- 投稿日:2020-03-25T21:20:59+09:00
一対多によるリレーション
自分用の備忘録も兼ねて実装にあたり苦労したので投稿します。
概要
- レストラン(親)は複数のメニュー(子)を持つ関係
- Java、SpringBootにて一対多によるリレーションを関係するエンティティに記述
- 親テーブル(@OneToMany)、子テーブル(@ManyToOne)使用
親テーブル
RestaurantsEntity.java@Entity @Table(name="restaurants") public class RestaurantsEntity { //各フィールド変数記述 略…… @OneToMany(mappedBy="restaurantId") private List<RestaurantMenuEntity> restaurantMenuEntityList; //下記setter/getter 略…… }「一対多」の一側のフィールドには、多側のエンティティのコレクションを保持させてます(private List<RestaurantMenuEntity> restaurantMenuEntityList;)。
@OneToManyアノテーションを付与し、mappedByで関連させる多側エンティティのフィールドを指定してます(mappedBy="restaurantId")。
子テーブル
RestaurantMenuEntity.java@Table(name="restaurantMenu") public class RestaurantMenuEntity { //各フィールド変数記述 略…… @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "restaurantId") private RestaurantMenuEntity restaurantId; //下記setter/getter 略…… }「多対一」の多側のフィールドには、一側のエンティティを保持させてます(private RestaurantMenuEntity restaurantId;)。
@ManyToOneアノテーションを付与することで、リレーションシップを定義しています。
nameで関連テーブルを結合させるために使用するカラム名を指定してます(name = "restaurantId")。
あとがき
まだまだ全てを理解できているわけではありませんが、ひとまず実装できました。
- 投稿日:2020-03-25T18:44:02+09:00
Javaのデザインパターン
目次
- デザインパターンの説明
- Facadeパターン
- Strategyパターン
- デザインパターンまとめ
- 参考文献
デザインパターン(概要)
- GoFという頭のいい人が考えた全23パターン
- 対象はオブジェクト指向言語
- 他にもいくつかの種類がある
- Javaの機能を活用して(主に)拡張性の向上を図っている
- 継承
- ポリモーフィズム
- カプセル化など
- 優秀なベテランはこう考えている!という考え方集
- 具体的な実装方法ではない
- 考え方を理解して自分のプログラムに応用
デザインパターン(効果的な使い方)
- 考え方を応用して自分のソースに反映する
- ≠パターンに合わせて実装する
- 効果が期待できる場合のみ使う
- ≠可能な限り適用する
- ≠デザインパターンの効力を妄信する
- 無理に使うと逆効果
- 状況に合わせて柔軟に適用判断する
- ≠設計時に適用判断をしたのでプログラムに絶対に反映する
デザインパターン(メリット・デメリット)
メリット
- 拡張性向上 オブジェクト指向の活用
- 再利用性向上 オブジェクト指向の活用
- 可読性向上 オブジェクト指向の活用・共通認識
- 伝達速度向上 共通認識
デメリット(問題点/リスク)
- 現在の思想・仕組みとの乖離(一部)
- 生産性低下
- パターンへの固執
- コードの複雑化
- 解釈の違いによる誤解や不要な議論(抽象的であるため)
デザインパターン(活用タイミング)
- クラス設計時
- リファクタリング時
- レビュー時
- レビュアーへの説明時間の短縮
- 双方がパターンを知っている場合のみ
- プログラミング調査時
- 読み解き時間の短縮
- 予測精度の向上
- パターンを知っている場合のみ
- プログラミング修正時
今回取り上げる2つのパターン
- 以下の観点でピックアップ
- 理解が容易
- 活用が容易
- 一定の効果が見込める
- 身近に例がある
- Facadeパターン
- Strategyパターン
Facadeパターン(概要)
- 複雑な処理の流れをクライアントの代わりに担うクラスを作成
- クライアント側はFacadeクラスを呼ぶだけで複雑な処理が可能
- クライアント側の処理がシンプルに
- 一般的に最も使用されているパターンで、ある程度無意識に仕様
- リファクタリングにも非常に有用
Facadeパターン(活用条件)
- 一連の処理で様々なクラスのそっどを呼ぶ必要がある
- 多数のクライアントから呼ばれる一般的な処理である
Facadeパターン(登場人物)
- Client
- 複雑な処理を実行したいクラス群
- Facadeクラスを呼び出す
- Facade
- 複雑な処理呼び出しを引き受けるクラス
- 実クラス群を呼び出す
- 実クラス群
- 複雑な処理の一部分を引き受けるクラスの集まり
- Facadeクラスに必要なタイミングでそれぞれ呼ばれる
Facadeパターン(イメージ)
Facadeパターン(メリット・デメリット)
メリット
- クライアントの簡素化による可読性向上
- 処理の追加・修正・削除の簡易化
- クライアントの追加・削除の簡易化
デメリット
- 不要なFacadeクラスの量産
Facadeパターン(まとめ)
- 複雑な処理をまとめて一つのクラスで実施
- クライアント側と処理の追加が容易になる
- 割と簡単に適用できる
- 用途を絞らないと無駄なクラスが増えて逆効果
Strategyパターン(概要)
- 条件分岐で処理を切り替えている部分をサブクラス化
- 条件増加時の既存ソースへの追加が最小限
- Stateパターンと酷似
Strategyパターン(登場人物)
- Strategy
- 戦略を利用するためのインターフェース
- 処理の種類定義と型の再利用を担う
- ConcreteStrategy
- Strategyの実装
- 実際の処理を担う
- Context
- Strategyを利用するクラス
- Strategy型の変数を持つ
- Strategy型の処理を呼び出すが実態は把握しない
- Client
- ContextにStrategyの型を渡す
- Contextの処理を呼び出す
Strategyパターン(活用条件)
- 条件分岐で類似処理を呼び出している
- 将来的に条件の増減が見込まれる
Strategyパターン(イメージ・未利用時)
Strategyパターン(イメージ・利用時)
Strategyパターン(メリット・デメリット)
メリット
- 処理Class追加時の影響範囲が明確
- 既存処理を修正しないため
- プログラム全体の処理把握が容易 ## デメリット(リスク)
- 無理な適用によるコードの複雑化
Strategyパターン(まとめ)
- 条件分岐で類似処理が走る場合に使用
- 既存ソースの影響範囲が絞れる
- Facadeよりちょっと面倒で複雑
- 処理の追加が見込まれない場合は労力の方が大きい
デザインパターン(まとめ)
- オブジェクト指向を活用して拡張性と再利用性を高めよう
- 可読性も上がる(こともある)
- そのまま使うのではなく考え方を当てはめる
- 組み合わせも可
- 〇〇パターンで!だけで通じると意思伝達が早くて楽
- 元がざっくりしたものなので解釈の違いがある
- 今回読んだ本でも解釈が異なるものがあった
- やりすぎると労力&工数の無駄
参考文献(敬称略)
- Java言語で学ぶデザインパターン
- 著者:結城 浩
- Javaデザインパターン徹底攻略
- 著者:日本ソフトウェアエンジニアリング(株)
- リファクタリング 既存のコードを安全に改善する
- 著者:Martin Fowler
- 訳 :児玉公信・友野昌夫・平澤章・梅澤貴史
- 事例で学ぶデザインパターン
- 劇的ビフォ◯アフターで学ぶデザインパターン
- 著者:karoten512
- URL:http://karoten512.hatenablog.com/entry/2017/10/21/134048



- 投稿日:2020-03-25T16:22:58+09:00
==演算子とeqalsメソッドの違い
どーも、ふぎとです。
今回はちょっとした備忘録。
==演算子とequalsメソッドとはどう違うのか?
結論を言うと、
「==演算子は同一性を判定し、
equalsメソッドは同一性及び同値性を判定する」という違いがあるそう。
「同一性の判定」とは
「同じインスタンスであるか否か」ということ。
「同値性の判定」とは
「インスタンスに格納されている値が同じであ
るか否か」ということ。例を以下に示します。
サンプルプログラム
public class Example{ public static void main(String[] args){ String s1 = "012"; String s2 = new StringBuilder("012").toString(); if(s1 == s2){ System.out.println("true"); }else{ System.out.println("false"); } if(s1.equals(s2)){ System.out.println("true"); }else{ System.out.println("false"); } } }"s1 == s2"は、「s1とs2は同一のインスタンスであるかどうか」が
判定されます。上のプログラムにおいて、s1とs2はそれぞれ独立した
インスタンスとして作成されています。したがって同じインスタンス
とは言えないので、falseが返ってきます。ちなみに、以下のように
書き換えるとs1==s2はtrueとなります。String s1 = "012"; String s2 = s1;一方、equalsメソッドは、最初にメソッド内で==演算子による同一
性の判定を行った後、同値性の判定を行います。ここで、s1とs2には
同じ"012"という文字列リテラルが格納されているので、s1.equals(s2)
は真となります。まとめ
・==演算子は同一性を判定する
・equalsメソッドは同一性及び同値性を判定する
・同一性の判定とは「同じインスタンスかどうか」
・同値性の判定とは「インスタンスに格納されて
いる値が同じかどうか」
- 投稿日:2020-03-25T14:36:44+09:00
ファッ⁉ enumってなんや?
どーも、ふぎとです。
最近はオブジェクト指向の学習を進める日々・・・。
進めるうち、classでもinterfaceでもない、
enumなる型に遭遇。調べてみると「列挙型」というものだそう。
列挙型?
列挙型はclassでもinterfaceでもない、「第3のクラス宣言」。
特徴は、宣言と同時にその型のインスタンスが生成される
ということ。そしてそれ以降、その型のインスタンスは生
成できず、宣言時に作られたインスタンスしか使えない。
この「間違った値を使えない性質」を「型の安全性が保証
されている」という(らしい)。public enum Language{ JAPANESE, ENGLISH, CHINESE }↑宣言した時点で、Language型のインスタンス"JAPANESE",
"ENGLISH","CHINESE"が作成される。どんな天才でもこれ
以降Language型のインスタンスを新たに作ることはできない使い方
列挙型のインスタンスを使うときは、"(型名).(列挙子=インスタンス名)"
という風に記述する。というのも列挙型のインスタンスは、型の宣言時
から存在するstaticなインスタンスだからだ(らしい)。import java.util.Arrays; import java.util.List; public class UseEnum{ public static void main(String[] args){ List<Country> list = Arrays.asList( new Country("Japan", Language.JAPANESE), new Country("America", Language.ENGLISH), new Country("England", Language.ENGLISH), new Country("CHINA", Language.CHINESE) ); list.forEach(System.out::println); } }まとめ
・列挙型enumはクラス宣言のひとつ
・特徴は「型の宣言と同時にインスタンスが生成される」こと
・「誤った値を指定できない」ことを「型の安全性が保障され
ている」という
・列挙型のインスタンスはstaticなインスタンスになる
・そのため使用時は"(型名).(列挙子)"の形で記述する(P.S.)
もっと勉強します(+o+)
- 投稿日:2020-03-25T11:37:56+09:00
java配列
宣言
長さ指定は必須
int[] a; // 初期化しない int[] a = new int[5]; // 0で初期化 int[][] a = new int[2][3]; // 二次元配列初期化
初期化しない時、初期値0
int[] a = {1, 2, 3}; // 長さ3 int[][] a = {{1,2},{3,4}}; // 二次元の初期化 f(new int[]{1, 2, 3}); // 関数の引数として by @saka1029長さ
- 属性。関数ではない。
- 長さは変更不可。
a.length a[0].length // 二次元の場合代入
- 添え字 0 始まり
- 最大添え字は length - 1
- 超えると「java.lang.ArrayIndexOutOfBoundsException」例外投げられる
- java.util.Arrays.fill(配列, 値) 指定値で配列全体を埋める
- java.util.Arrays.fill(配列, 開始位置, 完了位置, 値) 指定値で配列一部を埋める
a[n]; a[i][j]; // 二次元の場合追加、削除
- 配列直接追加、削除は不可。代わりにコピーをご参考。
コピー
- 配列.clone()
- System.arraycopy(元配列, 元開始位置, 新配列, 新開始位置, 長さ) ★私推奨
- java.util.Arrays.copyOf(元配列, 長さ)
- java.util.Arrays.copyOfRange(元配列, 開始位置, 終了位置)
clone()とarraycopy()の例を見よう
import java.util.Arrays; class Rec{ String str; public Rec(String s){str=s;} public String toString(){return str;} } public class Main { public static void main(String[] args) { int[] a = {1,2,3}; int[] b = a.clone(); a[1] = 7; System.out.println("a=" + Arrays.toString(a) + " b=" + Arrays.toString(b)); String[] c = {"a", "b", "c"}; String[] d = c.clone(); c[1] = "7"; System.out.println("c=" + Arrays.toString(c) + " d=" + Arrays.toString(d)); Rec[] e = {new Rec("e"), new Rec("f"), new Rec("g")}; Rec[] f = e.clone(); Rec[] g = new Rec[3]; Rec[] h = Arrays.copyOf(e, 5); Rec[] i = Arrays.copyOfRange(e, 2, 4); System.arraycopy(e, 0, g, 0, g.length); e[0] = new Rec("7"); e[1].str ="8"; g[2].str = "9"; System.out.println("e=" + Arrays.toString(e) + " f=" + Arrays.toString(f) + " g=" + Arrays.toString(g) + " h=" + Arrays.toString(h) + " i=" + Arrays.toString(i)); } }実行結果
a=[1, 7, 3] b=[1, 2, 3] <== b[1]は2のまま c=[a, 7, c] d=[a, b, c] <== d[1]はbのまま e=[7, 8, 9] f=[e, 8, 9] g=[e, 8, 9] h=[e, 8, 9, null, null] i=[9, null] <== f[0]はeのまま、f[1], g[1] は変わる、e[2],f[2],g[2]は変わる各種コピーの異同
- 各方法とも浅い(Shallow)コピー、つまりObjectの中身までコピーしてくれない。
- clone(), copyOf(), copyOfRange()はコピー先をnewする手間は不要。
- clone()は元と同じ配列を生成
- copyOf()はコピー先の長さ可変。短くなると切断、長くなる分0、false、nullなどで補完。
- copyOfRange()はコピー開始、終了位置(元配列の外でも可)可変
- arraycopy()は自分でコピー先を用意する手間かかるが、完全に自由
- 自分メモ:arraycopy()が制約少ない割りに、便利さ僅かしか損なわれてない、いろいろ覚えるより、これ一本で行こう。
一部取り出し
- System.arraycopy() 参考
ループ
for(int i=0; i<a.length; i++){ // do sth. here }文字列化
- java.util.Arrays.toString() // 配列展開してくれる
- java.util.Arrays.deepToString() // 多次元配列でも展開してくれる
import java.util.Arrays; int[] a = {1,2,3}; System.out.prontln("a=" + Arrays.toString(a)); int[][][] j = {{{1,2},{3,4},{5,6}},{ {7,8},{9,10},{11,12}}}; System.out.println("j=" + j + " aj=" + Arrays.toString(j) + " deepJ=" + Arrays.deepToString(j));出力
a=[1, 2, 3] j=[[[I@2a139a55 aj=[[[I@15db9742, [[I@6d06d69c] deepJ=[[[1, 2], [3, 4], [5, 6]], [[7, 8], [9, 10], [11, 12]]]sort
- java.util.Arrays .sort()
- java.util.Arrays.parallelSort() 並列ソート
検索
- java.util.Arrays.binarySearch() バイナリサーチ、事前にsort()が必須
- 自分メモ:SortedMapを検討
型変換
- java.util.Arrays.asList(配列) Listに変換
関連Class
上で紹介してない機能
- java.util.Arrays
- equals() / deepEquals()
- hashCode / deepHashCode()
- setAll() / parallelSetAll()
- parallelPrefix()
- spliterator()
- stream()
参考
- 投稿日:2020-03-25T10:55:23+09:00
AzurePipelinesでMavenプロジェクトのCI
以下の記事の続きで、今回はAzurePipelinesを使ってみます。
https://qiita.com/kasa_le/items/b152f91a61315a2b12b2Azure Pipelines
言わずとしれた、MicrosoftのクラウドサービスAzureの中の、Azure DevOpsに含まれるCIになります。
https://azure.microsoft.com/ja-jp/services/devops/特徴
Azure Repos(AzureのGitリポジトリサービス)だけでなく、Githubや汎用Gitとも接続できます(※)。
当然、.NETやC#のプロジェクトのビルド環境が充実していて、Windows開発者は、実質AppVeyorかこちらかの二者択一でしょうね。もっとも、少し前まではAppVeyorしかなかったので、選択肢ができたことは良いことではないでしょうか。
Visual StudioやVisual Studio Codeとの連携やExtensionが充実しているのも流石です。※ただし、SSH公開鍵方式での接続には非対応で、かつ、汎用Gitの場合は、Classic Editorというものでしか設定が出来ません。
料金
Azure Pipelinesのみの場合、5ユーザーまで、月1,800分まで1並列ジョブが無料で使えます。セルフホステッドの場合は、毎月の利用制限はありません(1並列ジョブ)。
成果物をアップロードするのはAzure Artifactsというのを使い、こちらは2GBまでは無料で使えます。詳しくはこちらで。
https://azure.microsoft.com/ja-jp/pricing/details/devops/azure-devops-services/実績
まあ、なんといっても、Microsoftですから(汗)
どうてもいいですけどEラーニングコースが、物語形式でとても読むのに疲れます(苦笑)
英語しか用意されてないのですが、かといってあれが日本語になっていても変なので、あえて訳を用意していないのかも^^;設定
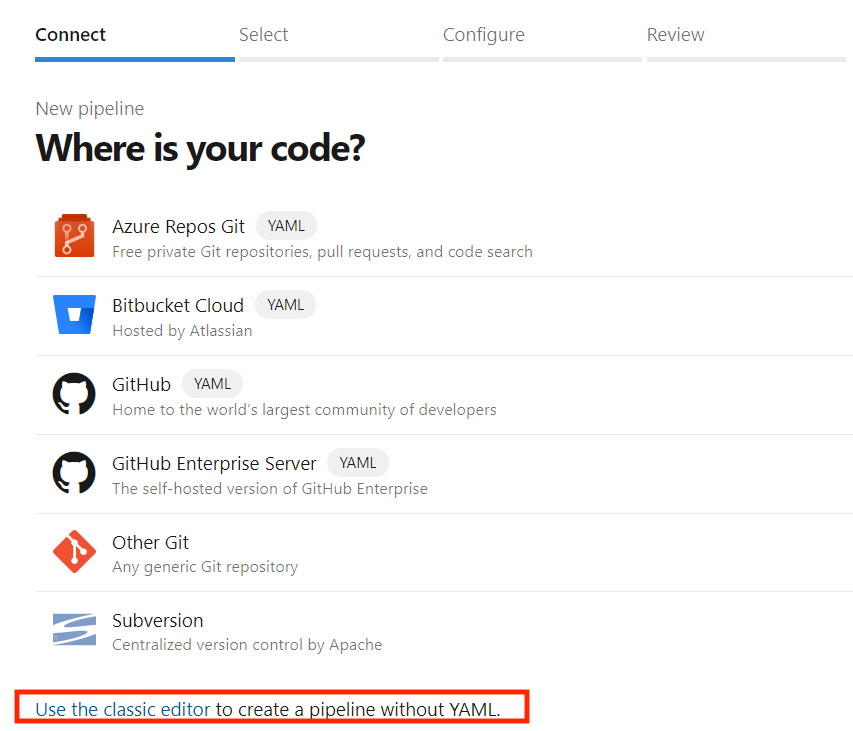
Classic Editorという物を使う方法と、
ymlファイルを書く方法と2種類あります。
基本的なMavenビルド、テストなら、テンプレートでMavenを選んだそのままでいけます。
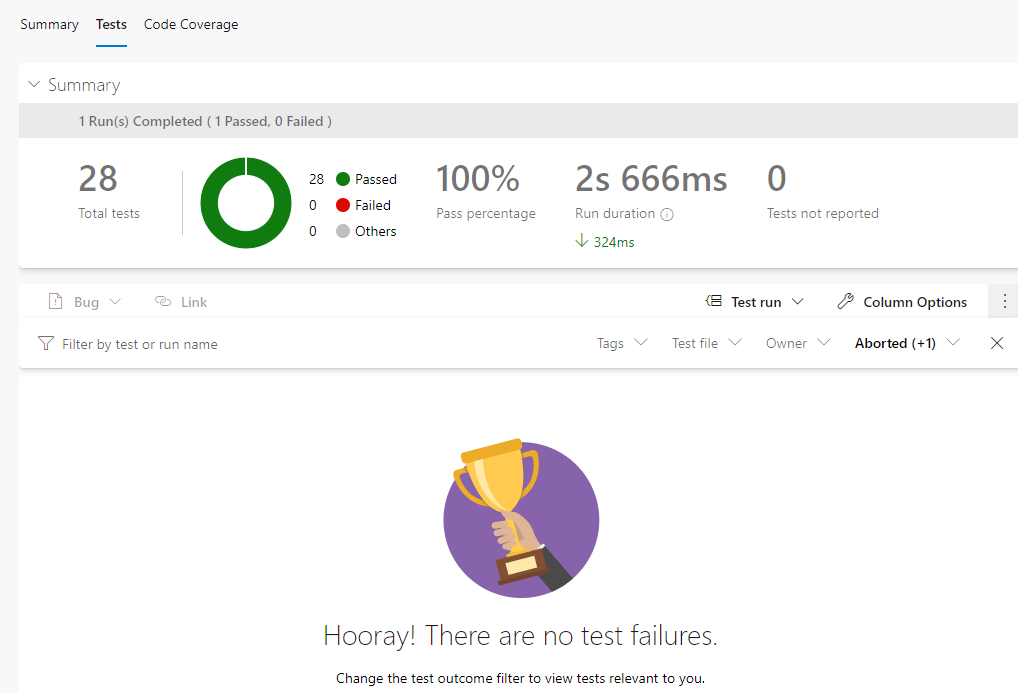
以下は、YAMLモードでのテンプレート初期設定のままです。JerseySampleはこの設定のままで行けました。azure-pipelines.yml# Maven # Build your Java project and run tests with Apache Maven. # Add steps that analyze code, save build artifacts, deploy, and more: # https://docs.microsoft.com/azure/devops/pipelines/languages/java trigger: - master pool: vmImage: 'ubuntu-latest' steps: - task: Maven@3 inputs: mavenPomFile: 'pom.xml' mavenOptions: '-Xmx3072m' javaHomeOption: 'JDKVersion' jdkVersionOption: '1.11' jdkArchitectureOption: 'x64' publishJUnitResults: true testResultsFiles: '**/surefire-reports/TEST-*.xml' goals: 'package'テスト結果はパイプラインのページで確認できます。
jdkVersionOptionの指定で、Version11が、1.11と指定しなければならないのが気持ち悪いですね(汗)Github同様、OpenJDKはAzul Zuluが使われます。(Azul Zuluは基本的に有償ですが、Azure Pipelinesでの使用は無償となっています。あれ?Github Actionsは??)
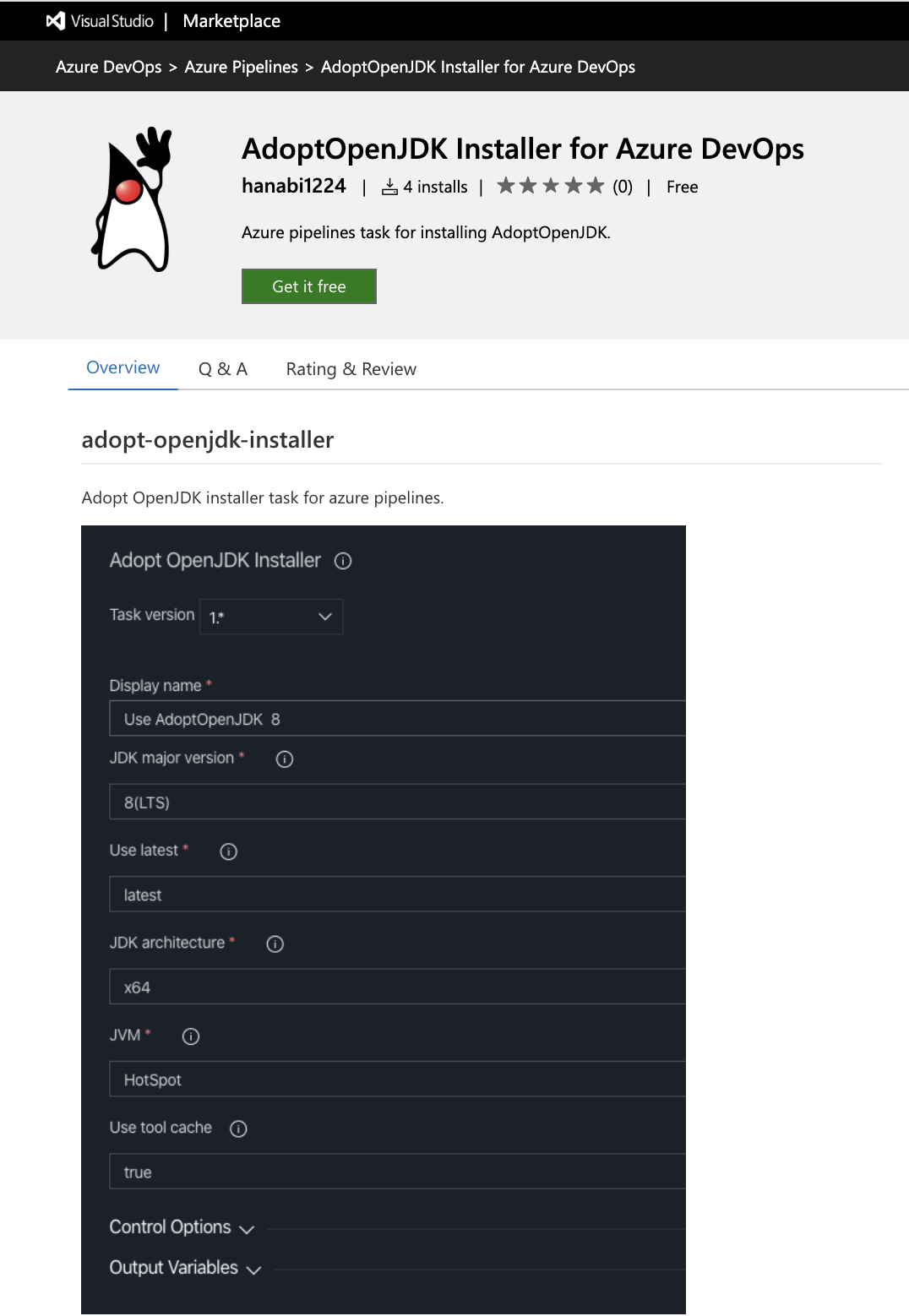
https://github.com/actions/virtual-environments/blob/master/images/linux/Ubuntu1804-README.md諸事情により、AdoptOpenJDKでもビルドできる必要があるので入れられるか調べたのですが、便利なExtensionを公開してくださっている方がいました。
https://marketplace.visualstudio.com/items?itemName=hanabi1224.adopt-openjdk-installer
こちらは、Classic Editorから使えます。
Classic Editorは、Pipelineを作るときに、YAMLではなくて[Classic Editor]という小さなリンクが最初のページに有るので、それをクリックすると使えます。
また、Classic Editorで作ったうえで、その
ymlを参考にすることも出来ます。
ただ、Classic Editorは非推奨になっているので、いつメニューから消えてもおかしくはありません。
感想
操作は割としやすいですが、メニュー構成はちょっと慣れが必要です。
英語のラーニングパスや下記の記事のチュートリアルを多少でもやっておかないと、どこに何があるか分かりづらいかもしれません。
https://docs.microsoft.com/ja-jp/azure/devops/pipelines/create-first-pipeline?view=azure-devops&tabs=java%2Cyaml%2Cbrowser%2Ctfs-2018-2個人的には、一番テスト結果が見やすいかなあと感じました。また、手動で実行するのもわかりやすくボタンがあるので良いですね。
Slackとの統合も簡単そうなのも良いです。
個人や小規模チームは無料枠でいけますし、サブスクリプションをすでに持っているような場合も使いやすいんじゃないでしょうか。ちなみに、最初の設定からビルド、テスト実行され、テスト結果を見られる状態にするまでは、他のCIサービスと比べて、Azure Pipelinesが一番早かったです。
追記
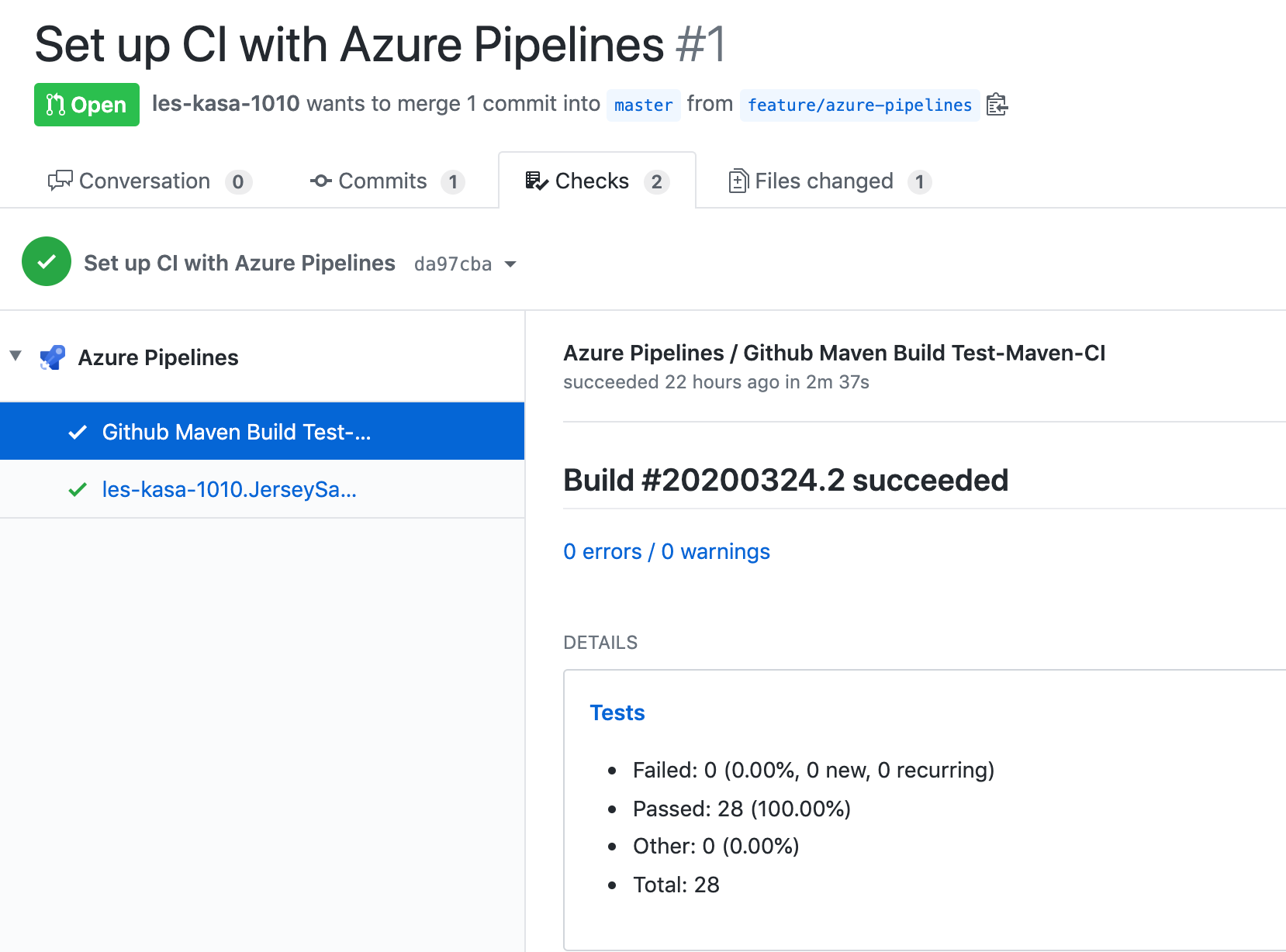
CI回したら、GithubにPRが作成されてCheckページにも表示が追加されていました。
これは便利なようですが、毎回PR作成も嫌なので、ちょっと調査が必要ですね・・・
- 投稿日:2020-03-25T02:56:06+09:00
Springのapplication.propertiesでシステム環境変数を扱う
はじめに
Spring(Boot)でアプリを作成する際にシステム環境変数から値を取得したい場合がある。
メモ書きも兼ねて取得方法を紹介する。どんな時にシステム環境変数を使うか
例えばDBに接続したい場合、
application.propertiesには以下のような設定をする必要がある。application.properties### DB接続設定値 ### spring.datasource.url=<データベースのURL> spring.datasource.username=<ユーザー名> spring.datasource.password=<パスワード>こういった場合、各設定値をシステム環境変数から取得するようにしておけば、以下のようなメリットが考えられる。
①環境ごとに設定ファイルを作成する必要が無くなる。
環境変数を前もって設定しておくか、実行時に設定するようにすれば、同じ設定ファイルを他の環境でも利用することが出来る。
各環境ごとの設定ファイル(例えば、application-devXX.properties)を複数作成し、管理するのは手間になるのでそれを省略できる。また、環境ごとに読み込むファイルを設定する処理をソースコードに書かなくてよくなる。(SpringBootではデフォルトで
application.propertiesが読み込まれるので)②セキュリティの向上につながる。
application.properties内にユーザー名やパスパスワードといった秘密にしたい情報をベタ書きした状態で、リモートリポジトリに上げてしまったりするとセキュリティの問題にもなりかねない。環境変数にしておけば、値は直接書かれないので安心してリモートリポジトリにpushできる。
application.properties内でシステム環境変数を利用する方法以下のようなフォーマットで設定する。
application.propertiesspring.datasource.url=${SPRING_DATASOURCE_URL} spring.datasource.username=${SPRING_DATASOURCE_USERNAME} spring.datasource.password=${SPRING_DATASOURCE_PASSWORD}例えば、
spring.datasource.username=${SPRING_DATASOURCE_USERNAME}について説明すると、①まずシステム環境変数に
SPRING_DATASOURCE_USERNAME=HogeHogeのような変数を追加しておく。
環境変数名は設定ファイルの対象の値の「.」を「_」に置換したうえで全部大文字にしたものにする。
spring.datasource.username⇒spring_datasource_username⇒SPRING_DATASOURCE_USERNAME②
application.properties内では、${SPRING_DATASOURCE_USERNAME}のようにシステム環境変数名を${}で囲った値にしておく。これでシステム環境変数を
application.propertiesから利用することができるようになる。注意点
eclipseやstsを使って開発をしている場合、システム環境変数を追加した後で、eclipse(sts)上でSpringBootアプリを起動したり、JUnitを実行しようとする際には一度再起動をした方がよい。
システム環境変数が読み取れずにエラーになる場合がある。おそらく、eclipse(sts)起動時にシステム環境変数を読み込みそれを利用しているため、起動中に環境変数を追加しても反映されないからだと思われるが詳しくは不明。
結果
設定ファイルからシステム環境変数が利用できる!!!!!(ワザップ)
- 投稿日:2020-03-25T00:15:33+09:00
AWS Lambda で Javaを使う ー実装編 - EC2を止める/立ち上げる
やりたいこと
Lambdaで実行するJavaでEC2を起動・停止する
(↓をJavaで書いてみて、ちょっとだけカスタマイズする。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/start-stop-lambda-cloudwatch/)目次
・Eclipse準備編
・登録実行編(次回以降)
・実装編 - EC2を止める/立ち上げる(今回)
・実装編 - CloudWatchの引数を確認するとりあえずクラス作成
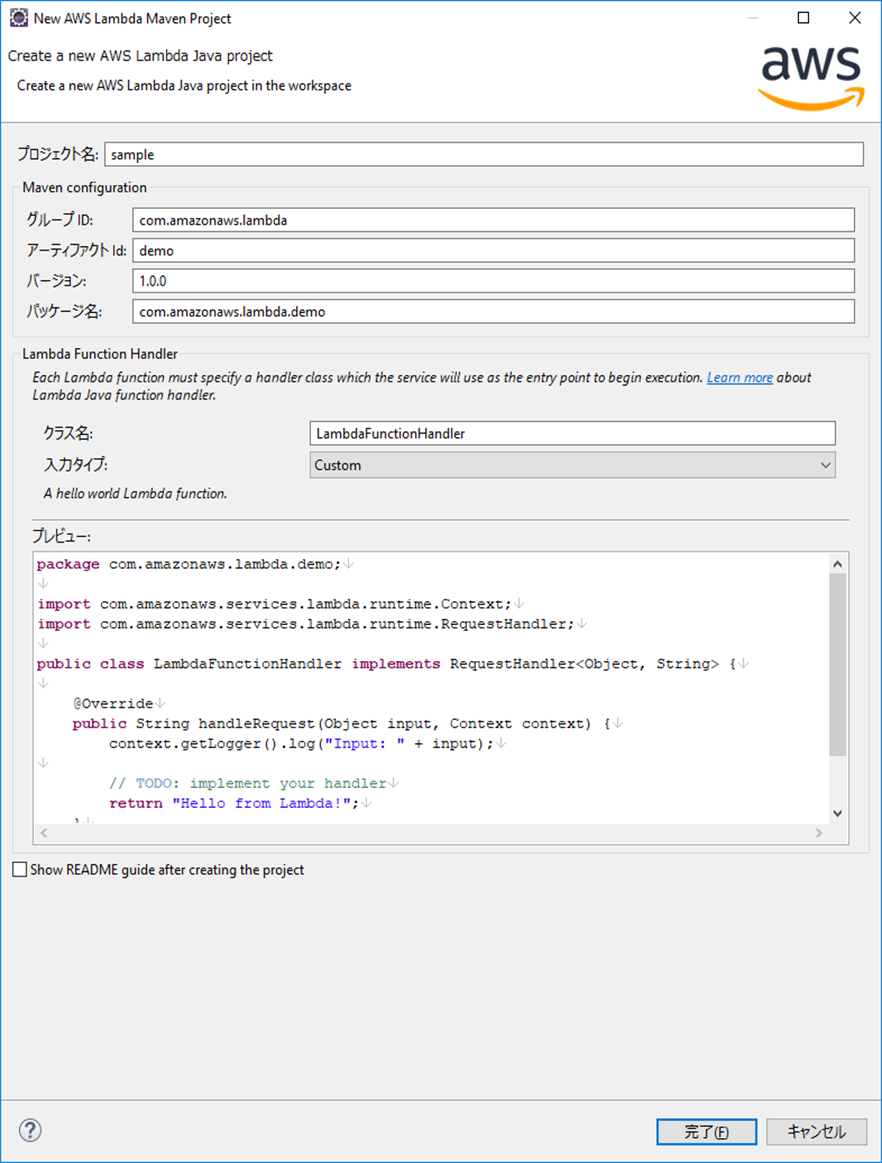
前回Eclipseでサンプルクラスを作成できるようにしたので、
それを使って、入力タイプ「Custom」のLambdaプロジェクトを作る。
でできるのが、こちら
LambdaFunctionHandler.javapackage com.amazonaws.lambda.demo; import com.amazonaws.services.lambda.runtime.Context; import com.amazonaws.services.lambda.runtime.RequestHandler; public class LambdaFunctionHandler implements RequestHandler<Object, String> { @Override public String handleRequest(Object input, Context context) { context.getLogger().log("Input: " + input); // TODO: implement your handler return "Hello from Lambda!"; } }handleRequestメソッドが作られるので、Lambdaで実行したい内容をゴリゴリ書いていく。
handlerの説明は下記を参照
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/java-handler.html
引数ではjsonを受け取ることができる。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/java-handler-pojo.htmlEC2をごにょごにょする
EC2オブジェクトを作成する
// EC2オブジェクトを作成 AmazonEC2 ec2 = AmazonEC2ClientBuilder.standard().withRegion("us-east-1").build();これで、引数のリージョンにあるEC2を操作できるようになる。
リージョンコードはここを参照
https://docs.aws.amazon.com/ja_jp/general/latest/gr/rande.html
今回は使わないが、Regionsという名前でEnumも準備されているので、下のクラスも使える。
com.amazonaws.regions.Regionsインスタンスを起動する
// 引数のリストに格納されたインスタンスIDを起動 StartInstancesResult ret = ec2.startInstances(new StartInstancesRequest(instanceIdList));これで、Listの中にあるインスタンスIDを起動できる。
インスタンスを停止する
// 引数のリストに格納されたインスタンスIDを停止 StopInstancesResult ret = ec2.stopInstances(new StopInstancesRequest(instanceIdList));起動と同じで、ListのインスタンスIDを停止できる。
起動、停止両方の戻り値で、AmazonWebServiceResultを継承している、ので下の様にできる。AmazonWebServiceResult<?> ret出来上がったのがこちら
引数を↓のようにして、複数のリージョン、インスタンスに対して操作をできるようにする。
{targets":[ { "action":"start" ,"targetReagion":"us-east-1" ,"targetInstances":"x-xxxxxxxxxxxxx" } ,{ "action":"stop" ,"targetReagion":"ap-northeast-1" ,"targetInstances":"y-yyyyyyyyyyy" } ]}この引数の例だとバージニア北部のx-xxxxxxxxxxxxxというインスタンスを起動して、
東京のy-yyyyyyyyyyyインスタンスを停止する。ActionEC2Instancespackage com.amazonaws.lambda.demo; import java.util.ArrayList; import java.util.List; import com.amazonaws.AmazonWebServiceResult; import com.amazonaws.services.ec2.AmazonEC2; import com.amazonaws.services.ec2.AmazonEC2ClientBuilder; import com.amazonaws.services.ec2.model.StartInstancesRequest; import com.amazonaws.services.ec2.model.StopInstancesRequest; import com.amazonaws.services.lambda.runtime.Context; import com.amazonaws.services.lambda.runtime.RequestHandler; import com.amazonaws.lambda.demo.ActionEC2Instances.Input; import com.amazonaws.lambda.demo.ActionEC2Instances.Output; public class ActionEC2Instances implements RequestHandler<Input, Output> { @Override public Output handleRequest(Input input, Context context) { context.getLogger().log("Input : " + input); Output output = new Output(); for (Target action : input.targets) { output.result.add(doAction(action)); } return output; } private String doAction(Target target) { AmazonEC2 ec2 = AmazonEC2ClientBuilder.standard().withRegion(target.targetReagion).build(); List<String> instances = target.targetInstances; AmazonWebServiceResult<?> ret = null; if ("start".equals(target.action)) { ret = ec2.startInstances(new StartInstancesRequest(instances)); } else if ("stop".equals(target.action)) { ret = ec2.stopInstances(new StopInstancesRequest(instances)); } else { return "Unexpected Action"; } return ret.toString(); } public static class Input { public List<Target> targets; @Override public String toString() { StringBuffer sbf = new StringBuffer(); for (Target target : targets) { sbf.append(target); } return sbf.toString(); } } public static class Target { private String action; private String targetReagion; private List<String> targetInstances; public String getAction() { return action; } public void setAction(String action) { this.action = action; } public String getTargetReagion() { return targetReagion; } public void setTargetReagion(String targetReagion) { this.targetReagion = targetReagion; } public List<String> getTargetInstances() { return targetInstances; } public void setTargetInstances(List<String> targetInstances) { this.targetInstances = targetInstances; } @Override public String toString() { StringBuffer sbf = new StringBuffer(); sbf.append("{action :").append(action).append(" targetReagion :").append(targetReagion) .append(" targetInstances :").append(targetInstances).append("}"); return sbf.toString(); } } public static class Output { public List<String> result = new ArrayList<String>(); } }追加したpom
<dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-core</artifactId> <version>1.11.719</version> </dependency> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-lambda-java-events</artifactId> <version>1.3.0</version> </dependency> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-lambda-java-core</artifactId> <version>1.1.0</version> </dependency> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-ec2</artifactId> <version>1.11.602</version> <scope>compile</scope> </dependency>