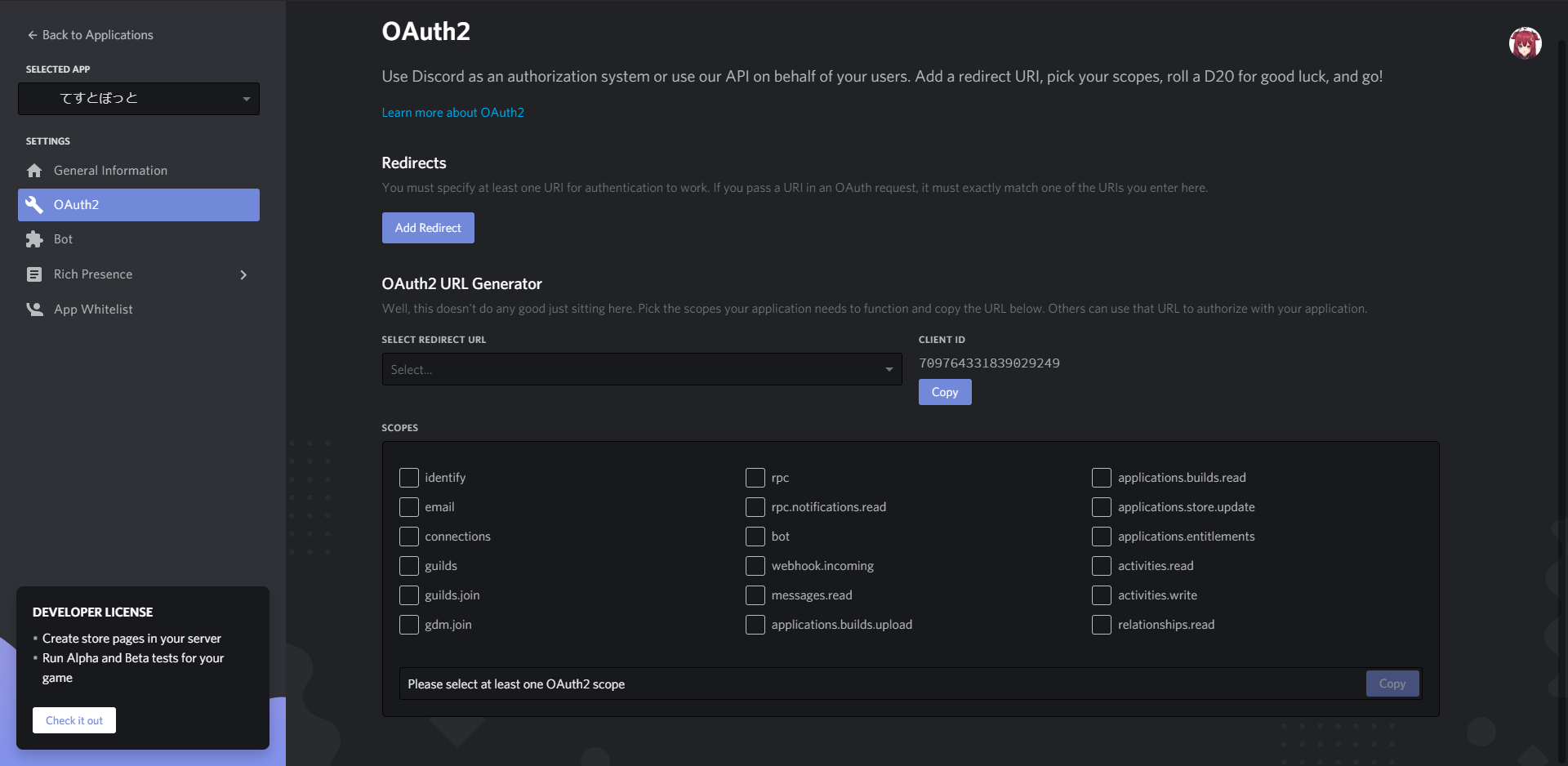
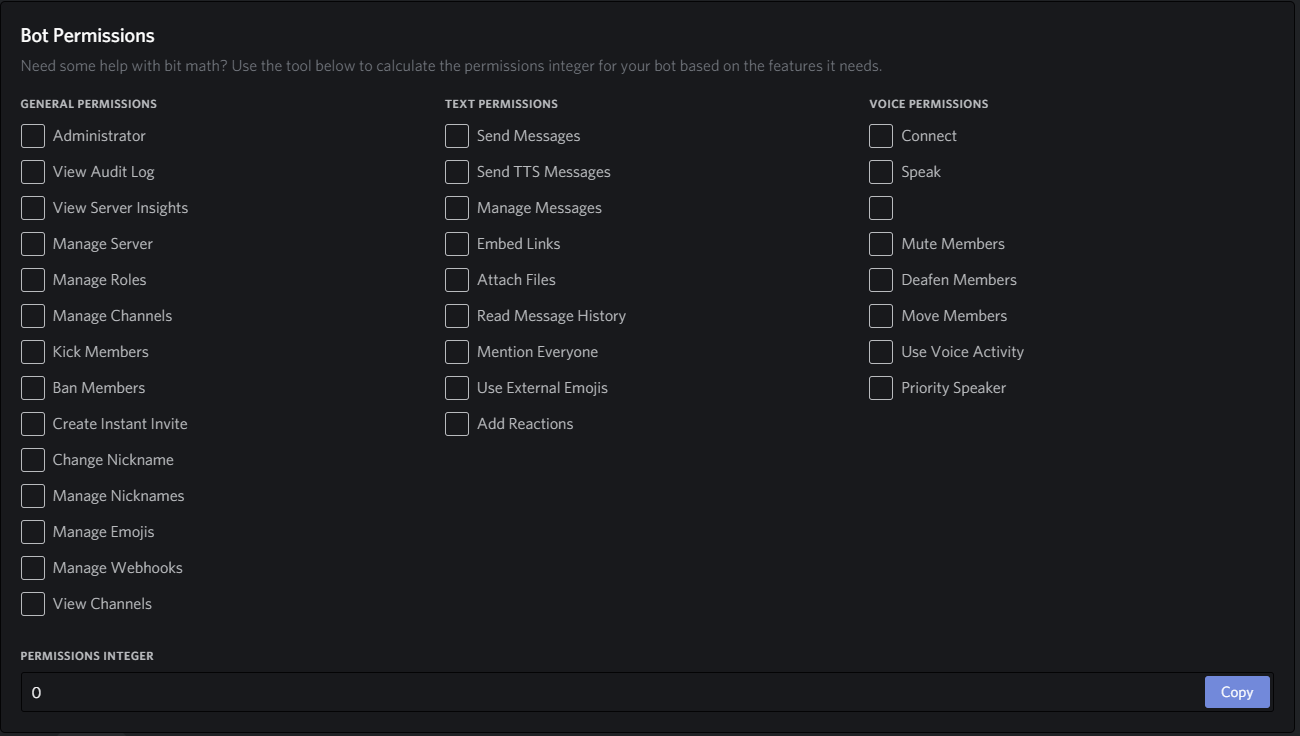
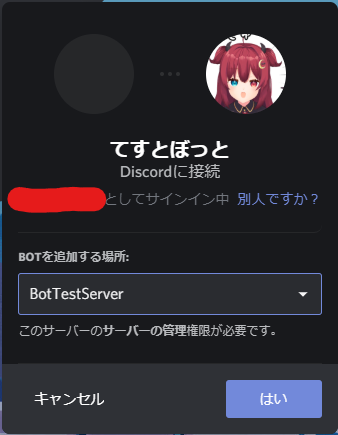
- 投稿日:2020-05-21T23:24:57+09:00
データサイエンティストへの道
はじめに
私は、 首都圏の理系大学に通う大学4年生です。
ありがたいことに早いうちに機械学習系のエンジニア職の内定をいただけました。
大学の研究室では、プログラミング言語のPythonを軸に機械学習を勉強しています。
でも、covitショックで大学の研究室にはいけなくなり、独自に勉強せねばならぬ...!
しかも、自分の実力が会社に入ってから通用するのか?勉強しなきゃ...!!!
となった僕が、今まで独学で勉強してきた物を紹介&リストアップStep1 : Pythonを理解しようぜ
機械学習やAIを勉強していくに当たって、Pythonの基本的な文法がわからんぞってなると行き詰まってしまいました。
そのため、僕が使ったPythonの勉強サイトは、こいつらです。Python以外の言語を勉強するのにも使える!EntryNo.1 : Progate
言わずと知れた、プログラミング学習サイト。
スライドと環境構築不要のエディター付きの学習サイトになっている。
解説がスライドなので、音楽を聴きながら勉強することができるのが個人的なGoodポイント。
とくにGoodなのは、後述するPaizaラーニングにもあるが、環境構築不要のエディターがあることが、初心者に優しい。
こいつだけで、結構な基礎を勉強することができる。
実際に他の言語とかも勉強することもできるし、まじで便利。おすすめ度:★★★☆☆
URL : https://prog-8.com/EntryNo.2 : Paizaラーニング
Paizaラーニングは、動画と環境構築不要のエディター付きの学習サイト。
前述のProgateと違うのが、スライドではなく動画であること。
しっかりと動画で、動いているところが見れるからしっかりと自分で手を動かしながらコードを構築することができるのがGood。また、Paizaの運営会社「paiza株式会社」は、HR(人材系)の事業をやっていることから、自分が勉強したプログラミング知識で就職活動をすることができるのがとてもよかった。
(自分もここで就職を決めることができた。)動画で基礎を勉強することができ、職にまでつなげることができるところがとてもよかった。
学習教材の内容も独自の内容なので、飽きずにやることができる。
progate同様こいつだけで、結構な基礎を勉強することができる。
実際に他の言語とかも勉強することもできるし、まじで便利。おすすめ度:★★★★☆
URL : https://paiza.jp/worksEntryNo.3 : ドットインストール
ドットインストールは、動画のみの学習サイト。
前述した二つのサイトに比べ、環境構築が必要な点がネックになっているからあまり使わなかった。ただ、強みとして前述した二つのサイトに比べて、カバーしている領域の広さがとても広い。
マイナーながら統計学をやっていれば一度は目にする「R」の講座があったり、「VBA」や「GAS」、「Docker」などの知ってたら地味に便利になる物の学習ができたり、最近では前述した二つにも増えてきたが、「AWS」の講座があったりとほんとに幅が広い。おすすめ度:★★☆☆☆
URL : https://dotinstall.com/
Step1まとめ
ここまで紹介してきたサイトのPythonの基礎を勉強することができれば、この後に記載する学習サイトでも特に苦労せずに以降できると思います。
全部やらずとも、一つだけ自分に合うと思うサイトを使えばいいと思います。
何をやれば良いかわからない人は、個人的にPaizaを使えば良いのではないかなと思っています。
就職にも繋がるって良くない?笑Step 2 機械学習・AIってなんだ?
Pythonの基礎がわかったところで、ここから機械学習について勉強をしました。
ここら辺から、僕はサイト以外にも本などを使って勉強をし始めました。EntryNo.1 : キカガク
キャッチコピーが
最先端を、最短距離で身につける。初学者から始められる学習サイト
基礎的なところから、しっかり勉強することができるサイト。
機械学習初心者から、中級者に上がるまでをサポートしてくれるようなサイト。大きく分けて、「自然言語」「画像処理」「ディープラーニング」 などの基礎的なところを無料で勉強することができるサイト。
tensorflowやpytorchのどちらかで勉強するコースが整っているが、基本的に自分の環境が整っている人向けという印象。
ただ、環境構築についてもチュートリアルで説明があるので、敷居は低め!
Google ColaboratoryというGoogle様が提供しているとても素晴らしいエディターでも一応勉強することはできる。おすすめ度:★★★★☆
URL : https://www.kikagaku.ai/EntryNo.2 : AI academy
ゴール別にカリキュラムを設定してくれるので、便利。
「AWS」「GCP」や「R」などの機械学習を扱う上で便利なその他ツールの解説などがドキュメント形式である便利なサイト。
Pythonの基本的な文法から立ち戻って勉強することができるが、基礎を勉強するならStep1のサイトの方がわかりやすかったなとか思ったり。
「画像認識」「動画認識」などの分野を勉強することができ、学べる幅が広い。ただ、深いところまで勉強するには、課金しなければいけないのだが、月額1000円ほどで勉強ができるので結構良いのではとか思って私は課金してます。環境構築についてもこのサイトにチュートリアルがあるので、しっかり自分のPCに環境を作ることもできる!
おすすめ度:★★★★☆
URL : https://aiacademy.jp/EntryNo.3 : aidemy
僕はまだあまり使いこなしていないが、AI・機械学習を勉強することができるサイト。
コース別に技能を習得することができるみたい。
あまり使ってないので、コメントは程々にしておきます。おすすめ度 : 未知数
URL : https://aidemy.net/書籍編
書籍で購入したいという方もたくさんいると思います。
僕が購入している書物をいくつか紹介します。
Python実践データ分析100本ノック
結構しっかりと勉強することができる。
データの配布もあり、分析をJupyterで行うことができるのがポイント高め。前処理大全
どちらかというとStep3であると便利な本。
辞書的な運用がメインになるけど、あると便利。Kaggleで勝つデータ分析の技術
Step3で紹介しているKaggleで使えるスキルについて書いてある本。
この本が出版されたときにKaggle上で日本のKagglerのスコアが異常に伸び、日本のKagglerが不正を疑われたとか噂がある本。
機械学習を志すなら、持っておいて損ないと思う一冊。AI白書
いるかいらないかでいうと微妙だけど、AI市場の動向はわかる。番外編
中学数学からはじめるAI(人工知能)のための数学入門
Youtuberの予備校のノリで学ぶ「大学の数学・物理」(通称:ヨビノリ)が、Aidemyとコラボした動画。
AIや機械学習のうらで動いている数学を解説してくれている動画になっており、しばらく数学とはご無沙汰だなと感じているそこのあなた!是非見てみると良いですよ!ヨビノリさんのYouTubeチャンネルはこちら
他の動画でも数学などを取り扱っているので、是非見てみてください。
言語処理100本ノック
言語処理にフォーカスをした物
東北大学の乾・岡崎研究室(当時)(現在は乾・鈴木研究室)の新人研修の一つであるプログラミング基礎勉強会で使われてきた物。Qiita上に答えのようなものが、いくつかあるので自分で勉強していくこともできると思います。
URL : https://nlp100.github.io/ja/
importについて詳しく知りたい...
まにゃpy@Python解説の猫さんのツイートのなかにあった良く分かるimportの話。
今まで、呪文のように唱えていたimportやfrom 〇〇 import ××についてシックリくる形で解説されています。Pythonのパッケージやモジュールをimportする方法は
— まにゃpy@Python解説の猫 (@uuyr112) May 18, 2020
import モジュール名
from パッケージ名 import モジュール名
import パッケージ名.モジュール名
from モジュール名 imoport 関数名
import モジュール名 as 〇〇
などがあります。これらの違いを詳しく解説しました。https://t.co/qgqaKs27t9URL : https://twitter.com/uuyr112/status/1262259224903421952?s=20
Step3 : 実際に分析してみよう!
ここまできたあなたは、きっと自分が成し遂げたいことを実現する能力を身につけていると思います。
ここから先の分析の勉強をするにあたって、方法としては大きく分けて、2つあると思います。
- コンペに参加する。
- 自分でデータを集める。 ## コンペへの参加 敷居が低いものとしては、コンペに参加することをあげることができます。 コンペとして有名なのは、
- Kaggle
- Quevico AI Competitions
- Signate
などがあると思います。
Kaggle
世界中のデータサイエンティストがしのぎを削るコンペ
最先端のアルゴリズムなどを使っている人もいるため、Kernelというコードを読んでいるだけでもとてもとても勉強になる。
ただ、データサイエンスの領域になると文化的側面やコンペ対象に深い知識がないと難しい。
そういった面で、外国発のコンペということもあって、難しいように感じる。Step2までとは違って、ほんとに難しい。
これをやるといきなり100点を目指さずに、不完全でも良いからアウトプットをしていくことの大切さを知る。
Kaggleチュートリアルは、いろんな方が出しているので、それをやっていくことで力を伸ばせるのでは?と思っています。みなさんお馴染みのメルカリについてのコンペもあり、ここから僕は入りました。
メルカリチュートリアル他に有名ところだとタイタニック号などもありますので、様々なチュートリアルを経てコンペにチャレンジしてみると良いかもしれないです。
Quevico AI Competitions
最近できたコンペ。
Instagramの広告で出てきた。コンペ数が少ないが、しっかりとstep2で勉強したことが生かせそうなコンペになってる。
言語が日本語なのも、嬉しいポイントSignate
日本発のデータサイエンスコンペ。
言語が日本語で、コビットチャレンジなどもあって、日本のデータサイエンスの中心地になればなと思っている。
人のkarnelが見れないのが少し残念自分でデータを集める。
自分でデータを集めるとなったら、やれることは無限大です。
ただ、追加で取得しなければいけない技術として、スクレイピングの技術が必要になります。スクレイピングは、様々なサイトで勉強できますが、AI academyである程度勉強できるので、一度こちらで勉強してみるのも良いかもしれないです。
個人的に使っているデータ収集の方法
Twitter developer
Twitter APIを取得することができる開発者アカウントの申請をすることができる。
意外とできることが多くて、可能性がすごく大きい。オープンソースのデータセットが手に入るサイト
自分でいつか使おうと思ってストックしているサイトです。
FineReportさんが公開しているデータ分析に必要なオープンデータ20選から抜粋したものです。
番外編
市場調査系レポート
変数選択などのアイディアを得ることができそうなレポートを提供してくれるサイト。
自分でいつか使おうと思ってストックです。博報堂生活総合研究所
博報堂が、収集したデータがレポート形式で、アップロードされているサイト。
マクロミル
市場調査事例や分析事例がレポート形式でみることができるサイト
DODA
就職状況のレポートをみることができる。
最後に
今まで勉強したサイトなどをリスト化しました。
これで、慌てて記憶の底からなんだったけなーと思わなくてすみそうです。笑
COVITショックがあり、GWあたりから無料で学べるツールサイトが多くなってきて、とても勉強のやりがいがある一方で、自分が目指している業界の競争率が高くなりそうで、焦っています。今後は動画解析などの技術を身につけて、TikTokの分析とかしてみたいなと思っています。
TikTokのAPIがあるみたいなので、チャレンジしたいと思っています。最後にここまで長い間読んでくださった方ありがとうございます。
参考文献
紹介サイトまとめ
- Progate様
- Paizaラーニング様
- ドットインストール様
- キカガク様
- AI academy様
- aidemy様
- Youtuberの予備校のノリで学ぶ「大学の数学・物理」様
- 乾・鈴木研究室様
- Kaggle様
- Quevico AI Competitions様
- Signate様
- まにゃpy@Python解説の猫様
- FineReport様
- Twitter developer様
- 日本本統計局様
- YouTubeデータセット様
- Google Trend Search様
- 博報堂生活総合研究所様
- マクロミル様
- DODA様
良質なコンテンツの提供ありがとうございます。
掲載してはいけない内容などありましたら、削除します。
- 投稿日:2020-05-21T22:19:12+09:00
Python: 日本語テキスト:単語の類似性から発話の特徴
単語の類似性を知る
発話テキストの形態素解析
Python: 日本語テキスト:形態素解析では
「分析対象データの読み込み」と「自然言語処理の前処理の基本」を学びました。
この投稿ではでは、これまでに学んだ内容を活かして、分析対象である「発話データセットの加工の手法」を学びます。
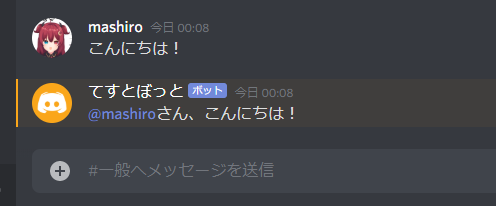
特に、単語の類似性に着目した前処理の実装を行います。今回のデータセットのフラグには
O破綻ではない発話
T破綻とは言い切れないが違和感のある発話
X明らかにおかしいと感じる発話、の3種類があります。ここでは、O破綻ではない発話 のフラグを元に処理していきます。
例題で出現する変数について
破綻ではない発話のみを抽出した変数df_label_text_Oの内容(49行目)
index と column が含まれるNumPy配列のndarrayです。0 1 1 O すみません、あなたは誰ですか? 24 O そうなんですか。高校野球がお好きなんですか? 48 O 甲子園でしょ? ... .. ... 2376 O そうですか。破綻ではない発話データセットを処理する際に用いる変数rowの内容(62行目)
rowは、tolist()を用いて
NumPy配列ndarrayのdf_label_text_OをPythonのリスト型に変換した値です。[['O', 'すみません、あなたは誰ですか?'], ['O', 'そうなんですか。高校野球がお好きなんですか?'], ['O', '甲子園でしょ?'], ... ['O', 'そうですか。']]例題はこちら
import os import json import pandas as pd import re from janome.tokenizer import Tokenizer # init100ディレクトリを指定 file_path = './6110_nlp_preprocessing_data/init100/' file_dir = os.listdir(file_path) # フラグと発話内容を格納する空のリストを作成 label_text = [] # JSONファイルを1ファイルずつ10ファイル分処理 for file in file_dir[:10]: # 読み込み専用モードで読み込み r = open(file_path + file, 'r', encoding='utf-8') json_data = json.load(r) # 発話データ配列`turns`から発話内容とフラグを抽出 for turn in json_data['turns']: turn_index = turn['turn-index'] # 発話ターンNo speaker = turn['speaker'] # 話者ID utterance = turn['utterance'] # 発話内容 # 先頭行はシステムの発話なので除外 if turn_index != 0: # 人の発話内容を抽出 if speaker == 'U': u_text = '' u_text = utterance else: a = '' for annotate in turn['annotations']: # 破綻かどうかのフラグを抽出 a = annotate['breakdown'] # フラグと人の発話内容をリストに格納 tmp1 = str(a) + '\t' + u_text tmp2 = tmp1.split('\t') label_text.append(tmp2) # リスト`label_text`をDataFrameに変換 df_label_text = pd.DataFrame(label_text) # 重複する行を削除 df_label_text = df_label_text.drop_duplicates() # 破綻ではない発話のみを抽出 df_label_text_O = df_label_text[df_label_text[0] == 'O'] t = Tokenizer() # 空の破綻ではない発話データセットを作成 morpO = [] # 分かち書きした単語を格納 tmp1 = [] tmp2 = '' # 1行ずつ読み込み # .values:indexやcolumnを除いて読み込み # .tolist:NumPy配列ndarrayをPythonのリスト型に変換 for row in df_label_text_O.values.tolist(): # 正規表現で数字とアルファベットの大文字・小文字を除去してください reg_row = re.sub('[0-9a-zA-Z]+', '', row[1]) reg_row = reg_row.replace('\n', '') # Janomeで形態素解析を行います for token in t.tokenize(reg_row): # 単語の表層系を`morpO`に追加してください tmp1.append(token.surface) tmp2 = ' '.join(tmp1) morpO.append(tmp2) tmp1 = [] # 形態素解析した単語を出力 pd.DataFrame(morpO)
単語文書行列とは
自然言語データを解析するには、単語データ(文章データ)を数値データへ変換すればよいと説明しました。
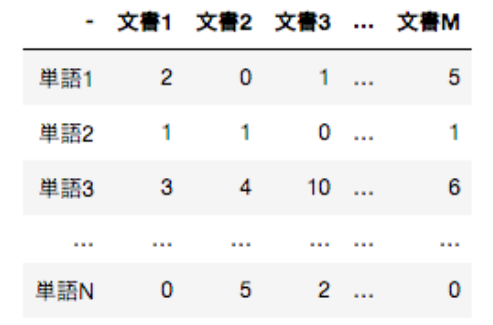
その変換の方法の一つに単語文書行列(term-document matrix)と呼ばれるものがあります。単語文書行列とは、文書に出現する単語の頻度 を表形式で表したものです。
各文書に含まれる単語データは形態素解析によって得ることができ
そこから各単語の出現数をカウントして数値データに変換しています。単語文書行列は、行方向に単語/列方向に文書、もしくはその逆の行方向に文書/列方向に
単語を並べた行列形式で表現されます。
全N種類の単語と全M個の文書があるとき、N行×M列の単語文書行列と呼びます。
図の単語文書行列は、文書1には単語1が2回、単語2が1回、単語3が3回、・・・、単語Nが0回
出現することを表しています。単語の出現回数をカウントするには Python標準ライブラリのcollections.Counter()を用いるなど方法はいくつかありますが ここではscikit-learn(サイキット・ラーン)のCountVectorizer()を用いて 単語文書行列を作成する一例を示します。 CountVectorizer()はテキストを単語に分割し、単語の出現回数を数えます。from sklearn.feature_extraction.text import CountVectorizer # `CountVectorizer()`を用いた変換器を生成します CV = CountVectorizer() corpus = ['This is a pen.', 'That is a bot.',] # `fit_transform()`で`corpus`の学習と、単語の出現回数を配列に変換します X = CV.fit_transform(corpus) print(X) >>> 出力結果 (0, 2) 1 (0, 1) 1 (0, 4) 1 (1, 0) 1 (1, 3) 1 (1, 1) 1 # `get_feature_names()`で学習した単語が入っているリストを確認します print(CV.get_feature_names()) >>> 出力結果 ['bot', 'is', 'pen', 'that', 'this'] # カウントした出現回数を`toarray()`でベクトルに変換して表示します print(X.toarray()) >>> 出力結果 # 行:`corpus`で与えた文章の順 # 列:`get_feature_names()`で確認した単語の順 [[0 1 1 0 1] [1 1 0 1 0]]使用例はこちら
import os import json import pandas as pd import numpy as np import re from janome.tokenizer import Tokenizer from sklearn.feature_extraction.text import CountVectorizer # init100ディレクトリを指定 file_path = './6110_nlp_preprocessing_data/init100/' file_dir = os.listdir(file_path) # フラグと発話内容を格納する空のリストを作成 label_text = [] # JSONファイルを1ファイルずつ10ファイル分処理 for file in file_dir[:10]: r = open(file_path + file, 'r', encoding='utf-8') json_data = json.load(r) # 発話データ配列`turns`から発話内容とフラグを抽出 for turn in json_data['turns']: turn_index = turn['turn-index'] speaker = turn['speaker'] utterance = turn['utterance'] if turn_index != 0: if speaker == 'U': u_text = '' u_text = utterance else: a = '' for annotate in turn['annotations']: a = annotate['breakdown'] tmp1 = str(a) + '\t' + u_text tmp2 = tmp1.split('\t') label_text.append(tmp2) # リスト`label_text`をDataFrameに変換し、重複を削除 df_label_text = pd.DataFrame(label_text) df_label_text = df_label_text.drop_duplicates() # 破綻ではない発話のみを抽出 df_label_text_O = df_label_text[df_label_text[0] == 'O'] t = Tokenizer() # 空の破綻ではない発話データセットを作成 morpO = [] tmp1 = [] tmp2 = '' # 数字とアルファベットの大文字・小文字を除去 for row in df_label_text_O.values.tolist(): reg_row = re.sub('[0-9a-zA-Z]+', '', row[1]) reg_row = reg_row.replace('\n', '') # Janomeで形態素解析 for token in t.tokenize(reg_row): tmp1.append(token.surface) tmp2 = ' '.join(tmp1) morpO.append(tmp2) tmp1 = [] # リスト形式からNumPy配列へ変換(arrayのほうが計算速度が速いため) morpO_array = np.array(morpO) # 単語の出現回数をカウントしてください cntvecO = CountVectorizer() # 学習を行い、単語の出現回数を配列に変換してください morpO_cntvecs = cntvecO.fit_transform(morpO_array) # ndarray配列に変換 morpO_cntarray = morpO_cntvecs.toarray() # DataFrame形式で単語の出現回数を表示 # columns(列):分割した単語 # index(行):元の発話データ pd.DataFrame(morpO_cntarray, columns=cntvecO.get_feature_names(), index=morpO).head(20)
1文字単語の注意
デフォルトでは1文字の単語はカウントされません。
日本語には1文字でも意味を持つ単語があるので、日本語を扱う場合には注意が必要です。
1文字の単語もカウントするにはCountVectorizer()にtoken_pattern='(?u)\b\w+\b'を指定します。CountVectorizer(token_pattern='(?u)\\b\\w+\\b')重みあり単語文書行列とは
単語の出現回数(頻度)を値として持つ単語文書行列では
どの文書においても普遍的に出現する単語(例えば「私」「です」など)の出現頻度が高くなる傾向があります。一方、特定の文書にのみ出現する単語の出現頻度が低くなり
単語から各文書を特徴付けることが難しくなります。
そのため、単語文書行列では単語の出現頻度 TF(Term Frequency)に 逆文書頻度 IDF(Inverse Document Frequency)を掛けた TF-IDF 値が多く利用されます。ある単語のIDF値は、log(総文書数/ある単語が出現する文書数)+ 1 で計算できます。
例えば、ある単語が全4文書中3文書に含まれていれば
IDF値は log(4/3)+1≒1.1 となり
特定の文書にのみ出現する単語ほどIDF値が大きくなります。IDF値が大きいということは、その単語の重要度が高く、その文書の特徴であると言えます。
TFからIDFを計算し、TFとIDFを掛けたTF-IDF値を算出することができます。
以下にTfidfVectorizer()を用いたTF-IDF値による重みあり単語文書行列を作成する一例を示します。
import numpy as np from sklearn.feature_extraction.text import TfidfVectorizer # 小数点以下を有効数字2桁で表示する np.set_printoptions(precision=2) docs = np.array([ "白 黒 赤", "白 白 黒", "赤 黒" ]) # `TfidfVectorizer()`を用いた変換器を生成します vectorizer = TfidfVectorizer(use_idf=True, token_pattern="(?u)\\b\\w+\\b") # `fit_transform()`で`docs`の学習と、重み付けされた単語の出現回数を配列に変換します vecs = vectorizer.fit_transform(docs) print(vecs.toarray()) # >> 出力結果 [[ 0.62 0.62 0.48] [ 0.93 0. 0.36] [ 0. 0.79 0.61]]①vectorizer = TfidfVectorizer()で ベクトル表現化(単語を数値化すること)を行う変換器を生成します。 ②use_idf=Falseにすると、tfのみの重み付けになります。 ③vectorizer.fit_transform()で、文書をベクトルに変換します。 引数には、空白文字によって分割された(分かち書きされた)配列を与えます。 ④toarray()によって出力をNumPyのndarray配列に変換します。np.set_printoptions()は、NumPy配列の表示のフォーマットを定める関数です。 print()で値を表示する際にのみ有効な設定で元の値は変わりません。 引数precision=には小数点以下の表示桁数を指定します。使用例はこちら
import os import json import pandas as pd import numpy as np import re from janome.tokenizer import Tokenizer from sklearn.feature_extraction.text import TfidfVectorizer # init100ディレクトリを指定 file_path = './6110_nlp_preprocessing_data/init100/' file_dir = os.listdir(file_path) # フラグと発話内容を格納する空のリストを作成 label_text = [] # JSONファイルを1ファイルずつ10ファイル分処理 for file in file_dir[:10]: r = open(file_path + file, 'r', encoding='utf-8') json_data = json.load(r) # 発話データ配列`turns`から発話内容とフラグを抽出 for turn in json_data['turns']: turn_index = turn['turn-index'] speaker = turn['speaker'] utterance = turn['utterance'] if turn_index != 0: if speaker == 'U': u_text = '' u_text = utterance else: a = '' for annotate in turn['annotations']: a = annotate['breakdown'] tmp1 = str(a) + '\t' + u_text tmp2 = tmp1.split('\t') label_text.append(tmp2) # リスト`label_text`をDataFrameに変換し、重複を削除 df_label_text = pd.DataFrame(label_text) df_label_text = df_label_text.drop_duplicates() # 破綻ではない発話のみを抽出 df_label_text_O = df_label_text[df_label_text[0] == 'O'] t = Tokenizer() # 空の破綻ではない発話データセットを作成 morpO = [] tmp1 = [] tmp2 = '' # 数字とアルファベットの大文字・小文字を除去 for row in df_label_text_O.values.tolist(): reg_row = re.sub('[0-9a-zA-Z]+', '', row[1]) reg_row = reg_row.replace('\n', '') # Janomeで形態素解析 for token in t.tokenize(reg_row): tmp1.append(token.surface) tmp2 = ' '.join(tmp1) morpO.append(tmp2) tmp1 = [] # リスト形式からNumPy配列へ変換(arrayのほうが計算速度が速いため) morpO_array = np.array(morpO) # ①ベクトル表現化を行う変換器を生成 tfidf_vecO = TfidfVectorizer(use_idf=True) # ②単語をベクトル表現に変換 morpO_tfidf_vecs = tfidf_vecO.fit_transform(morpO_array) # ③ndarray配列に変換 morpO_tfidf_array = morpO_tfidf_vecs.toarray() # DataFrame形式で単語(ベクトル表現)を表示してください pd.DataFrame(morpO_tfidf_array, columns=tfidf_vecO.get_feature_names(), index=morpO).head(20)
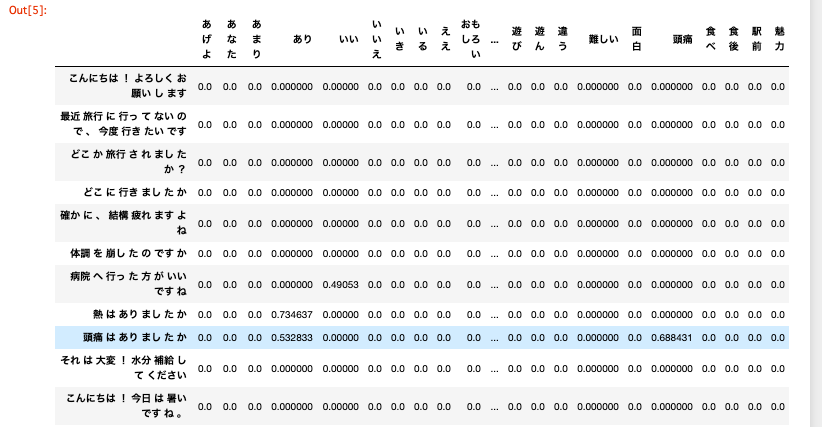
単語の類似度(相関)を計算
特徴量 とは、そのデータが持つ他のデータとは異なる特徴です。CountVectorizer()で作成した単語文書行列では単語の出現回数を
TfidfVectorizer()で作成した単語文書行列では単語のTF-IDF値を単語の特徴量としています。例えば、画像に写っている物体が犬か猫かを見分ける時
まず無意識に耳の形に目がいくのではないでしょうか。この場合、耳(を含む領域)が特徴量と言えます。
文書分類の問題では、各単語を特徴量として使用し、教師あり学習モデルを作成します。ここでは上記とは異なる、2つの単語の出現の仕方がどの程度似ているか
つまり類似度を特徴量とした、教師なし学習モデル を作成します。類似度を測る方法として身近なものは相関係数ですが
その他にベクトル同士の類似度を測る コサイン類似度や 集合同士の類似度を測る Jaccard係数 が有名です。ここでは、類似度を求めるのにpandas.DataFrameのcorr()メソッドを用い
各列間の相関係数を算出します。corr()メソッドはデータ型が数値型・ブール型の列が計算対象となり
文字列や欠損値NaNは除外されます。corr = DataFrame.corr()corr()の引数には相関係数の算出方法を以下より指定します。
'pearson':ピアソンの積率相関係数(デフォルト) 'kendall':ケンドールの順位相関係数 'spearman':スピアマンの順位相関係数使用例はこちら
import os import json import pandas as pd import numpy as np import re from janome.tokenizer import Tokenizer from sklearn.feature_extraction.text import TfidfVectorizer # init100ディレクトリを指定 file_path = './6110_nlp_preprocessing_data/init100/' file_dir = os.listdir(file_path) # フラグと発話内容を格納する空のリストを作成 label_text = [] # JSONファイルを1ファイルずつ10ファイル分処理 for file in file_dir[:10]: r = open(file_path + file, 'r', encoding='utf-8') json_data = json.load(r) # 発話データ配列`turns`から発話内容とフラグを抽出 for turn in json_data['turns']: turn_index = turn['turn-index'] speaker = turn['speaker'] utterance = turn['utterance'] if turn_index != 0: if speaker == 'U': u_text = '' u_text = utterance else: a = '' for annotate in turn['annotations']: a = annotate['breakdown'] tmp1 = str(a) + '\t' + u_text tmp2 = tmp1.split('\t') label_text.append(tmp2) # リスト`label_text`をDataFrameに変換し、重複を削除 df_label_text = pd.DataFrame(label_text) df_label_text = df_label_text.drop_duplicates() # 破綻ではない発話のみを抽出 df_label_text_O = df_label_text[df_label_text[0] == 'O'] t = Tokenizer() # 空の破綻ではない発話データセットを作成 morpO = [] tmp1 = [] tmp2 = '' # 数字とアルファベットの大文字・小文字を除去 for row in df_label_text_O.values.tolist(): reg_row = re.sub('[0-9a-zA-Z]+', '', row[1]) reg_row = reg_row.replace('\n', '') # Janomeで形態素解析 for token in t.tokenize(reg_row): tmp1.append(token.surface) tmp2 = ' '.join(tmp1) morpO.append(tmp2) tmp1 = [] # TF-IDF値による重みありの単語文書行列を作成 morpO_array = np.array(morpO) tfidf_vecO = TfidfVectorizer(use_idf=True) morpO_tfidf_vecs = tfidf_vecO.fit_transform(morpO_array) morpO_tfidf_array = morpO_tfidf_vecs.toarray() # 単語の出現回数をDataFrame形式に変換 dtmO = pd.DataFrame(morpO_tfidf_array, columns=tfidf_vecO.get_feature_names(), index=morpO).head(20) # 相関行列を作成 corr_matrixO = dtmO.corr().abs() # `.abs()` は絶対値を求めるメソッドです # 相関行列の表示 corr_matrixO
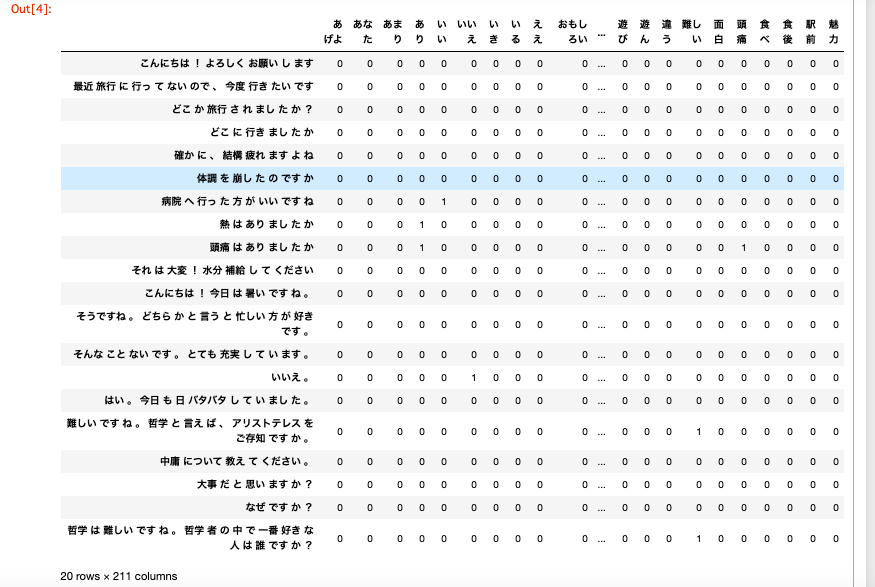
単語の類似性から発話の特徴を知る
類似度リストの作成
ここからは、前節で作成した2つの単語の相関係数を特徴量としたネットワーク分析によって
定量的な分析を行っていきます。ネットワーク分析を行うために、相関係数を行列形式からリスト形式へ変換します。
行列形式をリスト形式に変換するには pandas.DataFrameのstack()メソッドを用います。from pandas import DataFrame # DataFrameを用意 df=DataFrame([[0.1,0.2,0.3],[0.4,'NaN',0.5]], columns=['test1','test2','test3'], index=['AA','BB']) print(df) # >>> 出力結果 test1 test2 test3 AA 0.1 0.2 0.3 BB 0.4 NaN 0.5 # stack : 列から行への変換 print(df.stack()) # >>> 出力結果 AA test1 0.1 test2 0.2 test3 0.3 BB test1 0.4 test2 NaN test3 0.5 # unstack : 行から列への変換 print(df.unstack()) # >>> 出力結果 test1 AA 0.1 BB 0.4 test2 AA 0.2 BB NaN test3 AA 0.3 BB 0.5使用例はこちら
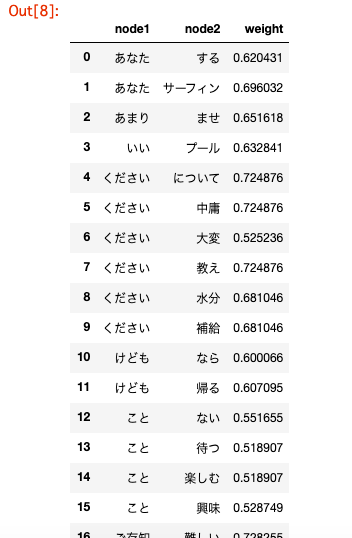
import os import json import pandas as pd import numpy as np import re from janome.tokenizer import Tokenizer from sklearn.feature_extraction.text import TfidfVectorizer # init100ディレクトリを指定 file_path = './6110_nlp_preprocessing_data/init100/' file_dir = os.listdir(file_path) # フラグと発話内容を抽出したリストを作成 label_text = [] for file in file_dir[:10]: r = open(file_path + file, 'r', encoding='utf-8') json_data = json.load(r) for turn in json_data['turns']: turn_index = turn['turn-index'] speaker = turn['speaker'] utterance = turn['utterance'] if turn_index != 0: if speaker == 'U': u_text = '' u_text = utterance else: a = '' for annotate in turn['annotations']: a = annotate['breakdown'] tmp1 = str(a) + '\t' + u_text tmp2 = tmp1.split('\t') label_text.append(tmp2) # 重複を削除し、破綻ではない発話のみを抽出 df_label_text = pd.DataFrame(label_text) df_label_text = df_label_text.drop_duplicates() df_label_text_O = df_label_text[df_label_text[0] == 'O'] # Janomeによる形態素解析 t = Tokenizer() morpO = [] tmp1 = [] tmp2 = '' for row in df_label_text_O.values.tolist(): reg_row = re.sub('[0-9a-zA-Z]+', '', row[1]) reg_row = reg_row.replace('\n', '') for token in t.tokenize(reg_row): tmp1.append(token.surface) tmp2 = ' '.join(tmp1) morpO.append(tmp2) tmp1 = [] # TF-IDF値による重みありの単語文書行列を作成 morpO_array = np.array(morpO) tfidf_vecO = TfidfVectorizer(use_idf=True) morpO_tfidf_vecs = tfidf_vecO.fit_transform(morpO_array) morpO_tfidf_array = morpO_tfidf_vecs.toarray() # DataFrame形式に変換し、相関行列を作成 dtmO = pd.DataFrame(morpO_tfidf_array, columns=tfidf_vecO.get_feature_names(), index=morpO) corr_matrixO = dtmO.corr().abs() # 相関行列`corr_matrixO`を列方向から行方向へ変換してください corr_stackO = corr_matrixO.stack() index = pd.Series(corr_stackO.index.values) value = pd.Series(corr_stackO.values) # 相関係数が0.5以上1.0未満のものを抽出 tmp3 = [] # 相関係数が0.5以上1.0未満の値を持つindex値のリスト tmp4 = [] # 相関係数が0.5以上1.0未満のvalue値のリスト for i in range(0, len(index)): if value[i] >= 0.5 and value[i] < 1.0: tmp1 = str(index[i][0]) + ' ' + str(index[i][1]) tmp2 = [s for s in tmp1.split()] tmp3.append(tmp2) tmp4 = np.append(tmp4, value[i]) tmp3 = pd.DataFrame(tmp3) tmp3 = tmp3.rename(columns={0: 'node1', 1: 'node2'}) tmp4 = pd.DataFrame(tmp4) tmp4 = tmp4.rename(columns={0: 'weight'}) # DataFrame`tmp3`と`tmp4`を横方向に連結してください df_corlistO = pd.concat([tmp3, tmp4], axis=1) # 作成したDataFrameを表示 df_corlistO.head(20)
類似度ネットワークの作成
ネットワークは対象と対象の 関係を表現する方法の一つです。
有名な例として、SNSにおける友だち関係のネットワークがあります。ネットワーク構造では 対象はノードで 関係はエッジで表現されます。エッジは重みを持ち、友だち関係のネットワークにおいては親密度にあたります。
親密であればあるほど重みの値は大きくなります。他にも、路線図や航空網、単語の共起・類似関係もネットワークで表現できます。
前節で作成した類似度リストのように、エッジに方向の概念がなく関係性のない言語群を可視化するには
無向グラフ(または 無向ネットワーク)を利用します。なお、重み付きのグラフをネットワークとも呼びます。
無向グラフとは、ネットワークを構成するエッジが方向性を持たないものです。
それとは逆に、エッジが方向性を持つものを有向グラフ(または有向ネットワーク)と呼びます。無向グラフ(無向ネットワーク)の作成
Pythonには NetworkX と呼ばれるライブラリがあります。
本セクションではこのライブラリを用いて、前節で作成した類似度リストの可視化を行います。# ライブラリ`NetworkX`をimport import networkx as nx # 無向グラフの作成 network = nx.from_pandas_edgelist(df, source='source', target='target', edge_attr=None, create_using=None)①df:グラフの元となるPandasのDataFrame名 ②source:ソースノードの列名 str(文字列型)またはint(整数型)で指定する ③target:対象ノードの列名 strまたはintで指定する ④edge_attr:それぞれのデータのエッジ(重み) strまたはint、iterable、Trueで指定する ⑤create_using:グラフのタイプ(オプション) 無向グラフ:nx.Graph(デフォルト) 有向グラフ:nx.DiGraphグラフ(ネットワーク)の可視化
# ライブラリ`Matplotlib`から`pyplot`をimport from matplotlib import pyplot # 各ノードの最適な表示位置を計算 pos = nx.spring_layout(graph) # グラフを描画 nx.draw_networkx(graph, pos) # Matplolibを用いてグラフを表示 plt.show()使用例はこちら
import os import json import pandas as pd import numpy as np import re from janome.tokenizer import Tokenizer from sklearn.feature_extraction.text import TfidfVectorizer import networkx as nx import matplotlib.pyplot as plt # init100ディレクトリを指定 file_path = './6110_nlp_preprocessing_data/init100/' file_dir = os.listdir(file_path) # フラグと発話内容を抽出したリストを作成 label_text = [] for file in file_dir[:10]: r = open(file_path + file, 'r', encoding='utf-8') json_data = json.load(r) for turn in json_data['turns']: turn_index = turn['turn-index'] speaker = turn['speaker'] utterance = turn['utterance'] if turn_index != 0: if speaker == 'U': u_text = '' u_text = utterance else: a = '' for annotate in turn['annotations']: a = annotate['breakdown'] tmp1 = str(a) + '\t' + u_text tmp2 = tmp1.split('\t') label_text.append(tmp2) # 重複を削除し、破綻ではない発話のみを抽出 df_label_text = pd.DataFrame(label_text) df_label_text = df_label_text.drop_duplicates() df_label_text_O = df_label_text[df_label_text[0] == 'O'] # Janomeによる形態素解析 t = Tokenizer() morpO = [] tmp1 = [] tmp2 = '' for row in df_label_text_O.values.tolist(): reg_row = re.sub('[0-9a-zA-Z]+', '', row[1]) reg_row = reg_row.replace('\n', '') for token in t.tokenize(reg_row): tmp1.append(token.surface) tmp2 = ' '.join(tmp1) morpO.append(tmp2) tmp1 = [] # TF-IDF値による重みありの単語文書行列を作成 morpO_array = np.array(morpO) tfidf_vecO = TfidfVectorizer(use_idf=True) morpO_tfidf_vecs = tfidf_vecO.fit_transform(morpO_array) morpO_tfidf_array = morpO_tfidf_vecs.toarray() # DataFrame形式に変換し、相関行列を作成 dtmO = pd.DataFrame(morpO_tfidf_array) corr_matrixO = dtmO.corr().abs() # 破綻ではない発話データセットの作成 corr_stackO = corr_matrixO.stack() index = pd.Series(corr_stackO.index.values) value = pd.Series(corr_stackO.values) tmp3 = [] tmp4 = [] for i in range(0, len(index)): if value[i] >= 0.5 and value[i] < 1.0: tmp1 = str(index[i][0]) + ' ' + str(index[i][1]) tmp2 = [int(s) for s in tmp1.split()] tmp3.append(tmp2) tmp4 = np.append(tmp4, value[i]) tmp3 = pd.DataFrame(tmp3) tmp3 = tmp3.rename(columns={0: 'node1', 1: 'node2'}) tmp4 = pd.DataFrame(tmp4) tmp4 = tmp4.rename(columns={0: 'weight'}) df_corlistO = pd.concat([tmp3, tmp4], axis=1) # ①無向グラフを作成 G_corlistO = nx.from_pandas_edgelist(df_corlistO, 'node1', 'node2', ['weight']) # ②作成したグラフを可視化 # レイアウトの設定 pos = nx.spring_layout(G_corlistO) nx.draw_networkx(G_corlistO, pos) plt.show()
類似度ネットワークの特徴
前節で可視化したグラフのように、実際のネットワークは複雑な構造が多いため
一見して特徴を把握することは困難です。このような場合には、何らかの指標をもって定量的に特徴を把握します。
その指標には、ネットワーク全体を把握するためのもの(大域的)もあれば
あるノードに着目して把握するもの(局所的)もあります。一般的に使用されている指標の例をいくつか挙げます。
次数:ノードが持つエッジの本数を表します。 次数分布:ある次数を持つノード数のヒストグラムを表します。 クラスタ係数:ノード間がどの程度密に繋がっているかを表します。 経路長:あるノードから他のノードへ至るまでの距離です。 中心性:あるノードがネットワークにおいて中心的な役割を果たす度合いを表します。それでは、前節で作成したネットワークについて、クラスタ係数と媒介中心性を計算し
特徴を見ていきます。このネットワークでは
クラスタ係数は単語間のつながり密度を
媒介中心性はネットワークにおける単語のハブ度合いを表します。破綻ではない発話と破綻である発話、それぞれのネットワークにおいて平均クラスタ係数を比較すると
破綻である発話の単語のほうが密につながっていることが分かります。また、媒介中心性の高い上位5単語を比較してみると
破綻ではない発話にはお盆休みに関する単語が
破綻である発話には早朝の野球に関する単語が中心的な役割を果たしていると推測できます。①破綻ではない発話 <平均クラスタ係数> 0.051924357 <媒介中心性の高い上位5単語> 休み、お盆、ここ、少ない、明け ②破綻である発話 <平均クラスタ係数> 0.069563257 <媒介中心性の高い上位5単語> 今度、ましょ、野球、早朝、かれ使用例はこちら
import os import json import pandas as pd import numpy as np import re from janome.tokenizer import Tokenizer from sklearn.feature_extraction.text import TfidfVectorizer import networkx as nx import matplotlib.pyplot as plt # init100ディレクトリを指定 file_path = './6110_nlp_preprocessing_data/init100/' file_dir = os.listdir(file_path) # フラグと発話内容を抽出したリストを作成 label_text = [] for file in file_dir[:10]: r = open(file_path + file, 'r', encoding='utf-8') json_data = json.load(r) for turn in json_data['turns']: turn_index = turn['turn-index'] speaker = turn['speaker'] utterance = turn['utterance'] if turn_index != 0: if speaker == 'U': u_text = '' u_text = utterance else: a = '' for annotate in turn['annotations']: a = annotate['breakdown'] tmp1 = str(a) + '\t' + u_text tmp2 = tmp1.split('\t') label_text.append(tmp2) # 重複を削除し、破綻ではない発話のみを抽出 df_label_text = pd.DataFrame(label_text) df_label_text = df_label_text.drop_duplicates() df_label_text_O = df_label_text[df_label_text[0] == 'O'] # Janomeによる形態素解析 t = Tokenizer() morpO = [] tmp1 = [] tmp2 = '' for row in df_label_text_O.values.tolist(): reg_row = re.sub('[0-9a-zA-Z]+', '', row[1]) reg_row = reg_row.replace('\n', '') for token in t.tokenize(reg_row): tmp1.append(token.surface) tmp2 = ' '.join(tmp1) morpO.append(tmp2) tmp1 = [] # TF-IDF値による重みありの単語文書行列を作成 morpO_array = np.array(morpO) tfidf_vecO = TfidfVectorizer(use_idf=True) morpO_tfidf_vecs = tfidf_vecO.fit_transform(morpO_array) morpO_tfidf_array = morpO_tfidf_vecs.toarray() # DataFrame形式に変換し、相関行列を作成 dtmO = pd.DataFrame(morpO_tfidf_array, columns=tfidf_vecO.get_feature_names(), index=morpO) corr_matrixO = dtmO.corr().abs() # 破綻ではない発話データセットの作成 corr_stackO = corr_matrixO.stack() index = pd.Series(corr_stackO.index.values) value = pd.Series(corr_stackO.values) tmp3 = [] tmp4 = [] for i in range(0, len(index)): if value[i] >= 0.5 and value[i] < 1.0: tmp1 = str(index[i][0]) + ' ' + str(index[i][1]) tmp2 = [s for s in tmp1.split()] tmp3.append(tmp2) tmp4 = np.append(tmp4, value[i]) tmp3 = pd.DataFrame(tmp3) tmp3 = tmp3.rename(columns={0: 'node1', 1: 'node2'}) tmp4 = pd.DataFrame(tmp4) tmp4 = tmp4.rename(columns={0: 'weight'}) df_corlistO = pd.concat([tmp3, tmp4], axis=1) # 無向グラフを作成 G_corlistO = nx.from_pandas_edgelist(df_corlistO, 'node1', 'node2', ['weight']) # 破綻ではない発話データセットに対して # ①平均クラスタ係数の計算 print('平均クラスタ係数') print(nx.average_clustering(G_corlistO, weight='weight')) print() # ②媒介中心性の計算 bc = nx.betweenness_centrality(G_corlistO, weight='weight') print('媒介中心性') for k, v in sorted(bc.items(), key=lambda x: -x[1]): print(str(k) + ': ' + str(v))
平均クラスタ係数の計算
すべてのノードのクラスタ係数の平均が高いほど、そのネットワークは密であると言えます。
クラスタ係数の平均はnx.average_clustering()を用いて算出します。nx.average_clustering(G, weight=None)①G graphを指定します。 (前節で作成した無向グラフG_corlistOのこと) ②weight 重みとして使用する数値を持つエッジを指定します。Noneの場合、各エッジの重みは1になります。媒介中心性の計算
あるノードがすべてのノード間の最短経路中にいくつ含まれているかによって求められます。
つまり、情報を効率的に伝える際に最も利用されるノードほど媒介性が高く、中心的であると言えます。nx.betweenness_centrality(G, weight=None)①G graphを指定します。 (前節で作成した無向グラフG_corlistOのこと) ②weight 重みとして使用する数値を持つエッジを指定します。Noneの場合、すべてのエッジの重みは等しいとみなされます。類似度ネットワークのトピック抽出
一つのネットワークは、複数の部分ネットワーク(=コミュニティ)によって成り立っています。
コミュニティ内の各ノードは、エッジで密につながっていることが特徴です。一つのネットワークの疎なエッジを取り除くと部分ネットワークに分割できます。
つまり、コミュニティが抽出できる=類似度の高いネットワークの抽出ができるということです。ネットワークの分割には
モジュラリティ(Modularity)と呼ばれる指標を用います。モジュラリティは
「一つのネットワークの総エッジ数に対するコミュニティ内のエッジ数の割合」から
「一つのネットワークのすべてのノードの出次数の合計(ネットワークのエッジ数 × 2 と等しい)に対する
コミュニティ内のノードの出次数の合計の割合」を引いた値で、分割の質を定量化します。モジュラリティの値が大きいほど、コミュニティ内のノードは密につながっていると言えます。
それでは、モジュラリティを用いてコミュニティを抽出してみます。
破綻ではない発話と破綻である発話、それぞれのネットワークにおいて
所属するノード数が最も多いコミュニティの単語を確認すると以下のような結果を得ました。①破綻ではない発話 お盆,しまい,ついつい,休み,切れ,困り,少ない,帰省,忘れ,怠け者,明け,続く,連休,集中 ②破綻である発話 お願い,くらい,ぐらい,それから,とる,どの,はまっ,もちろん,よい,作業,偏ら,割り勘,危険,待っ,心掛け,時間,栄養,油断,睡眠,食事破綻ではない発話には、例えば「お盆休みが少なくて帰省に困る」「連休が続くと休み明けに怠ける」などの
トピックがありそうだと推測できます。破綻である発話には、例えば「食事の栄養が偏らないように心がける」「十分な時間の睡眠をとる」などの
トピックがありそうです。同様に、他のコミュニティにもどのようなトピックが含まれているか単語から推測できるはずです。
モジュラリティを用いたコミュニティの抽出
greedy_modularity_communities(G, weight=None)①G graphを指定します。 (前節で作成した無向グラフG_corlistOのこと) ②weight 重みとして使用する数値を持つエッジを指定します。Noneの場合、すべてのエッジの重みは等しいとみなされます。使用例はこちら
import os import json import pandas as pd import numpy as np import re from janome.tokenizer import Tokenizer from sklearn.feature_extraction.text import TfidfVectorizer import networkx as nx import matplotlib.pyplot as plt from networkx.algorithms.community import greedy_modularity_communities # init100ディレクトリを指定 file_path = './6110_nlp_preprocessing_data/init100/' file_dir = os.listdir(file_path) # フラグと発話内容を抽出したリストを作成 label_text = [] for file in file_dir[:20]: r = open(file_path + file, 'r', encoding='utf-8') json_data = json.load(r) for turn in json_data['turns']: turn_index = turn['turn-index'] speaker = turn['speaker'] utterance = turn['utterance'] if turn_index != 0: if speaker == 'U': u_text = '' u_text = utterance else: a = '' for annotate in turn['annotations']: a = annotate['breakdown'] tmp1 = str(a) + '\t' + u_text tmp2 = tmp1.split('\t') label_text.append(tmp2) # 重複を削除し、破綻ではない発話のみを抽出 df_label_text = pd.DataFrame(label_text) df_label_text = df_label_text.drop_duplicates() df_label_text_O = df_label_text[df_label_text[0] == 'O'] # Janomeによる形態素解析 t = Tokenizer() morpO = [] tmp1 = [] tmp2 = '' for row in df_label_text_O.values.tolist(): reg_row = re.sub('[0-9a-zA-Z]+', '', row[1]) reg_row = reg_row.replace('\n', '') for token in t.tokenize(reg_row): tmp1.append(token.surface) tmp2 = ' '.join(tmp1) morpO.append(tmp2) tmp1 = [] # TF-IDF値による重みありの単語文書行列を作成 morpO_array = np.array(morpO) tfidf_vecO = TfidfVectorizer(use_idf=True) morpO_tfidf_vecs = tfidf_vecO.fit_transform(morpO_array) morpO_tfidf_array = morpO_tfidf_vecs.toarray() # DataFrame形式に変換し、相関行列を作成 dtmO = pd.DataFrame(morpO_tfidf_array, columns=tfidf_vecO.get_feature_names(), index=morpO) corr_matrixO = dtmO.corr().abs() # 破綻ではない発話データセットの作成 corr_stackO = corr_matrixO.stack() index = pd.Series(corr_stackO.index.values) value = pd.Series(corr_stackO.values) tmp3 = [] tmp4 = [] for i in range(0, len(index)): if value[i] >= 0.5 and value[i] < 1.0: tmp1 = str(index[i][0]) + ' ' + str(index[i][1]) tmp2 = [s for s in tmp1.split()] tmp3.append(tmp2) tmp4 = np.append(tmp4, value[i]) tmp3 = pd.DataFrame(tmp3) tmp3 = tmp3.rename(columns={0: 'node1', 1: 'node2'}) tmp4 = pd.DataFrame(tmp4) tmp4 = tmp4.rename(columns={0: 'weight'}) df_corlistO = pd.concat([tmp3, tmp4], axis=1) # 無向グラフを作成 G_corlistO = nx.from_pandas_edgelist(df_corlistO, 'node1', 'node2', ['weight']) # 破綻ではない発話データセットに対して # コミュニティ抽出 cm_corlistO = list(greedy_modularity_communities(G_corlistO, weight='weight')) # 各コミュニティに属するノードの表示 cm_corlistO




- 投稿日:2020-05-21T22:08:50+09:00
韻を扱いたいpart2
内容
前回入力データの分割方法に改良が必要なのでは?と感じたため、様々な分割方法を試してみる。入力データは前回同様某ラッパーの歌詞を使用。一応検証用として自分が温めていた韻をテーマにしたものも用意している。
分かち書きの場合
import MeCab mecab = MeCab.Tagger("-Owakati") mecab_text = mecab.parse(data).split()歌詞通りの「韻」を抽出できている部分もあるが、「数万円」で踏んでいるところが分かち書きによって「数、万、円」と分割されているため認識できていない。余談だが、
kakashiのconv.doに一度に多くのデータは渡せないようだ。text_data = [conv.do(text) for text in mecab_text]とした。ちなみに分かち書き後、母音に変換したwordの長さは最大8文字、平均2.16文字であった。細かく分け過ぎているので、分かち書きでの分割は適していないと言える。
このMeCabを使えるようにするまでに何回も挫けた。色んな記事を見過ぎたのかもしれない。こちらに感謝N-gramの場合
では、単にN文字ごとに分割していくとどうなるだろう。Nは4から試してみる。
def make_ngram(words, N): ngram = [] for i in range(len(words)-N+1): #全角スペースと改行を取り除く row = "".join(words[i:i+N]).replace("\u3000","").replace("\n","") ngram.append(row) return ngram体感だが、Nは5かそれ以上が良さそうである。(4以下だとスコアの差が付かない)そこそこ歌詞通りに韻を検出できている。試しに検証用データを入れてみると、一見気づかない韻が検出できた。wordが様々な切り取られ方をするのだから、スコアの付け方を変えてみる。
def make_score_ngram(word_a, word_b): score = 0 for i in range(len(word_a)): if word_a[-i:] == word_b[-i:]: score += i return score母音の一致を語尾から見ることによって、出力が見やすい。Nの値については
len(target_word_vo)(韻を探す元の言葉の母音の長さ)が良いだろう。自分がやりたいことが表現できてしまったような気がしている。
折角苦労してMeCabを使用できるようにして、「韻の数値化」も自分なりに考えたので、使いたい。この2つを組み合わせてみる。target_wordが絞れるのでは?!
「韻の数値化」では母音が合致する部分を探索し、合致している長さ
len(word[i:j)をスコアにしていた。このword[i:j]は「eoi」等の形をしており、この出現回数をカウントすれば、入力データ中で一番登場する母音が分かるはずだ。それを含む言葉をtarget_wordに指定すれば、多くのレコメンドが見込めるという考えである。申し訳程度に分かち書きと検証用に用意したテキストを使う。from pykakasi import kakasi import re from collections import defaultdict import MeCab with open("./test.txt","r",encoding="utf-8") as f: data = f.read() mecab = MeCab.Tagger("-Owakati") mecab_text = mecab.parse(data).split() kakasi = kakasi() kakasi.setMode('H', 'a') kakasi.setMode('K', 'a') kakasi.setMode('J', 'a') conv = kakasi.getConverter() text_data = [conv.do(text) for text in mecab_text] vowel_data = [re.sub(r"[^aeiou]+","",text) for text in text_data] dic_vo = {k:v for k,v in enumerate(vowel_data)} #voel_dataのインデックスで母音変換前のdataが分かるように辞書作成。 dic = {k:v for k,v in enumerate(mecab_text)} #新たなキーを追加する際に初期化を省きたいためdefaultdictを使用{母音:出現回数} dic_rhyme = defaultdict(int) for word_a in vowel_data: for word_b in vowel_data: if len(word_a) > len(word_b): word_len = len(word_b) for i in range(word_len): for j in range(word_len + 1): #カウントするのは2文字以上に限定 if word_b[i:j] in word_a and not len(word_b[i:j])<2: dic_rhyme[word_b[i:j]] += 1 else: word_len = len(word_a) for i in range(word_len): for j in range(word_len + 1): if word_a[i:j] in word_b and not len(word_a[i:j])<2: dic_rhyme[word_a[i:j]] += 1 #カウントが多かった順にソート dic_rhyme = sorted(dic_rhyme.items(), key=lambda x:x[1], reverse=True) print(dic_rhyme) #dic_rhymeの上位にきたものが含まれているものを探索。ここでは"ai"を使用 bool_index = ["ai" in text for text in vowel_data] for i in range(len(vowel_data)): if bool_index[i]: print(dic[i])登場頻度の高い母音の並びを取得し、どこで使われているか出力できた。しかしながら、分かち書きで細分化された言葉は分かりにくくなっていた。もしかしたら、もう少し長い韻があった可能性もある。
改良点
target_wordを絞るという用途では必要性を感じないが(自分が一番言いたいことを指定したいため)、どの母音の並びが頻出なのかは確認できても良いかもしれない。分かち書きで上手くいかなかったが、MeCabを利用して(
何度もいうが、使えるようになるまで四苦八苦した)改良したい。
また、N-gramを採用したことによって「韻の数値化」も簡潔にできたので、もう少し複雑に「韻」を定義し直せないか考える。(現状「っ」など考慮していない)
しかし、回り道をした。「韻の数値化」は韻を漏らさないよう、入力データに対応できるよう、自分なりに考え抜いたつもりのものだ。まさか引数を様々にスライスすることが入力データを様々にスライス(表現が違うかもしれません)で解決できるとは…というかそれに気付かないとは。基本が大事ですね。でもN-gramって意味のない日本語が出来ると感じませんか?ただ、「韻」の部分を強調して発音する等やり方はあるんです。やはり、簡単なデータ使ってとにかくやってみることが大事ってことですわ。
- 投稿日:2020-05-21T21:34:34+09:00
【自然言語処理100本ノック 2020】第2章: UNIXコマンド
はじめに
自然言語処理の問題集として有名な自然言語処理100本ノックの2020年版が4/6に公開されました。
この記事では、以下の第1章から第10章のうち、第2章: UNIXコマンドを解いてみた結果をまとめています。
- 第1章: 準備運動
- 第2章: UNIXコマンド
- 第3章: 正規表現
- 第4章: 形態素解析
- 第5章: 係り受け解析
- 第6章: 機械学習
- 第7章: 単語ベクトル
- 第8章: ニューラルネット
- 第9章: RNN, CNN
- 第10章: 機械翻訳
事前準備
回答にはGoogle Colaboratoryを利用しています。
Google Colaboratoryのセットアップ方法や基本的な使い方は、こちらの記事が詳しいです。
なお、以降の回答の実行結果を含むノートブックはgithubにて公開しています。第2章: UNIXコマンド
popular-names.txtは,アメリカで生まれた赤ちゃんの「名前」「性別」「人数」「年」をタブ区切り形式で格納したファイルである.以下の処理を行うプログラムを作成し,popular-names.txtを入力ファイルとして実行せよ.さらに,同様の処理をUNIXコマンドでも実行し,プログラムの実行結果を確認せよ.
まずは指定のデータをダウンロードします。
Google Colaboratoryのセル上で下記のコマンドを実行すると、カレントディレクトリに対象のテキストファイルがダウンロードされます。!wget https://nlp100.github.io/data/popular-names.txt【 wget 】コマンド――URLを指定してファイルをダウンロードする
10. 行数のカウント
行数をカウントせよ.確認にはwcコマンドを用いよ.
早速問題を解いていきます。
今回はpandasのデータフレームとして読み込んでから各問の処理を行っていきます。また、問題文の指示に従い、コマンドでの結果の確認も行っています。import pandas as pd df = pd.read_table('./popular-names.txt', header=None, sep='\t', names=['name', 'sex', 'number', 'year']) print(len(df)) # 確認 !cat ./popular-names.txt | wc -lpandasでcsv/tsvファイル読み込み
pandasで行数、列数、全要素数(サイズ)を取得
【 cat 】コマンド――設定ファイルの内容を簡単に確認する
【 wc 】コマンド――テキストファイルの文字数や行数を数える11. タブをスペースに置換
タブ1文字につきスペース1文字に置換せよ.確認にはsedコマンド,trコマンド,もしくはexpandコマンドを用いよ.
本問は、元データの区切り文字であるタブの置換を想定していると思われるため、すでに読み込んでいるデータフレームでは実施せず、コマンドでの確認のみ行っています。
# 確認 !sed -e 's/\t/ /g' ./popular-names.txt【 sed 】コマンド(基礎編その4)――文字列を置き換える/置換した行を出力する
12. 1列目をcol1.txtに,2列目をcol2.txtに保存
各行の1列目だけを抜き出したものをcol1.txtに,2列目だけを抜き出したものをcol2.txtとしてファイルに保存せよ.確認にはcutコマンドを用いよ.
col1 = df['name'].copy() col1.to_csv('./col1.txt', index=False) # 確認 !cut -f 1 ./popular-names.txt > ./col1_chk.txt !cat ./col1_chk.txtcol2 = df['sex'].copy() col2.to_csv('./col2.txt', index=False) # 確認 !cut -f 2 ./popular-names.txt > ./col2_chk.txt !cat ./col2_chk.txtpandasのインデックス参照で行・列を選択し取得
pandasでcsvファイルの書き出し
【 cut 】コマンド――行から固定長またはフィールド単位で切り出す
コマンドの実行結果・標準出力をファイルに保存13. col1.txtとcol2.txtをマージ
12で作ったcol1.txtとcol2.txtを結合し,元のファイルの1列目と2列目をタブ区切りで並べたテキストファイルを作成せよ.確認にはpasteコマンドを用いよ.
col1 = pd.read_table('./col1.txt') col2 = pd.read_table('./col2.txt') merged_1_2 = pd.concat([col1, col2], axis=1) merged_1_2.to_csv('./merged_1_2.txt', sep='\t', index=False) # 確認 !paste ./col1_chk.txt ./col2_chk.txtpandas.DataFrame, Seriesを連結する
【 paste 】コマンド――複数のファイルを行単位で連結する14. 先頭からN行を出力
自然数Nをコマンドライン引数などの手段で受け取り,入力のうち先頭のN行だけを表示せよ.確認にはheadコマンドを用いよ.
def output_head(N): print(df.head(N)) output_head(10) # 確認 !head -n 10 ./popular-names.txtPythonで関数を定義・呼び出し
pandas.DataFrame, Seriesの先頭・末尾の行を返す
【 head 】コマンド/【 tail 】コマンド――長いメッセージやテキストファイルの先頭だけ/末尾だけを表示する15. 末尾のN行を出力
自然数Nをコマンドライン引数などの手段で受け取り,入力のうち末尾のN行だけを表示せよ.確認にはtailコマンドを用いよ.
def output_tail(N): print(df.tail(N)) output_tail(10) # 確認 !tail -n 10 ./popular-names.txt16. ファイルをN分割する
自然数Nをコマンドライン引数などの手段で受け取り,入力のファイルを行単位でN分割せよ.同様の処理をsplitコマンドで実現せよ.
いろいろなやり方があると思いますが、ここではレコードの通番に対して、対象の数値の大きさで等分するqcutを適用することでファイルをN分割しています。
def split_file(N): tmp = df.reset_index(drop=False) df_cut = pd.qcut(tmp.index, N, labels=[i for i in range(N)]) print(df_cut.value_counts()) df_cut = pd.concat([df, pd.Series(df_cut, name='sp')], axis=1) return df_cut df_cut = split_file(10) print(df_cut.head()) # 確認 !split -l 200 -d ./popular-names.txt sppandas.DataFrame, Seriesのインデックスを振り直す
pandasのcut, qcut関数でビニング処理(ビン分割)
pandasでユニークな要素の個数、頻度(出現回数)をカウント
【 split 】コマンド――ファイルを分割する17. 1列目の文字列の異なり
1列目の文字列の種類(異なる文字列の集合)を求めよ.確認にはcut, sort, uniqコマンドを用いよ.
print(len(df.drop_duplicates(subset='name'))) # 確認 !cut -f 1 ./popular-names.txt | sort | uniq | wc -lpandas.DataFrame, Seriesの重複した行を抽出・削除
【 sort 】コマンド――テキストファイルを行単位で並べ替える
【 uniq 】コマンド――重複している行を削除する18. 各行を3コラム目の数値の降順にソート
各行を3コラム目の数値の逆順で整列せよ(注意: 各行の内容は変更せずに並び替えよ).確認にはsortコマンドを用いよ(この問題はコマンドで実行した時の結果と合わなくてもよい).
df.sort_values(by='number', ascending=False, inplace=True) print(df.head()) # 確認 !cat ./popular-names.txt | sort -rnk 3pandas.DataFrame, Seriesをソートする
19. 各行の1コラム目の文字列の出現頻度を求め,出現頻度の高い順に並べる
各行の1列目の文字列の出現頻度を求め,その高い順に並べて表示せよ.確認にはcut, uniq, sortコマンドを用いよ.
print(df['name'].value_counts().sort_values(ascending=False)) # 確認 !cut -f 1 ./popular-names.txt | sort | uniq -c | sort -rnおわりに
自然言語処理100本ノックは自然言語処理そのものだけでなく、基本的なデータ処理や汎用的な機械学習についてもしっかり学ぶことができるように作られています。
オンラインコースなどで機械学習を勉強中の方も、とても良いアウトプットの練習になると思いますので、ぜひ挑戦してみてください。
- 投稿日:2020-05-21T21:34:34+09:00
【自然言語処理100本ノック 2020】第2章の回答例
はじめに
自然言語処理の問題集として有名な自然言語処理100本ノックの2020年版が4/6に公開されました。
この記事では、以下の第1章から第10章のうち、第2章: UNIXコマンドを解いてみた結果をまとめています。
- 第1章: 準備運動
- 第2章: UNIXコマンド
- 第3章: 正規表現
- 第4章: 形態素解析
- 第5章: 係り受け解析
- 第6章: 機械学習
- 第7章: 単語ベクトル
- 第8章: ニューラルネット
- 第9章: RNN, CNN
- 第10章: 機械翻訳
事前準備
回答にはGoogle Colaboratoryを利用しています。
Google Colaboratoryのセットアップ方法や基本的な使い方は、こちらの記事が詳しいです。
なお、以降の回答の実行結果を含むノートブックはgithubにて公開しています。第2章: UNIXコマンド
popular-names.txtは,アメリカで生まれた赤ちゃんの「名前」「性別」「人数」「年」をタブ区切り形式で格納したファイルである.以下の処理を行うプログラムを作成し,popular-names.txtを入力ファイルとして実行せよ.さらに,同様の処理をUNIXコマンドでも実行し,プログラムの実行結果を確認せよ.
まずは指定のデータをダウンロードします。
Google Colaboratoryのセル上で下記のコマンドを実行すると、カレントディレクトリに対象のテキストファイルがダウンロードされます。!wget https://nlp100.github.io/data/popular-names.txt【 wget 】コマンド――URLを指定してファイルをダウンロードする
10. 行数のカウント
行数をカウントせよ.確認にはwcコマンドを用いよ.
早速問題を解いていきます。
今回はpandasのデータフレームとして読み込んでから各問の処理を行っていきます。また、問題文の指示に従い、コマンドでの結果の確認も行っています。import pandas as pd df = pd.read_table('./popular-names.txt', header=None, sep='\t', names=['name', 'sex', 'number', 'year']) print(len(df)) # 確認 !cat ./popular-names.txt | wc -lpandasでcsv/tsvファイル読み込み
pandasで行数、列数、全要素数(サイズ)を取得
【 cat 】コマンド――設定ファイルの内容を簡単に確認する
【 wc 】コマンド――テキストファイルの文字数や行数を数える11. タブをスペースに置換
タブ1文字につきスペース1文字に置換せよ.確認にはsedコマンド,trコマンド,もしくはexpandコマンドを用いよ.
本問は、元データの区切り文字であるタブの置換を想定していると思われるため、すでに読み込んでいるデータフレームでは実施せず、コマンドでの確認のみ行っています。
# 確認 !sed -e 's/\t/ /g' ./popular-names.txt【 sed 】コマンド(基礎編その4)――文字列を置き換える/置換した行を出力する
12. 1列目をcol1.txtに,2列目をcol2.txtに保存
各行の1列目だけを抜き出したものをcol1.txtに,2列目だけを抜き出したものをcol2.txtとしてファイルに保存せよ.確認にはcutコマンドを用いよ.
col1 = df['name'].copy() col1.to_csv('./col1.txt', index=False) # 確認 !cut -f 1 ./popular-names.txt > ./col1_chk.txt !cat ./col1_chk.txtcol2 = df['sex'].copy() col2.to_csv('./col2.txt', index=False) # 確認 !cut -f 2 ./popular-names.txt > ./col2_chk.txt !cat ./col2_chk.txtpandasのインデックス参照で行・列を選択し取得
pandasでcsvファイルの書き出し
【 cut 】コマンド――行から固定長またはフィールド単位で切り出す
コマンドの実行結果・標準出力をファイルに保存13. col1.txtとcol2.txtをマージ
12で作ったcol1.txtとcol2.txtを結合し,元のファイルの1列目と2列目をタブ区切りで並べたテキストファイルを作成せよ.確認にはpasteコマンドを用いよ.
col1 = pd.read_table('./col1.txt') col2 = pd.read_table('./col2.txt') merged_1_2 = pd.concat([col1, col2], axis=1) merged_1_2.to_csv('./merged_1_2.txt', sep='\t', index=False) # 確認 !paste ./col1_chk.txt ./col2_chk.txtpandas.DataFrame, Seriesを連結する
【 paste 】コマンド――複数のファイルを行単位で連結する14. 先頭からN行を出力
自然数Nをコマンドライン引数などの手段で受け取り,入力のうち先頭のN行だけを表示せよ.確認にはheadコマンドを用いよ.
def output_head(N): print(df.head(N)) output_head(10) # 確認 !head -n 10 ./popular-names.txtPythonで関数を定義・呼び出し
pandas.DataFrame, Seriesの先頭・末尾の行を返す
【 head 】コマンド/【 tail 】コマンド――長いメッセージやテキストファイルの先頭だけ/末尾だけを表示する15. 末尾のN行を出力
自然数Nをコマンドライン引数などの手段で受け取り,入力のうち末尾のN行だけを表示せよ.確認にはtailコマンドを用いよ.
def output_tail(N): print(df.tail(N)) output_tail(10) # 確認 !tail -n 10 ./popular-names.txt16. ファイルをN分割する
自然数Nをコマンドライン引数などの手段で受け取り,入力のファイルを行単位でN分割せよ.同様の処理をsplitコマンドで実現せよ.
いろいろなやり方があると思いますが、ここではレコードの通番に対して、対象の数値の大きさで等分するqcutを適用することでファイルをN分割しています。
def split_file(N): tmp = df.reset_index(drop=False) df_cut = pd.qcut(tmp.index, N, labels=[i for i in range(N)]) print(df_cut.value_counts()) df_cut = pd.concat([df, pd.Series(df_cut, name='sp')], axis=1) return df_cut df_cut = split_file(10) print(df_cut.head()) # 確認 !split -l 200 -d ./popular-names.txt sppandas.DataFrame, Seriesのインデックスを振り直す
pandasのcut, qcut関数でビニング処理(ビン分割)
pandasでユニークな要素の個数、頻度(出現回数)をカウント
【 split 】コマンド――ファイルを分割する17. 1列目の文字列の異なり
1列目の文字列の種類(異なる文字列の集合)を求めよ.確認にはcut, sort, uniqコマンドを用いよ.
print(len(df.drop_duplicates(subset='name'))) # 確認 !cut -f 1 ./popular-names.txt | sort | uniq | wc -lpandas.DataFrame, Seriesの重複した行を抽出・削除
【 sort 】コマンド――テキストファイルを行単位で並べ替える
【 uniq 】コマンド――重複している行を削除する18. 各行を3コラム目の数値の降順にソート
各行を3コラム目の数値の逆順で整列せよ(注意: 各行の内容は変更せずに並び替えよ).確認にはsortコマンドを用いよ(この問題はコマンドで実行した時の結果と合わなくてもよい).
df.sort_values(by='number', ascending=False, inplace=True) print(df.head()) # 確認 !cat ./popular-names.txt | sort -rnk 3pandas.DataFrame, Seriesをソートする
19. 各行の1コラム目の文字列の出現頻度を求め,出現頻度の高い順に並べる
各行の1列目の文字列の出現頻度を求め,その高い順に並べて表示せよ.確認にはcut, uniq, sortコマンドを用いよ.
print(df['name'].value_counts().sort_values(ascending=False)) # 確認 !cut -f 1 ./popular-names.txt | sort | uniq -c | sort -rnおわりに
自然言語処理100本ノックは自然言語処理そのものだけでなく、基本的なデータ処理や汎用的な機械学習についてもしっかり学ぶことができるように作られています。
オンラインコースなどで機械学習を勉強中の方も、とても良いアウトプットの練習になると思いますので、ぜひ挑戦してみてください。
- 投稿日:2020-05-21T20:53:10+09:00
matplotlibを使ってJupyterLab上でインタラクティブな3Dグラフを作成する
1. はじめに
- インタラクティブなグラフは、数値の挙動を確認する時に何かと便利です。
- また、3Dのグラフを表示した際には、インタラクティブに見る方向を変えられると便利です。
- Jupyter notebookを使っていた頃は、ipywidgetという仕組みを使って、インタラクティブに動くグラフを作れたのですが、現時点ではJupyterLabでは対応していないように思います。
- JupyterLab上でこのような仕組みについて紹介した記事が、私が調べた限りではあまり多くはなかったように思いましたので、投稿してみようと思いました。
2. 概要
matplotlibのwidgetという仕組みを使うと、GUI backendに依存せずに、Axesに配置するような形でインタラクティブなWidgetを作ることが可能です。
以下、widgetのドキュメントからの抜粋です。
Widgets that are designed to work for any of the GUI backends. All of these widgets require you to predefine a matplotlib.axes.Axes instance and pass that as the first arg.
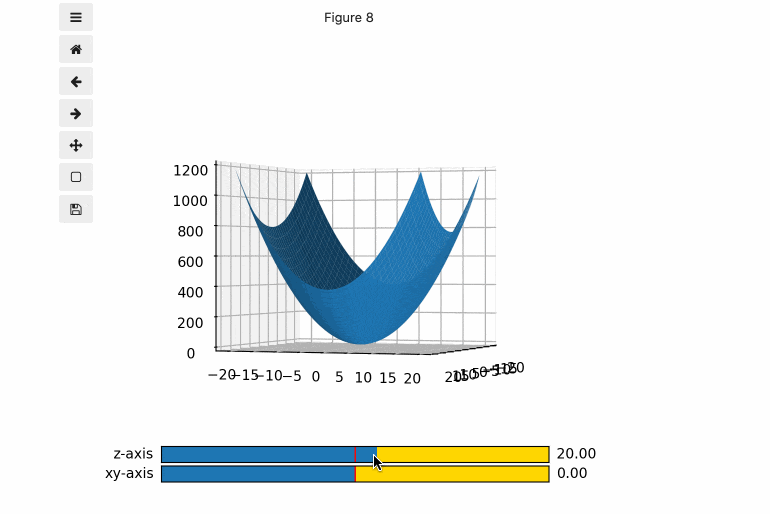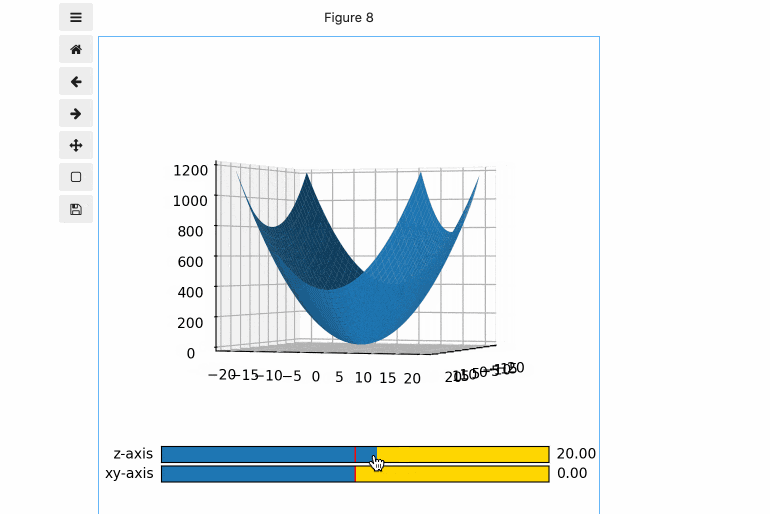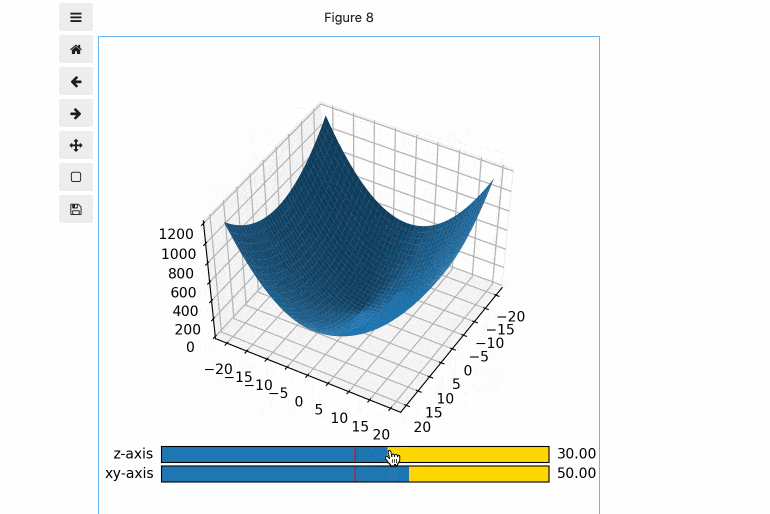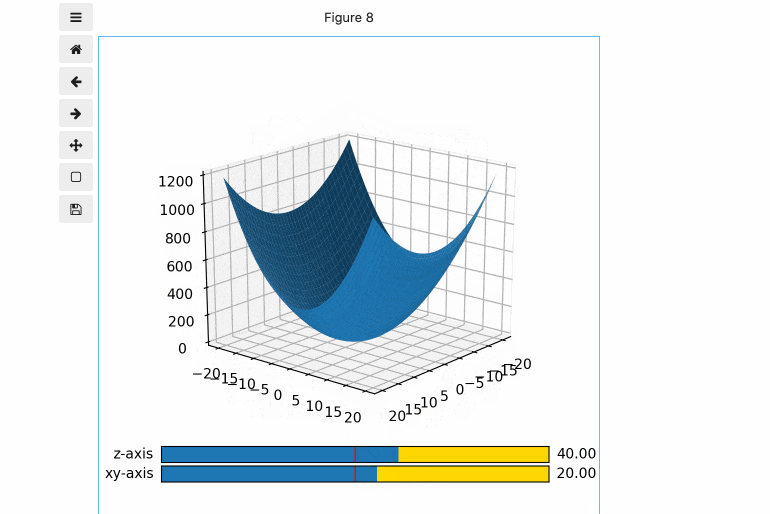
- JupyterLab上で、こんな感じのグラフが簡単に作れます。(このグラフはブラウザのJupyerLab上で動いています。)
3. 具体的なやり方
ということで、上のようなグラフの作成方法をご説明します。なお、以下をJupyterLab上で作りましたが、先ほどのご説明の通り、matplotlib.widgetはGUI Backendに依存しないということなので、Jupyter notebookはもちろん、LinuxやWindows, MacのGUI上でも同様の結果になるものと思います。(手元では試してませんが)
(1) 必要なライブラリをインポート
まず、必要なライブラリのインポートを行います。また、バックエンドをwidgetに設定する必要があります。
%matplotlib widget import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D from matplotlib.widgets import Slider import numpy as np(2) サンプルとして表示するデータを作成
ここでは、例として、$z=x^2+2y^2$のグラフを書いてみることにします。
x = y = np.arange(-20, 20, 0.5) X, Y = np.meshgrid(x, y) Z = X*X + 2 * Y*Y(3) Figureを作成
ご存知の通り、Figureは、matplotlibでグラフを書くキャンパスのようなものです。Figureの上にAxesを載せ、その上にPlotをしていくイメージです。
# Figureの設定 fig = plt.figure(figsize=(5,5))(4) Axesの作成
次に、Figure上にAxesを作成します。
- 今回は、3Dグラフのプロット用のAxesを1つ、Slider表示用のAxesを2つ作成します。
- どんなやり方でもいいのですが、今回はgridspecを使ってみました、
- 下をコードを実行することで、図のように、Figureを20x20に分割し、1-17行目に3Dグラフ描写用のAxesを、18, 19行目にそれぞれSlider用のAxesを配置できます。
# Figureの中に3Dグラフ、Slider用のAxesを追加 axcolor = 'gold' gs = fig.add_gridspec(20, 20) ax1 = fig.add_subplot(gs[:17,:], projection='3d') ax_slider_z = fig.add_subplot(gs[18,:], facecolor=axcolor) ax_slider_xy = fig.add_subplot(gs[19,:], facecolor=axcolor)(5) Sliderの設定
次に、Sliderオブジェクトを作成します。以下のコードでは、
- slider_zとslider_xyというSiderオブジェクトを作成し、それぞれ、上で作成したax_slider_z, ax_slider_xy上に描写
- Sliderの動く範囲は-180〜180
- Sliderの初期値としてz0(=0)を設定
- Sliderの動く幅としてdelta(=10)を設定
を行っています。
# Sliderの設定 z0 = 0 xy0 = 0 delta = 10 slider_z = Slider(ax_slider_z, 'z-axis', -180, 180, valinit=z0, valstep=delta) slider_xy = Slider(ax_slider_xy, 'xy-axis', -180, 180, valinit=xy0, valstep=delta)(6) 3Dグラフの見る角度の初期値を設定後、3Dグラフを表示。
次に、3Dグラフの、z軸周り、xy平面周りの見える角度の初期値を設定します。この数値を変化させることで、3Dグラフの見る角度を動かすことができます。
# 3Dグラフの見る方向の初期値を設定 ax1.view_init(elev=z0, azim=xy0) # 3Dグラフを表示 ax1.plot_surface(X, Y, Z)(7) Sliderを動かした時に呼ばれるコールバック関数を作成
次に、Sliderを動かした時に呼ばれるコールバック関数を作成します。ここで、3Dグラフを見る角度を指定し、グラフを再描写することで動くグラフを作成することができます。
# Sliderを動かした時に呼ばれるコールバック関数 def view_change(val): sz = slider_z.val sxy = slider_xy.val ax1.view_init(elev=sxy, azim=sz) fig.canvas.draw_idle()(8) コールバック関数の設定
最後に、Sliderオブジェクトに先ほど作成したコールバック関数を設定します。
slider_z.on_changed(view_change) slider_xy.on_changed(view_change) plt.show()以上で、JupyterLab上で簡単に動くグラフを作成することができます!
こちらにgistも置いておきましたので、よろしければお使いください。(上でご説明したものと同じですが。。。)

- 投稿日:2020-05-21T20:42:50+09:00
初めてのPython ~コーディング編2~
対象者
前回の記事の続きです。
本記事では前回の記事のgraph_plot.pyを元に話題をPythonのリストや条件分岐、ループ処理に移していきます。
全部すっ飛ばしても大丈夫な人は不連続な関数を描こうへどうぞ。目次
Pythonのリスト
前回の記事では、Pythonには配列が存在しないと述べました。
その代わり、Pythonにはリスト(List)と呼ばれるデータ構造が標準搭載されています。
今回はそれについて少し触れます。リストとは
まずリストについて簡単な説明から行います。
list_sample.py
list_sample.pyx = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] print(x) x.append(10) print(x) #print(x + 3) # TypeErrorが起こる print(x + [3]) print(x * 3) x = np.array(x) print(x) x = list(x) print(x)リストは配列と似た概念で、次のように用いることができます。
list_sample.pyx = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] print(x)この
x、numpy_calc.pyで定義したxと出力結果が同じになっていることに気づきましたか?
つまり、リストと配列は似たデータ構造であることがわかります。
その最大の違いはデータサイズが可変であることです。list_sample.pyx.append(10) print(x)10が追加されましたね。
このappendメソッドはリスト型のデータ構造が持っている関数1で、要素を追加するためのものです。
もちろんnumpy配列で同じことをしようとしてもエラーが出るだけです。
numpyでは一度定義した配列のサイズを変更するには(内部処理で)どこかに改めてコピーする必要があります。
その点リストは予め大きめにメモリを確保することで、要素を追加する際にかかるメモリ確保の時間を節約することができます。
要するにそれぞれメリット/デメリットがあるということです。
他にもリストには要素を削除する関数などもあります。
また、リストにはnumpy配列のブロードキャスト機能はありません。list_sample.py#print(x + 3) # TypeErrorが起こるただし次のようなことはできます。
list_sample.pyprint(x + [3]) print(x * 3)リスト同士の足し算であれば要素の追加になります。
リストと自然数の掛け算はリストそのものを数値の数だけ繰り返したリストとなります。2
その他の演算はTypeErrorが出てできません
さらに、numpy配列とリストは相互に変換もできます。list_sample.pyx = np.array(x) print(x) x = list(x) print(x)以上で本記事で必要なリストの知識の紹介はおしまいです。
要約すると
- リストはデータサイズが可変の配列のようなもの
- numpyとリストは相互に変換できる
だけ知っておけば本記事ではOKです。
条件分岐とループ処理
条件分岐とは「ある条件を満たすなら〇〇、そうでなければ××」という処理のことです。
(この処理は人間の意思決定とも似ているところがありますね)
ループ処理とは「ある条件を満たすまで同じ処理を繰り返す」という処理のことです。
(これは機械っぽい処理ですね)では具体的にどのようにコードを書くのか、実際にやっていきましょう。
if文Pythonの条件分岐と言えば
if文だけ3です。
C言語などをやったことのある人は「え、switchとかないの?」と思うかもしれませんね。
Pythonではswitch文の類はありません。いちいち書かなければいけません。面倒ですね。
初めての人にとっては覚えることが減ってラッキーかもしれません笑。
とりあえず、この条件分岐を使ってみましょう。
if_sample.py
if_sample.pyx = 5 if x > 0: # 条件式x > 0が真ならばここの処理 print("xは0より大きいです。") else: # 条件式x > 0が偽ならばここの処理 # つまりx <= 0ならばここの処理です if x == 0: # 条件式x == 0が真ならばここの処理 # <note> # ==は式の両辺が等しいか、という条件式です # 逆に、式の両辺が等しくないか、という演算は!=です print("xは0です。") else: # 条件式x == 0が偽ならばここの処理 # つまり、x != 0ならばここの処理です print("xは0より小さいです。") if x > 0: print("xは0より大きいです。") elif x == 0: print("xは0です。") else: print("xは0より小さいです。")この二つの
if文は全く同じ動作をします。
上の方はif elseのみ、下の方はif elif elseという文法を使って書いています。
見ての通りですが、if文の中にif文を書く(ネストする、といいます)ことができます。
もちろんもっとたくさんネストさせることも可能ですが、読みにくくなってしまうのでできるだけネストは少なめにするよう心がけましょう。
つまり下の方が読みやすいコードということですね。文法まとめ
if_grammer_summary.pyif (条件式1): # (条件式1)が真(True)ならここに記述された処理を実行 #-----ここから----- elif (条件式2): # (条件式1)が偽(False)で(条件式2)が真(True)ならここに記述された処理を実行 elif (条件式3): ... else: # 全ての条件式が偽(False)ならここに記述された処理を実行 #-----ここまで----- # 全て省略可能です。つまり最初のifだけでもOK。
for文とwhile文続いてループ処理です。
Pythonのループ処理にはforとwhileの二つがあります。
二つある理由はたまに使い分けたいことがあるからですが、for文をwhile文に、while文をfor文に、等価な処理を行うように変換できますのでお好みで...と言いたいですが、基本的にfor文を使うことを個人的にオススメします。
理由は後ほど...
for文まずは
for文から。
for_sample.py
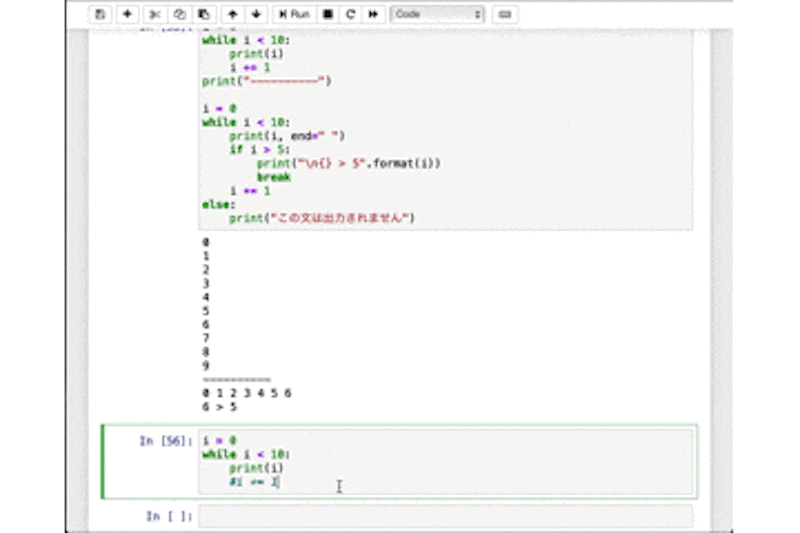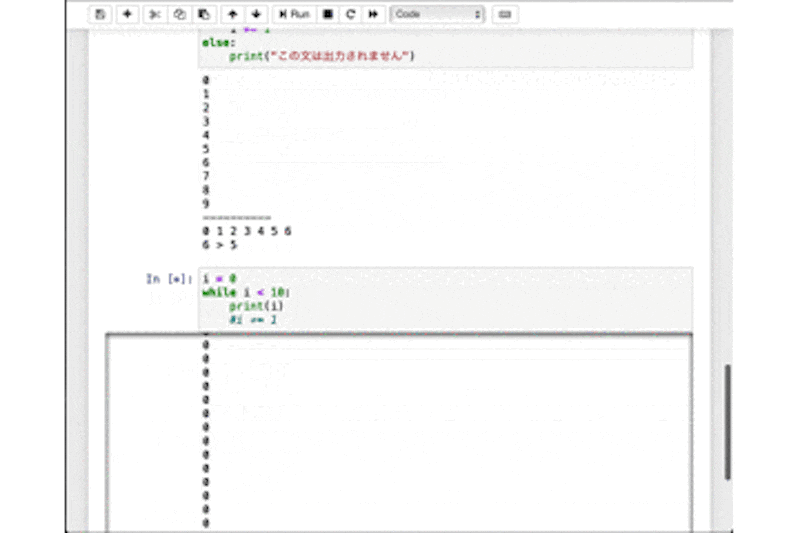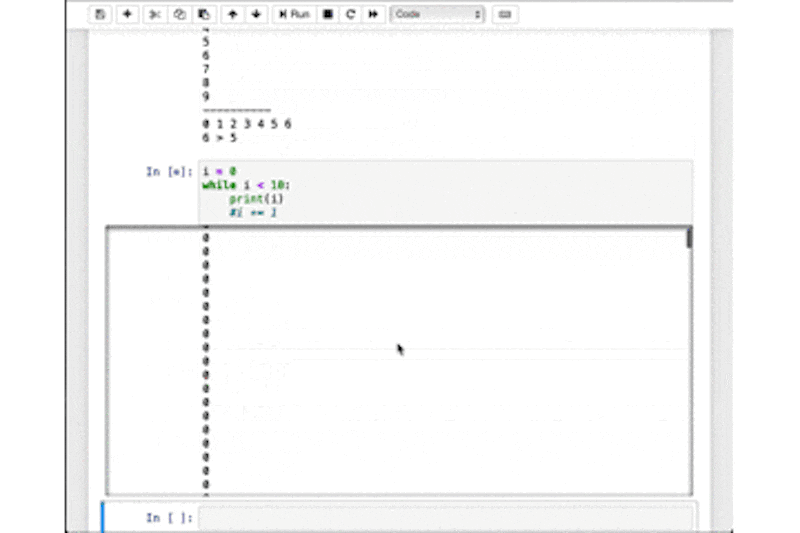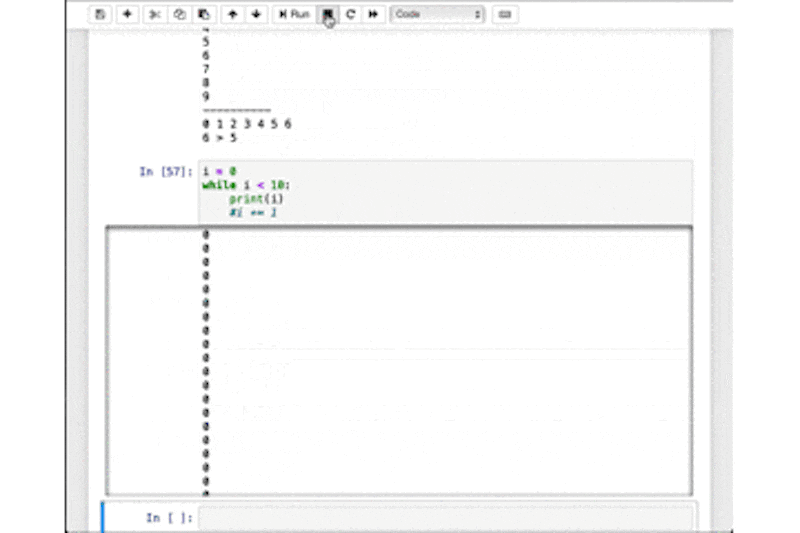
for_sample.pyfor i in range(10): print(i) print("----------") for i in range(1, 10): print(i, end=" ") if i > 5: print("\n{} > 5".format(i)) print("ループを抜けます") break else: print("この文は出力されません。")さて、上の方の
for文は0〜9まで、縦に並べて出力されます。
下の方は6までが横に並べて出力されて、「6 > 5」「ループを抜けます」と出力されて終わるはずです。
(ついでなのでいくつか紹介していない関数などを使っています。気になった方はググってみましょう。)
for文は文法を見た方がわかりやすいですね。for_grammer_summary.pyfor (変数名) in (配列やリストなど): (繰り返したい処理をここに書く) else: (ループが正常に終了した場合の処理やループが1度も実行されなかった時に行いたい処理をここに書く)
range関数は指定された数までのリストのようなもの4を返します。
break文はループを強制的に抜けるためのものです。
for文では、(配列やリストなど)で指定された数値が順番に(変数名)に代入されて処理が行われます。for_sample.pyの一つ目のループでは
- 変数
iに0が代入される0が出力される- 変数
iに1が代入される1が出力される- ...
のように処理が進みます。
二つ目のループは
for else文の紹介のために書きました。
Pythonでは他の言語には滅多にない、ループ処理にelseを使うことができます。
elseの中には、ループが正常に終了した時に行って欲しい処理を書きます。
つまり、break文でループを強制的に終了した場合はその処理が行われません。
あまり積極的に使うことはありませんが、ネストされたfor文を全て抜けたい時などによりスッキリしたコードを書くことができます。
nested_for.py
nested_for.py# elseあり for i in range(10): for j in range(10): print(i, j) if i * j > 10: # i = 2, j = 6でここに入ります break else: continue break # elseなし flag = False for i in range(10): for j in range(10): print(i, j) if i * j > 10: # i = 2, j = 6でここに入ります flag = True break if flag: break
continue文は以降の処理をスルーして次のループに移るためのものです。
while文次は
while文です。
while_sample.py
while_sample.pyi = 0 while i < 10: print(i) i += 1 print("----------") i = 0 while i < 10: print(i, end=" ") if i > 5: print("\n{} > 5".format(i)) break i += 1 else: print("この文は出力されません")このwhile_sample.pyはそれぞれfor_sample.pyと等価なループ処理となっていることが確認できると思います。
while文の文法は次の通りです。while_grammer_summary.pywhile (条件式): (繰り返したい処理をここに書く) else: (ループが正常に終了した場合の処理やループが1度も実行されなかった時に行いたい処理をここに書く)
while文の特徴は条件式が満たされる限りループ処理をすることですね。
for文では予めループする回数が決まるのに対して、while文は不定なことがあるのが大きな違いです。
これが個人的にwhile文を使わないようにして欲しい理由につながります。while_sample.pyの一つ目のループを以下のように変更して実行すると大量の
0が出力され続けます。
<<注意>>
実行する場合は止め方をよく頭に入れておいてください。while_sample.pyi = 0 while i < 10: print(i) #i += 1<<止め方>>
上部の■をクリックすれば止まります。
jupyter notebookでは簡単な操作で実行を中断できるので便利ですね〜
変数
iの値が変わらないためにいつまでも条件式i < 10が満たされ続けてしまい、処理が無限に行われてしまうためこのようなことが発生します。
このような状況を無限ループと言います。
今回は一生懸命書いたコードがなぜかエラーで動かない!
ではなく
一生懸命書いたコードがエラーもないのに反応しない!という状況になります。
初心者の頃は無限ループなんてそう簡単には気づけないためずーっと頭を悩ませることになりかねません。
以上の理由から、while文でなければ書けないようなループはまずないでしょうから、基本的にfor文を使用するようにしましょう。不連続な関数を描こう
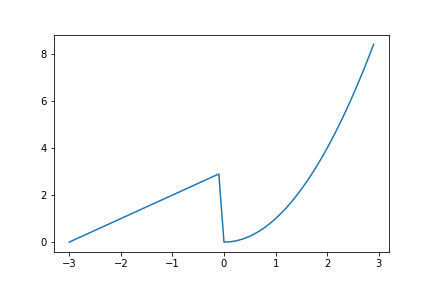
長くなりましたが、条件分岐とループ処理を用いて不連続な関数を書いてみましょう!
graph_plot.pyの関数fの部分を次のように変更しましょう。graph_plot.py# リストを用いたバージョン def f(x): result = [] for i in x: if i < 0: result.append(i + 3) else: result.append(i ** 2) return resultgraph_plot.py# numpy配列を用いたバージョン def f(x): result = np.zeros(len(x)) for i in range(len(x)): if x[i] < 0: result[i] = x[i] + 3 else: result[i] = x[i] ** 2 return resultこんな感じのグラフがプロットされればOKです。
めんどくさい?
めんどくさいって?間違いない。
ということでスマートな書き方も紹介しておきます。graph_plot.pydef f(x): return np.where(x < 0, x + 3, x ** 2)numpyの
where関数は俗にいう三項演算子というやつです。
詳しくはググりましょう。
ちなみに頑張れば標準の書き方でもそれなりにスマートになります。graph_plot.pydef f(x): return [i + 3 if i < 0 else i ** 2 for i in x]リスト内包表記と
if文の三項演算子を組み合わせたものですね。list_comprehension_grammer.py[(処理) for (変数名) in (配列やリストなど)]ternary_operator_grammer.py(条件式が真の時の処理) if (条件式) else (条件式が偽の時の処理)とはいえ読みにくいし複雑です。
パッケージの偉大さがよくわかります。初めてのPythonシリーズ記事
- 投稿日:2020-05-21T20:40:02+09:00
ノードごとのIDを振る
辞書型のASTのキーにルートIDを振っていく。
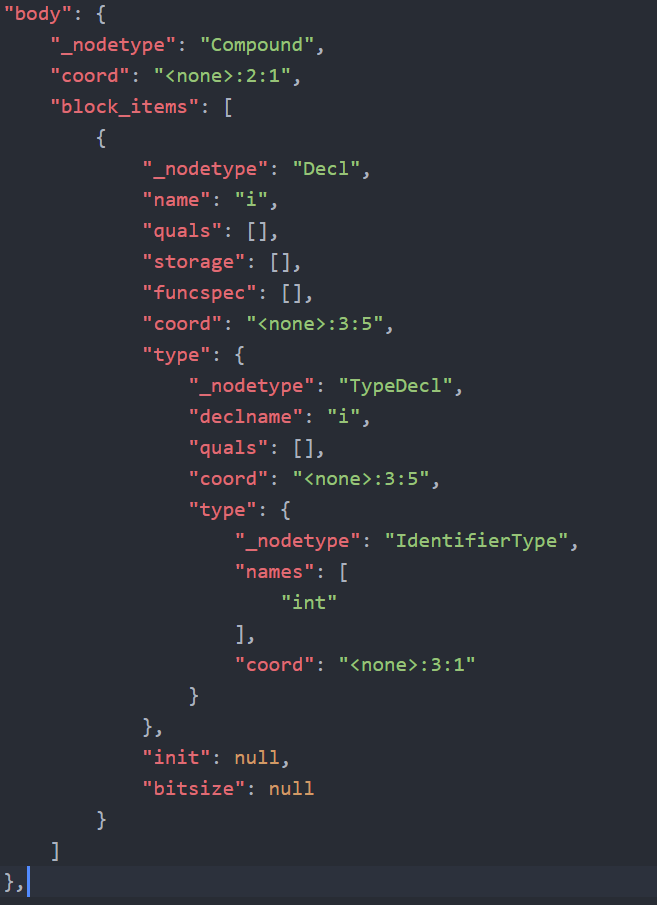
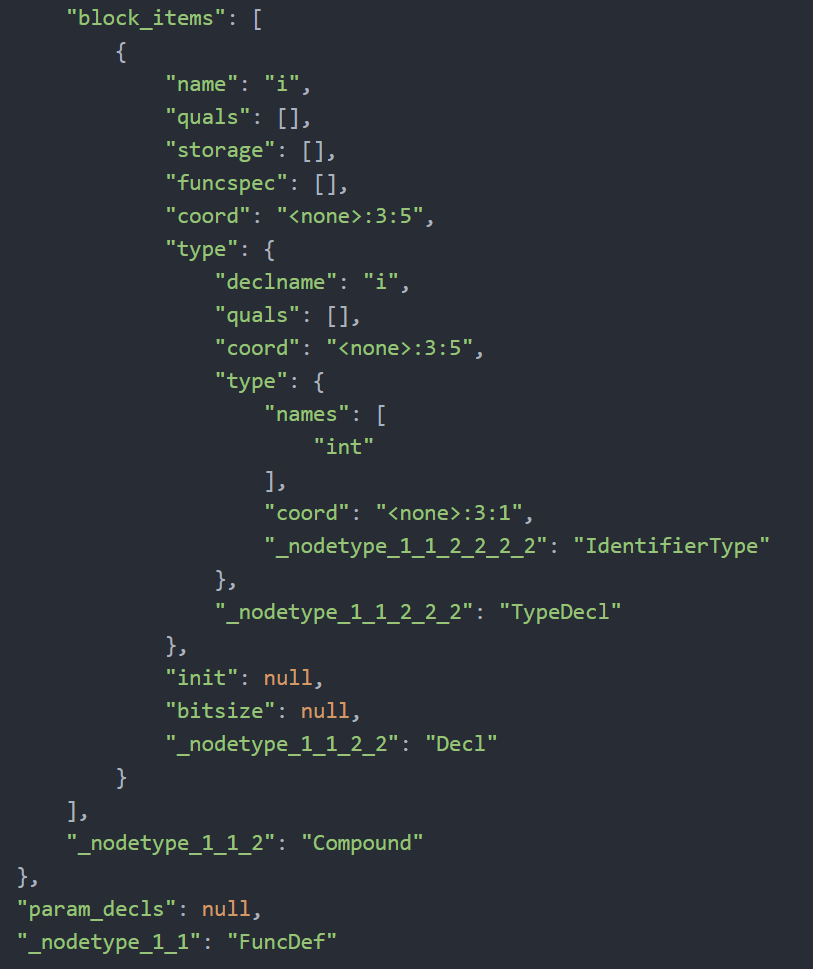
元ASTは入れ子状態になっているが、ルートIDに該当するものは入力されていない。そのため、元々のキー名+根からのルートをIDを入れたキー名に変更させた。変更前のASTの辞書型のキー名の一例
変更後のキー名の状態
今回は、キー名(_nodetype)のみにルートIDをプラスしました。
その他のキー名にもIDを入れようとしいる状態です。
- 投稿日:2020-05-21T20:28:46+09:00
ゼロから始めるLeetCode Day32「437. Path Sum III」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
その対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイト。
せっかくだし人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
前回
ゼロから始めるLeetCode Day30「581. Shortest Unsorted Continuous Subarray」基本的にeasyのacceptanceが高い順から解いていこうかと思います。
Twitterやってます。
そういえば一ヶ月分続きました。めでたい。
問題
437. Path Sum III
難易度はeasy。
Top 100 Liked Questionsのeasyがこれを入れて残り三問となりました。各ノードに整数値が含まれている二分木が与えられます。
ノードの値を合計して特定の値
sumになるパスの数を求めます。経路は親または葉で開始または終了する必要はありませんが、下方向に移動する必要があります(親ノードから子ノードへの移動のみ)。
なお、ツリーのノード数は1,000以下で、値の範囲は-1,000,000〜1,000,000です。
root = [10,5,-3,3,2,null,11,3,-2,null,1], sum = 8
10 / \ 5 -3 / \ \ 3 2 11 / \ \ 3 -2 1Return 3. The paths that sum to 8 are:
- 5 -> 3
- 5 -> 2 -> 1
- -3 -> 11
解法
再帰を使ったdfsで解きました。
# Definition for a binary tree node. # class TreeNode: # def __init__(self, val=0, left=None, right=None): # self.val = val # self.left = left # self.right = right class Solution: ans = 0 def pathSum(self, root: TreeNode, sum: int) -> int: def dfs(root,sums,start): if not root: return 0 sums -= root.val if sums == 0: self.ans += 1 dfs(root.left,sums,False) dfs(root.right,sums,False) if start: dfs(root.left,sum,True) dfs(root.right,sum,True) dfs(root,sum,True) return self.ans # Runtime: 940 ms, faster than 24.67% of Python3 online submissions for Path Sum III. # Memory Usage: 15.1 MB, less than 6.82% of Python3 online submissions for Path Sum III.最初は
rootとsumsだけでかけるかと思って書いていたのですが、どうもそれだけでは書けなかった(書けるかもしれないが今の私の頭では思いつかなかった)ので、discussを覗いたらほとんど一緒の解答があり、そこでは現在のnodeを始点として扱うためにbooleanを用いており、非常にすっきりとした実装ができたのでそのままこちらを載せておきます。それにしてもアルゴリズム強い人すごい・・・
もっと精進しなければならないですね。
良さげな解答があれば追記します。
- 投稿日:2020-05-21T20:22:47+09:00
[Python]04章-01 いろいろなデータ構造(リストの作成と要素の取り出し)
[Python]04章-01 リストの作成と要素の取り出し
この章ではPythonプログラムで扱うデータ構造について述べていきます。
その中で今回はリストについて触れていきたいと思います。オブジェクトとは
Pythonはオブジェクト指向言語と言われています。実は2章で扱った、文字列もオブジェクトというのですが、文字列というモノ(オブジェクト)に対して、動作(メソッド)をしたと思います。
今回扱うリストもオブジェクトの1つです。そういったオブジェクトに対して、また動作もできるようになります。
ただし、オブジェクトは理論的取り扱いが難しいので、詳細はオブジェクト指向の話をした際に詳細を伝えます。
リストの作成
数値リストの作成
Pythonでは関連のあるデータを1つにまとめて表現することができます。これをリスト*と言います。
Python Console より、以下のコードを入力してください。
>>>L = [10, 20, 30, 40, 50]上記のように、リストは[ ]で囲み、「,」で区切って表現します。Lという変数にはリストが代入されています。
以下のようにprint関数で、リストの中身を見ることができます。>>>print(L) [10, 20, 30, 40, 50]最初に「変数」のところでお話ししましたが、値には変数名のタグが付いているとお話ししました。
今回も、リストに対して、タグがつけられていることには変わりはありません。
リストの要素の確認
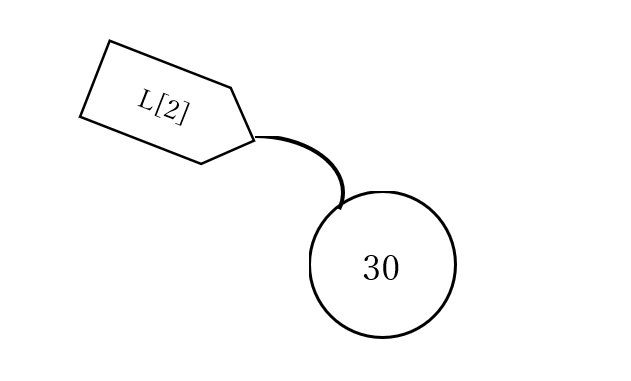
それぞれの値をリストの要素と言います。例えば、1つの要素を取り出すには、以下のように記載します。今回も文字列の時と同じで、リストの要素番号は0番目から始まります。
また、要素番号には文字列の時と同じで、マイナスの番号も当てることができます。
番号(その1) 0 1 2 3 4 番号(その2) -5 -4 -3 -2 -1 リスト内の数値 10 20 30 40 50 >>>L[2] 30 >>>L[-2] 40イメージでは以下のようになっています。
なお、もちろん、要素に存在しない番号を指定すると、以下のようにエラーとなります。
>>>L[5] Traceback (most recent call last): File "<input>", line 1, in <module> IndexError: list index out of range文字列のリスト
リストには数値だけでなく、文字列も代入が可能です。ただし、文字列の場合は「'」(シングルクオーテーション)または「"」(ダブルクオーテーション)で囲む必要があります。
Python Console より、以下のコードを入力してください。
>>>strL = ['Japan', 'China', 'Korea'] >>>print(strL) ['Japan', 'China', 'Korea'] >>>strL[1] 'China'strLという変数に、文字列のリストを作成し、要素を指定して出力させています。これは先ほどの数値のリストと同じですね。
リストの取り出し
02章-05でスライスについて説明しました。
リストでもスライスを適用できます。Python Console より、以下のコードを入力してください。lsという変数名にリストを代入して、変数の中身を出力させて確認します。
>>>ls = ['Japan', 'Canada', 'Australia', 'England', 'German', 'Italy', 'France'] >>>print(ls) ['Japan', 'Canada', 'Australia', 'England', 'German', 'Italy', 'France']変数lsの内容を要素番号を付与してまとめると以下のようになります。
番号(その1) 0 1 2 3 4 5 6 番号(その2) -7 -6 -5 -4 -3 -2 -1 リスト内の文字列 'Japan' 'Canada' 'Australia' 'England' 'German' 'Italy' 'France' 上記をもとにスライスを用いて説明していきます。
>>>ls[2:] ['Australia', 'England', 'German', 'Italy', 'France'] >>>ls[:5] ['Japan', 'Canada', 'Australia', 'England', 'German'] >>>ls[2:5] ['Australia', 'England', 'German'] >>>ls[:-3] ['Japan', 'Canada', 'Australia', 'England'] >>>ls[1:-3] ['Canada', 'Australia', 'England']まず、以下の結果について考えていきたいと思います。
>>>ls[2:] >>>ls[:5] >>>ls[2:5]02章-05の文字列のスライスのところでも説明した通り、数学的に考えてみるとわかりやすいかもしれません。ls[2:]については、以下の通りになります。(xについては番号と考えてください)
2≦xつまり、リストの要素番号が2以上の値はすべて出力するということになります。
ls[:3]やls[2:5]についても、それぞれ以下の通りになります。文字列の時と扱いはほぼ同じですね。x<5\\ 2≦x<5次に、以下のスライスを見ていきたいと思います。
>>>ls[:-3] >>>ls[1:-3]これは先ほどの表と組み合わせて考えるとわかりやすいと思います。
「-3」という要素は上の表では'German'ですが、今回は-3の要素番号は含まない、つまりx<-3となるので、上記の表でいうと「-7」「-6」「-5」「-4」(つまり['Japan', 'Canada', 'Australia', 'England'])が該当することになります。
ls[1:-3]についても、表と照らし合わせるとわかりやすいかもしれません。
最後に
今回はデータ構造の中で、リストについて述べました。リストについては今後Pythonでデータ分析を行ったりする際に必ず必要になるので、ぜひ押さえておきましょう。
次回は、リストの操作について述べていきたいと思います。【目次リンク】へ戻る

- 投稿日:2020-05-21T20:22:47+09:00
[Python]04章-01 いろいろなデータ構造(リストの作成と取り出し)
[Python]04章-01 リスト
この章ではPythonプログラムで扱うデータ構造について述べていきます。
その中で今回はリストについて触れていきたいと思います。オブジェクトとは
Pythonはオブジェクト指向言語と言われています。実は2章で扱った、文字列もオブジェクトというのですが、文字列というモノ(オブジェクト)に対して、動作(メソッド)をしたと思います。
今回扱うリストもオブジェクトの1つです。そういったオブジェクトに対して、また動作もできるようになります。
ただし、オブジェクトは理論的取り扱いが難しいので、詳細はオブジェクト指向の話をした際に詳細を伝えます。
リストの作成
数値リストの作成
Pythonでは関連のあるデータを1つにまとめて表現することができます。これをリスト*と言います。
Python Console より、以下のコードを入力してください。
>>>L = [10, 20, 30, 40, 50]上記のように、リストは[ ]で囲み、「,」で区切って表現します。Lという変数にはリストが代入されています。
以下のようにprint関数で、リストの中身を見ることができます。>>>print(L) [10, 20, 30, 40, 50]最初に「変数」のところでお話ししましたが、値には変数名のタグが付いているとお話ししました。
今回も、リストに対して、タグがつけられていることには変わりはありません。
リストの要素の確認
それぞれの値をリストの要素と言います。例えば、1つの要素を取り出すには、以下のように記載します。今回も文字列の時と同じで、リストの要素番号は0番目から始まります。
また、要素番号には文字列の時と同じで、マイナスの番号も当てることができます。
番号(その1) 0 1 2 3 4 番号(その2) -5 -4 -3 -2 -1 リスト内の数値 10 20 30 40 50 >>>L[2] 30 >>>L[-2] 40イメージでは以下のようになっています。
なお、もちろん、要素に存在しない番号を指定すると、以下のようにエラーとなります。
>>>L[5] Traceback (most recent call last): File "<input>", line 1, in <module> IndexError: list index out of range文字列のリスト
リストには数値だけでなく、文字列も代入が可能です。ただし、文字列の場合は「'」(シングルクオーテーション)または「"」(ダブルクオーテーション)で囲む必要があります。
Python Console より、以下のコードを入力してください。
>>>strL = ['Japan', 'China', 'Korea'] >>>print(strL) ['Japan', 'China', 'Korea'] >>>strL[1] 'China'strLという変数に、文字列のリストを作成し、要素を指定して出力させています。これは先ほどの数値のリストと同じですね。
リストの取り出し
02章-05でスライスについて説明しました。
リストでもスライスを適用できます。Python Console より、以下のコードを入力してください。lsという変数名にリストを代入して、変数の中身を出力させて確認します。
>>>ls = ['Japan', 'Canada', 'Australia', 'England', 'German', 'Italy', 'France'] >>>print(ls) ['Japan', 'Canada', 'Australia', 'England', 'German', 'Italy', 'France']変数lsの内容を要素番号を付与してまとめると以下のようになります。
番号(その1) 0 1 2 3 4 5 6 番号(その2) -7 -6 -5 -4 -3 -2 -1 リスト内の文字列 'Japan' 'Canada' 'Australia' 'England' 'German' 'Italy' 'France' 上記をもとにスライスを用いて説明していきます。
>>>ls[2:] ['Australia', 'England', 'German', 'Italy', 'France'] >>>ls[:5] ['Japan', 'Canada', 'Australia', 'England', 'German'] >>>ls[2:5] ['Australia', 'England', 'German'] >>>ls[:-3] ['Japan', 'Canada', 'Australia', 'England'] >>>ls[1:-3] ['Canada', 'Australia', 'England']まず、以下の結果について考えていきたいと思います。
>>>ls[2:] >>>ls[:5] >>>ls[2:5]02章-05の文字列のスライスのところでも説明した通り、数学的に考えてみるとわかりやすいかもしれません。ls[2:]については、以下の通りになります。(xについては番号と考えてください)
2≦xつまり、リストの要素番号が2以上の値はすべて出力するということになります。
ls[:3]やls[2:5]についても、それぞれ以下の通りになります。文字列の時と扱いはほぼ同じですね。x<5\\ 2≦x<5次に、以下のスライスを見ていきたいと思います。
>>>ls[:-3] >>>ls[1:-3]これは先ほどの表と組み合わせて考えるとわかりやすいと思います。
「-3」という要素は上の表では'German'ですが、今回は-3の要素番号は含まない、つまりx<-3となるので、上記の表でいうと「-7」「-6」「-5」「-4」(つまり['Japan', 'Canada', 'Australia', 'England'])が該当することになります。
ls[1:-3]についても、表と照らし合わせるとわかりやすいかもしれません。
最後に
今回はデータ構造の中で、リストについて述べました。リストについては今後Pythonでデータ分析を行ったりする際に必ず必要になるので、ぜひ押さえておきましょう。
次回は、リストの操作について述べていきたいと思います。【目次リンク】へ戻る
- 投稿日:2020-05-21T19:08:44+09:00
Python: 日本語テキスト:形態素解析
言語処理とテキストコーパス
自然言語処理とは
私たちが普段から話す言葉、書く文章などを
「自然言語」と言い自然言語をコンピュータに処理させる技術を
自然言語処理 (Natural Language Processing, NLP) と呼びます。自然言語処理は、形態素解析や構文解析、意味解析などの要素技術から成り立ちます。
これらの要素技術を複合して、例えば機械翻訳や音声認識、情報検索など、様々な場面で利用されています。自然言語は、本来人間同士が意思疎通を行うために生み出されたものです。
人間は、曖昧な表現を含む言葉が使われていても、それを解釈し意思疎通を図ることができます。
しかし、コンピュータはデータを正確、かつ高速に処理することを得意とするため曖昧な要素が含まれる自然言語を扱うのは苦手です。自然言語処理の例として、日本語のニュース文書をカテゴリーに分類することを考えてみます。
1つの文書に100文字程度の単語が含まれているとして、文書が10程度の量であれば、人間が目を通して手作業で分類することも可能です。しかし、文書が1,000程度の量であれば、コンピュータに処理を任せたくなります。では、コンピュータで自然言語を処理するにはどうすればよいでしょうか。
自然言語をコンピュータが処理しやすい形、つまり数値へ変換すればよいのです。自然言語は単語の集合です。単語を「何らかの方法」で数値データに変換できれば
機械学習やディープラーニングのアルゴリズムで分析が可能になります。この投稿では自然言語を数値データへ変換し
機械学習のアルゴリズムを用いてトピック抽出を行う方法を学びます。雑談対話コーパス
コーパスとは、自然言語の文書を大量に集めたデータです。自然言語は人間同士の意思疎通のための手段であるため
日本語に限らず英語やドイツ語など言語の種類だけ存在します。すべてを紹介することは難しいため、ここでは私たちに馴染みのある日本語コーパスを紹介します。
日本語コーパスは、有償/無償含め多数提供されています。その結果を用いて、文書分類やトピック抽出などを行うことができるのです。
青空文庫 現代日本語書き言葉均衡コーパス(BCCWJ) 雑談対話コーパス 名大会話コーパス(日本語自然会話書き起こしコーパス) 日本語話し言葉コーパス(CSJ) livedoorニュースコーパスこれらのコーパスはCSV形式やJSON形式、XML形式など様々なファイル形式で提供されています。
特に、JSON形式やXML形式は階層構造になっているため
必要なデータを取り出してCSVファイルに変換してから使用することをお薦めします。それではPythonのjsonライブラリを用いて、データの抽出を行ってみます。
データを抽出するには データが格納されている変数名 と 取得したいデータのキー を指定します。# ファイルを読み込み専用モードで読み込みます f = open("./6110_nlp_preprocessing_data/init100/1407219916.log.json", "r", encoding='utf-8') json_data = json.load(f) # `json_data`に含まれる'会話ID('dialogue-id')'を変数`dialogue`に取得します dialogue = json_data["dialogue-id"] print(dialogue) # >>> 出力結果 1407219916使用結果がこちら
import json # ファイルを読み取り専用モードで読み込み f = open("./6110_nlp_preprocessing_data/init100/1407219916.log.json", "r", encoding='utf-8') json_data = json.load(f) # 会話IDの取得 print("dialogue-id : " + json_data["dialogue-id"]) # 話者IDを取得 print("speaker-id : " + json_data["speaker-id"]) # 話者と発話内容を取得 for turn in json_data["turns"]: # 話者のキーは"speaker"、発話内容のキーは"utterance"です print(turn["speaker"] + ":" + turn["utterance"])
なおここで使用するコーパスは以下の通りです。
コーパス
雑談対話コーパス
対話システムのエラーを共同で分析することを目的としたデータで、人とシステムの会話(雑談)と、システムの返答すべてにラベルが付いています。ディレクトリ構造
ダウンロードしたデータは init100 と rest1046 のディレクトリに分かれており、init100 には100セットの雑談データ、rest1046 には1,046セットの雑談データが格納されています。その中の init100ディレクトリ のデータを使用します。
ファイル構造
データファイルはJSON形式で提供されており、大きく分けて人の発話(質問)データとシステムの発話(回答)データで構成されています。
1ファイルが1回の対話データです。データ構造
発話データは日本語の文章で表現されており、ファイル内の
'turns'キーの中に格納されています。
'utterance'が発話データで
'speaker'「U」が人、「S」がシステムの発話です。また、システムの発話データには、人の質問に対してシステムの回答が
破綻しているかどうかのフラグ(ラベル)である
'breakdown'やコメント'comment'が付与されています。フラグは
O破綻ではない発話、
T破綻とは言い切れないが違和感のある発話
X明らかにおかしいと感じる発話の3種類です。なお、'breakdown'は複数名のアノテータ('annotator-id')により付されているため
1つのシステムの回答に対し、複数の'breakdown'が存在します。以下にコーパスの一部を示します。
{ 'dialogue-id': '1407219916', 'group-id': 'init100', 'speaker-id': '12_08', 'turns': [ { 'annotations': [ { 'annotator-id': '01_A', 'breakdown': 'O', 'comment': '', 'ungrammatical-sentence': 'O' }, { 'annotator-id': '01_B', 'breakdown': 'O', 'comment': '', 'ungrammatical-sentence': 'O' }, ... { 'annotator-id': '15_A', 'breakdown': 'T', 'comment': 'まったく数値が違う', 'ungrammatical-sentence': 'O' } ], 'speaker': 'S', 'time': '2014-08-05 15:23:07', 'turn-index': 2, 'utterance': '最高気温は17度が予想されます??' }, { 'annotations': [], 'speaker': 'U', 'time': '2014-08-05 15:23:15', 'turn-index': 3, 'utterance': 'いやいや猛暑ですよ' }, ... }分析データの抽出
破綻しにくい発話を定量的に分析していきます。
分析を行うサンプルデータには、init100ディレクトリ内の10ファイルに含まれる
人の発話内容とそれに対するシステムの発話が破綻かどうかのフラグを使用します。分析に必要なデータを取得したら、まずはそこから重複している不要なデータを削除します。
重複データの削除
重複する要素を含む行を削除するにはPandasのdrop_duplicates()メソッドを用います。from pandas import DataFrame # インデックス番号0とインデックス番号2が重複しているDataFrameです df=DataFrame([['AA','Camela',150000,20000], ['BB','Camera',70000,10000], ['AA','Camela',150000,20000], ['AA','Video',3000,150]], columns=['CUSTOMER','PRODUCT','PRICE','DISCOUNT']) df # >>> 出力結果 CUSTOMER PRODUCT PRICE DISCOUNT 0 AA Camela 150000 20000 1 BB Camera 70000 10000 2 AA Camela 150000 20000 3 AA Video 3000 150 # 重複を含む行を削除します drop = df.drop_duplicates() drop # >>> 出力結果 CUSTOMER PRODUCT PRICE DISCOUNT 0 AA Camela 150000 20000 1 BB Camera 70000 10000 3 AA Video 3000 150使用例はこちら
import os import json import pandas as pd # init100ディレクトリを指定 file_path = './6110_nlp_preprocessing_data/init100/' file_dir = os.listdir(file_path) # フラグと発話内容を格納する空のリストを作成 label_text = [] # JSONファイルを1ファイルずつ10ファイル分処理 for file in file_dir[:10]: # 読み込み専用モードで読み込み r = open(file_path + file, 'r', encoding='utf-8') json_data = json.load(r) # 発話データ配列`turns`から発話内容とフラグを抽出 for turn in json_data['turns']: turn_index = turn['turn-index'] # 発話ターンNo speaker = turn['speaker'] # 話者ID utterance = turn['utterance'] # 発話内容 # 先頭行はシステムの発話なので除外 if turn_index != 0: # 人の発話内容を抽出 if speaker == 'U': u_text = '' u_text = utterance else: a = '' for annotate in turn['annotations']: # 破綻かどうかのフラグを抽出 a = annotate['breakdown'] # フラグと人の発話内容をリストに格納 tmp1 = str(a) + '\t' + u_text tmp2 = tmp1.split('\t') label_text.append(tmp2) # リスト`label_text`をDataFrameに変換 df_label_text = pd.DataFrame(label_text) # 重複する行を削除 df_label_text = df_label_text.drop_duplicates() df_label_text.head(25)
テキストの形態素解析
形態素解析とは
自然言語処理の手法の一つに
形態素解析 (Morphological Analysis) が上げられます。形態素解析とは、文法ルールや解析辞書データに基づいて文章を単語に分割し
それぞれに品詞を付与する処理です。「形態素」とは、その言語において意味を持つ最小の単位、つまり単語を指します。
ここでは、日本語の形態素解析をみていきます。【テキスト】今日は晴れます。 ↓ 【 形態素 】今日 | は | 晴れ | ます | 。 (名詞)(助詞)(動詞)(助動詞)(記号)形態素と形態素の間は、分かりやすいように「|」で区切りました。
例に挙げたような短文であれば、人手で文章を単語に分割することも可能ですが
実際に扱う文書に含まれる文章は長文ですので、コンピュータで処理を行うのが現実的です。コンピュータで形態素解析を実行するツールに形態素解析エンジンと呼ばれるものがあります。
形態素解析エンジンはインストールして実行するもの
Web APIとして呼び出せるもの
プログラミング言語のライブラリとして呼び出せるものなど
有償/無償含めて様々な形で提供されています。これらの主な違いは、形態素解析に使用する文法や辞書の違いです。ChaSen :奈良先端科学技術大学院大学 松本研究室が開発・提供。 JUMAN :京都大学 黒橋・河原研究室が開発・提供。 MeCab :工藤拓氏が開発・オープンソースとして提供。 Janome :打田智子氏が開発・Pythonライブラリとして提供。 Rosette Base Linguistics :ベイシステクノロジー社が開発・提供(有償)。MeCabを使った形態素解析と分かち書き
形態素解析エンジンMeCabを用いて日本語テキストの形態素解析と分かち書きを行ってみます。
形態素解析 ①Tagger()オブジェクトを用い、引数の出力モードに形態素の分割に使用する辞書を指定します。 ②何も指定しない場合は、MeCabの標準システム辞書を使用します。 ③parse('文字列')で指定した文字列を形態素に分割し、品詞などを付与した形態素解析結果を取得します。import MeCab k = MeCab.Tagger() print(k.parse('形態素解析したい言葉'))出力結果 形態素 名詞,一般,*,*,*,*,形態素,ケイタイソ,ケイタイソ 解析 名詞,サ変接続,*,*,*,*,解析,カイセキ,カイセキ し 動詞,自立,*,*,サ変・スル,連用形,する,シ,シ たい 助動詞,*,*,*,特殊・タイ,基本形,たい,タイ,タイ 言葉 名詞,一般,*,*,*,*,言葉,コトバ,コトバ EOS出力される形態素解析の結果は左から順に以下の通りです。
なお、()内の表記は、それぞれの属性の情報を取得する際の属性名です。表層形(surface)(文章中で使用されている単語) 品詞(part_of_speech) 品詞細分類1〜3(part_of_speech) 活用型(infl_type) 活用形(infl_form) 原形(base_form)(文章中で使用されている単語の原形) 読み(reading) 発音(phonetic)分かち書き
Tagger()オブジェクトの出力モードに('-Owakati')を指定すると
品詞などを付与せず、形態素ごとに区切りの空白を入れる分かち書きのみを行うことができます。import MeCab k = MeCab.Tagger('-Owakati') print(k.parse('分かち書きしたい言葉'))>>> 出力結果 分かち書き し たい 言葉その他の出力モード -Oyomi : 読みのみを出力 -Ochasen : ChaSen 互換形式 -Odump : すべての情報を出力使用例はこちら
import MeCab # 形態素解析 m = MeCab.Tagger() print(m.parse('すもももももももものうち')) # 分かち書き w = MeCab.Tagger('-Owakati') print(w.parse('すもももももももものうち'))
Janomeを使った形態素解析と分かち書き
続いて、形態素解析エンジンJanomeを用いて日本語テキストの形態素解析と分かち書きを行います。
形態素解析 ①Tokenizer()オブジェクトを作成し、tokenize()メソッドに形態素解析したい文字列を指定します。 ②形態素解析の出力結果の読み方はMeCabと同様です。from janome.tokenizer import Tokenizer # Tokenizerオブジェクトの生成 t = Tokenizer() tokens = t.tokenize("形態素解析したい言葉") for token in tokens: print(token)>>> 出力結果 形態素 名詞,一般,*,*,*,*,形態素,ケイタイソ,ケイタイソ 解析 名詞,サ変接続,*,*,*,*,解析,カイセキ,カイセキ し 動詞,自立,*,*,サ変・スル,連用形,する,シ,シ たい 助動詞,*,*,*,特殊・タイ,基本形,たい,タイ,タイ 言葉 名詞,一般,*,*,*,*,言葉,コトバ,コトバ分かち書き
tokenize()メソッドの引数にwakati=True を指定すると、分かち書きのみを行います。from janome.tokenizer import Tokenizer # Tokenizerオブジェクトの生成 t = Tokenizer() tokens = t.tokenize("分かち書きしたい言葉", wakati=True) for token in tokens: print(token)>>> 出力結果 分かち書き し たい 言葉その他機能
①品詞でフィルターをかけることができます。
除外したい場合は、除外したい品詞を指定します。 POSStopFilter(['接続詞', '記号', '助詞', '助動詞']) 取得したい場合は、取得したい品詞を指定します。 POSKeepFilter(['名詞'])②Analyzerは、形態素解析の前処理・後処理をテンプレート化するためのフレームワークです。
Analyzer(前処理, Tokenizerオブジェクト, フィルター) を渡します。
前処理の部分は以下のように設定します。char_filters = [UnicodeNormalizeCharFilter(), RegexReplaceCharFilter('正規表現', '変換したい文字')]UnicodeNormalizeCharFilter() Unicode文字列の表記揺れを正規化します。 引数は"NFKC"、"NFC"、"NFKD"、"NFD"のいずれかで、デフォルトはNFKCです。 例えば、全角の"ABC"は半角の"ABC"へ、半角の"カナ"は全角の"カナ"へなどの正規化を行います。 RegexReplaceCharFilter('正規表現', '変換したい文字') 正規表現パターンにマッチした文字列を置換します。from janome.tokenizer import Tokenizer from janome.tokenfilter import POSKeepFilter from janome.analyzer import Analyzer # Tokenizerオブジェクトの生成 t = Tokenizer() # 名詞のみを抽出するフィルターを生成 token_filters = [POSKeepFilter(['名詞'])] # フィルターを搭載した解析フレームワークの生成 analyzer = Analyzer([], t, token_filters) # 実行 for token in analyzer.analyze("フィルターをかけたい言葉"): print(token)>>> 出力結果 フィルター 名詞,一般,*,*,*,*,フィルター,フィルター,フィルター 言葉 名詞,一般,*,*,*,*,言葉,コトバ,コトバ使用例はこちら
from janome.tokenizer import Tokenizer from janome.tokenfilter import POSKeepFilter from janome.analyzer import Analyzer # 形態素解析オブジェクトの生成 t = Tokenizer() # 名詞のみ抽出するフィルターを生成 token_filters = [POSKeepFilter(['名詞'])] # フィルターを搭載した解析フレームワークの生成 analyzer = Analyzer([], t, token_filters) for token in analyzer.analyze('すもももももももものうち'): print(token)テキストの正規化
形態素解析に使用される辞書
形態素解析の 解析結果は辞書に依存しており
実行時は標準で備わっている「標準辞書」を使用して文章を単語へ分割し品詞を付与します。標準辞書には一般的な単語は収録されていますが
専門用語が含まれていたり、新語がアップデートされることは多くありません。このような場合、単語が不自然に分割されたり、品詞が未知語と解析されたりします。
【テキスト】私は東京タワーに行きます。 【解析結果】私 | は | 東京 | タワー | に | 行き | ます | 。これを防ぐには、標準辞書とは別にユーザー辞書を用意します。
ユーザー辞書の作成方法は、形態素解析エンジンによって異なるので
ここではユーザー辞書の存在のみ覚えておいてください。なお、無償で配布しているユーザー辞書もあるので目的に合わせて検索し
インストールしても良いかもしれません。(ただし、自己の判断と責任で利用するものとします。)テキストの正規化
形態素解析を実行する前に 不要な記号を削除 したり 表記を統一 するなど、表記揺れを 正規化する 作業を行います。
【テキスト】私は昨日,りんごを食べました。今日は、林檎ジュースを飲みます。 【正規化後】私は昨日、りんごを食べました。今日は、りんごジュースを飲みます。上記の例では、句点は「,」と「、」の2種類ありますが、意味は同じなので「、」に統一できます。
また、単語「りんご」と「林檎」も同様に統一できます。コンピュータで正規化を行う際、文字列の指定には 正規表現 (regular expression) を用います。
正規表現 (regular expression) とは、いくつかの文字列を一つの形式で表現することです。例えば、テキストに含まれるある文字列を検索するには、検索対象の文字列を次のように文字種で表します。[0-9] : 数字0~9の中の どれか1文字にマッチする [0-9a-z]+ : 数字0~9、英小文字a~zの中の 1文字以上にマッチするテキストに含まれるある文字列を取り除きたいときや置き換えを行う場合
re.sub()を用いますが、引数の取り除きたい文字列をこの正規表現で指定します。import re re.sub("取り除きたい文字列", "変換後の文字列", "取り除きたいテキスト")使用例はこちら
import re # 英数字を除外したテキストを出力 re.sub("[0-9a-zA-Z]+", "", "私は商品Aを10個買います。")



- 投稿日:2020-05-21T19:03:00+09:00
100日後にエンジニアになるキミ - 62日目 - プログラミング - 暗号について
昨日までのはこちら
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
暗号について
暗号とは何でしょうか?
暗号は第三者が見ても特別な知識なしでは読めないように変換する手法のことを言います。初期の古典暗号は、多くは紙と鉛筆のみで暗号化を行いますが、多少の道具を用いていました。
種類としては
古典暗号
暗号の作り方も鍵も秘密のアルゴリズムのみで数学的な安全性評価なし
換字式暗号
転置式暗号
スキュタレー暗号
シーザー暗号現代暗号
暗号アルゴリズムは公開され、鍵のみが秘密
暗号・復号のアルゴリズムは公開されているためプログラムとして実装可能
暗号の安全性は計算量を基に議論する共通鍵暗号系:
DES暗号,AES暗号
公開鍵暗号系:RSA暗号,ElGamal暗号こんな感じです。
暗号関連用語
以下に暗号で使われる用語を解説する
以下に暗号で使われる用語を解説します。
用語 説明 平文 (plaintext) 暗号化される前の文。 暗号文 (ciphertext) 平文を、独特の表記法によって第三者が読み解けないようにした通信文。 鍵 (key) 表記法のパラメータ。鍵が異なると平文が同じでも暗号文が異なる。 セキュリティパラメータ (security parameter) 暗号の安全性を表す尺度。鍵のサイズなどを指定する。 暗号化 (encryption; encode, encipher) 表記法に従って平文を暗号文に変換すること。 復号 (decryption; decode, decipher) 表記法に従って暗号文を平文に戻すこと。 攻撃 (attack) 暗号化に用いられた表記法の特定あるいは鍵を探索する行為。解読ともいう。 暗号解読 (cryptanalysis) 受信者以外の第三者が暗号文を通信文に戻そうとすること。 共通鍵 (common key; symmetric key) 共通鍵暗号において、暗号化にも復号にも用いられる鍵。秘密鍵ということもある。 公開鍵 (public key) 公開鍵暗号において、暗号化に使用する鍵。 秘密鍵 (private key) 公開鍵暗号において、復号に使用する鍵。 シーザー暗号(Caesar cipher)
「お前もか!!」で有名なシーザーさんの使っていた暗号だそうです。
方式は文字をシフトさせるだけのお手軽暗号化です。
鍵は何文字、という部分だけで特に秘密なものはありません
頑張れば読めてしまうであろう暗号ですね。
それでも昔は暗号として使えていたというわけです。実際にプログラムで暗号文を作ってみましょう。
英文字のみをシフトさせるとし
何文字シフトさせるかは可変にしています。def caesar_cipher_encrypt(plaintext, key): cipher = "" for p in list(plaintext): if 'A' <= p <= 'Z': cipher += chr((ord(p) - ord('A') + key)%26 + ord('A')) elif 'a' <= p <= 'z': cipher += chr((ord(p) - ord('a') + key)%26 + ord('a')) else: cipher += p return cipherこれで暗号化させる関数は出来上がりです、
復号もこれで行う事ができます。これで暗号化された文字を解読してみましょう。
zdwdvklqr jhvvbxxkd 53pdq ghdwktext = 'zdwdvklqr jhvvbxxkd 53pdq ghdwk' for i in range(1,26): print(i,caesar_cipher_encrypt(text, i))1 aexewlmrs kiwwcyyle 53qer hiexl
2 bfyfxmnst ljxxdzzmf 53rfs ijfym
3 cgzgynotu mkyyeaang 53sgt jkgzn
・・・23 watashino gessyuuha 53man death
これですね!!
23文字シフトさせたやつが答えっぽいです。スキュタレー暗号
スキュタレー暗号は棒に革紐を巻きつけて平文を書いて
革紐を外したら、それが暗号になるというものです。元の文字自体は変わらず文字の順番のみが変わるというものです。
このような関数でスキュタレー暗号を作ることができます。
def sq_cipher_encrypt(plaintext, num): cipher = "" c,b = 0,0 for i in range(len(plaintext)): cipher += plaintext[c] if c+num<len(plaintext): c+=num else: b+=1 c=b return ciphersq_cipher_encrypt('私の戦闘力は53マンです',4)'私力マのはン戦5で闘3す'
sq_cipher_encrypt('私力マのはン戦5で闘3す',3)'私の戦闘力は53マンです'
同じ棒がなかったら昔は解読できなかったとか言われているそうで
何事も暗号も辛抱(芯棒)が大事お後がよろしいようでwww
ヴィジュネル暗号
ヴィジュネル暗号は15~16世紀に考えられた換字式の暗号です。下記のヴィジュネル方陣と鍵を使って暗号化を行います。
例として鍵:
arm、平文:CODEとするとヴィジュネル方陣で
aとCの交わりはc,rとOはf,mとDはpというように
暗号文c, f, pが得られる。平文が鍵よりも長い場合、鍵を繰り返して用い最後の平文
Eはaとの交わりでeとなり、平文:CODEは暗号文:cfpeとなる。1文字づつシフトする文字が変わるため、鍵がないと複合が難しくなる。
参考:wikipedia
相当長い暗号文が与えられしかもそれがヴィジュネル暗号だと分かっているときは
頑張れば解読可能だったりします。# 暗号化 def encrypt( plain, key ): index , result = 0 , '' while index < len(plain): index2 = index % len(key) p_code = ord(plain[index]) - ord('a') k_code = ord(key[index2]) - ord('A') result += chr( (p_code + k_code) % 26 + ord('a') ) index += 1 return result # 復号化 def decrypt( cipher, key ): index , result = 0 , '' while index < len(cipher): index2 = index % len(key) c_code = ord(cipher[index]) - ord('a') k_code = ord(key[index2]) - ord('A') result += chr((c_code - k_code) % 26 + ord('a') ) index += 1 return result # 暗号化する文字の指定 plain_text = 'otexintexin birooon' # キーの指定 key_text = 'otupy' # 暗号化 cipher_text = encrypt( plain_text , key_text ) print( cipher_text ) # 復号化 decode_text = decrypt( cipher_text , key_text ) print( decode_text )isesmhsesmhaimsinn
otexintexinbirooonエニグマ(Enigma)
エニグマは人類史上最も有名な暗号だと思います。
第二次世界大戦でナチス・ドイツが用いたローター式暗号機で幾つかの型があり
暗号機によって作成される暗号も広義にはエニグマと呼ばれるようです。そもそも名前がかっこいい!!!
仕組みを説明すると死んでしまうのでこちらを参照ください。
こんなコードでエニグマを再現できるっぽいです。
import random import copy class Enigma: def __init__(self, s1, s2 = 0, s3 = 0): alpha = [chr(i) for i in range(ord("a"), ord("z") + 1)] adds = [' ', '?', '.', ','] self.orig = alpha+ adds self.c_num = len(self.orig) self.c_num2 = self.c_num * self.c_num self.rotor1 = self.make_rotor(s1) self.rotor2 = self.make_rotor(s2) self.rotor3 = self.make_rotor(s3) self.reflect = self.make_rotor(s1) self.plug = self.make_plug() def make_rotor(self, seed = 0): random.seed(seed) alpha = copy.copy(self.orig) random.shuffle(alpha) return alpha def make_plug(self, seed = 0): random.seed(seed) plug = copy.copy(self.orig) rp = random.sample(range(self.c_num), 6) for idx in range(0, 6, 2): plug[rp[idx]] , plug[rp[idx + 1]] = (plug[rp[idx + 1]] , plug[rp[idx]],) return plug def rotate(self, idx): self.rotor1.append(self.rotor1.pop(0)) if idx % self.c_num == 0 and idx / self.c_num != 0: self.rotor2.append(self.rotor2.pop(0)) if idx % self.c_num2 == 0 and idx / self.c_num2 != 0: self.rotor3.append(self.rotor3.pop(0)) def encode_c(self, ch): char = self.plug[self.orig.index(ch)] char = self.rotor1[self.orig.index(char)] char = self.rotor2[self.orig.index(char)] char = self.rotor3[self.orig.index(char)] if self.reflect.index(char) % 2 == 0: char = self.reflect[self.reflect.index(char) + 1] else: char = self.reflect[self.reflect.index(char) - 1] char = self.orig[self.rotor3.index(char)] char = self.orig[self.rotor2.index(char)] char = self.orig[self.rotor1.index(char)] char = self.orig[self.plug.index(char)] return char def encode(self, string): code_string = "" for idx, char in enumerate(string): code_string += self.encode_c(char) self.rotate(idx) return code_string# シードを設定 seed = 1 # 平文を設定 plain = 'hirabunoyabun' # 暗号化 enigma = Enigma(seed) enc = enigma.encode(plain) print("Encrypt : " , 'Seed : ' , seed , enc) # 復号化 enigma = Enigma(seed) dec = enigma.encode(enc) print("Decrypt : ", 'Seed : ' , seed , dec ) # 復号化(シード違い) seed2 = 2 enigma = Enigma(seed2) dec = enigma.encode(enc) print("Decrypt : ", 'Seed : ' , seed2 , dec )Encrypt : Seed : 1 adjpiqisrgxgp
Decrypt : Seed : 1 hirabunoyabun
Decrypt : Seed : 2 vssxdz,rqyhwqシードが分かってないと復号は大変です。
RSA暗号
RSA暗号は桁数が大きい合成数の素因数分解問題が困難であることを
安全性の根拠とした公開鍵暗号の一つです。現在、公開鍵暗号アルゴリズムの中では広く使われています。
仕組み
RSA暗号は
1.鍵生成アルゴリズム(公開鍵と秘密鍵の生成) 2.暗号化アルゴリズム(公開鍵による暗号化) 3.復号アルゴリズム(秘密鍵による複合)からなります。
鍵の生成には2つの素数P,Qを用いて 数値nを作ります。
この時に用いる素数の桁数(長さ)が暗号の強度になります。
n = p * q例:p,q (3,5) として
n = p * q = 3 * 5 = 15次に
φ(n)=(p-1)(q-1)を求める
(自然数nに関してnと互いに素なn未満の自然数の個数をφ(n)とする)例:
φ(n) = (3-1)(5-1) = 8公開鍵は
(e , n)となりますがeは(p - 1)(q - 1)未満かつ
(p - 1)(q - 1)と互いに素な数から適当に選べば良いようです。今回は
3とすることとします。そうすると 公開鍵は
(e, n) = (3, 15)となります。秘密鍵
dはd * e = l(modφ(n))を解くことで求められます。
今回は 秘密鍵d = 3とします。暗号化と復号化
暗号化(平文 m から暗号文 c を作成する):
c = ?? mod n
復号 (暗号文 c から元の平文 m を得る):m = ?? mod n平文
m = 3の場合(上記でn = 15,e = 3,d = 3)暗号化 :
c = 33 mod 15 = 27 mod 15 = 12
復号 :m = 123 mod 15 = 1728 mod 15 = 3RSAでは2048bit以上の大きさの鍵であれば安全であると言われていますが
コンピュータの進歩とともに、小さな鍵は破られています。以下はRSA暗号化の例です。
# RSA暗号の例 import random import fractions import warnings warnings.filterwarnings('ignore') class RSA(): plaintext = "" ciphertext = [] _e = _d = _n = 0 _p = _q = 0 _l = 0 def __init__(self): pass def __del__(self): pass def set_plaintext(self,str): self.plaintext = str def _random(self): digit = 10 return random.randrange(10**(digit - 1),10**digit) def get_public_key(self): return (self._e, self._n) def get_private_key(self): return (self._d, self._n) def get_key_data(self): return (self._l, self._p, self._q) def _lcm(self,p,q): return (p * q) // fractions.gcd(p, q) def _etension_euclid(self,x,y): c0, c1 = x, y a0, a1 = 1, 0 b0, b1 = 0, 1 while c1 != 0: m = c0 % c1 q = c0 // c1 c0, c1 = c1, m a0, a1 = a1, (a0 - q * a1) b0, b1 = b1, (b0 - q * b1) return c0, a0, b0 def _is_prime_number(self,q): cnt = 50 q = abs(q) if q == 2: return True if q < 2 or q & 1 == 0: return False d = (q - 1) >> 1 while d & 1 == 0: d >>= 1 for i in range(cnt): a = random.randint(1,q - 1) t = d y = pow(a, t, q) while t != q - 1 and y != 1 and y != q - 1: y = pow(y, 2, q) t <<= 1 if y != q - 1 and t & 1 == 0: return False return True def generate_key(self,p = 0,q = 0,e = 0,d = 0,n = 0,l = 0): if p == 0: while True: p = self._random() if self._is_prime_number(p):break self._p = p if q == 0: while True: q = self._random() if self._is_prime_number(q) and p != q:break self._q = q if n == 0: n = p * q self._n = n if l == 0: l = self._lcm(p - 1, q - 1) self._l = l if e == 0: while True: i = random.randint(2,l) if fractions.gcd(i, l) == 1: e = i break self._e = e if d == 0: _c, a, _b = self._etension_euclid(e, l) d = a % l self._d = d def encrypt(self): st = "" for i in map((lambda x: pow(ord(x), self._e,self._n)),list(self.plaintext)): self.ciphertext.append(i) st += str(i) return st def decrypt(self): cip = [] st = "" for i in list(self.ciphertext): tmp = chr(pow(i, self._d,self._n)) cip.append(tmp) st += str(tmp) return st # 平文を用意 input_text = '暗号化するよ' print("平文 m = " , input_text) # RSA rsa = RSA() rsa.set_plaintext(input_text) rsa.generate_key(0,0,65537) l , p , q = rsa.get_key_data() e , n = rsa.get_public_key() d , _n = rsa.get_private_key() print("素数 p = " , p) print("素数 q = " , q) print("公開鍵 n = " , n) print("l = " , l ) print("公開鍵 e = " , e) print("秘密鍵 d = " , d) print() # 暗号化 en = rsa.encrypt() print("C = " , en) # 複合化 de = rsa.decrypt() print("P = " ,de)平文 m = 暗号化するよ
素数 p = 6023748509
素数 q = 9563698961
公開鍵 n = 57609317356848599149
l = 14402329335315287920
公開鍵 e = 65537
秘密鍵 d = 10272622866156722673C = 30714984511718544149370906887949705420833394532467656627958137219747729009706991832334015687577370336953398010927394738
P = 暗号化するよと書いていますが正直RSA良く分かってませんので
間違っていたらすみません。まとめ
世の中には色々な暗号の仕組みがありWEBでも用いられています。
用語や簡単な暗号化、復号化のしくみは抑えておきましょう。君がエンジニアになるまであと38日
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython
- 投稿日:2020-05-21T18:58:12+09:00
seleniumからfortigate(6.0)管理画面にログイン〜ログアウトしてみる
やりたいこと
・webdriverで、ネットワーク機器の管理画面を操作してみたい。
・fortigateはRESTFULなインタフェースを持っているが、今回は考えない。何が嬉しいの?
・fortigate管理画面にログインできなくなるような特異故障を監視できるかも。
用意するもの
・Forigate(今回はFortigate60D 6.0.x)
・ubuntu 20.04
・selenium+firefoxが動く環境(https://qiita.com/gaichi/items/1ece50111b50f8de6453)下調べ(elementの調査方法)
・Firefoxにselenium IDE pluginを導入し、recordで記録した結果を見る。
・HTMLのソースから探し出す。
recordの記録ですが、操作をうまく拾えず、同じ操作でも異なる結果が出ることがあります。HTMLはなんとなく理解していますが、cssは全然理解していないので結構適当に探しました。ソース
#!/bin/python3 from selenium import webdriver from selenium.webdriver.firefox.options import Options import time USERNAME='admin' PASSWORD='password' LOGINURL='https://192.168.1.99/login' # ブラウザ起動 options = Options() options.binary_location = '/usr/bin/firefox' #options.add_argument('-headless') driver = webdriver.Firefox(options=options) # Fortigateログイン画面の取得 driver.get(LOGINURL) # ID,Passwordの入力 time.sleep(1) driver.find_element_by_id('username').send_keys(USERNAME) time.sleep(1) driver.find_element_by_id('secretkey').send_keys(PASSWORD) time.sleep(1) driver.find_element_by_name('login_button').click() time.sleep(5) # ↑管理画面の表示は時間がかかるので、長めに待つ。 # Adminメニューをクリック driver.find_element_by_class_name('admin-avatar').click(); time.sleep(2) # ログアウトをクリック driver.find_element_by_class_name('fa-sign-out').click(); time.sleep(10) # ブラウザーを終了 driver.quit()
- 投稿日:2020-05-21T18:35:06+09:00
インスタンス変数とは
そもそもインスタンスとは
インスタンスとは、クラスによって作られた実体のようなものです。
クラスとは設計図のことであり、クラス(設計図)によって作られたものをインスタンスと呼びます。具体的な例として、車の設計図を基にベンツを作ったとします。
ここでは車の設計図がクラスにあたり、ベンツがインスタンスになります。インスタンス変数とは
インスタンス変数とは、特定のインスタンス内でのみ通用する値のことです。
また、インスタンス変数と意味が混ざりがちな用語としてクラス変数があります。
2つの単語の違いについて先ほどの車の例で考えます。車の設計図に、「タイヤが4個」と「車の形」があったとします。
「タイヤが4個」という設計はどの車にも当てはまる設計であり、クラス内(設計図内)で共通の値になります。
言い換えると、どの車においてもタイヤは4個である必要があります。一方、「車の形」は車種によって異なります。
そのため、ベンツを作る場合にはこの形、プリウスを作るためにはこの形、といった風に各インスタンス内で用いられる車の形は異なります。
この各インスタンス内でのみ通用する値をインスタンス変数といいます。最後に
この記事は、自身の理解を確かめるために頭の中を文章に書き起こしたものです。
間違っている場合もありますので、その際はぜひご指摘ください。
- 投稿日:2020-05-21T18:33:21+09:00
cx_OracleからAutonomous Databaseに接続する際の高速化
初めに
本記事は、Autonomous Database で DRCP(データベース常駐接続プーリング)が使えるようになったので、お試ししてみる。の結果が芳しくなかったことを受け、少しクライアント側の環境を変えて試してみた結果となります。先に結論を書いてしまうと、
- 遅い原因はアプリケーションのロジック(処理の傾向)とDRCPの設定(チューニング)が合っていないため。残念ながらAutonomous環境ではDRCPのチューニングは不可
- DRCPを使用するよりも、cx_Oracleのコネクションプールを使用すると爆速
となります。
検証環境
- Oracle Cloud 大阪リージョン
- Computeインスタンス(テストアプリケーション実行環境):VM.Standard2.1
- OSイメージ:マーケットプレイスにあるOracle Cloud Developer Imange
- Databaseインスタンス:Autonomous Transaction Database 18c (1OCPU)
- ComputeインスタンスにてPython3を使用してテストアプリケーションを作成、300回接続を実施した時間を計測
DRCPで思ったほど早くならなかった原因の調査
まず、DRCPを利用しない検証アプリケーションのソースを提示します。
接続先の指定にはtnsnames.oraを使用しています。ですので、DRCPの利用はtnsnames.ora内にて指定しています。test1.py# -*- coding: utf-8 -*- import cx_Oracle import time USERID = 'admin' PASSWORD = '要置換' DESTINATION = 'atp_low' REPEAT_TIMES = 300 elapsed_times = [] for i in range(REPEAT_TIMES): t1 = time.time() connection = cx_Oracle.connect(USERID, PASSWORD, DESTINATION) t2 = time.time() connection.close() elapsed_times.append(t2 - t1) print(f'接続時間合計 : {sum(elapsed_times)}秒') print(f'接続時間平均 : {sum(elapsed_times) / REPEAT_TIMES}秒')次いで、DRCPを利用する検証アプリケーションのソースです。
test2.py# -*- coding: utf-8 -*- import cx_Oracle import time USERID = 'admin' PASSWORD = '要置換' DESTINATION = 'atp_low_pooled' REPEAT_TIMES = 300 elapsed_times = [] for i in range(REPEAT_TIMES): t1 = time.time() connection = cx_Oracle.connect(USERID, PASSWORD, DESTINATION, cclass='MYCLASS', purity=cx_Oracle.ATTR_PURITY_SELF) t2 = time.time() connection.close() elapsed_times.append(t2 - t1) print(f'接続時間合計 : {sum(elapsed_times)}秒') print(f'接続時間平均 : {sum(elapsed_times) / REPEAT_TIMES}秒')これらのアプリケーションを数回施行した結果、DRCP利用時でおおよそ倍近い性能になりました。元記事はSQL*Plusの起動時間も含んでいるので、元記事よりはよい結果となっていますが、それでも更なる性能が欲しいところです。
そこで、まずは通信の暗号化がボトルネックになっている可能性を考え、DB Server側をいじれるOracle Database Cloud Service(DBCS)に接続先を切り替え、暗号化の設定を外して試したところ、DRCPなしよりありの方が遅いという結果に。DRCPがない場合だけ高速化しました。つまり、通信の暗号化は、DRCP利用時は影響が軽微ということです。
ここで元記事作者と相談の上、DRCPのチューニング(MINSIZEの増加)をDBCS上で実施してみました。結果、DBCS環境では、通信を暗号化してもDRCPの接続速度が10倍程度になりました。直接的な原因は、DRCPのチューニング不足、アプリケーションのロジックに合った設定になっていなかったためと判断しました。
ここで問題なのは、ATPの場合、DRCPの設定を変更することができません。なので、結果的に、ATP(ADWでも同様だと思われます)では、今回の検証アプリケーションだと接続速度をそれなりレベルでしか向上させられない、ということです。
今回は単体アプリケーションから接続/切断を繰り返す形で実施していますが、1回の接続を実施するアプリケーションをテストツールで複数起動させ、繰り返し実行すると、また違った結果が出ると思われます。cx_Oracleのコネクションプール機能を試す
Python用のOracle Database接続ドライバであるcx_Oracleには、コネクションプールの機能が備わっています。この機能を利用すると、DRCPが存在しない状態であっても接続速度の高速化が期待できます。ということで以下のアプリケーションを試してみたところ、ATPへの接続でも非常に高速(300回接続しても1秒かからず)に稼働しました。Python(cx_Oracle)のような接続ドライバのコネクションプールが利用できる環境であればDRCPは不要そう、という、無慈悲な結論となりました。念のため、該当機能が存在しない環境のために、DRCP自体の存在意義はあると思います。
test3.py# -*- coding: utf-8 -*- import cx_Oracle import time USERID = 'admin' PASSWORD = '要置換' DESTINATION = 'atp_low' REPEAT_TIMES = 300 elapsed_times = [] pool = cx_Oracle.SessionPool(USERID, PASSWORD, DESTINATION, min=4, max=40, increment=1) for i in range(REPEAT_TIMES): t1 = time.time() connection = pool.acquire() t2 = time.time() pool.release(connection) elapsed_times.append(t2 - t1) pool.close() print(f'接続時間合計 : {sum(elapsed_times)}秒') print(f'接続時間平均 : {sum(elapsed_times) / REPEAT_TIMES}秒')各パターンの性能比
最後に、本記事で実施したテストの性能比のグラフを提示します。cx_Oracleのコネクションプール利用時のパフォーマンスが良すぎて、嘘っぽい感じになってしまいました。。。
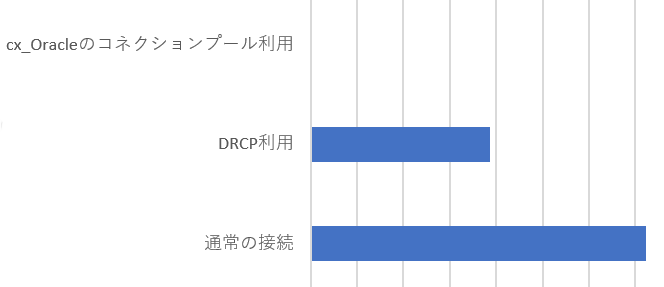
- 投稿日:2020-05-21T18:18:08+09:00
Deep Learning Specialization (Coursera) 自習記録 (C2W2)
はじめに
Deep Learning Specialization の Course 2, Week 2 (C2W2) の内容です。
(C2W2L01) Mini-batch gradient descent
内容
- $m = 5000000$ くらいのとき,training set を mini-batch に分けて,mini-batch 毎に forward propagation と back propagation を計算する
- mini-batch のほうが早く収束する
X^{\{1\}} = \left[ X^{(1)} \, X^{(2)} \, \cdots \, X^{(1000)}\right] \\ Y^{\{1\}} = \left[ Y^{(1)} \, Y^{(2)} \, \cdots \, Y^{(1000)}\right] \\ X^{\{2\}} = \left[ X^{(1001)} \, X^{(1002)} \, \cdots \, X^{(2000)}\right] \\ Y^{\{2\}} = \left[ Y^{(1001)} \, Y^{(1002)} \, \cdots \, Y^{(2000)}\right](C2W2L02) Understanding Mini-batch Gradient Descent
内容
- mini-batch gradient descent の場合,cost function $J^{\{t\}}$ は各 mini-batch の繰り返しに対して振動しながら減少する
- mini-batch の適切なサイズは,vectorization による計算の効率化の恩恵が得られる程度の大きさにする
- 典型的なサイズは $2^6$,$2^7$,$2^8$,$2^9$ など (メモリを効率的に使うために,2 の累乗)
- CPU/GPU のメモリサイズに収まらない mini-batch サイズだと,効率が悪い
- 2 の累乗をいくつか試して,効率的に計算できるサイズを探す
(C2W2L03) Exponentially Weighted Average
内容
参考
- 投稿日:2020-05-21T18:01:28+09:00
Python PyInstaller で急に No module named pyinstaller
いままで
py -m pyinstaller Test.py
でできていたはずなのに、メモものこっていたのに・・・ パスもあっているのに・・・
急に No module named pyinstaller とでてくるようになりました。環境
・Windodws10
・Python 3.8.3
・PyInstaller 3.6結論
pyinstaller → PyInstaller にしたら解決しました。
解決までの道のり
①そもそも pyinstaller はあるのか
windowsなので以下のコマンドでpyinstallerがあるかどうか確認する
py -m pip list
②出力されたリストにあるのはなんと
PyInstaller
大文字になってるじゃない以前からそうでしたっけ
自分の環境では
py -m PyInstaller Test.py
でできました。ただの自分の勘違いで最初から PyInstaller だったかもしれないですが、
それとも、pipでバージョンアップをしたからでしょうか。
とりあえず今回はこれで解決しました。
- 投稿日:2020-05-21T18:01:12+09:00
requirements.txtからpipenvに移行する
はじめに
まだまだ、Pythonのパッケージ管理に
requirements.txtを使っているなんて方は多いと思います。
わかりやすいですし、検索すると最初に出てくるためそのままという方が多いと思います。ただ、
requiments.txtだとパッケージ同士の依存関係が管理できないため、pipenvやpoetryなど様々なパッケージ管理ツールが推奨されています。今回、requimetns.txtからpipenvに変更することにしたのでそのときの手順をまとめます。
※poetryにはrequimetns.txtをimportする機能がないようです。手順
- pipenvのインストール
brew install pipenv
- requirements.txtからpipenvに移行
pipenv install -r requirements.txt # 依存関係を定義するlockファイルを生成 pipenv lock
- 投稿日:2020-05-21T16:45:43+09:00
responderとsqlite3で簡単なウェブサイトを作ってみたり
最近「Nuxt.jsとPythonで作る!ぬるさくAIアプリ開発入門」という本を読んで、その本でかなり新しいpythonのウェブフレームワークであるresponderが紹介されているので興味を持ってもっと調べて色々勉強した後、簡単なウェブサイトを作ってみたのです。
今回の目標のサイトは、SQLデータベースと接続して、データを表示したり、追加したり、更新したり、削除したりすることができるサイトです。
データベースは一番簡単であるsqlite3を使います。
使うモジュールについて
本の他に、responderとsqlite3の使い方については色んな方の記事を読みました。
responder
- Responder + WebSocketで簡易チャットアプリ
- Python+ResponderでWEBアプリケーションを構築する。
- はじめての Responder(Python の次世代 Web フレームワーク)
- 人間のためのイケてるPython WebFramework「responder」、そして作者のKenneth Reitzについて
sqlite3
これらの記事はとても参考になったので、ここでは基本な使い方については省略します。
構造
準備
データベースは簡単のためにSQLiteにします。
SQLiteは実際のサイトを作る時にはあまり向いていないが、MySQLやPostgreSQLとは違って、SQLiteは特にインストールする必要なく、最初からついているから便利です。
使うpythonモジュールは主にresponderとsqlite3だけです。
sqlite3はpythonの標準モジュールなので、インストールする必要があるのはresponderだけ。
responderの公式サイトではpipenvを使うと言われていますが、普通のpipでも簡単にインストールできます。
pip install responder機能
このような簡単なウェブサイトを作ります。
- サイトを操るのはたった一つのpythonファイル
- 各ページはresponderを通じてjinja2のテンプレートに成される
- ページはただ3つ
- - 全部のデータを閲覧したりダウンロードしたりできるインデックスページ
- - データを編集できるページ
- - エラーが出た時のページ
- スタイルシートも簡単なcssファイルだけど一応準備しておく
- formsとinputでデータを入力と編集する
- javascriptの出番はない
- データベースに収めるのはたった2列しかないテーブル
データベース
列名 データ型 名前 namae text レベル lv integer 今回の目標はただちゃんとデータベースに接続してやり取りできることを確認したいだけなので、簡単のために2列しかないテーブルにします。
このテーブルはSQLコードにすると
create table kyara (namae text,lv integer)ファイル
サイトは全部ただこの5つのファイルから成されます。
.htmlファイルはjinja2テンプレートです。jinja2は今まで使ったことはないが、ちょっとdjangoのテンプレートと似ています。
ちなみにファイルの名前は見ての通り「
とある魔術の禁書目録」からです。│- majutsu.py サーバ実行コード │─ index.html インデックスページ │- toaru.html データ表示と編集のページ │- no.html 間違ったことが起きる時に出るページ └─ librorum └─prohibitorum.css スタイルシート環境
OSやとpythonとresponderのバージョンが違ってもあまり問題ないと思いますが一応今回で試した時の環境を書いておきます。
- Mac OS 10.15.4 Catalina
- python 3.7.7
- conda 4.8.3
- responder 2.0.5
- jinja2 2.11.2
- starlette 0.12.13
コード
次は各ファイルの中のコードの説明。
htmlテンプレート
jinja2テンプレートのhtmlファイル
index.html
まずはインデックスページ。
<head> <meta charset="utf-8"> <title>とあるサイトのINDEX</title> <link rel="stylesheet" href="/librorum/prohibitorum.css" type="text/css" media="all"> </head> <body> <h3>とあるsqlite3のresponder</h3> <ul> {% for k in kyara %} <li> <a href="/toaru/{{ k[0] }}">{{ k[0] }}</a> lv {{ k[1] }} </li> {% endfor %} </ul> <form action="/insert" method="post"> <div>名前 <input type="text" name="namae"></div> <div>レベル <input type="text" name="lv"><br></div> <div><input type="submit" value="追加"></div> </form> <a href="/download">ダウンロード</a> </body>構成は
- データの列挙
- 新しいデータを追加するフォーム-
- データをダウンロードするリンクがあります。toaru.html
次は、とあるキャラのデータを表示したり編集したりするページ。
<head> <meta charset="utf-8"> <title>とある{{ namae }}のページ</title> <link rel="stylesheet" href="/librorum/prohibitorum.css" type="text/css" media="all"> </head> <body> <form action="/update/{{ namae }}" method="post"> <div>名前: <input type="text" name="namae" value="{{ namae }}"></div> <div>レベル: <input type="text" name="lv" value="{{ lv }}"></div> <input type="submit" value="更新"> </form> <form action="/delete/{{ namae }}" method="delete"> <input type="submit" value="削除"> </form> <div><a href="/">戻る</a></div> </body>構成は
- 編集できるキャラのデータのフォーム
- データを削除のボタン
- インデックスに戻るリンクno.html
そして、何かの間違いが起きたら出るページ。インデックスへ戻るリンクしかない。
<head> <meta charset="utf-8"> </head> <body> <h1>NO!!</h1> 空はこんなに青いのにお先は真っ暗<br><br> <a href="/">~- 戻る -~</a> </body>python
魔術を使ってサイトの全てを操るファイルです。大きいサイトなら色々なファイルに分解するべきだと思いますが、今回は小さいサイトなので、分ける必要なく一つのファイルにします。
全部のルートのコントローラーと、データベースに接続するコードは全てここに書いてあります。
majutsu.py
import responder,sqlite3,urllib,os # データを保存するファイル dbfile = 'dedicatus545.db' # APIオブジェクト api = responder.API(templates_dir='.', # テンプレートのフォルダ static_dir='librorum', # 静的ファイルのフォルダ static_route='/librorum') # 静的ファイルのルート # インデックスページ @api.route('/') def index(req,resp): with sqlite3.connect(dbfile) as conn: sql_select = ''' select * from kyara ''' # 全てのキャラのデータを表示する kyara = conn.execute(sql_select).fetchall() resp.html = api.template('index.html',kyara=kyara) # 各データ表示と編集のページ @api.route('/toaru/{namae}') def select(req,resp,*,namae): with sqlite3.connect(dbfile) as conn: sql_select = ''' select * from kyara where namae==? ''' # その名前を持つキャラのデータを取る kyara = conn.execute(sql_select,[namae]).fetchone() if(kyara): resp.html = api.template('toaru.html',namae=kyara[0],lv=kyara[1]) else: print('このページは存在しない') api.redirect(resp,'/no') # 存在しない名前が入れられる場合、エラーページへ # 何か間違っている場合のページ @api.route('/no') def no(req,resp): resp.html = api.template('no.html') # データ追加した後 @api.route('/insert') async def insert(req,resp): try: with sqlite3.connect(dbfile) as conn: param = await req.media() # フォームからのデータを取得 namae = param['namae'] lv = param['lv'] sql_insert = ''' insert into kyara (namae,lv) values (?,?) ''' # 新しいデータ追加 conn.execute(sql_insert,(namae,lv)) api.redirect(resp,'/') # インデックスページに戻る except Exception as err: print(f'Error: {type(err)} {err}') api.redirect(resp,'/no') # なにか間違いの場合 # データ更新した後 @api.route('/update/{namae0}') async def update(req,resp,*,namae0): try: with sqlite3.connect(dbfile) as conn: param = await req.media() # フォームからのデータを取得 namae = param['namae'] lv = param['lv'] sql_update = ''' update kyara set namae=?,lv=? where namae==? ''' # データ更新 conn.execute(sql_update,(namae,lv,namae0)) # データ表示のページに戻る **ここで名前はエスケープしないとエラーが出る場合があるのでurllib.parse.quoteが必要 api.redirect(resp,f'/toaru/{urllib.parse.quote(namae)}') except Exception as err: print(f'Error: {type(err)} {err}') api.redirect(resp,'/no') # 何か間違いがある場合 # データ削除した後 @api.route('/delete/{namae}') def delete(req,resp,*,namae): try: with sqlite3.connect(dbfile) as conn: sql_delete = ''' delete from kyara where namae==? ''' # データ削除 conn.execute(sql_delete,[namae]) api.redirect(resp,'/') # インデックスページに戻る except Exception as err: print(f'Error: {type(err)} {err}') api.redirect(resp,'/no') # 何か間違いが起こる場合 # データをロード @api.route('/download') def download(req,resp): with sqlite3.connect(dbfile) as conn: # データをjsonファイルに resp.media = conn.execute('select * from kyara').fetchall() # ファイルをダウンロードするためのページにするために、ヘッダに指定する resp.headers['Content-Disposition'] = 'attachment; filename=data.json' if(__name__=='__main__'): # 初めて実行した時、新たにテーブルを作っておく if(not os.path.exists(dbfile)): with sqlite3.connect(dbfile) as conn: sql_create = ''' create table kyara ( namae text, lv integer ) ''' conn.execute(sql_create) # サーバ開始 api.run()ルートは7つありますが、実際にテンプレートを使うの
- '/'
- '/toaru/{namae}'
- '/no'
3つだけ。
それに加えて
- '/insert'
- '/update/{namae0}'
- '/delete/{namae}'
これらはデータベースとのやり取りをして他のページにリダイレクトするのです。
'/insert'と'/update/{namae0}'のページはフォームからのデータを受け取る必要があってawaitが使われるのでasync関数にしています。
pythonのasyncとawaitについては最近勉強したばかりです。色んなqiita記事を読んで参考になったのですここで紹介しておきます
responderを使う時に、例え私達は直接asyncとawaitを書かなくても、そもそもresponderの中ではasyncとawaitで動く関数がいっぱいなので、非同期処理について理解しておいたらとても役に立ちます。
最後に、'/download'はデータベースの中の全部のデータをjsonファイルに保存するためのページです。
初めてサーバを実行する時にデータベースは作成されます。その後はデータベースを収めるファイル(ここではdedicatus545.dbという名前)が現れます。
responder.APIオブジェクトにはこのように設定されます
templates_dir = '.' static_dir = 'librorum' static_route = '/librorum'templates_dirはテンプレートのあるフォルダ。
デフォルトではtemplatesというフォルダにありますが、今回はフォルダを使わないので'.'に指定します。static_dirは静的ファイルのあるフォルダ。
デフォルトではstaticというフォルダですが、ここでは'librorum'にします。static_routeは静的ファイルのルートで、デフォルトでは'/static'ですが、同じように'/librorum'にする必要があります。
css
サイトのデサインは今回の主な目的ではないので、ちょっと見世物にできる程度に適当なcss
librorum/prohibitorum.css
div,li,h3 { padding: 2px; font-size: 20px; } input { border: solid #194 2px; font-size: 19px; } form { margin: 3; }実行と結果
コードの準備が完成したら、次はサーバ.pyコードの実行です。
python majutsu.pyそしてブラウザーで http://127.0.0.1:5042/ にアクセス。
ここではfirefoxで行きます。
何かの間違いがなければこのようなページは表示されるはずです。
まだデータが入っていないので、まずは追加してみます。
名前とレベルを入力して追加ボタンをクリックすると、データが追加されます。
試しにもう一つ追加。
「ダウンロード」のリンクをクリックしたら、データはjsonファイルにされてダウンロードできます。
ただこの方法ならjsonに変換する時にこのように漢字はユニコードになってしまいます。
[["\u4e0a\u6761\u5f53\u9ebb", 0], ["\u5fa1\u5742\u7f8e\u7434", 5]]これを避ける方法はこの記事で書いてあります https://qiita.com/nassy20/items/adc59c4b7abd202dda26
ただ、それでもfirefoxとかで調べたらちゃんと漢字に戻っているので、今回はこのままでも構いません。
次は、試しにフォームに何も入れずに追加ボタンをクリックすると、エラーが起きてこのページになります。
エラーが出る原因は、名前が入れられていないからreq.media()を使う時に、'namae'キーがなくてparam['namae']を呼ぶとエラーになります。
エラーを避けるためには.get()を使った方がいいですが、今回はそもそも空っぽにできる必要があるわけではないのでここではこのままでいいです。
インデックスに戻って、一つ名前をクリックしてリンクに入ったらデータ編集ページになります。
試しにレベルを空っぽにして、更新ボタンをクリックするとエラーが出てまたnoのページへ。
もう一度このページに戻って、今回ちゃんと新しいデータを入力して、ボタンをクリックしたら、データは更新されます。
インデックスに戻ったらデータはもうちゃんと更新したと確認できます。
最後に、また編集ページに入って削除ボタンをすると
そのデータは消えます。
これで全部の機能のテストは完了。
終わりに
こうやってresponderとsqlite3でウェブサイトができました。
ただ単純であまり使い物にならないウェブサイトかもしれませんが、本格的なサイトを作るための基本の練習としては使えると思います。
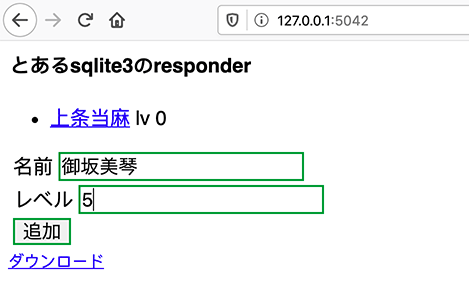
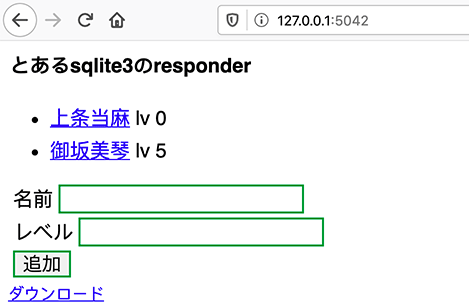

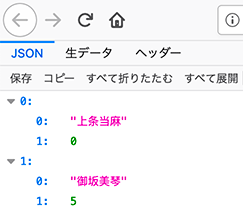

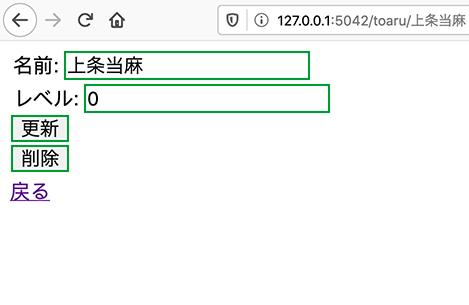

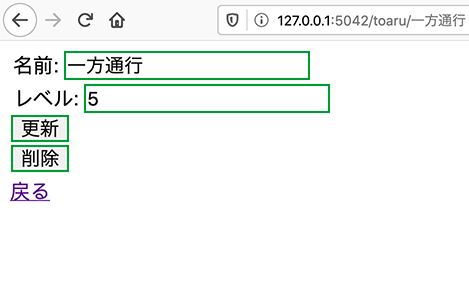
- 投稿日:2020-05-21T16:36:56+09:00
Python PyInstallerでexeファイル作成 並列処理だとPCが固まる
Pythonの並列処理をexeで実行したらPCが固まる
実行環境
・Windodws10
・Python 3.8.3
・PyInstaller 3.6コンソールから実行するとなんてことない並列処理が PyInstallerでexeファイルにしてクリックすると、 exeのプロセスが超たくさん立ち上がり、PCがフリーズしてしまう。絶望するくらい
※PyInstallerがPython3.8.3に対応していないのが原因かと思いきや今回の現象には関係ありませんでした。2020/5/21現在
結論
freeze_support() が必要
exeファイルで実行するとPCが固まるPython並列処理のサンプル
並列処理サンプルfrom multiprocessing import Pool ##### この場合は,引数の二乗を返す関数 ### def nijou(x): print( x*x ) ###### 並列計算させてみる ######### if __name__ == "__main__": p = Pool(4) p.map( nijou, range(10) )freeze_support()の記述が必要だった
メインモジュールの if name == 'main' の直後にこの関数を呼び出す必要があります
freeze_support() の行がない場合、フリーズされた実行可能形式を実行しようとすると RuntimeError
が発生するとのこと
freeze_support() の呼び出しは Windows 以外の OS では効果がありません。
さらに、もしモジュールが Windows の通常の Python インタプリタによって実行されているならば(プログラムがフリーズされていなければ) freeze_support() は効果がありませんとのこと参考はここ・multiprocessing プロセスベースの並列処理
※とりあえずできたからよいのですが、フリーズされた実行形式とはそもそもなんでしょうか?
わからないです。わかるかた教えてください。
exeファイルのことかしら。exeで実行しても固まらないfrom multiprocessing import Pool,freeze_support #freeze_supporを追加 ##### この場合は,引数の二乗を返す関数 ### def nijou(x): print( x*x ) ###### 並列計算させてみる ######### if __name__ == "__main__": freeze_support() #追加しました p = Pool(4) p.map( nijou, range(10) )
- 投稿日:2020-05-21T16:27:07+09:00
SeleniumでChromedriverのバージョンが違うと言われた時(Python)
SeleniumでChromedriverのバージョンが違うと言われた時(Python)
今回の問題:Chromedriverのバージョンエラー
久しぶりにSeleniumを使うと、なんか動かない、、
こんなことありませんか?
エラーコマンドを見るとSessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version 76こんなエラーが出ました。これはChromeとChromedriverのバージョンが違うとこんなことが起こってしまいます。
ではどうしたら良いのか? 答えは簡単です。バージョンを合わせてあげれば良いのです。解決方法
Chromeのバージョンを調べる
まずChromeを開きます。そして一番上のアイコンの隣の・(点)が三つ縦に並んだメニューを押します。その中の"ヘルプ"にいき、さらに"GoogleChromeについて"を押します。するとその先にChromeのバージョンを確認できるので。そこでバージョンを覚えてください。
Chromedriverをインストール
次にバージョンに適したChromedriverをインストールします。
pip install chromedriver-binary==76.0.3809.132 <--"この部分は先ほど確認したChromeのバージョンを記入"上記をターミナルで実行することでインストールできます。76.0.3809.132と書いているところはバージョンなので先ほど確認したChromeのバージョンに差し替えて実行して下さい。
ここでエラーが出ることがよくあると思います。そのエラーを読むと様々なバージョンが記されていることがあると思います。それは先ほど入力したバージョンのChromedriverがないけど、表示しているバージョンならあるよ!って意味なのでChromeのバージョンより一つしたのバージョンを選んで、再度上記のバージョン部分を書き換え実行してみて下さい。
- 投稿日:2020-05-21T15:58:37+09:00
UpNext2 開発記録#0 V2開発目標を立ててみる
第3回東京公共交通オープンデータチャレンジで最優秀賞を頂いたUpNextの、メジャーバージョンアップにそろそろ取り掛かってみます。せっかくなので、ソース公開だけでなく、試行錯誤含めた開発過程を記録公開していくことに、チャレンジします。今回は第ゼロ回です。
1. UpNextとは
UpNextは、現在の位置情報をもとに、交通オープンデータと照合して、最寄りの駅や今乗っている電車の時刻表を自動表示させるスマホアプリです。Flutterで作られています。操作を一切しなくても最適なナビ情報を表示できるのが、独自な部分です。位置や速度や時刻をもとに、歩いているのか、電車に乗っているのか、さらにはどの電車に乗っているのかを自動判別することで、これを実現しています。
Githubにソースが公開されています。
2. V2開発目標
V2作成にあたって、以下のような開発目標を立ててみました。
A. 旧版アーキで限界だった性能や精度の改善
旧版で不満だったのは、主に2点です。1つ目は、都心などで周辺に駅が多い場合に、交通オープンデータのAPIアクセスが多くなってフリーズに近い状態になってしまうことです。2つ目は、駅の位置情報と実際の駅ホームがかなり離れている場合が多く(特に東京駅京葉線は500m程度離れています)、駅判定の精度が高められないことです。
APIアクセスの件は、APIアクセスのキャッシュや先読みにより軽減はできますが、限界を感じていました。またAPIアクセスを前提としていると、嬉しいことにアプリ利用者が増えた際に、オープンデータAPIのセンター側にインパクトが大きくなります。よって、V2では、事前にデータダンプAPIを使って静的データは取得しておき、現在の運行情報などリアルタイム情報のみ動的に取得することにします。また、これにより、一部鉄道の電車時刻表情報など提供されていない情報について、旧版では動的に計算生成していたものを、事前生成しておくことが可能になり、性能改善も期待されます。
駅の位置情報の件は、交通オープンデータだけでは限界があります。そのため、交通オープンデータのサイトで紹介されていた他の機関のオープンデータを探索し、国交省のデータか使えそう、と目星をつけました。
これらの事前のデータ収集と前処理をPythonで記述し、得られたデータをもとにしたV2アプリをFlutterで記述することにします。
項 項目 備考 A1 静的データの事前取得 路線や時刻表といった数か月有効な静的データについて、都度必要な分を取得していたのを、事前一括取得してアプリに最初から保持させる。 A2 国交省の鉄道位置データの活用 国交省で提供されている駅位置や路線位置データを活用して、交通オープンデータと掛け合わせる。 B. 旧版で対応しきれなかった積み残し対応
性能や精度の改善に手間をとられて、対応しきれなかった点について、対応することを目標にします。
項 項目 備考 B1 UIの改善 Flutterの基本のリスト表示だけを使っていたが、もっとカラフルに鉄道路線図っぽく表示させる。できれば地図表示も行う。 B2 多言語対応 日本語以外にも対応させる。 B3 iOS対応 Androidだけの対応であったが、iOSにも対応させる。Flutter利用のため技術的課題は少ない。Appleの審査を通す手間と年貢支払いだけの問題である。 C. 内部的な開発スタイルの刷新
その他、内部的には以下のような、開発スタイルの刷新を行います。ちなみに、C1/C2は、すでに準備ができ、GitHubと連携してVSCodeでコミット〜PUSHができる状態になりました。
項 項目 備考 C1 GitHubによる版数管理 従来は版数管理をしていなかった。今回は開発過程を記録公開するため、GitHubを利用する。なおV1のGitHub公開は開発完了後にファイルコピーをしただけである。 C2 VSCodeの利用 従来はFlutter/Dartだけで作っておりAndroidStudioを利用。今回は前処理にPythonも使う予定であり、よい機会なのでVSCodeで開発する。 C3 テストの記述 個人開発なのでテストは書いていない。しかしUpNextにおいて、ある程度の規模の開発となる中で複雑なバグを踏んだ時、テストの必要性は痛感していた。勉強を兼ねて、ちゃんとテストを書くことにする。 3. 今後の展開
今後、開発が進捗した段階で、開発記録を投稿していきます。お楽しみにしてください。

- 投稿日:2020-05-21T15:51:03+09:00
Pyhton 通常使うプリンタ名の取得方法がわからない。
pythonで通常使うプリンタを変更するのはpythonからコマンドプロントを叩いて変更できた。
しかし通常使うプリンタ名を取得ができない。ご存知のお方ご教授よろしくお願いいたします。下記のプログラムはプリンタ変更のプログラム。
プリンタ変更プログラム.pyimport subprocess cmd = 'rundll32.exe printui.dll,PrintUIEntry /y /n "Microsoft Print to PDF"' returncode = subprocess.call(cmd)VBSでのコードがネットにあり(URL:https://ekafp7.blogspot.com/2016/12/blog-post.html)
同様に下記のようにアレンジして作成したが、3行目でエラーがでる。
objClassSet = objService.ExecQuery("Select * From Win32_Printer")
おそらく引数がだめなのかよくわかりませんがエラーがでます。通常で使うプリンタ取得プログラム.pyobjLocator = win32com.client.Dispatch("WbemScripting.SWbemLocator") objService = objLocator.ConnectServer objClassSet = objService.ExecQuery("Select * From Win32_Printer") for objClass in objClassSet: if objClass.Default: strName = objClass.Caption print(strName)
- 投稿日:2020-05-21T15:51:03+09:00
python 通常使うプリンタ名の取得方法がわからない。
pythonで通常使うプリンタを変更するのはpythonからコマンドプロントを叩いて変更できた。
しかし通常使うプリンタ名を取得ができない。ご存知のお方ご教授よろしくお願いいたします。下記のプログラムはプリンタ変更のプログラム。
プリンタ変更プログラム.pyimport subprocess cmd = 'rundll32.exe printui.dll,PrintUIEntry /y /n "Microsoft Print to PDF"' returncode = subprocess.call(cmd)VBSでのコードがネットにあり(URL:https://ekafp7.blogspot.com/2016/12/blog-post.html)
同様に下記のようにアレンジして作成したが、4行目でエラーがでる。
objClassSet = objService.ExecQuery("Select * From Win32_Printer")
おそらく引数がだめなのかよくわかりませんがエラーがでます。通常で使うプリンタ取得プログラム.pyimport win32com.client objLocator = win32com.client.Dispatch("WbemScripting.SWbemLocator") objService = objLocator.ConnectServer objClassSet = objService.ExecQuery("Select * From Win32_Printer") for objClass in objClassSet: if objClass.Default: strName = objClass.Caption print(strName)また、プリンタ一覧は下記のプログラムででましたが、デフォルトプリンタまでは出てこない。。
プリンタ一覧プログラム.pyimport win32com.client o = win32com.client.Dispatch("WScript.Network") prlist = o.EnumPrinterConnections() for pr in prlist: print(pr)
- 投稿日:2020-05-21T15:42:23+09:00
PyCharmをインストールしたが、`control + e`などのショートカットキーが機能しないときの対処法
経緯
JetBrains製品をよく使うのですが、新しくPyCharmをインストールした際に、
control + eやcontrol + aなどのショートカットが機能しないという状況に遭遇してちょっと困ったので、その解決方法をメモ。ちなみに、この時、
command + dなどのコマンドは機能した。環境
macOS Catalina 10.15.14
PyCharm 2020.1.1 (Community Edition)解決方法
1.
command + ,などでPreferencesを開く。
2.Keymapを選択。
3. 上の方にあるドロップダウン式のリストからmacOSを選択。
4. OKをクリック。
- 投稿日:2020-05-21T15:42:18+09:00
Python:自然言語処理における深層学習:回答文選択システムの実装
回答文選択システム
質問文に対して、回答文の候補がいくつか与えられて
その中から正しい回答文を自動で選択するシステムです。用いるデータセットは
Allen AIのTextbook Question Answeringというものです。"./nlp_data/"以下にtrain.jsonとval.jsonを用意しました。
train.jsonを訓練データ、val.jsonを評価データとして使ってください。
さて、一般に自然言語処理のタスクでは、データの前処理が必要になります。
前処理として分かち書きを活用します。
分かち書きとは文を単語に分割することです。英語の場合も分かち書きや、文字の正規化、単語のID化が必要になります。
そして自然言語処理で深層学習を使う場合、入力の全ての文の長さを統一しなければなりません。
何故ならば、そうでないと行列演算ができないからです。
この入力の文の長さを統一することをPaddingと言います。短い文は0を追加し、長すぎる文は削らなければなりません。
データの前処理
正規化・分かち書き
英語の正規化については、今回は最も基本的な大文字または小文字に統一という処理のみ扱います。
英文が文字列で与えられたとき、
s = "I am Darwin." s = s.lower() print(s) # => "i am darwin."次は分かち書きです。英語の分かち書きに用いられるツールの一つに
nltkというものがあります。nltkでは分かち書きの他にも見出し語化、語幹化なども使えますが
今回は簡単のため分かち書きのみを使います。from nltk.tokenize import word_tokenize t = "he isn't darwin." t = word_tokenize(t) print(t) # => ['he', 'is', "n't", 'darwin', '.']このようにisn'tはisとn'tに分割でき、ピリオドも1単語として分離できています。
使用例はこちら
import json from nltk.tokenize import word_tokenize import nltk nltk.download('punkt') with open("./nlp_data/train.json") as f: train = json.load(f) # trainはリストで、各要素に質問と回答の候補、答えが辞書型のデータとして格納されています。 # train[0] = {'answerChoices': {'a': 'solid Earth.', # 'b': 'Earths oceans.', # 'c': 'Earths atmosphere.', # 'd': 'all of the above'}, # 'correctAnswer': 'd', # 'question': 'Earth science is the study of'} target = train[0]["question"] # 小文字に統一 target = target.lower() # 分かち書き target = word_tokenize(target) print(target)単語のID化
単語のままではニューラルネットに入力として与えられないので
IDに変換する必要があります。ここでIDとは
Embedding Matrixの行に相当します。また、データに登場する単語全てにIDを付与すると
全体の語彙数が膨大になってしまう場合が多くあります。そこで、頻度が一定以上の単語のみにIDを与え
データをIDの列に変換します。また、辞書型.get(['key'])とすることでKeyに対応する Valueの値を取得することができます。dict_ = {'key1': 'earth','key2': 'science', 'key3':'is','key4': 'the', 'key5':'study', 'key6':'of'} print(dict_['key1']) print(dict_.get('key1'))使用例はこちら
import json from nltk.tokenize import word_tokenize import nltk nltk.download('punkt') with open("./nlp_data/train.json", "r") as f: train = json.load(f) def preprocess(s): s = s.lower() s = word_tokenize(s) return s sentences = [] for t in train: q = t['question'] q = preprocess(q) sentences.append(q) for i, a in t['answerChoices'].items(): a = preprocess(a) sentences.append(a) vocab = {} for s in sentences: for w in s: # vocab.get()で単語ごとに頻度を計算 vocab[w] = vocab.get(w, 0) + 1 word2id = {} word2id['<unk>'] = 0 for w, v in vocab.items(): if not w in word2id and v >= 2: # len()で単語にIDを付与 word2id[w] = len(word2id) target = preprocess(train[0]["question"]) target = [word2id.get(w, 0) for w in target] print(target)Padding
深層学習をする際、文章など長さがバラバラなデータはそのままでは行列演算ができないため、
強制的に末尾にダミーIDの0を追加したり、文末から必要なだけ単語を削除したりする
padding(とtruncating)を入力データに対して行う必要があります。kerasにはそのための便利な関数が用意されているので今回はそれを使います。
import numpy as np from keras.preprocessing.sequence import pad_sequences s = [[1,2], [3,4,5], [6,7,8], [9,10,11,12,13,14]] s = pad_sequences(s, maxlen=5, dtype=np.int32, padding='post', truncating='post', value=0) print(s) # => array([[ 1, 2, 0, 0, 0], # [ 3, 4, 5, 0, 0], # [ 6, 7, 8, 0, 0], # [ 9, 10, 11, 12, 13]], dtype=int32)このようにpaddingとtruncatingを行った上で、numpy配列にして返してくれます。
引数の説明は以下の通りです。
maxlen: 統一する長さ dtype: データの型 padding: 'pre'か'post'を指定し、前と後ろのどちらにpaddingするかを決める truncating: 'pre'か'post'を指定し、前と後ろのどちらをtruncatingするか決める value: paddingするときに用いる値使用例はこちら
import numpy as np from keras.preprocessing.sequence import pad_sequences # 引数にはこれを使ってください。 maxlen = 10 dtype = np.int32 padding = 'post' truncating = 'post' value = 0 # データ s = [[1,2,3,4,5,6], [7,8,9,10,11,12,13,14,15,16,17,18], [19,20,21,22,23]] # padding, truncatingをしてください。 s = pad_sequences(s,maxlen=10,dtype=np.int32,padding=padding,truncating=truncating,value=value) print(s)Attention-based QA-LSTM
全体像
これからいよいよ回答文選択システムを実装していきます。
学習モデルには
Attention-based QA-LSTMというものを分かりやすく改良したものを使います。モデルの全体像は図です。
①まずQuestionとAnswerを別々にBiLSTMに入力します。
②次に
QuestionからAnswerに対してAttentionをし
Questionを考慮したAnswerの情報を得ることができます。③その後にQuestionの各時刻の隠れ状態ベクトルの平均をとって(mean pooling)ベクトルqを得ます。
④一方でQuestionからAttentionを施した後、Answerの各時刻の隠れ状態ベクトルの平均をとって
ベクトルaを得ます。⑤最後にこの2つのベクトルを
のように
上式のベクトルを結合して
順伝播ニューラルネット、Softmax関数を経て2つのユニットからなる出力になります。この結合の仕方はFacebook researchが発表したInferSentという有名な手法を参考にしています。
このモデルの出力層はユニットが2つありますが
正解の回答文については[1,0]を、不正解の回答文については[0,1]を予測するように学習していきます
質問と回答のBiLSTM
Bidirectional LSTM(BiLSTM)とは 固有表現を認識する際に、後ろから読むことで左右両方向の文脈情報を捉えることができます。
使用例はこちら
from keras.layers import Input, Dense, Dropout from keras.layers.embeddings import Embedding from keras.layers.recurrent import LSTM from keras.layers.wrappers import Bidirectional from keras.models import Model vocab_size = 1000 # 扱う語彙の数 embedding_dim = 100 # 単語ベクトルの次元 seq_length1 = 20 # 質問の長さ seq_length2 = 10 # 回答の長さ lstm_units = 200 # LSTMの隠れ状態ベクトルの次元数 embedding = Embedding(input_dim=vocab_size, output_dim=embedding_dim) input1 = Input(shape=(seq_length1,)) embed1 = embedding(input1) bilstm1 = Bidirectional(LSTM(lstm_units, return_sequences=True), merge_mode='concat')(embed1) h1 = Dropout(0.2)(bilstm1) model1 = Model(inputs=input1, outputs=h1) input2 = Input(shape=(seq_length2,)) embed2 = embedding(input2) bilstm2 = Bidirectional(LSTM(lstm_units, return_sequences=True), merge_mode='concat')(embed2) h2 = Dropout(0.2)(bilstm2) model2 = Model(inputs=input2, outputs=h2) model1.summary() model2.summary()質問から回答へのAttention
下図の内容を行って見ます。
QuestionからAnswerへのAttentionであることに注意します。
使用例はこちら、前節に追加する形です。
from keras.layers import Input, Dense, Dropout from keras.layers.embeddings import Embedding from keras.layers.recurrent import LSTM from keras.layers.wrappers import Bidirectional from keras.layers.merge import dot, concatenate from keras.layers.core import Activation from keras.models import Model batch_size = 32 # バッチサイズ vocab_size = 1000 # 扱う語彙の数 embedding_dim = 100 # 単語ベクトルの次元 seq_length1 = 20 # 質問の長さ seq_length2 = 10 # 回答の長さ lstm_units = 200 # LSTMの隠れ状態ベクトルの次元数 hidden_dim = 200 # 最終出力のベクトルの次元数 embedding = Embedding(input_dim=vocab_size, output_dim=embedding_dim) input1 = Input(shape=(seq_length1,)) embed1 = embedding(input1) bilstm1 = Bidirectional(LSTM(lstm_units, return_sequences=True), merge_mode='concat')(embed1) h1 = Dropout(0.2)(bilstm1) input2 = Input(shape=(seq_length2,)) embed2 = embedding(input2) bilstm2 = Bidirectional(LSTM(lstm_units, return_sequences=True), merge_mode='concat')(embed2) h2 = Dropout(0.2)(bilstm2) # 要素ごとの積を計算する product = dot([h2, h1], axes=2) # サイズ:[バッチサイズ、回答の長さ、質問の長さ] a = Activation('softmax')(product) c = dot([a, h1], axes=[2, 1]) c_h2 = concatenate([c, h2], axis=2) h = Dense(hidden_dim, activation='tanh')(c_h2) model = Model(inputs=[input1, input2], outputs=h) model.summary()出力層、コンパイル
mean poolingから出力層までを実装します。
最後にsoftmax関数を使うことに注意します。
mean poolingには
from keras.layers.pooling import AveragePooling1D y = AveragePooling1D(pool_size=2, strides=1)(x)xのサイズは[batch_size, steps, features]
yのサイズは[batch_size, downsampled_steps, features]になります。
使用例はこちら
from keras.layers import Input, Dense, Dropout, Lambda, Reshape from keras.layers.embeddings import Embedding from keras.layers.recurrent import LSTM from keras.layers.wrappers import Bidirectional from keras.layers.merge import dot, concatenate, subtract, multiply from keras.layers.core import Activation from keras.layers.pooling import AveragePooling1D from keras import backend as K from keras.models import Model batch_size = 32 # バッチサイズ vocab_size = 1000 # 扱う語彙の数 embedding_dim = 100 # 単語ベクトルの次元 seq_length1 = 20 # 質問の長さ seq_length2 = 10 # 回答の長さ lstm_units = 200 # LSTMの隠れ状態ベクトルの次元数 hidden_dim = lstm_units * 2 # 最終出力のベクトルの次元数 def abs_sub(x): return K.abs(x[0] - x[1]) embedding = Embedding(input_dim=vocab_size, output_dim=embedding_dim) input1 = Input(shape=(seq_length1,)) embed1 = embedding(input1) bilstm1 = Bidirectional(LSTM(lstm_units, return_sequences=True), merge_mode='concat')(embed1) h1 = Dropout(0.2)(bilstm1) input2 = Input(shape=(seq_length2,)) embed2 = embedding(input2) bilstm2 = Bidirectional(LSTM(lstm_units, return_sequences=True), merge_mode='concat')(embed2) h2 = Dropout(0.2)(bilstm2) # 要素ごとの積を計算する product = dot([h2, h1], axes=2) # サイズ:[バッチサイズ、回答の長さ、質問の長さ] a = Activation('softmax')(product) c = dot([a, h1], axes=[2, 1]) c_h2 = concatenate([c, h2], axis=2) h = Dense(hidden_dim, activation='tanh')(c_h2) # ここで実装しています。 mean_pooled_1 = AveragePooling1D(pool_size=seq_length1, strides=1, padding='valid')(h1) mean_pooled_2 = AveragePooling1D(pool_size=seq_length2, strides=1, padding='valid')(h) mean_pooled_1 = Reshape((lstm_units * 2,))(mean_pooled_1) mean_pooled_2 = Reshape((lstm_units * 2,))(mean_pooled_2) sub = Lambda(abs_sub)([mean_pooled_1, mean_pooled_2]) mult = multiply([mean_pooled_1, mean_pooled_2]) con = concatenate([mean_pooled_1, mean_pooled_2, sub, mult], axis=-1) #con = Reshape((lstm_units * 2 * 4,))(con) output = Dense(2, activation='softmax')(con) model = Model(inputs=[input1, input2], outputs=output) model.summary() model.compile(optimizer="adam", loss="categorical_crossentropy")訓練
modelの構築が終わったらmodelの学習をします。
padding以外の前処理を全て終えてIDに変換したものを
./nlp_data/に用意した物とします。単語をIDに変換するための辞書は./nlp_data/word2id.jsonに保存してあることとします。
ファイル名は学習データが./nlp_data/preprocessed_train.json
評価データが./nlp_data/preprocessed_val.jsonです。preprocessed_train.jsonのデータは例えばこのようになっています。
{'answerChoices': {'a': [1082, 1181, 586, 2952, 0], 'b': [1471, 2492, 773, 0, 1297], 'c': [811, 2575, 0, 1181, 2841, 0], 'd': [2031, 1984, 1099, 0, 3345, 975, 87, 697, 1366]}, 'correctAnswer': 'a', 'question': [544, 0]}使用例はこちら
import json import numpy as np from keras.layers import Input, Dense, Dropout, Reshape from keras.layers.embeddings import Embedding from keras.layers.recurrent import LSTM from keras.layers.wrappers import Bidirectional from keras.layers.merge import dot, concatenate from keras.layers.core import Activation from keras.layers.pooling import AveragePooling1D from keras.models import Model from keras.preprocessing.sequence import pad_sequences with open("./nlp_data/word2id.json", "r") as f: word2id = json.load(f) batch_size = 500 # バッチサイズ vocab_size = len(word2id) # 扱う語彙の数 embedding_dim = 100 # 単語ベクトルの次元 seq_length1 = 20 # 質問の長さ seq_length2 = 10 # 回答の長さ lstm_units = 200 # LSTMの隠れ状態ベクトルの次元数 hidden_dim = 200 # 最終出力のベクトルの次元数 embedding = Embedding(input_dim=vocab_size, output_dim=embedding_dim) input1 = Input(shape=(seq_length1,)) embed1 = embedding(input1) bilstm1 = Bidirectional(LSTM(lstm_units, return_sequences=True), merge_mode='concat')(embed1) h1 = Dropout(0.2)(bilstm1) input2 = Input(shape=(seq_length2,)) embed2 = embedding(input2) bilstm2 = Bidirectional(LSTM(lstm_units, return_sequences=True), merge_mode='concat')(embed2) h2 = Dropout(0.2)(bilstm2) # 要素ごとの積を計算する product = dot([h2, h1], axes=2) # サイズ:[バッチサイズ、回答の長さ、質問の長さ] a = Activation('softmax')(product) c = dot([a, h1], axes=[2, 1]) c_h2 = concatenate([c, h2], axis=2) h = Dense(hidden_dim, activation='tanh')(c_h2) mean_pooled_1 = AveragePooling1D(pool_size=seq_length1, strides=1, padding='valid')(h1) mean_pooled_2 = AveragePooling1D(pool_size=seq_length2, strides=1, padding='valid')(h) con = concatenate([mean_pooled_1, mean_pooled_2], axis=-1) con = Reshape((lstm_units * 2 + hidden_dim,))(con) output = Dense(2, activation='softmax')(con) model = Model(inputs=[input1, input2], outputs=output) model.compile(optimizer="adam", loss="categorical_crossentropy") with open("./nlp_data/preprocessed_train.json", "r") as f: train = json.load(f) questions = [] answers = [] outputs = [] for t in train: for i, ans in t["answerChoices"].items(): if i == t["correctAnswer"]: outputs.append([1, 0]) else: outputs.append([0, 1]) # 以下のコードを埋めてください questions.append(t["question"]) answers.append(ans) questions = pad_sequences(questions, maxlen=seq_length1, dtype=np.int32, padding='post', truncating='post', value=0) answers = pad_sequences(answers, maxlen=seq_length2, dtype=np.int32, padding='post', truncating='post', value=0) outputs = np.array(outputs) # 学習させています model.fit([questions[:10*100], answers[:10*100]], outputs[:10*100], batch_size=batch_size) # ローカルで作業する場合は以下のコードを実行してください。 # model.save_weights("./nlp_data/model.hdf5") # model_json = model.to_json() # with open("./nlp_data/model.json", "w") as f: # json.dump(model_json, f)結果がこちら
テスト
最後に評価データを使ってテストをします。
2値分類なので
精度は正解率(Accuracy)
適合率(Precision)
再現率(Recall)を計算します。また、こちらで5epoch学習させた
学習済みモデル("./nlp_data/trained_model.hdf5")を用意しました。
使用例はこちら
import json import numpy as np from keras.models import model_from_json from keras.preprocessing.sequence import pad_sequences with open("./nlp_data/preprocessed_val.json", "r") as f: val = json.load(f) seq_length1 = 20 # 質問の長さ seq_length2 = 10 # 回答の長さ questions = [] answers = [] outputs = [] for t in val: for i, ans in t["answerChoices"].items(): if i == t["correctAnswer"]: outputs.append([1, 0]) else: outputs.append([0, 1]) questions.append(t["question"]) answers.append(ans) questions = pad_sequences(questions, maxlen=seq_length1, dtype=np.int32, padding='post', truncating='post', value=0) answers = pad_sequences(answers, maxlen=seq_length2, dtype=np.int32, padding='post', truncating='post', value=0) with open("./nlp_data/model.json", "r") as f: model_json = json.load(f) model = model_from_json(model_json) model.load_weights("./nlp_data/trained_model.hdf5") pred = model.predict([questions, answers]) pred_idx = np.argmax(pred, axis=-1) true_idx = np.argmax(outputs, axis=-1) TP = 0 FP = 0 FN = 0 TN = 0 for p, t in zip(pred_idx, true_idx): if p == 0 and t == 0: TP += 1 elif p == 0 and t == 1: FP += 1 elif p == 1 and t == 0: FN += 1 else: TN += 1 print("正解率:", (TP+TN)/(TP+FP+FN+TN)) print("適合率:", TP/(TP+FP)) print("再現率:", TP/(TP+FN))結果がこちら
Attentionの可視化
Attentionでは、文章sから文章tへのAttentionを施すにあたり
のようにsのj番目の単語がtのi番目の単語にどれくらい注目しているかを
aijが表していると言えます。このaijを(i,j) 成分に持つような行列AをAttention Matrixと呼びます。
Attention Matrixを見ればsとtの単語間にどのような関係があるのかを可視化することができます。質問単語(横軸)と回答単語(縦軸)で関係が深いものは白く表示されます。
使用例はこちら
import matplotlib.pyplot as plt import json import numpy as np from keras.layers import Input, Dense, Dropout, Reshape from keras.layers.embeddings import Embedding from keras.layers.recurrent import LSTM from keras.layers.wrappers import Bidirectional from keras.layers.merge import dot, concatenate from keras.layers.core import Activation from keras.layers.pooling import AveragePooling1D from keras.models import Model from keras.preprocessing.sequence import pad_sequences from keras.models import model_from_json import mpl_toolkits.axes_grid1 batch_size = 32 # バッチサイズ embedding_dim = 100 # 単語ベクトルの次元 seq_length1 = 20 # 質問の長さ seq_length2 = 10 # 回答の長さ lstm_units = 200 # LSTMの隠れ状態ベクトルの次元数 hidden_dim = 200 # 最終出力のベクトルの次元数 with open("./nlp_data/preprocessed_val.json", "r") as f: val = json.load(f) questions = [] answers = [] outputs = [] for t in val: for i, ans in t["answerChoices"].items(): if i == t["correctAnswer"]: outputs.append([1, 0]) else: outputs.append([0, 1]) questions.append(t["question"]) answers.append(ans) questions = pad_sequences(questions, maxlen=seq_length1, dtype=np.int32, padding='post', truncating='post', value=0) answers = pad_sequences(answers, maxlen=seq_length2, dtype=np.int32, padding='post', truncating='post', value=0) with open("./nlp_data/word2id.json", "r") as f: word2id = json.load(f) vocab_size = len(word2id) # 扱う語彙の数 embedding = Embedding(input_dim=vocab_size, output_dim=embedding_dim) input1 = Input(shape=(seq_length1,)) embed1 = embedding(input1) bilstm1 = Bidirectional( LSTM(lstm_units, return_sequences=True), merge_mode='concat')(embed1) h1 = Dropout(0.2)(bilstm1) input2 = Input(shape=(seq_length2,)) embed2 = embedding(input2) bilstm2 = Bidirectional( LSTM(lstm_units, return_sequences=True), merge_mode='concat')(embed2) h2 = Dropout(0.2)(bilstm2) # 要素ごとの積を計算する product = dot([h2, h1], axes=2) # サイズ:[バッチサイズ、回答の長さ、質問の長さ] a = Activation('softmax')(product) c = dot([a, h1], axes=[2, 1]) c_h2 = concatenate([c, h2], axis=2) h = Dense(hidden_dim, activation='tanh')(c_h2) mean_pooled_1 = AveragePooling1D( pool_size=seq_length1, strides=1, padding='valid')(h1) mean_pooled_2 = AveragePooling1D( pool_size=seq_length2, strides=1, padding='valid')(h) con = concatenate([mean_pooled_1, mean_pooled_2], axis=-1) con = Reshape((lstm_units * 2 + hidden_dim,))(con) output = Dense(2, activation='softmax')(con) # ここを解答してください prob_model = Model(inputs=[input1, input2], outputs=[a, output]) prob_model.load_weights("./nlp_data/trained_model.hdf5") question = np.array([[2945, 1752, 2993, 1099, 122, 2717, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]) answer = np.array([[2841, 830, 2433, 0, 0, 0, 0, 0, 0, 0]]) att, pred = prob_model.predict([question, answer]) id2word = {v: k for k, v in word2id.items()} q_words = [id2word[w] for w in question[0]] a_words = [id2word[w] for w in answer[0]] f = plt.figure(figsize=(8, 8.5)) ax = f.add_subplot(1, 1, 1) # add image i = ax.imshow(att[0], interpolation='nearest', cmap='gray') # add labels ax.set_yticks(range(att.shape[1])) ax.set_yticklabels(a_words) ax.set_xticks(range(att.shape[2])) ax.set_xticklabels(q_words, rotation=45) ax.set_xlabel('Question') ax.set_ylabel('Answer') # add colorbar divider = mpl_toolkits.axes_grid1.make_axes_locatable(ax) cax = divider.append_axes('right', '5%', pad='3%') plt.colorbar(i, cax=cax) plt.show()結果がこちら
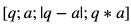
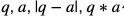

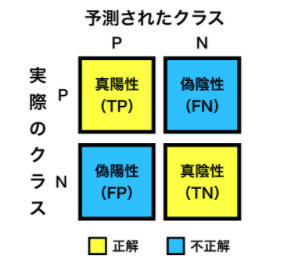


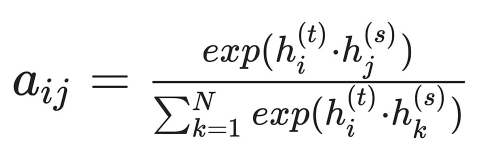
- 投稿日:2020-05-21T15:20:46+09:00
PySdie、PyQtをpytestする際に、pytest-qtを使う
はじめに
[本記事は記述途中で、更新予定です!]
以前、 「PySide & Pytest での テスト駆動開発 スタートアップ」にて、PySide + pytestする方法をまとめたが、以下のようなものをやっていた。
まずconftest.pyで、fixtureとして次を登録し、
conftest.py@pytest.fixture def base_window(): app = QApplication() mainWindow = QMainWindow() mainWindow.show() return mainWindowテストで、それを利用して、ウィジェットのスモークテストを行う
test_widget.pydef test_addWidget(base_widget): from MyCustomPySideLib,QCustomWidgets import QMyWidget tagWidget = QMyWidget() base_widget.setCentralWidget(tagWidget)ということをしていたが、どうやら別の方法を提供している人もいるらしいという事で調べてみた。
pytest-qtの導入
pytest-qtで、こういったところをシミュレートできる。
pytest-qtは、pytestのプラグインとして扱われる。インストールは、pipで行える。
pip install pytest-qtpytest-qtを使って書く
pytest-qtを使ってはじめのテストコードを書き直すとこうなる。
Widgetの追加テスト
test_widget.pydef test_addWidget(qtbot): from MyCustomPySideLib,QCustomWidgets import QMyWidget myWidget = QMyWidget() qtbot.addWidget(myWidget)
- 投稿日:2020-05-21T15:19:39+09:00
centos-sclo-rhのpythonでpoetry-virtualenv環境構築〜注意点
経緯
vaexを使おうとして、OSデフォルトのPython2.7.5ではバグ?により使えず、
Python2.7.17をインストールしてプロジェクトを続行をしようとしたら軽くハマったのでメモ。環境
CentOS 7.5.1804
Python2.7.17
Poetry 1.0.5
tcshインストール
pyenv等他のインストール方法も試したけど、他のマシンに環境構築するのも一番お手軽そうなsclo pythonを使うことにした。
sudo yum -y install centos-release-scl-rh sudo yum -y install python27本来ならここで、
/opt/rh/python27/enableがインストールされるはずだが、何故かされない時がある。
その場合手書きするか、python36などをインストールしてenableをコピーして改変するか。
enableはbashで書かれているので、tcshに書き直す。vim /opt/rh/python27/enable#!/usr/bin/env tcsh if ($?PATH) then setenv PATH /opt/rh/python27/root/usr/bin:${PATH} else setenv PATH /opt/rh/python27/root/usr/bin endif if ($?LD_LIBRARY_PATH) then setenv LD_LIBRARY_PATH /opt/rh/python27/root/usr/lib64:${LD_LIBRARY_PATH} else setenv LD_LIBRARY_PATH /opt/rh/python27/root/usr/lib64 endif if ($?MANPATH) then setenv MANPATH /opt/rh/python27/root/usr/share/man:${MANPATH} else setenv MANPATH /opt/rh/python27/root/usr/share/man endif if ($?PKG_CONFIG_PATH) then setenv PKG_CONFIG_PATH /opt/rh/python27/root/usr/lib64/pkgconfig:${PKG_CONFIG_PATH} else setenv PKG_CONFIG_PATH /opt/rh/python27/root/usr/lib64/pkgconfig endif if ($?XDG_DATA_DIRS) then setenv XDG_DATA_DIRS /opt/rh/python27/root/usr/share:${XDG_DATA_DIRS} else setenv XDG_DATA_DIRS /opt/rh/python27/root/usr/share endif有効化
tcshなので、他のシェルのように
scl enable python27 tcshは使えないので、直接enableをsourceし有効化。$ python -V Python 2.7.5 $ source /opt/rh/python27/enable $ python -V Python 2.7.17ちゃんとバージョン変わっていればOK.
poetry環境作成
p
enableをsourceしたシェルでpoetry init
すでにOS Pythonでvirtualenvを作っていたら、一度環境を削除し、poetry install
これでSCLO Pythonで環境が作成される。開発環境
ここまででターミナルから使う文には問題ないが、作成した環境のPythonをPyCharmから使おうとするとエラーが出て上手く行かなかった。
(エラーログ消失)原因は、enableで設定した環境変数が、PyCharmからだと設定されていないからだった。
あまり綺麗ではないが、python2.7をシェルスクリプトにしてしまい、python実行時にenableをsourceすれば解決出来た。cd `poetry env info --path`/bin mv python2.7 python2.7_original vim python2.7python2.7#!/usr/bin/env tcsh source /opt/rh/python27/enable `dirname $0`/python2.7_original $*
- 投稿日:2020-05-21T15:19:01+09:00
【備忘録】DiscordBot① Bot作成 ~ 特定の内容に返信
Discord Developer PortalでBotを作成する
Discordにログイン
Discord Developer PortalにアクセスしDiscordのアカウントでログイン。
Applicationタブに飛ばされる。
New Application の作成
右上の New Applicationをクリックして新規BotをDiscord側で作成する。
作成したBotの基本設定画面に飛ばされる。
画面左Botタブをクリック
画面右上Add botボタンをクリックした後yesをクリック。
Copyをクリックしてメモ帳か何かに書き写しておく。
※ほかの人にこの文字列が渡るとbotを導入したサーバーを荒らされる可能性があるため漏れないように。
漏れたと思ったときはRegenerateをクリックしてトークンを再生成するなどして対応すること。画面左OAth2タブをクリック
SCOPES枠内真ん中あたりにあるbotにチェックを入れる。
下にスクロールしてBot PermissionsでBotに与える権限を選ぶ。
自分で作ったテストサーバーに導入して遊ぶ分にはAdministrator(管理者権限)でかまわない。
権限を与えた後はSCOPE枠内の下に出てきたリンクをコピーしてアクセスする。
アクセスしたらBOTを追加する場所を選択しはいを押す。
また、管理者権限を与えている場合管理者権限を与えてよいか確認メッセージが出る。
PythonでBotの内容を書く
環境
Windows10 x64
Python3.7.7 x64
discord.py 1.2.5Pythonを導入
Python公式のDownloadsから対応バージョンのpythonをダウンロード。
Filesの内環境に合ったものをダウンロード。
今回はWin x64なのでWindows x86-64 executable installer
インストール画面はとりあえずOK連打
エディタを導入
今回はVisualStudioCodeを使用。
Dounloadからバージョンにあったものを使用。discord.pyをPIPで入れる
コマンドラインにて下記コマンドを実行
pip install discord.py
動かす
下記コードをDiscordBot.pyで保存し実行(async/await版)
# -*- coding: utf-8 -*- # ライブラリのインポート import discord import asyncio TOKEN = 'ここにコピーしたトークンを貼り付ける' client = discord.Client() # ボットの起動時に実行されるイベントハンドラを定義 @client.event async def on_ready(): print('Bot Launched') # メッセージの送信時に実行されるイベントハンドラを定義 @client.event async def on_message(message): if message.author.bot: pass elif message.content.startswith('こんにちは!'): send_message = f'{message.author.mention}さん、こんにちは!' await message.channel.send(send_message) #ボットを実行 client.run(TOKEN) #ここより下に書かれた処理はボットが停止するまで実行されないコマンドラインで下記コマンドをファイルのある場所で実行
python DiscordBot.py動作の様子