- 投稿日:2020-04-05T23:13:00+09:00
【Java】StreamAPIでズンドコキヨシ
はじめに
少し前に流行った「ズンドコキヨシ」を久しぶりにこちらの記事で見つけたので、私もJavaを使ってズンドコキヨシを作ってみることにしました。
ついでにfor文を封印して、StreamAPIの復習をしてみました。作成したコード
- 「ズン」もしくは「ドコ」のいずれかを格納した長さ5のListを作ります。
Stream.generate()を使う場合、Streamが無限に続かないようにlimitを付ける必要があります。- Listを半角スペースでJoinした結果が「ズン ズン ズン ズン ドコ」になるまで、
do~whileのループを繰り返します。
- 必ず1回はループに入るので、最初に終了条件を判定する
whileではなく、最後に終了条件を判定するdo~whileを使いました。- 最後に「キヨシ!!」を付け足して標準出力します。
ZundokoStream.javapackage zundoko; import java.util.List; import java.util.Random; import java.util.stream.Collectors; import java.util.stream.Stream; public class ZundokoStream { public static void main(String[] args) { Random rnd = new Random(); String[] zunDoko = { "ズン", "ドコ" }; String songLyrics = ""; do { List<String> phrases = Stream.generate(() -> zunDoko[rnd.nextInt(2)]) .limit(5) .collect(Collectors.toList()); songLyrics = String.join(" ", phrases); } while (!songLyrics.equals("ズン ズン ズン ズン ドコ")); System.out.print(songLyrics); System.out.println(" キヨシ!!"); } }実行結果ズン ズン ズン ズン ドコ キヨシ!!参考URL
- 投稿日:2020-04-05T18:25:38+09:00
ScalaはJVM上で動くんだよ
JREとJDK
JREは(Java Runtime Environment) で実行環境
JDKは(Java Development kit) で開発ツール
のことである。
scalaではJDKを使用する。コンパイル済みのプログラムを実行するだけであればJREでOK
プログラムをコンパイルする必要があるのならJDKが必要となる
JDKはJREも同梱するのでscalaではJDKをインストールすれば問題ない。コマンドの種類
JavaコマンドはJavaアプリケーションを起動するコマンド
JavacコマンドはjavaソースコードをコンパイルするためのコマンドscalaがJVM上で動くメリット
・OSの差異などに左右されずポータルな実行プログラムである。
・java標準ライブラリをはじめ、既存のjavaモジュールを呼び出すことができる。
今まで蓄積されたjavaのナレッジの恩恵を受けることができる・実行時パフォーマンスがある程度高速である。
JVM上で動くデメリット
メリットがあれば当然デメリットがあるというもの
・サーバアプリケーションなどの常時稼働の用途では問題にならないが、コマンドラインなどから都度実行する用途ではJVM起動時に一定の時間がかかることがネックとなる場合がある。
・Goなどの実行時のメモリフットプリントが小さい言語と比較すると、小規模なアプリケーションでもそれなりにメモリの使用量が大きい。
上記のデメリットがある。Scalaのイベント
近年サービス運営企業を中心に利用する企業が増加傾向にある。
アジア地域で最大級のScalaのカンファレンスが毎年東京で開催されている。その名も「Scala Matsuri」
次回の開催時には参加してみたいですね。開発環境
テキストエディタ派とIDE派が存在している。
参考書籍
- 投稿日:2020-04-05T17:47:54+09:00
mDNSでAndroidからRaspberryPiを探す
Raspberry Pi
avahi-daemonの設定
avahi-daemonのインストール(入っていなければ)
sudo apt-get install avahi-daemon設定変更
sudo vi /etc/avahi/avahi-daemon.confnoになっているとAndroid側で探索が出来なかった
avahi-daemon.conf[publish] publish-workstation=yesavahi-daemon.service再起動
sudo systemctl restart avahi-daemon.servicehost名確認
cat /etc/hostname <Hostname>Android
これをみた方が早いとは思う(参考)
https://developer.android.com/training/connect-devices-wirelessly/nsd.html許可取り
AndroidManifest.xml<uses-permission android:name="android.permission.INTERNET"/>メンバー変数
String TAG = "MainActivity"; //確認したホスト名に変えておく String serviceName = "<Hostname>"; private NsdManager nsdManager; private NsdManager.DiscoveryListener discoveryListener; private NsdManager.ResolveListener resolveListener; private NsdServiceInfo mService;イニシャライズ
@Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); nsdManager = (NsdManager)(getApplicationContext().getSystemService(Context.NSD_SERVICE)); initializeResolveListener(); initializeDiscoveryListener(); nsdManager.discoverServices(SERVICE_TYPE, NsdManager.PROTOCOL_DNS_SD, discoveryListener); }関数定義
public void initializeDiscoveryListener() { discoveryListener = new NsdManager.DiscoveryListener() { @Override public void onDiscoveryStarted(String regType) { Log.d(TAG, "Service discovery started"); } @Override public void onServiceFound(NsdServiceInfo service) { //見つかるのが<hostname>.local[<macアドレス>]みたいな感じだったのでcontainsで対応 if (service.getServiceName().contains(serviceName)) { nsdManager.resolveService(service, resolveListener); Log.d(TAG, "Same machine: " + serviceName); } } @Override public void onServiceLost(NsdServiceInfo service) { Log.e(TAG, "service lost: " + service); } @Override public void onDiscoveryStopped(String serviceType) { Log.i(TAG, "Discovery stopped: " + serviceType); } @Override public void onStartDiscoveryFailed(String serviceType, int errorCode) { Log.e(TAG, "Discovery failed: Error code:" + errorCode); nsdManager.stopServiceDiscovery(this); } @Override public void onStopDiscoveryFailed(String serviceType, int errorCode) { Log.e(TAG, "Discovery failed: Error code:" + errorCode); nsdManager.stopServiceDiscovery(this); } }; } public void initializeResolveListener() { resolveListener = new NsdManager.ResolveListener() { @Override public void onResolveFailed(NsdServiceInfo serviceInfo, int errorCode) { // Called when the resolve fails. Use the error code to debug. Log.e(TAG, "Resolve failed: " + errorCode); } @Override public void onServiceResolved(NsdServiceInfo serviceInfo) { Log.e(TAG, "Resolve Succeeded. " + serviceInfo); if (serviceInfo.getServiceName().equals(serviceName)) { Log.d(TAG, "Same IP."); return; } mService = serviceInfo; int port = mService.getPort(); InetAddress host = mService.getHost(); } }; }全文
MainActivity.javapublic class MainActivity extends AppCompatActivity { String TAG = "MainActivity"; //確認したホスト名に変えておく String serviceName = "<Hostname>"; private NsdManager nsdManager; private NsdManager.DiscoveryListener discoveryListener; private NsdManager.ResolveListener resolveListener; private NsdServiceInfo mService; // raspberry service type private static final String SERVICE_TYPE = "_workstation._tcp."; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); nsdManager = (NsdManager)(getApplicationContext().getSystemService(Context.NSD_SERVICE)); initializeResolveListener(); initializeDiscoveryListener(); nsdManager.discoverServices(SERVICE_TYPE, NsdManager.PROTOCOL_DNS_SD, discoveryListener); } public void initializeDiscoveryListener() { discoveryListener = new NsdManager.DiscoveryListener() { @Override public void onDiscoveryStarted(String regType) { Log.d(TAG, "Service discovery started"); } @Override public void onServiceFound(NsdServiceInfo service) { Log.d(TAG, "Service discovery success" + service); if (!service.getServiceType().equals(SERVICE_TYPE)) { Log.d(TAG, "Unknown Service Type: " + service.getServiceType()); } else if (service.getServiceName().equals(serviceName)) { Log.d(TAG, "Same machine: " + serviceName); } else if (service.getServiceName().contains("NsdChat")){ nsdManager.resolveService(service, resolveListener); } } @Override public void onServiceLost(NsdServiceInfo service) { Log.e(TAG, "service lost: " + service); } @Override public void onDiscoveryStopped(String serviceType) { Log.i(TAG, "Discovery stopped: " + serviceType); } @Override public void onStartDiscoveryFailed(String serviceType, int errorCode) { Log.e(TAG, "Discovery failed: Error code:" + errorCode); nsdManager.stopServiceDiscovery(this); } @Override public void onStopDiscoveryFailed(String serviceType, int errorCode) { Log.e(TAG, "Discovery failed: Error code:" + errorCode); nsdManager.stopServiceDiscovery(this); } }; } public void initializeResolveListener() { resolveListener = new NsdManager.ResolveListener() { @Override public void onResolveFailed(NsdServiceInfo serviceInfo, int errorCode) { // Called when the resolve fails. Use the error code to debug. Log.e(TAG, "Resolve failed: " + errorCode); } @Override public void onServiceResolved(NsdServiceInfo serviceInfo) { Log.e(TAG, "Resolve Succeeded. " + serviceInfo); if (serviceInfo.getServiceName().equals(serviceName)) { Log.d(TAG, "Same IP."); return; } mService = serviceInfo; int port = mService.getPort(); //欲しいhost名 InetAddress host = mService.getHost(); } }; } }
- 投稿日:2020-04-05T17:20:48+09:00
【Java】 Stream(filter, map, forEach, reduce)
概要
「streamで書いて!」と言われてメリットがわからなかったのでまとめる。
わかったこと
- streamめっちゃ便利。
- for文やif文のネストが減って見やすい。
- リストのインスタンス化をしなくてもよくて良い。
- .addとかも書かなくて良いから、コード量が減って良い。
filter : 条件の絞り込み
List<String> tanakaList = list.stream .filter(item -> item.getName.equals("田中")) .collect(Collectors.toList());<解説>
- 「list」をstreamで分解する。
- 「item」の中に「list」から要素を一つずつ取得して入れる。
filterで名前が"田中"のオブジェクトだけに絞り込む。- 分解していたstreamを集めて、collectでリストに変換する。
- 戻り値「tanakaList」にセットする。
<使って良かったこと>
- ネストが少ない。
- リストのインスタンス化を自分で書かなくて良い。
- セッターを書かなくて良い。
(list.add()で行数取ってたから、なくなってマジで良かった……)
<気になったこと>
if-elseのような分岐ができない。もしやりたい場合は、streamを2つ用意して、別の処理として書く必要がある。
sqlでソートしてデータ取得などした時にstreamを使うと、stream側でもう一度ソートの処理を書かないといけないので、ソート順を気ににする処理では使わないほうがいいかなと思った。
map:値の変換
List<String> nameList = list.stream .map(item -> item.getName) .collect(Collectors.toList());<解説>
- 「list」をstreamで分解する。
- 「item」の中に「list」から要素を一つずつ取得して入れる。
mapで「item」からメソッドを使って名前を取得し「item」の値を加工する。- 分解していたstreamを集めて、collectでリストに変換する。
- 戻り値「nameList」にセットする。
<使って良かったこと>
- ネストが少ない。
- リストのインスタンス化を自分で書かなくて良い。
- セッターを書かなくて良い。
- メソッドが使えるから、itemに何が入っているのか一目瞭然で良かった。
forEach:ループ処理
list.stream .filter(item -> !item.getName.equals("田中")) .forEach({ item -> throw new Exception( "don't tanaka exception." ) });<解説>
- 「list」をstreamで分解する。
- 「item」の中に「list」から要素を一つずつ取得して入れる。
filterで名前が"田中ではない"オブジェクトを絞り込む。forEachでループを回して、田中以外のオブジェクトがあった場合「田中じゃないよ」Exceptionをなげる。<使って良かったこと>
- ネストが少ない。
- for(String tanaka : list) すら書かなくて良い。
- どの場合に何を処理するのかが見やすい。
reduce:要素の集計
int total = list.stream() .reduce((base, value) -> { return base + value; });
リストの中身List<int> list = Lists.newArrayList(); list.add(1); list.add(2); list.add(3);<解説>
- 「list」をstreamで分解する。
- 「base」の中に「list」から要素を一つずつ取得して「最初の要素」を入れる。
- 「value」の中に「list」から要素を一つずつ取得して「次の要素」を入れる。
- 1回目にreduceが実行されるとき、base=1、value=2で実行される。
- 2回目はbase=2、value=3で実行される。
- 全て足したものをreturnし戻り値にセットする。
わからなかったこと
1:なぜ「item.getName」のようにメソッドが使えるのか。
-> 名前をSQLから取得したmodelクラス「Student」がある。
listを「List list」で定義すると、
Streamでlistを分解してitemに入れていることから、
itemの型は「Student」であることがわかる。
だから、Studentクラスに存在するメソッドが使える!!
getNameメソッドはStringを返すから、戻り値も問題ない。
Studentクラス@Data @Builder class Student { private String name; }
Stream.javaList<Student> list = Lists.newArrayList(); List<String> tanakaList = list.stream .map(item -> item.getName.equals()) .collect(Collectors.toList())まとめ
ラムダも使い慣れていなかったし、streamって何やねん状態だったけど、使ってみたら圧倒的にコード量が減ったから良かった。一番のメリットはネストの深さが一気に解消されたこと。こんな便利なの知ってしまったら、今後取り憑かれたように使っちゃうなと思った。だから、自分がまだ知らないデメリットとかあったら怖いなと思った。(でも、しばらくは使い倒すと思う、先輩教えてくれてありがとう……)
- 投稿日:2020-04-05T10:25:03+09:00
Java Gold SE8 に合格したお話
はじめに
やっとこさ「Oracle Certified Java Programmer, Gold SE 8」を取得できました。
結果としては正答率87%でした。(65%以上で合格) 受ける前不安でしたが案外やれましたね…。Javaの資格取るメリットとか、実際の試験に関する所感など書いていきます。
Java Gold SE8 ってなんぞや?
Oracleが認定するJavaプログラマの資格です。Bronze、Silver、Goldと3つあり
難易度は[Bronze < Silver < Gold] となっています。
受験料は税込みで3万ペリカくらいします。 これじゃ地上に出られない!!
あとGoldには取得条件があり、事前にSilverの資格を取得していることが必要条件となります。ちなみにSE8っていうのはJavaのバージョンのことを指しています。
Goldをの資格を取得する(学習する)メリット
Javaのクラスやメソッドの具体的な使い方等を網羅している感じですね。
あと、「Stream API」という分野が大きくフォーカスされています。
これを学習するとfor文とかif文とかいっぱい書いてて可読性の悪いコードも簡潔に書けるようになります。
他には、並列処理とかファイル操作とかデータベースの接続についても範囲に含まれます。(他にもありますが省略します)学習するメリットとしては下記のような感じだと思います。
- 簡潔に可読性の高いコードを書く技術が身に着けられる。
- 実務で実際に使われるようなメソッド等(ファイル操作とかデータベース接続とか)を理解することができる。
- 処理の高速化について知ることができる(並列処理、ここは結構難しいです笑)
つまり、
Silverではオブジェクト指向言語の特性について学習しますが、GoldではJavaのクラスやメソッドについて多く言及していることが分かるかと思います。ただしSilverと重複する部分も範囲には含まれています。Goldでの学習時間の目安
実務経験の浅い人がやるには学習量はそこそこ多いと思います。
ちなみに私は実務経験の浅い人に該当します。
120時間くらいの学習時間は見ておいた方がいいかも。(しっかり網羅して理解しようと思うならもっと必要だと思う)Goldでの学習の方法について
ここに関しては持論です。
まずは紫本でしっかり説明を見て自分でコーディングして動作確認しながら進めるのが良いと思います。
紫本は黒本と比べても解説が丁寧にされています。
コーディングした方が良い理由については、実際に動作させてみた方が納得感があるし、コーディングの途中に思わぬ発見があったりします。(コンパイルエラーとか) あと、本だけで勉強すると内容がなかなかインプットされません。概念やどういうメソッドがあるのか軽く頭に入った状態で黒本の問題に着手した方が精神的に安全な気がします。
全く何も知らない状態で黒本解こうとするとイライラするかも。(ちなみにSilverの時は黒本オンリーで勉強してました。解説丁寧だし。)Goldの試験について
Silverの試験と比較すると、引っ掛け問題的な要素は弱くなっているように思えました。
どちらかというとメソッドを使用した時の挙動とか理解できているかどうかが重要な感じ。
つまりしっかり勉強しているとしっかり点数が取れる印象でもあります。あと、やはり黒本が最強でした。 私は黒本と紫本両方使って学習しましたが
試験で高得点とれた要因としては確実に黒本です。 ただ、詳しく解説が書かれているのは紫本。
Javaの学習としては紫本、試験対策としては黒本ですね。 まあ個人的には両方使用することを推奨します。黒本が最強といった理由としては、まず既視感のある問題が多かったです。
学習としては良くないですが、たまたま答え覚えてたやつがそのまま出るみたいな。
そういう意味ではSilverと同じだったかもしれません。
関数型インターフェースやStreamAPIとか主要なとこしっかり網羅して、黒本の総合演習2周くらいしてればいい線いけるのかも。まあ後は、Silverと同じでキャンペーン中であれば再受験無料ってのがあるので絶対確認しておいた方がいいです。
- 投稿日:2020-04-05T01:07:16+09:00
EclipseでSpring pom.xmlでMaven構成問題
開発環境
- Windows 10
- Eclipse Version: Oxygen.3a Release (4.7.3a)
事象
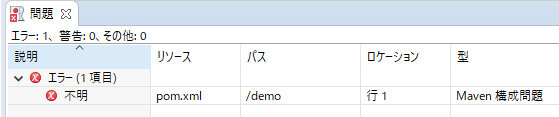
STSで新規作成したばかりのSpring Bootプロジェクトで、pom.xmlの1行目がエラーになる。
Eclipseは「pleiades-2019-03-java-win-64bit-jre_20190508」を使用。原因
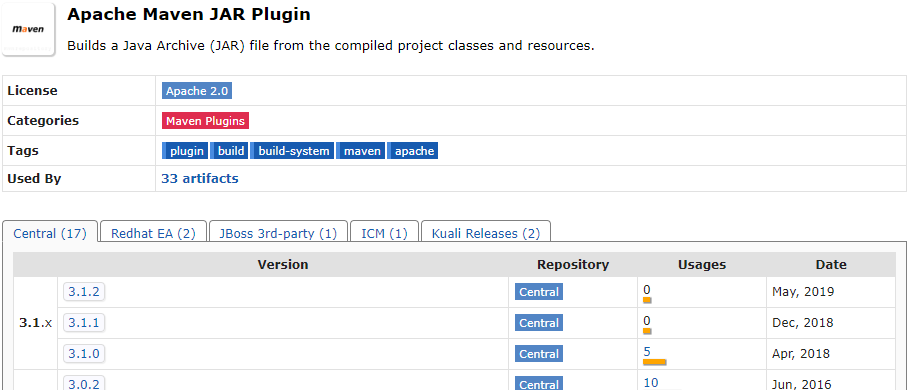
maven-jar-pluginの現時点での最新版3.1.2のバグ?
対処
npmrepositoryで確認すると3.1.2が最新。
バージョンを一つ落として3.1.1にすると解決。pom.xml<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.1.6.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.example</groupId> <artifactId>demo</artifactId> <version>0.0.1-SNAPSHOT</version> <name>demo</name> <description>Demo project for Spring Boot</description> <properties> <java.version>11</java.version> <!-- 追加 --> <maven-jar-plugin.version>3.1.1</maven-jar-plugin.version> </properties>暫定対処?
3.1.3が出たら直る?取りあえず暫定対処ということで。