- 投稿日:2020-03-29T23:56:04+09:00
Vue.js + AWS の組み合わせ
基本的なこと
Vue.jsの開発はVue-CLIを使うのが基本
まず前提として、Vue.jsは今となってはVue-CLI無しでの開発は"かなりキツイ"と捉えてください。
実際それほどでもないと言えばそうなんですが、Vue-CLIがかなり便利になってきたので、その恩恵を受けられない構成での開発を基本フロントは嫌がります。Laravel + Vue という悪習
そういうことなので、Laravelに入っていたVueを雛形にしてそのまま使ってしまっている場合は将来切り離すスケジュールを立てるべきです。
この構成は、通常LaravelMixでコンパイルするのでVue-CLIが使えません。移行には具体的に以下の作業が発生します。
- リポジトリの切り分け
- vue-routerを用いたSPAの対応
- APIのCORS対応
元々Laravelが担当していた機能は /home → /about のように『ルートが切り替わったら別のHTMLを表示する』という事をしていただけなので、ページ切替がフロントで管理できるようになった今となってはバックエンドのwebルートは完全に不要になりました。
恩恵として、フロント側でページ遷移した場合はリロードが発生しません。
リロードしてしまうとJSの変数に格納したデータが全て消えてなくなってしまうのですが、SPAは基本的にリロードが無いので、ページ遷移の度に同じデータをダウンロードしなくてもページ間でデータを共有できるようになり、サイトの高速化に繋がります。デプロイ環境
デプロイ環境に関してはサーバーもNode.js環境も必要ありません。S3だけで事足ります。
ブラウザがコンパイル済みのindex.htmlとそこでインポートされているJSやCSSファイルを読み出せればOKです。
完全に静的なファイルを置いておくだけで大丈夫なんです。
コンパイルにNode.js環境を必要としますが、後で出てくるAmplifyのビルド環境にNode.jsが入っていますので心配しなくて大丈夫です。やっちゃいけないこと
- Laravel+Vue.jsのようなバックエンドのリポジトリにVue.jsが付属する構成は難儀するので、LaravelはAPI専用にして後方に配置し、LaravelとVue.jsは別々のリポジトリで管理しましょう。
- とりあえずCodeStarでやろうとするのはNG。正解は全然別の所にあるAmplifyの方です(UI統一してくれ..)。似たようなものですが、より実践的な設定が簡単にできるのでAmplifyを使いましょう。
使用するAWSのサービス
- Amplify
Amplify
ほぼ対象のリポジトリを選択するだけで簡単に『リポジトリの更新を検知→自動テスト→自動デプロイ』のパイプラインが出来上がります。
たぶんSPA前提なのでS3のサーバーレス環境にデプロイされます。
AmplifyにはFrontセクションとBackendセクションがあり、上記がFrontセクションに該当します。
Backendセクションでは、Cognito、AppSync、Lambda、S3などを用いて自在にバックエンド開発ができます。
『Amplify = AWSフレームワーク』に近いものなので、基本的な部分はAmplifyで作成してしまい、追加サービスとして他のAPIを付け足していくという感じになっていくと思います。Amplifyについて詳しくはまた次回に書こうと思います。
- 投稿日:2020-03-29T22:00:55+09:00
OPTIONSにAccess-Control-Allow-Originが付けれない環境でのPOST送信時のCROS対処法
はじめに
別ドメインのサーバにブラウザ上からPOSTを送りたい場合に、特定の条件を満たしていないと必ずpreflightとしてOPTIONSを送信を行い、確認がとれた後にPOSTを送信します。
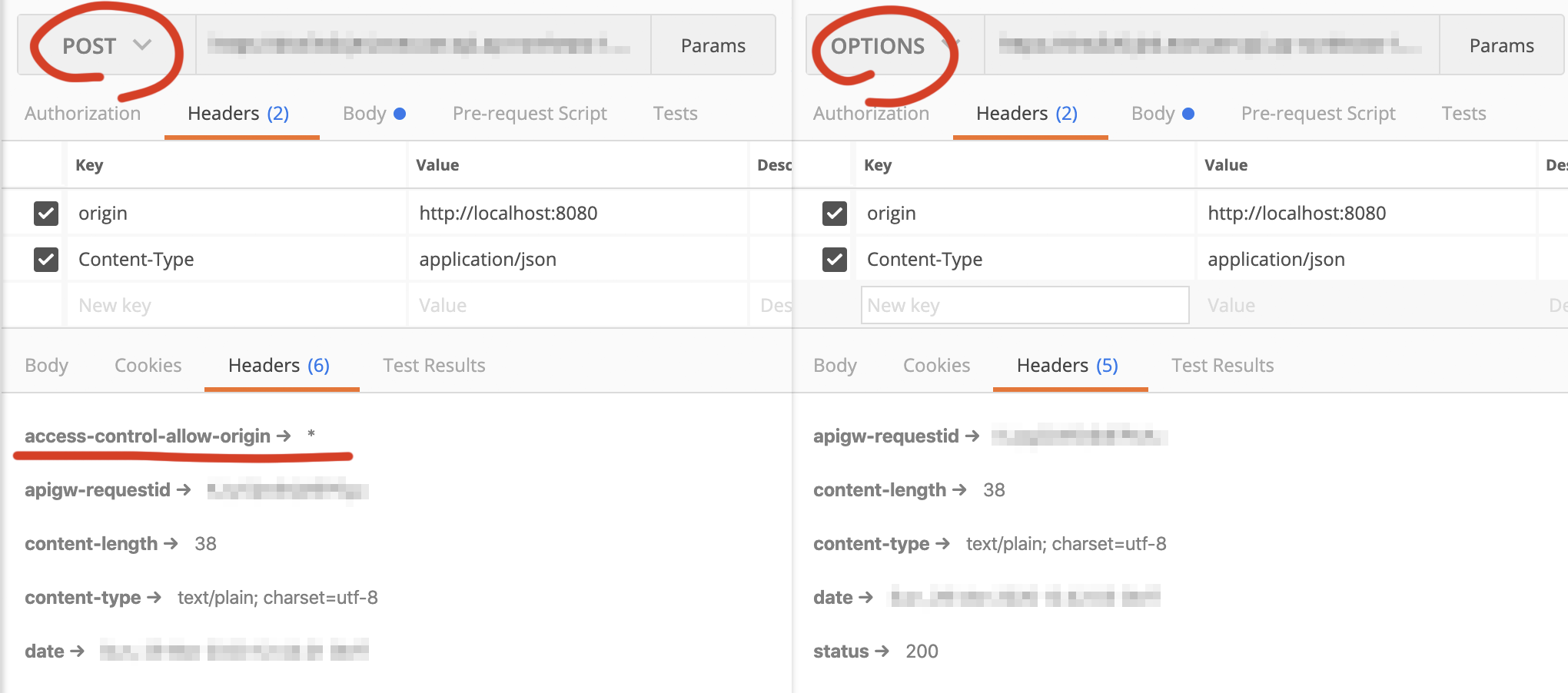
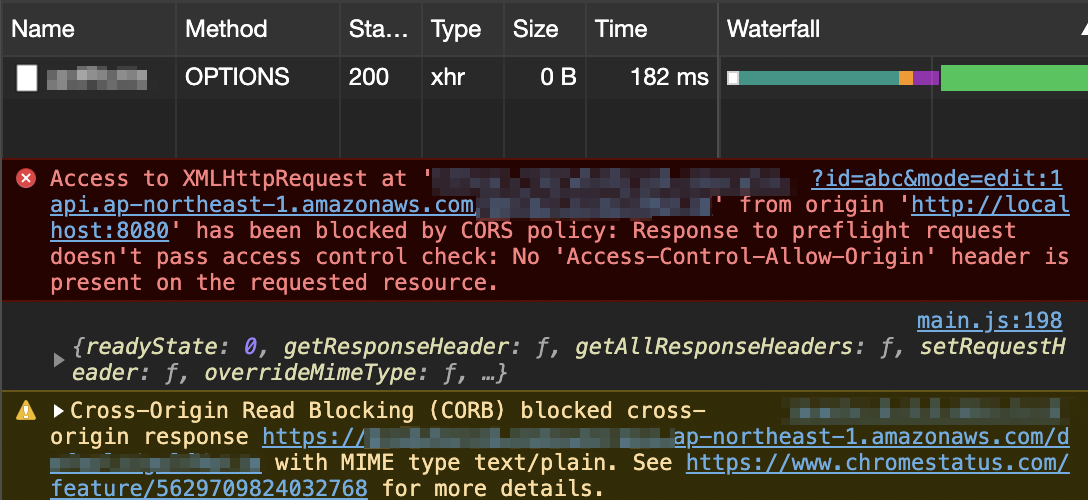
最近使えるようになったAWSのAPI GatewayのHTTP APIでは、CROS設定を行っていてもOPTIONSにはAccess-Control-Allow-Originはつきません。
そのため、ブラウザ側でPOSTを送信するまえにOPTIONSでCROS設定がされていないと拒否されてPOST送信にまでいきません。
既存のAPI GatewayのREST APIで設定するかLambdaなどから強制的にヘッダーをつけたりすれば問題なく送信することはできるようにはなりますが、HTTP APIでなんとかしたい!!となるとうまくいきません。
※ AWSのAPI GatewayのHTTP APIではLambdaからHeaderをつけるような書き方をしても、他のものはつくもののAccess-Control-Allow-OriginなどのCROS関係のヘッダーはつけても削除されてしまいました。悲しい。解決方法
ざっくりのピックアップですが、以下の条件の場合にはpreflightが飛ばないという仕様になっています。
細かい情報は下部の参考をみてください。
- HTTPリクエストメソッド
- GET, POST, HEAD。
- HTTPリクエストヘッダ
- Content-Type
- application/x-www-form-urlencoded
- multipart/form-data
- text/plain
そのためPOSTの Content-Type が application/json となってる場合には、上記のようにpreflightであるOPTIONSが飛びCROS設定がされていないためブラウザが拒否します。
なので、ajaxで送信時に
心で何かが叫んでますがContent-Type を text/plain とすればOPTIONSは飛ばす、すぐにPOST送信が行われるためHTTP APIのCROSの設定通りの挙動で送信が成功します。
同様にJavascriptのfatch apiを使ってjpegなどを送信する場合にはより心で何かが叫んでますがmultipart/form-dataなどとContent-Typeを偽って送信することで、開発環境からもクラウドに向けて送信することができます。参考
https://fetch.spec.whatwg.org/#cors-preflight-fetch
https://qiita.com/tomoyukilabs/items/81698edd5812ff6acb34
- 投稿日:2020-03-29T21:08:41+09:00
サーバーレスとは
概要
- サーバーレスとは何かの定義と特徴をまとめ、AWSの主なサービスおよびユースケースをまとめました
- 対象読者はサーバーレスの入門者およびサーバーレスで実装してみたいユースケースのある方です
定義
利用者によるサーバーのプロビジョニングやメンテナンス、耐障害性の確保が不要なサービス
プロビジョニングとは、必要に応じてネットワークやコンピューターの設備などのリソースを提供できるよう予測し、準備しておくこと
耐障害性は、何か障害が起きたときでもシステムのパフォーマンスを落とすことなくシステムを稼働し続けられる冗長構成のこと代表的なサーバーレスAWSサービス
Amazon QuickSight
クラウド駆動の高速なBI(ビジネスインテリジェンス)サービスAmazon Kinesis
動画とデータストリームをリアルタイムで収集、処理、分析するためのサービスAmazon Simple Queue Service
完全マネージド型のメッセージキューイングサービスAWS AppSync
GraphQLを使用してアプリケーションが必要なデータを正確に取得できるようにするマネージド型サービスAWS Lambda
サーバーのプロビジョニングや管理をすることなくコードを実行できるコンピューティングサービスAmazon DynamoDB
規模に関係なく高速で柔軟なパフォーマンスを実現するNoSQLデータベースサービスAmazon Personalize
アプリケーションを使用している顧客に対して開発者が個別のレコメンデーションを簡単に作成できるようにする機械学習サービスAmazon CloudWatch
AWSのリソースとアプリケーションのモニタリング/おブザーbアビリティサービスAWS Systems Manager
AWSで利用中のインフラストラクチャを可視化し、制御するためのサービスAmazon API Gateway
規模に応じたAPIの作成、公開、保守、モニタリング、保護を行えるサービスElastic Load Balancing
アプリケーションへのトラフィックを複数のターゲットに自動的に分散するサービスAmazon Cognito
シンプルでセキュアなユーザーのサインアップ、サインイン、アクセスコントロールの機能を実現するサービス主な特徴
- サーバーの管理が不要
- 事前に調達が不要
- 必要なときにプロビジョニング可能
- インフラの保守・運用をクラウドサービス事業者(AWSなど)が実施
- 価値に対する支払い
- 利用したリソースや処理時間等を元にした従量課金性
- 初期投資不要
- 柔軟なスケーリング
- 利用状況に応じてスケールアウト・スケールインを自動的に実施
- 自動化された高可用性
- 冗長化構成等の可用性、耐障害性を高める仕組みが組み込み済み
AWSにおけるユースケース
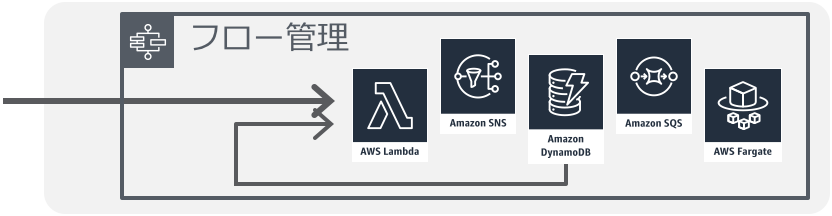
動的Web/モバイルバックエンド
リアルタイムモバイル/オフライン対応
業務系API/グループ企業間API
Private API記事(英語)
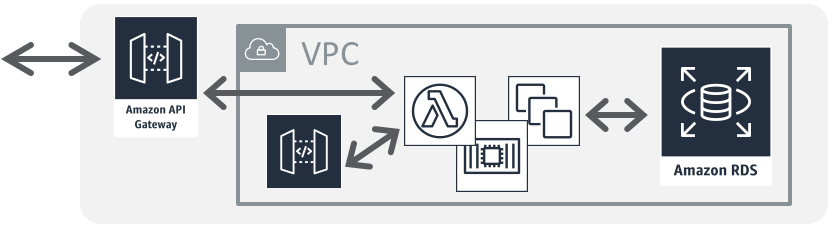
VPC Lambda記事
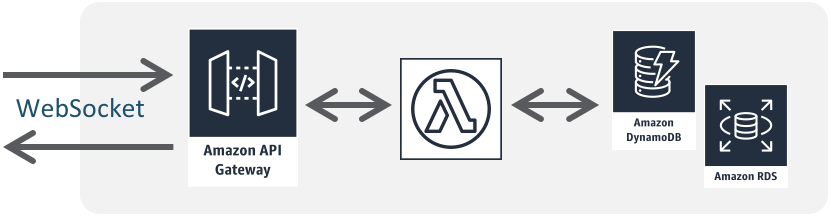
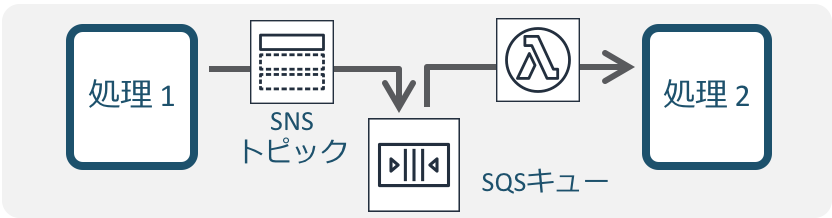
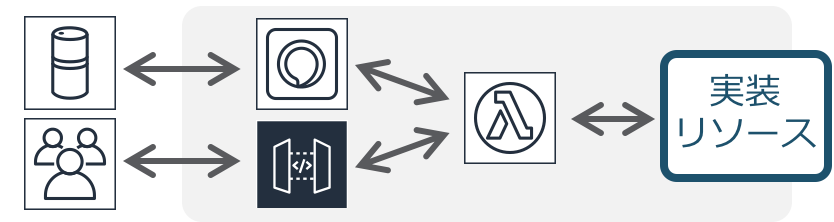
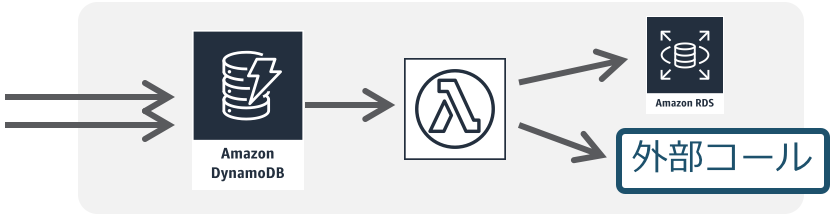
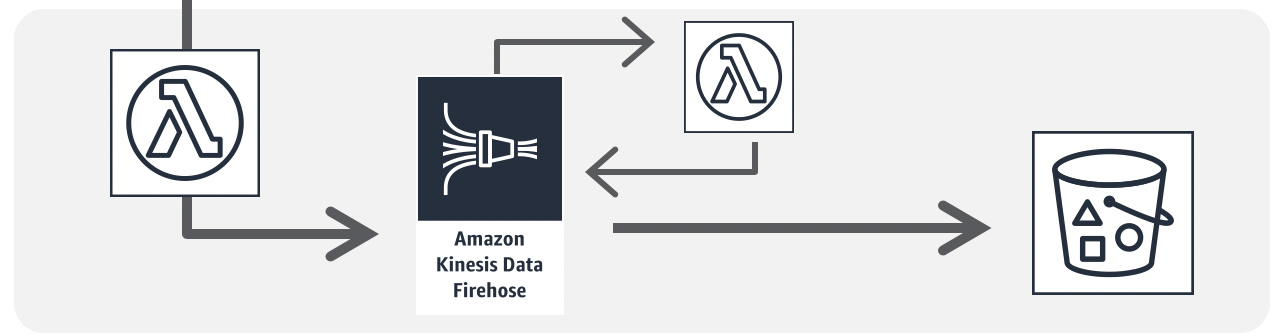
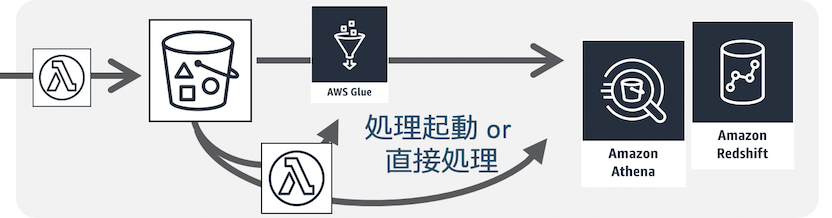
関連事例Push配信系・インタラクティブAPI
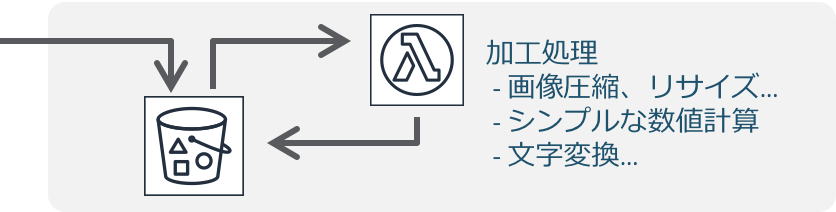
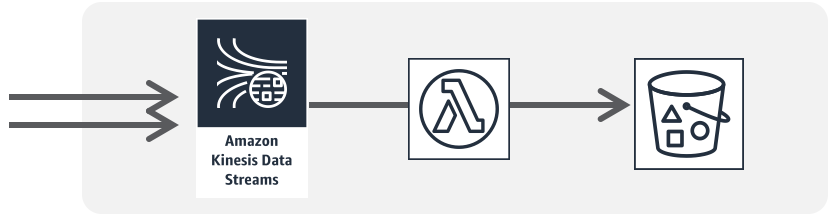
画像処理/シンプルなデータ加工
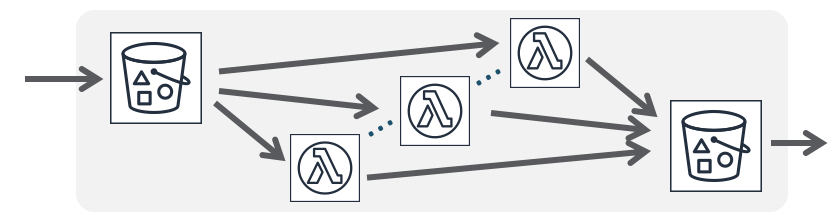
分散並列処理
イベント駆動の業務分散処理連携
アプリケーションフロー処理
流入データの連続処理
関連資料
参考アーキテクチャ
チュートリアル1
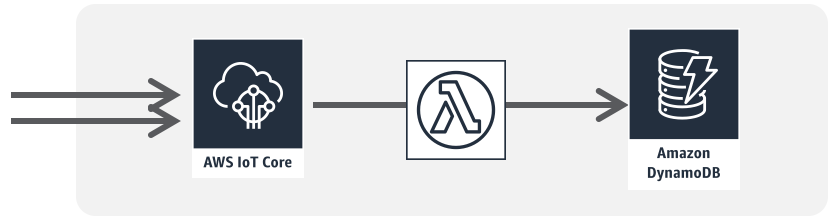
チュートリアル2IoTバックエンド
関連資料
関連事例動画
参考アーキテクチャ
ソリューション1(英語)
ソリューション2(英語)チャットボット/Alexaスキル
データ変更トリガー処理
ログデータ収集処理
データレイク周りのデータ加工
機械学習/ETLデータパイプライン
スケジュール・ジョブ/SaaSイベント












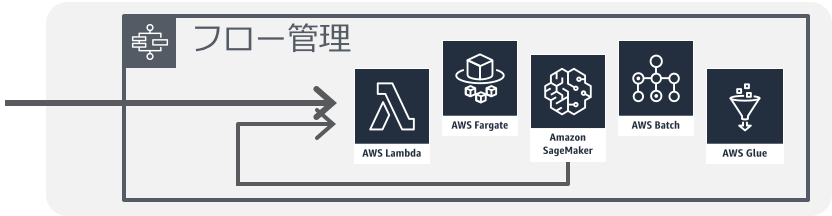
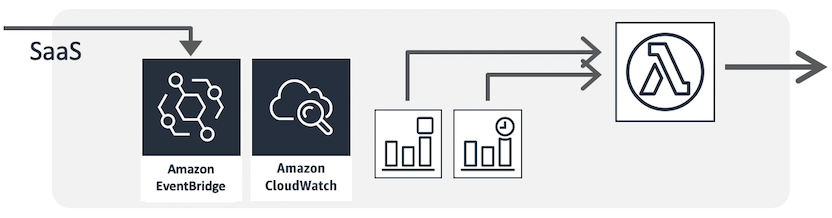
- 投稿日:2020-03-29T20:16:35+09:00
AuroraServerlessへcsv形式で一括データ挿入する
S3に置いたcsvファイルのデータをAuroraServerlessにdataAPIを介して挿入するlambda。
import json import csv import boto3 import os rdsData = boto3.client('rds-data') s3 = boto3.resource('s3') bucket = s3.Bucket('バケット名') tableName = "テーブル名" clusterArn = 'クラスターARN' secretArn = 'シークレットARN' def lambda_handler(event, context): # S3からファイル取得 bucket.download_file('S3上のファイル名.csv', '/tmp/保存時のファイル名.csv') # 最終的にAuroraServerlessに投げるSQL文 allSqlstr = "" # csv → json変換 with open('/tmp/names.csv') as csvfile: reader = csv.DictReader(csvfile, quotechar="'") #デフォルトだとダブルクオート for row in reader: # 辞書の全てのvalueを取得し、SQL文を組み立て sqlstr = "INSERT INTO " + tableName + " VALUES ( " for val in row.values(): sqlstr += "'" + str(val) + "'," allSqlstr += sqlstr[:-1] + " );" print("requestSQL:", allSqlstr) # AuroraServerless更新 res = rdsData.execute_statement( resourceArn = clusterArn, secretArn = secretArn, database = 'DB名', sql = allSqlstr) print (res) return 0
- 投稿日:2020-03-29T19:59:43+09:00
AWS Lambda で Javaを使う ー実装編Tips - ReagionとInstanceIDからInstance名を取得する
AWS Lambda で Javaを使う 目次
・Eclipse準備編
・登録実行編(いつか)
・実装編 - EC2を止める/立ち上げる
・実装編 - CloudWatchの引数を確認する
・実装編Tips - ReagionとInstanceIDからInstance名を取得するReagionとInstanceIDからInstance名を取得する
引数にReagionコードとInstanceIDを渡すと、Instance名を返してあげる。
また、二回目以降、同じReagionコードを渡した場合、Mapに格納している値を返却する。// <reagion id <<incetance id, incetance key name>> Map<String, Map<String, String>> resolveInstance = new HashMap<>(); private String getEC2InstanceKeyName(String targetReagion, String targetInstanceId) { if (!resolveInstance.containsKey(targetReagion)) { // <incetance id, incetance key name> Map<String, String> incetanceMap = new HashMap<>(); // Instance Id と Instance名を取得 (こんな大層なことしなくても取れそうな気もする。。でも、純正のEC2MetadataUtilsでは取れなさそうだった。) AmazonEC2 ec2 = AmazonEC2ClientBuilder.standard().withRegion(targetReagion).build(); DescribeInstancesResult ec2Info = ec2.describeInstances(); for(Reservation res : ec2Info.getReservations()) { for(Instance ins : res.getInstances()) { incetanceMap.put(ins.getInstanceId(), ins.getKeyName()); } } resolveInstance.put(targetReagion, incetanceMap); } return resolveInstance.get(targetReagion).get(targetInstanceId); }
- 投稿日:2020-03-29T19:49:25+09:00
AWS Lambda で Javaを使う ー実装編 - CloudWatchの引数を確認する
やりたいこと
Lambdaで実行するJavaで、CloudWatchに登録してある引数を取得する。
背景・経緯
前回の記事で作成したEC2の起動停止するLambdaファンクションを、
CloudWatchEventsのCronで、8時、9時、17時、18時など複数の時間帯で起動するようにしていた。
が、どのインスタンスをどの時間に起動するようにしたか忘れてしまい、
いちいちCloudWatchEventsに登録した引数を確認しなければならなかった。
面倒だったので、引数を取得するファンクションを作成した。
(メモを取ると、登録している引数とメモを同期させないといけないので、避けたかった。)AWS Lambda で Javaを使う 目次
・Eclipse準備編
・登録実行編(いつか)
・実装編 - EC2を止める/立ち上げる
・実装編 - CloudWatchの引数を確認する
・実装編Tips - ReagionとInstanceIDからInstance名を取得するとりあえずクラス作成
CloudWatchEventsをごにょごにょする
CloudWatchEventsオブジェクトを作成する
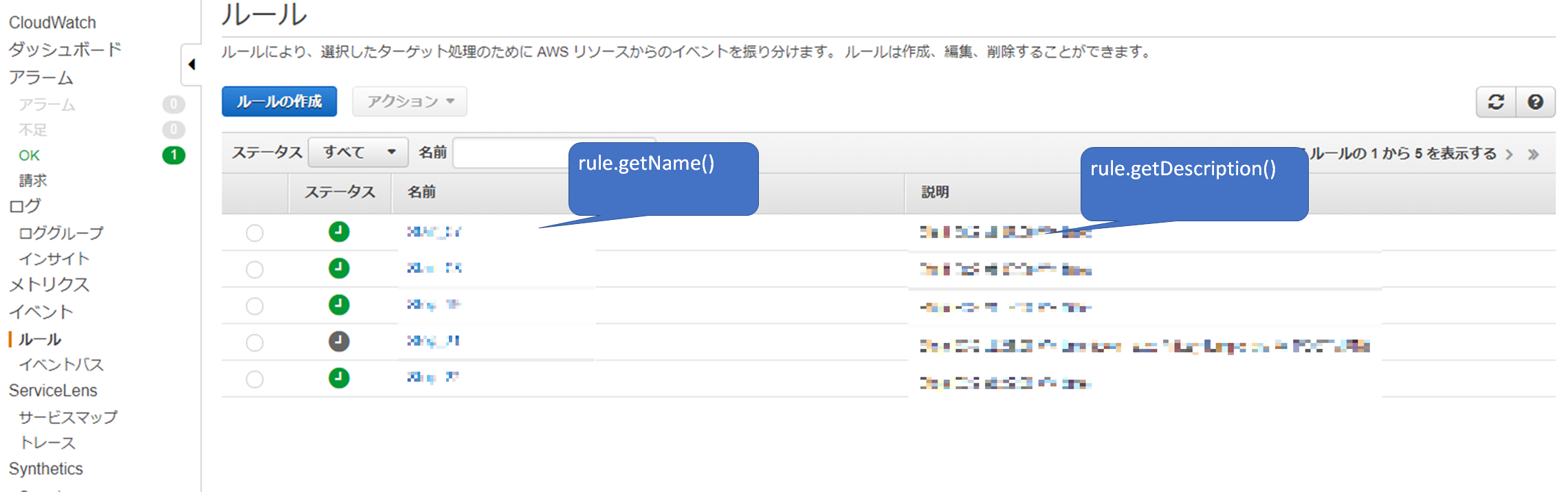
// CloudWatchEventsオブジェクトを作成 AmazonCloudWatchEvents event = AmazonCloudWatchEventsClientBuilder.defaultClient();CloudWatchEventsのルールを取得する
ListRulesResult retRule = event.listRules(new ListRulesRequest()); for(Rule rule : retRule.getRules()) { // rule.getName()、rule.getDescription() }コンソールでいうところのこの部分
メソッド名通り、ルールの名前と説明を取得できる。
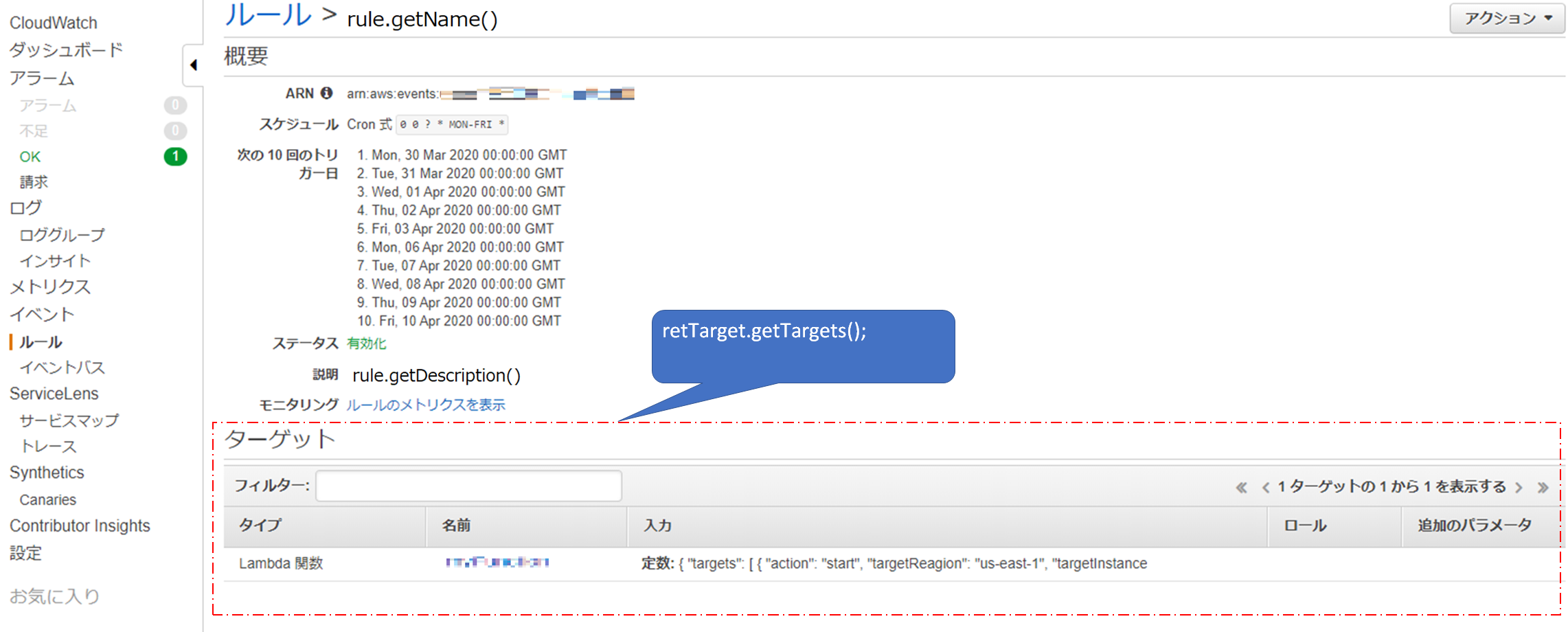
CloudWatchEventsのルールからターゲットを取得する
// get target information from rule ListTargetsByRuleRequest req = new ListTargetsByRuleRequest().withRule(rule.getName()); ListTargetsByRuleResult retTarget = event.listTargetsByRule(req); List<Target> cloudWatchTargets = retTarget.getTargets(); for (Target target : cloudWatchTargets) { // do loop each cloud watch rule's target }コンソールでいうところのこの部分
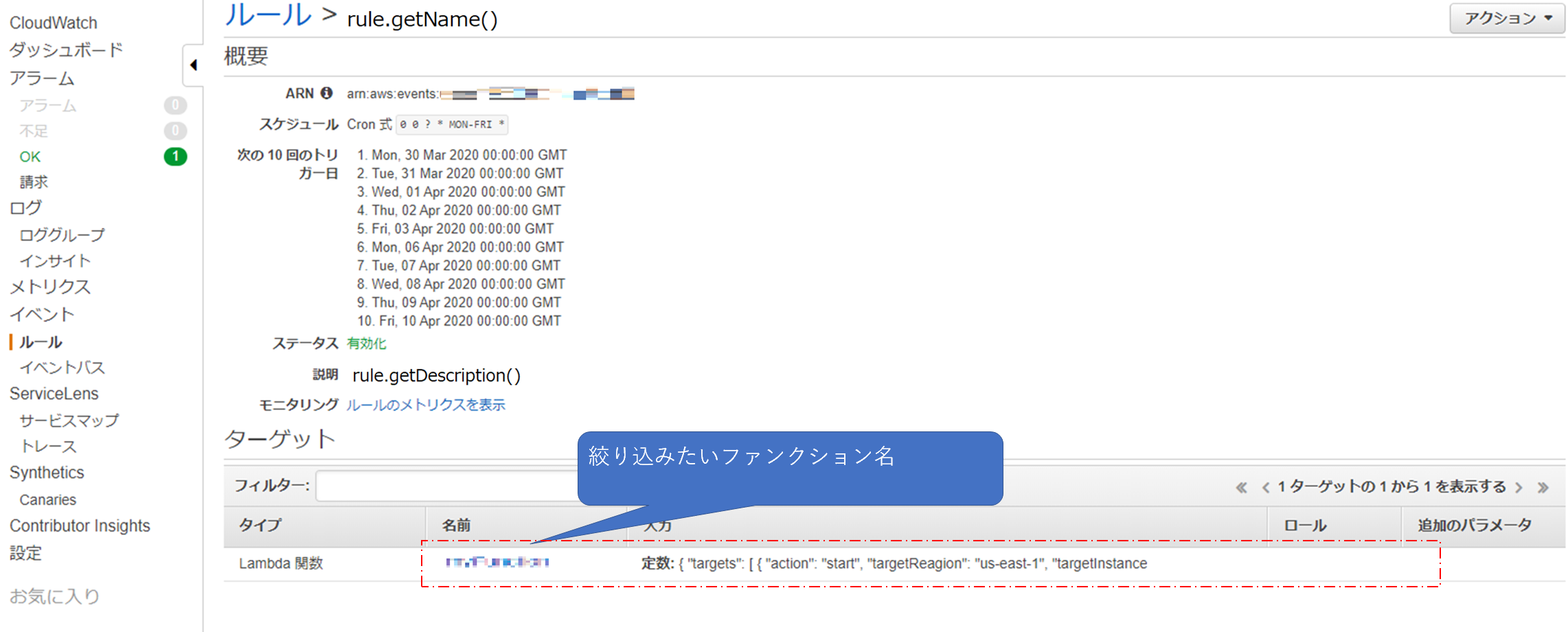
CloudWatchEventsのルールからターゲットの中からファンクション名で絞り込む
target.getArn()これで、各ターゲットが下記のような形で返却される
arn:aws:lambda:region:xxxxxx:function:functionNameなので、endWithで絞り込む
if (target.getArn().endsWith("絞り込みたいファンクション名")) { // }コンソールでいうところのこの部分(このコンソール画面の場合だとそもそも一つしかないので、やってもやらなくてもどちらでもいいのだけども。)
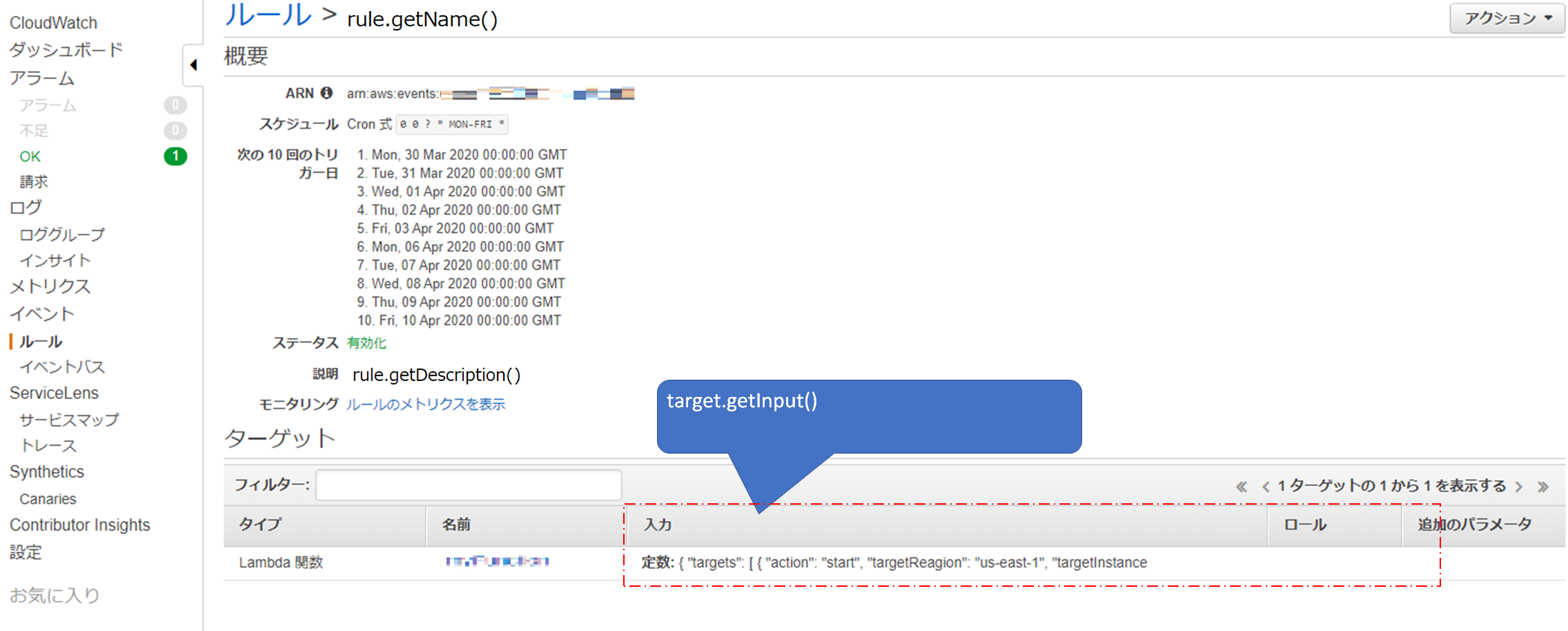
CloudWatchEventsのルールからターゲットの中から引数(入力)を取得する
target.getInput()コンソールでいうところのこの部分
// cloudWatch のInputをjsonで記載しているので jsonからbeanに変換 SomethingBean cloudWatchInput = Jackson.fromJsonString(target.getInput(), SomethingBean.class);あとは、今まで取得したCloudWatchEventsのルール名、説明、引数など出力したい形に整形して、outputに返してあげれば終了。
今回追加したPOM
<dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-cloudwatch</artifactId> <version>1.11.99</version> <scope>compile</scope> </dependency> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-events</artifactId> <version>1.11.719</version> <scope>compile</scope> </dependency>
- 投稿日:2020-03-29T19:03:28+09:00
AWS S3 上のデータをなるべく簡単に Splunk に取り込んでみる
はじめに
最近では AWS S3をベースとしたデータレイクを構築してデータをまとめているケースも多くあると思います。そこで今回はS3上のログをSplunkに取り込むまでをやってみたいと思います。いろいろな取り込み方法があるのですが、今回はとにかくシンプルかつ早い設定をテーマにやってみます。
設定の流れ
大きく分けると AWS上の設定とSplunk上の設定の2つが必要になります。
AWS上の準備・設定
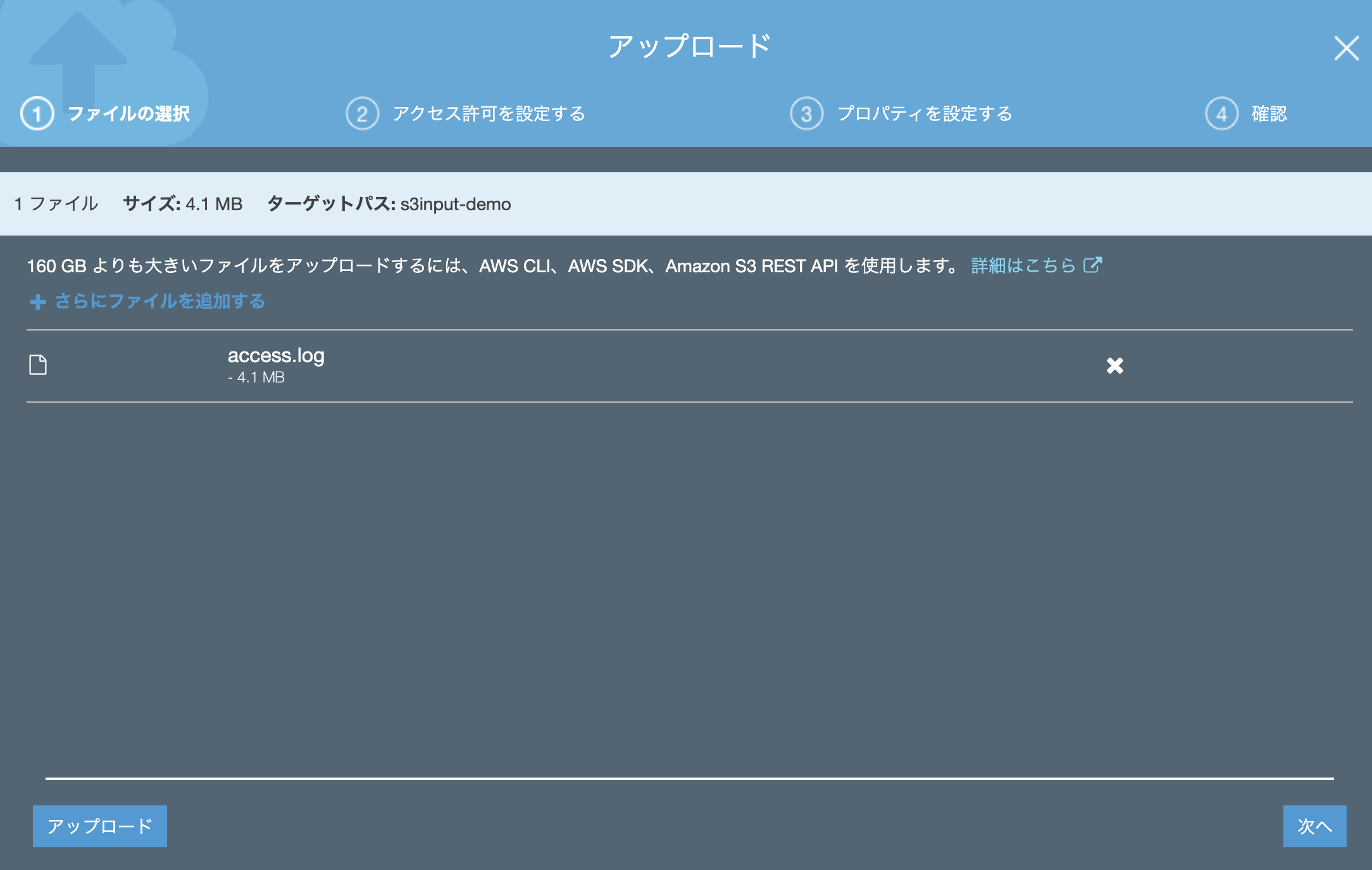
1. AWS S3 Bucket の作成
2. S3 上にデータをアップロード
3. IAMユーザー作成 & ポリシー作成しユーザーへの権限付与Splunk上の設定
4. APPの追加 (Add-on for AWS)
5. Configuration (IAM User追加)
6. Input設定AWS上の設定
1. AWS S3 Bucket の作成
まずは通常通り S3 Bucke を作成します。Publicアクセスはすべてブロックで大丈夫です。
2.S3上にデータをアップロード
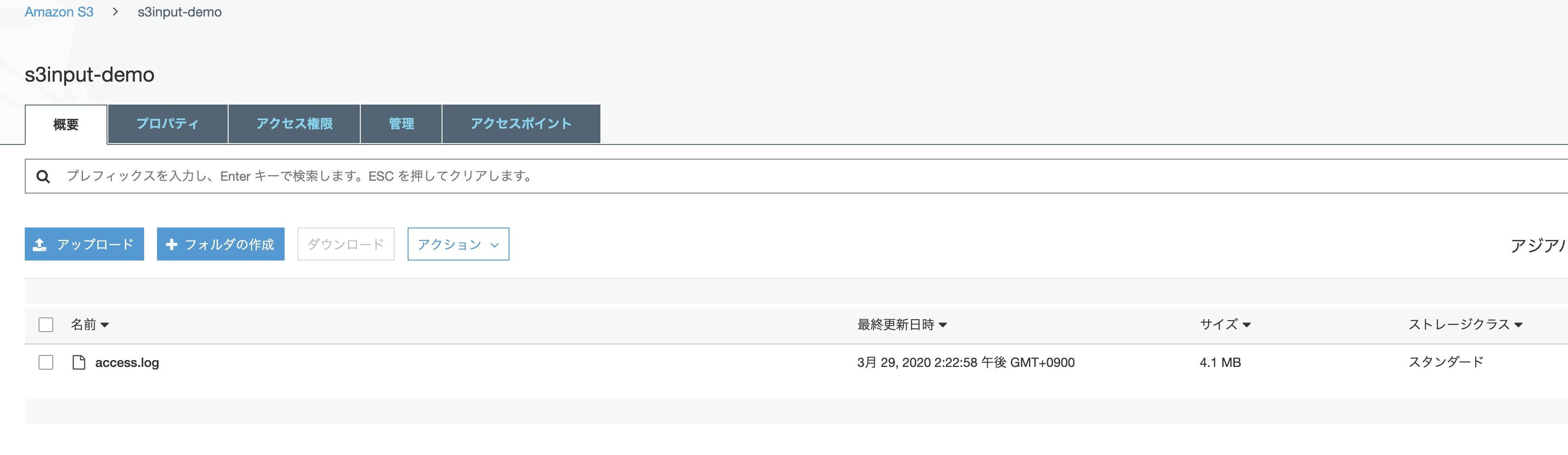
今回は Splunk tutorial data 内にある access.log をアップロードしてみます。
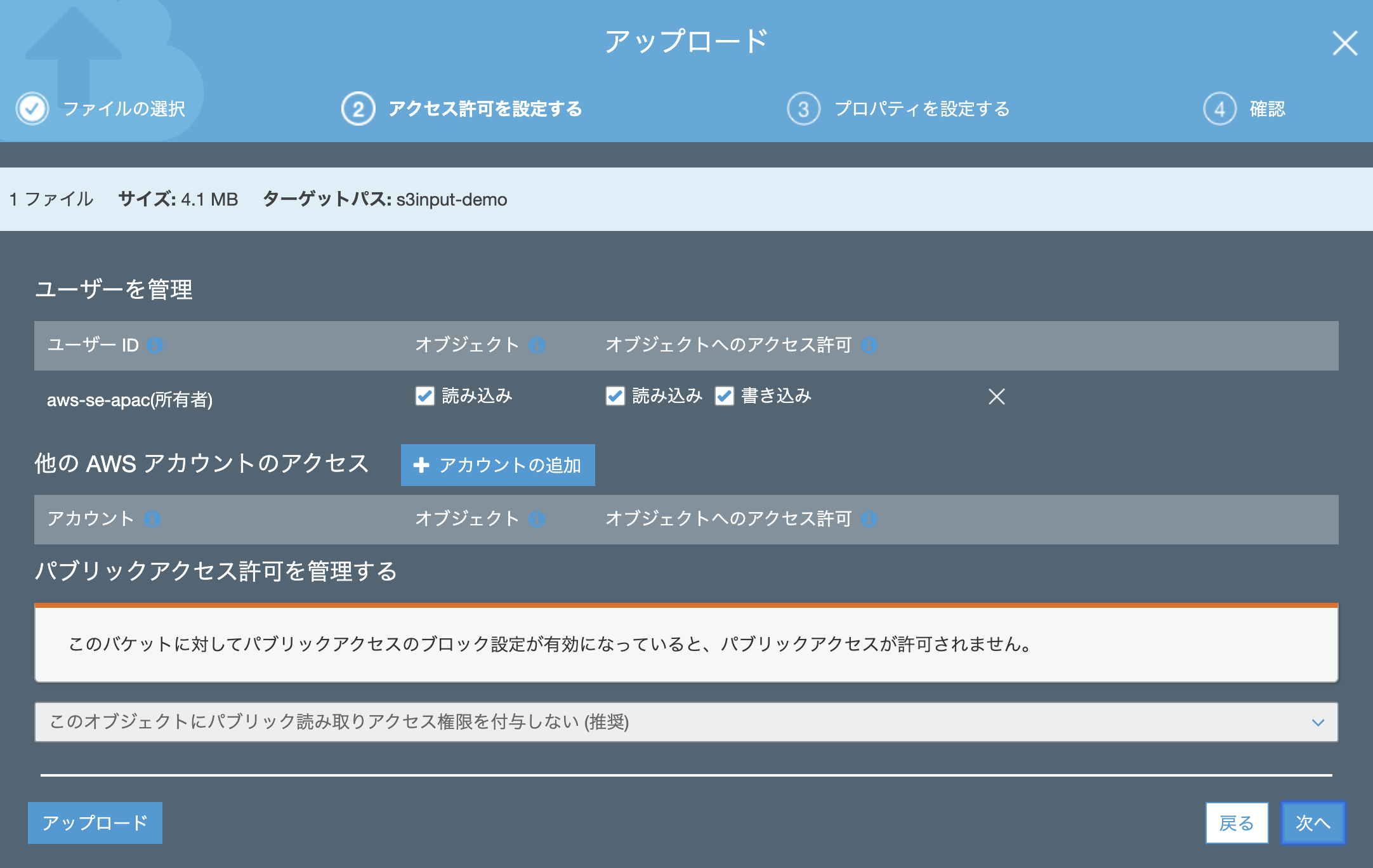
アクセス許可は特に追加する必要はありません。(デフォルトのままでOK)
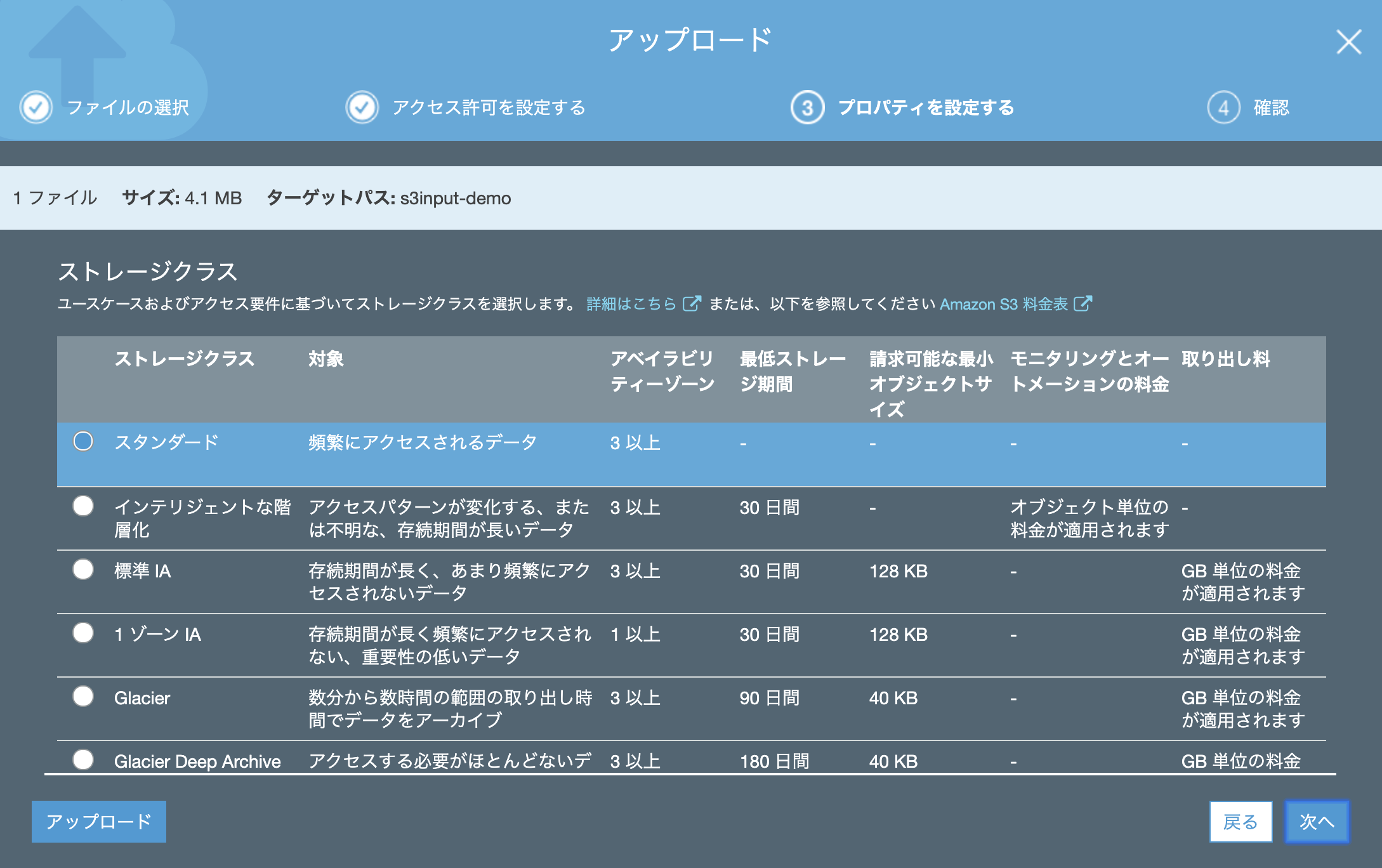
プロパティも「スタンダード」でアップします。(他のクラスでも多分大丈夫かと)
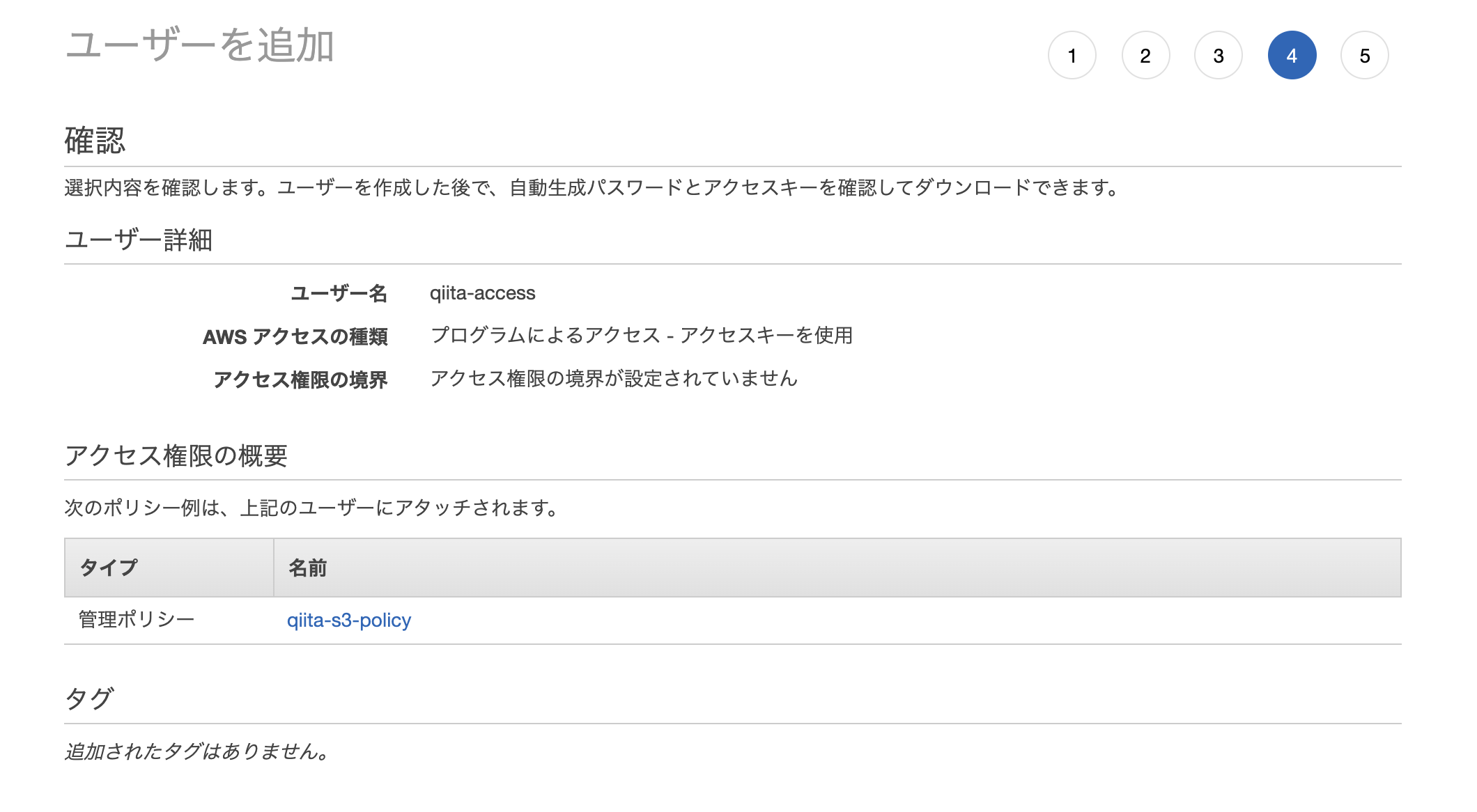
3. IAMユーザー作成
次に 外部からS3にアクセスできるようにユーザーと権限の設定をしていきます。まずはユーザー作成から。
[IAM]サービス -- [ユーザー」 -- [ユーザー追加]
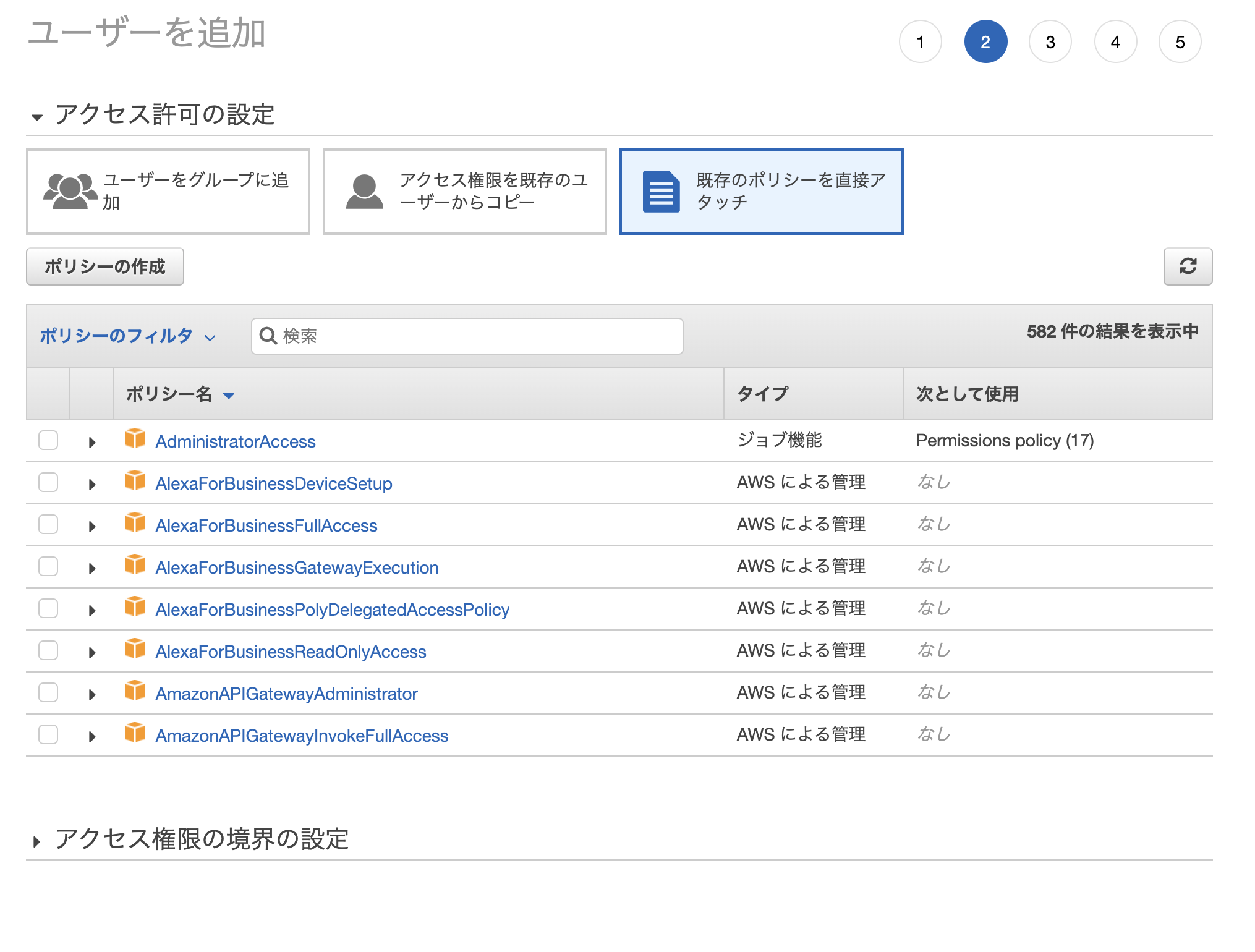
「プログラムによるアクセス」にチェックを入れるのを忘れずに!!次にアクセス許可設定ですが、「既存のポリシーを直接アタッチ」をクリックして、「ポリシーの作成」をクリック
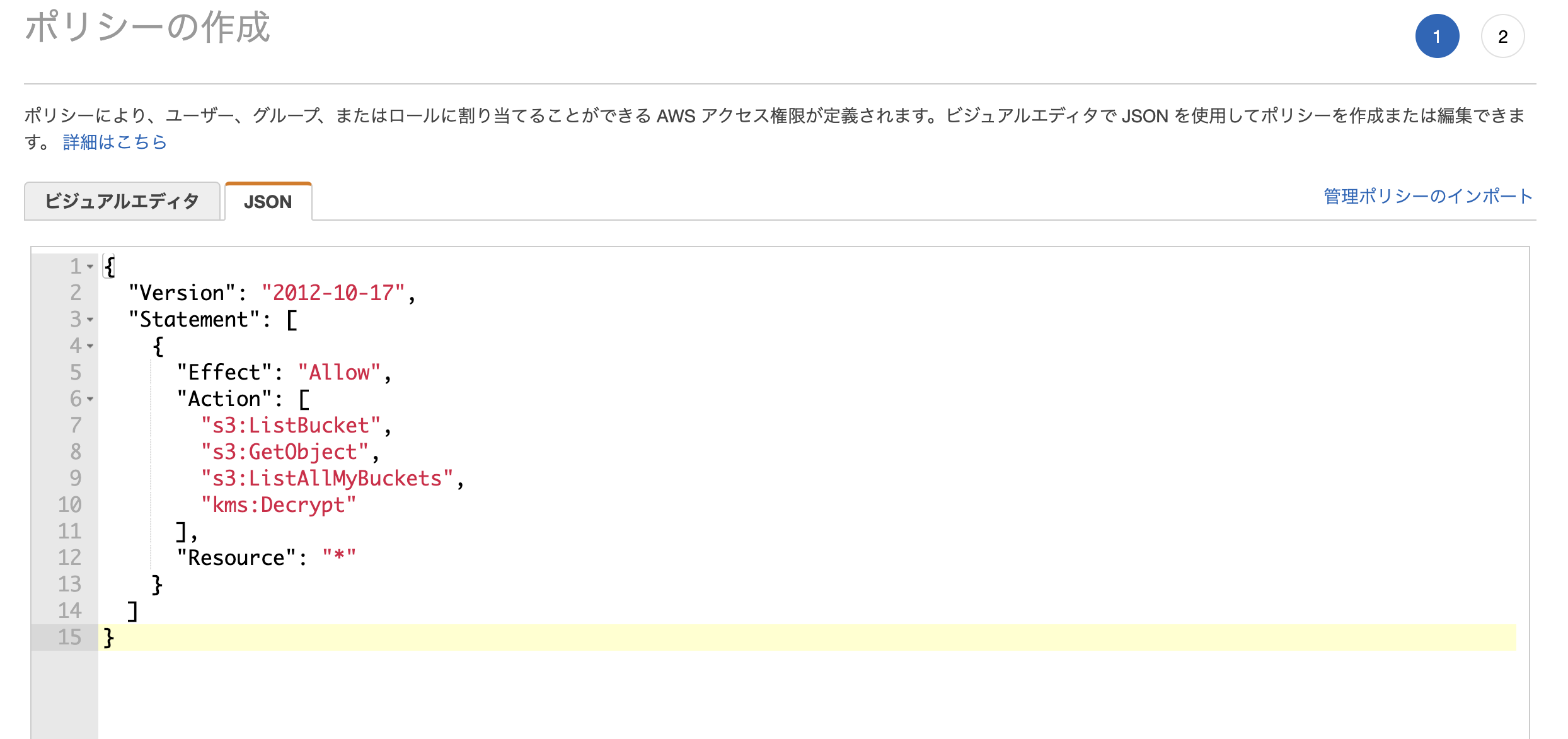
「ポリシー作成」 - [JSON] 設定画面にて以下のように上書き
(下をコピペして使ってください)
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetObject", "s3:ListAllMyBuckets", "kms:Decrypt" ], "Resource": "*" } ] }適当にポリシー名を作成して完成
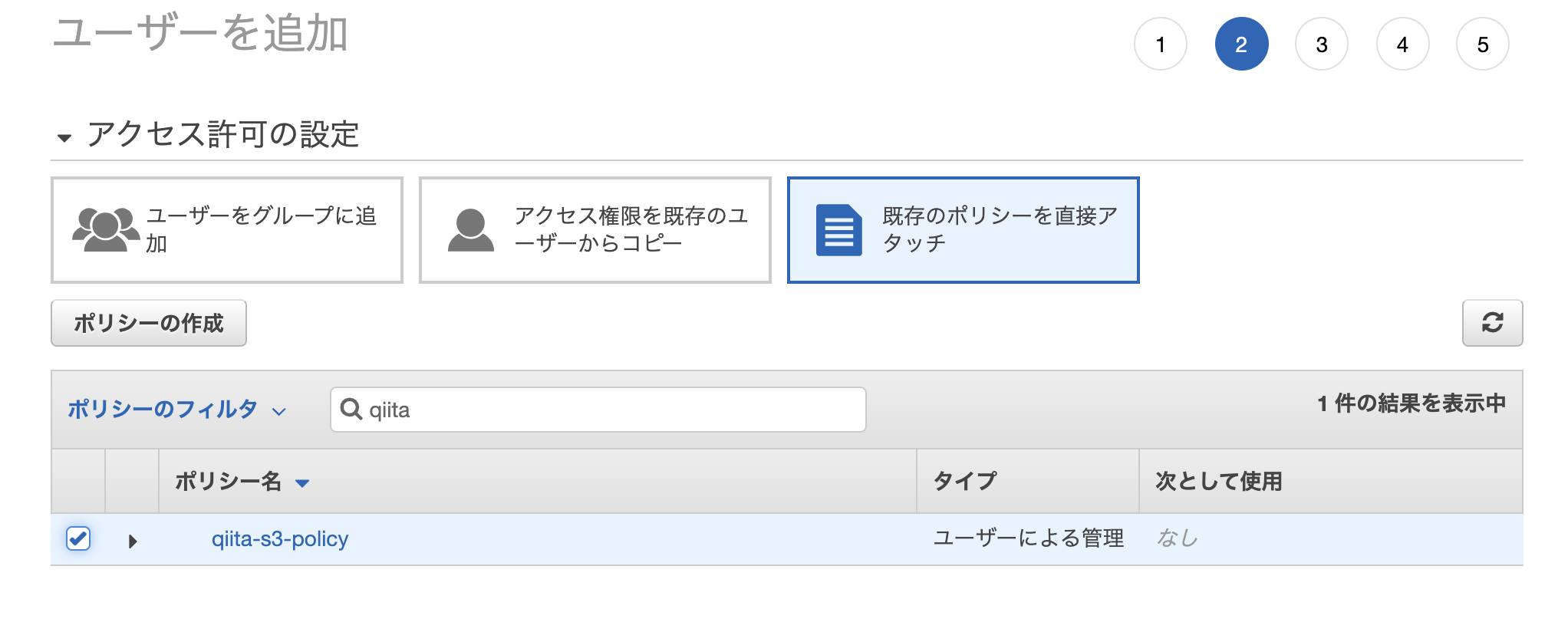
ポリシー追加画面に戻って、「更新」をしてから、作成したポリシーを追加する
タグは特に不要
ユーザー追加も不要
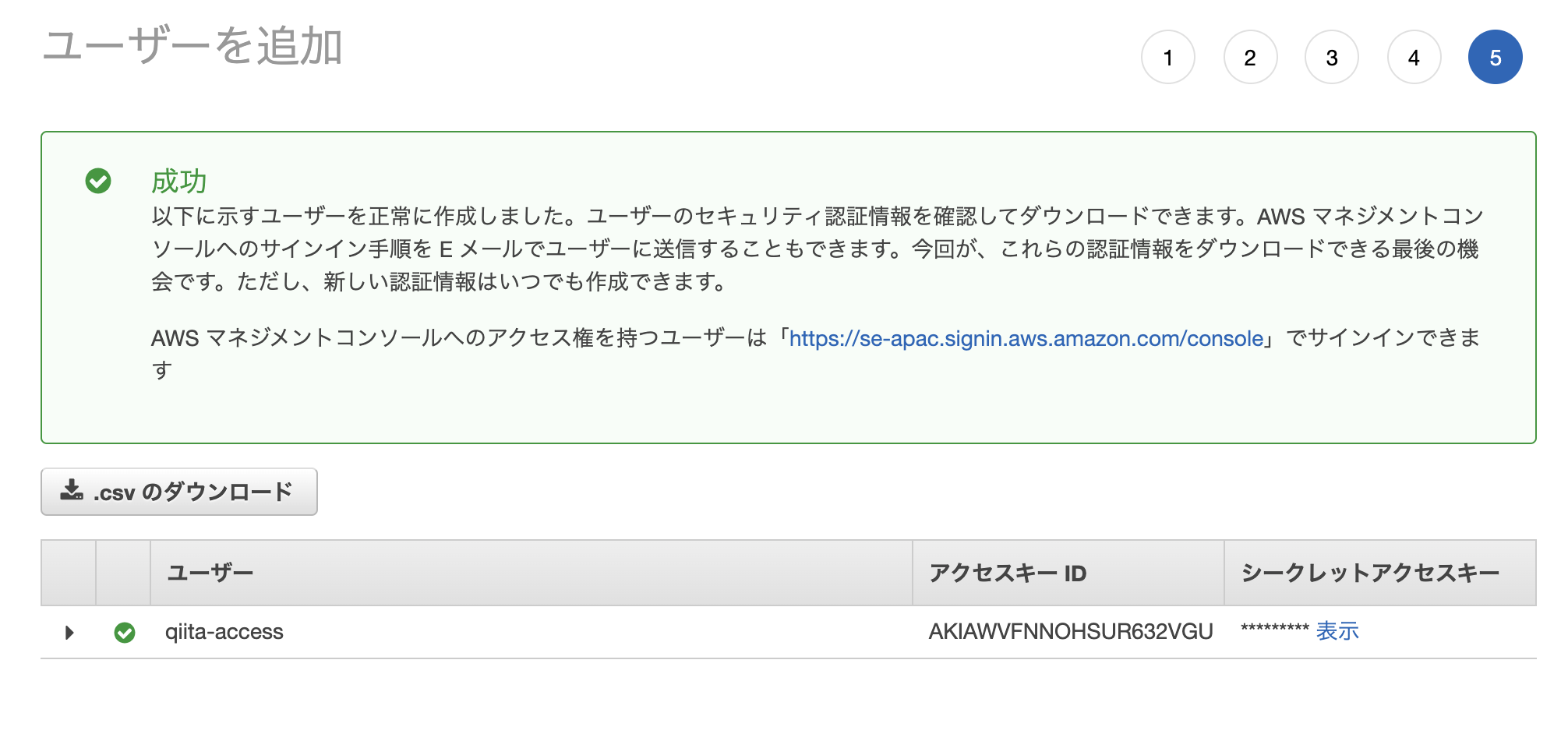
アクセスキーとシークレットアクセスキーは後で使うので大事に保存しておいてください。(csvをダウンロードしておく)
これで、AWS側の設定は終了です。
Splunk側の設定
4. APPの追加 (Add-on for AWS)
Splunk Add-On for AWS をSplunkにインストールします。
https://splunkbase.splunk.com/app/1876/ここではインストール方法については割愛します。
5.Configuration (User追加)
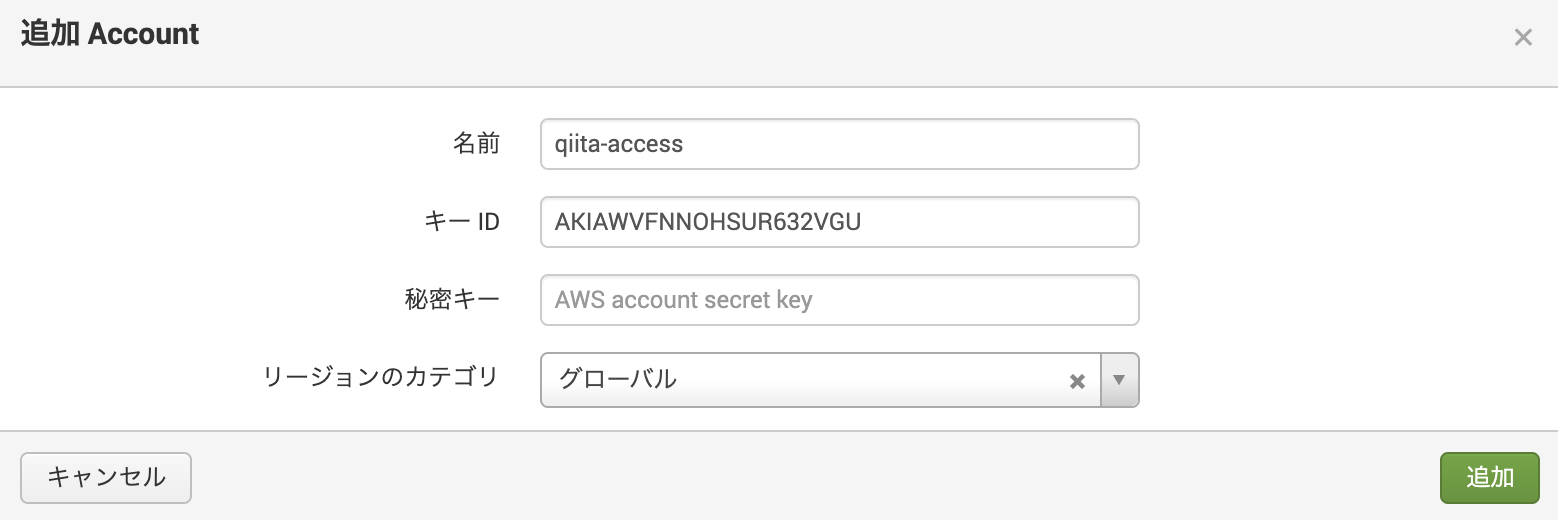
Splunk Add-on for AWS アプリを開き、 [Configuration] - [Account] に移動し、追加ボタンをクリック
3.で作成した AWS のユーザー (qiita-access)のアクセスキーとシークレットアクセスキーを入力
こんな感じでユーザーが追加されれば OK!
6. Input設定
それではおまたせしました。S3上のデータを取り込みましょう!! (イエーイ)
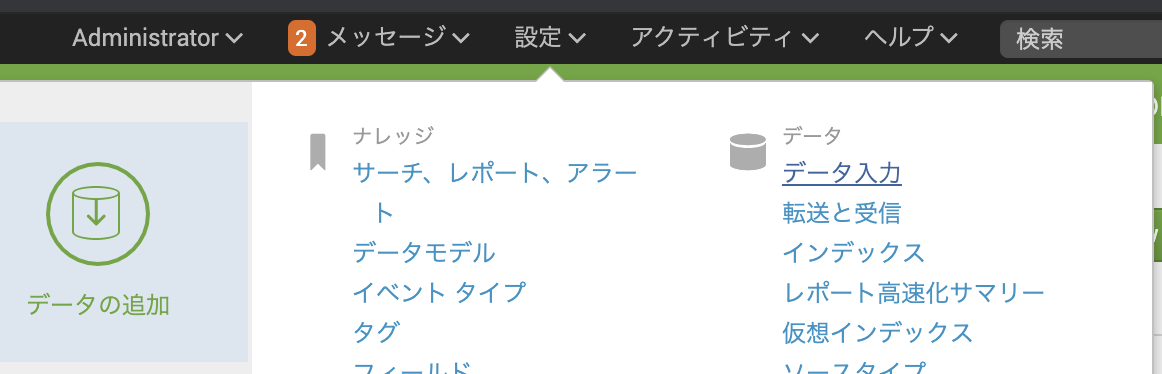
右上の「設定」ー「データ入力」 をクリック
[AWS S3] という項目があるので、 [add new] で追加します。
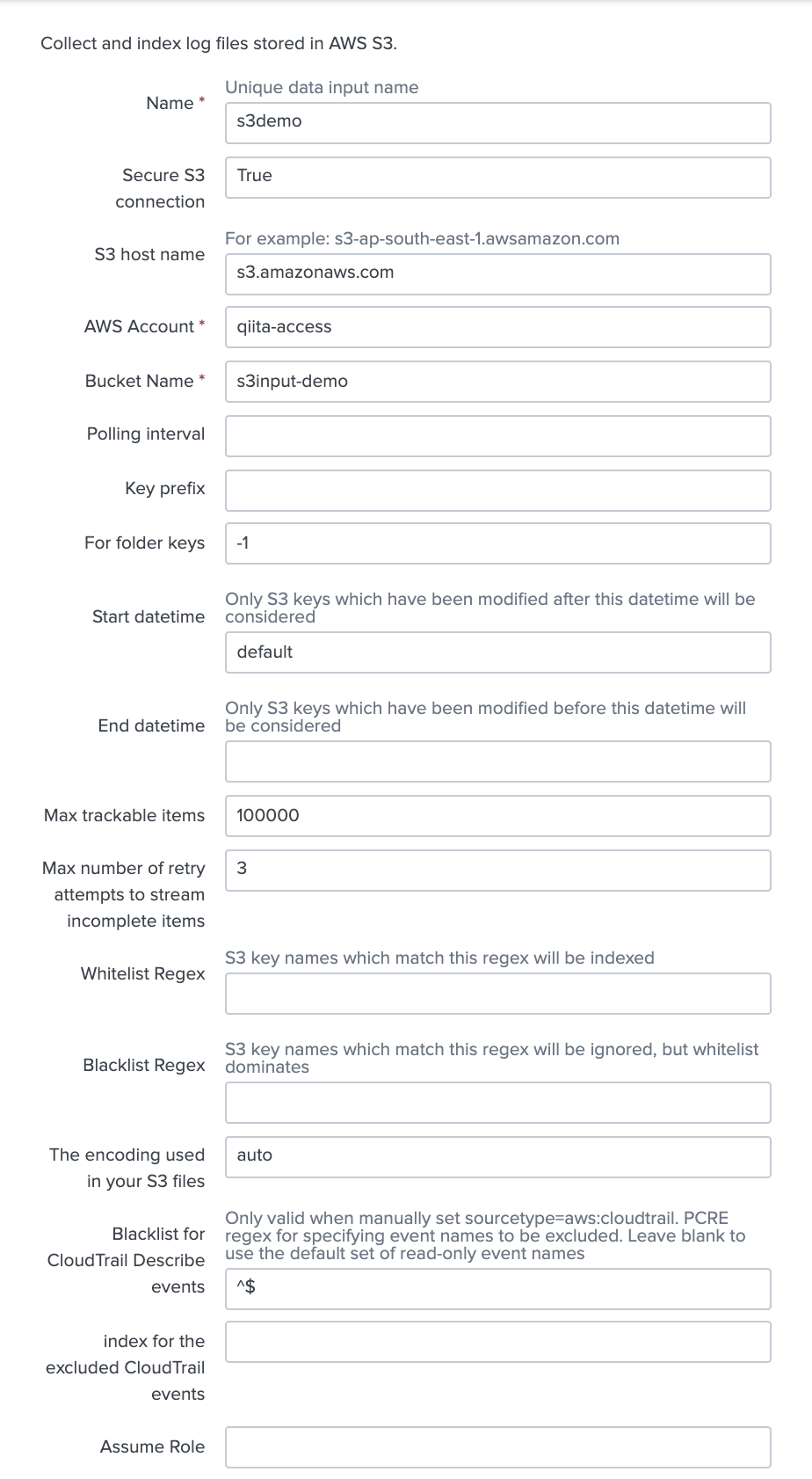
必須記入項目である以下の3つを入力。 (必要に応じて他の項目を入力してください)
・ Name : s3demo
・ AWS Account : qiita-access (先ほど追加したユーザー)
・ Bucket Name : s3input-demo (先ほど作成した S3 Bucket Name)
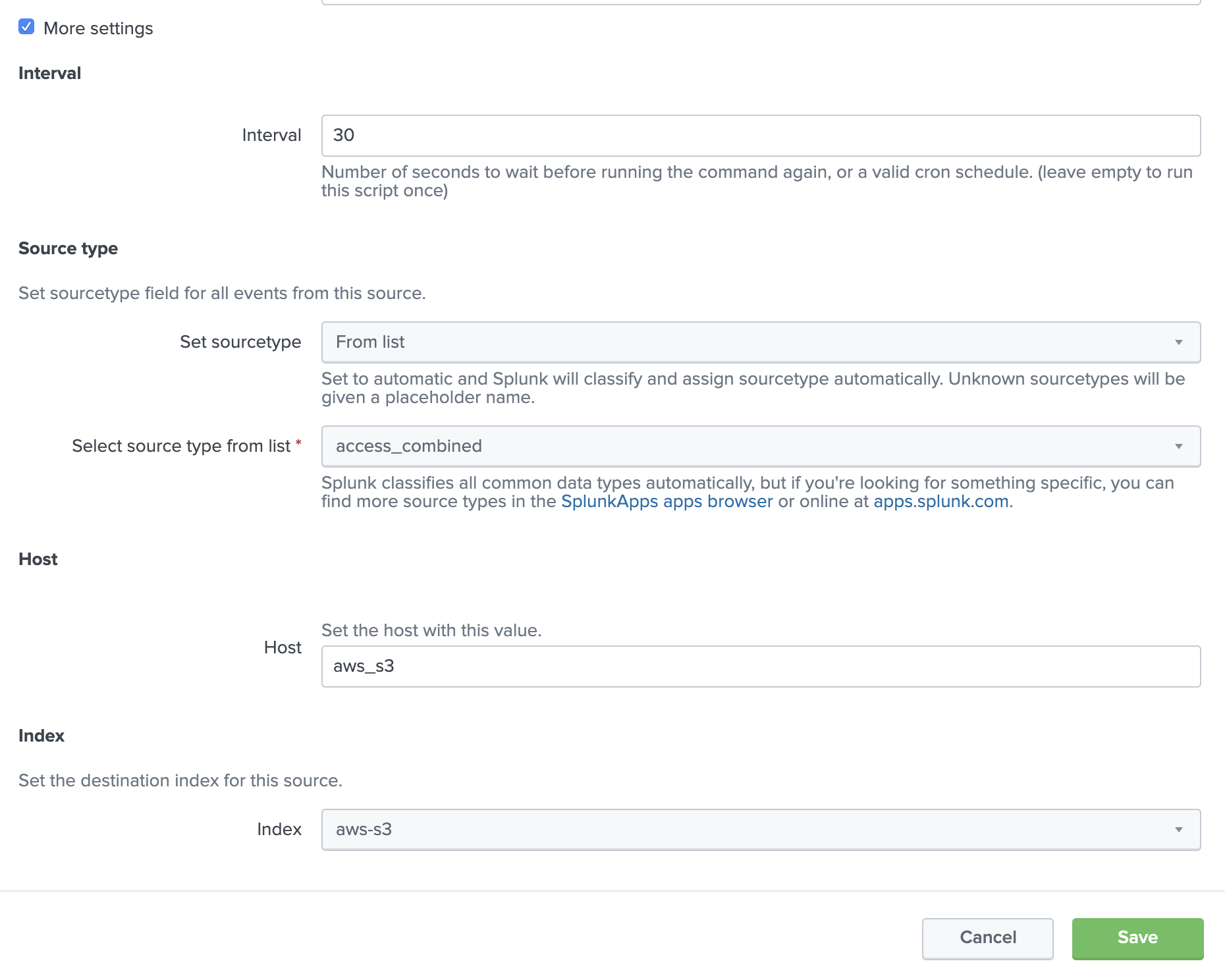
一番下の「more settings」チェックを入れて追加入力項目を編集します。
- Interval : 30 (default) <-- データを取りに行く Polling time
- Set Sourcetype : From list <-- データのソースタイプに併せて選択してください。今回はTutorial DataでSourcetypeがわかっているため access_combined を指定します。
- Host: aws_s3 <-- データのメタ情報として追加するHost名。今回は適当に入力しておきます。
- Index : aws-s3 <-- 今回S3上のデータをSplunk内のどのIndex に取り込むか。 予め aws-s3 という Indexを作ってあるためそれを指定します。
Splunk の設定も以上です。
データの確認
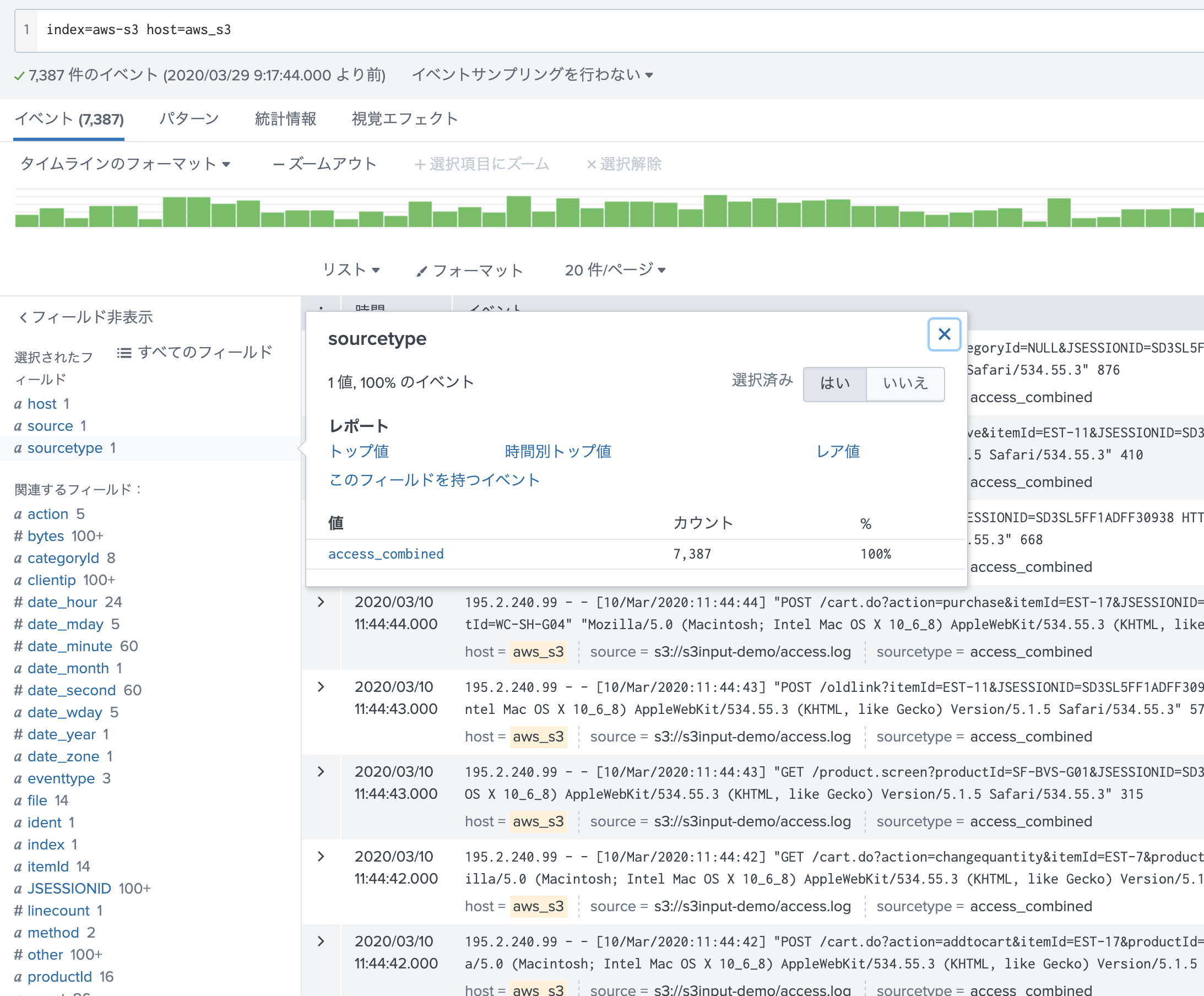
それでは、データが取り込めているか確認してみましょう!
ちゃんと、ソースタイプを理解して Field抽出もできております。
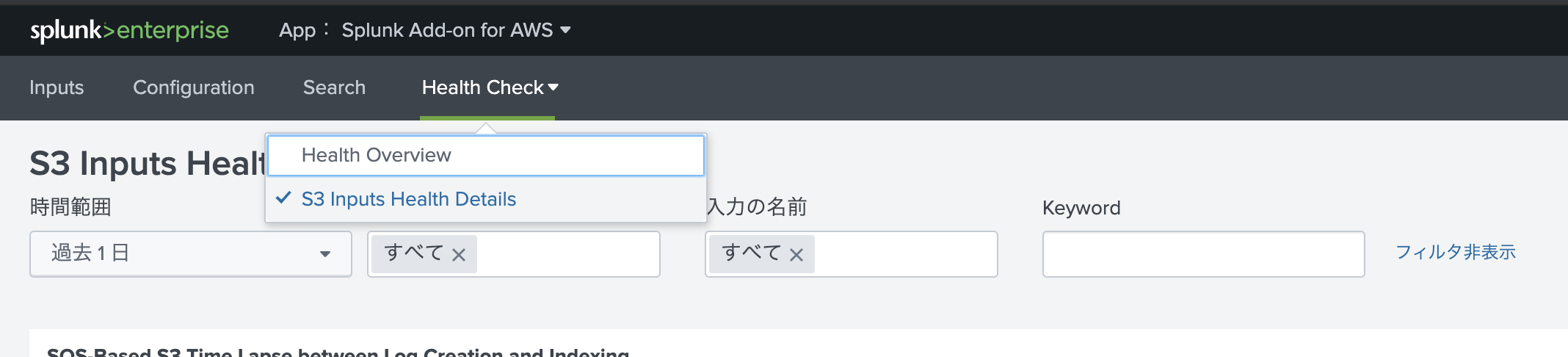
もし、データ取り込みがうまくいかない場合は、 Add-Onアプリの「Health Check」 - [S3 Inputs Health Details]からエラーを確認してみてください。
こんな感じでエラー情報が確認できます。(メッセージ内容は今回の取り込みのものではありません)
その他
ドキュメントに書かれていた利用時の追加情報です。
https://docs.splunk.com/Documentation/AddOns/released/AWS/S3#Configure_a_Generic_S3_input_using_Splunk_WebS3内の特定のデータのみ抽出したい場合
S3 Bucket単位で設定可能ですが、同じS3 Bucket内に様々なデータがある場合、全部を取り込むのはコストがかかるのでやりたくないですよね。
そのような場合に、特定のファイルのみ取り込むような設定ができます。Input設定の箇所で、オプション項目が沢山ありましたが、そこでファイル名の Prefix や 正規表現による White / Black List設定、Time Rangeによる設定などが可能です。詳細はこちらのマニュアルをご覧ください。
https://docs.splunk.com/Documentation/AddOns/released/AWS/S3#Configure_a_Generic_S3_input_using_Splunk_Web圧縮ファイルの対応
データ入力では、以下の圧縮形式をサポートしています。
ZIP、GZIP、TAR、またはTAR.GZ形式の単一ファイル
ZIP、TAR、またはTAR.GZ形式のフォルダを含む、または含まない複数のファイル
https://docs.splunk.com/Documentation/AddOns/released/AWS/S3#Configure_a_Generic_S3_input_using_Splunk_Web大量のデータ取り込みについて
S3 バケットに非常に多くのファイルが含まれている場合、1 つの S3 バケットに対して複数の S3 入力を設定することでパフォーマンスを向上させることができます。その際に同じファイルを重複して取り込まないように、各入力設定で取り込むファイルを分類しながら取り込む必要があります。また、1つの入力設定で1つのソースタイプしか指定できないため、データの種類が複数ある場合は、別の入力設定にした方が良さそうです。
Splunkでは、データ量が多いPull型取得の場合は SQSを使った取り込みを推奨しております。そうすることでQueueにデータを貯める事ができ、Add-On側を増やす事でスケールできるのと、再送してくれるためデータの信頼性が増します。また Kinesis Firehoseや Lamdaを使った Push型のデータ取り込みも推奨しております。
S3 上の古いデータについて
ベストプラクティスとして、S3バケットのコンテンツを積極的に収集する必要がなくなったらアーカイブしましょう。
AWSでは、入力がバケットをスキャンして新しいファイルや変更されたファイルを探すために使用するリストキーのAPIコールに課金されるため、古いS3キーを別のバケットやストレージタイプにアーカイブすることでコストを削減し、パフォーマンスを向上させることができます。
取り込みデータに関する注意点
S3 データ入力は、頻繁に変更されるファイルを読み込むことを目的としていません。ファイルがインデックス化された後に変更された場合、Splunk はそのファイルを再度インデックス化してしまい、データが重複してしまいます。
key/blacklist/whitelist オプションを使用して、後で変更されないことがわかっているファイルのみをインデックス化するよう設定してください。
最後に
今回はなるべく設定箇所が少ない Pull型の取り込み方法を紹介しました。今回の設定は比較的シンプルですぐに試す事ができますが、一方で大量のデータを裁くには向いていないのと、送信保証がないため、取りこぼしに気づけない可能性があります。それを補いためにはSQS/SNSを使った取り込みがあります。 また Streamingデータのように大容量のデータを裁くため、Kinesisや lamda を使った Push型の取り込みにも対応しております。また機会があればそちらにも挑戦してみたいと思います。
参考情報
Splunk Add-On for AWS Documents
https://docs.splunk.com/Documentation/AddOns/released/AWS/Description取り込みに必要な IAM Policy Permission
https://docs.splunk.com/Documentation/AddOns/released/AWS/ConfigureAWSpermissions#Configure_S3_permissionsSizin Information
https://docs.splunk.com/Documentation/AddOns/released/AWS/Sizingandcost





- 投稿日:2020-03-29T19:03:28+09:00
AWS S3 上のデータを Splunk に取り込んでみる
はじめに
最近では AWS S3をベースとしたデータレイクを構築してデータをまとめているケースも多くあると思います。そこで今回はS3上のログをSplunkに取り込むまでをやってみたいと思います。いろいろな取り込み方法があるのですが、今回はとにかくシンプルかつ早い設定をテーマにやってみます。
設定の流れ
大きく分けると AWS上の設定とSplunk上の設定の2つが必要になります。
AWS上の設定
1. AWS S3 Bucket の作成
2. S3 上にデータをアップロード
3. IAMユーザー作成 & ポリシー作成しユーザーへの権限付与Splunk上の設定
4. APPの追加 (Add-on for AWS)
5. Configuration (User追加)
6. Input設定AWS上の設定
1. AWS S3 Bucket の作成
まずは通常通り S3 Bucke を作成します。Publicアクセスはすべてブロックで大丈夫です。
2.S3上にデータをアップロード
今回は Splunk tutorial data 内にある access.log をアップロードしてみます。
アクセス許可は特に追加する必要はありません。(デフォルトのままでOK)
プロパティも「スタンダード」でアップします。(他のクラスでも多分大丈夫かと)
3. IAMユーザー作成
次に 外部からS3にアクセスできるようにユーザーと権限の設定をしていきます。まずはユーザー作成から。
[IAM]サービス -- [ユーザー」 -- [ユーザー追加]
「プログラムによるアクセス」にチェックを入れるのを忘れずに!!次にアクセス許可設定ですが、「既存のポリシーを直接アタッチ」をクリックして、「ポリシーの作成」をクリック
「ポリシー作成」 - [JSON] 設定画面にて以下のように上書き
(下をコピペして使ってください)
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetObject", "s3:ListAllMyBuckets", "kms:Decrypt" ], "Resource": "*" } ] }適当にポリシー名を作成して完成
ポリシー追加画面に戻って、「更新」をしてから、作成したポリシーを追加する
タグは特に不要
ユーザー追加も不要
アクセスキーとシークレットアクセスキーは後で使うので大事に保存しておいてください。(csvをダウンロードしておく)
これで、AWS側の設定は終了です。
Splunk側の設定
4. APPの追加 (Add-on for AWS)
Splunk Add-On for AWS をSplunkにインストールします。
https://splunkbase.splunk.com/app/1876/ここではインストール方法については割愛します。
5.Configuration (User追加)
Splunk Add-on for AWS アプリを開き、 [Configuration] - [Account] に移動し、追加ボタンをクリック
3.で作成した AWS のユーザー (qiita-access)のアクセスキーとシークレットアクセスキーを入力
こんな感じでユーザーが追加されれば OK!
6. Input設定
それではおまたせしました。S3上のデータを取り込みましょう!! (イエーイ)
右上の「設定」ー「データ入力」 をクリック
[AWS S3] という項目があるので、 [add new] で追加します。
必須記入項目である以下の3つを入力。 (必要に応じて他の項目を入力してください)
・ Name : s3demo
・ AWS Account : qiita-access (先ほど追加したユーザー)
・ Bucket Name : s3input-demo (先ほど作成した S3 Bucket Name)
一番下の「more settings」チェックを入れて追加入力項目を編集します。
- Interval : 30 (default) <-- データを取りに行く Polling time
- Set Sourcetype : From list <-- データのソースタイプに併せて選択してください。今回はTutorial DataでSourcetypeがわかっているため access_combined を指定します。
- Host: aws_s3 <-- データのメタ情報として追加するHost名。今回は適当に入力しておきます。
- Index : aws-s3 <-- 今回S3上のデータをSplunk内のどのIndex に取り込むか。 予め aws-s3 という Indexを作ってあるためそれを指定します。
Splunk の設定も以上です。
データの確認
それでは、データが取り込めているか確認してみましょう!
ちゃんと、ソースタイプを理解して Field抽出もできております。
もし、データ取り込みがうまくいかない場合は、 Add-Onアプリの「Health Check」 - [S3 Inputs Health Details]からエラーを確認してみてください。
こんな感じでエラー情報が確認できます。(メッセージ内容は今回の取り込みのものではありません)
その他
ドキュメントに書かれていた利用時の追加情報です。
https://docs.splunk.com/Documentation/AddOns/released/AWS/S3#Configure_a_Generic_S3_input_using_Splunk_WebS3内の特定のデータのみ抽出したい場合
S3 Bucket単位で設定可能ですが、同じS3 Bucket内に様々なデータがある場合、全部を取り込むのはコストがかかるのでやりたくないですよね。
そのような場合に、特定のファイルのみ取り込むような設定ができます。Input設定の箇所で、オプション項目が沢山ありましたが、そこでファイル名の Prefix や 正規表現による White / Black List設定、Time Rangeによる設定などが可能です。詳細はこちらのマニュアルをご覧ください。
https://docs.splunk.com/Documentation/AddOns/released/AWS/S3#Configure_a_Generic_S3_input_using_Splunk_Web圧縮ファイルの対応
データ入力では、以下の圧縮形式をサポートしています。
ZIP、GZIP、TAR、またはTAR.GZ形式の単一ファイル
ZIP、TAR、またはTAR.GZ形式のフォルダを含む、または含まない複数のファイル
https://docs.splunk.com/Documentation/AddOns/released/AWS/S3#Configure_a_Generic_S3_input_using_Splunk_Web大量のデータ取り込みについて
S3 バケットに非常に多くのファイルが含まれている場合、1 つの S3 バケットに対して複数の S3 入力を設定することでパフォーマンスを向上させることができます。その際に同じファイルを重複して取り込まないように、各入力設定で取り込むファイルを分類しながら取り込む必要があります。また、1つの入力設定で1つのソースタイプしか指定できないため、データの種類が複数ある場合は、別の入力設定にした方が良さそうです。
Splunkでは、データ量が多いPull型取得の場合は SQSを使った取り込みを推奨しております。そうすることでQueueにデータを貯める事ができ、Add-On側を増やす事でスケールできるのと、再送してくれるためデータの信頼性が増します。また Kinesis Firehoseや Lamdaを使った Push型のデータ取り込みも推奨しております。
S3 上の古いデータについて
ベストプラクティスとして、S3バケットのコンテンツを積極的に収集する必要がなくなったらアーカイブしましょう。
AWSでは、入力がバケットをスキャンして新しいファイルや変更されたファイルを探すために使用するリストキーのAPIコールに課金されるため、古いS3キーを別のバケットやストレージタイプにアーカイブすることでコストを削減し、パフォーマンスを向上させることができます。
取り込みデータに関する注意点
S3 データ入力は、頻繁に変更されるファイルを読み込むことを目的としていません。ファイルがインデックス化された後に変更された場合、Splunk はそのファイルを再度インデックス化してしまい、データが重複してしまいます。
key/blacklist/whitelist オプションを使用して、後で変更されないことがわかっているファイルのみをインデックス化するよう設定してください。
最後に
今回はなるべく設定箇所が少ない Pull型の取り込み方法を紹介しました。今回の設定は比較的シンプルですぐに試す事ができますが、一方で大量のデータを裁くには向いていないのと、送信保証がないため、取りこぼしに気づけない可能性があります。それを補いためにはSQS/SNSを使った取り込みがあります。 また Streamingデータのように大容量のデータを裁くため、Kinesisや lamda を使った Push型の取り込みにも対応しております。また機会があればそちらにも挑戦してみたいと思います。
参考情報
Splunk Add-On for AWS Documents
https://docs.splunk.com/Documentation/AddOns/released/AWS/Description取り込みに必要な IAM Policy Permission
https://docs.splunk.com/Documentation/AddOns/released/AWS/ConfigureAWSpermissions#Configure_S3_permissionsSizin Information
https://docs.splunk.com/Documentation/AddOns/released/AWS/Sizingandcost
- 投稿日:2020-03-29T17:57:00+09:00
[知識ゼロから30時間で]AWS認定クラウドプラクティショナーに合格する方法
この記事はなに?
先日、AWS認定クラウドプラクティショナーを取得したので
その時の学習方法を紹介する記事です。
取得前はAWSに関する知識ゼロでした。
学習時間は大体30時間くらい。この記事に向いている人
・AWSの知識ゼロの人
・効率的にAWS認定クラウドプラクティショナーに合格したい人AWSってなに?
AWSとは、Amazonが提供するクラウドサービスのこと。
余談なんですが、その他の有名なクラウドサービスとしては
GoogleのGCP、MicrosoftのAzureなんかがあるらしい。AWS認定クラウドプラクティショナーってなに?
AWSに関する知識を認定する資格がAWS認定試験です。
AWS認定試験の中でも一番基礎的なレベルの試験がAWS認定クラウドプラクティショナーです。
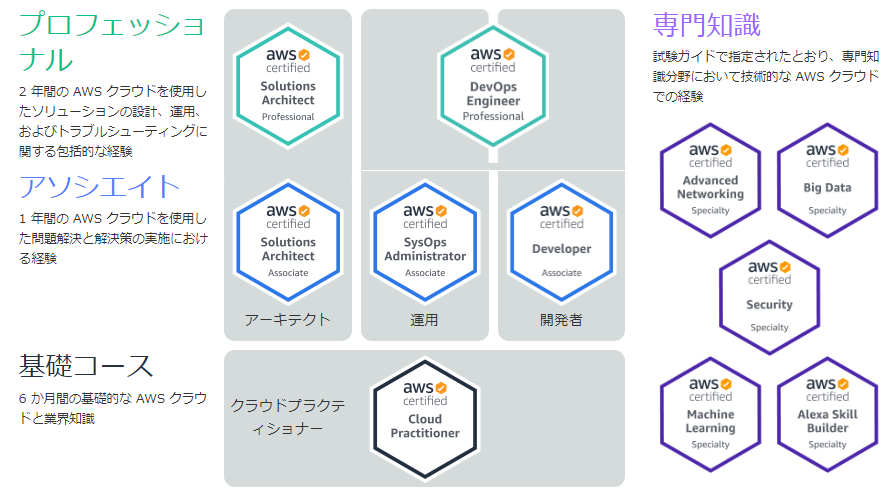
公式サイトによると、他のAWS認定試験との関係はこんな感じ。
全部で11種類の試験があるみたいですね。
<引用元公式サイト:https://aws.amazon.com/jp/certification/?nc2=h_ql_le_tc_c>
使用教材
使用した教材は
教科書1冊 & 問題集2冊です。教科書:
・AWS認定資格試験テキスト AWS認定 クラウドプラクティショナー
Amazonで単行本版とkindle版が売っていました。私は単行本版を買いましたが、紙質がちょっと固めで読んでいて手が疲れました。
内容は読みやすくてgood。各章ごとに練習問題があるので理解度を確認しながら読み進められる。問題集①:
・AWS認定 クラウドプラクティショナー 模擬問題集 Kindle版
Amazonのkindleで売っているものです。問題数は試験2回分と少なめですが、解説のわかりやすさが素晴らしい。問題集②:
・この問題だけで合格可能!AWS 認定クラウドプラクティショナー 模擬試験問題集(7回分455問)
Udemyで売っているものです。本番のような試験形式で問題を解けるのがうれしい。
問題数は試験7回分。
基本レベルが試験2回分、応用レベルが試験3回分、高難易度レベルが試験2回分掲載されています。
私はめんどくさかったので基本レベル2回分しか解いてません。合格するための手順
手順1 AWSサービスの全体像をつかむ
AWSのサービスっていっぱいあるんですが、それを一覧にしてまとめてくださった方がいます。
まずはこちらのリストにサラッと目を通しましょう。ぼーっと眺めるだけでOKです。AWSサービス一覧(2019/03版)※2020/01/03更新
私が最初にこれを見たとき、
「うわぁ、こんなにたくさんのサービス覚えるの無理ですやん」
てなったのですが、実際に覚える必要があるのは主要なサービスだけなのでビビらなくて大丈夫です。学習開始の段階で押さえておくべきなのは、
AWSのサービスが「コンピューティング」とか「ストレージ」とか「データベース」とか、
大まかな区分に分かれていること。その区分の中に複数のサービスがあること、です。いま学んでいるサービスはどの区分のサービスで、何を実現するサービスか、
同じ区分内のサービスとは何が違うのか、を意識すると効率よく学習できると思います。手順2 教科書で最低限の知識を得る
教科書を1回通読しましょう。
各章ごとに練習問題があるので解きながら読み進めるのがおすすめです。
私も練習問題を解きながら進めましたが、正解率はボロボロでした。
1回読んだだけではそんなもんです。気にせずサクサク進めましょう。手順3 ひたすら問題集を解く
ここからが本番です。
上でご紹介したkindleの問題集とUdemyの問題集をひたすら解きましょう。
Udemyの問題集は7回分ありますが、基本レベルの問題2回分だけで十分合格できました。kindleの問題集の試験2回分(65問×2)
Udemyの問題集(基本レベルのみ)の試験2回分(65問×2)合計4回分(65問×4)をひたすら解きまくりましょう。
最初はほとんど解けないと思います。
ですのでいきなり試験1回分(65問)全部解いてから答え合わせをするのは精神的につらいです(体験談)。
10問解いたら答え合わせする、くらいがおすすめです。これを試験問題2回分くらい行うと少しずつ解ける問題が増えてくると思います。
そうしたら時間を計測しながら65問全部解いてみましょう。私は最終的に4回分の試験問題を2、3周して
すべての試験で8割くらいとれるようにしました。試験本番
試験時間は90分だったのですが、
のんびり解いても30分くらいは時間が余りました。
少し見直しをして、残り時間25分ぐらいのところで試験終了ボタンを押しました。
試験結果はその場で画面に表示されます。
「合格」とだけ出て、テストの点数が何点なのか、どの分野が得意でどこが苦手なのか、
といった詳細は表示されませんでした。
5日以内にメールで詳細が送信される、とのことです。受験時には
顔写真付きの身分証+別の身分証が必要なので注意です。
私は運転免許証と保険証を持っていきました。最後に
この記事が少しでも皆様のお役に立てれば幸いです。



- 投稿日:2020-03-29T17:37:27+09:00
プルリクに対して検証環境を自動で起動/終了するプログラムを作ったら、検証が捗った話
記事の概要
GitHub Flowでの開発、つまり単純なプルリク運用での開発を、営業も巻き込んで実践したいと思い、そのような環境を作りました。その際、いくつか足りない機能を補うウェブアプリを作って公開したので、それに関する様々な話を書きます。
(実際にこのウェブアプリを使えるかどうかというよりは、似たようなフローで開発を改善できるといいなというような目的の話です。)ウェブアプリのリポジトリ
https://github.com/uniaim-event-team/pullre-kun
このウェブアプリの使い方と機能については、一応README.mdに書いていますが、この記事では少し背景的な話も含めて順番に書きます。
issue対応やその他追加開発などは絶賛募集中です。背景
開発に関するよくある課題
これまで、既存のウェブアプリ(サービス)の機能追加開発において、以下のような課題がありました。
- 検証が十分にできていない機能がある
- 追加した機能の使い方を十分にレクチャーできていない/一部の人にしか認知されず隠し機能になる
- 時間が経過するとみんなその機能の存在を忘れて隠し機能になる
- 実は画面を使えば普通に登録ができるデータ設定作業も開発側でやらざるを得なくなる
そもそもデータを普通の画面から登録できない隠し機能を作って運用してしまうGitHub フロー(を外部的な部分で充実させたフロー)の導入
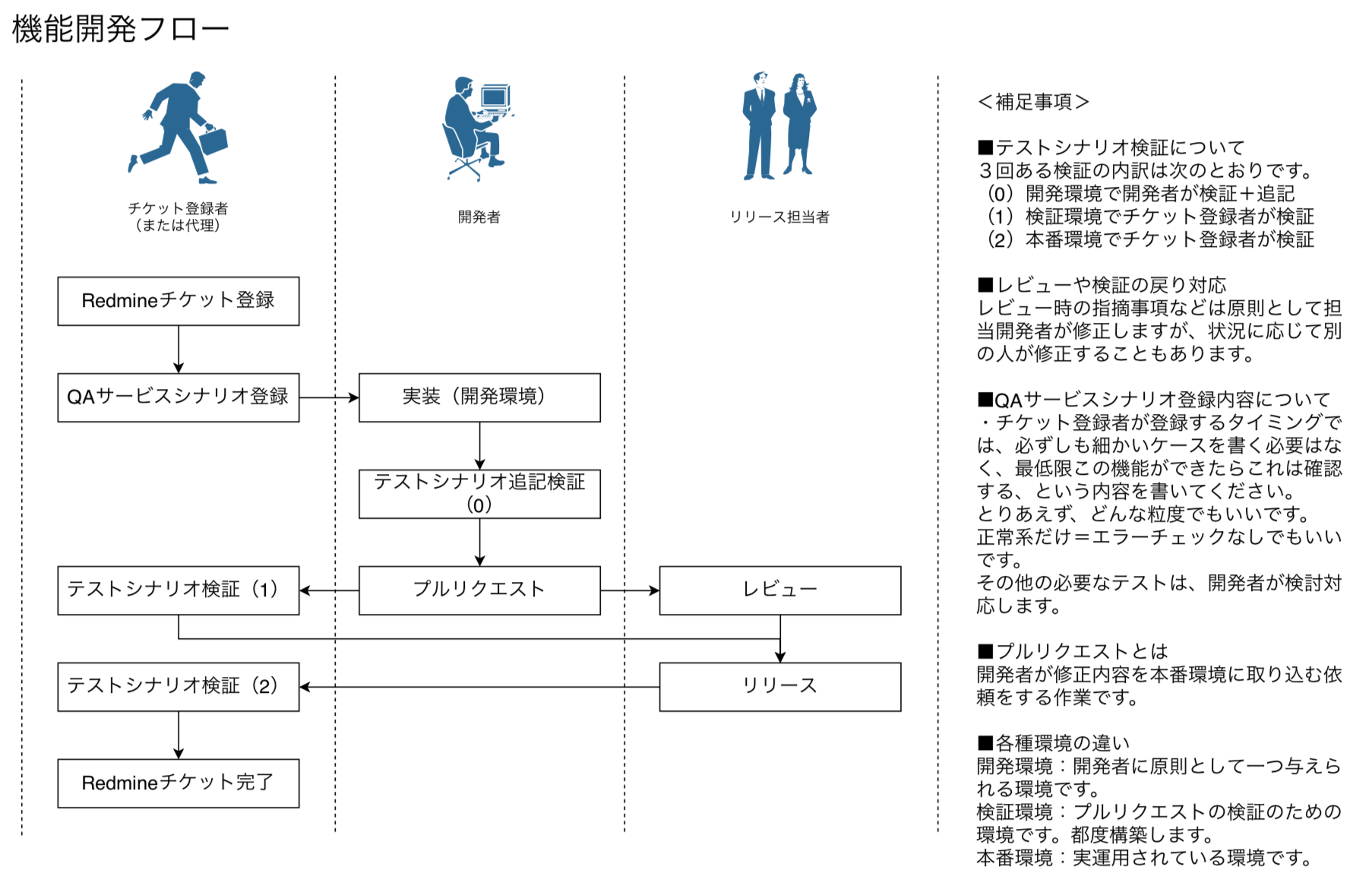
このような課題を解決するために、以下のようなフローでの運用を検討しました。
一般的な類似の作業フローと比較して、すこし強いのは「チケット登録者がテストシナリオまで書く」というところです。
これは色々と迷う部分があったのですが、以下のような点において、技術的に可能か不可能かで言えば可能と思い、信頼して踏み切ることにしました。
- いかに営業の人といえども、お客様に提供する際に、管理画面の最低限の操作説明などは、求められればできるべき。
- 末端のエンドユーザーや、その他システムを使う人が満足に利用できる事の確認は、むしろ技術に関する知識がない状態で実施する方が自然である。
- その際の確認項目を列挙することについて、カバレッジ等の観点は営業側には無いにしても、実際にお客様の前でやることのシミュレーションぐらいは、技術知識が無くても可能なはずである。
ただし、当然ですが、要求・要件を出した人が必ずしも網羅的な試験を書ききるということは不可能だと思うので、必要なものがあれば開発側で増やします。システム内部的に、どのような条件による分岐に依存しているかというような事は、要求・要件を出した時点で洗い出すのは難しく、また技術的な意味でそれらを網羅する試験を書くのは難しいと判断したからです。
フロー導入にあたっての課題
このフローの導入にあたっての、技術的な課題がいくつかあったのですが、概ね次の課題に集約されました。
- チケット登録者は、どの環境で検証するのか
例えば、テーブルの項目を追加したりする改修内容の場合、そのプルリクで定義されているスキーマを参照する必要があります。
開発者の環境でテストをするという方法も無くはないですが、開発者の開発作業は継続しているので、テスト中に使えなくなるという事も往々にして想定されます。また、別改修の影響で正常に動作しない、というような事もあり得て、これはお互いのためによくありません。そもそも、別の改修が一部含まれているソースでのテストは、純粋なプルリク内容に対するテストになっていないという問題もあります。では、それ用の検証環境を手動で作るのかというと、一日に一人が何個もプルリクを作る場合がある状況で、毎回手動でそれ用の検証環境を作るというのはちょっと大変です。
修正がJSだけで済むならばnetlifyのようなものもありますが、スキーマやデータセットを用意する部分に多くの課題があり、またそもそも対象プロジェクトの場合はサーバー側がPythonなので、ちょっと適用できませんでした。
dockerで解決しないのか
原理的にはdockerでも解決できるもので、実際にdockerを使って同様のことをやった話が、少なくとも3年前には存在しています!
Pull Request発行時にそのコミットIDでデプロイされた環境を自動構築してレビュー時/マージ前に確認しやすくする仕組みもともと自動テストを書いて、CircleCIで動かしていたので、ある程度はdockerでも動くのですが、一部の処理は単純にdockerを作るだけではうまく動かず(具体的にはwkhtmlを使ってhtmlをpdfに変換している処理で、途中でxvfbを使ったりしているところをすぐにdockerに載せることができなかった...そこはCircleCIでも動かしていない)、それ用のdockerを作ったりするのがめんどくさくて今に至ります。
実際にやったこと
方針は以下の通りです。
- 事前に検証用インスタンスをたくさん作って、ロードバランサーやDNSの設定をして、サーバープロセスが起動したら普通のアクセスができる状態にしておいた上で、インスタンスをoffにしておく
- DBはAuroraを開発環境含めて共有することにして、そのAuroraを作っておく
- プルリクがあれば、それを拾って検証用インスタンスをonにする
- 検証用インスタンス側で、そのインスタンスがcheckoutすべきコミットを識別して、そのコミットでサーバープロセスを起動する
- プルリクがクローズされたら、対応する検証サーバをoffにする
この、事前作業を除いたプルリクを処理する部分が、ウェブアプリで対応する部分です。
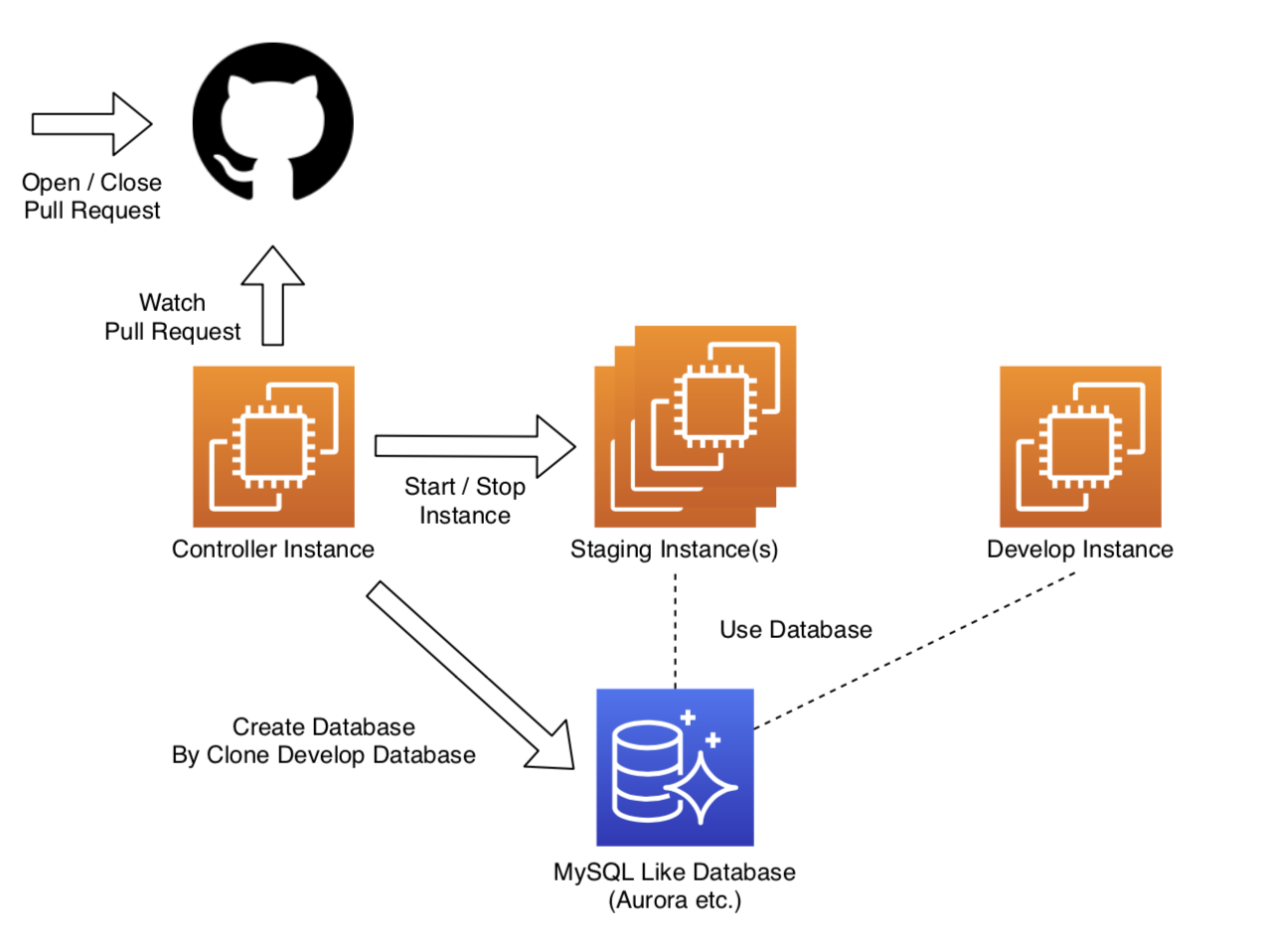
システム構成イメージは以下のとおりです。Controller Instanceでウェブアプリを動かし、Staging Instancesでは定期的にサーバープロセス起動用のバッチ処理を実行します。
実際に運用してみての所見
まだ運用を初めて数週間で、現状は新型コロナの影響などで通常の状態と違っている部分がありますが、とりあえず実画面でのテストは相当しやすくなったと思いました。開発検証者としても、従来、自分の環境でcheckoutしてスキーマ直したりなんやかんやしながらテストしていたものについて、自分の環境を全く触らずに検証できるようになり、とても楽です。
また、リリース前に非開発者を巻き込みやすくなったのも、大きな進歩かなと思います。ウェブアプリのインストール(セットアップ)方法
これはREADME.mdの記載内容と同じです。ほぼほぼGoogle翻訳です。
ec2インスタンスを作成する
EC2インスタンスを作成します。そして、そのうちの1つにポート5250を許可します。 1つは「コントローラーインスタンス」と呼ばれます。
その他は「ステージングインスタンス」と呼ばれます。IAMポリシーとユーザーを作成する
次のアクションを許可するIAMポリシーを作成します。
「ec2:DescribeInstances」
「ec2:StartInstances」
「ec2:StopInstances」ポリシーのリソースは、作成したインスタンスです。(注:DescribInstancesは全てのリソース対象になります)
そして、ポリシーをユーザー/ロールにアタッチし、アクセスキーとシークレットキーを保存します。gitをインストールする
インスタンス全体にgitをインストールします。
注:amazon linux2を使用している場合、$ sudo yum install gitステージングサーバーへのアプリケーションのセットアップ
アプリケーションをステージングサーバーに設定します。
python3をインストールする
インスタンス全体にpython3をインストールします。
注:amazon linux2を使用している場合、$ sudo yum install python3mysql-clientをインストールする
インスタンス全体にmysql-clientをインストールします。
注:amazon linux2を使用している場合、$ sudo yum install mysqlMySQLのようなデータベースを実行またはインストールします
MySQLのようなデータベースを実行またはインストールします。
プルレくん(pullre-kun)のクローン
プルレくんをクローンします。
install "requirements"
requirements(requirements.txtの内容)をインストールします。
get_basic_token.pyを実行します
コントローラインスタンスには基本認証があります。パスワードのトークン(ハッシュ)を作成し、app.iniに保存する必要があります。
app.iniファイルを作成する
app.iniファイルを作成します。サンプルはapp.ini.defaultです。そしてそれをインスタンス全体にデプロイします。
コントローラーサーバーのcrontabを編集する
コントローラサーバーのcrontabに次の行を追加します。
* * * * * cd /home/ec2-user/pullre-kun; python3 update_pull.pyステージングサーバーのcrontabを編集する
ステージングサーバーのcrontabsに次の行を追加します。
* * * * * cd /home/ec2-user/pullre-kun; python3 client.pyinit.pyを実行する
コントローラーサーバーで次のコマンドを実行します。
$ cd ~/pullre-kun $ python3 init.pypullre-kunアプリケーションを実行する
コントローラーサーバーで次のコマンドを実行します。
$ cd ~/pullre-kun $ nohup python3 app.py&サーバーを登録する
https://<your-domain>/server/listにアクセスすると、サーバー全体が表示されます。
次に、ステージングサーバーの登録ボタンをクリックします。
そして、https://<your-domain>/master/serverにアクセスし、各レコードのdb_schemaを更新します。ユーザーを登録する
https://<your-domain>/master/git_hub_usersにアクセスし、ユーザーを登録します。
「login」はgithubユーザーログイン、db_schemaはクローンの元のスキーマです。以上の手順で、プルリクがあれば自動的に検証環境が立ち上がるようになります。
その他の技術的な解説について
全体的にFlask + SQLAlchemyで、ただしサーバーとしてはCherryPyを使うという構成になっています。
希望がたくさんあれば、そのうち解説も書くかもしれません。(SQLAlchemyのmodelに合わせた汎用的なWTFormの使い方が少し特殊)
(この記事にコメントか、GitHubにissueを作って+1でお願いします。)
- 投稿日:2020-03-29T17:21:26+09:00
インベントリー/ナレッジ管理系のElasticsearchフロントアプリを1日で作る
はじめに
Elasticsearchを使って、インベントリーデータをささっと検索して必要な情報を取り出すようなアプリをゼロから1日で作る手順です。所持品やナレッジを分類データ化したものをパソコンやスマホから検索できるようにします。当然データ自体は自分で用意する必要があります。
作成するもの
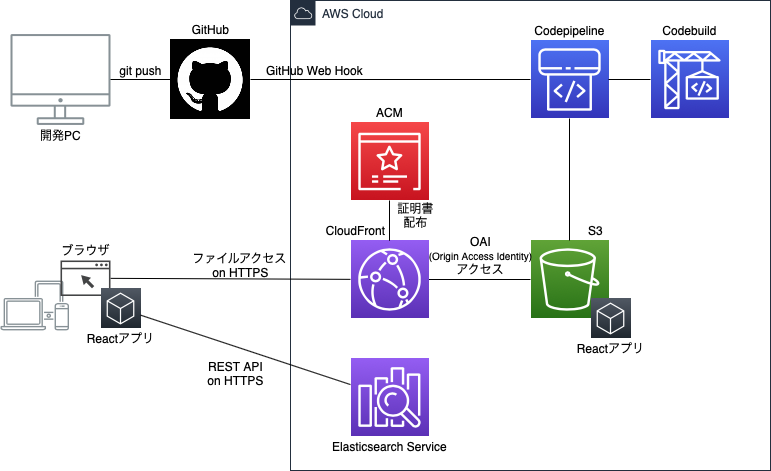
バックエンドはAmazon Elasticsearch Serviceを用意し、データはそこに蓄積します。
フロントエンドはブラウザで動作するReactアプリで、Reactivesearchというコンポーネントを活用して、Elasticsearch Serviceのデータを検索できるようにします。ブラウザ(のJavaScript)から直接Elasticsearch Serviceにアクセスします。
また、Reactアプリを自動でビルドしデプロイする環境もCodepipelineで作ります。アプリの画面イメージ
(この画面はインベントリー管理になっていませんが流用はできると思います)
インフラの概要図
環境
Elasticsearch v7.4
Node.js v13.10.1
React v16.13.0
Reactivesearch v3.5.0手順
詳細手順を記述した記事をこの順番でやっていけば作れます。右端の時間は、順調に進められたときの目安の時間です。
- Amazon Elasticsearch Serviceで検索できる状態まで最速で立ち上げる(30分)
- React版Reactivesearch v3を使ってゼロから最速でElasticsearchフロントアプリを作る(1時間)
- React版ReactivesearchアプリをiPhone縦でも見やすくする(15分)
- AWS S3 + CloudFrontでReactアプリをHTTPS公開するための正しい構成(1時間)
- AWS Codepipelineを使ってReactアプリのCI環境をゼロから作る(1時間)
- Bracketsエディタからgit pushボタンで自動でデプロイされるCI環境を作る(15分)
番外編
今回は対応していませんが、派生での参考記事です。
Amplifyを使えば今回と同等の環境はもっと簡単に作れます。ただし、制約はあります。
AWS Amplify Consoleを使ってReactアプリのCICD環境を10分で作るElasticsearch Serviceに認証を付けたいところですが、今回は制約から見送りました。
Amazon Elasticsearch ServiceのKibana Cognito認証設定をゼロから最小限の設定で実現する
- 投稿日:2020-03-29T16:53:09+09:00
Amazon Elasticsearch ServiceのKibana Cognito認証設定をゼロから最小限の設定で実現する
はじめに
Amazon Elasticsearch ServiceではIAMによる認証機能が提供されています。この記事では、最初にElasticsearch Serviceの認証について概要を説明した後、ElasticsearchのKibana利用時にこの認証機能を設定する手順について説明します。
Amazon Elasticsearch Service認証機能の理解
ソフトウェアのElasticsearchにはBasic認証などもありますが、Amazon Elasticsearch ServiceにはIAM認証しかありません。セキュリティ上はよいことですが、少し利用の敷居を上げることにはなります。
Amazon Elasticsearch Serviceでは、インフラ操作のAWS APIと、データ操作のElastcisearch APIの2種類のAPIがあり、そのどちらもIAM認証となります。AWS APIの方は、AWS CLIやSDKからの操作となるのでIAM認証もうまい具合に隠蔽してやってくれますが、Elasticsearch APIはクライアント側でIAM認証処理=HTTPリクエストへの署名をしないといけなく(Amazon Elasticsearch Service への HTTP リクエストの署名)、これがめんどうです。かつ、クライアントアプリ側では便利なコンポーネントなどを使うことも多いと思いますが、このコンポーネントがAWSのIAM認証に対応しているかが問題になってきます(現状、ほとんどしていません)。Amazon Elasticsearch ServiceがBasic認証にも対応していたらどれだけ簡単かと思う瞬間です。
たとえば、Elasticsearchのフロントアプリ開発を便利にするReactivesearchはIAM認証に対応していません。正確に言うと、有志によってAmazon API GatewayのIAM認証に対応させているケースはあります(Support for Signed Requests / AWS Elasticsearch #419)。が、やはりめんどうです。
その他、AWS Amplifyを使う方法もあります。AWS Amplifyは認証やバックエンドのめんどうな設定を隠蔽して簡単にしてくれる非常に便利なサービスです。Elasticsearchもバックエンドとして使えます。ただし、使い方はDynamoDB Streamsからのインプットに限定されておりAppSync経由での利用しかできなく、かなり画一的な使い方しかできません。Reactivesearchのようなコンポーネントからも使えません。
詳しくは、「Amazon Elasticsearch Service の認証・認可に関する面倒くさい仕様をなるべくわかりやすく説明する」が参考になります。
この記事では、AWSが標準で用意しているKibanaでのIAM認証設定のみを説明します。作成するもの
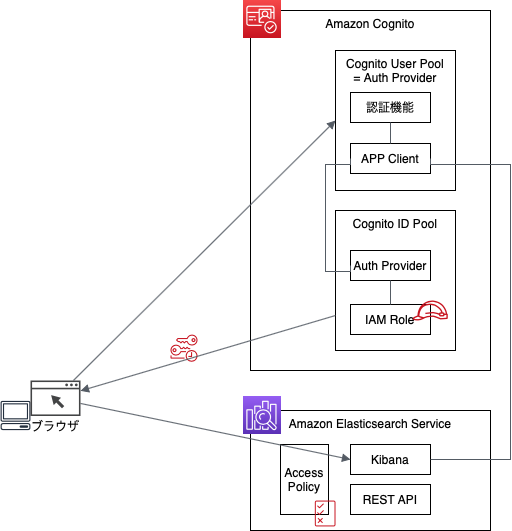
Amazon Elasticsearch Serviceには、Access Policy(通常のAWSサービスにおけるリソースポリシーと同等)機能が用意されており、ここでユーザとして(PolicyのPrincipleとして)IAMユーザやIAMロールを指定するとIAMによる認証が有効となります。Access PolicyのPrincipleを"*(アスタリスク)"とすることで認証なしのアクセスとなります。
ただし、実際にIAM認証を機能させるにはクライアント側での対応も必要です。Elasticsearch Serviceのインフラ系を操作する場合はAWS CLIなどがクライアントとなりIAM認証もそのなかで実現してくれます。Elasticsearch APIを利用する場合は、認証のUIをなんらか実現する必要があります。ここでは、Kibana(実際にはElasticsearch Service自体)をクライアントとし、Cognitoと連携して認証UIを提供する構成を示します。また、Kibanaログインユーザは管理者のみが登録して使用する想定とします。
認証の流れとしては、このようになります
1. Elasticsearch ServiceのKibanaエンドポイント(URL)にアクセスする
2. Cognito User Poolにリダイレクトされる
3. Cognitoの認証画面でユーザID/パスワードを入れて認証する
4. Cognito ID Poolにて、Kibana(CognitoでAPP Clientとして登録)に紐付けられたIAM Roleのセッションキーがブラウザに返される
5. セッションキー等認証情報を持って再度Kibanaエンドポイントにアクセスする
6. Access PolicyのポリシーにしたがってElasticsearchの権限が与えられるユーザ側の認証画面と流れは、「Kibanaにアクセスして確認」のとおり。
事前準備
- Amazon Elasticsearch Service環境(参考:「Amazon Elasticsearch Serviceで検索できる状態まで最速で立ち上げる」)
手順
CognitoでユーザープールとIDプールの入れ物を作り、ユーザープールにユーザ登録し、Elasticsearch ServiceでKibana認証を有効化する(自動的にCognitoに登録される)流れになります。
Cognitoの設定
ユーザープールの作成
自己サインアップを禁止し管理者のみにユーザ作成を許可するようにする点と、ドメイン名の設定以外はデフォルトの設定で作成します。
- AWS管理コンソールにログインし、Cognitoの画面に移動
- 「ユーザープールの管理」ボタンを押す
- 「ユーザプールを作成する」ボタンを押す
- プール名に識別するための任意の名前を入れ「デフォルトを確認する」ボタンを押す
- 左ペインの「ポリシー」をクリックする
- 「ユーザーに自己サインアップを許可しますか?」で「管理者のみにユーザーの作成を許可する」の方にチェックを入れ、「変更の保存」ボタンを押す(その他パスワードポリシーも変えたければ変更する)
- 「プールの作成」ボタンを押す
- 左ペインの「アプリの統合」にある「ドメイン名」をクリックする
- ドメイン名のプレフィックスに任意の名前を入れ、「使用可能かチェック」ボタンを押し、OKであれば「変更の保存」ボタンを押す
IDプールの作成
認証プロバイダーの設定などはあとからElasticsearchの設定のなかで自動で行われるのでここでは設定せず、すべてデフォルトの設定のまま作成します。
- 左上のグレーになっている「フェデレーティッドアイデンティティ」のリンクをクリックする
- 「新しいIDプールの作成」ボタンを押す
- 「IDプール名」に識別するための任意の名前を入れ、それ以外はデフォルトのまま(「認証されていない ID に対してアクセスを有効にする」にチェックを入れたまま、「認証プロバイダー」も設定しないままま)、「プールの作成」ボタンを押す
- 「Identify the IAM roles to use with your new identity pool」ではそのまま「許可」ボタンを押し、認証ユーザ用ロールと未認証ユーザ用ロールが作成される
- あとはそのまま「ダッシュボードに移動」ボタンを押し、元の画面に戻る
ユーザープールへのユーザ登録
Kibanaにアクセスするユーザを登録します。管理者がユーザ管理するよう設定するために、ユーザ自身が管理したいときに使うメールアドレス等も入れません。
- 左上のCognitoアイコンを押し、その後に出てくる「ユーザープール」ボタンを押す
- 対象となるユーザープールの名前をクリックする
- 左ペインの「全般設定」の「ユーザーとグループ」をクリックする
- 「ユーザーの作成」ボタンを押す
- ポップアップ画面で、ユーザー名を入れ、「この新規ユーザーに招待を送信しますか?」のチェックを外し、仮パスワードを入れ、電話番号とメールアドレスは空欄で、「電話番号を検証済みにしますか?」と「E メールを検証済みにしますか?」のチェックを外し「ユーザーの作成」を押す
- アカウントのステータスがFORCE_CHANGE_PASSWORDのユーザが作成される
Elasticsearch Serviceの設定
Kibana認証の有効化の設定
- AWS管理コンソールのElasticsearch Serviceの画面に移動
- 対象のドメイン名をクリックする
- 「ドメインの編集」ボタンを押す
- 「Amazon Cognito 認証」で、「Amazon Cognito 認証を有効化」にチェックを入れ、「リージョン」にアジアパシフィック(東京)を選び、「Cognito ユーザープール」「Cognito ID プール」で上で作成したものを選択し、IAM ロール名やロールポリシーはそのままで「送信」ボタンを押す(*1)
- ドメインのステータスがアクティブになるまで待つ
*1 この状態では、Cognito側のユーザープールとIDプールにElasticsearchのAPP Clientの設定が入れられるだけで、Kibanaで認証画面が出るようになるわけではありません。Cognitoのユーザープールのアプリクライアント(APP Client)やIDプールの認証プロバイダーにElasticsearchからの設定が入っていることが確認できます。
アクセスポリシーの設定
Cognitoで認証されたユーザに紐付けられるIAM Roleだけが、Elasticsearch APIを操作できるようにアクセスオリシーを設定します。
- Cognitoで認証されたユーザに適用されるIAM RoleのARN(識別するID)を確認するために、AWS管理コンソールのIAMの画面に移動
- 左ペインの「ロール」をクリックし開く
- デフォルトでは「Cognito_[IDプール名]Auth_Role」という名前でRoleが作られるため、この名前で検索し、「ロールARN」をコピーする
- AWS管理コンソールのElasticsearch Serviceの画面に移動
- 対象のドメイン名をクリックする
- 「アクション」ボタンから「アクセスポリシーの編集」をクリックする
- 「JSON定義のアクセスポリシー」で、下のKibana認証時のアクセスポリシー設定例のとおり記述し、「送信」ボタンを押す
- ドメインのステータスがアクティブになるまで待つ
Kibanaにアクセスして確認
- Elasticsearch Serviceのドメイン画面のKibanaのエンドポイント(URL)にアクセスする
- 登録したユーザID/パスワードを入れる
3. 新しいパスワードとメールアドレスをきかれるので入力する(*2)
4. Kibanaの画面が表示される*2 今回の設定とユーザ登録方法では、メールアドレスを入れてもとくにユーザにメールは届きません。またパスワードを忘れた際も、Forgot your password?リンクを押しても対応できません。管理者がAWS管理コンソールのCognito画面から登録し直す必要があります。
Kibana認証時のアクセスポリシー設定例
アクセスポリシー例{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::[アカウントID]:role/Cognito_[IDプール名]Auth_Role" }, "Action": "es:ESHttp*", "Resource": "arn:aws:es:ap-northeast-1:[アカウントID]:domain/[ドメイン名]/*" } ] }以上です。
Amazon Elasticsearch ServiceのIAM認証の制約
「Amazon Elasticsearch Service認証機能の理解」で書いたとおり、Elasticsearch Service自体とKibanaのエンドポイントURLが同じで、同じアクセスポリシーが適用されるため、KibanaでIAM認証を有効にすると、Elasticsearch APIもIAM認証となります。Elasticsearchクライアント側でIAM認証対応するのはすこしめんどうですし、自由にフロント側のコンポーネントを使いづらくもなります。
Reactivesearchなどをクライアントとして使う場合は、自分でIAM認証(HTTP署名)を実装するか、API Gateway(+Lambda)経由でのアクセスにしてIAM認証対応するか、認証は諦めてアクセスポリシーでのIPアドレス制限等でのアクセス制御にする必要があります。リンク
- 投稿日:2020-03-29T16:51:51+09:00
AWS Systems ManagerでEC2インスタンスを管理するための初期設定
AWS Systems Manager (SSM) を用いて、EC2インスタンスを管理するための初期設定について記載します。
AWS Systems Manager (SSM) とは
AWS Systems Manager (以下、SSM) は、AWSリソースの設定や状態を収集して閲覧したり、AWSリソースに対してタスクの自動実行が行える運用自動化サービスです。
最近、業務で使用していて、便利さを実感しているサービスの一つです。初期設定
ここから初期設定に入ります。
1. IAMロールの作成
管理対象のEC2インスタンスにアタッチするためのIAMロールを作成します。
このIAMロールは、EC2インスタンス内のSSMエージェントとSSMがやり取りするために必要になります。
「AmazonSSMManagedInstanceCore」というビルトインポリシーを割り当てます。
作成したIAMロールの信頼関係に「ssm.amazonaws.com」を追加します。
2. EC2インスタンスへのIAMロールのアタッチ
管理対象のEC2インスタンスに、先ほど作成したIAMロールをアタッチします。
3. EC2インスタンスへのSSMエージェントのインストール
デフォルトでSSMエージェントがインストールされたAMIと、インストールされていないAMIがあるので、以下のリンクをご確認ください。
SSMエージェントがインストールされていないOSについては、ダウンロードしインストールすることになります。
インストール方法についても以下のリンクをご確認ください。Windows インスタンスで SSM エージェント をインストールし設定する - AWS Systems Manager
Amazon EC2 Linux インスタンスで SSM エージェント をインストールし設定する - AWS Systems Manager4. EC2インスタンスからSSMエンドポイントへの通信設定
SSMを使用するためには、EC2インスタンスがSSMエンドポイントとHTTPS(443ポート)のアウトバウンドで通信できる必要があります。
インターネットに接続できない環境であれば、VPCエンドポイントを設定する必要があります。Systems Manager を使用したインターネットアクセスなしでのプライベート EC2 インスタンスの管理
マネージドインスタンスへの登録確認
上記の設定が完了すると、[マネージドインスタンス]に管理対象のEC2インスタンスが表示されます。
表示されていれば、EC2インスタンス内のSSMエージェントとSSMが通信できている証拠です。
動作確認
SSMから管理対象EC2インスタンスに向けて、コマンドを実行し、結果を確認してみたいと思います。
「AWS-RunShellScript」を選択し、対象インスタンス内でShellScriptコマンドを実行させます。
ここではコマンドとして、以下を実行させます。#!/bin/bash uname -a
実行結果を確認します。
さいごに
今回はSSMの初期設定について投稿しました。
次回はSSMを用いた運用自動化について投稿したいと思います。












- 投稿日:2020-03-29T15:37:44+09:00
CloudFormationテンプレートを1からしっかり理解しながらECS on Fargateなアプリを自動構築する(後編)
前提条件
前編で作ったALBとECS、中編で作ったデプロイの設定をもとにCodePipelineを使ってCI/CDパイプラインを作るので、それぞれ理解しておく。
前回から引き続き、記事中には、備忘のためにリファレンスに書かれていないデフォルト値を整理しておくが、2020年3月時点の情報であり、後でAWSが仕様を変えたとしても追従する予定はないので、挙動が違ったらリファレンスを見直してほしい。あと、今回の構成(ECS on FargateのBlue/Greenデプロイメント)以外の構成以外のデフォルト値まで調査はしていないのであしからず。
CI/CDパイプラインを作成する
IAMロールの作成
パイプライン中で作成しても良いのだけど、ロールが増えすぎてもなので、以下のような信頼関係のポリシで、CodePipeline, CodeCommit, CodeBuild, S3 あたりのもろもろにアクセス可能なポリシをアタッチしたIAMロールを作っておく(実際は、S3なんかはアクセス可能なバケットを絞るとかはあるのだろうけど)。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": "codepipeline.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }パラメータの設定
カスタマイズ箇所を極力減らすために、プロジェクト名をParameterに指定すれば書き換える箇所が減るといった考えにしておく。S3とそれ以外で別パラメータにしているのは、S3のバケット名に大文字が使えないから。パラメータグループをメタ設定に入れた方がキレイだけど、細かいことは一旦気にしない。
ApplicationName と DeploymentGroupName は、本当ならCloudFormation中でデプロイまで定義できれば !Ref できるので不要なパラメータなのだけど、ECSのBlue/Greenデプロイメントが未対応で、前回小細工をしているために入れておく(リソース定義に直接書き込んでしまっても良いけど)。Parameters: Prefix: Description: "Project name prefix" Type: "String" Default: "CFn-test" PrefixS3: Description: "Project name prefix for S3 Bucket" Type: "String" Default: "cfn-test" ApplicationName: Description: "ApplicationName on CodeDeploy" Type: "String" Default: "CFn-test-Application" DeploymentGroupName: Description: "DeploymentGroupName on CodeDeploy" Type: "String" Default: "CFn-test-DeploymentGroup"S3バケットの作成
CI/CDパイプライン中でアーティファクトを格納するためのS3バケットが必要なので作る。
例によって、どのプロパティも「必須:いいえ」ではあるが、何も指定しないとエラーになるので、何かしらは必須になるようだ。
最低限は、以下のような感じでバケット名があれば良い。Resources: S3BUCKET: Type: AWS::S3::Bucket Properties: BucketName: !Sub ${PrefixS3}-artifact-bucketS3は他にもプロパティたくさんある。
↓にあるように、PublicAccessBlockConfiguration がデフォルトでオフになるのは危ないんじゃない?と思いつつ、今回はテストなので一旦無視。ちゃんと実運用するときは考えよう。
プロパティ デフォルト値 AccelerateConfiguration 停止 AccessControl よく分からない… AnalyticsConfigurations なし BucketEncryption 無効 BucketName AWS払い出しの名前 CorsConfiguration なし? InventoryConfigurations 無効 LifecycleConfiguration ルールなし LoggingConfiguration 無効 MetricsConfigurations なし NotificationConfiguration 通知なし ObjectLockConfiguration すべてのオブジェクトに適用 ※リファレンス記載 ObjectLockEnabled 無効 PublicAccessBlockConfiguration オフ ReplicationConfiguration ルールなし Tags aws:cloudformation:stack-id/aws:cloudformation:stack-name/aws:cloudformation:logical-id VersioningConfiguration 無効 WebsiteConfiguration 無効 CodeBuildのプロジェクト作成
CodeBuildもプロパティが大量にあるので設定が大変…。
CODEBUILD: Type: AWS::CodeBuild::Project Properties: Name: !Sub ${Prefix}-build-project Source: Type: CODEPIPELINE BuildSpec: buildspec_container.yml Artifacts: Type: CODEPIPELINE Environment: Type: LINUX_CONTAINER ComputeType: BUILD_GENERAL1_SMALL Image: aws/codebuild/standard:3.0-19.11.26 PrivilegedMode: true Cache: Type: LOCAL Modes: - LOCAL_CUSTOM_CACHE ServiceRole: !Sub arn:aws:iam::${AWS::AccountId}:role/service-role/[CodeBuildの適切なロール]
プロパティ デフォルト値 Artifacts 必須 ※↓のアーティファクトで詳述 BadgeEnabled Sourceのプロパティが Type: CODEPIPELINEの場合は指定してはいけないCache キャッシュを使用しない Description なし EncryptionKey なし Environment 必須 ※↓の環境で詳述 LogsConfig なし Name AWS払い出しの名前 QueuedTimeoutInMinutes 480分 SecondaryArtifacts なし SecondarySources なし SecondarySourceVersions なし ServiceRole 必須 Source 必須 ※↓のソースで詳述 SourceVersion 最新のバージョン ※リファレンス記載 Tags なし TimeoutInMinutes 60分(リファレンス記載) Triggers よく分からない VpcConfig なし アーティファクトのプロパティについては以下。
今回は、ビルド生成物はECSに入れるものの、taskdef.json があるので、その格納先が必要。
ただし、Type: CODEPIPELINEの場合は、自動でいろいろやってくれるので、細かいことは考えなくてOK。
プロパティ デフォルト値 ArtifactIdentifier デフォルトのKMSのキー EncryptionDisabled Type: CODEPIPELINEの場合は無視Location Type: CODEPIPELINEの場合は無視Name Type: CODEPIPELINEの場合は無視NamespaceType Type: CODEPIPELINEの場合は無視OverrideArtifactName false Packaging Type: CODEPIPELINEの場合は無視Path Type: CODEPIPELINEの場合は無視Type 必須 ソースのプロパティについては以下。
これも、アーティファクト同様、Type: CODEPIPELINEの場合は、自動でいろいろやってくれるので、細かいことは考えなくてOK。
プロパティ デフォルト値 Auth よく分からない BuildSpec buildspec.yml GitCloneDepth Type: CODEPIPELINEの場合は無視GitSubmodulesConfig Type: CODEPIPELINEの場合は無視InsecureSsl Type: CODEPIPELINEの場合は無視Location Type: CODEPIPELINEの場合は無視ReportBuildStatus Type: CODEPIPELINEの場合は設定してはいけないSourceIdentifier なし? Type 必須 環境のプロパティについては以下。
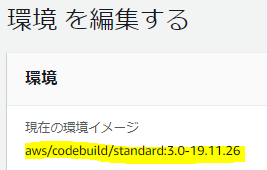
Image って何設定すりゃいいのよ?という感じだが、マネコンから作成したビルドプロジェクトの環境イメージ(↓これ)からコピペすれば良さそう。
あと、PrivilegedModeは日本語マネジメントコンソールの「特権付与」のチェックボックスに該当するもので、忘れるとDockerのビルドができないので注意。
プロパティ デフォルト値 Certificate なし ComputeType 必須 EnvironmentVariables なし Image 必須 ImagePullCredentialsType よく分からない PrivilegedMode なし RegistryCredential なし Type 必須 CodePipelineのパイプライン作成
CodePipelineはプロパティのサブ要素が複雑。
今回、デフォルト値はサブプロパティまで書いていく(必要な部分のみ)。
RoleArnについては↑に書いた通り、あらかじめ作成しておいたものを使用する。
プロパティ デフォルト値 ArtifactStore/ArtifactStores どちらか必須。指定なしの方は無効 DisableInboundStageTransitions なし Name AWS払い出しの名前 RestartExecutionOnUpdate RoleArn 必須 Stages 必須(↓のStageDeclaration) ArtifactStore のプロパティについては以下。
プロパティ デフォルト値 EncryptionKey よく分からない Location 必須 Type 必須 StageDeclaration のプロパティについては以下。
プロパティ デフォルト値 Actions 必須(↓のActionDeclaration) Blockers よく分からない Name 必須 ActionDeclaration のプロパティについては以下。
プロパティ デフォルト値 ActionTypeId 必須 Configuration 必須でないと書いてありながら、たぶん↓のConfigurationの設定をしないと動かない気がする InputArtifacts なし Name 必須 OutputArtifacts なし Region よく分からない RoleArn よく分からない。ユーザーガイドには「宣言されたアクションを実行する IAM サービスロールの ARN。これは、パイプラインの roleArn を介することが想定されています。」とあるのでパイプラインと同じARNを入れたらエラーになった。 RunOrder 必須 ActionTypeId のプロパティについては以下。
階層が深い……
ちなみに、日本語のドキュメントだとCategoryに指定可能な値が訳されてしまっていて設定可能な値が分からないという罠がある。英語に切り替えよう。
プロパティ デフォルト値 Category 必須 Owner 必須 Provider 必須 Version 必須 そして、Configuration の設定内容が超曲者で、頑張ってユーザーガイドを掘り下げていってここに辿り着かないと何を設定したら良いか分からないという……。
ActionTypeId の値によってパラメータが違うので、今回はCodeCommit、CodeBuild、CodeDeployToECS(CodeDeployと書きたいところだが、ECSのBlue/GreenデプロイメントはプロバイダをCodeDeployToECSに指定する) それぞれについて書いておく。
CodeCommit については以下。
プロパティ デフォルト値 RepositoryName 必須 BranchName 必須 PollForSourceChanges よく分からない CodeBuild については以下。
PrimarySource は、Type: CODEPIPELINEの場合は不要っぽい?
マネジメントコンソールの場合は、そもそもCodePipelineをソースに選択できないので、勝手がよく分からない。
プロパティ デフォルト値 ProjectName 必須 PrimarySource なし EnvironmentVariables なし CodeDeployToECS については以下。
プロパティ デフォルト値 ApplicationName 必須 DeploymentGroupName 必須 TaskDefinitionTemplateArtifact 必須 AppSpecTemplateArtifact 必須 AppSpecTemplatePath 必須 TaskDefinitionTemplatePath taskdef.json Image1~4ArtifactName なし Image1~4ContainerName なし さて、ここまでをまとめると、パイプライン制御のリソース定義は↓こうなる。RoleArnはあらかじめ作っておいたロールのARNを指定する。
appspec_container.yml は、Appspecファイルに合わせる。今回、自分が作った環境ではコンテナ用とそうでないもので定義を分けたために標準的な名前から外しているため、別名を指定した。PIPELINE: Type: AWS::CodePipeline::Pipeline Properties: Name: !Sub ${Prefix}-pipeline ArtifactStore: Location: !Ref S3BUCKET Type: S3 RoleArn: !Sub arn:aws:iam::${AWS::AccountId}:role/CodePipelineRole Stages: - Name: Source Actions: - RunOrder: 1 Name: Source ActionTypeId: Category: Source Owner: AWS Provider: CodeCommit Version: 1 Configuration: RepositoryName: testProject BranchName: master OutputArtifacts: - Name: SourceArtifact - Name: Build Actions: - RunOrder: 2 Name: Build ActionTypeId: Category: Build Owner: AWS Provider: CodeBuild Version: 1 Configuration: ProjectName: !Ref CODEBUILD InputArtifacts: - Name: SourceArtifact OutputArtifacts: - Name: BuildArtifact - Name: Deploy Actions: - RunOrder: 3 Name: Deploy ActionTypeId: Category: Deploy Owner: AWS Provider: CodeDeployToECS Version: 1 Configuration: ApplicationName: !Sub ${ApplicationName} DeploymentGroupName: !Sub ${DeploymentGroupName} AppSpecTemplateArtifact: SourceArtifact AppSpecTemplatePath: appspec_container.yml TaskDefinitionTemplateArtifact: SourceArtifact Image1ArtifactName: BuildArtifact Image1ContainerName: IMAGE1_NAME InputArtifacts: - Name: SourceArtifact - Name: BuildArtifact中編までのCloudFormationテンプレートやCLIを実行するシェルスクリプトを流した後に、今回のテンプレートを流し込めば完璧だ!
ALBの設定からECSの設定からパイプライン作成までを「ほぼ」自動化できた!やったー!
- 投稿日:2020-03-29T14:27:28+09:00
ただのWebエンジニアがaws認定11冠達成できた話
苦節、2年半。ようやくフルコンプできたので記事にしました。
来月からまた一つ増えて11冠ではフルコンプと呼べなくなってしまうのでなんとか滑り込み。
受かってホッとした。この記事はどういうスキルセットの人間がどういう過程で11冠したのかという感じの記事となります。
得意不得意、有効な方法とかは人それぞれだと思いますのでご参考までに目次
- スキルセット
- 俺的ランキング(難易度順)
- 勉強方法
スキルセット
- 今回でaws認定11冠
- しがないWebエンジニア
- 過去には広く浅くでサーバー構築してwebサービス作って運営して、ってことをやってる
- aws歴2年半くらい
- awsのインフラもけっこう浅いところまで
- フルスタックであり、ノンスタックでもある
まあWeb系なんでもやってた人です。昔は今ほど住み分けはできてなくて、デザイナーとプログラマーぐらい分けしかなかったです。
ちっちゃい会社だとインフラエンジニアなんてのも居なくて、出来る人とりあえずやるという感じでした。
エンジニアになる前から自宅の固定IPでサーバー立ててみてたりした俺がそこにハマった感じです。
以後、大抵の会社でインフラエンジニアを兼任するような流れに。
前職でもその流れでaws触り始めたんですが。触ったついでにSAA取ったのが始まり。俺的ランキング(難易度順)
あくまで俺的なやつです。
1位 機械学習 専門知識
これは単純に未知の領域すぎたから。
ただのWebエンジニアがaws認定の機械学習専門知識に合格した話に少し詳しく書いてます。
仕事では一切触ることのない領域だし、数学どっちかっていうと苦手だし。
不合格になった中でも最低スコアを叩き出したと思う。2位 ビックデータ専門知識
これも機械学習と同じような理由。機械学習と分野被ってる。
キネシスとかも業務で使う事がまだないんですよねー。
あとEMRもか。
そんなわけでこれも一回不合格くらってる。。3位 DevOps エンジニア – プロフェッショナル
アーキテクト3つ、SAPを取った後に受けたのがこれ。
日本語のリソースがなくなって、udemyを活用し始めました。
模試もボロボロだったし、けっこうやばいかなー、と思って受けたんだけどなんとかなってしまった。
案外、俺のスキルセットに一番近かったのかもしれない。4位 セキュリティ専門知識
これはソリューションアーキテクトの流れを受けてたし、比較的簡単に受かるかと思って受けたんだけど、読みが甘すぎて不合格くらった。
ただ、事前にちゃんと勉強しておけば一発合格いけたかもしんない、とは思う程度。
ちなみにこれが専門知識一発目。アソシエイト、プロフェッショナルに比べると一気に学ぶ手段がきつくなる。
専門知識の洗礼を受けました。5位 ソリューションアーキテクト – プロフェッショナル
アーキテクト3つ取った後に受けたのがこれ。
awsの王道的な分野で専門知識ほど深くはないんだけど、カバーしなきゃいけない範囲は広い。
模試とかボロボロだったしどうかな?って思ってたけど、 こちらのサイトの問題集解いてたら合格できました。アソシエイトとプロフェショナルのあたりはこちらにも書いてる
aws DevOps Proに合格して5冠になったのでこれまでも含めて書いてみる6位 高度なネットワーキング専門知識
理解するのめんどくさそうな問題がいっぱいでるんだろうな〜、って思って敬遠しつつ、結局最後にうけたやつ。
いうほどめんどくさい問題はでなかった。サンプル問題のイメージだとipアドレスがどうでネットマスクがどうでセキュリティグループが・・みたいなのがたくさんでるかと思ったけど。
詳細はこちらに。
https://qiita.com/ikegam1/items/3f332c7aec59472734e47位 ソリューションアーキテクト アソシエイト
受けたのは2017年12月らしい。もう細かい事は忘れました。
ただ、これは問題集とかが一番手厚いやつなので正直、どうとでもなる。
勉強方法はシンプル8位、9位 SysOps Administrator&デベロッパー アソシエイト
SAA取った勢いでだいたいどうにかなるやつ。
正直、どっちがどっちとかないけど、どちらかというとSysOpsの方が楽か。
というかSysOpsアソシエイト、なくなっても良くね?今はプラクティショナーとかもあるんだし。10位 Alexaスキルビルダー専門知識
これは趣味なので。スキルセット的にどんぴしゃでした。
サービス問題。11位 クラウドプラクティショナー
いわずもがな。
AWS系の会社だと営業さんでもとっちゃうようなやつ。
本来なら入門としてのやつなんだけど、登場したのがアソシエイト全部取った後ぐらいだったかな。
今更感はあったけど、冠の一つとしてほしいから一応取っておいた。まあそういう感じです。
業務とか趣味から遠いものがやはり難しいという感じでした。
あと専門知識はやはり深いですね。業務でカスりもしてないやつがわんさか出てくる。
こんなのコンサルの会社でもいかない限り役に立たない。(じゃあ何で取ってんだ。)勉強方法
認定ごとに勉強方法は違うので分けますが・・アソシエイトは情報ありふれてるし、問題集買って解いてみれ、って言う程度なので割愛します。
で、プロフェッショナルは別の記事で書いてるのでそれも割愛。
じゃあ、専門知識のやつですね。というかudemyのお話ですわ。専門知識の勉強法
- udemyで[
aws certified security speciality]みたいに検索する- 値引きの時期を見計らって買う
- 解く
- わからなかった問題が理解できなかったらblackbelt等で調べる
- 繰り返し解く
というアプローチが基本でした。
とりあえず、何がわからないかを知る事から始めます。いちおう説明しておきますとudemy( https://www.udemy.com/ )はオンライン学習のサイトで、教材をつくってくれた人を講師と呼び、そのコンテンツをお金を払って買う感じです。
おそらく、専門知識以外のコンテンツでも役に立ちます。アソシエイトとかは日本語のやつとかありますし。で、値引きについて。[
udemy 値引き いつ]でググるといくつかサイトが出てきます。
こんだけ値引きのタイミングやイベントが多いと定価で買うと損した気分になるやつです。
ミスドのドーナツ100円セール現象です。気をつけましょう。そしてudemyで教材を探す際に俺が気をつけてるポイント
- なるべく新しいものを選ぶ
- レビューをちゃんと見る。星がある程度ついていて評価が4前後のものを
- 動画コンテンツでもexamが1試験分ついてるやつもあっておすすめ
- 回答だけではなく解説があるものを選ぶ
- 講師の評価も参考にする
正直、外れなやつも多いです。ひどいやつは回答が間違ってる。間違ってると思ったら自分で調べましょう。
・・なお、udemyの回し者ではありません。。
Linux Academy使う方もおりますよね。俺はudemyで十分だったので手を出しませんでした。
最後に
俺の勉強法は90点をとる勉強法ではないですし、80点すら厳しいです。70点をとるための勉強法。
ポイントをなるべく抑えるという感じ。消去法とかになれてる必要があるかなと。だいたい解ける事を目指す。
あ、試験の最中の事も書いて終わりにします。試験の時の問題の解き方の俺的作法
- 問題の最後の
次のどのアプローチがこの要件を達成していますか? (2つ選択してください)のような問いかけの部分を最初に見る。何を問う問題なのかを先に知った上で問題を読む方が理解しやすい- サラっと読んで理解しにくかったらとりあえず回答に目を通しておく
- 問題の読み込みが必要なやつはざっくりと考えてざっくりと回答して、フラグをつけつつ次へ進む。確信がないやつもフラグをつけておく。
- 半分くらいの時間で全部解いたのち、フラグをつけたやつを遡りながら解いていく。考えてもわからないものは悩まない。
- 投稿日:2020-03-29T14:22:09+09:00
AWS アカウントについて
はじめに
AWSを始めるに当たって、アカウントをまず作成します。
下記のリンクからアカウントを作成することができます。
https://aws.amazon.com/jp/
- AWSアカウントを作ったらまずやること
- 作業用のIAMユーザーを作成する
- Cloud Trailを設定する
- 料金アラートを設定する
RootユーザとIAMユーザー
Rootユーザー
- 全てのAWSサービスを使用できる
- アカウントの設定変更、サポートプランの変更などはルートユーザのみ変更可
- 通常の作業にルートユーザを用いてはならない(※)
Rootアカウントの情報のパスワードが漏洩したり、試行錯誤によってパスワードが解析されてしまうのを防ぐために、MFA(Mutli-Factor Auhentication。多要素認証)という仕組みを備えている。
簡単に言うと、ログインするときにパスワードに加えて、もう一つ認証することで、二段階認証しないとサインインできないようにする仕組みになります。IAMの設定を開き、ダッシュボードのルートアカウントのMFAを有効化を開き設定する。
デバイスタイプにはいくつかあるのですが、仮想MFAデバイスを選択した場合、設定後にQRコードが表示されるので、端末(iphone、Android)にGoogle認証システムアプリをインストールし、そのQRコードを読み取る。
読み取り後、認証コードが表示されるので、その認証コードを認証コード1、2の欄に入力する。
サインアウトして、ルートアカウントで再びログインすると、パスワード入力後に、認証コードを聞かれるようになる。認証コードはGoogle認証システムアプリのコードを入力することでログインができる。IAMユーザ
- 割り当てられたIAMポリシーで許可されたAWSサービスを使用できる
- 利用者ごとに払い出し、通常の作業はこのIAMユーザで行う
- 投稿日:2020-03-29T14:05:17+09:00
サーバーレスWebアプリにメールフォームを追加実装する 〜 バックエンド編 〜
サーバーレスWebアプリにメールフォームを追加実装する 〜 バックエンド編 〜
はじめに
AWSを活用したサーバーレスWebアプリの制作で作ったWebアプリにメールフォームを追加実装します。
2部構成にしていて、先にフロントエンド編から見ると良いと思います。
サーバーレスWebアプリにメールフォームを追加実装する 〜 フロントエンド編 〜バックエンド
ベースとしたWebアプリはAppSyncを利用していますので、フロントエンドからメールを送るLambdaを呼び出す手段もAppSyncとします。
Lambda関数の作成
Lambda関数の新規作成時、実行ロールの選択と作成で「Amazon SNS 発行ポリシー」を加えておきます。
AppSyncにLambda呼び出しのIFを追加
すでに利用しているAppSyncにLambdaを呼び出すIFを追加します。
先日書いた以下の記事がさっそく役立ちますね。
AppSyncでLambdaを呼び出す上のLambdaをデータソースに加え、以下のようなIFをスキーマに追加し、リゾルバにアタッチします。
input ProcessSendMailInput { name: String! email: String! message: String! } type ProcessSendMailResult @aws_cognito_user_pools { statusCode: Int! body: String } type Mutation { processSendMail(input: ProcessSendMailInput!): ProcessSendMailResult @aws_cognito_user_pools :AWS SNSの設定
AppSync経由で送られてきた内容をメール通知するためのSNSをセットアップしてゆきます。
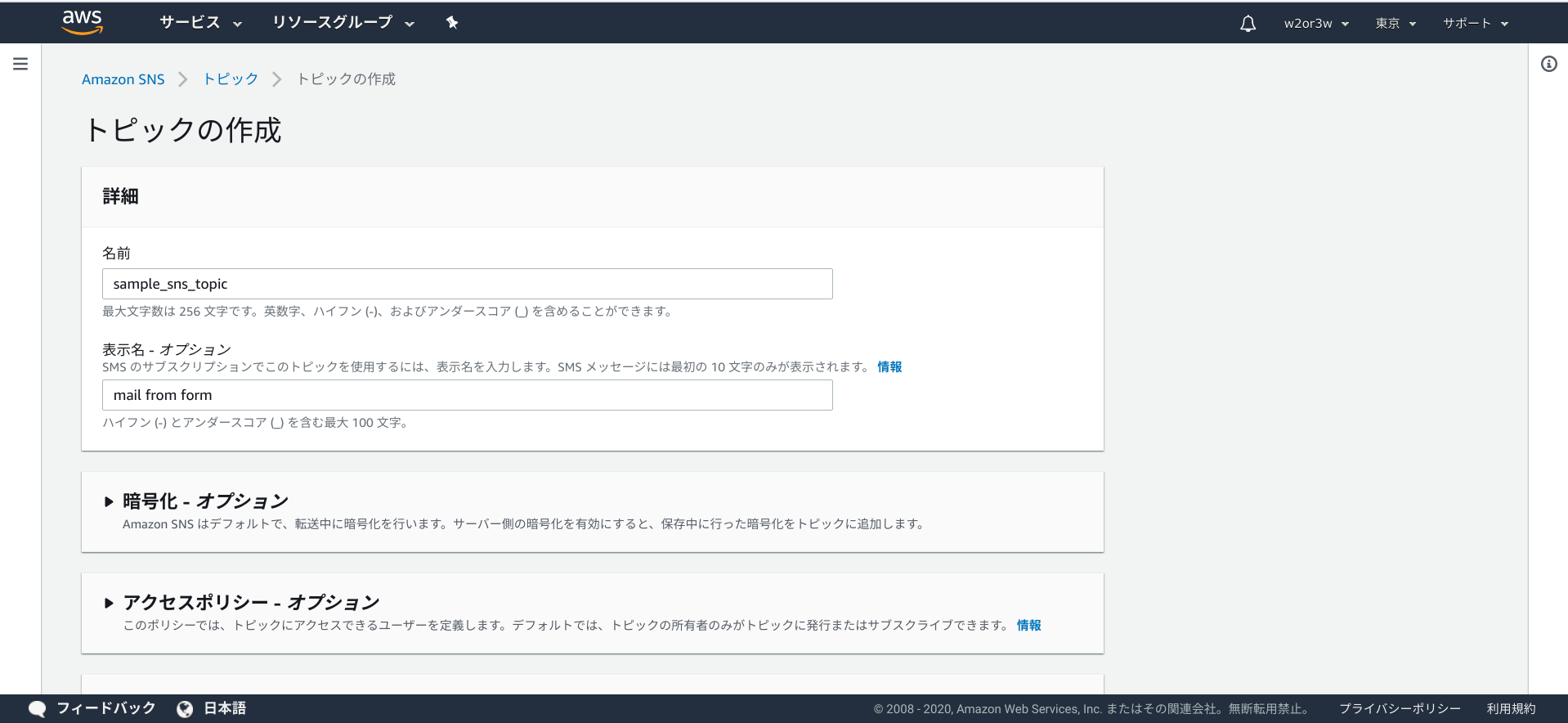
トピックの作成
最低限、名前のみの入力で良さそうです。
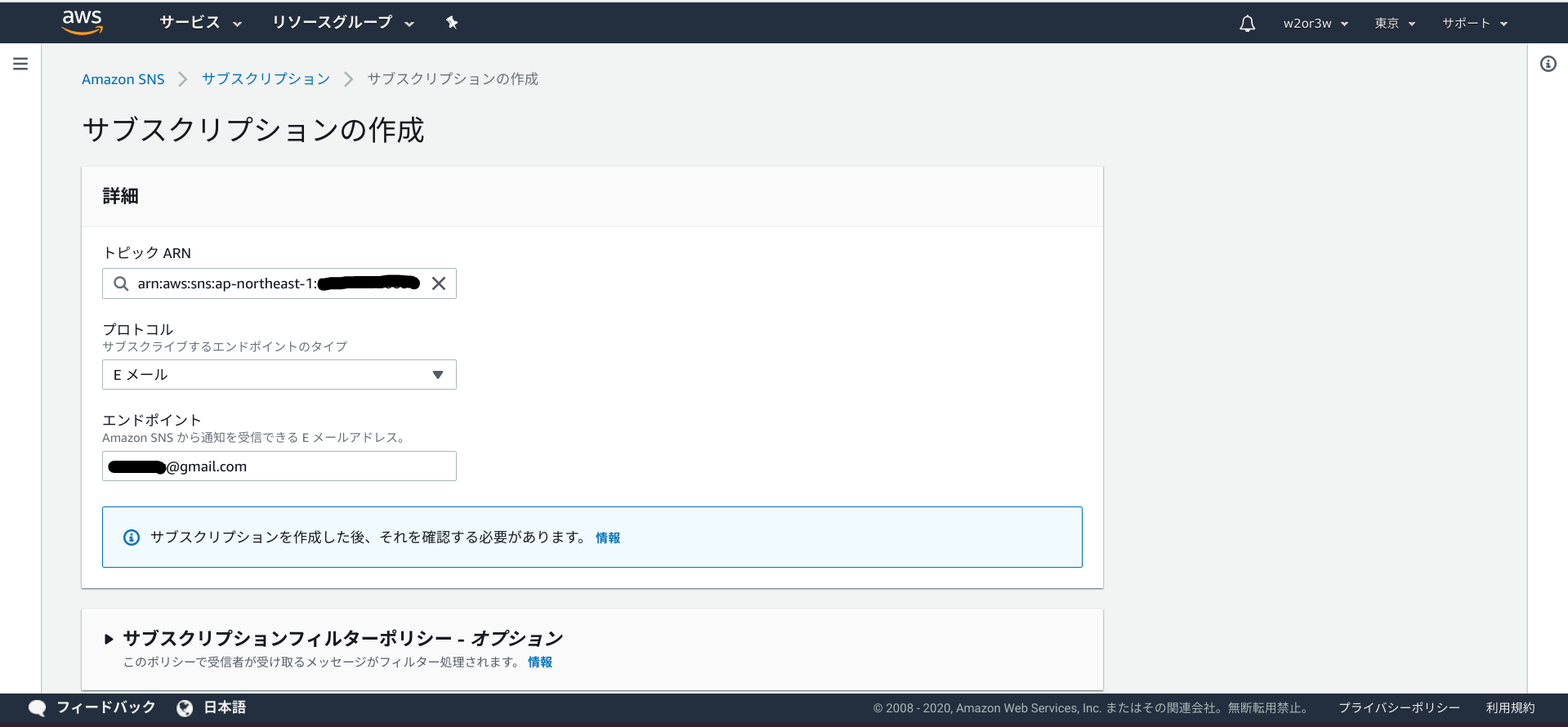
サブスクリプションの作成
作成したトピックに対して、サブスクリプションの作成を行います。
プロトコルは「Eメール」、エンドポイントは「送信先のメールアドレス」とします。
サブスクリプションを作成すると、エンドポイントに指定したメールアドレスに確認メールが送られてきます。
メール本文にある「Confirm subscription」リンクを選択すると、サブスクリプションの認証が完了してステータスが「保留中の確認」から「確認済み」になります。トピックの画面の右上にある「メッセージの発行」から、テストメールを送れるので、確認してみると良いと思います。
あと、トピック詳細にあるARNはあとでプログラムから利用します。Lambda関数の実装
AppSync経由で送られてきた内容をSNSで通知するPythonのコードです。
lambda_function.pyimport boto3 import json import logging logger = logging.getLogger() logger.setLevel(logging.INFO) sns = boto3.client("sns") TOPIC_ARN = "arn:aws:sns:ap-northeast-1:888888888888:sample_sns_topic" REQUEST_BODY_TEMPLATE = """ name : {0} email : {1} message : {2} """ def lambda_handler(event, context): try: logger.info(event) name = event["input"]["name"] email = event["input"]["email"] message = event["input"]["message"] requestBody = REQUEST_BODY_TEMPLATE.format(name, email, message) logger.info(requestBody) request = { "TopicArn": TOPIC_ARN, "Message": requestBody, "Subject": "mail from form by {0}".format(name) } response = sns.publish(**request) return { "statusCode": 200, "body": json.dumps("Email sent successfully.") } except Exception as e: logger.exception(e) return { "statusCode": 500, "body": json.dumps(e) }フロントエンドからAppSyncの呼び出し
フロントエンド偏へ記載してます。
あとがき
メールフォーム、思ってたよりも簡単でした。これだけなら工数1.0Hくらいですね。
ただ、いたずら防止のための仕掛けは別途必要だと思います。GoogleのreCAPTCHAっていうサービスを利用してみたいなと思ってるんですよね。
今度導入してみたらまた記事にしようと思います。

- 投稿日:2020-03-29T14:01:21+09:00
サーバーレスWebアプリにメールフォームを追加実装する 〜 フロントエンド編 〜
サーバーレスWebアプリにメールフォームを追加実装する 〜 フロントエンド編 〜
はじめに
AWSを活用したサーバーレスWebアプリの制作で作ったWebアプリにメールフォームを追加実装します。
フロントエンド・バックエンドの2部構成にしています。
バックエンド編はこちら。
サーバーレスWebアプリにメールフォームを追加実装する 〜 バックエンド編 〜フロントエンド
Vue.jsのWebアプリにメールフォーム用のページを追加します。
VeeValidateの利用
メールフォームの各入力値チェックのために、VeeValidateというものを利用しました。
VeeValidateとは、Vue.js用のバリデーションコンポーネントライブラリです。利用するために、まずはVeeValidateをプロジェクトにインストールする必要があります。
npm i vee-validate使い方などの詳細は以下のページを参照してください。
https://logaretm.github.io/vee-validate/overview.html#getting-startedコンポーネントの実装
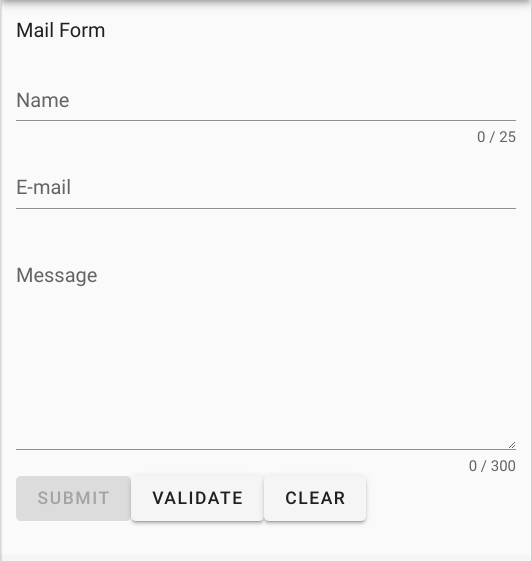
VeeValidateを利用してバリデーションを効かせたメールフォーム画面のコンポーネントを実装します。
デザインコンポーネントは例によってVuetifyを利用しています。
必要な入力項目をすべて適切に入力しないとSUBMITボタンが有効にならないようにバリデーションを効かせ、ただ、SUBMITボタンを押下しても入力内容をアラートするだけにしておきます。(バックエンドの呼び出しは後で実装します。)src/components/Mail.vue<template> <v-container> <p>Mail Form</p> <ValidationObserver ref="observer" v-slot="{ validate, reset, invalid }"> <ValidationProvider v-slot="{ errors }" name="name" rules="required|max:25"> <v-text-field label="Name" v-model="name" :counter="25" :error-messages="errors" required ></v-text-field> </ValidationProvider> <ValidationProvider v-slot="{ errors }" name="email" rules="required|email"> <v-text-field label="E-mail" v-model="email" :error-messages="errors" required ></v-text-field> </ValidationProvider> <ValidationProvider v-slot="{ errors }" name="contens" rules="required|max:300"> <v-textarea label="Message" v-model="message" :error-messages="errors" :counter="300" rows="8" required ></v-textarea> </ValidationProvider> <v-btn @click="onSubmit" :disabled="invalid">submit</v-btn> <v-btn @click="onValidate">validate</v-btn> <v-btn @click="onClear">clear</v-btn> </ValidationObserver> </v-container> </template> <script> import { required, email, max } from "vee-validate/dist/rules" import { extend, ValidationObserver, ValidationProvider, setInteractionMode } from "vee-validate" setInteractionMode("eager"); extend("required", { ...required, message: "{_field_} can not be empty", }); extend("max", { ...max, message: "{_field_} may not be greater than {length} characters", }); extend("email", { ...email, message: "Email must be valid", }); export default { name: "Mail", components: { ValidationProvider, ValidationObserver, }, data: () => ({ name: "", email: "", message: "", }), methods:{ async onSubmit(){ alert(this.name + " / " + this.email + " / " + this.message); }, onValidate(){ this.$refs.observer.validate(); }, onClear(){ this.name = ""; this.email = ""; this.message = ""; this.$refs.observer.reset(); } } } </script>実行結果
バックエンド
バックエンド編へ記載しています。
終わったら戻ってきてください。フロントエンドからAppSyncの呼び出し
バックエンドが済んだら、最後にWebアプリからの呼び出しです。
バックエンド編でAppSyncに追加したIF(processSendMail)をWebアプリからリクエストします。src/graphql/mutations.jsexport const processSendMail = ` mutation processSendMail($input: ProcessSendMailInput!) { processSendMail(input: $input) { statusCode body } } `;src/components/Mail.vue: <script> import { required, email, max } from "vee-validate/dist/rules" import { extend, ValidationObserver, ValidationProvider, setInteractionMode } from "vee-validate" import { Auth, API, graphqlOperation } from 'aws-amplify'; import { processSendMail } from "../graphql/mutations"; : methods:{ async onSubmit() { let apiResult = await API.graphql(graphqlOperation(processSendMail, {input : {name: this.name, email: this.email, message: this.message}}) ).catch(error => { console.error(error); }); },実行して、フォームに入力し、SUBMITボタン押下によりメールが届くことを確認してください。
あとがき
バックエンド編へまとめて書きます。
- 投稿日:2020-03-29T13:19:03+09:00
AWS 認定 高度なネットワーキング – 専門知識に合格してきた話
本日(3/29)の10:30開始の試験です。
受けたばかりでほくほくのやつをメモ書き程度ですが記しておきます。
もちろん、問題そのものについては何もかけません。me
- 今回でaws認定11冠
- しがないWebエンジニア
- 過去には広く浅くでサーバー構築してwebサービス作って運営して、ってことをやってる
- aws歴2年半くらい
- awsのインフラもけっこう浅いところまで
- フルスタックであり、ノンスタックでもある
やったこと
- Udemyで問題を解いた
- 英語わかんないけど家で自転車漕ぎながらUdemyの動画みた
- サンプル問題の日本語訳を解いた
- 直前でいくつかblackbeltを流し見した
9割方Udemyでした。
Udemy
詳しいことはまた別の記事で、とは思いますが、
ざっくりいうと専門知識は国内の情報が少なすぎてあんまり選択肢がないです。
基本、これで問題を解いて、解いた問題の理解を含め、同じ分野の問題が出た時に応用して考える、って流れでしょうか。サンプル問題の日本語訳
試験に向かう電車の中、こちらの記事を読ませていただきました。
AWS認定セキュリティ専門試験が発表されたのでサンプル問題を日本語訳してみたこれらの問題がそのまま出るってことはないけど、分野も難易度もまあまあ近かった気はする。
Blackbelt
いくつか問題を解いてて、このあたりが厚そうだと判断。
- Direct Connect
- Route53 (リゾルバとかフォワーダーとか)
- VPCピアリング
試験会場の近くのカフェでさらっとBlackbeltに目を通しました。
Direct Connectは使ったことなくてイメージしにくいところはあったものの、AwsのVGW使ってVPNを確立させてみたことはあったのでその知識が役に立った。
じゃないとBGPとかわかんないしね。あとはだいたい持ってた知識でいけたんだけど、あえていうのであればVPCフローログ周りかな。
試験
なんかみたことあるような問題が多くて45分で全部解けてしまった。(しかしハイスコアだったとは言ってない)
専門知識 のしょっぱなからある試験だし、機械学習とかビックデータに比べると信頼できる情報が多いですね。
これについてはudemy様々です。
udemyは値引きの時に利用するのが基本ですので、上手に使いましょう。いつも2000円とかそのくらいでコース買ってます。いずれ受けるやつを安い時にとりあえず買っておいたりとか。
- 投稿日:2020-03-29T12:58:53+09:00
デプロイ後、動作確認でエラーが出た!!エラー確認方法
はじめに
Qiita初投稿です。
プログラミングを初めて3ヶ月になる初学者です。
初めてデプロイ自分でしたので、その後のエラー対処がわからず躓きました。メモがわりに記述していきます。エラー
ローカルではうまく動作していた。
しかしデプロイ後、見れていたはずのページでエラーが、、、
加えて、何が原因のエラーなのかが分からない、、、
ちなみにAWSでデプロイしています。本番環境でのエラー確認方法
1. EC2にssh接続する
2. $cd /var/www/アプリケーション名
3. $cd current
4. $less log/production.logを実行する。
すると今までのログが表示されるので、エラー箇所を探す。
今回のエラー箇所は下から2行目の
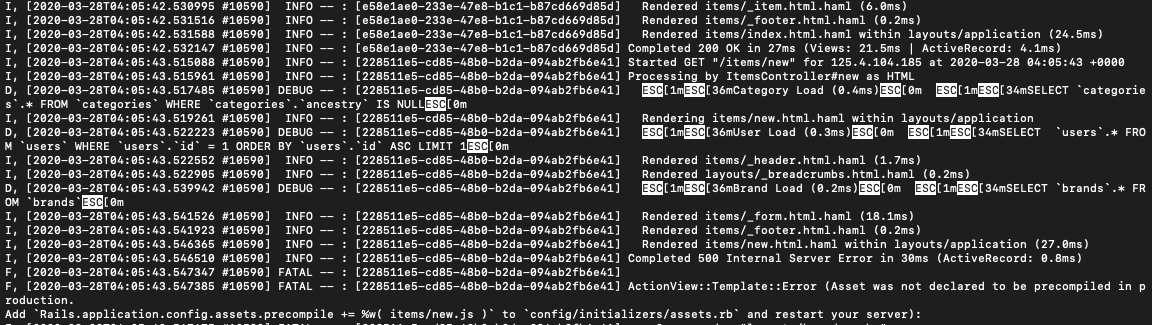
ActionView::Template::Error (Asset was not declared to be precompiled in production.
となります。
簡単にエラー文を訳すとassetがプリコンパイルされていないみたいなこと。アセットパイプラインとは
Ruby on Railsのアプリケーション内で使用したいJavaScriptやCSS、画像ファイルを「開発作業がしやすいようにファイルを分割してコーディングができるようにしつつ、最終的に一つのファイルに連結・圧縮する」仕組み。
つまり、JavaScriptやCSS、画像ファイルがHTML化されたファイルとひも付いてからWebブラウザ画面上に表示されるようになる。
本番環境ではこのアセットパイプラインが自動で通ってくれないため、手動で設定する必要がある。エラーの修正
エラー文の次の行に
AddRails.application.config.assets.precompile += %w( items/new.js )toconfig/initializers/assets.rb
と解決方法が書かれていた。
この文章の通り
config/initializers/assets.rbファイルに
Rails.application.config.assets.precompile += %w( items/new.js )の記述を加えることで解決した。おわりに
アセットパイプラインのエラーはよくあるらしい、、
初のデプロイ後のエラーで少し焦っていましたが、エラー文さえ見つけることができれば、なんとか解決できると思います。
*間違っていたらすいません。
参考URL
- 投稿日:2020-03-29T03:49:18+09:00
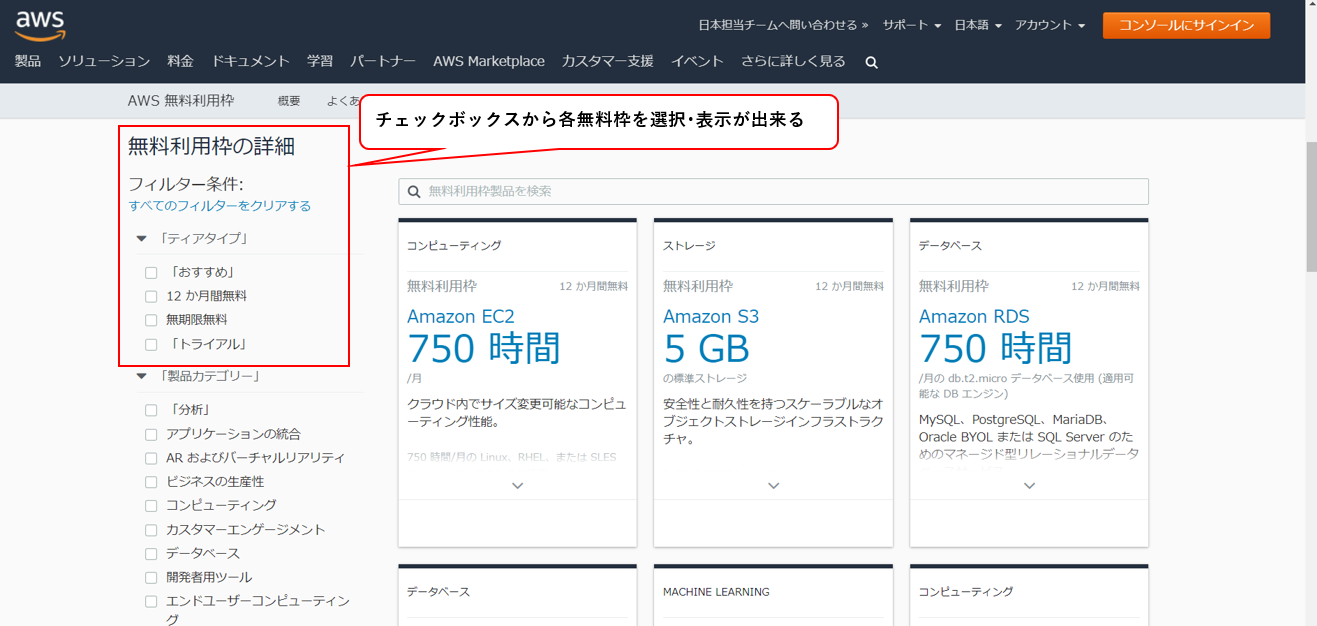
AWSの無料枠使用アラートが来たので確認してみた
無料分使用のアラートがくるまで
勉強用にアカウントを作成し、EC2を作成。作成して数日程で登録してあるメールアドレス宛に以下のアラートメールが来た。
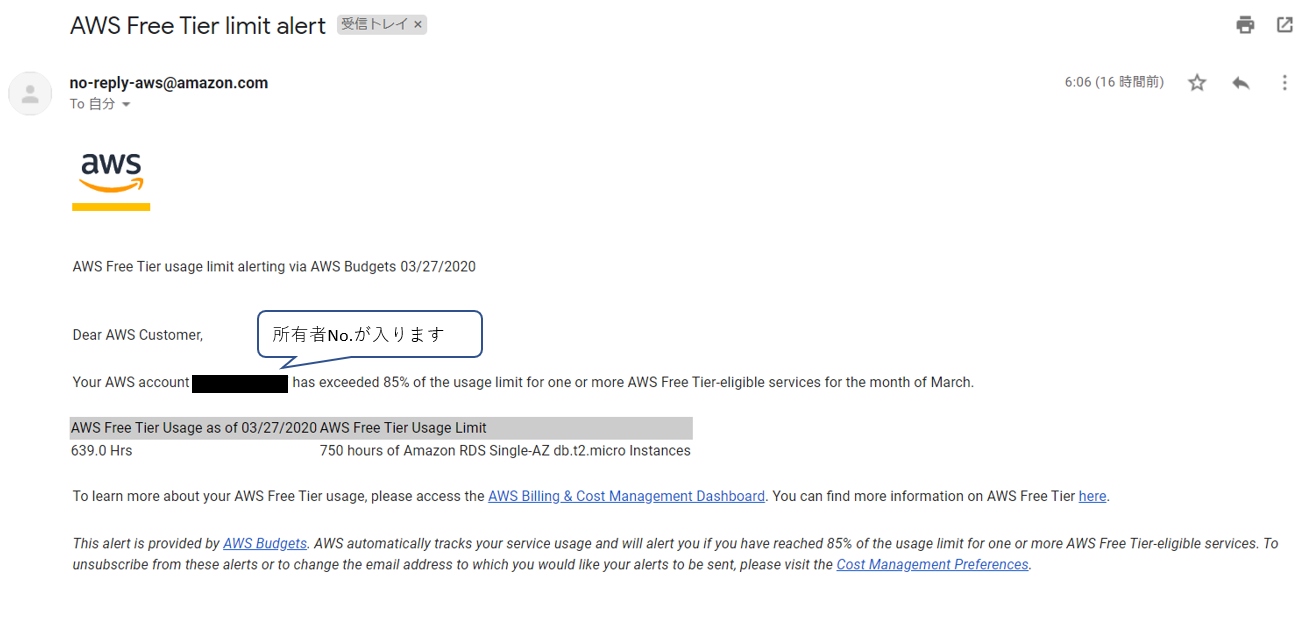
EC2インスタンス
・「EC2インスタンスの稼働時間の85%を使用したよ」という内容。インスタンスをしばらく立ち上げっぱなしにして置きアラームがどう出るか確認した。
無料使用時間が750時間なので月末近くになって通知。
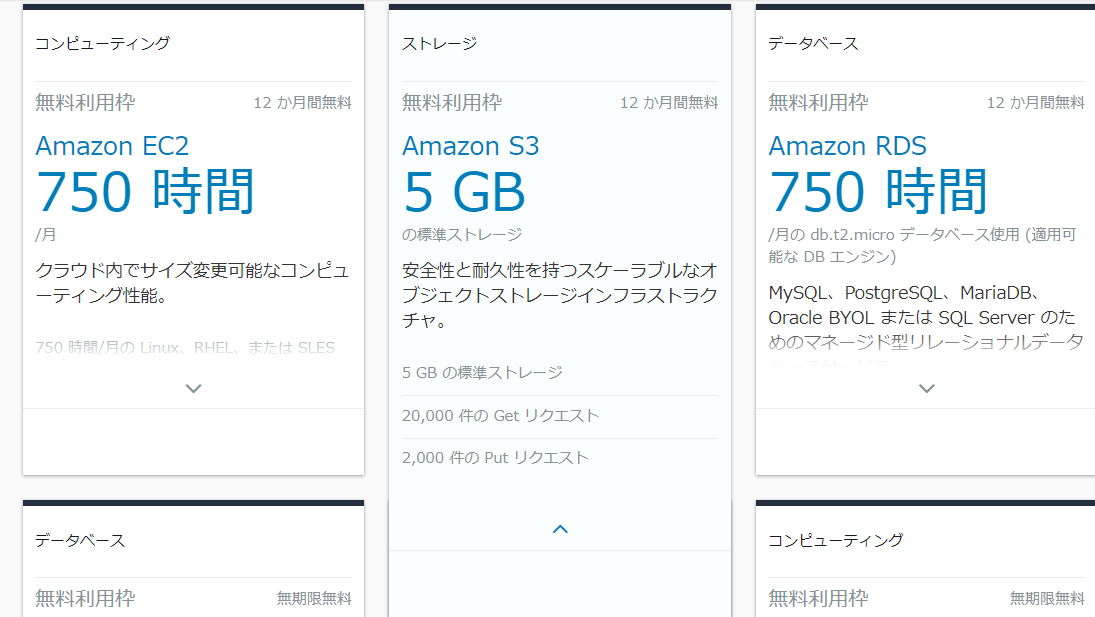
S3
リクエストの85%を使用したよという内容。
S3を設定して1~2日で来たので少し焦った。。あれこんなに使った覚えないけどという感じだった。
S3のリクエスト
AWS無料利用枠を確認してみた。
S3の欄を確認してみると「5GBの標準ストレージ」の大きい表示。
だが、その下を確認してみると、上記の他に、
・20,000件のGetリクエスト
・2,000件のPutリクエスト
・・・の表示が。通知に引っ掛かったのがこの要件だった。
これは見つけにくい、、、サービス毎に細かい要件があるようだ。
(Putリクエストだが、コンソールにログイン/ログアウトしただけでもカウントされているようだった…)アラートへの対応
・EC2・・・インスタンス名⇒「停止」を選択
⇒停止しておけば課金の対象にはならない。・S3・・・S3⇒対象のS3バケットを削除
停止及び削除する際は、削除可能なデータかどうか確認の後に対応。
終わりに
無料枠といっても割と幅が深い。
ただ無料枠といっても、初回の12か月無料枠や無期限無料枠があり、
使用したいサービスの無料分の枠を把握することで、コストを抑えつつ使用しようしていきたい。
AWS無料使用枠
- 投稿日:2020-03-29T00:41:46+09:00
VPCでネットワークを構築してみる
今回はAWSでVPCを作りながら、ネットワークの基礎を学んでいく!
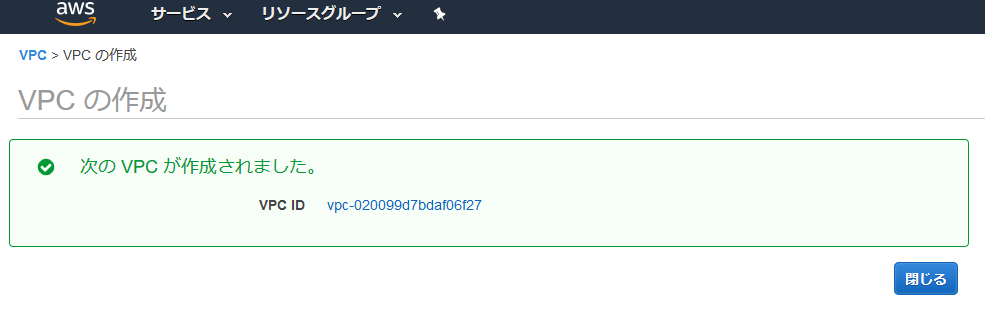
VPC作成
マネジメントコンソールでVPCを検索
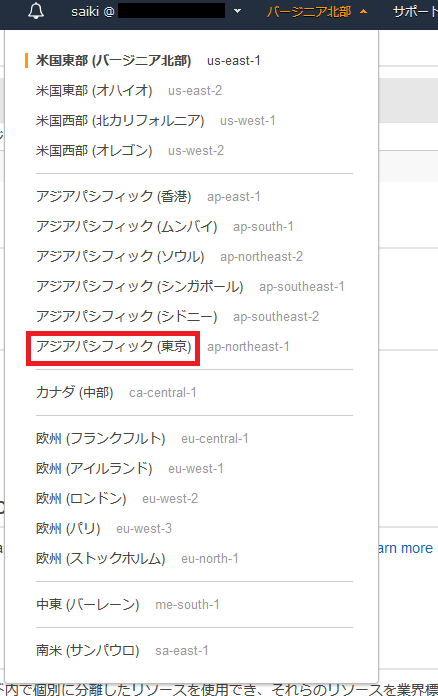
VPCの画面右上の地域の東京にする。
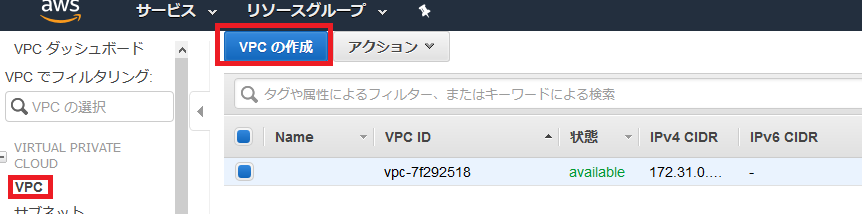
左側のメニューからVPCを選択し、VPC作成を選択。
以下の入力項目を設定し、右下の作成を選択。
作成されたので、閉じるを選択。
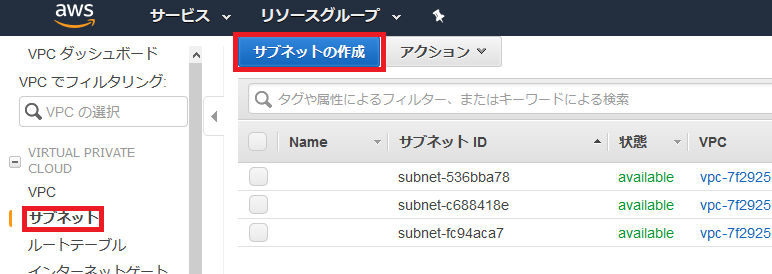
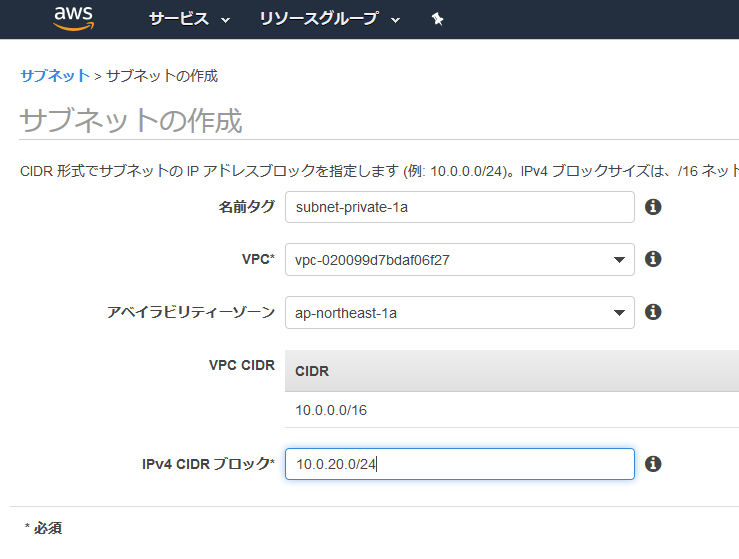
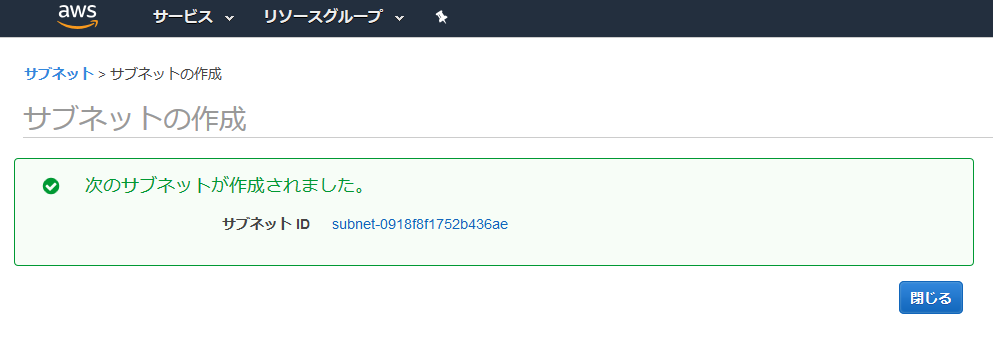
サブネットの作成
後に公開するサーバー(Webサーバー)と非公開のサーバー(DBサーバー)で分けたいので、作成したVPCの中にそれぞれサブネットを作成する。
公開するサーバーを作成
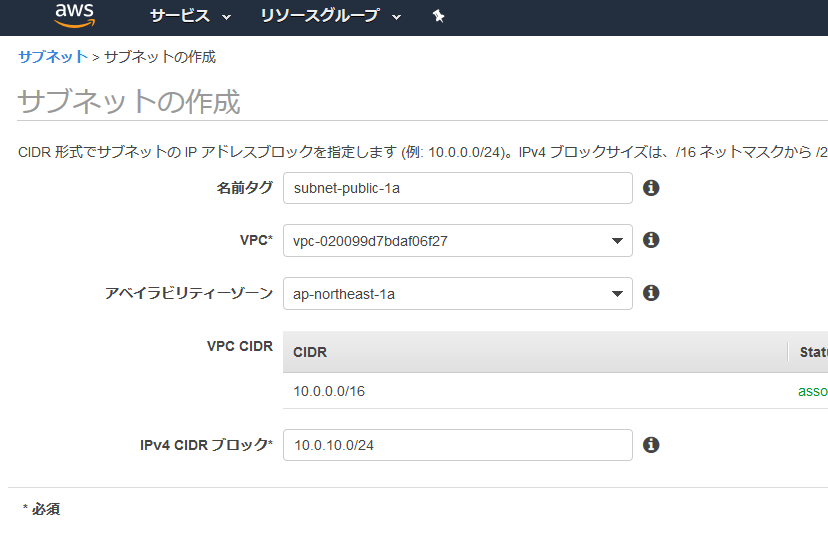
VPC画面の左側のメニューからサブネットを選択して、サブネットの作成を選択。
入力項目に入力して、作成ボタンを選択。VPCは先ほど作成したVPCを選択。
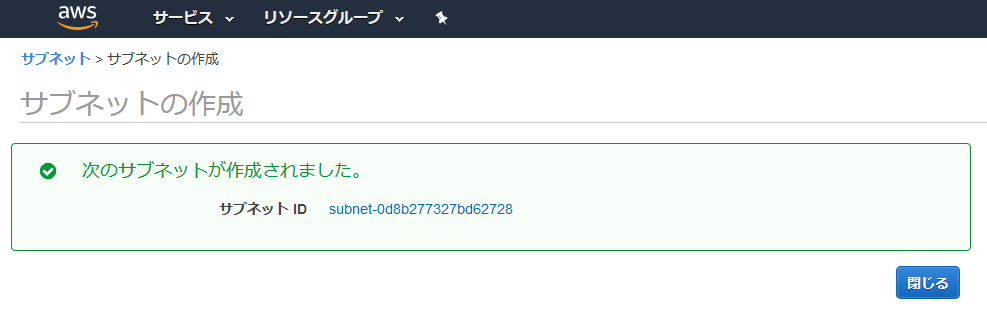
作成されたので閉じるを選択。
非公開のサーバーを作成
上記と同じような手順でもう一つ作成。
作成されたので、閉じるを選択。
ルーティングの設定
ルーティングの設定は、インターネットゲートウェイの作成してVPCにアタッチ、ルートテーブルの作成をしてサブネットに紐付けを行う。
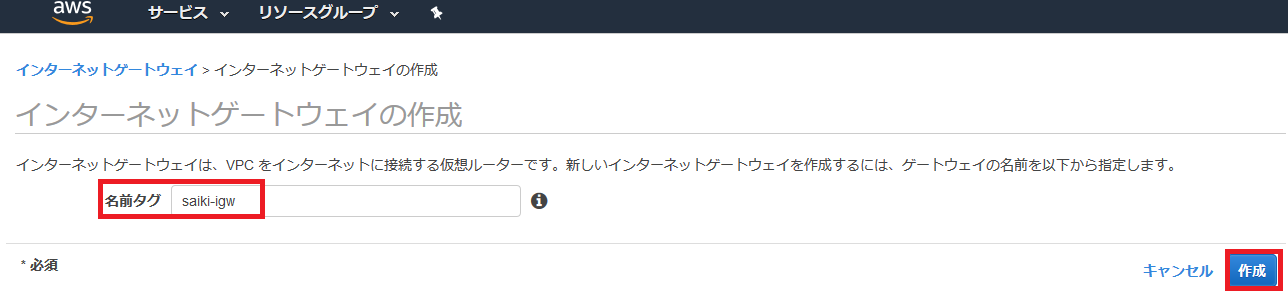
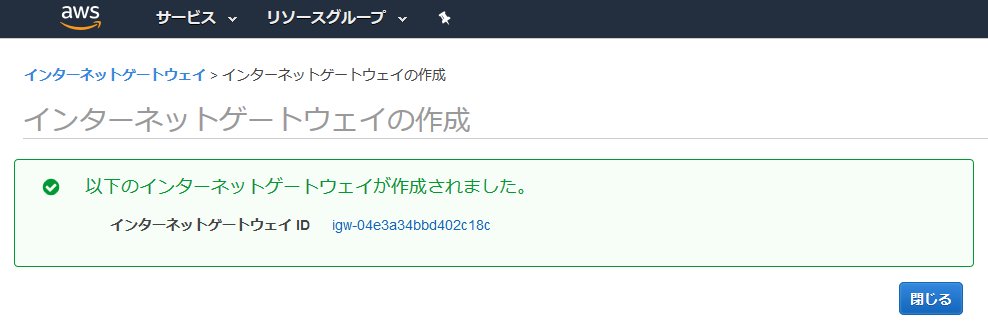
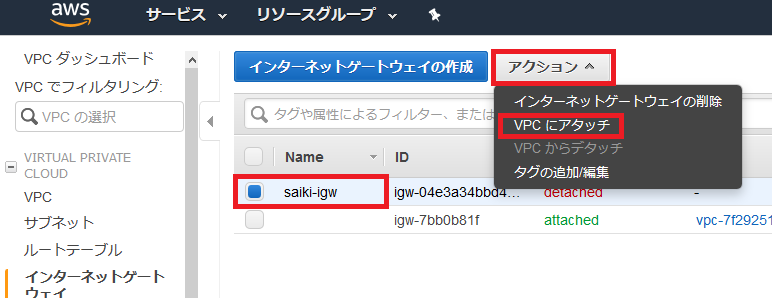
インターネットゲートウェイの作成とアタッチ
インターネットゲートウェイを選択して、インターネットゲートウェイの作成を選択。
名前を入力して、作成を選択。
作成されたので、閉じるを選択。
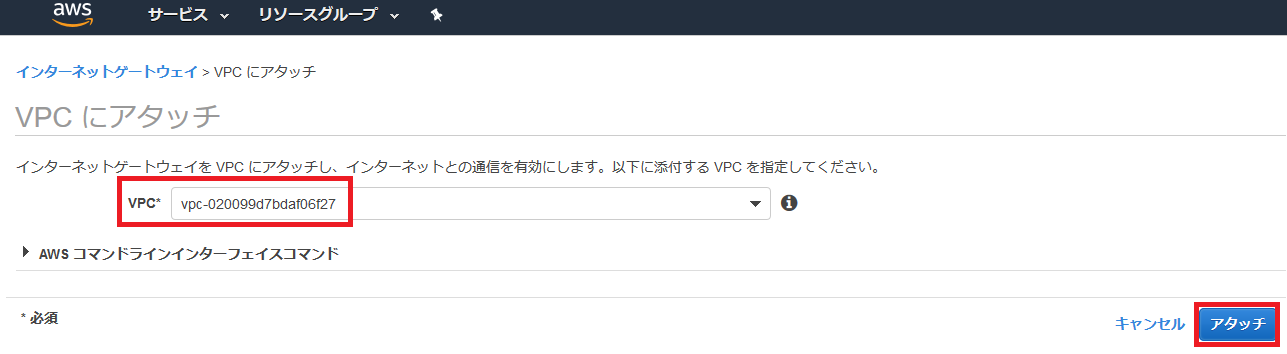
作成したゲートウェイの状態がディスアタッチになっているので、VPCにアタッチする。
先ほど作成したVPCを指定してアタッチ。
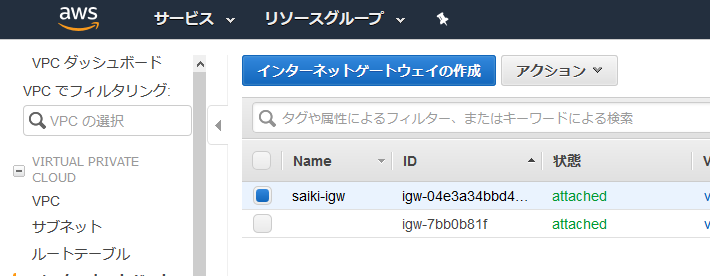
アタッチされた。
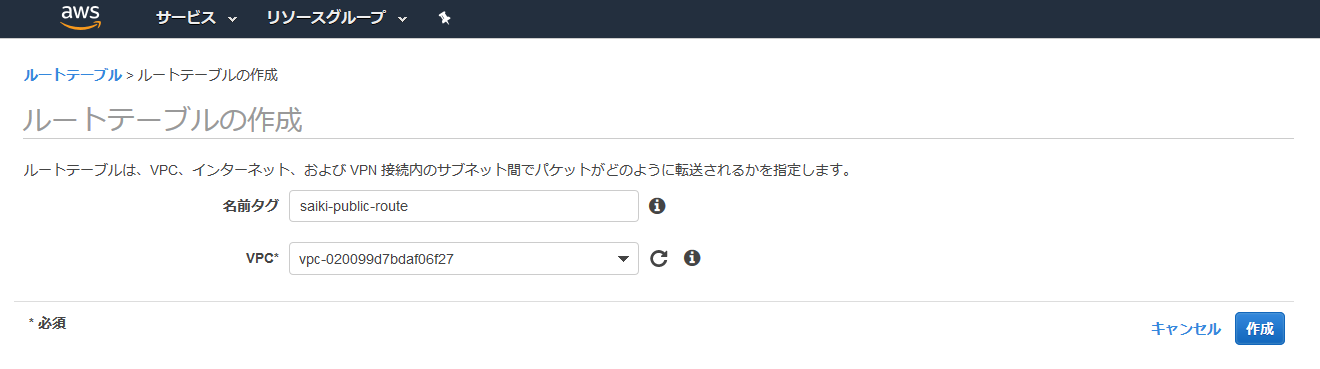
ルートテーブルの作成&サブネット紐付け
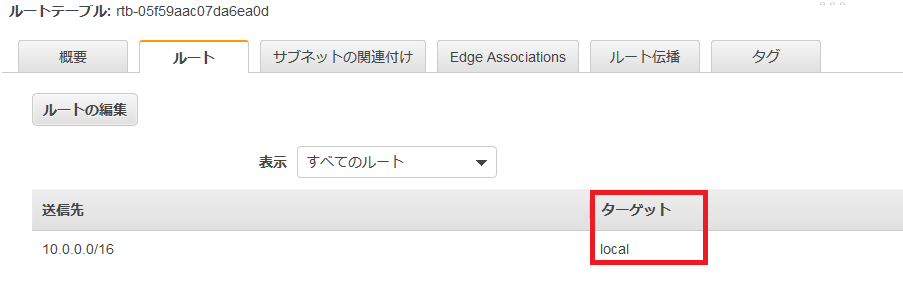
左側のメニューのルートテーブルを選択して、先ほど作成したVPCを選択。下のメニューのルートを選択するとターゲットがlocalになっていることが確認できる。このままではインターネットに接続できないので、ルートテーブルの作成を選択。
名前タグの入力とVPCを設定して作成を選択。
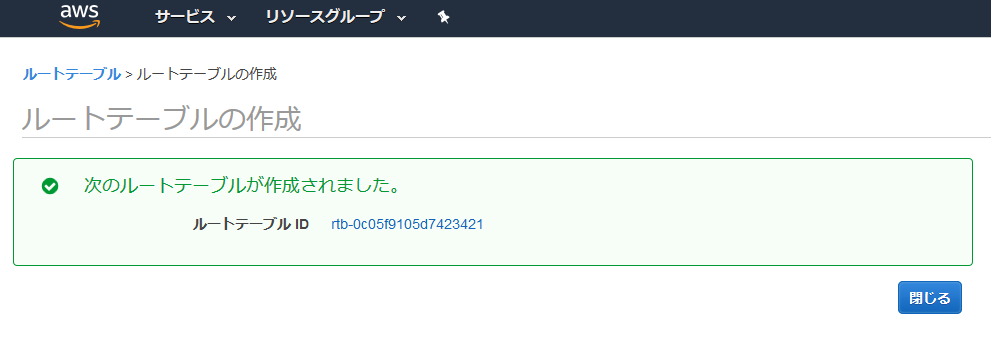
作成されたので、閉じる。
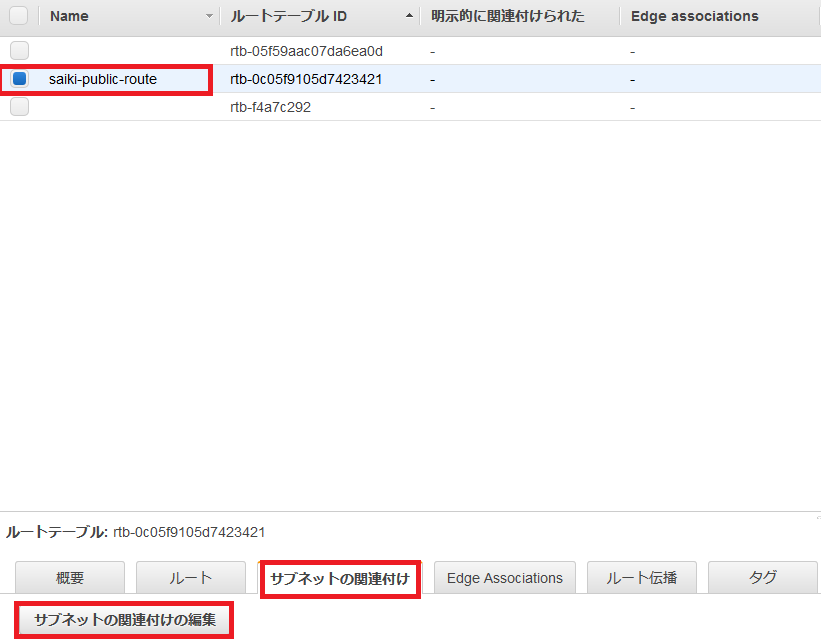
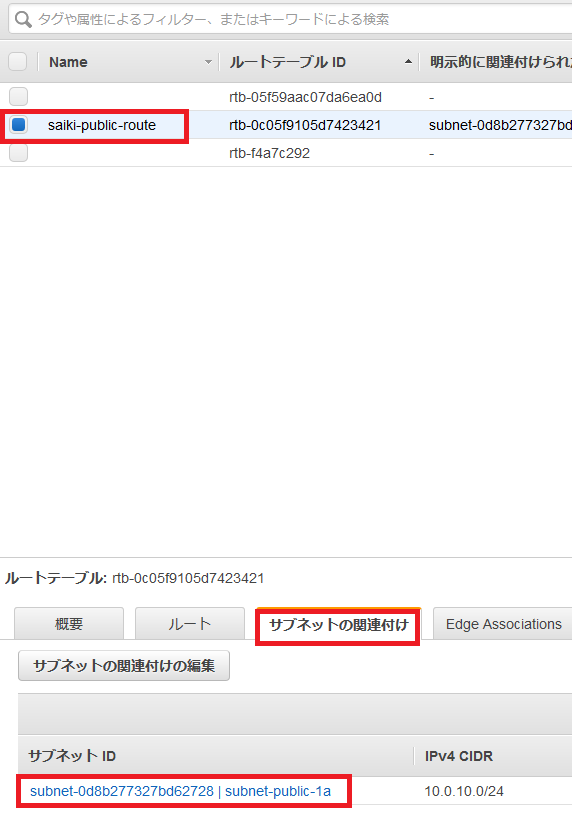
追加されたルートテーブルを選択し、サブネットの関連付けの編集を選択。
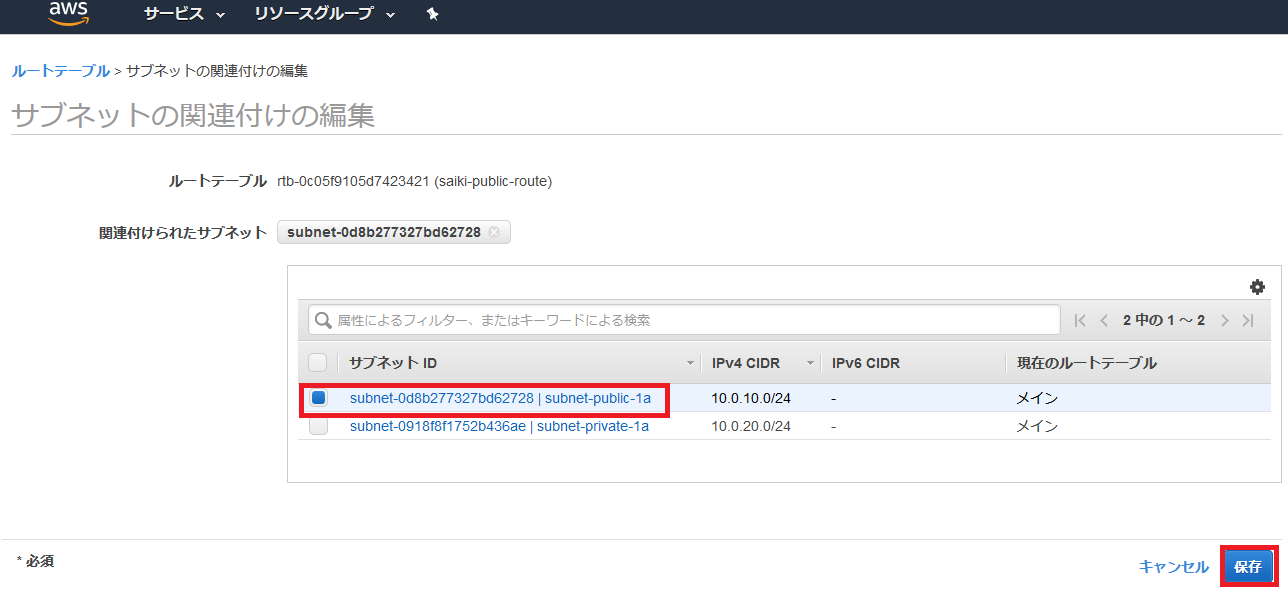
publicのサブネットを選択して保存。
publicのサブネットが関連付けられたことを確認。
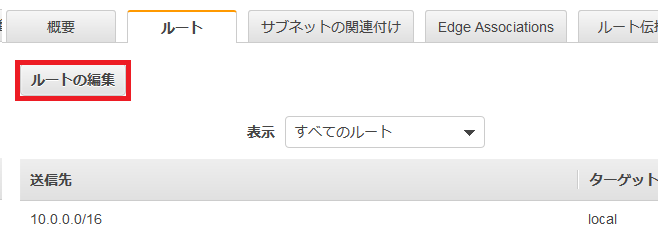
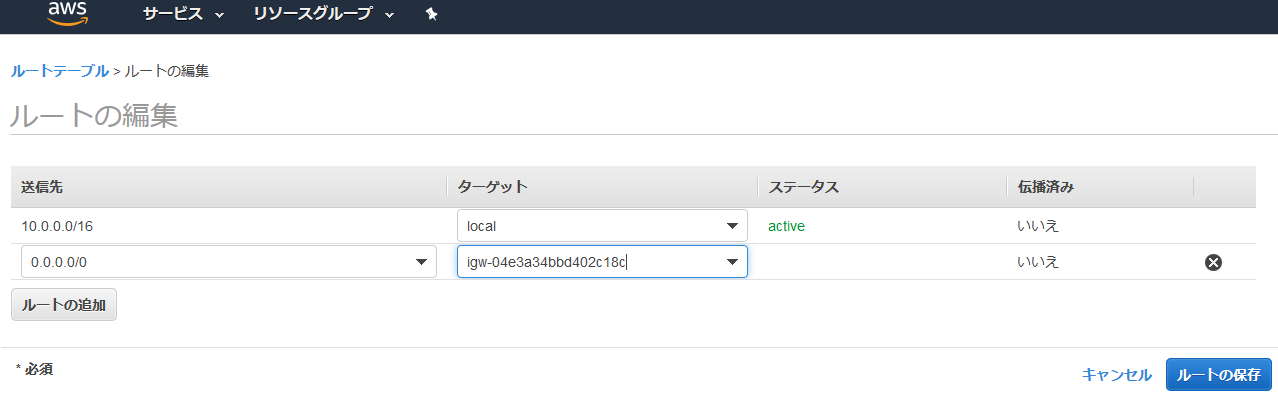
次にルートを編集する。ルートを選択して、ルートの編集を選択。
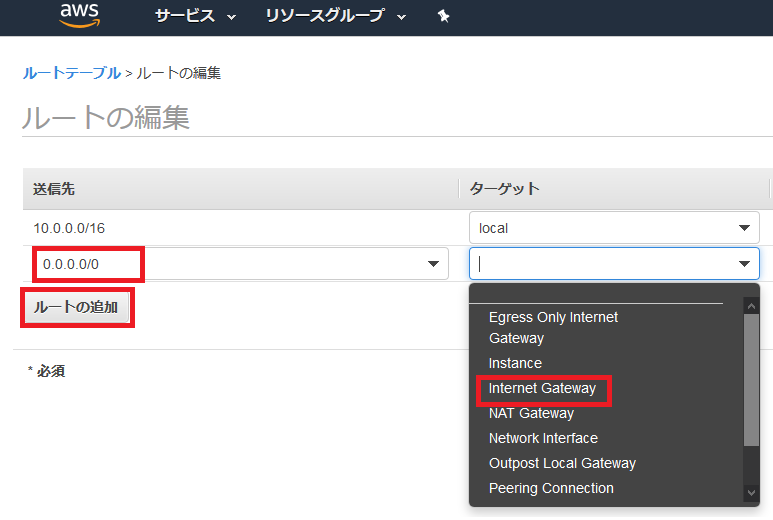
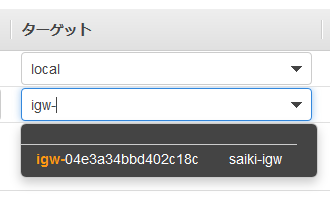
ルートの追加を選択して、送信先を入力。ターゲットをInternet Gatwayを選択すると、先ほど作成したインターネットゲートウェイが表示されるので選択する。
ルートの保存。
保存されたので閉じる。
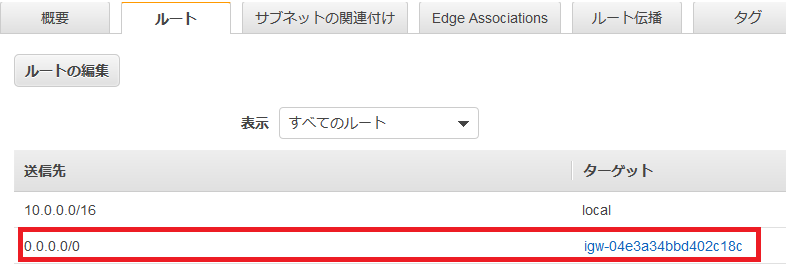
インターネットゲートウェイが設定されたかを確認。
終わりに
次回はこのVPCを使って、WebサーバーとDBサーバーを作成するので、その時にインターネットに繫がるかどうかもついでに確認していく!



- 投稿日:2020-03-29T00:27:01+09:00
投稿機能でS3に画像をアップロード機能
投稿機能の動作確認
今回は以下のことができるアプリとします。先に全ての投稿がうまく行くことを確認しましょう。もし不具合があるときの原因は「ローカルでの開発より後に行った作業」にあるので本番環境に上げる作業を確認してください。
①テキストのみの投稿
②画像のみの投稿
③テキストと画像両方の投稿
まず最初に、S3を使用する上でどうなると被害が出るのか確認します。
悪意を持ったユーザーにAWSのIDとパスワードが漏れてしまうことで被害が発生します。
AWSは従量制のサービスのため、他人がなりすましでログインして膨大な処理を行うと、それに対する支払いが発生してしまいます。
そのため以下の方法で手段で防ぎます。
AWS
①パスワードだけではログインできないようにする「二段階認証」
②ログインできたとしても機能をあまり使えなくする「IMAユーザー」
GitHub
③誤操作でIDやパスワードをpushしないように設定する「git-secrets」
があります。二段階認証
二段階認証は、あるサービスにログインする際に、通常パスワードに加えて、別の方法でも認証されないとログインできないようにする仕組みです。
万が一パスワードが漏れたとしても、それだけでは乗っ取られないため安全性を高めることができます。
今回は、以下のログイン時に二段階認証がされるようにします。
AWSへのルートユーザーでのログイン
AWSへのIAMユーザーでのログインAuthy
Authy二段階認証のためのアプリで、スマートフォン(iOS/Android)でもPCでも使うことができます。
Authyを起動するとパスワードが表示されるので、二段階認証の際にそれを入力します。パスワードは一定時間ごとに自動で変更されるます。
まず、Authyを自分のスマホにインストールしてください。
iOS版
(https://itunes.apple.com/jp/app/authy/id494168017?mt=8&uo=4&at=10lMo4)
Android版
(https://play.google.com/store/apps/details?id=com.authy.authy)
電話番号とメールアドレスを登録します。
登録後に"GET ACCOUNT VERIFICATION VIA"のメッセージが表示されるので、確認コード送付方法として「SMS」を選択します。
届いた確認コードをAuthyに入力したら、初期設定が完了です。
次に、AWSで二段階認証を行うための設定を行います。
1、AWSのヘッダー部分に表示されているアカウント名をクリックして、メニューの中から「マイセキュリティ資格情報」を選択します。
2、モーダル画面が表示されたら、「Continue to Security Credentials」をクリックします。
3、メニューの中の「多要素認証(MFA)」をクリックすると内容が展開されるので、「MFAの有効化」をクリックします。
4、モーダル画面の中から「仮想MFAデバイス」が選択し、続行をクリックします。
5、次の画面で「QRコードの表示」をクリックすると、QRコードが表示されます。
次に、スマホでAuthyを開きます。
1、AuthyにAWSアカウントを追加します。
2、Authyを開いたら、「Accounts」にある「+」ボタンをタップします。
3、カメラが起動するので、先ほどのQRコードを読み取ります。
4、設定画面を終了すると、二段階認証用のパスワードが表示さます。
30秒経つと自動的にそのパスワードは無効になるので注意してください。
5、このパスワードをAWSで入力します。
1つ目のパスワードを上の欄に、そのパスワードの次に表示されたパスワードを下の欄に入力します。
最後に「MFA」の割り当てをクリックして設定は完了です。
AWSのログイン時に追加でパスワードを求められるようになりますので、Authyで表示されたパスワードを入力します。IAMユーザー
最初にAWSで作ったアカウントはルートユーザーと呼ばれ、ルートユーザーでAWSにログインすると全ての機能を使うことができます。
そのため、万が一ルートユーザーのID・パスワードが漏洩し悪用されると、第三者が全ての機能を使えてしまいます。
それを防ぐために、使える機能を制限したユーザーを作成し、通常の作業はそのユーザーでログインし行うようにします。
この機能を制限したユーザーを作成できる機能がIAMです。
1、AWSログイン後に、検索のフォームにIAMと打ち込み、出てきた検索結果からIAMのページに飛んでください。
2、遷移先のページで、「個々のIAMユーザーの制作」をクリックし、「ユーザーの管理」をクリックしてください。
3、左上の「ユーザーを追加」をクリックしてください。
4、次に、作成するユーザーの名前を登録します。「ユーザー名」を入力し、アクセスの種類の「プログラムによるアクセス」をチェックし、次のステップをクリックしてください。
5、「既存のポリシーを直接アタッチ」から検索で「amazons3」を入力し、「AmazonS3FullAccess」に設定してください。
チェックを入れたら「次のステップ タグ」をクリックします。
6、「次のステップ: 確認」をクリックしてください。
7、最後に設定の確認をして大丈夫であれば、「ユーザーの作成」をクリックしてください。
※この時「アクセス権限の境界:アクセス権限の境界が設定されていません」という表示が追加でされていることもありますが、設定に問題はありません。
これでユーザーの作成が完了しました。
※忘れずに認証情報(csv)をダウンロードしておきましょう!IAMユーザーのパスワードを設定します。
1、IAMのメニューからヘッダーにある作成したIAMユーザーをクリックします。「認証情報」のタブをクリックし、「コンソールのパスワード」欄の「管理」をクリックします。
2、コンソールへのアクセス「有効化」、パスワードの設定「自動生成パスワード」をクリックします。
3、認証情報はダウンロードしておきます(csvファイルとしてダウンロードできます)。
作成したIAMユーザーでログインできることを確認します。
1、まずIAMのメニューからヘッダーにある作成したIAMユーザーをクリックし、ルートアカウントのサインアウトを行います。
2、先ほどダウンロードしたcredentialの情報を使ってログインします。一番右のURLにダウンロードしたcredentialの情報を貼り、User nameとPasswordを入力します。
ログインできれば成功です。IAMユーザーも二段階認証にしましす。
1、改めてログアウトし、ルートユーザーでログインしなおします。※二段階認証になっていることに注意してください。
2、再びIAMのユーザー選択画面から先ほど作成したユーザー名を選択し遷移したページ先で、「MFAデバイスの割当」の「管理」をクリックします。
3、あとは、ルートユーザーの時と同じように二段階認証の設定をします。git-secrets
誤操作でパスワードをGitHubにpushしてしまうと誰でも見られる状態になってしまいます。
git-secretsは、そのような誤操作を防いでくれるツールです。pushしようとしたコードをチェックし、パスワードだと推定されるような文字列が含まれている場合は、そこで処理が中断される仕組みです。
ターミナルから、Homebrewを経由してgit-secretsを導入します。
ターミナル$ cd ~/ $ brew install git-secretsgit-secretsが導入できたら、設定を適用したいリポジトリに移動して、git-secretsを有効化します。
ターミナル$ cd chatspace $ git secrets --installこれで、有効化を行なったリポジトリでgit-secretsを使用する準備ができました。
次に、「どのようなコードのコミットを防ぐのか」を設定していきます。
下記のコマンドを実行することで、secret_key, access_keyなど、アップロードしたくないAWS関連の秘密情報を一括で設定することができます。
ターミナル$ git secrets --register-aws --globalちなみに、現在のgit-secretsの設定は、下記のコマンドで確認することができます。
ターミナル$ git secrets --list今後作成する全てのリポジトリにgit-secretsが適用されるようにします。
ここまでの設定では、今後作成するリポジトリにはgit-secretsが適用されません。
ターミナル$ git secrets --install ~/.git-templates/git-secrets $ git config --global init.templatedir '~/.git-templates/git-secrets'GitHub Desktop経由でgit secretsを利用できるようにする場合は、追加の設定をします。
この時、FinderのアプリケーションフォルダのなかにGithub Desktopが入っているか確認してください。
入っていなければ適宜移動しましょう。
引き続きGitHub Desktopを利用する場合は、以下を実行します。
ターミナル$ sudo cp /usr/local/bin/git-secrets /Applications/GitHub\ Desktop.app/Contents/Resources/app/git/bin/git-secrets※上記コマンドでNo such file or directoryのエラーがでる場合
GitHub Desktopのバージョンが古い場合、上記のコマンドではなく、以下のコマンドでないと設定ができないことがあります。
ターミナル$ sudo cp /usr/local/bin/git-secrets /Applications/GitHub\ Desktop.app/Contents/Resources/git/bin/git-secretsこれで、事前に行うセキュリティ対策の作業は終了です。
S3で保存先を用意
S3でファイルがアップロードされる領域を準備します。
バケット
S3で、実際にデータが格納される場所のことをバケットと呼びます。バケットの名前はアクセスするときのURLとして使用されるため、まだ誰も付けたことがない名前を使う必要があります。
1、上のメニューバーに表示されている「サービス」をクリック、ストレージ内の「S3」をクリックします。
2、左上の「バケットの作成」をクリックします。バケットは、名前とリージョンを決めるだけで作成できます。
リージョンとは、バケットが実際に存在しているサーバーの場所です。以下の操作でバケットを作成します。
3、バケットの名前は任意で決めて大丈夫ですが、他のユーザーと重複した名称は使えません。
4、リージョンは 「アジアパシフィック(東京)」を選択します。入力できたら「次へ」をクリックします。
5、次の画面では変更は必要ないので、そのまま「次へ」をクリックします。
6、次は、セキュリティの設定を行います。今回はバケットポリシーを使用してセキュリティ設定を行います。6つ項目があり、順番に一番上はチェックを外し、次の2つはチェックしないで、次の2つはチェックを入れます。
一番下の「システムのアクセス許可の管理」の設定はチェックしないでください。
デフォルトの「Amazon S3 ログ配信グループにこのバケットへの書き込みアクセス権限を付与しない」のままで進めてください。
ここの設定が誤っているとファイルのアップロードができなくなります。設定できたら「次へ」をクリックします。
7、確認画面なので、問題なければ「パケットを作成」をクリックします。
バケットポリシー
どのようなアクセスに対してS3への読み書きを許可するか決めることができる仕組みです。今回は、作成したIAMユーザーからのアクセスのみを許可するよう設定していきます。バケットポリシー
どのようなアクセスに対してS3への読み書きを許可するか決めることができる仕組みです。今回は、作成したIAMユーザーからのアクセスのみを許可するよう設定していきます。
1、まずは先ほど作成したIAMユーザーの設定を確認します。メニューの「サービス」をクリックします。
2、一覧から「IAM」を検索し、表示されたメニューをクリックしてください。
3、「ユーザー」を選択し、先ほど作成したユーザー名をクリックします。
4、「IAM」ユーザーの一覧から、先ほど作成したユーザーを選びます。
IAMユーザーの情報が表示されるので、後ほど使うので「ユーザーのARN」をコピーして保存しておいてください。
5、次に、バケットポリシーの設定を行います。IAMの時と同じようにサービス一覧から S3を選びます。先ほど作成したバケットをクリックします。
6、「アクセス制限」をクリックし、そのなかの「バケットポリシー」をクリックし、赤枠の欄にポリシーの入力をします。
バケットポリシー{ "Version": "2012-10-17", "Id": "Policy1544152951996", "Statement": [ { "Sid": "Stmt1544152948221", "Effect": "Allow", "Principal": { "AWS": "************①****************" }, "Action": "s3:*", "Resource": "arn:aws:s3:::************②**********" } ] }上記の①に先ほどコピーして保存しておいた「ユーザーのARN」を、②に作成した「バケット名」を記述します。
【例】バケットポリシー{ "Version": "2012-10-17", "Id": "Policy1544152951996", "Statement": [ { "Sid": "Stmt1544152948221", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789012:user/upload_user" }, "Action": "s3:*", "Resource": "arn:aws:s3:::abc-test" } ] }これでS3のバケットの設定は完了です。これによって、データを保存するための入れ物が用意できた状態になりました。