class Example
def index
end
end
①example = Example.new
example.index //インスタンスから呼び出す →○
②Example.index //クラスから直接呼び出せない →こちらを使用する際はメソッドにself.をつける(self.index)
index //もちろんこれではエラー表示
class Example
def index
end
end
①example = Example.new
example.index //インスタンスから呼び出す →○
②Example.index //クラスから直接呼び出せない →こちらを使用する際はメゾットにself.をつける(self.index)
index //もちろんこれではエラー表示
DEPRECATION WARNING: Uniqueness validator will no longer enforce case sensitive comparison in Rails 6.1. To continue case sensitive comparison on the :name attribute in User model, pass `case_sensitive: true` option explicitly to the uniqueness validator.
# 小文字のjnchitoはすでに登録済みなのでNGuser.name='jnchito'user.valid?#=> false# 大文字のjnchitoはすでに未登録なのでOKuser.name='JNCHITO'user.valid?#=> true# 背後では以下のようなSQLが発行されている(BINARYが付く)# SELECT 1 AS one FROM `users` WHERE `users`.`name` = BINARY 'JNCHITO' LIMIT 1
# jnchitoはすでに登録済みなのでNG(大文字小文字を区別しない)user.name='jnchito'user.valid?#=> false# JNCHITOはすでに登録済みなのでNG(大文字小文字を区別しない)user.name='JNCHITO'user.valid?#=> false# 背後では以下のようなSQLが発行されるはず(BINARYが付かない)# SELECT 1 AS one FROM `users` WHERE `users`.`name` = 'JNCHITO' LIMIT 1
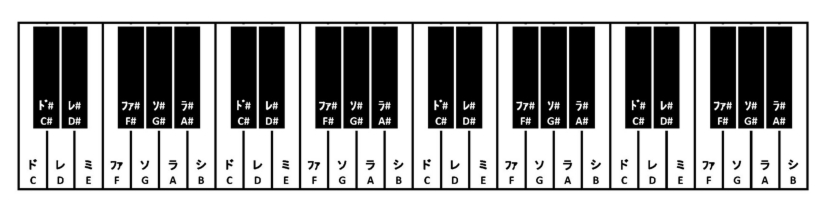
カラオケにはキーを変える機能があります。
+1するとキーが1つ上がります。
-1するとキーが1つ下がります。
たとえば「ドレミファソ」というメロディのキーを2つ上げると「レミファ#ソラ」になります。
「ドレミファソ」のようにカタカナだとプログラムで扱いづらいので、英語の読み方、つまりアルファベットに置き換えましょう。
ド レ ミ ファ ソ → C D E F G
レ ミ ファ# ソ ラ → D E F# G A
"C D E F |E D C |E F G A |G F E |C C |C C |CCDDEEFF|E D C "
実行例はこんな感じになります。
melody="C D E F |E D C |E F G A |G F E |C C |C C |CCDDEEFF|E D C "karaoke=KaraokeMachine.new(melody)karaoke.transpose(2)# => "D E F# G |F# E D |F# G A B |A G F# |D D |D D |DDEEF#F#GG|F# E D "karaoke.transpose(-1)# => "B C# D# E |D# C# B |D# E F# G# |F# E D# |B B |B B |BBC#C#D#D#EE|D# C# B "# 1オクターブ(12音)以上変えることもできるkaraoke.transpose(14)# => "D E F# G |F# E D |F# G A B |A G F# |D D |D D |DDEEF#F#GG|F# E D "
melody="C D E F |E D C |E F G A |G F E |C C |C C |CCDDEEFF|E D C "melody.split(/(\w#?)/)=>["","C"," ","D"," ","E"," ","F"," |","E"," ","D"," ","C"," |","E"," ","F"," ","G"," ","A"," |","G"," ","F"," ","E"," |","C"," ","C"," |","C"," ","C"," |","C","","C","","D","","D","","E","","E","","F","","F","|","E"," ","D"," ","C"," "]