- 投稿日:2020-03-25T23:27:02+09:00
自動更新
自動更新の機能
①何秒かおきに、JavaScriptを使ってブラウザに表示されているメッセージのうち最も新しいもののidをリクエストとして送る
②Railsのコントローラのアクションにてデータベースに保存されている最新のメッセージのidと①のidを比較し、①のidよりも大きいidを持つメッセージたちをレスポンスする
③JavaScriptを使って、レスポンスに含まれるメッセージたちをメッセージ一覧の最後に追加する表示されているメッセージのidの確認
jQueryを使って表示されている最新メッセージのidを取得できるようにします。そのため今回はmessagesテーブルとし、messagesテーブルのidを、HTMLの中に埋め込みます。
その時に利用できるのがカスタムデータ属性です。カスタムデータ属性
カスタムデータ属性とは、HTMLタグの属性の1種です。
【例】xxxx.html<p class="first-message">例えば、上記の例はpタグにclass属性を設定しています。このように、あるタグを使う時に情報を付加するために使用するものです。
属性として設定できる項目はタグごとに決まっていますが、自由に追加することができる属性がカスタム属性です。
【例】xxxx.html<p class="first-message" data-messege-id=120>カスタムデータ属性を使うときは、属性名を「data-」で始まる名称にします。
上記のように記述すれば、「message-id」という名前のカスタムデータ属性を設定できたことになります。
data-任意の名前=任意の値と書き、カスタムデータ属性を設定しておくことで、JavaScriptから簡単に値を取得できます。
jQueryでは、取得したDOMに対しdataというメソッドを利用することで、カスタムデータ属性の値を取得可能です。
【例】xxxx.html<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <script src="http://code.jquery.com/jquery-1.4.3.min.js"></script> </head> <body> <!-- カスタムデータ属性 --> <section id="blog" data-author="Taro" data-create-date="2013-04-10"> <h1>Hello World!</h1> <p>This is a sample text.</p> </section> <script> var blog = $("#blog"); //jQueryでカスタムデータ属性の値を取得 alert("author : " + blog.data('author')); alert("create date : " + blog.data('create-date')); </script> </body> </html>メッセージのidをカスタムデータ属性として追加
hamlの場合、カスタムデータ属性をつけます。
【例】example.haml%div{data: {message: {id: '1'}}} # 上記の記述で、以下のようにカスタムデータ属性が反映される # → <div data-message-id='1'>【例】_message.html.hamlの場合
_message.html.haml.message{data: {message: {id: message.id}}} # 以下省略新規投稿を取得できるよう
次に、今表示されているメッセージよりも新しい投稿があるのか確認する機能を追加します。確認するためには、以下の2つの機能が必要です。
①コントローラーに、新規投稿を確認するアクションがあること
②①のアクションを呼び出す仕組みがあること
ここでは、先に①の機能を実装していきます。
新規メッセージがあるか確認し、追加されている場合はそのデータを返すアクションを作成します。
このような、リクエストに対してJSONなどのデータを返すアクションはWebAPIで実装します。WebAPIとは
WebAPIはAPIの一種です。
まずAPIとは、アプリケーション開発者が外部に向けてアプリケーションの機能の一部を公開する仕組みです。
例えばTwitterのAPIを使用すれば、Twitterアプリを使うことなくつぶやきの情報を取得するなどの機能を使うことができます。
WebAPIは、HTTPやHTTPS通信を通じて利用するAPIのことです。例えば天気情報を公開しているAPIであれば、ブラウザのURL欄に必要なアドレス等を入力すればデータを取得することができます。apiディレクトリおよびコントローラを作成
APIとして機能するコントローラーを作成していきます。
①controllersディレクトリ直下にapiディレクトリを作成します。
②そのフォルダの中に今回はmessages_controller.rbというファイルを新規作成します。既存で同じ名前があっても、別に作成する必要があります。
③新規作成したapi/messages_controller.rbの中身を以下のように編集します。
【例】app/controllers/api/messages_controller.rbclass Api::MessagesController < ApplicationController def index end endRubyのクラス名は、一行目のように::で繋げて装飾することができます。これを、名前空間またはnamespaceといいます。
###名前空間(namespace)
名前空間をつけることにより、同様のクラス名で名付けたクラスを作ってもそれらを区別することができます。今回の場合はcontrollers/messages_controller.rbとcontrollers/api/messages_controller.rbが存在するとします。ですが、ディレクトリを分けているおかげで区別できます。
ただし、プログラムがクラスを判別する際はどのディレクトリに入っているかでの判別はできないため、名前空間を利用するルールになっています。こうすることで、Railsは間違えることなく2つのコントローラを区別するようプログラムされています。
イメージとしては、同じ苗字の人がいたとしても、部署名などをつければ該当者が一人になるこという感じです。indexアクションの完成
indexアクションの中には、新規で投稿されたメッセージのみをDBから取得する処理を書きます。
ビューに表示されている最新メッセージのidが送られてくる(後ほど実装します)ので、そのidより新しい投稿があるかをチェックします。whereメソッドを使ってidを検索条件にします。
【例】今回はMessageモデルとGroupモデルがあるとしますapp/controllers/api/messages_controller.rbclass Api::MessagesController < ApplicationController def index # ルーティングでの設定によりparamsの中にgroup_idというキーでグループのidが入るので、これを元にDBからグループを取得する group = Group.find(params[:group_id]) # ajaxで送られてくる最後のメッセージのid番号を変数に代入 last_message_id = params[:id].to_i # 取得したグループでのメッセージ達から、idがlast_message_idよりも新しい(大きい)メッセージ達のみを取得 @messages = group.messages.includes(:user).where("id > ?", last_message_id) end end次は、このアクションを呼び出すためのルーティングを設定します。
今回のようにnamespaceを使ったコントローラファイルをルーティングから指定する際は、以下のように書きます。namespace :ディレクトリ名 do ~ endroutes.rb〜省略〜 namespace :api do resources :messages, only: :index, defaults: { format: 'json' } end 〜省略〜namespace :ディレクトリ名 do ~ endと囲む形でルーティングを記述すると、そのディレクトリ内のコントローラのアクションを指定できます。
defaultsオプションを利用して、このルーティングが来たらjson形式でレスポンスするよう指定しています。
routes.rbの書き方については他にもオプションがあります。
参考記事
Railsのルーティングを極める (後編)
Railsのルーティング投稿内容のレスポンス
json形式でレスポンスするためのファイルを作成します。内容としては
①viewsフォルダに「api」フォルダを作成します
②apiフォルダに「messages」フォルダを作成します
③messagesフォルダ内に「index.json.jbuilder」を作成します
④index.json.jbuilderファイルを編集しますapp/views/api/messages/index.json.jbuilderjson.array! @messages do |message| json.content message.content json.image message.image.url json.created_at message.created_at.strftime("%Y年%m月%d日 %H時%M分") json.user_name message.user.name json.id message.id endメッセージは複数投稿されている可能性があるため、配列形式でarray!メソッドを使用してJSONを作成します。
jBuilderの設定
views/messages/create.json.jbuilderjson.content @message.content json.image @message.image.url json.created_at @message.created_at.strftime("%Y年%m月%d日 %H時%M分") json.user_name @message.user.name #idもデータとして渡す json.id @message.id取得した投稿データを表示
作成したアクションを動かすリクエストを実装します。まず、最新のメッセージのidを取得できていることを確認し、次にreloadMessagesという名前で関数を作成して、あとでこのメソッドを呼び出す想定で作成します。
最新メッセージのidを取得できることを確認
新規投稿だけを取得できるようにするには、今表示されている最新メッセージのidを取得する必要があります。
最初に、このidを取得できるか実験的にコードを記述します。コンソールで最新メッセージのidが取得できているかを確認します。message.js$(function(){ var last_message_id = $('.message:last').data("message-id"); console.log(last_message_id); 〜省略〜 })確認したら、このコードは一旦消します。
$('.message:last')
jQueryのオブジェクトの指定方法の1つに、:lastがあります。今回の場合は.messageというクラスがつけられた全てのノードのうち一番最後のノード、という意味になります。
1つ1つのメッセージが表示されているdivには.messageというクラスがついており、最新のメッセージは一番下、つまりページの中でも最後のノードということになります。これを利用して、一番最後のメッセージのidを取得しています。
ブラウザの検証ツールでデータベース上のidと同じidが表示されていることも確認します。message.jsの編集
次にjQueryからAPIを呼び出せるようにします。このロジックはreloadMessagesという名前で関数を作成してその中に書いていくことにします。
APIを呼ぶには正しいURLにリクエストを送信する必要があります。まず「どのURLをリクエストしたいのか」を確認します。
今回リクエストしたいのは/groups/id番号/api/messagesとします。
ajax関数のurlに何も指定しなかった場合、リクエストのURLは現在ブラウザに表示されているパスと同様になります。つまり今回の場合は、groups/id番号となります。
対してurlに文字列で値を指定すると、パスを指定することができます。今回の場合は相対パスで書くことで、自動的に現在ブラウザに表示されているURLの後に繋がる形になります。例えば現在のURLがgroups/3/messagesとして、urlに"hoge"と指定すればリクエストのURLはgroups/3/hogeとなります。
この法則を考えつつ、文字列で相対パスとなるようURLを指定します。
【例】message.js$(function() { 〜省略〜 var reloadMessages = function() { //カスタムデータ属性を利用し、ブラウザに表示されている最新メッセージのidを取得 var last_message_id = $('.message:last').data("message-id"); $.ajax({ //ルーティングで設定した通り/groups/id番号/api/messagesとなるよう文字列を書く url: "api/messages", //ルーティングで設定した通りhttpメソッドをgetに指定 type: 'get', dataType: 'json', //dataオプションでリクエストに値を含める data: {id: last_message_id} }) .done(function(messages) { console.log('success'); }) .fail(function() { alert('error'); }); }; });取得した最新のメッセージをブラウザのメッセージ一覧に追加します。
これまで作っているbuildHTMLメソッドを編集して、非同期で追加されるメッセージのHTMLにもdata-messege-idという名前のカスタムデータ属性をつけます。こうすることで、非同期で追加されるメッセージにもidを与えることができます。
【例】message.js〜省略〜 var buildHTML = function(message) { if (message.content && message.image) { //data-idが反映されるようにしている var html = `<div class="message" data-message-id=` + message.id + `>` + `<div class="upper-message">` + `<div class="upper-message__user-name">` + message.user_name + `</div>` + `<div class="upper-message__date">` + message.created_at + `</div>` + `</div>` + `<div class="lower-message">` + `<p class="lower-message__content">` + message.content + `</p>` + `<img src="` + message.image + `" class="lower-message__image" >` + `</div>` + `</div>` } else if (message.content) { //同様に、data-idが反映されるようにしている var html = `<div class="message" data-message-id=` + message.id + `>` + `<div class="upper-message">` + `<div class="upper-message__user-name">` + message.user_name + `</div>` + `<div class="upper-message__date">` + message.created_at + `</div>` + `</div>` + `<div class="lower-message">` + `<p class="lower-message__content">` + message.content + `</p>` + `</div>` + `</div>` } else if (message.image) { //同様に、data-idが反映されるようにしている var html = `<div class="message" data-message-id=` + message.id + `>` + `<div class="upper-message">` + `<div class="upper-message__user-name">` + message.user_name + `</div>` + `<div class="upper-message__date">` + message.created_at + `</div>` + `</div>` + `<div class="lower-message">` + `<img src="` + message.image + `" class="lower-message__image" >` + `</div>` + `</div>` }; return html; }; 〜省略〜reloadMessages関数からもHTMLを組み立てる関数を呼ぶようにします。
message.js$(function() { 〜省略〜 var reloadMessages = function() { //カスタムデータ属性を利用し、ブラウザに表示されている最新メッセージのidを取得 var last_message_id = $('.message:last').data("message-id"); $.ajax({ //ルーティングで設定した通りのURLを指定 url: "api/messages", //ルーティングで設定した通りhttpメソッドをgetに指定 type: 'get', dataType: 'json', //dataオプションでリクエストに値を含める data: {id: last_message_id} }) .done(function(messages) { //追加するHTMLの入れ物を作る var insertHTML = ''; //配列messagesの中身一つ一つを取り出し、HTMLに変換したものを入れ物に足し合わせる $.each(messages, function(i, message) { insertHTML += buildHTML(message) }); //メッセージが入ったHTMLに、入れ物ごと追加 $('.messages').append(insertHTML); }) .fail(function() { alert('error'); }); }; });数秒ごとにリクエストするように実装
jQueryには、一定時間が経過するごとに処理を実行することができる関数があります。それがsetInterval()関数です。
setInterval()関数
第一引数に動かしたい関数名を、第二引数に動かす間隔をミリ秒単位で渡すことができます。
今回は、reloadMessages関数を数秒おきに呼び出します。
【例】message.js$(function() { 〜省略〜 //$(function(){});の閉じタグの直上(処理の最後)に以下のように追記 setInterval(reloadMessages, 7000); });引数で渡している7000という数字は、7秒という意味になります。500にすると、0.5秒です。
メッセージを取得したら画面がスクロールできるように
スクロールを行うにはjQueryのanimate関数を利用します。
コードを追加する場所は、非同期通信が成功した場合行う処理の最後にします。
また更新するメッセージがなかった場合は.doneの後の処理が動かないよう、条件分岐を追加しています。さらに、フォームの中身を空にして、フォームを再度送信できるようにする処理も追記します。
【例】message.js$(function() { 〜省略〜 var reloadMessages = function() { //カスタムデータ属性を利用し、ブラウザに表示されている最新メッセージのidを取得 var last_message_id = $('.message:last').data("message-id"); $.ajax({ //ルーティングで設定した通りのURLを指定 url: "api/messages", //ルーティングで設定した通りhttpメソッドをgetに指定 type: 'get', dataType: 'json', //dataオプションでリクエストに値を含める data: {id: last_message_id} }) .done(function(messages) { if (messages.length !== 0) { #追加 //追加するHTMLの入れ物を作る var insertHTML = ''; //配列messagesの中身一つ一つを取り出し、HTMLに変換したものを入れ物に足し合わせる $.each(messages, function(i, message) { insertHTML += buildHTML(message) }); //メッセージが入ったHTMLに、入れ物ごと追加 $('.messages').append(insertHTML); $('.messages').animate({ scrollTop: $('.messages')[0].scrollHeight}); #追加 } #追加 }) .fail(function() { alert('error'); }); }; });自動更新が必要ない画面では行わないように
jQueryは今のところ全てのページにて発火するため、どの画面を見ていても自動更新処理が行われます。このままでは、メッセージ更新を行わないページにおいてエラーが発生したり、無駄なトラフィックが発生してしまいます。
「グループのメッセージ一覧ページ」を表示している時だけ自動更新が行われるようにコードを追加します。jQueryの正規表現にまつわるメソッドである、.matchを利用します。match
JavaScriptの文字列が利用できるメソッドです。引数に正規表現を取り、メソッドを利用した文字列にその正規表現とマッチする部分があれば、それを含む配列を返り値とします。
【例】example.jsvar str = "hogefuga" str.match(/hoge/); // → ["hoge", index: 1, input: "ghogefuga", groups: undefined]]返り値の値に含まれる他の情報は、一旦無視してしまって大丈夫です。
もしもマッチする部分がない場合、返り値はnullになります。そのため、自動更新を行うべきURLである場合のみ、という条件分岐を作ることができます。
【例】message.js$(function() { 〜省略〜 //$(function(){});の閉じタグの直上(処理の最後)に以下のように追記 if (document.location.href.match(/\/groups\/\d+\/messages/)) { setInterval(reloadMessages, 7000); } });matchメソッドの引数として書いている/\/groups\/\d+\/messages/の部分が正規表現です。正規表現は基本的には/と/で囲んだ部分で、/自体も正規表現に含めたい場合、直前に(バックスラッシュ)を付けます。
また、\d+の部分は、「桁無制限の数値」という意味になります。具体的には、\dが0 ~ 9までの数字のどれかを表し、+は+のついた文字が何文字でもマッチする、という特殊な意味を持ちます。
これで、URLにgroups/数字/messagesという部分があるページでない限り、reloadMessagesメソッドが動くことはありません。
- 投稿日:2020-03-25T22:58:50+09:00
Ruby 文字列関連まとめ、およびシンボルとの違い
1. はじめに
Rubyの文字列は
"hoge"、'hoge'、:hogeなど非常にややこしいと感じているのは自分だけでしょうか。
コロンがついている:hogeは正しくは文字列ではなくシンボルと呼ばれているものですが、非常に文字列と似ているため最初のうちは混乱すると思います。
本記事では主にこの3つについて解説します。
さらに、%Q(hoge)や%W(hoge)なんてものもありますが、こちらは使いどころが多くないため、簡単な解説に絞ります。2. "hoge"と'hoge'
ご存知、文字列の基本ですね。ダブルクオーテーションやシングルクオーテーションで囲うことで文字列であることを表します。ほとんどの言語で使われているので知っていると思います。
"hoge"と'hoge'のどちらを使うか
基本的にはどちらを使っても良いです。しかし、Rubyの使用上、「特殊文字」「式展開」を使うときは""で囲う必要があるため日頃から""を使うことをおすすめします。
特殊文字、式展開については以下で説明します。特殊文字
\n(改行)や\t(タブ)などのこと。(他にもあるので調べてみてください。)
以下の様にhello worldの中に特殊文字を入れた例で見てみる。hello.rbputs "He\nllo wor\tld" puts 'He\nllo wor\tld'実行結果は以下の様になります。
He llo wor ld He\nllo wor\tldダブルクォーテーションの方は改行とタブが入っていて、シングルクォーテーションの方は文字がそのまま出ていることがわかります。
式展開
#{}で囲むことで変数を出力したり、計算結果を出力できたりする。price.rbprice = 100 puts "税込価格は#{price * 110 / 100}円です。" puts '税込価格は#{price * 110 / 100}円です。'実行結果は以下の様になります。
税込価格は110円です。 税込価格は#{price * 110 / 100}円です。ちなみに式展開を利用せずに書くと以下の様になります。コードが長く見辛くなるため式展開は覚えておいた方が良いでしょう。
puts "税込価格は" + (price * 110 / 100).to_s + "です"3. :hoge
コロンがついたものはシンボルと言われるものです。他の言語にはないため戸惑う人も多いと思います。
内部的な詳しい解説は、他の人(例えばこちら)に任せるとして、簡単に説明します。シンボルの有用性
シンボルは、ソースコード上では文字列のように見え、内部的には整数値として管理されています。もちろん文字列はソースコード上でも内部的にも文字列として管理されています。
では内部的に整数値で管理することのなにがよいかというと、処理速度が上がるんですね。整数値は0~9の組み合わせですが、文字列は膨大な数の文字がありますから。極論、シンボルが嫌いなら一切使わずにコードを書くことも可能です。しかしせっかく開発者が用意してくれた便利な機能なのでどんどん使いましょう。
シンボルの使いどき
その文字列自体に意味があるときは文字列、意味がないときはシンボルを使いましょう。
わかりやすいのはハッシュのキーと値です。
例えば、人 = {名前 => 山田太郎, 住所 => 東京都}というハッシュがあったとします。
「山田太郎」や「東京都」はその文字自体に意味があります。もし全て整数に変換されてしまったらわけわかめですよね。
逆に「名前」や「住所」は、値を取り出すためのキーです。「山田太郎」は人[名前]、「東京都」は人[住所]で取り出せます。
別にハッシュを人 = [なーまーえ => 山田太郎, じゅーしょ => 東京都]として、人[なーまーえ]、人[じゅーしょ]で取り出してもいいですよね。こういうときにシンボルを使います。
ルーティングなどにもよく使われていますね。ハッシュでの利用
:hogeではなくhoge:という記述があって戸惑ったこともあるかもしれません。これもシンボルを表し、書き方が特殊なだけです。
先に述べた様に、シンボルはハッシュにおいてよく使われるので書きやすい特殊な書き方が用意されています。
下の3つはほぼ同じハッシュを表していますが、3つ目の書き方に後ろにコロンがついているのがわかると思います。これがhoge:の正体です。person.rb# シンボルを使わず定義 person = { "name" => "山田太郎", "address" => "東京都" } # シンボルを使って定義 person = { :name => "山田太郎", :address => "東京都" } # シンボルを使って特殊な書き方で定義 person = { name: "山田太郎", address: "東京都" }注意
キーを文字列で定義したときは取り出すときも文字列を指定、シンボルで定義したときは取り出すときもシンボルを指定する必要があるということに注意しましょう。
ハッシュの定義は慣れないうちは混乱すると思います。こちらの記事も参考にしてみてください。非常に整理されています。4. %Q()と%W()
あまり使うことはないかと思いますが、
"hoge"は%Q(hoge)、'hoge'は%q(hoge)と表すことができます。
これのメリットが感じられるのは中の文字列に"や'がたくさんある時です。
私は"山田"です。と表したいときは以下の様になり、エスケープする必要がない分%Q()のほうが可読性が高いことがわかります。sample.rbputs "私は\"山田\"です。" puts %Q(私は"山田"です。)また、文字列の配列を定義するときに有用なのが
%W()で、以下の2つは同じ配列を表します。
コンマ区切りでなくなっていることに注意しましょう。sample.rbputs [ "red", "blue", "yellow" ] puts %W( red blue yellow )こんなものもあるんだ程度に覚えていれば大丈夫でしょう。
5. さいごに
Rubyには、「使いこなせると便利だけど最初のうちは意味がわからない」ということが多い様に思います。シンボルもその一つでしょう。
基本的には文字列と変わらないけど、ハッシュのキーなどの文字列自体に意味のないものに使うべしと覚えましょう。質問などございましたらお気軽に。
@ruemura3
- 投稿日:2020-03-25T21:53:40+09:00
ArgumentErrorはActive Recordのメソッドが原因のときがあるよ【class_nameオプション】
ある日こんなエラーが出ました
???直訳・・・
『You tried to define an association named transaction on the model Product, but this will conflict with a method transaction already defined by Active Record. Please choose a different association name.』
『モデルProductにtransactionという名前の関連付けを定義しようとしましたが、Active Recordによって既に定義されているメソッドトランザクションと競合します。 別の関連付け名を選択してください。』
はて?
どこでメソッド名が被ったのか一晩考えました・・・原因
こちらのRailsドキュメントをみてびっくりしました。
元々定義されているActive Recordのメソッドに「transaction」があるんですね。
修正
修正方法としては2つありました。
- テーブル名を変える
- class_nameオプションを使ってメソッド名を変える
今回はすでにかなり実装を進めていたのでclass_nameオプションを使用することにしました。
class_nameオプションは普通は同じモデルを参照する外部キーを2つ以上もたせたいときに使用するそうです。
(使用例)
belongs_to :buyer, class_name: 'User', foreign_key: 'buyer_id' belongs_to :seller, class_name: 'User', foreign_key: 'seller_id'今回はメソッド名を「トランザクション」を「トレード」に。
product.rbclass Product < ApplicationRecord belongs_to :user has_one :trade, class_name:"Transaction", dependent: :destroy endtransaction.rbclass Transaction < ApplicationRecord belongs_to :user, optional: true belongs_to :product, optional: true end無事解決〜!
次回から肝に命じます・・・
参考


- 投稿日:2020-03-25T21:12:33+09:00
whereメソッドと正規表現で別テーブルの存在確認
概要
模擬フリマアプリ作成時、
別テーブルに該当のIDをもつレコードが存在するか確認し、存在すればテキストを表示させるところでかなり詰まったので備忘録としてまとめます。具体的には商品(Product)がPay.jpを通して決済がおきた時に、取り引き(Transaction)テーブルにproduct_idが保存される形となっています。
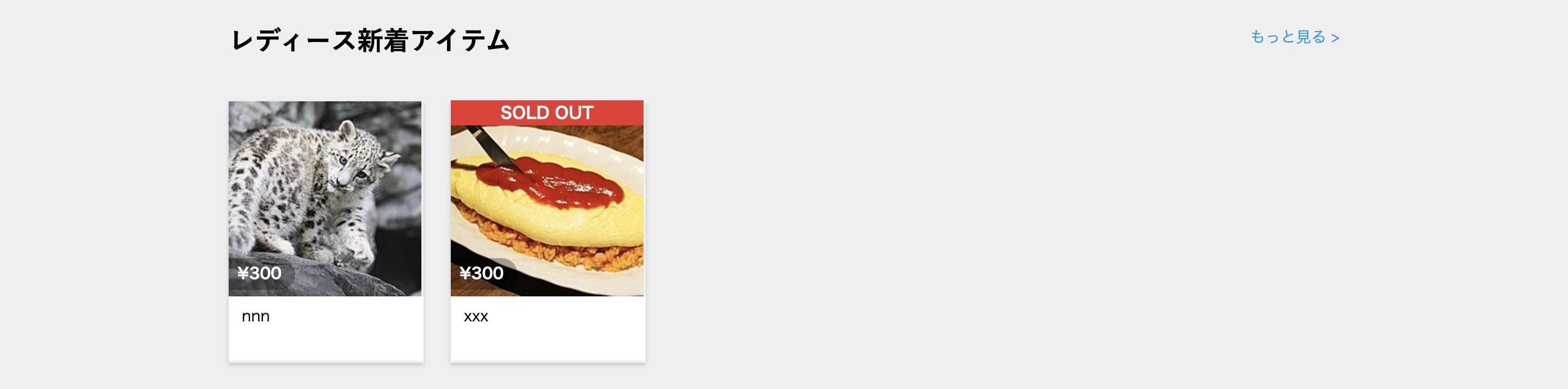
トップページでは商品をancestryを使ってカテゴリー別に一覧表示させており、商品が既に取り引き済だった場合に、「SOLD OUT」の文字を表示させます。
完成イメージ
各テーブル
class CreateProducts < ActiveRecord::Migration[5.2] def change create_table :products do |t| t.string :name, null: false t.integer :price, null: false t.references :user, null: false, foreign_key: true t.timestamps end end endclass CreateTransactions < ActiveRecord::Migration[5.2] def change create_table :transactions do |t| t.references :product, null: false, foreign_key: true t.references :user, null: false, foreign_key: true t.timestamps end end endコントローラー
class ProductsController < ApplicationController def index # カテゴリー別 一覧表示 # アンセストリーのID毎に10件ずつ商品を取得 @ladies_products = Product.where(category_id: 20..85).limit(10) @mens_products = Product.where(category_id: 91..144).limit(10) @appliances_products = Product.where(category_id: 408..434).limit(10) # カテゴリー別 Sold Out Check # idsと複数形になるところを気付くのにも時間がかかりました @ladies_transaction = Transaction.where(product_id: @ladies_products.ids) @mens_transaction = Transaction.where(product_id: @mens_products.ids) @appliances_transaction = Transaction.where(product_id: @appliances_products.ids) end endビュー
.top__genre-items - @ladies_products.each do |product| .top__genre-item = link_to product_path(product.id), class:"top__genre-item-link" do .top__genre-item-pict = image_tag product.images.first.image.url, alt:"商品画像", class: "top__genre-item-img" .top__genre-body .top__genre-body-price .top__genre-body-price--yen ¥ .top__genre-body-price--value = product.price .top__genre-body-name = product.name -# Sold Out Check -# @*****_transactionに値が入っているか確認 - if @ladies_transaction.present? -# @*****_transactionの配列に入っている一番最初の要素のproduct_idとeachで表示させているProductのIDが適合すればSOLD OUTを表示 - if @ladies_transaction.first.product_id == product.id .top__transaction-check .top__transaction-check--btn SOLD OUTfirstが肝でしたね・・・!
精進します・・・!以上となります
もっといい方法があればご教示くださいm(__)m
- 投稿日:2020-03-25T20:50:29+09:00
RailsでActionCableを使い、外部と通信を行う際のハマりポイント等。
この記事からわかること
RailsでActionCableを使う際、外部からデータを送信するための知見?(特に外部クライアントからサーバへの送信)
- その際のおハマりポイント
この記事の問題点
結局わからなかった問題点もあります。
- セキュリティ面
URLさえ知っていれば誰からでも受信します。これは問題ですね。
後実際にはwss使ったほうがいいのかもしれないです。
動作環境
$ rails -v Rails 6.0.2.2 $ ruby -v ruby 2.6.3p62 (2019-04-16 revision 67580) [x86_64-linux]Rubyの方はかなり古いかもしれないです。2.6.5にあげたつもりが、あげられてなかったっぽいです。
サンプルリポジトリ
wasuken/action-cable-sample-client
サーバ(受信)
こっちは日本語ソースたくさんあるので書かなくていいレベルだと思います。
まあ書きますが。
今回は開発環境でしか動かさないので、
config/development.rbconfig.action_cable.disable_request_forgery_protection = trueを挿入。
次にchannelを作成します。
$ rails g channel sample次に、URLの設定を行います。
今回は同じサーバで起動させます。
config/routes.rbmount ActionCable.server => '/cable'app/channels/sample_channel.rbclass SampleChannel < ApplicationCable::Channel def subscribed # stream_from "some_channel" stream_from "samples" end def receive(data) p data end def unsubscribed # Any cleanup needed when channel is unsubscribed end endreceivedではないです。receiveです。私はこれに気がつかなくてものすごい時間を潰しました。
クライアント(送信)
注意すべきはこっちでした。少なくとも私は日本語ソースを見つけることができませんでした。
それに加えて、今回はRails(ActionCable)のレールを
ちょっと外れた?使い方らしくちょっとめんどくさかったです。
私レベルのゴミにはかなりきついトピックでした。一日潰れました。
自分語りはどうでもいいので無視して、
海外ソースにはそれっぽいものがありました。
Connecting to Action Cable From Outside of Your Rails App
ArduinoからWebSocket飛ばしてる内容ですね。
前半の内容はこの記事の通りになります。
上記記事によると、
{"command": "subscribe", "identifier": { "channel": "<Channel Name>" }}これでコネクションが開くはずです。
こうして送信した後にデータを送信します。
{"command": "message", "data": {"hoge": "fuga"}}的な感じで送信すればいいです的な感じで記事に書いてあります。
素直に実装しましょう。
....思ったとおりに動きません。
私の環境ではエラーの中にこのような文言がありました。
RuntimeError - Unable to find subscription with identifieridentifierがない...?
そこで見つけたのが下記の記事でした。
ActionCable: Unable to find subscription with identifier... #25381
これの真ん中あたりにidentifier入れたサンプルがあり、もしやと思い入れてみると
無事受信するようになりました。
よって、正しくはこうです。
{"command": "message", "data": {"hoge": "fuga"}, "identifier": { "channel": "<Channel Name>" }}こうすると、dataの内容がサーバで記載したreceiveの引数として渡されます。
後JSONの渡し方にも注意が要ります。私はそれでさらに時間を潰しました。
wasuken/action-cable-sample-client
main.rbrequire "faye/websocket" require "eventmachine" require "json" EM.run { ws = Faye::WebSocket::Client.new('ws://localhost:3000/cable') ws.on :open do |event| p [:open] cmd = {command: "subscribe", identifier: {channel: "SampleChannel"}.to_json} ws.send(cmd.to_json) ws.send({command: "message", data: {}.to_json, identifier: {channel: "SampleChannel"}.to_json}.to_json) end ws.on :close do |event| p [:close, event.code, event.reason] ws = nil end }ここでもよくわからんポイントがあります。
to_jsonまつりになってます。
ここでto_jsonしないとどうなるのか。実際にやってみるとわかりますが、
JSONのパースエラーが発生します。
Could not execute command from ({"command"=>"subscribe", "identifier"=>{"channel"=>"SampleChannel"}}) [TypeError - no implicit conversion of Hash into String]:
まあ、Rails側で読み取らないといけないので仕方ないといえば仕方ない処理なのかもしれません。
エラー内容読んだら知識が多少ある人間ならばふーんってなると思いましたが、
私はここでもつまづきました。
蛇足
以下はくっさい自分語りが9割くらいなのでみなくてもいいです。
なんで書いたの
本文にもなかったとおり、ここらへん明確に書いてある日本語ソースや、
英語ソースも見つけることができなかったからです。
もっといい記事がでて、邪魔なら消します。
この記事が鬱陶しかったり、目障りなら修正依頼及び新しく記事を書いてください。
Qiitaは嫌いではない上に文章作るの好きですが、
私自身頭が悪い上に日本語が不自由で
迷惑かけるのが申し訳ないので可能であるならば頭のいい人はどんどん書いてほしい。
私からはLGTMしたり、ちやほやするぐらいしかできませんが。
発展した?使い方
送信側の話になりますが、
EMの中でイベント待ちみたいな感じで処理すると、こっち側から送信できなくないですか。
このままだとできません。しかし、Thread.newやらwsをグローバル変数化したりして
いわゆる力技?みたいなことをすると例えば
パケットをキャプチャしながら、サーバ側にキャプチャしたデータを送信したりもできます。
別のリポジトリのこのコード
になるんですが、とても汚くてまだ出せたものではないです。
いつか記事にしてみたいです。
参考サイト
Connecting to Action Cable From Outside of Your Rails App
ActionCable: Unable to find subscription with identifier... #25381
- 投稿日:2020-03-25T20:28:58+09:00
【Rails】FactoryBotの作り方(アソシエーション、Faker、画像の紐付け)
はじめに
今回はFactoryBotという存在は知っているけど、自分で作れって言われたら、ちょっと・・・と思う人に向けて、FactoryBotの作り方を記事にしました。
FactoryBotについての説明は割愛します。FactoryBotの作り方
基本的な構文はこれです。
FactoryBot.define do factory :user do first_name { "John" } last_name { "Doe" } admin { false } end end例えば、itemテーブル(商品)を作成するとしたら
- まず、FactoryBotの決まり文句を書きます。
factories/items.rbFactoryBot.define do factory :item do end end
- 次に、カラムを列挙します。
factories/items.rbFactoryBot.define do factory :item do name {"レモン"} # {}で囲っているとfactoryが生成された時に評価される price {3000} end end使い方、属性の上書きの仕方
create(:item)
create(:item, name: "リンゴ")アソシエーションの仕方
例えば、itemとuserが紐づいている場合、以下のように書く。
(userのfactoryBotも作成している必要がある)factories/items.rbFactoryBot.define do factory :item do name {"レモン"} price {3000} association :user, factory: :user # アソシエーション end end
association :user, factory: :userの部分は単にuserと省略できるfactories/items.rbFactoryBot.define do factory :item do name {"レモン"} price {3000} user # アソシエーション end end画像の紐付けの仕方
itemにimageが紐づいている時を想定します。
itemは必ずimageが紐づいており、imageは必ず紐づいたitemがあります。先ほどの通り、実装すると、以下のようになりますが、imageを作るときに、itemが必要で、itemはまだ作成されていないので、結論うまくいきません。
factories/items.rb# これはうまくいかない FactoryBot.define do factory :item do name {"レモン"} price {3000} user image end endafter(:build)を使用する必要があります。
これで、imageを一枚紐づけることができます。factories/items.rbFactoryBot.define do factory :item do name {"レモン"} price {3000} user after(:build) do |item| item.images << create(:image) end end endafter(:build)で保存される直前に処理を実行でき、複数のfactoryを同時に生成することができる
Fakerの使い方
FactoryBotと良く一緒に使われるのがFaker。
Fakerを使うメリットは、ランダムな文字列を生成してくれるところにある。
例えば、deviseを用いたユーザログインでは、emailがすでに登録されていたらそのemailを使うことができない。以下のようなFactoryを作成してしまうと
factories/users.rb# これはうまくいかない FactoryBot.define do factory :user do name {"テストユーザー"} email {"test@hello.com"} end end生成する際に、エラーが起こる
john = create(:user, name: "John") kevin = create(:user, name: "kevin") # emailが重複して作成できない!!Fakerを使用すると、ランダムに生成してくれて、エラーが起きない。
factories/users.rbFactoryBot.define do factory :user do name {"テストユーザー"} email { Faker::Internet.free_email } end end
- 投稿日:2020-03-25T20:20:16+09:00
sidekiqを使って非同期にメール送信処理をする方法
詰まったところ
sidekiqで非同期にメール送信処理を実行する様に実装していたら、メール送信のジョブが待機状態のまま実行されない不具合に遭いました。
結論・解決方法
公式にある通り、以下のコードを実行。
https://github.com/mperham/sidekiq/wiki/Active+Job#action-mailerbash$ bundle exec sidekiq -q default -q mailers次に、
deliverやdeliver_nowをdeliver_laterに変更。
deliver_laterとは、非同期にメール送信処理を行ってくれるメソッドである。
逆に、deliverとdeliver_nowは同期的にメール送信するメソッドである。〇〇_mailer.rb〇〇Mailer.deliver 〇〇Mailer.deliver_now↓
〇〇_mailer.rb〇〇Mailer.deliver_laterこれで治るはず(知らんけど)。
もしDockerを使っていたら
sidekiqコンテナをビルドする際に以下コマンドを実行させる。
docker-compose.ymlsidekiq: command: bundle exec sidekiq -q default -q mailers非同期処理を実装する前に
sidekiqで
perform_asyncを使って非同期処理をする前に、まずは〇〇Mailer.new.performで同期処理ができるか確認しようそもそもとしてそのコードに不備がないかを確認しましょう(僕は不備がありました)。。。。
perform_asyncは非同期になるので、binding.pryなどでデバッグはできません。
なので、〇〇_mailer.rb〇〇Mailer.new.perform(args)を実行して同期処理で正しく動作しているかを確認しましょう。
sidekiqのログを確認しよう
https://github.com/mperham/sidekiq/wiki/Monitoring#web-ui
sidekiqには、sidekiqで処理するジョブを閲覧できるダッシュボードを用意してくれています。
/sidekiqへアクセスすることで、ダッシュボードからエラーログの確認ができます。
エラーログを見ると、どの様なエラーが吐かれているかを確認できます。
sidekiqの処理に渡す引数のデータの型に気をつけよう
https://github.com/mperham/sidekiq/wiki/Best-Practices#1-make-your-job-parameters-small-and-simple
sidekiqに渡す引数のデータ型には制限があります。
シンボル、名前付きパラメーター、複雑なRubyオブジェクト(Date型やTime型など)は使用できません。
使用できる引数のデータの型は、JSONのデータ型のみです。
JSONのデータ型は以下です。
- 文字列 ("...")
- 数値 (123, 12.3, 1.23e4 など)
- ヌル値 (null)
- 真偽値 (true, false)
- オブジェクト ({ ... })
- 配列 ([...])
僕は引数に
Date型を渡していましたが、勝手にString型にされ他ので上記の様なエラーが起きました。
なので、Date型の引数をto_sで渡して、Worker内でto_dateすることで解決しました。
みなさんの問題解決に繋がったら幸いです。

- 投稿日:2020-03-25T20:20:16+09:00
sidekiqを使って非同期にメール送信処理をする方法。メール送信ジョブが待機状態のまま実行されない不具合の解決方法
結論・解決方法
公式にある通り、以下のコードを実行。
https://github.com/mperham/sidekiq/wiki/Active+Job#action-mailerbash$ bundle exec sidekiq -q default -q mailers次に、
deliverやdeliver_nowをdeliver_laterに変更。
deliver_laterとは、非同期にメール送信処理を行ってくれるメソッドである。
逆に、deliverとdeliver_nowは同期的にメール送信するメソッドである。〇〇_mailer.rb〇〇Mailer.deliver 〇〇Mailer.deliver_now↓
〇〇_mailer.rb〇〇Mailer.deliver_laterこれで治るはず(知らんけど)。
もしDockerを使っていたら
sidekiqコンテナをビルドする際に以下コマンドを実行させる。
docker-compose.ymlsidekiq: command: bundle exec sidekiq -q default -q mailers非同期処理を実装する前に
sidekiqで
perform_asyncを使って非同期処理をする前に、まずは〇〇Mailer.new.performで同期処理ができるか確認しようそもそもとしてそのコードに不備がないかを確認しましょう(僕は不備がありました)。。。。
perform_asyncは非同期になるので、binding.pryなどでデバッグはできません。
なので、〇〇_mailer.rb〇〇Mailer.new.perform(args)を実行して同期処理で正しく動作しているかを確認しましょう。
sidekiqのログを確認しよう
https://github.com/mperham/sidekiq/wiki/Monitoring#web-ui
sidekiqには、sidekiqで処理するジョブを閲覧できるダッシュボードを用意してくれています。
/sidekiqへアクセスすることで、ダッシュボードからエラーログの確認ができます。
エラーログを見ると、どの様なエラーが吐かれているかを確認できます。
sidekiqの処理に渡す引数のデータの型に気をつけよう
https://github.com/mperham/sidekiq/wiki/Best-Practices#1-make-your-job-parameters-small-and-simple
sidekiqに渡す引数のデータ型には制限があります。
シンボル、名前付きパラメーター、複雑なRubyオブジェクト(Date型やTime型など)は使用できません。
使用できる引数のデータの型は、JSONのデータ型のみです。
JSONのデータ型は以下です。
- 文字列 ("...")
- 数値 (123, 12.3, 1.23e4 など)
- ヌル値 (null)
- 真偽値 (true, false)
- オブジェクト ({ ... })
- 配列 ([...])
僕は引数に
Date型を渡していましたが、勝手にString型にされ他ので上記の様なエラーが起きました。
なので、Date型の引数をto_sで渡して、Worker内でto_dateすることで解決しました。
みなさんの問題解決に繋がったら幸いです。
- 投稿日:2020-03-25T20:08:48+09:00
rails c でのwebpacker インストールエラーについて
実行コマンドrails cエラーWebpacker configuration file not found[ディレクトリ]とりあえずwebpacker がないということなのでインストールしてみることにした。
実行コマンドrails webpacker:installノードのバージョンが古いということなので、ノードをインストールし直すこととした。
エラーWebpacker requires Node.js >= 8.16.0 and you are using 8.11.3 Please upgrade Node.js https://nodejs.org/en/download/ノードをnodebrewを使って管理
せっかくなので、nodebrewを使ってnodeバージョン管理するように変更することとした。
curl -L git.io/nodebrew | perl - setupexport PATH=$HOME/.nodebrew/current/bin:$PATHzshのため.zshrcの変更を適応させるようにした。
source ~/.zshrcnodebrew helpwebpackerのインストール
今度は問題なく実行された。
実行コマンドrails webpacker:install参考記事
ありがとうございました。
- 投稿日:2020-03-25T19:06:50+09:00
field_with_errorsによるレイアウト崩れを防ぐ
実装したいこと
新規会員登録機能バリデーションを設定し、入力項目にエラーがある場合はエラーメッセージとともに、入力ページに戻るように設定してします。
この時下の写真のようにレイアウト崩れが発生しますので、この事例について修正します。初回入力時
再入力時(レイアウト崩れ)

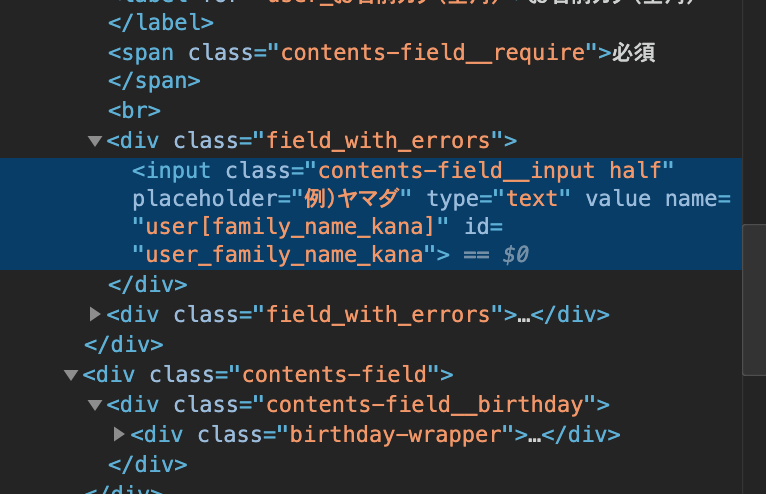
レイアウト崩れの原因
この事象の原因は、エラーが発生している時Railsが自動的に
field_with_errorsクラスを持つdivタグで、labelタグやinputタグを囲むことによって発生します。横並びになっている2つのinputタグそれぞれをdivダグで囲むため、改行されて表示されています。new.html.haml.contents-field = f.label :お名前(全角) %span.contents-field__require 必須 %br = f.text_field :family_name, class:"contents-field__input half", placeholder:"例)山田" = f.text_field :first_name, class:"contents-field__input half", placeholder:"例)太郎" .contents-field = f.label :お名前カナ(全角) %span.contents-field__require 必須 %br = f.text_field :family_name_kana, class:"contents-field__input half", placeholder:"例)ヤマダ" = f.text_field :first_name_kana, class:"contents-field__input half", placeholder:"例)タロウ"
解決方法
上記の事象に対する解決方法は2つが考えられます。
- 自動で読み込まれる
field_with_errorsタグを読み込まないように設定する。field_with_errorsに対してCSSをあてる今回は
field_with_errorsタグを読み込まないようにする方法で、以下のようにapplicaton.rbを編集します。applicaton.rbmodule FreemarketSample65d class Application < Rails::Application #以下を追加 config.action_view.field_error_proc = Proc.new { |html_tag, instance| html_tag } end end

- 投稿日:2020-03-25T18:45:06+09:00
warning: already initialized constant Rack::Utils::ParameterTypeError などのrack utils のエラーの解決例
1.どんなエラー?
デプロイをしたときにユニコーンのバージョンがローカルとずれてしまい、ユニコーンをダウングレードしたときにでたエラーで、連動して動けなくなってしまったgemを表示したものでした
2.解決方法
unicornの指定のバージョンを新しいものに変え(筆者はそのまま本番環境が新しいものになっていたためそのまま)、
RAILS_SERV_STATIC_FILE=1 bundle exec unicorn_rails -c config/unicorn.rb -E production -Dとすることで、おそらくこのエラーは解消しました。もう少し深掘りすると
bundle execをつけることで初期設定でbundle installで更新されないgemが更新されるため、このエラー文は解決できたと思われます。また、
bundle update -defaultすれば直るという記事がいくつか見受けられるのですが、筆者はこれでなかなか苦労したのでupdateコマンドは慎重に行われた方が良いと思います3.注意事項
筆者の場合はこのエラーを解決してもその他のエラーが残り、cssが当たらず引き続き試行錯誤を行なっているため、根本的な解決になっているかは不明なのであくまで参考程度にしていただければと思います。
もしかするとこの方法は、「動いていた頃のデータを使う」というその場しのぎの方法かもしれないため、うまくいったときでも最新のものが本番環境に反映されているか再度ご確認ください。4.後日談(エラー解決しました)
この方法であっていました。そのほかはnginxとunicorn.rbのpathミスを修正したら直りました
- 投稿日:2020-03-25T18:30:29+09:00
【Rails】テーブル同士を紐付けする手順を解説していく!
はじめに
Railsの学習のアウトプットとして簡単な掲示板を作成している際に、「データの紐付け」にて躓いたので
「紐付け」を行う目的とその手順について、自分用にまとめてみようと思います!※「ログイン機能」が実装してある事を前提に解説していきます。
紐付けとは何ぞや
テーブル同士を関連付ける事で、テーブル同士でデータを取得できるようにする作業。
紐付けをする目的
掲示板作成を例として、上述した二つのテーブルを
・「投稿用のテーブル(postsテーブル)」
・「ユーザーのテーブル(usersテーブル)」
に置き換えることにする。例えば
投稿テーブルには、投稿内容のデータ(カラム名をcontentとする)が保存され
ユーザーテーブルには、ユーザーの名前のデータ(カラム名をnameとする)が保存されているとします。
そうすると以下のように表せます。postsテーブル
id content 1 タピオカなう! 2 学校めんどい…… usersテーブル
id name 1 田中 2 鈴木 しかしながら上記2つのテーブルは別物であるため
投稿内容を見ただけでは、誰がどんな投稿したのかという判別がつきません。そうなると今度は、誰がその投稿をしたのかわかるようにさせたい訳です。
要するにデータの紐付けを行う目的とはこの例で言えば
誰がどの投稿をしたのかを区別することになります。紐付けを行う手順
それでは早速、掲示板作成を例として実際に紐付けを行ってみます。
しかし、いきなり紐付けしようとしても、何をどうすれば良いのかサッパリだと思いますから
何をどうしたら良いのか、その思考手順を挙げつつ実装を行っていきます。
1.まず、実装したい機能を挙げてみる
➡︎投稿ごとにユーザーを区別したい。
2.その機能を明確にしてみる
➡︎投稿ごとに、誰がその投稿をしたのかわかるように、ユーザー名を表示させる。
3.Railsにおけるデータのやり取りの仕組みを思い出す
➡︎ブラウザで何かしらの情報を表示させるためには、該当のアクション内で、データベースからデータを取得するための記述をする必要がある。
➡︎今回は「投稿に対して」、その投稿を行った「ユーザーの情報を」表示させたいので、投稿用のアクション内で、ユーザーのデータを取得すればいい。例
posts_controller.rbdef #(投稿表示用のアクション名) @post = Post.find_by(id: params[:id]) #ユーザーのデータを取得する処理 end4.ユーザーのデータを取得する(?)
➡︎それでは早速、ユーザーのデータを取得してみます。
例
posts_controller.rbdef #(投稿表示用のアクション名) @post = Post.find_by(id: params[:id]) @user = User.find_by(id: @post.X) #ユーザーのデータを取得する処理 end➡︎「X」って何だよ…と思ったかと思いますが、何者でもない仮のXだと思ってください。
➡︎何故仮のXを置いているかと言うと、今のままだと
Userモデルのidと一致可能な、Postモデルのデータが存在しないためです。
➡︎なのでこのXの部分に入れるためのカラムを、新しくpostsテーブルに作成する必要があります。こうして紐付けが始まります!5.postsテーブルにカラムを追加
➡︎「Userモデルのidと一致させるためのid」と言う意味で、「user_id」と言うカラム名にします。
➡︎新しくカラムを追加するためには、「rails g migration」コマンドを実行してあげる必要があります。
➡︎今回はuser_idカラムを、Postモデルに追加するので、以下のようにコマンドを実行しますターミナル$ rails g migration AddUserIdToPost user_id:integer➡︎「db/migrate」ディレクトリ内に、「(作成した日付の数字羅列)add_user_id_to_post.rb」ファイルが追加されている事を確認。
➡︎これで、Railsのアプリケーションフォルダ内にはファイルが作成されたので、この変更をデータベースに反映させます。ターミナル$ rails db:migrate➡︎上記のようにコマンドを実行したら、ターミナルで「rails dbconsole」コマンドを実行して、postsテーブルに「user_id」カラムが追加されている事を確認してください。
postsテーブル
id content user_id 1 タピオカなう! 2 学校めんどい…… 6.user_idカラムに、ユーザーのidを取得させる
➡︎もう一度、先ほどの投稿表示用のアクションを確認してみます。
posts_controller.rbdef #(投稿表示用のアクション名) @post = Post.find_by(id: params[:id]) @user = User.find_by(id: @post.user_id) #ユーザーのデータを取得する処理 end➡︎新たにカラムを作成したので、仮のXを「user_id」に変更しました。
➡︎ただし、まだこのままではuser_idカラムは空のままなので、参照するためのidがありません。
➡︎なので今から、user_idカラムに、その投稿をしたユーザーのidを取得させるための記述を行ます。
➡︎どうやって取得させるかと言うと、新規投稿アクション内の、newメソッドの引数にuser_idを渡し、user_idに「ログインしているユーザーのid」が保存されるようにします。例
posts_controller.rbdef #(新規投稿アクション名) @post = Post.new( content: params[:content], user_id: @current_user.id #ログインユーザーのidを取得して保存 ) #新規投稿保存後の処理 end➡︎これにより、これ以降に新規投稿が行われる度に、ログインしているユーザーのidが保存されるようになります。
postsテーブル
id content user_id 1 タピオカなう! 2 学校めんどい…… 3 納豆好き @current_user.id 4 ポンポンポン @current_user.id ➡︎idが1のユーザーが新規投稿を行えば、その投稿のuser_idには1が入るし、2のユーザーが新規投稿を行えば2が入ります。
➡︎これで、ユーザーのidを取得させることができました。7.ビューで表示
➡︎新規投稿するごとにログインユーザーのidが取得されるため、以下のように呼び出すと、「その投稿を行ったユーザーのid」と一致する「Userモデル内のid」を検索して取得してくれるようになります。
posts_controller.rbdef #(投稿表示用のアクション名) @post = Post.find_by(id: params[:id]) @user = User.find_by(id: @post.user_id) #ユーザーのデータを取得する処理 end➡︎これにより紐付けは完了したので、投稿詳細ページで表示していきます。
show.html.erb<%= @user.name %> <%= @post.content %>➡︎後はこれにCSSなどでスタイリングしてあげれば、投稿に対してユーザー名を表示できるようになるかと思います!
補足にもならない補足
本来ならば投稿詳細ページにだけでなく、別のページの投稿に対してもユーザーの情報を紐付けする必要があると思います。
そうした場合、他のアクションでユーザーの情報を取得する記述をすることになるため、重複することになります。同じ記述をするのは好ましくないため、ユーザーの情報を一挙に取得するためのメソッド(インスタンスメソッド)を定義する必要があるのですが
インスタンスメソッドに関する解説は、また次回したいと思います。まとめ
最後に、投稿とユーザーについての紐付けを行う手順をもう一度確認してみましょう。
1.まず、実装したい機能を挙げてみる
2.その機能を明確にしてみる
3.Railsにおけるデータのやり取りの仕組みを思い出す
4.該当アクション内に、ユーザーのデータを取得する処理を記述してみる(仮)
5.postsテーブルにカラムを追加
6.user_idカラムに、ユーザーのidを取得させる
7.ビューで表示
です!
最後に
Railsにつきましては、学習を始めて2週間の初学者も初学者ですので
Railsにおけるデータのやり取りについて慣れることが先決と考え、このように遠回りするような理解の仕方を取っています。
おかしな点などありましたら、その都度仰って頂けるととても幸いです。参考
- 投稿日:2020-03-25T18:17:49+09:00
【Rails】【DB】RailsのDBをMySQLに変更する方法
RailsのDBをMySQLにする方法を記載します。
まずはdatabase.ymlを記載していきます。database.yml編集
database.ymldevelopment: adapter: mysql2 encoding: utf8 database: [アプリケーション名]_development pool: 5 username: [任意のユーザ名] password: [任意のパスワード] host: localhost test: adapter: mysql2 encoding: utf8 database: [アプリケーション名]_test pool: 5 username: [任意のユーザ名] password: [任意のパスワード] host: localhost production: adapter: mysql2 encoding: utf8 database: [アプリケーション名]_production pool: 5 username: [任意のユーザ名] password: [任意のパスワード] host: localhost上記のように記載していきます。
[アプリケーション名]、[任意のユーザ名]、[任意のパスワード]はご自身のものを記載お願いします。
database.ymlについてはこちらをご参考ください。
続いてMySQLインストールをインストールしていきます。MySQLインストール
MySQLをインストールします。
Gemfilegem 'mysql2' : :これで
bundle installします。
MySQLではホスト名、ユーザー名、パスワードの指定が必要になので、設定をしてきます。ホスト名、ユーザー名、パスワード設定
MySQLにログインします。
$ mysql -u root : : mysql> create user 'ユーザー名'@'localhost' identified by 'パスワード'; mysql> select User,Host from mysql.user;
mysql> create user 'ユーザー名'@'localhost' identified by 'パスワード';ではホスト名、ユーザー名、パスワードを設定しています。
select User,Host from mysql.user;ではユーザーの登録が成功しているか確認を行っています。続いてユーザーにアカウント権限をつけます。
mysql> grant all on *.* to '[ユーザー名]'@'localhost';これで
MySQLでの設定は完了しました。
先ほどのdatabase.ymlに登録したユーザーとホスト名、パスワードを記載しましょう。データベース作成
続いてデータベースを作成して、マイグレーションしていきます。
$ rails db:create $ rails db:migrate
productionの場合は下記のようにデータベースを作成します。rails db:create RAILS_ENV=productionこれでRailsのDBをMySQLに変更することができました。
- 投稿日:2020-03-25T18:17:49+09:00
【Rails】【DB】RailsのDBをMySQL2に変更する方法
RailsのDBをMySQL2にする方法を記載します。
まずはdatabase.ymlを記載していきます。database.yml編集
database.ymldevelopment: adapter: mysql2 encoding: utf8 database: [アプリケーション名]_development pool: 5 username: [任意のユーザ名] password: [任意のパスワード] host: localhost test: adapter: mysql2 encoding: utf8 database: [アプリケーション名]_test pool: 5 username: [任意のユーザ名] password: [任意のパスワード] host: localhost production: adapter: mysql2 encoding: utf8 database: [アプリケーション名]_production pool: 5 username: [任意のユーザ名] password: [任意のパスワード] host: localhost上記のように記載していきます。
[アプリケーション名]、[任意のユーザ名]、[任意のパスワード]はご自身のものを記載お願いします。
database.ymlについてはこちらをご参考ください。
続いてMySQL2をインストールしていきます。MySQL2インストール
Gemfilegem 'mysql2' : :これで
bundle installします。
MySQLではホスト名、ユーザー名、パスワードの指定が必要になるので、設定をしてきます。ホスト名、ユーザー名、パスワード設定
MySQLにログインします。
$ mysql -u root : : mysql> create user 'ユーザー名'@'localhost' identified by 'パスワード'; mysql> select User,Host from mysql.user;
mysql> create user 'ユーザー名'@'localhost' identified by 'パスワード';ではホスト名、ユーザー名、パスワードを設定しています。
select User,Host from mysql.user;ではユーザーの登録が成功しているか確認を行っています。続いてユーザーにアカウント権限をつけます。
mysql> grant all on *.* to '[ユーザー名]'@'localhost';これで
MySQL2での設定は完了しました。
先ほどのdatabase.ymlに登録したユーザーとホスト名、パスワードを記載しましょう。データベース作成
続いてデータベースを作成して、マイグレーションしていきます。
$ rails db:create $ rails db:migrate
productionの場合は下記のようにデータベースを作成します。rails db:create RAILS_ENV=productionこれでRailsのDBをMySQL2に変更することができました。
- 投稿日:2020-03-25T17:49:00+09:00
accepts_nested_attributes_forを使わずに複数リソースを同時登録する(クイズアプリを例に)
想定読者
Railsを使ってポートフォリオを作成している方
特にクイズアプリを作成している方どういうときの話
私はクイズアプリを作ってるときにこの問題に当たりました。
一つのフォーム画面で、
①問題文
②選択肢1
③選択肢2
④選択肢3
⑤選択肢4
を同時に登録させたいとします。で、モデルはこんな感じです。
app/models/question.rbclass Question < ApplicationRecord has_many :choices, dependent: :destroy endapp/models/choice.rbclass Choice < ApplicationRecord belongs_to :question enddb/migrate/時間_create_choices.rbclass CreateChoices < ActiveRecord::Migration[5.2] def change create_table :choices do |t| t.references :question, foreign_key: true t.string :content, null: false t.boolean :is_answer t.timestamps end end end
- 「問題 has many 選択肢s」です。
- 選択肢テーブルはis_answerという「正答か誤答か」というカラムを持っています。
よって単純なform_withとモデルでは実装できません。フォームに合わせてDB設計を変える、みたいなのは本末転倒です。(私の記事で恐縮ですが、クイズアプリのDB設計に関して、以下記事を書きました)
https://qiita.com/kumackey/items/7ccbc949458bd0af22bd他にも、以下の例が思いつきます。
- 就活サイトのユーザ登録画面で、has manyな経歴を同時に登録する
- SNSのポスト投稿画面で、投稿自体とタグ複数を同時登録する
- レシピサイトで、レシピ名と、複数の手順を同時に登録する
accepts_nested_attributes_forではダメ?
非推奨らしいです。
実は私はaccepts_nested_attributes_forに関しては逆に詳しくないため、詳細は以下URL等をご覧いただければと思います。
https://moneyforward.com/engineers_blog/2018/12/15/formobject/
https://tech.recruit-mp.co.jp/server-side/rails-development-policy/
https://tech.libinc.co.jp/entry/2019/04/05/113000フォームオブジェクトを作る
app/forms/register_quiz_formclass RegisterQuizForm include ActiveModel::Model include ActiveModel::Attributes include ActiveModel::Validations attribute :question_content, :string attribute :correct_choice, :string attribute :incorrect_choice_1, :string attribute :incorrect_choice_2, :string attribute :incorrect_choice_3, :string validates :question_content, presence: true, length: { maximum: 140 } validates :correct_choice, presence: true, length: { maximum: 40 } validates :incorrect_choice_1, presence: true, length: { maximum: 40 } validates :incorrect_choice_2, length: { maximum: 40 } validates :incorrect_choice_3, length: { maximum: 40 } def save return false unless self.valid? question = Question.new(content: question_content) question.save # 問題文の登録 choice = question.choices.build(content: correct_choice, is_answer: true) choice.save # 正解選択肢の保存 question.choices.create(content: incorrect_choice_1, is_answer: false) question.choices.create(content: incorrect_choice_2, is_answer: false) question.choices.create(content: incorrect_choice_3, is_answer: false) # 不正解選択肢の登録 end endフォームオブジェクト自体に知見が無い方は、以下記事をご参照いただければと思います。
https://tech.medpeer.co.jp/entry/2017/05/09/070758
https://qiita.com/kamohicokamo/items/d2ea4d71f86d99261b1a
return false unless self.valid?によって、ヴァリデーションが通らないときにfalseを返します。これにより、コントローラーで使用する際も、以下のような実装が可能になります。if @register_quiz_form.save (ヴァリデーションが通ってsaveに成功したときの処理) else (ヴァリデーションが通らずsaveに失敗したときの処理) end
if @user.createに近い感覚で使うことができます。コントローラーとビュー
app/controllers/questions_controller.rbclass QuestionsController < ApplicationController def new @register_quiz_form = RegisterQuizForm.new end def create @register_quiz_form = RegisterQuizForm.new(create_question_params) if @register_quiz_form.save redirect_to (成功したときのパス) else render :new end end def create_question_params params.require(:register_quiz_form).permit( :question_content, :correct_choice, :incorrect_choice_1, :incorrect_choice_2, :incorrect_choice_3) end end※ 以下Viewですが、筆者がslimに慣れているのでslimで記述しています。erbに置き換えてお読み頂けると幸いです。
app/views/questions/new.html.slim= form_with model: @register_quiz_form, url: questions_path, local: true do |f| = render '(エラーメッセージ表示用のパーシャル)', object: @register_quiz_form .form-group = f.label :question_content = f.text_field :question_content, class: 'form-control' .form-group = f.label :correct_choice = f.text_field :correct_choice, class: 'form-control' .form-group = f.label :incorrect_choice_1 = f.text_field :incorrect_choice_1, class: 'form-control' .form-group = f.label :incorrect_choice_2 = f.text_field :incorrect_choice_2, class: 'form-control' .form-group = f.label :incorrect_choice_3 = f.text_field :incorrect_choice_3, class: 'form-control' = f.submit '登録する', class: 'btn btn-raised btn-success'ちなみにフォームブジェクトという設計は、ActiveRecordのattributesと、フォーム画面で表示させたいことが異なる、というケースのいずれでも効果を発揮します。
私はフォームオブジェクトが大好きすぎて、ポートフォリオには3つのフォームオブジェクトがあります。笑間違い等あればご指摘頂けると嬉しいです。
- 投稿日:2020-03-25T17:41:09+09:00
Railsチュートリアル4章目の続き〜クラスについて〜
Rubyにおけるクラス
Rubyではあらゆるものがオブジェクトである。オブジェクトはクラスを使用し、そこからインスタンスが生成されると。正直良く分かりませんね。笑
コンストラクタ
例えばダブルクォートを使って文字列のインスタンスを作成しましたが、これは文字列のオブジェクトを暗黙で作成するリテラルコンストラクタである。
>> s = "foobar" # ダブルクォートは実は文字列のコンストラクタ => "foobar" >> s.class => String上のコードでは、文字列がclassメソッドに応答しており、その文字列が所属するクラスを単に返していることがわかります。
コンストラクタとは?
オブジェクト指向のプログラミング言語で新たなオブジェクト新たなオブジェクトを生成する際に呼び出されて内容の初期化などを行う、関数、あるいはメソッドのこと。
暗黙のリテラルコンストラクタを使う代わりに、明示的に同等の名前付きコンストラクタを使うことができます。名前付きコンストラクタは、クラス名に対してnewメソッドを呼び出します。
>> s = String.new("foobar") # 文字列の名前付きコンストラクタ => "foobar" >> s.class => String >> s == "foobar" => true演習
1.1から10の範囲オブジェクトを生成するリテラルコンストラクタは何でしたか? (復習です)
a=1..10 => 1..102.今度はRangeクラスとnewメソッドを使って、1から10の範囲オブジェクトを作ってみてください。ヒント: newメソッドに2つの引数を渡す必要があります
b = Range.new[1..10] => 1..103.比較演算子==を使って、上記2つの課題で作ったそれぞれのオブジェクトが同じであることを確認してみてください。
a==b =>trueクラス継承
クラスについて学ぶとき、superclassメソッドを使ってクラス階層を調べてみるとよくわかります。superclassメソッドは指定することでこのクラスの一つ上のクラス何なのかを表示するメソッド。
>> s = String.new("foobar") => "foobar" >> s.class # 変数sのクラスを調べる => String >> s.class.superclass # Stringクラスの親クラスを調べる => Object >> s.class.superclass.superclass # Ruby 1.9からBasicObjectが導入 => BasicObject >> s.class.superclass.superclass.superclass => nilStringクラスのスーパークラスはObjectクラス
ObjectクラスのスーパークラスはBasicObjectクラス
BasicObjectクラスはスーパークラスを持たない
これはすべての Ruby のオブジェクトにおいて成り立ちます。クラス階層をたどっていくと、 Rubyにおけるすべてのクラスは最終的にスーパークラスを持たないBasicObjectクラスを継承している。
なるほど。みんな最終的にはBasicObjectクラスにつながっているんだねー。ある単語を前からと後ろからのどちらから読んでも同じ (つまり回文になっている) ならばtrueを返すpalindrome?メソッドを作成する
>> class Word >> def palindrome?(string) >> string == string.reverse >> end >> end => :palindrome?このクラスとメソッドは次のように使うことができる。
>> w = Word.new # Wordオブジェクトを作成する => #<Word:0x22d0b20> >> w.palindrome?("foobar") => false >> w.palindrome?("level") => trueもし上の例が少し不自然に思えるならば、勘が鋭いといえます。
(不自然と思えなかった自分は勘が鈍い。笑)
というのも、これはわざと不自然に書いたからだそうです。
Wordクラスは Stringクラスを継承するのが自然である。コンソールでWordクラスを定義する。
>> class Word < String # WordクラスはStringクラスを継承する >> # 文字列が回文であればtrueを返す >> def palindrome? >> self == self.reverse # selfは文字列自身を表します >> end >> end => :palindrome?上のコードは継承のためのRubyの Word < String 記法である。
こうすることで、新しいpalindrome?メソッドだけではなく、Stringクラスが扱えるすべてのメソッドがWordクラスでも使えるようになる。>> s = Word.new("level") # 新しいWordを作成し、"level" で初期化する => "level" >> s.palindrome? # Wordが回文かどうかを調べるメソッド => true >> s.length # WordはStringで扱える全てのメソッドを継承している => 5なるほど。すごい理解できた。つまりドラゴンボールでいうところのセルみたいな感じかな。魔貫光殺砲もかめはめ波も使えるみたいな。
上のコードはselfキーワードを用いることで、単語の文字を逆順にしたものが元の単語と同じであるかどうかのチェックを、Wordクラスの中から自分自身が持つ単語にアクセスすることで行なっている。Wordクラスの中では、selfはオブジェクト自身を指します。
self == self.reverse 単語が回文であるかどうかを確認できるということです17。なお、Stringクラスの内部では、メソッドや属性を呼び出すときのself.も省略可能です。 self == reverse といった省略記法でも、うまく動く。ユーザークラス
User クラスを最初から作成する。
アプリケーションのルートディレクトリにexample_user.rbファイルを作成
example_userで使うコード
class User attr_accessor :name, :email def initialize(attributes = {}) @name = attributes[:name] @email = attributes[:email] end def formatted_email "#{@name} <#{@email}>" end endattr_accessor :name, :emailユーザー名とメールアドレス (属性: attribute) に対応するアクセサー (accessor) をそれぞれ作成します。アクセサーを作成すると、そのデータを取り出すメソッドと、データに代入するメソッドをそれぞれ定義してくれる。
具体的には、この行を実行したことにより、インスタンス変数@nameとインスタンス変数@emailにアクセスするためのメソッドが用意されます。
Railsでは、インスタンス変数をコントローラ内で宣言するだけでビューで使えるようになる、といった点に主な利用価値がある。initializeは、Rubyの特殊なメソッドである。
User.newを実行すると自動的に呼び出されるメソッドです。
この場合のinitializeメソッドは、次のようにattributesという引数を1つ取ります。def initialize(attributes = {}) @name = attributes[:name] @email = attributes[:email] end上のコードで、attributes変数は空のハッシュをデフォルトの値として持つため、名前やメールアドレスのないユーザーを作ることができます (4.3.3を思い出してください。存在しないキーに対してハッシュはnilを返すので、:nameキーがなければattributes[:name]はnilになり、同じことがattributes[:email]にも言える)。
最後に、formatted_emailメソッドを定義する。このメソッドは、文字列の式展開を利用して、@nameと@emailに割り当てられた値をユーザーのメールアドレスとして構成します。
def formatted_email "#{@name} <#{@email}>" end@ 記号によって示されているとおり、@nameと@emailは両方ともインスタンス変数なので、自動的にformatted_emailメソッドで使えるようになります。
Railsコンソールを起動し、example_userのコードをrequireして、自作したクラスを試しに使ってみましょう。
>> require './example_user' # example_userのコードを読み込む方法 => true >> example = User.new => #<User:0x224ceec @email=nil, @name=nil> >> example.name # attributes[:name]は存在しないのでnil => nil >> example.name = "Example User" # 名前を代入する => "Example User" >> example.email = "user@example.com" # メールアドレスを代入する => "user@example.com" >> example.formatted_email => "Example User <user@example.com>"上のコードで、requireのパスにある’.’は、Unixの “カレントディレクトリ” (現在のディレクトリ) を表し、’./example_user’というパスは、カレントディレクトリからの相対パスでexample_userファイルを探すようにRubyに指示します。次のコードでは空のexample_userを作成します。次に、対応する属性にそれぞれ手動で値を代入することで、名前とメールアドレスを与えます (リスト 4.17でattr_accessorを使っているので、これで代入できるようになります)。次のコードは、
example.name = "Example User"
@name変数に"Example User"という値を設定します。同様にemail属性にも値を設定します。これらの値はformatted_emailメソッドで使われます。最後のハッシュ引数の波カッコを省略できることを説明しました。それと同じ要領でinitializeメソッドにハッシュを渡すことで、属性が定義済みの他のユーザを作成することができます。
演習
1.Userクラスで定義されているname属性を修正して、first_name属性とlast_name属性に分割してみましょう。また、それらの属性を使って "Michael Hartl" といった文字列を返すfull_nameメソッドを定義してみてください。最後に、formatted_emailメソッドのnameの部分を、full_nameに置き換えてみましょう (元々の結果と同じになっていれば成功です)
class User attr_accessor :first_name,:last_name, :email def initialize(attributes = {}) @first_name = attributes[:first_name] @last_name = attributes[:last_name] @email = attributes[:email] end def full_name @full_name = "#{@first_name} #{@last_name}" end def formatted_email "#{@full_name} <#{@email}>" end end2."Hartl, Michael" といったフォーマット (苗字と名前がカンマ+半角スペースで区切られている文字列) で返すalphabetical_nameメソッドを定義してみましょう。
full_name.splitとalphabetical_name.split(', ').reverseの結果を比較し、同じ結果になるかどうか確認してみましょう。[example_user.rb] class User attr_accessor :first_name,:last_name, :email def initialize(attributes = {}) @first_name = attributes[:first_name] @last_name = attributes[:last_name] @email = attributes[:email] end def full_name @full_name = "#{@first_name} #{@last_name}" end def alphabetical_name @alphabetical_name = "#{@last_name}, #{@first_name}" end def formatted_email "#{@full_name} <#{@email}>" end end[console] >>user.full_name.split => ["Michael", "Hartl"] >>user.alphabetical_name.split(', ').reverse => ["Michael", "Hartl"] >>user.full_name.split == user.alphabetical_name.split(', ').reverse => true今日はここまで。最後の方は結構難しかったです。
ちょっと4章に時間かけすぎましたかね。どんどん行きます。
- 投稿日:2020-03-25T17:36:23+09:00
Ruby on Railsの開発環境(仮想環境)の構築方法
はじめに
現在のバージョン:
macOS Catalina 10.15.3Ruby on Railsで環境構築を実施してみました。自身のPC(ローカル)に直接環境を構築すると現在のPCの設定に影響を与えてしまう可能性がある為、仮想環境を作りました。
仮想環境について
仮想環境とは自身のPCとは別のPCを仮想的に作ることです。(1台のPCで複数のPCを扱えるイメージ)
仮想環境は不要になればすぐに削除が可能です。仮想環境を構築
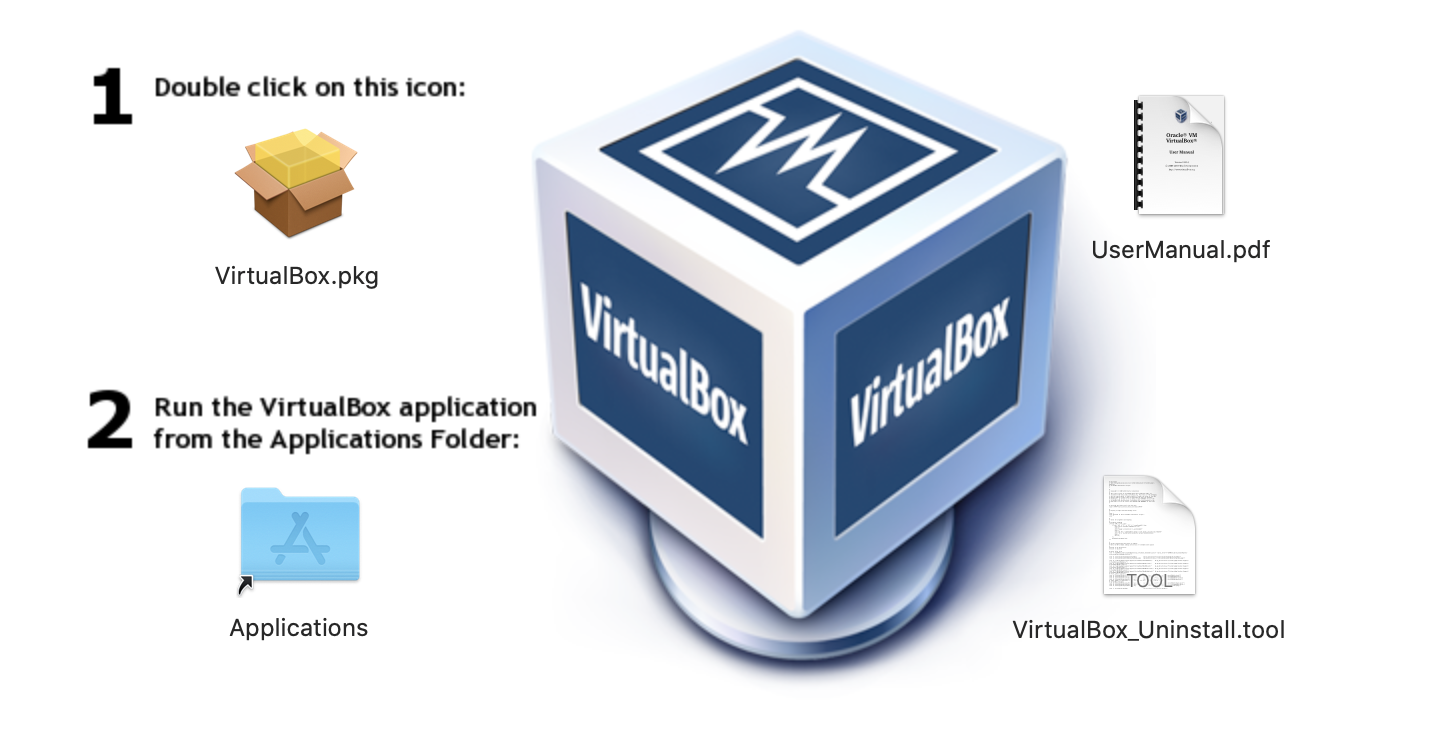
VirtualBoxをインストール
VirtualBox(バーチャルボックス)をインストールして、仮想環境を構築。
macOS:VirtualBox(6.0.14)ダウンロード
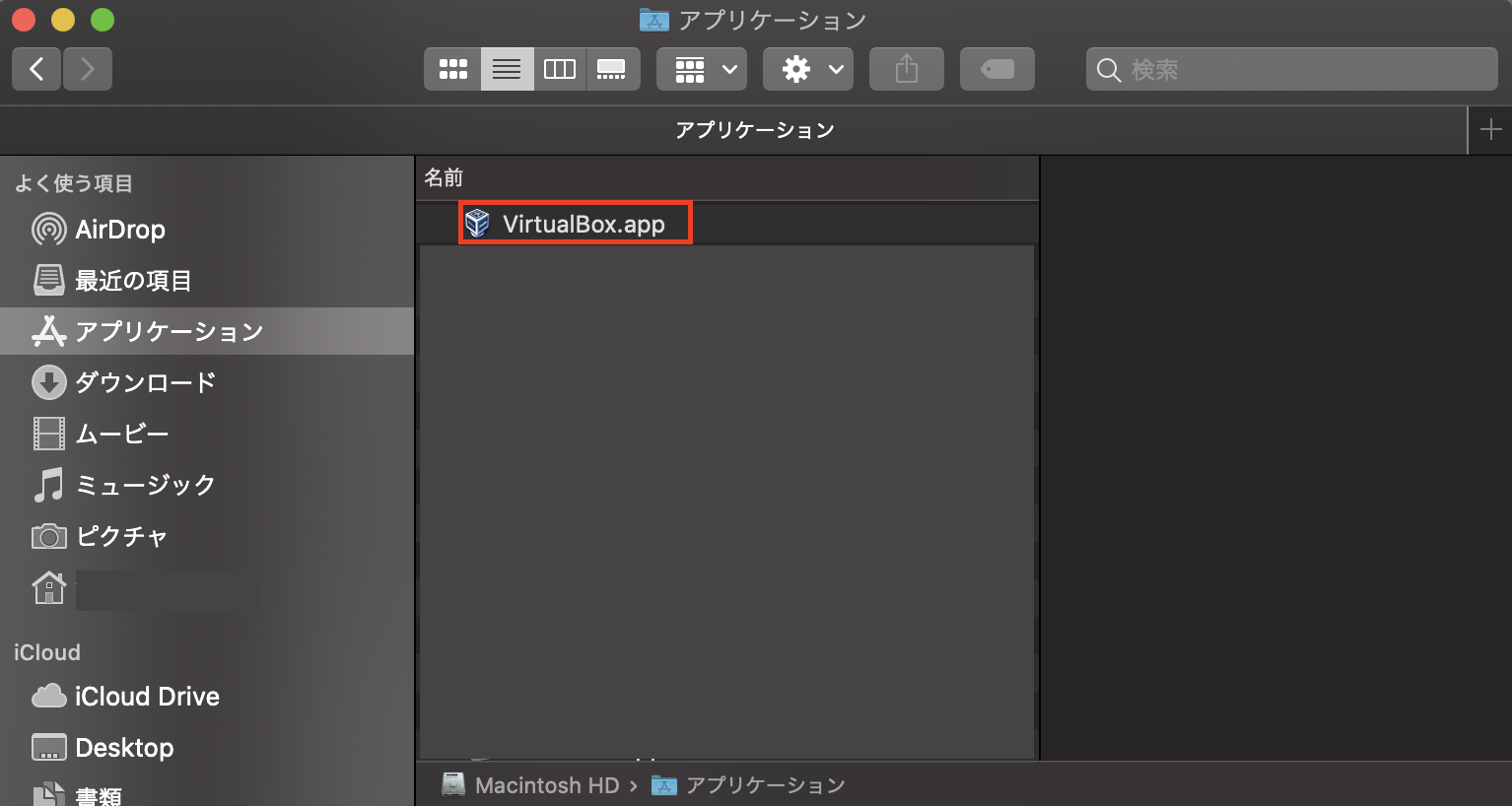
ダウンロード後開くと下記の画面になります。
「1」をダブルクリックして、インストール実施完了後「Applications」フォルダに追加されてます。インストール後以下のコマンドでバージョンが表示されるか確認。
$ vagrant box list
centos/7 (virtualbox, 1905.1)Vagrantをインストール
Vagrant(ベイグラント)をインストールして、仮想環境を管理・構築をします。Windows、Mac OS X、Linuxで動作します。
インストール後以下のコマンドでバージョンが表示されるか確認。
$ vagrant --version
Vagrant 2.2.4※macOSのバージョンによっては、以下の設定が必要になります。
アップルメニューから「システム環境設定」→「セキュリティとプライバシー」アイコンクリック→「一般」タブクリック→「開発元を確認できないため、開けませんでした」の「このまま開く」をクリックする。vagrant-vbguestプラグインをインストール
「vagrant-vbguest」は自分の環境と仮想環境のバージョンを自動で合わせてくれるVagrantのプラグインです。
Vagrant起動の準備をする際に、「vagrant-vbguest」プラグインのインストールがあると面倒な作業を肩代わりしてくれます。・インストール方法
ターミナルで以下コードの入力をする。
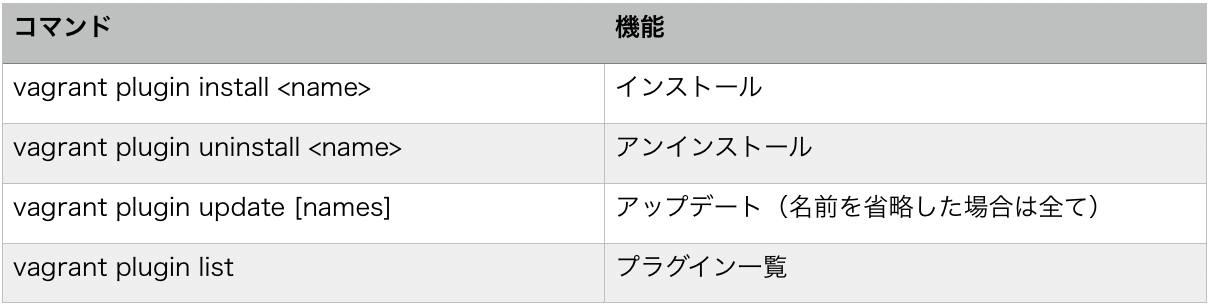
$ vagrant plugin install vagrant-vbguest参考にコマンド一覧も載せておきます。
Vagrantfileの作成
Vagrantfileの作成をしますが、その前に作業ディレクトリーの作成をします。
ターミナルでデスクトップに移動
$ cd Desktop
フォルダをデスクトップに作成する
$ mkdir フォルダ名
任意のフォルダに移動する
$ cd フォルダ名
フォルダ内に「vagrant」という名のフォルダを作成する
$ mkdir vagrant
vagrantフォルダに移動する
$ cd vagrantここからVagrantfileを作成していきます。
Vagrantfileを作成
$ vagrant init centos/7
コマンド実行後、Vagrantfileを作成されております。Vagrant起動
Vagrantの起動コマンド
$ vagrant up
初回の起動は、30分から3時間はかかります。以下のように表示がされると完了です。
完了後、以下のコマンドでシャットダウンして導入が完了です。
$ vagrant halt
※再度起動する際はVagrantの起動コマンド
$ vagrant upを実行してください。
- 投稿日:2020-03-25T17:08:36+09:00
wicked_pdfを導入するまで2020
環境
- OS
- 開発PC: macOS Mojave
- サーバー: Amazon Linux
- ruby 2.6.1
- Rails 5.2.2
初期段階
ミニマムで実装すると以下のようになります。
また、layoutで指定するファイルはapp/views/layoutsに配置する必要があります。ディレクトリ構成src ├── app │ ├── assets │ │ └── stylesheets │ │ └── sample │ │ └── sample.sass │ ├── controller │ │ └── sample │ │ └── sample_controller.rb │ └── views │ ├── sample │ │ ├── sample.html.slim │ └── layouts │ └── pdf_for_sample.html.slim └── Gemfilesample_controller.rbdef generate_pdf respond_to do |format| format.html { redirect_to sample_generate_pdf_path(format: :pdf)} format.pdf do if params[:debug].present? render pdf: 'sample', title: 'sample.pdf', encoding: 'UTF-8', layout: 'pdf_for_sample.html.slim', template: "sample/sample.html.slim", show_as_html: params[:debug].present? else render pdf: 'sample', title: 'sample.pdf', encoding: 'UTF-8', layout: 'pdf_for_sample.html.slim', template: "sample/sample.html.slim", show_as_html: params[:debug].present? end end end endpdf_for_sample.html.slimdoctype html html[lang="ja" xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" dir="ltr"] head / メインのcss = wicked_pdf_stylesheet_link_tag 'sample/sample', media: 'all' body .sample .sample-text コンテンツsample.html.slim# 空っぽGemfilegem 'wicked_pdf' gem 'wkhtmltopdf-binary'layoutとtemplateを使い分ける
最初は違いがわかりにくかったのですが、
layoutのファイルは共通、templateは個別のHTMLを描写するものとし、layoutからtemplateを呼び出す作りにするのが良さそうです。pdf_for_sample.html.slimdoctype html html[lang="ja" xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" dir="ltr"] head / メインのcss = wicked_pdf_stylesheet_link_tag 'sample/sample', media: 'all' body = yieldsample.html.slim.sample .sample-text コンテンツA4横向き&pdfファイル全体に背景画像を使いたい
筆者の場合A4かつ横向きで生成する必要があったので、
page_sizeとorientationを指定します。
(page_sizeはデフォルトでA4なので指定は不要ですが、可読性のため明示的に指定しました)sample_controller.rbdef generate_pdf respond_to do |format| format.html { redirect_to sample_generate_pdf_path(format: :pdf)} format.pdf do if params[:debug].present? render pdf: 'sample', title: 'sample.pdf', encoding: 'UTF-8', orientation: 'Landscape', #横向き page_size: 'A4', margin: { top: 0, bottom: 0, left: 0, right: 0 }, layout: 'pdf_for_sample.html.slim', template: "sample/sample.html.slim", show_as_html: params[:debug].present? else render pdf: 'sample', title: 'sample.pdf', encoding: 'UTF-8', orientation: 'Landscape', #横向き page_size: 'A4', margin: { top: 0, bottom: 0, left: 0, right: 0 }, layout: 'pdf_for_sample.html.slim', template: "sample/sample.html.slim", show_as_html: params[:debug].present? end end end end次にpdf全体を覆う背景画像を当て込みます。
デフォルトでmarginが設定されているので初期化し、かつA4に合うよう調整した結果、heightを991pxに設定しました。sample.sass.sample background: sample.png background-size: cover height: 991px画面遷移を行わず、PDFのファイルダウンロードまで行いたい
筆者のPJでは生成したpdfファイルはユーザーのPCにダウンロードされる想定でしたが、このままだと、「ボタンクリックなどでPDF生成実行→pdfファイル画面へ遷移→ダウンロードボタンをクリック→ファイルがダウンロードされる」と言うフローになり、やや煩雑です。
上記を「ボタンクリックなどでPDF生成実行→ファイルがダウンロードされる」と言うフローにするため、以下の記述に変更します。sample_controller.rbdef generate_pdf respond_to do |format| format.html { redirect_to sample_generate_pdf_path(format: :pdf) } format.pdf do if params[:debug].present? render pdf: 'sample', title: 'sample.pdf', encoding: 'UTF-8', orientation: 'Landscape', page_size: 'A4', margin: { top: 0, bottom: 0, left: 0, right: 0 }, layout: 'pdf_for_sample.html.slim', template: "sample/sample.html.slim", show_as_html: params[:debug].present? else pdf = render_to_string pdf: 'sample', title: 'sample.pdf', encoding: 'UTF-8', orientation: 'Landscape', page_size: 'A4', margin: { top: 0, bottom: 0, left: 0, right: 0 }, layout: 'pdf_for_sample.html.slim', template: "sample/sample.html.slim", show_as_html: params[:debug].present? send_data pdf, filename: "sample.pdf" end end end end
filename: "sample.pdf"でダウンロードされる際のファイル名が指定可能です。Amazon LinuxでRuntime errorになる
環境依存問題その1
ローカルで動作確認をしていざデプロイ!と思ったらPDF生成実行で500エラー(Runtime error)となり動かない...
どうやら、AmazonLinuxは動作環境外のようでした。
調べてみるとAmazonLinux対応版のブランチがあるようなので、指定したら正常に動作しました。Gemfilegem 'wicked_pdf' gem 'wkhtmltopdf-binary', git: 'https://github.com/entretechno/wkhtmltopdf_binary_gem', branch: 'amazon-linux'日本語が文字化けする
環境依存問題その2
PDF生成の際にはクライアントではなくサーバー側のフォントを参照するらしく、日本語が文字化けしてまともに動かない状態に。
そのためサーバーに日本語フォントをインストールした上で、cssからスタイルに適用します。
今回はyumで手軽にインストール可能なIPAフォントを利用しました。
(本当はnotoなどのgoogleフォントが使えれば尚良かったのですが、筆者の環境では正常に読み込めませんでした)sudo yum -y install ipa-gothic-fonts ipa-mincho-fontssample.sass.sample background: sample.png background-size: cover height: 991px .sample-text font-family: 'IPAMincho', 'IPA明朝'また、
serif、san-serifは、フォントをインストールしない状態でも描画可能だったので、試してみるといいかもしれません。最終形
上記をまとめると以下になります。
sample_controller.rbdef generate_pdf respond_to do |format| format.html { redirect_to sample_generate_pdf_path(format: :pdf) } format.pdf do if params[:debug].present? render pdf: 'sample', title: 'sample.pdf', encoding: 'UTF-8', orientation: 'Landscape', page_size: 'A4', margin: { top: 0, bottom: 0, left: 0, right: 0 }, layout: 'pdf_for_sample.html.slim', template: "sample/sample.html.slim", show_as_html: params[:debug].present? else pdf = render_to_string pdf: 'sample', title: 'sample.pdf', encoding: 'UTF-8', orientation: 'Landscape', page_size: 'A4', margin: { top: 0, bottom: 0, left: 0, right: 0 }, layout: 'pdf_for_sample.html.slim', template: "sample/sample.html.slim", show_as_html: params[:debug].present? send_data pdf, filename: "sample.pdf" end end end endpdf_for_sample.html.slimdoctype html html[lang="ja" xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" dir="ltr"] head / メインのcss = wicked_pdf_stylesheet_link_tag 'sample/sample', media: 'all' body = yieldsample.html.slim.sample .sample-text コンテンツsample.sass.sample background: sample.png background-size: cover height: 991px .sample-text font-family: 'IPAMincho', 'IPA明朝'Gemfilegem 'wicked_pdf' gem 'wkhtmltopdf-binary', git: 'https://github.com/entretechno/wkhtmltopdf_binary_gem', branch: 'amazon-linux'
- 投稿日:2020-03-25T15:52:22+09:00
rails風味のrubyってなにそれ美味しいの?
stylesheet_link_tag(* sources)リンク
引数として指定されたソースのスタイルシートリンクタグを返します。拡張子を指定しない場合、.css自動的に追加されます。最後の引数としてハッシュを渡すことにより、リンク属性を変更できます。歴史的な理由により、「media」属性は常に存在し、デフォルトは「screen」です。したがって、スタイルシートをすべてのメディアタイプに適用するには、「all」に明示的に設定する必要があります。
ここではrubyの基本的な知識をrails consoleを用いて勉強するらしい。
オブジェクトとメッセージ受け渡し
オブジェクトを直感的に理解することが大事らしい。
何種類かRubyにまつわる書籍読んだんだけどいまでによくわかっていない。オブジェクトとは (いついかなる場合にも) メッセージに応答するものらしい。文字列のようなオブジェクトについての説明をlengthというメッセージを用いて説明している。
"foobar".length # 文字列に "length" というメッセージを送る => 6オブジェクトに渡されるメッセージは、メソッドと呼ばれていて。メソッドの実体は、そのオブジェクト内で定義されたメソッドである。
Rubyの文字列は、次のようにempty?メソッドにも応答することができる。>> "foobar".empty? => false >> "".empty? => trueRubyでは、メソッドがtrueまたはfalseという論理値 (boolean) を返すことを、末尾の疑問符で示す慣習があります。 論理値は、特に処理の流れを変更するときに有用です。
>> s = "foobar" >> if s.empty? >> "The string is empty" >> else >> "The string is nonempty" >> end => "The string is nonempty"条件文を2つ以上含めたい場合は、elsif (else + if) という文を使います。
>> if s.nil? >> "The variable is nil" >> elsif s.empty? >> "The string is empty" >> elsif s.include?("foo") >> "The string includes 'foo'" >> end => "The string includes 'foo'"なお、論理値はそれぞれ && (and) や || (or)、! (not) オペレーターで表すこともできます。
>> x = "foo" => "foo" >> y = "" => "" >> puts "Both strings are empty" if x.empty? && y.empty? => nil >> puts "One of the strings is empty" if x.empty? || y.empty? "One of the strings is empty" => nil >> puts "x is not empty" if !x.empty? "x is not empty" => nilRubyでは、あらゆるものがオブジェクトである。したがって、nilもオブジェクトであり、これも多くのメソッドに応答する。ほぼあらゆるオブジェクトを文字列に変換するto_sメソッドを使うと
>> nil.to_s => ""空文字列が出力された。今度はnilに対してメソッドをチェーン (chain) して渡せることを確認する。
ここらへんで頭がこんがらがってきたな。>> nil.empty? NoMethodError: undefined method `empty?' for nil:NilClass >> nil.to_s.empty? # メソッドチェーンの例 => trueまだぎりぎりついてける。
puts "x is not empty" if !x.empty? --------------------------------------------------- >> string = "foobar" >> puts "The string '#{string}' is nonempty." unless string.empty? The string 'foobar' is nonempty. => nilああ???もうここらへんわからん笑
とりあえず説明が分かりづらいんだけどif文とunless文のコードが簡潔にまとめられるやり方を説明してるのかな?
とりあえずなんの説明もなくunlessキーワードていうのがでてきたな。progateにあったっけ?「unless」文とは
条件式が偽の場合の処理を記述するのに使われます。
みたいです。
だから上のやつは
もし変数stringの中に文字数が0じゃなかったら””内を出力しろ
みたいな感じかな?
わかりづらいって。笑演習
1."racecar" の文字列の長さはいくつですか? lengthメソッドを使って調べてみてください。
> "racecar".length => 72.reverseメソッドを使って、"racecar"の文字列を逆から読むとどうなるか調べてみてください。
> "racecar".reverse => "racecar"3.変数sに "racecar" を代入してください。その後、比較演算子 (==) を使って変数sとs.reverseの値が同じであるかどうか、調べてみてください。
> s==s.reverse => true4.リスト 4.9を実行すると、どんな結果になるでしょうか? 変数sに "onomatopoeia" という文字列を代入するとどうなるでしょうか? ヒント: 上矢印 (またはCtrl-Pコマンド) を使って以前に使ったコマンドを再利用すると一からコマンドを全部打ち込む必要がなくて便利ですよ。)
> puts "It's a palindrome!" if s == s.reverse It's a palindrome! => nil s="onomatopoeia" => "onomatopoeia" > puts "It's a palindrome!" if s == s.reverse => nil演習はこんな感じでした。あの、、演習2のやつだいぶ悩んじゃったよ。あれっ変わらなくね?って。笑
メソッドの定義
rails consoleの中でもアクションやヘルパーなどと同じ方法でメソッドを定義することができる。
>> def string_message(str = '') >> if str.empty? >> "It's an empty string!" >> else >> "The string is nonempty." >> end >> end => :string_message >> puts string_message("foobar") The string is nonempty. >> puts string_message("") It's an empty string! >> puts string_message It's an empty string!メソッドの引数を省略することも可能 (カッコですら省略可能です)。これは次のコードで
def string_message(str = '')引数にデフォルト値を含めているからである。(この例のデフォルト値はからの文字列である)このように設定するとstr変数に引数を渡すことも渡さないこともできる。引数を渡さない場合は指定のデフォルト値が自動的に使われる。
演習
1.リスト 4.10のFILL_INの部分を適切なコードに置き換え、回文かどうかをチェックするメソッドを定義してみてください。ヒント: リスト 4.9の比較方法を参考にしてください。
>> def palindrome_tester(s) >> if s==s.reverse >> puts "It's a palindrome!" >> else >> puts "It's not a palindrome." >> end >> end2.上で定義したメソッドを使って “racecar” と “onomatopoeia” が回文かどうかを確かめてみてください。1つ目は回文である、2つ目は回文でない、という結果になれば成功です。
> def palindrome_tester(s) > if s==s.reverse > puts "It's a palindrome!" > else > puts "It's not a palindrom." > end > end => :palindrome_tester > puts palindrome_tester("racecar") It's a palindrome! => nil > puts palindrome_tester("onomatopoeia") It's not a palindrom. => nil3.palindrome_tester("racecar")に対してnil?メソッドを呼び出し、戻り値がnilであるかどうかを確認してみてください (つまりnil?を呼び出した結果がtrueであることを確認してください)。このメソッドチェーンは、nil?メソッドがリスト 4.10の戻り値を受け取り、その結果を返しているという意味になります。
>>palindrome_tester("racecar").nil? =>It's a palindrome! => trueここでtitleヘルパーの値を振りかえってみると。。。
module ApplicationHelper # ページごとの完全なタイトルを返します。 # コメント行 def full_title(page_title = '') # メソッド定義とオプション引数 base_title = "Ruby on Rails Tutorial Sample App" # 変数への代入 if page_title.empty? # 論理値テスト base_title # 暗黙の戻り値 else page_title + " | " + base_title # 文字列の結合 end end endおおー。。。なんかわかるようになってる。
すげーな。railsチュートリアル。
ここらへんすごい大事だと思う。他のデータ構造
配列と範囲演算子
配列
配列 (array) は、特定の順序を持つ要素のリスト。配列を理解することは、ハッシュやRailsのデータモデルを理解するための重要な基盤となります。
ふむふむ
splitメソッド
文字列を自然に変換した配列を得ることができる。
>> "foo bar baz".split # 文字列を3つの要素を持つ配列に分割する => ["foo", "bar", "baz"] >> "fooxbarxbaz".split('x') => ["foo", "bar", "baz"] 他の文字を指定して区切ることもできる。=> ["foo", "bar", "baz"]
多くのコンピュータ言語の慣習と同様、Rubyの配列でもゼロオリジンを採用しています。これは、配列の最初の要素のインデックスが0から始まり、2番目は1...と続くことを意味する。
>> a = [42, 8, 17] => [42, 8, 17] >> a[0] # Rubyでは角カッコで配列にアクセスする => 42 >> a[1] => 8 >> a[2] => 17 >> a[-1] # 配列の添字はマイナスにもなれる! => 17ここa[-1]=17になってんだけど負の配列の添字は[0.1.2]=[-3.-2.-1]らしい。よってこれは17になります。
上で示したとおり、配列の要素にアクセスするには角カッコを使う。Rubyでは、角カッコ以外にも配列の要素にアクセスする方法が提供されている。>> a # 配列「a」の内容を確認する => [42, 8, 17] >> a.first => 42 >> a.second => 8 >> a.last => 17 >> a.last == a[-1] # == を使って比較する => true最後の行では、等しいことを確認する比較演算子==を使ってみました。この演算子や != (“等しくない”) などの演算子は、他の多くの言語と共通です。
>> x = a.length # 配列も文字列と同様lengthメソッドに応答する => 3 >> x == 3 => true >> x == 1 => false >> x != 1 => true >> x >= 1 => true >> x < 1 => false配列は、上記コードの最初の行のlengthメソッド以外にも、さまざまなメソッドに応答します。
>> a => [42, 8, 17] >> a.empty? => false >> a.include?(42) include? とは文字列や配列の要素に含まれる文字列に対して、指定した文字列が存在するか確認するときに使用。 => true >> a.sort => [8, 17, 42] >> a.reverse => [17, 8, 42] >> a.shuffle => [17, 42, 8] >> a => [42, 8, 17]上のどのメソッドを実行した場合にも、a自身は変更されていないという点にご注目ください。配列の内容を変更したい場合は、そのメソッドに対応する「破壊的」メソッドを使います。破壊的メソッドの名前には、元のメソッドの末尾に「!」を追加したものを使うのがRubyの慣習です。
>> a => [42, 8, 17] >> a.sort! => [8, 17, 42] >> a => [8, 17, 42]また、pushメソッド (または同等の<<演算子) を使って配列に要素を追加することもできます。
>> a.push(6) # 6を配列に追加する => [42, 8, 17, 6] >> a << 7 # 7を配列に追加する => [42, 8, 17, 6, 7] >> a << "foo" << "bar" # 配列に連続して追加する => [42, 8, 17, 6, 7, "foo", "bar"]最後の例では、要素の追加をチェーン (chain) できることを示しました。他の多くの言語の配列と異なり、Rubyでは異なる型が配列の中で共存できます (上の場合は整数と文字列)。
上では、文字列を配列に変換するのにsplitを使いました。joinメソッドはこれと逆の動作です。
>> a => [42, 8, 17, 6, 7, "foo", "bar"] >> a.join # 単純に連結する => "4281767foobar" >> a.join(', ') # カンマ+スペースを使って連結する => "42, 8, 17, 6, 7, foo, bar"範囲 (range) は、配列と密接に関係しています。to_aメソッドを使って配列に変換すると理解しやすいと思います。
>> 0..9 => 0..9 >> 0..9.to_a # おっと、9に対してto_aを呼んでしまっていますね NoMethodError: undefined method `to_a' for 9:Fixnum >> (0..9).to_a # 丸カッコを使い、範囲オブジェクトに対してto_aを呼びましょう => [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]0..9 は範囲として有効ですが、上の2番目の表記ではメソッドを呼ぶ際にカッコを追加する必要があることを示しています。
範囲は、配列の要素を取り出すのに便利です。
>> a = %w[foo bar baz quux] # %wを使って文字列の配列に変換 => ["foo", "bar", "baz", "quux"] >> a[0..2] => ["foo", "bar", "baz"]インデックスに-1という値を指定できるのは極めて便利です。-1を使うと、配列の長さを知らなくても配列の最後の要素を指定することができ、これにより配列を特定の開始位置の要素から最後の要素までを一度に選択することができます。
>> a = (0..9).to_a => [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >> a[2..(a.length-1)] # 明示的に配列の長さを使って選択 => [2, 3, 4, 5, 6, 7, 8, 9] >> a[2..-1] # 添字に-1を使って選択 => [2, 3, 4, 5, 6, 7, 8, 9]次のように、文字列に対しても範囲オブジェクトが使えます。
>> ('a'..'e').to_a => ["a", "b", "c", "d", "e"]演習
1.文字列「A man, a plan, a canal, Panama」を ", " で分割して配列にし、変数aに代入してみてください。a = "A man, a plan, a canal, Panama".split(",") => ["A man", " a plan", " a canal", " Panama"]2.今度は、変数aの要素を連結した結果 (文字列) を、変数sに代入してみてください。
s=a.join => "AmanaplanacanalPanama"3.変数sを半角スペースで分割した後、もう一度連結して文字列にしてください (ヒント: メソッドチェーンを使うと1行でもできます)。リスト 4.10で使った回文をチェックするメソッドを使って、(現状ではまだ) 変数sが回文ではないことを確認してください。downcaseメソッドを使って、s.downcaseは回文であることを確認してください。
=> "A man a plan a canal Panama" s.split => ["A", "man", "a", "plan", "a", "canal", "Panama"] s => "A man a plan a canal Panama" s.split.join => "AmanaplanacanalPanama" palindrome_tester(s.split.join) It's not a palindrome. => nil palindrome_tester(s.split.join.downcase) It's a palindrome! => nil4.aからzまでの範囲オブジェクトを作成し、7番目の要素を取り出してみてください。同様にして、後ろから7番目の要素を取り出してみてください。(ヒント: 範囲オブジェクトを配列に変換するのを忘れないでください)
('a'..'z').to_a => ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z"] > ('a'..'z').to_a[6] => "g"こんな感じですかね。
ブロック
配列と範囲はいずれも、ブロックを伴うさまざまなメソッドに対して応答することができます。ブロックは、Rubyの極めて強力な機能であり、かつわかりにくい機能でもあります。
>> (1..5).each { |i| puts 2 * i } 2 4 6 8 10 => 1..5上のコードでは、範囲オブジェクトである(1..5)に対してeachメソッドを呼び出しています。メソッドに渡されている{ |i| puts 2 * i }が、ブロックと呼ばれる部分です。|i|では変数名が縦棒「|」に囲まれていますが、これはブロック変数に対して使うRubyの構文で、ブロックを操作するときに使う変数を指定します。この場合、範囲オブジェクトのeachメソッドは、iという1つのローカル変数を使ってブロックを操作できます。そして、範囲に含まれるそれぞれの値をこの変数に次々に代入してブロックを実行します。
ブロックであることを示すには波カッコ で囲みますが、次のようにdoとendで囲んで示すこともできます。
>> (1..5).each do |i| ?> puts 2 * i >> end 2 4 6 8 10 => 1..5ブロックには複数の行を記述できます (実際ほとんどのブロックは複数行です)。RailsチュートリアルではRuby共通の慣習に従って、短い1行のブロックには波カッコを使い、長い1行や複数行のブロックにはdo..end記法を使っています。
>> (1..5).each do |number| ?> puts 2 * number >> puts '--' >> end 2 -- 4 -- 6 -- 8 -- 10 -- => 1..5今度はiの代わりにnumberを使っていることにご注目ください。この変数 (ブロック変数) の名前は固定されていません。
ブロックは見た目に反して奥が深く、ブロックを十分に理解するためには相当なプログラミング経験が必要です。そのためには、ブロックを含むコードをたくさん読みこなすことでブロックの本質を会得する以外に方法はありません9。幸いなことに、人間には個別の事例を一般化する能力というものがあります。ささやかですが参考のために、mapメソッドなどを使ったブロックの使用例をいくつか挙げてみます。
>> 3.times { puts "Betelgeuse!" } # 3.timesではブロックに変数を使っていない "Betelgeuse!" "Betelgeuse!" "Betelgeuse!" => 3 >> (1..5).map { |i| i**2 } # 「**」記法は冪乗 (べき乗) => [1, 4, 9, 16, 25] >> %w[a b c] # %w で文字列の配列を作成 => ["a", "b", "c"] >> %w[a b c].map { |char| char.upcase } => ["A", "B", "C"] >> %w[A B C].map { |char| char.downcase } => ["a", "b", "c"]上に示したように、mapメソッドは、渡されたブロックを配列や範囲オブジェクトの各要素に対して適用し、その結果を返します。また、後半の2つの例では、mapのブロック内で宣言した引数 (char) に対してメソッドを呼び出しています。こういったケースでは省略記法が一般的で、次のように書くこともできます (この記法を“symbol-to-proc”と呼びます)。
>> %w[A B C].map { |char| char.downcase } => ["a", "b", "c"] >> %w[A B C].map(&:downcase) => ["a", "b", "c"]演習
1.範囲オブジェクト0..16を使って、各要素の2乗を出力してください。
> (0..16).map{|i|i**2} => [0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100, 121, 144, 169, 196, 225, 256]2.yeller (大声で叫ぶ) というメソッドを定義してください。このメソッドは、文字列の要素で構成された配列を受け取り、各要素を連結した後、大文字にして結果を返します。例えばyeller(['o', 'l', 'd'])と実行したとき、"OLD"という結果が返ってくれば成功です。ヒント: mapとupcaseとjoinメソッドを使ってみましょう。
> def yeller(big_voice) 2.6.3 :013?> voice=big_voice.map{|i|i.upcase}.join 2.6.3 :014?> puts voice 2.6.3 :015?> end => :yeller 2.6.3 :016 > yeller(['o','l','d']) OLD => nil3.random_subdomainというメソッドを定義してください。このメソッドはランダムな8文字を生成し、文字列として返します。ヒント: サブドメインを作るときに使ったRubyコードをメソッド化したものです。
def random_subdomain puts ('a'..'z').to_a.shuffle[0..7].join end =>random_subdomain これを出力する。4.リスト 4.12の「?」の部分を、それぞれ適切なメソッドに置き換えてみてください。ヒント:split、shuffle、joinメソッドを組み合わせると、メソッドに渡された文字列 (引数) をシャッフルさせることができます。
def string_shuffle(s) s.split('').shuffle.join end string_shuffle("foobar")みたいな感じです。
ハッシュとシンボル
ハッシュは本質的には配列と同じ、インデックスとして整数値以外のものも使える点が配列と異なるハッシュのインデックス (キーと呼ぶのが普通です) は、通常何らかのオブジェクトです。例えば、次のように文字列をキーとして使えます。
>> user = {} # {}は空のハッシュ => {} >> user["first_name"] = "Michael" # キーが "first_name" で値が "Michael" => "Michael" >> user["last_name"] = "Hartl" # キーが "last_name" で値が "Hartl" => "Hartl" >> user["first_name"] # 要素へのアクセスは配列の場合と似ている => "Michael" >> user # ハッシュのリテラル表記 => {"last_name"=>"Hartl", "first_name"=>"Michael"}・ハッシュは、キーと値のペアを波カッコで囲んで表記する。
・ハッシュの波カッコは、ブロックの波カッコとはまったく別物である
・ハッシュは配列と似ていますがハッシュでは要素の「並び順」が保証されない。もし要素の順序が重要である場合は、配列を使う必要があります。ハッシュの1要素を角カッコを使って定義する代わりに、次のようにキーと値をハッシュロケットと呼ばれる=> によってリテラル表現するほうが簡単です。
>> user = { "first_name" => "Michael", "last_name" => "Hartl" } => {"last_name"=>"Hartl", "first_name"=>"Michael"}ハッシュのキーとしては、文字列よりもシンボルを使う方が一般的。
シンボルは文字列と似ていますが、クォートで囲む代わりにコロンが前に置かれている点が異なります。ハッシュのキーとしてシンボルを採用する場合、user のハッシュは次のように定義できる
>> user = { :name => "Michael Hartl", :email => "michael@example.com" } => {:name=>"Michael Hartl", :email=>"michael@example.com"} >> user[:name] # :name に対応する値にアクセスする => "Michael Hartl" >> user[:password] # 未定義のキーに対応する値にアクセスする => nil最後の例を見ると、未定義のハッシュ値は単純にnilであることがわかります。
>> h1 = { :name => "Michael Hartl", :email => "michael@example.com" } => {:name=>"Michael Hartl", :email=>"michael@example.com"} >> h2 = { name: "Michael Hartl", email: "michael@example.com" } => {:name=>"Michael Hartl", :email=>"michael@example.com"} >> h1 == h2 => true2つ目の記法は、シンボルとハッシュロケットの組み合わせを、次のようにキーの名前の (前ではなく) 後にコロンを置き、その後に値が続くように置き換えたもの.
{ :name => "Michael Hartl" } 上のコードと、 { name: "Michael Hartl" }というコードは等価になります
ハッシュの中にハッシュを定義できる
>> params = {} # 'params' というハッシュを定義する ('parameters' の略)。 => {} >> params[:user] = { name: "Michael Hartl", email: "mhartl@example.com" } => {:name=>"Michael Hartl", :email=>"mhartl@example.com"} >> params => {:user=>{:name=>"Michael Hartl", :email=>"mhartl@example.com"}} >> params[:user][:email] => "mhartl@example.com"配列や範囲オブジェクトと同様、ハッシュもeachメソッドに応答します。例えば、:successと:dangerという2つの状態を持つ flash という名前のハッシュについて考えてみましょう。
>> flash = { success: "It worked!", danger: "It failed." } => {:success=>"It worked!", :danger=>"It failed."} >> flash.each do |key, value| ?> puts "Key #{key.inspect} has value #{value.inspect}" >> end Key :success has value "It worked!" Key :danger has value "It failed."ここで、配列のeachメソッドでは、ブロックの変数は1つだけですが、ハッシュのeachメソッドでは、ブロックの変数はキーと値の2つになっていることに注意してください。したがって、 ハッシュに対してeachメソッドを実行すると、ハッシュの1つの「キーと値のペア」ごとに処理を繰り返します。
ところで、オブジェクトを表示するためにinspectを使うことは非常によくあることなので、 pメソッドというショートカットがある。
>> p :name # 'puts :name.inspect' と同じ :name演習
1.キーが'one'、'two'、'three'となっていて、それぞれの値が'uno'、'dos'、'tres'となっているハッシュを作ってみてください。その後、ハッシュの各要素をみて、それぞれのキーと値を"'#{key}'のスペイン語は'#{value}'"といった形で出力してみてください。
suuzi = { one: "uno", two: "dos", three: "tres"} => { :one=>"uno", :two=>"dos", :three=>"tres"} >> suuzi.each do |key, value| puts "'#{key.inspct} 'のスペイン語は'#{value.inspect}'" end 'one'のスペイン語は'uno' 'two'のスペイン語は'dos' 'three'のスペイン語は'tres' => {:one=>"uno", :two=>"dos", :three=>"tres"}2.person1、person2、person3という3つのハッシュを作成し、それぞれのハッシュに:firstと:lastキーを追加し、適当な値 (名前など) を入力してください。その後、次のようなparamsというハッシュのハッシュを作ってみてください。1.) キーparams[:father]の値にperson1を代入、2). キーparams[:mother]の値にperson2を代入、3). キーparams[:child]の値にperson3を代入。最後に、ハッシュのハッシュを調べていき、正しい値になっているか確かめてみてください。(例えばparams[:father][:first]がperson1[:first]と一致しているか確かめてみてください)
person1={first:"sato",last:"ichiro"} => {:first=>"sato", :last=>"ichiro"} person2={first:"sato",last:"hanako"} => {:first=>"sato", :last=>"hanako"} person3={first:"sato",last:"takashi"} => {:first=>"sato", :last=>"takashi"} params={} => {} params[:father]=person1 => {:first=>"sato", :last=>"ichiro"} params[:mother]=person2 => {:first=>"sato", :last=>"hanako"} params[:child]=person3 => {:first=>"sato", :last=>"takashi"} params => {:father=>{:first=>"sato", :last=>"ichiro"}, :mother=>{:first=>"sato", :last=>"hanako"}, :child=>{:first=>"sato", :last=>"takashi"}} params[:father][:last] => "ichiro" params[:child][:first] => "sato"3.userというハッシュを定義してみてください。このハッシュは3つのキー:name、:email、:password_digestを持っていて、それぞれの値にあなたの名前、あなたのメールアドレス、そして16文字からなるランダムな文字列が代入されています。
user={name:"yamada",email:"yamada@gmail.com",password_digest:"asdfghjk12345678"} => {:name=>"yamada", :email=>"yamada@gmail.com", :password_digest=>"asdfghjk12345678"}Ruby API (訳注: もしくはるりまサーチ) を使って、Hashクラスのmergeメソッドについて調べてみてください。次のコードを実行せずに、どのような結果が返ってくるか推測できますか? 推測できたら、実際にコードを実行して推測があっていたか確認してみましょう。
{ "a" => 100, "b" => 200 }.merge({ "b" => 300 }){ "a" => 100, "b" => 200 }.merge({ "b" => 300 }) => {"a"=>100, "b"=>300}うーむ。。。ここまでやったけどかなり難しい概念ですハッシュ。。。
ここで先述されているCSSの追加の行がやっと読めるようになると。。
とりあえずここまでとします。
頭が痛い。。。。
次はrails チュートリアル4章目の続きから行きます。
- 投稿日:2020-03-25T15:06:53+09:00
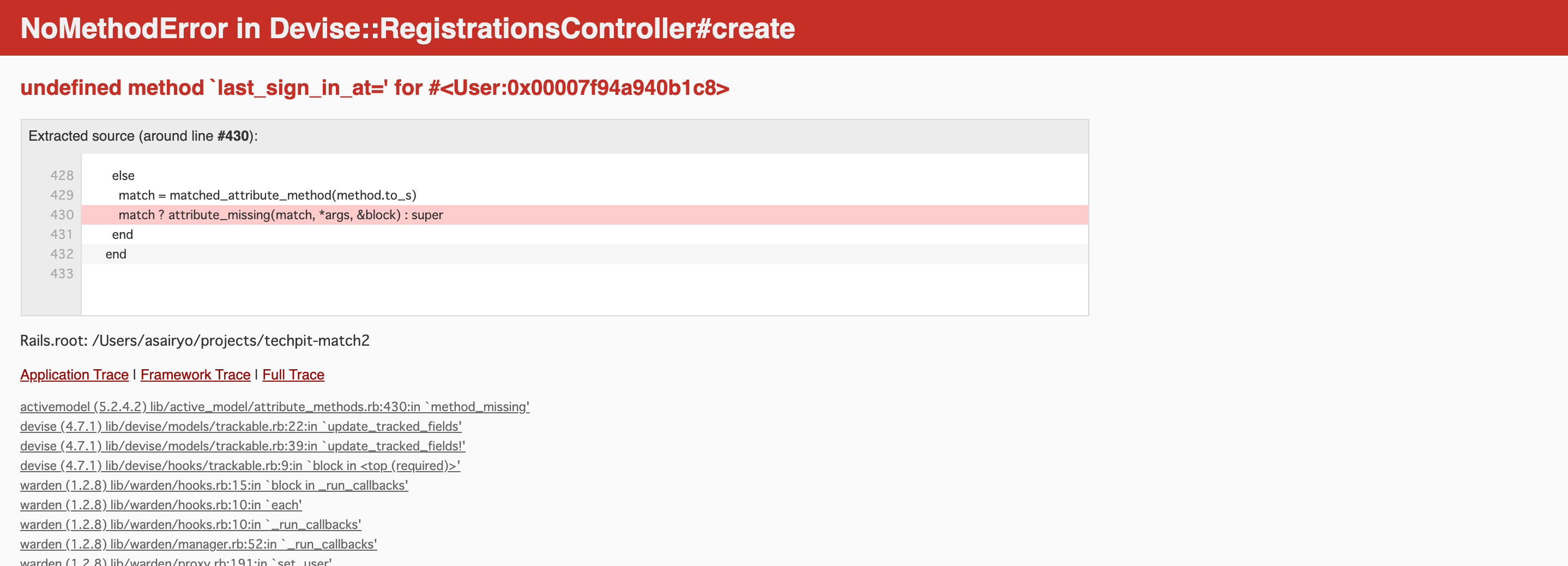
undefined method current_sign_in_atエラーが発生したのでやってみたこと。
ログインを実行すると、このようなエラーが発生。
エラー内容からuserモデル内のカラムにcurrent_sign_in_atがないのが原因のようだ。
というわけで、一度マイグレーションファイルをrails db:rollback
マイグレーションファイル内のcurrent_sign_in_atのコメントアウトを外し、raiis db:migrate
再度ログイン!
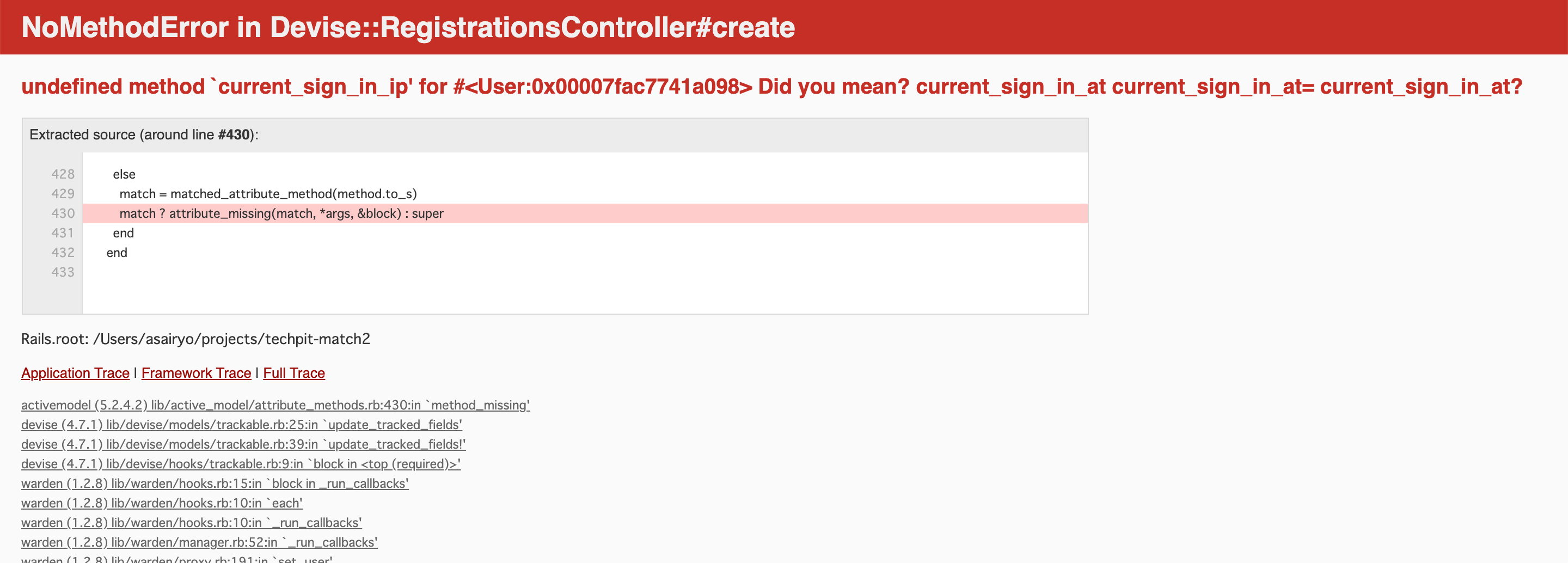
今度はこんなエラーが発生。
last_sign_in_atがカラムないにないらしい。 どうせなら一度で言って欲しいものだが、、、、
同様の作業を行い、raiis db:migrate
再度ログインすると、今度はこんなエラーが、、、
今度はcurrent_sign_in_ipが足りていないということか、、、
いっそのことTrackableのコメントアウトを全て外してしまえ!
## Trackable t.integer :sign_in_count, default: 0, null: false t.datetime :current_sign_in_at t.datetime :last_sign_in_at t.string :current_sign_in_ip t.string :last_sign_in_ip再度、raiis db:migrateをし、ログイン!
無事にログインできましたとさ
原因はよくわかりません。ただエラー解決できたのは一つの自信になったかな。

- 投稿日:2020-03-25T14:36:04+09:00
【Rails】【DB】database.yml
database.yml
Railsにおけるデータベースの設定ファイル。
Railsアプリケーションを作成すると自動的に生成され、デフォルトではSQLiteを使用する前提で作成されます。MySQL用のdatabase.yml
MySQL等のSQLite以外のデータベースを使用する前提で生成する場合は、アプリケーションを作成する際に明示的にオプションでデータベースを指定します。
$ rails new アプリケーション名 -d データベース $ rails new アプリケーション名 --database=データベース使用可能なデータベースは下記になります。
「mysql / oracle / postgresql / sqlite3 / frontbase / ibm_db / sqlserver / jdbcmysql / jdbcsqlite3 / jdbcpostgresql / jdbc」実際にRailsでアプリケーションを作成すると、
config/database.ymlファイルが自動生成されています。database.yml# MySQL. Versions 4.1 and 5.0 are recommended. # # Install the MYSQL driver # gem install mysql2 # # Ensure the MySQL gem is defined in your Gemfile # gem 'mysql2' # # And be sure to use new-style password hashing: # http://dev.mysql.com/doc/refman/5.0/en/old-client.html development: adapter: mysql2 encoding: utf8 database: sample_mysql_development pool: 5 username: root password: host: localhost # Warning: The database defined as "test" will be erased and # re-generated from your development database when you run "rake". # Do not set this db to the same as development or production. test: adapter: mysql2 encoding: utf8 database: sample_mysql_test pool: 5 username: root password: host: localhost production: adapter: mysql2 encoding: utf8 database: sample_mysql_production pool: 5 username: root password: host: localhost上記の設定ファイルのコマンドはそれぞれ下記の意味を示しています。
adapter: 使用するデータベース種類 encoding: 文字コード reconnect: 再接続するかどうか database: データベース名 pool: コネクションプーリングで使用するコネクションの上限 username: ユーザー名 password: パスワード host: MySQLが動作しているホスト名MySQLでは特にホスト名、ユーザー名、パスワードの指定が必要になってます。
ユーザ名はデフォルトでrootになっています。MySQL接続用のアカウント作成
MySQLではアカウント名、パスワード指定、ホスト名が必要になるのでそれぞれ設定していきます。
$ mysql -u root : : mysql> create user 'ユーザー名'@'localhost' identified by 'パスワード';
mysql -u rootでMySQLに接続をしアカウント名、パスワード、ホスト名を設定しました。mysql> select User,Host from mysql.user; : : mysql> grant all on *.* to '[ユーザー名]'@'localhost';
select User,Host from mysql.user;で作成されているかを確認し、grant all on *.* to '[ユーザー名]'@'localhost';をしアカウントに権限を付与しました。database.ymlの書き換え
設定したアカウント名、パスワード、ホスト名に変更します。
development: adapter: mysql2 encoding: utf8 reconnect: false database: [アプリ名]_development pool: 5 username:設定したユーザー名 password:設定したパスワード host: localhost test: adapter: mysql2 encoding: utf8 reconnect: false database: [アプリ名]_test pool: 5 username:設定したユーザー名 password:設定したパスワード host: localhost production: adapter: mysql2 encoding: utf8 reconnect: false database: [アプリ名]_production pool: 5 username:設定したユーザー名 password:設定したパスワード host: localhostこれでMySQLにデータベース作成等の操作ができようになりました。
mysql> create database database名
- 投稿日:2020-03-25T14:27:41+09:00
【Rails】Ransackで検索機能を作るときの細かいTips
Ransackとは
Railsのgemで、簡単に検索機能を実装することができます。
公式ドキュメントはこちらこの記事の目的
僕が使っていてハマったところや、欲しかったけどなかなか見つからなかった情報なんかを入れていきます(たまに更新します)
Ransackを使ったときの細かい?Tips
空欄で検索できないようにする
search_fieldの最後「required: true」が重要です。
hoge.html.haml.search_form = search_form_for(@q, url: search_path) do |f| = f.label :name, "keyword", placeholder:"商品名、一般名で検索できます" = f.search_field :standard_name_cont_all, required: true = f.submit "検索"
AND検索
*_all と足せばOKなのですが、検索窓に「鈴木 テニス」と入れても検索クエリは"鈴木 テニス"と一つにしかなりません。
コントローラーで分けてあげる必要があります。params[:q]['standard_name_cont_all'] = params[:q]['standard_name_cont_all'].split(/[\p{blank}\s]+/) @q = Product.ransack(params[:q]) @products = @q.result(distinct: true).page(params[:page]).order(price: 'DESC')大事なのはここですね、 .split(/[\p{blank}\s]+/)です
これを追加してあげると検索クエリが"鈴木"と"テニス"になるので、めでたくAND検索が可能になります。

- 投稿日:2020-03-25T14:05:21+09:00
GraphiQL-Rails を動かす
はじめに
Ruby on Rails で最低限のGraphQL サーバを実装し、GraphiQL からクエリを実行する方法を記載します。
本記事は、以下の基礎知識を前提としています。
- Ruby on Rails
- GraphQL
環境
本記事は以下の環境で実行しました。
- Ruby 2.7.0
- Rails 6.0.2.2
使用するgem は以下。
- graphql 1.10.5
- graphiql-rails 1.7.0
GraphQL とは
ここでは説明しません。GraphQL 公式サイト等を参照してください。
GraphiQL とは
GraphiQL IDE は、Web ブラウザ上でGraphQL のクエリやミューテーションを実行できるIDE です。また、GraphQL のSchema を確認できます。名称は「Graph i QL」。「i」がはさまっているので注意。
Ruby on Rails で動作させるには、Graphi-QLというgem を使用します。
GraphiQL-Rails を動かす
順を追って以下を説明していきます。
- Rails プロジェクト作成とgem のインストール
- GraphQL の初期化
- GraphiQL の設定
- GraphQL クエリの実装
- サンプルmodel の作成
- GraphQL Type の作成
- GraphQL クエリの作成
- GraphiQL の実行
Rails プロジェクト作成とgem のインストール
今回作成するのはGraphQL サーバなので、APIモードでrails プロジェクトを作成します。APIモードでなくても大丈夫なはず。
$ rails new example-proj --api $ cd example-projGemfile に以下を追加して、
gem 'graphql' gem 'graphiql-rails'bundle install すればOK。
$ bundle installGraphql の初期化
Rails プロジェクトにgraphql の基本構成を設定します。以下のコマンドを実行します。
$ rails g graphql:installこれにより、以下のファイル/ディレクトリが変更/追加されます。
- 変更
- config/routes.rb
- 追加
- app/controllers/graphql_controller.rb
- app/graphql/
app/graphql ディレクトリにはGraphQL 用のサブディレクトリやスーパークラス等が配置されています。詳細については GraphQL Ruby のドキュメントを参照してください。
GrapiQL の設定
GraphiQL を設定します。config/ruotes.rb に以下を追記します。
config/routes.rbRails.application.routes.draw do # ここから if Rails.env.development? mount GraphiQL::Rails::Engine, at: "/graphiql", graphql_path: "/graphql" end # ここまで追記 post "/graphql", to: "graphql#execute" end公式のドキュメントにAPI モードで使用する際の注意事項として「Rails 5 のAPI モードで使うときは application.rb に require "sprokets/railtie" が必要」とあるので、指示に従います。
If you're using Rails 5 in "API mode", you'll also need to add require "sprockets/railtie" to your application.rb.
config/application.rb に以下を追記します。
config/application.rbrequire "sprockets/railtie"ですが、これだけでは実行時にエラーになります(Loding...から進まなくなる)。そこで次の設定を追加します。ファイルがなければ追加しましょう。
app/assets/config/manifest.js//= link graphiql/rails/application.css //= link graphiql/rails/application.jsGraphQL クエリの実装
サンプルmodel の作成
簡単なサンプルとして、ユーザー情報のmodel を作成します。db:migrate を忘れずに。
$ rails g model User name:string email:string $ rake db:migrate確認用のデータを追加します。
$ rails c irb(main):001:0> User.create(name: "hoge", email: "hoge@example.com") irb(main):002:0> User.create(name: "fuga", email: "fuga@example.com")GraphQL Type の作成
GraphQL クエリの前に、まずGraphQL Type を作成します。
$ rails g graphql:object User id:ID! name:String! email:Stringここで設定するのはGraphQL Type なので、Rails のmodel とは型指定が異なることに注意。型末尾の ! はnull を許容しないことを示します。これにより、次のファイルが作成されます。
app/graphql/types/user_type.rbmodule Types class UserType < Types::BaseObject field :id, ID, null: false field :name, String, null: false field :email, String, null: true end endGraphQL クエリの作成
GraphQL クエリを作成します。app/graphql/types/query_type.rb を以下のとおり実装します。
app/graphql/types/query_type.rbmodule Types class QueryType < Types::BaseObject # Add root-level fields here. # They will be entry points for queries on your schema. field :users, [Types::UserType], null: false, description: "すべてのユーザを取得する" def users User.all end field :user, Types::UserType, null: false, description: "idを指定してユーザを取得する" do argument :id, Int, required: true end def user(id:) User.find(id) end end endこれで準備は完了です。
GraphQL クエリの実行
Rails サーバを起動します。
$ rails slocalhost:3000/graphiql にアクセスすると、GraphiQL IDE が表示されます。
クエリ構文の確認や、クエリを実行して確認できます。
まとめ
Ruby on Rails で簡単なGraphQL type とクエリを実装し、GraphiQL から操作してみました。GraphiQL は開発中だけでなくドキュメントとしても使えそうなので、GraphQL 開発では必須になりそうです。
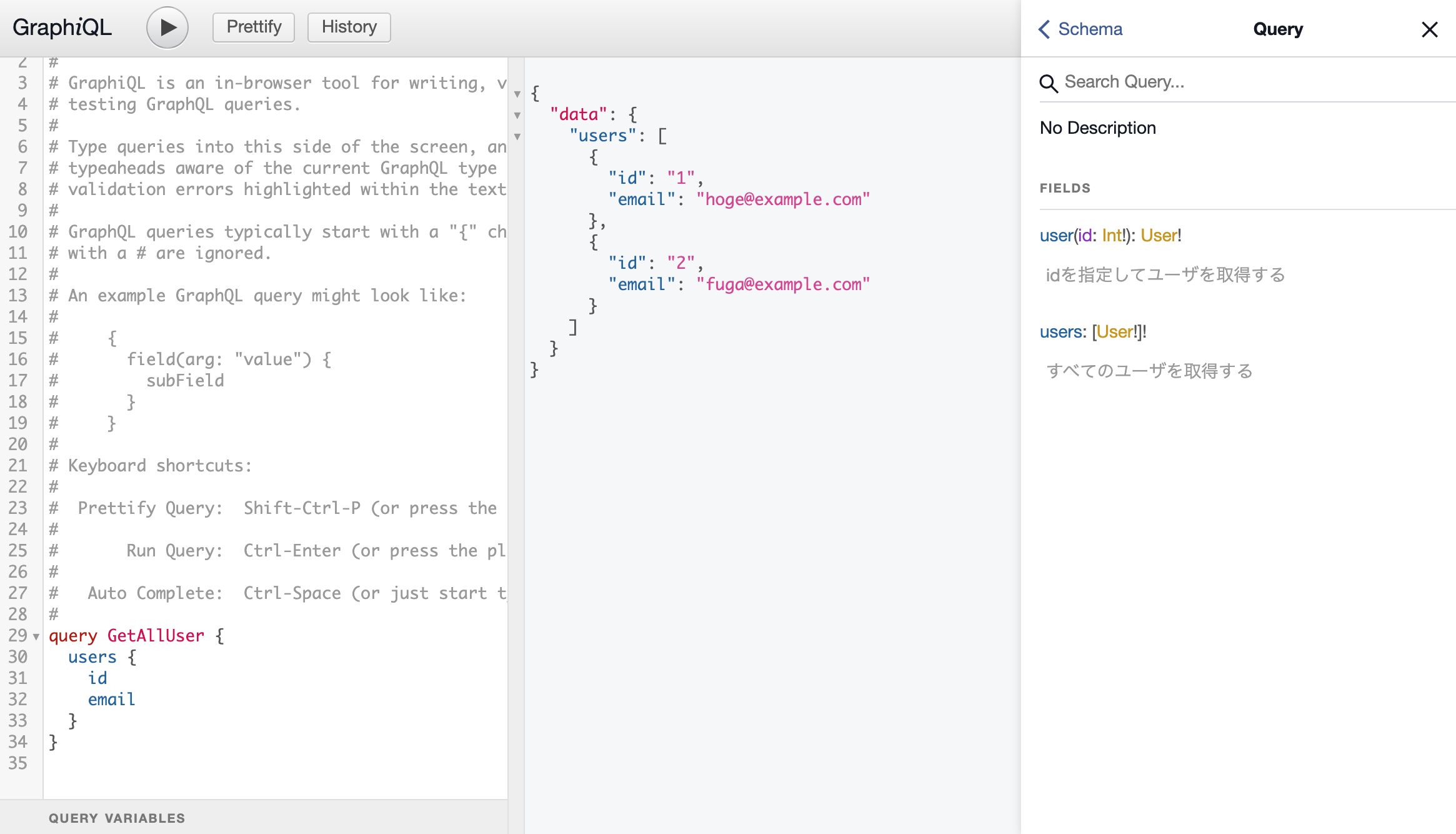
- 投稿日:2020-03-25T13:03:48+09:00
gem install railsができない人のためエラー解消法
gem install railsしてもrailsがインストールできなかったため、まとめておこうと思います。
実行環境
OS: MacOS
rubyバージョン管理:rbenv
シェル:zshエラー①内容
実行コマンド
gem installを行い、インストールできたかrails -vで確認をする。
gem install rails rails -vエラー内容
インストールは成功した風なのにインストールされていないと出てくる
「sudo gem install rails をしてくれ」ってなっているが、実行しても同様のエラーがでる。Rails is not currently installed on this system. To get the latest version, simply type: $ sudo gem install rails You can then rerun your "rails" command.原因
rbenvでrubyのバージョン管理を行っているとgemの参照先によってこのようなエラーが出るらしい。
基本は以下の方法で解決するらしいが、自分の環境では解消していない。詳しくは以下のQiita記事を参考
とても助かりましたありがとうございます。エラー②内容
gem install railsを行うと以下のようにインストールが成功しましたと出てくるが、rails -vを行うと同様にインストールできていないとエラーが出る。
実行コマンドgem install rails実行後のメッセージSuccessfully installed rails-6.0.2.2 Parsing documentation for rails-6.0.2.2 Done installing documentation for rails after 0 seconds 1 gem installed実行コマンドrails -v実行後のメッセージRails is not currently installed on this system. To get the latest version, simply type: $ sudo gem install rails You can then rerun your "rails" command.原因を探る
とりあえずwhichコマンドを使いどこから実行されているかを確認することにした。
実行コマンドwhich ruby //結果 ↓の違いがエラーの原因だと思われる。 /Users/hoge/.rbenv/shims/ruby実行コマンドwhich rails //結果 ↓の違いがエラーの原因だと思われる。 /usr/bin/railsこの処理を行うのがエラー①の内容のはずだが、どうやらzshrcの反映がうまくできてなかったみたい。
解決法
ターミナルの再起動をする!
結果はしょうもないことでしたが、 同様の症状になっている方が見えたら一度ターミナルを再起動して見てください。
- 投稿日:2020-03-25T11:57:26+09:00
Ruby 指定バージョンへの変更
◆Rubyのバージョン指定方法
自分用のコマンドライブラリです。ですが、同じお悩みの方はどうぞご利用ください。
表現がぶっきらぼうですが、そこはご容赦くださいませ〜〜。
◆コマンド一覧
◆希望する指定バージョン
rails:5.2.4 ⇨ 5.2.3
ruby:2.6.5 ⇨ 2.6.3
① アプリ作成時にbundleを動かさないように設定
ターミナル$ rails _5.2.3_ new アプリ名 --skip-bundle $ cd アプリ名② gemfileの記述バージョン変更
【例】
gem 'rails', '~> 5.2.4'
↓
gem 'rails', '5.2.3' にする。※rubyも指定バージョンに記述変更
③ .bash_profileへ記述
$ echo 'eval "$(rbenv init -)"' >> ~/.bash_profile④ エラー回避
※「N/A: version "N/A -> N/A" is not yet installed.」が出たのでこれで回避
※「You need to run "nvm install N/A" to install it before using it.」これをやれば回避できるんだろうけど放置$ nvm unalias default⑤ 初期化設定の反映
$ source ~/.bash_profile⑥ インストールしたversionを使用可能な状態にする⇒shimsへの反映
$ rbenv rehash⑦ 使用するバージョンの指定
※作成するプロジェクトのみでバージョン指定する場合は『rbenv local』
※全体でバージョン指定する場合は『rbenv global』$ rbenv local 2.6.3⑧ bundle install
$ bundle install --path=vendor/bundle ※ 「--path=vendor/bundle」 はあってもなくても大きく変化なし。詳細はリンクをチェック。【最後】バージョン確認
$ rbenv local 2.6.3
- 投稿日:2020-03-25T11:38:38+09:00
#Rails + rack-cors で CORS の ORIGINS を指定 / curl で動作確認 / request spec でテストケースを書く
Gem
rack-cors
CORS とは
- リソース共有のための仕組み。
- CORSを指定したからと言ってセキュリティ対策になるわけではなく、むしろ逆。ドメインを共有できるようになるので、セキュリティリスクは増す。
- CORSを許可する場合は、許可する ORIGINとしてワイルドカードを指定せず、可能であればホワイトリストを指定する。
- セキュリティ的なデフォルト挙動が「同一オリジンポリシー」に準拠したものであり、CORSがその間口を広げる。
設定
- Rails構成のAPIサーバーを想定
- localhost:3000 で API サーバーがつながるものとする
- application.rbに以下を設定してサーバーを再起動する
module App class Application < Rails::Application # Rails 5 config.middleware.insert_before 0, Rack::Cors do allow do # いろいろな形式で、複数指定できる origins 'example.com', 'https://yahoo.com', 'localhost:9999' resource '*', headers: :any, methods: [:get, :post, :options] end end endcurl での動作確認
- リクエストヘッダの Origin として Rails で 許可した ORIGIN を指定してリクエストする
- 実際のリクエスト元は 自分が利用しているシェルであり、 http://example.com ではないわけだが、ヘッダに指定することは可能だ。
curl --dump-header - "http://localhost:3000/v1/foo" -H "Origin: http://example.com" -H "Content-Type: application/json" HTTP/1.1 200 OK結果の例
HTTP/1.1 200 OK Access-Control-Allow-Origin: https://example.com Access-Control-Allow-Methods: GET, POST, OPTIONS ...
- プロトコルを問わずにORIGINが許可されているようだ。
- https や ftp のURLを ORIGIN に指定しても Access-Control-Allow-Origin が返ってくる。
curl --dump-header - "http://localhost:3000/v1/foo" -H "Origin: https://example.com" -H "Content-Type: application/json" HTTP/1.1 200 OKHTTP/1.1 200 OK Access-Control-Allow-Origin: https://example.com Access-Control-Allow-Methods: GET, POST, OPTIONS注意
Origin: http://example.com/のように末尾にスラッシュをつけると Access-Control-Allow-Origin が返ってこない。- たとえば Railsの設定で https だけを許可した場合、 リクエストで Origin に http を申告しても、Access-Control-Allow-Origin は返ってこない。
リクエストヘッダの Orign とは何なのか
- あくまでもクライアントの自己申告のようだ。実際のリクエスト送信元がなんであれ、自由に指定できる。別にリクエスト元のIPなどから生成されているわけではない。
- 仕様はクライアントによるはずだ。たとえばブラウザからのリクエスト送信であれば「Originを超えた、自分以外の場所にリクエストをする場合に、自動的に Origin ヘッダに、送信元の正しい Origin を付与する」というような仕様だと思うのだけれど。
- シェルの場合はクライアントとしての仕様があるわけではないので Origin の指定も自由だ。なので、リクエストヘッダとして Origin の指定しなければ、そもそも Origin のヘッダは送信されないみたいだ。たとえそれが Origin を超えたリクエストだろうと、なんだろうと。
- ヘッダを詐称するクライアントの攻撃は防ぐことはできないはずだ。
そんな自己申告の仕組みが脆弱性、セキュリティ対策とどう関係するのだろうか?
- CORSで外部リクエストを許可していた場合、第三者が踏み台のサイトを用意して、善意のユーザーがサーバーにリクエストするような処理を作っていた時に、脆弱性が生まれる場合がある。(クロスサイト系の攻撃って、そういうものですよね) (直接攻撃じゃなくて)
- ユーザーのクライアントであるブラウザは、悪意のある第三者のサイトから、サーバーにリクエストする場合でも、詐称しない、正しいOriginヘッダを投げる。この時にフロント側の制御として、悪意のある送信がおこなわれないようにブロックするということだろうか。
Rspec でリクエストのテストを書く
こんな感じで出来るはず
require "rails_helper" RSpec.describe type: :request do subject do get "/v1/foo", headers: { Origin: "http://example.com" } end it do subject expect(response.header["Access-Control-Allow-Origin"]).to eq "http://example.com" end end参考
CORS (Cross-Origin Resource Sharing) ってなに?
Original by Github issue
- 投稿日:2020-03-25T07:05:02+09:00
【18日目】Rails5 (投稿の制限)
はじめに
こんばんは。
今日もアウトプットしていきます。学習内容
- progate Rails 5
- progate Rails 6
バリテーション
不正なデータの保存を防ぐ
validates :content, {presence:true,length:{maximum:140}} #presence:trueで空の投稿を防ぐ #maximum:140で140字以上の投稿を防ぐ投稿時のリンク
if @post.save redirect_to("/posts/index") else redirect_to("/posts/#{@post.id}/edit") end直前の投稿の表示
通常は
1. 投稿失敗時にeditアクションに転送
2. データベースから編集前のデータの取得
3. editアクションで取得したデータの表示editアクションを経由しないようにする
renderメソッドを使うrender("posts/edit")エラーメッセージ
<% @post.errors.full_messages.each do |message| %> <div class="form-error"> <%= message %> </div> <% end %>フラッシュ
ページの上に一度だけ表示されるもの
if @post.save flash[:notice]="投稿を編集しました" #表示するメッセージ redirect_to("/posts/index") else render("posts/edit") end<% if flash[:notice]%> <div class="flash"> <%= flash[:notice]%> #フラッシュがある場合表示 </div> <% end %>所感
これまでなんとなく理解で進めてきましたが、
回答を見ないと進めない現状があるので、
明日は一度ストップしてこれまでの復習に充てたいと思います。
- 投稿日:2020-03-25T01:46:14+09:00
商品出品画面を作る②ActiveStorage(複数画像投稿)
ActiveStorageを使用して複数枚の画像を投稿する
先ずはここを見てくださいRailsガイド、導入方法とか書いてあります。
S3に接続するときは注意が必要ですね。そもそもActiveStorageは何がいいのか?
ActiveStorageの特徴としては画像をitemモデルとして扱えることでしょう。
どう言う事かと言うと、itemとimageが1:多の関係だとすると、テーブルを2個用意しないといけません。
そしてアソシエーションを組んで〜と言う処理をします。
削除や変更の時に処理が若干複雑になってしまいます。
そんな時、ActiveStorageならitemテーブルのみを対象に処理をすれば良いわけです。今回の要件
- 複数同時選択による複数枚の画像投稿
- 複数回選択による複数枚の画像投稿
- プレビュー表示
- 投稿枚数管理
- プレビューの削除
imet.rbhas_many_attached :imagesActiveStorageで複数画像を扱う為にモデルに記述
items_controller.rbdef new @item = Item.new @category_parent = Category.where("ancestry is null") end def create @item = Item.new(item_params) if @item.save redirect_to root_path else render :new end end private def item_params params.require(:item).permit(:name, :text, :category_id, :condition_id, :deliverycost_id, :pref_id, :delivery_days_id, :price, images: []).merge(user_id: current_user.id, boughtflg_id:"1") enddef item_paramsの images:[] がポイントです。
こうする事で、複数画像を受け取ることが出来ます。new.html.haml-# 画像部分 .sell-container__content .sell-title %h3.sell-title__text 出品画像 %span.sell-title__require 必須 .sell-container__content__max-sheet 最大10枚までアップロードできます .sell-container__content__upload .sell-container__content__upload__items .sell-container__content__upload__items__box %ul#output-box ここにプレビューが入ります %div#image-input{tabindex:"0"} = f.label :images, for: "item_images0", class: 'sell-container__content__upload__items__box__label', data: {label_id: 0 } do = f.file_field :images, multiple: true, class: "sell-container__content__upload__items__box__input", id: "item_images0", style: 'display: none;' ここに新しinputが入ります %pre %i.fas.fa-camera.fa-lg ドラッグアンドドロップ またはクリックしてファイルをアップロード .error-messages#error-image ここにエラーメッセージが入ります= f.file_fieldの multiple:true がポイントです
name属性がname="item[images][]"になっていると思います。
これにより、選択した画像を配列とし保持できるようになり、複数枚を同時に選択できるようになります。
item_new.js$(document).on('turbolinks:load', function(){ $('#image-input').on('change', function(e){ // 画像が選択された時プレビュー表示、inputの親要素のdivをイベント元に指定 //ファイルオブジェクトを取得する let files = e.target.files; $.each(files, function(index, file) { let reader = new FileReader(); //画像でない場合は処理終了 if(file.type.indexOf("image") < 0){ alert("画像ファイルを指定してください。"); return false; } //アップロードした画像を設定する reader.onload = (function(file){ return function(e){ let imageLength = $('#output-box').children('li').length; // 表示されているプレビューの数を数える let labelLength = $("#image-input>label").eq(-1).data('label-id'); // #image-inputの子要素labelの中から最後の要素のカスタムデータidを取得 // プレビュー表示 $('#image-input').before(`<li class="preview-image" id="upload-image${labelLength}" data-image-id="${labelLength}"> <figure class="preview-image__figure"> <img src='${e.target.result}' title='${file.name}' > </figure> <div class="preview-image__button"> <a class="preview-image__button__edit" href="">編集</a> <a class="preview-image__button__delete" data-image-id="${labelLength}">削除</a> </div> </li>`); $("#image-input>label").eq(-1).css('display','none'); // 入力されたlabelを見えなくする if (imageLength < 9) { // 表示されているプレビューが9以下なら、新たにinputを生成する $("#image-input").append(`<label for="item_images${labelLength+1}" class="sell-container__content__upload__items__box__label" data-label-id="${labelLength+1}"> <input multiple="multiple" class="sell-container__content__upload__items__box__input" id="item_images${labelLength+1}" style="display: none;" type="file" name="item[images][]"> <i class="fas fa-camera fa-lg"></i> </label>`); }; }; })(file); reader.readAsDataURL(file); }); });今回の1番の要所です
流れとしては
1. 画像を選択し、inputに保持させる
2. 保持された画像からファイルオブジェクトを取得する
3. プレビューを表示する(イベント元のイベント元のカスタムデータIDの番号を付加する)
4. 表示されているプレビューの数を数え、9以下なら次のinputを生成する(イベント元のカスタムデータIDの次の番号を付加する)ポイント
プレビューとinputはカスタムデータIDの番号で紐づけます。
data-image-id="${labelLength}"とdata-label-id="0"の部分です。input要素はidで区別します。
id="item_images${labelLength+1}" となっている部分です。
これは#image-inputの子要素labelの中から最後の要素のカスタムデータidを取得指定ます。
つまり、イベント元のカスタムデータIDの番号に+1しています。labelとinputは、labelのfor属性とinputのidで紐づける。
for="item_images${labelLength+1}"とid="item_images${labelLength+1}"の部分です。
ul要素の下のli要素がプレビューです。
その下のdiv要素の下がinputが囲われたlabelです。プレビューを削除する
item_new.js//削除ボタンが押された時 $(document).on('click', '.preview-image__button__delete', function(){ let targetImageId = $(this).data('image-id'); // イベント元のカスタムデータ属性の値を取得 $(`#upload-image${targetImageId}`).remove(); //プレビューを削除 $(`[for=item_images${targetImageId}]`).remove(); //削除したプレビューに関連したinputを削除 let imageLength = $('#output-box').children('li').length; // 表示されているプレビューの数を数える if (imageLength ==9) { let labelLength = $("#image-input>label").eq(-1).data('label-id'); // 表示されているプレビューが9枚なら,#image-inputの子要素labelの中から最後の要素のカスタムデータidを取得 $("#image-input").append(`<label for="item_images${labelLength+1}" class="sell-container__content__upload__items__box__label" data-label-id="${labelLength+1}"> <input multiple="multiple" class="sell-container__content__upload__items__box__input" id="item_images${labelLength+1}" style="display: none;" type="file" name="item[images][]"> <i class="fas fa-camera fa-lg"></i> </label>`); }; });後はCSSでデコレーションすればOKですね。
ただし、一つ問題があります。
複数同時選択を行うと不具合が発生する事です。
と言うのも、同時選択をすると一つのinputに複数の画像の情報が保持されるからです。
そうすると、プレビューを削除した時に、正常に動作しなくなってしまいます。
対策としては同時選択を出来ないようにする方法があります。
この場合、name属性にも手を加える必要があります。
それは今後試すことにします。今回は以上です

- 投稿日:2020-03-25T01:03:46+09:00
ユーザーの新規登録時に入力なしの初期値を設定する【Ruby on Rails】
目的
ユーザーの新規登録時に、直接入力させずにテーブルに初期値を保存させること。
使用する技術
- gem devise
実践
以下のテーブルが作成してあるとします。
Column Type Options username string null: false, unique: true string null: false, unique: true password string null: false coin integer null: false 今回は、ユーザー登録フォームで
- username
- password
の3項目をのみを入力させます。
ここで、coinカラムは入力させずに、初期値0としてテーブルに保存します。事前準備
すでに、gem deviseが導入され、コントローラとビューの作成が終了しているものとします。
(このような画面まで用意されている所からです)
deviseのカスタマイズ
ここからは、デバイスのカスタマイズを行っていきます。
初めにdeviseのコントローラを作成して編集できるようにします。$ rails g devise:controllers users
app/controller/users/のフォルダにコントローラが作成されました。
このフォルダ内のregistrations_controller.rbを使用していきます。次に、ルーティングを一度確認しておきます。
$ rails routes # 結果 Prefix Verb URI Pattern Controller#Action new_user_registration GET /users/sign_up(.:format) devise/registrations#new今のままでは、作成した
registrations_controller.rbが呼び出されていない状態なので、これを呼び出す記述をします。config/routes.rbRails.application.routes.draw do devise_for :users, controllers: { registrations: 'users/registrations', } enddevise導入時に自動的に記述された
devise_for :usersに続けて、このように記述します。
編集後、もう一度ルーティングを確認します。$ rails routes # 結果 Prefix Verb URI Pattern Controller#Action new_user_registration GET /users/sign_up(.:format) users/registrations#new
devise/registrations#new → users/registrations#new
に変わっていればOKです。コントローラに初期値を設定
コントローラにnewメソッドとcreateメソッドを定義していきます。
registrations_controller.rbclass Users::RegistrationsController < Devise::RegistrationsController # 省略 def new @user = User.new end def create @user = User.new(sign_up_params) unless @user.valid? flash.now[:alert] = @user.errors.full_messages render "devise/registrations/new" and return end @user[:coin] = 0 @user.save sign_in(:user, @user) redirect_to root_path end # 省略
registrations_controller.rbはコメントアウトで記述がされていて、Devise::RegistrationsControllerで最初からメソッドが定義されています。
カスタマイズするときは、コメントアウト部分を消してオーバーライド(上書き)していきます。重要なのは、ここです。
@user[:coin] = 0
@user = User.newの時点ではcoin: nilだったところに、0を代入します。
これで、coinカラムに0が入りました。あとはそのまま、データベースにレコードを登録 + ログイン + root_pathにリダイレクトを行っています。ちなみに補足しておくと、、
unless @user.valid? flash.now[:alert] = @user.errors.full_messages render "devise/registrations/new" and return endここは、バリデーションに引っ掛かったときにエラーメッセージを表示させて、登録フォームのページを返すということをしています。(これがない場合、登録されずにTOPページに遷移したりします)
最後に
ユーザーの新規登録の場合はdeviseをカスタマイズする必要がありましたが、
普通のテーブルであれば、new,createメソッドのどちらかに初期値を代入するだけで簡単に保存させられます。参考

- 投稿日:2020-03-25T00:44:13+09:00
Reinitialized existing Git repository in が出たときの対処法
はじめに
ただの備忘録のうちのひとつ。将来のために、、、
git init したときのやつ
$ git init Reinitialized existing Git repository in ~結論:やることない
特にやることない。Reinitializedとか言うから「初期化して最初から⁉」とか思ってたけどそうではないらしい。
関係ないけど
名前とメールの確認もたまにしたくなる
$git config --global --list user.name=hogehoge user.email=hoge@gmail.com参考
https://qiita.com/ragingalpaca/items/ef247e459ff2e7759ba9
https://hacknote.jp/archives/15745/