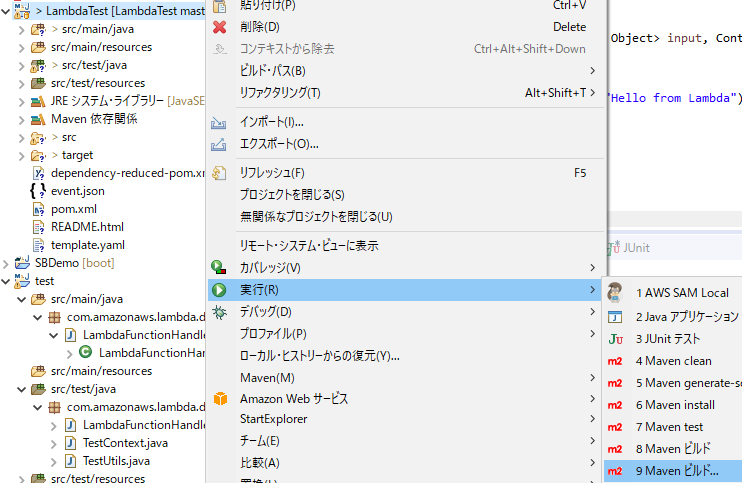
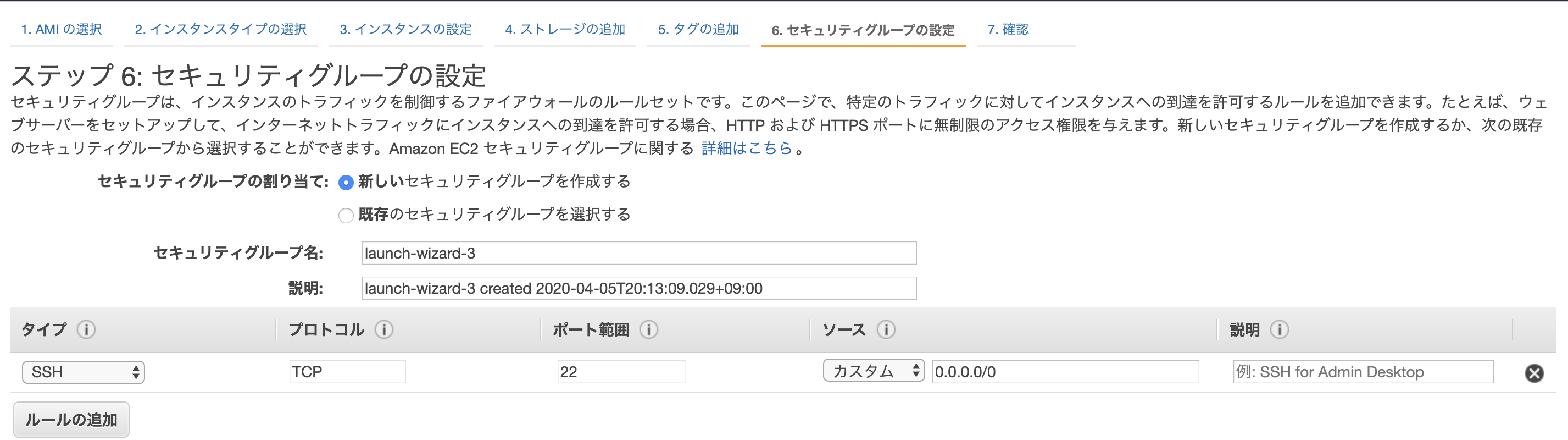
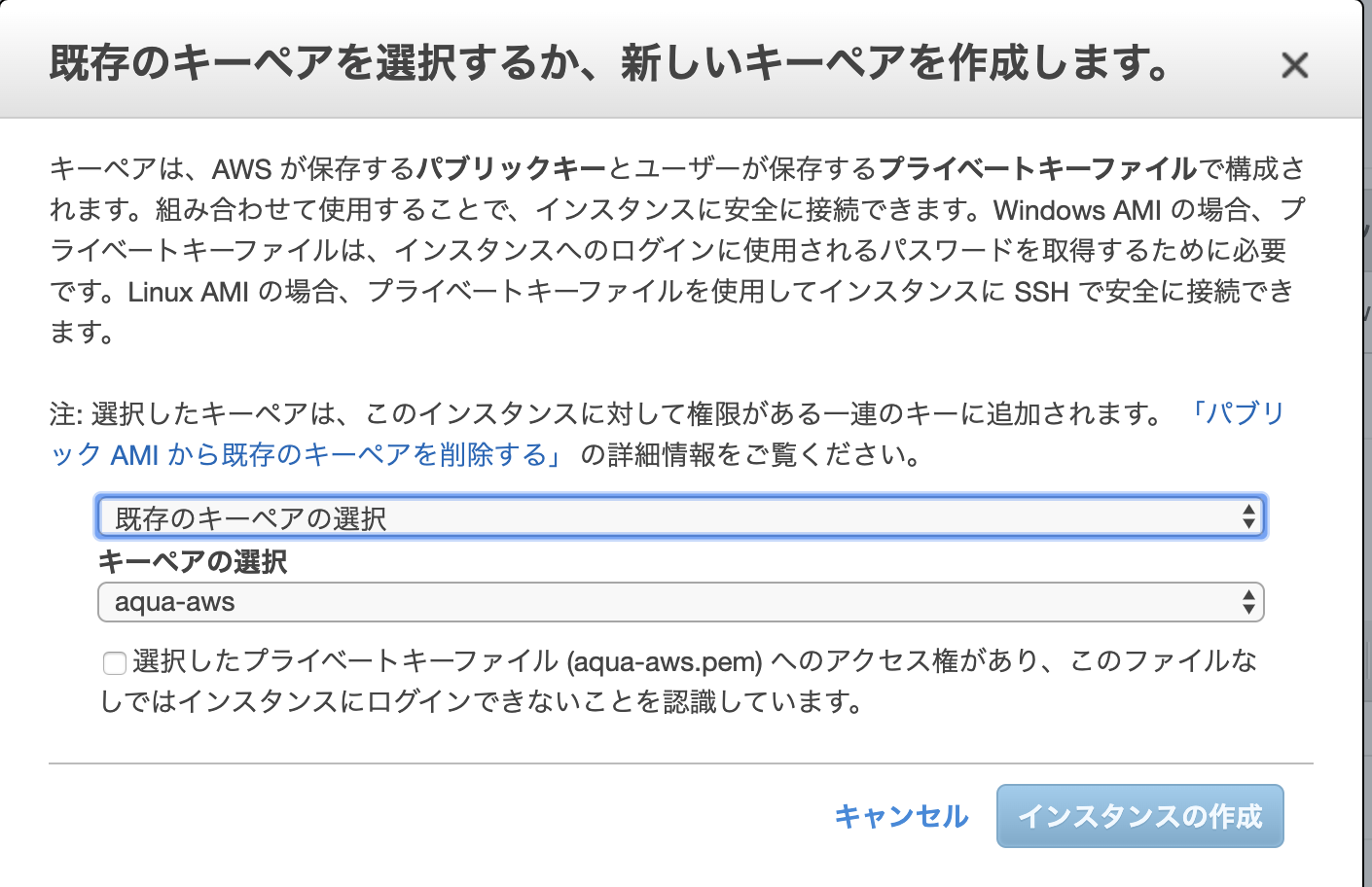
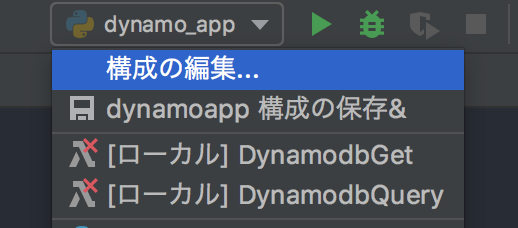
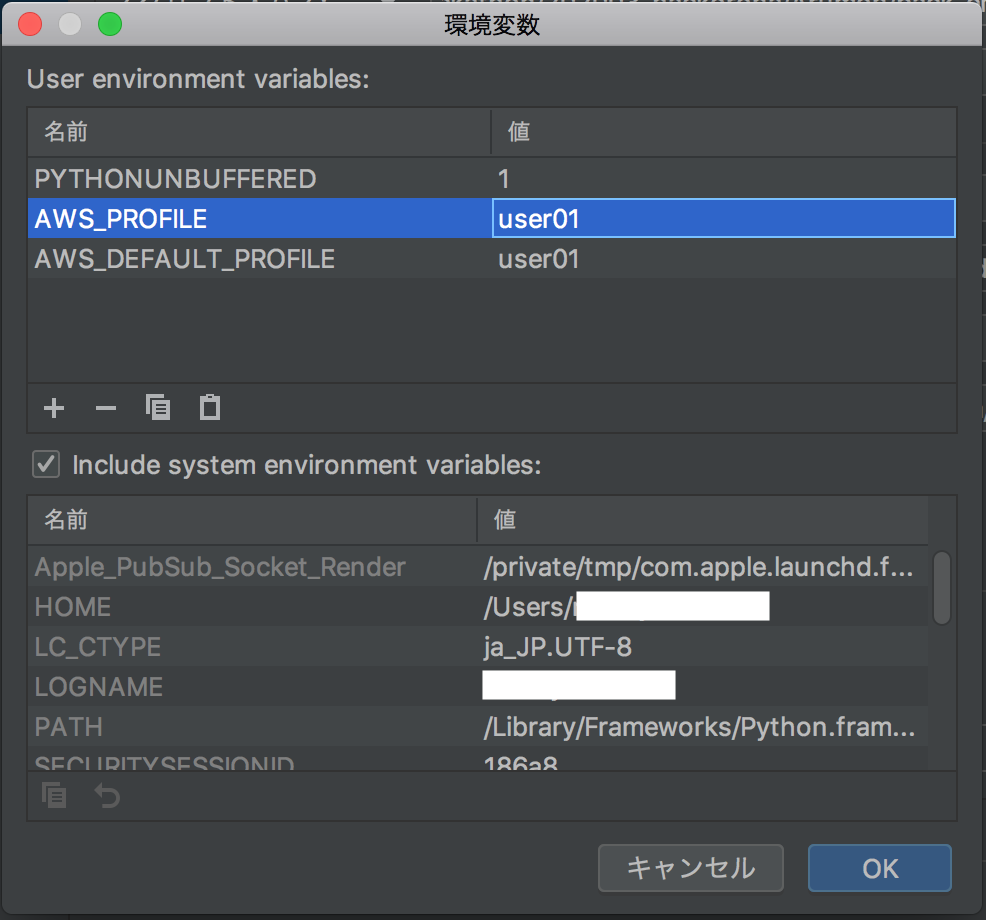
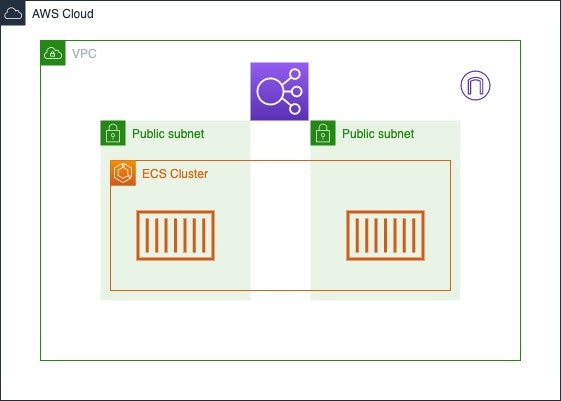
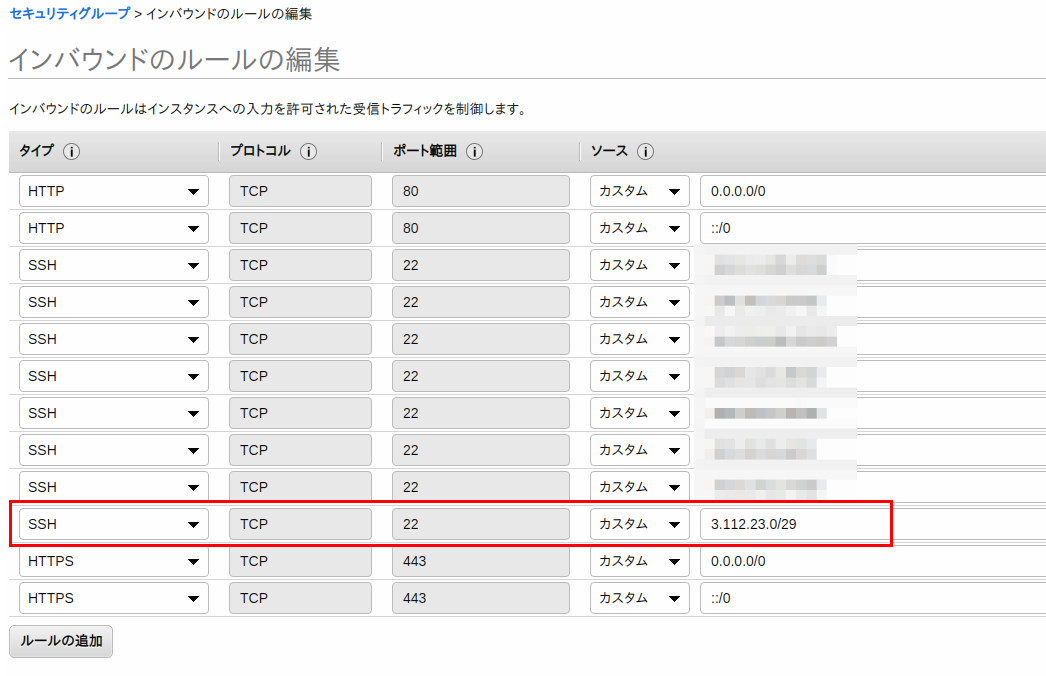
SAM Localは、ローカル環境でLambda関数を実行したり、DynamoDBに接続したりできるもの。
今回くらいのお試しだと、SAM Localの起動時間のオーバーヘッドの方が大きいので素直にアップロードしてテスト入力してみる方が早いけど、単体試験で回帰テストやるつもりならあっても良いかも。それとてJUnitでも良い気はするけど……
Unable to locate credentials. You can configure credentials by running "aws configure".
Error: Cannot perform an interactive login from a non TTY device
npm i @aws-cdk/aws-elasticloadbalancingv2
npm i @aws-cdk/aws-ecs
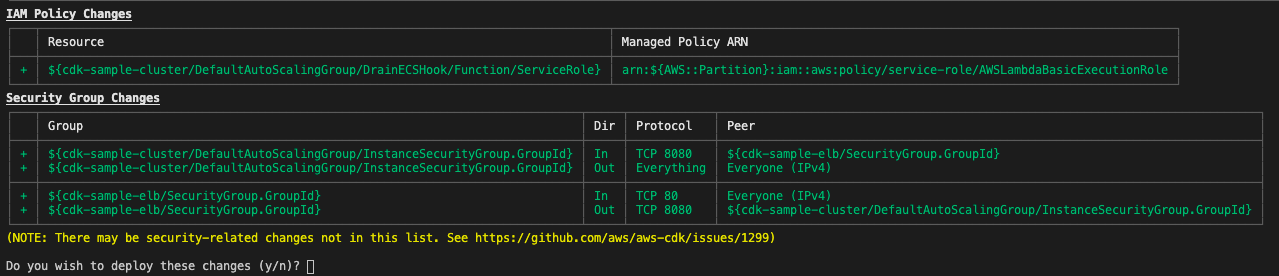
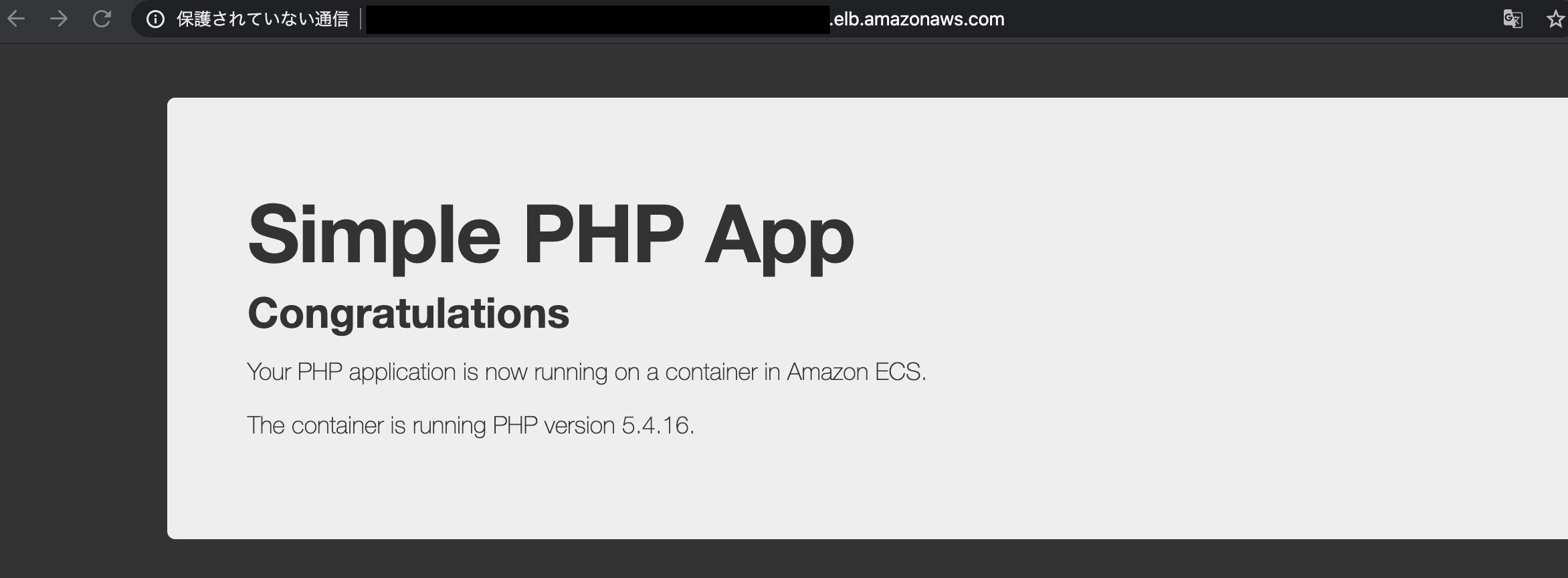
実装
.ts
import*ascdkfrom'@aws-cdk/core';// 使うモジュールimport*aselbfrom'@aws-cdk/aws-elasticloadbalancingv2';import*asec2from'@aws-cdk/aws-ec2';import*asecsfrom'@aws-cdk/aws-ecs';exportclassElbSampleStackextendscdk.Stack{constructor(scope:cdk.App,id:string,props?:cdk.StackProps){super(scope,id,props);// Create a clusterconstvpc=newec2.Vpc(this,'cdk-sample-vpc',{maxAzs:2});constcluster=newecs.Cluster(this,'cdk-sample-cluster',{vpc});cluster.addCapacity('DefaultAutoScalingGroup',{instanceType:ec2.InstanceType.of(ec2.InstanceClass.T2,ec2.InstanceSize.MICRO)});// Create Task DefinitionconsttaskDefinition=newecs.Ec2TaskDefinition(this,'cdk-sample-taskDef');constcontainer=taskDefinition.addContainer('web',{image:ecs.ContainerImage.fromRegistry('amazon/amazon-ecs-sample'),memoryLimitMiB:256});container.addPortMappings({containerPort:80,hostPort:8080,protocol:ecs.Protocol.TCP});// Create Serviceconstservice=newecs.Ec2Service(this,'cdk-sample-service',{cluster,taskDefinition});// Create ALBconstlb=newelb.ApplicationLoadBalancer(this,'cdk-sample-elb',{vpc,internetFacing:true});constlistener=lb.addListener('PublicListener',{port:80,open:true});// Attach ALB to ECS Servicelistener.addTargets('ECS',{port:80,targets:[service.loadBalancerTarget({containerName:'web',containerPort:80})],// include health check (default is none)healthCheck:{interval:cdk.Duration.seconds(60),path:'/health',timeout:cdk.Duration.seconds(5)}});newcdk.CfnOutput(this,'LoadBalancerDNS',{value:lb.loadBalancerDnsName});}}