- 投稿日:2020-03-29T23:28:17+09:00
ゼロから作るDeepLearningをJavaで勉強する。
※注意
この記事は、まだこの本を読み始めたばかりの私が自分のために書いている自己満要素が多いのでレベルが低い且つ
内容が間違っていたりおかしなコードになっている可能性があります。
あと用語の説明などはあまりしないので機械学習を知らない人には意味不明だと思います。
徐々にこの記事を更新していきます。(単層)パーセプトロンの実装
パーセプトロン:アルゴリズムの一種。
ニューラルネットワークのもととなったアルゴリズム。
活性化関数にステップ関数を用いる。
単層だと線形領域しか表現できない。コンストラクタにバイアスと各入力信号の重みを渡してANDやOR,NANDを表現する。
public class PerceptronSample { private double b, w1, w2; PerceptronSample(double b, double w1, double w2){ this.b = b; this.w1 = w1; this.w2 = w2; } int perceptron(int x1, int x2){ double tmp = (x1*w1 + x2*w2) + b; //総和 return tmp > 0 ? 1: 0; } public static void main(String[] args) { PerceptronSample perceptronSample = new PerceptronSample(-0.5, 0.3, 0.3); //バイアス, 入力1, 入力2 //今回はAND回路 System.out.println("" + perceptronSample.perceptron(0, 0) + perceptronSample.perceptron(1, 0) + perceptronSample.perceptron(0, 1) + perceptronSample.perceptron(1, 1) ); } }結果は0001となります。
多層パーセプトロンでXORを表現。
パーセプトロンの層を深くしたもの。
単層パーセプトロンでは解決できない問題を解決できる。XORはNANDとORとANDで表現する。
public class MultilayerPerceptronSample { private double b, w1, w2; MultilayerPerceptronSample(double b, double w1, double w2){ this.b = b; this.w1 = w1; this.w2 = w2; } int perceptron(int x1, int x2, MultilayerPerceptronSample m1, MultilayerPerceptronSample m2){ if (m1 != null && m2 != null){ int x[] = {x1, x2}; x1 = m1.perceptron(x[0], x[1], null, null); x2 = m2.perceptron(x[0], x[1], null, null); double tmp = (x1*w1 + x2*w2) + b; return tmp > 0.0 ? 1 : 0; }else { double tmp = (x1*w1 + x2*w2) + b; //総和 return tmp > 0.0 ? 1 : 0; } } public static void main(String[] args) { MultilayerPerceptronSample AND = new MultilayerPerceptronSample(-0.5, 0.3, 0.3); MultilayerPerceptronSample NAND = new MultilayerPerceptronSample(0.5, -0.3, -0.3); MultilayerPerceptronSample OR = new MultilayerPerceptronSample(-0.3, 0.5, 0.5); System.out.println(" " + AND.perceptron(0, 0, NAND, OR)+ AND.perceptron(1, 0, NAND, OR)+ AND.perceptron(0, 1, NAND, OR)+ AND.perceptron(1, 1, NAND, OR) ); } }
- 投稿日:2020-03-29T23:25:32+09:00
IF文を減らす重要なデザインパターン
導入
こんにちは。けちょんです。
皆さん、複雑なIF文を作ってしまっていませんか?
私が以前指摘され、改善したコードを紹介します。改善前
コード
public class Main { public static void main(String[] args) throws Exception { if (args[0].equals(ExecPattern.A.toString())) { exeA(args[1]); } else if (args[0].equals(ExecPattern.B.toString())) { exeB(args[1]); } else { throw new Exception("illigal request parameter"); } } private static void exeA(String input) { // something } private static void exeB(String input) { // something } }public enum ExecPattern { A, B }内容
実行時に渡した第1引数を用いて、IF文で処理を分岐させています。
実際にはロジッククラスを用意して、ロジック部分は外出ししていました。何が悪いか
この場合、新たに実行パターンCが追加される際に新たにIF文を追加する必要があります。
可読性が下がりますし、頻繁にコントローラクラスが頻繁に更新されることはあまり好ましいことではありません。
追加による修正が最小限になることが理想です。改善後
コード
abstract class ExecLogic { abstract void execute(String args); }Logicクラスが継承する抽象クラス。
今回でいうと、AクラスやBクラスが継承します。public class A extends ExecLogic { @Override void execute(String args) { // something } }public class B extends ExecLogic { @Override void execute(String args) { // something } }A,BクラスにはLogicを記載します。
public class Main { public static void main(String[] args) throws Exception { ExecLogic logic = (ExecLogic) Class.forName(args[0]).getDeclaredConstructor().newInstance(); //※1 logic.execute(args[1]); } }Mainクラスには、実行時引数から、A,Bクラスのインスタンスを生成して処理を実行しています。
※1:実行時引数から、A,Bクラスのインスタンスを生成しています。
余談ですが、Class.forName("className").newInstance()はJava9からdeprecatedされています。
Class.forName(args[0]).getDeclaredConstructor().newInstance()を使用しましょう。
参考:https://qiita.com/deaf_tadashi/items/3c3118e660861fb43434何が改善されたか
実際にCクラスを追加することを考えましょう。
修正内容は、Cクラスを追加して、中にロジックを書くだけです。
コントローラクラスには一切修正が不要になっています。
これで、追加時に修正を最小限にすることを達成しました。おまけ
実際には、実行時引数をバリデーションする処理が必要になると思います。
そこで修正箇所が増えるのも避ける必要があります。
以下のような実装にしましょう。private static boolean validate(String[] args) { boolean res = false; for (int i = 0; i < ExecPattern.values().length; i++) { if (ExecPattern.values()[i].toString().equals(args[0])) { res = true; } } return res; }
- 投稿日:2020-03-29T23:25:32+09:00
保守性を上げる重要なデザインパターン
導入
こんにちは。けちょんです。
皆さん、保守性の低いコードを作ってしまっていませんか?
私が以前指摘され、改善したコードを紹介します。改善前
コード
public class Main { public static void main(String[] args) throws Exception { if (args[0].equals(ExecPattern.A.toString())) { exeA(args[1]); } else if (args[0].equals(ExecPattern.B.toString())) { exeB(args[1]); } else { throw new Exception("illigal request parameter"); } } private static void exeA(String input) { // something } private static void exeB(String input) { // something } }public enum ExecPattern { A, B }内容
実行時に渡した第1引数を用いて、IF文で処理を分岐させています。
実際にはロジッククラスを用意して、ロジック部分は外出ししていました。何が悪いか
この場合、新たに実行パターンCが追加される際に新たにIF文を追加する必要があります。
保守性が低いですし、コントローラクラスが頻繁に更新されることはあまり好ましいことではありません。
追加による修正が最小限になることが理想です。改善後
コード
abstract class ExecLogic { abstract void execute(String args); }Logicクラスが継承する抽象クラス。
今回でいうと、AクラスやBクラスが継承します。public class A extends ExecLogic { @Override void execute(String args) { // something } }public class B extends ExecLogic { @Override void execute(String args) { // something } }A,BクラスにはLogicを記載します。
public class Main { public static void main(String[] args) throws Exception { ExecLogic logic = (ExecLogic) Class.forName(args[0]).getDeclaredConstructor().newInstance(); //※1 logic.execute(args[1]); } }Mainクラスでは、実行時引数からA,Bクラスのインスタンスを生成して、処理を実行しています。
※1:実行時引数から、A,Bクラスのインスタンスを生成しています。
余談ですが、Class.forName("className").newInstance()はJava9からdeprecatedされています。
Class.forName("className").getDeclaredConstructor().newInstance()を使用しましょう。
参考:https://qiita.com/deaf_tadashi/items/3c3118e660861fb43434何が改善されたか
実際にCクラスを追加することを考えましょう。
修正内容は、Cクラスを追加して、中にロジックを書くだけです。
コントローラクラスには一切修正が不要になっています。
これで、追加時に修正を最小限にすることを達成しました。おまけ
実際には、実行時引数をバリデーションする処理が必要になると思います。
そこで修正箇所が増えるのも避ける必要があります。
以下のような実装にしましょう。private static boolean validate(String[] args) { boolean res = false; for (ExecPattern execPattern : ExecPattern.values()) { if (execPattern.toString().equals(args[0])) { res = true; } } return res; }
- 投稿日:2020-03-29T23:17:54+09:00
新世代Javaプログラミングガイドの紹介(Java 言語拡張 プロジェクト「Amber」編)
この記事は新世代Javaプログラミングガイドの紹介(Java 12編)の続きです。
Java 言語拡張 プロジェクト「Amber」
書籍の最後はAmberプロジェクトについての解説で締めくくられています。
AmberプロジェクトはJava言語をより良い言語に拡張しようとして進められているプロジェクトですが、原著の出版時にはJavaのどのバージョンで使えるようになるか決まっていないものが多かったようです。
もちろん、翻訳書が発売された今でも決まっていないものがあります。
そんな 未来の機能 を含むAmberプロジェクトですが書籍では以下の5つについて解説させています。
- Amber プロジェクトの拡張 enum 型
- データクラスとその利用方法
- テキストブロック
- ラムダの改善ポイント
- パターンマッチング
Java14で使える機能
書籍発売時と違い、Java14が既にリリース済みです。
Java14では上記の機能のうち
- データクラス(Records)
- テキストブロック
- パターンマッチング
がPreview 機能として使うことができます。
テキストブロック
上記の中で個人的に早く正式リリースしてほしいのはテキストブロックです。
テキストブロックの機能はJava 13からPreview 版としてリリースされていますが、Java 14でもまだ正式リリースにはなっておらず、Java 15で正式リリースされると思われます。
Javaで文字列をリテラルで定義する場合、ダブルクォーテーション(")で囲みます。
テキストブロックでは文字列をダブルクォーテーション3つ(""")で囲むことで、改行やダブルクォーテーションなどをエスケープシーケンスを使うことなく定義できます。たとえば
<HTML> <BODY> <H1>Meaning of life</H1> </BODY> </HTML>といった文字列を定義するのに今までは
String html = "<HTML>" + "\n\t" + "<BODY>" + "\n\t\t" + "<H1>Meaning of life</H1>" + "\n\t" + "</BODY>" + "\n" + "</HTML>";のようにしていたのが
String html = """ <HTML> <BODY> <H1>Meaning of life</H1> </BODY> </HTML> """;とシンプルに書くことができます。
インデントの部分が気になるかもしれませんが、閉じる側のクォーテーション3つ(""")の前の空白と同じ分の空白が各行の先頭から取り除かれます。
結果、最初に示した文字列を生成することができます。
このように色々と便利な機能について進められているAmberプロジェクトについてわかりやすくまとめられており、さっと読むだけでも将来Java言語がどのように進化するのかが見えてくるようになると思います。以上、新世代Javaプログラミングガイドの紹介(Java 言語拡張 プロジェクト「Amber」編)でした。
- 投稿日:2020-03-29T21:05:14+09:00
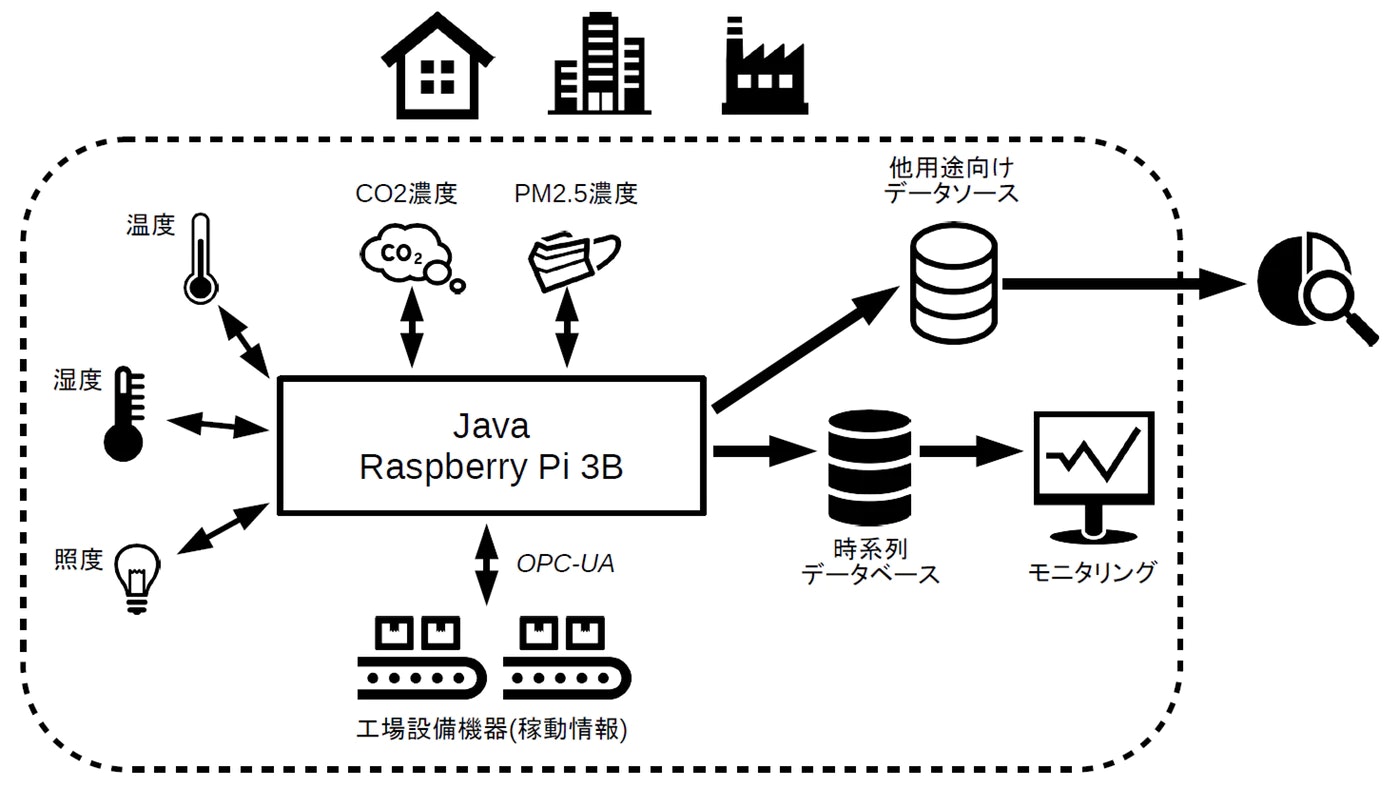
屋内環境を手軽にモニタリングする~⑨モーション検知(HC-SR501 / RCWL-0516)をJavaで取得する(GPIO / Pi4J)~
以前、こちらの記事で、屋内環境(自宅/オフィス/工場)で一般的な環境情報をモニタリングする簡易ツールについて書いたことがあります。このような環境情報のモニタリング用にツールにまとめられたオープンソースは意外と見当たらず、以下のコンセプトイメージを立てて、プライベートで作成しました。
各センサーならびに産業オートメーション機器から取得した情報を以下のように利用することができます。
- Webブラウザから時系列グラフでモニタリングする。(ダッシュボード)
- 他の用途で利用できるようにJSON化してMQTTで出力する。(オフライン分析用にクラウドやストレージに蓄積するとか、 何某かのイベントのトリガーに使うとか)
この簡易ツールは、最低限、センサーとRaspberry Pi 3B or 4Bで完結するように作成しました。今回、このツールをモーション検知センサーに対応してみました。
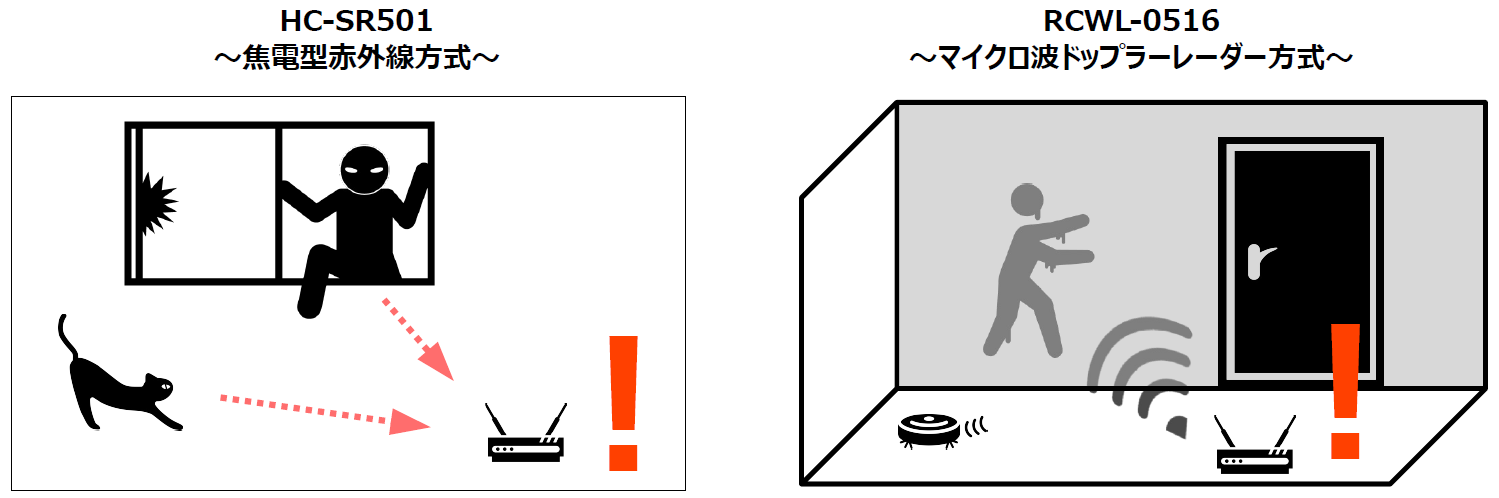
モーション検知センサーについて
今回、採用したモーション検知センサーは、以下の二種類です。
それぞれにJavaのライブラリ(hc-sr501-driver、rcwl-0516-driver)を作成してGithubで公開しています。OSとセンサーの設定手順も書いておきました。また、これらライブラリを組み込んだ環境情報モニタリングの簡易ツールは、こちらのGithubで公開しています。
これらのモーション検知センサーの利用イメージの例は、以下のような感じです。
- HC-SR501は、所謂「人感センサー」と呼ばれるタイプで、物体の熱源から放射される赤外線を使用します。最大検知距離は7mです。赤外線を使用しますので、間に遮るものがあると検知できません。
- RCWL-0516は、熱源の有無に関係なく物体の動きを検知できるよう、3.2GHzのマイクロ波を照射して、その反射波のドップラー遷移から物体の動きを検知するタイプです。最大検知距離は9mです。例えば、家屋の壁の向こう側の物体の動きにも反応します。この特徴は、用途によっては長所にも短所にもなると思います。
このような特徴を考慮して、用途に応じて使い分けられるように、二種類に対応しました。
Javaライブラリの基本的な使い方
Qiitaなので、コードの使い方のサンプルを少し掲載します。
- hc-sr501-driverの使い方
以下のサンプルコードでは、モーション検知信号の受信にGPIO12を使用しています。モーションを検知した際に呼び出される
handle()を実装しています。import com.pi4j.io.gpio.Pin; import com.pi4j.io.gpio.RaspiPin import io.github.s5uishida.iot.device.hcsr501.driver.HCSR501Driver; import io.github.s5uishida.iot.device.hcsr501.driver.IHCSR501Handler; public class MyHCSR501 { private static final Logger LOG = LoggerFactory.getLogger(MyHCSR501.class); public static void main(String[] args) { HCSR501Driver hcsr501 = HCSR501Driver.getInstance(RaspiPin.GPIO_12, new MyHCSR501Handler()); hcsr501.open(); // if (hcsr501 != null) { // hcsr501.close(); // } } } class MyHCSR501Handler implements IHCSR501Handler { private static final Logger LOG = LoggerFactory.getLogger(MyHCSR501Handler.class); private static final String dateFormat = "yyyy-MM-dd HH:mm:ss.SSS"; private static final SimpleDateFormat sdf = new SimpleDateFormat(dateFormat); @Override public void handle(String pinName, boolean detect, Date date) { LOG.info("[{}] {} {}", pinName, detect, sdf.format(date)); } }
- rcwl-0516-driverの使い方
以下のサンプルコードでは、モーション検知信号の受信にGPIO18を使用しています。モーションを検知した際に呼び出される
handle()を実装しています。import com.pi4j.io.gpio.Pin; import com.pi4j.io.gpio.RaspiPin import io.github.s5uishida.iot.device.rcwl0516.driver.RCWL0516Driver; import io.github.s5uishida.iot.device.rcwl0516.driver.IRCWL0516Handler; public class MyRCWL0516 { private static final Logger LOG = LoggerFactory.getLogger(MyRCWL0516.class); public static void main(String[] args) { RCWL0516Driver rcwl0516 = RCWL0516Driver.getInstance(RaspiPin.GPIO_18, new MyRCWL0516Handler()); rcwl0516.open(); // if (rcwl0516 != null) { // rcwl0516.close(); // } } } class MyRCWL0516Handler implements IRCWL0516Handler { private static final Logger LOG = LoggerFactory.getLogger(MyRCWL0516Handler.class); private static final String dateFormat = "yyyy-MM-dd HH:mm:ss.SSS"; private static final SimpleDateFormat sdf = new SimpleDateFormat(dateFormat); @Override public void handle(String pinName, boolean detect, Date date) { LOG.info("[{}] {} {}", pinName, detect, sdf.format(date)); } }どちらのコードもシンプルですね。なお、Pi4JというRaspberry PiのGPIOを使用するためのJavaライブラリを使用して作成しました。
最後に
簡易ツールでは、利用し易いように、これらのモーション検知をイベントとしてJSON形式でMQTTで送信します。これをトリガーに、続く何某かの処理(カメラやマイクをONにするとか)に繋げる、という用途が考えられます。なお、これらのモーション検知センサーが数百円で入手できるのは良いですね。
最後に、簡易ツールはこちらのGithubで公開しています。
一連の記事
このシリーズは、以下の記事から構成されます。
1. 動機とコンセプト
2. Bluetooth LEアドバタイズ信号をJavaでキャッチする(Bluetooth LE / bluez-dbus)
関連するGithubはこちら。
3. TI SensorTag CC2650から温度/湿度/照度などをJavaで取得する(Bluetooth LE / bluez-dbus)
関連するGithubはこちら。
4. MH-Z19BからCO2濃度をJavaで取得する(シリアル通信 / jSerialComm)
関連するGithubはこちら。
5. PPD42NSからPM2.5濃度をJavaで取得する(GPIO / Pi4J)
関連するGithubはこちら。
6. 産業オートメーション機器の稼動情報をJavaで取得する(OPC-UA / Eclipse Milo)
関連するGithubはこちら。
7. 簡易ツールにまとめる
関連するGithubはこちら。
8. 後記
9. モーション検知(HC-SR501 / RCWL-0516)をJavaで取得する(GPIO / Pi4J)(今回)
関連するGithubはこちら(HC-SR501)とこちら(RCWL-0516)。
- 投稿日:2020-03-29T19:59:43+09:00
AWS Lambda で Javaを使う ー実装編Tips - ReagionとInstanceIDからInstance名を取得する
AWS Lambda で Javaを使う 目次
・Eclipse準備編
・登録実行編(いつか)
・実装編 - EC2を止める/立ち上げる
・実装編 - CloudWatchの引数を確認する
・実装編Tips - ReagionとInstanceIDからInstance名を取得するReagionとInstanceIDからInstance名を取得する
引数にReagionコードとInstanceIDを渡すと、Instance名を返してあげる。
また、二回目以降、同じReagionコードを渡した場合、Mapに格納している値を返却する。// <reagion id <<incetance id, incetance key name>> Map<String, Map<String, String>> resolveInstance = new HashMap<>(); private String getEC2InstanceKeyName(String targetReagion, String targetInstanceId) { if (!resolveInstance.containsKey(targetReagion)) { // <incetance id, incetance key name> Map<String, String> incetanceMap = new HashMap<>(); // Instance Id と Instance名を取得 (こんな大層なことしなくても取れそうな気もする。。でも、純正のEC2MetadataUtilsでは取れなさそうだった。) AmazonEC2 ec2 = AmazonEC2ClientBuilder.standard().withRegion(targetReagion).build(); DescribeInstancesResult ec2Info = ec2.describeInstances(); for(Reservation res : ec2Info.getReservations()) { for(Instance ins : res.getInstances()) { incetanceMap.put(ins.getInstanceId(), ins.getKeyName()); } } resolveInstance.put(targetReagion, incetanceMap); } return resolveInstance.get(targetReagion).get(targetInstanceId); }
- 投稿日:2020-03-29T19:49:25+09:00
AWS Lambda で Javaを使う ー実装編 - CloudWatchの引数を確認する
やりたいこと
Lambdaで実行するJavaで、CloudWatchに登録してある引数を取得する。
背景・経緯
前回の記事で作成したEC2の起動停止するLambdaファンクションを、
CloudWatchEventsのCronで、8時、9時、17時、18時など複数の時間帯で起動するようにしていた。
が、どのインスタンスをどの時間に起動するようにしたか忘れてしまい、
いちいちCloudWatchEventsに登録した引数を確認しなければならなかった。
面倒だったので、引数を取得するファンクションを作成した。
(メモを取ると、登録している引数とメモを同期させないといけないので、避けたかった。)AWS Lambda で Javaを使う 目次
・Eclipse準備編
・登録実行編(いつか)
・実装編 - EC2を止める/立ち上げる
・実装編 - CloudWatchの引数を確認する
・実装編Tips - ReagionとInstanceIDからInstance名を取得するとりあえずクラス作成
CloudWatchEventsをごにょごにょする
CloudWatchEventsオブジェクトを作成する
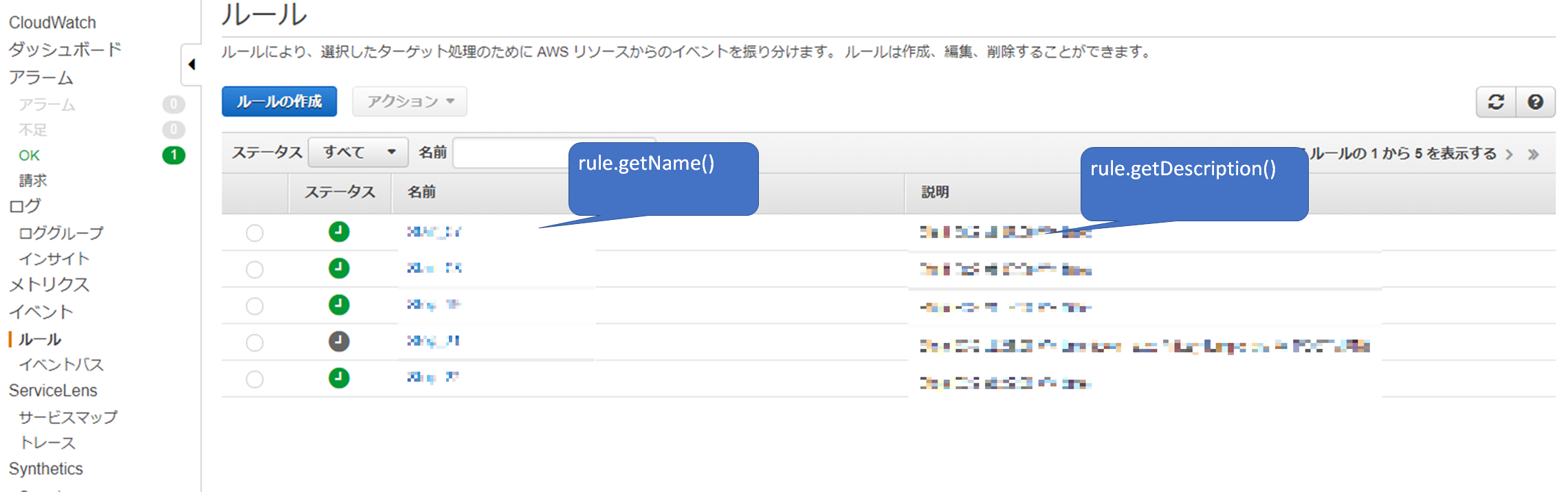
// CloudWatchEventsオブジェクトを作成 AmazonCloudWatchEvents event = AmazonCloudWatchEventsClientBuilder.defaultClient();CloudWatchEventsのルールを取得する
ListRulesResult retRule = event.listRules(new ListRulesRequest()); for(Rule rule : retRule.getRules()) { // rule.getName()、rule.getDescription() }コンソールでいうところのこの部分
メソッド名通り、ルールの名前と説明を取得できる。
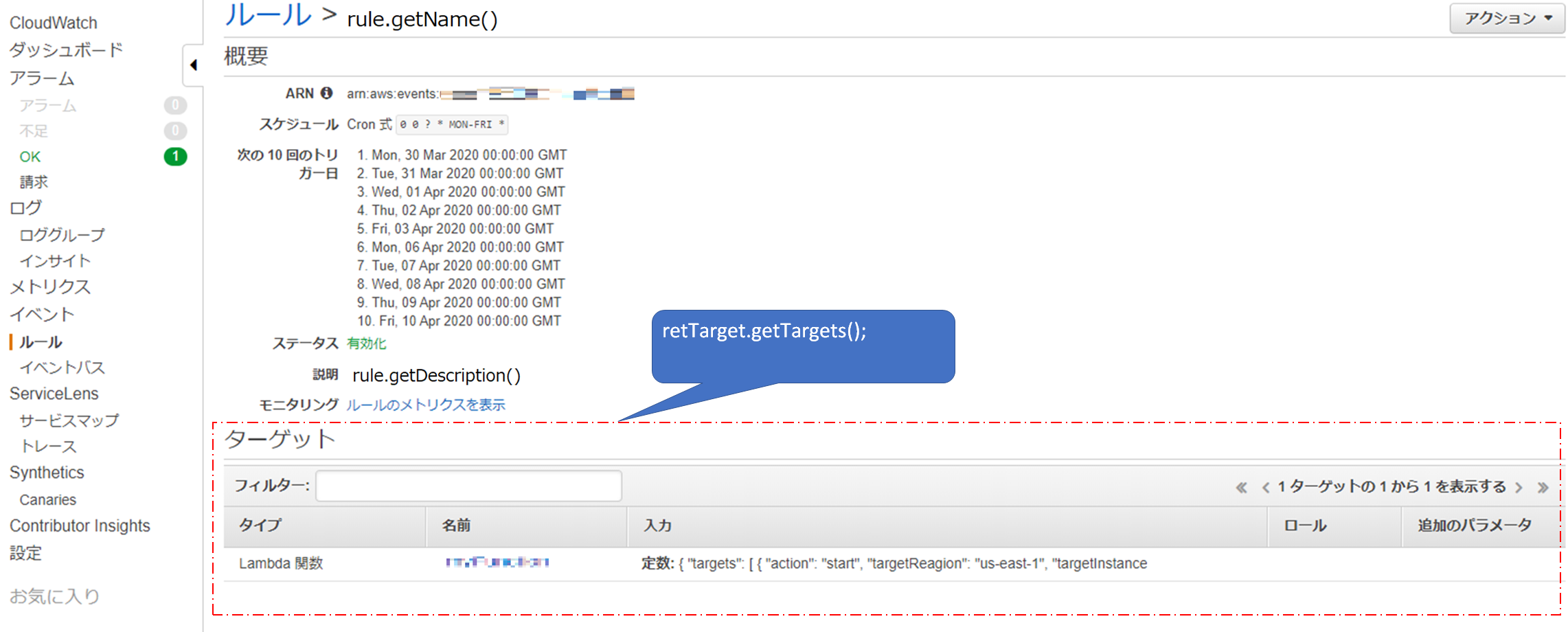
CloudWatchEventsのルールからターゲットを取得する
// get target information from rule ListTargetsByRuleRequest req = new ListTargetsByRuleRequest().withRule(rule.getName()); ListTargetsByRuleResult retTarget = event.listTargetsByRule(req); List<Target> cloudWatchTargets = retTarget.getTargets(); for (Target target : cloudWatchTargets) { // do loop each cloud watch rule's target }コンソールでいうところのこの部分
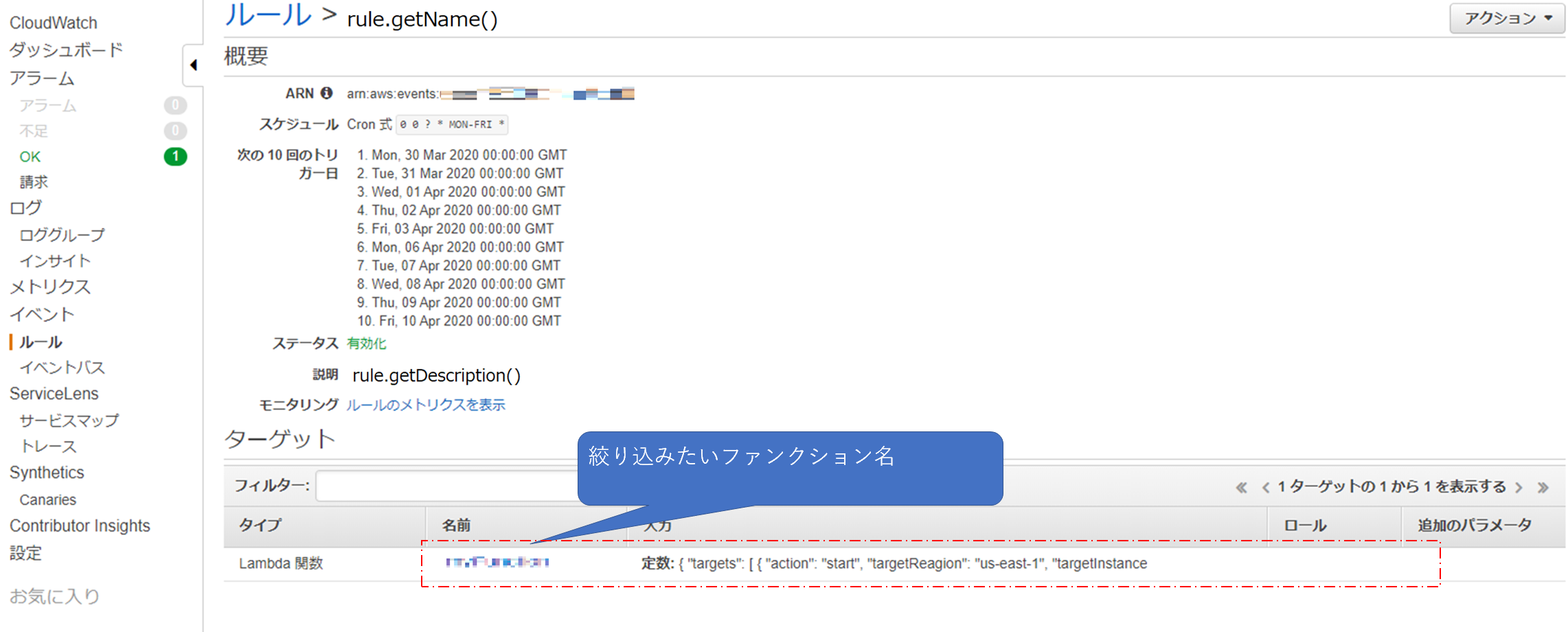
CloudWatchEventsのルールからターゲットの中からファンクション名で絞り込む
target.getArn()これで、各ターゲットが下記のような形で返却される
arn:aws:lambda:region:xxxxxx:function:functionNameなので、endWithで絞り込む
if (target.getArn().endsWith("絞り込みたいファンクション名")) { // }コンソールでいうところのこの部分(このコンソール画面の場合だとそもそも一つしかないので、やってもやらなくてもどちらでもいいのだけども。)
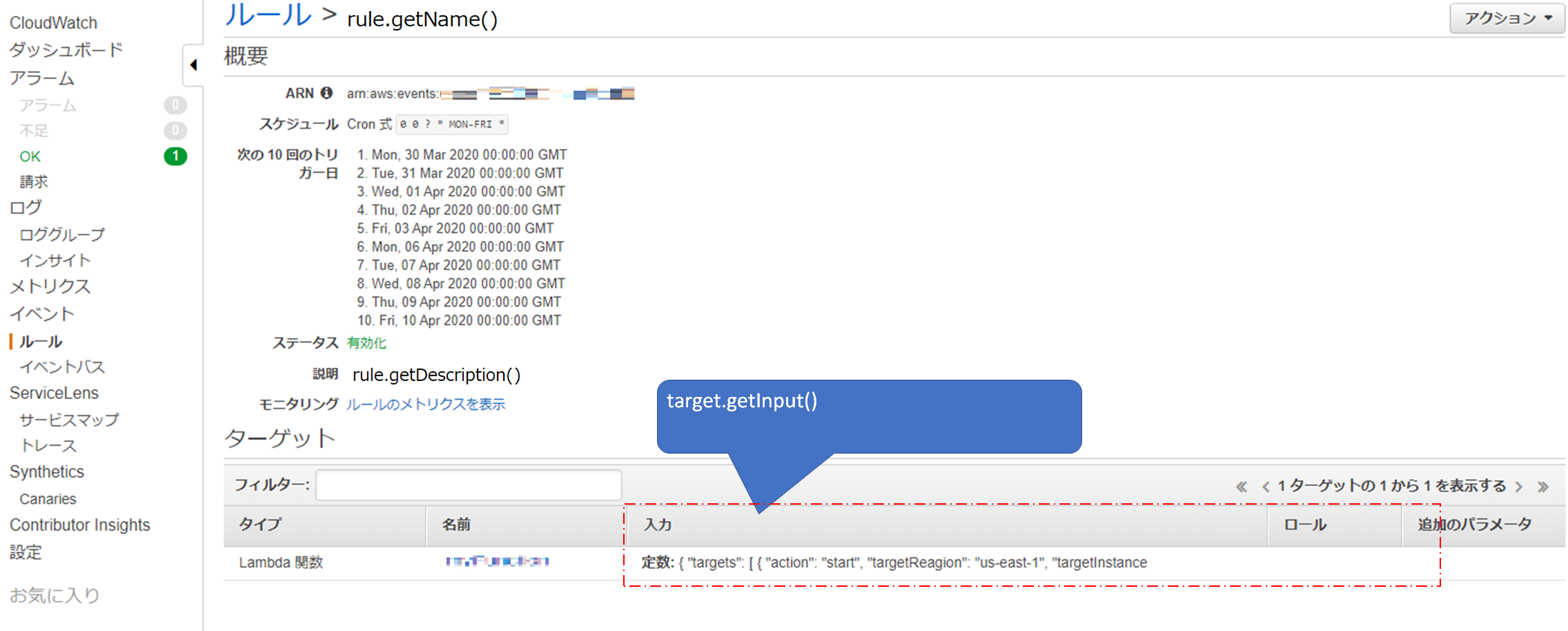
CloudWatchEventsのルールからターゲットの中から引数(入力)を取得する
target.getInput()コンソールでいうところのこの部分
// cloudWatch のInputをjsonで記載しているので jsonからbeanに変換 SomethingBean cloudWatchInput = Jackson.fromJsonString(target.getInput(), SomethingBean.class);あとは、今まで取得したCloudWatchEventsのルール名、説明、引数など出力したい形に整形して、outputに返してあげれば終了。
今回追加したPOM
<dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-cloudwatch</artifactId> <version>1.11.99</version> <scope>compile</scope> </dependency> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-events</artifactId> <version>1.11.719</version> <scope>compile</scope> </dependency>
- 投稿日:2020-03-29T18:50:52+09:00
新世代Javaプログラミングガイドの紹介(Java 12編)
この記事は新世代Javaプログラミングガイドの紹介(Java 11編)の続きです。
Java 12での変更点
Java 12では以下の2つについて書かれています。
- switch 式
- JDK 12のその他の改良点
switch 式
switch式はJava 12の正式な機能ではありません。
それどころかJava 13でも正式でなくJava 14からの正式な機能となります。
本ではプレビュー機能を使う方法としてコンパイル時や実行時に--enable-previewオプションを指定するよう解説されていますが、今はJava 14もリリースされているので、Java 14を使うならオプションなしで実行できます。
正直、今まであまりswitchを使ってこなかったのですが、今回のswitch式を使うと完結に安全なコードが書けるケースが増えるのではと思っています。
今までのswitchは何が問題だったのか、switch式でそれがどう改善されたのか、本ではサンプルコードとともにわかりやすく解説されています。JDK 12のその他の改良点
その他の改良点では以下の項目につい説明されています。
- Shenandoah GC: 一時停止が短い GC
- マイクロベンチマーク・スイート
- 仮想マシン(Java Virtual Machine: JVM)定数 API
- AArch64 版の一本化
- デフォルトの CDS アーカイブ
- G1用の中止可能な混在コレクション
- 未使用のコミットメモリの G1 からの迅速な返却
例に漏れず簡単な解説のみとなっていますが、そのような中で「デフォルトの CDS アーカイブ」については少し多めの解説となっています。しかもCDSに関してはJava 10の「AppCDS アプリケーション・クラスデータ共有」で詳しく解説されているにも関わらずです。
これは著者がこの機能について「ぜひ使ってほしい」との思いがあるからではないでしょうか。本意はわかりませんが、私はそのように感じました。
また、GCについての改良が常に行われているんだなとの印象も感じた内容でした。以上、新世代Javaプログラミングガイドの紹介(Java 12編)でした。
- 投稿日:2020-03-29T17:43:53+09:00
新世代Javaプログラミングガイドの紹介(Java 11編)
この記事は新世代Javaプログラミングガイドの紹介(Java 10編)の続きです。
Java 11での変更点
Java 11では以下の6つについて書かれています。
- ラムダパラメータのローカル変数構文
- Epsilon GC ― ガベージコレクタの改良
- HTTP クライアント API
- ZGC - 低遅延化とスケーラビリティの改善
- フライトレコーダとミッションコントロール
- JDK 11 のその他の改良点
ラムダパラメータのローカル変数構文
Java 11でLambda式のパラメータでvarが使えるようになりました。
というと「あれ? Lambda式のパラメータは元々型宣言はなくてもよかったんじゃ?」と思う人もいるかもしれません。
確かにLambda式では(int age) -> x > 100; (age) -> x > 100; x -> x > 100;のような記述ができ、1番目以外は型の指定を省略しています。
そしてパラメータでvarが使えるということは(var age) -> x > 100;のような書き方ができるとういうことです。
ちなみにvarを使った場合var age -> x > 100;のように
()を省略することはできません。
先ほどの例ではvarを使うことのメリットはありませんが、varを使えることで 型宣言をせずに アノテーションを付与することができるようになります。
つまり@Nullable var name -> name.length() > 32;のような記述ができるということです。varが使えない場合、具体的な型宣言をせずにアノテーションを使うことはできませんでした。
本ではこのような話について詳しく説明されています。Epsilon GC ― ガベージコレクタの改良
Epsilon GCとは「ガベージコレクトしない GC」です。
なんか矛盾したものに感じますが、Epsilon GCはメモリを開放しいので、アプリケーションがヒープメモリを使いつくすとJVMは皆さんご存じのOutOfMemoryErrorで終了します。
こんなEpsilon GCですが有用ないくつかの場面があります。HTTP クライアント API
Java 9で非標準のライブラリとして登場し、Java 10で修正が行われさらにJava 11で標準化されたHTTP クライアント APIについて詳しく説明されています。
Javaには1.1の時代からHttpURLConnectionクラスというのがありましたが、なぜ新たなHTTPライブラリの開発に至ったのかという解説から各クラスのメソッド一覧、具体的なコード例のサンプルまで初歩的な内容から具体的にかなり詳しく解説されています。
普段HTTP クライアントを使った開発を行っていない開発者にもわかりやすい内容となっていると思います。ZGC - 低遅延化とスケーラビリティの改善
Java 11ぽの実験的なGCとしてリリースされたZGC(Z ガベージコレクタ)についての説明です。
アプリケーションの遅延が10ミリを超えないことを約束したZGCの特徴やその仕組み、実際にZGCを使用するにあたってのコマンド例、オプションについて解説されています。フライトレコーダとミッションコントロール
高性能で低オーバーヘッドなプロファイラでJVMに組み込まれているJFR(Java フライトレコーダ)と、JFFが記録したデータの解析のためのツールであるJMC(Java ミッションコントロール)について、チュートリアル的に実際に使用する例を使って解説されています。
アプリケーションがクラッシュしたり予想外の動作をしている時に、原因調査のためにこれら知識が役立つでしょう。JDK 11 のその他の改良点
その他の改良点については以下の項目について説明されています。
- ネストに基づくアクセス制御
- 動的クラスファイル定数
- AArch64 イントリンシックの改善
- Java EE と CORBA モジュールの削除
- Curve25519 と Curve448 での鍵合意(Key agreement)
- Unicode 10
- ChaCha20 と Poly1305 の暗号アルゴリズム
- 単一ファイルソースコードのプログラム起動
- TLS 1.3
- Nashorn JavaScriptエンジンの廃止
- pack200 ツールと APIの廃止
どれも簡単に解説されているだけですが、単一ファイルソースコードのプログラム起動など(IDEを使わない場合に特に)便利な機能については知っておいたほうと思います。
以上、新世代Javaプログラミングガイドの紹介(Java 11編)でした。
- 投稿日:2020-03-29T14:57:43+09:00
Object MotherパターンとTest Data Builderパターン
はじめに
背景と目的
テストフィクスチャのセットアップは面倒で大変です。特に、複雑なオブジェクト構造のテストデータを準備するのは手間がかかる上に、冗長な記述によってテストコードのノイズが大きくなり可読性の低下を招きます。
本稿では、テストフィクスチャのセットアップのための代表的なデザインパターンであるObject MotherパターンとTest Data Builderパターンを説明し、また、改良のためのアイデアをご紹介します。サンプルコード
Java+JUnit5のサンプルコードをGitHubで公開しています。
テストフィクスチャとは
繰り返してテストを実行した際に同じ結果が得られることを保証するための一定の状態(環境やデータ)のことを
テストフィクスチャと呼びます。本投稿はその中でも、テスト実行に必要なデータのセットアップに焦点を当てます。サンプル
説明用のサンプルとして、図書管理アプリケーションを想定します。図書貸出管理サービス
LoanServiceをテスト対象(SUT:System Under Test)とし、貸出時のチェックを行うcheckメソッドを検証する以下のテストコードがあったとします。SimpleLoanServiceTest.javapublic class SimpleLoanServiceTest { private static final LocalDate TODAY = LocalDate.now(); private static final LocalDate YESTERDAY = TODAY.minusDays(1); private static final LocalDate A_WEEK_AGO = TODAY.minusDays(7); private LoanService sut; @BeforeEach void setup() { sut = new LoanService(TODAY); } ... @Test void 最大貸出数を超過する場合は貸出不可となる() { // Arrange Book book1 = new Book("枕草子"); Loan loan1 = new Loan(book1, A_WEEK_AGO, TODAY); Book book2 = new Book("源氏物語"); Loan loan2 = new Loan(book2, A_WEEK_AGO, TODAY); Loans loans = Loans.of(loan1, loan2); User user = new User("山本", TODAY, loans); Book[] books = new Book[]{new Book("竹取物語"), new Book("平家物語")}; // Act LoanCheckResult result = sut.check(user, books); // Assert assertThat(result.hasError, is(true)); assertThat(result.errorCode, is("LIMIT_EXCEEDED")); } @Test void 貸出中のものに返却期限切れがある場合は新たな貸出は不可となる() { // Arrange Book book1 = new Book("枕草子"); Loan loan1 = new Loan(book1, A_WEEK_AGO, TODAY); Book book2 = new Book("源氏物語"); Loan loan2 = new Loan(book2, A_WEEK_AGO, YESTERDAY); Loans loans = Loans.of(loan1, loan2); User user = new User("山本", TODAY, loans); Book book = new Book("竹取物語"); // Act LoanCheckResult result = sut.check(user, book); // Assert assertThat(result.hasError, is(true)); assertThat(result.errorCode, is("UNRETURNED_BOOKS")); } ...上記のテストコードには以下の問題点があります。
- Arrange節でテストデータをセットアップするコードが冗長かつテストケース間で重複している。
- 実際のプロダクションコードではもっと多くのオブジェクト、プロパティのセットアップが必要。
- テストケースとは無関係な値がノイズとなってテストの意図が汲み取りにくい。
- 例えば、本のタイトル
枕草子や日付定数TODAYがそのテストで意味のある値なのか単なるプレースホルダなのかわからない。これらの問題点をどのように解決すればよいでしょうか。
Object Motherパターン
単純にコードの重複を排除するということであれば、テストデータのセットアップ処理をテストクラス内にprivateメソッドとして切り出す手もありますが、複数のテストクラスに同じようなセットアップコードが重複して記述されてしまう危険性があります。
テストデータをセットアップするファクトリメソッドを一箇所に集めたのがObject Motherです。
以下はUserをセットアップするファクトリメソッドを提供するObject Motherです。UserMother.javapublic class UserMother { public static User aUserWithoutLoans() { Loans loans = Loans.empty(); return new User("USER", LocalDate.MAX, loans); } public static User aUserBorrowing2Books() { Loans loans = Loans.of(aLoan(), aLoan()); return new User("USER", LocalDate.MAX, loans); } public static User aUserBorrowing3Books() { Loans loans = Loans.of(aLoan(), aLoan(), aLoan()); return new User("USER", LocalDate.MAX, loans); } ...テストケースは以下のようになります。
ObjectMotherLoanServiceTest.java@Test void 最大貸出数を超過する場合は貸出不可となる() { // Arrange User user = UserMother.aUserBorrowing2Books(); Book[] books = BookMother.books(2); // Act LoanCheckResult result = sut.check(user, books); // Assert assertThat(result.hasError, is(true)); assertThat(result.errorCode, is("LIMIT_EXCEEDED")); }
Object Motherの特長として、ファクトリメソッドを一箇所にまとめることでテストクラスやテストケースをまたがっての再利用を促進する点が挙げられますが、最大の効用はデータのパターンに名前付けを行うことだと考えます。
適切な名前付けを行うことで、テストコードの可読性を高めることができます。例えば、User user = UserMother.aUserBorrowing2Books();というコードからはユーザー名や本のタイトル、日付といった(そのテストケースでは)ノイズとなる情報が排除され、「2冊の本を借りている任意のユーザー」というテスト条件が一目瞭然に読み取れるようになります。
一方で、Object Motherには以下のデメリットもあります。
- ファクトリメソッドが乱立し、
神クラス(God Class)になりがち。- 複数のテストが
Object Motherに依存するので、ファクトリメソッドを修正した場合に影響が広範に及ぶ。Test Data Builderパターン
Test Data BuilderはGoFのデザインパターンのひとつであるBuilderパターンを使ってテストデータをセットする手法です。
例を見ましょう。UserBuilder.javapublic class UserBuilder { private String name = "DEFAULT_NAME"; private LocalDate expirationDate = LocalDate.MAX; private Loans loans = Loans.empty(); public UserBuilder withLoans(Loans loans) { this.loans = loans; return this; } public UserBuilder withExpirationDate(LocalDate expirationDate) { this.expirationDate = expirationDate; return this; } public User build() { return new User(name, expirationDate, loans); } }テストコードは以下のようになります。
TestDataBuilderLoanServiceTest.java@Test void 貸出中のものに返却期限切れがある場合は新たな貸出は不可となる() { // Arrange Loan loan1 = new LoanBuilder().build(); Loan loan2 = new LoanBuilder().withDueDate(YESTERDAY).build(); Loans loans = Loans.of(loan1, loan2); User user = new UserBuilder().withLoans(loans).build(); Book book = new BookBuilder().build(); // Act LoanCheckResult result = sut.check(user, book); // Assert assertThat(result.hasError, is(true)); assertThat(result.errorCode, is("UNRETURNED_BOOKS")); }一般に
Test Data Builderは各プロパティのデフォルト値を定義しておき、デフォルト値を使ったオブジェクト生成は以下のようにBuilderを生成してbuildメソッドを呼び出すだけです。new LoanBuilder().build();デフォルト値から変更したいプロパティがあれば、Builderを生成した後にメソッドチェーンでつなげて記述して、最後に
buildメソッドを呼び出します。User user = new UserBuilder().withLoans(loans).build();
Test Data Builderはデフォルト値の利用や、メソッドチェーンを使った流暢なAPIによってテストコードの見通しをよくしますが、以下の欠点もあります。
- 再利用性はあまり高くない。
- (最初のテストコードに比べると改善されてはいるが)テストコードの冗長さは残り、テストの意図が伝わりづらい。
Test Data Builderの改良
Test Data Builderをベースとしつつ、その欠点を改善するテクニックを紹介します。
まず、new演算子でのオブジェクト生成はノイズなので、コンストラクタはprivateに変更し代わりにstaticなファクトリメソッドを用意します。UserBuilder.javaprivate UserBuilder() {} public static UserBuilder ofDefault() { return new UserBuilder(); }デフォルト値以外で、よく使用されるセットアップのパターンもファクトリメソッドで提供します。
UserBuilder.javapublic static UserBuilder borrowing(int numOfBooks) { UserBuilder builder = new UserBuilder(); List<Loan> loanList = new ArrayList<>(); for (int i = 0; i < numOfBooks; i++) { Loan loan = LoanBuilder.ofDefault().build(); loanList.add(loan); } builder.loans = Loans.of(loanList.toArray(new Loan[0])); return builder; }このファクトリメソッドを利用してテストコードを記述すると、コードがすっきりするとともに、ファクトリメソッドの
名前付けによって意図が明確になる効果があります。いわばDSL(ドメイン固有言語)を設計するようなものです。HybridLoanServiceTest.java@Test void 最大貸出数を超過する場合は貸出不可となる() { // Arrange User user = UserBuilder.borrowing(2).build(); Book[] books = BookBuilder.ofDefault().build(2); // Act LoanCheckResult result = sut.check(user, books); // Assert assertThat(result.hasError, is(true)); assertThat(result.errorCode, is("LIMIT_EXCEEDED")); }また、ネストされたオブジェクトのセットアップを柔軟にできるようにするために、コールバックを受け取るテクニックもあります。
以下のサンプルは、UserオブジェクトにネストされているLoanオブジェクトを、LoanBuilderを使ってセットアップするコールバックを受け取る例です。UserBuilder.javapublic UserBuilder borrowing(Consumer<LoanBuilder> callback) { LoanBuilder loanBuilder = LoanBuilder.ofDefault(); callback.accept(loanBuilder); loans.add(loanBuilder.build()); return this; }
UserBuilder側でLoanBuilderオブジェクトを生成し、受け取ったコールバックに貸し出すことから、このような実装パターンはLoanパターンと呼ばれます。※Loanという言葉が符合したのは、偶然です(^_^;)
利用するテストコードサンプルは以下です。コールバックはラムダ式で記述します。HybridLoanServiceTest.java@Test void 貸出中のものに返却期限切れがある場合は新たな貸出は不可となる() { // Arrange User user = UserBuilder.ofDefault() .borrowing(loanBuilder -> loanBuilder.noop()) .borrowing(loanBuilder -> loanBuilder.withDueDate(YESTERDAY)) .build(); Book book = BookBuilder.ofDefault().build(); // Act LoanCheckResult result = sut.check(user, book); // Assert assertThat(result.hasError, is(true)); assertThat(result.errorCode, is("UNRETURNED_BOOKS")); }まとめ
- 複雑なオブジェクト構造のテストデータのセットアップは冗長になりがちで、ベタに書いてしまうとテストコードの可読性が下がってしまいます。
Object MotherやTest Data Builderといったテストフィクスチャのセットアップに関わるパターンを活用し、テストコードをクリーンに保ちましょう。
- 投稿日:2020-03-29T13:57:48+09:00
新世代Javaプログラミングガイドの紹介(Java 10編)
Java 10以降の知識の整理に
2020/3/13「新世代Javaプログラミングガイド」という本が発売されました
この本は4部で構成されていて
- 第1部 Java 10
- 第2部 Java 11
- 第3部 Java 12
- 第4部 Java 言語拡張 プロジェクト「Amber」
となっています。
先日Java 14がリリースされたばかりなので最新のJavaのバージョンまで対応していなさそうですが、訳者がJava 13やJava 14についての追記や訳注をつけておりJava10からの変更点や新機能などについてわかりやすく整理されておりJavaに関わる仕事をしている人にはぜひ読んでほしい本だと感じました。
今回は上記4部のうちの「第1部 Java 10」の部分について感想などを述べたいと思います。
(内容についてはあまり深く解説いたしませんので、興味を持たれたら本を読むことをお勧めいたします)Java10 での変更点
Java 10については以下の4つについて書かれています。
- ローカル変数の型推論
- AppCDS アプリケーション・クラスデータ共有
- ガベージコレクタの最適化
- その他の改良点
ローカル変数の型推論
Javaで変数の型宣言で var が使えるようになったことはわりと多くのJavaユーザが知っている思いまが、書籍ではどのような場合にvarが使えるのか、どのような場合は使えないのかについて詳しく書かれています。
また、コードチェックという簡単なクイズ形式の確認問題がついています。自分の理解度を確かめるのに役立つと思います。
ただ、時々ひっかけというか直接本題とは関係ない問題もでたりしますが、その場合は解説に「この問題は、〇〇とは直接関係ありません」などのように補足されています。
そして最後にvarを使うことで(型を明示的に記述しないために)変数名のつけ方がより重要になるという意見にまで言及されています。AppCDS アプリケーション・クラスデータ共有
アプリケーション・クラスデータ共有はJavaアプリの起動パフォーマンの向上やメモリ使用量の削減などに役立つ便利な機能ですが、日本語でのまとまった情報が少ないと思います。
書籍では実際にコマンドを実行してアプリケーション共有アーカイブファイルを作成するサンプルがあり実際に試してみることができます。ガベージコレクタの最適化
Java 9でデフォルトとなったG1 GCについて簡単に解説した上で、Java 9までは単一スレッドを使って実行されていたフルGCがJava 10では並列フルGCが提供されたことについて書かれています。
また、G1 GCのログの読み方なども解説されており内部の動作について理解が深まるでしょうその他の改良点
その他の改良点では以下の項目について説明されています
- JDKのソースを単一リポジトリへ統合
- スレッドローカル・ハンドシェイク
- ネイティブヘッダー生成ツールの削除
- 追加のUnicode言語タグ拡張
- 代替メモリデバイスでのヒープ割り当て
- Javaで書かれた実験的なJITコンパイラ
- ルート証明書
- 時間に基づくリリースのバージョン付け
開発者が直接使えない機能が多く、どの項目も簡単に触れられているだけですがGraalの話が出たり(もうご存じの方も多いと思いますが)Javaのバージョン付けについて解説されています。
以上、新世代Javaプログラミングガイドの紹介(Java 10編)でした。
- 投稿日:2020-03-29T01:15:19+09:00
JVM・ガベージコレクションに関してまとめてみた
先日、業務でフルGCが発生しアプリケーションが止まってしまうことがありました。
そもそもフルGCとは何か、わからなかったのでそこから調べて、またGCってどれくらいの頻度で発生するのか気になったので、調べて実際にちょこっと触ってみたことを書いています。GCとは
簡単にいうと、JVM上に確保されたヒープ領域で、不要になったオブジェクトに紐づいているメモリを開放すること。
たとえば、以下のようなコードがあった場合には、Compnayのオブジェクトが100000個も作成されます。
ほっておくとメモリを圧迫してしまいます。
実際にはこんなコード書かないと思いますが、このように少しのあらゆるコードの箇所で、数多くのオブジェクトが作られメモリに乗っています。test.scalacase class Company(name: String) for(i 0 <- 100000 ) { val company = Company(s"企業-${i}") }JVMのヒープ領域の詳細
young・oldに大別されます。
youngはさらに、eden survivorという二つの空間に分けられます。オブジェクトは以下のようなライフサイクルになります。
オブジェクトライフサイクルobject生成 -> eden -> パンパンになる -> GC(マイナーガベージコレクション) -> 開放 or survivor/oldに昇格 -> パンパンになる -> GC(マイナーガベージコレクション) -> 開放 or oldに昇格 -> oldパンパン -> GC(フルガベージコレクション)注意点としては、どんなGCのアルゴリズムでも、マイナーGCが走るたびにアプリケーションのスレッドは全て停止されます。
なので、young領域が小さければ小さいほど頻繁にマイナーGCが走ります。(基本的には、頻繁に小さいGCが起きる方が良いらしい。)フルGCに関しては、GCアルゴリズムによって挙動がだいぶ違ってきます。アプリケーションスレッドを停止するものもあれば、並列でフルGCを走らせるものもあります。
フルGCがやることとしては、old領域から不要なオブジェクトを見つけて、メモリを開放し、ヒープをコンパクト化する(デフラグメンテーションする)なので、長い時間がかかります。
GCのチューニングをする際は、アプリケーションによるがこのフルGCを回避する方法を見つけることが肝になってきます。GCアルゴリズム
GCのアルゴリズムは以下の四つが存在します。
それぞれ特徴があるので、特徴をちょろっと書いていきます。シリアル型ガベージコレクター
- ヒープの処理を行うスレッドは一つ
- マイナーGCとフルGCの両方で、実行時にアプリケーションスレッドを停止する必要がある
スループット型ガベージコレクタ
- young領域の処理に複数のスレッドを利用するので、マイナーGCは上記のシリアル型よりも非常に高速
- old領域の処理にも複数のスレッドを利用することができる
- マイナーGCとフルGCの両方で、実行時にアプリケーションスレッドを停止する必要がある
CMSガベージコレクタ(コンカレント型)
- マイナーGCに関しては、上記の二つの処理と同じ
- フルGCの場合には、アプリケーションスレッドを停止しないように、一つか複数のスレッドをバックグラウンドでold領域のメモリ解放に当てている
- バックグラウンドで動かすことになるので、CPU利用率は上がる
- 処理時にコンパクト化を行わないので、ヒープのフラグメンテーション化が発生する。
- 断片化が進行し、割り当てるメモリが存在しなくなったら、他のGCアルゴリズムと同じようにアプリケーションスレッドを停止し、単一のスレッドを使って、old領域のコンパクト化やクリーンアップを行う。
G1ガベージコレクタ(コンカレント型)
- young領域、old領域で、複数のリージョンに分割されている
- マイナーGCに関しては。他のアルゴリズム同様
- フルGCに関しては、コンカレント型なのでバックグラウンドで実行されるので、アプリケーションスレッドを停止する必要がない
- old領域も複数のリージョンに分割されているので、使われているメモリを別のリージョンに移動するという形でコンパクト化を行っている
試してみる
ここまでで、GCの基礎をインプットしたので、実際にどんな感じでGCが発生しているのかを試してみました。
sbt(1.3.8) console上で、プログラムを書いてJVMのメトリクスを取得していきます。
sbtのJVMのチューニング
sbtを実行する配下に、
.jvmoptionsファイルを配置しておくと、そのファイルの中身をJVMのパラメータとして読み込まれます。.jvmopts-Xms1024M -Xmx1024M -Xss1024M -XX:MaxMetaspaceSize=1024M -XX:+UseSerialGC-Xms ・・・初期ヒープサイズ
-Xmx ・・・最大ヒープサイズ
-Xss ・・・スレッドスタックサイズ
-XX:MaxMetaspaceSize ・・・パーマネント領域のサイズ
-XX:+UseSerialGC ・・・GCアルゴリズムの指定(サンプルでは、シリアル型ガベージコレクタを指定しています)では、実際に
.jvmoptsに各項目の設定を行なって、プログラムを実行します。jvmのオプションは、上記の設定を同じ数値にします。
sbtプロセス~/jvm-test $ sbtjpsコマンドで、動いているjavaプロセスを確認できるので、上記で動かしたsbtのプロセスが存在することを確認する。
sbt-launch.jarが実行しているsbtのプロセスです。確認プロセス~/jvm-test$ jps 77057 sbt-launch.jar 56693 77100 Jps 3406 Main上記のプロセスでのGCメトリクスを表示します。
jstatコマンドでの-gcオプションを使うと、該当プロセスでのGCメトリクスを取得できます。
10はメトリクスを取得する間隔です。デフォルトの単位は、msになっています。~/jvm-test$ jstat -gc 77057 10実際にプログラムを書いて、gcメトリクスを取得していきます。
まず、プログラムを動かす前のGCメトリクスを確認します。➜ jvm_test jstat -gc 77057 S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT 34944.0 34944.0 0.0 0.0 279616.0 232912.0 699072.0 52034.1 59028.0 54605.4 7612.0 7243.9 0 0.000 3 0.157 0.157それぞれの詳しいことは、ドキュメントに書いています。
今回の分析をしていく中で、重要な物を書いていきます。S0C・・・Survivor領域0の現在の容量(KB)
S1C・・・Survivor領域1の現在の容量(KB)
S0U・・・Survivor領域0の利用率(KB)
S1U・・・Survivor領域1の利用率(KB)
EC・・・Eden領域の現在の容量(KB)
EU・・・Eden領域の現在の容量(KB)
YGC・・・若い世代のGCイベント数
FGC・・・古い世代のGCイベント数sbtプロセスを実行した段階では、まだオブジェクトは何も作成していないので、S0U・S1U・YGCは0になっています。
立ち上げた時点で、FGCの値は既に3になっているのですが、なぜかわかりません。。。またEUの値も0ではなく、プロセスを立ち上げた時点でEden領域のメモリは使われるのでしょうか。
以下のプログラムを動かしていきます。
1Mのオブジェクトをループで作成していきます。test.scalafor(i <- 0 to 1000) { val builder = new StringBuilder(1000000) }1秒間隔でメトリクスを取得しています。
~/jvm-test$ jstat -gc 77057 1000 S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT 34944.0 34944.0 0.0 0.0 279616.0 0.0 699072.0 52811.1 99532.0 86381.2 13556.0 12524.2 72 0.183 4 0.330 0.513 34944.0 34944.0 0.0 0.0 279616.0 0.0 699072.0 52811.1 99532.0 86381.2 13556.0 12524.2 111 0.246 4 0.330 0.575 34944.0 34944.0 0.0 0.0 279616.0 17278.5 699072.0 52811.1 99532.0 86381.2 13556.0 12524.2 151 0.308 4 0.330 0.637 34944.0 34944.0 0.0 0.0 279616.0 0.0 699072.0 52811.1 99532.0 86381.2 13556.0 12524.2 190 0.371 4 0.330 0.701EUとYGCの値が増えていることが確認できます。
上記のプログラムで作成したbuilerオブジェクトがまず、Eden領域に入り、その時点で走ったマイナーGCによって、Survivor領域には昇格せずに開放されているからです。次に、フルGCの確認をします。
フルGCを起こしやすいように、ヒープのサイズを以下のように小さく設定しておきます。.jvmopts-Xms100M -Xmx100M -Xss100M -XX:MaxMetaspaceSize=1024M今回実行するプログラムです。
test.scalaval builder1 = new StringBuilder(5000000)初めからEden領域の容量を超えるオブジェクトを作成します。
この場合、Eden領域には入らないので、いきなりold領域にオブジェクトが移動することになります。さらに、old領域の空き容量を超えているので、
フルGCを行なってからold領域に割り当てられます。~/jvm-test$ jstat -gc 87198 S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT 11264.0 11264.0 0.0 3961.1 11264.0 10713.2 68608.0 40401.1 95764.0 83780.1 13116.0 12384.1 43 0.114 3 0.166 0.279 10752.0 11264.0 10716.2 0.0 11264.0 274.5 68608.0 41973.0 98580.0 85517.2 13372.0 12405.6 48 0.131 4 0.268 0.399一行目と二行目で、FGCの値が違うのが確認できます。
ここで疑問なのが、YGCの値が43->48・S0Uの値も変化していることです。
つまりマイナーGCが実行され、もともとEdenにあったオブジェクトがSurvivor0領域に移動しています。
Eden領域以上のオブジェクトを割り当てようとすると、まずマイナーGCが走ってそれでもEden領域に入らなければ、old領域に割り当てられるというロジックなのかなと推測しています。まとめ
いろんな記事・ドキュメントを読んで、書いているロジック通りにはGCが動いていないように見えるところもありましたが、なんとなくGCに関して理解できました。
次回は、GCアルゴリズムでどのようにGC処理が違うのか、試したいと思います。
参考
- 投稿日:2020-03-29T01:15:19+09:00
JVM・GCの自分まとめ
先日、業務でフルGCが発生しアプリケーションが止まってしまうことがありました。
そもそもフルGCとは何か、わからなかったのでそこから調べて、またGCってどれくらいの頻度で発生するのか気になったので、調べて実際にちょこっと触ってみたことを書いています。GCとは
簡単にいうと、JVM上に確保されたヒープ領域で、不要になったオブジェクトに紐づいているメモリを開放すること。
たとえば、以下のようなコードがあった場合には、Compnayのオブジェクトが100000個も作成されます。
ほっておくとメモリを圧迫してしまいます。
実際にはこんなコード書かないと思いますが、このように少しのあらゆるコードの箇所で、数多くのオブジェクトが作られメモリに乗っています。test.scalacase class Company(name: String) for(i 0 <- 100000 ) { val company = Company(s"企業-${i}") }JVMのヒープ領域の詳細
young・oldに大別されます。
youngはさらに、eden survivorという二つの空間に分けられます。オブジェクトは以下のようなライフサイクルになります。
オブジェクトライフサイクルobject生成 -> eden -> パンパンになる -> GC(マイナーガベージコレクション) -> 開放 or survivor/oldに昇格 -> パンパンになる -> GC(マイナーガベージコレクション) -> 開放 or oldに昇格 -> oldパンパン -> GC(フルガベージコレクション)注意点としては、どんなGCのアルゴリズムでも、マイナーGCが走るたびにアプリケーションのスレッドは全て停止されます。
なので、young領域が小さければ小さいほど頻繁にマイナーGCが走ります。(基本的には、頻繁に小さいGCが起きる方が良いらしい。)フルGCに関しては、GCアルゴリズムによって挙動がだいぶ違ってきます。アプリケーションスレッドを停止するものもあれば、並列でフルGCを走らせるものもあります。
フルGCがやることとしては、old領域から不要なオブジェクトを見つけて、メモリを開放し、ヒープをコンパクト化する(デフラグメンテーションする)なので、長い時間がかかります。
GCのチューニングをする際は、アプリケーションによるがこのフルGCを回避する方法を見つけることが肝になってきます。GCアルゴリズム
GCのアルゴリズムは以下の四つが存在します。
それぞれ特徴があるので、特徴をちょろっと書いていきます。シリアル型ガベージコレクター
- ヒープの処理を行うスレッドは一つ
- マイナーGCとフルGCの両方で、実行時にアプリケーションスレッドを停止する必要がある
スループット型ガベージコレクタ
- young領域の処理に複数のスレッドを利用するので、マイナーGCは上記のシリアル型よりも非常に高速
- old領域の処理にも複数のスレッドを利用することができる
- マイナーGCとフルGCの両方で、実行時にアプリケーションスレッドを停止する必要がある
CMSガベージコレクタ(コンカレント型)
- マイナーGCに関しては、上記の二つの処理と同じ
- フルGCの場合には、アプリケーションスレッドを停止しないように、一つか複数のスレッドをバックグラウンドでold領域のメモリ解放に当てている
- バックグラウンドで動かすことになるので、CPU利用率は上がる
- 処理時にコンパクト化を行わないので、ヒープのフラグメンテーション化が発生する。
- 断片化が進行し、割り当てるメモリが存在しなくなったら、他のGCアルゴリズムと同じようにアプリケーションスレッドを停止し、単一のスレッドを使って、old領域のコンパクト化やクリーンアップを行う。
G1ガベージコレクタ(コンカレント型)
- young領域、old領域で、複数のリージョンに分割されている
- マイナーGCに関しては。他のアルゴリズム同様
- フルGCに関しては、コンカレント型なのでバックグラウンドで実行されるので、アプリケーションスレッドを停止する必要がない
- old領域も複数のリージョンに分割されているので、使われているメモリを別のリージョンに移動するという形でコンパクト化を行っている
試してみる
ここまでで、GCの基礎をインプットしたので、実際にどんな感じでGCが発生しているのかを試してみました。
sbt(1.3.8) console上で、プログラムを書いてJVMのメトリクスを取得していきます。
sbtのJVMのチューニング
sbtを実行する配下に、
.jvmoptionsファイルを配置しておくと、そのファイルの中身をJVMのパラメータとして読み込まれます。.jvmopts-Xms1024M -Xmx1024M -Xss1024M -XX:MaxMetaspaceSize=1024M -XX:+UseSerialGC-Xms ・・・初期ヒープサイズ
-Xmx ・・・最大ヒープサイズ
-Xss ・・・スレッドスタックサイズ
-XX:MaxMetaspaceSize ・・・パーマネント領域のサイズ
-XX:+UseSerialGC ・・・GCアルゴリズムの指定(サンプルでは、シリアル型ガベージコレクタを指定しています)では、実際に
.jvmoptsに各項目の設定を行なって、プログラムを実行します。jvmのオプションは、上記の設定を同じ数値にします。
sbtプロセス~/jvm-test $ sbtjpsコマンドで、動いているjavaプロセスを確認できるので、上記で動かしたsbtのプロセスが存在することを確認する。
sbt-launch.jarが実行しているsbtのプロセスです。確認プロセス~/jvm-test$ jps 77057 sbt-launch.jar 56693 77100 Jps 3406 Main上記のプロセスでのGCメトリクスを表示します。
jstatコマンドでの-gcオプションを使うと、該当プロセスでのGCメトリクスを取得できます。
10はメトリクスを取得する間隔です。デフォルトの単位は、msになっています。~/jvm-test$ jstat -gc 77057 10実際にプログラムを書いて、gcメトリクスを取得していきます。
まず、プログラムを動かす前のGCメトリクスを確認します。➜ jvm_test jstat -gc 77057 S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT 34944.0 34944.0 0.0 0.0 279616.0 232912.0 699072.0 52034.1 59028.0 54605.4 7612.0 7243.9 0 0.000 3 0.157 0.157それぞれの詳しいことは、ドキュメントに書いています。
今回の分析をしていく中で、重要な物を書いていきます。S0C・・・Survivor領域0の現在の容量(KB)
S1C・・・Survivor領域1の現在の容量(KB)
S0U・・・Survivor領域0の利用率(KB)
S1U・・・Survivor領域1の利用率(KB)
EC・・・Eden領域の現在の容量(KB)
EU・・・Eden領域の現在の容量(KB)
YGC・・・若い世代のGCイベント数
FGC・・・古い世代のGCイベント数sbtプロセスを実行した段階では、まだオブジェクトは何も作成していないので、S0U・S1U・YGCは0になっています。
立ち上げた時点で、FGCの値は既に3になっているのですが、なぜかわかりません。。。またEUの値も0ではなく、プロセスを立ち上げた時点でEden領域のメモリは使われるのでしょうか。
以下のプログラムを動かしていきます。
1Mのオブジェクトをループで作成していきます。test.scalafor(i <- 0 to 1000) { val builder = new StringBuilder(1000000) }1秒間隔でメトリクスを取得しています。
~/jvm-test$ jstat -gc 77057 1000 S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT 34944.0 34944.0 0.0 0.0 279616.0 0.0 699072.0 52811.1 99532.0 86381.2 13556.0 12524.2 72 0.183 4 0.330 0.513 34944.0 34944.0 0.0 0.0 279616.0 0.0 699072.0 52811.1 99532.0 86381.2 13556.0 12524.2 111 0.246 4 0.330 0.575 34944.0 34944.0 0.0 0.0 279616.0 17278.5 699072.0 52811.1 99532.0 86381.2 13556.0 12524.2 151 0.308 4 0.330 0.637 34944.0 34944.0 0.0 0.0 279616.0 0.0 699072.0 52811.1 99532.0 86381.2 13556.0 12524.2 190 0.371 4 0.330 0.701EUとYGCの値が増えていることが確認できます。
上記のプログラムで作成したbuilerオブジェクトがまず、Eden領域に入り、その時点で走ったマイナーGCによって、Survivor領域には昇格せずに開放されているからです。次に、フルGCの確認をします。
フルGCを起こしやすいように、ヒープのサイズを以下のように小さく設定しておきます。.jvmopts-Xms100M -Xmx100M -Xss100M -XX:MaxMetaspaceSize=1024M今回実行するプログラムです。
test.scalaval builder1 = new StringBuilder(5000000)初めからEden領域の容量を超えるオブジェクトを作成します。
この場合、Eden領域には入らないので、いきなりold領域にオブジェクトが移動することになります。さらに、old領域の空き容量を超えているので、
フルGCを行なってからold領域に割り当てられます。~/jvm-test$ jstat -gc 87198 S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT 11264.0 11264.0 0.0 3961.1 11264.0 10713.2 68608.0 40401.1 95764.0 83780.1 13116.0 12384.1 43 0.114 3 0.166 0.279 10752.0 11264.0 10716.2 0.0 11264.0 274.5 68608.0 41973.0 98580.0 85517.2 13372.0 12405.6 48 0.131 4 0.268 0.399一行目と二行目で、FGCの値が違うのが確認できます。
ここで疑問なのが、YGCの値が43->48・S0Uの値も変化していることです。
つまりマイナーGCが実行され、もともとEdenにあったオブジェクトがSurvivor0領域に移動しています。
Eden領域以上のオブジェクトを割り当てようとすると、まずマイナーGCが走ってそれでもEden領域に入らなければ、old領域に割り当てられるというロジックなのかなと推測しています。まとめ
いろんな記事・ドキュメントを読んで、書いているロジック通りにはGCが動いていないように見えるところもありましたが、なんとなくGCに関して理解できました。
次回は、GCアルゴリズムでどのようにGC処理が違うのか、試したいと思います。
参考