- 投稿日:2020-03-30T23:34:05+09:00
AWSのLambdaでタグのついているインスタンスの情報を辞書形式で取得する方法
EC2インスタンスを自動起動したり自動停止したりするLambdaをつくるときに使います。Lambdaをつくってもすぐに忘れるので残します。
Lambda関数
- ランタイム : Python3.8
# -*- coding: utf-8 -*- from __future__ import print_function import boto3 # インスタンスがあるリージョンを指定する REGION_NAME = 'us-east-2' # インスタンスの状態をリストで指定する STATE_LIST = ['running','stopped'] # インスタンスにつけているタグの名前をリストで指定する TAG_LIST = ['Name','AutoStop'] def get_instance_list(ec2): """ タグとステータスを指定してインスタンスを取得する. """ instances = ec2.describe_instances( Filters=[ {'Name': 'instance-state-name', 'Values': STATE_LIST}, {'Name': 'tag-key', 'Values': TAG_LIST} ] )['Reservations'] if len(instances) != 0: instances = instances[0]['Instances'] return instances def lambda_handler(event, context): ec2 = boto3.client('ec2', REGION_NAME) instances = get_instance_list(ec2) print(instances) return 0定数に設定する内容
関数を実行するための権限
上記の関数では
describe_instancesを使用するため、ec2:DescribeInstancesをIAMのポリシーに設定する必要がある。IAMポリシー例{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "ec2:DescribeInstances" ], "Resource": "*" } ] }取得できるインスタンス情報
取得できる辞書形式のインスタンス情報は、EC2 — Boto 3 Docs 1.12.31 documentation - describe_instancesの「Returns」に記載されている
Instancesキーの内容となる。

- 投稿日:2020-03-30T22:12:53+09:00
[AWS] AWS Certified Solutions Architect – Professional合格した!やほーーーん!
はじめに
この度(2ヶ月前)AWS Certified Solutions Architect - Professional 試験に合格しました!
だれかの役に立つことを祈り書きました!!
私のレベル感
現在新卒三年目の文系SEで、AWSの経験は1年とちょっとくらいになります。
AWSでは主にEC2、IAM、RDS、Route53、S3を主に使用していて、趣味の範囲でCode三兄弟やElastic Beanstalkを触ってる感じでした。
2019年の4月に受けたときはスコア:638で落ちました・・・(このときは一生受からんやろこれ・・・と思ってました)試験内容
これ読む人はだいたい知ってると思いますが試験については下記のような感じ
プロフェッショナル試験は、AWS におけるシステムの管理および 運用に関する 2年以上の実務経験を持つソリューションアーキテクト担当者を対象としています。 認定によって検証される能力 - AWS で、動的なスケーラビリティ、高可用性、耐障害性、信頼性を備えたアプリケーションを設計し、デプロイする - 提示された要件に基づくアプリケーションの設計とデプロイに適した AWS のサービスを選択する - AWS で複雑な多層アプリケーションを移行する - AWS でエンタープライズ規模のスケーラブルな運用を設計し、デプロイする - コストコントロール戦略を導入する 推奨される知識と経験 - AWS でのクラウドアーキテクチャの設計およびデプロイに関する 2 年以上の実践経験 - クラウドアプリケーション要件を評価し、AWS でアプリケーションの実装、デプロイ、プロビジョニングを行うためのアーキテクチャを提案する能力 - AWS CLI、AWS API、AWS CloudFormation テンプレート、AWS 請求コンソール、AWS マネジメントコンソールについての知識 - AWS Well-Architected フレームワークの 5 本の柱を説明し適用する - 主要な AWS テクノロジー (VPN、AWS Direct Connect など) を使用して、ハイブリッドアーキテクチャを設計する - エンタープライズの複数のアプリケーションやプロジェクトのアーキテクチャ設計に対し、共通するベストプラクティスガイダンスを提供する能力 - スクリプト言語についての知識 - Windows および Linux 環境についての知識 - ビジネスの目標をアプリケーションおよびアーキテクチャ要件に関連付ける - 継続的インテグレーションおよびデプロイのプロセスを設計する何故受けたか
- この時点でアソシエイト三冠していたので、挑戦意欲が沸いたため
- AWSを自分の強みにしたく、知識を増やしたかった
- 圧倒的承認欲求
職場内で、SAPを持っている人は少なく、チヤホヤされたいと邪な思いで受けました!!
(チヤホヤはされませんでした!!!!)勉強したこと
- AWS公式トレーニング(無料)
- 一番最初にやるべき、何をどう聞かれるのか理解する
- https://www.aws.training/Details/eLearning?id=34737 (問題形式のトレーニング)
- https://pages.awscloud.com/TRAINCERT_GOTOPRO_Registration.html (参考資料系)
- Black Belt
- サービスを簡単に理解するため、こちらのPDFを読む。感覚で理解できればOK
- よくある質問
- そもそもこのサービスは何の目的で利用して、他のサービスとの違い、特徴を理解する
- 開発者ガイド・ユーザガイド
- 一番時間をかけたInputがこれ
- 後述するUdemyの模擬試験でわからなかったところはこちらの資料を使って知識を深堀した。
- ホワイトペーパー
- そもそもAWSのサービスについての考えかたを理解する
- 何度も暗記するまで読み込む必要はないと思うが、できるだけたくさん読む
- Udemy
- JonBonseはUdemy内で最も良い模擬試験作ってると御仁
- 模擬テストが4つあり、解説が丁寧なので非常におすすめ!
- 模擬テストをアウトプットの中心にしつつ、開発者ガイド・ユーザガイドで知識を深めるサイクルを意識していた
- ただこれだけを勉強しても合格するのは厳しいと感じた
- DevelopersIO
- Classmethodが出してる開発者ブログ
- 初級から癖のある内容まで幅広く網羅
- 構築手順の参考に使った
- いつもありがとうございます!!
- AWS
- 触ってみよう!!!!
- AWSサービスを触ってみて、どのようなOptionがサービスごとにあり、どのようなソリューションを提示できるか理解する必要がある。
- Input・Outputの両方でAWSに触るようにしていた。
- 公式模擬試験
- 今回の受験時にはやらなかったが、初めての人は受けた方が良いと思う。
試験で聞かれたこと
- ほぼすべてのサービスが出題範囲(実際は違うが、そう感じさせられるほど色々なサービスについて聞かれる)
- Accociateの時はサービスの特徴を聞かれたが、Proは複数サービスのOptionの組み合わせの特徴を聞かれるイメージ。(より深い知識とサービス間の連携)
- シチュレーション毎にベストなOption、サービスの設定を抑える必要がある。
- データ移行、オンプレとのハイブリッドアーキテクチャに関しては(私が)普段経験しない事も多く聞かれたため、満遍なくサービス毎の特徴を理解する必要がある。
受けた感想
やっぱり難しすぎる。(スコアは761でした・・・ぎりぎり・・・)
- 試験時間が3時間あるが全て見直すことはできなかった。
- 問題の多さと問題一つ一つの長さが尋常ではないためしっかり問題演習はしたほうが良い。
- 前回受けたときと変えたことで一番良かったのは、開発者ガイド・ユーザガイドをしっかり読み曖昧な部分を無くすようにサービスを理解することに注力したこと。
- 三時間飲まず食わずでトイレにも行けないため体調管理をしっかりこなしつつ受験に臨む必要がある。
- おすすめはチョコラBBハイパーを試験受ける10分前に飲むこと。(一番高いやつを買うことで自分に暗示をかけ気分を高める)
試験には合格することができたが、試験を受けることで足りない知識が浮き彫りになったので、継続的な学習を心がけたいです!!

- 投稿日:2020-03-30T21:27:30+09:00
AWSアカウント作成時にSecurity Hubのマルチアカウント設定を行う
Security Hub のマルチアカウント設定
AWS Security Hub は AWS環境全体のセキュリティとコンプライアンスの状況を確認可能なサービスです。
Security Hubでは、特定アカウントをマスターアカウントとし、他のアカウントを招待して
マルチアカウントの親子関係を組むことができます。
以下のようにマルチアカウント設定を行うと、メンバーアカウントの結果をマスターアカウント側で
確認できるようになります。
この時、マスターとなるアカウントは AWS Organizations のマスターアカウントである必要はありません。
また組織外のアカウントを招待して連結することも可能です。
通常、セキュリティ用のアカウントを用意し、そちらに統合して管理する方がよいかと思います。連結を行う際、マスターアカウントから招待、メンバーアカウントからはその招待を承認する
という作業が必要なのですが、管理対象のアカウントが増えてくると都度作業するのはなかなか面倒です。GitHub 上で AWS Security Hub Multiaccount Scripts が公開されており、
IAM ロールおよび Python の実行環境を用意できれば、上記ステップを自動化できます。アカウント追加時に自動セットアップを行う
Multiaccount Scripts は既存アカウントへの設定が前提であるため、
新規アカウント作成時に自動でセットアップするための構成例を紹介します。前提
- AWS Organizations でアカウントが管理されている
- AWS Organizations の Master Account から New Account を作成する
- Security Hubのマスターアカウントである Security Account から New Accountを招待する
流れ
マスターアカウントで Lambda 関数を起動し、以下の内容を実行します。
- AWS Organizations で新規アカウントを作成 1
- Assume Role で Security Account から New Account へ招待を送る 2, 3
- 内部的には CreateMembers API と InviteMembers API の実行が必要
- Assume Role で New Account の Security Hub を有効化し4、招待を承認する5, 6
- 内部的には ListInvitaions APIで InvitationId を確認し、AcceptInvitaion API を実行
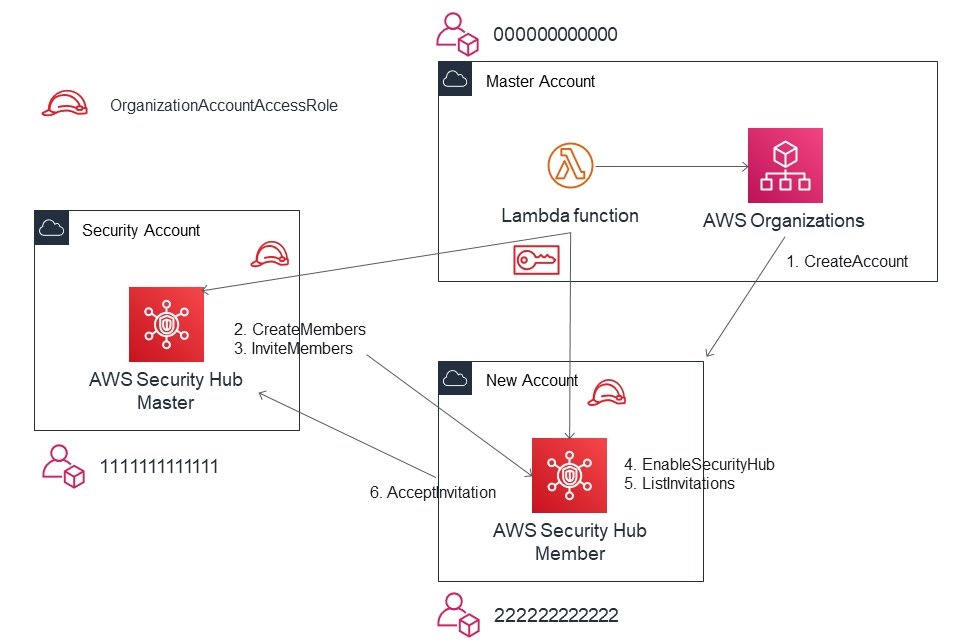
Lambda 関数の例
ランタイムは python3.8 を想定しています。
アカウント作成部分のコードは AWS Landing Zone の Account Vending Machine(AVM)を参考にしています。
AVM は AWS Service Catalog の製品として利用可能で、アカウントの作成と事前定義された
ベースライン設定をセットアップすることができますコードは 以下の GitHub リポジトリで公開されています。AWS Account Vending Machine
https://github.com/aws-samples/aws-account-vending-machine以降は簡略化のため、アカウント作成と Security Hub 有効化に絞った形で記載しますが、
上記をカスタマイズして、Security Hub の有効化以外にもアカウント作成時に必要な
サービスの設定を組み込んでしまえば、共通的なセットアップ作業を自動化できます。clinet の作成
指定されたサービスとリージョンで clinet を作成します。
Assume Role によるクレデンシャルが指定されている場合は、対象アカウントの一時認証情報で作成します。def get_client(service, region, credentials=None): """Returns the client for the specified region""" if credentials is None: client = boto3.client(service, region_name=region) else: client = boto3.client( service, region_name=region, aws_access_key_id=credentials['AccessKeyId'], aws_secret_access_key=credentials['SecretAccessKey'], aws_session_token=credentials['SessionToken'] ) return client新規アカウントの作成
アカウント名とメールアドレスから AWS Organizations で新規アカウントを作成し、アカウントIDを返します。
def create_account(account_name, email): """Create account by AWS Organizations""" account_id = 'None' org = get_client('organizations', 'us-east-1') try: logger.info("Trying to create the account with %s", email) create_account_response = org.create_account( Email=email, AccountName=account_name ) sleep(10) account_status = org.describe_create_account_status( CreateAccountRequestId=create_account_response['CreateAccountStatus']['Id'] ) except ClientError as err: logger.error("Create Account Request failed: %s", err.response['Error']['Message']) else: logger.info("Account Creation status: %s", account_status['CreateAccountStatus']['State']) if account_status['CreateAccountStatus']['State'] == 'FAILED': logger.error( "Account Creation Failed. Reason : %s", account_status['CreateAccountStatus']['FailureReason'] ) sys.exit(1) account_status = org.describe_create_account_status( CreateAccountRequestId=create_account_response['CreateAccountStatus']['Id'] ) account_id = account_status['CreateAccountStatus']['AccountId'] while account_id is None: logger.info("Waiting create new account. Retrying...") sleep(5) account_status = org.describe_create_account_status( CreateAccountRequestId=create_account_response['CreateAccountStatus']['Id'] ) account_id = account_status['CreateAccountStatus']['AccountId'] return account_idAssume Role
指定されたアカウントID に Assume Role して一時クレデンシャルを返します。
def assume_role(account_id): """Assume role to account""" sts = get_client('sts', 'us-east-1') role_arn = f'arn:aws:iam::{account_id}:role/OrganizationAccountAccessRole' try: assumed_role_object = sts.assume_role( RoleArn=role_arn, RoleSessionName="NewAccountSetUp" ) except ClientError as err: logger.error( "Assume Role Request failed: %s, %s", err.response['Error']['Message'], account_id ) sys.exit(1) return assumed_role_object['Credentials']招待の作成
Security Hub のマスターアカウトであるセキュリティアカウントから新規アカウントのIDと
メールアドレスを使用してを招待を送ります。
実際には CreateMembers API によりメンバーの関連付けを行ったあとに
InviteMembers API で招待を送っています。
この時点でメンバーアカウント側で Security Hub が有効化されていなくても招待することは可能です。def create_invitation(email, account_id, available_regions, audit_credentials): """Invite Account to Security Hub""" logger.info("Create Security Hub Invitation Start.") for region in available_regions: securityhub = get_client('securityhub', region, audit_credentials) try: securityhub.create_members( AccountDetails=[{ 'AccountId': account_id, 'Email': email }] ) response = securityhub.invite_members( AccountIds=[account_id] ) except ClientError as err: logger.error( "Create Invitation Request failed in %s: %s", region, err.response['Error']['Message'] ) sys.exit(1) else: if response['UnprocessedAccounts'] == []: logger.info("Invited: %s", region) else: logger.info("UnprocessedRegion: %s", region) logger.info("Create Security Hub Invitation Successed.")招待の承認
新規アカウントで Security Hub を有効化し、招待を承認します。
実際には ListInvitations API により InvitationId を確認し、
AcceptInvitation API で招待を承認します。def enable_securityhub(audit_account_id, available_regions, credentials): """Accept invitation from audit account""" logger.info("Enable Security Hub All Regions Start.") for region in available_regions: securityhub = get_client('securityhub', region, credentials) # Enalbe Security Hub try: securityhub.enable_security_hub() except ClientError as err: logger.error( "Enalbe Security Hub Request failed in %s: %s", region, err.response['Error']['Message'] ) sys.exit(1) # Accept Invitation try: response = securityhub.list_invitations() except ClientError as err: logger.error( "List Invitaion Request failed in %s: %s", region, err.response['Error']['Message'] ) sys.exit(1) if response['Invitations'] != []: try: securityhub.accept_invitation( MasterId=audit_account_id, InvitationId=response['Invitations'][0]['InvitationId'] ) except ClientError as err: logger.error( "Accept Invitation Request failed in %s: %s", region, err.response['Error']['Message'] ) sys.exit(1) else: logger.error("No Invitaions in %s", region) sys.exit(1) logger.info("Enabled Security Hub in %s", region) logger.info("Enalbe Security Hub All Regions Succeded.")全体
クリックで展開します。
lambda_function.pyimport os from logging import getLogger, INFO from time import sleep import sys import boto3 from botocore.exceptions import ClientError logger = getLogger() logger.setLevel(INFO) def get_client(service, region, credentials=None): """Returns the client for the specified region""" if credentials is None: client = boto3.client(service, region_name=region) else: client = boto3.client( service, region_name=region, aws_access_key_id=credentials['AccessKeyId'], aws_secret_access_key=credentials['SecretAccessKey'], aws_session_token=credentials['SessionToken'] ) return client def create_account(account_name, email): """Create account by AWS Organizations""" account_id = 'None' org = get_client('organizations', 'us-east-1') try: logger.info("Trying to create the account with %s", email) create_account_response = org.create_account( Email=email, AccountName=account_name ) sleep(10) account_status = org.describe_create_account_status( CreateAccountRequestId=create_account_response['CreateAccountStatus']['Id'] ) except ClientError as err: logger.error("Create Account Request failed: %s", err.response['Error']['Message']) else: logger.info("Account Creation status: %s", account_status['CreateAccountStatus']['State']) if account_status['CreateAccountStatus']['State'] == 'FAILED': logger.error( "Account Creation Failed. Reason : %s", account_status['CreateAccountStatus']['FailureReason'] ) sys.exit(1) account_status = org.describe_create_account_status( CreateAccountRequestId=create_account_response['CreateAccountStatus']['Id'] ) account_id = account_status['CreateAccountStatus']['AccountId'] while account_id is None: logger.info("Waiting create new account. Retrying...") sleep(5) account_status = org.describe_create_account_status( CreateAccountRequestId=create_account_response['CreateAccountStatus']['Id'] ) account_id = account_status['CreateAccountStatus']['AccountId'] return account_id def assume_role(account_id): """Assume role to account""" sts = get_client('sts', 'us-east-1') role_arn = f'arn:aws:iam::{account_id}:role/OrganizationAccountAccessRole' try: assumed_role_object = sts.assume_role( RoleArn=role_arn, RoleSessionName="NewAccountSetUp" ) except ClientError as err: logger.error( "Assume Role Request failed: %s, %s", err.response['Error']['Message'], account_id ) sys.exit(1) return assumed_role_object['Credentials'] def get_region_list(): """Return Available Region List""" ec2 = get_client('ec2', 'us-east-1') available_regions = map(lambda x: x['RegionName'], ec2.describe_regions()['Regions']) return list(available_regions) def create_invitation(email, account_id, available_regions, audit_credentials): """Invite Account to Security Hub""" logger.info("Create Security Hub Invitation Start.") for region in available_regions: securityhub = get_client('securityhub', region, audit_credentials) try: securityhub.create_members( AccountDetails=[{ 'AccountId': account_id, 'Email': email }] ) response = securityhub.invite_members( AccountIds=[account_id] ) except ClientError as err: logger.error( "Create Invitation Request failed in %s: %s", region, err.response['Error']['Message'] ) sys.exit(1) else: if response['UnprocessedAccounts'] == []: logger.info("Invited: %s", region) else: logger.info("UnprocessedRegion: %s", region) logger.info("Create Security Hub Invitation Successed.") def enable_securityhub(audit_account_id, available_regions, credentials): """Accept invitation from audit account""" logger.info("Enable Security Hub All Regions Start.") for region in available_regions: securityhub = get_client('securityhub', region, credentials) # Enalbe Security Hub try: securityhub.enable_security_hub() except ClientError as err: logger.error( "Enalbe Security Hub Request failed in %s: %s", region, err.response['Error']['Message'] ) sys.exit(1) # Accept Invitation try: response = securityhub.list_invitations() except ClientError as err: logger.error( "List Invitaion Request failed in %s: %s", region, err.response['Error']['Message'] ) sys.exit(1) if response['Invitations'] != []: try: securityhub.accept_invitation( MasterId=audit_account_id, InvitationId=response['Invitations'][0]['InvitationId'] ) except ClientError as err: logger.error( "Accept Invitation Request failed in %s: %s", region, err.response['Error']['Message'] ) sys.exit(1) else: logger.error("No Invitaions in %s", region) sys.exit(1) logger.info("Enabled Security Hub in %s", region) logger.info("Enalbe Security Hub All Regions Succeded.") def lambda_handler(event, context): """main""" account_name = os.environ['ACCOUNT_NAME'] email = os.environ['EMAIL'] audit_account_id = "111111111111" account_id = create_account(account_name, email) logger.info("Created acount: %s", account_id) # Assume Role New Account and Audit Account credentials = assume_role(account_id) audit_credentials = assume_role(audit_account_id) # Get Region List available_regions = get_region_list() # Secuirty Hub create_invitation(email, account_id, available_regions, audit_credentials) enable_securityhub(audit_account_id, available_regions, credentials)以上です。参考になれば幸いです。
- 投稿日:2020-03-30T19:37:38+09:00
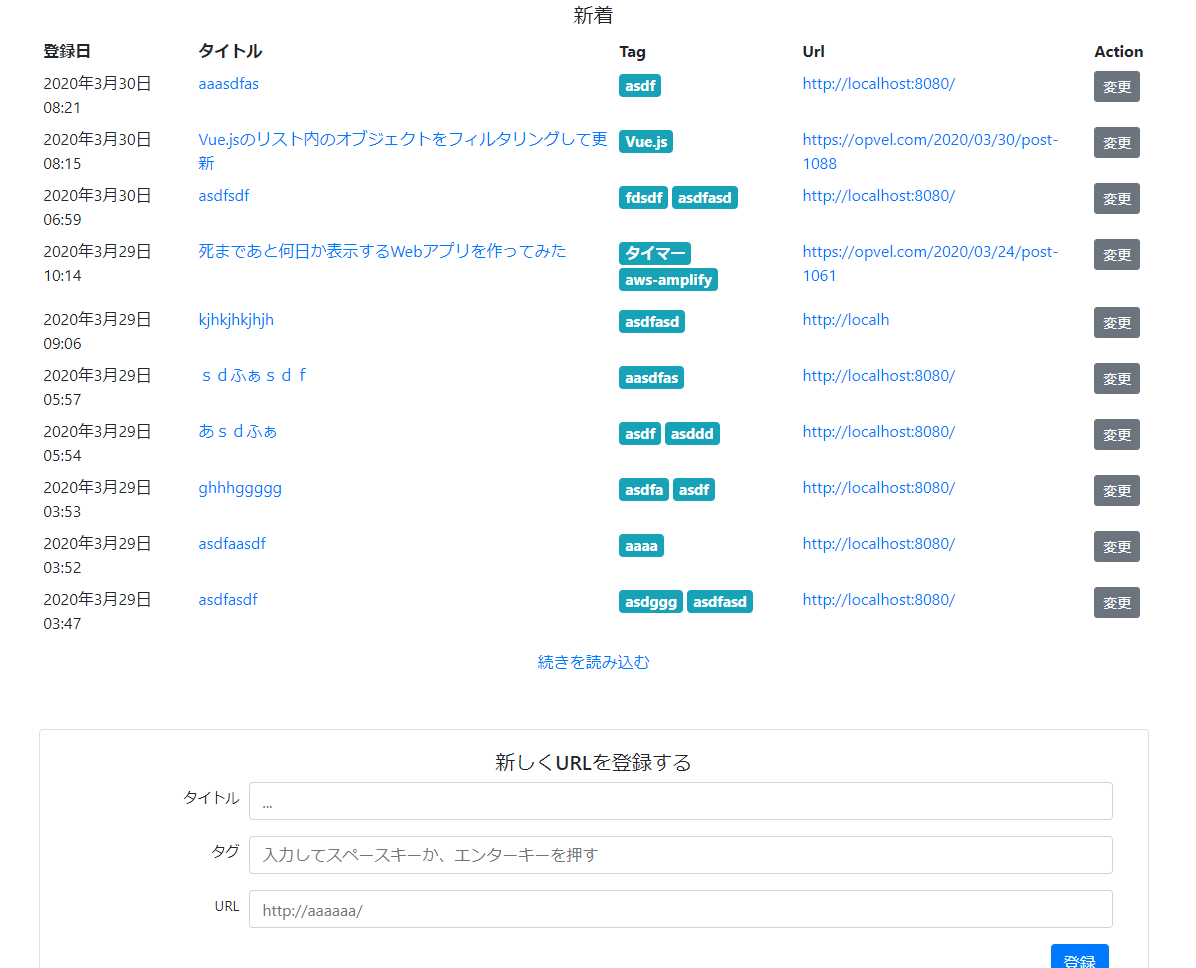
リンクを投稿できるだけのサイトを作ってみた
aws amplify の勉強を兼ねてリンクを投稿できるだけのサイトを作ってみました。
https://techlink.d2iaia9h9jeav.amplifyapp.com/
ページ下のフォームから登録できる。
タグをクリックすると、タグ検索ができる。
- 投稿日:2020-03-30T19:36:36+09:00
通勤時間でAWS Developer Associateに合格しよう!
はじめに
お久しぶりです。
新型コロナウイルスが猛威を振るっておりますがみなさまお元気でしょうか。
私この度、2月10日にAWS Certified Developer - Associate (DVA)に合格致しました。
今回の記事では、今後DVAへ挑戦される方向けに私が挑戦した際に参考にしたことや勉強方法などを共有しさせてください。私について
大学では農学を専攻しておりました。
就職の際にITに興味があり新卒でIT企業に入社しWebアプリケーションエンジニアとして2年目となります。入社以来の主な取得資格は下記です。
・ITパスポート 2018年
・Oracle認定JavaプログラマSE 7/8 Bronze 2018年
・AWS 認定ソリューションアーキテクト – アソシエイト 2019年
・Oracle認定JavaプログラマSE 8 Silver 2019年
・Webクリエイター能力認定 2019年
・情報処理技術者(基本情報技術者) 2019年
・AWS 認定デベロッパー – アソシエイト 2020年 ←744点なのでギリギリでした。業務ではAWSには触れておりません。
↑是非、使いこなしたい!
しかし、社内のAWS研修のトレーナーとして後輩に講義を行うことや、自学自習でAWSのサービスを使う機会はありました。今回DVAを取得しようと考えたのは、せっかく後輩に教えるのですから先輩として一つ資格でも取って「みんなも取れるよ!」というところを感じてもらいたかったというのが一番の理由です。
それでは、本題に入りましょう。
使用書籍と問題集
書籍
AWS認定アソシエイト3資格対策~ソリューションアーキテクト、デベロッパー、SysOpsアドミニストレーター~(2500円程)
問題集
Whizabs.com(2000円程)
勉強方法(勉強期間:約2ヶ月)
- 1ヶ月:参考書を1~2周してから、問題集解きまくり(参考書と問題解説を照らし合わせて問題の傾向を肌感で知る。知識を定着させる)
- 次の1ヶ月:問題解きまくり(参考書は分からなかった箇所のみ)
- 直前:理解できなかった問題を解き直したり、参考書で覚えておかないといけない箇所を再確認。
書籍について
購入当時(2019年5月)はDVA専用の書籍がなかった、また、SOA(SysOpsアドミニストレーターアソシエイト)の資格取得も視野に入れていたため上記の3資格対応用を使用しました。
みなさんが勉強する際にDVA専用の書籍が出版されていればそちらを使用してみるとよりDVAに特化した学習ができると思います。問題集について
海外の有料サイト(Whizabs)を使用しました。
↑※Google翻訳使用
理由としては、
①日本に比べ海外のほうがAWSに積極的
→資格取得者が重宝される
→資格取得目指す人が増える
→資格取得事業会社が市場のシェアを上げるために問題の質を高める
→★より本番に近い問題を扱うようになる
そのため日本のサイト(koiwa.clubなど)よりも海外のサイトを使用したほうがいいと考えました。
②他サイト(Udemy)よりも問題文も難易度も本番に近い。
③他サイト(Udemy)よりも解答が一問ごとに確認できるため移動中などの隙間時間でも勉強しやすい。(ほとんど通勤中に勉強していました。)
④無期限使用可能なので、資格更新の際にも再度使うことができる。
※問題集は各自で使いやすいものを選んでください。最後に
この資格を取ることでDeveloper(開発者)としてAWSを自在に使えるようになったわけではありませんが、後輩たちが自分の合格後に続々とSAA(ソリューションアーキテクトアソシエイト)に挑戦し合格していく姿を見て、やってきてよかったなとしみじみと思いました。彼らの今後に大いに期待です!
私としては、近々プロジェクトリーダーを担うことになりましたので、次はOracle Master Bronze(DB系)か情報技術者試験(応用技術者試験、プロジェクトマネージャ)を勉強していきたいと考えています。
読んでくださった方、ありがとうございます。
質問などありましたらお気軽にメッセージください。
SAA挑戦者もDVA挑戦者も、それ以外の資格挑戦者も応援しております。
- 投稿日:2020-03-30T19:36:36+09:00
通勤時間でAWS Certified Developer Associateを取得しよう!
1. はじめに
こんにちは。
この度、2月10日にDVA(AWS Certified Developer - Associate)に合格致しました。
今回の記事では、今後DVAへ挑戦される方向けに私が参考にしたことや勉強方法などを共有させてください。2. 私について
新卒でIT企業に入社しWebアプリケーションエンジニアとして2年目となります。
就職前は農学を学ぶ教育機関にいたためどちらかといえばITは未知でした。入社以来の主な取得資格は下記です。
2019年
・AWS 認定ソリューションアーキテクト – アソシエイト
・Oracle認定JavaプログラマSE 8 Silver
・情報処理技術者(基本情報技術者)
2020年
・AWS 認定デベロッパー – アソシエイト業務ではAWSには触れておりません。
社内のAWS研修のトレーナーとして後輩への講義を行う機会や自学自習でAWSのサービスを使う機会はありました。今回DVAを取得しようと考えたのは、せっかく後輩に教えるのですから先輩として資格の一つでも取って「私も取れる!」と感じてもらいたかったのが一番の理由です。
それでは、本題に入りましょう。
3. Results
勉強期間
約2ヶ月(平日のみ)
↑休日は休日にできることを楽しみたいです。勉強時間
約125時間(約50日(約2.5時間/1日))
↑実際は150時間程でしょうか。2.5時間の内訳
通勤時間:2時間(片道:1時間)
昼休憩中:30分
結果
744点(合格基準点は720点)
4. 使用書籍と問題集
書籍
AWS認定アソシエイト3資格対策~ソリューションアーキテクト、デベロッパー、SysOpsアドミニストレーター~(2500円程)
問題集
Whizabs.com(2000円程)
5. 勉強方法
1ヶ月:参考書を1~2周→問題集
↑参考書と問題解説を照らし合わせて問題の傾向を肌感で知る。知識を定着させる。
1ヶ月:問題集
↑参考書は分からなかった箇所のみ復習。
直前:分からなかった問題のみの解き直し。参考書で覚えておかないといけない箇所を再確認。※問題集は5周ほど繰り返しました。分からない問題が減るため周回スピードは上がりました。
6. 書籍について
購入当時(2019年5月)はDVA専用の書籍がなかった、また、SOA(AWS Certified SysOps Administrator - Associate)の資格取得も視野に入れていたため上記の3資格対応用を使用しました。
みなさんが勉強する際にDVA専用の書籍が出版されていればそちらを使用してみるとよりDVAに特化した学習ができるはずです。7. 問題集について
海外の有料サイト(Whizabs.com)を使用しました。※Google翻訳使用
理由としては、
①日本に比べ海外のほうがAWSに積極的
→資格取得者が重宝される
→資格取得目指す人が増える
→資格取得事業会社が市場のシェアを上げるために問題の質を高める
→★より本番に近い問題を扱うようになるはずだ。
そのため日本のサイト(koiwa.clubなど)よりも海外のサイトを使用したほうがいいと考えました。
②他サイト(Udemy)よりも問題文も難易度も本番に近い。
③解答が一問ごとに確認できるため移動中などの隙間時間でもスマートフォンで勉強しやすい。
↑総勉強時間の80%以上は通勤中でしたのでここは大事なポイント!
④無期限使用可能なので、資格更新の際にも再度使うことができる。
※問題集は各自で使いやすいものを選んでください。8. 最後に
この資格を取ることで開発者としてAWSを自在に使えるようになったわけではありませんが、後輩たちが自分の合格後に続々とSAA(AWS Certified Solutions Architect – Associate)に挑戦し合格する姿を見られてよかったなと思いました。
私としては近々プロジェクトリーダーを担うことになりますので、情報技術者試験(応用技術者試験、プロジェクトマネージャ)を勉強していきたいと考えています。あと、Oracle Master Bronze(DB系)も体系的に勉強したいです。
ご一読いただきありがとうございます。
少しでも受験される方の参考になれば幸いです。
質問などありましたらお気軽にメッセージいただければと思います。
- 投稿日:2020-03-30T15:46:09+09:00
MFAとAssume IAM Roles を使って環境でAWS SDKをGoで操作する
はじめに
マルチアカウント運用でAssumeRoleするかつ、MFA入力必須な場合、awscli等の操作も含めてややこしいですよね。awscliはともかく、AWS SDK for Goを使った上記の例が少いように見受けられたので残しておきます。
結論
MFAとAssume IAM Roles を使って環境でAWS SDKをGoで操作する方法は...
AssumeRoleTokenProviderを用います- MFAトークンを標準入力する場合は
stscreds.StdinTokenProviderを利用すると良いです
- そうすると、下記のような入力を求められるようになります
コード
例として、LambdaのCloudWatchLogsのLogStreamを検索するコードです。
AssumeRoleしつつMFAを利用する場合func main() { var ( logGroup = "/aws/lambda/<YourAppName>" logStreamPrefix = "2020/04/01" // 適当な日付 ) svc := cloudwatchlogs.New( session.Must(session.NewSessionWithOptions(session.Options{ SharedConfigState: session.SharedConfigEnable, AssumeRoleTokenProvider: stscreds.StdinTokenProvider, // MFAのときは必須 })), &aws.Config{ Region: aws.String(os.Getenv("AWS_REGION")), }, ) stm, err := svc.DescribeLogStreamsWithContext(ctx, &cloudwatchlogs.DescribeLogStreamsInput{ LogGroupName: aws.String(logGroup), LogStreamNamePrefix: aws.String(logStreamPrefix), NextToken: nil, }) if err != nil { log.Fatal(err) } for _, v := range stm.LogStreams { fmt.Println(aws.StringValue(v.LogStreamName), aws.Int64Value(v.CreationTime)) } }MFAトークンを正しく入力さえできれば、ログストリームの一覧を取得できたと思います。
参考
https://aws.amazon.com/jp/blogs/developer/assume-aws-iam-roles-with-mfa-using-the-aws-sdk-for-go/

- 投稿日:2020-03-30T15:35:39+09:00
Amazon EKSのチュートリアルを通して、Kubernetesによるコンテナ管理に触れてみる
Kubernetesをローカル環境で使用したことはありましたが、複数ホストをまたいだコンテナ管理に触れてみたいということで、Amazon EKSのチュートリアル をやってみました。ハマりポイントもあったので、勘所をまとめています。
前提
- クライアント側の作業はmacOSで実施
- macOSにはAWS CLIとkubectlをインストールしていること
- AWS CLI:1.18.10以上
- kubectl:クラスターのマイナーバージョンとの差分が1つ以内のバージョン(kubectlのインストールおよびセットアップ 参照)
たとえば、クライアントがv1.2であれば、v1.1、v1.2、v1.3のマスターで動作するはずです。最新バージョンのkubectlを使うことで、不測の事態を避けることができるでしょう。
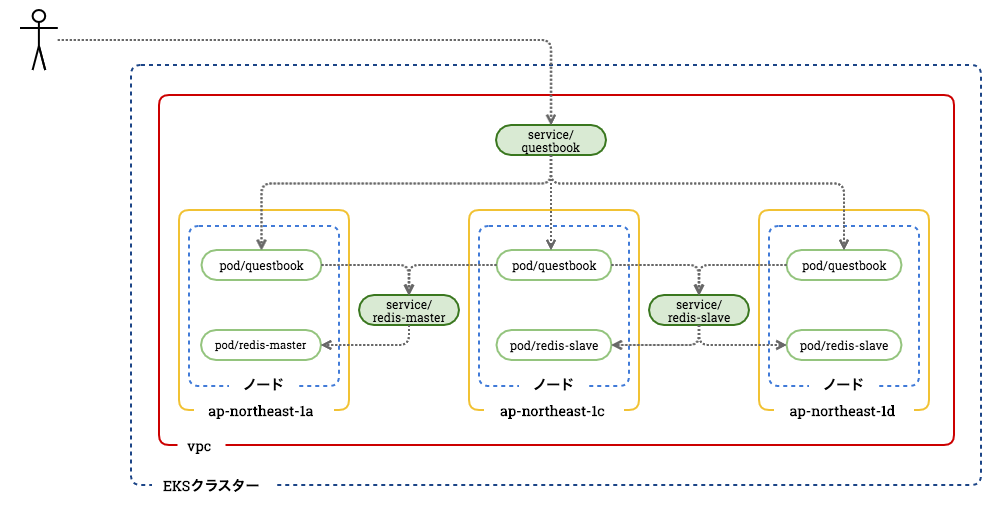
今回のゴール
今回構築するシステムの構成図はこちらです。
AWSリソースとKubernetesリソースを一緒に表現しているため、分かりにくいかもしれませんが、3つのAZ(サブネット)にまたがるWeb+Redisアプリケーションを構築します。EKSクラスターとは、Kubernetesの様々なリソースを管理する集合体のことを指します。Kubernetesリソースの基本説明
リソース名 用途 Node コンテナを配置するためのホスト(EC2に相当) Pod 複数のコンテナの集合体(単体のケースもある) Service Podの集合体への通信経路を定義 EKSの利用方法
2通りの方法が存在しますが、今回はAWSマネジメントコンソールで実施しています。
- eksctlを使用
- AWSマネジメントコンソールを使用
作業手順
以下の作業を順番に実施していきます。
※ 詳細は AWSマネジメントコンソールの開始方法 を参照EKSサービスロールを作成する
EKSクラスターが各種AWSリソースを参照・作成するために必要なIAMロールです。
下記のテンプレートを使用して、AWS CloudFormationコンソールでスタックを作成します。eks-service-role.yml--- AWSTemplateFormatVersion: '2010-09-09' Description: 'Amazon EKS Service Role' Resources: eksServiceRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - eks.amazonaws.com Action: - sts:AssumeRole ManagedPolicyArns: - arn:aws:iam::aws:policy/AmazonEKSServicePolicy - arn:aws:iam::aws:policy/AmazonEKSClusterPolicy Outputs: RoleArn: Description: The role that Amazon EKS will use to create AWS resources for Kubernetes clusters Value: !GetAtt eksServiceRole.Arn Export: Name: !Sub "${AWS::StackName}-RoleArn"EKSワーカーノードロールを作成する
EKSワーカーノードが各種AWSリソースを参照・作成するために必要なIAMロールです。
下記のS3テンプレートURLを指定して、AWS CloudFormationコンソールでスタックを作成します。EKSクラスターVPCを作成する
下記のS3テンプレートURLを指定して、AWS CloudFormationコンソールでスタックを作成します。
https://amazon-eks.s3-us-west-2.amazonaws.com/cloudformation/2019-11-15/amazon-eks-vpc-sample.yaml
今回、AZ (
ap-northeast-1a、ap-northeast-1c、ap-northeast-1d) にまたがる3つのパブリックサブネットを持つVPCを構築します。スタック作成中に
Template error: Fn::Select cannot select nonexistent value at index 2エラーが発生した場合
使用しているAWSアカウントでは、default subnetにap-northeast-1dが含まれていない可能性が高いので、以下のコマンドを実行してから、再度スタックの作成をしてみてください。$ aws ec2 create-default-subnet --availability-zone ap-northeast-1dEKSクラスターを作成する
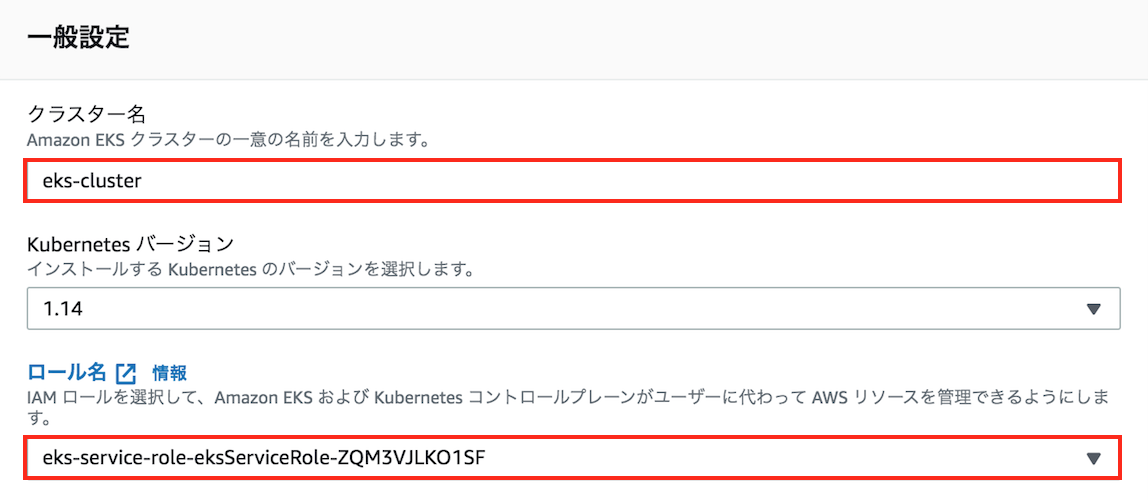
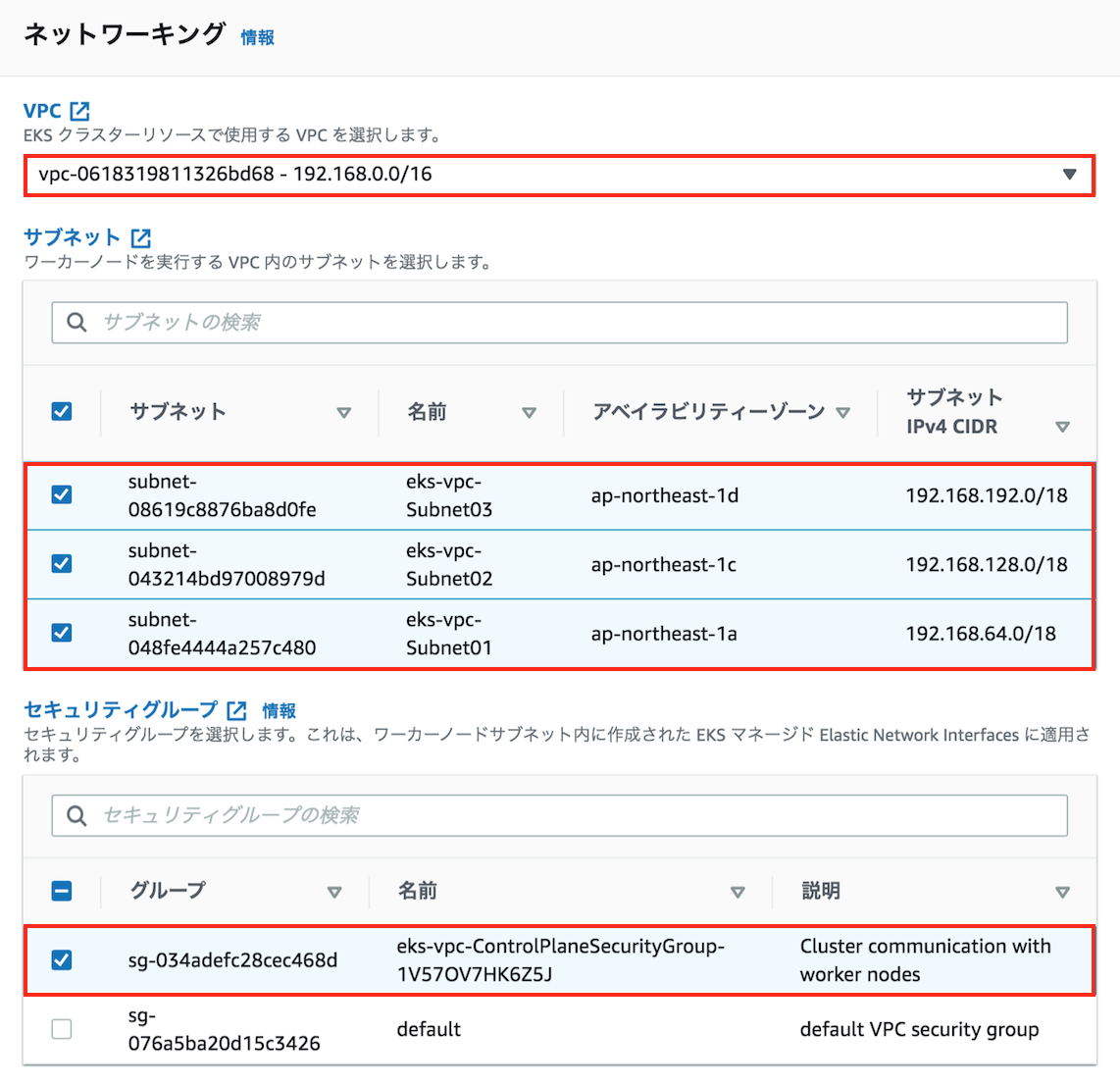
任意のクラスター名を入力して、事前に作成したEKSサービスロール、VPC、サブネット、セキュリティーグループを指定します。
kubeconfigファイルを作成する
$ aws eks --region ap-northeast-1 update-kubeconfig --name <cluster name> Added new context arn:aws:eks:ap-northeast-1:************:cluster/<cluster name> to /Users/********/.kube/config上記コマンドでkubectlのカレントの接続先にEKSクラスターが上書き設定されます。
※ kubeconfigについては、kubectlの接続設定ファイル(kubeconfig)の概要 を参照EKSノードグループを起動する
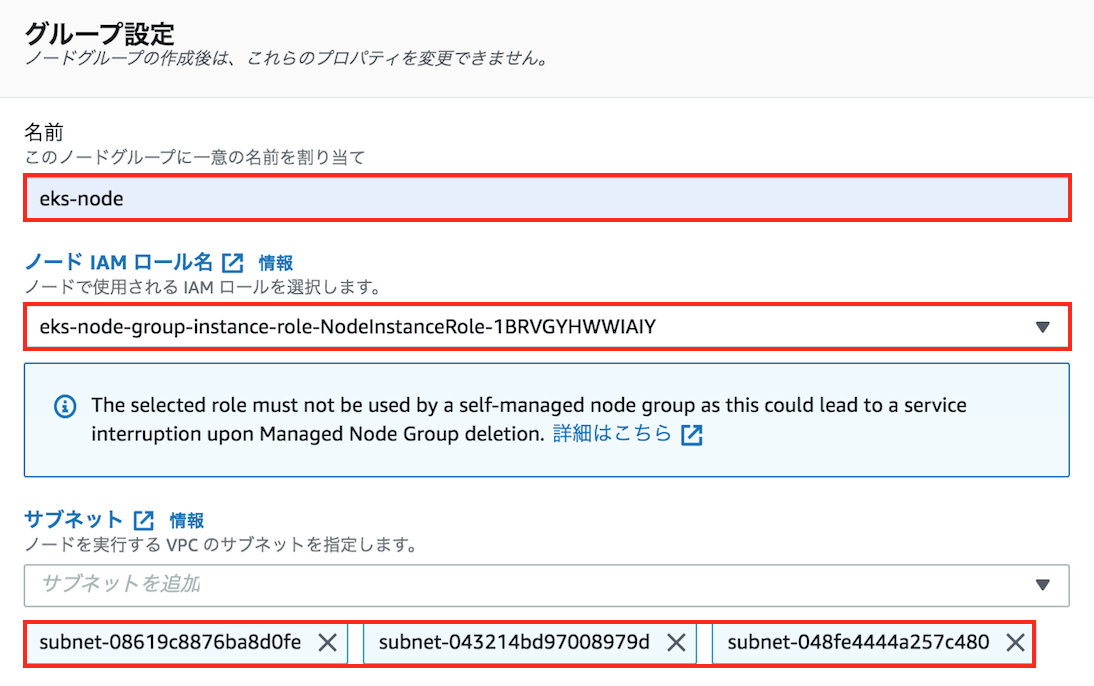
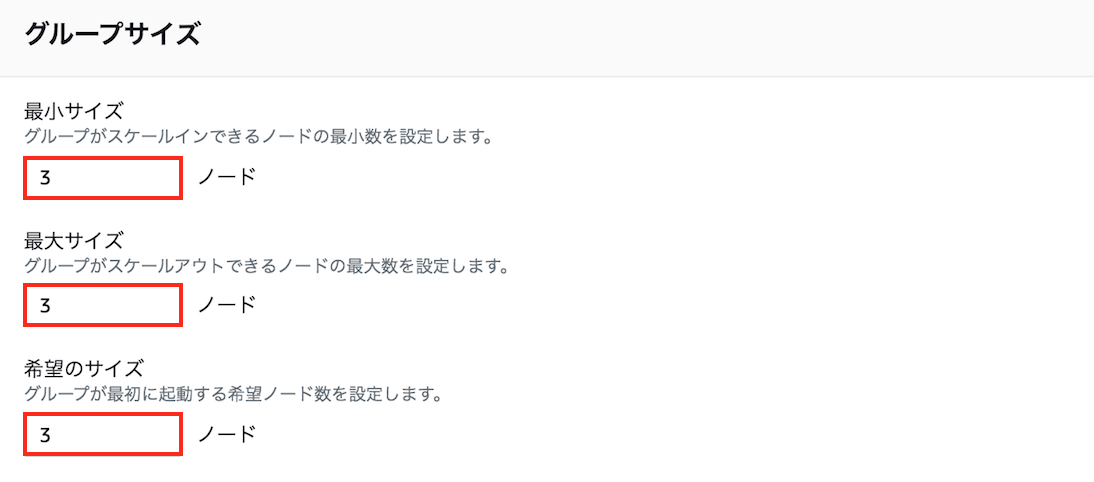
EKSクラスター上に、ノードグループを起動します。
任意のノードグループ名を入力して、事前に作成したEKSワーカーノードロール、サブネットを指定します。
ここではインスタンスタイプを指定しますが、重要なポイントとして、KubernetesはPod単位でプライベートIPアドレスが割り振られるため、ノード(=ホスト)に配置するPod数を計算して、適切なインスタンスタイプを選ぶ必要があります。例)T3系の最大IP数
インスタンスタイプ 最大ENI数(1) ENIあたりIP数(2) 最大IP数(1)×(2) t3.micro 2 2 4 t3.small 3 4 12 t3.medium 3 6 18 t3.large 3 12 36 ※ 詳細はElastic Network Interface を参照
なお、kube-systemと呼ばれるシステム用のNamespace上でもIPアドレスは利用されているため、それらを引いた数がPodで使用できるIP数となります。
$ kubectl get pod --namespace kube-system -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES aws-node-d5krq 1/1 Running 0 62m 192.168.220.97 ip-192-168-220-97.ap-northeast-1.compute.internal <none> <none> aws-node-flh75 1/1 Running 0 62m 192.168.152.228 ip-192-168-152-228.ap-northeast-1.compute.internal <none> <none> aws-node-mnpxl 1/1 Running 0 62m 192.168.113.251 ip-192-168-113-251.ap-northeast-1.compute.internal <none> <none> coredns-58986cd576-kc8xv 1/1 Running 0 95m 192.168.171.225 ip-192-168-152-228.ap-northeast-1.compute.internal <none> <none> coredns-58986cd576-rqwqs 1/1 Running 0 95m 192.168.225.139 ip-192-168-220-97.ap-northeast-1.compute.internal <none> <none> kube-proxy-j9lk5 1/1 Running 0 62m 192.168.152.228 ip-192-168-152-228.ap-northeast-1.compute.internal <none> <none> kube-proxy-jgmfb 1/1 Running 0 62m 192.168.220.97 ip-192-168-220-97.ap-northeast-1.compute.internal <none> <none> kube-proxy-rfjtd 1/1 Running 0 62m 192.168.113.251 ip-192-168-113-251.ap-northeast-1.compute.internal <none> <none>
最後にノード数ですが、こちらも事前に作成したサブネットや配置するリソースに応じて、適切な数を指定する必要があります。サンプルアプリケーションを起動する
ここからサンプルのゲストブックアプリケーションを作成します。
※ 詳細は ゲストブックアプリケーションを起動する を参照Redisマスターレプリケーションコントローラーを作成 (Pod作成)
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/examples/master/guestbook-go/redis-master-controller.jsonRedisマスターサービスを作成 (Service作成)
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/examples/master/guestbook-go/redis-master-service.jsonRedisマスターPodがノードグループのうち1ノードに配置され、そのPodへの通信経路であるServiceも作成されています。
$ kubectl get pod,svc -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod/redis-master-5l8nr 1/1 Running 0 9m25s 192.168.74.238 ip-192-168-113-251.ap-northeast-1.compute.internal <none> <none> NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 11h <none> service/redis-master ClusterIP 10.100.59.64 <none> 6379/TCP 4m31s app=redis,role=masterPodとServiceの関係性について、もう少し触れておくと、実行した下記の定義ファイルにあるように、PodのラベルとServiceのセレクタが合致した場合、対象のPodはそのServiceのターゲットとなり、Serviceを経由してトラフィックが流れる仕組みになっています。
redis-master-controller.json"template":{ "metadata":{ "labels":{ "app":"redis", "role":"master" } },redis-master-service.json"selector":{ "app":"redis", "role":"master" }Redisスレーブレプリケーションコントローラーを作成 (Pod作成)
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/examples/master/guestbook-go/redis-slave-controller.jsonRedisスレーブサービスを作成 (Service作成)
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/examples/master/guestbook-go/redis-slave-service.jsonRedisスレーブPod(レプリカ数2)がノードグループのうち2ノードに配置され、そのPodへの通信経路であるServiceも作成されています。
$ kubectl get pod,svc -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod/redis-master-5l8nr 1/1 Running 0 28m 192.168.74.238 ip-192-168-113-251.ap-northeast-1.compute.internal <none> <none> pod/redis-slave-hqpd2 1/1 Running 0 4m48s 192.168.192.184 ip-192-168-220-97.ap-northeast-1.compute.internal <none> <none> pod/redis-slave-nrnwk 1/1 Running 0 4m48s 192.168.133.49 ip-192-168-152-228.ap-northeast-1.compute.internal <none> <none> NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 11h <none> service/redis-master ClusterIP 10.100.59.64 <none> 6379/TCP 23m app=redis,role=master service/redis-slave ClusterIP 10.100.106.145 <none> 6379/TCP 4m34s app=redis,role=slaveゲストブックレプリケーションコントローラーを作成 (Pod作成)
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/examples/master/guestbook-go/guestbook-controller.jsonゲストブックサービスを作成 (Service作成)
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/examples/master/guestbook-go/guestbook-service.jsonゲストブックPod(レプリカ数3)がノードグループのうち3ノードに均等に配置され、そのPodへの通信経路であるServiceも作成されています。
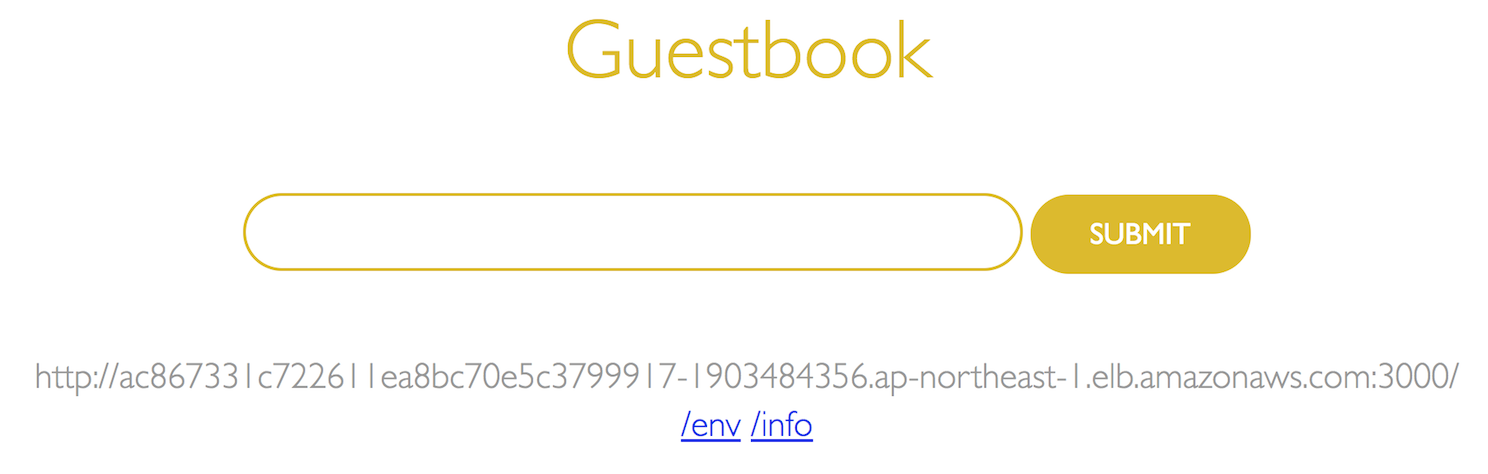
$ kubectl get pod,svc -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod/guestbook-2wcm6 1/1 Running 0 4m20s 192.168.222.236 ip-192-168-220-97.ap-northeast-1.compute.internal <none> <none> pod/guestbook-cnl46 1/1 Running 0 4m20s 192.168.124.194 ip-192-168-113-251.ap-northeast-1.compute.internal <none> <none> pod/guestbook-smjjm 1/1 Running 0 4m20s 192.168.160.43 ip-192-168-152-228.ap-northeast-1.compute.internal <none> <none> pod/redis-master-5l8nr 1/1 Running 0 38m 192.168.74.238 ip-192-168-113-251.ap-northeast-1.compute.internal <none> <none> pod/redis-slave-hqpd2 1/1 Running 0 14m 192.168.192.184 ip-192-168-220-97.ap-northeast-1.compute.internal <none> <none> pod/redis-slave-nrnwk 1/1 Running 0 14m 192.168.133.49 ip-192-168-152-228.ap-northeast-1.compute.internal <none> <none> NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR service/guestbook LoadBalancer 10.100.186.33 ac867331c722611ea8bc70e5c3799917-1903484356.ap-northeast-1.elb.amazonaws.com 3000:32317/TCP 4m13s app=guestbook service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 12h <none> service/redis-master ClusterIP 10.100.59.64 <none> 6379/TCP 33m app=redis,role=master service/redis-slave ClusterIP 10.100.106.145 <none> 6379/TCP 14m app=redis,role=slaveシステム構成も冒頭に説明した 今回のゴール 通りに作られているようです。
ゲストブックアプリケーションにブラウザでアクセス
http://ac867331c722611ea8bc70e5c3799917-1903484356.ap-northeast-1.elb.amazonaws.com:3000
無事、ゲストブックアプリケーションが表示されました。
さいごに
今回のチュートリアルでは、作成したRedisおよびゲストブックPodが、均等に各ノードに配置されています。これにはタネも仕掛けも分からず、どこか釈然としない気持ちになってしまいましたが、Kubernetesの公式ドキュメントに以下の一節を見つけました。
Node上へのPodのスケジューリングPodが稼働するNodeを特定のものに指定したり、優先条件を指定して制限することができます。 これを実現するためにはいくつかの方法がありますが、推奨されている方法はラベルでの選択です。 スケジューラーが最適な配置を選択するため、一般的にはこのような制限は不要です。
柔軟な指定もできるようですが、スケジューラー(Podのノードへの割り当てをつかさどるマスターコンポーネント)が頑張ってくれるようです。流石。

- 投稿日:2020-03-30T15:17:56+09:00
【AWS EC2】Amazon Linux2にMySQLのclientだけをインストールしてRDSに接続する方法
概要
- AWS EC2(AMI: Amazon Linux 2)にMySQLのクライアントだけをインストールしてRDS上のMySQLに接続する
環境
- AWS EC2
- OS: Amazon Linux 2
- AMI ID: amzn2-ami-hvm-2.0.20200304.0-x86_64-gp2
- RDS
- engine: MySQL Community
- version: 8.0.17
構築手順
1. すでにインストールされているmariadbを取り除く
- Amazon Linux2にはMariaDBがデフォルトでインストールされている
- 干渉したら困るので念のため削除しておく
$ yum list installed | grep mariadb mariadb-libs.x86_64 1:5.5.64-1.amzn2 installed $ sudo yum remove mariadb-libs Removed: mariadb-libs.x86_64 1:5.5.64-1.amzn2 Dependency Removed: postfix.x86_64 2:2.10.1-6.amzn2.0.3 Complete!2. mysql8.0のリポジトリを追加する
yum infoでmysql8.0がインストールできるか確認する- インストールできないのでmysql8.0のリポジトリを追加する
$ yum info mysql Loaded plugins: extras_suggestions, langpacks, priorities, update-motd 31 packages excluded due to repository priority protections Error: No matching Packages to list $ sudo yum localinstall -y https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm Installed: mysql80-community-release.noarch 0:el7-33. mysql8.0のリポジトリを有効化する
mysql80-community-release-el7-3.noarchの中にmysql5.7も入っている- 今回はmysql8.0をインストールしたい
- mysql5.7のリポジトリを無効化し、mysql8.0のリポジトリを有効化する
$ sudo yum-config-manager --disable mysql57-community $ sudo yum-config-manager --enable mysql80-community4. mysql-community-clientをインストールする
$ sudo yum install -y mysql-community-client Installed: mysql-community-client.x86_64 0:8.0.19-1.el7 Dependency Installed: mysql-community-common.x86_64 0:8.0.19-1.el7 mysql-community-libs.x86_64 0:8.0.19-1.el7 ncurses-compat-libs.x86_64 0:6.0-8.20170212.amzn2.1.3 Complete! $ mysql --version mysql Ver 8.0.19 for Linux on x86_64 (MySQL Community Server - GPL)5. RDSに接続する
- EC2からRDSへの3306ポートの通信は許可してあるものとする
$ mysql -h hoge.rds.amazonaws.com -P 3306 -u root -p Enter password: mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | +--------------------+ 3 rows in set (0.03 sec)参考
- 投稿日:2020-03-30T12:15:18+09:00
Apache Airflow on kubernetesのおためし構築(とりあえずたてる編)
はじめに(読み飛ばしていいよ)
Executorの選択
AirflowにはExecutorがいくつかありますが、今回使うのはkubernetes Executorです。
詳細は省きますが、Airflowには様々なExecutorがあります。 Celery executorを使用してkubernetes上に展開したぜ!というのもありますが、それとは異なるので注意。(まぁ、そもそもkubernetes使っているのにCelery executorを使用する例はなかなか少ないとは思いますが。その時の状況での判断です)kubernetes Executorの動作(ざっくりと)
kubernetes ExecutorではAirflowのscheduler部分とwebserver部分がPod化されます。同じPod内でschedulerコンテナ&webserverコンテナで動作させても良いし、別々のPodにしてもいい。基本schedulerやwebserverはmetadatabase DBへ通信しているだけで互いに直接通信しないので。 ※ちなみにスケジュールするDAG数が何千、タスク数が全部で万単位となるとschedulerの負荷がなかなかの物になるので注意。
kubernetes Executorでは、Operator毎に基本worker Podが立ち上がりタスクが処理されます。基本OperatorとPodは1:1です。(kubernetesPodOperatorなど例外はありますが。)
kubernets Executorの場合、タスク実行ログがそのworker Podがあった場所にしか残されません。なのでAirflow UIでログを見ようとした時、webserver のPodがそのタスクが実行されたnodeに立っていれば読み取れるかもしれませんが、それ以外の場合、ログがねえと言われます。したがって、Airflowの機能の一つを使って、ログはPod終了時にS3に投げてもらい、基本webseverはローカルにログがなければS3をみるようにします。
※ S3からのログ読み出しの場合、タスク実行途中のログ出力はリアルタイムではweb UIから見れません。S3にログがアップされるのはタスクの処理が終了し、Podが落ちる時だからです。Worker用のPodについて worker用のPodに使われるdocker imageは基本airflowが入ってないと動かんで! (kubernetesPodOperatorでPodから作られるPodを除く!) デフォルトではAirflowを立てた時に使ったimageが使用される。別のimageをしているすることも可能。(airflow.cfgでもOperator内でも指定できる)
構築
構築環境 (AWS を使用します。容量ざっくり。タイプはt系でも動くので安くしたければ変更)
- インスタンス m5.large → 計3台 EBSは30GBぐらいそれぞれにつけとく。
- kubernetes master 用 → 1台/3台
- Airflowのschedulerやwebserver, worker等のPod用 2台/3台
上記でkubernetesのクラスタくんどいてください。(EKS使えとかは言ってはいけない)
- RDS m5.large → 1台 SSD 30GBくらい
- PostgreSQL
- EFS (NFS) 30GBくらい
- kubernetsのnode間でデータ共有するため
(Airflow worker Pod等含め全てのPodが各nodeで同じDAGを読み取れないといけないので。)- S3 (Log吐き出し用)
Docker imageの作成 (Airflowのバージョンは1.10.9 でいくぜ)
フォルダ /AAA/BBB/CCC/内に下記のファイルを全部おこう
node全部にこのimageは必要だからね! 各nodeでそれぞれ同じように作ってもいいし、local registry使ってもいいね。Dockerfile
FROM python:3.6.10-slim #いらんもんも結構入っているような気がするが、嫌なら消すよろし。 RUN apt-get update --allow-releaseinfo-change -y && apt-get install -y \ --no-install-recommends curl \ --no-install-recommends gnupg2 \ wget \ libczmq-dev \ curl \ libssl-dev \ git \ libpq-dev \ inetutils-telnet \ bind9utils \ zip \ unzip \ gcc \ vim \ mariadb-client \ default-libmysqlclient-dev \ && apt-get clean RUN pip install --upgrade pip RUN pip install -U setuptools && \ pip install kubernetes && \ pip install cryptography && \ pip install psycopg2 RUN pip install apache-airflow==1.10.9 && \ pip install apache-airflow[ssh] && \ pip install apache-airflow[postgres] && \ pip install apache-airflow[password] && \ pip install apache-airflow[crypto] && \ pip install apache-airflow[s3] && \ pip install boto3==1.11.13 && \ pip install awscli --upgrade --user # ここ無くしていい。ただPod内からawsコマンド打ちたかったんや。 RUN echo export PATH='$PATH:$HOME/bin:$HOME/.local/bin' >> ~/.bashrc COPY airflow-test-env-init.sh /tmp/airflow-init.sh COPY bootstrap.sh /bootstrap.sh RUN chmod +x /bootstrap.sh ENTRYPOINT ["/bootstrap.sh"]airflow-init.sh
#!/usr/bin/env bash set -x # あらかじめ入っているexampleのdagは消す。(kube上だと色々めんどいねん) cd /usr/local/lib/python3.6/site-packages/airflow && \ rm -rf example_dags && \ cd /usr/local/lib/python3.6/site-packages/airflow/contrib && \ rm -rf example_dags && \ cd /usr/local/lib/python3.6/site-packages/airflow && \ airflow initdb && \ alembic upgrade heads && \ (airflow create_user --username airflow --lastname airflow --firstname jon --email airflow@apache.org --role Admin --password airflow || true)bootstrap.sh
#!/usr/bin/env bash if [[ "$1" = "webserver" ]] then exec airflow webserver fi if [[ "$1" = "scheduler" ]] then exec airflow scheduler fiAirflow入りのdocker image作成
docker build -t airflow:1.10.9 /AAA/BBB/CCC/metadatabase DB接続情報準備!
まず下準備
PostgreSQLの場合:
postgresql+psycopg2://ユーザ名:パスワード@DBのエンドポイント:ポート:番号/DB名
を一例として下記の様にハッシュ化する。>>import base64 >>dbinfo = postgresql+psycopg2://ユーザ名:パスワード@DBのエンドポイント:ポート:番号/DB名 >>base64.b64encode(dbinfo) XXXXXX ハッシュ化列 XXXXXXXXこのハッシュ化列は残しとこう!
※ ちゃんとDB作っといてね?kubeデプロイ用yaml作成
準備するファイルは5つ!
1. secret.yaml
2. volume.yaml
3. scheduler.yaml
4. webserver.yaml
5. configmaps.yamlsecret.yaml
apiVersion: v1 kind: Secret metadata: namespace: airflow01 name: airflow-secrets type: Opaque data: sql_alchemy_conn: !!!!!ここにBD接続情報のハッシュ化列!!!!!volume.yaml
--- kind: PersistentVolume apiVersion: v1 metadata: name: airflow-dags spec: accessModes: - ReadOnlyMany capacity: storage: 30Gi nfs: server: XXXXXXXX path: /efs/Vol_airflow/airflow01 --- kind: PersistentVolumeClaim apiVersion: v1 metadata: name: airflow-dags spec: accessModes: - ReadOnlyMany resources: requests: storage: 30Gischeduler.yaml
--- kind: Namespace apiVersion: v1 metadata: name: airflow01 labels: name: airflow01 --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: admin-rbac01 subjects: - kind: ServiceAccount name: default namespace: airflow01 roleRef: kind: ClusterRole name: cluster-admin apiGroup: rbac.authorization.k8s.io --- apiVersion: apps/v1 kind: Deployment metadata: namespace: airflow01 name: airflow spec: replicas: 1 selector: matchLabels: name: airflow app: airflow template: metadata: labels: name: airflow app: airflow spec: '''これは今は無視で affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 preference: matchExpressions: - key: node operator: In values: - for-scheduler ''' initContainers: - name: "init" image: airflow:1.10.9 imagePullPolicy: IfNotPresent volumeMounts: - name: airflow-configmap mountPath: /root/airflow/airflow.cfg subPath: airflow.cfg - name: airflow-dags mountPath: /root/airflow/dags env: - name: SQL_ALCHEMY_CONN valueFrom: secretKeyRef: name: airflow-secrets key: sql_alchemy_conn command: - "bash" args: - "-cx" - "./tmp/airflow-init.sh" containers: - name: scheduler image: airflow:1.10.9 imagePullPolicy: IfNotPresent args: ["scheduler"] env: - name: AIRFLOW__KUBERNETES__NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: SQL_ALCHEMY_CONN valueFrom: secretKeyRef: name: airflow-secrets key: sql_alchemy_conn volumeMounts: - name: airflow-configmap mountPath: /root/airflow/airflow.cfg subPath: airflow.cfg - name: airflow-dags mountPath: /root/airflow/dags volumes: - name: airflow-dags persistentVolumeClaim: claimName: airflow-dags - name: airflow-dags-fake emptyDir: {} - name: airflow-dags-git emptyDir: {} - name: airflow-configmap configMap: name: airflow-configmapwebserver.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: airflowweb01 namespace: airflow01 spec: replicas: 1 selector: matchLabels: name: airflowweb01 template: metadata: labels: name: airflowweb01 spec: ''' ここは今は無視で affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - airflow topologyKey: kubernetes.io/hostname namespaces: - airflow01 - airflow02 ''' containers: - name: webserver image: airflow:1.10.9 imagePullPolicy: IfNotPresent resources: requests: cpu: 200m memory: 10Mi ports: - name: webserver containerPort: 8080 args: ["webserver"] env: - name: AIRFLOW__KUBERNETES__NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: SQL_ALCHEMY_CONN valueFrom: secretKeyRef: name: airflow-secrets key: sql_alchemy_conn volumeMounts: - name: airflow-configmap mountPath: /root/airflow/airflow.cfg subPath: airflow.cfg - name: airflow-dags mountPath: /root/airflow/dags volumes: - name: airflow-dags persistentVolumeClaim: claimName: airflow-dags - name: airflow-dags-fake emptyDir: {} - name: airflow-dags-git emptyDir: {} - name: airflow-configmap configMap: name: airflow-configmap --- apiVersion: v1 kind: Service metadata: name: airflowweb01 spec: type: NodePort ports: - port: 8080 nodePort: 30809 selector: name: airflowweb01configmaps.yaml
comfogmapsはairflow.cfg(airflowの設定ファイル)が記述されているので長いです。ですので今回重要な部分だけ取り出して一部省略します。(公式gitから取ってきてね!)
kind: Namespace apiVersion: v1 metadata: name: airflow01 labels: name: airflow01 --- apiVersion: v1 kind: ConfigMap metadata: name: airflow-configmap namespace: airflow01 data: airflow.cfg: | [core] dags_folder = /root/airflow/dags #base_log_folder = /root/airflow/logs #logの保存先にs3を登録するぞ!remote_log_conn_id はconnection登録時のidだぞ!airflow connectionで調べよう!(登録せんでも動くけどな....なので適当でいい。) remote_logging = True remote_base_log_folder = s3://XXXXXXXXX/airflow-logs-01 remote_log_conn_id = idap01 encrypt_s3_logs = False logging_level = INFO fab_logging_level = INFO ...... ... !省略! .. dag_dir_list_interval = 60 job_heartbeat_sec = 5 #m5.largeなので2でOK? 占有しちゃうけどね。 max_threads = 2 run_duration = -1 num_runs = -1 processor_poll_interval = 1 scheduler_heartbeat_sec = 120 min_file_process_interval = 10 statsd_on = False statsd_host = localhost statsd_port = 8125 statsd_prefix = airflow min_file_parsing_loop_time = 5 print_stats_interval = 30 scheduler_health_check_threshold = 200 scheduler_zombie_task_threshold = 600 max_tis_per_query = 512 authenticate = False use_job_schedule = True ...... ... !省略! .. airflow_configmap = airflow-configmap worker_container_repository = airflow worker_container_tag = 1.10.9 worker_container_image_pull_policy = IfNotPresent delete_worker_pods = True dags_in_image = False dags_volume_claim = airflow-dags dags_volume_subpath = /efs/Vol_airflow/airflow01 logs_volume_claim = logs_volume_subpath = dags_volume_host = logs_volume_host = in_cluster = True namespace = airflow01 gcp_service_account_keys = worker_pods_creation_batch_size=100 ...... ... !省略! ..立てるぞ! kubectl applyコマンドだ!
kubectl apply -f secrets.yaml kubectl apply -f volumes.yaml kubectl apply -f airflow_scheduler.yaml kubectl apply -f airflow_webserver.yaml下記のようにPodが立っていれば成功だ!
>> kubectl get po -n airflow01 NAME READY STATUS RESTARTS AGE airflow-7fccbd497-nf9s4 1/1 Running 0 23d airflowweb01-5f58867588-gds9v 1/1 Running 0 20d終
- 投稿日:2020-03-30T11:34:17+09:00
AWS Athena API利用時にQUEUEDステータスが数十秒も引っかかることがある
引っかかった話
AWS Athena API(AWS SDK for JavaScript)を呼び出してるLambda関数で本当にたまにタイムアウトによるエラーが発生されました。
Lambda関数で設定して置いたタイムアウト時間は40秒で短い時間でしたが、平均2秒±1ぐらいのクエリ時間がたまに40秒を超えるのはおかしいでした。
Athenaの対象データ(S3 Objects)がどんどん増えてAhtenaのクエリが比較的に重くなることはありえますが、速度改善のためパーティショニングも真面目にしているクエリに40秒のタイムアウトに引っかかったのはQuery Running Time (RUNNING)とは違う原因でしょう。
(API呼び出しの前後に時間が秒以上かかるところもありませんでした)
また、AthenaにもAPIごとに 「1 秒あたりのデフォルトの呼び出し数」と 「バーストキャパシティー」のクォータがありますが、これに引っかかったら明確にFAILEDで返してくれるのでこの原因じゃないでした。もっと確認した結果、たまにQuery Queuing Time(QUEUED)が何十秒も掛かってたことがその原因でした。
QUEUEDステータスとは
QUEUEDステータスはクエリがサービスに提出されたことを示し、クエリがリソースを待ってキューに並んでいた時間(Query Queuing Time)で、Athenaはリソースを利用できる時点ですぐクエリを実行します。
つまり、このステータスは正常な状態で、Query Running Time (RUNNING)とは違います。
Athenaは最近までキューにあるクエリを「RUNNING」として表示してましたが、新しくメトリクスが追加されたそうです。
AWSから回答をもらったそうなstackoverflowの回答を見るとTake a look on Athena hook in Apache Airflow.
Athena has final states (SUCCEEDED, FAILED and CANCELLED) and intermediate states - RUNNING and QUEUED.
QUEUED is a normal state for a query before it got stared.
...
As part of the deployment of more granular metrics, Athena now includes a QUEUED status for queries.
This status indicates that an Athena query is waiting for resources to be allocated for processing.
Query flow is roughly:
SUBMITTED -> QUEUED -> RUNNING -> COMPLETED/FAILED試してみる
以下の通りタイムアウトを長くして何回もAPIでクエリを投げて、どのぐらいの頻度で長いQuery Queuing Timeが発生されるか見た結果、意外と頻繁に短いQuery Queuing Timeが発生され、激しい連続クエリを投げた場合は長いQuery Queuing Time時間がたまに発生されますね。
スキャンデータは176KBで2つの2種類のQuery内容をそれぞれ繰り替えながら実行しました。
API呼び出しLambda関数
test.js... (function loop() { if (time < 180) { athena.getQueryExecution(params, (err, data) => { console.log('Status : ' , data.QueryExecution.Status.State); if (data.QueryExecution.Status.State == 'SUCCEEDED'){ resolve(queryExecutionId); } else { if (data.QueryExecution.Status.State == 'FAILED') { console.error(err, err.stack); } const startMsec = new Date(); while (new Date() - startMsec < 1000); time+=1; loop(); } }); } else { reject('408 Request Timeout'); return false; } }()) ...動作テスト① Lambda関数を連続で3回連続実行する
番目 Query Queuing Time(sec) トータル処理実行時間(sec) 1 1 4 2 1 2 3 16 21 動作テスト② Lambda関数を連続で4回連続実行する
番目 Query Queuing Time(sec) トータル処理実行時間(sec) 1 1 3 2 1 4 3 1 4 4 1 3 動作テスト③ Lambda関数を連続で6回連続実行する
番目 Query Queuing Time(sec) トータル処理実行時間(sec) 1 1 3 2 1 3 3 1 5 4 0 1 5 1 2 6 1 4 動作テスト④ Lambda関数を連続で10回連続実行する
番目 Query Queuing Time(sec) トータル処理実行時間(sec) 1 1 3 2 1 2 3 1 3 4 1 2 5 1 3 6 1 2 7 0 1 8 1 3 9 0 1 10 1 2 動作テスト⑤ 長いQuery Queuing Timeが発生されるまで連続実行
番目 アクション 5秒以上のQuery Queuing Time(sec) 1 10回連続 x 2 10回連続 5秒、7秒が一回ずつ発生 3 10回連続 x 4 10回連続 x 5 20回連続 9秒、10秒、14秒、23秒、24秒、38秒、50秒が一回ずつ発生 最後に
自分は今回の対応で単純にタイムアウト時間を長く設定して長くなるケースを許して置きましたが、
クエリの結果を長く待てない利用ケースでしたら、サポートセンターに問い合わせして見た方が良さそうです。
GlueにもAthenaにもクォータがありますが正直にどのクォータに引っかかってQUEUEDになってしまうのか自分の中では不明で、
Query Queuing Timeが長くなるケースを避ける方法を引き続き調べて見るつもりです。
その方法をご存知な方はぜひコメントお願いいたします!※ 関連リンク
https://aws.amazon.com/about-aws/whats-new/2019/11/amazon-athena-adds-four-new-query-related-metrics/?nc1=h_lshttps://docs.aws.amazon.com/ja_jp/athena/latest/ug/service-limits.htmlhttps://stackoverflow.com/questions/57170330/athena-getqueryexecution-returns-a-status-of-running-for-1-minute-even-thoughhttps://stackoverflow.com/questions/57145967/aws-athena-concurrency-limits-number-of-submitted-queries-vs-number-of-runninghttps://prestosql.io/docs/current/connector/hive.html#aws-glue-catalog-configuration-properties

- 投稿日:2020-03-30T11:09:14+09:00
AWS Lambda で実行できるコマンドを作成する環境を作ってみた
いったい何の役に立つねんシリーズ。技術の無駄遣い担当の平野です。いや、今回の役に立つはず。
AWS Lambda で Python や Node のスクリプトを書いていると、「あー、この Linux コマンド使えたら便利なのに」と思うときが時々あります。
ということで、Lambda 用に簡単にコマンドを作成、取り出しできる Docker コンテナを作ってみました。
github:
https://github.com/qualitiaco/build-packdockerhub:
https://hub.docker.com/r/qualitiaco/lambda-build-pack今回は、これの解説と使い方を説明したいと思います。
AWS Lambda の実行環境
AWS Lambda で動作しているのと同様の Docker Image が AWS から公開されています。
github:
https://github.com/lambci/docker-lambdadockerhub:
https://hub.docker.com/u/lambci今回は、この dockerhub にある、lambci/lambda-base-2 を使ってビルドしてみました。
Build 環境と実行環境
lambci/lambda-base-2 のコンテナイメージには、latest タグと、build タグが存在します。
latest の方が、実際の runtime 環境のベースになるもののようで、lambda-base-2:latest に対して Python や NodeJS の環境が追加された物が lambda の実行環境になる、というようなイメージです。
実際、こちらには yum も gcc も実行時に必要なさそうなものは入っていません。
本物の AWS Lambda では Python や Node が必要とするライブラリも入っていますので、完全に同じというわけではありません。一方、biuld タグの方は、yum や git など開発に必要なものがいくつかインストールされています。
AWS Lambda で動作するバイナリファイルとライブラリの取り出し方法
基本的には lambda-base-2:build の環境上でコンパイルしてできたバイナリファイルを AWS Lambda に持って行って動かせばいいのですが、実行ファイルだけを持って行っても、必要なライブラリが Lambda 環境にない場合があります。
リンクされているものを全部持って行くと、これも大げさで、あまり現実的ではありません。そこで、lambda-base-2:build で作成した実行ファイルを lambda-base-2:latest の環境で検証し、足りないライブラリのみを抽出することで、AWS Lambda 上で必要十分なライブラリを用意することにしました。
Python が必要とするライプラリ等、多少重複する物もありますが、今回はどの Lambda でも動作する物を目指します。
どうしても小さくしたければ、lambci には Python 用のイメージ等もありますので、Dockerfile を変更することで簡単に実現できると思います。環境の作成
Docker の stage build を使って、lambda-base-2:latest の/usr/lib64 以下を lambda-base-2:build の/lib64.runtime に保存し、比較できるようにしました。
詳細な動作は、ソースをご覧ください。
https://github.com/qualitiaco/build-packAWS Lambda で動作するバイナリファイルとライブラリの取り出し
作成した Docker イメージを使用してみます。
今回は、シンプルだけどシンプルじゃなさそうな、dig コマンドを AWS Lambda で実行してみたいと思います。
必要なコマンドの取り出すスクリプト作成
まず、以下のような Shell Script を src/build.sh として作成します。
- AWS Lambda で実行したいコマンドを yum で作成するか、または、コンパイルします
- コマンドを\${OUTPUT_PATH}にコピーします
src/build.sh#!/bin/sh OUTPUT_PATH=${OUTPUT_PATH:-output} yum install -y bind-utils cp -a /usr/bin/dig ${OUTPUT_PATH}コマンドとライブラリの取り出し
docker を実行して、コマンドとライブラリを取り出します。
docker run -v $(pwd)/output:/output -v $(pwd)/src:/src -it --rm qualitiaco/lambda-build-pack取り出したライブラリの確認
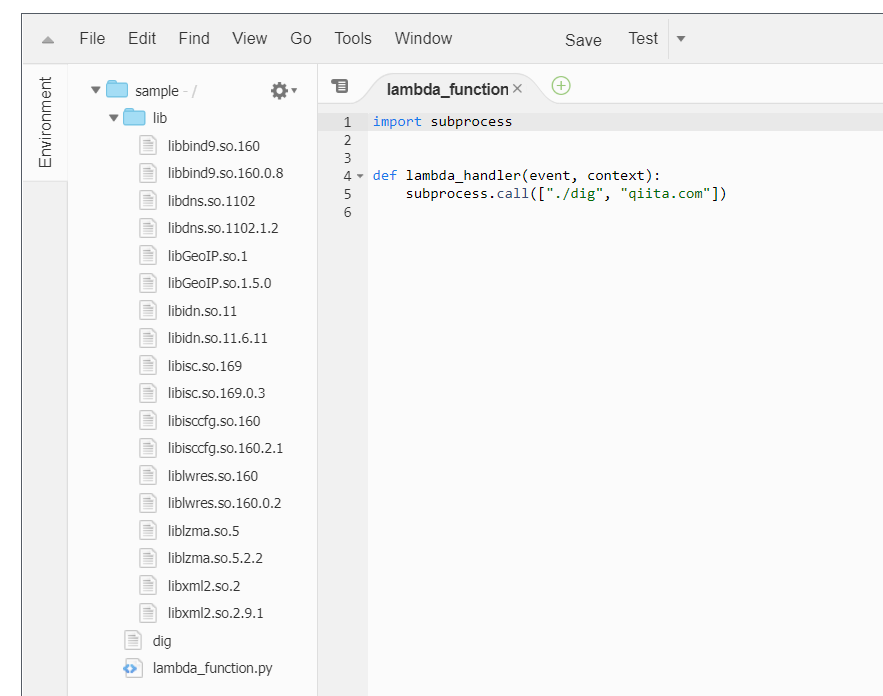
dig コマンドと、必要そうなライブラリが抽出されました。
. |-- output | |-- dig | `-- lib | |-- libGeoIP.so.1 -> libGeoIP.so.1.5.0 | |-- libGeoIP.so.1.5.0 | |-- libbind9.so.160 -> libbind9.so.160.0.8 | |-- libbind9.so.160.0.8 | |-- libdns.so.1102 -> libdns.so.1102.1.2 | |-- libdns.so.1102.1.2 | |-- libidn.so.11 -> libidn.so.11.6.11 | |-- libidn.so.11.6.11 | |-- libisc.so.169 -> libisc.so.169.0.3 | |-- libisc.so.169.0.3 | |-- libisccfg.so.160 -> libisccfg.so.160.2.1 | |-- libisccfg.so.160.2.1 | |-- liblwres.so.160 -> liblwres.so.160.0.2 | |-- liblwres.so.160.0.2 | |-- liblzma.so.5 -> liblzma.so.5.2.2 | |-- liblzma.so.5.2.2 | |-- libxml2.so.2 -> libxml2.so.2.9.1 | `-- libxml2.so.2.9.1 `-- src `-- build.shAWS Lambda で動かすコマンドの作成
今回は output/lambda_function.py として output の中に直接作成します。
output/lambda_function.pyimport subprocess def lambda_handler(event, context): subprocess.call(["./dig", "qiita.com"])qiita.com の DNS を引くだけのシンプルなプログラムです。
直下の lib/の下は気にしなくても参照されるようで、LD_LIBRARY_PATH 等の設定も必要ありませんでした。
もし、動作しなければ、そこを疑ってください。zip で固める
lambda にアップロードするために、zip で固めます。
シンボリックリンクを含みますので、「-y」オプションを付けるのを忘れないでください。cd output zip -9yr ../output.zip *lambda にアップロードして確認
あらかじめ Python 用の Lambda 関数を作成してからアップロードします。
いい感じです。
実行してみます。
ちゃんと、動作しているようです。
おわりに
今回わけあって作成して公開した Docker イメージ、qualitiaco/lambda-build-pack の紹介をしました。
応用した楽しいアイデアがあれば、ぜひお知らせください。
PullReq や間違いの指摘などもお待ちしております。github:https://github.com/qualitiaco/build-pack
dockerhub: https://hub.docker.com/r/qualitiaco/lambda-build-pack*本記事は @qualitia_cdevの中の一人、@hirachanさんに作成して頂きました。
*いったい何の役に立つねんシリーズ

- 投稿日:2020-03-30T11:00:09+09:00
AWSの資格についての整理・ソルーションアーキテクト受験準備
AWSて?
Amazon Web Service
仮想空間にサーバーを建てることが可能なサービス
他社もあるMicroSoft社:Azure, Google社 : GCP ( Google Cloud Plattfrom ) ...なんで使うの?(使ってメリット)
接近性
- 物理サーバーが不要(データーセンター)
- DashBoard(Console)を提供し、操作が便利
- サーバー・HDに詳しくない人もボタン操作でなんとかサーバーは立ち上げる
- 設計によってコスパが良い(Case by Case)
- 拡張性(Scale In, Scale Outが便利)
問題ないの?(デメリット)
- サービスの数が多すぎる(2020年1月基準191個のサービスが存在)
- 設定しなきゃいけないの多すぎる
- 設定によってコスパー悪いのがもっと多い
- 自分が運営するサービスがどの組み合わせが良いか誰も知らない
- AWS社も認識し、カウンセリングサービスを運営してる
- 独自の用語が多い(VPCて?ECSて?FARGATEは?) → learning curveが高い
- 世間の技術をAWSに得化するのが多いので、同じ技術もAWSで利用するためには別方法が必要(Docker,Elastic Searchなど)
悪いポイントが多いように見えるが、その分よく理解してる状況で運用するとものすごく便利だし、運用コストの減らせる(OnFrame対)
なぜ認定試験なんて受ける?(個人てきなものも含まれてます。)
- ちゃんとしたAWS運営チームがない以上該当設計が正しいとはいえない状態が続けている
- Onframe対コスパがいいと言われて使ったけど、もっと費用かかっている
- 良くない設計によって、安定的なperformanceが出ない、料金が高いなどの問題がある
- よりいいBest Practiceを発見し、導入するため
- 仕組みを理解した上で利用するものと、なんとな〜くこうでしょう的な感じで使うのは確かに佐がある
AWS資格は?
- AWS社で公式に認定してる資格
- レベル・コース・専門知識に分けられてる
- 2年単位更新が必要(新しい技術Stackから離れないようにするため)
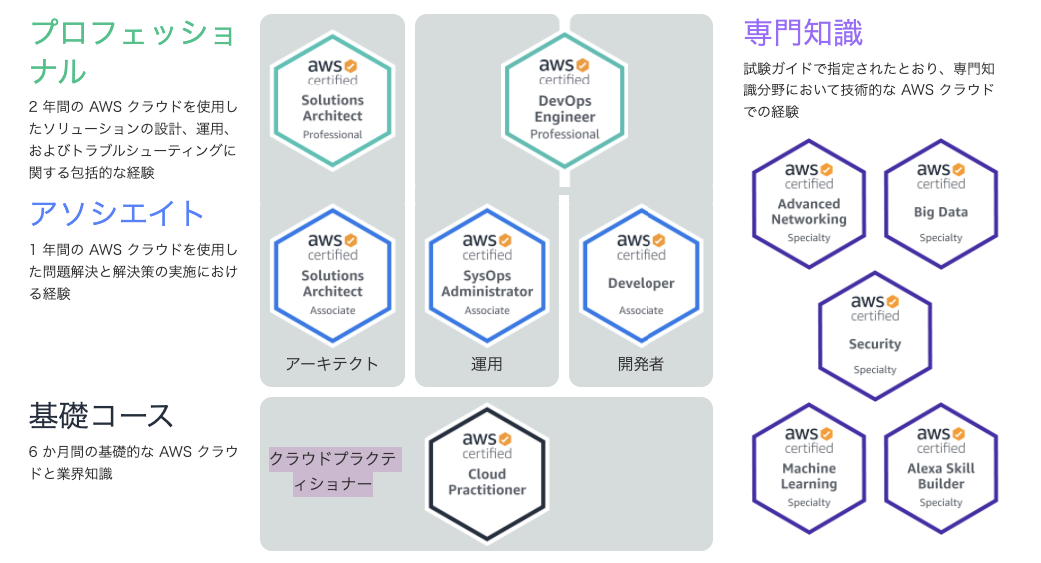
基礎レベル
アソシエイトレベル
プロフェショナルレベル
専門知識
資格ごとの受験金額
- 下記の金額は1回受けたときに金額、
- 更新又は前レベルの資格を取得してる場合は50%オフ可能
- 例)アソシエイト・ソルーションアーキテクト(15,000円)+プロフェショナル・ソルーションアーキテクト(15,000円) = 3万円
- 例2)プロフェショナル・ソルーションアーキテクト = 3万円
- 専門知識は論外
- 一気にプロフェショナルレベルが取得できるのであればいいが、難しいので順番踏むのがいいかと
区分 コース名 基本料金 基礎 クラウドプラクティショナー 11,000円 アソシエイト Solution Architecture 15,000円 SysOps Administrator - Developer - プロフェショナル Solution Architecture 30,000円 DevOps Engineer - 存問知識 Advanced Network - Security - Machine Learning - Big Data - Alexa Skill Builder - 筆者のチャレンジ項目はアソシエイト・ソルーションアーキテクトで、理由としては、一番受験の口コミも多いし、講義や、受験情報も多かったためです。
受験は65問、130分、選択時方の問題として構成されています。AWS 公式で現れてる「知識及び経験のオススメ項目」は下記になります。
- Computing, Networking, Storage及ぶ、database AWSサービスに対する実務経験
- AWSDeploy管理サービスに対する実務経験
- AWS基盤アプリケーションに対する技術要求項目を職別及ぶ定義
- 与えられた技術要求項目に与えられるAWSサービスを職別可能
- AWSプラットフォームで安全で、安定的なアプリケーションを構築する成功的な例に対する知識
- AWSにクラウドで後期をする時の基本的なアーキテクチャに対する理解
- AWS黒バルインプラに対する理解
- AWSと関連されてるネットワーク技術に対する理解
- AWSで提供するセキュリティー機能及びツールに対する理科、該当機能及び、ツールが既存サービスとどのように関連されてるのかに対する理解
テストに対する問題比率
- Design Resilient Architecture : 34%
- Define Performant Architectures : 24%
- Specify Secure Applications And Architectures : 26%
- Design Cost-Optimized Architectures 10%
- Define Operationally Excellent Architectures: 6%上記の情報でも確認できますが、アソシエイト・ソルーションアーキテクトはAWSで提供する主なサービスに対する理解・アーキテクチャ構成に対する受験です。 ページには受験対象について1年以上実際に設計した経験がありながら、ソルーションアーキテクトの役割をする人々て書かれてます。
実際AWS関連業務を1〜2年以上直接利用してみたらギリギリ合格かな…ていう話が口コミの一般論なので、VPCや、ネットワーク周りは基礎知識・実務経験なしでテスト勉強のみなら厳しいかもしれませんという話も多いです。(テスト問題見てもだいたいそうです。)筆者の場合、とりあえず関連サイト、AWS公式ドキュメントベースで勉強を進めて、テスト問題を溶けてみる方法で勉強をすすめる予定ですが、ネット上の一般論てきな話は、Udemyなどの講義サイトが一番ベストらしいです。
Udemy AWS Certification CoursesTIPS
AWS経験が少ない方について
プログラマの場合AWSにで普段使うサービスてEC2、RDS、Route53などで制限されてる場合が多い
最近になってはサーバレスが流行りながらLambdaだけつかう場合もある。
AWSの経験が多い方へのアドバイスが必要であれば、AWSのメインになるサービスを直接使って見ることです。 講義などでも主要サービスに対するHandsONなどを含めていし、ちゃんとして使ったことがなければ、必ずHandsonを参考しながら直接経験してみたほうがいいでしょう
アソシエイトの場合HandsOnとテスト予想問題を溶けてみることで十分に勉強になるはずです。VPCや、ネットワークの周りは直接設計した経験がなければ難しい場合もある、講義で追加的にAWS公式ドキュメントのシナリオ1,シナリオ2は必ず身につけることをおすすめします。CIDR,Public Subnet, Private Subnetの差、 NATがなぜ必要なのか、NATインスタンスと、NATGatewayとの差などは必ず身につけておくべきです。
シナリオ1:単一PublicSubnetを持ってるVPC
シナリオ2:PublicSubnetとPrivate SubnetがあるVPC(NAT)時間があればみること
Architecting for the Cloud : AWS Bets Practices whitepaper, October 2018
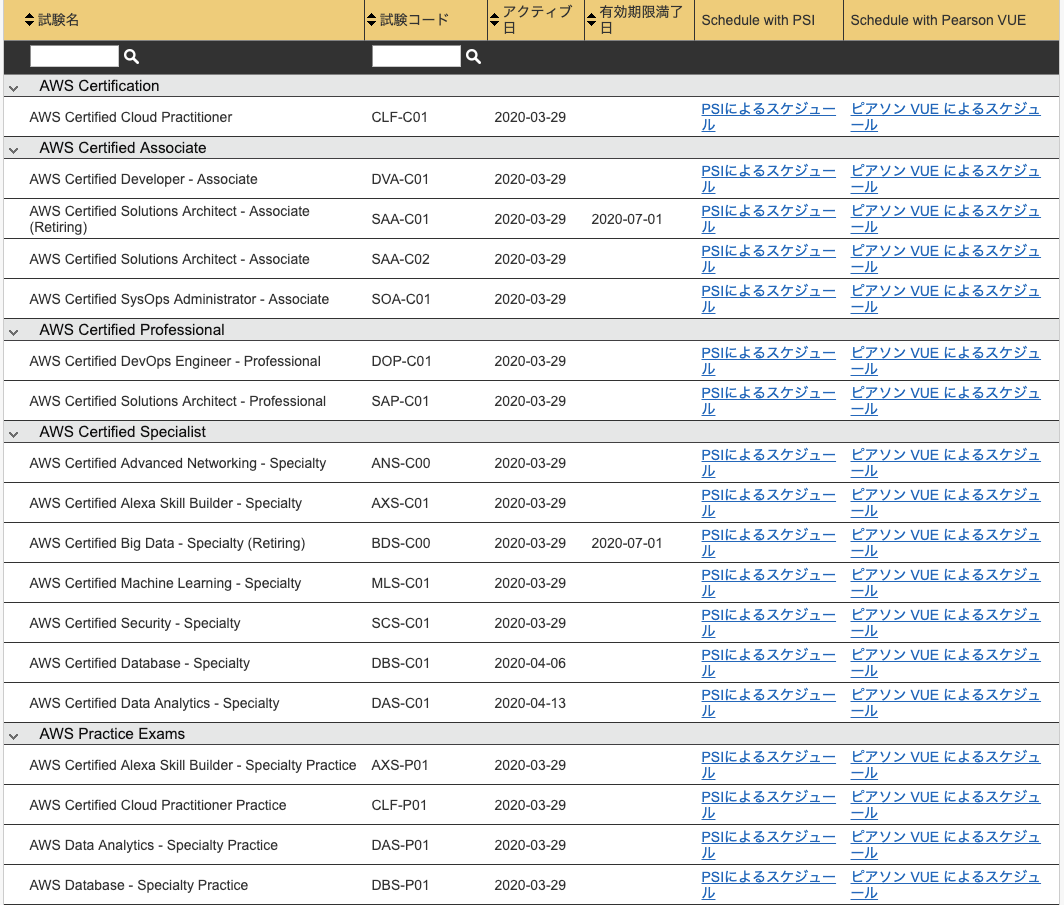
AWS Well-Architected webpage(various whitepapers linked)テストの申請と流れ
受験はAWS Certification 公式で申し込みします。
ログイン後My Profileで本人の英語名と、アドレス情報が正しく入ってるのかチェックしましょう
Homeになる新しいテスト予約するをクリックしたら横暴できるリストが出てくる
入力必修情報が色々あるので先にしないと進めません
入力が完了されたら下記のようにテスト可能のスケジュールが表示され、試験センタを選択できます。
主にPSIと、ピアソンVUEがあります。
日本ではピアソンVUEの受験センターが多いと思います。
テストは英語・日本語どちらでも選択可能です。
予約を完了するときにはお名前、住所などをもう一度正しいか確認してください。役に立つと嬉しいですが、もし間違ってる情報があればコメントでお願いします。
長い文書読んでいただきありがとうございます。
いい結果が出るように頑張りましょう!

- 投稿日:2020-03-30T09:17:30+09:00
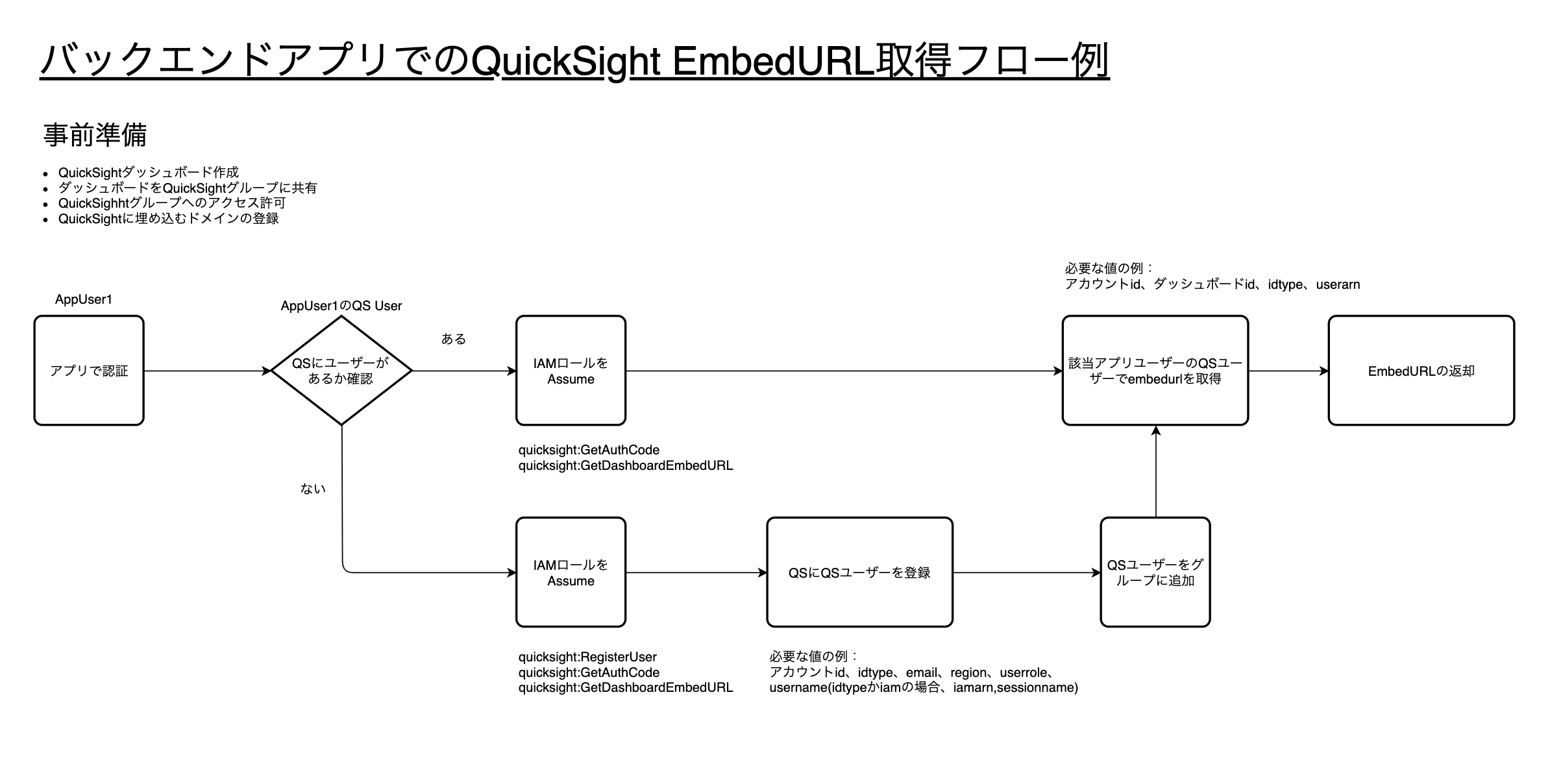
QuickSightのEmbedのバックエンドフロー
QuickSightのEmbedのフロー
こんな感じかな。自分用メモ
userArnでいろいろな認証を指定することができサポートしているようだ
GetDashboardEmbedUrl
https://docs.aws.amazon.com/quicksight/latest/APIReference/API_GetDashboardEmbedUrl.html
UserArn
Amazon QuickSightユーザーのAmazonリソースネーム(ARN)。QUICKSIGHTIDタイプで使用します。 これは、次のいずれかとして認証されたアカウント内のすべてのAmazon QuickSightユーザー(リーダー、作成者、または管理者)に使用できます。
- Active Directory(AD)ユーザーまたはグループメンバー
- 招待された非フェデレーションユーザー
- SAML、OpenID Connect、またはIAMフェデレーションを使用したフェデレーションシングルサインオンを通じて認証されたIAMユーザーとIAMロールベースのセッション。
- 投稿日:2020-03-30T08:42:00+09:00
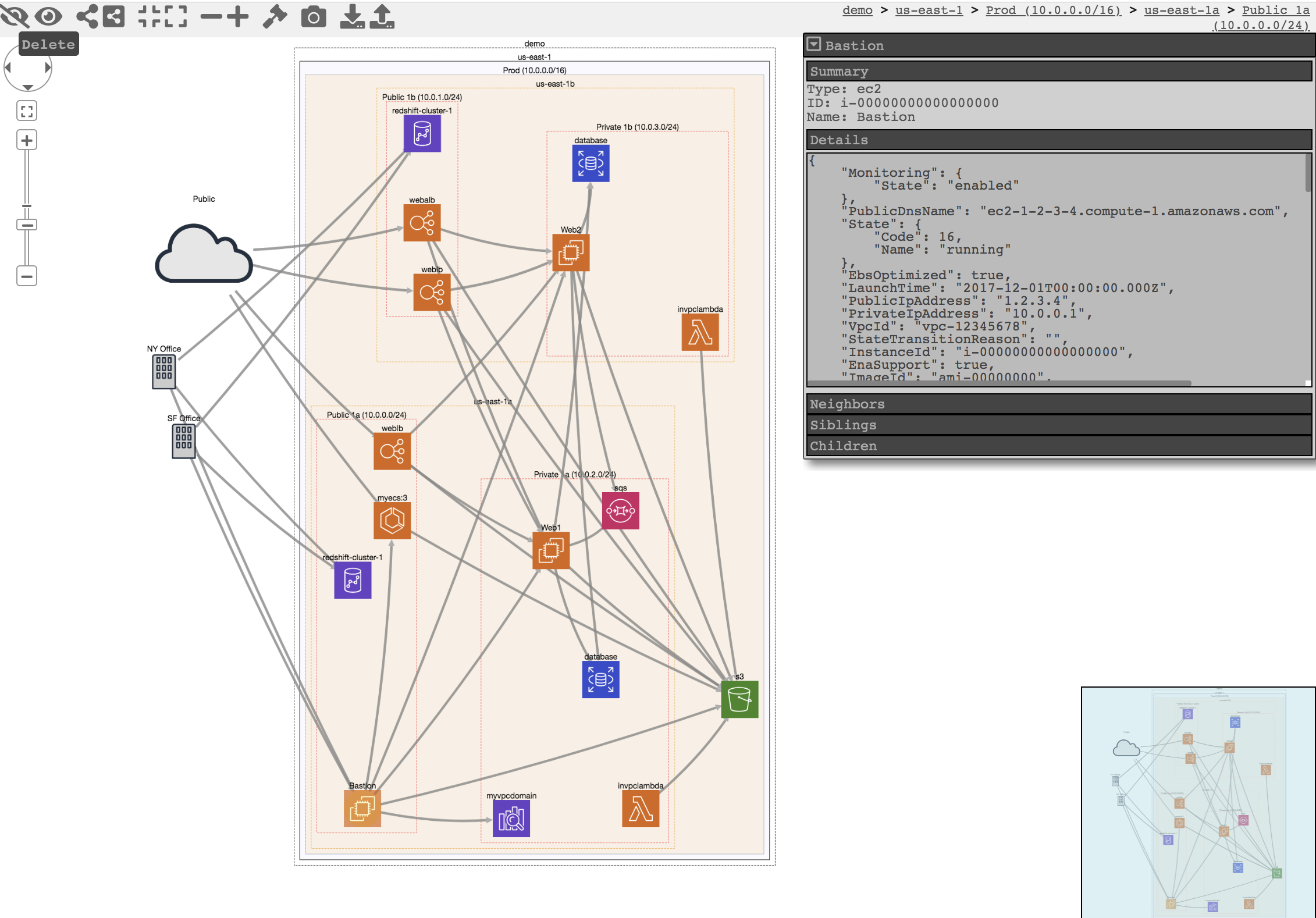
CloudMapperをDockerで動かして、AWSのネットワーク構成を可視化しよう。
こんにちは。
AWSいいですよね。
でも、AWSって一つ一つのサービスがしっかり役割分担されているので、いざ一つのシステムとしてネットワーク構成図がどうなっているのかをみようとすると頭がこんがらがっちゃうんです、私。そんなときCloudMapperにお世話になりたくなります。READMEを読んでいただければですが、現在のAWSのネットワーク構成図を自動生成してくれるやつです。
ただ、何度かチャレンジしているのですが、いつも何かが足りなくてうまく動かないんです、私。最近は何をやるにもDockerでやっちゃっているのでローカル環境もあんまり汚したくなくて...CloudMapper公式や他の方々もDockerで動くようにソースコードを公開していたりするんですが、なんでかうまく行かなかったりしたので、今回は自分でDockerfileから作ってみようという記事です。
前提
- AWSアカウントがあること
SecurityAuditとViewOnlyAccessの権限をもったIAM(以下、IAM_A)があること(よくわからなければ最悪AdministratorAccessの権限でもひとまずOK)IAM_AのアクセスキーIDとシークレットアクセスキーを払い出していること- DockerおよびDocker Composeが利用可能であること
CloudMapperが動くDockerイメージを作る
CloudMapperはPythonで動いているのでPythonのDockerイメージをベースに必要なパッケージをインストールしたDockerイメージを作るためのDockerfileを作成します。
DockerfileFROM python:latest RUN git clone https://github.com/duo-labs/cloudmapper.git && \ pip install \ jinja2 \ netaddr \ parliament \ policyuniverse \ pyjq \ pyyaml && \ apt update -qq && \ apt install -q -y vim最初に
gitでCloudMapperのソースコードをダウンロードしています。PythonのDockerイメージを使うと、READMEで必要と言われているパッケージはほとんど入っているようで、実際にCloudMapperを実行しようとしたときに追加で必要になったパッケージを
pipコマンドで追加してあげています。
vimはコンテナ内でファイルを編集したい時などに使いたいのでインストール。次にDocker Compose用のファイルを作ります。
docker-compose.ymlversion: "3" services: cm: build: . working_dir: /cloudmapper ports: - 8000:8000 environment: - AWS_ACCESS_KEY_ID=[IAM_AのアクセスキーID] - AWS_SECRET_ACCESS_KEY=[IAM_Aのシークレットアクセスキー] volumes: - ./config.json:/cloudmapper/config.jsonworking_dir
cloudmapperをgit cloneしているのでDockerイメージの中には/cloudmapperというディレクトリができています。そこをワーキングディレクトリにします。ports
CloudMapperのViewを表示するポートです。
8000がデフォルトなのでそれに合わせて。environment
ここで
IAM_AのアクセスキーIDとシークレットアクセスキーを環境変数に定義します。volumes
この後書きますが、CloudMapperが情報を取得しにいくAWS AccountのAccount IDを設定する
config.jsonが必要になるのでローカルのファイルをマウントするようにしています。コンテナの中で書き換えてもいいのですが、毎回書くのは面倒なのでローカルのファイルと同期しておきます。
config.jsonも作っておきましょう。CloudMapperのソースコードにあるconfig.json.demoを参考に以下のように書きます。config.json{ "accounts": [ { "id": "[AWSのAccount ID]", "name": "[識別名]", "default": true } ], "cidrs": {} }AWSのAccount IDはコンソールの「マイアカウント」から確認できます。(12桁の数字。もしどこ見ればいいの?って方はこの記事の最後のAppendix2のやり方とかみてみてください。)
ここまで準備ができたらDockerイメージをビルドします。
$ docker-compose buildCloudMapperをDockerコンテナで動かす
ビルドが完了したらコンテナの中でCloudMapperを動かしてみましょう!
まずコンテナを起動させて中に入ります。
$ docker-compose run --service-ports cm bash
--service-portsオプションはdocker-compose runコマンドを実行するときにdocker-compose.ymlの中のportsを適用させるためのオプションです。これがないとローカル環境からhttp://localhost経由でCloudMapperのWebページにアクセスできないので注意です。コンテナの中に入ったらAWSからデータを収集します。先ほどの
config.jsonでaccounts.nameでsampleという名前をつけたことにします。# python cloudmappler.py collectこのコマンドでAWSアカウントのネットワーク構成情報をめっちゃ取得してくれます。
全てのリージョンの全ての情報を取ってきているみたいで結構時間がかかります。
毎回これをやるのはきついんで何回もコンテナを消して立ち上げ直してとやる場合は、/cloudmapper/account-data/をマウントしておけばこの工程を省けます。(このディレクトリにデータを生成している工程なので)情報を取得できたらレポートを作成します。
# python cloudmapper.py prepare # python cloudmapper.py report --accounts sample最後に収集してレポートを作ったサイトを公開します。
# python cloudmapper.py webserver --publicさぁ!これで
http://localhost:8000にアクセスしてみましょう!
こちらは公式のイメージですが、こんな感じのページが表示されるはずです!まとめ
CloudMapperをDockerで動かすことができました!
READMEを見ると色々とパッケージのインストールなどが大変そうだな(実際つまづいた)という感じだったのですが、Dockerですっきりと動かせました〜。Appendix1: CloudMapperのヘルプ
READMEだけだとあんまりわからなかったのですが、
cloudmapper.pyはhelp機能がついてました。# python cloudmapper.py -h CloudMapper 2.8.2 usage: cloudmapper.py [access_check|amis|api_endpoints|audit|collect|configure|find_admins|find_unused|iam_report|prepare|public|report|sg_ips|stats|weboftrust|webserver] [...] access_check: [proof-of-concept] Check who has access to a resource amis: Cross-reference EC2 instances with AMI information api_endpoints: [Deprecated] Map API Gateway end-points audit: Identify potential issues such as public S3 buckets collect: Run AWS API calls to collect data from the account configure: Add and remove items from the config file find_admins: Find privileged users and roles in accounts find_unused: Find unused resources in accounts iam_report: Create IAM report prepare: Generate network connection information file public: Find publicly exposed services and their ports report: Create report sg_ips: Find all IPs are that are given trusted access via Security Groups stats: Print counts of resources for accounts weboftrust: Create Web Of Trust diagram for accounts webserver: Run a webserver to display network or web of trust map# python cloudmapper.py collect -h usage: cloudmapper.py [-h] [--config CONFIG] [--account ACCOUNT_NAME] [--profile PROFILE_NAME] [--clean] [--max-attempts MAX_ATTEMPTS] optional arguments: -h, --help show this help message and exit --config CONFIG Config file name --account ACCOUNT_NAME Account to collect from --profile PROFILE_NAME AWS profile name --clean Remove any existing data for the account before gathering --max-attempts MAX_ATTEMPTS Override Botocore config max_attempts (default 4)チェックしてみると使い方が良くわかるかもしれないです!(
webserverの--publicオプションはこれで見つけられた...)Appendix2: AWS Account IDを調べる
AWS Account IDはAWS CLIで取得することもできます。
この記事で作成したコンテナではAWS CLIを使えないのでDockerfileを少し更新します。DockerfileFROM python:latest RUN git clone https://github.com/duo-labs/cloudmapper.git && \ pip install \ + awscli \ jinja2 \ netaddr \ parliament \ policyuniverse \ pyjq \ pyyaml && \ apt update -qq && \ apt install -q -y vimビルドしてDockerコンテナの中で以下のコマンドを実行します。
# aws sts get-caller-identity { "UserId": "XXXXXXXXXXXXXXXXXXXX", "Account": "123456789012", "Arn": "arn:aws:iam::123456789012:user/xxxxxxxxxx" }ここの
Accountに表示されている数字列がAccount IDです。
参考:【小ネタ】AWS CLIでAWS Account IDが取れるようになりました! | Developers.IO
- 投稿日:2020-03-30T00:21:53+09:00
centos7 に Laravel6をインストール
centos7にLaravelを入れるまでの道のりです。
くっそ苦労しました。
たくさんの方の記事を参考にさせていただいた結果、最後に掲載している方々の記事が参考になったので、掲載させていただきます。環境
- AWS EC2(t2.micro)
- centos7
- Apache2.4系
- MySQL5.7系
- PHP7.2系
- composer
とりあえず必要なもろもろ
一つずつコマンドでやったほうがいいですが、めんどくさいのでシェルスクリプトにで入れます。
$ vi hoge.shとかでファイルを作成すればよいですね。
sudo bash hoge.shで使えます(hogeは適宣変えてください)centos_lamp.sh#!bin/bash #とりあえず必要なものいろいろ yum -y update #update yum install -y vim #vim yum install -y epel-release #epelリポジトリ yum install -y fish #fishシェル yum install -y httpd #Apache2.4 yum install -y wget #wgetコマンド yum install -y unzip #unzip # mysql5.7 yum localinstall https://dev.mysql.com/get/mysql80-community-release-el7-1.noarch.rpm -y yum-config-manager --disable mysql80-community yum-config-manager --enable mysql57-community yum install -y mysql-community-server # ApacheとMySQLの自動起動 systemctl start httpd mysqld systemctl enable httpd mysqld #PHP7.2系インストール yum -y update yum remove -y php* yum install -y https://rpms.remirepo.net/enterprise/remi-release-7.rpm yum -y install --enablerepo=remi,remi-php72 php php-devel php-mbstring php-pdo php-gd php-xml php-mcrypt php-zip php-mysqlスワップファイル作成
このままcomposerをインストールすると
t2.microのインスタンスだと、メモリー不足ですよーっていうエラーがでます。
なのでスワップファイルを作成して対処します。swap.sh#!bin/bash dd if=/dev/zero of=/swapfile bs=1M count=2048 chmod 600 /swapfile mkswap /swapfile swapon /swapfilecomposerインストール
PHPのパッケージ管理ソフトの
composerをインストールしていきます。composer_install.sh#!bin/bash yum -y update curl -sS https://getcomposer.org/installer | php mv composer.phar /usr/local/bin/composerそののちにLaravelインストーラを入れていきます。
$ composer global require "laravel/installer"パーミッションを変更していきます。
$ cd /var/www/ $ sudo chown -Rv root:$USER . $ sudo chmod -Rv g+rw .Laravelのプロジェクトを作成
プロジェクトを作成していきます。
今回作成するblogとします。$ cd /var/www/html $ composer create-project --prefer-dist laravel/laravel blog "6.*"これで
/var/www/html/にblogというディレクトリが作成され、Laravel6系がインストールされます。
/etc/httpd/httpd.confを編集して、ドキュメントルートを変更します。
設定ファイルを変更する前に、必ずファイルをバックアップしましょう。痛い目をみます。$ cp /etc/httpd/httpd.conf /etc/httpd/httpd.conf-org$ sudo vim /etc/httpd/httpd.conf Documentroot "/var/www/html/blog/public"
publicをつけないとだめでした設定ファイルを書き換えたら再起動します。
なにか問題があると、再起動に失敗します。$ sudo systemctl restart httpd次に、パーミッションを変更していきます
$ chmod -R 777 /var/www/html/blog/storage $ chmod -R 777 /var/www/html/blog/bootstrap/cacheここで
http://インスタンスのIPにアクセスしても、なんだかエラーが出てしまうんですよねー
エラー画面をスクショするのは忘れました。がこんな感じのエラーが出てましたThe stream or file "/var/www/html/blog/storage/logs/laravel.log" could not be opened: failed to open stream: Permission deniedんーよくわからないのでGoogle先生で調べたら、SELinuxを無効にすると良いみたいです。
SELinux無効化
SELinuxが有効になっているかは以下のコマンドで調べられます。
$ getenforce # 結果 Enforcing有効になってました
無効にします。$ cp -piv /etc/selinux/config /etc/selinux/config-org $ vim /etc/selinux/config #SELINUX=enforcing SELINUX=disabled #これにしますOS再起動します
shutdown -r nowこれでやっとLaravelの初期画面が見れるようになります!!!!!
大変でした。
参考にさせていただいた方々ありがとうございます。参考