- 投稿日:2020-03-29T23:07:59+09:00
静的サイトジェネレーター 11ty/eleventy をもっと使ってみる
はじめに
前回の記事で 11ty/eleventy(以下、11ty) の公式スタートガイドに則ってサンプルを作成してみました。
HTML テンプレートエンジン詰め合わせ 11ty/eleventy を使ってみる
上記の記事で紹介した内容は、スタートガイドによるファイル生成と front-matter を使用した機能のごく一部です。11ty の機能をさらに詳しく確認していくことが本記事の目的になります。
記事の概要
公式の スタータープロジェクト として、eleventy-base-blog というリポジトリが公開されています。
サンプルページはこちら。11ty を使用してブログコンテンツを含む静的サイトを構築する、というテンプレートページになっていますので、このページのソースを眺めつつ 11ty でできることを確認していきます。
前回記事で記述していますが、 11ty には CSS や JS ファイル周りのコンパイル/トランスパイルは含まれておらず、今回取り扱う eleventy-base-blog に関しても CSS, JS のコンパイル/トランスパイル環境は含まれていません。
CSS, JS の環境構築については後ほど別記事で記載予定です。ディレクトリ構成
HTML ファイルを生成する
.njkファイルと.mdファイル、.jsonファイルを中心にファイルを確認します。eleventy-base-blog/
├ _site/
├ package.json
├ .eleventy.js
├ _data/
| └ metadata.json
├ _includes/
| └ layouts/
| └ base.njk
| └ home.njk
| └ post.njk
| └ postslist.njk
├ index.njk
├ sample.njk (記事の都合上追加)
├ page-list.njk
├ archive.njk
├ tags.njk
├ tags-list.njk
├ 404.md
├ about/
| └ index.md
├ posts/
| └ posts.json
| └ firstpost.md
| └ secondpost.md
| └ thirdpost.md
| └ fourthpost.md
├ feed/
| └ feed.njk
| └ htaccess.njkこれらのファイルがコンパイルされることで、
_site/以下に HTML ファイルが生成されます。_site/の中身に関してはリストでは省略しています。
_includes/以下に保管したファイルは、コンパイル時に_site/に HTML ファイルが出力されません。特に設定がなければ、
index.njkはindex.htmlとして、
特定の名前のついたファイル(ex.archive.njk)はディレクトリ名をその名前としたindex.htmlファイルとして(ex.archive/index.html)出力されます。
出力される HTML のファイル名は、のちに述べる permalink の設定によって自由に変更することが出来ます。プロジェクトルート直下の
.eleventy.jsonは 11ty の動作に関する設定ファイルで、11ty の動作や入出力ディレクトリなどをカスタマイズしたい場合は主にこのファイルを触っていくことになります。また、eleventy-base-blog のリポジトリには元々存在しませんが、説明の便宜上
sample.njkを生成しています。こちらは本記事の説明の都合上追加したファイルですので、都度内容の変化するサンプルコードとして読んでいただければ幸いです。基本事項: YAML front-matterの参照
まず 11ty の基本的な使い方ですが、各ファイルに front-matter という記法で、変数やテンプレートファイルの読み込みを設定します。
front-matter は---で区切った YAML 形式で記述し、front-matter に記述した値は.njkファイルであれば、マスタッシュ記法{{}}にて参照することが可能です。sample.njk--- pageTitle: Hello 11ty txt: Hi --- <!doctype html> <html> <head> <title>{{ pageTitle }}</title> </head> <body> <p>{{ txt }}</p> </body> </html>このファイルは以下のように出力されます。
_site/sample/index.html<!doctype html> <html> <head> <title>Hello 11ty</title> </head> <body> <p>Hi</p> </body> </html>eleventy-base-blog のトップページを眺める
まずはトップページである
_site/index.htmlを生成するファイルを確認します。
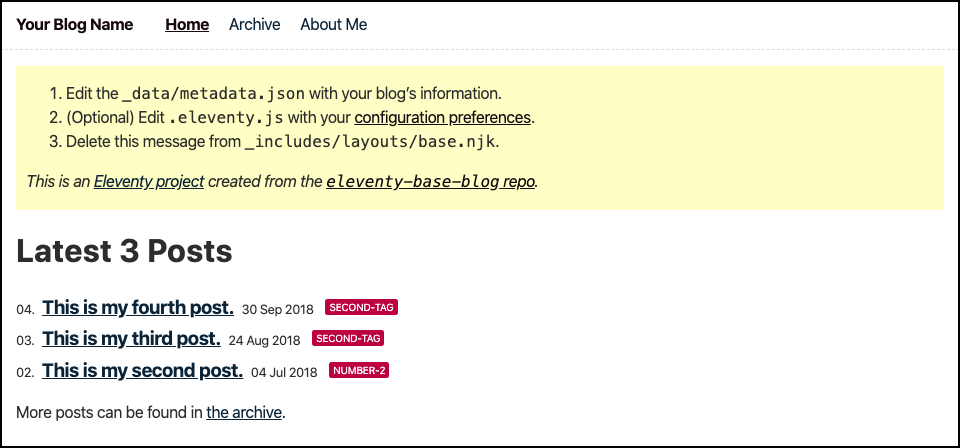
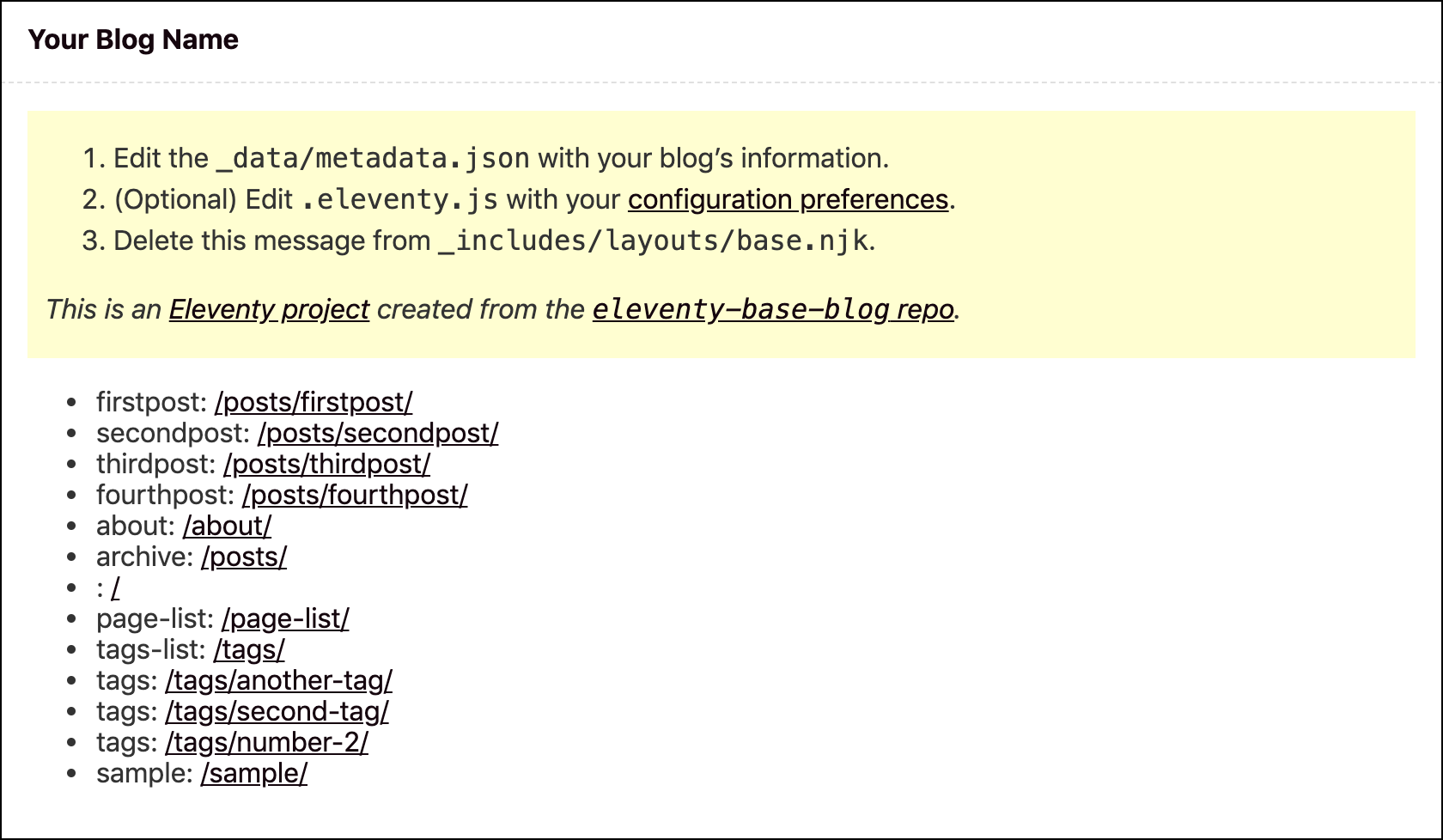
eleventy-base-blog のトップページは、以下キャプチャのようにブラウザで出力されます。
このトップページは以下のファイルから構成されています。
- base.njk
- home.njk
- index.njk
- postslist.njk
ページの中核を構成するのは
index.njkで、このファイルからテンプレートであるbase.njk,home.njk、インクルードファイルとしてpostslist.njkを読み込む、という形になっています。
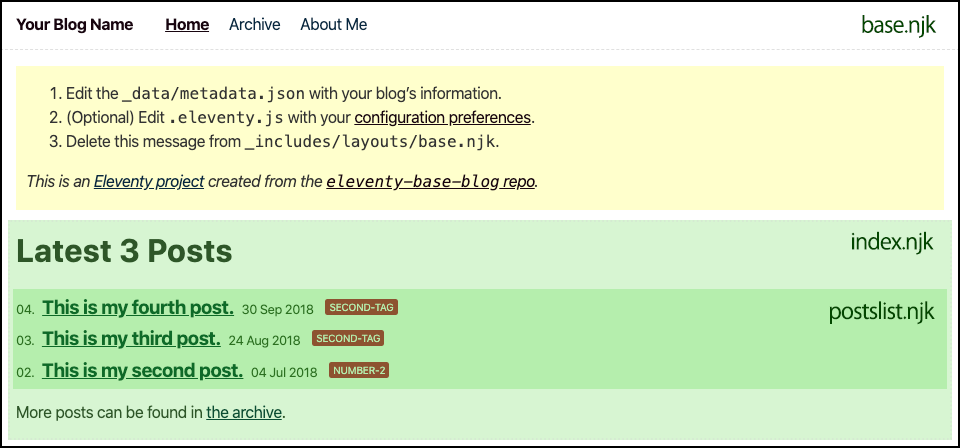
ブラウザ上の構成は以下キャプチャのようになります。
11ty によるテンプレート継承
layoutをキーとして_includes/内のファイルを指定することで、テンプレート継承を行うことができます。
eleventy-base-blog の index.html においては_include/layouts/home.njkをまずテンプレートとして指定しています。index.html--- layout: layouts/home.njk eleventyNavigation: key: Home order: 1 --- <h1>Latest 3 Posts</h1> {% set postslist = collections.posts | head(-3) %} {% set postslistCounter = collections.posts | length %} {% include "postslist.njk" %} <p>More posts can be found in <a href="{{ '/posts/' | url }}">the archive</a>.</p>
index/htmlのテンプレートとして指定されているhome.njkの中身はhome.njk--- layout: layouts/base.njk templateClass: tmpl-home --- {{ content | safe }}となっており、更に
base.njkをレイアウトとして持ちます。
front-matter に記載されているtemplateClass: tmpl-homeはbase.njkに渡り、<main>タグのクラス名条件分岐に使用されているようです。base.njk<!-- mainタグ部分 --> <main{% if templateClass %} class="{{ templateClass }}"{% endif %}> <div class="warning"> <ol> <li>Edit the <code>_data/metadata.json</code> with your blog’s information.</li> <li>(Optional) Edit <code>.eleventy.js</code> with your <a href="https://www.11ty.dev/docs/config/">configuration preferences</a>.</li> <li>Delete this message from <code>_includes/layouts/base.njk</code>.</li> </ol> <p> <em>This is an <a href="https://www.11ty.io/">Eleventy project</a> created from the <a href="https://github.com/11ty/eleventy-base-blog"> <code>eleventy-base-blog</code> repo</a>.</em> </p> </div> {{ content | safe }} </main>11ty では、このように入れ子構造でのテンプレート継承が可能です。
またbase.njkに渡されているtemplateClass: tmpl-homeのように、変数によってテンプレートの制御を行うこともできます。しかし 11ty の front-matter によるテンプレート継承では、 block 構文はサポートされていません。
11ty の front-matter ではなく、Nunjucks のテンプレート継承記法である{% extends %}でテンプレート継承を行うことで block 構文の使用が可能になりますが、こちらは front-matter との併用はできないようです。Eleventy Documentation: NUNJUCKS
SUPPORTED FEATURES
{% extends 'base.njk' %} looks in _includes/base.njk. Does not process front matter in the include file.JSON ファイルから変数を参照する
変数の管理は front-matter だけでなく、外部ファイルへの切り分けが可能です。
デフォルト設定ではプロジェクトルート直下の_data/内に保存された.jsonファイルはグローバルデータとして各ファイルから参照することができます。eleventy-base-blog では
_data/metadata.jsonがグローバルデータファイルとして保存されているので、base.njkのヘッダー部分を参考に、参照方法を確認してみます。base.njk<!--header部分--> <header> <h1 class="home"> <a href="{{ '/' | url }}">{{ metadata.title }}</a> </h1> {#- Read more about `eleventy-navigation` at https://www.11ty.dev/docs/plugins/navigation/ #} <ul class="nav"> {%- for entry in collections.all | eleventyNavigation %} <li class="nav-item{% if entry.url == page.url %} nav-item-active{% endif %}"> <a href="{{ entry.url | url }}">{{ entry.title }}</a> </li> {%- endfor %} </ul> </header>
h1タグ内の{{ metadata.title }}という記述にあるように、_data内のデータファイル名を含めて JSON オブジェクトを指定することで、グローバルデータを参照することができます。また、
_data/ディレクトリ外でも.11tydatafile.jsonという拡張子を用いて
- テンプレートファイル内のみで使用できるデータ(テンプレートデータファイル)
- ディレクトリ内で共通使用できるデータ(ディレクトリデータファイル)
を設定することができます。
11ty では一つのデータについて複数箇所で記述されている場合、影響範囲の狭いものが優先されます。
従って、グローバルデータファイル、テンプレートデータファイル、ディレクトリデータファイルに同じ変数についての記述があった場合、
テンプレートデータファイル(優先度 高) > ディレクトリデータファイル(優先度 中) > グローバルデータファイル(優先度 低) の順で反映されます。テンプレートデータファイルとして使用する場合
テンプレートファイル名と同様のファイル名.11tydatafile.jsonとして、テンプレートファイルと同じ場所に保存します。
eleventy-base-blog においての例としてはarchive.11tydatafile.jsonというファイルをプロジェクトルート直下に保存することでarchive.njk内のみで使用したいデータを JSON ファイルとして切り分けることができます。ディレクトリデータファイルとして使用する場合
ディレクトリ名と同様のファイル名.11tydatafile.jsonとして、使用したいディレクトリ直下に保存します。
eleventy-base-blog においての例としてはposts.11tydatafile.jsonというファイルをposts/に保存することで、posts/内のみで使用したいデータを JSON ファイルとして切り分けることができます。なお 11ty において
.mdファイルはデフォルトではliquidテンプレートとして前処理されるようで、マスタッシュ記法{{}}で変数を参照することができます。Eleventy Documentation: MARKDOWN
Markdown files are by default pre-processed as Liquid templates. You can change this default in your configuration file (or disable it altogether). To change this for a single template and not globally, read Changing a Template’s Rendering Engine.
パーマリンクを設定する
11ty のデフォルト設定では
index.njkはindex.htmlとして、
特定の名前のついたファイル(ex.archive.njk)は出力ディレクトリ名をその名前としたindex.htmlファイルとして(ex.archive/index.html)出力されます。
出力される URL やファイル名を制御したい場合、front-matter に permalink を指定します。archive.njkpermalink: /posts/上記の記述によって
archive.njkは_/site/post/index.htmlとして出力されます。
また、index.htmlではなくarchive.htmlとしたい場合は、拡張子を含め以下のように記述することができます。permalink: /posts/archive.html11ty の提供するデータを扱う
11ty がデフォルトで提供するデータとして、各ページに関するデータがあります。具体的には以下のデータが
pageオブジェクトとして保持されており、特別な設定無しでpageをキーに参照することができます。
- url : ページが出力されるURLが取得されます。
- fileSlug : 拡張子の除かれたソースファイル名が取得されます。1
- filePathStem : 拡張子の除かれたソースファイルのパスが取得されます。
- date : デフォルトではファイルの作成日が取得されます。2
- inputPath : ソースファイルのパスが取得されます。
- outputPath : 出力ファイルのディレクトリパスが取得されます。
日付を扱う
11ty では
{{ page.date }}でファイルの生成日や最終更新日を参照することができます。
例としてposts/firstpost.mdを取りあげますfirstpost.md--- title: This is my first post. description: This is a post on My Blog about agile frameworks. date: 2018-05-01 tags: - another-tag layout: layouts/post.njk ---上記の場合
{{ page.date }}で参照したデータはfirstpost.mdの front-matter で上書きされWed Jul 04 2018 09:00:00 GMT+0900 (日本標準時)が返されます。front-matter に date オブジェクトが無かった場合、11ty はデフォルトでファイルの作成日を返すようになっています。
また、日付ではなく date オブジェクトのプロパティとしてCreatedやLast Modifiedを指定することによって、ファイルの生成日や最終更新日を取得することができます。コレクションを使用する
11ty では作成した全てのページに関する情報を コレクション として保管します。
コレクションとして取得できるデータは以下のリストになります。
- inputPath : ソース入力ファイルへのフルパスが取得されます。
- fileSlug : 拡張子の除かれたソースファイル名が取得されます。1
- outputPath : 出力ファイルへのフルパスが取得されます。
- url : 各ページへのリンクに使用されるURLが取得されます。
- date : デフォルトではファイルの作成日が取得されます。2
- data : レイアウトから継承されたデータを含む、コンテンツのすべてのデータが取得されます。
- templateContent : レイアウトラッパーを含まない、テンプレートのレンダリングされたコンテンツが取得されます。
{{ collections.all }}で上記データオブジェクトを全ページ分取得することができます。
また、各ファイルの front-matter にtags: xxxを指定しておくことで、{{ collections.xxx }}によってtags: xxxを持つファイルに絞り込んだコレクションを取得できるようです。
sample.njkに、全ページのスラッグとURLを対応させたリストを出力する、簡単なサンプルコードを書いてみます。sample.njk--- layout: layouts/home.njk --- <ul> {% for post in collections.all %} <li> {{ post.fileSlug }}: <a href="{{ post.url }}">{{ post.url }}</a> </li> {% endfor %} </ul>以下キャプチャのように、各ページへのリンク集が作成されたかと思います。
ページネーションを使用する
eleventy-base-blog では
page-list.njkにて、各ページへのリンク集が作成されています。こちらは pagenation を使用しているようです。
ここでは特に front-matter に指定されている pagination オブジェクトに着目していきます。page-list.njk--- pagination: data: collections.all size: 20 alias: entries layout: layouts/home.njk permalink: /page-list/{% if pagination.pageNumber > 0 %}{{ pagination.pageNumber }}/{% endif %} --- <table> <thead> <th>URL</th> <th>Page Title</th> </thead> <tbody> {%- for entry in entries %} <tr> <td><a href="{{ entry.url }}"><code>{{ entry.url }}</code></a></td> <td>{{ entry.data.title }}</td> </tr> {%- endfor %} </tbody> </table>上記の
page-list.njkではdata: collections.allの記述によって、データソースをコレクションから20ページ分取得します。20ページ以上ある場合は
permalink: /page-list/{% if pagination.pageNumber > 0 %}{{ pagination.pageNumber }}/{% endif %}
の指定によって、次ページが自動生成されます。また、
alias: entriesの指定によって、colletions.allをentriesとして取得することができます。pagination の詳細な機能については公式ドキュメント PAGINATION のページをご参照ください。入出力ディレクトリ等の変更について
入出力のディレクトリ、グローバルデータディレクトリ等のパスは、11ty の設定ファイル
.eleventy.jsに設定を記述することで変更が可能です。
ディレクトリの設定はデフォルトでは以下のようになっています。
- 入力ディレクトリ(input): プロジェクトルート
- 出力ディレクトリ(output): _site
- インクルードディレクトリ(includes): _includes
- データディレクトリ(data): _data
以下のように dir オブジェクトを設定することで、これらの設定を上書きすることができます。
.eleventy.jsmodule.exports = { dir: { input: "views", output: "dist", includes: "my_includes", data: "lore" }, };他にも使用するテンプレートエンジンの設定やウォッチファーゲットの追加などの設定はこの
.eleventy.jsを変更することで行います。詳しくは公式ドキュメントの CONFIGURATION をご参照ください。感想
はじめに 11ty の使い方を確認していた時は「データが front-matter 一箇所にまとまって便利そうだなー」くらいに思っていたのですが、具体的な使用方法や設定方法、機能などを確認していくと、中〜大規模サイト構築に向けた機能があるだけでなく、環境構築の自由度が高く、柔軟性の高い静的サイトジェネレータであるという印象を持ちました。
自分の開発環境に合わせて、ディレクトリ構造のカスタマイズや SCSS のコンパイルなどと合わせた環境構築ができれば、静的サイト製作においてはかなり強力な静的サイトジェネレーターとして力を発揮してくれるのではないでしょうか。
次は現在の自身の開発環境に合わせて 11ty の環境構築を進めて行こうかと思っています。
ファイル名が
index.**となっている場合は親ディレクトリ名が返されます。詳細は ELEVENTY SUPPLIED DATA : fileSlug をご参照ください。 ↩詳細は CONTENT DATES をご参照ください。 ↩
- 投稿日:2020-03-29T21:16:31+09:00
読みやすいコードを書きたい!
この記事の趣旨
自分の学習のメモとして残します。
どなたかのお役に立てたら光栄です。こんな方におすすめです
・コードが見づらいと言われる
・初心に返りたい
このような方には何か発見があると思います。読みやすいコードとは?
ズバリ『良いコード』のこと。
良いコードは、他人がそのコードを見た時に短時間で理解できるコードのことを言います。逆に、分かりづらい・理解しづらいコードは解読に時間がかかります。それだけ開発の工数もかかってしまい、効率が良くありません。
では、良いコードの条件・要素を紐解いていきましょう!
●コードの命名に規則を
変数やメソッドは好きなように命名ができます。
ルールがありませんので、個人の好きなようにできます。
特に共同開発の現場などでは、「他人が見てわかる」を意識する必要があります。◎命名のポイント
【目的がわかる単語を使う】
例)new → new_account【汎用的な名前は避ける】
・一時的な変数などは避ける
・可読性を意識して【名前に情報を含める】
大文字、小文字をルールに沿って活用
【誤解されない名前を使う】
・何がしたいかが明確な名前
・説明的に長くなっても良いので、可読性重視
例)read_books → already_read_books●コードレイアウト
プログラムの挙動に影響はないが、可読性を大幅にあげることができる
◎レイアウトのポイント
・整列 :縦列を揃える。イコールの位置など縦が揃うと見やすい
・一貫性 :似たような構造は同じフォーマットに統一できないか検討
・ブロック化 :同じ系統の変数などをまとめてグループ化すること●コメント
・プログラムの動作を説明
・他の開発者がコードを読む際の理解を助ける
※多すぎても読むのに時間がかかるため、簡潔に◎コメントのポイント
・理由をコメントする :なぜそのコードを書いたか
・他の開発者へメモを残す:開発中のメモとして
・実際の例を記入する :コメントでは伝わりづらい時は、コメントとしてコードを記載まとめ
結局大事なことは
「人に対する思いやり」だなぁと。複数人で仕事をする以上、「自分だけ良ければそれで良い」という考えはNG。
誰もが見やすく、仕事をしやすい状況を自分が作り出す意識が大切。そのための知識や技術であると思う。
これからしっかり学んでいきましょう。
- 投稿日:2020-03-29T19:00:03+09:00
100日後にエンジニアになるキミ - 9日目 - HTML - HTMLの基礎4
HTMLの属性について
前回までであらかたタグの説明を行いました。
今回はタグに付けられる属性についてです。
HTML属性とは
HTMLの属性とは
HTMLのタグに対して何かしらの設定要素を付加するものです。特定のタグでしか使えないものと
全てのタグ共通で使えるもの(グローバル属性)があります。HTML属性の書き方
<タグ名 属性名="属性値" 属性名="属性値">タグを書いたら、その後ろにスペースを開けて
属性名を書き、属性値はイコール記号(=)を付けて書きます。属性値は引用符で囲み、引用符はダブルクォート
"を用います。主なグローバル属性
id
固有の名前を指定する属性(一般的に英数文字,先頭は数字以外同じidを使わない)class
分類名を指定する属性(一般的に英数文字,先頭は数字以外,スペースで区切りも有り)title
捕捉情報を指定する属性lang
言語を指定する属性style
スタイルを直接指定する属性(一般的にスタイルはCSSを用いるのが推奨)hidden
隠し属性 , コンテンツを隠す全てのタグで共通ですが、タグによっては効かないものもあります。
classやidなどはタグを管理するために使用するもので
id名(属性値)はHTMLの中では一意、class名は複数存在します。<div id="contentmain"> <div class="c1"> <div class="c1"> <p>コンテンツ</p> </div> </div> </div>cssではidやclassでデザインの適応箇所を決めたり
出し分けたりしています。スクレイピングではこの属性値を使って情報を取得するため
HTMLのタグと属性の構造を把握しておきましょう。タグ固有の属性
name
要素の名前,formやmetaタグなどでフィールドを識別のために使用するautoplay
audia,videoタグ,動画や音声が再生可能な時点で再生を開始するalt
imgタグなどの代替テキストdisabled
button , input , optionなどでコントロールを無効にするrequired
inputタグなどで必須よそを現すhref
a タグなどでリンク先を現すmaxlength
inputタグなどでの最大文字数minlength
inputタグなどでの最小文字数placeholder
inputタグなどでの入力ヒントselected
optionタグでの初期選択を現すsize
inputタグなどでのサイズ , 文字数に該当src
imgタグなどでのファイルなどのパス(URL)を指定するtype
inputタグなどでの要素の型を指定するvalue
inputタグなどでのデフォルト値を指定する※下記は指定できるがCSSでの対応が望ましい属性
width
imgタグなどで要素の幅height
imgタグなどで要素の高さcolor
fontタグなどでの色合いを指定border
imgタグなどでの境界線の幅bgcolor
bodyタグなどでの要素の背景色を指定するデザインに大きく関わる部分はHTMLでは直接指定をせずに
CSSファイル側でデザインを書いて適応させることがほとんどのため
HTML属性では指定しない方が良いかと思います。のちにCSSの方もやっていきますので
併せて覚えてください。まとめ
タグによって指定できる属性名、属性値が変わってくる。
ここに乗っていないものもあるので、あとは
自分で調べてみよう。君がエンジニアになるまであと91日
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython
- 投稿日:2020-03-29T17:01:20+09:00
Python × Flask × Tensorflow.Keras 猫の品種を予測するWebアプリ2
はじめに
Python × Flask × Tensorflow.Keras 猫の品種を予測するWebアプリで作ったPythonプログラムを変更しました。
変更内容
- 変更前
- 入力画像をファイル保存して扱う
- 変更後
- 入力画像をメモリに一時保存して扱う
変更ファイル
- sever.py
- 画像書き込み用バッファを確保
- 画像データをバッファに書き込む
- バイナリデータをbase64でエンコード
- utf-8でデコード
- 付帯情報を付与する
- HTMLに渡す
sever.pyfrom flask import Flask, render_template, request from tensorflow.keras.preprocessing.image import load_img from tensorflow.keras.models import load_model import numpy as np from image_process import examine_cat_breeds from datetime import datetime import os import cv2 import pandas as pd import base64 from io import BytesIO app = Flask(__name__) # モデル(model.h5)とクラスのリスト(cat_list)を読み込み model = load_model('model.h5') cat_list = [] with open('cat_list.txt') as f: cat_list = [s.strip() for s in f.readlines()] print('= = cat_list = =') print(cat_list) @app.route("/", methods=["GET","POST"]) def upload_file(): if request.method == "GET": return render_template("index.html") if request.method == "POST": # アプロードされたファイルをいったん保存する f = request.files["file"] #filepath = "./static/" + datetime.now().strftime("%Y%m%d%H%M%S") + ".png" #f.save(filepath) # 画像ファイルを読み込む # 画像ファイルをリサイズ input_img = load_img(f, target_size=(299, 299)) # 猫の種別を調べる関数の実行 result = examine_cat_breeds(input_img, model, cat_list) print("result") print(result) no1_cat = result[0,0] no2_cat = result[1,0] no3_cat = result[2,0] no1_cat_pred = result[0,1] no2_cat_pred = result[1,1] no3_cat_pred = result[2,1] # 画像書き込み用バッファを確保 buf = BytesIO() # 画像データをバッファに書き込む input_img.save(buf,format="png") # バイナリデータをbase64でエンコード # utf-8でデコード input_img_b64str = base64.b64encode(buf.getvalue()).decode("utf-8") # 付帯情報を付与する input_img_b64data = "data:image/png;base64,{}".format(input_img_b64str) # HTMLに渡す return render_template("index.html", input_img_b64data=input_img_b64data, no1_cat=no1_cat, no2_cat=no2_cat, no3_cat=no3_cat, no1_cat_pred=no1_cat_pred, no2_cat_pred=no2_cat_pred, no3_cat_pred=no3_cat_pred) if __name__ == '__main__': app.run(host="0.0.0.0")
- index.html
index.html<!DOCTYPE html> <html> <body> {% if no1_cat %} <img src="{{input_img_b64data}}" border="1" ><br> 予測結果<br> {{no1_cat}}:{{no1_cat_pred}}<br> {{no2_cat}}:{{no2_cat_pred}}<br> {{no3_cat}}:{{no3_cat_pred}}<br> <hr> {% endif %} ファイルを選択して送信してください<br> <form action = "./" method = "POST" enctype = "multipart/form-data"> <input type = "file" name = "file" /> <input type = "submit"/> </form> </body> </html>実行結果
画像は299×299で表示されます(モデルの入力サイズのまま・・・)

- 投稿日:2020-03-29T16:58:06+09:00
【曖昧さ回避】ブラウザレンダリングにおける「ファイルの読み込み」が意味するものとは
「ファイルの読み込み」とは
ブラウザレンダリングの仕組みを解説するサイトや書籍には、「ファイルを読み込んで〜」のような説明が多くあります。
自分がレンダリング工程を勉強しているときに、この「読み込み」という言葉がファイルのDownload(転送)を指すのか、ファイルのParse(解析)を指すのか、はたまたレンダリング全体のことを言っているのか、説明する場面によって意味が変わる曖昧な言葉だなーと感じていました。ここではブラウザレンダリングの仕組みについて、1.HTMLのみ、2.HTMLとCSS、3.HTMLとJavaScript、4.HTMLとCSSとJavaScriptの4パターンに分けて、レンダリングフローに定義された言葉に当てはめながら説明していきたいと思います。
(検証環境:Google Chrome バージョン: 80.0.3987.87)
ブラウザレンダリングの仕組みの大枠
ブラウザレンダリングのフローは大きく4つの工程に分けられ、それぞれの工程は更にいくつかの細かい工程に分けられます。
(参考:Webフロントエンド ハイパフォーマンス チューニング -久保田 光則 (著) )
- Loading(データのダウンロード・解析)
- Download
- Parse
- Scripting(JSの実行)
- Rendering(スタイルの計算、当て込み)
- Calculate Style
- Layout
- Painting(描画)
- Paint
- Rasterize
- Composite Layers
図を見ていると全ての工程がシリアル(直列)に進んでいくように誤解しやすいのですが、実際はそうではありません。
レンダリングエンジンがページ表示を最適化する中で、部分的にでも準備ができた段階で、都度次の工程に進むこともあります。本記事では主にLoading(Download、Parse)とScriptingの工程に関して、ファイルごとにどのように影響を及ぼし合い、レンダリングの処理順が決まっているかについて説明します。
RenderingやPaintingの工程を含むブラウザレンダリング全体の仕組みについては以下記事が詳しいです。
フロントエンジニアなら知っておきたいブラウザレンダリングの仕組みをわかりやすく解説! | LeapIn1.HTMLのみ
はじめに外部ファイル「読み込み」記述が一切ない純粋なHTMLファイルについて、
ブラウザ検索バーにURLを入力し、HTTPプロトコルで通信してページを表示する場合を考えます。
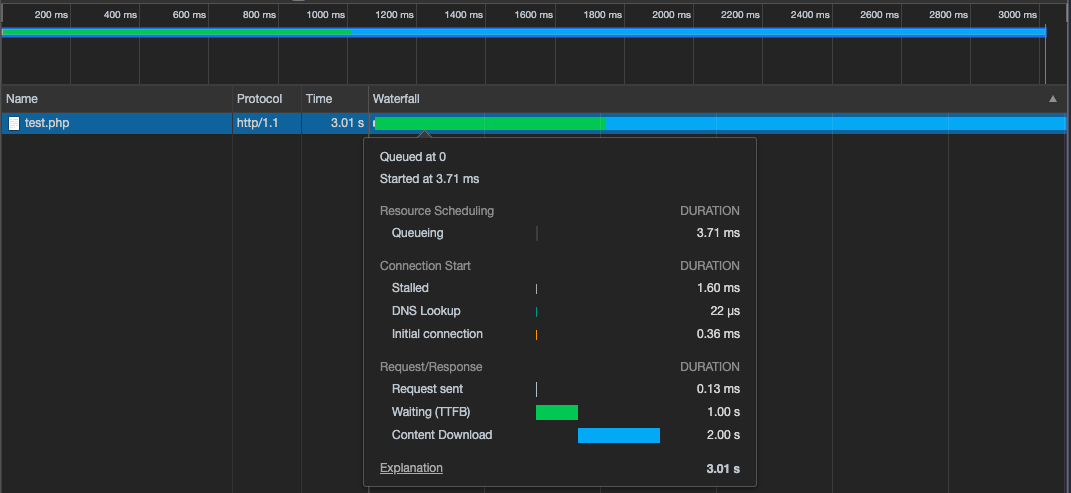
(参考:ネットワークやTCP/IPやHTTPの基本(初学者向け) - Qiita)レンダリングの工程としては、まずHTMLのDownloadが始まりますが、
ここでのポイントは、サーバからHTMLファイルなどのリソースが転送される手法は0か1の転送ではなく、
セグメントに分割しながら転送されるということです。
(どのくらいまとめて送るのかについてはサーバサイドで制御するようです)前提として、ブラウザはUX向上のため画面に何も表示されていない時間を短くするように動きます。
よって全てのHTMLDownloadが完了していなくても、転送されたHTMLセグメントを元にParse(DOMツリー構築)や後続の処理が進み、準備ができたDOMから画面描画が始まります。
上記はChrome DevToolsのNetworkパネルであり、一つのHTMLファイルをダウンロード完了するまでの解析図です。(テスト用にサーバサイド(PHP)でファイルの転送や解析速度を調整しています)Waiting(TTFB:Time To First Byte)とはファイル転送リクエストを送ってからクライアント側で最初のデータを受け取るまでにかかる時間(主にサーバサイドの処理時間)であり、Content Downloadとは最初のデータを受け取ってから全てのデータを受け取りきるまでにかかる時間です。
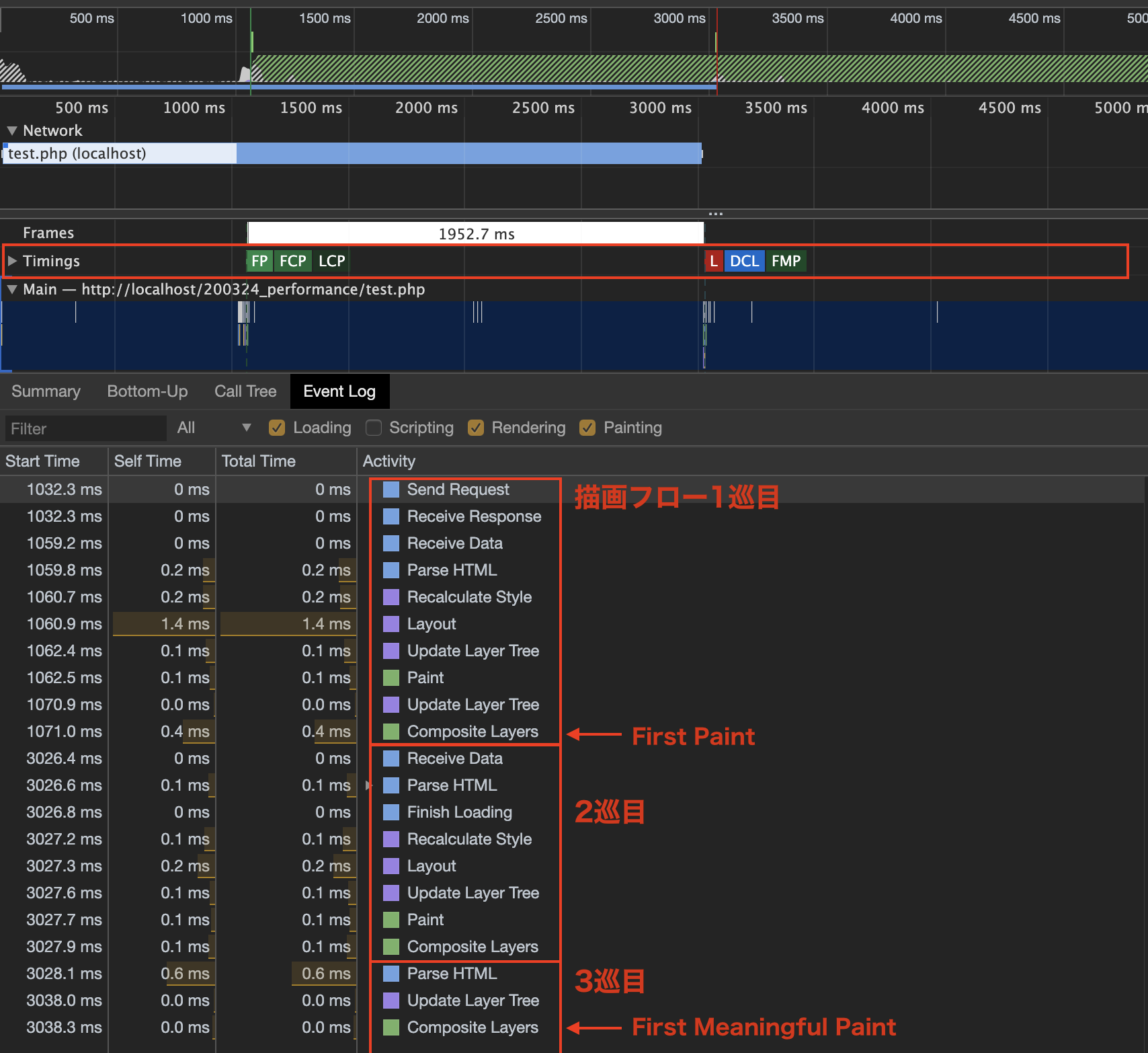
解析グラフによるとContent Downloadに合計2sかかっていますが、その間も転送されてきているデータを元に別の処理(Parse、Rendering、Painting)が都度進んで描画が始まっており、それは同Performanceパネルで解析することができます。↓
データを受け取る(Receive Data)たびに、HTMLParse(DOM構築)のフェーズを経て、Composite Layersまでの描画工程を完了していることが分かります。このように準備ができたところから都度描画が行われることで、First Paint(画面に最初になにかしらが描画されタイミング)や、First Meaningful Paint(画面に最初にユーザーに意味のある表示がされたタイミング)などの表示タイミング差が存在します。
参考:Ace the Lighthouse Audit: Best Practices for Consistent Interactivity | Lumavate
2.HTMLとCSS
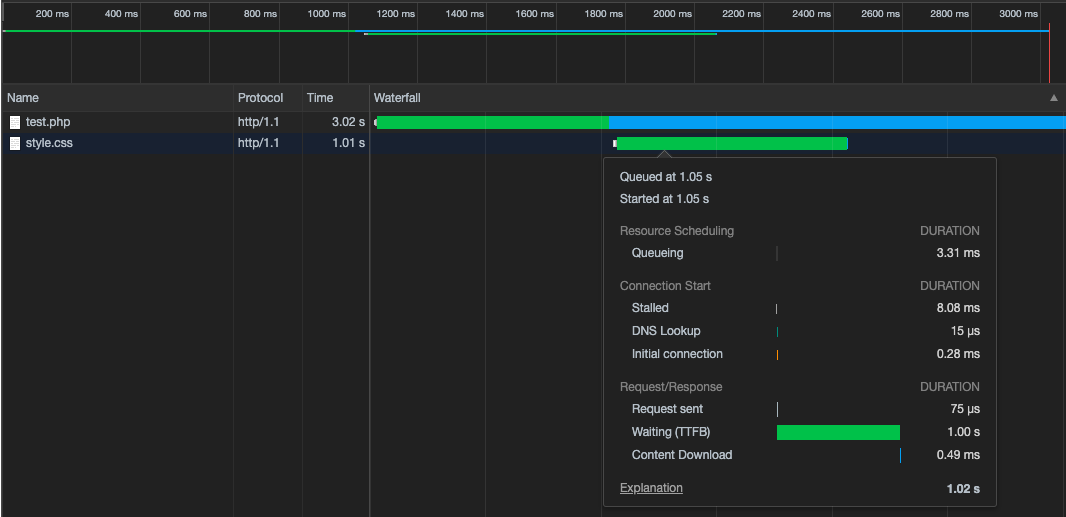
head要素の中のlink要素に外部CSS「読み込み」記述がある場合を考えます。HTML<!DOCTYPE html> <html> <head> <link rel="stylesheet" href="style.css" /> </head> <body> <!-- bodyの中身 --> </body> </html>CSSのDownload
この場合も、まずHTMLのDownload、Parseが始まり、解析途中で
link要素を見つけた段階でCSSのDownloadが始まります。↓
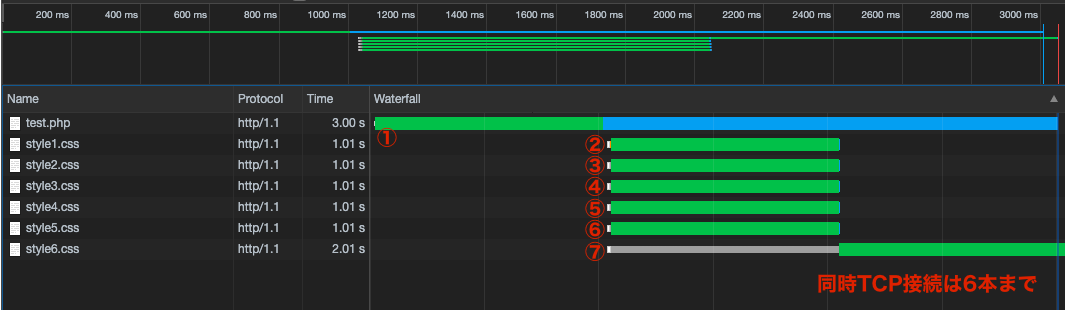
CSSのDownloadはHTMLのParseをブロックしないので、CSSDownload中もHTMLParseが並行して進みます。
そしてその先に再び外部CSS「読み込み」記述ががあれば、同時に複数のCSSDownloadが始まります。ただし、モダンブラウザでは(同じドメインの)TCP接続は同時に6本までという制限があるため、7本目以降の接続は前の接続の終了を待ってからとなります。
見ての通りこれではダウンロードしたいファイルが多いほどページ表示速度が遅くなってしまいます。そのため、対応策としてファイルを可能な限りまとめてリクエスト必要数を抑えたり、CDNなどを利用してあえて別ドメインから接続することでスループットを上げたり、一つのTCP接続で同時に複数のリクエスト/レスポンスを処理できるhttp/2プロトコルで通信するなどの手法が存在します。
参考:そろそろ知っておきたいHTTP/2の話 - Qiita
CSSのParse
CSSもHTMLと同様にDownloadの次の工程として、Parse(CSSOMの構築)の工程があります。
考慮すべき注意点は以下です。
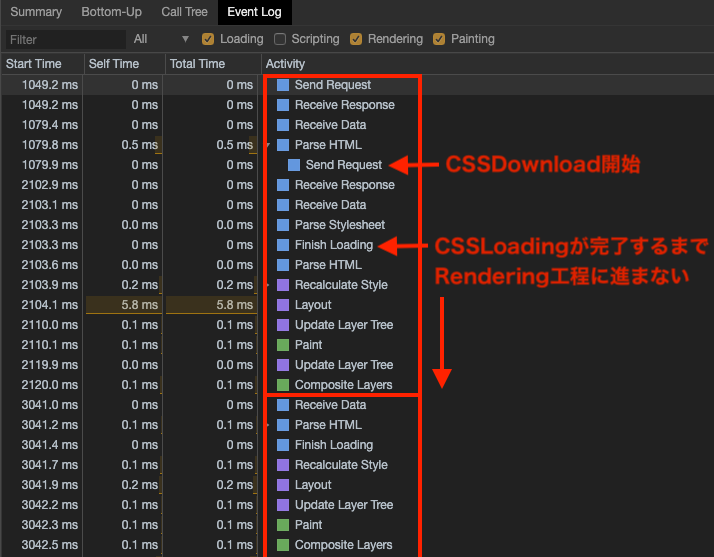
- CSSParseは見かけ上はHTMLParseと並行して行われる。
- HTMLは描画工程に進もうとするDOMの、直前までに記載されているCSSのLoading(Download、Parse)が完了しない限り、Renderingフローに進まない。(描画処理が行われない)
HTMLParseとCSSParseはどちらもレンダリングエンジンのmainスレッドで行われますが、mainスレッドでは同時に一つの処理しか行えないため、それぞれの処理が同時に走ることはありません。
ですが、HTMLParseのアイドル時間などにCSSParseが進むため、見かけ上は2つが並行して行われているように見えます。
(そもそもCSSParseにかかる時間はブラウザレンダリング全体の時間からすると極めて短く、議論に上がりにくい部分のようです。)また、CSSのLoadingが進行中の場合は、たとえHTMLParseが先に完了していてもRenderingなどの次の工程に進まず、結果として画面描画が行われません。
これはブラウザがFOUC(Flash of Unstyled Contentの略。スタイルがついていないコンテンツが一瞬表示されること)を防ぐために、CSSParseの完了を待ってスタイルが適応された画面描画を行おうとするためです。
上記Performanceパネル解析図を見ても、Finish Loading(CSSParseの完了)まで、Calculate StyleなどのRendering工程に進んでいない(画面描画が行われていない)ことが分かります。3.HTMLとJavaScript
以下のように
head要素の中にscript要素を記述して、外部JavaScriptファイルを「読み込む」場合を考えます。HTML<!DOCTYPE html> <html> <head> <script src="main.js"></script> </head> <body> <!-- bodyの中身 --> </body> </html>JSのDownloadとScripting
HTMLParseが始まって
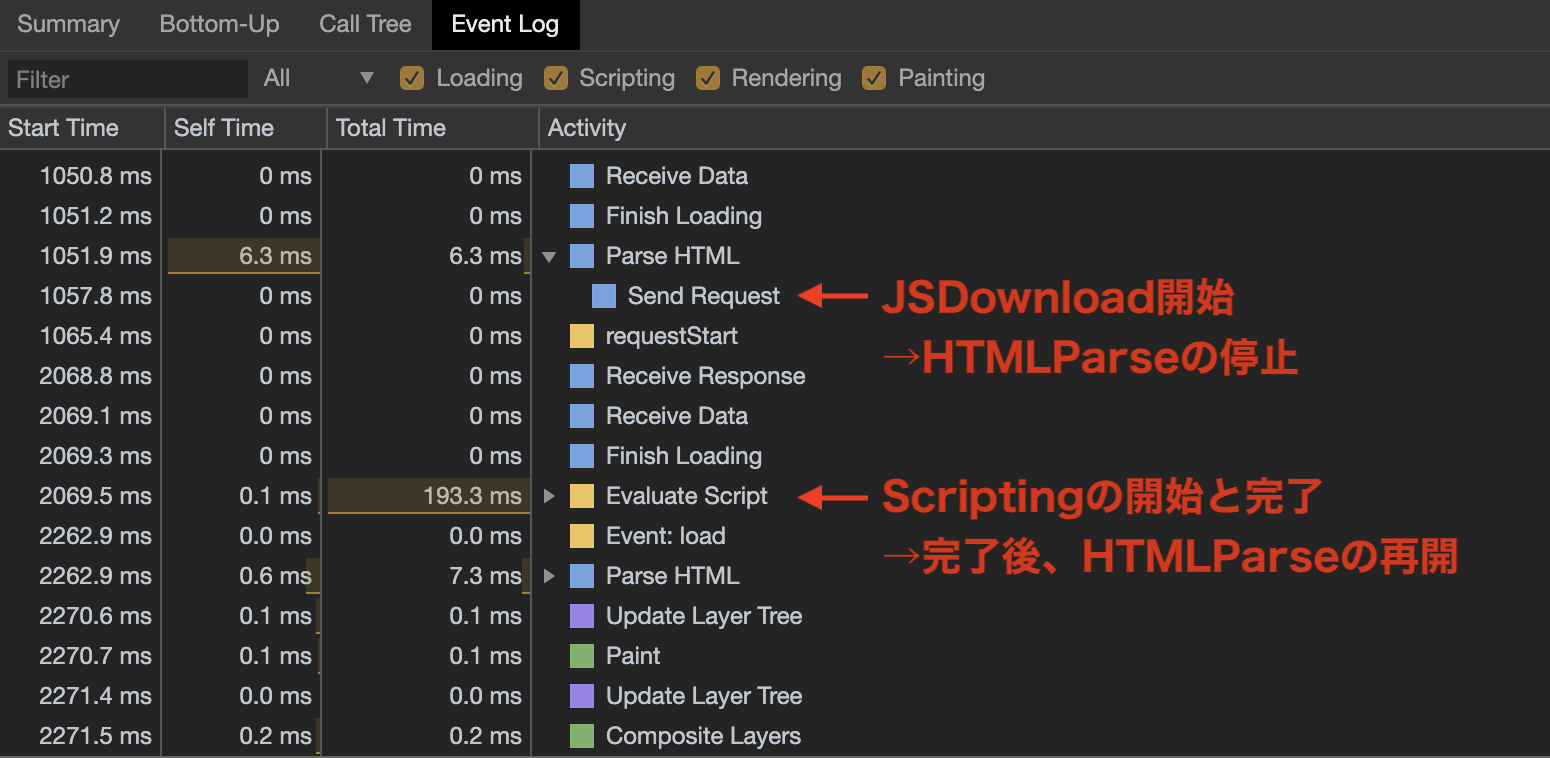
script要素に到達するとJSのDownloadが始まります。
その時に重要なポイントが、JSのDownloadとScripting(実行)はHTMLParseをブロックするということです。一度JSのDownloadが始まると、ダウンロードしたJSのScripting工程が完了しない限り、それ以降のHTMLParseが行われません。
これが、JSの記述はbodyの最後に記述するべきと言われる理由の一つです。
上記図より、Send RequestでJSDownloadが始まると、Evaluate Script工程が完了するまでHTMLParseが行われていないことが分かります。async属性とdefer属性
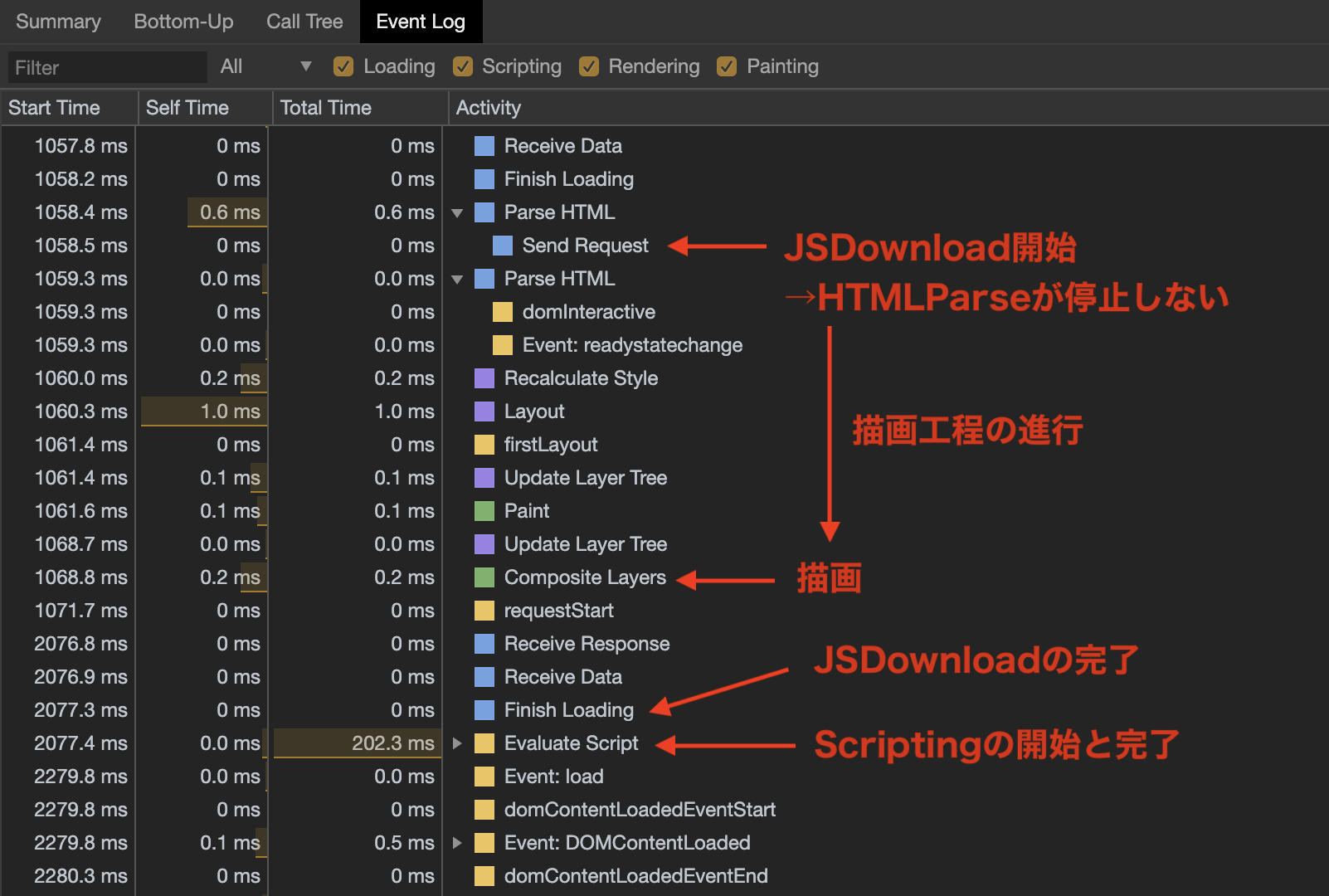
script要素によるJSの「読み込み」記述はそれ以降のHTMLParseをブロックしますが、script要素にasyncやdeferの属性をつけることによってJSのDownloadを非同期に行い、HTMLParseと同時に処理することができます。HTML<script src="main.js" async ></script> <!-- もしくは --> <script src="main.js" defer ></script>以下は先程と同じ記述で、
defer属性を使用したときのPerformanceパネルの解析結果です。
JSのDownloadが開始(send Request)しても、HTMLParseがブロックされずに先の工程に進み、最終的にComposite Layersまで完了して画面描画が行われているのが分かります。
その後JSのDownloadが完了した段階で、Scripting(Evaluate Script)処理が行われています。参考:scriptタグに async / defer を付けた場合のタイミング - Qiita
4.HTMLとCSSとJavaScript
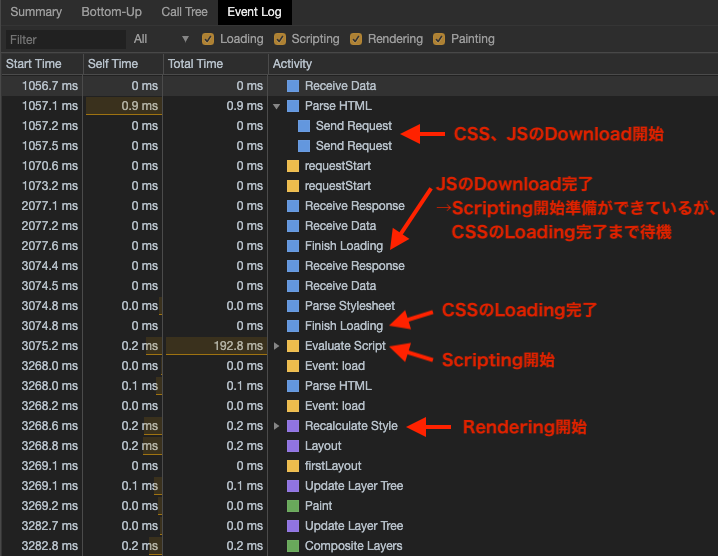
CSSとJavaScriptの両方の「読み込み」記述を書く場合です。
以下のようにlink要素の直下にscript要素を入れてみます。HTML<!DOCTYPE html> <html> <head> <link rel="stylesheet" href="style.css" /> <script src="main.js"></script> </head> <body> <!-- bodyの中身 --> </body> </html>CSSDownloadはHTMLParseをブロックしないため、HTMLParseは
script要素の記述に到達しJSのDownloadが始まります。
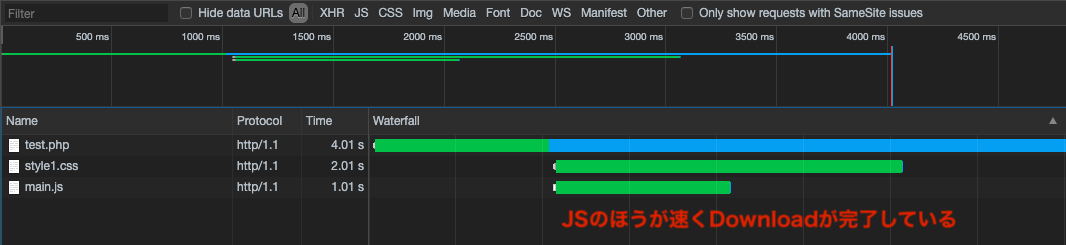
先程「HTMLは直前までのCSSLoading(Download、Parse)が完了していない限り、Renderingフローに進まない」と説明しましたが、実は同様にJSも直前までのCSSLoading(Download、Parse)が完了していない限り、Scriptingの工程に進まない性質があります。つまりこの場合、CSSよりもJSのほうが速くDownloadが完了したとしても、CSSParseが完了するまでScriptingが待機状態になるということです。
↑JSのほうがCSSよりも1s速くDownloadが完了していますが、
↑CSSのLoading(Download、Parse)完了を待ってから、Scripting(Evaluate Script)処理が実行されていることが分かります。参考:DOMContentLoaded周りの処理を詳しく調べてみました - Qiita
ブラウザのプリロード機能
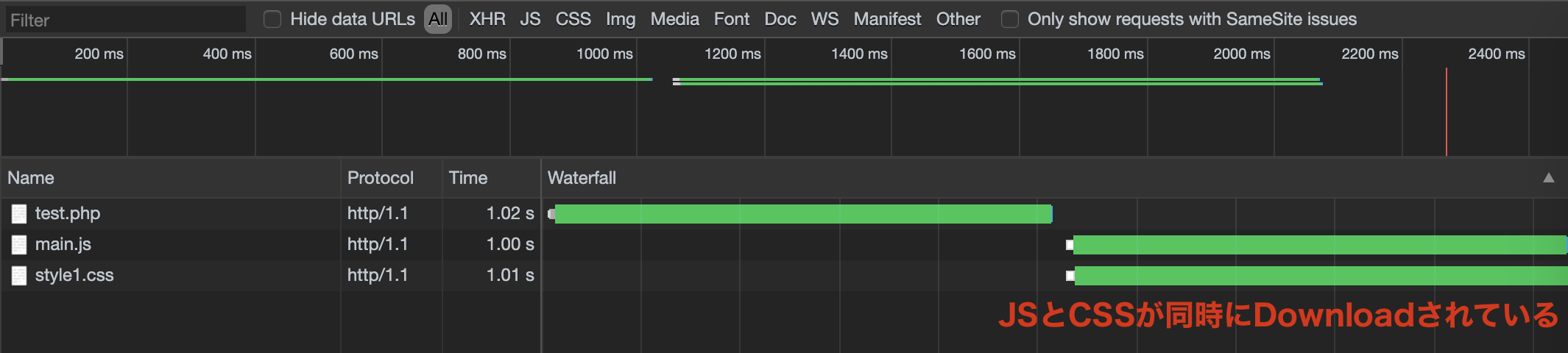
以下のようにJSの「読み込み」記述をCSSよりも前に書いた場合を考えます。
HTML<!DOCTYPE html> <html> <head> <script src="main.js"></script> <link rel="stylesheet" href="style.css" /> </head> <body> <!-- bodyの中身 --> </body> </html>
defer属性やasync属性がついていないscript要素による外部JSファイルの「読み込み」なので、JSのDownload、Scriptingが完了するまでそれ以下のHTMLParseが進まない、つまりCSSDownloadも進まないはずです。しかし、モダンブラウザではその限りではありません。
NetWorkパネルを見てみると、JSとCSSのDownloadが同時に行われていることが分かります。
実はChromeなどのモダンブラウザには、HTMLParseが進んでいない部分についてもDownloadが必要な記述がないか確認し、もしあれば事前にそのファイルのDownloadを開始する機能があります。(Preload Scanner)よってこの場合も、ブラウザはJSのDownload中にその先にあるCSSの「読み込み」記述を読み取り、CSSDownloadも同時に進めることでレンダリングを高速化しているのです。
※Preload Scanner機能で事前処理できるのはDownloadの工程だけです。ParseやScriptingの工程は本来のレンダリングフローに沿って行われます。
参考:rel="preload"を極めるために必要な2種類のプリロード機能 | Raccoon Tech Blog
まとめ
- HTMLはセグメントごとにDownloadが行われ、都度Parseなどの先の工程に進む
- CSSのDownloadはHTMLのParseをブロックしない
- CSSのParseは見かけ上はHTMLParseと並行して行われる
- HTMLは直前までのCSSLoading(Download、Parse)が完了していない限り、Renderingの工程に進まない
- JSのDownloadとScripting(実行)はHTMLのParseをブロックする
- JSも直前までのCSSLoading(Download、Parse)が完了しない限り、Scriptingの工程に進まない
誤った解釈等ございましたら、ご教授お願いいたします。。
参考
- Webフロントエンド ハイパフォーマンス チューニング -久保田 光則 (著)
- フロントエンジニアなら知っておきたいブラウザレンダリングの仕組みをわかりやすく解説! | LeapIn
- ネットワークやTCP/IPやHTTPの基本(初学者向け) - Qiita
- Ace the Lighthouse Audit: Best Practices for Consistent Interactivity | Lumavate
- そろそろ知っておきたいHTTP/2の話 - Qiita
- scriptタグに async / defer を付けた場合のタイミング - Qiita
- DOMContentLoaded周りの処理を詳しく調べてみました - Qiita
- rel="preload"を極めるために必要な2種類のプリロード機能 | Raccoon Tech Blog
- フロントエンドのパフォーマンスを徹底解説!ブラウザの気持ちで理解するHTML/Javascript/CSSの話 | Raccoon Tech Blog