- 投稿日:2020-03-29T17:57:44+09:00
ニューラルネットのオブジェクトに触ってみる
先日初めてTensorflowに触ってみましたが、今回はちょっとニューラルネットのオブジェクトに触ってみました。
最初に色々組もうとハイレベルな挑戦をしてみましたが、全く上手く動いてくれなかったので、基本を大切に・・・の精神で、超超初歩的なことを書いてみます。触ってみたのは、
tensorflow.layers.dense
という部分。
どうやら、NewralNetworkの”層”に相当するようです。
探してみると、以下のような例文がありました。hidden1 = tf.layers.dense(x_ph, 32, activation=tf.nn.relu)これを組んでいくと、結構複雑なことができそうです。
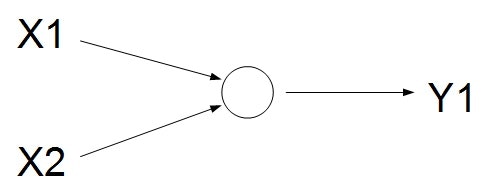
ただ、今回はシンプルに・・・以下のようなモデルを考えてみます。
入力は2個、出力は1個です。
もはやニューラルネットワークとはいえないような気もしますが・・・
これが理解できなきゃダメだろうと思って、まずはここからスタートしてみます。まずは、ニューラルネットワークの層を作ってみます。
newral_out = tf.layers.dense(x_ph, 1)これで、入力のはx_phで定義、出力の数が1個となるようです。
オプションで色々出来るそうですが、今回は単なる線形結合っぽいような感じでいってみます。
x_phは、データ入力用の箱のplaceholderで、今回は以下で定義しておきます。x_ph = tf.placeholder(tf.float32, [None, 2])サイズの[None 2]、Noneは入れる数のサンプル数で任意の数突っ込めるという意味で、2は入力する変数の数なので、ここでは2個(X1,X2)としておきます。
今回は、本当にシンプルに、以下の数式のアウトプットをy1相当としました。
y_1 = w_1 x_1 + w_2 x_2 + w_0任意の(x1,x2)とy1を適当に突っ込んでみて、上手くw_1,w_2,w_0が推定できるか??
という本当にシンプルな問題です。実はここまでいくと、最初のサンプルのコードがそのまま流用できるため、恐らく凄い簡単に実装できて、以下のような感じでいけそうです。
# Minimize the mean squared errors. loss = tf.reduce_mean(tf.square(newral_out - y_ph)) optimizer = tf.train.GradientDescentOptimizer(0.5) train = optimizer.minimize(loss)あとは、これを学習させていけばOKかな?
# initialize tensorflow session sess = tf.Session() sess.run(tf.global_variables_initializer()) for k in range(101): # shuffle train_x and train_y n = np.random.permutation(len(train_x)) train_x = train_x[n] train_y = train_y[n].reshape([len(train_y), 1]) # execute train process sess.run(train,feed_dict = { x_ph: train_x, # x is input data y_ph: train_y # y is true data })これで一旦動きそうなのですが、折角なので、NewralNetworkのパラメタがどういう挙動をしているか知りたい。
直接読む方法もあるようなのですが、色々難しそう。
問題としてもシンプルなので、折角なので自前の解析機能を考えてみました。考え方としては、最小二乗法でw0,w1,w2を求める方法。
ニューラルネットワークを仮想の線形近似方程式と見なして、そのパラメタをチェックしてみます。
まずは、入力するデータを{{x_1}_k},{{x_2}_k}と設定し、Newralを通して推測された情報を
{y^{(new)}}_k = Newral({{x_1}_k},{{x_2}_k})とします。この{y^{(new)}}_kは何らかの決定的な数値が入ります。
ニューラルネットの推定にはBiasがあるかもしれないので、それを加えた形の以下の方程式を考えます。{y^{(new)}}_k = w_1{x_1}_k + w_2{x_2}_k + w0このとき、w_1,w_2,w_0が未知数、他は数値が決定しているという状態。
ここで、各kにおいて、連立方程式として考えると以下のようになります。\left( \begin{matrix} {y^{(new)}}_1 \\ ... \\ {y^{(new)}}_K \\ \end{matrix} \right) = \left( \begin{matrix} {x_1}_1 & {x_2}_1 & 1 \\ ... & ... \\ {x_1}_K & {x_2}_K & 1 \\ \end{matrix} \right) \left( \begin{matrix} w_1 \\ w_2 \\ w_0 \\ \end{matrix} \right)ここまでくれば、単純な最小二乗法の問題に帰着します。簡単のため、
A = \left( \begin{matrix} {x_1}_1 & {x_2}_1 & 1 \\ ... & ... \\ {x_1}_K & {x_2}_K & 1 \\ \end{matrix} \right)と、おくと、
\left( \begin{matrix} w_1 \\ w_2 \\ w_0 \\ \end{matrix} \right) = \left( A^T A \right)^{-1} A^T \left( \begin{matrix} {y^{(new)}}_1 \\ ... \\ {y^{(new)}}_K \\ \end{matrix} \right)で、パラメタを求めることができそうです。
実際に真値を作るときには、w_1,w_2,w_0を何らかの数値に設定しておけば、その正解にどうやって近づいているか???を観察できれば、ニューラルネットワークの中身が少しだけ分かった気になれそうです(笑)というわけで、そんなコードの全体を貼り付けておきます。
import numpy as np #import matplotlib.pyplot as plt import tensorflow as tf # deta making??? N = 50 x = np.random.rand(N,2) # true param??? w = np.array([0.5,0.5]).reshape(2,1) # sum > 1.0 > 1 : else > 0 #y = np.floor(np.sum(x,axis=1)) y = np.matmul(x,w) train_x = x train_y = y # make placeholder x_ph = tf.placeholder(tf.float32, [None, 2]) y_ph = tf.placeholder(tf.float32, [None, 1]) # create newral parameter(depth=1,input:2 > output:1) newral_out = tf.layers.dense(x_ph, 1) # Minimize the mean squared errors. loss = tf.reduce_mean(tf.square(newral_out - y_ph)) optimizer = tf.train.GradientDescentOptimizer(0.5) train = optimizer.minimize(loss) # initialize tensorflow session sess = tf.Session() sess.run(tf.global_variables_initializer()) for k in range(101): if np.mod(k,10) == 0: # get Newral predict data y_newral = sess.run( newral_out ,feed_dict = { x_ph: x, # xに入力データを入れている y_ph: y.reshape(len(y),1) # yに正解データを入れている }) # check for newral_parameter(w0,w1,w2)??? # x_ext = np.hstack([x,np.ones(N).reshape(N,1)]) A = np.linalg.inv( np.matmul(np.transpose(x_ext),x_ext) ) A = np.matmul(A,np.transpose(x_ext)) w_ext = np.matmul(A,y_newral) # errcheck??? ([newral predict] vs [true value]) err = y_newral - y err = np.matmul(np.transpose(err),err) # check y_newral # check LS solution(approaching to NewralNet Parameter) # check predict NewralParam print('[%d] err:%.5f w1:%.2f w2:%.2f bias:%.2f' % (k,err,w_ext[0],w_ext[1],w_ext[2])) # shuffle train_x and train_y n = np.random.permutation(len(train_x)) train_x = train_x[n] train_y = train_y[n].reshape([len(train_y), 1]) # execute train process sess.run(train,feed_dict = { x_ph: train_x, # x is input data y_ph: train_y # y is true data })何も書いていませんでしたが、誤差は二乗和で求めることにしちゃいました。
この結果を見てみると・・・???[0] err:1.06784 w1:0.36 w2:0.36 bias:0.00 [10] err:0.02231 w1:0.45 w2:0.45 bias:0.06 [20] err:0.00795 w1:0.47 w2:0.47 bias:0.03 [30] err:0.00283 w1:0.48 w2:0.48 bias:0.02 [40] err:0.00101 w1:0.49 w2:0.49 bias:0.01 [50] err:0.00036 w1:0.49 w2:0.49 bias:0.01 [60] err:0.00013 w1:0.50 w2:0.50 bias:0.00 [70] err:0.00005 w1:0.50 w2:0.50 bias:0.00 [80] err:0.00002 w1:0.50 w2:0.50 bias:0.00 [90] err:0.00001 w1:0.50 w2:0.50 bias:0.00 [100] err:0.00000 w1:0.50 w2:0.50 bias:0.00真値のパラメタは、w1=0.5,w2=0.5,bias(w0)=0なので、30回ぐらい回るといい感じに収束してきている様子が見られました。
ニューラルネットワークというと、なんだか複雑そうな印象でしたが、ここまでシンプルにすることで、単なる線形結合と等価回路っぽくなるんですね。
玄人の方からすると当たり前だろうという結果かもしれませんが、私にとっては一つ大きな収穫となりました。こんな感じで、次はもうちょっと複雑なことにも挑戦してみようと思います!
- 投稿日:2020-03-29T17:28:00+09:00
3/29 備忘録 (deep-learning with python)
個人的にデータサイエンスの訓練に取り組んでいく中で、新しく触れた技術の復習、備忘録、アウトプットとして本記事を書いていく。
なるべく自分の言葉で表現できるように心がけていきたい。
誰かに向けた記事ではないのでご勘弁を。pandasのapply関数。
qiita.pydf[column]apply(lambda x: x + 'sample')データフレームの対象とする列の要素に対して、引数の中身の関数を適用させた、新たなデータフレームを作成する。
また、関数の中のxは、もとのデータフレームの中にある要素が入れられる。
今回は、列を指定することで、seriesオブジェクトに対して適応する形となった。pandasデータフレームの、任意の範囲の列を取り出す方法。
結論、python配列のスライスの要領で取り出すことができる。
これは、pandas データフレームオブジェクトの、loc,iloc属性を使う。
行、列の名前で引っ張ってくるときはloc属性、番号で引っ張ってくる時はiloc属性を使用する。qiita.pydf.loc[:, :column2] >>dfの、全ての行、最初からcolumn2列までを含めた列の要素を取得している。なお、pandasのスライスは、端っこの要素を含むようである。
pandasのデータフレームを、numpy配列に変換する。
には、.valuesを最後に着けてやると良い。
qiita.pydf.valuesこれで、numpy配列に変換してくれる。kerasのモデルに放り込むときは、こういった処理が必要である。
データフレームの列を使って、for文でループさせることができる
qiita.pyfor item in df[column_1]: .....しかし、できるにはできるが、あまり良い方法では無いのかもしれない。普通にpandasの備え付け関数を使ったほうが良さそうである。
re.split関数
文字列を分割することができるre.split()関数。第一引数に分割する区切り文字を、リストの中に入れ、クォーテーションで囲む。第二引数は分割する対象の文字列。
qiita.pybunsyo = '吾輩.は猫_であ/る。' re.split('[/._]', bunsyo)
- 投稿日:2020-03-29T16:19:25+09:00
NVIDIA Driverのアップデート手順とTensorflowの再構築
はじめに
UbuntuのNVIDIA GPU driverを430 => 435にアップデートしたらTensorflowがGPUモードで動作しなくなりました。435環境でTensorflowとCUDAを復活させるのに結構苦労したため、Driverのアップデート手順を書いてみました。
既にNVIDA DriverやCUDA一式をインストール済みの状態から始めていますので、クリーンな状態からインストールする場合は挙動が違うかも知れません。
動作環境
- Ubuntu 19.10
- GTX 1080 Ti
- NVIDIA driver 430 <= 今回導入
- CUDA 10.1
- cuDNN 7.6.5
- Tensorflow 2.1.0
- PyTorch 1.4.0
NVIDIA Driverを更新した以外は既に導入済です。TensorflowやPyTorchはCUDA 10.1を要求するため、最新のCUDA 10.2は使えません。
NVIDA Driverの更新
先ずは、以下のコマンドで使用可能なドライバを確認します。
ubuntu-drivers devices$ ubuntu-drivers devices == /sys/devices/pci0000:00/0000:00:01.0/0000:01:00.0 == modalias : pci:v000010DEd00001B06sv00001462sd00003602bc03sc00i00 vendor : NVIDIA Corporation model : GP102 [GeForce GTX 1080 Ti] driver : nvidia-driver-390 - distro non-free driver : nvidia-driver-440 - third-party free recommended driver : nvidia-driver-435 - distro non-free driver : nvidia-driver-430 - distro non-free driver : nvidia-driver-410 - third-party free driver : xserver-xorg-video-nouveau - distro free builtinインストール済みのバージョンは435ですが、440が使えます。では、440をインストール。
(注): 440は"third-party"と表記されているため、Ubuntu 19.10のデフォルトリポジトリだけだと見えないと思います。なぜ440が見えるかですが、後述するCUDA再インストールのためにNVIDIAのリポジトリを追加しているためだと思われます。
sudo apt-get install nvidia-driver-440再起動して、いらなくなった古いパッケージを削除。
sudo apt autoremove
nvidia-smiを実行するとdriverは440ですが、CUDAのバージョンが10.2だと言っています。435では10.1と表示されていたのですが・・$ nvidia-smi Sun Mar 29 11:33:33 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 440.64.00 Driver Version: 440.64.00 CUDA Version: 10.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 GeForce GTX 108... On | 00000000:01:00.0 On | N/A | | 0% 34C P8 12W / 280W | 229MiB / 11171MiB | 0% Default | +-------------------------------+----------------------+----------------------+nvccのバージョン(= CUDAのバージョン)は10.1と表示されます。
~$ nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2019 NVIDIA Corporation Built on Sun_Jul_28_19:07:16_PDT_2019 Cuda compilation tools, release 10.1, V10.1.243StackOvlowのポストによると、nvidia-smiコマンドはNVIDIA Driverと一緒にインストールされ、CUDA driver APIのバージョンを表示するようです。一方で、
nvcc -VはCUDA runtime APIのバージョンを表示する。つまり、driver APIとruntime APIを管理しているライブラリが異なるため、NVIDIA DriverとCUDAと別々にインストールするとこうなる模様です。ということで、この現象に関しては放置としました。
Tensorflowの再構築
ドライバの更新後にtensorflowを動かすと以下のエラーが出てCPUモードになってしまいます。
$ python Python 3.7.7 (default, Mar 26 2020, 15:48:22) [GCC 7.3.0] :: Anaconda, Inc. on linux Type "help", "copyright", "credits" or "license" for more information. >>> import tensorflow as tf 2020-03-29 11:32:12.334692: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libnvinfer.so.6'; dlerror: libnvinfer.so.6: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: :/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64 2020-03-29 11:32:12.334773: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libnvinfer_plugin.so.6'; dlerror: libnvinfer_plugin.so.6: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: :/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64 2020-03-29 11:32:12.334784: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:30] Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly. >>>当初はここで、CUDA 10.1が認識されなくなったと勘違いし、CUDAの再インストールに走って状況を悪化させました。これ、実はCUDAの問題ではなく、TensorRTのライブラリが消えたのが原因でした。以下のエラーメッセージに出てくるライブラリはTensorRTのものです。
・Could not load dynamic library 'libnvinfer.so.6'
・Could not load dynamic library 'libnvinfer_plugin.so.6'どうも、TensorFlow 2.1はGPUモードでの起動時にTensorRTのライブラリをチェックするようです。
ということでlibnvinferを再インストールします。先ずは、公式の手順で。$ sudo apt-get install --no-install-recommends libnvinfer6=6.0.1-1+cuda10.1 \ libnvinfer-dev=6.0.1-1+cuda10.1 \ libnvinfer-plugin6=6.0.1-1+cuda10.1 Reading package lists... Done Building dependency tree Reading state information... Done E: Unable to locate package libnvinfer6 E: Unable to locate package libnvinfer-dev E: Unable to locate package libnvinfer-plugin6登録済みのリポジトリには上記のパッケージがないようです・・
仕方がないので、以下のNVIDAのリポジトリから必要なファイルをダウンロードしてマニュアルでインストールします。
https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/ダウンロードするファイルはTensorRT 6対応の以下のファイルです(TensorRT 7はCUDA 10.2が必要なため使えません)
- libnvinfer6_6.0.1-1+cuda10.1_amd64.deb
- libnvinfer-dev_6.0.1-1+cuda10.1_amd64.deb
- libnvinfer-plugin6_6.0.1-1+cuda10.1_amd64.deb
- libnvinfer-plugin-dev_6.0.1-1+cuda10.1_amd64.deb
ライブラリには依存関係があるため、適当なサブディレクトリに4つのファイルを格納して、一気にインストールします。
sudo dpkg -i ./libnvinfer/*.debこれでTensorFlow(Keras)がめでたく復活しました!
CUDA 10.1の再インストール(おまけ)
最初にNVIDIA Driver 435を入れたときは、先の「libnvinfer問題」をCUDAが認識されなくなったと勘違いして、CUDAを一旦消して再インストールに走りました。CUDAを再インストールする手順についても、いつも迷うのでメモとして書いておきます。
NVIDAの公式手順ではCUDAのインストール方法には以下のオプションがあります。
- runfiles(local) : CUDA一式とインストール用のシェルスクリプトをダウンロードしてローカルでインストール → シェルスクリプトがCUDA 10.1でデフォルトのDriver 418をインストールしようとするようで、既に他のドライバをインストール済みの場合は警告が出ます。無視してインストールを強行するとシステムがおかしくなりそうなので止めました。
- deb(local or network) : aptのリポリトリを追加してインストールする
deb方式で、NVIDA公式にある
sudo apt-install cudaを実行すると、CUDA 10.2をインストールしようとして依存性のチェックでエラーとなります。Driver 440が入っているとデフォルトでは10.2をインストールしようとするのかもしれません。そこで、
sudo apt install cuda-10-1
で、バージョンを指定してインストールします。このコマンドでは依存パッケージとして;
- cuda-toolkit-10-1
- cuda-runtime-10-1
- cuda-demo-suite-10-1
をインストールしようとし、
$ apt show cuda-10-1 Package: cuda-10-1 Version: 10.1.243-1 Priority: optional Section: multiverse/devel Source: cuda Maintainer: cudatools <cudatools@nvidia.com> Installed-Size: 25.6 kB Depends: cuda-toolkit-10-1 (>= 10.1.243), cuda-runtime-10-1 (>= 10.1.243), cuda-demo-suite-10-1 (>= 10.1.243)さらに、cuda-runtime-10-1は依存パッケージとして
cuda-driversを含むため、ドライバを再インストールしてしまいます。$ apt show cuda-runtime-10-1 Package: cuda-runtime-10-1 Version: 10.1.243-1 Priority: optional Section: multiverse/devel Source: cuda Maintainer: cudatools <cudatools@nvidia.com> Installed-Size: 25.6 kB Depends: cuda-drivers (>= 418.87), cuda-libraries-10-1 (>= 10.1.243), cuda-license-10-1 (>= 10.1.243)ただし、apt install cuda-driversでインストールされるドライバは440なので悪さをすることはなさそうです。
$ apt show cuda-drivers Package: cuda-drivers Version: 440.64.00-1 Priority: optional440より前のドライバを使っており、それを更新したくない場合は、
cuda-toolkit-10-1のみをインストールしておく手もありそうです。$ apt show cuda-toolkit-10-1 Package: cuda-toolkit-10-1 Version: 10.1.243-1 Priority: optional Section: multiverse/devel Source: cuda Maintainer: cudatools <cudatools@nvidia.com> Installed-Size: 25.6 kB Depends: cuda-compiler-10-1 (>= 10.1.243), cuda-tools-10-1 (>= 10.1.243), cuda-samples-10-1 (>= 10.1.243), cuda-documentation-10-1 (>= 10.1.243), cuda-libraries-dev-10-1 (>= 10.1.243), cuda-nvml-dev-10-1 (>= 10.1.243), cuda-license-10-1 (>= 10.1.243)cuda-runtime-10-1のインストールをスキップすると、cuda-libraries-10-1が入りませんが、Tensorflowの動作には影響はなさそう。
おわりに
NVIDIA DriverとCUDA、さらにはTensorflowの依存関係がたまにおかしくなります(余計なアップデートをしなければよいだけの話だと思いますが・・)。そのたびに再インストールでハマるため、メモとして一連の手順をまとめてみました。
この3つは依存関係が複雑ですので、Dockerでサクッとやるのが一番手っ取り早いのかも知れません。
- 投稿日:2020-03-29T14:42:01+09:00
機械学習メモ
基礎
データフォーマット
- NHWC
- TensorFlow
- NCHW
- TensorRT
- OpenCV(
cv::dnn::blobFromImageで変換)- ncnn(
ncnn::Mat::from_pixelsで変換)width=3,height=2,3色の場合# NHWC R00 G00 B00 R01 G01 B01 R02 G02 B02 R10 G10 B10 R11 G11 B11 R12 G12 B12 # NCHW R00 R01 R02 R10 R11 R12 G00 G01 G02 G10 G11 G12 B00 B01 B02 B10 B11 B12Google Colaboratory
Googleドライブマウント、ファイルのアップロードとダウンロード
from google.colab import drive drive.mount("/content/drive") from google.colab import files files.download( "./test.h5") uploaded = files.upload()Object Detection モデル再学習の環境 (as of 2020/03/27)
AttributeError: module 'tensorflow' has no attribute 'contrib'対策
- Tensorflow 1.15を使用する
- Pythonパス設定 (
os.environ["PYTHONPATH"] = "/content/models/research:/content/models/research/slim:" + os.environ["PYTHONPATH"])%tensorflow_version 1.x import tensorflow as tf print(tf.__version__) !pip install pycocotools !git clone --depth 1 https://github.com/tensorflow/models %cd models/research/ !protoc object_detection/protos/*.proto --python_out=. !pip install . %cd /content # Modify python path and check script # %set_env PYTHONPATH=$PYTHONPATH:models/research:models/research/slim import os os.environ["PYTHONPATH"] = "/content/models/research:/content/models/research/slim:" + os.environ["PYTHONPATH"] !echo $PYTHONPATH !python models/research/object_detection/builders/model_builder_test.pyONNX
Keras2onnx
https://github.com/onnx/keras-onnx
import os os.environ["TF_KERAS"] = "1" # this must be before import keras2onnx (★important★) import onnx import keras2onnx model = tf.keras.models.load_model("conv_mnist.h5") onnx_model = keras2onnx.convert_keras(model, model.name) onnx.save(onnx_model, "conv_mnist.onnx") !lsncnn
https://qiita.com/iwatake2222/private/d604fb66a6963841acd3
https://qiita.com/iwatake2222/private/1e3cb4d73d5289d977a3
- 投稿日:2020-03-29T13:52:17+09:00
Label Smoothing
- 投稿日:2020-03-29T12:16:02+09:00
TensorFlow(GPU版) Installとお試しRNN 備忘録
概要
GPU対応TensorFlow(以下TF)のインストール手順を備忘録として残す。
- 実施期間: 2020年2月
- 環境:Ubuntu18.04LTS
- Python2.7, 3.6.9インストール済み
- GPU: GeForce GTX 1070背景
4年ほど昔、Ubuntuの使い方も見様見真似だったころに挑戦したのだが、うまくいかず諦めた経験があり今回再挑戦してみた。
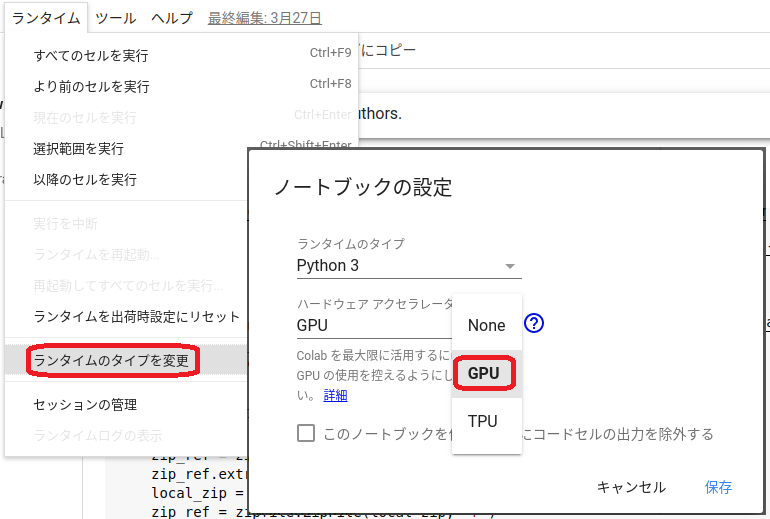
今はGoogle ColaboratoryのVM環境で、CUDA環境整備に悩まされることなくTF+Kerasを使った深層学習モデルで遊んでいる。使い勝手はほぼJupyter notebookと同じ。
[Colaboratoryのnotebook]ことモデリングについていえば自前PCのGPUを必ずしも使用する必要はない。
ただ、折角手元のデスクトップPCにはGPUが刺さっているので、これでモデルの教育させたいと思うのが人情(VMにはGPU無料使用時間に制限があるし)。
そこで安直にオフィシャルが下記に推奨するよう、TF Dockerイメージで横着して環境を作ろうかと考えた。「GPU サポートを含む TensorFlow の Docker イメージ(Linux 用のみ)を使用することをおすすめします。その場合セットアップに必要なのは NVIDIA® GPU ドライバだけです。」
楽チンできそうだが手順を読むと直感的に鵜呑みにできない。
他の選択肢も調べているなかで、素晴らしすぎるサイトを見つけた。ここによると、TFオフィシャル通りにするとUbuntu18.04対応状況の遅れから、はまる可能性が高いらしい。
これに従い以下手順を残す。Nvidia GPUドライバ更新
GPUドライバ396以降が必要らしい。
幸い430が入っていたので何もしなかったが、バージョンが古ければ下記の手順でUpdateする。sudo apt purge nvidia* sudo add-apt-repository ppa:graphics-drivers/ppa sudo apt install nvidia-driver-430 reboot nvidia-smi #reboot後、チェック3行目の "nvidia-driver-430" は2020年2月時点の最新版が430だから。
最新版は下記のPPAで都度確認できる。
https://launchpad.net/~graphics-drivers/+archive/ubuntu/ppaAnacondaのインストール
オフィシャルサイトから、最新インストール用shファイル(Anaconda3-2019.10-Linux-x86_64.sh)をダウンロードする。
Minicondaの時と同じようにDownloadsフォルダでbash実行しインストール$ cd Downloads $ bash Anaconda3-2019.10-Linux-x86_64.sh下記の2行をbashrcに追記する。追記したらsource ~/.bashrcすればcondaをコマンドとして認識する。
export PATH=/home/imo/anaconda3/bin:$PATH source /home/imo/anaconda3/etc/profile.d/conda.shAnacondaをUpdateする。
$ conda update conda $ conda update anaconda $ conda update python $ conda update --allconda仮想環境にTFインストール
前述の会心下記サイトを参考にインストールする。
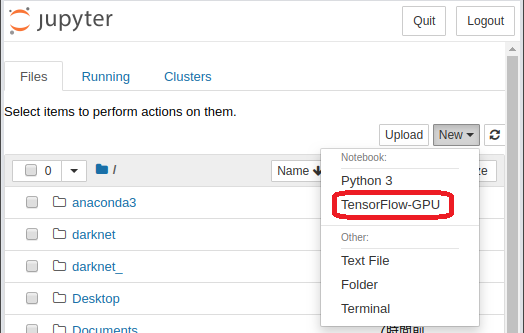
conda仮想環境(環境名はtf-gpu、表示名はTensorFlow-GPUとする)を作成する。
$ conda create --name tf-gpu $ conda activate tf-gpuconda仮想環境内でTFと関連ツールをインストールする。
(tf-gpu) conda install tensorflow-gpu (tf-gpu) conda install ipykernel jupyter (tf-gpu) python -m ipykernel install --user --name tf-gpu --display-name "TensorFlow-GPU" (tf-gpu) python -c 'import tensorflow as tf; print(tf.__version__)' #チェック 2.1.0がインストールされた (tf-gpu) conda install keras-gpu (tf-gpu) conda install pandas (tf-gpu) conda install scikit-learn (tf-gpu) conda install pillowJupyter notebookの起動する。
(tf-gpu) jupyter notebook
[Jupyter notebook]たったこれだけ。
RNNで動作確認
TFオフィシャルのチュートリアルのセルをコピペしRNNを実際に動作させてみた。
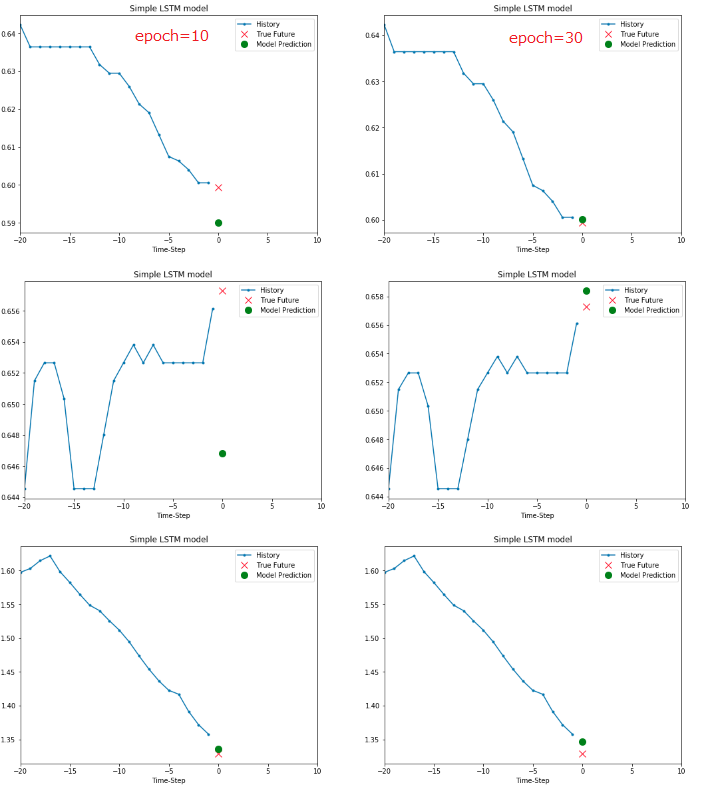
これはマックス・プランク研究所が提供する気象時系列データ(気温、湿度など14種類のデータ)でLSTM modelを学習させ、将来の気温を予測するチュートリアルである。
Part1が過去10分刻みの気温データで学習したモデルの予測で、Part2は気温、気圧、空気密度の3データで学習・予測させるもの。
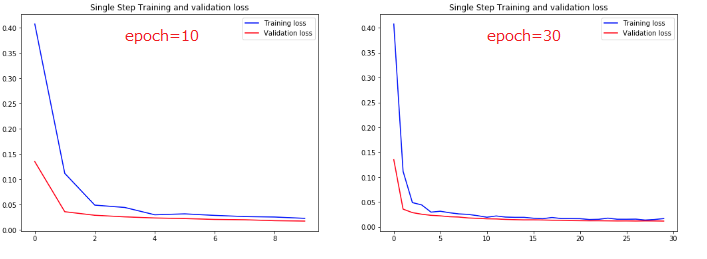
Part2の方が予測精度が向上することが実体験できる。参考までにPart1の結果だけ張り付ける。
チュートリアルの学習epoch数が10と控えめだったので、30まで伸ばしてみた。accuracyではなくlossで評価している。
TrainingもValidationもlossはともに収束しており、過学習の兆候はともに見られない。
なぜValidationの方がTrainingよりもlossが小さくなっているかはわからないので勉強が必要。
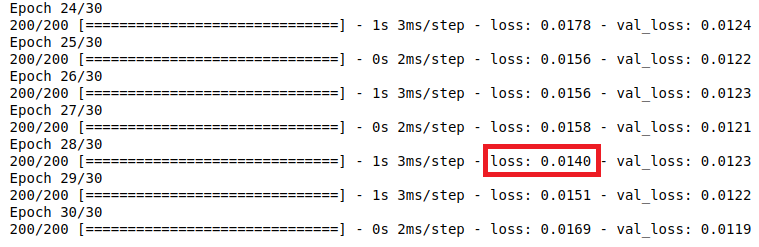
epoch=28でtrainingのlossが0.0140と最小値になってる。本来ならcallbackを組み込んでそこで学習が終わるようにすべき。
epoch=10の時のtraining loss=0.0228だったのでepoch=30の0.0169は明らかに改善しており、その結果が下図の予測結果に表れている。
赤Xが実際の温度で、緑○が予測気温。
ひと通り楽しんだらJupyter notebookが起動しているブラウザを閉じ、実行中のターミナルは[Ctrl]+[c]で終了させ、仮想環境を抜ける。
(tf-gpu) conda deactivateおまけ1 ~ Dockerのインストール ~
Docker版のTFもうまくいっていたので手順を残す。
参考にしたのは、本編で怪しいといった下記サイトで、実はDockerでも問題なかった。
https://www.tensorflow.org/install/dockersudo apt-get install apt-transport-https ca-certificates curl gnupg-agent software-properties-common curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - sudo apt-key fingerprint 0EBFCD88 sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" sudo apt-get update sudo apt-get install docker-ce docker-ce-cli containerd.io docker version #チェック sudo docker pull tensorflow/tensorflow:latest-gpu-jupyter sudo docker image