- 投稿日:2020-05-28T23:58:30+09:00
偶数か奇数か
偶数か奇数か判定するプログラム
言語習得の初期によく出てくる偶数か奇数かを判定するプログラムを改めて。
プログラム
python
pythonevenoroddjudge.pydef is_even(num): return num % 2 == 0 num = float(input()) print(is_even(num))julia
juliaevenoroddjudge.jlfunction is_even(num) return num % 2 == 0 end function asknumber() print("Enter a number: ") parse(Float64, readline()) end num = asknumber() is_even(num)juliaのコードではわざわざfunctionを使っているがif文でも書ける。それについてはまた違う記事で。ほかの言語も後で書きます。
- 投稿日:2020-05-28T23:53:17+09:00
自前でk-NN実装してみる
動機
機械学習関連の知識を再確認していて、まずは最も基本的な手法、k-NN法(k最近傍法)を勉強がてら自前で実装してみました。
k-NN法とは
まずはk-NNの概要からおさらいします。とてもシンプルでわかりやすいアルゴリズムなのですぐ理解できると思います。
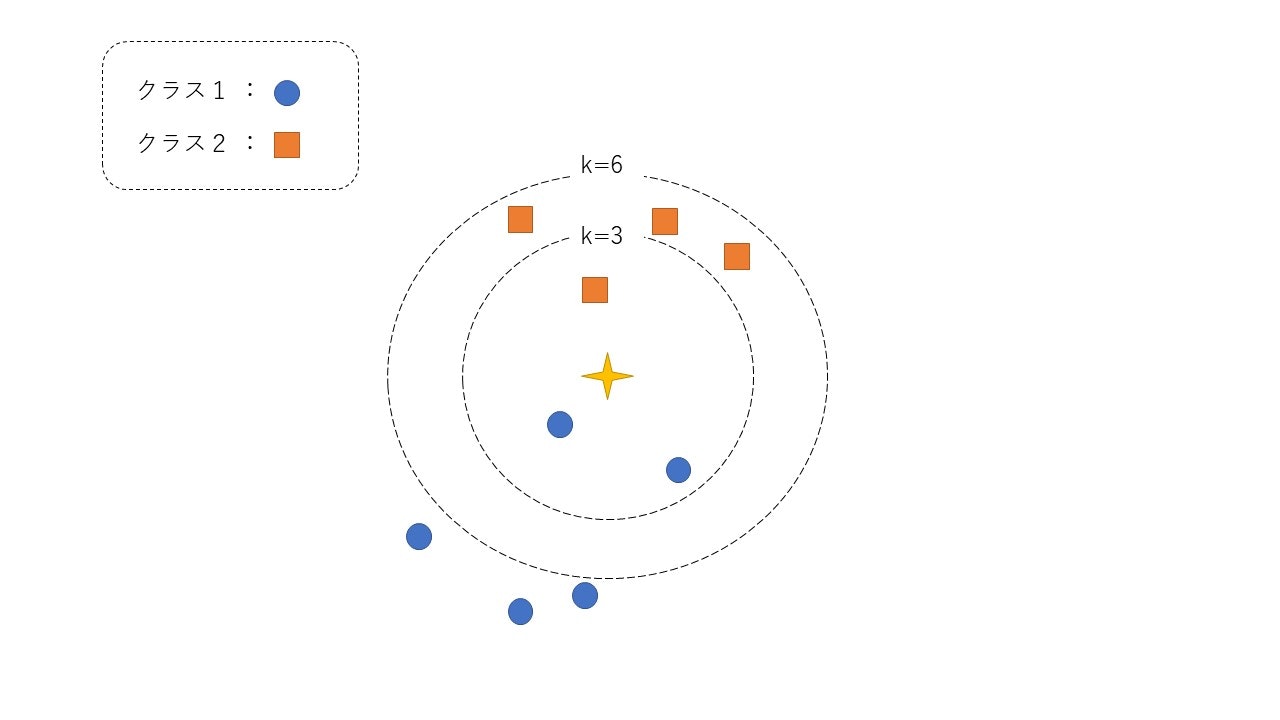
このアルゴリズムは下の図が全てです。
注目データは中心の星印です。まず与えられたデータに対して全てのデータ間の距離を計算します。例えばk=3のとき、注目データに最も近い上位3個のデータのラベルを見ます。この場合、クラス1が2個、クラス2は1個なので最頻値を取るクラス1に分類されます。一方で、k=6としてみると、クラス1が2個、クラス2が6個となるので、このデータはクラス2に分類されます。
このように与えられたデータは近いデータのラベルの多数決で決定されることになります。
ちなみにk=1のときは最近傍法とも呼ばます。
似たような名前の手法にk-means法がありますが、これは教師なしのクラスタリングの手法で、教師付き分類手法であるk-NN法とは異なった手法です。実装
それでは実際にPythonで実装していきたいと思います。
データセット
データセットは有名なIris Data Setを使います。
ますiris.dataをダウンロードして実際にデータを読み込みます。knn.pydata = np.loadtxt('iris.data', delimiter=',', dtype='float64',usecols=[0, 1, 2, 3]) labels = np.loadtxt('iris.data', delimiter=',', dtype='str',usecols=[4]) print(data.shape) print(labels.shape)(150, 4) (150,)このデータセットは4つの特徴量を持つ150個のデータとそのラベル(3クラス)で構成されています。
最近傍探索
今回はこれらのライブラリを使います。
knn.pyimport numpy as np from sklearn import model_selection from scipy.spatial import distance from sklearn.metrics import accuracy_score from statistics import mean, median,varianceまずは与えられた点に対して各データとの距離を計算します。
knn.pydistance_matrix = distance.cdist(test_data, train_data) indexes = np.argsort(distance_matrix, axis=1)次に与えられたデータの近傍k個のデータに対して、どのクラスのデータが何個あるのか数えます。
knn.pyclass_dict = {} for label in labels: class_dict[label] = 0 class_dict_list = [] for data_num, index in enumerate(indexes[:,:self.k]): class_dict_list.append(class_dict.copy()) for i in index: class_dict_list[data_num][self._labels[i]] += 1最後に最も多かったクラスのラベルを特定します。
knn.pypredict_class = [] for d in class_dict_list: max_class = max(d, key=d.get) predict_class.append(max_class)k-NNアルゴリズム自体はこれで全部です。
実行
今回は各クラスをランダムに半分に分けて、学習、実行の流れを20回繰り返します。実際の実行結果は以下のようになります。(ランダムにデータを分けるので、精度に多少の差は出ます。)
training number 1 ... knn accuracy : 0.9466666666666667 training number 2 ... knn accuracy : 0.9333333333333333 training number 3 ... knn accuracy : 0.9466666666666667 training number 4 ... knn accuracy : 0.9466666666666667 training number 5 ... knn accuracy : 0.9333333333333333 training number 6 ... knn accuracy : 0.92 training number 7 ... knn accuracy : 0.9466666666666667 training number 8 ... knn accuracy : 0.9466666666666667 training number 9 ... knn accuracy : 0.8933333333333333 training number 10 ... knn accuracy : 0.9466666666666667 training number 11 ... knn accuracy : 0.96 training number 12 ... knn accuracy : 0.96 training number 13 ... knn accuracy : 0.96 training number 14 ... knn accuracy : 0.96 training number 15 ... knn accuracy : 0.92 training number 16 ... knn accuracy : 0.96 training number 17 ... knn accuracy : 0.92 training number 18 ... knn accuracy : 0.9866666666666667 training number 19 ... knn accuracy : 0.9333333333333333 training number 20 ... knn accuracy : 0.96 ================================================= knn accuracy mean : 0.944 knn accuracy variance : 0.00042292397660818664このように、高い精度が実現できているのがわかると思います。
感想
シンプルなアルゴリズムだけあって非常に簡単に実装できました。今回のデータのように次元が小さく、少ないデータ数ならば非常に効果的です。
しかし、実際には高次元データに対して次元の呪いの効果でユークリッド距離が意味をなさなくなったり、大規模データセットでは時間計算量、空間計算量ともに実用的ではありません。
このような問題にはベクトルをハッシュ化したり、量子化したりする手法によって、メモリ消費量や計算量を削減する方法が提案されています。
実際のソースコードはgithub上で確認できます。
https://github.com/kotaYkw/machine_learning
- 投稿日:2020-05-28T23:43:44+09:00
Biopython Tutorial and Cookbook和訳(4.2)
4.2 Creating a SeqRecord
Using a SeqRecord object is not very complicated, since all of the information is presented as attributes of the class.
SeqRecord objectの使い方はそんなに複雑ではない、すべての情報はクラスの属性として明示されたからです。Usually you won’t create a SeqRecord “by hand”, but instead use Bio.SeqIO to read in a sequence file for you (see Chapter 5 and the examples below). However, creating SeqRecord can be quite simple.
通常SeqRecordオブジェクトを自分で生成しない、代わりにBio.SeqIOを使ってシーケンスファイルから読み込みます。(chap5と下のサンプルを参考してください)
しかしながら、SeqRecordの生成はとても簡単です。4.2.1 SeqRecord objects from scratch
To create a SeqRecord at a minimum you just need a Seq object:
Seqクラスを使うだけで最小限のSeqRecordオブジェクトを作れます。>>> from Bio.Seq import Seq >>> simple_seq = Seq("GATC") >>> from Bio.SeqRecord import SeqRecord >>> simple_seq_r = SeqRecord(simple_seq)Additionally, you can also pass the id, name and description to the initialization function, but if not they will be set as strings indicating they are unknown, and can be modified subsequently:
さらに、初期化の時にid、名前と解説を代入することができる。もしそうしなければ、それらの値はunknownで初期化されるが、後で修正しても大丈夫です。>>> simple_seq_r.id '<unknown id>' >>> simple_seq_r.id = "AC12345" >>> simple_seq_r.description = "Made up sequence I wish I could write a paper about" >>> print(simple_seq_r.description) Made up sequence I wish I could write a paper about >>> simple_seq_r.seq Seq('GATC')Including an identifier is very important if you want to output your SeqRecord to a file.
You would normally include this when creating the object:
もしSeqRecordをファイルとして出力したいなら、識別子を付けることがとても大事になります。通常はオブジェクトを生成する時に付け加えます。>>> from Bio.Seq import Seq >>> simple_seq = Seq("GATC") >>> from Bio.SeqRecord import SeqRecord >>> simple_seq_r = SeqRecord(simple_seq, id="AC12345")As mentioned above, the SeqRecord has an dictionary attribute annotations.
This is used for any miscellaneous annotations that doesn’t fit under one of the other more specific attributes.
上で述べたようにSeqRecordはアノテーションという辞書型の属性を持っています。
これは他の明確な属性にはまらない雑多なアノテーションに対して使います。Adding annotations is easy, and just involves dealing directly with the annotation dictionary:
アノテーションの追加は簡単で、直接辞書の中に追加すればいいです。>>> simple_seq_r.annotations["evidence"] = "None. I just made it up." >>> print(simple_seq_r.annotations) {'evidence': 'None. I just made it up.'} >>> print(simple_seq_r.annotations["evidence"]) None. I just made it up.Working with per-letter-annotations is similar, letter_annotations is a dictionary like attribute which will let you assign any Python sequence (i.e. a string, list or tuple) which has the same length as the sequence:
per-letter-annotationsの使い方も似ていて、letter_annotationsは辞書型でシーケンスデータを割り当てることができます。(i.e. 文字列, リスト あるいはタプル)>>> simple_seq_r.letter_annotations["phred_quality"] = [40, 40, 38, 30] >>> print(simple_seq_r.letter_annotations) {'phred_quality': [40, 40, 38, 30]} >>> print(simple_seq_r.letter_annotations["phred_quality"]) [40, 40, 38, 30]The dbxrefs and features attributes are just Python lists, and should be used to store strings and SeqFeature objects (discussed later in this chapter) respectively.
データベースへのクロスリファレンス(.dbxrefs)とフィーチャー情報はリスト型、それぞれ文字列およびSeqFeatureオブジェクトを格納するためいに使います。 (この章の後で述べます)4.2.2 SeqRecord objects from FASTA files
This example uses a fairly large FASTA file containing the whole sequence for Yersinia pestis biovar Microtus str. 91001 plasmid pPCP1, originally downloaded from the NCBI.
このサンプルではYersinia pestis菌の全シーケンスが含まれるかなりでかいFASTAファイルを使います。NCBIからダウンロードしました。This file is included with the Biopython unit tests under the GenBank folder, or online NC_005816.fna from our website.
Biopythonユニットテストを含むファイルはGenBankフォルダにあります、あるいは私たちのサイトからもファイルを取得できます。The file starts like this - and you can check there is only one record present (i.e. only one line starting with a greater than symbol):
このファイルは下記のような形で始まります - 今は一行しか載せてないですが(i.e.大なり記号から始まる一行)>gi|45478711|ref|NC_005816.1| Yersinia pestis biovar Microtus ... pPCP1, complete sequence TGTAACGAACGGTGCAATAGTGATCCACACCCAACGCCTGAAATCAGATCCAGGGGGTAATCTGCTCTCC ...Back in Chapter 2 you will have seen the function Bio.SeqIO.parse(...) used to loop over all the records in a file as SeqRecord objects.
Chapter 2で見たように関数Bio.SeqIO.parse(...)はSeqRecordオブジェクトファイルの全レコードをループします。The Bio.SeqIO module has a sister function for use on files which contain just one record which we’ll use here (see Chapter 5 for details):
ここで使うのは1レコードしか持たないファイルを読み込むためのBio.SeqIOモジュールにある類似の姉妹関数です。(詳細は第5章で述べます。)
※意味不明です。Now, let’s have a look at the key attributes of this SeqRecord individually – starting with the seq attribute which gives you a Seq object:
では、SeqRecordのメイン属性を見てみましょう - seq属性にアクセスしたらSeqオブジェクトを返してくれます。>>> record.seq Seq('TGTAACGAACGGTGCAATAGTGATCCACACCCAACGCCTGAAATCAGATCCAGG...CTG', SingleLetterAlphabet())Here Bio.SeqIO has defaulted to a generic alphabet, rather than guessing that this is DNA.
Bio.SeqIOが遺伝子アルファベットを返してくれた、推測するまでもなくそれはDNAです。If you know in advance what kind of sequence your FASTA file contains, you can tell Bio.SeqIO which alphabet to use (see Chapter 5).
もしあなたが予めFASTAファイルにどんなシーケンスデータが含まれると分かったら、Bio.SeqIOモジュールにどのアルファベットを使うのかを指定できます(5章を参照)。Next, the identifiers and description:
次は「識別子」と「説明」:>>> record.id 'gi|45478711|ref|NC_005816.1|' >>> record.name 'gi|45478711|ref|NC_005816.1|' >>> record.description 'gi|45478711|ref|NC_005816.1| Yersinia pestis biovar Microtus ... pPCP1, complete sequence'As you can see above, the first word of the FASTA record’s title line (after removing the greater than symbol) is used for both the id and name attributes.
上で見たように、FASTAファイル内のレコード行のタイトルの初文字(大なり記号>を取り除いた後)はidとname属性に両方に使われています。The whole title line (after removing the greater than symbol) is used for the record description. This is deliberate, partly for backwards compatibility reasons, but it also makes sense if you have a FASTA file like this:
タイトル全行(大なり記号>を取り除いた後)はレコードの説明に使われます。これはバックエンドとの互換性を取るための理由などがあります。しかも以下のようなFASTAファイルの場合はなおさらです。>Yersinia pestis biovar Microtus str. 91001 plasmid pPCP1 TGTAACGAACGGTGCAATAGTGATCCACACCCAACGCCTGAAATCAGATCCAGGGGGTAATCTGCTCTCC ...Note that none of the other annotation attributes get populated when reading a FASTA file:
注意するのはFASTAファイルを投入する初期では、他の属性は空となります。In this case our example FASTA file was from the NCBI, and they have a fairly well defined set of conventions for formatting their FASTA lines.
このコースでは私たちのサンプルFASTAファイルはNCBIから取得していて、FASTAレコードのフォーマットはかなり整備されています。This means it would be possible to parse this information and extract the GI number and accession for example.
However, FASTA files from other sources vary, so this isn’t possible in general.
つまり情報の分析およびGIナンバー、付加情報の抽出は可能になります。
しかし他のソース源では難しいことになるでしょう。4.2.3 SeqRecord objects from GenBank files
As in the previous example, we’re going to look at the whole sequence for Yersinia pestis biovar Microtus str. 91001 plasmid pPCP1, originally downloaded from the NCBI, but this time as a GenBank file.
前の例で、NCBIからダウンロードしたYersinia pestis菌の全シーケンスを見ました。今回はGenBankバージョンを見ましょう。Again, this file is included with the Biopython unit tests under the GenBank folder, or online NC_005816.gbfrom our website.
同じく、GenBankフォルダからBiopythonユニットテスト付きのファイルかを使うか、サイトから直接ダウンロードします。This file contains a single record (i.e. only one LOCUS line) and starts:
このファイルはシングルレコード(i.e. LOCUS 行はただ1行だけ)およぶstartsを含みます
※starts意味不明LOCUS NC_005816 9609 bp DNA circular BCT 21-JUL-2008 DEFINITION Yersinia pestis biovar Microtus str. 91001 plasmid pPCP1, complete sequence. ACCESSION NC_005816 VERSION NC_005816.1 GI:45478711 PROJECT GenomeProject:10638 ...Again, we’ll use Bio.SeqIO to read this file in, and the code is almost identical to that for used above for the FASTA file (see Chapter 5 for details):
同じく、Bio.SeqIOを使ってファイルを読み込み、FASTAファイルの時とほぼ同じやり方です。(詳細は第5章を参照):>>> from Bio import SeqIO >>> record = SeqIO.read("NC_005816.gb", "genbank") >>> record SeqRecord(seq=Seq('TGTAACGAACGGTGCAATAGTGATCCACACCCAACGCCTGAAATCAGATCCAGG...CTG', IUPACAmbiguousDNA()), id='NC_005816.1', name='NC_005816', description='Yersinia pestis biovar Microtus str. 91001 plasmid pPCP1, complete sequence.', dbxrefs=['Project:10638'])You should be able to spot some differences already! But taking the attributes individually, the sequence string is the same as before, but this time Bio.SeqIO has been able to automatically assign a more specific alphabet (see Chapter 5 for details):
すでにいくつかの違いを発見したはずですが、1個1個見ていきましょう、シーケンスに文字列は前と同じだが、今回Bio.SeqIOはもっと正確にアルファベットの種類を判定できました。(詳細は第5章を参照)The name comes from the LOCUS line, while the id includes the version suffix. The description comes from the DEFINITION line:
名前はLOCUS行、idがバージョン情報を含んでいます。説明はDEFINITION行から取りました。GenBank files don’t have any per-letter annotations:
GenBankファイルにper-letterアノテーションは存在しないです。>>> record.letter_annotations {}Most of the annotations information gets recorded in the annotations dictionary, for example:
多くのアノテーション情報はアノテーション辞書に収録されています。たとえば:>>> len(record.annotations) 11 >>> record.annotations["source"] 'Yersinia pestis biovar Microtus str. 91001'The dbxrefs list gets populated from any PROJECT or DBLINK lines:
リストdbxrefsはPROJECTあるいはDBLINK行の内容を反映します。>>> record.dbxrefs ['Project:10638']Finally, and perhaps most interestingly, all the entries in the features table (e.g. the genes or CDS features) get recorded as SeqFeature objects in the features list.
最後に、一番興味深いのは、フィーチャーテーブルのすべてのエントリ(e.g. genesあるいはCDSフィーチャー)がSeqFeatureオブジェクトとしてフィーチャーリストに保存されます。
- 投稿日:2020-05-28T23:23:17+09:00
Cisco覚書_EEMからPythonスクリプトを実行
何度shutdownしてもゾンビのように生き返る怖いスクリプト
IOS-XEでPythonスクリプトを動作する基本設定はCisco覚書_Pythonでconfig投入参照
スクリプト配置パス
パス:/flash/
ファイル:eem_script.py
guestshellに入ってファイル作成、またはファイルを転送isp-sw#guestshell [guestshell@guestshell ~]$ [guestshell@guestshell ~]$ cd /flash/ [guestshell@guestshell flash]$ vi eem_script.pyスクリプトの動作
Loopback55のIFを
no shutしてsh ip int briefでIF状態を表示する、という内容
今回はスクリプト実行のトリガーはEEMアプレットで指定するeem_script.pyimport sys from cli import cli,clip,configure,configurep, execute, executep intf= sys.argv[1:] intf = ''.join(intf[0]) print ('This script is going to unshut interface %s and then print show ip interface brief'%intf) if intf == 'loopback55': configurep(["interface loopback55","no shutdown","end"]) else : cmd='int %s,no shut ,end' % intf configurep(cmd.split(',')) executep('show ip interface brief')手動でスクリプトを起動する方法
EEMアプレットからだけではなく、EXECモードで手動でスクリプトを実行することもできる
※スクリプト中のsh ip int briefコマンドの実行はEXECモードからなのでEEMアプレットでは実行されない。isp-sw#guestshell run python /flash/eem_script.py loop55 This script is going to unshut interface loop55 and then print show ip interface brief Line 1 SUCCESS: int loop55 Line 2 SUCCESS: no shut Line 3 SUCCESS: end Interface IP-Address OK? Method Status Protocol Vlan1 unassigned YES NVRAM administratively down down ---省略--- Loopback13 10.13.13.13 YES manual up up Loopback55 10.55.55.55 YES TFTP up upEEMアプレット作成
設定モードにて
admindownのsyslogをトリガーにadminUPするスクリプトを実行する内容isp-sw(config)#event manager applet intshut isp-sw(config-applet)# event syslog pattern "Interface Loopback55, changed state to administratively down" isp-sw(config-applet)# action 0.0 cli command "en" isp-sw(config-applet)# action 1.0 cli command "guestshell run python /flash/eem_script.py loop55" isp-sw(config-applet)#endスクリプトのパスをconfig上で指定
設定モードにて
配置パスを指定isp-sw(config)#event manager directory user policy "flash:/"EEM起動状態確認
EXECモードにて
正常に登録されていれば表示されるisp-sw#sh event manager policy registered No. Class Type Event Type Trap Time Registered Name 1 applet user syslog Off Thu Mar 28 16:37:52 2020 intshut pattern {Interface Loopback55, changed state to administratively down} maxrun 20.000 action 0.0 cli command "en" action 1.0 cli command "guestshell run python /flash/eem_script.py loop55"手動shutdownしてみる
設定モードでshutdownコマンドを投入、ter monでログをターミナルに出力させて動作確認
ログからshurdown後に自動でUPしている。isp-sw(config-if)#shutdown isp-sw(config-if)# Mar 28 16:56:22.428 JST: %LINEPROTO-5-UPDOWN: Line protocol on Interface Loopback55, changed state to down Mar 28 16:56:22.428 JST: %LINK-5-CHANGED: Interface Loopback55, changed state to administratively down isp-sw(config-if)# Mar 28 16:56:29.880 JST: %LINEPROTO-5-UPDOWN: Line protocol on Interface Loopback55, changed state to up isp-sw(config-if)# Mar 28 16:56:29.880 JST: %LINK-3-UPDOWN: Interface Loopback55, changed state to up isp-sw(config-if)#イベントが発生した履歴を確認
EXECモードにて
successでEEMにより正常実行しているisp-sw#sh event manager history events No. Job Id Proc Status Time of Event Event Type Name 1 1 Actv success Thu Mar28 16:36:19 2020 syslog applet: intshut 2 2 Actv success Thu Mar28 16:43:43 2020 syslog applet: intshut 3 3 Actv success Thu Mar28 16:56:22 2020 syslog applet: intshut
確認機種とバージョン
機種:Catalyst3850
Ver:Cisco IOS XE 16.06.05 Everest
参考リンク
Programmability Configuration Guide, Cisco IOS XE Everest 16.6.x
- 投稿日:2020-05-28T23:12:43+09:00
言語処理100本ノック 2020【00~79 解答】
この記事は言語処理100本ノック 2020【第7章: 単語ベクトル】の続きです。
この記事では、第8章(70-79)の機械学習について扱います。
リンク
この記事にはコードのみを載せました。問題文や解き方の補足は下記のリンクを参考にしてください。
第8章: ニューラルネット
70. 単語ベクトルの和による特徴量
import pandas as pd import gensim import numpy as np train = pd.read_csv('train.txt',sep='\t',header=None) valid = pd.read_csv('valid.txt',sep='\t',header=None) test = pd.read_csv('test.txt',sep='\t',header=None) model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True) d = {'b':0, 't':1, 'e':2, 'm':3} y_train = train.iloc[:,0].replace(d) y_train.to_csv('y_train.txt',header=False, index=False) y_valid = valid.iloc[:,0].replace(d) y_valid.to_csv('y_valid.txt',header=False, index=False) y_test = test.iloc[:,0].replace(d) y_test.to_csv('y_test.txt',header=False, index=False) def write_X(file_name, df): with open(file_name,'w') as f: for text in df.iloc[:,1]: vectors = [] for word in text.split(): if word in model.vocab: vectors.append(model[word]) if (len(vectors)==0): vector = np.zeros(300) else: vectors = np.array(vectors) vector = vectors.mean(axis=0) vector = vector.astype(np.str).tolist() output = ' '.join(vector)+'\n' f.write(output) write_X('X_train.txt', train) write_X('X_valid.txt', valid) write_X('X_test.txt', test)71. 単層ニューラルネットワークによる予測
import torch import numpy as np X_train = np.loadtxt(base+'X_train.txt', delimiter=' ') X_train = torch.tensor(X_train, dtype=torch.float32) W = torch.randn(300, 4) softmax = torch.nn.Softmax(dim=1) print (softmax(torch.matmul(X_train[:1], W))) print (softmax(torch.matmul(X_train[:4], W)))72. 損失と勾配の計算
y_train = np.loadtxt(base+'y_train.txt') y_train = torch.tensor(y_train, dtype=torch.int64) loss = torch.nn.CrossEntropyLoss() print (loss(torch.matmul(X_train[:1], W),y_train[:1])) print (loss(torch.matmul(X_train[:4], W),y_train[:4])) ans = [] # 以下、確認 for s,i in zip(softmax(torch.matmul(X_train[:4], W)),y_train[:4]): ans.append(-np.log(s[i])) print (np.mean(ans))73. 確率的勾配降下法による学習
from torch.utils.data import TensorDataset, DataLoader class LogisticRegression(torch.nn.Module): def __init__(self): super().__init__() self.net = torch.nn.Sequential( torch.nn.Linear(300, 4), ) def forward(self, X): return self.net(X) model = LogisticRegression() ds = TensorDataset(X_train, y_train) # DataLoaderを作成 loader = DataLoader(ds, batch_size=1, shuffle=True) loss_fn = torch.nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.net.parameters(), lr=1e-1) for epoch in range(10): for xx, yy in loader: y_pred = model(xx) loss = loss_fn(y_pred, yy) optimizer.zero_grad() loss.backward() optimizer.step()74. 正解率の計測
def accuracy(pred, label): pred = np.argmax(pred.data.numpy(), axis=1) label = label.data.numpy() return (pred == label).mean() X_valid = np.loadtxt(base+'X_valid.txt', delimiter=' ') X_valid = torch.tensor(X_valid, dtype=torch.float32) y_valid = np.loadtxt(base+'y_valid.txt') y_valid = torch.tensor(y_valid, dtype=torch.int64) pred = model(X_train) print (accuracy(pred, y_train)) pred = model(X_valid) print (accuracy(pred, y_valid))75. 損失と正解率のプロット
%load_ext tensorboard !rm -rf ./runs %tensorboard --logdir ./runs from torch.utils.tensorboard import SummaryWriter writer = SummaryWriter() from torch.utils.data import TensorDataset, DataLoader class LogisticRegression(torch.nn.Module): def __init__(self): super().__init__() self.net = torch.nn.Sequential( torch.nn.Linear(300, 4), ) def forward(self, X): return self.net(X) model = LogisticRegression() ds = TensorDataset(X_train, y_train) # DataLoaderを作成 loader = DataLoader(ds, batch_size=1, shuffle=True) loss_fn = torch.nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.net.parameters(), lr=1e-1) for epoch in range(10): for xx, yy in loader: y_pred = model(xx) loss = loss_fn(y_pred, yy) optimizer.zero_grad() loss.backward() optimizer.step() with torch.no_grad(): y_pred = model(X_train) loss = loss_fn(y_pred, y_train) writer.add_scalar('Loss/train', loss, epoch) writer.add_scalar('Accuracy/train', accuracy(y_pred,y_train), epoch) y_pred = model(X_valid) loss = loss_fn(y_pred, y_valid) writer.add_scalar('Loss/valid', loss, epoch) writer.add_scalar('Accuracy/valid', accuracy(y_pred,y_valid), epoch)76. チェックポイント
from torch.utils.data import TensorDataset, DataLoader class LogisticRegression(torch.nn.Module): def __init__(self): super().__init__() self.net = torch.nn.Sequential( torch.nn.Linear(300, 4), ) def forward(self, X): return self.net(X) model = LogisticRegression() ds = TensorDataset(X_train, y_train) # DataLoaderを作成 loader = DataLoader(ds, batch_size=1, shuffle=True) loss_fn = torch.nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.net.parameters(), lr=1e-1) for epoch in range(10): for xx, yy in loader: y_pred = model(xx) loss = loss_fn(y_pred, yy) optimizer.zero_grad() loss.backward() optimizer.step() with torch.no_grad(): y_pred = model(X_train) loss = loss_fn(y_pred, y_train) writer.add_scalar('Loss/train', loss, epoch) writer.add_scalar('Accuracy/train', accuracy(y_pred,y_train), epoch) y_pred = model(X_valid) loss = loss_fn(y_pred, y_valid) writer.add_scalar('Loss/valid', loss, epoch) writer.add_scalar('Accuracy/valid', accuracy(y_pred,y_valid), epoch) torch.save(model.state_dict(), base+'output/'+str(epoch)+'.model') torch.save(optimizer.state_dict(), base+'output/'+str(epoch)+'.param')77. ミニバッチ化
import time from torch.utils.data import TensorDataset, DataLoader class LogisticRegression(torch.nn.Module): def __init__(self): super().__init__() self.net = torch.nn.Sequential( torch.nn.Linear(300, 4), ) def forward(self, X): return self.net(X) model = LogisticRegression() ds = TensorDataset(X_train, y_train) loss_fn = torch.nn.CrossEntropyLoss() ls_bs = [2**i for i in range(15)] ls_time = [] for bs in ls_bs: loader = DataLoader(ds, batch_size=bs, shuffle=True) optimizer = torch.optim.SGD(model.net.parameters(), lr=1e-1) for epoch in range(1): start = time.time() for xx, yy in loader: y_pred = model(xx) loss = loss_fn(y_pred, yy) optimizer.zero_grad() loss.backward() optimizer.step() ls_time.append(time.time()-start) print (ls_time)78. GPU上での学習
import time from torch.utils.data import TensorDataset, DataLoader class LogisticRegression(torch.nn.Module): def __init__(self): super().__init__() self.net = torch.nn.Sequential( torch.nn.Linear(300, 4), ) def forward(self, X): return self.net(X) model = LogisticRegression() device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model = model.to(device) ds = TensorDataset(X_train.to(device), y_train.to(device)) loss_fn = torch.nn.CrossEntropyLoss() ls_bs = [2**i for i in range(15)] ls_time = [] for bs in ls_bs: loader = DataLoader(ds, batch_size=bs, shuffle=True) optimizer = torch.optim.SGD(model.net.parameters(), lr=1e-1) for epoch in range(1): start = time.time() for xx, yy in loader: y_pred = model(xx) loss = loss_fn(y_pred, yy) optimizer.zero_grad() loss.backward() optimizer.step() ls_time.append(time.time()-start) print (ls_time)79. 多層ニューラルネットワーク
import time from torch.utils.data import TensorDataset, DataLoader class MLP(torch.nn.Module): def __init__(self): super().__init__() self.net = torch.nn.Sequential( torch.nn.Linear(300, 32), torch.nn.ReLU(), torch.nn.Linear(32, 4), ) def forward(self, X): return self.net(X) model = MLP() device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model = model.to(device) ds = TensorDataset(X_train.to(device), y_train.to(device)) loss_fn = torch.nn.CrossEntropyLoss() loader = DataLoader(ds, batch_size=1024, shuffle=True) optimizer = torch.optim.SGD(model.net.parameters(), lr=1e-1) for epoch in range(100): start = time.time() for xx, yy in loader: y_pred = model(xx) loss = loss_fn(y_pred, yy) optimizer.zero_grad() loss.backward() optimizer.step() with torch.no_grad(): y_pred = model(X_train.to(device)) loss = loss_fn(y_pred, y_train.to(device)) writer.add_scalar('Loss/train', loss, epoch) train_acc = accuracy(y_pred.cpu(),y_train.cpu()) writer.add_scalar('Accuracy/train', acc, epoch) y_pred = model(X_valid.to(device)) loss = loss_fn(y_pred, y_valid.to(device)) writer.add_scalar('Loss/valid', loss, epoch) valid_acc = accuracy(y_pred.cpu(),y_valid.cpu()) writer.add_scalar('Accuracy/valid', acc, epoch) print (train_acc, valid_acc)
- 投稿日:2020-05-28T22:30:03+09:00
OpenCV/Pythonで2値化
#!/usr/bin/env python # -*- coding: utf-8 -*- import cv2 import time def conv(): # 閾値の設定 threshold = 100 # 二値化(閾値100を超えた画素を255にする。) ret, img_thresh = cv2.threshold(img, threshold, 255, cv2.THRESH_BINARY) # 二値化画像の表示 cv2.imshow("img_th", img_thresh) cv2.waitKey() cv2.destroyAllWindows() def fps(video): fps = video.get(cv2.CAP_PROP_FPS) print("FPSの設定値、video.get(cv2.CAP_PROP_FPS) : {0}".format(fps)) # 取得するフレームの数 num_frames = 120 print("取得中 {0} frames".format(num_frames)) # 開始時間 start = time.time() # フレームを取得する #for i in range(0, num_frames): # ret, frame = video.read() # 終了時間 end = time.time() # Time elapsed seconds = end - start print("経過時間: {0} seconds".format(seconds)) # Calculate frames per second fps = num_frames / seconds print("計算したFPS : {0}".format(fps)) class FPS: def __init__(self): self.flag = False self.start = 0 self.end = 0 self.fps = 0 self.framecnt = 0 def calc_fps(self): if self.flag == False: self.start = time.time() self.flag = True else: diff = time.time() - self.start if diff > 1.0: self.fps = self.framecnt / diff self.framecnt = 0 self.start = time.time() self.framecnt += 1 return self.fps def test1(mode): URL = "http://172.23.64.38:8081/?action=stream" winname ="winname" cv2.namedWindow(winname, cv2.WINDOW_NORMAL) try : if mode == 0: s_video = cv2.VideoCapture(0) else: s_video = cv2.VideoCapture(URL) # 閾値の設定 threshold = 200 fpsobj = FPS() while True: start = time.time() end = time.time() seconds = end - start ret, srcimg = s_video.read() #cv2.imshow(winname,img) key = cv2.waitKey(1) & 0xff if key == ord('q'): break # 二値化(閾値100を超えた画素を255にする。) #cv2.threshold(画像, 閾値, 閾値を超えた場合に変更する値, 二値化の方法) ret, img = cv2.threshold(srcimg, threshold, 255, cv2.THRESH_BINARY) ksize=7 # アパーチャーサイズ 3, 5, or 7 など 1 より大きい奇数。数値が大きいほどぼかしが出る。 img = cv2.medianBlur(img,ksize) img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # RGB2〜 でなく BGR2〜 を指定 ret, img = cv2.threshold(img, 20, 255, cv2.THRESH_BINARY) #print("{}".format( fpsobj.calc_fps())) if ret: # 二値化画像の表示 cv2.imshow(winname, img) except: pass cv2.destroyAllWindows() if __name__ == "__main__": test1(1)C++
#include <opencv2/core.hpp> #include <opencv2/videoio.hpp> #include <opencv2/highgui.hpp> #include <iostream> #include <stdio.h> #include "opencv2/imgcodecs.hpp" #include "opencv2/highgui.hpp" #include "opencv2/imgproc.hpp" #include "opencv2/photo.hpp" // http://labs.eecs.tottori-u.ac.jp/sd/Member/oyamada/OpenCV/html/py_tutorials/py_imgproc/py_thresholding/py_thresholding.html Mat dst; int criteria = 100; int max = 255; for ( ;;) { cap.read( frame ); cv::threshold( frame, dst, criteria, max, THRESH_BINARY ); // binalized int ksize = 7;// # アパーチャーサイズ 3, 5, or 7 など 1 より大きい奇数。数値が大きいほどぼかしが出る。 cv::medianBlur( dst, dst, ksize ); cv::cvtColor( dst, dst, COLOR_BGR2GRAY );// # RGB2〜 でなく BGR2〜 を指定 cv::threshold( dst, dst, 20, max, THRESH_BINARY ); imshow( "Live", dst ); if ( waitKey( 5 ) >= 0 ) { break; } }
- 投稿日:2020-05-28T22:19:54+09:00
✨Pythonで簡単☆死後経過時間✨
もし、あなたの目の前に亡骸があったら?
(引用;名探偵コナン「甘く冷たい宅配便」)
コナン君が遺体を見つけた時、かなり最初の段階で死後経過時間について考えますよね?死亡推定時刻が分かれば大きく容疑者を絞り込むことができますしね\(^o^)/
そこで今回は死後経過時間について詳しい求め方を紹介します!例題
室温16℃に設定された冷蔵車に男性の遺体があった。男性の体重は86kg、コナン君が遺体の直腸内温度を計ったところ、27℃であった。男性の死後経過時間を求めよ。
ニュートンの冷却の法則
まず、簡略化した事象を考えてみましょう。コップに入れられた熱いコーヒーが周囲の温度(空気)によって冷まされる問題を考えます。この時、次の「ニュートンの冷却の法則」が近似的に成り立つと言われています。
ニュートンの冷却の法則を表す微分方程式は$\frac{dT}{dt} = -γ(T - T_s)$ (1)
で表されます。ここで、各文字は
$T$:湯の温度
$T_s$:周囲の温度
$\gamma$:冷却定数
を表しています。この微分法方程式は解析的に解くことができます。まず、(1)式の両辺を$T-T_s$で割ります。
$\frac{1}{T-T_s}dT = -γdt$両辺を積分して積分定数をCとすると、
$log (T - T_s) = -γt + C$
となります。この式をTについて解くと下式のようになります。
$T = T_s + e^{-γt + C}$ (2)
初期条件$T(0)=T_0$を課すと、積分定数Cは
$C = log (T_0-T_s)$となります。これを(2)式に代入すれば、解析解は以下で与えられます。
$T(t) = T_s + (T_0 - T_s) e^{-γt}$(また、これを変形して)
$\frac{T(t)-T_s}{T_0-T_s} = e^{-γt}$直腸温の連続測定による死後経過時間の推算
次に、ニュートンの冷却の法則を利用して死後経過時間を求めます。「直腸温の連続測定による死後経過時間の推算(早大院先進理工)」によると遺体の場合、微分方程式は次の様に変形されます。
(1) $\frac{T_r-T_e}{T_o-T_e}=1.25e^{B*t}-0.25e^{5B*t}$ $(T_e\le23.2)$
(2) $\frac{T_r-T_e}{T_o-T_e}=1.11e^{B*t}-0.11e^{10B*t}$ $(T_e\ge23.2)$
(3) $B=-1.2815(bW)^{-0.625}+0.0284$
ただし、
$T_r$は直腸温℃
$T_e$は環境温℃
$T_o$は死亡時の直腸温であり37.2℃とする
$T_e$は環境温℃で測定時間の平均値で一定とする
$W$死体の体重kg
$b=1$は補正係数
$B$はNewtonの冷却定数
$t$は死後経過時間(h)
とします。
これを元に早速今回の例題を解きましょう!import sympy def death_time(Tr,Te,W): Tr=Tr Te=Te W=W B = sympy.Symbol('B') t = sympy.Symbol('t') To = 37.2 b = 1 E = sympy.S.Exp1 equation1 = 1.25*(E**(B*t))-0.25*(E**(5*B*t))-(Tr-Te)/(To-Te) equation2 = 1.11*(E**(B*t))-0.11*(E**(10*B*t))-(Tr-Te)/(To-Te) equation3 = -1.2815*((b*W)**(-0.625))+0.0284-B if Te <= 23.2: print(sympy.solve([equation1,equation3])) else: print(sympy.solve([equation2,equation3])) death_time(27,16,86) #今回の問題の設定$ $参考文献によると$T_e$は環境温の平均を使いますが、今回は発見時の室温の16℃を$T_e$としました。
結果は言わなくても分かると思いますが、scipyでこんな累乗変数を含む計算を直接できるわけもなく、朝起きても計算を続けていました(泣)。参考文献通りに試行錯誤法の考えの元で解くことにしました。関数の微分を求め方程式を反復の都度解く処理が大きい為、上図の様に微分を差分で近似させたクリロフ部分交換法を用いて計算することにしました。
import math from scipy.optimize import newton_krylov import sympy #(3)式に相当する。体重(kg)からNewtonの冷却定数Bを算出。To(死亡時直腸温)は37.2とする def predict_B(W): W=W B = sympy.Symbol('B') b = 1 equation3 = -1.2815*((b*W)**(-0.625))+0.0284-B B = sympy.solve([equation3])[B] return B #(1)(2)式に相当。環境温Teで場合分け def predict_deathtime(W,Tr,Te,ta): Bx = predict_B(W) Tr,Te,ta = Tr,Te,ta E = sympy.S.Exp1 To = 37.2 def F(x): if Te <= 23.2: return 1.25*(E**(Bx*x))-0.25*(E**(5*Bx*x))-(Tr-Te)/(To-Te) else: return 1.11*(E**(Bx*x))-0.11*(E**(10*Bx*x))-(Tr-Te)/(To-Te) guess = ta sol = newton_krylov(F, guess, method='lgmres') print(sol) #(体重,直腸温,環境温,死後経過時間の初期値)の順で入力 #死後経過時間の初期値を0とするとヤコビアンが求められないので注意する predict_deathtime(86,27,16,2)出力結果17.19191007875492よって、今回の例題では17時間ほど前に死亡したことが分かりました!
参考文献
計算科学をはじめよう! ニュートンの冷却法則①
直腸温の連続測定による死後経過時間の推算(早大院先進理工)○(学)井上 幹康*(正)酒井 清孝(早大高等研)(正)山本 健一郎(防衛医大)(正)金武 潤

- 投稿日:2020-05-28T22:19:54+09:00
✨Pythonで簡単☆死後経過時間推定✨
もし、あなたの目の前に亡骸があったら?
コナン君が遺体を見つけた時、かなり最初の段階で死後経過時間について考えますよね?死亡推定時刻が分かれば大きく容疑者を絞り込むことができますしね\(^o^)/
そこで今回は死後経過時間について詳しい求め方を紹介します!例題
室温16℃に設定された冷蔵車に男性の遺体があった。男性の体重は86kg、コナン君が遺体の直腸内温度を計ったところ、27℃であった。男性の死後経過時間を求めよ。
ニュートンの冷却の法則
まず、簡略化した事象を考えてみましょう。コップに入れられた熱いコーヒーが周囲の温度(空気)によって冷まされる問題を考えます。この時、次の「ニュートンの冷却の法則」が近似的に成り立つと言われています。
ニュートンの冷却の法則を表す微分方程式は$\frac{dT}{dt} = -γ(T - T_s)$ (1)
で表されます。ここで、各文字は
$T$:湯の温度
$T_s$:周囲の温度
$\gamma$:冷却定数
を表しています。この微分法方程式は解析的に解くことができます。まず、(1)式の両辺を$T-T_s$で割ります。
$\frac{1}{T-T_s}dT = -γdt$両辺を積分して積分定数をCとすると、
$log (T - T_s) = -γt + C$
となります。この式をTについて解くと下式のようになります。
$T = T_s + e^{-γt + C}$ (2)
初期条件$T(0)=T_0$を課すと、積分定数Cは
$C = log (T_0-T_s)$となります。これを(2)式に代入すれば、解析解は以下で与えられます。
$T(t) = T_s + (T_0 - T_s) e^{-γt}$(また、これを変形して)
$\frac{T(t)-T_s}{T_0-T_s} = e^{-γt}$直腸温の連続測定による死後経過時間の推算
次に、ニュートンの冷却の法則を利用して死後経過時間を求めます。「直腸温の連続測定による死後経過時間の推算(早大院先進理工)」によると遺体の場合、微分方程式は次の様に変形されます。
$\frac{T_r-T_e}{T_o-T_e}=1.25e^{B*t}-0.25e^{5B*t}$ $(T_e\le23.2)$
$\frac{T_r-T_e}{T_o-T_e}=1.11e^{B*t}-0.11e^{10B*t}$ $(T_e\ge23.2)$
$B=-1.2815(bW)^{-0.625}+0.0284$
ただし、
$T_r$は直腸温℃
$T_e$は環境温℃
$T_o$は死亡時の直腸温であり37.2℃とする
$T_e$は環境温℃で測定時間の平均値で一定とする
$W$死体の体重kg
$b=1$は補正係数
$B$はNewtonの冷却定数
$t$は死後経過時間(h)
とします。
これを元に早速今回の例題を解きましょう!import sympy def death_time(Tr,Te,W): Tr=Tr Te=Te W=W B = sympy.Symbol('B') t = sympy.Symbol('t') To = 37.2 b = 1 E = sympy.S.Exp1 equation1 = 1.25*(E**(B*t))-0.25*(E**(5*B*t))-(Tr-Te)/(To-Te) equation2 = 1.11*(E**(B*t))-0.11*(E**(10*B*t))-(Tr-Te)/(To-Te) equation3 = -1.2815*((b*W)**(-0.625))+0.0284-B if Te <= 23.2: print(sympy.solve([equation1,equation3])) else: print(sympy.solve([equation2,equation3])) death_time(27,16,86) #今回の問題の設定$ $参考文献によると$T_e$は環境温の平均を使いますが、今回は発見時の室温の16℃を$T_e$としました。
結果は言わなくても分かると思いますが、scipyでこんな累乗変数を含む計算を直接できるわけもなく、朝起きても計算を続けていました(泣)。参考文献通りに試行錯誤法の考えの元で解くことにしました。関数の微分を求め方程式を反復の都度解く処理が大きい為、上図の様に微分を差分で近似させたクリロフ部分交換法を用いて計算することにしました。
import math from scipy.optimize import newton_krylov import sympy #(3)式に相当する。体重(kg)からNewtonの冷却定数Bを算出。To(死亡時直腸温)は37.2とする def predict_B(W): W=W B = sympy.Symbol('B') b = 1 equation3 = -1.2815*((b*W)**(-0.625))+0.0284-B B = sympy.solve([equation3])[B] return B #(1)(2)式に相当。環境温Teで場合分け def predict_deathtime(W,Tr,Te,ta): Bx = predict_B(W) Tr,Te,ta = Tr,Te,ta E = sympy.S.Exp1 To = 37.2 def F(x): if Te <= 23.2: return 1.25*(E**(Bx*x))-0.25*(E**(5*Bx*x))-(Tr-Te)/(To-Te) else: return 1.11*(E**(Bx*x))-0.11*(E**(10*Bx*x))-(Tr-Te)/(To-Te) guess = ta sol = newton_krylov(F, guess, method='lgmres') print(sol) #(体重,直腸温,環境温,死後経過時間の初期値)の順で入力 #死後経過時間の初期値を0によって微分値が求められないので注意する predict_deathtime(86,27,16,2)出力結果17.19191007875492よって、今回の例題では17時間ほど前に死亡したことが分かりました!
参考文献
計算科学をはじめよう! ニュートンの冷却法則①
直腸温の連続測定による死後経過時間の推算(早大院先進理工)○(学)井上 幹康*(正)酒井 清孝(早大高等研)(正)山本 健一郎(防衛医大)(正)金武 潤
- 投稿日:2020-05-28T22:16:47+09:00
pythonのrelative_to()で相対パスを指定しようとしたらはまった
概要
絶対パスから相対パスを取得するために以下のようなコードを実行した
import pathlib p = pathlib.Path() file_path = 'image-db' file_path_rel = p.cwd().relative_to(file_path)エラー
ValueError: '/directory/of/python' does not start with 'image-db'relative_to()の中身がカレントディレクトリより外にあると動かないらしい.
対策
os.path.reipath('行先', '起点')を使えば複雑な相対パスも取得できる.
file_path_rel = os.path.relpath(file_path, os.getcwd())参考サイト
- 投稿日:2020-05-28T21:54:37+09:00
lightgbmがdlopen(/Users/*site-packages/lightgbm/lib_lightgbm.so, 6): Library not loaded: */libomp/lib/libomp.dylib Referenced from: /Users/*/opt/anaconda3/lib/python3.6/site-packages/lightgbm/lib_lightgbm.so Reason: image not foundでエラーが出た。
よくわかりませんが、
brew install libomp pip uninstall lightgbm pip install lightgbmで解決しました。
- 投稿日:2020-05-28T21:37:56+09:00
PythonHack Hackフォルダ
- 投稿日:2020-05-28T21:28:49+09:00
【1日1写経】Classify_images_Using_Python & Machine Learning【Daily_Coding_003】
初めに
- 本記事は、python・機械学習等々を独学している小生の備忘録的な記事になります。
- 「自身が気になったコードを写経しながら勉強していく」という、きわめてシンプルなものになります。
- 建設的なコメントを頂けますと幸いです(気に入ったらLGTM & ストックしてください)。
お題:Classify_images_Using_Python & Machine Learning
今日のお題は、Classify_images_Using_Python & Machine LearningというYoutube上の動画です。犬やら猫らの画像を学習させてそれを判定する、といったものです。
Classify Images Using Python & Machine Learning
分析はyoutubeの動画にある通り、Google Colaboratryを使用しました。
それではやっていきたいと思います。
Step1: ライブラリのインポート~データの加工
import tensorflow as tf from tensorflow import keras from keras.models import Sequential from keras.layers import Dense, Flatten, Conv2D, MaxPool2D, Dropout from tensorflow.keras import layers from keras.utils import to_categorical import numpy as np import matplotlib.pyplot as plt plt.style.use('fivethirtyeight')次に
- データの読み込み
- データ型の確認
- データシェイプ確認
- いくつかのデータを確認
- 画像を一つ出力
までをやっていきます。
#1 from keras.datasets import cifar10 (x_train, x_test), (y_train, y_test) = cifar10.load_data() #2 print(type(x_train)) print(type(y_train)) print(type(x_test)) print(type(y_test)) #3 print('x_train shape:', x_train.shape) print('y_train shape:', y_train.shape) print('x_test shape:', x_test.shape) print('y_test shape:', y_test.shape) #4 index = 10 x_train[index] #5 img = plt.imshow(x_train[index])
何やら画像が見えてきました。次にこの画像に紐づいているラベルを見ていきます。
print('The image label is:', x_train[index])これを見ると
4というラベルがついていることがわかります。次に開設されてますが、このデータセットは10種類の画像が含まれています。# Get the image classification classification = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] # Print the image class print('The image class is:', classification[y_train[index][0]])なので、これは「鹿」の画像だそうです(よく画面にめっちゃ寄っても厳しい...)。
次に被説明変数yを
one_hot_encodingで、画像ラベルをNeural Networkに入れられる形に0 or 1(正しければ1、そうでなければ0)の数字を当てます。y_train_one_hot = to_categorical(y_train) y_test_one_hot = to_categorical(y_test) print(y_train_one_hot) print('The one hot label is:', y_train_one_hot[index])次にデータセットを標準化(0 - 1)にします。
x_train = x_train / 255 x_test = x_test / 255 x_train[index]これで凡そ加工はおしまいです。次にCNNモデルを組んでいきましょう!
Step2: モデルを構築
model = Sequential() model.add( Conv2D(32, (5,5), activation='relu', input_shape=(32,32,3))) model.add(MaxPool2D(pool_size=(2,2))) model.add( Conv2D(32, (5,5), activation='relu')) model.add(MaxPool2D(pool_size=(2,2))) model.add(Flatten()) model.add(Dense(1000, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(500, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(250, activation='relu')) model.add(Dense(10, activation='softmax'))次にモデルをコンパイルし、学習させていきます。
model.compile(loss= 'categorical_crossentropy', optimizer= 'adam', metrics= ['accuracy']) hist = model.fit(x_train, y_train_one_hot, batch_size = 256, epochs = 10, validation_split = 0.2)出来上がったmodelをtestデータでテストします。
model.evaluate(x_test, y_test_one_hot)[1] >> 0.6811000108718872うーん、動画でもそうでしたがあまり良い結果ではないですね。。。
とりあえずmatplotlibで精度と損失誤差を描画しておきます。
# Visualize the model accuracy plt.plot(hist.history['accuracy']) plt.plot(hist.history['val_accuracy']) plt.title('Model accuracy') plt.ylabel('Accuracy') plt.xlabel('Epoch') plt.legend(['Train', 'Val'], loc='upper left') plt.show()#Visualize the models loss plt.plot(hist.history['loss']) plt.plot(hist.history['val_loss']) plt.title('Model loss') plt.ylabel('Loss') plt.xlabel('Epoch') plt.legend(['Train', 'Val'], loc='upper right') plt.show()最後に適当な画像(今回はネコの画像)を使ってモデルで予測してみます。
# Test the model with an example from google.colab import files uploaded = files.upload() # show the image new_image = plt.imread('cat-xxxxx.jpeg') img = plt.imshow(new_image) # Resize the image from skimage.transform import resize resized_image = resize(new_image, (32,32,3)) img = plt.imshow(resized_image) # Get the models predictions predictions = model.predict(np.array([resized_image])) # Show the predictions predictions # Sort the predictions from least to greatest list_index = [0,1,2,3,4,5,6,7,8,9] x = predictions for i in range(10): for j in range(10): if x[0][list_index[i]] > x[0][list_index[j]]: temp = list_index[i] list_index[i] = list_index[j] list_index[j] = temp # Show the sorted labels in order print(list_index) # Print the first 5 predictions for i in range(5): print(classification[list_index[i]], ':', round(predictions[0][list_index[i]] * 100, 2), '%')結果は、
cat : 51.09 %
dog : 48.73 %
deer : 0.06 %
bird : 0.04 %
frog : 0.04 %とネコかイヌかほぼ判定できていない結果に(笑)モデルの精度がイマイチ且つ使った画像が良くなかったです。
最後に
今回はtensorflowとkerasを使った画像判定の勉強をしました。もちろん使い物になる精度出ないことは重々承知ですが、足掛かりとしては良かったかなと思います。
引き続きよろしくです。
(これまでの学習)
1. 【1日1写経】Predict employee attrition【Daily_Coding_001】
2. 【1日1写経】Build a Stock Prediction Program【Daily_Coding_002】
- 投稿日:2020-05-28T21:22:40+09:00
Pythonのlistの使い方まとめ
はじめに
一度は勉強したけど、「あれ?これってどうだったっけ...」という方向けのまとめです。
FE(基本情報技術者試験)でもPythonが選択できるようになりました。
本来なら今年の春試験が初の出題となる予定でしたがコロナの影響で中止となりましたね。そんなPythonのlistもFEの例題でバッチリ出題されているので、使い方をまとめてみました。
試験の直前に見返すも良し、普段のプログラミングで忘れがちなメソッドを思い出すも良し。
ぜひご活用ください。listの初期化
まずは基本のlistの宣言から。
alist = [] blist = [1, 1, 2, 3, 5, 8, 13] clist = list(range(5)) dlist = [i for i in range(10) if (i % 2 == 0)] # リスト内包表記 print(f"alist = {alist}\nblist = {blist}\nclist = {clist}\ndlist = {dlist}")outputalist = [] blist = [1, 1, 2, 3, 5, 8, 13] clist = [0, 1, 2, 3, 4] dlist = [0, 2, 4, 6, 8]代入とコピー
意外と盲点です。なので、以降のlistの扱いでは参照渡しと値渡しの両方を交えて説明します。
=でlistを代入
- 参照渡し
- 代入元(
alist)が変更 →blistも変わる.copy()メソッドの返り値を代入
- 値渡し
- 代入元(
alist)が変更 →clistは変化無しalist = [1, 2, 3] # 参照渡し blist = alist # 値渡し clist = alist.copy() def delete_middle(list_obj, msg): list_obj.pop(int(len(list_obj)/2)) print(msg, list_obj) delete_middle(alist, "alist =") print(f"blist = {blist}") print(f"clist = {clist}")outputalist = [1, 3] blist = [1, 3] clist = [1, 2, 3]listに要素を追加
- 要素を後ろに1つだけ追加
.append(x)メソッド- 指定したindexの場所に1つ追加
.insert(index, obj)メソッド- listにlistを追加
+operator(演算子)を使う- 演算後に
blistやclistの要素が変化してもdlistには影響なしalist = [1, 2, 3] blist = alist clist = alist.copy() # 4を後ろに追加 alist.append(4) # 1のindexに100を追加 alist.insert(1, 100) # listにlistを追加 dlist = blist + clist print(f"alist = {alist}\nblist = {blist}\nclist = {clist}\ndlist = {dlist}")alist = [1, 100, 2, 3, 4] blist = [1, 100, 2, 3, 4] clist = [1, 2, 3] dlist = [1, 100, 2, 3, 4, 1, 2, 3]listの中身を削除
indexを指定して削除
alist = [1, 3, 5, 7, 9] blist = alist clist = alist.copy() del alist[2] print(f"del alist[2] =>\n\talist = {alist}\n\tblist = {blist}\n\tclist = {clist}\n") alist.pop(2) print(f"alist.pop(2) =>\n\talist = {alist}\n\tblist = {blist}\n\tclist = {clist}")outputdel alist[2] => alist = [1, 3, 7, 9] blist = [1, 3, 7, 9] clist = [1, 3, 5, 7, 9] alist.pop(2) => alist = [1, 3, 9] blist = [1, 3, 9] clist = [1, 3, 5, 7, 9]値を指定して削除
先頭側にある値だけが削除されます。その値全てではありません。
alist = [1, 2, 2, 3, 3, 3] blist = alist clist = alist.copy() alist.remove(2) print(f"alist = {alist}\nblist = {blist}\nclist = {clist}")outputalist = [1, 2, 3, 3, 3] blist = [1, 2, 3, 3, 3] clist = [1, 2, 2, 3, 3, 3]一番後ろの項目を削除
.pop()に引数を入れなければ.pop(-1)と同じで、リストの最後の要素が消されます。alist = [1, 3, 5, 7, 9] blist = alist clist = alist.copy() alist.pop() print(f"alist.pop(2) =>\n\talist = {alist}\n\tblist = {blist}\n\tclist = {clist}")outputalist.pop() => alist = [1, 3, 5, 7] blist = [1, 3, 5, 7] clist = [1, 3, 5, 7, 9]全て削除
alist = [1, 2, 3] blist = alist clist = alist.copy() # alist = [] もやってることは同じ。 # alist = [] だと宣言と紛らわしいけど、開発チームのお好みで。 alist.clear() print(f"alist = {alist}\nblist = {blist}\nclist = {clist}")outputalist = [] blist = [] clist = [1, 2, 3]値の順番で並び替える
alist = [20, 1, 5, 13, 8] blist = alist clist = alist.copy() alist.sort() print(f"alist = {alist}\nblist = {blist}\nclist = {clist}")outputalist = [1, 5, 8, 13, 20] blist = [1, 5, 8, 13, 20] clist = [20, 1, 5, 13, 8]最初に現れる値のindexを調べる
alist = [333, 1, 333, 22, 333, 22] # 22が何番目にあるか index = alist.index(22) print(f"index = {index}")outputindex = 3値が何個含まれているか
alist = [0, 1, 1, 0, 1, 0 ,1, 0, 0] # 1が何回出てきたか count = alist.count(1) print(f"count = {count}")outputcount = 4さいごに
メジャーどころのlistのメソッドは抑えたかなと思います。
参照渡しと値渡しの挙動を説明したくて返って読みにくくなってしまいました。すみませんmm忘備録としてお使いいただければと幸いです。それでは。
- 投稿日:2020-05-28T20:32:41+09:00
【Python】Pythonを始めるにはまずはPythonをしっかり使えるようにしないとね
結論
MacにPythonをインストールして、Pythonを使えるようにする。
MacはPython2系が元々インストールされているが今回はPython3系をインストールする。背景
Pythonを始めるにはまずはPythonを使えるようにしなければならない。プログラミングを始めるにあたって一番はじめにつまずくのが環境構築。これからPythonを始めたいと思っている人の参考になるように手順を書きたいと思ったため。初心者向けのため仮想環境にインストールするなど複雑なことは考えない。
全体の流れ
① コマンド操作を覚える
② Pythonをインストールするコマンド操作を覚える
Pythonをインストールする前にMacのコマンド操作を覚えること。
これが少しできるだけでプログラミングも楽しくなる。ls # フォルダ内を表示する ls -a # 隠しファイルも含めファイルやフォルダを全て表示する cd # フォルダを移動する pwd # フォルダのパスを表示する touch # 空のファイルを作る mkdir # フォルダを作る mv # フォルダ・ファイルを移動する cp # コピーする rm # ファイルを削除する rm -r # フォルダを削除する open # ファイルを開くとりあえずこれだけ覚えておけばなんとなく操作できると思う。
Pythonをインストールする
- 公式サイトからPythonをダウンロードする。
https://www.python.org/downloads/
無事にインストールできたら下記のコマンドをターミナルに入力する。
インストールしたPythonのバージョンが表示されればOK。python3 --version
- PATHを設定する(PATHを通す)
.bash_profile(ホームディレクトリの直下に隠しファイルになっている)を確認する。
下記のような内容が記載されているはず。なければファイルを作成し、同じように書く。(PATHを通す)# Setting PATH for Python 3.8 # The original version is saved in .bash_profile.pysave PATH="/Library/Frameworks/Python.framework/Versions/3.8/bin:${PATH}" export PATH.bashrcに下記を記載する。なければファイルを作成し、同じように書く。
alias python=python3 alias pip=pip3さらに、.bash_profileに下記を追記する。
#.bashrc読み込み用 source ~/.bashrcこれでPATHを通すことができた。
MacではPython2系がインストールされているので、PATHを通すと今後の開発がスムーズになる。
いちいちPython3を入力しなくてもPythonで実行できるようになる。まとめ
プログラミングではじめにつまずくのが環境構築だ。PATHを通すっていうところでつまずくと思う。今回は細かい内容は書いていないが、とにかく手順どおりにやってみてほしい。これができれば、Pythonを始められる。
参考にした情報
- 投稿日:2020-05-28T20:10:23+09:00
Flask基本メモ
はじめに
私は、時々Flaskを使うのですが、使い方をよく忘れてしまうので、ここにメモをしておきます。
レスポンスを受け取るまで
インストール
まず、Flaskをインストールします。以下のコマンドを打ち込むだけで良いです。
$ pip install Flaskファイル
次に適当にサーバの動作を行うファイルを作ります。以下に示すのは、必要最低限の動作を行うものです。
app.pyfrom flask import Flask app = Flask(__name__) @app.route("/") def hello(): return "hello" if __name__ == "__main__": app.run(debug=True)サーバの稼働
そして次のコマンドをこのファイルが存在するディレクトリ上で打ち込みます。
$ python app.pyこれで
http://localhost:5000にアクセスするとhelloと帰ってくるようになりました。基本の関数の使い方
@app.route(URL, methods)
これはその後に来る関数をリクエストが来た際に走らせるようにするラッパーです。リクエストを受け取る場合は必ず使います。引数はそれぞれ、
URL: リクエストを受け取るURLのroute
methods: リクエストのメソッド
使い方としては以下のようなものがあります。また、URLから直接変数を得る方法などもあります。基本的な使い方
# http://localhost:5000/hogeにGETリクエストを送ることで動く @app.route("/hoge", methods=["GET"]) def hoge(): # ここで処理が行われるURLから変数を取得する
FlaskではURLの文字列をデータとして取り込むことができます。例えば以下の例では、
http://localhost:5000/hoge/fugaに対してGETメソッドを送ると、「hello! fuga」と返ってきます。@app.route("/hoge/<text>", methods=["GET"]) def hello(text): return "hello! " + textapp.run(host, path, debug)
ここではアプリの稼働を行います。それぞれの引数は、
host: アプリを稼働するipアドレス、デフォルトはlocalhost
port: アプリにアクセスできるポート、デフォルトは5000
debug: Trueの時はアプリ稼働時にデバッグ出力を行うこれらを使って、変更を加えるとしたら、以下のような感じになります。
app.run(host="0.0.0.0", port=8080, debug=True)hostを上のように設定しておくことで、外部のデバイスからでもこのコードを走らせているPCのアドレスが分かれば、アクセスできるようになります。
jsonの取り扱い
リクエストで受け取る方法
リクエストでjsonを受け取る時には、jsonモジュールを使用します。
from flask import Flask import json @app.route("/", methods=["POST"]) def hoge(): req_data = json.loads(request.data) return req_data["hoge"]json.loads関数を用いることで、jsonのデータを配列や辞書などのpythonで扱える形に変換しています。
レスポンスで出力する方法
レスポンスにjsonを含める場合には、Flaskのjsonify関数を使用します。
from flask import Flask, jsonify @app.route("/", methods=["GET"]) def hoge(): res_data = {"json_data": "hogehoge"} return jsonify(res_data)基本的にはデータをjsonifyで包んで送るだけです。
最後に
何か間違いや、足りない部分などがあれば教えていただけるとありがたいです。また、質問なども受け付けます。
- 投稿日:2020-05-28T20:02:32+09:00
Nanについての備忘録。
はじめに
これは自分用の備忘録なのでご了承を。
Nanについて
Nanは不動点少数における考え方であり、異常な数値であることを表している。
欠損値という名前がついておるようだ。
イメージは、エクセルで式を計算したときにでるエラーでいいかな。
Noneではないことに注意する。Nanの性質
Nanには重要な性質がある。
性質には、以下のものがある。・Nanを含む四則演算の結果はNanが返ってくる
・Nanの比較演算子は必ずFalseとなる通常の計算とは結果が異なるため、注意が必要。
numpyのisnan()関数
numpyに入っているisnan()はNanがあるかどうかを判定する関数。
そのため、if文などでこれを使うと、Trueが返ってくる。nansum()関数
欠損値を含む計算はNanが返ってきてしまうのだ。
けど、Nanを含む数値群を計算したい!という場合はnansum()を使う。
これを使うことで、Nanを除いた値の合計が計算される。
便利ねーーー。nan_to_num()関数
Nanを別のものに変えたいーーって時のための関数。
デフォルトでは、0に変更されて元のndarrayは変更されないみたい。
第一引数で変更する配列を指定して、第二引数で元の配列を保持するか指定、第三引数で置換する文字、数字を指定。
- 投稿日:2020-05-28T19:49:54+09:00
Ruby と Python で解く AtCoder ARC080 D シミュレーション
はじめに
AtCoder Problems の Recommendation を利用して、過去の問題を解いています。
AtCoder さん、AtCoder Problems さん、ありがとうございます。今回のお題
AtCoder Regular Contest D - Grid Coloring
Difficulty: 855今回のテーマ、シミュレーション
内容は難しいところはないと思いますが、実装に手間がかかりそうな問題です。
1 2 2 3 3 4 4 4 4 3 5 5 5 5 5与えられた数値で上から順に左右に塗りつぶせばOKです。
Ruby Array
ruby.rbh, w = gets.split.map(&:to_i) _ = gets.to_i a = gets.split.map(&:to_i) m = Array.new(h){Array.new(w, 0)} y, x, lr = 0, 0, 1 a.each_with_index do |n, v| n.times do m[y][x] = v + 1 x += lr if x == w y += 1 x = w - 1 lr = -1 elsif x < 0 y += 1 x = 0 lr = 1 end end end h.times do |i| puts m[i].join(' ') endjoin.rbputs m[i].join(' ') puts m[i] * ' '最近知ったのですが、
joinは上記の様に書くこともできます。Ruby Class
ruby.rbclass MASS def initialize(h, w) @h = h @w = w @m = Array.new(@h){Array.new(@w, 0)} @x = 0 @y = 0 @LR = 1 end def draw(v, n) n.times do @m[@y][@x] = v + 1 @x += @LR if @x == @w @y += 1 @x = @w - 1 @LR = -1 elsif @x < 0 @y += 1 @x = 0 @LR = 1 end end end def out @h.times do |i| puts @m[i].join(' ') end end end h, w = gets.split.map(&:to_i) _ = gets.to_i a = gets.split.map(&:to_i) m = MASS.new(h, w) a.each_with_index do |v, i| m.draw(i, v) end m.out今回の問題では、あまり有効ではないのですが、学習を兼ねて
classを使用してみました。
コード長が倍近くになりましたが、実行時間は変わらないようです。Python
python.pyfrom sys import stdin def main(): input = stdin.readline h, w = map(int, input().split()) _ = int(input()) a = list(map(int, input().split())) m = [[0] * w for _ in range(h)] x, y, LR, v = 0, 0, 1, 0 for n in a: v += 1 for _ in range(n): m[y][x] = str(v) x += LR if x == w: y += 1 x = w - 1 LR = -1 elif x < 0: y += 1 x = 0 LR = 1 for i in range(h): print(" ".join(m[i])) main()Python のコード長が長いのは、半角スペースもカウントしているからでしょうか。
Ruby Array Ruby Class Python コード長 (Byte) 392 631 603 実行時間 (ms) 17 18 25 メモリ (KB) 2428 3836 3828 まとめ
- ARC 080 D を解いた
- Ruby に詳しくなった
- Python に詳しくなった
- 投稿日:2020-05-28T19:33:56+09:00
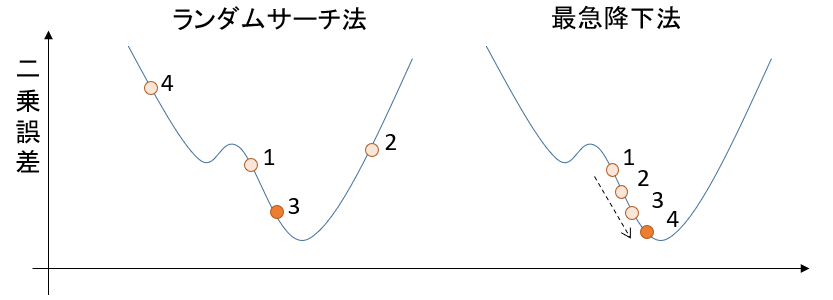
パラメータ最適化 2手法(ランダムサーチ法 と 最急降下法)~特徴と活用~
パラメータの最適化
実測データとモデルとの比較を行うとき、モデルの関数に含まれるパラメータの最適化は必須です。
大学に通っていた頃、自分の手でパラメータをちょっとずつ変えて最適化をしている努力家がいました。ソフトウェアが専門でない学科においては多少仕方のない光景ですが、やはりこういうのはプログラミングで解決しましょう。
今回紹介する2手法
- random search method (ランダムサーチ法)
- gradient descent method (最急降下法)
そもそもどのように最適化するのか
最適化プログラムの構成
これを何万回と繰り返し、最適なパラメータへと更新し続けます。
評価の仕方
最も一般的なのは、最小自乗法です。
今回の私のプログラムにも採用しています。誤差をそのままではなく2乗してから足すことで、実測とモデルの誤差を積算することができます。
random search method (ランダムサーチ法)
パラメータにランダムな値を入れて,評価関数が一番小さくなる値を見つける手法です。
gradient descent method (最急降下法)
評価関数の偏微分値を求め、評価関数が小さくなる向きに少しずつパラメータをずらしていく手法です。
2手法の比較
解の精度は、ランダムサーチ法 << 最急降下法
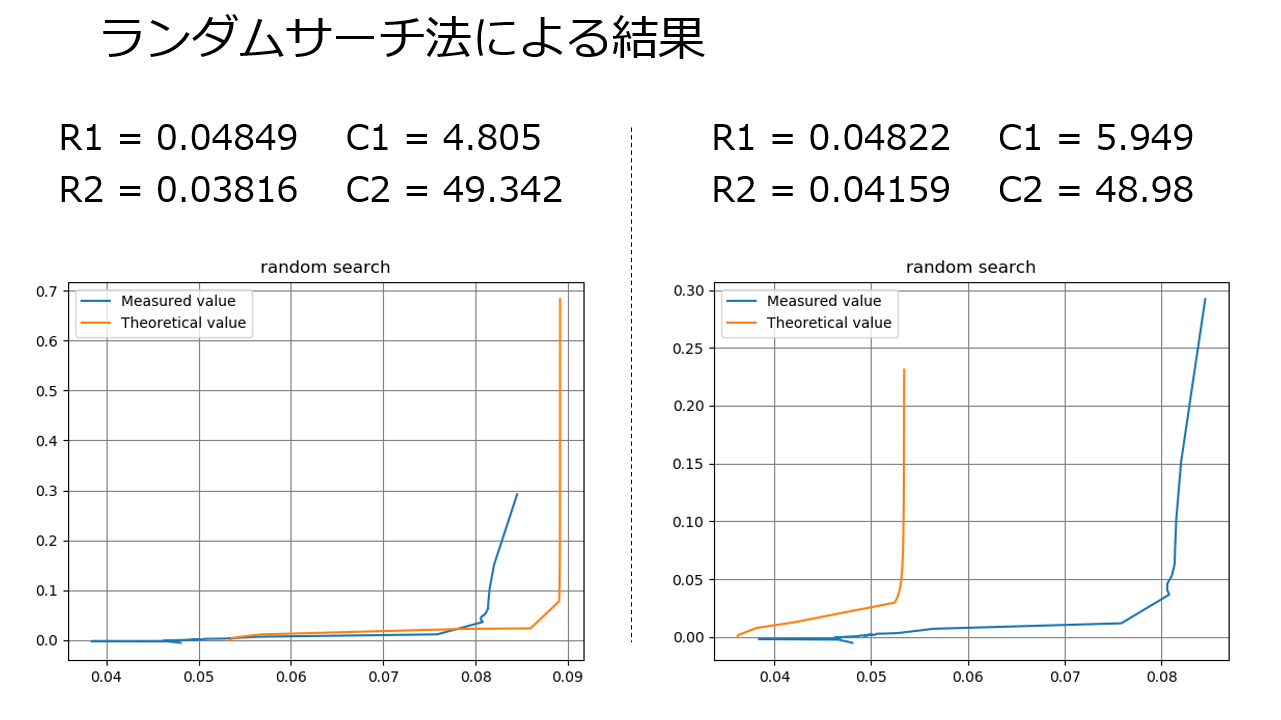
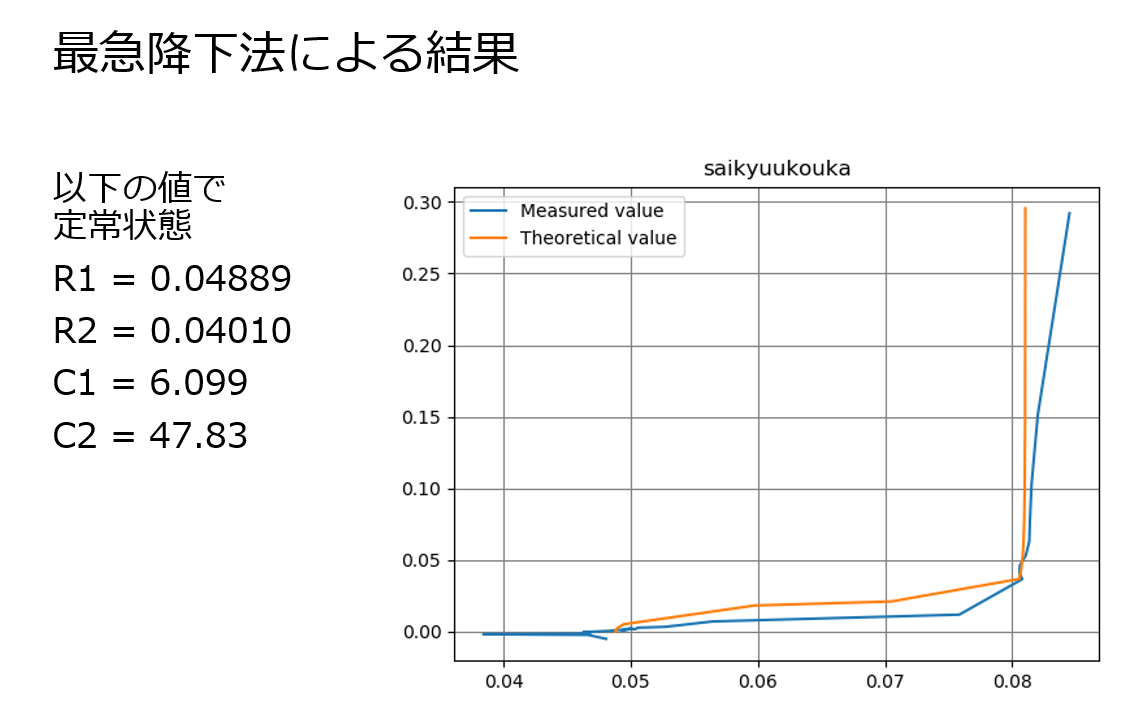
かなり精度に差があります。
ランダムサーチでは最適解に近づけば近づくほど、より最適なパラメータに近づくことが難しくなります。それに対して、最急降下法では堅実に最適解に近づくことができます。ランダムサーチ法の試行回数をかなり増やしたとしても、再急降下法より良い精度を出すことはほぼ不可能でしょう。
参考程度に、4パラメータの最適化で10万回の試行回数でプログラムを回した結果を見てみましょう。
悲しいことに、10万回ランダムサーチしても、毎回答えが違うしグラフは全然沿いません。
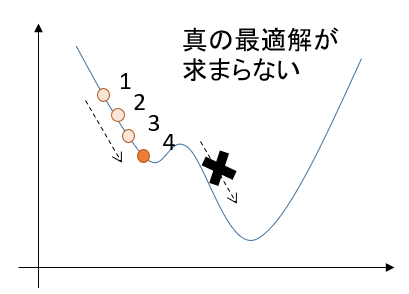
精度面は、最急降下法の圧勝ですね。最急降下法の欠点
そんな最急降下法にも致命的な欠点があります。
局所的な最適解にはまってしまうと、さらなる最適解があっても見つけられなくなるのです。
コンピュータに全てを委ねる最適化プログラムにおいて、「最適じゃない解」を出力する可能性があるのは見過ごせません。
2手法のコンビネーション
そこで、最も良い解決法が、「ランダムサーチ法と最急降下法のコンビネーション」です。
1. 大きな範囲を指定してランダムサーチをする。
2. 繰り返し行うことで最適な値があると推測される範囲を削っていく。
3. 最終的に、右に記した範囲になるまでランダムサーチを行う。
4. 最急降下法により最適解を求める。これで問題解決です。
最後に、2手法のコード
実測値データは私が回路の周波数応答の計測をしたときのものです。
ランダムサーチ法
random_search.py# random search method import random import numpy as np import math import matplotlib.pyplot as plt #----- data ----- freq = np.array([0.05, 0.1, 0.2, 0.4, 0.6061, 0.8, 1, 10,100]) ReR = np.array([0.005890792, 0.005824175, 0.005726238, 0.005501362, 0.005399829, 0.005244864, 0.0051687, 0.004736195, 0.004552081]) ImR = np.array([0.00476029, 0.002511934, 0.001470715, 0.000984505, 0.000808862, 0.000718529, 0.000655644, 0.00021882, -0.0000045569]) num=100000 # number of trials #---------------- lsv = 100000 Flist=[0 for i in range(num)] R1list=[0 for i in range(num)] R2list=[0 for i in range(num)] C1list=[0 for i in range(num)] C2list=[0 for i in range(num)] N = len(freq) R_opt = np.array([0j for i in range(N)]) theo = np.array([0j for i in range(N)]) R1_opt,R2_opt,C1_opt,C2_opt = 0,0,0,0 def init(): sv = 0 # squares value R1 = random.uniform(0.001, 0.01) R2 = random.uniform(0.001, 0.01) C1 = random.uniform(0, 500) C2 = random.uniform(0, 500) return sv,R1,R2,C1,C2 def func_theoretical(R1,R2,C1,C2,freq): c1 = 1/(2j * math.pi * freq * C1) c2 = 1/(2j * math.pi * freq * C2) c3 = R2 + c2 theo = R1 + c1*c3/(c1+c3) return theo def func_distance(ReR, ImR, theo): return (ReR - theo.real) **2 + (ImR + theo.imag) **2 #--- traials --- for i in range(num): sv,R1,R2,C1,C2 = init() for i in range(N): theo[i] = func_theoretical(R1,R2,C1,C2,freq[i]) sv += func_distance(ReR[i], ImR[i], theo[i]) if sv < lsv: lsv = sv R_opt = theo R1_opt,R2_opt,C1_opt,C2_opt = R1,R2,C1,C2 #---------------- #--- result --- print('number of trials :',num) print('Least Squares Value :',lsv) print('R1,R2,C1,C2 :' ,R1_opt,R2_opt,C1_opt,C2_opt) #--- graph --- plt.title('random search', loc='center') plt.plot(ReR,ImR, label="Measured value") plt.plot(R_opt.real, - R_opt.imag ,label="Theoretical value") plt.grid(color='gray') plt.legend(loc="upper left") plt.show()最急降下法
gradient_descent.pyimport random import numpy as np import math import matplotlib.pyplot as plt #--- data --- freq = np.array([0.05, 0.1, 0.2, 0.4, 0.6061, 0.8, 1, 10,100]) ReR = np.array([0.005890792, 0.005824175, 0.005726238, 0.005501362, 0.005399829, 0.005244864, 0.0051687, 0.004736195, 0.004552081]) ImR = np.array([0.00476029, 0.002511934, 0.001470715, 0.000984505, 0.000808862, 0.000718529, 0.000655644, 0.00021882, -0.0000045569]) #------------ #--- setting --- ParaList = [0.005, 0.0014, 138 , 546] #R1,R2,C1,C2 d = [0.00001, 0.000001, 0.1, 0.1] #d(R1,R2,C1,C2) num=1000 # number of trials pf=11 # print freqency #---------------- def func_lsv(): global freq, ReR, ImR, ParaList R1,R2,C1,C2 = ParaList for Freq, rer, imr in zip(freq, ReR, ImR): a = 1/(2j * math.pi * freq * C1) b = 1/(2j * math.pi * freq * C2) c = R2 + b R = R1 + a*c/(a+c) distance = (ReR - R.real) **2 + (ImR + R.imag) **2 lsv = sum(distance) return lsv def gradient_descent(N,Rs): global ParaList ParaList[N] = ParaList[N] - Rs lsv_under = func_lsv() ParaList[N] = ParaList[N] + 2 * Rs lsv_over = func_lsv() if lsv_under < lsv_over : ParaList[N] = ParaList[N] - 2 * Rs lsv = lsv_under else: lsv = lsv_over return ParaList, lsv #--- main --- cnt_pf=0 print(" R1 / R2 / C1 / C2 / Least Squares Value") for i in range(num): cnt_pf +=1 for N in range(4): ParaList, lsv = gradient_descent(N, d[N]) if cnt_pf == pf: print(ParaList,lsv) cnt_pf=0 Rbest=np.array([0j for i in range(len(freq))]) R1,R2,C1,C2 = ParaList for i in range(len(freq)): a = 1/(2j * math.pi * freq[i] * C1) b = 1/(2j * math.pi * freq[i] * C2) c = R2 + b Rbest[i] = R1 + a*c/(a+c) #--- result --- print('trials :',num) print('Least Squares Value: :', lsv) print('R1 ,R2, C1, C2 :',ParaList) #--- graph --- plt.title('saikyuukouka', loc='center') plt.plot(ReR,ImR, label="Measured value") plt.plot(Rbest.real, -Rbest.imag ,label="Theoretical value") plt.grid(color='gray') plt.legend(loc="upper left") plt.show()


- 投稿日:2020-05-28T19:33:39+09:00
PythonでのCloud Pak for Dataのオブジェクト操作例 (WML client, project_lib)
はじめに
Cloud Pak for Data (以下CP4D)の分析プロジェクトでNotebook (Jupyter Notebook)でモデルを作る場合、データの取り込みやモデルの格納、作ったモデルのデプロイなどを行うためのライブラリとしてwatson-machine-learning-client-V4 (以下WML client)1とproject_lib2があります。どちらもCP4DのNotebookの標準Python環境にデフォルトで入ってます。
この記事では、これらのライブラリの具体的な使い方を紹介します。なお、WML clientはURLを指定して認証も行うため、CP4D外のPython環境でも動作します。外部のバッチプログラムなどからCP4D内のモデルやデプロイメントなどのオブジェクト操作手段としても使えます。
(動作確認済バージョン)
- Cloud Pak for Data v2.5 / v3.0LA
- WML client v1.0.64
- project_lib v1.7.1
Notebookでのpipコマンドでの確認方法
!pip show watson-machine-learning-client-V4outputName: watson-machine-learning-client-V4 Version: 1.0.64 Summary: Watson Machine Learning API Client Home-page: http://wml-api-pyclient-v4.mybluemix.net Author: IBM Author-email: svagaral@in.ibm.com, nagiredd@in.ibm.com, kamigupt@in.ibm.com License: BSD Location: /opt/conda/envs/Python-3.6-WMLCE/lib/python3.6/site-packages Requires: urllib3, pandas, tabulate, requests, lomond, tqdm, ibm-cos-sdk, certifi Required-by:!pip show project_liboutputName: project-lib Version: 1.7.1 Summary: programmatic interface for accessing project assets in IBM Watson Studio Home-page: https://github.ibm.com/ax/project-lib-python Author: IBM Watson Studio - Notebooks Team Author-email: None License: UNKNOWN Location: /opt/conda/envs/Python-3.6-WMLCE/lib/python3.6/site-packages Requires: requests Required-by:CP4D上での主な操作と使用するライブラリ一覧
データ資産(Data Asset)、モデル(Models)、関数(Functions)、デプロイメント(Deployments)などを生成したり、保存したりできます。また、作成したデプロイメントを実行することも可能です。
分析プロジェクトに対する操作
データ資産は主にproject_libを使用し、モデル系はWML clientを使用します。
主な操作 使用するライブラリ データ資産からのデータの読み込み3 project_lib または、
pandas.read_csvで'/project_data/data_asset/ファイル名'を直接読むデータ資産へのファイルデータの出力4 project_lib データ資産の一覧表示 WML client モデルの保存 WML client モデルの一覧表示 WML client 関数の保存 WML client 関数の一覧表示 WML client デプロイメントスペース(分析デプロイメント)に対する操作
全てWML clientを使用します。
主な操作 使用するライブラリ データ資産へのファイルデータの出力 WML client データ資産の一覧表示 WML client モデルの保存 WML client モデルの一覧表示 WML client 機能(関数)の保存5 WML client 機能(関数)の一覧表示5 WML client デプロイメントの作成 WML client デプロイメントの一覧表示 WML client デプロイメントの実行 WML client WML clientのインポートと初期化
WML clientのインポート
from watson_machine_learning_client import WatsonMachineLearningAPIClientWML clientの初期化(認証)
接続先や認証情報を付与して、WML clientを初期化します。認証情報の取得方法は2種類ありますう。
- OS環境変数 USER_ACCESS_TOKEN の値を使う
- CP4Dユーザー名とパスワードを使う
1はCP4D上のNotebookで使える方法。もし、CP4D外の環境でWML clientを使うときは2です。
注意事項としては、
- instance_id は "wml_local" または "openshift" とします。マニュアルには前者が記載されてますが、後者を使うようガイドされたことがあります。実質的にはどちらでも動くようです。
- urlは、使用しているCP4D環境のURL(https://ホスト名 or IPアドレス(:ポート番号))とします。最後にスラッシュを付けないことがポイントです。付けたら後続の処理でエラーになります(ハマりポイント)。
- versionは、2.5の場合は"2.5.0"、3.0LAなら"3.0.0"、3.0GAなら"3.0.1"
方法1の場合import os token = os.environ['USER_ACCESS_TOKEN'] url = "https://cp4d.host.name.com" wml_credentials = { "token" : token, "instance_id" : "openshift", "url": url, "version": "3.0.0" } client = WatsonMachineLearningAPIClient(wml_credentials)方法2の場合# usernameとpasswordは、実際に認証に使うCP4Dユーザーのものを指定する url = "https://cp4d.host.name.com" wml_credentials = { "username":"xxxxxxxx", "password": "xxxxxxxx", "instance_id": "openshift", "url" : url, "version": "3.0.0" } client = WatsonMachineLearningAPIClient(wml_credentials)分析プロジェクトとデプロイメントスペースの切り替え
後続の処理の操作対象を、分析プロジェクト(default_project)かデプロイメントスペース(default_space)のどちらにするかをセットします。初期状態は分析プロジェクトにセットされています。
操作する対象を変更する場合は、この切替え操作を必ず実施するのを忘れないこと(ハマりポイント)。各IDの調べ方
分析プロジェクトのIDは、OS環境変数 PROJECT_ID に入っているものを使います。
分析プロジェクトのIDをセットproject_id = os.environ['PROJECT_ID']デプロイメントスペースのIDは、CP4D画面のデプロイメントスペースの「設定」にある「スペースGUID」で予め調べて置くか、以下の方法でclient.repository.list_spaces() で表示されるGUIDを使います。
デプロイメントスペースのIDを調べるclient.repository.list_spaces()output------------------------------------ -------------------- ------------------------ GUID NAME CREATED xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx DepSpaceName 2020-05-25T09:13:04.919Z ------------------------------------ -------------------- ------------------------デプロイメントスペースのIDをセットspace_id = "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"操作対象の切り替え
操作対象を分析プロジェクトに切り替えるclient.set.default_project(project_id)操作対象をデプロイメントスペースに切り替えるclient.set.default_space(space_id)データ資産の操作
データ資産の一覧表示 (分析プロジェクト)
WML clientを使用します。
# 分析プロジェクトに切り替え(切り替える必要がある場合のみ実施) client.set.default_project(project_id) # データ資産の一覧を表示 client.data_assets.list()データ資産の一覧表示 (デプロイメントスペース)
WML clientを使用します。
# Deployment Spaceに切り替え(切り替える必要がある場合のみ実施) client.set.default_space(space_id) # データ資産の一覧を表示 client.data_assets.list()データ資産からのデータの読み込み (分析プロジェクト)
Notebook画面の右上にあるデータボタン(0100と書いてある)をクリックし、該当のデータ資産名 > コードに挿入 > pandas DataFrame をクリックすることで、Notebook内のセルにコードが自動挿入されます。これを使うのが楽です。
CSVなどファイルの場合は、pandas.read_csvでデータを読むコードが自動挿入されます。df_data_XのXの部分は、挿入操作を繰り返すと自動的に増えていきます。
挿入コード(ファイルの場合)import pandas as pd df_data_1 = pd.read_csv('/project_data/data_asset/filename.csv') df_data_1.head()project_libを使ったファイルデータを読むコード例は製品マニュアル内に例がありますが、こんなコードです。
project_libを使ったファイルの読み込みfrom project_lib import Project project = Project.access() my_file = project.get_file("filename.csv") my_file.seek(0) import pandas as pd df = pd.read_csv(my_file)DBテーブルの場合は、前述の「コードに挿入」でproject_libを使ったコードが自動挿入されます。頭に
# @hidden_cellと入っているので、Notebookを共有する時にこのセルを含めない選択が可能です。6挿入コード(Db2テーブルSCHEMANAME.TBL1の例)# @hidden_cell # This connection object is used to access your data and contains your credentials. # You might want to remove those credentials before you share your notebook. from project_lib import Project project = Project.access() TBL1_credentials = project.get_connected_data(name="TBL1") import jaydebeapi, pandas as pd TBL1_connection = jaydebeapi.connect('com.ibm.db2.jcc.DB2Driver', '{}://{}:{}/{}:user={};password={};'.format('jdbc:db2', TBL1_credentials['host'], '50000', TBL1_credentials['database'], TBL1_credentials['username'], TBL1_credentials['password'])) query = 'SELECT * FROM SCHEMANAME.TBL1' data_df_1 = pd.read_sql(query, con=TBL1_connection) data_df_1.head() # You can close the database connection with the following code. # TBL1_connection.close() # To learn more about the jaydebeapi package, please read the documentation: https://pypi.org/project/JayDeBeApi/データ資産へのデータの保存 (分析プロジェクト)
pandasのデータフレームをCSVファイルとして保存する方法です。project_libを使います。
from project_lib import Project project = Project.access() project.save_data("filename.csv", df_data_1.to_csv(),overwrite=True)データ資産へのデータの保存 (デプロイメントスペース)
同様に、CSVファイルをデプロイメントスペースへ保存する方法です。デプロイメントスペースのデータ資産は、デプロイメントのバッチ実行時の入力データとして使用されます。
WML clientを使います。# pandasデータフレームをCSVファイルとして一旦出力。デフォルトでは/home/wsuser/work配下に格納される df_data_1.to_csv("filename.csv") # Deployment Spaceに切り替え(切り替える必要がある場合のみ実施) client.set.default_space(space_id) # データ資産として保存 asset_details = client.data_assets.create(name="filename.csv",file_path="/home/wsuser/work/filename.csv")保存したデータ資産のIDやhrefは、createの戻り値asset_details内に含まれています。IDやhrefはデプロイメントスペースでデプロイメントをバッチ実行する際に使用します。
# createの戻り値(メタ情報)の確認 asset_detailsoutput{'metadata': {'space_id': 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx', 'guid': 'yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy', 'href': '/v2/assets/zzzzzzzz-zzzz-zzzz-zzzz-zzzzzzzzzzzz?space_id=xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx', 'asset_type': 'data_asset', 'created_at': '2020-05-25T09:23:06Z', 'last_updated_at': '2020-05-25T09:23:06Z'}, 'entity': {'data_asset': {'mime_type': 'text/csv'}}}以下のように取り出します。
戻り値asset_detailsからのメタ情報の取得asset_id = client.data_assets.get_uid(asset_details) asset_href = client.data_assets.get_href(asset_details)戻り値asset_detailsからのメタ情報の取得(もう1つの方法)asset_id = asset_details['metadata']['guid'] asset_href = asset_details['metadata']['href']モデルの操作
準備としてモデルを作成しておく
例として、Irisのサンプルデータを使ったsckikt-learnのランダムフォレストモデルを作成します。
# Irisサンプルデータをロード from sklearn.datasets import load_iris iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['iris_type'] = iris.target_names[iris.target] # ランダムフォレストでモデルを作成 from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier X = df.drop('iris_type', axis=1) y = df['iris_type'] X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=0) clf = RandomForestClassifier(max_depth=2, random_state=0, n_estimators=10) model = clf.fit(X_train, y_train) # モデルの精度を確認 from sklearn.metrics import confusion_matrix, accuracy_score y_test_predicted = model.predict(X_test) print("confusion_matrix:") print(confusion_matrix(y_test,y_test_predicted)) print("accuracy:", accuracy_score(y_test,y_test_predicted))上記の
modelが学習済モデルです。モデルの保存 (分析プロジェクト)
分析プロジェクトへのモデルの保存は、デプロイのための必須操作ではないですが可能です。
WML clientを使用します。# 分析プロジェクトに切り替え(切り替える必要がある場合のみ実施) client.set.default_project(project_id) # モデルのメタ情報を記述 model_name = "sample_iris_model" meta_props={ client.repository.ModelMetaNames.NAME: model_name, client.repository.ModelMetaNames.RUNTIME_UID: "scikit-learn_0.22-py3.6", client.repository.ModelMetaNames.TYPE: "scikit-learn_0.22", client.repository.ModelMetaNames.INPUT_DATA_SCHEMA:{ "id":"iris model", "fields":[ {'name': 'sepal length (cm)', 'type': 'double'}, {'name': 'sepal width (cm)', 'type': 'double'}, {'name': 'petal length (cm)', 'type': 'double'}, {'name': 'petal width (cm)', 'type': 'double'} ] }, client.repository.ModelMetaNames.OUTPUT_DATA_SCHEMA: { "id":"iris model", "fields": [ {'name': 'iris_type', 'type': 'string','metadata': {'modeling_role': 'prediction'}} ] } } # モデルを保存。戻り値に作成したモデルのメタデータが含まれる model_artifact = client.repository.store_model(model, meta_props=meta_props, training_data=X, training_target=y)補足: モデルに含めるメタ情報
モデルに含めるメタ情報meta_propsで、INPUT_DATA_SCHEMAとOUTPUT_DATA_SCHEMAの指定は必須ではありませんが、デプロイ後のデプロイメント詳細画面でテスト実行をフォーム形式で指定したい場合は必須です。ここで指定した形式がフォーム入力の形式となります(ハマりポイント)。
指定可能なRUNTIME_UIDの調べ方
GUIDに表示された部分を、meta_props内のRUNTIME_UIDとして指定できます。# https://wml-api-pyclient-dev-v4.mybluemix.net/#runtimes client.runtimes.list(limit=200)output(CP4Dv2.5の場合)-------------------------- -------------------------- ------------------------ -------- GUID NAME CREATED PLATFORM do_12.10 do_12.10 2020-05-03T08:35:16.679Z do do_12.9 do_12.9 2020-05-03T08:35:16.648Z do pmml_4.3 pmml_4.3 2020-05-03T08:35:16.618Z pmml pmml_4.2.1 pmml_4.2.1 2020-05-03T08:35:16.590Z pmml pmml_4.2 pmml_4.2 2020-05-03T08:35:16.565Z pmml pmml_4.1 pmml_4.1 2020-05-03T08:35:16.537Z pmml pmml_4.0 pmml_4.0 2020-05-03T08:35:16.510Z pmml pmml_3.2 pmml_3.2 2020-05-03T08:35:16.478Z pmml pmml_3.1 pmml_3.1 2020-05-03T08:35:16.450Z pmml pmml_3.0 pmml_3.0 2020-05-03T08:35:16.422Z pmml ai-function_0.1-py3.6 ai-function_0.1-py3.6 2020-05-03T08:35:16.378Z python ai-function_0.1-py3 ai-function_0.1-py3 2020-05-03T08:35:16.350Z python hybrid_0.2 hybrid_0.2 2020-05-03T08:35:16.322Z hybrid hybrid_0.1 hybrid_0.1 2020-05-03T08:35:16.291Z hybrid xgboost_0.90-py3.6 xgboost_0.90-py3.6 2020-05-03T08:35:16.261Z python xgboost_0.82-py3.6 xgboost_0.82-py3.6 2020-05-03T08:35:16.235Z python xgboost_0.82-py3 xgboost_0.82-py3 2020-05-03T08:35:16.204Z python xgboost_0.80-py3.6 xgboost_0.80-py3.6 2020-05-03T08:35:16.173Z python xgboost_0.80-py3 xgboost_0.80-py3 2020-05-03T08:35:16.140Z python xgboost_0.6-py3 xgboost_0.6-py3 2020-05-03T08:35:16.111Z python spss-modeler_18.2 spss-modeler_18.2 2020-05-03T08:35:16.083Z spss spss-modeler_18.1 spss-modeler_18.1 2020-05-03T08:35:16.057Z spss spss-modeler_17.1 spss-modeler_17.1 2020-05-03T08:35:16.029Z spss scikit-learn_0.22-py3.6 scikit-learn_0.22-py3.6 2020-05-03T08:35:16.002Z python scikit-learn_0.20-py3.6 scikit-learn_0.20-py3.6 2020-05-03T08:35:15.965Z python scikit-learn_0.20-py3 scikit-learn_0.20-py3 2020-05-03T08:35:15.939Z python scikit-learn_0.19-py3.6 scikit-learn_0.19-py3.6 2020-05-03T08:35:15.912Z python scikit-learn_0.19-py3 scikit-learn_0.19-py3 2020-05-03T08:35:15.876Z python scikit-learn_0.17-py3 scikit-learn_0.17-py3 2020-05-03T08:35:15.846Z python spark-mllib_2.4 spark-mllib_2.4 2020-05-03T08:35:15.816Z spark spark-mllib_2.3 spark-mllib_2.3 2020-05-03T08:35:15.788Z spark spark-mllib_2.2 spark-mllib_2.2 2020-05-03T08:35:15.759Z spark tensorflow_1.15-py3.6 tensorflow_1.15-py3.6 2020-05-03T08:35:15.731Z python tensorflow_1.14-py3.6 tensorflow_1.14-py3.6 2020-05-03T08:35:15.705Z python tensorflow_1.13-py3.6 tensorflow_1.13-py3.6 2020-05-03T08:35:15.678Z python tensorflow_1.11-py3.6 tensorflow_1.11-py3.6 2020-05-03T08:35:15.646Z python tensorflow_1.13-py3 tensorflow_1.13-py3 2020-05-03T08:35:15.619Z python tensorflow_1.13-py2 tensorflow_1.13-py2 2020-05-03T08:35:15.591Z python tensorflow_0.11-horovod tensorflow_0.11-horovod 2020-05-03T08:35:15.562Z native tensorflow_1.11-py3 tensorflow_1.11-py3 2020-05-03T08:35:15.533Z python tensorflow_1.10-py3 tensorflow_1.10-py3 2020-05-03T08:35:15.494Z python tensorflow_1.10-py2 tensorflow_1.10-py2 2020-05-03T08:35:15.467Z python tensorflow_1.9-py3 tensorflow_1.9-py3 2020-05-03T08:35:15.435Z python tensorflow_1.9-py2 tensorflow_1.9-py2 2020-05-03T08:35:15.409Z python tensorflow_1.8-py3 tensorflow_1.8-py3 2020-05-03T08:35:15.383Z python tensorflow_1.8-py2 tensorflow_1.8-py2 2020-05-03T08:35:15.356Z python tensorflow_1.7-py3 tensorflow_1.7-py3 2020-05-03T08:35:15.326Z python tensorflow_1.7-py2 tensorflow_1.7-py2 2020-05-03T08:35:15.297Z python tensorflow_1.6-py3 tensorflow_1.6-py3 2020-05-03T08:35:15.270Z python tensorflow_1.6-py2 tensorflow_1.6-py2 2020-05-03T08:35:15.243Z python tensorflow_1.5-py2-ddl tensorflow_1.5-py2-ddl 2020-05-03T08:35:15.209Z python tensorflow_1.5-py3-horovod tensorflow_1.5-py3-horovod 2020-05-03T08:35:15.181Z python tensorflow_1.5-py3.6 tensorflow_1.5-py3.6 2020-05-03T08:35:15.142Z python tensorflow_1.5-py3 tensorflow_1.5-py3 2020-05-03T08:35:15.109Z python tensorflow_1.5-py2 tensorflow_1.5-py2 2020-05-03T08:35:15.079Z python tensorflow_1.4-py2-ddl tensorflow_1.4-py2-ddl 2020-05-03T08:35:15.048Z python tensorflow_1.4-py3-horovod tensorflow_1.4-py3-horovod 2020-05-03T08:35:15.019Z python tensorflow_1.4-py3 tensorflow_1.4-py3 2020-05-03T08:35:14.987Z python tensorflow_1.4-py2 tensorflow_1.4-py2 2020-05-03T08:35:14.945Z python tensorflow_1.3-py2-ddl tensorflow_1.3-py2-ddl 2020-05-03T08:35:14.886Z python tensorflow_1.3-py3 tensorflow_1.3-py3 2020-05-03T08:35:14.856Z python tensorflow_1.3-py2 tensorflow_1.3-py2 2020-05-03T08:35:14.829Z python tensorflow_1.2-py3 tensorflow_1.2-py3 2020-05-03T08:35:14.799Z python tensorflow_1.2-py2 tensorflow_1.2-py2 2020-05-03T08:35:14.771Z python pytorch-onnx_1.2-py3.6 pytorch-onnx_1.2-py3.6 2020-05-03T08:35:14.742Z python pytorch-onnx_1.1-py3.6 pytorch-onnx_1.1-py3.6 2020-05-03T08:35:14.712Z python pytorch-onnx_1.0-py3 pytorch-onnx_1.0-py3 2020-05-03T08:35:14.682Z python pytorch-onnx_1.2-py3.6-edt pytorch-onnx_1.2-py3.6-edt 2020-05-03T08:35:14.650Z python pytorch-onnx_1.1-py3.6-edt pytorch-onnx_1.1-py3.6-edt 2020-05-03T08:35:14.619Z python pytorch_1.1-py3.6 pytorch_1.1-py3.6 2020-05-03T08:35:14.590Z python pytorch_1.1-py3 pytorch_1.1-py3 2020-05-03T08:35:14.556Z python pytorch_1.0-py3 pytorch_1.0-py3 2020-05-03T08:35:14.525Z python pytorch_1.0-py2 pytorch_1.0-py2 2020-05-03T08:35:14.495Z python pytorch_0.4-py3-horovod pytorch_0.4-py3-horovod 2020-05-03T08:35:14.470Z python pytorch_0.4-py3 pytorch_0.4-py3 2020-05-03T08:35:14.434Z python pytorch_0.4-py2 pytorch_0.4-py2 2020-05-03T08:35:14.405Z python pytorch_0.3-py3 pytorch_0.3-py3 2020-05-03T08:35:14.375Z python pytorch_0.3-py2 pytorch_0.3-py2 2020-05-03T08:35:14.349Z python torch_lua52 torch_lua52 2020-05-03T08:35:14.322Z lua torch_luajit torch_luajit 2020-05-03T08:35:14.295Z lua caffe-ibm_1.0-py3 caffe-ibm_1.0-py3 2020-05-03T08:35:14.265Z python caffe-ibm_1.0-py2 caffe-ibm_1.0-py2 2020-05-03T08:35:14.235Z python caffe_1.0-py3 caffe_1.0-py3 2020-05-03T08:35:14.210Z python caffe_1.0-py2 caffe_1.0-py2 2020-05-03T08:35:14.180Z python caffe_frcnn caffe_frcnn 2020-05-03T08:35:14.147Z Python caffe_1.0-ddl caffe_1.0-ddl 2020-05-03T08:35:14.117Z native caffe2_0.8 caffe2_0.8 2020-05-03T08:35:14.088Z Python darknet_0 darknet_0 2020-05-03T08:35:14.059Z native theano_1.0 theano_1.0 2020-05-03T08:35:14.032Z Python mxnet_1.2-py2 mxnet_1.2-py2 2020-05-03T08:35:14.002Z python mxnet_1.1-py2 mxnet_1.1-py2 2020-05-03T08:35:13.960Z python -------------------------- -------------------------- ------------------------ --------他にもmeta_propsに含められるメタ情報はあり、作成したモデルがどのような条件下で作成されたのかを記録しておけるので、できるだけ付与しておくことが一般的にはおすすめです。
meta_propsに記述できるメタ情報
client.repository.ModelMetaNames.get()output['CUSTOM', 'DESCRIPTION', 'DOMAIN', 'HYPER_PARAMETERS', 'IMPORT', 'INPUT_DATA_SCHEMA', 'LABEL_FIELD', 'METRICS', 'MODEL_DEFINITION_UID', 'NAME', 'OUTPUT_DATA_SCHEMA', 'PIPELINE_UID', 'RUNTIME_UID', 'SIZE', 'SOFTWARE_SPEC_UID', 'SPACE_UID', 'TAGS', 'TRAINING_DATA_REFERENCES', 'TRAINING_LIB_UID', 'TRANSFORMED_LABEL_FIELD', 'TYPE']モデルの保存 (デプロイメントスペース)
WML clientを使用して、デプロイメントスペースにモデルを保存します。
その他の方法として、モデルを上記の操作で分析プロジェクトに保存した後、CP4D画面上で該当モデルの"プロモート"をクリックすることで、分析プロジェクトのモデルをデプロイメントスペースへコピー保存することでも同じ結果になります。# Deployment Spaceに切り替え(切り替える必要がある場合のみ実施) client.set.default_space(space_id) # モデルのメタ情報を記述 model_name = "sample_iris_model" meta_props={ client.repository.ModelMetaNames.NAME: model_name, client.repository.ModelMetaNames.RUNTIME_UID: "scikit-learn_0.22-py3.6", client.repository.ModelMetaNames.TYPE: "scikit-learn_0.22", client.repository.ModelMetaNames.INPUT_DATA_SCHEMA:{ "id":"iris model", "fields":[ {'name': 'sepal length (cm)', 'type': 'double'}, {'name': 'sepal width (cm)', 'type': 'double'}, {'name': 'petal length (cm)', 'type': 'double'}, {'name': 'petal width (cm)', 'type': 'double'} ] }, client.repository.ModelMetaNames.OUTPUT_DATA_SCHEMA: { "id":"iris model", "fields": [ {'name': 'iris_type', 'type': 'string','metadata': {'modeling_role': 'prediction'}} ] } } # モデルを保存。戻り値に作成したモデルのメタデータが含まれる model_artifact = client.repository.store_model(model, meta_props=meta_props, training_data=X, training_target=y)補足として、meta_props内に含めるメタ情報については、上にかいた「補足:モデルに含めるメタ情報」と同じなのでそちらを参照ください。
保存したモデルのIDは、戻り値model_artifact内に含まれています。IDはデプロイを作成する際に必要となります。以下のようにIDを取り出します。
戻り値からのIDの取得model_id = client.repository.get_model_uid(model_artifact)戻り値からのIDの取得(もう1つの方法)model_id = model_artifact['metadata']['guid']モデルの一覧表示 (分析プロジェクト)
# 分析プロジェクトに切り替え(切り替える必要がある場合のみ実施) client.set.default_project(project_id) # モデルの一覧を表示 client.repository.list_models()モデルの一覧表示 (デプロイメントスペース)
WML clientを使用します。
# Deployment Spaceに切り替え(切り替える必要がある場合のみ実施) client.set.default_space(space_id) # モデルの一覧を表示 client.repository.list_models()デプロイメントの操作 (デプロイメントスペースのみ)
WML clientを使用します。デプロイメントはBatch型とOnline型があります。作成するcreateにはデプロイするモデルのIDを与えます。
デプロイメントの作成(Online型)
Online型のデプロイdep_name = "sample_iris_online" meta_props = { client.deployments.ConfigurationMetaNames.NAME: dep_name, client.deployments.ConfigurationMetaNames.ONLINE: {} } deployment_details = client.deployments.create(model_id, meta_props=meta_props)デプロイは1,2分かかりますが、以下のような出力が出ればデプロイ成功です。
output####################################################################################### Synchronous deployment creation for uid: 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx' started ####################################################################################### initializing ready ------------------------------------------------------------------------------------------------ Successfully finished deployment creation, deployment_uid='yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy' ------------------------------------------------------------------------------------------------作成したデプロイメントのIDは、戻り値から以下のように取り出せます。
# ONLINE型デプロイメントのDeployment ID dep_id_online = deployment_details['metadata']['guid']デプロイメントの作成(Batch型)
Batch型のデプロイdep_name = "sample_iris_batch" meta_props = { client.deployments.ConfigurationMetaNames.NAME: dep_name, client.deployments.ConfigurationMetaNames.BATCH: {}, client.deployments.ConfigurationMetaNames.COMPUTE: { "name": "S", "nodes": 1 } } deployment_details = client.deployments.create(model_id, meta_props=meta_props)Successfullyと表示されたらデプロイ成功です。
作成したデプロイメントのIDは、戻り値から以下のように取り出せます。# BATCH型デプロイメントのDeployment ID dep_id_batch = deployment_details['metadata']['guid']デプロイメントの一覧表示
こちらもWML clientを使用します。
# list deployment client.deployments.list()デプロイメントの実行(Online型)
Online型のデプロイメントの実行では、スコアリング用の入力データ(JSON形式)を作成して、それをデプロイメントにRESTで投げ、予測結果を受け取ります。まず、サンプル入力データを作成します。
スコアリング実行用のサンプル入力データを生成# sample data for scoring (setosa) scoring_x = pd.DataFrame( data = [[5.1,3.5,1.4,0.2]], columns=['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)'] ) values = scoring_x.values.tolist() fields = scoring_x.columns.values.tolist() scoring_payload = {client.deployments.ScoringMetaNames.INPUT_DATA: [{'fields': fields, 'values': values}]} scoring_payloadoutput{'input_data': [{'fields': ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'], 'values': [[5.1, 3.5, 1.4, 0.2]]}]}Onlineデプロイメントの実行は、WML clientとrequestsの2つの方法が可能です。
WMLclientによるOnlineスコアリング実行prediction = client.deployments.score(dep_id_online, scoring_payload) predictionoutput{'predictions': [{'fields': ['prediction', 'probability'], 'values': [[0, [0.8131726303900102, 0.18682736960998966]]]}]}requestsの実行例は、CP4D画面のデプロイメント詳細画面にあるコードスニペットからコピペで使えます。
mltokenはAPIの認証トークンで、この記事の最初の方にあるWML clientの初期化(認証)でOS環境変数 USER_ACCESS_TOKEN から得たtokenがそのまま使用できます。
CP4D外の環境から実行する場合は、CP4D製品マニュアルの「ベアラー・トークンの取得」を実施して予め入手しておきます。import urllib3, requests, json # token = "XXXXXXXXXXXXXXXXXX" # url = "https://cp4d.host.name.com" header = {'Content-Type': 'application/json', 'Authorization': 'Bearer ' + token} dep_url = url + "/v4/deployments/" + dep_id_online + "/predictions" response = requests.post(dep_url, json=scoring_payload, headers=header) prediction = json.loads(response.text) predictionoutput{'predictions': [{'fields': ['prediction', 'probability'], 'values': [['setosa', [0.9939393939393939, 0.006060606060606061, 0.0]]]}]}もしCP4Dのドメインが自己署名証明書を使っていてrequests.postが証明書チェックで失敗する場合は、requests.postのオプション
verify=Falseを使うと暫定的に回避できます。ご利用は自己責任で。デプロイメントの実行(Batch型)
Batch型のデプロイメントの実行では、入力データとなるCSVファイルを予めデプロイメントスペースのデータ資産に登録しておき、そのデータ資産のhrefを指定します。
入力データの準備# サンプルとしてIris学習データXの先頭5行をCSV化 X.head(5).to_csv("iris_test.csv") # デプロイメントスペースに切り替え(切り替える必要がある場合のみ実施) client.set.default_space(space_id) # データ資産への登録 asset_details = client.data_assets.create(name="iris_test.csv",file_path="/home/wsuser/work/iris_test.csv") asset_href = client.data_assets.get_href(asset_details)Batchスコアリング実行# 実行ジョブのメタ情報を作成 job_payload_ref = { client.deployments.ScoringMetaNames.INPUT_DATA_REFERENCES: [{ "location": { "href": asset_href }, "type": "data_asset", "connection": {} }], client.deployments.ScoringMetaNames.OUTPUT_DATA_REFERENCE: { "location": { "name": "iris_test_out_{}.csv".format(dep_id_batch), "description": "testing csv file" }, "type": "data_asset", "connection": {} } } # バッチ実行(create_jobすると実行される) job = client.deployments.create_job(deployment_id=dep_id_batch, meta_props=job_payload_ref) job_id = client.deployments.get_job_uid(job)実行結果のステータスは、以下のコードで確認できます。プログラムに組み込む場合は、completedになるまでループを回すと良いと思います。
client.deployments.get_job_status(job_id)output# 実行中の場合 {'state': 'queued', 'running_at': '', 'completed_at': ''} # 実行完了の場合 {'state': 'completed', 'running_at': '2020-05-28T05:43:22.287357Z', 'completed_at': '2020-05-28T05:43:22.315966Z'}以上です。
他にも、Python関数を保存したりデプロイしたりできますが、機会があれば追記 or 別の記事で書きます。
詳細は、WML client リファレンスガイド watson-machine-learning-client(V4) および、CP4D v2.5 製品マニュアル Python クライアントを使用したデプロイを参照。WML clientリファレンスガイドは随時更新される可能性があるので注意。 ↩
詳細は、CP4D v2.5 製品マニュアル Python 用の project-lib の使用を参照 ↩
データの読み込みは、Notebook画面の右上にあるデータボタン(0100と書いてある)をクリックし、該当のデータ資産名 > コードに挿入 > pandas DataFrame をクリックすることで、Notebook内のセルにコードが自動挿入されます。標準では、ファイルの場合はpandas.read_csvのコードが、DBテーブルの場合はproject_libのコードが挿入されるようです。 ↩
WML clientでも可能ですが、格納されたファイルが本来のデータ資産とは異なる領域にファイルが保存され、ダウンロードするとファイル名が不正になるなど問題が確認されているため、WML clientでのデータ資産への保管はオススメしません。その方法もこの記事には書きません。 ↩
デプロイメントスペースの画面上は、関数が「機能」と表現されています。日本語訳が統一されておらずイマイチな気がしますが。 ↩
CP4D v2.5 製品マニュアル ノートブックでの機密コード・セルの非表示を参照 ↩
- 投稿日:2020-05-28T19:03:04+09:00
100日後にエンジニアになるキミ - 69日目 - プログラミング - ファイル操作について
昨日までのはこちら
100日後にエンジニアになるキミ - 66日目 - プログラミング - 自然言語処理について
100日後にエンジニアになるキミ - 63日目 - プログラミング - 確率について1
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
今回はファイルの読み込みについてで、言語はPython言語を用います。
ファイルの読み込み
Pythonでファイルの読み込みをする方法はたくさんあります。
まずはデータファイルがどんな形式なのかによって方法が変わってきます。
テキストファイル(.txt)
拡張子が
.txtのものはテキストファイルです。
単純に文章を保存したものはテキストファイルで、文章の長さなどの決まりはなく
改行を入れると複数行をファイルにまとめることができます。テキストファイルの読み込みは1行ずつ行います。
下記がテキストファイルの読み込みの例です。with open(ファイルパス) as ファイル変数: 処理
with openの構文で読み込みを行います。
openではファイルパスを指定することでファイルの読み込みができます。読み込んだ後の操作をするためにファイル変数として格納し処理を行う際に使います。
プログラムと同じ場所に置いたテキストファイルを読み込みする例です。
with open('higedan_list.txt') as _r: for row in _r: print(row)溶ける 絵の具 みたい イレギュラー 独り 何 ひとつ ...
for文を用いると1行ずつ文字列として処理が行えます。
上手くやれば、普通のテキストエディターでは開くことができない
長大なサイズのファイルの中も見ることができます。CSVファイル(.csv)
CSV(Comma-Separated Values)
,カンマで区切られた形式のファイル形式です。
縦、横で数が揃うような表形式のファイルになっています。1行目は通常はヘッダー行として扱われ表頭としてのデータが書き込まれていることが多いです。
その場合、データ行は2行目以降になります。注意点として
,カンマをデータに含む場合は"で囲まれている場合があります。
,は通常、区切りの文字として扱われるため、データとしての,は
囲み文字で囲んでおかないとデータの列数などがずれてしまうことになります。データを書き込む際や、読み込みをする際には気をつけましょう。
Python言語では
csvライブラリでCSVファイルの読み込みができます。
通常は,区切りですが、区切り文字を引数delimiterで指定ができます。
TAB区切りのファイルなども読み込みすることができます。import csv with open(csvファイル名) as ファイル変数: csv変数 = csv.reader(ファイル変数) 処理 with open(csvファイル名) as ファイル変数: csv変数 = csv.reader(ファイル変数 , delimiter='区切り文字') 処理データフレームとして読み込みをしたい場合は
pandasライブラリを用います。import pandas as pd データフレーム変数名 = pd.read_csv(ファイルパス)読み込んでみると次のようになります。
import pandas as pd df = pd.read_csv('tabelog_star_data.csv') df.head()
夜価格低 昼価格低 星 コメント数 ブックマーク数 0 5000 1000 3.15 63 4763 1 2000 1000 3.37 15 1202 2 10000 3000 3.64 85 3340 3 3000 999 3.29 51 2568 4 5000 999 3.36 21 1522 JSONファイル(.json)
jsonは辞書形式の文字列で書かれたファイルです。
テキストファイルとして読み込みすることもできますが、単純な文字列ではなく
辞書形式で読み込みするのであればjsonファイルとして読み込みをする必要があります。import json with open(jsonファイル名) as ファイル変数: 変数 = json.load(ファイル変数)読み込みするとこうなります。
import json with open('json.json') as _r: js = json.load(_r) print(js){'1': [1, 2, 3], '2': [3, 5, 6]}
ZIPファイル(.zip)
ZIPファイルは圧縮形式のファイルで複数個のファイルを1つにまとめたファイルです。
そのためZIPの中身のファイルが何かを知りたい場合は以下のようなコードになります。import zipfile with zipfile.ZipFile(zipファイルパス) as zipファイル変数: for 変数 in zipファイル変数.namelist(): print(変数.encode('文字コード'))
ZIPではパスワード設定などもできるので展開方法は下記の通りです。import zipfile #zipの全展開 with zipfile.ZipFile(zipファイルパス) as zipファイル変数: zipファイル変数.extractall(出力先ディレクトリ) #zipのパスワード入力展開 with zipfile.ZipFile(zipファイルパス) as zipファイル変数: zipファイル変数.extractall(出力先ディレクトリ,pwd='パスワード') #zipのファイル指定展開 with zipfile.ZipFile(zipファイルパス) as zipファイル変数: zipファイル変数.extract('ファイル名',出力先ディレクトリ)GZIP(.gz)
ZIPと似ていますが1つのファイルを圧縮したファイル形式です。
そのため中身は1つしかありません。ファイルを展開しながら中身を見るのは以下のようなコードです。
import gzip with gzip.open(GZIPファイルパス,'r') as gzipファイル変数: 処理:圧縮されているので、for文内で展開されるのは文字列ではなくバイトコードになったりするので気をつけましょう。
画像ファイル(.jpg , .png , .gif)
画像ファイルの読み込みは
PILライブラリで行うことができます。from PIL import Image, ImageFilter, ImageOps #画像を読み込みする im = Image.open(ファイルパス) #画像のサイズ print(im.size) #画像のフォーマット print(im.format) #画像のRGB最大最小値 print(im.getextrema()) #画像のメタ情報 print(im.mode)(432, 288)
PNG
((0, 255), (0, 255), (0, 255), (255, 255))
RGBAエクセルファイル(.xlsx)
エクセルファイルの読み込みはpandasライブラリなどで行うことができます。
pandasライブラリの場合はシートをそのままデータフレームとして読み込みします。import pandas as pd データフレーム変数名 = pd.read_excel(ファイルパス, sheet_name='シート名')読み込んでみると次のようになります。
import pandas as pd df = pd.read_excel('tabelog_star_data.xlsx',sheet_name='シート01') df.head()
夜価格低 昼価格低 星 コメント数 ブックマーク数 0 5000 1000 3.15 63 4763 1 2000 1000 3.37 15 1202 2 10000 3000 3.64 85 3340 3 3000 999 3.29 51 2568 4 5000 999 3.36 21 1522 ファイルの書き込み
テキスト形式のファイルであれば読み込みと同じような手順で書き込みができます。
with open(ファイルパス,'w') as ファイル変数: 処理読み込みとの違いは
openの引数に'w'が追加されることです。
'w'は上書き、'a'は追記で書き込みを行います。画像の場合は
PILライブラリなどで書き込みすることができます。from PIL import Image Image変数.save(ファイルパス)まとめ
よく使うファイル形式のものだけですが、業務ではファイルの読み込み作業はかなり多いので
色々覚えておくと楽です。他にも様々なデータ形式があり、都度読み込み方法が変わるので
自分が使うファイル形式のやり方を調べてみましょう。君がエンジニアになるまであと31日
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython
- 投稿日:2020-05-28T18:53:50+09:00
Python と仲良くなろう #0(環境構築編)
はじめに
この記事は社内のインフラエンジニアの方々に Python を通してプログラミングと仲良くなってもらうことを目的として Qiita:Team へ投稿したものの再編集版となります。
目標としてはオライリーの「退屈なことは Python にやらせよう」を読んで内容を理解できるようになるくらいを考えています。
が、著者はまだこの本を読んでいません。
また、著者はマウス操作が嫌いなため随所に偏った思想の発言が見受けられますが予めご了承ください。前提
弊社の都合上、全員 Mac を使っていることを想定しています。
Windows はごめんなさい。Ubuntu on Windows とか使えば似たようなことができます。たぶん。環境準備
まずは Python をコーディング・実行するための環境を準備しましょう。
コンソール
なんだかんだプログラミングにはコンソールが大切です。
個人の哲学がある人はこのセクションは飛ばしましょう。
zsh とか fish とかまで行ったら著者の領域外です。
だってそもそも ssh 先で同じシェルが使えない時点で詰みでしょ、そんなん。Mac 標準の terminal でもいいですが、なんだかんだ便利なので iTerm2 を使いましょう。
ダウンロードページからダウンロードしてインストールしましょう。
.zip をダウンロードして解凍したらアプリケーションフォルダに入れましょう。
(今後、
コンソール(Console)ターミナル(Terminal)iTermはすべてこのiTerm2を前提に話をします。)アプリケーションフォルダに入れたら起動しましょう。
ここからは基本的にマウス操作よりもキーボード操作を優先します。
ショートカット(⌘+スペース or Ctrl+スペース)で spotlight を起動します。
起動したらitermを入力して iTerm2 を起動します。
Alfread 使ってる人はいい感じに起動してください。私は使ってないので知りません。
あと、最初だけはインデックスが間に合わずに起動できないかも知れません。その場合は諦めてダブルクリックしましょう。最初にやっておくと便利なので単語移動の設定をしましょう。
ここでもショートカットです。
iTerm をフォーカスして⌘+,を押して Preference を開きます。Profile > Keys > + クリック
Click to Set をクリックしてフォーカスしたら
alt(option) + →を押して下のセレクトボックスからActionからSend Escape Sequenceを選択、Escの欄にfを入れて設定します。
同じようにalt + ←にはSend Escape Sequenceにbを設定します。
これで CLI 上で word 単位の移動ができます。この便利さにはいつか気づくことでしょう。
なお、k-nishigaki はこれの他にログ保存くらいしか設定していません。
デフォルトで便利ですね、iTerm2。
これ以上の設定をしたい人は自分で調べて設定していきましょう。欲が生まれたあなたならできます。Editor (VS Code) セットアップ
エディタ(Editor)は大切です。他に哲学のある人は読み飛ばしてください。
iTerm2 を入れたあなたなら(たぶん) Vim が使えます。入れてなくても普通に Terminal で使えますが。
しかしここで Vim の話はしません。奥が深すぎて解説できないので、他の猛者に任せます。いくらでもでてくることでしょう。Emacs 宗派の方はそのまま Emacs で突き進んでください。
余談ですが、著者も元は Emacs でしたのでちょっとした入力時には Emacs like な操作を行っています。
Ctrl + f, b, a, k, n あたりは鉄板ですよね。閑話休題。
著者が Vim をより習得するために参考にしたのは↓のあたりです。
https://qiita.com/hachi8833/items/7beeee825c11f7437f54
https://qiita.com/nyantera/items/4bf29ca6f11bc797a9cbVim の話ここまで。
ここから先は Visual Studio Code を使います。
今すぐ無料でダウンロードしましょう。
zip なのでインストール方法は iTerm2 と同じです。わかりやすいですね。
インストールしたら同様に spotlight で起動しましょう。
マウス操作はあなたの大切な時間を毎回、数秒単位で奪っていきます。
数秒と言えど毎日繰り返す行為は積み重なれば多くの損失です。
数回繰り返し行えばvsと入力するだけで vs code が起動することでしょう。ついでに
この先の説明で面倒を回避するために必要なのでコンソールから VS Code を起動できるように設定しましょう。
VS Code を開いたらF1を押し、コマンドパレットを開いたらそのままShellと入力します。
するといい感じにShell Command: Install 'code' command in PATHというコマンドが選択されているかと思います。まよわずそのままクリックしましょう。
するとなんかいい感じに成功した雰囲気の通知が出ると思います。出ろ。
ここではコンソールが起動したままと思われるので、その場合はコンソールにウィンドウをフォーカスし、一度
⌘+qを押して終了しておきましょう。
何かに付けて困ったり困る前に再起動の精神です。さて、VS Code に戻ります。うっかり終了していたらまた VS Code を起動してください。もちろん spotlight でキーボードから起動しましょうね。
起動したら左の四角いやつをクリックし、Search 欄に
pythonを入力しましょう。
そして一番上のPythonを Install しましょう。これで十分です。
なお、個人的に良いエディタの条件は
- 起動が早い
- 動作が早い
- Plugin が充実している
- かつ、Plugin install が手軽
です。いくつか Editor を渡り歩けば、あなただけの究極の Editor に出会えることでしょう。
なお、著者はプログラマではないのでぶっちゃけ全然こだわりがありません。pyenv + virtual env のセットアップ
色々と宗派の対立はあります(↓)が、ここでは pyenv + virtualenv で進めます。
https://qiita.com/ganariya/items/1bf870275bad7b5ab506なお、ここから先はすべて私見ですが、個人的にとても重要です。
プログラミング初学者が一番心の折れるポイント、それはプログラミング言語実行環境のセットアップです。
もう少し詳しく言うと セットアップしてみたけどその手順がアレで再現性を失ってしまう ことです。
プログラムの最も素敵なところは 同じ環境で実行すれば同じ結果が得られるという再現性 です。(※極論です)
究極的には どこで、どんな環境でプログラミングしても同じ結果を得られる という多幸感は重要です。(※持論です)
そのために とても簡単にセットアップ でき、かつ 自分の端末以外でも再現が容易 な環境を用意しましょう。まぁ全てはここに書いてあるので転載です。
https://qiita.com/niwak2/items/5490607be32202ce1314pyenv install
Mac には Homebrew という
ちょっと前まで sudo 必要で割と面倒事が多かった便利なツールがあります。
便利なものはひたすら便利に使っていくべきです。コンソールを開いて↓の入力をしましょう。
なお、行頭につけている$マークは「一般ユーザ(非 root ユーザ)である」ということを意味していますが、特に気にせず、その先の word を入力して Enter を押してください。
ズラズラ勝手に文字列が流れますが怖がることはありません。
それらはすべてあなたに「私は今こんな処理をしています」というメッセージです。
機械との対話はすでに始まっています。$ brew install pyenvたぶん、↓とは違うメッセージが出るでしょう。
$ brew install pyenv Updating Homebrew... ==> Auto-updated Homebrew! Updated 4 taps (mackerelio/mackerel-agent, homebrew/cask-versions, homebrew/core and homebrew/cask). ==> New Formulae (以下略)
(略)
重要なのは最後のほうに出力されたメッセージです。
そこに「Sucess!」とかそんな感じのメッセージが表示されていれば完璧です。
それは機械が教えてくれたおめでたいメッセージです。素直に受け取りましょう。virtualenv install
pyenv と同様に virutalenv をインストールしていきましょう。
インストールするパッケージの名前はpyenv-virutalenvです。
お間違いの無いよう。$ brew install pyenv-virtualenvここでもズラズラ出ますが、それは機械からのコミュニケーションです。
すべてを受け止めましょう。おまじない
ここで、プログラミング、及び環境構築によくあるおまじないを唱えます。
これは実はおまじないでもなんでもなく、機械との対話に必要な行為なのですが、詳しく説明するとこの記事の3倍くらい必要になるので諦めます。ごめんなさい。Vim は面倒なので、VS Code でやりましょう。
コンソールを開いて↓を入力して Enter してください。
たぶん VS Code が起動するはずです。
起動しなかったらごめんなさい。頑張って~/.bash_profileを開いてください。なお、これは shell 操作で重要な TIPS ですが、入力途中に Tab を押すことでその先の word を(可能な場合に)補完することができます。
試しにcode ~/.bash_まで入力したところで Tab を押してみてください。
おそらくcode ~/.bash_profileが一気に入力されるはずです。
これを「タブ補完」と呼びます。
また、補完の候補が複数ある場合に Tab を2回連続で押すと、候補をすべて出力してくれたりします。
覚えるべきはコマンドの全文ではなく、使い方です。詳細なコマンドを忘れてしまってもタブ補完で思い出すことが可能です。
Google 日本語入力でもタブは役立ちますのでぜひ覚えてください。
ぜひ連打していきましょう。閑話休題。↓をコンソールで入力します。
$ code ~/.bash_profileすると VS Code が起動すると思います。起動しろ。
もしかすると色々記述されたファイルが開くかも知れませんが、無視してそのファイルの一番下の空いてるところに↓をコピー&ペーストします。ここは面倒なのでコピペでいいです。## Set path for pyenv export PYENV_ROOT="${HOME}/.pyenv" if [ -d "${PYENV_ROOT}" ]; then export PATH=${PYENV_ROOT}/bin:$PATH eval "$(pyenv init -)" eval "$(pyenv virtualenv-init -)" fi
記述したら
⌘+sで保存しましょう。
保存という行為もキーボードショートカットです。
マウス操作はあなたの時間を奪っています。Hello, world!!
プログラミングの第一歩といえば Hello, world!
初めての「コーディング」
さて、ここまで来ればもう Python でのプログラミングを行う準備は十分です。
最後の事前準備として、デスクトップにpython_trialという名前でフォルダを作っておいてください。
なお、これもコンソールで実行可能です。コンソールを開いて↓を入力しましょう。$ mkdir ~/Desktop/python_trialこれでデスクトップ上に
python_trialという名前のフォルダが作成されます。
(~というのはホームフォルダを表しています。理解しなくても問題ありませんが興味あればリンク先とか調べてみてください。)終わったら VS Code を開き、
⌘+nを押しましょう。可能な限りキーボードで操作しましょう。
マウス操作はあなたの大切な時間を損ないます。新しいタブで
Untitled-1が開かれますね。
ここからあなたの素敵なプログラミングライフの始まりです。
最初に、今から記述するファイルが Python のコードであるということを明示すると便利なことが多いので、何を記述するまでもなくいきなり保存してみましょう。
保存は⌘+sです。マウス操作は時間を無駄にする行為と認識しましょう。
保存する名前はなんでも構いませんが、ここでは慣例に従ってhello_world.pyとしておきましょう。
なお、重要なのはファイル名ではなく拡張子です。
Editor は基本的に拡張子でファイルを判断します。
これが Python のコードを記述しているファイルだということを示すために.pyという拡張子だけは崩さず保存しましょう。
保存場所は先程作成したデスクトップのpython_trialにしましょう。してください。
保存したらそのまま VS Code で↓のコードを コピー&ペースとは決してせず すべて手打ちしましょう。
これは著者の個人的な意見ですが、手で打つことはコピペより遥かに学習効率を上げます。なお、打っている途中に
(とか打った途端、自動で()が入力され、その上で()の間にカーソルを移動されるかも知れません。
これは Editor の素敵な「補完機能」です。
エンジニアは面倒事が嫌いです。()と連続で打つことすら嫌いです。それを自動で入力してくれる機能なのです。
ぜひ気持ち悪がらず、積極的に活用していきましょう。機械と仲良くなりましょう。print("hello world!")
打ち終わったら
⌘+sで保存します。
繰り返しますが、マウス操作は時間を無駄にする行為です。最初の「コード実行」
保存したら今度はコンソールを開きます。
spotlight を開いてitermと入力してもいいですが、iTerm2 を起動済みなら⌘+Tabを駆使して iTerm2 をフォーカスするのもいいでしょう。
マウスで選択する?あなたは GUI に毒されている!今すぐそのマウスを手放しなさい!!コンソールで↓を入力します。
Tab をたくさん押していきましょう。補完が効いていくはずです。$ cd ~/Desktop/python_trial/これは
~/Desktop/python_trial/というフォルダにcurrent directoryを変更するという意味のコマンドです。
コマンドはプログラミングと切っても切れない関係にある技です。恐れず使っていきましょう。pyenv の設定
さぁ、ここで最初に準備した pyenv の出番です!
以下のコマンドをコンソールで実行しましょう。
$ pyenv install 3.6.9 (おそらく↓のような表示がされます) python-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Downloading Python-3.6.9.tar.xz... -> https://www.python.org/ftp/python/3.6.9/Python-3.6.9.tar.xz Installing Python-3.6.9... python-build: use readline from homebrew python-build: use zlib from xcode sdk Installed Python-3.6.9 to /Users/k-nishigaki/.pyenv/versions/3.6.9これは
pyenvという Python 全体の環境管理アプリケーションに python v.3.6.9 を install するコマンドです。(※3.6.9の理由はこの時点で最新っぽかったからです)
時間は結構かかります。
終わったら、次に以下のコマンドを実行しましょう。$ pyenv virtualenv 3.6.9 python_trialするといい感じに
pyenvにpython v.3.6.9がpython_trialという名前でセットされます。
確認してみましょう。$ pyenv versions | grep python_trial 3.6.9/envs/python_trial python_trialバッチリ設定されてそうですね。
ですが、これではまだ不十分です。次に↓のコマンドを打ちましょう。$ pyenv local python_trial (python_trial) hogehoge$実行するとコンソールの頭に
(python_trial)という文字がついたかと思います。ついてないかも。ついてなかったらついてる気分でそのまま行きましょう。これこそが pyenv + virtualenv の真骨頂です。
これは「今いるフォルダがpython v.3.6.9/python_tiralという環境の支配下にある」ということを意味しています。
この有用性はきっと後々ご理解いただけるかと思いますが、この時点では「今いるフォルダでは python v.3.6.9 が使える」という認識でいるとです。
では python v.3.6.9 が動いていることを確認しましょう。
↓のコマンドを実行します。$ python --version Python 3.6.9
きっちり Python 3.6.9 であるということがわかりましたね。
ではこのまま、先程コーディングした python スクリプトを実行してみましょう。
↓をコンソールで実行します。$ python hello_world.py hello, world!きっとこのように表示されたはずです。
「ここまで準備してたったこれだけ?」と思うかも知れません。
しかし、これであなたは「Python 3.6.9 が実行可能な環境であれば、どんなところでもhello, world!という文字列をコンソールに出力させる技術」を手に入れました。
これは実に多くのプログラミングに通じる基礎技術です。
あなたはまさに今、プログラミングとプログラムの実行という大きな技術を手に入れました。
ここまで来られたあなたならこの先多くのプログラミング技術を習得できるはずです。次回予告
次回は変数と関数を扱う予定です。
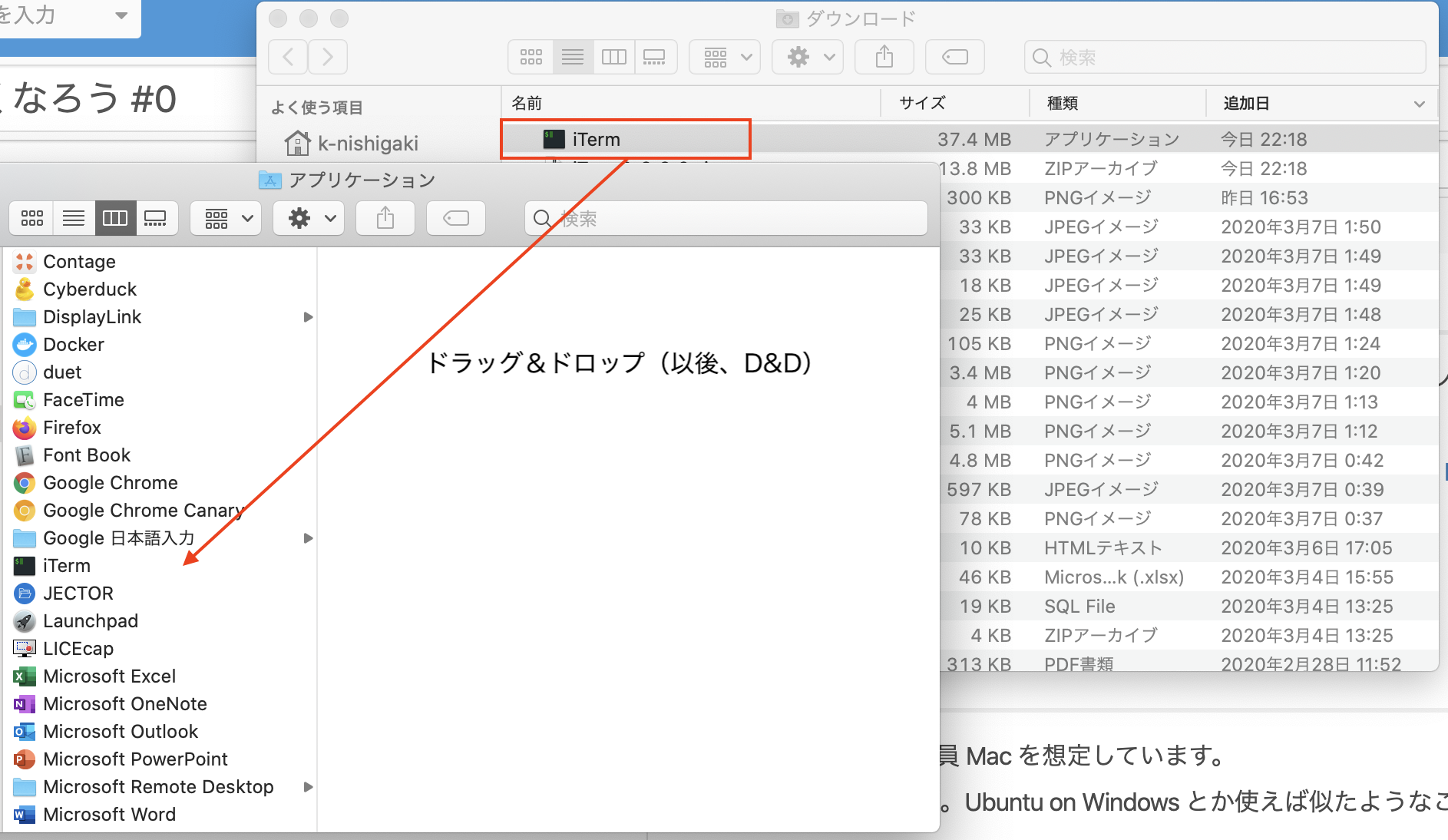
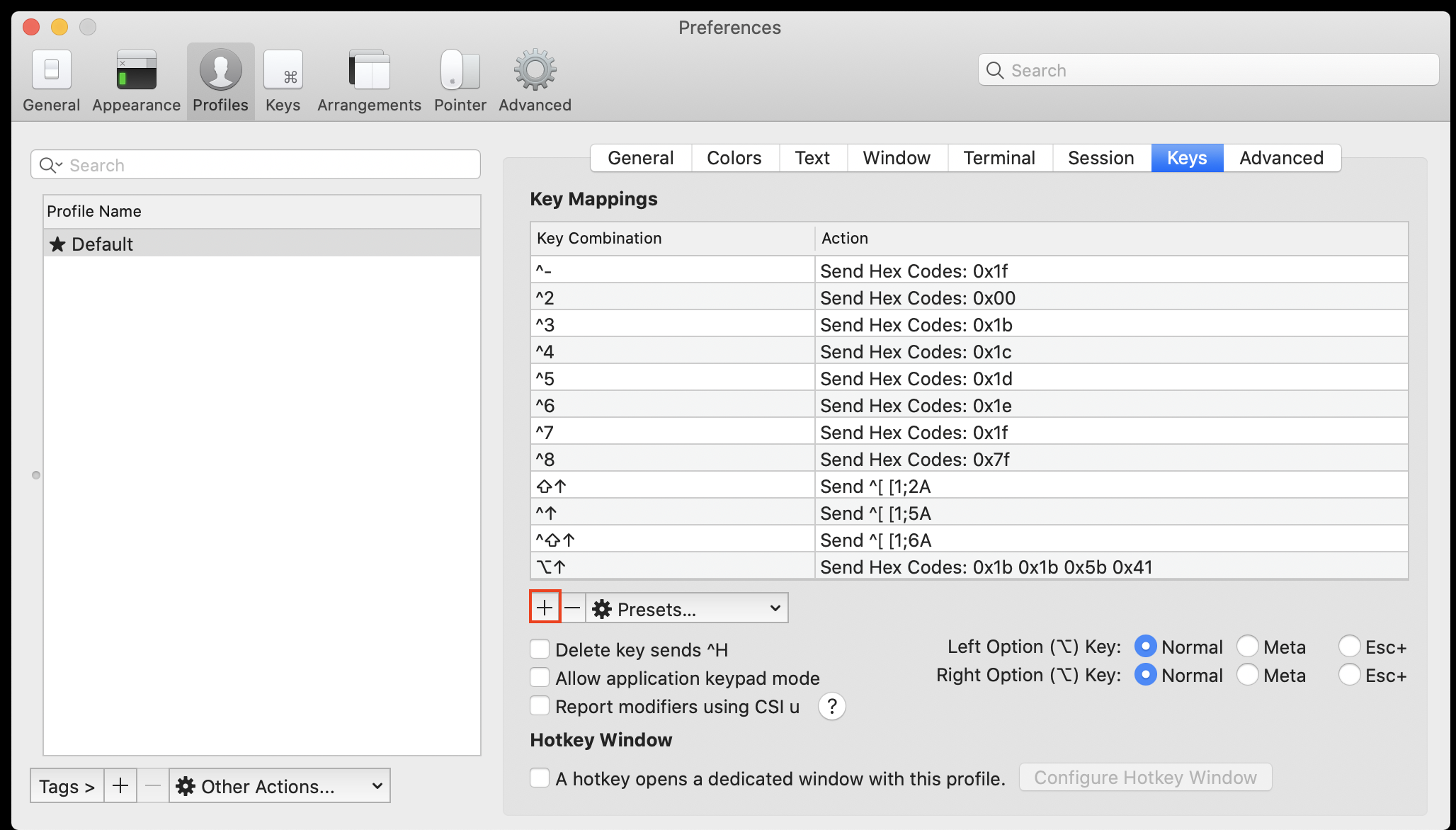
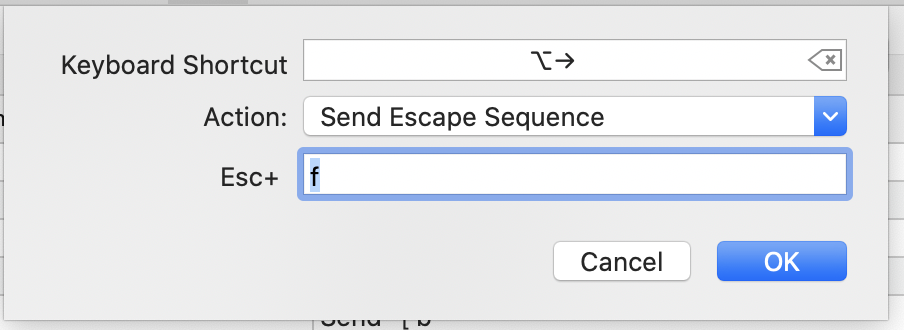
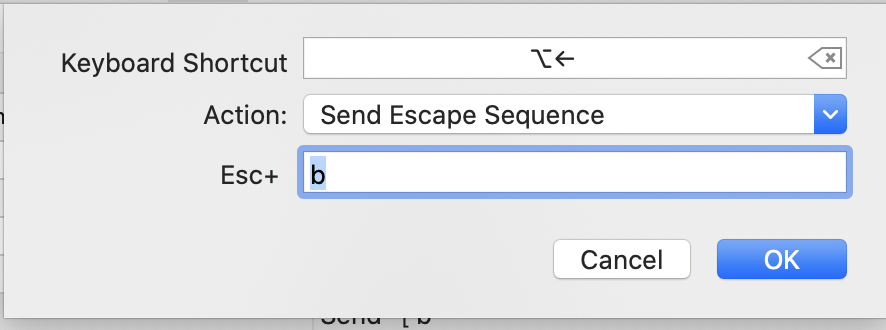


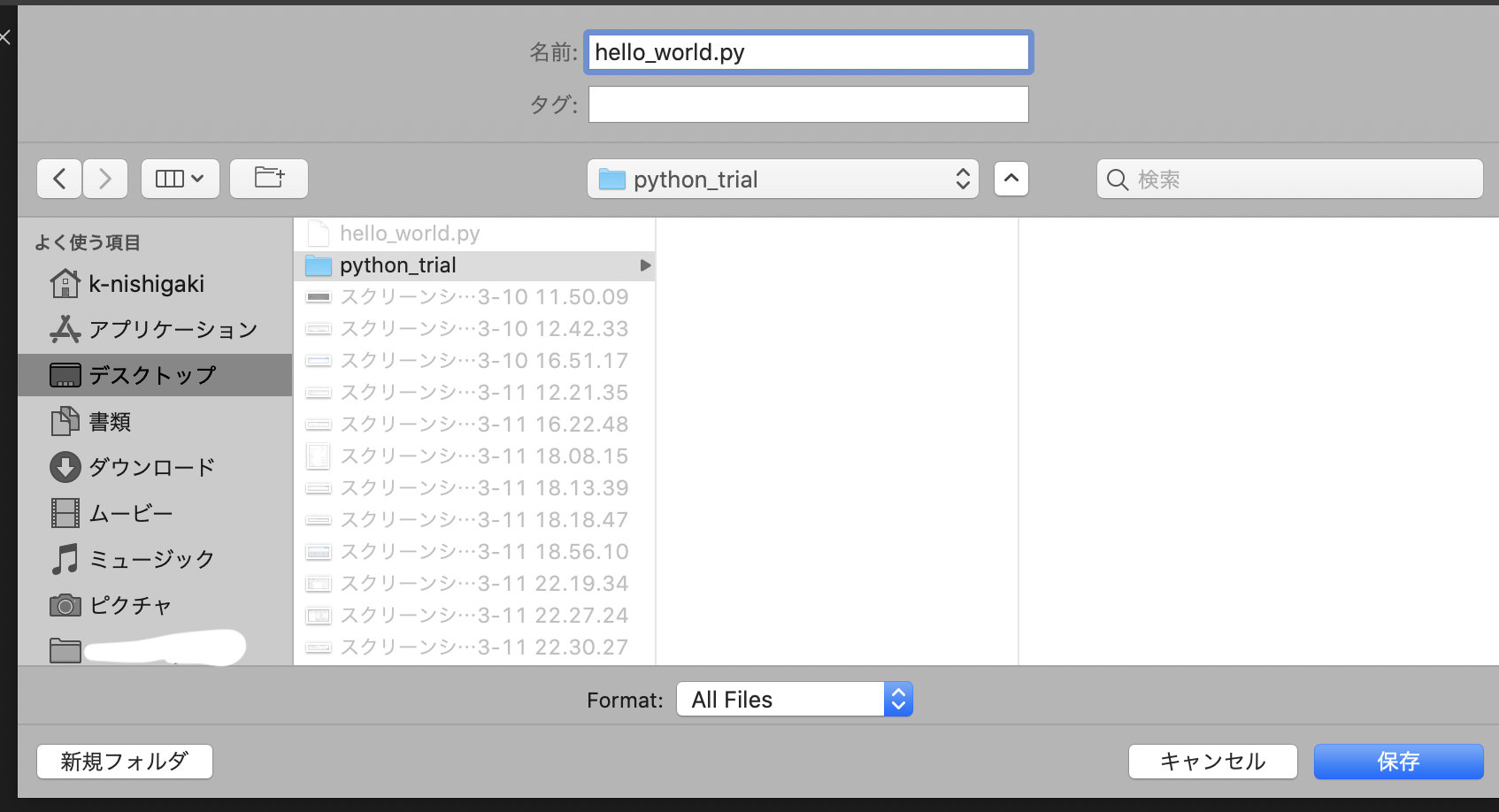

- 投稿日:2020-05-28T18:53:05+09:00
chrome driverのバージョンエラー"Message: session not created: This version of ChromeDriver only supports Chrome version 81"について
環境:
mac OS Catalina
バージョン.10.15.4chrome driverを毎日稼働させいますが、
ある日から突然下記のエラーメッセージが出て稼働しない現象が発生しました。Message: session not created: This version of ChromeDriver only supports Chrome version 81原因として、
chrome driverが最近アップデートされversion.83に自動更新されていたことでした。対応策として、
chromeのバージョンをダウングレードするということで、
アプリケーションをversion.81を再度インストールしましたが
自動更新され同じことの繰り返しの結果になりました。なので、chromedriver側を変更することにしました。
しかし、一筋縄ではなかったので忘備録として記載します。コマンドで、下記を入力してインストールし
version.83に更新されたことを確認しましたが改善されず。
zsh
pip3 install --upgrade pip chromedriver-binary
chromedriverの公式サイトからインストールしても改善されず。
https://chromedriver.chromium.org/結果として、homebrewを利用してインストールしたことを思い出し、
下記を実行brew tap homebrew/cask brew cask install chromedriverすると、メッセージで
"インストールしてるよ!!”って出るので、brew cask reinstall chromedriver再インストールを実行しました。
そして、
seleniumを使用しようとしたら、
「"chromedriver"は開発元を検証できないため開けません。」
と表示されたので、
https://qiita.com/apukasukabian/items/77832dd42e85ab7aa568
こちらを参照させて頂き、無事解決しました。その後は無事稼働しました。
- 投稿日:2020-05-28T18:26:16+09:00
Pythonを使い始める
Pythonエントリークローラー
これは私の最初のpythonプロジェクトです、ここで共有してください〜
- 現在、大まかな機能として、ユーザーが映画のチケットや電車のチケットの購入などのイベントを受け取る製品を開発しています。 次に、アプリはSMSを読み取り、SMSを解析し、時刻と場所を取得し、バックグラウンドで自動的にメモを作成して、イベントの1時間前にユーザーに通知します
- このプロジェクトは
python3のバージョンを使用しますinit.py# -*- coding: UTF-8 -*- # import need manager module import MongoUtil import FileUtil import conf_dev import conf_test import scratch_airport_name import scratch_flight_number import scratch_movie_name import scratch_train_number import scratch_train_station
- 投稿日:2020-05-28T18:09:50+09:00
Python初心者がFlaskでLINEbotを作ることになった(Heroku+ClearDB編)
この記事の概要
仕事で初めてLINEbotを作ることになったので、本番稼働環境で試す前に
Herokuでチャットサーバを立てて動作確認を行うことにしました。
この記事は、Git, Heroku CLI(コマンドラインインターフェイス)を利用して
Flask + MySQLのLINEbotを作成する方法についてです。
今回は、Dockerfileを利用してHerokuアプリを作ります。前回までのあらすじ
■Python初心者がFlaskでLINEbotを作ることになった(Flaskざっくり解説編)
→Flaskってなによ、という方はこちらへどうぞ。■Docker-ComposeでFlask + SQLAlchemy+ MySQLを使えるようにする
→Herokuの前に、ローカル開発環境整えるにはどうするのよ、という方はこちらへ。
データベースにひたすらPeterさんを増減させるだけのWebサンプルを置いています。■本記事ではいよいよLINEを通して動作するアプリケーションを作るよ!
(初心者過ぎて前置きが長かった)本記事の参考
大変勉強になりました。ありがとうございます。
・Herokuデプロイ方法【Heroku+Flask+MySQL】
・Rails on DockerをHerokuでDeployするまで
・【Windows】docker-composeを使ってmy.cnfの共有は気を付けよう!(?=?問題など)
・Flask + Herokuでアプリを動かすサンプルアプリ:オウム返し+発言記録bot
『LINEでユーザーがbotに対して発言する→botが発言内容を記録する→botが発言内容をオウム返しする』といった仕様のサンプルアプリを例にとって、Herokuを使ったbot開発を進めます。
準備
・LINE Developersにアカウント登録する。
LINEアカウント(私はビジネスアカウント(個人)を作りました)でログインし、
プロバイダー作成→チャンネル作成まで進めておきます。
詳しいところは割愛します。・Herokuアカウントを作成する。
・Gitをインストールして、コマンドラインから使えるようにしておく。
ソースコードを用意する
基本は参考記事を見つつ、前回作ったものと、オウム返しbotのソースコードをミックス&アレンジしている形です。
ローカル環境にもHeroku同じ動作環境を作りたいので、docker-compose.ymlも用意しています。
(Herokuでは使用しませんが、個別に外すのがめんどくさいので他の諸々と一緒にGit pushしちゃいます)
Dockerでローカル環境を作っていたものを、Herokuに持っていくにあたり、ディレクトリ構造が前回より変わっています。ツリー構造
$ tree /f │ docker-compose.yml │ Dockerfile │ Procfile │ requirements.txt │ run.py │ ├─docker │ └─db │ └─Register │ app.py │ config.py │ database.py │ __init__.py │ └─models │ models.py └─ __init__.py
docker-compose.ymlローカル環境構築用に準備します。
Herokuでこのファイルは使いませんが、Herokuで使うデータベースをマイグレーション管理するため、ローカル環境の準備が必要になるので用意しています。MySQLが日本語で文字化けしないよう、前回の
docker-compose.ymlからコマンド--skip-character-set-client-handshakeを追加しています。
これがなくても、動作は問題ないのですが、MySQLサーバに入ってコンソール上で結果を表示させると日本語が?????となってしまいます。
ちょっと戸惑うのでコマンドで直すようにします。docker-compose.ymlversion: '3' services: flask: container_name: register-python build: . ports: - 5050:5000 #ホスト側は使っていないポート:Docker側は5000番ポート links: - mysql privileged: true volumes: - .:/project tty: true environment: TZ: Asia/Tokyo FLASK_ENV: 'development' #デバッグモードON FLASK_APP: 'run.py' #起動用アプリの設定 command: flask run -h 0.0.0.0 mysql: container_name: register-db image: mysql:5.5 environment: MYSQL_ROOT_PASSWORD: root MYSQL_DATABASE: register MYSQL_USER: hoge MYSQL_PASSWORD: huga TZ: 'Asia/Tokyo' command: mysqld --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --skip-character-set-client-handshake volumes: - ./docker/db/data:/var/lib/mysql - ./docker/db/sql:/docker-entrypoint-initdb.d ports: - 3306:3306 #ホスト側は使っていないポート:Docker側は3306番ポート
Dockerfile下から2行のFlask環境設定は、Heroku CLIでも設定しますが念のため入れています。
DockerfileFROM python:3.6 ARG project_dir=/project/ ADD ./requirements.txt $project_dir WORKDIR $project_dir RUN pip install -r requirements.txt RUN export FLASK_ENV=development #Herokuではdocker-compose使えないので追記 RUN export FLASK_APP='run.py' #Herokuではdocker-compose使えないので追記
Procfileheroku.ymlを使って構築する方法もあるそうですが、勉強中のためProcfileを使います。
いずれheroku.ymlが理解できたらAppendixとして追記するかも…。HerokuでFlaskを使うときのお決まりの書き方です。
今回アプリの起動にrun.pyを使うので、run:appの記載になっています。
manage.pyなど、起動ファイル名を変える場合はmanage:appに変えるなどアレンジしてください。
(DockerfileなどのFLASK_APP設定もあわせて変更してください。)Procfileweb: gunicorn run:app --log-file=-
requirements.txt前回記事で使用していたライブラリに加えて、
LINEの機能を利用するためのline-bot-sdk、
HerokuでPythonを動かすためのWSGIサーバgunicornをインストールします。WSGIサーバは勉強不足でうまく説明できない…すいません。
Flaskを動かしてくれるアプリケーションサーバ、という理解です。とんかつのツナギみたいな感覚で使ってます(適当)requirements.txtFlask sqlalchemy flask-sqlalchemy flask-migrate pymysql line-bot-sdk gunicorn
run.pyrun.py# -*- coding: utf-8 -*- from Register.app import app if __name__ == '__main__': app.run()
Register/app.pyRegister/app.py# -*- coding: utf-8 -*- from flask import Flask, request, abort from .database import init_db, db from .models import Message from .config import Channel_access_token, Channel_secret #ログ出力用(printはWinコマンドプロンプトで日本語が文字化けする) from pprint import pprint #LINEbot from linebot import LineBotApi, WebhookHandler from linebot.exceptions import InvalidSignatureError, LineBotApiError from linebot.models import MessageEvent, TextMessage, TextSendMessage def create_app(): app = Flask(__name__) app.config.from_object('Register.config.Config') init_db(app) #LINE環境設定 line_bot_api = LineBotApi(Channel_access_token) handler = WebhookHandler(Channel_secret) @app.route('/callback', methods=['POST']) def callback(): signature = request.headers['X-Line-Signature'] body = request.get_data(as_text=True) try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' #テキストメッセージイベントのハンドラーを追加 @handler.add(MessageEvent, message=TextMessage) def handle_message(event): #LINEのユーザーIDを取得 user_id = event.source.user_id #送られてきたメッセージをテキストとして取得 input_msg = event.message.text #DBに保存 message = Message( line_user_id = user_id, message = input_msg ) db.session.add(message) db.session.commit() print('メッセージ登録:{}'.format(message)) #返答はオウム返し line_bot_api.reply_message(event.reply_token,TextSendMessage(text=input_msg)) return app app = create_app()
@handler.add(MessageEvent, message=TextMessage)で、LINEからテキストメッセージをもらった時の機能を追加しています。
テキストメッセージなので、画像や位置情報なんかを送られてもこのハンドラーは機能しません。
(それ用のハンドラーを追加しないといけない。)
def handle_message(event):以下は、実際にどういう動作をするのかを定義しています。
Messageテーブルに、LINEで使われるユーザIDと送られてきたメッセージをそのまま保存し、メッセージをオウム返ししています。
Register/config.pyRegister/config.py# -*- coding: utf-8 -*- import os class DevelopmentConfig: # Flask DEBUG = True #MySQL SQLALCHEMY_DATABASE_URI = 'mysql+pymysql://{user}:{password}@{host}/{database}?charset=utf8mb4'.format(**{ 'user': os.getenv('DB_USER', '[DBユーザ]'), 'password': os.getenv('DB_PASSWORD', '[DBパスワード]'), 'host': os.getenv('DB_HOST', '[DBホスト]'), 'database': os.getenv('DB_DATABASE', '[データベース名]') }) SQLALCHEMY_TRACK_MODIFICATIONS = False SQLALCHEMY_ECHO = False Config = DevelopmentConfig #LINEチャンネル設定 Channel_access_token = '[チャンネルアクセストークン]' Channel_secret = '[チャンネルシークレット]'DB設定は、最初はローカル環境の設定にします。(ローカル環境でマイグレーションの準備をする必要があるので)
Register/database.pyRegister/database.py# -*- coding: utf-8 -*- from flask_sqlalchemy import SQLAlchemy from flask_migrate import Migrate db = SQLAlchemy() def init_db(app): db.init_app(app) Migrate(app, db)
Register/__init__.pyファイルだけ作成しておきます。
(中身は空です。)
Register/models/models.pyRegister/models/models.py# -*- coding: utf-8 -*- from datetime import datetime from Register.database import db class Message(db.Model): __tablename__ = 'message' message_id = db.Column(db.Integer, primary_key=True, autoincrement=True) line_user_id=db.Column(db.String(255), nullable=False) message = db.Column(db.String(255), nullable=False) created_at = db.Column(db.DateTime, nullable=False, default=datetime.now) updated_at = db.Column(db.DateTime, nullable=False, default=datetime.now, onupdate=datetime.now) def __repr__(self): return '<message_id = {message_id}, line_user_id = {line_user_id}, message = {message}>'.format( message_id=self.message_id, line_user_id=self.line_user_id, message=self.message )
Register/models/__init__.pyRegister/models/__init__.py# -*- coding: utf-8 -*- from .models import Message __all__ = [ Message ]コマンドライン操作でHerokuアプリケーションと連携DBを作成する
ソースコードを用意したら、Herokuの環境準備を行います。
Herokuログイン
コマンドラインから、Herokuにログインします。
Heroku CLIをダウンロードしていない場合は、Heroku Dev Centerからダウンロードします。$ heroku loginブラウザ上でログインを促されるので、画面に従いログインします。
完了したらブラウザは閉じて大丈夫です。Herokuコンテナログイン
Dockerのイメージを使ってデプロイできるように、Heroku Container Registryにログインします。
$ heroku container:login
Login Succeededと出たらOK。Herokuアプリ作成
Heroku CLIを使って新しいHerokuアプリを作成します。
今回は、line-registerという名前のアプリを作ります。
(記事作成後にアプリ自体は削除しています)アプリ名が他の人のHerokuアプリと競合してしまうと作成できません。
アプリ名を省略すると、勝手に名前を付けてくれます。$ heroku create line-register Creating ⬢ line-register... done https://line-register.herokuapp.com/ | https://git.heroku.com/line-register.gitローカルで作成したdocker imageをHerokuのContainer Registryにpushする
Dockerfileのあるディレクトリに移動し、以下のコマンドを打ちます。
$ heroku container:push web -a line-registerheroku container:push web だけだとエラーが出てしまったので、
-a [herokuアプリ名]で対象のアプリを指定しています。これで、Dockerfileのイメージをもとにビルドしてくれるようになります。
Webサーバとして起動するので、webを指定します。データベースを作成する
今回はposgreではなくMySQLを使いたいので、ClearDBのアドオンを使います。
ClearDBはMySQLの機能を提供しているクラウドサービスです。
Herokuのアプリにデータベースの機能を持たせることができないので、このアドオンにとてもお世話になります。Herokuでアドオンを使う場合は、あらかじめクレジットカードの登録が必要なので、ブラウザ上で登録しておきます。
一番小さいプランのigniteを設定しておけば無料なので、登録カードから決済されることはありません。$ heroku addons:create cleardb:igniteheroku環境変数設定
ClearDBの作成が完了した後、データベースの設定内容を確認します。
$ heroku config # 以下が出力されます CLEARDB_DATABASE_URL: mysql://[username]:[password]@[hostname]/[db_name]?reconnect=trueコンフィグの情報を、以下に書き換えます。(
mysql→mysql2)heroku config:set DATABASE_URL='mysql2://[username]:[password]@[hostname]/[db_name]?reconnect=true'Herokuで、必要となる環境変数をコマンドラインから設定していきます。
#DBの設定 $ heroku config:add DB_USERNAME="[username]" $ heroku config:add DB_PASSWORD="[password]" $ heroku config:add DB_HOSTNAME="[hostname]" $ heroku config:add DB_NAME="[db_name]" #LINEチャンネルの設定 $ heroku config:set YOUR_CHANNEL_SECRET="[チャンネルシークレット]" $ heroku config:set YOUR_CHANNEL_ACCESS_TOKEN="[チャンネルアクセストークンの欄の文字列]" #Flaskの環境設定 $ heroku config:set FLASK_ENV='development' $ heroku config:set FLASK_APP="run.py" #worker起動数を変更(無料プランだとR14メモリエラーが起きがちのため) $ heroku config:set WEB_CONCURRENCY=1最後のworkerについては、以下の記事を参考にさせていただきました。
HerokuでR14/R15エラーが起こった時の対処法ローカル環境でマイグレート準備
Herokuにデプロイすると、
flask db initflask db migrateが機能しなくなっていしまいます。
実際やってみると、エラーは出ないのですが、migrationsファイルがHeroku上に作成できないことがわかります。
そのため、ローカル環境でinitmigrateを行い、作成されたmigrationディレクトリをHerokuにアップロードし、upgradeを実行するという流れでDBの管理を行います。ということで、ここまで来たら、ローカル環境でDockerコンテナを立ち上げ、pythonサーバに入ります。
そして、以下を操作します。$ flask db init $ flask db migrate
Docker-compose.ymlで/projectをボリュームに設定しているので、
migrationディレクトリはhost側のプロジェクトフォルダの直下に作成されるはずです。SQLAlchemyのConfigを編集
次はHerokuにソースコードを持って行って操作するので、
Configのデータベース設定をローカルからClearDBの設定に直します。Herokuデプロイ
いよいよ、Dockerイメージからコンテナをリリースし、migrationsディレクトリとソースコードを含むプロジェクトファイルをマルっとHerokuに持っていきます。
$ heroku container:release web $ git push heroku masterこれを行った際、私の環境では以下のようにheroku.ymlを作成するよう怒られました。
remote: =!= Your app does not include a heroku.yml build manifest. To deploy your app, either create a heroku.yml: https://devcenter.heroku.com/articles/build-docker-images-heroku-yml remote: Or change your stack by running: 'heroku stack:set heroku-18' remote: Verifying deploy... remote: remote: ! Push rejected to line-register.今回はheroku.yml使わないので、素直にスタックを変更することにしました。
$ heroku stack:set heroku-18この後、git pushは成功し、アプリの配置が完了しました。
Herokuにテーブルを作成する
ローカルで作成しておいたmigrationsフォルダを引き継いで、テーブルの作成を行います。
heroku run flask db upgradeこれで、ClearDB上に
messageテーブルが作成されます。これで、Herokuにデプロイが完了しました!
LINEコンソール設定
HerokuアプリにLINEチャンネルからアクセスするため、LINE側の設定を変更します。
まず、LINE Developersにログインし、作成したチャンネルを選択します。
LINEのwebhookアドレスを入力、webhookを有効化する
Messaging API設定から、Webhook URLを設定します。
URLは、https://[Herokuアプリ名].herokuapp.com/callbackという形式になります。Webhookの利用はONにします。
すぐ下にある「応答メッセージ」「挨拶メッセージ」は無効にしておきましょう。
LINEでチャンネル登録して、テスト実施
チャンネルのQRコードやIDを利用して、友達登録します。
実際にメッセージを送って、動作を確かめてみます。
オウム返しされていれば、LINE上のテストはOKです。MySQLにデータが登録されていることを確認
送ったメッセージが登録されているかは、MySQL Workbenchなどを利用して確認します。
app.pyを改良して、Webブラウザからデータを確認できるようにしてもよいと思います。
- 投稿日:2020-05-28T17:55:25+09:00
[Python] DFS ABC155D
ABC155D
小さい順に K 番目の値を求めよ
⇒ x 以下のものが K 個以上あるような、最小の x を求めよ内容は下記の引用である。この投稿は私的メモである。
ABC155【D問題の復習】文字起こしをするくらいの勢いで解説動画を復習したら、二分探索の苦手感が減ってきたAtCoder Beginner Contest 155(ABC155) A~E解説
サンプルコードn,k=map(int,input().split()) arr=list(map(int,input().split())) arr=sorted(arr) nc=0 zc=0 pc=0 # 負数の数(nc)、0の数(zc)、正数の数(pc)を数える for i in range(n): if arr[i]<0: nc+=1 elif arr[i]==0: zc+=1 else: pc+=1 # 積が負となるペアの個数を求める ncc=nc*pc # 積が0となるペアの個数を求める zcc=zc*(nc+pc)+(zc*(zc-1))//2 # 積が正となるペアの個数を求める pcc=(nc*(nc-1))//2+(pc*(pc-1))//2 # K番目の値が負の場合 if k <= ncc: arr1=[] arr2=[] # 負数、正数をそれぞれ昇順に並べる for i in range(n): if arr[i] < 0: arr1.append(-arr[i]) elif arr[i] > 0: arr2.append(arr[i]) arr1=arr1[::-1] c1=len(arr1) c2=len(arr2) l = 0 # left r = 10**18+1 # right 答えでもある # 負数のマイナスを取って計算しているため積の大小が逆転するので、大きなほうからK番目 # 小さなほうから(積が負となるペアの個数-K)番目の値を求める k = ncc-k while r-l != 1: mid=(l+r)//2 # 区間の中間値を更新 cnt=0 pos=c2-1 # 区間[left, right)でのしゃくとり法 # 各負数ごとに積が勝手に決めた値midよりも小さくなる正数の個数を求め足し合わせる for i in range(c1): while pos!=-1: if arr2[pos] > mid//arr1[i]: pos-=1 else: break cnt+=pos+1 # 勝手に決めた値mid以下の個数が(積が負となるペアの個数-K)個以上であれば真の値はmid以下 if cnt > k: r = mid # rightをmidに更新してやり直し # そうでなければ真の値はmid以上 else: l = mid # leftをmidに更新してカウントやり直し # 負数のマイナスを取って計算したので最後にマイナスを付けて出力する print(-r) # K番目の値が0の場合 elif k <= (ncc+zcc): print(0) # K番目の値が正の場合 else: arr1=[] arr2=[] for i in range(n): #負数、正数をそれぞれ昇順に並べる if arr[i] < 0: arr1.append(-arr[i]) elif arr[i] > 0: arr2.append(arr[i]) arr1=arr1[::-1] c1=len(arr1) c2=len(arr2) l=0 r=10**18+1 k -= (ncc+zcc) #正数の中で小さい順にK番目の数を調べたいので負数、0の数を取り除く while r-l != 1: mid=(l+r)//2 cnt1=0 pos1=c1-1 # 各負数ごとに積が勝手に決めた値midよりも小さくなる負数の個数を求め足し合わせる(しゃくとり法) for i in range(c1): tmp=0 while pos1 != -1: if arr1[pos1] > mid//arr1[i]: pos1-=1 else: break tmp+=pos1+1 # 各要素について、自身を2回選んだ場合の積が勝手に決めた値mid以下なら条件を満たすペアの個数を1減らす if arr1[i]**2 < mid: tmp-=1 cnt1+=tmp cnt1 = cnt1//2 #上記の処理では同じペアが2回数えられているので個数を半分にする cnt2=0 pos2=c2-1 # 各正数ごとに積が勝手に決めた値midよりも小さくなる正数の個数を求め足し合わせる(しゃくとり法) for i in range(c2): tmp=0 while pos2!=-1: if arr2[pos2] > mid//arr2[i]: pos2-=1 else: break tmp+=pos2+1 if arr2[i]**2 < mid: tmp-=1 #各要素について、自身を2回選んだ場合の積が勝手に決めた値mid以下なら条件を満たすペアの個数を1減らす cnt2+=tmp cnt2=cnt2//2 #上記の処理では同じペアが2回数えられているので個数を半分にする cnt=cnt1+cnt2 if cnt >= k: #勝手に決めた値mid以下の個数がK個以上であれば真の値はmid以下 r = mid else: #そうでなければ真の値はmid以上 l = mid print(r)
- 投稿日:2020-05-28T17:51:42+09:00
深層学習/ゼロから作るディープラーニング2 第8章メモ
1.はじめに
名著、「ゼロから作るディープラーニング2」を読んでいます。今回は8章のメモ。
コードの実行はGithubからコード全体をダウンロードし、ch08の中で jupyter notebook にて行っています。2.Attention
下記は、Seq2seqモデルにおける、Attentionの概要図です。
Decoderの全ての時刻のLSTMとAffineの間にAttentionを挟みます。そして、Encoderの各時刻の隠れベクトル(hs0〜hs4)をまとめたhsを、全てのAttentionへ入力します。
各Attentionでは、LSTMからの入力とhsの類似度(ベクトル積)を計算し、隠れベクトル(hs0〜hs4)の重要度を確率分布で求めます。そして、隠れベクトルをその確率分布で重み付けし合成したものをAffineへ送ります。
Attentionレイヤ内部の模式図とそこで行われている行列演算イメージ(バッチサイズN=1の場合)です。
まず、Attention_weightの部分です。Encoderのベクトルhs0〜hs4とDecoderのベクトルhの積を求め、それぞれ列方向(axis=2)で足した数値は、2つののベクトルの類似度が高いほど大きくなります。この数値にSoftmaxを通すと、ベクトルhs0〜hs4をどういう重み付けでアテンション(参照)すべきかを表すベクトルaが得られます。
次に、Weight_Sumの部分です。ベクトルhs0〜hs4とベクトルaの積を求め、行方向(axis=1)で足したベクトルCは、アテンション(参照)すべき情報を重み付けして合成(足し算)したベクトルになります。これをAffineへ送ることで、Affineでは従来のLSTMからの情報にプラスして、その時参照すべきEncoder側の情報も得ることが出来るわけです。
ちなみに、x = (N, T, H) の np.sum(x, axis = ?)を計算する場合、axis=0のときはN軸を消すようにsum(バッチ方向の足し算)し、axis=1のときはT軸を消すようにsum(行方向の足し算)し、axis=2のときはH軸を消す様にsum(列方向の足し算)します。
Attention_weight のコードを見てみましょう。
class AttentionWeight: def __init__(self): self.params, self.grads = [], [] self.softmax = Softmax() self.cache = None def forward(self, hs, h): N, T, H = hs.shape # hrはブロードキャストで使うため、repeatせず次元のみ合わせる hr = h.reshape(N, 1, H) #.repeat(T, axis=1) t = hs * hr # ベクトルの積を取る s = np.sum(t, axis=2) # 列方向の足し算 a = self.softmax.forward(s) # 各隠れベクトルの重要度を表す確率分布aを計算 self.cache = (hs, hr) return a def backward(self, da): hs, hr = self.cache N, T, H = hs.shape ds = self.softmax.backward(da) dt = ds.reshape(N, T, 1).repeat(H, axis=2) # (N, T, H)に変換 dhs = dt * hr dhr = dt * hs dh = np.sum(dhr, axis=1) return dhs, dh順伝播の、t = hs * hr はブロードキャストで計算するので、hrのrepeatはしていません。次に、Weight_sumも見てみましょう。
class WeightSum: def __init__(self): self.params, self.grads = [], [] self.cache = None def forward(self, hs, a): N, T, H = hs.shape # arはブロードキャストで使うため、repeatせず次元のみ合わせる ar = a.reshape(N, T, 1) #.repeat(T, axis=1) t = hs * ar # ベクトルの積をとる c = np.sum(t, axis=1) # 行方向の足し算 self.cache = (hs, ar) return c def backward(self, dc): hs, ar = self.cache N, T, H = hs.shape dt = dc.reshape(N, 1, H).repeat(T, axis=1) dar = dt * hs dhs = dt * ar da = np.sum(dar, axis=2) return dhs, da順伝播の、t = hs * ar はブロードキャストで計算するので、arのrepeatはしていません。この2つのクラスをまとめて、
class Attentionを構成します。class Attention: def __init__(self): self.params, self.grads = [], [] self.attention_weight_layer = AttentionWeight() self.weight_sum_layer = WeightSum() self.attention_weight = None def forward(self, hs, h): a = self.attention_weight_layer.forward(hs, h) out = self.weight_sum_layer.forward(hs, a) self.attention_weight = a return out def backward(self, dout): dhs0, da = self.weight_sum_layer.backward(dout) dhs1, dh = self.attention_weight_layer.backward(da) dhs = dhs0 + dhs1 return dhs, dさらに、時刻への対応を行うために、
class TimeAttentionにまとめます。class TimeAttention: def __init__(self): self.params, self.grads = [], [] self.layers = None self.attention_weights = None def forward(self, hs_enc, hs_dec): N, T, H = hs_dec.shape out = np.empty_like(hs_dec) self.layers = [] self.attention_weights = [] for t in range(T): layer = Attention() out[:, t, :] = layer.forward(hs_enc, hs_dec[:,t,:]) self.layers.append(layer) self.attention_weights.append(layer.attention_weight) return out def backward(self, dout): N, T, H = dout.shape dhs_enc = 0 dhs_dec = np.empty_like(dout) for t in range(T): layer = self.layers[t] dhs, dh = layer.backward(dout[:, t, :]) dhs_enc += dhs dhs_dec[:,t,:] = dh return dhs_enc, dhs_decそれでは、この Attention機構を使った seq2seq のサンプルコード (日付フォーマットの変換) train.py を動かしてみましょう。
import sys sys.path.append('..') import numpy as np import matplotlib.pyplot as plt from dataset import sequence from common.optimizer import Adam from common.trainer import Trainer from common.util import eval_seq2seq from attention_seq2seq import AttentionSeq2seq from ch07.seq2seq import Seq2seq # データの読み込み (x_train, t_train), (x_test, t_test) = sequence.load_data('date.txt') char_to_id, id_to_char = sequence.get_vocab() # 入力文を反転 x_train, x_test = x_train[:, ::-1], x_test[:, ::-1] # ハイパーパラメータの設定 vocab_size = len(char_to_id) wordvec_size = 16 hidden_size = 256 batch_size = 128 max_epoch = 10 max_grad = 5.0 model = AttentionSeq2seq(vocab_size, wordvec_size, hidden_size) # model = Seq2seq(vocab_size, wordvec_size, hidden_size) # model = PeekySeq2seq(vocab_size, wordvec_size, hidden_size) optimizer = Adam() trainer = Trainer(model, optimizer) acc_list = [] for epoch in range(max_epoch): trainer.fit(x_train, t_train, max_epoch=1, batch_size=batch_size, max_grad=max_grad) correct_num = 0 for i in range(len(x_test)): question, correct = x_test[[i]], t_test[[i]] verbose = i < 10 correct_num += eval_seq2seq(model, question, correct, id_to_char, verbose, is_reverse=True) acc = float(correct_num) / len(x_test) acc_list.append(acc) print('val acc %.3f%%' % (acc * 100)) model.save_params() # グラフの描画 x = np.arange(len(acc_list)) plt.plot(x, acc_list, marker='o') plt.xlabel('epochs') plt.ylabel('accuracy') plt.ylim(-0.05, 1.05) plt.show()
2epoch以降は精度100%です。さすが、Attentionの威力ですね。
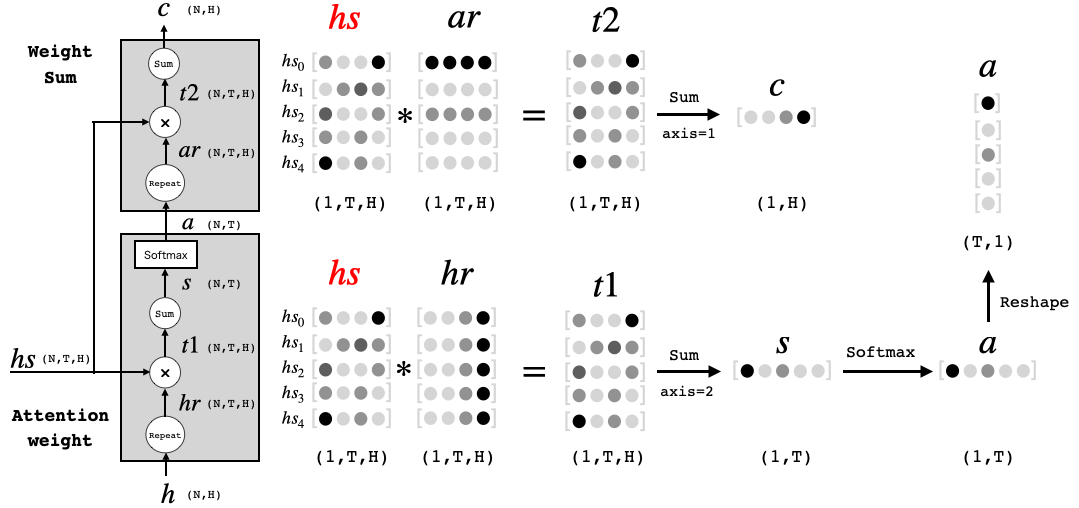
- 投稿日:2020-05-28T16:48:30+09:00
Numpy覚書_行列
Numpyを使って基本的な行列作成と計算
(e資格対策として覚書)
n行m列の行列
例として3行2列の$A=\begin{pmatrix} 1 & 1 \\ 2 & 4 \\ 3 & 1 \end{pmatrix}$を作成
>>> A=np.array([[1,1],[2,4],[3,1]]) >>> >>> A array([[1, 1], [2, 4], [3, 1]])行列の行数・列数・要素数を確認
以下例はshapeで行数・列数を取得、sizeで全要素数を取得
>>> A=np.array([[1,2,3],[4,3,2]]) >>> >>> A.shape ## 行数・列数 (2, 3) >>> >>> A.shape[0] ## 行数・列数は別々に分けて出力もできる 2 >>> >>> A.shape[1] 3 >>> row, col = A.shape ## 行数・列数は別々の変数にもできる >>> >>> row 2 >>> >>> col 3正方行列(square matrix)と判定
行要素の数と列要素の数が一致する行列。サイズがn 行 n 列で正方形の形になる
以下例で$A=\begin{pmatrix} 1 & 2 & 3 \\ 4 & 3 & 2 \end{pmatrix}$と$\begin{pmatrix} 1 & 2 \\ 2 & 3 \end{pmatrix}$の2つでそれぞれ行数$.shape[0]$と列数$.shape[1]$を求め、値を比較して正方行列かどうか判定、$B$はTrueで正方行列
>>> A=np.array([[1,2,3],[4,3,2]]) >>> >>> np.array_equal(A.shape[0],A.shape[1]) False >>> >>> B=np.array([[1,1],[2,4]]) >>> >>> np.array_equal(B.shape[0],B.shape[1]) Trueランダムな整数を要素とする行列
例1はランダムな数字を使って1行3列の行列を作成
例2は3-6(7は含まない)までのランダムな整数を使って2行3列の行列を作成>>> np.random.rand(3) ### 例1 array([0.4449089 , 0.70920233, 0.59915992]) >>> np.random.randint(3,7,size=(2,3)) ### 例2 array([[3, 6, 4], [5, 3, 6]])ゼロ行列(zero matrix)
すべての要素が0の行列を作成
例として2行2列のゼロ行列$W=\begin{pmatrix} 0 & 0 \\ 0 & 0 \end{pmatrix}$を作成
>>> W=np.zeros((2,2,)) >>> >>> W array([[0., 0.], [0., 0.]])すべての要素が1の行列
例として2行2列のすべての要素が1の$W=\begin{pmatrix} 1 & 1 \\ 1 & 1 \end{pmatrix}$を作成
>>> W=np.ones((2,2,)) >>> >>> W array([[1., 1.], [1., 1.]])単位行列(identity matrix)
主対角線上の要素がすべて1でその他はすべて0であるもの。記号は$E$と示す。
例として3行3列の$E=\begin{pmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{pmatrix}$を作成
>>> E = np.eye(3) >>> >>> E array([[1., 0., 0.], [0., 1., 0.], [0., 0., 1.]])転置行列(transposed matrix)
$m $行$n$列の行列の要素を入れ替えてできる$n$行$m$列の行列のこと。転置行列は行列$A$に対して$A^{T}$と示す
例えば$\begin{pmatrix} 2 & 3 & 1 \\ 5 & 7 & 0 \end{pmatrix}$の転置行列の$\begin{pmatrix} 2 & 5 \\ 3 & 7 \\ 1 & 0 \end{pmatrix}$を求める
>>> A=np.array([[2,3,1],[5,7,0]]) >>> >>> A array([[2, 3, 1], [5, 7, 0]]) >>> >>> AT=A.T >>> >>> AT array([[2, 5], [3, 7], [1, 0]])対称行列(symmetric matrix)と判定
自身の転置行列と一致するような正方行列
行列$A$に対して$A=A^{T}$となる。以下例は$\begin{pmatrix} 1 & 7 & 3 \\ 7 & 4 & 5 \\ 3 & 5 & 6 \end{pmatrix}$とその転置行列を求めて比較。結果Trueとなるので対称行列
>>> A=np.array([[1,7,3],[7,4,5],[3,5,6]]) >>> >>> A array([[1, 7, 3], [7, 4, 5], [3, 5, 6]]) >>> >>> AT=A.T >>> >>> np.array_equal(A,AT) True行列の積(matrix product)
行列$A$と$B$の積は$AB$で表し$A$の列の数と$B$の行の数が一致している場合に限りnp.dotで求められる。行列の積は右からかけた時と左からかけた時で解は事なる。
以下例で$A=\begin{pmatrix} 2 & 1 \\ 1 & 3 \end{pmatrix}$と$B=\begin{pmatrix} 2 & 1 \\ 1 & 2 \end{pmatrix}$の積$AB$を求める。
>>> A=np.array([[2,1],[1,3]]) >>> >>> B=np.array([[2,1],[1,2]]) >>> >>> AB=np.dot(A,B) >>> >>> AB array([[5, 4], [5, 7]]) >>> >>> BA=np.dot(B,A) >>> >>> BA array([[5, 5], [4, 7]])行列の内積(Frobenius Product)
np.dotでは1行n列で示す行列$A$と$B$はn次元の横ベクトルとみなしてベクトルの内積を返すらしい。内積は各$n$番目の要素をそれぞれ掛けて全ての要素分の結果を合計したスカラー値になる。
右側の行ベクトルを縦べクトルの形に変換すれば内積の値が行列として返る。以下の1は、4次元の行ベクトル$a=\begin{pmatrix} \ 0 & 0 & 0 & 0\end{pmatrix}$と $b=\begin{pmatrix} \ 0 & 0 & 0 & 0\end{pmatrix}$の内積$a\cdot b$を求める。
2は、$b$を列ベクトルに変換したので行列の積になる>>> a=np.array([2,2,2,3]) >>> >>> b=np.array([1,2,3,4]) >>> >>> np.dot(a,b) ### 1 ベクトルaとbの内積がスカラーで返る 24 >>> np.dot(b,a) ### 1 ベクトルaとbの内積なのでかける順番を問わず結果は同じ 24 >>> >>> b_col=([[2],[2],[2],[3]]) ### 2 bを1次元4列の行列にする >>> >>> np.dot(a,b_col) ### 2 bを1次元4列の行列として結果が返る array([24]) >>>逆行列(inverse matrix)
正方行列Aに対して右から掛けても左から掛けても単位行列$E$となるような行列のこと
行列$A$に対して逆行列を$A^{-1}$で示すと
$AA^{-1}=A^{-1}A=E$ が成り立つ例として2行2列の行列$A=\begin{pmatrix} 2 & 3 \\ 2 & 4 \end{pmatrix}$を作成してその逆行列$A^{-1}$を求める
>>> A=np.array([[2,3],[2,4]]) >>> >>> AI=np.linalg.inv(A) >>> >>> AI array([[ 2. , -1.5], [-1. , 1. ]])正則行列(regular matrix)
正方行列で逆行列を持つ行列のこと。すべての行列が逆行列を持つとは限らない。
以下例で$AA^{-1}=A^{-1}A=E$が確認できたので$A$も$AI$も正則行列
>>> A=np.array([[1,1],[2,4]]) >>> >>> AI=np.linalg.inv(A) >>> >>> np.dot(A,AI) array([[1., 0.], [0., 1.]]) >>> >>> np.dot(AI,A) array([[1., 0.], [0., 1.]])
- 投稿日:2020-05-28T16:43:43+09:00
RaspberryPiで個人最適化フォトフレームの実装
動機
ラズパイでフォトフレームを実装してみましょう。
ラズパイでフォトフレームはn番煎じ使い古されたテーマですが、従来のものには不満がありました。というのも、写真の厳選が面倒臭いことです。
例えば友人から送ってもらった写真やカメラの写真などをフォトフレームで表示させる時・厳選して入れると大変、あるいは枚数が少なく、すぐに見飽きる
・逆に全部突っ込むとミス写真も取り込まれる、恥ずかしい写真が表示される事故が起きるというジレンマがあります。
この問題を解決すべく、写真の表示を最適化したフォトフレームを作成します。使用者は好きな時に
・その写真をスキップ
・その写真の表示頻度を下げる
・その写真を二度と表示しないという操作を行うことができます。こうして調整された表示頻度を保存、更新します。
つまりとりあえず全部の写真を入れて、使っていくうちに調整してやろう、というコンセプトです。全体のソースコードはページ下に掲載します。
用意
・Raspberry Pi
今回は家にあったラズパイ3 model Bを使用。別にどの世代でも可。・3.5インチディスプレイ
写真表示用に使います。Amazonで2000円くらいのを買ったらドライバが古く使えず...
他社製のドライバを入れると画面だけは映るようになったもののタッチパネルがご臨終に。仕様
ただ写真を表示するだけなら、
fbi image.jpgだけで事足ります。
しかし細かい仕様の実現や、外部との連携などの拡張性を考え、今回は全てpythonで記述することにします。
画像を扱うならOpenCVなどがメジャーですが、今回はゲーム用モジュールであるpygameを利用していきます。今回の仕様としては
①DropBoxから自動で画像を取得(未実装)
②スライドショー形式で画像を表示
③画像のスキップや表示頻度を下げる、二度と表示させないなどをボタンで操作
④そうして調整された頻度を保存、更新
とします。主に③のためにpygameを選択しています。画像の自動取得
作成中
画像の表示
画像を表示するためには、ウィンドウの作成からする必要があります。
import pygame from pygame.locals import * import sys pygame.init() screen =pygame.display.set_mode((400,300)) pygame.mouse.set_visible(False) pygame.display.set_caption("Photo")
pygame.init()で初期化を行い、
display.set_mode()で画面のサイズを指定します。
(なお引数としてFULLSCREENを入れることでフルスクリーンになりますが、フルスクリーンでバグると終了が大変になるのでデバッグ中はやらない方がよさそうです。)フォトフレームとしてマウスカーソルがあるのは不格好なので
pygame.mouse.set_visible(False)で消します。
img =pygame.image.load("file.jpg") img = pygame.transform.scale(img1,(400,300)) rectimg = img.get_rect() screen.fill((0,0,0)) screen.blit(img,rect_img) pygame.display.update()ここが画像の描写部分です。
image.loadで画像を一枚読み込んできます。
screen.fillでRGB背景色を指定します。今回は黒です。
screen.blitで画像を貼り付け、最後のdisplay.update()で画面を更新、表示されます。
以上の操作で画像は表示できます。では次にスライドショーを実装していきましょう。スライドショーの実装
スライドショーとはつまり、
・時間を計測する
・時間が経過したら新しい画像を読み込み、表示という処理なわけです。
そこで、画像が表示された際にその時間を保存します。start_time = pygame.time.get_ticks()そしてwhile(1)のループを回しながら、
time_since_start = pygame.time.get_ticks() - start_time if time_since_start>10000: breakとすることで実現できます。
pygame.time.get_ticks()によって時間を取得でき、単位はmsなので、この例では10秒ごとに切り替わります。(実際には写真のロード時間が加算されます。)画像のスキップ機能
10秒を待たずして切り替えられるようにします。
具体的にはボタンを押すと次の画像を表示させる機能です。
今回は手軽な物理ボタンがなかったため、キーボードを接続し利用します。また、なんとこのままでは終了させる機能ができません。
そこでESCを押したときにはプログラムを終了させるようにもします。for event in pygame.event.get(): if event.type == KEYDOWN: if event.key == K_ESCAPE: pygame.quit() sys.exit() if event.key == K_z: flugloop = Falseまず発生したイベントをループで取り出していき、それがキーを押されたものだったら処理を実行します。
K_ESCAPE がESCキー、K_zがzキーです。
このように、K_aなどで任意のキーが押された時の挙動を実装できます。ESCキーならif文の中で即終了処理、zキーが押されたならスキップフラグを立て、次の画像へと移ります。
画像の表示頻度の変更
さて、これでスライドショーができましたが、表示頻度を減らしたい写真や、二度と見たくない写真の処理を追加します。
画像の表示ではパスを指定して読み込んでいました。その読み込みの部分を重み付きランダムに変更します。photonum = list(range(1,len(w)+1)) filenum = random.choices(photonum,weight) filename = str(filenum[0]) + ".jpg" pygame.image.load(filename)あらかじめ画像の名前を1.jpg, 2.jpg等にしておきます。
ここで、二行目random.choicesが重み付けランダムで選ぶ関数です。
photonumには1~枚数分の番号が入ったlistで
weightにはそれぞれの画像の重みが整数値で入っています。
この2つをrandom.choicesにわたすことで、その重みに従ってphotonumの中から選択してくれます。
そして選択された画像ファイルが読み込まれます。あとはこの
weightを操作してやるだけです。今回はテキストファイルに改行区切りで
weightを保存します。
また、重みは初期値を整数値10とします。data = open('data.txt') weight =[] for line in data: weight.append(int(line)) data.close()これで一行ずつ
data.txtから重みを読み取り、weightに格納します。これで、先程出てきたKEYDOWNを用いて、
if event.key == K_x: flugloop =False weight[filenum-1] = 0とすればxが押された時に重みを0にし、その写真は二度と表示されないようになります。
同じようにデクリメントすればその写真が表示される頻度を減らせます。さて、このlistは当然終了したら失われます。そこで
data.txtに書き込むことで保存しましょう。
ESCキーの挙動に付け加えます。if event.key == K_ESCAPE f = open("data.txt",'w') for i in weight: f.write(str(i)) f.write("\n") f.close() pygame.quit() sys.exit()こうすることで次回起動時も設定が引き継がれます。
ソースコード全体
サンプルコード
#photo.py import pygame from pygame.locals import * import sys import random def get_image(w=[]): photonum = list(range(1,len(w)+1)) filenum = random.choices(photonum,w) #画像をランダムで取り出し filename = str(filenum[0]) + ".jpg" return pygame.image.load(filename).convert_alpha(),filenum[0] #戻り値は画像とそのID def main(): data = open('data.txt') #重み付けの読み込み weight =[] for line in data: weight.append(int(line)) data.close() while(1):#画像を1枚表示させる pygame.init() screen =pygame.display.set_mode((400,300),FULLSCREEN) pygame.mouse.set_visible(0) pygame.display.set_caption("test") x=get_image(weight) img1 = x[0] filenum = x[1] img2 = pygame.transform.scale(img1,(400,300)) rect_img2 = img2.get_rect() screen.fill((0,0,0)) screen.blit(img2,rect_img2) #画像の表示 pygame.display.update() #画面の更新 start_time = pygame.time.get_ticks() #時間計測開始 flugloop = True while(1): #操作を受け付けるためのループ time_since_start = pygame.time.get_ticks() - start_time #時間の計測 if time_since_start>10000: #10秒たったらbreak,次の画像表示へ break if flugloop ==False: #フラグがたっていればbreak,次の画像表示へ break for event in pygame.event.get(): #操作の受付け if event.type == QUIT: pygame.quit() sys.exit() if event.type == KEYDOWN: if event.key == K_ESCAPE: #escが押されたら f = open("data.txt",'w') #表示頻度を保存 for i in weight: f.write(str(i)) f.write("\n") f.close() pygame.quit() #プログラム終了 sys.exit() if event.key == K_SPACE: #スペースキーが押されたら重みを減らして次の画像へ flugloop = False if weight[filenum-1] >3: weight[filenum-1] -=1 if event.key == K_x: #xキーが押されたら重みを0に、二度と表示しない flugloop =False weight[filenum-1] = 0 if event.key == K_z: flugloop =False main()今後の拡張性
DropBoxからの写真自動追加の実装。
物理ボタンの設置。
ウェブカメラを使って、よく注視する写真の重みをあげてよく表示させる、などをやると、表示頻度の重み調整が更に楽になりそう。
- 投稿日:2020-05-28T16:03:21+09:00
ゼロから始めるLeetCode Day39「494. Target Sum」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
その対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイト。
せっかくだし人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
前回
ゼロから始めるLeetCode Day38「208. Implement Trie (Prefix Tree)」基本的にeasyのacceptanceが高い順から解いていこうかと思います。
Twitterやってます。
問題
自然数の配列
numsと自然数Sが与えられます。
+と-が与えられるので、配列を全て足すか引いてSの値と一致させるような組み合わせの数を返してください。Input: nums is [1, 1, 1, 1, 1], S is 3.
Output: 5
Explanation:-1+1+1+1+1 = 3
+1-1+1+1+1 = 3
+1+1-1+1+1 = 3
+1+1+1-1+1 = 3
+1+1+1+1-1 = 3There are 5 ways to assign symbols to make the sum of nums be target 3.
こんな感じです。
言いたいことは例から分かると思います。解法
class Solution: def calc(self,nums,index,sums,S): if index == len(nums): if sums == S: self.count += 1 else: self.calc(nums,index+1,sums+nums[index],S) self.calc(nums,index+1,sums-nums[index],S) def findTargetSumWays(self, nums: List[int], S: int) -> int: self.count = 0 self.calc(nums,0,0,S) return self.count # Time Limit Exceeded最初Bruteforceで解こうと思って書いたのですが時間切れになっちゃいました。
なので書き換えました。
from functools import lru_cache class Solution: def findTargetSumWays(self, nums: List[int], S: int) -> int: @lru_cache(None) def calc(index,S): if index == 0: return int(nums[0] == S) + int(-nums[0] == S) return calc(index-1, S - nums[index]) + calc(index-1, S + nums[index]) return calc(len(nums)-1, S) # Runtime: 240 ms, faster than 74.28% of Python3 online submissions for Target Sum. # Memory Usage: 31.5 MB, less than 50.00% of Python3 online submissions for Target Sum.ゼロから始めるLeetCode Day25「70. Climbing Stairs」
でも登場した@lru_cacheを使ってヘルパー関数としてcalcを用意して実装しました。良い感じで実装できたので、学習を続けて形に残しておくのは大事ですね。
今回はこのあたりで。おつかれさまでした。
- 投稿日:2020-05-28T15:55:29+09:00
株価の時系列データ(日足)の取得
株価の日足データをpythonで取得したい
ふと、株価データの解析をしてみたくなり、やり方を考えてみました。
株関連の前提知識がないので、本当はこんなことしなくても良いのかも知れません。
でもまあこれでも取得できたので、とりあえず公開します。手法
以下の3つの行程を経て、データの取得を試みました。
1.pandas.read_html で、日足データを取得
変なサイトは使いたくなかったので、Yahoo Fainance からデータを読み取らせていただくことに。
pandas.read_html というのは、htmlの中から「これ、表っぽいなー」というものを抽出してくれます。なので戻り値は dataframe の入った list です。
Yahoo Fainance は以下の写真のようなページで、明らかに表は1つなのですが、あくまでも表っぽいものを抽出するので上の「パナソニック(株) 978.5 前日比 ...」みたいなところも抽出します。
その解決策として、取得したい表に合わせてif文でふるいにかけました。
2.datetime関数 で、連続した日付を取得
望みの期間のデータを取得するには、その期間をurlで指定してあげないといけません。
Yahoo Fainance では、一度に20個のデータの表示が限界です。
欲しいデータが20個以下なら、与えられた日付をただurlに埋め込めば全データ取得出来るのですが、それ以上のデータ数が欲しいときにはうまく取得出来ません。そこで、指定した期間の日付データリストを作成する関数を作って、間の期間でも指定できるようにしようと考えました。
daterange.pyfrom datetime import datetime from datetime import timedelta def daterange(start, end): # -----make list of "date"--------------------------- for n in range((end - start).days): yield start + timedelta(n) #---------------------------------------------------- start = datetime.strptime(str(day_start), '%Y-%m-%d').date() end = datetime.strptime(str(day_end), '%Y-%m-%d').date() list_days = [i for i in daterange(start, end)]ここでの start と end はtatetime関数といい、日付専用の関数です。
足したり引いたりすることは出来ません。datetime.html(n)
datetime.deltaは、datetime関数の日付の足し引きに使われます。
第一引数はdaysなので、ここではstartからendの日数分だけ順に1日ずつ足されてyieldされます。yieldという関数を見慣れていない人もいるかもしれないので説明すると、yieldというのは戻り値を小分けにして返すことが出来る関数です。
ここでは大したメリットはありませんが、一度に大きなリストが返ってくるような関数だとたくさんのメモリを一度に消費してしまうことになるので、そういうときにyieldはメモリ消費の抑制に貢献してくれます。グラフの可視化
普通に表示しても良かったのですが、暇つぶしにfft(高速フーリエ変換)したグラフも表示させてみました。
最後にコード
ついでにパナソニックとソニーと日系平均の銘柄コードも記載したので使ってみてください。
get_stock.pyimport pandas import numpy as np import matplotlib.pyplot as plt import csv from datetime import datetime from datetime import timedelta def get_stock_df(code, day_start, day_end):# (Stock Code, start y-m-d, end y-m-d) # -----colmn name------------------------------------ # 日付、始値、高値、安値、終値、出来高、調整後終値 #Date, Open, High, Low, Close, Volume, Adjusted Close #---------------------------------------------------- print("<<< Start stock data acquisition >>>") print("code:{0}, from {1} to {2}".format(code, day_start, day_end)) def get_stock_df_under20(code, day_start, day_end):# (Stock Code, start y-m-d, end y-m-d) # -----source: Yahoo Finance---------------------------- # Up to 20 data can be displayed on the site at one time #------------------------------------------------------- sy,sm,sd = str(day_start).split('-') ey,em,ed = str(day_end).split('-') url="https://info.finance.yahoo.co.jp/history/?code={0}&sy={1}&sm={2}&sd={3}&ey={4}&em={5}&ed={6}&tm=d".format(code,sy,sm,sd,ey,em,ed) list_df = pandas.read_html(url,header=0) for i in range(len(list_df)): if list_df[i].columns[0] == "日付": df = list_df[i] return df.iloc[::-1] #------------------------------------------------------- def daterange(start, end): # -----make list of "date"--------------------------- for n in range((end - start).days): yield start + timedelta(n) #---------------------------------------------------- start = datetime.strptime(str(day_start), '%Y-%m-%d').date() end = datetime.strptime(str(day_end), '%Y-%m-%d').date() list_days = [i for i in daterange(start, end)] pages = len(list_days) // 20 mod = len(list_days) % 20 if mod == 0: pages = pages -1 mod = 20 start = datetime.strptime(str(day_start), '%Y-%m-%d').date() end = datetime.strptime(str(day_end), '%Y-%m-%d').date() df_main = get_stock_df_under20(code, list_days[0], list_days[mod-1]) for p in range(pages): df = get_stock_df_under20(code, list_days[20*p + mod], list_days[20*(p+1) + mod-1]) df_main = pandas.concat([df_main, df]) print("<<< Completed >>> ({0}days)".format(len(df_main))) return df_main def graphing(f, dt): # データのパラメータ N = len(f) # サンプル数 dt = 1 # サンプリング間隔 t = np.arange(0, N*dt, dt) # 時間軸 freq = np.linspace(0, 1.0/dt, N) # 周波数軸 # 高速フーリエ変換 F = np.fft.fft(f) # 振幅スペクトルを計算 Amp = np.abs(F) # グラフ表示 plt.figure(figsize=(14,6)) plt.rcParams['font.family'] = 'Times New Roman' plt.rcParams['font.size'] = 17 plt.subplot(121) plt.plot(t, f, label='f(n)') plt.xlabel("Time", fontsize=20) plt.ylabel("Signal", fontsize=20) plt.grid() leg = plt.legend(loc=1, fontsize=25) leg.get_frame().set_alpha(1) plt.subplot(122) plt.plot(freq, Amp, label='|F(k)|') plt.xlabel('Frequency', fontsize=20) plt.ylabel('Amplitude', fontsize=20) plt.ylim(0,1000) plt.grid() leg = plt.legend(loc=1, fontsize=25) leg.get_frame().set_alpha(1) plt.show() nikkei = "998407.O" panasonic = "6752.T" sony = "6758.T" # code info "https://info.finance.yahoo.co.jp/history/?code=" df = get_stock_df(panasonic,"2016-5-23","2019-5-23") #graphing(df["終値"],1) csv = df.to_csv('./panasonic.csv', encoding='utf_8_sig')