- 投稿日:2020-05-21T23:54:23+09:00
JavaとJavaScriptでwebブラウザとのソケット通信②
背景
過去記事:https://qiita.com/take4eng/items/d0b009c48ee8c3fe420a
上記の過去記事に記述しているように、Javaでサーバープログラムを作成しソケット通信を実施。
⇒ HTTP通信をゴリ押しで解析しているため、無駄に複雑なコードになっている。Java EEにはsocket通信に関するAPIが多数存在し、非常に簡単に実装することが可能。
既に多くの人がまとめてくれてはいるが、実装した内容をまとめておく。便利なAPIが用意されているのにゴリ押しで解析なんて誰もやらないよね
そりゃググってもなかなか出てこないわ…実践内容
- WebSocket API の使用方法
- APIを使用したサーバープログラムを作成
- 過去記事内のクライアントプログラムコードを編集しチャットアプリ作成
WebSocket API の使用方法
基本的なWebSocket APIについて説明する。
ここで紹介するもの以外にも多数のAPIが存在するが、必要ならググると良い。Endpointクラスの作成
import javax.websocket.server.ServerEndpoint; @ServerEndpoint("/コンテキストパス") public class SanpleEndpoint { }
- ServerEndpointクラスをインポート
- クラスにアノテーション@ServerEndpointを付与
- ファイルの場所を示すコンテキストパスを記述
処理メソッドの作成
/* 各クラスをインポートしておく import javax.websocket.OnClose; import javax.websocket.OnError; import javax.websocket.OnMessage; import javax.websocket.OnOpen; import javax.websocket.Session; */ //クライアントと接続したときの処理 @OnOpen public void onOpen(Session session) { } //クライアントからメッセージを受け取ったときの処理 @OnMessage public void onMessage(String message) { } //エラーが発生したときの処理 @OnError public void onError(Throwable error) { } //クライアントと接続が切れたときの処理 @OnClose public void onClose(Session session) { }
- 必要なクラスをインポート
- メソッドに対応した各アノテーションを付与
- 引数は必要に応じて変更 , 追加可能
APIを使用したサーバープログラムを作成
サーバープログラムimport java.io.IOException; import java.util.Set; import java.util.concurrent.CopyOnWriteArraySet; import javax.websocket.OnClose; import javax.websocket.OnMessage; import javax.websocket.OnOpen; import javax.websocket.Session; import javax.websocket.server.ServerEndpoint; // Webソケットのサーバ側クラスであること表すアノテーション。 // 引数(wSck)はクライアントから接続時、使われるURIを表す。 @ServerEndpoint(value = "/wSck") public class SocketFree2 { //クライアントのセッションスレッドを作成(クライアント毎にそれぞれのセッションを保存) //Set:重複要素のないコレクション //CopyOnWriteArrayList:java.util.Setをスレッドセーフにしたもの private static Set<Session> user = new CopyOnWriteArraySet<>(); @OnOpen//クライアントと接続したとき public void onOpen(Session mySession) { System.out.println("connect ID:"+mySession.getId());//session.getId():セッションIDを取得 user.add(mySession);//クライアント毎のセッションをリストに追加 } @OnMessage//クライアントからデータが送信されたとき public void onMessage(String text , Session mySession) {//引数は送信されたテキストと送信元のセッション System.out.println(text); //getAsyncRemote():RemoteEndpointのインスタンスを取得 //sendText(String):クライアントにテキストを送信 for (Session user : user) { user.getAsyncRemote().sendText(text); System.out.println(user.getId()+"番目に"+mySession.getId()+"番目のメッセージを送りました!"); } if(text.equals("bye")) onClose(mySession);//textが「bye」なら切断する } @OnClose//クライアントが切断したとき public void onClose(Session mySession) { System.out.println("disconnect ID:"+mySession.getId()); user.remove(mySession);//切断したクライアントのセッションをリストから削除 try { mySession.close();//closeメソッドで切断 } catch (IOException e) { System.err.println("エラーが発生しました: " + e); } } }コードの解説
1.クラスにEndpointアノテーション@ServerEndpointを付与し、コンテキストパスを記述
@ServerEndpoint(value = "/wSck")2.各クライアントを識別するリストを作成
private static Set<Session> user = new CopyOnWriteArraySet<>();3.onOpenメソッド:クライアントのセッションをリストに追加
user.add(mySession);4.onMessageメソッド:受信したテキストをそのままクライアントへ送信
⇒ for文で接続しているクライアント全員に送信する
user.getAsyncRemote().sendText(text);5.onCloseメソッド:接続が切れたクライアントを削除
5-1.userリストから削除:user.remove(mySession);
5-2.セッションを削除し接続を切る:mySession.close();実行結果
クライアントプログラムのアドレスを変更し、webブラウザで実行。
※コード内容は過去記事を参照
var wSck= new WebSocket("ws://localhost:8080/プロジェクト名/コンテキストパス");
(今回なら"ws://localhost:8080/freeWeb2/wSck")
送信した内容が表示されるチャットアプリが完成。
複数のブラウザからのアクセスにも対応している。感想
APIを使用することで非常に簡単にソケット通信を行うことができた。
過去記事で記述しのものと比べるとコードの記述量は約1/4。すごい。超簡単。他にもエンコード、デコード処理やjsonデータの扱いについても簡単にできるらしい。
今回は使用していないが、本格的な開発をするなら必要になるだろう。
詳細は参考ページを参照。参考ページ
- 投稿日:2020-05-21T22:08:10+09:00
javaでアルゴリズム入門 - 探索編(bit全探索)
記事の概要
自分の勉強兼メモでまとめている記事シリーズです。第四弾。
こちらの記事の続きです。
javaでアルゴリズム入門 - 探索編(幅優先探索)
今回の記事では
- bit全探索
について勉強します。
演算の解説もしっかり目にやってるので是非。bit全探索
ちょっと前までこれがバイナリサーチのことだと思ってましたが違うみたいですね。
どんな探索なのかというところから調べてみましょうか。調べてみました。
ある集合の中の一つ一つに対して(多分)2択の選択肢があるとき、全パターンを探索するときのやり方のようです。
わかりづらいですかね?さっそくではありますが例題を紹介します。例:AtCoder - abc167-c「Skill Up」
問題文・入力例などはここをクリックして表示
※できるだけ問題リンクを参照してください
(セクション開始)
【問題文】
競技プログラミングを始めた高橋くんは、学びたいアルゴリズムが M 個あります。 最初、各アルゴリズムの理解度は 0 です。
高橋くんが書店に行くと、N 冊の参考書が売っていました。i 番目の参考書 (1≤i≤N) は Ci 円で売られていて、購入して読むことで、各 j(1≤j≤M) について j 番目のアルゴリズムの理解度が Ai,j 上がります。 また、それ以外の方法で理解度を上げることはできません。
高橋くんの目標は M 個すべてのアルゴリズムの理解度を X 以上にすることです。高橋くんが目標を達成することが可能か判定し、可能な場合は目標を達成するのに必要な金額の最小値を計算してください。【制約】
入力はすべて整数
1≤N,M≤12
1≤X≤10^5
1≤Ci≤10^5
0≤Ai,j≤10^5【入力】
入力は以下の形式で標準入力から与えられる。N M X C1 A1,1 A1,2 ⋯ A1,M C2 A2,1 A2,2 ⋯ A2,M ⋮ CN AN,1 AN,2 ⋯ AN,M【出力】
高橋くんが目標を達成できないならば -1 を、 そうでなければ目標を達成するのに必要な金額の最小値を出力せよ。(セクション終了)
この問題みたいに、i番目の本を「買う・買わない」の2択になっているところがthe・bit全探索問題みたいな感じです。
参考書はN冊あり、1冊1冊について「買う・買わない」の2択を決めますので、2^N回の探索が必要になるという事ですね。
↓
1冊目 2冊目 3冊目 4冊目 ・・・ N冊目 買う
or
買わない買う
or
買わない買う
or
買わない買う
or
買わない買う
or
買わない買う
or
買わないこの通りですね。N冊それぞれに対して2択があるので2^N通りです。
ここで、買う = 1 , 買わない = 0とすると、2進数チックに表す事ができます。桁上位からN,N-1,N-2,...,3,2,1冊目とすると、例えばN=5のとき、
「01001」は4冊目と1冊目を買うという意味ですね。ちなみに数学的にいうと、「参考書N冊の購入是非の部分集合の個数」とも言えます。
参考書N冊の集合を{1,2,3,...,N-1,N}とすると、例えば1冊目と3冊目を買うときの部分集合は{1,3}と表せますね。
この「部分集合の個数」も2^Nで表せます。「部分集合に加えるのか加えないのか」の2択を各参考書(このときの参考書のことを数学的には元とか要素とかいいます)に適用すれば良いので。例えば3冊の購入是非の部分集合は以下の通りとなります。
{000}・・・1冊も買わない {001}・・・1冊目だけ買う {010}・・・2冊目だけ買う {011}・・・1冊目と2冊目を買う {100}・・・3冊目だけ買う {101}・・・1冊目と3冊目を買う {110}・・・2冊目と3冊目を買う {111}・・・3冊すべて買うちょうど2^3 = 8通りとなることがよくわかりますね。
ではjavaの回答例を見てみましょう。
【回答例】
main.javaimport java.util.ArrayList; import java.util.List; import java.util.Scanner; public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); // 参考書数 int n = sc.nextInt(); // 習得したいアルゴリズム数 int m = sc.nextInt(); // 習得目標理解度 int x = sc.nextInt(); // n番目の参考書の値段 int[] costs = new int[n]; // n番目の参考書のm番目のアルゴリズムの上昇理解度 int[][] a = new int[n][m]; // 入力の受け取り for (int i = 0; i < n; i++) { costs[i] = sc.nextInt(); for (int j = 0; j < m; j++) { a[i][j] = sc.nextInt(); } } // m番目のアルゴリズムの理解度、参考書コストのtmp変数と、loop毎の参考書コストを覚えておく変数、アルゴリズム習得達成したかの変数 int[] aTmp = new int[m]; int costTmp = 0; List<Integer> costsSave = new ArrayList<>(); boolean mastered = true; /* * ここからbit全探索 */ for (int i = 0; i < 1 << n; i++) { // bit全探索の全通りのloop for (int j = 0; j < n; j++) { // 1loop毎にどの参考書を買うかの判定(j冊目を買うかどうか) if ((1 & i >> j) == 1) { // ここに引っかかった = 買う対象に追加(j冊目購入) for (int h = 0; h < m; h++) { // j冊目の参考書を買ったときのm番目のアルゴリズムの理解度上昇 aTmp[h] += a[j][h]; } // j冊目の値段 costTmp += costs[j]; } } // 参考書を買い終わったので、アルゴリズムを覚えられたかどうかの判定の上、値段を保持 for (int h = 0; h < m; h++) { if (aTmp[h] < x) { // アルゴリズムを1つでも覚えられていない場合、NG mastered = false; break; } } if (mastered) { // 合計値段を一時格納 costsSave.add(costTmp); } // 後始末 for (int h = 0; h < m; h++) { aTmp[h] = 0; } costTmp = 0; mastered = true; } // listのうち最小の値を出力。リストがnullなら"-1"を出力 int ans = Integer.MAX_VALUE; if (costsSave.isEmpty()) { ans = -1; } else { for (int cost : costsSave) { if (ans > cost) { ans = cost; } } } System.out.println(ans); } }こんな感じです。なにやら普段javaを書いているときには見慣れない記号を2回くらい使ってますね。
「ここからbit全探索」ってところの
for (int i = 0; i < 1 << n; i++)
と、
「ここに引っかかった = 買う対象に追加(j冊目購入)」の
if ((1 & i >> j) == 1)
ですね。「&」「<<」「>>」は「bit演算子」と呼ばれています。
詳しい処理は ggっていただいて、簡単に説明しますと、「&」は論理積、「<<」や「>>」はbit列を右または左にシフトをするものです。(例)
01001 & 11000 = 01000
01001 << 1 = 10010
00100 >> 1 = 00010bit毎の論理積を取る、右や左へのシフトがわかったでしょうか。ここはさらっといきます。
ではコードの説明をします。
まずは
for (int i = 0; i < 1 << n; i++)
こちらです。
このfor文の繰り返し条件の部分、i < 1 << nに注目しましょう。
まず最初の記号"<"(iの右にあるやつ)は不等号で間違いなさそうです。
で、1 << nの「<<」がbit演算子(厳密にいうとシフト演算子)です。
1 << nの意味ですが、「1をn回左にシフト」を意味しています。
例えば1を1回左にシフトすると、「10」です(2進法で表しています。10進法だと2ですね)。同様に
1を2回左にシフトすると、「100」です(2進法で表しています。10進法だと4(=2^2)ですね)。
1を3回左にシフトすると、「1000」です(2進法で表しています。10進法だと8(=2^3)ですね)。
1を4回左にシフトすると、「10000」です(2進法で表しています。10進法だと16(=2^4)ですね)。イメージ
そもそも今回の全探索の回数としては、n冊の参考書対して買う・買わないの通りなので2^N通りを考えたかったのですね。つまりこのfor文を書き換えると、
for (int i = 0; i < Math.pow(2,n); i++)
とも書き換えられるわけです。なんとなく分かったでしょうか。では次にいきます。
if ((1 & i >> j) == 1)
これがわかりづらかったんですよね。。
if文のカッコの中を日本語に直すと「1と i>>j の論理積が1と等しいかどうか」です。例えばi=5、j=2としましょう。
(この問題的にいうと5回目の探索、3冊目の購入是非の検討をしている途中です。)
5を二進数に直すと0101、これを2回右シフトすると以下のような感じです。
で、これと1(0001)の論理積をとります。1と論理積を取るということは、最下桁が1かどうかを判定していることがわかりますでしょうか。
2回シフトして最下桁が1ということは言い換えると最下桁から2個左を見て1かどうかを見ているわけですね。つまり下からj桁目が1かどうかを判定しているわけです。それが1だったら購入の対象とする、と言った感じです。「ここからbit全探索」のところのfor文で全パターンの探索、
次のfor文「1loop毎にどの参考書を買うかの判定(j冊目を買うかどうか)」でそのパターンで買う本の特定をしているわけです。ちょっと難しいですかね。
試しに具体的な入力例を入れて処理を追ってみましょうか。【入力例】
3 3 10 60 2 2 4 70 8 7 9 50 2 3 9n = 3 , m = 3 , x = 10
0冊目のコスト、アルゴリズムの理解度0,1,2
1冊目のコスト、アルゴリズムの理解度0,1,2
2冊目のコスト、アルゴリズムの理解度0,1,2
の順番でしたね。わかりやすく0スタートで数えてます。じゃあbit全探索いきましょう。
n = 3なので、
「ここからbit全探索」のloopは
for(int i = 0 ; i < 1 << 3 ; i++)
で、1 << 3は、0001を3回左にシフトするので1000となります。つまり8ですね。
ぴったり2^3になっています。i = 0 から i = 7 まで順番に見てみましょう。適宜二進数に直していきます。
jで見ようとしている桁を太字で表しています。i = 0(000)のとき
j = 0のとき(i = 000)
if ((1 & 000 >> 0) == 1)ではないため、0冊目は買わない
j = 1のとき(i = 000)
if ((1 & 000 >> 1) == 1)ではないため、1冊目は買わない
j = 2のとき(i = 000)
if ((1 & 000 >> 2) == 1)ではないため、2冊目は買わない
i = 1(001)のとき
j = 0のとき(i = 001)
if ((1 & 001 >> 0) == 1)であるため、0冊目は買う
j = 1のとき(i = 001)
if ((1 & 001 >> 1) == 1)ではないため、1冊目は買わない
j = 2のとき(i = 001)
if ((1 & 001 >> 2) == 1)ではないため、2冊目は買わない
i = 2(010)のとき
j = 0のとき(i = 010)
if ((1 & 010 >> 0) == 1)ではないため、0冊目は買わない
j = 1のとき(i = 010)
if ((1 & 010 >> 1) == 1)であるため、1冊目は買う
j = 2のとき(i = 010)
if ((1 & 010 >> 2) == 1)ではないため、2冊目は買わない
i = 3(011)のとき
j = 0のとき(i = 011)
if ((1 & 011 >> 0) == 1)であるため、0冊目は買う
j = 1のとき(i = 011)
if ((1 & 011 >> 1) == 1)であるため、1冊目は買う
j = 2のとき(i = 011)
if ((1 & 011 >> 2) == 1)ではないため、2冊目は買わない
i = 4(100)のとき
j = 0のとき(i = 100)
if ((1 & 100 >> 0) == 1)ではないため、0冊目は買わない
j = 1のとき(i = 100)
if ((1 & 100 >> 1) == 1)ではないため、1冊目は買わない
j = 2のとき(i = 100)
if ((1 & 100 >> 2) == 1)であるため、2冊目は買う
i = 5(101)のとき
j = 0のとき(i = 101)
if ((1 & 101 >> 0) == 1)であるため、0冊目は買う
j = 1のとき(i = 101)
if ((1 & 101 >> 1) == 1)ではないため、1冊目は買わない
j = 2のとき(i = 101)
if ((1 & 101 >> 2) == 1)であるため、2冊目は買う
i = 6(110)のとき
j = 0のとき(i = 110)
if ((1 & 110 >> 0) == 1)ではないため、0冊目は買わない
j = 1のとき(i = 110)
if ((1 & 110 >> 1) == 1)であるため、1冊目は買う
j = 2のとき(i = 110)
if ((1 & 110 >> 2) == 1)であるため、2冊目は買う
i = 7(111)のとき
j = 0のとき(i = 111)
if ((1 & 111 >> 0) == 1)であるため、0冊目は買う
j = 1のとき(i = 111)
if ((1 & 111 >> 1) == 1)であるため、1冊目は買う
j = 2のとき(i = 111)
if ((1 & 111 >> 2) == 1)であるため、2冊目は買ういかがでしょうか?ちょうど1になっている桁だけ買う、とできていますね。
買う参考書がどれかわかったらあとは計算するだけなのでそこの処理については飛ばしますね。書いてる私もいざ実装して、と言われたら実装できなさそうなのであとは練習です。
AtCoderの以下の問題とか練習になるのであとで解こうと思います。練習あるのみ!!!
AtCoder - abc079-c「Train Ticket」
AtCoder - abc128-c「Switches」
いったんここまでで探索編は終わりにします。
全探索、二分探索、深さ優先探索、幅優先探索、bit全探索について勉強してきましたがいかがでしょうか。興味のある方はリンクを追ってみてくださいね。
ちょっと練習期間ということでこれらの探索を練習したら今度はDPやダイクストラについても勉強していけたらな、と思います。
お付き合いいただきありがとうございました。それでは。


- 投稿日:2020-05-21T21:39:22+09:00
マイクロサービス開発を容易にするDaprをJavaで利用してみた
はじめに
Microsoft Build2020を見てDistributed Application Runtime のDaprが中々面白そうでした。
チュートリアルがNode.jsだったので参考にしつつQuarkusからDaprを利用するサンプルを作ってみました。Daprって?
Daprはサイドカー(Proxy)によりサービス間呼び出し、ステート管理、サービス間メッセージングなどの非機能要件を実現する事でマイクロサービスの実装を簡単にするマイクロソフトによって開発されているフレームワークです。
OSSで開発されているため下記より利用できます。サイドカーという事でIstioなどのサービスメッシュと同じものかと思っていたのですが、セッションを聴いていると少し違う感じで、ファイルやステート管理(データ永続化)、あるいはKafkaなどのキューイングを抽象化する役割もあるようでした。どちらかというとJavaEEのJNDIとかDataSourceやJCA(Java Connector Architecture)の類な感じがします。
おじさんなら「これ進研ゼミでやったやつだ」っていうチャンスですね!WeblogicなんかのJavaEEコンテナだとこの辺はそもそも同じメモリ空間にいたりT3で喋ってると思いますが、Daprと各アプリケーションはHTTPないしはgRPCで喋ります。
とりあえずDaprを動かしてみる
実際のチュートリアルをやる前にとりあえず動かしてみましょう。今回はgRPCは面倒なのでRESTを実装します。とりあえずmvnコマンドでQuarkusのテンプレートを作って実行します。
$ mvn io.quarkus:quarkus-maven-plugin:1.4.2.Final:create \ -DprojectGroupId=dev.nklab \ -DprojectArtifactId=dapr-app \ -DprojectVersion=1.0.0-SNAPSHOT \ -DclassName="dev.nklab.example.dapr.HelloResource" $ cd dapr-app $ ./mvnw quarkus:dev別ターミナルからcurlでアクセスしてみます。
$ curl http://localhost:8080/hello helloアプリケーションの動作が確認できたところでDaprをインストールします。k8sは特になくても動作しますがDockerは事前に入れて置く必要があるようです。
$ curl -fsSL https://raw.githubusercontent.com/dapr/cli/master/install/install.sh | /bin/bash $ dapr initインストールはこれで完了です。以下のエラーが出たらたぶん
dapr initを忘れています。exec: "daprd": executable file not found in $PATH続いて、先ほど作ったQuarkusアプリケーションを以下のコマンドでDaprでラッピングして実行します。
$ dapr run --app-id javaapp --app-port 8080 --port 3500 ./mvnw quarkus:dev ... ℹ️ Updating metadata for app command: ./mvnw quarkus:dev ✅ You're up and running! Both Dapr and your app logs will appear here.
--app-portはQuarkusのポート番号、--portはDaprのポート番号です。ではcurlでDaprにアクセスしてみましょう。$ curl http://localhost:3500/v1.0/invoke/javaapp/method/hello helloDaprがサイドカー、すなわちProxyとして動作してるので
8080ではなく3500で裏側のアプリにアクセスできたことがわかります。
javaappの部分は先ほど実行時に指定したaap-idです。invokeで裏側のアプリに連携する処理になるようです。Redisを使ったState管理を行う
アプリケーションの仕様
ではHello WorldのStep1からStep5までを実施ます。
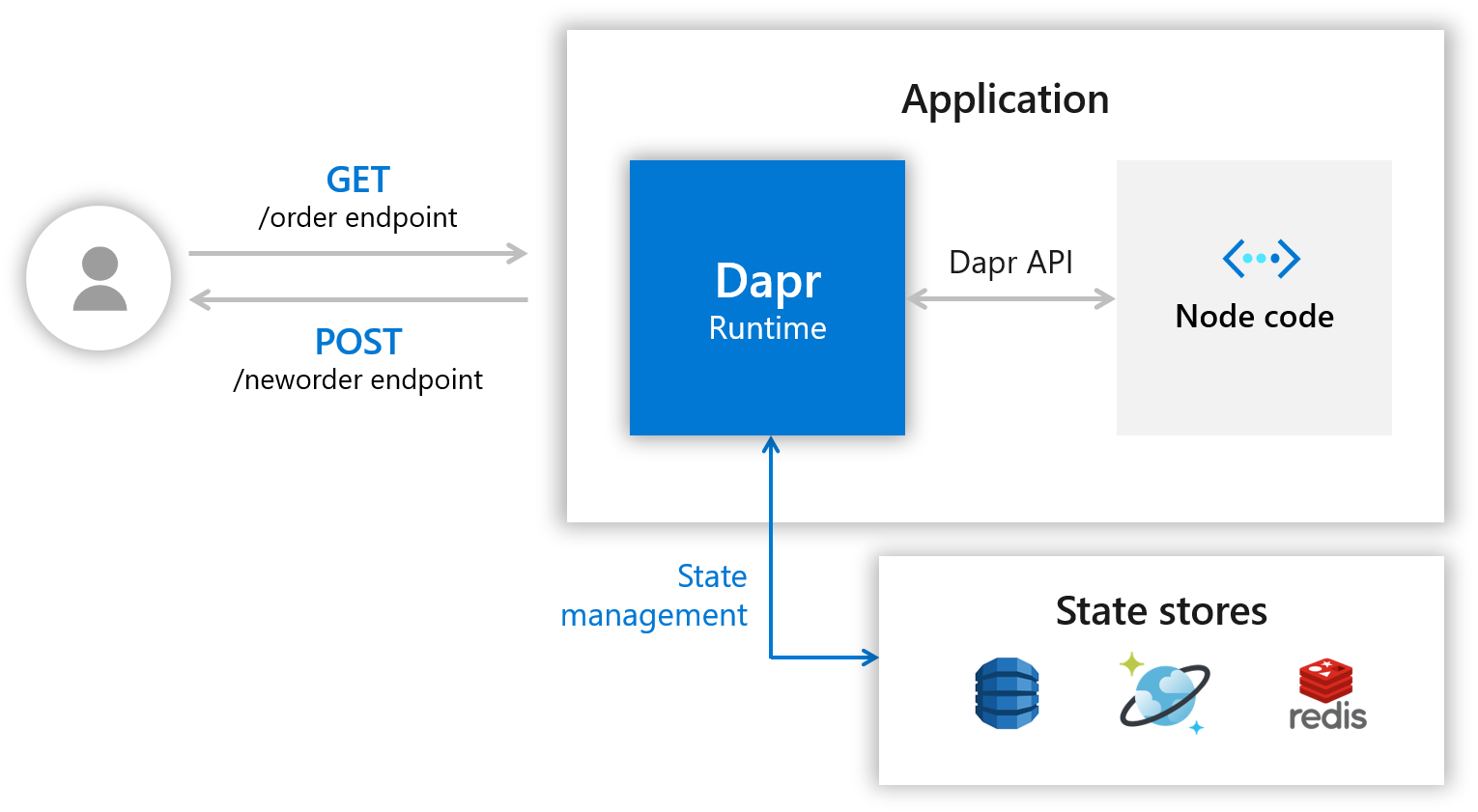
今回実装るすアプリは以下のような構成になっています。
ユーザがDapr経由でApplication(Java)にリクエストを送り、アプリケーションからDaprのAPIを叩きDaprを経由してRedisに書き込みます。アプリケーションはあくまでDaprとしか会話しないので、データの永続化にRedisを直接経由しないのは面白いですね。
仕様としてはユーザは以下のようなPOSTリクエストをApplicationに投げます。
{ "data": { "orderId": "42" } }このデータはRedisに以下の形式で保存されます。
[{ key: "order", value: ここにorderIdを格納 }]また、ApplicationにGETリクエストを投げると現在のorderIdを返します。
アプリケーションの実装
では、アプリケーションを実装していきます。今回はJSONを使うのでQuarkusにライブラリを追加しておきます。
$ ./mvnw quarkus:add-extension -Dextensions="quarkus-resteasy-jsonb" $ ./mvnw quarkus:add-extension -Dextensions="quarkus-resteasy-jackson"続いてアプリケーションを以下のように修正します。
HelloResource.java@Path("/") @Produces(MediaType.APPLICATION_JSON) @Consumes(MediaType.APPLICATION_JSON) public class HelloResource { @ConfigProperty(name = "daprapp.daprport") String daprPort; String stateStoreName = "statestore"; @GET @Path("/order") public Map<String, Object> order() throws IOException, InterruptedException { return Map.of("orderId", get(stateUrl() + "/order").body()); } @POST @Path("/neworder") public HttpResponse neworder(Map<String, Map<String, Object>> data) throws IOException, InterruptedException { System.out.println("orderId: " + data.get("data").get("orderId")); var items = List.of(Map.of("key", "order", "value", data.get("data").get("orderId"))); return post(stateUrl(), items); } private String stateUrl() { return "http://localhost:" + daprPort + "/v1.0/state/" + stateStoreName; } private HttpResponse<String> post(String url, List<Map<String, Object>> items) throws IOException, InterruptedException, JsonProcessingException { var mapper = new ObjectMapper(); var client = HttpClient.newHttpClient(); var request = HttpRequest.newBuilder() .uri(URI.create(url)) .POST(HttpRequest.BodyPublishers.ofString(mapper.writeValueAsString(items))) .setHeader("Content-Type", "application/json") .build(); return client.send(request, HttpResponse.BodyHandlers.ofString()); } private HttpResponse<String> get(String url) throws InterruptedException, IOException { var client = HttpClient.newHttpClient(); var request = HttpRequest.newBuilder() .uri(URI.create(url)) .GET() .setHeader("Content-Type", "application/json") .build(); return client.send(request, HttpResponse.BodyHandlers.ofString()); } }JAX-RSとして特別なことはしてないので詳細は省きますが、
neworderが登録用のエンドポイント、orderが参照用のエンドポイントです。それぞれのメソッドの中で
http://localhost:3500/v1.0/state/statestoreにアクセスしています。これはDaprのステート管理APIのエンドポイントです。
今回はこのステート管理APIの実体がRedisになります。ステート管理APIのリクエストとレスポンスは前述したとおり以下のようなJSONになります。[{ key: 値, value: 値 }]ステート管理の実装にRedisを設定する
続いてステート管理の実装にRedisを設定します。と言っても既に設定済みなので確認だけします。
実は先ほどdapr runをしたタイミングでcomponentsというディレクトリができています。こちらのstatestore.yamlにどのストアと繋ぐかを記載するようです。components/statestore.yamlapiVersion: dapr.io/v1alpha1 kind: Component metadata: name: statestore spec: type: state.redis metadata: - name: redisHost value: localhost:6379 - name: redisPassword value: "" - name: actorStateStore value: "true"おそらくここをRDBなどに書き換えれば別の実装になるんではなかろうかと思われます。
テスト
それでは実装は完了したので動作確認をします。まずはDaprを起動します。
$ dapr run --app-id javaapp --app-port 8080 --port 3500 ./mvnw quarkus:dev続いてリクエストを投げます。
$ curl -X POST -H "Content-Type: application/json" -d '{"data": { "orderId": "41" } }' http://localhost:3500/v1.0/invoke/javaapp/method/neworder {} $ curl http://localhost:3500/v1.0/invoke/javaapp/method/order {"orderId":"\"41\""}投げたリクエストした値が格納されそれが取得できたのが確認できたかと思います。なお、POSTはDaprコマンドで以下のように書くこともできます。
$ dapr invoke --app-id javaapp --method neworder --payload '{"data": { "orderId": "41" } }'まとめ
とりあえずDaprをJavaから使ってみました。RESTなので特に問題なく実装できました。
DaprはIstio以上にJavaEE感がやはりあって、Daprそのものはともかくこの考え方自体は開発の容易性の観点で正しい方向の気がします。
DAOパターンを含めてサービスやデータの実体は隠蔽するのは基本的な考え方ですし、非機能はインフラ側に可能な限り溶けこました方がいいので。一方で永続化層もProxyを経由するとなれば例えgRPCを使っても一定のオーバーヘッドは避けられないと思われます。この辺りを設計でどう対応していくかが今後求められていくのだと思います。
Dapr自体はまだ出来たばかりで荒削りなところも多そうですが、今後もう少し触っていきたいと思います。
それではHappy Hacking!
参考リンク
- 投稿日:2020-05-21T20:47:09+09:00
GlassFishでjava.io.IOExceptionとなった時の対応方法
- 環境
- Red Hat Enterprise Linux Server release 6.3 (Santiago)
- java version "1.7.0_79"
- GlassFish 4.1
事象 : GlassFishで大量データ処理中にjava.io.IOExceptionになった
[2020/05/21 17:41:07.805][656b5aef53f][][FATAL] - java.io.IOException: java.lang.InterruptedException org.glassfish.grizzly.nio.transport.TCPNIOTransportFilter.handleRead(TCPNIOTransportFilter.java:92) org.glassfish.grizzly.filterchain.TransportFilter.handleRead(TransportFilter.java:173) org.glassfish.grizzly.filterchain.ExecutorResolver$9.execute(ExecutorResolver.java:119) org.glassfish.grizzly.filterchain.DefaultFilterChain.executeFilter(DefaultFilterChain.java:284) org.glassfish.grizzly.filterchain.DefaultFilterChain.executeChainPart(DefaultFilterChain.java:201) org.glassfish.grizzly.filterchain.DefaultFilterChain.read(DefaultFilterChain.java:351) org.glassfish.grizzly.filterchain.FilterChainContext.read(FilterChainContext.java:695) org.glassfish.grizzly.http.io.InputBuffer.blockingRead(InputBuffer.java:1119) org.glassfish.grizzly.http.server.io.ServerInputBuffer.blockingRead(ServerInputBuffer.java:95) org.glassfish.grizzly.http.io.InputBuffer.fill(InputBuffer.java:1143) org.glassfish.grizzly.http.io.InputBuffer.read(InputBuffer.java:353) org.apache.catalina.connector.InputBuffer.read(InputBuffer.java:267) org.apache.catalina.connector.CoyoteInputStream.read(CoyoteInputStream.java:270) sun.nio.cs.StreamDecoder.readBytes(StreamDecoder.java:283) sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:325) sun.nio.cs.StreamDecoder.read(StreamDecoder.java:177) java.io.InputStreamReader.read(InputStreamReader.java:184) java.io.BufferedReader.fill(BufferedReader.java:154) java.io.BufferedReader.readLine(BufferedReader.java:317) java.io.BufferedReader.readLine(BufferedReader.java:382) ...省略...原因 : アプリケーションの実行時間がタイムアウトしたから
アプリケーションの実行時間を設定する設定
configs.config.network-config.protocols.protocol.http.request-timeout-secondsを指定していないことが問題だった。Glassfishのデフォルトのタイムアウトは15分です。
これは様々な状況で発生する可能性があります。
例えば、リクエストがタイムアウト時間内に応答を返さない長時間実行アクションを起動した場合、サーバへのリクエストがHTTPS経由で行われ、HTTP (またはその逆)しかサポートしていない場合、HTTP接続プールで利用可能な接続がもうない場合などです。
java - GRIZZLY0023 Glassfish warning - Stack Overflow対応 : domain.xmlのhttp.request-timeout-secondsの設定をする
今回は、設定していないためタイムアウトが15分になっていたので無制限の「-1」に設定した。
domain.xml<configs> <config name="server-config"> <network-config> <protocols> <protocol name="http-listener-1"> <http max-post-size-bytes="20971520" default-virtual-server="server" max-connections="250" request-timeout-seconds="-1">GlassFish管理画面(http://localhost:4848)で設定する場合は、
server-config>Network Config>Network Listeners> {対象のListener} > [HTTP]タブ >Request Timeout:
Glassfish 3.1.2から「-1」は設定できないらしいが設定したら
java.io.IOExceptionが発生しなくなった・・・でも管理画面で見ると初期値の900秒(15分)になっている・・・不思議Unfortunately you can't set it to -1 to have no limit since Glassfish 3.1.2.
java - GRIZZLY0023 Glassfish warning - Stack OverflowPayaraでもできるんだろうか?

- 投稿日:2020-05-21T20:04:24+09:00
JavaでWeb開発をするときによく使うものたち
はじめに
この記事では、Javaにおけるシステム開発でよく使うライブラリやフレームワークを
簡単に解説します。
技術選定時に、少しでも参考になれば幸いです。JDK
・Oracle JDK
有償サポート付きのJdkです。毎月1ユーザー2.5ドルかかる代わりに、
オラクル社のLTSとお墨付きがあります。
セキュリティをかなり重視する場合や、サポートがあると安心な場合はこちらを使うことをオススメします。・Open JDK
無料のjdkです。基本的な性能や昨日は上のものと何も変わりません。
個人開発などではこちらを使うことをオススメします。IDE、エディタ
・Eclipse
Javaエンジニアとしてキャリアを歩み始めたなら、おそらく誰もが耳にしたことあるIDEです。
実際には、Javaのみではなく多くの言語を扱うことができます。
私も実務では何度もお世話になってきました。
昨今のエディタと比べると、動作が重たい、プラグインが少なめなことがありますが、
現役でバリバリ使えるIDEです。
類似するツールに、Spring Tool Suite(STS)というものがあります。・microSoft VS Code
Node.jsのライブラリ、Electron等を用いて、webの技術をベースに作成されたオープンソースの軽量エディタです。
JavaScriptやPythonといった言語での使用例が多いですが、
Java Extension Packという拡張機能の集合を導入することで、Eclipseにひけを取らない快適な開発環境が簡単に構築できます。Webフレームワーク
・Struts2
最近ではあまり採用例は聞かないですが、Javaにおいて一世を風靡したフレームワークです。
MVCモデルを採用しており、ActionクラスというクラスにWebアプリケーションの処理を記述し、
struts.xmlという設定ファイルに遷移先を記述する方法で開発を行います。・Spring MVC
おそらく、採用例知名度共にJavaフレームワークの中ではNo.1のフレームワークです。
全言語でもRuby on railsと同じくらいと個人的に思っています。
他のフレームワークと比べてDB連携やトランザクション管理において担ってくれる範囲が広いです。
依存性の注入(DI)という方法で、ソースコードの記述を簡潔にし、アスペクト指向プログラミングをサポートしてくれます。
従来は設定ファイルの作成・メンテナンスが面倒といった問題もあったのですが(Spring特有の問題ではない)、Spring Bootという問題点を解消したフレームワークも存在します。・Play Framework
Java、というよりScalaのフレームワークとして有名かつ人気ですが、当然Javaも使えます。
上記のフレームワークに比べ、軽量で環境構築も容易な上、設定ファイルの記述も簡単です。
routesファイルというファイルにルーティングの設定を記述し、画面からの要求に応じてどの処理を呼び出すかを決定します。
Ruby on railsの影響を受けたフレームワークの一つですので、
素早い開発を行いたい場合や、Ruby on railsやDjangoでの開発の経験者がJavaを勉強する時におすすめのフレームワークです。ライブラリ
※数が多いので、印象的なものを書いています。
・JUnit
説明不要ともいえる、Javaにおけるユニットテストライブラリです。
AssertEquals()や、Test、Setup等のアノテーションを用いて簡潔かつ何をしているかわかりやすいテストを記述することができます。・Jython
JVM上で動作するPythonを提供するライブラリです。(現在の最終バージョンはPython2系)
Javaで開発をしているが、Pythonのライブラリを呼び出したいといった場面に有効です。・Apach POI
JavaでエクセルやCSVを作成する時に使えるライブラリです。
Javaの標準APIよりも高機能で、より簡潔に開発を行うことができます。
メモリを結構使う点に注意が必要です。バージョン管理
※両方ともJavaに限ったものではありません。
・SVN
近年ではレガシー環境の代名詞として扱われることも多い気がしますが、
まだまだ現役です。
下記Gitに比べ、ExcelやWordなどのドキュメント管理に長けている反面、
ローカルコミットができず、途中段階のソースコードをリポジトリ管理するには苦難が伴う場合があることが難点です。
開発者に強い権限を持たせたくない場合にオススメです。
(あとGitに移行しようという説得がなぜかかなり難しいのも難点です)・Git
上記のSVNと比べ、ドキュメントの管理は苦手(バイナリデータとして扱われる)ですが、
ブランチを簡単に作成できる、マージに制約が少ないなど、有り余るメリットがあります。
新規開発の場合はこちらをオススメします。おわりに
私は個人開発ではOpenJdk + VSCode + Play + Git
実務ではOracleJdk+ Eclipse + Spring + SVNで作業を行うのですが、
個人開発の構成が結構オススメです。JMockitやJenkins、ビルドツール周りも今後記載していこうと思っています。
また、これを載せて欲しいという物があればコメント欄に書いていただければ嬉しいです。
- 投稿日:2020-05-21T18:53:09+09:00
alpineでbazelをビルドする
背景
- alpineでbazelを使いたい
- デフォルトのapkリポジトリに存在しない1
- Bazeliskはalpineのサポートをしていない
- コンパイルに時間がかかるのでビルド済みdockerイメージとして使えるようにしたい
コンパイルのためのdocker image
./compile.shでコンパイルしているgitリポジトリがあったので、参考に一部拝借・抜粋してdockerfileにしました。
bazel-buildFROM python:3.8-alpine3.11 ARG bazel_ver=3.1.0 ENV JAVA_HOME=/usr/lib/jvm/default-jvm \ PATH="$JAVA_HOME/bin:${PATH}" \ BAZEL_VERSION=3.1.0 RUN apk add --virtual .bazel_build --no-cache g++ gcc \ bash zip unzip cmake make linux-headers openjdk8 && \ wget -q "https://github.com/bazelbuild/bazel/releases/download/${BAZEL_VERSION}/bazel-${BAZEL_VERSION}-dist.zip" \ -O bazel.zip && \ mkdir "bazel-${BAZEL_VERSION}" && \ unzip -qd "bazel-${BAZEL_VERSION}" bazel.zip && \ rm bazel.zip && \ cd "bazel-${BAZEL_VERSION}" && \ sed -i -e 's/-classpath/-J-Xmx6096m -J-Xms128m -classpath/g' \ scripts/bootstrap/compile.sh && \ EXTRA_BAZEL_ARGS=--host_javabase=@local_jdk//:jdk ./compile.sh && \ cp -p output/bazel /usr/bin/ && \ cd ../ && rm -rf "bazel-${BAZEL_VERSION}" && \ bazel version && \ apk del --purge .bazel_buildあとは
docker buildしてpushするだけ注意点
ソースからコンパイルを行う場合は、openjdk11対応していないのでopenjdk8を入れる
sedで置き換えている箇所はJavaのヒープ・メモリのサイズを指定している。指定しないとメモリを食い尽くして途中で落ちるケースがある。The system is out of resources. Consult the following stack trace for details. java.lang.OutOfMemoryError: Java heap space参考文献
apkのtestingリポジトリに存在するが、導入したいモジュールがこのバージョンに対応してないため使用しない ↩
- 投稿日:2020-05-21T18:29:40+09:00
macOS Catalina で "エラー: メイン・クラス○○が見つからなかったかロードできませんでした" と言われたら
今回はMacOSさんがとっても優秀過ぎて勝手に沼にハマった私の備忘録です。
環境
macOS Catallina
なにがあったか
私が久しぶりにJavaのソースコードを書いていてターミナルからコンパイルしたくなった時のことです。
javac -cp "classpathをいろいろ" -d 出力先ディレクトリ ./package名/Example.javaと普通に打ちます。
classファイルが生成されます。
ここまでは順調でした。$ cd 出力先ディレクトリ $ java package名/Example エラー: メイン・クラスExampleが見つからなかったかロードできませんでしたorz
やらかしました。
いろいろ調べた結果、最終的には事なきを得たのでよくあるパターンと共に記事にしてみました。
(後の伏線になるのですが、今回私はDesktopディレクトリ以下で作業していました。)
同じことやらかした人に届けこの想い…。Pattern1 ディレクトリ構成が違う
今回
調子に乗ってsrcディレクトリとbinディレクトリに分けていて、
さらにパッケージも分けていましたので、まずディレクトリ構成からです。これを最初にやっておくとエラー様の言う通り(場所の勘違いなどから)本当にclassファイルがない場合もここで発覚します。
project/ ├src/package名/ │ └─Example.java └bin/package名/ └─Example.class問題なかったです。
Pattern2 mainメソッドが無い
javaで実行するclassにはmainメソッドが必須です。
たまに書いてなくておなじみのエラーを出している人を見ます。Pattern3 環境変数CLASSPATH
私は使ったことなかったので意識したことなかったですが、これを下手に設定して失敗するパターンもあるようです。
$ echo $CLASSPATH $まぁ使ったこと無いので当然ですけど大丈夫でした。
ここまで来るとなにがいけないのか。。。
Pattern4 macOSさんかしこい
いろいろ試して疲れた頃、(そもそもこんなに発覚しないことある…?)o.(;´Д`)とか思いだしました。
そこで、まさかと考えて「システム環境設定」→「セキュリティとプライバシー」を見ると
こいつぁひでぇや!
はい解決です。まとめ
皆さんはこんなしょうもない設定してないと思うのですが、ネットで
"エラー: メイン・クラス○○が見つからなかったかロードできませんでした"
について調べても解決できず、エラーも権限の問題なのにそれがわかりにくかったので、後に現れるかもしれない私と同じミスをする人のために書いてみました。

- 投稿日:2020-05-21T14:19:40+09:00
UbuntuにxamppインストールからのJDBCの動作確認
はじめに
WebサーバとJDBCの仕組みを勉強するために,xamppを使って自分でつくってみたときの手順です.
Ubuntuでやってる人が少ないのか,同じようなエラーに遭遇した人が少なかったので記事にしてみました.
勉強用に作っているので,あえて統合開発環境Eclipseは使用していません.バージョン等情報
仮想マシン:VMware Workstation 15 Player
ゲストOS:Ubuntu 18.04LTS
xammp:7.4.5xamppのインストール
xamppは下記サイトでインストーラーをダウンロードし,適当にインストールしてください.
何も困ることはないはず.
https://ja.osdn.net/projects/xampp/インストールが完了すると,/optのなかにlammpフォルダが出来上がっているはずです.
下記コマンドを入力するとApacheとMySQLとProFTPDが立ち上がります.$ sudo /opt/lampp/lampp startちなみに停止するときは,
$ sudo /opt/lampp/lampp stopです.
ウェブブラウザのアドレスに「localhost」と入力し,立ち上げたWebサーバに入れることを確認します.
入れない場合の対処法
下記nmapコマンドで,ポート80番が開いているか確認してみてください.$ nmap localhost開いてなければ,Ubuntuのファイアウォールではじかれてる可能性が高いです.
下記ufwコマンドでポート80番(http)を開放し,再度nmapコマンドで空いたかどうか確認してください.$ sudo ufw allow 80ちなみに,Ubuntuはデフォルトでポート80番は閉じてます.
80番ポートを開放すると,セキュリティリスクが上がるので注意してください.データベースの作成
次にテスト用のデータベースを作成します.
ウェブブラウザで「UbuntuのIPアドレス」にアクセスし,右上のphpMyAdminに入り,
rootでログインします.「ユーザアカウント」タブを開き,「ユーザアカウントを追加する」を選択します.
「ユーザ名」「ホスト名」「パスワード」を入力し,
今回はこのように設定しました.
ユーザ名:piyo
ホスト名:localhost
パスワード:piyopass「ユーザアカウント専用データベース」欄の「同名のデータベースを作成してすべての特権を与える.」にチェックを入れたのち,一番下の「実行」ボタンを押して,アカウントを生成します.
これで,アカウントとアカウントと同名のデータベースが作成できました.とりあえずテスト用のデータを入力していきます.
テーブル名:book
カラム:(id(int型),name(VARCHAR型),price(int型),data(DATE型))挿入タブを選択し,適当にデータを入れます.
下記SQLコマンドはそのときのコマンドです.
ウェブブラウザのインターフェースで挿入できるので,下記コマンドを直接入力する必要はありません.INSERT INTO `book` (`id`, `name`, `price`, `date`) VALUES ('1', '1st_chapter', '777', '2020-05-21');MySQL設定
次に,MySQLにアクセスできるように設定します.
まずは,ファイアウォールの設定で,ポート3306番(MySQL)を開けます.
$ sudo ufw allow 3306次に,MySQLのskip-networkingオプションをoffにします.
ホームディレクトリに.my.mcnfファイルを作成し,以下の2行のテキストを入力します.~/.my.cnf[mysqld] skip-networking = offこれがかなり重要だったのですが,skip-networkingオプションをoffにしないと,3306番ポート経由でアクセスできません.
ちなみにMySQLのバージョンによって設定ファイルのデフォルトの設定などが違うそうで,かなり苦労しました.
ちなみに設定ファイルの作り方は下記ファイルに書いてありました./etc/mysql/my.cnf# # The MySQL database server configuration file. # # You can copy this to one of: # - "/etc/mysql/my.cnf" to set global options, # - "~/.my.cnf" to set user-specific options. # # One can use all long options that the program supports. # Run program with --help to get a list of available options and with # --print-defaults to see which it would actually understand and use. # # For explanations see # http://dev.mysql.com/doc/mysql/en/server-system-variables.html # This will be passed to all mysql clients # It has been reported that passwords should be enclosed with ticks/quotes # escpecially if they contain "#" chars... # Remember to edit /etc/mysql/debian.cnf when changing the socket location. # Here is entries for some specific programs # The following values assume you have at least 32M ram !includedir /etc/mysql/conf.d/MySQLの設定を読み込ませるため,xamppごと再起動します.
$ sudo /opt/lampp/lampp restartポート3306番が開いているか確認します.
$ netstat -lt作成したアカウントで入れるか試します.
下記コマンドでSQLにログインします.
パスワード入力を求められますので入力します.$ /opt/lampp/bin/mysql -u piyo -h localhost -pきちんとログインできなければ,アカウントの設定を見直してください.
ログインした状態で,下記コマンドを入力します.SHOW VARIABLES LIKE 'skip_networking';表示結果が下記のようにskip_networkingがoffになっていたら,設定完了です.
+-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | skip_networking | OFF | +-----------------+-------+これでSQL側の準備は完了です.
JDBCの設定
次にJDBCの準備をします.
まずはaptコマンドで必要なライブラリをインストールします.$ sudo apt-get install libmysql-javajavaのコンパイル時にmysql.jarが読み込まれるように,CLASSPATHに追加しときます.
$ echo "export CLASSPATH=$CLASSPATH:/usr/share/java/mysql.jar" >> ~/.bashrcコンパイル時に毎回-cpオプションしてもいいのですが,面倒くさいのでbashに追加しときました.
下記のサンプルコードを用意します.test.javaimport java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.SQLException; public class test{ public static void main(String[] args){ final String URL = "jdbc:mysql://localhost:3306/piyo";//ホスト名:localhost データベース名:piyo final String USER = "piyo";//ユーザ名 final String PASS = "piyopass";//パスワード String SQL = "select * from book;";//SQL分(データベースbookを選択) //JDBCがインポートできているか確認 try{ Class cls = Class.forName("com.mysql.jdbc.Driver"); System.out.println("JDBC sucess"); }catch(ClassNotFoundException e){ e.printStackTrace(); System.exit(1); } //JBDCを使用してデータベースにアクセス try( Connection conn = DriverManager.getConnection(URL, USER, PASS);//SQLにログイン PreparedStatement ps = conn.prepareStatement(SQL)){//SQL文の実行 try(ResultSet rs = ps.executeQuery()){//rsにデータベース情報を格納 while(rs.next()){//選択カラムの更新 System.out.println(//読み込んだカラムの表示 rs.getInt("id") + " " + rs.getString("name") + " " + rs.getString("price") +" "+ rs.getDate("date")); } }catch(SQLException e){//データベース情報の取得エラー e.printStackTrace(); System.exit(1); } }catch(SQLException e){//ログインもしくはSQL分の実行エラー e.printStackTrace(); System.exit(1); }finally{ System.out.println("finish");//何事もなければ実行 System.exit(0); } } }コンパイル&実行します.
$ javac test.java $ java testここで,
java.sql.SQLException: No suitable driver found
エラーが発生した場合は,/usr/share/java/mysql.jarが読み込みされていない可能性があるので,
もう1度CLASSPATHを見直してください.
下記のように出力されればOKです.JDBC success 1 1st_chapter 777 2020-05-21 finishまとめ
Ubuntu環境でxmappをインストールし,JDBCでSQLコマンドを叩き,結果を取得することができました.
今後はJDBCを使ってブラウザに結果を表示させたりしたいですね.謝辞
bld1509様
UbuntuにJDBCをインストールする際に助かりました
https://bld1509.hatenadiary.org/entry/20080624/1214317382itdevats様
skip-networkingのトラブルシューティングでお世話になりました.
https://qiita.com/itdevat/items/ca5184dc8445380b966eITSakura様
サンプルコード作成の参考になりました.
https://itsakura.com/java-mysql
- 投稿日:2020-05-21T13:38:34+09:00
An unsupported Java version エラーを消す方法
Visual Studio Code で Salesforce Apex Extension をインストールした際に表示される Java のバージョンエラーですが、特に実害もなかったのでずっと放置していました。ところが最近になってウェブセミナーの実施中に飛び出してくと格好悪いと思い、一念発起して解消しておくことにしました。今回は、その方法についてのご紹介です。
エラーの内容
エラーはメッセージは以下の通りで、Java 8 か 11 を使ってね、というメッセージとともに設定方法(英語)へのリンクが表示されます。
An unsupported Java version was detected. Download and install Java 8 or Java 11 to run the extensions. For more information, see Set Your Java Version.
Java 11 をダウンロードとインストール
設定方法(英語)のページでは、以下の 4 つの JDK での設定方法が紹介されているので、環境に合ったものを選びましょう。
- AdoptOpenJDK
- Zulu
- Oracle Java 11
- Oracle Java 8
私の場合は、Salesforce コミュニティの先輩方に教えてもらった Zulu にしました。
Salesforce のデータローダーもシステム要件として Zulu OpenJDK バージョン 11 を指定しているので合わせておくことにします。VS Coce の設定
あとは、設定方法(英語)のページの指示に従って VS Code の設定ファイルに以下の記述を追記します。
setting.json{ "salesforcedx-vscode-apex.java.home": "/Library/Java/JavaVirtualMachines/zulu-11.jdk/Contents/Home" }これで、エラーとはおさらば出来るはずです。


- 投稿日:2020-05-21T00:19:19+09:00
java(継承)
継承を用いたクラスの定義
元のHeroクラス
public class Hero { String name = "勇者"; int hp = 100; //戦う public void attack(Matango m) { System.out.println(this.name + "攻撃!"); m.hp -= 5; System.out.println("5ポイントダメージをあたえた!"); } //逃げる public void run() { System.out.println(this.name + "は逃げ出した!"); } }継承を使わないSuperHeroクラス
public class SuperHero { String name = "勇者"; int hp = 100; boolean flying; //戦う public void attack(Matango m) { System.out.println(this.name + "攻撃!"); m.hp -= 5; System.out.println("5ポイントダメージをあたえた!"); } //逃げる public void run() { System.out.println(this.name + "は逃げ出した!"); } //飛ぶ public void fly() { this.flying = true; System.out.println("飛び上がった!"); } //着地する public void land() { this.flying = false; System.out.println("着地した!"); } }戦う、逃げるが重複している。
Heroクラスを変更した場合、SuperHeroクラスも変更しないといけない。継承を使用したSuperHeroクラス
public class SuperHero extends Hero{ boolean flying; //飛ぶ public void fly() { this.flying = true; System.out.println("飛び上がった!"); } //着地する public void land() { this.flying = false; System.out.println("着地した!"); } }
extend 元となるクラス名でHeroクラスを継承する。