- 投稿日:2020-05-28T23:39:35+09:00
Xamppの初期設定
Xamppの初期設定について紹介します。
作業環境
OS:Windows 10
エディション:HOME
バージョン:2004
Xampp:バージョン7.4.6※Xamppのインストール方法はこちらで解説しています。
【環境構築】Windows10にXAMMPをインストールする方法php.iniの設定を変更する
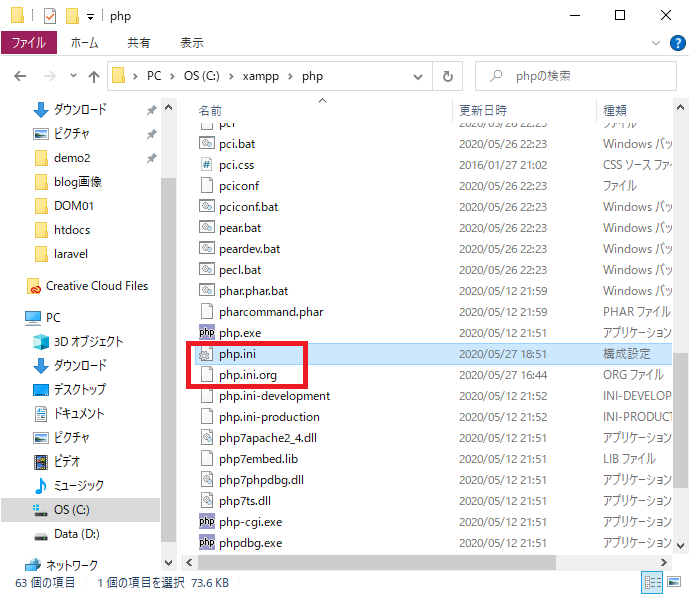
「Cドライブ」→「xampp」→「php」を開きます。設定を変更する前に「php.ini」をコピーして、「php.ini.org」などと書いてバックアップをしておきます。1.日本語化けを防ぐ
「php.ini」を開きます。
「mbstring.substitute_character」
「mbstring.substitute_character」で検索すると、下記のような記述が見つかります。
php.ini; substitute_character used when character cannot be converted ; one from another ; http://php.net/mbstring.substitute-character ;mbstring.substitute_character = none「mbstring.substitute_character」は無効な文字があった場合に代わりに表示する文字を指定します。今回はデフォルトの値のまま無効な文字は何も表示しない設定の「none」としておきます。
一番下の行はコメントがついて無効になっているので、下記のようにコメントアウトして、無効な文字は何も表示しない設定に変更します。
php.inimbstring.substitute_character = none
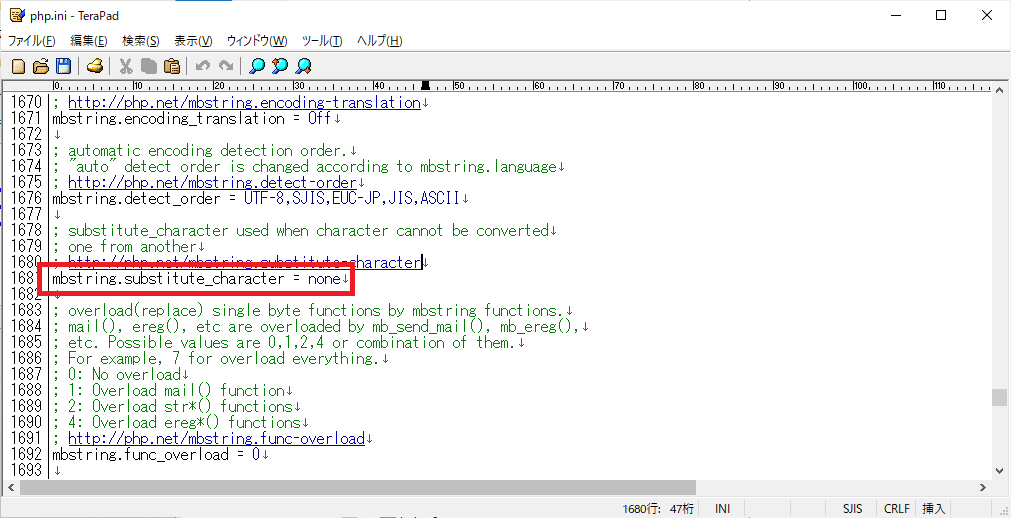
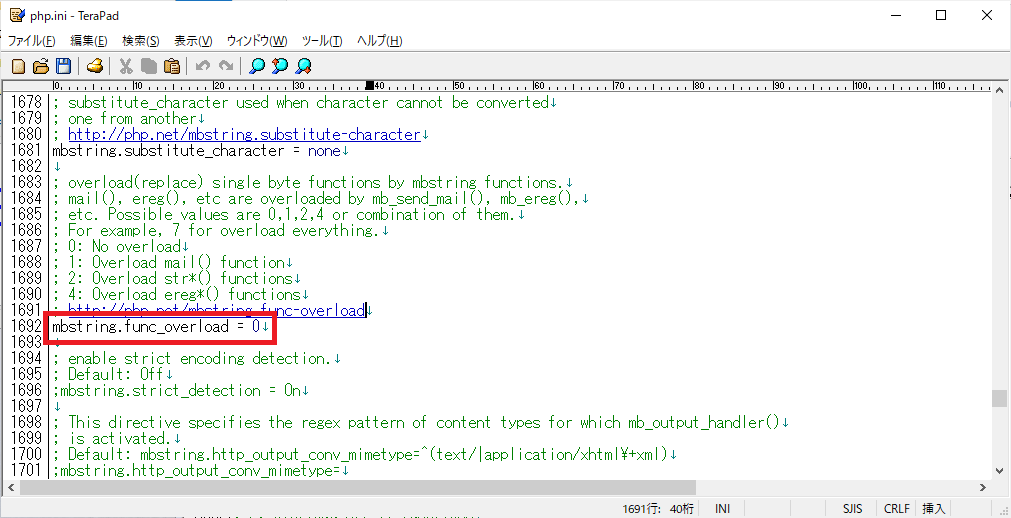
「mbstring.func_overload」
「mbstring.func_overload」で検索すると、下記のような記述が見つかります。
php.ini; overload(replace) single byte functions by mbstring functions. ; mail(), ereg(), etc are overloaded by mb_send_mail(), mb_ereg(), ; etc. Possible values are 0,1,2,4 or combination of them. ; For example, 7 for overload everything. ; 0: No overload ; 1: Overload mail() function ; 2: Overload str*() functions ; 4: Overload ereg*() functions ; http://php.net/mbstring.func-overload ; mbstring.func_overload = 0「mbstring.func_overload」はシングルバイト対応の関数をマルチバイト対応の関数でオーバーロードするどうかの設定です。自動でオーバーロードされると予期せぬ不具合が発生することもありますのでオーバーロードしない「0」としておきます。
先程と同様に、一番下の行はコメントついて無効になっているので、下記のようにコメントアウトして、オーバーロードをしない設定に変更します。
php.inimbstring.func_overload = 0
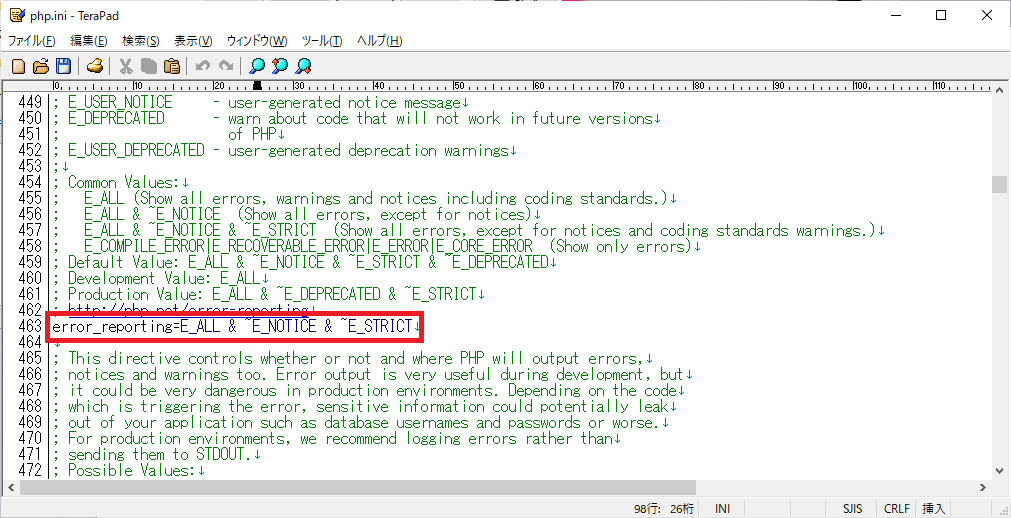
2.「Notice」のエラーを非表示にする
PHPのエラーには色々ありますが、「Notice」は「通知」という意味の英単語で、あまり重要ではないエラーです。「Notice」のエラー表示が出ると不便なので、表示をオフにします。
「error_reporting」と検索すると、下の行が見つかります。php.inierror_reporting=E_ALL & ~E_DEPRECATED & ~E_STRICTこの行を以下のように変更すると、「Notice」のエラーが非表示になります。
php.inierror_reporting=E_ALL & ~E_NOTICE & ~E_STRICT
MySQLのパスワードを設定する
Xamppはデフォルトだとパスワードが設定されていないので、パスワードを設定します。
1.phpMyAdminでパスワードを設定する
Xamppを起動し、「Apache」と「MySQL」を起動し、「MySQL」の横の「Admin」を選びます。
「MySQL」が起動するので、「ユーザーアカウント」を選びます。
「localhost」の「特権を編集」を選びます。
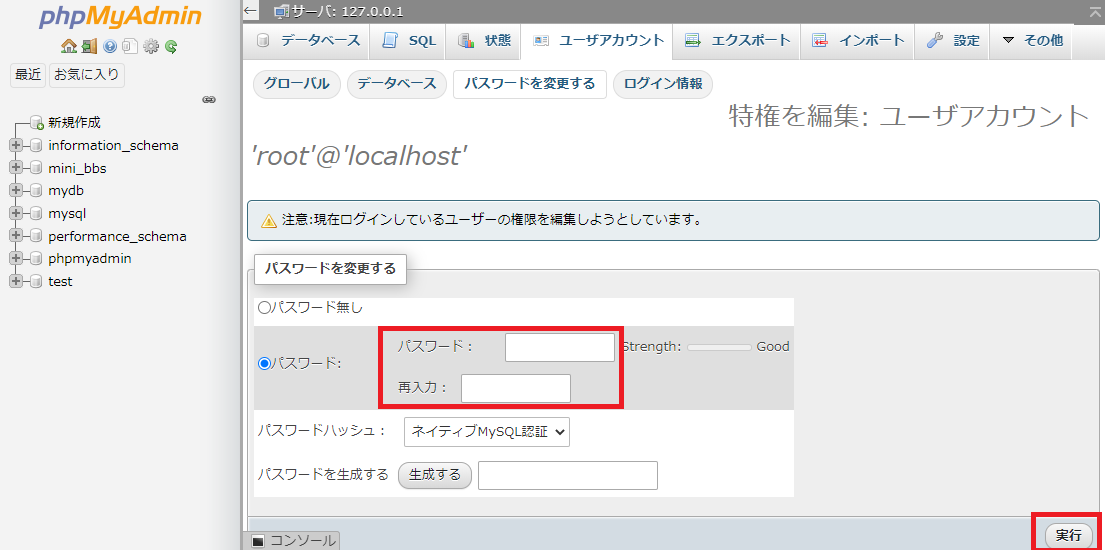
「パスワードを変更する」を選びます。
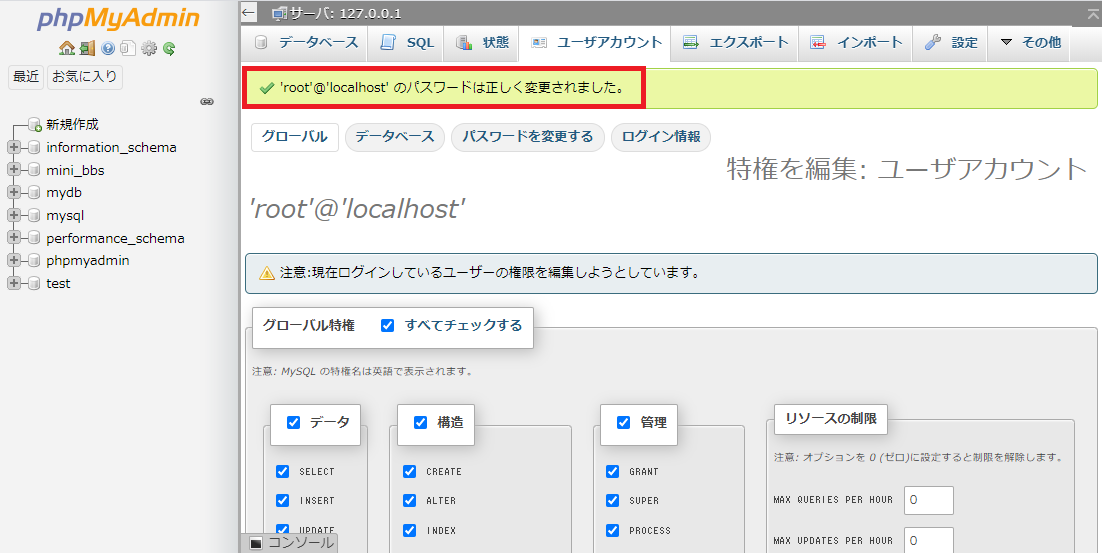
パスワードを2回入力し、右下の「実行」を選びます。
「'root'@'localhost' のパスワードは正しく変更されました。」と表示されれば、パスワードの設定が完了です。
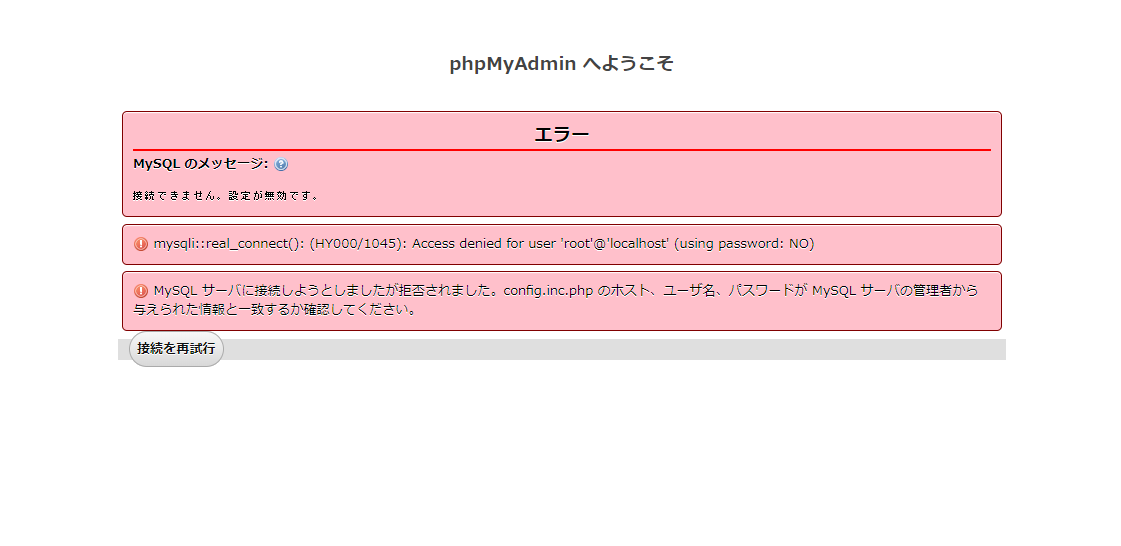
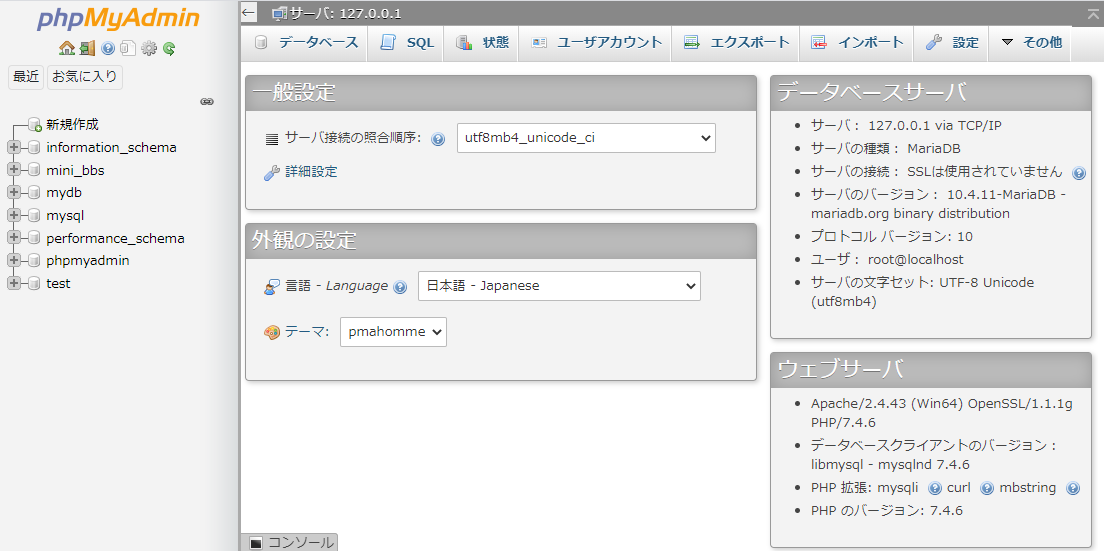
Xamppを再起動し、「Apache」と「MySQL」を起動し、「MySQL」の横の「Admin」を選ぶと、以下の画面が表示され、パスワードが設定できたことが確認できます。
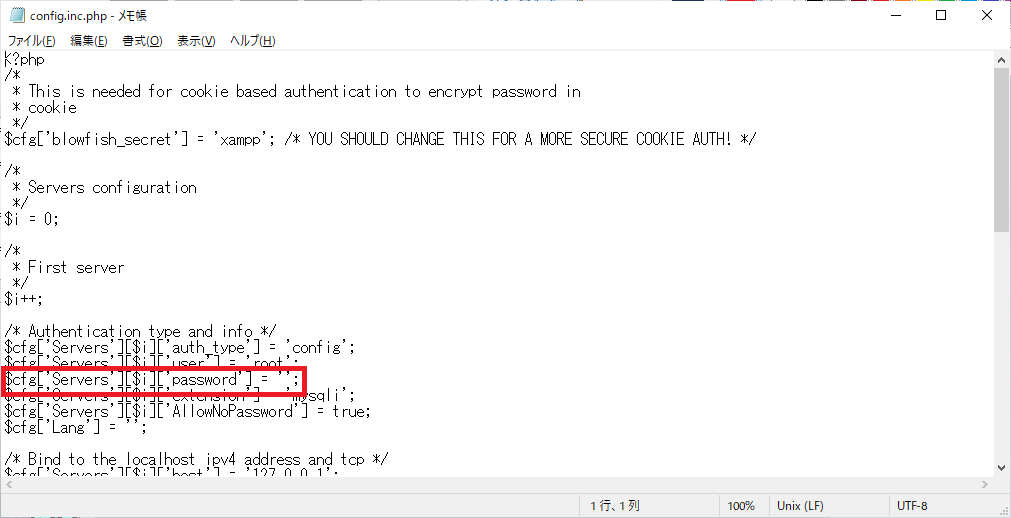
2.「config.inc.php」にパスワードを追記
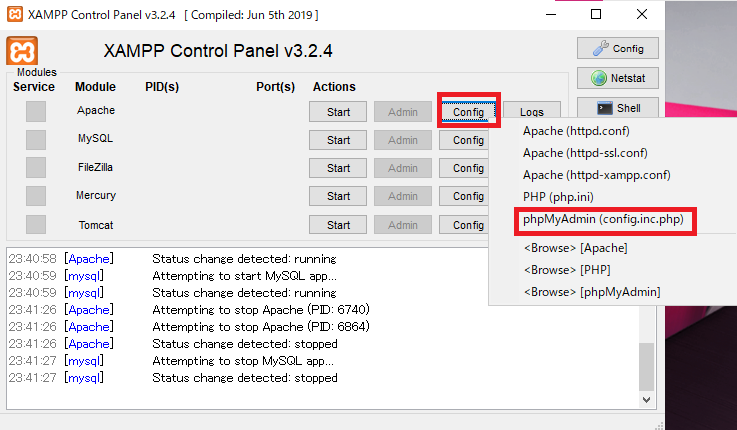
「Apache」→「Config」→「phpMyAdmin(config.inc.php)」を選びます。
上記の部分に先程設定したパスワードを追記します。
「Apache」と「MySQL」を起動し、「MySQL」の横の「Admin」を選ぶと、以下の画面が表示され、ログインできるようになります。
以上、Xamppの初期設定についてご紹介しました。
参考サイト
- 投稿日:2020-05-28T20:36:40+09:00
MySQL : group by句を使って、データ数を日時ごとでグループ化して表す
はじめに
インターネット上のニュース記事をスクレイピングしていた際、一時間ごとにどのくらい新着記事が増えているかを表すことがありました。
googleスプレッドシート等にあるピボットテーブルを使えば簡単に表示できますが、mysqlのgroup_by機能を使っても同じように表示できたので、まとめておこうと思います。ピボットテーブルで表す
今回は以下のように、ニュース記事が発行された時間が「published_at」としてスプレッドシート、mysqlにあらかじめ保存されています。
1日のうちで、一時間ごとの新着記事数を表したいので、「published_at 年-月-日」、「published_at 時」を行要素として、「published_at」の
COUNTAを値としてテーブルを作成します。
ピボットテーブルではこのように表すことができます。
mysqlでピボットテーブルを再現する
以下はピボットテーブルを再現するsqlです。
select date_format(published_at, '%Y-%m-%d'), date_format(published_at, '%H'), count(*) from articles group by date_format(published_at, '%Y-%m-%d'), date_format(published_at, '%H') with rollup;表示したいフィールドは
selectで選んでおきます。ピボットテーブルを再現したいので、published_atの年月日、時間、取得数を表示するように選びます。スプレッドシートとの対応としては、
- 「published_at 年-月-日」 -> date_format(published_at, '%Y-%m-%d')
- 「published_at 時」 -> date_format(published_at, '%H')
- 「published_atの
COUNTA」 -> count(*)になります。published_atは
date_formatでフォーマットが必要です。countはワイルドカードで十分です。
グループ化したいデータはgroup byで選択します。published_atの年月日、時間でグループ化したいので、selectのときと同様に選択します。
またwith rollupを使うことで1日の取得合計数を表示することができます。以下の結果が得られます。
+---------------------------------------+---------------------------------+----------+ | date_format(published_at, '%Y-%m-%d') | date_format(published_at, '%H') | count(*) | +---------------------------------------+---------------------------------+----------+ | 2020-05-23 | 06 | 1 | | 2020-05-23 | NULL | 1 | | 2020-05-24 | 11 | 1 | | 2020-05-24 | 19 | 1 | | 2020-05-24 | 20 | 1 | | 2020-05-24 | NULL | 3 | | 2020-05-25 | 03 | 1 | | 2020-05-25 | 08 | 1 | | 2020-05-25 | 10 | 2 | | 2020-05-25 | 11 | 1 | | 2020-05-25 | 12 | 1 | | 2020-05-25 | 13 | 3 | | 2020-05-25 | 15 | 3 | | 2020-05-25 | 17 | 1 | | 2020-05-25 | 19 | 2 | | 2020-05-25 | 20 | 1 | | 2020-05-25 | 21 | 1 | | 2020-05-25 | 22 | 1 | | 2020-05-25 | NULL | 18 | | 2020-05-26 | 00 | 2 | | 2020-05-26 | 05 | 4 | | 2020-05-26 | 06 | 5 | | 2020-05-26 | 07 | 1 | | 2020-05-26 | 08 | 2 | | 2020-05-26 | 09 | 1 | | 2020-05-26 | 10 | 3 | | 2020-05-26 | 11 | 5 | | 2020-05-26 | 12 | 5 | | 2020-05-26 | 14 | 3 | | 2020-05-26 | 15 | 6 | | 2020-05-26 | 16 | 8 | | 2020-05-26 | 17 | 19 | | 2020-05-26 | 18 | 18 | | 2020-05-26 | 19 | 9 | | 2020-05-26 | 20 | 15 | | 2020-05-26 | 21 | 17 | | 2020-05-26 | 22 | 13 | 以下省略ピボットテーブルと同様な表が得られています。
with rollupにより、1日の合計取得数がNULLの欄に出力されています。上の例ではピボットテーブルをできるだけ再現するために年月日と時間をわざわざ分けましたが、date_formatでフォーマットするときに日時を一緒にすることで簡略的にほしい結果を得ることもできます。
select date_format(published_at, '%Y-%m-%d %H'), count(*) from articles group by date_format(published_at, '%Y-%m-%d %H');実行結果
+------------------------------------------+----------+ | date_format(published_at, '%Y-%m-%d %H') | count(*) | +------------------------------------------+----------+ | 2020-05-23 06 | 1 | | 2020-05-24 11 | 1 | | 2020-05-24 19 | 1 | | 2020-05-24 20 | 1 | | 2020-05-25 03 | 1 | | 2020-05-25 08 | 1 | | 2020-05-25 10 | 2 | | 2020-05-25 11 | 1 | | 2020-05-25 12 | 1 | | 2020-05-25 13 | 3 | | 2020-05-25 15 | 3 | | 2020-05-25 17 | 1 | | 2020-05-25 19 | 2 | | 2020-05-25 20 | 1 | | 2020-05-25 21 | 1 | | 2020-05-25 22 | 1 | | 2020-05-26 00 | 2 | | 2020-05-26 05 | 4 | | 2020-05-26 06 | 5 | | 2020-05-26 07 | 1 | | 2020-05-26 08 | 2 | | 2020-05-26 09 | 1 | | 2020-05-26 10 | 3 | | 2020-05-26 11 | 5 | | 2020-05-26 12 | 5 | | 2020-05-26 14 | 3 | | 2020-05-26 15 | 6 | | 2020-05-26 16 | 8 | | 2020-05-26 17 | 19 | | 2020-05-26 18 | 18 | | 2020-05-26 19 | 9 | | 2020-05-26 20 | 15 | | 2020-05-26 21 | 17 | | 2020-05-26 22 | 13 | 以下省略簡略版では
with rollupが使えませんが、先程までと同様の結果が得られています。


- 投稿日:2020-05-28T11:38:26+09:00
Rails 6.0で"Uniqueness validator will no longer enforce case sensitive comparison in Rails 6.1."という警告が出たときの対処法
はじめに
MySQLを使っている既存のRailsアプリケーションをRails 6.0にアップデートすると、次のような警告が出ることがあります。
DEPRECATION WARNING: Uniqueness validator will no longer enforce case sensitive comparison in Rails 6.1. To continue case sensitive comparison on the :name attribute in User model, pass `case_sensitive: true` option explicitly to the uniqueness validator.(翻訳)
非推奨の警告: UniquenessバリデータはRails 6.1で「強制的に大文字小文字を区別する比較」をしなくなります。Userモデルの:name属性について引き続き「大文字小文字を区別する比較」を使い続けたい場合は、uniquenessバリデータに対して明示的にcase_sensitive: trueオプションを指定してください。警告が出るのは次のようにuniquenessバリデータを使っている部分です。
class User < ApplicationRecord validates :name, uniqueness: true endとりあえず、こんなふうに
case_sensitiveオプションを付けると警告は出なくなります。class User < ApplicationRecord # こうすれば警告は出なくなる、が!!! validates :name, uniqueness: { case_sensitive: true } endしかし、深く考えずにオプションを付けるのはあまりよくありません。
というわけで、この記事ではこの警告に対する対処方法を詳しく説明していきます。Rails 5.2以前の仕様(と問題)
前提としてこの問題はMySQLを使っている場合に発生します。PostgreSQLを使っている場合は通常問題になりません。
詳しい話は省略しますが、MySQLにはcollationという概念があります。
デフォルトではutf8mb4_unicode_ciというようなcollationになっており、この場合はデータベースに保存された文字列の大文字小文字を区別しません。つまり、"jnchito"という名前を検索するのに、
WHERE name = 'jnchito'というSQLを発行しても、WHERE name = 'JNCHITO'というSQLを発行してもどちらもヒットします。しかし、Rails 5.2以前のuniquenessバリデータはデフォルトで親切にも大文字小文字を区別する比較をしてくれます。
なので、DBに"jnchito"がすでに保存されている場合は、次のように振る舞います。
# 小文字のjnchitoはすでに登録済みなのでNG user.name = 'jnchito' user.valid? #=> false # 大文字のjnchitoはすでに未登録なのでOK user.name = 'JNCHITO' user.valid? #=> true # 背後では以下のようなSQLが発行されている(BINARYが付く) # SELECT 1 AS one FROM `users` WHERE `users`.`name` = BINARY 'JNCHITO' LIMIT 1一見これはありがたい仕様のように見えますが、次のような思わぬデメリットがあります。
- DB上のユニーク制約に一致しないため、バリデーションの結果が100%信用できない
- DB上のINDEXが効率良く使えないため、DBの負荷が大きくなる
実際、先ほど挙げたコードは以下のような矛盾した振る舞いをします。
(DB側にユニーク制約が付けられていた場合)# 大文字の"JNCHITO"なら検証エラーなしだから保存できそうだ user.name = 'JNCHITO' user.valid? #=> true # 保存実行・・・あれっ、DBのユニーク制約違反に引っかかって例外が発生しちゃった!! user.save #=> ActiveRecord::RecordNotUnique: # Mysql2::Error: Duplicate entry 'JNCHITO' for key 'users.index_users_on_name'RailsでMySQLを使っているとこのような問題がたびたび発生していたようです。
(僕は普段PostgreSQLを使っているので気づいていませんでしたが)(Rails 6.0ではなく)Rails 6.1で導入される仕様
この問題を回避するため、Rails 6.1のuniquenessバリデータはデフォルトで大文字小文字を区別しなくなります。
というか、厳密には「Rails側では素直にSQLを発行して、大文字小文字の区別はDB側の設定に任せる」という仕様になります。これにより、DB側の機能をフル活用できるようになるため、上で挙げていた、
- DB上のユニーク制約に一致しないため、バリデーションの結果が100%信用できない
- DB上のINDEXが効率良く使えないため、DBの負荷が大きくなる
といった問題が発生しなくなります。
たとえば、DBに"jnchito"がすでに保存されている場合、Rails 6.1ではおそらく次のような振る舞いになるはずです。
# jnchitoはすでに登録済みなのでNG(大文字小文字を区別しない) user.name = 'jnchito' user.valid? #=> false # JNCHITOはすでに登録済みなのでNG(大文字小文字を区別しない) user.name = 'JNCHITO' user.valid? #=> false # 背後では以下のようなSQLが発行されるはず(BINARYが付かない) # SELECT 1 AS one FROM `users` WHERE `users`.`name` = 'JNCHITO' LIMIT 1Rails 6.0は6.1の仕様変更に向けて、開発者にコードやDB設定の見直しを促す
しかし、Rails 6.1の仕様変更は「思わぬデメリット」を避けられるのと引き換えに、「大文字小文字の区別をしなくなる」という振る舞いの変化を招いてしまいます。
そこで、Rails 6.0ではRails 5.2以前の振る舞いを保ちつつ、「Rails 6.1は振る舞いが変わるよ!今のうちにどうしたいか決めて!」と、開発者に変更を促します。それが冒頭に紹介した警告です。
大文字小文字を区別する場合
Rails 5.2時代と同様に大文字小文字を区別したい場合は、明示的に
case_sensitive: trueのオプションを付ければ警告は消えます。ただし、DB側のcollationに変更がなければ、
- DB上のユニーク制約に一致しないため、バリデーションの結果が100%信用できない
- DB上のINDEXが効率良く使えないため、DBの負荷が大きくなる
という問題を抱えたままになってしまいます。
class User < ApplicationRecord # 警告は出なくなるが、DB側のcollationを変えなければ「思わぬデメリット」は残ったまま validates :name, uniqueness: { case_sensitive: true } endこうした問題を解消したい場合は、Rails側のコードを修正するのではなく、DB側のcollationを
utf8mb4_binのような「大文字小文字を区別するcollation」に変更する必要があります。(collationを変更する手順はここでは割愛します)DB側のcollationが大文字小文字を区別するようになっていれば、Railsのuniquenessバリデータの振る舞いとミスマッチがなくなるので警告は出なくなります。(
case_sensitiveオプションを指定する必要はありません)class User < ApplicationRecord # DB側のcollationを変えればcase_sensitiveオプションは不要。警告も「思わぬデメリット」も発生しない validates :name, uniqueness: true end大文字小文字を区別しない場合
大文字小文字を区別しなくていい場合は明示的に
case_sensitive: falseを指定します。
こうすればDB側のcollationもRailsのuniquenessバリデータも大文字小文字を区別しなくなるので、ミスマッチが解消され、警告も表示されなくなります。ただし、この場合はアプリケーションの挙動が変わってしまうので、ユーザーに混乱を招いたりしないか、よく検討する必要があります。
class User < ApplicationRecord # 警告は出なくなる。「思わぬデメリット」もなくなる。が、Rails 5.2と挙動が変わる validates :name, uniqueness: { case_sensitive: false } endまた、Rails 6.1にアプリケーションをアップグレードしたあとは
case_sensitive: falseのオプションを外しても問題ありません。(デフォルトで大文字小文字を区別しなくなるため)class User < ApplicationRecord # Rails 6.1ではcase_sensitiveをなくしてしまってもOK validates :name, uniqueness: true end参考:Rails 5.2〜6.1の振る舞いまとめ
この話は「MySQL側のcollation」と「uniquenessバリデータの
case_sensitiveオプション」と「Railsのバージョン」の組み合わせによって話がいろいろと変わってきます。それぞれの組み合わせで何が起きるか、以下の表にまとめておきます。
最終的には上の表の「DB側とRailsのミスマッチ?」欄が"NO"になる組み合わせが実現できれば理想的な状態、となります。
参考文献
- Rails 6.0でDeprecatedになるActive Recordの振る舞い3つ - かみぽわーる
- Deprecate mismatched collation comparison for uniquness validator by kamipo · Pull Request #35350 · rails/rails
- 本当にあったRailsの怖い話
謝辞
この件についてはRailsコミッタのkamipoさんにTwitter上で質問して丁寧に回答していただきました(参考)。kamipoさん、どうもありがとうございました!

- 投稿日:2020-05-28T11:02:40+09:00
【備忘録】database.ymlにおいてMySQLとPostgreSQLの設定切り替え
MySQLの設定
databse.ymldefault: &default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: socket: /tmp/mysql.sockPostgreSQLの設定
databse.ymldefault: &default adapter: postgresql pool: 5 timeout: 5000 encoding: unicode