- 投稿日:2020-05-28T23:59:29+09:00
Route53でドメインを購入方法
目的
個人アプリを制作していてssl化が必要だったため
筆者の備忘録ssl化がどうして必要なのか
sllとはサーバとブラウザ間の通信を暗号化させる役割を担っているいます。
暗号化することにより、ハッカー、盗聴などを防ぎ、データ送受信を安全に行うことができるようです。
鍵のついたサイト下がsslしているサイトです。urlの頭にはhttpsと書いてあるサイトです。(httpではない)
わかりやすく言うとsslは、
安全なサイトの証明!今までは、決済(クレジットカード等)や個人情報に関わるページ等でsll化すればよかったが、セキリティーに対する高まりから「常時ssl化」が必要になっているようです。
Google ChromeでもSSL対応されていないWebサイトに対して警告アラートがでています。
つまり、サイトを作る際にはssl化をしていないとクライアントに使われないことが分かります。前提条件
AWS、ALB(Application Load Balancer)、ec2、を活用します。
ssl化までの手順
Route53でドメインを購入(有料です) <=今回はここ
AWS Certificate Manager(ACM)でSSL証明書の発行
ロードバランサーでALBにhttpsの設定を入れて作成
Route53でAレコードのエイリアスを作成Route53でドメインの購入
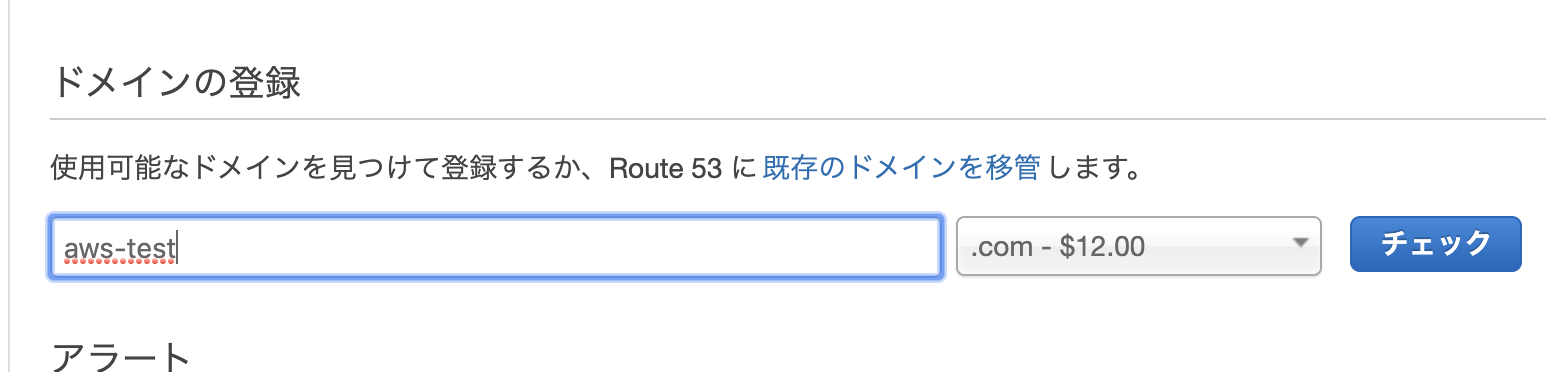
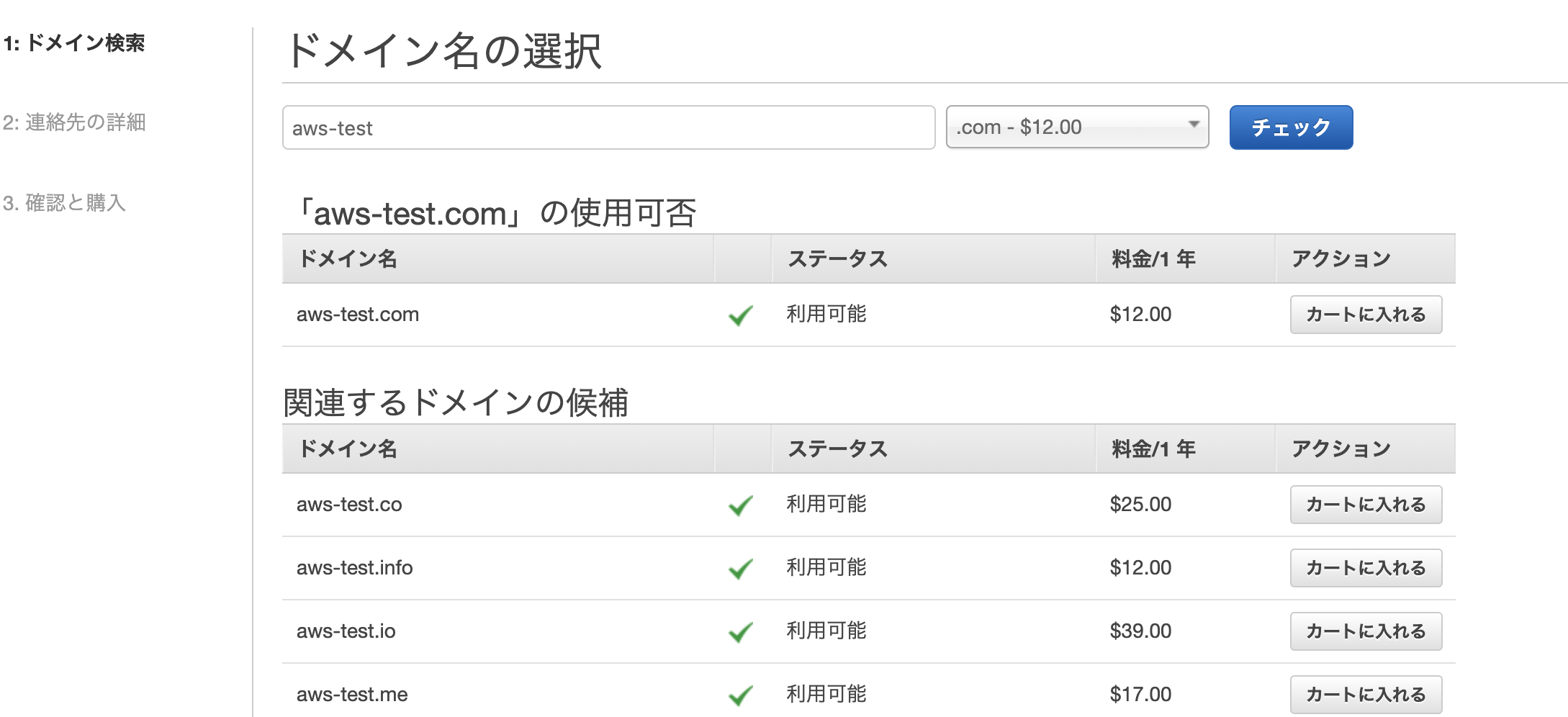
AWSのサービスからRoute53を選択
ドメイン登録で好きな名前でドメイン名を記入 チェックを選択
ドメイン名がかぶっていいなければ
カートに入れて購入

- 投稿日:2020-05-28T22:35:06+09:00
AWS 利用方法メモ(EC2、EBS)
書いてあること
- EC2、EBSの利用方法メモ
EC2インスタンスを起動
- EC2
- インスタンスを起動
- AMIを選択
- インスタンスタイプを選択
- 次のステップ
- 次のステップ
- 次のステップ
- 次のステップ
- タイプの「HTTP」「HTTPS」を追加
- 確認と作成
- 起動
- キーペア名を入力
- キーペアのダウンロード
- インスタンスの作成
SSH接続(Mac)
- pemファイルを
.sshディレクトリにコピー- 下記コマンドでSSH接続
# パーミッション設定 $ chmod 600 ~/.ssh/●●●.pem # SSH接続 $ ssh -i ~/.ssh/●●●.pem ec2-user@パブリックIPまたはパブリックDNSSSH接続(Windows)
ppkファイルを生成
WindowsでPuTTYやWinSCPでSSH接続する際に必要なppkファイルを生成する
- PuTTYgenを起動
- Conversions
- Import key
- 変換するpemキーを選択
- Save private key
PuTTYでSSH接続
- PuTTYを起動
- ホスト名を入力 ※EC2説明タブの「パブリックDNS」を確認
- SSH⇒認証のキーペアファイルで変換したppkファイルを選択
- 開く
- Security Alertではいを選択
- ユーザー名に
ec2-userを入力- Enter
EC2にhttpサーバー(Apache)を構築
- 下記コマンドでhttpサーバーをインストール
- EC2のパブリックDNS、またはパブリックIPで表示確認
bash# 管理者ユーザーに変更 $ sudo su - # OSを最新化 $ yum -y update # Apacheをインストール $ yum install -y httpd # Apacheを起動 $ systemctl start httpd $ systemctl status httpd # Apacheの自動起動を有効化 $ systemctl enable httpd # HTMLファイルを作成 $ cd /var/www/html $ vi index.html # Apacheを再起動 $ systemctl restart httpdindex.html<html> <head> <title>AWS httpd test</title> </head> <body> <h1>Hello World!!</h1> <p>test test test</p> </body> </html>Elastic IPを割り当て
- EC2
- 対象のインスタンスをチェック
- アクション
- インスタンスの状態
- 停止
- 停止する
- Elastic IP
- Elastic IPアドレスの割り当て
- 割り当て
- 対象のIPアドレスを選択
- Actions
- Elastic IPアドレスの関連付け
- 関連付けるインスタンス・IPアドレスを選択
- 関連付ける
- インスタンスのIPアドレスが割り当てられたことを確認
Elastic IPの解除・解放
- 対象のIPアドレスを選択
- Actions
- Elastic IPアドレスの関連付けを解除
- 関連付け解除
- Actions
- Elastic IPアドレスの解放
- 解放
シェルスクリプトによるインスタンス自動構築
- EC2からインスタンスを構築
- 「3.インスタンスの設定」ページ下部の
ユーザーデータにシェルスクリプトを入力#!/bin/bash # 日本語設定 cp /usr/share/zoneinfo/Japan /etc/localtime sed -i 's|^ZONE=[a-zA-Z0-9\.\-\"]*$|ZONE="Asia/Tokyo"|g' /etc/sysconfig/clock echo "LANG=ja_JP.UTF-8" > /etc/sysconfig/i18n # ホスト名 sed -i 's/^HOSTNAME=[a-zA-Z0-9\.\-]*$/HOSTNAME=test/g' /etc/sysconfig/network hostname 'test' # Apache sudo yum -y update sudo yum install -y httpdカスタムAMI
- EC2
- 対象のインスタンスをチェック
- アクション
- インスタンスの状態
- 停止
- 停止する
- アクション
- イメージ
- イメージの作成
- 必要事項を入力
- イメージの作成
- 閉じる
- AMI
- 起動
スナップショット
- EC2
- ボリューム
- アタッチ済情報から割り当てられているインスタンスを確認
- 対象のボリュームを選択
- アクション
- スナップショットの作成
- 必要事項を入力
- スナップショットの作成
- スナップショットを復元するインスタンスを停止
- 復元するインスタンスに割り当てられたボリュームの説明タブから、アベイラビリティゾーンとアタッチするパス(例えば
/dev/xvda)を確認する- アクション
- ボリュームのデタッチ
- デタッチする
- スナップショット
- 復元するスナップショットを選択
- アクション
- ボリュームの作成
- 復元するインスタンスと同じアベイラビリティゾーンを選択
- ボリュームの作成
- 復元されたボリュームを選択
- アクション
- ボリュームのアタッチ
- インスタンスを選択
- デバイスに確認していたパスを入力(例えば
/dev/xvda)- アタッチ
- インスタンスを起動
- 投稿日:2020-05-28T21:22:44+09:00
AWS DiscoveryService
AWS DiscoveryService
AWS Application Discovery Service では、オンプレミスサーバーに関する使用状況と設定のデータを収集することで、AWS クラウドへの移行を計画できます。Application Discovery Service は AWS Migration Hub と統合されています。これにより、移行ステータスの情報が 1 つのコンソールに集約されるため、移行の追跡が簡単になります。検出したサーバーを表示し、これらをアプリケーションとしてグループ化して、各アプリケーションの移行ステータスをホームリージョンの Migration Hub コンソールから追跡できます。
検出されたすべてのデータは、AWS Migration Hub ホームリージョンに保存されます。したがって、検出および移行アクティビティを実行する前に、Migration Hub コンソールまたは CLI コマンドを使用してホームリージョンを設定する必要があります。データは、Microsoft Excel や AWS 分析ツール (Amazon Athena や Amazon QuickSight など) にエクスポートして分析できます。
Application Discovery Service API を使用して、検出したサーバーのシステムパフォーマンスと使用状況データをエクスポートできます。このデータをコストモデルに取り込むことで、これらのサーバーを AWS で実行した場合のコストを計算します。さらに、サーバー間に存在するネットワーク接続に関するデータをエクスポートできます。この情報により、サーバー間のネットワーク依存関係を確認し、サーバーをアプリケーションとしてグループ化して、移行計画に役立てることができます
Application Discovery Service では、2 つの方法で、オンプレミスのサーバーを検出して関連データを収集します。
- エージェントレス検出
- VMware vCenter を通じて AWS Agentless Discovery Connector (OVA ファイル) をデプロイします。検出コネクタ を設定すると、vCenter に関連付けられている仮想マシン (VM) とホストが識別されます。検出コネクタ は、静的な設定データとして、サーバーのホスト名、IP アドレス、MAC アドレス、ディスクリソースの割り当てを収集します。さらに、VM ごとに使用状況データを収集し、CPU、RAM、ディスク I/O などのメトリクスの平均とピークの使用率を計算します。
- エージェントベース検出
- VM と物理サーバーのそれぞれに AWS Application Discovery Agent をデプロイします。エージェントのインストーラは Windows および Linux オペレーティングシステムで使用できます。これにより、静的な設定データ、詳細な時系列のシステムパフォーマンス情報、着信/発信のネットワーク接続、および実行中のプロセスが収集されます。
Application Discovery Service は、AWS パートナーネットワーク (APN) のパートナーが提供するアプリケーション検出ソリューションと統合できます。これらのサードパーティー製ソリューションを使用すると、検出コネクタや検出エージェントを使用せずに、オンプレミス環境の詳細を Migration Hub に直接インポートできます。サードパーティーのアプリケーション検出ツールは、AWS Application Discovery Service をクエリしたり、パブリック API を使用して Application Discovery Service データベースに書き込んだりできます。このようにして、Migration Hub にデータをインポートして表示できるため、アプリケーションをサーバーに関連付けたり、移行を追跡したりできます。
VMware の検出に関する詳細
VMware vCenter 環境で実行されている仮想マシン (VM) がある場合は、検出コネクタ を使用してシステム情報を収集できます。各 VM にエージェントをインストールする必要はありません。代わりに、このオンプレミスアプライアンスを vCenter 内にロードし、このアプライアンスですべてのホストと VM を検出することを許可します。
検出コネクタ は使用しているオペレーティングシステムの種類を問わず、vCenter で実行されている各 VM のシステムパフォーマンス情報とリソース使用状況をキャプチャします。ただし、各 VM の「内部を見る」ことはできません。したがって、各 VM で実行されているプロセスや使用されているネットワーク接続を判断することはできません。移行計画に役立てるために、このレベルの詳細が必要な場合や既存の VM の一部の詳細を確認する場合は、必要に応じて 検出エージェント をインストールできます。
また、VMware でホストされている VM の場合は、検出コネクタ と 検出エージェント の両方を使用して 検出を同時に実行できます。
- 投稿日:2020-05-28T20:22:10+09:00
eksctl でクラスター作成して Fargate 利用し ALB Ingress Controller デプロイまで
EKS とは
AWS が提供しているマネージド型の Kubernetes サービスです。
この記事では、具体的な構成をもとに実際に触ってみることで理解を深めることを目標とします。EKS で作成した Kubernetesクラスターとは別に
Docker Desktop などで作成した Kubernetesクラスターを触りつつ進めると分かりやすかったです。
(何か Error があった際にも切り分けや原因究明が容易になります)
?クラスターの切り替えは Docker アイコンからワンクリックで可能なので Docker Desktop がお薦めです。クラスターの作成方法
AWS EKS (Elastic Kubernetes Service) を利用して Kubernetes クラスターのセットアップ、デプロイまで行います。
開始方法は2通りあります。
- EKS コンソールからクラスター作成
- eksctl でクラスター作成
今回は VPC やセキュリティグループなど必要なリソースも併せて自動設定できる
eksctlを用いてセットアップを行いたいと思います。
参考: Getting Started with eksctl - Amazon EKSまた、内部で稼働しているコンテナ (EC2) マネジメントサービスである Fargate を利用するため、こちらの公式 Blog も参考にします。
参考: Amazon EKS on AWS Fargate Now Generally Available | AWS News Blog環境
Kubernetes 1.14
AWS EKS
AWS Fargate
Docker for mac
Mojavi 10.14.6バージョンについて
⚠
Kubernetes 1.14系は脆弱性が報告されているバージョンです!
(わたしの検証時は未報告でした)
別バージョンでの検証をオススメします。
CVE-2019-11247: API server allows access to custom resources via wrong scope · Issue #80983 · kubernetes/kubernetesVulnerable versions:
- Kubernetes 1.7.x-1.12.x
- Kubernetes 1.13.0-1.13.8
- Kubernetes 1.14.0-1.14.4
- Kubernetes 1.15.0-1.15.1Fixed versions:
- Fixed in v1.13.9
- Fixed in v1.14.5
- Fixed in v1.15.2
- Fixed in master参照
Amazon EKS での AWS Fargate の開始方法 - Amazon EKS
EKS の下準備
AWS CLI インストール
$ brew install awscli --upgrade --user
hostname doesn't matchというエラーが出た場合は?
=> 確認: Python のバージョンは 2.7.9 以上か確認をIAMユーザー
- 必要に応じて検証用のユーザーを作成
- 使用する IAM ユーザーにてアクセスキーを作成する
- AWS CLI に AWS 認証情報を設定する
必要に応じて検証用のユーザーを作成
IAMユーザーに権限がうまく振れていないとクラスター作成で失敗します。
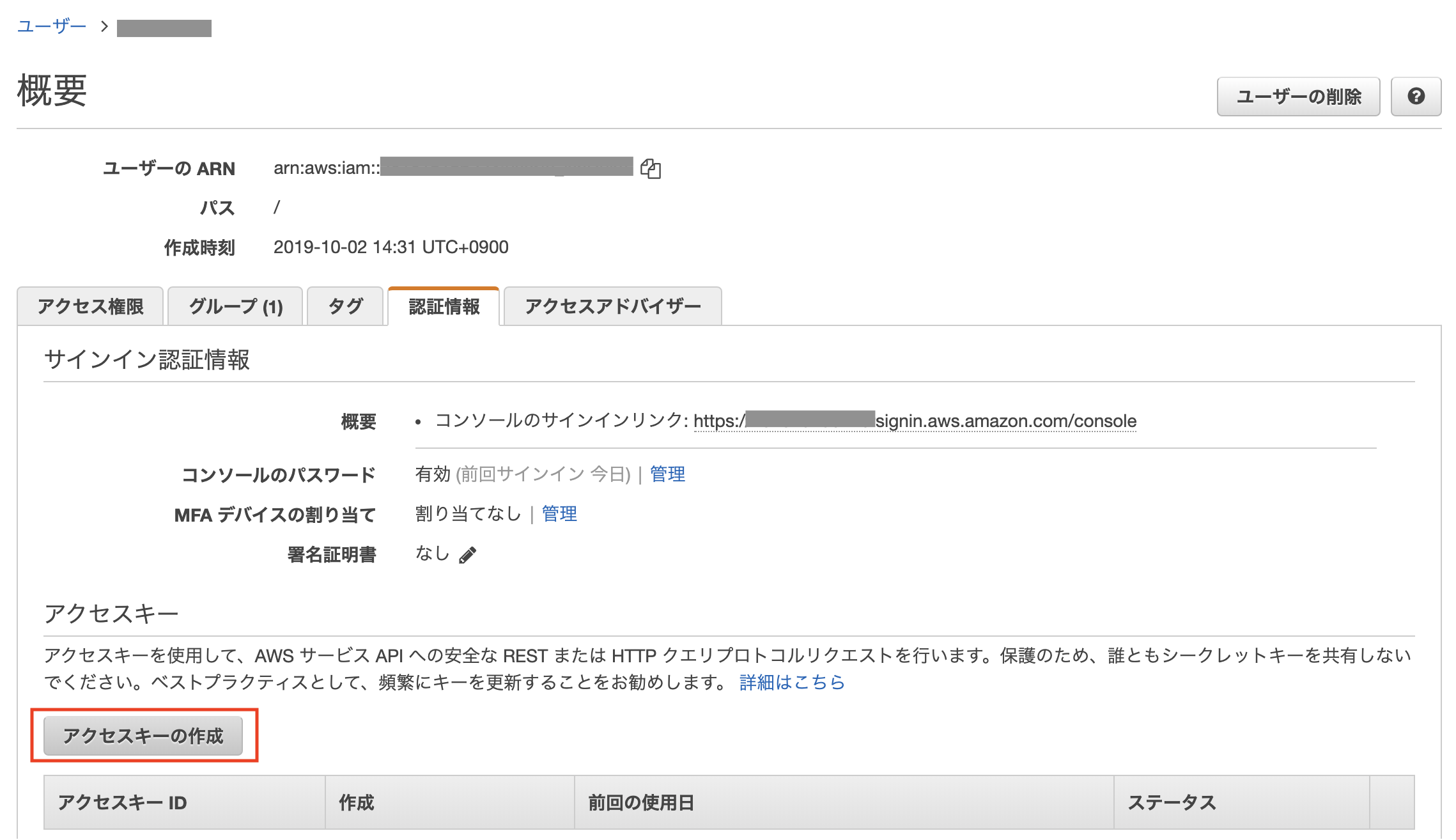
検証段階では 小さく検証 & 権限を大きめに振る で試してみて、少しずつ権限を狭めていくと、効率よく進められるのでオススメです。使用する IAM ユーザーにてアクセスキーを作成する
IAM のコンソール画面から、アクセスキーを作成します。
AWS Access Key IDとAWS Secret Access Keyが発行されるので保存する。AWS CLI に AWS 認証情報を設定する
$ aws configureを実行すると
AWS CLI によってアクセスキー、シークレットアクセスキー、AWSリージョン、出力形式、以上4つの情報の入力が求められる。これらは自動的にdefaultという名前のプロファイル設定群に保存される。(既に設定してある場合は上書きされるので注意!)
~/.aws以下の config と credentials ファイルで確認可能。- 手動修正するなどして、複数プロファイル管理も可能。
- 参考: 名前付きプロファイル - AWS Command Line Interface
$ aws configure AWS Access Key ID [None]: ?***** AWS Secret Access Key [None]: ?***** Default region name [None]: ap-northeast-1 Default output format [None]: json複数プロファイル設定などの詳しい方法は以下の記事にまとめてあります。
AWS CLI設定のアレコレeksctl インストール
AWS がサードパーティー的に保有している brew 形式のリポジトリをインストールします。
$ brew tap weaveworks/tapeksctl をインストールします。
$ brew install weaveworks/tap/eksctlインストールできたか確認。
$ eksctl versionクラスターを作成します。
コマンド実行したら約15分待つ。
$ eksctl create cluster --name demo-cluster --region ap-northeast-1 --fargate内部で Cloud Formation が実行されているため、時間がかかります。
コーヒーでも飲みながら待ちます☕クラスターの確認
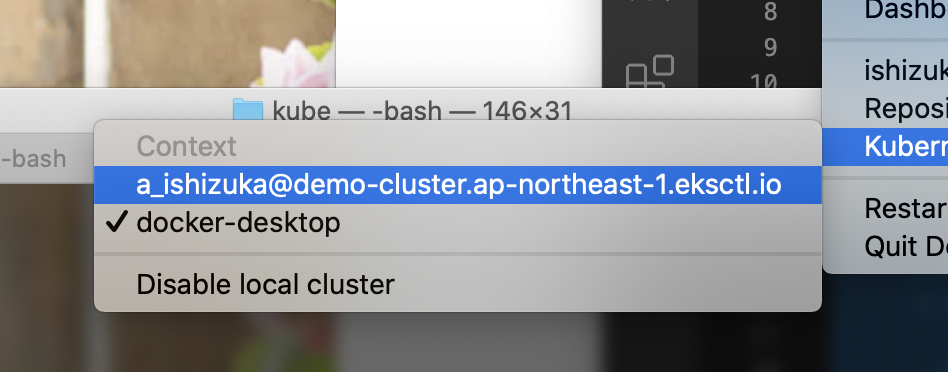
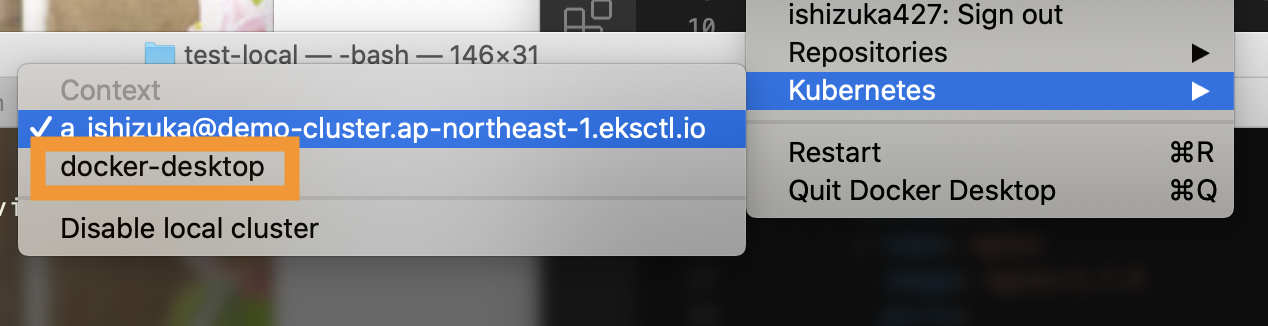
メニューバーにある Docker アイコンから切り替えることができます。
ノード一覧を表示
ノード一覧を表示させたところ
fargate が動いていました。$ kubectl get nodes NAME STATUS ROLES AGE VERSION fargate-ip-***-***-***-**.ap-northeast-1.compute.internal Ready <none> 9d v1.14.8-eks fargate-ip-***-***-***-***.ap-northeast-1.compute.internal Ready <none> 9d v1.14.8-ekskube-system が動いていることも確認。
$ kubectl get po --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system coredns-d784dc748-pkfqv 1/1 Running 0 9d kube-system coredns-d784dc748-t9pq5 1/1 Running 0 9dEKS 用のマニフェストファイル作成
マニフェストファイルは用途によってオブジェクトが何種類かあります。
シングルファイルにまとめても、マルチファイルとして別々にファイルを作成しても OK です。
- Deployment
- Service
- Ingress
- Secret
- ServiceAccount
などなど。。
今回は deployment.yml と service.yml を作成して検証を行います。作業場所を作成
$ mkdir kube $ cd kube/単一の nginx Deployment を作成
下記の内容で deployment.yml を作成 / 編集します。
nginx-deployment.yml を作成$ vi nginx-deployment.ymlnginx-deployment.ymlapiVersion: extensions/v1beta1 kind: Deployment metadata: name: nginx spec: replicas: 1 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.5 ports: - containerPort: 80$ kubectl apply -f nginx-deployment.yml deployment.extensions/nginx createdPod 一覧を表示させます。
$ kubectl get pod NAME READY STATUS RESTARTS AGE nginx-954765466-zmj5p 0/1 Pending 0 9s全ネームスペースの、Pod一覧を表示させます。
// kubernets 1.13まで $ kubectl get pods --all-namespaces // kubernetes 1.14以降 $ kubectl get pod -A全ネームスペースの、サービス一覧を表示させます。
$ kubectl get svc --all-namespaces NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE default kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 9d kube-system kube-dns ClusterIP 10.100.0.10 <none> 53/UDP,53/TCP 9dService 作成
以下の内容で service.yml を 作成 / 編集します。
nginx-service.yml という yaml ファイルを作成。$ vi nginx-service.ymlnginx-service.ymlapiVersion: v1 kind: Service metadata: name: nginx spec: selector: app: nginx ports: - name: http protocol: TCP port: 80 targetPort: 80 externalIPs: - 10.100.0.1service を作成します。
$ kubectl apply -f nginx-service.yml service/nginx created追加されているかの確認。
$ kubectl get svc --all-namespaces NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE default kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 9d default nginx ClusterIP 10.100.77.190 10.100.0.1 80/TCP 10s kube-system kube-dns ClusterIP 10.100.0.10 <none> 53/UDP,53/TCP 9ddeployment.yml で設定した Pod を色々な角度で見てみる
Podの詳細を表示
結構な情報量。。
$ kubectl describe pod nginx?実行すると
下記のような詳細が表示されます。Name: nginx-954765466-zmj5p Namespace: default Priority: 0 Node: docker-desktop/192.168.65.3 Start Time: Fri, 31 Jan 2020 20:33:22 +0900 Labels: app=nginx pod-template-hash=5754944d6c Annotations: <none> Status: Running IP: 10.1.0.141 Controlled By: ReplicaSet/nginx-deployment-5754944d6c Containers: nginx: Container ID: docker://0ae17409e095d3a13c4bca879fc7095f92d0effd221b0053cf024acb809b358d Image: nginx:1.7.9 Image ID: docker-pullable://nginx@sha256:e3456c851a152494c3e4ff5fcc26f240206abac0c9d794affb40e0714846c451 Port: 80/TCP Host Port: 0/TCP State: Running Started: Sun, 23 Feb 2020 19:30:16 +0900 Ready: True Restart Count: 0 Environment: <none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from default-token-slqvm (ro) Conditions: Type Status Initialized True Ready True ContainersReady True PodScheduled True Volumes: default-token-slqvm: Type: Secret (a volume populated by a Secret) SecretName: default-token-slqvm Optional: false QoS Class: BestEffort Node-Selectors: <none> Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s node.kubernetes.io/unreachable:NoExecute for 300s Events: <none> Name: nginx-deployment-5754944d6c-9d6lf Namespace: default Priority: 0 Node: docker-desktop/192.168.65.3 Start Time: Fri, 31 Jan 2020 20:33:22 +0900 Labels: app=nginx pod-template-hash=5754944d6c Annotations: <none> Status: Running IP: 10.1.0.140 Controlled By: ReplicaSet/nginx-deployment-5754944d6c Containers: nginx: Container ID: docker://ac1c96d75b4e32ce7ab8eecd4e0ede68077e55bbf03c1a655d3a870b421d711c Image: nginx:1.7.9 Image ID: docker-pullable://nginx@sha256:e3456c851a152494c3e4ff5fcc26f240206abac0c9d794affb40e0714846c451 Port: 80/TCP Host Port: 0/TCP State: Running Started: Sun, 23 Feb 2020 19:30:16 +0900 Ready: True Restart Count: 0 Environment: <none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from default-token-slqvm (ro) Conditions: Type Status Initialized True Ready True ContainersReady True PodScheduled True Volumes: default-token-slqvm: Type: Secret (a volume populated by a Secret) SecretName: default-token-slqvm Optional: false QoS Class: BestEffort Node-Selectors: <none> Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s node.kubernetes.io/unreachable:NoExecute for 300s Events: <none>Pod のログを参照する
以下のコマンドで Pod のログを表示することが出来ます。
$ kubectl logs <pod-name>api-server のログを表示させてみました。
$ kubectl logs kube-apiserver-docker-desktop -n kube-system Flag --insecure-port has been deprecated, This flag will be removed in a future version. I0223 10:30:03.769470 1 server.go:560] external host was not specified, using 192.168.65.3 I0223 10:30:03.772335 1 server.go:147] Version: v1.15.5 I0223 10:30:05.417959 1 plugins.go:158] Loaded 10 mutating admission controller(s) successfully in the following order: NamespaceLifecycle,LimitRanger,ServiceAccount,NodeRestriction,TaintNodesByCondition,Priority,DefaultTolerationSeconds,DefaultStorageClass,StorageObjectInUseProtection,MutatingAdmissionWebhook. (〜略〜)外からPodにアクセスしてみる (port foward編)
service.yml を書かなくても
起動できているかの確認であれば、 port foward で確認することができます。Pod の一覧を表示。
こちらはレプリカ数 1 で起動しているので、ひとつだけ表示されます。$ kubectl get pods NAME READY STATUS RESTARTS AGE nginx-954765466-zmj5p 1/1 Running 0 5h59mport foward でローカルから繋げられるようにします。
$ kubectl port-forward nginx-954765466-zmj5p 8080:80 Forwarding from 127.0.0.1:8080 -> 80 Forwarding from [::1]:8080 -> 80 Handling connection for 8080
問題なく表示できました?
掃除方法
$ kubectl get deployment NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 2/2 2 2 26ddeployment の削除。
$ kubectl delete deployment nginx-deployment deployment.extensions "nginx-deployment" deleted疑問
:
kubectl applyとkubectl createの違いどちらもマニフェストファイルを指定して構築するさいに使うコマンド
kubectl apply -f <マニフェストファイル>kubectl create -f <マニフェストファイル>apply は URL 指定で、 create はカレントにある yml ファイルを指定するときに使っている。
具体的な違いを調べてみます。kubectl apply はオブジェクトが存在しなければ作成し、存在すれば差分を反映してくれる便利なコマンドです。(略)apply 以外の create, replace などのサブコマンドは、現在のオブジェクトの状態を意識して操作をする必要があります。
なるほど〜〜
サブコマンド オブジェクトが存在しない オブジェクトが存在する apply 新規作成 ( POST )
create エラー
replace patch delete (上記URLから引用)
結論⭐: kubectl applyが優秀
docker-desktop?マニフェストファイルを構築
メニューバーにある Docker アイコンから docker-desktop に切り替えます。
$ ls sample-deployment.yml sample-service.ymldeployment.yml
$ vi sample-deployment.ymlsample-deployment.ymlapiVersion: apps/v1 kind: Deployment metadata: name: sample-app labels: app: sample-app spec: replicas: 2 selector: matchLabels: app: sample-app strategy: type: Recreate template: metadata: labels: app: sample-app spec: containers: - image: aoi1/tofu-sample-app:1.0 name: sample-app ports: - containerPort: 3000 name: sample-appservice.yml
$ vi sample-service.ymlsample-service.ymlapiVersion: v1 kind: Service metadata: name: sample-app spec: type: NodePort selector: app: sample-app ports: - name: "http-port" protocol: "TCP" port: 80 targetPort: 3000※
type:NodePortでクラスタ外からアクセスが可能Service が適用されているか見てみる
$ kubectl applyで作成していきます。$ kubectl apply -f sample-deployment.yml deployment.apps/sample-app created $ kubectl apply -f sample-service.yml service/sample-app createdService が作成されているか確認します。
$ kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 26d sample-app NodePort 10.109.160.47 <none> 80:32763/TCP 73sブラウザで Service の Port にアクセスしてみます。
わーい、できました ?
Deployment だけでは、 port foward してあげないとブラウザからの確認ができませんでした。
Service を作成することで IP アドレスが固定され、ブラウザから確認することができます。Kubernetesの Service についてまとめてみた
Service の役割
PodはNodeに散らばっているため、それぞれのPodと通信しようとしたら、愚直にIPアドレスを指定して通信することになります。
また、K8sの特性上、NodeのIPアドレスは一定になりません。
突然Podと通信できなくなる可能性があります。
ということは、複数のPod,NodeのIPアドレスをクライアントが意識せずに単一のエンドポイントで通信する方法が必要になります。
上記の事象に対する解決策としてPod,Nodeの存在を抽象化し、Podとの通信に単一のエンドポイントを提供するのがServiceの主な役割になります。EKS 用マニフェストファイルを再構築
EKS クラスターに切り替えます。
EKS クラスターで docker-desktop 同様に yaml ファイルを作成して
ブラウザで Service の Port にアクセスしてみましたが、表示されませんでした。
ぐぬぬなぜ表示されないのか
ユーザーのアプリケーションのいくつかの部分において(例えば、frontendsなど)、ユーザーのクラスターの外部にあるIPアドレス上でServiceを公開したい場合があります。 (〜略〜)
LoadBalancer: クラウドプロバイダーのロードバランサーを使用して、Serviceを外部に公開します。Amazon EKS クラスターで実行されている Kubernetes Services を公開するにはどうすればよいですか ?
注意 : Amazon EKS は、Load Balancer を通じて Amazon Elastic Compute Cloud (Amazon EC2) インスタンスワーカーノードで実行されるポッドに対して Network Load Balancer と Classic Load Balancer をサポートしています。Amazon EKS は、AWS Fargate で実行されるポッドの Network Load Balancer および Classic Load Balancer をサポートしていません。
EC2 上のワーカーノードにおいてはロードバランサーのサポートあるけれど
Fargate の場合はないらしいです。Fargate イングレスの場合、Amazon EKS で ALB Ingress Controller (最小バージョン 1.1.4) を使用するのがベストプラクティスです。
Fargate を使う際には、ALB Ingress Controller を使いましょう
とのことです!ということで
LoadBalancerを指定して、 Fargate 上で Service の公開ができなかったというのは、 むしろ期待値である ということが判明したので検証を続けます。
外部から表示させてみたいので、ベストプラクティスである ALB Ingress Controller の使用をしてみたいと思います。ALB Ingress Controller の検証
ここを参考に進めます。
Amazon EKS の ALB Ingress ControllerAWS ALB Ingress Controller for Kubernetesは、kubernetes.io/ingress.class: alb 注釈を付けて Ingress リソースがクラスターで作成されるたびに、Application Load Balancer (ALB) および必要な AWS サポートリソースの作成をトリガーするコントローラーです。
GitHub にソース上がっていました。
https://github.com/kubernetes-sigs/aws-alb-ingress-controllerガイドコーナーです。 Route53 を使うときは、このファイルを参考にします。
Spec - AWS ALB Ingress Controller一度、単一 Service 構成で Ingress を検証してみます。
Ingress - Kubernetes$ ls sample-deployment.yml sample-ingress.yml sample-service.ymldeployment.yml
$ vi sample-deployment.ymlsample-deployment.ymlapiVersion: apps/v1 kind: Deployment metadata: name: sample-app labels: app: sample-app spec: replicas: 2 selector: matchLabels: app: sample-app strategy: type: Recreate template: metadata: labels: app: sample-app spec: containers: - image: aoi1/tofu-sample-app:1.0 name: sample-app ports: - containerPort: 3000 name: sample-appservice.yml
$ vi sample-service.ymlsample-service.ymlapiVersion: v1 kind: Service metadata: name: sample-app spec: type: NodePort selector: app: sample-app ports: - name: "http-port" protocol: "TCP" port: 80 targetPort: 3000ingress.yml
$ vi sample-ingress.ymlsample-ingress.ymlapiVersion: networking.k8s.io/v1beta1 kind: Ingress metadata: name: sample-app annotations: kubernetes.io/ingress.class: alb spec: backend: serviceName: sample-app servicePort: 80
ingressを作成。$ kubectl apply -f sample-ingress.yml ingress.networking.k8s.io/sample-app created$ kubectl get ingress NAME HOSTS ADDRESS PORTS AGE sample-app * 80 107s準備
サブネットと ALB の紐付け
使用する VPC のサブネットにタグを付けて、そのサブネットを使用できることを
ALB Ingress Controller に伝える必要があります。※ ekctl を使用してクラスターをデプロイした場合は、タグがすでに適用されているため不要。
IAM OIDC プロバイダーを作成し、クラスターに関連付け
$ eksctl utils associate-iam-oidc-provider \ --region ap-northeast-1 \ --cluster demo-cluster \ --approveIAM OIDC プロバイダーってなんだろう
- Kubernetes サービスアカウントに対するきめ細やかな IAM ロール割り当ての紹介 | Amazon Web Services ブログ
- [アップデート] EKSでIAMロールを使ったPod単位のアクセス制御が可能になりました! | Developers.IOなるほどなるほど~
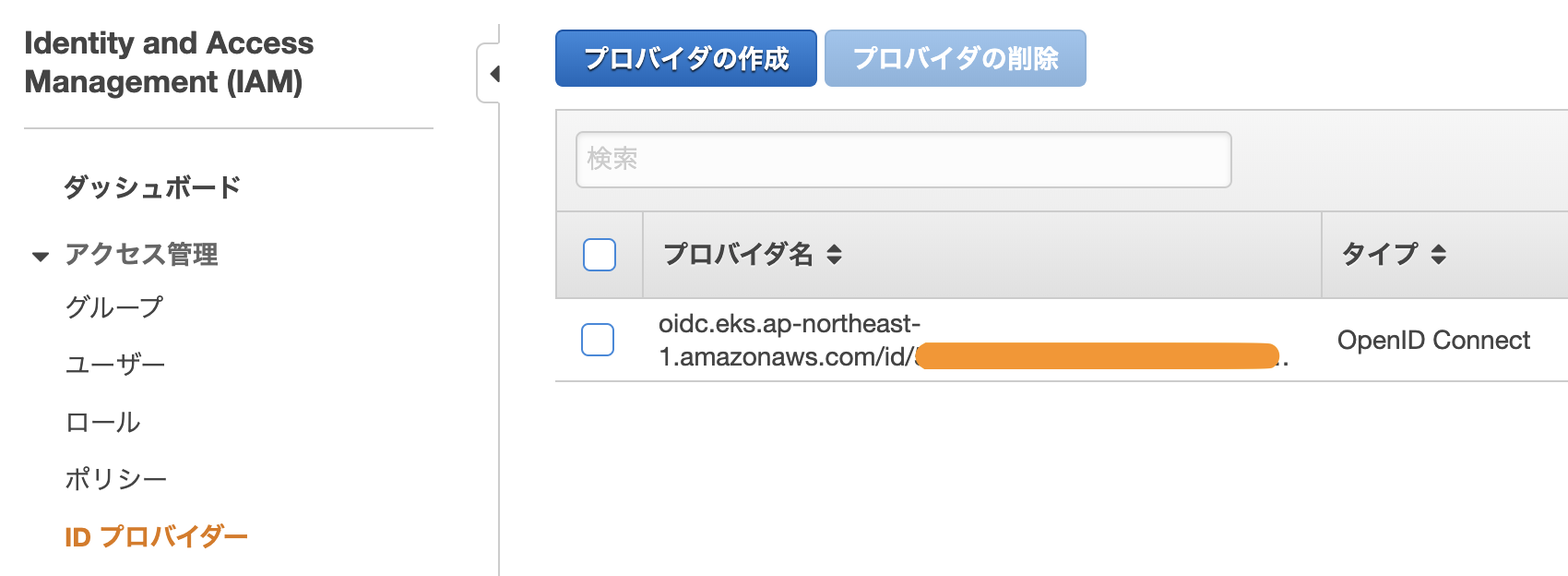
$ eksctl utils associate-iam-oidc-provider --region ap-northeast-1 --cluster demo-cluster --approve [ℹ] eksctl version 0.13.0 [ℹ] using region ap-northeast-1 [ℹ] will create IAM Open ID Connect provider for cluster "demo-cluster" in "ap-northeast-1" [✔] created IAM Open ID Connect provider for cluster "demo-cluster" in "ap-northeast-1"IAM コンソールで確認。
できました?
IAM ポリシーの作成
ユーザーに代わって AWS API を呼び出すことを
ALB Ingress Controller Pod に許可するための
ALBIngressControllerIAMPolicy という IAM ポリシーを作成。$ aws iam create-policy \ --policy-name ALBIngressControllerIAMPolicy \ --policy-document https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/iam-policy.json実行してみました。
$ aws iam create-policy --policy-name ALBIngressControllerIAMPolicy --policy-document https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/iam-policy.json { "Policy": { "PolicyName": "ALBIngressControllerIAMPolicy", "PermissionsBoundaryUsageCount": 0, "CreateDate": "2020-03-04T05:24:33Z", "AttachmentCount": 0, "IsAttachable": true, "PolicyId": "ANPAWRYCWNNWLBILX6M2P", "DefaultVersionId": "v1", "Path": "/", "Arn": "arn:aws:iam::*********:policy/ALBIngressControllerIAMPolicy", "UpdateDate": "2020-03-04T05:24:33Z" } }
- alb-ingress-controller という名前の Kubernetes サービスアカウントを kube-system 名前空間に作成。
- クラスターロールと ALB Ingress Controller で使用するクラスターロールバインディングを作成。
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/rbac-role.yaml clusterrole.rbac.authorization.k8s.io/alb-ingress-controller created clusterrolebinding.rbac.authorization.k8s.io/alb-ingress-controller created serviceaccount/alb-ingress-controller createdALB Ingress Controller の IAM ロールを作成し
このロールを前のステップで作成したサービスアカウントにアタッチする。以下のコマンドは、 eksctl で作成したクラスターでのみ使用できる。
$ eksctl create iamserviceaccount \ --region ap-northeast-1 \ --name alb-ingress-controller \ --namespace kube-system \ --cluster demo-cluster \ --attach-policy-arn arn:aws:iam::***********:policy/ALBIngressControllerIAMPolicy \ --override-existing-serviceaccounts \ --approve実行した。アタッチできました。
$ eksctl create iamserviceaccount --region ap-northeast-1 --name alb-ingress-controller --namespace kube-system --cluster demo-cluster --attach-policy-arn arn:aws:iam::***********:policy/ALBIngressControllerIAMPolicy --override-existing-serviceaccounts --approve [ℹ] eksctl version 0.13.0 [ℹ] using region ap-northeast-1 [ℹ] 1 iamserviceaccount (kube-system/alb-ingress-controller) was included (based on the include/exclude rules) [!] metadata of serviceaccounts that exist in Kubernetes will be updated, as --override-existing-serviceaccounts was set [ℹ] 1 task: { 2 sequential sub-tasks: { create IAM role for serviceaccount "kube-system/alb-ingress-controller", create serviceaccount "kube-system/alb-ingress-controller" } } [ℹ] building iamserviceaccount stack "eksctl-demo-cluster-addon-iamserviceaccount-kube-system-alb-ingress-controller" [ℹ] deploying stack "eksctl-demo-cluster-addon-iamserviceaccount-kube-system-alb-ingress-controller" [ℹ] serviceaccount "kube-system/alb-ingress-controller" already exists [ℹ] updated serviceaccount "kube-system/alb-ingress-controller"ALB Ingress Controller をデプロイ
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/alb-ingress-controller.yaml deployment.apps/alb-ingress-controller createdALB Ingress Controller のデプロイマニフェストを編集。
--ingress-class=alb 行の後にクラスター名の行を追加する。
Fargate で ALB Ingress Controller を実行している場合は、 VPC ID の行と、クラスターの AWS リージョン名も追加する必要がある。
一部抜粋$ kubectl edit deployment.apps/alb-ingress-controller -n kube-system spec: containers: - args: - --ingress-class=alb - --cluster-name=demo-cluster - --aws-vpc-id=vpc-*********** - --aws-region=ap-northeast-1全部
$ kubectl edit deployment.apps/alb-ingress-controller -n kube-systemselfLink: /apis/apps/v1/namespaces/kube-system/deployments/alb-ingress-controller uid: *********** spec: progressDeadlineSeconds: 600 replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: app.kubernetes.io/name: alb-ingress-controller strategy: rollingUpdate: maxSurge: 25% maxUnavailable: 25% type: RollingUpdate template: metadata: creationTimestamp: null labels: app.kubernetes.io/name: alb-ingress-controller spec: containers: - args: - --ingress-class=alb - --cluster-name=demo-cluster - --aws-vpc-id=vpc-*********** - --aws-region=ap-northeast-1 image: docker.io/amazon/aws-alb-ingress-controller:v1.1.4 imagePullPolicy: IfNotPresent name: alb-ingress-controller resources: {} terminationMessagePath: /dev/termination-log terminationMessagePolicy: File dnsPolicy: ClusterFirst restartPolicy: Always schedulerName: default-scheduler securityContext: {} serviceAccount: alb-ingress-controller serviceAccountName: alb-ingress-controller terminationGracePeriodSeconds: 30 status: availableReplicas: 1 conditions: - lastTransitionTime: "2020-03-04T07:57:41Z" lastUpdateTime: "2020-03-04T07:57:41Z" message: Deployment has minimum availability. reason: MinimumReplicasAvailable status: "True" type: Available - lastTransitionTime: "2020-03-04T07:51:13Z" lastUpdateTime: "2020-03-04T07:57:41Z" message: ReplicaSet "alb-ingress-controller-***********" has successfully progressed. reason: NewReplicaSetAvailable status: "True" type: Progressing observedGeneration: 2 readyReplicas: 1 replicas: 1 updatedReplicas: 1ALB Ingress Controller が実行されていることを確認。
良さそう。$ kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE alb-ingress-controller-*********** 1/1 Running 0 97s coredns-d784dc748-fmkzx 1/1 Running 0 23h coredns-d784dc748-r28sm 1/1 Running 0 23hサンプルアプリケーションをデプロイ
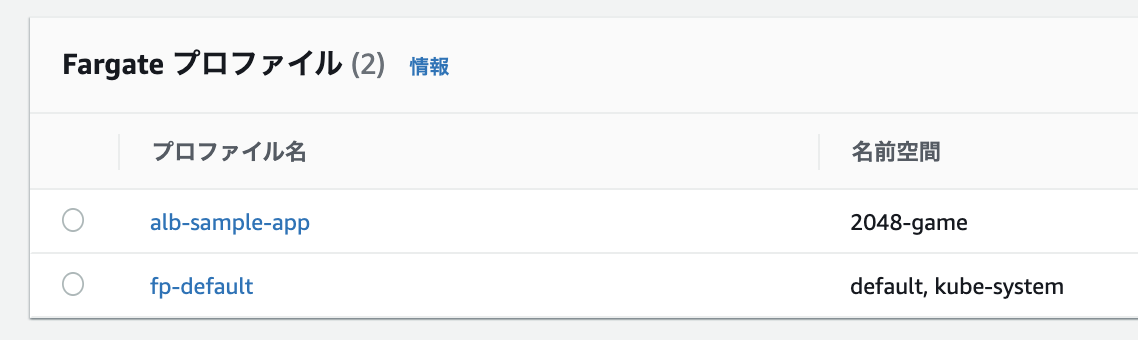
サンプルアプリケーションの名前空間を含む Fargate プロファイルを作成する。
$ eksctl create fargateprofile --cluster demo-cluster --region ap-northeast-1 --name alb-sample-app --namespace 2048-game [ℹ] creating Fargate profile "alb-sample-app" on EKS cluster "demo-cluster" [ℹ] created Fargate profile "alb-sample-app" on EKS cluster "demo-cluster"できました?
マニフェストファイルをダウンロードして適用し
- Kubernetes の名前空間
- Deployment
- Serviceを作成$ kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/2048/2048-namespace.yaml namespace/2048-game created $ kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/2048/2048-deployment.yaml deployment.apps/2048-deployment created $ kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/2048/2048-service.yaml service/service-2048 created入力マニフェストファイルをダウンロード
$ curl -o 2048-ingress.yaml https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/2048/2048-ingress.yaml
2048-ingress.yamlファイルを編集。
既存のalb.ingress.kubernetes.io/scheme: internet-facing行の下に
行alb.ingress.kubernetes.io/target-type: ipを追加する。$ vi 2048-ingress.yaml2048-ingress.yamlapiVersion: extensions/v1beta1 kind: Ingress metadata: name: "2048-ingress" namespace: "2048-game" annotations: kubernetes.io/ingress.class: alb alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/target-type: ip labels: app: 2048-ingress spec: rules: - http: paths: - path: /* backend: serviceName: "service-2048" servicePort: 80入力したマニフェストファイルを適用
$ kubectl apply -f 2048-ingress.yaml ingress.extensions/2048-ingress created作成に数分かかるのでコーヒーを飲みながら待ちます。
Ingress リソースが作成されたことを確認する。$ kubectl get ingress/2048-ingress -n 2048-game NAME HOSTS ADDRESS PORTS AGE 2048-ingress * cc1babba-2048game-2048ingr-*************.ap-northeast-1.elb.amazonaws.com 80 5m50s指定された ADDRESS にアクセスする。
http://cc1babba-2048game-2048ingr-6fa0-*********.ap-northeast-1.elb.amazonaws.com/
できました?



- 投稿日:2020-05-28T19:57:41+09:00
【AWS】S3ストレージの種類についてのアウトプット
はじめに
現在、AWSソリューションアーキテクトの学習をしております。
今回は、S3ストレージの種類(ストレージクラス)についてアウトプットしていきます。S3ストレージの種類
S3標準
アクセス頻度の高いデータ向けのストレージクラス。
特徴
- イレブンナインの高い耐久性(99.999999999%の耐久性)
- オブジェクト作成時にデフォルトで選択されている
用途
- アクセス頻度が高いデータ(配信画像・映像、分析データなど)
S3 Intelligent-Tiering
アクセス頻度を自動判別し、最もコスト効率のよいストレージクラスに自動的にデータを移動させるストレージクラス。
特徴
- 「高頻度」と「低頻度」のアクセス階層が組み込まれている
- 連続で30日アクセスされていないオブジェクトは自動的に「低頻度」のアクセス階層へ移動
- モニタリングと自動化のために料金が発生
用途
- アクセスパターンが変化するデータ
- 不明な存続期間が長いデータ
S3標準-低頻度アクセス(S3標準 - IA)
アクセス頻度は低いものの、必要となった際にすぐに取り出せる必要があるデータに最適なストレージクラス。
特徴
- S3標準と同じ耐久性と性能
- S3標準よりも利用料は安い
- データを取り出すのに料金がかかる
用途
存続期間が長く頻繁にアクセスされないデータ
S3 1ゾーン - 低頻度アクセス(S3標準 - IA)
複数のアベイラビリティーゾーンへの複製が不要なデータの保存に最適なストレージクラス。
特徴
- 一つのアベイラビリティーゾーンにデータが保存される
- 他のストレージクラスと比べて可用性は低い
- 「S3標準-低頻度アクセス」よりもコストを20%削減することができる
用途
- アクセス頻度が低いデータ(S3標準-IA)と同様
- 存続期間が長い重要性の低いデータ
S3 Glacier
長期保管するデータ等、アーカイブ用途で利用するストレージクラス。
例えると、バックアップテープを別サイトに保存しておくといった感じになります。
特徴
- データ取り出し手続きが必要(数分~数時間)
- ストレージクラスの中で最もコストが低い
- 耐久性はイレブンナイン(99.999999999%)
用途
アクセス頻度が低いデータの長期保存
S3ストレージクラス比較
特徴 S3標準 S3 Intelligent-Tiering S3標準-IA S3標準 1ゾーン - 1A S3 Glacier 耐久性:99.999999999 〇 〇 〇 〇 〇 複数アベイラビリティーゾーン 〇 〇 〇 × 〇 可用性設計 99.99% 99.9% 99.9% 99.5% 99.99% 取り出し料金 なし なし 発生 発生 発生 取り出し手続き なし なし なし なし 必要 用途まとめ
ストレージクラス 用途 S3標準 アクセス頻度の高いデータ(例:モバイルやゲームのアプリケーション、コンテンツ配信等) S3 Intelligent-Tiering 未知のアクセスパターンのデータ、アクセスパターンが変化するデータ S3標準-IA アクセス頻度は低いが、必要に応じて取り出しが必要なデータ S3標準 1ゾーン - 1A オンプレミスデータ、容易に再作成可能なデータのセカンダリバックアップ S3 Glacier データのアーカイブ用 参考記事
この1冊で合格! AWS認定ソリューションアーキテクト - アソシエイト テキスト&問題集
AWS CLIからS3ストレージクラスを操作する
- 投稿日:2020-05-28T18:48:49+09:00
CDK(TypeScript)で既存のS3 Bucket上のLambdaを指定する
aws-cdkでの環境構築メモです。
特定のBucketへのPutをトリガーに発火するLambdaを作っています。
ただし、Lambdaのコードベースはcdk管理外のS3で管理されているものとします。1. fromCfnParametersのdefault値で無理やり当てる
... /* S3 */ const originalVideoBucket = new Bucket(this, `OriginalVideoBucket` , { bucketName: resources.originalVideoS3Bucket.name, removalPolicy: cdk.RemovalPolicy.DESTROY, // RETAIN versioned: true, publicReadAccess: false, }); const fn = new lambda.Function(this, 'OriginalVideoAssetUploaded', { functionName: resources.originalVideoUploaded.lambdaName, runtime: lambda.Runtime.GO_1_X, handler: 'main', memorySize: 128, code: lambda.Code.fromCfnParameters({ bucketNameParam: new CfnParameter(this, "OriginalVideoBucketLambdaSourceBucket" , { default: <既存のS3Bucket>, }), objectKeyParam: new CfnParameter(this, "OriginalVideoBucketLambdaSourceS3Key" , { default: <既存のS3Key>, }), }), }); fn.addEventSource(new eventSource.S3EventSource(originalVideoBucket , { events: [ EventType.OBJECT_CREATED], }))2. Bucket.fromBucketName
const resourceBucketRef = Bucket.fromBucketName(this , `resource` , resources.resourceS3Bucket.name); const regionalUserApiLambda = new lambda.Function(this, 'RegionalUserApi', { functionName: resources.userApi.lambdaName, runtime: lambda.Runtime.GO_1_X, handler: 'main', memorySize: 128, timeout : Duration.seconds(10), code: lambda.Code.fromBucket(resourceBucketRef , resources.userApi.lambdaS3Key) });3.
@aws-cdk/aws-samの方のCfnFunctionを使うimport * as Sam from "@aws-cdk/aws-sam" .... .... const samFunction = new Sam.CfnFunction(this, 'OriginalVideoAssetUploaded', { functionName: resources.originalVideoUploaded.lambdaName, codeUri: { bucket : <既存のS3Bucket>, key: <既存のS3Key> }, handler: 'main', runtime: 'go1.x', memorySize: 128, timeout: 3, events: { "mys3event": { type : `S3`, properties : { bucket : originalVideoBucket.bucketName, events : `s3:ObjectCreated:*`, }, }, }, });こっちのパターンはs3 eventの方がうまく設定されないのでちょっとCloudformationとしての構文出力と照らし合わせて検証中です
- 投稿日:2020-05-28T18:47:29+09:00
CodeBuildのテストレポート機能が一般公開されたから使ってケチつけてみた
TL; DR
コードカバレッジの表示はできませんので、期待するとガッカリするかもしれません。
今後よくなっていくことを信じて待ちましょう!はじめに
AWSのCodeBuildで、2019年11月25日にテストレポートのサポート機能(以降、テストレポート機能と呼ぶ)がプレビュー公開されていました。
参考:AWS CodeBuild で新たにテストレポートをサポート開始
また、2020年5月22日になり、テストレポート機能が一般公開されました。
参考:AWS CodeBuild テストレポートの一般公開が開始
この機能がどのようなものなのか、実際に動かして確かめてみたくありませんか?
ということで、実際に試してみます。
決して「昨年末に試してみたけど記事を書損ねて流行に乗遅れたから挽回してみた」記事ではありません。事前知識
CodeBuildってなんやねん、テストレポートってなんやねん、という方は、ざっと流し読みしてみてください。
CodeBuildとは
AWSでCI/CD環境を構築する際にお世話になる、「クラウドで動作する完全マネージド型のビルドサービス」です。
参考:AWS CodeBuild とは - AWS CodeBuild
AWSでサービスをビルドする際や、自動テストを実施したりする際に、よくお世話になります。
似たようなサービスとして、 GitHub Actions や CircleCI が挙げられます。
テストレポートとは
ここで言うテストレポートとは、テスト結果のテスト件数や実行時間を集計したファイル(いわゆるJUnitのXMLファイル)のことです。
現在では多種多様なフォーマットがあるので、XMLフォーマット以外にもたくさんあります。参考:JUnitの実行結果のXMLフォーマット | Developers.IO
CodeBuildのテストレポート機能では、上記テストレポートファイルを組込むことで、テスト結果を可視化できます。
似たようなサービスとして、 CircleCIにおけるテストメタデータの収集 が挙げられますね。......え、 Codecov や Coveralls をなぜ挙げないのか?
そのうちわかります。実際に試してみた
CodeBuildで、実際にテストレポート機能の動作確認をしてみましょう。
CodeCommitとCodeBuildのプロジェクトを新規作成する
CodeBuildでソースコードをビルドする(今回は、単純に自動テストだけを実施するが、以降この作業をビルドと呼ぶ)ためのプロジェクト、および、CodeBuildにソースコードを喰わせるためのCodeCommitリポジトリを、それぞれ新規作成します。
今回は、動作確認のために新規作成しますが、ほとんどのプロジェクトでは既存のCodeBuildが存在すると思うので、本節は飛ばしても構いません。また、CodeCommitを使わずにGitHubなどを利用している場合は、CodeCommitは必要ありません。
CodeCommitおよびCodeBuildのプロジェクトを新規作成する方法については、ここでは省略します。
参考:
CodeCommitにソースコードをプッシュする
CodeCommitに、CodeBuildでビルドするためのソースコードをプッシュします。
動作確認ができればなんでも良いので、好きな言語で試してみましょう。
つまり僕はPerlで試してみるわけです。まず、テストコードです
sample.tuse strict; use warnings; use Test::More; subtest 'サンプルテスト' => sub { my $test = "pass"; ok $test; }; done_testing;本当に、なんの変哲もない最小単位のテストコードです。
これを実行するためには、下記コマンドを使います。
sample.tファイルの実行prove sample.t # 実行結果 # # sample.t .. ok # All tests successful. # Files=1, Tests=1, 0 wallclock secs ( 0.03 usr 0.01 sys + 0.06 cusr 0.02 csys = 0.12 CPU) # Result: PASSCodeBuildでは、buildspec.ymlファイルにより動作を定義できるため、こちらも作ります。
buildspec.ymlversion: 0.2 phases: install: commands: - yum install -y perl-devel expat-devel - curl -L https://cpanmin.us/ -o cpanm && mv cpanm /usr/bin/cpanm && chmod +x /usr/bin/cpanm - curl -fsSL --compressed https://git.io/cpm > cpm && mv cpm /usr/bin/cpm && chmod +x /usr/bin/cpm build: commands: - cpm install -g TAP::Harness - cpm install -g TAP::Harness::JUnit Test::Deep XML::NamespaceSupport XML::SAX::Base XML::SAX XML::SAX::Expat XML::Simple - prove -lv -j5 --harness TAP::Harness::JUnit sample.t reports: sample-test-report: files: - junit_output.xml
buildフェーズにおける、最後のprove -lv -j5 --harness TAP::Harness::JUnit sample.tがテスト実行コマンドです。
「sample.tファイルの実行」との大きな違いとして、TAP::Harness::JUnitライブラリを用いてテストレポートファイルjunit_output.xmlを生成しています。また、 reports における sample-test-report で、上記
junit_outpu.xmlファイルを取得しています。
ここで、CodeBuildのテストレポート機能で表示されるファイルを指定しています。
以降、Perl固有のCodeBuildでの説明です。
installフェーズでは、 cpm コマンドの実行環境を構築しています。
perl-develライブラリは cpanm コマンド(具体的には、依存モジュールであるExtUtils::MakeMaker)をインストールする際に、またexpat-develライブラリはTAP::Harness::JUnitモジュール(具体的には、依存モジュールであるXML::Parser)をインストールする際に、それぞれ必要なライブラリです。
buildフェーズでは、 cpm コマンドで、TAP::Harness::JUnitモジュールおよび依存モジュールをインストールしています。
なぜか依存モジュールを自動でインストールしてくれなかったので、自身で使っているPCにインストールした際に表示された依存モジュールをコピペしました。
また、XML::SAX::Expatモジュールのインストールが時々失敗しますが、原因は不明です。
テストレポートファイル生成には、他にもTAP::Formatter::JUnitモジュールがありますが、依存モジュールを自動でインストールしてくれない問題により、Mooseモジュールの大量依存モジュールのインストールが大変で、途中で諦めてしまいました。
参考:
- CodeBuildに関するもの
- Perlに関するもの
- cpanmをインストールする色んな方法 - ノウハウブログ - カンタローCGI
- skaji/cpm: fast CPAN client
- Test::More - テストを書くためのもう一つのフレームワーク - perldoc.jp
- 複数 prove して TAP::Harness::JUnit が出力する結果を merge する - soh335 memo
- CentOS7にcpanminusを導入する - 偏った言語信者の垂れ流し
- [Perl]XML::Parserがインストールできないときの対処法 · DQNEO起業日記
- jenkinsでコードメトリクス、カバレッジレポートの表示 - notebook
CodeBuildで自動テストする
上記2ファイルを入れたリポジトリで、CodeCommit経由でCodeBuildを走らせます。
CodeBuildによるビルドは、手動で構いません。1点だけTispなのですが、CloudWatch Logsへのログ出力オプションはオンにしておくと良いです。
実行フローの確認が容易に出来ます。参考:AWS CodeBuild でのビルドの実行 - AWS CodeBuild
CodeBuildでビルド通過後にテストレポートを確認する
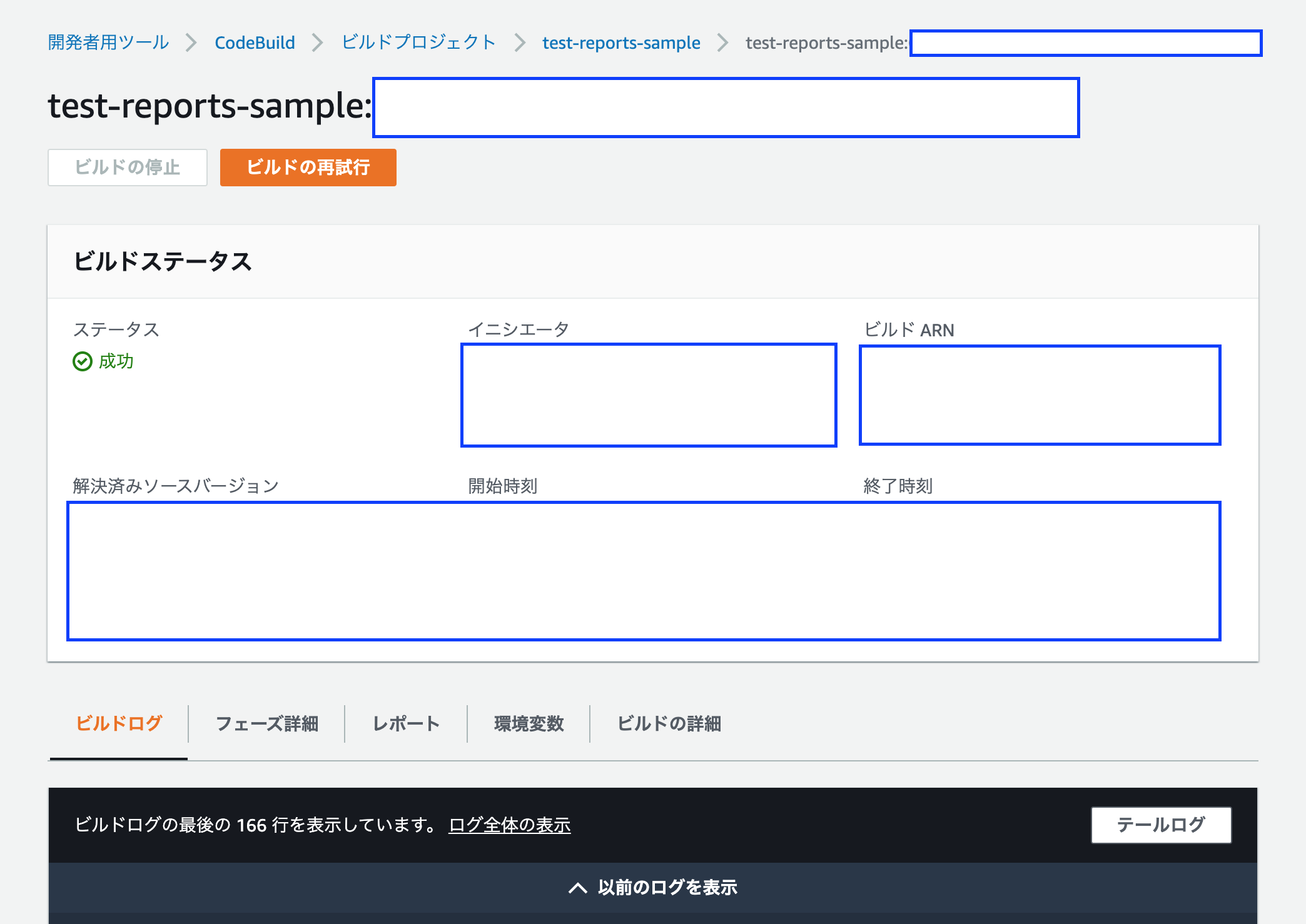
CodeBuildでビルドが完了したら、テストレポートを確認しましょう。
CodeBuildにtest-reports-sampleビルドプロジェクトを作成した場合、下記のような画面でビルド成功がわかると思います。
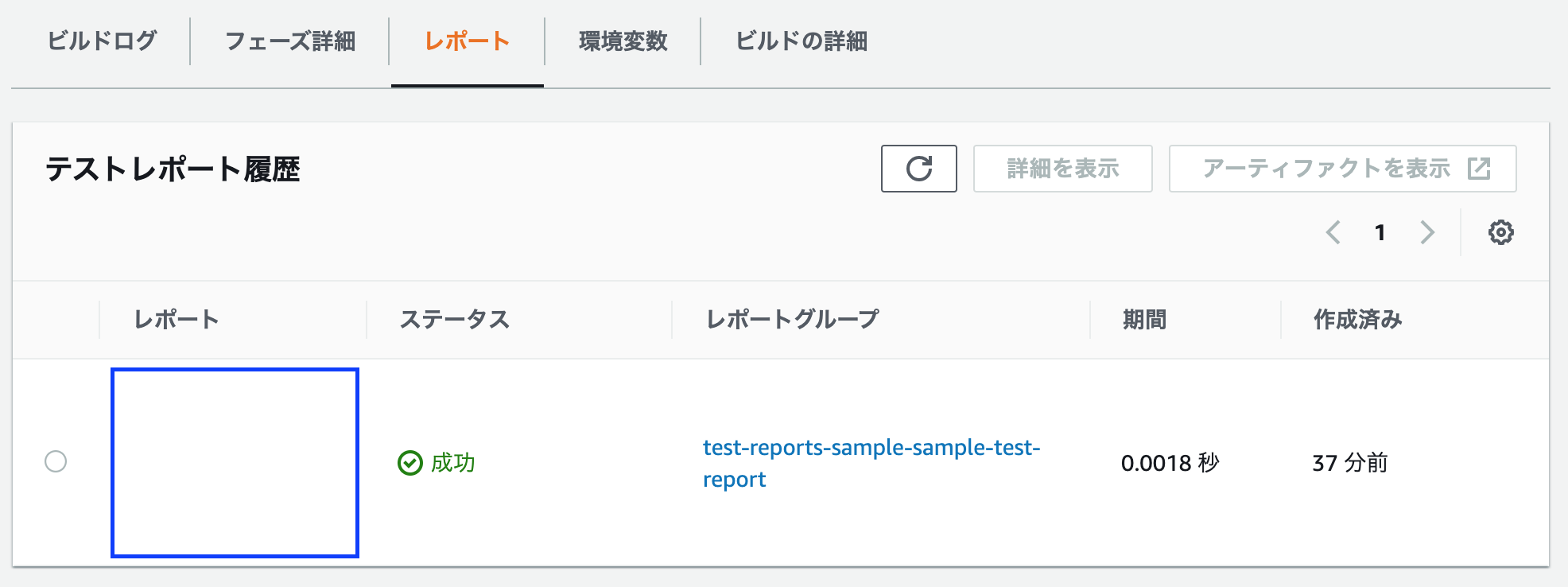
その中のレポートタブを選択します。
レポートタブ内には、CodeBuildにおけるビルド時のレポートが、一覧でリンクされます。
そのリンクを選択することで、テストレポート画面に移動します。
今回は、 buildspec.yml ファイルで定義した sample-tests-report のテストレポートを確認します。
レポート名は、
{CodeBuildのビルドプロジェクト名}-{CodeBuildのテストレポート名}:UUIDとなっています。
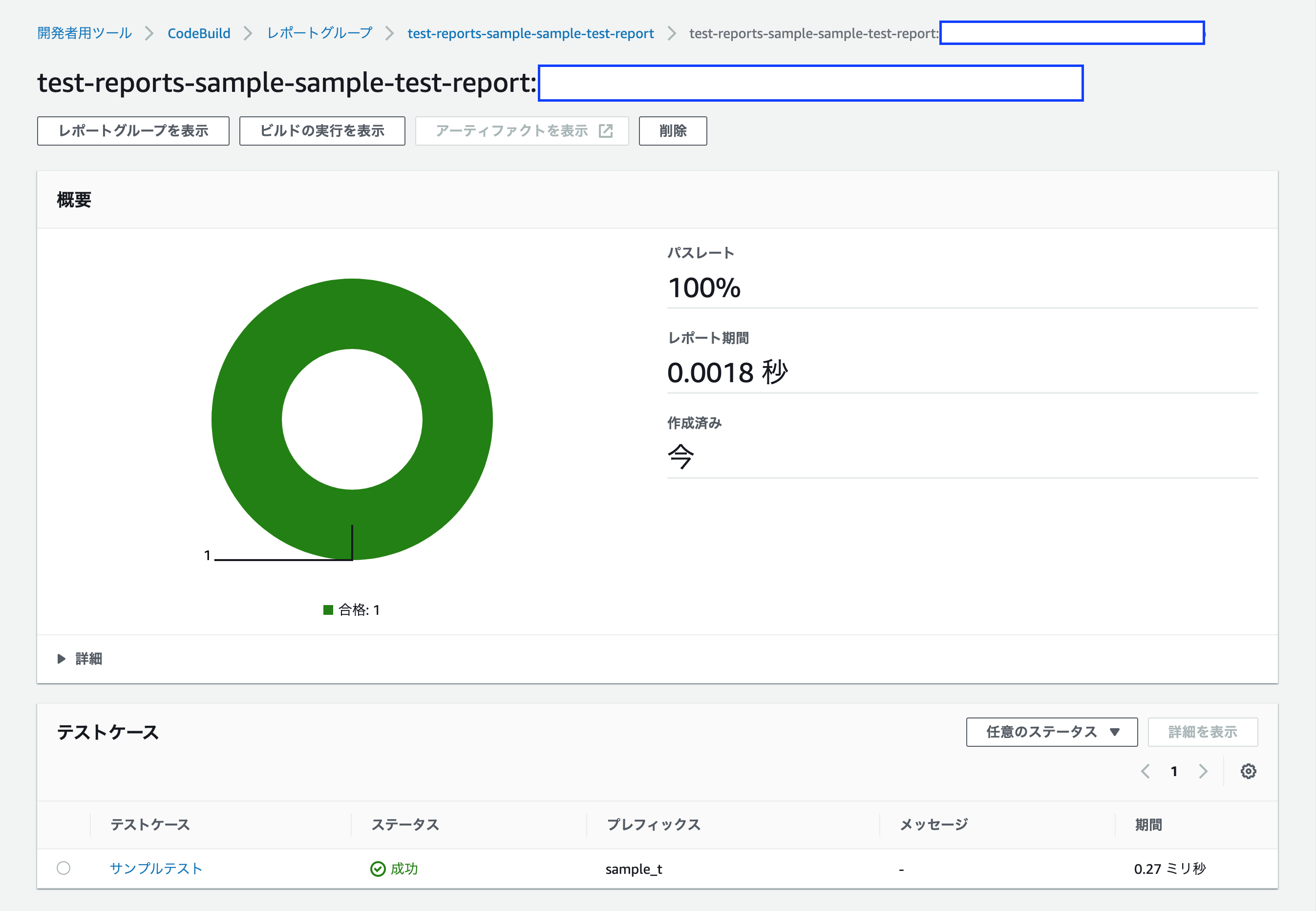
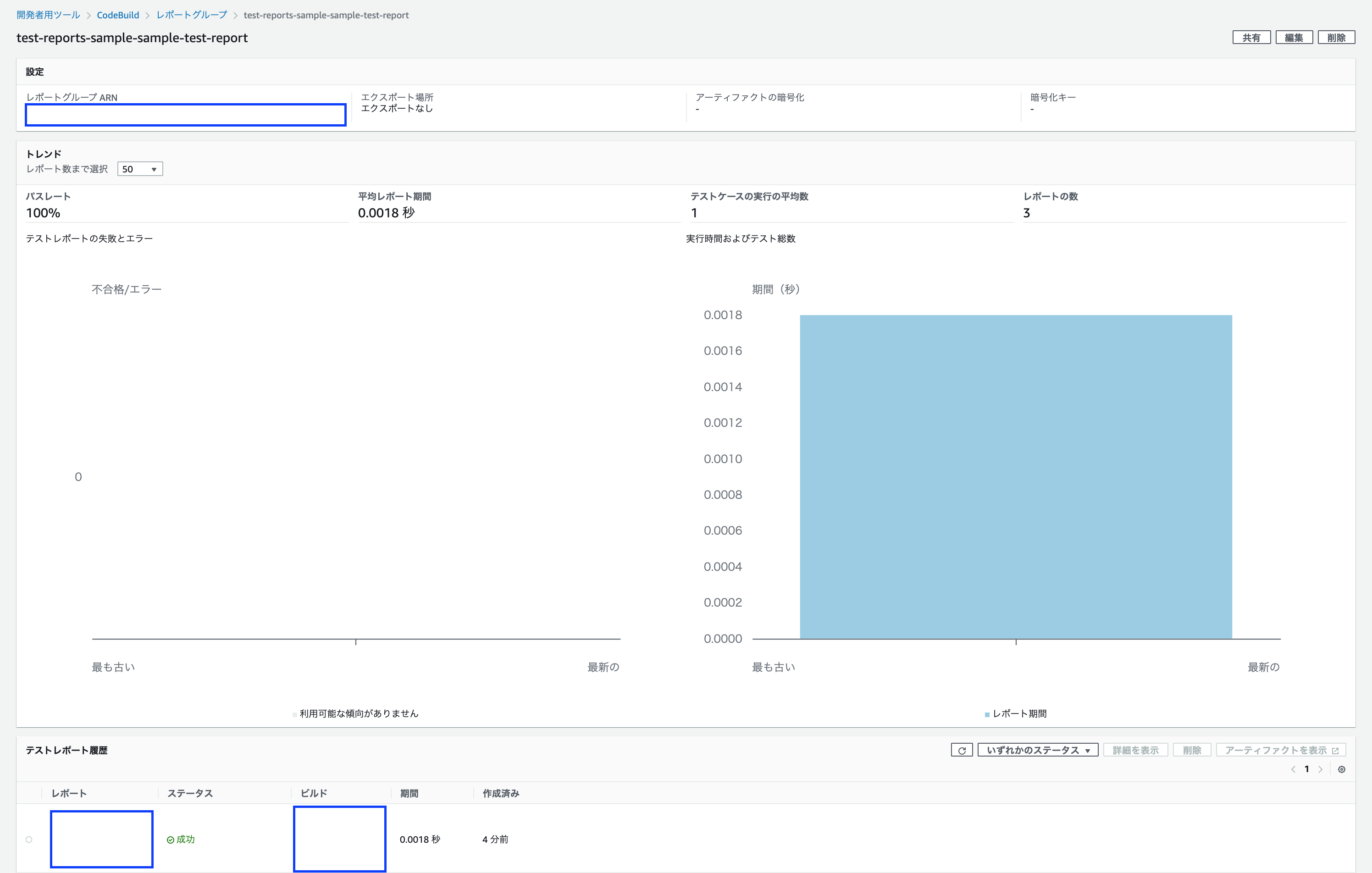
今回、 test-reports-sample ビルドプロジェクトで sample-test-report を表示する設定にしたため、このようなよくわからない表示になっています。
全テスト項目が通っていること(パスレート 100%)や、テスト実行時間(レポート期間 0.0018秒)がわかります。また、左上の「レポートグループを表示」ボタンを押下することで、歴代のテストレポートの遷移がわかります。
レポートグループ名はレポート名におけるUUIDを除いた際の名前です。
歴代のテスト通過率(パスレート 100%)、平均テスト実行時間(平均レポート期間 0.0018秒)、平均テストケース数(テストケースの実行の平均数 1)がわかると思います。
テストが失敗すると、CodeBuild自体も失敗判定となります。
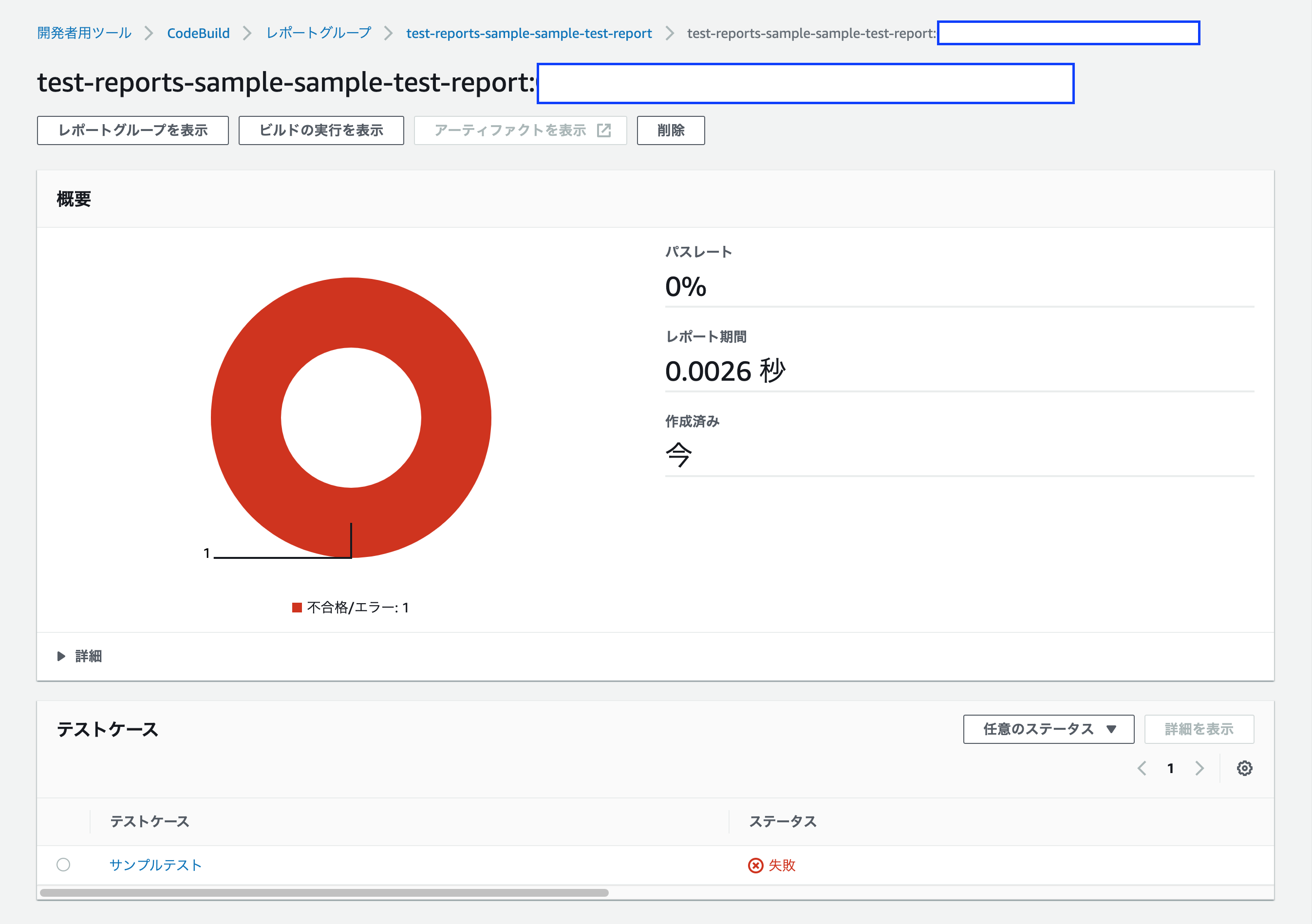
テストが失敗した場合は、次のようなレポート画面になります。
パスレートが 0% となっていることが、ひと目でわかります。
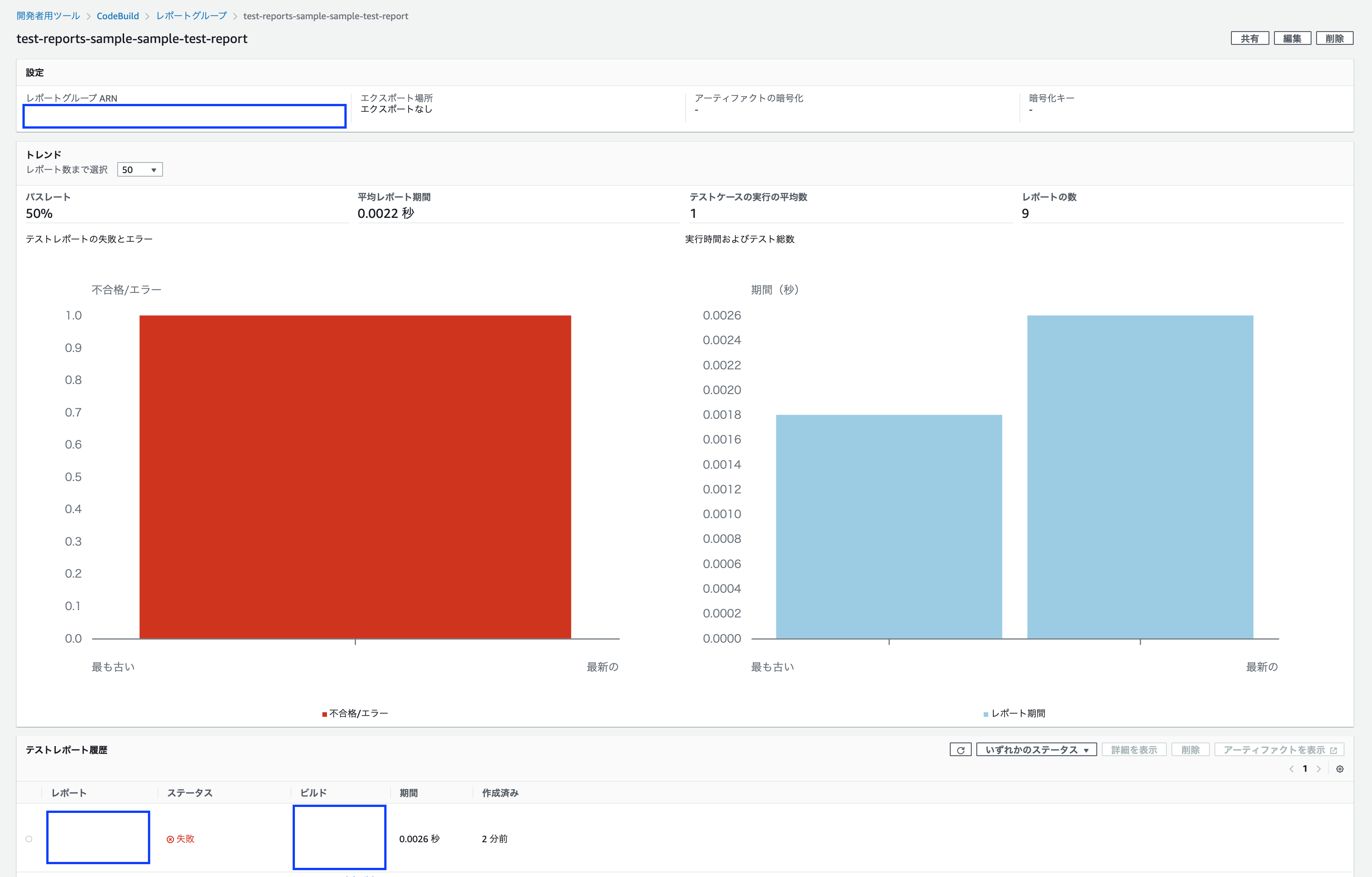
レポートグループ画面については、次の通りです。
歴代のテスト通過率が半分 (50%) になっていることがわかります。
また、「実行時間およびテスト総数」のグラフが2つになり、「テストレポートの失敗とエラー」のグラフが1つ表示されていることが、痛々しいほどに伝わります。
二度とコケるテストをしたくなくなりますね!CodeBuildテストレポート機能の利点/欠点
機能自体は理解できたので、CodeBuildテストレポート機能の利点と欠点を、それぞれ書いていきます。
利点
せっかく作ってくれたのだから、いい面を見つけてあげたいですね。
グラフィカルなUIでテスト結果が確認できる
以前までは、CodeBuildのテスト結果は全てCloudWatch LogsのCUIライクな表示でしか確認できませんでした。
これがGUIによるグラフィカルな表示になったことで、見やすくなった......かもしれません。別サービスを契約しなくて良い
今後のアップデート次第では、CodecovやCoverallsなどの別サービスを契約する必要が無くなる可能性があります。
CodeCommitを使う際はプライベートリポジトリの場合が多いため、プライベートリポジトリの場合は有料契約になってしまう上記サービスを使わなくても良い点は、利点として十分かと思います。......絵空事にならないことを期待します。
欠点
本記事を書くきっかけとなっている内容です。
ずばり、現状のCodeBuildテストレポート機能は、使えるとは言い難いです。
それがなぜなのか、また、どのようなサービスであれば良いのか、例を交えて説明します。テストカバレッジを表示できない
最大の欠点は、コードカバレッジを表示できない点だと言えます。
CodeBuildのテストレポート機能は、そもそもコードカバレッジを表示するとは一言も言ってないため、しっかり考えれば納得せざるをえません。
しかし、テストレポート機能と言うからには、やはりコードカバレッジの表示は欲しかったです。
だって最初の円グラフを見て、まさかコードカバレッジは出せないなんて思わなかったよ!平均テスト通過率/平均実行数の意味がわからない
ぶっちゃけ、直前以外のテスト通過率もテスト実行数も、あまり使わない気がします。
大事なのは、直前のテスト通過率と直前のテスト実行数だと思うのですが、なぜ平均値を出しているのか、よくわかりません。
しかも、1度でもテストで失敗してしまうと(理論上)100%には二度と戻らないのも、悲しいです。最終のテスト通過率を大きく表示するか、通過率(または成功率)の折れ線グラフにするといいのではないでしょうか。
テスト実行数についても同様です。
折れ線グラフにすることで、テスト量の遷移が伝わりやすいと思います。失敗数グラフが心臓に悪い
一度でもテストで失敗してしまうと、レポートグループ画面の「テストレポートの失敗とエラー」に棒グラフが1つ追加されます。
この項目には、テストが成功しても棒グラフは追加されません。つまり、失敗後に修正して再テストが成功したとしても、「テストレポートの失敗とエラー」の画面では、失敗していた頃の黒歴史を常に見せつけられるわけです。
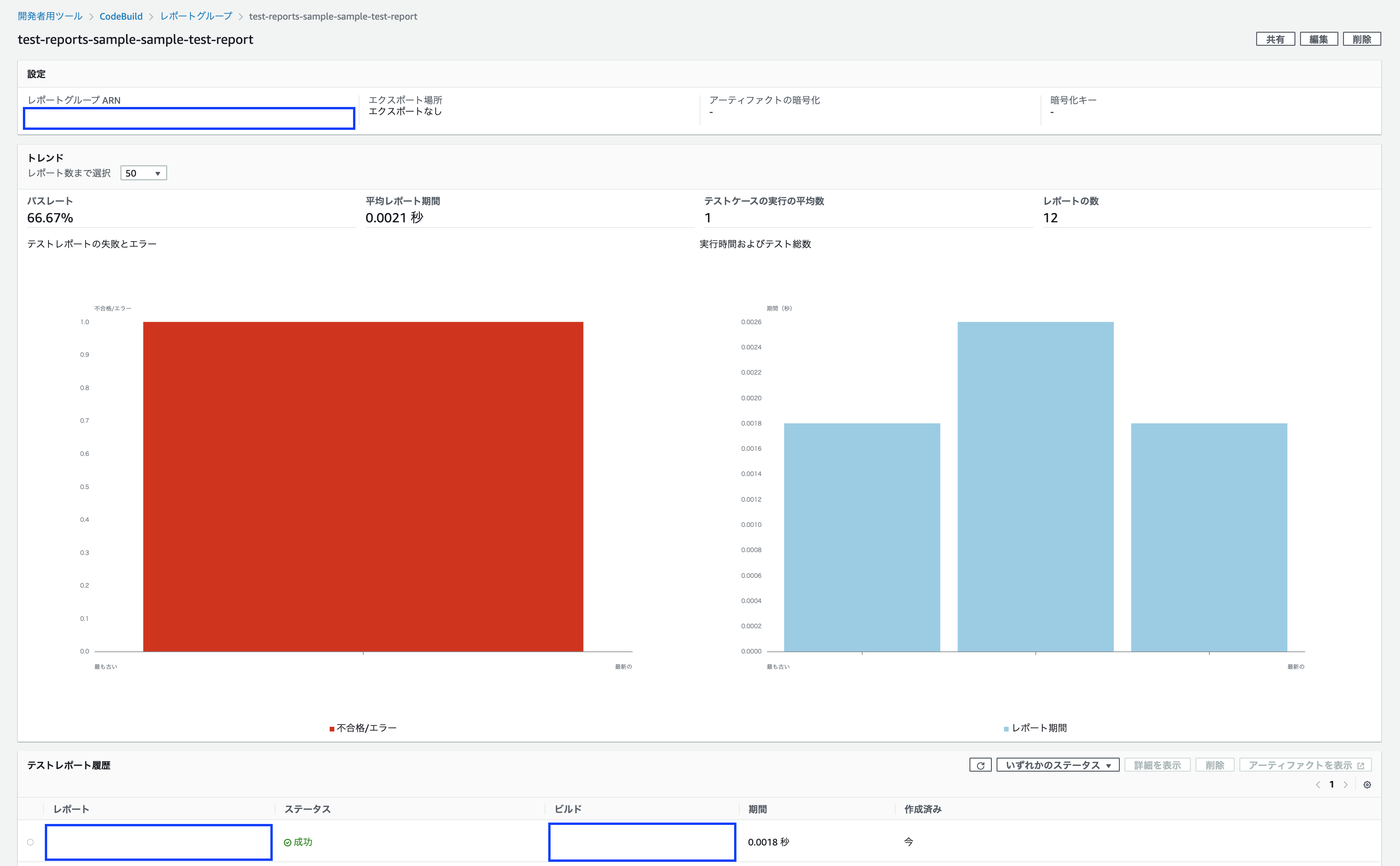
例えば、3回目でテストが成功した際の画面は、下記の通りです。
テストレポート履歴では、最後のテストレポートでステータスが成功になっていることがわかります。
......いや、でも真っ赤なんですけど!この画面を見て、テストが成功していると感じる人は殆どいないと思います。
このUIはどうにかならなかったんでしょうか。
まあUIがよろしくないのはAWSの伝統かもしれませんが。失敗時の棒グラフを表示するのは大事だと思いますが、成功時の棒グラフも同じグラフ内に欲しいですね。
というか、去年のAWSブログには成功時棒グラフがあるのに、なぜ消したんでしょうか。
参考:Test Reports with AWS CodeBuild | AWS DevOps Blog
おわりに
AWSにおけるCodeBuildのテストレポート機能は、昨年末に新登場したばかりの機能であり、お世辞にもいい機能であるとは思えません。
しかし、今後の進化によっては他サービスを脅かす存在にもなるため、注視していきたい機能です。何卒、コードカバレッジの導入を、お願いします!!!
おまけ
本記事は、単なる二番煎じ記事であることを報告します......
参考:自動テストがより便利に!!CodeBuildのテストレポート機能がGAされました!! | Developers.IO
- 投稿日:2020-05-28T18:30:54+09:00
SnowBall
AWS Snowball デバイスとは
AWS Snowball サービスでは、物理ストレージデバイスを使用して、Amazon Simple Storage Service (Amazon S3) とオンサイトのデータストレージロケーション間で、インターネットよりも高速に大量のデータを転送します。AWS Snowball を使用すると、時間と費用を節約できます。Snowball には、ジョブの作成、データの追跡、ジョブの完了までのステータスの追跡に使用できる強力なインターフェイスが用意されています。
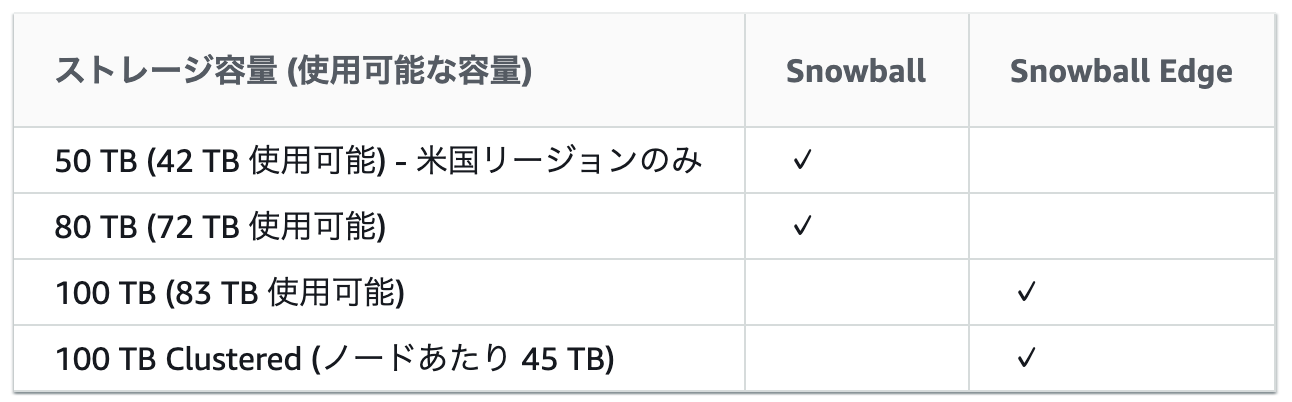
AWS Snowball デバイスの相違点
Snowball と Snowball Edge は 2 つの異なるデバイスです。
AWS Snowball ハードウェアの相違点
ストレージ容量
インポートの仕組み
各インポートジョブには、1 つの Snowball アプライアンス を使用します。AWS Snowball マネジメントコンソール またはジョブマネジメント API でジョブを作成すると、当社から Snowball が配送されます。Snowball が数日でお手元に届いたら、ネットワークに接続し、Amazon S3 にインポートするデータを Snowball クライアント または Snowball 用 Amazon S3 Adapter を使用して Snowball に転送します。
データ転送が完了したら、AWS に Snowball を返送します。その後、AWS でデータを Amazon S3 にインポートします。
エクスポートの仕組み
各エクスポートジョブでは任意の数の Snowball アプライアンス を使用できます。AWS Snowball マネジメントコンソール または ジョブ管理 API でジョブを作成すると、Amazon S3 でリストオペレーションが起動されます。このリストオペレーションによって、ジョブがパートに分割されます。各ジョブパートの最大サイズは約 80 TB であり、各ジョブパートに関連付けられる Snowball は 1 つだけです。ジョブパートが作成されると、最初のジョブパートが [Preparing Snowball] ステータスになります。
その後すぐに、Snowball へのデータのエクスポートが開始されます。通常、データのエクスポートには 1 営業日かかります。ただし、この処理に長くかかる場合もあります。エクスポートが完了すると、AWS はリージョンのキャリアへ Snowball の集荷を手配します。Snowball が数日でお客様のデータセンターまたはオフィスに届いたら、Snowball をネットワークに接続して、サーバーにインポートするデータを Snowball クライアント または Snowball 用 Amazon S3 Adapter を使用して転送します。
データ転送が終了したら、Snowball を AWS に返送します。当社では、返送されたエクスポートジョブパートの Snowball を受領すると、Snowball の完全消去を実行します。この消去作業は National Institute of Standards and Technology (NIST) 800-88 基準に準拠しています。このステップにより、特定のジョブパートが完了します。他にもジョブパートがある場合は、次のジョブパートが発送準備されます。
AWS Snowball のネットワークのベストプラクティス
ワークステーションがデータ転送のボトルネックになると考えられるため、ワークステーションには、プロセス、メモリ、ネットワーキングの面で高レベルの要求に応える強力なコンピューターを使用することを強くお勧めします。
ワークステーションはローカルでデータをホストする必要があります。パフォーマンス上の理由から、データを転送するときは、Snowball を使用してネットワーク全体のファイルを読み込みことをおすすめしません。ネットワーク全体でデータを転送する必要がある場合、Snowball にコピーする前にローカルのキャッシュをバッチして、コピーオペレーションができるだけ速く処理できるようにします。
データ転送を高速化するために、複数のターミナルでそれぞれコピーオペレーションを使用して、Snowball クライアント のインスタンスを同時に実行できます。
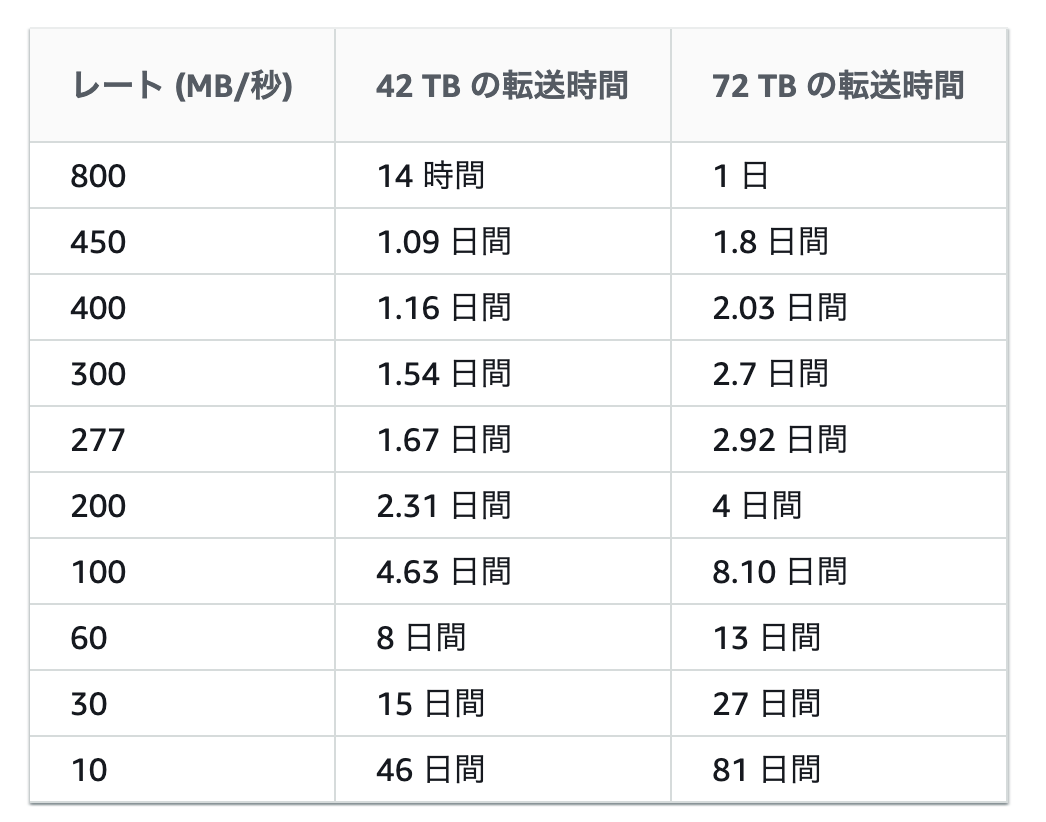
AWS Snowball のパフォーマンス
データ転送の高速化
- 一度に複数のコピーオペレーションを実行
- ファイルではなくディレクトリを転送
ペタバイト単位のデータを効率的に転送する方法
大規模な転送の計画
ステップ 1: 何をクラウドに移行するのかを理解する
ステップ 2: ワークステーションを準備する
ステップ 3: 目標転送速度を計算する
ステップ 4: 何台の Snowball が必要かを特定する
ステップ 5: AWS Snowball マネジメントコンソール を使ってジョブを作成する
ステップ 6: データを転送セグメントに分割する
並列データ転送
Snowball を使って高速でデータを転送するには、並列転送が効果的な場合があります。並列転送は、以下のいずれかのシナリオで行います。
1 台の Snowball を接続した 1 台のワークステーションで複数の Snowball クライアント のインスタンスを使用する
1 台の Snowball を接続した複数のワークステーションで複数の Snowball クライアント のインスタンスを使用する
複数の Snowball を接続した複数のワークステーションで複数の Snowball クライアント のインスタンスを使用する
Snowball を使ったデータ転送
- Snowball クライアント
- Snowball 用 Amazon S3 Adapter


- 投稿日:2020-05-28T17:53:38+09:00
AWS認定クラウドプラクティショナー合格体験記
はじめに
AWS認定クラウドプラクティショナーの資格を取得することができたので、文系出身でエンジニア1年目だった私がどうやって合格できたのか、自身の振り返りの意味も込め、勉強法やおすすめのテキストなどをまとめました。
資格取得を目指している人のお役に立てれば幸いです。クラウドプラクティショナーとは?
AWS認定試験の中でも一番難易度の易しい、登竜門的な位置づけにある資格です。
公式ドキュメントによると以下の通りです。認定によって検証される能力
・AWS クラウドとは何かということ、およびベーシックなグローバルインフラストラクチャについて定義できる
・AWS クラウドのベーシックなアーキテクチャ原理を説明できる
・AWS クラウドの価値提案について説明できる
・AWS プラットフォームの主なサービスと一般的なユースケース (例: コンピューティング、分析など) について説明できる
・AWS プラットフォームのセキュリティとコンプライアンスのベーシックな側面、および共有セキュリティモデルについて説明できる
・請求、アカウントマネジメント、料金モデルを明確に理解している
・ドキュメントや技術サポートのソースを特定できる (例: ホワイトペーパー、サポートチケットなど)
・AWS クラウドにおけるデプロイと運用のベーシックで重要な特徴を説明できる
推奨される知識と経験
・テクノロジー、マネジメント、販売、購買、またはファイナンスの分野で最低 6 か月の AWS クラウド使用経験がある
・IT サービスのベーシックな知識と、AWS クラウドプラットフォームにおけるそれらのサービスの使用に関する知識がある
引用:AWS 認定クラウドプラクティショナーソリューションアーキテクトと違って設計部分は出題されないので、要はAWSの基礎を全体的に把握していることが必要と思って頂ければ大丈夫です。
試験概要
形式 実施形式 時間 受験料金 複数の選択肢と複数の答えがある問題 テストセンター 試験完了までに90 分 11,000 円(税別) 試験はAWS Training & Certification(Amazonアカウントでサインイン可能)で予約することができます。※模擬試験も同様
勉強方法
その①:テキストを読んでAWSの概要を理解する
わたしは以下の本で基礎知識のインプットをすることから始めました。
最短突破 AWS認定ソリューションアーキテクト アソシエイト 合格教本
ソリューションアーキテクトアソシエイト(以下SAA)のテキストですが、逆にこれやってもSAA受からないんじゃ?っていう内容なので、難しすぎることはありません。安心してください。笑
(というかわたしが買ったときにはクラウドプラクティショナー用のテキストはなかった)AWS特有の用語なども全く分からない状態からのスタート(しかもエンジニア1年目なのでそもそも知識が圧倒的に足りない)だったので、まずはこのテキストを読んで、クラウドサービスとは?その中でのAWSの特徴や位置づけとは?といったかなり基礎的な部分から入りました。
色々なサービスがあるので、このテキストを何度も読み込んで、各サービスがどんな機能や特徴を持っているのかなどを頭に叩き込みました。その②:実際にAWSコンソールを操作する
わたしの場合、AWSの運用保守担当となってから資格取得を目指し始めたので、現場で毎日AWSコンソールを操作していました。(
ぶっちゃけこれが一番デカかった。)
なので、資格を取りたかったらまずは個人のAWSアカウント作成することを強くおすすめします。
AWSには無料利用枠がたくさんあるので、実際にEC2(仮想サーバ)やRDS(データベース)などを構築しても、その範囲内であれば請求が来ることはありません。わたしも社内の勉強会でハンズオンをやるために個人のアカウントを作成しましたが、無事に無料で使用することができました。
以下URLの手順に沿って「請求額が$0を超えたらメール通知を送る」設定を入れておくと、メールが来ない限りは無料で使えてるんだなーと安心して利用することができます。
AWS の予想請求額をモニタリングする請求アラームの作成その③:模擬試験を解いてみる
ある程度知識がついてきたら、一旦模擬試験を解いてみると良いです。
(ちなみにわたしは先ほど「その①」で紹介した本に付いていたSAAの模擬試験を解いたとき、3割くらいしか取れなくて一気にテンションが下がりました。)
AWS Training & Certificationにログインすれば、クラウドプラクティショナーの模擬試験を受けることが可能(※)なので、モチベーション下げたくない人はSAAではなくクラウドプラクティショナーの模擬を解くことをおすすめします。笑※模擬試験の受け方は以下の通りです。(若干わかりづらいのでご注意ください)
1.AWS Training & Certificationにログイン
2.「認定」をクリック
3.CertMetrics用のAWS認定アカウントを作成
4.AWS認定アカウントでCertMetricsにログイン
5.「新しい試験の予約」をクリック
6.「AWS Practice Exams」から「AWS Certified Cloud Practitioner Practice」のピアソンかPSIかどちらかをクリック
(模擬試験は自端末で受けるため、テストセンターの場所は関係ないのでどっちを選んでも変わりません)
7.「Pay for exam」をクリック
8.Amazonアカウントで料金を支払い、模擬試験を受けるただしAWS Training & Certificationの模擬試験は問題数が少なく、制限時間も30分に設定されているので、正直この模擬試験の結果はそんなにあてになりません。
難易度も実際の本試験に比べたらとても易しかったです。
あと何より本試験同様、解答がもらえない・・
どこをどう間違えたのか振り返れないので、復習することができません・・・
まあ本試験の雰囲気をつかむことはできるので受けといた方が無難ではありますが。こっちのほうがおすすめです。
AWS認定 クラウドプラクティショナー 模擬問題集
こちらは模擬試験2回分で、問題数も本試験と同じ65問、解答もついてます。
なんとkindle unlimited対象なので、もともと会員だった私は即ポチりました。
難易度もこちらのほうが本試験に近かったです。あとkindleならスマホからも見れるので、通勤中に電車の中でなど、スキマ時間を使って効率よく勉強することができます。
その④:模擬試験を解く→間違えた問題を復習、を繰り返す
ある程度問題が解けるようになった後は、これを繰り返すのが一番効率的でした。
どんな問題を間違える率が高いのか自分で分析して、足りない知識はテキストやホワイトペーパー、BlackBeltの動画を視聴することで再度インプットするようにしました。
ただ、ホワイトペーパーは日本語のものが少ない&動画は結構長いので、AWSサービス別資料のスライドもおすすめです。あと、AWS公式リセラーのクラスメソッドさんが運営しているブログもとてもわかりやすいので、おすすめです。
現場でもよく参照しています。
Developers.IO produced by Classmethod
AWS公式のわかりにくいドキュメントをかなり噛み砕いて説明してくれるので、公式のドキュメントでよくわからなかった時にはかなりお世話になっています。勉強期間
約半年間勉強しました。
平日は通勤中にテキストを読む程度で、休日に動画を見たり、模擬試験を解いたりしていました。受験後の感想
受験してみてまず思ったのは、やっぱり思ったよりも本試験の方が難しかった!です。
結構勉強したのですが、合格点ギリギリの741点しか取れなかったので(合格点は700点)、SAAを取るにはどれだけ勉強しなきゃいけないんだろう・・とちょっと途方に暮れる気持ちにもなりました。
ネットで検索すると2週間で取りましたとかいう猛者もたくさん出てくるのですが、正直、わたしには絶対無理だなと思いました。
出題される範囲が広いので、セキュリティやらネットワークやらの知識も必要になってくるし、もちろんAWSのサービス(例えばデータベースならRDSやDynamoDBにどういった特性や違いがあるかなど)についての知識も必要で、結構大変でした。
恐らく2週間で取れるような方はそもそもエンジニアとしてのキャリアが長い人だと思うので、私のようにエンジニア1年目だったり文系出身だったりする人は、あまり舐めてかからないほうが得策だと思います。笑以上です。最後まで読んでくれてありがとうございました。
- 投稿日:2020-05-28T17:26:05+09:00
Amazon WorkSpacesを導入して自宅から会社のネットワークにつないでみる
Amazon WorkSpacesとは
AWS(Amazon Web Services)が提供する仮想デスクトップサービスです。
今回は在宅ワーク時に、自宅の環境ではVPNが使えなかったため、Amazon WorkSpaces(以下「WorkSpaces」という)の仮想マシンから会社のネットワークにVPNで接続した際の手順を紹介します。
※前提条件として、AWSアカウントは取得済み、VPCとサブネットまで設定済みとして話を進めます。ディレクトリサーバー作成
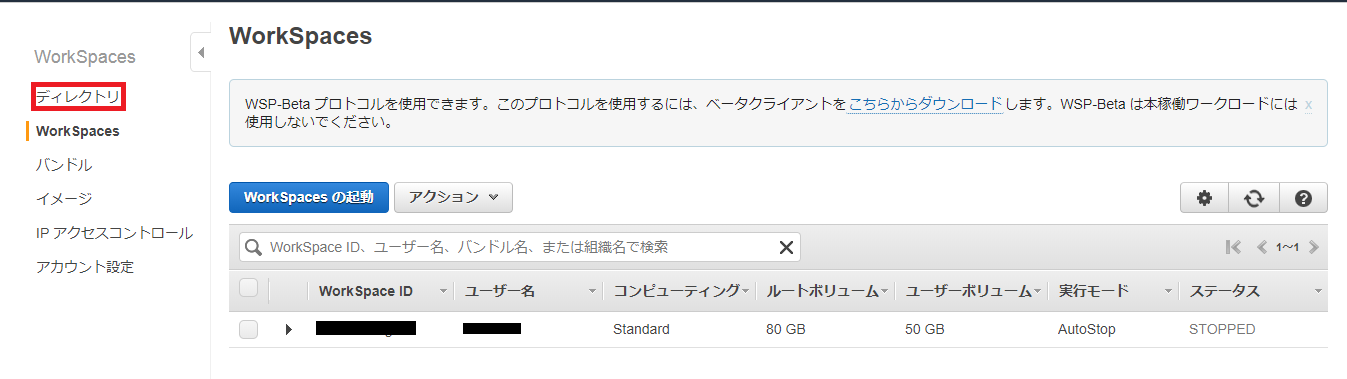
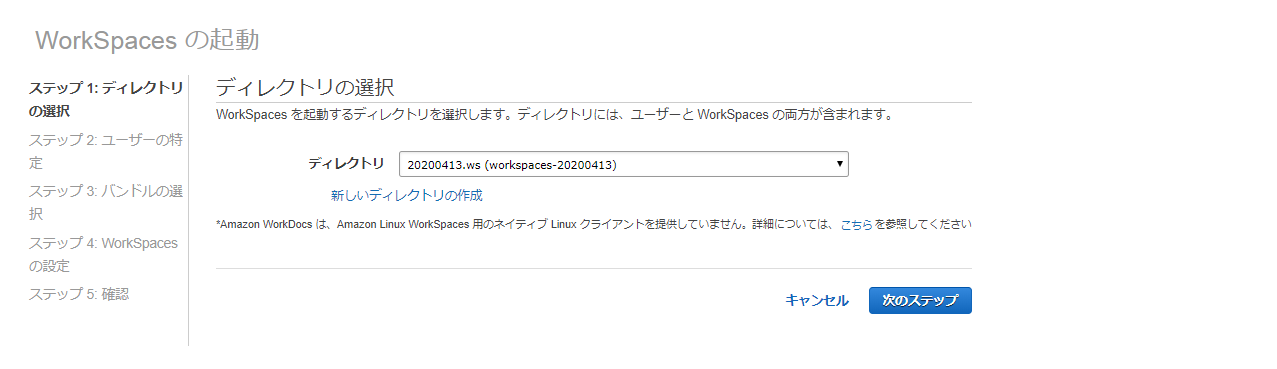
AWS マネジメントコンソール画面>エンドユーザーコンピューティング>WorkSpaces をクリック。
WorkSpaces画面>ディレクトリ をクリック。
※画像では一覧に作成済みのWorkSpacesが表示されていますが、初期状態では一覧は何も表示されません。
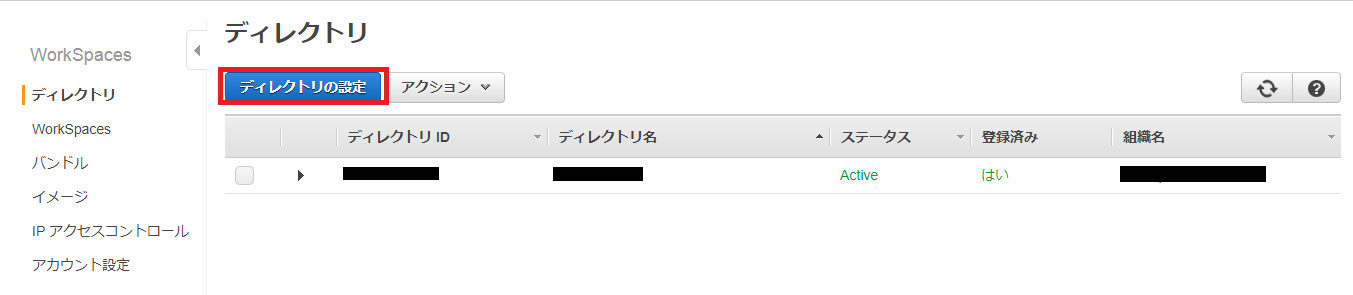
ディレクトリ画面>ディレクトリの設定 をクリック。
※画像では一覧に作成済みのディレクトリが表示されていますが、初期状態では一覧は何も表示されません。
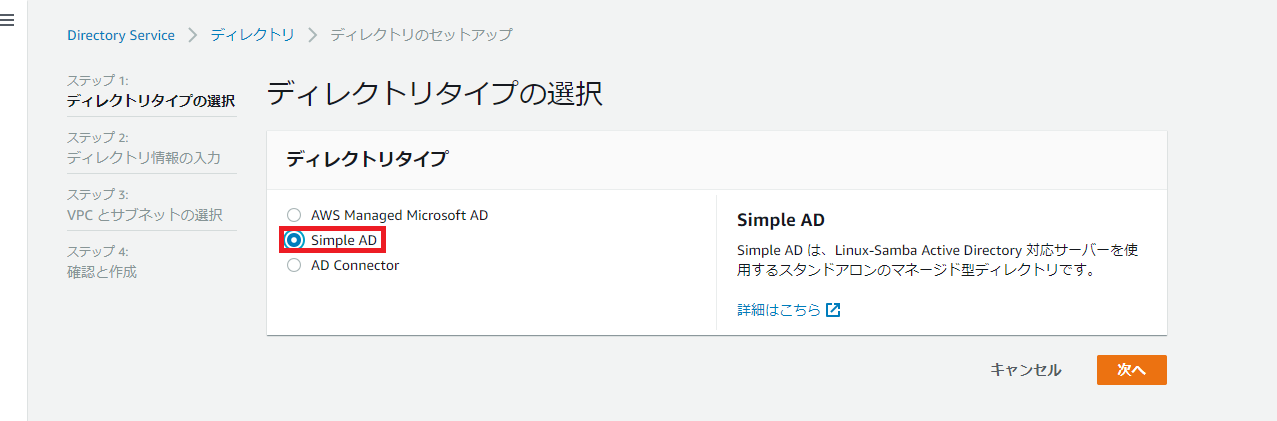
ディレクトリのセットアップ画面が表示されます。ディレクトリタイプはSimple ADを選択。
ディレクトリ情報を入力していきます。
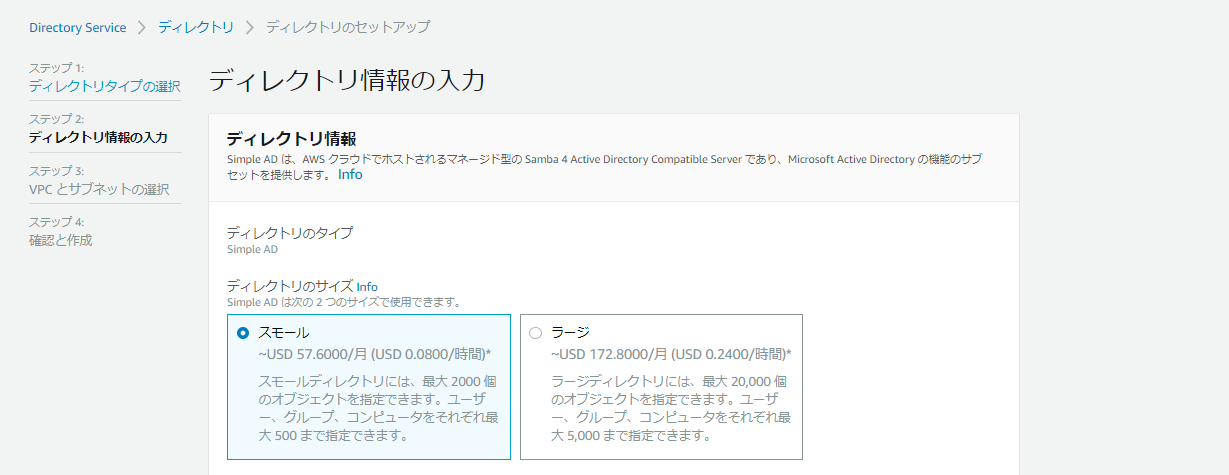
ディレクトリのサイズ
今回はスモールを選択組織名
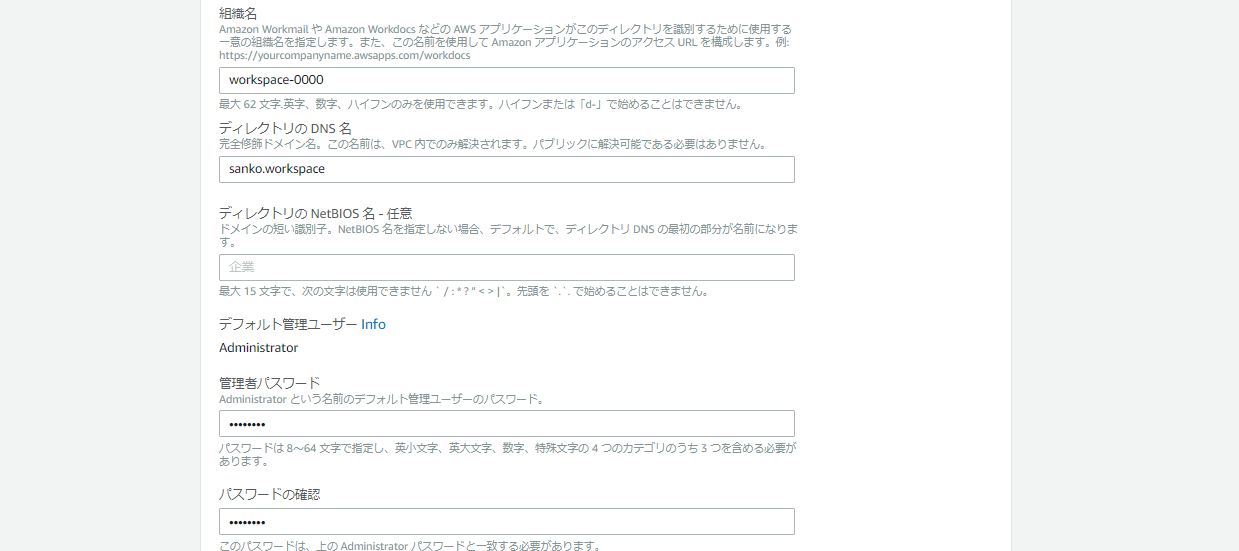
URLになります。ディレクトリのDNS名
ローカルでしか使われないため、自由に設定して大丈夫です。管理者パスワード
WorkSpacesに接続する際に必要になります。入力後忘れないようにしましょう。
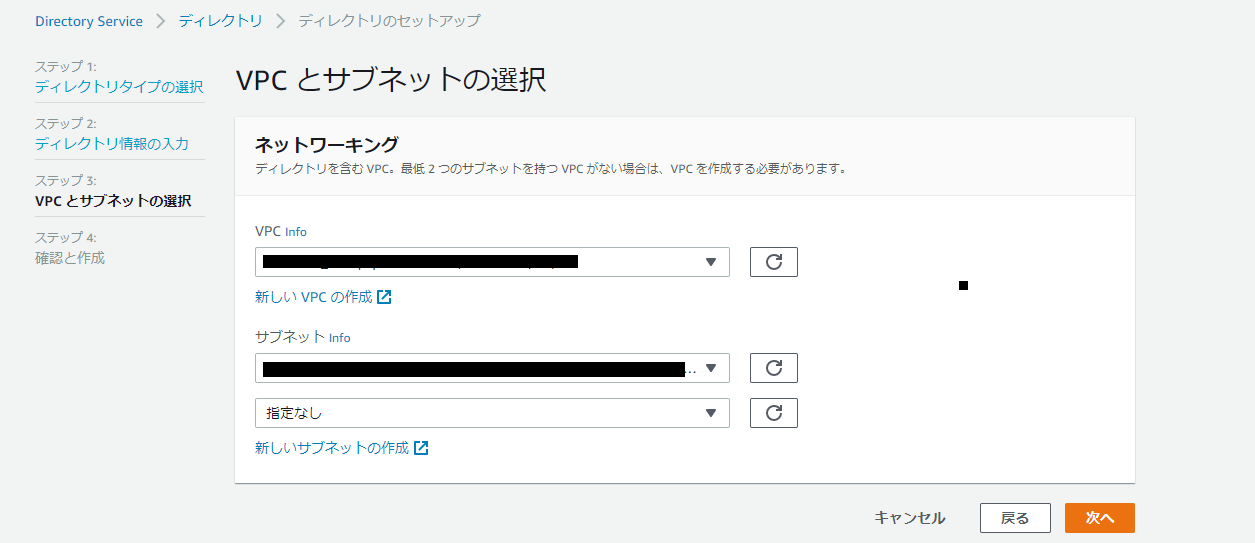
VPC とサブネットを設定します。
設定したらディレクトリを作成しましょう。WorkSpaces作成
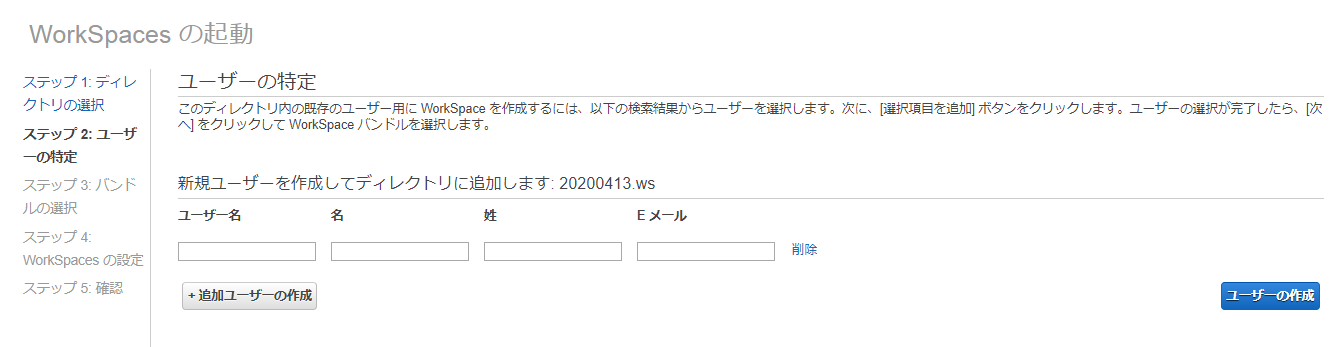
WorkSpaces画面>WorkSpacesの起動 をクリックし、先ほど作成したディレクトリを指定します。
任意のユーザーを作成します。
バンドルを選択します。VPNでネットワークにつなぐだけなので、最低限のものにします。
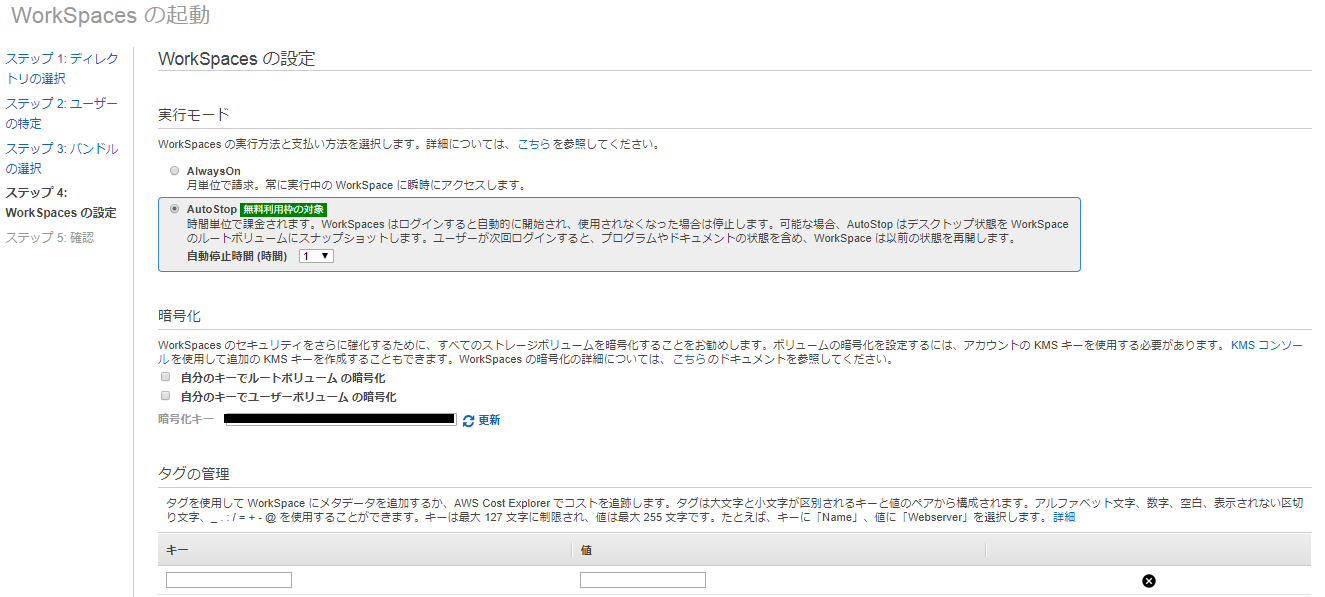
WorkSpacesの設定をしていきます。
実行モード
時間単位で課金されるAuto Modeを選択。暗号化
今回は特に設定しません。タグ
タグを設定します。
確認をして問題がなければ作成しましょう。
これでWorkSpacesの作成は完了です。WorkSpacesに接続
WorkSpacesの作成が完了すると、ユーザー作成時に登録したメールアドレスにメールが届きます。
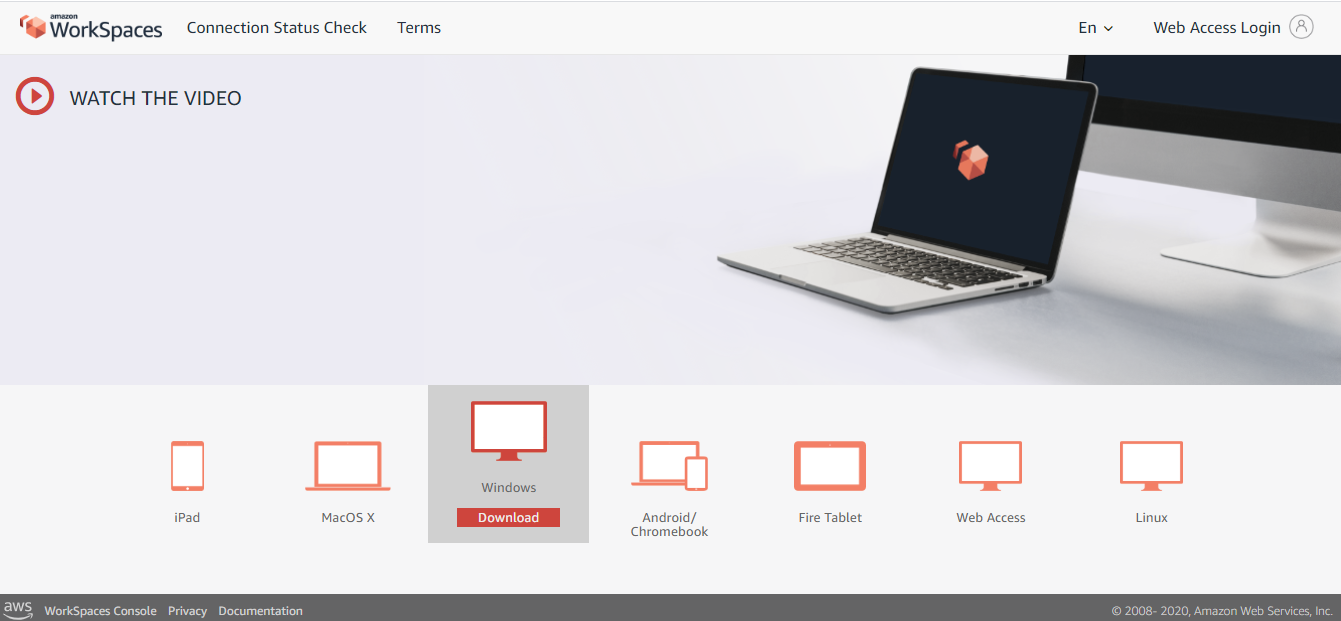
メールのURLをクリックするとユーザー認証画面が表示されるので、パスワードだけ入力してユーザーを認証します。
ユーザー認証後、WorkSpaceクライアントダウンロードページを開き、自身の環境に合わせたクライアントをダウンロードしてください。
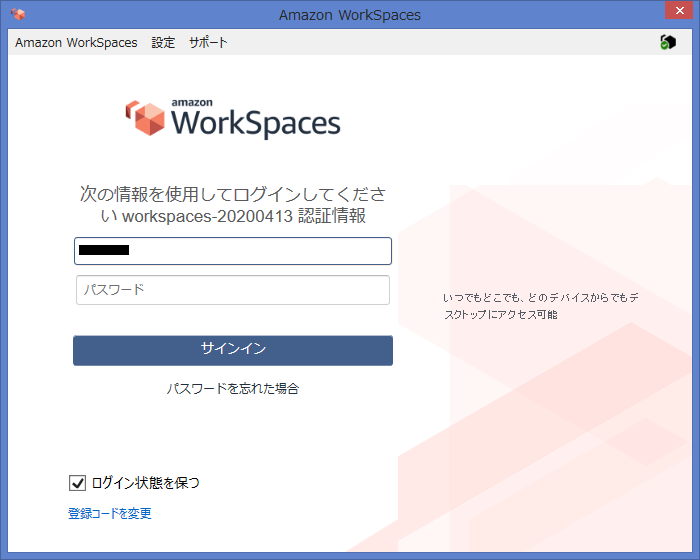
インストールしたらアプリを起動します。初回起動時は登録コードを要求されるので、メールに記載されている登録コードを入力してください。
登録コードを入力すると、ログイン画面になります。ユーザー名、パスワードを入力してログインしてください。
ログインに成功すれば、仮想デスクトップ画面が表示されます。
VPN設定
ここからは全て仮想デスクトップ上での作業となります。
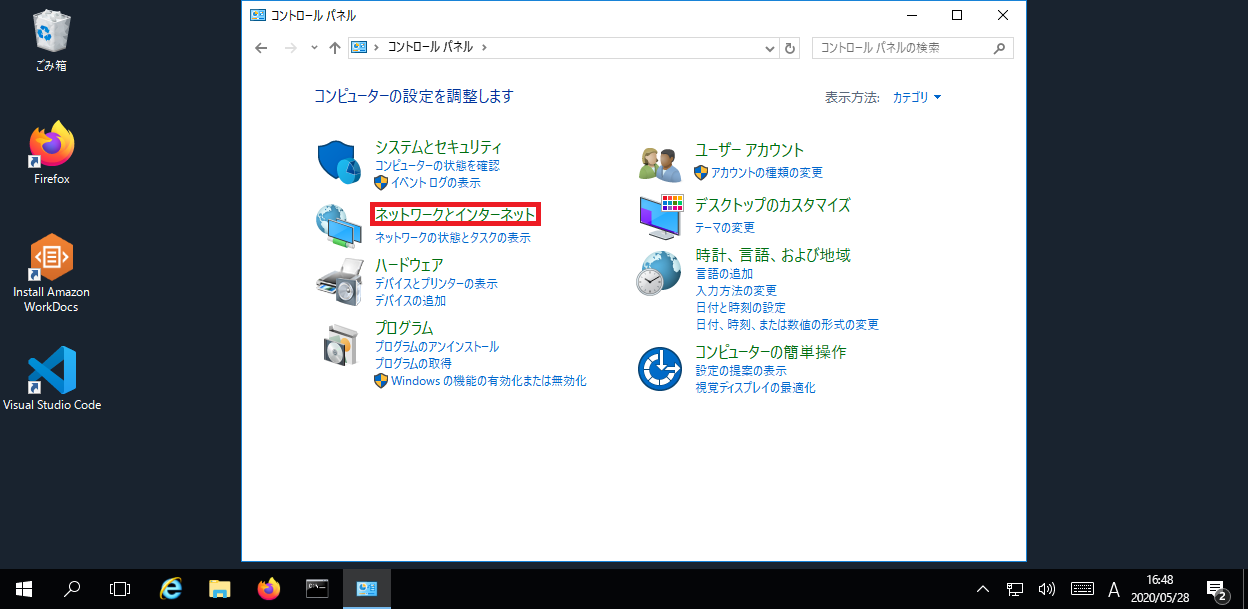
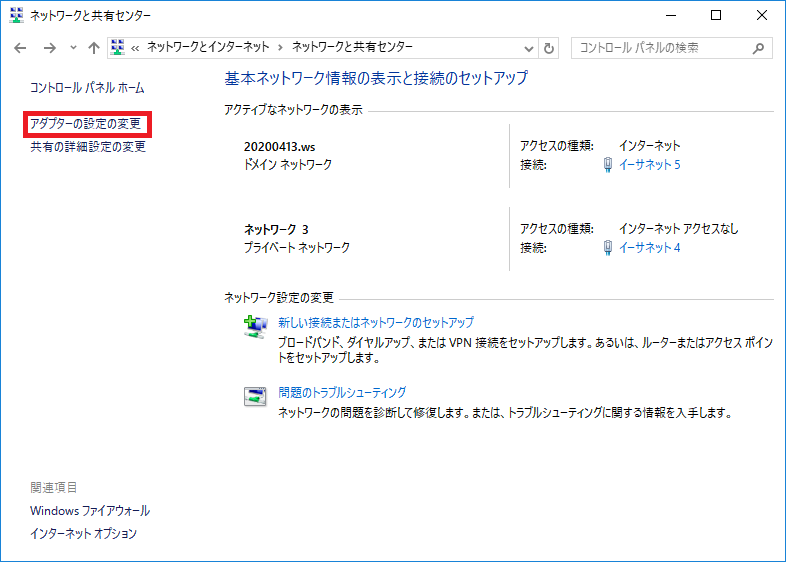
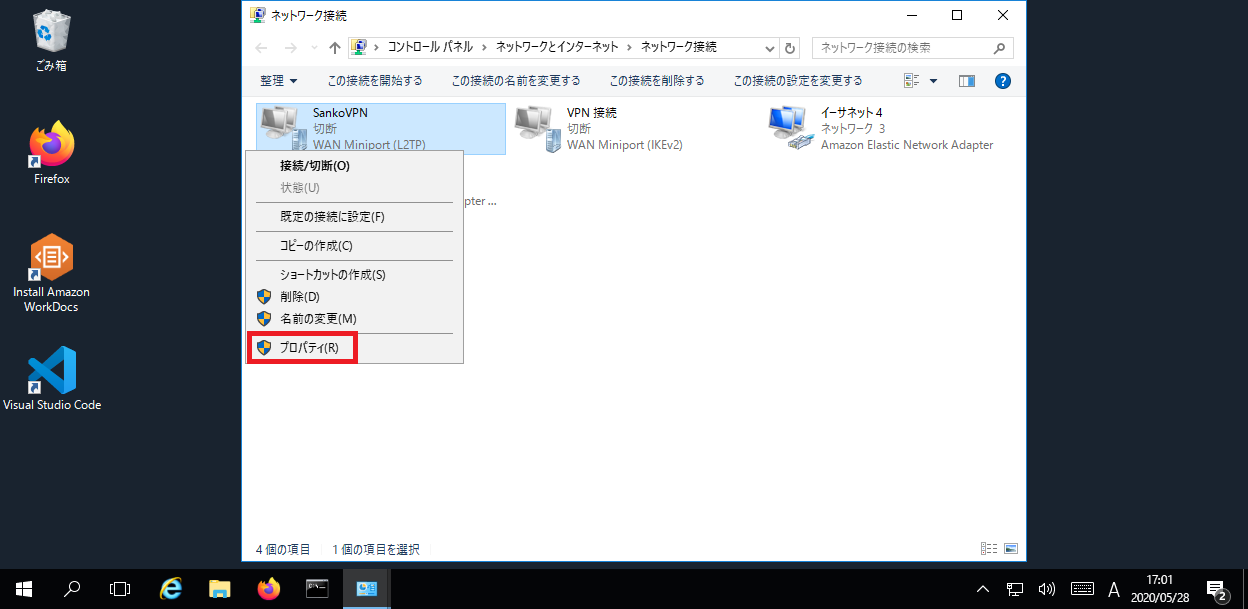
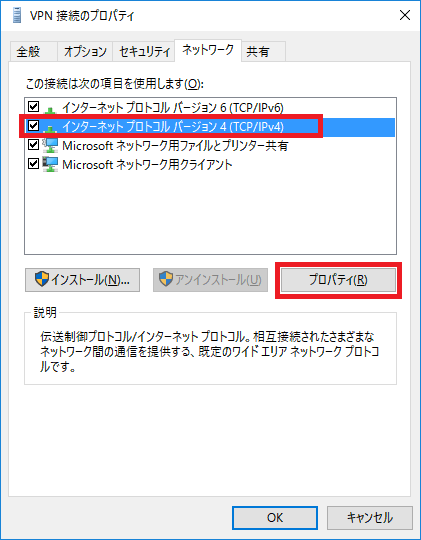
また、ネットワーク設定は私の職場の環境となりますので、ご自身の環境に合わせた設定をお願いします。コントロールパネル>ネットワークとインターネット をクリック。
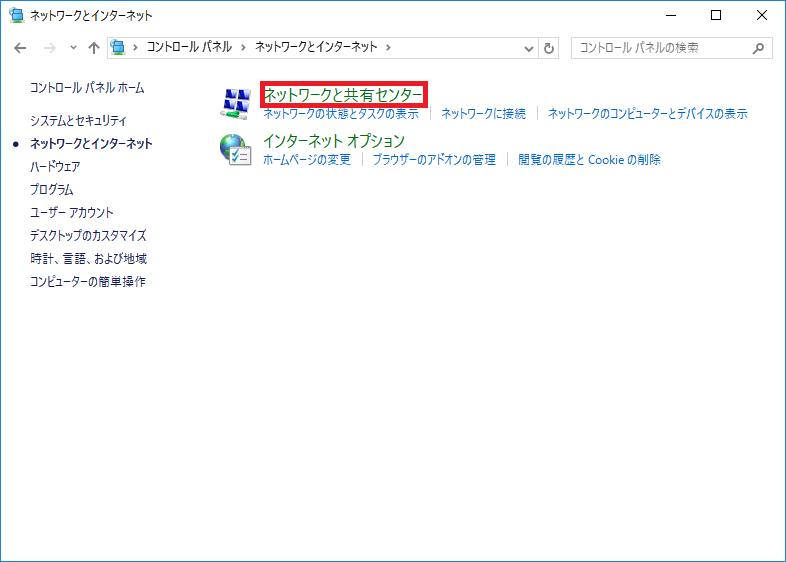
ネットワークと共有センターをクリック。
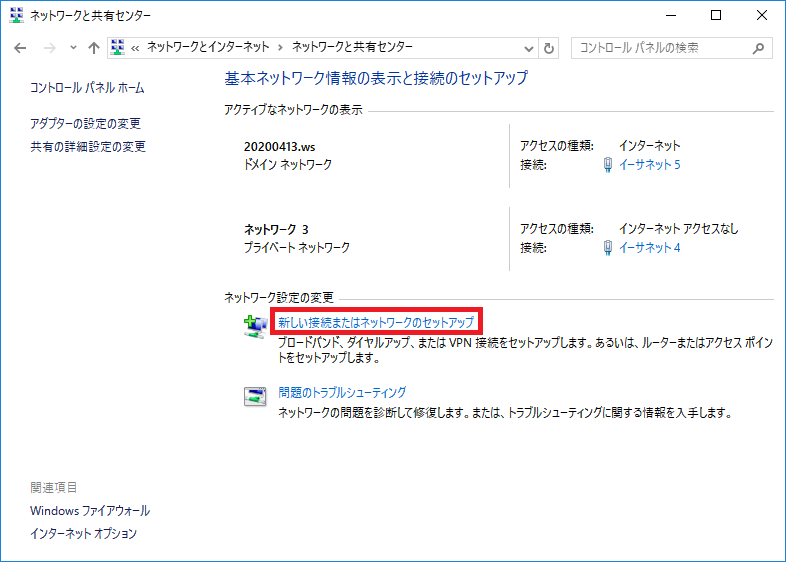
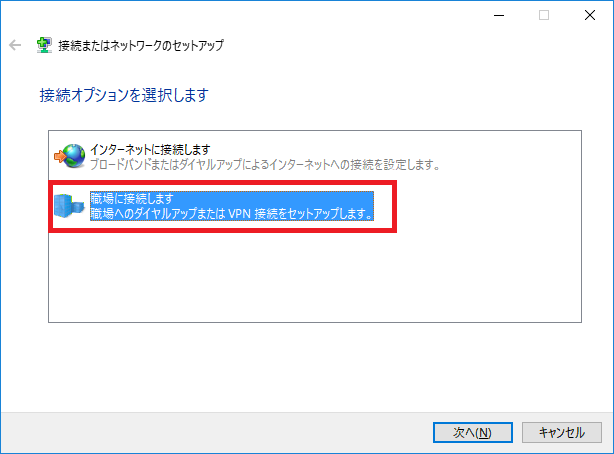
新しい接続またはネットワークの選択 をクリック。
職場に接続します をクリック。
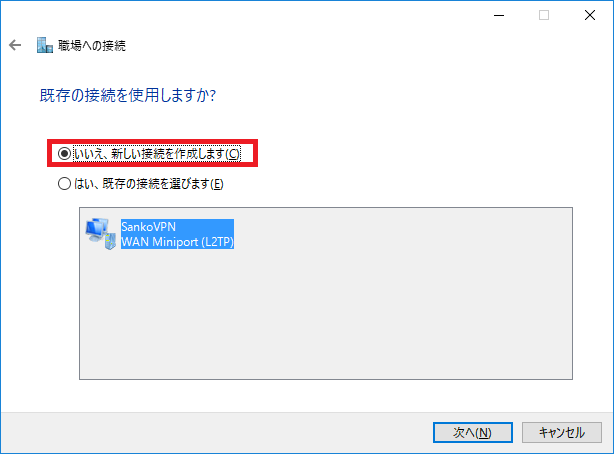
いいえ、新しい接続を作成します をクリック。
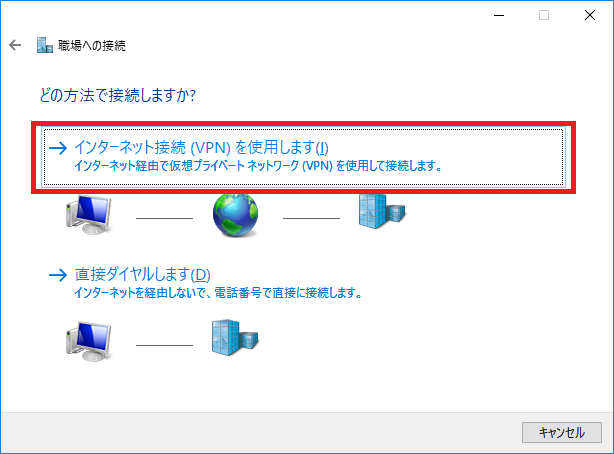
インターネット接続(VPN)を使用します をクリック。
インターネットアドレスに職場のIPを入力します。
ネットワークと共有センター画面>アダプターの設定の変更 をクリック。
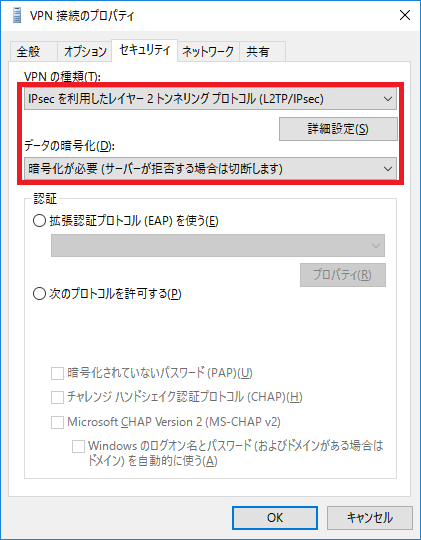
先ほど作成したアダプター>プロパティ をクリック。
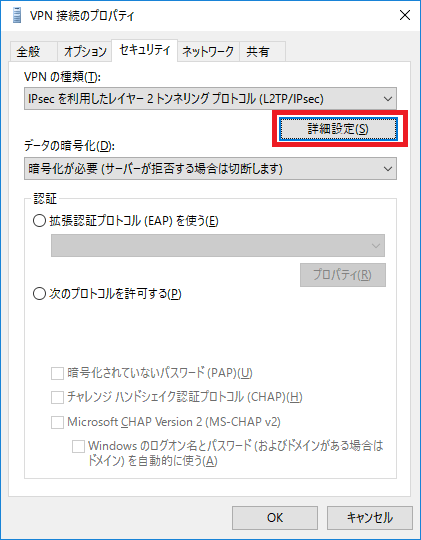
セキュリティタブをクリックして、VPNの種類、データの暗号化を設定します。
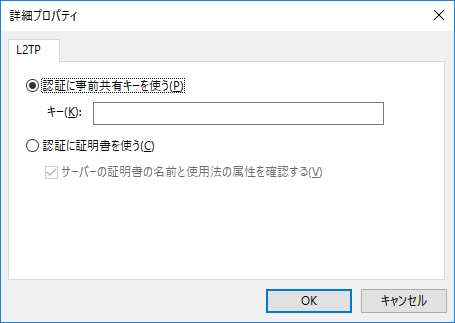
セキュリティタブ>詳細設定 をクリック。
認証に事前共有キーを使う を選択してキーを入力する。
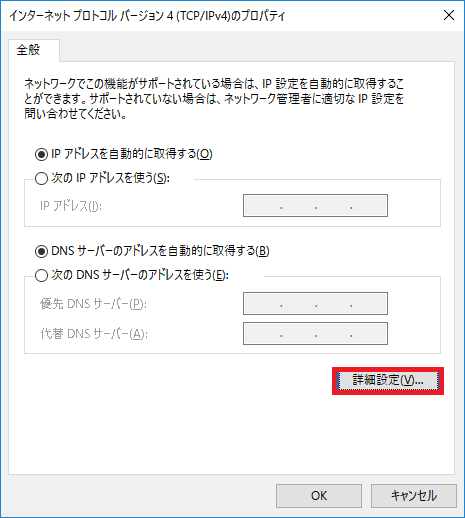
ネットワークタブ画面>インターネットプロトコルバージョン4>プロパティ をクリック。
詳細設定 をクリック。
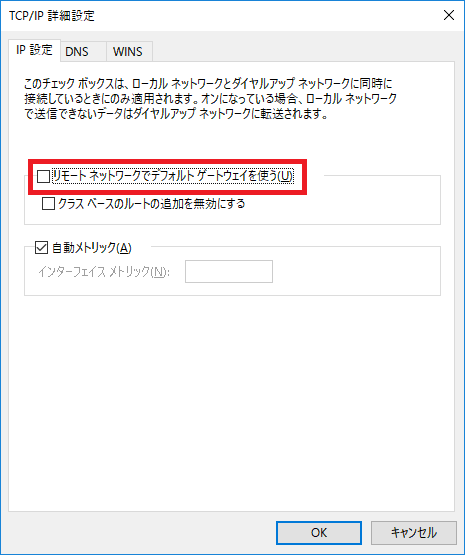
IP設定タグ>リモートネットワーク… を解除。
ツールバーから先ほど設定したVPNを選択し、ユーザー名、パスワードを入力。
接続済みとなれば設定完了です。






- 投稿日:2020-05-28T17:21:05+09:00
S3
S3
Amazon Simple Storage Service(Amazon S3)はインターネット用のストレージです。Amazon S3 を使用すると、データの大きさにかかわらず、ウェブ上のどんな場所からでもいつでも保存、取得することができます。シンプルかつ直感的なウェブインターフェイスの AWS マネジメントコンソール を用いて、これらのタスクを実行することができます。
Amazon S3 を最大限に活用するには、いくつかの簡単なコンセプトを理解する必要があります。Amazon S3 は、データをオブジェクトとしてバケットに保存します。オブジェクトは、ファイルと、オプションとしてそのファイルを記述する任意のメタデータで構成されています。Amazon S3 にオブジェクトを保管するには、バケットに保管するファイルをアップロードします。ファイルをアップロードする際に、オブジェクトと任意のメタデータにアクセス許可を設定することができます。
Amazon S3 の高度な機能
このガイドの例では、バケットの作成、バケットへのデータのアップロードとバケットからのダウンロード、データの移動と削除といった、基本的なタスクを実行する方法を示しています。次の表では、よく使用される Amazon S3 の高度な機能をまとめています。一部、AWS マネジメントコンソール で利用できないもの、Amazon S3 API の使用が必要なものがありますのでご注意ください。
リンク 機能 リクエスタ支払いバケット 顧客がダウンロードしたものに支払いができるように、バケットを環境設定する方法について学びます。 Amazon S3 での BitTorrent の使用 BitTorrent (ファイル配布のためのオープンなピアツーピアプロトコル) を使用します。 バージョニング Amazon S3 のバージョニング機能について学びます。 静的ウェブサイトのホスティング Amazon S3 で静的ウェブサイトをホストする方法を学びます。 オブジェクトのライフサイクル管理 バケットのオブジェクトのライフサイクルを管理する方法を学びます。ライフサイクルの管理には、オブジェクトの失効やアーカイブ (オブジェクトの S3 S3 Glacier ストレージクラスへの移行) が含まれます。 リクエスタ支払いバケット
一般に、Amazon S3 のバケットのストレージおよびデータ転送にかかるコストはすべて、そのバケット所有者が負担します。ただしバケット所有者は、バケットをリクエスタ支払いバケットとして設定することができます。リクエスタ支払いバケットの場合、リクエストおよびバケットからのデータのダウンロードにかかるコストは、所有者でなくリクエストを実行したリクエスタが支払います。データの保管にかかるコストは常にバケット所有者が支払います。
通常は、データを共有したいが、他者がデータにアクセスする際に発生する費用を負担したくない場合に、リクエスタ支払いバケットを設定します。たとえば、郵便番号リスト、参照データ、地理空間情報、ウェブクロールデータといった、大規模なデータセットを利用できるようにする際にリクエスタ支払いバケットを設定します。
リクエスタ支払いバケットに関するリクエストはすべて認証する必要があります。リクエストの認証により、Amazon S3 はリクエスタを特定し、リクエスタ支払いバケットの使用に対して課金できるようになります。
リクエスタがリクエストを送る前に AWS Identity and Access Management (IAM) ロールを引き受ける際に、ロールが属するアカウントにリクエストの料金が発生します。IAM ロールの詳細については、IAM ユーザーガイドの「IAM ロール」を参照してください。
バケットをリクエスタ支払いバケットとして設定すると、リクエスタは、リクエストに x-amz-request-payer を (POST、GET、HEAD リクエストの場合はヘッダーに、REST リクエストの場合はパラメータとして) 含めることで、リクエストとデータのダウンロードに課金されることを了解している旨を示す必要があります。
Amazon S3 Transfer Acceleration
Amazon S3 Transfer Acceleration を使用すると、クライアントと S3 バケットの間で、長距離にわたるファイル転送を高速、簡単、安全に行えるようになります。Transfer Acceleration では、Amazon CloudFront の世界中に分散したエッジロケーションを利用しています。エッジロケーションに到着したデータは、最適化されたネットワークパスで Amazon S3 にルーティングされます。
Amazon S3 Transfer Acceleration を使用する理由
次のような場合は、バケットに対する Transfer Acceleration の使用が推奨されます。
中央のバケットに対して世界中のお客様からアップロードが行われる。
大陸間で定期的にギガバイトからテラバイト単位のデータを転送する。
Amazon S3 へのアップロード時にインターネット経由で利用可能な帯域幅を十分に活用できていない。
S3 バケットの請求および使用状況レポート
- 請求レポート
- 使用状況レポート
Amazon S3 アクセスポイントを使用したデータアクセスの管理
Amazon S3 アクセスポイントは、S3 の共有データセットへの大規模なデータアクセスの管理を簡素化します。アクセスポイントは、バケットにアタッチされた名前付きのネットワークエンドポイントで、S3 オブジェクトのオペレーション (GetObject や PutObject など) を実行するために使用できます。各アクセスポイントには、そのアクセスポイントを介したすべてのリクエストに S3 が適用する個別のアクセス許可とネットワークコントロールがあります。各アクセスポイントは、基になるバケットにアタッチされたバケットポリシーと連動して機能するカスタマイズされたアクセスポイントポリシーを適用します。Virtual Private Cloud (VPC) からのリクエストのみを受け付けるようにアクセスポイントを設定することで、プライベートネットワークへの Amazon S3 データアクセスを制限できます。また、アクセスポイントごとにカスタムのブロックパブリックアクセスを設定することもできます。
CORS(Cross-Origin Resource Sharing)によるクロスドメイン通信の傾向と対策
https://dev.classmethod.jp/articles/cors-cross-origin-resource-sharing-cross-domain/S3 バッチオペレーション の実行
S3 バッチオペレーション を使用して Amazon S3 オブジェクトで大規模なバッチオペレーションを実行できます。S3 バッチオペレーション は、指定する Amazon S3 オブジェクトのリスト上で単一のオペレーションを実行できます。単一のジョブは、エクサバイトのデータがある何十億というオブジェクトで指定したオペレーションを実行できます。Amazon S3 は、進捗状況の追跡、通知の送信、全アクションの詳細な完了レポートの保存を行い、完全マネージド型で監査可能なサーバーレスのサービスを提供します。AWS マネジメントコンソール、AWS CLI、AWS SDK、または REST API から、S3 バッチオペレーション を使用できるようになりました。
レプリケーション
レプリケーションでは、異なる Amazon S3 バケット間でオブジェクトを自動的に非同期コピーできます。オブジェクトのレプリケーション用に設定されたバケットは、同じ AWS アカウントが所有することも、異なるアカウントが所有することもできます。オブジェクトを異なる AWS リージョン間でコピーすることも、同じリージョン内でコピーすることもできます。
オブジェクトのレプリケーションを有効にするには、レプリケーション設定をレプリケート元バケットに追加します。最小設定では、以下を指定する必要があります。
- Amazon S3 がオブジェクトをレプリケートするレプリケート先バケット。
- Amazon S3 がユーザーのためにオブジェクトをレプリケートできる AWS Identity and Access Management (IAM) ロール
オブジェクトレプリケーションの種類
異なる AWS リージョン内の Amazon S3 バケット間でオブジェクトをコピーするには、クロスリージョンレプリケーション (CRR) を使用します。
同一の AWS リージョン内の Amazon S3 バケット間でオブジェクトをコピーするには、同一リージョンレプリケーション (SRR) を使用します。
レプリケーションを使用する理由
- メタデータを保持しながらオブジェクトをレプリケートする
- オブジェクトを異なるストレージクラスにレプリケートする
- オブジェクトのコピーを別の所有権で保持する
- オブジェクトを 15 分以内にレプリケートする
SRR を使用する場合
- ログを 1 つのバケットに集約する
- 複数のバケットまたは複数のアカウントにログを保存している場合、ログを 1 つのリージョン内バケットに簡単にレプリケートできます。これにより、ログを一箇所でよりシンプルに処理できます。
- 本番稼働用アカウントとテストアカウント間のライブレプリケーションを設定する
レプリケーションの要件
- レプリケート元とレプリケート先の両方のバケットで、バージョニングを有効にする必要があります。
- Amazon S3 には、ユーザーに代わってレプリケート元バケットのオブジェクトをレプリケート先バケットにレプリケートするアクセス許可が必要です。
- ソースバケットで S3 オブジェクトロック が有効になっている場合、レプリケート先バケットでも S3 オブジェクトロック が有効になっている必要があります。
- 投稿日:2020-05-28T17:20:26+09:00
EFS
Amazon Elastic File System とは
Amazon Elastic File System (Amazon EFS) は、AWS クラウドサービスおよびオンプレミスリソースで使用するための、シンプルでスケーラブル、かつ伸縮自在なフルマネージド型の NFS ファイルシステムを提供します。アプリケーションを停止させることなく、オンデマンドでペタバイト規模までスケールするよう設計されており、ファイルの追加や削除に応じて自動的に拡張/縮小されるため、拡張に対応するための容量のプロビジョニングや管理は不要になります。Amazon EFS には、ファイルシステムをすばやく簡単に作成および設定できるシンプルなウェブサービスインターフェイスがあります。このサービスでは、ユーザーに代わってすべてのファイルストレージインフラストラクチャを管理するため、複雑なデプロイ、パッチ適用、および複雑なファイルシステム設定の保守を行う必要がありません。
Amazon EFS はネットワークファイルシステムバージョン 4 (NFSv4.1 および NFSv4.0) プロトコルをサポートするので、現在お使いのアプリケーションやツールも Amazon EFS とシームレスに動作します。複数の Amazon EC2 インスタンスが 1 つの Amazon EFS ファイルシステムに同時にアクセスすることができるため、複数のインスタンスまたはサーバーで実行されているワークロードとアプリケーションに共通のデータソースを提供できます。
概要
Amazon EFS は AWS クラウド内のファイルストレージを提供します。Amazon EFS を使用すると、ファイルシステムを作成し、ファイルシステムを Amazon EC2 インスタンス、 にマウントし、ファイルシステムとの間でデータの読取りおよび書込みを行うことができます。Network File System バージョン 4.0 および 4.1 (NFSv4) プロトコルを使用して、Amazon EFS ファイルシステムを自分の VPC にマウントできます。Amazon EFS マウントヘルパーと組み合わせて現行世代の Linux NFSv4.1 クライアントを使用することをお勧めします。
VPC 内の Amazon EFS ファイルシステムにアクセスするには、VPC に 1 つ以上のマウントターゲットを作成します。マウントターゲットは、Amazon EFS ファイルシステムをマウントできる NFSv4 エンドポイントの IP アドレスを提供します。Domain Name Service (DNS) 名を使用してファイルシステムをマウントします。そうすると EC2 インスタンスと同じアベイラビリティーゾーンの EFS マウントターゲットの IP アドレスとして解決されます。AWS リージョンのアベイラビリティーゾーンごとに 1 つのマウントターゲットを作成できます。VPC のアベイラビリティーゾーンに複数のサブネットがある場合、サブネットの 1 つにマウントターゲットを作成します。次に、アベイラビリティーゾーンのすべての EC2 インスタンスがそのマウントターゲットを共有します。
Amazon EFS と Amazon EC2 の連携
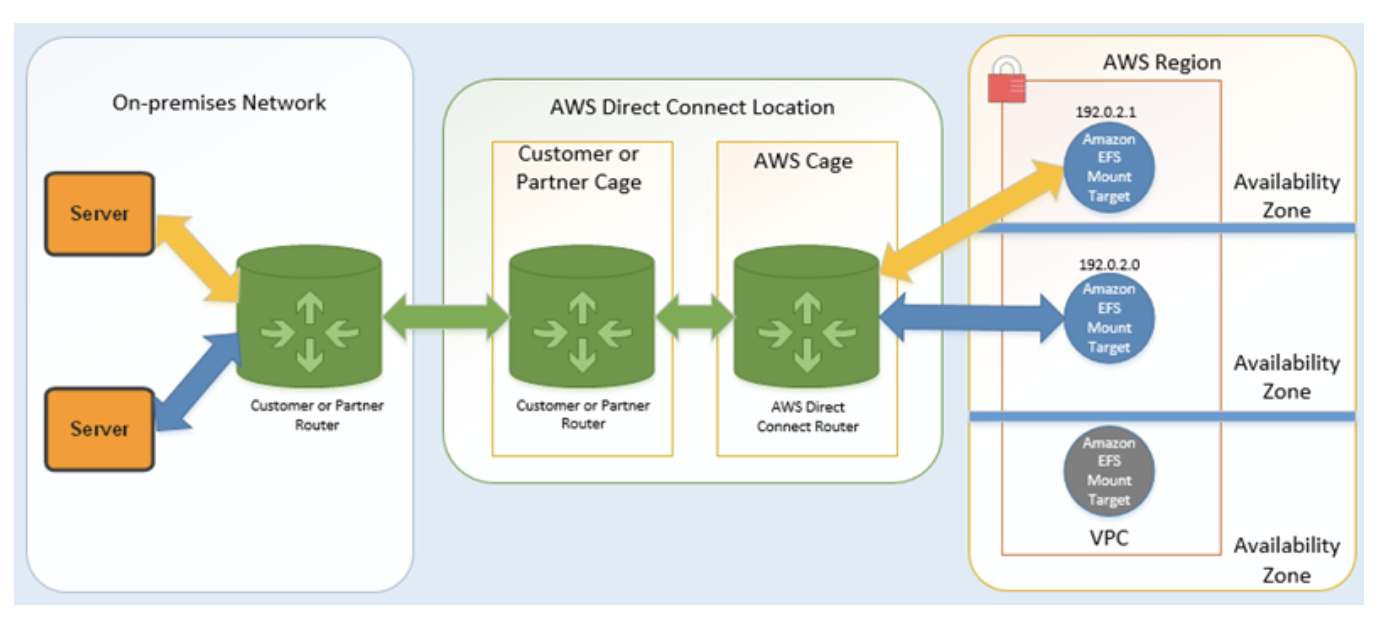
Amazon EFS が AWS Direct Connect と AWS マネージド VPN で動作する仕組み
オンプレミスサーバーと VPC の間に AWS Direct Connect接続を使用してそのマウントターゲットのサブネットに到達できる場合は、VPC で任意のマウントターゲットを使用できます。オンプレミスサーバーから Amazon EFS にアクセスするには、オンプレミスサーバーから NFS ポート (2049) へのインバウンドトラフィックを許可するために、マウントターゲットセキュリティグループにルールを追加する必要があります。
Amazon EFS と AWS Backup の連携
ファイルシステムの包括的なバックアップの実装では、Amazon EFS と AWS Backup を使用できます。AWS Backup は、クラウドおよびオンプレミスの AWS サービス間でのデータバックアップの集中化と自動化を容易にする完全マネージド型バックアップサービスです。AWS Backup を使用すると、バックアップポリシーを集中的に設定し、AWS リソースのバックアップアクティビティを監視できます。Amazon EFS は常にバックアップオペレーションよりもファイルシステムオペレーションを優先します。
ストレージクラスとライフサイクル管理
Amazon EFS ファイルシステムでは 2 つのストレージクラスを利用できます。
低頻度アクセス – 低頻度アクセス (IA) ストレージクラスは、低コストのストレージクラスで、アクセス頻度が低く長期間保存されるファイルをコスト効率よく格納するように設計されています。
スタンダード – スタンダードストレージクラスは、頻繁にアクセスされるファイルを格納するために使用されます。
EFS ライフサイクルの管理
Amazon EFS のライフサイクル管理は、ファイルシステムの費用対効果の高いファイルストレージを自動的に管理します。有効にすると、ライフサイクル管理により、設定された期間アクセスされなかったファイルは、低頻度アクセス (IA) ストレージクラスに移行されます。その期間は、ライフサイクルポリシーを使用して定義します。
Amazon EFS のライフサイクル管理は、ファイルシステムの費用対効果の高いファイルストレージを自動的に管理します。有効にすると、ライフサイクル管理により、設定された期間アクセスされなかったファイルは、低頻度アクセス (IA) ストレージクラスに移行されます。その期間は、ライフサイクルポリシーを使用して定義します。
ライフサイクル管理によってファイルが IA ストレージクラスに移動されると、ファイルは無期限に残ります。Amazon EFS ライフサイクル管理では、内部タイマーを使用して、ファイルが最後にアクセスされた時間が追跡されます。公開されている POSIX ファイルシステムの属性は使用されません。スタンダードストレージのファイルが読み書きされるたびに、ライフサイクル管理タイマーはリセットされます。
ディレクトリの内容を一覧表示するなどのメタデータオペレーションは、ファイルアクセスとしてカウントされません。ファイルの内容を IA ストレージに移行するプロセスの間、ファイルはスタンダードストレージクラスに格納され、スタンダードストレージ料金で請求されます。
ライフサイクル管理は、ファイルシステム内のすべてのファイルに適用されます。
ライフサイクルポリシーの使用
ライフサイクルポリシーを設定して、EFS がファイルをいつ IA ストレージクラスに移行するか定義します。ファイルシステムには、ファイルシステム全体に適用される 1 つのライフサイクルポリシーがあります。選択したライフサイクルポリシーによって定義された期間内にファイルがアクセスされなかった場合、Amazon EFS はファイルを IA ストレージクラスに移行します。次のように、4 つのライフサイクルポリシーのうち 1 つを Amazon EFS ファイルシステム用に指定できます。
- AFTER_7_DAYS
- AFTER_14_DAYS
- AFTER_30_DAYS
- AFTER_60_DAYS
- AFTER_90_DAYS
AWS Budgets による Amazon EFS ファイルシステムのコストの管理
AWS Budgets を使用して、Amazon EFS ファイルシステムのコストを計画および管理できます。
AWS Budgets は AWS Billing and Cost Management コンソールから使用できます。AWS Budgets を使用するには、EFS ファイルシステムの月次コスト予算を作成します。コストが予算額を超えると予測される場合に通知されるように予算を設定し、必要に応じて予算を維持するための調整を行うことができます。
AWS Budgets の使用時には、コストが関連付けられます。通常の AWS アカウントの場合、最初の 2 つの予算は無料です。コストなど、AWS Budgets の詳細については、AWS Billing and Cost Management ユーザーガイド の「Budgets によるコスト管理」を参照してください。
予算のパラメータを使用して、アカウント、AWS リージョン、サービス、またはタグレベルで EFS のコストと使用量を管理するためのカスタム予算を設定できます。以下のセクションでは、AWS Budgets により EFS ファイルシステムのコスト予算を設定する方法について概説しています。コスト予算の作成には、コスト配分タグを使用します。

- 投稿日:2020-05-28T16:55:50+09:00
AWS CLI on dockerで死なないためのalias設定
.zshrcとか.bashrcなどに書いておく内容
長くなってしまいました。
変数評価のところをもうすこしきれいに書きたいのですが、動いているので一旦お披露目します。AWS_PAGER=cat alias aws='docker run --rm -ti \ -v ~/.aws:/root/.aws \ -v $(pwd):/aws \ -v ~/.ssh:/root/ssh \ $(for _e in AWS_PAGER AWS_ACCESS_KEY_ID AWS_CA_BUNDLE AWS_CONFIG_FILE AWS_DEFAULT_OUTPUT AWS_DEFAULT_REGION AWS_PROFILE AWS_ROLE_SESSION_NAME AWS_SECRET_ACCESS_KEY AWS_SESSION_TOKEN AWS_SHARED_CREDENTIALS_FILE;\ do \ if [ "x$(eval echo \$$_e)" != "x" ];\ then \ echo -n " --env $(echo ${_e})=$(eval echo \$$_e) ";\ fi;\ done) \ amazon/aws-cli'経緯
AWS CLI v2になり、いくつかの理由により on docker で動かそうとしたところ以下のような挙動を確認し、こう動かしたいという要望を持ちました。
- cli_pager を ~/.aws/config に設定しているのに反映されてな差そうな挙動を示します。具体的にはless/moreのようなものが間に挟まっているように見えます。
- dockerコンテナに対して環境変数を可能な限り引き渡してあげたい(公式ドキュメントでは動作の確認のための最小限の利用方法のみの記載となっています)
cli_pager についてはあまり大きな問題になってないようなので、僕の端末環境に依存するものじゃないかと推測しています。
いずれにしても、
- 環境変数は全部引き渡したほうがよい
- pager を使わない = cat にすればいいんじゃね?
というような理由により、aws cli on docker における(そこそこ)気の利いたaliasを書いてみることにしました。
挙動の説明らしきもの
環境変数全部渡し
$for _e in ...以降でAWS CLIが取り扱う変数を列挙し、設定が行われている場合にはdockerコンテナに対して環境変数を引き渡します。aws cliをdockerで動かすとcli_pagerを正しく評価しない?
~/.aws/config には
[default] region=us-west-2 output=json cli_pager=のような記述を行っていますが、どうしてもless(more?)を使いたいようです。
僕の意図した挙動ではないので、一行目でcatをpagerとして指定しています。
別の何かをフィルタにする際には随時env pager="hoge" aws ...のような手続きにすることとします。
- 投稿日:2020-05-28T16:22:53+09:00
エクセルから参照するオンプレのSQLserverをAWSに移行する
社内ではエクセルでのマスタ管理が一般的
SQLserverでのマスタ管理を行う前の状況:
どこの部署でも使用するような社員名簿のような人事マスタが、人事部や情報システム部と交流のある一部の人だけが使える状態となっていた。最新情報が使えるのは人事部、情報システム部だけで、他の方は手に入れた人事マスタの情報を自分で更新している状況であった。
そんな非効率で不公平な状況を改善する為に、SQLserverで社内DBを構築した。SQLserverを選定したのはエクセルから直接最新データを読み込める為、VBA等での作り込みが不要になる為であった。社内DBは余っていたデスクトップパソコン上に構築したので、利用者が増えるにつれてパワー不足が顕著になってきたので、AWS(RDS)に移行することにした。
RDS上に.bakを復元する方法で悩む
OS上に構築した場合は.bakを置いたディレクトリを指定するだけで復元できたが、RDSの場合はS3に置く必要があるとのこと。S3にバケットを作成し、RDSからアクセスできるようロールを設定。
RDSにSqlServerManagementStudioで接続して、下記のクエリを実行することで復元が実施できた。
最初は復元に失敗したが、S3へのアクセス権できないというメッセージであったので、権限を見直したことで解決。exec msdb.dbo.rds_restore_database @restore_db_name='データベース名', @s3_arn_to_restore_from='arn:aws:s3:::保存先とファイル名.bak';上記クエリの実行状況は下記のクエリで確認可能。
exec msdb.dbo.rds_task_status
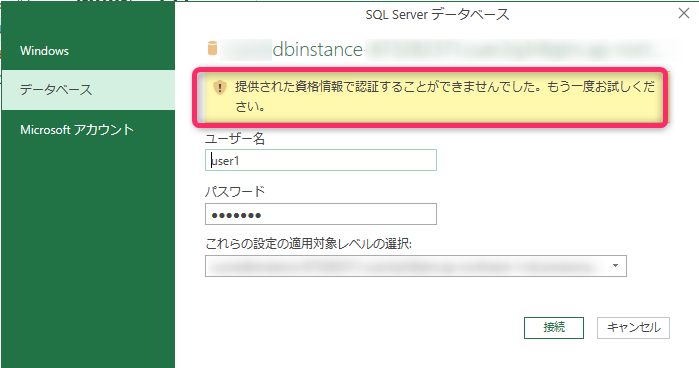
AWS(RDS)上にデータ移行したのに社内からエクセルからアクセスできない
ダイレクトコネクトで社内とAWSが繋がっているので、社内からアクセスできるはずなのに、アクセスできず。確認するとAWSのセキュリティグループの設定に問題があったので、設定見直すことで解決。しかし、SQLserverのユーザーが認証できないというエラーが発生。
既存のユーザーがある状態で.bakを復元すると既存のユーザーアカウントでアクセスできなくなるらしい
.bakを復元すると「ログインユーザー」と「データベースのユーザー」この2つに不整合が生じ、今回の現象が発生しているということを理解。不整合を解消するクエリとして紹介されていた下記のクエリを試してみた。
下記は参考にさせて頂いたサイトです。
http://www.3s-sys.co.jp/blog/2017/01/25/1071/
https://sql-oracle.com/sqlserver/?p=143USE [データベース名] EXEC sp_change_users_login 'Update_One','[現在データベースに登録してあるユーザ名]','[ログインしたいユーザー名]'が、解決せず。。。
解決
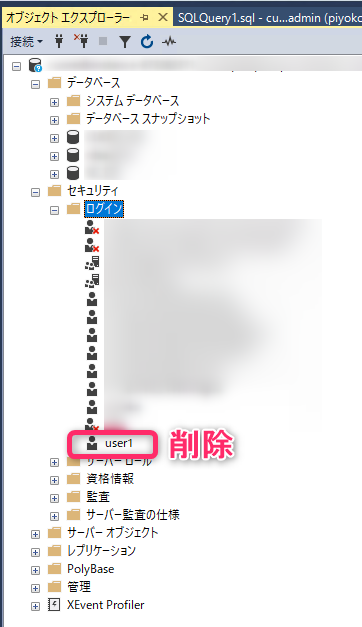
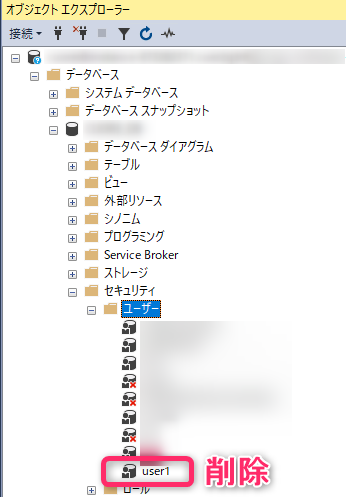
「ログインユーザー」と「データベースのユーザー」の不整合が原因なら、SqlServerManagementStudioでそれぞれのユーザーを手動で削除して再作成すれば解決できるのでは?と考え、実行してみたところ、解消できました。
「ログインユーザー」削除
「データベースのユーザー」削除
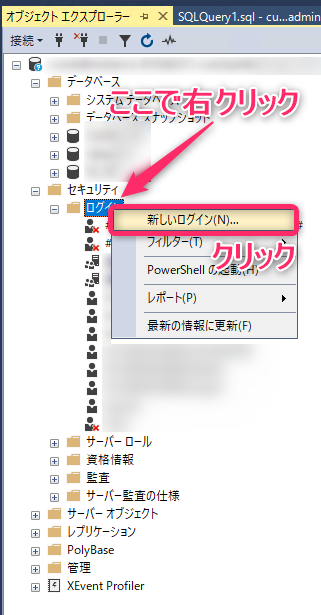
ユーザーの再作成
再作成したユーザーは権限もなくなっているので、Grantで各テーブルやビューの閲覧権限を付与してして移行が完了しました。
- 投稿日:2020-05-28T16:22:41+09:00
Amazon Elastic Block Store (Amazon EBS)
Amazon Elastic Block Store (Amazon EBS)
Amazon Elastic Block Store (Amazon EBS) は、EC2 インスタンスで使用するためのブロックレベルのストレージボリュームを提供します。EBS ボリュームの動作は、未初期化のブロックデバイスに似ています。これらのボリュームは、デバイスとしてインスタンスにマウントできます。同じインスタンスに複数のボリュームをマウントしたり、一度に複数のインスタンスにボリュームをマウントすることができます。これらのボリューム上にファイルシステムを構築できます。また、これらのボリュームをブロックデバイスを使用する場合と同じ方法で使用できます (ハードドライブとして使用するなど)。インスタンスにアタッチされているボリュームの設定は動的に変更できます。
暗号化シナリオ
- 暗号化されていないボリュームを復元する (デフォルトでの暗号化が有効になっていない場合)
- 暗号化されていないボリュームを復元する (デフォルトでの暗号化が有効になっている場合)
- 暗号化されていないスナップショットをコピーする (デフォルトでの暗号化が有効になっていない場合)
- 暗号化されていないスナップショットをコピーする (デフォルトでの暗号化が有効になっている場合)
- 暗号化ボリュームを再暗号化する
- 暗号化スナップショットを再暗号化する
- 暗号化されたボリュームと暗号化されていないボリュームとの間でデータを移行する
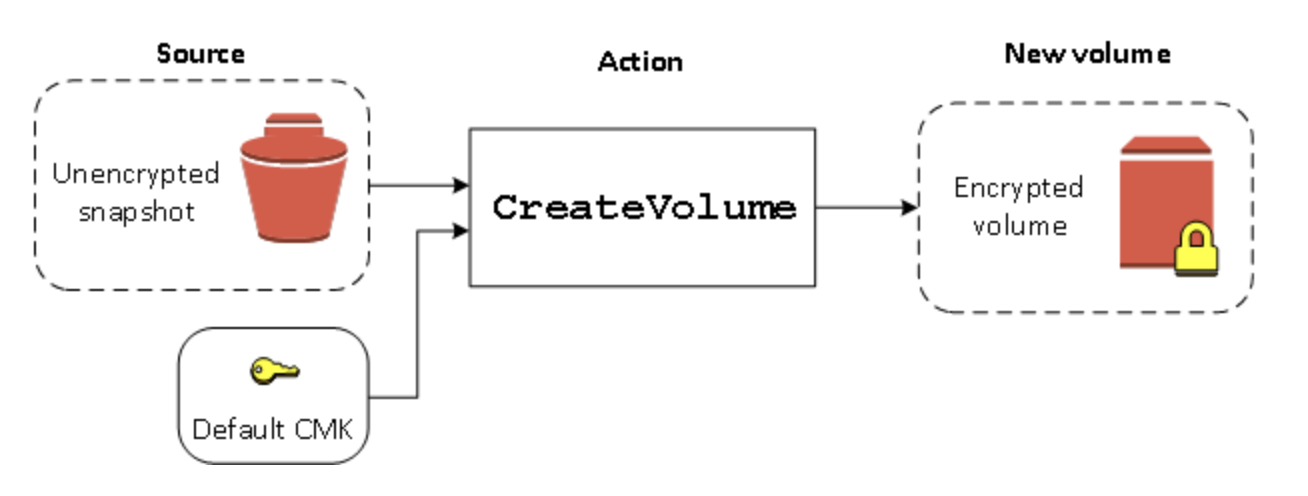
暗号化されていないボリュームを復元する (デフォルトでの暗号化が有効になっていない場合)
デフォルトでの暗号化を有効にしないと、暗号化されていないスナップショットから復元されたボリュームは、デフォルトで暗号化されません。
暗号化されていないボリュームを復元する (デフォルトでの暗号化が有効になっている場合)
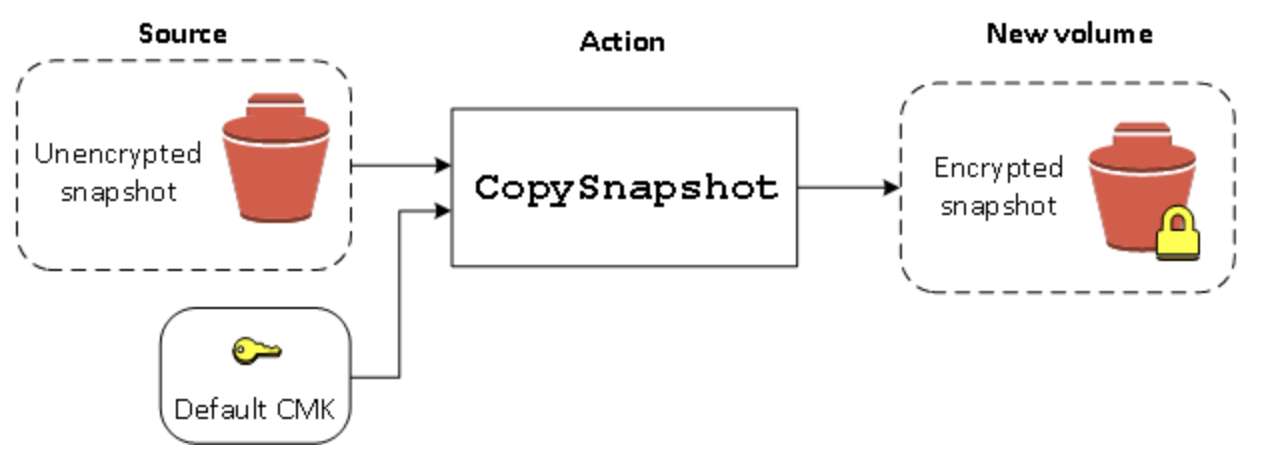
暗号化されていないスナップショットをコピーする (デフォルトでの暗号化が有効になっていない場合)
暗号化されていないスナップショットをコピーする (デフォルトでの暗号化が有効になっている場合)
デフォルトでの暗号化を有効にした場合、暗号化されていないスナップショットのコピーには暗号化が必須であり、デフォルトの CMK を使用する場合は、暗号化パラメータは必要ありません。
暗号化ボリュームを再暗号化する
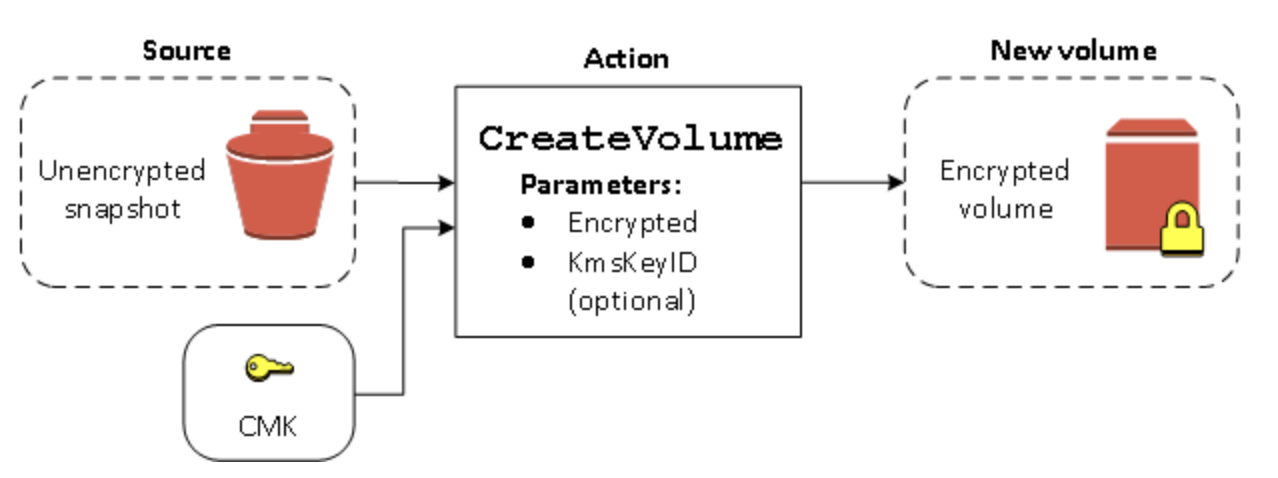
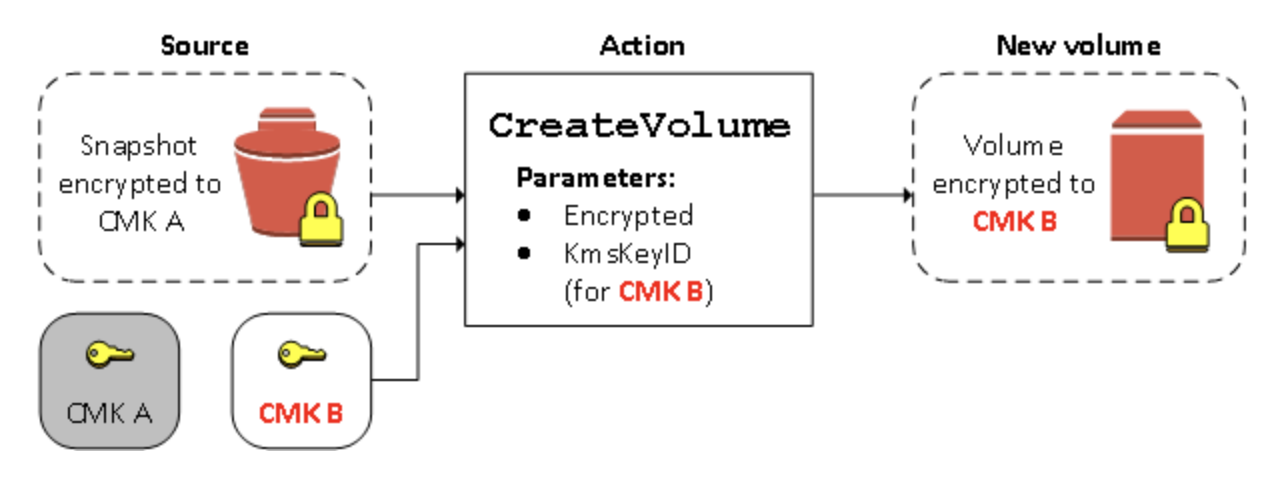
CreateVolume アクションが暗号化されたスナップショットに対して実行されるときは、別の CMK でそれを再暗号化することができます。以下の図は、そのプロセスを示したものです。この例では、CMK A と CMK B の 2 つの CMK を所有しています。ソーススナップショットは CMK A によって暗号化されています。ボリュームの作成中に、パラメータとして指定された CMK B のキー ID を使用して、ソースデータは自動的に復号され、次に CMK B によって再暗号化されます。
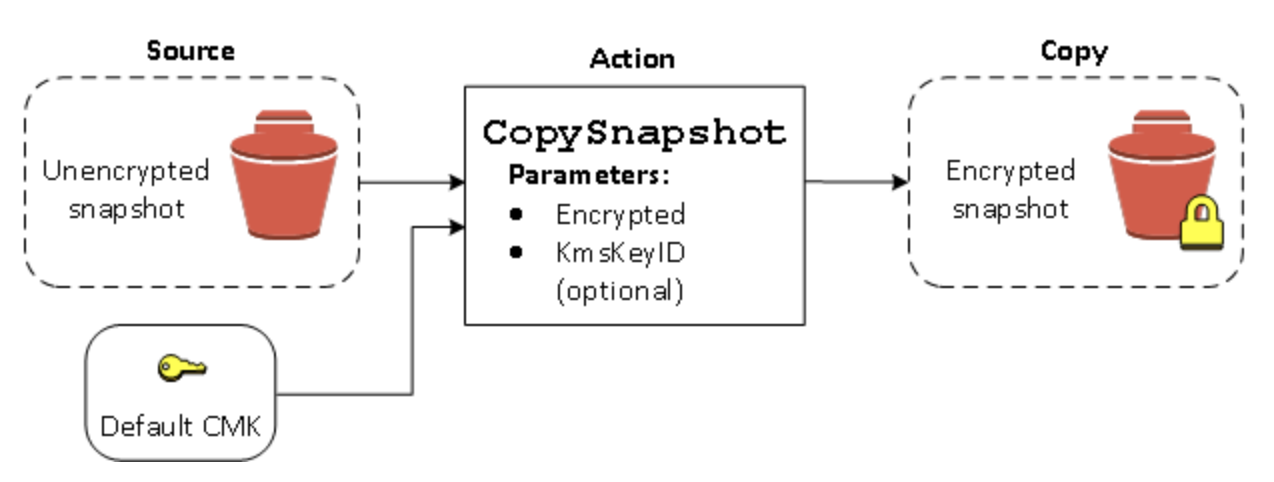
暗号化スナップショットを再暗号化する
スナップショットをコピー時に暗号化する機能により、すでに暗号化された自己所有のスナップショットに新しい対称 CMK を適用できます。結果として作成されたコピーから復元されたボリュームには、新しい CMK を使用してのみアクセスすることができます。以下の図は、そのプロセスを示したものです。この例では、CMK A と CMK B の 2 つの CMK を所有しています。ソーススナップショットは CMK A によって暗号化されています。コピー中に、パラメータとして指定された CMK B のキー ID を使用して、ソースデータは自動的に CMK B によって再暗号化されます。
Amazon EBS 高速スナップショット復元
Amazon EBS 高速スナップショット復元を使用するとスナップショットからボリュームを作成でき、このボリュームは作成時に完全に初期化された状態になります。これにより、ブロックの初回アクセス時における I/O オペレーションのレイテンシーがなくなります。高速スナップショット復元を使用して作成されたボリュームでは、プロビジョンドパフォーマンスをすべて即座に提供できます。

- 投稿日:2020-05-28T15:45:55+09:00
マイグレーションについて
ツールを使ったAWSへのサーバー移行の考察
https://dev.classmethod.jp/articles/consider-servers-lift/移行ツール
- SMS
- VMware vSphere または Windows Hyper-V 上の仮想マシンを EC2 へ移行 (レプリケーション) するサービス
- CloudEndure
- オンプレミスの各サーバーにエージェントをインストールします。 エージェントがサーバーのディスク上のデータブロックをレプリケーションします。
AWS にもレプリケーション先の他に CloudEndure サーバーが必要です。
サーバー移行方式
- 増分移行
- SMS や CloudEndure で継続的に増分レプリケーションをしておき 本番移行直前にサービスを停止し静止点を取って 完全な形で同期をとる方式です。
- Migration Once DataSynchronize Many
- レプリケーションはあるタイミングで一度切り実施、 その後はアプリケーションに必要なデータのみを差分でコピーしていく方式です。
- サーバーを重要度で区分して、重要度が高いサーバー群は MODM で、 それ以外は一旦増分移行を行い次フェーズで ”AWS ならでは機能” を使うように構成していくという ハイブリッドなサーバー移行がベターだと考えます。
DB移行方式
- DMS
- 特別なドライバーやソフトウェアを必要することなく オンプレミスのデータベースから AWS 上のデータベースへデータレプリケーションを行います。
- 同一プラットフォーム同士だけではなく、異なるプラットフォーム (Oracle から PostgeSQL) 間のデータレプリケーションも可能です。
- ネイティブ機能を使った DB 移行
VMware Cloud on AWS
VMware vSphere ベースのオンプレミス環境を AWS 上のベアメタルへ移行し稼働させるサービス
クリーンインストール
まっさらな EC2 を起動し、そのうえに必要なアプリケーションやパッケージをインストールします。 一通りのセットアップが完了したらデータ移行を行います。
- 投稿日:2020-05-28T14:39:37+09:00
AWSメモ
1-2
AZ-dは使用してない?
* グローバルサービス:Route53、IAM、CloudFront
* リージョンサービス:VPC、DynamoDB、Lambda
* アベイラビリティサービス:サブネット、EC2、RDS1-4 ネットワークサービス
VPCの主なサービス
- VPC
- サブネット
- ルートテーブル
- IGW
- IGWをアタッチしたVPC=パブリックサブネットだが、どうやって確認する?
- Elastic IP
- エンドポイント
- ゲートウェイ型はS3 or DynamoDB。それ以外はインターフェイス型。
- NATゲートウェイ
- プライベートサブネットからインターネットに接続する際に使用。
- NATゲートウェイを使用しない際はNATインスタンスを構築する。冗長化が必要。
- NATゲートウェイを利用する際の設定を知りたい。
- ピアリング接続
- 異なるAWSアカウント間でも接続可能。実際やってる?
セキュリティの主なサービス
- セキュリティグループ
- インスタンス単位
- ネットワークACL
- サブネット単位
ELB
- CLB/ALB/NLBのパラメータを確認したい。
- Connection Drainingって使ってる?
- 外部ELB=internet-facing、内部ELB=Internal、スキームで確認
- クロスゾーン負荷分散って使用してる?
Auto Scaling
使用してない?
Route53
- パブリックホストゾーンとプライベートホストゾーンがあって、プライベートホストゾーンは.local
Direct Connect
使用してない?
仮想プライベートゲートウェイ
使用してない?
CloudFront
- esaを見れば理解できるかも。ディストリビューション、オリジン、エッジロケーション
- オリジンとしてS3を指定する事が多い気がする。
- SSL証明書はどうやって差し替えるんだろう?
- 署名付きURL/カスタムエラーページ/地域制限/ストリーミング配信らへんのパラメータ深掘り
1-5 コンピューティングサービス
EMR
- 大量データを迅速に処理するWebサービス
ECS
使用してない?
VM Import/Export
使用してない?
1-6 ストレージサービス
S3
- 署名付きURL:一定時間アクセスを許可するURL
- マルチパートアップロード:大容量のオブジェクトを分割してアップロードする機能
- クロスリージョンレプリケーション:別のリージョンにオブジェクトを自動的に複製する機能
- 投稿日:2020-05-28T13:39:03+09:00
BeanStalk
Beanstalk
[初心者向け]AWS Elastic Beanstalk
https://qiita.com/yShig/items/2120bba6649321623cad
- 投稿日:2020-05-28T13:34:47+09:00
CodeDeploy
CodeDeploy コンピューティングプラットフォームの概要
- EC2/オンプレミス
- AWS Lambda
- Amazon ECS
CodeDeploy デプロイタイプの概要
- インプレイスデプロイ
- デプロイグループの各インスタンス上のアプリケーションが停止され、最新のアプリケーションリビジョンがインストールされて、新バージョンのアプリケーションが開始され検証されます。ロードバランサーを使用すれば、各インスタンスがデプロイ中に登録解除され、デプロイ完了後にサービスに復元されるようにすることができます。インプレイスデプロイは、EC2/オンプレミス compute platform を使用するデプロイでのみ使用できます。
- Blue/Green デプロイ
- EC2/オンプレミス compute platform の Blue/Green
- デプロイグループのインスタンス (元の環境) がインスタンスの別のセット (置き換え先環境) に置き換えられます。
- AWS Lambda compute platform の Blue/Green
- トラフィックは、現在のサーバーレス環境から、更新された Lambda 関数のバージョンの環境に移行されます。検証テストを実行する Lambda 関数を指定し、トラフィックの移行が発生する方法を選択できます。AWS Lambda compute platform のデプロイはすべて、Blue/Green デプロイです。
- Amazon ECS compute platform の Blue/Green
- トラフィックは、Amazon ECS サービス内のアプリケーション元のバージョンのタスクセットから、同じサービスの置き換えタスクセットに移行されます。デプロイメント設定を使用して、トラフィックの移行を線形または Canary に設定できます。指定されたロードバランサーリスナーのプロトコルとポートは、本稼働トラフィックを再ルーティングするために使用されます。デプロイ中、テストリスナーは、検証テストの実行中に設定された置換タスクセットにトラフィックを配信するために使用することができます。
- 線形
- トラフィックを毎回、同じ増分、同じ間隔 (分) で移行します。事前定義された複数の線形オプションから選択し、増分ごとに移行するトラフィックの割合 (%) と増分間の間隔 (分) を指定できます。
- Canary
- トラフィックを 2 回の増分で移行します。事前定義された複数の Canary オプションから選択し、最初の増分および間隔でトラフィックを更新済みタスクセットに移行する割合 (%) を分単位で指定できます。次に 2 回目の増分で残りのトラフィックを移行します。
- 投稿日:2020-05-28T10:50:20+09:00
アメリカのAWS(Amazon EC2)からのDDos攻撃への対処法
この話はAWSにおけるDDos攻撃の対処法ではなく、
AWSからDDos攻撃を受けた話です。
厳密に言うと、AWSを経由した攻撃だと思われます。DDos攻撃の内容
攻撃元
アメリカのAWSのデータセンター
Amazon EC2を使っている模様
攻撃手法
HTTPで凸
運営しているWEBサービスの割と負荷が高いところを突かれた(ページングが必要なところ数百箇所)Amazon EC2で攻撃元が大量増殖
移動攻撃のように攻撃元IPをどんどん移り変えながら分散攻撃
一つあたりは検知システムの網にかからない程度に、少し間を空けて、幾重かに凸を繰り返す対処法
攻撃元のIPを手作業で全遮断
(一般ユーザーを誤って遮断するのだけは避けたかったので、システムで自動判別するのは難しいと判断)。
攻撃元がどんどん増えつつあり、1個ずつだと時間かかるので、広範囲に一気に遮断しました。
以下遮断リストです。同じ攻撃をくらった方は参考にしてください。
※アメリカのAWSのデータセンターが使っているIPです。広範囲に指定しているので、末端はその他も入っているかもしれませんので、ご了承ください。攻撃元IP(広範囲)
100.24.0.0/16 100.25.0.0/16 100.26.0.0/16 100.27.0.0/16 100.20.0.0/16 107.21.0.0/16 107.22.0.0/16 107.23.0.0/16 174.129.0.0/16 18.204.0.0/16 18.205.0.0/16 18.206.0.0/16 18.207.0.0/16 18.208.0.0/16 18.209.0.0/16 18.210.0.0/16 18.212.0.0/16 18.213.0.0/16 18.214.0.0/16 18.215.0.0/16 18.232.0.0/16 18.234.0.0/16 18.235.0.0/16 184.72.0.0/16 184.73.0.0/16 204.236.0.0/16 23.20.0.0/16 23.22.0.0/16 3.208.0.0/16 3.209.0.0/16 3.210.0.0/16 3.214.0.0/16 3.215.0.0/16 3.216.0.0/16 3.218.0.0/16 3.219.0.0/16 3.220.0.0/16 3.221.0.0/16 3.222.0.0/16 3.223.0.0/16 3.224.0.0/16 3.225.0.0/16 3.226.0.0/16 3.227.0.0/16 3.228.0.0/16 3.229.0.0/16 3.230.0.0/16 3.231.0.0/16 3.232.0.0/16 3.233.0.0/16 3.234.0.0/16 3.235.0.0/16 3.80.0.0/16 3.81.0.0/16 3.82.0.0/16 3.83.0.0/16 3.84.0.0/16 3.85.0.0/16 3.86.0.0/16 3.87.0.0/16 3.88.0.0/16 3.89.0.0/16 3.90.0.0/16 3.91.0.0/16 3.92.0.0/16 3.93.0.0/16 3.94.0.0/16 3.95.0.0/16 34.200.0.0/16 34.201.0.0/16 34.202.0.0/16 34.203.0.0/16 34.204.0.0/16 34.205.0.0/16 34.206.0.0/16 34.207.0.0/16 34.224.0.0/16 34.225.0.0/16 34.226.0.0/16 34.227.0.0/16 34.228.0.0/16 34.229.0.0/16 34.230.0.0/16 34.231.0.0/16 34.232.0.0/16 34.234.0.0/16 34.234.0.0/16 34.235.0.0/16 34.236.0.0/16 34.237.0.0/16 34.238.0.0/16 34.239.0.0/16 35.153.0.0/16 35.168.0.0/16 35.170.0.0/16 35.171.0.0/16 35.172.0.0/16 35.173.0.0/16 35.174.0.0/16 35.175.0.0/16 50.17.0.0/16 50.19.0.0/16 52.2.0.0/16 52.200.0.0/16 52.201.0.0/16 52.202.0.0/16 52.203.0.0/16 52.204.0.0/16 52.205.0.0/16 52.207.0.0/16 52.23.0.0/16 52.3.0.0/16 52.4.0.0/16 52.54.0.0/16 52.55.0.0/16 52.70.0.0/16 52.71.0.0/16 52.72.0.0/16 52.73.0.0/16 52.86.0.0/16 52.87.0.0/16 52.90.0.0/16 52.91.0.0/16 54.144.0.0/16 54.145.0.0/16 54.146.0.0/16 54.147.0.0/16 54.152.0.0/16 54.156.0.0/16 54.157.0.0/16 54.158.0.0/16 54.159.0.0/16 54.160.0.0/16 54.161.0.0/16 54.162.0.0/16 54.163.0.0/16 54.164.0.0/16 54.165.0.0/16 54.166.0.0/16 54.167.0.0/16 54.172.0.0/16 54.173.0.0/16 54.174.0.0/16 54.175.0.0/16 54.196.0.0/16 54.197.0.0/16 54.198.0.0/16 54.204.0.0/16 54.205.0.0/16 54.208.0.0/16 54.209.0.0/16 54.210.0.0/16 54.211.0.0/16 54.208.0.0/16 54.221.0.0/16 54.224.0.0/16 54.225.0.0/16 54.226.0.0/16 54.227.0.0/16 54.234.0.0/16 54.235.0.0/16 54.236.0.0/16 54.237.0.0/16 54.242.0.0/16 54.243.0.0/16 54.80.0.0/16 54.81.0.0/16 54.82.0.0/16 54.83.0.0/16 54.84.0.0/16 54.85.0.0/16 54.86.0.0/16 54.87.0.0/16 54.88.0.0/16 54.89.0.0/16 54.90.0.0/16 54.91.0.0/16 54.92.0.0/16 54.80.0.0/16 54.80.0.0/16 54.80.0.0/16 75.101.0.0/16攻撃元IP(超広範囲 ※急いでいる人向け)
これだけ遮断すれば、とりあえず時間稼げます(汗)。
※攻撃数が少なかったIPは省いてあります。3.0.0.0/8 18.0.0.0/8 34.0.0.0/8 35.0.0.0/8 52.0.0.0/8 54.0.0.0/8 100.0.0.0/8 107.0.0.0/8 184.0.0.0/8手口考察
ここからは推測になりますが、
アクセスログにスマホからアクセスしたログも残っていたので、攻撃の引き金は、日本国内のスマホ(Android、iOSどちららも)がウイルスに感染?それからアメリカのAWSを経由して凸になっているような??Amazon EC2をこれだけ使っていたら、攻撃者はお金がけっこうかかっていると思いますが、身代金でも請求するつもりだったのだろうか。
- 投稿日:2020-05-28T10:28:47+09:00
AWS Update 5/28
Data Lifecycle Manager が cron 式に基づくスケジューリングと、週単位、月単位、および年単位のスケジュールを含む追加のバックアップ間隔をサポート
Data Lifecycle Manager (DLM) ポリシーのスケジューリング入力として cron 式を提供できるようになりました。cron 式を使用すると、ポリシーでカスタムスケジュールを柔軟に指定できます。
さらに、今回のリリースにより、DLM のバックアップ間隔が拡張され、すでに利用可能な時間単位および日単位のスケジュールに加えて、週単位、月単位、および年単位のスケジュールがサポートされるようになりました。これにより、バックアップ間隔を 1 時間から 1 年の間のいずれかにすることができます。
ポリシーを使用して EBS ボリュームスナップショットの作成および保持を自動化する DLM は、2018 年 7 月にローンチされました。それ以降、当社は、DLM の使いやすさを向上させ、より頻繁なバックアップサポートやスナップショットのクロスリージョンコピーなどの機能で災害復旧のユースケースをサポートしてきました。本日、柔軟性を高めるべく、DLM を拡張して、追加のバックアップ間隔と cron 式に基づくスケジューリングのサポートを開始します。
AWS Systems Manager Explorer が AWS Compute Optimizer のレコメンデーションのマルチアカウント、マルチリージョンの概要の提供を開始
本日より、AWS Systems Manager Explorer は、ワークロードのコストとパフォーマンスを改善するのに役立つ AWS Compute Optimizer のレコメンデーションの概要の提供を開始します。Systems Manager Explorer は、運用のダッシュボードであり、パッチのコンプライアンスやインスタンスの詳細などの運用データのビューを提供し、運用上の問題を調査および修正する必要がある場所を確認するのに役立ちます。Compute Optimizer は、Amazon Elastic Compute Cloud (Amazon EC2) インスタンスのレコメンデーションを提供するため、最大の影響をもたらす最適化の機会をすばやく特定できます。Systems Manager Explorer の 1 つの集約ビューで、すべての運用データと Compute Optimizer のレコメンデーションを確認できるようになりました。
この新機能により、Systems Manager Explorer を使用して、複数のアカウントまたは組織全体にわたる Compute Optimizer のレコメンデーションを表示できます。さらに、Compute Optimizer の概要でレコメンデーションを選択して、現在のインスタンスタイプ、推奨されるインスタンスタイプ、両者の料金の差など、EC2 インスタンスの詳細のリストを表示できます。次に、このデータをフィルタリングし、結果をコンマ区切り値 (.csv) ファイルにエクスポートして、Amazon Simple Notification Service (Amazon SNS) 通知を発行できます。Systems Manager Automation を使用してインスタンスのサイズを変更し、推奨される EC2 インスタンスタイプに変更することもできます。
Amazon Connect が問い合わせフローエディタ内の複数のブロックの選択のサポートを開始
複数のブロックを同時に選択して、それらを問い合わせフロー内のグループとして再配置できるようになりました。これにより、時間と労力を節約できます。以前は、一連のブロックを移動するには、各ブロックを個別にドラッグアンドドロップする必要がありました。この機能では、一度に 1 つのブロックをドラッグするという、イライラし、エラーが発生しやすく、時間がかかる繰り返しのタスクを、数秒で終わる 1 回の作業に置き換えるものです。
- 投稿日:2020-05-28T10:24:27+09:00
ECS
ECS
Amazon Elastic Container Service (Amazon ECS) は、クラスターで Docker コンテナを簡単に実行、停止、管理できる非常にスケーラブルで高速なコンテナ管理サービスです。Amazon ECS が管理するサーバーレスインフラストラクチャにクラスターをホストするには、Fargate 起動タイプを使用してサービスまたはタスクを起動します。また、EC2 起動タイプを使用して、現在管理している Amazon Elastic Compute Cloud (Amazon EC2) インスタンスのクラスターにタスクをホストすることで、さらに強力な統制力を得ることができます。
コンテナとイメージ
Amazon ECS にアプリケーションをデプロイするには、アプリケーションコンポーネントがコンテナで実行されるように設計する必要あります。Docker コンテナは標準化されたソフトウェア開発用のユニットであり、コード、ランタイム、システムツール、システムライブラリなど、ソフトウェアアプリケーションの実行に必要なものがすべて含まれています。コンテナは、イメージと呼ばれる読み取り専用テンプレートから作成されます。
イメージは通常、Dockerfile から構築されます。これは、コンテナに含まれるすべてのコンポーネントを指定するプレーンテキストファイルです。これらのイメージはその後レジストリに保存され、そこからクラスターにダウンロードして実行できます。
タスク定義
Amazon ECS でアプリケーションを実行する準備をするには、タスク定義を作成する必要があります。タスク定義とは、アプリケーションを構成する 1 つ以上 (最大 10 個) のコンテナを記述する JSON 形式のテキストファイルです。アプリケーションの設計図と考えることができます。タスク定義はアプリケーションのさまざまなパラメータを指定します。タスク定義パラメータには、使用するコンテナ、使用する起動タイプ、アプリケーションのコンテナインスタンスで開くポート、タスクのコンテナが使用するデータボリュームなどがあります。タスク定義で利用できる具体的なパラメータは、使用する起動タイプに応じて変化します。
タスクとスケジューリング
タスクはクラスター内のタスク定義のインスタンス化です。Amazon ECS でアプリケーションのタスク定義を作成した後、クラスターで実行するタスクの数を指定できます。
Fargate 起動タイプを使用する各タスクには独自の分離境界があり、基盤となるカーネル、CPU リソース、メモリリソース、または Elastic Network Interface は別のタスクと共有されません。
Amazon ECS タスクスケジューラは、クラスターへのタスク配置を担当します。いくつかの異なるスケジュールオプションを使用できます。たとえば、指定された数のタスクを同時に実行および保持するサービスを定義できます。
クラスター
Amazon ECS を使用してタスクを実行する場合、リソースの論理グループ化であるクラスターにタスクを配置します。クラスター内のタスクで Fargate 起動タイプを使用する場合、Amazon ECS がクラスターリソースを管理します。EC2 起動タイプを使用する場合、クラスターはユーザー自身が管理するコンテナインスタンスのグループです。Amazon ECS コンテナインスタンスは Amazon ECS コンテナエージェントを実行している Amazon EC2 インスタンスです。Amazon ECS は指定されたレジストリからコンテナイメージをダウンロードし、そのイメージをクラスター内で実行します。
コンテナエージェント
コンテナエージェントは、Amazon ECS クラスター内の各インフラストラクチャリソース上で実行されます。リソースの現在実行中のタスクおよびリソース使用状況に関する情報を Amazon ECS に送信し、Amazon ECS からリクエストを受信したときはいつでもタスクを開始および停止します。
AWS Fargate での Amazon ECS
AWS Fargate は、Amazon ECS とともに使用して Amazon EC2 インスタンスでサーバーまたはクラスターを管理する必要なくコンテナを実行できるテクノロジーです。AWS Fargate を使用すると、コンテナを実行するために仮想マシンのクラスターをプロビジョニング、設定、スケールする必要がありません。これにより、サーバータイプの選択、クラスターをスケールするタイミングの決定、クラスターのパッキングの最適化を行う必要がなくなります。
Fargate 起動タイプを使用してタスクやサービスを実行する場合、アプリケーションをコンテナにパッケージ化し、CPU およびメモリ要件を指定して、ネットワーキングおよび IAM ポリシーを定義してから、アプリケーションを起動します。各 Fargate タスクは、独自の分離境界を持ち、基本となるカーネル、CPU リソース、メモリリソース、または Elastic Network Interface を別のタスクと共有しません。
タスク定義
Fargate での Amazon ECS タスクは、使用可能なすべてのタスク定義パラメータをサポートしているわけではありません。一部のパラメータはサポートされていません。また、Fargate タスクでは動作が異なるパラメータがあります。
次のタスク定義パラメータは Fargate 起動タイプでは無効です。
ネットワークモード
Fargate の Amazon ECS タスク定義では、ネットワークモードが awsvpc に設定されている必要があります。awsvpc ネットワークモードでは、各タスクに独自の Elastic Network Interface を提供します。
ネットワーク設定は、サービスを作成する場合、またはタスクを手動で実行する場合にも必要
ログ記録
Fargate の Amazon ECS タスク定義はログ設定の awslogs、splunk、firelens、および fluentd ログドライバーをサポートします。
awslogs ログドライバーは、ログ情報を Amazon CloudWatch Logs に送信するように Fargate タスクを設定します。以下に、awslogs ログドライバーが設定されているタスク定義のスニペットを示します。
"logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group" : "/ecs/fargate-task-definition", "awslogs-region": "us-east-1", "awslogs-stream-prefix": "ecs" }タスクストレージ
Fargate タスクでは、次のデータボリューム形式がサポートされています。
- EFS
- 非永続ストレージの場合エフェメラルストレージ。
タスクとサービス
タスクネットワーキング
Fargate の Amazon ECS を使用するタスクでは、awsvpc ネットワークモードが必要です。これは各タスクに Elastic Network Interface を提供します。このネットワークモードを使用したタスクの実行またはサービスの作成時に、ネットワークインターフェイスにアタッチするサブネットを 1 つ以上、またはネットワークインターフェイスに適用するセキュリティグループを 1 つ以上、指定する必要があります。
パブリックサブネットを使用している場合は、ネットワークインターフェイスにパブリック IP アドレスを指定するかどうかを決定します。パブリックサブネットの Fargate タスクを使用してコンテナイメージをプルするには、タスクの Elastic Network Interface に、インターネットへのルートまたはリクエストをインターネットにルーティングできる NAT ゲートウェイを持つパブリック IP アドレスが割り当てられている必要があります。プライベートサブネット内の Fargate タスクでコンテナイメージをプルするには、リクエストをインターネットにルーティングするためにプライベートサブネットに NAT ゲートウェイがアタッチされている必要があります。
awsvpc ネットワークモードを使用するタスクを含むサービス (例: 起動タイプが Fargate のサービス) では、Application Load Balancer および Network Load Balancer のみサポートされており、Classic Load Balancer はサポートされていません。また、このようなサービス用にターゲットグループを作成する場合は、ターゲットタイプとして instance ではなく、ip を選択する必要があります。これは、awsvpc ネットワークモードを使用するタスクは、Amazon EC2 インスタンスではなく、Elastic Network Interface に関連付けられているためです
Fargate Spot
Amazon ECS キャパシティープロバイダーを使用すると、Amazon ECS タスクで Fargate と Fargate Spot キャパシティーの両方を使用できます。
Fargate タスクのリタイア
AWS によりタスクをホストしている基盤のハードウェアで回復不可能な障害が検出されるか、セキュリティの問題がパッチ適用される必要がある場合、Fargate タスクのリタイアが予定されます。ほとんどのセキュリティパッチは、ユーザーの操作を必要とせずに、またはタスクを再起動する必要なく、透過的に処理されます。しかし、特定の問題については、タスクを再起動する必要があります。
予定されたリタイア日になると、タスクは AWS によって停止または終了されます。タスクがサービスの一部で、自動的に停止された場合、サービスのスケジューラにより、そのタスクを置き換える新しいタスクが開始されます。スタンドアロンタスクを使用する場合は、タスクのリタイアの通知が送信されます。詳細については、「タスクのリタイア」を参照してください。
Fargate Savings Plans
Savings Plans は、AWS の使用料金を大幅に削減できる料金モデルです。1〜3 年の期間、1 時間 につき USD 単位で一定の使用量を守ることにより、その使用に対する料金が低くなります。
使用できる AWS Fargate プラットフォームのバージョン
- Fargate プラットフォームバージョン ‐ 1.4.0
- 永続的なタスクストレージとして Amazon EFS ファイルシステムボリュームを使用するサポートを追加
- エフェメラルタスクストレージを 20 GB に増加
- タスクとの間のネットワークトラフィック動作を更新しました。プラットフォームバージョン 1.4 以降、すべての Fargate タスクは単一の Elastic Network Interface (タスク ENI と呼ばれる) を受け取り、すべてのネットワークトラフィックは VPC 内でこの ENI を通過し、VPC フローログを通じて表示されます。
- CloudWatch Container Insights には、Fargate タスクのネットワークパフォーマンスメトリクスが含まれます。
Amazon ECS タスク定義
Amazon ECS で Docker コンテナを実行するには、タスク定義が必要です。以下に示しているのは、タスク定義で指定できるパラメータです。
- タスクの各コンテナで使用する Docker イメージ
- 各タスクで、またはタスク内の各コンテナで使用する CPU とメモリの量
- 使用する起動タイプ。この起動タイプにより、タスクをホストするインフラストラクチャが決定される
- タスクのコンテナで使用する Docker ネットワーキングモード
- タスクで使用するログ記録設定
- コンテナが終了または失敗した場合にタスクを実行し続けるかどうか
- コンテナの開始時に実行するコマンド
- タスクのコンテナで使用するデータボリューム
- タスクが使用する IAM ロール
アプリケーションのアーキテクチャ
Fargate 起動タイプを使用する場合
以下の場合は、複数のコンテナを同じタスク定義に配置する必要があります。
コンテナが同じライフサイクルを共有している (同時に起動および終了する必要がある).
実行基盤となるホストが同じになるようにコンテナを実行する (つまり、あるコンテナが、localhost ポート上の別のコンテナを参照する) 必要がある。
コンテナにリソースを共有させる必要がある.
コンテナでデータボリュームを共有している。
EC2 起動タイプを使用する場合
networkmode
ECSでEC2インスタンスを利用する際のネットワークモードについて調べてみた
https://dev.classmethod.jp/articles/ecs-networking-mode/機密データの指定
Amazon ECS を使用すると、AWS Secrets Manager シークレットまたは AWS Systems Manager パラメータストアのパラメータに機密データを保存してコンテナの定義でそれを参照することによって、コンテナに機密データを挿入できます。
以下の方法でシークレットをコンテナに公開できます。
機密データを環境変数としてコンテナに挿入するには、secrets コンテナ定義パラメータを使用します。
コンテナのログ設定内の機密情報を参照するには、secretOptions コンテナ定義パラメータを使用します。
Amazon ECS タスクのスケジューリング
Amazon Elastic Container Service (Amazon ECS) は、タスクとコンテナの柔軟なスケジュール機能を提供する、共有状態のオプティミスティックな並列システムです。Amazon ECS スケジューラは Amazon ECS API から提供される同じクラスターの状態情報を利用して、適切な配置を決定します。
Fargate 起動タイプを使用する各タスクには独自の分離境界があり、基盤となるカーネル、CPU リソース、メモリリソース、または Elastic Network Interface は別のタスクと共有されません。
Amazon ECS には、サービススケジューラ (長期実行タスクおよびアプリケーション用に)、タスクを手動で実行する機能 (バッチジョブまたは単一実行タスク用)、および Amazon ECS でクラスターにタスクを配置する機能があります。また、タスク配置戦略と制約事項を指定できます。これにより、複数のアベイラビリティーゾーンに分散させるなど、選択した設定に基づいてタスクを実行できるようになります。さらに、カスタムのスケジューラやサードパーティー製スケジューラを統合することもできます。
サービススケジューラ
サービススケジューラは、長期実行するステートレスサービスおよびアプリケーションに適しています。サービススケジューラにより、指定したスケジュール戦略が順守され、タスクが失敗したときに (基盤となるインフラストラクチャに何らかの理由で障害が発生した場合などに) タスクが再スケジュールされます。
利用できる 2 つのサービススケジューラ戦略があります。
* REPLICA
* レプリカスケジュール戦略では、クラスター全体で必要数のタスクを配置して維持します。デフォルトでは、サービススケジューラによってタスクはアベイラビリティーゾーン間で分散されます。タスク配置の戦略と制約を使用すると、タスク配置の決定をカスタマイズできます。
* DAEMON
* デーモンのスケジュール戦略では、指定したすべてのタスク配置制約を満たすクラスター内のアクティブなコンテナインスタンスごとに、1 つのタスクのみをデプロイします。この戦略を使用する場合、タスクの必要数や配置戦略、サービスの Auto Scaling ポリシーを指定する必要はありません。
* Fargate タスクは DAEMON スケジューリング戦略をサポートしていません。Amazon ECS デプロイタイプ
Amazon ECS デプロイタイプは、サービスが使用するデプロイメント戦略を決定します。デプロイタイプには、ローリング更新、Blue/Green、外部の 3 つがあります。
- ローリング更新
- CodeDeploy を使用した Blue/Green デプロイ
- 外部デプロイ
ローリング更新
ローリング更新デプロイタイプは Amazon ECS により制御されます。これには、コンテナの現在実行されているバージョンを最新バージョンに置き換えるサービススケジューラも含まれます。ローリング更新中にサービスに対して Amazon ECS が追加または削除するタスク数は、デプロイ設定により制御されます。デプロイ設定はサービスデプロイメント中に許可されているタスクの最小数と最大数で構成されます。
CodeDeploy を使用した Blue/Green デプロイ
Blue/Green デプロイタイプでは、CodeDeploy によって制御される Blue/Green デプロイモデルを使用します。このデプロイタイプでは、本番稼働用トラフィックを送信する前にサービスの新しいデプロイメントを検証することができます。
Blue/Green デプロイ中にトラフィックを移行するには、次の 3 つの方法があります。
- Canary
- トラフィックを 2 回の増分で移行します。事前定義された複数の Canary オプションから選択し、最初の増分および間隔でトラフィックを更新済みタスクセットに移行する割合 (%) を分単位で指定できます。次に 2 回目の増分で残りのトラフィックを移行します。
- 線形
- トラフィックを毎回、同じ増分、同じ間隔 (分) で移行します。事前定義された複数の線形オプションから選択し、増分ごとに移行するトラフィックの割合 (%) と増分間の間隔 (分) を指定できます。
- 一括
- すべてのタスクを元のタスクセットから更新済みタスクセットに同時に移行します。
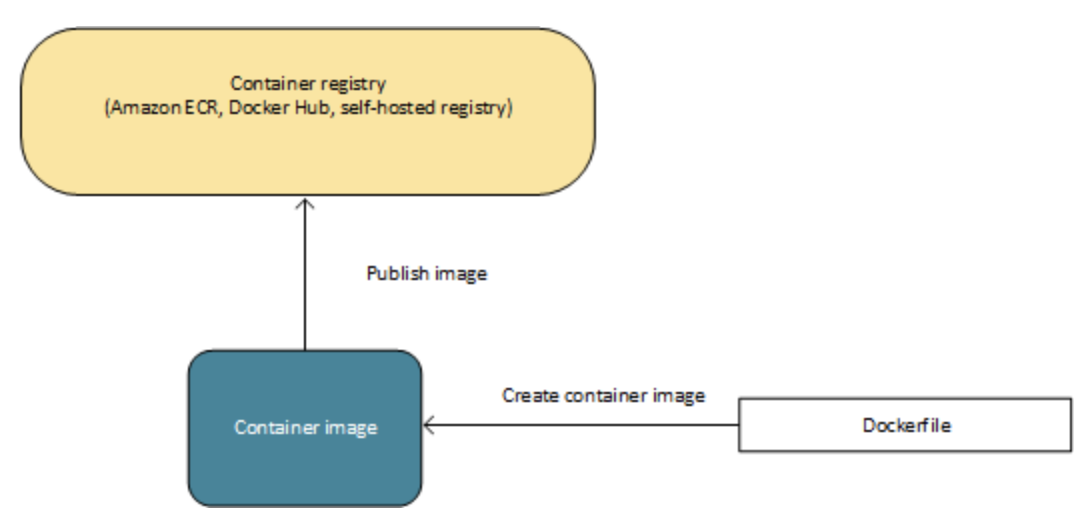
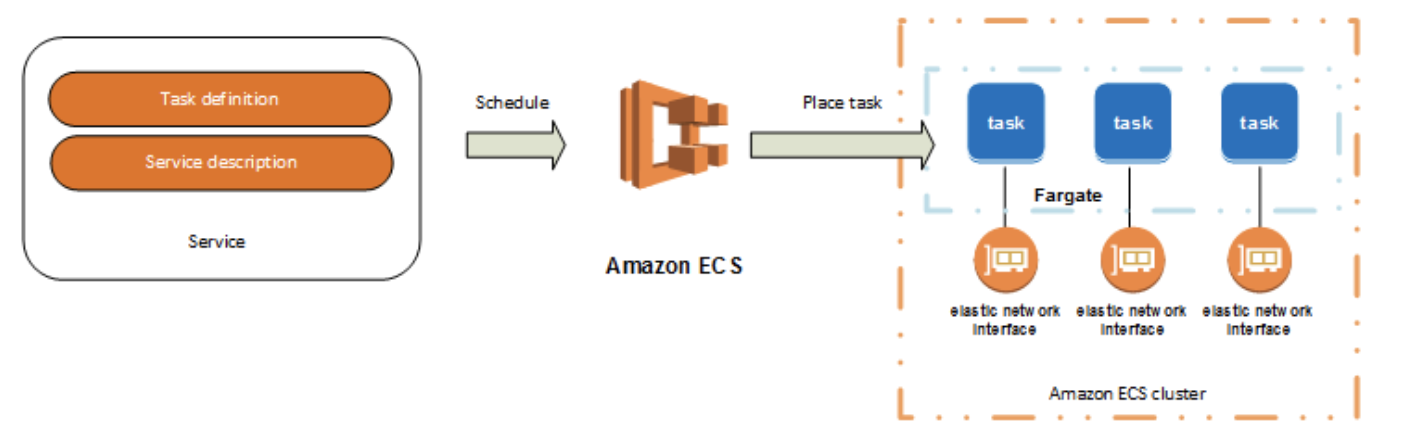
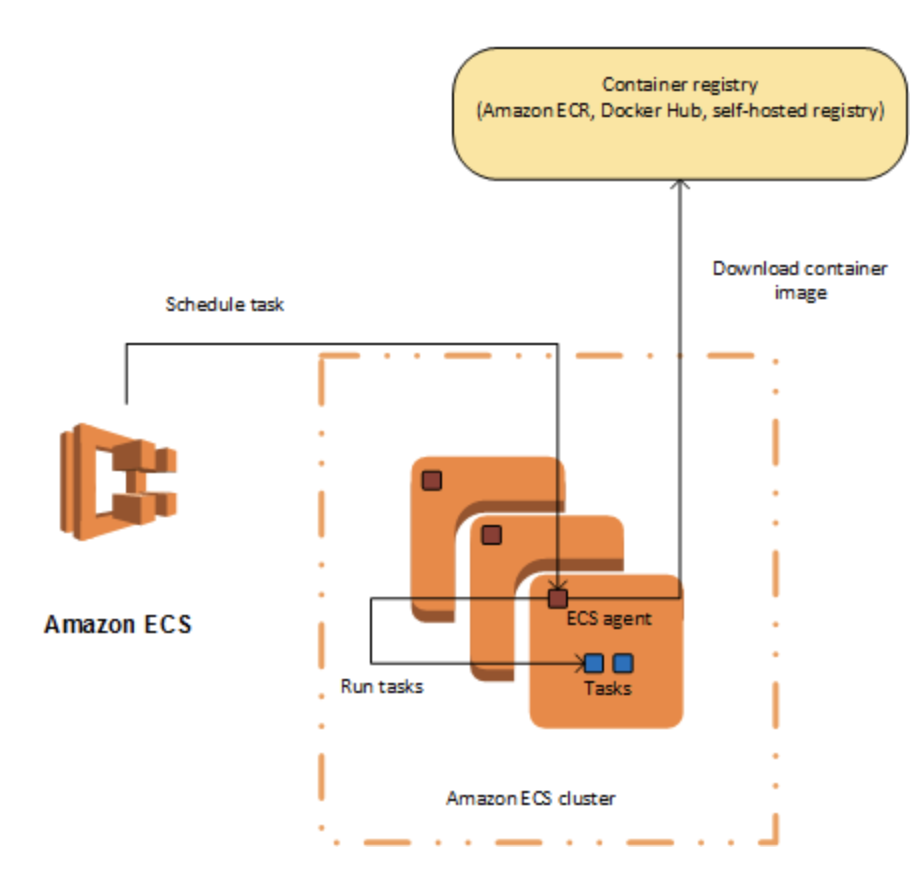
- 投稿日:2020-05-28T09:19:37+09:00
AWS 利用方法メモ(IAM)
書いてあること
- IAMの利用方法メモ
ポリシー
- ポリシー
- ポリシーの作成
- 対象のサービスを選択
- すべてのアクション、すべてのリソースをチェック ※必要に応じて最低限をチェック
- さらにアクセス許可を追加
- ポリシーの確認
- ポリシーの作成
グループ
- グループ
- 新しいグループの作成
- 次のステップ
- 設定するポリシーをチェック
- 次のステップ
- グループの作成
ユーザー
- ユーザー
- ユーザーを追加
- 必要事項を入力
- 次のステップ
- 追加するIAMグループをチェック
- 次のステップ
- 次のステップ
- ユーザーの作成
ロール
ロールを作成
- ロール
- ロールの作成
- 対象のサービスを選択
- 次のステップ
- 設定するポリシーをチェック
- 次のステップ
- タグを追加
- ロールの作成
サービスへ割当て
- サービスを選択
- 対象をチェック
- アクション
- インスタンスの設定
- IAMロールの割り当て/置換
- ロールを選択
- 適用
- 閉じる
- 投稿日:2020-05-28T00:24:50+09:00
Terraform実行環境の構築
はじめに
現在Cloudformationを学習しているのですが、ついでにTerraformも学習したいと思います。
AWSで試しますのでAWSアカウント作成とIAMユーザの設定をしておいてください。Terraform実行環境の作成
Terraformのインストール
Terraformをインストールする方法は3つあります、
- 直接PCにインストール
- tfenvでインストール
- 公式dockerイメージを使う
切替が楽そうなtfenvでTerraformをインストールします。
実行環境はMacです。% brew install tfenv % tfenv --version tfenv 2.0.0インストール可能な一覧を確認します。
% tfenv list-remote 0.12.25 0.12.24 #~~~省略~~~ 0.1.1 0.1.0最新の
0.12.25をインストールします。% tfenv install 0.12.25 #~~~省略~~~ Installation of terraform v0.12.25 successful. To make this your default version, run 'tfenv use 0.12.25'指示通り
tfenv use 0.12.25を行います。% tfenv use 0.12.25 Switching default version to v0.12.25 Switching completedterraformコマンドが使えるか確認します。
% terraform --version Terraform v0.12.25インストールできました!
AWSのキーをリポジトリに含めないようにする
git secretsコマンドをインストールして、AWSのクレデンシャル情報をリポジトリに含まないようにします。詳細はこちらの記事が参考になります。
git-secretsはじめました
% brew install git-secrets以下は端末全体でAWSのクレデンシャル保護を有効化しています。
% git secrets --register-aws --global % git secrets --install ~/.git-templates/git-secrets % git config --global init.templatedir '~/.git-templates/git-secrets'試しにcommitしたらちゃんとエラ〜が出ました。
% mkdir workspace/aws/terraform && cd workspace/aws/terraform % git init % echo "aws_secret_access_key = ABcDe1F2hIjkl3nop45sTUv6XYz7aBcDEFghIJKL" > secret.txt % git add . % git commit -m "git secrets-test" secret.txt:1:aws_secret_access_key = ABcDe1F2hIjkl3nop45sTUv6XYz7aBcDEFghIJKL [ERROR] Matched one or more prohibited patterns実行環境ができたので次回からリソースの作成していきます。