- 投稿日:2020-03-23T23:41:57+09:00
Aurora Serverless が起きるまで待つ
例えば AWS Lambda + Amazon CloudWatch Events で定期的にどこかからデータをひっこ抜いてきて適当に Amazon RDS にでも突っ込んでおくかという場合に、普通の Provisioned インスタンスだと少なくとも数千円/月はかかってしまうが Aurora Serverless にすれば使っていないときは勝手に寝てくれるので格安で済むのではないか。1
ただしこのアイデアにはひとつ問題があって、Aurora Serverless が起きるのが遅いということ。
DB クライアントから接続を試みると寝ていた Aurora Serverless は起動し始めるが、接続を受け入れられるようになるまでの間にクライアントがタイムアウトしてしまうなんてこともある。
そこで、使うときはあらかじめ Aurora Serverless を起動 (Capacity を増加) させるリクエストを送っておいて、起動した (Capacity が 0 以上になった) タイミングで DB クライアントから接続すれば良いのではないか。
Lambda Function の実装
Aurora Serveless が起きるまで待って後は何もしないという Lambda Function を実装してみる。
ランタイムは Python 3.8 を使った。
import asyncio import boto3 def is_aurora_serverless_up(client, identifier: str) -> bool: """Aurora Serverless が起動中かどうかを返す""" response = client.describe_db_clusters(DBClusterIdentifier=identifier) assert response['ResponseMetadata']['HTTPStatusCode'] == 200 assert len(response['DBClusters']) > 0 assert response['DBClusters'][0]['EngineMode'] == 'serverless' return response['DBClusters'][0]['Capacity'] > 0 async def wake_aurora_serverless_up(client, identifier: str, capacity: int = 2): """Aurora Serverless を起動する""" if is_aurora_serverless_up(client, identifier): return response = client.modify_current_db_cluster_capacity(DBClusterIdentifier=identifier, Capacity=capacity) assert response['ResponseMetadata']['HTTPStatusCode'] == 200 for i in range(10): await asyncio.sleep(i ** 2) if is_aurora_serverless_up(client, identifier): return raise TimeoutError() async def main(): client = boto3.client('rds') await wake_aurora_serverless_up(client, 'mycluster') def lambda_handler(event, context): asyncio.get_event_loop().run_until_complete(main())あとやる必要があること。
- 実行するために
rds:DescribeDBClustersとrds:ModifyCurrentDBClusterCapacityの権限が必要なのでそれっぽい IAM Role を作成して Lambda Function に割り当てておく- Lambda Function のタイムアウト設定のデフォルト値 3秒 だと絶対に終わらないので 3分 とかに設定しておく
今回は asyncio で実装しているが asyncio.sleep で使っているだけなのであまり意味はない。普通に time.sleep でもいい。asyncio で実装しておくと PostgreSQL クライアントとして asyncpg が選べるというメリットはある。
実行してみる
試しに実行してみると以下のようなことがわかる。
- Aurora Serverless が起動するまでに 15秒 くらいかかる
- 起動した (capacity > 0 になった) としてもすぐに DB クライアントから接続できるわけではなく、そこから更に 10 秒くらい待つ。
結局待つので前とあまり変わっていないが、DB クライアントがタイムアウトしなくなったのでこれはこれでよし。
最後に
ここまでやってから「これ普通に DB クライアントの接続タイムアウトを長めに設定しておくだけで解決したのでは?????」ということに気づいてしまった。
えっ・・・?
あっ、はい・・・。
- 投稿日:2020-03-23T22:53:00+09:00
ゼロから作るDeepLearning① 6章「学習に関するテクニック」
ゼロから作るDeepLearning①の6章でいい感じの実装ができたので、備忘録。
Jupyterも公開するので、間違っていればご指摘いただけると幸いです。
書籍ではデータセットをローカルにダウンロードしていましたが、せっかくsklearnにmnistなどの学習用のデータセットがあるので、sklearnからimportするだけで済むように、コードを調整しました。
jupyter notebook公開用@githubSGD(Stochastic Gradient Descent:確率的勾配降下法)
損失関数の勾配に一定の学習係数をかけた値を重みから差し引くことで、各ネットワークの重みを調整する方法。式として表すと
W(調整後の重み) = W(調整前の重み) - η * dL/dW(学習係数*損失関数の勾配)
AdaGrad法
学習の進み具合によって学習係数を小さくしていき、各ネットワークの重みを調整する方法。式として表すと
h(調整後の勾配の履歴) = h(調整前の勾配の履歴) - dL/dW * dL/dW(損失関数の勾配の二乗)
W(調整後の重み) = W(調整前の重み) - η* h**(-1/2) * dL/dW(学習係数 勾配の履歴*損失関数の勾配)
Momentum法
勾配が大きいほど大きく学習し、勾配が小さい場合は学習を小さくして、各ネットワークの重みを調整する方法(いい表現が見つかりませんでした。。。。)。式として表すと
v(調整後の重みの履歴) = αv(調整前の重みの履歴) - η * dL/dW(学習係数*損失関数の勾配)
αは0.9などで設定するのが普通だそうです。W(調整後の重み) = W(調整前の重み) + v
- 投稿日:2020-03-23T22:52:47+09:00
機械学習のアルゴリズム(2クラス分類から多クラス分類へ)
はじめに
以前、「機械学習の分類」で取り上げたアルゴリズムについて、その理論とpythonでの実装、scikit-learnを使った分析についてステップバイステップで学習していく。個人の学習用として書いてるので間違いなんかは大目に見て欲しいと思います。
これまで、2クラス分類問題として、単純パーセプトロン、ロジスティック回帰、そしてサポートベクターマシン(基本編・応用編)を扱ってきました。
ただ、あくまで2クラスの分類だったので、それらを多クラスの分類に拡張することを考えてみます。最初ロジスティック回帰とサポートベクターマシンの多クラス化を一緒に書いてしまおうと思っていたんですが、意外と奥が深かったのと、意外ときちんと書いていないサイトも多く、理論的な背景だけで1記事になってしまいました。例によって参考になったのは下記のサイト。ありがとうございました。
- 機械学習 第7回 分類(多クラス分類)→大学の講義資料ですかね?
- 【翻訳】scikit-learn 0.18 User Guide 1.12. 多クラスアルゴリズムと多ラベルアルゴリズム
- One-vs-RestとOne-vs-Oneを実装してみた
- 多クラス分類ロジスティック回帰の実装
2クラス分類→多クラス分類への拡張
$N$種類の特徴量に対し、出力$y$で$c$種類の分類を行うことを考えます。例えば(リンゴ|ミカン|バナナ)を分類するとか0〜9の数字を分類するとかそういう類のやつですね。アルゴリズム自体が多クラス分類に対応しているものもあるんですが、ロジスティック回帰やサポートベクターマシンなど2クラス分類器をこの分類問題に対応させるためのアプローチとしては、以下の手法が代表的です。
- One vs Rest(All)
- One vs One
- 多クラスソフトマックス(softmax)
順番に考えていきましょう。
One-vs-Rest(All)
One-vs-Rest(One-vs-Allと記述される場合もある)は、その名の通り、あるクラスと残りのクラスに分割して分類するやり方です。
例としてリンゴ、ミカン、バナナの3クラスを分類するために、下図のように(リンゴ-その他)、(ミカン-その他)、(バナナ-その他)という3つの分類器を作ります。
実際には各分類器の境界で例えばリンゴともバナナともとれる領域があるんですが、そういう場合は各分類器の出力の強さなどを使ってどちらかに決めるなどの処理が必要になります。
クラスの数だけ分類器を用意すればいいので計算量は次に説明するOne-vs-Oneよりは少なくてすみます。
One-vs-One
One-vs-Restとは違い、任意の2つのクラスを選んで2クラス分類します。組み合わせの数はクラス数を$n$とすると、$ n C_2$種類の分類器が必要になります。
例えば10クラスを分類する場合、One-vs-Restでは10種類の分類器があれば大丈夫でしたが、One-vs-Oneになると、$_{10}C_2=45$種類の分類器が必要になってしまいます。最終的な分類は各分類器の多数決で決めます。
線形回帰ではなく、モデルにカーネル法を使った場合はこちらを使うことがあるみたいです。実際に、scikit-learnのドキュメントを参照すると以下のような扱いになっているようです。
- sklearn.linear_model.LogisticRegression→One-vs-Rest
- sklearn.svm.SVC→0.19まではOne-vs-One、それ以降はOne-vs-Rest
- sklearn.svm.LinearSVC→One-vs-Rest
多クラスソフトマックス
多クラスソフトマックスは、最近ではニューラルネットワークでよく用いられます。モデルの出力に対し、どのクラスが一番可能性が高いかという数値をソフトマックス関数を用いて学習します。
ソフトマックス関数について説明する前に、One-hot Encodingについて先に説明します。One-Hot Encoding
One-Hot Encodingは端的に言えば、ひとつだけが1であとは0というベクトルを指します。例を出すと、ある特徴量が
果物 リンゴ ミカン リンゴ バナナ となっていたとします。これを下記のように書き換えます。
果物_リンゴ 果物_ミカン 果物_バナナ 1 0 0 0 1 0 1 0 1 0 0 1 このような形にすることで、先ほどあげたOne-vs-Rest(One)の分類に分割できることと、次に述べるソフトマックス関数の計算に持って行きやすいという利点があります。また、Pandasのget_dummies()関数やsikit-learnのOneHotEncoderクラスが使えます。
ソフトマックス関数
ソフトマックス関数は、複数の出力を合計が1(100%)になるような確率分布に変換してくれる関数です。ソフトマックス関数は下のような形をしています。
y_i=\frac{e^{x_{i}}}{\sum_{j=1}^{n}e^{x_{j}}} \\ \sum_{i=1}^{n}y_i=1$y$は$n$次元のベクトルで、出力も同様です。先ほどの例で、(リンゴ,ミカン,バナナ)=[3,8,1]と出力されたとすると、ソフトマックス関数の出力は[0.7,99.2,0.1]となり、ミカンの可能性が一番高いことになります。
ちなみに2クラス分類は、上の式でn=2なので\begin{align} y_1&=\frac{e^{x_{1}}}{e^{x_1}+e^{x_2}} \\ &=\frac{\frac{e^{x_{1}}}{e^{x_{1}}}}{\frac{e^{x_{1}}}{e^{x_{1}}}+e^{x_2-x_1}} \\ &=\frac{1}{1+e^{x_2-x_1}} \end{align}となります。これはシグモイド関数そのものです。
ソフトマックス関数の微分
ソフトマックス関数の微分は
\dfrac{\partial y_i}{\partial x_j}= \begin{cases}y_i(1-y_i)&i=j\\-y_iy_j&i\neq j\end{cases}です。
ソフトマックス関数による多クラス分類
クラス数が$c$、入力が$\boldsymbol{x}=(x_0, x_1,\cdots,x_n)$とする($x_0$はバイアス)。パラメータを$(n+1)$×$c$の大きさを持った$\boldsymbol{W}$とする。
\boldsymbol{z}=\boldsymbol{W}^T\boldsymbol{x}をモデルとして$\boldsymbol{W}$を最適化します。
そのためには、ロジスティック回帰と同じように、クロスエントロピー誤差関数$E$を求めます。尤度関数を$l$とすると、$l$は全てのクラス、全てのサンプルに対する確率分布で表すことができる。$i$番目のサンプルにおけるクラス$j$のソフトマックス関数の出力を$\varphi_{ij}^{t_{ij}}$とすると、
l=\prod_{i=1}^{n}\prod_{j=1}^{c}\varphi_{ij}^{t_{ij}}となる。尤度を最大化したいのですが、$l$の対数をとり、-1をかけた関数をクロスエントロピー誤差関数とし、
\begin{align} E&=-\log(l) \\ &=-\log\left(\prod_{i=1}^{n}\prod_{j=1}^{c}\varphi_{ij}^{t_{ij}}\right) \\ &= -\frac{1}{n}\sum_{i=1}^{n}\sum_{j=1}^{c}t_{ij}\log\varphi_{ij} \end{align}が損失関数となる。損失関数の微分は、
\begin{align} \frac{\partial E}{\partial w} &= -\frac{1}{n}\sum_{i=0}^n(t_{il}-\varphi_{il})x_{ij} \\ &=-\frac{1}{n}\boldsymbol{x}^T(\boldsymbol{t}-\phi) \end{align}となります。(計算省略)
あとは、$E$を最小化するために勾配法を使えばパラメータ$\boldsymbol{W}$を求めることができます。
まとめ
2クラス分類を多クラス分類へ拡張する方法についてまとめました。1つは2クラス分類を単純に繰り返す方法。もう一つはソフトマックス関数を使い、クラスごとの確率分布を求める方法でした。
探し方が悪かったのか、あまりこの辺の方法を詳しくまとめてるページが少なかったので時間がかかったのとソフトマックス関数を使った分類はかなり複雑でした。
次回以降、Pythonのコードに落として行きたいと思っています。

- 投稿日:2020-03-23T22:51:12+09:00
Pythonを利用したスクレイピング
概要
- モチベーション:日々追加されるニュースについて、その日時・ヘッドライン・urlを集めたい
- BeautifulSoupを利用する
- なお、本稿はPython 3.x系, UNIXの利用を前提とした記述となっています。
0. パッケージ
- スクレイピングに利用:
BeautifulSoup,httplib2,time- データ格納に利用:
re,pandas,datetimeimport pandas as pd from bs4 import BeautifulSoup import httplib2 import re import time from datetime import datetime1. Webデータのスクレイプ
- url末尾が動的に変化するページを対象とする(e.g.
http://~/page/1;http://~/page/2; ... etc.)- 以下1〜5ではでは
num = 1として説明。任意の整数が入ることを想定している。- ここでは、
soup = BeautifulSoup(content, 'lxml')により、soupに当該ページのデータを格納するのが目標。num = 1 h = httplib2.Http('.cache') base_url = "http://~/page" url=base_url+ str(num) response, content = h.request(url) content = content.decode('utf-8') soup = BeautifulSoup(content, 'lxml')2. スクレイプしたデータの絞り込み:個々のニュース
- 1. において
soupに格納されたデータのうち、必要な情報を抜き出す(投稿日時・ヘッドライン・記事のurlについて、個々のニュースをリストアップする)- ここでは、
'div'タグがついたもののうち、"id"の値が"primary"であるものを抽出し、dataに格納する(ホームページに含まれる様々な情報のうち、個々のニュースに関する情報のみを抽出)。data = soup.find_all('div', {"id": "primary"})3. 日時の取得・タイムスタンプの整形
- 2.にて得た
dataに含まれるニュースのリストから、そのタイムスタンプを抽出し、datesに格納する。dataはfind_allにて抽出を行っているため、そこからさらにfind_allで抽出を行う際に、data[0]と指定している点に注意。datesのデータは、日時だけでなく、時刻等の情報を含んでいる。ここでは日時のみを使用するため、日時のみを抽出し、tempに格納する。- さらに、
tempをdatetime型に変換し、listに格納する。元データに%d/%m/%Yのタイプと、%Y-%m-%dのタイプが混在しているため、indexを用いて場合分けを行い、datetime型に変換している。dates = data[0].find_all('span', class_ = 'posted-on') temp = [] for item in dates: date = item.text temp.append(date[1:11].split()) dlist = [] for item in temp: index = item[0].find("/") if index != -1: dlist.append(datetime.strptime(item[0], '%d/%m/%Y').date()) else: dlist.append(datetime.strptime(item[0], '%Y-%m-%d').date())4. ヘッドライン、urlの取得
- 2.で得た
dataに含まれるニュースのリストから、個々のニュースのヘッドライン・urlを取得し、newdataに格納する。- そのそれぞれを、
tlist(ヘッドライン... タイトルのt),ulist(url)に格納する。- ここでは、ヘッドラインについて、エスケープシークエンス(\n|\r|\t)を取り除く作業を行なっている。
newdata = data[0].find_all('h2', class_ ='entry-title') tlist = [] ulist = [] for item in newdata: urls = re.search('href="(?P<URL>.+?)"', str(item)).group('URL') titles = item.get_text() ulist.append(urls) tlist.append(re.sub(r'\n|\r|\t', '', titles))5. 取得した情報をデータフレームにまとめる
- ここでは
pandasを利用し、目標であるヘッドライン一覧(日時・記事タイトル・url)のデータフレームを作成する。- このデータフレームが最終的に求める結果となる。
list_headline = pd.DataFrame({'date':dlist, 'headline':tlist, 'url':ulist})6. 関数化
- 1.に記したように、ここまでは
num = 1として説明を進めてきたが、以下では、複数のページに対して同じ作業を行う場合を考える。- 各ページが同じ構造をしていると仮定すれば、以上の1.~4.を関数化し、ページの切り替えを変数にて司るのが有効であるといえる。
- ここでは、
numを変数として設定し、numの値に即し、同じ構造のページが自動的に取得できるとする。(1.におけるurl=base_url+ str(num)がこれを定義している)- 関数化するには、
defにて関数名(ここではheadline)と変数(ここではnum)を宣言し、関数の中身はインデントして記述する(詳細は下記「実際のコード」を参照)。- 最後に、(5.で述べたように、この作業で最終的に求める結果である)データフレームを返り値として指定している。
def headline(num): h = httplib2.Http('.cache') base_url = "http://~/page" url=base_url+ str(num) # 中略 # return list_headline7. コードの繰り返し実施
- ここでは、
numの値が1から5をとるとして、コードを実施するとする。- まず、
num=1の場合に関数を実行し、headlinesに格納する。空のオブジェクトに対してループを使った格納が行えないためである。- サーバーへの負担回避のため、スクリプトの実行に5秒間の待機時間を設定している(
time.sleep(5))。- その上で、
numが2から5を取る場合について、forを用いて繰り返し関数を適用し、得られた結果をheadlinesに追加していく(既存のheadlinesのデータフレームに対し、新たなデータフレームを積み上げていくイメージ)。print(i)はエラーチェックのために利用している。headlines = headline(1) time.sleep(5) for i in range (2,5): temp = headline(i) headlines = pd.concat([headlines, temp]) time.sleep(5) print (i)8. 保存
- 7.によって得られた結果を保存する。
- ここでは、.csv, .xlsxの2つの保存方法を紹介している。
#headlines.to_csv(datetime.today().strftime("%Y%m%d")+'FILENAME.csv') ## 基本的には.csvの方が利用しやすくおすすめ headlines.to_excel('/Users/USERNAME/FOLDERNAME/'+ datetime.today().strftime("%Y%m%d")+'FILENAME.xlsx') ## excel形式の方が良い場合はこちら実際のコード
- 以上、1~8をまとめると、以下のようなコードとなる。
- ホームページアドレス(
base_url)、保存先(上記8.参照)は架空の数値を挿入しているため、このコードを直接利用しても結果が得られない点は留意願いたい。- また、ホームページの構造により、ページアドレスのナンバリング(本稿ではアドレスの末尾が
page1,page2, ... と変化していくと想定)が異なるほか、タグの構成も千差万別である。実際の利用にあたっては、ページのソースコードをよく確認されたい。- スクレイピングを禁止しているホームページも存在する。よく確認するようにしてほしい。
import pandas as pd from bs4 import BeautifulSoup import httplib2 import re import time from datetime import datetime def headline(num): h = httplib2.Http('.cache') base_url = "http://~/page" url=base_url+ str(num) response, content = h.request(url) soup = BeautifulSoup(content, 'lxml') data = soup.find_all('div', {"id": "primary"}) dates = data[0].find_all('span', class_ = 'posted-on') temp = [] for item in dates: date = item.text temp.append(date[1:11].split()) dlist = [] for item in temp: index = item[0].find("/") if index != -1: dlist.append(datetime.strptime(item[0], '%d/%m/%Y').date()) else: dlist.append(datetime.strptime(item[0], '%Y-%m-%d').date()) newdata = data[0].find_all('h2', class_ ='entry-title') tlist = [] ulist = [] for item in newdata: urls = re.search('href="(?P<URL>.+?)"', str(item)).group('URL') titles = item.get_text() ulist.append(urls) tlist.append(re.sub(r'\n|\r|\t', '', titles)) list_headline = pd.DataFrame({'date':dlist, 'headline':tlist, 'url':ulist}) return list_headline headlines = headline(1) time.sleep(5) for i in range (2,5): temp = headline(i) headlines = pd.concat([headlines, temp]) time.sleep(5) print (i) #headlines.to_csv(datetime.today().strftime("%Y%m%d")+'FILENAME.csv') headlines.to_excel('/Users/USERNAME/FOLDERNAME/'+ datetime.today().strftime("%Y%m%d")+'FILENAME.xlsx') ## excel形式の方が良い場合はこちら
- 投稿日:2020-03-23T22:34:14+09:00
Pythonで毎日AtCoder #14
はじめに
前回
14日目#14
今日はBです。
考えたこと
ABC081-B
ABC081-Bは$A_i$が偶数のときは2で割り切れるまで割ります。奇数のときはすぐにquitしてます。n = int(input()) a = list(map(int,input().split())) counter = [] for i in range(n): count = 0 if a[i] % 2 == 0: while a[i] % 2 == 0: a[i] //= 2 count += 1 counter.append(count) else: print(0) quit() print(min(counter))
ABC087-B
ABC087-Bは思考停止で3重ループしてます。a = int(input()) b = int(input()) c = int(input()) x = int(input()) ans = 0 for i in range(a+1): for j in range(b+1): for k in range(c+1): price = 500 * i + 100 * j + 50 * k if price == x: ans += 1 print(ans)
ABC083-B
ABC083-BはNが$10^4$程度なので全てのNについて調べています。$1\leq i \leq n$のiをstrにして桁ごとに合計してifで分けています。n, a, b = map(int,input().split()) ans = 0 for i in range(n+1): i = str(i) k = 0 for j in range(len(i)): k += int(i[j]) if k <= b and k >= a: ans += int(i) print(ans)
ABC088-B
ABC088-Bはお互いに最適な動きをするので、残っている最大のカードを取ります。なので、sortして1個ずつ合計しています。別にプレイヤーごとに分けなくても、それぞれで差分とってもいい。n = int(input()) a = list(map(int,input().split())) a.sort(reverse=True) alice = 0 bob = 0 for i in range(n): if i % 2 == 0: alice += a[i] else: bob += a[i] print(alice-bob)
ABC085-B
ABC085-Bは同じ大きさの餅は置けないので、setで重複無しにしてsortしています。n = int(input()) d = {int(input()) for _ in range(n)} d = list(d) d.sort() print(len(d))まとめ
Bくらいは解ける。明日のCからが本番!
では、また
- 投稿日:2020-03-23T22:22:15+09:00
OpenCVでトリミングする方法
個人的な備忘録&Qiita投稿テストです
元の画像
トリミングを行う
import cv2 # 画像を読み込んでリサイズ pic_url = "lena.jpg" img = cv2.imread(pic_url) #画像行列[矩形上部のy座標:矩形下部のy座標, 矩形左部のx座標:矩形右部のx座標] cut_img = img[0:200,0:200] while True: cv2.imshow("img", cut_img) # qキーが押されたら途中終了 if cv2.waitKey(25) & 0xFF == ord('q'): cv2.destroyAllWindows() break結果
ポイントは
画像行列[矩形上部のy座標:矩形下部のy座標, 矩形左部のx座標:矩形右部のx座標]
というところでしょうか。


- 投稿日:2020-03-23T21:22:07+09:00
【Django】開発に地味に便利なスクリプト集
Djangoの開発ではcliを叩くことが多くなりがちですが、
オプションとか覚えてられないかつ面倒なので、よくPipenv等のタスクランナー機能を用います。
私はpoetry派なのでpoetry scriptsをよく使います。(poetryはタスクランナー機能という名目でscripts機能を実装していないことに留意)また、
django_extensionsを用いれば、欲しい機能もすでに使用可能なことが多いです。過去の投稿でも、runserverを行うスクリプトを紹介しました。
【Poetry】Poetry script で Django の runserver を起動 - Qiita
今回はこの他に、自分のプロジェクトで使っているスクリプトを紹介します。環境
- Python 3.7.4
- poetry 1.0.5
- django-extensions 2.2.8
django-extensions
django-extensionsは、Django開発用のアプリケーションで、様々な便利機能を用意してくれるパッケージです。
django-extensionsをインストールし、INSTALLED_APPSに追加しておきます。$ pip install django-extensionsINSTALLED_APPS = [ ... 'django_extensions', # 追加 ]scripts
私はパッケージ管理にPoetryを使用しているので、poetry scriptsを使用しています。
poetry scriptsを利用する利点として、仮想環境外で実行しても、一度仮想環境内に入り、仮想環境内でタスクを実行してくれる点があります。
テストだけ確認したい、URLだけ一覧表示したいという時や、仮想環境に関して理解がない人も一行のコマンドで実行出来るのは侮れません。以前の投稿と同じく、subprocessパッケージを利用してコマンド実行を行います。
shell_plus
django-extensionsといえばの機能で、shell_plusという機能があります。
Django shellを拡張しており、補完や事前インポート等を行ってくれ、かなり便利です。def shell_plus(): cmd = ["python", "manage.py", "shell_plus"] subprocess.run(cmd)URLを表示
django-extensionsには、DjangoアプリケーションのすべてのURLを出力をする機能があります。
APIドキュメントの作成時などかなり重宝します。
--formatオプションでは、出力形式を変更出来ます。def url(): cmd = ["python", "manage.py", "show_urls", "--format", "aligned", "--force-color"] subprocess.run(cmd)ソース内のTODOを表示
django-extensionsのnotes機能を用いれば、
pyファイルとHTMLファイル内のTODO, FIXME, BUG, HACK, WARNING, NOTEなどを抽出し、一覧表示してくれます。
これが地味に便利で、一日の始めのTODO確認をCLIでできるのが良いです。
ファイルへのPathも表示されるので、VSCodeであればCtrl + クリックでそのまま開けます。def todo(): cmd = ["python", "manage.py", "notes"] subprocess.run(cmd)
- 出力
$ python manage.py notes /home/user/workspace/app/web/views.py: * [ 18] TODO sort filter /home/user/workspace/app/web/models.py: * [ 11] TODO 例外処理 /home/user/workspace/app/web/forms.py: * [ 32] TODO バリデーション追加テストを実行
Djangoのテスト機能には、並列実行機能があります。
勿論その実行数にはCPUのコア数が関わってくるのですが、コア数は環境によって異なります。
multiprocessing.cpu_count()を用い、動的にコア数を取得してテストの並列実行を行います。
-vはverboseです。import multiprocessing def test(): core_num = multiprocessing.cpu_count() # core_numとすると、subprocessが一つの実行プロセスとなるため、テストが上手く動かない。 cmd = ["python", "manage.py", "test", "--force-color", "-v", "2", "--parallel", f"{core_num - 1}"] subprocess.run(cmd)マイグレーションファイルを削除
データベースリセット時には、マイグレーションファイルをすべて消去します。
開発初期にはそこそこの頻度で行うので、削除スクリプトを作成しておくのが楽です。import os import glob BASE_DIR = os.path.dirname(os.path.dirname(__file__)) # このファイルの場所によって変更 def clean_migration(): migration_files = glob.iglob('**/migrations/[0-9][0-9][0-9][0-9]*.py', recursive=True) for migration_file in migration_files: os.remove(os.path.join(BASE_DIR, migration_file)) print(f"Deleted {migration_file}")データベースのリセット
データベースの削除と再作成を1コマンドで行う機能が、django-extensionsに用意されています。
def reset_db(): cmd = ["python", "manage.py", "reset_db"] subprocess.run(cmd)ER図の生成
django-extensionsの機能を用いると、ER図をmodel定義から自動生成してくれます。
この機能を用いるには、GraphvizおよびPython用アダプタpygraphvizが必要ですが、
1コマンドで最新のER図を作成してくれるのは最高です。def graph(): cmd = ["python", "manage.py", "graph_models", "-a", "-g", "-o", "--arrow-shape", "normal", "graph.png"] subprocess.run(cmd)models.pyのあるアプリ名表示
models.pyの存在するアプリ名を表示します。
大したコードではないですが、makemigrationsを行う際チェックする時に役立ちます。
python manage.py startapp appとしているディレクトリ構成で、モデルを記述しないアプリはmodels.pyを削除する必要があります。import glob def main(): model_files = glob.iglob('**/models.py', recursive=True) for model_file in model_files: path_split = model_file.split("/") print(path_split[-2])
これらに加え、django runserverを強化する
runserver_plus、admin.pyを自動生成してくれるadmin_generator等がありますが、自分自身使用したことがないため一覧にはありません。
- 投稿日:2020-03-23T21:14:46+09:00
Splunkでカスタムサーチコマンドを作成する
Splunkのサーチバーで使うコマンドが自作できる(Splunkでは自作したコマンドを「カスタムサーチコマンド」と呼ぶらしい)と聞いたので試してみました。なお、この投稿はUbuntu18.04で検証していますので、他のOSの場合は作成方法が違うかもしれませんのでご了承ください。
カスタムサーチコマンドを登録する
プログラムを作成する前にまず登録を行います。登録するには、
/opt/splunk/etc/apps/search/local/commands.confに以下のような文を追加します。Splunkの初回インストールの直後は、
/opt/splunk/etc/apps/search/配下にlocalフォルダすらないので、localフォルダを作成しcommands.confも新規作成します。/opt/splunk/etc/apps/search/local/commands.conf[hoge] filename = test.py streaming = true[ ]で囲まれた中の文字がサーチバーで記載するカスタムサーチコマンド名になり、このコマンドが呼び出されると
filename=で書かれているプログラム名を実行します。カスタムサーチコマンドの本体の作成
プログラムの本体は
/opt/splunk/etc/apps/search/bin/のフォルダに作成します。プログラム名はcommands.confに記入したプログラム名test.pyと同じにします。今回作ったプログラムは、前のSPLの出力結果を受け取り、その結果をファイルtest.datに文字列として出力して、内容を変えずそのまま次のSPLに渡すものとなっています。/opt/splunk/etc/apps/search/bin/test.pyimport splunk.Intersplunk data,dummy1,dummy2 = splunk.Intersplunk.getOrganizedResults(input_str=None) with open('test.dat','w') as f: f.write(str(data)) splunk.Intersplunk.outputResults(data)作成が完了したら、splunkの設定からSplunkを再起動します。
test.pyは再起動しなくても変更が反映されますが、commands.confは再起動しないと変更が反映されません。検証データを準備する
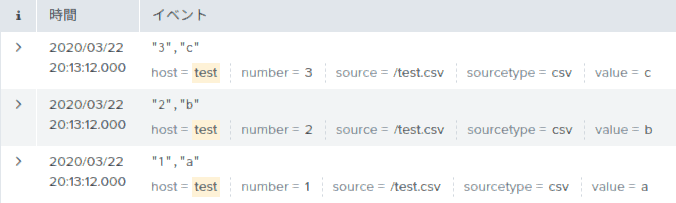
以下のような3行のデータを作成しました。これをパイプでカスタムサーチコマンドに渡して、どのようなデータ構造として受け取れるのか検証します。
プログラムの実行
下のSPLを実行します。
host = test | hoge実行後に
test.pyと同じフォルダにtest.datが作成されたと思います。内容を見ると、下のような3つの辞書(正確にはsplunk.util.OrderedDictというクラス)が入ったリストを見ることができます。各辞書は検証データの1件に対応し、辞書のキーと値はフィールドとその値に対応していることがわかります。これらを書き換えれば、次のSPLへ好きな結果を送ることができます。[ {'_cd': '15:6', '_serial': '0', 'value': 'c', 'eventtype': '', '_sourcetype': 'csv', 'splunk_server_group': '', 'timestamp': 'none', '_indextime': '1584679520', 'host': 'test.csv', 'linecount': '1', 'sourcetype': 'csv', 'source': '/home/dummy/test.csv', 'number': '3', 'splunk_server': 'unepc', '_bkt': 'main~15~760BD339-BFFA-48BA-81BF-3CE2BF8CA860', '_eventtype_color': '', 'index': 'main', '_raw': '"3","c"', '_time': '1584679468', '_si': 'dummy\nmain', 'punct': '"",""'}, {'_cd': '15:5', '_serial': '1', 'value': 'b', 'eventtype': '', '_sourcetype': 'csv', 'splunk_server_group': '', 'timestamp': 'none', '_indextime': '1584679520', 'host': 'test.csv', 'linecount': '1', 'sourcetype': 'csv', 'source': '/home/dummy/test.csv', 'number': '2', 'splunk_server': 'unepc', '_bkt': 'main~15~760BD339-BFFA-48BA-81BF-3CE2BF8CA860', '_eventtype_color': '', 'index': 'main', '_raw': '"2","b"', '_time': '1584679468', '_si': 'dummy\nmain', 'punct': '"",""'}, {'_cd': '15:4', '_serial': '2', 'value': 'a', 'eventtype': '', '_sourcetype': 'csv', 'splunk_server_group': '', 'timestamp': 'none', '_indextime': '1584679520', 'host': 'test.csv', 'linecount': '1', 'sourcetype': 'csv', 'source': '/home/dummy/test.csv', 'number': '1', 'splunk_server': 'unepc', '_bkt': 'main~15~760BD339-BFFA-48BA-81BF-3CE2BF8CA860', '_eventtype_color': '', 'index': 'main', '_raw': '"1","a"', '_time': '1584679468', '_si': 'dummy\nmain', 'punct': '"",""'} ]なお、カスタムサーチコマンドは、前のSPLの結果を50件くらいに小分けして受け取っているようです。つまり、プログラムを起動し最初の50件を処理し終了したら、またプログラムを起動し次の50件を処理し終了する・・・を繰り返しています。そのため、50件以上だと(このプログラムは上書き保存のため)最後に受け取った結果しか見ることができません。
おわりに
今回は初歩的なカスタムサーチコマンドを作成することを目的としました。今後はカスタムサーチコマンドのパラメータやエラー表示などについて記載していきたいと思います。
動作環境
Ubuntu 18.04.4 LTS
Splunk 8.0.2.1
- 投稿日:2020-03-23T21:05:59+09:00
Pythonエラー対応メモ: "...does not support argument 0 of type float..."
Python / 機械学習の初心者です。
データ型に対するエラー対応のメモを残します。発生した状況
pythonのプログラム内で、以下のような計算をした際にエラーが発生した。
import numpy as np def sigmoid(x) return (1 / (1 + np.exp(-x))) hoge = sigmoid(3) #ここでエラー発生TypeError: loop of ufunc does not support argument 0 of type float which has no callable exp method判明した原因
- どうやら、numpyのライブラリの計算にあてる引数に、int型のデータが含まれているとエラーが出るらしい(参考欄のGitHub URL参照)。
- 引数への計算処理前にfloat型へとデータ型変更をすると良い。
解決策
- sigmoid(x)のxのデータ型をfloatであると明示することで解決した。
def sigmoid(x) x = x.float() return (1 / (1 + np.exp(-x))) hoge = sigmoid(3) # -> エラーは起こらず正しく計算できた参考
補言
- ディープラーニング作成時、シグモイド関数を利用するタイミングでこのエラーが発生しました。引数のxには配列が入るのですが、配列の各要素がint型をしていたために今回の問題を起こしたようです。
- データ型を宣言しなくてもある程度動くのがPythonの特徴の1つだと改めて認識し、データ型を明示した計算を心がけたほうが良いということなのだろうと思いました。
(以上)
- 投稿日:2020-03-23T21:03:21+09:00
【VSCode】PythonのlanguageServerが起動しなくなった
突然VSCode拡張、PythonのLanguageServerのダウンロードが途中で停止してしまうようになった。
タスクバーの下に以下のような表示が出たまま、進まず。Downloading Microsoft Python Language Server... 31634 of 32423 KB(98%)【出力】パネルの
Python Language Serverタブには、Downloading https://pvsc.azureedge.net/python-language-server-stable/Python-Language-Server-linux-x64.0.5.31.nupkg...と表示されており、これ以上は進まない状況。
ログファイルからは詳細が読み取れず、再起動やPython拡張の別バージョンをインストールしてみたりしたが、上手くいかず。
手動でソースをunzipし、起動できるようにしたので、手順を示す。languageServerなしでは話にならない。
環境
- Visual Studio Code 1.43.1
- Remote - SSH 0.50.1
- Python Extension 2020.3.69010
- CentOS 7
Windows 10のVScodeから、CentOS7にリモート接続している。PythonLanguageServerが起動しなかったのはCentOS上。
2020/03/23時点の環境なので、参考にする場合は注意。languageServerの削除
Python拡張機能の本体は、
~/.vscode-server/extensions/ms-python.python-YYYY.m.XXXXXの中にある。
この中のlanguageServer.0.XX.XがlanguageServer本体。languageServerを手動で配置するので、languageServerを削除する。
配置する用のディレクトリを作成しておく。名前はlanguageServerで始まる名前であれば良いようだ(未確認)。$ rm -rf languageServer.0.XX.X/ $ mkdir languageServer/languageServerのDL
パネルに表示されていたURLから、languageServerをDL。
.nupkgを.zipにリネームする。~$ wget https://pvsc.azureedge.net/python-language-server-stable/Python-Language-Server-linux-x64.0.5.31.nupkg ~$ mv Python-Language-Server-linux-x64.0.5.31.nupkg Python-Language-Server-linux-x64.0.5.31.zip展開、配置
unzipする。
~$ unzip Python-Language-Server-linux-x64.0.5.31.zip -d ~/.vscode-server/extensions/ms-python.python-2020.3.69010/languageServer/これで展開はできたのだが、このまま起動すると権限の関係でエラーが出る。
実行ファイルであるlanguageServer/Microsoft.Python.LanguageServerに実行権限を与えておく。~$ sudo chmod 775 ~/.vscode-server/extensions/ms-python.python-2020.3.69010/languageServer/Microsoft.Python.LanguageServer起動
この時点で起動できる気がするのだが、起動してみると
[Error - 16:29:06] Starting client failed Launching server using command dotnet failed.という表示が。dotnetをインストールすればいいのだが、自分で配置するとdotnetが必要になるのはよくわからない。。。
.NETインストール
依存ライブラリ
$ yum install -y libunwind libicuリポジトリ追加
$ rpm --import https://packages.microsoft.com/keys/microsoft.asc $ vi /etc/yum.repos.d/dotnetdev.repo[packages-microsoft-com-prod] name=packages-microsoft-com-prod baseurl=https://packages.microsoft.com/yumrepos/microsoft-rhel7.3-prod enabled=1 gpgcheck=1 gpgkey=https://packages.microsoft.com/keys/microsoft.ascインストール
$ yum list | grep dotnet $ yum -y install dotnet-sdk-3.1.200確認
$ dotnet --version 3.1.200起動成功
自分の環境では、これでlanguageServerが起動した。
正直なところ意味があるのかはわからないが、settings.jsonに以下を追記するとのこと。{ "python.downloadLanguageServer": false, "python.jediEnabled": false, }参考
Can the language server be installed manually_ · Issue #1698 · microsoft_python-language-server
Downloading Python-Language-Server too slowly in China_ · Issue #1916 · microsoft_python-language-server
- 投稿日:2020-03-23T20:50:45+09:00
PythonでGraphvizを用いて有向グラフを作成した時のメモ
PythonでGraphvizを用いて有向グラフを作成した時のメモ
動作環境
- Windows10 (64bit)
- Python 3.8.1
- Graphviz 2.38
環境構築
まずは Windows に Graphviz をインストールする.
https://graphviz.gitlab.io/pages/Download/Downloadwindows.html
今回は msi の方をダウンロードした.
ダウンロード後実行し,ウィザードに従ってインストールする.
インストール後,パスを通しておく.次に pip で graphviz をインストールする.
pip install graphviz実際にやってみる
まずは簡単なものから.
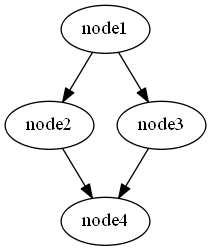
コードの例
from graphviz import Digraph graph = Digraph(format="png") # ノードを追加 graph.node("node1") graph.node("node2") graph.node("node3") graph.node("node4") # 辺を追加 graph.edge("node1", "node2") graph.edge("node1", "node3") graph.edge("node2", "node4") graph.edge("node3", "node4") # 画像を保存 # 拡張子はいらない graph.render("image/output") # 画像を表示 graph.view()出力
コードの説明
from graphviz import Digraph graph = Digraph(format="png")有向グラフを作成するため,Digraph をインポートする.
png の他に,pdf や svg などでも出力できる.# ノードを追加 graph.node("node1") graph.node("node2") graph.node("node3") graph.node("node4")ノードを作成する.与えた引数がノードの中に描かれる.
# 辺を追加 graph.edge("node1", "node2") graph.edge("node1", "node3") graph.edge("node2", "node4") graph.edge("node3", "node4")辺を作成する.第1引数→第2引数の向きに矢印が付く.
以下のように,ノードを作成していなくてもここで指定すれば新たにノードが作成される.
# 辺を追加 graph.edge("node1", "node2") graph.edge("node1", "node3") graph.edge("node2", "node4") graph.edge("node3", "node4") # 作成していないノードを指定 graph.edge("A", "B")出力は以下のようになる.
グラフの見た目を変える
ノードの形状や色を変えることができる.
形状の変更
コードの例
from graphviz import Digraph graph = Digraph(format="png") # ノードを追加 graph.attr("node", shape="square") # 形を正方形にする graph.node("node1") graph.node("node2") graph.attr("node", shape="star") # 形を星形にする graph.node("node3") graph.node("node4") graph.node("node5", shape="circle") # 個別に設定可能 graph.node("node6") # 辺を追加 graph.edge("node1", "node2") graph.edge("node1", "node3") graph.edge("node2", "node4") graph.edge("node3", "node4") graph.edge("node4", "node5") graph.edge("node4", "node6") # 画像を保存 # 拡張子はいらない graph.render("image/output2") # 画像を表示 graph.view()出力
コードの説明
# ノードを追加 graph.attr("node", shape="square") # 形を正方形にする graph.node("node1") graph.node("node2") graph.attr("node", shape="star") # 形を星形にする graph.node("node3") graph.node("node4") graph.node("node5", shape="circle") # 個別に設定可能 graph.node("node6")attr メソッドを用いるとすべてのノードの設定を変更できる.
shape="(形)"とすると形を指定できる.ノードの作成時に形を指定すると,そのノードの設定のみを変更できる.
色の変更
コードの例
from graphviz import Digraph graph = Digraph(format="png") # 見た目の設定 graph.attr("node", style="filled", fillcolor="black", color="red") # ノードの色設定 graph.attr("edge", color="cyan") # 辺の色設定 # ノードを追加 graph.node("node1", style="filled", fillcolor="palegreen", fontcolor="blue") graph.node("node2", style="filled", fillcolor="yellow") graph.node("node3", fontcolor="magenta") graph.node("node4", style="filled", fillcolor="#808080") graph.node("node5", fontcolor="white") # 辺を追加 graph.edge("node1", "node2") graph.edge("node1", "node3") graph.edge("node2", "node4") graph.edge("node3", "node4") graph.edge("node3", "node5") # 画像を保存 # 拡張子はいらない graph.render("image/output3") # 画像を表示 graph.view()出力
コードの説明
# 見た目の設定 graph.attr("node", style="filled", fillcolor="black", color="red") # ノードの色設定 graph.attr("edge", color="cyan") # 辺の色設定 # ノードを追加 graph.node("node1", style="filled", fillcolor="palegreen", fontcolor="blue") graph.node("node2", style="filled", fillcolor="yellow") graph.node("node3", fontcolor="magenta") graph.node("node4", style="filled", fillcolor="#808080") graph.node("node5", fontcolor="white")形を変えた時のように,attr メソッドを用いることで全体の設定をすることができる.第1引数を
"node"や"edge"とすることで,ノードや辺の設定ができる.塗りつぶす場合は
style="filled",fillcolor="(色)"とする.
文字の色を変更する場合はfontcolor="(色)"とする.
色はカラーコードで指定することもできる.ノードを作成するときに個別に設定することもできる.
参考

- 投稿日:2020-03-23T20:35:44+09:00
TensorFlowを動かしてみた
Google先生が出している機械学習ライブラリ、TensorFlowを動かしてみました。
Pythonで触れるとのこと。
インストールはAnacondaからpipコマンドで入れてみます。
以下のサイトなどを参考にしてみます。TensorFlowをWindowsにインストール Python初心者でも簡単だった件
最初は上手く動かなかったのですが、TensorFlowのVersionをちょっと古いのに指定すると何とか動いてくれました。
というわけで、早速チュートリアル???のコードを動かしてみる。
GetStartでゲットできるコード、簡単な線形回帰分析で試してみます。
以下のサイトを参考にしてみました。多分もっともわかりやすいTensorFlow 入門 (Introduction)
y=0.1x+0.3
のプロット上の点を100点ほどサンプル取得して、0.1とか0.3という方程式のパラメタを推定するという問題。
import tensorflow as tf import numpy as np # Create 100 phony x, y data points in NumPy, y = x * 0.1 + 0.3 x_data = np.random.rand(100).astype(np.float32) y_data = x_data * 0.1 + 0.3 # Try to find values for W and b that compute y_data = W * x_data + b # (We know that W should be 0.1 and b 0.3, but Tensorflow will # figure that out for us.) W = tf.Variable(tf.random_uniform([1], -1.0, 1.0)) b = tf.Variable(tf.zeros([1])) y = W * x_data + b # Minimize the mean squared errors. loss = tf.reduce_mean(tf.square(y - y_data)) optimizer = tf.train.GradientDescentOptimizer(0.5) train = optimizer.minimize(loss) # Before starting, initialize the variables. We will 'run' this first. init = tf.initialize_all_variables() # Launch the graph. sess = tf.Session() sess.run(init) # Fit the line. for step in range(201): if step % 20 == 0: print((step, sess.run(W), sess.run(b))) sess.run(train) # Learns best fit is W: [0.1], b: [0.3]TensorFlowの使い方という意味ではとても良いサンプルなんだろうけど、どうしてもAPIがブラックボックス化していてよくわからない。
自分なりに、色々考えて何をやっているかを分析してみました。
どうやら、w,bというパラメタを初期値を適当に決めて、最小二乗のコスト関数に対して最急勾配法を用いて収束演算をしているようです。アルゴリズム自体は大したことは無く、評価関数に対してパラメタの1回偏微分を更新量としてアップデートすればOK。
具体的には・・・サンプルを以下のように定義する。(今回の例ではN=100っぽい)\left\{ \left( x_n,y_n \right) \right\}_{n=1}^Nこのとき、x_nとy_nの関係は以下のようになるように構成しています。
(今回の例では、w=0.1,b=0.3が真値)y_n=wx_n+bそして、コスト関数はというと、残差の二乗和なので、以下のようになります。
w、bは初期パラメータと考えればOKです。L(w,b)=\sum_{n=1}^N \left(y_n - (wx_n+b) \right)^2もちろん、w,bが正しい値のときには、めでたく
L(w,b)=0となるので、Lを最小化するw,bを探せばよいわけですね。
最急勾配法では、初期パラメタの更新を1回偏微分で実施するので、それぞれ求めておきます。
\frac{\partial}{\partial w}L(w,b)=-2\sum_{n=1}^N \left( y_n - (wx_n+b)\right)x_n\frac{\partial}{\partial b}L(w,b)=-2\sum_{n=1}^N \left( y_n - (wx_n+b)\right)これを利用すると、あるパラメタ初期値、w^(k),b^(k)を更新するには以下のようにしていくようです。
\left( \begin{matrix} w^{(k+1)} \\ b^{(k+1)} \end{matrix} \right) = \left( \begin{matrix} w^{(k)} \\ b^{(k)} \end{matrix} \right) - \alpha \left( \begin{matrix} \frac{\partial L}{\partial w} \\ \frac{\partial L}{\partial b} \end{matrix} \right) \\ = \left( \begin{matrix} w^{(k)} \\ b^{(k)} \end{matrix} \right) + 2\alpha \left( \begin{matrix} \sum (y_n - (wx_n+b))x_n \\ \sum (y_n - (wx_n+b)) \end{matrix} \right)大変申し訳ないのですが、天下り的に、係数αを以下のように決めます。これはTensorFlowのライブラリに渡す係数の特徴から決めています。
\alpha = \frac{1}{N} \betaβ・・・なんか名前があるんだろうか?ここを収束の設定パラメタとして最初に決めるようです。今回のサンプルだとβ=0.5とします。
というわけで、自前のClassを作って検証してみます。
以下の感じでどうでしょうか?
class calcWB: def __init__(self,x,y,w,b): self.x = x self.y = y self.w = w self.b = b # get length of sample data self.N = len(x) def run(self,beta): # calculate current redisual residual = self.y - (self.w*self.x + self.b) # calc dL/dw dw = -2*np.dot(residual,self.x) # calc dL/db db = -2*sum(residual) # calc alpha alpha = beta/self.N # update param(w,b) self.w = self.w - alpha*dw self.b = self.b - alpha*db return self.w,self.b初期化用のメソッドと、学習用のrunというメソッドの2つのみ。
これを使って、最初のサンプルを変更すると、以下のようになりそうです。# setting param init data w_init = np.random.rand()-.5 b_init = np.random.rand()-.5 # GradientDescentOptimizer parameter beta = 0.5 # Create 100 phony x, y data points in NumPy, y = x * 0.1 + 0.3 x_data = np.random.rand(100).astype(np.float32) y_data = x_data * 0.1 + 0.3 # Try to find values for W and b that compute y_data = W * x_data + b # (We know that W should be 0.1 and b 0.3, but TensorFlow will # figure that out for us.) #W = tf.Variable(tf.random_uniform([1], -10, 10)) W = tf.Variable(w_init) #b = tf.Variable(tf.zeros([1])) b = tf.Variable(b_init) y = W * x_data + b # Minimize the mean squared errors. loss = tf.reduce_mean(tf.square(y - y_data)) optimizer = tf.train.GradientDescentOptimizer(beta) train = optimizer.minimize(loss) # Before starting, initialize the variables. We will 'run' this first. init = tf.global_variables_initializer() # Launch the graph. sess = tf.Session() sess.run(init) # create calcWB object objCalcWB = calcWB(x_data,y_data,w_init,b_init) # Fit the line. for step in range(201): sess.run(train) w_tmp,b_tmp = objCalcWB.run(beta) if step % 20 == 0: #print(step, sess.run(W), sess.run(b)) print('[from TensorFlow] k=%d w=%.10f b=%.10f' % (step, sess.run(W), sess.run(b))) print('[from calcWB] k=%d w=%.10f b=%.10f' % (step,w_tmp,b_tmp)) # Learns best fit is W: [0.1], b: [0.3]実行結果を見てみると・・・
[from TensorFlow] k=0 w=0.4332985282 b=0.2284004837 [from calcWB] k=0 w=0.4332985584 b=0.2284004998 [from TensorFlow] k=20 w=0.1567724198 b=0.2680215836 [from calcWB] k=20 w=0.1567724287 b=0.2680215712 [from TensorFlow] k=40 w=0.1113634855 b=0.2935992479 [from calcWB] k=40 w=0.1113634986 b=0.2935992433 [from TensorFlow] k=60 w=0.1022744998 b=0.2987188399 [from calcWB] k=60 w=0.1022745020 b=0.2987188350 [from TensorFlow] k=80 w=0.1004552618 b=0.2997435629 [from calcWB] k=80 w=0.1004552578 b=0.2997435619 [from TensorFlow] k=100 w=0.1000911444 b=0.2999486625 [from calcWB] k=100 w=0.1000911188 b=0.2999486686 [from TensorFlow] k=120 w=0.1000182480 b=0.2999897301 [from calcWB] k=120 w=0.1000182499 b=0.2999897517 [from TensorFlow] k=140 w=0.1000036523 b=0.2999979556 [from calcWB] k=140 w=0.1000036551 b=0.2999979575 [from TensorFlow] k=160 w=0.1000007242 b=0.2999995947 [from calcWB] k=160 w=0.1000007308 b=0.2999995937 [from TensorFlow] k=180 w=0.1000001431 b=0.2999999225 [from calcWB] k=180 w=0.1000001444 b=0.2999999224 [from TensorFlow] k=200 w=0.1000000909 b=0.2999999523 [from calcWB] k=200 w=0.1000000255 b=0.2999999832となり、大体小数点以下7桁ぐらいまであっているので、考え方としてはよさそうです。
なるほど、TensorFlowのGradientDescentOptimizerがやっていることを少し理解できた気がします。
- 投稿日:2020-03-23T20:24:14+09:00
PyTorchのtochtextで文書分類
はじめに
torchtextを利用して文書分類を行う実装の流れを公式のtutorialに沿って説明します。また、公式のtutorialに付随しているGoogle Colabolatryではerrorになっている部分を修正した上でコードを掲載します。
開発環境
Google Colabolatry
事前知識
N-gramといった、自然言語処理の基礎用語
文書分類の流れ
torchtextを利用して文書分類を行う場合、実装は以下のような流れになります。コードについては次節で見るため、この説では概要だけ記載します。
1. pip install
2. moduleのimport
3. datasetの格納、train, testへの分割
4. modelの定義
5. modelのinstance化、batch生成用の関数定義
6. train, test用の関数定義
7. train, testの実行コード
前述の流れをtutorialに載っているコードで確認していきます。
1. pip install
ほぼ出オチですが、公式ではこのコードが原因でerrorを発生させています。具体的には2行目が原因です。
!pip install torch<=1.2.0 !pip install torchtext %matplotlib inlineこのまま実行した場合、後述するmoduleのimportで以下のようなerrorが発生します。
from torchtext.datasets import text_classificationImportError: cannot import name 'text_classification'
正しいコードは以下のようになります。また、torchtextのversionが変わることでruntimeの初期化が求められることがあります。その際はrestart runtimeを実行し、再度上から順にセルを実行すれば良いです (2回目のpip install後にはrestart runtimeを押す必要は無いです)。
!pip install torch<=1.2.0 !pip install torchtext==0.5 %matplotlib inline原因はtorchtextのversionです。何も指定しないでpip installを行うと0.3.1がinstallされてしまいます。text_classificationは0.4以降で実装されているため、0.3のままでは利用できません。なお、上記では0.5に固定していますが0.4以降であれば問題ありません。
2. moduleのimport
import torch import torchtext from torchtext.datasets import text_classification NGRAMS = 2 import os3. datasetの格納、train, testへの分割
if not os.path.isdir('./.data'): os.mkdir('./.data') train_dataset, test_dataset = text_classification.DATASETS['AG_NEWS']( root='./.data', ngrams=NGRAMS, vocab=None) BATCH_SIZE = 16 device = torch.device("cuda" if torch.cuda.is_available() else "cpu")4. modelの定義
embedding → linearというシンプルな流れになっています。また、init_weightでは重みの初期化を一様分布から生成した重みで行なっています。
import torch.nn as nn import torch.nn.functional as F class TextSentiment(nn.Module): def __init__(self, vocab_size, embed_dim, num_class): super().__init__() self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=True) self.fc = nn.Linear(embed_dim, num_class) self.init_weights() def init_weights(self): initrange = 0.5 self.embedding.weight.data.uniform_(-initrange, initrange) self.fc.weight.data.uniform_(-initrange, initrange) self.fc.bias.data.zero_() def forward(self, text, offsets): embedded = self.embedding(text, offsets) return self.fc(embedded)5. modelのinstance化、batch生成用の関数定義
VOCAB_SIZE = len(train_dataset.get_vocab()) EMBED_DIM = 32 NUN_CLASS = len(train_dataset.get_labels()) model = TextSentiment(VOCAB_SIZE, EMBED_DIM, NUN_CLASS).to(device) def generate_batch(batch): label = torch.tensor([entry[0] for entry in batch]) text = [entry[1] for entry in batch] offsets = [0] + [len(entry) for entry in text] offsets = torch.tensor(offsets[:-1]).cumsum(dim=0) text = torch.cat(text) return text, offsets, label6. train, test用の関数定義
from torch.utils.data import DataLoader def train_func(sub_train_): # Train the model train_loss = 0 train_acc = 0 data = DataLoader(sub_train_, batch_size=BATCH_SIZE, shuffle=True, collate_fn=generate_batch) for i, (text, offsets, cls) in enumerate(data): optimizer.zero_grad() text, offsets, cls = text.to(device), offsets.to(device), cls.to(device) output = model(text, offsets) loss = criterion(output, cls) train_loss += loss.item() loss.backward() optimizer.step() train_acc += (output.argmax(1) == cls).sum().item() # Adjust the learning rate scheduler.step() return train_loss / len(sub_train_), train_acc / len(sub_train_) def test(data_): loss = 0 acc = 0 data = DataLoader(data_, batch_size=BATCH_SIZE, collate_fn=generate_batch) for text, offsets, cls in data: text, offsets, cls = text.to(device), offsets.to(device), cls.to(device) with torch.no_grad(): output = model(text, offsets) loss = criterion(output, cls) loss += loss.item() acc += (output.argmax(1) == cls).sum().item() return loss / len(data_), acc / len(data_)7. train, testの実行
正しく学習できている場合は0.9以上のaccuracyを達成できます。
import time from torch.utils.data.dataset import random_split N_EPOCHS = 5 min_valid_loss = float('inf') criterion = torch.nn.CrossEntropyLoss().to(device) optimizer = torch.optim.SGD(model.parameters(), lr=4.0) scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1, gamma=0.9) train_len = int(len(train_dataset) * 0.95) sub_train_, sub_valid_ = \ random_split(train_dataset, [train_len, len(train_dataset) - train_len]) for epoch in range(N_EPOCHS): start_time = time.time() train_loss, train_acc = train_func(sub_train_) valid_loss, valid_acc = test(sub_valid_) secs = int(time.time() - start_time) mins = secs / 60 secs = secs % 60 print('Epoch: %d' %(epoch + 1), " | time in %d minutes, %d seconds" %(mins, secs)) print(f'\tLoss: {train_loss:.4f}(train)\t|\tAcc: {train_acc * 100:.1f}%(train)') print(f'\tLoss: {valid_loss:.4f}(valid)\t|\tAcc: {valid_acc * 100:.1f}%(valid)')解説
追記予定です
終わりに
現在、text_classificationのソースコードを読んでいます。その部分も後々掲載しようと思います。
- 投稿日:2020-03-23T20:24:02+09:00
ROSの環境セットアップ①
ROS1インストール
興味がありいろいろいじっています。今回はROS1 Melodic をインストールします。
個人的な備忘録として。なるべく小さめに。対象環境
Ubuntu 18.04 (Virtual Box上)
ROS1 Melodicインストール
ROS1パッケージ一括インストールの流れで行きます。
ROSのバージョンをmelodicに指定。install_1$ export ROS_DISTRO=melodicROSをインストールする許可を取る。
install_2$ sudo sh -c 'echo "deb http://packages.ros.org/ros/ubuntu $(lsb_release -sc) main" > /etc/apt/sources.list.d/ros-latest.list'keyの設定
install_3$ sudo apt-key adv --keyserver hkp://ha.pool.sks-keyservers.net:80 --recv-key C1CF6E31E6BADE8868B172B4F42ED6FBAB17C654更新
install_4$ sudo apt updateインストール
install_5$ sudo apt install ros-$ROS_DISTRO-desktop-full python-rosinstall python-rosinstall-generator python-wstool build-essential python-catkin-toolsそのあと、ROS1の依存関係を解決するrosdepのデータベースを更新し、環境設定のためのセットアップスクリプトを読み込んで終わりです。
rosdepの初期化
install_6$ sudo rosdep init $ rosdep update環境構築
install_7$ echo "source /opt/ros/$ROS_DISTRO/setup.bash" >> ~/.bashrc $ echo "source `catkin locate --shell-verbs`" >> ~/.bashrc $ source ~/.bashrcgazeboのインストールも行います。
$ curl -sSL http://get.gazebosim.org | sh $ sudo apt install ros-$ROS_DISTRO-gazebo-ros-pkgs ros-$ROS_DISTRO-gazebo-ros-control以上です。いろいろと遊んでみます。
参考文献
[1] ROS講座02 インストール https://qiita.com/srs/items/e0e0a9dc3f94c2d3348e
[2] ROS2ではじめよう 次世代ロボットプログラミング - 近藤豊ありがとうございました。
- 投稿日:2020-03-23T20:11:50+09:00
集計表とグラフ、HeatMapの作成
はじめに
広島県警のオープンデータを用いてデータサイエンスの実習を行いました。
このデータを処理するにあたって行ってきた手法とどんな結果が得られたか紹介していきます。
オープンデータから集計表とグラフ、HeatMapを作成するヒントになればいいと思っています。
動作環境
- OSX
- pyenv Python3.6.5
- Jupyter 1.0.0
- Pandas 0.23.0
- Numpy 1.14.3
- matplotlib 2.2.2
- seaborn 0.8.1
- geopy 1.20.0
- folium 0.10.0
参考サイト
https://www.pref.hiroshima.lg.jp/site/police/list426-1967.html
上のURLからデータを取得して、以下のようなPandasやNumpyで集計と分析を行い、その集計表をmatplotlibを使いグラフ化したりします。
以下のようなHeatMapを生成するところまでを紹介します。
2018年度版のデータはこのようになってます。
コード作成
csvデータは複数ある場合はglobを使い読み込んでいきます。globは引数に指定されたパターンにマッチするものを取得できます。これによりコードの量を減らせます。
test.py# 分析ファイルフォルダ:広島, ファイル拡張子:csv files = glob.glob("./都道府県/広島/*.csv") res_hirosima = None for file in files: tmp = pd.read_csv(file, encoding="SHIFT-JIS") #csvファイルの読み込み if res_hirosima is None: res_hirosima = tmp else: res_hirosima= res_hirosima.append(tmp, sort=True) # res_hirosimaとzyusyo_csvを”住所”で連結 res_hirosima_zyusyo = pd.merge(res_hirosima, zyusyo_csv, on = "住所", how="outer")HeatMapの作成のためには座標情報(経度・緯度)とマップが必要になります。
そこでGoogle Map Platformで経度緯度情報を取得し、geopy経由でGoogleMapに表示します。
経度・緯度を取得するためには時間とお金がかかるため、後でこのデータをcsvファイルを作成します。
経度・緯度を取得するためには都道府県・市町村・町丁目の項目の文字列を足し合わせます。Google Maps Platformの仕様上細かい住所情報が必要なためです。そして新たに「住所」というcolumnsを作成したDataFrameにconcatメソッドを用いて連結しいていきます。
res_hirosima["住所"] = res_hirosima['都道府県(発生地)'] + res_hirosima['市区町村(発生地)'] + res_hirosima["町丁目(発生地)"] # res_hirosimaとzyusyo_csvを”住所”で連結 res_hirosima_zyusyo = pd.merge(res_hirosima, zyusyo_csv, on = "住所", how="outer")作成したデータをcsvファイルに出力し、to_csv_out1.csvとします。
HeatMapの作成はこのcsvファイルを使用します。
Pandasとnumpyとmatplotlibを使い集計を行いグラフで作成します。
”発生時(時期)”と”発生件数”のDataFrameを作ります。
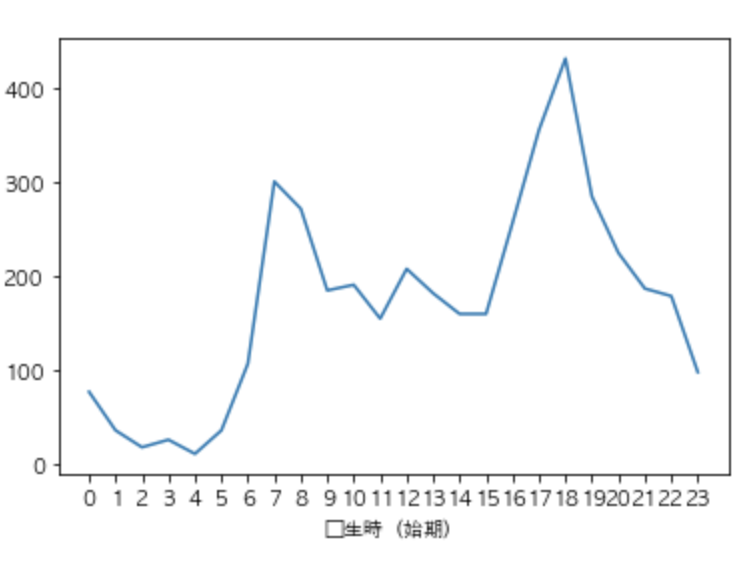
発生時(時期)に”不明”という要素が含まれていることがわかったので全てNa Nに変換します。
変換した後dropnaで全て削除します。
また、発生時(始期)の要素をto_numericを用いてfloat型に変換します。
#res_hirosima_zyusyo["発生時(始期)"]にある要素"不明"をNaNに変換 res_hirosima_zyusyo.loc[res_hirosima_zyusyo["発生時(始期)"] == "不明", "発生時(始期)"] = None res_hirosima_zyusyo["発生件数"] = 1 # 数値のみの行に変換 res_hirosima_zyusyo['発生時(始期)'] = pd.to_numeric( res_hirosima_zyusyo['発生時(始期)'] ) # res_hirosima_zyusyoにあるNaNの除去 time = res_hirosima_zyusyo.loc[:, ["発生時(始期)", "発生件数"]].dropna() #犯罪の多い時間帯をグラフで表示するためにres_hirosima_zyusyoを加工 #変数:time time.head(5)Groupyを使い時間帯ごとの発生件数
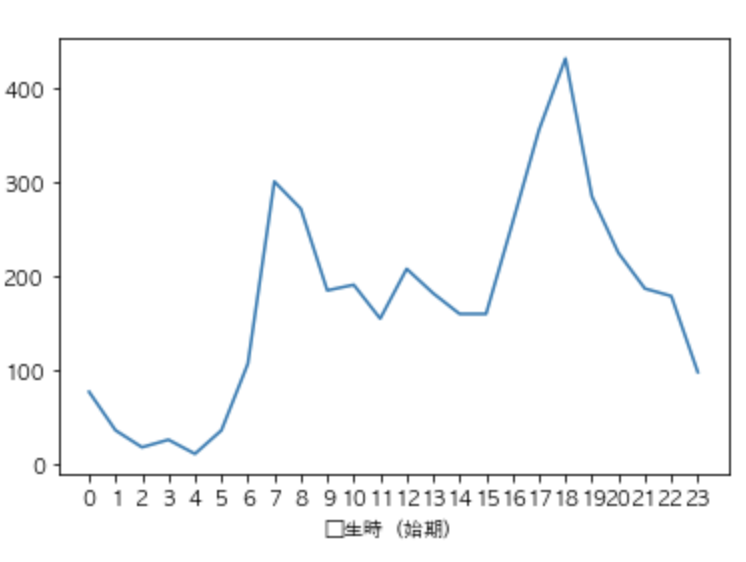
grouped = time["発生件数"].groupby(time["発生時(始期)"]) #変数:time #時刻に対する合計発生件数を表示 time = grouped.sum()Matplotlibを用いグラフを出力します。
この時、x軸にメモリが表示されていないのでxticksを使い0〜23まで表示します。
#どの時間帯に犯罪が多いか調べるためグラフで表示 time.plot() plt.xticks(np.arange(0, 24, 1))
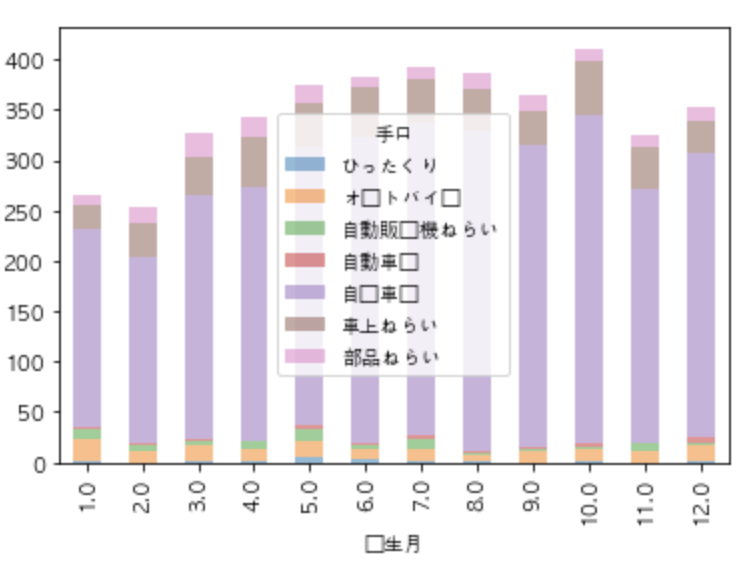
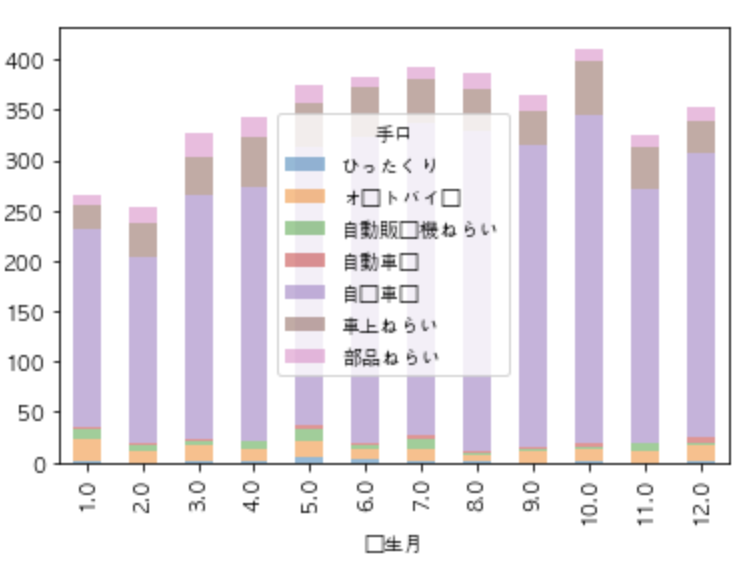
月ごとの犯罪種類の比較をpivot_tableを用いて集計します。pivot_tableはカテゴリごとにグルーピングして量的データの統計量の確認が便利だからです。
res_hirosima_zyusyoから必要な情報(手口・発生件数・発生月)を取り出します。
それを月ごとの種類別発生件数をグラフで表示します。
#res_hirosima_zyusyoを加工 month = res_hirosima_zyusyo.loc[:, ["手口", "発生月", "発生件数"]] month.head(5) #変数:month #一月あたりの手口別比率 month = pd.pivot_table(month, values="発生件数",index="発生月", columns="手口", aggfunc="sum") #NaNを0に変換 month =month.fillna(0) month.plot.bar(stacked=True, alpha=0.5)
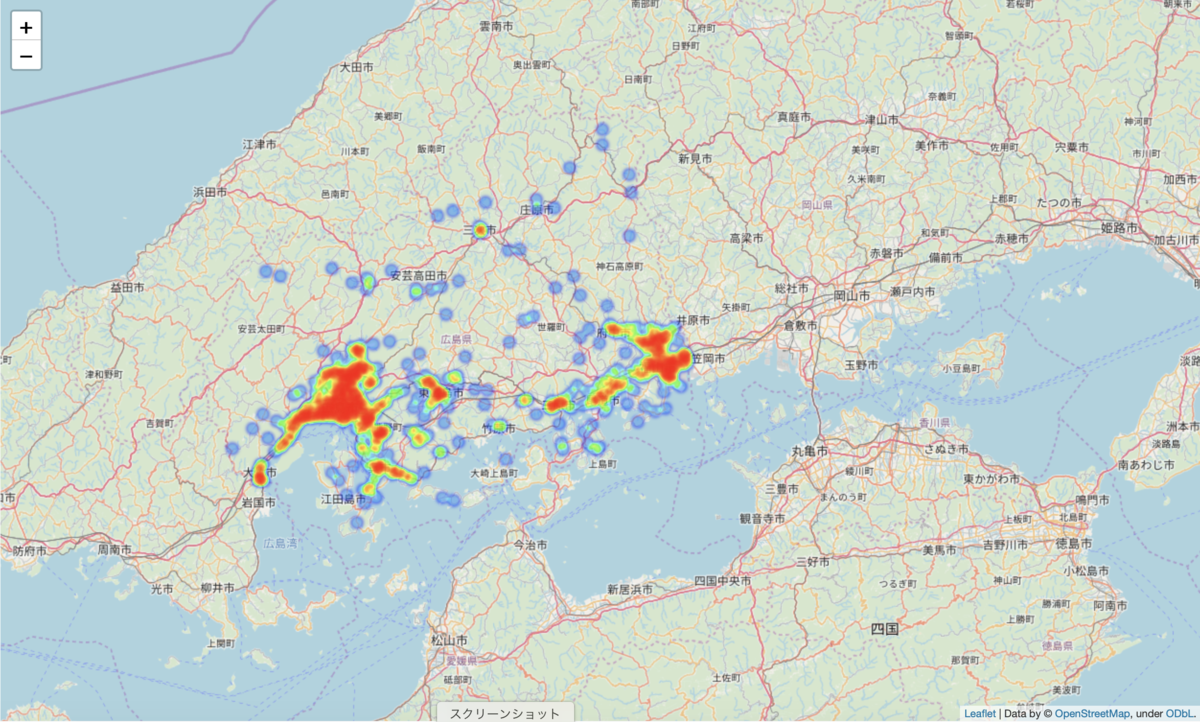
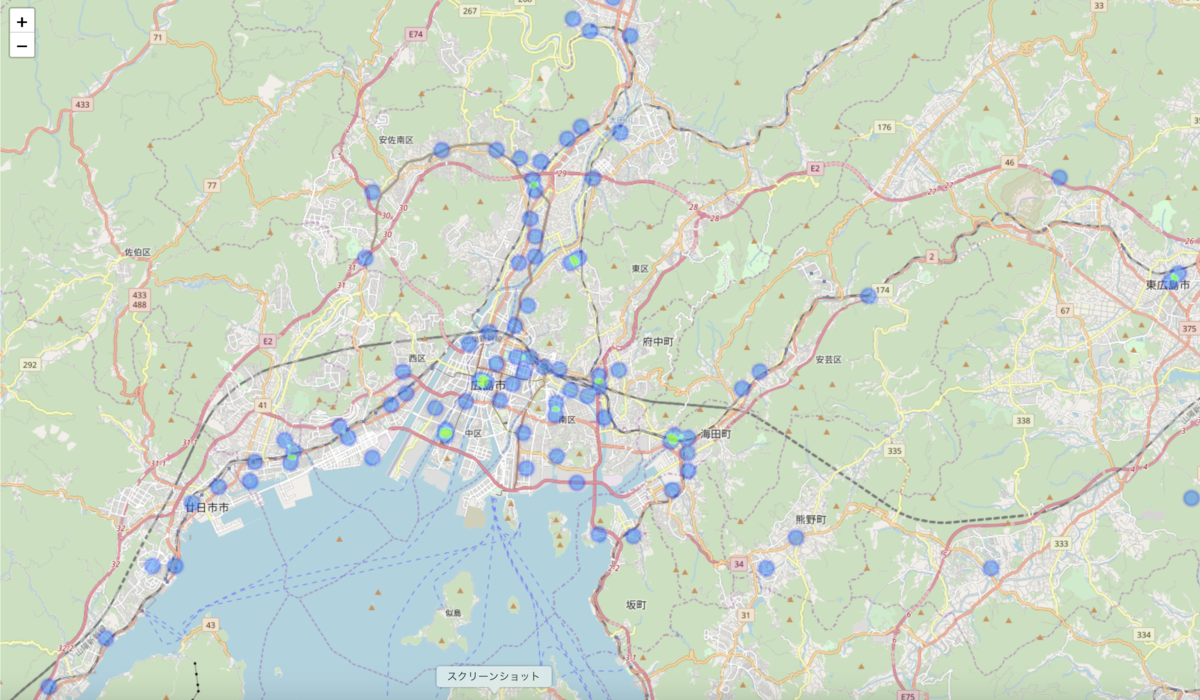
HeatMap作成
HeatMap作成のためにlocを使いres_hirosima_zyusyoから"latitude"と"longitude"を取り出します。
longitudegは地図上喉この情報を追加するのかをs指定に使います。
HeatMapに情報を追加するにはDataFrameではなくlistである必要があるのでvalues.tolist()を使いlist化します。
#分析ファイルのフォルダ:lat_lon, ファイル拡張子: csv #lat_lon.csvの内容: 犯罪が発生した場所に対する経度と緯度 #lat_lon = pd.read_csv("lat_lon.csv") lat_lon = res_hirosima_zyusyo.loc[:, ["latitude", "longitude"]] # メソッドを用いてDataFrameをlistに変換 lat_lon = pd.DataFrame(lat_lon.loc[:, ["latitude", "longitude"]]).values.tolist()以下のようなコードでプロットしていきます。
locationで表示位置を決め、tileを指定、zoom_startでどのくらい全体を見るか決めます。
そしてlistにある経度緯度情報をもとにHeatMapに情報を追加していきます。
m = folium.Map( location=[34.4,132.5], tiles='OpenStreetMap', zoom_start=12) list = lat_lon_7 HeatMap(list, radius=10, blur=3).add_to(m)
上記のような結果となりました。

- 投稿日:2020-03-23T19:45:51+09:00
ライントレースプログラム
はじめに
このページは,
の1ページです.
全体を見たい場合は上記ページへお戻りください.概要
本ページでは,以下の動画の様に,Telloで床に置いたトラロープを検出してライントレースさせます.
Telloで虎ロープを画像処理ライントレース。#tello pic.twitter.com/xS3NnusxNP
— hsgucci404 (@hsgucci404) December 9, 2019
使っているのは,画像処理の入門である「色検出」です.
色検出プログラム
を少し書き換えるだけで,これが実現できます.
トラロープを使った理由は「20m程度の長さを持つ色付きロープのなかで,一番安かったから」です(^^;
googleショッピング検索'トラロープ 20m'
画像処理を行うためには,単色で太いロープが望ましいのですが,十分な長さのある太いロープがなかなか見つからず,あったとしても数千円もしたので諦めました.「将来は工事現場でドローンで荷物搬送をする」とか言い訳しておきます(-_-;
ライントレースロボットの歴史
ロボットのプログラミングの入門でよくあるのは,ラインからはみ出さないように走り続けるという「ライントレース」ですね.
「ライントレースロボット」「ライントレースカー」「ライントレーサー」などと呼ばれ,専用の商品も多数販売されています.
LEGO MINDSTORMSでもライトセンサーの練習で作ります.ライントレースのロボコンで有名なものは,やはり『ジャパンマイコンカーラリー』でしょう.
歴史も古く,スピードも強烈です.
参考URL: Youtube検索"マイコンカーラリー"工場内の搬送ロボットでもライントレース技術は使われており,ラインを追いかけることは,もはやロボットプログラミングの基本中の基本と言っても良いでしょう.
ライントレースロボットでは一般的に,検出距離が数センチ以下の反射型フォトインタラプタ(ラインセンサーと呼称)を使ってラインの位置を検出し,駆動用モータやステアリングサーボへの出力を調整する制御プログラムを書きます.
カメラでライントレース
しかし,近年のCPU技術の発達に伴って,カメラを用いた画像処理技術も発展したため,
「いつまで地面のラインを検出する専用センサを使ってんだよ?」
と言い出す輩も出てくる様になりました.
(マイコンカーラリーもそうですが,多くのロボコンは中・高生の教育のためにあるので,「入門は誰しも簡単な物から」「ルールを高度化できない」なんですけどね...)最近話題の『DonkeyCar』『AWS DeepRacer』『JetRacer』では,
Raspberry PiやJetson Nanoを使ってディープラーニングでコースを学習し,
カメラ映像のみでコースを自動走行するレースが普通に行われています.
以下参考動画
Qiita記事用
— hsgucci404 (@hsgucci404) March 16, 2020
「DonkeyCar基本コース走行」 pic.twitter.com/bmMlrLzHj4ジャパンマイコンカーラリーでも,2020年からCamera Classが正式競技になりました.
以上の様に,カメラでライントレースをするというのも,徐々に「当たり前」になりつつあります.
ドローンでライントレース?
本記事では,地上の車ではなく,空飛ぶドローンでライントレースをさせます.
幸い,Telloはカメラ映像が取得でき,簡単なコマンドで移動ができるので,練習台には最適です.きっと将来は「マイコンドローンラリー」とか「自律ドローンレース」とかが行われると信じて,時代を先取りしてみましょう!(^^
前提条件
ホームフォルダにTello-Pythonがインストールされているという前提で話を進めます.
Linuxマシンであれば /home/(ユーザー名)/ に,Tello-Pythonというフォルダがあることになります.
詳しくは Tello-Pythonのダウンロード を御覧ください.
今回の作業内容
以前の記事 色検出プログラム のプログラムをコピー&改変して,ライントレースに対応させます.
作業ディレクトリの作成
まずは,色検出のプログラム
Tello-CV-colorをコピーして,新しいプロジェクト(ディレクトリ)Tello-CV-linetraceを作ります.Tello-CV-colorをディレクトリごとコピー$ cd ~/Tello-Python/ $ cp -R Tello-CV-color Tello_CV_linetrace $ cd Tello-CV-linetracetello.pyとlibh264decoder.soのコピーの手間など考えると,フォルダごとコピーが一番楽ですね.
次に,色検出のプログラムで最後に作った
main_control.pyをコピーして,新しいファイルmain_linetrace.pyを作ります.コントロールプログラムを別名にコピー$ cp main_control.py ./main_linetrace.py以下,この
main_linetrace.pyを書き換えていきます.ラインを検出してTelloが追いかけるプログラム
main_linetrace.py
プログラム本体である
main_linetrace.pyは,以下のコードを参考に書き換えてください.
書き加えの手間を省くのであれば,ここ を右クリックして[名前を付けて保存]機能でファイル保存してください.main_linetrace.py#!/usr/bin/env python # -*- coding: utf-8 -*- import tello # tello.pyをインポート import time # time.sleepを使いたいので import cv2 # OpenCVを使うため import numpy as np # メイン関数 def main(): # Telloクラスを使って,droneというインスタンス(実体)を作る drone = tello.Tello('', 8889, command_timeout=.01) current_time = time.time() # 現在時刻の保存変数 pre_time = current_time # 5秒ごとの'command'送信のための時刻変数 time.sleep(0.5) # 通信が安定するまでちょっと待つ # トラックバーを作るため,まず最初にウィンドウを生成 cv2.namedWindow("OpenCV Window") # トラックバーのコールバック関数は何もしない空の関数 def nothing(x): pass # トラックバーの生成 cv2.createTrackbar("H_min", "OpenCV Window", 0, 179, nothing) cv2.createTrackbar("H_max", "OpenCV Window", 128, 179, nothing) # Hueの最大値は179 cv2.createTrackbar("S_min", "OpenCV Window", 128, 255, nothing) cv2.createTrackbar("S_max", "OpenCV Window", 255, 255, nothing) cv2.createTrackbar("V_min", "OpenCV Window", 128, 255, nothing) cv2.createTrackbar("V_max", "OpenCV Window", 255, 255, nothing) a = b = c = d = 0 # rcコマンドの初期値を入力 b = 40 # 前進の値を40に設定 flag = 0 #Ctrl+cが押されるまでループ try: while True: # (A)画像取得 frame = drone.read() # 映像を1フレーム取得 if frame is None or frame.size == 0: # 中身がおかしかったら無視 continue # (B)ここから画像処理 image = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR) # OpenCV用のカラー並びに変換する small_image = cv2.resize(image, dsize=(480,360) ) # 画像サイズを半分に変更 bgr_image = small_image[250:359,0:479] # 注目する領域(ROI)を(0,250)-(359,479)で切り取る hsv_image = cv2.cvtColor(bgr_image, cv2.COLOR_BGR2HSV) # BGR画像 -> HSV画像 # トラックバーの値を取る h_min = cv2.getTrackbarPos("H_min", "OpenCV Window") h_max = cv2.getTrackbarPos("H_max", "OpenCV Window") s_min = cv2.getTrackbarPos("S_min", "OpenCV Window") s_max = cv2.getTrackbarPos("S_max", "OpenCV Window") v_min = cv2.getTrackbarPos("V_min", "OpenCV Window") v_max = cv2.getTrackbarPos("V_max", "OpenCV Window") # inRange関数で範囲指定2値化 bin_image = cv2.inRange(hsv_image, (h_min, s_min, v_min), (h_max, s_max, v_max)) # HSV画像なのでタプルもHSV並び kernel = np.ones((15,15),np.uint8) # 15x15で膨張させる dilation_image = cv2.dilate(bin_image,kernel,iterations = 1) # 膨張して虎ロープをつなげる #erosion_image = cv2.erode(dilation_image,kernel,iterations = 1) # 収縮 # bitwise_andで元画像にマスクをかける -> マスクされた部分の色だけ残る masked_image = cv2.bitwise_and(hsv_image, hsv_image, mask=dilation_image) # ラベリング結果書き出し用に画像を準備 out_image = masked_image # 面積・重心計算付きのラベリング処理を行う num_labels, label_image, stats, center = cv2.connectedComponentsWithStats(dilation_image) # 最大のラベルは画面全体を覆う黒なので不要.データを削除 num_labels = num_labels - 1 stats = np.delete(stats, 0, 0) center = np.delete(center, 0, 0) if num_labels >= 1: # 面積最大のインデックスを取得 max_index = np.argmax(stats[:,4]) #print max_index # 面積最大のラベルのx,y,w,h,面積s,重心位置mx,myを得る x = stats[max_index][0] y = stats[max_index][1] w = stats[max_index][2] h = stats[max_index][3] s = stats[max_index][4] mx = int(center[max_index][0]) my = int(center[max_index][1]) #print("(x,y)=%d,%d (w,h)=%d,%d s=%d (mx,my)=%d,%d"%(x, y, w, h, s, mx, my) ) # ラベルを囲うバウンディングボックスを描画 cv2.rectangle(out_image, (x, y), (x+w, y+h), (255, 0, 255)) # 重心位置の座標を表示 #cv2.putText(out_image, "%d,%d"%(mx,my), (x-15, y+h+15), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 0)) cv2.putText(out_image, "%d"%(s), (x, y+h+15), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 0)) if flag == 1: # a=c=d=0, b=40が基本. # 左右旋回のdだけが変化する. # 前進速度のbはキー入力で変える. dx = 1.0 * (240 - mx) # 画面中心との差分 # 旋回方向の不感帯を設定 d = 0.0 if abs(dx) < 50.0 else dx # ±50未満ならゼロにする d = -d # 旋回方向のソフトウェアリミッタ(±100を超えないように) d = 100 if d > 100.0 else d d = -100 if d < -100.0 else d print('dx=%f'%(dx) ) drone.send_command('rc %s %s %s %s'%(int(a), int(b), int(c), int(d)) ) # (X)ウィンドウに表示 cv2.imshow('OpenCV Window', out_image) # ウィンドウに表示するイメージを変えれば色々表示できる # (Y)OpenCVウィンドウでキー入力を1ms待つ key = cv2.waitKey(1) if key == 27: # k が27(ESC)だったらwhileループを脱出,プログラム終了 break elif key == ord('t'): drone.takeoff() # 離陸 elif key == ord('l'): drone.land() # 着陸 elif key == ord('w'): drone.move_forward(0.3) # 前進 elif key == ord('s'): drone.move_backward(0.3) # 後進 elif key == ord('a'): drone.move_left(0.3) # 左移動 elif key == ord('d'): drone.move_right(0.3) # 右移動 elif key == ord('q'): drone.rotate_ccw(20) # 左旋回 elif key == ord('e'): drone.rotate_cw(20) # 右旋回 elif key == ord('r'): drone.move_up(0.3) # 上昇 elif key == ord('f'): drone.move_down(0.3) # 下降 elif key == ord('1'): flag = 1 # 追跡モードON elif key == ord('2'): flag = 0 # 追跡モードOFF drone.send_command('rc 0 0 0 0') elif key == ord('y'): # 前進速度をキー入力で可変 b = b + 10 if b > 100: b = 100 elif key == ord('h'): b = b - 10 if b < 0: b = 0 # (Z)5秒おきに'command'を送って、死活チェックを通す current_time = time.time() # 現在時刻を取得 if current_time - pre_time > 5.0 : # 前回時刻から5秒以上経過しているか? drone.send_command('command') # 'command'送信 pre_time = current_time # 前回時刻を更新 except( KeyboardInterrupt, SystemExit): # Ctrl+cが押されたら離脱 print( "SIGINTを検知" ) drone.send_command('streamoff') # telloクラスを削除 del drone # "python main.py"として実行された時だけ動く様にするおまじない処理 if __name__ == "__main__": # importされると"__main__"は入らないので,実行かimportかを判断できる. main() # メイン関数を実行プログラム解説
色検出のプログラムは,オレンジ色のカラーコーンを追いかけて左右旋回するプログラムでした.
これと異なる点は,大きく分けて3つです.
- 画像処理を行う領域を,画面下側480x110だけに絞った
- トラロープのまだら模様を検出するため,膨張処理を行った
- 前進/後進を行うrcコマンドが0だったものを40にした
- キー入力で前進/後進の速度を増減できるようにした
1. ROIの設定
色検出でも使った
main_bgr.pyでTelloの画像を見てみると,
下の写真の様に遠くまでロープが見えています.
あまり遠くまで色検出しても意味がないので,今回は画像処理領域を狭くします.
これを,注目領域,すなわちRegion Of Interest(ROI)を切り出す,と言います.参考URL:Python/OpenCVのROI抽出!領域の切り出しとコピー
実際にはこの様に記述します.
画像の# (B)ここから画像処理 image = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR) # OpenCV用のカラー並びに変換する small_image = cv2.resize(image, dsize=(480,360) ) # 画像サイズを半分に変更 bgr_image = small_image[250:359,0:479] # 注目する領域(ROI)を(0,250)-(359,479)で切り取る hsv_image = cv2.cvtColor(bgr_image, cv2.COLOR_BGR2HSV) # BGR画像 -> HSV画像画像を取り込んで480x360に縮小した画面から,更に下側480x110だけ切り出して,以降はそれを使います.
Pythonだと新規image = 元image[ 上端y:下端 , 左端x:右端x ]の様に書くだけで部分画像を取り出せるので簡単です.この480x110だけの画像で二値化・ラベリング・重心計算を行い,最大ラベルを持つオブジェクトを追従しています.
2. 二値化画像の膨張
上で示した画像のように,トラロープはオレンジと黒が交互に並んでいます.
これをinRange関数で範囲指定二値化を行うと,一本のロープではなく,切断された断片として認識してしまいます.『二値化画像が分断してしまう』時に便利な手法が,膨張/収縮処理です.
参考URL:モルフォロジー変換・膨張処理で二値画像を一回り太らせる
・収縮処理で二値画像を一回り削ると思えばよいです.
膨張はcv2.dilate,収縮はcv2.erodeで行います.
膨張収縮処理を行う範囲は,kernel配列の中を1で埋めることで決めます.# inRange関数で範囲指定二値化 bin_image = cv2.inRange(hsv_image, (h_min, s_min, v_min), (h_max, s_max, v_max)) # HSV画像なのでタプルもHSV並び kernel = np.ones((15,15),np.uint8) # 15x15で膨張させる dilation_image = cv2.dilate(bin_image,kernel,iterations = 1) # 膨張して虎ロープをつなげる一般的な画像処理では,4近傍や8近傍で膨張収縮を行うのですが,
今回は力技,なんと15x15画素で膨張処理を行っています!
つまり,ある画素が白(255)だったとき,その周囲15画素全てを白に塗り替えるのです.
ちょっと広すぎ(-_-;;こうすることで,トラロープの切断された二値化画像を無理やり太らせ1つに繋げてしまおう,という作戦です.
3. 前進のコマンド入力
色検出のプログラムでは左右に旋回を行うので,以下の初期化を行い,制御プログラムで旋回の
dの値をP制御していました.rcコマンドの数値初期化部a = b = c = d = 0 # rcコマンドの初期値を入力今回は,旋回しながら前進させたいので,以下の初期化も記述しています.
前進のrcコマンドに一定値を入力b = 40 # 前進の値を40に設定40という値は,何回か実験したうえで決めた移動速度です.
これ以上速いとコースアウトしてしまいました.4. 前進速度の可変
OpenCVウィンドウのキー入力部分には,以下の様に追記してあります.
OpenCVウィンドウのキー入力部分elif key == ord('y'): # 前進速度をキー入力で可変 b = b + 10 if b > 100: b = 100 elif key == ord('h'): b = b - 10 if b < 0: b = 0
yキーを押すことでbの値を+10,
hキーを押すことでbの値を-10,
できるようにしてあります.30ぐらいが適正値だと思いますが,色々変えて試せるようにしてあります.
プログラムの実行
プログラム本体はmain_linetrace.pyです.
プログラムの実行$ python main_linetrace.py今までと同様にctrl+cを押すことで,プログラムを終了することもできますが,
OpenCVが作ったウィンドウでESCキーを押して終了するのが良いでしょう.操作系
操作系は以下の様になっています.
1キーで色追従のフィードバック制御がON(有効)になり,
2キーでOFF(無効)になります.
yキーで前進速度を10増加させ,
hキーで10減少させます.
フィードバック制御がONになると,Telloは初期速度(40)で前進しながら左右旋回を行います.
操作手順
tキーで離陸させる.- 上下前後左右の移動キーで,顔が連続して認識できる位置(安全な位置)までTelloを手動操作する.
1キーを押してフィードバック制御を開始させる.- Telloが一定速度で前進し始める.
- もしTelloの前進速度が速すぎる場合,
hキーで速度を落とす.逆にyキーで増速もできる.2キーを押して制御を終了させ,移動キーでTelloを止める.lキーで着陸させる.Tello SDKのrcコマンドを使って操作しているので,機体が流れ始めた際に止めるのは手動操作だけです.(移動コマンドは応答が遅いので使っていません)
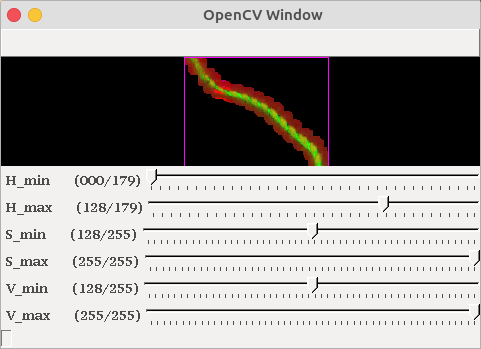
実行結果
プログラムを実行すると,以下の様に最大面積を持つラベルが表示されます.
このオブジェクトの重心位置が,画面中心のX座標240に移動するように旋回制御がかかります.
上図の様に,綺麗にロープが見えるようになるには,離陸後の高度から2回程度
sキー(下降)を押すと良いでしょう.ロープを検出していることを確認したら,1キーを押して自動制御させます.
うまくいけば,冒頭で紹介した動画の様にTelloがライントレースします.おわりに
今回は,色検出の応用として,トラロープを検出してトレースさせてみました.
個人的に残念に思う点を以下に挙げてみます.
- 前進/旋回だけの二次元平面の動きでしかない
- ディープラーニングなどの所謂AI処理ではなく,単なる色検出
まだまだ,発展の余地がありますね.
個人的な妄想希望では,ドローンレースのリングをAIで通り抜けてみたいんですよ〜.


- 投稿日:2020-03-23T19:08:24+09:00
お勧めのtf.kerasのカスタムレイヤーの書き方と変数名の挙動
はじめに
tf.kerasのカスタムレイヤーでの名前の挙動についてドキュメントにない挙動を見つけたので、そのお知らせです。
ここで言っている"変数名"とはPythonの文法での変数名ではなく、Tensorflowの変数(tf.Variable)に付ける名前(引数として要求される)のことです。お勧めの書き方の前に変数名についてちょっと説明。
変数名の具体例
下のサンプルコードのself.v1やself.v2のことではなく、my_variable1やmy_variable2のことです。
import tensorflow as tf # カスタムレイヤーのサンプルコード # 自作の全結合層 class MyLayer(tf.keras.layers.Layer): def __init__(self, output_dim): super().__init__() self.output_dim = output_dim # バイアス項 # 入力データのサイズには依存していない self.v1 = self.add_weight(name='my_variable1', shape=[output_dim]) def build(self, input_shape): # affine行列 # 入力データのサイズに依存している self.v2 = self.add_weight(name='my_variable2', shape=[input_shape[1], self.output_dim]) self.built = True def call(self, inputs, **kwargs): return tf.matmul(inputs, self.v2) + self.v1このあたりの内容は公式のチュートリアルにある内容です。
何か問題があるのか?
とりあえず実行
実際に実行して確認してみます。
model = MyLayer(output_dim=3) # buildメソッドは初めてデータを入力したときに実行されるので、適当なデータを入れる x = tf.random.normal(shape=(3, 5)) y = model(x) print(model.trainable_variables)↓これが名前 [<tf.Variable 'my_variable1:0' shape=(3,) dtype=float32, numpy=array([-0.56484747, 0.00200152, 0.42238712], dtype=float32)>, ↓これが名前 <tf.Variable 'my_layer/my_variable2:0' shape=(5, 3) dtype=float32, numpy= array([[ 0.47857696, -0.04394728, 0.31904382], [ 0.37552172, 0.22522384, 0.07408607], [-0.74956644, -0.61549807, -0.41261673], [ 0.4850598 , -0.45188528, 0.56900233], [-0.39462167, 0.40858668, -0.5422235 ]], dtype=float32)>]
my_variable1:0とmy_layer/my_variable2:0。
何か余計なものがついているけど、変数の名前はそれぞれmy_variable1とmy_variable2であると確認できたので、OK。本当にそうでしょうか?
レイヤーを重ねた場合
さっきの例に続けて実行してみます。
# 自作のレイヤーを重ねた場合 model = tf.keras.Sequential([ MyLayer(3), MyLayer(3), MyLayer(3) ])↓
[<tf.Variable 'my_variable1:0' shape=(3,) dtype=float32, (略)>, <tf.Variable 'sequential/my_layer_1/my_variable2:0' shape=(5, 3) dtype=float32, (略))>, <tf.Variable 'my_variable1:0' shape=(3,) dtype=float32, (略)>, <tf.Variable 'sequential/my_layer_2/my_variable2:0' shape=(3, 3) dtype=float32, (略)>, <tf.Variable 'my_variable1:0' shape=(3,) dtype=float32, (略)>, <tf.Variable 'sequential/my_layer_3/my_variable2:0' shape=(3, 3) dtype=float32, (略)]my_variable1がいっぱいですね(泣)。
区別できません。Tensorboardで変数のヒストグラムを描いても名前が衝突しまくりで訳がわかりませんでした。
お勧めのカスタムレイヤーの書き方
class MyLayer(tf.keras.layers.Layer): def __init__(self, output_dim): super().__init__() self.output_dim = output_dim def build(self, input_shape): # バイアス項 # 入力データのサイズには依存していない self.v1 = self.add_weight(name='my_variable1', shape=[output_dim]) # affine行列 # 入力データのサイズに依存している self.v2 = self.add_weight(name='my_variable2', shape=[input_shape[1], self.output_dim]) self.built = True def call(self, inputs, **kwargs): return tf.matmul(inputs, self.v2) + self.v1単純に全ての変数をbuildメソッド内で宣言するだけです。
Tensorflowもバージョン2になってからは、define by runなので、モデルやレイヤーの順序を最初に実行するまで解決できないのだと思います。
そのせいで、__init__メソッドとbiuldメソッドでは大きな違いになっているのだと思います。ちなみにtf.keras.layers.Denseなどはすべてbuildメソッド内で宣言しているので、安心して使えます。
まとめ
カスタムレイヤーで変数を宣言するときはbuildメソッド内で必ず宣言する。
__init__メソッドでは宣言しない。余談
名前の処理の挙動の解説
末尾の:0って何?
Tensorflowの仕様で自動で追加されます。
マルチGPUなどで実行する場合は、GPUごとに変数のコピーが作られるので、それぞれに0, 1, 2, ...と順に番号が振られます。
このあたりの仕様はバージョン1の頃も同じです。バージョン2ではtf.distribute.MirroredStrategyなどを利用してマルチGPUで上と同様のことをすると確認できます。
先頭のmy_layerは何?
my_layerはMyLayerに明示的に名前を設定しなかったときのデフォルトの名前です。
クラス名を自動でスネークケースに変換しています。また、2個目の例でtf.keras.Sequentialを使った場合はmy_layer_1, my_layer_2, my_layer_3となっています。
これは名前の衝突を避けるために末尾に自動的に追加されます。
1個目の例でmy_layerがある状態で、2個目の例を続けて実行しているので、このようになっています。これもバージョン1の頃と同じ挙動だと思います。
少なくともTensorflowのラッパーライブラリdm-sonnetでは同様の処理がされます。
- 投稿日:2020-03-23T18:55:03+09:00
【DanceDanceRevolution】グルーブレーダーの値から難易度(足)を予測することは可能か?
DanceDanceRevolution1 は KONAMI が開発している音楽ゲームのひとつです。DanceDanceRevolution には譜面ごとに難易度が振られていて2,その譜面をプレイするのがどれほど難しいかを示しています。
それとは別に,グルーブレーダーという仕組みがあって,その譜面の傾向を示します。各要素は以下の 5 通りです。
- STREAM
- 平均密度。曲中のオブジェ数が多いほど高くなる。
- VOLTAGE
- 最高密度。最もオブジェが多い 4 拍のオブジェ数が多いほど高くなる。
- AIR
- 跳躍頻度。同時踏みや踏んではいけないオブジェが多いほど高くなる。
- FREEZE
- 拘束度。どこかのパネルを踏み続ける拍が多いほど高くなる。
- CHAOS
- 変則度。細かいリズムや変速が多いほど高くなる。
グルーブレーダーの数値は譜面自体から厳密に計算されて求めることができます。計算式は公開されていませんが,有志のプレイヤーによってかなりの精度で明らかにされています。
一方で難易度の数値は制作側によって人為的に決定されています。そのため,バージョンアップのタイミングなどで難易度の見直しなどが行われる場合があります。
では,グルーブレーダーの数値から難易度を推定することは可能でしょうか。やってみましょう。
環境
- Python3 + JupyterLab
- Matplotlib
- NumPy
- Pandas
- PyCM
- SciPy
- Seaborn
前準備
インポートなどをしておきます。
import math from pathlib import Path import matplotlib.pyplot as plt import numpy as np import pandas as pd import seaborn as sns from pycm import ConfusionMatrix from scipy.optimize import minimize, differential_evolution, Boundsdef ustd_coefficient(n): try: return math.sqrt(n / 2) * math.gamma((n - 1) / 2) / math.gamma(n / 2) except OverflowError: return math.sqrt(n / (n - 1.5)) def std_u(a): return np.std(a) * ustd_coefficient(len(a)) oo = math.inf各譜面のデータを読み込みます。データとして,2020-03-19 当時の BEMANI wiki から旧曲と DanceDanceRevolution A20 の新曲のデータを CSV にしておきました。こちらに配置しておきます。今回は旧曲をフィッティングに使用する訓練データ,新曲を評価データとします。では,読み込んで DataFrame にしていきます。
old_csv = Path('./old.csv') new_csv = Path('./new.csv') train_df = pd.read_csv(old_csv) test_df = pd.read_csv(new_csv) display(train_df) display(test_df)
VERSION MUSIC SEQUENCE LEVEL STREAM VOLTAGE AIR FREEZE CHAOS 0 DanceDanceRevolution A 愛言葉 BEGINNER 3 21 22 7 26 0 1 DanceDanceRevolution A 愛言葉 BASIC 5 34 22 18 26 0 2 DanceDanceRevolution A 愛言葉 DIFFICULT 7 43 34 23 26 7 3 DanceDanceRevolution A 愛言葉 EXPERT 11 63 45 21 25 28 4 DanceDanceRevolution A 天ノ弱 BEGINNER 3 20 25 0 0 0 ... ... ... ... ... ... ... ... ... ... 3390 DanceDanceRevolution 1st PARANOiA EXPERT 11 67 52 25 0 17 3391 DanceDanceRevolution 1st TRIP MACHINE BEGINNER 3 25 26 5 0 0 3392 DanceDanceRevolution 1st TRIP MACHINE BASIC 8 47 40 14 0 4 3393 DanceDanceRevolution 1st TRIP MACHINE DIFFICULT 9 52 40 30 0 7 3394 DanceDanceRevolution 1st TRIP MACHINE EXPERT 10 56 53 36 0 12 3395 rows × 9 columns
VERSION MUSIC SEQUENCE LEVEL STREAM VOLTAGE AIR FREEZE CHAOS 0 DanceDanceRevolution A20 おーまい!らぶりー!すうぃーてぃ!だーりん! BEGINNER 3 18 21 5 16 0 1 DanceDanceRevolution A20 おーまい!らぶりー!すうぃーてぃ!だーりん! BASIC 7 37 28 18 39 0 2 DanceDanceRevolution A20 おーまい!らぶりー!すうぃーてぃ!だーりん! DIFFICULT 12 60 56 54 55 21 3 DanceDanceRevolution A20 おーまい!らぶりー!すうぃーてぃ!だーりん! EXPERT 15 95 99 30 25 100 4 DanceDanceRevolution A20 革命パッショネイト BEGINNER 3 16 16 1 35 0 ... ... ... ... ... ... ... ... ... ... 380 DanceDanceRevolution A20 50th Memorial Songs -The BEMANI History- EXPERT 13 63 79 14 62 63 381 DanceDanceRevolution A20 50th Memorial Songs -二人の時 ~under the cherry bl... BEGINNER 3 17 20 3 46 0 382 DanceDanceRevolution A20 50th Memorial Songs -二人の時 ~under the cherry bl... BASIC 7 40 33 36 29 0 383 DanceDanceRevolution A20 50th Memorial Songs -二人の時 ~under the cherry bl... DIFFICULT 9 50 46 47 3 6 384 DanceDanceRevolution A20 50th Memorial Songs -二人の時 ~under the cherry bl... EXPERT 12 73 60 60 15 32 385 rows × 9 columnsさらに,各グルーブレーダーの数値を標準化していきます。訓練データの平均が 0 で標準偏差が 1 になるようにし,同様の操作を評価データにも行います。
grs = ['STREAM', 'VOLTAGE', 'AIR', 'FREEZE', 'CHAOS'] sgrs = ['S_{}'.format(gr) for gr in grs] m = {} s = {} for gr, sgr in zip(grs, sgrs): v = train_df.loc[:, gr].values v_t = test_df.loc[:, gr].values m[gr] = np.mean(v) s[gr] = std_u(v) train_df[sgr] = (v - m[gr]) / s[gr] test_df[sgr] = (v_t - m[gr]) / s[gr] display(train_df.loc[:, sgrs]) display(test_df.loc[:, sgrs])
S_STREAM S_VOLTAGE S_AIR S_FREEZE S_CHAOS 0 -0.981448 -0.838977 -0.636332 0.056063 -0.661167 1 -0.534364 -0.838977 -0.160513 0.056063 -0.661167 2 -0.224844 -0.405051 0.055768 0.056063 -0.441192 3 0.462978 -0.007285 -0.030744 0.014296 0.218735 4 -1.015839 -0.730495 -0.939125 -1.029883 -0.661167 ... ... ... ... ... ... 3390 0.600542 0.245838 0.142280 -1.029883 -0.126941 3391 -0.843883 -0.694335 -0.722844 -1.029883 -0.661167 3392 -0.087279 -0.188088 -0.333538 -1.029883 -0.535467 3393 0.084676 -0.188088 0.358562 -1.029883 -0.441192 3394 0.222240 0.281999 0.618099 -1.029883 -0.284066 3395 rows × 5 columns
S_STREAM S_VOLTAGE S_AIR S_FREEZE S_CHAOS 0 -1.08462 -0.87514 -0.72284 -0.36161 -0.66117 1 -0.43119 -0.62201 -0.16051 0.599036 -0.66117 2 0.359805 0.39048 1.396711 1.26731 -0.00124 3 1.563493 1.945381 0.358562 0.014296 2.481343 4 -1.1534 -1.05594 -0.89587 0.431967 -0.66117 ... ... ... ... ... ... 380 0.462978 1.222171 -0.33354 1.55968 1.318614 381 -1.11901 -0.9113 -0.80936 0.891406 -0.66117 382 -0.32802 -0.44121 0.618099 0.181364 -0.66117 383 0.015894 0.028875 1.093917 -0.90458 -0.47262 384 0.806889 0.535122 1.656248 -0.40338 0.344436 385 rows × 5 columnsそして,各譜面のグルーブレーダーを示す 2 階テンソルと,各譜面の難易度を示す 1 階テンソルを抜き出しておきます。
train_sgr_arr = train_df.loc[:, sgrs].values test_sgr_arr = test_df.loc[:, sgrs].values train_level_arr = train_df.loc[:, 'LEVEL'].values test_level_arr = test_df.loc[:, 'LEVEL'].values最小二乗法による重回帰分析
重回帰分析は以下のような考え方によります。
説明変数群 $x_n$ と目的変数 $y$ があります。今回の場合説明変数とはグルーブレーダーの各値のことです。目的変数とは難易度です。このとき,
$$
y' = k_0 + k_1x_1 + k_2x_2 + \cdots + k_nx_n
$$
なる係数群 $k_n$ と $y’$ を考えたとき,$m$ 個のデータの二乗誤差 $e^2 := \sum_{i = 1}^m\left(y'_i - y_i\right)^2$ が最も小さくなるような $k_n$ を探索していきます。今回は,このような最適化問題を SciPy を使用した差分進化法で求めていきます。まず,最小化したい関数を定義します。先程の $e^2$ です。
def hadprosum(a, b): return (a * b).sum(axis=1) def estimate(x, sgr_arr): x_const = x[0] x_coef = x[1:] return hadprosum(sgr_arr, x_coef) + x_const def sqerr(x): est = estimate(x, train_sgr_arr) return ((est - train_level_arr) ** 2).sum()これを SciPy の
differential_evolution関数に与えます。探索範囲に関しては色々試しながら十分と思われる範囲をズドンで与えています。bounds = Bounds([0.] * 6, [10.] * 6) result = differential_evolution(sqerr, bounds, seed=300) print(result)fun: 5170.056057917698 jac: array([-0.00236469, 0.14933903, 0.15834303, 0.07094059, 0.01737135, 0.1551598 ]) message: 'Optimization terminated successfully.' nfev: 3546 nit: 37 success: True x: array([8.04447683, 2.64586828, 0.58686288, 0.42785461, 0.45934494, 0.4635763 ])この結果をみると,最も影響を与えているのは STREAM で,そのあとに VOLTAGE,CHAOS,FREEZE,AIR と続いているようです。
では,実際に得られたパラメータを使って評価を行ってみます。
まずは予測用の関数を定義します。この関数にパラメータとグルーブレーダーのテンソルを与えると予測された難易度のテンソルが返ります。
def pred1(x, sgr_arr): est = estimate(x, sgr_arr).clip(1., 19.) return np.round(est).astype(int)この関数の返り値と実際の難易度を,PyCM の
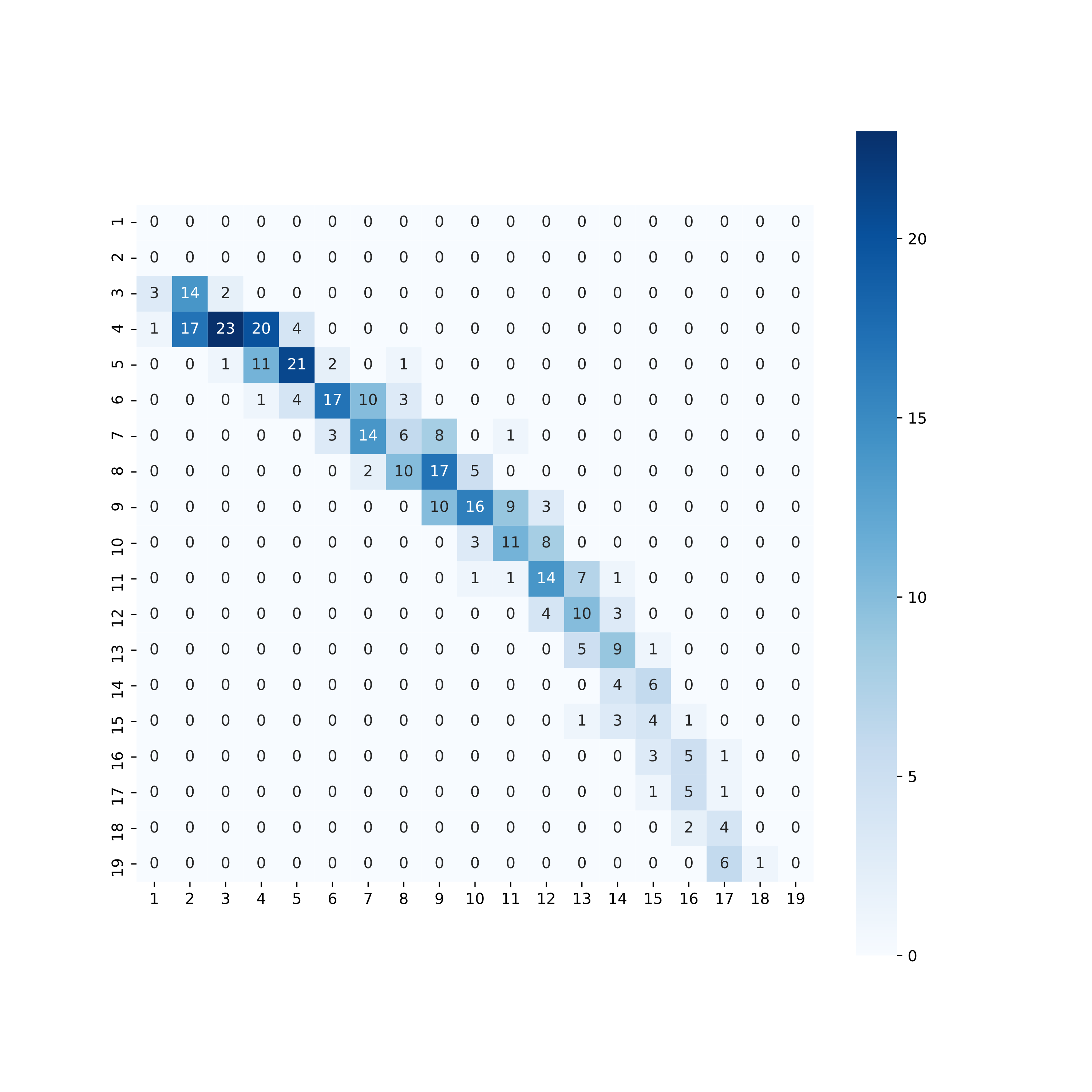
ConfusionMatrixに与えることで,混同行列オブジェクトが生成されます。これのプロパティにアクセスし,正解率とマクロ F 値を求めていきます。train_pred1_arr = pred1(result.x, train_sgr_arr) test_pred1_arr = pred1(result.x, test_sgr_arr) train_cm1 = ConfusionMatrix(train_level_arr, train_pred1_arr) test_cm1 = ConfusionMatrix(test_level_arr, test_pred1_arr) print('====================') print('Train Score') print(' Accuracy: {}'.format(train_cm1.Overall_ACC)) print(' Fmeasure: {}'.format(train_cm1.F1_Macro)) print('====================') print('Test Score') print(' Accuracy: {}'.format(test_cm1.Overall_ACC)) print(' Fmeasure: {}'.format(test_cm1.F1_Macro)) print('====================')==================== Train Score Accuracy: 0.33431516936671574 Fmeasure: 0.2785969345790368 ==================== Test Score Accuracy: 0.3142857142857143 Fmeasure: 0.24415916194348555 ====================正解率は 31.4% となりました。これは期待していたよりもだいぶ低い結果です。混同行列を Seaborn でヒートマップ化して見てみます。
plt.figure(figsize=(10, 10), dpi=200) sns.heatmap(pd.DataFrame(test_cm1.table), annot=True, square=True, cmap='Blues') plt.show()
横軸が実際の難易度,縦軸が予測された難易度です。これを見ると,低い難易度の曲は高く,一定以上の難易度に関しては低く評価され,さらに高い難易度になると一転して過大評価しているようです。ヒートマップは直線ではなく内側に曲がって弓なりの形状を描いています。
最尤推定法による (順序) ロジスティック回帰分析
続いてロジスティック回帰分析を試してみます。ロジスティック回帰分析はなんらかの確率を目的変数にとる分析に向いています。以下のような式を考えます。
$$
y' = \frac{1}{1 + \exp\left[-\left(k_0 + k_1x_1 + k_2x_2 + \cdots + k_nx_n\right)\right]}
$$
この $y'$ は 0 から 1 の値をとります。$m$ 個のデータで目的変数 $y$ が 0 か 1 かで定まっているとき,尤度 $l = \prod_{i = 1}^m yy' + (1 - y)(1 - y')$ を最大化することを考えます。数式で書くと分かりづらいですが,$y'$ は 陽性である確率であり,$y$ が 1 すなわち陽性であればそのまま $y'$ を,$y$ が 0 すなわち陰性であれば陰性の確率つまり 1 から $y'$ を除いた値を使用するということです。$(0, 1)$ となる $y’$ をどんどんかけていけばその値は小さくなりすぎて計算機では扱いづらくなるため,対数尤度 $\log l = \sum_{i = 1}^m \log \left[yy' + (1 - y)(1 - y')\right]$ を最大化するのが普通です。今回は陰性か陽性かではなく,順序のあるクラスのどこに属するかを扱います。こういう場合定数項 $k_0$ のみが異なる複数のロジスティック曲線を想定し,“難易度 2 以上である確率”, “難易度 3 以上である確率”,と考えます。“難易度 2 である確率” は “難易度 3 以上である確率” から “難易度 2 以上である確率” を引いたものですから,これによって尤度を求めることができます。
まず,計算のために難易度をワンホット形式の 2 階テンソルに変換しておきます。
train_level_onehot_arr = np.zeros(train_level_arr.shape + (19,)) for i, l in np.ndenumerate(train_level_arr): train_level_onehot_arr[i, l - 1] = 1.つづいて最小化すべき関数を与えます。最小化なので上記の対数尤度にマイナスをつけたものを定義します。
def upperscore(x, sgr_arr): x_const = np.append(np.append(oo, x[:18].copy()), -oo) # 1以上の確率1と20以上の確率0のために両端に無限大を挿入 x_coef = x[18:] var = np.asarray([hadprosum(sgr_arr, x_coef)]).T cons = np.asarray([x_const]) return 1 / (1 + np.exp(-(var + cons))) def score(x, sgr_arr): us = upperscore(x, sgr_arr) us_2 = np.roll(us, -1) return np.delete(us - us_2, -1, axis=1) # ずらして引き,末尾を削除して各難易度の確率を得る def mloglh(x): sc = score(x, train_sgr_arr) ret = -(np.log((sc * train_level_onehot_arr).sum(axis=1).clip(1e-323, oo)).sum()) return ret探索を行います。先程に比べてかなり時間がかかるので注意です。
bounds = Bounds([-60.] * 18 + [0] * 5, [20.] * 18 + [10] * 5) result = differential_evolution(mloglh, bounds, seed=300) print(result)fun: 4116.792196474322 jac: array([ 0.00272848, 0.00636646, -0.00090949, 0.00327418, -0.00563887, -0.00291038, -0.00509317, 0.00045475, 0.00800355, 0.00536602, -0.00673026, 0.00536602, 0.00782165, -0.01209628, 0.00154614, -0.0003638 , 0.00218279, 0.00582077, 0.04783942, 0.03237801, 0.01400622, 0.00682121, 0.03601599]) message: 'Optimization terminated successfully.' nfev: 218922 nit: 625 success: True x: array([ 14.33053717, 12.20158703, 9.97549255, 8.1718939 , 6.36190483, 4.58724228, 2.61478521, 0.66474105, -1.46625252, -3.60065138, -6.27127806, -9.65032254, -14.06390123, -18.287351 , -23.44011235, -28.39033479, -32.35825176, -43.38390248, 6.13059504, 2.01974223, 0.64631137, 0.67555403, 2.44873606])今回は STREAM > CHAOS > VOLTAGE > FREEZE > AIR となっており,CHAOS のほうが大きく影響しているのがわかります。
こちらも実際に評価を行ってみましょう。
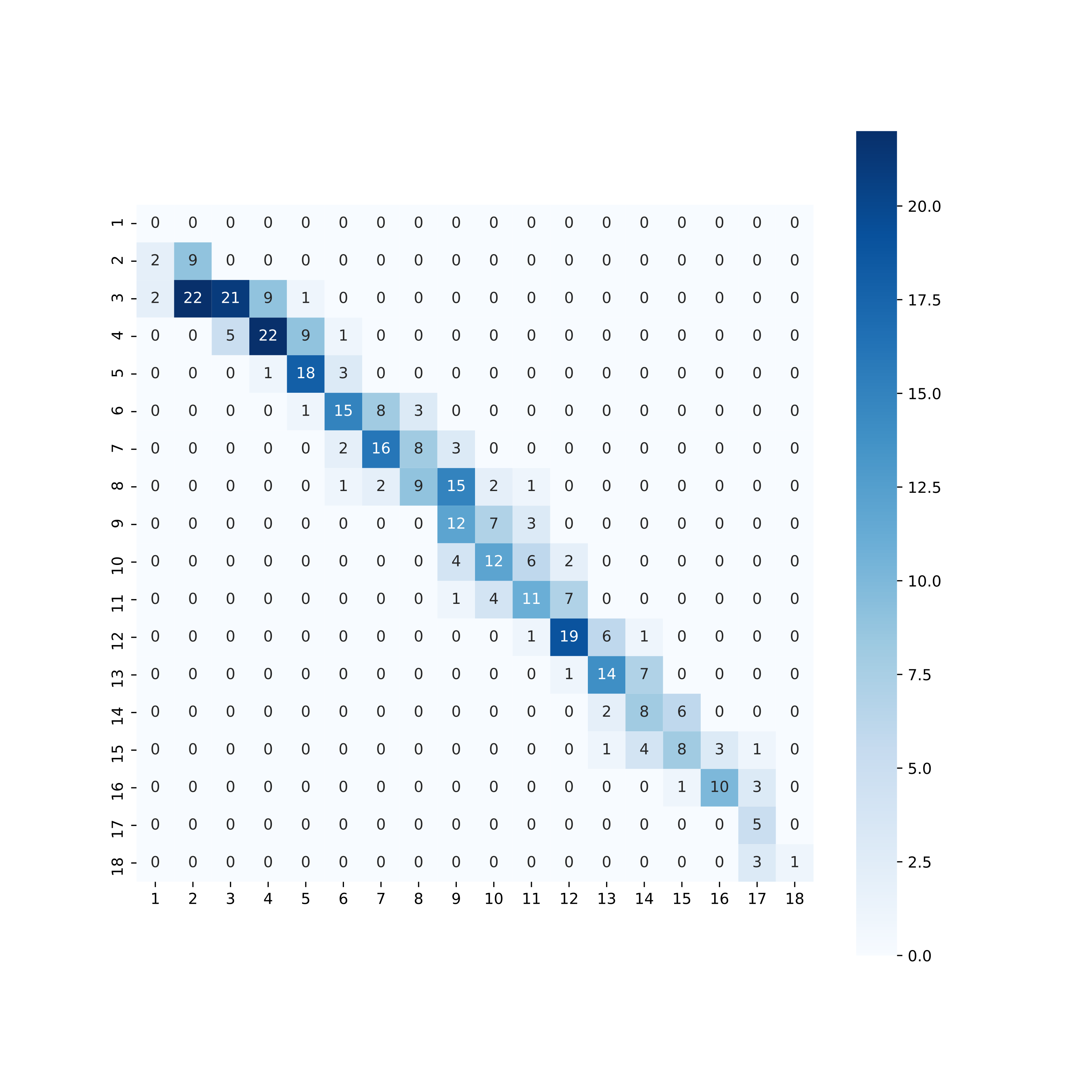
def pred2(x, sgr_arr): sc = score(x, sgr_arr) return np.argmax(sc, axis=1) + 1 train_pred2_arr = pred2(result.x, train_sgr_arr) test_pred2_arr = pred2(result.x, test_sgr_arr) train_cm2 = ConfusionMatrix(train_level_arr, train_pred2_arr) test_cm2 = ConfusionMatrix(test_level_arr, test_pred2_arr) print('====================') print('Train Score') print(' Accuracy: {}'.format(train_cm2.Overall_ACC)) print(' Fmeasure: {}'.format(train_cm2.F1_Macro)) print('====================') print('Test Score') print(' Accuracy: {}'.format(test_cm2.Overall_ACC)) print(' Fmeasure: {}'.format(test_cm2.F1_Macro)) print('====================')==================== Train Score Accuracy: 0.4960235640648012 Fmeasure: 0.48246495009640167 ==================== Test Score Accuracy: 0.5454545454545454 Fmeasure: 0.5121482282311358 ====================今度は 54.5% の正解率となりました。先程よりはかなり改善されていますが,まだまだです。
plt.figure(figsize=(10, 10), dpi=200) sns.heatmap(pd.DataFrame(test_cm2.table), annot=True, square=True, cmap='Blues') plt.show()
こちらはおおむね直線上に出ていますが,低難易度と高難易度がやはりイマイチです。
結論
結論としては,“それっぽい値を得ることはできるが,実用できる域には至らない” といったところでしょうか。今回の試みは StepMania の譜面に難易度をつける参考にできればなと思って行いましたが,やはり最終的にはプレイして調整する必要がありそうですね。
それともうひとつ,ロジスティック回帰では当然各定数項が大小関係の制約を受けるわけですが,今回のコードでは乱数によっては制約通りにいかず,異常な値で収束判定となる可能性があります3。SciPy の最適化関数では不等式での制約を与えることができるのですが,どうも私のほうでは未知の形の制約が渡されたみたいなエラーが出てうまくいきませんでした。探索時間も無駄になるのでこちら解決できた方がいれば教授願いたいです。
- 投稿日:2020-03-23T18:32:08+09:00
Boto3(AWS SDK for Python)の利用する認証情報
Boto3の利用する認証情報は「Credentials — Boto 3」にまとめられており、8か所から規定の順序で認証情報が検索されます。
認証情報の検索順序
Boto3はパラメーターやプロファイルなど複数の方法で認証情報を取得しようとする。その方法と順序は「Configuring Credentials - Credentials — Boto 3」にあって、該当部分の拙訳は以下の通り。
boto3の資格情報検索メカニズムは、以下のリストに沿って検索し、資格情報を見つけたらそこで停止することです。Boto3が資格情報を検索する順序は:
boto.client()メソッドにパラメーターで渡された資格情報Sessionオブジェクトの生成時にパラメーターで渡された資格情報- 環境変数
- 共有された認証情報ファイル(
~/.aws/credentials)- AWS設定ファイル(
~/.aws/config)- ロールの引き受けの提供
- Boto2設定ファイル(
/etc/boto.cfg and ~/.boto)- IAMロールを構成されたAmazon EC2インスタンス上ではそのインスタンスメタデータサービス
これらのうち、APIアクセスキーとAPIシークレットキー、または名前付きプロファイルを使用するものについて、以下で見ていきます。
1.
client()メソッド、resource()メソッドでの直接指定
boto3.client()メソッドまたはboto3.session.Session().client()メソッドに、以下をパラメータで指定します。
キー 指定値 aws_access_key_id APIアクセスキー aws_secret_access_key APIシークレットキー aws_session_token (多要素認証時)セッショントークン 以下は対話型シェルでの実行例です。
>>> import boto3 >>> client = boto3.client('iam', aws_access_key_id='YOURACCESSKEY', aws_secret_access_key='YOURSECRETKEY') >>> client.list_users()
client()ではなくresource()(boto3.resource()またはboto3.session.Session().resource())メソッドを使う場合でも、上記の3パラメータを指定できます。>>> import boto3 >>> resource = boto3.resource('iam', aws_access_key_id='YOURACCESSKEY', aws_secret_access_key='YOURSECRETKEY') >>> list(resource.users.all())2.
Sessionオブジェクトの生成時にパラメーターで渡された資格情報認証情報の指定
boto3.session.Session()でsessionオブジェクトを生成する際に、以下をパラメータで指定します。生成されたSessionオブジェクトからclient()メソッドで生成されたクライアントやresource()メソッドで生成されたリソースはこの資格情報を使用します。
キー 指定値 aws_access_key_id APIアクセスキー aws_secret_access_key APIシークレットキー aws_session_token (多要素認証時)セッショントークン 以下は対話型シェルでの実行例です。
>>> import boto3 >>> session = boto3.session.Session(aws_access_key_id='YOURACCESSKEY', aws_secret_access_key='YOURSECRETKEY') >>> client = session.client('iam') >>> client.list_users()プロファイルの指定
boto3.session.Session()でsessionオブジェクトを生成する際に、以下をパラメータで指定します。指定された名前付きプロファイルに構成されている認証情報が使用されます。生成されたSessionオブジェクトからclient()メソッドで生成されたクライアントやresource()メソッドで生成されたリソースはこの資格情報を使用します。
キー 指定値 profile_name プロファイル名 以下は対話型シェルでの実行例です。
>>> import boto3 >>> session = boto3.session.Session(profile_name='YOURPROFILENAME') >>> client = session.client('iam') >>> client.list_users()3. 環境変数
認証情報の指定
以下を環境変数で指定します。前項まででの明示的な認証情報の指定がない場合、これが使われます。
環境変数名 指定値 AWS_ACCESS_KEY_ID APIアクセスキー AWS_SECRET_ACCESS_KEY APIシークレットキー AWS_SESSION_TOKEN (多要素認証時)セッショントークン 以下はbash環境で上記環境変数を設定後、Pythonの対話型シェルを呼び出しての実行例です。
$ export AWS_ACCESS_KEY_ID=YOURACCESSKEY $ export AWS_SECRET_ACCESS_KEY=YOURSECRETKEY $ python3 Python 3.6.9 (default, Nov 7 2019, 10:44:02) [GCC 8.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import boto3 >>> client = boto3.client('iam') >>> client.list_users()プロファイルの指定
以下を環境変数で指定します。前項まででの明示的な認証情報の指定がない場合、この指定された名前付きプロファイルに構成されている認証情報が使用されます。
環境変数名 指定値 AWS_PROFILE プロファイル名 以下はbash環境で上記環境変数を設定後、Pythonの対話型シェルを呼び出しての実行例です。
$ export AWS_PROFILE=YOURPROFILENAME $ python3 Python 3.6.9 (default, Nov 7 2019, 10:44:02) [GCC 8.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import boto3 >>> client = boto3.client('iam') >>> client.list_users()4. 共有された認証情報ファイル(
~/.aws/credentials)ここまでの認証情報がない場合、認証情報ファイル(
~/.aws/credentials)内にdefaultプロファイルとして構成されている認証情報が使われます。これは通常、AWS CLIを最初に使うときにaws configureコマンドで設定されています。詳細は「AWS CLI のかんたん設定」を参照してください。5. AWS設定ファイル(
~/.aws/config)ここまでの認証情報がない場合、AWS設定ファイル(
~/.aws/config)内にdefaultプロファイルとして構成されている認証情報があれば、これが使われます。ただし通常は、AWS設定ファイル内で管理しているプロファイル情報はリージョン(region)とデフォルトの出力形式(output)で、認証情報は含まれていません。7. Boto2設定ファイル(
/etc/boto.cfg and ~/.boto)ここまでの認証情報がない場合、Boto2設定ファイルが存在すればそこに格納された認証情報が確認されます。Boto2設定ファイルはデフォルトでは
/etc/boto.cfgまたは~/.botoに設置されます。以下が内容例です。# Example ~/.boto file [Credentials] aws_access_key_id = foo aws_secret_access_key = barこれは後方互換性のための動作で、Boto2設定ファイルはCredentialsセクション以外無視されます。
認証方法と指定方法と優先順位
Boto3で利用できる認証情報には、(1)APIアクセスキーとAPIシークレットキー、(2)デフォルトプロファイル、(3)名前付きプロファイル、(4)ロール(ここでは詳細は触れませんでした)による認証の4種類が可能ということになります。これとここまでの指定方法を対応付けると、次のようになります。
認証方法 指定方法 APIアクセスキーとAPIシークレットキー 1、2、3、4、5、7 デフォルトプロファイル 4 名前付きプロファイル 2、3 ロール 6、8 想定した認証方式が使われていないと思ったときには、より優先順位が高い指定方法で別の指定がされていないかを確認することも必要そうです。
例えば
AWS_PROFILE環境変数で名前付きプロファイルを指定していても、もしboto3.session.Session()で別のプロファイル名が指定されてしまえば、そちらが優先されてしまいます。意図的にやっている場合は気づくでしょうが、デフォルト値がどこかで入り込んでいたりすると分かりにくくなりそうです。参考
boto3の認証について。
- [Credentials — Boto 3](https://boto3.amazonaws.com/v1/documentation/api/latest/guide/configuration.html]
AWSの認証情報ファイルと設定ファイルについて。
- 設定ファイルと認証情報ファイルの設定 - AWS Command Line Interface
- 名前付きプロファイル - AWS Command Line Interface
- AWS CLI のかんたん設定 - AWS CLI の設定 - AWS Command Line Interface
boto3の各メソッドについて。
- boto3.client()
- boto3.reference()
- boto3.session.Session().client()
- boto3.session.Session().resource()
- boto3.session.Session()
Boto2設定ファイルについて。
- 投稿日:2020-03-23T18:19:31+09:00
Pythonで音声解析をしよう#1 FFT編
Pythonで音声解析をしよう
本記事では,Pythonの音声解析のいろはを順を追って紹介していきます.
事前条件
- Pythonがインストール済み
- cmdからpyまたはpythonでpythonのインタプリタが起動できる
私の環境
- Windows10 Home 64bit
- Python3.7.4
- Visual Studio Code(VSCode)
- Vim(マジで好き)
必要なPythonライブラリ
- numpy
- wave
- matplotlib.pyplot
インポート設定import numpy as np import matplotlib.pyplot as plt第一章 ~データの用意~
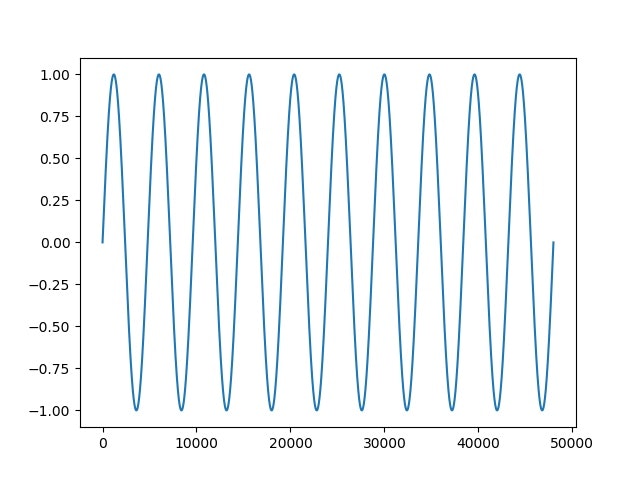
適当な音声データを読み込んで解析するのが流れとしては良いと思いますが,まずは簡単のためにデータを作成します.正弦波を以下のようにして作ってみましょう.
正弦波の作成def make_wave(): fs = 48000 # サンプリングレート f = 10 # 周波数 t = np.linspace(0,1,fs) # 1秒を48,000分割 y = np.sin(2*np.pi*f*t) # 正弦波を作成 return y後に再利用したいので,関数にしておきます.
第二章 ~プロットしてみよう~
では,用意した波をプロットして外観を見てみましょう.
プロットsig = make_wave() plt.plot(sig) plt.show()たしかに,10回振動する波が作成されていますね.
このとき,横軸は単純にデータ数なので,0~48,000まであります.
第三章 ~解析編の前に~
ここまでのコードをまとめると,以下のようになります.
まとめ# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt def make_wave(): fs = 48000 f = 10 t = np.linspace(0,1,fs) y = np.sin(2*np.pi*f*t) return y def main(): sig = make_wave() plt.plot(sig) plt.show() if __name__ == '__main__': main()非常に単純なコードですが,これだけでデータの作成,確認ができちゃいます.
pythonって便利ですね.
次回,解析についてまとめるので,今回は短いですが以上で失礼します.次章 ~Fast Fourier Transform~
高速フーリエ変換について
- 投稿日:2020-03-23T15:01:10+09:00
Pythonとyieldとreturnと時々yield from
Pythonでのyield
Pythonでは関数内で
yieldを使うとGeneratorとして使える。
例えばdef foo(): for i in range(10): yield iとして書いて、
for k in foo(): print(k)と書くと0から9までの値が表示される。
Pythonでのyieldとreturnの併用
例えば、
def hoge(): for i in range(10): yield i return i+1みたいに書いた時、これを実行した場合には yield の結果のみが帰ってくる。
これはPythonの仕様であって、Generator内におけるreturnはStopIterationとして扱われているのが理由。
なので、基本的にyieldとreturnの併用というのは難しい、と考えても差し支えはない。
むしろ、yieldがGenerator内においてはreturnとしての機能を果たすので、基本的には
yieldかreturnのどちらかに絞るのが良い。無理してでも併用する
何か理由があってreturnと併用したい場合には、
yield fromを使えばreturnに設定した値を取得する
ことが出来るようになる。
例えば、def buzz(): i = 0 for j in range(10): i += j yield j return iのような関数を書いたとして、returnまで欲しい場合には別個に新たな関数を用意して次のように
書いてあげるとreturnの値まで取得ができる。def getter(): x = yield from buzz() yield xただし、
yield fromは関数内でしか記述できない手法なのでそこは注意しなければならない。まとめ
- yield を使えばGeneratorを生成できる
- yield と return の併用は厳しい
- yield fromを使えばreturnの値までを取得が出来る。
- yield fromは関数内でしか使えない
- 結局はyieldかreturnに絞ったほうが良い。
- 投稿日:2020-03-23T14:36:55+09:00
【python】formatメソッドの使い方を実例で解説
pythonのformatメソッドの使い方
formatメソッドでできること
- 引数で定義した値/文字列を代入できる
- 引数は複数設定できる
- 文字列・数値・変数で設定できる
- 幅のを広くする
- 左寄せ、右寄せ、中央寄せ
- 空白を埋める
- 千の位にカンマを設定
- %表示にする(数値100倍)
- 数値に+符号をつける
- 小数点の桁数を指定
- 固定小数点表記(e)
- 引数の中で変数を指定
- 日付データを指定した文字列に変換
formatメソッドの使い方
(1)引数で定義した値/文字列を代入する
基本構文
{}.format(A)
└ Aの内容が{}の中に入る例(基本形)'{}駅の天気は晴れ'.format('渋谷') #出力 #'渋谷駅の天気は晴れ'
(2)引数に複数の値を指定
{n}.format(A,B,C,,,)
└ n:引数の番号(何個目か)を指定(0から)
└ 番号の指定がない場合は0インデックス番号の有無による指定
例(インデックス番号なし)'{}駅の天気は晴れ'.format('渋谷','新宿','目白','池袋') #出力 #'渋谷駅の天気は晴れ'例(インデックス番号0)'{0}駅の天気は晴れ'.format('渋谷','新宿','目白','池袋') #出力 #'渋谷駅の天気は晴れ'例(インデックス番号1)'{1}駅の天気は晴れ'.format('渋谷','新宿','目白','池袋') #出力 #'新宿駅の天気は晴れ'例(インデックス番号4)'{4}駅の天気は晴れ'.format('渋谷','新宿','目白','池袋') #出力(エラー) #IndexError: Replacement index 4 out of range for positional args tupleインデックス番号に対応するデータがない場合はエラーとなる。
複数回呼び出す
1つの引数
{0}{0}{0},,,.format(A)
└ 設置した{0}に引数の値が入る例(1つの引数を複数回呼び出す)'{0}の天気。{0}区、{0}駅の天気は晴れ'.format('渋谷') #出力 #'渋谷の天気。渋谷区、渋谷駅の天気は晴れ'インデックス番号に0を指定しないとエラーになる。
{ }の中のインデックス番号が0から順に自動設定されるため。例(エラー事例)'{}の天気。{}区、{}駅の天気は晴れ'.format('渋谷') #出力(エラー) #IndexError: Replacement index 1 out of range for positional args tuple
引数が複数ある場合
例(引数複数。番号指定なし)'{}の天気。{}区、{}駅の天気は晴れ'.format('AAAA','BBBB','CCCC','DDDD') #出力 #'AAAAの天気。BBBB区、CCCC駅の天気は晴れ'インデックス番号が自動設定される
- 1つ目の{ } = {0}
- 2つ目の{ } = {1}
- 3つ目の{ } = {2}
・・・
例(引数複数。番号指定あり①)'{0}の天気。{1}区、{2}駅の天気は晴れ'.format('AAAA','BBBB','CCCC','DDDD') #出力 #'AAAAの天気。BBBB区、CCCC駅の天気は晴れ'番号なしと同じ結果になる。
例(引数複数。番号指定あり②)'{3}の天気。{2}区、{2}駅の天気は晴れ'.format('AAAA','BBBB','CCCC','DDDD') #出力 #'DDDDの天気。CCCC区、CCCC駅の天気は晴れ'・順不同
・同じ番号を複数回設定できる
(3)文字列・数値・変数で設定
例(文字列・数値・変数で設定)mountain = '北岳' altitude = '3193' '{}で{}番目に高い山は{}。標高は{}m'.format('日本',2,mountain,altitude) #出力 #'日本で2番目に高い山は北岳。標高は3193m'・文字列:日本
・数値:2
・変数(文字列):mountain
・変数(数値):altitude
(4)幅を広くする(width)
{:n}.format()
└「:」以下書式設定
└「n」0以上の整数
└ 単位はバイト
└ 最小幅は引数のバイト数分になる例(幅の設定)'{:2}書式で隙間を設定'.format('A') #出力「'A 書式で隙間を設定'」・引数「A」:1バイト
・幅の設定 :2バイト
⇒ 幅2バイト(1バイト分の隙間)
例(幅の設定「引数の方が大きい」)'{:2}書式で隙間を設定'.format('AAAAA') #出力「'AAAAA書式で隙間を設定'」・引数「AAAAA」:5バイト
・幅の設定 :2バイト
⇒ 幅5バイト
例(幅の設定「幅0」)'{:0}書式で隙間を設定'.format('A') #出力(エラー) #「ValueError: '=' alignment not allowed in string format specifier」
(5)テキスト配置(align)の指定
記号 配置 < 左寄せ ^ 中央寄せ > 右寄せ 使い方
{<n}.format()
└「<」:左寄せ。alineの記号
└「n」:幅(0以上の整数)
例(左寄せ)'{:<10}書式で隙間を設定'.format('AAA') #出力 #「'AAA 書式で隙間を設定'」例(中央寄せ)'{:^10}書式で隙間を設定'.format('AAA') #出力 #「' AAA 書式で隙間を設定'」例(右寄せ)'{:>10}書式で隙間を設定'.format('AAA') #出力 #「' AAA書式で隙間を設定'」例(配置を個別に設定)'1つ目「{:<7}」。2つ目「{:^7}」。3つ目「{:>7}」'.format('AAA','BBB',333) #出力 # '1つ目「AAA 」。2つ目「 BBB 」。3つ目「 333」'
(7)空白を埋める
配置の指定が必要。
ゼロで埋める
{0<n}.format()
└ 「0」:0で埋める
└ 「<」:左寄せ。配置指定
ゼロで埋める(左寄せ)'「{:0<10}」隙間をゼロで埋める'.format('AAA') #出力 # '「AAA0000000」隙間をゼロで埋める'ゼロで埋める(中央寄せ)'「{:0^10}」隙間をゼロで埋める'.format('AAA') #出力 # '「000AAA0000」隙間をゼロで埋める'隙間が奇数の場合は後ろが多くなる。
ゼロで埋める(右寄せ)'「{:0>10}」隙間をゼロで埋める'.format('AAA') #出力 # '「0000000AAA」隙間をゼロで埋める'
任意の文字で埋める
{@<n}.format()
└ 「@」:任意の文字。この場合「@」
└ 「<」:配置指定。この場合左寄せ・埋める文字は1桁のみ
・半角・全角どちらでも可
・2桁以上はエラー@で埋める(左寄せ)'「{:@<10}」隙間を埋める'.format('AAA') #出力 # '「AAA@@@@@@@」隙間を埋める'★で埋める(中央寄せ)'「{:★^10}」隙間を埋める'.format('AAA') #出力 # '「★★★AAA★★★★」隙間を埋める'数値の5で埋める(右寄せ)'「{:5<10}」隙間をゼロで埋める'.format('AAA') #出力 # '「AAA5555555」隙間をゼロで埋める'2桁以上の文字列(エラー)'「{:★★^10}」隙間をゼロで埋める'.format('AAA') #出力(エラー) # ValueError: Invalid format specifier2桁以上の数値(エラー)'「{:11<10}」隙間をゼロで埋める'.format('AAA') #出力(エラー) # ValueError: Invalid format specifier
(7)千の位にカンマを設定
'{:,}'.format()
└「:」以下書式設定
└「,」千の位にカンマ例(千の位にカンマ)'{:,}'.format(123456789) #出力 # '123,456,789'
(8)%表示にする(数値100倍)
'{:.n%}'.format()
└「:」以下書式設定
└「.n」小数点以下の桁数(デフォルト6)
└ 数値は100倍される%表示(デフォルト)'{:%}'.format(1) #出力 # '100.000000%'%表示(小数点以下非表示)'{:.0%}'.format(1) #出力 # '100%'%表示(小数点以下2桁)'{:.2%}'.format(1) #出力 # '100.00%'%表示(小数点以下15桁)'{:.15%}'.format(1) #出力 # '100.000000000000000%'デフォルトの6桁以上も設定可能。
(9)数値に+符号をつける
'{:+}'.format()
└「:」以下書式設定
└「+」プラス/マイナスの符号をつけるデフォルトはマイナスの符号のみ。
└ '{:-}'と同じ(設定は不要)+符号をつける'1つめ「{:+}」。2つ目「{:+}」。3つ目「{:+}」'.format(-500, 300, 2.56) #出力 # '1つめ「-500」。2つ目「+300」。3つ目「+2.56」'
(10)小数点の桁数を指定
'{:.nf}'.format()
└「:」以下書式設定
└「.n」小数点の桁数(0からの整数)
└ デフォルト「:.nf」なしは、入力値分
└ 四捨五入小数点(デフォルト)'{}'.format(1.23) #出力 # '1.23'小数点(2桁)'{:.2f}'.format(1.23456789) #出力 # '1.23'小数点(0桁)'{:.0f}'.format(1.234345678) #出力 # '1'小数点(12桁)'{:.12f}'.format(1.234345678) #出力 # '1.234345678000'
(11)固定小数点表記(e)
'{:.ne}'.format()
└「:」以下書式設定
└「.n」小数点の数
└デフォルト「.n」なしは小数点6桁固定小数点(デフォルト)'{:e}'.format(123456789) #出力 # '1.234568e+08'固定小数点(2桁)'{:.2e}'.format(123456789) #出力 # '1.23e+08'固定小数点(小数点なし)'{:.0e}'.format(123456789) #出力 # '1e+08'固定小数点(引数が小数点)'{:.0e}'.format(123.456789) #出力 # '1e+02'
(12)引数の中で変数を指定
'{a}{b}{c},,,'.format(a='AAA',b=111,c='CCC')
└ 引数内で変数を指定
└ インデックス番号で指定できない
└ 数値や文字列と一緒に使えない
```python:引数の中で変数を指定
'{a}で{b}番目に高い山は{c}。'.format(a='日本',b=2,c='北岳')出力
'日本で2番目に高い山は北岳。'
```python:変数と文字列はエラー '{a}で{b}番目に高い山は{2}。'.format(a='日本',b=2,北岳) #出力(エラー) # SyntaxError: positional argument follows keyword argument変数と数値はエラー'{a}で{1}番目に高い山は{c}。'.format(a='日本',2,c='北岳') #出力(エラー) # SyntaxError: positional argument follows keyword argumentインデックス番号で指定できない'{0}で{1}番目に高い山は{2}。'.format(a='日本',b=2,c='北岳') #出力(エラー) # IndexError: Replacement index 0 out of range for positional args tupleインデックス番号指定なしもNG'{}で{}番目に高い山は{}。'.format(a='日本',b=2,c='北岳') #出力(エラー) # IndexError: Replacement index 0 out of range for positional args tuple
(13)日付データを指定した文字列に変換
datetimeモジュールの日付を指定した書式(文字列)に変換できる。
datetime.date型import datetime as dt past = dt.date(2017,1,3) "{0:%Y年%#m月%#d日}".format(past) #出力 # "{0:%Y年%#m月%#d日}".format(past)datetime.datetime型import datetime as dt today = dt.datetime.now() "{0:%Y年%m月%d日---%I時%M分%S秒}".format(today) #出力 # '2020年03月20日---02時08分39秒'個別に抜き出す(月と秒)import datetime as dt today = dt.datetime.now() "{0:%#m月、%S秒}".format(today) #出力 # '3月、52秒'ご参考:日付の書式を変更する方法
- 投稿日:2020-03-23T14:04:08+09:00
Python、例外処理について
例外処理についてメモ
例外処理とは途中でエラーが発生してプログラムが中断しないようにする処理
例えば以下を実行してみる。list = [1,2,3,4,'a',5,6] for i in list: print(i/10)とすると、
0.1 0.2 0.3 0.4 --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-21-78c5fd70e082> in <module> 2 3 for i in list: ----> 4 print(i/10) TypeError: unsupported operand type(s) for /: 'str' and 'int'"a"表記のためエラーが発生し、プログラムが中断してしまう。
そこで、エラー表記をする。for i in list: try: print(i/10) except: print("Error")0.1 0.2 0.3 0.4 Error 0.5 0.6うまくいった。
- 投稿日:2020-03-23T13:52:50+09:00
Python、for〜(range)について
- 投稿日:2020-03-23T13:31:50+09:00
PyTorchにおける時系列データ読み込みの方法
概要
今回は、PyTorchにおけるシーケンスデータ入力の方法について、まとめてみました。
いろいろと至らぬ面もあるかと存じますが、技術的なご指導いただけると幸いです。
当記事でご理解いただけるのは、PyTorchにおけるデータセットを固定長の動画像の塊にして、読み込む方法についてです。特に、UCSD DATASETのような、動画像として保存されているのではなく、フォルダーごとに連番画像として保存されているようなデータセットを扱うことを想定しております。DATASET/
├ train/
│ └ img_0001.png ← 動画の1フレーム目
│ └ img_0002.png ← 動画の2フレーム目
│ └ img_0003.png :
│ :
└ test/PyTorchを使って、LSTMを教師なし学習させていろいろとやりたかったのですが、動画像のロードモジュールが存在しなかった(私の調べでは)ので、しぶしぶ自作に至った次第です。
想定としては、画像形式のデータセットをまず読み込み、そこから一定の固定長を持つ動画像(部分時系列)を作成し、それをバッチサイズ分固めて、LSTMに学習させるという流れになります。
1. PyTorchにおけるデータセットの読み込み法
PyTorchでは、学習用データセットの読み込みのための、DatasetやDataLoaderクラスが用意されていて、オブジェクト宣言時に与えたdirの中に存在するデータを、1epoch毎にbatchsize分用意してくれるので、学習時に非常に便利です。
こちらを参考にすると、読み込み関連で、以下3つの登場人物が存在します。
- transforms
- データの前処理を担当するモジュール
- Dataset
- データとそれに対応するラベルを1組返すモジュール
- データを返すときにtransformsを使って前処理したものを返す。
- DataLoader
- データセットからデータをバッチサイズに固めて返すモジュール
一般的には、transformsにて、データセットの前処理(標準化やサイズ変換など)について設定し、次にDatasetを使ってラベルとの対応付けと前処理を適用し、最後にDataLoaderでバッチサイズ分の塊にして返すという流れになると思います。
しかし、これは、データセットの入力がi.i.d.であればの話であり、シーケンスデータを入力としたい場合は問題です。
シーケンスデータ、特に動画像データを扱えるモジュールがほしいので、考えてみました。2. Datasetクラスの継承・拡張
まずベースとなるのはDatasetクラスなので、これを継承し、Dsを親クラス(スーパークラス)としたsubクラス(Seq_Dataset:SD)を宣言します。
変更したいmethodのみ改めてSD上で記述することになります。(未定義のmethodは自動的にオーバーライドされます。)
基本的にDatasetクラスを継承し、拡張する際には、__len__および__getitem__に対する変更を記述することになります。
特に、__getitem__において、読み込んだDatasetオブジェクト(今回は画像データ)に対する処理(動画像変換)を記述します。今回想定している流れは、
transformで前処理設定→ImageFolder(Dataset)で画像データ読み込みと処理→最後にSeq_Datasetにて、固定長の動画像(部分時系列)を作り、更にそれのバッチサイズ分返すになります。以下に、今回Dsを拡張したSDクラスを載せます。各関数について簡単に説明いたします。
dataset.pyclass Seq_Dataset(Dataset): def __init__(self, datasets ,time_steps): self.dataset = datasets self.time_steps = time_steps channels = self.dataset[0][0].size(0) img_size = self.dataset[0][0].size(1) video = torch.Tensor() self.video = video.new_zeros((time_steps,channels,img_size,img_size)) def __len__(self): return len(self.dataset)-self.time_steps def __getitem__(self, index): for i in range(self.time_steps): self.video[i] = self.dataset[index+i][0] img_label =self.dataset[index] return self.video,img_label
__init__においては、単純に必要な変数を定義しているのみです。今回は固定長、つまりtime_steprsを引数としました。また、videoという変数は、固定長の部分時系列を格納するtensorであり、0で初期化しています。ここに詠みこんだdatasetsの中にある画像データを格納する形になります。
__len__においては、データの総数を返すのみです。今回はまず読み込んだ画像データを、最終的に固定長の動画像にして返すので、その総数はlen(dataset)-time_stepsとなります。
__getitem__においては、time_steps分の部分時系列を生成し、videoに代入して戻しています。ここで、画像に対するレベルの操作に関しても記述可能です。今回は教師なし学習を行う背景があるため、labelに関しては何も指定せず、そのまま画像の値を代入するという暴挙に出ています。ラベル指定の方法に関しては、他を参照すればあると参考例がたくさんあると思います。(他力本願ですみません)3.Seq_Datasetの使用例
実際に学習する際には、data_loaderオブジェクトを用いて、forで回してモデルを学習させる形になると思います。data_loader取得までの手順としては以下の通りで、各変数を定義して、ImageFolder→Seq_Dataset→DataLoaderという流れになります。
main.pydata_dir = "./data/train/" time_steps = 10 num_workers = 4 dataset = datasets.ImageFolder(data_dir, transform=transform) data_ = dataset.Seq_Dataset(dataset, time_steps) data_loader = DataLoader(data_, batch_size=opt.batch_size, shuffle=True, num_workers=num_workers)最終的に出力される部分時系列tensorのshapeは、[batchsize,timesteps,channels,imgsize,imgsize]を有します。
今後はこの自作したモジュールを使って、PyTorchでのLSTM実装などを公開できればと思っています。
最後までご覧頂き、ありがとうございまいた。
- 投稿日:2020-03-23T12:43:01+09:00
Pythonを用いてディレクトリ直下のディレクトリからファイルを再帰的にコピー
はじめに
- ディレクトリ直下のディレクトリからファイルを再帰的に処理する際に、基本的にはLinux環境を使用しているためシェルコマンドを利用します
- しかし、Windows環境のみしか利用できない環境でファイルの再帰的なコピーを行う場合、コマンドプロンプトを用いることが非常に面倒だったので、Pythonを利用してコピーする例を紹介します
実装
- 関数の引数でコピー元のパスとコピー先のパスを与えます
- inputとoutputのパスをファイル実行時の引数として与えてもいいと思います
ファイル構成としては、以下のような例を考えます
C:/Users/input/
├ 01
├ 01_01.jpg
├ 01_02.jpg
├ 02
├ 02_01.jpg
├ 02_02.jpg上記のJPGをコピーします
関数
import os import glob import shutil def copyfiles(input, output): ifiles = os.listdir(input) for s in ifiles: ifiles_all = input+ "/" + s fs = glob.glob(ifiles_all + "/*") for f in fs: fname = f.split("\\")[-1] # fileの名前 ofullname = output + "/" + fname shutil.copyfile(f, ofullname) input = "C:/Users/input" output = "C:/Users/output" copyfiles(input, output)
- 投稿日:2020-03-23T11:16:33+09:00
MicroPythonにCモジュールを追加するために...
とりあえず簡単な関数を実装してみる。
どれもmicropythonでできることなのでCで実装する必要はないけど、
今後何かしらをCで実装する必要が出てきたときのために最低限の確認。ドキュメントが見当たらなくてgitに上がっているmicropythonのコードを追いかけて実装したので別の方法があるかも...(ご存知の方はご指摘いただけると幸いです。)
- 文字列を引数にとってリターン
STATIC mp_obj_t return_str(mp_obj_t str_obj) { const char *str = mp_obj_str_get_str(str_obj); return mp_obj_new_str(str, strlen(str)); }list操作
- 作成
STATIC mp_obj_t list_new() { mp_obj_t list_items[] = { mp_obj_new_int(123), mp_obj_new_float(456.789), mp_obj_new_str("hello", 5), }; return mp_obj_new_list(3, list_items); }
- append
//追加したいitemがint型の場合 STATIC mp_obj_t list_append(mp_obj_t list_obj, mp_obj_t item_int_obj) { mp_int_t item_obj = mp_obj_get_int(item_int_obj); mp_obj_t item = mp_obj_new_int(item_obj); mp_obj_list_append(list_obj, item); return list_obj; }
- remove
// 削除したいitemがint型の場合 STATIC mp_obj_t list_remove(mp_obj_t list_obj, mp_obj_t item_int_obj) { mp_int_t item_obj = mp_obj_get_int(item_int_obj); mp_obj_t item = mp_obj_new_int(item_obj); mp_obj_list_remove(list_obj, item); return list_obj; }dict操作
- 作成
STATIC mp_obj_t dict_new() { mp_obj_t dict_obj = mp_obj_new_dict(3); mp_obj_dict_store(dict_obj, mp_obj_new_str("test_key1", 9), mp_obj_new_int(123)); mp_obj_dict_store(dict_obj, mp_obj_new_str("test_key2", 9), mp_obj_new_float(456.789)); mp_obj_dict_store(dict_obj, mp_obj_new_str("test_key3", 9), mp_obj_new_str("hello", 5)); return dict_obj; }
- 追加、変更
//追加したい要素が['str型': 'str型']の場合 STATIC mp_obj_t dict_store(mp_obj_t dict_obj, mp_obj_t key_str_obj, mp_obj_t value_str_obj) { mp_obj_dict_get_map(dict_obj); const char *key = mp_obj_str_get_str(key_str_obj); const char *val = mp_obj_str_get_str(value_str_obj); mp_obj_dict_store(dict_obj, mp_obj_new_str(key, strlen(key)), mp_obj_new_str(val, strlen(val))); return dict_obj; }
- 削除
// 削除したいkeyがstr型の場合 STATIC mp_obj_t dict_delete(mp_obj_t dict_obj, mp_obj_t key_str_obj) { mp_obj_dict_get_map(dict_obj); const char *del_key = mp_obj_str_get_str(key_str_obj); mp_obj_dict_delete(dict_obj, mp_obj_new_str(del_key, strlen(del_key))); return dict_obj; }MicroPythonから呼び出せるようにするには...
// 呼び出す関数 STATIC mp_obj_t return_str(mp_obj_t str_obj) { const char *str = mp_obj_str_get_str(str_obj); return mp_obj_new_str(str, strlen(str)); } STATIC MP_DEFINE_CONST_FUN_OBJ_1(return_str_obj, return_str); // モジュールとして定義 STATIC const mp_rom_map_elem_t example_module_globals_table[] = { // micropythonでimportするときの名前 {MP_ROM_QSTR(MP_QSTR___name__), MP_ROM_QSTR(MP_QSTR_example)}, // micropythonから関数を呼び出すときの名前 {MP_ROM_QSTR(MP_QSTR_return_str), MP_ROM_PTR(&return_str_obj)}, }; STATIC MP_DEFINE_CONST_DICT(example_module_globals, example_module_globals_table); const mp_obj_module_t example_cmodule = { .base = {&mp_type_module}, .globals = (mp_obj_dict_t *)&example_module_globals, };上記のように.Cを作ってmicropythonのソースに追加してビルドする。
micropythonからは、import example example.return_str()のようにして使う。
- 投稿日:2020-03-23T10:53:05+09:00
Apache Spark を Jupyter Notebook で試す (on ローカル Docker
以前 Spark を使ってたのですが今は使ってなくて,
そのうち忘れそうなので基本をメモしておくことにしました.(全体的に聞きかじりの知識なので間違ってる点はコメント・編集リクエストを期待します)
使う
Jupyter + PySpark な環境が動く Docker イメージが用意されているので,ローカルで試すには便利です:
https://hub.docker.com/r/jupyter/pyspark-notebook/PySpark とは,という話ですが,Spark 自体は Scala だけど,
Python で使えるやつがあってそれが PySpark だという話があります.IPC でがんばってるという仕組みになっていたはずなので,
Scala <-> Python の変換のコストが結構でかいうんぬんみたいな話題もあります.さて,使ってみましょう:
docker run -it -p 8888:8888 jupyter/pyspark-notebookこれを実行すると Terminal に 8888 番にトークンがついた URL が流れてくるので,
(To access the notebook, ...のあたり)
おもむろにアクセスすると Jupyter のページが出てきて,
Jupyter Notebook でコーディングできる簡単環境のできあがりです.
ここの
NewからNotebook: Python3を選択すれば Notebook を開けます
試す
動くかどうかのテストコードは以下で,サンプルからとってきました (https://jupyter-docker-stacks.readthedocs.io/en/latest/using/specifics.html#in-a-python-notebook):
from pyspark.sql import SparkSession spark: SparkSession = SparkSession.builder.appName("SimpleApp").getOrCreate() # do something to prove it works spark.sql('SELECT "Test" as c1').show()
SparkSessionというやつはよくわからないけど,
Spark 自体のインスタンスみたいなものという認識です.これを実行して表がでれば OK です:
データを扱う
こういうデータを対象にしてみましょう:
idnamegenderage1 サトシ male 10 2 シゲル male 10 3 カスミ female 12 入力と定義
Python で素朴にデータを定義するとこうなりますね:
from typing import List, Tuple Trainer = Tuple[int, str, str, int] trainers: List[Trainer] = [ (1, 'サトシ', 'male', 10), (2, 'シゲル', 'male', 10), (3, 'カスミ', 'female', 12), ]各行の型は Python の
typingでいうTuple[int, str, str, int]となりますね.で,Spark でもスキーマの定義があります:
from pyspark.sql.types import StructField, StructType, StringType, IntegerType trainers_schema = StructType([ StructField('id', IntegerType(), True), StructField('name', StringType(), True), StructField('gender', StringType(), True), StructField('age', IntegerType(), True), ])これで Spark 側での列のスキーマを定義できます.
Python で定義したデータを Spark の
DataFrameに変換するにはこうします:from pyspark.sql import DataFrame trainers_df: DataFrame = spark.createDataFrame( spark.sparkContext.parallelize(trainers), trainers_schema )これで
trainers_dfというDataFrameができました.データソースとして CSV とか MySQL とかそういうものから読み込めるので,
実際にはコード上で定義するよりそういうデータソースから読み込むことになるでしょう.
(場合により後述する JDBC とか,Hadoop の設定が必要です)これをダンプして確認したい場合はこうします:
trainers_df.show()そうすると,表に整形されたテキストが数行出力されます:
+---+------+------+---+ | id| name|gender|age| +---+------+------+---+ | 1|サトシ| male| 10| | 2|シゲル| male| 10| | 3|カスミ|female| 12| +---+------+------+---+集計と出力
ダンプではなく値をもらうには
.collect()すればいいです:result = trainers_df.collect() print(result)CSV に書き出すときはこういう雰囲気で
DataFrameを書き出します:trainers_df.coalesce(1).write.mode('overwrite').csv("path/to/output.csv")入力同様,他にも S3, MySQL とか Elasticsearch とかいろいろ出力先がある雰囲気です.
.coalesce(1)はパーティションごとの分割されているデータを,
1つのパーティションに coalesce するというものです.
こうしないと,分割されたまま CSV 出力されます.Hadoop の
hdfsコマンドをつかって,
分割されたものを1つにまとめて取得するという手段もあります.基本的に遅延評価になっていて,
.collect()みたいな操作をしてはじめて評価されるようになっているので,
そんなに頻繁に集計はしないはずです.基本
これだけではただ表示しただけでまったく意味がないので適当な操作をしてみましょう:
trainers_df.createOrReplaceTempView('trainers'); male_trainers_df = spark.sql(''' SELECT * FROM trainers WHERE gender = 'male' ''') male_trainers_df.show()これはこういう結果を得ます:
idnamegenderage1 サトシ male 10 2 シゲル male 10
DataFrame.createOrReplaceTempView(name)はDataFrameを,
一時的な SQL の View として登録することができるものです.これで
spark.sql(query)で登録した View を対象に SQL の操作した結果の DF を得ることができるので,
こうすれば,全く臆することなく慣れ親しんだ SQL を使って Spark を使うことができて,
心理的障壁も学習コストも低いというマジックになっています.View に登録しなくても,
DataFrameのままコードで記述するという方法もあります:male_trainers_df = trainers_df.filter(trainers_df['gender'] == 'male')こっちのほうが使いやすいケースもあるのでケースバイケースですね.
応用
SQL を使うことができるのだから,基本的な操作では別に問題ないのですが,
たいてい Spark を使いたいケースというのはなにかユーザー定義の操作をしたい状況になっていそうですね.たとえば自分が過去やりたかったケースとしては,
「記事本文を形態素解析して分かち書きする」というものがあって,
これは SQL だけでは実現しがたいですね.ただ,Python 上であれば MeCab があるので,
MeCab のライブラリを使って形態素解析してやれば何も考えなくても分解されてやってくるので,
僕のように全然わかってなくてもとりあえず MeCab に投げればいけるという手段をとれます.そういう操作を Spark 上で
DataFrameに対して行うにはどうすればいいかというと,
UDF (User-Defined Function) を定義するといいです.(※
DataFrameではなく RDD というものに対しては直接lambdaを適用できるという技がありますが,
これはパフォーマンスが悪いというのがあります).UDF を定義するには次のような定義を行います:
from pyspark.sql.functions import udf @udf(StringType()) def name_with_suffix(name: str, gender: str) -> str: return name + {'male': 'くん', 'female': 'さん'}.get(gender, '氏') spark.udf.register('name_with_suffix', name_with_suffix)UDF となる関数に
@udf(ReturnType)デコレーターを適用することで,
その関数は UDF として定義できるようになります.
それを Spark SQL で使うにはspark.udf.register(udf_name, udf)して登録すれば,
COUNT()とかと同じ用にそのまま使えます.ちなみにデコレーターを使わなくても,
udf_fn = udf(fn)すれば既存の関数を適用できます.この例としてあげたものは
genderに応じて,
nameにgenderに応じた suffix をつけるというものです.
この関数を UDF として適用してみましょう:dearest_trainers = spark.sql(''' SELECT name_with_suffix(name, gender) FROM trainers ''') dearest_trainers.show()結果はこうなります:
name_with_suffix(name, gender)サトシくん シゲルくん カスミさん 今回の例であれば SQL でも
CASEを駆使して書けるというご意見がありますが,そのとおりです.やりたいことによっては便利に使えるでしょう.
UDF
さて,前述した形態素解析して分かち書きするというものですが,
これはイメージとしてこのような関数になります
(実際には MeCab をカッコよく使います):import re # 半角/全角スペースや約物で文字列を分割する @udf(ArrayType(StringType())) def wakachi(text: str) -> List[str]: return [ word for word in re.split('[ !…]+', text) if len(word) > 0 ]これを適用するのも同じくそのまま使えば OK です.
サンプルコードを今一度データを変更しつつ書いてみます:Trainer = Tuple[int, str, str, int, str] trainers: List[Trainer] = [ (1, 'サトシ', 'male', 10, 'ポケモン ゲット だぜ'), (2, 'シゲル', 'male', 10, 'このおれさまが せかいで いちばん! つよいって ことなんだよ!'), (3, 'カスミ', 'female', 12, 'わたしの ポリシーはね… みず タイプ ポケモンで せめて せめて …せめまくる ことよ!'), ] trainers_schema = StructType([ StructField('id', IntegerType(), True), StructField('name', StringType(), True), StructField('gender', StringType(), True), StructField('age', IntegerType(), True), ]) trainers_df = spark.createDataFrame( spark.sparkContext.parallelize(trainers), trainers_schema ) trainers_df.createOrReplaceTempView('trainers'); wakachi_trainers_df = spark.sql(''' SELECT id, name, wakachi(comment) FROM trainers ''') wakachi_trainers_df.show()ここでポイントになるのは,
今回の UDF はstrを受け取ってList[str]として展開するということですね.
これを実行してみるとこうなります:
idnamewakachi(comment)1 サトシ [ポケモン, ゲット, だぜ] 2 シゲル [このおれさまが, せかいで, い... 3 カスミ [わたしの, ポリシーはね, みず... 展開されたセルはリストになっていて,
列のなかに更に列がある入れ子状態になっています.これをそれぞれの
strを列として展開したい場合どうすればいいかというと,
展開する関数を更に適用すればいいです:from pyspark.sql.functions import explode wakachi_trainers_df = spark.sql(''' SELECT id, name, explode(wakachi(comment)) FROM trainers ''') wakachi_trainers_df.show()
explodeという関数があるので,
これを適用すれば入れ子になった要素がそれぞれの列として展開されます:
idnamecol1 サトシ ポケモン 1 サトシ ゲット 1 サトシ だぜ 2 シゲル このおれさまが 2 シゲル せかいで 2 シゲル いちばん 2 シゲル つよいって 2 シゲル ことなんだよ 3 カスミ わたしの 3 カスミ ポリシーはね 3 カスミ みず 3 カスミ タイプ 3 カスミ ポケモンで 3 カスミ せめて 3 カスミ せめて 3 カスミ せめまくる 3 カスミ ことよ ジョイン
さらなるポイントとして
DataFrameどうしのJOINができます.
普通の MySQL とかのJOINと変わらずに結合につかうカラムを指定して,
それをもとにDataFrameを結合するものです.サンプルコードを更に追加して
JOINを使ってみます:Pkmn = Tuple[int, int, str, int] pkmns: List[Pkmn] = [ (1, 1, 'ピカチュウ', 99), (2, 1, 'リザードン', 99), (3, 2, 'イーブイ', 50), (4, 3, 'トサキント', 20), (5, 3, 'ヒトデマン', 30), (6, 3, 'スターミー', 40), ] pkmns_schema = StructType([ StructField('id', IntegerType(), True), StructField('trainer_id', IntegerType(), True), StructField('name', StringType(), True), StructField('level', IntegerType(), True), ]) pkmns_df = spark.createDataFrame( spark.sparkContext.parallelize(pkmns), pkmns_schema ) pkmns_df.createOrReplaceTempView('pkmns'); trainer_and_pkmns_df = spark.sql(''' SELECT * FROM trainers INNER JOIN pkmns ON trainers.id = pkmns.trainer_id ''') trainer_and_pkmns_df.show()
idnamegenderagecommentidtrainer_idnamelevel1 サトシ male 10 ポケモン ゲット だぜ 1 1 ピカチュウ 99 1 サトシ male 10 ポケモン ゲット だぜ 2 1 リザードン 99 3 カスミ female 12 わたしの ポリシーはね… みず タ... 4 3 トサキント 20 3 カスミ female 12 わたしの ポリシーはね… みず タ... 5 3 ヒトデマン 30 3 カスミ female 12 わたしの ポリシーはね… みず タ... 6 3 スターミー 40 2 シゲル male 10 このおれさまが せかいで いちばん... 3 2 イーブイ 50 ちなみに
INNER JOIN,OUTER JOINの他に種類がいっぱいあります.
こちらの記事がわかりやすいので引用します:https://qiita.com/ryoutoku/items/70c35cb016dcb13c8740
これで集合操作ができるので便利という感じです.
各
JOINの概念はこのページのベン図がわかりやすいので引用します:https://medium.com/@achilleus/https-medium-com-joins-in-apache-spark-part-1-dabbf3475690
ポイントとしてやはり
JOINはコストがかかっていて遅いです.
クラスタを組んでたとしたら,各所に分散したデータから見つけてJOINして戻してとかそういう操作が行われているようです.ので,後述するパフォーマンスチューニングが必要になってきます.
パフォーマンス
現実のケースとして,膨大なデータセットと格闘するのはそうとう辛いものがあります.
というのも,4時間とかかかるものだったら,最後の方で落ちたらまたやり直しかとなって,
二回ミスると一日の業務時間を捧げたことになってしまって残業が確定します.なので,そういうパフォーマンスを改善するために,
JOINの効率を上げるようにデータを削減したり,
パーティションの区切りかたを変えたり,
パーティションをなるべくクラスタ上に小さく断片化させないような工夫が必要です.Broadcast Join というもので,あえて全クラスタにデータセットを重複して配置することで,
JOIN時にデータセットの検索のコストを下げるとかそういうものもあります.重要なテクニックとして,
各チェックポイント的なところで適宜 DataFrame を.cache()しておくことで,
パフォーマンスが劇的に改善されるというものもあります.パフォーマンスについての公式ページを見るとそういうテクニックがあって参考になります:
https://spark.apache.org/docs/latest/sql-performance-tuning.html#broadcast-hint-for-sql-queries
MySQL
さて,よくあるのが MySQL のデータベースから読み込んでうんぬんしたいというのがあります.
このケースでは MySQL を扱うために JDBC の MySQL コネクタを用意する必要がありますが,
こちらのかたのエントリと,その Docker イメージが参考になります:
- https://cloudfish.hatenablog.com/entry/2018/08/03/191424
- https://hub.docker.com/r/cloudfish/pyspark-notebook/dockerfile
しかしながら,MySQL は Spark では扱いづらいみたいなところもあります.
(いろいろハマりポイントがあります)実際
Spark が威力を発揮するのは:
- データがとにかくでかい
- 適用したい処理が互いに依存しない
- 各操作に副作用がなくて内部の操作で完結する (外の API への操作とかがない)
というものだと思っています.
あと Spark は複数台でクラスタを作って worker に仕事をさせるのがキモなので,
現実的には AWS におまかせするということで,Amazon EMR とか AWS Glue でやるのがよさそうですね.
ローカルだとクラスタを作らずに動くので,本気の巨大データを打ち込んでもパフォーマンスは出ずに恩恵にはあずかれないからです.メモリの限界にぶち当たったり,
節約できても処理全体にバッチ流して二週間かかりますみたいな巨大データだと,
素朴なものでも自前で分割して複数プロセスにわけて実行とかすればできるかもしれないけど,
Spark にできることなら任せるのもよさげです.

- 投稿日:2020-03-23T10:48:39+09:00
SQLAlchemyで複数のデータベースに接続
DB情報の設定
config.pyclass SystemConfig: SQLALCHEMY_DATABASE_URI = 'mysql+pymysql://{user}:{password}@{host}/{db_name}?charset=utf8'.format(**{ 'user': 'sample_user', 'password': 'passwd', 'host': 'host', 'db_name': 'sample_db_1' }) SQLALCHEMY_BINDS = {"second_sample_db": SECOND_SAMPLE_DATABASE} SECOND_SAMPLE_DATABASE = 'mysql+pymysql://{user}:{password}@{host}/{db_name}?charset=utf8'.format(**{ 'user': 'sample_user', 'password': 'passwd', 'host': 'host', 'db_name': 'sample_db_2' }) Config = SystemConfig起動時のファイル設定
database.pyfrom flask_sqlalchemy import SQLAlchemy db = SQLAlchemy() def init_db(app): db.init_app(app)__init__.pyimport config from flask import Flask from api.database import db def create_app(): app = Flask(__name__) # config.pyを読み込む app.config.from_object('config.Config') db.init_app(app) return app app = create_app()app.pyfrom api import app if __name__ == '__main__': app.run()DBのモデル
model.pyfrom database import db class SecondSample(db.Model): __bind_key__ = 'second_sample_db' #config.pyで設定したもの __tablename__ = 'second_sample_table' id = db.Column(db.Integer, primary_key=True) name = db.Column(db.String) date = db.Column(db.DATETIME) def __init__(self, id, name, date): self.id = id self.name = name self.date = date
- 投稿日:2020-03-23T10:17:14+09:00
【Python】OpenCVによる画像の画素へのアクセスと切り取り (初心者向け)
はじめに
OpenCVを用いて画像をどうやって切り取るかを解説します。一応前回の続きなので、もしこの記事でわからないところがあれば、ご覧ください。
環境
MacOS Mojave
Python 3.7使用画像
以下の画像 (neko.jpg) を使用します。
画像の大きさを確認
以下のコードで画像の大きさを確認できます。
#ライブラリの読み込み import cv2 import matplotlib.pyplot as plt img = cv2.imread("neko.jpg") print(img.shape)以上のコードを実行すると、以下の結果が出ます。
(900, 1600, 3)これは、縦が900ピクセル、横が1600ピクセル、チャンネル数が3という意味です。チャンネル数はカラー画像の場合はGBRの3つなので、3になります。グレースケールだと、白色の度合いだけなので、チャンネル数は1となります。
画像の座標
Opencvにおいて、画像の座標軸は以下のようになります。
位置を(x,y)とするとき、原点(0,0)は図のように左上にきます。画像を扱う場合は下方向がy軸の正の方向になるので注意してください。
この画像の大きさは縦が900ピクセル、横が1600ピクセルなので、画像の末端のピクセルのx,y座標はそれぞれ899,1599となります。900、1600にならないのは、原点0から数えているためです。画像の座標へのアクセス
画像の座標を以下のように指定すると、その位置の色の値を取得することができます。
img = cv2.imread("neko.jpg") print(img[450,800])出力[153 161 190]これは、座標(450,800)の位置の色が(R,G,B) = (153,161,190)であることを示しています。
また、以下のようにすると座標を複数指定できるようになります。print(img[450:650,800:1000])[[[153 161 190] [153 161 190] [152 160 189] ... [169 178 205] [169 178 205] [169 178 205]] [[152 160 189] [152 160 189] [153 161 190] ... [169 178 205] [169 178 205] [169 178 205]] [[151 159 188] [152 160 189] [154 162 191] ... [171 178 205] [172 179 206] [172 179 206]] ... 以下省略。。。[]の中にある":"は私たちが普段数字の範囲を表す時に使う"~"と同じと考えてください。上の例では、座標(450,800)から(649,999)までの範囲の色の情報を出力しています。
任意の位置で切り取り
指定した画像の範囲を別のオブジェクトに入れれば、その位置を切り出した画像を得ることができます。
#ライブラリの読み込み import cv2 import matplotlib.pyplot as plt img = cv2.imread("neko.jpg") #指定した画素をimg_trimに代入 img_trim = img[450:650,800:1000] #色を変更 img_trim = cv2.cvtColor(img_trim, cv2.COLOR_BGR2RGB) #表示 plt.imshow(img_trim) plt.show()
以上のような画像が出力されれば成功です!(畳なので切り取りが行われているかどうかわかりずらいですが。。。笑)
次回は画像の拡大縮小反転など、こねくり回す作業を解説したいと思いますTwitterやってます
今後の記事の情報や質疑応答など色々やりたいと思うのでよければ、フォローお願いします、、、!
https://twitter.com/ryuji33722052