- 投稿日:2020-03-30T23:34:05+09:00
AWSのLambdaでタグのついているインスタンスの情報を辞書形式で取得する方法
EC2インスタンスを自動起動したり自動停止したりするLambdaをつくるときに使います。Lambdaをつくってもすぐに忘れるので残します。
Lambda関数
- ランタイム : Python3.8
# -*- coding: utf-8 -*- from __future__ import print_function import boto3 # インスタンスがあるリージョンを指定する REGION_NAME = 'us-east-2' # インスタンスの状態をリストで指定する STATE_LIST = ['running','stopped'] # インスタンスにつけているタグの名前をリストで指定する TAG_LIST = ['Name','AutoStop'] def get_instance_list(ec2): """ タグとステータスを指定してインスタンスを取得する. """ instances = ec2.describe_instances( Filters=[ {'Name': 'instance-state-name', 'Values': STATE_LIST}, {'Name': 'tag-key', 'Values': TAG_LIST} ] )['Reservations'] if len(instances) != 0: instances = instances[0]['Instances'] return instances def lambda_handler(event, context): ec2 = boto3.client('ec2', REGION_NAME) instances = get_instance_list(ec2) print(instances) return 0定数に設定する内容
関数を実行するための権限
上記の関数では
describe_instancesを使用するため、ec2:DescribeInstancesをIAMのポリシーに設定する必要がある。IAMポリシー例{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "ec2:DescribeInstances" ], "Resource": "*" } ] }取得できるインスタンス情報
取得できる辞書形式のインスタンス情報は、EC2 — Boto 3 Docs 1.12.31 documentation - describe_instancesの「Returns」に記載されている
Instancesキーの内容となる。

- 投稿日:2020-03-30T23:25:13+09:00
Djangoで、WEBアプリケーションを作ってみた
はじめに
本記事は、Djnagoで、WEBアプリケーションを作成したした際の備忘録として書いたものである。
前提条件
- OS環境は、Virtualboxで稼働中のCentOS8.1です。以下、OS詳細情報となります。
# cat /etc/centos-release CentOS Linux release 8.1.1911 (Core)
- 本記事では、AdminLTEを用いたTOPページの作成及びログインユーザのみのアクセス制限をDjangoで実装した内容です。 それを全5章分の記事にまとめました。
実施手順
①Django 環境構築
②Django 環境設定&管理者サイト表示
③Django アプリケーション設定
④Django デザイン設定
⑤Django ログイン機能の実装※まだ、仮段階で作っているので、修正予定です。
最後に
Djangoは、色々用意されていて便利だが、それを理解するまでに少し時間がかかってしまった。
この記事は、そんな私が今後見返した時に思い出せるように書いたものなので、
みすぼらしい箇所がいくつかあると思いますがご了承ください(´;ω;`)
- 投稿日:2020-03-30T22:38:15+09:00
ニューラルネットでの簡単な分類モデル
前回に引続き、ニューラルネットについての勉強をしてみました。
今回は、簡単な分類モデルの構築に挑戦。
以下の2つの変数を準備します。0 \le x_1,x_2 \le 1そして、2つの和によって、以下のような分類をしてみる。
t(x_1,x_2) = \left\{ \begin{matrix} 0 & (x_1 + x_2 < 1) \\ 1 & (x_1 + x_2 \ge 1) \end{matrix} \right.こんなシンプルなモデルを実装してみます。
0層??のニューラル考え方としては、以下の数式を検討します。y(x_1,x_2) = \sigma(w_1 x_1 + w_2 x_2 + w_0)ただし、σはシグモイド関数で、そのアウトプットは[0,1]に限定されます。これが本当特徴的で、y<0.5なら分類A、y>0.5なら分類B、のような意味を持たせているようです。実はこれって結構肝の部分な気がします。ニューラルネットでは、w1,w2,w0を調整することで、答えを出すような仕組み。ということで、誤差を見積もるファンクションを検討すると、この場合は交差エントロピーになるようです。具体的には、x1,x2に対して正解tを与えたとき、その交差エントロピーは以下のように表現されます。
E(w_1,w_2,w_0) = - (t \ln y + (1-t) \ln (1-y) )詳細は、「パターン認識と機械学習」などを参照していただく(p.235あたり)として、ざっくりとしたイメージとしては・・・。0<y<1に注意して
- yをクラスAの確率と見なす(t=1のとき)
- 1-yをクラスBの確率と見なす(t=0のとき)
すると、tが与えられたときの確率p(t)は、X^0=1を利用して式を1本化することで
p(t)= y^t (1-y)^{1-t}となるようです。あとはログをとれば、E(w1,w2,w0)の式が導出されます。これを各サンプルごとに掛け算するので、各yiに対して
p(t)= \prod_i y_i^t (1-y_i)^{1-t}となるので、ログをとって
\ln p(t)= \sum_i (t \ln y_i + (1-t) \ln (1-y_i) )となります。これは正解率の和のような感じなので、合っているほど値が大きくなります。そこで、最適化(最小化)問題として解くために符号を反転させてEを定義しました。繰り返しますが、以下の交差エントロピーになります。(複数サンプルバージョン)
E(w_1,w_2,w_0) = - \sum_i (t \ln y_i + (1-t) \ln (1-y_i) )では、実際にソースコードを書いてみます。
まずは、変数部分。# make placeholder x_ph = tf.placeholder(tf.float32, [None, 3]) t_ph = tf.placeholder(tf.float32, [None, 1])x_phは入力部分、本当は2つのはずですが、w0用のダミー変数(1固定)を入れておきました。これはいらないかも?
t_phは出力部分で、正解を与えるためのものです。0か1が入ります。そして、これに入れるサンプルデータは適当に乱数で設定します。
# deta making??? N = 1000 x = np.random.rand(N,2) # sum > 1.0 -> 1 : else -> 0 t = np.floor(np.sum(x,axis=1)) # ext x x = np.hstack([x,np.ones(N).reshape(N,1)])xを2つ作ったのち、yを作って、その後、ダミー変数を1個追加してます。これによって、xは1サンプルで3次元となっています。yはx1+x2が1以上のときに1、1未満では0となるように、小数点切捨てを利用して作成しています。
そして、ニューラルネットワークの層はとりあえず2つほど準備。
# create newral parameter(depth=2,input:3 > middle:30 > output:1) hidden1 = tf.layers.dense(x_ph, 30, activation=tf.nn.relu) newral_out = tf.layers.dense(hidden1, 1, activation=tf.nn.sigmoid)あとは、交差エントロピーを定義して、最小化するように学習を定義します。単なるコピペですね。収束アルゴリズム設定など、まだよくわかっていません。
# Minimize the cross entropy ce = -tf.reduce_sum(t_ph * tf.log(newral_out) + (1-t_ph)*tf.log(1-newral_out) ) optimizer = tf.train.AdamOptimizer() train = optimizer.minimize(ce)というわけで、上記を適当に組み合わせて、全体のソースを作ってみました。
import numpy as np import tensorflow as tf # deta making??? N = 1000 x = np.random.rand(N,2) # sum > 1.0 > 1 : else > 0 t = np.floor(np.sum(x,axis=1)) # ext x x = np.hstack([x,np.ones(N).reshape(N,1)]) train_x = x train_t = t # make placeholder x_ph = tf.placeholder(tf.float32, [None, 3]) t_ph = tf.placeholder(tf.float32, [None, 1]) # create newral parameter(depth=2,input:3 > middle:30 > output:1) hidden1 = tf.layers.dense(x_ph, 30, activation=tf.nn.relu) newral_out = tf.layers.dense(hidden1, 1, activation=tf.nn.sigmoid) # Minimize the cross entropy ce = -tf.reduce_sum(t_ph * tf.log(newral_out) + (1-t_ph)*tf.log(1-newral_out) ) optimizer = tf.train.AdamOptimizer() train = optimizer.minimize(ce) # initialize tensorflow session sess = tf.Session() sess.run(tf.global_variables_initializer()) for k in range(1001): if np.mod(k,100) == 0: # get Newral predict data y_newral = sess.run( newral_out ,feed_dict = { x_ph: x, # xに入力データを入れている }) ce_newral = sess.run( ce ,feed_dict = { x_ph: x, # xに入力データを入れている t_ph: t.reshape(len(t),1) # yに正解データを入れている }) sign_newral = np.sign(np.array(y_newral).reshape([len(t),1]) - 0.5) sign_orig = np.sign(np.array(t.reshape([len(t),1])) - 0.5) NGCNT = np.sum(np.abs(sign_newral-sign_orig))/2 # check predict NewralParam print('[%d] loss %.2f hit_per:%.2f' % (k,ce_newral,(N-NGCNT)/N)) # shuffle train_x and train_t n = np.random.permutation(len(train_x)) train_x = train_x[n] train_t = train_t[n].reshape([len(train_t), 1]) # execute train process sess.run(train,feed_dict = { x_ph: train_x, # x is input data t_ph: train_t # t is true data }) # test用 x = np.array([0.41,0.5,1]).reshape([1,3]) loss_newral = sess.run( newral_out ,feed_dict = { x_ph: x, # xに入力データを入れている }) # <0.5なら成功かな print(loss_newral)これを動かすと以下のようになります。
[0] loss 727.36 hit_per:0.35 [100] loss 587.68 hit_per:0.78 [200] loss 465.78 hit_per:0.89 [300] loss 358.70 hit_per:0.93 [400] loss 282.45 hit_per:0.94 [500] loss 230.54 hit_per:0.96 [600] loss 194.34 hit_per:0.97 [700] loss 168.11 hit_per:0.98 [800] loss 148.34 hit_per:0.98 [900] loss 132.93 hit_per:0.99 [1000] loss 120.56 hit_per:0.99 [[0.27204064]]lossと書かれたところは、交差エントロピーの値、徐々に減っている様子が分かります。(変数名変えろよ・・・と突っ込み)
そして、hit_perは、学習データに対しての正解率。1.00で100%となりますが、99%の成功率のようです。
最後に、適当なテスト、x1=0.45,x2=0.5を入れたときのニューラルネットのアウトプットを出しています。この場合は、クラスBのt=0のはずなので、アウトプットは0.5より小さければ正解、かつ、0.5に近いほど迷っていると読み取れます。今回は0.27なので結構自信を持って答えてOKそうです。最後に正解の出し方について、ちょっとだけ書いておきます。ポイントはNGの数を出しているところだと思います。以下一部ピックアップ。
# get Newral predict data y_newral = sess.run( newral_out ,feed_dict = { x_ph: x, # xに入力データを入れている }) sign_newral = np.sign(np.array(y_newral).reshape([len(t),1]) - 0.5) sign_orig = np.sign(np.array(t.reshape([len(t),1])) - 0.5) NGCNT = np.sum(np.abs(sign_newral-sign_orig))/2y_newralには、xから推定した分類情報が[0,1]の範囲で入っています。この数値は、0.5より大きいか小さいかで、どちらの分類に入るか、という意味なので、それを判別できる形に変換する必要があります。そこで、0.5という数値を引いて、[-0.5,0.5]の範囲に平行移動してから、符号だけ取り出して、+1か-1のどちらかが選択されるようにしました。同様の処理を、t(正解)に対しても実施して、+1/-1の正解値を生成。
この二つは同じ値のときに正解、違う値のときには不正解なのですが、パターンを書き出すと、以下のような関係にあります。
推定値 正解値 推定の正しさ 推定値-正解値 1 1 OK 0 1 -1 NG 2 -1 1 NG -2 -1 -1 OK 0 そこで、sum(abs(推定値-正解値))/2を計算することによって、NGの数が数えられます。これを利用することで、正解率???HIT率が計算できました。
めでたく動いたわけですが、ニューラルネットの設定をもっとシンプルに、中間層なしでやると、収束に時間がかかったり、やりすぎて途中でゼロ割???っぽいことが起きるようでした。
例えば以下のような設定で行くと・・・newral_out = tf.layers.dense(x_ph, 1, activation=tf.nn.sigmoid)結果は???
[0] loss 761.80 hit_per:0.50 [100] loss 732.66 hit_per:0.50 [200] loss 706.48 hit_per:0.50 [300] loss 682.59 hit_per:0.50 [400] loss 660.61 hit_per:0.50 [500] loss 640.24 hit_per:0.54 [600] loss 621.26 hit_per:0.62 [700] loss 603.52 hit_per:0.70 [800] loss 586.88 hit_per:0.76 [900] loss 571.22 hit_per:0.80 [1000] loss 556.44 hit_per:0.84 [[0.52383685]]となって、なんだかいまひとつようです。何がどう利いているのか???私もまだまだ理解不足ですが、ある程度中間層があることで、何かが起きて、上手くいっているようです。
どこまで増やせばどんな状態になるのか?その辺りの理論も追々勉強していきたいと思います。
- 投稿日:2020-03-30T22:35:27+09:00
ウイイレのデータ集計自動化してみた Part4
ウイイレのデータ集計自動化してみた Part4
~WEBアプリケーション化してみよう!の一歩目!~
■はじめに
- どうもヤジュンです。 最近本業が忙しくて、記事を書くことができませんでした...(ださすぎ)
今回の記事は、 作成してきたソフトの「WEBアプリケーション化」を目指した一歩目の軌跡 を紹介します。
※本記事はシリーズものなので、前回記事と読み合わせることをお勧めします。
※本記事のソフトは、Pythonで作成しています。■参考URL■目的
- WEBアプリケーション化の第一歩として、
「ブラウザで対話的に動作するグラフを作成する」ことにしました。
※筆者はWEBアプリ作成の経験も知識もありません。■ライブラリの選定
今回使用したのはDashです。
グラフ表示と相性がよく、APIが綺麗にラップされているので、簡単に使用できます。
(図は、Dashで作成されたアプリの例!かっこいい!)
今後、どこまでアプリをリッチしていくかは何も計画してないので、
djangoで作っても良かったかも!!
プロジェクトの終着点が見えてない場合は、拡張機能ベースでライブラリを選定しておいて問題ないと思っています。■実際に使用してみよう!
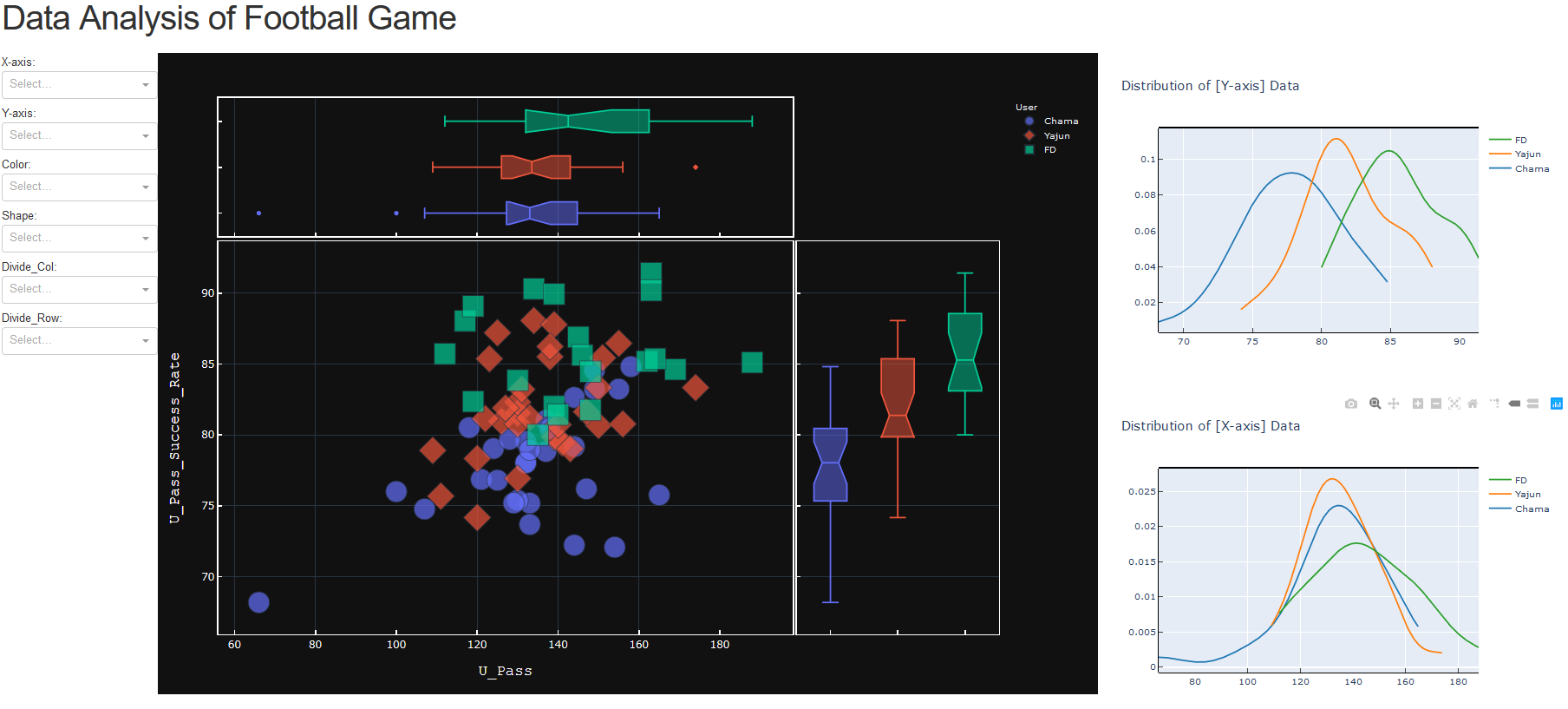
- デモとして作成した図の外観はこちら!
中央図は、part2の記事で書いたものと同じです。
X/Y軸の2つのパラメータ分布に対して、3つ目のパラメータがどのような関係を持っているかを、マーカーの色や形で分かるグラフです。右の2つの図は、中央図のX/Y軸パラメータのカーネル密度推定です。
※ざっくり「計測してない未知のデータを推定するために、計測データから作られたモデル」です!左のドロップリストからの入力で、グラフの各種パラメータを変更することが可能です。
では、左のドロップリストをベースに、操作方法を説明していきます!▶X-axis & Y-axis
- X/Y軸にセットするパラメータを選択できます。
ここにセットされたデータは、上で述べたように、右図の分布図ともリンクしています。
下のGifでは、X軸に「攻撃エリア中央の比率」Y軸に「パス成功率」をセットしています。
▶Color & Shape
- プロットの形と色を、どのパラメータによって分けるかを指定できます。
Colorのセット値は、右図の分布図の線ともリンクしています。
下のGifでは、試合結果の「勝」「敗」「分」で、プロットの色と形を変更しています。
▶Divide_Col & Divide_Row
- 情報が多すぎて図を見づらい場合、X/Y軸のパラメータによってグラフを分割できます。 下のGifでは、試合結果の「勝」「敗」「分」でグラフを分割しています。
■本変更のメリット
メリットは、以下の2つです。
「情報毎にソフトウェアを書き換える必要がない」
「解析者とユーザがデータをリアルタイムに見れる」
例えば、大会の解説者が「この大会ではカウンター主体のチームは、苦戦してますね」といっても、解説者の感覚は観衆に伝わらないことがあります。
そういった場面で、大会のデータから、「ポゼッション」や「ボール奪取数」などをグラフで見せることで、観衆の理解を助けるのです。「たしかに!データからもポゼッション45%以下のチームはほとんど勝ててないですね!」みたいな感じ市場やコミュニティを広げるには、何も分からないエントリー層への敷居をどれだけ下げれるかが重要です。データの可視化は手段の一つとして有力だと思います。
■ソフト開発の裏話
- 実は、アプリ開発より内部で使用するAPI作成のが難しかったりするんです。
アルゴリズムを組み合わせて、期待する能力にするには数学的センスが必要だったりするんです。 ただ、導線を考えて「使いやすい」「分かりやすい」「カッコいい」UIを作るのは、API作成と同じくらい難しいと思います。
ユーザを意識した開発は楽しくて、燃えますけどね!笑■今後の展望
- 以下の機能を追加します。
▼将来は、ソフトの基本機能は無料で使えるようにして、一部のサービスはマネタイズしたい
- 動画解析
- 他プレイヤーのデータライブラリへのデータアクセス権
- データアナリスト(しかも国体準優勝者)による個人用レポート分析
- 月次/週次くらいでユーザ全体の傾向をまとめたレポート配信
- 大会ごとの分析
とか■おわり
今回はここまで!!
アプリの配信はまだまーだ先です。力と工数不足です(´;ω;`)
これからも続けて行くので、Part5をお楽しみに!!PS:テスターの方にお願いした30試合って多かったかも。。。汗
30試合分提出してくださったのは、ちゃまさんとFDさんだけです笑■参考URL




- 投稿日:2020-03-30T21:52:05+09:00
Progate Python編 (2)
ProgateのPythonを全て終えたので感想を書きます。
正直少しでも他の言語をかじっていれば、まあまあ簡単にできるのではないでしょうか?
今度からは、Railsチュートリアルをやっていく予定です。
- 投稿日:2020-03-30T21:39:37+09:00
Poetry - Pipenv の代替
(追記 7000 秒ほど頑張ったが Resolving dependencies が終わらなかったので利用を諦めました。なんだこりゃ!)
Python の環境作成に今まで Pipenv という物を使っていた。node で言うと npm みたいな物だ。これがあまりにも遅いと苦情が出たので違うやつを探していたところ、検索すると Poetry https://python-poetry.org/ が比較的メジャーっぽい事が分かったので使ってみる。
Poetry とは、ある Python プロジェクトに必要なライブラリを簡単に準備する仕組みだ。他の Python プロジェクトと混ざらないように閉じた環境を作ってその中にライブラリをインストールする。Python 自体の実行ファイル選択には pyenv という別の仕組みを使う。Node の NPM と比較すると次のようになる。
- 閉じた環境の作成:
- Python:
poetry installで環境を作成してライブラリをインストールする。
- ライブラリ本体は Virtual environment path という所に入る。
- Node:
npm installで環境を作成してライブラリをインストールする。
- ライブラリ本体は、
node_modulesディレクトリに入る。- 実行ファイルの選択:
- Python:
pyenv local (version)で Python のバージョンを指定する。
- ディレクトリで勝手にバージョンが切り替わる。
.python-versionに使うバージョンが記載される。- pyenv にも、pyenv-virtualenv という環境を作るプラグインがあるが使わない。
- Node:
nodebrew use (version)等で Node のバージョンを指定する。
- 特にディレクトリごとにバージョンを変える機能は無いと思う。
始め方
Poetry インストール
curl -sSL https://raw.githubusercontent.com/python-poetry/poetry/master/get-poetry.py | pythonPoetry インストール後
$HOME/.poetry/binをパスに追加する。poetry 自体の更新
poetry self updatepyenv で Python バージョンを選択する
インストール可能バージョンを調べる
pyenv install --list3.7.7 をインストール
pyenv install 3.7.7このディレクトリでは 3.7.7 を使う。
pyenv local 3.7.7プロジェクトの開始
サンプルプロジェクトの作成
poetry new poetry-demopyproject.toml もしくは poetry.lock に基づいてライブラリをインストール。デフォルトで dev 用もインストールする。
poetry installpyproject.toml だけを見てライブラリを更新
poetry update(ここまで書いて実運用しているプロジェクトに適用してみたところ、Pipenv 並に遅いのか poetry install が終了しないので悩み中)
- 投稿日:2020-03-30T21:27:30+09:00
AWSアカウント作成時にSecurity Hubのマルチアカウント設定を行う
Security Hub のマルチアカウント設定
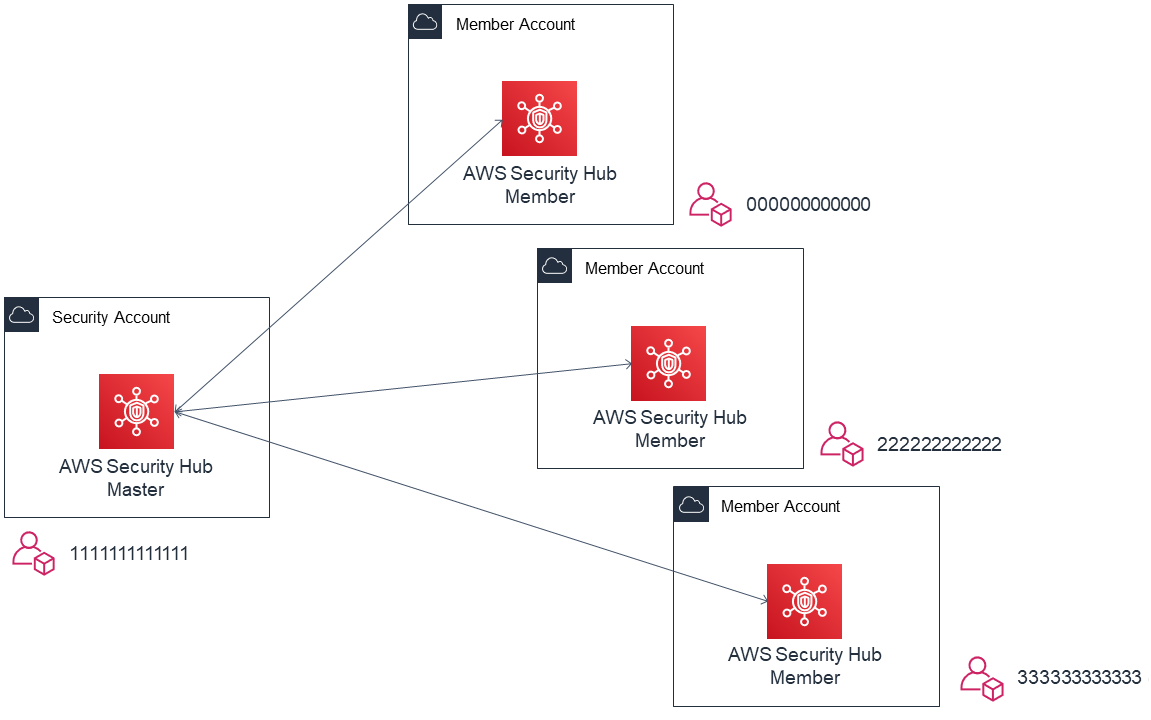
AWS Security Hub は AWS環境全体のセキュリティとコンプライアンスの状況を確認可能なサービスです。
Security Hubでは、特定アカウントをマスターアカウントとし、他のアカウントを招待して
マルチアカウントの親子関係を組むことができます。
以下のようにマルチアカウント設定を行うと、メンバーアカウントの結果をマスターアカウント側で
確認できるようになります。
この時、マスターとなるアカウントは AWS Organizations のマスターアカウントである必要はありません。
また組織外のアカウントを招待して連結することも可能です。
通常、セキュリティ用のアカウントを用意し、そちらに統合して管理する方がよいかと思います。連結を行う際、マスターアカウントから招待、メンバーアカウントからはその招待を承認する
という作業が必要なのですが、管理対象のアカウントが増えてくると都度作業するのはなかなか面倒です。GitHub 上で AWS Security Hub Multiaccount Scripts が公開されており、
IAM ロールおよび Python の実行環境を用意できれば、上記ステップを自動化できます。アカウント追加時に自動セットアップを行う
Multiaccount Scripts は既存アカウントへの設定が前提であるため、
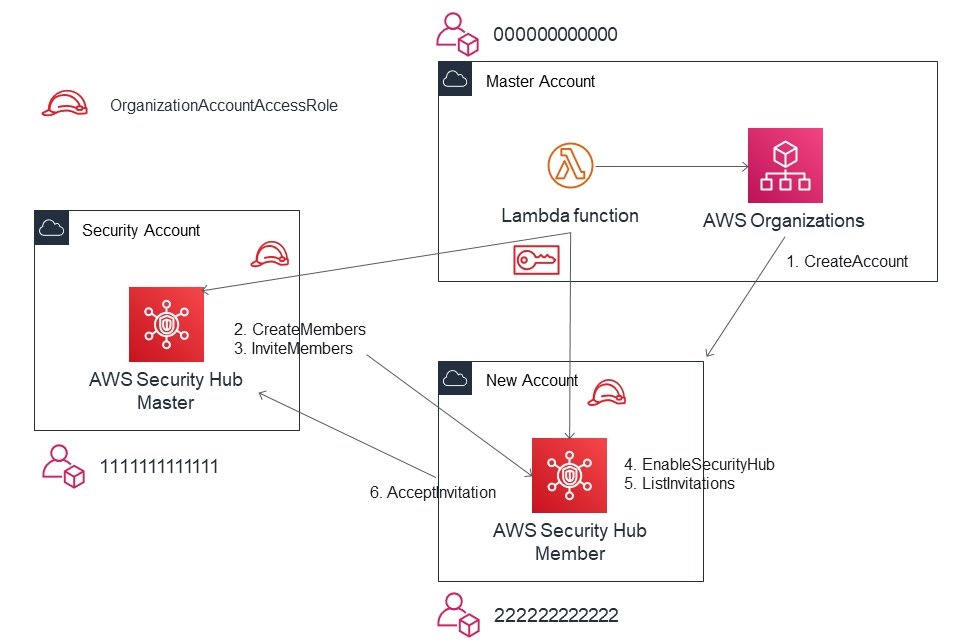
新規アカウント作成時に自動でセットアップするための構成例を紹介します。前提
- AWS Organizations でアカウントが管理されている
- AWS Organizations の Master Account から New Account を作成する
- Security Hubのマスターアカウントである Security Account から New Accountを招待する
流れ
マスターアカウントで Lambda 関数を起動し、以下の内容を実行します。
- AWS Organizations で新規アカウントを作成 1
- Assume Role で Security Account から New Account へ招待を送る 2, 3
- 内部的には CreateMembers API と InviteMembers API の実行が必要
- Assume Role で New Account の Security Hub を有効化し4、招待を承認する5, 6
- 内部的には ListInvitaions APIで InvitationId を確認し、AcceptInvitaion API を実行
Lambda 関数の例
ランタイムは python3.8 を想定しています。
アカウント作成部分のコードは AWS Landing Zone の Account Vending Machine(AVM)を参考にしています。
AVM は AWS Service Catalog の製品として利用可能で、アカウントの作成と事前定義された
ベースライン設定をセットアップすることができますコードは 以下の GitHub リポジトリで公開されています。AWS Account Vending Machine
https://github.com/aws-samples/aws-account-vending-machine以降は簡略化のため、アカウント作成と Security Hub 有効化に絞った形で記載しますが、
上記をカスタマイズして、Security Hub の有効化以外にもアカウント作成時に必要な
サービスの設定を組み込んでしまえば、共通的なセットアップ作業を自動化できます。clinet の作成
指定されたサービスとリージョンで clinet を作成します。
Assume Role によるクレデンシャルが指定されている場合は、対象アカウントの一時認証情報で作成します。def get_client(service, region, credentials=None): """Returns the client for the specified region""" if credentials is None: client = boto3.client(service, region_name=region) else: client = boto3.client( service, region_name=region, aws_access_key_id=credentials['AccessKeyId'], aws_secret_access_key=credentials['SecretAccessKey'], aws_session_token=credentials['SessionToken'] ) return client新規アカウントの作成
アカウント名とメールアドレスから AWS Organizations で新規アカウントを作成し、アカウントIDを返します。
def create_account(account_name, email): """Create account by AWS Organizations""" account_id = 'None' org = get_client('organizations', 'us-east-1') try: logger.info("Trying to create the account with %s", email) create_account_response = org.create_account( Email=email, AccountName=account_name ) sleep(10) account_status = org.describe_create_account_status( CreateAccountRequestId=create_account_response['CreateAccountStatus']['Id'] ) except ClientError as err: logger.error("Create Account Request failed: %s", err.response['Error']['Message']) else: logger.info("Account Creation status: %s", account_status['CreateAccountStatus']['State']) if account_status['CreateAccountStatus']['State'] == 'FAILED': logger.error( "Account Creation Failed. Reason : %s", account_status['CreateAccountStatus']['FailureReason'] ) sys.exit(1) account_status = org.describe_create_account_status( CreateAccountRequestId=create_account_response['CreateAccountStatus']['Id'] ) account_id = account_status['CreateAccountStatus']['AccountId'] while account_id is None: logger.info("Waiting create new account. Retrying...") sleep(5) account_status = org.describe_create_account_status( CreateAccountRequestId=create_account_response['CreateAccountStatus']['Id'] ) account_id = account_status['CreateAccountStatus']['AccountId'] return account_idAssume Role
指定されたアカウントID に Assume Role して一時クレデンシャルを返します。
def assume_role(account_id): """Assume role to account""" sts = get_client('sts', 'us-east-1') role_arn = f'arn:aws:iam::{account_id}:role/OrganizationAccountAccessRole' try: assumed_role_object = sts.assume_role( RoleArn=role_arn, RoleSessionName="NewAccountSetUp" ) except ClientError as err: logger.error( "Assume Role Request failed: %s, %s", err.response['Error']['Message'], account_id ) sys.exit(1) return assumed_role_object['Credentials']招待の作成
Security Hub のマスターアカウトであるセキュリティアカウントから新規アカウントのIDと
メールアドレスを使用してを招待を送ります。
実際には CreateMembers API によりメンバーの関連付けを行ったあとに
InviteMembers API で招待を送っています。
この時点でメンバーアカウント側で Security Hub が有効化されていなくても招待することは可能です。def create_invitation(email, account_id, available_regions, audit_credentials): """Invite Account to Security Hub""" logger.info("Create Security Hub Invitation Start.") for region in available_regions: securityhub = get_client('securityhub', region, audit_credentials) try: securityhub.create_members( AccountDetails=[{ 'AccountId': account_id, 'Email': email }] ) response = securityhub.invite_members( AccountIds=[account_id] ) except ClientError as err: logger.error( "Create Invitation Request failed in %s: %s", region, err.response['Error']['Message'] ) sys.exit(1) else: if response['UnprocessedAccounts'] == []: logger.info("Invited: %s", region) else: logger.info("UnprocessedRegion: %s", region) logger.info("Create Security Hub Invitation Successed.")招待の承認
新規アカウントで Security Hub を有効化し、招待を承認します。
実際には ListInvitations API により InvitationId を確認し、
AcceptInvitation API で招待を承認します。def enable_securityhub(audit_account_id, available_regions, credentials): """Accept invitation from audit account""" logger.info("Enable Security Hub All Regions Start.") for region in available_regions: securityhub = get_client('securityhub', region, credentials) # Enalbe Security Hub try: securityhub.enable_security_hub() except ClientError as err: logger.error( "Enalbe Security Hub Request failed in %s: %s", region, err.response['Error']['Message'] ) sys.exit(1) # Accept Invitation try: response = securityhub.list_invitations() except ClientError as err: logger.error( "List Invitaion Request failed in %s: %s", region, err.response['Error']['Message'] ) sys.exit(1) if response['Invitations'] != []: try: securityhub.accept_invitation( MasterId=audit_account_id, InvitationId=response['Invitations'][0]['InvitationId'] ) except ClientError as err: logger.error( "Accept Invitation Request failed in %s: %s", region, err.response['Error']['Message'] ) sys.exit(1) else: logger.error("No Invitaions in %s", region) sys.exit(1) logger.info("Enabled Security Hub in %s", region) logger.info("Enalbe Security Hub All Regions Succeded.")全体
クリックで展開します。
lambda_function.pyimport os from logging import getLogger, INFO from time import sleep import sys import boto3 from botocore.exceptions import ClientError logger = getLogger() logger.setLevel(INFO) def get_client(service, region, credentials=None): """Returns the client for the specified region""" if credentials is None: client = boto3.client(service, region_name=region) else: client = boto3.client( service, region_name=region, aws_access_key_id=credentials['AccessKeyId'], aws_secret_access_key=credentials['SecretAccessKey'], aws_session_token=credentials['SessionToken'] ) return client def create_account(account_name, email): """Create account by AWS Organizations""" account_id = 'None' org = get_client('organizations', 'us-east-1') try: logger.info("Trying to create the account with %s", email) create_account_response = org.create_account( Email=email, AccountName=account_name ) sleep(10) account_status = org.describe_create_account_status( CreateAccountRequestId=create_account_response['CreateAccountStatus']['Id'] ) except ClientError as err: logger.error("Create Account Request failed: %s", err.response['Error']['Message']) else: logger.info("Account Creation status: %s", account_status['CreateAccountStatus']['State']) if account_status['CreateAccountStatus']['State'] == 'FAILED': logger.error( "Account Creation Failed. Reason : %s", account_status['CreateAccountStatus']['FailureReason'] ) sys.exit(1) account_status = org.describe_create_account_status( CreateAccountRequestId=create_account_response['CreateAccountStatus']['Id'] ) account_id = account_status['CreateAccountStatus']['AccountId'] while account_id is None: logger.info("Waiting create new account. Retrying...") sleep(5) account_status = org.describe_create_account_status( CreateAccountRequestId=create_account_response['CreateAccountStatus']['Id'] ) account_id = account_status['CreateAccountStatus']['AccountId'] return account_id def assume_role(account_id): """Assume role to account""" sts = get_client('sts', 'us-east-1') role_arn = f'arn:aws:iam::{account_id}:role/OrganizationAccountAccessRole' try: assumed_role_object = sts.assume_role( RoleArn=role_arn, RoleSessionName="NewAccountSetUp" ) except ClientError as err: logger.error( "Assume Role Request failed: %s, %s", err.response['Error']['Message'], account_id ) sys.exit(1) return assumed_role_object['Credentials'] def get_region_list(): """Return Available Region List""" ec2 = get_client('ec2', 'us-east-1') available_regions = map(lambda x: x['RegionName'], ec2.describe_regions()['Regions']) return list(available_regions) def create_invitation(email, account_id, available_regions, audit_credentials): """Invite Account to Security Hub""" logger.info("Create Security Hub Invitation Start.") for region in available_regions: securityhub = get_client('securityhub', region, audit_credentials) try: securityhub.create_members( AccountDetails=[{ 'AccountId': account_id, 'Email': email }] ) response = securityhub.invite_members( AccountIds=[account_id] ) except ClientError as err: logger.error( "Create Invitation Request failed in %s: %s", region, err.response['Error']['Message'] ) sys.exit(1) else: if response['UnprocessedAccounts'] == []: logger.info("Invited: %s", region) else: logger.info("UnprocessedRegion: %s", region) logger.info("Create Security Hub Invitation Successed.") def enable_securityhub(audit_account_id, available_regions, credentials): """Accept invitation from audit account""" logger.info("Enable Security Hub All Regions Start.") for region in available_regions: securityhub = get_client('securityhub', region, credentials) # Enalbe Security Hub try: securityhub.enable_security_hub() except ClientError as err: logger.error( "Enalbe Security Hub Request failed in %s: %s", region, err.response['Error']['Message'] ) sys.exit(1) # Accept Invitation try: response = securityhub.list_invitations() except ClientError as err: logger.error( "List Invitaion Request failed in %s: %s", region, err.response['Error']['Message'] ) sys.exit(1) if response['Invitations'] != []: try: securityhub.accept_invitation( MasterId=audit_account_id, InvitationId=response['Invitations'][0]['InvitationId'] ) except ClientError as err: logger.error( "Accept Invitation Request failed in %s: %s", region, err.response['Error']['Message'] ) sys.exit(1) else: logger.error("No Invitaions in %s", region) sys.exit(1) logger.info("Enabled Security Hub in %s", region) logger.info("Enalbe Security Hub All Regions Succeded.") def lambda_handler(event, context): """main""" account_name = os.environ['ACCOUNT_NAME'] email = os.environ['EMAIL'] audit_account_id = "111111111111" account_id = create_account(account_name, email) logger.info("Created acount: %s", account_id) # Assume Role New Account and Audit Account credentials = assume_role(account_id) audit_credentials = assume_role(audit_account_id) # Get Region List available_regions = get_region_list() # Secuirty Hub create_invitation(email, account_id, available_regions, audit_credentials) enable_securityhub(audit_account_id, available_regions, credentials)以上です。参考になれば幸いです。
- 投稿日:2020-03-30T21:09:02+09:00
jpgをpngに変換しても透明度がいじれなかったからなんとかした
はじめに
pythonでjpgをpngに変換しても透明度がいじれなかったので,力業で解決した話
環境
- Windows 10
- VSCode
- Python 3.7.3
単純に変換してみる
「python convert jpg to png」とかでググるとPillowが出てくると思います.
公式を見ながら下記のようにインストール
pip install Pillowここを参考にサンプルを書くと
jpgToPNG.pyfrom PIL import Image #絶対パスも可 img = Image.open('input.jpg') img.save('output.png')これで一応PNGができるが,透明度をいじるソースを書くとエラーをはく
ちなみに,ペイントを使って変換した画像はきちんと透明度をいじれる問題点
しばらく,うんうんうなりながらググっていたら
上記のサイトがヒット
なるほど,pngをjpgに変換してもRGBAのAが残る場合がある(解釈あってる?)ということなら,逆の場合もあるのかもしれないというわけで,上記のサイトを参考にチェックするソースを作成
checkPNG.pyfrom PIL import Image path_png1 = "output1.png" #透明度編集できないPNG path_png2 = "output2.png" #ペイントで変換した,透明度編集できるPNG image = np.asarray(Image.open(path_png1)) print(Image.open(path_png1)) print(image.shape) image = np.asarray(Image.open(path_png2)) print(Image.open(path_png2)) print(image.shape)結果<PIL.PngImagePlugin.PngImageFile image mode=RGB size=1920x1080 at 0x1762DB300B8> (1080, 1920, 3) <PIL.PngImagePlugin.PngImageFile image mode=RGBA size=1920x1080 at 0x176252F92B0> (1080, 1920, 4)たしかに,編集できないPNGはRGB modeになってる.
解決
原因が分かったので,解決していきます.
png画像とjpg画像の取り扱いの注意点によるとopen()のあとにconvert()を付けるとmodeを変更できるようです.
なので,以下のように実装
jpgToPNG.pyfrom PIL import Image rgba_img = Image.open('input.jpg').convert('RGBA') rgba_img.save('output.png') print(rgba_img) print(np.asarray(rgba_img).shape)結果<PIL.Image.Image image mode=RGBA size=1920x1080 at 0x1CF941EF9E8> (1080, 1920, 4)結果も問題ありませんし,無事透明度をいじることが出来ました.
以上です.
- 投稿日:2020-03-30T21:08:10+09:00
いいね・RTされてないツイートを一括削除する
毎日手で消すのめんどうなので自動にした
いいね・RTされているツイートだけ残して、低クオリティツイートを消したい場合に使う。
import tweepy def main(): # 自分のを設定 CK = '' CKS = '' AT = '' ATS = '' auth = tweepy.OAuthHandler(CK, CKS) auth.set_access_token(AT, ATS) api = tweepy.API(auth) # 抽出 tweet_data = [] for tweet in tweepy.Cursor(api.user_timeline,screen_name = "自分のスクリーンネーム",exclude_replies = 任意).items(): if tweet.favorite_count == 0 and tweet.retweet_count == 0: tweet_data.append(tweet.id) # 削除 for deltw in tweet_data: api.destroy_status(deltw)参考というかパクり元
https://qiita.com/i_am_miko/items/a2e5168e619ed37afeb9
今後
リプライを受けているツイートは消したくないから、これをまんまコピーしてLambdaにのせて日次削除している。Twythonだけどこの辺りも参考になりそう。今後はまんまコピーしているやつをTweepyの処理に置き換える作業をしたい。
- 投稿日:2020-03-30T20:19:24+09:00
坂本俊之『作ってわかる! アンサンブル学習アルゴリズム入門』の誤植情報を集める
坂本俊之『作ってわかる! アンサンブル学習アルゴリズム入門』(C&R研究所, 2019)
出版社サイトを見ても誤植情報がどこにも無かったので集めてみます。
ページ 誤 正 3 というの本書の目的となります というのが本書の目的となります 13 通常。決定木をベースとして使用しますが 通常、決定木をベースとして使用しますが 36 「scikir-learn」 「scikit-learn」 40, 44 pred.argmaxprob.argmax43 回帰分類における評価関数 回帰における評価関数 50~53 ncolnrow57 ZeroRuleより悪い結果とる ZeroRuleより悪い結果となる 57 数ら必要な大きさの配列を用意して ? 62 次元数とNとすると 次元数をNとすると 62 SGDではデータを少しずつ処理できるというため SGDではデータを少しずつ処理できるため 68 クラス変数 インスタンス変数 81 決定木アルゴリズムの目的とします 決定木アルゴリズムの目的です 85 データの個枢軸 データの個数軸 88 「score」変数も作成しまておきます 「score」変数も作成しておきます 89, 94 def make_loss(self, x, y, l, r)def make_loss(self, x, y)102 差左右のノード 左右のノード 111 ノード内の枝を削除するれば ノード内の枝を削除すれば 117 def criticalscore(node, x, y, score_max)def criticalscore(node, score_max)119 テストデータを別にするときの割合を表す「pruntest」 テストデータを別にするときの割合を表す「splitratio」 120 まずプルーニング際に まずプルーニングの際に 121 一番上のコードは間違い。p126のコードが正しい
- 投稿日:2020-03-30T20:14:00+09:00
PythonでMongoDBのODMを使用しよう
前書
この記事はPythonでMongoDBを入門しようという記事の続編になりますが、
前回の記事を読んでいなくても内容がわかる構成にしています。
もしMongoDBに興味があれば、最後まで付き合っていただけると幸いです。環境構築
MongoDB
この記事ではDockerを使用して環境構築行います。
ローカル内で直接MongoDBを入れたい方は前回の記事を参考にしてください。docker-compose.ymlversion: '3.1' services: mongo: image: mongo restart: always ports: - 27017:27017 environment: MONGO_INITDB_ROOT_USERNAME: root MONGO_INITDB_ROOT_PASSWORD: example mongo-express: image: mongo-express restart: always ports: - 8081:8081 environment: ME_CONFIG_MONGODB_ADMINUSERNAME: root ME_CONFIG_MONGODB_ADMINPASSWORD: exampleコンテナを立ち上げます。
docker-compose up -d mongo mongo-expressMongo Expressにアクセス、表示出来たらMongoDBの環境構築は完了です。
Python
Python側は
mongoengineというライブラリを使用します。pip install mongoengine試しに接続します。
デフォルトで入ってるlocalデータベースに接続してみます。test.pyfrom mongoengine import connect connect(db='local', username="root", password="example", host='192.168.99.100', port=27017, authentication_mechanism='SCRAM-SHA-1', authentication_source='admin' )実行し、エラーが出なければ成功です。
その他の接続方法はこちらを参考にしてくださいPythonでMongoDBを入門しよう
MongoDBのODM
ODMとは何か、文字通りで言うとオブジェクトドキュメントマッピングになります。
MongoDBのようなドキュメントデータベースにオブジェクトをマッピングします。
使用するメリットとしてはデータの構造を縛れることです。実例を見ていきます
test.pyfrom mongoengine import connect, Document, EmbeddedDocument, \ StringField, IntField, DateTimeField, ListField, EmbeddedDocumentField from datetime import datetime connect(db='company', username="root", password="example", host='192.168.99.100', port=27017, authentication_mechanism='SCRAM-SHA-1', authentication_source='admin' ) class Employee(EmbeddedDocument): """ 社員詳細 """ name = StringField(required=True) age = IntField(required=False) SCALE_CHOICES = ( ("venture", "ベンチャー"), ("major", "大手") ) class Company(Document): """ 会社モデル """ name = StringField(required=True, max_length=32) scale = StringField(required=True, choices=SCALE_CHOICES) created_at = DateTimeField(default=datetime.now()) members = ListField(EmbeddedDocumentField(Employee))
Djangoやsqlalchemy使用してモデルを定義したことがあれば、馴染む構成になっています。
実際に定義されたモデルを使用してデータをMongoDBに入れてみます。
下記のコードをtest.pyに追記し、実行します。
テスト用のデータベースをあらかじめ作る必要はありません。
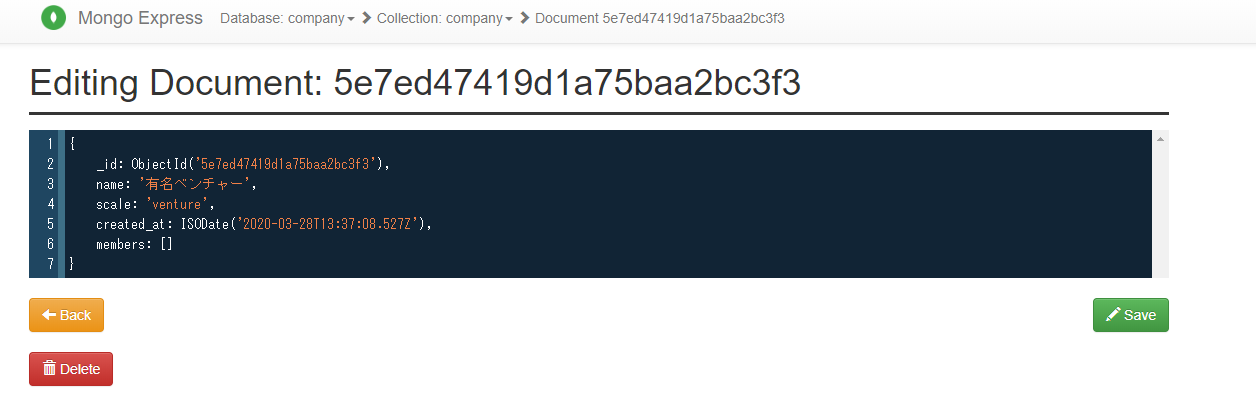
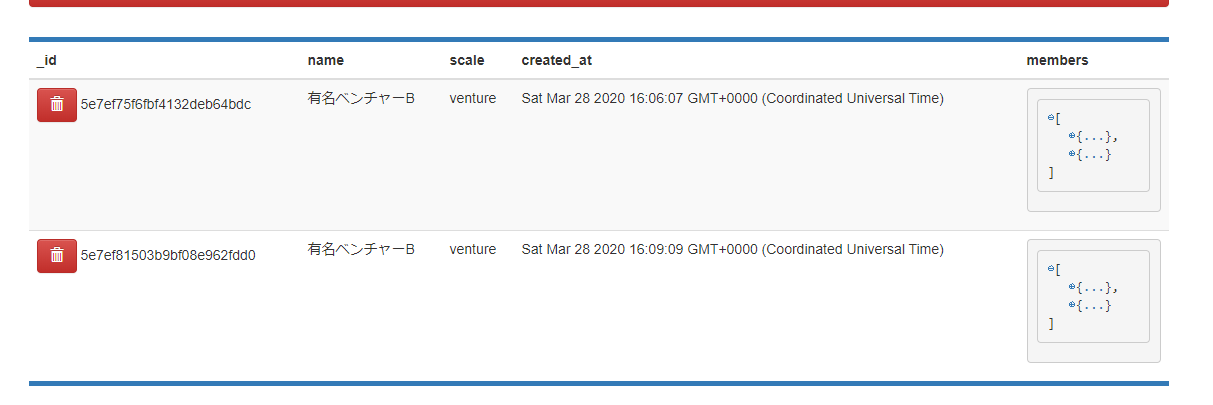
test.pyclass TestMongoEngine: def add_one(self): c_obj = Company( name="有名ベンチャー", scale="venture", ) c_obj.save() return c_obj if __name__ == "__main__": t = TestMongoEngine() t.add_one()Mongo Expressから、データが入れられたことが確認できます。
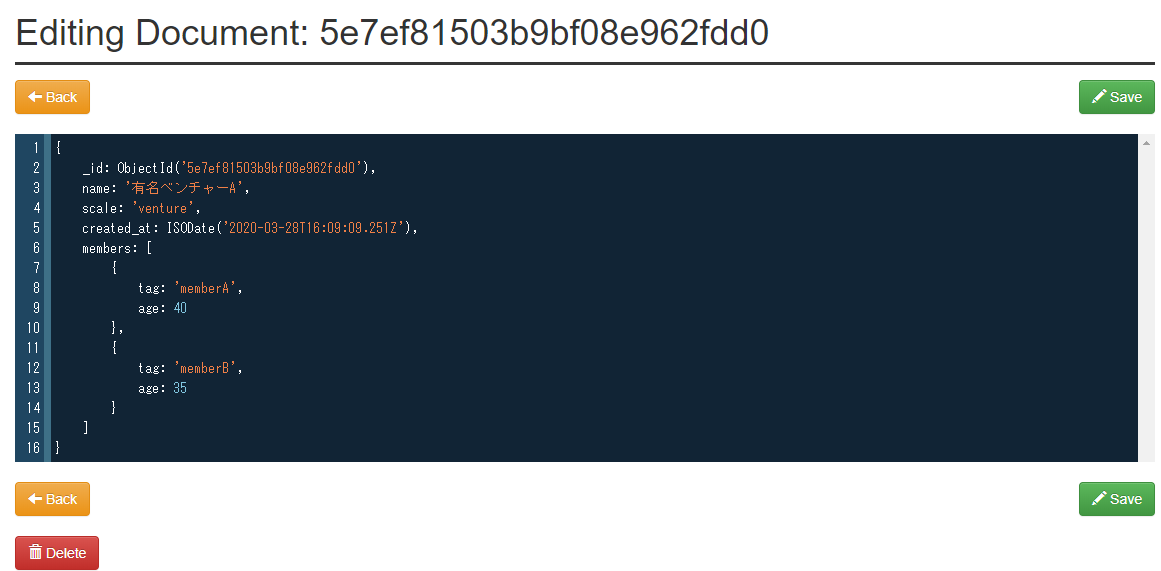
EmbeddedDocumentFieldはモデルの内部に更に構造を定義したい場合に、使用すると役に立つので使ってみます。先ほど
test.pyに追記されたコードを以下のように修正し、再度実行します。test.pyclass TestMongoEngine: def add_one(self): member1 = Employee( name="memberA", age=40, ) member2 = Employee( name="memberB", age=35, ) c_obj = Company( name="有名ベンチャーA", scale="venture", members=[member1, member2] ) c_obj.save() return c_obj if __name__ == "__main__": t = TestMongoEngine() t.add_one()Mongo Expressから結果を確認します。
ODM使用してCRUD
C(Create)新規追加する例は最初の例で紹介したので、データの読み込みから紹介していきます。
R(Retrieve)データの読み込み
単一読み込み
先程新規追加したデータベースから一つのデータを読み込みます。
test.py... class TestMongoEngine: def get_one(self): return Company.objects.first() if __name__ == "__main__": t = TestMongoEngine() rest = t.get_one() print(rest.id) print(rest.name)結果
5e7ed47419d1a75baa2bc3f3 有名ベンチャー全部読み込み
test.py... class TestMongoEngine: def get_more(self): return Company.objects.all() if __name__ == "__main__": t = TestMongoEngine() rest = t.get_more() print(rest)結果
[<Company: Company object>, <Company: Company object>, <Company: Company object>]id検索で読み込み
test.py... class TestMongoEngine: def get_from_oid(self, oid): return Company.objects.filter(pk=oid).first() if __name__ == "__main__": t = TestMongoEngine() rest = t.get_from_oid("5e7ed47419d1a75baa2bc3f3") print(rest.id) print(rest.name)結果
5e7ed47419d1a75baa2bc3f3 有名ベンチャー補足
データ読み込みする際に順番を並び替えたい場合、
metaを会社モデルに追記します。test.pyclass Company(Document): """ 会社モデル """ name = StringField(required=True, max_length=32) scale = StringField(required=True, choices=SCALE_CHOICES) created_at = DateTimeField(default=datetime.now()) members = ListField(EmbeddedDocumentField(Employee)) meta = { 'ordering': ['-created_at'] # metaを追記 }データの更新(Update)
単一のデータ修正
test.py... class TestMongoEngine: def update(self): rest = Company.objects.filter(name="有名ベンチャー").update_one(name="普通のベンチャー") return rest if __name__ == "__main__": t = TestMongoEngine() rests = t.update()実行後、Mongo Expressからデータ変更されたことが確認できます。
複数のデータ修正
MongoDBに
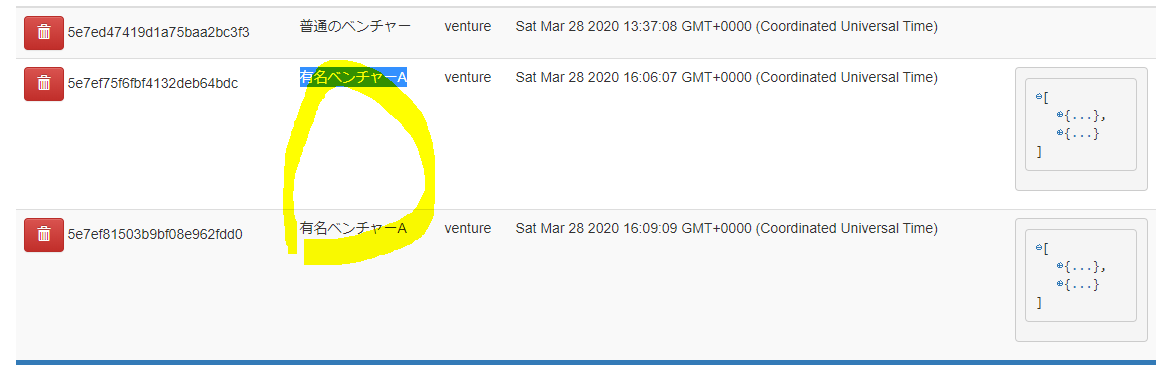
nameが有名ベンチャーAになってる記録が二つ存在します、それらを修正していきます。
test.pyclass TestMongoEngine: def update(self): rest = Company.objects.filter(name="有名ベンチャーA").update(name="有名ベンチャーB") return rest if __name__ == "__main__": t = TestMongoEngine() rests = t.update() print(rests)実行結果
2Mongo Expressからもデータ修正されたことが確認できます。
データの削除(Delete)
単一のデータ削除
test.pyclass TestMongoEngine: def delete(self): rest = Company.objects.filter(name="普通のベンチャー").first().delete() return rest if __name__ == "__main__": t = TestMongoEngine() rests = t.delete() print(rests)実行後
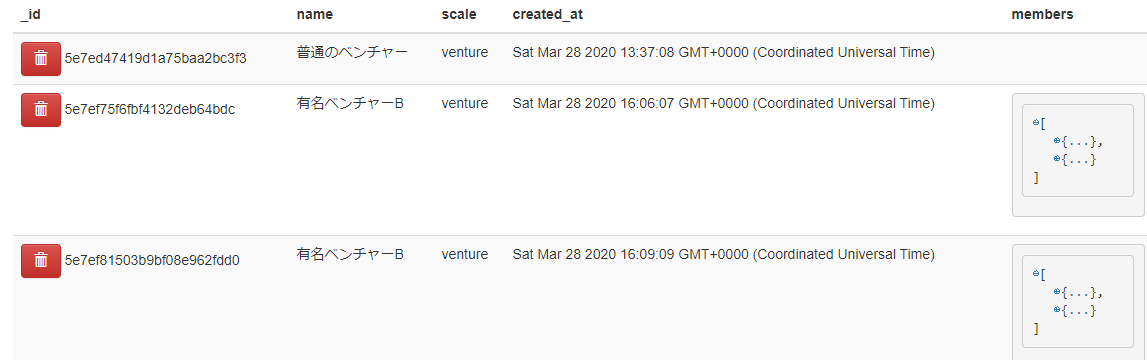
複数のデータ削除
nameが有名ベンチャーBになってる二件のデータを削除します。test.py... class TestMongoEngine: def delete(self): rest = Company.objects.filter(name="有名ベンチャーB").delete() return rest if __name__ == "__main__": t = TestMongoEngine() rests = t.delete() print(rests)実行結果
2Mongo Expressから確認すると、CompanyDBに入ってるデータすべてが削除されました。
後書
MongoEngineのドキュメント
今度時間あればFlaskとMongoDB使用してWebサービス作る記事を書きたいと思います。

- 投稿日:2020-03-30T18:46:29+09:00
AtCoder Beginner Contest 085 過去問復習
所要時間
感想
簡単な回ですが、D問題は基本的かつ良い問題と感じました。
今回はAtCoderVirtualContestを利用しました。A問題
8で置き換えればよい。
文字列はイミュータブルなので、一回分割する(一つ目)かリストに変更して置換する(二つ目)のどちらかだと思います。answerA1.pys=input() print(s[:3]+"8"+s[4:])answerA2.pys=list(input()) s[3]="8" print("".join(s))B問題
同じ直径の餅を使うことはできないので重複するものを除いて考えれば良い。そのためにはsetを使えば良い。
answerB.pyn=int(input()) d=[int(input()) for i in range(n)] print(len(set(d)))C問題
yは1000の倍数なので全て1000で割って考えればよく、10i+5j+k=y(0<=i,j,k<=n,i+j+k=n)という方程式を考えます。このような不等式は係数が大きいところから決めると良くこの問題ではi→j→kの順に決めます。0~y//10がiの候補で0~(y-i*10)//5がjの候補になり、kが決定します。以上を全てのiおよびjについて試すことで題意を満たす答えを求めることができます。
answerC.pyfrom sys import exit n,y=map(int,input().split()) y//=1000 for i in range(y//10+1): #k:いくら残ってるか #l:何枚使ったか k1=y-i*10 for j in range(k1//5+1): k=k1-j*5 l=i+j if k==n-l and i>=0 and j>=0 and k>=0: print(str(i)+" "+str(j)+" "+str(k)) exit() print("-1 -1 -1")D問題
魔物を倒すまでにどの刀を何回振りどの刀を投げるか決めることができれば順番によらず決めることができます。
まず、どの刀を何回振るかについてですが、どの刀も複数回振ることができてよりポイントの高い刀を振るべきなので、最もポイントの高い刀のみ(ポイント$a_k$)を振り続けるのが最適となります。
次に、どの刀を投げるかについですが、ポイント$a_k$よりも(投げた際の)ポイントが低い刀は投げる必要がありません(ポイント$a_k$の刀をその代わりに振った方がポイントが高いので)。従って、投げる刀はポイント$a_k$よりも(投げた際の)ポイントが高い刀全てになります。
以上の考察より、まずはポイント$a_k$よりも(投げた際の)ポイントが高い刀は全て投げるものと仮定してHポイントから順に引いていき、その全てを投げると仮定しても魔物にHポイント以上のダメージを与えられない場合はポイント$a_k$の刀を必要なだけ振れば良いです。answerD.pyimport math n,h=map(int,input().split()) ab=[list(map(int,input().split())) for i in range(n)] ab.sort(reverse=True) k=ab[0][0] ab.sort(reverse=True,key=lambda x:x[1]) ans=0 while h>0: if ans==n: break if k<=ab[ans][1]: h-=ab[ans][1] ans+=1 else: break if h<=0: print(ans) else: print(ans+math.ceil(h/k))

- 投稿日:2020-03-30T18:39:03+09:00
PythonによるWeb APIをEXE化する
はじめに
ときどき以下のすべてを満たしたいというご要望をいただくことがあります。
- Pythonで作ったAIをWindowsアプリに組み込みたい
- AIのインターフェースはWeb APIにしたい
- リモートサーバと通信したくない
- Pythonやその他のツール等はインストールしたくない
色々やり方はあると思いますが、
- AIの機能をPythonのWebフレームワークでAPI化し、
- そのPythonファイルをEXEファイルに変換してアプリ本体に同梱し、
- アプリ本体からEXEを実行すればこれを実現できます。
今回は以下を使います。
- OS:Windows 10
- Python:3.7.7 (インストール済みを前提)
- Webフレームワーク:Flask
- EXE化:PyInstaller
(ちなみにFastAPI × uvicornだと、2020/3/30時点では問題がありました。 https://github.com/pyinstaller/pyinstaller/pull/4664 )
手順
FlaskとPyInstallerをインストールします。
コマンドプロンプトなどで、
pip install flask pyinstallerWeb APIを公開するPythonファイルを作ります。
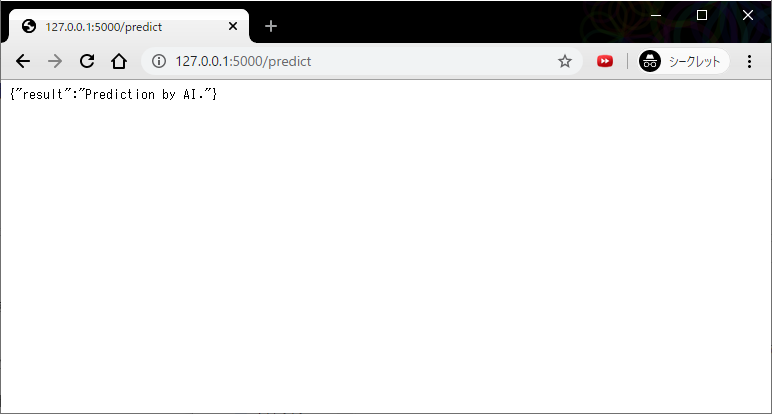
main.pyfrom flask import Flask app = Flask(__name__) @app.route('/predict') def predict(): """ AIによる予測を返すAPIのつもり """ return {'result': 'Prediction by AI.'} if __name__ == '__main__': app.run()上記ファイルのあるディレクトリに移動し、
pyinstaller main.py --onefile
distディレクトリにmain.exeができているので、試しに実行してみる。dist\main.exeTraceback (most recent call last): File "site-packages\PyInstaller\loader\rthooks\pyi_rth_pkgres.py", line 13, in <module> File "c:\users\user\appdata\local\programs\python\python37\lib\site-packages\PyInstaller\loader\pyimod03_importers.py", line 623, in exec_module exec(bytecode, module.__dict__) File "site-packages\pkg_resources\__init__.py", line 86, in <module> ModuleNotFoundError: No module named 'pkg_resources.py2_warn' [24508] Failed to execute script pyi_rth_pkgres上のように、
ModuleNotFoundErrorになる場合は、main.pyと同階層に生成されたmain.specファイルをテキストエディタで編集する。
具体的には、hiddenimportsに見つからなかったモジュール名を含める。main.spec# -- 略 -- hiddenimports=[], # -- 略 --↓次のように修正して保存。
main.spec# -- 略 -- hiddenimports=['pkg_resources.py2_warn'], # -- 略 --pyファイルではなく、修正したspecファイルを指定して、pyinstallerを実行。
pyinstaller main.spec --onefile再度動作確認。
dist\main.exeWeb APIが公開されていることをざっくり確認。
実際はC#などのアプリからこのEXEを実行し(要プロセス管理)、おなじくアプリからHttpクライアントでアクセスすることになります。
- 投稿日:2020-03-30T18:39:03+09:00
EXEを叩いてPythonのWeb APIを起動
はじめに
ときどき以下のようなご要望をいただくことがあります。
- Pythonで作ったAIをWindowsアプリに組み込みたい
- AIのインターフェースはWeb APIにしたい
- リモートサーバと通信したくない
- Pythonやその他のツール等はインストールしたくない
色々やり方はあると思いますが、
- AIの機能をPythonのWebフレームワークでAPI化し、
- そのPythonファイルをEXEファイルに変換してアプリ本体に同梱し、
- アプリ本体からEXEを実行すればこれを実現できます。
今回は以下を使います。
- OS:Windows 10
- Python:3.7.7 (インストール済みを前提)
- Webフレームワーク:Flask
- EXE化:PyInstaller
(ちなみにFastAPI × uvicornだと、2020/3/30時点では問題がありました。 https://github.com/pyinstaller/pyinstaller/pull/4664 )
手順
FlaskとPyInstallerをインストールします。
コマンドプロンプトなどで、
pip install flask pyinstallerWeb APIを公開するPythonファイルを作ります。
main.pyfrom flask import Flask app = Flask(__name__) @app.route('/predict') def predict(): """ AIによる予測を返すAPIのつもり """ return {'result': 'Prediction by AI.'} if __name__ == '__main__': app.run()上記ファイルのあるディレクトリに移動し、
pyinstaller main.py --onefile
distディレクトリにmain.exeできているので、試しに実行してみる。dist\main.exeTraceback (most recent call last): File "site-packages\PyInstaller\loader\rthooks\pyi_rth_pkgres.py", line 13, in <module> File "c:\users\user\appdata\local\programs\python\python37\lib\site-packages\PyInstaller\loader\pyimod03_importers.py", line 623, in exec_module exec(bytecode, module.__dict__) File "site-packages\pkg_resources\__init__.py", line 86, in <module> ModuleNotFoundError: No module named 'pkg_resources.py2_warn' [24508] Failed to execute script pyi_rth_pkgres上のように、
ModuleNotFoundErrorになる場合は、main.pyと同階層に生成されたmain.specファイルをテキストエディタで編集する。
具体的には、hiddenimportsに見つからなかったモジュール名を含める。main.spec# -- 略 -- hiddenimports=[], # -- 略 --↓次のように修正して保存。
main.spec# -- 略 -- hiddenimports=['pkg_resources.py2_warn'], # -- 略 --pyファイルではなく、修正したspecファイルを指定して、pyinstallerを実行。
pyinstaller main.spec --onefile再度動作確認
dist\main.exeWeb APIが公開されていることをざっくり確認。
実際はC#などのアプリからこのEXEを実行し(要プロセス管理)、おなじくアプリからHttpクライアントでアクセスすることになります。
- 投稿日:2020-03-30T17:58:56+09:00
『アルゴリズム図鑑』のアルゴリズムをPython3で実装(ヒープソート編)
この記事について
この記事では筆者が『アルゴリズム図鑑』を読んで学んだアルゴリズムについて、Python3での実装例を紹介したいと思います。今回のアルゴリズムはヒープソートです。筆者は素人です。色々教えていただけると幸いです。
筆者はPython2のことをよく知りませんが、自分がPython3を使ってるっぽいことだけはわかっています(Python3.6.0かな?)。そのため、記事のタイトルではPython3としました。
ヒープソートについて
問題設定とアプローチについてざっくりとだけ説明します。「ヒープ」というデータ構造を使います。ヒープについて詳しくは『アルゴリズム図鑑』を参照ください。
問題
与えられた数の列に対して、小さい数から順に並べ替えた列を返す。
例:
5, 2, 7, 3, 6, 1, 4
→ 1, 2, 3, 4, 5, 6, 7アプローチ
与えられた数を降順ヒープ(根が最大)に格納し、「根から値をとる→一番左に置く」を繰り返す。詳細は『アルゴリズム図鑑』を参照。
実装コードと実行結果
実装したコードを以下に示します。最初に少し考え方を説明します。
なお、勉強のためあえて実装してみましたが、Python では標準ライブラリで heapq というモジュールが用意されているようなので、実用的にはそれを使うといいと思います( https://docs.python.org/ja/3/library/heapq.html )。
考え方
配列の要素の順番に意味を想定して、ヒープというデータ構造を実現します。『アルゴリズム図鑑』のヒープソートの項の補足を見ていただければわかりやすいかと思います。
また、ヒープ(2分ヒープ)では要素の番号を1から始めると便利なのでそのようにします(Wikipedia 二分ヒープ#ヒープの実装)。
ざっくり言うと下記のような感じ。
- 配列 heap に値を格納していく
- heap[0] は無視する(ダミーの値を入れておく)
- heap[1] が根
- heap[2]とheap[3]はheap[1]の子、heap[4]とheap[5]はheap[2]の子、heap[6]とheap[7]はheap[3]の子、...
コード
最初に変数dataに代入されているリストが処理対象の数の列です。
あと、このコードはわかりにくいかもしれないので、いくつか関数を定義して見通しがよくなった(?)バージョンのコードを、補足として最下部に記載します。どちらがいいかご意見いただければ幸いです。
heap_sort.pydata = [5, 2, 7, 3, 6, 1, 4] print("input :" + str(data)) data_len = len(data) heap = [0] #第0要素はダミー(ヒープでは1から数えると計算しやすい) #入力されたデータを順にヒープに格納する(ヒープは都度再構築する) for i in range(0, data_len): heap.append(data[i]) if i > 0: child = i + 1 parent = child // 2 while(heap[parent] < heap[child]): heap[parent], heap[child] = heap[child], heap[parent] if parent > 1: child = parent parent = child // 2 else: #根まで達しているので、ここで抜ける break #ヒープの根から値を取り出していく(ヒープは都度再構築する) output_data = list() #出力用の配列 for i in range(0, data_len): #根の値をコピー output_data.insert(0, heap[1]) #根の値を削除し、ヒープを再構築 heap[1] = heap[-1] heap.pop(-1) parent = 1 while(len(heap) >= 2 * parent + 1): if len(heap) == 2 * parent + 1: if heap[parent] < heap[2 * parent]: heap[parent], heap[2 * parent] = heap[2 * parent], heap[parent] #これより先、枝はないので抜ける break else: if heap[2 * parent] > heap[2 * parent + 1]: child = 2 * parent else: child = 2 * parent + 1 if heap[parent] < heap[child]: heap[parent], heap[child] = heap[child], heap[parent] parent = child else: break print("output :" + str(output_data))実行結果
$ python heap_sort.py input :[5, 2, 7, 3, 6, 1, 4] output :[1, 2, 3, 4, 5, 6, 7]終わりに
気づいた点などあればご指摘、ご質問いただければと思います。特にコードの書き方の改善点などあれば勉強になるなと思います。
また実装コードのテストや他のアルゴリズムとの速さ比較についてヒント等いただければ幸いです。(ろくにテストしていません(^^;)
補足
上記のコードで、いくつか関数を定義して見通しがよくなった(?)バージョンのコードです。
heap_sort_2.pydef parent_of(child): return child // 2 def left_child_of(parent): return 2 * parent def right_child_of(parent): return 2 * parent + 1 def heap_size(heap): return len(heap[1:]) data = [5, 2, 7, 3, 6, 1, 4] # data = [43, 1, -4, 91, 46, -609] print("input :" + str(data)) data_len = len(data) heap = [0] #第0要素はダミー(ヒープでは1から数えると計算しやすい) #入力されたデータを順にヒープに格納する(ヒープは都度再構築する) for i in range(0, data_len): heap.append(data[i]) if i > 0: child = i + 1 parent = parent_of(child) while(heap[parent] < heap[child]): heap[parent], heap[child] = heap[child], heap[parent] if parent > 1: child = parent parent = parent_of(child) else: #根まで達しているので、ここで抜ける break #ヒープの根から値を取り出していく(ヒープは都度再構築する) output_data = list() #出力用の配列 for i in range(0, data_len): #根の値をコピー output_data.insert(0, heap[1]) #根の値を削除し、ヒープを再構築 heap[1] = heap[-1] heap.pop(-1) parent = 1 while(heap_size(heap) >= left_child_of(parent)): if heap_size(heap) == left_child_of(parent): child = left_child_of(parent) if heap[parent] < heap[child]: heap[parent], heap[child] = heap[child], heap[parent] #これより先、枝はないので抜ける break else: if heap[left_child_of(parent)] > heap[right_child_of(parent)]: child = left_child_of(parent) else: child = right_child_of(parent) if heap[parent] < heap[child]: heap[parent], heap[child] = heap[child], heap[parent] parent = child else: break print("output :" + str(output_data))
- 投稿日:2020-03-30T17:55:55+09:00
【python】表の行・列を削除する方法(dropメソッドのオプション一覧)
【python】表の行・列を削除する方法(dropメソッドのオプション一覧)
PandasのDataFrameの表の要素を削除する方法。
dropメソッドのオプションについて実際の使い方を踏まえたまとめ。とりあえずこれだけ押さえておけばOK。
▶dropメソッド・オプション一覧早見表
目次
1.dropメソッド・オプション一覧早見表
オプション 記述例 内容 (columns=label) df.drop(columns=['a','b']) (index=label) df.drop(index=['A','B'] 行A,Bを削除 (label) df.drop(['A','B']) 行A,Bを削除 (label, axis=1) df.drop(['a','b'] axis=1) 列a,bを削除 (label, axis='index') df.drop(['A','B'], axis='index') 行A,Bを削除 (label, axis='columns') df.drop(['a','b'], axis='columns') 列a,bを削除 (errors='ignore') df.drop(['aaa'], axis='columns', errors='ignore') エラーを無視 (inplace=True) df.drop(['A','B'], inplace=True) 上書きする
- 「df」:表の入った変数
- デフォルトは上書きせず別のオブジェクトを作成
- 「index=」と「columns=」または「axis=1」のどちらかのみで行列の指定が可能。
実例
使用する表
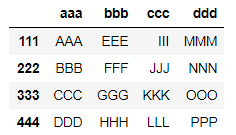
4行4列+行列見出しの下記表を使用。
表のコードimport pandas as pd listA = ['AAA', 'BBB', 'CCC', 'DDD'] listB = ['EEE', 'FFF', 'GGG', 'HHH'] listC = ['III', 'JJJ', 'KKK', 'LLL'] listD = ['MMM', 'NNN', 'OOO', 'PPP'] df = pd.DataFrame(listA) df[1] = listB df[2] = listC df[3] = listD df.columns = ['aaa', 'bbb', 'ccc', 'ddd'] df.index = [111,222,333,444] df
2.dropメソッドで行列を削除
①drop(label, axis)
②drop(index=label)
③drop(columns=label)
①drop(label, axis)
dropメソッドのオプション、「label」(行列名)とaxis(軸の指定)で、指定して行列の削除が可能。
基本の型
df.drop(label, axis=A)
└「df」:表データ(DataFrame型)
└「drop()」:ドロップメソッド
└「label」:削除する行/列名
└「axis=A」:Aで行か列の指定▼ポイント
- axisで行、列どちらかを指定。
- axsiの指定方法は4パターンある。
- 元の表はそのままで、新しいDataFrameオブジェクトが生成される。
- 間違って消しても復元できる▼4つのaxisの指定方法
値 記述例 内容 0 axis=0(省略可) 行名で指定。デフォルト。省略可 1 axis=1 列名で指定 index axis='index' 行名で指定 columns axis='columns' 列名で指定 行名で削除
①axis=0(省略可)
②axis='index'(1-1) axis=0
df.drop([label1,label2,,,])
└ axis=0は省略可
▼1列のみ指定
df.drop([111])=df.drop(111)(axis=0)省略df.drop(333) #出力 aaa bbb ccc ddd 111 AAA EEE III MMM 222 BBB FFF JJJ NNN 444 DDD HHH LLL PPP(axis=0)省略なしdf.drop(333, axis=0) #出力 aaa bbb ccc ddd 111 AAA EEE III MMM 222 BBB FFF JJJ NNN 444 DDD HHH LLL PPP
▼複数列指定列名の複数指定df.drop([111,333]) #出力 aaa bbb ccc ddd 222 BBB FFF JJJ NNN 444 DDD HHH LLL PPP
(1-2) axis='index'
オプションに「axis='index'」を指定しても、省略(axis=0)と同じになる。
df.drop([label1,label2,,,], axis='index')axis='index'df.drop([111,333]) #出力 aaa bbb ccc ddd 222 BBB FFF JJJ NNN 444 DDD HHH LLL PPP
行名で削除
①axis=1
②axis='columns'(1-3) axis=1
df.drop([label1,label2,,,], axis=1)
└ axis=1の「1」が列名の行を指す。▼1列のみ指定
1列の場合[ ]はなくても同じ処理になる。
df.drop(['AAA'], axis=1)
df.drop('AAA', axis=1)(axis=1)df.drop('bbb', axis=1) #出力 aaa ccc ddd 111 AAA III MMM 222 BBB JJJ NNN 333 CCC KKK OOO 444 DDD LLL PPP
▼複数列指定列名の複数指定df.drop(['bbb','ddd'], axis=1) #出力 aaa ccc 111 AAA III 222 BBB JJJ 333 CCC KKK 444 DDD LLL
(1-4) axis='columns'
オプションに「axis='columns'」を指定しても、axis=1と同じになる。
df.drop([label1,label2,,,], axis='columns')axis='columns'df.drop(['bbb','ddd'], axis='columns') #出力 aaa ccc 111 AAA III 222 BBB JJJ 333 CCC KKK 444 DDD LLL
②drop(index=label)
行名を指定して削除
df.drop(index=label)index=labeldf.drop(index=[222,444]) #出力 aaa bbb ccc ddd 111 AAA EEE III MMM 333 CCC GGG KKK OOO下記3つと同じ。
df.drop(label)
df.drop(label, axis=0)
df.drop(label, axis='index')
③drop(columns=label)
行名を指定して削除
df.drop(columns=label)index=labeldf.drop(columns=['ddd','bbb']) #出力 aaa ccc 111 AAA III 222 BBB JJJ 333 CCC KKK 444 DDD LLL下記2つと同じ。
df.drop(label, axis=1)
df.drop(label, axis='columns')
3.dropメソッドのその他オプション
①上書きを許可する
dropメソッドはデフォルトでは、元の表は変更せず新しいオブジェクトを生成する。
(間違って削除しても戻せる)この機能をオフにするオプション。
inplace=True
└ デフォルトは「False」上書きを許可df.drop(columns=['ddd','bbb'], inplace=True) df #出力 aaa ccc 111 AAA III 222 BBB JJJ 333 CCC KKK 444 DDD LLL元の表(df)が書き変わっている。
②エラーを表示させない
オプションで
errors='ignore'を設定すると、エラーを無視できる。
└ デフォルトは「errors='raise'」
▼エラーの例:既に削除上書きした列を再度削除エラーの例df.drop(columns=['ddd','bbb'], inplace=True) #出力 #KeyError: "['ddd' 'bbb'] not found in axis"
▼errors='ignore'オプションを使用した場合エラー無視df.drop(columns=['ddd','bbb'], inplace=True, errors='ignore')何も表示されない。
- 投稿日:2020-03-30T17:18:30+09:00
【濃厚】1日あればわかるPython入門
2020年、全人類の必修科目として、Pythonが選ばれました。
ですから、この記事を読んだら必ず机に向かってPythonの勉強をしましょう。
また、必ず ”Looks Good To Me!” と叫び、LGTMボタンとストックボタン押すのをを忘れないようにしてください。…茶番は以上です。
1日かけて書いたので、真面目な話、LGTMボタンとか押していただくと励みになります。
イントロ
なぜPythonを勉強するのかという話ですが、それがわかっているからこそ、あなたはこの記事を読んでいるはずです。
というわけで省略します。次に、この記事の内容についてですが、完全に網羅した内容といったわけではなく、もっと詳しいリファレンスのようなものが見たい場合はnote.nkmk.meをご覧ください。
また、この記事は非常に長いため、cmd + F でサイト内検索をすると捗るかもしれません
あるいは、markdownでごっそりコピーして好き勝手に書き換えてもらっても構いません。最後に、この記事は超初心者に向けたものではなく、初心者に向けたものです。
では、始めていきましょう。
注意
>>>の後に書かれているのは出力結果です。通常とは逆ですが、みなさんがコピーしやすい用に配慮しました。環境構築
とりあえずGoogle Colabを使ってPythonを動かしてください。
それから先のステップに関しては、「スクリプティング」でお伝えします。データ型と演算子
この章で扱うデータ型は以下の4つです。残りは次の章で扱います。
int型: 整数
str型: 文字列
float型: 浮動小数点数
bool型: True/False
演算子は以下の通り
+: 足し算
-: 引き算
*: 掛け算
/: 割り算
%: 割り算した後の余り
**: べき乗
//: 割り算後、整数への切り捨て
…etc複合代入演算子(+=とか*=とか)もあります。こちらをご覧ください
int
print((1 + 2 + 3)/2) >>> 3.0 x = 9*7+5*7 y = 6 print(x//y) >>> 16
float
整数以外で表せないデータに要注意(人数など)
Tips)
こんなことが起きます。(詳しくはこちら)# 0.1+0.1+0.1はfloat型なので、0.3と等しくならない print(.1 + .1 + .1 == .3) >>> False
str
a = "my" b = "phone" print(a+b) #だと"myphone"と出力され、 >>> myphone print(a+" "+b) #だと"my phone"と出力されます >>> my phone #また、文字列に'が入っている場合、 a = 'he's phone' #ではなくて a = 'he\'s phone' #としなければいけません #ちなみに、 a ="he's phone" #として"で囲う方法もあります。 #len関数というものもあり、 print(len("ababa") / len("ab")) >>> 2.5 #また、 print(len(835)) #とすると、 >>> TypeError: object of type 'int' has no len() #となります
bool
True/False or 1/0 として出力されることが多いです。
比較演算子一覧
<
>
<=
>=
==
!=論理演算子一覧
and
or
nota = 2 print(a == 2) >>> True
変数
a = 1 print(a) >>> 1 a = 2 print(a) >>> 2Tips)
- ここでは紹介しませんが、変数名につけてはならないものがあります
- 変数名で単語をつなげるとき、’ _ ’ (アンダースコア)を使います
タイプの見分け方と変換
#type() print(type(4)) >>> int print(type(3.7)) >>> float print(type('this')) >>> str print(type(True)) >>> bool #例えば、こんなデータがあるとします a = "12" b = "3" #この時、a+bの数値(15)を出力するには c = int(a)+int(b) print(str(c)) #と書かなければいけません。
文字列メソッド
文字列メソッドは、str型専用の機能のことです
#islower() print("Taiyaki wo tabetai".islower()) >>> False #format() print("Mohammed has {} balloons".format(27)) >>> Mohammed has 27 balloons animal = "dog" action = "bite" print("Does your {} {}?".format(animal, action)) >>> Does your dog bite? maria_string = "Maria loves {} and {}" print(maria_string.format("math", "statistics")) >>> Maria loves math and statistics文字列メソッド(分割)
new_str = "The cow jumped over the moon." new_str.split() >>> ['The', 'cow', 'jumped', 'over', 'the', 'moon.'] new_str.split(' ', 3) #最初の3つがスペースごとに分割される >>> ['The', 'cow', 'jumped', 'over the moon.'] new_str.split('.') >>> ['The cow jumped over the moon', ''] new_str.split(None, 3) >>> ['The', 'cow', 'jumped', 'over the moon.']データ構造
ここでは前章では扱えなかった辞書やリストといったデータ構造に触れていきます。
リスト
- プロバティ
- 変更可能
- 順序が決まっている
#リスト型にはどのデータタイプの値も組み合わせられます。 #リスト型は下のように作ります。 a = [0, 1, 5, 3.4, False] #int, float, boolが入っています。 a[2] #インデックスは0から始まるので5です。 >>> 5 a[-1] #最後から1番目ということを示しています >>> False #値の更新 a[2] = 8.3 print(a) >>> [8.3, 1, 5, 3.4, False] #末尾への要素の追加 append() a.append(3) #リストの末尾に追加されます print(a) >>> [8.3, 1, 5, 3.4, False, 3] #指定箇所への要素の追加 insert() a.insert(3, 4) #a[3]に4を追加 print(a) >>> [8.3, 1, 5, 3.4, 4, False, 3] #末尾の要素の削除 pop() a.pop() print(a) >>> [8.3, 1, 5, 3.4, 4, False] #スライスもできます a[2:4] #2-4を取り出していますが、4は含みません >>> [5, 3.4] #len() print(len("ababa") / len("ab")) >>> 2.5 #max() a = [1,2,3,4,5] print(max(a)) >>> 3 #min() a = [1,2,3,,4,5] print(max(a)) >>> 1 #sorted a = [2,3,44,2] print(sorted(a)) >>> [2,2,3,44] #join new_str = "\n".join(["a", "b", "c", "d"]) print(new_str) >>> a >>> b >>> c >>> d name = "-".join(["García", "O'Kelly"]) print(name) >>> García-O'Kelly
inornot in(bool型で出力されます)‘this’ in ‘this is a string’ >>> True ‘in’ in ‘this is a string’ >>> True ‘isa’ in ‘this is a string’ >>> False 5 not in [1, 2, 3, 4, 6] >>> True 5 in [1, 2, 3, 4, 6] >>> False
- リストと文字列の違い
#リストは変更可能 my_lst = [1, 2, 3, 4, 5] my_lst[0] = ‘one’ print(my_lst) >>> [‘one’, 2, 3, 4, 5] #文字列は不変(以下の二行は機能しない) greeting = “Hello there” greeting[0] = ‘M’
セット
- プロバティ
- 特定の順序のない要素のコンテナ
numbers = [1, 2, 6, 3, 1, 1, 6] unique_nums = set(numbers) print(unique_nums) >>> {1, 2, 3, 6}
- 色々なメソッドがあります
#add() fruit = {"apple", "banana", "orange", "grapefruit"} # define a set print("watermelon" in fruit) # check for element fruit.add("watermelon") # add an element print(fruit) print(fruit.pop()) # remove a random element print(fruit) >>> False >>> {'watermelon', 'apple', 'orange', 'grapefruit', 'banana'} >>> watermelon >>> {'apple', 'orange', 'grapefruit', 'banana'} #pop() a = [1, 2, 2, 3, 3, 3, 4, 4, 4, 4] b = set(a) #{1,2,3,4} b.add(5) #{1,2,3,4,5} b.pop() #ランダムな要素の削除 print(b) #{2,3,4,5}
辞書
- プロバティ
- 辞書は、複数のオブジェクトを保存できます
- リストを辞書のキーとして使うことはできません
elements = {"Japan": 1, "China": 3, "US": 29} print(elements["Japan"]) >>> 1 elements["Italy"] = 39 print(elements) >>> {'Japan': 1, 'China': 3, 'US': 29, 'Italy': 39} #in, get print("UK" in elements) >>> False print(elements.get("France")) >>> None #is, is not n = elements.get("Mexico") print(n is None) >>> True print(n is not None) >>> False
- is と == の使い分け
a = [1, 2, 3] b = a c = [1, 2, 3] print(a == b) >>>True print(a is b) >>> True print(a == c) >>> True print(a is c) >>> False
タプル
- プロバティ
- だいたいリストと一緒
- 順番を変えられない
- データが不変 → リストより機能が少ない(その代わりシンプル)
length, width, height = 52, 40, 100 print("その正方形の大きさは {} x {} x {}".format(length, width, height))
複合データ構造
コンテナーを他のコンテナーに組み込んで、複合データ構造が作れます。
elements = {"hydrogen": {"number": 1, "weight": 1.00794, "symbol": "H"}, "helium": {"number": 2, "weight": 4.002602, "symbol": "He"}} #アクセスするには helium = elements["helium"] # get the helium dictionary hydrogen_weight = elements["hydrogen"]["weight"] # get hydrogen's weight #キーの追加 oxygen = {"number":8,"weight":15.999,"symbol":"O"} # create a new oxygen dictionary elements["oxygen"] = oxygen # assign 'oxygen' as a key to the elements dictionary print('elements = ', elements) >>> elements = {"hydrogen": {"number": 1, "weight": 1.00794, "symbol": 'H'}, "helium": {"number": 2, "weight": 4.002602, "symbol": "He"}, "oxygen": {"number": 8, "weight": 15.999, "symbol": "O"}} #辞書の値の追加 elements = {'hydrogen': {'number': 1, 'weight': 1.00794, 'symbol': 'H'}, 'helium': {'number': 2, 'weight': 4.002602, 'symbol': 'He'}} elements['hydrogen']['is_noble_gas'] = False elements['helium']['is_noble_gas'] = True print(elements) >>> {'hydrogen': {'number': 1, 'weight': 1.00794, 'symbol': 'H', 'is_noble_gas': False}, 'helium': {'number': 2, 'weight': 4.002602, 'symbol': 'He', 'is_noble_gas': True}}
覚えておきたいデータ型とデータ構造の違い
- データ構造は、さまざまなデータ型を含めることができるコンテナです。
- リストはデータ構造の例です。
- すべてのデータ構造はデータ型です。
制御フロー
if
a = 12 if a <= 2: print(a) #スペース4つ elif a <= 4: print(a) else: #全部違ったら print("全部違うよ(笑)") 全部違うよ(笑)
- 比較演算子一覧
x < y x <= y x > y x >= y x != y X == y x is y x is not y x in y x not in y
for
numbers = [0, 1, 2] for number in numbers: print(number) >>> 0 >>> 1 >>> 2 #break numbers = [0, 1, 2] for number in numbers: if number == 1: print("1が出たらストップです") break print(number) >>> 0 >>> 1が出たらストップです #continue for number in numbers: if number == 1: print("1が出たらスキップします") continue print(number) else: print("やっと終わった!") >>> 0 >>> 1が出たらスキップします >>> 2 >>> やっと終わった! #enumerate() インデックスをつけられる numbers = [0, 1, 2] for a, number in enumerate(numbers, 13): print(a, number) >>> 13 0 >>> 14 1 >>> 15 2 #zip() numbers = [0, 1, 2] numbers_2 = [4, 5, 6] for number, number_2 in zip(numbers, numbers_2): print(number, number_2) >>> 0 4 >>> 1 5 >>> 2 6 #range() for i in range(3): print(i) >>> 0 >>> 1 >>> 2より詳しくはこちらを見てください
リスト内包表記
#普通に書く cities = ["new york", "tokyo", "paris"] capitalized_cities = [] for city in cities: capitalized_cities.append(city.title()) #title()は大文字に変換 print(capitalized_cities) >>> ['New York', 'Tokyo', 'Paris'] #リスト内包表記で書く cities = ["new york", "tokyo", "paris"] capitalized_cities = [city.title() for city in cities] print(capitalized_cities) >>> ['New York', 'Tokyo', 'Paris'] #[式 for 変数名 in 変更可能オブジェクト]
dict(for)
a = {"Apple": 100, "microsoft": 120, "gizmodo": 200} for kabuka in a: print(kabuka) >>> Apple >>> microsoft >>> gizmodo #キーだけが出力されます #key() #keyだけ出力したい場合 a = {"Apple": 100, "microsoft": 120, "gizmodo": 200} for kabuka in a.keys(): print(kabuka) >>> Apple >>> microsoft >>> gizmodo #values() a = {"Apple": 100, "microsoft": 120, "gizmodo": 200} for kabuka in a.values(): print(kabuka) >>> 100 >>> 120 >>> 200 #items() a = {"Apple": 100, "microsoft": 120, "gizmodo": 200} for kabuka in a.items(): print(kabuka) >>> ('Apple', 100) >>> ('microsoft', 120) >>> ('gizmodo', 200)
while
a = 2 while a == 2: print(a) #break a = 2 while a < 8: print(a) if a == 4: print("5月といえば") break a += 1 >>> 2 >>> 3 >>> 4 >>> 5月といえば #他にもcontinueやelseなどがあります。forと似ています。
forとwhileの使い分け
for:
反復回数がわかっているか有限の場合
while:
条件が満たされるまで反復する場合関数
関数の定義と呼び出し
#定義 def a(): print(a) #呼び出し a() >>> a
引数と戻り値
#引数(下のprice) def how_much_price(price): if (price == 100): print("安いな") elif(price == 300): print("高いな") else: print("いらない") how_much_price(300) >>> 高いな #戻り値(return) def triple(x): return 3 * x x = triple(4) print(x) >>> 12returnの使い道:
- 何らかの値を呼び出し元に返したいとき
- 関数から脱出させ、呼び出し元に処理を返したいとき
スコープ
スコープは、プログラムのどの部分から変数を参照または使用できるかを指します。
スコープの種類を決め、どこかで同じ名前の変数が使われていたりしてエラーが起きることを防ぎます。
関数内でその変数のスコープを作った場合、使えるのはスコープの中限定ですが、関数外で作った場合、どこでも使えます。
docstring
関数は再利用可能です。なので、その関数の使用方法と目的をコメントで残す、それがdocstringです。
特に詳細について触れませんので、自分で調べてください。def apple(sweet): """Appleは美味しい""" return sweet
ラムダ式, 無名関数
複雑な関数には向きませんが…
#通常 def qiita(a, b): return a*b #ラムダ qiita = lambda x,y: x*y #どちらも呼び出すときは qiita(a, b)
イテレータとジェネレータ
イテラブル, イテレータ:
イテラブルは、リストなど、一度に1つの要素を返すことができるオブジェクト。enumerate()などの組み込み関数の多くはイテレータを返すジェネレータ:
関数を使用してイテレータを作成する方法。クラスを使用してイテレータを定義することもできる。戦争を招きたくないので、詳細な説明はこちらを読んでみてください。
ジェネレータ式
ジェネレータとリスト内包表記を組み合わせるとスマートなジェネレータがかけます。
list = [x**2 for x in range(10)] #リスト print(list) >>> [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] iter_list = (x**2 for x in range(10)) # イテレーター print(iter_list) >>> <generator object <genexpr> at 0x7facbc79f5e8>スクリプティング
Pythonのインストール前に
まず前提として、MacはUNIXベースですが、Windowsは違うので、Windowsユーザーの方はGit BashをインストールしてUNIXコマンドを使えるようにしてください。また、コンピューターにもともと入っているPythonは使えないことに注意してください。
またMac, Linuxユーザーは、$ python —versionと入力してPython 3.x.xと表示される場合、新規インストールは不要です。(もちろんインストールしても構いません)
anacondaでPythonのインストール
ネットで調べてください。Pythonは3.6.5以降をお勧めします。
$ conda —versionでバージョンが確かめられます。(インストールされていれば)
atomのインストールとセットアップ
atomをインストールした後、色々なパッケージのインストール, 設定変更が必要です。
日本語メニュー:
japanese-menuからインストールインデント:
ご存知の通り、Pythonはインデントがスペース4つ分なので、Tab Lengthを2から4に変更してください。これでTab1つでインデントできます。文法チェッカー
PEP8に基づき、小姑のように文法をチェックし、警告してくれるプラグイン。それがPylintです。テーマ
お気に入りのテーマを探す旅は一生続きます。デバッグ方法
エラーを探す簡単でシンプルな方法として、CLIでPythonコードを実行するというものがあります。例えば、atomで新しいファイルa.pyを作成し、エラーが発生するコード#a.py def a print(a) >>> aを入力し、cliで
$ python a.pyと入力すると
File "/Users/my_name/Documents/a.py", line 1 def a ^ SyntaxError: invalid syntaxとエラーが出てきます。
以上で、環境構築は終わりです。ここからはPython文法の最後の部分です。
入力データを使う input
name = input("Enter your name: ") print("Hello there, {}!".format(name.title())) number = input("好きな数字を入力して") print("あなたの精神年齢は"+number+"歳です。")
エラーと例外に対処するには
主にエラーには2つの種類があります。
構文エラーと例外です。
構文エラーはともかく、例外処理が大切になってきます。print(5/0) #エラーが起きます >>> ZeroDivisionError: division by zero #try, except try: print(5/0) except ZeroDivisionError as err: print(err) >>> division by zeroより詳しくは、こちらをご覧ください。
ファイルの読み書き
#読み取り r f = open('my_path/my_file.txt', 'r') file_data = f.read() f.close() #書き込み w f = open('my_path/my_file.txt', 'w') f.write("Hello there!") f.close() #with 自動的に閉じる with open('my_path/my_file.txt', 'r') as f: file_data = f.read()
スクリプトのインポート
#スクリプトのインポート import helloworld #.py拡張子はいらない #名前を変更する場合 import helloworld as hw
標準ライブラリの使い方
#2種類のインポート方法がある import math from math import math.floor #名前を変えたい場合 from module_name import object_name as new_name #ライブラリの全モジュールを使う予定なら import module_name module_name.object_name #としてオブジェクトにアクセスする
3rdパーティーライブラリの使い方
pip install packege_nameとしてインストールすることも可能ですが、anacondaを使っている場合はcondaコマンドを使ったほうが無難です。インストールした後はimportして標準ライブラリと同じように使えます。
オススメ&基本ライブラリは以下の通りです。
- IPython
- requests
- Flask
- Django
- BS
- purest
- PyYAML
- NumPy
- Pandas
- matplotlib
- ggplot
- pillow
- pytz
…etc
インタプリタ
cliで
pythonと打って出てくる>>>というものがインタープリターです。コードを編集するのが難しいのが欠点です。ですから、多くの場合cliでpythonを使う場合はIPythonを使います。
おめでとう!
この記事を読み終えたら、Pythonのことはなんとなくわかったと思います。ですから次は、もっと実践的な内容に進みましょう。AtCoderや機械学習, Djangoを使ったWebアプリ制作などです。
またいつか、会いましょう。(もしよければ次の記事「オブジェクト指向入門」も読んでください。)
あとがき
疲れた…けど、
3/31 17:45にはオブジェクト指向入門,
4/1 17:45には NumPy入門, Matplolib入門, Pandas入門を公開するのでお楽しみに!...それにしてもMacが欲しい
- 投稿日:2020-03-30T17:18:30+09:00
1日あればわかるPython入門
2020年、全人類の必修科目として、Pythonが選ばれました。
ですから、この記事を読んだら必ず机に向かってPythonの勉強をしましょう。
また、必ず ”Looks Good To Me!” と叫び、LGTMボタンとストックボタン押すのをを忘れないようにしてください。…茶番は以上です。
1日かけて書いたので、真面目な話、LGTMボタンとか押していただくと励みになります。
イントロ
なぜPythonを勉強するのかという話ですが、それがわかっているからこそ、あなたはこの記事を読んでいるはずです。
というわけで省略します。次に、この記事の内容についてですが、完全に網羅した内容といったわけではなく、もっと詳しいリファレンスのようなものが見たい場合はnote.nkmk.meをご覧ください。
また、この記事は非常に長いため、cmd + F でサイト内検索をすると捗るかもしれません
あるいは、markdownでごっそりコピーして好き勝手に書き換えてもらっても構いません。最後に、この記事は超初心者に向けたものではなく、初心者に向けたものです。
では、始めていきましょう。
注意
>>>の後に書かれているのは出力結果です。通常とは逆ですが、みなさんがコピーしやすい用に配慮しました。環境構築
とりあえずGoogle Colabを使ってPythonを動かしてください。
それから先のステップに関しては、「スクリプティング」でお伝えします。データ型と演算子
この章で扱うデータ型は以下の4つです。残りは次の章で扱います。
int型: 整数
str型: 文字列
float型: 浮動小数点数
bool型: True/False
演算子は以下の通り
+: 足し算
-: 引き算
*: 掛け算
/: 割り算
%: 割り算した後の余り
**: べき乗
//: 割り算後、整数への切り捨て
…etc複合代入演算子(+=とか*=とか)もあります。こちらをご覧ください
int
print((1 + 2 + 3)/2) >>> 3.0 x = 9*7+5*7 y = 6 print(x//y) >>> 16
float
整数以外で表せないデータに要注意(人数など)
Tips)
こんなことが起きます。(詳しくはこちら)# 0.1+0.1+0.1はfloat型なので、0.3と等しくならない print(.1 + .1 + .1 == .3) >>> False
str
a = "my" b = "phone" print(a+b) #だと"myphone"と出力され、 >>> myphone print(a+" "+b) #だと"my phone"と出力されます >>> my phone #また、文字列に'が入っている場合、 a = 'he's phone' #ではなくて a = 'he\'s phone' #としなければいけません #ちなみに、 a ="he's phone" #として"で囲う方法もあります。 #len関数というものもあり、 print(len("ababa") / len("ab")) >>> 2.5 #また、 print(len(835)) #とすると、 >>> TypeError: object of type 'int' has no len() #となります
bool
True/False or 1/0 として出力されることが多いです。
比較演算子一覧
<
>
<=
>=
==
!=論理演算子一覧
and
or
nota = 2 print(a == 2) >>> True
変数
a = 1 print(a) >>> 1 a = 2 print(a) >>> 2Tips)
- ここでは紹介しませんが、変数名につけてはならないものがあります
- 変数名で単語をつなげるとき、’ _ ’ (アンダースコア)を使います
タイプの見分け方と変換
#type() print(type(4)) >>> int print(type(3.7)) >>> float print(type('this')) >>> str print(type(True)) >>> bool #例えば、こんなデータがあるとします a = "12" b = "3" #この時、a+bの数値(15)を出力するには c = int(a)+int(b) print(str(c)) #と書かなければいけません。
文字列メソッド
文字列メソッドは、str型専用の機能のことです
#islower() print("Taiyaki wo tabetai".islower()) >>> False #format() print("Mohammed has {} balloons".format(27)) >>> Mohammed has 27 balloons animal = "dog" action = "bite" print("Does your {} {}?".format(animal, action)) >>> Does your dog bite? maria_string = "Maria loves {} and {}" print(maria_string.format("math", "statistics")) >>> Maria loves math and statistics文字列メソッド(分割)
new_str = "The cow jumped over the moon." new_str.split() >>> ['The', 'cow', 'jumped', 'over', 'the', 'moon.'] new_str.split(' ', 3) #最初の3つがスペースごとに分割される >>> ['The', 'cow', 'jumped', 'over the moon.'] new_str.split('.') >>> ['The cow jumped over the moon', ''] new_str.split(None, 3) >>> ['The', 'cow', 'jumped', 'over the moon.']データ構造
ここでは前章では扱えなかった辞書やリストといったデータ構造に触れていきます。
リスト
- プロバティ
- 変更可能
- 順序が決まっている
#リスト型にはどのデータタイプの値も組み合わせられます。 #リスト型は下のように作ります。 a = [0, 1, 5, 3.4, False] #int, float, boolが入っています。 a[2] #インデックスは0から始まるので5です。 >>> 5 a[-1] #最後から1番目ということを示しています >>> False #値の更新 a[2] = 8.3 print(a) >>> [8.3, 1, 5, 3.4, False] #末尾への要素の追加 append() a.append(3) #リストの末尾に追加されます print(a) >>> [8.3, 1, 5, 3.4, False, 3] #指定箇所への要素の追加 insert() a.insert(3, 4) #a[3]に4を追加 print(a) >>> [8.3, 1, 5, 3.4, 4, False, 3] #末尾の要素の削除 pop() a.pop() print(a) >>> [8.3, 1, 5, 3.4, 4, False] #スライスもできます a[2:4] #2-4を取り出していますが、4は含みません >>> [5, 3.4] #len() print(len("ababa") / len("ab")) >>> 2.5 #max() a = [1,2,3,4,5] print(max(a)) >>> 3 #min() a = [1,2,3,,4,5] print(max(a)) >>> 1 #sorted a = [2,3,44,2] print(sorted(a)) >>> [2,2,3,44] #join new_str = "\n".join(["a", "b", "c", "d"]) print(new_str) >>> a >>> b >>> c >>> d name = "-".join(["García", "O'Kelly"]) print(name) >>> García-O'Kelly
inornot in(bool型で出力されます)‘this’ in ‘this is a string’ >>> True ‘in’ in ‘this is a string’ >>> True ‘isa’ in ‘this is a string’ >>> False 5 not in [1, 2, 3, 4, 6] >>> True 5 in [1, 2, 3, 4, 6] >>> False
- リストと文字列の違い
#リストは変更可能 my_lst = [1, 2, 3, 4, 5] my_lst[0] = ‘one’ print(my_lst) >>> [‘one’, 2, 3, 4, 5] #文字列は不変(以下の二行は機能しない) greeting = “Hello there” greeting[0] = ‘M’
セット
- プロバティ
- 特定の順序のない要素のコンテナ
numbers = [1, 2, 6, 3, 1, 1, 6] unique_nums = set(numbers) print(unique_nums) >>> {1, 2, 3, 6}
- 色々なメソッドがあります
#add() fruit = {"apple", "banana", "orange", "grapefruit"} # define a set print("watermelon" in fruit) # check for element fruit.add("watermelon") # add an element print(fruit) print(fruit.pop()) # remove a random element print(fruit) >>> False >>> {'watermelon', 'apple', 'orange', 'grapefruit', 'banana'} >>> watermelon >>> {'apple', 'orange', 'grapefruit', 'banana'} #pop() a = [1, 2, 2, 3, 3, 3, 4, 4, 4, 4] b = set(a) #{1,2,3,4} b.add(5) #{1,2,3,4,5} b.pop() #ランダムな要素の削除 print(b) #{2,3,4,5}
辞書
- プロバティ
- 辞書は、複数のオブジェクトを保存できます
- リストを辞書のキーとして使うことはできません
elements = {"Japan": 1, "China": 3, "US": 29} print(elements["Japan"]) >>> 1 elements["Italy"] = 39 print(elements) >>> {'Japan': 1, 'China': 3, 'US': 29, 'Italy': 39} #in, get print("UK" in elements) >>> False print(elements.get("France")) >>> None #is, is not n = elements.get("Mexico") print(n is None) >>> True print(n is not None) >>> False
- is と == の使い分け
a = [1, 2, 3] b = a c = [1, 2, 3] print(a == b) >>>True print(a is b) >>> True print(a == c) >>> True print(a is c) >>> False
タプル
- プロバティ
- だいたいリストと一緒
- 順番を変えられない
- データが不変 → リストより機能が少ない(その代わりシンプル)
length, width, height = 52, 40, 100 print("その正方形の大きさは {} x {} x {}".format(length, width, height))
複合データ構造
コンテナーを他のコンテナーに組み込んで、複合データ構造が作れます。
elements = {"hydrogen": {"number": 1, "weight": 1.00794, "symbol": "H"}, "helium": {"number": 2, "weight": 4.002602, "symbol": "He"}} #アクセスするには helium = elements["helium"] # get the helium dictionary hydrogen_weight = elements["hydrogen"]["weight"] # get hydrogen's weight #キーの追加 oxygen = {"number":8,"weight":15.999,"symbol":"O"} # create a new oxygen dictionary elements["oxygen"] = oxygen # assign 'oxygen' as a key to the elements dictionary print('elements = ', elements) >>> elements = {"hydrogen": {"number": 1, "weight": 1.00794, "symbol": 'H'}, "helium": {"number": 2, "weight": 4.002602, "symbol": "He"}, "oxygen": {"number": 8, "weight": 15.999, "symbol": "O"}} #辞書の値の追加 elements = {'hydrogen': {'number': 1, 'weight': 1.00794, 'symbol': 'H'}, 'helium': {'number': 2, 'weight': 4.002602, 'symbol': 'He'}} elements['hydrogen']['is_noble_gas'] = False elements['helium']['is_noble_gas'] = True print(elements) >>> {'hydrogen': {'number': 1, 'weight': 1.00794, 'symbol': 'H', 'is_noble_gas': False}, 'helium': {'number': 2, 'weight': 4.002602, 'symbol': 'He', 'is_noble_gas': True}}
覚えておきたいデータ型とデータ構造の違い
- データ構造は、さまざまなデータ型を含めることができるコンテナです。
- リストはデータ構造の例です。
- すべてのデータ構造はデータ型です。
制御フロー
if
a = 12 if a <= 2: print(a) #スペース4つ elif a <= 4: print(a) else: #全部違ったら print("全部違うよ(笑)") 全部違うよ(笑)
- 比較演算子一覧
x < y x <= y x > y x >= y x != y X == y x is y x is not y x in y x not in y
for
numbers = [0, 1, 2] for number in numbers: print(number) >>> 0 >>> 1 >>> 2 #break numbers = [0, 1, 2] for number in numbers: if number == 1: print("1が出たらストップです") break print(number) >>> 0 >>> 1が出たらストップです #continue for number in numbers: if number == 1: print("1が出たらスキップします") continue print(number) else: print("やっと終わった!") >>> 0 >>> 1が出たらスキップします >>> 2 >>> やっと終わった! #enumerate() インデックスをつけられる numbers = [0, 1, 2] for a, number in enumerate(numbers, 13): print(a, number) >>> 13 0 >>> 14 1 >>> 15 2 #zip() numbers = [0, 1, 2] numbers_2 = [4, 5, 6] for number, number_2 in zip(numbers, numbers_2): print(number, number_2) >>> 0 4 >>> 1 5 >>> 2 6 #range() for i in range(3): print(i) >>> 0 >>> 1 >>> 2より詳しくはこちらを見てください
リスト内包表記
#普通に書く cities = ["new york", "tokyo", "paris"] capitalized_cities = [] for city in cities: capitalized_cities.append(city.title()) #title()は大文字に変換 print(capitalized_cities) >>> ['New York', 'Tokyo', 'Paris'] #リスト内包表記で書く cities = ["new york", "tokyo", "paris"] capitalized_cities = [city.title() for city in cities] print(capitalized_cities) >>> ['New York', 'Tokyo', 'Paris'] #[式 for 変数名 in 変更可能オブジェクト]
dict(for)
a = {"Apple": 100, "microsoft": 120, "gizmodo": 200} for kabuka in a: print(kabuka) >>> Apple >>> microsoft >>> gizmodo #キーだけが出力されます #key() #keyだけ出力したい場合 a = {"Apple": 100, "microsoft": 120, "gizmodo": 200} for kabuka in a.keys(): print(kabuka) >>> Apple >>> microsoft >>> gizmodo #values() a = {"Apple": 100, "microsoft": 120, "gizmodo": 200} for kabuka in a.values(): print(kabuka) >>> 100 >>> 120 >>> 200 #items() a = {"Apple": 100, "microsoft": 120, "gizmodo": 200} for kabuka in a.items(): print(kabuka) >>> ('Apple', 100) >>> ('microsoft', 120) >>> ('gizmodo', 200)
while
a = 2 while a == 2: print(a) #break a = 2 while a < 8: print(a) if a == 4: print("5月といえば") break a += 1 >>> 2 >>> 3 >>> 4 >>> 5月といえば #他にもcontinueやelseなどがあります。forと似ています。
forとwhileの使い分け
for:
反復回数がわかっているか有限の場合
while:
条件が満たされるまで反復する場合関数
関数の定義と呼び出し
#定義 def a(): print(a) #呼び出し a() >>> a
引数と戻り値
#引数(下のprice) def how_much_price(price): if (price == 100): print("安いな") elif(price == 300): print("高いな") else: print("いらない") how_much_price(300) >>> 高いな #戻り値(return) def triple(x): return 3 * x x = triple(4) print(x) >>> 12returnの使い道:
- 何らかの値を呼び出し元に返したいとき
- 関数から脱出させ、呼び出し元に処理を返したいとき
スコープ
スコープは、プログラムのどの部分から変数を参照または使用できるかを指します。
スコープの種類を決め、どこかで同じ名前の変数が使われていたりしてエラーが起きることを防ぎます。
関数内でその変数のスコープを作った場合、使えるのはスコープの中限定ですが、関数外で作った場合、どこでも使えます。
docstring
関数は再利用可能です。なので、その関数の使用方法と目的をコメントで残す、それがdocstringです。
特に詳細について触れませんので、自分で調べてください。def apple(sweet): """Appleは美味しい""" return sweet
ラムダ式, 無名関数
複雑な関数には向きませんが…
#通常 def qiita(a, b): return a*b #ラムダ qiita = lambda x,y: x*y #どちらも呼び出すときは qiita(a, b)
イテレータとジェネレータ
イテラブル, イテレータ:
イテラブルは、リストなど、一度に1つの要素を返すことができるオブジェクト。enumerate()などの組み込み関数の多くはイテレータを返すジェネレータ:
関数を使用してイテレータを作成する方法。クラスを使用してイテレータを定義することもできる。戦争を招きたくないので、詳細な説明はこちらを読んでみてください。
ジェネレータ式
ジェネレータとリスト内包表記を組み合わせるとスマートなジェネレータがかけます。
list = [x**2 for x in range(10)] #リスト print(list) >>> [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] iter_list = (x**2 for x in range(10)) # イテレーター print(iter_list) >>> <generator object <genexpr> at 0x7facbc79f5e8>スクリプティング
Pythonのインストール前に
まず前提として、MacはUNIXベースですが、Windowsは違うので、Windowsユーザーの方はGit BashをインストールしてUNIXコマンドを使えるようにしてください。また、コンピューターにもともと入っているPythonは使えないことに注意してください。
またMac, Linuxユーザーは、$ python —versionと入力してPython 3.x.xと表示される場合、新規インストールは不要です。(もちろんインストールしても構いません)
anacondaでPythonのインストール
ネットで調べてください。Pythonは3.6.5以降をお勧めします。
$ conda —versionでバージョンが確かめられます。(インストールされていれば)
atomのインストールとセットアップ
atomをインストールした後、色々なパッケージのインストール, 設定変更が必要です。
日本語メニュー:
japanese-menuからインストールインデント:
ご存知の通り、Pythonはインデントがスペース4つ分なので、Tab Lengthを2から4に変更してください。これでTab1つでインデントできます。文法チェッカー
PEP8に基づき、小姑のように文法をチェックし、警告してくれるプラグイン。それがPylintです。テーマ
お気に入りのテーマを探す旅は一生続きます。デバッグ方法
エラーを探す簡単でシンプルな方法として、CLIでPythonコードを実行するというものがあります。例えば、atomで新しいファイルa.pyを作成し、エラーが発生するコード#a.py def a print(a) >>> aを入力し、cliで
$ python a.pyと入力すると
File "/Users/my_name/Documents/a.py", line 1 def a ^ SyntaxError: invalid syntaxとエラーが出てきます。
以上で、環境構築は終わりです。ここからはPython文法の最後の部分です。
入力データを使う input
name = input("Enter your name: ") print("Hello there, {}!".format(name.title())) number = input("好きな数字を入力して") print("あなたの精神年齢は"+number+"歳です。")
エラーと例外に対処するには
主にエラーには2つの種類があります。
構文エラーと例外です。
構文エラーはともかく、例外処理が大切になってきます。print(5/0) #エラーが起きます >>> ZeroDivisionError: division by zero #try, except try: print(5/0) except ZeroDivisionError as err: print(err) >>> division by zeroより詳しくは、こちらをご覧ください。
ファイルの読み書き
#読み取り r f = open('my_path/my_file.txt', 'r') file_data = f.read() f.close() #書き込み w f = open('my_path/my_file.txt', 'w') f.write("Hello there!") f.close() #with 自動的に閉じる with open('my_path/my_file.txt', 'r') as f: file_data = f.read()
スクリプトのインポート
#スクリプトのインポート import helloworld #.py拡張子はいらない #名前を変更する場合 import helloworld as hw
標準ライブラリの使い方
#2種類のインポート方法がある import math from math import math.floor #名前を変えたい場合 from module_name import object_name as new_name #ライブラリの全モジュールを使う予定なら import module_name module_name.object_name #としてオブジェクトにアクセスする
3rdパーティーライブラリの使い方
pip install packege_nameとしてインストールすることも可能ですが、anacondaを使っている場合はcondaコマンドを使ったほうが無難です。インストールした後はimportして標準ライブラリと同じように使えます。
オススメ&基本ライブラリは以下の通りです。
- IPython
- requests
- Flask
- Django
- BS
- purest
- PyYAML
- NumPy
- Pandas
- matplotlib
- ggplot
- pillow
- pytz
…etc
インタプリタ
cliで
pythonと打って出てくる>>>というものがインタープリターです。コードを編集するのが難しいのが欠点です。ですから、多くの場合cliでpythonを使う場合はIPythonを使います。
おめでとう!
この記事を読み終えたら、Pythonのことはなんとなくわかったと思います。ですから次は、もっと実践的な内容に進みましょう。AtCoderや機械学習, Djangoを使ったWebアプリ制作などです。
またいつか、会いましょう。(もしよければ次の記事「オブジェクト指向入門」も読んでください。)
あとがき
疲れた…けど、
3/31 17:45にはオブジェクト指向入門,
4/1 17:45には NumPy入門, Matplolib入門, Pandas入門を公開するのでお楽しみに!...それにしてもMacが欲しい
- 投稿日:2020-03-30T16:53:25+09:00
データサイエンティスト向けVSCodeでのPython実行、Jupyter環境の構築
Pythonでデータ分析する人は、ブラウザからJupyter notebookやJupyter Labを使う方が多いと思います。そんな人達向けに書いたVSCodeの勧めです。
また、この記事は今後書く予定のデータサイエンティスト向けPythonパッケージの作り方の記事の一部となる予定です。
Anacondaがダウンロードしてあるという仮定で話を進めていきます.(Anacondaインストール時に同時にVSCodeをインストールするのではなく別途インストール)
また各ソフトのバージョン違い等によって画面の表示が異なる場合もあると思います。その場合は適宜調べてください。
環境
備考 OS Windows10 conda 4.8.3 Anaconda Promptで conda -VAnaconda 2020.02 Anaconda Promptで conda list anacondaPython 3.8.2 VSCode 1.43.2 また、データサイエンスということで、Kaggleのタイタニック号のデータを使うことにしますが、データはなくてもVSCodeでのPython実行環境の構築はできるので、大丈夫です。
VS Codeのインストール
VS Codeをインストールしてください。基本,何も考えずに[次へ]でいいと思います。
VS Codeについては詳しくはこの記事など参照。わからないことや戸惑うところがあれば、まずこの記事を読めば、なんとなく全体像を把握でき、トラブルの対処となると思います。
Visual Studio Codeの使い方、基本の「キ」Anacondaでの仮想環境の立ち上げ
Anaconda Promptを立ち上げ、
conda create -n 好きな環境名 python=Pythonバージョンで仮想環境を立ち上げてください。
今回は環境名は
titanicとします。
そして仮想環境を起動します。conda activate titanicここから必要なモジュールをインストールします。例として
pandasをインストールしておきましょう。conda install pandasVSCodeでPythonコードを実行してみる
ここからVS CodeでのPythonを実行してみます。スタートメニューでVSCodeと検索し、VSCodeを立ち上げてください。
流れとしては
- Pytho拡張機能をインストール
- プログラムを書く
- Python実行環境を整える
- プログラムを実行という流れになります。順番に説明します。
Pytho拡張機能をインストール
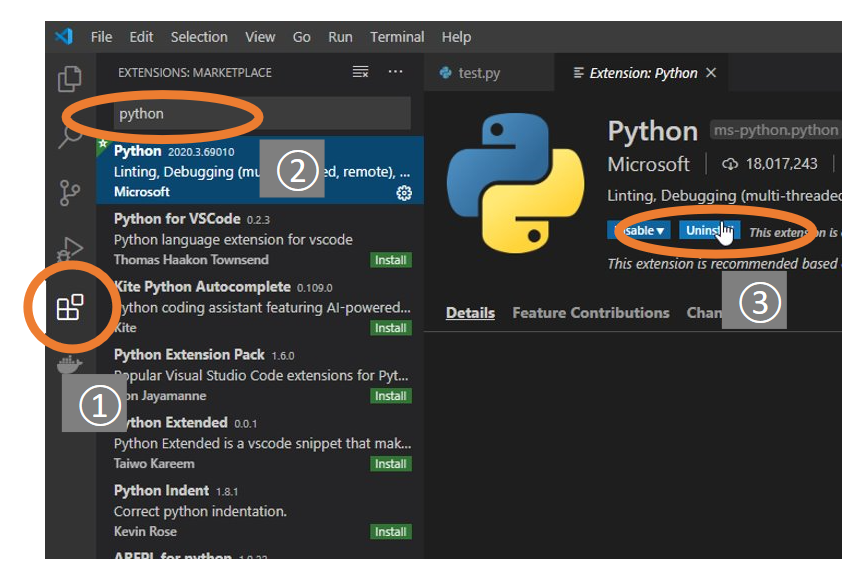
まずVSCodeが開いたら、①左端のサイドバーからExtensionsをクリックし、②pythonと検索します。そして③Microsoft製のPytho拡張機能をインストールします。プログラムを書く
フォルダを開き、実際のプログラムを書きます。
VSCodeの上のメニューバーからFile>Open Folderを選び、これからプログラムを作っていきたいフォルダを開きます。
フォルダを開いたらテスト用のpyファイルを作ります。
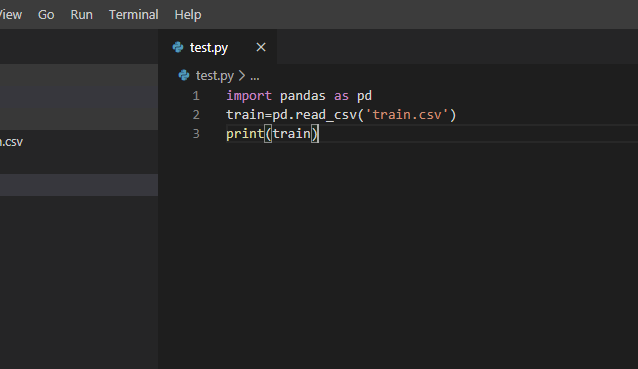
適当なプログラムを作成します。訓練データを読み込み表示するプログラムです。
データがない場合はprint('Hello')などの適当なプログラムで大丈夫ですです。このプログラムをpython上で実行してみます。
Python実行環境を整える
実行環境をCommand Promptに変更する
VSCodeでの実行環境(Terminal)をCommand Promptに変更します。
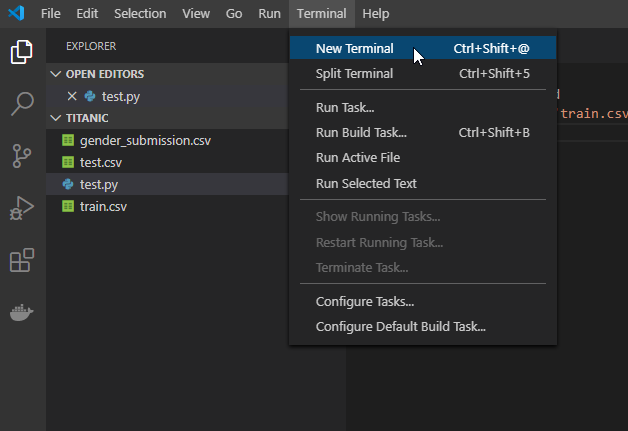
次に上のメニューバーからTerminal>New Terminalを選択します。

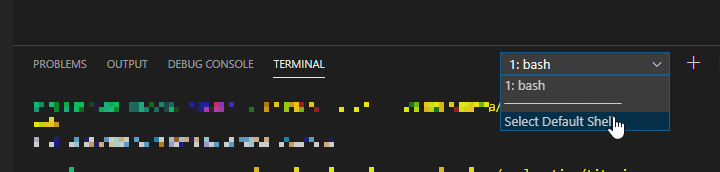
するとウィンドウ下部にターミナルがひらきます。
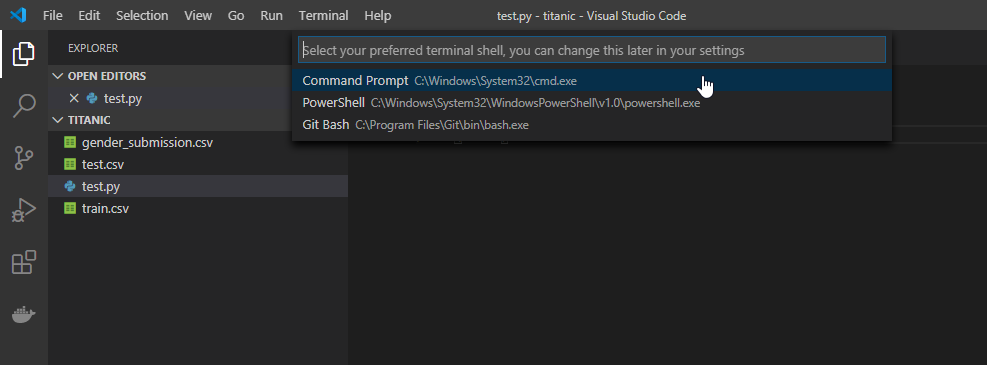
次にこのターミナルの右上の「1:bash」(表示名は違うかもしれません)のプルダウンメニューから「Select Default Shell」を選択します。
そうすると、上の画像のように上からターミナルの種類を選べるようになるので、「Command Proompt」を選択してください。
これはTerminalがbashやPowerShellのままだとPythonが実行できないから変更します。(Windowsの場合だけかもしれません)
Pythonインタプリタを設定する。
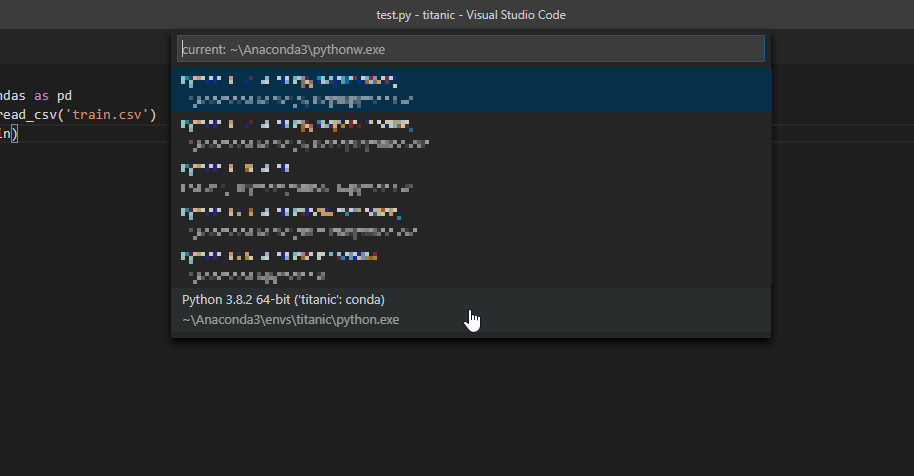
次にPythonコードを実行するためのインタプリタ(実行環境)を設定します。
①
Ctrl+Shift+Pを押し、VSCodeのコマンドパレットを開き、②python selectと検索します。そして③Python Select Interpreterを選択します。
そして先程作った「好きな環境名」の環境を選択します。今回の場合はtitanic:condaです。
そうすると上図のようにフォルダ内に.vscode>setting.jsonというjsonファイルが作られます。そのファイルには指定した環境のpython.exeの場所が記載されています。PythonインタプリタにAnacondaの環境名が現れない
ただ、同じように操作したとしても、PythonインタプリタにAnacondaの環境名が現れない場合があると思います。これはAnacondaのインストール場所をデフォルトから変えた場合などが考えられます。
その場合は以下の記事を参考に環境変数PATHなどを設定してください。
VS Code で Anaconda の Python デバッグ 環境構築(Visual Studio Code)
また、VSCodeがPC上のPythonインタプリタを検索しきれていない場合もあるので、VSCodeを再起動して数秒待ってからもう一度
Python Select Interpreterを選択し直すなどしてみてください。Pythonの実行設定を設定する
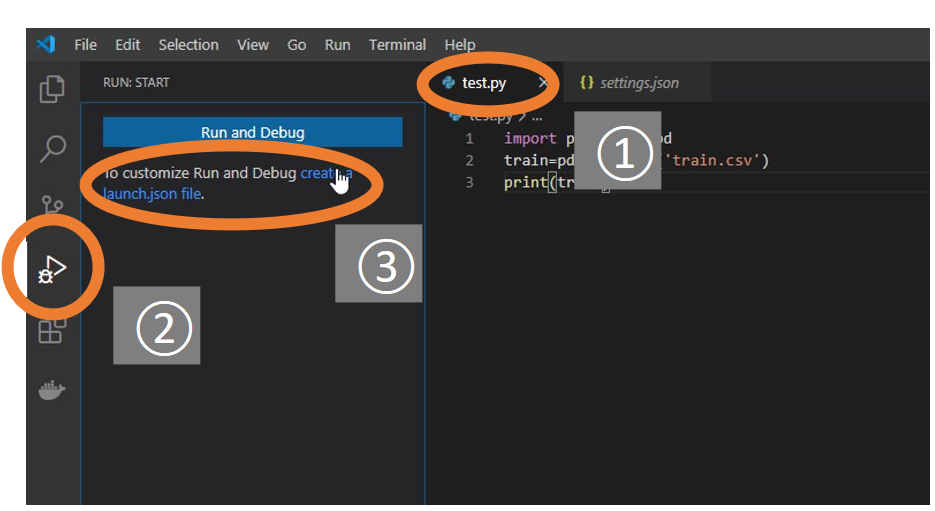
①VSCodeでpythonコード(ここでは
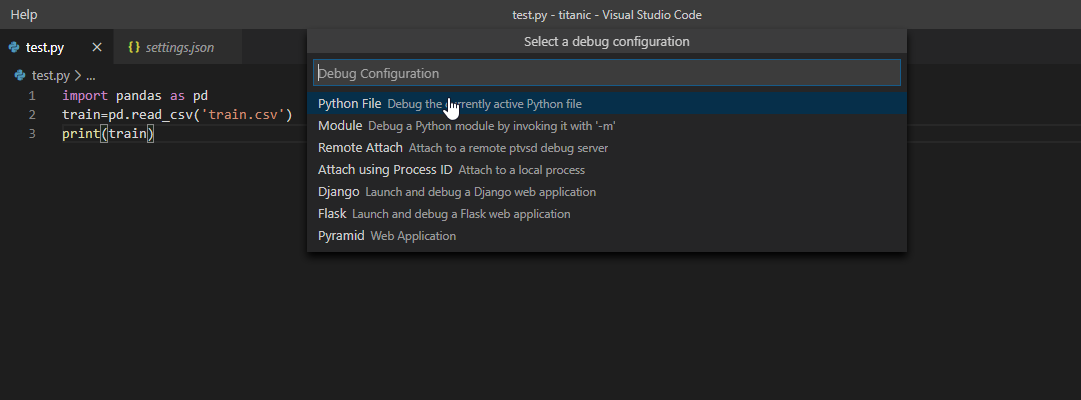
test.py)を開いた状態で、②左端のサイドバーのRunを選択し、③create a launch.json fileを選択してください。
Debug ConfigurationでPython Fileを選択してください。
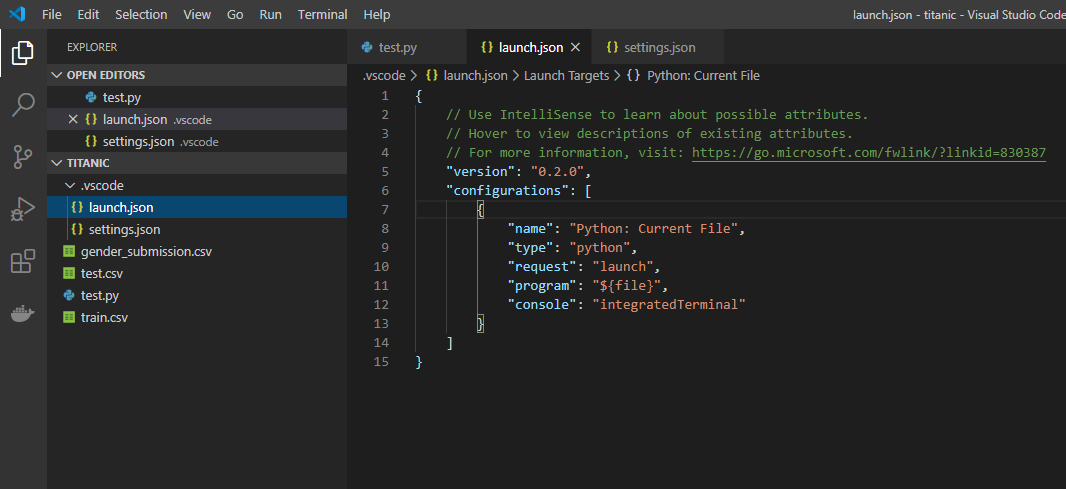
そうすると上図のようにフォルダ内に.vscode>launch.jsonというjsonファイルが作られます。このファイルはPythonの実行設定が記載されています。プログラムを実行する
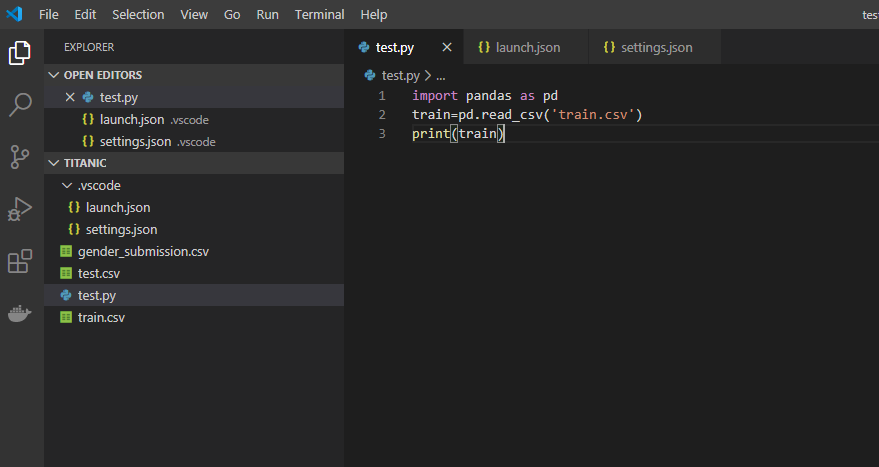
実行したいコード(ここではtest.py)を開いた状態で、F5キーを押すことでコードが実行できます。
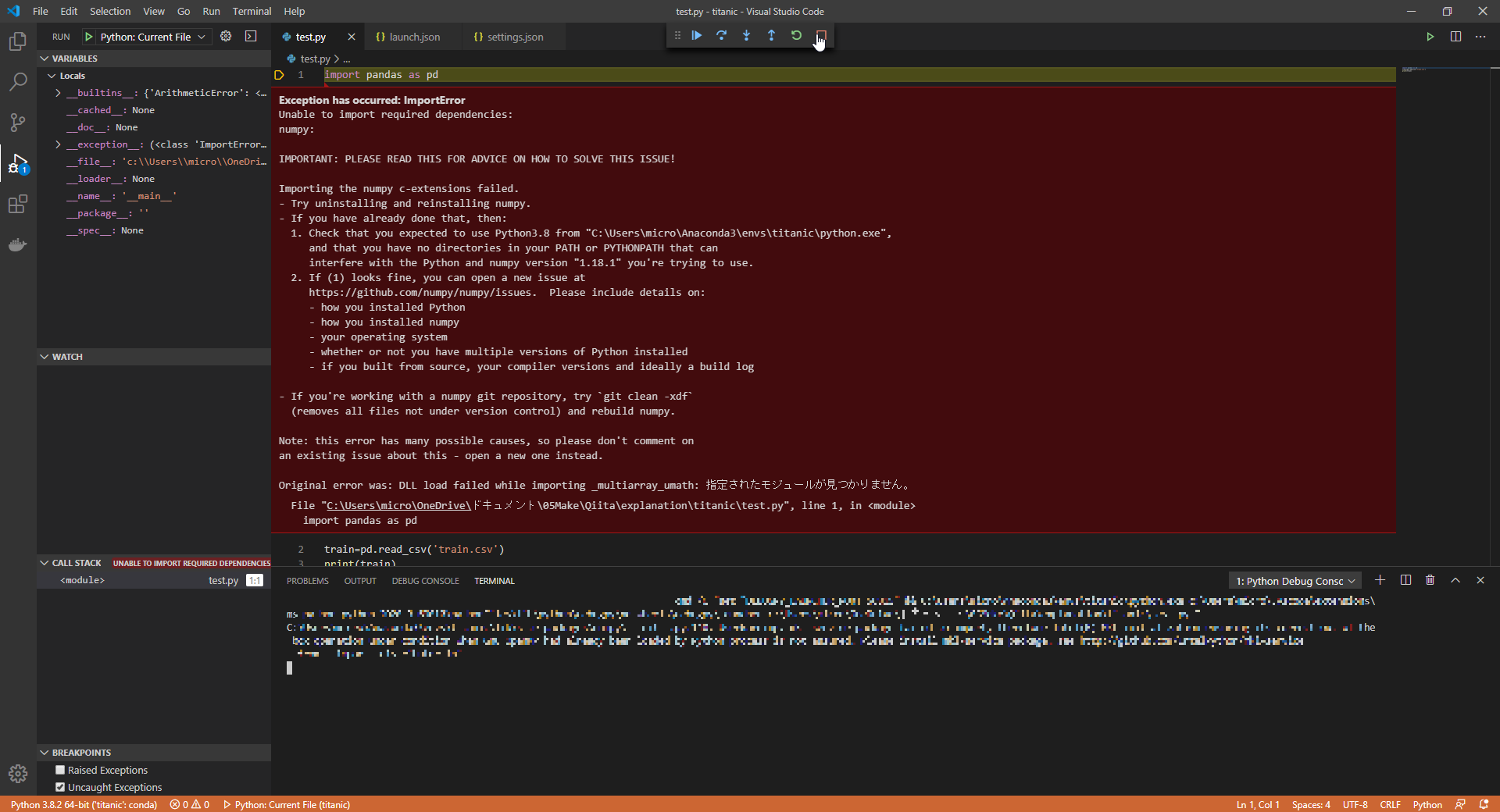
ただ初回の一回の実行は上図のようにエラーになってしまうと思います。
その場合は実行したときに現れる上図のようなボタンの赤い四角のボタン(Stop)をクリックし、実行をストップしてください。
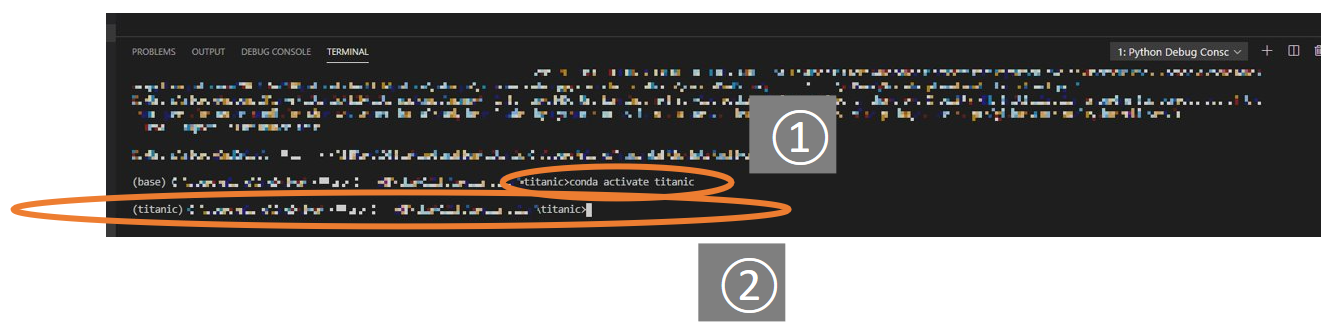
実行を止めると、上図のように、環境が自分の環境(今回は
titanic)に切り替わることがわかります。
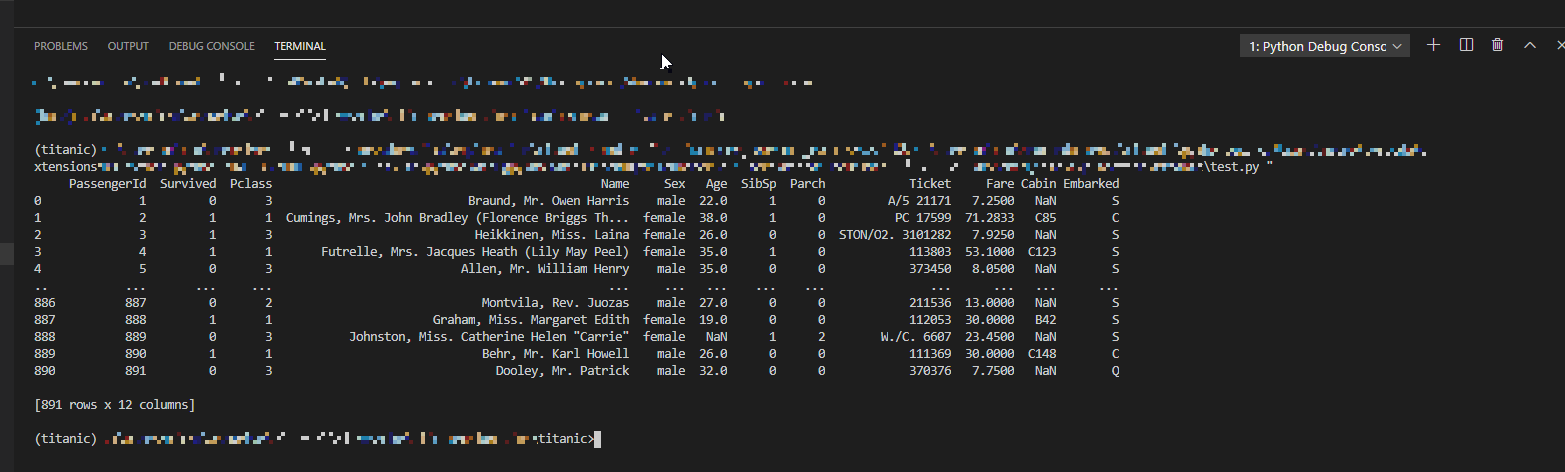
この状態で再度F5キーを押すと、上図のようにコードが実行でき、訓練データの中身が出力されました。設定が終わったので、これ以降はVSCodeで
F5キーを押すだけでPythonを実行できるようになります。デバッグの活用
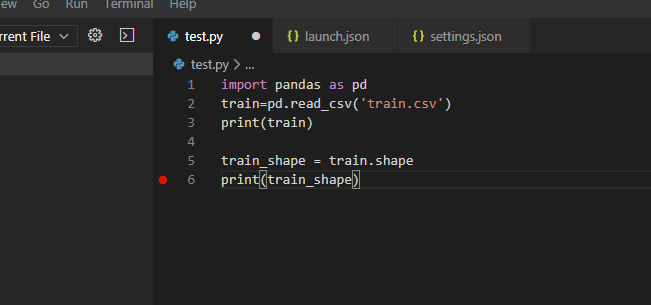
VSCodeのPython実行には様々な機能があります。
上図のように訓練データをの形状を表示するようにtest.pyを書き換えます。そしてprint(train_shape)となっている6行目でF9キーを押します。そうすると、この行の左端に赤い点が表示されます。これをブレークポイントといいます。そしてこの状態でF5キーを押して実行すると、
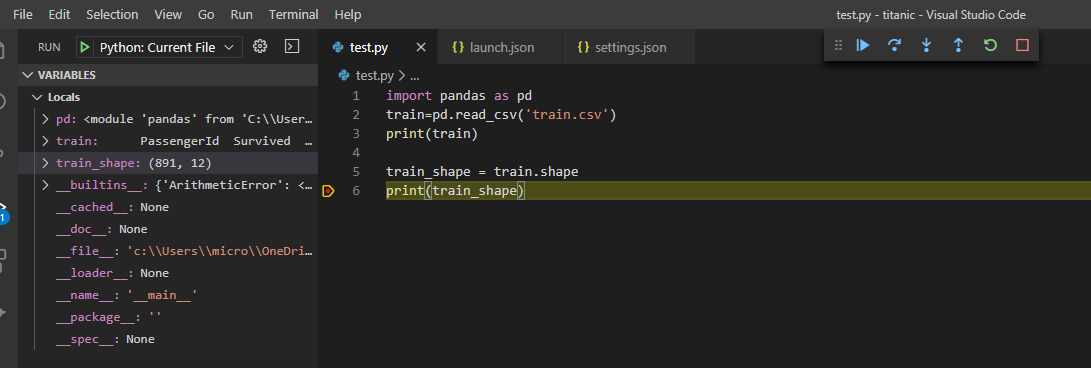
上図のように6行目で実行が一時停止し、その時宣言されている変数(ここではtrain_shape)が左のサイドバーに表示されています。このようにブレークポイントを用いることで、プログラムのバグ取り(=デバッグ)が捗ると思います。他にも様々な機能があるので、下の記事などを読んで、各自調べてみてください。
VS CodeでPythonコードのデバッグも楽々!! (1/4)
Jupyter Notebookの実行
ただ、データ分析する際は、データの可視化がしやすいJupyter Notebookを使うことが多いと思います。実はVSCodeではJupyterも実行することができます!
conda install jupyterまず、Anaconda Promptで自分の環境(今回は
titanic)にJupyterをインストールします。
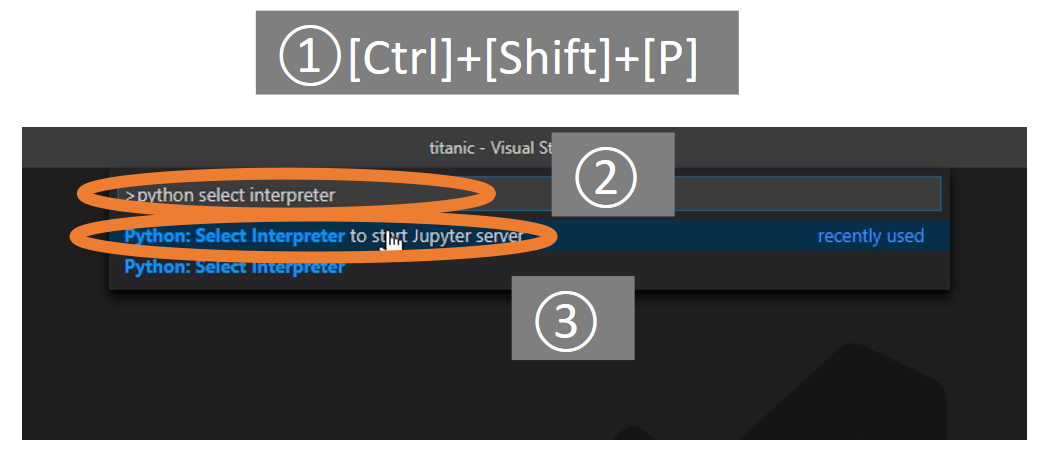
そしてVSCodeで①
Ctrl+Shift+Pを押し、VSCodeのコマンドパレットを開き、②python select interpreterと入力します。そして③python select interpreter to start jupyter serverと入力します
そして先程と同様に「好きな環境名」(今回の場合はtitanic:conda)の環境を選択します。
そしてJupyterを実行するためにipynbファイルを作成します。
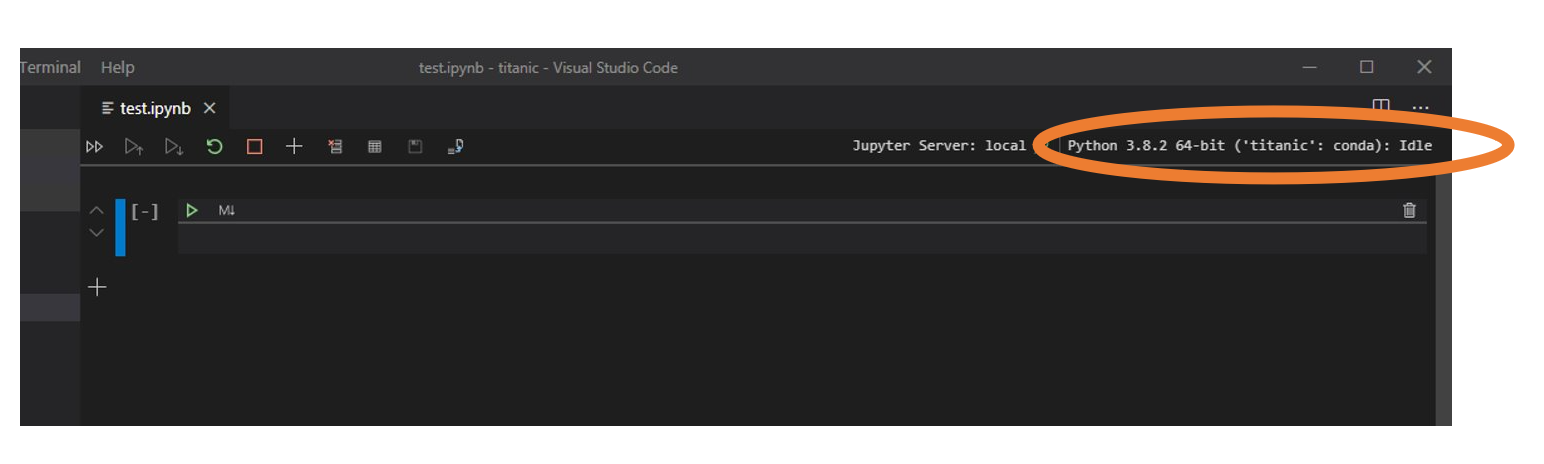
このipynbファイルを開いたときに、右上の環境名が指定した環境になっているか確認してください。別の環境名になっていた場合はここをクリックしサイド指定してください。
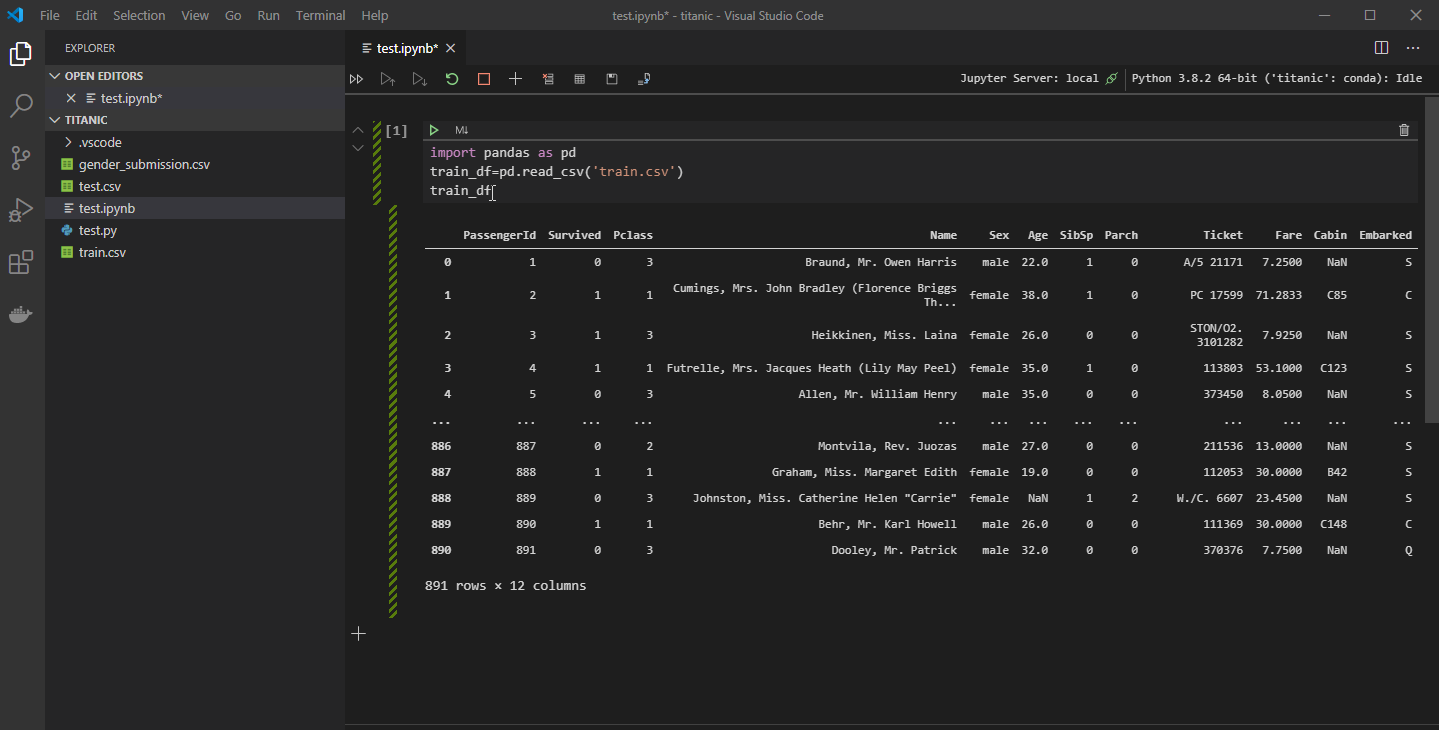
これでJupyterも実行できるようになりました。ただ、VSCodeのJupyterは不安定で、動かないことも多いです。その場合はいつものように、ブラウザからJupyterを使ってください。
終わりに
ここまで長々と説明してきましたが、正直ただ単にこれだけだとデータ分析にVSCodeを使うメリットは少ないように思います。
実際、Jupyter Notebookでもnbextensionsのvariable inspector等でも同じことはできるからです。
後日アップロード予定のデータサイエンティスト向けPythonパッケージの作り方で説明する、Pythonのパッケージ化と組み合わせると、様々なメリットが見えてきます。そちらの記事もよろしくおねがいします。






- 投稿日:2020-03-30T16:53:25+09:00
VSCodeでのPython、Jupyter実行環境の構築方法
VSCodeでのPython、Jupyter実行環境の構築方法をまとめました。Anacondaを使います。
また、Pythonでデータ分析する人は、ブラウザからJupyter notebookやJupyter Labを使う方が多いと思います。そんな人にもVSCodeはお勧めです。
また、この記事は今後書く予定のデータサイエンティスト向けPythonパッケージの作り方の記事の一部となる予定です。
Anacondaがダウンロードしてあるという仮定で話を進めていきます.(Anacondaインストール時に同時にVSCodeをインストールするのではなく別途インストール)
また各ソフトのバージョン違い等によって画面の表示が異なる場合もあると思います。その場合は適宜調べてください。
環境
備考 OS Windows10 conda 4.8.3 Anaconda Promptで conda -VAnaconda 2020.02 Anaconda Promptで conda list anacondaPython 3.8.2 VSCode 1.43.2 また、例としてKaggleのタイタニック号のデータを使うことにしますが、データはなくてもVSCodeでのPython実行環境の構築はできるので用意しなくても大丈夫です。
VS Codeのインストール
VS Codeをインストールしてください。基本,何も考えずに[次へ]でいいと思います。
VS Codeについては詳しくはこの記事など参照。わからないことや戸惑うところがあれば、まずこの記事を読めば、なんとなく全体像を把握でき、トラブルの対処となると思います。
Visual Studio Codeの使い方、基本の「キ」Anacondaでの仮想環境の立ち上げ
Anaconda Promptを立ち上げ、
conda create -n 好きな環境名 python=Pythonバージョンで仮想環境を立ち上げてください。
今回は環境名は
titanicとします。
そして仮想環境を起動します。conda activate titanicここから必要なモジュールをインストールします。例として
pandasをインストールしておきましょう。conda install pandasVSCodeでPythonコードを実行してみる
ここからVS CodeでのPythonを実行してみます。スタートメニューでVSCodeと検索し、VSCodeを立ち上げてください。
流れとしては
- Pytho拡張機能をインストール
- プログラムを書く
- Python実行環境を整える
- プログラムを実行という流れになります。順番に説明します。
Pytho拡張機能をインストール
まずVSCodeが開いたら、①左端のサイドバーからExtensionsをクリックし、②pythonと検索します。そして③Microsoft製のPytho拡張機能をインストールします。プログラムを書く
フォルダを開き、実際のプログラムを書きます。
VSCodeの上のメニューバーからFile>Open Folderを選び、これからプログラムを作っていきたいフォルダを開きます。
フォルダを開いたらテスト用のpyファイルを作ります。
適当なプログラムを作成します。訓練データを読み込み表示するプログラムです。
データがない場合はprint('Hello')などの適当なプログラムで大丈夫ですです。このプログラムをpython上で実行してみます。
Python実行環境を整える
実行環境をCommand Promptに変更する
VSCodeでの実行環境(Terminal)をCommand Promptに変更します。
次に上のメニューバーからTerminal>New Terminalを選択します。
するとウィンドウ下部にターミナルがひらきます。
次にこのターミナルの右上の「1:bash」(表示名は違うかもしれません)のプルダウンメニューから「Select Default Shell」を選択します。
そうすると、上の画像のように上からターミナルの種類を選べるようになるので、「Command Proompt」を選択してください。
これはTerminalがbashやPowerShellのままだとPythonが実行できないから変更します。(Windowsの場合だけかもしれません)
Pythonインタプリタを設定する。
次にPythonコードを実行するためのインタプリタ(実行環境)を設定します。
①
Ctrl+Shift+Pを押し、VSCodeのコマンドパレットを開き、②python selectと検索します。そして③Python Select Interpreterを選択します。
そして先程作った「好きな環境名」の環境を選択します。今回の場合はtitanic:condaです。
そうすると上図のようにフォルダ内に.vscode>setting.jsonというjsonファイルが作られます。そのファイルには指定した環境のpython.exeの場所が記載されています。PythonインタプリタにAnacondaの環境名が現れない
ただ、同じように操作したとしても、PythonインタプリタにAnacondaの環境名が現れない場合があると思います。これはAnacondaのインストール場所をデフォルトから変えた場合などが考えられます。
その場合は以下の記事を参考に環境変数PATHなどを設定してください。
VS Code で Anaconda の Python デバッグ 環境構築(Visual Studio Code)
また、VSCodeがPC上のPythonインタプリタを検索しきれていない場合もあるので、VSCodeを再起動して数秒待ってからもう一度
Python Select Interpreterを選択し直すなどしてみてください。Pythonの実行設定を設定する
①VSCodeでpythonコード(ここでは
test.py)を開いた状態で、②左端のサイドバーのRunを選択し、③create a launch.json fileを選択してください。
Debug ConfigurationでPython Fileを選択してください。
そうすると上図のようにフォルダ内に.vscode>launch.jsonというjsonファイルが作られます。このファイルはPythonの実行設定が記載されています。プログラムを実行する
実行したいコード(ここではtest.py)を開いた状態で、F5キーを押すことでコードが実行できます。
ただ初回の一回の実行は上図のようにエラーになってしまうと思います。
その場合は実行したときに現れる上図のようなボタンの赤い四角のボタン(Stop)をクリックし、実行をストップしてください。
実行を止めると、上図のように、環境が自分の環境(今回は
titanic)に切り替わることがわかります。
この状態で再度F5キーを押すと、上図のようにコードが実行でき、訓練データの中身が出力されました。設定が終わったので、これ以降はVSCodeで
F5キーを押すだけでPythonを実行できるようになります。デバッグの活用
VSCodeのPython実行には様々な機能があります。
上図のように訓練データをの形状を表示するようにtest.pyを書き換えます。そしてprint(train_shape)となっている6行目でF9キーを押します。そうすると、この行の左端に赤い点が表示されます。これをブレークポイントといいます。そしてこの状態でF5キーを押して実行すると、
上図のように6行目で実行が一時停止し、その時宣言されている変数(ここではtrain_shape)が左のサイドバーに表示されています。このようにブレークポイントを用いることで、プログラムのバグ取り(=デバッグ)が捗ると思います。他にも様々な機能があるので、下の記事などを読んで、各自調べてみてください。
VS CodeでPythonコードのデバッグも楽々!! (1/4)
Jupyter Notebookの実行
ただ、データ分析する際は、データの可視化がしやすいJupyter Notebookを使うことが多いと思います。実はVSCodeではJupyterも実行することができます!
conda install jupyterまず、Anaconda Promptで自分の環境(今回は
titanic)にJupyterをインストールします。
そしてVSCodeで①
Ctrl+Shift+Pを押し、VSCodeのコマンドパレットを開き、②python select interpreterと入力します。そして③python select interpreter to start jupyter serverと入力します
そして先程と同様に「好きな環境名」(今回の場合はtitanic:conda)の環境を選択します。
そしてJupyterを実行するためにipynbファイルを作成します。
このipynbファイルを開いたときに、右上の環境名が指定した環境になっているか確認してください。別の環境名になっていた場合はここをクリックしサイド指定してください。
これでJupyterも実行できるようになりました。ただ、VSCodeのJupyterは不安定で、動かないことも多いです。その場合はいつものように、ブラウザからJupyterを使ってください。
終わりに
ここまで長々と説明してきましたが、正直ただ単にこれだけだとデータ分析にVSCodeを使うメリットは少ないように思います。
実際、Jupyter Notebookでもnbextensionsのvariable inspector等でも同じことはできるからです。
後日アップロード予定のデータサイエンティスト向けPythonパッケージの作り方で説明する、Pythonのパッケージ化と組み合わせると、様々なメリットが見えてきます。そちらの記事もよろしくおねがいします。
- 投稿日:2020-03-30T16:46:58+09:00
Google Cloud APIを使ってお手軽に感情分析入門
この記事を読むと
・順番通り進めていくと、GoogleCloudAPI NaturalLanguageの「エンティティ分析」「感情分析」「公文・品詞解析」が実行できます。
・GoogleCloudAPI NaturalLanguage公式チュートリアルへの抵抗感が減ります
この記事を書いた理由
「Google Cloud APIを使って感情分析したい」と思い立ったものの、APIを使うだけなので簡単そうに見えて意外と詰まりました。GoogleCloudPlatform公式日本語ドキュメントで、詳細な入門やチュートリアルが用意されているものの、独自の用語が多すぎて何を言っているのかさっぱりでした。
また、ストレスだったのが環境構築。後述しますが、別にローカルに環境構築をしなくてもブラウザから実行できるので、まずはそちらで試してみると良いかと思います。さて、苦戦した折りに素晴らしい入門資料と出会いました。
本記事は基本的にこちらの資料の通りに書いています。実はこれもGoogle公式資料なんですよね。
(Google様・・・尊い・・・)
Codelab/Next17-Tokyo/「Natural Language API でエンティティと感情を分析する」
ただ、こちらの資料が2017年のものなので古い部分は適宜修正したり、省略されている部分を補ったりしています。
マークダウンで引用になっている箇所はそのままコピペです(手抜き)。そのうち自分の言葉で噛み砕いて置き換えます。環境
・Google Chrome
・Google Cloud Shell
(要はブラウザが開けるPCがあればOKです)準備
Google Cloud Platform Consoleアカウントを作成(orログイン)
Google Cloud Platform Consoleを開き、自身のGoogleアカウントでログインします。
プロジェクトを作成
Create projectもしくは新しいプロジェクトを作成をクリックしてプロジェクトを作成します。project-nameは任意の名前を入力してください。
ここでプロジェクトIDが発行されるので、メモしておいてください(後から確認することも可能です)。
プロジェクトができたら、Strat Cloud ShellでGoogleCloudConsoleを開いておきましょう。APIを有効化
画面右の
メニュー⇨APIとサービスと開き、画面中央上の+ APIとサービスを有効化をクリック。
languageなりnlpなりで検索して、Google Cloud Natural Language APIをenableにしてください。
ここで、Billing(支払い情報)の追加を求められることがありますが、画面の指示通りクレジットカードやデビットカードを追加してください。Cloud APIを使用するために必要なアカウント情報ですが、基本的に料金請求はされないので安心してください。APIキーを作成
APIとサービス⇨認証情報と開き、認証情報を作成をクリック。
すると現れるメニューからAPIキーを選択します。生成されたAPIキーをコピー。
リクエストするたびにAPIキーの値を挿入しなくてすむように、生成したAPIキーを環境変数に保存しましょう。キーの保存はCloud Shellで行えます。
先ほどコピーしたAPIキーをAPI_KEY=?????に入れて、下記のコードを実行してください。export API_KEY=?????実行
エンティティ分析リクエストを作成
1 つ目の Natural Language API メソッドは 、analyzeEntities です。API はこのメソッドを使ってテキストからエンティティ(人物、場所、イベントなど)を抽出します。API のエンティティ分析を試すために、最近のニュース記事にあった以下のような文章を使用してみましょう。
LONDON — J. K. Rowling always said that the seventh Harry Potter book, "Harry Potter and the Deathly Hallows," would be the last in the series, and so far she has kept to her word.
Natural Language API へのリクエストは request.json ファイル内で作れます。
最初にこのファイルをCloud Shellで作成します。
おなじみのtouchコマンドを使って作成しましょう。touch request.json一応、ファイルが作成されているか確認しましょう。おなじみのlsコマンドを使ってディレクトリやファイルを表示してみます。
ls
request.jsonが作成されていますね。他に色々あるのはデフォルトなのでスルーでOKです。次に、作成したファイルをコマンドラインエディターで開きます。vimでも何でも良いですが、下記が一番簡単かと思います。
edit request.json自分の request.jsonファイルに以下を追加して、変更を保存します。
Macならcommand+Sですね。あるいはブラウザから操作するなら画面右上のFile⇨Saveとクリック。request.json{ "document":{ "type":"PLAIN_TEXT", "content":"LONDON — J. K. Rowling always said that the seventh Harry Potter book, ‘Harry Potter and the Deathly Hallows,' would be the last in the series, and so far she has kept to her word." } }このリクエストの中で、これから送信しようとしているテキストを Natural Language API に伝えます。サポートされている type の値は PLAIN_TEXT または HTML です。コンテンツ内で、分析するために Natural Language API へ送信するテキストを渡します。Natural Language API は、テキスト処理用として Goolge Cloud Storage に保存されているファイルの送信もサポートしています。Google Cloud Storage からファイルを送信する場合は、content を gcsContentUri に置き換えて、Google Cloud Storage 内のテキスト ファイルの uri の値を設定します。
Natural Language API を呼び出す
ここからは、以下の curl コマンドを使用して、前の手順で保存しておいた API キー環境変数と一緒に、リクエスト本文を Natural Language API に渡します(すべてを 1 つのコマンドラインにします)。
curlはAPIを呼び出すときによく使われますね。
key=????に自分のAPIキーを入れて、下記コードを実行します。curl "https://language.googleapis.com/v1beta1/documents:analyzeEntities?key=????" \ -s -X POST -H "Content-Type: application/json" --data-binary @request.jsonレスポンスの開始は、以下のようになります。
{ "entities": [ { "name": "Rowling", "type": "PERSON", "metadata": { "wikipedia_url": "http://en.wikipedia.org/wiki/J._K._Rowling" }, "salience": 0.56932539, "mentions": [ { "text": { "content": "J. K.", "beginOffset": -1 } }, { "text": { "content": "Rowling", "beginOffset": -1 } } ] }, ... ] }レスポンスの中で、API が文章から 4 つのエンティティを検出したことがわかります。各エンティティについて、エンティティの type(タイプ)、関連する Wikipedia の URL(存在する場合)、salience(セイリエンス)、およびテキスト内でそのエンティティが出現した場所のインデックスが得られます。セイリエンスとは 0~1 の数値で、テキスト全体に対するそのエンティティの突出性を指しています。前述の文章では、「Rowling」が最も高い値を返しています。これは、彼女がこの文章の主語だからです。Natural Language API は別の方法で、言及された同じエンティティを認識することもできます。たとえば、「Rowling」と「J.K.Rowling」、そして「Joanne Kathleen Rowling」さえも、すべて Wikipedia の同じエントリーを指しています。
Natural Language API で感情を分析する
エンティティの抽出以外にも、Natural Language API を使うとテキスト ブロックの感情分析を行えます。JSON リクエストには前述のリクエストと同じパラメーターが含まれますが、今回はテキストを変更して、より強い感情を持った内容にしてみましょう。ご自分の request.json ファイルを以下のものに置き換えてください。そして content をお好きなテキストに自由に置き換えてみてください。
request.json{ "document":{ "type":"PLAIN_TEXT", "content":"I love everything about Harry Potter. It's the greatest book ever written." } }次に、リクエストを API の analyzeSentiment エンドポイントに送信します。command lineで下記を実行します。key=????にはAPIキーを入れてください。
curl "https://language.googleapis.com/v1beta1/documents:analyzeSentiment?key=????" \ -s -X POST -H "Content-Type: application/json" --data-binary @request.json以下のようなレスポンスが返されます。
request.json{ "documentSentiment": { "polarity": 1, "magnitude": 1.8 }, "language": "en" }感情のメソッドは、polarity(極性)と magnitude(強度)という 2 つの値を返します。polarity は -1.0~1.0 の数値で、文がどれだけポジティブまたはネガティブかを示します。magnitude は 0~∞ の数値で、polarity とは無関係に、文中で表現されている感情の重みを表します。文の重みが大きいテキスト ブロックの長さが増せば、それだけ magnitude の値も高くなります。上記の文の polarity は 100 % ポジティブで、「love」や「greatest」、「ever」という単語が magnitude の値に関係しています。
構文と品詞を解析する
ここからは、Natural Language API の 3 つ目のメソッドであるテキスト アノテーションを見てみましょう。テキストの言語的な詳細について踏み込んで調べます。annotateText は、テキストの感情的要素と構文的要素について、完全な詳細がわかる高度なメソッドです。API を使えば、テキストに含まれる各単語について、その単語の品詞(名詞、動詞、形容詞など)と、その単語が文内の他の単語とどのように関係しているのか(動詞の原形なのか、修飾語句なのか)がわかります。
シンプルな文章を使って試してみましょう。JSON リクエストは前述のものと似ていますが、ここでは features キーを加えます。このキーで、構文アノテーションを実行したいことを API に伝えます。ご自分の request.json を以下の内容に置き換えてください。
request.json{ "document":{ "type":"PLAIN_TEXT", "content":"Joanne Rowling is a British novelist, screenwriter and film producer." }, "features":{ "extractSyntax":true } }次に、API の annotateText メソッドを呼び出します。command lineで下記を実行します。key=????にはAPIキーを入れてください。
curl "https://language.googleapis.com/v1beta1/documents:annotateText?key=????" \ -s -X POST -H "Content-Type: application/json" --data-binary @request.jsonレスポンスには、文章内の各トークンについて、以下のようなオブジェクトが返されます。
{ "text": { "content": "Joanne", "beginOffset": -1 }, "partOfSpeech": { "tag": "NOUN" }, "dependencyEdge": { "headTokenIndex": 1, "label": "NN" }, "lemma": "Joanne" }レスポンスを詳しく見てみましょう。partOfSpeech からは、「Joanne」が名詞であることがわかります。dependencyEdge には、テキストの依存構文木の作成に使用できるデータが含まれています。本来この構文木は、文章中の単語が互いにどのような関係なのかを示す図です。上記の文章の依存構文木は以下のようになります。
注記:以下の Natural Language デモを使用すると、ブラウザでご自分の依存構文木を作成できます。https://cloud.google.com/natural-language/
上記のレスポンスの headTokenIndex は、「Joanne」を指す弧を持つトークンのインデックスです。この場合、文章内の各トークンを配列内の 1 単語と捉えることができ、「Joanne」に対する headTokenIndex の値 1 は、構文木でつながっている「Rowling」という単語を参照しています。NN(修飾語句 noun compound(名詞複合語)の略式表記)のラベルは、文章内でのその単語の役割を表しています。「Joanne」は、この文章の主語である「Rowling」を修飾しています。lemma(見出語)はこの単語の正規化形式です。たとえば、run、runs、ran、running という単語の lemma はすべて run になります。lemma の値は、ある単語が大きなテキスト全体をとおしてどれだけ出現するかを調べるのに役立ちます。
終わりに
お疲れ様です!これで貴方もエンティティ分析や感情分析を使えるようになりました(実はかなりすごいことです)。
参考文献
Codelab/Next17-Tokyo/「Natural Language API でエンティティと感情を分析する」
スラスラ読める Pythonふりがなプログラミング
初学者には最も分かりやすいPythonの入門書です。最初はとにかく分かりやすいものを使って学んでいきましょう。プログラミング超初心者が初心者になるためのPython入門(1) セットアップ・文字列・数値編
初心者に親切で、『スラスラ読める〜』よりとても良く扱う内容のレベルが上がります(難しすぎない)。Kindle unlimitedで無料なので、『スラスラ読める〜』と併用して基礎を固めると良いでしょう。入門 Python 3(オライリー)
「入門」と銘打っていますが少なくとも初学者向きではないです。ただ、ある程度Pythonの基本に慣れてから開くとより理解が深まる良書です。まず手元に置いておいて、適切な段階で本格的に使い始めると良いと思います。増補改訂Pythonによるスクレイピング&機械学習 開発テクニック
その言語の仕様や文法の理解を深めることは重要ですが、アウトプットありきで学習するとモチベーションが維持しやすいです。本書はスクレイピング×機械学習というPythonを学ぶ最もメジャーな動機を一冊でカバーできる良書です。ただし、いきなり本書から入ると難しいと思うので、まずは焦らず基本を丁寧に抑えていきましょう。独学プログラマー Python言語の基本から仕事のやり方まで
ある程度インプットを済ませ、いよいよ実際の仕事に移る準備をしたい時に参考になる名著です。相性もありますが、割と早い段階で使っても理解できるかもしれません。
- 投稿日:2020-03-30T16:30:57+09:00
MLの予測がはずれる要因は? ~要因調査を決定木で~
予測モデルの精度を上げたい
けど、どうしたらいいだろう…そもそも予測が外れる原因って何だろう??
そうだ、予測が外れている原因を決定木で可視化できないかな?という試み。
(理論的に間違っている部分もあるかもしれないけど)
分析の流れとかも載せようと思うので、データの処理とかやったことはあまりはしょらずに書く。
データの読み込み、前処理、データの確認、モデル構築・精度確認、要因調査という流れで書いていく。
多分長くなる。
本題はこの章 → 決定木で予測が外れた顧客の特徴の可視化使用データ
KaggleのTelco Customer Churnのデータを使用する。
https://www.kaggle.com/blastchar/telco-customer-churn
これは電話会社の顧客に関するデータであり、解約するか否かを目的変数とした2値分類問題。
各行は顧客を表し、各列には顧客の属性が含まれている。
各列は以下のようになっている。(kaggleのカラム説明文をGoogle翻訳)customerID:お客様ID gender:顧客が男性か女性か SeniorCitizen:お客様が高齢者かどうか(1、0) Partner:お客様がパートナーを持っているかどうか(はい、いいえ) Dependents:顧客に扶養家族がいるかどうか(はい、いいえ) tenure:顧客が会社に滞在した月数 PhoneService:お客様が電話サービスを利用しているかどうか(はい、いいえ) MultipleLines:顧客が複数の回線を持っているかどうか(はい、いいえ、電話サービスなし) InternetService:顧客のインターネットサービスプロバイダー(DSL、光ファイバー、いいえ) OnlineSecurity:お客様がオンラインセキュリティを持っているかどうか(はい、いいえ、インターネットサービスなし) OnlineBackup:お客様がオンラインバックアップを持っているかどうか(はい、いいえ、インターネットサービスなし) DeviceProtection:お客様がデバイスを保護しているかどうか(はい、いいえ、インターネットサービスなし) TechSupport:お客様が技術サポートを利用しているかどうか(はい、いいえ、インターネットサービスなし) StreamingTV:お客様がストリーミングTVを持っているかどうか(はい、いいえ、インターネットサービスなし) StreamingMovies:顧客がストリーミング映画を持っているかどうか(はい、いいえ、インターネットサービスなし) Contract:お客様の契約期間(月々、1年、2年) PaperlessBilling:お客様がペーパーレス請求を行っているかどうか(はい、いいえ) PaymentMethod:顧客の支払い方法(電子小切手、郵送小切手、銀行振込(自動)、クレジットカード(自動)) MonthlyCharges:顧客に毎月請求される金額 TotalCharges:顧客に請求される合計金額 Churn:顧客が解約したかどうか(はいまたはいいえ)データの概要
データの中身をざっと見ていく。
基本的な情報
# パッケージインポート import pandas as pd from sklearn import datasets import numpy as np import matplotlib.pyplot as plt import seaborn as sns import sklearn from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score from sklearn.metrics import precision_score from sklearn.metrics import recall_score from sklearn.metrics import f1_score from sklearn import preprocessing from sklearn import tree from sklearn.externals.six import StringIO import pydotplus from IPython.display import Image from dtreeviz.trees import dtreeviz import xgboost.sklearn as xgb plt.style.use('seaborn-darkgrid') %matplotlib inline # データ読み込み df=pd.read_csv('WA_Fn-UseC_-Telco-Customer-Churn.csv') churn=df.copy() print(churn.info()) display(churn.head())
欠損行
欠損値に変更
TotalChargesカラムは数値だが、半角空白の行が存在するので数値の型になっていない。
なので空白をNanに変換して数値型に変換する。# 半角空白をNanに変更 churn.loc[churn['TotalCharges']==' ', 'TotalCharges']=np.nan # floatに変更 churn['TotalCharges']=churn['TotalCharges'].astype(float) print(churn.info()) display(churn.head())
TotalChargesカラムをfloatに変換完了。欠損行の補完
次にTotalChargesのNanを補完する作業を行う。
この時カテゴリーによってTotalChargesの偏りが最も大きいカテゴリー変数を使ってNanを埋めた方が、単純にTotalChargesの平均値を使ってNanを埋めるより予測に有効な補完ができると思われる。
なので方針としてはカテゴリー変数ごとのTotalChargesの平均値をNanに埋めることにする。
まずNanを除外したデータフレームを作成し、カテゴリー変数とTotalChargesのみのデータフレームを作成する。# Nan行を削除したデータフレームの作成 churn2=churn[churn.isnull().any(axis=1)==False].copy() churn2['TotalCharges']=churn2['TotalCharges'].astype(float) # カテゴリー変数+TotalChargesのデータフレームの作成 # dtypeがobject型のデータのみ抽出 churn2_TotalCharges=churn2.select_dtypes(include=['object']).drop('customerID',axis=1) # TotalChargesを追加 churn2_TotalCharges['TotalCharges']=churn2['TotalCharges'] print(churn2_TotalCharges.info())
Nan行除外により7,043→7,032行になった。
次にどのカテゴリー変数がTotalChargesと関係ありそうか可視化して見てみる。# TotalChargesを抜いたカテゴリー変数名のリストを定義 obj_columns=churn2_TotalCharges.columns.values obj_columns=obj_columns[~(obj_columns == 'TotalCharges')] # 各カテゴリー変数ごとにTotalChargesのヒストグラムを描いてみる fig=plt.figure(figsize=(12,10)) for i in range(len(obj_columns)): col=obj_columns[i] youso=churn2_TotalCharges[col].unique() ax=plt.subplot(round(len(obj_columns)/np.sqrt(len(obj_columns))), round(len(obj_columns)/np.sqrt(len(obj_columns))), i+1) for j in range(len(youso)): sns.distplot(churn2_TotalCharges[churn2_TotalCharges[col]==youso[j]]['TotalCharges'], bins=30, ax=ax, kde=False, label=youso[j]) ax.legend(loc='upper right') ax.set_ylabel('Freq') ax.set_title(col) plt.tight_layout() fig.suptitle("TotalCharges hist", fontsize=15) plt.subplots_adjust(top=0.92) plt.show()
'MultipleLines', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies'
→この辺のカテゴリー変数で、カテゴリーごとにTotalChargesの分布が大きく異なる感じがある。
ここからテキトーにTotalChargesの平均を求めるカテゴリー変数を選んでもいいけど、できれば定量的に判断したい気もする。では本題とは違うけど、ここでも決定木を使って判断してみようと思う。
CARTはジニ不純度(とかエントロピー)と情報利得をもとに目的変数を最もよく分ける説明変数の分岐を生成する。
理論的な話は、「はじめてのパターン認識」か、以下のようなサイトを参照。
https://dev.classmethod.jp/articles/2017ad_20171211_dt-2/つまりTotalChargesを目的変数にCARTを適用すれば、TotalChargesを最もよく分ける説明変数が第1分岐に来るはずである。
実際にやってみる。# 新しくデータフレームをコピーしておく churn2_TotalCharges_trans=churn2_TotalCharges.copy() # カテゴリー変数をlabel encoding for column in churn2_TotalCharges_trans.columns: le = preprocessing.LabelEncoder() le.fit(churn2_TotalCharges_trans[column]) churn2_TotalCharges_trans[column] = le.transform(churn2_TotalCharges_trans[column]) display(churn2_TotalCharges_trans)
# 決定木モデル構築 clf = tree.DecisionTreeRegressor(max_depth=1) # カテゴリー変数だけのデータフレームを説明変数に、TotalChargesを目的変数に clffit = clf.fit(churn2_TotalCharges_trans.drop('TotalCharges',axis=1).values\ , churn2_TotalCharges_trans['TotalCharges'].values) # 決定木の可視化 dot_data = StringIO() tree.export_graphviz(clffit, out_file=dot_data,\ feature_names=churn2_TotalCharges_trans.drop('TotalCharges',axis=1).columns.values,\ class_names=True,\ filled=True, rounded=True) graph = pydotplus.graph_from_dot_data(dot_data.getvalue()) Image(graph.create_png())
'DeviceProtection'がTotalChargesを最もよく分ける変数なので、この変数のカテゴリーごとのTotalChargesの平均値でNanを埋めて補完する。# DeviceProtectionごとのTotalChargesの平均を求める churn2_TotalCharges_mean=churn2.groupby(['DeviceProtection'])[['TotalCharges']].mean().reset_index().rename(columns={'TotalCharges':'TotalCharges_mean'}) # DeviceProtectionごとのTotalChargesの平均をNan含むデータフレームにマージ churn=pd.merge(churn,churn2_TotalCharges_mean,on=['DeviceProtection'],how='left') # Nanを補完 churn.loc[(churn.isnull().any(axis=1)==True), 'TotalCharges']=churn['TotalCharges_mean'] # TotalChargesの平均カラムを削除 churn=churn.drop('TotalCharges_mean',axis=1) # Nan行の確認 display(churn[churn.isnull().any(axis=1)==True])Nanは補完された。
データの俯瞰
欠損値も無くなりデータが完成したので、連続値変数、カテゴリー変数のデータ俯瞰を実施していく。
# Churn:解約のYes or No割合の円グラフ pie=churn.groupby(['Churn'])[['customerID']].count().reset_index() fig=plt.figure(figsize=(8,8)) ax=plt.subplot(1,1,1) texts = ax.pie(pie['customerID'], labels=pie['Churn'], counterclock=False, startangle=90, autopct="%1.1f%%") for t,t2 in texts[1],texts[2]: t.set_size(18) t2.set_size(18) ax.set_title('Churn ratio', fontsize=20) plt.show()
# 連続変数だけを取り出してデータフレーム作成 churn_select=churn.select_dtypes(include=['number']).copy() # カテゴリー変数だけを取り出してデータフレーム作成(後で使う) churn_select_obj=churn.select_dtypes(include=['object']).copy() churn_select_obj['SeniorCitizen']=churn_select['SeniorCitizen'] # 目的変数追加 churn_select['Churn']=churn['Churn'] churn_select=churn_select.drop('SeniorCitizen',axis=1) # label encoding le = preprocessing.LabelEncoder() le.fit(churn_select['Churn']) # Churn Yes:1、No:0 churn_select['Churn'] = le.transform(churn_select['Churn']) # 連続変数のpairplot sns.pairplot(data=churn_select, hue='Churn', diag_kind='hist',plot_kws={'marker': '+', 'alpha': 0.5},diag_kws={'bins': 20}) plt.show()
# カテゴリー変数名のリスト col=churn_select_obj.columns.values[1:] col2=col[~(col == 'Churn')] # 横軸Churn、縦軸カテゴリーごとのcountのbarplot fig=plt.figure(figsize=(10,10)) churn_num=churn.copy() churn_num['num']=1 for i in range(len(col2)): ax=plt.subplot(round(len(col2)/np.sqrt(len(col2))),round(len(col2)/np.sqrt(len(col2))),i+1) sns.barplot(data=churn_num.groupby(['Churn',col2[i]])[['num']].count().reset_index(),x='Churn',y='num',hue=col2[i],ax=ax) ax.legend(loc='upper right') ax.set_ylabel('count') ax.set_title(col2[i]+' count') plt.tight_layout() plt.show()
やや不均衡データだなーとか、tenureやTotalChargesが大きい方が解約しない傾向だなーとか、Contractが年払いだったら解約者あんまりいないなー、genderは関係なさそうだなーとか考えたりする。モデル構築
データを見たのでモデルを作ってみる。
# LabelEncodingしたデータフレームchurn_encodeを作る churn_encode=churn.copy() columns=list(churn_encode.select_dtypes(include=['object']).columns.values) for column in columns: le = preprocessing.LabelEncoder() le.fit(churn_encode[column]) churn_encode[column] = le.transform(churn_encode[column]) churn_encode=churn_encode.drop('customerID',axis=1)# Train, Testデータを作る関数 def createXy(df, col, target, test_size=0.3, random_state=0): # 説明変数と目的変数の分離 dfx=df[col] dfy=df[target] X_train, X_test, y_train, y_test = train_test_split(dfx, dfy, test_size=test_size, random_state=random_state) print('TrainX Size is {}'.format(X_train.shape)) print('TestX Size is {}'.format(X_test.shape)) print('TrainY Size is {}'.format(y_train.shape)) print('TestY Size is {}'.format(y_test.shape)) return X_train, y_train, X_test, y_test今回は面倒なのでとりあえず特徴量の選定とかハイパラの調整とかは無しで。
# 説明変数名 colx=churn_encode.columns.values[:-1] # 目的変数名 coly='Churn' X_train, y_train, X_test, y_test = createXy(churn_encode, colx, coly, test_size=0.3, random_state=0) # XGBoostでモデルを作る xgb_model = xgb.XGBClassifier() xgb_model.fit(X_train, y_train) print('Train accuracy_score',xgb_model.score(X_train, y_train)) y_true=y_test.values y_pred=xgb_model.predict(X_test) # Testデータの精度の確認 print('Test accuracy_score',accuracy_score(y_true, y_pred)) print('Test precision_score',precision_score(y_true, y_pred)) print('Test recall_score',recall_score(y_true, y_pred)) print('Test f1_score',f1_score(y_true, y_pred))結果:
Train accuracy_score 0.8267748478701825Test accuracy_score 0.7946048272598202
Test precision_score 0.6307692307692307
Test recall_score 0.5189873417721519
Test f1_score 0.5694444444444443# Confution Matrixも見る result=pd.DataFrame({'y_true':y_true,'y_pred':y_pred}) result['dummy']=1 display(result.pivot_table(result,index='y_true',columns='y_pred',aggfunc='count').fillna(0))1:解約、0:未解約
さて、ここまででようやくモデルの精度の確認まで完了。
次から予測が外れた原因を見てみる。決定木で予測が外れた顧客の特徴の可視化
ようやく本題。
予測が外れたのはどんな特徴の顧客だろうか?ということを決定木で見てみたい。
前述したが、決定木のCARTアルゴリズムはジニ不純度(とかエントロピー)と情報利得をもとに目的変数を最もよく分ける説明変数の分岐を生成する。なので予測が当たった or 外れたの2値を目的変数として決定木を描けば、予測が当たった or 外れたということを最もよく分ける説明変数の分岐が生成できると思われる。
まずは予測が当たった・外れたを示す列を作る# X_testのコピーを作り新たな変数を追加する churn_test=X_test.copy() churn_test['true']=y_true churn_test['pred']=y_pred churn_test['RightOrWrong']=0 # y_trueとy_predが一致してた場合RightOrWrong=1とする churn_test.loc[(churn_test['true']==churn_test['pred']),'RightOrWrong']=1 display(churn_test.groupby(['RightOrWrong'])[['pred']].count()) display(churn_test)予測が外れた顧客は2,113人中434人
この434人にはどういう傾向があるのか決定木で可視化してみる。# 木の深さ3(テキトー) clf = tree.DecisionTreeClassifier(max_depth=3) # 'true','pred','RightOrWrong'を抜いた説明変数、'RightOrWrong'を目的変数 clffit = clf.fit(churn_test.drop(['true','pred','RightOrWrong'],axis=1), churn_test['RightOrWrong']) # dtreevizで可視化 viz = dtreeviz(\ clffit,\ churn_test.drop(['true','pred','RightOrWrong'],axis=1),\ churn_test['RightOrWrong'],\ target_name='RightOrWrong',\ feature_names=churn_test.drop(['true','pred','RightOrWrong'],axis=1).columns.values,\ class_names=[0,1], histtype='bar'\ ) print('Data Count ',len(churn_test)) display(viz)Data Count 2113
どうやらContractが木の最上位に来ているので、予測が当たった or 外れたということを最もよく分ける説明変数らしい。
Contractが0=月々払いの人達の予測が外れる傾向。逆に1=年払い、2=2年払いの人たちはかなりの割合で予測は当たっているっぽい。
月々払いの人達の中でも、InternetServiceが2=Noの人は予測が当たる傾向で、0=DSL、1=Fiber optic(光ファイバー)の人たちは外れている人も多いとかがわかる。
ここで前に出していたグラフをもう一度見てみる。
Contractが月々払いの人はChurnのYesもNoも多いし、InternetServiceが光ファイバーの人はChurnのYesもNoも多いなどが読み取れる。
(インターネットサービス使っている人が解約する傾向って、回線遅いから不満を持っているんじゃ?笑)
こういう人たちはChurnのYes, Noの傾向が見えづらいので予測が外れやすいのかなと考えられそうだし、実際に決定木で可視化した結果、予測が外れてしまう傾向にあることがわかった。
TotalChargesも木に出てきているけど、ある程度値が大きくなると予測精度の傾向は変わらなさそう。
とりあえずこれら結果を踏まえて、合成変数とか、clippingとかした変数を追加して、もう一度モデルを作り精度を確認してみる。fig=plt.figure(figsize=(10,10)) ax1=plt.subplot(2,2,1) ax2=plt.subplot(2,2,2) ax3=plt.subplot(2,2,3) ax4=plt.subplot(2,2,4) # TotalChargesのヒストグラム ax1.hist(X_train['TotalCharges'].values,bins=20) ax1.set_title('X_train TotalCharges') ax2.hist(X_test['TotalCharges'].values,bins=20) ax2.set_title('X_test TotalCharges') # TotalChargesをClipping upperbound, lowerbound = np.percentile(X_train['TotalCharges'].values, [0, 90]) TotalCharges_train = np.clip(X_train['TotalCharges'].values, upperbound, lowerbound) ax3.hist(TotalCharges_train,bins=20)# TotalChargesのヒストグラム ax3.set_title('X_train TotalCharges clipping') # TotalChargesをClipping upperbound, lowerbound = np.percentile(X_test['TotalCharges'].values, [0, 90]) TotalCharges_test = np.clip(X_test['TotalCharges'].values, upperbound, lowerbound) ax4.hist(TotalCharges_test,bins=20)# TotalChargesのヒストグラム ax4.set_title('X_test TotalCharges clipping') plt.show()
# 変数を加えた新しいTrain, Testを作る new_X_train=X_train.copy() new_X_test=X_test.copy() # TotalChargesをClippingしたものに変更 new_X_train['TotalCharges']=TotalCharges_train new_X_test['TotalCharges']=TotalCharges_test # ContractとInternetServiceの合成変数を作る new_X_train['Contract_InternetService']=new_X_train['Contract'].astype(str)+new_X_train['InternetService'].astype(str) new_X_test['Contract_InternetService']=new_X_test['Contract'].astype(str)+new_X_test['InternetService'].astype(str) # ContractとInternetServiceの合成変数をLabelEncoding le = preprocessing.LabelEncoder() le.fit(new_X_train['Contract_InternetService']) new_X_train['Contract_InternetService'] = le.transform(new_X_train['Contract_InternetService']) le = preprocessing.LabelEncoder() le.fit(new_X_test['Contract_InternetService']) new_X_test['Contract_InternetService'] = le.transform(new_X_test['Contract_InternetService'])# モデルを構築 xgb_model = xgb.XGBClassifier() xgb_model.fit(new_X_train, y_train) print('Train accuracy_score',xgb_model.score(new_X_train, y_train)) y_true=y_test.values y_pred=xgb_model.predict(new_X_test) # 精度の検証 print('') print('Test accuracy_score',accuracy_score(y_true, y_pred)) print('Test precision_score',precision_score(y_true, y_pred)) print('Test recall_score',recall_score(y_true, y_pred)) print('Test f1_score',f1_score(y_true, y_pred)) # 混同行列の確認 result=pd.DataFrame({'y_true':y_true,'y_pred':y_pred}) result['dummy']=1 display(result.pivot_table(result,index='y_true',columns='y_pred',aggfunc='count').fillna(0))結果:
Train accuracy_score 0.8253549695740365Test accuracy_score 0.7998106956933271
Test precision_score 0.6406926406926406
Test recall_score 0.5352622061482821
Test f1_score 0.5832512315270936最初の結果(再掲):
Train accuracy_score 0.8267748478701825Test accuracy_score 0.7946048272598202
Test precision_score 0.6307692307692307
Test recall_score 0.5189873417721519
Test f1_score 0.5694444444444443混同行列
1:解約、0:未解約
結果:
最初の結果(再掲):
すべての評価指標でTestデータに対する精度が向上した。まとめ
データの読み込み、前処理、データの確認、モデル構築・精度確認、予測が外れる要因調査まで全部記述した。
この記事の本題は決定木で予測が外れる要因を調べられるのではないか?という考えを実践したこと。
理論とか解釈が間違っていたらゴメンナサイ。
PoCとかでお客さんに、予測モデルの現状の問題点とか報告するときとかに便利かもしれないと思った。
学習曲線とかも出しつつ、決定木の結果も見せて、「データが足りないかもー」とか、「この辺で予測が外れて詰まっているのでこんな感じで対処しよかなーって思ってますー」とかお客さんと議論するのも良い。
そういう話の中でドメイン知識が豊富なお客さんから「そういえばこんなデータもあって変数に加えられるかも?」とか思い付きがあったりして助けられる場面もあると思われる。
決定木は見やすいからね!SHAP値載せてもいいけど、お客さんには分かりづらいかもしれないし、説明も難しい。おまけ(SHAP)
SHAP値でも予測が外れた時の顧客の傾向を確認してみる。
(まだ理解しきれていないので解釈の仕方を間違えているかもしれない。)
やり方は以下のKooさんのブログを参照。
SHAPを使って機械学習モデルと対話するimport shap # XGBoostでモデルを作る xgb_model = xgb.XGBClassifier() xgb_model.fit(X_train, y_train) #notebook内でJavascriptを動かすための呪文らしい shap.initjs() #modelと解釈したいデータを渡す。 X_test=X_test.reset_index().drop('index',axis=1)# indexを初期化しておく explainer = shap.TreeExplainer(model=xgb_model) shap_values = explainer.shap_values(X=X_test) # summary_plot shap.summary_plot(shap_values,X_test)
summary_plotを見る。
色が赤いほどその変数の値が高く、青いほどその変数の値が低いことを表し、横軸がSHAP値になる。
点が個々のサンプルを表し、特徴量は予測全体への影響力が大きい順に上から並んでいるので、Contractが最も影響力が大きい。
Contractが0=月々払いは予測に対して正の影響(つまり解約する方向の予測)を与え、1=年払い、2=2年払いは予測に対しては負の影響(つまり解約しない方向の予測)を与えていると読み取る。
月々払いは予測に対して正の影響(つまり解約する方向の予測)を与えているのがそもそも外れる原因なんだろうなぁ。とか考える。次に予測が当たった顧客、外れた顧客がどの変数で引っ張られて最終的な予測が出たのか、予測の典型的なパターンを可視化してみる。
# 予測が外れたindex、当たったindexを取得 make_index=X_test.copy() make_index['y_pred']=y_pred make_index['y_true']=y_true make_index['tf']=0 make_index.loc[aaa['y_true']!=aaa['y_pred'], 'tf']=1 miss=make_index[make_index['tf']==1].index.values nonmiss=make_index[make_index['tf']==0].index.values # decision_plotで当たった人の可視化 shap.decision_plot(explainer.expected_value\ , shap_values[nonmiss[:50]], X_test.iloc[nonmiss[:50],:]\ ,link="logit",ignore_warnings = True, feature_order='hclust') # decision_plotで外れた人の可視化 shap.decision_plot(explainer.expected_value\ , shap_values[miss[:50]], X_test.iloc[miss[:50],:]\ ,link="logit",highlight=range(len(miss[:20])),ignore_warnings = True, feature_order='hclust')当たった顧客
外れた顧客
色が赤いほど解約する方向(=1)に向かい、青いほど解約しないという方向(=0)に向かうことを示している。
これを見るとContractやtenureに大きく引っ張られて最終的な予測結果になっていることが見えるが、外れた顧客はContractやtenureにより間違った予測に引っ張られている傾向も見える。
これら結果から特徴量としてContractやtenureに何かしら手を加える方法を考えたりしてもいいかもしれない。以上!
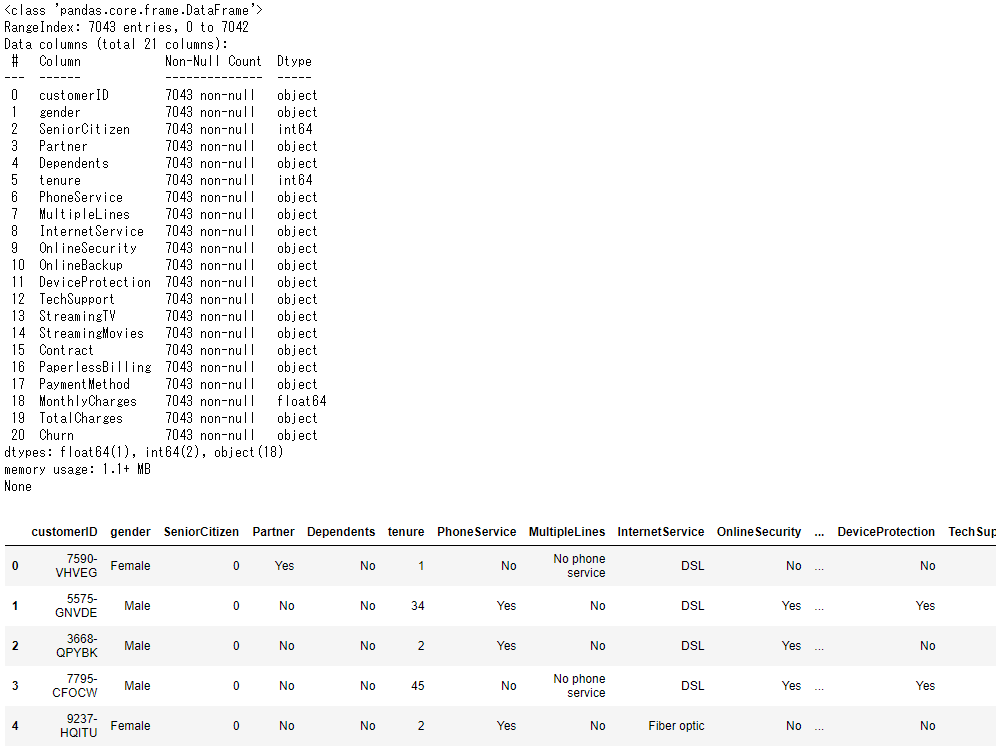

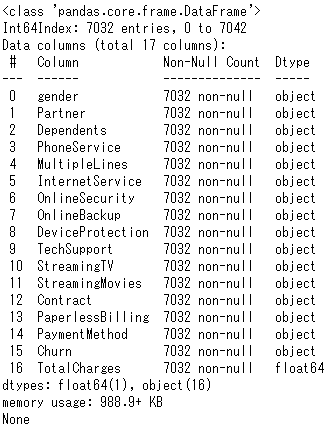
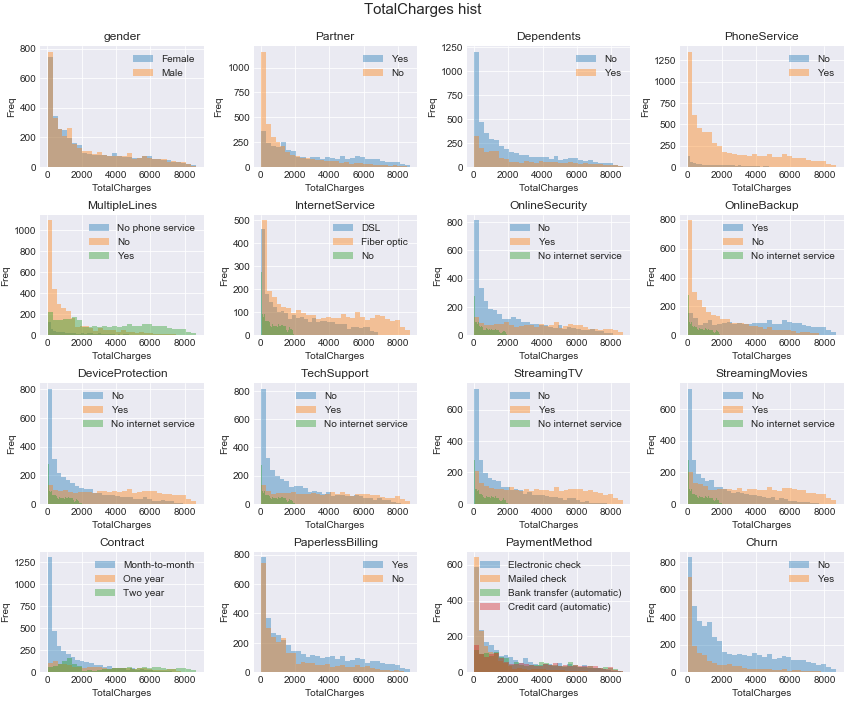
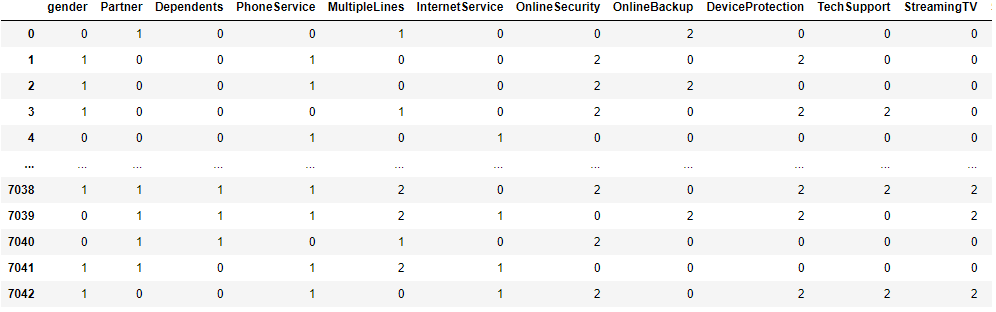
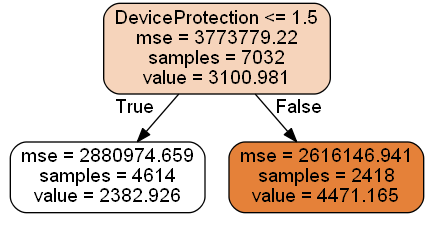

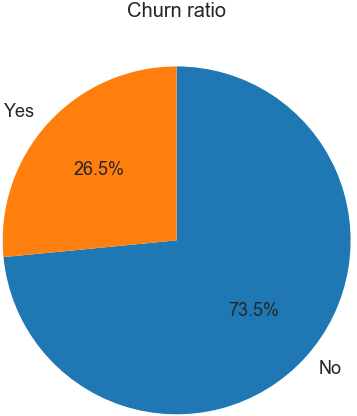

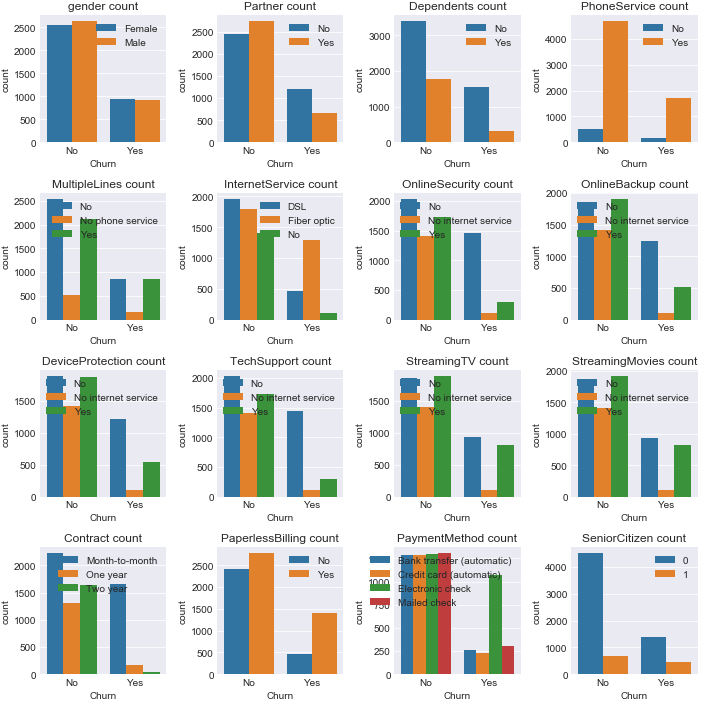


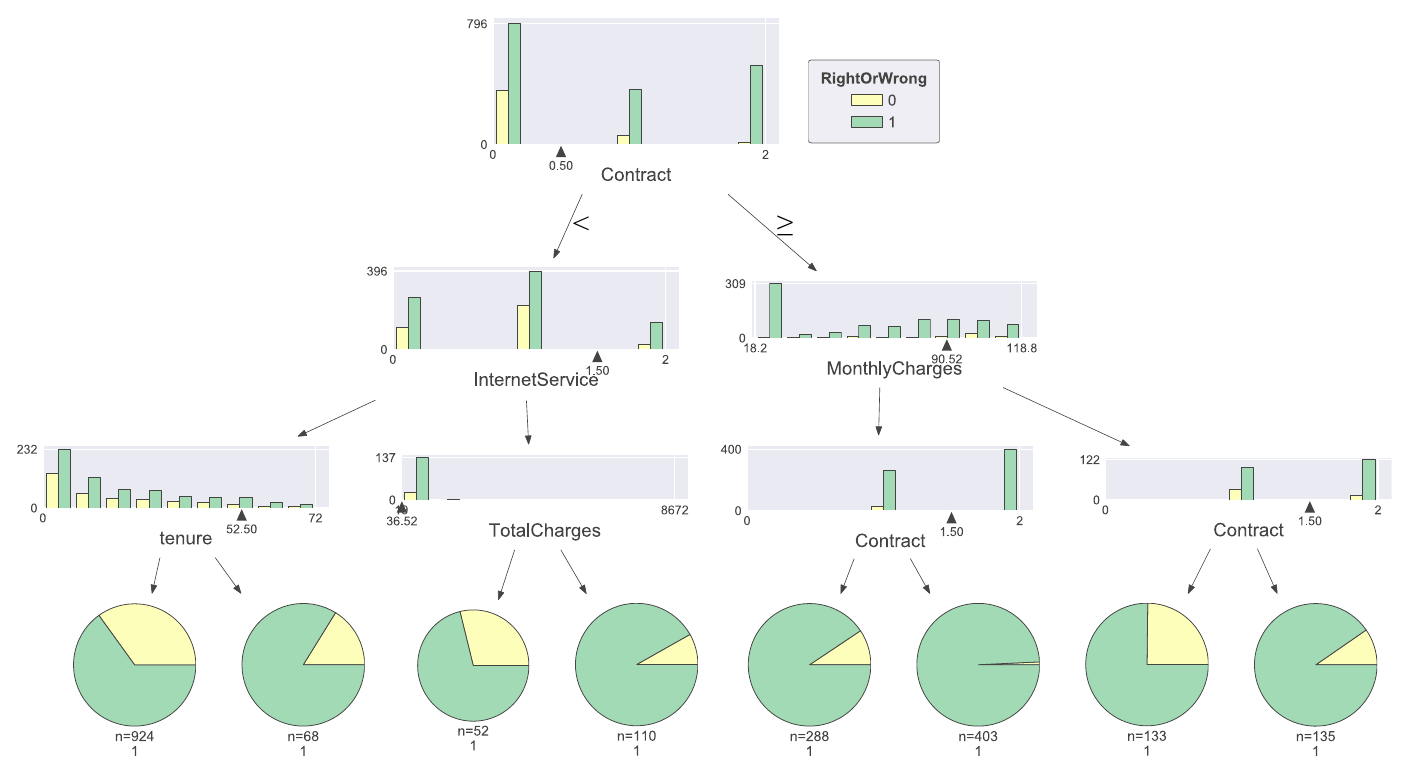
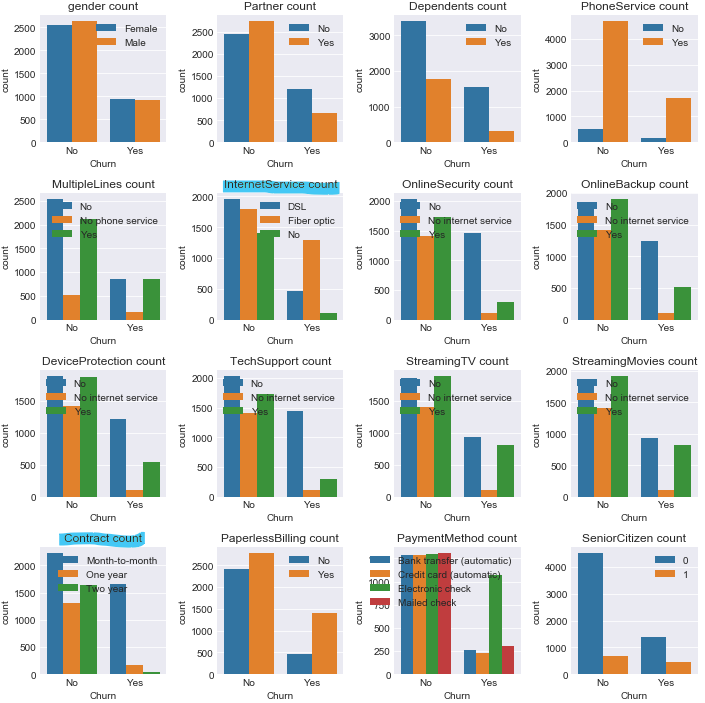
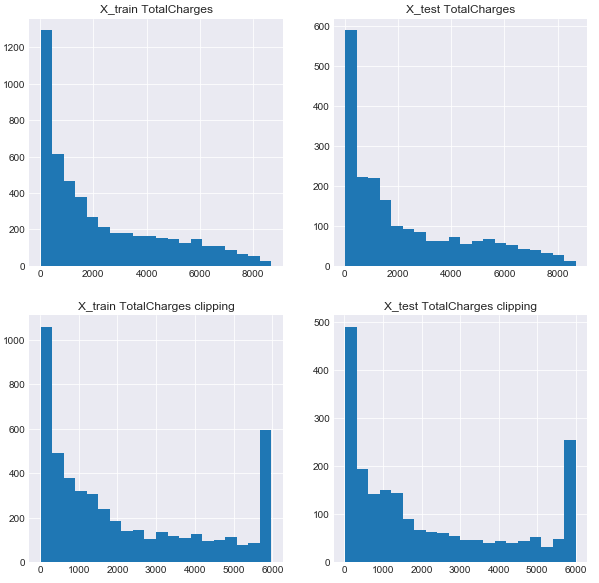


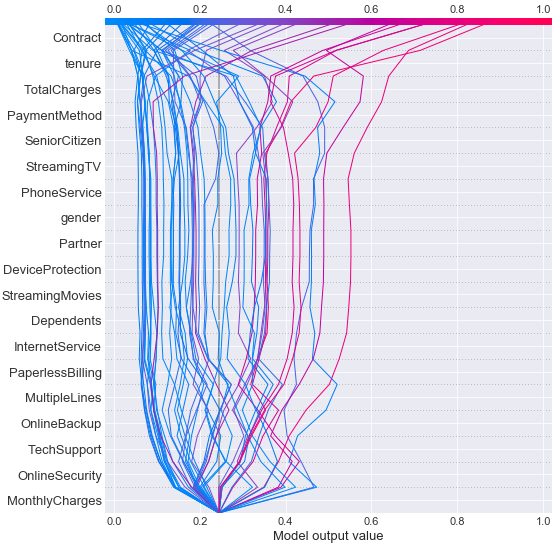

- 投稿日:2020-03-30T16:25:10+09:00
clickを使ってサブサブコマンドを作る - netsted sub-sub command -
概要
pythonでコマンドライン解析ツールを使ってコマンドラインツールを作る場合、用いられるモジュールは大きく分けて以下の3つ。
- argparse
- click
- fire
argparseは標準ライブラリと言うことで何も考えずに使えるという利点がありclickは標準モジュールではない故に標準ライブラリでは実装しづらい事を簡単に実装できるようになっている。
なお、fireについては使ったことがないのと、コマンドライン解析ツールの紹介を目的としている記事ではないのでここではこれ以上の比較・説明は割愛する。
clickを使ったサブコマンドの作成方法
clickを使ったサブコマンドの作成方法は以下の通り。
実際に動作するプログラムを作るならば以下のようになる。
import click @click.group() def cli(): pass @cli.command() def initdb(): click.echo('Initialized the database') @cli.command() def dropdb(): click.echo('Dropped the database') def main(): cli() if __name__ == "__main__": main()$ python3 cli.py Usage: cli.py [OPTIONS] COMMAND [ARGS]... Options: --help Show this message and exit. Commands: dropdb initdb$ python3 cli.py dropdb Dropped the database $ python3 cli.py dropdb --help Usage: cli.py dropdb [OPTIONS] Options: --help Show this message and exit.$ python3 cli.py initdb --help Usage: cli.py initdb [OPTIONS] Options: --help Show this message and exit.$ python3 cli.py initdb Initialized the databaseサブサブコマンドの作り方
上記は
program command <options>とする場合の作り方がだが
昨今のkubectl等はkubectl get pods <options>のようにサブコマンドを二つ受け取るような物が増えてきている。
従って自身が作る場合はどのようにすれば良いか。clickのドキュメントを読んでもサブコマンドの作り方は書いてあるがサブサブコマンドの作り方は書いていない。
いくつかドキュメントやWebを探し回って以下の方法が綺麗だと思ったので作ってみた。. ├── modules │ ├── sub1.py │ └── sub2.py └── cli.pyimport click from modules import sub1 from modules import sub2 @click.group() def cli(): pass def main(): cli.add_command(sub1.sub1cli) cli.add_command(sub2.sub2cli) cli() if __name__ == "__main__": main()import click @click.group() def sub1cli(): pass @sub1cli.command() def sub1cmd1(): click.echo('sub1cmd1') @sub1cli.command() def sub1cmd2(): click.echo('sub1cmd2')import click @click.group() def sub2cli(): pass @sub2cli.command() def sub2cmd1(): click.echo('sub2cmd1') @sub2cli.command() def sub2cmd2(): click.echo('sub2cmd2')このように、clickの add_command でclick.groupを追加してやると作れる。
$ python3 cli.py Usage: cli.py [OPTIONS] COMMAND [ARGS]... Options: --help Show this message and exit. Commands: sub1cli sub2cli$ python3 cli.py sub1cli Usage: cli.py sub1cli [OPTIONS] COMMAND [ARGS]... Options: --help Show this message and exit. Commands: sub1cmd1 sub1cmd2$ python3 cli.py sub2cli Usage: cli.py sub2cli [OPTIONS] COMMAND [ARGS]... Options: --help Show this message and exit. Commands: sub2cmd1 sub2cmd2
- 投稿日:2020-03-30T15:50:09+09:00
Qiitaの記事をGitHub Pages + VuePressに移行する
@mima_ita さんの記事 Qiitaの記事をGitHubに移行する - Qiita を読んで、私も移行したくなったので(?)書きます。
サルベージ後→GitHub Pages+VuePressで公開するお話です。
なお目的が元記事とはちょっとズレたところにあるのでPRとかは出していません。成果物はここ: perpouh/blog
Vuepressの準備
既にあるので割愛します。公式の手順に従ってください。
qiita_exporterの準備
Qiitaの記事をGitHubに移行するを参考に行ってください。
アクセストークン取得の際はread_qiitaとwrite_qiitaのふたつにチェックを入れました。write使わなかったけど。あと、元のコードのままだと私の環境では動かなかったので、ファイル先頭に
# -*- coding: utf-8 -*- # %%を入れました。このあたりって環境によるのかしらん?
画像ファイル保存先の変更
画像は
imageではなく.vuepress/public/assets/imgに保存したいのでパスを書き換えます。
表示は/blog/assets/img/になります(vuepressの設定にもよる)
あんまりハードコードしたくない気はするんですけど、何回も使う種類のスクリプトじゃないし別にいいかあと思ってガリガリ書いています。if not os.path.exists(dst): os.mkdir(dst) - if not os.path.exists(dst + '/image'): - os.mkdir(dst + '/image')def fix_image(dst_folder, line): """Qiitaのサーバーの画像ファイルから自分のリポジトリのファイルを表示するように修正する.""" images = re.findall(r'https://qiita-image-store.+?\.(?:png|gif|jpeg|jpg)', line) if not images: return line for url in images: name = url.split("/")[-1] - download(url, dst_folder + '/image/' + name) + download(url, dst_folder + '/../.vuepress/public/assets/img/' + name) ix = line.find(url) - line = line.replace(url, '/image/' + name) + line = line.replace(url, '/blog/assets/img/' + name) return lineタイトルと日付を本文に含めたかったので以下を追加。
for i in items: text = fix_markdown(github_url, dst, i['body'], dict_title) with open(dst + '/' + i['title'] + '.md', 'w', encoding='utf-8') as md_file: + md_file.write("#" + i['title'] + "\n") + md_file.write("最終更新日:" + datetime.strptime(i['updated_at'], '%Y-%m-%dT%H:%M:%S+09:00').strftime('%Y年%m月%d日') + "\n\n") md_file.write(text)ファイルが取れたのでここで一旦ビルドしてみて、大丈夫そうだということを確認しました。
サイドバーにリンクを作成する
記事への動線が無いのでリンクを作ります。
本当はコマンド一個でぺろっとやりたいけどまあこの程度のコピペは許容としますか……import os if __name__ == '__main__': filelist = os.listdir('../blog/qiita') for item in filelist: # 末尾3文字(.md)を取り除く print("['qiita/"+item[-4::-1][-1::-1]+"', '"+item[-4::-1][-1::-1]+"']")こんなのが出ます。
['qiita/macでgit管理をはじめる', 'macでgit管理をはじめる'], ....DS_Storeまで入ってきてしまったのでそれは手作業で取り除きました。
これを.vuepress/config.jsにコピペします。サイドバーの詳細についても公式を参照してください。Qiitaに引っ越し記事を投稿する
ソースはここを参考にQiita への記事更新を API 経由で行ってみる - Qiita書きました。
記事タイトルをそのまま移管先URL扱いできたのでif __name__ == "__main__": argvs = sys.argv token = argvs[1] user = argvs[2] qiitaApi = qiita_api.QiitaApi(token) items = qiitaApi.query_user_items(user) for item in items: execute(item, token) breakdef parse(item): return { 'title': item['title'], 'qiita_id': item['id'], 'tags': item['tags'], 'body': f''' この記事はGitHub Pagesへ移動しました。\n "https://perpouh.github.io/blog/qiita/{item['title']}.html" ''', 'tweet': False, 'private': False, }などとこねこねしてみたのですが
ループしないようにしてすら動かすのが怖すぎて胃が痛くなったのでやめました(クソザコメンタル)
気が向いたら手動でやるかもしれません(おまけ)VuePress自動ビルド
GitHubActionsでやっています。
GitHub Actions による GitHub Pages への自動デプロイ - Qiita
自動で動くことそのものよりも手動で触らないようなファイル(デプロイ後ファイル)をmasterブランチに置かなくて済むのがすてき。
- 投稿日:2020-03-30T15:12:28+09:00
Google Colaboratoryと手元の環境で、結果が微妙に異なっていた原因
手元にあるPC(Ubuntu+GeForce RTX2080Ti)とGoogle Colaboratoryとで、実行結果が微妙に異なっていた原因について調べてみました。
自分用のメモと投稿の練習も兼ねて、記録しておきます。きっかけ
機械学習の勉強のため、CIFAR-10のデータセットを用いたチュートリアルをいろいろ試していました。
Google Colaboratoryも使えれば作業効率が上がると思って試したところ結果が異なっていたため、手元の環境と同時利用するにも不便かと思い原因を探っていました。手元の環境では、TensorFlowは1.15.0、kerasは2.3.1を使用しています。
Google Colaboratoryの方では「%tensorflow_version 1.x」指定で使用しており、TensorFlowは1.15.2が使用されているようで、Kerasは2.2.4-tfのようです。どう異なっていたか
Google Colaboratoryでは
これくらいなのが、手元の環境では同一コードでも
こんな感じになってしまいました。ひどい。
何度試してみても、上下幅が大きいことには変わりませんでした。解決策
いろいろ試してみた結果、
from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Conv2D, MaxPool2D, Flatten, BatchNormalization from keras.optimizers import Adam, RMSprop from keras.utils import to_categorical from keras.callbacks import EarlyStopping, ModelCheckpoint from keras.preprocessing.image import ImageDataGenerator from keras.datasets import cifar10これを
from tensorflow import keras from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Dropout, Activation, Conv2D, MaxPool2D, Flatten, BatchNormalization from tensorflow.keras.optimizers import Adam, RMSprop from tensorflow.keras.utils import to_categorical from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint from tensorflow.keras.preprocessing.image import ImageDataGenerator from tensorflow.keras.datasets import cifar10このように「from keras.*」の部分を「from tensorflow.keras.*」と書き換え、「from tensorflow import keras」行を追加したところ改善されました。
修正後の結果
手元の環境でも、このくらいに落ち着きました。詳しい人から見ると当たり前のことだったりするのかもしれませんが、こういうケースもあるんだなぁ、くらいで見ていただければと。
ちなみに、Google Colaboratory環境の方は書き換えてもあまり変わりませんでした。
Kerasのバージョンが「2.2.4-tf」となっていることから、「tensorflow.keras.*」と指定しなくても、TensorFlowに組み込まれたKerasが使用されるということかもしれません。
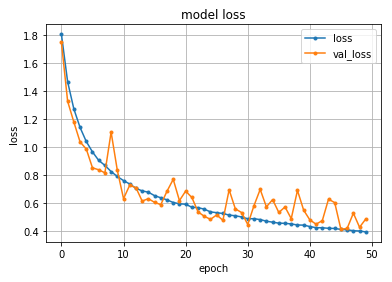
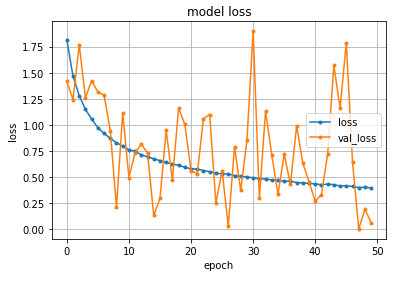
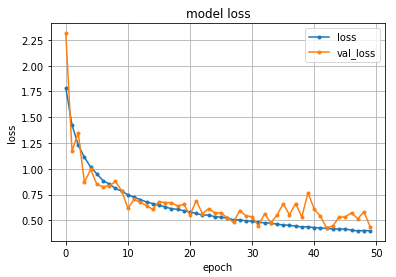
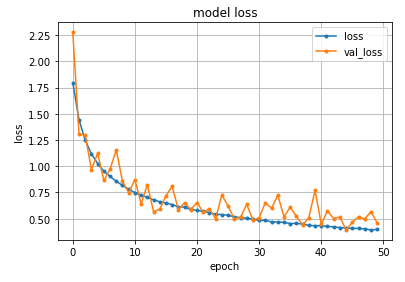
- 投稿日:2020-03-30T15:11:11+09:00
[Python]漢字をひらがなに変換してくれる便利なライブラリ
pykakasiを使うことで漢字、ひらがな、カタカナの変換を簡単に行うことができます。
コマンドプロンプトで以下のコマンドを入力することでライブラリをインストールすることが可能になります。
pip install pykakasi使用例
test.pyfrom pykakasi import kakasi kakasi = kakasi() kakasi.setMode('J', 'H') #漢字からひらがなに変換 kakasi.setMode("K", "H") #カタカナからひらがなに変換 conv = kakasi.getConverter() str = '東京タワー' print(conv.do(str))実行結果
python test.py とうきょうたわーこんな感じで変換することができるので機会があればぜひ使ってみて下さい。
- 投稿日:2020-03-30T15:08:38+09:00
測定データの解析②-ヒストグラムとフィッティング,lmfitのすゝめ-
まえがき
某日ミーティング、
教「T君、このグラフのフィットもうちょっとうまくできない?」
「フィットする範囲を変えたり重み付けをすることってできない?」
T 「・・・やってみます」といった具合でフィッティングに手を加えたいとのこと。気まぐれに解析手順の変更を求められることが多く、それに対応するのは中々に大変。その場でパパっとできるようになりたいです。
今回はscipy.optimize.curve_fitではなく、新しくlmfitというライブラリを取り入れてみます。
scipyを使ったフィッティングは測定データの解析①-scipyフィッティングの覚書-にて行いました。
コーディングはJupyter上で行っております&Jupyter推奨です。lmfitをうまく紹介できればいいなと思います。
GithHubにもnotebookとサンプルデータがあります。こちらから
lmfit について
lmfitはscipy.optimizeの上位互換として開発されています。
フィッティングする際にパラメータを拘束したり、誤差に重みづけをすることができます。
オブジェクトに色々な情報を追加していきながら最後にfitコマンドを実行して最適化…といった感じで動くようです。使い慣れるとscipyよりも便利かと思います。今回の実験
測定器からはパルスデータが得られました。まず、パルスの波高値でヒストグラムを作ります。その後、フィッティングを行い、スペクトルの鋭さを評価します。
加えて、lmfitの重みづけオプションを使うことで鋭さの改善を試みます。データの読み込み
測定器から掃きだされたパルスデータをpandasで読み込みます。今回もtkinterを使ってファイルパスを繋ぎます。
.ipynbimport tkinter from tkinter import filedialog import numpy as np import pandas as pd root = tkinter.Tk() root.withdraw() file = filedialog.askopenfilename( title='file path_', filetypes=[("csv","csv")]) if file: pulse = pd.read_csv(file,engine='python',header=0,index_col=0) pulse.iloc[:,[0,1,2]].plot()
データ3つ分だけプロットしてみます。
50点目付近で最大波高値が得られるように掃き出してくれていました。ヒストグラムの作成
最大波高値でヒストグラムを作成します。
ヒストグラムを作る際、横軸の刻み幅を決めなくてはなりません。
今回はSturgesの公式に従い、ビン数: k=1+Log2(n)としました。
注※np.histogramは度数(count)と同じ数だけの幅を返します。.ipynbbins = int(1+np.log2(pulse.shape[1]))#Sturgesの公式 count, level = np.histogram(pulse.max(),bins=bins) level = np.array(list(map(lambda x:(level[x]+level[x+1])/2,range(level.size-1)))) #度数とサイズを揃える level = np.array(list(map(lambda x:(level[x]+level[x+1])/2,range(level.size-1)))) import matplotlib.pyplot as plt plt.plot(level,count,marker='.',linestyle='None') plt.show()
右側にちょこっと山ができていました。50以降のデータ切り離して右側の山について再度分布を作ってみます。
.ipynbmask = pulse.max()>50#bool値のアレイを作る pulse = pulse.loc[:,mask]#パルスデータをマスキング bins = int(1+np.log2(pulse.shape[1]))#Sturgesの公式 count, level = np.histogram(pulse.max(),bins=bins) level = np.array(list(map(lambda x:(level[x]+level[x+1])/2,range(level.size-1)))) plt.plot(level,count,marker='o',linestyle='None') plt.show()
正規分布っぽいものが現れました。lmfitを使ってフィッティング
import~ の所を見て頂くとわかりますが、lmfitはいくつかのクラスオブジェクトを使ってフィッティングを行います。
フィッティング関数はガウス分布で、以下の通りです。ピークの中心は$\mu$、分布のバラつきは$\sigma$によって与えられます。ampは振幅項です。
$$f_{\left(x\right)}=\frac{amp}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{\left(x-\mu \right)^2}{2\sigma^2}\right)$$
まず、Modelクラスにフィットさせる関数を与えます。
次に、Parametersクラスを作成し、そこに初期値を与えます。
Modelクラスには.make_params()メソッドがあり、与えた関数の第二引数以降で勝手にParametersオブジェクト作ってくれます。.ipynbfrom lmfit import Model, Parameters, Parameter def gaussian(x,amp,mu,sigma): out = amp / (sigma * np.sqrt(2 * np.pi)) * np.exp(-(x - mu)**2 /(2 * sigma**2)) return out model = Model(gaussian)#フィッティングする関数を代入、モデルオブジェクト作成 pars = model.make_params()#Parametersオブジェクト生成 pars
作ったParametersオブジェクトはParameterオブジェクトの集合になっています。それぞれのパラメータには辞書っぽくアクセスできるようになっています。そこから.setメソッドで
・初期値 value
・パラメータの上限・下限、max, min : -np.inf~np.inf まで
・フィッティング前後で値を変化させるかどうか(拘束) vary=True or False
について、それぞれいじることができます。.ipynbpars['mu'].set(value=70) pars['amp'].set(value=1) pars['sigma'].set(value=1) pars
すごく大雑把ですが初期値を与えました。
パラメータを細かく設定できるうえにDataFrameライクなテーブルで表示される。クールだ・・・。フィッティングを実行します
.ipynbresult = model.fit(data=count,params=pars,x=level) result
結果がこんな感じに表示されました。.fitを実行すると新たにModelResultオブジェクトが生成されるようです。
生成されたオブジェクトは.plot_fit()メソッドを持っていました。この機能で可視化します。
.best_valuesメソッドを使うことで、最適化されたパラメータを辞書型で取り出すことができます。
.ipynbopt = result.best_values opt['mu']/opt['sigma']鋭さを$\frac{\mu}{\sigma}$で評価しました。23.67でした。
横軸の刻み幅を変えてみた
・Scottの公式
$$h = \frac{3.49\sigma}{ n^\frac{1}{3} }$$
で刻み幅を定義してみました。せっかくなので$\sigma$もフィッティングで求めたやつをつかいます。.ipynbh = 3.49 * opt['sigma'] / (pulse.shape[1] **(1/3))#Scottの公式 r = pulse.max().max()-pulse.max().min() bins = int(r/h) count, level = np.histogram(pulse.max(),bins=bins) level = np.array(list(map(lambda x:(level[x]+level[x+1])/2,range(level.size-1)))) plt.plot(level,count,marker='o',linestyle='None') plt.show()
刻み幅が狭くなって、その分度数の最大値が小さくなりましたが、分布の形は大丈夫そうです。
代入するdataとxの値だけ入れ替えて同様にフィッティング。
鋭さは・・・24.44。0.77だけ改善。誤差に重み付けをしてみた
ここからが本件。
$\mu\pm\sigma$の範囲を強めに、かつ、63未満の重みを0にフィッティングしたいとのことでした。
.fit内のweightsオプションを指定することで重み付けができるみたいです。.ipynbs = (level>opt['mu']-opt['sigma']) * (level<opt['mu']+opt['sigma']) weight = (np.ones(level.size) + 4*s)*(level>63) result3 = model.fit(data=count,params=pars,x=level,weights=weight)↓重み&結果
見た目あんまり変わっていませんが、よく見ると少しだけ下に引っ張られている気がします。
鋭さは・・・25.50。 0.06だけ更に鋭くなりました。フィット後の点は、.best_fitメソッドを使うとarray型で呼び出すことができます。csvを作るときに便利でした。
無事、課題解決…まとめ
今回はModel.make_params()でパラメータを自動生成しましたが、Parameters()で空のクラスを直接生成し、そこに.addメソッドで変数を追加していく方法もあります。
複数のオブジェクトを使ってフィッティングするので、最初は戸惑いました。どこにどのメソッドが対応しているのか、混乱しがちでした。しかし、使い慣れてくるとParameter(s)のありがたみを感じるかと思います。
lmfitを日本語で解説しているサイトが少なかったことがこの記事を書き始めたきっかけでもありました。もっといいライブラリがあるのでしょうか…? ご教授いただければ幸いです。今後、後輩君が困らずに済むでしょう。
公式リファレンスを読みながらコードを書いたのは初めてでした(笑)。研究成果がかかっている分、やるしかない。今後はもうちょっと生活に結び付きそうな技術を習得したいですし、持っている技術を様々な方面に活用できるようにもなりたいです。クリエイティブになりたい。
以上、python関連の進捗でした。教授に報告してもしょうがなかった(誰もpythonやってない)ので、この場を借りて報告致します。私のデータ解析を気長に待っていただいたこと、この点につきまして、教授には深く感謝を申し上げます。

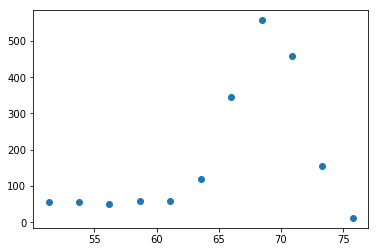
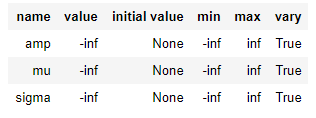
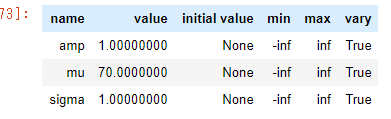
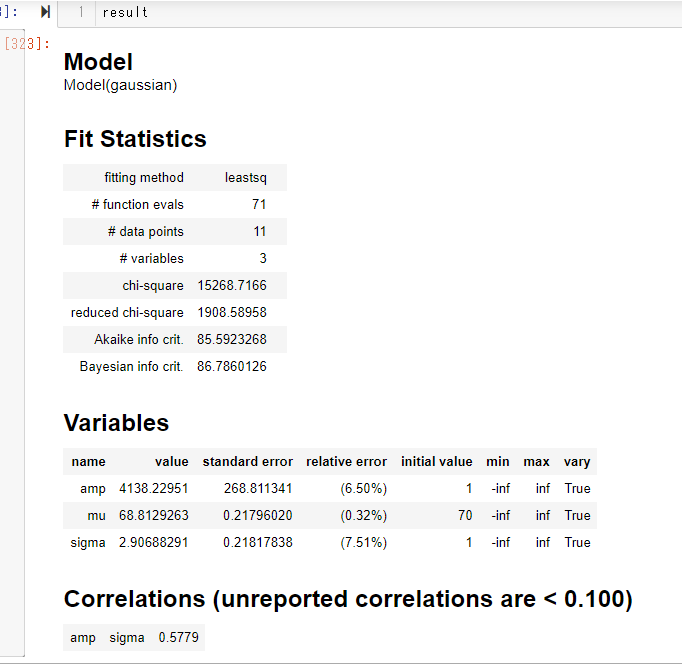


- 投稿日:2020-03-30T14:53:40+09:00
Pythonでアルファベット文字列をN文字分ずらす
AtCoderのABC146 B問題で、Unicodeに慣れ親しむ機会がありました。
アルファベット文字列を「N文字分ずらす」とは「アルファベット順でN文字後ろのものに変換する」動作を表し、'Z'の次は'A'に戻るとします。上述のB問題でも同様の定義です。
組み込み関数
ord()とchr()Python3には組み込み関数
ord()とchr()が実装されており、文字とそのUnicodeコードポイントを互いに変換して返してくれます。
参考:Python3.8公式ドキュメント#ordsample>>> ord('A') 65 >>> ord('D') 68 >>> chr(65) 'A' >>> chr(70) 'F'分かったように「Unicodeコードポイント」とか言ってますが、「いろんな文字記号を数字と1対1対応させて表してる世界なんやな」ぐらいの認識で突破です。
日本語が、とかいろんな表し方が、とかは奥が深い世界なので良さそうな本に丸投げします。どうやら大文字のアルファベットに関しては'A'がコード65で、そこから10進数の連番になっていますね。
ちなみに大文字と小文字の間にはsample>>> ord('Z') 90 >>> chr(91) '[' >>> chr(92) '\\' >>> chr(93) ']' >>> chr(94) '^' >>> chr(95) '_' >>> chr(96) '`' >>> chr(97) 'a'と、いくつか記号が挟まってました。へー。
実装の注意点
引数でお気づきかもしれませんが
ord()もchr()も一文字の変換を想定しています。
文字列Sを変換する際には空文字列''に、for文で一文字づつ変換しては結合してを繰り返します。そして'Z'から'A'に戻る時も考慮するため、
元の文字コードポイントにN加えた整数を26で割った余りを、'A'のコードポイントに足し合わせることで変換後の文字コードポイントを算出します。rot_n.pydef rot_n(s, n): answer = '' for letter in s: answer += chr(ord('A') + (ord(letter)-ord('A')+n) % 26) return answer確認してみます。
test_rot>>> rot_n('ABCDEFGHIJKLMNOPQRSTUVWXYZ', 13) 'NOPQRSTUVWXYZABCDEFGHIJKLM'AtCoder B問題での提出はコチラ↓
b.pydef rot_n(): n = int(input()) s = input() answer = '' for letter in s: answer += chr(ord('A') + (ord(letter)-ord('A')+n) % 26) print(answer) if __name__ == '__main__': rot_n()ちなみに変換後の文字列Sを元に戻す(N文字前にずらす)関数は
derot_n.pydef derot_n(s, n): answer = '' for letter in s: answer += chr(ord('Z') - (ord('Z')-ord(letter)+n) % 26) return answerとなります。
test_derot>>> derot_n('NOPQRSTUVWXYZABCDEFGHIJKLM', 13) 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'雑記:ROT N?
冒頭で書いたAtCoderの問題で知りました。
13文字後ろにずらす簡単な暗号であるROT13を一般化してたんですね。
- 投稿日:2020-03-30T14:50:43+09:00
Python はじめから勉強 Hour7:クラスの使い方
Python はじめから勉強 Hour7:クラスの使い方
- Pythonで何かしようとしたときに、まずサンプルスクリプトを探してなんとなく実行してた私が、
- 自動実行でREST API叩いて、結果の確認、VM操作までやってみたいと思う7時間
- 既にクラスを「使う」ことはできましたが「設計」についても考え見ましょう
学習資料
- たった 1日で基本が身に付く! Python超入門
過去の投稿
- Python はじめから勉強 Hour1:Hello World
- Python はじめから勉強 Hour2:制御文
- Python はじめから勉強 Hour3:関数
- Python はじめから勉強 Hour4:オブジェクト指向①
- Python はじめから勉強 Hour5:オブジェクト指向②
- Python はじめから勉強 Hour6:よく使うデータ型:タプル型・セット型・辞書型
環境
- Windows
- Python Ver3系
クラスを使う目的
- クラスは複雑な処理をきれいにまとめることで、より分かりやすいプログラムを書くための文法です。
- より分かりやすい=可読性が高い、メンテナンスしやすい、再利用しやすい
- クラスを使わなくてもコーディングできますが大量の変数と大量の関数が必要になり、努力のわりに報われないことになります。
- 変数についても「emp_name」を最初は一般社員向けの変数として作っていた(暗黙的に)。そのため役員用に使うと後々のコードでエラーになる場合もあり、開発者が意図しない使い方をされるケースがあります。クラスを使うとプログラムの文法を使って強制的に守らせることができます。
クラスの文法について
- クラスは以下のような形で作られます。
- クラスとメソッドの定義
- データ(インスタンス変数)の定義
- クラスはインスタンスを作るための設計図で、インスタンスはそこから作られる実体です。そのため、インスタンスにどういう内部データやメソッドをもたせるかをクラスで定義します。
- ひとまずクラスはこんな感じです(オブジェクト指向な記述方法ではありません)
- スクリプト内にクラスを定義することはできますが、小さなスクリプトでは良いですが、別ファイルとして作成してメインのスクリプトファイルと分けることをお勧めします。
Importされるファイル(読み込まれる側のファイル)mymodule.py
class MyClass: def plus(self, a, b): return a + b def minus(self, a, b): return a - bImportするファイル(実行される側のファイル ) sample.py
import mymodule # 読み込むファイルを宣言(拡張子はいらない) my_ins = mymodule.MyClass() # MyClassのインスタンス化 a = my_ins.plus(5, 3) # MyClassのメソッドを使う print(a) b = my_ins.minus(5, 3) print(b)実行結果
C:\script>sample.py 8 2 C:\script>クラスを使うプログラム
- ビンゴゲームのプログラム
- 1~99の数字をランダムに取り出す(もちろん重複なし)
ビンゴクラス bingo.py
import random class Bingo: def __init__(self): self.balls = list(range(1, 100)) def get_ball(self): random.shuffle(self.balls) return self.balls.pop() def has_ball(self): return len(self.balls) !=0Importするファイル(実行される側のファイル ) bingo_go.py
import bingo bingo = bingo.Bingo() while bingo.has_ball(): print(bingo.get_ball())実行結果
C:\script>bingo_go.py 71 15 69 5 27 76 ・ ・ ・ # 0~99の値がランダムに取り出される
- かなりスッキリしたコードになったのではないでしょうか?
- クラスを作成することで変数やデータの受け渡しが明確になっていると思いますので、余計な変数の値の確認が不要でデバッグも楽だと思います。
今回のまとめ
クラスの作成を簡単ですが、整理しました。
クラスからインスタンス化することでデータが扱いやすくなりました。
オブジェクト指向型のコーディングには程遠いですが、再利用しやすいクラスを作ることができました。
どういう動きをしたいかを考えながら設計することで良いクラスができるのかなと
名言・ライトニングトーク用
- 使い方は分かってきたけど、何かを作るには程遠いような。。。。。。
- 投稿日:2020-03-30T14:32:44+09:00
Python3の演算子メモ
記号 意味 + 足し算 - 引き算 * 掛け算 ** べき乗 / 割り算 // 小数点以下切り捨ての割り算 % 割り算の余り