- 投稿日:2020-03-25T23:53:07+09:00
pythonでLDAPにデータの追加取得をする
はじめに
認証やツリー構造のデータの管理などでLDAPが使用されます。RDBと比べるとLDAPは使用される機会が少なく使用方法も異なるのでpythonでLDAPを操作する方法をまとめます。さらにLDAP認証のサンプルは色々なところで紹介されていますが、もっと簡単にするためシンプルな例を紹介します。
環境準備
LDAPサーバ
LDAPサーバは、UbuntuやCentosにldapをインストールしてもできますがdockerイメージがあったため、そちらを使用します。
dockerイメージのpull
dockerイメージは単純にpullするだけです。
docker pull osixia/openldapdockerイメージの起動
イメージの起動時にldapのパスワードとトップのドメイン、各ポートのマウントをしておきます。dockerネットワークを利用している場合は、ポートのマウントはせずにネットワークとIPアドレスの設定をします。
docker run -p 389:389 -p 636:636 --env LDAP_DOMAIN="sample-ldap" --env LDAP_ADMIN_PASSWORD="LdapPass" --name LDAPSERVER --detach osixia/openldap結果
> docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 4f6e1b4eaf29 osixia/openldap "/container/tool/run" 2 hours ago Up 2 hours 0.0.0.0:389->389/tcp, 0.0.0.0:636->636/tcp LDAPSERVERLdapライブラリのインストール
クライアントはpythonで使用するのでLDAPクライアントのライブラリ
ldap3をpipでインストールします。pip install ldap3LDAPの操作
LDAPのサーバとクライアントの用意ができたため、これから操作のソースを作成していきます。
LDAPへのログイン
LDAPへの操作にはログインが必要なため、まずはログインをします。LDAPサーバのIPアドレスやポート番号、タイムアウト等必要な設定を追加したServerクラスを設定します。そのServerクラスを使用してConnectionクラスを生成します。この時にはLDAPサーバへ接続されず、
bind()で始めて接続されます。dcとpasswordはdocker run時に指定した値になり、cnはデフォルトはadminになります。main.pyconn = Connection(server, 'cn=admin,dc=sample-ldap', password='LdapPass') result = conn.bind() print(result)結果
> python main.py' Truebindの結果がTrueとなっているため、LDAPサーバへ接続ができたことが分かります。
ドメイン
接続ができたため次はLDAPの追加と取得をしていきます。
LDAPはトップからdc、ou、cnの順にツリー構造で構成されているため、まずはdcから追加と取得していきます。ドメインの追加
サンプルコードは上のソースの続きになります。作成したコネクションの
add関数の第一引数に追加したいdcとトップのdcをつなげた文字列を指定して、第二引数に'domain'を指定します。この時に第一引数の文字列のカンマの後にスペースを入れるとエラーするので注意してください。main.py# ドメインの追加 dc_result = conn.add('dc=sample-component,dc=sample-ldap', 'domain') print(dc_result)結果
True実行結果はバインドと同じでaddの結果としてTrueが返ってきたため、追加できたことがわかります。
ドメインの取得
サンプルコードは上のソースの続きになります。上で追加したdcを取得します。
conn.search()の第一引数に調べたいLDAPのパスを指定します。第二引数はdomainを指定します。その結果、conn.entriesにsample-componentの情報が取得できます。main.py# ドメインの取得 conn.search('dc=sample-component,dc=sample-ldap', '(objectclass=domain)') print(conn.entries)結果
True [DN: dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-25T22:35:26.491599 ]今回は、第二引数にdomainを指定してドメインを検索しているので対象の1個のentriesが取得できます。後ほどソースを載せますが第二引数に他の値を入れると複数取得できます。
オーガニゼーション
LDAPのdcが追加できたので次はouの追加と取得していきます。
オーガニゼーションの追加
サンプルコードは上のソースの続きになります。作成したコネクションの
add関数の第一引数に追加したいouとdcをつなげた文字列を指定して、第二引数に'organizationalUnit'を指定します。main.py# ドメインの追加 ou_result = conn.add('ou=sample-unit,dc=sample-component,dc=sample-ldap', 'organizationalUnit') print(ou_result)結果
True実行結果はバインドと同じでaddの結果としてTrueが返ってきたため、追加できたことがわかります。
オーガニゼーションの取得
サンプルコードは上のソースの続きになります。上で追加したouを取得します。
conn.search()の第一引数に検索したいパスを指定します。第二引数はorganizationalUnitを指定します。その結果、conn.entriesにsample-unitの情報が取得できます。main.py# オーガニゼーションの取得 conn.search('ou=sample-unit,dc=sample-component,dc=sample-ldap', '(objectclass=organizationalUnit)') print(conn.entries) # dc指定のオーガニゼーションの取得 conn.search('dc=sample-component,dc=sample-ldap', '(objectclass=organizationalUnit)') print(conn.entries)結果
[DN: ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-25T23:27:36.594396] [DN: ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-25T23:27:36.604398 , DN: ou=sample-unit2,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-25T23:27:36.604398 ]第一引数にオーガニゼーションを検索している場合は対象の1個のentriesが取得できます。ドメインを検索している場合は、ドメインが含んでいるouの数だけ複数取得できます。
コモンネーム
LDAPのouが追加できたので次はcnの追加と取得していきます。
コモンネームの追加
サンプルコードは上のソースの続きになります。作成したコネクションの
add関数の第一引数に追加したいcnとouとdcをつなげた文字列を指定して、第二引数に'inetOrgPerson'を指定して、第三引数に付加情報を指定します。main.py# ドメインの追加 cn_result = conn.add('cn=sample-name,ou=sample-unit,dc=sample-component,dc=sample-ldap', 'inetOrgPerson', {'sn':'sample'}) print(cn_result)結果
True実行結果はバインドと同じでaddの結果としてTrueが返ってきたため、追加できたことがわかります。
コモンネームの取得
サンプルコードは上のソースの続きになります。上で追加したcnを取得します。
conn.search()の第一引数に検索したいパスを指定します。第二引数はinetOrgPersonを指定します。その結果、conn.entriesにsample-nameの情報が取得できます。main.py# コモンネームの取得 conn.search('cn=sample-name,ou=sample-unit,dc=sample-component,dc=sample-ldap', '(objectclass=inetOrgPerson)') print(conn.entries) # ou指定のコモンネームの取得 conn.search('ou=sample-unit,dc=sample-component,dc=sample-ldap', '(objectclass=inetOrgPerson)') print(conn.entries) # dc指定のコモンネームの取得 conn.search('dc=sample-component,dc=sample-ldap', '(objectclass=inetOrgPerson)') print(conn.entries)結果
[DN: cn=sample-name,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-25T23:36:41.125246 ] [DN: cn=sample-name,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-25T23:36:41.156378 , DN: cn=sample-name2,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-25T23:36:41.157365 , DN: cn=sample-name3,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-25T23:36:41.157365 , DN: cn=sample-name1,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-25T23:36:41.157365 ] [DN: cn=sample-name,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-25T23:51:20.773638 , DN: cn=sample-name2,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-25T23:51:20.773638 , DN: cn=sample-name3,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-25T23:51:20.774650 , DN: cn=sample-name1,ou=sample-unit,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-25T23:51:20.774650 , DN: cn=sample-name,ou=sample-unit1,dc=sample-component,dc=sample-ldap - STATUS: Read - READ TIME: 2020-03-25T23:51:20.774650 ]第二引数にinetOrgPersonを指定してコモンネームを検索している場合は対象の1個のentriesが取得できます。オーガニゼーションやドメインを検索している場合はそれぞれが含んでいるcnの数だけ複数取得できます。
おわりに
LDAPに関しては、LDAP認証として使用しただけなので今回のようにLDAPのドメインから追加したりそれぞれのディレクトリから検索方法を変えて検索することはしていませんでした。使用するのに癖はありますが、思った以上にシンプルな方法で値を取得できるのでツリー構造のデータならこちらの方がRDBより使いやすくなるかもしれません。次は他の操作も見ていきます。
- 投稿日:2020-03-25T23:51:57+09:00
Stanzaの実行
StanzaというNLPライブラリがでたので、installして処理を実行してみた。
パイプラインというのは、入力テキストを前処理、トークン化、レンマ化、品詞タギング、依存関係解析、ラベルづけのようなフローである。Stanzaではそれら一連のパイプライン処理を組み立てる。
READMEには英語しかなかったので、日本語のケースでの実行を試した。
download可能な言語としては、こちら。66の言語についてモデルが用意されている。
install
https://stanfordnlp.github.io/stanza/#getting-started
に従えば良い。
import stanza stanza.download('ja')で、日本語のモデルをdownloadしよう。
downloadがすみ次第、以下で日本語の文章の解析が可能。
nlp = stanza.Pipeline('ja') # stanza.Pipeline()だと'en'のモデルを呼び出そうとするので注意。 doc = nlp("幼時から父は、私によく、金閣のことを語った。") print(doc.sentences[0].print_dependencies())以下のように出力される。
2020-03-25 23:35:09 INFO: Loading these models for language: ja (Japanese): ======================= | Processor | Package | ----------------------- | tokenize | gsd | | pos | gsd | | lemma | gsd | | depparse | gsd | ======================= 2020-03-25 23:35:09 INFO: Use device: cpu 2020-03-25 23:35:09 INFO: Loading: tokenize 2020-03-25 23:35:09 INFO: Loading: pos 2020-03-25 23:35:09 INFO: Loading: lemma 2020-03-25 23:35:10 INFO: Loading: depparse 2020-03-25 23:35:11 INFO: Done loading processors! ('幼時', '3', 'nmod') ('から', '1', 'case') ('父', '8', 'nsubj') ('は', '3', 'case') ('、', '3', 'punct') ('私', '8', 'iobj') ('に', '6', 'case') ('よく', '14', 'advcl') ('、', '8', 'punct') ('金閣', '12', 'nmod') ('の', '10', 'case') ('こと', '14', 'obj') ('を', '12', 'case') ('語っ', '0', 'root') ('た', '14', 'aux') ('。', '14', 'punct') None係り受けタグはこちらに詳しい。
あとで気づいたが、こういう記事もあった。
https://dev.classmethod.jp/articles/python-stanford-nlp/pipeline
- 投稿日:2020-03-25T23:31:19+09:00
Pythonで、位置情報から花粉情報を送るLINEBotを作った。
(1)背景
・いつもこの時期から花粉に悩まされる。
・今年はコロナもあって花粉症者は辛い。
・マスク不足。
・pythonとscraping、herokuを使って何か作ってみたい。
・アウトプットイメージ ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
(2)環境構築
デスクトップに、ディレクトリline_kafunを作成。
line-sdkを扱うmain.pyと、Yahoo天気情報から花粉情報を収集するweather.pyを作成。ディレクトリ構成は以下の通り。
line_kafun ├main.py ├weather.py ├Procfile ├runtime.txt └requirements.txt必要なパッケージをインストール。
pip install flask pip install line-bot-sdk pip install beautifulsopu4 pip install gunicorn pip install lxml pip install requests(3)main.py
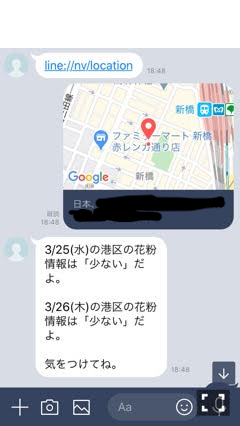
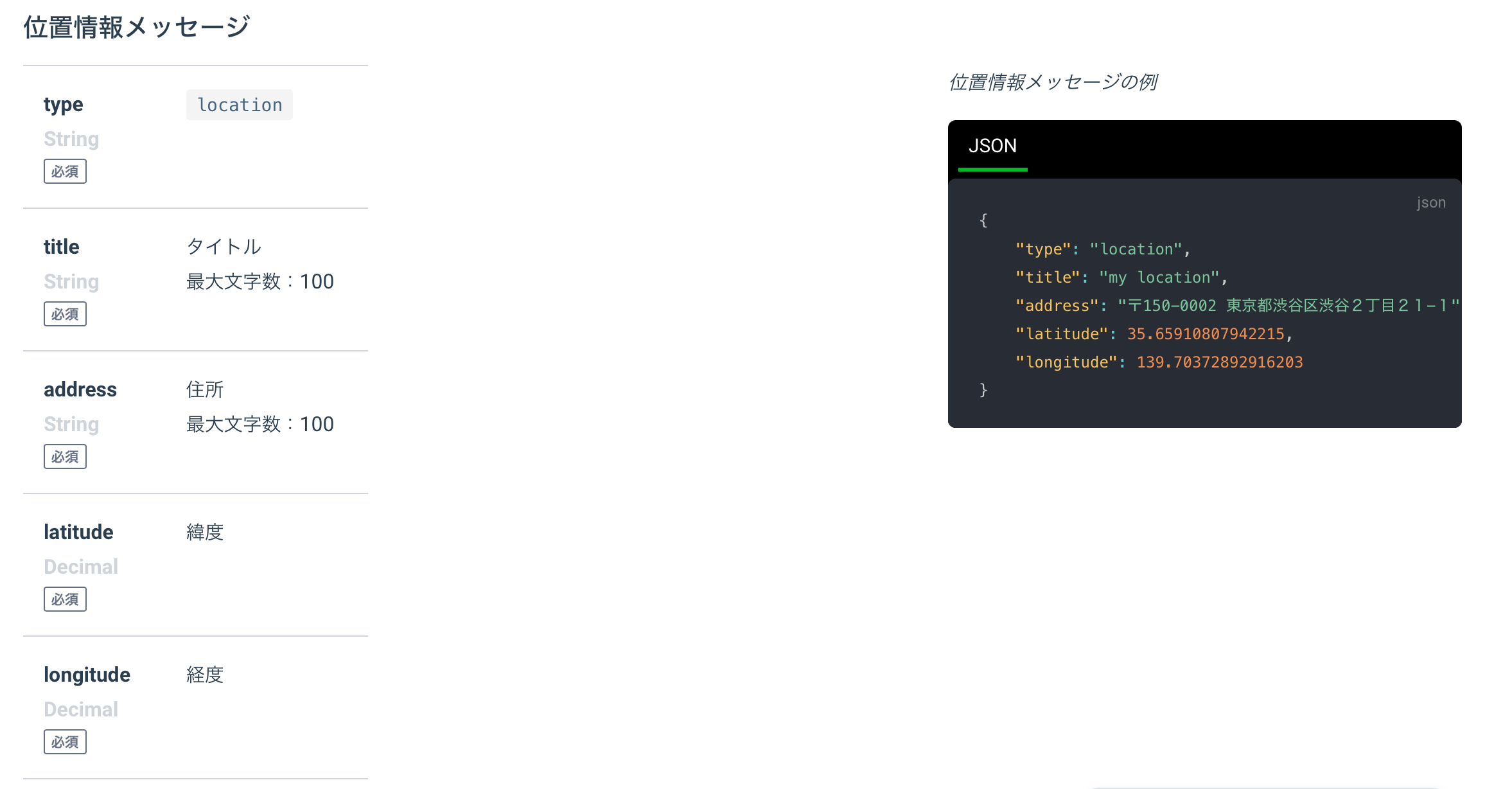
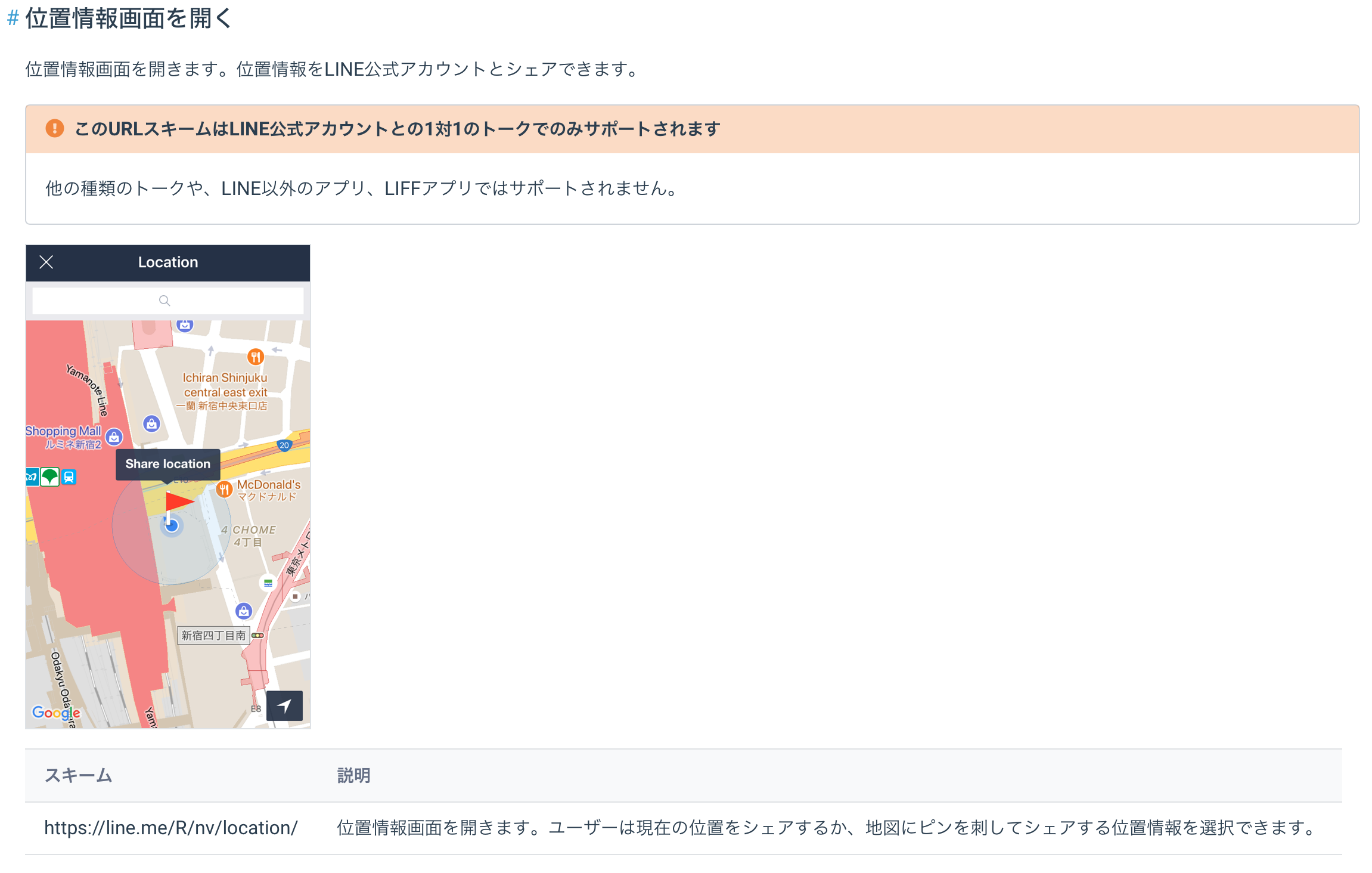
main.pyfrom flask import Flask, request, abort from linebot import ( LineBotApi, WebhookHandler ) from linebot.exceptions import ( InvalidSignatureError ) from linebot.models import ( MessageEvent, TextMessage, TextSendMessage,LocationMessage ) import os import weather as wt #weather.pyをインポート app = Flask(__name__) #Herokuの環境変数設定 YOUR_CHANNEL_ACCESS_TOKEN = os.environ["YOUR_CHANNEL_ACCESS_TOKEN"] YOUR_CHANNEL_SECRET = os.environ["YOUR_CHANNEL_SECRET"] line_bot_api = LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN) handler = WebhookHandler(YOUR_CHANNEL_SECRET) @app.route("/") def hello_world(): return "hello world!" @app.route("/callback", methods=['POST']) def callback(): signature = request.headers['X-Line-Signature'] body = request.get_data(as_text=True) app.logger.info("Request body: " + body) try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' @handler.add(MessageEvent, message=TextMessage) def handle_message(event): if '花粉' in event.message.text: line_bot_api.reply_message( event.reply_token, TextSendMessage(text='現在の位置情報は?'), TextSendMessage(text='https://line.me/R/nv/location/'), ] ) @handler.add(MessageEvent, message=LocationMessage) def handle_location(event): text = event.message.address result = wt.get_weather(text) line_bot_api.reply_message( event.reply_token, TextSendMessage(text=result + '\uDBC0\uDC20') ) if __name__ == "__main__": port = int(os.getenv("PORT", 5000)) app.run(host="0.0.0.0", port=port)補足説明
・text = event.message.addressの箇所のaddressは、linedevelopersのapiリファレンスを参考にした。
・ TextSendMessageの箇所はLINEapiリファレンスのURLスキームを参考にした。
・なお、URLスキームは1対1のトークのみで利用可能であり、グループでの利用は不可。
・'\uDBC0\uDC20'は絵文字で、LINE BOTで「LINEの絵文字」を使うを参考にした。(4)weather.py
Yhaooから花粉情報をスクレイピング。
weather.pyimport requests from bs4 import BeautifulSoup import re import lxml def get_weather(text): location = re.findall('\d{3}-\d{4}',text) location2 = location[0].replace('-','') url1 = "https://weather.yahoo.co.jp/weather/search/?p={}".format(location2) url2 = "" #1つ目のurlからhtmlの情報を取得し、そこから2つ目のurlを取得 res = requests.get(url1) res.encoding = res.apparent_encoding html_doc = res.text soup = BeautifulSoup(html_doc,"lxml") content_1 = soup.find_all(id = 'rsltmuni') for i in content_1: content_2 = i.find('a') url2 = 'https:' + content_2.get('href') #2つ目のurlから今日と明日の日付を取得(today、nextday) res = requests.get(url2) res.encoding = res.apparent_encoding html_doc = res.text soup = BeautifulSoup(html_doc,"lxml") content_3 = soup.find_all('p',class_='date') today = content_3[0].get_text() nextday = content_3[1].get_text() #今日と明日の花粉状況を取得 content_4 = soup.find_all('p',class_='flying') today_kafun = content_4[0].get_text() nextday_kafun = content_4[1].get_text() #エリアを取得 content_5 = soup.find_all('h2',class_='yjM') area = content_5[0].get_text() result = today + 'の' + area + 'は' + '「{}」'.format(today_kafun) + 'だよ。' + '\n' +'\n'+ nextday + 'の' + area + 'は' + '「{}」'.format(nextday_kafun) + 'だよ。' + '\n' +'\n' + '気をつけてね。' return result(5)Herokuへデプロイと、LINE DevelopersのWebhook設定
最後に必要なファイル(requirements.txt、Procfile、runtime.txt)を作成し、Herokuへデプロイする。デプロイ方法は多くのサイトで紹介しているので割愛。詳細はHeroku、Flask、SQLAlchemyで掲示板を作るを参考。
また、LINE DevelopersのWebhook設定もこれも多くのサイトで紹介しているので割愛。詳細はLINE BOT(オウム返し)を作るを参考。出来上がった、LINEBotに、”花粉”と入力すると位置情報を聞いてくるので、タップすると、花粉情報を取得できる(完成)。
- 投稿日:2020-03-25T23:02:48+09:00
Python初心者のための前処理作法 まとめ(Pandasのデータフレーム)
Python初心者です。
Pandasでのデータフレーム操作に関して、操作説明単体では豊富に記事があるものの、前処理に関しての勘所・目的をあわせて解説された記事がないように感じたので、
学習メモとして作成することにしました。想定読者
- Python初心者 ∋ わし
- Pandasに触りはじめた方
本稿を読んだら出来るようになること
- pandasライブラリを使ってデータフレームを読みこむ際、最初に何をするべきか、前処理の目的とその具体的手順を両方とも理解できる
- 特に、CSVファイルを読み込んだ後の処理がラクに行えるようになる
前提
- 本論でのコードの記述は、すべて下記を書いた後に行っています。dfは適宜読者様のデータフレームに置き換えてご覧いただきたいです。
- 統計学の入門コンテンツでよく用いられる、タイタニック号の乗客データをイメージしていますが、出てくるデータは本稿作成用のフィクションです。
- データフレームそのものの作り方や読み込み方、行列の編集方法についてはふれていません。後日記事化する予定です。
import pandas as pd df = pd.read_csv("hogehoge/test.csv", usecols = ['PassengerId','Sex','Age'], header = 1)本論I | データを概観する
1.目視での確認
- headメソッド、tailメソッドを使って目視でデータの中身を確認する
- columnsメソッド、indexメソッドを用いて、行と列の名前を確認しておく
- 目的:誤ったファイルの読み込みをしていないか、想定通りにデータを読み込めているか確認する
# 先頭 / 末尾の2行を列挙。2には確認したい行数を指定(省略すると6が指定される) print(df.head(2)) print(df.tail(2)) print("列名:",df.columns) print("行名(index):"df.index) """ ↓のように表示される: # head PassengerId Sex Age 0 1 female 23.0 1 2 male 48.0 # tail PassengerId Sex Age 998 999 female 41.0 999 1000 male 15.0 列名:Index(['PassengerId', 'Sex', 'Age'], dtype='object') 行名:RangeIndex(start=0, stop=1000, step=1) """
- この結果から、例えば以下のような確認ができる:
- Sexは文字列で格納されているんだな、
- 行名にRangeIndexうんたらと返されたので、行名には通し番号のインデックスが付いているだけだな(特に名前はついていないんだな)、またデータの個数が1000個あるんだな
- RangeIndex(start=0, stop=1000, step=1)は、「0から初めて1ごとに、1000の数値未満でインデックスを付ける」なので、0から999までのインデックスでデータ個数(行数)が1000個です
2.データ型の確認
- dtypesアトリビュートを用いる
- アトリビュート -> メソッドのようにデータフレームの後に
.hogeとくっつける- 目的:使用するライブラリによってはデータ型を混合させての計算はエラーを起こす原因となるので、後にそれを取り除くため(後述)。
print(df.dtypes) """ 以下のように表示されます PassengerId int64 Sex object Age float64 """
- この結果から、例えば以下のような争点を生み出せると思います:
- 1)Sexはmaleやfemaleのような文字列として格納されている。計算に用いるために、0 / 1のようなダミー値をふったほうが良いのではないか。
- 2)Ageはfloat(浮動小数点型)に対しPassengerIdはint(整数型)。どちらも計算に使うし、どちらかに統一したほうが良いのではないか。
3.欠損値(NaN)の確認と置換
- isnullメソッド、anyメソッドを組み合わせて用い、除外する
- これらの組み合わせにより「NaNが一つでも含まれる列」を検知できる
- 目的:欠損値は計算結果全体に悪影響を及ぼすのでそれを除外しておくため(後述)。
print(df.isnull().any()) """ 結果は以下のように表示されます PassengerId False Sex False Age True dtype: bool """
- ここからの示唆としては、「Age列にNaNが存在するので、これを取り除く可能性があるようだ」ということです。
- 処理方法(NaNの存在する行を消すのか、NaNを0とかで置き換えるのか、Age列そのものを消すのか、等)はケースによります。
4.基礎統計量の確認
- describeメソッドを用いて基礎統計量を確認しよう
- 各列の合計値、算術平均値、標準偏差、四分位数を教えてくれる
- 目的:分析対象データの概観をし、外れ値がないか確認する
print(df.describe()) """ PassengerId Age count 1000.000000 884.000000 mean 446.000000 29.699118 std 257.353842 14.526497 min 1.000000 3.100000 25% 215.500000 20.125000 50% 430.000000 27.000000 75% 703.500000 39.000000 max 1000.000000 80.000000 """
- 得られる示唆:
- Ageのminが3.1とあるが、head/tailで確認した通り年齢は整数(浮動小数点型だけど)で記録されているようだ。この3.1はデータ取得者の31のミスではないか?確認が必要だ。
- 統計量の読み方に注意しましょう
- PassengerId(乗客番号)の統計量に意味はない
- Sex列はobject型なので、自動で除外してくれています
本論II | 基本的な処理を行う
1.欠損値を処理する
- 今回の場合、例えば「年齢のNaNは0にしよう。今後年齢の平均値を算出する際などは、0以外の値を分析対象にしよう」などと考え、NaNを0に変換する。
- locにて「Age列の値がNaNである行のAge列全部」(日本語ややこしいけど)を抽出し0を代入する
# 前章にてNaNの存在が確認された列に対して変換をほどこす df.loc[df['Age'].isnull(), 'Age'] = 0 # 正しく処理が行えたか確認 print(df.isnull().any()) """ 以下のように表示されます。前章cと比較されたい。 PassengerId False Sex False Age False dtype: bool """2.データの種類やデータ型を統一する
- 前章に基づき、データ型を統一する作業を行う
- astypeメソッドを用いて列単位でデータ型を変換する
- 今回の場合、①PassengerIdをfloat64型に変更し、②Sexにダミー変数として0 / 1を割り当て(てそれもfloat64型にす)る、の2つが必要
# PassengerIdの型変更 df.PassengerId = df.PassengerId.astype('float64') # Sexのダミー値割当(maleは0、femaleは1とする) & float64化 df.Sex[df.Sex=='male'] = 0 df.Sex[df.Sex=='female'] = 1 df.Sex = df.Sex.astype('float64') #正しく処理が行えたか確認 print(df.dtypes) """ 以下のように表示されます: PassengerId float64 Sex float64 Age float64 """おわりに
- 基本的な前処理の流れと手順をまとめました。どんなデータを分析する場合においても、このような前処理の必要性は必ず出てくるものと思われます。ご感想などあればお寄せいただけますと幸いです。筆者も初心者なので一層勉強していきます。
参考
- 投稿日:2020-03-25T22:59:31+09:00
Pythonで毎日AtCoder #16
はじめに
前回
今日もCです。今日で例題は終わりです。#16
考えたこと
ABC049-C
ぜんぜん分からなかったので、解説を見ました。ふむふむ、文字列を逆にすればerの区別しなくていいのか。
文字列を逆にしたあとは、ひたすらif文にしてます。s = str(input()) s = ''.join(list(reversed(s))) t = 0 while t <= len(s): if s[t:t+5] == 'maerd': t += 5 continue elif s[t:t+7] == 'remaerd': t += 7 continue elif s[t:t+5] == 'esare': t += 5 continue elif s[t:t+6] == 'resare': t += 6 continue elif t == len(s): print('YES') quit() else: break print('NO')Python3 → 33ms
PyPy3 → 189ms
スライス処理はPyPyよりもPythonの方が早い?
ABC086-C
(0,0)から(x,y)に移動するときに必要なマンハッタン距離?をdとすると、t>=dなら時間内に到着できます。また、(d - t) % 2 == 0ならば、t未満で到着しても隣りのマスと目的のマスを往復できるので、t時に到着可能です。n = int(input()) l = [list(map(int,input().split())) for _ in range(n)] for i in range(n): t = l[i][0] x = l[i][1] y = l[i][2] d = x + y if d <= t and (d - t) % 2 == 0: continue else: print('No') quit() print('Yes')Python3 → 369ms
PyPy3 → 585msまとめ
今回で例題は全部解いたので、次回からは類題を解いていきます!
では、また
- 投稿日:2020-03-25T20:34:54+09:00
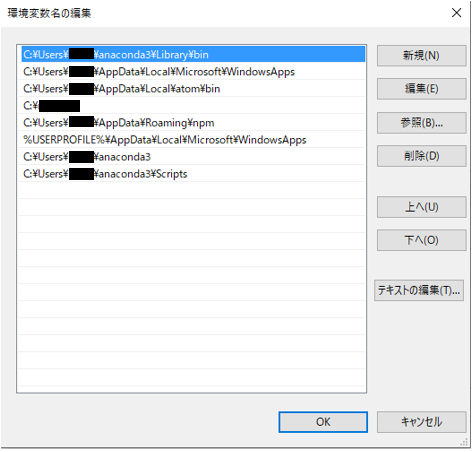
Anaconda3のインストール
こんにちは。
ca ci cu ce coと打つと、か し く せ こ となることに不満のFaguriです。(英語ができない)環境
Windows 10 Home 64bit
注意
誤字脱字が多いです。
見つけたら、ぜひぜひ遠慮せずに、コメントで教えてください。Anacondaのインストール
公式サイトにアクセスし、
赤枠で囲んだところをクリックし、
自分の環境に合わせてダウンロードしてください
もしわからないなら32bitにしておいてください
ダウンロードしたのを管理者で実行
Next>をクリック
暇な人は読みなさい
そしてI Agree をクリック
これは、自分のユーザーだけにインストールしますか、それとも全部のユーザーにインストールしますかをです。
自分だけだったら、Just Meほかのユーザーも使うのであれば、All Usersをクリックしてください。
許可をしてくださいと出たらはいをクリックしましょう。
特に理由がなければ、Next> をクリック
あまりやらないほうがいいともいわれてますが、どちらにもチェックをつけて、Install!
インストール中
Next>
これもNext>(Next大好きおじさん)
チェック入れると、チュートリアルがあるみたいなのですが今回はなしで。
Finish!おまけ
Anaconda Navigatorを起動
めんどくさいのでそれぞれの機能はほかの人を参考に!
(表を書くMarkDownの書き方を知らない(言い訳))終わりに
まあこれでPython環境が整いましたね。
頑張りましょう!
あとAnaconda使い方わかるとめっちゃいいよ。












- 投稿日:2020-03-25T20:31:59+09:00
VAEの異常検知の精度向上を考える
深層距離学習、生成モデルを用いた様々な異常検知手法が提案されています。
その中でも2018年度人工知能学会全国大会で発表された、複雑な工業製品をVAEで異常検知する際に有用な非正則化項を用いた異常検知手法を用いて実験しました。その手法の中で正常な部分に誤って異常判定が起きる問題、具体的には標準偏差出力層σが過少に評価されることによる過大な異常判定が生じる問題があり、その解決手法を検討しました。
今回は、データ拡張による精度向上効果を検証します。
(データ拡張とは…画像に変換処理(反転、拡大、縮小など)を加えることで、学習データの「水増し」を行う。水増しされることで同じ画像が学習されることが少なくなるので汎化性能が改善される。)自己紹介
こんにちは。
ProsConsでリサーチインターンをしているmaharudaです。会社のベンチマーキング業務体験の一環として、特に異常検知手法の一つとして用いられるVAEに関する記事を書かせていただくこととなりました。
よろしくおねがいします!目的
非正則化項を用いた異常検知手法で実験している際に生じた問題点の一つ、正常部分の誤った異常判定の改善。
VAEを用いた異常検知
データXを潜在変数z(元データより次元が少ない)に変換するニューラルネットワークをエンコーダー、潜在変数zを再構成して元のデータを復元するニューラルネットワークをデコーダーと呼びます。入力データと再構成されたデータがなるべく同じになるように学習させます。
以上のアーキテクチャをオートエンコーダー(AE)と呼びます。
そしてAEの潜在変数を確率分布に押し込めたものをVAEと呼びます。
以下の記事で詳しく解説されているので参考にしてください。・Variational Autoencoder徹底解説
(https://qiita.com/kenmatsu4/items/b029d697e9995d93aa24)一般的に、VAEを用いる異常検知は、エンコーダーに入れる前のデータとそれをVAEで再構成したデータとの差分を異常として検知することにより実現します。
複雑な工業製品の異常検知に有用な手法
工業製品は様々な要素から構成されています。
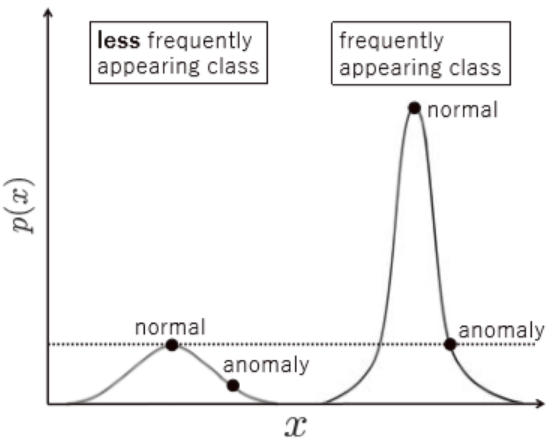
例えば歯車でいうと歯車の平らな表面、歯の部分や中心の穴などからです。
頻繁に出る画像要素は尤度がたまにしか出ない画像要素よりも高くなります。そのため損失関数を異常検知の関数として用いると頻繁にでる画像の異常とみなす閾値はたまにしかでない画像のそれよりも大きくなります(頻繁に出る画像においては異常部分もたまにしか出ない画像における異常部分よりも頻繁に出る、ということです)。
図1.工業製品画像における尤度の直感的な図解(論文より)以下の論文で画像が属するグループの複雑さや頻度の影響を除去できる手法が提案されています。
これを用いると複雑な工業製品(単純な部分にも異常がでるような対象物)の画像に対して異常検知をすることができます。・深層生成モデルによる非正規化異常度を用いた工業製品の異常検知
(https://confit.atlas.jp/guide/event-img/jsai2018/2A1-03/public/pdf?type=in)VAEの損失関数は
で表せます。(論文より)一般的にはVAEの異常検知の評価にこの損失関数$L_{VAE}$を用いるのですが、
$L_{VAE}$から$D_{VAE}$と$A_{VAE}$を差し引いた$M_{VAE}$とすることで同じ閾値で異常判定できるように改良しています。$M_{VAE}$はデータ$x$の平均とデータ$x$の差分の二乗を分子に持ち、潜在的にデータ$x$の不確かさや複雑さを表している標準偏差$\sigma_x$を分母に持つ関数です。
後述しますがこの$M_{VAE}$の分母にある$σ_x$が小さすぎることで問題を引き起こします。
この論文で取り上げられている手法は以下の記事で詳しく解説されているので参考にしてください。・Variational Autoencoderを使った画像の異常検知 前編
(https://qiita.com/shinmura0/items/811d01384e20bfd1e035)早速この手法を用いて異常検知をしてみましょう。
検証結果
小さな白い歯車を異常検知の対象として用いました。
結果の画像は左から
・異常部分をヒートマップで表した画像
・元画像
です。<正常画像>
<異常あり画像1>
異常:右側の歯が欠けている
<異常あり画像2>
異常:すべての歯が摩耗している
異常な部分(歯車の歯が欠けている部分)を検出してくれていますが、
正常な部分(白い歯車の表面)にも異常判定がでてしまっています。仮説
VAEでは、再構成の不確かさに関して標準偏差$\sigma_x$が調整されることにより、$A_{VAE}$と$M_{VAE}$のバランスが取れるように学習が行われる。(論文より)
とあるように損失関数を減らす方向に学習は進むため学習時に$M_{VAE}$が大きな状態であるとは考えにくいです。
学習時は平均ベクトル$\mu_x$が$x$に限りなく近づいており、$\sigma_x$が非常に小さな値でも$M_{VAE}$を小さく抑えることができており、そのため異常検出時に$(\mu_x-x)^2$が少しでも大きくなると$M_{VAE}$が跳ね上がってしまうと考えられます。
以下で解決策を模索していきます。解決策(データの拡張)
損失関数を下げようとする方向に学習は進みます。
一方でデータが水増しされたことで学習時に$\mu_x$と$x$が近づきにくくなります。
そうすることで$σ_x$が小さくなりすぎるのを防ごうと思います。パターン1
もとの画像の各ピクセルのRGBの値をそれぞれ2(4,6,8,10)下げた画像をデータに加えます。
データの量は6倍になります。加工前の画像 RGBそれぞれから10差し引いた画像
<正常画像>
<異常あり画像1>
異常:右側の歯が欠けている
<異常あり画像2>
異常:すべての歯が摩耗している
うーん。誤って異常判定しています。
パターン2
俗に言うソルトペッパーノイズをいれました。
白点と黒点の比は1:1にしました。
加工前の画像 ノイズの比率0.4%
<正常画像>
<異常あり画像1>
異常:右側の歯が欠けている
<異常あり画像2>
異常:すべての歯が摩耗している
割といい感じ。
完全に除去とまではいきませんが正常な部分にかかっていたヒートマップが少なくなっていますね。考察
パターン2については良い方向に結果がでており、データを拡張することでデータに多様性が生じて、$μ$と$x$に差分がうまれて$σ$が小さくなりすぎないことがわかりました。
正常部分を誤って異常判定するこの問題に対するデータ拡張の有用性が示されました。またパターン1では精度向上しなかったことを踏まえ、データ拡張の中でも有用と言える場合と言えない場合があることがわかりました。
今回行った検証実験に関しては、均一にRGBを下げるよりも部分的に白(0,0,0)もしくは黒(255,255,255)のピクセルを設ける方が異なる画像としてうまく特徴量を抽出でき過学習を防ぐことができたと言えます。
したがって明暗を変更した画像の拡張は形状情報に関与せず、本質的な複雑さに影響をあたえておらず、対してソルトペッパーノイズの画像の拡張は形状情報を変更しており本質的な複雑さが増えているために有効に働いたと考えられます。
よって、これに関しては仮説段階ですが、形状情報を変更した画像の方がデータ拡張に有用である可能性があります。結論として、データ拡張は非正則化項を用いた異常検知手法における標準偏差出力層$σ$の過小評価を防ぐことができる。データ拡張に形状情報が変更された画像を用いるか否かが有効性に関与している可能性がある。ということが言えると思われます。
インターンを終えて
一ヶ月という短い期間にもかかわらず機械学習に関して深くまで学ぶことができました。
Pros ConsではGemini eyeという、工業製品の外観検査AIを開発しています。そのベンチマーキング業務という形で業務に携わらせていただき、非常に有意義な経験でした。居心地のよい会社で働かせていただきありがとうございました。
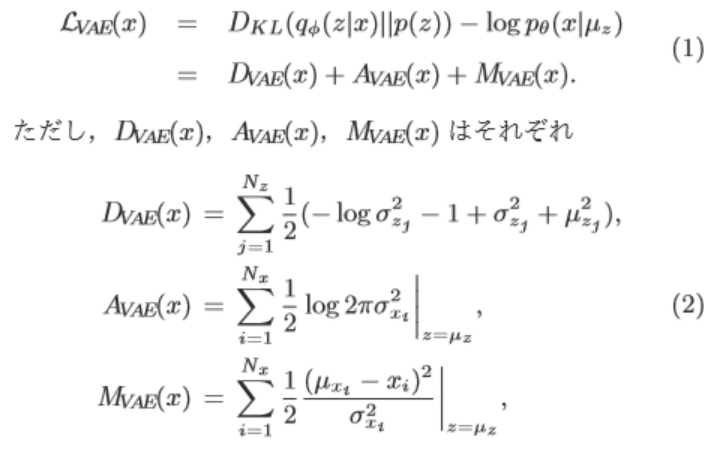











- 投稿日:2020-03-25T18:40:49+09:00
[小ワザ] zip(*[lists])を用いてN-gramを作成する
この記事は・・・
zip(*[lists])の挙動の理解に時間がかかった為、備忘録として書きました。はじめに
現在、自然言語処理系のKaggleコンペに取り組んでいます。
コンペ参加者のノートブックの中に、探索的データ分析(Exploratory Data Analysis : EDA)を行う目的で N-gramのリストを作成する関数を発見しました。from wordcloud import STOPWORDS # STOPWORDSのリストを取得 def generate_ngrams(text, n_gram=1): token = [token for token in text.lower().split(' ') if token != '' if token not in STOPWORDS] ngrams = zip(*[token[i:] for i in range(n_gram)]) return [' '.join(ngram) for ngram in ngrams] # 試しに generate_ngrams()を使ってみる text = "I wanna be a deep python engineer" ngrams = generate_ngrams(text, n_gram=2) print(ngrams)実行結果['wanna deep', 'deep python', 'python engineer']なるほど、引数
n_gramを変えることで、引数textをトークナイズし、ストップワードは取り除いた上でリスト形式のN-gramのリストを返してくれる関数みたいですね。
なんとなくそのままスルーしそうになりましたが、ngrams = zip(*[token[i:] for ...の一行が気になりました。
少し考えてみましたが、直感的に理解できなかった。。。のでノートブックで色々トライして理解してみることにしました。結論
*演算子をつけることで、各リストから、先頭要素から順番に、同じインデックスの要素を取り出して新しいリストを作ることができます。
公式ドキュメントのzip(*iterables)の項目によると、zip() に続けて * 演算子を使うと、zip したリストを元に戻せます:
つまり、unzipを行っていることになるそうです。
また、同様のテーマを取り上げたQiitaの記事にもあるように、「行と列を変換している」とイメージすると直感的に理解しやすいかもしれません。「N-gramを作成する」という目的で、
zip(*[lists])を使うとするならば、中身のリストは、トークンのリストから先頭の要素を1つずつ削除したリストをn個並べるリストだと良さそうです。
上記の関数では[token[i:] for i in range(n_gram)]が正に目的のリストを作成しています。
綺麗なコードだなと感心しました。理解のためにトライしたこと
理解のために実行したコードをだらだらと記しています。。。
zip(*[lists])のlists部分を正しく理解してみた。token = ["wanna", "deep", "python", "engineer"] # 関数実行で得られる tokenのリスト n_gram = 3 # トライグラムのコーパスを作る lists = [token[i:] for i in range(n_gram)] print(lists)実行結果[['wanna', 'deep', 'python', 'engineer'], ['deep', 'python', 'engineer'], ['python', 'engineer']]分かりづらいので
zip(*[lists])の中身のリスト部分を重複しない数字に置き換えてみた。for nums in zip(*[1,2,3,4], [5,6,7], [8,9]): print(nums)実行結果(1, 5, 8) (2, 6, 9)3つのリストの1番目要素を取り出したリスト、2番目要素を取り出したリストが作られました。
- 投稿日:2020-03-25T18:40:49+09:00
小ワザ : zip(*[lists])を用いてN-gramを作成する
この記事は・・・
zip(*[lists])の挙動の理解に時間がかかった為、備忘録として書きました。はじめに
現在、自然言語処理系のKaggleコンペに取り組んでいます。
コンペ参加者のノートブックの中に、探索的データ分析(Exploratory Data Analysis : EDA)を行う目的で N-gramのリストを作成する関数を発見しました。from wordcloud import STOPWORDS # STOPWORDSのリストを取得 def generate_ngrams(text, n_gram=1): token = [token for token in text.lower().split(' ') if token != '' if token not in STOPWORDS] ngrams = zip(*[token[i:] for i in range(n_gram)]) return [' '.join(ngram) for ngram in ngrams] # 試しに generate_ngrams()を使ってみる text = "I wanna be a deep python engineer" ngrams = generate_ngrams(text, n_gram=2) print(ngrams)実行結果['wanna deep', 'deep python', 'python engineer']なるほど、引数
n_gramを変えることで、引数textをトークナイズし、ストップワードは取り除いた上でリスト形式のN-gramのリストを返してくれる関数みたいですね。
なんとなくそのままスルーしそうになりましたが、ngrams = zip(*[token[i:] for ...の一行が気になりました。
少し考えてみましたが、直感的に理解できなかった。。。のでノートブックで色々トライして理解してみることにしました。結論
*演算子をつけることで、各リストから、先頭要素から順番に、同じインデックスの要素を取り出して新しいリストを作ることができます。
公式ドキュメントのzip(*iterables)の項目によると、zip() に続けて * 演算子を使うと、zip したリストを元に戻せます:
つまり、unzipを行っていることになるそうです。
また、同様のテーマを取り上げたQiitaの記事にもあるように、「行と列を変換している」とイメージすると直感的に理解しやすいかもしれません。「N-gramを作成する」という目的で、
zip(*[lists])を使うとするならば、中身のリストは、トークンのリストから先頭の要素を1つずつ削除したリストをn個並べるリストだと良さそうです。
上記の関数では[token[i:] for i in range(n_gram)]が正に目的のリストを作成しています。
綺麗なコードだなと感心しました。理解のためにトライしたこと
理解のために実行したコードをだらだらと記しています。。。
zip(*[lists])のlists部分を正しく理解してみた。token = ["wanna", "deep", "python", "engineer"] # 関数実行で得られる tokenのリスト n_gram = 3 # トライグラムのコーパスを作る lists = [token[i:] for i in range(n_gram)] print(lists)実行結果[['wanna', 'deep', 'python', 'engineer'], ['deep', 'python', 'engineer'], ['python', 'engineer']]分かりづらいので
zip(*[lists])の中身のリスト部分を重複しない数字に置き換えてみた。for nums in zip(*[1,2,3,4], [5,6,7], [8,9]): print(nums)実行結果(1, 5, 8) (2, 6, 9)3つのリストの1番目要素を取り出したリスト、2番目要素を取り出したリストが作られました。
- 投稿日:2020-03-25T18:40:49+09:00
zip(*[lists])を用いてN-gramを作成する
この記事は・・・
zip(*[lists])の挙動の理解に時間がかかった為、備忘録として書きました。はじめに
現在、自然言語処理系のKaggleコンペに取り組んでいます。
コンペ参加者のノートブックの中に、探索的データ分析(Exploratory Data Analysis : EDA)を行う目的で N-gramのリストを作成する関数を発見しました。from wordcloud import STOPWORDS # STOPWORDSのリストを取得 def generate_ngrams(text, n_gram=1): token = [token for token in text.lower().split(' ') if token != '' if token not in STOPWORDS] ngrams = zip(*[token[i:] for i in range(n_gram)]) return [' '.join(ngram) for ngram in ngrams] # 試しに generate_ngrams()を使ってみる text = "I wanna be a deep python engineer" ngrams = generate_ngrams(text, n_gram=2) print(ngrams)実行結果['wanna deep', 'deep python', 'python engineer']なるほど、引数
n_gramを変えることで、引数textをトークナイズし、ストップワードは取り除いた上でリスト形式のN-gramのリストを返してくれる関数みたいですね。
なんとなくそのままスルーしそうになりましたが、ngrams = zip(*[token[i:] for ...の一行が気になりました。
少し考えてみましたが、直感的に理解できなかった。。。のでノートブックで色々トライして理解してみることにしました。結論
*演算子をつけることで、各リストから、先頭要素から順番に、同じインデックスの要素を取り出して新しいリストを作ることができます。
公式ドキュメントのzip(*iterables)の項目によると、zip() に続けて * 演算子を使うと、zip したリストを元に戻せます:
つまり、unzipを行っていることになるそうです。
また、同様のテーマを取り上げたQiitaの記事にもあるように、「行と列を変換している」とイメージすると直感的に理解しやすいかもしれません。「N-gramを作成する」という目的で、
zip(*[lists])を使うとするならば、中身のリストは、トークンのリストから先頭の要素を1つずつ削除したリストをn個並べるリストだと良さそうです。
上記の関数では[token[i:] for i in range(n_gram)]が正に目的のリストを作成しています。
綺麗なコードだなと感心しました。理解のためにトライしたこと
理解のために実行したコードをだらだらと記しています。。。
zip(*[lists])のlists部分を正しく理解してみた。token = ["wanna", "deep", "python", "engineer"] # 関数実行で得られる tokenのリスト n_gram = 3 # トライグラムのコーパスを作る lists = [token[i:] for i in range(n_gram)] print(lists)実行結果[['wanna', 'deep', 'python', 'engineer'], ['deep', 'python', 'engineer'], ['python', 'engineer']]分かりづらいので
zip(*[lists])の中身のリスト部分を重複しない数字に置き換えてみた。for nums in zip(*[1,2,3,4], [5,6,7], [8,9]): print(nums)実行結果(1, 5, 8) (2, 6, 9)3つのリストの1番目要素を取り出したリスト、2番目要素を取り出したリストが作られました。
- 投稿日:2020-03-25T18:20:25+09:00
【メモ】Amazon Linux 2 でDjangoを動かす
OSを最新の状態にする
$ sudo yum update -ypythonを入れる
pythonに必要な物を入れる
$ sudo yum install git gcc zlib-devel libffi-devel bzip2-devel readline-devel openssl-devel sqlite-develpyenvを入れる
$ git clone https://github.com/yyuu/pyenv.git ~/.pyenvパスを通す
$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo -e 'if command -v pyenv 1>/dev/null 2>&1; then\n eval "$(pyenv init -)"\nfi' >> ~/.bash_profile $ exec "$SHELL" -lpyenvで入れれるpythonの最新バーションを調べる
$ pyenv install --list最新のバージョンのpythonを入れる
$ pyenv install 3.8.1インストールしたpythonをデフォルトで使うようにする
$ python -V Python 2.7.16 $ pyenv versions * system (set by /home/ec2-user/.pyenv/version) 3.8.1 $ pyenv global 3.8.1 $ pyenv versions system * 3.8.1 (set by /home/ec2-user/.pyenv/version) $ pyenv rehash $ python -V Python 3.8.1Djangoを入れる
pyenvで入れたパッケージにpipもはいっているので、pip本体をアップグレードしてから、Djangoをインストール
$ pip install --upgrade pip $ pip install Django Pillowディレクトリを作ってその中にDjangoプロジェクトを作成
$ cd /var/www $ mkdir django $ django-admin startproject config .DB
MySQLをインストール
$ sudo rpm -ivh http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm $ yum install mysql-community-server $ mysqld --version mysqld Ver 5.7.29 for Linux on x86_64 (MySQL Community Server (GPL))DB接続
Djangoはmysqlclientを推奨。PyMySQLはなるべく使わない。
$ sudo yum install mysql-devel $ pip install mysqlclient接続の確認
$ python manage.py dbshell # 本番用の設定ファイルを使う $ python manage.py dbshell --settings=config.settings.productiongunicorn
$ pip install gunicorngunicornを使ってDjangoを起動してみる
$ gunicorn config.wsgi --bind=[プライベートIP] # 本番用の設定ファイルを使う $ gunicorn config.wsgi --bind=[プライベートIP] --env DJANGO_SETTINGS_MODULE=config.settings.productionnginx
$ sudo amazon-linux-extras install nginx1.12 -y $ sudo cp -a /etc/nginx/nginx.conf /etc/nginx/nginx.conf.back $ sudo systemctl start nginx.service # 自動起動 $ sudo systemctl enable nginx.service $ systemctl is-enabled nginx.service enabled$ sudo vim /etc/nginx/conf.d/django.confserver { listen 80; server_name [パブリックIP や elb やドメイン]; location /static { alias /var/www/manage/static; } location / { proxy_pass http://127.0.0.1:8000; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_set_header X-Forwarded-Proto $scheme; } }$ gunicorn config.wsgi --daemon --bind 127.0.0.1:8000 $ gunicorn config.wsgi --daemon --bind 127.0.0.1:8000 --env DJANGO_SETTINGS_MODULE=config.settings.production確認できたらプロセスをkill
$ sudo lsof -i:8000 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME gunicorn 13502 ec2-user 5u IPv4 68558 0t0 TCP [プライベートIP].ap-northeast-1.compute.internal:irdmi (LISTEN) gunicorn 13504 ec2-user 5u IPv4 68558 0t0 TCP ip-[プライベートIP].ap-northeast-1.compute.internal:irdmi (LISTEN) $ sudo kill -9 13502 13504systemctlコマンド登録
sudo vim /etc/systemd/system/project.service[Unit] Description=gunicorn After=network.target [Service] WorkingDirectory=/var/www/django ExecStart=/home/ec2-user/.pyenv/shims/gunicorn --bind 127.0.0.1:8000 config.wsgi:application --env DJANGO_SETTINGS_MODULE=config.settings.production [Install] WantedBy=multi-user.target参考
- 投稿日:2020-03-25T18:19:55+09:00
【メモ】Djnago開発環境
pyenvを入れる
$ git clone https://github.com/yyuu/pyenv.git ~/.pyenv$ export PYENV_ROOT="$HOME/.pyenv" $ export PATH="$PYENV_ROOT/bin:$PATH" $ eval "$(pyenv init -)"最新のpythonを入れる
最新のpythonを調べる
$ pyenv install --list最新のpythonをインストール
$ pyenv install 3.8.1$ pyenv local 3.8.1 $ python -V Python 3.8.1pipenvを入れる
$ pip install pipenvpipenvでインストールすると通常、
~/.local/share/virtualenvs/に入るが、プロジェクト直下の.venvに入るようにする。.venvは仮想環境に入ったときに自動的に作成される。$ echo 'export PIPENV_VENV_IN_PROJECT=1' >> ~/.bash_profilepipenvの仮想環境内で使用するpythonのバージョンを指定する
$ pipenv --python 3.8仮想環境に入る。
$ pipenv shelldjango │── Pipfile │── Pipfile.lock └── .venvパッケージ管理
$ pipenv install django django-bootstrap4 $ pipenv install --dev django-debug-toolbar django-webpack-loader #開発環境のみpipenvはデフォルトではプレリリース版のパッケージをインストールすることはできません。以下のようにPipfileに設定を追加する必要があります。
Pipfile[pipenv] allow_prereleases = trueDjangoプロジェクト
pipenvの仮想環境内でプロジェクトを作成
$ django-admin startproject config .django │── config │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py │── Pipfile │── Pipfile.lock ├── .venv └── manage.pyセッティングファイルを分割
django ├── config │ ├── __init__.py │ ├── settings │ │ ├── __init__.py │ │ ├── base.py # 共通の設定 │ │ ├── production.py # 本番環境だけに適用したい設定 │ │ ├── development.py # 開発環境だけに適用したい設定 │ │ └── test.py # テストだけに適用したい設定 │ ├── urls.py │ └── wsgi.py │── Pipfile │── Pipfile.lock ├── .venv └── manage.pyディレクトリが変わったので、base.pyの
BASE_DIRを修正base.py- BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) + BASE_DIR = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))production.py# 本番環境だけに適用したい設定 from .base import * DEBUG = Truedevelopment.py# 開発環境だけに適用したい設定 from .base import * DEBUG = Falseアプリケーション作成
python manage.py startapp test_appdjango ├── config │── Pipfile │── Pipfile.lock ├── .venv │── manage.py └── test_app ├── __init__.py ├── admin.py ├── apps.py ├── migrations ├── models.py ├── tests.py └── views.pyテンプレートをまとめる
base.pyTEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', + 'DIRS': [os.path.join(BASE_DIR, "templates")], 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', ], }, }, ]django ├── config │── Pipfile │── Pipfile.lock ├── .venv │── manage.py │── templates │ └── test_app └── test_app ├── __init__.py ├── admin.py ├── apps.py ├── migrations ├── models.py ├── tests.py └── views.pystaticをまとめる
アプリケーションをまとめる
参考
https://fclef.jp/20191103/
https://studygyaan.com/django/best-practice-to-structure-django-project-directories-and-files
- 投稿日:2020-03-25T18:09:19+09:00
プログラミングを技術目線ではなく、もたらす結果をモチベーションにコードを書いた、プログラミング初心者の末路(僕パターン)
前置き
まずこの記事の対象者は"非エンジニア"です。
非エンジニアである僕が、プログラミングスキルを身につけることを目指し、その過程でどんな取り組みをしたかを説明するしょーもない記事です。
ちなみに今はプログラマーとしてやっています、というオチはなく今も勉強中ですし、そもそも勉強の一貫でこうして記事を書いてあるので、突然カバディ部の顧問にさせられた教師が、そのスポーツのルールを覚えるのと並行して部員にカバディを教えるのと同じような図になると思います。
それでもよければ記事をご覧いただき、「あ、自分が思ってた不満って他の人も感じてたのか」みたいな気持ちになってもらえればいいなと思います。
第一回 『Googleカレンダーの内容を LINE に飛ばしてくれるBOT作りたい』
僕はフリーのカメラマンとしてお仕事をすることがあるのですが、よく「空いているスケジュールはいつでしょうか?」とクライアント様からご相談いただくことがあります。
僕としては、いくつか候補日を用意していただけると嬉しいなと思いつつ「この日この時間と、この日この時間なら空いていますよ!」と回答しています。
が、とうとう面倒くさくなってしまいました、、、
というのも僕は勤めている会社の文化で「自分のスケジュールは公私関係なく、移動時間も含めて全てGoogleカレンダーに記載しているからです」変わった会社ですよね〜。でもおかげで会議のスケジュール決めたりとかはスムーズに話せます。みんなのGoogleカレンダー見て、空いてる時間帯にスケジュールを飛すだけなので。
さて、この文化をフリーのお仕事でも生かしたいと思ったのがタイトルのきっかけです!
「Googleカレンダー共有すればいいだけじゃん?」とか
「Googleカレンダースクショしたの送ればいいじゃん?」って
思った方おられるかもしれませんが、それだとイマイチなんですよ。
だって「スケジュール教えてください!」って聞いた時、カレンダーだけ渡されるとイラッとしませんか?何様だよと。
なんというか、需要と供給の輪郭がはっきり出過ぎるんですよね。(意味不)LINE Bot であれば「今週のスケジュール」みたいなラフな聞き方ができていいと思うんですよね。気を使わなくていいし。
だから僕が求めたのは
クライアントになりそうな方に、"僕のスケジュールを言うBot"を LINE に友達登録してもらい、お仕事が発生しそうになったら、その Bot にスケジュールを聞いてもらう
という一連のプロセスを確立することでした。ちょうど通っているプロトアウトスタジオ (https://protoout.studio/) というプログラミングスクール?で、 API についての授業を受けたので、うまいことできないかなと手を動かしたわけです。
やったこと
1.有料記事を購入した。
2.記事通りやっているが動作せず、職場のプログラマーに聞いた
3.結局動かず teratail で質問してみた
4.teratail で基礎から学べと言われ、書籍を購入してちょっと読んだ
5.しかし有料記事進めれず、結局簡単にできそうな無料の記事みてプログラム作った
6.それは動いて少し嬉しかった。←イマココ
1.有料記事を購入した。
URL は貼りませんが、note で公開されていた記事で『LINE Botを使ってGoogleカレンダーの予定を確認したり、予定を追加できるようにしましょう』という内容のものでした。「これだよ!欲しかったのは!!」
と有料でしたが割とあっさり購入し、早速手を動かし始めました。
が、基本を押さえていない僕の"ソースコードコピぺ術"ではすぐに限界がきてしまいました。ちなみに、基礎を押さえていない僕がなんとかコードを理解しようと試した手法は、似た結果をもたらす(今回で言うと LINE Bot でGoogleカレンダーを操作すること)、他の記事のソースコードを探し、メインのコードとの類似点を見つけて、他の記事のコメントアウトの内容をメインのコードにも置き換えて見てみるというものでした。
意味がわからないって?
要は、”中国語わからなくても、「なんか日本語にも同じ漢字があるぞ」って気づけば、そこから中国語の内容を推測できる"みたいなのに近いです。
結果...
2.記事通りやっているが動作せず、職場のプログラマーに聞いた動かせませんでした。やはり意味がわかりませんでした。
なので、めちゃくちゃ忙しい職場のプログラマーを捕まえて聞いてみたところ、部分的にではありますが、つまずいていたところを教えてくれました。
本当はもっと聞きたかったのですが、彼は何処かへ去っていってしまいました。そして、部分的に教えてもらった内容は記事の内容と異なっており、記事の内容を進めていくには、記事通りのコードを書いて先に進まないと結局動かなくなることが判明したため、いよいよ万策尽きてきました。ここまでで6時間くらい使ってます。(どうでもいい)
3.結局動かず teratail で質問してみた
teratail という、"プログラマー向けYahoo知恵袋"のようなサービスがあることを知り、淡い期待で投稿してみました。
大体、投稿して30分くらいで反応をもらえたのはよかったですね。実際の投稿記事
↓
https://teratail.com/questions/248595?modal=q-comp質問のやりとりから僕の初心者度合が伺えたかと思います。
さて、親切に対応してもらえましたが、教えていただいた内容を実行することができない僕の未熟さがバレてしまい、早々に基礎の学習を勧めていただきました。
4.teratail で基礎から学べと言われ、書籍を購入してちょっと読んだ
https://www.amazon.co.jp/dp/4295002089/ref=cm_sw_em_r_mt_dp_U_5RWEEbE1TKTNM買って読みました。前半のみ。内容はわかりやすかったです。
(なぜ Python の本買ってんだ、と思われるかもしれませんが、僕が有料記事で困っていた内容は Python の記述だったからです)この辺りでなんとなく「有料記事、コードの記述足りてないところあるかも??」と思いました。
というのも、これまでの過程で「全く理解できない」という訳ではなくなったからです。記述の意味もなんとなくわかるようになり、そこで気づいたのが実行に必要な関数の指定が記事で書かれていないということです。(知ったような口を聞いています。よくわかってません)
まぁでもそんな状況になり、いよいよ疲れてきました。
5.しかし有料記事進めれず、結局簡単にできそうな無料の記事みてプログラム作った
原因はわかりつつありましたが、これまでに時間をかけすぎて、心も体も消耗していました。
「このままでは忙しさにかまけて手を動かさなくなるな」と思ったので、自分がやりたいと思っていた機能をガッツリ削り"LINE Bot にGoogleカレンダーのスケジュールが飛んでくる"というプログラムがかければ良しとし、改めて記事探しの旅に出ました。
そしていい感じの記事を見つけました。↓
https://qiita.com/imajoriri/items/e211547438967827661fGAS(Google Apps Script) と LINE Notify を触るだけでよかったので、なんとか動かすところまで進めました。(コピぺだけど)
6.それは動いて少し嬉しかった。←イマココ
プログラムが動くとすごく嬉しいということがわかりました。たとえコピぺでも。
"自分の言うことを聞いてくれた"という感覚が確かにあり、なんとも癖になる感じでした。
無理やり話のオチ
今回、技術的に達成できたことはなかったのですが、やりたいことやろうとして消耗するより、小さい成功体験するほうが、結果的に課題に対して長く取り組める体質になれそうだな。という気づきがありました。
あとは、もっと人に質問できるようにならないと、何かを作るときは効率悪いなと思いました。
"人に質問できない人"の考え方として(僕もそのタイプ)、自分が何をやりたいのかを明確に把握していないことが実はよくあります。(僕)
自分が何をやりたいかを把握していないまま、手段だけを人に質問してしまうので、質問される方は、適切な回答に悩んでしまい怪訝な顔をされてしまう。ということがあると思います。(僕)
質問する方も、実は自分のハードルを上げていて、そもそもどんな手段があるかわからないのに、手段について聞く。という自分の首を締めるようなやり方を無意識的にやっていると思います。(僕)
そういった自分の経験から、人に相談するとき、もっとも力を入れるコミュニケーションは、"自分はこう言うことをしたい"ということだけに絞るようにしました。
本当はもう少し相手のことを考えたコミュニケーションがしたいのですが、まだまだそこまで手が回らないという状況です。
きっと周りには迷惑をかけているのでしょう。
スミマセン...と言うことで、非エンジニアのしょーもない記事でした。
ここまで読んでくださりありがとうございました。

- 投稿日:2020-03-25T17:57:59+09:00
[memo] BigQueryのScheduleとCloud FunctionsでGCSにテーブル情報をデータ送信
TODO
BigQueryにて設定したスケジュールが実行完了後にGCSにテーブル情報をCSVに変換してファイルを送信するようにする
- Pub/SubをトリガーにしたCloud Functionsの送信処理の実装
- BigQueryでスケジュールの設定
Pub/SubをトリガーにしたCloud Functionsの送信処理の実装
Pub/Subの設定
- Cloud FunctionsのトリガーとなるTopic IDを入力
例: 「example-1」を設定
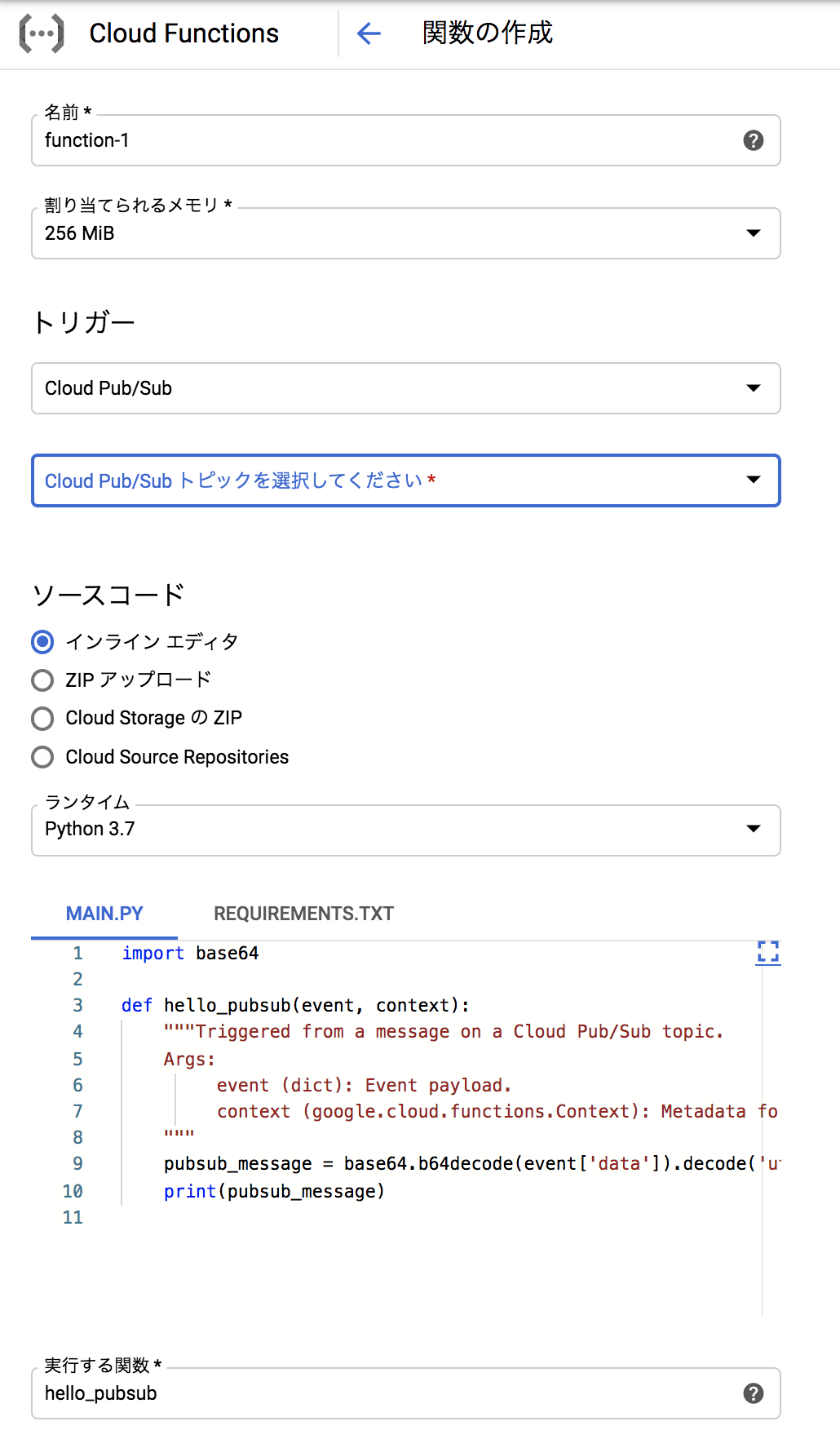
Cloud Functionsの設定
トリガーが発火した際に
GCSにBQのテーブルを参照して
CSVを送信するようにするスクリプトを配置
- トリガーは「Cloud Pub/Sub」で設定する 上記で、「example-1」を選択
- 言語は好みで、今回はPythonでインラインの実装
REQUIREMENTS.TXTでは必要なモジュールなどを記載
MAIN.PYで実際に動作するものを記載実装内容はBQ上で生成された昨日のテーブルの情報をGCSに送るようにする
- REQUIREMENTS.TXT
# pip でインストールされるもの google-cloud-bigquery
- MAIN.PY
from google.cloud import bigquery from datetime import date, timedelta def export_table(event, context): client = bigquery.Client() yesterday = date.today() - timedelta(days=1) project = "project_name" dataset_id = "data_set_name" table_id = "table_name_yyyymmdd_" + yesterday.strftime('%Y%m%d') destination_uri = "gs://{}/{}".format("dir_name", yesterday.strftime('%Y%m%d')+".csv") dataset_ref = client.dataset(dataset_id, project=project) table_ref = dataset_ref.table(table_id) extract_job = client.extract_table( table_ref, destination_uri, location="US", ) extract_job.result()最後に「export_table」を実行関数として入力
BigQueryでスケジュールの設定
BigQueryの機能の一つとして提供されている「スケジュール」があるので、利用する
有効なクエリを記載し、そのスケジュールの新規作成から入る
下の方にあるPub/Subの入力で「example-1」を設定することによって、
テーブルが生成されたタイミングでトリガーが発火するようになる。以上で、BigQueryにて設定したスケジュールが実行完了後にGCSにテーブル情報をCSVに変換してファイルを送信するようになる
あとがき
Rundeckのオンプレのサーバをクラウドに移行した際に
サービスアカウントが切り替わっており、BQの実行権限が付与されてなかった。
内容自体は「BQ内で完結するテーブル生成」と「GCSにそのテーブルデータを送信」といった
結構小規模な機能の利用だったので、GCPで完結するようにした。大した内容では無いので、ココで実装したメモを残します。
- 投稿日:2020-03-25T17:03:27+09:00
Visual Studio Online の始め方 ~環境構築時代の終焉~
GitHub
https://github.com/RZ-git/vso-test-environment
Visual Studio Online始め方メモ
1.Visual Studio Onlineって? クラウド版IDEで、ネット環境さえあれば使えるVisual Studio Codeみたいなもの。 2. 始め方 公式サイトに飛ぶ https://visualstudio.microsoft.com/ja/services/visual-studio-online/ [開始する] => [Create environment] 環境名、連携するGitリポジトリのURLを入力 マシンタイプを選択 Createするとビルドが開始されるから1分くらい待つ 後は拡張機能入れたりする。 ※ファイル作ったりすると。足りない拡張機能に関するポップアップが右下に出るから迷うことはない ここまで5分程度 3.料金体系 接続している間は課金される4.使ってみて 環境構築迄のスピードが速い。速すぎる。 予め開発に必要な環境が整ってる。アップデートとかはしてくれるかは不明。 Gitは連携もしてるし当然インストールされてる。
- 投稿日:2020-03-25T15:06:29+09:00
python selenium chromedriver beautifulsoup
サンプルコード1 (シンプルに表示をするだけ)
import time from selenium import webdriver import chromedriver_binary driver = webdriver.Chrome() driver.get('https://xxx') time.sleep(2) # 2秒のウェイト driver.close() driver.quit()サンプルコード2(headlessモード:表示をしない & beautifulsoupでパース)
from bs4 import BeautifulSoup import time from selenium import webdriver import chromedriver_binary from selenium.webdriver.chrome.options import Options option = Options() option.add_argument('--headless') driver = webdriver.Chrome(options=option) driver.get('https://xxx') time.sleep(2) # 2秒のウェイト # パースする場合 soup = BeautifulSoup( driver.page_source,'html.parser') driver.close() driver.quit()
- 投稿日:2020-03-25T13:45:19+09:00
python beautifulsoup requests glob find_all
サンプルコード1 (urlを指定)
import requests from bs4 import BeautifulSoup url = 'https://xxx' r = requests.get(url) soup = BeautifulSoup(r.text, 'html.parser') #pタグのテキストを表示 tag_p = soup.find_all('p') for p in tag_p: print(p.text) #--- 以下は、find_allメソッドの例(findメソッドも同じ) --- #属性の指定 ids = soup.find_all(id='sample') #属性の指定(class) clss = soup.find_all(class_='sample') #タグ名と属性を指定 divs = soup.find_all('div', class_='sample') #複数のタグ tags = soup.find_all(['a', 'b', 'c'])サンプルコード2 (ファイルを指定)
from glob import glob from bs4 import BeautifulSoup # 同一ディクトリ内のhtmファイルを対象とする時 files = glob('*.htm') for file in files: ff = open( file, 'r' ,encoding='utf-8' ).read() soup = BeautifulSoup( ff ,'html.parser') #pタグのテキストを表示 tag_p = soup.find_all('p') for p in tag_p: print(p.text)
- 投稿日:2020-03-25T13:45:19+09:00
python beautifulsoup requests
- 投稿日:2020-03-25T13:45:19+09:00
python beautifulsoup requests find_all
サンプルコード
import requests from bs4 import BeautifulSoup url = 'https://xxx' r = requests.get(url) soup = BeautifulSoup(r.text, 'html.parser') #pタグのテキストを表示 tag_p = soup.find_all('p') for p in tag_p: print(p.text) #--- 以下は、find_allメソッドの例 --- #属性の指定 ids = soup.find_all(id='sample') #属性の指定(class) clss = soup.find_all(class_='sample') #タグ名と属性を指定 divs = soup.find_all('div', class_='sample') #複数のタグ tags = soup.find_all(['a', 'b', 'c'])
- 投稿日:2020-03-25T13:24:59+09:00
AirSimをはじめてみる(Joystick操作、Python操作)
はじめに
Microsft製OSSのフライトシミュレータAirSimを試してみる。環境は下記のとおり。
項目 バージョン OS Windows10 Python 3.7 AirSim 1.2.2Windows インストール
- マップ毎にビルドされたバイナリ版をインストール済み。
- 下記のAssetから任意のzipをダウンロード。今回は
Blocks.zipとAfrica.zipを入手。
https://github.com/Microsoft/AirSim/releases- zipを展開して中にある
run.batを実行。
- 初回は必要なランタイム(UnrealEngine, VisualStudio)のインストールを促されるので従う。
- GPUなしPCでは表示が厳しい。下記を参考に
run.batを編集してクオリティを抑える必要あり。
https://microsoft.github.io/AirSim/docs/use_precompiled/run.bat修正例。run.batstart Blocks -ResX=640 -ResY=480 -windowed実機プロポで操作
- 実機用プロポ(ラジオ送信機)でマニュアル飛行できることを確認済み。
- 使用したプロポはこちら。
https://betafpv.com/products/literadio-2-radio-transmitter- AirSim起動後にプロポをUSB接続したらJoyStickとして認識される。
Microsoft製のフライトシミュレーターであるAirSimを試している。LiteRadio2は挿すだけでjoystickとして簡単に認識したけど、キーバインドの変更方法がわからないぞ。要ビルド?
— H.Fujikawa (@hfujikawa77) March 24, 2020
あとMinibookではさすがにカクカク。 pic.twitter.com/ojak3DKPEB- キーバインドの変更方法がわからないのでまともに使えてないので継続調査要。
- この辺のソースを修正してビルドが必要?
https://github.com/microsoft/AirSim/blob/master/Unreal/Plugins/AirSim/Source/SimJoyStick/SimJoyStick.cpp#L50
https://github.com/microsoft/AirSim/blob/master/docs/remote_control.mdPythonから操作
- GithubからAirSimのプロジェクトをCloneしてAirSim起動後に下記Pythonスクリプトを実行する。
https://github.com/microsoft/AirSim/blob/master/PythonClient/multirotor/hello_drone.py- 実行手順。
pip installの個所は実行者の環境によって異なる可能性あり。$ git clone https://github.com/microsoft/AirSim $ cd ./AirSim/PythonClient/multirotor $ pip install opencv-python $ pip install msgpack-rpc-python $ python hello_drone.py
- 飛行するところ。
わかりにくいけど、PythonスクリプトからAirSim上のドローンの離陸を実行。#AirSim pic.twitter.com/dXEMFzm4Pn
— H.Fujikawa (@hfujikawa77) March 24, 2020hello_drone.pyを見ると離着陸、移動など参考になるコードがある。
用途 コード例 機体接続 client = airsim.MultirotorClient() 機体状態取得 state = client.getMultirotorState() 離陸 client.takeoffAsync().join() 移動 client.moveToPositionAsync(-10, 10, -10, 5).join() まとめ
AirSimを使うことでプロポによるマニュアル操作、Pythonをつかったプログラミング操作のシミュレーションができることがわかった。
- 投稿日:2020-03-25T11:36:51+09:00
新型コロナウィルスCOVID-19の各国の感染傾向と医療の対応状況(情報追加)を見てみよう.
はじめに
新型コロナウィルスCOVID-19が世界中に拡がり.その驚異がニュースで毎日・毎時間アナウンスされています.ただその報道の多くは日本の感染状況が中心であり,世界の感染状況となると大きく感染者が増えている一部の国のみに感じます.ただ,そういった世界の悲惨な状況をみると,日本はまだ安心できるように思え,感染が停滞もしくは収束してきているようにも感じます.
でも,実際どういう状況なのか,公開されている情報をもとに,日本を含む世界各国の感染状況を調べてみました.
私が作成したコードはGithubにおいてありますので,よろしければダウロードしてご使用ください.新型コロナウィルスの感染状況
この考察を行うきっかけとなったのがニューヨーク・タイムズの Which Country Has Flattened the Curve for the Coronavirus?(2020年3月19日報道)になります.一部をここで紹介します.
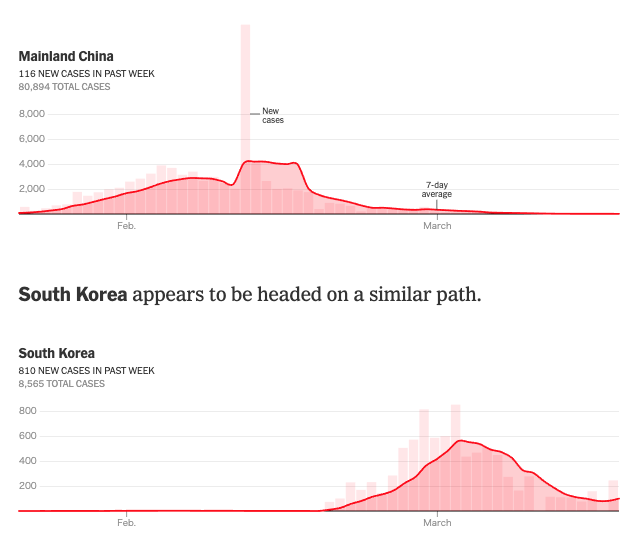
中国と韓国の新規感染者数の傾向(©The New York Times)中国と韓国の新規感染者数の7日間の移動平均のトレンドをみると,移動の制限などの各国の対策が良好な結果を生み出しており,両国ともに新規の感染者数が大きく減少しています.一方,同じアジアのシンガポール,香港および台湾は,2月の半ばにはその対応によって減少傾向がみられましたが,3月中旬から徐々に増加傾向がみられます.
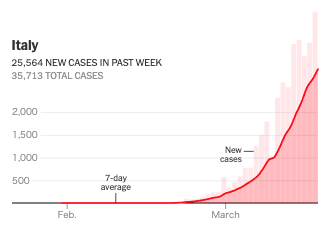
シンガポール,香港および台湾の新規感染者数の傾向(©The New York Times)また,深刻な被害が報告されているイタリアは,その感染者数が大きく増加しているのがわかります.
イタリアの新規感染者数の傾向(©The New York Times)ここでは, Johns Hopkins Universityが公開しているデータを用いて作られています. これは3月19日の記事であり,各国が行っている対策によって現状がどう変化したのか,好転しているのかそれとも悪化しているのか.日々公開されているデータをベースに現状を正しく把握および認識するために同様の結果を求めてみます.
現在の感染状況を把握する
Johns Hopkins Universityが公開しているデータが日々更新している”time_series_covid19_confirmed_global.csv”をインプットデータとして,各国の日々の新規感染者数,およびその7日間の移動平均のトレンドを求めます.ここで積算感染者数ではなく新規感染者数としているのは,日々の変化を見える化することにより,各国の対策により状況がどのように変わっているのか,また世界の各国の傾向がどうであるのか,ひと目で見ることに意味があると考えているからです.
コードの実行環境は,Google Colaboratoryを利用しています.
Googleのアカウントをお持ちの方は,ドライブにファイルをアップしてご自身で実行してみてください.自分ごととして,関心度が大きく増します.ここでは,代表的なコードとそのアウトプットの紹介をします.
全体はコードはGithubにてご確認ください.まずは下記のコードを実行し,データをダウンロードします.データは日々更新されており,日本時間の午前9時(UT時間の0時)に更新されます.データのソースについては,Johns Hopkins University@githubをご確認ください.
例えば,日本の報告データに間違いがあると,pull requestで提案するなどのフィードバックがかけられています.#git clone でCODIV-19のデータを使えるようにダウンロードする. !git clone https://github.com/CSSEGISandData/COVID-19.gitその後,下記を実行することでデータを確認します.
path = '/content/COVID-19/csse_covid_19_data/csse_covid_19_time_series/' df = pd.read_csv(path + 'time_series_covid19_confirmed_global.csv')では,登録されている国・地域の情報を確認します.
country = df['Country/Region'].unique() print(country) print('Number of country/region: ' + str(len(country)))実行結果は以下となります. 全部で170カ国・地域の情報があります.
['Afghanistan' 'Albania' 'Algeria' 'Andorra' 'Angola' 'Antigua and Barbuda' 'Argentina' 'Armenia' 'Australia' 'Austria' 'Azerbaijan' 'Bahamas' 'Bahrain' 'Bangladesh' 'Barbados' 'Belarus' 'Belgium' 'Benin' 'Bhutan' 'Bolivia' 'Bosnia and Herzegovina' 'Brazil' 'Brunei' 'Bulgaria' 'Burkina Faso' 'Cabo Verde' 'Cambodia' 'Cameroon' 'Canada' 'Central African Republic' 'Chad' 'Chile' 'China' 'Colombia' 'Congo (Brazzaville)' 'Congo (Kinshasa)' 'Costa Rica' "Cote d'Ivoire" 'Croatia' 'Cruise Ship' 'Cuba' 'Cyprus' 'Czechia' 'Denmark' 'Djibouti' 'Dominican Republic' 'Ecuador' 'Egypt' 'El Salvador' 'Equatorial Guinea' 'Eritrea' 'Estonia' 'Eswatini' 'Ethiopia' 'Fiji' 'Finland' 'France' 'Gabon' 'Gambia' 'Georgia' 'Germany' 'Ghana' 'Greece' 'Guatemala' 'Guinea' 'Guyana' 'Haiti' 'Holy See' 'Honduras' 'Hungary' 'Iceland' 'India' 'Indonesia' 'Iran' 'Iraq' 'Ireland' 'Israel' 'Italy' 'Jamaica' 'Japan' 'Jordan' 'Kazakhstan' 'Kenya' 'Korea, South' 'Kuwait' 'Kyrgyzstan' 'Latvia' 'Lebanon' 'Liberia' 'Liechtenstein' 'Lithuania' 'Luxembourg' 'Madagascar' 'Malaysia' 'Maldives' 'Malta' 'Mauritania' 'Mauritius' 'Mexico' 'Moldova' 'Monaco' 'Mongolia' 'Montenegro' 'Morocco' 'Namibia' 'Nepal' 'Netherlands' 'New Zealand' 'Nicaragua' 'Niger' 'Nigeria' 'North Macedonia' 'Norway' 'Oman' 'Pakistan' 'Panama' 'Papua New Guinea' 'Paraguay' 'Peru' 'Philippines' 'Poland' 'Portugal' 'Qatar' 'Romania' 'Russia' 'Rwanda' 'Saint Lucia' 'Saint Vincent and the Grenadines' 'San Marino' 'Saudi Arabia' 'Senegal' 'Serbia' 'Seychelles' 'Singapore' 'Slovakia' 'Slovenia' 'Somalia' 'South Africa' 'Spain' 'Sri Lanka' 'Sudan' 'Suriname' 'Sweden' 'Switzerland' 'Taiwan*' 'Tanzania' 'Thailand' 'Togo' 'Trinidad and Tobago' 'Tunisia' 'Turkey' 'Uganda' 'Ukraine' 'United Arab Emirates' 'United Kingdom' 'Uruguay' 'US' 'Uzbekistan' 'Venezuela' 'Vietnam' 'Zambia' 'Zimbabwe' 'Dominica' 'Grenada' 'Mozambique' 'Syria' 'Timor-Leste' 'Belize' 'Laos' 'Libya'] Number of country/region: 170中国や米国は,州レベルで区分されているものもありますが,以下のコードを実行し国レベルのデータに変換します.
また, ここでは緯度・経度情報が不要なため削除します.df1 = df.groupby('Country/Region', as_index=False).sum()そして,現在のデータは列が日付になっているため,行と列を変換してグラフ化します.
対象国のトレンドグラフは以下を実行し求めます.df1 = df.groupby('Country/Region', as_index=False).sum()次に,ダウンロードしたデータは積算感染者数であるため,各日の差分をとることで,新規感染者数に変換します.
df2 = df1.diff(1)そして,以下を実行し7日間の移動平均を求めます.
#過去七日間の平均値を算出する. for i in range(len(df2.columns)): df2[df2.columns[i]+'_7-dayAverage'] =df2[df2.columns[i]].rolling(7).mean().round(1)それでは,日本を例に新規感染者数のトレンドを求めます.
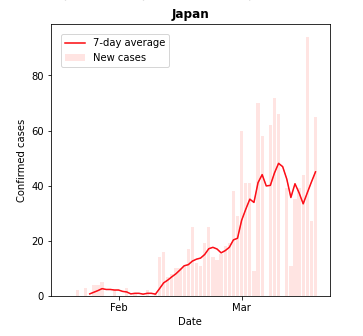
#日本の感染傾向を視覚化する. import matplotlib.ticker as ticker #列番号の取得 id_japan = df2.columns.get_loc('Japan') #対象国に変更すると,それぞれの国のトレンドを求めることができます. #グラフ化 fig, ax = plt.subplots(figsize=(5, 5)) ax.bar(x = df2.index, height = df2[str(df2.columns[id_japan])], color = 'mistyrose', label = "New cases") ax.plot(df2.index, df2[str(df2.columns[id_japan + len(country)])], color = 'red',label = "7-day average") ax.set_xlabel("Date") ax.set_ylabel("Confirmed cases") plt.rcParams["font.size"] = 10 ax.xaxis.set_major_locator(ticker.MultipleLocator(30.00)) ax.xaxis.set_major_formatter(mdates.DateFormatter('%b')) plt.title(str(df2.columns[id_japan]),fontweight="bold") plt.legend(bbox_to_anchor=(0, 1), loc='upper left', borderaxespad=1, fontsize=10) plt.show()
これをみるとわかりますが,2月も増加傾向でしたが,3月にはいってその増加率が大きくなっているのがわかります.
厚生労働省の報告によると,新型コロナウィルスの潜伏期間が1-12.5日(多くは5-6日)とされていることから, 2月27日の政府発表により"ここ1、2週間が極めて重要な時期"として学校の臨時休業などの移動を制限する措置がとられましたが,それでも増加が見られます.
次に韓国の状況を見てみます.
韓国は2月に韓国慶尚北道大邱(テグ)地域にて多くの感染者の報告がありましたが,その後の移動制限などの対策により,新規感染者数が大きく減少しているのがわかります.韓国の対策とその結果は大きく参考になると思います.韓国の対策の詳細については,こちらの記事が参考になります.
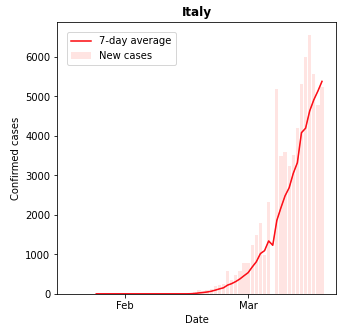
次に,連日 新型コロナウィルスの感染拡大が報告されているイタリアを見てみます.
大きく移動制限の措置が全土にとられた3月10日から2週間ほどたっていますが,新型コロナウィルスの潜伏期間を考えても,残念ながら今も増加傾向にあります. ただ,その増加率が少し減少しているようにも見えているのは期待したいところです.
各国の感染状況(2020年3月25日現在)
これまで,代表的ないくつかの国を対象に新規感染者のトレンドをみましたが,最後に世界各国の傾向をグラフ化します.
#世界各国の感染傾向のグラフ化 fig, ax = plt.subplots(dpi=100, figsize=(60, 120)) plt.subplots_adjust(wspace=0.4, hspace=0.6) plt.gca().spines['right'].set_visible(False) plt.gca().spines['top'].set_visible(False) plt.gca().spines['left'].set_visible(False) plt.gca().spines['bottom'].set_visible(False) plt.tick_params(labelbottom=False) plt.tick_params(bottom=False) for i in range(len(country)): ax = fig.add_subplot(20, 10, i+1) ax.bar(x = df2.index, height = df2[str(df2.columns[i])], color = 'mistyrose', label = "New cases") ax.plot(df2.index, df2[str(df2.columns[i + len(country)])], color = 'red',label = "7-day average") ax.set_xlabel("Date") ax.set_ylabel("Confirmed cases") plt.rcParams["font.size"] = 10 ax.xaxis.set_major_locator(ticker.MultipleLocator(30.00)) ax.xaxis.set_major_formatter(mdates.DateFormatter('%b')) plt.title(str(df2.columns[i]),fontweight="bold") plt.legend(bbox_to_anchor=(0, 1), loc='upper left', borderaxespad=1, fontsize = 7) # general title plt.suptitle("Where Countries Are on the Curve", fontsize=13, fontweight=0, color='black', style='italic', y=1.02) dt_today = datetime.date.today() plt.savefig(str(dt_today) + "_COVID-19_timeseries.png") #表示のみの場合は無効もしくは削除してください. plt.savefig(str(dt_today) + "_COVID-19_timeseries.jpg") #表示のみの場合は無効もしくは削除してください.この結果の画像は少し大きいのですが,以下に起きます(2020年3月25日現在).
コードを実行すれば各国の情報がすべて閲覧できますので,ぜひご自身で試してください.
ここから,新型コロナウィルスの感染は世界的に増加傾向であり,新たなフェーズに移っているのことを感じます.コードや結果はgithubにおいてありますので,よろしければダウロードして使ってください.
おわりに
The New York Timesの記事に印象を受け,各国の新規感染者数の傾向を可視化してみました.
自分でデータを扱ってみるとこの状況が自分ごとになり,関心が高まっています.
最近では,毎朝コードを実行し,その状況を”自分ごと”として確認し,状態について考え報道を見ています.この記事の考察は素人の個人が行ったものであり,何かを保証するものではないことをご理解ください.
ここで共有した情報やコードが新型コロナウィルスの感染対応に貢献できることを願い,また,新型コロナウィルスの感染縮小に向けて日々取り組まれている全ての方々に感謝いたします.
ご指摘・ご意見等ありましたらいただければ嬉しいです.
ディスカッションできることを願っています.記事更新(2020年3月25日)
同じくJohns Hopkins Universityが公開しているデータにRecovered(回復者数)や死亡者数(Deaths)のデータもあるため,それを用いて感染者数とそれらとの関係から,各国の医療体制やその対応状況について考察してみます.
下記を実行し,回復者および死亡者数も含めた情報をインプットします.
path = '/content/COVID-19/csse_covid_19_data/csse_covid_19_time_series/' df_c = pd.read_csv(path + 'time_series_19-covid-Confirmed.csv') #感染者数 df_r = pd.read_csv(path + 'time_series_19-covid-Recovered.csv') #回復者数 df_d = pd.read_csv(path + 'time_series_19-covid-Deaths.csv') #死亡者数データのフォーマットは感染者数と同じため同様の処理をしていきます.
感染者は数日後に回復しているため,感染者数と回復者数との傾向から,回復までの日数を求めてみました.
td_d = datetime.timedelta(days=16) #回復日数を16日と仮定する. df2_r.index = df2_r.index - td_d #回復者数の日付を16日前にシフトする. df2_rこれでデータが揃いましたので,感染者数,回復者数,死亡者数および仮定した回復日をシフトした回復者数のトレンドをグラフ化します.
これらのデータはすべて積算になります.#各国の感染傾向を視覚化する. import matplotlib.ticker as ticker #列番号の取得 id_x = df.columns.get_loc('Singapore') #シンガポールを代表として求める.関心のある国に変えることで,各国の状況を閲覧する. #グラフ化 fig, ax1 = plt.subplots(figsize=(8, 8)) ax1.plot(df.index, df[str(df.columns[id_x -2*len(country)])], color = 'red',label = "Confirmed Cases") ax1.plot(df.index, df[str(df.columns[id_x - len(country)])], color = 'green',label = "Recovered") ax1.plot(df.index, df[str(df.columns[id_x ])], color = 'yellow',label = "Deaths") ax1.plot(df2_r.index, df2_r[str(df2_r.columns[id_x -2*len(country)])], color = 'blue',label = "Shifterd Recovered") ax1.set_xlabel("Date") ax1.set_ylabel("Confirmed Cases - Recovered") plt.rcParams["font.size"] = 10 ax1.xaxis.set_major_locator(ticker.MultipleLocator(30.00)) ax1.xaxis.set_major_formatter(mdates.DateFormatter('%b')) plt.title(str(df.columns[id_x]),fontweight="bold") ax1.legend(loc='upper left', borderaxespad=1, fontsize = 10) plt.show()先程の新規感染者の傾向にて,当初対策がうまく機能していたと思われるシンガポールをみてみます.
これより,16日前にシフトされた回復者数(青)のトレンドは,感染者数(赤)のトレンドとほぼ重なっており,回復に至る日数は16日で正しそうです.
それに対して,死亡者数(黄色)は,感染者数が急激に増加している3月中旬以降でほぼ0に近い値を維持しており,現状は医療環境が安定しているように思えます.
ただ,ここで急激に増加している感染者に対して,多くの感染者が回復に至るのか,不安も感じます.次に,日本の場合を見てみます.
2月中旬までは,感染者数とシフトした回復者数がほぼ一致しており,この期間は多くの感染者が回復にいたっています.
一方,それ以降はシフトした回復者数が感染者数との乖離が大きくなっており,死亡者数も少し増加傾向が見られます.
感染者が単純に回復に至るまでの日数が16日以上必要になっているだけならばいいのですが,この乖離が医療環境の要因とすると,今後が大きく懸念されます.
先程,東京都知事が記者会見を行い,現在”重大局面”にいることが示されました.これ以上乖離させないためにも,という判断なのかもしれません.次に,医療崩壊がニュースで報道されているイタリアを見てみます.
イタリアは,2月下旬までの感染者数であれば,現状の医療設備でも回復させることができるキャパシティはあったように思えます.
ただ,先の2つの国と比べて,3月に入ってからの感染者数の増加率が高く,また死亡者数の増加も同じく高いことがわかります.
これだけでは現状がわかりませんが,この傾向からかなり厳しい医療環境であることが伺われます.次に,イタリアの山岳地帯の小国であるサン・マリノを見てみます.
イタリア内にある国であるため,イタリアと同じく3月に入ってから急激に感染者数が増加しています.
また,死亡者数は回復者数を上回っており,現地では十分な医療体制が組まれていないことが推察されます.最後に,世界の各国のデータに対して同様の解析処理をした結果を示します.
今回は回復日数を16日に固定しましたが,各国の医療環境や制度の違いもあり,それぞれに適した値にするのが良いかもしれません.
また,アメリカは3月中旬から感染者数が急激に増加したこともあり,情報が少ないためにここから推測することは難しいかと思います.新規感染者数の推移と,今後の回復者数および死亡者数の関係の2つの視点から,各国の対策が機能できているのかどうか,考察していきたいと思います.
こちらのコードもGithubにアップしてありますので,よろしければダウロードしてご使用ください.
参考記事
Which Country Has Flattened the Curve for the Coronavirus?(2020年3月19日報道)
2019-nCoV Global Cases ( by Johns Hopkins CSSE) Visualization(Dash Board)
2019 Novel Coronavirus COVID-19 (2019-nCoV) Data Repository by Johns Hopkins CSSE
新型コロナウイルスに関するQ&A(一般の方向け)@厚生労働省












- 投稿日:2020-03-25T11:36:51+09:00
新型コロナウィルスCOVID-19の各国の感染傾向を求めてみよう.
はじめに
新型コロナウィルスCOVDI-19が世界中に拡がり.その驚異がニュースで毎日・毎時間アナウンスされています.ただその報道の多くは日本の感染状況が中心であり,世界の感染状況となると大きく感染者が増えている一部の国のみに感じます.ただ,そういった世界の悲惨な状況をみると,日本はまだ安心できるように思え,感染が停滞もしくは収束してきているようにも感じます.
でも,実際どういう状況なのか,公開されている情報をもとに,日本を含む世界各国の感染状況を調べてみました.
私が作成したコードはGithubにおいてありますので,よろしければダウロードしてご使用ください.新型コロナウィルスの感染状況
この考察を行うきっかけとなったのがニューヨーク・タイムズの Which Country Has Flattened the Curve for the Coronavirus?(2020年3月19日報道)になります.一部をここで紹介します.
中国と韓国の新規感染者数の傾向(©The New York Times)中国と韓国の新規感染者数の7日間の移動平均のトレンドをみると,移動の制限などの各国の対策が良好な結果を生み出しており,両国ともに新規の感染者数が大きく減少しています.一方,同じアジアのシンガポール,香港および台湾は,2月の半ばにはその対応によって減少傾向がみられましたが,3月中旬から徐々に増加傾向がみられます.
シンガポール,香港および台湾の新規感染者数の傾向(©The New York Times)また,深刻な被害が報告されているイタリアは,その感染者数が大きく増加しているのがわかります.
イタリアの新規感染者数の傾向(©The New York Times)ここでは, Johns Hopkins Universityが公開しているデータを用いて作られています. これは3月19日の記事であり,各国が行っている対策によって現状がどう変化したのか,好転しているのかそれとも悪化しているのか.日々公開されているデータをベースに現状を正しく把握および認識するために同様の結果を求めてみます.
現在の感染状況を把握する
Johns Hopkins Universityが公開しているデータが日々更新している”time_series_covid19_confirmed_global.csv”をインプットデータとして,各国の日々の新規感染者数,およびその7日間の移動平均のトレンドを求めます.ここで積算感染者数ではなく新規感染者数としているのは,日々の変化を見える化することにより,各国の対策により状況がどのように変わっているのか,また世界の各国の傾向がどうであるのか,ひと目で見ることに意味があると考えているからです.
コードの実行環境は,Google Colaboratoryを利用しています.
Googleのアカウントをお持ちの方は,ドライブにファイルをアップしてご自身で実行してみてください.自分ごととして,関心度が大きく増します.ここでは,代表的なコードとそのアウトプットの紹介をします.
全体はコードはGithubにてご確認ください.まずは下記のコードを実行し,データをダウンロードします.データは日々更新されており,日本時間の午前9時(UT時間の0時)に更新されます.データのソースについては,Johns Hopkins University@githubをご確認ください.
例えば,日本の報告データに間違いがあると,pull requestで提案するなどのフィードバックがかけられています.#git clone でCODIV-19のデータを使えるようにダウンロードする. !git clone https://github.com/CSSEGISandData/COVID-19.gitその後,下記を実行することでデータを確認します.
path = '/content/COVID-19/csse_covid_19_data/csse_covid_19_time_series/' df = pd.read_csv(path + 'time_series_covid19_confirmed_global.csv')では,登録されている国・地域の情報を確認します.
country = df['Country/Region'].unique() print(country) print('Number of country/region: ' + str(len(country)))実行結果は以下となります. 全部で170カ国・地域の情報があります.
['Afghanistan' 'Albania' 'Algeria' 'Andorra' 'Angola' 'Antigua and Barbuda' 'Argentina' 'Armenia' 'Australia' 'Austria' 'Azerbaijan' 'Bahamas' 'Bahrain' 'Bangladesh' 'Barbados' 'Belarus' 'Belgium' 'Benin' 'Bhutan' 'Bolivia' 'Bosnia and Herzegovina' 'Brazil' 'Brunei' 'Bulgaria' 'Burkina Faso' 'Cabo Verde' 'Cambodia' 'Cameroon' 'Canada' 'Central African Republic' 'Chad' 'Chile' 'China' 'Colombia' 'Congo (Brazzaville)' 'Congo (Kinshasa)' 'Costa Rica' "Cote d'Ivoire" 'Croatia' 'Cruise Ship' 'Cuba' 'Cyprus' 'Czechia' 'Denmark' 'Djibouti' 'Dominican Republic' 'Ecuador' 'Egypt' 'El Salvador' 'Equatorial Guinea' 'Eritrea' 'Estonia' 'Eswatini' 'Ethiopia' 'Fiji' 'Finland' 'France' 'Gabon' 'Gambia' 'Georgia' 'Germany' 'Ghana' 'Greece' 'Guatemala' 'Guinea' 'Guyana' 'Haiti' 'Holy See' 'Honduras' 'Hungary' 'Iceland' 'India' 'Indonesia' 'Iran' 'Iraq' 'Ireland' 'Israel' 'Italy' 'Jamaica' 'Japan' 'Jordan' 'Kazakhstan' 'Kenya' 'Korea, South' 'Kuwait' 'Kyrgyzstan' 'Latvia' 'Lebanon' 'Liberia' 'Liechtenstein' 'Lithuania' 'Luxembourg' 'Madagascar' 'Malaysia' 'Maldives' 'Malta' 'Mauritania' 'Mauritius' 'Mexico' 'Moldova' 'Monaco' 'Mongolia' 'Montenegro' 'Morocco' 'Namibia' 'Nepal' 'Netherlands' 'New Zealand' 'Nicaragua' 'Niger' 'Nigeria' 'North Macedonia' 'Norway' 'Oman' 'Pakistan' 'Panama' 'Papua New Guinea' 'Paraguay' 'Peru' 'Philippines' 'Poland' 'Portugal' 'Qatar' 'Romania' 'Russia' 'Rwanda' 'Saint Lucia' 'Saint Vincent and the Grenadines' 'San Marino' 'Saudi Arabia' 'Senegal' 'Serbia' 'Seychelles' 'Singapore' 'Slovakia' 'Slovenia' 'Somalia' 'South Africa' 'Spain' 'Sri Lanka' 'Sudan' 'Suriname' 'Sweden' 'Switzerland' 'Taiwan*' 'Tanzania' 'Thailand' 'Togo' 'Trinidad and Tobago' 'Tunisia' 'Turkey' 'Uganda' 'Ukraine' 'United Arab Emirates' 'United Kingdom' 'Uruguay' 'US' 'Uzbekistan' 'Venezuela' 'Vietnam' 'Zambia' 'Zimbabwe' 'Dominica' 'Grenada' 'Mozambique' 'Syria' 'Timor-Leste' 'Belize' 'Laos' 'Libya'] Number of country/region: 170中国や米国は,州レベルで区分されているものもありますが,以下のコードを実行し国レベルのデータに変換します.
また, ここでは緯度・経度情報が不要なため削除します.df1 = df.groupby('Country/Region', as_index=False).sum()そして,現在のデータは列が日付になっているため,行と列を変換してグラフ化します.
対象国のトレンドグラフは以下を実行し求めます.df1 = df.groupby('Country/Region', as_index=False).sum()次に,ダウンロードしたデータは積算感染者数であるため,各日の差分をとることで,新規感染者数に変換します.
df2 = df1.diff(1)そして,以下を実行し7日間の移動平均を求めます.
#過去七日間の平均値を算出する. for i in range(len(df2.columns)): df2[df2.columns[i]+'_7-dayAverage'] =df2[df2.columns[i]].rolling(7).mean().round(1)それでは,日本を例に新規感染者数のトレンドを求めます.
#日本の感染傾向を視覚化する. import matplotlib.ticker as ticker #列番号の取得 id_japan = df2.columns.get_loc('Japan') #対象国に変更すると,それぞれの国のトレンドを求めることができます. #グラフ化 fig, ax = plt.subplots(figsize=(5, 5)) ax.bar(x = df2.index, height = df2[str(df2.columns[id_japan])], color = 'mistyrose', label = "New cases") ax.plot(df2.index, df2[str(df2.columns[id_japan + len(country)])], color = 'red',label = "7-day average") ax.set_xlabel("Date") ax.set_ylabel("Confirmed cases") plt.rcParams["font.size"] = 10 ax.xaxis.set_major_locator(ticker.MultipleLocator(30.00)) ax.xaxis.set_major_formatter(mdates.DateFormatter('%b')) plt.title(str(df2.columns[id_japan]),fontweight="bold") plt.legend(bbox_to_anchor=(0, 1), loc='upper left', borderaxespad=1, fontsize=10) plt.show()
これをみるとわかりますが,2月も増加傾向でしたが,3月にはいってその増加率が大きくなっているのがわかります.
厚生労働省の報告によると,新型コロナウィルスの潜伏期間が1-12.5日(多くは5-6日)とされていることから, 2月27日の政府発表により"ここ1、2週間が極めて重要な時期"として学校の臨時休業などの移動を制限する措置がとられましたが,それでも増加が見られます.
次に韓国の状況を見てみます.
韓国は2月に韓国慶尚北道大邱(テグ)地域にて多くの感染者の報告がありましたが,その後の移動制限などの対策により,新規感染者数が大きく減少しているのがわかります.韓国の対策とその結果は大きく参考になると思います.韓国の対策の詳細については,こちらの記事が参考になります.
次に,連日 新型コロナウィルスの感染拡大が報告されているイタリアを見てみます.
大きく移動制限の措置が全土にとられた3月10日から2週間ほどたっていますが,新型コロナウィルスの潜伏期間を考えても,残念ながら今も増加傾向にあります. ただ,その増加率が少し減少しているようにも見えているのは期待したいところです.
各国の感染状況(2020年3月25日現在)
これまで,代表的ないくつかの国を対象に新規感染者のトレンドをみましたが,最後に世界各国の傾向をグラフ化します.
#世界各国の感染傾向のグラフ化 fig, ax = plt.subplots(dpi=100, figsize=(60, 120)) plt.subplots_adjust(wspace=0.4, hspace=0.6) plt.gca().spines['right'].set_visible(False) plt.gca().spines['top'].set_visible(False) plt.gca().spines['left'].set_visible(False) plt.gca().spines['bottom'].set_visible(False) plt.tick_params(labelbottom=False) plt.tick_params(bottom=False) for i in range(len(country)): ax = fig.add_subplot(20, 10, i+1) ax.bar(x = df2.index, height = df2[str(df2.columns[i])], color = 'mistyrose', label = "New cases") ax.plot(df2.index, df2[str(df2.columns[i + len(country)])], color = 'red',label = "7-day average") ax.set_xlabel("Date") ax.set_ylabel("Confirmed cases") plt.rcParams["font.size"] = 10 ax.xaxis.set_major_locator(ticker.MultipleLocator(30.00)) ax.xaxis.set_major_formatter(mdates.DateFormatter('%b')) plt.title(str(df2.columns[i]),fontweight="bold") plt.legend(bbox_to_anchor=(0, 1), loc='upper left', borderaxespad=1, fontsize = 7) # general title plt.suptitle("Where Countries Are on the Curve", fontsize=13, fontweight=0, color='black', style='italic', y=1.02) dt_today = datetime.date.today() plt.savefig(str(dt_today) + "_COVID-19_timeseries.png") #表示のみの場合は無効もしくは削除してください. plt.savefig(str(dt_today) + "_COVID-19_timeseries.jpg") #表示のみの場合は無効もしくは削除してください.この結果の画像は少し大きいのですが,以下に起きます(2020年3月25日現在).
コードを実行すれば各国の情報がすべて閲覧できますので,ぜひご自身で試してください.
ここから,新型コロナウィルスの感染は世界的に増加傾向であり,新たなフェーズに移っているのことを感じます.コードや結果はgithubにおいてありますので,よろしければダウロードして使ってください.
おわりに
The New York Timesの記事に印象を受け,各国の新規感染者数の傾向を可視化してみました.
自分でデータを扱ってみるとこの状況が自分ごとになり,関心が高まっています.
最近では,毎朝コードを実行し,その状況を”自分ごと”として確認し,状態について考え報道を見ています.ここで共有した情報やコードが新型コロナウィルスの感染対応に貢献できることを願い,また,新型コロナウィルスの感染縮小に向けて日々取り組まれている全ての方々に感謝いたします.
参考記事
Which Country Has Flattened the Curve for the Coronavirus?(2020年3月19日報道)
2019-nCoV Global Cases ( by Johns Hopkins CSSE) Visualization(Dash Board)
2019 Novel Coronavirus COVID-19 (2019-nCoV) Data Repository by Johns Hopkins CSSE
新型コロナウイルスに関するQ&A(一般の方向け)@厚生労働省



- 投稿日:2020-03-25T11:26:24+09:00
ディープラーニング初心者がCNNでギター分類をしてみた話
概要
既にQiita上で試している方もいらっしゃいましたが、自身の勉強も兼ねて
CNN(ResNet)を使ってギター画像の分類をやってみたのでその過程で試したこと、
参考になりそうなことを紹介します。(まとめていないので若干汚いですがコードも載せていきます)目次
- 具体的な分類方法
- 前処理について
- 学習方法について
- 学習結果について
- 試して遊んでみる
- まとめ
具体的な分類方法について
ギター画像をスクレイピングにより取得し、それに前処理を施して画像を水増しします。
水増しした画像を用いてCNNの一手法であるResNetをファインチューニングさせることで、
学習コストをあまりかけずに機械学習させてみようと思います。ラベルについて
画像の収集が比較的簡単そうな以下の機種を選びました。
- Fender製
- ストラトキャスター
- テレキャスター
- ジャズマスター
- ジャガー
- ムスタング(含む類似機種)
- Gibson製
- レスポール
- SG
- ES-335
- フライングV
- その他
- アコースティックギター各種
前処理について
まずは画像を収集するところからです。今回はiCrawlerを用いて収集しました。
一般的にはGoogle画像検索から収集するものが多いですが、2020/3/12現在、Google側の仕様変更により
ツールが機能しなくなっているようなので今回はBingから画像を収集しました。crawling.pyimport os from icrawler.builtin import BingImageCrawler searching_words = [ "Fender Stratocaster", "Fender Telecaster", "Fender Jazzmaster", "Fender Jaguar", "Fender Mustang", "Gibson LesPaul", "Gibson SG", "Gibson FlyingV", "Gibson ES-335", "Acoustic guitar" ] if __name__ == "__main__": for word in searching_words: if not os.path.isdir('./searched_image/' + word): os.makedirs('./searched_image/' + word) bing_crawler = BingImageCrawler(storage={ 'root_dir': './searched_image/' + word }) bing_crawler.crawl(keyword=word, max_num=1000)収集した後は、使えそうにない画像(ギター全身が写っていないもの、文字が入っているもの、手などの映り込みがあるもの等)を手動で省きました。
その結果、各ラベルごとに100~160枚程度の画像を集めることができました。(crawlメソッドにmax_num=1000を指定しましたが、400枚程度しか集めてきてくれませんでした)続いて、収集した画像に前処理を施していきます。今回は45°ずつ画像を回転させ、反転させる処理を施しました。なので結果は16倍に増えて各ラベルごとに1600枚~2000枚程度の画像になりました。
image_preprocessing.pyimport os import glob from PIL import Image import numpy as np from sklearn.model_selection import train_test_split #圧縮する画像のサイズ image_size = 224 #トレーニングデータの数 traindata = 1000 #テストデータの数 testdata = 300 #入力フォルダ名 src_dir = './searched_image' #出力フォルダ名 dst_dir = './input_guitar_data' #識別するラベル名 labels = [ "Fender Stratocaster", "Fender Telecaster", "Fender Jazzmaster", "Fender Jaguar", "Fender Mustang", "Gibson LesPaul", "Gibson SG", "Gibson FlyingV", "Gibson ES-335", "Acoustic guitar" ] #画像の読み込み for index, label in enumerate(labels): files =glob.glob("{}/{}/all/*.jpg".format(src_dir, label)) #画像を変換したデータ X = [] #ラベル Y = [] for file in files: #画像を開く img = Image.open(file) img = img.convert("RGB") #===================#正方形に変換する#===================# width, height = img.size #縦長なら横に拡張する if width < height: result = Image.new(img.mode,(height, height),(255, 255, 255)) result.paste(img, ((height - width) // 2, 0)) #横長なら縦に拡張する elif width > height: result = Image.new(img.mode,(width, width),(255, 255, 255)) result.paste(img, (0, (width - height) // 2)) else: result = img #画像サイズを224x224にそろえる result.resize((image_size, image_size)) data = np.asarray(result) X.append(data) Y.append(index) #===================#データの水増し#===================# for angle in range(0, 360, 45): #回転 img_r = result.rotate(angle) data = np.asarray(img_r) X.append(data) Y.append(index) #反転 img_t = img_r.transpose(Image.FLIP_LEFT_RIGHT) data = np.asarray(img_t) X.append(data) Y.append(index) #正規化(0~255->0~1) X = np.array(X,dtype='float32') / 255.0 Y = np.array(Y) #交差検証用にデータを分割する X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=testdata, train_size=traindata) xy = (X_train, X_test, y_train, y_test) np.save("{}/{}_{}.npy".format(dst_dir, label, index), xy)前処理した結果を各ラベルごとにnpyファイルに保存しておきます。
学習方法について
今回はCNNの代表的な手法 ResNetを使って学習させてみようと思います。
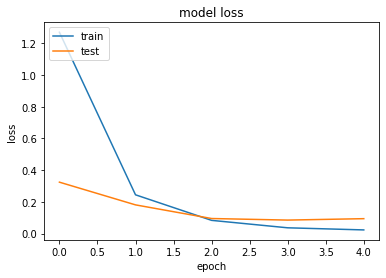
所有してるPCにNVIDIA製GPUがついていないことから、このまま学習させようとするとCPUのみでの計算となり膨大な時間がかかるため,Google Colabを使用したGPGPU環境で以下のコードを実行・学習をさせました。(Colabの使い方,ファイルのアップロード方法等については省略します)import gc import keras from keras.applications.resnet50 import ResNet50 from keras.models import Sequential, Model from keras.layers import Conv2D, MaxPooling2D from keras.layers import Activation, Dropout, Flatten, Dense, Input from keras.callbacks import EarlyStopping from keras.utils import np_utils from keras import optimizers from sklearn.metrics import confusion_matrix import numpy as np import matplotlib.pyplot as plt #クラスラベルの定義 classes = [ "Fender Stratocaster", "Fender Telecaster", "Fender Jazzmaster", "Fender Jaguar", "Fender Mustang", "Gibson LesPaul", "Gibson SG", "Gibson FlyingV", "Gibson ES-335", "Acoustic guitar" ] num_classes = len(classes) #読み込む画像のサイズ ScaleTo = 224 #メイン関数の定義 def main(): #学習データの読み込み src_dir = '/content/drive/My Drive/機械学習/input_guitar_data' train_Xs = [] test_Xs = [] train_ys = [] test_ys = [] for index, class_name in enumerate(classes): file = "{}/{}_{}.npy".format(src_dir, class_name, index) #個別の学習ファイルを持ってくる train_X, test_X, train_y, test_y = np.load(file, allow_pickle=True) #データをひとつにまとめる train_Xs.append(train_X) test_Xs.append(test_X) train_ys.append(train_y) test_ys.append(test_y) #まとめたデータを結合する X_train = np.concatenate(train_Xs, 0) X_test = np.concatenate(test_Xs, 0) y_train = np.concatenate(train_ys, 0) y_test = np.concatenate(test_ys, 0) #ラベル付けする y_train = np_utils.to_categorical(y_train, num_classes) y_test = np_utils.to_categorical(y_test, num_classes) #機械学習モデルの生成 model, history = model_train(X_train, y_train, X_test, y_test) model_eval(model, X_test, y_test) #学習の履歴を表示させる model_visualization(history) def model_train(X_train, y_train, X_test, y_test): # ResNet50のロード。全結合層は不要なので include_top=False input_tensor = Input(shape=(ScaleTo, ScaleTo, 3)) resnet50 = ResNet50(include_top=False, weights='imagenet', input_tensor=input_tensor) # 全結合層の作成 top_model = Sequential() top_model.add(Flatten(input_shape=resnet50.output_shape[1:])) top_model.add(Dense(256, activation='relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(num_classes, activation='softmax')) # ResNet50と全結合層を結合してモデルを作成 resnet50_model = Model(input=resnet50.input, output=top_model(resnet50.output)) """ #ResNet50の一部の重みを固定 for layer in resnet50_model.layers[:100]: layer.trainable = False """ # 多クラス分類を指定 resnet50_model.compile(loss='categorical_crossentropy', optimizer=optimizers.SGD(lr=1e-3, momentum=0.9), metrics=['accuracy']) resnet50_model.summary() #学習の実行 early_stopping = EarlyStopping(monitor='val_loss', patience=0, verbose=1) history = resnet50_model.fit(X_train, y_train, batch_size=75, epochs=25, validation_data=(X_test, y_test), callbacks=[early_stopping]) #モデルの保存 resnet50_model.save("/content/drive/My Drive/機械学習/guitar_cnn_resnet50.h5") return resnet50_model, history def model_eval(model, X_test, y_test): scores = model.evaluate(X_test, y_test, verbose=1) print("test Loss", scores[0]) print("test Accuracy", scores[1]) #混同行列の算出 predict_classes = model.predict(X_test) predict_classes = np.argmax(predict_classes, 1) true_classes = np.argmax(y_test, 1) print(predict_classes) print(true_classes) cmx = confusion_matrix(true_classes, predict_classes) print(cmx) #推論が終わったらモデルを消去する del model keras.backend.clear_session() # ←これです gc.collect() def model_visualization(history): # 損失値をグラフ表示 plt.plot(history.history['loss']) plt.plot(history.history['val_loss']) plt.title('model loss') plt.ylabel('loss') plt.xlabel('epoch') plt.legend(['train', 'test'], loc='upper left') plt.show() # 正解率をグラフ表示 plt.plot(history.history['acc']) plt.plot(history.history['val_acc']) plt.title('model accuracy') plt.ylabel('accuracy') plt.xlabel('epoch') plt.legend(['train', 'test'], loc='upper left') plt.show() if __name__ == "__main__": main()今回は重みを固定させないほうがval acc等の結果がよかったため、各レイヤの重みも再度学習させています。
コード上では100エポック分学習させていますが、実際にはEarly Stoppingにより実際には5エポック目で学習が終了しました。学習結果について
結果は以下の通りになりました。
test Loss 0.09369107168481061 test Accuracy 0.9744混同行列も出しておきます。
[[199 0 1 0 0 0 0 0 0 0] [ 0 200 0 0 0 0 0 0 0 0] [ 2 5 191 2 0 0 0 0 0 0] [ 1 0 11 180 6 0 2 0 0 0] [ 0 2 0 0 198 0 0 0 0 0] [ 0 0 0 0 0 288 4 0 6 2] [ 0 2 0 0 0 0 296 0 2 0] [ 0 0 0 0 0 0 0 300 0 0] [ 0 0 0 0 0 0 0 0 300 0] [ 0 0 0 0 0 0 0 1 0 299]]
1エポック終了の時点でかなり学習が進んでいることがわかります。
試して遊んでみる
保存したモデルを基に推論を試してみようと思います。今回は初めて触ったFlaskを使って非常に初歩的なWebアプリケーションにしてみました。
graphing.pyimport matplotlib.pyplot as plt from PIL import Image import numpy as np def to_graph(image, labels, predicted): #=======#プロットして保存する#=======# fig = plt.figure(figsize=(10.24, 5.12)) fig.subplots_adjust(left=0.2) #=======#横棒グラフを書く#=======# ax1 = fig.add_subplot(1,2,1) ax1.barh(labels, predicted, color='c', align="center") ax1.set_yticks(labels)#y軸のラベル ax1.set_xticks([])#x軸のラベルを消す # 棒グラフ内に数値を書く for interval, value in zip(range(0,len(labels)), predicted): ax1.text(0.02, interval, value, ha='left', va='center') #=======#判別した画像を入れる#=======# ax2 = fig.add_subplot(1,2,2) ax2.imshow(image) ax2.axis('off') return fig def expand_to_square(input_file): """長方形の画像を正方形に変換する input_file: 変換するファイル名 返り値: 変換された画像 """ img = Image.open(input_file) img = img.convert("RGB") width, height = img.size #縦長なら横に拡張する if width < height: result = Image.new(img.mode,(height, height),(255, 255, 255)) result.paste(img, ((height - width) // 2, 0)) #横長なら縦に拡張する elif width > height: result = Image.new(img.mode,(width, width),(255, 255, 255)) result.paste(img, (0, (width - height) // 2)) else: result = img return resultpredict_file.pypredict_file.py import io import gc from flask import Flask, request, redirect, url_for from flask import flash, render_template, make_response from keras.models import Sequential, load_model from keras.applications.resnet50 import decode_predictions import keras import numpy as np from PIL import Image from matplotlib.backends.backend_agg import FigureCanvasAgg import graphing classes = [ "Fender Stratocaster", "Fender Telecaster", "Fender Jazzmaster", "Fender Jaguar", "Fender Mustang", "Gibson LesPaul", "Gibson SG", "Gibson FlyingV", "Gibson ES-335", "Acoustic guitar" ] num_classes = len(classes) image_size = 224 ALLOWED_EXTENSIONS = set(['png', 'jpg', 'gif']) app = Flask(__name__) def allowed_file(filename): return '.' in filename and filename.rsplit('.',1)[1].lower() in ALLOWED_EXTENSIONS @app.route('/', methods=['GET', 'POST']) def upload_file(): if request.method == 'POST': if 'file' not in request.files: flash('ファイルがありません') return redirect(request.url) file = request.files['file'] if file.filename == '': flash('ファイルがありません') return redirect(request.url) if file and allowed_file(file.filename): virtual_output = io.BytesIO() file.save(virtual_output) filepath = virtual_output model = load_model('./cnn_model/guitar_cnn_resnet50.h5') #画像を正方形に変換する image = graphing.expand_to_square(filepath) image = image.convert('RGB') #画像サイズを224x224にそろえる image = image.resize((image_size, image_size)) #画像からnumpy配列に変更し正規化を行う data = np.asarray(image) / 255.0 #配列の次元を増やす(3次元->4次元) data = np.expand_dims(data, axis=0) #学習したモデルを使って推論をする result = model.predict(data)[0] #推論結果と推論した画像をグラフで描画する fig = graphing.to_graph(image, classes, result) canvas = FigureCanvasAgg(fig) png_output = io.BytesIO() canvas.print_png(png_output) data = png_output.getvalue() response = make_response(data) response.headers['Content-Type'] = 'image/png' response.headers['Content-Length'] = len(data) #推論が終わったらモデルを消去する del model keras.backend.clear_session() gc.collect() return response return ''' <!doctype html> <html> <head> <meta charset="UTF-8"> <title>ファイルをアップロードして判定しよう</title> </head> <body> <h1>ファイルをアップロードして判定しよう!</h1> <form method = post enctype = multipart/form-data> <p><input type=file name=file> <input type=submit value=Upload> </form> </body> </html> '''ちなみになのですが、Keras上で学習や推論を何回も繰り返すとメモリ上にデータが溢れてしまうようで、コード上で明示的に消去してやらないといけないようです。(colab上でも同様のようです)
参考URL↓
kerasで繰り返し学習するとメモリ使用量が増えちゃう問題を対策したあと、実際に作ってみたウェブアプリのソースコードを載せておきます。↓
ギター分類ウェブアプリ試して遊んでみる
所有している楽器で実際に試してみました。
まずはジャズマスターから
やはり類似しているところの多いジャガーにも反応していますね。
ただ他のネットから入手したほかの画像だと99%ジャズマスターだと判定されることもあるので一概に分類精度が悪いとは言えないでしょう。続いてストラトキャスター
こちらはほぼ確実にストラトキャスターであることが判定されました。若干コントラストが暗めでも特に問題はないようですね。では学習させていないベースを判定させるとどうなるでしょうか。手持ちのジャズベースタイプで試してみました。
ムスタングと判定されることはわからなくもないのですが、SGの確率もそれなりに高い点であることが気になります。ツノの部分が似てなくもないような…?まとめ
今回はCNNの一手法であるResNetをファインチューニングさせることにより、比較的作成が容易ながらも精度の高い分類器を作ることができました。
しかしながら、CNNなどの一部の機械学習はなぜ結果がそうなったのか説明し難い点は拭えません。
そこで時間があればGrad-CAMなどの可視化手法を今後は試そうと思います。以上です。




- 投稿日:2020-03-25T10:08:55+09:00
【python】range関数の使い方を具体例で解説
【python】range関数の使い方を具体例で解説
感覚的に使っていることが多いrange関数の使い方。
知っておくと幅が広がり便利。
目次
1. range関数でできること
■指定した範囲にある数値を一つの組として算出できる。
例:「初期値:0、範囲の終わり:9、変化量:1」という3つの情報から、「0,1,2,3,4,5,6,7,8」という9つの要素を返す。
※範囲の終わりの数値は含まない(未満となる)。その値に達したら終了という意味。
■初期値と変化量は省略可。
例:「範囲の終わり:5」という1つの情報から、「0,1,2,3,4」という5つの要素を返す。
2. range関数の基本構文
range(x, y, z)
- 使う要素は3つだけ
- 「x」:初期値。省略可。デフォルト0
- 「y」:範囲の終わり。省略不可。
- 「z」:変化量。省略可。デフォルト1
- 範囲の終わりは未満。
- 指定した数値は含まれない。
- その値に達したら終了という意味。
- 要素は整数
- マイナスも使える
- 小数点(float)は使えない
- 要素は「整数」「変数」どちらも使える
- 要素は最低1つ
- 範囲の終わりのみ指定。(上記では変数「z」)
- 出力はrange型
- range関数を実行するだけでは中身を見れない
- 指定範囲に該当するデータがない場合は、出力は空になる(エラーにはならない)
要素の数で分類
以下の3つの記述が使える。
①range(y):要素1つ
②range(x,y):要素2つ
③range(x,y,z):要素3つ
■python公式の説明(URL)
range(stop)
range(start, stop[, step])・stop:範囲の終わりを指定する整数(or変数)。
・start:初期値を指定する整数(or変数)。
・step:変化量を指定する整数(or変数)。
3. range型とは?
range関数の出力結果。指示内容が確認できる。
変化量を指定しない場合は、「初期値」と「範囲の終わり」の2つの数値を返す。
※「初期値」を省略していても0が表示される。変化量も指定した場合は「初期値」「範囲の終わり」「変化量」の3つの数値を返す。
▼終わり値のみ指定した場合のrange型出力結果
終わり値のみ指定(int)range(10) #出力結果 # range(0, 10)終わり値のみ指定(変数)a = 10 range(a) #出力結果 # range(0, 10)
▼初期値と変化量も指定した場合のrange型出力結果初期値も指定(int)range(5,99) #出力結果 # range(5, 99)初期値と変化量も指定(int)range(5,99,11) #出力結果 # range(5,99,11)初期値と変化量も指定(変数)a = 5 b = 99 c = 11 range(a,b,c) #出力結果 # range(5,99,11)
4. range関数の実行結果の中身を確認する方法(一例)
range型ではどんな数値が格納されているのかわからない。中身をサクッと確認する方法。
①listにする
②配列番号を指定する
③for文で取り出す①listにする
list型(例1)list(range(10)) #出力 # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]list型(例2)a = range(10) list(a) #出力 # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]list型(例3)a = 5 b = 99-10 c = 3*4 list(range(a,b,c)) #出力 # [5, 17, 29, 41, 53, 65, 77]
②配列番号を指定する
配列番号を指定range(3,9)[4] #出力 # 7
range(3,9)の出力は[3, 4, 5, 6, 7, 8]
4番目(0から数えて)は7になる。
③for文で取り出す
for文とprintメソッドを使えば、中身を1つずつ出力できる。
for文で取り出す(例1:要素1つ)for a in range(5): print(a) #出力 0 1 2 3 4for文で取り出す(例2:要素2つ)for b in range(4,8): print(b) #出力 4 5 6 7for文で取り出す(例3:要素3つ)for c in range(9,30,7): print(c) #出力 9 16 23for文で取り出す(例4:変数)A =range(9,30,7) for a in A: print(a) #出力 9 16 235. マイナスを使う
初期値や範囲、変化量にマイナスを使うこともできる。(指定した数値ずつ減らす)
初期値マイナス(例1)list(range(-3, 2)) #出力 # [-3, -2, -1, 0, 1]初期値・終わり値マイナス(例2)list(range(-12, -6)) #出力 # [-12, -11, -10, -9, -8, -7]「初期値<終わり値」(変化量がプラスの場合。デフォルト「+1」)
範囲内に数値がない場合は中身が空になる(エラーではない)
変化量マイナス(例3)a =range(5,1,-1) list(a) #出力 # [5, 4, 3, 2]変化量マイナス・変数で指定(例4)a = 10 b = -4 * 4 c = -6 A = range(a,b,c) list(A) #出力 # [10, 4, -2, -8, -14]
6. 範囲内に要素がない場合
データが空になるだけ。エラーにはならない。
プラスの範囲(例1)list(range(10,5)) #出力 # []マイナスの範囲(例2)list(range(-5, -10)) #出力 # []変化量マイナス(例2)list(range(-5, 10, -2)) #出力 # []7. エラー発生事例
小数点(float)
エラー:小数点(float)range(1.25) #出力 # TypeError: 'float' object cannot be interpreted as an integer文字列(str)
エラー:文字列(str)range("AAA") #出力 # TypeError: 'str' object cannot be interpreted as an integer
- 投稿日:2020-03-25T08:25:54+09:00
【python】関数とメソッドの違い
【忘備録】pythonの関数とメソッドの違い
オブジェクトの後に「.」でつながり「( )」がつくものはメソッドだと思っていたが、range()は関数と呼ばれている。
調べたところ、メソッドと関数は使い分けられていたので、そのまとめ。
関数とメソッドの違い
①メソッド
特定のクラスでしか使えない。
例:replaceメソッド
list(配列)には使えないが、str(文字列)には使える。listにreplaceは使えないlist = ['AAA', 'BBB', 'CCC'] list.replace("A","B") #出力 # AttributeError: 'list' object has no attribute 'replace'strなら使えるlist = ['AAA', 'BBB', 'CCC'] str(list).replace("A","B") #出力 # "['BBB', 'BBB', 'CCC']"
②関数
幅広いオブジェクトに使える(特定のクラスで縛られない)。
pythonにデフォルトで組み込まれている、組み込み関数が該当。
主要な組み込み関数
関数 内容 type() 型を返す tuple() tuple型に変換する str() 文字列に変換する set() set型に変換する range() 指定範囲に含まれる整数を返す open() ファイルを開く list() list型に変換する len() 要素の数を返す int() 整数を返す(小数点以下切り捨て) format() 書式を変更する ・組み込み関数の一覧はこちら
例:str関数
tupleに使えるA = 1,2,3,4,5 type(A) #出力:tuple type(str(A)) #出力 # strlistに使えるB = [1,2,3,4,5] type(B) #出力:list type(str(B)) #出力 # strsetに使えるC = {1,2,1,5,2,3,4,5} type(C) #出力:set type(str(C)) #出力 # str
- 投稿日:2020-03-25T02:21:29+09:00
某動画サイト風にTwitter検索結果を流す【python】
某アイドルがniconicoでの配信をしていないので、先代アイドルに比べなんとなく生放送が寂しい…
→生放送の推奨ハッシュタグ付きツイートをオーバーレイすればいいのでは?というわけでPythonでTwitterの検索結果を某動画サイト風に流すプログラムを作りました。
イメージ図
キャプチャは https://www.youtube.com/watch?v=G4aogUF_M_Y より。環境
Windows10
Python3.7.6後述するtkinterの"-transparentcolor"がかなり環境依存なため、Linux,Mac環境では別の記法で実現する必要があります。これらの環境の人は適宜ググってください()
大まかな流れ
TwitterAPIに登録し、ConsumerKey,ConsumerSecret,AccessToken,AccessTokenSecretを取得する。
tkinterで透明なFrameを作る
Tweepyで任意の検索ワードでの検索結果を取得し、取得結果の文字列に適当な処理を施したものをLabelのtextとしてある座標に配置する。
配置したLabelをnmsごとにx座標を少しずらして再帰的に呼び出すことでコメが流れる様子を再現する。
約5秒間隔で画面外までコメントが移動している行をみつけ、そこに対し再検索した結果を再配置。
コード全体
清書も推敲もしていない動けばいいや魂のスパゲッティがココに転がっています。
selfをしっかり理解したい今日この頃。仕様
初回起動時にTwitterAPIのCK,CS,AT,ASをユーザに入力させてconfig.iniに保存。2回目以降はconfig.iniから変数の値を読みだしてTwitterAPIの認証を試みる。
2020年3月某日現在、TwitterAPIは15分で180回検索できるので、コメントの取得は5秒に1回行われる。ただし、画面外に流れたコメントが現れるまで定期的に観察して、現れたら即コメントの取得を行う。
流れるコメントを左クリックでfavourite,右クリックでRTを行い、それぞれ赤、緑にハイライトされる。
なお、再度クリックするとハイライトはキャンセルされるが、unfavourite,unRTは未実装である。(時間ができれば作ります…)解説
(誰が読むんだって感じですが一応解説...)
まず、適当な
word=input()に対し、tweepyを用いてauth = tweepy.OAuthHandler(CK, CS) auth.set_access_token(AT, AS) api = tweepy.API(auth) results=api.search(q=word,count=num_comment)をしてユーザがTwitterAPIを使用できるか確認する。
失敗した場合はreAuth()に移行して認証成功するまでCK,CS,AT,ASを入力させ、成功したらconfig.iniに書き込む。
configparserに関しては
pythonプログラムにおける設定ファイル管理モジュール~configparserの使い方と注意点~
を参照。次に、フルスクリーンでtkinterのFrameを背景が透明になるように生成する。ディスプレイの解像度は以下で取得できる。
from ctypes import windll ww=windll.user32.GetSystemMetrics(0)#width wh=windll.user32.GetSystemMetrics(1)#heightこれを
ttk.Frame()のwidth,heightに与えればよい。
透明なFrameは
tkinterで背景が透過するFrameを作る【Python】
で作れる。コメントが動画の上に流れるようにしたいので、
root.wm_attributes("-topmost", True)として、rootが最前面にくるように設定。コメントにURLが含まれていると無駄に長くなってしまうので
tweepyでURLを含むツイートを除外する
のようにexURL()で除外する。
また、コメントに改行が含まれているとlabelが複数行にわたってしまいコメントが重なってしまうので、text.replace("\n"," ")と置換。コメントの取得結果
resultsは最初はnowdatalistにコピーし、約5秒ごとにコメントの更新を行うget_comment()で書き換える行の要素をresults[i]に書き換えることで、画面上にあるコメントの管理をnowdatalistにて行っている。(まだ執筆中…)
今後実装したい機能
- unfavourite,unRT
- GUIで任意のタイミングで以下の変数を変更可能にする
fontsize、コメント数、コメントの長さ上限、コメントのデフォルトの速度及びコメの長さによる加速度、URL,RTを含むかどうか(検索ワードはそれほどころころ変更しないと思うので再起動で解決してもらいたい)

- 投稿日:2020-03-25T02:19:12+09:00
勾配法を用いた鞍点探索
1. 鞍点とは
鞍点は勾配が0かつ、ある方向からは極小を、ある方向からは極大をとるような点を指します。機械学習におけるGANや、化学反応経路探索における遷移状態に代表されるように様々な分野で重要なテーマです。
GANは本物そっくりのデータを生成する生成器(generator)と、本物と生成されたデータを判別する判別器(discriminator)によって構成されています。生成器では極大を、判別器では極小をとるように学習します。
化学反応では、安定した種々の原料から、ポテンシャルエネルギー曲面上の鞍点を通り、より安定な化合物へと変化します。
本記事では勾配法を用いた鞍点探索を行います。この手法は簡単なモデルにおいては有効ですが、複雑なモデル(e.g. 量子化学等)ではやや不安定な挙動を示すため、改良出来次第追記します。
この記事に興味が面白かったらLGTM!をお願いします。2. 鞍点の定義
鞍点を次のように記述します。目的関数を$y=f(\boldsymbol{x})$、$\boldsymbol{x}=(x_1,x_2,\cdots,x_n)^\rm{T}$、極小値に対応する単位ベクトルを$\boldsymbol{b}=(b_1,b_2,\cdots,b_n)^\rm{T}$、極大値に対応する単位ベクトルを$\boldsymbol{c}=(c_1,c_2,\cdots,c_n)^\rm{T}$と定義します。このとき$f$の勾配が$0$となり、かつ $y=f(\boldsymbol{x}+\boldsymbol{b}t)$が $t$に関して$t=0$で極小値をとり、$y=f(\boldsymbol{x}+\boldsymbol{c}t)$が $t$に関して$t=0$で極大値をとる点が鞍点です。数式で表すと次の通りです。
鞍点$\boldsymbol{x}=\boldsymbol{x}_0$において、
\left.\frac{\partial f(\boldsymbol{x})}{\partial \boldsymbol{x}}\right |_{\boldsymbol{x}=\boldsymbol{x}_0}= 0\\ \left.\frac{\partial^2 f(\boldsymbol{x}+\boldsymbol{b}t)}{\partial t^2}\right |_{\boldsymbol{x}=\boldsymbol{x}_0, t=0} > 0\\ \left.\frac{\partial^2 f(\boldsymbol{x}+\boldsymbol{c}t)}{\partial t^2}\right |_{\boldsymbol{x}=\boldsymbol{x}_0, t=0} < 0が成立します。
例として $y=x_1^2-x_2^2$を考えます。$x_1=0$、$x_2=0$ において勾配が$0$になり、かつ $\boldsymbol{b}=(1, 0)^\rm{T}$において $y=(0+1 t)^2-(0+0 t)^2=t^2$は$t=0$で極小値をとり、 $\boldsymbol{c}=(0, 1)^\rm{T}$において $y=(0+0 t)^2-(0+1t)^2=-t^2$は$t=0$で極大値をとります。従ってこの点は鞍点であると推定できます。
3. 鞍点探索
この手法では初期化と探索の2過程をとります。初期化では適切な$\boldsymbol{b}$と$\boldsymbol{c}$の初期値を見つけます。探索では鞍点を勾配に従って探索します。
3.1 初期化
先述のとおり $\boldsymbol{b}$は極大値に、$\boldsymbol{c}$は極小値に対応します。まずは$y=f(\boldsymbol{x}+\boldsymbol{b}t)$の $t$に関する2階微分が最大になるような $\boldsymbol{b}$を決定します。簡単のために再急降下法による反復法を用います。数式で表すと次の通りです。
\mathrm{grad}\ \boldsymbol{b}_1 \leftarrow \frac{1}{\delta} \left( \nabla f \left(\boldsymbol{x}+\delta \boldsymbol{b} \right) - \nabla f \left(\boldsymbol{x}-\delta \boldsymbol{b} \right) \right)\\ \mathrm{grad}\ \boldsymbol{b}_2 \leftarrow \mathrm{grad}\ \boldsymbol{b}_1 - \left( \boldsymbol{b} \cdot \mathrm{grad}\ \boldsymbol{b}_1 \right)\boldsymbol{b}\\ \boldsymbol{b} \leftarrow \boldsymbol{b} + \epsilon_1 \ \mathrm{grad}\ \boldsymbol{b}_2\\ \boldsymbol{b} \leftarrow \frac{\boldsymbol{b}}{\mathrm{norm} \left(\boldsymbol{b}\right)}\\微小量を$\delta$、学習率を$\epsilon_1$としました。第1式は$n$次元ユークリッド空間の基底に対する微分です。工夫として、勾配を利用できるように式変形を行いました。これをそのまま更新量とすると単位ベクトルである $\boldsymbol{b}$に対して適切ではないため、第2式で単位球面上に沿った $\boldsymbol{b}$の更新量に変換する必要があります。第3式は極大値に向かって更新、第4式では単位ベクトルにするため規格化します。
同様に$y=f(\boldsymbol{x}+\boldsymbol{c}t)$の $t$に関する2階微分が最大になるような $\boldsymbol{c}$を決定します。数式で表すと次の通りです。\mathrm{grad}\ \boldsymbol{c}_1 \leftarrow \frac{1}{\delta} \left( \nabla f \left(\boldsymbol{x}+\delta \boldsymbol{c} \right) - \nabla f \left(\boldsymbol{x}-\delta \boldsymbol{c} \right) \right)\\ \mathrm{grad}\ \boldsymbol{c}_2 \leftarrow \mathrm{grad}\ \boldsymbol{c}_1 - \left( \boldsymbol{c} \cdot \mathrm{grad}\ \boldsymbol{c}_1 \right)\boldsymbol{c}\\ \boldsymbol{c} \leftarrow \boldsymbol{c} - \epsilon_1 \ \mathrm{grad}\ \boldsymbol{c}_2\\ \boldsymbol{c} \leftarrow \frac{\boldsymbol{c}}{\mathrm{norm} \left(\boldsymbol{c}\right)}$\boldsymbol{b}$との相違点は第3式で極小値の方向に更新している点です。収束判定として$\mathrm{grad}\ \boldsymbol{b}_2$および$\mathrm{grad}\ \boldsymbol{c}_2$を用いることができます。
3.2 鞍点探索
探索は先ほどの$\mathrm{grad}\ \boldsymbol{b}_2$および $\mathrm{grad}\ \boldsymbol{c}_2$を用います。$-\mathrm{grad}\ \boldsymbol{b}_2$の方向には極小値が、 $\mathrm{grad}\ \boldsymbol{c}_2$の方向は極大値が存在するため、これに従って更新することで鞍点へ到達できます。数式で表すと次の通りです。
\boldsymbol{x} \leftarrow \boldsymbol{x} + \epsilon_2 \ \left( -\mathrm{grad}\ \boldsymbol{b}_2 +\mathrm{grad}\ \boldsymbol{c}_2 \right)また$\boldsymbol{x}$の更新に従って $\mathrm{grad}\ \boldsymbol{b}_2$と $\mathrm{grad}\ \boldsymbol{c}_2$もまた変化しているため、初期化で行った $\boldsymbol{b}$と $\boldsymbol{c}$も同時に行う必要があります。
4. 実装
上記のアルゴリズムに従って種々の関数の鞍点を導出しました。更新方法は再急降下法を使用、Pythonにて実行しました。赤線が極小値ベクトル、緑線が極大値ベクトルです。
・関数 $y=x_1^2-x_2^2$
初期値$x_1=-2$、$x_2=-1$
微小量$\delta=0.001$
学習率$\epsilon_1=0.1$、$\epsilon_1=0.1$
結果
鞍点$x_1=-0.0003$、$x_2=-0.001$
$\boldsymbol{b}=(1,0)^\rm{T}$、$\boldsymbol{c}=(0,1)^\rm{T}$初期化
鞍点探索
・関数 $y=x_1^2+x_2^3-x_2$
初期値$x_1=-2$、$x_2=-0.5$
微小量$\delta=0.05$
学習率$\epsilon_1=0.1$、$\epsilon_1=0.1$
結果
鞍点$x_1=-0.0011$、$x_2=-0.5774$
$\boldsymbol{b}=(1,0)^\rm{T}$、$\boldsymbol{c}=(0,1)^\rm{T}$初期化
鞍点探索
5. 課題
改善点として、勾配法なため、共役勾配法や機械学習における種々のオプティマイザ(e.g. Momentum、RMSProp、Adam、RAdam)およびwegstain法が利用可能です。
問題点として安定性が悪いことが考えられます。化学反応予測に利用できる鞍点探索に利用できるかと考えましたが、おかしな構造で収束してしまいました。また初期値によっては鞍点に収束しません。以下に例を示します。これは先ほどの例の初期値が異なるものです。・関数 $y=x_1^2+x_2^3-x_2$
初期値$x_1=-2$、$x_2=-0.5$
微小量$\delta=0.05$
学習率$\epsilon_1=0.1$、$\epsilon_1=0.1$初期化
鞍点探索
この例では $x_2$の方向が極小値をとり、 $x_1$の向きが極大値をとるように $\boldsymbol{b}$および $\boldsymbol{c}$が更新されてしまっています。従って3次関数の極小値に向かって更新しつつ、2次関数の坂をぐんぐんと登っていってしまっています。
6. 結言
本記事では勾配法を用いた鞍点探索を行いました。視認性のため2変数関数の例を示しましたが、実際は任意変数関数を用いることができます。質問等がございましたらコメントにて返信いたします。式変形やソースコードのご要望がありましたらお気軽にコメントしてください。
7. ソースコード(2次関数)
「計算1 初期化」のところに関数や初期値、学習率等の設定があります。クラスSDGの内容を種々のオプティマイザに変更することができます。
import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D from datetime import datetime np.set_printoptions(precision=4, floatmode='maxprec') class SDG: def __init__(self, learning_rate): self.learning_rate = learning_rate def solve(self, coord, gradient): return coord - self.learning_rate*gradient class SaddlePoint: def __init__(self, function, gradient, coordinate, delta=1.0e-3, learning_rate=0.5, max_iteration=1000, judgment1=1.0e-8, judgment2=1.0e-8, log_span=100): """ 初期化コンストラクタ function --目的関数 differential --関数の1階微分 coordinates --初期座標 delta --微小値 learning_rate --学習率 judgment --収束判定1 judgment --収束判定2 log_span --ログの表示間隔 """ self.function = function self.gradient = gradient self.coordinate = coordinate.copy() self.dim = len(coordinate) self.delta = delta self.learning_rate = learning_rate self.max_iteration = max_iteration self.judgment1 = judgment1 self.judgment2 = judgment2 self.log_span = log_span # 基底ベクトル self.b = np.random.rand(self.dim) self.b /= np.linalg.norm(self.b) self.c = np.random.rand(self.dim) self.c /= np.linalg.norm(self.c) # SDG self.sdg_b_init = SDG(learning_rate) self.sdg_c_init = SDG(learning_rate) self.sdg_b_solv = SDG(learning_rate) self.sdg_c_solv = SDG(learning_rate) self.sdg_a_solv = SDG(learning_rate) def initialize(self): """ 初期化する関数。適切なb,cを決定する 返り値 --極小値方向ベクトルb, 極大値方向ベクトルc """ # 勾配 gradient = self.gradient # 座標b coordinate = self.coordinate # 基底ベクトル b = self.b.copy() c = self.c.copy() # 更新量 diff_b = np.zeros_like(b) diff_c = np.zeros_like(c) # 学習率 learning_rate = self.learning_rate # 微小値 delta = self.delta # 規格化 norm = np.linalg.norm # 判定 judgement1 = self.judgment1 # ログ間隔 log_span = self.log_span # SDG sdg_b = self.sdg_b_init sdg_c = self.sdg_c_init z, _ = gradient(coordinate) print("-----Initialization of b has started.-----") for i in range(self.max_iteration): # 1階微分 z_b1, grad_b1 = gradient(coordinate + delta*b) z_b2, grad_b2 = gradient(coordinate - delta*b) # 変化量計算 nabla_b = (grad_b1 - grad_b2)/delta grad_b = nabla_b - (np.dot(b, nabla_b))*b # 更新 b = sdg_b.solve(b, -grad_b) # 規格化 b /= norm(b) # 収束判定 error = np.linalg.norm(grad_b) if i%log_span == 0: print("Iteration = {}, Error = {}".format(i, error)) if error < judgement1: print("Converged! Iteration = {}, Error = {}".format(i, error)) break self.b = b.copy() print() print("-----Initialization of c has started.-----") for i in range(self.max_iteration): # 勾配計算 z_c1, grad_c1 = gradient(coordinate + delta*c) z_c2, grad_c2 = gradient(coordinate - delta*c) # 変化量計算 nabla_c = (grad_c1 - grad_c2)/delta grad_c = nabla_c - (np.dot(c, nabla_c))*c # 更新 c = sdg_c.solve(c, grad_c) # 規格化 c /= norm(c) # 収束判定 error = np.linalg.norm(grad_c) if i%log_span == 0: print("Iteration = {}, Error = {}".format(i, error)) if error < judgement1: print("Converged! Iteration = {}, Error = {}".format(i, error)) break self.c = c.copy() print() print("Result") print("b = {}".format(self.b)) print("c = {}".format(self.c)) print() return self.b, self.c def solve(self): """ 鞍点を探索する 返り値 --鞍点座標coordinate, 極小値方向ベクトルb, 極大値方向ベクトルc """ # 勾配 gradient = self.gradient # 座標、座標をまとめたもの coordinate = self.coordinate.copy() coordinate_Array = coordinate.copy() # 基底ベクトル b = self.b.copy() c = self.c.copy() # 更新量 diff_b = np.zeros_like(b) diff_c = np.zeros_like(c) # 学習率 learning_rate = self.learning_rate # 微小値 delta = self.delta # 規格化 norm = np.linalg.norm # 判定 judgement1 = self.judgment1 judgement2 = self.judgment2 # ログ間隔 log_span = self.log_span # SDG sdg_a = self.sdg_a_solv sdg_b = self.sdg_b_solv sdg_c = self.sdg_c_solv print("-----Saddle-point solver has started.-----") for i in range(self.max_iteration): # 1階微分 z_b1, grad_b1 = gradient(coordinate + delta*b) z_b2, grad_b2 = gradient(coordinate - delta*b) z_c1, grad_c1 = gradient(coordinate + delta*c) z_c2, grad_c2 = gradient(coordinate - delta*c) grad_through_b = (z_b1-z_b2) / (2.0*delta) grad_through_c = (z_c1-z_c2) / (2.0*delta) # 2階微分 z, _ = gradient(coordinate) grad2_through_b = (z_b1-2.0*z+z_b2) / delta**2.0 grad2_through_c = (z_c1-2.0*z+z_c2) / delta**2.0 # 更新 # coordinate = sdg_a.solve(coordinate, # grad_through_b*b/(np.linalg.norm(grad_through_b)+np.linalg.norm(grad2_through_b)) # -grad_through_c*c/(np.linalg.norm(grad_through_c)+np.linalg.norm(grad2_through_c))) coordinate = sdg_a.solve(coordinate, grad_through_b*b - grad_through_c*c) coordinate_Array = np.vstack([coordinate_Array, coordinate]) # 収束判定 error_coordinate = np.linalg.norm(grad_through_b**2 + grad_through_c**2) # b,cの更新 nabla_b = -(grad_b1 - grad_b2)/delta grad_b = nabla_b - (np.dot(b, nabla_b))*b # 更新 b = sdg_b.solve(b, grad_b) # 規格化 b /= norm(b) # 収束判定 error_b = np.linalg.norm(grad_b) nabla_c = (grad_c1 - grad_c2)/delta grad_c = nabla_c - (np.dot(c, nabla_c))*c # 更新 c = sdg_c.solve(c, grad_c) # 規格化 c /= norm(c) # 収束判定 error_c = np.linalg.norm(grad_c) if i%log_span == 0: print("B converged! Iteration = {}, Error = {}".format(i, error_b)) print("C converged! Iteration = {}, Error = {}".format(i, error_c)) print("Iteration = {}, Error = {}".format(i, error_coordinate)) print() if error_coordinate < judgement2: print("Converged! Iteration = {}, Error = {}".format(i, error_coordinate)) break self.coordinate = coordinate.copy() self.b = b.copy() self.c = c.copy() print() print("Result") print("coordinate = {}".format(self.coordinate)) print("b = {}".format(self.b)) print("c = {}".format(self.c)) print() return self.coordinate, coordinate_Array, self.b, self.c # ============================================================================= # 計算1 初期化 # ============================================================================= def f(x): # 関数 return x[0]**2 - x[1]**2 def gradient_f(x): # 関数の1階微分 return f(x), np.array([2*x[0], -2*x[1]]) x_init = np.array([-2.0, -1.0], dtype="float") saddlePoint = SaddlePoint(f, gradient_f, x_init, delta=1e-3, learning_rate=0.1, max_iteration=100, judgment1=1.0e-5, judgment2=1.0e-5, log_span=1) b, c = saddlePoint.initialize() # 初期化 # ============================================================================= # グラフ描画 (2D) # ============================================================================= t = np.linspace(-1.0, 1.0, 100) tb = np.linspace(x_init-1.0*b, x_init+1.0*b, 100) tc = np.linspace(x_init-1.0*c, x_init+1.0*c, 100) fb = f(tb.T) fc = f(tc.T) plt.xlabel("t") plt.ylabel("z") plt.plot(t, fb, c="red") plt.plot(t, fc, c="green") plt.savefig("file/" + str(datetime.now().strftime("%Y_%m_%d_%H_%M_%S")) + "_2d1.png", dpi=300) plt.show() # ============================================================================= # グラフ描画 (3D) # ============================================================================= # ワイヤーフレーム fig = plt.figure(figsize=(6, 6)) ax = fig.add_subplot(111, projection='3d') ax.set_xlabel("x") ax.set_ylabel("y") ax.set_zlabel("z") X = np.linspace(-2.5, 2.5, 50) Y = np.linspace(-2.5, 2.5, 50) X, Y = np.meshgrid(X, Y) Z = f([X,Y]) # 基底ベクトル width = 1.0 bt = np.linspace(x_init-width*b,x_init+width*b,10) bz = f(bt.T) ct = np.linspace(x_init-width*c,x_init+width*c,10) cz = f(ct.T) # 軌跡 zArray = f(x_init) # 表示 ax.plot_wireframe(X,Y,Z,color="gray",linewidth=0.2) # ワイヤーフレーム ax.plot(bt[:,0],bt[:,1],bz,color="red") # 極小 ax.plot(ct[:,0],ct[:,1],cz,color="green") # 極大 ax.scatter(x_init[0],x_init[1],f(x_init),color="blue") # 軌跡 plt.savefig("file/" + str(datetime.now().strftime("%Y_%m_%d_%H_%M_%S")) + "_3d1.png", dpi=300) plt.show() # ============================================================================= # 計算2 鞍点探索 # ============================================================================= x, xArray, b, c = saddlePoint.solve() # 鞍点計算 # ============================================================================= # グラフ描画 (2D) # ============================================================================= t = np.linspace(-1.0, 1.0, 100) tb = np.linspace(x-1.0*b, x+1.0*b, 100) tc = np.linspace(x-1.0*c, x+1.0*c, 100) fb = f(tb.T) fc = f(tc.T) plt.xlabel("t") plt.ylabel("z") plt.plot(t, fb, c="red") plt.plot(t, fc, c="green") plt.savefig("file/" + str(datetime.now().strftime("%Y_%m_%d_%H_%M_%S")) + "_2d2.png", dpi=300) plt.show() # ============================================================================= # グラフ描画 (2D) # ============================================================================= # ワイヤーフレーム fig = plt.figure(figsize=(6, 6)) ax = fig.add_subplot(111, projection='3d') ax.set_xlabel("x") ax.set_ylabel("y") ax.set_zlabel("z") X = np.linspace(-2.5, 2.5, 50) Y = np.linspace(-2.5, 2.5, 50) X, Y = np.meshgrid(X, Y) Z = f([X,Y]) # 基底ベクトル width = 1.0 bt = np.linspace(x-width*b,x+width*b,10) bz = f(bt.T) ct = np.linspace(x-width*c,x+width*c,10) cz = f(ct.T) # 軌跡 zArray = f(xArray.T) # 表示 ax.plot_wireframe(X,Y,Z,color="gray",linewidth=0.2) # ワイヤーフレーム ax.plot(bt[:,0],bt[:,1],bz,color="red") # 極小 ax.plot(ct[:,0],ct[:,1],cz,color="green") # 極大 ax.scatter(xArray[:,0],xArray[:,1],zArray,color="blue") # 軌跡 ax.text(xArray[0,0],xArray[0,1],zArray[0], "start") ax.text(xArray[-1,0],xArray[-1,1],zArray[-1], "goal") plt.savefig("file/" + str(datetime.now().strftime("%Y_%m_%d_%H_%M_%S")) + "_3d2.png", dpi=300) plt.show()

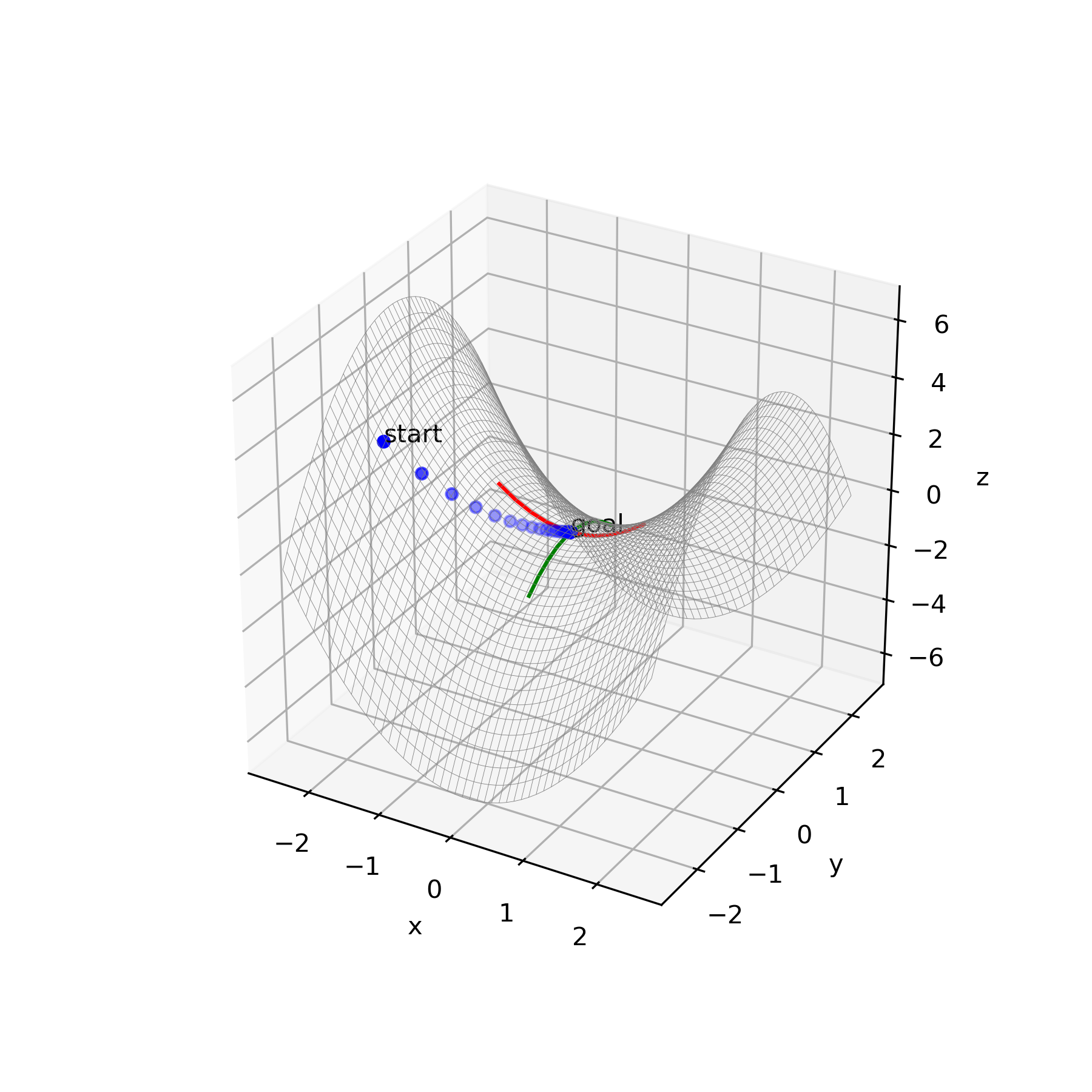
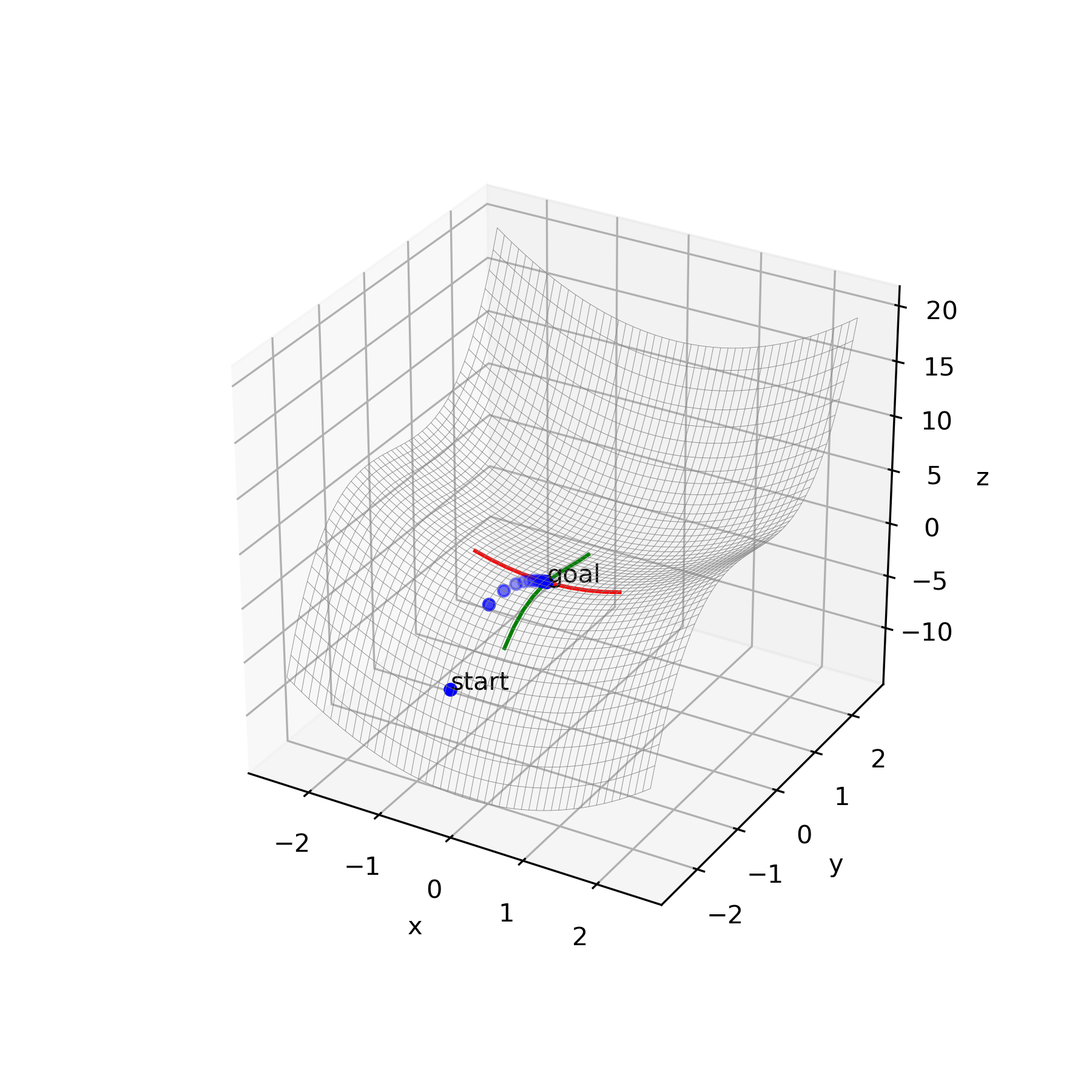
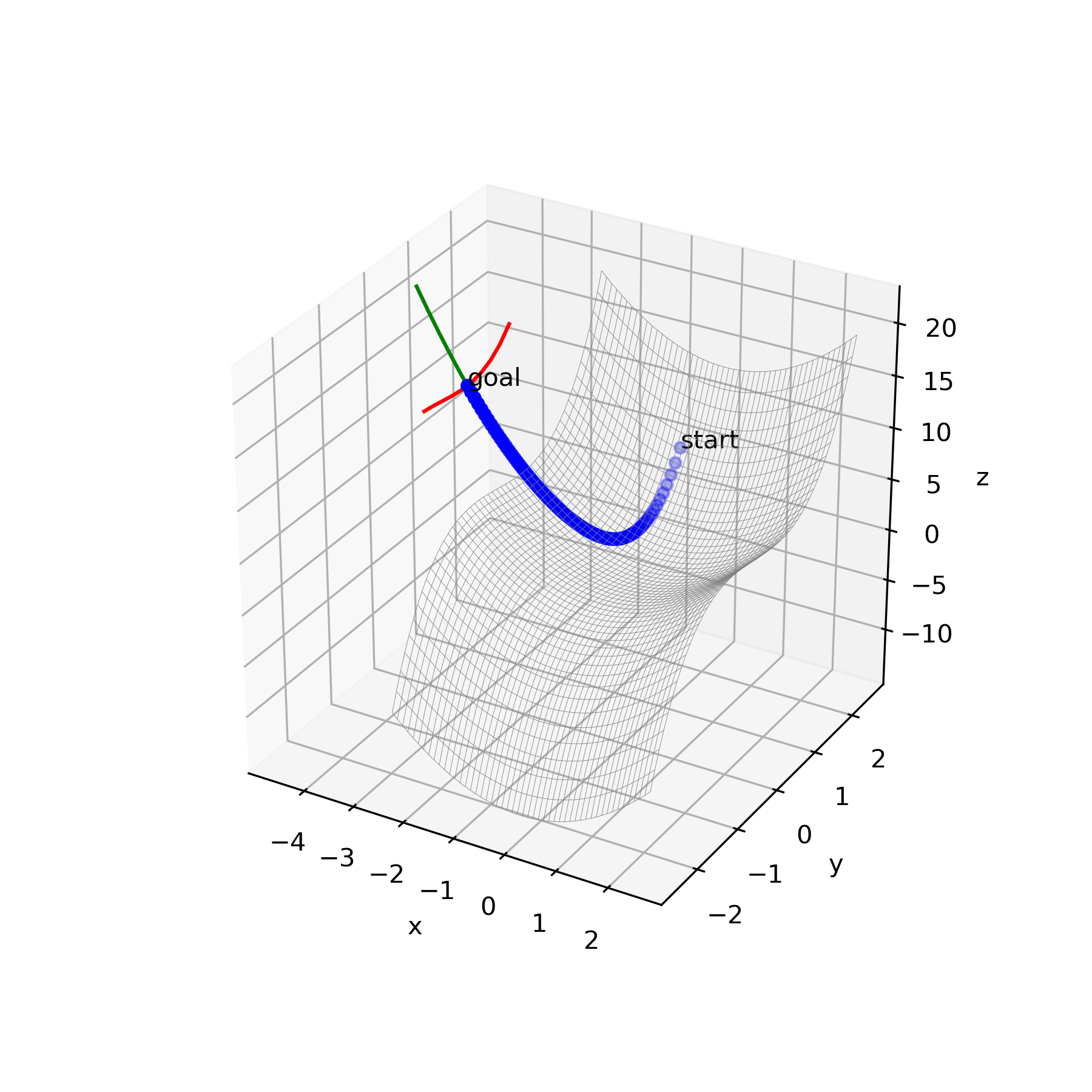
- 投稿日:2020-03-25T02:05:41+09:00
【Python】Atomで競技プログラミング用の環境構築(input()使えます!)【Mac】
Atomで競プロに必須のPythonの標準入力
input()
が使用できる環境構築の情報がググってもあんまりなかった...
ので記事にしてみます!
たぶん全作業30分かかりません!超簡単!
ちなみにMacです。Windowでもできるかは不明!python3のインストール
公式サイトからダウンロード
Atomのインストール、初期設定
以下の記事が参考になりました!
atom・pythonで競技プログラミングのテスト環境構築その他やる事
ホームディレクトリ(同階層にはダウンロードとかデスクトップとかあるよ)
に「python」というフォルダを作ってそのフォルダ内に
- input.txt
- test.py
の2ファイルを作る。
これで準備完了。イメージはこんな感じ↓
ターミナルの操作
以下の5個くらいコマンド・操作を知ってればいける。
clearターミナルをクリアする
pwd現在のフォルダの場所を確認できる
cd pythonホームディレクトリに作った「python」フォルダに移動
python3 test.py < input.txtpython3で実行
キーボードの上矢印ボタンこれまで入力したコマンドみれます
一度環境構築してしまえば
あとは、キーボードの上矢印ボタンでpython3 test.py < input.txtを選んでEnterを押すだけで実行できます!おまけ
ちなみにターミナルのコンピューター名・ユーザー名を非表示にしたい場合はこちらが参考になりました!
Macのターミナルで最初のコンピューター名・ユーザー名を消すなにかあればコメントください!
おわり!
- 投稿日:2020-03-25T02:00:57+09:00
Python3 で 十字キーが入力された判定をとる方法
はじめに
この記事を書いた直後に、
https://docs.python.org/ja/3/library/curses.html#constants
このページを見つけました。以下の記事はほぼほぼ虚無です。まえがき
自分用のメモです。愚直実装です。
やりたいことは十字キーなど特殊な文字が入力されたことを検知することです。前提としてUnicode制御文字の知識があることが望ましいです。
wikipedia詰まったところ
getchは入力を1文字ごとに取得します。しかし、矢印キーは3回文字分の入力がありました。 例えば上矢印は
27 91 65とはいってきます。このままでは、矢印キーなどの特殊なキーを判定することができないばかりか、望まない入力を受け取ってしまいます。そこで、以下のように実装しました。ソース
getch 1文字の入力を受け取る関数
ord は文字をUnicodeに変換する関数、
chr はUnicodeを文字に変換する関数です。
自分用のデバッグも兼ねて、冗長なコードになっています。# inputの代わりに、1文字ずつ入力を受け取る関数を用意。 # try の中はWindows用、except 野中はLinux用 try: from msvcrt import getch except ImportError: import sys import tty import termios def getch(): fd = sys.stdin.fileno() old = termios.tcgetattr(fd) try: tty.setraw(fd) return sys.stdin.read(1) finally: termios.tcsetattr(fd, termios.TCSADRAIN, old) # Unicode制御文字のエイリアス EOT = 3 TAB = 9 ESC = 27 # メインループ while True: key = ord(getch()) if key == EOT: break elif key == TAB: print('keydown TAB') elif key == ESC: key = ord(getch()) if key == ord('['): key = ord(getch()) if key == ord('A'): print('keydown uparrow') continue elif key == ord('B'): print('keydown downarrow') continue elif key == ord('C'): print('keydown leftarrow') continue elif key == ord('D'): print('keydown rightarrow') continue else: message = f'keydown {chr(key)}' print(message)実行した結果
きちんと判定が取れているのがわかります。終わりに
今回はコードが冗長になるため実装しませんでしたが、特殊なキーを入力したときのUnicodeを見て、条件分岐で全列挙すれば、判定がとれます。この記事の類似コードはアプリケーションを自作するときに役に立つかもしれません。他にいい書き方を知っている人がいたら教えてください。
参考
- 投稿日:2020-03-25T01:53:28+09:00
jupyter-notebookの導入時不具合を一つ解決したのでメモ
プログラミングほぼ初心者です。パイソン入門の為、jupyter-notebook(Ver6.03)を入れてコマンドプロンプトから起動してみると、エラーがおきました(下記)。調べてる中でなんとなく思いついた方法を試してみたら、うまくいったのでとりあえずのメモです。
★環境:
Windows10(build:18363.720)
anaconda(ver 1.7.2)、phython(ver 3.7.6)、jupyter-notebook(ver 6.0.3)エラー内容
User\HOGE\anaconda3\lib\site-packages\zmq\backend\cython\__init__.py", line 6, in <module> from . import (constants, error, message, context, ImportError: DLL load failed: 指定されたモジュールが見つかりません。全然進まないし、ウェブの動きもディレクトリを移動しない状態になり、色々調べていたら、Qiitaで記事を発見。
同じバグではないですが、どうやらanaconda3\Library\binについて、環境変数Path内の優先度の問題で機能していないっぽい様子。。。もしかしたら、これもそうかもしれない・・・消すのは怖かったので、パスをとおしてたユーザー環境変数のPATH内の順序を入れ替え、優先度を変えてみました。
対策
※\anaconda3\Library\binを一番上にしました。
……そうしたら、なんとうまくインストールできるように!
というわけで、確認は全然取ってないけど多分環境変数の競合でインストール障害が起きて多っぽいので、環境変数の順位を入れ替えたら大丈夫っぽい??ということでした。その後
このまま、一番上にしてても大丈夫なのか…と心配に思い、シャットダウンをする前に、順位を戻しました。jupyter-notebookの方は軽く触ってですが、問題はなく動いてそうです。
下手な文章でしたが、以上です。m(__)m