- 投稿日:2020-04-05T23:36:26+09:00
Pythonで新型コロナの統計データを取得&分析してみた:ジョンズホプキンス大学のデータ編
はじめに
久しぶりに Quiita に投稿します。
最近、新型コロナウイルスのパンデミックに関する統計データを分析することを始めました(仕事ではなく個人のライフワーク?として)。
そして幾つかブログに記事にアップしています。
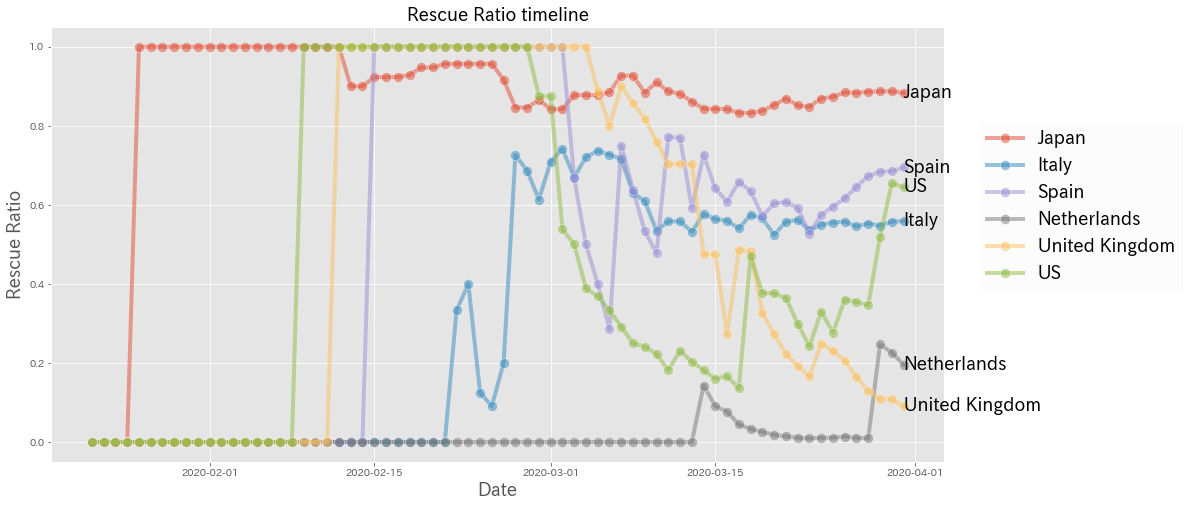
- 新型コロナの救命率から見た各国の状況:救命率が極めて低いあの先進国がとった政策とは?│YUUKOU's 経験値
- 新型コロナの救命率の推移から読み解く:米国の底力、危機的なイギリス、オランダ、推移が美し過ぎる中国│YUUKOU's 経験値例えば、救命率についての時系列推移をプロットしたチャートをデータ分析の成果として掲載していたりします。(感染者のカウント基準が国によって違う点はあるものの、データを見る限り日本は世界的に見ても医療現場が優秀であることがうかがえます)
今回は、ジョンズホプキンス大学が提供している新型コロナウイルス統計データを分析するための下準備のコードを共有したいと思います。
このコードを使えば、新型コロナウイルス統計のデータフレームが生成され、思い思いのデータ分析に取り組む準備ができると思います。
ぜひご活用いただけると、微力ながら貢献できると幸いです。
データダウンロード&加工処理
ジョンズホプキンス大学は、github上に全世界の新型コロナウイルス感染の統計データ(しかも時系列で!)で公開しています。
- 再掲:ジョンズホプキンス大学の公開データ処理全体の流れとしては、
urllibを使ってデータを取得した後、加工します。
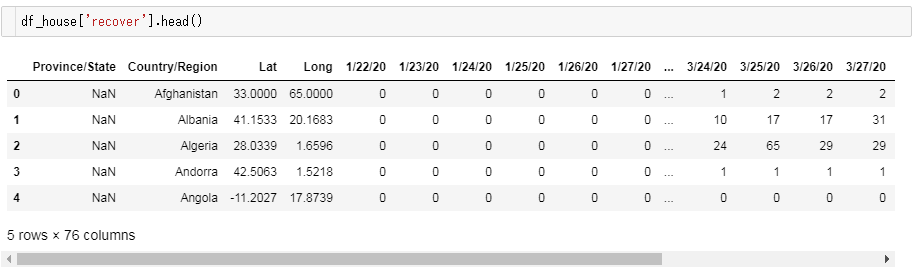
ジョンズホプキンス大学が公開している統計データには、感染確認者数(confirmed)、死亡者数(deaths)、治癒者数(recovered)の3つが含まれています。
また、その粒度は、各国の地域単位まで記録しているレコードもあります。
今回は国単位に集約して分析します。ただし、注意点が一つあります。
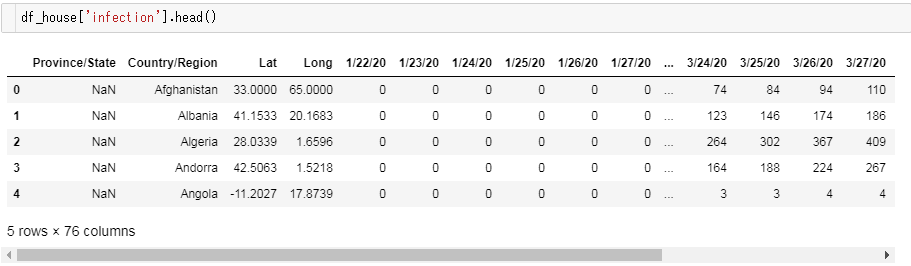
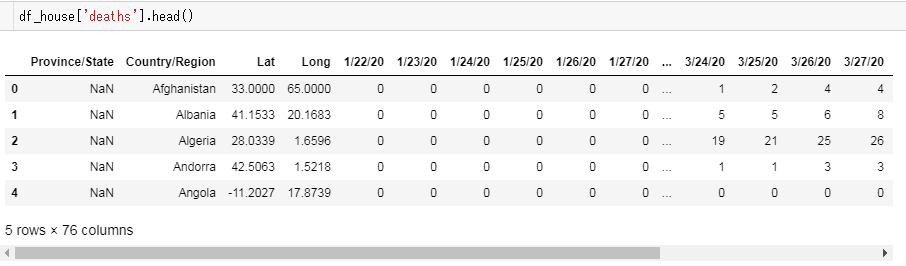
時系列といっても、列方向に日付ごとのカラムがズラリと何十個も並んでいるので、それを使いやすい構造に変換しなければなりません。例えば、こんなデータフレームです。(感染確認者数の場合)
日付らしきカラムが並んでいるのが分かりますね。
時系列カラムを行方向に構造変換し、国ごとに集約すれば、扱いやすいオーソドックスなデータフレームに落ち着きます。
今回は、Jupyter Notebook 上で実装しました。
なので、エントリに掲載したコードをそのまま上から順番に張り付けて実行すれば動くと思います。
クローラークラスの実装
クローラークラスを定義します。
名前はそのまんまですね。他のノートブックでも使いまわしそうなので、とりあえずクラス化しておきました。import urllib import json import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import numpy as np import io from dateutil.parser import parse from tqdm import tqdm, tqdm_notebook class Crowler(): def __init__(self): """ クローラークラス """ self._ua = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) '\ 'AppleWebKit/537.36 (KHTML, like Gecko) '\ 'Chrome/55.0.2883.95 Safari/537.36 ' def fetch(self, url): """ URLを指定し、HTTPリクエストを実行する。 :param url: :return: リクエスト結果(html) """ req = urllib.request.Request(url, headers={'User-Agent': self._ua}) return urllib.request.urlopen(req)各種設定
クローラーインスタンスの宣言と、各データソースのURLを定義します。
# クローラーインスタンス cr = Crowler() # 感染者推移の時系列データ url_infection = 'https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv' # 死亡者の時系列データ url_deaths = 'https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv' # 治癒者の時系列データ url_recover = 'https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv'各データソースの取得
3つのデータソースをクローリングして、いったんデータフレームに変換します。
url_map = {'infection': url_infection, 'deaths': url_deaths, 'recover': url_recover} df_house = {} for _k, _url in url_map.items(): _body_csv = cr.fetch(_url) df_house[_k] = pd.read_csv(_body_csv)
df_houseは、3つのデータフレームを格納する辞書です。
中身は次のようになっています。
確認感染者数のデータフレーム
死亡者数のデータフレーム
治癒者数のデータフレーム
テーブル構造の変換
日付型に変換する関数の準備
時系列カラムは
3/27/20のような形式で、Python のdateutil.parser.parseではそのままでは変換できません。
泥臭いのですが、いったん標準的なYYYY-mm-dd形式に変換するための関数を用意します。def transform_date(s): """ '3/15/20' 形式の日付を '2020-03-15' のように 'YYYY-mm-dd' 形式に直す """ _chunk = str(s).split('/') return '20{year}-{month:02d}-{day:02d}'.format(year=_chunk[2], month=int(_chunk[0]), day=int(_chunk[1]))各データフレームを変換する
3つのデータフレームのそれぞれにおいて、時系列のカラムを行に変換します。
dateというカラムに時系列を持たせるように変換します。df_buffer_house = {} for _k, _df in df_house.items(): df_buffer_house[_k] = {'Province/State':[], 'Country/Region':[], 'date': [], _k: []} _col_dates = _df.columns[4:] for _k_date in tqdm(_col_dates): for _idx, _r in _df.iterrows(): df_buffer_house[_k]['Province/State'].append(_r['Province/State']) df_buffer_house[_k]['Country/Region'].append(_r['Country/Region']) df_buffer_house[_k]['date'].append(transform_date(_k_date)) df_buffer_house[_k][_k].append(_r[_k_date])Jupyter Notebook上で実行すると、次のようにプログレスバーを表示しながら変換を進めて行きます。
100%|██████████████████████████████████████████| 72/72 [00:05<00:00, 12.37it/s]
100%|██████████████████████████████████████████| 72/72 [00:05<00:00, 12.89it/s]
100%|██████████████████████████████████████████| 72/72 [00:05<00:00, 13.27it/s]
3つのデータフレームの構造がだいぶマシになったので、あとは結合するだけなのですが、そこで注意点があります。
感染者数(
infection)や死亡者数(deaths)では、Province/Stateが複数記録されているが、治癒数(recover) では国単位という記録がされていることがあります。
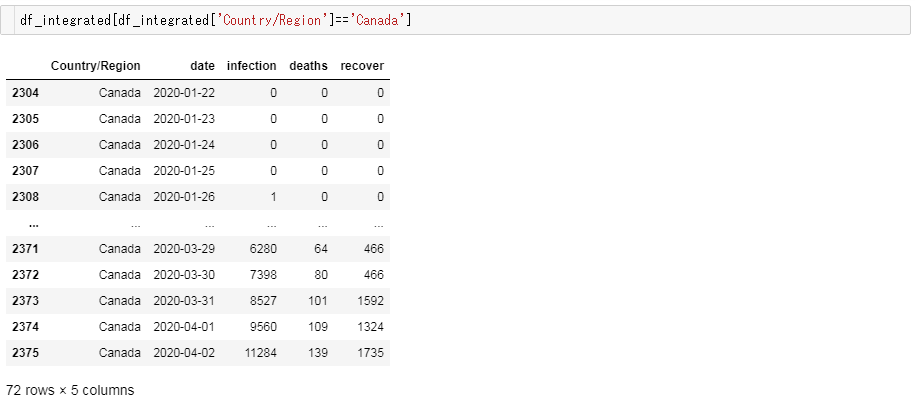
例)Canadaよって、各データフレームごとに国ごとに集約してから結合する必要があるのです。
df_integrated = pd.DataFrame() col_integrated = ['Country/Region', 'date'] df_chunk = {} for _k, _df_dict in df_buffer_house.items(): _df_raw = pd.DataFrame.from_dict(_df_dict) # 'Country/Region' ごとに集約する _df_grouped_buffer = {'Country/Region':[], 'date':[] , _k:[]} for _idx, _grp in tqdm(_df_raw.groupby(col_integrated)): _df_grouped_buffer['Country/Region'].append(_idx[0]) _df_grouped_buffer['date'].append(_idx[1]) _df_grouped_buffer[_k].append(_grp[_k].sum()) df_chunk[_k] = pd.DataFrame.from_dict(_df_grouped_buffer) df_integrated = df_chunk['infection'].merge(df_chunk['deaths'], on=col_integrated, how='outer') df_integrated = df_integrated.merge(df_chunk['recover'], on=col_integrated, how='left')実行します。
100%|██████████████████████████████████| 13032/13032 [00:08<00:00, 1621.81it/s]
100%|██████████████████████████████████| 13032/13032 [00:08<00:00, 1599.91it/s]
100%|██████████████████████████████████| 13032/13032 [00:07<00:00, 1647.02it/s]
動作確認
先ほどの例で挙げたカナダがちゃんとしたデータに変換されているか確かめてみましょう。
大丈夫そうですね!
Nan で欠落するレコードが多発している様子もなく、時系列順に数値が推移している様子も確認できました!変換後の統計データを使った分析例
こうして変換して得られた新型コロナウイルスの統計データを使った分析コードの例を紹介したいと思います。
救命率、感染終息度の計算
救命率の計算
救命率とは、ここでは治療が終了した患者数(Closed Cases)(※)のうち、治癒した患者数(Total Recovered Cases)の割合と定義したいと思います。
※治療が終了した患者(Closed Cases)は、次のように分けられます。
(1) 治癒した患者(Recovered Cases)
(2) 死亡した患者(Death Cases)$$Resuce Ratio(救命率) = \frac{TotalRecovered(治癒した患者数)}{ClosedCases(治療が終了した患者数)}$$
感染終息度の計算
各国の感染が、どれくらい終息に近づいているのかを表した数字です。
感染者累計に対して、どれくらいの患者の治療が終了しているのか、その割合で表します。$$Phase Position(感染終息度) = \frac{Closed Case(治療が終了した患者数)}{Total Case(感染者数累計)}$$
Phase Positionは、0.0 ~ 1.0の値を取ります。
0.0に近いほど感染フェーズが序盤であることを表します。
1.0に近づくほど感染フェーズが終盤であることを表します。計算コード例
df_grouped = df_integrated df_grouped['date'] = pd.to_datetime(df_grouped['date']) # 救命率の計算 df_grouped['rescue_ratio'] = df_grouped['recover']/(df_grouped['recover'] + df_grouped['deaths']) df_grouped['rescue_ratio'] = df_grouped['rescue_ratio'].fillna(0) # 感染終息度の計算 # 治療終了患者数 = 治癒した患者数 + 死亡した患者数 df_grouped['phase_position'] = (df_grouped['recover'] + df_grouped['deaths'])/df_grouped['infection']計算結果の確認
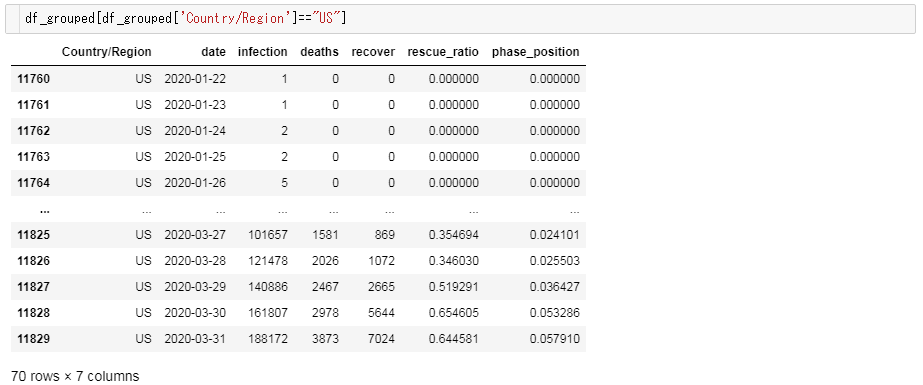
米国を例に、計算結果を確認してみましょう。
すると以下のようなデータフレームが表示されます。
米国はまだまだ感染の序盤であり、救命率は持ち直しつつあるものの依然として厳しい状況にあることがうかがえます。
まとめと分析エントリの紹介
ということで、新型コロナウイルスの統計データを分析するための下準備のコードを紹介させていただきました。
ジョンズホプキンス大学の統計データは、現在世界で注目されているデータソースの一つですので、ぜひ皆さんの様々な分析アイディアを試行錯誤して、積極的に情報発信していただけると良いのではないかと思います!ということで、まずは言いだしっぺからということで、私が執筆した新型コロナ分析エントリをご紹介して、締めくくりたいと思います。
- 新型コロナの救命率から見た各国の状況:救命率が極めて低いあの先進国がとった政策とは?│YUUKOU's 経験値
- 新型コロナの救命率の推移から読み解く:米国の底力、危機的なイギリス、オランダ、推移が美し過ぎる中国│YUUKOU's 経験値
- 新型コロナウイルス・世界各国の感染フェーズを数値化した結果:ぶっちぎりで米国ヤバイ│YUUKOU's 経験値

- 投稿日:2020-04-05T23:09:09+09:00
猿でも分かるPython入門 (その1)
はじめに
こんにちは、Rikuと申します。軽く自己紹介をさせていただきますと、普段はコンサルタントとして働いており、プログラミングは基本趣味でコードを書く程度、という人間です。それでも、エクセルなどでは行えない大容量データを用いる場合や高度な分析を行う場合は仕事でもコードを書くことはあり、データ活用が一つのビジネストレンドになりつつある昨今では何かとコードを書く機会は増えつつあります。そのため──コンサルタントという職業上必ずしも必須ではないのですが──後輩からも「エンジニアになりたいわけではないが、分析を自分で進められるようになりたいからデータ分析のためのプログラミングを教えてほしい!」などと言われることは多々あります。そこで色々と初心者向けの記事を捜してみたところ、日本語ではプログラミングのプの字も知らない超初心者向けにPythonの扱い方について体系的にまとめた記事がほとんどないことに気づき、自信の知識の伝達の練習も兼ねてここで知識ゼロ超初心者向けのPython解説を行おうと思った次第です。
本記事はPythonの入門者から初心者への橋渡し的な記事にしようと思っており、4,5回分の記事になる予定です。内容としては、変数や型などのプログラミングの基本的なお作法、パッケージの利用方法、NumPyの使い方、といったところまでを扱う予定です。これらの記事が少しでも初学者の助けになれば幸いです。目次
- Pythonって何???
- 四則演算プラスアルファ
- 変数と型
1. Pythonって何???
Pythonはオランダのプログラマー、グイド・ヴァンロッサム (Guido van Rossum)によって生み出されたプログラミング言語のひとつです。元々趣味の一環として開発されたこの言語ですが、オープンソースで無料で使えることと、パッケージ構築が容易なことから、現在では非常に多くのエンジニアに使用される言語となっています。
一見、プログラミング言語というと何かしらのアプリケーションの開発のために用いられるものだと思いがちですが、このPythonという言語は高度な分析を進める武器としても使える言語であり、本記事ではデータ分析に焦点を当てた解説を行おうと思います。2. 四則演算プラスアルファ
では、コードを書いてみましょう! え、まだ何の説明もされてないのに? と思うかもしれませんが、プログラミングは習うよりも慣れの世界です。
では、まずPythonに簡単な電卓での計算をしてもらうための方法をご紹介します。
とりあえず、具体的には以下の表を参照してください。
やりたいこと コード コード記入例 記入例に対するアウトプット 足し算 + 5+8 13 引き算 - 13-5 8 掛け算 * 9*6 54 割り算 / 8/5 1.6 指数計算 ** 4**2 16 余り(mod) % 18%7 4 表示 print() print(13) 13 ※厳密には"print()"によって計算結果を表示させる指示をだすため、"5+8"とコードを書いただけでは、5+8が計算されただけで13とは表示されません、13と表示させるためには"print(5+8)"と書く必要があります。
それでは、実際にコードを書いてみましょう。以下の計算を行うコードを書いてみてください。
問1. 7+10を計算させ、計算結果を表示させる
問2. 5÷8を計算させ、計算結果を表示させる
問3. 8の3乗を計算させ、計算結果を表示させる解答は以下のようになります。
#問1の解答 print(7+10) #print()は「()内のものを表示しろ」という命令ですので、上記のコードを書いてプログラムを走らせると、17という答えを返してくれます。 #問2の解答 print(5/8) #同じく、上記のコードを走らせると0.625という答えを返してくれます。 #問3の解答 print(8**3) #同じく、8の3乗である、544を返すコードです。とりあえず、「Pythonでは電卓程度のことはできるよ!」と言えるレベルになっていただけたでしょうか?
3. 変数と型
さて、1行で済む簡単な数式の計算であればこれでできるようになりました。しかし、複雑な分析になればなるほど、おそらく一度計算した数式を"再利用"したくなることがあると思います。例えば、「(3+4-5*5+8/2+3-1*55)/88*12+45-652*2」という計算結果を後の分析でも使用したい場合、毎回毎回この式を書いていては大変ですよね。また、分析において仮定が変化する場合もあります。例えば、1ドル110円で分析を進めていたけど、1ドル115円になったときにはどのような結果になるのかが知りたい。でも、そんなときに全体のコードに"110"という数字が100回出てきていたら、それをすべて修正するのは非常に手間です。そこで登場するのが変数です。
例えば、アメリカから2ドルの製品Aを輸入するとしましょう。この時にかかるコストは製品の値段プラス13%の関税。そして今の相場は1ドル110円です。この場合の日本円でのコストを計算するとき、今までの方法では
print(2*110*1.13)と記述して計算することができます。では、変数を使うとどうなるのか。
price = 2 exchange = 110 tax = 0.13 totalprice = price*exchange*(1+tax) print(totalprice)と記述することができます。
2(ドル)という数字をpriceという変数に、110(円/ドル)という数字をexchangeに、0.13という数字をtaxという変数に、そしてこれらを掛け合わせるという数式をtotalpriceという変数に格納しているわけです。
こうすることで、以降モノの値段が変わった場合はpriceを、為替が変動した場合はexchangeを、税率が変化した場合はtaxの数字をいじってコードを再び走らせればまた新しい結果を見ることができます。
また、このものの値段を別の分析に使用したい場合は、わざわざ「2*110*1.13」と打たなくても、totalpriceと入力するだけで、値段を参照してくれるようになるのです。さて、変数を扱う上で必要になるのが型という概念です。これまでは数値だけを扱ってきましたが、今後分析を行うにあたって数値以外のものも変数に格納したいということが発生します。しかし、例えば"値段"という言葉を先ほどのpriceに格納することはできません。priceには既に数値が入っており、"値段"という文字列を格納することはできなくなってしまっているからです。このように、変数に何かを格納すると、その格納したものに応じて変数の性質が変わってきてしまい、変数の性質のことを型と呼びます。
例えば、aという数値型の変数に13を格納し、bという数値型の変数に2を格納すると、a+bで13+2の計算を行うことができます。しかし、もしcという文字列型の変数に3を格納した場合、この3は数字ではなく文字とみなされ、文字と数字を足すことはできませんのでa+cを計算しても13+3の計算は行えません。(ちなみに、dという文字列型の変数に5が入力されていた場合、c+dは文字列同士の足し算となるので3+5ではなく、35という文字列になります。)
では、試しに先ほど利用した変数taxの型を調べてみましょう。型を調べるにはtype()と入力することで調べることができます。tax = 0.13 type(tax)上記のコードを実行すると、"float"という結果を返します。これはtaxという変数がfloat型であることを意味します。float型とは、数値(小数点を含む)を表す型です。
代表的な型には以下のようなものがあります。このほかにもまだまだたくさんの型がありますが、初期的には以下の型を頭に入れておけば問題ないでしょう。
型 例 数値(整数) int 13 数値(浮動小数点数) float 13.54 文字列 string 値段 ブーリアン(yes or no) boolean true 各変数がどのような方になるのかは、その変数に格納するものによって決定します。以下の例をご覧ください。
price = 2 #整数を格納しているのでint型 tax = 0.13 #少数を格納しているのでfloat型 mark = "値段" #文字列を格納しているのでstring型 check = True #trueを格納しているのでboolean型さて、変数、そして型の概念を理解していただけたでしょうか? 次回は1週間後辺りに更新する予定です。
- 投稿日:2020-04-05T22:44:59+09:00
Pythonで毎日AtCoder #27
はじめに
前回
昨日のABC161は+65でした。次に1200パフェくらいで茶色になれます。#27
問題843diff
1TLE。
考えたこと
本番で解けなかった問題でした。グラフだと思っていたら、グラフ的な考えでなくても解けました。
$(i,j)(i,j\in Z,1\leq i < j\leq N)$な点を考えた時に、$i,j$の最短距離の個数を求める問題です。
これだけだと簡単ですが、この問題ではX-Y間に距離1で移動できる辺が用意されています。ですので、最短距離は$min(ショートカットを使わない、ショートカットを使う)$で考えます。ショートカットを使わない場合は、$j-i$になります。使う場合は$|y-j|+|x-i|+1$になります。第一項でj-Y間の距離、第二項でX-i間の距離を求めショートカットの距離1を足しています。n, x, y = map(int,input().split()) ans = [0]*(n-1) for i in range(1,n+1): for j in range(i+1,n+1): ans[min(j-i,abs(x-i)+1+abs(y-j))-1] += 1 for k in range(n-1): print(ans[k])最初はansにappendして最後にcountしていたのですが、countだとO(N)になって計算量が増えてTLEしてしまいます。そこで、ans[距離]に+1していって最後に出力しています。
まとめ
グラフ感があったのに思ったよりも簡単だった。では、また。おやすみなさい
- 投稿日:2020-04-05T22:36:11+09:00
TokyoCoronaオープンデータから指数関数curve_fitで単純な予測を行ってみる
コロナ感染が広まっております。
何も対策をしない(もしくは効果がなかった)場合、一般的には指数関数に沿って
感染者数が広がっていきます。東京コロナサイトでは感染実数が日々公表されておりますが
予測は出ておりません。指数関数curve_fitにより、将来予測値を算出し
グラフ描画をここでは行います。(もちろん、結果通りになることは望んでおらず
対策により一日も早く収束に向かうことを切に願っております。土日は外出せずこもってます)import pandas as pd from pathlib import Path from datetime import datetimeBASEDIR = Path('.') FILE_PATH = 'https://stopcovid19.metro.tokyo.lg.jp/data/130001_tokyo_covid19_patients.csv' df = pd.read_csv(str(FILE_PATH))# 予測期間 TO_PERIODS = 7 # グラフ描画のための諸々を生成します target_columns = ['公表_年月日','患者_年代'] df_select = df[target_columns] list_now = list(df_select.groupby('公表_年月日').count().index) today = datetime.today() today.strftime('%Y-%m-%d') list_to = list(pd.date_range(today.strftime('%Y-%m-%d'), periods=TO_PERIODS, freq='D').strftime('%Y-%m-%d')) list_total = list_now + list_tocurve_fitを用いて指数関数fit前提として演算
from scipy.optimize import curve_fit import numpy as np import matplotlib.pyplot as plt # 近似式の定義 def nonlinear_fit(x, a, b): return a * x ** b # 一旦仮のx軸データを生成 array_now_x = np.linspace(0, len(list_now)-1, len(list_now)) # 指数関数を想定してcurve_fit実行 param, cov = curve_fit(nonlinear_fit, array_now_x, array_now_y,maxfev=1000)指数関数fit処理により得たパラメータで
先日付値を算出するlist_total_y = [] for num, values in enumerate(list_total): list_total_y.append(nonlinear_fit(num, param[0], param[1])) # 公表データから日毎の感染者数を算出 array_now_y = df_select.groupby('公表_年月日').count()['患者_年代'].valuesグラフ描画します。
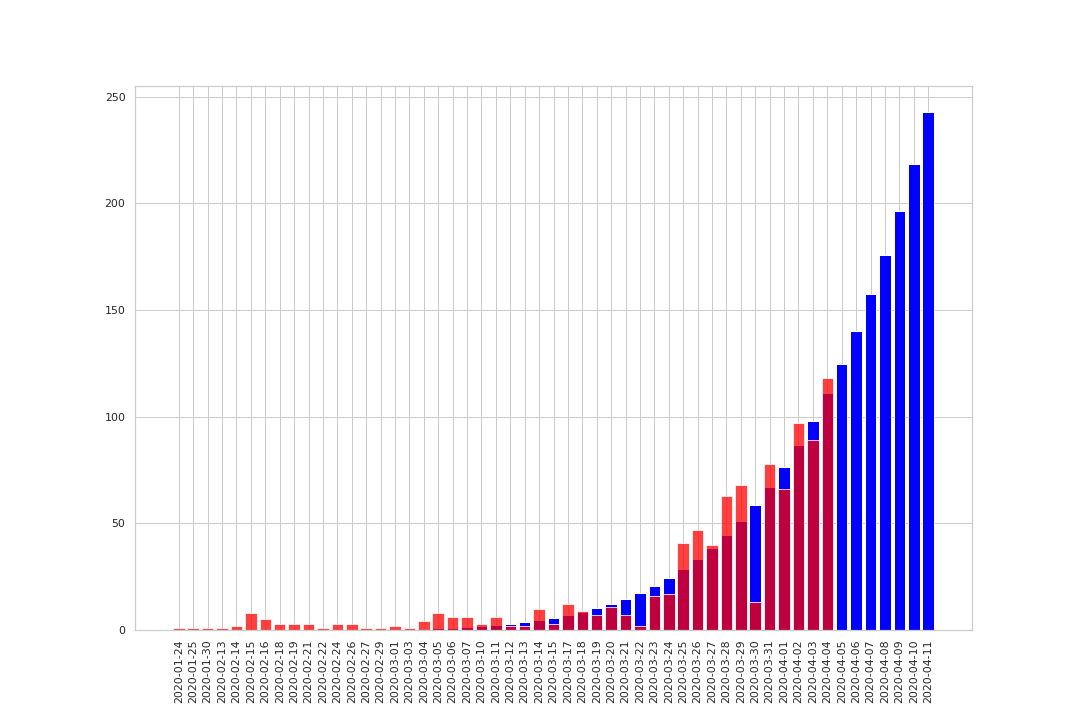
import seaborn as sns import matplotlib.pyplot as plt sns.set() sns.set_style('whitegrid') fig, ax = plt.subplots(1, 1, figsize=(15, 10)) ax.bar(list_total, list_total_y, color='blue') ax.bar(list_now, array_now_y, color='red',alpha=0.75) plt.xticks(rotation=90) plt.savefig('TokyoCorona_20200403.png') plt.show()
- 投稿日:2020-04-05T22:36:11+09:00
Tokyoコロナ:オープンデータから指数関数curve_fitで単純な予測を行ってみる
コロナ感染が広まっております。
何も対策をしない(もしくは効果がなかった)場合、一般的には指数関数に沿って
感染者数が広がっていきます。東京コロナサイトでは感染実数が日々公表されておりますが
予測は出ておりません。指数関数curve_fitにより、将来予測値を算出し
グラフ描画をここでは行います。(もちろん、結果通りになることは望んでおらず
対策により一日も早く収束に向かうことを切に願っております。土日は外出せずこもってます)データは公式サイトから。
https://stopcovid19.metro.tokyo.lg.jp/
通常はよる更新されているようですが、翌日にてグラフ描画の前提です。import pandas as pd from pathlib import Path from datetime import datetimeBASEDIR = Path('.') FILE_PATH = 'https://stopcovid19.metro.tokyo.lg.jp/data/130001_tokyo_covid19_patients.csv' df = pd.read_csv(str(FILE_PATH))# 予測期間 TO_PERIODS = 7 # グラフ描画のための諸々を生成します target_columns = ['公表_年月日','患者_年代'] df_select = df[target_columns] list_now = list(df_select.groupby('公表_年月日').count().index) today = datetime.today() today.strftime('%Y-%m-%d') list_to = list(pd.date_range(today.strftime('%Y-%m-%d'), periods=TO_PERIODS, freq='D').strftime('%Y-%m-%d')) list_total = list_now + list_tocurve_fitを用いて指数関数fit前提として演算
from scipy.optimize import curve_fit import numpy as np import matplotlib.pyplot as plt # 近似式の定義 def nonlinear_fit(x, a, b): return a * x ** b # 一旦仮のx軸データを生成 array_now_x = np.linspace(0, len(list_now)-1, len(list_now)) # 指数関数を想定してcurve_fit実行 param, cov = curve_fit(nonlinear_fit, array_now_x, array_now_y,maxfev=1000)指数関数fit処理により得たパラメータで
先日付値を算出するlist_total_y = [] for num, values in enumerate(list_total): list_total_y.append(nonlinear_fit(num, param[0], param[1])) # 公表データから日毎の感染者数を算出 array_now_y = df_select.groupby('公表_年月日').count()['患者_年代'].valuesグラフ描画します。
import seaborn as sns import matplotlib.pyplot as plt sns.set() sns.set_style('whitegrid') fig, ax = plt.subplots(1, 1, figsize=(15, 10)) ax.bar(list_total, list_total_y, color='blue') ax.bar(list_now, array_now_y, color='red',alpha=0.75) plt.xticks(rotation=90) plt.show()
- 投稿日:2020-04-05T22:34:38+09:00
ブラックジャックの戦略を強化学習で作ってみる(②gymに環境を登録)
はじめに
Pythonと強化学習の勉強を兼ねて,ブラックジャックの戦略作りをやってみました.
ベーシックストラテジーという確率に基づいた戦略がありますが,それに追いつけるか試してみます.こんな感じで進めていきます
1. ブラックジャック実装
2. OpenAI gymの環境に登録 ← 今回はここ
3. 強化学習でブラックジャックの戦略を学習OpenAIのgymとは
強化学習の研究環境として使われるプラットフォームです.
CartPoleや迷路などの環境(ゲーム)が用意されており,簡単に強化学習を試すことができます.
OpenAI Gymの環境は,エージェントからの行動を受け取り,その結果としてその次の状態と報酬を返す共通のインターフェースを持っています.
インストールは以下のように簡単にできますが,詳しい方法は他のページを参考にしてください.以下,インストールが終わってるものとして説明します.pip install gym今回はこのOpenAI Gymの環境に自分で作ったブラックジャックを登録して,強化学習できるようにします.
強化学習のおさらい
まず簡単に強化学習のおさらいから.
「環境」から「状態」を観測し,「エージェント」がそれに対して「行動」を起こします.「環境」は「エージェント」に更新された「状態」と「報酬」をフィードバックします.
強化学習の目的は,将来にわたって得られる「報酬」の総和を最大化する「行動」の仕方(=方策)を獲得することです.ブラックジャックに強化学習の要素を当てはめる
今回のブラックジャックでは,次のように強化学習を考えます.
- 環境:ブラックジャック
- エージェント:Player
- 状態:Playerのカード,Dealerのカードなど
- 行動:Playerの選択.HitやStandなど
- 報酬:勝負で得られるチップ
OpenAI Gymに環境を登録する手順
次の手順で自作の環境をOpenAI Gymに登録します.
- OpenAI Gymのgym.Envを継承したブラックジャック環境のクラス「BlackJackEnv」を作成する
- gym.envs.registration.register 関数を使って環境を登録し,BlackJack-v0というIDで呼び出せるようにする
開発環境
- Windows 10
- Python 3.6.9
- Anaconda 4.3.0 (64-bit)
- gym 0.15.4
ファイル構成
ファイル構成は以下のようにします.
__init__.pyという名前のファイルが2つあるので注意してください.└─ myenv ├─ __init__.py ---> BlacJackEnvを呼び出す └─env ├─ __init__.py ---> BlackJackEnvのある場所を示す ├─ blackjack.py ---> BlacJackのゲーム自体 └─ blackjack_env.py ---> OpenAI Gymのgym.Envを継承したBlackJackEnvクラスを作るそれでは手順に沿って,環境を登録します.
OpenAI Gymのgym.Envを継承したブラックジャック環境のクラス「BlackJackEnv」を作成する
myenv/env/blackjack.py
前回作成したブラックジャックのコードをそのまま置きます.
下のblackjack_env.pyでインポートして使います.myenv/env/blackjack_env.py
OpenAI Gymに登録したいBlackJackのゲーム環境「BlackJackEnv」クラスを作ります.
gym.Envを継承して,以下の3つのプロパティと5つのメソッドを実装します.プロパティ
- action_space:Player(エージェント)がどんな行動を選択できるかを表す.
- observation_space:Player(エージェント)が観測できるゲーム環境の情報
- reward_range:報酬の最小値から最大値の範囲
メソッド
- reset:環境をリセットするためのメソッド.
- step: 環境においてアクションを実行し,その結果を返すメソッド.
- render:環境を可視化するメソッド.
- close:環境を閉じるためのメソッド.学習終了時に使います.
- seed:ランダムシードを固定するメソッド.
action_spaceプロパティ
Stand, Hit, Double Down, Surrenderの4つの行動がとれることを表しています.
action_spaceself.action_space = gym.spaces.Discrete(4)observation_spaceプロパティ
Playerの手札の合計点,Dealerの開示されている手札の点,ソフトハンド(Playerの手札にAが含まれる)を示すフラグ,PlayerがHit済みか示すフラグの4つの状態を観測します.
それぞれの最大値,最小値を決めます.observation_spacehigh = np.array([ 30, # player max 30, # dealer max 1, # is_soft_hand 1, # hit flag true ]) low = np.array([ 2, # player min 1, # dealer min 0, # is_soft_hand false 0, # hit flag false ]) self.observation_space = gym.spaces.Box(low=low, high=high)reward_rangeプロパティ
報酬の範囲を決めます.ここでは獲得できるチップの最小値と最大値が含まれるように決めています.
reward_rangeself.reward_range = [-10000, 10000]resetメソッド
self.doneの初期化,self.game.reset_game()でPlayer, Dealerの手札の初期化,チップを賭ける(Bet),カードの配布(Deal)を行います.
self.doneはstepメソッドで触れる通り,勝敗がついているかを示すブール値です.
self.observe()で4つの状態を観測して返します.
ただし今回は,Playerの所持チップは減らないものとして学習させることとしました.reset()def reset(self): # 状態を初期化し,初期の観測値を返す # 諸々の変数を初期化する self.done = False self.game.reset_game() self.game.bet(bet=100) self.game.player.chip.balance = 1000 # 学習中は所持金がゼロになることはないとする self.game.deal() # self.bet_done = True return self.observe()stepメソッド
Playerは環境に対してStand, Hit, Double down, Surrenderいずれかの行動をとります.プレーヤーのターンが終了していればチップの精算を行います.最後に以下の4つの情報を返します.
- obserbation:観測した環境の状態.
- reward:アクションによって獲得した報酬の量.
- done:もう一度環境をリセットすべきかどうかを示すブール値.BlackJackでは勝敗がついたかどうかを示すブール値.
- info:デバッグに役立つ情報を設定できるdictionary.
またこの学習環境においては,Hitした後にDouble downやSurrenderをした場合にはルール違反ということでペナルティを与えることとしました.
step()def step(self, action): # action を実行し,結果を返す # 1ステップ進める処理を記述.戻り値はobservation, reward, done(ゲーム終了したか), info(追加の情報の辞書) if action == 0: action_str = 's' # Stand elif action == 1: action_str = 'h' # Hit elif action == 2: action_str = 'd' # Double down elif action == 3: action_str = 'r' # Surrender else: print(action) print("未定義のActionです") print(self.observe()) hit_flag_before_step = self.game.player.hit_flag self.game.player_step(action=action_str) if self.game.player.done: # プレーヤーのターンが終了したとき self.game.dealer_turn() self.game.judge() reward = self.get_reward() self.game.check_deck() print(str(self.game.judgment) + " : " + str(reward)) elif action >= 2 and hit_flag_before_step is True: reward = -1e3 # ルールに反する場合はペナルティを与える else: # プレーヤーのターンを継続するとき reward = 0 observation = self.observe() self.done = self.is_done() return observation, reward, self.done, {}なお今回,render, close, seedメソッドは使いません.
blackjack_env.pyのコード全体は次のようになります.
myenv/env/blackjack_env.pyimport gym import gym.spaces import numpy as np from myenv.env.blackjack import Game class BlackJackEnv(gym.Env): metadata = {'render.mode': ['human', 'ansi']} def __init__(self): super().__init__() self.game = Game() self.game.start() # action_space, observation_space, reward_range を設定する self.action_space = gym.spaces.Discrete(4) # hit, stand, double down, surrender high = np.array([ 30, # player max 30, # dealer max 1, # is_soft_hand 1, # hit flag true ]) low = np.array([ 2, # player min 1, # dealer min 0, # is_soft_hand false 0, # hit flag false ]) self.observation_space = gym.spaces.Box(low=low, high=high) self.reward_range = [-10000, 10000] # 報酬の最小値と最大値のリスト self.done = False self.reset() def reset(self): # 状態を初期化し,初期の観測値を返す # 諸々の変数を初期化する self.done = False self.game.reset_game() self.game.bet(bet=100) self.game.player.chip.balance = 1000 # 学習中は所持金がゼロになることはないとする self.game.deal() # self.bet_done = True return self.observe() def step(self, action): # action を実行し,結果を返す # 1ステップ進める処理を記述.戻り値はobservation, reward, done(ゲーム終了したか), info(追加の情報の辞書) if action == 0: action_str = 's' # Stand elif action == 1: action_str = 'h' # Hit elif action == 2: action_str = 'd' # Double down elif action == 3: action_str = 'r' # Surrender else: print(action) print("未定義のActionです") print(self.observe()) hit_flag_before_step = self.game.player.hit_flag self.game.player_step(action=action_str) if self.game.player.done: # プレーヤーのターンが終了したとき self.game.dealer_turn() self.game.judge() reward = self.get_reward() self.game.check_deck() print(str(self.game.judgment) + " : " + str(reward)) elif action >= 2 and hit_flag_before_step is True: reward = -1e3 # ルールに反する場合はペナルティを与える else: # プレーヤーのターンを継続するとき reward = 0 observation = self.observe() self.done = self.is_done() return observation, reward, self.done, {} def render(self, mode='human', close=False): # 環境を可視化する # human の場合はコンソールに出力.ansi の場合は StringIO を返す pass def close(self): # 環境を閉じて,後処理をする pass def seed(self, seed=None): # ランダムシードを固定する pass def get_reward(self): # 報酬を返す reward = self.game.pay_chip() - self.game.player.chip.bet return reward def is_done(self): if self.game.player.done: return True else: return False def observe(self): if self.game.player.done: observation = tuple([ self.game.player.hand.calc_final_point(), self.game.dealer.hand.calc_final_point(), # Dealerのカードの合計点 int(self.game.player.hand.is_soft_hand), int(self.game.player.hit_flag)]) else: observation = tuple([ self.game.player.hand.calc_final_point(), self.game.dealer.hand.hand[0].point, # Dealerのアップカードのみ int(self.game.player.hand.is_soft_hand), int(self.game.player.hit_flag)]) return observationgym.envs.registration.register 関数を使って環境を登録し,BlackJack-v0というIDで呼び出せるようにする
myenv/__init__.py
gym.envs.registration.register関数を使ってBlackJackEnvをgymに登録します.
ここでBlackJack-v0というIDでmyenvディレクトリの下のenvディレクトリの下にあるBlackJackEnvというクラスを呼び出すことを宣言します.myenv/__init__.pyfrom gym.envs.registration import register register( id='BlackJack-v0', entry_point='myenv.env:BlackJackEnv', )myenv/env/__init__.py
ここで
BlakcJackEnvクラスがmyenvディレクトリの下のenvディレクトリの下にあるblackjack_env.pyの中にあることを宣言します.myenv/env/__init__.pyfrom myenv.env.blackjack_env import BlackJackEnv強化学習させるには
強化学習のコードの中で,
env = gym.make('BlackJack-v0')とすると環境を使うことができます.今回は環境の登録がメインなので割愛しますが,次の記事はこれを作成します.
終わりに
自作したブラックジャックのゲームをOpenAI Gymの環境に登録してみました.
自作した環境に対して,何を行動とし,何を状態として観測し,何を報酬とするのか,そして1ステップとはどこからどこまでなのかと,よくよく考えながら作らなければいけないことを実感できました.
はじめは1ステップの長さをとんでもなく長く設定してしまっていました...次は,この環境を使ってブラックジャックの戦略を学習させてみたいと思います.
参考にさせていただいたサイト/書籍

- 投稿日:2020-04-05T22:17:25+09:00
Pythonで基礎から機械学習 「ベイズ入門からPRMLへ」
はじめに
この「Pythonで基礎から機械学習」シリーズの目的や、環境構築方法、シリーズの他の記事などは以下まとめページを最初にご覧下さい。
今回は、ベイズを勉強しようとしたのですが、恥ずかしながら自分のレベルではちゃんと説明できるほど理解できませんでした。
調べるうちに色々有用と思われるサイトや書籍をまとめました。また自分が再チャレンジするためと、こんな情報でも役にたつ人がいるかもしれないので、恥を忍んでここに公開します。
ベイズとは?
全くうまく説明できる自信が無いので、分かりやすいと思われるサイトをリンクします。一言でベイズといっても、ベイジアンとかベイズ統計学とかベイズ推定とかベイズの定理とか、ベイズと名がつくものが色々あって初心者は混乱しがちです。
多項式あてはめで眺めるベイズ推定~今日からきみもベイジアン~
ベイズの定理
ベイズ統計学の根幹をなす(と思う)定理です。式は以下の通りです。
$P(X)$:事象 $X$ が起きる確率
$P(Y|X)$ :事象 $X$ が起きたもとで事象 Y が起きる確率P(A|B) = \frac{P(B|A)P(A)}{P(B)}この式自体は、そこまで難しいものではなく、条件付き確率から求めることができます。以下のヨビノリたくみ先生の動画が分かりやすいと思います。
その他、参考になりそうなリンクをはっておきます。
ベイズの応用例
ベイズの応用例は多岐に渡ります。よく例に挙げられるのは以下です。
- 迷惑メールの分類
- 確率ロボットの分野(SLAM等)
- 検査の罹患率(病気である確率)算出
- 機械学習・ディープラーニング
迷惑メールの例は、以下参照下さい。
具体例でわかる!ベイズ推定とベイズの定理検査の罹患率は、今ホットな話題ですね。以下の記事もベイズを用いて計算されています。
COVID-19 日本国内の潜在的な陽性者数を推定する試み機械学習・ディープラーニングとも関係が深く深層学習はガウス過程という話もあるようです。正直全然理解しきれていません。精進したいと思います。
PRML(パターン認識と機械学習)
PRMLはPattern Recognition and Machine Learningの略で、日本では「パターン認識と機械学習」という名前で売られている本のことです。ネットでは黄色本とか、ビショップ本とか呼ばれることが多いです。これはほぼベイジアンのための本で、ベイジアンになるためには、これを読まないといけないと言われている本です(多分)。
正直私は全然読みこなせていません。
PRML原著
黄色本、買おうとすると高いのですが、実は英語版であればPDFが無料で公開されています。
PRML、英語版はPDFが無料公開されていることをフォロワーさんに教えていただく。そして、中身に微かに見覚えあるのでこれ挫折済みのやつだ https://t.co/yJBtbp1JxI
— からあげ (@karaage0703) October 16, 2019「Pattern Recognition and Machine Learning by Christopher Bishop」と書かれているリンクをクリックするとダウンロードできます。
PRML解説
多くの解説がネットにあります。本書だけでは途方にくれてしまう方は、ガイドとしてどうぞ。私はこれらがあっても、全然読みこなせませんでした。
パターン認識と機械学習の学習 普及版
main.pdfというリンクからダウンロードできます。PRMLのアルゴリズムをPython(ほぼNumpyだけ)で実装
まとめ
ベイズに関しては、ほぼリンクだけで終わってしまいました。ちゃんと理解してからまとめようと思ったのですが、調べた内容がいつまでも下書きのまま残ってしまっているのも勿体無い気がしたので、一区切りということで公開することにしました。
他、初学者に役立つ情報あればありがたいです。いつかPRMLを読みこなして立派なベイジアンになりたいなと思っています。
- 投稿日:2020-04-05T22:15:00+09:00
FastAPIを使ってとりあえず、swaggerにそれっぽいAPIの使い方を表示したい
概要
とにかく、とりあえず、FastAPIのswaggerの画面にAPIからのレスポンスの形を定義したり、
レスポンスのサンプルを表示したりしたい人向けの記事。ぼくがそうだったのだけれども、そういう記事やblogが見つけられなくて、
ひとまずチュートリアルを一通りこなしたのもあって、
同じ目的を持つ人の一助けになればと思って書いた。前提
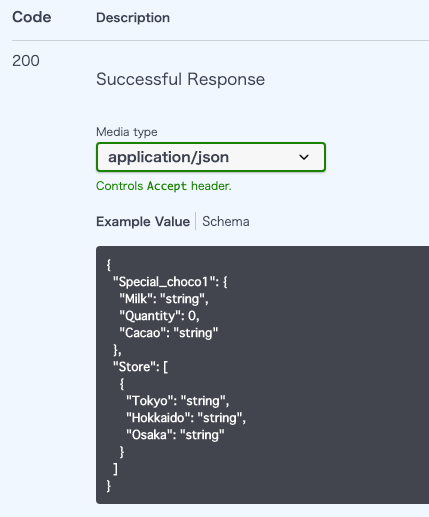
- こういう形のデータがレスポンスとして返ってくるとする。
{ "Special_choco1": { "Milk": "many", "Quantity": 5, "Cacao": "a little" }, "Store":[ { "Tokyo": "sibuya", "Hokkaido": "sapporo", "Osaka": "nanba" } ] }
FastAPIのバージョンは 0.52.0
main.pyに書く
app=FastAPI() って書くファイルに書く。きっと他にもっと良い書き方がある。
まずはレスポンスの形を定義する
from fastapi import FastAPI from pydantic import BaseModel from typing import List class choco_model(BaseModel): Milk: str Quantity: int Cacao: str class Store_model(BaseModel): Tokyo: str Hokkaido: str Osaka: str class Special_choco(BaseModel): Special_choco1: choco_model Store: List[Store_model] app = FastAPI() @app.get("/api/v1/chocolate/{name}") async def making_choco(name: str): return # 後略。前提に記載したJSONが変える様な感じのものを書くイメージ。Example Valueに定義したモデルを表示させる
デコレータのところのresponse_modelに定義したいモデルを指定する。
そうすると、swaggerのExample Value のところに表示されるようになる。# 前略) app = FastAPI() @app.get("/api/v1/chocolate/{name}", response_model=Special_choco) async def making_choco(name: str): return # 後略。前提に記載したJSONが変える様な感じのものを書くイメージ。こんな感じ。
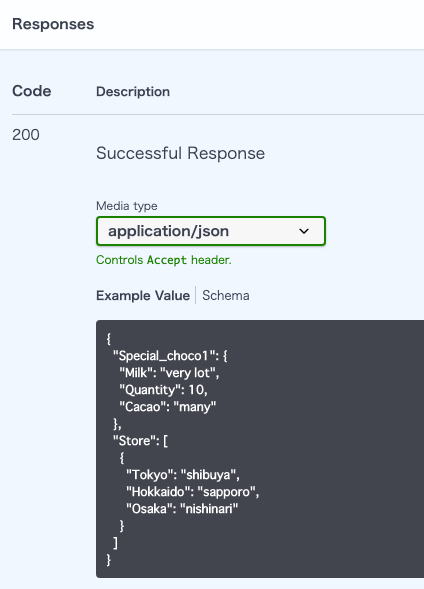
より具体的にExample Valueを表示する。
型やデータの構造だけではなく、具体的にどんな値が返ってくるのかを表示するには、
定義の部分に表示したいデータを以下のように、class Config 内に記載する。
そうすると、具体的な値がexample value の欄に入った状態で表示される。from fastapi import FastAPI from pydantic import BaseModel from typing import List class choco_model(BaseModel): Milk: str Quantity: int Cacao: str class Config: schema_extra = { "example": { "Milk": "very lot", "Quantity": 10, "Cacao": "many", } } class Store_model(BaseModel): Tokyo: str Hokkaido: str Osaka: str class Config: schema_extra = { "example": { "Tokyo": "shibuya", "Hokkaido": "sapporo", "Osaka": "nishinari", } } # 後略以下のように表示される。
最後に
チュートリアルはボリュームが多いけども、やっておくとためになるのよいです。
- 投稿日:2020-04-05T22:11:03+09:00
機械学習のお勉強〜matplotlib編〜
機械学習のお勉強〜matplotlib編〜
今回はmatplotlibの勉強をしたのでそのアウトプットをします。
1.matplotlibとは?
データの可視化をしてくれる外部ライブラリです。
numpy,pandasと同様Pythonには最初は入ってないけどAnacondanには最初からインストールされています。2.データの可視化をすると何がいいの?
外れ値を素早く見つけることができます。
例えばお菓子の値段の統計を取っていたとします。
1個100円前後のお菓子の中に1個1万円のお菓子のデータがあったらおかしいですよね?
そのおかしいデータを瞬時に見つけるのはとても難しいですが、グラフなどでデータを可視化することで瞬時に見つけることができます。ここ1つだけ変な点があるなぁ?ってなります(笑)
3.基本的な使用方法
インポート
test.ipynb#matplotlibのインポート import matplotlib.pyplot as plt %matplotlib inline上記を実行しましょう。
%matplotlib inlineはJupyterNotebookで使うときだけ使用しましょう。
今回はpyplotの機能だけ使うのでpyplotだけインポートします。グラフの描画
test.ipynb#グラフのサイズの設定(4×4) plt.figure(figsize=(4,4)) #グラフの作成 plt.plot([1,2,3,4,5],[6,7,8,9,10],label='test') #x軸の名称 plt.xlabel('x軸') #y軸の名称 plt.ylabel('y軸') #グラフタイトル plt.title('タイトル') #上記凡例をグラフに反映 plt.legend() #グラフを表示 plt.show()基本的な関数は上記。
plt.show()に関しては記載しなくてもグラフは表示するので好みでどうぞ。xの2乗のグラフを記載するなら、、、
test.ipynbimport numpy as np #1~10の配列をxに代入 x = np.arange(0,11,1) #yの値をxの2乗にする y = x ** 2 plt.plot(x,y,label='y = x^2') #x軸の名称 plt.xlabel('x軸') #y軸の名称 plt.ylabel('y軸') #グラフタイトル plt.title('y = x^2') #上記凡例をグラフに反映 plt.legend() #グラフを表示 plt.show()これで出来ます。
複数のグラフを表示する。
次に複数のグラフを表示する方法を記載します。
test.ipynb#2行2列 トータルのサイズが8×8のグラフを作成 fig,ax = plt.subplots(2,2,figsize=(8,8)) #x,y,zの範囲を設定 x = np.arange(0,11,1) y = x ** 2 z = x ** 3 #グラフの作成 ax[0,0].plot(x,x,label='x = x',color='red') ax[0,1].plot(x,y,label='y = x^2'),color='green') ax[1,0].plot(x,z,label='z = x^3'),color='blue') #グラフの設定 for i in range(2): for j in range(2): ax[i,j].set_xlabel('x軸') ax[i,j].set_ylabel('y軸') ax[i,j].legend() plt.tight_layout()figに全体のサイズに縦横8サイズのグラフを作成
その中に縦横2サイズのグラフを4つ作成しています。tight_layout関数は、グラフ同士被らないようにする関数です。
その他グラフの作成
これまでは棒グラフのみでしたが他のグラフももちろん作成できます。
test.ipynb#円グラフ plt.pie() #ヒストグラム plt.hist() #散布図 plt.scatter()引数は割愛していますが、円グラフ、ヒストグラムは各データの割合や推移
散布図は組データの確認に使うので興味があれば調べてみてください!4.まとめ
機械学習これまでやってきましたが楽しいです!
普段こういういろいろなことが可能な言語をしてきていなかったため、出来ることが多いのはいいなぁ・・・ってなります。
明日以降もアウトプットに投稿しますが、拙くなってしまうのは見逃してください・・・以上
- 投稿日:2020-04-05T22:07:46+09:00
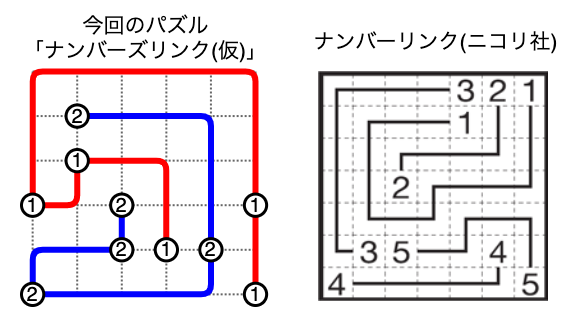
ナンバーリンク風のパズルを制約充足問題として定式化し制約ソルバーで解く
はじめに
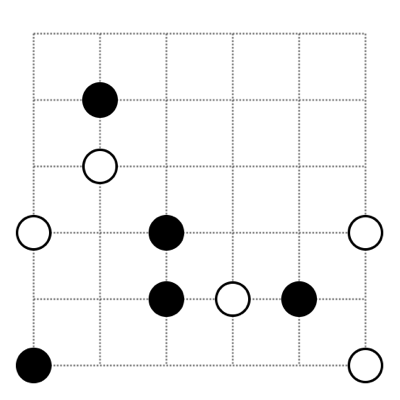
きっかけは、こんなパズル。
○どうし、●どうしをそれぞれ1本の線でつなぎなさい。
ただし、線は点線にそって引き、途中で交わったり分かれたりしないようにしなさい。
この例題は盤面のサイズも小さいので、直感でも以下の解が比較的かんたんに見つかります。
この記事では、このようなパズルを制約充足問題として定式化して、制約ソルバーのSugar1を使って自動で解くことを目指します。
方針
「ナンバーズリンク(仮)」
さて、まず本パズルですが、自動で解くやり方を色々調べているうちに、いわゆる「ナンバーリンク2」と呼ばれるパズルに似ていることに気づきました。試しに、上記例題の○と●を数字の(1)と(2)に置き換えたものと、注釈2にリンクを貼ったニコリ社のホームページにある例題を並べました。
まぁ、似てます。同じ数字どうしを1本の線でつなぐ、という基本的なルールは同じ。一方で、複数の点を1本でつなぎ、その始点と終点が決まっていない、というポイントがナンバーリンクとは少し異なります。そこでこのパズルを、「複数の」同じ数字どうしをつなぐ、という意を込めて「ナンバーズリンク(仮)」と名付けます。
このナンバーズリンクの自動解法について、当初は、経路探索アルゴリズム(A*アルゴリズム3など)を用いたアプローチ4をベースに試行錯誤していました。が、、、ナンバーズリンクでは、複数の地点を通過する順番が不定で経路の探索空間が大きく、私の力では盤面が7x7や8x8のサイズでも解にたどり着くことができませんでした。残念。。。
そこで今回は、ナンバーリンクの解き方としてメジャーと思われる、制約ソルバーで解くアプリーチで進めてみます。
制約ソルバー
まず、制約ソルバーとは、制約充足問題の解を探索するプログラムのことを指します。ここで、制約充足問題とは、以下のようなものです5。
制約充足問題は、以下を満たす組$(X,D,C)$で与えられる。
- $X$: 変数の有限集合
- $D$: 各変数のドメイン(有限な値領域、整数)を与える関数
- $C$: $X$上の制約の有限集合要は、変数と、変数の取り得る値と、その制約、ということですね。これらを決めることができれば、あとは、制約ソルバーが高速に解いて変数の値を決めてくれます6。
ちなみに、この制約充足問題や制約ソルバー(CSPソルバー)ですが、情報処理学会のSLDM研究会7というところが2012年から毎年開催しているアルゴリズムコンテスト8のWEBサイトを見て、今回初めて知りました。このコンテストで取り組んでいるのは、ナンバーリンクやそれをアレンジしたパズルの自動解法。研究会の特性からも、電子回路の自動配線アルゴリズムの研究が背景にあるようですが、制約ソルバー自体は、割当問題やスケジューリング問題など、幅広い応用が可能なようです。
「ナンバーズリンク(仮)」の制約モデル
というわけで、過去のナンバーリンク解法なども参考に、ナンバーズリンクの制約モデルを作ってみました9。
まず、盤面は、各節点を頂点とし、隣接する節点の間に辺がある有向グラフとして考えます10。
制約モデルの骨子は以下の3つの制約です。
- 節点と辺を通る線は多くても1本(交差や枝分かれもなし)
- 同じ数字同士を線でつなぐ
- 同じ数字は全て1本の線でつながる
この中で、特に制約3がナンバーズリンクに特有の制約となります。
制約モデルの詳細は、次で具体的に示します。実装
今回は、制約ソルバーとしてSugar1を、SATソルバーとしてcryptominisat11を用いました12。
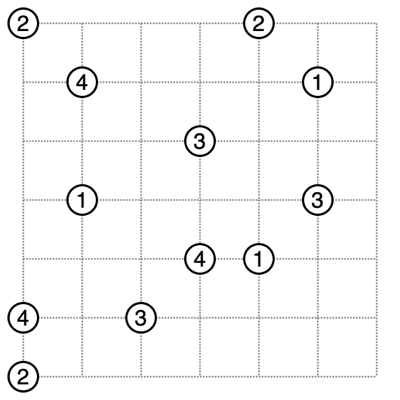
まず、ナンバーズリンクの問題は以下のようなテキストで表現します。入力データ例(冒頭のナンバーズリンク問題を表したテキストデータ)000000 020000 010000 102001 002120 200001このような入力データに基づいて制約モデル(CSPファイル)を作りSugarを実行するコードをPythonで書きました。参考までに、コード(NumbersLink_CSP.py)と、本コードで生成されるCSPファイル例(上記の入力データ例から生成されるもの)を以下に置いておきます。
あり得る解は全て求められるよう、得られた解を除外するような条件をCSPファイルに追記して制約ソルバーを再実行する、ということをしています。また、自動で解を求めるだけではなく、自動で問題を作ることもできるようにしてみました。問題をランダムに作って解く、を繰り返すことで、筋の良い問題を作ろうとするものです。
制約モデルの詳細
実装した制約モデルについて、CSPでの表現も一部交えて説明します。
制約1:節点と辺を通る線は多くても1本(交差や枝分かれもなし)
- 節点$u$と節点$v$の間の辺$(u,v)$について
- $辺(u,v) \in \{0,1\}$ ※線がある場合は1、ない場合は0
- $辺(u,v) + 辺(v,u) \leq 1$ ※線は多くてもどちらかの向き1本
(int hr_2_1 0 1) ;右向きの辺 (int hl_2_1 0 1) ;左向きの辺 (int vu_2_1 0 1) ;上向きの辺 (int vd_2_1 0 1) ;下向きの辺(<= (+ hr_2_1 hl_2_1) 1) ;右向きと左向きの辺を足して1以下 (<= (+ vu_2_1 vd_2_1) 1) ;上向きと下向きの辺を足して1以下
- 節点$u$について
- $入次数(u) \in \{0,1\}$ ※節点に入る線の本数
- $出次数(u) \in \{0,1\}$ ※節点から出る線の本数
- $入次数(u) = 辺(u_{上},u) + \cdots + 辺(u_{右},u)$ ※入次数=周囲の節点から入る線の本数
- $出次数(u) = 辺(u,u_{上}) + \cdots + 辺(u,u_{右})$ ※出次数=周囲の節点に出る線の本数
(int di_2_1 0 1) ;入次数 (int do_2_1 0 1) ;出次数(= di_2_1 (+ hr_1_1 hl_2_1 vd_2_0 vu_2_1)) ;入次数は周辺から節点に入る辺の和 (= do_2_1 (+ hl_1_1 hr_2_1 vu_2_0 vd_2_1)) ;出次数は周辺の節点に出る辺の和制約2:同じ数字同士を線でつなぐ
- はじめに数字が配置されなかった節点$u$について
- $数(u) = \{0,1,2, \cdots ,最大数\}$ ※配置する数は1以上、0は線なしを表す
- $入次数(u) = 出次数(v)$ ※線は通過するか通らない
(domain number (0 1 2)) ;数値は0~2(0は線が通過しないことを表す) (int x_2_1 number) ;数 (int i_2_1 0) ;はじめに数字が配置されなかった場合0 (= di_2_1 do_2_1) ;入次数=出次数
- はじめに数字$n$が配置された節点$u$ (全$m$個) について
- $数(u) = n$
- いずれか1つ: $入次数(u) = 0 \cap 出次数(u) = 1$ ※始点
- いずれか1つ: $入次数(u) = 1 \cap 出次数(u) = 0$ ※終点
- 他の$m-2$個: $入次数(u) = 1 \cap 出次数(u) = 1$ ※通過点
(int x_1_2 1) ;はじめに数字1が配置された節点 (int i_1_2 1) ;はじめに数字が配置された場合、配置された数字 (count 0 (di_1_2 di_0_3 di_5_3 di_3_4 di_5_5) eq 1) ;いずれか1つが入次数0 (count 0 (do_1_2 do_0_3 do_5_3 do_3_4 do_5_5) eq 1) ;いずれか1つが出次数0 (count 1 ((+ di_1_2 do_1_2) (+ di_0_3 do_0_3) (+ di_5_3 do_5_3) (+ di_3_4 do_3_4) (+ di_5_5 do_5_5)) eq 2) ;いずれか2つが入次数と出自数の和が1 ;上記の3式の組み合わせにより、いずれか1つが始点、いずれか1つが終点、残りが通過点、となる
- 全ての節点$u$と節点$v$について
- $辺(u,v) > 0 \Rightarrow 数(u) = 数(v)$ ※同じ数字同士を線でつなぐ
(=> (> hr_2_1 0) (= x_2_1 x_3_1)) ;つながった節点は同じ数 (=> (> hl_2_1 0) (= x_2_1 x_3_1)) ;つながった節点は同じ数制約3:同じ数字は全て1本の線でつながる
- 節点$u$($数(u)=n$)について
- $入次数(u) = 0, 出次数(u) = 1 \Rightarrow 順序(u) = 0$ ※始点の順序は0
- $入次数(u) = 1, 出次数(u) = 0 \Rightarrow 順序(u) = m-1$ ※終点の順序はm-1
(=> (and (= di_1_2 0) (= do_1_2 1)) (= o_1_2 0)) ;始点の順序は0 (=> (and (= di_1_2 1) (= do_1_2 0)) (= o_1_2 4)) ;終点の順序はm-1
- はじめに数字が配置されなかった節点$u$と節点$v$について
- $辺(u,v) > 0 \Rightarrow 順序(v) = 順序(u)$
(=> (and (> hr_2_1 0) (= i_3_1 0)) (= o_2_1 o_3_1)) (=> (and (> hl_2_1 0) (= i_2_1 0)) (= o_2_1 o_3_1))
- はじめに数字$n$が配置された節点$v$について
- $辺(u,v) > 0 \Rightarrow 順序(v) = 順序(u) + 1$ ※通過するときに順序を+1
(=> (and (> hr_2_1 0) (> i_3_1 0)) (= o_3_1 (+ o_2_1 1))) (=> (and (> hl_2_1 0) (> i_2_1 0)) (= o_2_1 (+ o_3_1 1)))実行例
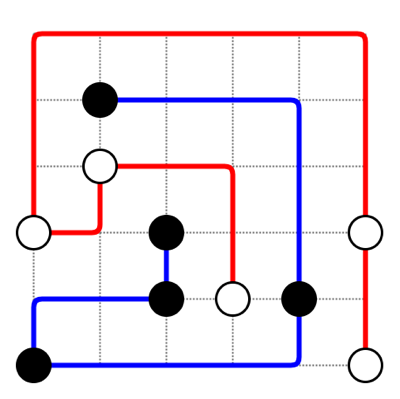
作ったPythonコードで上記入力データ例を解いた結果は、こうなります。
mbp:puzzle nikotan$ python NumbersLink_CSP.py --solver --map map_6x6_1-2_5.txt --tmp tmp width : 6 height: 6 ===================== [result: 1] + - + - + - + - + - + | | + 2 - + - + - + + | | | + 1 - + - + + + | | | | | 1 - + 2 + + 1 | | | | + - + - 2 1 2 + | | | 2 - + - + - + - + 1 ===================== num satisfiable results = 1 elapsed_time = 1.132[sec]サイズも小さく簡単な問題ですが、解が正しく求まっています。
また、この解が唯一の解であると判定されています。真偽は、、、たぶん合ってますよね?おわりに
パズルの制約(ルール)を定式化するだけでパズルが解けてしまう13、というのは、当たり前のようで難しいこと、だと思います。CSPソルバーやSATソルバーの強力さを実感できました。また、問題を自動で解くことができると、問題を自動で作ることもできる、というのも大変面白い気付きでした。
というわけで、これも小規模ですが、ランダムに作った問題を解く、という自作自演行為をプログラムにひたすら繰り返させて見つけた問題の一例を以下に紹介し、本記事を締めさせていただきます。
盤面上の同じ数字のペアを線でつなぐパズル。参考:[ナンバーリンク - Wikipedia] [ナンバーリンクの遊び方、ルール、解き方 | WEBニコリ] ↩
グラフ探索アルゴリズムの一種。参考:[よくわかるA*(A-star)アルゴリズム (Unity2Dのサンプルコードつき) - Qiita] [2009-07-13 | Pashango’s Blog] ↩
電子回路設計の分野などでは、A*アルゴリズムなどの経路探索アルゴリズムとRip-up and Rerouteと呼ばれる手法などを組み合わせたアプローチが古くから研究されているようです。参考:[ナンバーリンクの解探索について考えてみた – PSYENCE:MEDIA] ↩
実際には、制約ソルバーは制約充足問題をさらにSAT(Boolean satisfiability testing)と呼ばれる論理式集合に変換し、SATソルバーが充足可能かを判定します。近年、このSATソルバーに様々な技術が導入されて大幅な性能向上(高速化)が進んでおり、SATソルバーを利用する制約ソルバーを実用的なものにしているそうです。 ↩
2012年から毎年、ナンバーリンクをアレンジした題材でアルゴリズムコンテストを行っているようです。参考:[DAシンポジウム アルゴリズムデザインコンテスト] [DA Symposium, Algorithm Design Contest] ↩
高速化などの改良の余地がまだまだ残ってそうです。 ↩
有向グラフとしたのは、後述する制約3を表現するためです。当初は無向グラフとしていましたが、無向グラフでは制約3をうまく表現できませんでした。 ↩
macbook proで環境を構築しましたが、特に手こずることはありませんでした。参考:Sugarと制約ソルバーcryptominisatの開発環境の構築 | コマログ ↩
ナンバーリンクだけでなく、様々なパズルが制約ソルバーで解かれているようです。参考:パズルをSugar制約ソルバーで解く ↩
- 投稿日:2020-04-05T22:03:42+09:00
AtCoder Judge System Update Test Contest 202004 参戦記
AtCoder Judge System Update Test Contest 202004 参戦記
初の全完で、順位も上位9%という. なんで rated じゃないんですか!(机をバンバン).
A - Walking Takahashi
2分で突破. すでに日に当たっている場合は、現在位置が答え. 現在位置がL未満ならLが答え、現在位置がRを超えているのならRが答え.
S, L, R = map(int, input().split()) if L <= S <= R: print(S) elif S < L: print(L) elif S > R: print(R)B - Picking Balls
6分で突破. R と B に分別して、Rを小さい順に表示した後、Bを小さい順に表示するだけ. 小さい順は当然 sort するだけ.
N = int(input()) R = [] B = [] for _ in range(N): X, C = input().split() if C == 'R': R.append(int(X)) elif C == 'B': B.append(int(X)) R.sort() B.sort() if R: print('\n'.join(str(r) for r in R)) if B: print('\n'.join(str(b) for b in B))C - Numbering Blocks
12分で突破. N がせいぜい9なんだから総当りをすればいいだけ. itertools.permutations 愛してる.
from itertools import permutations a1, a2, a3 = map(int, input().split()) a = [a1, a2, a3] N = a1 + a2 + a3 result = 0 for p in permutations(range(1, N + 1)): X = [p[:a1], p[a1:a1 + a2], p[a1 + a2:]] flag = True for i in range(3): for j in range(1, a[i]): if X[i][j] <= X[i][j - 1]: flag = False for i in range(1, 3): for j in range(a[i]): if X[i][j] <= X[i - 1][j]: flag = False if flag: result += 1 print(result)D - Calculating GCD
23分半で突破. ナイーブにやると O(1010) で TLE. X を全ての A と GCD を取るのは、全ての A の GCD と X の GCD を取るのと同じ. これで X が 1 にならない場合は O(105) になり片付いた. X が 1 になった場合の操作回数だが、A の GCD を順に取っていって変わったところだけが候補になるので、変わったところだけをチェックするようにする. これでどのくらいオーダーが下がるのかは不明だけど、直感的には大きく下がるはずなので、提出したら無事 AC.
from math import gcd N, Q = map(int, input().split()) A = list(map(int, input().split())) S = list(map(int, input().split())) gcd_a = A[0] a = [(1, A[0])] for i in range(1, N): t = gcd(gcd_a, A[i]) if t != gcd_a: gcd_a = t a.append((i + 1, gcd_a)) for i in range(Q): X = S[i] t = gcd(gcd_a, X) if t != 1: print(t) else: for j, g in a: if gcd(X, g) != 1: continue print(j) break追記: みんなにぶたんで解いているようなので、にぶたんでも解いてみたw
from math import gcd N, Q = map(int, input().split()) A = list(map(int, input().split())) S = list(map(int, input().split())) for i in range(N - 1): A[i + 1] = gcd(A[i + 1], A[i]) for i in range(Q): X = S[i] t = gcd(A[-1], X) if t != 1: print(t) else: ng = -1 ok = N - 1 while ok - ng > 1: m = (ok + ng) // 2 if gcd(X, A[m]) == 1: ok = m else: ng = m print(ok + 1)
- 投稿日:2020-04-05T20:51:39+09:00
【python】クラスのselfを理解する。self有無の実行結果からselfの役割を学ぶ。
【python】クラスのselfを理解する。self有無の実行結果からselfの役割を学ぶ。
pythonを始めた人はだれもが疑問に思い、
そこら中にコンテンツが溢れている内容。自分用に改めて整理。
■まとめ
・クラス内のメソッドの引数はデフォルトで1つ設定が必要
└ ないとエラー
└習慣的にselfを使用・selfは任意
└selfじゃなくても動く・クラス内の変数を使う場合は、self.変数とする。
└ x=123を使うなら「self.x」・グローバル変数はクラス内でもそのまま使える
■検証内容
・self有無での動作の違い
・selfじゃなくてもいい
・defのクラス内外での違い
・クラス内のメソッドで引数を設定する
・クラス内の変数を使う
self有無での動作の違い
self有無で動作の違いをみるために、下記のようなクラスを作成。
▼確認用のクラス
class1class class1: def method1(self): print("method1を実行しました") x = class1() x.method1() #出力 # method1を実行しました
▼selfがない場合selfなしclass class1: def method1(): print("method1を実行しました") x = class1() x.method1() #出力 # TypeError: method1() takes 0 positional arguments but 1 was given■エラー
method1() takes 0 positional arguments but 1 was givenクラスの中に定義したメソッド「method1」は引数をとらない(0個)なのに、1個与えられたとなっている。
実行した処理でも()の中は空で引数は入力していない。(通常であれば引数0)
x.method1()
■原因
クラスの中のメソッドを実行する場合、自動的にインスタンス自身が引数として与えられる。<例>
x.method1( )→ 引数1
x.method1('A', 'B')→ 引数3
■対処
クラスの中のメソッドはデフォルトで引数を最低1つ与えておく必要がある。⇛ その引数が「self」
なお、引数はself以外でもいい。selfを使うのが習慣。
selfじゃなくてもいい
▼self以外の文字にした場合
引数のselfを「a」と「あいうえお」に置き換えた場合。
self以外の文字①class class1: def method1(a): print("method1を実行しました") x = class1() x.method1() #出力 # method1を実行しましたself以外の文字②class class1: def method1(あいうえお): print("method1を実行しました") x = class1() x.method1() #出力 # method1を実行しましたどちらも問題なく実行。
defのクラス内外での違い
定義したメソッドをクラスの外に持ってきた場合、当然ながら引数デフォルトで引数が渡されることはない。
※クラスの中のdefで定義した関数はメソッドと呼ぶ。
※クラスの外は関数。クラスの外def method1(): print("method1を実行しました") method1() #出力 # method1を実行しました
クラス内のメソッドと逆で、引数を1つだけ渡すとエラーが出る。エラーdef method1(): print("method1を実行しました") method1('A') #出力 # TypeError: method1() takes 0 positional arguments but 1 was givenエラー:method1() takes 0 positional arguments but 1 was given
引数は0個なのに1個余計なのがきたというエラー。
クラス内のメソッドで引数を設定する
クラス内ではデフォルトで1つ引数を設定するため、その他の引数を設定する場合は、通常よりも1つ多く設定する必要がある。(self + αになる)
引数を設定する場合class class2: def weather(self, day, sky): print(day + 'の天気は' + sky + 'です。') x = class2() x.weather('今日', '晴れ') #出力 # 今日の天気は晴れです。クラス内のweatherメソッドの引数は「self」「day」「sky」の3つを設定。
▼「self」を「a」にした場合
もちろん「self」以外でも正常に動く。self以外class class2: def weather(a, day, sky): print(day + 'の天気は' + sky + 'です。') x = class2() x.weather('今日', '晴れ') #出力 # 今日の天気は晴れです。
クラス内の変数を使う
クラスの大きなメリットはクラス内でのみ有効な関数や変数を設定できること。(グローバルにならない)
クラス内の変数を使うには「self」と組み合わせる必要がある。
▼クラス内の変数を使うクラス内で定義した変数「x=123」をメソッドの中で呼び出すには「self.x」とする必要がある。
class3class class3: x = 123 def method1(self): print(self.x) cls = class3() cls.method1() #出力 # 123
▼selfをつけない場合「self.x」のselfがないとエラーになる。
xのみclass class3: x = 123 def method1(self): print(x) cls = class3() cls.method1() #出力 # NameError: name 'x' is not definedエラー:name 'x' is not defined
クラス内にある「x=123」は「x」ではない。
▼グローバル変数を使うclassの外で定義された変数を使う場合は、selfは不要。
グローバル変数を使うx = 123 class class3: def method1(self): print(x) cls = class3() cls.method1() #出力 # 123selfを使うことで、グローバル変数なのか、クラス内の変数なのかを明確に使い分けできる。
▼self以外
ちなみにself以外でも動く。self以外class class3: x = 123 def method1(あいうえお): print(あいうえお.x) cls = class3() cls.method1() #出力 # 123
selfってなに、、と思っていたが、使い方がわかると便利だし、必要なものだなと思う。
- 投稿日:2020-04-05T20:47:02+09:00
PostgreSQLのNotifyを使ってGraphQL Subscriptionを実装する(バックエンド構築編)
前置き
前提
- prisma2インストール済み
- docker環境インストール済み
- 記事内のgqlgenはエイリアスに登録して使っています。
- gqlgenとprisma2のliftをある程度使っている人向け
サンプル
https://github.com/graphql-lab/subscription-with-postgres-notifyこんな感じの作っていきます
最終的にpythonのスクリプトを叩くと
異なる端末の画面がリアルタイムに更新されるというもの
これを応用すればスクレイピングした結果を定期的にwebサイトにつぶやかせる、というbotが
作れるかと
下準備
gqlgen initからビルドし、必要なディレクトリを作って...とやっても良いのですが
今回はgqlgenの使い方の記事という事ではないので割愛します。
という事で今回は
gqlkitというdockerベースのgraphqlサービスフレームワークを使っていきます。
gqlkitの内容としては
マイグレーションツールにprisma2のliftを、
サーバー構築にgqlgenを使っていて
あとは、handlerやmiddlewareなど、
よく使うであろう機能のディレクトリを詰め合わせただけの他愛もないシンプルなフレームワークです。
任意のディレクトリで下記のリポジトリをクローンします。git clone git@github.com:gqlkit-lab/gqlkit.git subscription-with-postgres-notifyクローンできたらPostgreSQLとDB確認用のpgwebをdocker-composeで立ち上げましょう。
cd subscription-with-postgres-notify docker-compose up -dschema.prisma
PostgreSQLサーバーが立ち上がったら
早速、DBへのマイグレーション作業をやっていきます。schema.prismadatasource db { provider = "postgresql" url = "postgresql://postgres:postgres@localhost:5432/postgres?schema=public" } model messages { id String @default(cuid()) @id text String created_at DateTime @default(now()) updated_at DateTime @updatedAt }cd gqlkit-server/lift prisma2 lift save prisma2 lift upこれでpgwebで確認すると
Tablesのところにmessagesというテーブルが追加されているはずです。
ちなみに今回、ORMはgormを使うのでテーブル名の命名規則は複数形にしなければならない点に注意です。schema.graphql
次に、
schema.graphqlを書きgqlgenでresolver等をビルドしていきます。
ここまで来れば、もうサーバー側の実装は半分は終わった感じです。schema.graphqltype Query { readMessages: [Message!]! } type Subscription { messageCreated: Message! } type Message { id: ID! text: String! created_at: String updated_at: String! }cd ../ # gqlkit-serverのルート gqlgenPostgreSQLのテーブルを監視するためのSQL関数を用意する
※ここからが今回の本題となります。
PostgreSQLの監視、通知の仕組みを有効にするためには以下のようなSQLを実行する必要があるようです。
下記のSQLは簡単に言えば
INSERTやUPDATE文が実行された際の
イベントを検知するトリガーと、イベントをキャッチして何らかの処理を行うハンドラを
PostgreSQLデータベースに組み込む為のSQLといったところです。
参考にさせて頂いたのはこちらです。begin; create or replace function 「イベント名」_handler () returns trigger language plpgsql as $$ declare channel text := TG_ARGV[0]; payload_json json; begin payload_json = json_build_object(「ペイロード」); PERFORM pg_notify(channel, payload_json::text); RETURN NULL; end; $$; CREATE TRIGGER 「イベント名」_trigger AFTER 「SQLのメソッド名(INSERT、UPDATE、DELETEなど)」 ON 「テーブル名」 FOR EACH ROW EXECUTE PROCEDURE 「イベント名」_handler('「テーブル名」'); commit;これをpgwebのqueryのところで叩いてしまっても良いとは思うのですが
それでは、少々不格好ですのでgormで叩いてやるというふうにしてみます。
servantというディレクトリを作りPGNotifyBuilderというパッケージを作ります
dropTriggerという関数はこれによって
graphqlサーバーを起動した際に一旦、古いトリガーを全て削除し
throwNotificationSQLに書いてあるSQLで再度トリガーを作り直します。
dropTriggerが無いとトリガーの重複でエラーが発生してしまうのでここがポイントです。servant/PGNotifyBuilder/PGNotifyBuilder.gopackage PGNotifyBuilder import ( "fmt" "log" "github.com/jinzhu/gorm" _ "github.com/lib/pq" ) type Receive struct { DBConnect string EventName string Table string SqlMethod string Payload string } type PgTrigger struct { Tgname string } func dropTrigger(db *gorm.DB, tableName string) { var triggers []*PgTrigger db.Table("pg_trigger").Select("tgname").Scan(&triggers) for _, trigger := range triggers { sql := fmt.Sprintf(`DROP TRIGGER IF EXISTS %s ON %s CASCADE;`, trigger.Tgname, tableName) db.Exec(sql) } } func throwNotificationSQL(eventName string, table string, sqlMethod string, payload string) string { re := fmt.Sprintf( ` begin; create or replace function %s_handler () returns trigger language plpgsql as $$ declare channel text := TG_ARGV[0]; payload_json json; begin payload_json = json_build_object(%s); PERFORM pg_notify(channel, payload_json::text); RETURN NULL; end; $$; CREATE TRIGGER %s_trigger AFTER %s ON %s FOR EACH ROW EXECUTE PROCEDURE %s_handler('%s'); commit; `, eventName, payload, eventName, sqlMethod, table, eventName, table) return re } func Serve(r *Receive) { db, err := gorm.Open("postgres", r.DBConnect) defer db.Close() if err != nil { log.Fatal(err) } dropTrigger(db, r.Table) db.Exec(throwNotificationSQL(r.EventName, r.Table, r.SqlMethod, r.Payload)) }続いて、
servant/PGNotifyBuilder/PGNotifyBuilder.goを
server.goに読み込みます。package main import ( "gqlkit/env" "gqlkit/handler" pgnb "gqlkit/servant/PGNotifyBuilder" "log" "net/http" "github.com/go-chi/chi" "github.com/go-chi/chi/middleware" "github.com/rs/cors" ) func main() { // Payloadはschema.prismaのmessagesモデルを参考に pgnb.Serve(&pgnb.Receive{ DBConnect: env.DB_CONNECT, EventName: "message_created", Table: "messages", SqlMethod: "INSERT", Payload: ` 'id', NEW.id, 'text', NEW.text, 'created_at', NEW.created_at, 'updated_at', NEW.updated_at `, }) r := chi.NewRouter() cors := cors.New(cors.Options{ AllowedOrigins: []string{env.GQL_SERVER_ALLOW_ORIGIN}, AllowedMethods: []string{"GET", "POST", "OPTIONS"}, AllowedHeaders: []string{"Accept", "Authorization", "Content-Type", "X-CSRF-Token"}, }) r.Use(middleware.SetHeader("Content-Type", "application/json")) r.Use(cors.Handler) r.Handle("/", handler.Playground()) r.Handle("/query", handler.Graphql()) log.Printf("connect to http://localhost:%s/ for GraphQL playground", env.GQL_SERVER_PORT) log.Fatal(http.ListenAndServe(":"+env.GQL_SERVER_PORT, r)) }GraphQLサーバーのresolverを書く
まずは、resolver.go
resolver.gopackage graph import "gqlkit/graph/model" // This file will not be regenerated automatically. // // It serves as dependency injection for your app, add any dependencies you require here. type Resolver struct { messages []*model.Message message *model.Message }続いて
schema.resolvers.goReadMessages
schema.resolvers.gofunc (r *queryResolver) ReadMessages(ctx context.Context) ([]*model.Message, error) { db, err := gorm.Open("postgres", env.DB_CONNECT) defer db.Close() if err != nil { return nil, fmt.Errorf(err.Error()) } db.Order("created_at desc").Find(&r.messages) return r.messages, nil }MessageCreated
schema.resolvers.gofunc (r *subscriptionResolver) MessageCreated(ctx context.Context) (<-chan *model.Message, error) { event := make(chan *model.Message) reportProblem := func(ev pq.ListenerEventType, err error) { if err != nil { fmt.Println(err.Error()) } } listener := pq.NewListener(env.DB_CONNECT, 10*time.Second, time.Minute, reportProblem) err := listener.Listen("messages") if err != nil { panic(err) } go func() { for { select { case n := <-listener.Notify: err = json.Unmarshal([]byte(n.Extra), &r.message) if err != nil { fmt.Println(err) } event <- r.message } } }() return event, nil }テスト用のPython scriptを用意する
以上でGraphQLサーバーの構築はできましたので
GraphQLサーバーがちゃんと、Subscriptionの通知結果を返すのかテストする為のスクリプトを書きます。
別にpythonでなくてもいいですし
GraphQLサーバーにCreateMessageというmutationを作ってテストしてもいいのですが
今回は、pythonでスクレイピングした内容をPostgreSQLにINSERTした際に
通知をするという今後の想定もあるという事で敢えてpythonを使います。docker-compose.ymlファイルがある階層にcreate-messageというディレクトリを作ります。
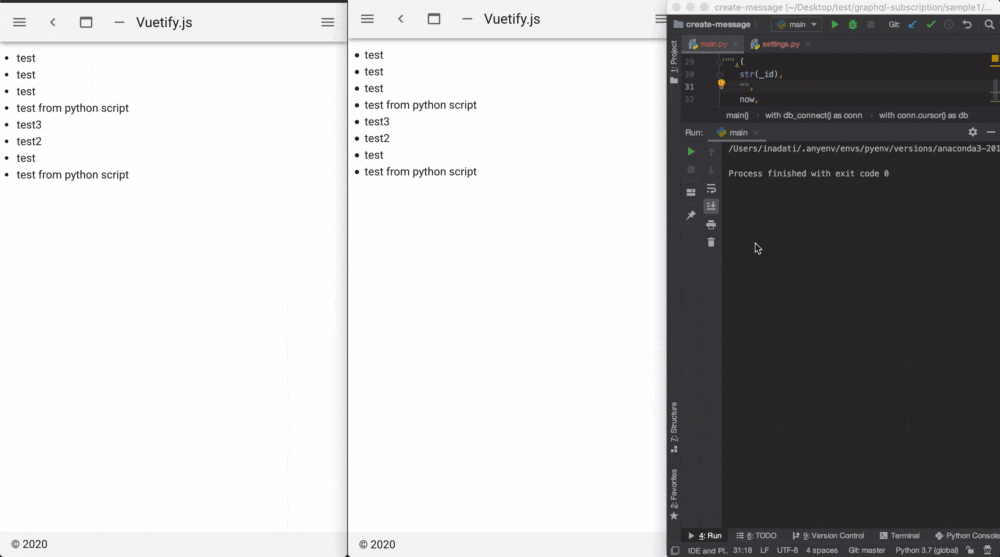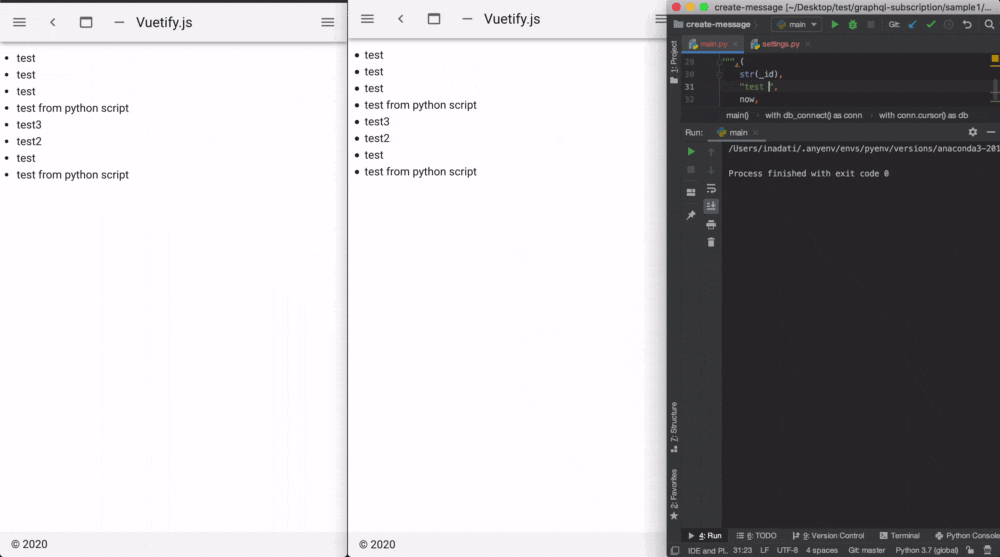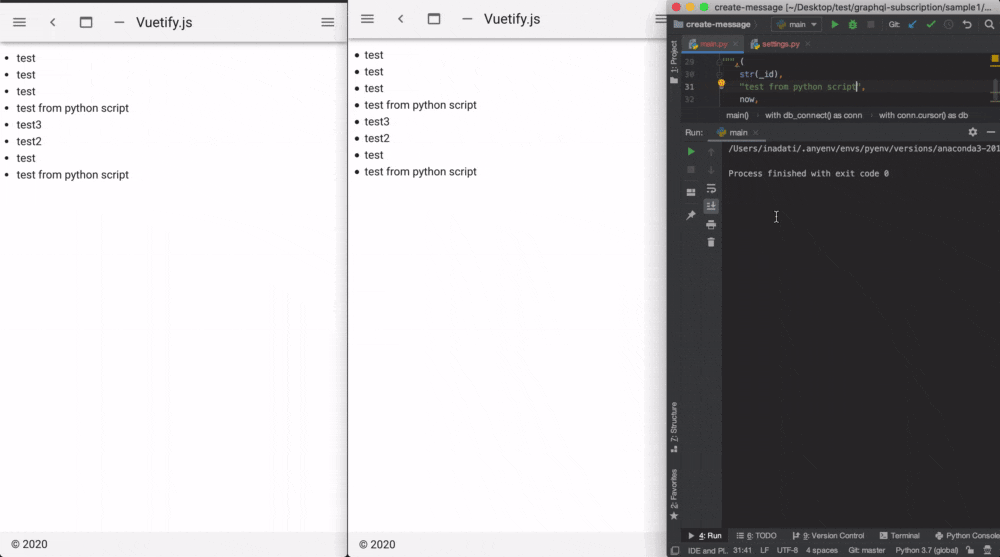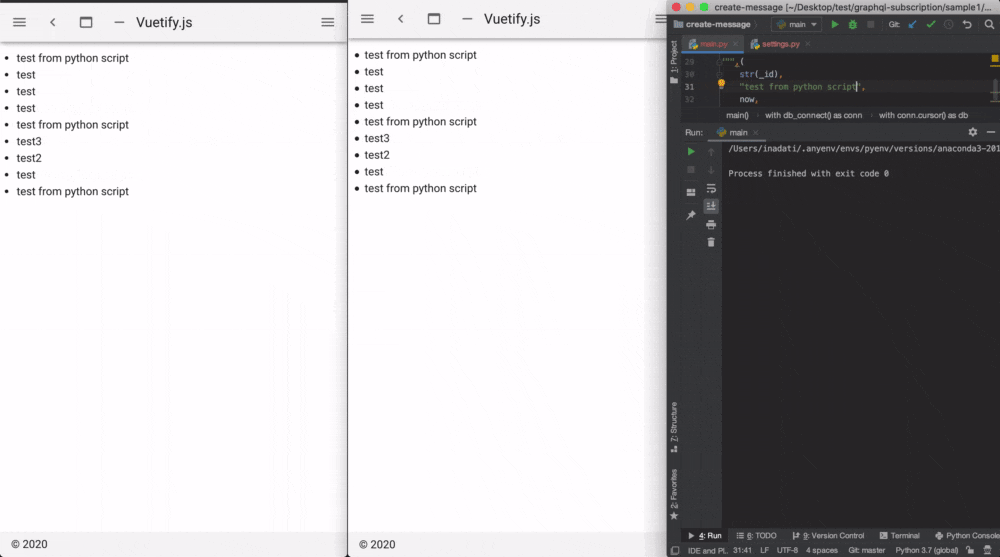
mkdir create-message cd create-message touch main.pymain.pyimport psycopg2 import uuid from datetime import datetime, timedelta, timezone def db_connect(): return psycopg2.connect("host=localhost port=5432 user=postgres dbname=postgres password=postgres sslmode=disable") def main(): with db_connect() as conn: with conn.cursor() as db: _id = uuid.uuid4() jst = timezone(timedelta(hours=+9), 'JST') now = datetime.now(jst) now = now.isoformat(timespec='seconds') db.execute(""" INSERT INTO messages ( id, text, created_at, updated_at ) VALUES (%s,%s,%s,%s); """,( str(_id), "test from python script", now, now )) if __name__ == '__main__': main()GraphQLサーバーを起動する
GraphQLサーバーを起動する前にenv.goファイルの
godotenvのコメントアウトを外します。
ここまでのソースコード内で登場していたenv.〇〇がこれで読み込めるようになります。
gqlkit-serverのルートで下記を実行します。go run server.gohttp://localhost:8080 でGraphQL Playgroundを開きます。
Playgroundで下記Queryを実行します。
ローダーが回り出し
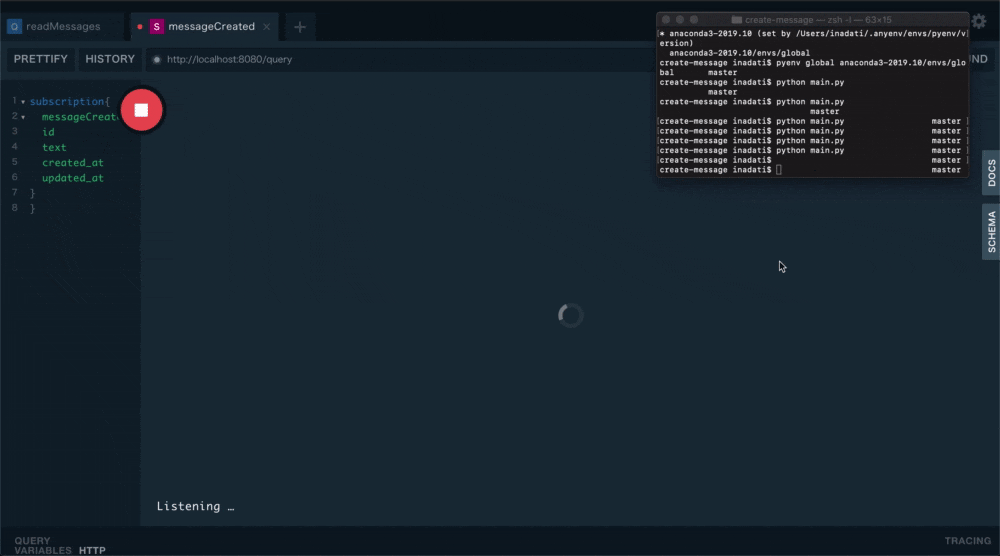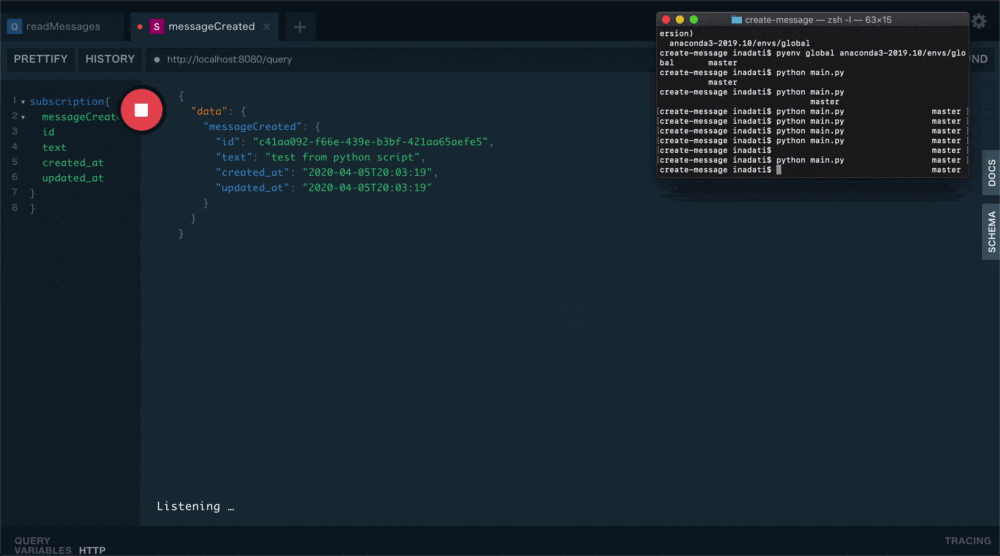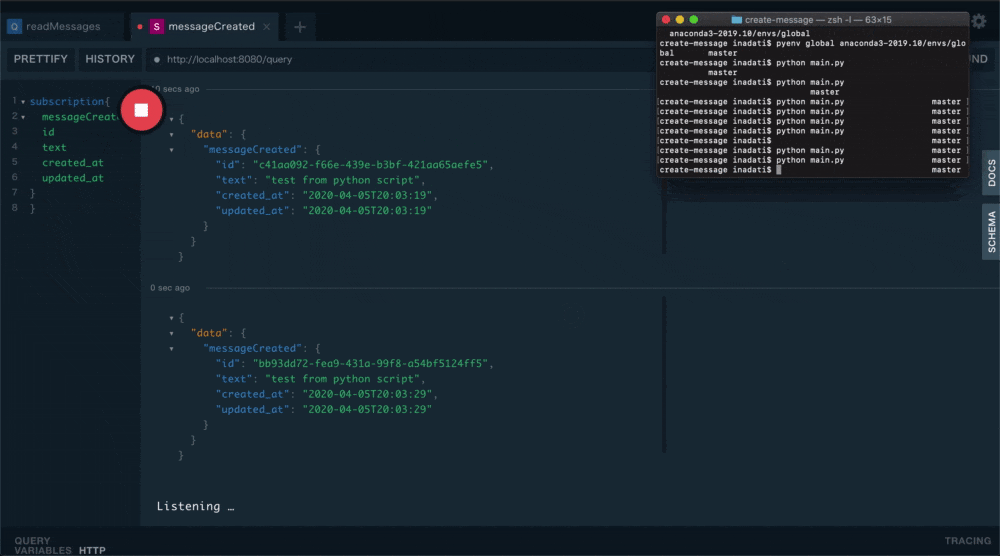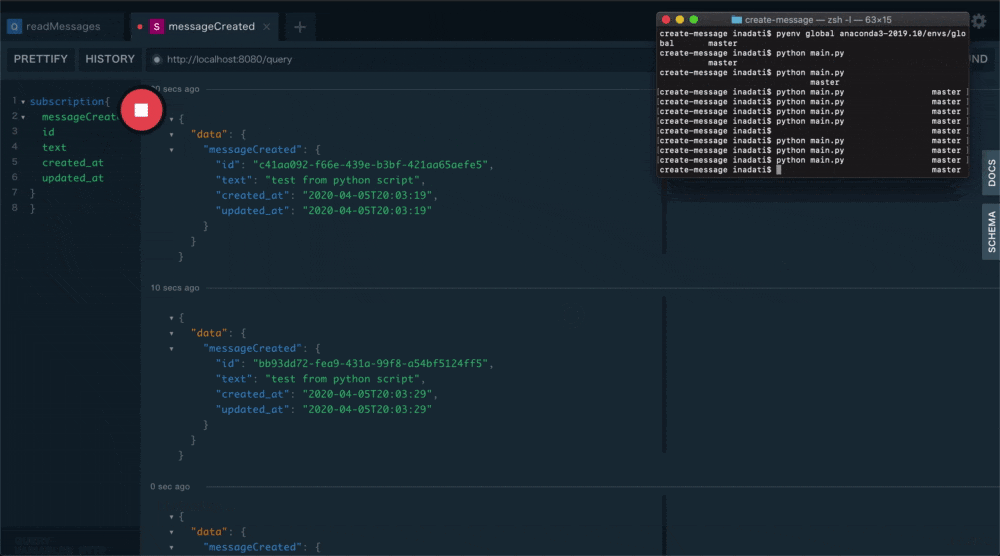
通知待ち状態になります。subscription{ messageCreated{ id text created_at updated_at } }実際にpythonのscriptを実行してみます。
textにはtest from python scriptとでも入れておきましょう。python main.pyするとこんな感じに通知が取れるはずです。
まとめ
以上が、PostgreSQLのNotifyを使ってGraphQL Subscriptionを実装する方法の
バックエンド実装部分でした。
次回はnuxt.jsでのフロントエンド実装例をご紹介します。
- 投稿日:2020-04-05T20:44:10+09:00
いろんな空白文字を削除する(python)
概要
半角スペース、全角スペースを始めとする色んな種類のスペースをまとめて削除する方法をまとめます。
環境
macOS Catalina バージョン10.15.4
python 3.8.0コード
改行コード、タブ、スペースなどをまとめて削除
str.split()を使う#\u3000は全角スペース text = "a\u3000 b\t\nc\r\n" text = ''.join(text.split())改行コード(\r\nや\n)だけをまとめて削除
str.splitlines()を使うtext = "a\u3000 b\t\nc\r\n" text = ''.join(text.splitlines())改行コードを除くいくつかのスペース(例えば全角スペース、半角スペース、タブ)をまとめて削除
str.translate()を使うtext = "a\u3000 b\t\nc\r\n" table = str.maketrans({ '\u3000': '', ' ': '', '\t': '' }) text = text.translate(table)他にもたくさん削除したい文字がある場合は、
str.maketrans()の引数を内包型表記で書くと楽です。text = "a\u3000 b\t\nc\r\nd\x0ce\x0bf" table = str.maketrans({ v: '' for v in '\u3000 \x0c\x0b\t' #もしくは['\u3000',' ','\x0c','\x0b','\t'] }) text = text.translate(table)補足:正規表現の利用
コメントで正規表現を使う方法について、アドバイスいただきましたので、以下にまとめさせていただきます。コメントありがとうございます。
import re #改行、タブ、スペースなどをまとめて削除 text = "a\u3000\n\n b\t\nc\r\nd\x0ce\x0b\rf\r\n" text = re.sub(r"\s", "", text) #改行コード(\r\nや\n)だけをまとめて削除 text = "a\u3000\n\n b\t\nc\r\nd\x0ce\x0b\rf\r\n" text = re.sub(r"[\r\n]", "", text) #改行コードを除くいくつかのスペース(例えば全角スペース、半角スペース、タブ)をまとめて削除 text = "a\u3000\n\n b\t\nc\r\nd\x0ce\x0b\rf\r\n" text = re.sub(r"[\u3000 \t]", "", text)参考
- 投稿日:2020-04-05T20:28:31+09:00
[Python] Headless Chrome を AWS Lambda で動かす
- serverless-chromeをダウンロード
- 以下の
chromium 64.0.3282.167で動作確認した- https://github.com/adieuadieu/serverless-chrome/releases/tag/v1.0.0-37
chromedriverをダウンロード
- 以下の
chromedriver_linux64.zipで動作確認した- https://chromedriver.storage.googleapis.com/index.html?path=2.37/
実行権限付与
chmod 777 <ダウンロードしたファイル>
chromeフォルダにダウンロードしたファイルを入れて、zipに固めるLambdaレイヤーにzipをアップロード
Lambdaレイヤーにseleniumをアップロード
Lambda関数に上記2つのレイヤーを追加
以下のようなコードで実行できる
from selenium import webdriver from selenium.webdriver.chrome.options import Options def lambda_handler(event, context): options = Options() options.binary_location = '/opt/chrome/headless-chromium64' options.add_argument('--headless') options.add_argument('--no-sandbox') options.add_argument('--single-process') options.add_argument('--disable-dev-shm-usage') browser = webdriver.Chrome('/opt/chrome/chromedriver2_37_linux', chrome_options=options) browser.get('https://www.google.com') title = browser.title browser.close() browser.quit() return {"title": title}参考
https://blog.ikedaosushi.com/entry/2018/12/22/231421
https://qiita.com/nabehide/items/754eb7b7e9fff9a1047d環境
macOS 10.15.4
Python 3.7.7
- 投稿日:2020-04-05T19:47:03+09:00
10次元立方体を眺める
pythonで10次元立方体を2次元に射影して回転アニメーションを生成します.
結果
10D cube projected into 2D pic.twitter.com/T4sUQgqm7b
— S.Tabayashi (@tabayashi0117) 2020年4月5日コード
(矢印を押すと展開します)
import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation import matplotlib.collections as mc # from mpl_toolkits.mplot3d import Axes3D import itertools import time def generate_rotation_2d(dim=3, axis1=0, axis2=1): """回転行列を生成する Args: dim(int): 次元 axis1(int): 回転面の軸のインデックス axis2(int): 回転面の軸のインデックス Returns: function: 回転行列 """ def rotation_2d(theta): """回転行列 Args: theta(float): 回転角 Returns: np.2darray: 回転行列 """ rotation_matrix = np.zeros((dim, dim)) for i in range(dim): rotation_matrix[i,i] = 1 rotation_matrix[axis1, axis1] = np.cos(theta) rotation_matrix[axis1, axis2] = -np.sin(theta) rotation_matrix[axis2, axis1] = np.sin(theta) rotation_matrix[axis2, axis2] = np.cos(theta) return rotation_matrix return rotation_2d def prod_rotation(theta, rotation_2d_list, dim): """回転行列の積をとる""" # 単位行列を生成 rotation_matrix = np.identity(dim) # すべての回転行列の積をとる for rotation in rotation_2d_list: rotation_matrix = rotation_matrix @ rotation(theta) return rotation_matrix def plot_cube(dim=3): """立方体を図示する""" # 回転行列の全体 rotation_2d_list = [generate_rotation_2d(dim, axis1, axis2) for axis1, axis2 in itertools.combinations(range(dim),2)] # 頂点全体を生成 vertex_list = [np.array(list(coordinate)).reshape(-1,1) for coordinate in itertools.product(*[[-1/2,1/2] for _ in range(dim)])] # エッジのインデックス全体を生成 edge_index_list = [] for comb in itertools.combinations(range(len(vertex_list)),2): if np.sum(np.abs(np.array(vertex_list[comb[0]]) - np.array(vertex_list[comb[1]]))) == 1: edge_index_list.append(comb) # 速度(設定用) speed = 4/dim # 回転角 theta = (np.pi /180) * speed # 回転行列を生成 rotation_matrix = prod_rotation(theta, rotation_2d_list, dim) # 回転角で何回回転したかカウント cnt = -1 def update(frame): plt.cla() nonlocal vertex_list, edge_index_list, rotation_matrix, dim, theta, cnt if cnt > 0: vertex_list = [rotation_matrix @ v for v in vertex_list] x = np.concatenate([v[0] for v in vertex_list]) y = np.concatenate([v[1] for v in vertex_list]) # z = np.concatenate([v[2] for v in vertex_list_rotated]) lim = 1. + 0.1 * dim ax.set_xlim([-lim, lim]) ax.set_xlabel("X") ax.set_ylim([-lim, lim]) ax.set_ylabel("Y") ax.set_axis_off() ax.scatter(x,y, s=40/dim, c="red", alpha=0.6) # 線のリスト. [(x0, y0), (x1, y1)]が1つの線 lines = [[vertex_list[i1][:2].flatten(), vertex_list[i2][:2].flatten()] for i1, i2 in edge_index_list] colors = ["blue" for i in range(len(edge_index_list))] plt.text( 0.96, 0.96, f"$\Theta$: {theta*cnt*(180/np.pi)%360.0:.2f}[deg]", ha='right', va='top', transform=ax.transAxes ) # 複数の線を追加 lc = mc.LineCollection(lines, colors=colors, linewidths=1.0/dim) ax.add_collection(lc) cnt += 1 fig, ax = plt.subplots(figsize=(5,5)) ani = animation.FuncAnimation(fig, update, interval = 20, frames = int((np.pi*4)/theta)+1) ani.save(f'cube/cube_{dim}d_to_2d_720.mp4', writer="ffmpeg", dpi=145) if __name__ == "__main__": for dim in range(2,11): start = time.time() plot_cube(dim=dim) elapsed_time = time.time() - start print(f"dim: {dim}, elapsed_time:{elapsed_time}[sec]")数学的なうんちく
2次元の回転行列は
\begin{pmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{pmatrix}です.
3次元の回転は
\begin{pmatrix} \cos\theta & -\sin\theta & 0 \\ \sin\theta & \cos\theta & 0 \\ 0 & 0 & 1 \end{pmatrix} , \qquad \begin{pmatrix} \cos\theta & 0 & -\sin\theta \\ 0 & 1 & 0 \\ \sin\theta & 0 & \cos\theta \end{pmatrix} , \qquad \begin{pmatrix} 1 & 0 & 0 \\ 0 & \cos\theta & -\sin\theta \\ 0 & \sin\theta & \cos\theta \end{pmatrix}の組み合わせで表現できます.
なので,自然な拡張として,N次元の回転を以下の行列の組み合わせで表現することができます:
\begin{align} & \qquad \qquad \small{\text{i-th}} \qquad \qquad \small{\text{j-th}} \\ & \begin{pmatrix} 1 & \cdots & 0 & \cdots & 0 & \cdots & 0 \\ \vdots & \ddots & \vdots & & \vdots && \vdots \\ 0 & \cdots & \cos\theta & \cdots & -\sin\theta & \cdots & 0 \\ \vdots & & \vdots & & \vdots && \vdots \\ 0 & \cdots & \sin\theta & \cdots & \cos\theta & \cdots & 0 \\ \vdots & & \vdots & & \vdots &\ddots & \vdots \\ 0 & \cdots & 0 & \cdots & 0 & \cdots & 1 \end{pmatrix} \begin{matrix} \\ \\ \small{\text{i-th}} \\ \\ \small{\text{j-th}} \\ \\ \\ \end{matrix} , \qquad 1\le i < j \le N . \end{align}これを実装したのが上のコードです.
課題
14次元までは上のコードで30分程度の計算時間で済んだのですが,それ以上次元を上げようとすると処理が終わらなくなりました.
処理が重くなりすぎたのは,回転行列による積の演算ではなく,頂点と辺のプロットでした.
N次元立方体の頂点の数は$2^N$,辺の数は$2^{N-1}N$です.
頂点の数は,10次元で1024, 20次元で1048576, 30次元で1073741824.
辺の数は,10次元で5120, 20次元で10485760, 30次元で16106127360.
恐ろしい増えっぷりですね.
その他の次元(観賞用)
— S.Tabayashi (@tabayashi0117) April 5, 2020— S.Tabayashi (@tabayashi0117) April 5, 2020— S.Tabayashi (@tabayashi0117) April 5, 202012D pic.twitter.com/0u2YvMkxpI
— S.Tabayashi (@tabayashi0117) April 5, 202014D pic.twitter.com/aNgFnMZfXY
— S.Tabayashi (@tabayashi0117) April 5, 2020無限次元へ
本記事で行ったプロットから察するに,無限次元立方体も2次元に射影すると,ほとんどいたる角度から見たとき「だいたい円盤」っぽく見えるんだろうとは思うのですが,実際のところはどうなんでしょうね?
高次元は不思議なことが多いのですが,それを遥かに超えた無限次元はまったく想像がつきません.
- 投稿日:2020-04-05T19:21:17+09:00
スプラトゥーンの動画を解析してみました
スプラトゥーン動画解析してみた
スプラトゥーンの観戦動画から、プレイヤーの位置情報を解析してみました。
元ネタは、北海道甲子園(?)のイカ自慢コンテストで有名チームの解析を行ってるかたがいて、興味があったので自分もやってみました。解析結果
INPUTは観戦視点の動画。
OUTPUTは各プレイヤーの位置情報の分布です。
例えばある試合の4人の位置情報は以下でした。
シューターのほうがステージをまんべんなく動いてることが分かりますねー。■リッター
■スパッタリー
■プライム
■スクイク
解析方法
こんな感じです
①観戦動画を撮る(地味にハードル高い。説明は割愛)
②動画を白黒変換
③白黒変換された動画から、各プレイヤー名の画像を抜き出す
④openCVのパターンマッチングで位置情報取得
⑤④で取得した位置情報の周辺も適当に重みづけして位置情報を画像で出力
⑥ステージ画像を⑤の画像を合成解析方法の詳細
①観戦動画を撮る
キャプチャーボード買いました。
配信者探してプラべ混ぜてもらいました。②動画を白黒変換
グレースケールに変換して、220を閾値にして白黒変換しました。
ソース雰囲気だけ書くと以下。もっと便利な方法ある気もするけど。color2gray.py# 閾値の設定 threshold = 220 fmt = cv2.VideoWriter_fourcc('m', 'p', '4', 'v') # ファイル形式(ここではmp4) #グレースケールの場合は、ライターの最後の引数をFalseにする(カラーの場合はTrueか省略) out = cv2.VideoWriter('./video/g_area_1_gray_2.mp4', fmt, frame_rate, (width,height),False) # ライター作成 while(cap.isOpened()): ret, frame = cap.read() if ret==True: #グレースケール化 gray_cv = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY) # 二値化(閾値thresholdを超えた画素を255にする。) ret, img_thresh = cv2.threshold(gray_cv, threshold, 255, cv2.THRESH_BINARY) # write the flipped frame out.write(img_thresh) #output.aviにframe毎書込み cv2.imshow('gray_cv',img_thresh) #グレースケールframeを表示 if cv2.waitKey(1) & 0xFF == ord('q'): break else: break③白黒変換された動画から、各プレイヤー名の画像を抜き出す
ここは手作業。。。
一応画像切り取り用のソースは以下。cutImage.pyimport cv2 playerImg = cv2.imread('./XXX.jpg') playerImg = playerImg[0:30, 80:150]#ここで切り取る箇所指定 cv2.imwrite('./YYY.jpg', playerImg) cv2.imshow('playerImg',playerImg) cv2.waitKey(0) cv2.destroyAllWindows()④openCVのパターンマッチングで位置情報取得
openCVでパターンマッチングする。
1フレーム毎に位置情報がタプルで返却されるので、リストに保持。
マッチングにはいくつかアルゴリズムがあるみたいで、どれがいいかは良く分からん。比較するのもめんどくさいから適当に選んだ。
ソースは雰囲気以下。getLocation.py###読み込む動画(②で白黒変換した動画)### cap = cv2.VideoCapture('./grayMovie.mp4') ###テンプレート画像(#③で切り取ったプレイヤー名の画像)### template = cv2.imread('./XXX.jpg',0) ###パターンマッチングのアルゴリズム### method = cv2.TM_CCOEFF #位置情報のリスト player1_locations = [] ###パターンマッチング### while(cap.isOpened()): ret, frame = cap.read() if ret==True: # Apply template Matching frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) res = cv2.matchTemplate(frame,template,method) min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res) # If the method is TM_SQDIFF or TM_SQDIFF_NORMED, take minimum if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]: top_left = min_loc else: top_left = max_loc bottom_right = (top_left[0] + w, top_left[1] + h) center = ((top_left[0]+bottom_right[0])//2,(top_left[1]+bottom_right[1])//2) player1_locations.append(center)⑤④で取得した位置情報の周辺も適当に重みづけして位置情報を画像で出力
取得した位置情報だけを画像にマッピングするとなんとも微妙な見た目になるので、”映え”るためにしました。
作成された2次元配列で数値が大きい場所ほど、長く居座ってることになります。
ソース割愛しますが、数値が大きいほど色を濃くして、プレイヤーの位置情報を画像にします。makeLocationImg.py#player1のmap上の統計情報を2次元配列で定義 player1_location_statistics_around = np.array([[0] * (width) for i in range(height)], dtype=float) #player1のmap上の統計情報を計算 for x,y in player1_locations: x=int(x) y=int(y) player1_location_statistics_around[y:y+50,x-50:x+50] += 1 player1_location_statistics_around[y:y+30,x-30:x+30] += 1 player1_location_statistics_around[y:y+20,x-20:x+20] += 2 player1_location_statistics_around[y:y+10,x-10:x+10] += 3 player1_location_statistics_around[y:y+5,x-5:x+5] += 5⑥ステージ画像を⑤の画像を合成
ステージの画像と⑤のプレイヤーの位置情報の画像を合成して完成?gosei.pyimport cv2 stageImg = cv2.imread('./stage_pic/hujiSport.jpg') player1LocationImg = cv2.imread('./XXX.png') dst = cv2.addWeighted(stageImg, 1.0, player1LocationImg, 1.0, 0) cv2.imwrite('./result.jpg', dst) cv2.imshow('location',dst) cv2.waitKey(0) cv2.destroyAllWindows()終わりに
スプラトゥーン好きなので、楽しく実装できました。
誤認識してしまうところもあって完璧ではないですが、結構お手軽に可視化できてopenCVのパターンマッチングすげーってなりましね。
もっといい実装(精度高いとか、画像映えするアイデアとか)あったら教えてほしいです。読んで頂いてありがとうございました。




- 投稿日:2020-04-05T19:17:56+09:00
【python】公式ドキュメントのsuite(スイート)やexpression(式)とは何?
【python】公式ドキュメントのsuite(スイート)やexpression(式)とは何?
Pythonの公式ドキュメントに出てくるsuiteが気になったのでメモ。
サクッとまとめると、
・suiteとは「:」の後の処理
・expressionは代入式や配列など
例えば、if文で「もしAならBする」内容の場合下記のようになる。
・expressioin(式)= A
・suite = B
suiteの意味
ちなみに、カタカナだとスイートだけど甘いやデザートなどのsweet(sweets)とはスペルが違う。suiteは一組とか一揃いという名詞。
if文やfor文など特定の文の中で使われる処理(ひとセット)という意味。
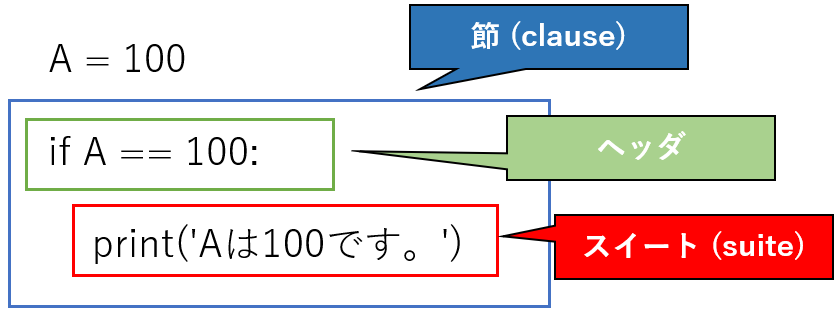
■suite
公式ページのif文、try文などの構文内に記述されている。
公式ページにもsuiteに関する記述があるが長い、、
複合文は、一つ以上の '節 (clause)' からなります。節は、ヘッダと 'スイート (suite)' からなります。一つの複合文を成す各節のヘッダは、全て同じインデントレベルに置かれます。各節のヘッダは一意に識別するキーワードで始まり、コロンで終わります。スイートは、節によって制御される文の集まりです。スイートは、ヘッダがある行のコロンの後にセミコロンで区切って置かれた一つ以上の単純文、または、ヘッダに続く行で一つ多くインデントされた文の集まりです。後者の形式のスイートに限り、さらに複合文をネストできます。
ようするに
suite = 特定の条件における処理if文やfor文で、「:」の後に記述する処理のこと。
公式ページでは「:」の直後に記述しているが、一般的には改行してインデントで表示する部分。
例えば超簡単な下記if文の場合、
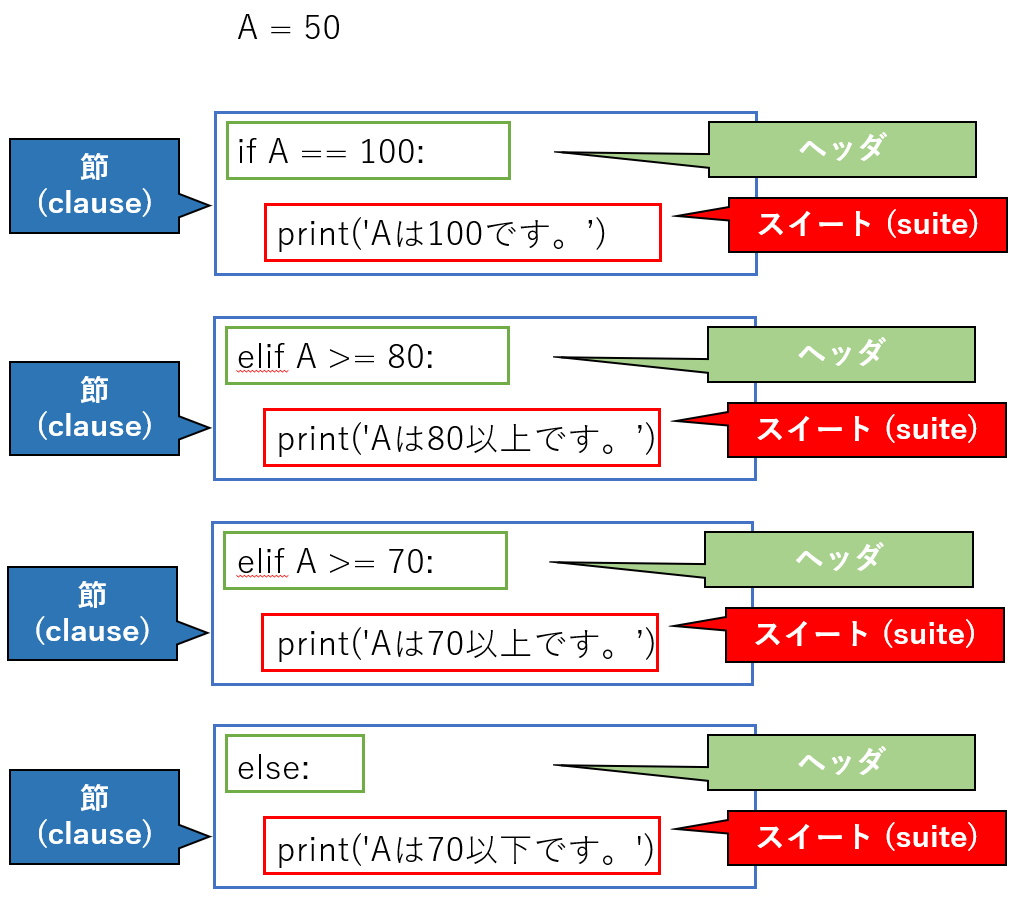
if文の例A = 90 if A == 100: print('Aは100です。')節 (clause)、ヘッダ、スイート(suite)の関係は次のようになる。
▼公式ページの書き方
公式ページの書き方だと改行なし。
これでも同じように動く。if文の例A = 90 if A == 100:print('Aは100です。')
▼節(clause)について
条件分岐する場合は節が複数できることになる。suiteも各節毎にできる。if文の例②A = 50 if A == 100: print('Aは100です。') elif A >= 80: print('Aは80以上です。') elif A >= 70: print('Aは70以上です。') else: print('Aは70以下です。')
■expression
こちらもsuite同様に公式ページのif文、try文などの構文内に記述されている。
expressionの種類
上記の構文の中にもいくつかのepressionが存在する。
①assignment_expression
②expression_list
③expression
①assignment_expression
正式名称は「代入式」。
if文やwhile文で用いられている。何らかの文字と数値が不等号で結ばれたもの。
A == 100
B >= 80
など。
②expression_list
正式名称は「式のリスト」。(よくわからん、、)
listやrangeのように一まとまり(イテラブル)な要素を表した式。
for文で使われている。
range(10)
[1,2,3,4,5,6,7,8,9]
[1:100]
など。
③expression
正式名称は「条件式」。
ブール演算をする式(Ture or Falseの2択を返す)や、ラムダ式(無名関数)。
try文のexceptの中や、with文で使われる。
関数やエラーなど、オブジェクトになるもの。with open('sample.txt', 'a') as f:
except ZeroDivisionError as e:
except TypeError as e:
など。
▼公式ページ
・複合文
・expression
_stmt
こちらは補足ですが、
各構文の先頭に書かれている、「_stmt」は「statement」の略で「〇〇文」という意味。▼例
try_stmt:try文
try1_stmt:try1文
for_stmt:for文
if_stmt:if文
など。「::=」で〇〇文の公式はコレですというのを示している。
公式ドキュメントは専門用語も多く書き方も見慣れないが、読めるようになればpythonの理解もより正確で早くなる(はず)。








- 投稿日:2020-04-05T19:17:56+09:00
【python】スイートそれって甘いの?公式ドキュメントのsuiteやexpressionについて
【python】スイートそれって甘いの?公式ドキュメントのsuiteやexpressionについて
Pythonの公式ドキュメントに出てくるsuite(スイート)が気になったのでメモ。
サクッとまとめると、
・suiteとは「:」の後の処理
・expressionは代入式や配列など
例えば、if文で「もしAならBする」内容の場合下記のようになる。
・expressioin(式)= A
・suite = B
suiteの意味
ちなみに、カタカナだとスイートだけど甘いやデザートなどのsweet(sweets)とはスペルが違う。suiteは一組とか一揃いという名詞。
if文やfor文など特定の文の中で使われる処理(ひとセット)という意味。
■suite
公式ページのif文、try文などの構文内に記述されている。
公式ページにもsuiteに関する記述があるが長い、、
複合文は、一つ以上の '節 (clause)' からなります。節は、ヘッダと 'スイート (suite)' からなります。一つの複合文を成す各節のヘッダは、全て同じインデントレベルに置かれます。各節のヘッダは一意に識別するキーワードで始まり、コロンで終わります。スイートは、節によって制御される文の集まりです。スイートは、ヘッダがある行のコロンの後にセミコロンで区切って置かれた一つ以上の単純文、または、ヘッダに続く行で一つ多くインデントされた文の集まりです。後者の形式のスイートに限り、さらに複合文をネストできます。
ようするに
suite = 特定の条件における処理if文やfor文で、「:」の後に記述する処理のこと。
公式ページでは「:」の直後に記述しているが、一般的には改行してインデントで表示する部分。
例えば超簡単な下記if文の場合、
if文の例A = 90 if A == 100: print('Aは100です。')節 (clause)、ヘッダ、スイート(suite)の関係は次のようになる。
▼公式ページの書き方
公式ページの書き方だと改行なし。
これでも同じように動く。if文の例A = 90 if A == 100:print('Aは100です。')
▼節(clause)について
条件分岐する場合は節が複数できることになる。suiteも各節毎にできる。if文の例②A = 50 if A == 100: print('Aは100です。') elif A >= 80: print('Aは80以上です。') elif A >= 70: print('Aは70以上です。') else: print('Aは70以下です。')
■expression
こちらもsuite同様に公式ページのif文、try文などの構文内に記述されている。
expressionの種類
上記の構文の中にもいくつかのepressionが存在する。
①assignment_expression
②expression_list
③expression
①assignment_expression
正式名称は「代入式」。
if文やwhile文で用いられている。何らかの文字と数値が不等号で結ばれたもの。
A == 100
B >= 80
など。
②expression_list
正式名称は「式のリスト」。(よくわからん、、)
listやrangeのように一まとまり(イテラブル)な要素を表した式。
for文で使われている。
range(10)
[1,2,3,4,5,6,7,8,9]
[1:100]
など。
③expression
正式名称は「条件式」。
ブール演算をする式(Ture or Falseの2択を返す)や、ラムダ式(無名関数)。
try文のexceptの中や、with文で使われる。
関数やエラーなど、オブジェクトになるもの。with open('sample.txt', 'a') as f:
except ZeroDivisionError as e:
except TypeError as e:
など。
▼公式ページ
・複合文
・expression
_stmt
こちらは補足ですが、
各構文の先頭に書かれている、「_stmt」は「statement」の略で「〇〇文」という意味。▼例
try_stmt:try文
try1_stmt:try1文
for_stmt:for文
if_stmt:if文
など。「::=」で〇〇文の公式はコレですというのを示している。
公式ドキュメントは専門用語も多く書き方も見慣れないが、読めるようになればpythonの理解もより正確で早くなる(はず)。
- 投稿日:2020-04-05T19:15:51+09:00
[論文読み]Self supervised learning論文解説 part1 ~dense tracking発展の歴史~
はじめに
最近ちょくちょく耳にするself supervised learningの論文を解説していきます。
といってもself supervisedの論文はたくさんあるので,今回はdense trackingと呼ばれるタスクに絞って現在に到るまでの発展の過程を追っていきます。
解説する次の論文は5本です。[1] Tracking emerges by colorizing videos1(2018) 略称 Vid. Color
[2] Learning Correspondence from the Cycle-consistency of Time2 (2019) 略称CycleTime
[3] Self-supervised Learning for Video Correspondence Flow3(2019) 略称 CorrFlow
[4]:Joint-task Self-supervised Learning for Temporal Correspondence4(2019) 略称 UVC
[5]: MAST: A Memory-Augmented Self-Supervised Tracker5(2020) 略称 MAST5本目の論文はCVPR2020に採択された最新の論文で、これはpart2(近日公開予定)で解説します。
1~4本目は5本目の論文にself supervisedの比較手法として挙げられているものです。
したがってpart1,2を合わせて読むことでdense trackingタスクの流れを追えるようにしたつもりです。
図1 dense tracking(self supervised系)性能比較5使用している図は特に断りがない場合紹介元の論文から引用しています。
Tracking Emerges by Colorizing Videos1
動画系self supervisedの代表的な論文になります。まずはデモを見てください。
Our latest work shows that learning to colorize videos causes visual tracking to emerge automatically!
— Carl Vondrick (@cvondrick) June 27, 2018
Blog: https://t.co/FDVzJmmZ7h
Paper: https://t.co/U4jS83iI7B@alirezafathi @kevskibombom @sguada @abhi2610 pic.twitter.com/R3vMR3raFJこのデモでやっていることの基本的な考え方はOptical Flowと同じです。(optical flowのわかりやすい解説)
時刻$T-1$のフレームの各pixelが時刻$T$のフレームのどこのpixelに相当するかを予測させています。最初のフレームで、追跡してほしい対象のpixelをmaskにより指定してあげれば、その後のフレームでもpixelの移動を捉えることで、その対象を追跡することが可能になるわけです。またmaskだけでなく、関節位置といったkeypointのtrackingも同様の考え方で行うことができます。
図2 labelデータのtracking
このようなタスクをフレーム間のピクセルの密な対応づけという意味でdense trackingと呼んだりします。Colorization
ではどのように学習させるのでしょうか?optical flow予測など従来のネットワークはアノテーションとして正解optical flowを与えていました。しかしこの論文ではアノテーションを一切必要としない学習を提案しています。それがVideo colorizationです。
図3 動画を利用したカラー復元Target,Referenceの2枚のフレームを一回グレースケールに変換してしまって、それぞれCNNに通すことでpixelの移動を予測しpixel位置の対応関係(pointer)を得ます。そしてTarget Frameのカラーをpointerを用いてReference Frameのカラーからコピーしてあげることで予測させるのです。
こうすることで予測した色付けとTarget Frameの実際の色で予測が正しいかのlossが計算でき、optical flowのアノテーションがなくとも学習が可能になります。具体的な計算方法について説明します。目標はTarget frameのカラーをReference frameのカラーからコピーするためのpointerを作ること。数式でかけば次のように表せます。
$$y_{j}=\sum_{i} A_{i j} c_{i}$$$y_{j}$はTarget frameのj番目のpixelの予測カラー、$c_{i}$はReference frameのi番目のpixelカラーです。数式がわかりにくい場合は参考記事も見てみてください
そして$A_{i j}$はi番目のpixelからj番目のpixelへの変換行列。すなわちpointerです。今回は$A_{i,j}$の要素をsofmaxにより0~1することで複数のpixelを参照できるようにしています。
図4 ネットワーク構造
まず上図のようにReference frame,Target frameともにグレースケールに変換した後,CNNに通しそれぞれの特徴ベクトル$f$を得ます。
さてpointerを作るためにはReference frameのi番目のpixelとTarget frameのj番目のpixelの類似度がわかればよいので、内積をとってあげます。
$$A_{i,j}=f_{i}^Tf_{j}$$ただ今回は類似度を0~1の確率として正規化したいので,softmaxをかけたものを使用します。
$$A_{i j}=\frac{\exp \left(f_{i}^{T} f_{j}\right)}{\sum_{k} \exp \left(f_{k}^{T} f_{j}\right)}$$これでpointerができたので後は次のようにTarget frameのカラーで誤差計算すれば完成です。
\min _{\theta} \sum_{j} \mathcal{L}\left(y_{j}, c_{j}\right)補足としてこの論文では,問題を簡易化するためにRGB値をそのまま予測するのではなく,Lab空間へ変換した後データセット内でkmeansによるクラスタリングを行い16種類のクラスタに分割、そして分類された色のクラス分類(cross entropy loss)で定式化しています。
以上がこの論文で提案しているself supervisedの枠組みになります。
あえてGray scaleに変換することで変換前の色をlabelとして使用するなんて頭良すぎ!って感じですね。
動画で同じ物体の同じ箇所は(少なくとも短フレーム間では)同一の色を持っているという前提を上手く利用し自動的にラベルを作ることに成功しています。
以降はこの論文を起点としたself supervised発展の歴史を追っていきます。Learning Correspondence from the Cycle-consistency of Time 2
次はCVPR2019の論文を紹介します。略称はCycleTimeです。
この手法はColorizationとは違い,Cycle consistencyという考えを用いてラベルを自動生成しています。
図5 cycle consistencyCycle consistencyは簡単に言うと、「行ってまた帰ってきたら元の状態と一致するはず」という考え方です。
上図のようにまず動画を逆再生し、時刻$T$の物体位置から時刻$T-1$における位置を予測、時刻$T-1$の予測から時刻$T-2$の位置を予測します。今度は逆に順再生して時刻$T-2$の予測から時刻$T-1$,$T$を予測すると、最初に指定した時刻$T$の物体位置と順再生で戻ってきた時刻$T$の位置予測は一致するはずです。
これを比較してLossを計算するのがcycle consistencyになります。では論文の内容を詳しく見ていきましょう。
提案手法
図6 ネットワーク図予測はpatch単位で行われます。すなわち$T-i+1$から適当に切り取ったpatchが$T-i+2$の画像のどこに相当するか予測することを考えます。
これはネットワーク$\mathcal{T}$によって行われますので中身を見ていきましょう。
$\mathcal{T}$はまず時刻$T-i+2$の画像,$I_{T-i+2}$と時刻$T-i+1$の画像から切り取られたpatch $p_{T-i+1}$の両方をResnetベースのエンコーダーに通し、それぞれの特徴map $x^I,x^p$を抽出します。
次は先ほどと同様にして,内積を取ってあげれば類似度行列$A(i,j)$が取得できます。
$$A(j, i)=\frac{\exp \left(x^{I}(j)^{\top} x^{p}(i)\right)}{\sum_{j} \exp \left(x^{I}(j)^{\top} x^{p}(i)\right)}$$ただ今回は色の対応だけでなく、位置座標の対応も見たいので座標を変換する処理が必要になります。
そこでさらに、行列$A(j, i)$を浅いネットワークに通すことで、幾何変換のパラメータである$\theta$を出力させてあげます。あとは$\theta$にしたがって$I_{T-i+2}$を座標変換してあげれば$T-i+2$における予測patchを取得できることになります。
同様にして$T-i+2$から$T-i+3$を予測させ‥ということを繰り返すと連続した$i$フレーム($t-i$から$t-1$)の順再生予測は次のように書けます。
$$\mathcal{T}^{(i)}\left(x_{t-i}^{I}, x^{p}\right)=\mathcal{T}\left(x_{t-1}^{I}, \mathcal{T}\left(x_{t-2}^{I}, \ldots \mathcal{T}\left(x_{t-i}^{I}, x^{p}\right)\right)\right)$$また逆再生も同じように
$$\mathcal{T}^{(-i)}\left(x_{t-1}^{I}, x^{p}\right)=\mathcal{T}\left(x_{t-i}^{I}, \mathcal{T}\left(x_{t-i+1}^{I}, \ldots \mathcal{T}\left(x_{t-1}^{I}, x^{p}\right)\right)\right)$$
とかけるのでこの2つの式を組み合わせるとcycle consistency lossは次のようになります。\mathcal{L}_{l o n g}^{i}=l_{\theta}\left(x_{t}^{p}, \mathcal{T}^{(i)}\left(x_{t-i+1}^{I}, \mathcal{T}^{(-i)}\left(x_{t-1}^{I}, x_{t}^{p}\right)\right)\right)$l_{\theta}$はpatchの座標のずれをMSEで計算する関数です。
また位置だけでなく、patchどうしの特徴mapの差も計算してあげます
\mathcal{L}_{s i m}^{i}=-\left\langle x_{t}^{p}, \mathcal{T}\left(x_{t-i}^{I}, x_{t}^{p}\right)\right\rangleCycle consitencyの基本的な考え方は以上です。
ただ、このままだと次のように物体が一度隠れて、また見えるような場合に対応できません。
図7 cycle consistencyが難しい場合(左:顔の正面が見えなくなる。右:フレームアウトを挟む)上図を見ると、隣り合ったフレーム間では対応づけることが難しい場合でも、離れたフレームなら対応づけることができそうです。
そこでこの論文では時系列的に隣接した画像だけでなく、$i$フレームskipさせた予測も入れています。\mathcal{L}_{s k i p}^{i}=l_{\theta}\left(x_{t}^{p}, \mathcal{T}\left(x_{t}^{I}, \mathcal{T}\left(x_{t-i}^{I}, x_{t}^{p}\right)\right)\right)長かったですが最終的なlossは以上3つのlossを足して,
\mathcal{L}=\sum_{i=1}^{k} \mathcal{L}_{s i m}^{i}+\lambda \mathcal{L}_{s k i p}^{i}+\lambda \mathcal{L}_{l o n g}^{i}と書くことができます。
数式が長くなりましたが、ざっくりとでもCycle consistencyの雰囲気を掴んでいただけたら嬉しいです。Self-supervised Learning for Video Correspondence Flow3
前2つの論文で,Colorizationとcycle-consistencyという2つのself supervised手法を見てきました。次はその両方を組み合わせた論文を紹介します。略称はColorFlowです。
図8 アルゴリズムの認識イメージこの論文は最初に紹介したVideo Colorization論文の課題点を挙げ、それを解決する手法を提案する構成になっています。
挙げられている課題点に関しては次の2点です。課題1:カラー情報をグレースケールにしてからmatchingを行っているのでせっかくのカラー情報が欠落してしまっている。
課題2:予測するフレームが長くなるにしたがって間違った予測が蓄積してしまい予測がドリフトしてしまうこれを踏まえた上で提案手法を見ていきましょう。
提案手法
課題1
カラー画像をグレースケールに落としてからCNNに入れて予測させるのは、matchingの予測にRGBカラーの情報が使えませんので,かなりもったいないことをしています。しかしself supervisedとして学習させるために何らかのボトルネックをかけることは必要です。
そこでこの手法では単純にgrayscaleに落とすのではなく、RGBチャネルをランダムに0にするという形でボトルネックをかけます。(下図参照) またさらに、輝度やコントラストなどの摂動も追加します。
図9 ボトルネックの改良こうすることによりカラー情報をある程度保持したまま学習が可能になります。またそれだけでなく,ランダムにチャネルを0にすること自体が,dropoutの効果を期待でき、輝度の変化を加えることでdata augementationも自動的に行うことができます。
単純にグレースケールに落とすよりかなりのロバスト性向上が見込めます。
なおテスト時はRGBそのまま入れるだけでよいので簡単です課題2
当たり前ですが、比較する画像が時間的に離れていると予測は難しくなります。特にオクルージョンや形状変化などがあれば対応点を見つけるのはより困難になってきます。また、一度予測がずれるとその予測を元に次のフレームを予測しようとするので誤差が蓄積し、どんどん予測がドリフトしてしまいます。この論文ではそのようなLong-termにおける問題に対し、モデル予測のカラーを時々ground truthのカラーとしても使うということを提案しています。
\hat{I}_{n}=\left\{\begin{array}{ll}\psi\left(A_{(n-1, n)}, I_{n-1}\right) & (1) \\ \psi\left(A_{(n-1, n)}, \hat{I}_{n-1}\right) & (2)\end{array}\right.上の式(1)は時刻$n-1$の画像$I_{n-1}$を用いて時刻$n$の色$\hat{I}_{n}$を予測していますが,
ときどき、(2)のように$I_{n-1}$の代わりに直前の予測である$\hat{I}_{n-1}$を用いて予測させます。こうすることで、予測が外れた状態からtrackが復元することを試みています。
予測カラーを用いる割合はモデルが学習するにつれて上げていきます。
なお、この考え方はScheduled Samplingと呼ばれSeq2Seqで広く用いられる手法とのこと。そして最後に長期的な予測でもcycle consistecyによる制約もかけることで、さらにロバスト性を向上させています。
最終的なlossは次式のようになります。L=\alpha_{1} \cdot \sum_{i=1}^{n} \mathcal{L}_{1}\left(I_{i}, \hat{l}_{i}\right)+\alpha_{2} \cdot \sum_{j=n}^{1} \mathcal{L}_{2}\left(I_{j}, \hat{l}_{j}\right)$L_{1}, L_{2}$はそれぞれcycle consistencyのforward backwardそれぞれにおけるカラー予測誤差です。注意点として論文では2番目の論文のようにcycle consistency loss自体は使っていません。あくまでcolorizationがmainでcycle consistencyはLong-termに対応するためのregularizerとして使っています。
Joint-task Self-supervised Learning for Temporal Correspondence 4
次の論文はNeurIPS2019からです。略称はUVCだそうです。(名前の由来がわからなかったので分かる方いたら教えてください)
さてこの論文の特徴ですが、pixelレベルのマッチングを行う前にbounding box予測を挟むことにあります。
下図を見てください。
図10 pixelレベルによるマッチング(図下)とboxレベルでのマッチング(図上)の比較図(b)はこれまでの論文のようにpixelレベルのみでマッチングさせたものです。例えば黄色の線を例にとると,赤い服を来た人物が2人いるため間違った対応になってしまっています。
このように、pixelレベルのマッチングはオブジェクトの細かい変化をみる分には有効ですが、objectの意味的な要素(回転やviewpointに不変)でmatchingさせるのは向いていないことがわかります。
対してbounding boxによる検出はその真逆で互いに相補的な関係にあると考えられます。
したがって最初に図(a)のようにbox領域を検出してしまってから、その領域内でpixelレベルのマッチング予測をさせればいいのでは?というのが論文の趣旨になります。提案手法
図11 ネットワーク図図の前半部でbox領域を検出(Region-level localization),後半で見つけた領域内でのpixelマッチングを行います(Fine-grained matching)
Region level localization
目標はReference frameで切り取られたパッチがTarget frameのどこに相当するかのbboxを見つけることです。例のごとくどちらもグレースケールに落とした後、CNNに通し、おなじみの類似度行列を計算します。
$$A_{i j}=\frac{\exp \left(f_{1 i}^{\top} f_{2 j}\right)}{\sum_{k} \exp \left(f_{1 k}^{\top} f_{2 j}\right)}, \quad \forall i \in\left[1, N_{1}\right], j \in\left[1, N_{2}\right]$$ここらへんまでは2番目に紹介した論文(CycleTime)の手順と似てますね。CycleTimeではこの行列から位置座標を対応づけるためにさらに追加のネットワークに通していました。しかしこの論文では$A_{i j}$はほぼスパース(行列の要素は対応する1つのpixleのみが1で他の要素は0)になるはずで次のような式で位置座標を変換しています。
$$l_{j}^{12}=\sum_{k=1}^{N_{1}} l_{k}^{11} A_{k j}, \quad \forall j \in\left[1, N_{2}\right]$$ここで$l_{j}^{mn}$は画像$n$の$j$番目のピクセルに移動する画像$m$の座標です。補足記事2項を参照
この式を用いると$p_{1}$のどのピクセル座標が$f_{2}$の各ピクセルに移動するかがわかります。
また、反対に$l_{j}^{21}$を求めると,$p_{1}$が$f_{2}$のどこの座標にあるかがわかります。
ここで$l_{j}^{21}$の平均をとれば,bounding box中心$C^{21}$が計算できます。
$C^{21}=\frac{1}{N_{1}} \sum_{i=1}^{N_{1}} l_{i}^{21}$
bounding box中心が見積もれたのでboxの大きさも定義してしまいましょう。$w$,$h$は単純に$l_{j}^{21}$の各座標と中心$C$とのずれの平均値で定義します。
$$\hat{w}=\frac{2}{N_{1}} \sum_{i=1}^{N_{1}}\left|x_{i}-C^{21}(x)\right|_{1}$$以上により、無事$f_{2}$内のbboxを見積もることができました。
このbboxで$f_{2}$を切り取った特徴map $p_{2}$を次のFine-grained matchingに利用します。Fine-grained matching
図12 ネットワーク(Fine-grained matching部)あとは最初のの論文と同様に、$p_{1}$,$p_{2}$で類似度行列$A_{pp}$を計算してカラー復元させればいいことになります。ただこの論文では、直接pointerでカラーをコピーしてくるのではなく、Encoder-Decoder方式でカラー予測させています(図参照)。この論文では、これの利点として直接$A_{pp}$を使うよりもCNNによるembeddingを挟んでいますので,よりglobal contextualな情報を用いれることと主張しています。
Loss
使用するLossは大きくわけて3種類あります。1つ目はカラー復元が正しくできているかのLoss(論文中に数式の記載はないですが実装だとL1 lossで比較してました)
2つめはconcentration regularizationと言われるbbox予測に関する制約項です。これはbbox内のピクセルは移動しても近い位置にくるだろうという仮定の元、pixelができるだけ集まるようにします。(下図左側参照)
図13 lossに使用する2つの正則化のイメージL_{c}=\left\{\begin{array}{ll}0, & \left\|l_{j}^{21}(x)-C^{21}(x)\right\|_{1} \leq w \text { and }\left\|l_{j}^{21}(y)-C^{21}(y)\right\|_{1} \leq h \\ \frac{1}{N_{1}} \sum_{j=1}^{N_{1}}\left\|l_{j}^{21}-C^{21}\right\|_{2}, & \text { otherwise }\end{array}\right.bboxからはみ出た対応点に罰則をかけることで一箇所だけまったく別の場所に対応づけられるといったことを防ぐことができます。
3つめはOrthogonal regularizationという制約項です。これは2フレーム間のCycle consistecyと本質的には同じものです。
Cycle consistencyはフレーム1からフレーム2に変換した後、フレーム2からフレーム1に変換したら元に戻るという考えでした。ここで、フレーム間座標$l$,特徴map $f$の対応関係はbboxの章で説明したように以下の関係がありました。l^{\hat{1} 2}=l^{11} A_{1 \rightarrow 2}, \quad l^{\hat{1} 1}=l^{\hat{1} 2} A_{2 \rightarrow 1}\hat{f}_{2}=f_{1} A_{1 \rightarrow 2}, \quad \hat{f}_{1}=\hat{f}_{2} A_{2 \rightarrow 1}ここでCycle consistencyが成り立つためには$A_{1 \rightarrow 2}^{-1}=A_{2 \rightarrow 1}$が成立していれば良いことがわかります。
さてここでピクセル対応が1対1で行われているとするなら、$f_{1} f_{1}^{\top}=f_{2} f_{2}^{\top}$で示されるように、色の絶対量(color energy)は変わっていないと仮定できます。補足記事3項参照
以上を用いると$A_{2 \rightarrow 1}=A_{1 \rightarrow 2}^{-1}=A_{1 \rightarrow 2}^{\top}$のように$A$が互いに直行していればCycle consistencyは成立していることが導けます。
導出
\hat{f}_{2}=f_{1} A_{1 \rightarrow 2}で両辺転置して
$$f_{2}^{\top}=(f_{1} A_{1 \rightarrow 2})^{\top}=A_{1 \rightarrow 2}^{\top}f_{1}^{\top}$$
よって
$$f_{2}f_{2}^{\top}=f_{1} A_{1 \rightarrow 2}A_{1 \rightarrow 2}^{\top}f_{1}^{\top}$$
これが$f_{1} f_{1}^{\top}=f_{2} f_{2}^{\top}$を満たすので
$A_{1 \rightarrow 2}^{-1}=A_{1 \rightarrow 2}^{\top}$が成り立つ
よって,$f_{1}$と$A_{1 \rightarrow 2}^{\top}A_{1 \rightarrow 2}f_{1}$のMSE lossをとればCycle consistency lossを簡単に計算できます。これがOrthogonal regularizationになります。無論座標$l$に関しても同様に計算します。
認識例 (著者githubから)
まとめ
以上dense tracking系self supervisedの論文を4本紹介しました。
この4本は類似研究で共通する部分も多いですが、その中で少しづつdense tracking手法が改善されていく流れを感じて頂けたのではないでしょうか。
個人的な反省点としては数式多めの解説で自分史上一番難しい記事になってしまったのではないかと危惧しております。(指摘などあればコメントください)
ただグレースケールを着色したり,順再生と逆再生を繰り返すなど面白いideaでラベルなし学習を可能にしているところは本当に面白く魅力的なので,読んだ方にも伝わって頂けたら幸いです。
また近日公開予定のpart2も見てください
Vondrick, C., Shrivastava, A., Fathi, A., Guadarrama, S., & Murphy, K. (2018). Tracking emerges by colorizing videos. Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 11217 LNCS, 402–419. https://doi.org/10.1007/978-3-030-01261-8_24 ↩
Wang, X., Jabri, A., & Efros, A. A. (2019). Learning Correspondence from the Cycle-consistency of Time. Retrieved from https://arxiv.org/abs/1903.07593 ↩
Lai, Z. (2019). Self-supervised Learning for Video Correspondence Flow. Retrieved from https://arxiv.org/abs/1905.00875 ↩
Li, X., Liu, S., De Mello, S., Wang, X., Kautz, J., & Yang, M.-H. (2019). Joint-task Self-supervised Learning for Temporal Correspondence. Retrieved from https://arxiv.org/abs/1909.11895 ↩
Lai, Z., Lu, E., & Xie, W. (2020.). MAST: A Memory-Augmented Self-Supervised Tracker. Retrieved from https://arxiv.org/abs/2002.07793 ↩

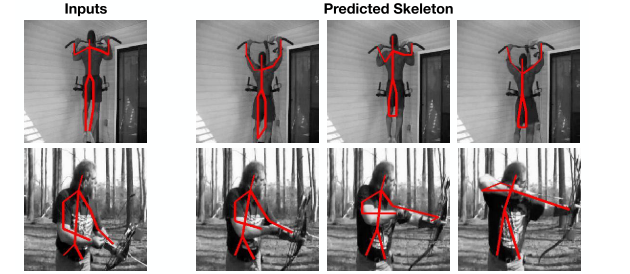
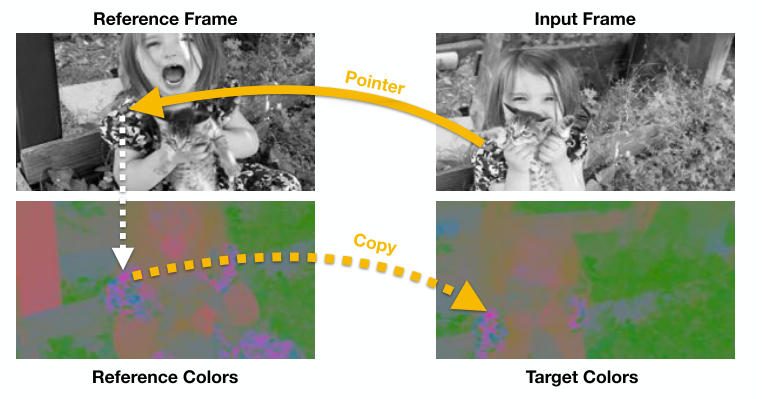
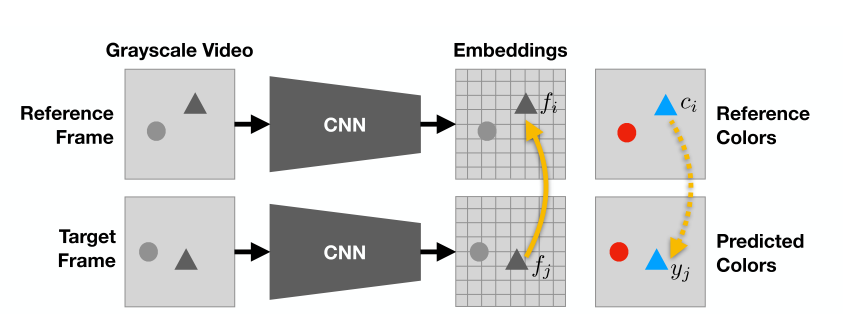

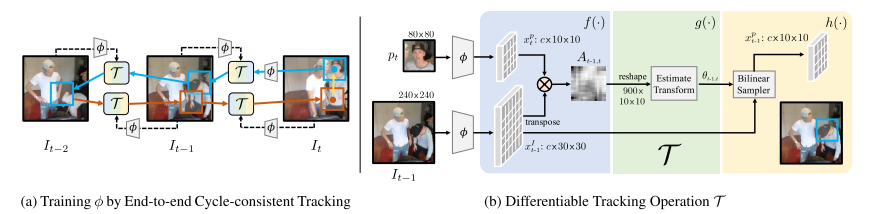
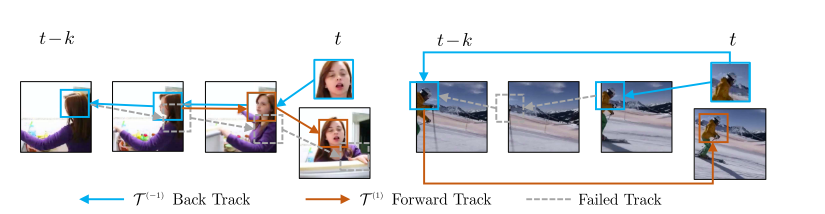
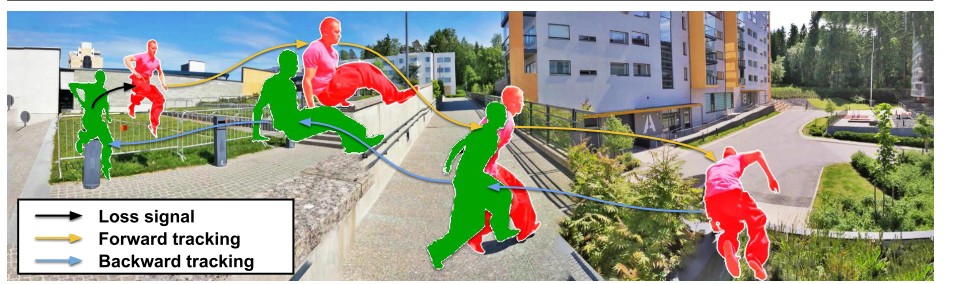
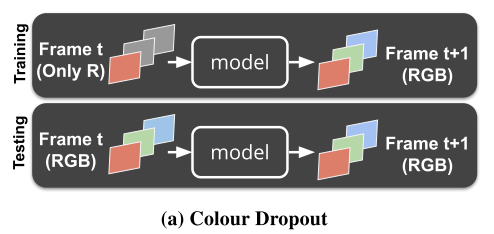

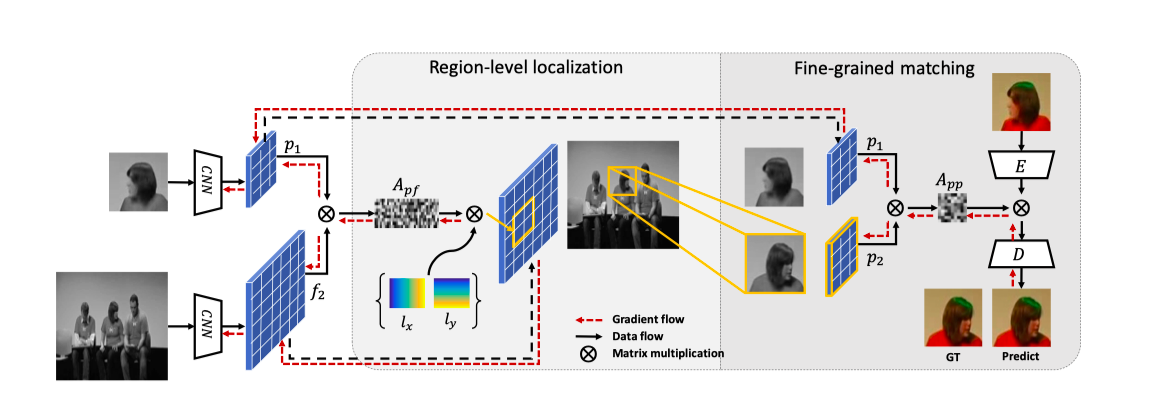
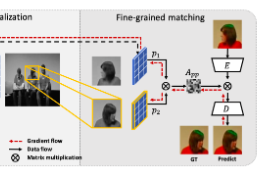
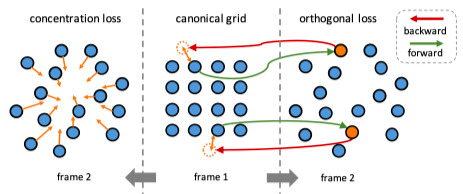


- 投稿日:2020-04-05T19:11:57+09:00
ELMoとBERTを使って多義語に対して単語の類似度判定をする
概要
文脈を考慮した単語分散表現(埋め込みベクトル)を計算するエンコーダーモデルであるELMoが複数の意味を持つ多義語を区別できるかどうか、単語の類似度を計算することで検証します。多義語とは例えば次のようなものです。
- What do you mean? (どういう意味?)
- a mean person (ケチな人)
- the mean value (平均値)
同じ検証を近年の自然言語処理モデルのデファクトスタンダードであるBERTに対しても行い、結果を比較します。
環境・使用モデル
計算はすべてGoogle Colaboratory上で行いました。
モデルはELMo, BERTともに英語の学習済みモデルをファインチューニングなしでそのまま使います。ELMoはTensorFlow Hub、BERTは公式リポジトリのものを使用します。
問題設定
Word2vecやGloVeといったモデルでは一つの単語に対して一つの埋め込みベクトルが得られるため、多義語がどういった意味で使われているのかを区別することはできません。一方、ELMoやBERTといったモデルでは、同じ単語であっても文脈によって異なる埋め込みベクトルが得られるため、多義語を使われている意味によって区別することが可能だと期待できます。
今回は、「右」「正しい」「権利」という意味を持つ"right"を例にとり、以下の例文を使います。
「右」という意味
My right arm is broken.
Cover your right eye.
Please turn right at the next corner.
I got into the right lane.「正しい」という意味
Your opinion is more or less right.
I got the answer right.
Please try to make things right again.
It was quite right of you to refuse the offer.「権利」という意味
I don't have a right to access that computer.
Everyone has a right to enjoy his liberty.
She has the right to criticize the government.
Every person has a right to defend themselves.これらの例文を学習済みモデルに入力して"right"に対応する埋め込みベクトルを取り出し、コサイン類似度
cossim(\mathbf{u} ,\mathbf{v} ) = \frac{\mathbf{u} \cdot \mathbf{v}}{|\mathbf{u}| \, |\mathbf{v}|}を計算することで、同じ意味の"right"どうしの類似度が高くなるかを調べます。
実装
必要なライブラリをインポートします。TensorFlowのバージョンはELMo、BERTともに1.x系を使用しますが、2020年3月27日以降、Google Colaboratoryのデフォルトは2.x系になっていますので、マジックコマンド
%tensorflow_version 1.xで1.x系を指定しています。import json import numpy as np import matplotlib.pyplot as plt import seaborn as sns %tensorflow_version 1.x import tensorflow as tf import tensorflow_hub as hub検証に使う文章を用意します。BERTでは入力データをファイルから読み込ませる必要があるのでテキストファイルにも書き込んでおきます。
right_texts = ["My right arm is broken", "Cover your right eye", "Please turn right at the next corner", "I got into the right lane", "Your opinion is more or less right", "I got the answer right", "Please try to make things right again", "It was quite right of you to refuse the offer", "I don't have a right to access that computer", "Everyone has a right to enjoy his liberty", "She has the right to criticize the government", "Every person has a right to defend themselves",] with open('right_texts.txt', mode='w') as f: f.write('\n'.join(right_texts))コサイン類似度の相関行列を計算する関数を用意しておきます。
def cos_sim(v1, v2): return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2)) def calc_sim_mat(arr): num = len(arr) # number of vectors contained in arr sim_mat = np.zeros((num, num)) norm = np.apply_along_axis(lambda x: np.linalg.norm(x), 1, arr) # norm of each vector normed_arr = arr / np.reshape(norm, (-1,1)) for i, vec in enumerate(normed_arr): sim = np.dot(normed_arr, np.reshape(vec, (-1,1))) sim = np.reshape(sim, -1) # flatten sim_mat[i] = sim return sim_matELMo
ELMoはTensorFlow Hubの学習済みモデル(v3)を使用します。使い方は本家ページに書いてありますが、
も参考にしました。(実は今回の記事を書こうと思ったのは上記の記事を読んだのがきっかけです。)
ELMoモジュールは、スペースで区切られた文章を入力するモード
signature="default"と単語ごとに分割したトークンのリストを入力するモードsignature="tokens"がありますが、今回は後者を使います。そのため、tokenizerという関数を用意して、文章をトークン化・パディングしています。elmo_url = "https://tfhub.dev/google/elmo/3" def tokenizer(texts): PAD = "" tokens = [s.lower().split() for s in texts] lengths = [len(t) for t in tokens] max_len = max(lengths) tokens = [t + [PAD] * (max_len - len(t)) for t in tokens] return tokens, lengths def elmo_embed(texts): tokens, lengths = tokenizer(texts) elmo = hub.Module(elmo_url, trainable=False) embeddings = elmo( inputs={ "tokens": tokens, "sequence_len": lengths }, signature="tokens", as_dict=True) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) sess.run(tf.tables_initializer()) embeddings = sess.run(embeddings) return tokens, embeddings計算を実行して埋め込みベクトルを出力します。
tokens, elmo_embeddings_dict = elmo_embed(right_texts) print(elmo_embeddings_dict.keys()) # dict_keys(['lstm_outputs1', 'lstm_outputs2', 'word_emb', 'sequence_len', 'elmo', 'default'])TensorFlow Hubのページで説明してある通り、ELMoモジュールの出力は各種の埋め込みベクトルを収納した辞書です。各keyの説明は以下の通りです。
word_emb: the character-based word representations with shape [batch_size, max_length, 512].lstm_outputs1: the first LSTM hidden state with shape [batch_size, max_length, 1024].lstm_outputs2: the second LSTM hidden state with shape [batch_size, max_length, 1024].elmo: the weighted sum of the 3 layers, where the weights are trainable. This tensor has shape [batch_size, max_length, 1024]default: a fixed mean-pooling of all contextualized word representations with shape [batch_size, 1024].
word_embは1層目の文脈を考慮しない埋め込み層の出力です。このベクトルだけ次元が512ですが、他のベクトルと和を取るときには、word_embベクトルを2つ結合して次元を1024にしているようです。
原論文にある通り、ELMoの出力はword_emb、lstm_outputs1、lstm_outputs2の3つの埋め込みベクトルを訓練可能な係数で線形和を取ったもので、それがelmoに収められています。今回は下流タスクの訓練はしないので、モジュールを呼ぶときにtrainable=Falseを指定したのですが、その場合ELMoベクトルの係数がどうなるのかについてはTensorFlow Hubでは言及されていません。今回の計算で得られたベクトルの値を調べたところ、どうやら係数は単純に1/3ずつになっているようです。また、trainable=Trueを指定してもELMoベクトルの値は変わりませんでしたので、訓練可能な重みの初期値もすべて1/3のようです。
defaultは文章内のすべての単語のELMoベクトルの平均をとったものです。文章全体の分散表現と解釈できるものだと思います。
sequence_lenは上の説明には含まれていませんが、各文章のトークン数を収めたリストです。原論文によると、LSTMの1層目の出力は構文的(syntactic)な情報を、2層目は意味的(semantic)な情報を捉える傾向があるそうなので、今回はタスクの内容を鑑みて
lstm_outputs2を使うこととします。
以下の関数で"right"の埋め込みベクトルのみを取り出します。def my_index(l, x, default=False): return l.index(x) if x in l else default def find_position(tokens, word): pos = [my_index(t, word) for t in tokens] assert False not in pos return pos def extract_elmo_vectors(embeddings_dict, tokens, word, layer): embeddings = embeddings_dict[layer] num_sentences = embeddings.shape[0] vec_dim = embeddings.shape[2] vectors = np.zeros((num_sentences, vec_dim)) pos = find_position(tokens, word) for i in range(num_sentences): vectors[i] = embeddings[i][pos[i]][:] return vectorselmo_vectors = extract_elmo_vectors(elmo_embeddings_dict, tokens, 'right', 'lstm_outputs2') print(elmo_vectors.shape) # (12, 1024) elmo_sim_mat = calc_sim_mat(elmo_vectors)これで、各文章の"right"に対する埋め込みベクトル
elmo_vectorsと類似度の相関行列elmo_sim_matが得られました。結果を見る前にBERTでも同じ計算をします。BERT
BERTは下流タスクに対して教師あり学習によりファインチューニングして使うことを念頭に置いたモデルですが、bert-as-serviceのように文章の分散表現を得るためのエンコーダーとして使うこともできます。今回はBERTを使って単語の分散表現を計算します。
まず、BERTの公式リポジトリをクローンします。
!git clone https://github.com/google-research/bert.gitモデルは
BERT-Base, Uncasedを使うことにします。学習済みのパラメータをダウンロードして展開します。!wget https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip && \ unzip uncased_L-12_H-768_A-12.zip && \ rm uncased_L-12_H-768_A-12.zip埋め込みベクトルを取り出すためのコードは公式リポジトリに
extract_features.pyが用意されていますので、以下のように実行するだけです。--input_fileで用意したインプットファイルを指定、--output_fileは出力を保存する任意の名前のjsonlファイルを指定します。続く3つの引数は上でダウンロードした学習済みモデルを指定しています。--layersは埋め込みベクトルとして使う出力層を指定するもので、今回は最後から2番目を使います。!python ./bert/extract_features.py \ --input_file=right_texts.txt \ --output_file=right_output.jsonl \ --vocab_file=uncased_L-12_H-768_A-12/vocab.txt \ --bert_config_file=uncased_L-12_H-768_A-12/bert_config.json \ --init_checkpoint=uncased_L-12_H-768_A-12/bert_model.ckpt \ --do_lower=True \ --layers -2出力されたjsonlファイルから目的の単語トークンに対応した埋め込みベクトルを取り出す関数を用意します。こちらのページを参考にしました。
def extract_bert_vectors(input_path, target_layer=-2, target_token): with open(input_path, 'r') as f: output_jsons = f.readlines() vectors = [] for output_json in output_jsons: output = json.loads(output_json) for feature in output['features']: if feature['token'] != target_token: continue for layer in feature['layers']: if layer['index'] != target_layer: continue vectors.append(layer['values']) return np.array(vectors)"right"に対応するベクトルを取り出して、類似度の行列を計算します。
bert_vectors = extract_bert_vectors('./right_output.jsonl', target_layer=-2, target_token='right') print(bert_vectors.shape) # (12, 768) bert_sim_mat = calc_sim_mat(bert_vectors)結果
それでは、計算結果をプロットしてみます。seabornのheatmapを使ったプロット用の関数を定義します。
def show_sim_mat(sim_mat, texts, title=None, export_fig=False): sns.set(font_scale=1) g = sns.heatmap( sim_mat, vmin=0, vmax=1, cmap="YlOrRd") g.set_xticklabels(texts, rotation='vertical') g.set_yticklabels(texts, rotation=False) if title: plt.title(title, fontsize=24) if export_fig: plt.savefig(export_fig, bbox_inches='tight') plt.show()ELMoとBERTの結果に対して実行します。
show_sim_mat(elmo_sim_mat, right_texts, title='ELMo') show_sim_mat(bert_sim_mat, right_texts, title='BERT')結果は以下の通りになりました。"right"に対応したベクトルの類似度をプロットしていますが、ラベルには文章全体を表示しています。同じ意味で"right"が使われている文章を4つずつ並べましたので、4つずつの対角ブロックの色が濃く、それ以外の非対角部分の色が薄くなるのが理想なのですが、いかがでしょうか。
まず、どちらの図でも、「権利」の意味の最後のブロックの類似度が明らかに高くなっているのが見て取れます。この"right"はどれも"have/has"や"to"とセットで使われており、文の構造も似通っているので、他の意味と区別しやすいというのは納得のいく結果ではないでしょうか。「右」と「正しい」に関しては、「権利」ほどはっきりとは区別できていませんが、最初の2文のように同じ意味どうしの類似度が確かに高くなっているところも見受けられます。
ELMoとBERTの比較に関しては、目で見る限りはBERTのほうが良さそうです。しかし、コサイン類似度はモデルによって全体的な値の水準が異なる傾向があるため、類似度の値そのものよりも類似度の順序を見ることが重要です。そこで最後に、類似度の順序に基づいた定量的な指標を導入して、両モデルを比較します。
以下の関数で類似度ポイントを定義します。
block_sizeは単語が同じ意味で使われている文章の数のことで、今の例だと4です。各文章ごとに類似度が高い順に並べて、順位がblock_size位以内に実際に同じ意味で使われている文章が入るとポイントが加算されます。ただし、順位1位は常に自分自身なので除きます。今の場合だと2位から4位までに同じ意味で"right"が使われている文章が入れば得点となります。ポイントは最高点が1になるように正規化しています。各文章に対する類似度ポイントがpoints_arrに収納され、av_pointはそれらの平均です。def eval_sim_points(sim_mat, block_size): num_data = len(sim_mat) points_list = [] for i in range(num_data): block_id = int(i / block_size) points = np.array([1 if (block_id * block_size <= j and j < (block_id+1) * block_size) else 0 for j in range(num_data)]) sorted_args = np.argsort(sim_mat[i])[::-1] sorted_points = points[sorted_args] point = np.mean(sorted_points[1:block_size]) points_list.append(point) points_arr = np.array(points_list) av_point = np.mean(points_arr) return av_point, points_arr実行した結果は以下の通りです。
# ELMo elmo_point, elmo_points_arr = eval_sim_points(elmo_sim_mat, 4) print(np.round(elmo_point, 2)) # 0.61 print(np.round(elmo_points_arr, 2)) # [0.33 0.33 0. 0.67 0.67 0.67 0.67 0. 1. 1. 1. 1. ]# BERT bert_point, bert_points_arr = eval_sim_points(bert_sim_mat, 4) print(np.round(bert_point, 2)) # 0.78 print(np.round(bert_points_arr, 2)) # [1. 1. 0.67 1. 0.67 0.33 0.33 0.33 1. 1. 1. 1. ]データ数が少ないため信頼度に疑問は残りますが、定量化したことで結果をはっきりと評価できるようになりました。平均点はELMo: 0.61、BERT: 0.78とBERTに軍配が上がりました。文章ごとのポイントを見ると、「権利」の意味の4文はどちらのモデルもすべて満点となっており、「右」の意味の4文はBERTが高得点を出しているのがわかります。「正しい」の意味の4文はどちらのモデルも苦戦していますが、こちらは平均するとELMoのほうが良い結果を出しています。
おわりに
ELMoは文脈を考慮した単語分散表現を与えると言われているものの、このような実験を見たことがなかったので記事にまとめてみました。ここで試した例に関しては、ELMoもBERTもある程度は文脈を捉えて多義語を区別できるという結果となりました。
最後に定量的な評価指標を導入したので、埋め込みベクトルとして使う出力層を変えた時の結果の比較も、後から追記したいと思います。
- 投稿日:2020-04-05T19:05:50+09:00
[Python] pip3のパッケージを AWS Lambda 上でimportできるようにする
AWS Lambda レイヤーにパッケージ用のレイヤーを追加する。
パッケージを配置したフォルダを作成
pip3 install -t python/lib/python3.7/site-packages <パッケージ名>
python3.7の箇所は適宜置き換える
pythonフォルダをzipに固めるレイヤーにアップロード
パッケージを利用したい関数にレイヤーを追加する
import <パッケージ名>で使えるようになる参考
https://blog.ikedaosushi.com/entry/2018/12/22/231421
環境
macOS 10.15.4
Python 3.7.7
- 投稿日:2020-04-05T19:05:36+09:00
pandas to_sqlで複数テーブルを一斉に更新
方法
pandasでのトランザクションは、SQLAlchemyの
engine.begin()を使って、以下のように実装できます。こうすることで、各テーブルの更新に時間が掛かってしまうような場合でも時間差なく同時に更新を反映できますし、失敗時にはロールバックもできます。
withを使うことで、自動的にコミットの処理が呼び出されます。(失敗時はロールバック)from sqlalchemy import create_engine engine = create_engine(url) with engine.begin() as conn: df1.to_sql('table1', conn, if_exists='append') df2.to_sql('table2', conn, if_exists='append')注意点
withブロックの中でコミットが走ってしまうようなクエリを流してしまうと、そこでコミットされてしまいます。
参考: Statements That Cause an Implicit Commit例えば、
to_sqlのオプションif_existsを'replace'にした場合は、DROP TABLEが走るので、テーブルごとに更新が発生してしまいます。with engine.begin() as conn: df1.to_sql('table1', conn, if_exists='replace') df2.to_sql('table2', conn, if_exists='replace') # DROP TABLEが呼び出されて、table1の更新がコミットされてしまう。テーブルの中身を全部更新する場合は、一度別名でテーブルを作ってRENAME TABLEで入れ替えるのが良いようです。
from sqlalchemy import create_engine engine = create_engine(url) df1.to_sql('table1_new', engine, if_exists='replace') df2.to_sql('table2_new', engine, if_exists='replace') engine.execute(''' RENAME TABLE table1 to table1_old, table1_new to table1 table2 to table2_old, table2_tmp to table2; ''' )
- 投稿日:2020-04-05T18:53:10+09:00
AtCoder Beginner Contest 161 復習
今回の成績
今回の感想
先週のABCがミスのオンパレードだったのですが、今週はうまくいきました。
D問題で50分近く使ってしまい、いつものパフォーマンスに落ち着いてしまいそうだったので粘りを見せることができてよかったです。
まだまだE問題を時間内に解けないなどの課題があるのでもっと精進をしていきたいです。
F問題まで載せているのは今のところ(2020/04/05現在)僕だけのようなので、復習の際に参考にしていただけるとありがたいです。A問題
操作を順に行うとどのように入れ替わるか考えれば良いです。
また、print(z,x,y)とすることでz,x,yの間に空白を入れて出力できることを発見しました。これから使っていきたいと思います。A.pyx,y,z=map(int,input().split()) print(z,x,y)B問題
sが総得票数なので、s/4m以上のものの数がm以上かどうかを判定すれば良いです。
B.pyn,m=map(int,input().split()) b=list(map(int,input().split())) s=sum(b) a=[i for i in b if i>=s/(4*m)] print("Yes" if len(a)>=m else "No")C問題
nがk以上の場合はnをn-kに置き換えます。nがk以下の場合はk-nに置き換えます。また、nがk以下の場合はk-nに置き換えてもnはk以下のままです。
したがって、一つ目の操作の間はkで割った余りは変わらず、二つ目の操作の間はn%kまたはk-n%kで変わりません。
よって、min(n%k,k-n%k)を出力すれば良いです。C.pyn,k=map(int,input().split()) n=n%k print(min(n,k-n))D問題
まず樹形図を書いていました。樹形図を書いているうちにi桁目とi+1桁目の間に関係があるのではないかと気づきました。そこで1桁目から2桁目でどうなるか実験してみると以下のようになりました。
実験の結果から、ルンルン数を文字列として扱えばi桁のルンルン数の後ろ側に"i桁のルンルン数のi桁目との差の絶対値が1以下"の数字を付け足せばi+1桁目のルンルン数を作ることができることがわかります。また、上記の実験を見ればわかるように、i桁目が0または9の場合は後ろに付け足す数字は二通りでそれ以外の場合は三通りであることがわかります。(✳︎)
したがって、それぞれの桁について上記の操作を行って配列に格納していき、その配列に含まれる要素の合計がkを超えたら上記の操作を行うのを終わらせ、その中のk番目を求めれば良いです。(✳︎)…コンテスト中は前側にも付け足してしまっていたので重複をsetで除いていました。一つ目のコードになります。二つ目のコードは後ろ側のみに付け足しているコードになります。
answerD.pyk=int(input()) ans=[[i for i in range(1,10)]] d=9 while d<k: ans.append([]) for i in ans[-2]: x=str(i) y=int(x[0]) if y==1: ans[-1].append(str(y)+x) ans[-1].append(str(y+1)+x) elif 2<=y<=8: ans[-1].append(str(y-1)+x) ans[-1].append(str(y)+x) ans[-1].append(str(y+1)+x) else: ans[-1].append(str(y-1)+x) ans[-1].append(str(y)+x) z=int(x[-1]) if z==0: ans[-1].append(x+str(z)) ans[-1].append(x+str(z+1)) elif 1<=z<=8: ans[-1].append(x+str(z-1)) ans[-1].append(x+str(z)) ans[-1].append(x+str(z+1)) else: ans[-1].append(x+str(z-1)) ans[-1].append(x+str(z)) ans[-1]=list(set(ans[-1])) d+=len(ans[-1]) l=len(ans[-1]) v=sorted([int(i) for i in ans[-1]]) print(v[k-(d-l)-1])answerD_better.pyk=int(input()) ans=[[i for i in range(1,10)]] d=9 while d<k: ans.append([]) for i in ans[-2]: x=str(i) z=int(x[-1]) ans[-1].append(x+str(z)) if z<=8: ans[-1].append(x+str(z+1)) if z>=1: ans[-1].append(x+str(z-1)) d+=len(ans[-1]) ans[-1].sort() print(ans[-1][k-d-1])E問題
解説を見てなるほどとなりました。忘れた頃に解き直したい良問だと思います。
この問題を見た時に、区間→"imosか累積和"という短絡的な思考をしてしまいました。そのようなアルゴリズム中心で問題の解き方を考えるのは強くなるのを阻害する考え方だと思っているのでやめていきたいです。
今回はこのような考えに警鐘を鳴らすような問題であったと自分では思っています。なぜなら、全ての基本は貪欲法で計算量を落としたい時にアルゴリズムを使うからです。ここでは貪欲法を用いて考えていきます。(✳︎)
この問題で前から順に働ける日を考えていくとします。この時i番目に選んだ働ける日は何を意味するでしょうか。解答にも書いてある通り、働ける日を前から選んだ時にi番目に選び得るの中で最も早い日ということです。つまり、i番目に選ぶ日はその日以降にしか現れないということです。逆に、後ろから順に働ける日を考えていくと、j番目に選んだ働ける日はその日以前にしか現れないということです。また、働くのはちょうどk日なので後ろから数えてj番目の日は前から数えるとk-j+1番目の日であることに注意が必要です。
以上より、前から数えてi番目に選ぶ日について、x日以降かつy日以前でなければならないという情報が得られました。x<yの場合はi番目の日として複数の候補がありますが、x=yの場合はi番目の日としてx(=y)以外に候補がありません。
したがって、前からと後ろからでそれぞれ順番に働ける日をk日数えて、前から数えてi番目に働く日が同じ場合のみ出力すれば答えを求めることができます。
この問題も納得はでき同じような問題がでたら再現はできそうですが、初見で取り組みたい問題でした。時間が足りずコンテスト後に答えを見て気づいて悔しい思いをしたので、しっかり六問を解き切れるように全体的にもっとスピードをあげれるように努力したいと思います。(✳︎)…貪欲法はアルゴリズムではないという立場です。
answerE.pyn,k,c=map(int,input().split()) s=input() l=[-1]*k r=[-1]*k nowl=0 indl=0 while nowl<n and indl<k: for i in range(nowl,n): if s[i]=="o": l[indl]=i nowl=i+c+1 indl+=1 break nowr=n-1 indr=k-1 while nowr>=0 and indr>=0: for i in range(nowr,-1,-1): if s[i]=="o": r[indr]=i nowr=i-c-1 indr-=1 break for i in range(k): if l[i]==r[i]: print(l[i]+1)F問題
k($\neq$1)がnの約数であると仮定します。ここでnをkで割り切れなくなるまでkで割ると、その後はnをn-kで置き換える(n mod kは変わらない$\leftrightarrow$nはkで割り切れないまま)ことになります。したがって、C問題と同様に考えれば、n mod kが1であれば最終的にnは1になると言えます。
また、kがnの約数ではなかった場合はnをn-kで置き換える操作しかできないので、n mod kが1になるかのみをチェックすれば良いです。また、n mod kが1になるのは、nを1にするまでn-kに入れ替える操作をl回行った時にl*k+1=n$\leftrightarrow$l*k=n-1になることから、kがn-1の約数であれば良いことがわかります。(✳︎)
以上より、下のコードではmake_divisors(自分で約数列挙のコードを用意してなかったので、こちらの記事のコードを参考にさせていただきました。)で約数を全て求めた後に、それぞれの約数をkとして上記のn mod kのチェックを行いました。
コンテスト中に書いたコードを今一度チェックしたところかなり適当にコードを書いていたので、しっかり考察してからコードを書くように直していきたいです。(✳︎)…kがnの約数ではない時kがn-1の約数になるというのは背理法などで示すことができます。
answerF.pydef make_divisors(n): divisors = [] for i in range(1, int(n**0.5)+1): if n % i == 0: divisors.append(i) if i != n // i: divisors.append(n//i) divisors.sort() return divisors n=int(input()) x=make_divisors(n) l=len(x) ans=0 for i in range(l): k=n if x[i]==1: continue while k%x[i]==0: k//=x[i] if k%x[i]==1: ans+=1 y=make_divisors(n-1) l2=len(y) ans2=0 for i in range(l2): k=n if y[i]==1: continue while k%y[i]==0: k//=y[i] if k%y[i]==1: ans2+=1 print(ans+ans2)answerF_better.pydef make_divisors(n): divisors = [] for i in range(1, int(n**0.5)+1): if n % i == 0: divisors.append(i) if i != n // i: divisors.append(n//i) divisors.sort() return divisors def all_pattern(l): global n ans=0 for ds in make_divisors(l)[1:]: k=n while k%ds==0: k//=ds ans+=(k%ds==1) return ans n=int(input()) print(all_pattern(n)+all_pattern(n-1))


- 投稿日:2020-04-05T18:45:59+09:00
【強化学習】自作ライブラリでDQN
TL;DR
自作のReplay Bufferライブラリcpprb を使って、DQNを実装してみた。
高い自由度と効率性を兼ね備えている(つもりな)のでおすすめ。
1. 背景と経緯
Open AI/Baselines や Ray/RLlib のような、強化学習一式の環境を利用すると、ちょっとしたコードで様々なアルゴリズムを試してみることができる。
例えば、Open AI/Baselinesで、AtariのPongをDQNで学習させるには以下のコマンドを実行するだけで良いと公式READMEに記載されている。
python -m baselines.run --alg=deepq --env=PongNoFrameskip-v4 --num_timesteps=1e6一方、既存のアルゴリズムをテストするのは簡単だけれども、研究者やライブラリ開発者が新しい独自アルゴリズムを作ろうとした際に、どこから手をつけていいのか大きすぎて大変だと思う。
強化学習の研究をしている友人もTensorFlowなどの深層学習のライブラリは利用するものも、他の部分は独自に実装してた(ようであった)。
そんな2018年の暮れ頃、その友人から「Cythonって興味ある? Pythonで実装しているReplay Bufferが、(状況によっては)深層学習の学習部分なみに遅くて、Cythonでスピードアップを図りたいんだけど」(記憶)と誘われて実装始めたのが cpprb である。
(その友人は、cpprbとTensorFlow 2.x を利用して、tf2rlという強化学習ライブラリを公開していて、こちらも超おすすめ!)
2. 特徴
そんな背景もあって実装はじめた cpprb なので、高い自由度と効率性に主眼をおいて開発している。
2.1 高い自由度
バッファに保存する変数名・サイズ・型を
dict形式で指定することで自由に決めることができる。例えば、極端な例だが、
next_next_obs,previous_act,secondary_rewardなんてものも保存することができる。import numpy as np from cpprb import ReplayBuffer buffer_size = 1024 # shape と dtype を変数ごとに指定できる。デフォルトは、{"shape":1,"dtype": np.float32} rb = ReplayBuffer(buffer_size, {"obs": {"shape": (3,3)}, "act": {"shape": 3, "dtype": np.int}, "rew": {}, "done": {}, "next_obs": {"shape": (3,3)}, "next_next_obs": {"shape": (3,3)}, "previous_act": {"shape": 3, "dtype": np.int}, "secondary_reward": {}}) # Key-Value 形式で指定する (初期化時に指定した変数が不足していると `KeyError`) rb.add(obs=np.zeros(shape=(3,3)), act=np.ones(3,dtype=np.int), rew=0.5, done=0, next_obs=np.zeros(shape=(3,3)), next_next_obs=np.ones(shape=(3,3)), previous_act=np.ones(3,dtype=np.int), secondary_reward=0.3)2.2 効率性
Prioritized Experience Replayの遅さの原因であるSegment TreeをCython経由で、C++実装しているため、かなり早い。
ベンチマークを見る限り速度で圧勝している。(2020年4月現在。最新版はプロジェクトサイトへ)
注意: 強化学習全体では、Segment Treeの速度だけではなくて、うまく探索を並列化させるなどの対策が重要
3. インストール
(情報が古くなってるかもしれないので、最新のインストール方法も参照)
3.1 バイナリインストール
PyPIに公開しているので、pip(や類似のツール)を用いてインストールすることができる。
Windows/Linux向けには、wheel形式のバイナリを配布しているので、多くの場合は何も考えずに以下のコマンドでインストールすることができる。
(注:venvやdocker等仮想環境の利用を推奨。)pip install cpprb注: macOSは標準の開発ツールチェインの一部になっている clang が、 C++17 の機能の
std::shared_ptrの配列型への特殊化を未実装のためコンパイルできずバイナリを配布できていない。3.2 ソースからインストール
ソースコードから各自ビルドする必要がある。ビルドには以下が必要である。
- GCC >= 7.2(?)
環境変数
CCとCXXにg++を指定してビルドを実行する必要がある。3. DQN実装
Google Colab 上で動作するDQNを書いてみた
まずは、必要なライブラリをインストール
!apt update > /dev/null 2>&1 !apt install -y xvfb x11-utils python-opengl > /dev/null !pip install gym cpprb["all"] tensorflow > /dev/null %load_ext tensorboardimport os import datetime import io import base64 import numpy as np from google.colab import files, drive import gym import tensorflow as tf from tensorflow.keras.models import Sequential,clone_model from tensorflow.keras.layers import InputLayer,Dense from tensorflow.keras.optimizers import Adam from tensorflow.keras.callbacks import EarlyStopping,TensorBoard from tensorflow.summary import create_file_writer from scipy.special import softmax from tqdm import tqdm_notebook as tqdm from cpprb import create_buffer, ReplayBuffer,PrioritizedReplayBuffer import cpprb.gymJST = datetime.timezone(datetime.timedelta(hours=+9), 'JST') a = cpprb.gym.NotebookAnimation() %tensorboard --logdir logs# DQNテスト: モデル作成 gamma = 0.99 batch_size = 1024 N_iteration = 101 N_show = 10 per_train = 100 prioritized = True egreedy = True loss = "huber_loss" # loss = "mean_squared_error" dir_name = datetime.datetime.now(JST).strftime("%Y%m%d-%H%M%S") logdir = os.path.join("logs", dir_name) writer = create_file_writer(logdir + "/metrics") writer.set_as_default() env = gym.make('CartPole-v0') env = gym.wrappers.Monitor(env,logdir + "/video/", force=True,video_callable=(lambda ep: ep % 50 == 0)) observation = env.reset() model = Sequential([InputLayer(input_shape=(observation.shape)), # 4 for CartPole Dense(64,activation='relu'), Dense(64,activation='relu'), Dense(env.action_space.n)]) # 2 for CartPole target_model = clone_model(model) optimizer = Adam() tensorboard_callback = TensorBoard(logdir, histogram_freq=1) model.compile(loss = loss, optimizer = optimizer, metrics=['accuracy']) a.clear() rb = create_buffer(1e6, {"obs":{"shape": observation.shape}, "act":{"shape": 1,"dtype": np.ubyte}, "rew": {}, "next_obs": {"shape": observation.shape}, "done": {}}, prioritized = prioritized) action_index = np.arange(env.action_space.n).reshape(1,-1) # ランダムの初期探索 for n_episode in range (1000): observation = env.reset() for t in range(500): action = env.action_space.sample() # アクションのランダム選択 next_observation, reward, done, info = env.step(action) rb.add(obs=observation,act=action,rew=reward,next_obs=next_observation,done=done) observation = next_observation if done: break for n_episode in tqdm(range (N_iteration)): observation = env.reset() for t in range(500): if n_episode % (N_iteration // N_show)== 0: a.add(env) actions = softmax(np.ravel(model.predict(observation.reshape(1,-1),batch_size=1))) actions = actions / actions.sum() if egreedy: if np.random.rand() < 0.9: action = np.argmax(actions) else: action = env.action_space.sample() else: action = np.random.choice(actions.shape[0],p=actions) next_observation, reward, done, info = env.step(action) rb.add(obs=observation, act=action, rew=reward, next_obs=next_observation, done=done) observation = next_observation sample = rb.sample(batch_size) Q_pred = model.predict(sample["obs"]) Q_true = target_model.predict(sample['next_obs']).max(axis=1,keepdims=True)*gamma*(1.0 - sample["done"]) + sample['rew'] target = tf.where(tf.one_hot(tf.cast(tf.reshape(sample["act"],[-1]),dtype=tf.int32),env.action_space.n,True,False), tf.broadcast_to(Q_true,[batch_size,env.action_space.n]), Q_pred) if prioritized: TD = np.square(target - Q_pred).sum(axis=1) rb.update_priorities(sample["indexes"],TD) model.fit(x=sample['obs'], y=target, batch_size=batch_size, verbose = 0) if done: break if n_episode % 10 == 0: target_model.set_weights(model.get_weights()) tf.summary.scalar("reward",data=sum_reward,step=n_episode) rb.clear() a.display()4. 結果
rewardの結果。
6. まとめ
強化学習向けReplay Bufferを提供する自作ライブラリ cpprb を利用して、DQNを実装した。
cpprb は高い自由度と効率性を重視して開発している。
興味を持ってくれた人は、試してみて issueやマージリクエストをぜひ。(英語が好ましいけど、日本語でもOK)
参考リンク
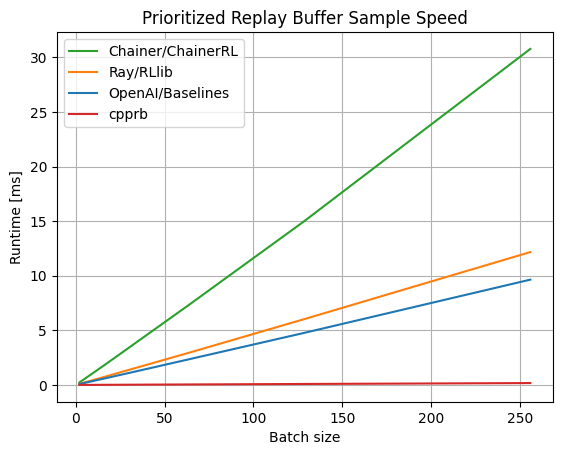
- 投稿日:2020-04-05T18:37:37+09:00
Python(tensorflow.keras×flask×gunicorn)×Heroku 〜git push heroku masterできない編〜
はじめに
前回作成したPythonアプリをherokuにデプロイしてみようとしたけど、Compiled slug sizeが500MBオーバーでherokuにpushできなかった備忘録
git -> heroku の方法を試してみた(github -> heroku の方法もあるらしい)
前回作成したPythonアプリ
Python × Flask × Tensorflow.Keras 猫の品種を予測するWebアプリ2環境
macOS
Python3.7.5試した方法
参考:公式チュートリアル
Heroku用の用意
1.gunicornをインストール
pip install gunicorn2.ファイル用意
requirements.txtFlask==1.1.2 tensorflow==2.1.0 numpy==1.18.2 Pillow==7.1.1 gunicorn==20.0.4Procfileweb: gunicorn app:app --log-file -runtime.pypython-3.7.53.gitにデプロイ
モデルは100MB以上あるためBucketeerに入れる予定・・・
参考:HerokuでTensorFlowのAPIをホストした話folder |- app.py #元sever.py |- image_process.py |- templates | |- index.html |- requirements.py |- runtime.py |- ProcfileHeroku Command Line Interface (CLI)をインストール
1.herokuコマンドを使えるようにする
terminal$ brew install heroku/brew/heroku2.Pythonアプリをherokuにデプロイする
terminal$ heroku login $ heroku create アプリ名 #herokuにリポジトリを作成する? $ heroku git:remote -a アプリ名 #gitとherokuのリポジトリ(アプリ名)を紐付ける3.herokuにPythonプログラムをpushする
terminal$ git push heroku master?ここでerrorメッセージが出てしまいpushできませんでした
?Compiled slug size: 518M is too large (max is 500M).を解決しないとダメのようです
?tensorflowが400M以上を占めているらしい.困ったerrorメッセージ(略) remote: -----> Discovering process types remote: Procfile declares types -> web remote: remote: -----> Compressing... remote: ! Compiled slug size: 518M is too large (max is 500M). remote: ! See: http://devcenter.heroku.com/articles/slug-size remote: remote: ! Push failed remote: Verifying deploy... remote: remote: ! Push rejected to (アプリ名). remote: To https://git.heroku.com/(アプリ名).git ! [remote rejected] master -> master (pre-receive hook declined) error: failed to push some refs to 'https://git.heroku.com/(アプリ名).git'
- 投稿日:2020-04-05T18:37:37+09:00
Python(tensorflow.keras×flask×gunicorn)×Heroku 〜git push heroku masterできない〜
はじめに
前回作成したPythonアプリをherokuにデプロイしてみようとしたけど、Compiled slug sizeが500MBオーバーでherokuにpushできなかった備忘録
git -> heroku の方法を試してみた(github -> heroku の方法もあるらしい)
前回作成したPythonアプリ
Python × Flask × Tensorflow.Keras 猫の品種を予測するWebアプリ2環境
macOS
Python3.7.5試した方法
参考:公式チュートリアル
Heroku用の用意
1.gunicornをインストール
pip install gunicorn2.ファイル用意
requirements.txtFlask==1.1.2 tensorflow==2.1.0 numpy==1.18.2 Pillow==7.1.1 gunicorn==20.0.4Procfileweb: gunicorn app:app --log-file -runtime.pypython-3.7.53.gitにデプロイ
モデルは100MB以上あるためBucketeerに入れる予定・・・
参考:HerokuでTensorFlowのAPIをホストした話folder |- app.py #元sever.py |- image_process.py |- templates | |- index.html |- requirements.py |- runtime.py |- ProcfileHeroku Command Line Interface (CLI)をインストール
1.herokuコマンドを使えるようにする
terminal$ brew install heroku/brew/heroku2.Pythonアプリをherokuにデプロイする
terminal$ heroku login $ heroku create アプリ名 #herokuにリポジトリを作成する? $ heroku git:remote -a アプリ名 #gitとherokuのリポジトリ(アプリ名)を紐付ける3.herokuにPythonプログラムをpushする
terminal$ git push heroku master?ここでerrorメッセージが出てしまいpushできませんでした
?Compiled slug size: 518M is too large (max is 500M).を解決しないとダメのようです
?tensorflowが400M以上を占めているらしい.困ったerrorメッセージ(略) remote: -----> Discovering process types remote: Procfile declares types -> web remote: remote: -----> Compressing... remote: ! Compiled slug size: 518M is too large (max is 500M). remote: ! See: http://devcenter.heroku.com/articles/slug-size remote: remote: ! Push failed remote: Verifying deploy... remote: remote: ! Push rejected to (アプリ名). remote: To https://git.heroku.com/(アプリ名).git ! [remote rejected] master -> master (pre-receive hook declined) error: failed to push some refs to 'https://git.heroku.com/(アプリ名).git'
- 投稿日:2020-04-05T18:30:42+09:00
pandas形式のfileの読み込み
0. 本記事の内容
この記事はデータ分析をするための、ファイルを読み込み、出力の方法をメモとして残すものです。
1.参考サイト
pandasでcsv/tsvファイル読み込み(read_csv, read_table)
2. jupyther- notebookでのCSV読み込み
df = pd.read_csv('train.csv', sep = ',', na_values = '.', header = None)Tips 読み込みタイプ
csvファイルの読み込みはread_csv()、tsvファイル(タブ区切り)の読み込みはread_table()
Tips データの区切り
カンマでもタブでもないデータの区切りの場合、引数(sepかdelimiter)で区切り文字の指定が可能。
Tips 読み込みデータにheaderがない場合
標準で読み込みデータの1行目はheaderとして扱われる。読み込みデータにheaderがない場合は、
header = Noneと指定する。Tips 読み込みデータにheaderがある場合
headerの読み込み位置を
header=2などで、明示的に指定する。指定個所以前は読み込まれない。Tips 読み込みデータ型
データ読み込み時に、データ型を指定する場合は2通りある。1つ目は
dtype = strとして指定する場合。これは読み込みデータすべてに適応される。2つ目はdtype={'b': str, 'c': str}と辞書形式で指定する。Tips 欠損値の扱い
データ読み込み時に欠損値として扱いたい場合は、
na_values = ["-","."]と指定することで、欠損値扱いすることができる。3. Google ColaboratoryでのCSV読み込み
1.アイコンクリック
2.Mount Drive選択
3.自動でこの部分が追加される3以降.別画面にてColaboratoryと連携をするアカウントを求められるので、選択。その後IDが発行されるため、IDをコピーしてColaboratoryに貼り付け。
pd.reac_csv()にて以下の通り、パスを指定をするdata_fixed = pd.read_csv("/content/drive/My Drive/ColabNotebooks/XXX.csv")それ以降のCSVファイルの読み込みは
2. jupyther- notebookでのCSV読み込みと同じ。3.2 ローカルからアップロード
以下コマンドにて、ローカルからアップロードをするファイルをせんたk
from google.colab import files uploaded = files.upload() import io df = pd.read_csv(io.StringIO(uploaded['XXX.csv'].decode('utf-8')))XXX.csvはアップロードをしたCSVファイルです。
4.Google ColaboratoryへのCSVファイル出力
出力形式は以下の通り。
df.to_csv("/content/drive/My Drive/Colab Notebooks/XXX.csv")5.ブラウザ経由でローカルへダウンロード(Google ColaboratoryとJupyter-notebook共通)
df.to_csv('XXX.csv' , index=False) files.download('XXX.csv')Tips indexの省略
データ出力時に
index部分が必要ない場合は、index = Falseと指定する。kaggleでcommitする際にindexが必要ないケースが多いため個人的には役立つ。
- 投稿日:2020-04-05T18:25:48+09:00
numpyで綺麗な円を描く
OpenCVのcircleは適当なので、もっと綺麗な円を書きましょう。半径
rの円の画像は、中心からr-1以下の距離では1、r以上の距離では0、その間ではr-距離とすることとします。import math, cv2, numpy as np # r must be greater than 0. def circle(r): c = math.ceil(r - 1) s = c * 2 + 1 return np.clip(r - np.sqrt(np.sum((np.stack(( np.tile(np.arange(s), (s, 1)), np.repeat(np.arange(s), s).reshape((-1, s)) )) - c) ** 2, axis=0)), 0, 1) # r must be greater than 0. width must be greater than 0 and less than r. def outline_circle(r, width): circ = circle(r) icirc = circle(r - width) ch, cw = circ.shape ich, icw = icirc.shape sx = (cw - icw) // 2 sy = (ch - ich) // 2 ex = sx + icw ey = sy + ich circ[sy:ey, sx:ex] = np.amax(np.stack((circ[sy:ey, sx:ex] - icirc, np.zeros((ich, icw)))), axis=0) return circ def save_cv2_circle(file_name, r, thickness = -1): s = r * 2 + 1 cv2.imwrite(file_name, cv2.circle(np.zeros((s, s), dtype=np.uint8), (r, r), r, 255, thickness)) def save_circle(file_name, c): im = (np.around(c) * 255).astype(np.uint8) cv2.imwrite(file_name, im) save_circle('/tmp/circle10.jpg', circle(11)) save_cv2_circle('/tmp/cv2_circle10.jpg', 10) save_circle('/tmp/circle10_outline.jpg', outline_circle(11, 1)) save_cv2_circle('/tmp/cv2_circle10_outline.jpg', 10, 1)
/tmp/circle10.jpg
/tmp/cv2_circle10.jpg
/tmp/circle10_outline.jpg
/tmp/cv2_circle10_outline.jpg
違いは一目瞭然ですね。




- 投稿日:2020-04-05T18:18:08+09:00
Google Colaboratoryを使って無料で第一原理計算
最近、新型コロナで実験ができない人のために「物性実験家のための無料でできる第一原理計算入門」
https://cometscome.github.io/DFT/build/
という記事を書いているのですが、その過程でGoogle Colabだけで第一原理計算をする方法がわかりましたので、こちらでもシェアしたいと思います。必要なもの
- ブラウザ
- Googleのアカウント
使うソフト
- Quantum Espresso:第一原理計算ソフト
- Atomic Simulation Environment (ASE):原子分子シミュレーションのためのPythonライブラリ https://qiita.com/cometscome_phys/items/4af134de6d959a7718b9
Quantum Espressoのインストール
Google ColabでQuantum Espressoを使うためには、Qunatum Espressoをソースからコンパイルする必要がありますが、以下のような方法で可能であることがわかりました。
ポイントは、FFTW3をインストールしておくことです。!git clone https://github.com/QEF/q-e.git !apt-get install -y libfftw3-3 libfftw3-dev libfftw3-doc %cd q-e !DFLAGS='-D__OPENMP -D__FFTW3 -D__MPI -D__SCALAPACK' FFT_LIBS='-lfftw3' ./configure --enable-openmpソースをダウンロードし、FFTW3をインストール、そしてコンパイル準備をしています。
次に、!make pwでQuantum Espressoのコアのコードであるpw.xを実行できます。
あとはポストプロセスツールである、pp:make ppもインストールしておきましょう。
さて、Google colaboratoryでOSSをビルドする
にありますように、ここでコンパイルしたバイナリは12時間後に消滅してしまいます。
ですので、from google.colab import drive drive.mount('/content/drive')を実行してご自分のGoogle Driveにバイナリを保存しておきましょう。次に使うときはこれを解凍して使います。
%cd /content/ !zip -r /content/drive/'My Drive'/q-e.zip q-eとしてq-e.zipを保存しておきます。
Quantum Espressoを実行できるように、環境変数を設定します。つまり、
import os os.environ['PATH'] = "/content/q-e/bin:"+os.environ['PATH']とします。
ASEのインストール
ASEのインストールは簡単で、
!pip install aseで入ります。
第一原理計算のテスト
では、実際に第一原理計算をやってみましょう。
NaClの構造最適化
NaClのディレクトリを作成し、移動します。
%cd /content !mkdir NaCl %cd NaClそして、擬ポテンシャルをダウンロードします。
!wget https://www.quantum-espresso.org/upf_files/Na.pbesol-spn-kjpaw_psl.1.0.0.UPF !wget https://www.quantum-espresso.org/upf_files/Cl.pbesol-n-kjpaw_psl.1.0.0.UPFこれはNaClディレクトリに入りました。
次に、
from ase.build import bulk from ase.calculators.espresso import Espresso from ase.constraints import UnitCellFilter from ase.optimize import LBFGS import ase.io pseudopotentials = {'Na': 'Na.pbesol-spn-kjpaw_psl.1.0.0.UPF', 'Cl': 'Cl.pbesol-n-kjpaw_psl.1.0.0.UPF'} rocksalt = bulk('NaCl', crystalstructure='rocksalt', a=6.0) calc = Espresso(pseudopotentials=pseudopotentials,pseudo_dir = './', tstress=True, tprnfor=True, kpts=(3, 3, 3)) rocksalt.set_calculator(calc) ucf = UnitCellFilter(rocksalt) opt = LBFGS(ucf) opt.run(fmax=0.005) # cubic lattic constant print((8*rocksalt.get_volume()/len(rocksalt))**(1.0/3.0))を実行すれば、NaClの構造最適化ができます。このコードでは擬ポテンシャルの場所を
pseudo_dirで指定しています。今回は今いるディレクトリですね。Cuのバンド図
次に、Cuのバンド図を計算してみます。
Cuのディレクトリを作成します。
%cd /content !mkdir Cu %cd Cu擬ポテンシャルをダウンロードします。
!wget https://www.quantum-espresso.org/upf_files/Cu.pz-d-rrkjus.UPF自己無撞着計算をして、電子密度を決定します。電子密度が決定されれば、各k点での計算をすることでバンド図を 描くことができます。
from ase import Atoms from ase.build import bulk from ase.calculators.espresso import Espresso atoms = bulk("Cu") pseudopotentials = {'Cu':'Cu.pz-d-rrkjus.UPF'} input_data = { 'system': { 'ecutwfc': 30, 'ecutrho': 240, 'nbnd' : 35, 'occupations' : 'smearing', 'smearing':'gauss', 'degauss' : 0.01}, 'disk_io': 'low'} # automatically put into 'control' calc = Espresso(pseudopotentials=pseudopotentials,kpts=(4, 4, 4),input_data=input_data,pseudo_dir = './') atoms.set_calculator(calc) atoms.get_potential_energy() fermi_level = calc.get_fermi_level() print(fermi_level)そして、バンド図のための計算をします。
input_data.update({'calculation':'bands', 'restart_mode':'restart', 'verbosity':'high'}) calc.set(kpts={'path':'GXWLGK', 'npoints':100}, input_data=input_data) calc.calculate(atoms)ここで、kptsのpathに好きなブリルアンゾーンの点を入れることで、簡単にバンド図を描くことができるのがASEの面白い点です。
最後にバンド図を計算します。
import matplotlib.pyplot as plt bs = calc.band_structure() bs.reference = fermi_level bs.plot(emax=40,emin=5)
これで、ブラウザだけで第一原理計算を実行できるようになりました。