- 投稿日:2020-05-21T21:23:42+09:00
AWS の Workspaces のマシンに起動後に既存のEIPを割り当てる方法
AWS の Workspaces に EIP を割り当てるのは、あらたに EIP を取得して割り当てるのは簡単ですが、既に持っている EIP を割り当てたい場合はどうしたらいいかという記事になります。
これは、既に作ってしまった Workspaces では、どうしようもないのですが、まずはディレクトリの設定で、グローバルIP をもらわない設定にしてから、あらたに Workspaces で適当なものを選んで起動させます。そうすると、プライベート IP は持っているが、グローバル IP は持っていない Workspaces が出来上がります。
ネットワークインターフェースに行って、Workspaces のプライベート IP と同じプライベート IP を持つネットワークインターフェースを覚えておき、それに既存の EIP を割当てます。
コツとしては、Workspaces のディレクトリ設定でパブリック IP の割り当てをしない設定にすることです。そうしないと、既存の EIP を割り当てようとした時に、既にグローバル IP が割り当てられているので割り当てできません、となってしまいます。
- 投稿日:2020-05-21T20:51:06+09:00
Laravel勉強 その1 サーバのセットアップ、DockerでのLaravel環境構築
目的
- 勉強のため、Laravel 7.xの公式ドキュメントを読み解いていく。
- 今回はそのための準備として、Dockerを使用して環境を構築する。
EC2の構築~セットアップ
今回は勉強なので、AWSの無料枠を利用する。
インスタンスタイプはt2.micro、OSはAmazon Linux2で作成。参考
EC2(Amazon-Linux-2)にNginxを入れてブラウザで確認するまで2018冬 [画像で解説] Nginx編
rootでのPWログインをON
セキュリティ的には微妙なところもあるかもしれないが、いちいちsudo打たなければいけないのも面倒なので。。。
rootのPWを設定
# sudo su # passwdsshの設定ファイル変更
# vi /etc/ssh/sshd_configPermitRootLogin yes PasswordAuthentication yessshd再起動
# systemctl restart sshdec2-userの無効化
セキュリティ的に消した方がいいよ、という記事を見つけた。確かに。
# userdel ec2-userEC2を日本時間と日本語に対応させる
# yum update -y # timedatectl set-timezone Asia/Tokyo # localectl set-locale LANG=ja_JP.UTF-8 # localectl set-keymap jp106パッケージを自動更新させる
yum-cronのインストール
# yum install yum-cron -yyum-cronとは?
yum-cron パッケージは、アップデートを自動的に確認し、ダウンロードし、適用するための便利な方法を提供します。
パッケージをインストールするとすぐに yum-cron パッケージの cron ジョブが有効になり、特別な設定は必要ありません。通常の日次 cron ジョブの実行時に、このジョブが実行します。yum-cronを編集
# vi /etc/yum/yum-cron.conf/etc/yum/yum-cron.confapply_updates = yescronの自動起動をON
# systemctl status yum-cron # systemctl start yum-cron # systemctl enable yum-cronLaravel開発環境構築
参考
Docker × PHP7.3 × Laravel環境作ってみた
Docker・Docker Composeのインストール
Dockerインストール # amazon-linux-extras install docker Dockerサービス起動 # systemctl start docker.service サービスの起動確認 # systemctl status docker Dockerの自動起動設定 # systemctl enable docker 試しにDockerコマンド実行 # docker infoDocker Composeインストール # curl -L https://github.com/docker/compose/releases/download/1.25.4/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose # chmod +x /usr/local/bin/docker-compose Docker Composeのインストールを確認 # docker-compose --version docker-compose version 1.25.4, build 8d51620aディレクトリ作成
以下の構成を想定しています。
project
├ docker-compose.yml
├ docker
│ ├ db
│ │ ├ data
│ │ ├ sql
│ │ └ my.cnf
│ ├ nginx
│ │ ├ default.conf
│ ├ php
│ │ ├ php.ini
│ │ └ Dockerfile
└ serverとのこと。(太字はディレクトリ)
# cd /var # mkdir project # mkdir project/docker project/server # mkdir project/docker/{php,nginx,db} # ll -d `find ./project` drwxr-xr-x 4 root root 34 May 21 19:08 ./project drwxr-xr-x 4 root root 30 May 21 19:08 ./project/docker drwxr-xr-x 2 root root 6 May 21 19:08 ./project/docker/db drwxr-xr-x 2 root root 6 May 21 19:08 ./project/docker/nginx drwxr-xr-x 2 root root 6 May 21 19:08 ./project/docker/php drwxr-xr-x 2 root root 6 May 21 19:08 ./project/server別にvarじゃなくてもいいけど、なんとなくvarで。
swap領域の有効化
過去の経験上、これをやらないとこける。
# /bin/dd if=/dev/zero of=/var/swap.1 bs=1M count=1024 1024+0 records in 1024+0 records out 1073741824 bytes (1.1 GB) copied, 13.537 s, 79.3 MB/s # /sbin/mkswap /var/swap.1 mkswap: /var/swap.1: insecure permissions 0644, 0600 suggested. Setting up swapspace version 1, size = 1024 MiB (1073737728 bytes) no label, UUID=8be78b55-de6d-4ed4-9f9a-7a48f3dc30ae # /sbin/swapon /var/swap.1 swapon: /var/swap.1: insecure permissions 0644, 0600 suggested.docker-compose.yml作成
docker-composer.ymlversion: '3' services: php: container_name: php build: ./docker/php volumes: - ./server:/var/www nginx: image: nginx container_name: nginx ports: - 80:80 volumes: - ./server:/var/www - ./docker/nginx/default.conf:/etc/nginx/conf.d/default.conf depends_on: - php db: image: mysql:5.7 container_name: db environment: MYSQL_ROOT_PASSWORD: ****(パスワードを記載しておく) MYSQL_DATABASE: test_db TZ: 'Asia/Tokyo' command: mysqld --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci volumes: - ./docker/db/data:/var/lib/mysql - ./docker/db/my.cnf:/etc/mysql/conf.d/my.cnf - ./docker/db/sql:/docker-entrypoint-initdb.d ports: - 3306:3306Dockerfile作成
phpコンテナの構築時に、以下のDockerfileを使用する。
DockerfileFROM php:7.3-fpm COPY php.ini /usr/local/etc/php/ RUN apt-get update \ && apt-get install -y zlib1g-dev libzip-dev mariadb-client \ && docker-php-ext-install zip pdo_mysql #Composer install COPY --from=composer:latest /usr/bin/composer /usr/bin/composer ENV COMPOSER_ALLOW_SUPERUSER 1 ENV COMPOSER_HOME /composer ENV PATH $PATH:/composer/vendor/bin WORKDIR /var/www RUN composer global require "laravel/installer"各行の処理については、Dockerfileリファレンスを参照。
php.ini作成
phpの設定ファイル。
php.ini[Date] date.timezone = "Asia/Tokyo" [mbstring] mbstring.internal_encoding = "UTF-8" mbstring.language = "Japanese"default.conf作成
nginxの設定ファイル。
default.confserver { listen 80; root /var/www/public; index index.php; location / { try_files $uri $uri/ /index.php$is_args$args; } location ~ \.php$ { fastcgi_split_path_info ^(.+\.php)(/.+)$; fastcgi_pass php:9000; fastcgi_index index.php; include fastcgi_params; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; fastcgi_param PATH_INFO $fastcgi_path_info; } }php.ini作成
mysqlの設定ファイル。
my.cnf[mysqld] character-set-server=utf8mb4 collation-server=utf8mb4_unicode_ci [client] default-character-set=utf8mb4Laravelプロジェクト作成
docker起動 # docker-compose up -d (略) Creating php ... done Creating db-host ... done Creating nginx ... done 起動の確認 # docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 9fdcb0da6745 nginx "nginx -g 'daemon of…" 2 minutes ago Up 2 minutes 0.0.0.0:80->80/tcp nginx e1394b974a68 project_php "docker-php-entrypoi…" 3 minutes ago Up 2 minutes 9000/tcp php cbc7a83db192 mysql:5.7 "docker-entrypoint.s…" 3 minutes ago Up 2 minutes 0.0.0.0:3306->3306/tcp, 33060/tcp db phpコンテナに入る # docker-compose exec php bash root@eec8f5f9ebe2:/var/www# Laravelプロジェクト作成 # laravel new (略) Application ready! Build something amazing.Laravelまわりのディレクトリのパーミッション変更
# sudo chmod 2775 /var/project/server # find /var/project/server -type d -exec sudo chmod 2775 {} + # find /var/project/server -type f -exec sudo chmod 0664 {} + # sudo chmod -R 777 /var/project/server/storage/ # sudo chmod -R 777 /var/project/server/bootstrap/cacheセキュリティグループの編集
今回環境を作成したEC2について、PORT:80からのインバウンド通信を許可するように編集する。
動作確認
動作確認をして、Laravelの白い画面が出てくればOK。
- 投稿日:2020-05-21T20:07:57+09:00
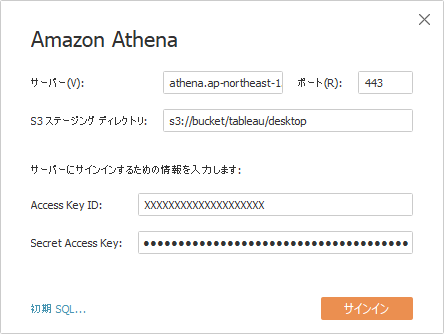
Tableau Desktop から Amazon Athena への接続
Tableau Desktop データソース接続 > Amazon Athena
サーバ: athena.【目的のDBがあるリージョン】.amazonaws.com
ポート: 443
S3ステージングディレクトリ: 【下記アクセスキーの権限で書込み可能なS3バケットおよびディレクトリ】
Access Key ID: 【目的のDBへ接続可能なIAMユーザのアクセスキーID】
Secret Access Key: 【上記アクセスキーIDに対応するシークレットアクセスキー】
【参考】
https://dev.classmethod.jp/articles/tableau103-new-features-connect-to-athena/
- 投稿日:2020-05-21T18:10:17+09:00
AWSのサービスが多くてパニックになっている方へ
AWSのサービス多すぎ問題に対する処方箋になればいいなと。。。
概要
以下のようなお悩みをお持ちの方向けです。
- AWSのサービスが多すぎて覚えられない
- AWSのサービスの適用範囲が分からない
- 全体を俯瞰できる図が欲しい
本記事は2020年5月時点の情報で作成しています。
全てのサービスは網羅していません。サービスの区分けについてのみの内容です。そもそもの用語
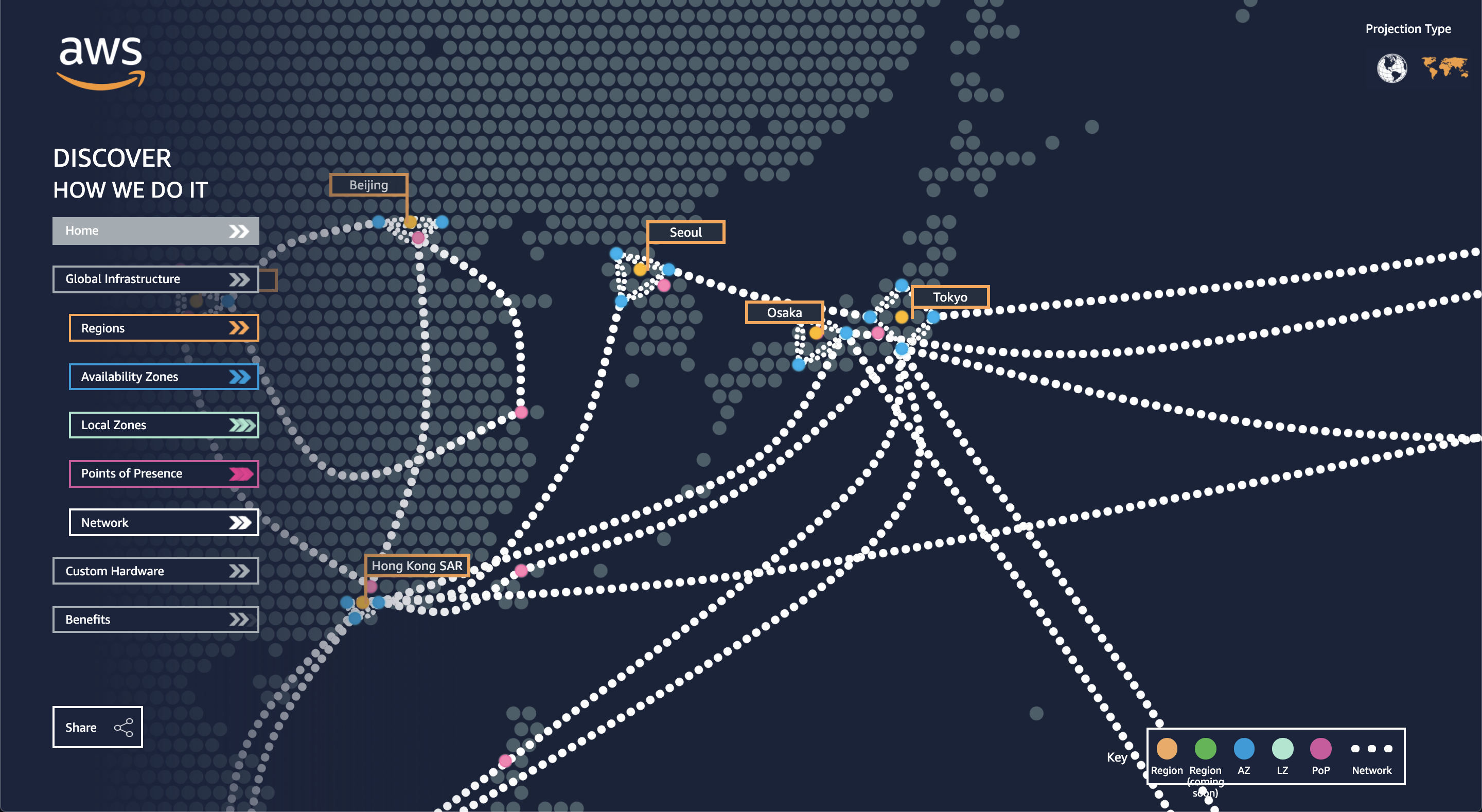
アベイラビリティゾーン(AZ)
AWSが保有する物理的なデータセンタ群のこと。日本だと6箇所存在します。
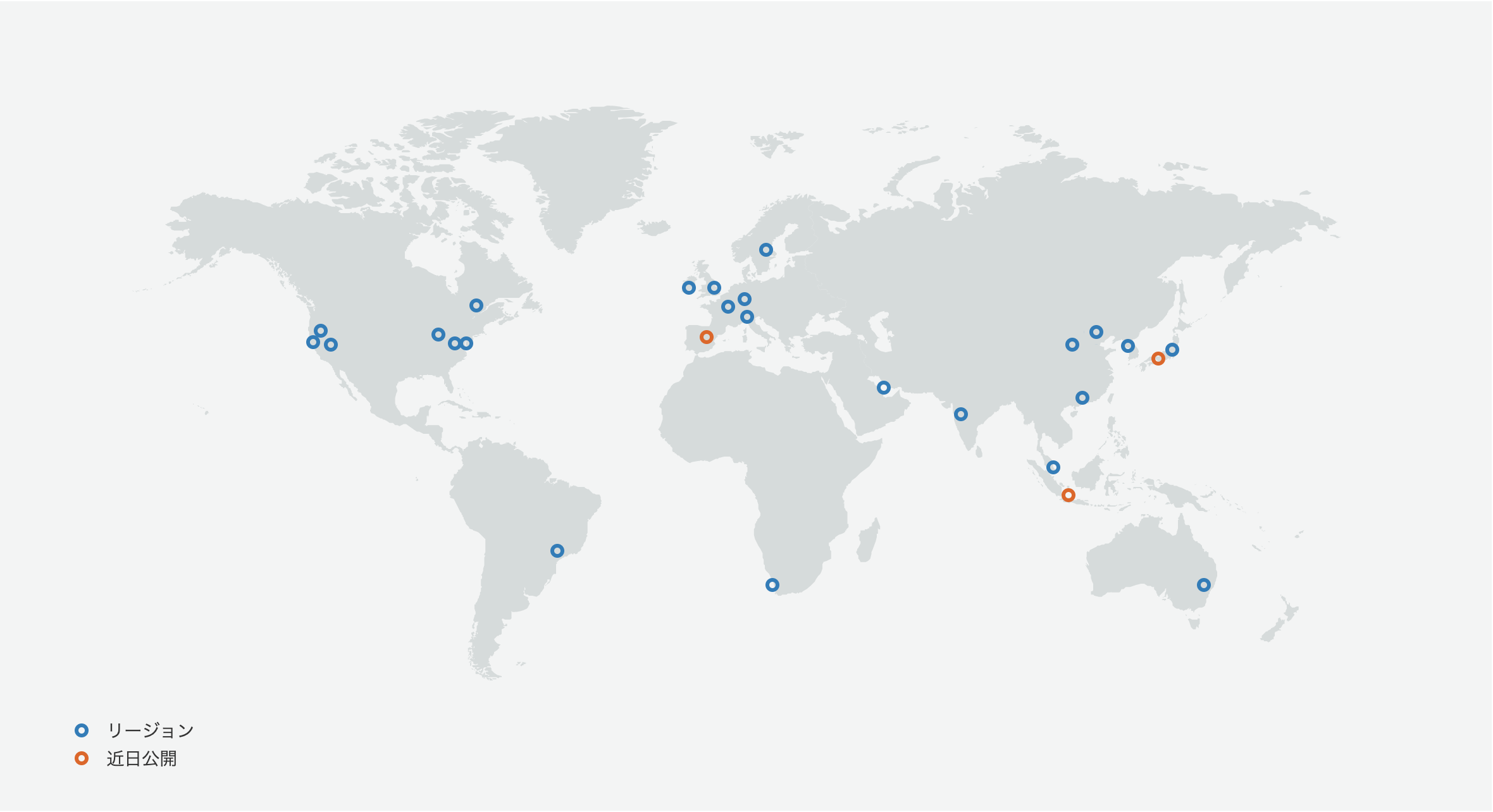
出典:https://infrastructure.aws/リージョン
複数のAZが存在する世界24箇所の地域のこと。日本だと2箇所(東京、大阪)存在します。
出典:https://aws.amazon.com/jp/about-aws/global-infrastructure/AWS東京リージョンで大規模障害か
出典:https://xtech.nikkei.com/atcl/nxt/news/18/07639/リージョンで障害が発生すれば、リージョンに含まれるAZももちろん障害の範囲に含まれます。
冗長構成を考える場合は複数リージョンでシステムを構成しておくほうが安全です。
予算と要相談ですが…..(止まって困るシステムなら別リージョンは必須)サービスの種類
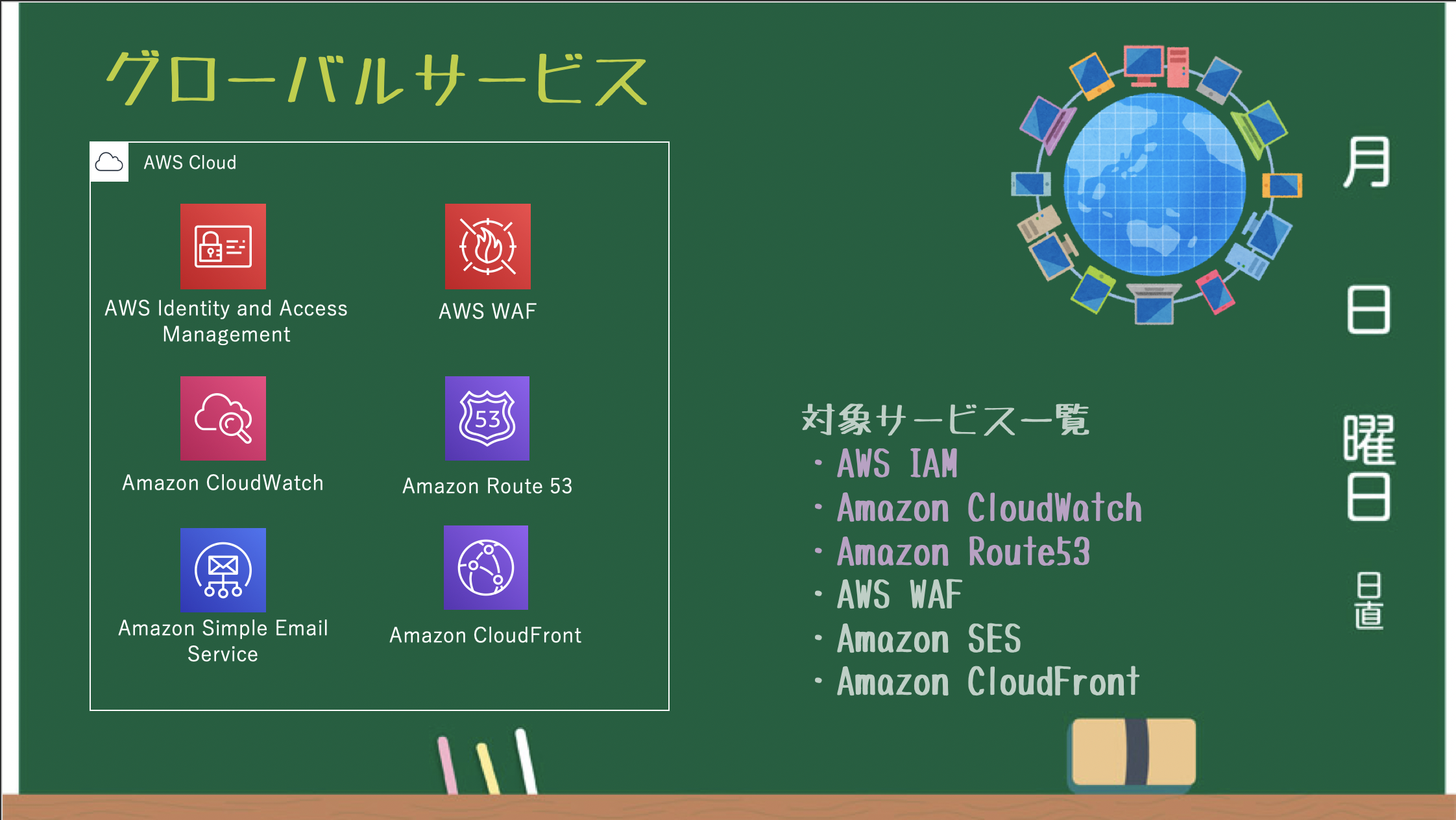
グローバルサービス
どこのリージョンからでも共通のサービスとして利用できるグローバルサービス。
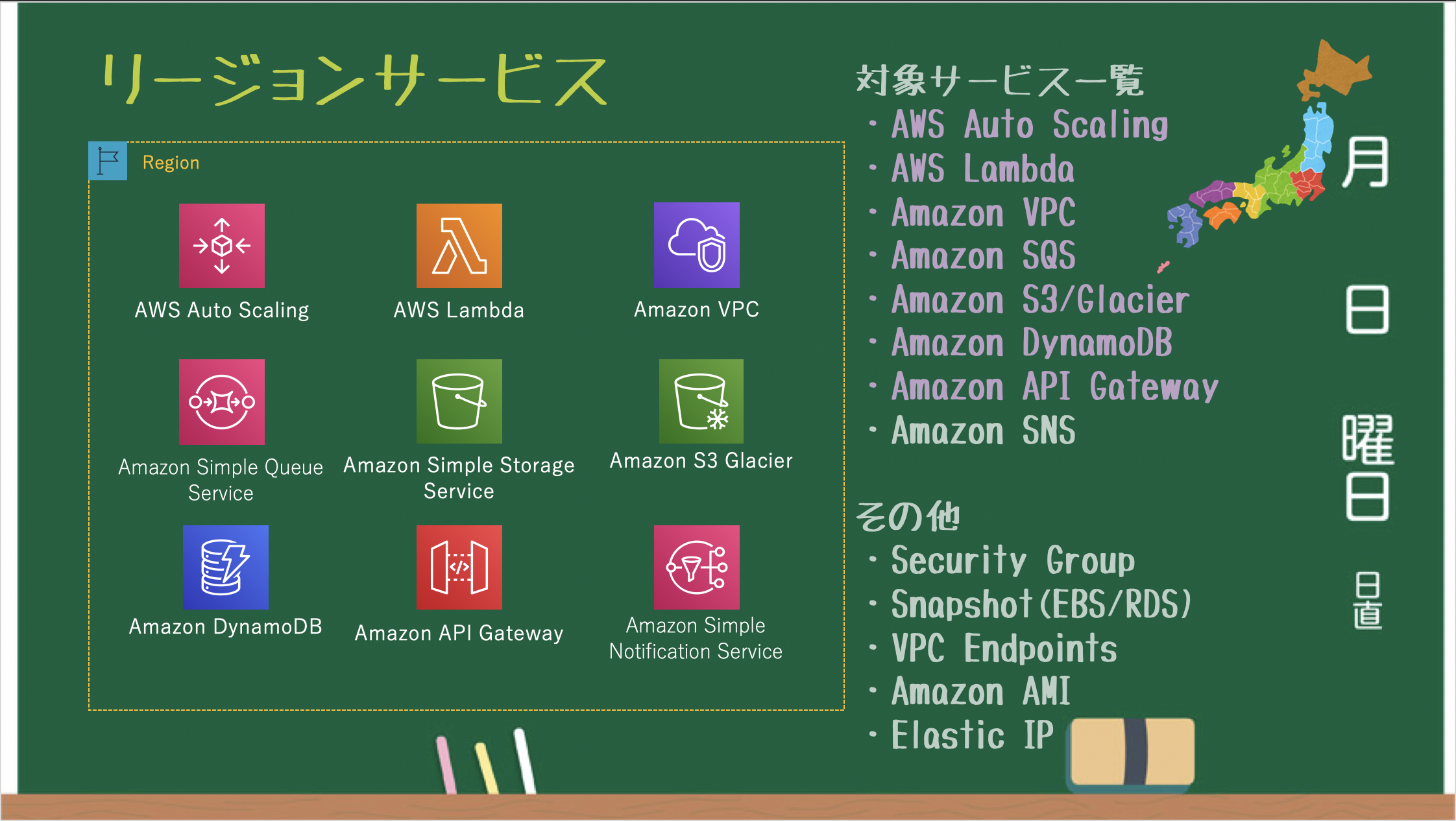
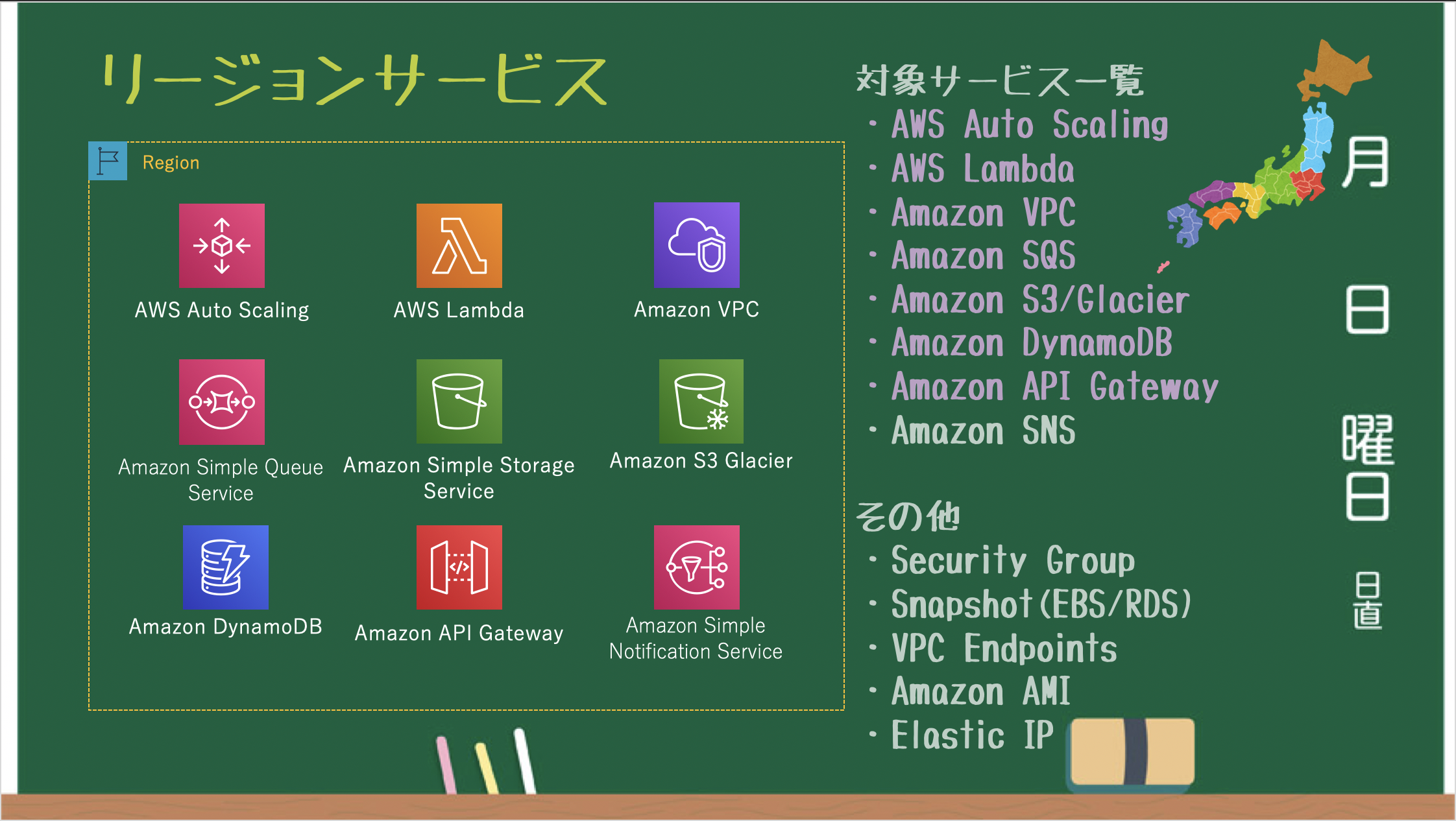
リージョンサービス
リージョンごとに作成・管理されるリージョンサービス。
※VPC毎に必要となる Security Group / VPC Endpoints / VPC Peering / EIP も リージョンサービス
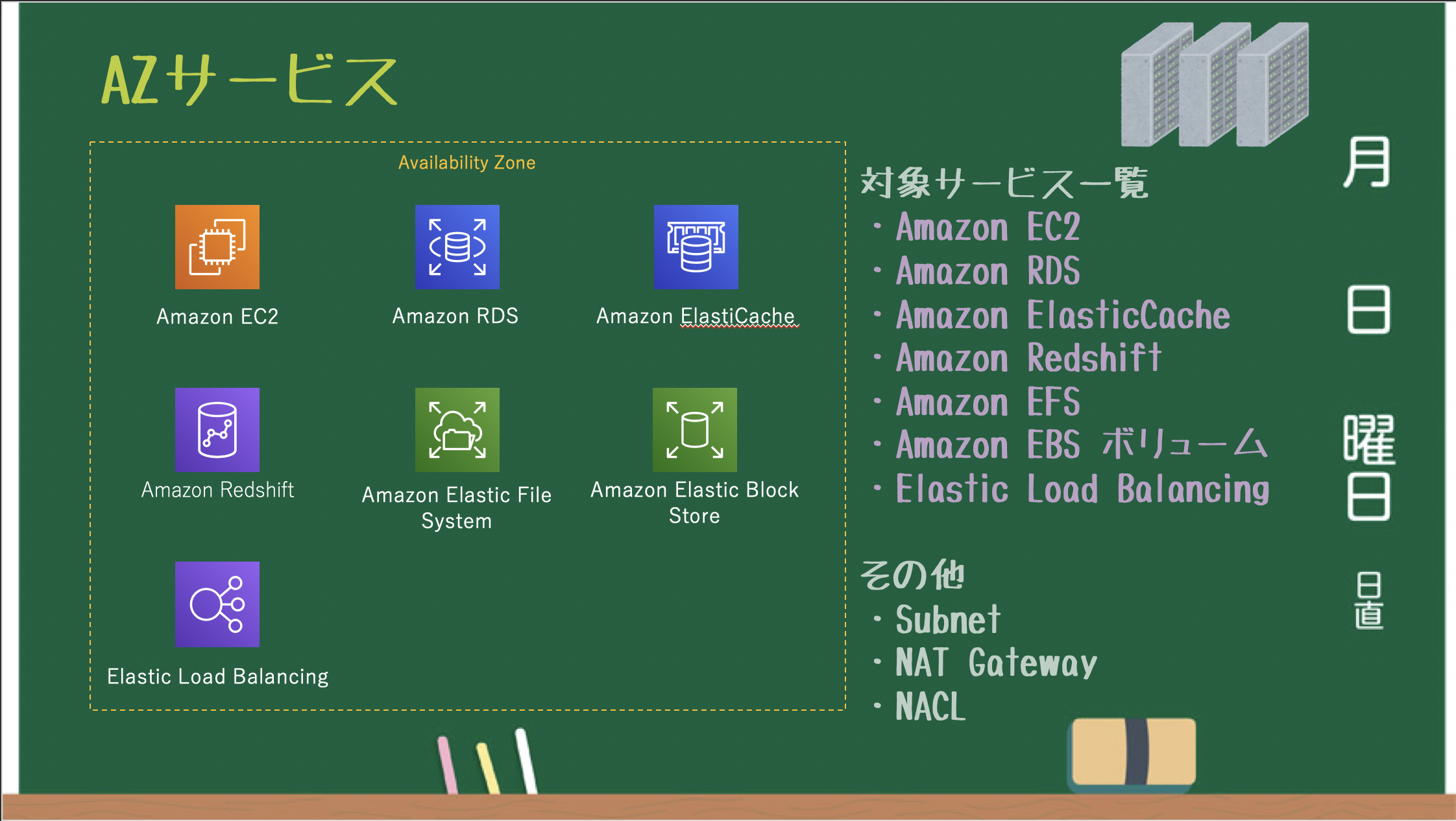
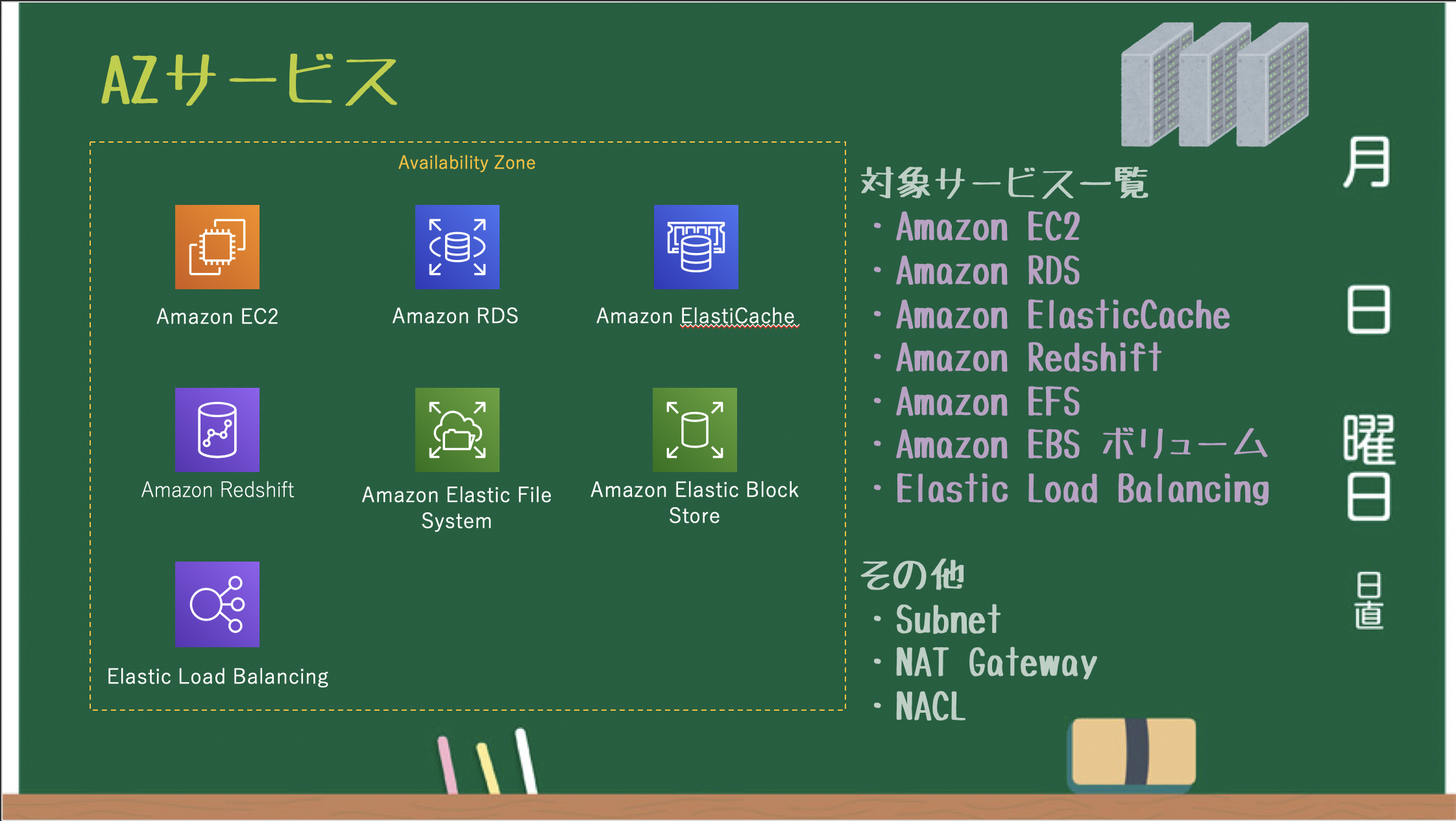
※バックエンドで S3 を利用している EBS Snapshot / AMI も リージョンサービスAZサービス
AZごとに作成・管理されるAZサービス。
※サブネット単位で必要となる NAT Gateway / NACL も AZ サービス
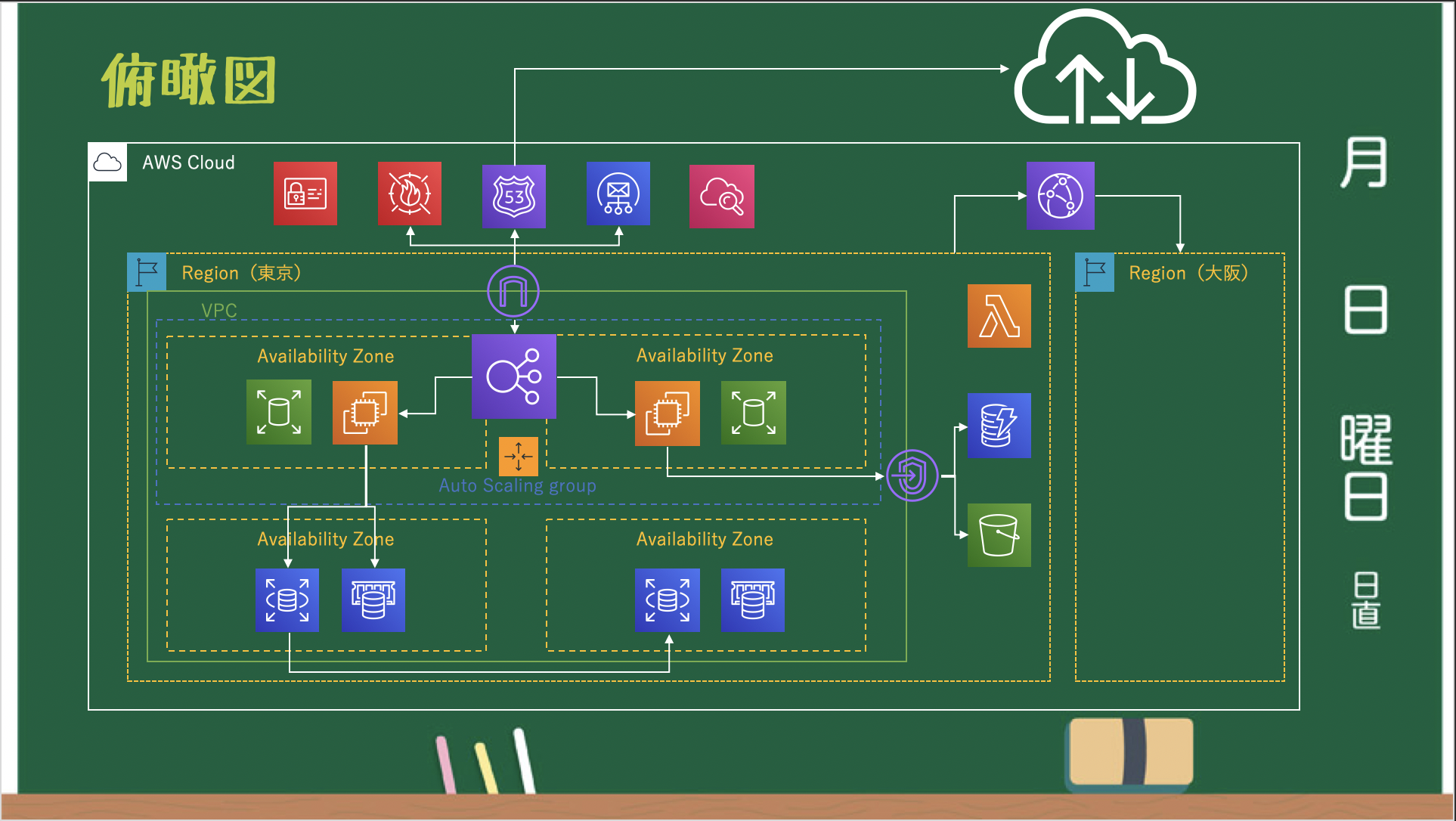
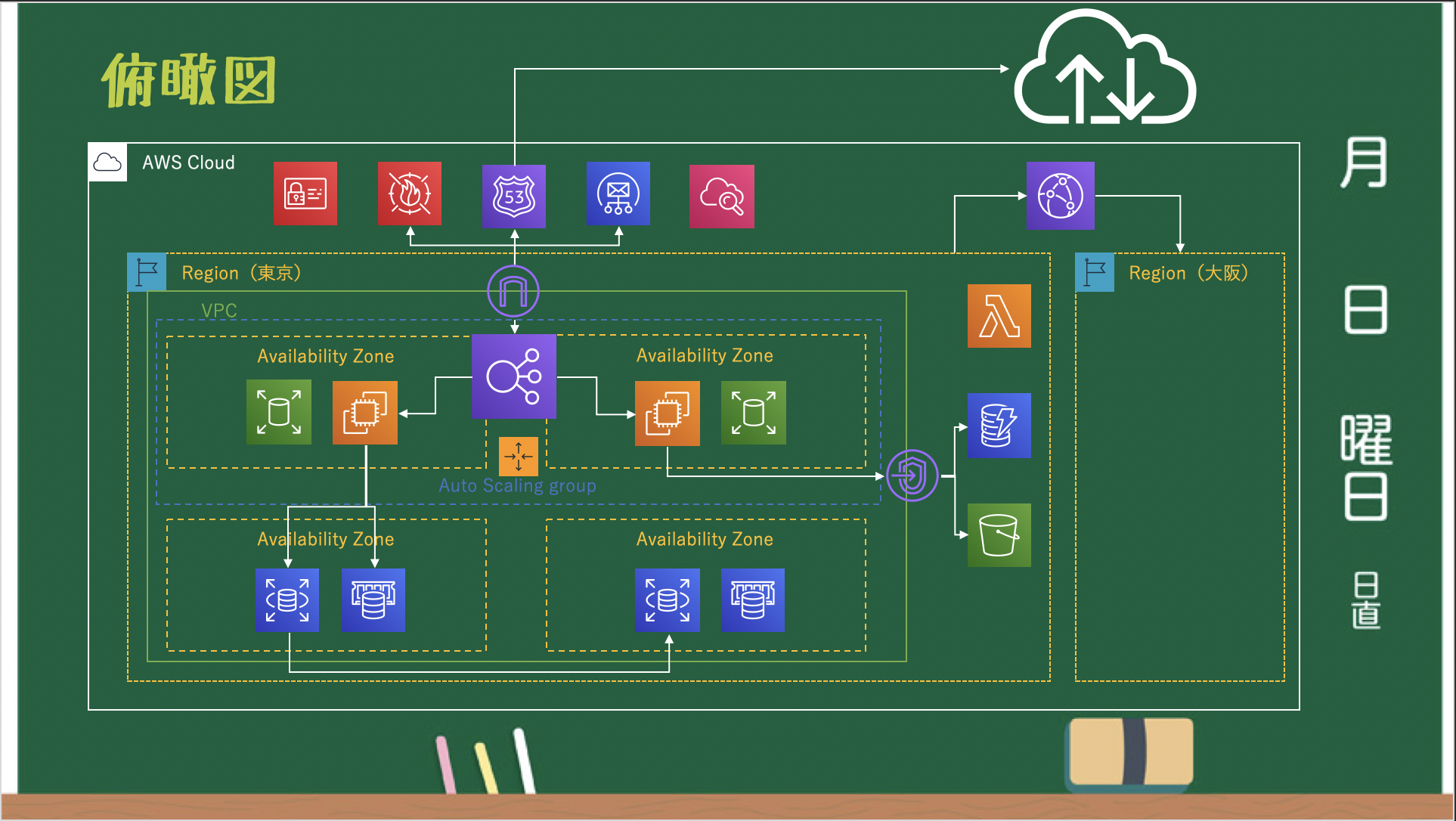
※AZ単位で設定する EBS / Placement Group も AZ サービス俯瞰図
グローバル、リージョン、AZサービスの関係性は以下の通りです。
処理範囲はAZだけどサービスの所属はリージョンだったり、
一見リージョンのサービスっぽく見えるが実態はAZをまたがっているだけ、というように
複数サービスに関係があるサービスは混乱しやすいので見極めが大事になってきます。また、1つのリージョン内の AZ サービス間であればプライベート IP アドレスで接続できます。
リージョンサービスの場合、基本的にはグローバル IP アドレスで接続しなければいけないので注意しましょう。最後に
耳タコかもしれないですが、AWS触るのであれば資格試験の勉強から取り組むことをお勧めします。
ソリューションアーキテクト アソシエイトであれば、サービスを体系的に学ぶことができます。書いている内容に誤りや不備があればコメントをお願いしますmm
おまけ
AWSアーキテクチャアイコンからAWSのアイコン素材を落とせます。
提案時などの資料作成に役立つかと思います!


- 投稿日:2020-05-21T18:10:17+09:00
AWSのサービス多すぎ問題について
AWSのサービス多すぎ問題に対する処方箋になればいいなと。。。
概要
以下のようなお悩みをお持ちの方向けです。
- AWSのサービスが多すぎて覚えられない
- AWSのサービスの適用範囲が分からない
- 全体を俯瞰できる図が欲しい
本記事は2020年5月時点の情報で作成しています。
全てのサービスは網羅していません。サービスの区分けについてのみの内容です。そもそもの用語
アベイラビリティゾーン(AZ)
AWSが保有する物理的なデータセンタ群のこと。日本だと6箇所存在します。
出典:https://infrastructure.aws/リージョン
複数のAZが存在する世界24箇所の地域のこと。日本だと2箇所(東京、大阪)存在します。
出典:https://aws.amazon.com/jp/about-aws/global-infrastructure/AWS東京リージョンで大規模障害か
出典:https://xtech.nikkei.com/atcl/nxt/news/18/07639/リージョンで障害が発生すれば、リージョンに含まれるAZももちろん障害の範囲に含まれます。
冗長構成を考える場合は複数リージョンでシステムを構成しておくほうが安全です。
予算と要相談ですが…..(止まって困るシステムなら別リージョンは必須)サービスの種類
グローバルサービス
どこのリージョンからでも共通のサービスとして利用できるグローバルサービス。
リージョンサービス
リージョンごとに作成・管理されるリージョンサービス。
※VPC毎に必要となる Security Group / VPC Endpoints / VPC Peering / EIP も リージョンサービス
※バックエンドで S3 を利用している EBS Snapshot / AMI も リージョンサービスAZサービス
AZごとに作成・管理されるAZサービス。
※サブネット単位で必要となる NAT Gateway / NACL も AZ サービス
※AZ単位で設定する EBS / Placement Group も AZ サービス俯瞰図
グローバル、リージョン、AZサービスの関係性は以下の通りです。
処理範囲はAZだけどサービスの所属はリージョンだったり、
一見リージョンのサービスっぽく見えるが実態はAZをまたがっているだけ、というように
複数サービスに関係があるサービスは混乱しやすいので見極めが大事になってきます。また、1つのリージョン内の AZ サービス間であればプライベート IP アドレスで接続できます。
リージョンサービスの場合、基本的にはグローバル IP アドレスで接続しなければいけないので注意しましょう。最後に
耳タコかもしれないですが、AWS触るのであれば資格試験の勉強から取り組むことをお勧めします。
ソリューションアーキテクト アソシエイトであれば、サービスを体系的に学ぶことができます。書いている内容に誤りや不備があればコメントをお願いしますmm
おまけ
AWSアーキテクチャアイコンからAWSのアイコン素材を落とせます。
提案時などの資料作成に役立つかと思います!
- 投稿日:2020-05-21T17:30:48+09:00
Laravel勉強 その1 EC2にnginxをインストール
目的
- 勉強のため、Laravel 7.xの公式ドキュメントを読み解いていく。
- 今回はそのための準備として、EC2上にnginxをインストールする。
- ちなみに筆者はApacheの経験はあるものの、nginxについては素人。
参考
EC2(Amazon-Linux-2)にNginxを入れてブラウザで確認するまで2018冬 [画像で解説] Nginx編
EC2の構築~セットアップ
今回は勉強なので、AWSの無料枠を利用する。
インスタンスタイプはt2.micro、OSはAmazon Linux2で作成。EC2を日本時間と日本語に対応させる
# sudo yum update -y # sudo timedatectl set-timezone Asia/Tokyo # sudo localectl set-locale LANG=ja_JP.UTF-8 # sudo localectl set-keymap jp106パッケージを自動更新させる
yum-cronのインストール
# sudo yum install yum-cron -yyum-cronとは?
yum-cron パッケージは、アップデートを自動的に確認し、ダウンロードし、適用するための便利な方法を提供します。
パッケージをインストールするとすぐに yum-cron パッケージの cron ジョブが有効になり、特別な設定は必要ありません。通常の日次 cron ジョブの実行時に、このジョブが実行します。yum-cronを編集
# sudo vi /etc/yum/yum-cron.conf/etc/yum/yum-cron.confapply_updates = yescronの自動起動をON
# systemctl status yum-cron # sudo systemctl start yum-cron # sudo systemctl enable yum-cronrootでのPWログインをON
セキュリティ的には微妙なところもあるかもしれないが、いちいちsudo打たなければいけないのも面倒なので。。。
rootのPWを設定
# sudo su # passwdsshの設定ファイル変更
# vi /etc/ssh/sshd_configPermitRootLogin yes PasswordAuthentication yessshd再起動
# systemctl restart sshdec2-userの無効化
セキュリティ的に消した方がいいよ、という記事を見つけた。確かに。
# userdel ec2-userとりあえずセットアップはこんなところ。
Nginxのインストール
Amazon Linux2にはExtrasレポジトリというものがあるらしい。
yum installではなくこちらを使う。提供されているトピック(ソフトウェア)の一覧取得
# amazon-linux-extras NOTE: The livepatch extra is in public preview, not meant for production use 0 ansible2 available [ =2.4.2 =2.4.6 =2.8 =stable ] 2 httpd_modules available [ =1.0 =stable ] 3 memcached1.5 available [ =1.5.1 =1.5.16 =1.5.17 ] 5 postgresql9.6 available [ =9.6.6 =9.6.8 =stable ] 6 postgresql10 available [ =10 =stable ] 8 redis4.0 available [ =4.0.5 =4.0.10 =stable ] 9 R3.4 available [ =3.4.3 =stable ] 10 rust1 available [ =1.22.1 =1.26.0 =1.26.1 =1.27.2 =1.31.0 =1.38.0 =stable ] 11 vim available [ =8.0 =stable ] 13 ruby2.4 available [ =2.4.2 =2.4.4 =2.4.7 =stable ] 15 php7.2 available [ =7.2.0 =7.2.4 =7.2.5 =7.2.8 =7.2.11 =7.2.13 =7.2.14 =7.2.16 =7.2.17 =7.2.19 =7.2.21 =7.2.22 =7.2.23 =7.2.24 =7.2.26 =stable ] 17 lamp-mariadb10.2-php7.2 available [ =10.2.10_7.2.0 =10.2.10_7.2.4 =10.2.10_7.2.5 =10.2.10_7.2.8 =10.2.10_7.2.11 =10.2.10_7.2.13 =10.2.10_7.2.14 =10.2.10_7.2.16 =10.2.10_7.2.17 =10.2.10_7.2.19 =10.2.10_7.2.22 =10.2.10_7.2.23 =10.2.10_7.2.24 =stable ] 18 libreoffice available [ =5.0.6.2_15 =5.3.6.1 =stable ] 19 gimp available [ =2.8.22 ] 20 docker=latest enabled [ =17.12.1 =18.03.1 =18.06.1 =18.09.9 =stable ] 21 mate-desktop1.x available [ =1.19.0 =1.20.0 =stable ] 22 GraphicsMagick1.3 available [ =1.3.29 =1.3.32 =1.3.34 =stable ] 23 tomcat8.5 available [ =8.5.31 =8.5.32 =8.5.38 =8.5.40 =8.5.42 =8.5.50 =stable ] 24 epel available [ =7.11 =stable ] 25 testing available [ =1.0 =stable ] 26 ecs available [ =stable ] 27 corretto8 available [ =1.8.0_192 =1.8.0_202 =1.8.0_212 =1.8.0_222 =1.8.0_232 =1.8.0_242 =stable ] 28 firecracker available [ =0.11 =stable ] 29 golang1.11 available [ =1.11.3 =1.11.11 =1.11.13 =stable ] 30 squid4 available [ =4 =stable ] 31 php7.3 available [ =7.3.2 =7.3.3 =7.3.4 =7.3.6 =7.3.8 =7.3.9 =7.3.10 =7.3.11 =7.3.13 =stable ] 32 lustre2.10 available [ =2.10.5 =2.10.8 =stable ] 33 java-openjdk11 available [ =11 =stable ] 34 lynis available [ =stable ] 35 kernel-ng available [ =stable ] 36 BCC available [ =0.x =stable ] 37 mono available [ =5.x =stable ] 38 nginx1 available [ =stable ] 39 ruby2.6 available [ =2.6 =stable ] 40 mock available [ =stable ] 41 postgresql11 available [ =11 =stable ] 42 php7.4 available [ =stable ] 43 livepatch available [ =stable ]詳細を確認
# amazon-linux-extras info nginx1.12 NOTE: The livepatch extra is in public preview, not meant for production use nginx1.12 has end-of-support date of 2019-09-20 nginx1.12 recommends nginx # yum install nginxインストール
# amazon-linux-extras install nginx1.12 4 *nginx1.12=latest enabled [ =1.12.2 ]Nginxのバージョン・モジュールを確認
# nginx -v nginx version: nginx/1.12.2 # nginx -V nginx version: nginx/1.12.2 built by gcc 7.3.1 20180303 (Red Hat 7.3.1-5) (GCC) built with OpenSSL 1.0.2k-fips 26 Jan 2017 TLS SNI support enabled configure arguments: --prefix=/usr/share/nginx --sbin-path=/usr/sbin/nginx --modules-path=/usr/lib64/nginx/modules --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --http-client-body-temp-path=/var/lib/nginx/tmp/client_body --http-proxy-temp-path=/var/lib/nginx/tmp/proxy --http-fastcgi-temp-path=/var/lib/nginx/tmp/fastcgi --http-uwsgi-temp-path=/var/lib/nginx/tmp/uwsgi --http-scgi-temp-path=/var/lib/nginx/tmp/scgi --pid-path=/run/nginx.pid --lock-path=/run/lock/subsys/nginx --user=nginx --group=nginx --with-file-aio --with-ipv6 --with-http_auth_request_module --with-http_ssl_module --with-http_v2_module --with-http_realip_module --with-http_addition_module --with-http_xslt_module=dynamic --with-http_image_filter_module=dynamic --with-http_geoip_module=dynamic --with-http_sub_module --with-http_dav_module --with-http_flv_module --with-http_mp4_module --with-http_gunzip_module --with-http_gzip_static_module --with-http_random_index_module --with-http_secure_link_module --with-http_degradation_module --with-http_slice_module --with-http_stub_status_module --with-http_perl_module=dynamic --with-mail=dynamic --with-mail_ssl_module --with-pcre --with-pcre-jit --with-stream=dynamic --with-stream_ssl_module --with-google_perftools_module --with-debug --with-cc-opt='-O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector-strong --param=ssp-buffer-size=4 -grecord-gcc-switches -specs=/usr/lib/rpm/redhat/redhat-hardened-cc1 -m64 -mtune=generic' --with-ld-opt='-Wl,-z,relro -specs=/usr/lib/rpm/redhat/redhat-hardened-ld -Wl,-E'Nginxの起動
Nginxプロセスの起動
# systemctl start nginx.service # systemctl status nginx.service ● nginx.service - The nginx HTTP and reverse proxy server Loaded: loaded (/usr/lib/systemd/system/nginx.service; disabled; vendor preset: disabled) Active: active (running) since 木 2020-05-21 17:18:15 JST; 18s ago Process: 23185 ExecStart=/usr/sbin/nginx (code=exited, status=0/SUCCESS) Process: 23181 ExecStartPre=/usr/sbin/nginx -t (code=exited, status=0/SUCCESS) Process: 23180 ExecStartPre=/usr/bin/rm -f /run/nginx.pid (code=exited, status=0/SUCCESS) Main PID: 23188 (nginx) CGroup: /system.slice/nginx.service tq23188 nginx: master process /usr/sbin/nginx mq23190 nginx: worker process 5月 21 17:18:15 ip-172-31-33-80.ap-northeast-1.compute.internal systemd[1]: Starting The nginx HTTP and reverse proxy server... 5月 21 17:18:15 ip-172-31-33-80.ap-northeast-1.compute.internal nginx[23181]: nginx: the configuration file /etc/nginx/nginx.conf... ok 5月 21 17:18:15 ip-172-31-33-80.ap-northeast-1.compute.internal nginx[23181]: nginx: configuration file /etc/nginx/nginx.conf tes...ful 5月 21 17:18:15 ip-172-31-33-80.ap-northeast-1.compute.internal systemd[1]: Failed to read PID from file /run/nginx.pid: Invalid ...ent 5月 21 17:18:15 ip-172-31-33-80.ap-northeast-1.compute.internal systemd[1]: Started The nginx HTTP and reverse proxy server. Hint: Some lines were ellipsized, use -l to show in full.Nginxにアクセス
# curl -I localhost HTTP/1.1 200 OK Server: nginx/1.12.2 Date: Thu, 21 May 2020 08:19:18 GMT Content-Type: text/html Content-Length: 3520 Last-Modified: Wed, 28 Aug 2019 19:52:13 GMT Connection: keep-alive ETag: "5d66db6d-dc0" Accept-Ranges: bytesNginxの自動起動設定
現状の確認
どちらを使用してもOK # systemctl is-enabled nginx.service disabled # systemctl list-unit-files --type=service | grep nginx nginx.service disabled有効化、確認
# sudo systemctl enable nginx.service Created symlink from /etc/systemd/system/multi-user.target.wants/nginx.service to /usr/lib/systemd/system/nginx.service. # systemctl is-enabled nginx.service enabledLaravelにあわせてNginxの設定とかもいじる必要がありそうだが、まだLaravelも入れていないので入れてから考えることにする。
- 投稿日:2020-05-21T15:54:55+09:00
Glueの使い方的な㊺(Python shellでPythonから他の.pyを読み込む)
概要
GlueのPython Shellのコードの中から、別のPythonコードを読み込み実行する
手順
Glueのジョブ作成
Glueの画面で"ジョブ"->[ジョブの追加]をクリックし、以下を入力します。
- 名前:se2_job28
- ロール:(適切な任意のもの)
- Type:Python shell
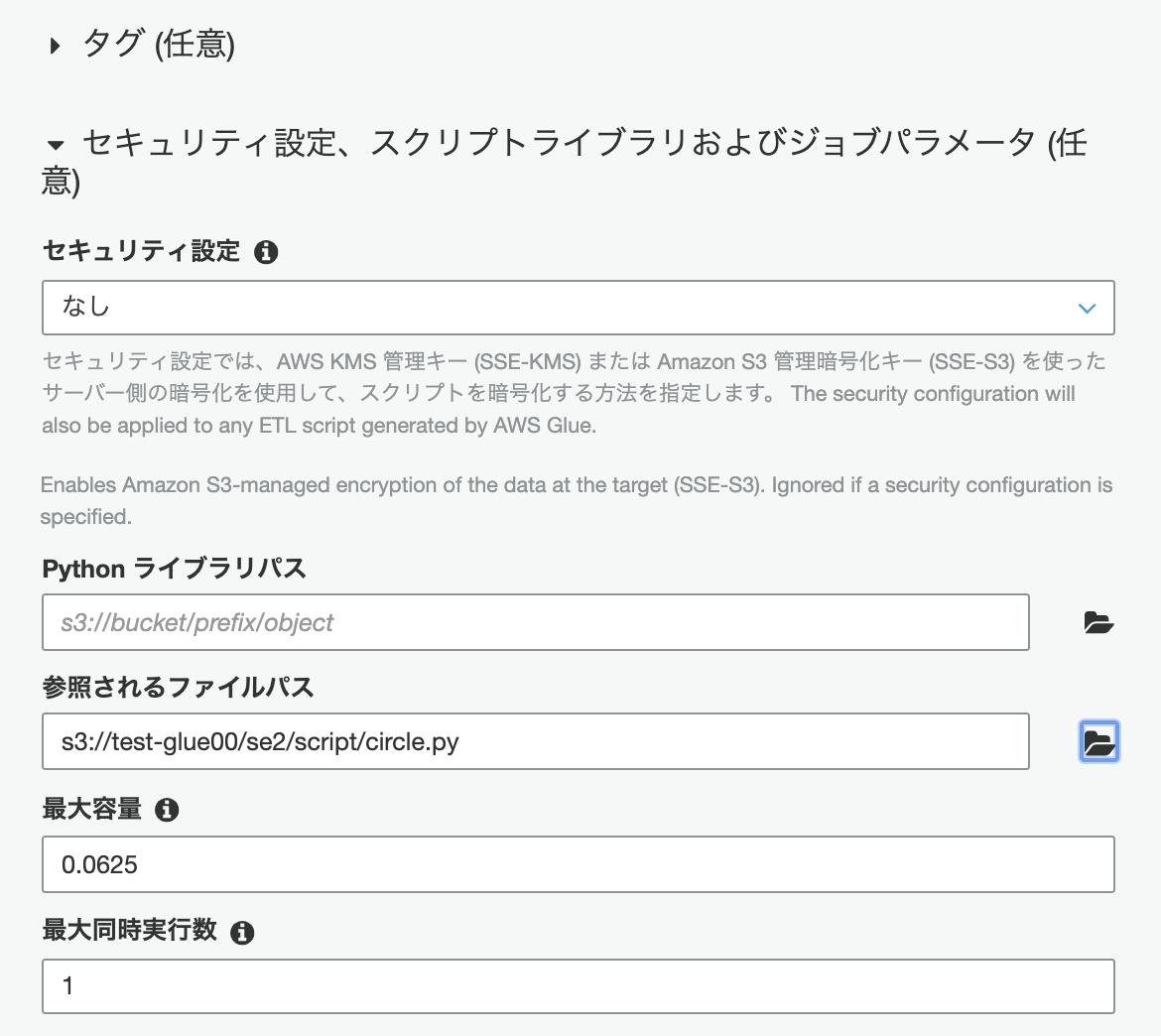
引き続き以下を入力します。以下の"参照されるファイルパス"に内部で読み込むファイル名をS3パスと合わせて記入します。
- 参照されるファイルパス:s3://test-glue00/se2/script/circle.py(任意のファイルパスとファイル名)
この画面で[次へ]をクリックし、次の画面で[ジョブを保存してスクリプトを編集する]をクリックします。
呼び出すコード
S3のs3://test-glue00/se2/script/に配置しておく。circle.pydef calc_area(r): return r ** 2 * 3.14 print('hello circle.py')ジョブのコード
se2_job28import circle # 半径3の円の面積 circle = circle.calc_area(3) print(circle) print('hello se2_job28')ジョブのコードを貼り付け、ジョブを実行します。
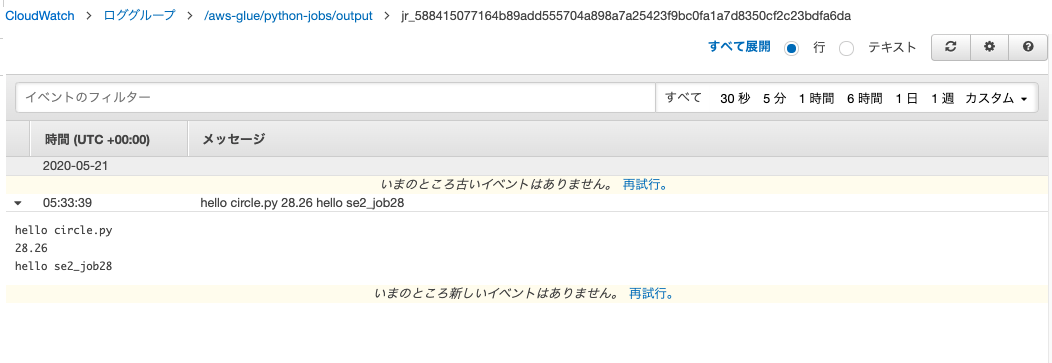
実行後のログ
呼び出すコードとGlueジョブコードのprintの出力結果が出ている
こちらも是非
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f


- 投稿日:2020-05-21T14:54:34+09:00
クラウド初心者のAWS入門(第7回)
第7回 DNSの設定
今回はVPCに対してDNSホスト名を設定していこうと思います。
設定するDNSホスト名は、パブリックIPと同様でインスタンスを再起動すると変更されてしまいます。
「Elastic IP」を使用することで、DNSホスト名も固定化できるようなので、今度やってみます。順番に進めていきたいと思います。
- DNSホスト名の有効化
- インスタンス側でDNSホスト名の確認
- WebブラウザからDNSホスト名でのアクセス
- nslookupで確認
DNSホスト名の有効化
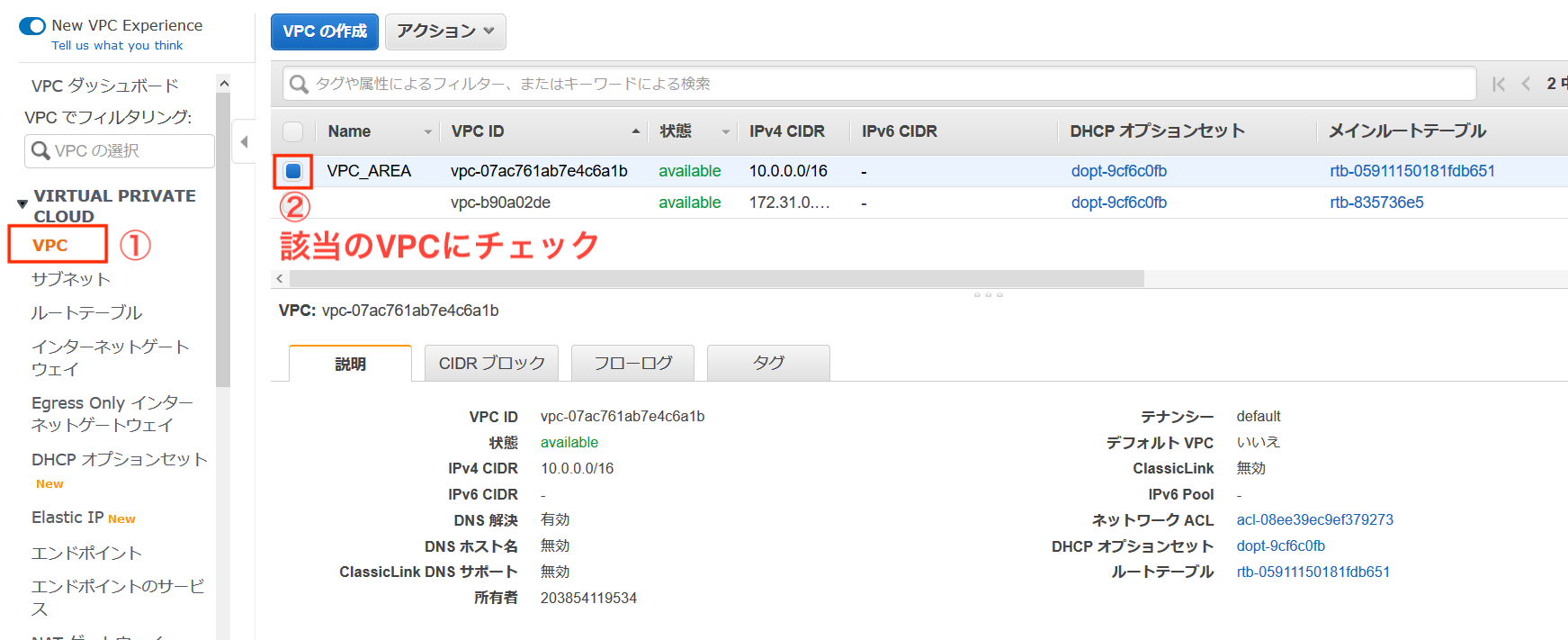
VPCマネジメントコンソールから進めていきます。
まずは作成したVPCにチェックを入れます。
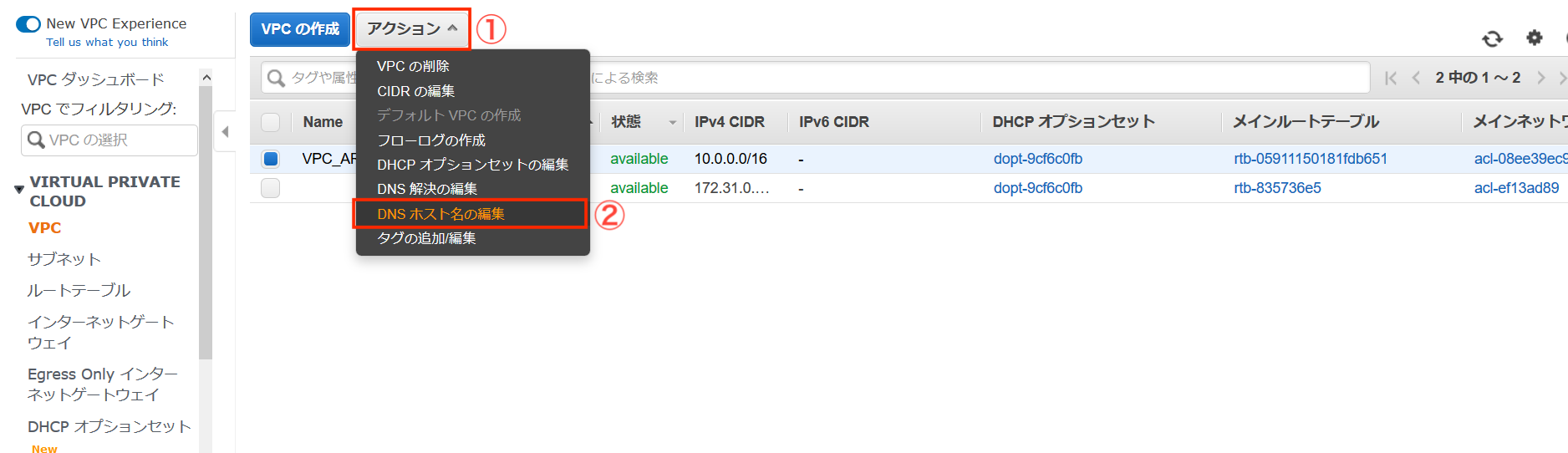
「アクション」から「DNSホスト名の編集」を選択します。
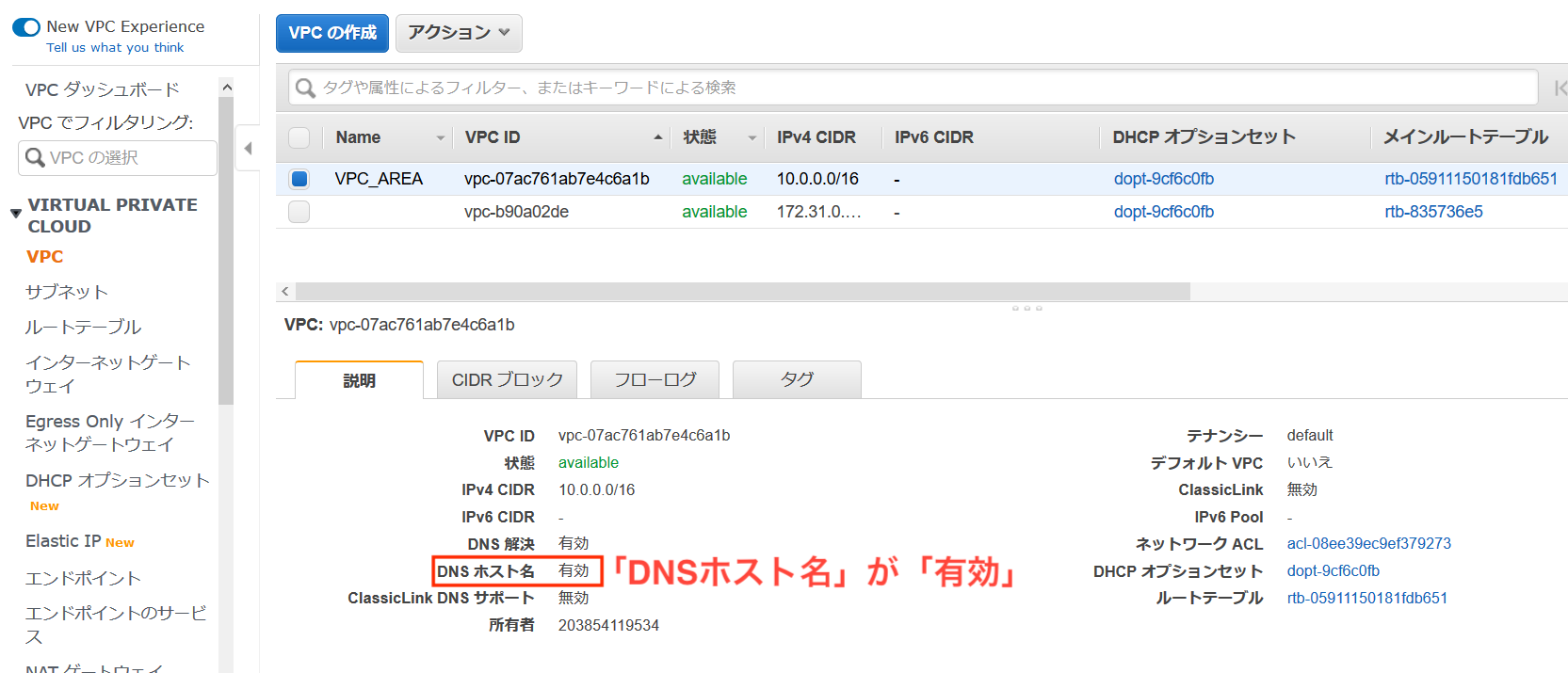
DNSホスト名の編集から「DNSホスト名」にチェックを入れ「保存」します。
設定を終え、「DNSホスト名」が「有効」になっていることを確認します。
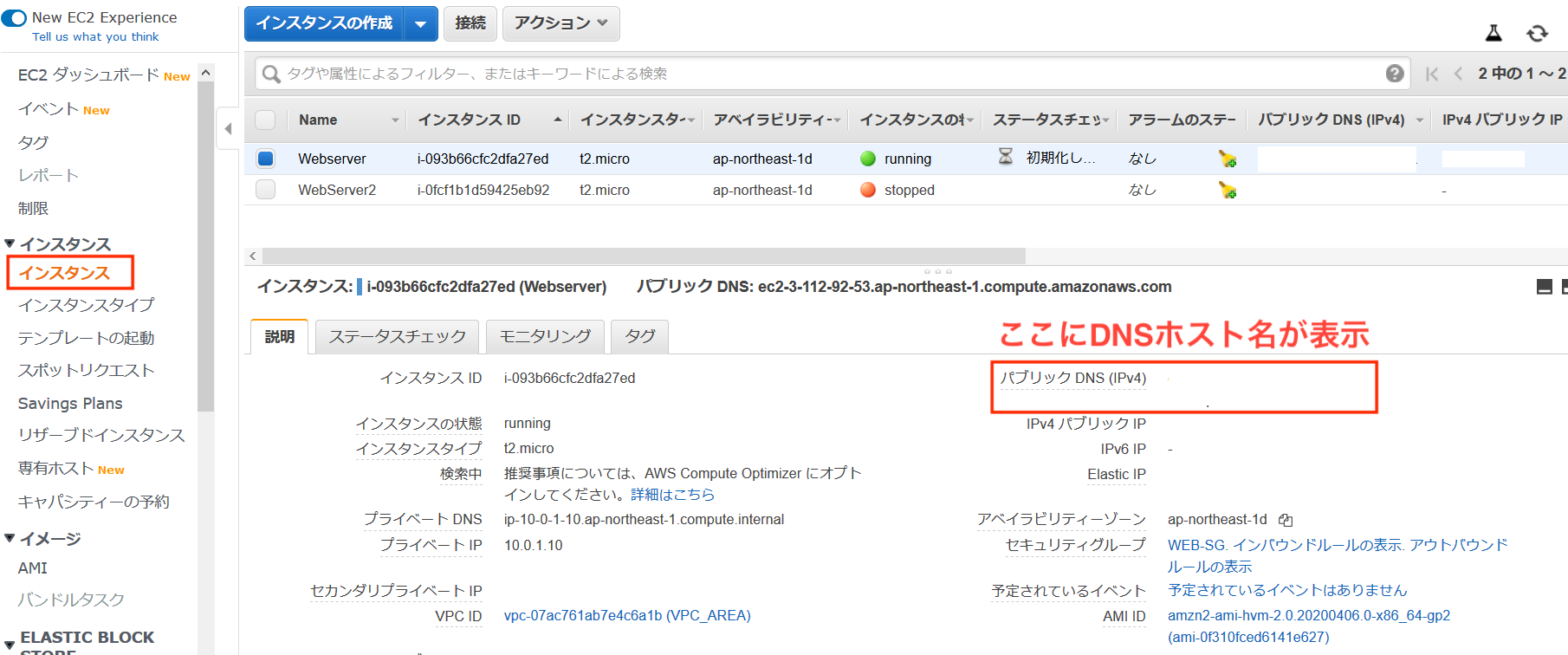
インスタンス側でも変化があるので確認していきます。
インスタンス側にもDNSホスト名が設定されていることを確認できました。
なお、長いDNSホスト名ですが、階層ごとに以下の意味合いがあるそうです。
5レベル 4レベル 3レベル 2レベル 1レベル ec2-xx-xxx-xx-xx ap-northeast-1 compute amazonaws com インスタンス固有 リージョン サービス(EC2とか) AWSドメイン comドメイン 最後に動作確認をしていきます。
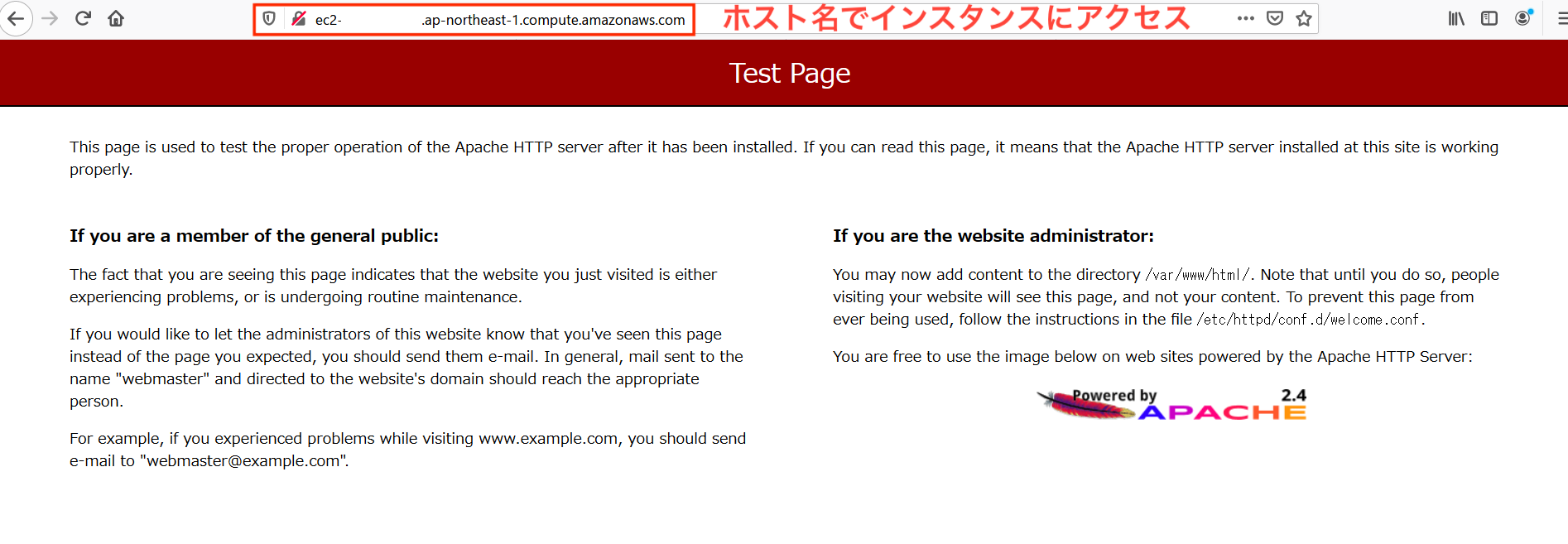
まずはWebブラウザからホスト名アクセス。
任意のブラウザに「http://"DNSホスト名"」でアクセスしてみます。
アクセスできました!
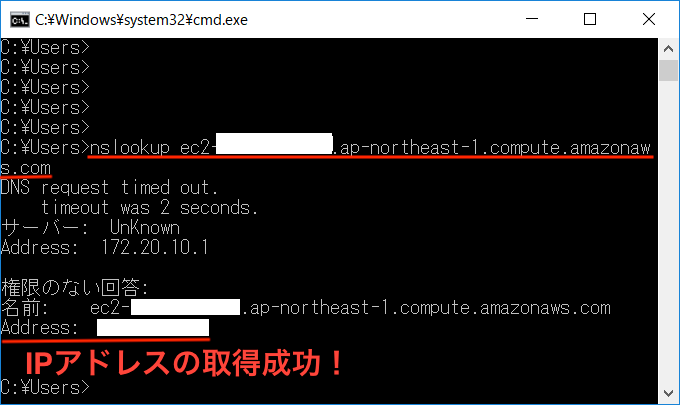
参考に・・パブリックIPからDNSホスト名を引くことももちろんできました。
今回は以上です、ありがとうございました。
次回はプライベートサブネット側を構築していきます。参考文献
いつもお世話になっております。
Amazon Web Services 基礎からのネットワーク&サーバー構築

- 投稿日:2020-05-21T13:22:54+09:00
AWS ChatBot
AWS Chatbotとは
ついに来た! AWS Chatbot が一般公開(GA)になりました! Slack連携が捗ります!
https://dev.classmethod.jp/articles/aws-chatbot-generally-available/AWSチャットボットは、DevOpsとソフトウェア開発チームがAmazon ChimeとSlackのチャットルームを使用してAWSクラウドの運用イベントを監視および応答できるようにするAWSサービス
AWS Chatbot 機能
- SlackとAmazon Chime
- 事前定義されたAWS Identity and Access Management(IAM)ポリシーテンプレート
AWS Chatbotは、AWS Identity and Access Management(IAM)を介してチャットルーム固有のアクセス許可コントロールを提供します。AWS Chatbotの定義済みテンプレートを使用すると、特定のチャネルまたはチャットルームに関連付ける必要なアクセス許可を簡単に選択して設定できます。
- 通知を受け取る
AWSチャットボットを使用して、運用インシデントやその他のイベントに関する通知を、運用アラーム、セキュリティアラート、予算の逸脱など、サポートされているソースから受信します。AWS Chatbotコンソールで通知を設定するには、通知を受信するチャネルまたはチャットルームを選択してから、通知をトリガーするAmazon Simple Notification Service(Amazon SNS)トピックを選択
- Slackを使用してAWS CLIから診断情報を取得
AWS Chatbotは、ほとんどのAWSサービスの読み取り専用コマンドをサポートしているため、デスクトップおよびモバイルデバイス上のSlackからAWSリソースに関する診断情報を簡単に取得できます。中央の場所からリアルタイムで診断情報を取得することにより、チームはイベントをより迅速に分析して対応できます。Lambda関数を呼び出してワークフローを開始したり、Slackからの簡単なコマンドでAWSサポートケースを作成したりすることもできます。
AWS Chatbotの仕組み
AWSチャットボットは、Amazon Simple Notification Service(Amazon SNS)トピックを使用して、AWSサービスからSlackおよびAmazon Chimeチャットルームにイベントおよびアラーム通知を送信します。SlackとAmazon Chimeのユーザーは、SNSトピックをSlackチャネルまたはAmazon Chime Webhookにマッピングします。Slackの場合、Slack管理者がSlackワークスペースに対するAWSチャットボットのサポートを承認すると、ワークスペース内の誰でもAWSチャットボットをSlackチャネルに追加できます。
AWS Chatbotを他のAWSサービスで使用する
- AWSの請求とコスト管理
- AWS CloudFormation
- AWS開発者ツールの通知
- Amazon CloudWatchアラーム
- Amazon CloudWatchイベント
AWSの請求とコスト管理
AWS Billing and Cost Managementは、AWSアカウント所有者がサービスの使用、サービスのコスト、インスタンスの予約を計画するのに役立ちます。これは、ブレンドされていないコスト、サブスクリプション、払い戻し、およびリザーブドインスタンスを追跡する特定のタイプの予算を使用して行います。サービスは、AWS予算アラートをAmazon SNSトピックに送信します。次に、AWS ChatbotでAmazon SNSトピックをマッピングして、それらの通知をチャットルームに送信します。
AWS CloudFormation
AWS Chatbotは、Amazon SNSトピックを介したAWS CloudFormation通知をサポートしています。AWSチャットボットでの使用が有効になっているSNSトピックのサポートを有効にするには、各AWS CloudFormationスタック構成でそれらを選択します。
AWS開発者ツールの通知
AWSは、ソフトウェア開発プロジェクトを作成、管理、および操作するためのクラウドベースの開発者ツールのスイートを提供します。AWS開発ツールスイートには、AWS CloudFormationスタック、AWS CodeBuild、AWS CodeCommit、AWS CodeDeploy、AWS CodePipelineなどのAWSサービスが含まれています。これらのサービスのAmazon SNSトピックサブスクリプションをAWSチャットボットにリダイレクトできます。例えば、AWS CodeCommitリポジトリまたはAWS CodePipelineのパイプラインのイベントに関する通知を開発チームのSlackチャネルに表示する場合は、開発者ツールコンソールでそれらのリソースの通知を設定し、使用するSNSトピックを統合できますAWS Chatbotでのこれらの通知。詳細については、次に、これらの通知に使用されるSNSトピックをAWSチャットボットと統合します。詳細については、次に、これらの通知に使用されるSNSトピックをAWSチャットボットと統合します。
Amazon CloudWatchアラーム
AWSサービスのパフォーマンスと運用メトリックを監視し、しきい値に違反したときに通知を送信するには、Amazon CloudWatchでアラームを作成できます。CloudWatchは、Amazon SNS通知を送信するか、アラームの状態が変化したときにアクションを実行します。Alarmsアクションは、チャットルームで閲覧するためのAWSチャットボットへの通知を転送するアマゾンSNSトピックに通知を送信します。
CloudWatchアラームアクションがレポートできる、任意のAWSサービスの任意のメトリクスは、SNSトピックによってAWSチャットボットを介してチャットルームに共有することもできます。これには、Amazon Elastic Compute Cloud(Amazon EC2)などのサービスのアラームが含まれます。
Amazon CloudWatchイベント
Amazon SNSトピックをCloudWatchイベントルールにマップしてから、それをAWS ChatbotコンソールのSlackチャネルまたはAmazon Chime Webhookにマップします。サービスイベントがルールに一致すると、ルールのAmazon SNSトピックが通知をチャットルームに送信します。
AWS Config
AWS Configモニタリングでは、Amazon CloudWatchイベントルール を設定して、AWS Configイベント通知をAmazon SNSトピックに転送します。次に、そのトピックをAWSチャットボットにマッピングして、チャットルームでのイベント通知を追跡できます。
Amazon GuardDuty
GuardDutyは、セキュリティインシデントと脅威を調査結果を通じて報告します。結果はGuardDutyコンソールに表示され、自動的にCloudWatchイベントとして表示されます。次に、Amazon CloudWatchイベントルールを作成します。これにより、これらのイベントは、選択したSNSトピックへの通知として表示されます。次に、そのSNSトピックをAWS ChatbotのSlackチャネルまたはAmazon Chime Webhookにマッピングします。
AWS Health DashBoard
AWS HealthはCloudWatchイベント通知を直接サポートしています。 AWS HealthのCloudWatchイベントルールを設定し、AWSチャットボットにマッピングされたSNSトピックを指定します。
AWS Security Hub
AWS Security Hubは、AWSアカウント全体の高優先度のセキュリティアラートとコンプライアンスステータスの包括的なビューを提供します。Security Hubは、Amazon GuardDuty、Amazon Inspector、Amazon Macieなどの複数のAWSサービスからのセキュリティ結果を集約、整理、および優先順位付けします。Security Hubを使用すると、AWSサービスから、およびAWSパートナーツールから、アカウント全体のセキュリティ結果を収集して優先順位を付ける作業が軽減されます。
Security HubはCloudWatchイベントルールとの2種類の統合をサポートしています。どちらもAWS Chatbotがサポートしています。
- 標準CloudWatchイベント
Security Hubはすべての調査結果をCloudWatchイベントに自動的に送信します。生成された検出結果をAmazon Simple Storage Service(Amazon S3)バケット、修正ワークフロー、またはSNSトピックに自動的にルーティングするCloudWatchイベントルールを定義できます。この方法を使用して、すべてのセキュリティハブの結果、または特定の特性を持つすべての結果を、AWSチャットボットがサブスクライブするSNSトピックに自動的に送信します。
- セキュリティハブカスタムアクション
Security Hubでカスタムアクションを定義する これらのアクションに応答するようにCloudWatchイベントルールを構成します。イベントルールは、SNSトピック設定を使用して、通知をAWS ChatbotがサブスクライブするSNSトピックに転送します。
AWS Systems Manager
AWS Systems Managerを使用すると、AWS上のインフラストラクチャを表示および制御できます。Systems Managerコンソールを使用して、複数のAWSサービスの運用データを表示し、AWSリソース全体の運用タスクを自動化できます。Systems Managerは、管理対象インスタンスをスキャンし、検出されたポリシー違反を報告または修正することにより、セキュリティとコンプライアンスを維持するのに役立ちます。
AWS Chatbotは、次のSystems Managerイベントをサポートしています。
- Configuration compliance
- Automation
- Run command
- State manager
- Parameter store
SlackチャネルからAWS CLIコマンドを実行する
AWS CLI構文を使用して、AWSアカウントのSlackチャネルで直接コマンドを実行できます。AWS Chatbotを使用すると、診断情報の取得、Lambda関数の呼び出し、AWSリソースのサポートケースの作成を行うことができます。
SlackでAWSチャットボットとやり取りすると、入力を解析し、コマンドを実行する前に欠落しているパラメーターの入力を求めます。
Slackでのコマンドの使用
SlackワークスペースでAWSチャットボットを設定したら、Slackで次の接頭辞を付けてコマンドを実行
SlackチャットルームでのAWS CLIコマンドの実行には、次の制限が適用
- AWS Chatbotは、AWSリソースを作成、削除、または構成するコマンド
- AWS Chatbotを介してコマンドを呼び出すと、待ち時間が発生する場合があります。
- AWS Chatbotロールの権限に関係なく、ユーザーはSlackチャネル内でIAM、AWS Security Token Service、またはAWS Key Management Serviceコマンドを実行
- Amazon S3サービスコマンドは、lsやcpなどのLinuxスタイルのコマンドエイリアスをサポートしています。AWS Chatbotは、SlackのコマンドのAmazon S3コマンドエイリアスをサポートしていません。
- ユーザーは、AWSサービスの秘密キーまたはキーペアを表示または復号化したり、IAM認証情報を渡したりすることはできません。
- SlackチャネルでAWS CLIコマンドメモリを使用することはできません(つまり、ユーザーが上矢印キーまたは下矢印キーを押すと、最近のコマンドが表示されます)。Slackチャネルに各AWS CLIコマンドを入力するか、コピーして貼り付ける必要があります。
- Slackチャネルを通じてAWSサポートケースを作成できます。Slackチャネルからこれらのケースに添付ファイルを追加することはできません。
- Slackチャネルは、標準のAWS CLIページネーションをサポートしていません。
AWS Chatbotを使用してコマンドを実行するためのアクセス許可の管理
- ReadOnlyコマンドの権限
- Lambda-Invokeコマンドの権限
- AWSサポートコマンドのアクセス許可
Slackチャネルで複数のアカウントがコマンドを使用できるようにする
同じSlackチャネルの複数のAWSアカウントに対してAWS Chatbotを設定できます。そのチャネルでAWSチャットボットを初めて使用する場合、使用するアカウントを尋ねられます。AWSチャットボットは7日間アカウントの選択を記憶します。
チャネルのデフォルトアカウントを変更するに@aws set default-account は、リストからアカウントを入力して選択します。
AWSチャットボットのモニタリング
- Amazon CloudWatch
- Amazon CloudWatch Logs
- Trail
AWS Chatbotのトラブルシューティング
AWSチャットボットへのSNSトピックサブスクリプションでは、[生のメッセージ配信を有効にする]設定が有効になっています。
AWS ChatbotへのSNSトピックサブスクリプションの[ 生のメッセージ配信を有効にする] 機能を有効にしないでください
- 投稿日:2020-05-21T13:07:06+09:00
CloudWatch Synthetics & Puppeteer ことはじめ
今さらながらCloudWatch SyntheticsでWebサイトの監視をしたのでまとめます。
この記事の内容
- CloudWatch Syntheticsのために手動でS3バケットとIAM Roleを作る
- ローカル環境にPuppeteerをインストールしてNode.jsのコードを書く
- Googleのトップページに「猫 wikipedia」を入力して検索する
- トップにWikipediaの記事が出てこなかったら異常事態なのでスクショを撮ってCloudWatchでアラートを上げることにする
- このコードをCloudWatch Syntheticsに持って行ってCanaryを作成する
きちんとした環境構築などはしていません。非常に意識の低い内容となっています。。
まず最初に:勝手にバケットやIAMを作ってほしくない
最初のセットアップで
s3://cw-syn-results-999999999999-ap-northeast-1というS3バケット、CloudWatchSyntheticsRole-canary-123-4567890abcdeというIAM Roleが勝手に作られるのでちょっと気分が良くありません。手動で作ることにします。(気にしない人は次へ進みましょう)
IAM Role作成手順
空のIAM Roleを作る
IAM RoleのPathは
/service-role/である必要があるようです。現状コンソールからはそのようなIAM Roleを作成することはできない(無条件で/になる)のでCLIを叩きましょう。このようなJSONを作っておいて、
policy.json{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "lambda.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }これで希望通りのPathを持った空のIAM Roleが作成できます。
aws iam create-role --role-name cloudwatch-synthetics --path /service-role/ --assume-role-policy-document file://policy.jsonIAM Policyをアタッチする
必要な権限を記述したインラインポリシーをアタッチして終わりです。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetBucketLocation" ], "Resource": [ "arn:aws:s3:::YOUR-BUCKET-NAME/*" ] }, { "Effect": "Allow", "Action": [ "logs:CreateLogStream", "logs:PutLogEvents", "logs:CreateLogGroup" ], "Resource": [ "arn:aws:logs:ap-northeast-1:999999999999:log-group:/aws/lambda/*" ] }, { "Effect": "Allow", "Action": [ "s3:ListAllMyBuckets" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Resource": "*", "Action": "cloudwatch:PutMetricData", "Condition": { "StringEquals": { "cloudwatch:namespace": "CloudWatchSynthetics" } } } ] }スクリプトの文法が良く分からんしテスト実行が遅い
CloudWatch Syntheticsの実体はAWS Lambda (Node.js)で、裏でHeadless ChromeをPuppeteer経由で動かしています。遅いのも当然ですしスクリーンショットに日本語が出てこないのも当然です(フォントを入れるにはLambdaの容量制限が厳しすぎます)。そこでローカルでコードを書いてから持って行くのが良さそうなのでその準備をします。なお今回Dockerは使っていませんのでよろしくお願いします。
ローカルでPuppeteerを動かす準備をする
新しめのNode.js をインストールする
n packageを使う方法が最もお手軽ですが、一時的に動かなかったという報告があったのでうまくやってください。なお2020/5/20時点においてCloudWatch SyntheticsはNode.js v10を利用しているそうです。そんなに複雑な文法を使わなければv12でもまあ問題はないでしょう。
依存モジュールをインストールする
公式の手順にある通り、必要なものを全部突っ込みます。勢いが大切です。
Debian/Ubuntusudo apt install ca-certificates fonts-liberation gconf-service libappindicator1 libasound2 libatk-bridge2.0-0 libatk1.0-0 libc6 libcairo2 libcups2 libdbus-1-3 libexpat1 libfontconfig1 libgbm1 libgcc1 libgconf-2-4 libgdk-pixbuf2.0-0 libglib2.0-0 libgtk-3-0 libnspr4 libnss3 libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6 lsb-release wget xdg-utilsCentOSsudo yum install alsa-lib.x86_64 atk.x86_64 cups-libs.x86_64 GConf2.x86_64 gtk3.x86_64 ipa-gothic-fonts libXcomposite.x86_64 libXcursor.x86_64 libXdamage.x86_64 libXext.x86_64 libXi.x86_64 libXrandr.x86_64 libXScrnSaver.x86_64 libXtst.x86_64 pango.x86_64 xorg-x11-fonts-100dpi xorg-x11-fonts-75dpi xorg-x11-fonts-cyrillic xorg-x11-fonts-misc xorg-x11-fonts-Type1 xorg-x11-utils空のディレクトリを作って初期化する
mkdir hello-puppeteer; cd $_; npm init -yPuppeteerをインストールする
npm install --save puppeteerサンプルコードを書いて実行してみる
公式のサンプルコードをちょっと変更して持ってきました。
index.jsconst puppeteer = require('puppeteer'); (async () => { const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto('https://www.google.com'); await page.screenshot({path: 'example.png'}); await browser.close(); })();さっそく実行しましょう。
node index.jsうまく行けば同じディレクトリの中にGoogleのトップページのスクリーンショット、
example.pngという画像ファイルが生成されているはずです。
おめでとうございます! ここまでで最低限のコードは書けるようになりました!(フォントがないので日本語は全部文字「?」になってしまっています。どうせAWSに持って行くとこれは避けられないので諦めましょう)
CSS SelectorとXPath
単なる死活監視ならこれでオッケーですが、検索や検索結果検証を行うためにはHTML内の要素を探し出して取得する必要があります。そのために必要な武器がCSS Selectorです。XPathに慣れている人はXPathでもいいです。どちらもHTMLのツリー構造をたどり、必要な要素――文字を入力したりボタンを押したり文字列を探し出したり――を探し出すのに使うことができます。こちらの記事がとても参考になりました。
puppeteerでの要素の取得方法 - Qiita (@go_sagawaさん)
XPathの文法はそれなりに複雑ですし、スクレイピングを柔軟に1行うためにはある程度きちんと書く必要がありますが、対象のWebサイトの構造が固定であるという前提があれば何も覚える必要はありません。Chromeで対象の要素を右クリックし、「要素を調査」で開発者ツールを開き、対象の要素がハイライトされていることを確認したら、そこでさらに右クリックして「Copy XPath」をクリックするだけです。
コードを書いてみよう
XPath版
必要なXPathが入手できたので実際にコードを書いてみます。
index.js (XPathバージョン)const puppeteer = require('puppeteer'); (async () => { const browser = await puppeteer.launch(); const page = await browser.newPage(); const searchTextboxXPath = '//*[@id="tsf"]/div[2]/div[1]/div[1]/div/div[2]/input'; const firstSearchResultXPath = '//*[@id="rso"]/div[1]/div/div/div[1]/a/h3'; await page.goto("https://www.google.com"); // 検索テキストボックスが見つかるまで待つ(タイムアウト3秒) await page.waitForXPath(searchTextboxXPath, { timeout: 3000 }); // テキストボックスを取得(XPathでは配列で結果が返るので最初の要素を取る) const textbox = (await page.$x(searchTextboxXPath))[0]; // フォーカスを合わせるために1回クリックしておく await textbox.click(); // ディレイを入れつつキー入力 await page.keyboard.type("猫 wikipedia", { delay: 100 }); // エンターキーを押す。検索画面に移動するはず await page.keyboard.press('Enter'); // 見出しが出てくるまで待つ(タイムアウト3秒) await page.waitForXPath(firstSearchResultXPath, { timeout: 3000 }); // 見出しを取得(これも配列なので最初の1個を取る) const firstSearchResult = (await page.$x(firstSearchResultXPath))[0]; // 文字列を取得するためのやり方 const result = await (await firstSearchResult.getProperty('textContent')).jsonValue(); await page.screenshot({ path: "example.png" }); if (result !== "ネコ - Wikipedia") { throw new Error("Wikipedia dokka itta nya!!!"); } await browser.close(); })();CSS Selector版
ほとんど変わりませんがCSS Selector版も書いておきます。
index.js (CSS Selectorバージョン)const puppeteer = require('puppeteer'); (async () => { const browser = await puppeteer.launch(); const page = await browser.newPage(); const searchTextboxSelector = '#tsf input[type="text"]'; const firstSearchResultSelector = '#rso div.r > a > h3'; await page.goto("https://www.google.com"); // 検索テキストボックスが見つかるまで待つ(タイムアウト3秒) await page.waitFor(searchTextboxSelector, { timeout: 3000 }); // テキストボックスを取得 const textbox = (await page.$(searchTextboxSelector)); // フォーカスを合わせるために1回クリックしておく await textbox.click(); // ディレイを入れつつキー入力 await page.keyboard.type("猫 wikipedia", { delay: 100 }); // エンターキーを押す。検索画面に移動するはず await page.keyboard.press('Enter'); // 見出しが出てくるまで待つ(タイムアウト3秒) await page.waitFor(firstSearchResultSelector, { timeout: 3000 }); // 見出しを取得 const firstSearchResult = (await page.$(firstSearchResultSelector)); // 文字列を取得するためのやり方 const result = await (await firstSearchResult.getProperty('textContent')).jsonValue(); // スクショを取っておく await page.screenshot({ path: "example.png" }); // 求める値になっているかチェック if (result !== "ネコ - Wikipedia") { throw new Error("Wikipedia dokka itta nya!!!"); } await browser.close(); })();CloudWatch Syntheticsにコピペしよう
「ハートビートのモニタリング」を選ぶとひな形のコードが出てきます。
var synthetics = require('Synthetics'); const log = require('SyntheticsLogger'); const pageLoadBlueprint = async function () { // INSERT URL here const URL = "https://google.com"; let page = await synthetics.getPage(); // 中略 }; exports.handler = async () => { return await pageLoadBlueprint(); };
pageオブジェクトは既に与えられているので、セレクタ宣言部分からawait browser.close()手前までをコピペすればいいですね。またスクリーンショットはローカルに保存することはできないのでawait synthetics.takeScreenshot("hoge"); await synthetics.takeScreenshot("fuga", "piyo");などとSyntheticsの提供するメソッドを使う必要があります。(引数に与えた文字列がハイフンで結合されてファイル名になり、png形式で保存されます)
CloudWatchのアラームを作成する
CloudWatch Syntheticsからも直接アラームは作成できますが、アラームの名前が勝手に決まってしまうためちょっとイケていません。アラームを作ったらChatbot経由でSlack通知をするなどしたら監視は完成です。
Chromeが生成するXPathをそのまま使うとちょっと要素が増減したりしただけで動かなくなったりします ↩
- 投稿日:2020-05-21T12:49:11+09:00
terraformでeksを管理しつつ、managed nodegroupをspot起動させる
前提
- managed nodegroup自体がspot起動をサポートしていない
- eksctlで作るnodegroupはspot起動がサポートされている。
以下のような設定でspot起動できた。(要awscli)
resource "aws_eks_cluster" "default" { name = "default" role_arn = module.aws-iam-role-eks-cluster.aws_iam_role.this.arn vpc_config { subnet_ids = [ module.vpc.aws_subnet.private[0].id, module.vpc.aws_subnet.private[1].id, ] } version = "1.16" } resource "aws_eks_node_group" "default" { cluster_name = aws_eks_cluster.default.name node_group_name = "default" node_role_arn = module.aws-iam-role-eks-worker.aws_iam_role.this.arn instance_types = [ "t2.small", ] subnet_ids = [ module.vpc.aws_subnet.private[0].id, module.vpc.aws_subnet.private[1].id, ] scaling_config { desired_size = 1 min_size = 1 max_size = 10 } release_version = "1.16.8-20200507" version = "1.16" lifecycle { ignore_changes = [ scaling_config[0].desired_size ] } } data "aws_launch_template" "default" { filter { name = "tag:eks:cluster-name" values = [split(":", aws_eks_node_group.default.id)[0]] } } locals { mixed_instances_policy = { LaunchTemplate = { LaunchTemplateSpecification = { LaunchTemplateId = data.aws_launch_template.default.id Version = tostring(data.aws_launch_template.default.latest_version) } } InstancesDistribution = { OnDemandBaseCapacity= 0 OnDemandPercentageAboveBaseCapacity = 0 } } } resource "null_resource" "this" { triggers = { launch_template_change = data.aws_launch_template.default.latest_version autoscaling_group_change = aws_eks_node_group.default.resources[0].autoscaling_groups[0].name } provisioner "local-exec" { command = <<-EOT aws autoscaling update-auto-scaling-group \ --mixed-instances-policy '${jsonencode(local.mixed_instances_policy)}' \ --auto-scaling-group-name ${aws_eks_node_group.default.resources[0].autoscaling_groups[0].name} EOT interpreter = ["/bin/bash", "-c"] } }説明
- aws_eks_node_groupはmanaged nodegroup
- 実態はautoscaling groupとlaunch template
awscliで自動作成されるautoscaling groupでspotを使うようにmixed-instances-policyを更新している
resource "null_resource" "this" { triggers = { launch_template_change = data.aws_launch_template.default.latest_version autoscaling_group_change = aws_eks_node_group.default.resources[0].autoscaling_groups[0].name } provisioner "local-exec" { command = <<-EOT aws autoscaling update-auto-scaling-group \ --mixed-instances-policy '${jsonencode(local.mixed_instances_policy)}' \ --auto-scaling-group-name ${aws_eks_node_group.default.resources[0].autoscaling_groups[0].name} EOT interpreter = ["/bin/bash", "-c"] } }null_resourceのtriggersを使うことで更新された場合にコマンドを実行できる。
備考
- managed nodegroupのspotの公式サポートはよこい、、
- 投稿日:2020-05-21T11:22:00+09:00
AWS SAM CLI で Lambda Layers が ビルドできるようになったよ
Building Layers
https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/building-layers.html$ sam build layer-logical-idSMA CLI のバージョンが 0.50.0 以上である必要があります。
$ sam --version SAM CLI, version 0.50.0SAM CLI の基本的な使い方については、以前 Qiita にあげたのでこちらも参照いただければと思います。
AWS SAM CLI 再入門 2019.12
https://qiita.com/hayao_k/items/7827c3778a23c514e196簡単な例
sam init で作成できる Python 3.8 の Hello World Example を例に考えます。
$ sam init --runtime python3.8 $ cd sam-app $ tree . ├── events │ └── event.json ├── hello_world │ ├── app.py │ ├── __init__.py │ └── requirements.txt ├── README.md ├── template.yaml └── tests └── unit ├── __init__.py └── test_handler.pyrequirement.txt を確認すると requests モジュールを使用していることがわかります。
(実際は app.py ではコメントアウトされているのですが。。)hello_world/requirements.txtrequestsこれをレイヤー化するする場合、template.yaml の Resources を以下のように書き換えます。
template.yamlResources: HelloWorldFunction: Type: AWS::Serverless::Function Properties: CodeUri: hello_world/ Handler: app.lambda_handler Runtime: python3.8 Layers: - !Ref MyLayer Events: HelloWorld: Type: Api Properties: Path: /hello Method: get MyLayer: Type: AWS::Serverless::LayerVersion Properties: Description: Layer description ContentUri: 'my_layer/' CompatibleRuntimes: - python3.8 Metadata: BuildMethod: python3.8SAM CLI で Lambda Layers をビルドするには レイヤーリソース (例では MyLayer)の
メタデータ属性として BuildMethod を記述する必要があります。Metdata: BuildMethod: python3.8ContentUri に 記載したディレクトリを作成し、requirements.txt を移動します。
mkdir ./my_layer mv ./hello_world/requirements.txt ./my_layer/sam build MyLayer でレイヤーをビルドできます。
単に sam build とした場合はアプリケーション全体がビルドされます。$ sam build MyLayer Building layer 'MyLayer' Running PythonPipBuilder:ResolveDependencies Running PythonPipBuilder:CopySource Build Succeeded Built Artifacts : .aws-sam/build Built Template : .aws-sam/build/template.yaml Commands you can use next ========================= [*] Invoke Function: sam local invoke [*] Deploy: sam deploy --guided前述のとおり template.yaml に BuildMethod を指定していないとエラーになります。
$ sam build MyLayer Layer <samcli.lib.providers.sam_function_provider.SamFunctionProvider object at 0x7f3147f93f90> is missing BuildMethod Metadata. Error: Build method missing in layer MyLayer..aws-sam ディレクトリ配下に requests モジュールがダウンロードされていることがわかります。
$ tree -a -L 5 . ├── .aws-sam │ └── build │ ├── MyLayer │ │ └── python │ │ ├── certifi │ │ ├── certifi-2020.4.5.1.dist-info │ │ ├── chardet │ │ ├── chardet-3.0.4.dist-info │ │ ├── idna │ │ ├── idna-2.9.dist-info │ │ ├── requests │ │ ├── requests-2.23.0.dist-info │ │ ├── requirements.txt │ │ ├── urllib3 │ │ └── urllib3-1.25.9.dist-info │ └── template.yaml ├── events │ └── event.json ├── .gitignore ├── hello_world │ ├── app.py │ └── __init__.py ├── my_layer │ └── requirements.txt ├── README.md ├── template.yaml └── tests └── unit ├── __init__.py └── test_handler.pyあとはいつもどおり sam deploy すれば OK です。
$ sam deploy or $ sam deploy --guided非常にシンプルかつ、簡単に実行できました。
ただ複数のランタイムバージョンやネイティブバイナリを扱う場合などは
これだけだと物足りない場合もあるかもしれません。
このあたりは 以前 docker-lambda を使用して Lambda Layers を作成する記事を書いたので
興味のある方は参照いただければと思います。Lambda Layersを作成する時はdocker-lambdaやyumdaが便利
https://qiita.com/hayao_k/items/a6fd8ecfb1f937246314簡単ですが、以上です。
参考になれば幸いです。
- 投稿日:2020-05-21T11:10:37+09:00
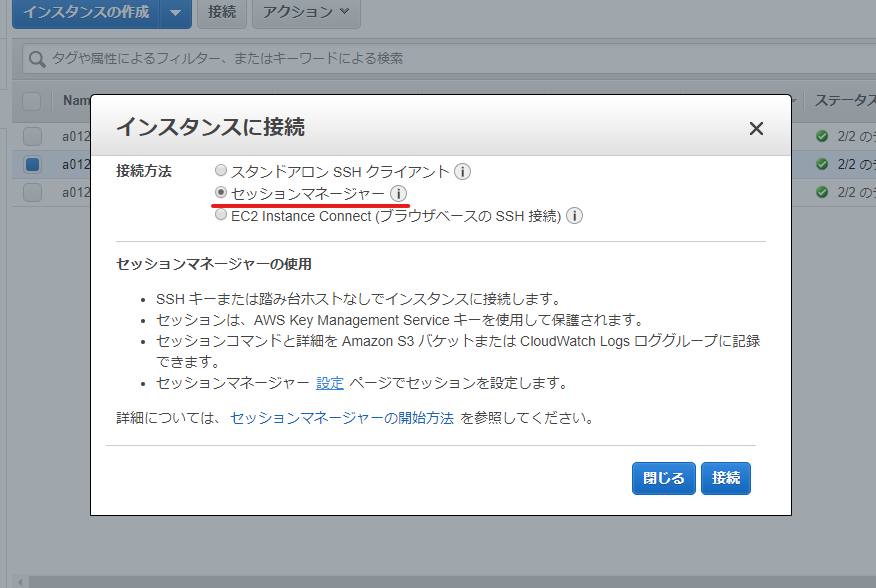
AWS SessionManagerを使ったEC2接続とアクセス制限のやり方
目次
- はじめに
- AWS SessionManagerを利用した接続の種類
- Webブラウザ版
- AWSCLI版
- AWSCLI版・ポート転送
- AWS SessionManager接続のアクセス制限方法
- AWS SessionManagerが利用するssm-userの特権の変更方法
はじめに
AWSではEC2インスタンスへ接続する方法として、AWS Session Manager が提供されています。こちらの機能は AWS Systems Manager の一部として 2018年9月にリリース されました。その後、 ポート転送の機能追加 や EC2コンソールへの統合 などを経て、現在はかなり活用しやすくなったと感じています。
AWS Session Managerでは、EC2インスタンスへの接続ポリシーをIAMで管理できるのが特徴です。従来のSSH接続と比べてセキュリティを強化し、運用コストを削減できます。
ただ実際に導入を進めると、AWSCLIの導入可否やファイル転送の有無など、利用者の要件に応じて幾つかの方法から選んでもらう必要があり、利用者向けの説明を念入りに行う必要がありました。
そこで今回は、現時点で利用できるSSMエージェントを利用したEC2インスタンスへの接続方法を整理してみます。
AWS SessionManagerを利用した接続の種類
まず、AWS SessionManagerの利用者側の要件として、3つのポイントを確認しておきます。
- 追加のアプリケーション(awscli+session-manager-plugin)をインストールしてもよいか
- WinSCP等のファイル転送ソフトを利用するか
- リモートデスクトップを利用するか
要件に応じて、以下の3種類から適切な接続方法を選択します。
いずれの場合も、EC2インスタンスにはSSMエージェントが必要です。Amazon Linux以外ではインストールが必要ですので AWS Systems Manager ユーザーガイド - SSM エージェント の使用 を参照してください。
それぞれの接続方法について説明します。
Webブラウザ版
Webブラウザ上でAWSマネジメントコンソールに接続して、SessionManager画面から利用します。アプリケーションの追加導入ができない場合、利用できるのはマネジメントコンソール版のみとなります。テキストのコピー&ペースト処理など、TeraTermのような専用のターミナルアプリに比べて出来ることが少ないので、対応不可能な業務もありそうです。また、現時点でファイルの転送機能は無く、基本的にインスタンス内のデータを表示することしかできません。
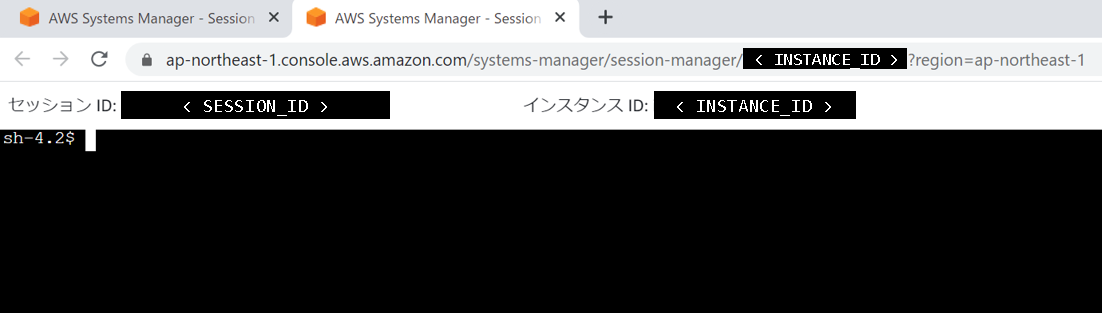
AWSCLI版
AWSCLIコマンド経由で、EC2インスタンスのシェルにログインする方法です。Webブラウザ版と同様にファイル転送機能はありません。普段から使い慣れたAWSCLIを利用できるので、使い勝手を重視する場合はこちらを利用するのが良いと思います。
PS> aws ssm start-session --profile <AWSCLI に設定済みのプロファイル名> ` --target <EC2インスタンスID>AWSCLI版・ポート転送
AWSCLI版のポート転送機能では、クライアントとEC2インスタンス間にトンネル接続を作成できます。トンネル接続を利用すると、任意のアプリケーションを使ってEC2インスタンス上のアプリケーションと安全に接続できます。例えば、WinSCPのようなGUI経由のファイル送受信や、リモートデスクトップ接続などでも、セキュリティグループでSSHポートやRDPポートを開放する必要がありません。
PS> aws ssm start-session --profile <AWSCLIに設定済みのプロファイル名> ` --target <EC2インスタンスID> ` --document-name AWS-StartPortForwardingSession ` --parameters '{\"portNumber\": [\"<EC2 インスタンス側のポート番号>\"],\"localPortNumber\": [\"<ローカル側のポート番号>\"]}'AWS SessionManager接続のアクセス制限方法
SSMエージェントは、Linuxの場合はrootアクセス権限、Windowsの場合はSYSTEMアクセス権限を使用して、EC2インスタンスへアクセスします。SSMエージェントで接続できるIAMユーザやIAMロールと、対象のEC2インスタンスの特権アクセスを持つこととは、イコールです。
そのため、特権行使できる範囲を適切な方法で限定する必要があります。
IAMポリシーを使用してインスタンス単位で接続を限定する方法
AWSのユーザーガイド では、IAMポリシーを使用したアクセス制限方法が掲載されています。
例えば、以下のようにインスタンスIDを含んだIAMポリシーを使用して、特定のインスタンスだけに接続許可を与えることも可能です。ただし、TerminateSessionを限定するため、終了できるセッションは自分で作成したセッションのみです。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ssm:StartSession" ], "Resource": [ "arn:aws:ec2:us-east-2:123456789012:instance/i-1234567890EXAMPLE", "arn:aws:ec2:us-east-2:123456789012:instance/i-abcdefghijEXAMPLE", "arn:aws:ec2:us-east-2:123456789012:instance/i-0e9d8c7b6aEXAMPLE" ] }, { "Effect": "Allow", "Action": [ "ssm:TerminateSession" ], "Resource": [ "arn:aws:ssm:*:*:session/${aws:username}-*" ] } ] }その他にも、EC2タグに基づいて制限する方法などもありますので、詳細は AWS Systems Manager ユーザーガイド - 追加の Session Manager 用のサンプル IAM ポリシー を参照してください。
AWS SessionManagerが利用するssm-userの特権の変更方法
IAMポリシーを使用した接続許可設定を紹介しましたが、実際にはEC2インスタンス内においても、利用者ごとに制約を設けたいシーンは多いと思います。
Linuxの場合に限られますが、そのような場合は、AWS SessionManagerが利用するssm-userアカウントの特権を修正することで対応が可能です。
SSMエージェントが利用するssm-userアカウントは、以下のファイルに特権設定を作成しています。
/etc/sudoers.d/ssm-agent-users# User rules for ssm-user ssm-user ALL=(ALL) NOPASSWD:ALL例えば、以下のように変更することで、OSグループごとに特権を割り当てることができます。
/etc/sudoers.d/ssm-agent-users# User rules for ssm-user ssm-user ALL=(%admin,%devel) ALL Defaults:ssm-user targetpw修正後の設定内容は以下の通りです。
- ssm-userは、adminグループ or develグループ に所属するユーザとして、全てのコマンドを実行できる
- 実行時はグループに所属するユーザのパスワードを必要とする
実際に利用する際は、以下のように ssm-userから各ユーザに切り替えて、特権昇格が可能です。
sh-4.2$ sudo -iu tanaka <-- adminグループに所属するtaroユーザー [sudo] password for tanaka: ******** <-- taroユーザーのパスワード taro@web01 [~] <-- adminグループの権限を取得まとめ
AWS Session Managerを利用した接続方法と、アクセス制限方法を紹介しました。
AWS Session Managerによるポリシーの一元化は、今後のセキュリティ強化と運用コスト削減のための、ひとつの解となりそうです。AWSの機能アップデートに合わせて、利用者側の環境も積極的に追従していきたいですね。
以上です。

- 投稿日:2020-05-21T09:36:40+09:00
インフラ用語まとめ
はじめに
【この記事を書いたきっかけ】
AWSでデプロイを行ったが用語の理解が甘かったので、自分でまとめていつでも振り返ることができるようにする為。IPアドレス
「IPアドレス(Internet Protocol Address)」は、インターネット接続中のコンピュータの識別をする番号のことで、いわばインターネット上の住所のこと。
インターネット間のデータのやりとりは、IPアドレスを使って行われている。
インターネットで使われるIPアドレスは世界中に一つしかない。ドメイン
「ドメイン」はIPアドレスをわかりやすい名前にしたもの。
「aaa.com」や「aaa.site」など
ドメインもIPアドレスと同じく世界中に一つしかない。ドメインはIPアドレスをわかりやすい名前にしたものなので、コンピュータ同士の接続にはIPアドレスが必要。
ドメイン名をIPアドレスに変換する仕組みを「DNS(Domein Nama System)」という。Webサーバ
「サーバ」はサービスを提供するコンピュータのこと。
Webサイトの表示に使うサーバのことをWebサーバという。「物理サーバ」と「仮装サーバ」
サーバには「物理サーバ」と「仮装サーバ」の2つに分けられる。
「物理サーバ」・・・実体のハードウェア1台に1つのサーバを構築する。
「仮装サーバ」・・・実体のハードウェア内に複数のサーバを構築できる。OS
「OS(Operating System)」はコンピュータを動かす為に必要なソフトウェア。
ユーザー(利用者)とコンピュータ、アプリケーションの仲介の役割を担っている。<例>
・ユーザーがキーボードで文字を打った際に、ブラウザ(画面上)に表示できる
・アプリケーションで書いたプログラムを実行ソフトウエア
ソフトウエアはコンピュータを動かすプログラムのこと。ミドルウェア
ミドルウェアはOSとアプリケーションの中間に位置し、OS上で動作するソフトウェア。
ミドルウェアではOSの機能を拡張したり、アプリケーションの共通機能や処理を提供する。
これによって、アプリケーションを作らなくても、Webサービスやデータベースサービスなどの汎用的な機能を利用できる。ミドルウェアの種類
Webサーバソフト
「Webサーバソフト」はWebサービスの通信を行う。
ユーザーのWebブラウザから送られてくるリクエストに対し、HTMLや画像などWebページを構成するコンテンツを送信する。
【例】Apache、Nginx、IISデータベース管理ソフト
「データベース管理ソフト」は、データの保存や検索を行う。
データを管理し、このデータベースに送られたリクエストに対して、データの作成や更新、削除、データ返信の処理を行う。
【例】MySQL、Oracle、Postgresメールサーバソフト
「メールサーバソフト」は、電子メールの受信や送信を行う。
【例】Postfix、Sendmailアプリケーション
アプリケーションはコンピュータでユーザーの用途や業務に応じて作成したプログラム。OSはコンピュータのそのものの稼働に必要なソフトウエアだが、アプリケーションはユーザーがコンピュータに何らかの処理をさせる為、任意で作成される。
アプリケーションはプログラミング言語(Ruby・Java)で書かれているのが特徴。
クラウドコンピューティング
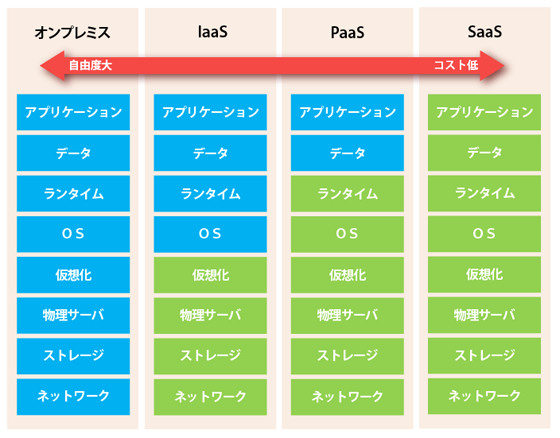
「クラウドコンピューティング(cloud computing)」は、従来はPCにインストールして使っていたハードウェアやソフトウェアを、ネットワークを通じて利用できる方式。これにより、ネットワーク上にあるコンピューティングシステム(サーバやストレージ、データベース、ネットワーク、ソフトウェア、分析など)を必要に応じて利用できる。
画像引用:https://www.pinterest.jp/pin/331647960036774735/オンプレミス
全ての環境を自分で構築し、運用する。
代表的なサービス:クラウドサービスではないlaas(Infrastructure as a Service)
イァースまたはアイアースと読む。
ハードウェア部分、ネットワーク部分をクラウドサービスとして提供。
代表的なサービス:AWS EC2、GCP GCEPaas(Platform as a Service)
パースと読む。
OSまでの環境、OS上でアプリケーションを動かす環境をクラウドサービスとして提供。
代表的なサービス:HEROKU、SalesforceSaas(Software as a Service)
サースと読む。
アプリケーション、アプリケーション内のデータすべてクラウドサービスとして提供。
代表的なサービス:iCloud、Slack、Gmail
- 投稿日:2020-05-21T08:17:22+09:00
【AWS】そもそもAWSとは?
はじめに
現在、AWSソリューションアーキテクトアソシエイト(AWS-SAA)の資格取得を目指しています。
その中でAWSの概要について学びました。
今回は、そもそもAWSとは何か?ということについてアウトプットしていきたいと思います。そもそもAWSとは?
「Amazon Web Services」の略になります。
代表的なパブリッククラウドサービスになります。他にも代表的なパブリッククラウドは、AzureやGCP(Google Cloud Platform)があります。
「AWS」はAmazonの関連企業です。
最初は、Amazon自身のインフラ基盤を支えるために作られました。
その後に、自社ではなく他社にもインフラ基盤を貸し出そうという考えでスタートしたのが「AWS」です。リージョン/アベイラビリティーゾーン/エッジロケーション
アベイラビリティーゾーン
互いに近くに立地しているデータセンターの集まりになります。
一言でいうと、地域内のデータセンターになります。
各アベイラビリティーゾーンは、火災や地震などの火災、電力やネットワークの障害が発生した場合にも、
他のアベイラビリティーゾーンに影響がない場所に立地しています。※住所は非公開
リージョン
アベイラビリティーゾーンを地域ごとにグループ分けしたものになります。
一言でいうと、地域のことになります。
日本であれば、東京リージョンと大阪リージョンがあります。
エッジロケーション
コンテンツキャッシュ、DNSサービス、セキュリティの機能を提供しているロケーションになります。
リージョンよりも数が多く、100箇所以上に配置されています。リージョンやアベイラビリティゾーンとは全く別のデータセンターになります。
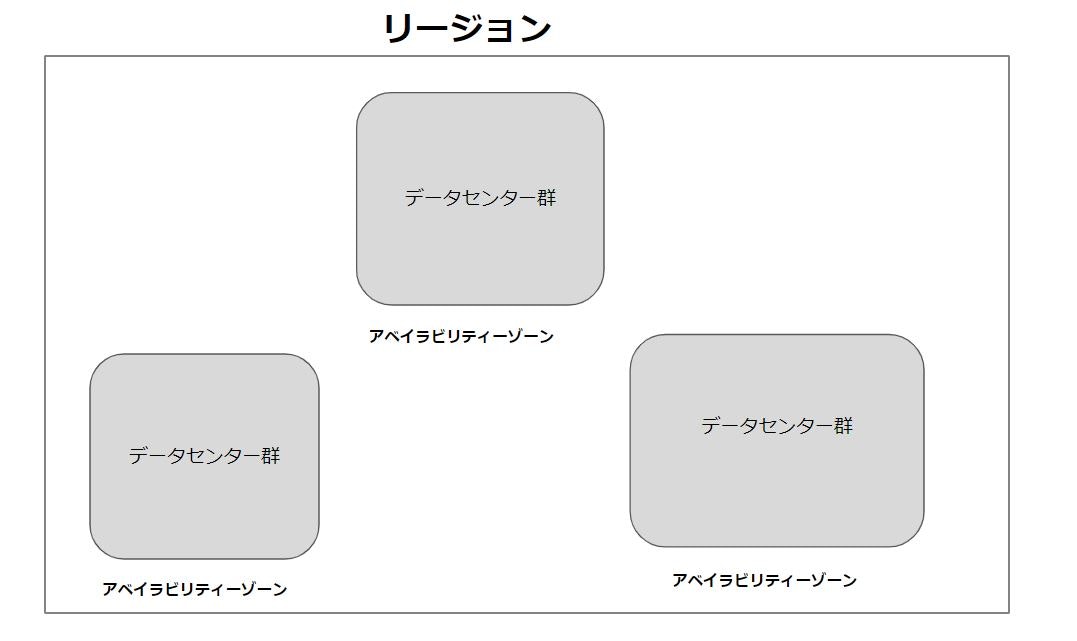
アベイラビリティーゾーンとリージョンを図で表す
東京リージョンならば、その中にデータセンター群がこちらの図のように存在するという形になります。
参考
- 投稿日:2020-05-21T06:26:49+09:00
AWS認定12冠を達成したので、おすすめの学習方法を伝授します!
はじめに
AWSが公開している12種類の認定資格全てに合格しました。私が実践した学習方法を中心におすすめしたい学習方法をまとめてみましたので、これから受験される方の参考になれば幸いです。
経歴
12冠を達成した時の経歴はエンジニア歴5年、AWS利用歴4年です。
現在は新卒で入社したSIerでインフラエンジニアのロールで勤務しています。クラウドを基盤とするプロジェクトにアサインされることが多く、非機能要件定義/システム設計/構築/運用設計を主に担当しています。業務で扱うAWSサービスはEC2/VPC/S3といった基本的なサービスが多いです。プロフェッショナルや専門知識レベルに出てくるほとんどのサービスはハンズオンセミナーや趣味で少し触ったことがある程度です。
難易度
完全に私の主観ですが、各試験の難易度は以下です。
いかに効率良く、短い時間で学習するか
これから共有する学習方法は私なりに考えた、試験範囲を効率良く学習し、短い学習時間で試験合格を目指す学習方法になります。そのため、これから共有する学習方法で試験に合格できたとしても、すぐに試験範囲のサービスが使いこなせるようにはなりません。使いこなすためには学習で得た知識をベースに業務なりを通じて技術を身に付けていく必要があると思います。
ちなみに、私の実績として1つの認定資格に対する学習時間は長くて約60時間、短いと約10時間です。
共有する学習方法の方針
これから共有する学習方法の方針についてざっくり概要を説明します。
演習問題を解きまくる!
兎にも角にも演習問題を解きまくります。ドキュメントを読み込むようなインプットよりも、演習問題を解くようなアウトプットの方が断然記憶に残るらしいです。
後ほど紹介しますが、無料のもの、有料のもの、AWSから提供されているもの、udemy等のサードパーティから提供されているものなど様々です。インプットは程々にして、できる限り多くの演習問題を掻き集めて解きまくりましょう。答え合わせをする際にはなぜその解答になるのかを理解できるようにしてください。解答と解説が用意されていない演習問題もありますので、公式ドキュメントやブログ記事から解答を探し出すことも必要です。できれば、満点を取れるまで何度も解くことをおすすめします。
公式ドキュメントやホワイトペーパーは最初から全部読み込もうとしない!
AWSは各AWSサービスの仕様やベストプラクティスをドキュメントやホワイトペーパーとして公開しています。
これらのドキュメントは最初から全て読み込もうとはせずに、演習問題を解く中で、参照することをおすすめします。演習問題を通して、試験問題に出てきそうな箇所をピンポイントに学習していくのが良いと思います。
演習問題をやらなくても、ここに書かれている内容を全て覚えることができれば、試験には合格できると思います。しかし、ドキュメントの量が膨大で一体何時間かかるか分かりません。。学習方法
では、私が実践した中からおすすめする学習方法を共有します。必ずしも全てやる必要はありません。各々自分に合った学習コンテンツで学習してください。
先駆者の方々のまとめ記事を見る
多くの方がAWS認定のまとめ記事や合格体験記を公開しています。これらを読んでまずはどういったAWSサービスが出題されるのかを把握しましょう。個人的にはJayendra's Blogに認定試験毎に対象のAWSサービスがまとまっており、大変参考になりました。
BlackBeltを読む
受験する認定試験に出題されるAWSサービスを把握したら、BlackBeltで対象のAWSサービスの概要を学習しましょう。BlackBeltはAWSサービス毎にスライドでまとまっている資料となります。図が豊富で概要を理解するためにはもってこいの資料です。
AWSトレーニングルームのeラーニングを受講する
AWSは学習コンテンツとして、試験対策向けのeラーニングを無料で提供しています。2020年5月の段階ではアソシエイト/プロフェッショナル/専門知識レベルのいくつかの認定試験でコンテンツが用意されています。それぞれの講座の中で模擬問題も用意されています。数少ないプロフェッショナル/専門知識レベルの学習コンテンツのため、プロフェッショナル/専門知識レベルを受験する方は必ず受講するようにしましょう!
英語のみの講義もありますが、英語が苦手な方はChromeの翻訳ツールを活用すれば文章部分は問題ありません。私も基本翻訳ツールを使って勉強しました。
- Exam Readiness: AWS Certified Solutions Architect – Associate (Digital)
- Exam Readiness: AWS Certified Developer – Associate (Digital)
- Exam Readiness: AWS Certified SysOps Administrator - Associate
- Exam Readiness: AWS Certified Solutions Architect – Professional
- Exam Readiness: AWS Certified DevOps Engineer – Professional
- Exam Readiness: AWS Certified Alexa Skill Builder - Specialty (Japanese)
- Exam Readiness: AWS Certified Machine Learning - Specialty (Japanese)
- Exam Readiness: AWS Certified Data Analytics - Specialty
- Exam Readiness: AWS Certified Database - Specialty
- Exam Readiness: AWS Certified Security - Specialty
- Exam Readiness: AWS Certified Advanced Networking - Specialty (Digital)
認定試験対策用のクラスルームトレーニング(集合研修)を受講する
認定試験によっては試験対策用のクラスルームトレーニングが不定期で開催されています。1日で約¥70,000かかる研修ですが、その分質も良く、大変参考になる研修です。高額なため、会社に受講料を出してもらえるようであれば、受講してみても良いかもしれません。私も会社に受講料を出してもらって、ソリューションアーキテクト - プロフェッショナルのクラスルームトレーニングに参加したことがあります。
演習問題を1つ解いたら講師の方が解説してくれるを繰り返すという内容でした。研修中に使用したドキュメントは研修が終わった後も参照できるので、演習問題を繰り返し解きましょう。
サンプル問題を解く
認定試験毎に10問のサンプル問題がPDFファイルで無料で公開されています。できれば、全問正解できるくらいまで繰り返し解きましょう。
模擬試験を受験する
認定試験毎に20問の模擬試験を受験することができます。
受験後も繰り返し解けるように、問題文と選択肢の画面を試験時間中にスクショしておきましょう。
また、試験実施後は正答率しか分からず、各問の回答が分かりません。そのため、公式ドキュメント等の記事を調べて、自分で答えを見つける必要があります。
できれば、全問正解できるくらいまで繰り返し解きましょう。通常、1つの模擬試験に受験料として¥2,000~¥4,000の値段設定がされています。ですが、認定資格に合格する毎に特典として模擬試験の無料バウチャーが発行されますので、ぜひ活用しましょう。
ちなみに、2020年5月現在で高度なネットワーキング - 専門知識のみ模擬試験が用意されていません。。
AWS Inovateの認定試験対策セッションを受講する
AWS Inovateというオンラインカンファレンスが定期的に開催されています。セッションの受講は全て無料です。セッションの中に認定試験対策用のセッションがあるので、タイミングが合えばぜひ受講しましょう。2020年度はソリューションアーキテクト - プロフェッショナルのセッションがあったようです。
公式のStudy Guide本
いくつかの認定試験でAWS公式からStudy Guide本が販売されています。書籍自体は全て英語になります。購入すると模擬問題が数百問掲載されている学習Webサイトに登録することができます。こちらはchromeの翻訳ツールを活用すれば日本語で学習することができます。高度なネットワーキング - 専門知識については学習コンテンツの種類が少ないため、購入を検討してみても良いかもしれません。
私は高度なネットワーキング - 専門知識のStudy Guide本を購入しました。ただし、登録したWebサイトで模擬問題だけ解いて、本体の書籍の方は読めていません。。
- AWS Certified Solutions Architect Official Study Guide: Associate Exam
- AWS Certified SysOps Administrator Official Study Guide: Associate Exam (英語)
- AWS Certified Advanced Networking Official Study Guide: Specialty Exam (English Edition)
サードパーティから提供されている模擬問題を解く
サードパーティからも様々な形態で模擬問題が提供されています。私が知っている範囲でいくつかご紹介します。
日本語の対策本
2020年5月現在、クラウドプラクティショナー/アソシエイトレベルの認定試験については日本語のAWS認定対策本が数冊出版されています。大半の書籍には模擬問題が付いています。模擬問題目当てだけでなく、日本語でまとまった書籍を読んで学習したいという方も購入を検討してみてください。
また、2020年7月29日にセキュリティ - 専門知識の日本語対策本が出版されるようです。
その他のプロフェッショナル/専門知識レベルの日本語対策本は今の所出版される予定は無いようです。
Udemy
UdemyではAWS認定試験対策用の講座が多くあります。大半の講座には模擬問題が付いています。模擬問題オンリーの講座もあったりします。Udemyを受講する際のポイントをいくつか共有します。
英語の講座でも日本語に翻訳して学習できる
プラクティショナー/アソシエイトレベルであれば、日本語の講座がいくつかありますが、プロフェッショナル/専門知識レベルにおいては英語の講座が大半です。英語が苦手な人でも、Chromeの翻訳ツールを使えば文章は日本語で学習できるので大丈夫です。動画の場合は字幕を日本語に翻訳できるようですが、分かりにくかったりするようです。
模擬問題の解答が間違っている場合がある
提供されている模擬問題において解答が間違っている場合があります。そういった講座を受験しないように、なるべく評価が高い & 評価数が多い講座を受講しましょう。
専門知識レベルの試験だと、そもそも講座自体の数が少なく、人気講座が無かったりするので、底評価の講座を割り切って受講するのも1つの選択肢としてあります。その場合は全ての解答を疑って学習しましょうセール中に購入しよう
Udemyはほぼ毎月セールがあります。セール中は90%オフくらいで購入できる講座が多いので、必ずセール中に購入するようにしましょう。
Udemyセール次はいつ?300講座以上受講した管理人の、最大95%offで買うための極意!
微妙だったらキャンセルしよう
購入して1ヶ月以内であれば、キャンセルできます。ちょっと受講してみて微妙だなと感じた場合はキャンセルしちゃいましょう。
ただ、キャンセルしまくるとBANされる場合もあるようなので、ちゃんと概要を見て、購入するかは1度検討しましょう。Kindleで購入できる英語の模擬問題集
Amazonで【aws certified solutions architect professional】とかで検索するといくつか英語の模擬問題集が出てきます。あまり出回っていないプロフェッショナル/専門知識レベルの問題集も多くあります。安いものであれば、¥1,000くらいで購入できます。また、kindle Unlimitedで読めるものもあります。私は1ヶ月無料体験でKindle Unlimitedに加入し、学習が終わったら退会しました。
英語が苦手という方にはDeepL用の翻訳ブックマークレットの利用をおすすめします。こちらも解答が間違ってたりするものが多いので、学習時は自分で調べていく必要があります。私が実践した詳細な学習方法
いくつかの専門知識試験に関して、私が実際に試した学習方法を別記事にまとめています。上記で紹介した学習方法を中心に行なっていますので、ぜひ参考にしてみてください。
- AWS認定 機械学習 - 専門知識に合格したので、実践した勉強方法を共有します
- AWS認定 Alexaスキルビルダー - 専門知識に合格したので、実践した勉強方法を共有します
- AWS認定 データベース - 専門知識に合格したので、実践した勉強方法を共有します
- AWS認定 データ分析 - 専門知識に合格したので、実践した勉強方法を共有します
- AWS認定 高度なネットワーキング - 専門知識に合格したので、実践した勉強方法を共有します
Tips
本試験の受験料が実質半額になる
認定資格に合格すると特典として別の認定資格の受験料が半額になるバウチャーがもらえます。つまり、合格する毎に連鎖的にバウチャーがもらえるので、1発合格を続ければ最初の1つ目以外は全て半額で受験できます。プロフェッショナル/専門知識の受験料は通常¥30,000と高額なので、バウチャーをどんどん活用しましょう。
再受験すると同じ問題が出る場合がある
私は高度なネットワーキング - 専門知識のみ1度不合格となっており、2回受験しています。その際、2度目に受けた時の試験問題が1度目の時と比べて9割程が同じ問題でした。なので、受験中に不合格になりそうと感じたら分からなかった問題の概要を覚えて、受験が終わったらすぐにスマホにメモる等して後で復習できるようにしてみても良いかもしれません。ですが、基本は解くことと見直しに試験時間を使うようにしましょう。
12冠を目指した理由
元々資格勉強は嫌いでは無かったので、毎年2つ受験するくらいのペースでコツコツ自己研鑽として受験していました。周りや外部をみると、アソシエイトレベルまでの資格を持ってる方は大勢いましたが、プロフェッショナル/専門知識まで持ってる方は少ないと感じていました。ましてや全て取得している方は日本で数人くらいしかいないんじゃないかなと思っていました。せっかくやるなら最後までやりきってその数人の中に食い込めれば、自分の市場価値も少しは上がるだろうと思い、12冠を目指すようになりました。
おわりに
資格をたくさん持っているからと言って、デキるエンジニアになれるとは思っていません。資格を取得するまでに身につけた知識は携わっている業務や周りの人に還元することで初めて活かされてくると思います。自分も今後はどんどんそういったことができるように活動していきたいと思います。
この記事を読んでAWS触ってみよう、勉強しようと思ってくれる方が増えてくれれば幸いです。
AWS楽しいですよ。
- 投稿日:2020-05-21T00:19:28+09:00
MQTT待ち受け方法改善
はじめに
こちらは以下の記事の続きになります
【MQTT】AWS IoT CoreとSoracom Beamを使ってデバイスとお喋りしてみた
結論からですが、こちらの記事で書いたMQTT待ち受け方法では、安定して動作しませんでした。
ネットワークの問題があり、wifiや有線での環境であれば問題ない可能性はあります。ただ、SoracomのSIMを使わない選択肢はなかったので
色々改善を試みた結果、以下の方法が一番安定して動作しました安定版ソース
mqtt_sub.pyimport paho.mqtt.client as mqtt import subprocess import json import requests import logging LOG_DIR = '/var/log/fluent/' LOG_FILE = LOG_DIR + 'aws_iot_sub.log' LOG_FORMAT = '[%(asctime)s %(levelname)s] %(message)s' SORACOM_METADATA_URL = 'http://metadata.soracom.io/v1/subscriber' logging.basicConfig(filename=LOG_FILE, level=logging.DEBUG, format=LOG_FORMAT) logger = logging.getLogger("logger") def get_imsi(): subscriber = json.loads(requests.get(SORACOM_METADATA_URL).text) return subscriber["imsi"] def on_connect(client, userdata, flag, rc): logger.info("Connected with result code " + str(rc)) device_imsi = get_imsi() logger.info("start subscribe : " + str(rc)) client.subscribe(str(device_imsi), 1) def on_disconnect(client, userdata, flag, rc): logger.error("Unexpected disconnection. rc: " + str(rc)) def on_message(client, userdata, message): msg_pay = json.loads(message.payload)["message"] logger.info('received data = ' + msg_pay) if msg_pay == "REBOOT": reboot = "sudo reboot" subprocess.call(reboot, shell=True) else: pass def on_subscribe(client, userdata, mid, granted_qos): logger.info("on_subscribe mid : " + str(mid) + " granted_qos : " + str(granted_qos)) def on_unsubscribe(client, userdata, mid): logger.info("on_unsubscribe : " + str(mid)) def main(): try: client = mqtt.Client() client.on_connect = on_connect client.on_disconnect = on_disconnect client.on_message = on_message client.on_subscribe = on_subscribe client.on_unsubscribe = on_unsubscribe client.connect("beam.soracom.io", 1883) logger.info("start loop forever") # ネットワークが切れた時のエラーハンドリングはpahoに任せる client.loop_forever() except Exception as err: logger.error("main exception: " + err) if __name__ == "__main__": main()改善前のだめだったところ
前提条件として、SoracomのSIMで通信を行うデバイスで動作させるプログラムです。
どのSIMでも同様だとは思いますが、SoracomのSIMでは、ネットワーク状況が悪かったり、セッションが切れることがあります。
その際のエラーハンドリングとして、以下対策を行なっていました。while True: try: mqttClient.subscribe(str(imsi), 1, customCallback) time.sleep(1) except Exception as err: pass電波が悪い際にsubscribeがExceptionとなりpythonが落ちるためtry/exceptでループするように実装していましたが、こちらが強引でした。
初めの何度かは想定通りに、再度subscribeを行うのですが、
何回も繰り返していくうちにプロセス自体が死んでしまい、待ち受けが行えない状態が発生していました。エラーの内容として出力されているのは、
"Subscribe error:のみでこれといった原因はわかりませんでした。
そのため、ネットワークのエラーが発生したとしても、自力で復旧してくれるライブラリを探しました。
改善後のいいところ
まず、ネットワークが悪い状況になってもプロセスは死なず、復旧すれば、再びMQTTを待ち受けできる状態となります。
それが数時間続いたとしても同様です。今回は、自前で復旧する処理を実装したくなかったので、その観点でライブラリを選びました。
client.loop_forever()とすれば、ネットワークが悪くなったとしても、自動で復旧制御をしてくれます
ここ数ヶ月運用していますが、特に問題は起こっていません。
AWS SDK(AWSIoTPythonSDK)を使っていて、安定しない場合は、pahoも検討してみてください。よりMQTTライフを!!