- 投稿日:2020-03-29T23:43:19+09:00
多倍長演算の活用①
多倍長演算の活用
Python の多倍長演算を活用して、処理の簡潔化・高速化を行う方法について書きます。
本記事では、整数の各bitをフラグとみてbit演算する処理について、次の記事では整数を要素とする配列の処理について書きます。
後半、一部ネタバレを含むのでご注意ください。ナップサック問題
例えば、次のような問題を考えます。
$N$ 個の荷物があり、 $i$ 番目の荷物の重さは $w_i$ です。これらから重さの合計が $W$ 以下となるようにいくつかの荷物を選ぶとき、重さの最大値を求めよ。
この問題を解くには、順番に荷物を見て、その時点でどの重さにできるかのリストを更新できれば良いです。
配列を用いる方法
配列でこれを表す場合、大きさ $W+1$ の配列 $X = [x_0,\ \dots,\ x_{W}]$ を用意して、荷物を前から順に見て、その時点で荷物で重さ $i$ にできるのであれば $X_i = 1$ 、そうでなければ $X_i = 0$ とすることで $O(W * N)$ 回の処理でできます。配列は使いまわせば $1$ 次元で大丈夫です( $X[j][i]$ を $j$ 番目までの荷物を見たときに $i$ にできるか、とみて $2$ 次元配列にすることもできます)。
test.pyA = [3, 5, 7, 11] # 荷物の重さ W = 20 # 重さの最大値 X = [0] * (W+1) X[0] = 1 # 最初は重さ0だけ可能 for a in A: for i in range(a, W+1)[::-1]: # 同じ荷物を2回使わないように、大きい方から更新する if X[i-a] == 1: X[i] = 1 print(X) # [1, 0, 0, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0]bit演算を用いる方法
bit演算で行う場合は、重さ $i$ にできる場合には $s$ の下から $i$ 番目のbitを $1$ にして、そうでなければ $s$ の下から $i$ 番目のbitを $0$ にします。重さ $a$ の荷物の更新処理は、 $s$ に、 $s$ を $a$ だけ左シフトしたものと ${\rm bitwize}\ or$ を取れば良いです。この方法だと $O(N)$ 回のbit演算で解くことができます。wordsizeを $w$ として $a$ bitのbit演算の計算時間が $O(a/w)$ でできるとすると全体の計算時間は $O(W * N / w)$ です。
test.pyA = [3, 5, 7, 11] # 荷物の重さ s = 1 # 最初は0番目のbitだけ立てる for a in A: s |= s << a print(bin(s)) # 0b100101011011101110110101001最後の結果は、配列の方法と左右反転していることに注意してください。ただし、この方法では、 $W$ を超えた部分も計算してしまっているところが無駄になっています。これをやめたければ、毎回 $m = (1<<W) - 1$ と ${\rm bitwize}\ and$ を取れば良いです。もう一つの方法としては、最初 $W$ 番目のbitを立てておき、更新を右シフトで行う方法もあります。これなら不要な部分は勝手に削除されるので高速です。
test.pyA = [3, 5, 7, 11] # 荷物の重さ W = 20 s = 1 << W # 最初はW番目のbitだけ立てる for a in A: s |= s >> a print(bin(s)) # 0b100101011011101110110AGCの過去問
(ネタバレ防止のためリンク先は記載していません。リンク先に飛んで確認してください。)
こちらの 問題 をbit演算で解くことを考えます。
本問では、入力を適当に2進法で受け取った後、 ① 二項係数テーブルの計算、 ② 与えられた数値との bitwize and 、 ③ それらのすべての xor の取得、をすべてbit演算で行うことができます。先にいくつか準備します。
二項係数 mod 2
maspyさんのアイデアをお借りして、bit演算で $_NC_k\ {\rm mod}\ 2\ (k = 0,\ 1,\ \dots,\ N)$ のテーブルを $O(\log N)$ 回のbit演算で求めます。
これすごい。
— きり (@kiri8128) March 22, 2020
nCkが奇数となるすべてのkをlogn回のbit演算で計算できるのか。 https://t.co/qOOpHy2H9J要は $N$ の下から $i$ 番目のbitが立っていれば、
s |= s << iすれば良いですね。 $N$ のLSB(least significant bit)はN & (-N)で求められるので、下記のようにできます。test.pyN = 9 s = 1 while N: i = N & -N s |= s << i N ^= i print(bin(s)) # 0b1100000011全ビットの xor
$k$ bitの整数 $N$ の、すべてのビットのxorを取ります。これは $O(\log k) = O(\log\log N)$ 回のbit演算で可能です。具体的には、popcountを計算する要領で、各桁の情報を集約させていきます。popcountの取得のアイデアは、いろんな記事(例えば こちら )で書かれているので適当に調べてください。
桁数が大きくなる場合(数万 bit になる場合)のpopcountは下の「類題」でも出てきます。xor を取るだけなら、マスクなどがいらない分、簡潔になります。
test.pydef popcount_parity(n): for i in range(n.bit_length().bit_length()): n ^= n >> (1 << i) return n & 1AC コード(参考)
(ちょっとコードが汚いですが)これを使った ACコード です。他の Python の AC に比べると、ずいぶん高速になっていることが分かるかと思います。
その他の類題
(ネタバレ防止のため、リンクのみの記載としています。リンクに飛んで確認してください。)
たくさんある気がしたけど思いつかない(他にもあったら教えてください)。
類題 1
まさに本記事で扱った方法で処理できます。最後の popcount を取るところも bit 演算で処理すると高速です(この制約なら $1$ 桁ずつ見ても一瞬ですが)。
類題 2
こちらも、最初の考察の後は似たような処理でできます。
類題 3
10000 bit 程度保存する必要がありますが、十分高速に処理できます。
$x$ の $i$ 番目のビットが立っているかを確認する際に、x & (1<<i) > 0または(x>>i) & 1 > 0のようなことをやりますが、これを桁数分だけやると $2$ 乗になりそうなので (未確認) 、その場合は一度s = bin(x)のように文字列にしてしまえばその後の判定は各 $O(1)$ でできます。
(追記)よく考えればこれも LSB と bit_length() 、あるいは popcount の二分探索などでやっても良かったですね。マニアックな方法
元ネタはこどふぉの 問題 です。ややマニアックですが、工夫すれば bit 演算でいろんなことができるというのを知っていただきたいので説明します。
ポイントだけ説明するとこんな感じです。
$S, E, T$ からなる長さ $K$ の文字列が $N$ 個あります。 $S, E, T$ からなる長さ $K$ の文字列 $A$ 、 $B$ について、 $C = f(A, B)$ を
① $A[i] = B[i]$ なら $C[i] = A[i]$
② $A[i] != B[i]$ なら $C[i] != A[i]$ かつ $C[i] != B[i]$
で定めます( $A[i]$ は $A$ の $i$ 番目の文字を表します)。例えば、 $A = "SSE"$ かつ $B = "SET"$ なら $C="STS"$ です。
$N$ 個の文字列の異なる $3$ 個 $A$ 、 $B$ 、 $C$ の選び方で、 $f(A, B) = C$ を満たすものの個数を求めよ。実は適当に文字列を整数に変換しておくと、 $f(A, B)$ が $O(1)$ 回の多倍長演算で計算できます。その方法を説明します。
3種類の文字があるので、$1$ bitで $1$ 文字を表すことはできません。 $2$ bitあれば情報を持たせることはできますが、その後の演算が自然に行えないので、ここでは $7$ bitで $1$ 文字を表すことにします。具体的には、 $S$ を $0000100$ 、$E$ を $0001000$ 、 $T$ を $0010000$ で表します。左右 $2$ bit ずつはダミーで必ずゼロになりますが、後の計算のために追加しています。
結論を言うと、
$$
f(A, B) = (m - (A\ {\rm or}\ B))\ {\rm xor}\ ((((A\ {\rm and}\ B) >> 2) * 31) \ {\rm and}\ m)
$$
で計算できます。ただし、 $m$ は $2$ 進表記で $0011100$ を $K$ 個並べた整数です。1つ目のカッコ内は、 $x$ と $y$ が異なるとき、 「 $x$ でも $y$ でもないやつ」を表してくれるのでOKです(今思えば - は ^ でも良かった)。
ただし $x$ と $y$ が一致するときは $111\ {\rm xor}\ x$ になってしまうので、小細工して全体に $111$ を $xor$ したいです。具体的には、(x & y) >> 2に31をかけると $x$ と $y$ が一致するときのみ $1$ がたくさん出てきます。左右にはみ出てしまう可能性があるので、最後にマスクすればOKです。このはみ出た分が邪魔しないようにダミーを付けたのでした。test.pyN, K = map(int, input().split()) X = [int(input().replace("S", "0000100").replace("E", "0001000").replace("T", "0010000"), 2) for _ in range(N)] D = {x: 1 for x in X} m = int("0011100" * K, 2) ans = 0 for i in range(N): for j in range(i+1, N): if (m - (X[i] | X[j])) ^ (((X[i] & X[j]) >> 2) * 31 & m) in D: ans += 1 print(ans // 3)こんな感じで、工夫をすると bit 演算だけでいろいろできることが分かるかと思います。ただし複雑になりすぎると余計時間がかかることもあるので、並行処理のメリット(ざっくり wordsize 倍ぐらいの高速化?)と比較して適当に判断してください。
もし他にも面白いことができるよ、というご意見あれば教えてください。次回は整数を要素とする配列の bit 演算による処理について説明します。
- 投稿日:2020-03-29T23:35:21+09:00
PythonでLINEトークの履歴を解析して送信文字数などを数える
概要
LINEトーク履歴を解析し、各話者の発言文字数、投稿スタンプ数、写真数を数える方法を説明します。
彼女に私ばかり喋ってるといわれたので、送りあったラインの文字数、スタンプ数,写真の数を数えてみた.結果、彼女が倍くらい喋ってた. pic.twitter.com/G5Cs84t4d1
— しまじろう@はかせちゃれんじ (@shimajiroxyz) December 3, 2017結婚1周年なので妻とのLINEを解析した。
— しまじろう@はかせちゃれんじ (@shimajiroxyz) March 17, 2019
妻が夫の2倍喋っているのは結婚(同棲)前後で変わらず。
ただ妻も夫もやりとりする文字数は同棲後に有意に減っていた(p<.01)
そこで昼夜に分けて数えると、夜の文字数の減少が顕著だった。
同棲後は夜に直接喋れるためLINEの使用量が減ったと考えられる。 pic.twitter.com/kafepaCZXs環境
Google Colaboratory上で、pythonで解析しました。
LINEトーク履歴のダウンロード
LINEアプリからトーク履歴をダウンロードします。
スマホから行います。
やり方は下記の「LINEでトーク履歴をメールに送信・Keepに保存」の項を参照してください。
LINEのトーク履歴をバックアップする方法LINEトーク履歴の構造
トーク履歴はプレーンテキストで下記のように書かれています。
[LINE] 投稿者2(相手の名前)とのトーク履歴 保存日時:2020/03/19 11:26 2014/10/13(月) 13:47 投稿者1 こんにちは 13:48 投稿者2 [スタンプ] 13:48 投稿者1 "コンドルが!!!! 壁に!!!! めり込んどる!!!!!" 13:48 投稿者1 [スタンプ] 13:48 投稿者1 [写真] 13:48 投稿者2 [スタンプ] 2014/10/14(火) 23:34 投稿者1 ☎ 通話時間 0:07 23:35 投稿者2 ☎ 通話をキャンセルしました 23:34 投稿者2 おやすみ ...(略)1、2行目はタイトルと保存日時
3行目は空行で、4行目からトーク履歴です。
4行目以降、投稿日を示す行と、投稿時間、投稿者、投稿文字列がタブ区切りで書かれた行が続きます。途中で改行が行われる投稿文字列は、ダブルクオテーションで囲った上で、複数行にわたって表示されます。
スタンプ、写真(画像)を送信した場合は投稿文字列がそれぞれ[スタンプ]、[写真]となります。
通話をした場合、キャンセルした場合はそれぞれ、「☎ 通話時間 0:07」「☎ 通話をキャンセルしました」と書かれます。ファイルのアップロード
Google Drive上で、解析用のColaboratoryファイル(analysis.ipynbとします)を作成します。
そして、トーク履歴(line_talk_history.txtとします)を同じフォルダ内にアップロードします。
トーク履歴のGoogleColaboratoryからの読み込み
GoogleDriveのフォルダをpythonから読み込めるように、Colaboratory上で下記を実行します。
#GoogleDriveをマウントする from google.colab import drive drive.mount('/content/drive/') #解析用のフォルダに移動し、トーク履歴を読み込む %cd /content/drive/My\ Drive/path/to/directory log_text = open('line_talk_history.txt','r').read()実行すると下記のように認証キー入力を求められるので、URLをクリックして適切なGoogleアカウントを選びキーを発行して、枠にコピペしてください。
マウントができたらline_talk_history.txtが存在するパスに移動し、ファイルを読み込みます。
"/content/drive/My\ Drive"がGoogleDrive上での「マイドライブ」の場所になるので、そこを基準にパスを指定してください。
cdなどのシェルコマンドをGoogleColaboratory上で使う場合は%を頭に書きます。
移動したらopenで読み込みます。トーク履歴構造の整理
トーク履歴は「日付」「トーク本文」「改行されたトーク本文の残り」の行が混在しているので、そのままでは解析しにくいです。
line_talk_history.txt<注:#以降は筆者による注釈> 2014/10/13(月) #「日付」 13:47 投稿者1 こんにちは #「トーク本文」 13:48 投稿者2 [スタンプ] #「トーク本文」 13:48 投稿者1 "コンドルが!!!! #「トーク本文」 壁に!!!! #「改行されたトーク本文の残り」 めり込んどる!!!!!" #「改行されたトーク本文の残り」 13:48 投稿者1 [スタンプ] #「トーク本文」 ...(略)そこで、1行ごとにタイムスタンプ、投稿者、本文の情報が書かれるように構造を整理します。
年度ごと、月ごとなどの集計がしやすいように、タイムスタンプは年、月、日、曜日、時、分の情報に分けます。
最終的に下記のように、各行が「年, 月, 日, 曜日, 時, 分, 投稿者, 本文」という形式になるようにします。トーク本文中の改行はとりあえず<br>で置き換えることにします。>> logs [ ['2014', '10, '13', '月', '13', '47', '投稿者1', 'こんにちは'], ['2014', '10, '13', '月', '13', '48', '投稿者2', '[スタンプ]'], ['2014', '10, '13', '月', '13', '48', '投稿者1', '"コンドルが!!!!<br>壁に!!!!<br>めり込んどる!!!!!"'], ['2014', '10, '13', '月', '13', '48', '投稿者1', '[スタンプ]'], ... ]これを実行するために下記コードを実行します。
logs_textの4行目以降を「空行」「日付」「トーク本文」「改行されたトーク本文の残り」のいずれかであるか判定して、処理を分けています。analysis.ipynb#1行ごとにタイムスタンプ、投稿者、本文が記載されるようにトーク履歴を整理する #タイムスタンプは年、月、日、曜日、時、分の情報に分ける #最終的に各行が「年,月,日,曜日,時,分,投稿者,本文」という形式で記述されるようにする。 logs = [] year, month, date, weekday = '', '', '', '' hour, minute, name = '', '', '' #log_txtの各行は「空文字」「日付」「トーク本文」「改行されたトーク本文の残り」の4種類のいずれかになるので、 #どの種類かを判断して処理を分ける #「空行」「トーク本文」「日付」の順に判定し、いずれにも該当しない場合は「改行されたトーク本文の残り」とみなす。 for i,log in enumerate(log_text.splitlines()[3:]): #「空文字」の場合何もしない if log == '': continue #「トーク本文」であるかを判定する #トーク本文である必要条件は、タブで分けて長さ3個以上、 #かつ最初の要素が時刻形式、つまり23以下の数字、コロン、59以下の数字の並びであること #これはあくまで必要条件であって、この条件を満たしていても、 #「改行されたトーク本文の残り」である可能性を厳密には排除できないが、厳密に排除するのはたぶん無理なので、このくらいで妥協する talkelem = log.split('\t') timeelem = talkelem[0].split(':') #タブで分けた要素数が3以上、かつ、タブで分けた最初の要素をコロンで分けた要素数が2 if len(talkelem) >= 3 and len(timeelem) == 2: #タブで分けた最初の要素をコロンで分けた2要素をそれぞれ時、分と仮定する tHour = timeelem[0] tMinute = timeelem[1] #時、分がそれぞれ数字(整数)を表し、かつ、時、分として妥当な範囲の数字であるかを判定する if tHour.isdecimal() and int(tHour) <= 23 and int(tHour) >= 0 and tMinute.isdecimal() and int(tMinute) <= 59 and int(tMinute) >= 0: name = talkelem[1] hour, minute = tHour, tMinute content = '\t'.join(talkelem[2:]) #条件が満たされれば日付情報とともに、logsに追加する logs.append([year,month,date,weekday,hour,minute,name,content]) continue #タブで分けた長さが3以上だが、「トーク本文」ではないとき、「改行されたトーク本文の残り」とみなす #レアなケースと考えられるので念の為、行番号を出力しておく else: print('warning: very rare case') content = '\t'.join(talkelem) logs[-1][-1]+=('<br>'+content) continue #「日付」であるかを判定する #「日付」である必要条件は、タブで分けて長さ1、かつスラッシュで分けて長さ3、 #かつタブで分けたときの第一要素が西暦として無理のない4桁の数字、第二要素が月を表す2桁の数字、第三要素が日を表す2桁の数字、 #かつラスト3文字は「(」+「曜日」+「)」となっていること #「トーク本文」の判定と同様に、これはあくまで必要条件であって、この条件を満たしていても、 #「改行されたトーク本文の残り」である可能性を厳密には排除できないが、厳密に排除するのはたぶん無理なので、このくらいで妥協する elif len(talkelem) == 1 and len(log) == 13 and len(log.split('/')) == 3 and log[-3] == '(' and log[-1] == ')' and log[-2] in ['月','火','水','木','金','土','日']: #スラッシュでスプリットした3要素をそれぞれ年、月、日と仮定する dateelem = log[:-3].split('/') tYear, tMonth, tDate = dateelem[0], dateelem[1],dateelem[2] #年、月、日がそれぞれ妥当な範囲の数値文字列であるか判定する #条件が満たされたとき、年、月、日、曜日の情報を更新する if tYear.isdecimal() and int(tYear) <= 2100 and int(tYear) >= 1900 and tMonth.isdecimal() and int(tMonth) <= 12 and int(tMonth) >= 1 and tDate.isdecimal() and int(tDate) <= 31 and int(tDate) >= 1: year, month, date, weekday = tYear, tMonth, tDate, log[-2] continue #タブで分けたが長さが1だが、「日付」ではないとき、「改行されたトーク本文の残り」とみなす #レアなケースと考えられるので念の為、行番号を出力しておく else: print('warning: very rare case at line:',i) content = '\t'.join(talkelem) logs[-1][-1]+=('<br>'+content) continue #「空行」「トーク本文」「日付」のいずれでもないとき、「改行されたトーク本文の残り」とみなす else: #print('linebreak detected', i,log) content = '\t'.join(talkelem) logs[-1][-1]+=('<br>'+content) continue集計
構造が整理できたら送信文字数、スタンプと写真の送信回数をカウントします。
通話の情報はとりあえず無視します。
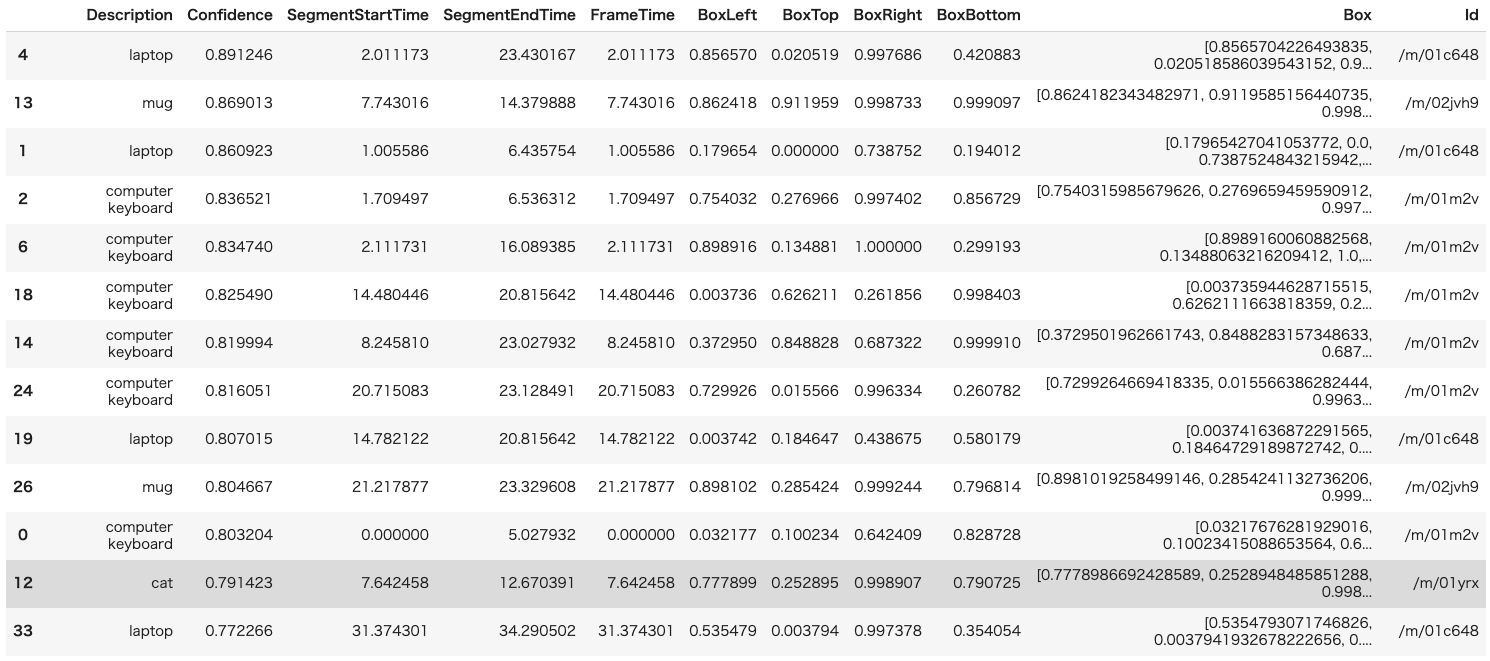
リンクを送信していることがあってそれも本当は分離したいのですが、本文と区別するのが面倒なので、とりあえず送信文字数に含めています。analysis.ipynb#月ごとの送信文字数、スタンプ・写真の送信回数をカウントする #通話の情報はとりあえず無視する #URLの送信は別途処理したほうが望ましそうだが、本文からの分離が面倒なので、とりあえずは送信文字数に含める result = {} for log in logs: year, month, date, weekday = log[0],log[1],log[2],log[3] hour, minute,name,content = log[4],log[5],log[6],log[7] #通話の情報は無視する if content == '☎ 通話をキャンセルしました': continue if content.startswith('☎ 通話時間'): continue #年、月が初めて登場した場合、カウント用の要素をプリセットする if year not in result: result[year]={} #1,2,3番目の数字をそれぞれ送信文字数、スタンプ送信回数、写真送信回数とする if month not in result[year]: result[year][month] = {'投稿者1': [0,0,0],'投稿者2':[0,0,0]} #本文がスタンプや写真、通話の場合、加算しない #スタンプの場合 if content == '[スタンプ]': result[year][month][name][1] += 1 #写真の場合 elif content == '[写真]': result[year][month][name][2] += 1 #その他の場合(文字数を加算) else: result[year][month][name][0] += len(content) #出力 for v in result: for v2 in result[v]: print(v,v2,result[v][v2])月ごとだけでなく、曜日ごとや時間帯ごとなどの集計も上のコードを少し書き換えればできます。
あとは結果をエクセルなどに貼り付けてグラフ化すると最初に載せたようなグラフを作れます。
うまく解析すれば、時期ごとのやりとりの活発さの違いなど興味深いデータが得られるかもしれません。

- 投稿日:2020-03-29T23:08:48+09:00
[メモ] ディープラーニングでの汎化性能検証時のtest_splitと交差検証法の違い
Python / ディープラーニング初心者です。
ニューラルネットワーク実装時に調べた汎化性能の検証法について、
以下の通りメモを残します。疑問に感じたこと
- k分割交差検証法( k-fold cross-validation / kCV)という汎化性能の検証方法がある(参考1)
- 学習用のデータをk個に分割し、k-1個を学習用、1個を性能評価用に用いるという学習をk回繰り返す方法
- sklearn.modelselection.traintest_split(TTS)を用いて、手元のデータを学習用データとテスト用データに分けて汎化性能を検証することがあるのをもともと知っていた
- a.基本的にTTSを複数回繰り返したものがkCVという認識で良いか?
- b.TTSよりもkCVのほうがモデルの汎化性を正確に評価できるという認識でよいか?
回答
- a.そう思われる。加えて、kCV時にはもれなくすべてのk個分割を検証用に用いることができる。
- b.そのように思われる。
- TTSを1回だけすると、検証用に用いるデータは学習データとして絶対に用いることができなくなるために、検証用データの選択方法次第では学習に不要な偏りが生じてしまう可能性がある。kCVならそれを克服できる(参考2)。
- kCVにも、「k個の各分割内にデータの偏りがあった場合に学習結果にバイアスがかかってしまう(犬のデータしか入っていない分割と、猫のデータデータしか入ってない分割に分けられているなど)」デメリットが指摘されている。これに対する対抗策としては、層化k分割交差検証(Stratified kCV)などが挙げられる(参考1)。
まとめ
めっさ当たり前のことなんでしょうけどメモとして残します。
参考
- 投稿日:2020-03-29T23:06:18+09:00
年賀状をpythonを使って他己分析してみた
開発の動機
毎年送りあう年賀状…
部屋の整理をしていたら、先輩や後輩からもらった年賀状がたくさん出てきた。
これを何か役立てないかと考えた。そこで閃いたのが、他人から見た自分を年賀状を通じて可視化できるのではなかろうかと思いついた。
いわゆる他己分析が年賀状を通じてできるのではないだろうかと思った。考えてみれば、自分が他の人に書くときは、去年のその人の印象やエピソードなんかを交えて書く。
これは他人も同じなのではないかと考えた。年賀状を形態素解析して、自分に対する印象を抽出できるはず…
それをワードクラウドにして、自分の他人に対する印象を可視化しようと思った。作り方
1 年賀状の文面の打ち込み(データ入力)
まず、分析するデータを集める必要があるので、年賀状の内容をエクセルにまとめる。
こんな感じで、あけおめ・ことよろ系のしょうもない挨拶は省いたもので入力した。
なるべく、自分の印象やエピソードに関連する文言のみを入力するようにした。2 データをまとめる
次に、入力したエクセルを一つのデータにまとめる
import xlrd wb = xlrd.open_workbook('/nenga2020.xlsx') sheet = wb.sheet_by_name('Sheet1') col_values = sheet.col_values(0) text="" for i in col_values: text=text+i print(text)これで、textに年賀状の文面がすべて入っていることになる。
3 形態素解析&ワードクラウド作成
とうとうここから形態素解析&ワードクラウドの作成をする。
import MeCab import wordcloud, codecs m = MeCab.Tagger("") text = text.replace('\r', '') parsed = m.parse(text) splitted = ' '.join( [x.split('\t')[0] for x in parsed.splitlines()[:-1] if x.split('\t')[1].split(',')[0] in ["名詞","形容詞","形容動詞"] ]) wordc = wordcloud.WordCloud(font_path='HGRGM.TTC', background_color='white', contour_color='steelblue', contour_width=2).generate(splitted) wordc.to_file('nenga2020.png')これで年賀状で書かれた印象について、解決できる。
splitted = ' '.join( [x.split('\t')[0] for x in parsed.splitlines()[:-1] if x.split('\t')[1].split(',')[0] in ["名詞","形容詞","形容動詞"] ])のところで、品詞を名詞,形容詞,形容動詞に絞っている。
これは自分の印象の抽出を目的にしているから。まとめ
コード全体
import xlrd import MeCab import wordcloud, codecs wb = xlrd.open_workbook('/nenga2020.xlsx') sheet = wb.sheet_by_name('Sheet1') col_values = sheet.col_values(0) text="" for i in col_values: text=text+i m = MeCab.Tagger("") text = text.replace('\r', '') parsed = m.parse(text) splitted = ' '.join( [x.split('\t')[0] for x in parsed.splitlines()[:-1] if x.split('\t')[1].split(',')[0] in ["名詞","形容詞","形容動詞"] ]) wordc = wordcloud.WordCloud(font_path='HGRGM.TTC', background_color='white', contour_color='steelblue', contour_width=2).generate(splitted) wordc.to_file('nenga2020.png')そして完成した他己分析のワードクラウドはこちら。
剣道部関連から多くの年賀状をもらったので、関連ワードが多い…
面白いとか有能とか尊敬とかのワードが他人からの自分の印象であると考察される。

- 投稿日:2020-03-29T22:54:20+09:00
Pubmedの.xmlデータをpythonで処理する
はじめに
この記事は、Pubmedで検索で引っかかった文献データ(xml形式)をpythonで読み込む方法についての自分用メモです。
お気付きの点がありましたらご指摘いただけますと幸いです。
処理したいデータ
一件のデータは以下のような感じです。実際は複数件のデータを処理したいですが、まずは一件ずつ処理できるようにします。
001.xml<PubmedArticle> <MedlineCitation Status="Publisher" Owner="NLM"> <PMID Version="1">12345678</PMID> <DateRevised> <Year>2020</Year> <Month>03</Month> <Day>27</Day> </DateRevised> <Article PubModel="Print-Electronic"> <Journal> <ISSN IssnType="Electronic">1873-3700</ISSN> <JournalIssue CitedMedium="Internet"> <PubDate> <Year>2020</Year> <Month>Mar</Month> </PubDate> </JournalIssue> <Title>Journal of XXX</Title> </Journal> <ArticleTitle>Identification of XXX.</ArticleTitle> <AuthorList CompleteYN="Y"> <Author ValidYN="Y"> <LastName>Sendai</LastName> <ForeName>Shiro</ForeName> <Initials>S</Initials> <AffiliationInfo> <Affiliation>Sendai, Japan.</Affiliation> </AffiliationInfo> </Author> <Author ValidYN="Y"> <LastName>Tohoku</LastName> <ForeName>Taro</ForeName> <Initials>T</Initials> <AffiliationInfo> <Affiliation>Miyagi, Japan.</Affiliation> </AffiliationInfo> </Author> </AuthorList> <Language>eng</Language> <PublicationTypeList> <PublicationType UI="D016428">Journal Article</PublicationType> </PublicationTypeList> <ArticleDate DateType="Electronic"> <Year>2020</Year> <Month>03</Month> <Day>23</Day> </ArticleDate> </Article> <CitationSubset>IM</CitationSubset> </MedlineCitation> <PubmedData> <PublicationStatus>aheadofprint</PublicationStatus> <ArticleIdList> <ArticleId IdType="pubmed">32213359</ArticleId> <ArticleId IdType="pii">S0031-9422(19)30971-9</ArticleId> <ArticleId IdType="doi">10.1016/j.phytochem.2020.112349</ArticleId> </ArticleIdList> </PubmedData> </PubmedArticle>基本的な使い方の理解
xmlを読むためのライブラリーを読み込みます。
001.pyimport xml.etree.ElementTree as ETファイルからxmlデータを読み込みます。
複数のデータが改行2つ区切りで並んでいるようなので、splitで分割してリストにします。002.pytest_data = open("./xxxx/pubmed.xml", "r") contents = test_data.read() records = contents.split('\n\n')1つ目の文献データ(records[0])をET.fromstring()で読み込んで変数rootにしまいます。
rootをtype()で調べると、Elementオブジェクトであることがわかります。003.pyroot = ET.fromstring(records[0]) type(root) #<class 'xml.etree.ElementTree.Element'>root.tagでtagを確認できるとのことです。確認してみます。
004.pyroot.tag #'PubmedArticle'1つのデータについては、ざっくり言えば以下のような形になっています。root.tagで、一番外側のtagにアクセスできました。
002.xml<PubmedArticle> <MedlineCitation> </MedlineCitation> <PubmedData> </PubmedData> </PubmedArticle><PubmedArticle>の内側には2つの要素(MedlineCitationとPubmedData)があり、これには添字を使ってアクセスできます。添字を使ってアクセスし、さらにtypeを調べます。
005.pyroot[0] #<Element 'MedlineCitation' at 0x10a9d5b38> type(root[0]) #<class 'xml.etree.ElementTree.Element'> root[1] #<Element 'PubmedData' at 0x10aa78868> type(root[1]) #<class 'xml.etree.ElementTree.Element'>どちらもElementオブジェクトであることがわかります。
要するに、全部のノードがElementオブジェクトということのようです。
Elementオブジェクトはイテレーションができ、子ノードを1つずつ取り出して処理できます。for i in root: print(i.tag)Elementのタグは、.tagで調べることができ、.attribでそのtagにつけられた属性と属性値を調べられます。
root[0].tag #'MedlineCitation' root[0].attrib #{'Status': 'Publisher', 'Owner': 'NLM'} type(root[0].attrib) #<class 'dict'> #辞書クラスElementオブジェクトへのアクセス方法
3つありそうです。いずれも、tagを1つまたは複数指定できます。タグ全体をクォーテーションで囲み、タグを複数指定する場合はタグ間をスラッシュで区切ります。
1. find('tag1/tag2')
2. findall('tag1/tag2')
3. iter('tag1/tag2')1の場合はElementオブジェクトが返りますが、2の場合はElementオブジェクトのlistが、3の場合はイテレーション用のオブジェクト?が返ります。確認してみます。
root.find('MedlineCitation/DateRevised/Year') #<Element 'Year' at 0x10a9f8ae8> root.findall('MedlineCitation') #[<Element 'MedlineCitation' at 0x10a9d5b38>] root.iter('Author') #<_elementtree._element_iterator object at 0x10aa65990> #for文でイテレーションしてみます。 for i in root.iter('Author'): print(i) #<Element 'Author' at 0x10aa6e9f8> #<Element 'Author' at 0x10aa6ec28>findall()では、Elementオブジェクトの子ノードのみを調べ、iter()では、Elementオブジェクトのすべての子ノード、孫ノード、ひ孫ノード...を調べるようです。
Elementオブジェクトの値へのアクセス
Elementオブジェクトは2つ値を持っています。属性値とテキストデータです。属性値はElementオブジェクトに対して.get('プロパティ名')で得ることができます。あるいは、.attrib['プロパティ名']でも良いようです。
#.get()を使うか、 root.find('MedlineCitation').get('Status') #'Publisher' #.attrib()を使うか、 root.find('MedlineCitation').attrib['Status'] #'Publisher'またElementオブジェクトに対して.textとすると、テキストデータが取得できます。
ここでテキストデータと言っているのは、タグで囲まれた部分、下の例で言えば2020がそうです。
<Year>2020</Year>find()でElementオブジェクトへのパスを指定して値を取得してみます。
root.find('MedlineCitation/Article/Journal/JournalIssue/PubDate/Year').text #'2020'複数いるAuthorについての情報を得るには、findall()で得たリストをイテレーションします。
for x in root.findall('MedlineCitation/Article/AuthorList/Author'): x.find('LastName').text #著者の苗字 x.find('ForeName').text #著者の名 x.find('AffiliationInfo/Affiliation').text #著者の所属doi(ドキュメント識別子)については、タグELocationIDに記述されていますが、タグELocationIDには、いくつか属性値をとるものがあり、EIdType="doi"の場合のテキストデータを得る必要があります。
for x in root.findall('MedlineCitation/Article/ELocationID'): if(x.get('EIdType') == 'doi'): x.textレコードが、ReviewなのかJournal Articleなのか、区別する必要がありますがこれは、PublicationTypeに書いてあります。ただしPublicationTypeは複数あることが普通で、その中に値がReviewであるものがあればReviewということのようです。
例えばReviewのレコードを見ると以下のようあります。
<PublicationTypeList> <PublicationType UI="D016428">Journal Article</PublicationType> <PublicationType UI="D016454">Review</PublicationType> <PublicationType UI="D013485">Research Support, Non-U.S. Gov't</PublicationType> </PublicationTypeList>なので、reviewなのかどうかは、
isReview = False for x in root.findall('MedlineCitation/Article/PublicationTypeList'): if (x.text == 'Review'): isReview = TRUEとかすると良いと思います。
その他取得したいかもしれない情報も含め、ここまでをまとめると
import xml.etree.ElementTree as ET test_data = open("./pubmed.xml", "r") contents = test_data.read() records = contents.split('\n\n') root = ET.fromstring(records[0])#とりあえず1件目のみ。 # 著者情報 for x in root.findall('MedlineCitation/Article/AuthorList/Author'): x.find('LastName').text #著者の苗字 x.find('ForeName').text #著者の名 x.find('AffiliationInfo/Affiliation').text #著者の所属 # Reviewかどうかの判定 isReview = False for x in root.findall('MedlineCitation/Article/PublicationTypeList'): if (x.text == 'Review'): isReview = TRUE # doi for x in root.findall('MedlineCitation/Article/ELocationID'): if(x.get('EIdType') == 'doi'): x.text #PMID root.find('MedlineCitation/PMID').text #論文タイトル root.find('MedlineCitation/Article/ArticleTitle').text #ジャーナル名 root.find('MedlineCitation/Article/Journal/Title').text #出版年 root.find('MedlineCitation/Article/Journal/JournalIssue/PubDate/Year').text #出版月 root.find('MedlineCitation/Article/Journal/JournalIssue/PubDate/Month').text #言語 root.find('MedlineCitation/Article/Language').textとすれば良いと思います。上のコードでは一件だけの処理ですが、
for record in records: root = ET.fromstring(record) #処理を記述としてやればいいですね。
これでxmlデータがあれば、一気に必要な情報を抜き出すことができるようになりました。あとはどう整形するか、考えるだけですね。
これでxmlのデータの取り扱い方がわかりました。
- 投稿日:2020-03-29T22:48:28+09:00
Prorate Python編(1)
今日ProgateのPhthon のⅠ〜Ⅲまでをやりました。
感想としては、c++に形は結構似て入るものの、やはり別物であるから少しなれが必要かなと感じました。まだ終わってないのでなんとも言えませんが、明日に残りを終わらせたいと思います。
- 投稿日:2020-03-29T22:22:53+09:00
PythonのTinkerを使ってお絵かきツール
完成イメージ
コード
sample.pyimport tkinter as tk # 黒(black)の点を描画(数字を大きくすると、大きな点になります。) def myMotion(mouse): cv.create_oval(mouse.x - 1, mouse.y - 1, mouse.x + 1, mouse.y + 1, fill = "black") win = tk.Tk() cv = tk.Canvas(win, width = 600, height = 400) cv.create_rectangle(0, 0, 600, 400, fill = "white") cv.pack() win.bind("<B1-Motion>", myMotion) win.mainloop()解説
クリックを押している間だけマウスの位置に点(小さい円)を描画しています。

- 投稿日:2020-03-29T22:22:53+09:00
PythonのTinkerを使ってお絵かき
完成イメージ
コード
sample.pyimport tkinter as tk # 黒(black)の点を描画(数字を大きくすると、大きな点になります。) def myMotion(mouse): cv.create_oval(mouse.x - 1, mouse.y - 1, mouse.x + 1, mouse.y + 1, fill = "black") win = tk.Tk() cv = tk.Canvas(win, width = 600, height = 400) cv.create_rectangle(0, 0, 600, 400, fill = "white") cv.pack() win.bind("<B1-Motion>", myMotion) win.mainloop()解説
クリックを押している間だけマウスの位置に点(小さい円)を描画しています。
- 投稿日:2020-03-29T22:10:19+09:00
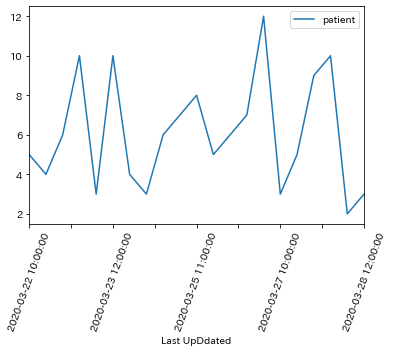
【python】時系列データをプロット
時系列データを解析するとき、目的変数がどのように変化しているかを
時系列で確認するために、グラフとして可視化します。手順
①日付カラムをインデックス化
df.set_index('Date')
②プロット
df.plot()
plt.xticks(rotation=70)
③後の処理のために元に戻す
df = df.reset_index()date.pyimport pandas as pd import matplotlib.pyplot as plt df = pd.read_csv('dataset.csv') df.head() """ 出力 patient Last UpDdated 0 5.0 2020-03-22 10:00:00 1 4.0 2020-03-22 11:00:00 2 6.0 2020-03-22 12:00:00 3 10.0 2020-03-23 10:00:00 4 3.0 2020-03-23 11:00:00 """ # 日付をインデックスにする df = df.set_index('Last UpDdated') df.head(3) """出力 Last UpDdated patient 2020-03-22 10:00:00 5.0 2020-03-22 11:00:00 4.0 2020-03-22 12:00:00 6.0 """ # プロット df.plot() # X軸のラベルの角度をかえる plt.xticks(rotation=70)
date.py# 後の処理のためインデックスを戻しておく df = df.reset_index() df.head(3) """出力 Last UpDdated patient 0 2020-03-22 10:00:00 5.0 1 2020-03-22 11:00:00 4.0 2 2020-03-22 12:00:00 6.0 """
- 投稿日:2020-03-29T22:01:54+09:00
Pythonでのファイル・フォルダパス操作
Pythonでのファイル・フォルダパス操作
メイン環境のversionが2.7なので、ver3.0以降では情報が異なる可能性があります。
ご容赦ください。<os.path.exists> フォルダやファイルの存在を調べる
フォルダが存在するかどうか
import os folderpath = ("C:\\test_folder\\test1") print(os.path.exists(folderpath)) # Trueos.path.existsを利用する事で指定したフォルダが存在しているかどうかを調べる事が出来ます。
結果はboolで返ります。フォルダパスを指定する際にはエスケープシーケンス
\に注意が必要です。
r を付けてr"C:\Users\xxx\desktop\xxx"と表記するか、
もしくは\を文字列として認識させるために\\を用いて、"C:\\Users\\xxx\\desktop\\xxx"と記述する方法があります。ファイルが存在するかどうか
import os filepath = ("C:\\test_folder\\test1\\sample.txt") print(os.path.exists(filepath)) # True直接ファイル名を指定すれば、ファイルの有無を調べる事が出来ます。
<os.path.isfile>ファイルが存在する事を判定
import os filepath = ("C:\\test_folder\\test1\\sample") print(os.path.isfile(filepath)) # True指定のファイルが存在する場合Trueが返ります。
フォルダだった場合や、ファイルが存在しない場合は、Falseが返ります。<os.path.isdir>フォルダが存在する事を判定
import os filepath = ("C:\\test_folder\\test1") print(os.path.isdir(filepath)) # True指定のフォルダが存在する場合Trueが返ります。
ファイルだった場合や、存在しない場合はFalseが返ります。<os.listdir>フォルダの中のファイルの詳細を調べる
import os folderpath = ("C:\\test_folder\\test1") print(os.listdir(folderpath)) #['test2''test1.bmp','test1.txt']指定のフォルダに存在するファイル、フォルダがリストに格納されます。
サブフォルダ内のデータは表示されません。<os.walk>サブフォルダの中身まで調べる
import os filepath = ("C:\\test_folder\\test1") for i in os.walk(filepath): print(i) #('C:\\test_folder\\test1', ['test2'], ['test1-A.txt', 'test1-B.txt']) #('C:\\test_folder\\test1\\test2', [], ['test2-A.txt', 'test2-B.txt'])タプルが作成されます。
(フォルダパス、サブフォルダ名、ファイル名)の三要素で構成されています。
出力情報は適当。例)ファイル名だけを抽出する
import os filepath = ("C:\\test_folder") for folder,subfolder,filename in os.walk(filepath): print(filename) #['test1-A.txt', 'test1-B.txt'] #['test2-A.txt', 'test2-B.txt']folder,subfolder,filenameの三要素でfor文を回し、filenameのみをprintしています。
実際の利用時にはデータの加工が必要ですね。まとめ
2.7と3.0で大きな違いはなさそう。
参考にしたページ
- 投稿日:2020-03-29T21:37:11+09:00
サイゼリヤの間違い探しを解く(ヒントになる)プログラムを作ってみた
こんにちは。初投稿です。
先日サイゼリヤに行った際の待ち時間20分ぐらい数人でサイゼリヤの間違い探しをやって、見つけられませんでした...(ムズすぎる...)
ということで、画像処理で解けないかな〜と思い、やってみました。OpenCVのいい勉強にもなりました。やりたいこと
OpenCVのライブラリを使って、サイゼリヤが公式で出している画像データ(https://www.saizeriya.co.jp/entertainment/) を加工して間違い探しを自動化したい!!!
実際にやることは、
- 画像を加工する(余白の削除、半分に分割)
- 画像の差分を計算
- 差分情報を元の画像に表示
という感じです。
コードはGitHubにあげてみました。実行環境
macOS Mojave 10.14.4
Python 3.6.7
OpenCV 3.4.1画像を加工する
ダウンロードすると、「比較する画像がくっついている」+「謎の余白がある」ということに気がつきます。
(周りも白なのでわかりづらい...) サイゼリヤのサイトより引用まずはじめに余白部分の削除からしたいと思います。
空白の削除の流れは、
- グレースケール画像にする
- 2値化する
- 輪郭を抽出する
- 輪郭の中から座標が最小になるものと最大になるものをx,yそれぞれ取得して切り取るhttps://qiita.com/trami/items/e25eb70a59a51ae4f7ba#どのようにして余白削除を行うのかの記事を参考にさせていただいております。
OpenCVでのグレースケール化の関数が
gray.pygray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) # グレースケール化2値化の関数が
binary.pyr, binary = cv2.threshold(gray, 0, 255,cv2.THRESH_OTSU) #2値化画像の切り取りの関数が
cut_img.pyimg = img[y1:y2,x1,x2] #(x1,y1)から(x2,y2)を切り取るという感じです。
これらを組み合わせていくとここまでのコードがsaizeriya.pyimport cv2 import numpy as np img = cv2.imread('diff.png') #画像の読み込み height, width, d = img.shape #高さ、幅、深さ gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) # グレースケール化 r, binary = cv2.threshold(gray, 0, 255,cv2.THRESH_OTSU) #しきい値200で2値化 contours = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)[0] #輪郭の抽出、余白の削除 x1 = [] #x座標の最小値 y1 = [] #y座標の最小値 x2 = [] #x座標の最大値 y2 = [] #y座標の最大値 for i in range(1, len(contours)): ret = cv2.boundingRect(contours[i]) x1.append(ret[0]) y1.append(ret[1]) x2.append(ret[0] + ret[2]) y2.append(ret[1] + ret[3]) x1_min = min(x1) y1_min = min(y1) x2_max = max(x2) y2_max = max(y2) img = img[0:600, x1_min:x2_max]実行結果が以下の通りです。うまくカットできていることがわかります。
次に画像を半分にカットします。
saizeriya.pyheight, width,d= img.shape #高さ、幅、深さ(切り出したものの大きさ) midle = int(width/2) img1 = img[0:height,0:midle-3] img2 = img[0:height,midle-8:width-11] #実は、横幅が少し違う...ここでやばかったのは、実は2つの画像の端のキレている部分が若干違うということでした。
その調整は結局手作業でカットする部分を調整しました。画像の差分を計算
次に画像の差分を計算します。
画像の差分はnumpy配列同士の引き算でもできますが、実際に実行してみると差分がわかりづらい(少しの色の違い、場所の少しのずれも差分として表示してしまう)ので、今回はOpenCVのabsdiff関数を使いました。absdiff関数は、二つの画像の差の絶対値を求めることができます。
saizeriya.py#差分を表示 result = np.copy(img1) #結果の画像を格納する配列 add = np.copy(img1) #結果の画像を格納する配列 #result = img1-img2 # 差分の計算 result = cv2.absdiff(img1, img2) # 差分の計算(absdiff)実行結果
参考に配列同士の引き算で実行した時の結果です。
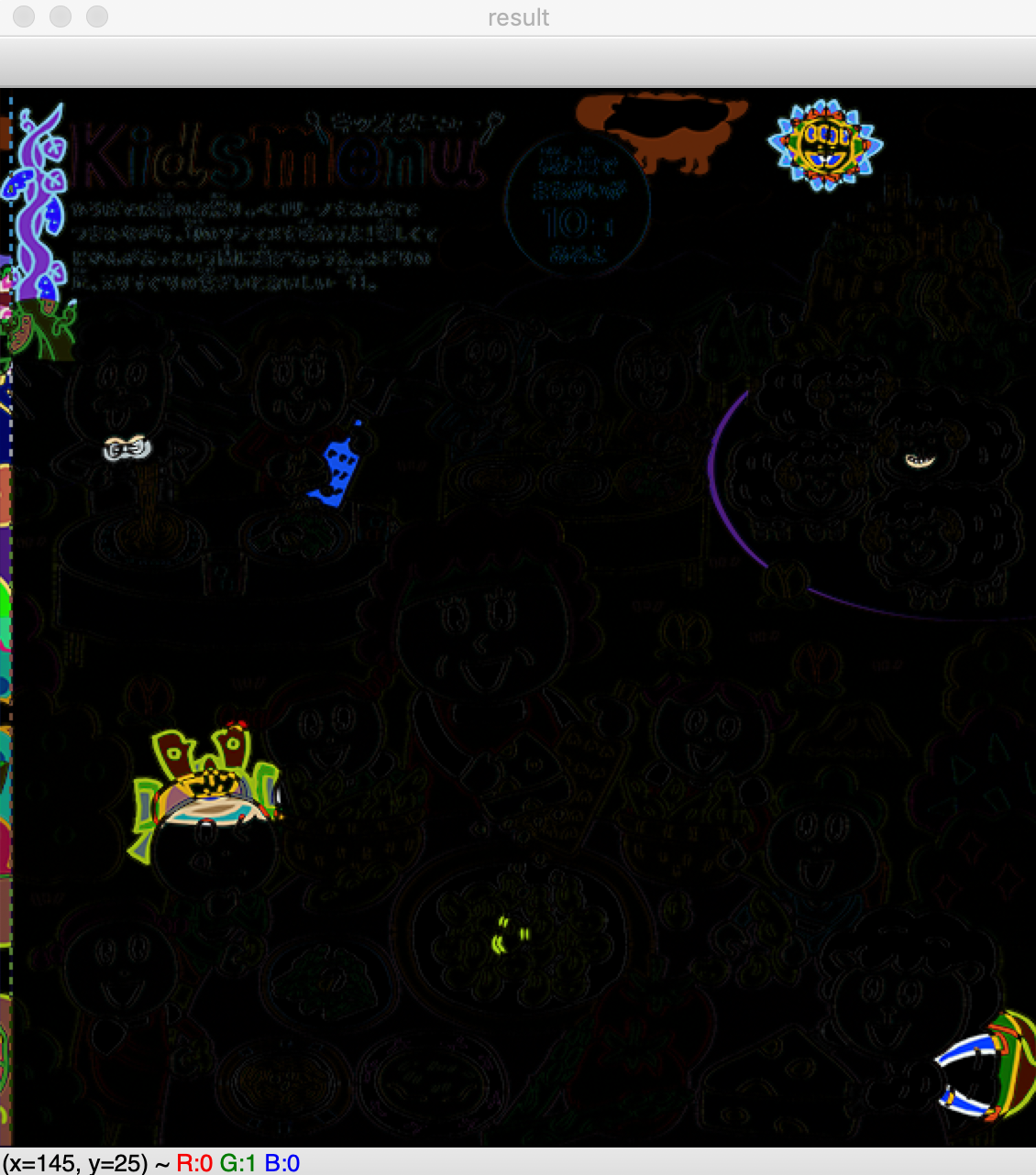
流石にこれはどこが違うのかわからない...差分情報を元の画像に表示
これでは、どこに差があるかわからないので、元の画像と合成したいと思います。
元のグレー画像+差分画像(カラー)を合成します。使う関数はadd関数です。また、cvtCOLOR関数で元のカラー画像を
カラー3次元配列→グレー2次元配列→グレー2次元配列
で処理します。
saizeriya.pyimg3 = cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY) # グレースケール化 img3 = cv2.cvtColor(img3,cv2.COLOR_GRAY2BGR) # グレースケールのままカラー画像にする print(img3.shape) print(result.shape) add = cv2.add(img3,result) # 画像を合成する #画像の表示 cv2.imshow('all',img) cv2.imshow('image',add) cv2.imshow('result',result) cv2.waitKey(0) #何かしらのキーが押されるまで待つ cv2.destroyAllWindows() #すべてのWindowを破棄実行結果
これでだいたいどこが違うかわかるようになりました。
って8個しか見つからない!!!!
あと2つ教えてください...
あくまで、補助するツールでした。
12月の間違い探しは9個見つけれました





- 投稿日:2020-03-29T20:47:16+09:00
pythonでLDAPにデータの移動変更削除をする(WriterとReader編)
はじめに
前回と前々回はLDAPの追加と取得を行いました。今回は、削除やデータ移動、名前の変更など他の機能をまとめます。
名前の変更
コネクションのみ使用した名前の変更
cnのみ変更したい場合はConnectionの
modify_dn()を使用して変更できます。変更前のdnと変更後のcnを指定することでcnのみ変更することができます。以下の例は前々回でまとめたのでConnectionの接続は端折っています。main.py# 更新前に表示する obj_cn_name = ObjectDef('inetOrgPerson', conn) data_reader = Reader(conn, obj_cn_name, 'ou=sample-unit,dc=sample-component,dc=sample-ldap') print(data_reader.search()) print('=======================') # modify_dnに移動対象のdnと変更後のcnを指定する conn.modify_dn('cn=sample-name,ou=sample-unit,dc=sample-component,dc=sample-ldap', 'cn=sample-rename') # 更新後に表示する data_reader2 = Reader(conn, obj_cn_name, 'ou=sample-unit,dc=sample-component,dc=sample-ldap') print(data_reader2.search())結果
[DN: cn=sample-name,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-29T19:24:03.368406 cn: sample-name objectClass: inetOrgPerson sn: sample ] ======================= [DN: cn=sample-rename,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-29T19:24:03.448482 cn: sample-rename objectClass: inetOrgPerson sn: sample ]変更前後のLDAPの値を見るとcnがsample-nameからsample-renameに変更されていることがわかります。また、中の値もそのまま移動されていることがわかります。
Writerを使用した名前の変更
Writerを使用した名前の変更はWriterの
entry_rename()を使用して変更できます。Connectionと異なり、Writer読み込み時に変更前のパスを指定してentry_rename()には変更後の名前をフルパスで与えます。main.py# 更新前に表示する obj_cn_name = ObjectDef('inetOrgPerson', conn) data_reader = Reader(conn, obj_cn_name, 'ou=sample-unit,dc=sample-component,dc=sample-ldap') print(data_reader.search()) print('=======================') # 移動対象をWriterに読み込ませる data_reader = Reader(conn, obj_cn_name, 'cn=sample-name,ou=sample-unit,dc=sample-component,dc=sample-ldap') data_reader.search() data_writer = Writer.from_cursor(data_reader) # 変更後のパスをフルで指定 data_writer[0].entry_rename('cn=sample-rename,ou=sample-unit,dc=sample-component,dc=sample-ldap') # 変更結果の反映 data_writer.commit() # 更新後に表示する data_reader2 = Reader(conn, obj_cn_name, 'ou=sample-unit,dc=sample-component,dc=sample-ldap') print(data_reader2.search())結果
[DN: cn=sample-name,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-29T19:40:09.898199 cn: sample-name objectClass: inetOrgPerson sn: sample ] ======================= [DN: cn=sample-rename,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-29T19:40:10.017186 cn: sample-rename objectClass: inetOrgPerson sn: sample ]変更前後のLDAPの値を見るとConnectionの変更と同様に、cnがsample-nameからsample-renameに変更されて中の値もそのまま移動されていることがわかります。
エンティティの移動
コネクションのみ使用したエンティティの移動
エンティティを他のパスに移動させたい場合も上と同様Connectionの
modify_dn()を使用して変更できます。移動対象のdnと変更後のcn、変更後のdnを指定することでエンティティを移動させることができます。以下の例は前々回でまとめたのでConnectionの接続は端折っています。main.pyfrom ldap3 import Server, Connection, ObjectDef, Reader, Writer server = Server('localhost') conn = Connection(server, 'cn=admin,dc=sample-ldap', password='LdapPass') conn.bind() # 更新前に表示する obj_cn_name = ObjectDef('inetOrgPerson', conn) data_reader = Reader(conn, obj_cn_name, 'dc=sample-component,dc=sample-ldap') print(data_reader.search()) print('=======================') # 移動する conn.modify_dn('cn=sample-name,ou=sample-unit,dc=sample-component,dc=sample-ldap', 'cn=sample-name', new_superior='ou=sample-unit-move,dc=sample-component,dc=sample-ldap') # 更新後に表示する data_reader2 = Reader(conn, obj_cn_name, 'dc=sample-component,dc=sample-ldap') print(data_reader2.search())結果
[DN: cn=sample-name,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-29T20:01:02.190680 cn: sample-name objectClass: inetOrgPerson sn: test st: sample , DN: cn=sample-name2,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-29T20:01:02.194679 cn: sample-name2 objectClass: inetOrgPerson sn: test st: sample ] ======================= [DN: cn=sample-name,ou=sample-unit-move,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-29T20:01:02.233686 cn: sample-name objectClass: inetOrgPerson sn: test st: sample , DN: cn=sample-name2,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-29T20:01:02.236675 cn: sample-name2 objectClass: inetOrgPerson sn: test st: sample ]cnがsample-nameのouがsample-unitからsample-unit-moveに移動していることが分かります。さらに先ほどと同様に中の属性も一緒に移動されています。
Writerを使用したエンティティの移動
Writerを使用したエンティティの移動はWriterの
entry_move()を使用して変更できます。entry_rename()と同じ使い方で、Writer読み込み時に変更前のパスを指定してentry_move()には変更後のパスをフルパスで与えます。ここでは、移動後のエンティティの名前はパスに入れてはいけないこと、存在しないパスには移動できないことに気をつけてください。main.py# 更新前に表示する obj_cn_name = ObjectDef('inetOrgPerson', conn) data_reader = Reader(conn, obj_cn_name, 'dc=sample-component,dc=sample-ldap') print(data_reader.search()) print('=======================') # 移動対象をWriterに読み込ませる data_reader = Reader(conn, obj_cn_name, 'cn=sample-name,ou=sample-unit,dc=sample-component,dc=sample-ldap') data_reader.search() data_writer = Writer.from_cursor(data_reader) # 値を移動する data_writer[0].entry_move('cn=sample-name,ou=sample-unit-move,dc=sample-component,dc=sample-ldap') # 変更結果の反映 data_writer.commit() # 更新後に表示する data_reader2 = Reader(conn, obj_cn_name, 'dc=sample-component,dc=sample-ldap') print(data_reader2.search())結果
[DN: cn=sample-name,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-29T20:08:33.946805 cn: sample-name objectClass: inetOrgPerson sn: test st: sample , DN: cn=sample-name2,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-29T20:08:33.952774 cn: sample-name2 objectClass: inetOrgPerson sn: test st: sample ] ======================= [DN: cn=sample-name,ou=sample-unit-move,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-29T20:08:34.045188 cn: sample-name objectClass: inetOrgPerson sn: test st: sample , DN: cn=sample-name2,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-29T20:08:34.051225 cn: sample-name2 objectClass: inetOrgPerson sn: test st: sample ]cnがsample-nameのouがsample-unitからsample-unit-moveに移動していることが分かります。さらに先ほどと同様に中の属性も一緒に移動されています。
削除
コネクションのみ使用した削除
エンティティを削除したい場合はConnectionの
delete()を使用します。この関数にdnを指定すると削除できます。以下の例は前々回でまとめたのでConnectionの接続は端折っています。main.py# 削除前に表示する conn.search('ou=sample-unit,dc=sample-component,dc=sample-ldap', '(objectclass=inetOrgPerson)') print(conn.entries) print('=======================') # パスを指定して削除 ou_result = conn.delete('cn=sample-name2,ou=sample-unit,dc=sample-component,dc=sample-ldap') print(ou_result) # 削除後に表示する conn.search('ou=sample-unit,dc=sample-component,dc=sample-ldap', '(objectclass=inetOrgPerson)') print(conn.entries)結果
[DN: cn=sample-name,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-29T20:19:59.281937 , DN: cn=sample-name2,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-29T20:19:59.281937 ] ======================= True [DN: cn=sample-name,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-29T20:19:59.322233 ]削除後にsample2のcnが消えていることがわかります。
取得と合わせることで全削除もできます。
main.pyconn.search('dc=sample-component,dc=sample-ldap', '(objectclass=inetOrgPerson)') for entry in conn.entries: del_result = conn.delete(entry.entry_dn) print(del_result)Writerを使用した削除
エンティティを削除したい場合はWriterの
entry_delete()を使用します。今までのWriterを使用した操作と同様にWriterを生成した後にエンティティのentry_delete()を呼ぶだけです。以下の例は前々回でまとめたのでConnectionの接続は端折っています。main.py# 更新前に表示する obj_cn_name = ObjectDef('inetOrgPerson', conn) data_reader = Reader(conn, obj_cn_name, 'ou=sample-unit,dc=sample-component,dc=sample-ldap') print(data_reader.search()) print('=======================') # 移動対象をWriterに読み込ませる data_reader = Reader(conn, obj_cn_name, 'cn=sample-name,ou=sample-unit,dc=sample-component,dc=sample-ldap') data_reader.search() data_writer = Writer.from_cursor(data_reader) # 値を削除する data_writer[0].entry_delete() data_writer.commit() # 更新後に表示する data_reader2 = Reader(conn, obj_cn_name, 'ou=sample-unit,dc=sample-component,dc=sample-ldap') print(data_reader2.search())結果
[DN: cn=sample-name,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-29T20:30:26.155112 cn: sample-name objectClass: inetOrgPerson sn: test st: sample , DN: cn=sample-name2,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-29T20:30:26.160111 cn: sample-name2 objectClass: inetOrgPerson sn: test st: sample ] ======================= [DN: cn=sample-name2,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-29T20:30:26.264725 cn: sample-name2 objectClass: inetOrgPerson sn: test st: sample ]削除後の結果を見るとsample-nameのcnがなくなっていることがわかります。
これも検索条件を変えると全削除ができます
main.py# 上位のパスをWriterに読み込ませる data_reader = Reader(conn, obj_cn_name, 'dc=sample-component,dc=sample-ldap') data_reader.search() data_writer = Writer.from_cursor(data_reader) # 値をすべて削除する for data_entity in data_writer: data_entity.entry_delete()おわりに
LDAPを操作する上で必要な追加・検索・削除・変更をまとめることができました。さらにRDBには無い移動であったり名前の変更であったりとディレクトリ操作特有のものも出てきました。このように似たようにデータを保存する機能を持っていたとしてもRDBとLDAPは明確に違う点があるためうまく使い分けるとより便利になるのではないかと思いました。
- 投稿日:2020-03-29T20:40:42+09:00
pythonでのアルゴリズム、チートシート
はじめに
これは python でアルゴリズムをとくためのチートシートです。
他の言語でよく書くけど、pythonでどうかくっけ?
みたいな人向けですざっくりの表
書きたいこと 実装 補足 forで2から12まで3こ飛ばしで呼ぶ for i in range(2,12,3): 読み取る str=input() 一行読み取りです 分ける str.split(区切り文字) 指定なしで空白区切り 文字列の長さを測る len(文字列) ifでandを使う if(hoge and piyo) ifでorを使う if(hoge or piyo) if else if elif 他の時はif else そのまま listを使う hoge = [] listに足す hoge.append("test") listにlistを入れる hoge.extend(piyo) listの最大値 max(list) listの最小値 min(list) listのソート hoge=sorted(piyo) もともとのリストを崩さない 文字列の文字を取り出す str = "asdf" str[0] はa ()ではないので注意 多次元配列を作る list = [[0] * m for i in range(n)] キャスト int("2") str(8) 階乗 print(math.factorial(5)) import math 組み合わせの上の補足
名前 意味 permutations 任意の数を選んで、並び変える combinations 任意の数を選ぶ combinations_with_replacement 重複を許す組み合わせ これを置き換えて使う
hoge.pyimport math import itertools list2 = [1,2,3] p_list = list(itertools.permutations(list2, 2)) print(p_list) #[(1, 2), (1, 3), (2, 1), (2, 3), (3, 1), (3, 2)] print(len(p_list)) #6 print(p_list[0][1]) #2 for v in itertools.permutations(list2,2): print(v) # (1, 2) # (1, 3) # (2, 1) # (2, 3) # (3, 1) # (3, 2) # # v[0]やv[1]で各要素を呼ぶことも可能 for v in itertools.permutations(list2,2): print(v[0])組み合わせの数だけ
from scipy.special import comb # a = comb(n, r) a = comb(n, r, exact=True)
- 投稿日:2020-03-29T20:29:59+09:00
AtCoder Beginner Contest 160 復習
今回の成績
今回の感想
地力はついていたはずが三週間ぶりのコンテストで緊張してしまい実力を発揮できずに終わってしまいました。
C問題までは合計約7分で終わらせたにも関わらず、D問題以降が頭がバグって解けませんでした(F問題は見てません。)。
焦っている状態で平常心に戻すことも大事なのですが、重要なテストの時は必ずホワイトアウトになってしまうので、ホワイトアウトになることを前提にしてコンテストを頑張るしかないのではと思っています(ホワイトアウトになってしまう方いたら対処法を教えていただけると幸いです。)。
また、圧倒的な実力(青コーダー以上)があれば確実に解けると思うので近道は精進しかないかなと思っています。
追記:一生競プロやらねえとコンテスト直後には思ったのですが精進したいという気持ちが勝るようです。思うようにレートが伸びてませんが、夏休み前までは努力を続けたいと思います。A問題
A問題は三項演算子を使うと早いです。
A.pys=input() print("Yes" if s[2]==s[3] and s[4]==s[5] else "No")B問題
500→5の順に優先度が高いのでそのように計算する。
B.pyx=int(input()) y=x//500 z=(x-y*500)//5 print(y*1000+z*5)C問題
それぞれの家の間を一回だけ通って全ての家を通るのが最短距離であることがわかります。1番目の家からN番目の家まで順に辿ると仮定すると、一周Kメートルの湖の周りよりも1番目の家とN番目の家の間の距離の分だけ短くなることがわかります。したがって、Kメートル-(隣り合う家の距離のうち最大のもの)が求める答えとなります。
C.pyk,n=map(int,input().split()) a=list(map(int,input().split())) ma=0 for i in range(n-1): ma=max(ma,a[i+1]-a[i]) print(k-max(ma,a[0]+k-a[n-1]))D問題
$n=10^3$なので$O(n^2)$でも通ることに気づかず時間を溶かしました。頭が悪すぎる。
まず計算量の見積もりは基本中の基本な上にサンプルケース3を試した(サンプルで実験するのも基本)ところうまくいっておらず、結局コンテスト後に確認したところ数え忘れてるパターンがありました…。
まず、この問題で特徴的なのはXとYが繋がれている点です。さらに、最短距離なのでX-Yは一回しか通らないことに注意すると(i,j)を定めた時にX-Yを通るか通らないかで場合分けすれば良いのではないかと考えることができます。
この思考の転換をできると一気に簡単な問題に落とすことができます。X-Yを通らない場合の最短距離はj-iで、通る場合の最短距離は$abs(X-i)+abs(j-Y)+1$になります(1はX-Yの最短距離)。
これを全ての(i,j)に試して$O(n^2)$であり、最短距離1~n-1のどれになるかを別に用意した配列に順に記録していくことで答えを求めることができます。この問題で一番学んだのは
サンプルすら合わなかったらサンプルを手で書いて自分の考察が正しいかどうかを見直す
ですね。
answerD.pyn,x,y=map(int,input().split()) ans=[[1000000]*n for i in range(n)] for i in range(n-1): for j in range(i+1,n): ans[i][j]=min(j-i,abs(x-1-i)+1+abs(y-1-j)) _ans=[0]*(n-1) for i in range(n-1): for j in range(i+1,n): _ans[ans[i][j]-1]+=1 for i in range(n-1): print(_ans[i])E問題
この問題もD問題で焦ってしまってできませんでしたが難しくありませんでした。
問題文の誤読などが酷く、無色のりんごを一個以上選ばなければならないと勘違いしていました。
さらに、赤のりんごと緑のりんごを選びながら同時に無色のりんごを選んでいたためコードがかえって複雑になっていました。
結局同時に選んでしまうと赤のりんごと緑のりんごをどちらから先に選んだかで対称性が崩れ、数え忘れるケースが出てきてしまいます。そこで、ここではその対称性を保つために、赤のりんごをx個と緑のりんごをx個美味しさが大きいものから順に無色のりんごの美味しさによらずに選びます(それぞれx個より多くy個より多く選んでも食べるx+y個の候補に含まれないことに注意する必要があります。)。
ここまでしたあとで無色のりんごをいくつ選ぶか考えればよく、美味しさの大きい順に選んでいきます。また、選んだx個の赤のりんごとy個の緑のりんごのどちらとも無色のりんごは交換可能なので、赤のりんごと緑のりんごをまとめて美味しさの小さい順に並べて小さいものから順に無色のりんごと入れ替えていけば良いです(無色のりんごの方が美味しさが小さい場合は入れ替える必要はないので、この時にりんごの美味しさの総和は最大となります。)。
また、自分は見た瞬間に類題を思い出してheapqを使ってしまったのですが、きちんと方針を立てていればheapqも使わず解けるようでした(Writer解)。一つ目がheapqを使った解法のコード、二つ目がheapqを使わない解法のコードになります。answerE.pyimport heapq x,y,a,b,c=map(int,input().split()) def _int(x): return -int(x) p=list(map(_int,input().split())) q=list(map(_int,input().split())) r=list(map(_int,input().split())) heapq.heapify(p) heapq.heapify(q) heapq.heapify(r) ans=[] heapq.heapify(ans) for i in range(x): _p=heapq.heappop(p) heapq.heappush(ans,-_p) for i in range(y): _q=heapq.heappop(q) heapq.heappush(ans,-_q) #ansは小さい順、rは大きい順 for i in range(x+y): if len(r)==0:break _ans=heapq.heappop(ans) _r=-heapq.heappop(r) if _r>=_ans: heapq.heappush(ans,_r) else: heapq.heappush(ans,_ans) break print(sum(ans))answerE_better.pyx,y,a,b,c=map(int,input().split()) p=sorted(list(map(int,input().split())),reverse=True)[:x] q=sorted(list(map(int,input().split())),reverse=True)[:y] r=sorted(list(map(int,input().split())),reverse=True) p.extend(q) ans=sorted(p) #ansは小さい順、rは大きい順 for i in range(x+y): if len(r)==i or r[i]<ans[i]: break else: ans[i]=r[i] print(sum(ans))F問題
DとEが解けなかったショックが大きいので今回はFは解きません。またの機会に解きたいと思います。

- 投稿日:2020-03-29T18:36:21+09:00
深層学習/シグモイド関数の誤差逆伝播
1.はじめに
シグモイド関数の誤差逆伝播についてまとめる
2.シグモイド関数の微分
シグモイ度関数の微分は、美しくシンプルな形をしている。
sigmoid関数:
sigmoid(x) = \frac{1}{1+e^{-x}}sigmoid関数の微分:
sigmoid'(x) = \frac{1}{1+e^{-x}} * ( 1 - \frac{1}{1+e^{-x}})3.シグモイド関数のコード
従って、シグモイド関数の誤差逆伝播コードも以下の様にシンプルとなる。
Class Sigmoid(object): def __init__(self, x): self.x = x def forward(self): y = 1.0 / (1.0 + np.exp(- self.x)) self.y = y return y def backward(self, grad_to_y): grad_to_x = grad_to_y * self.y * (1.0 - self.y) return grad_to_x
- 投稿日:2020-03-29T18:19:19+09:00
ZEIT NowでFlaskをデプロイする
NOWを使ってPython(Flask)をどうさせようとしたら苦戦した。公式ドキュメントも見づらいので改めてまとめる。
Flaskを最低限動かす
Flaskを動かすだけならこれで動作する。now.jsonの builds が重要なポイント。
index.pyfrom flask import Flask app = Flask(__name__) @app.route("/") def index(): return "hello"requirements.txtflask==1.0.2now.json{ "version": 2, "builds": [{ "src": "index.py", "use": "@now/python" }] }複数のルーティングに対応する
問題点
index.pyに
/helloを処理するルーティングを追加したとする。index.pyfrom flask import Flask app = Flask(__name__) @app.route("/") def index(): return "hello" @app.route("/hello") def world(): return "world"404になっている様子
この状態でデプロイして
/helloにアクセスすると404になってしまう。
now.jsonにroutesを追加し回避する
適切に処理するためには、now.jsonを編集し、routesを追加する。これで、どんなリクエストでもwsgiのrootで処理されるようになる。
now.json{ "version": 2, "builds": [{ "src": "index.py", "use": "@now/python" }], "routes": [{ "src": "/.*", "dest": "/" }] }正常にリクエストをさばけている様子
すべてのパスをFlaskが処理するようになっている様子
routesを追加したため、存在しないパスへリクエストが来ると必ずFlask経由で処理される。
404ページをカスタマイズする
Flaskの公式ドキュメントのカスタムエラーページを見てカスタマイズできる
index.pyfrom flask import Flask, jsonify app = Flask(__name__) @app.route("/") def index(): return "hello" @app.route("/hello") def world(): return "world" @app.errorhandler(404) def resource_not_found(e): return jsonify(error=str(e)), 404様子
- 投稿日:2020-03-29T18:17:04+09:00
(自分用メモ) Python のメタクラスとメタプログラミング
クラス (or クラス宣言) は第一級オブジェクト
参考:
- https://note.crohaco.net/2016/python-metaclass/
- https://qiita.com/fujimisakari/items/0d4786dd9ddeed4eb702
クラスを宣言するということは、type クラスのインスタンスを作成していることと等価。
class C: ... ≡ C = type('C', ...)クラス生成のカスタマイズ
参考:
この、type インスタンス生成をカスタマイズするのが
metaclass指定。メタクラスMをtypeのサブクラスとして宣言し、__new__メソッドをオーバーライドすることにより、あるクラス宣言時のクラス生成をカスタマイズできる:class C(metaclass=M): ...すべてのクラス生成時に強制的に
Mを適用することはできないと推測している [要調査]。インスタンス生成のカスタマイズ
参考:
インスタンス生成のカスタマイズはクラスの
__new__および__init__を定義 (オーバーライド) して行う。
特に、__new__をカスタマイズすることにより、生成が意図されたクラス (c = C(...)のC) 以外のクラスインスタンスを生成して返す事が可能になる。これは例えばファクトリクラスの実装に使える。
一方、御存知の通り、__init__は生成されたインスタンスの初期化 (プロパティの設定など) に使用される。未調査:
__prepare__今度調べる。
- 投稿日:2020-03-29T18:02:26+09:00
指数分布を丁寧に理解してPythonで描画する
はじめに
統計を勉強していると必ず出てくる指数分布ですが、例の確率分布の式が中々頭に入ってこなかったので確率分布の導出から丁寧に追って理解しようと考えました。イメージを掴むためにPythonで描画も行います。
参考
指数分布の理解とその分布の描画を行うに当たって下記を参考にさせていただきました。
- 【大学数学】指数分布(具体例やその意味、ポアソン分布との関係)【確率統計】
- 統計学入門 (基礎統計学Ⅰ) 東京大学教養学部統計学教室
- Maximum Likelihood for the Exponential Distribution, Clearly Explained! V2.0
指数分布の理解
指数分布とは何か
\begin{equation} f(x)= \left\{ \begin{aligned} &\lambda \mathrm{e}^{-\lambda x} &(x\geq0) \\ &0 &(x<0)\\ \end{aligned} \right. \end{equation}指数分布とは単位時間当たりに平均$\lambda$回起こる事象の発生間隔が$x$単位時間である確率を表す確率分布です。確率密度関数は上記のように与えられます。
指数分布は下記のような例に用いられます。
- 災害が発生する間隔
- 故障時間が一定であるシステムの偶発的な故障が発生する間隔
- 店においてある客が来てから次の客が来るまでの間隔
また、期待値が$\frac{1}{\lambda}$で分散が$\frac{1}{\lambda^2}$であるという性質があります。
指数分布のかたち
それでは実際に分布を描画します。
下記の3つの例を考えて「次の客が来店するまでの時間間隔の確率分布」を描画してみます。
- 1時間当たり平均5人が来店する店($\lambda = 5$)
- 1時間当たり平均10人が来店する店($\lambda = 10$)
- 1時間当たり平均15人が来店する店($\lambda = 15$)
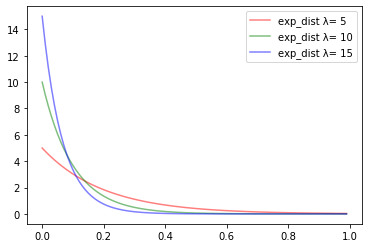
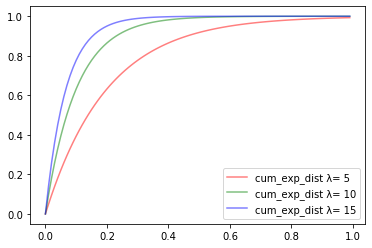
import numpy as np import matplotlib.pyplot as plt def exp_dist(lambda_, x): return lambda_ * np.exp(- lambda_*x) x = np.arange(0, 1, 0.01) y1= [exp_dist(5,i) for i in x] y2= [exp_dist(10,i) for i in x] y3= [exp_dist(15,i) for i in x] plt.plot(x, y1, color="red" ,alpha=0.5, label="exp_dist λ= %d" % 5) plt.plot(x, y2, color="green" ,alpha=0.5, label="exp_dist λ= %d" % 10) plt.plot(x, y3, color="blue" ,alpha=0.5, label="exp_dist λ= %d" % 15) plt.legend() plt.show()
$\lambda$の値が小さければ小さいほど減少の仕方は緩やかになりますが$\lambda$の値がどうであれ必ず単調減少する、というところがポイントです。間隔的にも1時間で平均5人お客さんが来る店よりも、平均15人来る店の方が、次のお客さんが間隔空けずにすぐに来るであろうということがわかると思います。
また更にポイントなのが$\lambda$の値がどうであれ$x=0$に近いほど確率密度が高くなるということです。すぐに次のお客様が来る確率が最も高いというのはおかしいのではないか?という違和感がある方もいらっしゃると思いますが、これは指数分布の無記憶性という性質に由来しています。何かが1回起きたかから次も起きやすいということではなくて、完全にランダムで発生している事象と捉えるため、発生しない時間がずっと続くよりもすぐに発生する確率の方が高くなるということです。(前の事象が発生したか否かについては完全に忘れ去れているという意味で無記憶)
指数分布の累積分布関数
私たちの日常の感覚としてより知りたいのは、次のお客さんがきっかり10分後に来る確率、よりも10分以内に来る確率の方だと思います。そこで事象の発生間隔が$x$単位時間以内である確率を考えます。確率を足し合わせる、つまり積分をして求める必要があります。
{\begin{eqnarray} F(x) &=& \int_0^x f(x) dx \\ &=& \int_0^x \lambda \mathrm{e}^{-\lambda x} dx \\ &=& \lambda\int_0^x \mathrm{e}^{-\lambda x} dx \\ &=& \lambda\left[\frac{1}{-\lambda}\mathrm{e}^{-\lambda x}\right]^x_0 \\ &=& -\mathrm{e}^{-\lambda x} - (-1) \\ &=& 1 - \mathrm{e}^{-\lambda x} \\ \end{eqnarray}}この累積分布関数もまた下記の3つの例を考えて描画してみます。
- 1時間当たり平均5人が来店する店($\lambda = 5$)
- 1時間当たり平均10人が来店する店($\lambda = 10$)
- 1時間当たり平均15人が来店する店($\lambda = 15$)
def cum_exp_dist(lambda_, x): return 1 - np.exp(-lambda_ * x) x = np.arange(0, 1, 0.01) y1= [cum_exp_dist(5,i) for i in x] y2= [cum_exp_dist(10,i) for i in x] y3= [cum_exp_dist(15,i) for i in x] plt.plot(x, y1, color="red" ,alpha=0.5, label="cum_exp_dist λ= %d" % 5) plt.plot(x, y2, color="green" ,alpha=0.5, label="cum_exp_dist λ= %d" % 10) plt.plot(x, y3, color="blue" ,alpha=0.5, label="cum_exp_dist λ= %d" % 15) plt.legend() plt.show()
このような1を最大値として単調増加しているグラフになることがわかります。
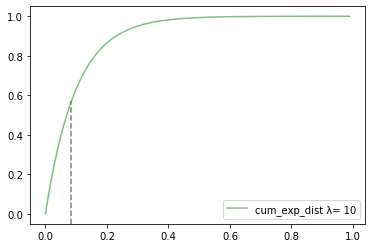
1つ具体例をあげて確率を計算してみます。
ex)1時間に平均10人来店する店で5分以内に次のお客さんが来店する確率{\begin{eqnarray} F(x) &=& 1 - \mathrm{e}^{-10・\frac{1}{12}} \\ &=& 0.565 \end{eqnarray}}グラフ上では下記のポイントにあたります。
指数分布の導出
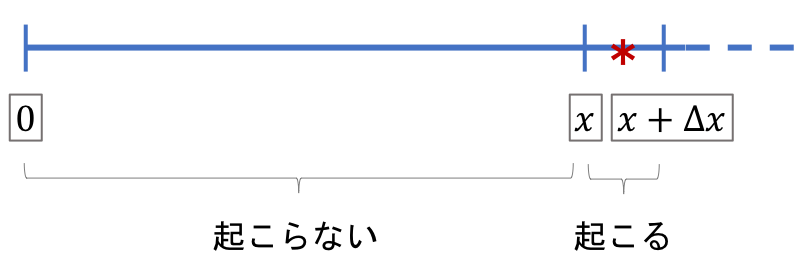
それでは指数分布の導出を考えていきます。
時間$x$までは事象が発生しない状況が続き、$x$と$x+Δx$の区間で初めて事象が発生すると考えます。($Δx$は微小区間)その時、$x$と$x+Δx$の区間で初めて事象が発生する確率は下記の等式で表すことができます。
f(x)Δx = (1 - F(x))・\lambdaΔx$f(x)Δx$はそもそもの確率密度関数の定義から$Δx$の間に事象が発生する確率を表しているとわかります。また右辺は$x$までに事象が発生しない確率($(1 - F(x))$)と、$x$から$x+Δx$の間に事象が発生する確率($\lambdaΔx$)を掛け合わせています。
無記憶性により、$x$までに事象が発生する確率と$x$から$x+Δx$の間に事象が発生する確率は独立であるため、そのまま掛け合わせることができます。
それでは$\lambdaΔx$がどこから来ているのかを以下で書いていきます。
微小区間$Δx$は1単位時間を$n$等分($n$は十分に大きい)しているものなので下記が成り立ちます。Δx・n=1今回は単位時間に平均$\lambda$回起こる事象を考えてることから、上記式を用いて各々の微小区間において事象が発生する確率を考えると以下のようになります。
p = \frac{\lambda}{n} = \lambdaΔxこれで$\lambdaΔx$の意味がわかりました。それでは最初にあげた式を展開していきます。
{\begin{eqnarray} f(x)Δx &=& (1 - F(x))・\lambdaΔx \\ f(x)&=& \lambda - \lambda F(x) \\ f'(x)&=& -\lambda f(x) \end{eqnarray}}2行目から3行目の展開では両辺を$x$で微分しています。
$f'(x)= -\lambda f(x)$は微分方程式の形になっていますが、微分をしても形が変わらない関数であるということを考えると簡単に指数関数であることがわかります。
f(x) = C・\mathrm{e}^{-\lambda x}$C$は定数なので何でもよいのですが、これを積分すると累積分布関数になる必要があります。従って、必然的に$\int_0^∞f(x)=1$であるという制約がかかります。その制約を用いて定数$C$の値を定めます。
{\begin{eqnarray} \int_0^∞f(x) &=& \int_0^∞ C・\mathrm{e}^{-\lambda x} \\ &=& C\int_0^∞ \mathrm{e}^{-\lambda x} \\ &=& C\left[\frac{1}{-\lambda}\mathrm{e}^{-\lambda x}\right]^∞_0 \\ &=& C\left[\frac{1}{-\lambda}\mathrm{e}^{-\lambda x}\right]^∞_0 \\ &=& -C(\frac{1}{-\lambda})\\ &=& \frac{C}{\lambda}\\ \\ 1 &=& \frac{C}{\lambda} \end{eqnarray}}$\int_0^∞f(x)=1$という制約があるため、
{\begin{eqnarray} 1 &=& \frac{C}{\lambda} \\ C &=& \lambda \\ \end{eqnarray}}上記から$f(x) = \lambda \mathrm{e}^{-\lambda x}$を導き出すことができました。
指数分布のパラメータの最尤推定
続いて指数分布のパラメータの最尤推定を考えていきます。
最尤推定とはあるパラメータ$\theta$に従う確率密度関数を$f(x;\theta)$とした時、尤度関数$L(\theta;x)=f(x;\theta)$が最大となるような推定量$\theta=\hat\theta$を最尤推定量と呼びます。$\lambda = \theta$の指数分布に独立に従うを乱数を生成した時$x_1,x_2,\cdots,x_n$が出力されたとします。この時の$\lambda = \theta$の最尤推定量を考えます。
L(\theta ; x) = \theta \mathrm{e}^{-\theta x}今回データが$x_1,x_2,\cdots,x_n$と$n$個与えられており、それらはすべて独立に生成されたものであるため、尤度関数は下記のように表すことができます。
\begin{eqnarray*}L(\theta ;x_1,x_2,\cdots,x_n)= L(\theta ;x_1)×L(\theta ;x_2)×\cdots ×L(\theta ;x_n) \end{eqnarray*}上記を指数分布に当てはめると下記のようになります。
\begin{eqnarray*}L(\mu,\sigma ;x_1,x_2,\cdots,x_n)= \displaystyle\prod_{k=1}\theta\mathrm{e}^{-\theta x} \end{eqnarray*}上記尤度関数が最大になるような$\theta$を求めればよいのですが、対数尤度関数に変換してその最大値を求めるタスクに置き換えても同様な結果が得られるため、対数尤度関数に変換します。
\begin{eqnarray*} \log(L(\mu,\sigma ;x_1,x_2,\cdots,x_n))&=& \log(n\theta) + \log( \mathrm{e}^{-\theta (x_1 + x_2 + \cdots, + x_n)}) \\ &=& n\log(\theta) -\theta (x_1 + x_2 + \cdots, + x_n) \\ \end{eqnarray*}$ l(\theta)=\log (L(\theta ;x_1,x_2,\cdots,x_n))$と置いて$l(\theta)$を$\theta$で微分します。
{\begin{eqnarray*} \frac{\partial l(\theta)}{\partial\theta}&=&\frac{\partial}{\partial\theta}(n\log(\theta) -\theta (x_1 + x_2 + \cdots, + x_n)) \\ &=& n・\frac{1}{\theta} - (x_1 + x_2 + \cdots, + x_n) \end{eqnarray*}}ここらから$\frac{\partial l(\theta)}{\partial\theta}=0$と置いて$\theta$について解きます。
{\begin{eqnarray*} n・\frac{1}{\theta} - (x_1 + x_2 + \cdots, + x_n) &=& 0 \\ n・\frac{1}{\theta} &=& (x_1 + x_2 + \cdots, + x_n)\\ \theta &=& \frac{n}{x_1 + x_2 + \cdots, + x_n} \\ \end{eqnarray*}}こちらで指数分布のパラメータの最尤推定量が$\frac{n}{x_1 + x_2 +\cdots,+x_n}$であることがわかりました。
この最尤推定量を具体例に当てはめて考えてみます。ある店において、お客さんが来店する間隔を5回計測してみたとします。
- 開店から1人目が来店するまでの時間:20分
- 1人目が来店してから2人目が来店するまでの時間:15分
- 2人目が来店してから3人目が来店するまでの時間:20分
- 3人目が来店してから4人目が来店するまでの時間:15分
- 4人目が来店してから5人目が来店するまでの時間:20分
来店間隔が指数分布に従うとした時、上記データから得られるパラメータ$\lambda$の最尤推定量は下記のようになります。
{\begin{eqnarray*} \frac{5}{\frac{1}{3} + \frac{1}{4} + \frac{1}{3} + \frac{1}{4} + \frac{1}{3}} \fallingdotseq 3.33 \\ \end{eqnarray*}}与えられたデータから最尤推定を行うと、お客さんの来店間隔は単位時間(1時間)当たり平均$3.33$回来店されるとした時の指数分布に従うと考えられることがわかりました。
Next
指数関数について大まかに理解することができました。今後も統計関連の記事を投稿していければと思っています。
- 投稿日:2020-03-29T18:00:56+09:00
(◎◎) {退屈なことはPythonにやらせよう).........(へ?ほなPythonに宿題やらせるわ} (゜)(゜)
みなさんは退屈なことをPythonにやらせましたか?
私はやらせていませんでした
このC-3POみたいなロボットが芝をかっている表紙の書籍
Pythonの良書として有名で、読んだ人も多いのではないでしょうか?
ではこの本を読んで実際に退屈なことをPythonにやらせた人はいますか?
結構少ないのではないでしょうか?読んで満足する人が多いかと思います。
私もその一人でした。1年ほど前に一度読んだだけ。。。でしたAI研修はじめました
最近はAIがおバズりになられておりますね。いろいろな会社でAIの導入を始めているそうな。
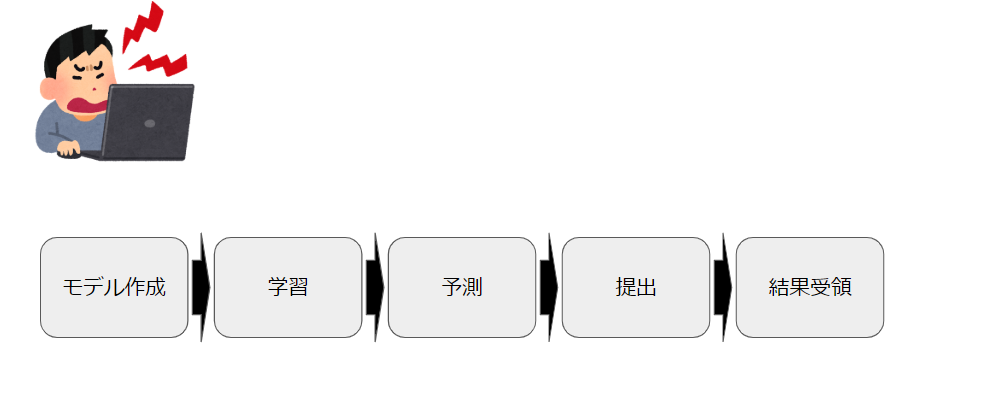
私の勤めている会社も例外ではなく、AI研修というものを導入始めました。その研修の中で自分で機械学習モデルを作成して、手書き文字の予測を行うという課題がありました。
※Kaggleのdigit recognizerとほとんど一緒です。課題の流れ
1. モデル作成
ディープラーニングのモデルを定義します。
ここでディープラーニングの層をいくつにするか、各層のノードをいくつにするか?
といったようなモデルの全体的な構成と細かいチューニングを行います。
2. 学習
正解のラベルと手書き文字の画像が対になったデータ(訓練データ)を渡して、モデルを学習させます。
ここで、学習データの一部を検証用データ(3.予測を参照)に見立てて、仮の予測結果を測定することができます。仮の予測結果が高いモデルを以降の作業に使用します。3. 予測:
手書き文字の画像だけのデータ(検証データ)を渡して、手書き文字の予測を行います。
予測はCSVファイルとして出力されます。4. 提出:
予測CSVファイルを研修会社が用意したWebサーバにブラウザ経由でアップロードします。
5. 結果受領:
webサーバ上にて予測結果の精度が表示されます。
上記1-5を繰り返して、合格点の精度を取得せよというのが課題でした。
作業ゲー
何回か繰り返していて、これルーチンワークだなと思うようになりました。
モデルの大枠が決まればあとはモデルのパラメータをチューニングして、学習->予測→提出を繰り返しているだけなんですよ。しかも待ち時間がすごく長い!!
これって自動化できないかなと考えるようになりました。Let's automation with python
では退屈なことをPythonにやらせていきましょう。
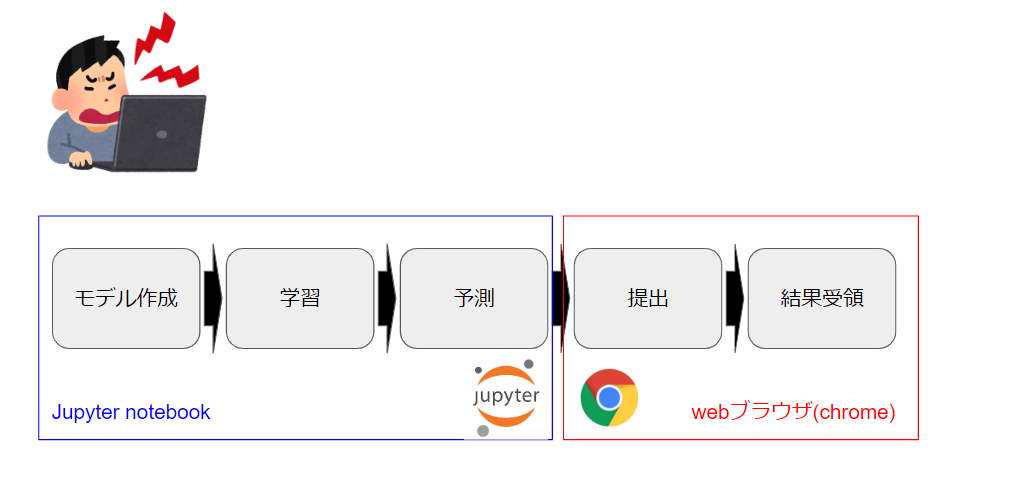
もう一度課題の流れを整理
モデル作成/学習/予測
Jupyter notebookという対話型のpython実行環境で行います。
Jupyter notebookで書いたコードをpythonのクラス/関数にして、それにチューニングに使用するパラメータを引数として渡すことで自動化を実現できると考えました。jupyternotebookのコードをpythonファイルに変換する方法について
https://qiita.com/abts/items/25bb611b6d83e646abdd提出結果/結果受領
予測にて出力されるCSVファイルをgoogle chrome経由でアップロード用のサイトにアップロードします。
WebブラウザはSeleniumというPythonのライブラリを使用することで自動化することができそうです。Seleniumについて
https://qiita.com/Chanmoro/items/9a3c86bb465c1cce738a制約 : 一日5ファイルしかアップロードできない
予測CSVファイルは一日5ファイルまでしかアップロードできないという制限がありました。
これがなければ上記の処理をループでひたすら回すということができて楽だったのですが。。。
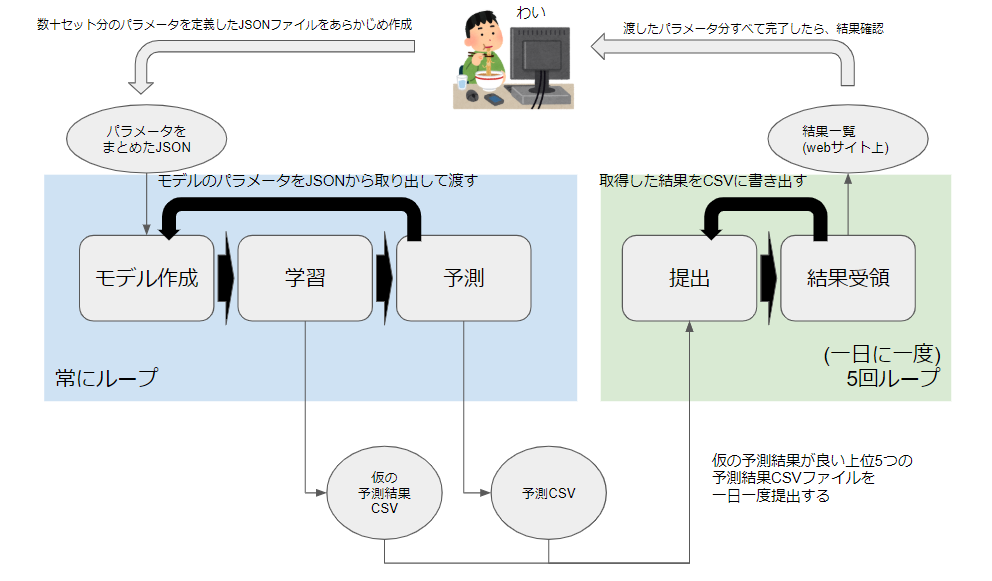
ここは工夫する必要がありそうです。自動化の流れ
人間のやること
- JSONファイルにモデルに渡すパラメータを事前に数十/数百セット定義しておきます。
- 渡したパラメータ分すべて処理が終了するまで漫画とかyoutubeを見ます。
- すべて完了した後は結果を確認して、目標を達成していたら終了、結果をもとに次のパラメータを考える
Python君のやること
モデル作成/学習/予測
ここはひたすらループ処理になります。
- JSONファイルからモデルに使用するパラメータを取得
- モデル作成
- 学習(この時に算出される仮の予測精度をCSVに格納していく)
- 予測(1ループごとに1つの結果CSVが作成されます)
提出/結果受領
一日一回、深夜12時を超えたタイミングに5回だけループします。
5回というのは、一日の提出上限回数です。
- まず仮の予測結果が格納されているCSVを確認して、上位5つの予測CSVを抽出する
- 抽出したCSVを1ループずつ提出する
- アップロードに表示される予測結果を取得してCSVに書き込む
実装(コーディング)
その前に
さすがに研修会社さんのアップロードサイトについては公開することができないので、今回は代わりにkaggleのdigit recognizerを使用します。基本的な流れは変わりません。
またkaggleにはアップロード用のAPIがありますが、今回それについてはツッコまないように (-_-)
あくまでこれは再現としてみていただけると幸いです。では実際に使用したコードについて簡単に説明します。
コード
機械学習クラス
ai.pyfrom itertools import product import os import pandas as pd import numpy as np np.random.seed(2) from keras.utils.np_utils import to_categorical # convert to one-hot-encoding from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPool2D from keras.optimizers import RMSprop from keras.preprocessing.image import ImageDataGenerator from keras.callbacks import ReduceLROnPlateau from sklearn.model_selection import train_test_split class MnistModel(object): def __init__(self, train_data_name='train.csv', test_data_csv='test.csv'): input_dir = self.get_dir_path('input') train_data_path = os.path.join(input_dir, train_data_name) test_data_path = os.path.join(input_dir, test_data_csv) #Load the data self.train = pd.read_csv(train_data_path) self.test = pd.read_csv(test_data_path) def get_dir_path(self, dir_name): """ Function to directory path Params: dir_name(str): The name of directory Return: str: The directory path """ base_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) data_directory = os.path.join(base_dir, dir_name) return data_directory def learning_and_predict(self, csv_file_path, config): label = self.train["label"] train = self.train.drop(labels=["label"], axis=1) # Normalize the data train = train / 255.0 test = self.test / 255.0 # Reshape image in 3 dimensions (height = 28px, width = 28px , canal = 1) train = train.values.reshape(-1, 28, 28, 1) test = test.values.reshape(-1, 28, 28, 1) # Encode labels to one hot vectors (ex : 2 -> [0,0,1,0,0,0,0,0,0,0]) label = to_categorical(label, num_classes=10) # Set the random seed random_seed = 2 # Split the train and the validation set for the fitting X_train, X_val, Y_train, Y_val = train_test_split(train, label, test_size=0.1, random_state=random_seed) model = Sequential() model.add(Conv2D(filters=32, kernel_size=(5, 5), padding='Same', activation='relu', input_shape=(28, 28, 1))) model.add(Conv2D(filters=32, kernel_size=(5, 5), padding='Same', activation='relu')) model.add(MaxPool2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='Same', activation='relu')) model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='Same', activation='relu')) model.add(MaxPool2D(pool_size=(2, 2), strides=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(256, activation="relu")) model.add(Dropout(0.5)) model.add(Dense(10, activation="softmax")) optimizer = RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0) model.compile(optimizer=optimizer, loss="categorical_crossentropy", metrics=["accuracy"]) datagen = ImageDataGenerator( featurewise_center=False, # set input mean to 0 over the dataset samplewise_center=False, # set each sample mean to 0 featurewise_std_normalization=False, # divide inputs by std of the dataset samplewise_std_normalization=False, # divide each input by its std zca_whitening=False, # apply ZCA whitening rotation_range=config['ROTATION_RANGE'], # randomly rotate images in the range (degrees, 0 to 180) zoom_range=config['ZOOM_RANGE'], # Randomly zoom image width_shift_range=config['WIDTH_SHIFT_RANGE'], # randomly shift images horizontally (fraction of total width) height_shift_range=config['HEIGHT_SHIFT_RANGE'], # randomly shift images vertically (fraction of total height) horizontal_flip=False, # randomly flip images vertical_flip=False) # randomly flip images datagen.fit(X_train) learning_rate_reduction = ReduceLROnPlateau( monitor='val_acc', patience=3, verbose=1, factor=0.5, min_lr=0.00001 ) epochs = 1 batch_size = 86 history = model.fit_generator( datagen.flow( X_train, Y_train, batch_size=batch_size ), epochs=epochs, validation_data=( X_val, Y_val ), verbose=2, steps_per_epoch=X_train.shape[0] // batch_size, callbacks=[learning_rate_reduction]) results = model.predict(test) results = np.argmax(results, axis=1) results = pd.Series(results, name="Label") submission = pd.concat([pd.Series(range(1, 28001), name="ImageId"), results], axis=1) submission.to_csv(csv_file_path, index=False) return history.history['val_acc'][0]今回の機械学習のモデルは以下を参考(丸パクリ)して作成しました。
https://www.kaggle.com/yassineghouzam/introduction-to-cnn-keras-0-997-top-6learning_and_predictメソッドにてモデル作成/学習/予測をすべて行います。
configがパラメータを格納したリストになります。datagen = ImageDataGenerator( .... rotation_range=config['ROTATION_RANGE'], # randomly rotate images in the range (degrees, 0 to 180) zoom_range=config['ZOOM_RANGE'], # Randomly zoom image width_shift_range=config['WIDTH_SHIFT_RANGE'], # randomly shift images horizontally (fraction of total width) height_shift_range=config['HEIGHT_SHIFT_RANGE'], # randomly shift images vertically (fraction of total height) .... datagen.fit(X_train)今回はImageDataGenerator(画像拡張)のパラメータをチューニングの対象にしています。
※なんのことかわからない人は、とりあえず機械学習モデルのパラメータの一つなんだと思っておいてください。パラメータ定義JSON
{ "CONFIG": [ { "ROTATION_RANGE": 10, "ZOOM_RANGE": 0.1, "WIDTH_SHIFT_RANGE": 0.1, "HEIGHT_SHIFT_RANGE": 0.1 }, { "ROTATION_RANGE": 10, "ZOOM_RANGE": 0.1, "WIDTH_SHIFT_RANGE": 0.1, "HEIGHT_SHIFT_RANGE": 0.2 }, { "ROTATION_RANGE": 10, "ZOOM_RANGE": 0.1, "WIDTH_SHIFT_RANGE": 0.1, "HEIGHT_SHIFT_RANGE": 0.3 }, { "ROTATION_RANGE": 10, "ZOOM_RANGE": 0.1, "WIDTH_SHIFT_RANGE": 0.1, "HEIGHT_SHIFT_RANGE": 0.4 } ] }webアップロード用クラス
予測CSVをwebサイトにアップロードするためのクラスになります。
主にseleniumにて実装されています。import os import time from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC DRIVER_FILE_PATH = 'C:\Drivers\chromedriver_win32\chromedriver.exe' DRIVER_FILE_NAME = 'chromedriver' TIMEOUT = 30 class BaseBrowserOperator(object): """ Base model of browser operator """ def __init__(self, headless = False): driver_path = os.path.join(os.path.dirname(DRIVER_FILE_PATH), DRIVER_FILE_NAME) if headless == True: options = webdriver.ChromeOptions() options.add_argument('--headless') self.browser = webdriver.Chrome(driver_path, options=options) else: self.browser = webdriver.Chrome(driver_path) def __del__(self): self.browser.close() class BrowserOperator(BaseBrowserOperator): """ The browser operator model """ def go_to_page(self, url): """ Function to go to a page Params: url(str): The url of page """ self.browser.get(url) def click(self, element_xpath, wait=True): """ Function to click the page's element TODO: implement finding element method other than xpath Params: element_xpath(str): The xpath of element be clicked wait(boolean): If disable waiting, please give False. """ if wait: self.wait_element(element_xpath) self.browser.find_element_by_xpath(element_xpath).click() def input_value(self, element_xpath, value, wait=True): """ Function to input value to page's element TODO: implement finding element method other than xpath Params: element_xpath(str): The xpath of element be clicked value(str): The value be inputed wait(boolean): If disable waiting, please give False. """ if wait: self.wait_element(element_xpath) self.browser.find_element_by_xpath(element_xpath).send_keys(value) def get_value(self, element_xpath, wait=True): """ Function to get value from page's element Params: element_xpath(str): The xpath of element be clicked wait(boolean): If disable waiting, please give False. Returns: str: Value from page's element """ if wait: self.wait_element(element_xpath) return self.browser.find_element_by_xpath(element_xpath).text def import_cookies(self): """ Function to import cookie informations """ cookies = self.browser.get_cookies() for cookie in cookies: self.browser.add_cookie({ 'name': cookie['name'], 'value': cookie['value'], 'domain': cookie['domain'], }) def wait_element(self, element_xpath): """ Function to wait to appear element on page TODO: implement finding element method other than xpath Params: element_xpath(str): The xpath of element be used to wait """ WebDriverWait(self.browser, TIMEOUT).until(EC.element_to_be_clickable((By.XPATH, element_xpath))) def wait_value(self, element_xpath, value, timeout=300): """ Function to wait until element's value equal the specific value Params: element_xpath(str): The xpath of element be used for wait value(str): The used value for wait timeout(int): The waiting timeout(sec) """ state = '' sec = 0 while not state == value: state = self.browser.find_element_by_xpath(element_xpath).text time.sleep(1) if sec > timeout: raise TimeoutError("Timeout!! The value wasn't available") sec += 1各メソッドは以下のように使用します。
- go_to_page
- 指定のURLに遷移するためのメソッドです。
- click
- webページの要素をクリックするためのメソッドです。
- waitを使用することで、要素がクリックできる状態になるまで待機することができます
- input_value
- webページの入力欄に、文字を入力するためのメソッドです。
- waitを使用することで、要素がクリックできる状態になるまで待機することができます
- get_value
- webページの要素から値を取得するメソッドです。
- waitを使用することで、要素がクリックできる状態になるまで待機することができます
- import_cookies
- cookieをインポートします
kaggleにて予測CSVファイルのアップロードは以下のコードで実現できます。
def upload_csv_to_kaggle(self, file_path): """ Function to upload csv file to kaggle Params: file_path(str): The path of csv file uploaded """ uploader = BrowserOperator() # kaggleのページに遷移 uploader.go_to_page( 'https://www.kaggle.com/c/digit-recognizer' ) # Sign inボタンをクリック uploader.click( '/html/body/main/div[1]/div/div[1]/div[2]/div[2]/div[1]/a/div/button' ) # Sign in with google をクリック uploader.click( '/html/body/main/div/div[1]/div/form/div[2]/div/div[1]/a/li/span' ) # メールアドレスを入力 uploader.input_value( '/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[1]/div/form/span/section/div/div/div[1]/div/div[1]/div/div[1]/input', GOOGLE_MAILADDRESS ) uploader.click( '/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[2]/div/div[1]/div' ) # パスワードを入力 uploader.input_value( '/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[1]/div/form/span/section/div/div/div[1]/div[1]/div/div/div/div/div[1]/div/div[1]/input', GOOGLE_PASSWORD ) uploader.click( '/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[2]/div/div[1]/div/span/span' ) time.sleep(10) # sleepいれないとうまくいかんなかった # クッキーをインポート uploader.import_cookies() # digit recognizerのCSV提出画面に遷移 uploader.go_to_page('https://www.kaggle.com/c/digit-recognizer/submit') time.sleep(30) # sleepいれないとうまくいかんなかった # ファイルアップロード uploader.input_value( '/html/body/main/div[1]/div/div[5]/div[2]/div/div[3]/div[2]/div[2]/div[1]/div[2]/div[1]/div/input', file_path, wait=False ) # コメントの入力 uploader.input_value( '/html/body/main/div[1]/div/div[5]/div[2]/div/div[3]/div[2]/div[2]/div[2]/div[2]/div/div/div/div[2]/div/div/textarea', 'test' ) uploader.wait_element( '/html/body/main/div[1]/div/div[5]/div[2]/div/div[3]/div[2]/div[2]/div[1]/div[2]/div[1]/ul/li/div/span[1]') uploader.click('/html/body/main/div[1]/div/div[5]/div[2]/div/div[3]/div[2]/div[2]/div[3]/div[2]/div/a') uploader.wait_value( '/html/body/main/div[1]/div/div[5]/div[2]/div/div[2]/div[2]/div/div[3]/div[1]/div[1]/span', 'Complete' )課題実行用クラス
homeworker.pyimport csv import datetime import json import os import time import retrying from mnist_auto.models.operator import BrowserOperator from mnist_auto.models.ai import MnistModel DEFAULT_DAILY_SCORES_DIR = 'daily_scores' DEFAULT_CSVS_DIR = 'results' DEFAULT_UPLOADED_SCORE_FILE_NAME = 'uploaded_score.csv' DEFAULT_KAGGLE_DAILY_LIMIT = 5 COLUMN_DATETIME = 'DATETIME' COLUMN_SCORE = 'SCORE' GOOGLE_MAILADDRESS = 'xxxx@google.com' GOOGLE_PASSWORD = 'password' class BaseHomeworker(object): """ Base model of homeworker """ def __init__(self, daily_score_dir_name, csvs_dir_name): self.daily_score_dir_path = self.get_dir_path(daily_score_dir_name) self.csvs_dir_path = self.get_dir_path(csvs_dir_name) def get_dir_path(self, dir_name): """ Function to get directory path if direcotry doen't exist, The direcotry will be made Params: dir_name(str): The directory name Returns: str: The directory path """ base_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) dir_path = os.path.join(base_dir, dir_name) if not os.path.exists(dir_path): os.mkdir(dir_path) return dir_path class Homeworker(BaseHomeworker): """ The homeworker model """ def __init__(self): super().__init__(daily_score_dir_name=DEFAULT_DAILY_SCORES_DIR, csvs_dir_name=DEFAULT_CSVS_DIR) self.uploaded_scores = [] self.config = self.get_confing() self.mnist_model = MnistModel() def get_confing(self, config_file_name='config.json'): """ Function to get configuration with json format Params: config_file_name(str): The name of config file Return: dict: The dict including config """ base_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) config_file_path = os.path.join(base_dir, config_file_name) json_file = open(config_file_path, 'r') return json.load(json_file) def write_daily_to_file(self, date_ymd, date_ymdhm, score): """ Function to write daily data to file Params: date_ymd(str): The formatted date (YYYYmmdd) date_ymdhm(str): The formatted date (YYYYmmddHHMM) score(int): The score """ date_ymd = date_ymd + '.csv' file_path = os.path.join(self.daily_score_dir_path, date_ymd) with open(file_path, 'a', newline='') as csv_file: fieldnames = [COLUMN_DATETIME, COLUMN_SCORE] writer = csv.DictWriter(csv_file, fieldnames=fieldnames) writer.writerow({ COLUMN_DATETIME: date_ymdhm, COLUMN_SCORE: score }) def upload_csv_files(self, date_ymd, num=DEFAULT_KAGGLE_DAILY_LIMIT): """ Function to upload designated number csv files Params: data_ymd(str): The formatted data num(int): The number of file that will be uploaded """ targets_uploaded = self.get_tops(date_ymd, num) for target in targets_uploaded: file_path = os.path.join(self.daily_score_dir_path, target[COLUMN_DATETIME]) + '.csv' try: self.upload_csv_to_kaggle(file_path) except retrying.RetryError: continue def get_tops(self, date_ymd, num): """ Function to get data that have some high score from daily data Params: num(int): The number of data that will be gotten Return: list: The list that includes some highest data """ file_name = date_ymd + '.csv' file_path = os.path.join(self.daily_score_dir_path, file_name) scores = [] with open(file_path, 'r') as csv_file: reader = csv.reader(csv_file) for row in reader: scores.append({ COLUMN_DATETIME: row[0], COLUMN_SCORE: row[1] }) sorted_list = sorted(scores, key=lambda x: x[COLUMN_SCORE], reverse=True) if len(sorted_list) < num: num = len(sorted_list) return sorted_list[:num] @retrying.retry(stop_max_attempt_number=3) def upload_csv_to_kaggle(self, file_path): """ Function to upload csv file to kaggle Params: file_path(str): The path of csv file uploaded """ uploader = BrowserOperator() uploader.go_to_page( 'https://www.kaggle.com/c/digit-recognizer' ) uploader.click( '/html/body/main/div[1]/div/div[1]/div[2]/div[2]/div[1]/a/div/button' ) uploader.click( '/html/body/main/div/div[1]/div/form/div[2]/div/div[1]/a/li/span' ) uploader.input_value( '/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[1]/div/form/span/section/div/div/div[1]/div/div[1]/div/div[1]/input', GOOGLE_MAILADDRESS ) uploader.click( '/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[2]/div/div[1]/div' ) uploader.input_value( '/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[1]/div/form/span/section/div/div/div[1]/div[1]/div/div/div/div/div[1]/div/div[1]/input', GOOGLE_PASSWORD ) uploader.click( '/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[2]/div/div[1]/div/span/span' ) time.sleep(10) uploader.import_cookies() uploader.go_to_page('https://www.kaggle.com/c/digit-recognizer/submit') time.sleep(30) uploader.input_value( '/html/body/main/div[1]/div/div[5]/div[2]/div/div[3]/div[2]/div[2]/div[1]/div[2]/div[1]/div/input', file_path, wait=False ) uploader.input_value( '/html/body/main/div[1]/div/div[5]/div[2]/div/div[3]/div[2]/div[2]/div[2]/div[2]/div/div/div/div[2]/div/div/textarea', 'test' ) uploader.wait_element( '/html/body/main/div[1]/div/div[5]/div[2]/div/div[3]/div[2]/div[2]/div[1]/div[2]/div[1]/ul/li/div/span[1]') uploader.click('/html/body/main/div[1]/div/div[5]/div[2]/div/div[3]/div[2]/div[2]/div[3]/div[2]/div/a') uploader.wait_value( '/html/body/main/div[1]/div/div[5]/div[2]/div/div[2]/div[2]/div/div[3]/div[1]/div[1]/span', 'Complete' ) def work(self): """ Function to run a series of tasks 1. learning and prediction with parameter (It's written on json) one prediction results is outputed as one csv 2. Writing learning's score (acc) to another csv. 3. Once a day, uploading result csv files to kaggle in high score order """ last_upload_time = datetime.datetime.now() for config in self.config['CONFIG']: now = datetime.datetime.now() now_format_ymdhm = '{0:%Y%m%d%H%M}'.format(now) now_format_ymd = '{0:%Y%m%d}'.format(now) if (now - last_upload_time).days > 0: last_upload_time = now self.upload_csv_files() csv_file_name = now_format_ymdhm + '.csv' csv_file_path = os.path.join(self.csvs_dir_path, csv_file_name) score = self.mnist_model.learning_and_predict(csv_file_path=csv_file_path, config=config) self.write_daily_to_file(date_ymd=now_format_ymd, date_ymdhm=now_format_ymdhm, score=score)workメソッドがメインとなる部分です。
結果発表
ほとんど寝てるだけで、課題をパスすることができました!
各研修受講生のアップロードした回数が表示されるのですが、私だけ桁違いでしたw
みなさんも退屈なことはPythonにやらせましょう!!では!

- 投稿日:2020-03-29T17:57:52+09:00
webにあるzip fileをpandasに読み込ませる
ローカルにzipをダウンロード -> 解凍 -> pandasに読み込ませるより、
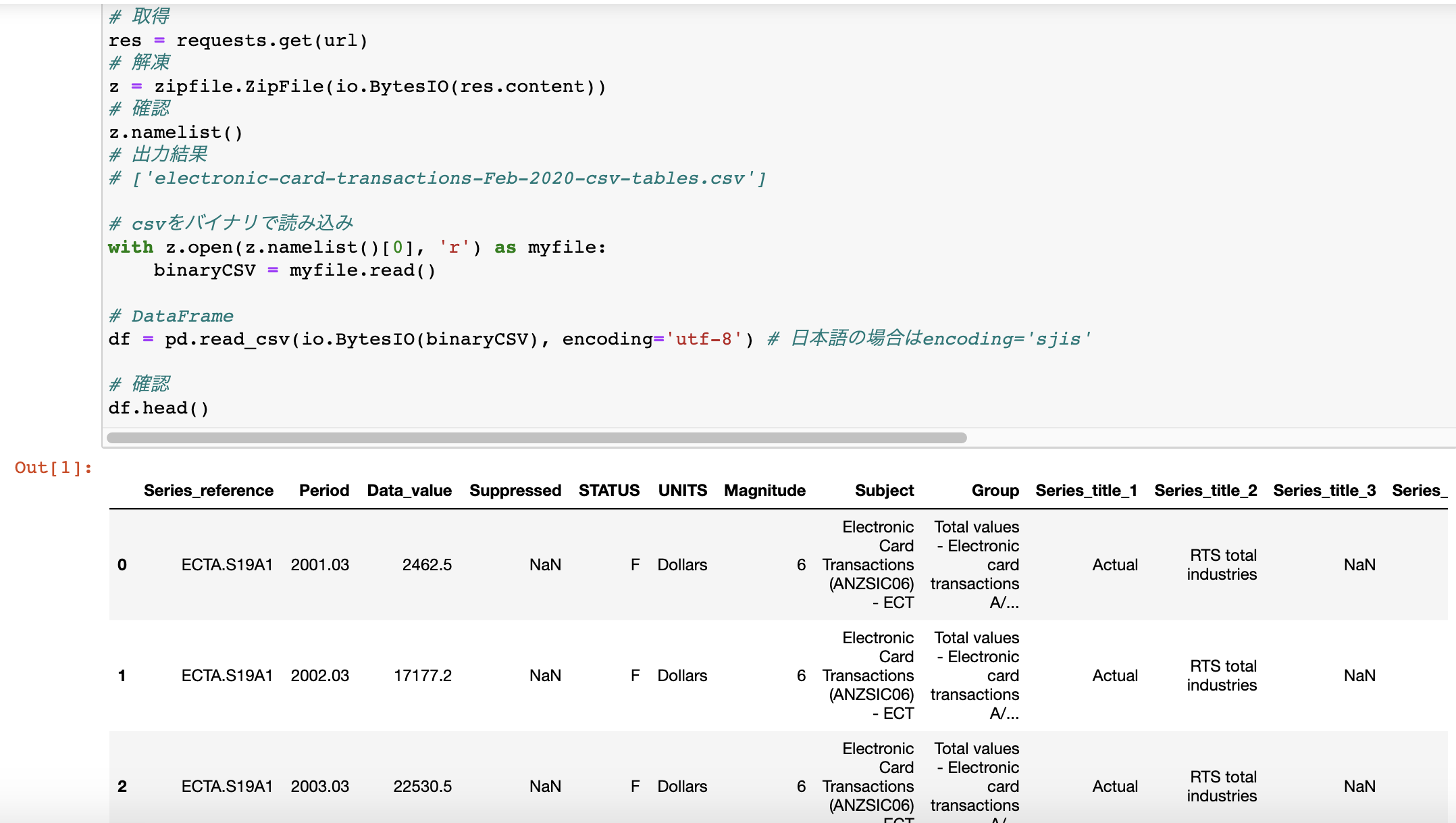
メモリに積まれたままdataframeに落としたかったためのメモimport requests import zipfile import io import pandas as pd # url url = "https://www.stats.govt.nz/assets/Uploads/Electronic-card-transactions/Electronic-card-transactions-February-2020/Download-data/electronic-card-transactions-february-2020-csv.zip" # 取得 res = requests.get(url) # 解凍 z = zipfile.ZipFile(io.BytesIO(res.content)) # 確認 z.namelist() # 出力結果 # ['electronic-card-transactions-Feb-2020-csv-tables.csv'] # csvをバイナリで読み込み with z.open(z.namelist()[0], 'r') as myfile: binaryCSV = myfile.read() # DataFrame df = pd.read_csv(io.BytesIO(binaryCSV), encoding='utf-8') # 日本語の場合はencoding='sjis' # 確認 df.head()
- 投稿日:2020-03-29T17:57:44+09:00
ニューラルネットのオブジェクトに触ってみる
先日初めてTensorflowに触ってみましたが、今回はちょっとニューラルネットのオブジェクトに触ってみました。
最初に色々組もうとハイレベルな挑戦をしてみましたが、全く上手く動いてくれなかったので、基本を大切に・・・の精神で、超超初歩的なことを書いてみます。触ってみたのは、
tensorflow.layers.dense
という部分。
どうやら、NewralNetworkの”層”に相当するようです。
探してみると、以下のような例文がありました。hidden1 = tf.layers.dense(x_ph, 32, activation=tf.nn.relu)これを組んでいくと、結構複雑なことができそうです。
ただ、今回はシンプルに・・・以下のようなモデルを考えてみます。
入力は2個、出力は1個です。
もはやニューラルネットワークとはいえないような気もしますが・・・
これが理解できなきゃダメだろうと思って、まずはここからスタートしてみます。まずは、ニューラルネットワークの層を作ってみます。
newral_out = tf.layers.dense(x_ph, 1)これで、入力のはx_phで定義、出力の数が1個となるようです。
オプションで色々出来るそうですが、今回は単なる線形結合っぽいような感じでいってみます。
x_phは、データ入力用の箱のplaceholderで、今回は以下で定義しておきます。x_ph = tf.placeholder(tf.float32, [None, 2])サイズの[None 2]、Noneは入れる数のサンプル数で任意の数突っ込めるという意味で、2は入力する変数の数なので、ここでは2個(X1,X2)としておきます。
今回は、本当にシンプルに、以下の数式のアウトプットをy1相当としました。
y_1 = w_1 x_1 + w_2 x_2 + w_0任意の(x1,x2)とy1を適当に突っ込んでみて、上手くw_1,w_2,w_0が推定できるか??
という本当にシンプルな問題です。実はここまでいくと、最初のサンプルのコードがそのまま流用できるため、恐らく凄い簡単に実装できて、以下のような感じでいけそうです。
# Minimize the mean squared errors. loss = tf.reduce_mean(tf.square(newral_out - y_ph)) optimizer = tf.train.GradientDescentOptimizer(0.5) train = optimizer.minimize(loss)あとは、これを学習させていけばOKかな?
# initialize tensorflow session sess = tf.Session() sess.run(tf.global_variables_initializer()) for k in range(101): # shuffle train_x and train_y n = np.random.permutation(len(train_x)) train_x = train_x[n] train_y = train_y[n].reshape([len(train_y), 1]) # execute train process sess.run(train,feed_dict = { x_ph: train_x, # x is input data y_ph: train_y # y is true data })これで一旦動きそうなのですが、折角なので、NewralNetworkのパラメタがどういう挙動をしているか知りたい。
直接読む方法もあるようなのですが、色々難しそう。
問題としてもシンプルなので、折角なので自前の解析機能を考えてみました。考え方としては、最小二乗法でw0,w1,w2を求める方法。
ニューラルネットワークを仮想の線形近似方程式と見なして、そのパラメタをチェックしてみます。
まずは、入力するデータを{{x_1}_k},{{x_2}_k}と設定し、Newralを通して推測された情報を
{y^{(new)}}_k = Newral({{x_1}_k},{{x_2}_k})とします。この{y^{(new)}}_kは何らかの決定的な数値が入ります。
ニューラルネットの推定にはBiasがあるかもしれないので、それを加えた形の以下の方程式を考えます。{y^{(new)}}_k = w_1{x_1}_k + w_2{x_2}_k + w0このとき、w_1,w_2,w_0が未知数、他は数値が決定しているという状態。
ここで、各kにおいて、連立方程式として考えると以下のようになります。\left( \begin{matrix} {y^{(new)}}_1 \\ ... \\ {y^{(new)}}_K \\ \end{matrix} \right) = \left( \begin{matrix} {x_1}_1 & {x_2}_1 & 1 \\ ... & ... \\ {x_1}_K & {x_2}_K & 1 \\ \end{matrix} \right) \left( \begin{matrix} w_1 \\ w_2 \\ w_0 \\ \end{matrix} \right)ここまでくれば、単純な最小二乗法の問題に帰着します。簡単のため、
A = \left( \begin{matrix} {x_1}_1 & {x_2}_1 & 1 \\ ... & ... \\ {x_1}_K & {x_2}_K & 1 \\ \end{matrix} \right)と、おくと、
\left( \begin{matrix} w_1 \\ w_2 \\ w_0 \\ \end{matrix} \right) = \left( A^T A \right)^{-1} A^T \left( \begin{matrix} {y^{(new)}}_1 \\ ... \\ {y^{(new)}}_K \\ \end{matrix} \right)で、パラメタを求めることができそうです。
実際に真値を作るときには、w_1,w_2,w_0を何らかの数値に設定しておけば、その正解にどうやって近づいているか???を観察できれば、ニューラルネットワークの中身が少しだけ分かった気になれそうです(笑)というわけで、そんなコードの全体を貼り付けておきます。
import numpy as np #import matplotlib.pyplot as plt import tensorflow as tf # deta making??? N = 50 x = np.random.rand(N,2) # true param??? w = np.array([0.5,0.5]).reshape(2,1) # sum > 1.0 > 1 : else > 0 #y = np.floor(np.sum(x,axis=1)) y = np.matmul(x,w) train_x = x train_y = y # make placeholder x_ph = tf.placeholder(tf.float32, [None, 2]) y_ph = tf.placeholder(tf.float32, [None, 1]) # create newral parameter(depth=1,input:2 > output:1) newral_out = tf.layers.dense(x_ph, 1) # Minimize the mean squared errors. loss = tf.reduce_mean(tf.square(newral_out - y_ph)) optimizer = tf.train.GradientDescentOptimizer(0.5) train = optimizer.minimize(loss) # initialize tensorflow session sess = tf.Session() sess.run(tf.global_variables_initializer()) for k in range(101): if np.mod(k,10) == 0: # get Newral predict data y_newral = sess.run( newral_out ,feed_dict = { x_ph: x, # xに入力データを入れている y_ph: y.reshape(len(y),1) # yに正解データを入れている }) # check for newral_parameter(w0,w1,w2)??? # x_ext = np.hstack([x,np.ones(N).reshape(N,1)]) A = np.linalg.inv( np.matmul(np.transpose(x_ext),x_ext) ) A = np.matmul(A,np.transpose(x_ext)) w_ext = np.matmul(A,y_newral) # errcheck??? ([newral predict] vs [true value]) err = y_newral - y err = np.matmul(np.transpose(err),err) # check y_newral # check LS solution(approaching to NewralNet Parameter) # check predict NewralParam print('[%d] err:%.5f w1:%.2f w2:%.2f bias:%.2f' % (k,err,w_ext[0],w_ext[1],w_ext[2])) # shuffle train_x and train_y n = np.random.permutation(len(train_x)) train_x = train_x[n] train_y = train_y[n].reshape([len(train_y), 1]) # execute train process sess.run(train,feed_dict = { x_ph: train_x, # x is input data y_ph: train_y # y is true data })何も書いていませんでしたが、誤差は二乗和で求めることにしちゃいました。
この結果を見てみると・・・???[0] err:1.06784 w1:0.36 w2:0.36 bias:0.00 [10] err:0.02231 w1:0.45 w2:0.45 bias:0.06 [20] err:0.00795 w1:0.47 w2:0.47 bias:0.03 [30] err:0.00283 w1:0.48 w2:0.48 bias:0.02 [40] err:0.00101 w1:0.49 w2:0.49 bias:0.01 [50] err:0.00036 w1:0.49 w2:0.49 bias:0.01 [60] err:0.00013 w1:0.50 w2:0.50 bias:0.00 [70] err:0.00005 w1:0.50 w2:0.50 bias:0.00 [80] err:0.00002 w1:0.50 w2:0.50 bias:0.00 [90] err:0.00001 w1:0.50 w2:0.50 bias:0.00 [100] err:0.00000 w1:0.50 w2:0.50 bias:0.00真値のパラメタは、w1=0.5,w2=0.5,bias(w0)=0なので、30回ぐらい回るといい感じに収束してきている様子が見られました。
ニューラルネットワークというと、なんだか複雑そうな印象でしたが、ここまでシンプルにすることで、単なる線形結合と等価回路っぽくなるんですね。
玄人の方からすると当たり前だろうという結果かもしれませんが、私にとっては一つ大きな収穫となりました。こんな感じで、次はもうちょっと複雑なことにも挑戦してみようと思います!
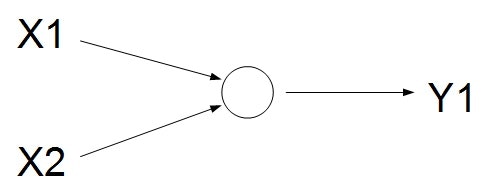
- 投稿日:2020-03-29T17:48:35+09:00
[python] 画像ファイル名を連番に変える
やりたいこと
画像のファイル名を連番に変える。
[変更前]
a.jpg
b.jpg
c.jpg
[変更後]
0001.jpg
0002.jpg
0003.jpg準備
・pythonは既にインストールしている前提
・名前を連番にしたい画像を任意のフォルダ(今回はimage)に集めるコードを作成
import os import glob files = glob.glob('image/*') for idx, f in enumerate(files): ftitle, fext = os.path.splitext(f) os.rename(f, format(idx, '04d')+fext)1.imageフォルダ内の画像の名前を取得
files = glob.glob('image/*')2.画像分だけ名前変更処理を繰り返す
for idx, f in enumerate(files):enumrateによりidxには数字が入り、forで繰り返すたびに数字が1ずつ繰り上がります。
3.ファイル名を分解
ftitle, fext = os.path.splitext(f)ftitle:ファイル名 ftext:拡張子
例えば、a.jpgならftitleには「a」、ftextには「.jpg」が入ります。4.ファイル名を変更
os.rename(f, format(idx, '04d')+fext)
- 投稿日:2020-03-29T17:37:27+09:00
プルリクに対して検証環境を自動で起動/終了するプログラムを作ったら、検証が捗った話
記事の概要
GitHub Flowでの開発、つまり単純なプルリク運用での開発を、営業も巻き込んで実践したいと思い、そのような環境を作りました。その際、いくつか足りない機能を補うウェブアプリを作って公開したので、それに関する様々な話を書きます。
(実際にこのウェブアプリを使えるかどうかというよりは、似たようなフローで開発を改善できるといいなというような目的の話です。)ウェブアプリのリポジトリ
https://github.com/uniaim-event-team/pullre-kun
このウェブアプリの使い方と機能については、一応README.mdに書いていますが、この記事では少し背景的な話も含めて順番に書きます。
issue対応やその他追加開発などは絶賛募集中です。背景
開発に関するよくある課題
これまで、既存のウェブアプリ(サービス)の機能追加開発において、以下のような課題がありました。
- 検証が十分にできていない機能がある
- 追加した機能の使い方を十分にレクチャーできていない/一部の人にしか認知されず隠し機能になる
- 時間が経過するとみんなその機能の存在を忘れて隠し機能になる
- 実は画面を使えば普通に登録ができるデータ設定作業も開発側でやらざるを得なくなる
そもそもデータを普通の画面から登録できない隠し機能を作って運用してしまうGitHub フロー(を外部的な部分で充実させたフロー)の導入
このような課題を解決するために、以下のようなフローでの運用を検討しました。
一般的な類似の作業フローと比較して、すこし強いのは「チケット登録者がテストシナリオまで書く」というところです。
これは色々と迷う部分があったのですが、以下のような点において、技術的に可能か不可能かで言えば可能と思い、信頼して踏み切ることにしました。
- いかに営業の人といえども、お客様に提供する際に、管理画面の最低限の操作説明などは、求められればできるべき。
- 末端のエンドユーザーや、その他システムを使う人が満足に利用できる事の確認は、むしろ技術に関する知識がない状態で実施する方が自然である。
- その際の確認項目を列挙することについて、カバレッジ等の観点は営業側には無いにしても、実際にお客様の前でやることのシミュレーションぐらいは、技術知識が無くても可能なはずである。
ただし、当然ですが、要求・要件を出した人が必ずしも網羅的な試験を書ききるということは不可能だと思うので、必要なものがあれば開発側で増やします。システム内部的に、どのような条件による分岐に依存しているかというような事は、要求・要件を出した時点で洗い出すのは難しく、また技術的な意味でそれらを網羅する試験を書くのは難しいと判断したからです。
フロー導入にあたっての課題
このフローの導入にあたっての、技術的な課題がいくつかあったのですが、概ね次の課題に集約されました。
- チケット登録者は、どの環境で検証するのか
例えば、テーブルの項目を追加したりする改修内容の場合、そのプルリクで定義されているスキーマを参照する必要があります。
開発者の環境でテストをするという方法も無くはないですが、開発者の開発作業は継続しているので、テスト中に使えなくなるという事も往々にして想定されます。また、別改修の影響で正常に動作しない、というような事もあり得て、これはお互いのためによくありません。そもそも、別の改修が一部含まれているソースでのテストは、純粋なプルリク内容に対するテストになっていないという問題もあります。では、それ用の検証環境を手動で作るのかというと、一日に一人が何個もプルリクを作る場合がある状況で、毎回手動でそれ用の検証環境を作るというのはちょっと大変です。
修正がJSだけで済むならばnetlifyのようなものもありますが、スキーマやデータセットを用意する部分に多くの課題があり、またそもそも対象プロジェクトの場合はサーバー側がPythonなので、ちょっと適用できませんでした。
dockerで解決しないのか
原理的にはdockerでも解決できるもので、実際にdockerを使って同様のことをやった話が、少なくとも3年前には存在しています!
Pull Request発行時にそのコミットIDでデプロイされた環境を自動構築してレビュー時/マージ前に確認しやすくする仕組みもともと自動テストを書いて、CircleCIで動かしていたので、ある程度はdockerでも動くのですが、一部の処理は単純にdockerを作るだけではうまく動かず(具体的にはwkhtmlを使ってhtmlをpdfに変換している処理で、途中でxvfbを使ったりしているところをすぐにdockerに載せることができなかった...そこはCircleCIでも動かしていない)、それ用のdockerを作ったりするのがめんどくさくて今に至ります。
実際にやったこと
方針は以下の通りです。
- 事前に検証用インスタンスをたくさん作って、ロードバランサーやDNSの設定をして、サーバープロセスが起動したら普通のアクセスができる状態にしておいた上で、インスタンスをoffにしておく
- DBはAuroraを開発環境含めて共有することにして、そのAuroraを作っておく
- プルリクがあれば、それを拾って検証用インスタンスをonにする
- 検証用インスタンス側で、そのインスタンスがcheckoutすべきコミットを識別して、そのコミットでサーバープロセスを起動する
- プルリクがクローズされたら、対応する検証サーバをoffにする
この、事前作業を除いたプルリクを処理する部分が、ウェブアプリで対応する部分です。
システム構成イメージは以下のとおりです。Controller Instanceでウェブアプリを動かし、Staging Instancesでは定期的にサーバープロセス起動用のバッチ処理を実行します。
実際に運用してみての所見
まだ運用を初めて数週間で、現状は新型コロナの影響などで通常の状態と違っている部分がありますが、とりあえず実画面でのテストは相当しやすくなったと思いました。開発検証者としても、従来、自分の環境でcheckoutしてスキーマ直したりなんやかんやしながらテストしていたものについて、自分の環境を全く触らずに検証できるようになり、とても楽です。
また、リリース前に非開発者を巻き込みやすくなったのも、大きな進歩かなと思います。ウェブアプリのインストール(セットアップ)方法
これはREADME.mdの記載内容と同じです。ほぼほぼGoogle翻訳です。
ec2インスタンスを作成する
EC2インスタンスを作成します。そして、そのうちの1つにポート5250を許可します。 1つは「コントローラーインスタンス」と呼ばれます。
その他は「ステージングインスタンス」と呼ばれます。IAMポリシーとユーザーを作成する
次のアクションを許可するIAMポリシーを作成します。
「ec2:DescribeInstances」
「ec2:StartInstances」
「ec2:StopInstances」ポリシーのリソースは、作成したインスタンスです。(注:DescribInstancesは全てのリソース対象になります)
そして、ポリシーをユーザー/ロールにアタッチし、アクセスキーとシークレットキーを保存します。gitをインストールする
インスタンス全体にgitをインストールします。
注:amazon linux2を使用している場合、$ sudo yum install gitステージングサーバーへのアプリケーションのセットアップ
アプリケーションをステージングサーバーに設定します。
python3をインストールする
インスタンス全体にpython3をインストールします。
注:amazon linux2を使用している場合、$ sudo yum install python3mysql-clientをインストールする
インスタンス全体にmysql-clientをインストールします。
注:amazon linux2を使用している場合、$ sudo yum install mysqlMySQLのようなデータベースを実行またはインストールします
MySQLのようなデータベースを実行またはインストールします。
プルレくん(pullre-kun)のクローン
プルレくんをクローンします。
install "requirements"
requirements(requirements.txtの内容)をインストールします。
get_basic_token.pyを実行します
コントローラインスタンスには基本認証があります。パスワードのトークン(ハッシュ)を作成し、app.iniに保存する必要があります。
app.iniファイルを作成する
app.iniファイルを作成します。サンプルはapp.ini.defaultです。そしてそれをインスタンス全体にデプロイします。
コントローラーサーバーのcrontabを編集する
コントローラサーバーのcrontabに次の行を追加します。
* * * * * cd / home / ec2-user / pullre-kun; python3 update_pull.pyステージングサーバーのcrontabを編集する
ステージングサーバーのcrontabsに次の行を追加します。
* * * * * cd / home / ec2-user / pullre-kun; python3 client.pyinit.pyを実行する
コントローラーサーバーで次のコマンドを実行します。
$ cd〜/ pullre-kun $ python3 init.pypullre-kunアプリケーションを実行する
コントローラーサーバーで次のコマンドを実行します。
$ cd〜/ pullre-kun $ nohup python3 app.py&サーバーを登録する
https://<your-domain>/server/listにアクセスすると、サーバー全体が表示されます。
次に、ステージングサーバーの登録ボタンをクリックします。
そして、https://<your-domain>/master/serverにアクセスし、各レコードのdb_schemaを更新します。ユーザーを登録する
https://<your-domain>/master/git_hub_usersにアクセスし、ユーザーを登録します。
「login」はgithubユーザーログイン、db_schemaはクローンの元のスキーマです。以上の手順で、プルリクがあれば自動的に検証環境が立ち上がるようになります。
その他の技術的な解説について
全体的にFlask + SQLAlchemyで、ただしサーバーとしてはCherryPyを使うという構成になっています。
希望がたくさんあれば、そのうち解説も書くかもしれません。(SQLAlchemyのmodelに合わせた汎用的なWTFormの使い方が少し特殊)
(この記事にコメントか、GitHubにissueを作って+1でお願いします。)
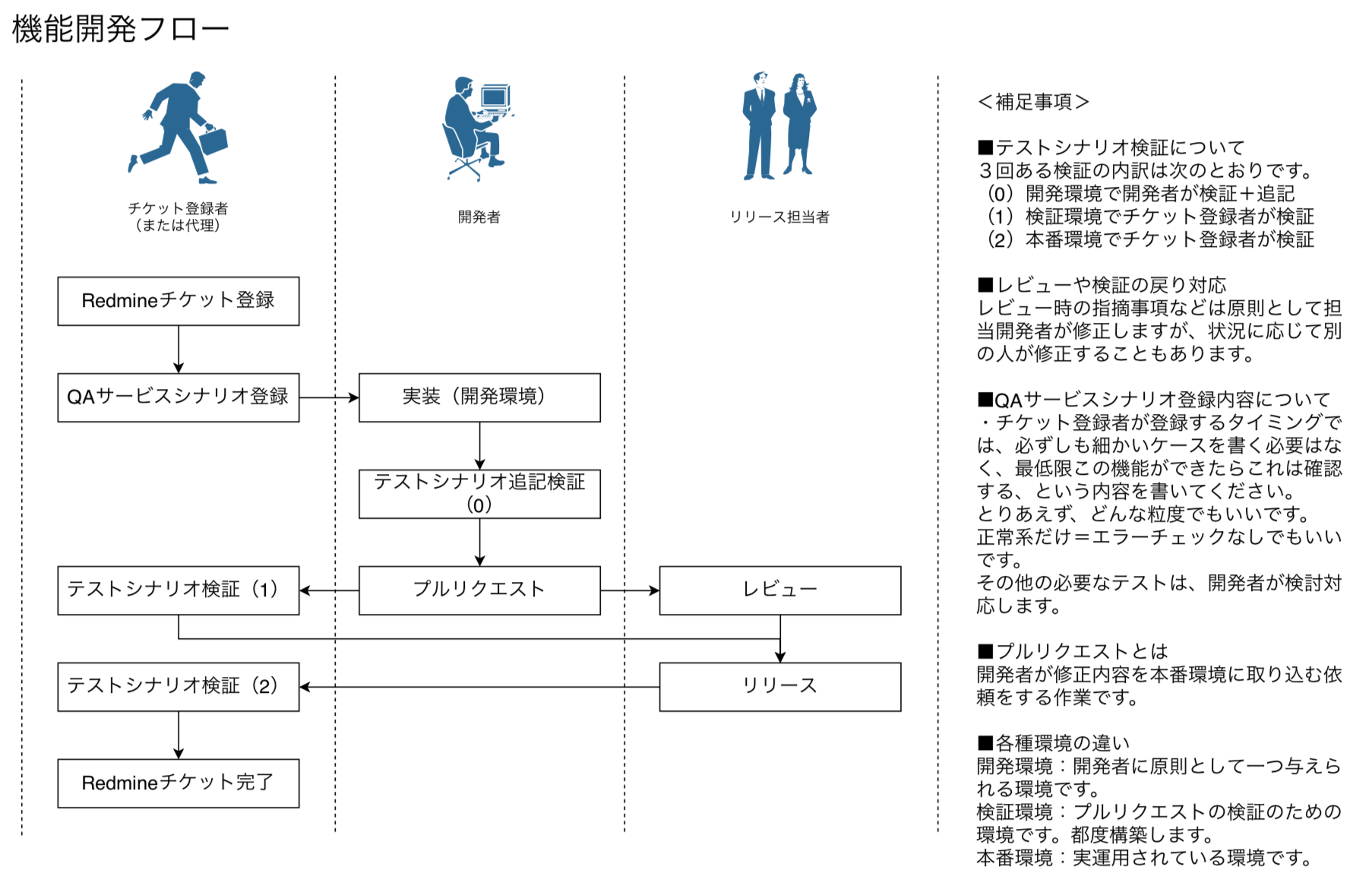
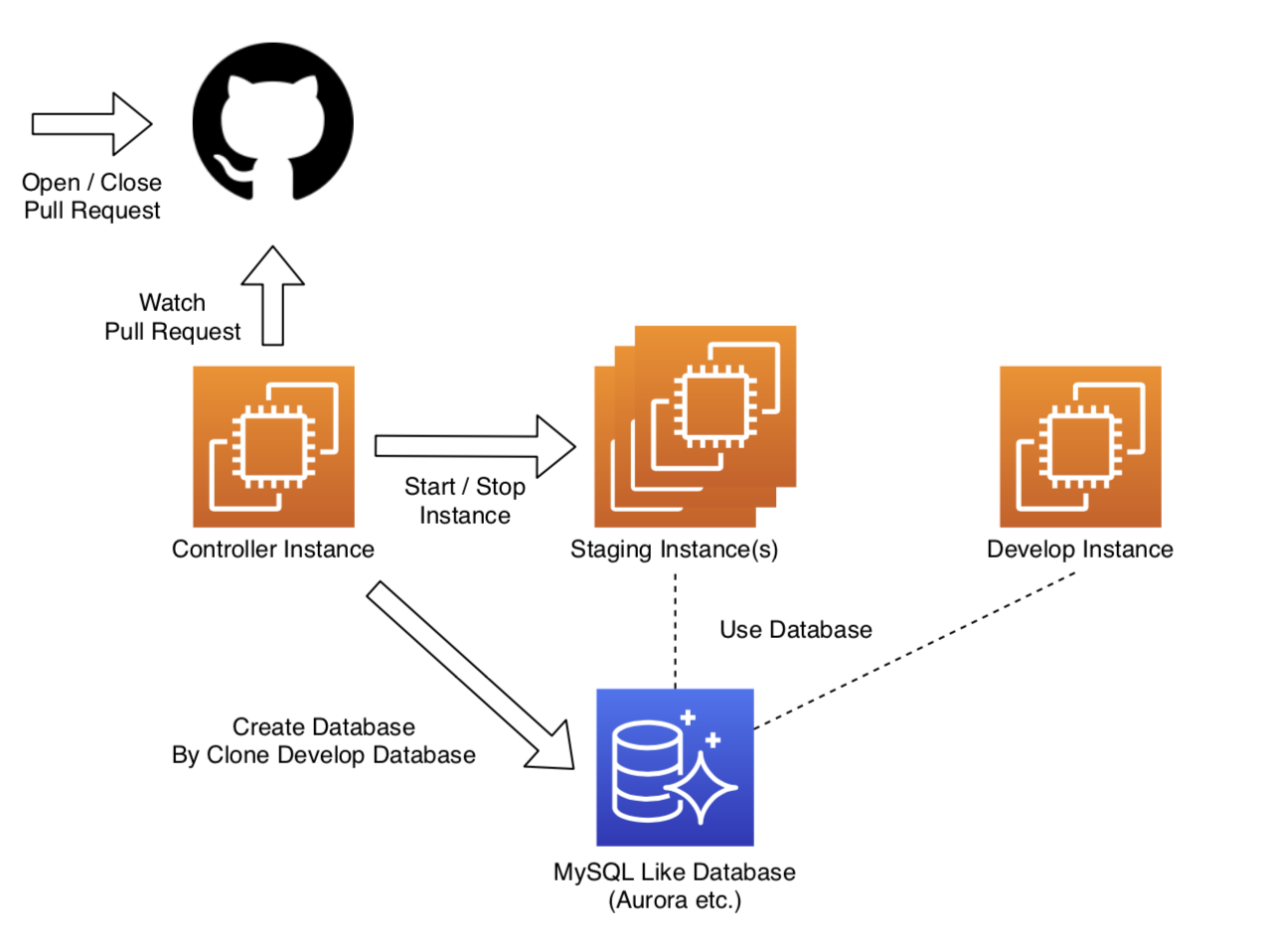
- 投稿日:2020-03-29T17:09:08+09:00
【SIRモデル入門】Diamond Princess号のフィッティング結果を考察する♬
気になっていたデータそれは、DiamondPrincess号のデータである。
さぞ、美しいデータが残っているかと思ったが、がっかりでした。
しかし、一応やれるのでフィッティングしてみました。
方法は先ほどの【SIRモデル入門】COVID-19データをフィッティングしてみる♬と同様に実施しています。DiamondPrincess号のデータ
以下のように、治癒率は80%超えて、終息してきています。
死亡率も1.4%程度なので、世界の各国の現状と比較すれば、誇れる数字だと思います。
フィッティングの結果
ということで、前回のSIRモデルで早速フィッティングしてみました。
結果は以下のとおりになりました。
N=5*N0つまり感染者の5倍としています。
実際は、乗組員など3700人位だったと思いますが、この系も医療従事者などの追加の対象者が不明なのでざっくり推定して5倍にしました。
今回も、治癒者の曲線は捨てています。
同時に一致させようとすると全くフィッティング出来ません。得られたパラメータは以下のとおりです。
各国の値と比較すると、大きな値になっています。{\begin{align} \beta &= 1.04e^{-4}\\ \gamma &= 1.49e^{-1}\\ N &= 3610\\ R0 &= 2.52\\ R(27.3.2020) &= 0.29\\ \end{align} }結果の評価
つまり、感染も治癒(実際には隔離)も素早く進んだことがうかがえます。
そうです!
感染しても、SIRモデルではその感染者が隔離されると他へ感染しなくなり、まさしくこの場合はremovedされたことになります。
したがって、今回も治癒者はこのremovedされた人々が別ルートで治癒するので、この方程式とは無関係に回復するということだと解釈しました。
このように考察すると、DiamondPrincess号のケースは特殊ですが、いい対策が取れたとも評価出来ると思います。まとめ
・DiamondPrincess号のデータを表示した
・SIRモデルで感染数のフィッティングを実施した
・隔離の効果について議論した・今回の議論を踏まえて各国の結果を評価する
- 投稿日:2020-03-29T17:01:20+09:00
Python × Flask × Tensorflow.Keras 猫の品種を予測するWebアプリ2
はじめに
Python × Flask × Tensorflow.Keras 猫の品種を予測するWebアプリで作ったPythonプログラムを変更しました。
変更内容
- 変更前
- 入力画像をファイル保存して扱う
- 変更後
- 入力画像をメモリに一時保存して扱う
変更ファイル
- sever.py
- 画像書き込み用バッファを確保
- 画像データをバッファに書き込む
- バイナリデータをbase64でエンコード
- utf-8でデコード
- 付帯情報を付与する
- HTMLに渡す
sever.pyfrom flask import Flask, render_template, request from tensorflow.keras.preprocessing.image import load_img from tensorflow.keras.models import load_model import numpy as np from image_process import examine_cat_breeds from datetime import datetime import os import cv2 import pandas as pd import base64 from io import BytesIO app = Flask(__name__) # モデル(model.h5)とクラスのリスト(cat_list)を読み込み model = load_model('model.h5') cat_list = [] with open('cat_list.txt') as f: cat_list = [s.strip() for s in f.readlines()] print('= = cat_list = =') print(cat_list) @app.route("/", methods=["GET","POST"]) def upload_file(): if request.method == "GET": return render_template("index.html") if request.method == "POST": # アプロードされたファイルをいったん保存する f = request.files["file"] #filepath = "./static/" + datetime.now().strftime("%Y%m%d%H%M%S") + ".png" #f.save(filepath) # 画像ファイルを読み込む # 画像ファイルをリサイズ input_img = load_img(f, target_size=(299, 299)) # 猫の種別を調べる関数の実行 result = examine_cat_breeds(input_img, model, cat_list) print("result") print(result) no1_cat = result[0,0] no2_cat = result[1,0] no3_cat = result[2,0] no1_cat_pred = result[0,1] no2_cat_pred = result[1,1] no3_cat_pred = result[2,1] # 画像書き込み用バッファを確保 buf = BytesIO() # 画像データをバッファに書き込む input_img.save(buf,format="png") # バイナリデータをbase64でエンコード # utf-8でデコード input_img_b64str = base64.b64encode(buf.getvalue()).decode("utf-8") # 付帯情報を付与する input_img_b64data = "data:image/png;base64,{}".format(input_img_b64str) # HTMLに渡す return render_template("index.html", input_img_b64data=input_img_b64data, no1_cat=no1_cat, no2_cat=no2_cat, no3_cat=no3_cat, no1_cat_pred=no1_cat_pred, no2_cat_pred=no2_cat_pred, no3_cat_pred=no3_cat_pred) if __name__ == '__main__': app.run(host="0.0.0.0")
- index.html
index.html<!DOCTYPE html> <html> <body> {% if no1_cat %} <img src="{{input_img_b64data}}" border="1" ><br> 予測結果<br> {{no1_cat}}:{{no1_cat_pred}}<br> {{no2_cat}}:{{no2_cat_pred}}<br> {{no3_cat}}:{{no3_cat_pred}}<br> <hr> {% endif %} ファイルを選択して送信してください<br> <form action = "./" method = "POST" enctype = "multipart/form-data"> <input type = "file" name = "file" /> <input type = "submit"/> </form> </body> </html>実行結果
画像は299×299で表示されます(モデルの入力サイズのまま・・・)

- 投稿日:2020-03-29T16:55:31+09:00
深層学習/行列積の誤差逆伝播
1.はじめに
行列積の誤差逆伝播が分かりにくかったので、まとめておく。
2.スカラー積の誤差逆伝播
スカラー積の誤差逆伝播から復習すると、
勾配を行う対象をLとし、あらかじめ$\frac{\partial L}{\partial y}$が分かっているものとすると、連鎖律から
これは問題ないですよね。3.行列積の誤差逆伝播
ところが、行列積になると直感と変わって来ます。
なんか、ピンと来ませんよね。なので、具体的に確認します。
設定は、2つのニューロンXと4つの重みWの内積を経てニューロンYに接続されていると考えます。
1)最初に、$\frac{\partial L}{\partial X}$を求めます。まず、これらを事前に計算しておきます。
この計算を途中で利用しながら、
2)次に、$\frac{\partial L}{\partial y}$を求めます。まず、これらを事前に計算しておきます。
この計算を途中で利用しながら、
4.行列積の順伝播、逆伝播のコード
x1=X, x2=Y, grad=$\frac{\partial L}{\partial y}$とすると、
class MatMul(object): def __init__(self, x1, x2): self.x1 = x1 self.x2 = x2 def forward(self): y = np.dot(self.x1, self.x2) self.y = y return y def backward(self, grad): grad_x1 = np.dot(grad, self.x2.T) grad_x2 = np.dot(self.x1.T, grad) return (grad_x1, grad_x2)
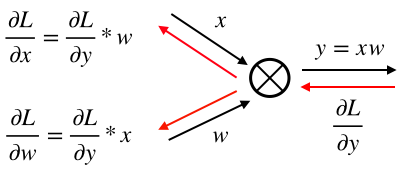
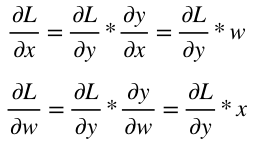
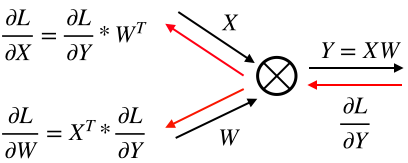
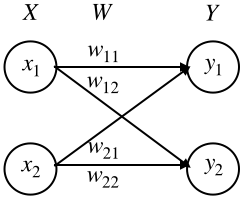
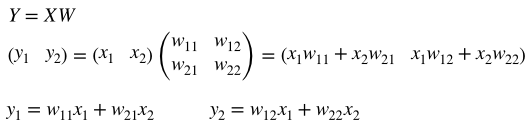
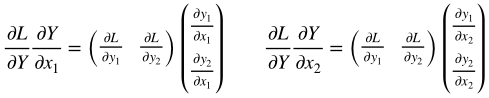
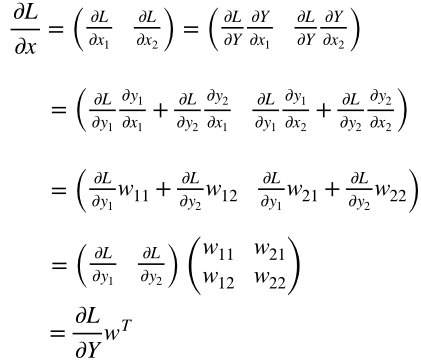
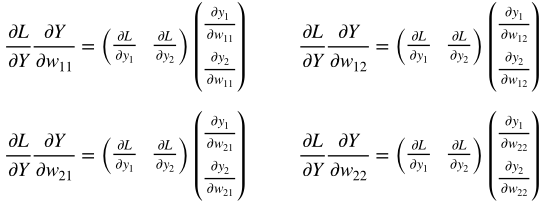
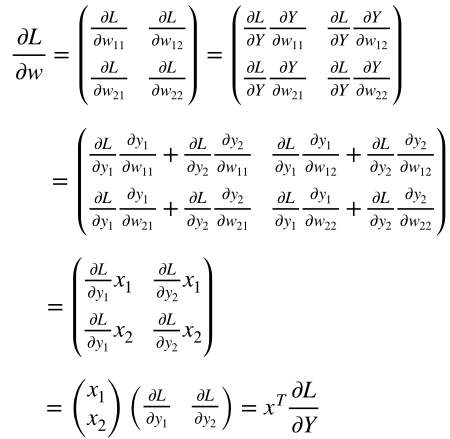
- 投稿日:2020-03-29T16:49:38+09:00
backtestingを使用した投資自動売買botの性能評価
モチベーション
前回の記事ではOANDA REST APIを使用したFXの過去データ収集を行いました。
今回はそのデータをもとに、投資自動売買botの戦略評価の方法について記載します。
TL;DR → backtestingのドキュメントやり方
環境構築
単純に↓だけです
pip install backtesting説明いらない人向けコード
usd_jpy_4hというDBに前回の記事で取得したデータが入っている想定で記載します。
またテクニカル分析用のパッケージであるtalibも使用しています。こちらもpipで簡単に落とせます。
talibのドキュメントはこちらimport talib as ta import pandas as pd from backtesting import Backtest, Strategy from backtesting.lib import crossover import db_access def get_raw_data(query): engine = db_access.get_engine() return pd.read_sql(query, engine) def get_macd(close, fastperiod=6, slowperiod=13, signalperiod=4): macd, macdsignal, macdhist = ta.MACD(close, fastperiod=fastperiod, slowperiod=slowperiod, signalperiod=signalperiod) return macd, macdsignal, macdhist query = "select distinct * from usd_jpy_4h where datetime between '2019/09/01' and '2020/03/01' order by datetime" raw_data = get_raw_data(query) df = raw_data[["datetime","open","high","low","close","volume"]].copy() df.columns = ['Datetime', 'Open', 'High', 'Low', 'Close', 'Volume'] df['Datetime'] = pd.to_datetime(df['Datetime']) df = df.reset_index().set_index('Datetime') class MacdStrategy(Strategy): macd_fastperiod = 6 macd_slowperiod = 13 macd_signalperiod = 4 profit_pips = 50 loss_pips = 50 profit = profit_pips * 0.01 loss = loss_pips * 0.01 def init(self): self.macd, self.signal, self.hist = self.I(get_macd, self.data.Close, self.macd_fastperiod, self.macd_slowperiod, self.macd_signalperiod) def next(self): if (crossover(self.signal, self.macd)): self.buy(sl=self.data.Close[-1] - self.loss, tp=self.data.Close[-1] + self.profit) elif (crossover(self.macd, self.signal)): self.sell(sl=self.data.Close[-1] + self.loss, tp=self.data.Close[-1] - self.profit) bt = Backtest(df, MacdStrategy, cash=100000, commission=.00004) output = bt.run() print(output)output
Start 2019-09-01 20:00:00 End 2020-02-28 20:00:00 Duration 180 days 00:00:00 Exposure [%] 74.9074 Equity Final [$] 98647 Equity Peak [$] 101404 Return [%] -1.35297 Buy & Hold Return [%] 1.81654 Max. Drawdown [%] -2.7724 Avg. Drawdown [%] -0.518637 Max. Drawdown Duration 162 days 00:00:00 Avg. Drawdown Duration 21 days 18:00:00 # Trades 66 Win Rate [%] 50 Best Trade [%] 0.457344 Worst Trade [%] -0.68218 Avg. Trade [%] -0.0215735 Max. Trade Duration 10 days 00:00:00 Avg. Trade Duration 2 days 02:00:00 Expectancy [%] 0.275169 SQN -0.538945 Sharpe Ratio -0.0655224 Sortino Ratio -0.107821 Calmar Ratio -0.00778153 _strategy MacdStrategy dtype: objectコード説明
inputデータ作成
raw_data = get_raw_data(query) df = raw_data[["datetime","open","high","low","close","volume"]].copy() df.columns = ['Datetime', 'Open', 'High', 'Low', 'Close', 'Volume'] df['Datetime'] = pd.to_datetime(df['Datetime']) df = df.reset_index().set_index('Datetime')ここでDBにあるデータを取得し、backtesting用の整形しています。
backtestinではpandasのDataframeで、カラム名が'Open', 'High', 'Low', 'Close', 'Volume'(なくてもOK)、となっていることを期待してます。
またdatetime型でindexをつけておくことを推奨しています。
https://kernc.github.io/backtesting.py/doc/examples/Quick%20Start%20User%20Guide.htmlYou bring your own data. Backtesting ingests data as a pandas.DataFrame with columns 'Open', 'High', 'Low', 'Close', and (optionally) 'Volume'. Such data is easily obtainable (see e.g. pandas-datareader, Quandl, findatapy, ...). Your data frames can have other columns, but these are necessary. DataFrame should ideally be indexed with a datetime index (convert it with pd.to_datetime()), otherwise a simple range index will do.
売買戦略作成
class MacdStrategy(Strategy): macd_fastperiod = 6 macd_slowperiod = 13 macd_signalperiod = 4 profit_pips = 50 loss_pips = 50 profit = profit_pips * 0.01 loss = loss_pips * 0.01 def init(self): self.macd, self.signal, self.hist = self.I(get_macd, self.data.Close, self.macd_fastperiod, self.macd_slowperiod, self.macd_signalperiod) def next(self): if (crossover(self.signal, self.macd)): self.buy(sl=self.data.Close[-1] - self.loss, tp=self.data.Close[-1] + self.profit) elif (crossover(self.macd, self.signal)): self.sell(sl=self.data.Close[-1] + self.loss, tp=self.data.Close[-1] - self.profit)売買戦略は
from backtesting import Strategyを継承して作成します。
今回はテクニカル指標の1つであるMacdがクロスした際に売買を行う戦略でプログラムを書いています。
投資戦略においては、ある時系列曲線が別の曲線と交差した際に発火する戦略が多いです。crossover()を使用することでその戦略を簡単に記載することができます。
https://kernc.github.io/backtesting.py/doc/backtesting/lib.html#backtesting.lib.crossover
他にも便利な機能がたくさんあるのでぜひドキュメントを見てみてください。変数の最適化
stats = bt.optimize( macd_fastperiod = [6, 8, 10, 12], macd_slowperiod = [13, 19, 26], macd_signalperiod = [4, 7, 9], profit_pips = [30, 50, 70, 90], loss_pips = [20, 30, 40, 50] )
Backtest.optimize()を使用することで、売買戦略でしようした変数に対して最適な値・組み合わせをテストすることができます。
ここでは手である程度決めた値を定義していますが[i for i in range(10)]みたいな形で定義しても良いかもしれません(処理重くなりそうですが)
最適パラメータはoptimize()実行後、stats._strategyにて確認できます
- 投稿日:2020-03-29T16:12:53+09:00
オブジェクト指向入門-オブジェクトに子を産ませる。
Pythonによる進化シュミレーションのパーツを作りながら、メモとして記事を書いています。
前回の記事はこちら(オブジェクト指向入門-オブジェクトの内部状態を変更しよう)今回は仮想個体に子を産ませるメソッド(reproduction)の下書きを作りました。
reproductionメソッドにはcopyモジュールのdeepcopyを用いています.reproduction.py#reproduction の実装 import copy #reproductionでdeepcopyを使います。 class SampleIndividual: def __init__(self,x,y,z): self.state_x = x self.state_y = y self.state_z = z def mutation(self): # 内部状態の変異用method。 self.state_x = 10 def reproduction(self): # 子供を産むmethod self.child = copy.deepcopy(self) self.child.mutation() # 内部状態の変異 return self.child以下出力です。ちゃんとmotherとchildは別インスタンスになっています。
出力mother = SampleIndividual(5,5,5) # 親の作成 child = mother.reproduction() # 子の作成 print(vars(child)) #=> {'state_x': 10, 'state_y': 5, 'state_z': 5} print("mother id:{}".format(id(mother))) # 別インスタンスかの確認 print("child id:{}".format(id(child))) #=> 4453353808 #=> 4453466064以上です。閲覧ありがとうございました。
- 投稿日:2020-03-29T16:00:16+09:00
gremlinpythonの使い方覚書
記事の内容
GraphDBであるGremlinをPythonで使ってみました。
使い方をメモしますライブラリの準備
GremlinをPythonで扱うためのライブラリをインストールします
pip install gremlinpython実装
ライブラリのインポート
from gremlin_python import statics from gremlin_python.structure.graph import Graph from gremlin_python.process.graph_traversal import __ from gremlin_python.process.strategies import * from gremlin_python.driver.driver_remote_connection import DriverRemoteConnectionコネクションの作成
graph = Graph() # Gremlinのコネクション作成 g = graph.traversal().withRemote(DriverRemoteConnection('ws://localhost:8182/gremlin','g'))DriverRemoteConnectionの第一引数でGremlinサーバーの情報を渡す
第二引数では"g"を渡しているが、この"g"が何を指しているのかは不明
サーバー起動時に以下のログが出力されており、この"g"だと思われる。[INFO] ServerGremlinExecutor - A GraphTraversalSource is now bound to [g] with graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]何らかの設定ファイルで変更出来そうな気がするが、現時点でそこまでは調べることが出来ていない。
データ登録
データ登録をして、登録したデータを取得してみる
g.addV('tarouo').property('name', 'tarou').toSet() g.addV('tarouo').property('name', 'kotarou').toSet() name = g.V().has('name', 'tarou').valueMap().toList() print(name)結果
[{'name': ['tarou']}]取得結果はdictで返ってくる。何故か登録したnameはlist形式
データの取得は部分一致ではなく完全一致プロパティの追加
登録したデータにプロパティを追加する
1項目追加
tarou = g.V().has('name', 'tarou').toList()[0] g.V(tarou).property('from', 'Tokyo').toSet() tarou = g.V(tarou).valueMap().toList()[0] print(tarou)結果
{'name': ['tarou'], 'from': ['Tokyo']}複数項目追加
g.V(tarou).property('from', 'Tokyo').property('age', 20).toSet() tarou = g.V(tarou).valueMap().toList()[0] print(tarou)結果
{'name': ['tarou'], 'from': ['Tokyo'], 'age': [20]}.property()を繋げることで複数項目追加することが可能
更新
既に登録済みのプロパティを別の値で登録すると更新される
g.V(tarou).property('from', 'Kanagawa').property('age', 30).toSet() tarou = g.V(tarou).valueMap().toList()[0] print(tarou)プロパティの削除
出来そうな感じがするがやり方分からず・・。
やり方が判明したら更新します。データ削除
g.V().drop() g.E().drop() g.V().drop().iterate() g.E().drop().iterate()iterate無しだと最初の1件が削除される。
iterate有りだと全て削除される。エッジの追加
tarouとkotarouにエッジを追加します
tarou = g.V().has('name', 'tarou').toList()[0] kotarou = g.V().has('name', 'kotarou').toList()[0] g.addE('follow').from_(tarou).to(kotarou).toSet() edgeList = g.E().toList() for edge in edgeList: print(edge)結果
e[267][259-follow->261]ID259とID261がfollowの関係で繋がっていることが取得できました。
tarou = g.V().has('name', 'tarou').toList()[0] kotarou = g.V().has('name', 'kotarou').toList()[0] magotarou = g.V().has('name', 'magotarou').toList()[0] g.addE('son').from_(tarou).to(kotarou).toSet() g.addE('son').from_(kotarou).to(magotarou).toSet() g.addE('grandchild').from_(tarou).to(magotarou).toSet()こんな感じでエッジを追加できる
e[298][288-son->290] e[299][290-son->292] e[300][288-grandchild->292]エッジの情報を取得する
特定の点と関係があるリスト(値)を取得
valueList = g.V(tarou).both().valueMap(True).toList() for value in valueList: print(value)結果
{<T.id: 1>: 498, <T.label: 4>: 'kotarou', 'name': ['kotarou']} {<T.id: 1>: 500, <T.label: 4>: 'magotarou', 'name': ['magotarou']}tarouと関係を設定しているkotarouとmagotarouの情報を取得出来ました。
valueMapの引数を設定しない
Trueを設定しないと最低限のデータだけになります。
{'name': ['kotarou']} {'name': ['magotarou']}特定の点と関係があるリスト(エッジ)を取得
g.V(tarou).bothE() g.V(tarou).bothE().valueMap().toList() g.V(tarou).bothE().valueMap(True).toList()三種類のやり方で取得してみます
# edge list 1.. e[597][587-son->589] e[599][587-grandchild->591] # edge list 2.. {} {} # edge list 3.. {<T.id: 1>: 597, <T.label: 4>: 'son'} {<T.id: 1>: 599, <T.label: 4>: 'grandchild'}一応、取得出来ました。
g.V()はValue関係の操作だと思ったので、g.E()でエッジ関係のデータを取得出来るのかなと思ったのですが、上手く取得出来ませんでした。おわりに
ネットワーク分析に使えるかなと思いGremlinの使い方を少し調べていたのですが、GraphDBの概念を理解しないとやはり難しいなという印象を受けました。
記載した内容以外にも面白い使い方が分かれば記事を更新していこうと思います。
- 投稿日:2020-03-29T15:53:40+09:00
Video Intelligence APIで動画の物体検出をする
やること
動画のどのフレームのどの位置にどんなものが映っているかを特定する。
googleのVideo Intelligence APIを使用して動画から物体検出を行う。
本記事で紹介するコードは公式の入門ガイドをベースにした実装になっている。準備
Video Intelligence API
公式ガイドのAPIに対する認証までを完了してサービスアカウントキーファイルを取得しておく。
google colaboratory
実装と結果の確認はgoogle colaboratoryを使用する。
こちらの記事にあるようにサービスアカウントキーファイルをcolaboratoryにアップロードしておく。
毎回やるのが面倒な場合はマウントするgoogle driveに入れておく方法もあるがうっかり共有してしまわないように注意が必要である。解析対象の画像
Video Intelligence API では
- GCPのStorageに保存してある動画ファイル
- ローカルに保存してある動画ファイル
を解析することができる。GCPのStorageに保存してある動画ファイルを使用する場合はAPIの料金の他、Storageに使用料金がかかるので、ちょっと試して見る程度であればローカルがおすすめ。
今回は「ローカルに保存してある動画ファイル」を解析する手法で行うため、google driveに解析したい動画を保存しておき、colaboratoryにドライブをマウントしておく。
ドライブのマウントはcolaboratoryの左側のペインから可能。
なお、動画を用意する場合はVideo Intelligence APIの利用料金について考慮する。
【補足】Video Intelligence APIの利用料(2020年3月現在)
Video Intelligence APIは解析する動画の長さ(尺)に応じて従量課金される。
長さは分単位で計算され、1分未満は切り上げになるので以下の3つのパターンでアノテーションを行った場合全て同じ利用料となる。
- 2分30秒の動画を1つ
- 1分30秒の動画と30秒の動画を1つずつ
- 30秒の動画を3つ
各アノテーションの料金は以下の通り
機能 最初の 1,000 分 1,000 分超 ラベル検出 無料 $0.10/分 ショット検出 無料 $0.05/分、ラベル検出を利用している場合は無料 不適切コンテンツ検出 無料 $0.10/分 音声文字変換 無料 $0.048/分(音声文字変換の課金対象は対応言語の en-US のみ) オブジェクト トラッキング 無料 $0.15/分 テキスト検出 無料 $0.15/分 ロゴ検出 無料 $0.15/分 Celebrity recognition 無料 $0.10/分 実装
videointelligenceを使用する準備
videointelligenceのクライアントをインストールする
!pip install -U google-cloud-videointelligencevideointelligenceのクライアントを作成する
まず、APIに対する認証で取得したサービスアカウントキーファイルを使用して認証を行う。
service_account_key_nameはcolaboratoryにアップロードしたサービスアカウントキーファイルのパス。import json from google.cloud import videointelligence from google.oauth2 import service_account # APIの認証 service_account_key_name = "{YOUR KEY.json}" info = json.load(open(service_account_key_name)) creds = service_account.Credentials.from_service_account_info(info) # クライアントを作成 video_client = videointelligence.VideoIntelligenceServiceClient(credentials=creds)APIを実行する
まず動画をドライブから読み込む。
# 処理対象の動画を指定して読み込む import io path = '{YOUR FILE PATH}' with io.open(path, 'rb') as file: input_content = file.read()次にAPIを実行して結果を取得する
features = [videointelligence.enums.Feature.OBJECT_TRACKING] timeout = 300 operation = video_client.annotate_video(input_content=input_content, features=features, location_id='us-east1') print('\nProcessing video for object annotations.') result = operation.result(timeout=timeout) print('\nFinished processing.\n')結果の確認
検出されたオブジェクトの一覧を表示する
jupyter notebookはpandasのDataFrameを良い感じに勝手に描画してくれるので、レスポンスから必要な情報だけ抜き取ってDataFrameを生成する。
今回はレスポンスの
object_annotationsから以下のものを取得する。
カラム名 内容 ソース Description オブジェクトの説明(名前) entity.description Confidence 検出の信頼性 confidence SegmentStartTime オブジェクトが映っているセグメントの開始時間 segment.start_time_offset SegmentEndTime オブジェクトが映っているセグメントの終了時間 segment.end_time_offset FrameTime オブジェクトが検出されたフレームが動画の先頭から何秒目にあるか frames[i].time_offset Box{XXX} オブジェクトのbounding boxの各辺の座標を100分率にしたもの frames[i].normalized_bounding_box # 検出されたobjectを一覧表示する import pandas as pd columns=['Description', 'Confidence', 'SegmentStartTime', 'SegmentEndTime', 'FrameTime', 'BoxLeft', 'BoxTop', 'BoxRight', 'BoxBottom', 'Box', 'Id'] object_annotations = result.annotation_results[0].object_annotations result_table = [] for object_annotation in object_annotations: for frame in object_annotation.frames: box = frame.normalized_bounding_box result_table.append([ object_annotation.entity.description, object_annotation.confidence, object_annotation.segment.start_time_offset.seconds + object_annotation.segment.start_time_offset.nanos / 1e9, object_annotation.segment.end_time_offset.seconds + object_annotation.segment.end_time_offset.nanos / 1e9, frame.time_offset.seconds + frame.time_offset.nanos / 1e9, box.left, box.top, box.right, box.bottom, [box.left, box.top, box.right, box.bottom], object_annotation.entity.entity_id ]) # 膨大になるので、とりあえず各セグメントの最初のframeだけ break df=pd.DataFrame(result_table, columns=columns) pd.set_option('display.max_rows', len(result_table)) # Confidenceでソートして表示 df.sort_values('Confidence', ascending=False)実行すると以下のような結果が得られる。
オブジェクトが検出されたフレームを静止画で一覧表示する
まず、上述の
time_offsetの情報をもとに動画からフレームを抜き出す。
動画から静止画の取得はopenCVを使用する。切り出す静止画をフレームで指定する必要があるため、動画のFPSとtime_offset(秒)からおおよそのフレーム数を算出する。import cv2 images = [] cap = cv2.VideoCapture(path) if cap.isOpened(): fps = cap.get(cv2.CAP_PROP_FPS) for sec in df['FrameTime']: # fpsと秒から何フレーム目かを計算する cap.set(cv2.CAP_PROP_POS_FRAMES, round(fps * sec)) ret, frame = cap.read() if ret: images.append(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))次に、
openCVのrectangleで切り出したそれぞれの静止画に映っているオブジェクトに枠を付ける。
rectangleは描画したい長方形の左上と右下の頂点を指定する必要があるためこの2点を得る必要がある。
APIから返却されるnormalized_bounding_boxの中には4辺の情報(left,top,right,bottom)があり、例えば以下の画像でpersonの位置を示すboxのleftの値はl(画像の左端からboxの左端までの幅) / width(画像全体の幅)なのでleftの値から頂点1(pt1)のx座標を求める場合はwidth * leftと逆算すれば良い。
メソッドを適当に用意しておく。
# 画像上の座標を求める def ratio_to_pics(size_pics, ratio): return math.ceil(size_pics * ratio) # box から左上と右下の頂点を得る def rect_vertex(image, box): height, width = image.shape[:2] return[ ( ratio_to_pics(width, box[0]), ratio_to_pics(height, box[1]) ), ( ratio_to_pics(width, box[2]), ratio_to_pics(height, box[3]) ) ]上記のメソッドを使用して枠の頂点の位置を計算しながら、実際に枠を画像に書き込んでいく。
python
boxed_images = []
color = (0, 255, 255)
thickness = 5
for index, row in df.iterrows():
image = images[index]
boxed_images.append(cv2.rectangle(image, *rect_vertex(image, row.Box), color, thickness = thickness))
最後に各画像にDescriptionとConfidenceを添えて表示する。
なお、動画の尺や検出されたオブジェクトの数によってはすべて表示すると時間がかかるためConfidenceにしきい値を設けている。import math import matplotlib.pyplot as plt # confidenceで適当に足切りする min_confidence = 0.7 # figureの諸々を設定する col_count = 4 row_count = math.ceil(len(images) / col_count) fig = plt.figure(figsize = (col_count * 4, row_count * 3), dpi = 100) num = 0 # 静止画を並べて表示する for index, row in df.iterrows(): if row.Confidence < min_confidence: continue num += 1 fig.add_subplot(row_count, col_count, num, title = '%s : (%s%s)' % (row.Description, round(row.Confidence * 100, 2), '%')) plt.imshow(boxed_images[index], cmap='gray') plt.axis('off')実行すると以下のような結果が得られる。
参考
Colaboratory 上から Cloud Video Intelligence API を使い、動画を解析した結果を表示する。
公式の入門ガイド