- 投稿日:2020-03-24T23:46:54+09:00
[TensorFlow] AIを車両鉄に入門させてみた
はじめに
ディープラーニング技術が身近になり、ググってみると色々なものを画像認識させるサンプルがたくさん見つかるようになりました。
結果が分かりやすくて見ていて楽しいので、n番煎じながら自分も何か認識させてみたくなったのですが、動物とか好きな女優さんとかを認識させるのはみんなやってるので、別のネタでやりたい。ということで、鉄道車両の画像を学習データとして、入力画像に写っている車両の形式をディープラーニング技術で当てさせてみました。もっとも、レベル感は電車に興味を持ち始めた小さい子供と同程度だと思いますが。
↓このような車両の画像を入力して「E231系500番台」と当てさせることを目指します。
開発環境
- Ubuntu 18.04
- Python 3.6.9
- TensorFlow 2.1.0 (CPU)
問題設定
与えられた鉄道車両の外装写真に対して、5つの選択肢の中から1つを当てるようなニューラルネットワークのモデルを学習してみましょう!
今回はJR東日本の車両形式のうち、東京近郊で走っている5種類を対象とします。人間が見れば帯の色などでパッと判別できますが、どの部分が車両なのかを計算機に分からせるのは大変かもしれません。車両画像の例
ここの画像は自前です。
(1) E231系500番台(山手線)
(2) E233系0番台(中央線快速・青梅線・五日市線)
(3) E233系1000番台(京浜東北・根岸線)
(4) E233系8000番台(南武線)
(5) E235系0番台(山手線の新型車)
データ集め
こちらの記事を参考にしました。
TensorFlowで画像認識「〇〇判別機」を作る - QiitaGoogle画像検索で出てきた画像を自動ダウンロードさせます。
pip install google_images_download googleimagesdownload -k 山手線 googleimagesdownload -k 中央線快速 googleimagesdownload -k E235 : :集めた画像の中で、車両の外装が写っている写真だけを使います。以下のような画像は使いません。
- 車両が写っていない画像(路線図や駅舎だけが写っているなど)
- 複数の車両・編成が写っている画像
- 内装の写真
- 鉄道模型
- CG画像
いろいろなキーワードで試して、最終的に1形式あたり100枚以上の画像を集めます。今回は5種類で合計540枚となりました。
全然数が足りなそうですが、これでも結構大変なんですよ…。キーワードを変えても同じ画像しかヒットしなかったりとか。次に、集めた画像を、クラスごとにフォルダに分けて配置します。
- images/
- E231-yamanote/
- E231系500番台(山手線)の画像 115枚
- E233-chuo/
- E233系0番台(中央線快速など)の画像 124枚
- E233-keihintohoku/
- E233系1000番台(京浜東北・根岸線)の画像 75枚
- E233-nanbu/
- E233系8000番台(南武線)の画像 101枚
- E235-yamanote/
- E235系0番台(山手線の新型車)の画像 125枚
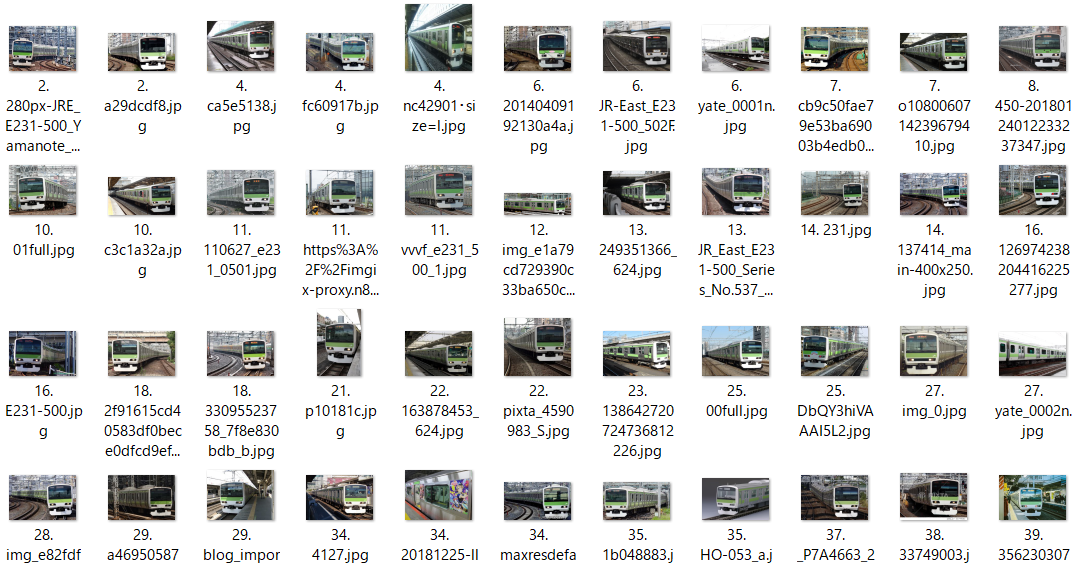
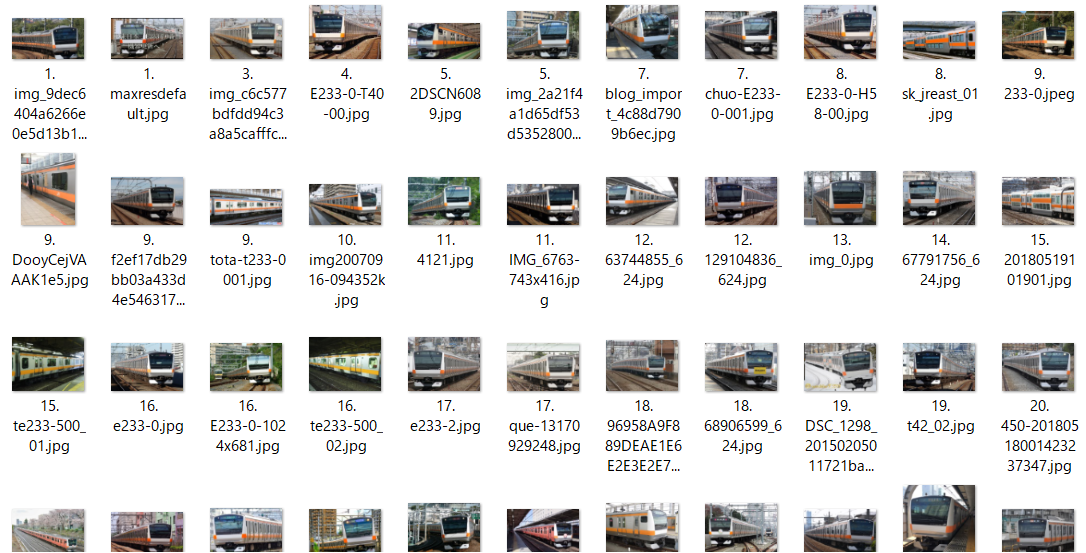
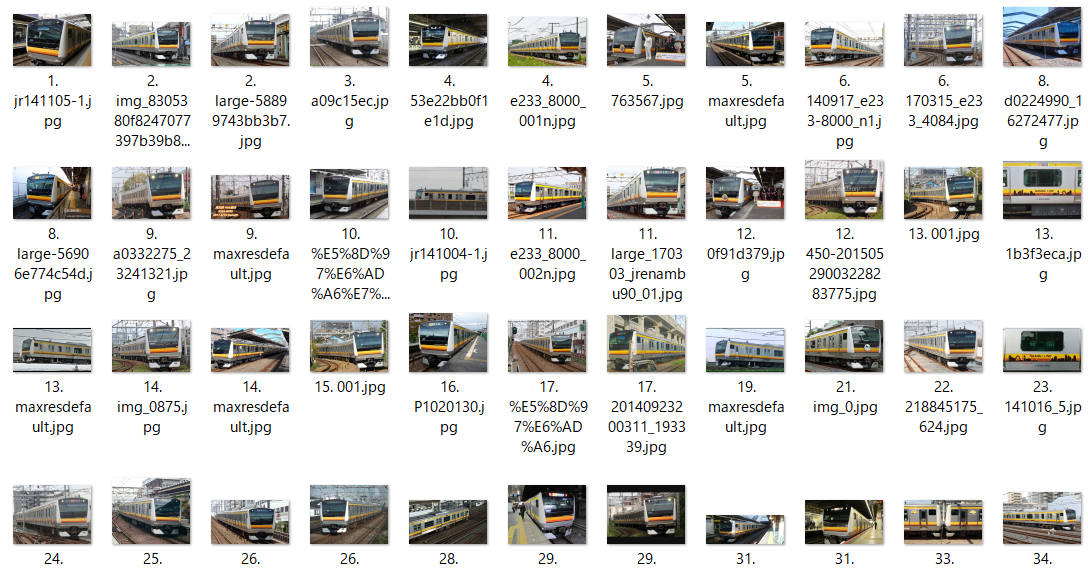
実際に集まった画像
(1) E231系500番台(山手線)
(2) E233系0番台(中央線快速・青梅線・五日市線)
(3) E233系1000番台(京浜東北・根岸線)
(4) E233系8000番台(南武線)
(5) E235系0番台(山手線)
モデル学習のコード
さて、画像が準備できたらいよいよ学習です。
基本的には以下の記事の内容を参考にしました。
GPUを使ってVGG16をFine Tuningして、顔認識AIを作って見た - Qiita今回の各形式は色が全然違う(山手線は2つありますが見た目がかなり違う)ので、女優さんの顔を識別するよりは簡単なタスクではないかと思いますが、それでもわずか500枚程度の画像では厳しいでしょう。
このデータの少なさに対処するため、VGG16の学習済みモデルを利用してファインチューニングを行います。VGG16のモデルはTensorFlow (Keras) から別途パッケージのインストールなしに利用できます。
Keras:VGG16、VGG19とかってなんだっけ?? - QiitaVGG16は鉄道車両とは関係ない1000クラスの画像分類を行うモデルですが、学習されている重みが画像の識別に有効な特徴量を表現していると考え、出力に近い層だけを今回のタスクに合わせて取り替えて学習してしまいます。それによって最初のモデルの学習データとは全く関係ない識別問題が解けるようになるらしい。あら不思議。
入力を128×1281のカラー画像とし、VGG16のモデルを通した後に、全結合層256ユニット・Dropout・全結合層(出力層)5ユニットを付けます。
今回追加した全結合層と、VGG16の出力層に最も近いConv2D-Conv2D-Conv2Dの部分の重みだけを学習させ、残りのConv2D層は学習済みのパラメータから動かしません。入力画像は、各所で紹介されているように
ImageDataGeneratorで拡大縮小や左右反転といったゆらぎを与えて学習に使います。元画像は500枚程度ですが、各エポックで毎回異なるゆらぎが与えられるので、それでデータを水増ししたことになるようです。
Python - Keras ImageDataGeneratorについて|teratailtrain.pyimport tensorflow as tf from tensorflow.keras.layers import Dense, Input, Flatten, Dropout from tensorflow.keras.optimizers import SGD from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau from tensorflow.keras.models import Model from tensorflow.keras.applications import VGG16 from tensorflow.keras.preprocessing.image import ImageDataGenerator import matplotlib.pyplot as plt # 学習設定 batch_size = 32 epochs = 30 # 特徴量の設定 # classesはサブフォルダの名前に合わせる classes = ["E231-yamanote", "E233-chuo", "E233-keihintohoku", "E233-nanbu", "E235-yamanote"] num_classes = len(classes) img_width, img_height = 128, 128 feature_dim = (img_width, img_height, 3) # ファイルパス data_dir = "./images" # === 画像の準備 === datagen = ImageDataGenerator( rescale=1.0 / 255, # 各画素値は[0, 1]に変換して扱う zoom_range=0.2, horizontal_flip=True, validation_split=0.1 ) train_generator = datagen.flow_from_directory( data_dir, subset="training", target_size=(img_width, img_height), color_mode="rgb", classes=classes, class_mode="categorical", batch_size=batch_size, shuffle=True) validation_generator = datagen.flow_from_directory( data_dir, subset="validation", target_size=(img_width, img_height), color_mode="rgb", classes=classes, class_mode="categorical", batch_size=batch_size) # 画像数を取得し、1エポックのミニバッチ数を計算 num_train_samples = train_generator.n num_validation_samples = validation_generator.n steps_per_epoch_train = (num_train_samples-1) // batch_size + 1 steps_per_epoch_validation = (num_validation_samples-1) // batch_size + 1 # === モデル定義 === # 学習済みのVGG16モデルをベースに、出力層だけを変えて学習させる # block4_poolまでのパラメータは学習させない vgg16 = VGG16(include_top=False, weights="imagenet", input_shape=feature_dim) for layer in vgg16.layers[:15]: layer.trainable = False # 今回のモデルを構築 layer_input = Input(shape=feature_dim) layer_vgg16 = vgg16(layer_input) layer_flat = Flatten()(layer_vgg16) layer_fc = Dense(256, activation="relu")(layer_flat) layer_dropout = Dropout(0.5)(layer_fc) layer_output = Dense(num_classes, activation="softmax")(layer_dropout) model = Model(layer_input, layer_output) model.summary() model.compile(loss="categorical_crossentropy", optimizer=SGD(lr=1e-3, momentum=0.9), metrics=["accuracy"]) # === 学習 === cp_cb = ModelCheckpoint( filepath="weights.{epoch:02d}-{loss:.4f}-{val_loss:.4f}.hdf5", monitor="val_loss", verbose=1, mode="auto") reduce_lr_cb = ReduceLROnPlateau( monitor="val_loss", factor=0.5, patience=1, verbose=1) history = model.fit( train_generator, steps_per_epoch=steps_per_epoch_train, epochs=epochs, validation_data=validation_generator, validation_steps=steps_per_epoch_validation, callbacks=[cp_cb, reduce_lr_cb]) # === 正解率の推移出力 === plt.plot(range(1, len(history.history["accuracy"]) + 1), history.history["accuracy"], label="acc", ls="-", marker="o") plt.plot(range(1, len(history.history["val_accuracy"]) + 1), history.history["val_accuracy"], label="val_acc", ls="-", marker="x") plt.ylabel("accuracy") plt.xlabel("epoch") plt.legend(loc="best") plt.savefig("accuracy.png") plt.show()学習の推移
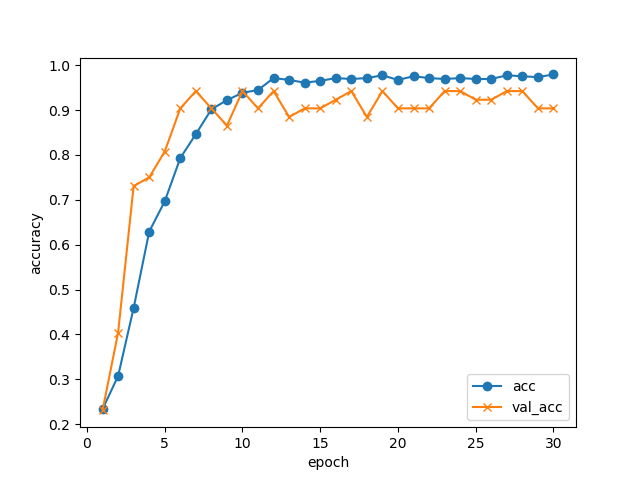
30エポック回して、学習データ・検証データでの正解率の推移はこんな感じになりました。
GPUなしのノートPCでCPUをぶん回して(4コアフル稼働で)学習させましたが、1エポックが1分程度でしたので、全部で30分程度で終わっています。
10エポックあたりで検証データの正解率は止まっていますが、5択問題で正解率94%まで来ています。データが少ない割にはよく頑張りましたね!
ModelCheckpointの機能により、各エポック終了ごとにモデルを自動的に保存しています。今回、検証データの損失が最も小さかったのは17エポック目のモデルweights.17-0.1049-0.1158.hdf5だったので、これを識別に使います。import numpy as np print(np.argmin(history.history["val_loss"]) + 1) # 17(毎回変わる可能性があります)注意点
Optimizerを
SGDとしていますが、これをAdamなどにするとうまく収束してくれません。
これは、おそらくファインチューニングだからだと思われます。詳しくは以下の記事で。
[TensorFlow] OptimizerにもWeightがあるなんて - Qiita車両を識別させる
冒頭に挙げた各画像を、実際に識別させてみましょう。
predict.pyimport sys def usage(): print("Usage: {0} <input_filename>".format(sys.argv[0]), file=sys.stderr) exit(1) # === 入力画像のファイル名を引数から取得 === if len(sys.argv) != 2: usage() input_filename = sys.argv[1] import numpy as np import tensorflow as tf from tensorflow.keras.preprocessing import image # 特徴量の設定 classes = ["E231-yamanote", "E233-chuo", "E233-keihintohoku", "E233-nanbu", "E235-yamanote"] num_classes = len(classes) img_width, img_height = 128, 128 feature_dim = (img_width, img_height, 3) # === モデル読込み === model = tf.keras.models.load_model("weights.17-0.1049-0.1158.hdf5") # === 入力画像の読み込み === img = image.load_img(input_filename, target_size=(img_height, img_width)) x = image.img_to_array(img) x = np.expand_dims(x, axis=0) # 学習時と同様に値域を[0, 1]に変換する x = x / 255.0 # 車両形式を予測 pred = model.predict(x)[0] # 結果を表示する for cls, prob in zip(classes, pred): print("{0:18}{1:8.4f}%".format(cls, prob * 100.0))入出力例
先程の
predict.pyのコマンドライン引数に画像ファイル名を与えると、識別結果が出力されます。python3 predict.py filename.jpgここで紹介する入力サンプルはすべて自前です。
なお、ここに掲載するために画像の一部を加工していますが、実際の学習・識別時にはオリジナルのまま入力しています。(1) E231系500番台(山手線)
E231-yamanote 99.9974% E233-chuo 0.0000% E233-keihintohoku 0.0000% E233-nanbu 0.0004% E235-yamanote 0.0021%文句なしの正解ですね。
(2) E233系0番台(中央線快速・青梅線・五日市線)
E231-yamanote 0.0023% E233-chuo 97.3950% E233-keihintohoku 0.0101% E233-nanbu 2.5918% E235-yamanote 0.0009%これも全く問題なし。
(3) E233系1000番台(京浜東北・根岸線)
駅名標や人が写っていて、機械にとっては識別が難しそうな画像ですが…。E231-yamanote 2.0006% E233-chuo 0.9536% E233-keihintohoku 34.9607% E233-nanbu 6.5641% E235-yamanote 55.5209%山手線E235系の確率が高くなりました。条件悪いですし横からの画像ですし、やむを得ないか。
ちなみに、なぜこれだけ横からの画像かというと、たまたま自分で京浜東北線の電車を正面から撮った画像がなかったからです…(汗)
(4) E233系8000番台(南武線)
E231-yamanote 0.1619% E233-chuo 7.9535% E233-keihintohoku 0.0309% E233-nanbu 91.7263% E235-yamanote 0.1273%正解の南武線に高い確率をつけましたが、中央線快速と少し迷った様子。もっとも、フォルムはほぼ同じで色違いなだけなのですが、それなら京浜東北線と迷ったっていいのでは。
(5) E235系0番台(山手線)
E231-yamanote 0.0204% E233-chuo 0.0000% E233-keihintohoku 0.0027% E233-nanbu 0.0002% E235-yamanote 99.9767%これは問題ないですね。
その他
E231-yamanote 0.2417% E233-chuo 0.0204% E233-keihintohoku 2.1286% E233-nanbu 0.0338% E235-yamanote 97.5755%本当は3番目が正解なのですが、山手線の新型車と思ってしまったようです。なぜ。。。
E231-yamanote 47.2513% E233-chuo 0.0898% E233-keihintohoku 0.4680% E233-nanbu 6.5922% E235-yamanote 45.5986%2番目が正解なのですが、なぜか山手線を推してきます。単に横からの画像にはE235を推してくる説も?
南武線の確率が少し出ているのは、右端の標識の黄色に反応したのでしょうか(実際どうかはわかりません)。まとめ
Google画像検索で集めた500枚程度の鉄道車両の画像を使って、5種類の車両形式を識別するモデルを学習してみました。
学習済みのモデル (VGG16) の一部を流用して学習することによって、GPUなしのPCでも30分程度でそこそこ識別できるモデルができたようです。間違えるパターンもありますが、計算リソースとデータ量の割には善戦した方ではないかと思います。意外と手軽に作れて面白かったです。本気でやるならもっといろいろな方向からの画像データを集めないとダメですし、車両の部分を切り出すとかも必要だと思います。
顔の判別だったらOpenCVなどで顔の切り出しがすぐにできますが、車両の場合は物体検出のアノテーションからでしょうね…。
元記事の通り150×150でもよかったのですが、VGG16を通すと画像サイズが縦横それぞれ1/32になるので、32の倍数にしておこうかとなんとなく思った次第です。オリジナルのVGG16学習に使われた224×224だとメモリが足りなくなってしまいました(Windows 10でTensorFlowをうまく動かせず、仮想マシン上のLinuxで動かしているためでしょう)。 ↩








- 投稿日:2020-03-24T22:28:13+09:00
Kerasモデル(.h5)をTensorFlowモデル(.pb)に変換して使用する方法
KerasモデルをTensroFlowモデルに変換したい
Keras(今回は、TensorFlow内蔵のKerasを使用する前提です)で学習したモデル(.h5)をTensorFlowモデル(.pb)に変換して使いたくなったときに色々ハマったのでメモです。
バージョンは以下の前提です。
- TensorFlow==1.15.0
- Mac OS 10.13.6(変換時)
- Keras==2.3.1(変換時)
モデルの学習時と変換時でTensorFlowのバージョンは合わせておくのが良いでしょう。単体のKerasは変換のときのみ使用します(学習時は、TensorFlow内蔵のKerasのみでOKです)。私の環境では、Kerasのバージョンが、新し過ぎてもエラーになったので注意しましょう。
学習
この記事の本題ではないので省略します。TensorFlow内蔵のKerasで学習して下さい。今回はGoogle Colaboratoryを使用しました。学習に関して詳しく知りたい方は、Keraのチュートリアルや以下参考記事を参照下さい。
ラズパイマガジン2020年2月号にAI特集記事を寄稿しました
「Google Colaboratory」を使って簡単にディープラーニングで画像認識ができるチュートリアル
KerasモデルとTensorFlowモデルの変換
以下リポジトリのkeras_to_tensorflow.pyというスクリプトで変換できます。
GitHub:amir-abdi/keras_to_tensorflowただ、そのままだと私の環境では不都合だったので、forkして修正したリポジトリを用意しました。
GitHub:karaage0703/keras_to_tensorflow
変更点は以下です。
- TensorFlow内臓のKerasで学習したモデルが読み込めなかったので修正
- pbデータを確認するスクリプトを追加
使用する場合は、以下でcloneして変更したブランチをcheckoutして下さい。
$ git clone https://github.com/karaage0703/keras_to_tensorflow $ git checkout develop変換するコマンドはREADMEに書いてありますが、スクリプトと同じディレクトリに
mode.h5というKerasモデルを置いた場合は以下となります。$ python keras_to_tensorflow.py --input_model="model.h5" --output_model="model.pb"TensorFlow内蔵のKerasで学習した場合、最初
ValueError: Unknown initializer: GlorotUniformというエラーが出たので、以下のようにスクリプトをTensorFlow内蔵のKerasを使用するように書き換えて対応しています。- model = keras.models.load_model(input_model_path) + model = tf.keras.models.load_model(input_model_path)他、Kerasのバージョンによっては、以下のようなエラーが出たので、冒頭のKerasのバージョンに変えることで対処しました。
Error while reading resource variable dense/bias from Container: localhost. This could mean that the variable was uninitialized. Not found: Container localhost does not exist h5 pbTensorFlowモデルの中身確認
TensorFlowモデル(.pb)に変換できましたが、どう使えばよいのかわかりませんね。
そのためにpbファイルの中身を確認するスクリプトを用意しました。以下コマンドで、先ほど作成したpbファイルの中身をチェックできます。
$ python check_pb.py -m='model.pb' --logdir='LOGDIR'ずらずらと、モデルのレイヤーの情報がテキストで表示されます。
TensorBoardを使えば、きれいに可視化された情報が見れます。TensorBoardは、以下コマンドを実行して下さい。
$ tensorboard --logdir='LOGDIR'あとは、ブラウザ(Google Chromeを使いました)で以下アドレスにアクセスします。
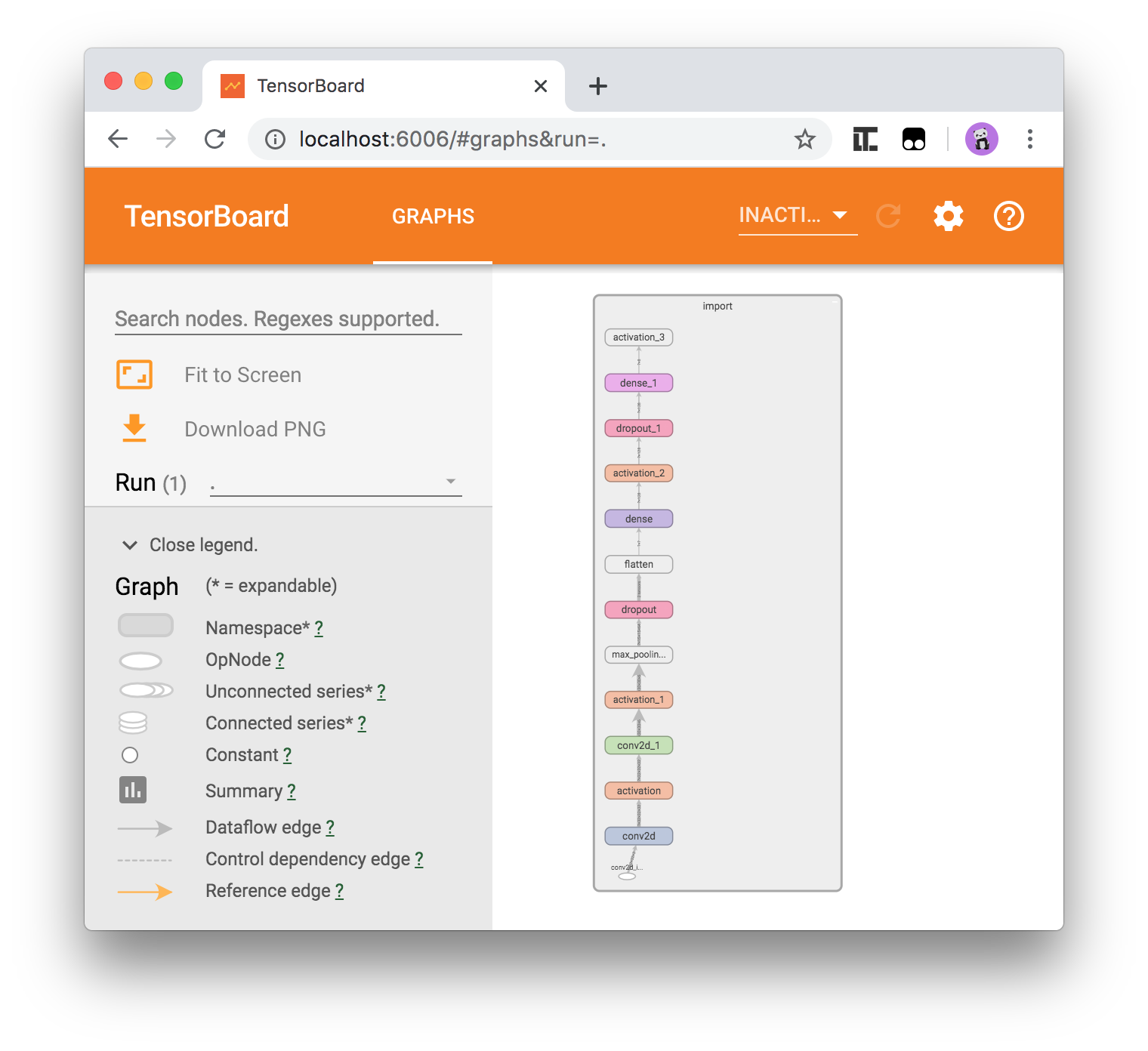
http://localhost:6006/最初画面に
importというテキストが表示されているので、ダブルクリックすると以下のようにモデルの中身が表示されます。
これでpbファイルの中身が見えましたね。
変換したpbファイルの使い方
入力のレイヤーが
import/conv2d_input:0で出力のレイヤーがimport/activation_3/Softmax:0と分かったので、例えば入力に対してモデルの出力を得たい場合は、モデルを読み込んだ後に以下のように書きます。output_tensor = sess.graph.get_tensor_by_name('import/activation_3/Softmax:0') output = sess.run(output_tensor, feed_dict = {'import/conv2d_input:0': X}) print(output)画像の推論をする場合の簡単な例を、リポジトリに
load_pb.pyという名前で保存してあります。まとめ
KerasモデルをTensorFlowモデルに変換して使用するまでをまとめてみました。変換するまでしか書いてなくて、どう使ってよいかちょっと手間取ったのでまとめてみました。しかし、やはり生TensorFlowはできれば触りたくないですね。
参考リンク
- 投稿日:2020-03-24T22:00:37+09:00
[TensorFlow] OptimizerにもWeightがあるなんて
はじめに
TensorFlow (Keras) のLayerオブジェクトは重み(Weight)を持っています。全結合層 ${\bf y} = {\bf W} {\bf x} + {\bf b}$ の行列 ${\bf W}$ とバイアスのベクトル ${\bf b}$ が代表的ですね。
実はOptimizerにもWeightがあります。学習を中断して続きから再開するとか、Fine-Tuningを行うときなど、「すでに途中まで学習が進んでいる」状態では、このWeightの存在を意識しないと痛い目に遭うという話です。何を今更と言われるかもしれませんが。
検証環境
- Ubuntu 18.04
- Python 3.6.9
- TensorFlow 2.1.0 (CPU)
現象
まずはハマった内容をご紹介しましょう。
3エポック学習させた後、Optimizerを最初と同じ設定で再作成し、モデルを再コンパイルした後、同じデータで再度3エポック回します。実行している本人は、全部で6エポック分学習させた気になっていますが…?
(分かりやすいように例を単純化しています)import numpy as np import tensorflow as tf from tensorflow.keras.datasets import mnist from tensorflow.keras.layers import Dense, Input from tensorflow.keras.optimizers import Adam from tensorflow.keras.models import Model # 乱数シード固定 tf.random.set_seed(1) # データ作成:現象が分かりやすいようにSubsetで試す (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train[0:1000, :] y_train = y_train[0:1000] x_test = x_test[0:100, :] y_test = y_test[0:100] feature_dim = 28*28 num_classes = 10 # 前処理をする # 画素は[0, 1]のfloat32型に変換する x_train = x_train.reshape((-1, feature_dim)).astype("float32") / 255.0 x_test = x_test.reshape((-1, feature_dim)).astype("float32") / 255.0 # ラベルもfloat32型にする y_train = y_train.reshape((-1, 1)).astype("float32") y_test = y_test.reshape((-1, 1)).astype("float32") # モデル定義 layer_input = Input(shape=(feature_dim,)) fc1 = Dense(512, activation="relu")(layer_input) layer_output = Dense(num_classes, activation="softmax")(fc1) model = Model(layer_input, layer_output) model.summary() optimizer = Adam(lr=0.003) model.compile( loss="sparse_categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"]) # まずは普通に3epoch学習する epochs = 3 batch_size = 32 model.fit( x=x_train, y=y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test)) # Layerの重みを引き継いで続きから学習するつもりで # Modelを再コンパイル optimizer = Adam(lr=0.003) model.compile( loss="sparse_categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"]) # もう3epoch学習 model.fit( x=x_train, y=y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test))結果、このようなことが起きます。
Train on 1000 samples, validate on 100 samples Epoch 1/3 1000/1000 [==============================] - 1s 919us/sample - loss: 0.8494 - accuracy: 0.7360 - val_loss: 0.3652 - val_accuracy: 0.9000 Epoch 2/3 1000/1000 [==============================] - 0s 225us/sample - loss: 0.2397 - accuracy: 0.9340 - val_loss: 0.3003 - val_accuracy: 0.9000 Epoch 3/3 1000/1000 [==============================] - 0s 209us/sample - loss: 0.1146 - accuracy: 0.9700 - val_loss: 0.2830 - val_accuracy: 0.9000 Train on 1000 samples, validate on 100 samples Epoch 1/3 1000/1000 [==============================] - 1s 787us/sample - loss: 0.1515 - accuracy: 0.9560 - val_loss: 0.3035 - val_accuracy: 0.9200 Epoch 2/3 1000/1000 [==============================] - 1s 575us/sample - loss: 0.0608 - accuracy: 0.9820 - val_loss: 0.2220 - val_accuracy: 0.9300 Epoch 3/3 1000/1000 [==============================] - 0s 384us/sample - loss: 0.0190 - accuracy: 0.9980 - val_loss: 0.2319 - val_accuracy: 0.9100注目していただきたいのは、最初の3エポック目のTraining Lossよりも、次の1エポック目のTraining Lossのほうが大きくなってしまっている (0.1146 → 0.1515) 点です。
一度に6エポック学習させた場合は、以下のように綺麗にTraining Lossが落ちていきます。
(乱数シードを固定しているため、最初の3エポック分の結果は全く同じです)epochs = 6 batch_size = 32 model.fit( x=x_train, y=y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test))Train on 1000 samples, validate on 100 samples Epoch 1/6 1000/1000 [==============================] - 1s 911us/sample - loss: 0.8494 - accuracy: 0.7360 - val_loss: 0.3652 - val_accuracy: 0.9000 Epoch 2/6 1000/1000 [==============================] - 0s 291us/sample - loss: 0.2397 - accuracy: 0.9340 - val_loss: 0.3003 - val_accuracy: 0.9000 Epoch 3/6 1000/1000 [==============================] - 0s 427us/sample - loss: 0.1146 - accuracy: 0.9700 - val_loss: 0.2830 - val_accuracy: 0.9000 Epoch 4/6 1000/1000 [==============================] - 0s 279us/sample - loss: 0.1008 - accuracy: 0.9710 - val_loss: 0.2584 - val_accuracy: 0.9200 Epoch 5/6 1000/1000 [==============================] - 0s 266us/sample - loss: 0.0420 - accuracy: 0.9950 - val_loss: 0.2393 - val_accuracy: 0.9300 Epoch 6/6 1000/1000 [==============================] - 0s 305us/sample - loss: 0.0188 - accuracy: 0.9990 - val_loss: 0.2104 - val_accuracy: 0.9200今回は簡単な例なのですぐにまたTraining Lossが小さくなっていきますが、複雑な問題だとせっかく時間を掛けて途中まで学習させた成果が台無しになってしまいます。
何が起きたの?
ここで冒頭の「OptimizerにもWeightがあります」という話につながります。
Layerの重みを更新する場合、古典的な手法(SGD: 確率的勾配降下法)では、重みから「損失関数の偏微分係数に学習率を掛けたもの」を引きます。しかし、収束に時間が掛かるので、過去の情報に基づいて重みの変化量をうまく調整し、速く収束させる工夫が考えられてきました。Optimizer : 深層学習における勾配法について - Qiita
ところが、Optimizerオブジェクトを何も考えずに再作成してしまうと、この「過去の情報」が消えてしまい、重みの調整に悪影響を及ぼしてしまいます。この「過去の情報」こそがOptimizerのWeightです。
上の参考ページの数式で言えば、$h_t, m_t, v_t$ のように、Layerの重み ${\bf w}_t$ 以外の情報を使って重みの更新を行っているアルゴリズムが存在しますね。もし学習を一旦中断し、続きから実行したい場合には、これらの情報を保存しておかなければなりません。以下のようにすると、Optimizerオブジェクトに含まれるWeightの値を確認できます。
print(optimizer.get_weights()) print(model.optimizer.get_weights()) # ModelのプロパティでもOptimizerを取得可能Optimizerの再作成とモデルの再コンパイルを行わない場合を試しましょう。以下のコードのうち2回目の方をコメントアウトします。
# optimizer = Adam(lr=0.003) # model.compile( # loss="sparse_categorical_crossentropy", # optimizer=optimizer, # metrics=["accuracy"])すると、2回目の学習を始めたときもTraining Lossはちゃんと減少しています。
Train on 1000 samples, validate on 100 samples Epoch 1/3 1000/1000 [==============================] - 1s 1ms/sample - loss: 0.8494 - accuracy: 0.7360 - val_loss: 0.3652 - val_accuracy: 0.9000 Epoch 2/3 1000/1000 [==============================] - 0s 278us/sample - loss: 0.2397 - accuracy: 0.9340 - val_loss: 0.3003 - val_accuracy: 0.9000 Epoch 3/3 1000/1000 [==============================] - 0s 307us/sample - loss: 0.1146 - accuracy: 0.9700 - val_loss: 0.2830 - val_accuracy: 0.9000 Train on 1000 samples, validate on 100 samples Epoch 1/3 1000/1000 [==============================] - 0s 243us/sample - loss: 0.1010 - accuracy: 0.9710 - val_loss: 0.2640 - val_accuracy: 0.9200 Epoch 2/3 1000/1000 [==============================] - 0s 263us/sample - loss: 0.0355 - accuracy: 0.9960 - val_loss: 0.2206 - val_accuracy: 0.9100 Epoch 3/3 1000/1000 [==============================] - 0s 235us/sample - loss: 0.0132 - accuracy: 1.0000 - val_loss: 0.2102 - val_accuracy: 0.9200古典的なOptimizer (SGD) の場合
SGDを使う場合、時間によって変化する量はLayerの重み ${\bf w}_t$ だけであり、それ以外の内部状態を持たないので、この影響を受けないと思われます。試しに
Adamの代わりにSGDを使ってみます。import numpy as np import tensorflow as tf from tensorflow.keras.datasets import mnist from tensorflow.keras.layers import Dense, Input #from tensorflow.keras.optimizers import Adam from tensorflow.keras.optimizers import SGD from tensorflow.keras.models import Model # (中略) optimizer = SGD(lr=0.003) model.compile( loss="sparse_categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"]) # まずは普通に3epoch学習する epochs = 3 batch_size = 32 model.fit( x=x_train, y=y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test)) # Layerの重みを引き継いで続きから学習するつもりで # Modelを再コンパイル optimizer = SGD(lr=0.003) model.compile( loss="sparse_categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"]) # もう3epoch学習 model.fit( x=x_train, y=y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test))以下のように、Training Lossは減少し続けています。もっとも、
Adamより収束がかなり遅いのですが。Train on 1000 samples, validate on 100 samples Epoch 1/3 1000/1000 [==============================] - 1s 848us/sample - loss: 2.2205 - accuracy: 0.2150 - val_loss: 2.1171 - val_accuracy: 0.4200 Epoch 2/3 1000/1000 [==============================] - 0s 227us/sample - loss: 2.0913 - accuracy: 0.3970 - val_loss: 2.0141 - val_accuracy: 0.5700 Epoch 3/3 1000/1000 [==============================] - 0s 226us/sample - loss: 1.9763 - accuracy: 0.5210 - val_loss: 1.9227 - val_accuracy: 0.5900 Train on 1000 samples, validate on 100 samples Epoch 1/3 1000/1000 [==============================] - 1s 738us/sample - loss: 1.8722 - accuracy: 0.5890 - val_loss: 1.8374 - val_accuracy: 0.6700 Epoch 2/3 1000/1000 [==============================] - 0s 211us/sample - loss: 1.7773 - accuracy: 0.6350 - val_loss: 1.7565 - val_accuracy: 0.7000 Epoch 3/3 1000/1000 [==============================] - 0s 277us/sample - loss: 1.6879 - accuracy: 0.6660 - val_loss: 1.6832 - val_accuracy: 0.7100先ほどと同様に、6エポック一気に学習した場合はこんな感じです。2回に分けた場合とほぼ変わりません。
(4エポック目以降の値が微妙に異なりますが、この誤差はどこから来るのでしょうね?)Epoch 1/6 1000/1000 [==============================] - 1s 802us/sample - loss: 2.2205 - accuracy: 0.2150 - val_loss: 2.1171 - val_accuracy: 0.4200 Epoch 2/6 1000/1000 [==============================] - 0s 233us/sample - loss: 2.0913 - accuracy: 0.3970 - val_loss: 2.0141 - val_accuracy: 0.5700 Epoch 3/6 1000/1000 [==============================] - 0s 259us/sample - loss: 1.9763 - accuracy: 0.5210 - val_loss: 1.9227 - val_accuracy: 0.5900 Epoch 4/6 1000/1000 [==============================] - 0s 266us/sample - loss: 1.8719 - accuracy: 0.5920 - val_loss: 1.8376 - val_accuracy: 0.6500 Epoch 5/6 1000/1000 [==============================] - 0s 315us/sample - loss: 1.7764 - accuracy: 0.6410 - val_loss: 1.7552 - val_accuracy: 0.6900 Epoch 6/6 1000/1000 [==============================] - 0s 273us/sample - loss: 1.6873 - accuracy: 0.6680 - val_loss: 1.6806 - val_accuracy: 0.7100
SGDにはWeightはありません…と思いきや、謎の値が出てきます。print(optimizer.get_weights()) # Result: [192]いろいろ試したところ、どうも学習した累計バッチ数が入っているようです。先ほどの参考ページの記法でいえば $t$ ですね。ただSGDの場合、$t$ の値そのものは(手法の原理上)重みの更新に影響を及ぼさないはずですので、これ以上は深く立ち入りません(例えばAdamは $t$ の値も使っていますね)。
対処法
今回のような面倒事にならないようにする方法としては
- 数エポック学習させた後、同じデータで続きから学習させる場合は、OptimizerのWeightを保存しておく
- Fine-Tuningなど、最初とは別のデータで続きから学習させる場合は、Optimizerとして内部状態を持たないSGDを使う (Momentum-SGDは使っても大丈夫のはず)
のが良いのではと思われます(特に2点目は自信なし…)。
OptimizerのWeightを保存する方法
Modelオブジェクトに対し
save()すれば、LayerのWeightだけでなく、設定したOptimizerの情報やWeightの値も含めてファイルに保存できます。model.save("model.h5", save_format="h5") exit()
tf.keras.models.load_model()でモデルを読み込むと、前の情報を引き継いだ状態で学習できます。
独自のLayerやCallbackを指定して作成したモデルの場合はcustom_objects引数を指定する必要がありますが、ここでは触れません。
tf.keras.models.load_model | TensorFlow Core v2.1.0import tensorflow as tf from tensorflow.keras.datasets import mnist feature_dim = 28*28 num_classes = 10 # データ作成 (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train[0:1000, :] y_train = y_train[0:1000] x_test = x_test[0:100, :] y_test = y_test[0:100] # 前処理をする # 画素は[0, 1]のfloat32型に変換する x_train = x_train.reshape((-1, feature_dim)).astype("float32") / 255.0 x_test = x_test.reshape((-1, feature_dim)).astype("float32") / 255.0 # ラベルもfloat32型にする y_train = y_train.reshape((-1, 1)).astype("float32") y_test = y_test.reshape((-1, 1)).astype("float32") # モデル読み込み model = tf.keras.models.load_model("model.h5") # print(model.optimizer.get_weights()) # 続きから学習 epochs = 3 batch_size = 32 model.fit( x=x_train, y=y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test))その他
Fine-tuningを使って少ない画像データから効率よく学習モデルを作成する方法 | AI coordinator
# TODO: ここでAdamを使うとうまくいかない
# Fine-tuningのときは学習率を小さくしたSGDの方がよい?とコメントが書かれていますが、おそらく同じ現象が起きているかもしれません?
- 投稿日:2020-03-24T07:15:25+09:00
【Windows】GPUでKerasを利用するメモ【Tensorflow-GPU】
構成
OS: Windows10 Home
CPU:Intel製 Corei7-4790
GPU: GTX1660 Super(NVIDIA製のGPUならなんでもいい)
Python: 3.6.10
Keras: 2.2.4
Tensorflow: 1.14.0
Cuda: 10.0
numpy: 1.16.4
sklearn: 0.22.21.Windows Visual Studio C++のインストール
インストールページ
https://docs.microsoft.com/ja-jp/visualstudio/install/install-visual-studio?view=vs-2019
ここから、VisualStudioをインストールします。
今回は、2019年版をインストール。
インストール時に「C++ ワークロードを使用したデスクトップ開発」を必ず選択してください。2.NVIDIA Driverのインストール
https://www.nvidia.co.jp/Download/index.aspx?lang=jp
こちらのURLから自分のGPUを選択し、NVIDIAドライバをダウンロードします。
ダウンロードされたexeファイルを実行して、インストールします。3.cuDNNのダウンロード
https://developer.nvidia.com/rdp/cudnn-download
こちらのサイトから『cuDNN v7.6.5 for CUDA 10.0』をダウンロードする
次に、フォルダで「C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v.10.0」を開いてください。
解凍したフォルダの中にbin,include,libと3つのフォルダがあります。
binの中のファイルはbinのフォルダの中に、includeの中のファイルはincludeフォルダの中に、libの中のファイルはlibフォルダの中に上書き保存してください。4.tensorflow-gpuのインストール
まず普通のtensorflowがインストールされている場合、
アンインストールしてからインストールする必要がある。pip uninstall tensorflow pip install numpy==1.16.4 pip install tensorflow-gpu==1.14.0 pip install keras==2.2.4 pip install sklearnグラフ描画やデータ処理に使いそうなものも併せてインストールしておく。
下は、インストールしなくてもいいです。pip install matplotlib pip install pandas pip install pillow pip install opencv-python pip install opencv-contrib-python5.GPU版Tensorflowが認識しているかチェックする
from tensorflow.python.client import device_lib device_lib.list_local_devices()長文が出力されると思いますが、
その中の一行に、device_type: "GPU"やname: "/device:GPU:0"などの文字があればOKです。6.やっぱりテストはMNISTで。
testといったらMNIST。
MNISTで速度検証します。import time import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D from keras.optimizers import RMSprop (x_train, y_train), (x_test, y_test) = mnist.load_data() model = Sequential() model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(Conv2D(64, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax')) x_train = x_train.reshape(x_train.shape[0], 28, 28, 1) x_test = x_test.reshape(x_test.shape[0], 28, 28, 1) x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 y_train = keras.utils.to_categorical(y_train, 10) y_test = keras.utils.to_categorical(y_test, 10) start_time = time.time()#スタート時間計測 model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy']) history = model.fit(x_train, y_train, batch_size=128, epochs=10, verbose=1, validation_data=(x_test, y_test)) score = model.evaluate(x_test, y_test, verbose=0) print('loss:', score[0]) print('accuracy:', score[1]) end_time = time.time() - start_time#終了時間を計測 print("学習時間:", str(round(end_time, 3)), "秒でした。")GPU版での出力結果:48.13 秒
CPU版での出力結果:530.26秒10倍以上も速度が違いました!!
終わりに
個人でDeepLearningしたいという思いから古いPCにグラボ突っ込んでAIマシンをセッティングしました。
また、お金がたまったらもっとメモリのあるGPUや2枚刺しをしたいなと思います。
ではまた。