${PORT_SSHD}-i \${FILE_SSH_KEY_SECRET} = 作成した鍵ファイルを指定。
-l ec2-user = ログインするユーザ名を指定。
-p \${PORT_SSHD} = 使用するポートを指定する。変更している場合に使用。6.インスタンスメタデータの取得
インスタンスメタデータとはインスタンスがもつ情報を検索するための情報。
インスタンスを作成したときのAMIIDや持っているインスタンスタイプの情報を知りたいといったとき、
メタデータにアクセスするとメタデータをキーに実体となる情報(AMIIDやインスタンスタイプ)が得られる。
インスタンスメタデータにはv1とv2がある。
v2はv1に比べてセキュア。セッショントークン、PUTリクエストを利用してメタデータにアクセスすることで
v1よりもセキュアになっている。
サーバーワークスさんの書いたブログがわかりやすかった。
★InstanceMetaDataV2を分かりやすく解説してみる~Serverworksトークンの取得.EC2_METADATA_TOKEN=$( \ curl -s \ -X PUT "http://169.254.169.254/latest/api/token" \ -H "X-aws-ec2-metadata-token-ttl-seconds: ${EC2_METADATA_SECOND}" \ ) \ && echo ${EC2_METADATA_TOKEN}${EC2_METADATA_SECOND} = セッショントークンの有効期限。秒指定。
EC2メタデータのヘッダ設定.EC2_METADATA_HEADER="X-aws-ec2-metadata-token: ${EC2_METADATA_TOKEN}" \ && echo ${EC2_METADATA_HEADER}メタ情報一覧の取得.curl -H "${EC2_METADATA_HEADER}" \ http://169.254.169.254/latest/meta-data/インスタンスタイプの取得.EC2_INSTANCE_TYPE=$( \ curl -s -H "${EC2_METADATA_HEADER}" \ http://169.254.169.254/latest/meta-data/instance-type \ ) \ && echo ${EC2_INSTANCE_TYPE}インスタンスIDの取得.EC2_INSTANCE_ID=$( \ curl -s -H "${EC2_METADATA_HEADER}" \ http://169.254.169.254/latest/meta-data/instance-id \ ) \ && echo ${EC2_INSTANCE_ID}作成時に使用したAMIIDの取得.EC2_IMAGE_ID=$( \ curl -s -H "${EC2_METADATA_HEADER}" \ http://169.254.169.254/latest/meta-data/ami-id \ ) \ && echo ${EC2_IMAGE_ID}グローバルIPの取得.EC2_PUBLIC_IP=$( \ curl -s -H "${EC2_METADATA_HEADER}" \ http://169.254.169.254/latest/meta-data/public-ipv4 \ ) \ && echo ${EC2_PUBLIC_IP}所属するAZの取得.EC2_AZ_NAME=$( \ curl -s -H "${EC2_METADATA_HEADER}" \ http://169.254.169.254/latest/meta-data/placement/availability-zone \ ) \ && echo ${EC2_AZ_NAME}所属するリージョン情報.EC2_REGION_NAME=$( \ curl -s -H "${EC2_METADATA_HEADER}" \ http://169.254.169.254/latest/meta-data/placement/availability-zone \ | sed -e 's/[a-z]*$//' \ ) \ && echo ${EC2_REGION_NAME}※リージョンのメタデータはないのでAZのメタデータを取得したあとにAZを示すアルファベットをカットする。
7.インスタンスの破棄
インスタンスIDの取得.ARRAY_EC2_INSTANCE_IDS=$( \ aws ec2 describe-instances \ --filters Name=tag-key,Values=Name \ Name=tag-value,Values=${EC2_INSTANCE_TAG_NAME} \ Name=instance-state-name,Values=running \ --query Reservations[].Instances[].InstanceId \ --output text \ ) \ && echo ${ARRAY_EC2_INSTANCE_IDS}${EC2_INSTANCE_TAG_NAME} = インスタンス名
インスタンスの削除.aws ec2 terminate-instances \ --instance-ids ${ARRAY_EC2_INSTANCE_IDS}実行するとステータスが"shutting-down"に変わる。
削除後の確認.aws ec2 describe-instances \ --filters Name=tag-key,Values=Name \ Name=tag-value,Values=${EC2_INSTANCE_TAG_NAME} \ Name=instance-state-name,Values=running \ --query Reservations[].Instances[].Tags[].Value \ --output text8.セキュリティグループの設定(インバウンドルール削除)
インバウンドルールの削除.aws ec2 revoke-security-group-ingress \ --group-name ${EC2_SECURITY_GROUP_NAME} \ --protocol ${EC2_SECURITY_GROUP_PROTOCOL} \ --port ${EC2_SECURITY_GROUP_PORT} \ --cidr ${EC2_SECURITY_GROUP_CIDR}与える引数はauthorize-security-group-ingressを実行したときと同じ。
--group-name \${EC2_SECURITY_GROUP_NAME} → セキュリグループ名。
--protocol \${EC2_SECURITY_GROUP_PROTOCOL} → セキュリグループのプロトコル(tcp | udp | ICMP)を指定。
--port \${EC2_SECURITY_GROUP_PORT} → 許可するポート番号を指定。
--cidr \${EC2_SECURITY_GROUP_CIDR} → 許可するIPを指定。9.キーペアの削除
キーペアの削除.aws ec2 delete-key-pair \ --key-name ${EC2_KEY_PAIR_NAME}※OS内からも秘密鍵のファイルを削除することを忘れないように。
10.デフォルトVPCの削除
作成は1コマンドだが、依存関係があるため削除はそれぞれ消していく必要がある。
ちなみにコンソールから消すときとAWS CLIから消す場合とでは挙動が異なる。
コンソールからだとインスタンス、VPCピアリング、NATゲートウェイ、インタフェースエンドポイントがない状態であればサブネット、セキュリティグループ、NACL、ルートテーブル、ゲートウェイエンドポイント、IGW、DHCPオプションはAWS側で削除してくれる。
コマンドだと事前に手動で消しておく必要がある。VPCIDの取得.EC2_VPC_ID=$( \ aws ec2 describe-vpcs \ --filters Name=isDefault,Values=true \ --query 'Vpcs[].VpcId' \ --output text \ ) \ && echo ${EC2_VPC_ID}IgwIDの取得.EC2_IGW_ID=$( \ aws ec2 describe-internet-gateways \ --filters Name=attachment.vpc-id,Values=${EC2_VPC_ID} \ --query "InternetGateways[].InternetGatewayId" \ --output text \ ) \ && echo ${EC2_IGW_ID}IGWのデタッチ.aws ec2 detach-internet-gateway \ --internet-gateway-id ${EC2_IGW_ID} \ --vpc-id ${EC2_VPC_ID}IGWの削除.aws ec2 delete-internet-gateway \ --internet-gateway-id ${EC2_IGW_ID}サブネットIDの取得.ARRAY_EC2_SUBNET_IDS=$( \ aws ec2 describe-subnets \ --filters Name=vpcId,Values=${EC2_VPC_ID} \ --query 'Subnets[].SubnetId' \ --output text \ ) \ && echo ${ARRAY_EC2_SUBNET_IDS}サブネット削除.for i in ${ARRAY_EC2_SUBNET_IDS}; do aws ec2 delete-subnet \ --subnet-id ${i} doneサブネットの数分ループで回して削除する
デフォルトVPCの削除.aws ec2 delete-vpc \ --vpc-id ${EC2_VPC_ID}
- 投稿日:2020-06-01T21:42:25+09:00
AWSで行う監視の体系化
はじめに
最近、サーバ監視やるとしてAWSだったらZabbix用意しなくても何とかなるのではと思い、
今AWSだけでサーバ監視するならどこまでできるのか調べてみた。監視でやりたいこと
基本的な監視をAWSでどこまでできるかって結論、現状以下のようなマルバツ表だと思っています。
今回は黄色の部分を手を動かしてみてどこまでできるか記事にしました。
メモリ監視、ディスク監視(Monitering Scripts)
※ Cloud9上で実行する場合。
AWS公式の手順を抜粋しているだけなので、必要があれば原文を見てください。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/mon-scripts.html
- IAMロール作成 まずはIAMロールに付けるポリシーから作成。
・IAMポリシー
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "cloudwatch:GetMetricStatistics", "cloudwatch:PutMetricData", "cloudwatch:ListMetrics", "ec2:DescribeTags" ], "Effect": "Allow", "Resource": [ "*" ] } ] }IAMポリシーを作成後、IAMロールに紐づけ、監視対象のEC2にアタッチ
2.必要なパッケージのインストール
$ sudo yum install -y perl-Switch perl-DateTime perl-Sys-Syslog perl-LWP-Protocol-https perl-Dig・CPANでさらにインストール
$ sudo cpan ↓CPAN内で実行 > install YAML > install LWP::Protocol::https > install Sys::Syslog > install Switch ↓任意の場所に配置 $ curl https://aws-cloudwatch.s3.amazonaws.com/downloads/CloudWatchMonitoringScripts-1.2.2.zip -O $ unzip CloudWatchMonitoringScripts-1.2.2.zip3.テスト
Cloud9上に作成した「moniter」ディレクトリに上記の「aws-scripts-mon」を配置している場合。
/home/ec2-user/environment/moniter/aws-scripts-mon/mon-put-instance-data.pl --mem-util --mem-avail --disk-space-avail --disk-space-util --disk-path=/CloudWatchのメトリクスに「System/Linux」が追加されており、そこからグラフ表示などできることが確認できた。
定期実行する場合は、Cronなどを使用すればよい。
(この後出てくるAWS Run Commandでも可能)ここまでの参考:https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/mon-scripts.html
http監視(CloudWatch Synthetics)
今までhttp監視のために何かしらサーバを用意する必要があったように思うが(lambdaしかり)、
AWSの新サービスでhttp監視がCloudWatchからできるようになっていた。CloudWatchのSyntheticsコンソールから一気に設定できるので容易に始められるのもgood。
- Canary作成 Cloudwatch > Synthetics > Canaryを作成ボタンを押下してCanary作成開始。
・設計図はハートビートのモニタリングを選択。
・Canaryビルダーには監視したいURLを入力する。
・スクリプトエディタは特に変更なし。(上記の内容が自動で入力される仕様)
スクリプトエディタの中身を見るとhttpステータスが200かどうかで判別していることが分かる。・Canary作成中にスケジュールも設定できる。
・データ保持期間の設定もここからできる。データは最大12か月まで保持できる模様。
・アラームも同じ画面で設定でき、手間が少ない。
2.上記の設定だけでhttp監視は設定完了
これだけの設定で、任意のURLに対してhttp監視できることが分かった。
アラームにAWS SNSのメール設定をしておけば、httpステータスが200以外になったときに
アラートメールを飛ばすことができた。ただし、CloudWatchのアラートの仕様上、メール文面からはどのURLがエラーとなっているかは
アラート名から推測する形になるのでアラート名は分かりやすいものにする必要があると感じた。
また、文面のカスタマイズ性が必要なら、まだZabbixが必要ということになるかと思う。UIはすごく見やすかった。
コマンド監視(AWS Systems Manager Run Command + CloudWatch Events)
CloudWatch EventsでRun Commandを定期実行できるので、
これをやればコマンド監視できるかと思い、試してみた。やった感想としては、かなり手順がめんどくさいし使いにくかったが、
なんとかできはした。AWS Run Commandでは、CloudWatch Logsに実行結果を飛ばせたので、
CloudWatch Logsでフィルターかけてアラートを発報すれば何とかなると思ったが、
CloudWatch EventsからRun Commandを設定する際には実行結果の出力先を設定する項目がなく、
素直にCloudWatch Logsと連携できなかった。そのため、
・Run Commandでシェルをたたき
・シェル内に、コマンドとCloudWatch Logsへの送信を書く
ことでCloudWatch Logsと連携させた。1.監視対象のEC2にSSM Agentをインストール
ここはAWS公式で詳しく載っているので割愛。
(参考:https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/sysman-manual-agent-install.html)
今回はSSMコンソール上から「高速セットアップ」を使用してEC2にAgentをインストールした。2.CloudWatch Logsのロググループ、ログストリームの作成
■ロググループの作成 aws logs create-log-group --log-group-name moniter-group ■ログストリームの作成 aws logs create-log-stream --log-group-name moniter-group --log-stream-name moniter-group-0013.スクリプト作成
#!/bin/sh DATE=`date +"%Y/%m/%d %H:%M:%S" -d "9 hours"` DATE_LINUX=`date +%s%3N` COM1=`sudo service httpd status` SPACE=" : " MESSAGE1=$DATE$SPACE$COM1 SEQUENCE_TOKEN=`cat /home/ec2-user/environment/moniter/cloudwatch_sequenceToken | jq .nextSequenceToken` aws logs put-log-events \ --log-group-name moniter-group \ --log-stream-name moniter-group-005 \ --log-events timestamp=$DATE_LINUX,message="$MESSAGE1" \ --sequence-token ${SEQUENCE_TOKEN:1:-1} \ > /home/ec2-user/environment/moniter/cloudwatch_sequenceTokenひとまずコマンドでサービスの状態を監視する想定として、
「sudo service httpd status」コマンドを実行することにした。今回は考えるのが面倒だったので、とりあえず「/home/ec2-user/environment/moniter/cloudwatch_sequenceToken」というファイルに
sequence-tokenの値を上書き&参照していく仕様にした。スクリプト中ではjsonを使うために「jq」コマンドを使用している。
デフォルトではインストールされていないので、別途インストールが必要。sudo yum install jqハマりどころとしては、「aws logs put-log-events」コマンドにおいて
timestampは13桁のUNIXTimeでないといけないこと、
CloudWatch Logsに送信した際に返ってくるsequence-tokenを次の送信時に使用しないといけないこと。
ただし、初回はsequence-tokenを送ってはいけないので、あらかじめ
下記で一回送信しておくとよい。aws logs put-log-events --log-group-name moniter-group --log-stream-name moniter-group-001 --log-events timestamp=1590995877,message="test"4.CloudWatch EventsからRun commandの設定
CloudWatch Eventsを新規に作成する。
・スケジュール :任意に設定。Cron式も書ける
・ターゲット :SSM Run Command
・ドキュメント :AWS-RunShellScript(Linux)
・ターゲットキー:今回はインスタンスIDでコマンド実行対象のEC2を識別したかったので
InstanceIdsを入力
・ターゲット値 :対象とするインスタンスのIDを入力
・Commands :sh [絶対パス]/[スクリプト名] (例:sh /home/ec2-user/environment/moniter/xxx.sh)ここまでで、特定のコマンドを対象のEC2に実行し、実行結果をCloudWatch Logsに飛ばすところまでいけた。
あとは、CloudWatch Logsで特定の文言で拾ってアラート飛ばすだけ。5.メトリクスフィルターの作成
WloudWatch > ロググループから作成したロググループを選択し、
メトリクスフィルターを作成する。・下記例
・フィルターパターン stop ・フィルター名 service-moniter-filter ・メトリクス名 service-moniter-metrics-name ・メトリクス名前空間 service-moniter-metrics-namespace ・メトリクス値 1 ・デフォルト値 0デフォルト値を0にしておかないと、エラー出ないときにデータ不足といわれてしまうので注意。
6.AWS SNSの設定
AWS SNSでメール送信設定ができる。この手順はすぐに完了するような内容。・トピック 名前:moniter-email ・サブスクリプション プロトコル:Eメール メールアドレス:(受け取るメールアドレスを記載)設定後、確認メールが来るので確認のURLにアクセスする。
7.上記の設定でやっとのことコマンド監視設定が完了
ここまでやってやっとコマンド監視ができた。
実際に動かしてみたが問題なく検知&アラート発報できていた。コマンドをまとめてシェルに書いておけば、まとめてコマンド実行して監視できるかと思ったが、
CloudWatchのアラートの仕様では発報されたメールにはアラート名しかないので、
メールから失敗したコマンドを判別したいなら、実行するコマンドの数だけ上記設定が必要となる。・メール例
Alarm Details: - Name: service-moniter-alarm - Description: - State Change: OK -> ALARM - Reason for State Change: Threshold Crossed: 1 out of the last 1 datapoints [1.0 (01/06/20 09:59:00)] was greater than or equal to the threshold (1.0) (minimum 1 datapoint for OK -> ALARM transition).コマンド監視が必要な場合は、現状AWSの機能だけでコマンド監視しようとすると少しキツいという印象だった。
やはりこの場合も現時点ではZabbixが必要な場合もあると思う。プロセス監視(外部参照)
こちらはDeveloperIOで詳しく書かれていたのでそちらを参照します。
https://dev.classmethod.jp/articles/cloudwatchagent-process-monitor-action/ログ監視(外部参照)
ログ監視については特定のログをCloudWatch Logsに送ることができれば、
上記コマンド監視で行っていたフィルター&アラートで監視できると思います。CloudWatch Logsに送るまでの手順は別の方が詳しく書いてくださっていたのでそちらを参照します。
https://qiita.com/chocomintkusoyaro/items/d2d0011d6dfb2bc7fdf4終わりに
AWSマネージドの監視について一通り検証したが、
Zabbixなどの監視システム不要な時代は近いのかもしれないと思った。
(私の考えが古いだけで、AWSの監視で本番運用しているトコも多くあるかもしれない。)ただ、現状監視のレポートを見る場所が分散していたり、
メールも可読性が悪く、アラートの詳細が文面から把握できない場合もあるので
まだまだZabbixは使うと思う。
今後の動向を追いながら少しづつAWSマネージドに寄せて運用負荷を減らしていきたいと思った。また、Cloud Watch Agentをまだ使い倒せていないのでいろいろいじってみて
考えをアップデートしていきたい。








- 投稿日:2020-06-01T21:14:53+09:00
【ELB基本設定】 ELBを作成し、httpアクセスをロードバランシングする
目標
ELBを作成し、httpアクセスをロードバランシングすること
1. バックエンドインスタンスの作成(注意手順以外は省略)
①httpd自動起動用ユーザデータ(※)を設定する
※ 内容は以下
#!/bin/bash
yum update -y
amazon-linux-extras install -y lamp-mariadb10.2-php7.2 php7.2
yum install -y httpd mariadb-server
systemctl start httpd
systemctl enable httpd
usermod -a -G apache ec2-user
chown -R ec2-user:apache /var/www
chmod 2775 /var/www
find /var/www -type d -exec chmod 2775 {} \;
find /var/www -type f -exec chmod 0664 {} \;
echohostname> /var/www/html/index.html②80番ポートのセキュリティグループを空ける
③インスタンス作成を実行する(ロードバランシング検証のため複数インスタンス作成する、同一VPC内に作成すること)
④ブラウザから作成したインスタンスのパブリックIPアドレスを入力し、httpアクセスを検証する(※)。
※パブリックDNS名がブラウザ上に表示されればOK⑤作成したインスタンス詳細画面より、VPCID及びサブネットID、セキュリティグループ名を確認する(ELB作成時に利用)
2. ELBの作成
①ロードバランサーの作成をクリック
②ALBを利用する
③ロードバランサの詳細設定(※)を行う
※設定情報は以下
名前: 任意
スキーム: インターネット向け
IPアドレスタイプ: ipv4
リスナー: HTTPプロトコル80番ポート
VPC: バックエンドインスタンスのVPCID
アベイラビリティゾーン: バックエンドインスタンスのサブネットID
③ELBのセキュリティグループを設定する(※)
※バックエンドインスタンスにアタッチした既存セキュリティグループを利用
④ターゲットグループ作成、ヘルスチェック設定(※)
※今回はターゲットグループ名のみ入力で他はデフォルト設定のままとした
⑤ターゲットの登録
ELBバックエンドインスタンスを登録する
⑥設定内容確認後、ELB作成実施
⑦作成したELBのステータスが「active」になっていることを確認
⑧ターゲットグループ内インスタンスへのヘルスチェックが正常であることを確認
3. 疎通検証
①ELB詳細画面からDNS名を取得
②取得したDNS名を利用してブラウザアクセス
⇒アクセス毎に異なるバックエンドインタンスへ接続されることを確認出来たらOK(キャッシュアクセスを防ぐため一方のアクセスにはブラウザシークレットモードを利用する)















- 投稿日:2020-06-01T18:51:38+09:00
ALB + CognitoでGoogleアカウント認証をかける
この記事はクラスメソッドさんの記事『Amazon CognitoユーザープールLambdaトリガーでALB認証のメールアドレスを制限する | Developers.IO]』の手順をちょっと(うまくいかないところを試行錯誤しつつ)詳しく書いたものです。
何ができるか
認証機能など何もないWebアプリがEC2で動いているとします。このEC2を
- ALBの下にぶら下げる
- Cognitoの仕組みを使い、特定のGoogleアカウントでログインしているときだけアクセスできるようにする
という仕組みをサーバーレス(AWS ALB + Amazon Cognito + Google Cloud Platform + AWS Lambda)で構築します。
前置き:ALB + Cognitoの何が混乱を招くか
Amazon Cognitoは素晴らしいサービスなのですが、「ユーザープール」と「IDプール」があり、初歩的なこと1であればどちらを使っても似たようなことができるので話がとっちらかる傾向にあります。
また、さらにややこしいことにGoogleはOpenIDプロバイダでもあり、Cognitoを使わなくてもALBのOIDC認証でGoogleアカウント認証ができてしまったりします(G Suiteを利用している場合、組織内アカウントのみを認証対象とすることでCognitoを使わずに済ませることも可能です)。この記事では
- ALBのOIDC認証機能は使わない
- Cognitoのユーザープールを使う
- CognitoのIDプールは使わない
ということを明確にしておきます。
やっていく
実際に手を動かして進めていきましょう。
Google Cloud Platformで新規プロジェクト作成
Google Cloud Platformのコンソールにログインし、適当な名前でプロジェクトを作成します。
スクリーンショット
OAuth同意画面作成
【ナビゲーションメニュー > APIとサービス > OAuth同意画面】と進み、OAuth同意画面を作成します。
G Suiteを利用している場合、ここで「内部」を選択することができます2。「内部」を選ぶと、組織外部のGoogleアカウントはこのプロジェクトで認証をパスすることはできなくなります。これはつまり何を間違えても外部の人が認証を通ってしまうことがあり得ないということを意味しますので、特に必要がなければ「内部」の方が安全です。
スクリーンショット
見ての通り、必要なスコープはデフォルトで付いてくるので特に追加する必要はありません。とりあえず名前だけ入力して保存します。
ここで一応:スコープってなんだっけ
OAuthを使ったシステムでは、ユーザーがアプリケーションへ直接パスワード等を送るのではなく、「アプリケーションがこんな権限(=スコープ)を要求してるけどどうする?」とGoogleのドメイン上で認証画面が表示されるというのがキモでした。スコープを増やせばGmailを送信したりGoogle Driveへアクセスしたりできるようになるわけですが、ここにある
email profile openidは無条件でくっついてくる最低限のスコープだということになります。OAuth 2.0クライアントID作成
続いて【認証画面】へ移動し、「認証情報を作成」→「OAuthクライアントID」と進んで「作成」をクリックします。
「アプリケーションの種類」は「ウェブアプリケーション」を選択して「作成」ボタンを押します。
スクリーンショット

OAuth 2.0クライアントIDが作成され、ポップアップでクライアントIDとクライアントシークレットが表示されます。この値をメモっておきます。
なお、この値はいつでも【認証情報 > OAuth 2.0クライアントID】を開けば参照できますからポップアップは閉じてしまっても大丈夫です。
スクリーンショット
ALBの準備(前半)
こちらについては軽く触れるだけにします。
- ACMで適当な証明書を用意しておく
- インターネット向けのALBを作る
- HTTPSでアクセスを受け付け、証明書を割り当てる
- ターゲットグループはとりあえず空で作る
- Route 53などでALBに
hello-cognito.example.comというような名前を割り当てるhttps://ALBのFQDNでALBにアクセスができるようになればOK- リスナーのルール編集画面を開いておく
この画面は後で触ります。
Cognitoの準備
ユーザープールを作成する
新たにユーザープールを作成します。適当に名前を決めて、「デフォルトを確認する」→「プールを作成する」でいいです。
スクリーンショット
アプリクライアント作成
続けてアプリクライアントを作成します。
- トークンの有効期限を適当な値(デフォルト値に設定)
- 不要な「SRP (セキュアリモートパスワード) プロトコルベースの認証を有効にする」のチェックを外す
これでアプリクライアントIDが作成されます。アプリクライアントIDは後でALBのリスナーに設定します。
スクリーンショット
ドメイン名決定
Amazon Cognitoドメインを決めます(この操作により新たに取得されます)。
ここで決めたhttps://YOUR-DOMAIN-NAME.auth.ap-northeast-1.amazoncognito.comは後で使うのでメモっておきます。
スクリーンショット
Googleとの紐付け
【フェデレーション > IDプロバイダー】を開き、「アプリID」と「アプリシークレット」に先ほどメモっておいた値を入力します。承認スコープは
email profile openidとして「Googleの更新」をクリックします。
スクリーンショット
属性マッピング変更
【フェデレーション > 属性マッピング】を開き、「Google」タブからemailのマッピングを行って「変更の保存」をクリックします。
スクリーンショット
アプリクライアント設定
アプリクライアントの設定からスクリーンショットの通りに各種設定を行います。
コールバックURLはhttps://ELBに割り当てたFQDN/oauth2/idpresponseになります。
(※このパスはALBが横取りして認証に使うため、EC2が/oauth2/idpresponseというリクエストを受け取ることはありません)
保存すると「ホストされたUI」リンクが有効になりますが、こちらをクリックする前にGoogle側の設定を済ませます。
Google側の設定
Googleの設定画面に戻り、
- 承認済みのJavaScript生成元:
https://ELBに割り当てたFQDN- 承認済みのリダイレクトURI:
- 「ドメイン名」で決めた値 +
/oauth2/idpresponseを入力します。ここは一字一句違ってもエラーになるので気をつけましょう。
スクリーンショット
Cognitoで動作確認
Cognitoの画面に戻り、「ホストされたUIを起動」リンクをクリックします。「Continue with Google」画面が出てきてGoogleログインが促されましたか?
最終的にhttps://ALBのFQDN/oauth2/idpresponse?code=...へリダイレクトされれば問題ありません。
スクリーンショット
ALBのルール設定
ALBのリスナーからルール設定画面に戻り、ルールを設定します。「詳細設定」の中の「スコープ」は全部揃えるということで3
email profile openidにしておきます。
動作確認
いよいよ
https://ALBのFQDNにアクセスしてみます。
Google認証が求められた上でEC2にアクセスできれば何もかもがうまく行ったということになります。
同時にHTTPS化もできてうれしいですね。
ログインできるGoogleアカウントを決める
これでGoogleアカウント認証はできたのですが、今のままではどんなアカウントでも認証が通ってしまうため、事実上認証はないに等しい状態です。Lambda関数でカスタムのチェックを行いましょう。
Lambda関数を作る
これから作るLambda関数がやるべきことはたった2つです。(したがってIAM Roleも最低限の権限で良いです)
- 引数のオブジェクトからメールアドレスを取り出す
- 問題ないなら引数をそのまま返す。認証を拒否するなら例外をスローして異常終了させる
リスナーのスコープとして
email profile openidを指定した場合、「サインアップ前」トリガーLambda関数にはこんなオブジェクトが渡されます。{ "version": "1", "region": "ap-northeast-1", "userPoolId": "ap-northeast-1_wycr1qYwL", "userName": "google_999999999999999999999", "callerContext": { "awsSdkVersion": "aws-sdk-unknown-unknown", "clientId": "1iaca7vca5rl5dgpqc7ibd7em5" }, "triggerSource": "PreSignUp_ExternalProvider", "request": { "userAttributes": { "cognito:email_alias": "", "cognito:phone_number_alias": "", "email": "itsumo.itsumo.nemui@gmail.com" }, "validationData": {} }, "response": { "autoConfirmUser": false, "autoVerifyEmail": false, "autoVerifyPhone": false } }この中からメールアドレスを取り出して、ドメインなり何なりで判定を行えばいいだけです。Node.jsだとどうもうまく行かなかったのでPython 3.7で書きました。
def lambda_handler(event, context): print(event) email = event["request"]["userAttributes"]["email"] if email == "itsumo.itsumo.nemui@gmail.com": print("It's me! OK! OK!") return event raise Exception("bye-bye!")これをトリガーに設定すれば終わりです。なお、トリガーを設定してから実際にトリガーが呼ばれるようになるまでには若干のタイムラグがあるようです。
スクリーンショット



















- 投稿日:2020-06-01T15:11:16+09:00
SpringBootアプリをGithubActionsでEC2に自動デプロイする
はじめに
前回の記事 でGithubActionsを使ってBeanstalkへのデプロイが簡単に行えることがわかりました。
今回は実際に社内で運用しているEC2に自動デプロイできるworkflowを書いてみます。せっかくなので、インスタンス作成直後のまっさらな状態のEC2に対しても、自動でセットアップしてデプロイできるようにしたいと思います。
前提
- パブリックサブネットに配置したEC2があること
- EC2にSSHできる秘密鍵があること
- Githubのアカウントがあること
開発環境
macOS Catalina
OpenJDK 1.8
SpringBoot 2.2.6
Gradle 6.3大まかな作業の流れ
- デプロイ用のSpringBootアプリを用意する
- RepositoryのSecretsに秘密鍵を登録する
- workflowを書く
- pushして自動デプロイを確認
1. デプロイ用のSpringBootアプリを用意する
まずはデプロイして動作確認するためのSpringBootのアプリを作成します。
例によってサクっと spring initializr で GradleProject に lombok, Spring Web をdependenciesに追加して作成 します。build.gradleplugins { id 'org.springframework.boot' version '2.2.6.RELEASE' id 'io.spring.dependency-management' version '1.0.9.RELEASE' id 'java' } group = 'com.example' version = '0.0.1-SNAPSHOT' sourceCompatibility = '1.8' configurations { compileOnly { extendsFrom annotationProcessor } } repositories { mavenCentral() } dependencies { implementation 'org.springframework.boot:spring-boot-starter-web' compileOnly 'org.projectlombok:lombok' annotationProcessor 'org.projectlombok:lombok' testImplementation('org.springframework.boot:spring-boot-starter-test') { exclude group: 'org.junit.vintage', module: 'junit-vintage-engine' } } test { useJUnitPlatform() }このプロジェクトに対し、次の変更を加えていきます。
1-1. 完全な実行可能Jarのビルド設定を
build.gradleに追加デプロイするアプリをサービスとして実行するため、完全に実行可能なJarを生成 するようにします。
以下のbootJarタスクをbuild.gradleに追加します。build.gradlebootJar { launchScript() }1-2. Controllerを作成
動作確認用の簡単なControllerを作成しておきます。
DemoController.java@RestController public class DemoController { @GetMapping("/demo") public String demo() { return "Hello Actions demo!!"; } }1-3. ポート番号80で待ち受け
EC2でHTTP通信を待ち受けるため
application.propertiesを編集してポート80を設定します。application.propertiesserver.port=80以上でアプリの準備は完了です。
1-4. アプリの動作確認
EC2にデプロイする前に、アプリが正しく動作することを確認しておきます。
以下のコマンドでjarをビルドします。$ ./gradlew buildすると、
build/libs内にjarが生成されるので、ローカルでアプリを起動してみます。
完全に実行可能なJar で作成しているため、jarを直接叩いて実行できることを確認しておきます。$ ./build/libs/actions-0.0.1-SNAPSHOT.jar起動後、ブラウザで
http://localhost/demoにアクセスしてみます。
上のイメージのように、先ほど作成したControllerのレスポンスが表示されていれば、アプリの準備は完了です。
2. RepositoryのSecretsに秘密鍵を登録する
作成したプロジェクトをGithubにプッシュしてリポジトリを作成し、いよいよ
workflowの作成を行います。
その前に、このworkflowではEC2へSSH接続を行うため、秘密鍵情報をSecretsに登録しておきます。今回は
AWS_EC2_PRIVATE_KEYという名前で秘密鍵情報を登録します。
EC2インスタンス作成時に作った〜.pemファイル、またはssh-keygenなどで生成したキーペアの秘密鍵ファイルの中身のテキストをまるっとコピーして貼り付けます。
3. workflowを書く
EC2へのデプロイのため、普段手作業でSCPとSSHでjarファイルのコピー&サービスの(再)起動を行なっていたものを
workflow化しました。やってることは、EC2に
javaをインストール/var/apps/(アプリ名)/(アプリ名).jarと(アプリ名).confファイルを配置/etc/systemd/system/(アプリ名).serviceファイルを配置sudo systemctl start(or restart) (アプリ名)でサービス起動です。
出来上がった
workflowファイルは以下になります。.github/workflows/ec2-deploy.ymlname: Gradle build and Deploy to ec2 on: push: branches: [ master ] env: EC2_USER: 'ec2-user' EC2_HOST: (your ec2 public ip address.) SRC_PATH: 'build/libs/*.jar' DEST_DIR: '/var/apps' APP_NAME: 'actions' JAVA_VERSION: '1.8' JAVA_OPTS: '-Xms1024M -Xmx1024M' RUN_ARGS: '--spring.profiles.active=prod' jobs: deploy: name: Gradle build and Deploy to ec2 runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Set up JDK. uses: actions/setup-java@v1 with: java-version: ${{ env.JAVA_VERSION }} - name: Grant execute permission for gradlew run: chmod +x gradlew - name: Build with Gradle run: ./gradlew build - name: SCP EC2 Copy app file env: PRIVATE_KEY: ${{ secrets.AWS_EC2_PRIVATE_KEY }} run: | echo "$PRIVATE_KEY" > private_key && chmod 600 private_key ssh -t -o StrictHostKeyChecking=no -i private_key ${EC2_USER}@${EC2_HOST} "sudo mkdir -p $DEST_DIR/$APP_NAME && sudo chmod -R 777 $DEST_DIR/$APP_NAME" scp -i private_key ${SRC_PATH} ${EC2_USER}@${EC2_HOST}:${DEST_DIR}/${APP_NAME}/${APP_NAME}.jar - name: SSH EC2 Setup and Deploy uses: appleboy/ssh-action@v0.0.9 with: key: ${{ secrets.AWS_EC2_PRIVATE_KEY }} username: ${{ env.EC2_USER }} host: ${{ env.EC2_HOST }} envs: DEST_DIR,JAVA_VERSION,APP_NAME,JAVA_OPTS,RUN_ARGS script: | echo "===== yum update =====" sudo yum update -y echo "===== check java install =====" if java -version 2>&1 >/dev/null | grep "java version\|openjdk version" ; then echo "already installed java." else echo "install java." TARGET=$(yum search java | grep "$JAVA_VERSION.*devel\." | awk '{print $1}') echo "install target name -> $TARGET" sudo yum install -y ${TARGET} echo "JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")" | sudo tee -a /etc/profile source /etc/profile fi echo "===== check conf file =====" if [ -f ${DEST_DIR}/${APP_NAME}/${APP_NAME}.conf ]; then echo "already exist conf file for $APP_NAME" else echo "create conf file for $APP_NAME" cat <<EOL | sudo tee -a ${DEST_DIR}/${APP_NAME}/${APP_NAME}.conf export LANG="ja_JP.UTF8" JAVA_OPTS="$JAVA_OPTS" RUN_ARGS="$RUN_ARGS" EOL fi echo "===== check exist service file =====" if [ -f /etc/systemd/system/${APP_NAME}.service ]; then echo "already exist service file for $APP_NAME" else echo "create service file for $APP_NAME" cat <<EOL | sudo tee -a /etc/systemd/system/${APP_NAME}.service [Unit] Description = ${APP_NAME} app [Service] ExecStart = ${DEST_DIR}/${APP_NAME}/${APP_NAME}.jar Restart = always Type = simple User = root Group = root SuccessExitStatus = 143 [Install] WantedBy = multi-user.target EOL fi echo "===== application (re)start =====" sudo systemctl daemon-reload if sudo systemctl status ${APP_NAME} 2>&1 | grep "Active: active (running)" ; then echo "${APP_NAME} app restart!!" sudo systemctl restart ${APP_NAME} else echo "${APP_NAME} app start!!" sudo systemctl start ${APP_NAME} fiまっさらなEC2にもデプロイできるようにしたため、セットアップ系のSSHのコマンドラインが多いです。
以下に簡単に内容を説明します。workflowの内容
masterブランチへPush、マージされた場合にこのworkflowが動く様に設定しています。on: push: branches: [ master ]以下は
workflow内で参照する環境変数です。
デプロイするアプリやサーバによって可変な部分を定義しています。env: EC2_USER: 'ec2-user' EC2_HOST: (your ec2 public ip address.) SRC_PATH: 'build/libs/*.jar' DEST_DIR: '/var/apps' APP_NAME: 'actions' JAVA_VERSION: '1.8' JAVA_OPTS: '-Xms1024M -Xmx1024M' RUN_ARGS: '--spring.profiles.active=prod'
EC2_HOSTとAPP_NAMEはサーバ、アプリ毎に設定を変えて利用します。
定数名 説明 EC2_USER ec2へssh接続する時のユーザ名(ec2-userのままでOK) EC2_HOST 【要変更】 ec2のパブリックIPアドレス SRC_PATH ビルドされたjarファイルのパス DEST_DIR ec2側のアプリを配置するディレクトリのパス APP_NAME 【要変更】 アプリ名。gradleでビルドされた.jarを ${APP_NAME}.jarにリネームして、ec2の${DEST_DIR}にコピーするJAVA_VERSION ビルドや実行する時のJavaのバージョン。EC2にもこのバージョンのjavaがインストールされる JAVA_OPTS アプリ起動時のオプション RUN_ARGS アプリの起動引数。上記例ではSpringのプロファイルを prodに切り替えている以下は
./gradlew buildを実行するまでのStepです。
(ほぼ、公式の雛形Java with Gradleのままです)jobs: deploy: name: Gradle build and Deploy to ec2 runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Set up JDK. uses: actions/setup-java@v1 with: java-version: ${{ env.JAVA_VERSION }} - name: Grant execute permission for gradlew run: chmod +x gradlew - name: Build with Gradle run: ./gradlew build以下で、ビルドした
.jarファイルをsshとscpでEC2サーバーにコピーします。
ここで先ほど登録した秘密鍵情報AWS_EC2_PRIVATE_KEYからファイルを復元してsshとscpの秘密鍵ファイルとして指定します。- name: SCP EC2 Copy app file env: PRIVATE_KEY: ${{ secrets.AWS_EC2_PRIVATE_KEY }} run: | echo "$PRIVATE_KEY" > private_key && chmod 600 private_key ssh -t -o StrictHostKeyChecking=no -i private_key ${EC2_USER}@${EC2_HOST} "sudo mkdir -p $DEST_DIR/$APP_NAME && sudo chmod -R 777 $DEST_DIR/$APP_NAME" scp -i private_key ${SRC_PATH} ${EC2_USER}@${EC2_HOST}:${DEST_DIR}/${APP_NAME}/${APP_NAME}.jarここまででEC2の
/var/apps/(アプリ名)/(アプリ名).jarの配置までが完了します。
以降でEC2の初期セットアップとアプリの起動を行います。EC2の初期セットアップとアプリのサービス起動まで
workflowで複数行のsshコマンドを記述可能にする便利なサードバーティ製のActionsがあったので、それを使ってsshコマンドを書いていきます。https://github.com/marketplace/actions/ssh-remote-commands
このActionsの
script: |以降にマルチラインのコマンドを記述できるようになります。
注意点として、このscript:内で参照する環境変数は、envs:に指定してあげる必要があります。以下は
echoログとsudo yum updateを実行しています。- name: SSH EC2 Setup and Deploy uses: appleboy/ssh-action@v0.0.9 with: key: ${{ secrets.AWS_EC2_PRIVATE_KEY }} username: ${{ env.EC2_USER }} host: ${{ env.EC2_HOST }} envs: DEST_DIR,JAVA_VERSION,APP_NAME,JAVA_OPTS,RUN_ARGS script: | echo "===== yum update =====" sudo yum update -y以降、セットアップ用のコマンドが続きます。
初回のみ実行するようにIFで条件判定を行いつつ、順に・・・
- Javaのインストール(未インストールの時のみ)
echo "===== check java install =====" if java -version 2>&1 >/dev/null | grep "java version\|openjdk version" ; then echo "already installed java." else echo "install java." TARGET=$(yum search java | grep "$JAVA_VERSION.*devel\." | awk '{print $1}') echo "install target name -> $TARGET" sudo yum install -y ${TARGET} echo "JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")" | sudo tee -a /etc/profile source /etc/profile fi
- アプリ起動オプション用の
(アプリ名).confファイルの作成(未作成の時のみ)echo "===== check conf file =====" if [ -f ${DEST_DIR}/${APP_NAME}/${APP_NAME}.conf ]; then echo "already exist conf file for $APP_NAME" else echo "create conf file for $APP_NAME" cat <<EOL | sudo tee -a ${DEST_DIR}/${APP_NAME}/${APP_NAME}.conf export LANG="ja_JP.UTF8" JAVA_OPTS="$JAVA_OPTS" RUN_ARGS="$RUN_ARGS" EOL fi↑IF文のインデントがなく読み辛いですが、
cat << EOL~EOLの間を.confファイルに出力しているためです。
- アプリのサービス登録用に
/etc/systemd/system/(アプリ名).serviceファイルの作成(未作成の時のみ)echo "===== check exist service file =====" if [ -f /etc/systemd/system/${APP_NAME}.service ]; then echo "already exist service file for $APP_NAME" else echo "create service file for $APP_NAME" cat <<EOL | sudo tee -a /etc/systemd/system/${APP_NAME}.service [Unit] Description = ${APP_NAME} app [Service] ExecStart = ${DEST_DIR}/${APP_NAME}/${APP_NAME}.jar Restart = always Type = simple User = root Group = root SuccessExitStatus = 143 [Install] WantedBy = multi-user.target EOL fi以上で、EC2の初期セットアップが完了し、アプリをサービスとして実行できるようになりました。(
.confや.serviceは、予め雛形ファイルを用意しておいて、jarと一緒にアップロードしても良いかもしれません)最後に、アプリのサービスの(再)起動を行います。
echo "===== application (re)start =====" sudo systemctl daemon-reload if sudo systemctl status ${APP_NAME} 2>&1 | grep "Active: active (running)" ; then echo "${APP_NAME} app restart!!" sudo systemctl restart ${APP_NAME} else echo "${APP_NAME} app start!!" sudo systemctl start ${APP_NAME} fi4. pushして自動デプロイを確認
いよいよアプリの自動デプロイを試してみます。
workflowがプロジェクトの.github/workflows/ec2-deploy.ymlにあることを確認して、masterブランチに対してCommit&Pushしてみましょう。GithubのプロジェクトのRepositoryのActionsタブから実行中のタスクが確認できます。
このように全て✅がついていれば正常に完了です。
念の為、SSHのセットアップ状況のログもみてみましょう。
SSH EC2 Setup and DeployのStepの詳細を見ると、Javaのインストール、confserviceファイルの作成、アプリの起動まで成功していました。EC2にブラウザからアクセスして動作確認
無事にデプロイが完了したので、ブラウザから
http://(ec2のパブリックIP)/demo
にアクセスしてみます。
まっさらなEC2に、無事に初回セットアップ&デプロイが行えました!
アプリの再リリースも行えるか動作確認
初回デプロイだけでなく、再デプロイが行えることも確認するために、Controllerの一部の文言を変更して再度Commit&Pushしてみます。
DemoController.java@RestController public class DemoController { @GetMapping("/demo") public String demo() { return "Hello CI/CD demo!!"; } }再デプロイ時のSSHのセットアップ状況を見ると、期待通りに
already ...でSkipされ、アプリのrestartが行われています。
最後にブラウザをリロードしてみます。
無事に再デプロイされ、アプリの変更が反映されました!
まとめ
workflowでSSHを使うことで、EC2への自動デプロイも簡単に行えるようになりました。
特に、サードパーティの ssh-remote-commands は今後も重宝しそうです。参考
今回の
workflow作成に辺り、以下の記事を参考にさせていただきました。








- 投稿日:2020-06-01T15:11:16+09:00
SpringBootアプリをGithubActionsでEC2にデプロイしてみた
はじめに
前回の記事 でGithubActionsを使ってBeanstalkへのデプロイが簡単に行えることがわかりました。
今回は実際に社内で運用しているEC2にデプロイできるworkflowを書いてみます。せっかくなので、インスタンス作成直後のまっさらな状態のEC2に対しても、自動でセットアップしてデプロイできるようにしたいと思います。
前提
- パブリックサブネットに配置したEC2があること
- EC2にSSHできる秘密鍵があること
- Githubのアカウントがあること
開発環境
macOS Catalina
OpenJDK 1.8
SpringBoot 2.2.6
Gradle 6.3大まかな作業の流れ
- デプロイ用のSpringBootアプリを用意する
- RepositoryのSecretsに秘密鍵を登録する
- workflowを書く
- pushして自動デプロイを確認
1. デプロイ用のSpringBootアプリを用意する
まずはデプロイして動作確認するためのSpringBootのアプリを作成します。
例によってサクっと spring initializr で GradleProject に lombok, Spring Web をdependenciesに追加して作成 します。build.gradleplugins { id 'org.springframework.boot' version '2.2.6.RELEASE' id 'io.spring.dependency-management' version '1.0.9.RELEASE' id 'java' } group = 'com.example' version = '0.0.1-SNAPSHOT' sourceCompatibility = '1.8' configurations { compileOnly { extendsFrom annotationProcessor } } repositories { mavenCentral() } dependencies { implementation 'org.springframework.boot:spring-boot-starter-web' compileOnly 'org.projectlombok:lombok' annotationProcessor 'org.projectlombok:lombok' testImplementation('org.springframework.boot:spring-boot-starter-test') { exclude group: 'org.junit.vintage', module: 'junit-vintage-engine' } } test { useJUnitPlatform() }このプロジェクトに対し、次の変更を加えていきます。
1-1. 完全な実行可能Jarのビルド設定を
build.gradleに追加デプロイするアプリをサービスとして実行するため、完全に実行可能なJarを生成 するようにします。
以下のbootJarタスクをbuild.gradleに追加します。build.gradlebootJar { launchScript() }1-2. Controllerを作成
動作確認用の簡単なControllerを作成しておきます。
DemoController.java@RestController public class DemoController { @GetMapping("/demo") public String demo() { return "Hello Actions demo!!"; } }1-3. ポート番号80で待ち受け
EC2でHTTP通信を待ち受けるため
application.propertiesを編集してポート80を設定します。application.propertiesserver.port=80以上でアプリの準備は完了です。
1-4. アプリの動作確認
EC2にデプロイする前に、アプリが正しく動作することを確認しておきます。
以下のコマンドでjarをビルドします。$ ./gradlew buildすると、
build/libs内にjarが生成されるので、ローカルでアプリを起動してみます。
完全に実行可能なJar で作成しているため、jarを直接叩いて実行できることを確認しておきます。$ ./build/libs/actions-0.0.1-SNAPSHOT.jar起動後、ブラウザで
http://localhost/demoにアクセスしてみます。
上のイメージのように、先ほど作成したControllerのレスポンスが表示されていれば、アプリの準備は完了です。
2. RepositoryのSecretsに秘密鍵を登録する
作成したプロジェクトをGithubにプッシュしてリポジトリを作成し、いよいよ
workflowの作成を行います。
その前に、このworkflowではEC2へSSH接続を行うため、秘密鍵情報をSecretsに登録しておきます。今回は
AWS_EC2_PRIVATE_KEYという名前で秘密鍵情報を登録します。
EC2インスタンス作成時に作った〜.pemファイル、またはssh-keygenなどで生成したキーペアの秘密鍵ファイルの中身のテキストをまるっとコピーして貼り付けます。
3. workflowを書く
EC2へのデプロイのため、普段手作業でSCPとSSHでjarファイルのコピー&サービスの(再)起動を行なっていたものを
workflow化しました。やってることは、EC2に
javaをインストール/var/apps/(アプリ名)/(アプリ名).jarと(アプリ名).confファイルを配置/etc/systemd/system/(アプリ名).serviceファイルを配置sudo systemctl start(or restart) (アプリ名)でサービス起動です。
出来上がった
workflowファイルは以下になります。.github/workflows/ec2-deploy.ymlname: Gradle build and Deploy to ec2 on: push: branches: [ master ] env: EC2_USER: 'ec2-user' EC2_HOST: (your ec2 public ip address.) SRC_PATH: 'build/libs/*.jar' DEST_DIR: '/var/apps' APP_NAME: 'actions' JAVA_VERSION: '1.8' JAVA_OPTS: '-Xms1024M -Xmx1024M' RUN_ARGS: '--spring.profiles.active=prod' jobs: deploy: name: Gradle build and Deploy to ec2 runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Set up JDK. uses: actions/setup-java@v1 with: java-version: ${{ env.JAVA_VERSION }} - name: Grant execute permission for gradlew run: chmod +x gradlew - name: Build with Gradle run: ./gradlew build - name: SCP EC2 Copy app file env: PRIVATE_KEY: ${{ secrets.AWS_EC2_PRIVATE_KEY }} run: | echo "$PRIVATE_KEY" > private_key && chmod 600 private_key ssh -t -o StrictHostKeyChecking=no -i private_key ${EC2_USER}@${EC2_HOST} "sudo mkdir -p $DEST_DIR/$APP_NAME && sudo chmod -R 777 $DEST_DIR/$APP_NAME" scp -i private_key ${SRC_PATH} ${EC2_USER}@${EC2_HOST}:${DEST_DIR}/${APP_NAME}/${APP_NAME}.jar - name: SSH EC2 Setup and Deploy uses: appleboy/ssh-action@v0.0.9 with: key: ${{ secrets.AWS_EC2_PRIVATE_KEY }} username: ${{ env.EC2_USER }} host: ${{ env.EC2_HOST }} envs: DEST_DIR,JAVA_VERSION,APP_NAME,JAVA_OPTS,RUN_ARGS script: | echo "===== yum update =====" sudo yum update -y echo "===== check java install =====" if java -version 2>&1 >/dev/null | grep "java version\|openjdk version" ; then echo "already installed java." else echo "install java." TARGET=$(yum search java | grep "$JAVA_VERSION.*devel\." | awk '{print $1}') echo "install target name -> $TARGET" sudo yum install -y ${TARGET} echo "JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")" | sudo tee -a /etc/profile source /etc/profile fi echo "===== check conf file =====" if [ -f ${DEST_DIR}/${APP_NAME}/${APP_NAME}.conf ]; then echo "already exist conf file for $APP_NAME" else echo "create conf file for $APP_NAME" cat <<EOL | sudo tee -a ${DEST_DIR}/${APP_NAME}/${APP_NAME}.conf export LANG="ja_JP.UTF8" JAVA_OPTS="$JAVA_OPTS" RUN_ARGS="$RUN_ARGS" EOL fi echo "===== check exist service file =====" if [ -f /etc/systemd/system/${APP_NAME}.service ]; then echo "already exist service file for $APP_NAME" else echo "create service file for $APP_NAME" cat <<EOL | sudo tee -a /etc/systemd/system/${APP_NAME}.service [Unit] Description = ${APP_NAME} app [Service] ExecStart = ${DEST_DIR}/${APP_NAME}/${APP_NAME}.jar Restart = always Type = simple User = root Group = root SuccessExitStatus = 143 [Install] WantedBy = multi-user.target EOL fi echo "===== application (re)start =====" sudo systemctl daemon-reload if sudo systemctl status ${APP_NAME} 2>&1 | grep "Active: active (running)" ; then echo "${APP_NAME} app restart!!" sudo systemctl restart ${APP_NAME} else echo "${APP_NAME} app start!!" sudo systemctl start ${APP_NAME} fiまっさらなEC2にもデプロイできるようにしたため、セットアップ系のSSHのコマンドラインが多いです。
以下に簡単に内容を説明します。workflowの内容
masterブランチへPush、マージされた場合にこのworkflowが動く様に設定しています。on: push: branches: [ master ]以下は
workflow内で参照する環境変数です。
デプロイするアプリやサーバによって可変な部分を定義しています。env: EC2_USER: 'ec2-user' EC2_HOST: (your ec2 public ip address.) SRC_PATH: 'build/libs/*.jar' DEST_DIR: '/var/apps' APP_NAME: 'actions' JAVA_VERSION: '1.8' JAVA_OPTS: '-Xms1024M -Xmx1024M' RUN_ARGS: '--spring.profiles.active=prod'
EC2_HOSTとAPP_NAMEはサーバ、アプリ毎に設定を変えて利用します。
定数名 説明 EC2_USER ec2へssh接続する時のユーザ名(ec2-userのままでOK) EC2_HOST 【要変更】 ec2のパブリックIPアドレス SRC_PATH ビルドされたjarファイルのパス DEST_DIR ec2側のアプリを配置するディレクトリのパス APP_NAME 【要変更】 アプリ名。gradleでビルドされた.jarを ${APP_NAME}.jarにリネームして、ec2の${DEST_DIR}にコピーするJAVA_VERSION ビルドや実行する時のJavaのバージョン。EC2にもこのバージョンのjavaがインストールされる JAVA_OPTS アプリ起動時のオプション RUN_ARGS アプリの起動引数。上記例ではSpringのプロファイルを prodに切り替えている以下は
./gradlew buildを実行するまでのStepです。
(ほぼ、公式の雛形Java with Gradleのままです)jobs: deploy: name: Gradle build and Deploy to ec2 runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Set up JDK. uses: actions/setup-java@v1 with: java-version: ${{ env.JAVA_VERSION }} - name: Grant execute permission for gradlew run: chmod +x gradlew - name: Build with Gradle run: ./gradlew build以下で、ビルドした
.jarファイルをsshとscpでEC2サーバーにコピーします。
ここで先ほど登録した秘密鍵情報AWS_EC2_PRIVATE_KEYからファイルを復元してsshとscpの秘密鍵ファイルとして指定します。- name: SCP EC2 Copy app file env: PRIVATE_KEY: ${{ secrets.AWS_EC2_PRIVATE_KEY }} run: | echo "$PRIVATE_KEY" > private_key && chmod 600 private_key ssh -t -o StrictHostKeyChecking=no -i private_key ${EC2_USER}@${EC2_HOST} "sudo mkdir -p $DEST_DIR/$APP_NAME && sudo chmod -R 777 $DEST_DIR/$APP_NAME" scp -i private_key ${SRC_PATH} ${EC2_USER}@${EC2_HOST}:${DEST_DIR}/${APP_NAME}/${APP_NAME}.jarここまででEC2の
/var/apps/(アプリ名)/(アプリ名).jarの配置までが完了します。
以降でEC2の初期セットアップとアプリの起動を行います。EC2の初期セットアップとアプリのサービス起動まで
workflowで複数行のsshコマンドを記述可能にする便利なサードバーティ製のActionsがあったので、それを使ってsshコマンドを書いていきます。https://github.com/marketplace/actions/ssh-remote-commands
このActionsの
script: |以降にマルチラインのコマンドを記述できるようになります。
注意点として、このscript:内で参照する環境変数は、envs:に指定してあげる必要があります。以下は
echoログとsudo yum updateを実行しています。- name: SSH EC2 Setup and Deploy uses: appleboy/ssh-action@v0.0.9 with: key: ${{ secrets.AWS_EC2_PRIVATE_KEY }} username: ${{ env.EC2_USER }} host: ${{ env.EC2_HOST }} envs: DEST_DIR,JAVA_VERSION,APP_NAME,JAVA_OPTS,RUN_ARGS script: | echo "===== yum update =====" sudo yum update -y以降、セットアップ用のコマンドが続きます。
初回のみ実行するようにIFで条件判定を行いつつ、順に・・・
- Javaのインストール(未インストールの時のみ)
echo "===== check java install =====" if java -version 2>&1 >/dev/null | grep "java version\|openjdk version" ; then echo "already installed java." else echo "install java." TARGET=$(yum search java | grep "$JAVA_VERSION.*devel\." | awk '{print $1}') echo "install target name -> $TARGET" sudo yum install -y ${TARGET} echo "JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")" | sudo tee -a /etc/profile source /etc/profile fi
- アプリ起動オプション用の
(アプリ名).confファイルの作成(未作成の時のみ)echo "===== check conf file =====" if [ -f ${DEST_DIR}/${APP_NAME}/${APP_NAME}.conf ]; then echo "already exist conf file for $APP_NAME" else echo "create conf file for $APP_NAME" cat <<EOL | sudo tee -a ${DEST_DIR}/${APP_NAME}/${APP_NAME}.conf export LANG="ja_JP.UTF8" JAVA_OPTS="$JAVA_OPTS" RUN_ARGS="$RUN_ARGS" EOL fi↑IF文のインデントがなく読み辛いですが、
cat << EOL~EOLの間を.confファイルに出力しているためです。
- アプリのサービス登録用に
/etc/systemd/system/(アプリ名).serviceファイルの作成(未作成の時のみ)echo "===== check exist service file =====" if [ -f /etc/systemd/system/${APP_NAME}.service ]; then echo "already exist service file for $APP_NAME" else echo "create service file for $APP_NAME" cat <<EOL | sudo tee -a /etc/systemd/system/${APP_NAME}.service [Unit] Description = ${APP_NAME} app [Service] ExecStart = ${DEST_DIR}/${APP_NAME}/${APP_NAME}.jar Restart = always Type = simple User = root Group = root SuccessExitStatus = 143 [Install] WantedBy = multi-user.target EOL fi以上で、EC2の初期セットアップが完了し、アプリをサービスとして実行できるようになりました。(
.confや.serviceは、予め雛形ファイルを用意しておいて、jarと一緒にアップロードしても良いかもしれません)最後に、アプリのサービスの(再)起動を行います。
echo "===== application (re)start =====" sudo systemctl daemon-reload if sudo systemctl status ${APP_NAME} 2>&1 | grep "Active: active (running)" ; then echo "${APP_NAME} app restart!!" sudo systemctl restart ${APP_NAME} else echo "${APP_NAME} app start!!" sudo systemctl start ${APP_NAME} fi4. pushして自動デプロイを確認
いよいよアプリの自動デプロイを試してみます。
workflowがプロジェクトの.github/workflows/ec2-deploy.ymlにあることを確認して、masterブランチに対してCommit&Pushしてみましょう。GithubのプロジェクトのRepositoryのActionsタブから実行中のタスクが確認できます。
このように全て✅がついていれば正常に完了です。
念の為、SSHのセットアップ状況のログもみてみましょう。
SSH EC2 Setup and DeployのStepの詳細を見ると、Javaのインストール、confserviceファイルの作成、アプリの起動まで成功していました。EC2にブラウザからアクセスして動作確認
無事にデプロイが完了したので、ブラウザから
http://(ec2のパブリックIP)/demo
にアクセスしてみます。
まっさらなEC2に、無事に初回セットアップ&デプロイが行えました!
アプリの再リリースも行えるか動作確認
初回デプロイだけでなく、再デプロイが行えることも確認するために、Controllerの一部の文言を変更して再度Commit&Pushしてみます。
DemoController.java@RestController public class DemoController { @GetMapping("/demo") public String demo() { return "Hello CI/CD demo!!"; } }再デプロイ時のSSHのセットアップ状況を見ると、期待通りに
already ...でSkipされ、アプリのrestartが行われています。
最後にブラウザをリロードしてみます。
無事に再デプロイされ、アプリの変更が反映されました!
まとめ
workflowでSSHを使うことで、EC2への自動デプロイも簡単に行えるようになりました。
特に、サードパーティの ssh-remote-commands は今後も重宝しそうです。参考
今回の
workflow作成に辺り、以下の記事を参考にさせていただきました。
- 投稿日:2020-06-01T14:10:43+09:00
はじめての機械学習をデプロイしてみた(後編)
はじめに
前回の記事の Amazon sagemaker のチュートリアルの続きです。
次に、データを SageMaker インスタンスにダウンロードして、データフレームにロードする必要があります。
次のコードをコピーして実行します。try: urllib.request.urlretrieve ("https://d1.awsstatic.com/tmt/build-train-deploy-machine-learning-model-sagemaker/bank_clean.27f01fbbdf43271788427f3682996ae29ceca05d.csv", "bank_clean.csv") print('Success: downloaded bank_clean.csv.') except Exception as e: print('Data load error: ',e) try: model_data = pd.read_csv('./bank_clean.csv',index_col=0) print('Success: Data loaded into dataframe.') except Exception as e: print('Data load error: ',e)
次に、データをシャッフルし、トレーニングデータとテストデータに分割します。トレーニングデータ
(顧客の70%)がモデルのトレーニングループ中に使用されます。
勾配ベースの最適化を使用して、モデルパラメータを繰り返し調整します。
モデルエラーを最小化していきます。テストデータ
(顧客の30%を、残りの)モデルの性能を評価し、目に見えないデータに、訓練されたモデルのデフォルト値を測定するために使用されます。次のコードを新しいコードセルにコピーし、[run]を選択してデータをシャッフルおよび分割します。
train_data, test_data = np.split(model_data.sample(frac=1, random_state=1729), [int(0.7 * len(model_data))]) print(train_data.shape, test_data.shape)
ステップ4.データからモデルをトレーニングする
トレーニングデータセットを使用して機械学習モデルをトレーニングします。
ビルド済みXGBoostモデルを使用するには、トレーニングデータのヘッダーと最初の列を再フォーマットし、S3バケットからデータをロードする必要があります。
次のコードを新しいコードセルにコピーし、[Run]を選択してデータを再フォーマットしてロードします。
pd.concat([train_data['y_yes'], train_data.drop(['y_no', 'y_yes'], axis=1)], axis=1).to_csv('train.csv', index=False, header=False) boto3.Session().resource('s3').Bucket(bucket_name).Object(os.path.join(prefix, 'train/train.csv')).upload_file('train.csv') s3_input_train = sagemaker.s3_input(s3_data='s3://{}/{}/train'.format(bucket_name, prefix), content_type='csv')次に、Amazon SageMaker セッションをセットアップし、XGBoost モデルのインスタンス(推定器)を作成し、モデルのハイパーパラメーターを定義する必要があります。
次のコードを新しいコードセルにコピーし、[ 実行 ] を選択します。sess = sagemaker.Session() xgb = sagemaker.estimator.Estimator(containers[my_region],role, train_instance_count=1, train_instance_type='ml.m4.xlarge',output_path='s3://{}/{}/output'.format(bucket_name, prefix),sagemaker_session=sess) xgb.set_hyperparameters(max_depth=5,eta=0.2,gamma=4,min_child_weight=6,subsample=0.8,silent=0,objective='binary:logistic',num_round=100)データが読み込まれ、XGBoost 推定器が設定されたら、次のコードを次のコードセルにコピーして[実行]を選択することにより、ml.m4.xlarge インスタンスで勾配最適化を使用してモデルをトレーニングします。
数分後、生成されるトレーニングログの表示を開始する必要があります。
xgb.fit({'train': s3_input_train})成功すればこのようにログが出てきます。
コンソール上でもこのように、トレーニングジョブが立ち上がっています。
ステップ5.モデルをデプロイする
このステップでは、トレーニング済みモデルをエンドポイントにデプロイし、CSVデータを再フォーマットしてロードしてから、モデルを実行して予測を作成します。
サーバーにモデルをデプロイし、アクセス可能なエンドポイントを作成するには、次のコードを次のコードセルにコピーして、[ 実行 ] を選択します。
xgb_predictor = xgb.deploy(initial_instance_count=1,instance_type='ml.m4.xlarge')銀行商品に登録されたテストデータの顧客がいるかどうかを予測するには、次のコードを次のコードセルにコピーして、[ Run ] を選択します。
test_data_array = test_data.drop(['y_no', 'y_yes'], axis=1).values #load the data into an array xgb_predictor.content_type = 'text/csv' # set the data type for an inference xgb_predictor.serializer = csv_serializer # set the serializer type predictions = xgb_predictor.predict(test_data_array).decode('utf-8') # predict! predictions_array = np.fromstring(predictions[1:], sep=',') # and turn the prediction into an array print(predictions_array.shape)
ステップ6.モデルのパフォーマンスを評価する
このステップでは、機械学習モデルのパフォーマンスと精度を評価します。
以下のコードをコピーして貼り付け、[Run]を選択します。
混合行列と呼ばれるテーブルの実際の値と予測値を比較します。
cm = pd.crosstab(index=test_data['y_yes'], columns=np.round(predictions_array), rownames=['Observed'], colnames=['Predicted']) tn = cm.iloc[0,0]; fn = cm.iloc[1,0]; tp = cm.iloc[1,1]; fp = cm.iloc[0,1]; p = (tp+tn)/(tp+tn+fp+fn)*100 print("\n{0:<20}{1:<4.1f}%\n".format("Overall Classification Rate: ", p)) print("{0:<15}{1:<15}{2:>8}".format("Predicted", "No Purchase", "Purchase")) print("Observed") print("{0:<15}{1:<2.0f}% ({2:<}){3:>6.0f}% ({4:<})".format("No Purchase", tn/(tn+fn)*100,tn, fp/(tp+fp)*100, fp)) print("{0:<16}{1:<1.0f}% ({2:<}){3:>7.0f}% ({4:<}) \n".format("Purchase", fn/(tn+fn)*100,fn, tp/(tp+fp)*100, tp))予測に基づいて、テストデータの90%の顧客に対して、顧客が預金証書を正確に登録すると予測したと、結論付けることができます。
登録済みの精度は65%(278/429)で、90%(10,785 / 11,928)登録しませんでした。
ステップ7.リソースを終了する
このステップでは、Amazon SageMaker 関連のリソースを終了します。
重要※
アクティブに使用されていないリソースを終了すると、コストが削減されます。
リソースを終了しないと、料金が発生します。Amazon SageMaker エンドポイントと S3 バケット内のオブジェクトを削除するには、次のコードをコピーして貼り付け、実行します。
sagemaker.Session().delete_endpoint(xgb_predictor.endpoint) bucket_to_delete = boto3.resource('s3').Bucket(bucket_name) bucket_to_delete.objects.all().delete()
感想
ただデータを用意するだけではなく、訓練したりテストしたり、様々なデータが機械学習には必要であることが分かったと思います。
さらにその精度を評価したり。本当に結果が正しいものかを推測する必要もあります。
今回はコンソール画面ではなく、Jupyter-notebook 上でほとんど完結する内容でした。
あまり使い慣れていない方でも気軽に試せるので、ぜひ実際にやってみてください。公式リンク







- 投稿日:2020-06-01T11:57:53+09:00
Amazon Chime SDK新機能を使ってホワイトボードを実装した件
この記事はこちらでも紹介しています。
https://cloud.flect.co.jp/entry/2020/06/01/115652前回は、Amazon Chime SDKのVirtual背景の作り方についてご紹介しました。
https://qiita.com/wok/items/962929e63bc98e4033b9
今回も引き続きAmazon Chime SDKのお話をしたいと思います。
さて、先日Amazon がAmazon Chime SDKの新機能追加を発表したのをご存知でしょうか。
本機能は、Amazon Chimeで使われているデータ通信路を間借りすることで、会議の参加者間でデータメッセージのやり取りを可能にする機能です。発表にも書かれているとおり、これにより例えば会議室参加者間でホワイトボードを共有したり、絵文字のやり取りを簡単に行えたりします。また、活用の仕方によっては、参加者のミュートを強制するなど会議室の状態制御を行うことも可能になります。
ということで今回は、早速この機能を使ってホワイトボードを作ってみましたのでご紹介したいと思います。
今回作ったホワイトボードの挙動はこんな感じです。
Amazon Chimeとシグナリング
今回のAmazon Chime SDKの追加機能は、もともとAmazon Chimeで使われているシグナリング通信を間借りして実現されているようです。Amazon Chimeのビデオ会議はWebRTCという技術を用いて実現されていますが、この制御を行う際に用いられている通信がシグナリング通信です。具体的には、WebRTCではブラウザ間でP2Pの通信を行うのですが、この通信を開始するために相手の宛先を特定したり、暗号通信の鍵交換をしたりするときに用いられます。また、P2P通信と言ってもFirewallを越えた通信を行う場合にはTURNという中継サーバを経由する必要がありますが、こういった経路に関する情報交換もシグナリング通信で行われます。
WebRTCの全体像とシグナリングの関係はこちらのページが詳しいので、詳しく知りたい方は参照ください。
Amazon Chimeは、様々なネットワーク環境下においてもビデオ会議を簡単に開始できるように、マネージドな中継サーバやシグナリング通信の通信路を提供しています。今回追加された機能はこのシグナリングを行うマネージドな通信路を活用して、任意のデータメッセージをやり取りできるようにしています。なので、開発者はメッセージング用サーバを用意する必要がなく、簡単にビデオ会議システムに共有ホワイトボードなどを追加することができます。
API概観
新たに提供されたメソッドは下記の3つです。
本機能では、Topicというタグをつけてデータメッセージに送受信します。
まず、各クライアントではTopic毎に処理を定義したコールバック関数を登録しておきます。そして、送信側がTopicと共にデータメッセージを送信すると、そのデータメッセージを受け取ったクライアントはTopicに応じたコールバック関数を呼び出し処理を行います。内部処理、特にデータの流れの詳細は不明ですが、おそらく一般的なpublish/subscribeモデルで動いていると思われます。
今回使用してみて、とても使いやすい機能だと感じました。
なお、本機能では、データメッセージのPublisherが、そのデータメッセージのTopicをsubscribeしていても、そのデータメッセージを受信できないので、注意が必要かもしれません。
私は、PublisherとSubscriberがお互いの関係性を全く無視できるようにするのが、publish/subscribeモデルの利点だと思っているので、PublsherとSubscriberが同じソフトウェア(セッション)だとデータを受信できないというのは、ちょっとだけ違和感がありました。(個人的には、未だに自分のプログラムのバグかも?とも思ってます。)今回のホワイトボードのようなリアルタイムにPublisherのUIに情報を反映する必要があるものについては、受信時のフィルタリングをしなくてよく、ありがたいとも言えますので、個人の感じ方次第だとは思いますが。新たに提供されたメソッド
データ送信
https://aws.github.io/amazon-chime-sdk-js/interfaces/audiovideofacade.html#realtimesenddatamessageデータ購読登録
- データ購読解除
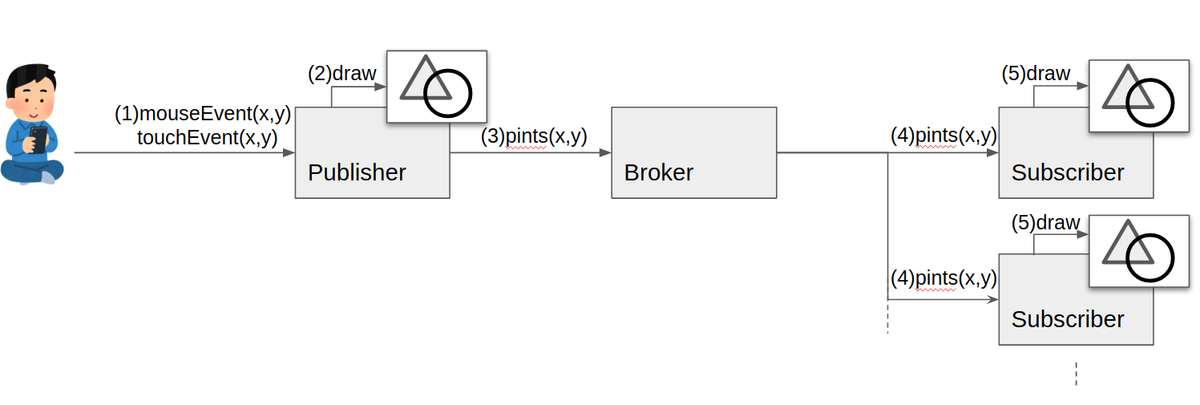
共有ホワイトボードの処理の概要
今回作成した共有ホワイトボードの大まかな処理の流れは次のとおりです。
- Publisherのブラウザのキャンバス(HTMLCanvasElemnt)上でマウスイベント/タッチイベントを検出し、座標を特定
- Publisherのキャンバス上に描画
- 座標をデータメッセージとしてBroker(Chime)に送信 (realtimeSendDataMessage)
- Brokerから各Subscribersに座標を送信
- 各Subscribersのキャンバスに描画
前述の通りPublisherは、自分の送信するデータメッセージを受信することができないので、自分のキャンバスに描画してからデータメッセージを送信する必要があります。
ホワイトボードのようにユーザ操作を遅延なくUIに反映させたいアプリケーションを作る場合はデータメッセージ送信前に自身のUIに反映させる方がユーザ体験上良いので、Publisherがデータメッセージを受信できる、できないにかかわらず同じような作りにはなるとは思いますが。
むしろ、Publisherは、自分の送信するデータメッセージを受信することができないので、Publisherで受信データを破棄しなくて良いので実装が楽かもしれません。
実装
サブスクライブ設定
realtimeSubscribeToReceiveDataMessageでsubscribeするtopicと対応するコールバック関数を登録するラッパ関数の例です。ここでは、データメッセージの受領時に、app.app.receivedDataMessageを呼び出すコールバック関数を定義して引数として使っています。なお、app.app.receivedDataMessage自体は別の場所で任意の処理を定義しておいてください。
export const setRealtimeSubscribeToReceiveDataMessage = (app:App, audioVideo:AudioVideoFacade, topic:string) =>{ const receiveDataMessageHandler = (dataMessage: DataMessage): void => { app.receivedDataMessage(dataMessage) } audioVideo.realtimeSubscribeToReceiveDataMessage(topic, receiveDataMessageHandler) }データメッセージ送信
realtimeSendDataMessageを用いてデータメッセージを送る処理例です。
ホワイトボードに描画を行うために、始点と終点の座標、ストローク情報、線の太さなどをjosn化して送信しています。sendDrawsingBySignal = (targetId: string, mode:string, startXR:number, startYR:number, endXR:number, endYR:number, stroke:string, lineWidth:number)=>{ const gs = this.props as GlobalState const message={ action: 'sendmessage', data: JSON.stringify({ cmd : MessageType.Drawing, targetId : targetId, startTime : Date.now(), mode : mode, startXR : startXR, startYR : startYR, endXR : endXR, endYR : endYR, stroke : stroke, lineWidth : lineWidth }) } gs.meetingSession?.audioVideo.realtimeSendDataMessage(MessageType.Drawing.toString(), JSON.stringify(message)) }動作デモ
ホワイトボード
作成したホワイトボード機能の動きはこのような感じになります。このデモは授業のホワイトボードを模擬したものとなります。右側で描画した内容が左側に反映されているのが分かるでしょうか?
画面共有上での描画
また、このホワイトボードをオーバレイの形で作ってあげると、Amazon Chime SDKの画面共有機能と併用しながらプレゼンをすることができます。
FLECT Amazon Chime Meeting
今回説明した機能は、現在FLECT研究開発室で、ビデオ会議を使った新機能のテストベッドに組み込まれています。
下記のリポジトリに公開していますので、ご興味を持たれましたらアクセスしてみてください。https://github.com/FLECT-DEV-TEAM/FLECT_Amazon_Chime_Meeting
最後に
今回は、Amazon Chime SDKの最新機能を用いてホワイトボードを作成してみました。
日本では先日、緊急事態宣言の解除が発表されました。しかし、まだまだ教室に多くの人を集めて授業をするのは難しそうです。
また、同様に接客を行うにも、なかなかFace-to-Faceで接客というのもリスクがあり、難しいかもしれません。
ビデオ会議と共有ホワイトボードで、こういった課題に対応するというのも選択肢の一つではないかと思います。次回は、またAmazon Chimeで遊ぶか、以前紹介したマルチバーコードリーダの技術的な内容をご紹介するかをしようと思ってます。
では。




- 投稿日:2020-06-01T10:37:48+09:00
AWS Update6/1
AWS SAM が新たに AWS Step Functions をサポート
CodePipeline が新しいアクションタイプでの Step Functions の呼び出しをサポート
AWS Fargate がプラットフォームバージョン 1.4 においてデフォルトでエフェメラルストレージに保存されたデータの暗号化を開始
Network Load Balancer が TLS ALPN ポリシーのサポートを開始
Elastic Load Balancing の Network Load Balancer で、Application-Layer Protocol Negotiation (ALPN) ポリシーのサポートが開始されました。ALPN は、すべての主要ブラウザでサポートされている TLS 拡張であり、HTTP/2 などの TLS 接続確立後に使用されるプロトコルのネゴシエーションを可能にします。ALPN ポリシーを使用すれば、アプリケーションの TLS HTTP/2 トラフィックの復号/暗号化を Network Load Balancer にオフロードできるようになり、サービスのセキュリティ体制が向上し、運用上の複雑さも軽減されます。
ALPN ポリシーを Network Load Balancer の TLS リスナーにアタッチするだけで開始できます。ポリシーは、アプリケーションのプロトコル要件に応じていつでも表示、変更が可能です。ALPN を有効にすると、Network Load Balancer の TLS アクセスログを使用して、成功または失敗した ALPN ネゴシエーションの追跡、クライアントのプロトコル設定リストの表示、異常の識別、接続問題のデバッグを行えます。
Amazon ECS が Spinnaker v1.20 でコンテナヘルスチェックとロードバランサービューをローンチ
- 投稿日:2020-06-01T09:23:39+09:00
EC2が最大72%割引になる柔軟な料金モデル『Savings Plans』勉強会に参加した
勉強会の基本情報
- 【日 時】 2020年5月27日 10:30~11:00
- 【会 場】 オンライン
- 【参加費】 無料
- 【主 催】 アマゾン ウェブ サービス ジャパン株式会社
- 【申し込み】 リンク
概要
- AWSのコスト最適化手法
- Savings Plansの概要と種類
- Savings Plans導入方法と推奨契約期間
内容
AWSのコスト最適化手法
- いろいろなコスト最適化手法があるが、効果と構成変更のコストを考えないといけない
インスタンスタイプとストレージタイプの最適化
- 効果: 大きいが、時期によっていつでも変更が必要で、作業も必要
- コスト: タイプ変更だけなので、特に大きい作業がいらない
マネージドサービス活用
- 効果: 非常に大きい
- 構成変更: 一部必要
- 例えば、EC2上に構築したWebサービスをマネージドサービスへ変更すると、コード構成の変更を考えて、性能とかも考えないといけない。
スポットインスタンス活用
- 効果: 非常に大きい
- 制限: 実行タイミングの制限があって、バッチ処理などがよく利用できる
割引オプッションの活用
- リザーブどインスタンス
- リザーブどキャバシティー
- [new] Saving Plans
Savings Plansの概要と種類
概要
- EC2の定常的な利用を1年間または3年間利用コミット契約することで、”最大”72%のコスト削減できる新割引プラン、アーキテクチャを変更せずにすぐにコスト削減できる
- 以前のスタンダードリからの改善点
- インスタンス単位の契約ではなく、合計利用金額のコミットに
- 契約後のOSの変更が可能に
- 契約後のテナンシーの変更が可能に
種類
- Compute Savings Plans
- コミット金額を指定するだけ
- 最大66%割引
- EC2 Instance Saving Plans
- リージョンとインスタンスファミリーを指定する必要がある
- コミット金額も指定する
- 最大72%割引
Savings Plans導入方法と推奨契約期間
- 管理画面に以下の項目を設定するだけ
- Savings Plansのタイプ
- 契約期間
- コミット金額
- 支払いオプッション(全額前支払い、一部支払い、前支払いなし)
- 契約期間が1年と3年
- プロジェクトは19ヶ月以上の継続的な利用が見込まれるなら、3年期間の検討が必要ある
感想
- 初めてのプロジェクトに対しての導入方法を考える
- 運用のために、利用金額がいくらか
- 本番にEC2利用された金額がいくらか
- 上の2点より、コミット金額を決める
- 前支払いの割引が大きいなので、プロジェクトリーダーと相談する
- 投稿日:2020-06-01T08:45:51+09:00
ずっと完全無料で使えるクラウドサービスの調べ
はじめに
AWSをはじめとする大手クラウドサービスでは、12ヶ月無料やクーポン、1カ月〇〇までは無料で使用できる、というのが基本だと思っていました。
ずっと完全無料のサービス(無制限)があるというのは、一部しか知りませんでした。そのサービスはけっこう多いということを知ったので、確認する方法を備忘しておきたいと思います。Amazon Web Services(AWS)
メニュー「料金」→「AWS無料利用枠」 無期限無料でフィルタ
- AWSに限らずクラウドサービスは数え切れないほどあるが、下記URLは各サービスを1行で説明しているため、わかりやすくなっている。
https://gigazine.net/news/20200528-aws-one-line-explanation/
Google Cloud
https://cloud.google.com/?hl=ja
「料金」→「GCPの無料サービス」 Always Freeプロダクト
https://cloud.google.com/free?hl=ja
MS Azure
https://azure.microsoft.com/ja-jp/
「無料ではじめる」ボタン を押下
https://azure.microsoft.com/ja-jp/free/
「いつでも無料なのは、どの製品ですか。」を確認
IBM Cloud
https://www.ibm.com/jp-ja/cloud
メニュー「料金体系」→「Lite」 Free IBM Cloud services
https://www.ibm.com/jp-ja/cloud/free最近、請求について揉めていたIBM Cloudですが、クレジットカード不要のサービスでいろいろ使ってみてからのほうがよいかと思います。(請求くらいました・・)
参考URL








- 投稿日:2020-06-01T08:45:51+09:00
ずっと完全無料で使えるクラウドサービスの調べ方
はじめに
AWSをはじめとする大手クラウドサービスでは、12ヶ月無料やクーポン、1カ月〇〇までは無料で使用できる、というのが基本だと思っていました。
ずっと完全無料のサービス(無制限)があるというのは、一部しか知りませんでした。そのサービスはけっこう多いということを知ったので、確認する方法を備忘しておきたいと思います。Amazon Web Services(AWS)
メニュー「料金」→「AWS無料利用枠」 無期限無料でフィルタ
- AWSに限らずクラウドサービスは数え切れないほどあるが、下記URLは各サービスを1行で説明しているため、わかりやすくなっている。
https://gigazine.net/news/20200528-aws-one-line-explanation/
Google Cloud
https://cloud.google.com/?hl=ja
「料金」→「GCPの無料サービス」 Always Freeプロダクト
https://cloud.google.com/free?hl=ja
MS Azure
https://azure.microsoft.com/ja-jp/
「無料ではじめる」ボタン を押下
https://azure.microsoft.com/ja-jp/free/
「いつでも無料なのは、どの製品ですか。」を確認
IBM Cloud
https://www.ibm.com/jp-ja/cloud
メニュー「料金体系」→「Lite」 Free IBM Cloud services
https://www.ibm.com/jp-ja/cloud/free最近、請求について揉めていたIBM Cloudですが、クレジットカード不要のサービスでいろいろ使ってみてからのほうがよいかと思います。(請求くらいました・・)
参考URL
- 投稿日:2020-06-01T01:39:17+09:00
SSL化へ ロードバランサーでALBにhttpsの設定を入れて作成
目的
個人アプリでssl化が必要だったためSSL証明書の発行が求められた。
筆者の備忘録前提条件
AWS、ALB(Application Load Balancer)、ec2、を活用します。
開発環境 rails unicorn nginxssl化までの手順
Route53でドメインを購入(有料です)
AWS Certificate Manager(ACM)でSSL証明書の発行
ロードバランサーでALBにhttpsの設定を入れて作成 <=今回はここ
Route53でAレコードのエイリアスを作成ロードバランサーについて
ロードバランサーとは、その名の通りサーバーにかかる負荷を、平等に振り分けるための装置のことを指します。これによって1つのサーバーにかかる負担を軽減したり、停止状態を防ぐことができたりします。
サーバの数を増やすことで負荷がかかりすぎている一つあたりの負荷が減る作戦。
仕事で例えるなら1人で大量の仕事を抱え込むオーバーワークで倒れてしまう。だから社員のみんなで分担して仕事を分け合おうねということだろう。言い換えるならその仕事の量が多すぎたら多数のサーバもともにダウンしてまう。そのために大量のサーバつまりコストが必要なのだろう。*今回はawsでssl発行書を発行したため、ロードバランサーを使用した。
ロードバランサーでALBにhttpsの設定を入れて作成
awsのコンソールEC2の飛び、横のタブからロードバランサーを選択し、ロードバランサーの作成をクリック
ALB(Application Load Balancer)を選択。手順1 ロードバランサーの設定
名前は区別が付く名前に
リスナー:ロードバランサーのプロトコル => HTTPSを選択
アベイラビリティーゾーンは2つ以上選択します。ポイント
リスナーは
究極的にはリクエストした側がhttpで通したいのかhttps通したいのかを聞いているにで
今回はssl化が目的なのでhttpsを選択。手順2 セキリティ設定の構成
証明書タイプ:ACMから証明書を選択する(事前にSSL証明書を発行したため)
証明書の名前に事前にSSL証明書を選択手順3 セキュリティグループの設定
既存のセキリティグループでもよし
今回は新しくセキリティグループを作成し、
HTTPSを選択手順4 ルーティングの設定
ALBはターゲットグループにルーティングが行える
ALBはターゲットグループと呼ばれる別々のサーバグループに対してインスタンスを紐付け、ルーティングを設定することができます。
直接的にインスタンスを設定していたELBとは違って、サービスを独立させて実行することもでき、ルーティングのルール定義も複数作成可能です。ポイント
ルーティングは、どのインスタンスと結びつけたいかだから
紐付けたいインスタンスのポートに合わせよう。
そのためhttpsを選択せず今回は、httpを選択した。ヘルスチェックは、同様にhttp:/80を選択(ここは検証していません)
手順5 ターゲットの登録
紐付けたいインスタンスを登録させる。
手順 6: 確認
設定がただしか確認する。
確認後ALBが作成される。最後にターゲットグループの紐付けたインスタンスを確認する
横のタブからターゲットグループを選択
作成したターゲットがロードバランサーとつながっているか確認し
登録済みのターゲットのステータスがhealthyになっているか確認する。
ここがしっかり紐付いていなかっため筆者は痛い目にあった。






- 投稿日:2020-06-01T00:59:55+09:00
TerraformでVPC、サブネット、インターネットゲートウェイを作成する
はじめに
現在CloudformationとTerraformを学習しています。
先日以下記事を書きました。
CloudFormationでVPC、サブネット、インターネットゲートウェイを作成するこれと同じようなこと(=全く同じではない)をTerraformで作成しました。
まだどちらもそこまで試してないですが、Terraformの方が良い感触です。環境% terraform --version Terraform v0.12.26ディレクトリ構造
Terraformではディレクトリを役割、環境毎に分けた方が良いとのことです。
今回は役割ごと分割にします。結果以下のようなディレクトリ構造としました。% tree . ├── README.md ├── main.tf ├── modules │ ├── ec2 │ │ ├── Create-ec2.tf │ │ └── variables.tf │ ├── rds │ │ ├── Create-rds.tf │ │ └── variables.tf │ └── vpc │ ├── Create-vpc.tf │ └── variables.tf ├── outputs.tf ├── terraform.tfstate └── variables.tfコード
main.tfの作成
Terraformルートディレクトリに設置した
main.tfは簡潔にした方が良いとのことです。
この後作成するvpcモジュールと、プロバイダー情報(今回はAWS)を記載します。./main.tfprovider "aws" { region = "ap-northeast-1" version = "~> 2.16" } module create-vpc { source = "./modules/vpc" }変数の作成
vpcに関する変数なので、
modules/vpcディレクトリ内にvariables.tfを作成し、変数を定義します。./modules/vpc/variables.tfvariable vpc { description = "VPCのCidr。サブネットはこのCidrから増分させていく。" default = "10.2.0.0/16" } variable NameTag { description = "各リソース名につける接頭語" default = "Terraform" }vpcを作成するコード本体の作成
サブネットなど同一構成の場合は作成したい数分
count = intを定義する。
* サブネットのCidrを定義する場合はcidrsubnet(aws_vpc.MYVPC.cidr_block, 8, count.index)と書くと便利。./modules/vpc/Create-vpc.tfdata "aws_availability_zones" "available" { state = "available" } # Cretae VPC resource "aws_vpc" "MyFirstVPC" { cidr_block = var.vpc enable_dns_hostnames = true enable_dns_support = true tags = { Name = "${var.NameTag}-VPC" } } # Cretae IGW resource "aws_internet_gateway" "igw" { vpc_id = aws_vpc.MyFirstVPC.id tags = { Name = "${var.NameTag}-IGW" } } # Cretae Subnets resource "aws_subnet" "public" { count = 2 vpc_id = aws_vpc.MyFirstVPC.id cidr_block = cidrsubnet(aws_vpc.MyFirstVPC.cidr_block, 8, count.index) #10.2.0.0/24,10.2.1.0/24 map_public_ip_on_launch = true availability_zone = data.aws_availability_zones.available.names[count.index] tags = { Name = "${var.NameTag}-PublicSubnet${count.index}" } } resource "aws_subnet" "private" { count = 2 vpc_id = aws_vpc.MyFirstVPC.id cidr_block = cidrsubnet(aws_vpc.MyFirstVPC.cidr_block, 8, count.index + 2) #10.2.2.0/24,10.2.3.0/24 map_public_ip_on_launch = false availability_zone = data.aws_availability_zones.available.names[count.index] tags = { Name = "${var.NameTag}-PrivateSubnet${count.index}" } } # Cretae RouteTables resource "aws_route_table" "public" { vpc_id = aws_vpc.MyFirstVPC.id tags = { Name = "${var.NameTag}-PublicRT" } } resource "aws_route_table" "private" { vpc_id = aws_vpc.MyFirstVPC.id tags = { Name = "${var.NameTag}-PrivateRT" } } # Cretae Route resource "aws_route" "public" { route_table_id = aws_route_table.public.id gateway_id = aws_internet_gateway.igw.id destination_cidr_block = "0.0.0.0/0" } # Association RouteTables resource "aws_route_table_association" "public" { count = 2 subnet_id = aws_subnet.public[count.index].id route_table_id = aws_route_table.public.id } resource "aws_route_table_association" "private" { count = 2 subnet_id = aws_subnet.private[count.index].id route_table_id = aws_route_table.private.id }コードの実行
% terraform plan % terraform apply参考文献