- 投稿日:2020-03-24T23:46:54+09:00
[TensorFlow] AIを車両鉄に入門させてみた
はじめに
ディープラーニング技術が身近になり、ググってみると色々なものを画像認識させるサンプルがたくさん見つかるようになりました。
結果が分かりやすくて見ていて楽しいので、n番煎じながら自分も何か認識させてみたくなったのですが、動物とか好きな女優さんとかを認識させるのはみんなやってるので、別のネタでやりたい。ということで、鉄道車両の画像を学習データとして、入力画像に写っている車両の形式をディープラーニング技術で当てさせてみました。もっとも、レベル感は電車に興味を持ち始めた小さい子供と同程度だと思いますが。
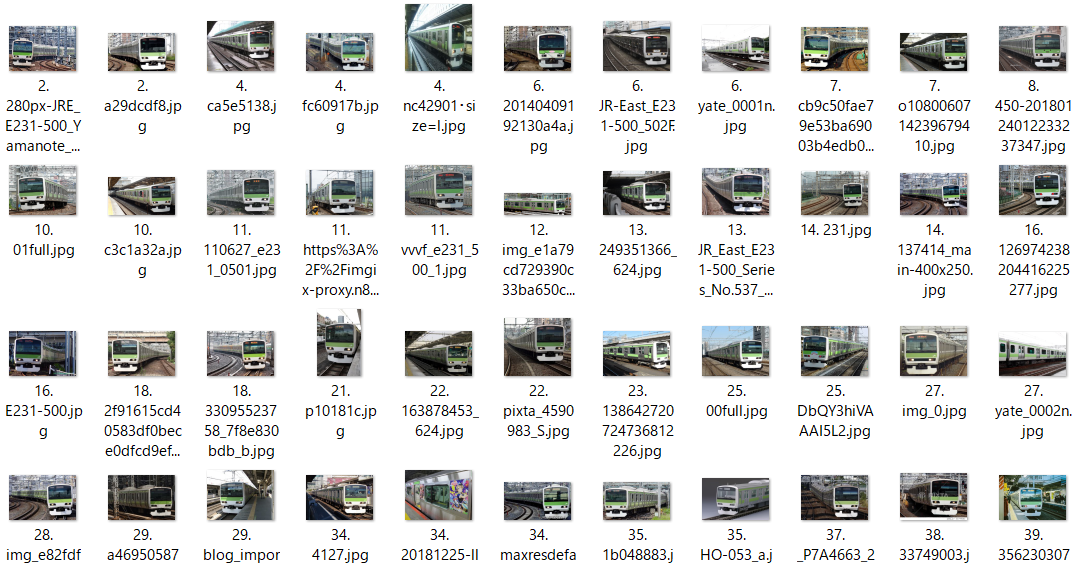
↓このような車両の画像を入力して「E231系500番台」と当てさせることを目指します。
開発環境
- Ubuntu 18.04
- Python 3.6.9
- TensorFlow 2.1.0 (CPU)
問題設定
与えられた鉄道車両の外装写真に対して、5つの選択肢の中から1つを当てるようなニューラルネットワークのモデルを学習してみましょう!
今回はJR東日本の車両形式のうち、東京近郊で走っている5種類を対象とします。人間が見れば帯の色などでパッと判別できますが、どの部分が車両なのかを計算機に分からせるのは大変かもしれません。車両画像の例
ここの画像は自前です。
(1) E231系500番台(山手線)
(2) E233系0番台(中央線快速・青梅線・五日市線)
(3) E233系1000番台(京浜東北・根岸線)
(4) E233系8000番台(南武線)
(5) E235系0番台(山手線の新型車)
データ集め
こちらの記事を参考にしました。
TensorFlowで画像認識「〇〇判別機」を作る - QiitaGoogle画像検索で出てきた画像を自動ダウンロードさせます。
pip install google_images_download googleimagesdownload -k 山手線 googleimagesdownload -k 中央線快速 googleimagesdownload -k E235 : :集めた画像の中で、車両の外装が写っている写真だけを使います。以下のような画像は使いません。
- 車両が写っていない画像(路線図や駅舎だけが写っているなど)
- 複数の車両・編成が写っている画像
- 内装の写真
- 鉄道模型
- CG画像
いろいろなキーワードで試して、最終的に1形式あたり100枚以上の画像を集めます。今回は5種類で合計540枚となりました。
全然数が足りなそうですが、これでも結構大変なんですよ…。キーワードを変えても同じ画像しかヒットしなかったりとか。次に、集めた画像を、クラスごとにフォルダに分けて配置します。
- images/
- E231-yamanote/
- E231系500番台(山手線)の画像 115枚
- E233-chuo/
- E233系0番台(中央線快速など)の画像 124枚
- E233-keihintohoku/
- E233系1000番台(京浜東北・根岸線)の画像 75枚
- E233-nanbu/
- E233系8000番台(南武線)の画像 101枚
- E235-yamanote/
- E235系0番台(山手線の新型車)の画像 125枚
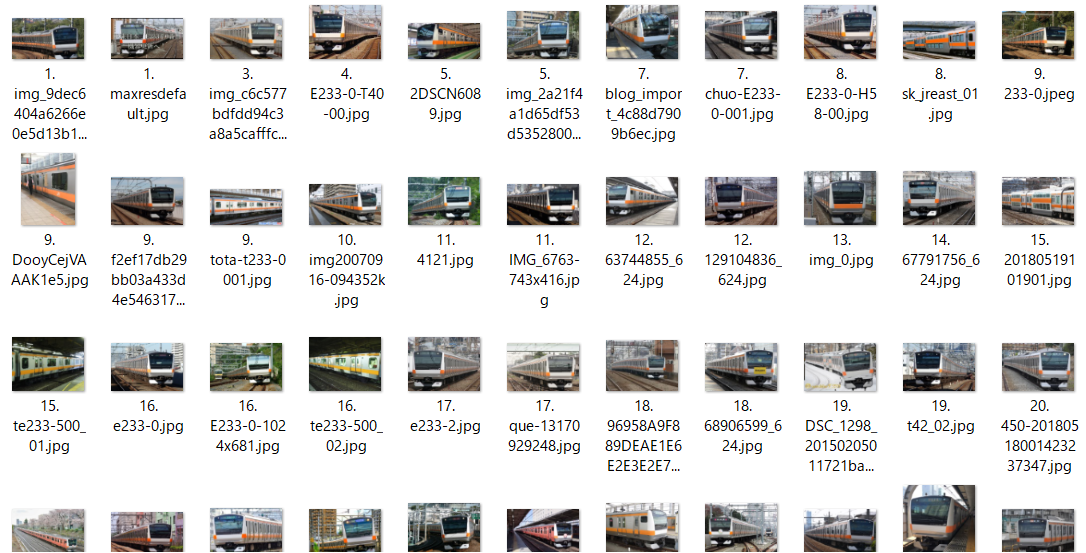
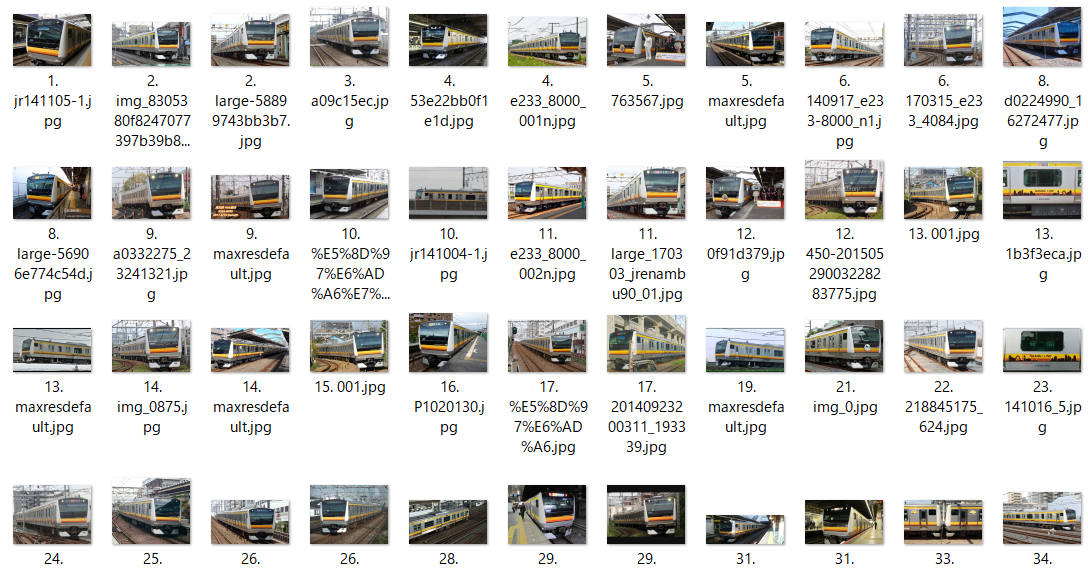
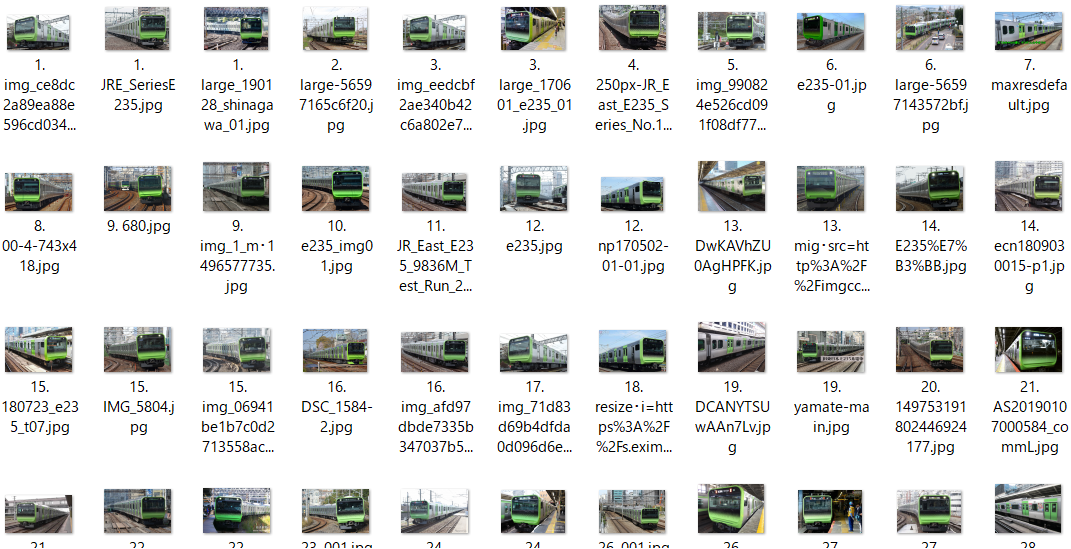
実際に集まった画像
(1) E231系500番台(山手線)
(2) E233系0番台(中央線快速・青梅線・五日市線)
(3) E233系1000番台(京浜東北・根岸線)
(4) E233系8000番台(南武線)
(5) E235系0番台(山手線)
モデル学習のコード
さて、画像が準備できたらいよいよ学習です。
基本的には以下の記事の内容を参考にしました。
GPUを使ってVGG16をFine Tuningして、顔認識AIを作って見た - Qiita今回の各形式は色が全然違う(山手線は2つありますが見た目がかなり違う)ので、女優さんの顔を識別するよりは簡単なタスクではないかと思いますが、それでもわずか500枚程度の画像では厳しいでしょう。
このデータの少なさに対処するため、VGG16の学習済みモデルを利用してファインチューニングを行います。VGG16のモデルはTensorFlow (Keras) から別途パッケージのインストールなしに利用できます。
Keras:VGG16、VGG19とかってなんだっけ?? - QiitaVGG16は鉄道車両とは関係ない1000クラスの画像分類を行うモデルですが、学習されている重みが画像の識別に有効な特徴量を表現していると考え、出力に近い層だけを今回のタスクに合わせて取り替えて学習してしまいます。それによって最初のモデルの学習データとは全く関係ない識別問題が解けるようになるらしい。あら不思議。
入力を128×1281のカラー画像とし、VGG16のモデルを通した後に、全結合層256ユニット・Dropout・全結合層(出力層)5ユニットを付けます。
今回追加した全結合層と、VGG16の出力層に最も近いConv2D-Conv2D-Conv2Dの部分の重みだけを学習させ、残りのConv2D層は学習済みのパラメータから動かしません。入力画像は、各所で紹介されているように
ImageDataGeneratorで拡大縮小や左右反転といったゆらぎを与えて学習に使います。元画像は500枚程度ですが、各エポックで毎回異なるゆらぎが与えられるので、それでデータを水増ししたことになるようです。
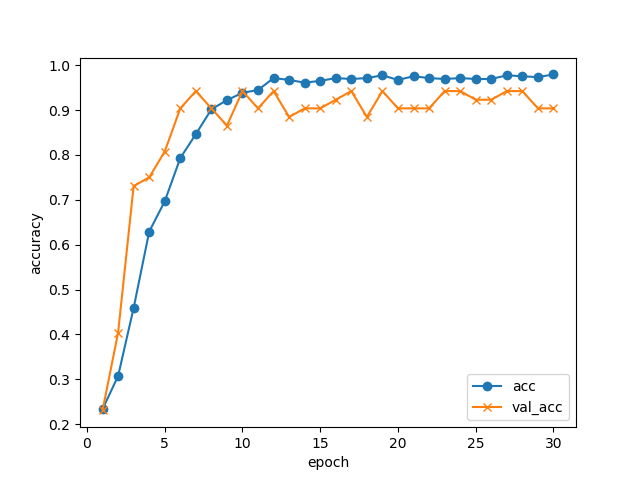
Python - Keras ImageDataGeneratorについて|teratailtrain.pyimport tensorflow as tf from tensorflow.keras.layers import Dense, Input, Flatten, Dropout from tensorflow.keras.optimizers import SGD from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau from tensorflow.keras.models import Model from tensorflow.keras.applications import VGG16 from tensorflow.keras.preprocessing.image import ImageDataGenerator import matplotlib.pyplot as plt # 学習設定 batch_size = 32 epochs = 30 # 特徴量の設定 # classesはサブフォルダの名前に合わせる classes = ["E231-yamanote", "E233-chuo", "E233-keihintohoku", "E233-nanbu", "E235-yamanote"] num_classes = len(classes) img_width, img_height = 128, 128 feature_dim = (img_width, img_height, 3) # ファイルパス data_dir = "./images" # === 画像の準備 === datagen = ImageDataGenerator( rescale=1.0 / 255, # 各画素値は[0, 1]に変換して扱う zoom_range=0.2, horizontal_flip=True, validation_split=0.1 ) train_generator = datagen.flow_from_directory( data_dir, subset="training", target_size=(img_width, img_height), color_mode="rgb", classes=classes, class_mode="categorical", batch_size=batch_size, shuffle=True) validation_generator = datagen.flow_from_directory( data_dir, subset="validation", target_size=(img_width, img_height), color_mode="rgb", classes=classes, class_mode="categorical", batch_size=batch_size) # 画像数を取得し、1エポックのミニバッチ数を計算 num_train_samples = train_generator.n num_validation_samples = validation_generator.n steps_per_epoch_train = (num_train_samples-1) // batch_size + 1 steps_per_epoch_validation = (num_validation_samples-1) // batch_size + 1 # === モデル定義 === # 学習済みのVGG16モデルをベースに、出力層だけを変えて学習させる # block4_poolまでのパラメータは学習させない vgg16 = VGG16(include_top=False, weights="imagenet", input_shape=feature_dim) for layer in vgg16.layers[:15]: layer.trainable = False # 今回のモデルを構築 layer_input = Input(shape=feature_dim) layer_vgg16 = vgg16(layer_input) layer_flat = Flatten()(layer_vgg16) layer_fc = Dense(256, activation="relu")(layer_flat) layer_dropout = Dropout(0.5)(layer_fc) layer_output = Dense(num_classes, activation="softmax")(layer_dropout) model = Model(layer_input, layer_output) model.summary() model.compile(loss="categorical_crossentropy", optimizer=SGD(lr=1e-3, momentum=0.9), metrics=["accuracy"]) # === 学習 === cp_cb = ModelCheckpoint( filepath="weights.{epoch:02d}-{loss:.4f}-{val_loss:.4f}.hdf5", monitor="val_loss", verbose=1, mode="auto") reduce_lr_cb = ReduceLROnPlateau( monitor="val_loss", factor=0.5, patience=1, verbose=1) history = model.fit( train_generator, steps_per_epoch=steps_per_epoch_train, epochs=epochs, validation_data=validation_generator, validation_steps=steps_per_epoch_validation, callbacks=[cp_cb, reduce_lr_cb]) # === 正解率の推移出力 === plt.plot(range(1, len(history.history["accuracy"]) + 1), history.history["accuracy"], label="acc", ls="-", marker="o") plt.plot(range(1, len(history.history["val_accuracy"]) + 1), history.history["val_accuracy"], label="val_acc", ls="-", marker="x") plt.ylabel("accuracy") plt.xlabel("epoch") plt.legend(loc="best") plt.savefig("accuracy.png") plt.show()学習の推移
30エポック回して、学習データ・検証データでの正解率の推移はこんな感じになりました。
GPUなしのノートPCでCPUをぶん回して(4コアフル稼働で)学習させましたが、1エポックが1分程度でしたので、全部で30分程度で終わっています。
10エポックあたりで検証データの正解率は止まっていますが、5択問題で正解率94%まで来ています。データが少ない割にはよく頑張りましたね!
ModelCheckpointの機能により、各エポック終了ごとにモデルを自動的に保存しています。今回、検証データの損失が最も小さかったのは17エポック目のモデルweights.17-0.1049-0.1158.hdf5だったので、これを識別に使います。import numpy as np print(np.argmin(history.history["val_loss"]) + 1) # 17(毎回変わる可能性があります)注意点
Optimizerを
SGDとしていますが、これをAdamなどにするとうまく収束してくれません。
これは、おそらくファインチューニングだからだと思われます。詳しくは以下の記事で。
[TensorFlow] OptimizerにもWeightがあるなんて - Qiita車両を識別させる
冒頭に挙げた各画像を、実際に識別させてみましょう。
predict.pyimport sys def usage(): print("Usage: {0} <input_filename>".format(sys.argv[0]), file=sys.stderr) exit(1) # === 入力画像のファイル名を引数から取得 === if len(sys.argv) != 2: usage() input_filename = sys.argv[1] import numpy as np import tensorflow as tf from tensorflow.keras.preprocessing import image # 特徴量の設定 classes = ["E231-yamanote", "E233-chuo", "E233-keihintohoku", "E233-nanbu", "E235-yamanote"] num_classes = len(classes) img_width, img_height = 128, 128 feature_dim = (img_width, img_height, 3) # === モデル読込み === model = tf.keras.models.load_model("weights.17-0.1049-0.1158.hdf5") # === 入力画像の読み込み === img = image.load_img(input_filename, target_size=(img_height, img_width)) x = image.img_to_array(img) x = np.expand_dims(x, axis=0) # 学習時と同様に値域を[0, 1]に変換する x = x / 255.0 # 車両形式を予測 pred = model.predict(x)[0] # 結果を表示する for cls, prob in zip(classes, pred): print("{0:18}{1:8.4f}%".format(cls, prob * 100.0))入出力例
先程の
predict.pyのコマンドライン引数に画像ファイル名を与えると、識別結果が出力されます。python3 predict.py filename.jpgここで紹介する入力サンプルはすべて自前です。
なお、ここに掲載するために画像の一部を加工していますが、実際の学習・識別時にはオリジナルのまま入力しています。(1) E231系500番台(山手線)
E231-yamanote 99.9974% E233-chuo 0.0000% E233-keihintohoku 0.0000% E233-nanbu 0.0004% E235-yamanote 0.0021%文句なしの正解ですね。
(2) E233系0番台(中央線快速・青梅線・五日市線)
E231-yamanote 0.0023% E233-chuo 97.3950% E233-keihintohoku 0.0101% E233-nanbu 2.5918% E235-yamanote 0.0009%これも全く問題なし。
(3) E233系1000番台(京浜東北・根岸線)
駅名標や人が写っていて、機械にとっては識別が難しそうな画像ですが…。E231-yamanote 2.0006% E233-chuo 0.9536% E233-keihintohoku 34.9607% E233-nanbu 6.5641% E235-yamanote 55.5209%山手線E235系の確率が高くなりました。条件悪いですし横からの画像ですし、やむを得ないか。
ちなみに、なぜこれだけ横からの画像かというと、たまたま自分で京浜東北線の電車を正面から撮った画像がなかったからです…(汗)
(4) E233系8000番台(南武線)
E231-yamanote 0.1619% E233-chuo 7.9535% E233-keihintohoku 0.0309% E233-nanbu 91.7263% E235-yamanote 0.1273%正解の南武線に高い確率をつけましたが、中央線快速と少し迷った様子。もっとも、フォルムはほぼ同じで色違いなだけなのですが、それなら京浜東北線と迷ったっていいのでは。
(5) E235系0番台(山手線)
E231-yamanote 0.0204% E233-chuo 0.0000% E233-keihintohoku 0.0027% E233-nanbu 0.0002% E235-yamanote 99.9767%これは問題ないですね。
その他
E231-yamanote 0.2417% E233-chuo 0.0204% E233-keihintohoku 2.1286% E233-nanbu 0.0338% E235-yamanote 97.5755%本当は3番目が正解なのですが、山手線の新型車と思ってしまったようです。なぜ。。。
E231-yamanote 47.2513% E233-chuo 0.0898% E233-keihintohoku 0.4680% E233-nanbu 6.5922% E235-yamanote 45.5986%2番目が正解なのですが、なぜか山手線を推してきます。単に横からの画像にはE235を推してくる説も?
南武線の確率が少し出ているのは、右端の標識の黄色に反応したのでしょうか(実際どうかはわかりません)。まとめ
Google画像検索で集めた500枚程度の鉄道車両の画像を使って、5種類の車両形式を識別するモデルを学習してみました。
学習済みのモデル (VGG16) の一部を流用して学習することによって、GPUなしのPCでも30分程度でそこそこ識別できるモデルができたようです。間違えるパターンもありますが、計算リソースとデータ量の割には善戦した方ではないかと思います。意外と手軽に作れて面白かったです。本気でやるならもっといろいろな方向からの画像データを集めないとダメですし、車両の部分を切り出すとかも必要だと思います。
顔の判別だったらOpenCVなどで顔の切り出しがすぐにできますが、車両の場合は物体検出のアノテーションからでしょうね…。
元記事の通り150×150でもよかったのですが、VGG16を通すと画像サイズが縦横それぞれ1/32になるので、32の倍数にしておこうかとなんとなく思った次第です。オリジナルのVGG16学習に使われた224×224だとメモリが足りなくなってしまいました(Windows 10でTensorFlowをうまく動かせず、仮想マシン上のLinuxで動かしているためでしょう)。 ↩








- 投稿日:2020-03-24T23:38:59+09:00
Pythonで毎日AtCoder #15
はじめ
前回
今日からC。書くの忘れていたので一問だけです。#15
考えたこと
昨日のB問題の類題です。forループを3つから2つに減らすことでTLEを防いでいます。n ,y = map(int,input().split()) for i in range(n+1): for j in range(n+1): noguti = (y - (i * 10000 + j * 5000)) // 1000 if noguti + i + j == n and noguti >= 0: print(i,j,noguti) quit() print(-1,-1,-1)ちなみに、Python3→1567ms、PyPy3→276msでした。PyPyつよい
まとめ
昨日の類題だったので、すぐにできた。Python3とPyPy3で結構な速度差があるので、for文使うのはPyPyを使ったほうがいいかな。では、また
- 投稿日:2020-03-24T23:23:50+09:00
atcoder よく使う関数, アルゴリズムのリスト, その他高速化の為のtipsなど
atcoderでよく(?)使うアルゴリズムや関数のリスト.
備忘録, コピペ用関数など. 勉強しながら更新します.基本的な処理
辞書関連
辞書の要素をリストにして管理する.
良く忘れるので.
N = int(input()) dic = {} for i in range(N): x, y = map(int, input().split()) dic.setdefault(x, []).append(y)for 文を回すときは
dic : キー
dic.values() : 要素
dic.items() : キーと要素高速化
出力に関して
あんまり出力について気にして無かったが, for分の中で毎回print()すると思っている以上に計算速度に影響している可能性がある.
ex)
ABC089 D問題
上の書き方 : 約 1000ms前後
下の書き方 : 約 500ms前後
と500ms近い差でした.#遅い出力 for i in range(N): #処理 print("計算結果") #速い出力 ans = [] for i in range(N): #処理 ans.append("計算結果") print(*ans, sep = "\n")numpy vs list
脳みそが整理されたら書く.
アルゴリズム
bit全探査(指数関数のオーダーでの全探査)
問題例 atcoder ABC119:C, ABC147:Cなど
$N < 10$程度(底が2なら15くらいまで可能?)なら有効. 2進数ならシフト演算での実装するのが普通そう
参考文献 : http://iatlex.com/python/base_change
bit全探査のアルゴリズムは : https://qiita.com/gogotealove/items/11f9e83218926211083an = int(input()) bit_base = 4#bit_base^nの全探査になる. def Base_10_to_n(X, n):#10進数をbit_base進数に変換 X_dumy = X out = '' while X_dumy>0: out = str(X_dumy%n)+out X_dumy = int(X_dumy/n) return out for i in range(bit_base**n): s = Base_10_to_n(i, bit_base) s = s.zfill(n) for num, j in enumerate(s): #問題に応じた処理を書く print(ans)nCr をpで割った余りの算出の高速化
よく使う
問題例 : atcoder ABC151:E, ABC145:D など公式
$a$は$b$で割り切れるとする.
$$ pが素数の時,\ a / b \equiv a * b^{(p-2)} \ (mod \ p) $$
が成り立つ.
- $a$を$b$で割って得られる整数を$p$で割った余りを求めるという作業は $b^{(p-2)}$をかけて$p$で割った余りを求めるという作業で代替できる.
#階乗のリストを作成する frac = [1] for i in range(N): frac.append(frac[i]*(i+1)%p) #上の公式を用いてcombの計算を行う def comb(n, k, mod): a=frac[n] b=frac[k] c=frac[n-k] return (a * pow(b, mod-2, mod) * pow(c, mod-2, mod)) % modunion find
要素をいくつかの木構造で分けて管理するような場合に有効. (ABC 157 D問題とか)
参考文献:?ホンdef find(x):#xの親を見つける if par[x] < 0: return x else: par[x] = find(par[x]) return par[x] def unite(x,y):#要素xとyを併合させる x,y=find(x),find(y)#xとyの親の検索 if x!=y:#親が異なる場合併合させる if x>y: x,y=y,x#小さい方をxとする. これにより要素の値が小さいものを優先して木の根とする. par[x]+=par[y] #値を無向木の要素数の和にする. par[y]=x #枝側は根の位置を格納 def same(x, y):#要素xと要素yが同じ無向木に所属しているかを判定する return find(x) == find(y)#同じ値を持つか否か def size(x):#要素xが所属する無向木の大きさを返す return-par[find(x)] n = int(input()) #要素の数 par = [-1] * n #parは木の根の情報を持つ配列, xが根元ならpar[x]はその無向木に所属する要素の数を, そうでない場合は所属する根元のparにおける位置を示す数値が格納される.
- 投稿日:2020-03-24T23:02:18+09:00
tkinterで背景が透過するFrameを作る【Python】
tkinterで背景が透明なFrameを作る。
環境
Windows10
Python3.7※本記事ではWin環境のみ扱います。他OSでは正常に動かない可能性が高い。
サンプルコード
from tkinter import ttk import tkinter root=tkinter.Tk() root.wm_attributes("-transparentcolor", "snow") #root.attributes("-alpha",0.5) ttk.Style().configure("TP.TFrame", background="snow") f=ttk.Frame(master=root,style="TP.TFrame",width="400",height="300") f.pack() label=ttk.Label(master=root,text="薄くならないで…",foreground="red",background="snow") label.place(x=150,y=150) root.mainloop()
root.wm_attributesのtransparentcolorに透過させたい色を指定する。今回はsnowに設定。
これより、backgroundがsnowなfとlabelの背景が透明になる。実行結果
FrameとLabelの背景が透過して後ろの壁紙が見えています。若干Labelにsnowが見えていますが、これはどうにもなりません(気持ち悪い)-alphaオプション
上のコードの
root.wm_attributes("-transparentcolor", "snow")を
root.attributes("-alpha",0.5)のようにすると確かに-alphaの値で透明度を[0,1]で変更することができます。
しかし、
このようにrootにあるLabelなどオブジェクト全体に透過率が適用されるので注意が必要。参考
【Python】【TkInter】透明なFrameを生成する
↑Mac環境下ではこの記事の内容で再現できるそうです(手元に環境がないので未確認)。Linuxでも再現できないか調べはしたが、結局解決できず...
上のサンプルコードをそのまま手元のubuntu18.04.4環境下で実行すると、Traceback (most recent call last): File "hoge.py", line 5, in <module> root.wm_attributes("-transparentcolor", "snow") File "/usr/lib/python3.6/tkinter/__init__.py", line 1788, in wm_attributes return self.tk.call(args) _tkinter.TclError: bad attribute "-transparentcolor": must be -alpha, -topmost, -zoomed, -fullscreen, or -typeとなった。
- 投稿日:2020-03-24T22:59:25+09:00
10分間で画像認識モデル構築byKeras~機械学習への第一歩~
はじめに
この記事を読むと?
難解でとっつにくいイメージのある機械学習について、実際にコードを動かしながら、最短で体験することができます。
なぜこの記事を書いたのか
機械学習やディープラーニング学ぶ方(またはこれから始める方)が増えています。
今は優れた書籍やオンライン上の教材が豊富にあり、多様な選択肢があります。素晴らしい時代ですね。
しかし残念ながら、何かしらの教材で挑んでみたものの、実際に機械学習を実装する手前で挫折してしまう方も少なくないと感じています(そしてそれは本人の能力のせいではなく、わずかな周囲の環境やタイミングといった運によるものが大きいと思います)。
機械学習を習得するためには、PythonやRといったプログラミング言語の習得はもちろん、ある程度の数学の素養や、環境構築が必要です。それらでつまずき、「自らの手で機械学習を動かす」という経験をできないのはとても惜しいことです。そこで私が提案したいのは、本格的な勉強を始める前にまずざっとでいいので、「ゴールを体験して全体像を概観する」ということです(=機械学習の場合はコピペで良いのでモデルを構築してみること)。
ゴールの見えないマラソンを続けることは非常に困難ですが、ゴールに至るまでの道筋が明確に見えてさえいれば、その足取りは確かになることでしょう。
また、最初にゴールを意識することで学習効率が高まるという効果も期待できます。「機械学習」や「ディープラーニング」と聞くと難しそうですが、実はモデルを作るだけなら簡単にできます。環境構築も不要です。
忙しいあなたの時間を、今日という一日の10分間だけ機械学習を学ぶこと使ってみませんか?
対象者
・機械学習に興味がある人
・これから機械学習の勉強を始める人
・勉強を始めたけど序盤で躓き、中々アウトプットまで進めない人環境
・Google Chrome
・Google Colaboratory
(Chromeブラウザさえ開ければ、PCはMacでもWindowsでも何でも大丈夫です)セットアップ
今回はローカルに環境を構築せず、ブラウザ上から「Google Colaboratory」というクラウド実行環境を使います。
初めて聞く方も身構えないでください!Colaboratoryとは「ブラウザから簡単に使えて、無料の、高性能の機械学習・ディープラーニングを実行できる環境」です。流石Google様です。
高価なGPU機材が必要なイメージがあるかもしれませんが、必ずしもそうではないんですね。Colaboratoryへサインアップ
さあ、Colaboratoryを始めましょう!
Colaboratoryは個人のGoogleアカウントに紐づいています。
下記URLから、ご自身のGoogleアカウントでColaboratoryでログインしてください。これで完了です!!!なんと、Googleアカウントでログインするだけなんですね。なんて簡単でしょうか。
ファイル作成
さて、次は実際にコードを書くための場所を作成しましょう。
といっても、驚くほど簡単なので安心してください。
スクショの通り、画面右上の「ファイル」タブから「ノートブックを新規作成」をクリックしてください。
これで作成が完了しました!
このままでも良いですが、せっかくなのでファイル名を変えてみましょう。
「firstStep.ipynb」とでもしましょうか。(面倒な方はスキップしてOKです)
やってみよう!~kerasで画像認識~
さあ、いよいよ本番です。機械学習の世界へ入門してみましょう。
今回は「ゴールを経験する」ということが目的なので、コードをコピペするだけでOKです。
コードの説明の意味は今は理解せずとも良く、「ふーん」とでも聞き流してください。基本モジュールのインポート
まず、各種モジュールをインポートしましょう。
import tensorflow as tf import keras import numpy as np from matplotlib import pyplot %matplotlib inline import os import distutils if distutils.version.LooseVersion(tf.__version__) < '1.14': raise Exception('This notebook is compatible with TensorFlow 1.14 or higher, for TensorFlow 1.13 or lower please use the previous version at https://github.com/tensorflow/tpu/blob/r1.13/tools/colab/fashion_mnist.ipynb')機械学習を勉強している方ならおなじみですね。
tensorflowモジュールとnumpyモジュールを、それぞれtf,npと扱いやすい名前をつけてインポートしています。tensorflowとkerasをそれぞれインポートしています。実は
import kerasは省略しても今回のコードは問題なく動作します。そもそもkerasはtensorflowのラッパー言語、つまりtensorflowを簡単に扱えるようにしたものですので、バックエンドではtensorflowが動いています。できるようにしたものです。分かりやすいのでわざわざkerasもインポートしています。numpyは、機械学習の膨大な計算を高速に行うためのモジュールです。numpyのおかげで機械学習やデータサイエンスはPythonが主流になりました。
matplotlibは出力結果をグラフ等で可視化するためのモジュールです。
osモジュールはMacのterminalやWidowsのcommand lineのような、OSっぽいことを実行できるようになります。ディレクトリ操作とかですね。
distutils?これは耳慣れない方も多いでしょう。Python公式ドキュメントで調べてみましょう。
Distutilsの紹介-Python3.8.0ドキュメント
disututilsモジュールはPython標準のパッケージ管理ツールです。
import distutilsの次のif文は、TensorFlowのver.を管理しています。
(if文にこんな使い方あるんですね。面白い〜)データセットの準備
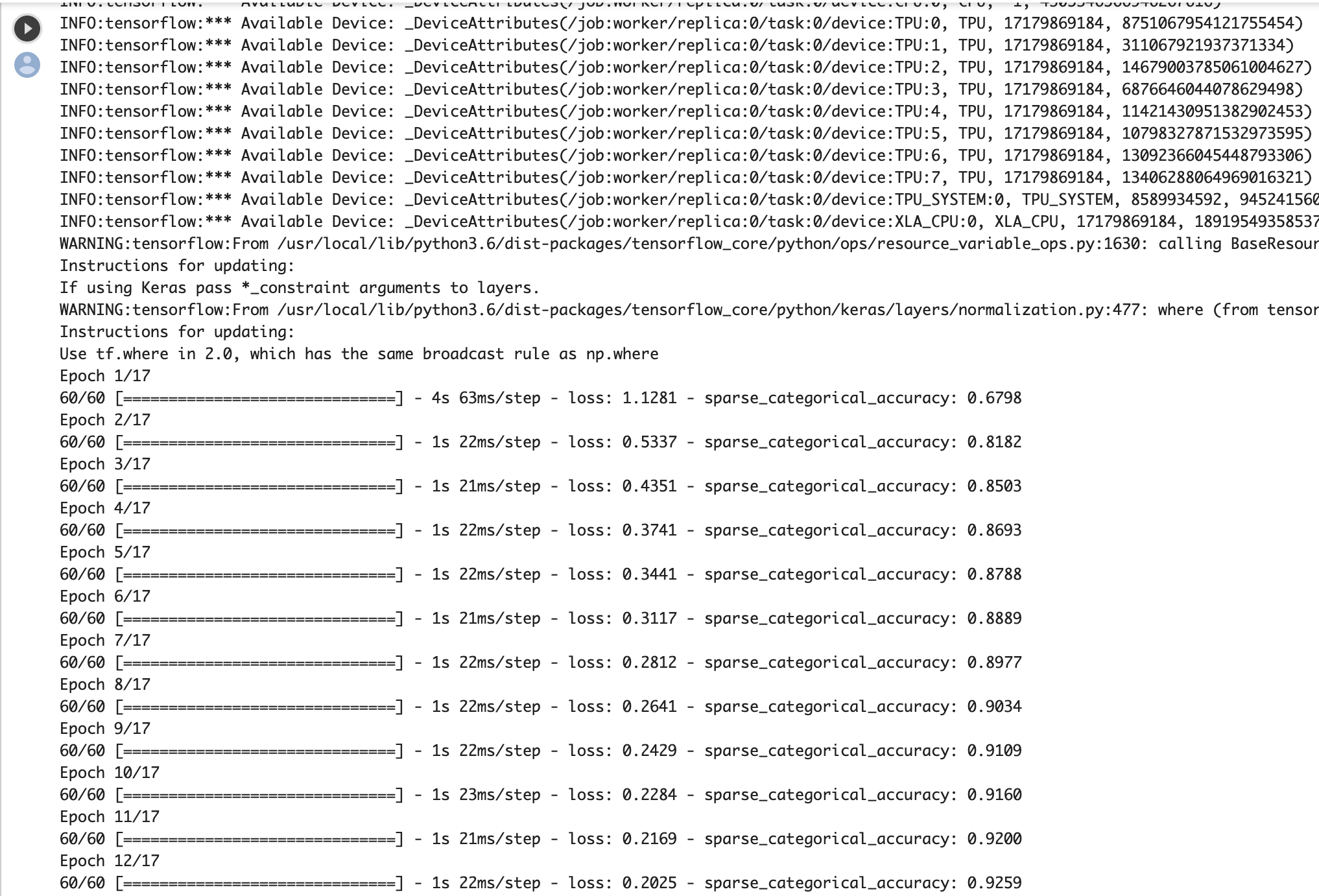
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data() # add empty color dimension x_train = np.expand_dims(x_train, -1) x_test = np.expand_dims(x_test, -1)今回はtensorflowに備え付けのサンプル用のデータセットを使うのうで、別途インポートする必要はありません。
Python中級者の書き方として、複数の変数にまとめて値を代入することができます。これも機械学習を勉強している方にはお馴染みの書き方ですね。モデルの定義
def create_model(): model = tf.keras.models.Sequential() model.add(tf.keras.layers.BatchNormalization(input_shape=x_train.shape[1:])) model.add(tf.keras.layers.Conv2D(64, (5, 5), padding='same', activation='elu')) model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2,2))) model.add(tf.keras.layers.Dropout(0.25)) model.add(tf.keras.layers.BatchNormalization(input_shape=x_train.shape[1:])) model.add(tf.keras.layers.Conv2D(128, (5, 5), padding='same', activation='elu')) model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2))) model.add(tf.keras.layers.Dropout(0.25)) model.add(tf.keras.layers.BatchNormalization(input_shape=x_train.shape[1:])) model.add(tf.keras.layers.Conv2D(256, (5, 5), padding='same', activation='elu')) model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2,2))) model.add(tf.keras.layers.Dropout(0.25)) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(256)) model.add(tf.keras.layers.Activation('elu')) model.add(tf.keras.layers.Dropout(0.5)) model.add(tf.keras.layers.Dense(10)) model.add(tf.keras.layers.Activation('softmax')) return model層毎にドロップアウトとバッチ正規化を施した、3層から成るCNNでモデルを構築します。
(強そうな用語の連続パンチですね!ここでは一旦スキップしてください)モデルの訓練
訓練データを使って、モデルを訓練しましょう。
下記コードを実行してみると・・・?resolver = tf.contrib.cluster_resolver.TPUClusterResolver('grpc://' + os.environ['COLAB_TPU_ADDR']) tf.contrib.distribute.initialize_tpu_system(resolver) strategy = tf.contrib.distribute.TPUStrategy(resolver) with strategy.scope(): model = create_model() model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3, ), loss='sparse_categorical_crossentropy', metrics=['sparse_categorical_accuracy']) model.fit( x_train.astype(np.float32), y_train.astype(np.float32), epochs=17, steps_per_epoch=60, validation_data=(x_test.astype(np.float32), y_test.astype(np.float32)), validation_freq=17 ) model.save_weights('./fashion_mnist.h5', overwrite=True)ギュイーンとEpochが1/60から60/60になるまで更新されていきます!かっこいい!
これは何が起こっているのかというと、実際にニューラルネットワークで学習が行われていく要素を可視化してくれているんですね(なので、非表示にすることも可能です)。
動画で掲載できなくて残念ですが、AIっぽくてとてもテンションが上がる光景です。
コードをコピペするだけで簡単に実行できるので、是非ご自分の目で確かめてください。訓練済みモデルでファッション画像を予測
前節を経て、今の我々は訓練済みのモデルを持っています。
早速使ってみましょう!LABEL_NAMES = ['t_shirt', 'trouser', 'pullover', 'dress', 'coat', 'sandal', 'shirt', 'sneaker', 'bag', 'ankle_boots'] cpu_model = create_model() cpu_model.load_weights('./fashion_mnist.h5') def plot_predictions(images, predictions): n = images.shape[0] nc = int(np.ceil(n / 4)) f, axes = pyplot.subplots(nc, 4) for i in range(nc * 4): y = i // 4 x = i % 4 axes[x, y].axis('off') label = LABEL_NAMES[np.argmax(predictions[i])] confidence = np.max(predictions[i]) if i > n: continue axes[x, y].imshow(images[i]) axes[x, y].text(0.5, 0.5, label + '\n%.3f' % confidence, fontsize=14) pyplot.gcf().set_size_inches(8, 8) plot_predictions(np.squeeze(x_test[:16]), cpu_model.predict(x_test[:16]))すると、下記のような結果が出力されます。
10種類の服のジャンルを予測、分類することができました!しかもなかなか高精度ですね。終わりに
お疲れ様でした。そしておめでとうございます!
これであなたは「機械学習のモデルを実装したことがある」と言う資格があります。
実はコード自体は短いし、実行するだけなら難しくないんですね。
「機械学習のプログラミングってこんな感じか〜」となんとなく感じて頂けたでしょうか。最後に、今回の記事の概要を復習しましょう。
・機械学習の勉強はまずモデルを構築してみるのがおすすめ
・モデル構築だけなら機械学習は超簡単
・15分間でkerasで画像認識をしてみよう(必要なのはChromeが開けるPCのみ)次は是非、機械学習の仕組みやPythonのコードについて理解することにチャレンジしてみてください。
参考文献
Fashion MNIST with Keras and TPUs-SeedBank
本記事のコードは「SeedBank」より引用させて頂いています。


- 投稿日:2020-03-24T22:57:16+09:00
5代血統表内に漢字の馬名が含まれるここ最近の競走馬を調べる【スクレイピング】
はじめに
(以下、競馬用語を注釈無しで使用していきますのでご了承下さい。)
なんとなく5代血統表に漢字の馬名が入っている馬がどれくらいいるのか気になったので競馬データベースサイト「JBISサーチ」のページをスクレイピングして調べてみました。
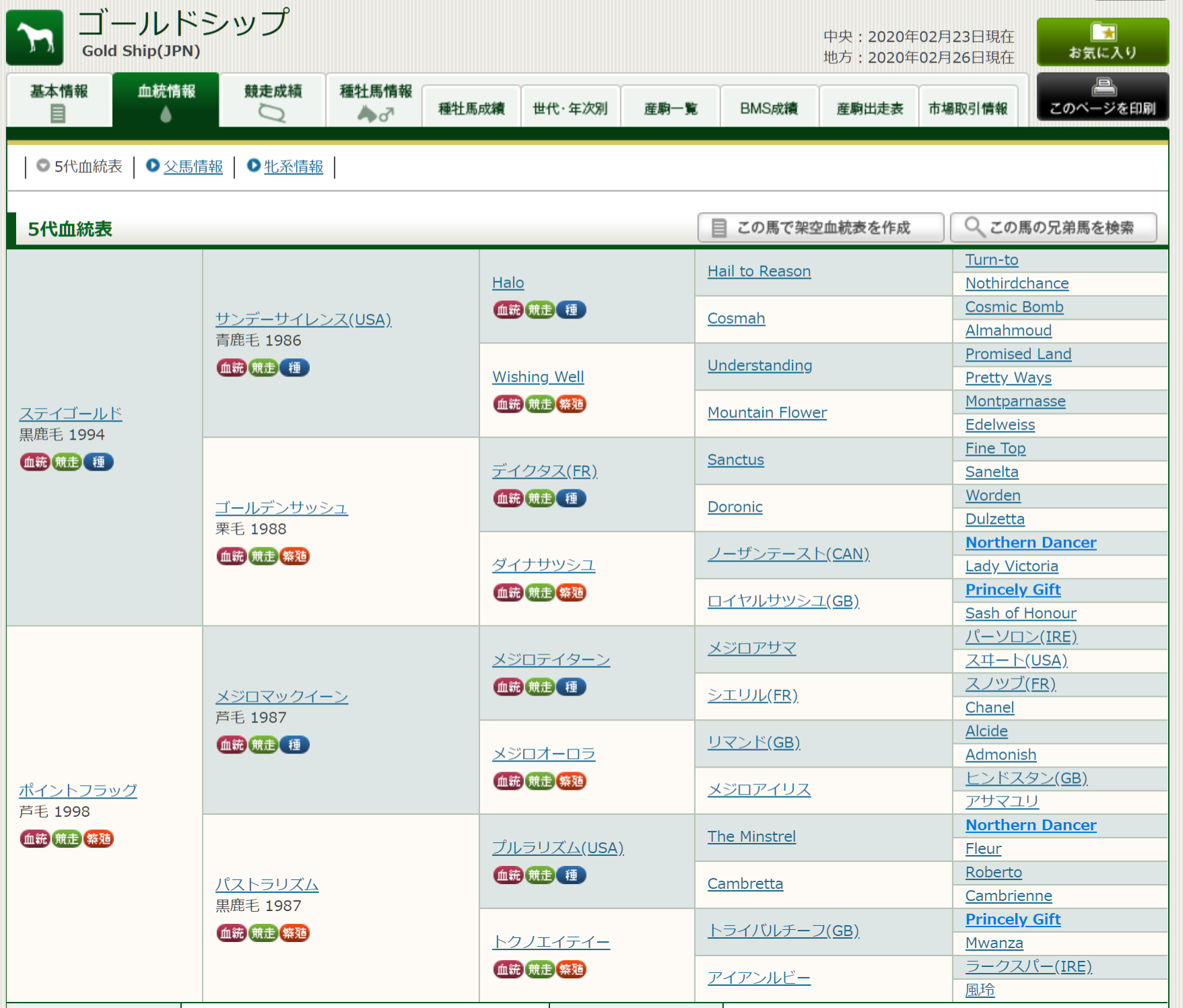
近年活躍した競走馬で、5代血統表内に漢字の馬名がある馬といえばゴールドシップが一番有名でしょう。
5代母が1959年生の「風玲」という馬です。昔は競走馬名にカタカナ使用の制限があっても、繁殖登録名には漢字が使えたという時代があった(60年くらい前まで?)ので、競走馬時代と異なる名で繁殖入りした馬や、輸入された際に漢字の名前をつけられた馬がいます。
人間よりも世代交代のサイクルが早いことや、血統の淘汰などを考えると、未だに5代以内に漢字の馬名がある馬は貴重と言えるでしょう。調査対象
今回はゴールドシップ号と同じ2009年生まれの馬から2019年まで生まれた馬について調査対象にし、「風玲」のような漢字のみの馬名だけではなく「カバーラツプ二世」のような一部に漢字を含む馬名についてもマッチ対象にします。
準備
使用環境・ツール等
Windows 10
Python3.7.6(Anaconda)
Scrapy
ScrapyCloud
MongoDB
Metabaseなど取得・保存する情報
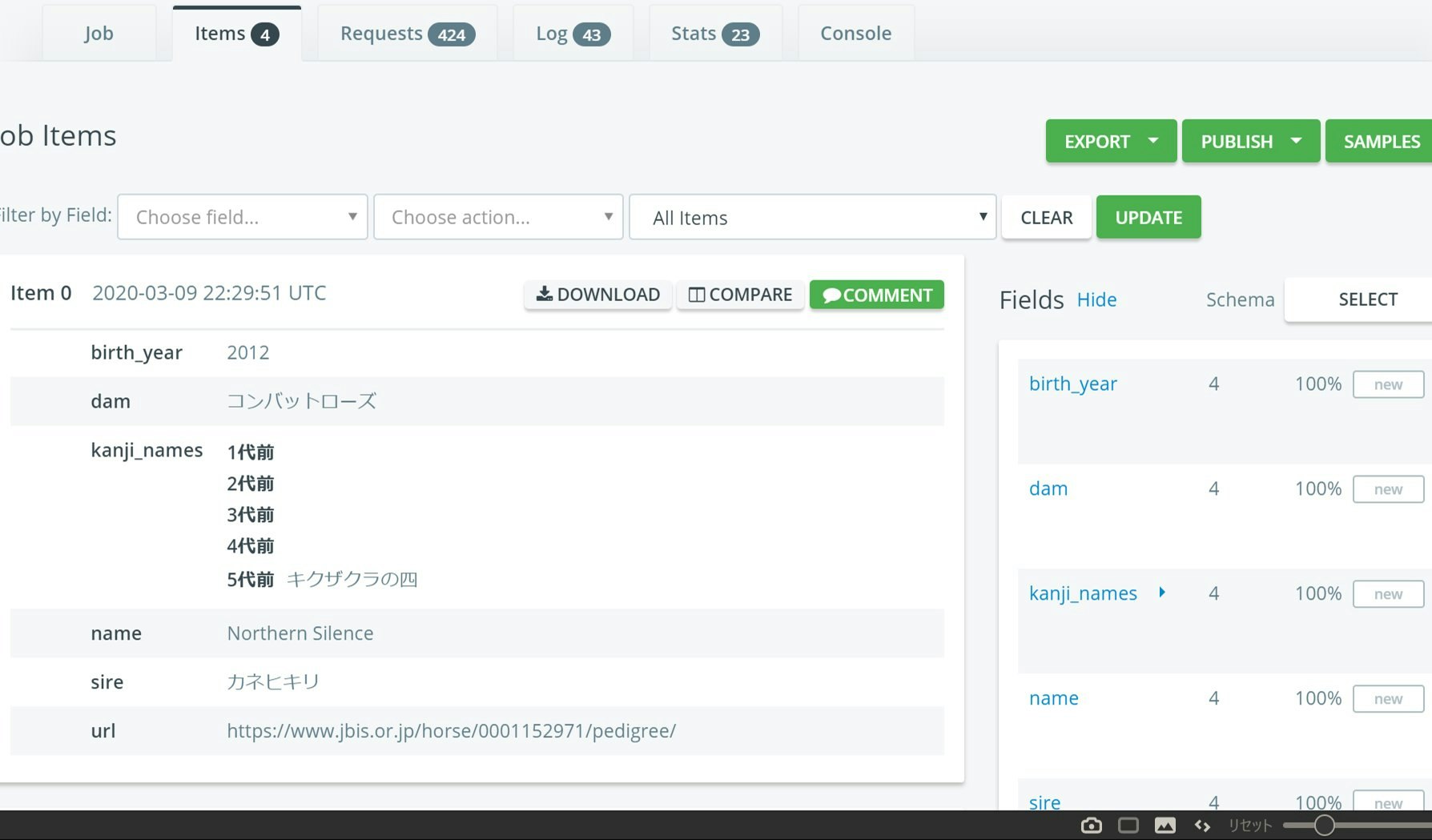
血統表内の馬名に漢字があった場合は
その馬の
- 馬名・誕生年・父・母馬名・血統表のURL など基本的な情報
- n代前ごとの漢字馬名のリスト
についての情報を保存します。
各馬の血統表ページにはJBISサーチの検索結果ページからクロールし、5代血統表内の情報をスクレイピングします。
ページ構造
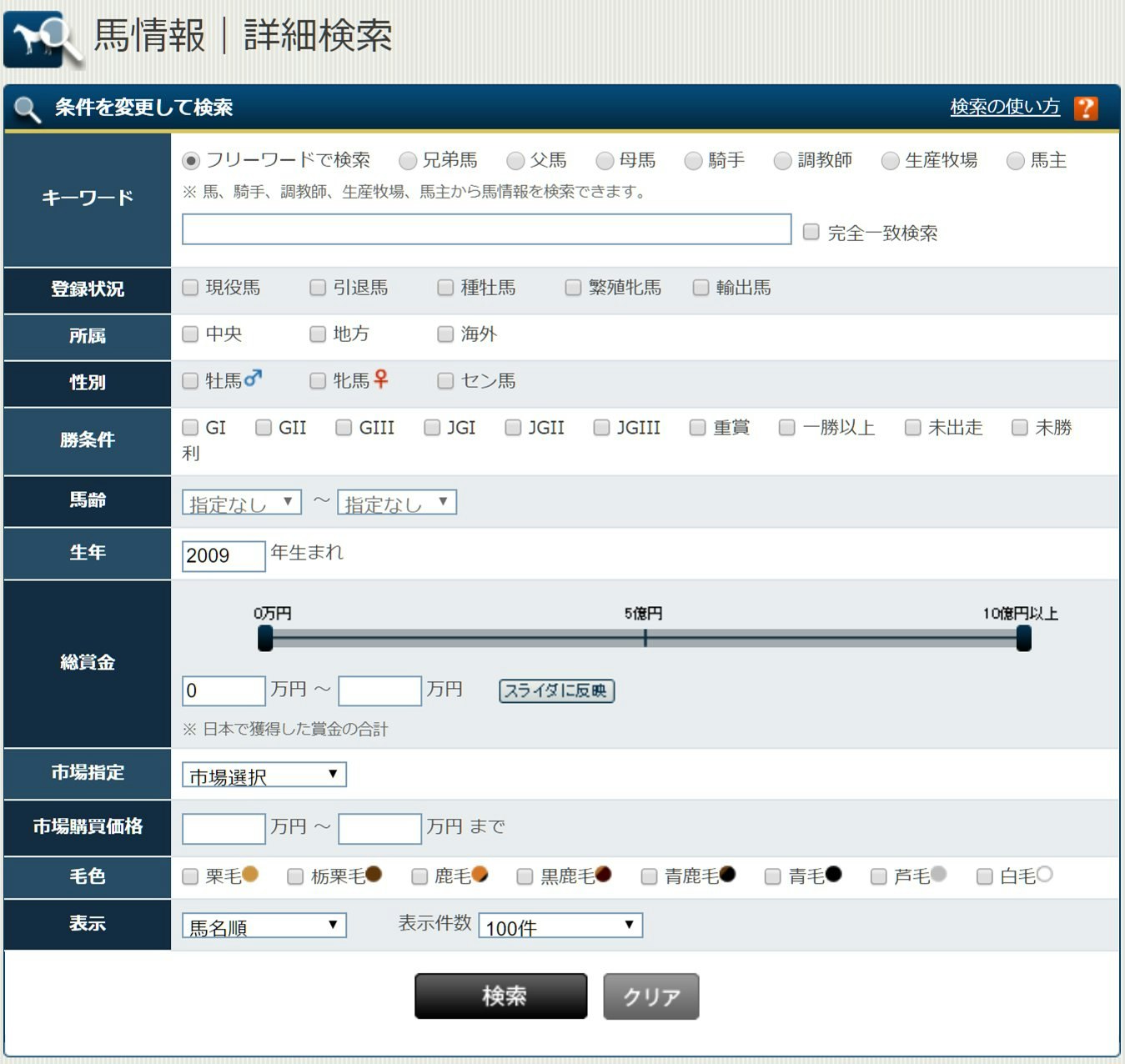
検索結果ページ
まずこちらが検索窓です。
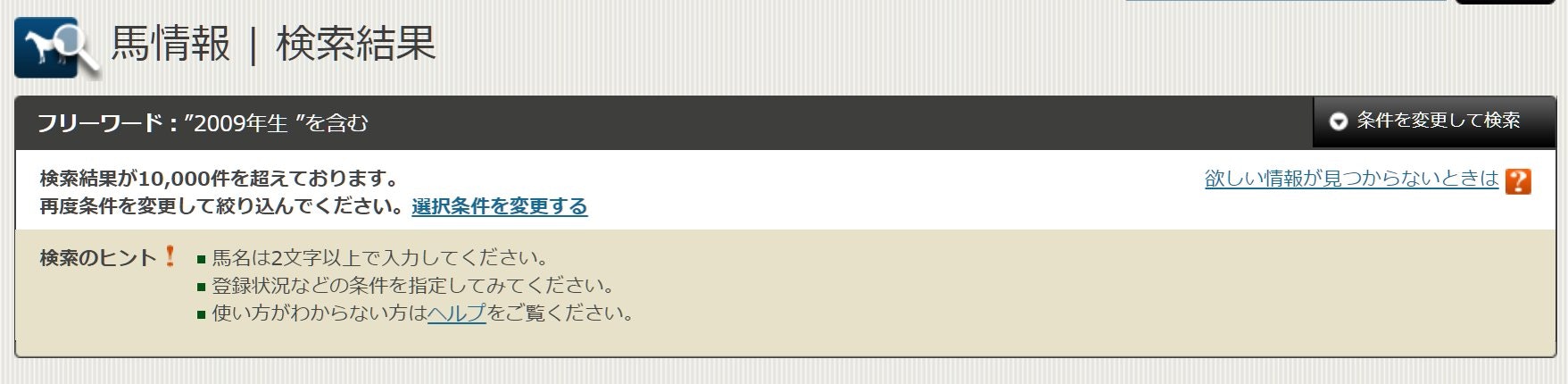
今回は2009年~2019年生まれの馬が対象なのでとりあえず「生年」に「2009」と入れてみますが…
検索結果が10000件を超えるとNGがでてしまいます。色々な条件を指定することが出来ますが、今回は生年に加え性別を指定していきたいと思います。
軽種馬の生産頭数を検索してみた結果や、性比に偏りは無さそうなことを考えると、この2つ条件を組み合わせていくことで、対象期間内のすべての馬の情報を検索結果からたどることができそうです。
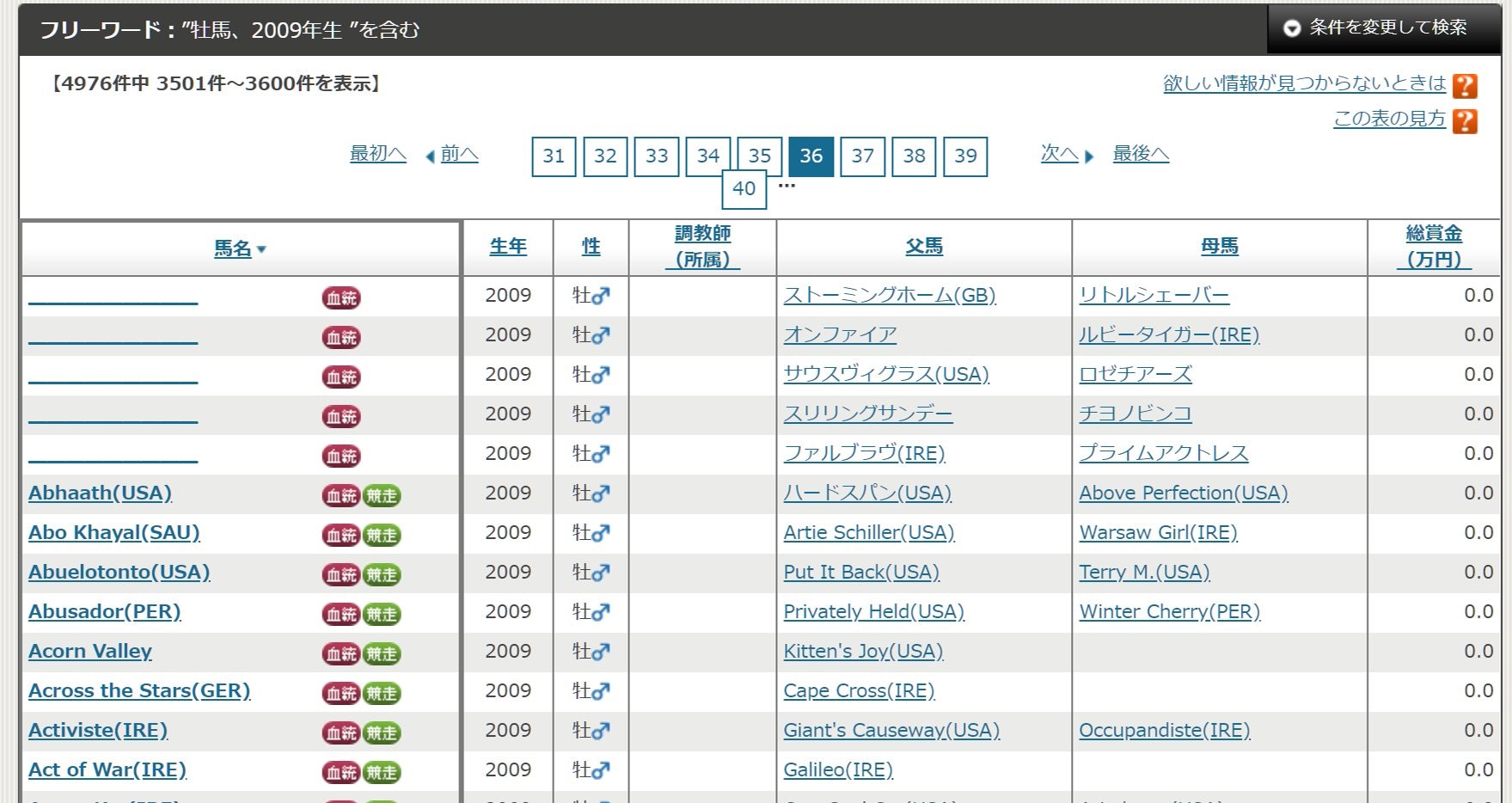
この「牡馬、2009年生」の検索結果(100件表示)を馬名で昇順ソートすると、36ページ目からアルファベットの名前がずらりと並び、千数百件ものアルファベット馬名が登録されていることがわかります。
これらの外国馬は基本的にクローリング対象から除外しようと思います。
が、検索オプションで「輸出馬」を指定することができるため、そちらを指定して検索結果に出てきた馬に関してはクローリング対象に含めたいと思います。(なので、日本から輸出された馬の子孫に該当する馬があった場合は拾えないということになります。が、いたとしても誤差程度…と思いたい…)
クローリング時のリクエスト数やプログラムの実行時間の短縮も考えると無駄撃ちはなるべく減らしていきたいです。検索結果ページのURLから不要なクエリパラメータを取り除くとこんな感じになります。
https://www.jbis.or.jp/horse/result/?sid=result&sex=(性別)&birth=(生年)&sort=name&items=100&page=1&order=A
性別のパラメータは牡馬がsex_1,牝馬がsex_2,セン馬がsex_3です。
あとは誕生年・ソート=名前順・100件ずつ表示・ページ番号・並びが昇順(ASC)です。上記のURLを元に、クエリパラメータの性別・生年の部分を変更したURLを生成してクローリングの基点として使用します。
クローリングの動作としては
1.事前に用意した、基点となるURLのページを取得
2.各馬の血統表ページを取得
3.2がすべて終わったら「次へ」部分のURLのページを取得し2に戻る
4.「次へ」が無くなったら1に戻る
といった感じです。
2については前述した外国馬(馬名がアルファベットの馬)を除外するため、少々ややこしくなっています。
どんな馬でもクローリング対象にするのであれば検索結果の馬名の横の赤い「血統」アイコンのリンク先をクロールすれば用が足りるのですが今回は、1.馬名の先頭がアルファベットで始まるかどうかを判定する
2.アルファベットで始まらない場合、馬名部分のURL(\https://www.jbis.or.jp/horse/(各馬ごとの識別番号)/) に /pedigree/ を足して(https://www.jbis.or.jp/horse/(各馬ごとの識別番号)/pedigree/) にして血統表のページを取得する。という指定をします。
参考:【Scrapy】抜き出したURLを修正・加工する
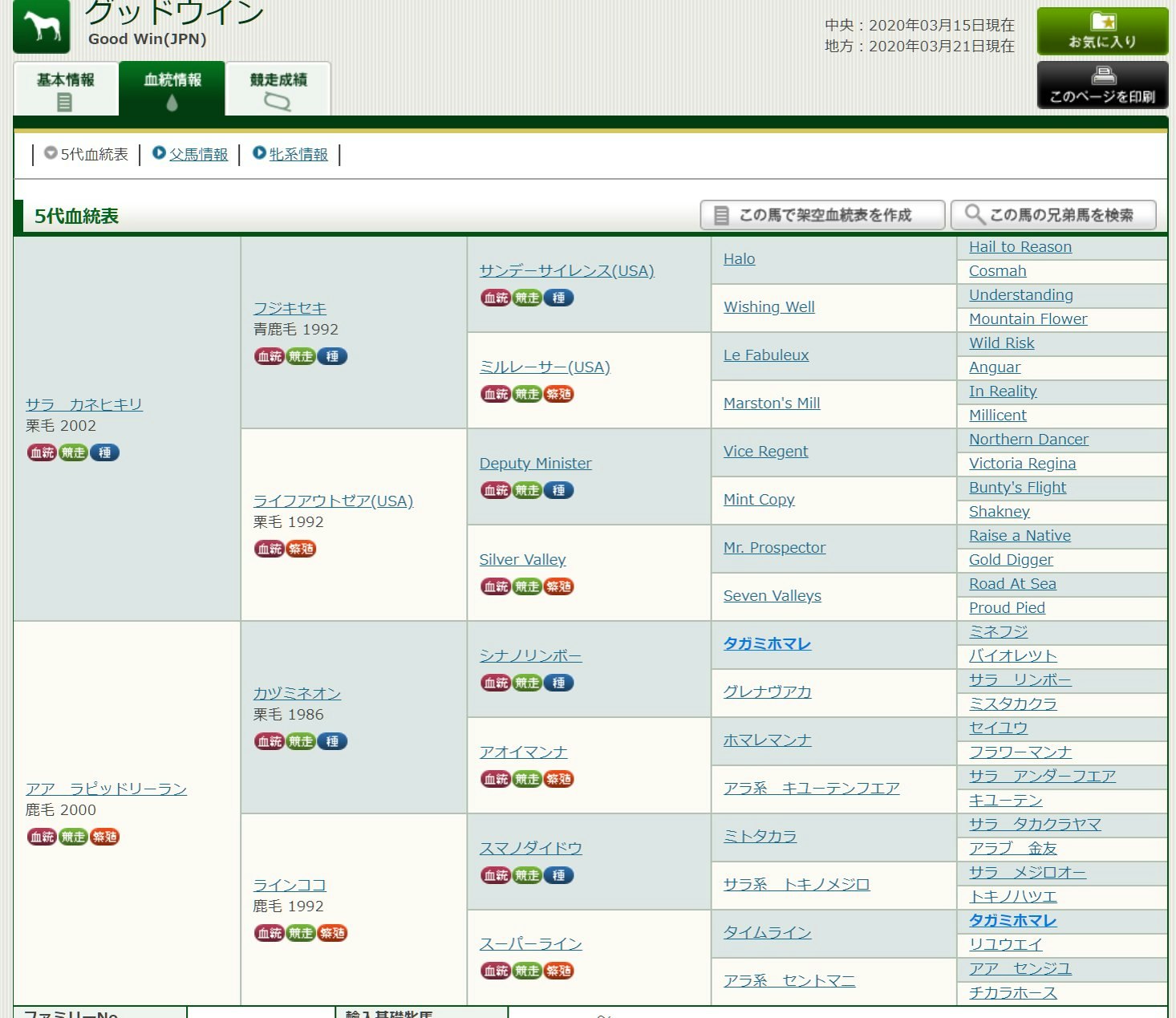
血統表ページの詳細
血統表のtableの
th[rowspan="16"] が 父母(1世代前)
td[rowspan="8"] が2世代前
td[rowspan="4"] が3世代前
td[rowspan="2"] が4世代前
td:not([rowspan="8"]):not([rowspan="4"]):not([rowspan="2"])が5世代前
といったCSSセレクタで指定できます。それぞれのテーブルのセル内のリンクテキストが漢字の正規表現パターンにマッチするか調べ、マッチする場合は世代ごとのリストに格納します。
漢字の正規表現パターンがマッチした場合は
世代ごとのリストをvalueとして持つdict
ページの上部のh1属性からその馬の「名前」
th[rowspan="16"]部分から「父」・「母」の名前
そのページの「URL」
その馬の「誕生年」を保存します。
誕生年に関しては血統表ページ内には存在しないので、リクエストヘッダーのreferrerから検索結果ページのクエリパラメータのbirthの値を取得します。実践
Scrapy
今回はScrapyフレームワークを使ってクロール・スクレイピングします。
基本的なセットアップ・プロジェクトなどは省略。クローラー本体。色々と命名が適当すぎますが…
kanji_pedigree.pyimport scrapy import urllib.parse from scrapy.spiders import CrawlSpider, Rule from jbis.items import HorseItem from scrapy.linkextractors import LinkExtractor from . import url_generator class KanjiPedigreeSpider(CrawlSpider): name = 'kanji_pedigree' allowed_domains = ['www.jbis.or.jp'] start_urls = url_generator.main() #開始するURLを生成する関数 rules = [ Rule(LinkExtractor(restrict_css='.next a')), #リンクの正規表現パターン Rule(LinkExtractor( allow=r'.*/horse/[0-9].*', restrict_css=r'th.cell-br-no > a', restrict_text=r'^(?![a-zA-Z]).+$', #アルファベットで始まる馬名を除外 process_value= lambda x:x + "pedigree/" #URLの最後にpedigree/くっつけて直接血統表ページに飛ぶ ),callback='parse_pedigree'), ] # pattern = '.*[\u2E80-\u2FDF\u3005-\u3007\u3400-\u4DBF\u4E00-\u9FFF\uF900-\uFAFF\U00020000-\U0002EBEF]+.*' #漢字の正規表現パターン def parse_pedigree(self, response): kanji_names = {} one_gen_ago = response.css('th[rowspan="16"] > a::text').re(self.pattern) two_gen_ago = response.css('td[rowspan="8"] > a::text').re(self.pattern) three_gen_ago = response.css('td[rowspan="4"] > a::text').re(self.pattern) four_gen_ago = response.css('td[rowspan="2"] > a::text').re(self.pattern) five_gen_ago = response.css('td:not([rowspan="8"]):not([rowspan="4"]):not([rowspan="2"]) > a::text').re(self.pattern) kanji_names['1代前'] = one_gen_ago if len(one_gen_ago) != 0 else None kanji_names['2代前'] = two_gen_ago if len(two_gen_ago) != 0 else None kanji_names['3代前'] = three_gen_ago if len(three_gen_ago) != 0 else None kanji_names['4代前'] = four_gen_ago if len(four_gen_ago) != 0 else None kanji_names['5代前'] = five_gen_ago if len(five_gen_ago) != 0 else None if list(kanji_names.values()).count(None) != 5: # item = HorseItem() item['name'] = response.css('h1.hdg-l1-02::text').get() #馬名 item['sire'] = response.css('tr:nth-child(1) a::text').get() #父馬 item['dam'] = response.css('tr:nth-child(17) th a::text').get()#母馬 item['kanji_names'] = kanji_names #血統表内の漢字を含む馬名 item['birth_year'] = int(urllib.parse.parse_qs(response.request.headers.get('Referer', None).decode('utf-8'))['birth'][0]) item['url'] = response.url yield itemurl_generator.pyimport urllib.parse START_YEAR = 2009 # END_YEAR = 2009 ITEMS = '100' def main(): url = 'https://www.jbis.or.jp/horse/result/?sid=result&page=1&order=A&' return [url + urllib.parse.urlencode({'items':ITEMS,'sex':'sex_' + str(sex_param),'birth':str(year)}) for year in range(START_YEAR,END_YEAR+1,1) for sex_param in range(1,4,1)] # 輸出馬については下記を使用 # return [url + urllib.parse.urlencode({'entry':'entry_5','items':ITEMS,'sex':'sex_' + str(sex_param),'birth':str(year)}) for year in range(START_YEAR,END_YEAR+1,1) for sex_param in range(1,4,1)]items.pyimport scrapy class HorseItem(scrapy.Item): name = scrapy.Field() sire = scrapy.Field() dam = scrapy.Field() kanji_names = scrapy.Field() birth_year = scrapy.Field() url = scrapy.Field()settings.pyBOT_NAME = 'jbis' SPIDER_MODULES = ['jbis.spiders'] NEWSPIDER_MODULE = 'jbis.spiders' # Obey robots.txt rules ROBOTSTXT_OBEY = True DOWNLOAD_DELAY = 3 # ページダウンロード間隔3秒空ける。 FEED_EXPORT_ENCODING = 'utf-8' # スクレイピング結果を出力する際にUTF-8でエンコードする。Scrapy Cloud
今回のプログラムはリクエスト数が多く、実行時間がかかると思われるため、プログラムの実行についてはScrapy Cloudというホスティングサービスを利用しました。
無料枠だと連続1時間しか実行できないのでわざわざ有料プラン(1ヶ月1000円弱)に登録してしまいました…
登録後にマイページのCode&Deploysという項目のページを見ると
$ pip install shub $ shub login API key: hogehoge $ shub deploy fugafugaというコマンドラインの見本みたいのがあり、そのままコピペすればデプロイ出来そうに見えますが、requirements.txtやyamlの作成が必要でした。
参考:【Python】Scrapy Cloudにデプロイする
をデプロイしたSpiderを実行すると
スクレイピング結果がitemsタブにモリモリ保存されていきます。保存されたitemはJSON、CSVなどの形式で全部まとめて・又は1アイテム単位で保存できるようになっています。一度、setting.pyでHTTPキャッシュ設定をTrueにしたままデプロイしてしまったのですが、途中でScrapyCloudの実行環境のストレージ容量がいっぱいになってしまいエラーになってしまいました。なので大規模なスクレイピングをする場合はオフにしておいたほうがいいです。
MongoDB
保存したJSONをMongoDBにimportします。
MongoDB CompassでJSONファイルを選んでimportを試みるとうんともすんとも言わず。
JSONと言っても行末にカンマを使ってはいけないなどMongo独自のルールがあるらしい。
参考:公式ドキュメントここはしょうがないのでPythonでJSONを読み込む→MongoDBに保存というプログラムを書いて無事JSONのデータをMongoDBのコレクションに加えることができました。
Metabase
Metabaseというデータ可視化ツールが面白そうなので使ってみた。
参考:MetabaseをWindowsにインストールする
MongoDB上のデータをきれいに表示してくれます。以下、表やグラフの画像はMetabaseの表示をスクショしたものです。結果
想定外のマッチ
ローカル環境で動作を確認している際に気づいたが、いわゆる「サラ系」「アラ系」の血が入っている馬だと、血統表内の馬名の前に「サラ系」「アラ系」などの文字が混じっていて"系"の部分が漢字としてマッチしてしまいます。
これに関してはそれ程数が多くないだろうと判断し結果からは手動で除外しました。
詳細
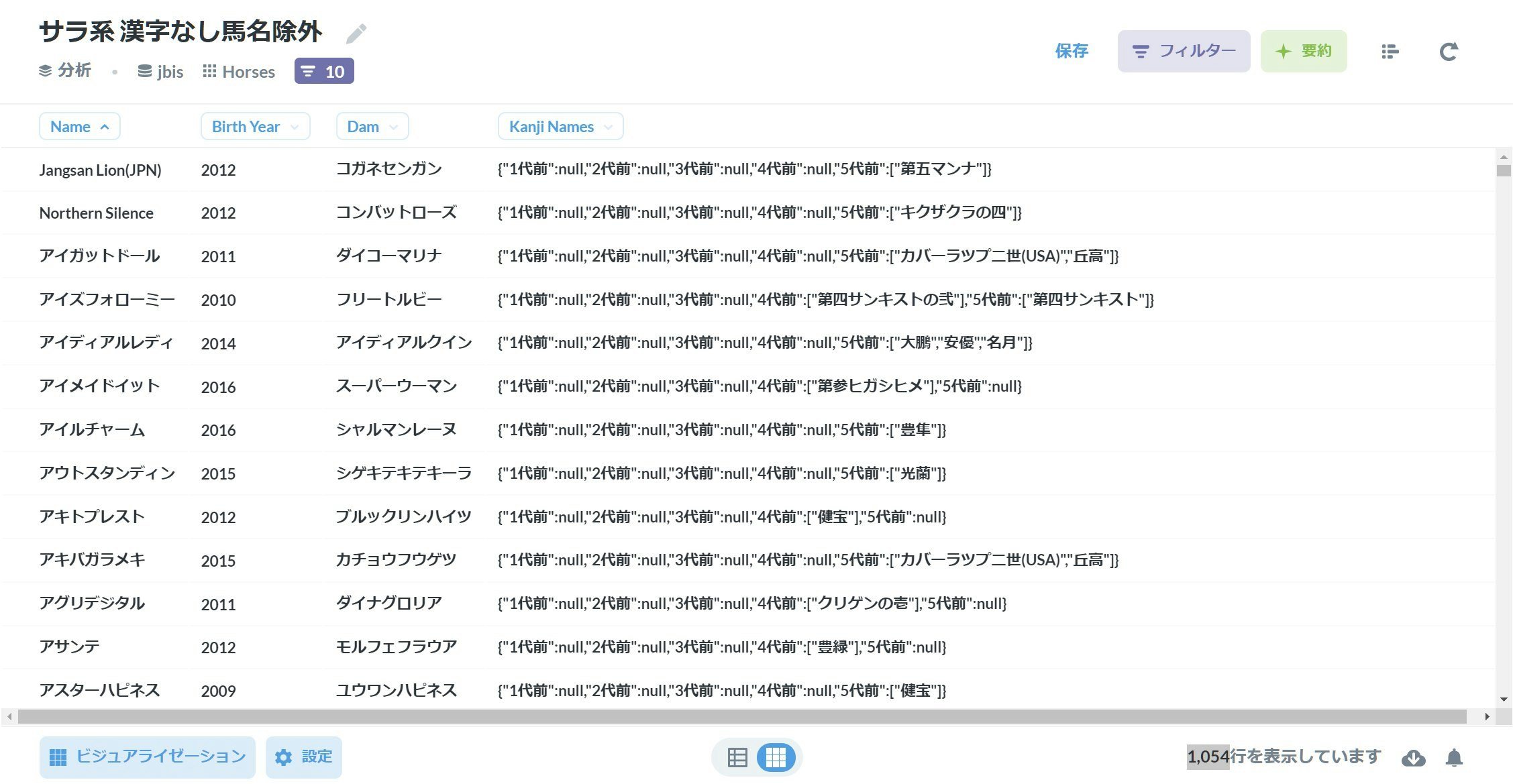
上記の条件にあてはまり、尚且つ血統表内に漢字馬名を含まない馬を手動で除外し、輸出馬の検索結果ページからスクレイピングしたアイテムを加えた結果、
2009年から2019年に生まれ血統登録された馬のうち、5代血統表内に漢字を含む馬名があるのは1054頭いるということがわかりました(無論、私が設けた条件に漏れがなく・プログラム自体に瑕疵がない場合…ですが)
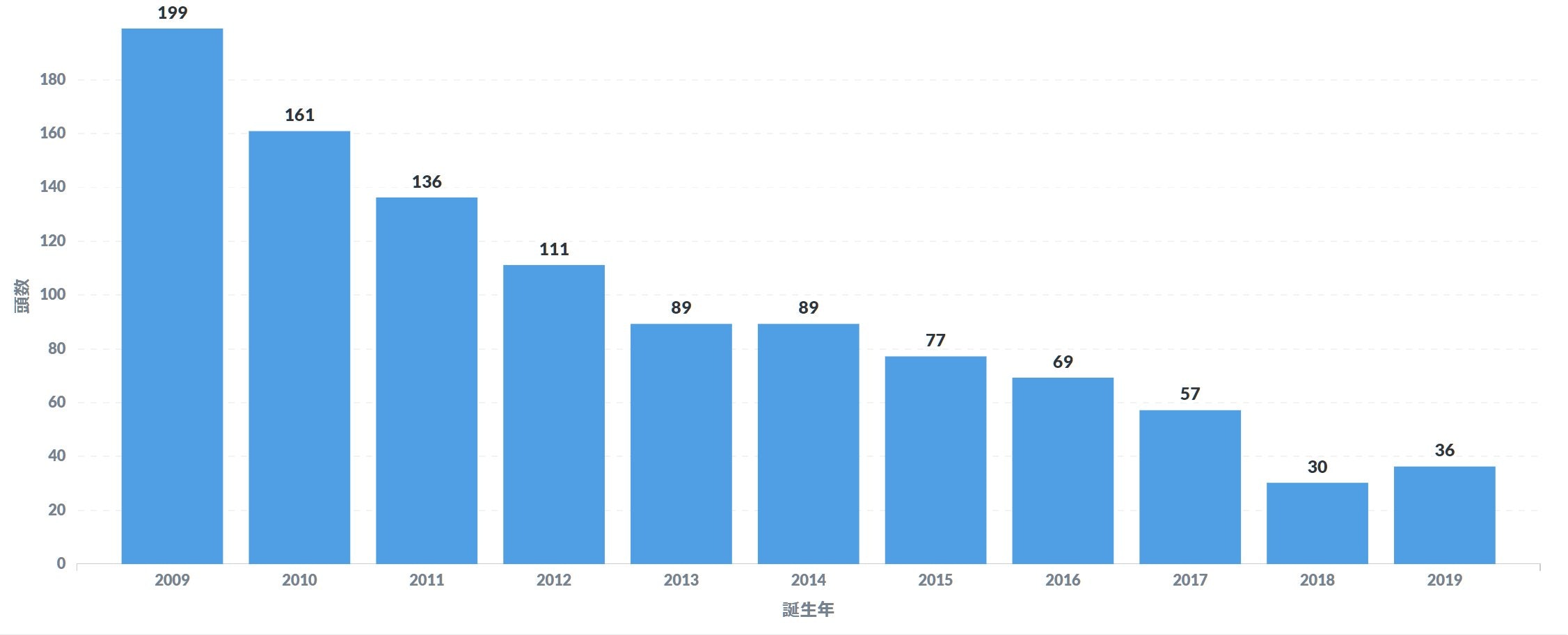
年ごとに見ると2018年→2019年で少し増えていますが、基本的には年々減少する傾向にあり、ここ十年で1/5ほどになっていることがわかりました。
1世代前・2世代前
1・2世代前に漢字の馬名持ちの馬は…さすがにいませんでした。どちらも「サラ系」が引っ掛かっただけです。
3世代前
こちらは15頭いました。
が、このうち競走馬とデビューしているのはイナズマクロス(91年クイーンカップG3勝ち)の産駒2頭や3代母に「風玲」持ちの1頭など7頭のみで、残りの「耐良」を3代母にもち、謎の種牡馬「デザートショット」「ゴールディヒダカ」を父とする8頭はなんと100%の純血アラブ馬(!)でした。
ネットで検索してみた感じだと馬術競技向けに生産されているようですが、現代の日本で純血アラブ馬が生産されているとは驚きです。4世代前
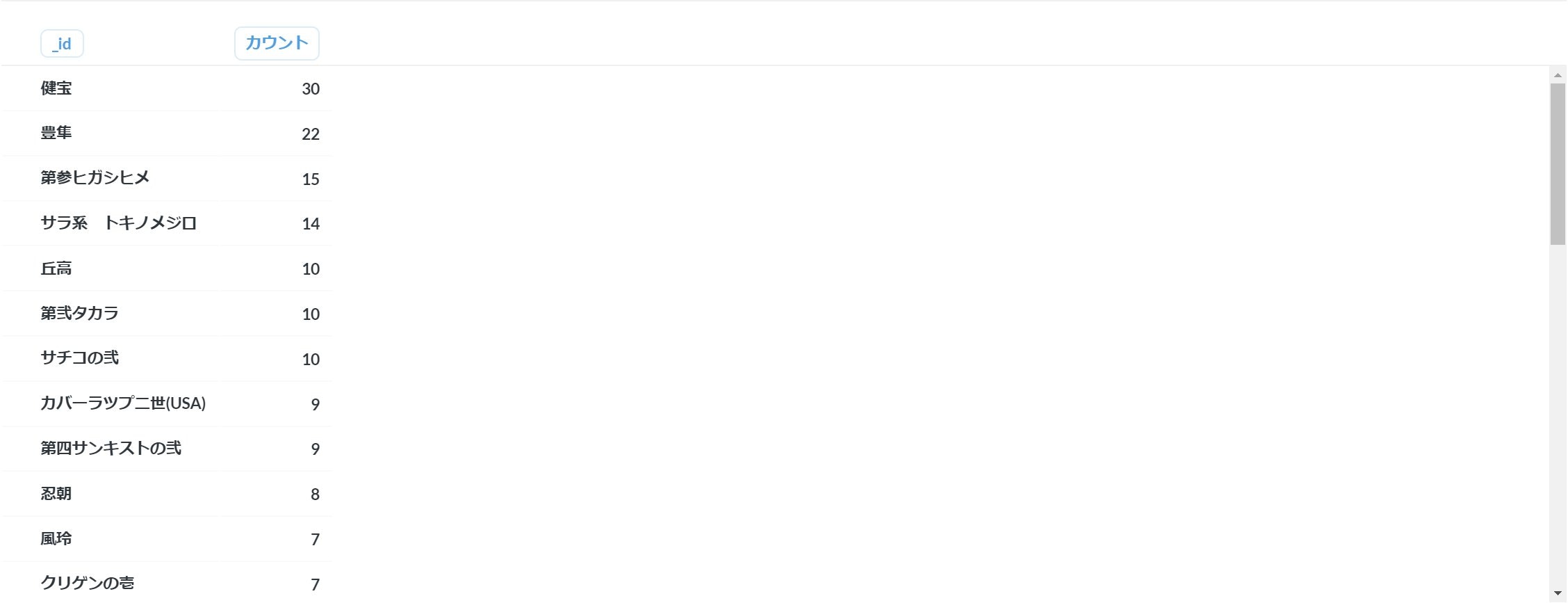
ここまで来ると一気に増えて208頭(3世代前との重複含む)が該当し、それらは72頭の母馬から生まれていることがわかりました。
登場回数順で集計するとこんな感じになります。
Metabaseはネストした配列の中身を集計するにはデータベースのクエリを直接書かなければならないので注意。
4代前の配列の中身の要素でカウント・降順ソートするクエリの例 [ { $project: { name: 1, kanji_names: 1 }}, { $unwind: "$kanji_names.4代前" }, { $group: { _id: "$kanji_names.4代前", count: { $sum: 1 }}}, { $sort: { count: -1 } } ]登場回数が一番多かったのが4代母が健宝=1962年桜花賞馬ケンホウというのが30頭
次に多かったのが4代母豊隼でこの馬は孫がホウヨウボーイだそう。面白かったのは4代前に「耐良」が2つマッチした2011年生まれの名無しの純血アラブ馬さん。
どんなもんかと思って血統表を確認すると…とんでもないインブリードだ…。5世代前
926頭(3・4世代前との重複含む)が該当し、それらは285頭の母馬から生まれていることがわかりました。
登場回数順で集計するとこんな感じです。
一番多かった「丘高」=(クモワカ)はかなりドラマチックな来歴を持つ馬なので是非wikipediaなどご覧になって下さい。
直系の牝系だけではなくワカオライデンなど種牡馬経由で丘高を持ってる馬もあった感じです。
ここに載ってるようなのは昔の競馬関係の書籍などで見覚えがある馬の名前が多いですね~。
数が数なので個々の馬に関して調べていくのはやめときます(´・ω・`)最後に
- 漢字馬名が父由来か母由来か、も調べるとよかったかも
- 99%後者だろうけど
- データを収集してもそれをどう利用するか?という点が一番困ったのでその辺もうちょっと考えられるようになっていけたらなと…。
- 参考書籍:Pythonクローリング&スクレイピング[増補改訂版] ―データ収集・解析のための実践開発ガイドー
- 参考サイトは本文中に都度記してあります。
- 誤りや質問などございましたら、コメント欄にお願いします。





- 投稿日:2020-03-24T22:38:57+09:00
100日連続実装生活 2日目
2日目
GoogleAnalytics StandardをBigQueryにエクスポートする
GoogleAnalytics(以降 GA)をBigQueryにエクスポートしたいけど、GA360は高くて無理!
って思っていたので、GAのAPIを使って、GCS経由でBigQueryにエクスポートするのを実装しました。
まだ、少ししか試していないので、完ぺきではないかと思いますが、毎日投稿する関係上、悪しからず...笑大まかな流れ
- GA APIを使ってrawデータ取得
- pythonでcsvに整形
- GCSにエクスポート
- GCSからBigQueryにエクスポート
この流れで紹介していきます!
GA APIを使ってrawデータ取得
GA API クイックスタート
上のページを参考にクイックスタートをパクります。
すると、rawデータを取得してくれるではありませんか!ついでにライブラリもインストールしておきます。
pip install --upgrade google-api-python-client pip install oauth2clientこのサンプルを自分好みに変更していきます。
まずは一度に取得できる量が少ないのと、毎日更新したいので、日付を変更していきます。from datetime import datetime,timedelta maxSize = 10000 dt_now = datetime.datetime.now() yesterday = dt_now - timedelta(days=1) yesterday = yesterday.strftime("%Y-%m-%d")...とここまで来て、素晴らしい記事があることに気が付きました。
こんな素晴らしい記事読んでいれば、もっと早く完成したのに...笑
わかりやすい記事(神様)
Google Analytics APIを利用して無料版でもrawデータをBigQueryにエクスポートする方法
終わり
ということで、わざわざ書かなくても記事があったので今回はこれで!
一応まとまったファイルになっているものが先ほどの記事にはなかったので、コピペするのも面倒な人向けに一応Gitに挙げておきます。コード
Day2も無事終了!
まずは3日坊主にならないことが目標です!笑
- 投稿日:2020-03-24T22:00:37+09:00
[TensorFlow] OptimizerにもWeightがあるなんて
はじめに
TensorFlow (Keras) のLayerオブジェクトは重み(Weight)を持っています。全結合層 ${\bf y} = {\bf W} {\bf x} + {\bf b}$ の行列 ${\bf W}$ とバイアスのベクトル ${\bf b}$ が代表的ですね。
実はOptimizerにもWeightがあります。学習を中断して続きから再開するとか、Fine-Tuningを行うときなど、「すでに途中まで学習が進んでいる」状態では、このWeightの存在を意識しないと痛い目に遭うという話です。何を今更と言われるかもしれませんが。
検証環境
- Ubuntu 18.04
- Python 3.6.9
- TensorFlow 2.1.0 (CPU)
現象
まずはハマった内容をご紹介しましょう。
3エポック学習させた後、Optimizerを最初と同じ設定で再作成し、モデルを再コンパイルした後、同じデータで再度3エポック回します。実行している本人は、全部で6エポック分学習させた気になっていますが…?
(分かりやすいように例を単純化しています)import numpy as np import tensorflow as tf from tensorflow.keras.datasets import mnist from tensorflow.keras.layers import Dense, Input from tensorflow.keras.optimizers import Adam from tensorflow.keras.models import Model # 乱数シード固定 tf.random.set_seed(1) # データ作成:現象が分かりやすいようにSubsetで試す (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train[0:1000, :] y_train = y_train[0:1000] x_test = x_test[0:100, :] y_test = y_test[0:100] feature_dim = 28*28 num_classes = 10 # 前処理をする # 画素は[0, 1]のfloat32型に変換する x_train = x_train.reshape((-1, feature_dim)).astype("float32") / 255.0 x_test = x_test.reshape((-1, feature_dim)).astype("float32") / 255.0 # ラベルもfloat32型にする y_train = y_train.reshape((-1, 1)).astype("float32") y_test = y_test.reshape((-1, 1)).astype("float32") # モデル定義 layer_input = Input(shape=(feature_dim,)) fc1 = Dense(512, activation="relu")(layer_input) layer_output = Dense(num_classes, activation="softmax")(fc1) model = Model(layer_input, layer_output) model.summary() optimizer = Adam(lr=0.003) model.compile( loss="sparse_categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"]) # まずは普通に3epoch学習する epochs = 3 batch_size = 32 model.fit( x=x_train, y=y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test)) # Layerの重みを引き継いで続きから学習するつもりで # Modelを再コンパイル optimizer = Adam(lr=0.003) model.compile( loss="sparse_categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"]) # もう3epoch学習 model.fit( x=x_train, y=y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test))結果、このようなことが起きます。
Train on 1000 samples, validate on 100 samples Epoch 1/3 1000/1000 [==============================] - 1s 919us/sample - loss: 0.8494 - accuracy: 0.7360 - val_loss: 0.3652 - val_accuracy: 0.9000 Epoch 2/3 1000/1000 [==============================] - 0s 225us/sample - loss: 0.2397 - accuracy: 0.9340 - val_loss: 0.3003 - val_accuracy: 0.9000 Epoch 3/3 1000/1000 [==============================] - 0s 209us/sample - loss: 0.1146 - accuracy: 0.9700 - val_loss: 0.2830 - val_accuracy: 0.9000 Train on 1000 samples, validate on 100 samples Epoch 1/3 1000/1000 [==============================] - 1s 787us/sample - loss: 0.1515 - accuracy: 0.9560 - val_loss: 0.3035 - val_accuracy: 0.9200 Epoch 2/3 1000/1000 [==============================] - 1s 575us/sample - loss: 0.0608 - accuracy: 0.9820 - val_loss: 0.2220 - val_accuracy: 0.9300 Epoch 3/3 1000/1000 [==============================] - 0s 384us/sample - loss: 0.0190 - accuracy: 0.9980 - val_loss: 0.2319 - val_accuracy: 0.9100注目していただきたいのは、最初の3エポック目のTraining Lossよりも、次の1エポック目のTraining Lossのほうが大きくなってしまっている (0.1146 → 0.1515) 点です。
一度に6エポック学習させた場合は、以下のように綺麗にTraining Lossが落ちていきます。
(乱数シードを固定しているため、最初の3エポック分の結果は全く同じです)epochs = 6 batch_size = 32 model.fit( x=x_train, y=y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test))Train on 1000 samples, validate on 100 samples Epoch 1/6 1000/1000 [==============================] - 1s 911us/sample - loss: 0.8494 - accuracy: 0.7360 - val_loss: 0.3652 - val_accuracy: 0.9000 Epoch 2/6 1000/1000 [==============================] - 0s 291us/sample - loss: 0.2397 - accuracy: 0.9340 - val_loss: 0.3003 - val_accuracy: 0.9000 Epoch 3/6 1000/1000 [==============================] - 0s 427us/sample - loss: 0.1146 - accuracy: 0.9700 - val_loss: 0.2830 - val_accuracy: 0.9000 Epoch 4/6 1000/1000 [==============================] - 0s 279us/sample - loss: 0.1008 - accuracy: 0.9710 - val_loss: 0.2584 - val_accuracy: 0.9200 Epoch 5/6 1000/1000 [==============================] - 0s 266us/sample - loss: 0.0420 - accuracy: 0.9950 - val_loss: 0.2393 - val_accuracy: 0.9300 Epoch 6/6 1000/1000 [==============================] - 0s 305us/sample - loss: 0.0188 - accuracy: 0.9990 - val_loss: 0.2104 - val_accuracy: 0.9200今回は簡単な例なのですぐにまたTraining Lossが小さくなっていきますが、複雑な問題だとせっかく時間を掛けて途中まで学習させた成果が台無しになってしまいます。
何が起きたの?
ここで冒頭の「OptimizerにもWeightがあります」という話につながります。
Layerの重みを更新する場合、古典的な手法(SGD: 確率的勾配降下法)では、重みから「損失関数の偏微分係数に学習率を掛けたもの」を引きます。しかし、収束に時間が掛かるので、過去の情報に基づいて重みの変化量をうまく調整し、速く収束させる工夫が考えられてきました。Optimizer : 深層学習における勾配法について - Qiita
ところが、Optimizerオブジェクトを何も考えずに再作成してしまうと、この「過去の情報」が消えてしまい、重みの調整に悪影響を及ぼしてしまいます。この「過去の情報」こそがOptimizerのWeightです。
上の参考ページの数式で言えば、$h_t, m_t, v_t$ のように、Layerの重み ${\bf w}_t$ 以外の情報を使って重みの更新を行っているアルゴリズムが存在しますね。もし学習を一旦中断し、続きから実行したい場合には、これらの情報を保存しておかなければなりません。以下のようにすると、Optimizerオブジェクトに含まれるWeightの値を確認できます。
print(optimizer.get_weights()) print(model.optimizer.get_weights()) # ModelのプロパティでもOptimizerを取得可能Optimizerの再作成とモデルの再コンパイルを行わない場合を試しましょう。以下のコードのうち2回目の方をコメントアウトします。
# optimizer = Adam(lr=0.003) # model.compile( # loss="sparse_categorical_crossentropy", # optimizer=optimizer, # metrics=["accuracy"])すると、2回目の学習を始めたときもTraining Lossはちゃんと減少しています。
Train on 1000 samples, validate on 100 samples Epoch 1/3 1000/1000 [==============================] - 1s 1ms/sample - loss: 0.8494 - accuracy: 0.7360 - val_loss: 0.3652 - val_accuracy: 0.9000 Epoch 2/3 1000/1000 [==============================] - 0s 278us/sample - loss: 0.2397 - accuracy: 0.9340 - val_loss: 0.3003 - val_accuracy: 0.9000 Epoch 3/3 1000/1000 [==============================] - 0s 307us/sample - loss: 0.1146 - accuracy: 0.9700 - val_loss: 0.2830 - val_accuracy: 0.9000 Train on 1000 samples, validate on 100 samples Epoch 1/3 1000/1000 [==============================] - 0s 243us/sample - loss: 0.1010 - accuracy: 0.9710 - val_loss: 0.2640 - val_accuracy: 0.9200 Epoch 2/3 1000/1000 [==============================] - 0s 263us/sample - loss: 0.0355 - accuracy: 0.9960 - val_loss: 0.2206 - val_accuracy: 0.9100 Epoch 3/3 1000/1000 [==============================] - 0s 235us/sample - loss: 0.0132 - accuracy: 1.0000 - val_loss: 0.2102 - val_accuracy: 0.9200古典的なOptimizer (SGD) の場合
SGDを使う場合、時間によって変化する量はLayerの重み ${\bf w}_t$ だけであり、それ以外の内部状態を持たないので、この影響を受けないと思われます。試しに
Adamの代わりにSGDを使ってみます。import numpy as np import tensorflow as tf from tensorflow.keras.datasets import mnist from tensorflow.keras.layers import Dense, Input #from tensorflow.keras.optimizers import Adam from tensorflow.keras.optimizers import SGD from tensorflow.keras.models import Model # (中略) optimizer = SGD(lr=0.003) model.compile( loss="sparse_categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"]) # まずは普通に3epoch学習する epochs = 3 batch_size = 32 model.fit( x=x_train, y=y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test)) # Layerの重みを引き継いで続きから学習するつもりで # Modelを再コンパイル optimizer = SGD(lr=0.003) model.compile( loss="sparse_categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"]) # もう3epoch学習 model.fit( x=x_train, y=y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test))以下のように、Training Lossは減少し続けています。もっとも、
Adamより収束がかなり遅いのですが。Train on 1000 samples, validate on 100 samples Epoch 1/3 1000/1000 [==============================] - 1s 848us/sample - loss: 2.2205 - accuracy: 0.2150 - val_loss: 2.1171 - val_accuracy: 0.4200 Epoch 2/3 1000/1000 [==============================] - 0s 227us/sample - loss: 2.0913 - accuracy: 0.3970 - val_loss: 2.0141 - val_accuracy: 0.5700 Epoch 3/3 1000/1000 [==============================] - 0s 226us/sample - loss: 1.9763 - accuracy: 0.5210 - val_loss: 1.9227 - val_accuracy: 0.5900 Train on 1000 samples, validate on 100 samples Epoch 1/3 1000/1000 [==============================] - 1s 738us/sample - loss: 1.8722 - accuracy: 0.5890 - val_loss: 1.8374 - val_accuracy: 0.6700 Epoch 2/3 1000/1000 [==============================] - 0s 211us/sample - loss: 1.7773 - accuracy: 0.6350 - val_loss: 1.7565 - val_accuracy: 0.7000 Epoch 3/3 1000/1000 [==============================] - 0s 277us/sample - loss: 1.6879 - accuracy: 0.6660 - val_loss: 1.6832 - val_accuracy: 0.7100先ほどと同様に、6エポック一気に学習した場合はこんな感じです。2回に分けた場合とほぼ変わりません。
(4エポック目以降の値が微妙に異なりますが、この誤差はどこから来るのでしょうね?)Epoch 1/6 1000/1000 [==============================] - 1s 802us/sample - loss: 2.2205 - accuracy: 0.2150 - val_loss: 2.1171 - val_accuracy: 0.4200 Epoch 2/6 1000/1000 [==============================] - 0s 233us/sample - loss: 2.0913 - accuracy: 0.3970 - val_loss: 2.0141 - val_accuracy: 0.5700 Epoch 3/6 1000/1000 [==============================] - 0s 259us/sample - loss: 1.9763 - accuracy: 0.5210 - val_loss: 1.9227 - val_accuracy: 0.5900 Epoch 4/6 1000/1000 [==============================] - 0s 266us/sample - loss: 1.8719 - accuracy: 0.5920 - val_loss: 1.8376 - val_accuracy: 0.6500 Epoch 5/6 1000/1000 [==============================] - 0s 315us/sample - loss: 1.7764 - accuracy: 0.6410 - val_loss: 1.7552 - val_accuracy: 0.6900 Epoch 6/6 1000/1000 [==============================] - 0s 273us/sample - loss: 1.6873 - accuracy: 0.6680 - val_loss: 1.6806 - val_accuracy: 0.7100
SGDにはWeightはありません…と思いきや、謎の値が出てきます。print(optimizer.get_weights()) # Result: [192]いろいろ試したところ、どうも学習した累計バッチ数が入っているようです。先ほどの参考ページの記法でいえば $t$ ですね。ただSGDの場合、$t$ の値そのものは(手法の原理上)重みの更新に影響を及ぼさないはずですので、これ以上は深く立ち入りません(例えばAdamは $t$ の値も使っていますね)。
対処法
今回のような面倒事にならないようにする方法としては
- 数エポック学習させた後、同じデータで続きから学習させる場合は、OptimizerのWeightを保存しておく
- Fine-Tuningなど、最初とは別のデータで続きから学習させる場合は、Optimizerとして内部状態を持たないSGDを使う (Momentum-SGDは使っても大丈夫のはず)
のが良いのではと思われます(特に2点目は自信なし…)。
OptimizerのWeightを保存する方法
Modelオブジェクトに対し
save()すれば、LayerのWeightだけでなく、設定したOptimizerの情報やWeightの値も含めてファイルに保存できます。model.save("model.h5", save_format="h5") exit()
tf.keras.models.load_model()でモデルを読み込むと、前の情報を引き継いだ状態で学習できます。
独自のLayerやCallbackを指定して作成したモデルの場合はcustom_objects引数を指定する必要がありますが、ここでは触れません。
tf.keras.models.load_model | TensorFlow Core v2.1.0import tensorflow as tf from tensorflow.keras.datasets import mnist feature_dim = 28*28 num_classes = 10 # データ作成 (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train[0:1000, :] y_train = y_train[0:1000] x_test = x_test[0:100, :] y_test = y_test[0:100] # 前処理をする # 画素は[0, 1]のfloat32型に変換する x_train = x_train.reshape((-1, feature_dim)).astype("float32") / 255.0 x_test = x_test.reshape((-1, feature_dim)).astype("float32") / 255.0 # ラベルもfloat32型にする y_train = y_train.reshape((-1, 1)).astype("float32") y_test = y_test.reshape((-1, 1)).astype("float32") # モデル読み込み model = tf.keras.models.load_model("model.h5") # print(model.optimizer.get_weights()) # 続きから学習 epochs = 3 batch_size = 32 model.fit( x=x_train, y=y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test))その他
Fine-tuningを使って少ない画像データから効率よく学習モデルを作成する方法 | AI coordinator
# TODO: ここでAdamを使うとうまくいかない
# Fine-tuningのときは学習率を小さくしたSGDの方がよい?とコメントが書かれていますが、おそらく同じ現象が起きているかもしれません?
- 投稿日:2020-03-24T21:33:42+09:00
PandasとMatplotlibでApacheのアクセスログを解析する
概要
ApacheやTomcatなどのアクセスログを解析しようと思っても、意外といいツールってありませんよね。様々な出力形式に対応していて、必要な情報だけをフィルタリングし、手軽に分かりやすく視覚化できるようなツールがあればいいのですが、なかなか見つかりません。
そこで、データ分析の世界では定番のPandasやMatplotlibを利用して、Jupyter Notebook上でApacheのアクセスログを解析、視覚化することが簡単にできるか試してみました。
※Pandas、Matplotlib、Jupyter Notebookのインストールについては、すでに多くの分かりやすい記事がありますので、ここでは触れません。
アクセスログを読み込む
必要なライブラリーのインポート
まずは最低限必要なPandasとMatplotlibをインポートします。
import pandas as pd from pandas import DataFrame, Series import matplotlib.pyplot as plt環境設定
好みに応じて、環境設定します。
# グラフなどはNotebook内に描画 %matplotlib inline # DataFrameの列の最大文字列長をデフォルトの50から150に変更 pd.set_option("display.max_colwidth", 150)アクセスログのロード
アクセスログのロード方法については、このブログエントリーを参考にしました。アクセスログをロードする前に、それに必要な型解析用の関数を定義します。
from datetime import datetime import pytz def parse_str(x): return x[1:-1] def parse_datetime(x): dt = datetime.strptime(x[1:-7], '%d/%b/%Y:%H:%M:%S') dt_tz = int(x[-6:-3])*60+int(x[-3:-1]) return dt.replace(tzinfo=pytz.FixedOffset(dt_tz))そして、
pd.read_csv()でアクセスログをロードします。私の手元にあったアクセスログは少し出力形式が異なっていたので、以下のように修正しました。今回は簡略化のため、一部のカラムだけを抽出しています。df = pd.read_csv( '/var/log/httpd/access_log', sep=r'\s(?=(?:[^"]*"[^"]*")*[^"]*$)(?![^\[]*\])', engine='python', na_values='-', header=None, usecols=[0, 4, 6, 7, 8, 9, 10], names=['ip', 'time', 'response_time', 'request', 'status', 'size', 'user_agent'], converters={'time': parse_datetime, 'response_time': int, 'request': parse_str, 'status': int, 'size': int, 'user_agent': parse_str})アクセスログを解析する
アクセスログをロードしたら、解析してみましょう。
データを加工せずに確認
まずはファイルの先頭と最後の5行ずつを確認します。
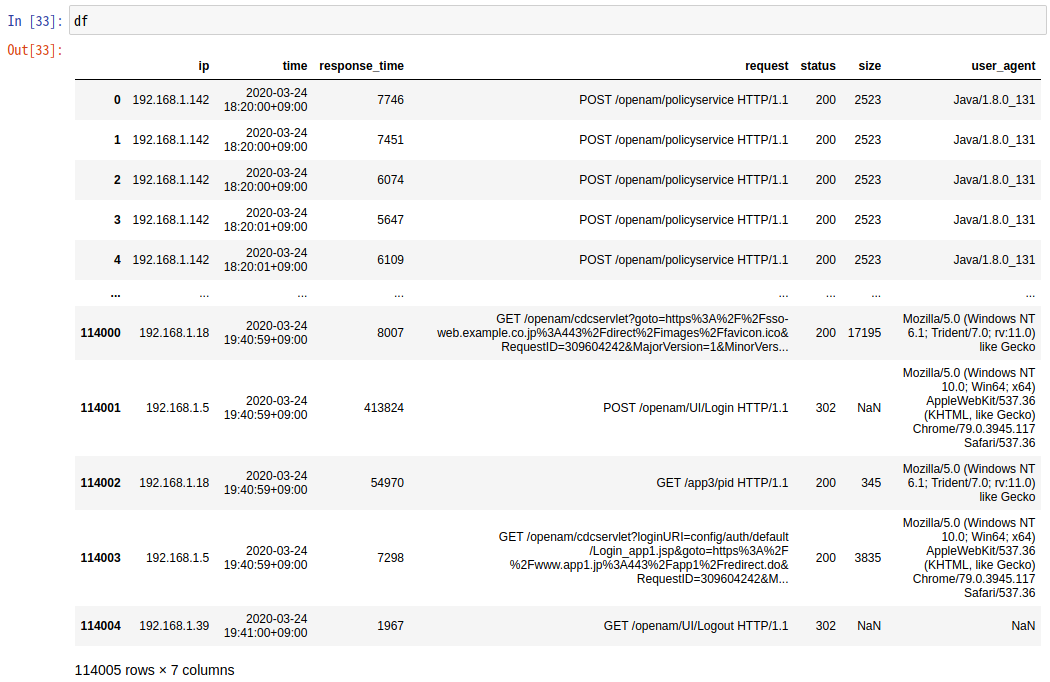
df
03月24日の18:20から1時間20分ほどで114,004件のリクエストがあったことが分かります。
応答時間の集計結果確認
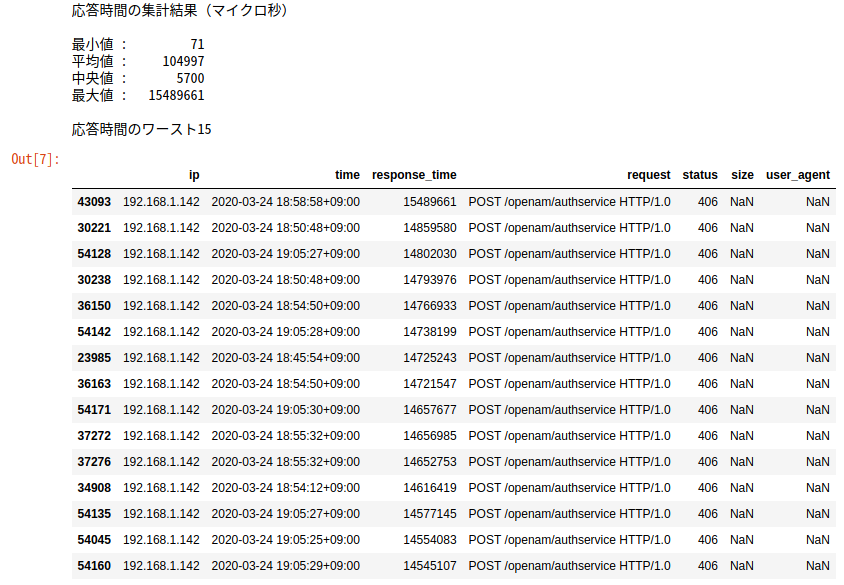
応答時間の平均値や最大値を表示してみましょう。
print('応答時間の集計結果(マイクロ秒)\n') print('最小値 : {}'.format(str(df['response_time'].min()).rjust(10))) print('平均値 : {}'.format(str(round(df['response_time'].mean())).rjust(10))) print('中央値 : {}'.format(str(round(df['response_time'].median())).rjust(10))) print('最大値 : {}'.format(str(df['response_time'].max()).rjust(10))) print('\n応答時間のワースト15') df.sort_values('response_time', ascending=False).head(15)
応答時間のワースト15件は、いずれもOpenAMの認証サービスへのリクエストで、15秒ほどかけてHTTPステータス406のレスポンスが返っていました。OpenAMと連携するアプリケーションとの間で問題が発生していたことが分かります。
欠損値の確認
応答時間のワースト15を見ると、
size(レスポンスのサイズ)とuser_agent(ユーザーエージェント)がNaNになっています。欠損値がどの程度あるのか確認してみましょう。df.isnull().sum()
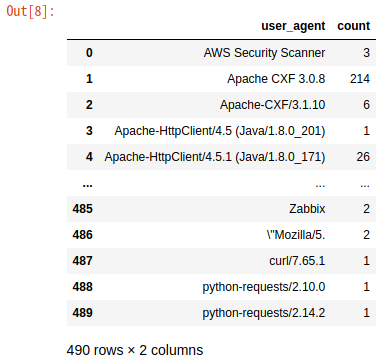
sizeがNaNなものは、リダイレクトなどです。また、3割ほどのuser_agentが不明です。OpenAMにアクセスするのは、エンドユーザーのブラウザーだけではないので、その中には「User-Agent」ヘッダーが未指定なものが多いということでしょう。他にはどのようなユーザーエージェントがあるのか調べてみましょう。ユーザーエージェントの確認
ua_df = DataFrame(df.groupby(['user_agent']).size().index) ua_df['count'] = df.groupby(['user_agent']).size().values ua_df
なんと490種類もありました。エンドユーザーだけでなく、多数のアプリケーションが連携しているので、このような結果になったようです。
アクセスログを視覚化する
ここまで全く視覚化していないので、イマイチ面白くなかったかと思います。円グラフなどで表示してみましょう。まずは、レスポンスのステータスコードの割合を円グラフで描いてみます。
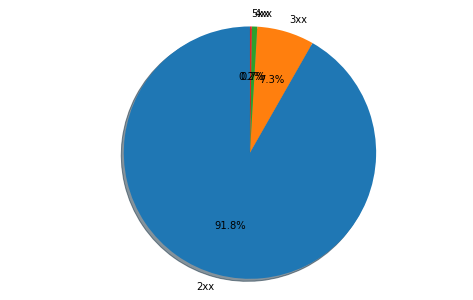
plt.figure(figsize = (5, 5)) labels = ['2xx', '3xx', '4xx', '5xx'] plt.pie(df.groupby([df['status'] // 100]).size(), autopct = '%1.1f%%', labels = labels, shadow = True, startangle = 90) plt.axis('equal') df.groupby([df['status'] // 100]).size() plt.show()
うーん、割合が低いステータスコードのラベルが重なってよく見えないですね...
視覚化のためのユーティリティー関数を定義
ということで、少数の要素(1%以下の割合のもの)を「others」(その他)にまとめる関数を定義しておきます。Matplotlibの機能を使えば、こういった関数は不要かもしれませんが、見つけられなかったので、簡単なものをつくってみました。
# DataFrame用 def replace_df_minors_with_others(df_before, column_name): elm_num = 1 for index, row in df_before.sort_values([column_name], ascending=False).iterrows(): if (row[column_name] / df_before[column_name].sum()) > 0.01: elm_num = elm_num + 1 df_after = df_before.sort_values([column_name], ascending=False).nlargest(elm_num, columns=column_name) df_after.loc[len(df_after)] = ['others', df_before.drop(df_after.index)[column_name].sum()] return df_after # 辞書用 def replace_dict_minors_with_others(dict_before): dict_after = {} others = 0 total = sum(dict_before.values()) for key in dict_before.keys(): if (dict_before.get(key) / total) > 0.01: dict_after[key] = dict_before.get(key) else: others = others + dict_before.get(key) dict_after = {k: v for k, v in sorted(dict_after.items(), reverse=True, key=lambda item: item[1])} dict_after['others'] = others return dict_afterユーザーエージェントの視覚化
では、この関数を使用して、次はユーザーエージェントの種類を円グラフで表示してみましょう。
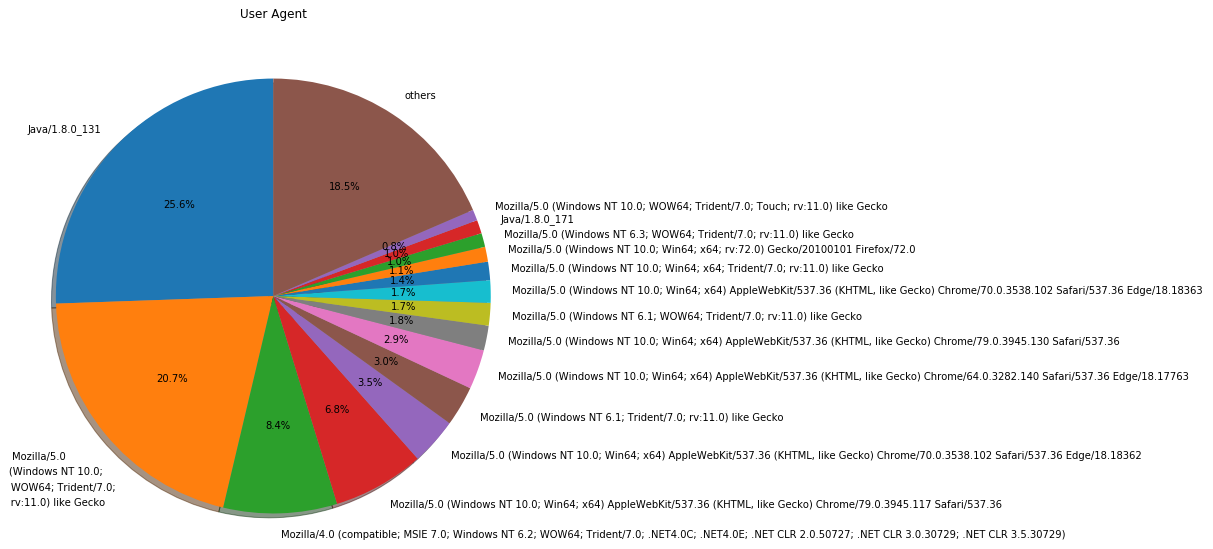
plt.figure(figsize = (15, 10)) ua_df_with_others = replace_df_minors_with_others(ua_df, 'count') plt.pie(ua_df_with_others['count'], labels = ua_df_with_others['user_agent'], autopct = '%1.1f%%', shadow = True, startangle = 90) plt.title('User Agent') plt.show()
「User-Agent」ヘッダーを直接表示しても、イマイチ分かりづらいですね。「Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko」って何でしょう...
ということで、Wootheeというライブラリーを利用して分かりやすい表示に変換してみます。以下のコマンドでインストールします。
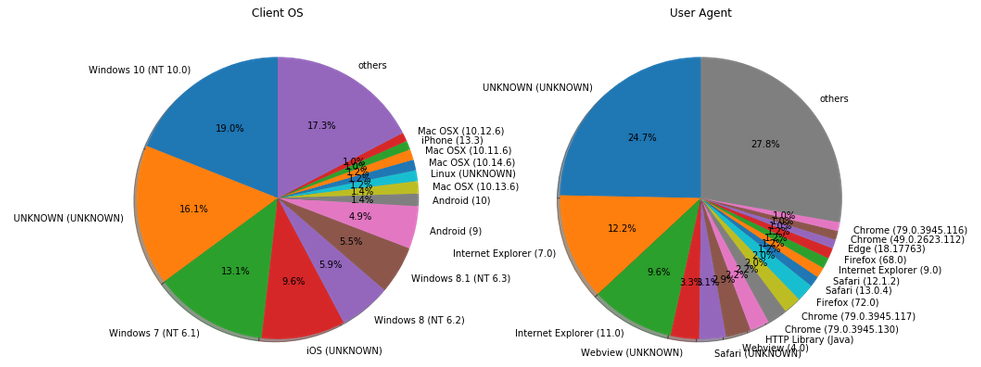
$ pip install wootheeこれを利用して、クライアントのOSとユーザーエージェントを円グラフで表示してみます。
import woothee ua_counter = {} os_counter = {} for index, row in ua_df.sort_values(['count'], ascending=False).iterrows(): ua = woothee.parse(row['user_agent']) uaKey = ua.get('name') + ' (' + ua.get('version') + ')' if not uaKey in ua_counter: ua_counter[uaKey] = 0 ua_counter[uaKey] = ua_counter[uaKey] + 1 osKey = ua.get('os') + ' (' + ua.get('os_version') + ')' if not osKey in os_counter: os_counter[osKey] = 0 os_counter[osKey] = os_counter[osKey] + 1 plt.figure(figsize = (15, 10)) plt.subplot(1,2,1) plt.title('Client OS') os_counter_with_others = replace_dict_minors_with_others(os_counter) plt.pie(os_counter_with_others.values(), labels = os_counter_with_others.keys(), autopct = '%1.1f%%', shadow = True, startangle = 90) plt.subplot(1,2,2) plt.title('User Agent') ua_counter_with_others = replace_dict_minors_with_others(ua_counter) plt.pie(ua_counter_with_others.values(), labels = ua_counter_with_others.keys(), autopct = '%1.1f%%', shadow = True, startangle = 90) plt.show()
「UNKNOWN」が増えてしまいましたが、分かりやすくはなったでしょうか。それにしても、いまだにWindowsでIE使ってる人が多いですね...
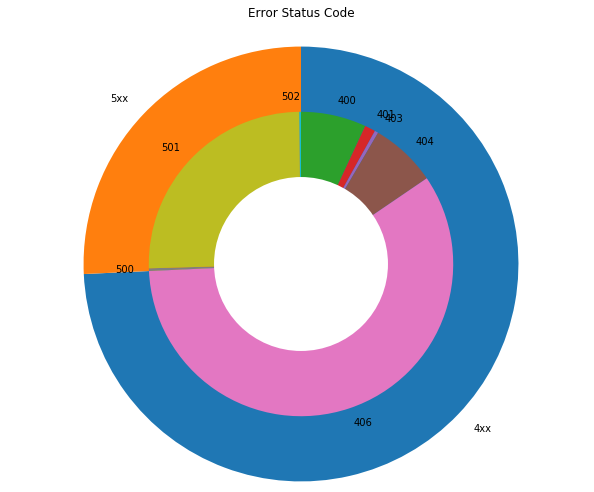
エラーレスポンスのステータスコードの視覚化
次にエラーとなったレスポンスのステータスコード(400以上)の割合を見てみましょう。
error_df = df[df['status'] >= 400] plt.figure(figsize = (10, 10)) labels = ['4xx', '5xx'] plt.pie(error_df.groupby([error_df['status'] // 100]).count().time, labels=labels, counterclock=False, startangle=90) labels2 = ['400', '401', '403', '404', '406', '500', '501', '502'] plt.pie(error_df.groupby(['status']).count().time, labels=labels2, counterclock=False, startangle=90, radius=0.7) centre_circle = plt.Circle((0,0),0.4, fc='white') fig = plt.gcf() fig.gca().add_artist(centre_circle) plt.title('Error Status Code') plt.show()
一般的にはあまり見慣れないステータスコード406のエラーレスポンスが多いのが、このアクセスログの特徴ですね。
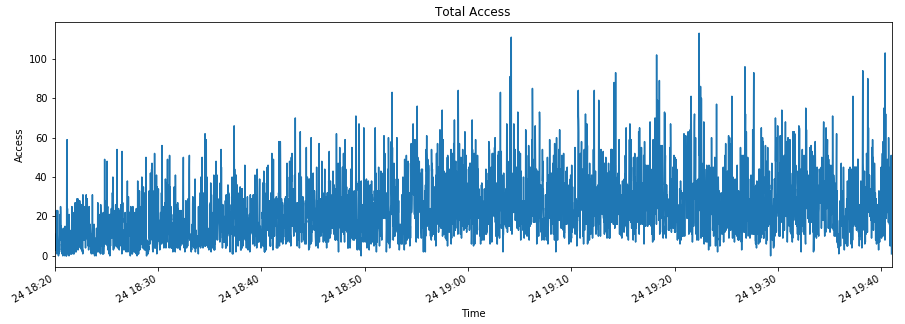
負荷の状況の視覚化
では、違うグラフを出力してみましょう。まずは負荷の状況を確認します。
plt.figure(figsize = (15, 5)) access = df['request'] access.index = df['time'] access = access.resample('S').count() access.index.name = 'Time' access.plot() plt.title('Total Access') plt.ylabel('Access') plt.show()
コンスタントにアクセスがあり、時々秒間100件以上を超えるような状況です。
レスポンスのサイズと時間の関係性の視覚化
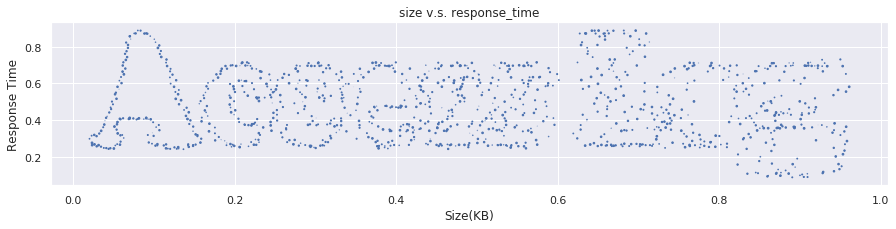
レスポンスのサイズと時間に何らかの関係性があるか見てみましょう。
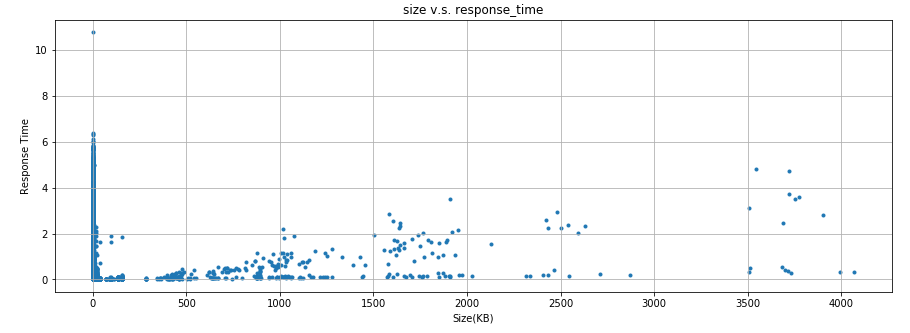
plt.figure(figsize = (15, 5)) plt.title('size v.s. response_time') plt.scatter(df['size']/1000, df['response_time']/1000000, marker='.') plt.xlabel('Size(KB)') plt.ylabel('Response Time') plt.grid()
明確な関係性は無いものの、レスポンスのサイズが0でなければ、サイズが大きいほど時間がかかる傾向が無いとも言えないですね。
最後に
アクセスログの解析にPandasとMatplotlibは使えると思います。これらのライブラリーを使いこなせるようになれば、トラブルシューティングにも十分に活用できそうです。
まだ思い付きでつくった試作段階ですが、GitHubにもコミットしておきます。

- 投稿日:2020-03-24T20:30:50+09:00
PyTorch C++ VS Python(2019年度版)
Deep Learningのフレームワークといえば,PyTorch,Tensorflow,Kerasなどたくさんの種類があります.
今回は,その中でも私がよく使わせていただいてるPyTorchに注目していこうと思います!実はこのPyTorch,Python版だけではなく,C++版がリリースされているのはご存知でしょうか?
このおかげで,もしC++のプログラムの処理の一部としてDeep Learningを使いたいとなったときに,容易に組み込むことができるようになるのです!そんなC++版のPyTorchですが,私は「C++はコンパイル型言語だからもしかしたらPython版より速いのでは?」と気になりました.
そこで,今回は実際に「C++とPythonでどのくらい速度に差が有るのか?」を調べてみました!
また,精度についても気になったのでついでに調べてみました.比較実験に使用するもの
フレームワーク
今回は表題の通り「PyTorch」のC++版を使用します.
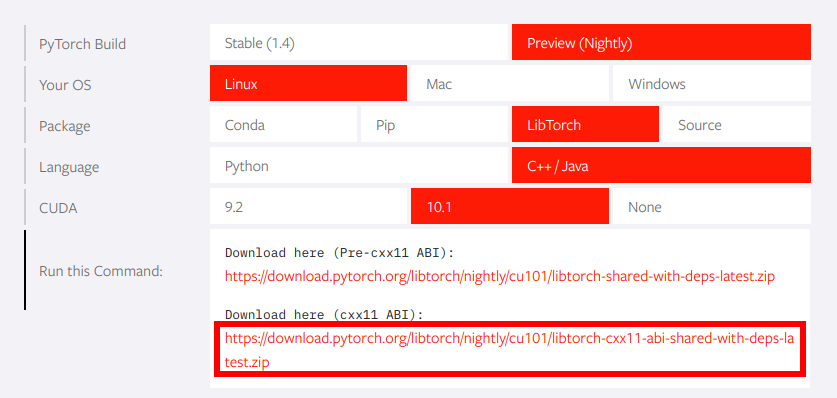
以下のサイトからダウンロードできるのでしてみてください!PyTorch公式:https://pytorch.org/
私は以上のような設定でダウンロードしました.
「Preview(Nightly)版」は常に最新のファイルが置かれるようになっています.
しかし,開発途中のものであるため,安定版を使用したい場合は「Stable(1.4)」を選択しましょう.また,一番下の「Run this Command」が結構重要で,CXXのビルドバージョンが11以上の人は下の方を選択するのをおすすめします.
現在はほとんどCXX17なので,下で大丈夫かと思います.
上を選ぶと,他のライブラリのリンクエラー等が発生して色々大変です.モデル
今回は,畳み込みオートエンコーダ(Convolutional Autoencoder)を使用します.
私のGitHubから取得可能→https://github.com/koba-jon/pytorch_cppこのモデルは,入力画像(高次元)を潜在空間(低次元)に写像し,今度はこの潜在変数(低次元)をもとに画像(高次元)を生成し,これと入力画像との誤差を最小化することが目的です.
学習を終えたこのモデルは,高次元の画像から低次元の空間を通って再び高次元の画像を生成できるため,学習用画像をより特徴付ける潜在空間を得ることができています.
つまり,次元圧縮の役割があり,いわゆる非線形的な主成分分析とも言えます.
これは,次元の呪いの解消,転移学習,異常検知のような様々な用途があり非常に便利です.それでは,使用するモデルの構造について説明します.
- 画像のサイズが,1度の畳み込みで1/2倍,逆畳み込みで2倍
- 学習の安定化・収束の加速化
- 潜在変数の取り得る範囲が実数全て
- 画素値の取り得る範囲が[-1, 1]
これらの効果を期待して,以下のネットワークを構築しました.
Operation Kernel Size Stride Padding Bias Feature Map BN Activation Input Output 1 Convolution 4 2 1 False 3 64 ReLU 2 64 128 True ReLU 3 128 256 True ReLU 4 256 512 True ReLU 5 512 512 True ReLU 6 512 512 7 Transposed Convolution 512 512 True ReLU 8 512 512 True ReLU 9 512 256 True ReLU 10 256 128 True ReLU 11 128 64 True ReLU 12 64 3 tanh データセット
- CelebA(Large-scale CelebFaces Attributes)データセット
http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html今回は,セレブなお方の顔画像(カラー)を202,599枚集めたデータセットであるCelebAデータセットを使用します.
画像サイズが178×218[pixel]と,逆畳み込みの際に少々不都合が生じるため,今回は64×64[pixel]にリサイズしました.
また,その内9割(182,340枚)を学習用画像に,1割(20,259枚)をテスト用画像に使用しました.これを先ほどのモデルに入力すると,潜在空間は(C,H,W)=(512,1,1)となります.もし,128×128[pixel]またはそれ以上の画像を入力した場合,中間層はSpatialな潜在空間になります.
比較対象
今回は,「C++とPythonでどの程度速度が異なるのか」を調査するのがメインですが,以下の5種類の環境下での速度および性能も加えて比較していきたいと思います.
- CPUメイン稼働
- Python
- C++
- GPUメイン稼働
- Python
- 非決定論的
- 決定論的
- C++
1. メインで稼働させるユニットの違い(CPU or GPU)
- CPU
「直列的で」「複雑な」命令を処理するのが得意- GPU
「並列的で」「単純な」命令を処理するのが得意以上の特徴から分かる通り,画像を扱うDeep Learningでは,計算速度において圧倒的にGPUが有利であることが分かります.
(1) Pythonによる実装
- CPUを使用する場合
CPU.pydevice = torch.device('cpu') # CPUを使用 model.to(device) # モデルをCPUに移す image = image.to(device) # データをCPUに移す
- GPUを使用する場合
GPU.pydevice = torch.device('cuda') # デフォルトのGPUを使用 device = torch.device('cuda:0') # 1番目のGPUを使用 device = torch.device('cuda:1') # 2番目のGPUを使用 model.to(device) # モデルをGPUに移す image = image.to(device) # データをGPUに移す(2) C++による実装
- CPUを使用する場合
CPU.cpptorch::Device device(torch::kCPU); // CPUを使用 model->to(device); // モデルをCPUに移す image = image.to(device); // データをCPUに移す
- GPUを使用する場合
GPU.cpptorch::Device device(torch::kCUDA); // デフォルトのGPUを使用 torch::Device device(torch::kCUDA, 0); // 1番目のGPUを使用 torch::Device device(torch::kCUDA, 1); // 2番目のGPUを使用 model->to(device); // モデルをGPUに移す image = image.to(device); // データをGPUに移す2.決定論的か否かの違い(GPUメイン稼働&Pythonに限る)
Python版のPyTorchには,GPUを用いた学習の場合,cuDNNを用いて学習の速度を向上させるという操作がされています.
しかし,C++とは異なり,学習の速度が向上するからと言って,再び学習を回したら必ずしも全く同じ状況を再現できるとは限りません.
そこで,PyTorch公式は,再現性を担保するためには以下のようにcuDNNの挙動を決定論的にする必要があり,それと同時に速度が低下すると明言しています.
https://pytorch.org/docs/stable/notes/randomness.html
Deterministic mode can have a performance impact, depending on your model. This means that due to the deterministic nature of the model, the processing speed (i.e. processed batch items per second) can be lower than when the model is non-deterministic.
エンジニアの立場においては,再現性の有無について気にする場合があるため,また再現性の有無によって速度に変化が生じるため,今回の速度の比較に含めました.
C++の「rand」関数とは異なり,乱数の初期値を何も設定しないとランダムになってしまうので,Pythonで再現性を担保するためには,明示的に乱数の初期値を設定する必要があります.
(乱数の初期値の設定が速度に影響を与えることはありません.)実装については以下の通りです.
- 決定論的な場合
deterministic.pyseed = 0 torch.manual_seed(seed) torch.cuda.manual_seed(seed) np.random.seed(seed) random.seed(seed) torch.backends.cudnn.deterministic = True # 速度が低下する代わりに決定論的 torch.backends.cudnn.benchmark = False # 速度が低下する代わりに決定論的
- 非決定論的な場合
non_deterministic.pytorch.backends.cudnn.deterministic = False # 非決定論的である代わりに高速化 torch.backends.cudnn.benchmark = True # 画像サイズが変化しない場合に高速化3. プログラミング言語間の実装の違い
実装したい内容自体が同じでもプログラミング言語が変わることで,記法やルールが変わったり,必要なライブラリが変わったり,ということが発生します.
PythonとC++は共にオブジェクト指向言語なので概念自体は似ていますが,何よりPythonはインタプリタ型,C++はコンパイル型なので,C++に動的型付けが通用しないことを踏まえながら実装しなければなりません.
また,PyTorchのC++ APIは現在発展途上であるため,一部の機能が整備されてないことも考慮しなければいけません.これらの点を踏まえ,Python,C++間での実装の違い,および私が実装したプログラムについて紹介します.
(1) ライブラリの使用状況
現在一般的に書かれているPythonのライブラリの使用状況に加え,C++で実装する場合に推奨するライブラリ,および私が実際に書いたプログラムのライブラリの使用状況についても記載します.
Python(推奨) C++(推奨) C++(自作) コマンドライン引数の処理 argparse boost::program_options boost::program_options モデルの設計 torch.nn torch::nn torch::nn 前処理(transform) torchvision.transforms torch::data::transforms(実行前に多彩な前処理する場合)
or
自作(実行後に多彩な前処理する場合)自作(OpenCV使用) データセットの取得(datasets) torchvision.datasets(Pillow使用) 自作(OpenCV使用) 自作(OpenCV使用) データローダー(dataloader) torch.utils.data.DataLoader torch::data::make_data_loader(クラス分類の場合)
or
自作(クラス分類以外の場合)自作(OpenMP使用) 損失関数(loss) torch.nn torch::nn torch::nn 最適化手法(optimizer) torch.optim torch::optim torch::optim 誤差逆伝搬法(backward) torch.Tensor.backward() torch::Tensor::backward() torch::Tensor::backward() プログレスバー tqdm boost 自作 現時点(2020/03/24)では,以上のような感じになります.
PyTorchのライブラリをC++で使う場合は,クラス名や関数名がPythonとほとんど同じです.
これは,製作者側がユーザーに配慮してのことだそうです.非常にありがたいですね!次に,C++でPyTorchのプログラムを書く際に,特に気をつけたほうが良い点について記載します.
(2) モデルの設計
以下,私が書いたプログラムの一部を抜粋して記載します.
networks.hpp(一部抜粋)using namespace torch; namespace po = boost::program_options; struct ConvolutionalAutoEncoderImpl : nn::Module{ private: nn::Sequential encoder, decoder; public: ConvolutionalAutoEncoderImpl(po::Variables_map &vm); torch::Tensor forward(torch::Tensor) x; } TORCH_MODULE(ConvolutionalAutoEncoder);モデルを設計する際は,Python同様に「torch::nn」クラスを使用します.
また,モデルを作成する際は構造体を使用します.(クラスのバージョンもありますが,少し複雑になるっぽい)
この際に注意するべきことがPython同様に,nn::Moduleを継承するということです.
ここについては,Pythonの書き方と同じですね.次に重要なのが,構造体の名前を「[モデル名]Impl」にし,構造体の下に「TORCH_MODULE([モデル名])」を追加 することです.
これをしないと,モデルを保存したり,読み込んだりすることができなくなります.
また,「TORCH_MODULE([モデル名])」とすることで普通の構造体「ConvolutionalAutoEncoderImpl」をモデル用の構造体「ConvolutionalAutoEncoder」として宣言できるようになりますが,おそらく内部でクラスの継承をさらにおこなっている?(予想)ため,メンバ変数にアクセスする場合は「model->to(device)」のように,「->」(アロー演算子)を使う必要があるので注意してください.次に,上記の件に関連しますが,nnクラスのモジュールを使用する際の注意点について説明します.
Python同様に「nn::Sequential」を使用することができます.C++で「nn::Sequential」にモジュールを追加していくためには,vector型のように「push_back」を使います.
ここで,「push_back」関数を呼ぶためには,「->」(アロー演算子)を使用することに気をつけてください.
実装例は以下のような感じです.networks.cpp(一部抜粋・改変)nn::Sequential sq; sq->push_back(nn::Conv2d(nn::Conv2dOptions(3, 64, /*kernel_size=*/4).stride(2).padding(1).bias(false))); sq->push_back(nn::BatchNorm2d(64)); sq->push_back(nn::ReLU(nn::ReLUOptions().inplace(true)));(3) transform・datasets・dataloaderの自作
transform,datasets,dataloaderを自作する上では,テンソル型のデータを他の変数に渡す際に「.clone()」を使って渡すことです.私はここでハマりました.
テンソル型は計算グラフを扱う関係で?(予想),このように設定しないとテンソル内の値が変わる可能性があります.transforms.cpp(一部抜粋)void transforms::Normalize::forward(torch::Tensor &data_in, torch::Tensor &data_out){ torch::Tensor data_out_src = (data_in - this->mean) / this->std; data_out = data_out_src.clone(); return; }(4) その他のプログラム
その他のプログラムについては,ほとんどPython版と同じでハマるところは特にありません.
また,Python版とは異なる部分で少し使いにくいなと思ったクラスは自作しました.
具体的なプログラムは,以下のGitHubから見れますので参考にしてください.
https://github.com/koba-jon/pytorch_cpp/tree/master/ConvAEもしかしたら,ソースコードの解説記事も書くかもしれません.
もし,「ここがおかしい」という意見がありましたら,大歓迎ですので是非コメントしてください.プログラミング言語間で共通化させた項目
基本的には,Pythonで有るライブラリがC++には無いといったように,どうしようもない箇所以外は,ほとんど同じと思ってもらって構いません.
また,GitHubのプログラムから変えてないと思ってもらって結構です.具体的には,Python版とC++版を比較する上で,以下の内容を共通化させました.
- 画像サイズ(64×64×3)
- 画像の種類(学習方法Aの画像群=学習方法Bの画像群)
- バッチサイズ(16)
- 潜在空間のサイズ(1×1×512)
- 最適化手法(Adam,learning rate=0.0001,β1=0.5,β2=0.999)
- モデルの構造
- モデルの初期化方法
- 畳み込み層,逆畳み込み層:平均0.0,標準偏差0.02
- バッチノーマライゼーション:平均1.0,標準偏差0.02
- データのロード方法
- 「datasets」クラスの初期化時にはパスのみ取得し,実際に動作させる時に初めてパスをもとに画像を読み込む.
- 「datasets」クラスの稼働時に,1組のデータ(1枚の画像と1個のパス)のみを読み込む.
- 「datasets」クラスの稼働時に,「transform」を実行する.
- 「DataLoader」クラスの稼働時に,並列的にミニバッチのデータを「datasets」クラスから読み込む.
- データセットのシャッフル方法
- 学習時はシャッフルするが,推論時はシャッフルしない.
- エポックごとに,データを入力する一番最初にシャッフルする.
実験結果
比較する各対象において,celebAの64×64の画像182,340枚を用いて,L1誤差を最小化するように,1[epoch]だけ畳み込みオートエンコーダモデルをミニバッチ学習させました.
その際の「1[epoch]当たりの時間」および「GPUのメモリ使用量」を調べました.ここで,「1[epoch]当たりの時間」はtqdmや自作した関数の処理時間も含まれています.
これについては,それが合計の処理時間にほとんど影響を与えなかったという点と,実際にPyTorchを使うときはビジュアライズもあったほうが便利だから使う人が多い点から含めました.また,その学習済みモデルを用いて,テスト画像20,259枚を使って1枚ずつモデルに入力し,テストしました.
その際の「順伝搬の平均速度」および「入力画像と出力画像のL1誤差」も調べました.そして,「実行ファイル」と「nvidia-smi」以外のものは一切立ち上げずに(Ubuntu起動時に最初から稼働しているものはそのまま),学習・テストしました.
CPU(Core i7-8700) GPU(GeForce GTX 1070) Python C++ Python C++ 非決定論的 決定論的 学習 時間[time/epoch] 1時間04分49秒 1時間03分00秒 5分53秒 7分42秒 17分36秒 GPUメモリ[MiB] 2 9 933 913 2941 テスト 速度[seconds/data] 0.01189 0.01477 0.00102 0.00101 0.00101 L1誤差(MAE) 0.12621 0.12958 0.12325 0.12104 0.13158 C++はコンパイル型言語です.
したがって,インタプリタ型言語のPythonに勝つ...かと思いきやどちらもいい勝負でした.学習時間に関しては,CPUはほとんど同じ,GPUはC++がPythonより2倍以上遅いことがわかりました.(なぜ?)
この結果ですが,CPUは同じくらいでGPUのときだけ大きく異なるので,PyTorch C++版のGPUにおける処理の整備が完璧になっておらず,GPUによる順伝搬,逆伝搬が最適化されていない可能性,あるいはCPUで得たミニバッチのデータをGPUに移す際に時間がかかっている,という可能性がありそうです.GPUのメモリ使用量もなぜか多いです.(ReLUのinplaceをTrueにしてるのに...)
また,推論(テスト)の速度や性能についてもPythonとほとんど変化ないため,現状はPythonで全然問題ないかもしれません.
Python(GPU)の決定論的・非決定論的の結果ですが,公式が明言している通り決定論的のほうが遅くなりました.
やはり,ここの時間は変わりますね.結論
学習速度
- 1位:Python版(非決定論的,GPUメイン稼働)
- 2位:Python版(決定論的,GPUメイン稼働)
- 3位:C++版(GPUメイン稼働)
- 4位:CPUメイン稼働(Python版,C++版 同程度)
推論速度
- 1位:GPUメイン稼働(Python版,C++版 同程度)
- 2位:CPUメイン稼働(Python版,C++版 同程度)
性能
- どれも同程度
おわりに
今回はPyTorchのPython版とC++版で,速度と性能を比較しました.
その結果,性能においてはPythonとC++はほとんど変わらないため,C++のPyTorchを使っても問題ないと思いました.
しかし,現段階では,速度を求めてC++のPyTorchをやるというのは,あまりオススメできないかもしれません.もしかしたら,C++のAPIはまだ発展途上であるため,今後大幅に改善されるかもしれませんね!
今後に期待です!参考URL
- 投稿日:2020-03-24T19:39:02+09:00
【Python初心者メモ】データ分析前の欠損値NaNの確認の重要性と方法
Python / 機械学習初心者です。
データ分析をしようと意気込んだ結果、欠損値の確認を怠ったことでつかえてしまったので反省としてメモを残します。結論
- データ分析に入る前に、欠損値の有無の確認を行うべきである
- 欠損値が見られる場合は、欠損値以外のデータを上書きするか、欠損値が含まれる行を除外して分析をするなど、何らかの対策をとるべきである
起こったこと
- Kaggleというデータ分析コンテストに参加した際、すべて目視で確認することができない量のデータを分析した
- その際、欠損値(NaN)の存在に気づかず、プログラムが大量のNaNだらけになってしまい、エラーが止まらなかった
欠損値とは
- Not a Number / NaN
- 計算の処理結果が表せない場合の特殊表現
- 詳細を追おうとすると大変にディープな勉強が必要そうなので、本稿ではふれません
- 他の数との演算結果をNaNで返す性質があるため、プログラム内に1つでもNaNが含まれると、計算結果が正しく求められなくなる可能性がある
1 + NaNの演算結果はNaNである対策 - データ分析開始時のすすめ
- ①まず、何よりも最初に、データの欠損値の有無を確認する
isnull().any()を活用する
- データフレームにおいて、欠損値が含まれる列を教えてくれる
- 下記の用にdf_exampleに対して欠損値を確認すると、人口やGDPについては欠損値の存在をTrueで確認できる(北朝鮮の人口が正確にわからないのかな、などと想像も出来る)
#例:countries.csvに各国の基礎統計データが入っているとする import pandas as pd df_example = pd.read_csv("hogehoge/example.csv").copy() print(df_example.isnull().any())#例 Id False Name False Population True GDP True Region False life_expct False
- ②欠損値の存在が確認された列において置換作業を行う
- 列全体がNaNで構成される場合の別の削除方法や、欠損値の置換ではなく行自体の削除を行う場合の処理は割愛します。
# 欠損値存在列が判明したところで df_example.loc[df_example['Population'].isnull(), 'Population'] = 0注意
- この場合、置換する先の値が適切なものかどうか、後の計算で何を留意するべきか、注意されたい。
- 例えば、上記のように人口を0と置換した場合、2パターンありえるだろう:
- 「このデータは人口の多い国TOP30をに対して分析するからこれで問題がない」
- 「このデータからは平均人口を割り出す分析をするから、その際は『人口の値が0でない国』のみを計算対象にして、分母分子の値に不備の内容にしよう」
まとめ
- データを与えられたら、それにとびついていきなり分析をはじめるのではなく、欠損値の確認から行うことが大切。
参考
(以上)
補言
- 筆者はディープラーニングの入力層に欠損値がまぎれこんでしまったために、後の分析が全く有用でなくなるという経験をし、本稿を書くに至りました。
- 欠損値の確認以外にも、ヒストグラムを描いて外れ値を探すなど、分析前の確認工程・データクレンジングの工程は多々あるかと思います。本稿では2020/03/24時点では言及を控えましたが、それらについても調べたうえでいずれ追記したいと考えています。
- 投稿日:2020-03-24T19:10:17+09:00
Google Compute Engine (Ubuntu 16.04) で快適なPython環境作り
概要
本記事では,GCEのUbuntuにおいて,Python環境を作ります.
(vimの設定等は適宜ご自身で行ってください.)
具体的にやることは以下です.
- サービスアカウント→ユーザーアカウントに変更
- zshを入れる
- Pythonを入れる
- Powerline-shellでカスタマイズ
- Jupyter notebookを使えるようにする
- Stackdriver Monitoring Agentを入れる.
初期設定
初期状態では,サービスアカウントが内部で使われます.
色々と面倒なので,自分のユーザーアカウントでログインしておくことを推奨します.gcloud init色々聞かれるので,言われたとおりに認証して,verification codeを貼ります.
zshの導入
まず,zshをinstallします.
sudo apt-get install zsh -yその後,デフォルトのshellをzshにしたいのですが,パスワードがわからないため,
chshコマンドが動きません.(やり方あったら教えて欲しい)
そのため,vim ~/.bashrcなどでbashrcを開いて,末尾に
exec /usr/bin/zshを挿入します.これでデフォルトのshellがzshになりました.
oh-my-zshを入れる
続いて,oh-my-zshを入れます.
(個々人のこだわりがあるかと思うので,こだわりのあるかたは Python環境の構築 までスキップしてください.)sh -c "$(curl -fsSL https://raw.githubusercontent.com/robbyrussell/oh-my-zsh/master/tools/install.sh)"デフォルトのシェルを変えるかみたいなこと聞いてきますが当然
noにしてください.外部プラグインとして,以下を入れます.
- zsh-syntax-highlight
- zsh-autosuggest
- zsh-history-substring-search
- zsh-completions
git clone https://github.com/zsh-users/zsh-syntax-highlighting.git ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-syntax-highlighting git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions git clone https://github.com/zsh-users/zsh-history-substring-search ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-history-substring-search git clone https://github.com/zsh-users/zsh-completions ${ZSH_CUSTOM:=~/.oh-my-zsh/custom}/plugins/zsh-completions一旦ここで,zshrcを変更しましょう.
~/.zshrcexport ZSH="${HOME}/.oh-my-zsh" ZSH_THEME="candy" plugins=( git pip pyenv virtualenv zsh-syntax-highlighting zsh-autosuggestions history-substring-search zsh-completions ) source $ZSH/oh-my-zsh.sh編集したら,一旦読み込みます.
source ~/.zshrcPython環境の構築
pyenvとvirualenvを使ったよくある仮想環境構築を行います.
まずは,pyenvとvirtualenvをインストールします.sudo apt-get install -y make build-essential libssl-dev zlib1g-dev libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev xz-utils tk-dev libxml2-dev libxmlsec1-dev libffi-dev git clone https://github.com/pyenv/pyenv.git ~/.pyenv echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zshenv echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zshenv echo -e 'if command -v pyenv 1>/dev/null 2>&1; then\n eval "$(pyenv init -)"\nfi' >> ~/.zshenv source ~/.zshenv git clone https://github.com/pyenv/pyenv-virtualenv.git $(pyenv root)/plugins/pyenv-virtualenv echo 'eval "$(pyenv virtualenv-init -)"' >> ~/.zshenv source ~/.zshenv好きなバージョンのPythonをインストールします.
例えばこのような感じ.pyenv install 3.6.5 pyenv virtualenv 3.6.5 default_env pyenv global default_envpowerline-shellのインストール
ここもこだわりがある人はSkipしてください.
まず,現在の仮想環境にpowerline-shellを入れます.pip install powerline-shellその後,再びzshrcを以下のように編集してください.
~/.zshrcexport ZSH="${HOME}/.oh-my-zsh" ZSH_THEME="candy" function powerline_precmd() { PS1="$(powerline-shell --shell zsh $?)" } function install_powerline_precmd() { for s in "${precmd_functions[@]}"; do if [ "$s" = "powerline_precmd" ]; then return fi done precmd_functions+=(powerline_precmd) } if [ "$TERM" != "linux" ]; then install_powerline_precmd fi plugins=( git pip pyenv virtualenv zsh-syntax-highlighting zsh-autosuggestions history-substring-search zsh-completions ) source $ZSH/oh-my-zsh.sh export LC_ALL="en_US.UTF-8" export LANG=ja_JP.UTF-8 #---------------------- 以下,私的設定なので割愛してください ----------------------# #historyファイル指定 HISTFILE=$HOME/.zsh-history HISTSIZE=1000 SAVEHIST=10000 #コマンドじゃなければ cd する setopt auto_cd # 補完候補を一覧表示 setopt auto_list # TAB で順に補完候補を切り替える setopt auto_menu # カッコの対応などを自動的に補完 setopt auto_param_keys # ディレクトリ名の補完で末尾の / を自動的に付加し、次の補完に備える setopt auto_param_slash # コマンドミスった時のcorrect setopt correct # 補完候補一覧でファイルの種別をマーク表示 setopt list_types # 明確なドットの指定なしで.から始まるファイルをマッチ setopt globdots # ファイル名の展開でディレクトリにマッチした場合 末尾に / を付加 setopt mark_dirs # 語の途中でもカーソル位置で補完 setopt complete_in_word # カーソル位置は保持したままファイル名一覧を順次その場で表示 setopt always_last_prompt # ビープを鳴らさない setopt nobeep # vcs有効化 setopt prompt_subst # #以降をコメントとして扱う setopt interactive_comments # ヒストリの共有 setopt share_history # ヒストリに追加されるコマンドが古いものと同じなら古いものを削除 setopt hist_ignore_all_dups更にカスタマイズします.
mkdir -p ~/.config/powerline-shell && powerline-shell --generate-config >以下の2ファイルを作成します.
~/.config/powerline-shell/original_color.pyfrom powerline_shell.themes.default import DefaultColor class Color(DefaultColor): USERNAME_FG = 15 USERNAME_BG = 4 USERNAME_ROOT_BG = 1 HOSTNAME_FG = 15 HOSTNAME_BG = 10 HOME_SPECIAL_DISPLAY = False PATH_FG = 15 PATH_BG = 70 CWD_FG = 231 SEPARATOR_FG = 0 READONLY_BG = 1 READONLY_FG = 7 REPO_CLEAN_FG = 14 REPO_CLEAN_BG = 0 REPO_DIRTY_FG = 3 REPO_DIRTY_BG = 0 JOBS_FG = 4 JOBS_BG = 8 CMD_PASSED_FG = 255 CMD_PASSED_BG = 136 CMD_FAILED_FG = 255 CMD_FAILED_BG = 1 SVN_CHANGES_FG = REPO_DIRTY_FG SVN_CHANGES_BG = REPO_DIRTY_BG VIRTUAL_ENV_BG = 31 VIRTUAL_ENV_FG = 231 AWS_PROFILE_FG = 7 AWS_PROFILE_BG = 2 TIME_FG = 255 TIME_BG = 246~/.config/powerline-shell/config.json{ "segments": [ "virtual_env", "aws_profile", "ssh", "cwd", "git", "git_stash", "jobs", "read_only", "newline", "set_term_title", "svn", "time", "exit_code" ], "cwd": { "max_depth": 4, "max_dir_size": 10, "full_cwd": 1 }, "mode": "patched", "theme": "~/.config/powerline-shell/original_color.py" }注意
- 仮想環境内にpowerline-shellがないとおかしくなりますので毎回
pip installしてください.- 文字化けする場合は,以下を参考にフォントを入れるとなおります.(自分は
Roboto Mono for Powerlineを使ってます)Jupyter Notebookの設定
そのままだとJupyterが使えないので設定します.
以下のサイトのjupyterの設定以降を行えばJupyterを使えます.
参考:https://rf00.hatenablog.com/entry/2018/01/01/160820※sshが切れるとJupyterが落ちちゃうので,tmuxを立ててその中でJupyterを使うことを推奨します.
Stack Driver Monitoring Agentを入れる
GCEのリソース監視にStack Driver Monitoring Agentをお勧めします.
入れると詳しいメモリー使用率などがこちらの右上のHOSTタブの隣のAgentタブから確認できるようになります.
(ただし,別途課金がかかるので注意)公式の通りにインストールします.
デフォルトだと1分ごとにデータを送信しますが,課金量が気になるので3分毎にデータを送信するように変更します.sudo vim /etc/stackdriver/collectd.conf/etc/stackdriver/collectd.confInterval 180 # Interval 60から変更 # 以下変更なし
- 投稿日:2020-03-24T18:38:17+09:00
kivyを使ってGUIプログラミング ~その5 画像でボタンを作る~
はじめに
前回は、いろいろなボタンについて紹介をしました。またボタン関係です。以前、ボタンに画像をはっつけようとしてうまくできなかったので、ちょっと調べてみました。備忘録的な感じになると思います。ついでに、使い方の例を示したいと思います(タイトルの内容がメインではないものが出来上がってしまいましたが。。。)
間違えていた方法
単純に
ButtonのウィジェットにImageをadd_widgetして使おうとしてました。こんな感じになると思います。画像の後ろにボタンががっつり写ってしまい不恰好な感じがしますね。(たぶんいろいろ書けば、見た目はなんとかなるかもしれませんが)それと、ボタンの位置をずらすと、画像がついてきてくれなかったりと訳が分からないです。そのため、以前は実装を諦めてしまいました。やることこんな感じになります。
画像ボタンはこう作る!
画像ボタンを作るには
kivy.uix.behaviorsというモジュールを用います。behaviors.ButtonBehaviorを用いることで、ラベルや画像などにボタンの機能を付与することができます。そのほかにも色々できるようです!
https://kivy.org/doc/stable/api-kivy.uix.behaviors.html
ソースコードは、下記の通りです。
behaviors.ButtonBehaviorとボタンにしたいもの、ここではImageを継承した新しいクラスを作成します。そしてImageの画像を変更し、ボタンを押した時の画像、話した時の画像を指定してあげるとうまいこと動作します。from kivy.app import App from kivy.uix.image import Image from kivy.uix.behaviors import ButtonBehavior class MyButton(ButtonBehavior, Image): def __init__(self, **kwargs): super(MyButton, self).__init__(**kwargs) # 適当な画像 self.source = 'data/val2017/000000000285.jpg' def on_press(self): # 押した時の画像 self.source = 'data/val2017/000000000776.jpg' def on_release(self): # 元の画像に戻す self.source = 'data/val2017/000000000285.jpg' class SampleApp(App): def build(self): return MyButton() SampleApp().run()トグルボタンを使いたい場合には、
ToggleButtonBehaviorを継承してください。from kivy.app import App from kivy.uix.image import Image from kivy.uix.behaviors import ToggleButtonBehavior class MyButton(ToggleButtonBehavior, Image): def __init__(self, **kwargs): super(MyButton, self).__init__(**kwargs) self.source = 'data/val2017/000000000285.jpg' def on_state(self, widget, value): if value == 'down': self.source = 'data/val2017/000000000776.jpg' else: self.source = 'data/val2017/000000000285.jpg' class SampleApp(App): def build(self): return MyButton() SampleApp().run()画像ボタンを使って作ったもの
画像ボタンの作り方を調べているうちに、いつの間にか画像ビュアーができていました。
イメージはこんな感じです。
任意の画像フォルダーの画像をスクロールビューに全て表示して、クリックした画像ボタンの画像が上のImageに表示されるような感じです。
ソース
できたものは下のような感じです。
import os import cv2 import numpy as np from kivy.app import App from kivy.uix.image import Image from kivy.uix.boxlayout import BoxLayout from kivy.uix.gridlayout import GridLayout from kivy.uix.scrollview import ScrollView from kivy.uix.behaviors import ToggleButtonBehavior from kivy.clock import Clock from kivy.graphics.texture import Texture #画像ボタンクラス class MyButton(ToggleButtonBehavior, Image): def __init__(self, **kwargs): super(MyButton, self).__init__(**kwargs) #画像ボタンの画像名を格納 self.source = kwargs["source"] #画像を編集できるようにテクスチャーとして扱う self.texture = self.button_texture(self.source) # トグルボタンの状態、状態によって画像が変化する def on_state(self, widget, value): if value == 'down': self.texture = self.button_texture(self.source, off=True) else: self.texture = self.button_texture(self.source) # 画像を変化させる、押した状態の時に矩形+色を暗く def button_texture(self, data, off=False): im = cv2.imread(data) im = self.square_image(im) if off: im = self.adjust(im, alpha=0.6, beta=0.0) im = cv2.rectangle(im, (2, 2), (im.shape[1]-2, im.shape[0]-2), (255, 255, 0), 10) # 上下反転 buf = cv2.flip(im, 0) image_texture = Texture.create(size=(im.shape[1], im.shape[0]), colorfmt='bgr') image_texture.blit_buffer(buf.tostring(), colorfmt='bgr', bufferfmt='ubyte') return image_texture # 画像を正方形にする def square_image(self, img): h, w = img.shape[:2] if h > w: x = int((h-w)/2) img = img[x:x + w, :, :] elif h < w: x = int((w - h) / 2) img = img[:, x:x + h, :] return img # 画像の色を暗くする def adjust(self, img, alpha=1.0, beta=0.0): # 積和演算を行う。 dst = alpha * img + beta # [0, 255] でクリップし、uint8 型にする。 return np.clip(dst, 0, 255).astype(np.uint8) class Test(BoxLayout): def __init__(self, **kwargs): super(Test, self).__init__(**kwargs) # 読み込むディレクトリ image_dir = "data/val2017" # 縦配置 self.orientation = 'vertical' # 画像ファイルの名前を管理 self.image_name = "" # 画像を表示するウィジェットの準備 self.image = Image(size_hint=(1, 0.5)) self.add_widget(self.image) # 画像ボタンを配置する、スクロールビューの定義 sc_view = ScrollView(size_hint=(1, None), size=(self.width, self.height*4)) # スクロールビューには1つのウィジェットしか配置できないため box = GridLayout(cols=5, spacing=10, size_hint_y=None) box.bind(minimum_height=box.setter('height')) # 画像ボタンの一括定義、グリッドレイアウトに配置 box = self.image_load(image_dir, box) sc_view.add_widget(box) self.add_widget(sc_view) # 画像ボタンの読み込み def image_load(self, im_dir, grid): images = sorted(os.listdir(im_dir)) for image in images: button = MyButton(size_hint_y=None, height=300, source=os.path.join(im_dir, image), group="g1") button.bind(on_press=self.set_image) grid.add_widget(button) return grid # 画像をボタンを押した時、画像ウィジェットに画像を表示 def set_image(self, btn): if btn.state=="down": self.image_name = btn.source #画面を更新 Clock.schedule_once(self.update) # 画面更新 def update(self, t): self.image.source = self.image_name class SampleApp(App): def build(self): return Test() SampleApp().run()少し解説
上の説明では、 ボタンの画像が切り替わるだけで、ボタンが押されているのかよく分からない状態だったと思います。そこで、画像を押した時に枠がついて画像が少し暗くなって押したことがわかるような処理を追加しました。また、グリッドレイアウトに綺麗に並べるために、画像の中心でトリミングする処理も加えております。
画像ボタンクラスには、ボタンとなる画像のファイル名を格納している変数
sourceがあり、それを用いてこの関数で画像名からopencvで画像の処理をします。また、処理した画像を使うには、textureを使う必要があるため、返り値にtextureを指定しております。※
textureについてはその3で解説したので今回は省略いたします。# 画像を変化させる、押した状態の時に矩形+色を暗く def button_texture(self, data, off=False): im = cv2.imread(data) im = self.square_image(im) if off: im = self.adjust(im, alpha=0.6, beta=0.0) im = cv2.rectangle(im, (2, 2), (im.shape[1]-2, im.shape[0]-2), (255, 255, 0), 10) # 上下反転 buf = cv2.flip(im, 0) image_texture = Texture.create(size=(im.shape[1], im.shape[0]), colorfmt='bgr') image_texture.blit_buffer(buf.tostring(), colorfmt='bgr', bufferfmt='ubyte') return image_textureアプリ側のボタンを押した時の処理ですが、ボタンを押した時に、画面上部の
Imageのsourceを変更するだけでは、画像は変化しません。画像を変えるためには、画面を更新する必要が必要です。そのため、画像を押した時に、Clockを一度動かして画面を更新しております。# 画像をボタンを押した時、画像ウィジェットに画像を表示 def set_image(self, btn): if btn.state=="down": self.image_name = btn.source #画面を更新 Clock.schedule_once(self.update) # 画面更新 def update(self, t): self.image.source = self.image_name参考文献
・OpenCV - 画像の明るさやコントラストを変更、ガンマ補正など - Pynote
画像を暗くする処理のソースを参考にいたしました。・COCO Dataset
今回使用させていただいた画像のリンクです。




- 投稿日:2020-03-24T17:55:14+09:00
【Python】OpenCVによる顔検出 (Haar Cascade)
はじめに
今回はOpenCVを用いて、顔か検出をやってみたいと思います。顔検出の手法は色々あるのですが、今回はHaar cascadeを用います。
環境
MacOS Mojave
Python 3.7Haar Casecade?
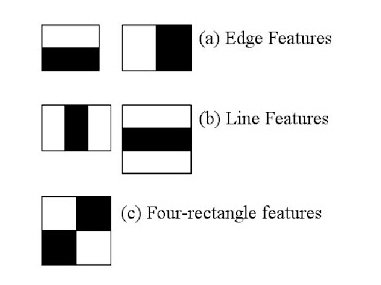
顔っぽさを表す特徴量 (Haar特徴量) から、これは顔であるかないかを判断する分類器のことです。この分類器は、高速化の為に複数の分類器が結合してできていることから、Cascade (結合) 分類器と呼ばれます。Haar特徴量は以下のような白黒の特徴量が用いられます。
図. Haar特徴量
(画像引用元:http://labs.eecs.tottori-u.ac.jp/sd/Member/oyamada/OpenCV/html/py_tutorials/py_objdetect/py_face_detection/py_face_detection.html)なんだこの白黒は、、、と思ったんじゃないでしょうか。少し人間の顔がどうなっているのかを考えてみましょう。
人間の顔って高度に抽象化すると、大体は以下のようになるのではないでしょうか (ならないか...w)
図. 高度に抽象化された顔上図から、例えば目元は左から"黒白黒"の色の配置になっていると思いませんか。
図. 高度に抽象化された顔の白と黒の配置この高度に抽象化された顔っぽい白と黒の配置を表したのがHaar特徴量です。
入力画像から任意の領域を切り出し、この特徴量がたくさん存在すれば、顔だと判断します。
図. 顔だと判断された画像 (目元など、Haar特徴量がたくさん存在する)
(画像引用元:http://labs.eecs.tottori-u.ac.jp/sd/Member/oyamada/OpenCV/html/py_tutorials/py_objdetect/py_face_detection/py_face_detection.html)ここではざっくりとしたイメージの解説だけなので、詳細を知りたい方は以下の論文を読んでみてください。
https://www.cs.cmu.edu/~efros/courses/LBMV07/Papers/viola-cvpr-01.pdf顔検出
では、haar cascadeを用いて人の顔を認識してみたいと思います。画像は以下の画像 (woman.jpg) を使用しました。
実行したコードは以下のようになります。
import cv2 import matplotlib.pyplot as plt #画像の読み込み (画像1066x1600) img = cv2.imread("woman.jpg") #顔のカスケード分類器を読み込む face_cascade = cv2.CascadeClassifier("haarcascades/haarcascade_frontalface_default.xml") #画像をグレースケールにする gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #顔検出を実行! faces = face_cascade.detectMultiScale(gray) #facesに顔の位置が入っているので、for文で読み取る for (x,y,w,h) in faces: #矩形を顔の位置に矩形を描画する img = cv2.rectangle(img,(x,y),(x+w,y+h),(0,0,255),10) #色の順番を変更する img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) #出力 plt.imshow(img) plt.show()結果
ちゃんと認識されてますね!
次にコードの中のポイントだけ解説していきます。カスケード分類器の読み込み
#顔のカスケード分類器を読み込む face_cascade = cv2.CascadeClassifier("haarcascades/haarcascade_frontalface_default.xml")この部分では、上記で述べた顔を分類するためのcascade分類器を読み込んでいます。もし
OpenCV(4.2.0) /Users/travis/build/skvark/opencv-python/opencv/modules/objdetect/src/cascadedetect.cpp:1689: error: (-215:Assertion failed) !empty() in function 'detectMultiScale'のようなメッセージが出てきたら、多分カスケード分類器のxmlファイルががないので、以下からダウンロード (もしくはclone) してください。
https://github.com/opencv/opencvダウンロードしたら、data/haarcascadesのフォルダを自分のpythonファイル(またはipynb)と同じフォルダ内にいれて実行してください。
矩形描画
for (x,y,w,h) in faces: #矩形を顔の位置に矩形を描画する img = cv2.rectangle(img,(x,y),(x+w,y+h),(0,0,255),10)顔の位置は(x,y,幅,高さ)で出力されます。これは以下のようになります。
cv2.reactangleの引数は以下のようになります。
cv2.reactangle(画像,(左上x,左上y),(右下x,右下y),(色),線の太さ)
終わりに
カスケード分類器は顔だけでなく胴体や下半身、猫なども検出できます。近々その記事も執筆したいと思います。もし、記事に対してのご意見、誤りなどがあればコメントください。
Twitterでも発信をしてます。もしよければフォローお願いします、、、!
https://twitter.com/ryuji33722052



- 投稿日:2020-03-24T17:16:50+09:00
wikipediaとfasttextによるトピックに沿ったキーワード選択
概要
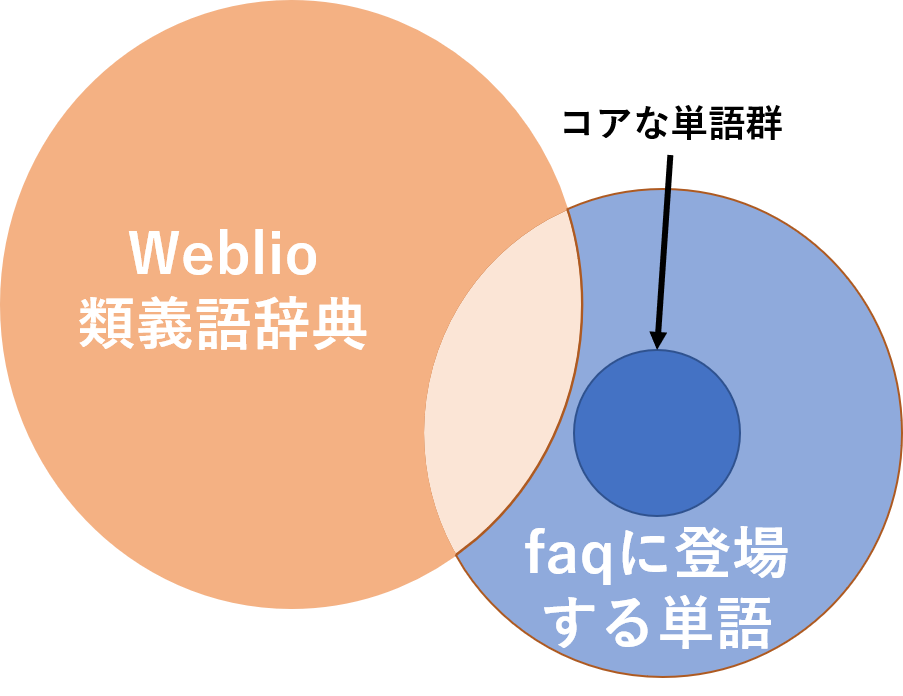
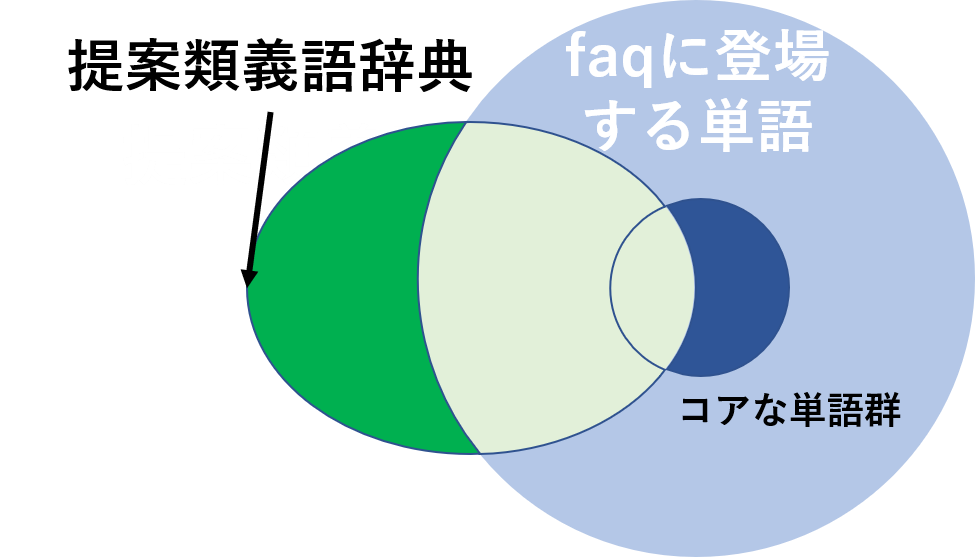
チャットボットの開発をしている株式会社サイシードでインターンをしていて,特定の会社のfaqチャットボットに使う類義語辞典の作成を行っていた.類義語辞典の作成を行う上で,現在使用されているのがweblio提供のオープンな類義語辞典である.しかし,これには使用しづらい単語や特定の会社の固有の単語などが少ないことがあげられる.簡単に表すと下のベン図のようなことになっている.そこで,wikipediaとfasttextを用いることであるトピックに沿った単語を選択し,もう一個下のような図になるようにより少ない単語でよりカバー範囲の高い類義語辞典を作成することが目標である.
実際やったことの概要
- トピックをいくつか準備しwikipediaのページを抜き出す
- 二つのトピックを選び,fasttextでベクトル化し,機械学習で分類できるかを調査
- fasttextがトピックの言葉を区別することができることが確認できれば,fasttextを用いて会社に使われやすい単語はより簡単に選択してくることが可能だと思われる.
- トピック単語セットが現状の類義語辞典に比べてどれくらいのfaq内の単語のカバーが可能かを確認
使用環境
- centos 7.3
- python 3.7
- mecab
- インストール方法
- これは最新版のインストール方法で自分はかなり古いものを使っているため,変えることでよりよくなるかも
- fasttext
- wikipediaデータ
詳細な部分と結果
まず,試したトピックは以下の通り
トピック単語の一覧word_cand = ["車","料理","旅行","システム","Office","Windows","金融","保険","スマートフォン","化粧品","某飲料会社","某化粧品会社"]wikipediaから特定のトピックを選択するときにページのカテゴリー内にそのトピックの単語が入っていた場合,そのページ内の単語をトピック単語の候補とした.
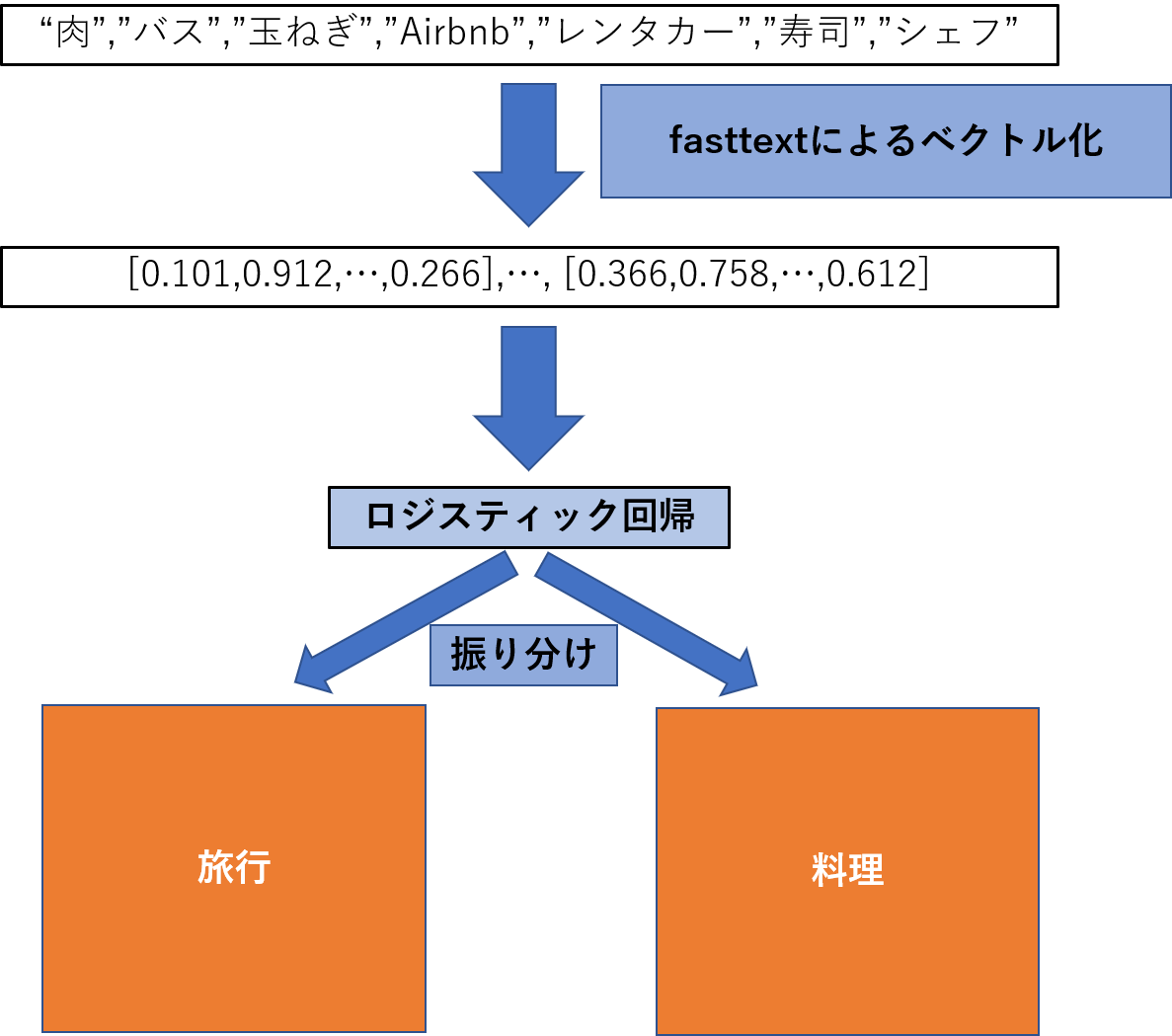
一つのトピックを1ドキュメントとして,tf-idfを計算し,トピックごとの単語を分別できるかを確認した.
この分別とは例えば車と料理のtf_idfの上位10単語が以下のような感じだとする.料理 = ['肉', 'スープ', '具', '以子', '鶏肉', '演', 'タマネギ', '牛肉', 'シェフ', '寿司'] 旅行 = ['列車', 'ストウ', 'イブン・バットゥータ', '近畿日本ツーリスト', 'ピースボート', 'Airbnb', '貸切', 'レンタカー', 'WILLER', 'ツアー']料理の中には料理に関係が深そうな単語が,旅行の中には旅行に関係の深そうな単語が存在している.
これをfasttextと線形回帰によって以下の図のようなことをしたい.
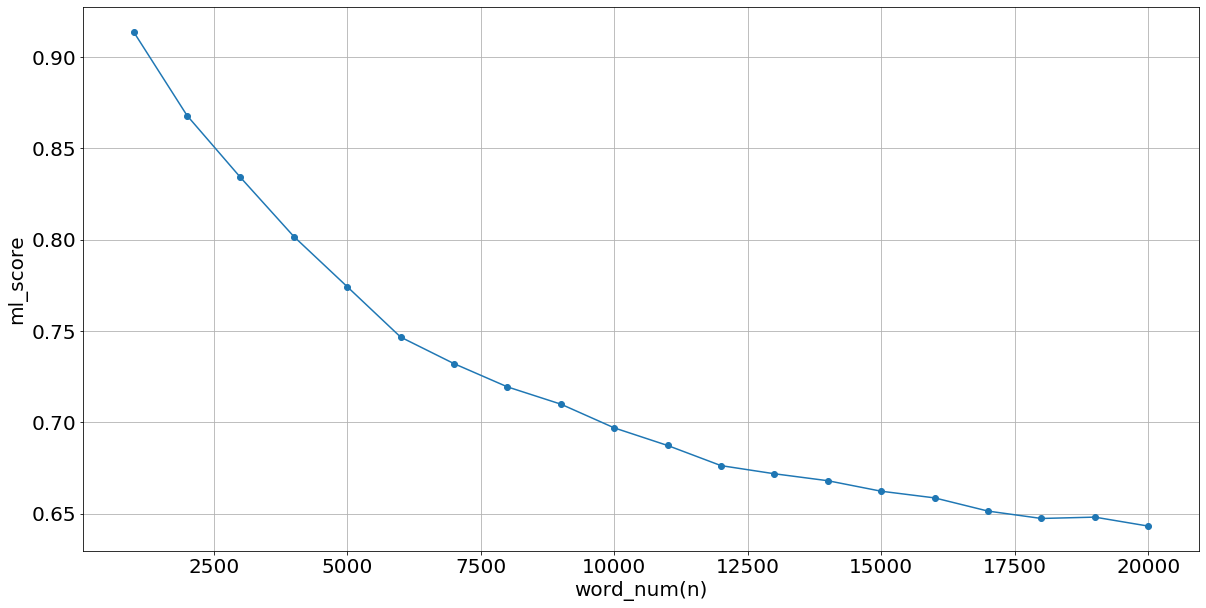
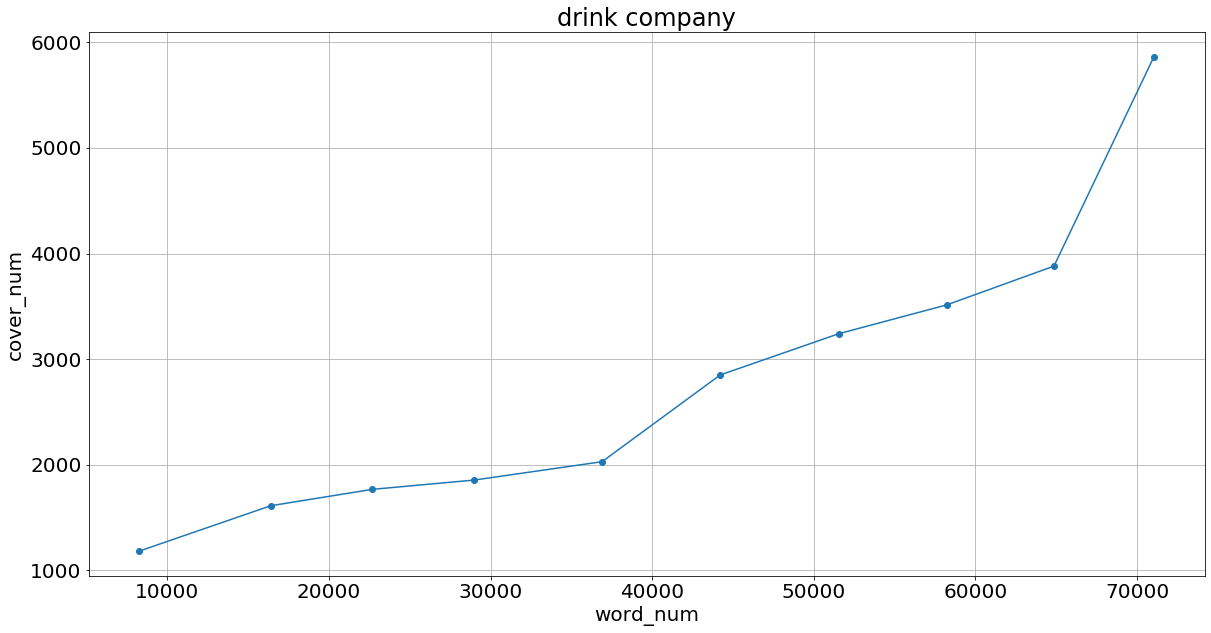
そして上位n単語を選んで75%をtrain,残りをtestにした時の線形回帰によるaccuracy(どれくらいtestデータが正確にクラスタに分けられたかを)を下のグラフとして結果を示す.
このようにtf_idfの高い場所ではかなりの正答率がある.
tf_idfを使うことによってよりトピックに沿った単語を選べる.
そしてよりトピックに沿った単語を選ぶことができた時ほど,正答率がよくなっている.よってfasttextの空間にはトピックごとのクラスタの様なものが存在し,それらは線形的に分けることができている.
そしてwikiデータの中からtf_idfを使って選択し,fasttext使用して単語数を増やすことでトピックに沿った単語を選ぶことができることが予想できる.次に,サイシードが持つ某旅行代理店と某飲料会社の実際のfaqの中でどの程度カバー単語数があるのかを確かめた.
カバー単語数とは簡単に言うと上のベン図の重なっている部分である.
しかし,単語ごとに使われているコア単語やあまり使われていない単語がベン図に表しているように存在する.
そこでカバー単語数は単なる単語数ではなく,カバーできた単語の使用数を足し合わせたものである.
某旅行代理店は”旅行”のトピック,某飲料会社には"某飲料会社"のトピックの単語たちを使った.
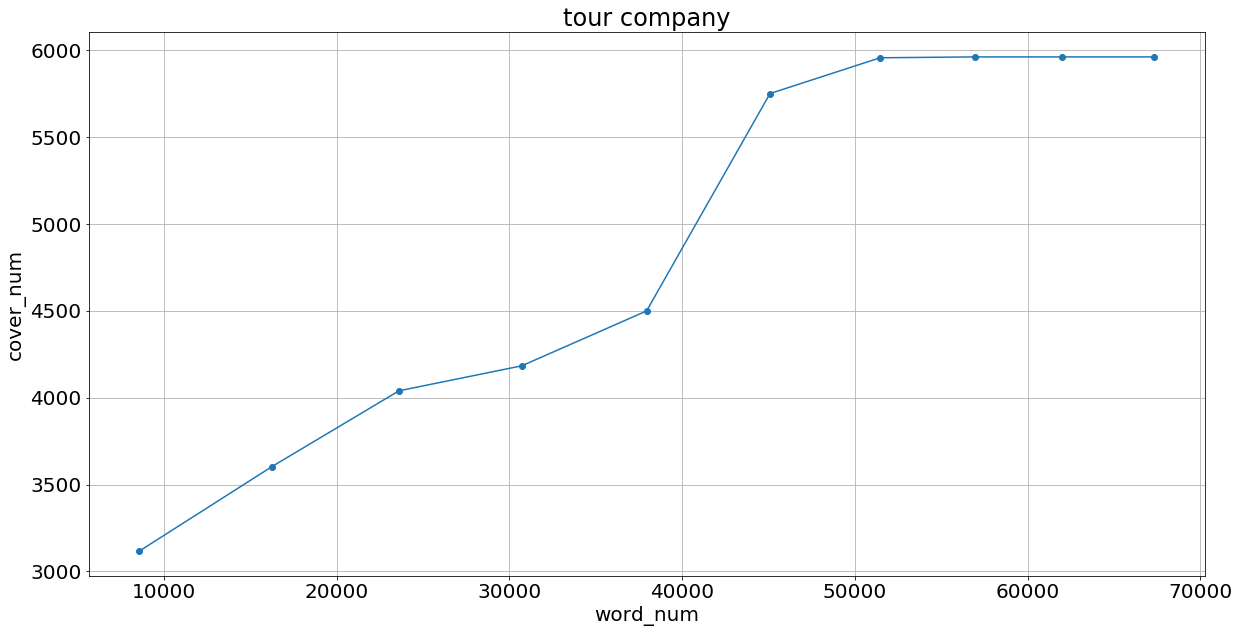
ここでは上位10000単語まで1000単語づつ選択し,選択した単語をfasttextでの類似度合いが上位5単語かつ類似度が0.4以上であるものを追加することでトピックの言葉をさらに増やす.
ともに某旅行代理店と某飲料会社の結果が以下のようになる.
従来の類義語辞典と比較した場合が以下の表のようになる.
言葉の数 カバー単語数 言葉の数/カバー単語数 weblio 144256 9040 0.062 wiki+fast 56936 5963 0.105
言葉の数 カバー単語数 言葉の数/カバー単語数 weblio 144256 5387 0.037 wiki+fast 71042 5863 0.082 この結果からより某旅行会社では少ない単語でそれなりのカバー単語数,某飲料会社では少ない単語でよりよいカバー単語数を示せた.
この違いは某飲料会社では商品名などが存在するため,従来の類義語辞典には載っていないが使われる回数の多い単語が存在するからだと考えられる.
某飲料会社のカバー単語数が最後飛躍的によくなっているのはtf_idfの都合上一般的使われてる言葉が最初には含まれておらず,そこが追加された結果によると考えられる.まとめ
従来の類義語辞典より効率のよい類義語辞典を作成することができた.ただ,まだ改善点がいくつも存在する.今回は頻出だがどのドキュメントにも使われている単語はtf_idfの性質上選ばれづらい.そのためほかに一般単語集のようなデータを使用することで,さらにカバーできることが想像できる.方法としては,某飲料会社ではなく飲料などあいまいな単語をトピックにし,そこに”某飲料会社”のトピックの単語を上乗せする.すると,一般的な言葉が入りやすくなり改善が見られると想像できる.
- 投稿日:2020-03-24T17:11:24+09:00
本物の凶暴ワニ画像をKerasで100ワニ風ににこにこニューラルスタイル変換する
ニューラルスタイル変換とは
ニューラルスタイル変換とはあるターゲット画像を、他の画像のスタイル(質感)に変換して新たな画像を生成する機械学習のテクニックの一つです。街や人の画像をゴッホ風に変えたりするアプリで使われている技術ですね。
ではこの技術を使って今回は本物の、今にも人を食べてしまいそうな凶暴なワニ画像を、100日後に死ぬワニ風にスタイル変換して優しいにこにこワニに変換できるか試してみたいと思います。
(それにしてもこの画像のにいちゃん大丈夫か、、、気をつけないと死んじゃうよ!)
やることは基本的には元の画像のコンテンツ(画像の骨組みといったマクロな構造)を維持した上で、100ワニ風の漫画タッチのスタイル(質感)を取り入れます。ディープラーニングでは常にある達成したいことを指定する損失関数を定義して、その損失関数を最小化することで目的の達成を目指します。今回の例の物凄くざっくりした最小化したい損失関数のイメージはこんなです↓損失関数 = (本物のワニ画像コンテンツ - 生成画像コンテンツ) + (100ワニのスタイル - 生成画像のスタイル)
参考はKeras制作者のこの本↓です。ほぼこの本にそっているので詳細気になる方は是非購入してみてください。
PythonとKerasによるディープラーニング環境
Google Colabを使います。構成が不要でGPUへの無料アクセスができるので簡単に画像の処理を行うことができます。使う画像はGoogle Driveに保存しておいてGoogle Colabから画像を読み込みます。
Kerasを使ったニューラルスタイル変換 in Google Colab
まずは処理したいターゲット画像とスタイル画像をgoogle driveに保存しておきます。保存したらgoogle colabでノートブックを開きます。そこでgoogle driveにアクセスするために↓を実行し、google drive側でアクセスを許可してください。するとauthorization codeが手に入るのでこれを下記のコード実行後に出てくるフォームに入力します。
from google.colab import drive drive.mount('/content/drive')次に画像のpathを定義しておきます。ついてでに処理した画像が同じようなサイズになるよう処理しておきます。
import keras keras.__version__ from keras.preprocessing.image import load_img, img_to_array # ターゲット画像のpath。pathは自分が保存した場所に書き換えてください。 target_image_path = '/content/drive/My Drive/Colab Notebooks/wani/wani2.png' # スタイル画像のpath。pathは自分が保存した場所に書き換えてください。 style_reference_image_path = '/content/drive/My Drive/Colab Notebooks/wani/100wani.png' # 生成画像サイズ width, height = load_img(target_image_path).size img_height = 400 img_width = int(width * img_height / height)次にVGG19でやり取りする画像の読み込み、前処理、後処理を行う補助関数を作っておきます。
import numpy as np from keras.applications import vgg19 def preprocess_image(image_path): img = load_img(image_path, target_size=(img_height, img_width)) img = img_to_array(img) img = np.expand_dims(img, axis=0) img = vgg19.preprocess_input(img) return img def deprocess_image(x): x[:, :, 0] += 103.939 x[:, :, 1] += 116.779 x[:, :, 2] += 123.68 x = x[:, :, ::-1] x = np.clip(x, 0, 255).astype('uint8') return x続いてVGG19を定義します。
from keras import backend as K target_image = K.constant(preprocess_image(target_image_path)) style_reference_image = K.constant(preprocess_image(style_reference_image_path)) # 生成画像を保持するプレースホルダー combination_image = K.placeholder((1, img_height, img_width, 3)) # 3つの画像を1つのバッチにまとめる input_tensor = K.concatenate([target_image, style_reference_image, combination_image], axis=0) # 3つの画像からなるバッチを入力として使用するVGG19を構築 # このモデルには学習済みのImageNetの重みが読み込まれます model = vgg19.VGG19(input_tensor=input_tensor, weights='imagenet', include_top=False) print('Model loaded.')損失関数を定義します。
# コンテンツの損失関数 def content_loss(base, combination): return K.sum(K.square(combination - base)) # スタイルの損失関数 def gram_matrix(x): features = K.batch_flatten(K.permute_dimensions(x, (2, 0, 1))) gram = K.dot(features, K.transpose(features)) return gram def style_loss(style, combination): S = gram_matrix(style) C = gram_matrix(combination) channels = 3 size = img_height * img_width return K.sum(K.square(S - C)) / (4. * (channels ** 2) * (size ** 2)) # 全変動損失関数 def total_variation_loss(x): a = K.square( x[:, :img_height - 1, :img_width - 1, :] - x[:, 1:, :img_width - 1, :]) b = K.square( x[:, :img_height - 1, :img_width - 1, :] - x[:, :img_height - 1, 1:, :]) return K.sum(K.pow(a + b, 1.25))最小化の対象となる最終的な損失関数(これら3つの関数の加重平均)を定義します。
outputs_dict = dict([(layer.name, layer.output) for layer in model.layers]) content_layer = 'block5_conv2' style_layers = ['block1_conv1', 'block2_conv1', 'block3_conv1', 'block4_conv1', 'block5_conv1'] total_variation_weight = 1e-4 style_weight = 1. content_weight = 0.025 loss = K.variable(0.) layer_features = outputs_dict[content_layer] target_image_features = layer_features[0, :, :, :] combination_features = layer_features[2, :, :, :] loss += content_weight * content_loss(target_image_features, combination_features) for layer_name in style_layers: layer_features = outputs_dict[layer_name] style_reference_features = layer_features[1, :, :, :] combination_features = layer_features[2, :, :, :] sl = style_loss(style_reference_features, combination_features) loss += (style_weight / len(style_layers)) * sl loss += total_variation_weight * total_variation_loss(combination_image)勾配降下法のプロセスを定義
grads = K.gradients(loss, combination_image)[0] fetch_loss_and_grads = K.function([combination_image], [loss, grads]) class Evaluator(object): def __init__(self): self.loss_value = None self.grads_values = None def loss(self, x): assert self.loss_value is None x = x.reshape((1, img_height, img_width, 3)) outs = fetch_loss_and_grads([x]) loss_value = outs[0] grad_values = outs[1].flatten().astype('float64') self.loss_value = loss_value self.grad_values = grad_values return self.loss_value def grads(self, x): assert self.loss_value is not None grad_values = np.copy(self.grad_values) self.loss_value = None self.grad_values = None return grad_values evaluator = Evaluator()やっと最後に実行です!
from scipy.optimize import fmin_l_bfgs_b #from scipy.misc import imsave import imageio import time result_prefix = 'style_transfer_result' iterations = 30 # Run scipy-based optimization (L-BFGS) over the pixels of the generated image # so as to minimize the neural style loss. # This is our initial state: the target image. # Note that `scipy.optimize.fmin_l_bfgs_b` can only process flat vectors. x = preprocess_image(target_image_path) x = x.flatten() for i in range(iterations): print('Start of iteration', i) start_time = time.time() x, min_val, info = fmin_l_bfgs_b(evaluator.loss, x, fprime=evaluator.grads, maxfun=20) print('Current loss value:', min_val) # Save current generated image img = x.copy().reshape((img_height, img_width, 3)) img = deprocess_image(img) fname = result_prefix + '_at_iteration_%d.png' % i #imsave(fname, img) imageio.imwrite(fname, img) end_time = time.time() print('Image saved as', fname) print('Iteration %d completed in %ds' % (i, end_time - start_time))画像を出力します
from scipy.optimize import fmin_l_bfgs_b from matplotlib import pyplot as plt # コンテンツ画像 plt.imshow(load_img(target_image_path, target_size=(img_height, img_width))) plt.figure() # スタイル画像 plt.imshow(load_img(style_reference_image_path, target_size=(img_height, img_width))) plt.figure() # 生成画像 plt.imshow(img) plt.show()出力結果
出力結果は、、、、、、、、、、
なんかイメージしていたのと違う!!!!!全然ポップで優しいワニ感無し!!!!!!
まぁ、これがディープラーニングあるあるなのですが、とりあえず割と簡単にGoogle ColabやKerasを使えばディープラーニングが試せることは体験して頂けたのではないでしょうか。こちらのコードで自分でいろいろな画像処理を試せるので皆さんも是非試してみてください。ほんとKerasすごい。再掲しておきますが今回のコードはほぼこちら↓の本のままです。


- 投稿日:2020-03-24T16:54:29+09:00
GoogleColaboratoryでsympy(>=1.4)を使うときに数式をlatexで表示する方法
解決方法
!pip install --upgrade sympyfrom sympy import * def custom_latex_printer(expr, **options): from IPython.display import Math, HTML from google.colab.output._publish import javascript url = "https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.7/MathJax.js?config=TeX-AMS_CHTML" javascript(content="""window.MathJax = { tex2jax: { inlineMath: [ ['$','$'] ], processEscapes: true } };""") javascript(url=url) return latex(expr, **options) init_printing(use_latex="mathjax", latex_printer=custom_latex_printer)解説
Latex output from sympy does not correctly display in Google Colaboratory Jupyter notebooks - Stack Overflow
などの、検索してよく出てくる方法は sympy1.4 以降では不十分です。Release Notes for 1.4 · sympy/sympy Wiki · GitHub
- By default, LaTeX output in the Jupyter notebook is framed with \$\displaystyle ...\$. This prevents it from being centered in PDF output from nbconvert (see https://github.com/jupyter/notebook/issues/4060). (#15625 by @mgeier)
(LaTex出力のデフォルトがインライン数式モードになった。)
- 投稿日:2020-03-24T16:47:58+09:00
Blender 2.82 or later + python 開発環境のメモ
背景
Blender + python で開発環境を整えたい.
Blender 内臓のエディタやコンソールは使いづらいので, vscode から使ったりしたい
自前 add-on の開発デバッグや, bpy 関数の振る舞いをお手軽調べたい, など.環境
- Ubuntu 18.04
- Blender 2.82a or later
基本情報
blender の python を直接叩いても,
import bpyはできないです.
blender を経由して python を動かす必要があります.コマンドラインから python コンソールを開く
How can I run blender from command line or a python script without opening a GUI?
https://blender.stackexchange.com/questions/1365/how-can-i-run-blender-from-command-line-or-a-python-script-without-opening-a-gui$ blender --background --python-consoleとすれば python コンソール出ます.
VSCode で使う.
https://github.com/JacquesLucke/blender_vscode
https://github.com/AlansCodeLog/blender-debugger-for-vscode
このあたりが使えそうです.
Advanced な内容
ありがとうございます.
BlenderのC++アドオンで高速にデータを受け渡す (LuxBlendにおける手法)
https://qiita.com/vipper36/items/3e6012c3c770ade0d412[Blender] GitHubとTravisCIを用いてBlenderアドオンのテストを自動化する
https://qiita.com/nutti/items/fe3f3f14168155df5916Blender をビルドする
上記 blender as module や, 何かしら特殊なことをしたいときはソースコードからビルドするのが手っ取り早いでしょう.
https://wiki.blender.org/wiki/Building_Blender
ソースコードや, 依存ライブラリの prebuilt binary を落としたのち,
基本 make するだけでビルドできます.
git submodule を忘れずに行いましょう.
そうしないとfile INSTALL cannot find "/home/mdriftmeyer/DeveloperProjects/Blender-Repository/blender/release/datafiles/locale/languages".という locale 周りでのエラーがでます.
https://developer.blender.org/T37760
Blender 自体のビルドは, Ubuntu では prebuilt binary があるので, そんなに時間かかりません.
Threadripper 1950X で 5 分くらいでした.Blender as module
Blender 自体を python module(
libbpy.so)にするビルドがあります.https://wiki.blender.org/wiki/Building_Blender/Other/BlenderAsPyModule
これにより, 好きな python インタプリタなどで
import bpyできるので, 開発が捗るのが想定されますが, Ubuntu だとハードルが高いです.prebuilt ではうまくいかない.
ビルドコマンド自体は単純です.
$ make bpy(内部では cmake を呼んでいるので, その cmake 設定をみてみるとよいでしょう)
まず, bpy.so は shared lib でリンクされますが, prebuilt libs は
.aしかないです. 一応 relocatable のようですが,.aが依存している system のライブラリも .a とリンクするので(e.g. libpng.a), libpng.a や gomp.a (OpenMP)のリンク時にエラーが出ます.libpng.a は, apt で入っていると
/usr/lib/..のほうを見に行ってしまうので, いったん apt で消すなりして, prebult libs 側の libpng.a とリンクするようにすれば解決できます.
が, libpng.a は消せないときもあるでしょうから, Docker あたりでbpy.soをビルドするのが無難かもしれません.gomp(OpenMP) は環境にもよります. 何かしらコンパイラをいれていると,
/usr/lib/...にある libgomp.a とリンクしようとしてしまっているかもしれません.これもファイルを消せばいいですが... やはり Docker でビルドがいいかもしれません.
また,
WITH_MEM_JEMALLOCを off にしてビルドしないと,cannot allocate memory in static TLS block
というエラーが import 時に出ます.
https://devtalk.blender.org/t/problem-with-running-blender-as-a-python-module/7367
CMake 設定を見ると, Linux のときは一応 OFF になっているはずなのですが, なぜか反映されません.
依存ライブラリをソースからビルドするのは...
$ make depsで, 依存ライブラリをソースからビルドすることができます.
ただし, yasm(なぜアセンブラが必要?! と思ったら video codec 系で使っている) やら, システムの boost とかちあったり, LLVM を一からビルドとかでめんどいです.
少なくとも OpenVDB はなぜか boost 周りでうまくビルドできませんでした. VDB 使わないならとりあえず off でビルドするのも手でしょうか.
TODO
- Blender as module のビルドと動作をいろいろ試す.
- 投稿日:2020-03-24T16:46:16+09:00
pythonでExcelを扱う
まあこれを見ればよいよ、というだけの話ではあるが。
https://note.nkmk.me/python-pandas-read-excel/pandasだけではなくて、xlrdもインストールする必要があることに注意。
sample.pyimport sys import pandas as pd # 読み込むXLSファイル excel_file = sys.argv[1] print('ファイル名⇒', sys.argv[1]) if __name__== '__main__': file = pd.ExcelFile(excel_file) # "parent"というシートを読み込む sheet_df = file.parse("parent") for j,series in sheet_df.iterrows(): # 行ごとの処理 parent_xxx(series)
- 投稿日:2020-03-24T16:29:32+09:00
TA-Lib
公式 GitHub indicators.py import talib """ 単純移動平均(SMA: Simple Moving Average) 60日単純移動平均 timeperiod=60 """ def SMA(price): sma = talib.SMA(price) return sma """加重移動平均(WMA: Weighted Moving Average)""" def WMA(price): wma = talib.WMA(price) return wma """指数移動平均(EMA: Exponential Moving Average)""" def EMA(price): ema = talib.EMA(price) return ema """2重指数移動平均(DEMA: Double Exponential Moving Average)""" def DEMA(price): dema = talib.DEMA(price) return dema """3重指数移動平均(TEMA: Triple Exponential Moving Average)""" def TEMA(price): tema = talib.T3(price) return tema """三角移動平均(TMA: Triangular Moving Average)""" def TRIMA(price): trima = talib.TRIMA(price) return trima """Kaufmanの適応型移動平均(KAMA: Kaufman Adaptive Moving Average)""" def KAMA(price): kama = talib.KAMA(price) return kama """MESAの適応型移動平均(MAMA: MESA Adaptive Moving Average)""" def MAMA(price): mama, fama = talib.MAMA(price) return mama, fama """トレンドライン(Hilbert Transform - Instantaneous Trendline)""" def TRENDLINE(price): trendline = talib.HT_TRENDLINE(price) return trendline """ ボリンジャー・バンド(Bollinger Bands) 15日ボリンジャー・バンド timeperiod=15, nbdevup=2, nbdevdn=2, matype=0 """ def BBANDS(price): upperband, middleband, lowerband = talib.BBANDS(price, timeperiod=20, nbdevup=2, nbdevdn=2, matype=0) return upperband, middleband, lowerband """MidPoint over period""" def MIDPOINT(price): midpoint = talib.MIDPOINT(price) return midpoint """変化率(ROC: Rate of change Percentage)""" def ROC(price): roc = talib.ROCP(price) return roc """モメンタム(Momentum)""" def MOM(price): mom = talib.MOM(price) return mom """ RSI: Relative Strength Index 21日RSI timeperiod=21 """ def RSI(price): rsi = talib.RSI(price) return rsi """MACD: Moving Average Convergence/Divergence""" def MACD(price): macd, signal, hist = talib.MACD(price) return macd, signal, hist """APO: Absolute Price Oscillator""" def APO(price): apo = talib.APO(price) return apo """PPO: Percentage Price Oscillator""" def PPO(price): ppo = talib.PPO(price) return ppo """CMO: Chande Momentum Oscillator""" def CMO(price): cmo = talib.CMO(price) return cmo """ヒルベルト変換 - Dominant Cycle Period""" def DCPERIOD(price): dcperiod = talib.HT_DCPERIOD(price) return dcperiod """ヒルベルト変換 - Dominant Cycle Phase""" def DCPHASE(price): dcphase = talib.HT_DCPHASE(price) return dcphase """ヒルベルト変換 - Phasor Components""" def PHASOR(price): inphase, quadrature = talib.HT_PHASOR(price) return inphase, quadrature """ヒルベルト変換 - SineWave""" def SINE(price): sine, leadsine = talib.HT_SINE(price) return sine, leadsine """ヒルベルト変換 - Trend vs Cycle Mode""" def TRENDMODE(price): trendmode = talib.HT_TRENDMODE(price) return trendmode
- 投稿日:2020-03-24T16:18:51+09:00
RealnessGANを実装してみた
RealnessGANという新しいGANがあるようですが、日本語の情報がほとんどなさそうなので。
実装してCIFAR-10について学習させました。論文はReal or Not Real, that is the Questionです。
論文の著者による実装も参考にしました。
ここの実装も参考になります。RealnessGANを使うとDCGANでもきれいに学習できるらしいです。
https://github.com/kam1107/RealnessGAN/blob/master/images/CelebA_snapshot.png概要
普通のGANではDiscriminator(識別器)の出力は「Realness(現実っぽさ)」を表すスカラー値です。
この論文では、Realnessの確率分布を出力するDiscriminatorを使うことが提案されています。Discriminatorが出力する情報が増えることで、Generator(生成器)の学習もよりうまくいくらしいです。
論文によると、普通のDCGANの構造でも1024×1024の顔画像(FFHQデータセット)の学習に成功したとか。
FFHQデータセットの学習結果記号の意味
- $D$ Discriminator(識別器)
- $G$ Generator(生成器)
- $\boldsymbol{z}$ Generatorに入れるノイズ(潜在表現)
- $\mathcal{A}_0$ 偽物の画像に対するAnchor($D$の正解として与えるRealnessの分布?)
- $\mathcal{A}_1$ 本物の画像に対するAnchor
- $p_{\mathrm{data}}(\boldsymbol{x})$ データセットからランダムに選んで画像$\boldsymbol{x}$が出てくる確率?
- $p_g(\boldsymbol{x})$ ランダムに選んだ$\boldsymbol{z}$から$G(\boldsymbol{z})$が画像$\boldsymbol{x}$になる確率?
手法
普通のGANのDiscriminatorが出力するのは連続なスカラー値「Realness」です。
一方、RealnessGANのDiscriminatorが出力するのはRealnessの離散確率分布であるようです。
例えばD(\mbox{画像}) = \begin{bmatrix} \mbox{画像のRealnessが }1.0\mbox{ である確率} \\ \mbox{画像のRealnessが }0.9\mbox{ である確率} \\ \vdots \\ \mbox{画像のRealnessが }-0.9\mbox{ である確率} \\ \mbox{画像のRealnessが }-1.0\mbox{ である確率} \\ \end{bmatrix}みたいになるようです。
この離散化されたRealnessの値を論文ではOutcomeと呼んでいるようです。
確率分布はDiscriminatorの生の出力について、チャンネル方向のソフトマックスを取ることで求められるようです。また、Realnessの確率分布についての正解データを論文ではAnchorと呼んでいるみたいです。
例えば\mathcal{A}_0 = \begin{bmatrix} \mbox{偽物の画像のRealnessが }1.0\mbox{ である確率} \\ \mbox{偽物の画像のRealnessが }0.9\mbox{ である確率} \\ \vdots \\ \mbox{偽物の画像のRealnessが }-0.9\mbox{ である確率} \\ \mbox{偽物の画像のRealnessが }-1.0\mbox{ である確率} \\ \end{bmatrix}\mathcal{A}_1 = \begin{bmatrix} \mbox{本物の画像のRealnessが }1.0\mbox{ である確率} \\ \mbox{本物の画像のRealnessが }0.9\mbox{ である確率} \\ \vdots \\ \mbox{本物の画像のRealnessが }-0.9\mbox{ である確率} \\ \mbox{本物の画像のRealnessが }-1.0\mbox{ である確率} \\ \end{bmatrix}Realnessの値域、Anchorの分布などは自由にカスタムできるようです。
目的関数
論文によると目的関数は
\max_{G} \min_{D} V(G, D) = \mathbb{E}_{\boldsymbol{x} \sim p_{\mathrm{data}}}[\mathcal{D}_{\mathrm{KL}}( \mathcal{A}_{1} || D(\boldsymbol{x}) )] + \mathbb{E}_{\boldsymbol{x} \sim p_{g}}[\mathcal{D}_{\mathrm{KL}}( \mathcal{A}_{0} || D(\boldsymbol{x}) )]. \tag{3}らしいです。
そこからGenerator $G$の目的関数を取り出すと、(G_{\mathrm{objective1}}) \quad \min_{G} - \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}}[\mathcal{D}_{\mathrm{KL}}( \mathcal{A}_{0} || D(G(\boldsymbol{z}))]. \tag{18}となるらしいのですが、これだと学習がうまくいかないらしいです。
そこで論文では$G$について、二つの目的関数が提案されています。(G_{\mathrm{objective2}}) \quad \min_{G} \quad \mathbb{E}_{\boldsymbol{x} \sim p_{\mathrm{data}}, \boldsymbol{z} \sim p_{\boldsymbol{z}}}[\mathcal{D}_{\mathrm{KL}}( D(\boldsymbol{x}) || D(G(\boldsymbol{z}))] - \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}}[\mathcal{D}_{\mathrm{KL}}( \mathcal{A}_{0} || D(G(\boldsymbol{z}))], \tag{19}(G_{\mathrm{objective3}}) \quad \min_{G} \quad \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}}[\mathcal{D}_{\mathrm{KL}}( \mathcal{A}_{1} || D(G(\boldsymbol{z}))] - \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}}[\mathcal{D}_{\mathrm{KL}}( \mathcal{A}_{0} || D(G(\boldsymbol{z}))]. \tag{20}実験をしてみたところ、この$G$についての三つの目的関数のうち、式(19)の$G_{\mathrm{objective2}}$が一番よかったらしいです。
まとめると、
\begin{align} \min_{D} & \quad \mathbb{E}_{\boldsymbol{x} \sim p_{\mathrm{data}}}[\mathcal{D}_{\mathrm{KL}}( \mathcal{A}_{1} || D(\boldsymbol{x}))] + \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}}[\mathcal{D}_{\mathrm{KL}}( \mathcal{A}_{0} || D(G(\boldsymbol{z}) ))] \\ \min_{G} & \quad \mathbb{E}_{\boldsymbol{x} \sim p_{\mathrm{data}}, \boldsymbol{z} \sim p_{\boldsymbol{z}}}[\mathcal{D}_{\mathrm{KL}}( D(\boldsymbol{x}) || D(G(\boldsymbol{z})))] - \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}}[\mathcal{D}_{\mathrm{KL}}( \mathcal{A}_{0} || D(G(\boldsymbol{z})))] \end{align}となります。
$\mathbb{E}_ {\boldsymbol{x} \sim p_{\mathrm{data}}}[\cdots]$、$\mathbb{E}_ {\boldsymbol{z} \sim p_{\boldsymbol{z}}}[\cdots]$、$\mathbb{E}_ {\boldsymbol{x} \sim p_{\mathrm{data}}, \boldsymbol{z} \sim p_{\boldsymbol{z}}}[\cdots]$の部分はミニバッチの平均を取ればいい?論文によるとAnchorを$\mathcal{A} _0 = [1, 0]$、$\mathcal{A} _1 = [0, 1]$とすると、目的関数が普通のGANと同じ形になるからRealnessGANは普通のGANを一般化したものであると考えられるらしいです。
雑多な情報
論文にはいくつかの議論と学習の工夫が載っているので、それらをまとめました。
Outcomeの数
Outcome(Discriminatorの出力の次元)を増やすほどいいらしいです。
Outcomeを増やした場合、Generator $G$を更新する回数を増やすといいらしい?Anchorの選択
偽物の画像のAnchor$\mathcal{A} _0$と本物の画像のAnchor$\mathcal{A} _1$とのKLダイバージェンスが大きいほどいいらしいです。
特徴リサンプリング
Discriminatorの出力次元を2倍して、平均と標準偏差として正規分布からサンプリングすると性能が上がるらしいです。
Githubのソースだと標準偏差はそのまま使わず、$2$で割ってから指数をとっているみたいです(つまりもとの出力は分散の対数)。
特に学習の後半で学習が安定するようです。
下のコードではやっていません。コード
CIFAR-10について学習させます。
realness_gan.pyimport numpy import torch import torchvision # KLダイバージェンスを計算する関数 # epsilonはlogでNaNが出ないように入れる def kl_divergence(p, q, epsilon=1e-16): return torch.mean(torch.sum(p * torch.log((p + epsilon) / (q + epsilon)), dim=1)) # torch.nn.Sequentialにreshapeを入れられるように class Reshape(torch.nn.Module): def __init__(self, *shape): super(Reshape, self).__init__() self.shape = shape def forward(self, x): return x.reshape(*self.shape) class GAN: def __init__(self): self.noise_dimension = 100 self.n_outcomes = 20 self.device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') self.discriminator = torch.nn.Sequential( torch.nn.Conv2d( 3, 32, 3, padding=1), torch.nn.ReLU(), torch.nn.AvgPool2d(2), torch.nn.Conv2d(32, 32, 3, padding=1), torch.nn.ReLU(), torch.nn.AvgPool2d(2), torch.nn.Conv2d(32, 32, 3, padding=1), torch.nn.ReLU(), torch.nn.AvgPool2d(2), torch.nn.Conv2d(32, 32, 3, padding=1), torch.nn.ReLU(), Reshape(-1, 32 * 4 * 4), torch.nn.Linear(32 * 4 * 4, self.n_outcomes), ).to(self.device) self.generator = torch.nn.Sequential( torch.nn.Linear(self.noise_dimension, 32 * 4 * 4), Reshape(-1, 32, 4, 4), torch.nn.Conv2d(32, 32, 3, padding=1), torch.nn.ReLU(), torch.nn.Upsample(scale_factor=2), torch.nn.Conv2d(32, 32, 3, padding=1), torch.nn.ReLU(), torch.nn.Upsample(scale_factor=2), torch.nn.Conv2d(32, 32, 3, padding=1), torch.nn.ReLU(), torch.nn.Upsample(scale_factor=2), torch.nn.Conv2d(32, 3, 3, padding=1), torch.nn.Sigmoid(), ).to(self.device) self.discriminator_optimizer = torch.optim.Adam(self.discriminator.parameters(), lr=0.0001, betas=[0.0, 0.9]) self.generator_optimizer = torch.optim.Adam(self.generator.parameters(), lr=0.0001, betas=[0.0, 0.9]) # ここでAnchorを計算する # Githubにある著者の実装にならって乱数のヒストグラムを取る normal = numpy.random.normal(1, 1, 1000) # 平均+1、標準偏差1の正規分布 count, _ = numpy.histogram(normal, self.n_outcomes, (-2, 2)) # -2から+2までのヒストグラムを取る self.real_anchor = count / sum(count) # 合計が1になるように正規化 normal = numpy.random.normal(-1, 1, 1000) # 平均-1、標準偏差1の正規分布 count, _ = numpy.histogram(normal, self.n_outcomes, (-2, 2)) self.fake_anchor = count / sum(count) self.real_anchor = torch.Tensor(self.real_anchor).to(self.device) self.fake_anchor = torch.Tensor(self.fake_anchor).to(self.device) def generate_fakes(self, num): mean = torch.zeros(num, self.noise_dimension, device=self.device) std = torch.ones(num, self.noise_dimension, device=self.device) noise = torch.normal(mean, std) return self.generator(noise) def train_discriminator(self, real): batch_size = real.shape[0] fake = self.generate_fakes(batch_size).detach() # Discriminatorの出力についてソフトマックスをとって確率にする real_feature = torch.nn.functional.softmax(self.discriminator(real), dim=1) fake_feature = torch.nn.functional.softmax(self.discriminator(fake), dim=1) loss = kl_divergence(self.real_anchor, real_feature) + kl_divergence(self.fake_anchor, fake_feature) # 論文の式(3) self.discriminator_optimizer.zero_grad() loss.backward() self.discriminator_optimizer.step() return float(loss) def train_generator(self, real): batch_size = real.shape[0] fake = self.generate_fakes(batch_size) real_feature = torch.nn.functional.softmax(self.discriminator(real), dim=1) fake_feature = torch.nn.functional.softmax(self.discriminator(fake), dim=1) # loss = -kl_divergence(self.fake_anchor, fake_feature) # 論文の式(18) loss = kl_divergence(real_feature, fake_feature) - kl_divergence(self.fake_anchor, fake_feature) # 論文の式(19) # loss = kl_divergence(self.real_anchor, fake_feature) - kl_divergence(self.fake_anchor, fake_feature) # 論文の式(20) self.generator_optimizer.zero_grad() loss.backward() self.generator_optimizer.step() return float(loss) def step(self, real): real = real.to(self.device) discriminator_loss = self.train_discriminator(real) generator_loss = self.train_generator(real) return discriminator_loss, generator_loss if __name__ == '__main__': transformer = torchvision.transforms.Compose([ torchvision.transforms.RandomHorizontalFlip(), torchvision.transforms.ToTensor(), ]) dataset = torchvision.datasets.CIFAR10(root='C:/datasets', transform=transformer, download=True) iterator = torch.utils.data.DataLoader(dataset, batch_size=128, drop_last=True) gan = GAN() n_steps = 0 for epoch in range(1000): for iteration, data in enumerate(iterator): real = data[0].float() discriminator_loss, generator_loss = gan.step(real) print('epoch : {}, iteration : {}, discriminator_loss : {}, generator_loss : {}'.format( epoch, iteration, discriminator_loss, generator_loss )) n_steps += 1 if iteration == 0: fakes = gan.generate_fakes(64) torchvision.utils.save_image(fakes, 'out/{}.png'.format(n_steps))結果
0エポック目(1ステップ目)
10エポック目(3901ステップ目)
100エポック目(39001ステップ目)
500エポック目(195001ステップ目)
この実装だとBatch NormalizationもSpectral Normalizationも特徴リサンプリングも使っていないですが、まあまあ生成できているようです。





- 投稿日:2020-03-24T16:13:17+09:00
【python】pipとは?コマンド一覧と使い方を実例で解説
【python】pipとは?コマンド一覧と使い方を実例で解説
pythonでモジュールやパッケージをインストールするときに使うpipが気になったのでそのまとめ。
バージョン管理もアップグレードも簡単にできる。追加方がわかっているとなかなか便利。
目次
1. pipとは?
python公式のパッケージ管理システム。
インストールしたpythonの中に入っている。Pip Installs Packages(またはPython)の略。
読み方はピップ。pythonに公式に登録されたパッケージのインストールやアンインストールが出来る。
<補足>
pythonのパッケージはPyPIで管理されている。
└ Python Package Indexの略
└ 呼び名:パイパイ
└ 公式ページ:https://pypi.org/コマンドでPyPIにアクセスし、ファイルをインストールしたりするのがpip。
2. pipでできること
モジュールやパッケージの
- インストール
- 削除
- バージョン確認
- 一覧表示(インストール済み)
- アップデート
- ダウンロード(インストールはしない)
など
3. pipの主要コマンド一覧早見表
コマンド 内容 pip install パッケージ名 パッケージのインストール pip install -U パッケージ名 アップグレード pip install --update パッケージ名 アップグレード pip install パッケージ名==バージョン インストール(バージョン指定) pip list インストール済みパッケージ名とバージョン一覧 pip freeze インストール済みパッケージ名とバージョン一覧 pip list --outdate 最新版になっていないもののみ表示 pip -V pipのバージョン情報を表示 pip show パッケージ名 バージョン情報などを表示 pip download パッケージ名 最新ファイルをDL(インストールはしない) pip help pipの主要コマンドとオプション一覧を表示 pip コマンド -h コマンドの内容とオプションを表示
※コマンドについて
・パスが通っている場合:pip
・パスが通っていない場合:py -m pip
└ 「python -m pip」と同じ事例はパスが通っている場合の記述。
4. インストールコマンド
4-1. 通常のインストール
4-2. アップグレード
4-3. バージョンを指定してインストール(ダウングレードができる)
4-1. 通常のインストール
pip install パッケージ名
└例「pip install selenium」既にインストールされている場合は、「Requirement already satisfied:」と表示される。
4-2. アップグレード
pip install -U パッケージ名
pip install --upgrade パッケージ名
└ 例1:「pip install -U selenium」
└ 例2:「pip install -U pip」
(pipを最新版にアップグレード)オプションは「-U」「--update」どちらでもOK。
既に最新の場合は「Requirement already up-to-date:」と表示される
4-3. バージョンを指定してインストール
pip install パッケージ名==バージョン
└ 例:「pip install dash==1.9.0」旧バージョンのインストール(ダウングレード)も可能。
5. バージョンの確認
▼まとめて確認
5-1. pip list
5-2. pip freeze
5-3. 最新版になっていないものだけを確認▼個別に確認
5-4. pipのバージョン確認
5-5. パッケージのバージョン確認
まとめて確認
5-1.pip list
list形式でパッケージ名とバージョンを表示。
pip list> pip list Package Version -------------------- ---------- attrs 19.3.0 backcall 0.1.0 bleach 3.1.0 certifi 2019.11.28 chardet 3.0.4 Click 7.0 colorama 0.4.3 dash 1.9.0 dash-core-components 1.8.0 dash-html-components 1.0.2 ・ ・ ・5-2.pip freeze
基本機能は「pip list」と同じ。
表示形式が異なる。freezeは表示方法を指定できる(らしい)> pip freeze attrs==19.3.0 backcall==0.1.0 bleach==3.1.0 certifi==2019.11.28 chardet==3.0.4 Click==7.0 colorama==0.4.3 dash==1.9.0 dash-core-components==1.8.0 dash-html-components==1.0.2 ・ ・ ・
5-3. 最新版になっていないものだけを確認
pip list --outdate
パッケージ名、現在インストールされているバージョン、最新バージョンを表示。> pip list --outdate Package Version Latest Type -------------------- ------- ------ ----- bleach 3.1.0 3.1.3 wheel Click 7.0 7.1.1 wheel dash 1.9.0 1.9.1 sdist dash-core-components 1.8.0 1.8.1 sdist dash-table 4.6.0 4.6.1 sdist decorator 4.4.1 4.4.2 wheel idna 2.8 2.9 wheel ・ ・ ・5-4. pipのバージョン確認
pip -V
└「-V」は大文字。
※「-v」小文字は別のオプションバージョンと保存先のパスを表示。
> pip -V pip 20.0.2 from c:\users\appdata\local\programs\python\lib\site-packages\pip (python 3.8)
5-5. パッケージのバージョン確認
pip show パッケージ名
└例:「pip show selenium」バージョン情報、公式URL、製作者、保存先のパスなどがわかる。
> pip show selenium Name: selenium Version: 3.141.0 Summary: Python bindings for Selenium Home-page: https://github.com/SeleniumHQ/selenium/ Author: UNKNOWN Author-email: UNKNOWN License: Apache 2.0 Location: c:\users\appdata\local\programs\python\lib\site-packages Requires: urllib3 Required-by:
6. ダウンロード
pip download パッケージ名
└例:「pip download selenium」インストールはせずに最新のファイルをダウンロードしたい場合に使える。
7. ヘルプの表示
7-1. pipのコマンドとオプション一覧
7-2. 各コマンドのヘルプ
7-1. pipのコマンドとオプション一覧
pip help
コマンドとオプションの一覧が見れる
> pip help Usage: pip <command> [options] Commands: install Install packages. download Download packages. uninstall Uninstall packages. freeze Output installed packages in requirements format. list List installed packages. show Show information about installed packages. check Verify installed packages have compatible dependencies. config Manage local and global configuration. search Search PyPI for packages. wheel Build wheels from your requirements. hash Compute hashes of package archives. completion A helper command used for command completion. debug Show information useful for debugging. help Show help for commands. General Options: -h, --help Show help. --isolated Run pip in an isolated mode, ignoring environment variables and user configuration. -v, --verbose Give more output. Option is additive, and can be used up to 3 times. -V, --version Show version and exit. -q, --quiet Give less output. Option is additive, and can be used up to 3 times (corresponding to WARNING, ERROR, and CRITICAL logging levels). --log <path> Path to a verbose appending log. --proxy <proxy> Specify a proxy in the form [user:passwd@]proxy.server:port. --retries <retries> Maximum number of retries each connection should attempt (default 5 times). --timeout <sec> Set the socket timeout (default 15 seconds). --exists-action <action> Default action when a path already exists: (s)witch, (i)gnore, (w)ipe, (b)ackup, (a)bort. --trusted-host <hostname> Mark this host or host:port pair as trusted, even though it does not have valid or any HTTPS. --cert <path> Path to alternate CA bundle. --client-cert <path> Path to SSL client certificate, a single file containing the private key and the certificate in PEM format. --cache-dir <dir> Store the cache data in <dir>. --no-cache-dir Disable the cache. --disable-pip-version-check Don't periodically check PyPI to determine whether a new version of pip is available for download. Implied with --no-index. --no-color Suppress colored output --no-python-version-warning Silence deprecation warnings for upcoming unsupported Pythons.
7-2. 各コマンドのヘルプ
pip コマンド -h
└例:「pip install -h」各コマンドの用途とオプションが確認できる。
> pip install -h Usage: pip install [options] <requirement specifier> [package-index-options] ... pip install [options] -r <requirements file> [package-index-options] ... pip install [options] [-e] <vcs project url> ... pip install [options] [-e] <local project path> ... pip install [options] <archive url/path> ... Description: Install packages from: - PyPI (and other indexes) using requirement specifiers. - VCS project urls. - Local project directories. - Local or remote source archives. pip also supports installing from "requirements files", which provide an easy way to specify a whole environment to be installed. Install Options: -r, --requirement <file> Install from the given requirements file. This option ・ ・ ・
8. pipとpip3の違い
pipには、「pip2」「pip3」など、pythonのバージョン毎にpipのコマンドが用意されている。
■pythonのバージョンが混在していない場合
「pip」が該当するバージョンのpipと同じになる。
python3系のみ:「pip」=「pip3」
python2系のみ:「pip」=「pip2」
■バージョンが混在している場合
python3系:「pip3」
python2系:「pip」、「pip2」
- 投稿日:2020-03-24T15:51:42+09:00
Watson Studio上のnotebookからIBM Cloud Object Storage(ICOS)へのFileの読み書き - project-libを使う -
Notebookでコードを書く際、データをファイル経由でロードするのはごく頻繁にあるケースです。ローカルのPC上でjupyter Notebookを動かしている場合は、普通のpythonのお作法で読み書きすれば問題ないですのですが、Watson StudioのNotebook上では恒久的にファイルを読み書きする場合は、一般的にはProjectに紐ついたIBM Cloud Object Storage(以下ICOS)に対してファイルの読み書きをします。
方法はいくつかあります。ICOSはAWS S3互換のオブジェクトストレージなので、AWS S3と同様の方法も使えます。またWatson StudioのNotebookのGUIから
Insert pandas DataFramesやInsert StreamingBody objectを使ってコード生成する方法もあります。あとはWatson StudioのNotebook専用となりますが、割と簡単に書けるproject-libを使う方法があります。ここではこの方法の1つ、
project-libを使った方法を説明します。その他の方法は結構Qiita内でも記事になっていますので、容易に見つかると思います。また、ICOSを使用しない別の方法としてlinuxのコマンドを直接Notebookから実行する方法もあります。他のサーバーかファイルをwget取得、他のサーバーへwputでファイルを保存する方法もあります。こちらはファイルをwget/wputできるサーバーがあることが前提となりますので、ここでは説明しません。
尚ここに書いてある情報はWatson Studioのドキュメント「Using project-lib for Python」の情報を元にしています。
0. 前提はWatson StudioのProjectが作成済みであること
前提は既にWatson StudioのProjectが作成済みであることです。もしまだ作成済みでなく、方法がわからない場合は
を参考にまずプロジェクトを作成してから以下を開始してください。
1. Projectを開く
作成済みProjectを開いてください。
方法がわからない場合は
ログイン後、作成済Projectの表示方法を参考にして開いてください。2. 前準備
Access tokenの作成
project-libを使うには、関連付けされたICOSを含むプロジェクトの環境にアクセスできるAccess tokenを最初に作成しておく必要があります。
これは一度プロジェクトに対して作成してあればよいです。2-1: 上部メニューから「Settings」をクリックします。
2-2: 下にスクロールして「Access tokens」を表示します。右側に表示された「New token
」をクリックします。
2-3: 「New Token」のウィンドウが表示されますので、「Name」と「Access role for project」を設定し、「Create」をクリックします。
- Name: 適当にわかりやすい名前(半角で)
- Access role for project: 状況に応じて以下を選択します。
- 読み込みだけの場合は「Viewer」
- 読み込みおよび書き込みもしたい場合は「Editor」
この記事では読み込みおよび書き込み方法を説明しますので、「Editor」を設定した状態に設定しました。
「Access tokens」に設定したtokenが表示されているのを確認します。
これで
project-libを使うNotebook外での準備が完了しました。3: Notebookを開く
既にファイルを読み書きしたいNotebookがあればそれを開いてください。
新たに作ってもよいです。作り方が不明の場合は
Watson StudioでJupyter Notebookを使おう! -3. Notebookの作成-を参照して作成してください。4: 読み込ませたいファイルをICOSにアップロード
最初にも説明しましたが、
Watson StudioのNotebook上では恒久的にファイルを読み書きする場合は、一般的にはProjectに紐ついたIBM Cloud Object Storage(以下ICOS)に対してファイルの読み書きをします。よって何かしらローカル環境(PC)にファイルがある場合は、ICOSにまずファイルをアップロードします。既にアップロード済みの場合は5に進んでください。
4-1: 右上の[0100]アイコン(File and Add Data)アイコンをクリックします。
尚、Notebookは編集モードでないとこのアイコンはクリックできません。もし編集モードになっていない場合は、「えんびつ」アイコンがあると思いますので、そちらをクリックして編集モードにしてください。
4-2: 表示された「Drop files here or browse for files to upload.」が書いてある四角いエリアに、アップロードしたいファイルをドラッグ&ドロップします。あるいは「browse」をクリックするとファイルダイアログが表示されますので、そこから選択します。
しばらくするとファイルがロードされ、ロードしたファイル名が下に表示されます。
5:
Project tokenのInsert5-1: 上部メニューの
(縦の・・・)をクリックし、「Insert Project Token」をクリックします。
#2. 前準備 `Access tokenの作成でAcess Tokenを作成してないと、このメニューは表示されないので、もし表示されてない場合は、#2. 前準備 `Access tokenの作成を実施しているか確認してください。
一番上のセルにhidden_cellとして
project-libを使うためのライブラリを読み込み、設定したProject tokenを使用して必要なコードが書かれたセルが挿入されます。notebookの下の方で作業していたとしても、必ず一番上のセルに挿入されるので、見当たらない場合は一番上のセルまでsスクロールしてください。
5-2: セルをクリックして以下のいずれかの方法で実行をします。
- [ctrl] + [Enter] を入力
- [Shift] + [Enter] を入力
- 上のメニューから
ボタンをクリック
実行が完了すると以下の部分に数字が入ります。
これでnotebookの準備は完了です。この作業はnotebook毎に1回必要です。
6: ファイル読み書き方法
では早速notebook上でProjectのICOS経由ファイルを読み書きしてみましょう。#5で挿入されたセルは実行済みの前提です。
6.1: ICOS <-> notebook VM間のファイルのコピー
よく本などに載っているサンプルコードでファイルを扱うものは、localのストレージ直で読み書きするものです。notebookの場合、notebookを編集状態にするたびにVMが立ち上がりますので、その領域にファイルをコピーしておけば、localのストレージにあるのと同じですので、サンプルコードはそのまま使えます。逆にサンプルコードで保存した場合は、VM領域にコピーされてますので、notebookを閉じる前に、ICOSにコピーしておけば、notebookを閉じてもファイルは保存され、ダウンロードも可能です。
ICOSからVMへのコピー
#Copy a file in project ICOS to VM csv_file_name = 'train.csv' csv_file = project.get_file(csv_file_name) csv_file.seek(0) with open(csv_file_name,'wb') as out: out.write(csv_file.read())コピーができたかどうかは以下のコマンドをセルで実行すれば確認できます。
!を先頭につけるとVMのOSコマンド(Linuxコマンド)が実行できます。!ls -la実行例:
VMからICOSへのコピー
上記でVM上にコピーしたファイルをICOSにコピーします。コピーしたファイル名は
copy_train.csvとしています。#Copy a file in VM to project ICOS with open('train.csv','rb') as f: project.save_data('copy_train.csv', f, overwrite=True)確認は一旦notebookを閉じて行います。「1.Save」して「2.Project名をクリックして」notebookを閉じてください。Projectの画面が開きます。
Assetsタブの
Data assetsの下にコピーしたファイルがあります:
以下はその他直接読み書きする方法です。
pandasのDataFrameにICOSから読み込む
csv_file_name = 'train.csv' csv_file = project.get_file(csv_file_name) csv_file.seek(0) import pandas as pd df_csv= pd.read_csv(csv_file) df_csv実行例:
pandasのDataFrameからICOSにCSV保存
上記で読み込んだDataFrame, df_csvをcopy_train.csvという名前でICOSに保存します。
project.save_data("copy_train.csv", df_csv.to_csv(index=False), overwrite=True)確認方法はVMからICOSへのコピーと同じです。
VisualRecognition のAPIのパラメーターとして渡す
イメージファイルをICOSにアップロードしておいて、それをWatsonのVisial Recognitionの認識ファイルとして渡すサンプルです。
sushi.jpgファイルがprojectのICOSにアップロードされているとします。下記の2つはVisualRecognition のsdkを使う前準備です。
!pip install --upgrade "ibm-watson>=4.0.1,< 5.0"
XXXXXXXXXXXXXXには使用するVisual RecognitionのAPIKEYを入れてください。#Visual Recognition API_KEY='XXXXXXXXXXXXXX' #replace XXXXXXXXXXXXXX to your APIKEY from ibm_watson import VisualRecognitionV3 from ibm_cloud_sdk_core.authenticators import IAMAuthenticator authenticator = IAMAuthenticator(API_KEY) visual_recognition = VisualRecognitionV3( version='2018-03-19', authenticator=authenticator )以下がproject-libを使ったサンプルコードです:
import json image_file = project.get_file("sushi.jpg") image_file.seek(0) classes = visual_recognition.classify( images_file=image_file, images_filename='sushi.jpg', threshold='0.6', accept_language='ja').get_result() #結果確認 print(json.dumps(classes, indent=2, ensure_ascii=False))ICOSの画像表示
sushi.jpgという画像ファイルがprojectのICOSにアップロードされているとします。以下のコードでnotebook上に表示できます。#Image image_file = project.get_file("sushi.jpg") image_file.seek(0) from IPython.display import Image Image(data=image_file.read())以上です。
7: まとめ
いかがでしたか? 最初に設定が必要ですが、一度設定すれば以外に簡単にコードが書けたと思います。project.get_file()で戻ってくるのはio.BytesIOなのでいろいろ書けると思いますので、Watson Studioのドキュメント「Using project-lib for Python」の情報を参考に他にもいろいろお試しいただければと思います。
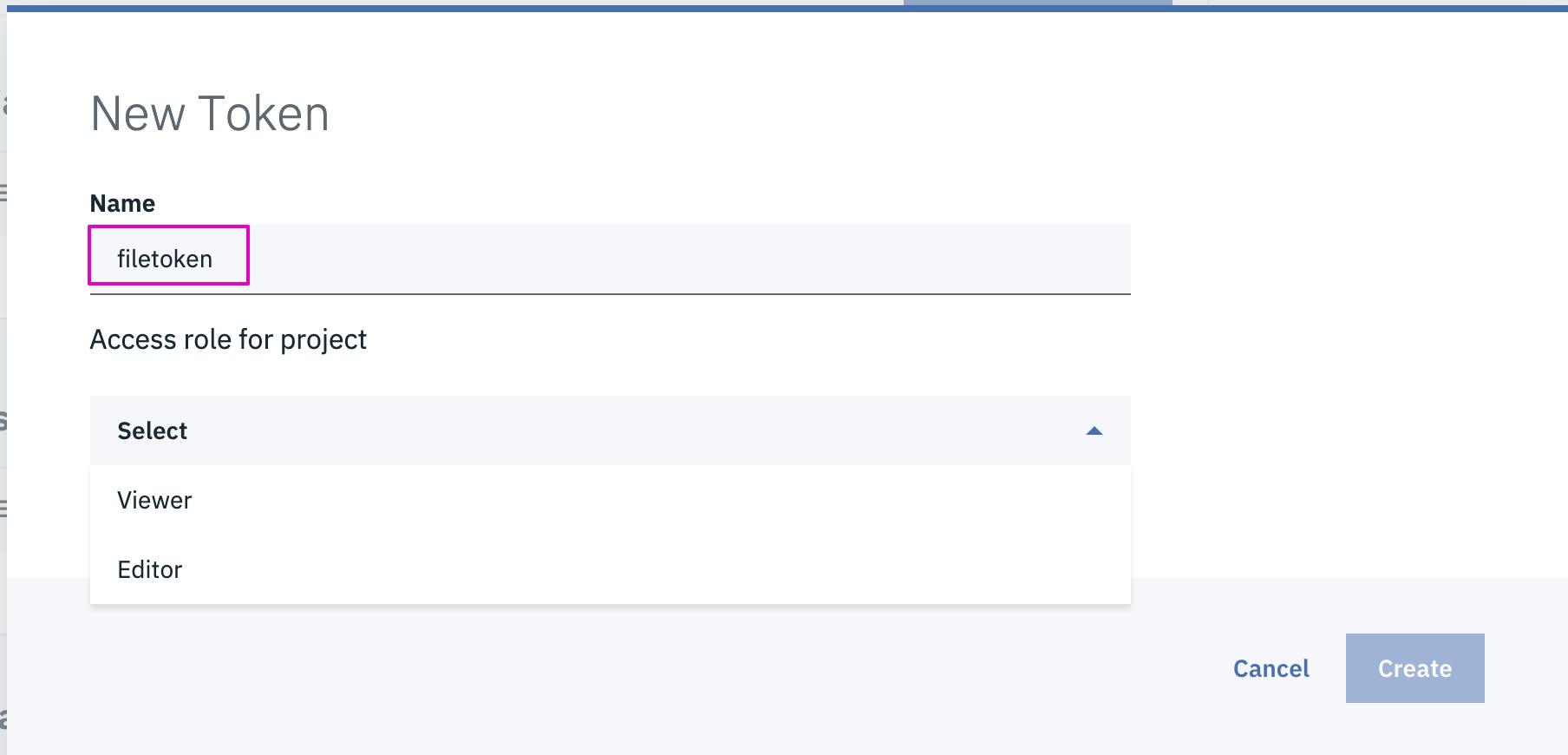

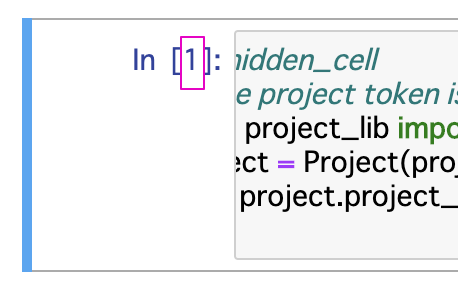

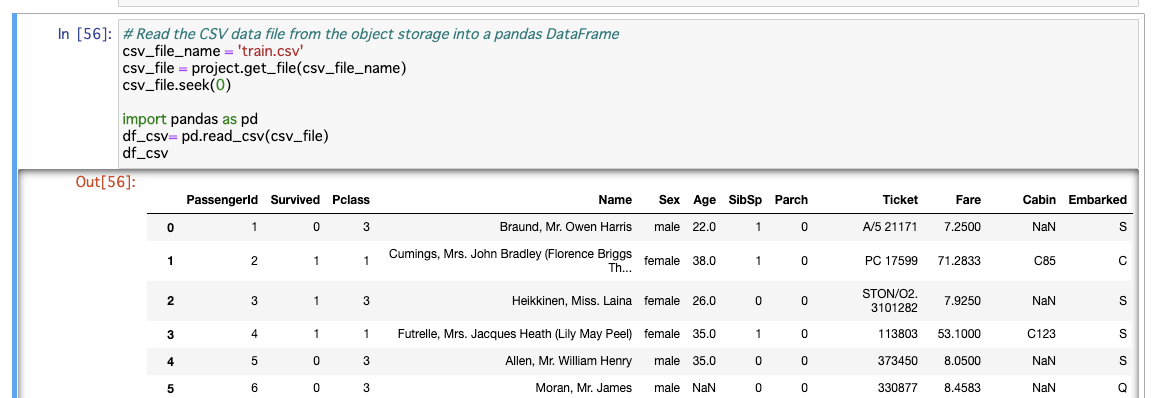
- 投稿日:2020-03-24T15:40:34+09:00
1分で実装! PythonでLINE Notify
はじめに
Pythonで長〜い処理をするときに、
「終わるまで暇だけど、終わったらすぐ作業に取り掛かりたいから時間を無駄にしたくない!」
「エラーが起きたらすぐ対応したい!」
「けど、ずっとパソコンに張り付いて見てるのは疲れる」と、思っているそこの貴方!
この記事を読めば、一生そんな無駄な時間とはおさらば出来ます。LINE Notifyとは
LINEが提供しているAPIで、特別な認証なしにpythonのコードから自動でLINEにメッセージを送信できるようになります。(なお、これはLINEBotとは別物です)
実装の流れ
記事のコードをコピペ(10秒) --> トークン取得(30秒) --> 最後に少し手を加えて... 完了!
実装
コピペ
それでは、このコードを main.py なり、好きなファイルの末尾にコピペしてください。
コピペコード.pydef notify(message): import requests url = "https://notify-api.line.me/api/notify" token = "" # ここには後で取得するトークンを入力します headers = {"Authorization": "Bearer " + token} message = message payload = {"message": message} requests.post(url, headers=headers, params=payload)トークン取得
(ここから画像が多いです、どんどん流して行ってもらって構いません)
トークンを取得します。
LINE Notifyのマイページを開きます。リンクはこちら
ご自身のLINEアカウントでログインしてください。
「トークンを発行する」を押します。
ここでは「1:1でLINE Notifyから通知を受け取る」を選択してください。(詳しくは後述)
トークン名を記入してください、どんなものでも構いません。(ここではtest としています)
すると、トークンが発行されます。ここでは伏せてありますが、「g7YIhv7W...」と言ったような文字列が発行されます。これは必ずどこかにメモしておいてください。
もしメモを忘れてしまったら、もう一度新しいトークンを発行してください。(そんなに大ごとではありません)
これでトークンの取得は完了です。仕上げ
それでは、取得したトークンをコピペコードに入力してください。
コピペコード.pydef notify(message): import requests url = "https://notify-api.line.me/api/notify" token = "g7YIhv7W..." # ここに取得したトークンを入力してください headers = {"Authorization": "Bearer " + token} message = message payload = {"message": message} requests.post(url, headers=headers, params=payload)最後に、初めにコピペコードをペーストしたファイルに一行だけ書き加えます。
以下のコードを好きなところに挿入してください。仕上げ.pymessage = "すべての処理が終了しました" # ここには好きなメッセージを入力してください notify(message)これで完了です。
notify(message)が呼び出されたときにお手持ちのスマホやパソコンのLINEにメッセージが届くようになります。<使用例>
長い処理を実行するとき。
使用例1.py# 長い処理... message = "処理が終了しました!" notify(message) def notify(message): import requests url = "https://notify-api.line.me/api/notify" token = "g7YIhv7W..." # ここに取得したトークンを入力してください headers = {"Authorization": "Bearer " + token} message = message payload = {"message": message} requests.post(url, headers=headers, params=payload)エラーが起こったとき。
使用例2.pywhile True: try: ... # メインの処理 except Exception as e: message = e notify(message) def notify(message): import requests url = "https://notify-api.line.me/api/notify" token = "g7YIhv7W..." # ここに取得したトークンを入力してください headers = {"Authorization": "Bearer " + token} message = message payload = {"message": message} requests.post(url, headers=headers, params=payload)最後に
このコピペコードのまま使用するのでもちろんOKですが、工夫の仕方によっていろんなことができます。ただ単に処理が終わったお知らせやエラーが起こったことを伝えるだけでなく、終了時間やどれくらいの時間がかかったか、どんなエラーが起こったかなどもお知らせすると面白いかもしれません。
また、今回はトークンを発行する際に「1:1でLINE Notifyから通知を受け取る」を選択しましたが、他にグループなども選択することができます。
いろいろ試して、自分だけのオリジナルテンプレートを作ってください。
- 投稿日:2020-03-24T15:14:47+09:00
Blender python で pip で pytorch や opencv などの module をインストールするメモ(2.82a or later)
背景
Blender で OpenCV や dlib など使って 3D 顔データを可視化したり, pytorch と連携して機械学習と組み合わせしたりしたい.
環境
- Ubuntu 18.04
- Blender 2.82a(python3.7.4)
pip のインストール
最初の状態では, pip が入っていないので, ensurepip
https://docs.python.org/ja/3/library/ensurepip.htmlでインストールします.
$ /path/to/blender/2.82/python/bin/python3.7m -m ensurepipこのあと,
-m pipで使えるようになります.$ /path/to/blender/2.82/python/bin/python3.7m -m pipC/C++ コンパイルが必要なモジュール
dlib など, pip 時にソースコードからコンパイルが必要なモジュールもあります.
Python 3.7 開発環境(ヘッダファイル)が必要になります.
Blender には Python.h などが入っていません.システムの python dev を使う
Ubuntu 18.04 ですと, apt で python3.7-dev を入れて,
$ env CXXFLAGS="-I/usr/include/python3.7m" /path/to/blender/2.82/python/bin/python3.7m -m pip install dlibなどと, CXXFLAGS でヘッダパスを追加すればばとりあえずが, pyconfig.h が異なるので, 少し不安です.
Python ソースコードからヘッダファイルを取得(推奨)
python のソースコードを落としてきて, blender 側の
/path/to/blender/2.82/python/include/python3.7mにヘッダ関連をインストールするのが安全かとおもいます.これで C/C++ コンパイルが必要なモジュールもインストールできるはずです!
Blender Python のコンソールで import できるはずです!
TODO
- miniconda や virtualenv で, blender python の環境を使って仮想環境をセットアップできないか調べる
- Blender をソースコードからビルドして, python 開発環境整えやすいようにする.
- Blender のオフラインモード(CLI モード)でもきちんと動くか確認する(バッチ処理用)
blender --background --python-consoleでいけます.

- 投稿日:2020-03-24T14:44:53+09:00
AtCoder Beginner Contest 076 過去問復習
所要時間
感想
ここ三週間留学していて競プロをやらずにゲームに怠けていました。精進を再開したいと思います。
D問題で基本的なミスをやらかして萎えました。最近精進していないのが目に見えてわかりました…。A問題
求めたいのはパフォーマンスなので注意
answerA.pyr=int(input()) g=int(input()) print(g*2-r)B問題
貪欲に前から評価していけば良い。
answerB.pyn=int(input()) k=int(input()) x=1 for i in range(n): x=min(x+k,2*x) print(x)C問題
辞書順というのを上手く使いたかったのですが、そこにこだわりすぎずにやれたのがよかったです。
Sの何番目の文字がTの一番最初の文字に相当するかで|S|-|T|+1通りありそのそれぞれに対しそのようなSが実際に存在するかを確認していきます。また、辞書順最小のものを考えたいので?で未確定のものはaで置き換えるようにします。これを順に試していき、最終的に候補の中で辞書順が最小のものを出力すれば題意を満たす答えを出力することができます。answerC.pys=input() l=len(s) t=input() k=len(t) cand=[] for i in range(l-k+1): new="" for j in range(l): if i<=j<i+k: if s[j]=="?": new+=t[j-i] else: if s[j]==t[j-i]: new+=t[j-i] else: break else: if s[j]=="?": new+="a" else: new+=s[j] if len(new)==l: cand.append(new) cand.sort() if len(cand)==0: print("UNRESTORABLE") else: print(cand[0])D問題
考察も大変だし実装もそこそこ大変だしさすが青問題って感じですね。
まず、この問題では適当に速度を定めると速度制限に引っかかるので、速度を順番に決める必要があることがわかります。また、異なる速度の区間がある時、最小の速度の区間から順にその区間内の速度を決めていけばどの区間の速度制限も守ったまま全ての区間における速度を定めることができるとわかります(逆に最小の速度でない区間から決めると速度制限を満たさない場合が存在してしまいます。)。
ここで、まずは区間内の速度について区間の最初と最後の速度がどうなるかを考えます。その速度は他の区間のうち速度が定まっている区間からどれだけの秒数離れているかを考えれば、その定まってる区間から今考えている区間まで移動してくる際に最大の速度がどうなるかを求めることができます。この計算をそれぞれの速度が定まっている区間について行い、最小の速度が求める答えとなります。また、隣り合う区間については前の区間の最後の速度が次の区間の最初の速度に等しいことも注意が必要です。
以上のような計算を行うことによりそれぞれの区間の最初と最後の速度がどうなるかは求まりましたが、その区間内でできるだけ速度を上げる必要があります。仮に、その区間での最大の速度を?とすると以下のような計算式で?を求めることができ、その結果その区間でどれだけの距離を最大で進むことができるかを求めることができます。これを全ての区間についてで足し合わせることにより最大の距離を求めることができます。
一つ目のコードはバチャコン中に書いていたコードで、二つ目のコードはそのコードの重複部分を変えたコードになります。
answerD.pyimport heapq n=int(input()) inf=10000000000000 #始まりと終わりを保持 #同じオブジェクトにするやつで一時間溶かした、しね ans=[[-1,-1] for i in range(n)] ans[-1][1]=0 ans[0][0]=0 t=list(map(int,input().split())) v=list(map(int,input().split())) v2=[] for i in range(n): heapq.heappush(v2,(v[i],i)) for i in range(n): #print(ans) y=heapq.heappop(v2) #print(y[1]) #print(ans[y[1]]) #print(y) #始まりをまずは決める if ans[y[1]][0]==-1: #print(2) now1=0 ansi1=inf for j in range(y[1]-1,-1,-1): #print(ans1) if ans[j][1]!=-1: ansi1=min(ansi1,ans[j][1]+now1) now1+=t[j] if ans[j][0]!=-1: ansi1=min(ansi1,ans[j][0]+now1) now1=0 for j in range(y[1],n): if ans[j][0]!=-1: ansi1=min(ansi1,ans[j][0]+now1) now1+=t[j] if ans[j][1]!=-1: ansi1=min(ansi1,ans[j][1]+now1) ans[y[1]][0]=min(ansi1,y[0]) ans[y[1]-1][1]=ans[y[1]][0] #print(ansi1) if ans[y[1]][1]==-1: #print(3) now2=0 ansi2=inf for j in range(y[1],-1,-1): if ans[j][1]!=-1: ansi2=min(ansi2,ans[j][1]+now2) now2+=t[j] if ans[j][0]!=-1: ansi2=min(ansi2,ans[j][0]+now2) now2=0 for j in range(y[1]+1,n): if ans[j][0]!=-1: ansi2=min(ansi2,ans[j][0]+now2) now2+=t[j] if ans[j][1]!=-1: ansi2=min(ansi2,ans[j][1]+now2) ans[y[1]][1]=min(ansi2,y[0]) ans[y[1]+1][0]=ans[y[1]][1] #print(ansi2) answer=0 for i in range(n): h=min((t[i]+sum(ans[i]))/2,v[i]) answer+=((h**2-ans[i][0]**2)/2) answer+=((h**2-ans[i][1]**2)/2) answer+=(h*(t[i]+sum(ans[i])-2*h)) print(answer) #print(ans)answerD_better.pyimport heapq n=int(input()) inf=10000000000000 ans=[[-1,-1] for i in range(n)] ans[-1][1],ans[0][0]=0,0 t=list(map(int,input().split())) v=list(map(int,input().split())) v2=[] for i in range(n): heapq.heappush(v2,(v[i],i)) def next(y,wh): global ans,n ansi=inf if wh: r1,r2=range(y[1]-1,-1,-1),range(y[1],n) else: r1,r2=range(y[1],-1,-1),range(y[1]+1,n) now=0 for j in r1: if ans[j][1]!=-1: ansi=min(ansi,ans[j][1]+now) now+=t[j] if ans[j][0]!=-1: ansi=min(ansi,ans[j][0]+now) now=0 for j in r2: if ans[j][0]!=-1: ansi=min(ansi,ans[j][0]+now) now+=t[j] if ans[j][1]!=-1: ansi=min(ansi,ans[j][1]+now) if wh: ans[y[1]][0]=min(ansi,y[0]) ans[y[1]-1][1]=ans[y[1]][0] else: ans[y[1]][1]=min(ansi,y[0]) ans[y[1]+1][0]=ans[y[1]][1] for i in range(n): y=heapq.heappop(v2) if ans[y[1]][0]==-1:next(y,True) if ans[y[1]][1]==-1:next(y,False) answer=0 for i in range(n): h=min((t[i]+sum(ans[i]))/2,v[i]) answer+=((h**2-ans[i][0]**2)/2) answer+=((h**2-ans[i][1]**2)/2) answer+=(h*(t[i]+sum(ans[i])-2*h)) print(answer)

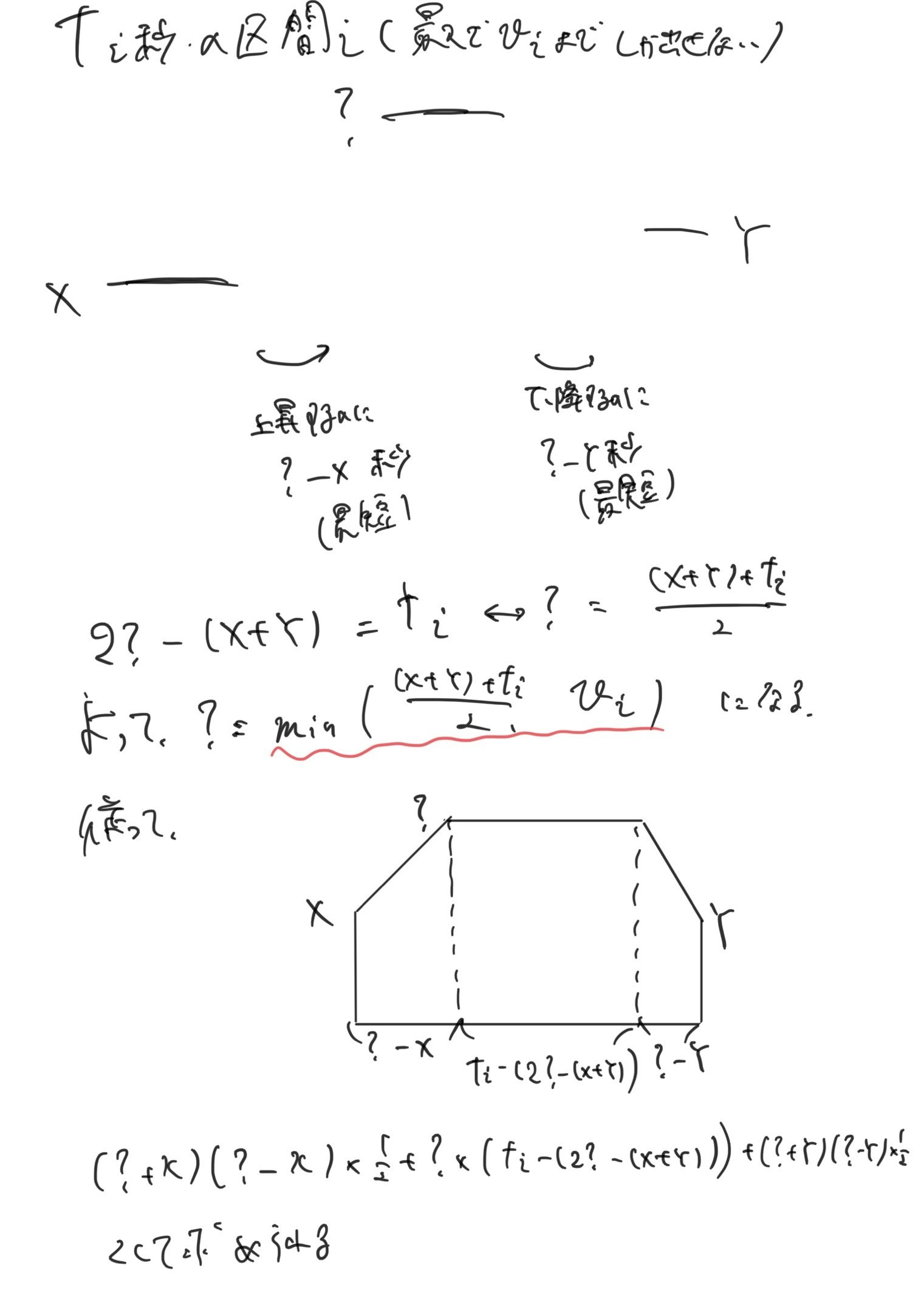
- 投稿日:2020-03-24T14:39:10+09:00
Splunk カスタムサーチコマンド (custom search command) 作成 その2
前回は、はじめの一歩で Splunk のカスタムサーチコマンド (Custom Search Command) として、引数を取らずにイベントをひとつだけ生成するコマンドを作成しました。
今回は、引数を取り、引数で指定した個数のイベントを生成するようにコマンドをブラシアップします。
前回までのおさらい
前回: 「Splunk カスタムサーチコマンド (custom search command) 作成 ― はじめの一歩 ― - Qiita」
Generating commands タイプのカスタムサーチコマンド
generatehelloを作成しました。前回までに作成した HelloWorld.py#!/usr/bin/env python import sys import os import time sys.path.insert(0, os.path.join(os.path.dirname(__file__), "..", "lib")) from splunklib.searchcommands import \ dispatch, GeneratingCommand, Configuration, Option, validators @Configuration() class HelloWorldCommand(GeneratingCommand): """ %(synopsis) ##Syntax %(syntax) ##Description %(description) """ def generate(self): return [{"_time": time.time(), "greeting": "hello, world"}] dispatch(HelloWorldCommand, sys.argv, sys.stdin, sys.stdout, __name__)このプログラムには、次のような課題があります。
- イベントは一つのみです。
- 「イベント」には表示されず、明示的にフィールドを参照しなければ "hello, world" が表示されません。
今回は、これを解消していきます。
Splunk 公式ブログ "Building custom search commands in Python part I – A simple Generating command" をベースとしています。(少し変更しています)一つめの課題: イベント個数の指定
イベントの個数を指定できるようにします。
引数の指定方法 (受け取り方法)
引数は、デコレータ Option で指定します。
ここでは、簡単に Option をクラスとして呼び出して指定する方法で利用することにします。
作成した
class HelloWorldCommandの中で、下のようにして呼び出します。Option( )from splunklib.searchcommands import Option @Configuration() class HelloWorldCommand(GeneratingCommand): count = Option()単に
countという変数に値を格納するだけでなく、SPL 文のコマンドの引数としてcountを使用することも Option() によって同時に設定されています。SPL 文では、| generatehello count=3というように指定します。Option クラスは、"Module structure - Python classes | Documentation | Splunk Developer Program" に記載があり、その API の説明が "splunklib.searchcommands — Splunk SDK for Python API Reference" の参照となっていますが、なかなか解読が難しいドキュメントです。
- class splunklib.searchcommands.Option(fget=None, fset=None, fdel=None, doc=None, name=None, default=None, require=None, validate=None)¶
Represents a search command option.
Required options must be specified on the search command line.
Example:
Short form (recommended). When you are satisfied with built-in or custom validation behaviors.
from splunklib.searchcommands.decorators import Option from splunklib.searchcommands.validators import Fieldname total = Option( doc=''' **Syntax:** **total=***<fieldname>* **Description:** Name of the field that will hold the computed sum''', require=True, validate=Fieldname())
Option()の引数はclass splunklib.searchcommands.Option(fget=None, fset=None, fdel=None, doc=None, name=None, default=None, require=None, validate=None)となっています。
fget、fset、fdelは、Option()内部において Python built-in 関数 (デコレータ) のpropertyに渡される引数で、それぞれ、参照、代入、解放 (del) のための関数を指定しますが、ここでは頭の片隅に留めておけばよいでしょう。
(Python property の使い方に慣れた方なら、ご存知のことと思います)
doc、name、default、require、validateは覚えておくべき引数です。
引数 説明 doc 引数の説明を書きます。 name 引数の名前を指定します。省略時は代入先の変数名と同じ名前が設定されます。 default 引数省略時のデフォルト値を設定します。 require 引数が必須かどうかを設定します。boolean型 (True/False) validate 引数の型を設定します。 name は、省略すると、代入先の変数名と同じ名前がサーチコマンドの引数名になりますが、逆に言えば、name を指定することで、変数名とは別な引数名を設定することができます。
validate は、splunklib.searchcommands.validators で定義されているものですが、SDK を覗くしかないようです。(説明は省略)
Boolean()..... *Code()..... *Duration()..... *Fieldname()File()..... *Integer()..... *List()..... *Map()..... *Match()OptionName()RegularExpression()..... *Set()..... *が定義されています。
(import *で読み出した場合は、Boolean,Code,Duration,File,Integer,List,Map,RegularExpression,Setのみ)参照先のブログのサンプルから少し変えて、
require=Falseで、整数値、default=1としてみましょう。引数 count の設定count = Option(require=False, validate=validators.Integer(), default=1)繰り返し出力
countが引数として与えられます (省略時は 1) ので、これに合わせて繰り返し出力を行います。前回は
return [{"_time": time.time(), "greeting": "hello, world"}]としましたが、今回はすべての処理を待たずに値を返したいので、
returnでリストを返すのではなく、yield で個々のイベントを返すようにします。for i in range(0, self.count): yield {"_time": time.time(), "greeting": "hello, world"}全体
ここまでを統合すると、プログラムは次のようになります。名前を変えて
HelloWorld2.pyとします。引数を指定できるようにした HelloWorld2.py#!/usr/bin/env python import sys import os import time sys.path.insert(0, os.path.join(os.path.dirname(__file__), "..", "lib")) from splunklib.searchcommands import \ dispatch, GeneratingCommand, Configuration, Option, validators @Configuration() class HelloWorldCommand(GeneratingCommand): """ %(synopsis) ##Syntax %(syntax) ##Description %(description) """ count = Option(require=False, validate=validators.Integer(), default=1) def generate(self): for i in range(0, self.count): yield {"_time": time.time(), "greeting": "hello, world"} dispatch(HelloWorldCommand, sys.argv, sys.stdin, sys.stdout, __name__)動作テスト
開発環境内で動作テストを行います。
HelloWorld2.py の動作確認$ python3 HelloWorld2.py __EXECUTE__ count=3 < /dev/null _time,__mv__time,greeting,__mv_greeting 1584952340.0804844,,"hello, world", 1584952340.0816362,,"hello, world", 1584952340.0816433,,"hello, world",Splunk 環境への導入と動作確認
Splunk 環境での App 登録は前回行ったので、修正した
HelloWorld2.pyをhelloword/binにコピーします。
前回同様、オーナやグループ、パーミッションに気をつけてください。Splunk 環境へのコピーcp HelloWorld2.py /opt/splunk/etc/apps/helloworld/bin/名前を変えたので
default/commands.confも修正します。カスタムサーチコマンド名はgeneratehello2とします。commands.conf# [commands.conf]($SPLUNK_HOME/etc/system/README/commands.conf.spec) # Configuration for Search Commands Protocol version 2 [generatehello] filename = HelloWorld.py chunked = true python.version = python3 [generatehello2] filename = HelloWorld2.py chunked = true python.version = python3btool でのチェックを行った後、debug/refresh か Splunk の再起動を行います。
Splunk 上での動作確認
サーチで
| generatehello count=3と入力してみます。
3イベントの出力ができました。
二つめの課題: "hello, world" のイベント出力
ここまでのところ、左側の「関連するフィールド」の部分には
greetingがあり、そこをクリックすると "hello, world" の文字が出てきますが、イベントの表示には出てきません。これは、
_rawフィールドを明示的に指定することで表示できるようになります。
ここでは、単純に、greeting と同じものを_rawに入れて出力させます。_raw フィールドの設定greeting_msg = "hello, world" for i in range(0, self.count): yield {"_time": time.time(), "greeting": greeting_msg, "_raw": greeting_msg}全体は以下の通り。
_raw フィールドの設定を行った HelloWorld2.py#!/usr/bin/env python import sys import os import time sys.path.insert(0, os.path.join(os.path.dirname(__file__), "..", "lib")) from splunklib.searchcommands import \ dispatch, GeneratingCommand, Configuration, Option, validators @Configuration() class HelloWorldCommand(GeneratingCommand): """ %(synopsis) ##Syntax %(syntax) ##Description %(description) """ count = Option(require=False, validate=validators.Integer(), default=1) def generate(self): greeting_msg = "hello, world" for i in range(0, self.count): yield {"_time": time.time(), "greeting": greeting_msg, "_raw": greeting_msg} dispatch(HelloWorldCommand, sys.argv, sys.stdin, sys.stdout, __name__)一つめの時と同様、開発環境で動作確認 → Splunk 環境へコピー → btool によるチェック → Splunk のサーチで確認します。
開発環境での動作確認$ python3 HelloWorld2.py __EXECUTE__ count=3 < /dev/null _time,__mv__time,greeting,__mv_greeting,_raw,__mv__raw 1584954369.7098827,,"hello, world",,"hello, world", 1584954369.7099497,,"hello, world",,"hello, world", 1584954369.7099597,,"hello, world",,"hello, world",
_rawフィールドが増えていることを確認します。Splunk 環境へのコピーcp HelloWorld2.py /opt/splunk/etc/apps/helloworld/bin/(
$SPLUNK_HOME=/opt/splunkです)Splunk のサーチで動作を確認します。 ("
| generatehello2 count=3")
「イベント」フィールドに表示されるようになりました。
まとめ
前回の「Splunk カスタムサーチコマンド (custom search command) 作成 ― はじめの一歩 ― - Qiita」で作成した Generating commands 型のカスタムサーチコマンドをブラシアップしました。
count引数で、出力するイベント数を指定できるようにしました。_rawフィールドを出力し、サーチ結果に「イベント」が表示されるようにしました。ここまでできると、Eventing commands に進むのも楽になるのではないでしょうか。
- 投稿日:2020-03-24T14:34:17+09:00
colaboratoryデフォルトで入っているライブラリバージョン一覧 メモ
pythonバージョン表示
import platform print("python " + platform.python_version())ライブラリのバージョン表示
import pkg_resources for dist in pkg_resources.working_set: print(dist)一覧
python 3.6.9 zmq 0.0.0 zipp 3.1.0 zict 1.0.0 yellowbrick 0.9.1 xlwt 1.3.0 xlrd 1.1.0 xgboost 0.90 xarray 0.14.1 wrapt 1.11.2 wordcloud 1.5.0 widgetsnbextension 3.5.1 wheel 0.34.2 Werkzeug 1.0.0 webencodings 0.5.1 wcwidth 0.1.8 wasabi 0.6.0 vega-datasets 0.8.0 urllib3 1.24.3 uritemplate 3.0.1 umap-learn 0.3.10 tzlocal 1.5.1 typing 3.6.6 typing-extensions 3.6.6 tweepy 3.6.0 traitlets 4.3.3 tqdm 4.28.1 tornado 4.5.3 torchvision 0.5.0 torchtext 0.3.1 torchsummary 1.5.1 torch 1.4.0 toolz 0.10.0 thinc 7.0.8 Theano 1.0.4 tflearn 0.3.2 textgenrnn 1.4.1 textblob 0.15.3 text-unidecode 1.3 testpath 0.4.4 terminado 0.8.3 termcolor 1.1.0 tensorflow 1.15.0 tensorflow-probability 0.7.0 tensorflow-privacy 0.2.2 tensorflow-metadata 0.21.1 tensorflow-hub 0.7.0 tensorflow-gan 2.0.0 tensorflow-estimator 1.15.1 tensorflow-datasets 2.0.0 tensorboardcolab 0.0.22 tensorboard 1.15.0 tensor2tensor 1.14.1 tblib 1.6.0 tabulate 0.8.6 tables 3.4.4 sympy 1.1.1 statsmodels 0.10.2 stable-baselines 2.2.1 srsly 1.0.1 sqlparse 0.3.0 SQLAlchemy 1.3.13 sphinxcontrib-websupport 1.2.0 Sphinx 1.8.5 spacy 2.1.9 sortedcontainers 2.1.0 snowballstemmer 2.0.0 smart-open 1.9.0 sklearn 0.0 sklearn-pandas 1.8.0 six 1.12.0 simplegeneric 0.8.1 Shapely 1.7.0 setuptools 45.2.0 setuptools-git 1.2 Send2Trash 1.5.0 semantic-version 2.8.4 seaborn 0.10.0 scs 2.1.1.post2 scipy 1.4.1 scikit-learn 0.22.1 scikit-image 0.16.2 s3transfer 0.3.3 s3fs 0.4.0 rsa 4.0 rpy2 2.9.5 retrying 1.3.3 resampy 0.2.2 requests 2.21.0 requests-oauthlib 1.3.0 regex 2019.12.20 QtPy 1.9.0 qtconsole 4.7.1 pyzmq 17.0.0 PyYAML 3.13 PyWavelets 1.1.1 pytz 2018.9 python-utils 2.3.0 python-slugify 4.0.0 python-rtmidi 1.4.0 python-louvain 0.13 python-dateutil 2.6.1 python-chess 0.23.11 pytest 3.6.4 pystan 2.19.1.1 PySocks 1.7.1 pysndfile 1.3.8 pyrsistent 0.15.7 pypng 0.0.20 pyparsing 2.4.6 PyOpenGL 3.1.5 pymystem3 0.2.0 pymongo 3.10.1 PyMeeus 0.3.6 pymc3 3.7 Pygments 2.1.3 pyglet 1.4.10 pyemd 0.5.1 PyDrive 1.3.1 pydotplus 2.0.2 pydot 1.3.0 pydot-ng 2.0.0 pydata-google-auth 0.3.0 pycparser 2.19 pycocotools 2.0.0 pyasn1 0.4.8 pyasn1-modules 0.2.8 pyarrow 0.14.1 py 1.8.1 ptyprocess 0.6.0 psycopg2 2.7.6.1 psutil 5.4.8 protobuf 3.10.0 prompt-toolkit 1.0.18 promise 2.3 prometheus-client 0.7.1 progressbar2 3.38.0 prettytable 0.7.2 pretty-midi 0.2.8 preshed 2.0.1 prefetch-generator 1.0.1 portpicker 1.3.1 pluggy 0.7.1 plotnine 0.6.0 plotly 4.4.1 plac 0.9.6 pip 19.3.1 pip-tools 4.2.0 Pillow 6.2.2 pickleshare 0.7.5 pexpect 4.8.0 patsy 0.5.1 pathlib 1.0.1 parso 0.6.2 pandocfilters 1.4.2 pandas 0.25.3 pandas-profiling 1.4.1 pandas-gbq 0.11.0 pandas-datareader 0.7.4 palettable 3.3.0 packaging 20.1 osqp 0.6.1 opt-einsum 3.1.0 openpyxl 2.5.9 opencv-python 4.1.2.30 opencv-contrib-python 4.1.2.30 okgrade 0.4.3 oauthlib 3.1.0 oauth2client 4.1.3 nvidia-ml-py3 7.352.0 numpy 1.17.5 numexpr 2.7.1ipp numba 0.47.0 np-utils 0.5.12.1 notebook 5.2.2 nltk 3.2.5 nibabel 2.3.3 networkx 2.4 nbformat 5.0.4 nbconvert 5.6.1 natsort 5.5.0 music21 5.5.0 murmurhash 1.0.2 multitasking 0.0.9 multiprocess 0.70.9 msgpack 0.5.6 mpmath 1.1.0 mpi4py 3.0.3 moviepy 0.2.3.5 more-itertools 8.2.0 mlxtend 0.14.0 mkl 2019.0 mizani 0.6.0 mistune 0.8.4 missingno 0.4.2 mir-eval 0.5 mido 1.2.6 mesh-tensorflow 0.1.9 matplotlib 3.1.3 matplotlib-venn 0.11.5 MarkupSafe 1.1.1 Markdown 3.2.1 magenta 0.3.19 lxml 4.2.6 lunardate 0.2.0 lucid 0.3.8 lmdb 0.98 llvmlite 0.31.0 lightgbm 2.2.3 librosa 0.6.3 knnimpute 0.1.0 kiwisolver 1.1.0 kfac 0.2.0 Keras 2.2.5 keras-vis 0.4.1 Keras-Preprocessing 1.1.0 Keras-Applications 1.0.8 kapre 0.1.3.1 kaggle 1.5.6 jupyter 1.0.0 jupyter-core 4.6.2 jupyter-console 5.2.0 jupyter-client 5.3.4 jsonschema 2.6.0 jpeg4py 0.1.4 joblib 0.14.1 jmespath 0.9.4 Jinja2 2.11.1 jieba 0.42.1 jedi 0.16.0 jdcal 1.4.1 jaxlib 0.1.38 jax 0.1.58 itsdangerous 1.1.0 ipywidgets 7.5.1 ipython 5.5.0 ipython-sql 0.3.9 ipython-genutils 0.2.0 ipykernel 4.6.1 intervaltree 2.1.0 intel-openmp 2020.0.133 inflect 2.1.0 imutils 0.5.3 importlib-metadata 1.5.0 imgaug 0.2.9 imblearn 0.0 imbalanced-learn 0.4.3 imagesize 1.2.0 imageio 2.4.1 image 1.5.28 idna 2.8 ideep4py 2.0.0.post3 hyperopt 0.1.2 humanize 0.5.1 httplib2shim 0.0.3 httplib2 0.11.3 httpimport 0.5.18 html5lib 1.0.1 holidays 0.9.12 HeapDict 1.0.1 h5py 2.8.0 gym 0.15.6 gunicorn 20.0.4 gspread 3.0.1 gspread-dataframe 3.0.4 grpcio 1.27.1 greenlet 0.4.15 graphviz 0.10.1 graph-nets 1.0.5 googledrivedownloader 0.4 googleapis-common-protos 1.51.0 google 2.0.3 google-resumable-media 0.4.1 google-pasta 0.1.8 google-colab 1.0.0 google-cloud-translate 1.5.0 google-cloud-storage 1.16.2 google-cloud-language 1.2.0 google-cloud-datastore 1.8.0 google-cloud-core 1.0.3 google-cloud-bigquery 1.21.0 google-auth 1.7.2 google-auth-oauthlib 0.4.1 google-auth-httplib2 0.0.3 google-api-python-client 1.7.11 google-api-core 1.16.0 glob2 0.7 gin-config 0.3.0 gevent 1.4.0 geopy 1.17.0 geographiclib 1.50 gensim 3.6.0 gdown 3.6.4 gast 0.2.2 future 0.16.0 fsspec 0.6.2 folium 0.8.3 Flask 1.1.1 fix-yahoo-finance 0.0.22 filelock 3.0.12 featuretools 0.4.1 feather-format 0.4.0 fbprophet 0.5 fastrlock 0.4 fastprogress 0.2.2 fastdtw 0.3.4 fastai 1.0.60 fancyimpute 0.4.3 fa2 0.3.5 et-xmlfile 1.0.1 entrypoints 0.3 en-core-web-sm 2.1.0 editdistance 0.5.3 ecos 2.0.7.post1 easydict 1.9 earthengine-api 0.1.213 dopamine-rl 1.0.5 docutils 0.15.2 docopt 0.6.2 dm-sonnet 1.35 dlib 19.18.0 Django 3.0.3 distributed 1.25.3 dill 0.3.1.1 descartes 1.1.0 defusedxml 0.6.0 decorator 4.4.1 datascience 0.10.6 dataclasses 0.7 dask 2.9.2 daft 0.0.4 Cython 0.29.15 cymem 2.0.3 cycler 0.10.0 cvxpy 1.0.25 cvxopt 1.2.4 cupy-cuda101 6.5.0 cufflinks 0.17.0 crcmod 1.7 coveralls 0.5 coverage 3.7.1 convertdate 2.2.0 contextlib2 0.5.5 community 1.0.0b1 colorlover 0.3.0 cmake 3.12.0 cloudpickle 1.2.2 Click 7.0 chart-studio 1.0.0 chardet 3.0.4 chainer 6.5.0 cffi 1.14.0 certifi 2019.11.28 cachetools 3.1.1 bz2file 0.98 bs4 0.0.1 branca 0.3.1 Bottleneck 1.3.1 botocore 1.14.15 boto3 1.11.15 boto 2.49.0 bokeh 1.4.0 blis 0.2.4 bleach 3.1.0 beautifulsoup4 4.6.3 backports.weakref 1.0.post1 backports.tempfile 1.0 backcall 0.1.0 Babel 2.8.0 autograd 1.3 audioread 2.1.8 attrs 19.3.0 atomicwrites 1.3.0 atari-py 0.2.6 astropy 4.0 astor 0.8.1 asgiref 3.2.3 altair 4.0.1 albumentations 0.1.12 alabaster 0.7.12 absl-py 0.9.0 xkit 0.0.0 screen-resolution-extra 0.0.0 python-apt 1.6.5+ubuntu0.2 pygobject 3.26.1 GDAL 2.2.2
- 投稿日:2020-03-24T14:30:42+09:00
Python、正規表現について
正規表現についてよく使いそうなものをメモ。
・Mac
・python<メモ内容>
① ”.”は 改行以外の任意の1文字(数字含む)
② matchは、先頭からマッチするかを判定する関数、マッチする場合はmatchオブジェクト(正規表現をまとめたもの)を返し、マッチしなければNONEを返す。
③ searchは、途中でマッチするかどうかを判定する関数。2箇所ある場合は最初の1箇所のみ返す。マッチする場合はmatchオブジェクトを返し、マッチしなければNONEを返す。
④ splitは指定した文字で分割する関数、返り値はリスト型
⑤ findallは、指定した文字を全て返す関数、返り値はリスト型(1)例題
import re text1 = 'abcde' text2 = 'a' text3 = '1234' text4 = 'a1234' text5 = 'a1234a567' text6 = '住所は123-3456東京都中央区999-9999' text7 = '〒123-1234東京都中央区999-9999' text8 = '〒1231234東京都中央区9999999' text9 = '〒123-1234:東京都:中央区999-9999' text10 = '〒123-1234 東京都 中央区:999-9999'(2)実行内容
①text1 = 'abcde'の場合
print(re.match('.',text1)) print(re.match('abc',text1)) print(re.match('abc$',text1)) print(re.match('\d\d',text1))実行結果
<re.Match object; span=(0, 1), match='a'> <re.Match object; span=(0, 3), match='abc'> None None②text2 = 'a'の場合
print(re.match('.',text2)) print(re.match('abc',text2)) print(re.match('abc$',text2)) print(re.match('\d\d',text2))実行結果
<re.Match object; span=(0, 1), match='a'> None None None③text3 = '1234'の場合
print(re.match('.',text3)) print(re.match('abc',text3)) print(re.match('abc$',text3)) print(re.match('\d\d',text3))実行結果
<re.Match object; span=(0, 1), match='1'> None None <re.Match object; span=(0, 2), match='12'>④text4 = 'a1234'の場合
print(re.match('.',text4)) print(re.match('abc',text4)) print(re.match('abc$',text4)) print(re.match('\d\d',text4))実行結果
<re.Match object; span=(0, 1), match='a'> None None None⑤text5 = 'a1234a567'の場合
print(re.match('\d{2}',text5)) print(re.search('\d{2}',text5))実行結果
None <re.Match object; span=(1, 3), match='12'>⑥text6 = '住所は123-3456東京都中央区999-9999'の場合
print(re.match('\d{2}',text6)) print(re.search('\d{2}',text6)) print(re.match('\d{3}-\d{4}',text6)) print(re.search('\d{3}-\d{4}',text6)) print(re.search('.\d{3}-\d{4}',text6))実行結果
None <re.Match object; span=(3, 5), match='12'> None <re.Match object; span=(3, 11), match='123-3456'> <re.Match object; span=(2, 11), match='は123-3456'>⑦text7 = '〒123-1234東京都中央区999-9999'の場合
print(re.match('\d{3}-\d{4}',text7)) print(re.search('\d{3}-\d{4}',text7)) print(re.search('.\d{3}-\d{4}',text7)) print(re.findall('\d{3}-\d{4}',text7)) print(re.findall('\d{3}\d{4}',text7)) print(re.findall('.\d{3}-\d{4}',text7))実行結果
None <re.Match object; span=(1, 9), match='123-1234'> <re.Match object; span=(0, 9), match='〒123-1234'> ['123-1234', '999-9999'] [] ['〒123-1234', '区999-9999']⑧text8 = '〒1231234東京都中央区9999999'の場合
print(re.findall('\d{3}\d{4}',text8))実行結果
['1231234', '9999999']⑨text9 = '〒123-1234:東京都:中央区999-9999'の場合
print(re.split('[:]',text9))実行結果
['〒123-1234', '東京都', '中央区999-9999']⑩text10 = '〒123-1234 東京都 中央区:999-9999'の場合
print(re.split('[,]',text9))実行結果
['〒123-1234:東京都:中央区999-9999']
- 投稿日:2020-03-24T14:21:36+09:00
Youtube字幕の色を、投稿者側で文章ごとに変更する。
初めに
初めまして。ご覧いただきありがとうございます。
Youtubeの字幕機能について、いろいろ試してみました。
また、字幕に色を付けるための簡単なツールも作成してみましたので、公開してみようと思います。
字幕のテスト - Youtube(音はありません)このようにYoutubeの字幕を色付きで表示させられます。
調べてもあまり情報が出てこなかったので、参考程度にまとめてみたいと思います。きっかけ
Youtubeでこの動画を見ていました。
なんとなくで字幕を付けると・・・
設定もしてないのに色は変わるしフォントもなんか違うし。
本当にすごいので見てみてください。今回はフォントの変更方法には触れません。
調べてもよくわからなかったので、もし情報があれば追加したいと思います。やり方
ここから詳しい手順を説明します。
コード作成ツールについて
作成ツールを使用して字幕ファイルを作成する手順です。
1. ツールをダウンロードする
windows10のみで動作確認しています。他のOSでは動くかどうか確認できていません。
以下からダウンロードし、どこでもいいので保存、解凍してください。色付き字幕作成ツール (Googleドライブにリンクします)
解凍後、次のような構成になっていることを確認してください。
色付き字幕作成ツール ――――――― ダウンロードした字幕ファイルはこの中に入れてください。――― 拡張子は変更せず、ファイル名を「captions」として保存してください |―― 設定ファイル ―――――― 使用する色と指定文字.txt |―― 色指定ファイル.txt |―― 原色大辞典 ビビットカラー |―― 使用する色と指定文字 記述方法.txt |―― 色指定ファイル 記述方法.txt |―― 色付き字幕作成ツール.exe2. 動画の字幕をダウンロードする
ツールは、sbv形式とsrt形式の字幕ファイルに対応しています。
srt形式の字幕ファイルをダウンロードするために、下記ページを利用します。リンクが許可されているか不明なため、URLは記載しません。
Webで「YOUTUBE動画の字幕をダウンロードするCGI」と検索してください。
利用方法等は、作者様のページをご覧ください。保存先は、「ダウンロードした字幕ファイルはこの中に入れてください。」というフォルダに保存します。
名前を「captions」として保存してください。名前が違うと読み込みません。3. 設定ファイルを確認、編集する
設定方法については、「使用する色と指定文字 記述方法.txt」と「色指定ファイル 記述方法.txt」を参照してください。
デフォルトでは、12色使用可能で、すべての字幕を赤色で表示します。4. 「色付き字幕作成ツール.exe」を実行する
黒い画面が表示されますので、指示に従い作成してください。
エラーメッセージが表示された場合や、一瞬だけ画面が現れ消えてしまう場合はファイル読み込みエラーです。設定ファイル等に間違いがないか確認してください。
どうしても解決しない場合はコメント等で連絡してください。字幕の仕様について
Youtubeには、Youtubeのサイトで字幕を追加する以外に字幕ファイルをアップロードすることができるようになっています。
詳しくは下記の公式ページをご覧ください。このツールでは、この中のSAMIファイルというものを使用しています。
作成例
例として、今回は以下の文章を色を付けて表示してみたいと思います。
①吾輩は猫である。名前はまだ無い。
②どこで生れたかとんと見当けんとうがつかぬ。
③何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。
④吾輩はここで始めて人間というものを見た。
⑤しかもあとで聞くとそれは書生という人間中で一番獰悪どうあくな種族であったそうだ。引用 - 吾輩は猫である (夏目漱石)
この例では、それぞれの文章を、
①赤色(#ff0000)
②桃色(#ffc0cb)
③橙色(#ffa500)
④緑色(#008000)
⑤青色(#0000ff)
として、5秒(5000ミリ秒)間ずつ表示させていきます。色の選択は、カラーコードを使用します。
下記ページを参考にしてください。ここからは、上記手順通りに行います。
1. 字幕ファイルをダウンロードし、保存する
Youtube公式ページで字幕を作成後手順に沿ってダウンロードするとこのようなファイルとなります。
captions.srt1 00:00:00,000 --> 00:00:05,000 吾輩は猫である。名前はまだ無い。 2 00:00:05,000 --> 00:00:10,000 どこで生れたかとんと見当けんとうがつかぬ。 3 00:00:10,000 --> 00:00:15,000 何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。 4 00:00:15,000 --> 00:00:20,000 吾輩はここで始めて人間というものを見た。 5 00:00:20,000 --> 00:00:28,000 しかもあとで聞くとそれは書生という人間中で一番獰悪どうあくな種族であったそうだ。2. 設定ファイルを編集する
まず、「使用する色と指定文字.txt」を編集します。
今回は色を五色使用しますが、デフォルトのままでは表示したい色がないため追加します。
指定文字は、「a,b,c,d,e」とします。
a~eの部分が追加分です。使用する色と指定文字.txt1:#ff0000 2:#ff007f 3:#ff00ff 4:#7f00ff 5:#0000ff 6:#007fff 7:#00ffff 8:#00ff7f 9:#00ff00 10:#7fff00 11:#ffff00 12:#ff7f00 a:#ff0000 b:#ffc0cb c:#ffa500 d:#008000 e:#0000ff次に「色指定ファイル.txt」を編集します。
今回は一文ずつ色を変化させるので、次のように編集します。色指定ファイル.txta b c d eこのように記述すると、一文目に「a(#ff0000)」、二文目に「b(#ffc0cb)」のように、先ほど指定した文字とカラーコードが対応して指定されます。
すべて同じ色で表示する場合は、一行目だけに「all 使いたい色の指定文字」のように記述もできます。詳しくは記述方法のファイルを参照してください。3. ツールを実行
うまく設定ができていれば、次のようなファイルが完成します。
(sample.smiとして保存しています)sample.smi<SAMI> <HEAD> <SAMIParam> Metrics {time:ms;} Spec {MSFT:1.0;} </SAMIParam> </HEAD> <BODY> <SYNC Start=0><font color="#ff0000"><b>吾輩は猫である。名前はまだ無い。</b></font> <SYNC Start=5000><font color="#ffc0cb"><b>どこで生れたかとんと見当けんとうがつかぬ。</b></font> <SYNC Start=10000><font color="#ffa500"><b>何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。</b></font> <SYNC Start=15000><font color="#008000"><b>吾輩はここで始めて人間というものを見た。</b></font> <SYNC Start=20000><font color="#0000ff"><b>しかもあとで聞くとそれは書生という人間中で一番獰悪どうあくな種族であったそうだ。</b></font>4. Youtubeに投稿!
あとは字幕ファイルをアップロードして終了です。
アップロードについては検索すればたくさん情報が出てきますので、そちらを参考にしてください。字幕のテスト - Youtube(音はありません)
上記ファイルをアップロードしてみた動画です。
最後に
最後までご覧いただきありがとうございました。
ツールはpythonで作成しています。初心者なため完成度は高くありませんが、個人が趣味程度に作成したものですので暖かい目で見てくださればうれしいです。字幕に個性を出したい方、Youtuberなどの方に参考にしていただけたら幸いです。
それでは!

