- 投稿日:2020-05-21T23:15:37+09:00
UILabelの三点リーダーの位置のバラツキの調査
※調査記事の為、誤りが含まれている可能性があります。
はじめに
様々なアプリでUILabelが使われていますが、UILabelにおいて指定の領域を超えた文字数を保有する場合、領域外の文字は三点リーダー以降切り捨てられます。(見た目上は)
そこで、UILabelの三点リーダーの位置のバラつきが気になったので試してみました。試した内容
下記で試した文字列の長さに対して、UILabelのwidthは短い長さに設定しました。
文字列 三点リーダーより前の文字列の文字数 三点リーダー aaaaaaaaaaaaaaaaaa 2 (下)
aaaaaaaaaaaaaaaaaaあ 2 あaaaaaaaaaaaaaaa 2 aaaaaaaaaaaaaaaaあaaaaaaaa 2 あaああああああああああ 1 あああああああああ 1 (中)
ああaa 1 仮説
文字列の末尾がマルチバイト文字か否かで三点リーダーの位置が変わると考えていました。
しかし、上記の結果を見る限りでは「三点リーダーで切り捨てられる最初の文字」がマルチバイト文字か否かで三点リーダーの位置が変わります。
- シングルバイト文字(アルファベットや数字など):下
- マルチバイト文字(ひらがなや漢字など):中
最後に
色々なアプリを覗いてみると、三点リーダーの位置がバラバラなことが分かるので見てみると良いかも知れません。
- 投稿日:2020-05-21T23:02:29+09:00
UITextViewの文字を複数リンク化させる方法
はじめに
iOSが意外に苦手なリンク化
HTMLみたいにタグで囲った範囲をリンク化する!みたいに出来たら便利なのですが、出来ないのでリンク化したい文字列の場所とタップした位置でゲームみたいに当たり判定でリンクをタップしたか判定します!
ViewController + Storyboardで解説
Storyboard(Xibでも可)にUITextViewを貼り付ける
制約も適当に張ります。
UITextViewにTapGestureを張ります!
こんな感じ!
Storyboardとコードをつなげる
Controlキーを押しながら、TextViewをひっぱりコードに張りますー
(ちなみにエディタを分割して開くには、ファイルをoptionキーを押しながらクリックします)
TapGestureもコードにつなげておきます〜
以下のようになりました!
import UIKit class ViewController: UIViewController { @IBOutlet weak var messageTextView: UITextView! override func viewDidLoad() { super.viewDidLoad() } @IBAction func didTapMessageView(_ sender: UITapGestureRecognizer) { } }本題
messageTextViewの初期設定をしてあげます
仕様にもよりますが、以下の制御があったほうが理想だと思います。
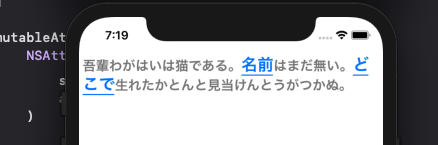
messageTextView.isUserInteractionEnabled = true messageTextView.isEditable = false messageTextView.isSelectable = false messageTextView.isScrollEnabled = false@IBOutlet weak var messageTextView: UITextView! { didSet { messageTextView.isUserInteractionEnabled = true messageTextView.isEditable = false messageTextView.isSelectable = false messageTextView.isScrollEnabled = false let mutableAttributedString = NSMutableAttributedString() let normalAttirbutes: [NSAttributedString.Key: Any] = [ .foregroundColor: UIColor.gray, .font: UIFont.monospacedSystemFont(ofSize: 18, weight: .medium) ] let linkAttributes: [NSAttributedString.Key: Any] = [ .foregroundColor: UIColor.link, .underlineStyle: NSUnderlineStyle.single.rawValue, .font: UIFont.monospacedSystemFont(ofSize: 22, weight: .medium) ] mutableAttributedString.append( NSAttributedString( string: "吾輩わがはいは猫である。", attributes: normalAttirbutes ) ) mutableAttributedString.append( NSAttributedString( string: "名前", attributes: linkAttributes ) ) mutableAttributedString.append( NSAttributedString( string: "はまだ無い。", attributes: normalAttirbutes ) ) mutableAttributedString.append( NSAttributedString( string: "どこで", attributes: linkAttributes ) ) mutableAttributedString.append( NSAttributedString( string: "生れたかとんと見当けんとうがつかぬ。", attributes: normalAttirbutes ) ) messageTextView.attributedText = mutableAttributedString } }次にタップ時の挙動を記述していきます。
@IBAction func didTapMessageView(_ sender: UITapGestureRecognizer) { guard let text = messageTextView.text else { return } let name = "名前" let pos = "どこで" let nameRange = (text as NSString).range(of: name) let posRange = (text as NSString).range(of: pos) let location = sender.location(in: messageTextView) let textPosition = messageTextView.closestPosition(to: location) let tapPosition = messageTextView.offset(from: messageTextView.beginningOfDocument, to: textPosition!) if NSLocationInRange(tapPosition, nameRange) { print("たま") } if NSLocationInRange(tapPosition, posRange) { print("縁側") } }結果
終わり
ポイントはNSLocationInRangeで毎回当たり判定的なものを行なって毎回処理を走らせるところです!
これをUIViewControllerRepresentableすればSwiftUIでも行けるのかも?
今度試してみます!


- 投稿日:2020-05-21T21:18:21+09:00
URLsessionを用いたHTTPリクエストの方法(Swift, Xcode)
はじめに
APIKitやAlamofireなどのライブラリを使わず標準のURLsessionを用いたHTTPリクエストを実行するを簡単にまとめました。
1. URLsession手順
- URLを生成
- URLRequestを生成
- 必要なパラメーターを付与
- 通信を行う
- レスポンスで受け取ったdata, response, errorの処理を行う
2.基本のコード
Get
基本は以下のコードのようになります。
let url = URL(string: "https://hogehoge.hoge")! //URLを生成 var request = URLRequest(url: url) //Requestを生成 let task = URLSession.shared.dataTask(with: request) { (data, response, error) in //非同期で通信を行う guard let data = data else { return } do { let object = try JSONSerialization.jsonObject(with: data, options: []) // DataをJsonに変換 print(object) } catch let error { print(error) } } task.resume()Post, Put
PostやPutにしたい場合はrequest.httpMethodを使います。
let url = URL(string: "https://hogehoge.hoge")! var request = URLRequest(url: url) request.httpMethod = "POST" // Postリクエストを送る(このコードがないとGetリクエストになる) let task = URLSession.shared.dataTask(with: request) { (data, response, error) in guard let data = data else { return } do { let object = try JSONSerialization.jsonObject(with: data, options: []) print(object) } catch let error { print(error) } } task.resume()3. Body, Header, Queryを付与したいときのコード
Bodyを付与(Get)
let url = URL(string: "https://hogehoge.hoge")! var request = URLRequest(url: url) request.httpBody = "email=hoge@hoge.com&username=hogehoge".data(using: .utf8) // 例)emailとpasswordを付与する場合Headerを付与(Get)
let url = URL(string: "https://hogehoge.hoge")! var request = URLRequest(url: url) request.setValue("application/json", forHTTPHeaderField: "Content-Type") //jsonでヘッダーに付与 request.allHTTPHeaderFields = ["Token": "snsjetnglsdfnm"] // 例) ヘッダーにトークンを付与する場合Queryを付与(Get)
var urlComponents = URLComponents(string: "https://hogehoge.hoge")! //URLComponentsでURLを生成 urlComponents.queryItems = [ URLQueryItem(name: "email", value: "hoge@hoge.com"), // 例) emailとpasswordを付与 URLQueryItem(name: "username", value: "hogehoge") //クエリを追加したければ、ここに書いていく ] var request = URLRequest(url: urlComponents.url!) → 生成されるリクエスト "https://hogehoge.hoge/email=hoge@hoge.com&username=hogehoge"参考
下記のサイトを見ながら実装したので詳細はこちらをご確認ください。
URLSessionを用いた通信 - GitHub
HTTP GETとPOST(Swift)
【Swift】URLSessionまとめ
- 投稿日:2020-05-21T16:16:49+09:00
【Swift】@testable import no such module “xxx” というエラーが出る

- 投稿日:2020-05-21T08:51:47+09:00
画面サイズに合わせてパーツの大きさを変える(初心者向け)
こんにちは。プログラミング初心者兼Swift初心者です。
storyboardのオートレイアウトで画面サイズが変わっても、部品の位置はある程度決めることができますが、大きさを変えることができないので「小さい画面だとキツキツ、大きい画面だと余白ができる」なんてことがありました。
そこで画面サイズを元にして、動的に部品サイズを変更することができたのでコードを載せておきます。//今回はImageViewの大きさを変更します @IBOutlet weak var imageView: UIImageView! //画面サイズを取得 let screenSize = UIScreen.main.bounds.size override func viewDidLoad() { super.viewDidLoad() //imageViewの横幅を画面サイズの80%にする let ivWidth = screenSize.width * 0.8 //imageViewの縦幅は横幅の0.666....倍 let ivHeight = ivWidth * 0.66 //あとから左右中央にするのでy座標と大きさをここで決める imageView.frame = CGRect(x: 0, y: screenSize.height / 6, width: ivWidth, height: ivHeight) //左右中央に指定 imageView.center.x = screenSize.width / 2 }簡略化するためにUIImageViewのアスペクト比や画面サイズを元に定数で書いていますが、変数に格納したほうがいいですね笑
- 投稿日:2020-05-21T06:51:34+09:00
「VNDocumentCameraViewController」を使ってドキュメントをスキャンし、「VNDetectTextRectanglesRequest」を使って日本語の文字画像を抽出
「Vision」について:
「Vision」は、画像や動画などの入力を処理できる多くの機械学習アルゴリズムを含むフレームワークです。テキストを処理する既存の関数「VNRecognizeTextRequest」がありますが、これは英語しかサポートしませんのでご注意ください。また、「Qitta」で「VNRecognizeTextRequest」を検索すると、それに関する記事がすでに出ています。
この記事では、検出された日本語テキストの周りに長方形を描く方法が説明されています。
フレームワークのコンポーネント
VNDocumentCameraViewController(VisionKit):これはiOSフレームワークに組み込まれているスキャナーサポートで、用紙の長方形の領域を自動的に検出します。それからユーザーはボタンをクリックしてドキュメントの画像を撮影し、その画像データをデリゲートで受け取ることができます。
VNDetectTextRectanglesRequest「Vision」フレームワークの関数で、テキストがある領域の境界ボックスを取得できます。
VNDetectTextRectanglesRequestを使用する理由
VNRecognizeTextRequestは日本語をサポートしていないためですVNDetectTextRectanglesRequestで認識された領域を切り抜き、その結果を独自のテキスト認識アルゴリズムに入力できます。この場合、VNDetectTextRectanglesRequestに文字ごとに結果を表示するように要求すれば、各文字を認識できます。さあ始めましょう。
ドキュメントをスキャンする
VNDocumentCameraViewControllerの実装は簡単です:import VisionKit@IBAction func actionPresentVision(){ let documentCameraViewController = VNDocumentCameraViewController() documentCameraViewController.delegate = self present(documentCameraViewController, animated: true) }ユーザーが撮影した画像を受け取るプログラムデリゲートも実装する必要があります:
extension ViewController: VNDocumentCameraViewControllerDelegate { func documentCameraViewController(_ controller: VNDocumentCameraViewController, didFinishWith scan: VNDocumentCameraScan) { if let firstImage = scan.imageOfPage(at: 0).cgImage { //TODO processImage(input: firstImage) controller.dismiss(animated: true, completion: nil) } } func documentCameraViewControllerDidCancel(_ controller: VNDocumentCameraViewController) { controller.dismiss(animated: true, completion: nil) } }押すと "actionPresentVision" を呼び出す
UIButtonを Storyboard に追加します。そして画面に画像を表示するprocessImage関数を設定します。@IBOutlet weak var imageView: UIImageView! func processImage(input: CGImage) { let image = UIImage(cgImage: input) imageView.image = image }
(Keep Scan -> Save)
画像の部分ができたので、機械学習の部分にとりかかりましょう:
機械学習を使ってテキストを認識する
まず、フレームワークをインポートします:
import Vision次に、前回の記事で書いたように、機械学習による結果を処理するためのハンドラーを設定し、
VNImageRequestHandlerを使って画像データをリクエストにインプットする必要があります。アニメ画像の昼/夜認識システムの作成:(2/3) そのモデルと「Vision」フレームワークを用いて新規画像からラベルを取得する。
前述の記事では
VNCoreMLRequestを 使っていますが、ここではVNDetectTextRectanglesRequestを使うことにもご注意ください:func processImage(input: CGImage) { let request = VNDetectTextRectanglesRequest { (request, error) in //ここに結果が表示されます if let results = request.results as? [VNTextObservation] { print(results) } } //次にリクエストに画像を受け渡します let handler = VNImageRequestHandler(cgImage: input, options: [:]) DispatchQueue.global(qos: .userInteractive).async { do { try handler.perform([request]) } catch { print(error) } } }こちらが得られた結果です:
[ <VNTextObservation: 0x282a34fa0> CCD5518B-FC57-42E2-8475-7E4883F3782A requestRevision=1 confidence=1.000000 boundingBox=[0.186391, 0.678969, 0.568047, 0.0543175], <VNTextObservation: 0x282a348c0> DCEC8A13-FC2F-4D55-A2C0-D88EAEAF304C requestRevision=1 confidence=1.000000 boundingBox=[0.363905, 0.550836, 0.224852, 0.0557103], <VNTextObservation: 0x282a34d20> 93FEE50E-D6B6-49F4-983E-C8025D45A4EC requestRevision=1 confidence=1.000000 boundingBox=[0.381657, 0.39624, 0.198225, 0.051532], <VNTextObservation: 0x282a34aa0> 2215CEAB-09B5-40E2-86C0-5DC33F354057 requestRevision=1 confidence=1.000000 boundingBox=[0.372781, 0.236072, 0.210059, 0.051532], <VNTextObservation: 0x282a34c80> E88AA596-EF6E-4CD1-B19B-AC7EE7A30936 requestRevision=1 confidence=1.000000 boundingBox=[0.372781, 0.0759053, 0.215976, 0.0501393] ]紙にはちょうど5つの単語が書かれています!各「VNTextObservation」は画像内の各単語のバウンディングボックスを表しています。
あとは、結果を画面上に視覚的に表示できるようにするだけです。:
視覚的に表示
func drawBoundingBox(forResult: VNTextObservation) { let outline = CALayer() //バウンディングボックスの座標はパーセンテージとして与えられます。実際の画面の座標に変換する必要があります let x = forResult.topLeft.x * imageView.frame.width let y = (1 - forResult.topLeft.y) * imageView.frame.height ///横幅と高さは「boundingBox」から取得できます let width = forResult.boundingBox.width * imageView.frame.width let height = forResult.boundingBox.height * imageView.frame.height outline.frame = CGRect(x: x, y: y, width: width, height: height) outline.borderColor = UIColor.green.cgColor outline.borderWidth = 3 imageView.layer.addSublayer(outline) }また、「drawBoundingBox」を呼び出すようにリクエストを変更するのを忘れないでください。
let request = VNDetectTextRectanglesRequest { (request, error) in if let results = request.results as? [VNTextObservation] { for result in results { DispatchQueue.main.async { self.imageView.image = UIImage(cgImage: input) self.drawBoundingBox(forResult: result) } } } }こちらが結果です。:
パラメーターを「forResult.characterBoxes」に変更すれば、「drawBoundingBox」の同じコードを使って各文字のバウンディングボックスを描画することもできます。
一部のバウンディングボックスが表示されない場合がありますが、これは正常です。機械学習には限界があり、光の当たり具合が適切ではないと不正確なデータを返してしまうことがあるからです。
コード
コードはこちらにあります: https://github.com/mszopensource/VisionTextDetection
次のステップ
日本語の文字を認識する機械学習モデルをトレーニングし、「forResult.characterBoxes」の各文字の画像を用いて各文字を認識させることができます。その方法は既に別記事で執筆済みです:
1.「Core ML」モデルを「Create ML」で既存のラベル付けされたアニメ画像を入力として用いてトレーニングする。
2. そのモデルと「Vision」フレームワークを用いて新規画像からラベルを取得する。


- 投稿日:2020-05-21T06:51:34+09:00
VNDocumentCameraViewController を使ってドキュメントをスキャンし、VNDetectTextRectanglesRequest を使って日本語の文字画像を抽出
「Vision」について:
「Vision」は、画像や動画などの入力を処理できる多くの機械学習アルゴリズムを含むフレームワークです。テキストを処理する既存の関数「VNRecognizeTextRequest」がありますが、これは英語しかサポートしませんのでご注意ください。また、「Qitta」で「VNRecognizeTextRequest」を検索すると、それに関する記事がすでに出ています。
この記事では、検出された日本語テキストの周りに長方形を描く方法が説明されています。
フレームワークのコンポーネント
VNDocumentCameraViewController(VisionKit):これはiOSフレームワークに組み込まれているスキャナーサポートで、用紙の長方形の領域を自動的に検出します。それからユーザーはボタンをクリックしてドキュメントの画像を撮影し、その画像データをデリゲートで受け取ることができます。
VNDetectTextRectanglesRequest「Vision」フレームワークの関数で、テキストがある領域の境界ボックスを取得できます。
VNDetectTextRectanglesRequestを使用する理由
VNRecognizeTextRequestは日本語をサポートしていないためですVNDetectTextRectanglesRequestで認識された領域を切り抜き、その結果を独自のテキスト認識アルゴリズムに入力できます。この場合、VNDetectTextRectanglesRequestに文字ごとに結果を表示するように要求すれば、各文字を認識できます。さあ始めましょう。
ドキュメントをスキャンする
VNDocumentCameraViewControllerの実装は簡単です:import VisionKit@IBAction func actionPresentVision(){ let documentCameraViewController = VNDocumentCameraViewController() documentCameraViewController.delegate = self present(documentCameraViewController, animated: true) //以前に追加したレイヤーを削除する for layer in imageView.layer.sublayers ?? [] { layer.removeFromSuperlayer() } }ユーザーが撮影した画像を受け取るプログラムデリゲートも実装する必要があります:
extension ViewController: VNDocumentCameraViewControllerDelegate { func documentCameraViewController(_ controller: VNDocumentCameraViewController, didFinishWith scan: VNDocumentCameraScan) { if let firstImage = scan.imageOfPage(at: 0).cgImage { //TODO processImage(input: firstImage) controller.dismiss(animated: true, completion: nil) } } func documentCameraViewControllerDidCancel(_ controller: VNDocumentCameraViewController) { controller.dismiss(animated: true, completion: nil) } }押すと "actionPresentVision" を呼び出す
UIButtonを Storyboard に追加します。そして画面に画像を表示するprocessImage関数を設定します。@IBOutlet weak var imageView: UIImageView! override func viewDidLoad() { super.viewDidLoad() imageView.contentMode = .scaleToFill } func processImage(input: CGImage) { let image = UIImage(cgImage: input) imageView.image = image }
(Keep Scan -> Save)
画像の部分ができたので、機械学習の部分にとりかかりましょう:
機械学習を使ってテキストを認識する
まず、フレームワークをインポートします:
import Vision次に、前回の記事で書いたように、機械学習による結果を処理するためのハンドラーを設定し、
VNImageRequestHandlerを使って画像データをリクエストにインプットする必要があります。アニメ画像の昼/夜認識システムの作成:(2/3) そのモデルと「Vision」フレームワークを用いて新規画像からラベルを取得する。
前述の記事では
VNCoreMLRequestを 使っていますが、ここではVNDetectTextRectanglesRequestを使うことにもご注意ください:func processImage(input: CGImage) { let request = VNDetectTextRectanglesRequest { (request, error) in //ここに結果が表示されます if let results = request.results as? [VNTextObservation] { print(results) } } //次にリクエストに画像を受け渡します let handler = VNImageRequestHandler(cgImage: input, options: [:]) DispatchQueue.global(qos: .userInteractive).async { do { try handler.perform([request]) } catch { print(error) } } }こちらが得られた結果です:
[ <VNTextObservation: 0x282a34fa0> CCD5518B-FC57-42E2-8475-7E4883F3782A requestRevision=1 confidence=1.000000 boundingBox=[0.186391, 0.678969, 0.568047, 0.0543175], <VNTextObservation: 0x282a348c0> DCEC8A13-FC2F-4D55-A2C0-D88EAEAF304C requestRevision=1 confidence=1.000000 boundingBox=[0.363905, 0.550836, 0.224852, 0.0557103], <VNTextObservation: 0x282a34d20> 93FEE50E-D6B6-49F4-983E-C8025D45A4EC requestRevision=1 confidence=1.000000 boundingBox=[0.381657, 0.39624, 0.198225, 0.051532], <VNTextObservation: 0x282a34aa0> 2215CEAB-09B5-40E2-86C0-5DC33F354057 requestRevision=1 confidence=1.000000 boundingBox=[0.372781, 0.236072, 0.210059, 0.051532], <VNTextObservation: 0x282a34c80> E88AA596-EF6E-4CD1-B19B-AC7EE7A30936 requestRevision=1 confidence=1.000000 boundingBox=[0.372781, 0.0759053, 0.215976, 0.0501393] ]紙にはちょうど5つの単語が書かれています!各「VNTextObservation」は画像内の各単語のバウンディングボックスを表しています。
あとは、結果を画面上に視覚的に表示できるようにするだけです。:
視覚的に表示
func drawBoundingBox(forResult: VNTextObservation) { let outline = CALayer() //バウンディングボックスの座標はパーセンテージとして与えられます。実際の画面の座標に変換する必要があります let x = forResult.topLeft.x * imageView.frame.width let y = (1 - forResult.topLeft.y) * imageView.frame.height ///横幅と高さは「boundingBox」から取得できます let width = forResult.boundingBox.width * imageView.frame.width let height = forResult.boundingBox.height * imageView.frame.height outline.frame = CGRect(x: x, y: y, width: width, height: height) outline.borderColor = UIColor.green.cgColor outline.borderWidth = 3 imageView.layer.addSublayer(outline) }また、「drawBoundingBox」を呼び出すようにリクエストを変更するのを忘れないでください。
let request = VNDetectTextRectanglesRequest { (request, error) in if let results = request.results as? [VNTextObservation] { for result in results { DispatchQueue.main.async { self.imageView.image = UIImage(cgImage: input) self.drawBoundingBox(forResult: result) } } } }こちらが結果です。:
パラメーターを「forResult.characterBoxes」に変更すれば、「drawBoundingBox」の同じコードを使って各文字のバウンディングボックスを描画することもできます。
一部のバウンディングボックスが表示されない場合がありますが、これは正常です。機械学習には限界があり、光の当たり具合が適切ではないと不正確なデータを返してしまうことがあるからです。
コード
コードはこちらにあります: https://github.com/mszopensource/VisionTextDetection
次のステップ
日本語の文字を認識する機械学習モデルをトレーニングし、「forResult.characterBoxes」の各文字の画像を用いて各文字を認識させることができます。その方法は既に別記事で執筆済みです:
1.「Core ML」モデルを「Create ML」で既存のラベル付けされたアニメ画像を入力として用いてトレーニングする。
2. そのモデルと「Vision」フレームワークを用いて新規画像からラベルを取得する。
- 投稿日:2020-05-21T06:51:34+09:00
VNDetectTextRectanglesRequest: 機械学習を用いて日本語の単語の領域を検出します。
「Vision」について:
「Vision」は、画像や動画などの入力を処理できる多くの機械学習アルゴリズムを含むフレームワークです。テキストを処理する既存の関数「VNRecognizeTextRequest」がありますが、これは英語しかサポートしませんのでご注意ください。また、「Qitta」で「VNRecognizeTextRequest」を検索すると、それに関する記事がすでに出ています。
この記事では、検出された日本語テキストの周りに長方形を描く方法が説明されています。
フレームワークのコンポーネント
VNDocumentCameraViewController(VisionKit):これはiOSフレームワークに組み込まれているスキャナーサポートで、用紙の長方形の領域を自動的に検出します。それからユーザーはボタンをクリックしてドキュメントの画像を撮影し、その画像データをデリゲートで受け取ることができます。
VNDetectTextRectanglesRequest「Vision」フレームワークの関数で、テキストがある領域の境界ボックスを取得できます。
VNDetectTextRectanglesRequestを使用する理由
VNRecognizeTextRequestは日本語をサポートしていないためですVNDetectTextRectanglesRequestで認識された領域を切り抜き、その結果を独自のテキスト認識アルゴリズムに入力できます。この場合、VNDetectTextRectanglesRequestに文字ごとに結果を表示するように要求すれば、各文字を認識できます。さあ始めましょう。
ドキュメントをスキャンする
VNDocumentCameraViewControllerの実装は簡単です:import VisionKit@IBAction func actionPresentVision(){ let documentCameraViewController = VNDocumentCameraViewController() documentCameraViewController.delegate = self present(documentCameraViewController, animated: true) //以前に追加したレイヤーを削除する for layer in imageView.layer.sublayers ?? [] { layer.removeFromSuperlayer() } }ユーザーが撮影した画像を受け取るプログラムデリゲートも実装する必要があります:
extension ViewController: VNDocumentCameraViewControllerDelegate { func documentCameraViewController(_ controller: VNDocumentCameraViewController, didFinishWith scan: VNDocumentCameraScan) { if let firstImage = scan.imageOfPage(at: 0).cgImage { //TODO processImage(input: firstImage) controller.dismiss(animated: true, completion: nil) } } func documentCameraViewControllerDidCancel(_ controller: VNDocumentCameraViewController) { controller.dismiss(animated: true, completion: nil) } }押すと "actionPresentVision" を呼び出す
UIButtonを Storyboard に追加します。そして画面に画像を表示するprocessImage関数を設定します。@IBOutlet weak var imageView: UIImageView! override func viewDidLoad() { super.viewDidLoad() imageView.contentMode = .scaleToFill } func processImage(input: CGImage) { let image = UIImage(cgImage: input) imageView.image = image }
(Keep Scan -> Save)
画像の部分ができたので、機械学習の部分にとりかかりましょう:
機械学習を使ってテキストを認識する
まず、フレームワークをインポートします:
import Vision次に、前回の記事で書いたように、機械学習による結果を処理するためのハンドラーを設定し、
VNImageRequestHandlerを使って画像データをリクエストにインプットする必要があります。アニメ画像の昼/夜認識システムの作成:(2/3) そのモデルと「Vision」フレームワークを用いて新規画像からラベルを取得する。
前述の記事では
VNCoreMLRequestを 使っていますが、ここではVNDetectTextRectanglesRequestを使うことにもご注意ください:func processImage(input: CGImage) { let request = VNDetectTextRectanglesRequest { (request, error) in //ここに結果が表示されます if let results = request.results as? [VNTextObservation] { print(results) } } //次にリクエストに画像を受け渡します let handler = VNImageRequestHandler(cgImage: input, options: [:]) DispatchQueue.global(qos: .userInteractive).async { do { try handler.perform([request]) } catch { print(error) } } }こちらが得られた結果です:
[ <VNTextObservation: 0x282a34fa0> CCD5518B-FC57-42E2-8475-7E4883F3782A requestRevision=1 confidence=1.000000 boundingBox=[0.186391, 0.678969, 0.568047, 0.0543175], <VNTextObservation: 0x282a348c0> DCEC8A13-FC2F-4D55-A2C0-D88EAEAF304C requestRevision=1 confidence=1.000000 boundingBox=[0.363905, 0.550836, 0.224852, 0.0557103], <VNTextObservation: 0x282a34d20> 93FEE50E-D6B6-49F4-983E-C8025D45A4EC requestRevision=1 confidence=1.000000 boundingBox=[0.381657, 0.39624, 0.198225, 0.051532], <VNTextObservation: 0x282a34aa0> 2215CEAB-09B5-40E2-86C0-5DC33F354057 requestRevision=1 confidence=1.000000 boundingBox=[0.372781, 0.236072, 0.210059, 0.051532], <VNTextObservation: 0x282a34c80> E88AA596-EF6E-4CD1-B19B-AC7EE7A30936 requestRevision=1 confidence=1.000000 boundingBox=[0.372781, 0.0759053, 0.215976, 0.0501393] ]紙にはちょうど5つの単語が書かれています!各「VNTextObservation」は画像内の各単語のバウンディングボックスを表しています。
あとは、結果を画面上に視覚的に表示できるようにするだけです。:
視覚的に表示
func drawBoundingBox(forResult: VNTextObservation) { let outline = CALayer() //バウンディングボックスの座標はパーセンテージとして与えられます。実際の画面の座標に変換する必要があります let x = forResult.topLeft.x * imageView.frame.width let y = (1 - forResult.topLeft.y) * imageView.frame.height ///横幅と高さは「boundingBox」から取得できます let width = forResult.boundingBox.width * imageView.frame.width let height = forResult.boundingBox.height * imageView.frame.height outline.frame = CGRect(x: x, y: y, width: width, height: height) outline.borderColor = UIColor.green.cgColor outline.borderWidth = 3 imageView.layer.addSublayer(outline) }また、「drawBoundingBox」を呼び出すようにリクエストを変更するのを忘れないでください。
let request = VNDetectTextRectanglesRequest { (request, error) in if let results = request.results as? [VNTextObservation] { for result in results { DispatchQueue.main.async { self.imageView.image = UIImage(cgImage: input) self.drawBoundingBox(forResult: result) } } } }こちらが結果です。:
パラメーターを「forResult.characterBoxes」に変更すれば、「drawBoundingBox」の同じコードを使って各文字のバウンディングボックスを描画することもできます。
一部のバウンディングボックスが表示されない場合がありますが、これは正常です。機械学習には限界があり、光の当たり具合が適切ではないと不正確なデータを返してしまうことがあるからです。
コード
コードはこちらにあります: https://github.com/mszopensource/VisionTextDetection
次のステップ
日本語の文字を認識する機械学習モデルをトレーニングし、「forResult.characterBoxes」の各文字の画像を用いて各文字を認識させることができます。その方法は既に別記事で執筆済みです:
1.「Core ML」モデルを「Create ML」で既存のラベル付けされたアニメ画像を入力として用いてトレーニングする。
2. そのモデルと「Vision」フレームワークを用いて新規画像からラベルを取得する。
- 投稿日:2020-05-21T01:00:10+09:00
【Swift】SVProgressHUDの表示がiOS13以上だとおかしくなる
結構古くからある「SVProgressHUD」というローダーのライブラリがあります。
癖が無くて使いやすいのですが、iOS13.0で動かしてみたら画面中央では無く何故か左上の隅っこに表示されてしまいました。
対応策
AppDelegate.swift
static var standard: AppDelegate { return UIApplication.shared.delegate as! AppDelegate }SceneDelegate.swift
func scene(_ scene: UIScene, willConnectTo session: UISceneSession, options connectionOptions: UIScene.ConnectionOptions) { guard let _ = (scene as? UIWindowScene) else { return } AppDelegate.standard.window = window }以上のように変更するとiOS13系でもローディングが中央に表示されるようになった。