- 投稿日:2020-03-23T23:41:57+09:00
Aurora Serverless が起きるまで待つ
例えば AWS Lambda + Amazon CloudWatch Events で定期的にどこかからデータをひっこ抜いてきて適当に Amazon RDS にでも突っ込んでおくかという場合に、普通の Provisioned インスタンスだと少なくとも数千円/月はかかってしまうが Aurora Serverless にすれば使っていないときは勝手に寝てくれるので格安で済むのではないか。1 2
ただしこのアイデアにはひとつ問題があって、Aurora Serverless が起きるのが遅いということ。
DB クライアントから接続を試みると寝ていた Aurora Serverless は起動し始めるが、接続を受け入れられるようになるまでの間にクライアントがタイムアウトしてしまうなんてこともある。
そこで、使うときはあらかじめ Aurora Serverless を起動 (Capacity を増加) させるリクエストを送っておいて、起動した (Capacity が 0 以上になった) タイミングで DB クライアントから接続すれば良いのではないか。
Lambda Function の実装
Aurora Serveless が起きるまで待って後は何もしないという Lambda Function を実装してみる。
ランタイムは Python 3.8 を使った。
import asyncio import boto3 def is_aurora_serverless_up(client, identifier: str) -> bool: """Aurora Serverless が起動中かどうかを返す""" response = client.describe_db_clusters(DBClusterIdentifier=identifier) assert response['ResponseMetadata']['HTTPStatusCode'] == 200 assert len(response['DBClusters']) > 0 assert response['DBClusters'][0]['EngineMode'] == 'serverless' return response['DBClusters'][0]['Capacity'] > 0 async def wake_aurora_serverless_up(client, identifier: str, capacity: int = 2): """Aurora Serverless を起動する""" if is_aurora_serverless_up(client, identifier): return response = client.modify_current_db_cluster_capacity(DBClusterIdentifier=identifier, Capacity=capacity) assert response['ResponseMetadata']['HTTPStatusCode'] == 200 for i in range(10): await asyncio.sleep(i ** 2) if is_aurora_serverless_up(client, identifier): return raise TimeoutError() async def main(): client = boto3.client('rds') await wake_aurora_serverless_up(client, 'mycluster') def lambda_handler(event, context): asyncio.get_event_loop().run_until_complete(main())あとやる必要があること。
- 実行するために
rds:DescribeDBClustersとrds:ModifyCurrentDBClusterCapacityの権限が必要なのでそれっぽい IAM Role を作成して Lambda Function に割り当てておく- Lambda Function のタイムアウト設定のデフォルト値 3秒 だと絶対に終わらないので 3分 とかに設定しておく
今回は asyncio で実装しているが asyncio.sleep で使っているだけなのであまり意味はない。普通に time.sleep でもいい。asyncio で実装しておくと PostgreSQL クライアントとして asyncpg が選べるというメリットはある。
実行してみる
試しに実行してみると以下のようなことがわかる。
- Aurora Serverless が起動するまでに 15秒 くらいかかる
- 起動した (capacity > 0 になった) としてもすぐに DB クライアントから接続できるわけではなく、そこから更に 10 秒くらい待つ。
結局待つので前とあまり変わっていないが、DB クライアントがタイムアウトしなくなったのでこれはこれでよし。
最後に
ここまでやってから「これ普通に DB クライアントの接続タイムアウトを長めに設定しておくだけで解決したのでは?????」ということに気づいてしまった。
えっ・・・?
あっ、はい・・・。
- 投稿日:2020-03-23T21:46:16+09:00
チャットアプリにAWSのS3(ストレージサービス)を導入
- 投稿日:2020-03-23T20:17:04+09:00
【AWS】IAMユーザーのMFAの設定をマストにする
概要
- AWS IAMのドキュメントのチュートリアルでMFAのマスト化は(ベストプラクティス的にも)最低限行なっておいたほうが良いと感じたので、その手法をまとめました
- 対象読者はIAM管理、IAMのベストプラクティスにのっとったセキュリティ管理に興味のある方です
0. 事前準備
IAMのダッシュボードで、AWSマネジメントコンソールへのアクセスのみ許可されたテストユーザー(test_user)を作成し、ポリシーやアクセス許可が一切行われていないテストグループ(TestGroup)を作成してください
1. MFAサインインを強制するポリシーの作成
- 管理者権限のあるIAMでAWSマネジメントコンソールにサインインしてください。(ルートユーザでのサインインはベストプラクティス上非推奨です。)
- IAMコンソールを開きます
- 左側のナビゲーションメニューからポリシーを選択し、左上の青色のポリシーの作成を選択してください
- デフォルトではビジュアルエディタが選択されているので、JSONたぶに切り替え、jsonをコピペしください。
- 右下の青色のポリシーの確認を選択してください(構文エラーがある場合は報告されます)
- 確認ページでポリシー名として好きな名前(例えば
ForceMFAなど)を入力してください。- ポリシーの詳細としては適当に(
This policy allows users to manage their own passwords and MFA devices but nothing else unless they authenticate with MFA.など)入力してください。(英文のみ許可されています。)json
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowViewAccountInfo", "Effect": "Allow", "Action": [ "iam:GetAccountPasswordPolicy", "iam:GetAccountSummary", "iam:ListVirtualMFADevices" ], "Resource": "*" }, { "Sid": "AllowManageOwnPasswords", "Effect": "Allow", "Action": [ "iam:ChangePassword", "iam:GetUser" ], "Resource": "arn:aws:iam::*:user/${aws:username}" }, { "Sid": "AllowManageOwnAccessKeys", "Effect": "Allow", "Action": [ "iam:CreateAccessKey", "iam:DeleteAccessKey", "iam:ListAccessKeys", "iam:UpdateAccessKey" ], "Resource": "arn:aws:iam::*:user/${aws:username}" }, { "Sid": "AllowManageOwnSigningCertificates", "Effect": "Allow", "Action": [ "iam:DeleteSigningCertificate", "iam:ListSigningCertificates", "iam:UpdateSigningCertificate", "iam:UploadSigningCertificate" ], "Resource": "arn:aws:iam::*:user/${aws:username}" }, { "Sid": "AllowManageOwnSSHPublicKeys", "Effect": "Allow", "Action": [ "iam:DeleteSSHPublicKey", "iam:GetSSHPublicKey", "iam:ListSSHPublicKeys", "iam:UpdateSSHPublicKey", "iam:UploadSSHPublicKey" ], "Resource": "arn:aws:iam::*:user/${aws:username}" }, { "Sid": "AllowManageOwnGitCredentials", "Effect": "Allow", "Action": [ "iam:CreateServiceSpecificCredential", "iam:DeleteServiceSpecificCredential", "iam:ListServiceSpecificCredentials", "iam:ResetServiceSpecificCredential", "iam:UpdateServiceSpecificCredential" ], "Resource": "arn:aws:iam::*:user/${aws:username}" }, { "Sid": "AllowManageOwnVirtualMFADevice", "Effect": "Allow", "Action": [ "iam:CreateVirtualMFADevice", "iam:DeleteVirtualMFADevice" ], "Resource": "arn:aws:iam::*:mfa/${aws:username}" }, { "Sid": "AllowManageOwnUserMFA", "Effect": "Allow", "Action": [ "iam:DeactivateMFADevice", "iam:EnableMFADevice", "iam:ListMFADevices", "iam:ResyncMFADevice" ], "Resource": "arn:aws:iam::*:user/${aws:username}" }, { "Sid": "DenyAllExceptListedIfNoMFA", "Effect": "Deny", "NotAction": [ "iam:CreateVirtualMFADevice", "iam:EnableMFADevice", "iam:GetUser", "iam:ListMFADevices", "iam:ListVirtualMFADevices", "iam:ResyncMFADevice", "sts:GetSessionToken" ], "Resource": "*", "Condition": { "BoolIfExists": { "aws:MultiFactorAuthPresent": "false" } } } ] }2. テストグループにポリシーを関連づける
- IAMコンソールの左側のナビゲーションメニューでグループを選択します
- 検索ボックスに事前準備で作成したテストグループ(TestGroupなど)を入力し、選択してください
- デフォルトでアクセス許可のタブが選択されているので、その下の青色のポリシーのアタッチを選択してください
- 検索ボックスで先ほど作成したポリシー(ForceMFA)を入力し、チェックボックスをオンにします(まだ変更保存はしない)
- さらに、そのテストユーザーに認証を与えるポリシーにチェックを付けます(例えばEC2に対するフルアクセスを許可する場合は
AmazonEC2FullAccessのチェックボックスをオンにします)- 右下の青色のポリシーのアタッチを選択してください
3. テストユーザーでアクセスをテストする
- 作成したテストユーザーでAWSアカウントにサインインしてください(URL:
https://<alias or account ID number>.signin.aws.amazon.com/console)- Amazon EC2コンソールを開き、一切の捜査権限がないことを確認してください
- 右上のナビゲーションバーを選択し、マイセキュリティ資格情報を選択してください
- ここでMFA認証を有効にしてください
- コンソールからサインアウトし、もう一度テストユーザーとしてサインインしてください(このときMFAが有効になっているはずです)
- Amazon EC2コンソールを開き、全てのアクションを実行することができることを確認してください(ただし、EC2以外のコンソールに移動すると、アクセス拒否されていることが確認できます)
- 投稿日:2020-03-23T19:49:14+09:00
API Gateway のカスタムドメイン設定方法と困った話 ( CONNECTION_REFUSED )
API Gateway のカスタムドメイン設定で困った話
AWS(Amazon Web Service)のAPI Gatewayで、カスタムドメインを設定した時に色々トラブったのでメモを残します。
原因はかなりクダらないのですが、私のような初心者には割とありがちなのかも...?カスタムドメイン設定手順
メモがてら。route53に該当する独自ドメインが登録済みであることを前提とします。
独自ドメインをhoge.com、API用のサブドメインをapi.hoge.comとして説明します。
また、APIは東京リージョンで稼働するものとします。
それぞれ該当箇所を変更しながら作業してください。Certificate Managerで証明書を作る
セキュリティ、ID、およびコンプライアンスの項にあります。
- 右上のリージョンを東京に変更
- 証明書のリクエストをクリック
- パブリック証明書のリクエストを選択
- ドメイン名の追加 ドメイン名を入力する(api.hoge.com)
- 検証方法 DNSの検証を選択
- お好みでタグをつける(空白可能)
- 確定とリクエストボタンをポチる
- 検証 ドメイン名の横の矢印を押すと「Route 53でのレコードの作成」なるボタンがある。ポチる
- 確認画面で作成ボタンをポチる
- 「成功」となったら右下の続行ボタンをポチ
- すると証明書一覧に跳ぶのでしばらく待つ
- 該当の証明書の状況が「発行済み」になったら完了!
このうち1.のリージョン変更を忘れがちです。(2敗)
お気をつけあそばせ。API Gatewayでカスタムドメインを設定する
該当するAPIのリソースを表示する画面まで行ってください。
- 左のメニューから「カスタムドメイン名」を選択する
- 作成をポチる
- ドメイン名を入力(api.hoge.com)
- エンドポイントタイプはリージョン TLSはお好みで(1.2でよさろう)
- 先ほど作ったACM 証明書を選択
- 作成をぽちっとな
- ちゃんとできていればカスタムドメイン名の一覧にapi.hoge.comがいるはず
- api.hoge.comを選択する
- ドメイン名の詳細が出てきたら一番下の「API マッピングを設定」をぽちっとな
- 新しいマッピングを追加をぽちっとな
- APIから対応するAPIを、ステージから送りたいステージを選択
- パスは基本空白でOK
- 追加したら右下の保存ボタンをぽちっとな
最後にRoute53からちょいと設定
Route53で、ホストゾーンからhoge.comの設定に移ります。
- 上のレコードセットの作成をクリック
- 名前はapi.hoge.comの内apiを空欄に入力
- タイプはA - IPc4アドレス
- エイリアスではいを選択
- ターゲット名の入力をクリックすると、それっぽい対象がずらーッと出てくる
- その中からAPI Gatewayの対応するものを選択
- そのまま作成をぽちっとな
これで一連の作業は完了です!
アクセスしてみよう!
どれ、http://api.hoge.com/hoge っと...
おっ、キレそーーーーー!!!
ゴミみたいな理由
× http://api.hoge.com/hoge
〇 http s ://api.hoge.com/hogeそもそも
どうにもHTTPSでしかアクセスできないっぽいです。
調べればわかることでしたね...5日ぐらい溶けました。〆
何だかんだ簡単にカスタムドメイン登録出来ちゃいます。
ほぼ知識無からでも、REST APIを作って公開できちゃうんだからすごい世の中ですよね...
本当にありがてえ限りです。
(何か間違っている点がありましたら、ご指摘いただけると幸いです)
- 投稿日:2020-03-23T18:32:08+09:00
Boto3(AWS SDK for Python)の利用する認証情報
Boto3の利用する認証情報は「Credentials — Boto 3」にまとめられており、8か所から規定の順序で認証情報が検索されます。
認証情報の検索順序
Boto3はパラメーターやプロファイルなど複数の方法で認証情報を取得しようとする。その方法と順序は「Configuring Credentials - Credentials — Boto 3」にあって、該当部分の拙訳は以下の通り。
boto3の資格情報検索メカニズムは、以下のリストに沿って検索し、資格情報を見つけたらそこで停止することです。Boto3が資格情報を検索する順序は:
boto.client()メソッドにパラメーターで渡された資格情報Sessionオブジェクトの生成時にパラメーターで渡された資格情報- 環境変数
- 共有された認証情報ファイル(
~/.aws/credentials)- AWS設定ファイル(
~/.aws/config)- ロールの引き受けの提供
- Boto2設定ファイル(
/etc/boto.cfg and ~/.boto)- IAMロールを構成されたAmazon EC2インスタンス上ではそのインスタンスメタデータサービス
これらのうち、APIアクセスキーとAPIシークレットキー、または名前付きプロファイルを使用するものについて、以下で見ていきます。
1.
client()メソッド、resource()メソッドでの直接指定
boto3.client()メソッドまたはboto3.session.Session().client()メソッドに、以下をパラメータで指定します。
キー 指定値 aws_access_key_id APIアクセスキー aws_secret_access_key APIシークレットキー aws_session_token (多要素認証時)セッショントークン 以下は対話型シェルでの実行例です。
>>> import boto3 >>> client = boto3.client('iam', aws_access_key_id='YOURACCESSKEY', aws_secret_access_key='YOURSECRETKEY') >>> client.list_users()
client()ではなくresource()(boto3.resource()またはboto3.session.Session().resource())メソッドを使う場合でも、上記の3パラメータを指定できます。>>> import boto3 >>> resource = boto3.resource('iam', aws_access_key_id='YOURACCESSKEY', aws_secret_access_key='YOURSECRETKEY') >>> list(resource.users.all())2.
Sessionオブジェクトの生成時にパラメーターで渡された資格情報認証情報の指定
boto3.session.Session()でsessionオブジェクトを生成する際に、以下をパラメータで指定します。生成されたSessionオブジェクトからclient()メソッドで生成されたクライアントやresource()メソッドで生成されたリソースはこの資格情報を使用します。
キー 指定値 aws_access_key_id APIアクセスキー aws_secret_access_key APIシークレットキー aws_session_token (多要素認証時)セッショントークン 以下は対話型シェルでの実行例です。
>>> import boto3 >>> session = boto3.session.Session(aws_access_key_id='YOURACCESSKEY', aws_secret_access_key='YOURSECRETKEY') >>> client = session.client('iam') >>> client.list_users()プロファイルの指定
boto3.session.Session()でsessionオブジェクトを生成する際に、以下をパラメータで指定します。指定された名前付きプロファイルに構成されている認証情報が使用されます。生成されたSessionオブジェクトからclient()メソッドで生成されたクライアントやresource()メソッドで生成されたリソースはこの資格情報を使用します。
キー 指定値 profile_name プロファイル名 以下は対話型シェルでの実行例です。
>>> import boto3 >>> session = boto3.session.Session(profile_name='YOURPROFILENAME') >>> client = session.client('iam') >>> client.list_users()3. 環境変数
認証情報の指定
以下を環境変数で指定します。前項まででの明示的な認証情報の指定がない場合、これが使われます。
環境変数名 指定値 AWS_ACCESS_KEY_ID APIアクセスキー AWS_SECRET_ACCESS_KEY APIシークレットキー AWS_SESSION_TOKEN (多要素認証時)セッショントークン 以下はbash環境で上記環境変数を設定後、Pythonの対話型シェルを呼び出しての実行例です。
$ export AWS_ACCESS_KEY_ID=YOURACCESSKEY $ export AWS_SECRET_ACCESS_KEY=YOURSECRETKEY $ python3 Python 3.6.9 (default, Nov 7 2019, 10:44:02) [GCC 8.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import boto3 >>> client = boto3.client('iam') >>> client.list_users()プロファイルの指定
以下を環境変数で指定します。前項まででの明示的な認証情報の指定がない場合、この指定された名前付きプロファイルに構成されている認証情報が使用されます。
環境変数名 指定値 AWS_PROFILE プロファイル名 以下はbash環境で上記環境変数を設定後、Pythonの対話型シェルを呼び出しての実行例です。
$ export AWS_PROFILE=YOURPROFILENAME $ python3 Python 3.6.9 (default, Nov 7 2019, 10:44:02) [GCC 8.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import boto3 >>> client = boto3.client('iam') >>> client.list_users()4. 共有された認証情報ファイル(
~/.aws/credentials)ここまでの認証情報がない場合、認証情報ファイル(
~/.aws/credentials)内にdefaultプロファイルとして構成されている認証情報が使われます。これは通常、AWS CLIを最初に使うときにaws configureコマンドで設定されています。詳細は「AWS CLI のかんたん設定」を参照してください。5. AWS設定ファイル(
~/.aws/config)ここまでの認証情報がない場合、AWS設定ファイル(
~/.aws/config)内にdefaultプロファイルとして構成されている認証情報があれば、これが使われます。ただし通常は、AWS設定ファイル内で管理しているプロファイル情報はリージョン(region)とデフォルトの出力形式(output)で、認証情報は含まれていません。7. Boto2設定ファイル(
/etc/boto.cfg and ~/.boto)ここまでの認証情報がない場合、Boto2設定ファイルが存在すればそこに格納された認証情報が確認されます。Boto2設定ファイルはデフォルトでは
/etc/boto.cfgまたは~/.botoに設置されます。以下が内容例です。# Example ~/.boto file [Credentials] aws_access_key_id = foo aws_secret_access_key = barこれは後方互換性のための動作で、Boto2設定ファイルはCredentialsセクション以外無視されます。
認証方法と指定方法と優先順位
Boto3で利用できる認証情報には、(1)APIアクセスキーとAPIシークレットキー、(2)デフォルトプロファイル、(3)名前付きプロファイル、(4)ロール(ここでは詳細は触れませんでした)による認証の4種類が可能ということになります。これとここまでの指定方法を対応付けると、次のようになります。
認証方法 指定方法 APIアクセスキーとAPIシークレットキー 1、2、3、4、5、7 デフォルトプロファイル 4 名前付きプロファイル 2、3 ロール 6、8 想定した認証方式が使われていないと思ったときには、より優先順位が高い指定方法で別の指定がされていないかを確認することも必要そうです。
例えば
AWS_PROFILE環境変数で名前付きプロファイルを指定していても、もしboto3.session.Session()で別のプロファイル名が指定されてしまえば、そちらが優先されてしまいます。意図的にやっている場合は気づくでしょうが、デフォルト値がどこかで入り込んでいたりすると分かりにくくなりそうです。参考
boto3の認証について。
- [Credentials — Boto 3](https://boto3.amazonaws.com/v1/documentation/api/latest/guide/configuration.html]
AWSの認証情報ファイルと設定ファイルについて。
- 設定ファイルと認証情報ファイルの設定 - AWS Command Line Interface
- 名前付きプロファイル - AWS Command Line Interface
- AWS CLI のかんたん設定 - AWS CLI の設定 - AWS Command Line Interface
boto3の各メソッドについて。
- boto3.client()
- boto3.reference()
- boto3.session.Session().client()
- boto3.session.Session().resource()
- boto3.session.Session()
Boto2設定ファイルについて。
- 投稿日:2020-03-23T12:31:43+09:00
複数のディレクトリ内のファイルをaws cliでs3へアップロード
aws cli でのエラー
findで、現在のディレクトリ以下に存在するディレクトリ内のファイルをまるっとs3にあげたいなと。
そこで再帰的にfind . -type d | aws s3 cp - s3://${S3_BUCKET} --recursiveのようにしたら
Reason: exit status 255でエラー。
ドキュメントによると、エラー内容は↓とのこと。255: コマンドが失敗しました。リクエストが送信された AWS CLI または AWS サービスのいずれかでエラーが生成されました。
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/cli-usage-returncodes.html--debugオプションをつける
CodeBuildには正しい権限を付与しているはず。。。
--debugオプションで検証。Streaming currently is only compatible with non-recursive cp commandsと怒られていました。...ですよね。
コマンドの修正
find . -type d | while read dir do aws s3 cp $dir s3://$S3_BUCKET/$dir --recursive done
./dir内のファイルはs3の/dir/以下に、./dir2内のファイルは/dir2/以下に無事アップロード完了。
- 投稿日:2020-03-23T12:22:02+09:00
AWSで設計する SAP NetWeaver 可用性と災害対策 その2
はじめに
前項(その1)ではSAPで可用性を担保しなければならないコンポーネントと概要、そしてVeritas InfoScale の役割について紹介しました。ベリタスの災害対策モデルを使って手堅くクラウド移行を実現することでミッションクリティカルなシステムを安心してパブリッククラウドへ移行することが可能ですし、全てのコンポーネントをAWSで構成する場合もベリタスは安心して業務が継続できるシナリオをご用意しています。
サポートされる構成例は?
InfoScale は次のシナリオでSAP NetWeaverベースのアプリケーションインスタンスを監視および制御できます。
•1つのAZにすべてのSAPインスタンスを構成するケース
•複数のAZで構成するSAPインスタンスを構成するケース
•InfoScale エージェントを使用した SAP Web Dispatcher HA 構成
•SAPインスタンスのオンプレミスからAWSへのフェールオーバー
•クロスリージョンで構成するSAP on AWSAWSにすべてのSAPインスタンスを構成する場合
この場合、2つのEC2インスタンスがそれぞれSAPスタンドアロンエンキューサーバーとSAPエンキュー複製サーバー用に構成されています。SAPセントラルサービスインスタンス(メッセージまたはエンキュー)に障害が発生するとSAPNWエージェントはレプリケーションサーバーに切り替えます。フェイルオーバーシナリオはSAPの高可用性認定ガイドラインに従って機能します。
InfoScale SAPNWエージェントはエンキューサーバーおよびエンキューレプリケーションサーバーの以下のフェイルオーバーシナリオを実現します。
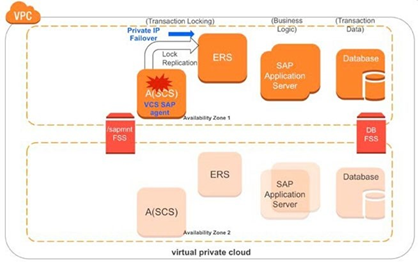
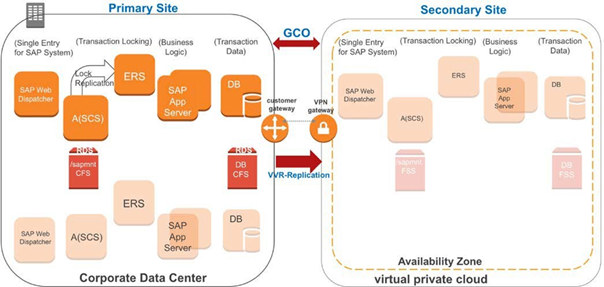
1つのAZで構成されたSAPアプリケーションインスタンスの場合
仮想ホスト名を使用してSAP Central Serviceインスタンスをインストールおよび構成し、仮想ホスト名が他のすべてのSAPインスタンスホストから解決できることを確認します。
この場合、エンキューサーバーとエンキュー複製サーバーのインスタンスは同じAZに存在します。エンキューまたはレプリケーションパラメータをTRUE(enque / server / replication = true)に設定すると、すべてのエンキューロックがエンキューサーバーにレプリケートされ、レプリケーションサーバーで使用可能になります。エンキューサーバーのインスタンスが失敗するか、利用できなくなると、SAPNWエージェントは障害を検出し、エンキューサーバーのエンキューレプリケーションサーバーノードへのフェイルオーバーを自動的にトリガします。結果、エンキューレプリケーションサーバーはエンキューサーバーに変換されます。
図-2(左)、 図-3(右)です。具体的には左側でSAP A(SCS)インスタンスに障害が発生し、右側のようにフェールオーバー後にエンキューレプリケーションサーバーがエンキューサーバーに変換されます。障害がクリアされてフェールバックが完了すると、エンキューレプリケーションサーバーはエンキュー サーバーからエンキューロックのレプリケートを開始します。
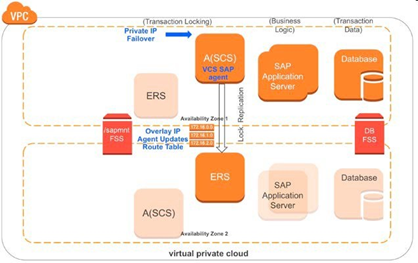
複数のAZで構成された SAP アプリケーションインスタンス
このユースケースではSAP エンキューおよび SAP エンキューレプリケーションインスタンスは、最初にアベイラビリティーゾーン1で実行されます。SAP ダイアログと SAP データベースインスタンスは 同じ AZ 内にあるか、複数の AZ に分散されています。
図 4 – FSSでディスクストレージをアクティブ/アクティブで同期させた複数のアベイラビリティーゾーンのSAP フェールオーバーSAP エンキューサーバーに障害が発生すると、SAPNW エージェントは自動的にエンキューレプリケーションサーバーにフェイルオーバーさせ、レプリケートされたエンキューロックをエンキューレプリケーションサーバーからロードします。この場合、InfoScale のAWS IP および IP エージェントは仮想 IP のフェールオーバーを行います。
図 5 – マルチAZでのエンキューサーバーのフェールオーバーが完了次の図はエンキューレプリケーションサーバーがアクティブで、エンキュートランザクションロックがAZの2にレプリケートされていることを示しています。
図 6 - AZ2 にレプリケートされたエンキュートランザクションロック障害が発生した状態がクリアされ、以前のエンキュー (ASCS) サーバーでメンテナンスが完了したら、前のエンキュー サーバーでエンキュー レプリケーション サーバーを再起動できます。SAPNW および SAPComponents エージェントを使用して、エンキュートランザクションロックを失うことなく、AZ間でエンキューレプリケーションインスタンスを切り替えることができます。InfoScaleは、SAP データベースおよび SAP ダイアログインスタンスの単一障害点を排除します。詳細については、InfoScale のマニュアル「Cluster Server Agent for SAP NetWeaver Installation and Configuration Guide」をご覧ください。
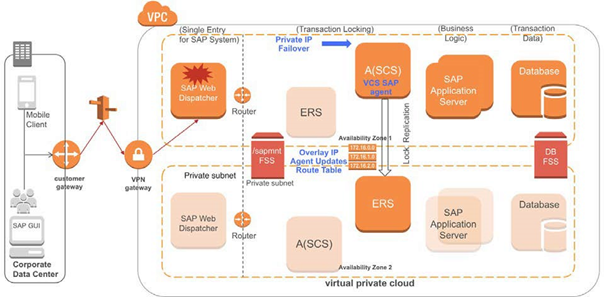
InfoScaleエージェントを使用した SAP WEB Dispatcher HA
SAPComponents エージェントと AWS Route53 エージェントは連携してAZ全体で SAP Web ディスパッチャーインスタンスを監視および制御します。このユースケースではSAP Web ディスパッチャーはエラスティックIP ではなくプライベートIP で設定および管理されます。仮想 IPは異なるAZで同じホスト名にカスタマイズされます。
SAP Web ディスパッチャーが AZ で使用できなくなった場合、SAPComponents エージェントは同じ仮想ホスト名を使用して別の AZ にフェールオーバーします。このシナリオではクライアントはAZ 間で同じホスト名で接続することができ、これは AWS Route53 エージェントによって管理されます。
次の図は複数のAZにまたがる一般的な SAP の構成パターンです。SAP Web ディスパッチャーインスタンスはAZ 1 でアクティブであり、AZ 2ではスタンバイです。
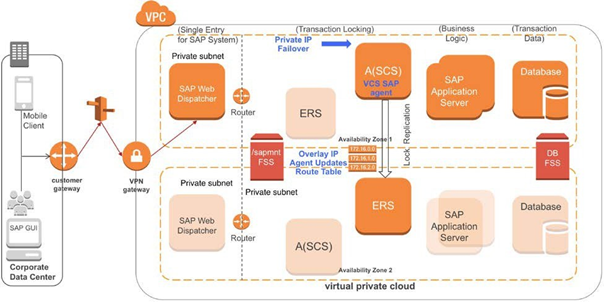
図 7 - 複数のAZにまたがる SAP 構成次の図はSAPComponents エージェントが障害を検出し、インスタンスを別の AZ にフェールオーバーする準備ができていることを示しています。
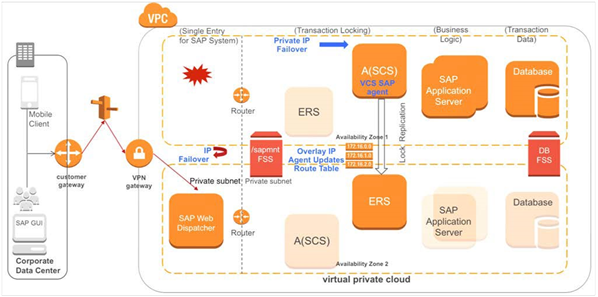
図 8 – SAP Webディスパッチャーのフェールオーバー
次の図はSAP Web ディスパッチャーがアベイラビリティーゾーン 2 にフェールオーバーしたことを示しています。AWS Route53 エージェントはフェールオーバーポリシーに従い、Web ディスパッチャーホスト名の DNS レコードを変更します。これにより、Web ベースのクライアントの接続が容易になります。
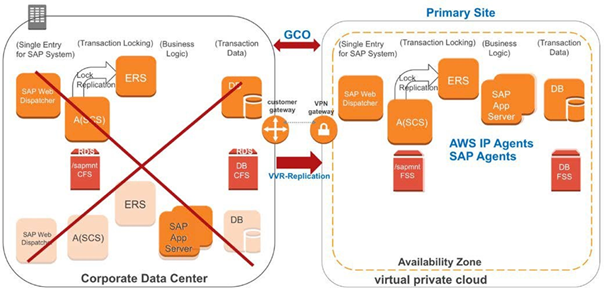
図 9 – AWS Route53 エージェントのフェールオーバーオンプレミスのSAPから AWS へのフェールオーバー
このユースケースは、すべての SAP アプリケーションインスタンスをプライマリサイトとしてオンプレミスに構成しています。 sapmnt、トランス、データベース・データ・ボリューム、ログ・ボリュームなどの共有ディスクコンポーネントは InfoScale CFS で構成されます。VVR はサイト間でのデータのレプリケーションを管理します。AWS (セカンダリサイト) では、ストレージボリュームは Amazon EBS に割り当てられ、冗長化を実現するために FSS を使用しています。次の図はVVR によるオンプレミスと AWS の間のレプリケーションを使った DR のシナリオを示しています。
図 10 – 本番サイトからAWSへのDRを実現するためのプリケーションプライマリサイトで障害が発生するとすべての SAP アプリケーションインスタンスとデータベースインスタンスが AWS にフェイルオーバーされます。なお、障害発生時でなくても、手動でAWSに切り替えることも可能です。AWS IP および AWS Route53 エージェントはAWS で仮想 IP と仮想ホスト名を管理します。次の図はフェールオーバー後の環境を示しています。
図 11 – DR フェールオーバー後のAZでの起動オンプレミスと AWS 間での DR の設定
オンプレミス サイトと AWS間で DR 環境を構成する為のステップは、以下のようになります。
1. オンプレミスと AWSを接続する VPN を構成します。
2. クラスタを構成する全てのシステムに Veritas InfoScaleをインストールしてセットアップします。具体的な手順については、Veritas InfoScale のインストールガイドを参照してください。
3. SAP の推奨するLUNを割り当て、VxVMおよびVxFSのコマンドを使用してCFSディスクグループとボリュームを作成します。
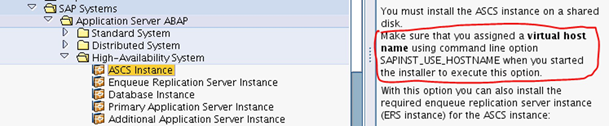
4. SAP のデータ領域様に次のファイルシステムをオンプレ上の稼働系システムでマウントします。/sapmnt/<SID> /usr/sap/trans /usr/sap/<SID>/ASCSxx /usr/sap/<SID>/ERSxx /usr/sap/<SID>/DVEBMGSxx /usr/sap/<SID>/Dxx5.オンプレミスのシステムに SAP関連コンポーネントをインストールしてセットアップします。ERP、CRM、SCM、SRMなどのSAPアプリケーションを実行できる事を確認します。SAP NetWeaver の導入時には、次のように仮想ホスト名を使用して高可用性オプションを選択する必要があります。
SAPINST_USE_HOSTNAME=<virtual_host_name>
個々のインスタンスが異なるホスト名で構成されていることを確認し、仮想ホスト名を用いることを確認します。
- オンプレミスと AWS 間のレプリケーションを構成します。データセンターから AWS までのレプリケーションに必要なすべてのポートが有効になっていることを確認します。具体的な手順については Veritas InfoScale Replication Administrator's Guideを参照してください。
次のような次の環境を準備します。
a. Amazon EC2 インスタンスを作成します。
b. 必要な SSD または標準の Amazon EBS ボリュームを接続します。
c. VxVM/VxFS および FSSを使用してディスクグループとボリュームを構成します。
d. 異なるEC2 インスタンスの EBS ボリューム間のデータ共有のために FSS を設定します。
e. すべての SAP 共有ボリュームと SAP データベースボリュームをマウントします。具体的な手順についてはStorage Foundation Cluster File System High Availability 管理者ガイド を参照してください。ベリタスは、AWS で SAP NetWeaver の設定を確認するために次の EBS ボリュームタイプをテストしています。
• gp2 (SSD)
• Standard (magnetic disks)※FSS はすべての EBS ボリュームタイプをサポートします
- SAP アプリケーションインスタンス、AWS IP エージェント、および AWS Route53 エージェントの InfoScale クラスターサービスグループとリソースを設定します。
- 最初はオンプレミスのデータセンターで SAP に関連するコンポーネント全体をオンラインにします。
- 初期データ同期が完了し、VVR が AWS (セカンダリサイト) にデータのレプリケートを開始したことを確認します。
AWSリージョン間をフェールオーバーするSAP
AWSの異なるリージョンを跨ってのフェールオーバーシナリオは、オンプレミスと AWS の間のフェールオーバーシナリオと同等です。したがって、AWS リージョン間でのフェールオーバーを同様に設定し、データのレプリケーションと冗長化に VVR を使用することもできます。これによりアクティブなサイト (リージョン) で障害が発生した場合に、より優れた RPO と RTO を実現できます。引き続き FSS を使用してAWS リージョン内のストレージを管理します。
おわりに
いかがでしたでしょうか。ちょっと長かったですね。5つのユースケースについてご理解いただけたでしょうか。次回はインスタンスの最適化と実際のコードスニペットについてお送りします。前置きが長い!
商談のご相談はこちら
本稿からのお問合せをご記入の際には「お問合せ内容」に#GWCのタグを必ずご記入ください。ご記入いただきました内容はベリタスのプライバシーポリシーに従って管理されます。


- 投稿日:2020-03-23T08:51:53+09:00
AWSサーバレス環境における必要最低限の監視設定 ( ECS + Fargate 編 )
AWSでちょっとしたプロダクト(MVP)をECS+Fargateが開発したようなケースでアプリケーションを運用開始したときに、とりあえずそこまで手間はかけたくないけど最低限の監視はしたいという場合のために、箇条書き程度ですが、必要設定項目を整理してみました。
もしこういういった観点も必要だよねというのがありましたらご指摘いただけますと幸いです。
前提条件
- ECS + Fargate 環境でアプリケーションを運用する環境
- EC2を利用したサーバー運用がないこと
- ECS Serviceに対してAuto Scaling Groupが適用されていること
- アプリケーションの要件的に 24/365監視を専属のインフラチームが対応するほどではないこと
- 夜間にアラートがなったら PagerDuty等のインフラチームのメンバーの電話を鳴らすような仕組みは今回は対象外です
- インフラの監視にはあまりコストはかけたくなく、監視に関するツールはAWS内になるべく閉じたいこと
- CloudTrail, AWS Configの設定が有効であること
- 後述するGuardDutyを使用するためには、AWSリソース操作の証跡を残す必要があるため
セキュリティ監視
- Trusted Advisor で警告が無いかを定期的に確認します
- 1ヶ月に一回ぐらいは、IAM Userの使用状況や設定状況を定期的に棚卸しをします
- GuardDutyで異常な通知を受けた場合は対応します
- GuardDutyはAWS ChatbotによるSlack通知設定が可能なため、基本的には異常時にSlack通知が飛ぶようにしてそこだけ見ていれば大丈夫なようにします
- 参考: AWS ChatBotでGuardDutyアラートをSlack通知
- Personal Health Dashboardでインシデントが発生した場合は対応します
- Personal Health Dashboard はAWS ChatbotによるSlack通知設定が可能なため、基本的には異常時にSlack通知が飛ぶようにしてそこだけ見ていれば大丈夫なようにします
- 参考: AWS Chatbot を使って AWS Personal Health Dashboardの通知をいい感じにSlackに通知する
外形監視
- 以下の観点でサービスが正しく動作しているか、ユーザー影響の把握のための監視をおこないます
- 5xxステータスコードを返していないか
- レスポンスタイムに異常無いか
- Cloudwatch Synthetics でアプリケーションのエンドポイントの外形監視を行います
- Canaryを作成するとblueprintが発行されるので、timeout値を定義修正してレスポンスタイムが一定値を超えた場合をエラーとするように任意で変更します
- 異常時はCloudwatch alermイベントが発行されるのでSNSで通知を受け取ってLambda経由でslackに通知します
- なお、Cloudwatch alermのイベントをSNS経由でLambdaからslack通知をする際は blueprintを使用しますが、通常のCloudwatch alertのイベントのメッセージの構造が微妙に違うので以下のように修正します。
- alarm_name = message['AlarmName'] - new_state = message['NewStateValue'] - reason = message['NewStateReason'] + alarm_name = message['detail']['alarmName'] + new_state = message['detail']['state']['value'] + reason = message['detail']['state']['reason']リソース監視
- マネージドなリソースでもCPUやストレージなどリソース制限があるものに対して監視をおこないます
- 例えばRDSのStorageのオートスケーリングが有効の場合はコスト面だけ監視していれば大丈夫かと思います
- Cloudwatch Metricsでひとつひとつの監視項目にたいしてCloudwatch Alermのイベント設定をおこないます
- Cloudwatch alermをSNSで受け取って lambda経由でslackに通知します
- ECRのイメージスキャンを有効にして、脆弱性の監視を行います
アプリケーション監視
- Sentryでアプリケーションのエラー監視を行います
- アプリケーションのエラー監視だけはAWSのサービスだけだと効率よく検知、分析ができないので外部サービスを利用します
- Sentryはチーム利用は最低料金は月26ドルですが、複数のPJを跨って使用が可能なので、会社でまるっと契約して利用すると効率よく低コストでアプリケーションのエラー監視ができるかと思います
- 個人のPJの場合は無料枠でも利用ができます
- 基本的には Slack channel に異常時に通知が飛ぶようにできるので、そこだけ見ていれば大丈夫なようにしておきます
- アプリケーションのログはCloudWatch logsで閲覧できるようにしておきます
- 障害発生時の調査材料としてアプリケーションのログは CloudWatch logsで見れるようにしておきます
コスト監視
- コストが必要以上にかかっていないかを確認します。
- PJによってはインフラの予算が決まっていると思うので、料金が上回りそうな場合は通知を受け取るような仕組みを作っておきます
- 参考: AWSサービス毎の請求額を毎日Slackに通知してみた
参考
- 投稿日:2020-03-23T01:28:36+09:00
Fargate 導入概要 メモ
Fargate のメモ
Fargate
AWS で簡単に Docker コンテナを動かせるサービス。
ただし、独自の概念が多く、慣れる必要がある。筆者は以前に導入を試みて、挫折した。今日(2020/03/23)試してみたら、ドキュメントが良くなったのか、オンボーディングが良くなったのか、意外とすんなり理解できたので、記録しておく
なぜ Fargate なのか
前提として
- PV 換算すると 月20万PVほどのアクセスのWebサービスを運用している
- インフラエンジニアが不在なので、あまり煩わしい作業はしたくない
- かといって、 EC2 はプロビジョニングとか面倒だし、ElasticBeanstalk はデプロイに時間かかるし小回りが効かない(経験談)
- とりあえず動けばOKなサービスに適用する(本サービスではなく、LP + アルファな感じ。Next.js利用)
AWS には EKS など魅力的なサービスがあるが、意外と高い。コントロールパネルを動かしているだけで、15000円くらいかかるらしい(と、AWS の方に言われた)
さくっとサービス動かすだけなら、 Fargate の方が簡単で安いらしい(と、AWS の方に言われた)
値下げされたのも大きい。
EKS でも、 EKS + Fargate とかあるので、どうせならシンプルな方にしたい。ので、再入門した。
独自概念の説明
登場人物は4人。
- Cluster
- Service
- Task
- Task Definition
- Elastic Container Registry (ECR)
色々あって戸惑うが、このうち、 Service と Task Definition だけ考えれば良い(多分)
Task Definition
多分これが大事で、 Task Definition は Docker Image の定義だと考えれば良い。 Docker Image だけで完結できれば楽なのだが、バージョニングとかの関係でこうなっていると思う。
オブジェクト指向的に考えると、 Task Definition はクラス、 Task はクラスのインスタンス、である。
AWS EC2的に考えると、 Task Definition は AMI、Task はEC2 Instance、 である。Service
基本的には、 Task Definition を定義して、 Service にその Task Definition を適用する。
Task Definition を Service に適用すると、 Task が作成される。つまり、 Private/PublicIP アドレスなどは Task に割り当てられる。ECR
ECR はただ Docker Image をプッシュするだけなので、特に難しいことは一切ない。ログインが必要なくらいだが、 「View push commands」 押せば難しいことはない。
運用
今回は、導入なので、非常に簡単な Web API をデプロイしてみることにした。具体的には下記。
app.jsrequire('http') .createServer((req, res) => { console.log(req.headers) res.end('ok') }) .listen(3000)FROM node:12.16.1-alpine WORKDIR /app ADD app.js /app CMD node app.js環境構築
Cluster + Service を作成し、 Task Definition を定義して、 ALB や Route 53 の設定をすれば、意外と素直に動いてくれる。
なお、Task に割り当てられた Public IP address を叩いても、動く。 Fargate 公式デモの Nginx のクラスタも、この方式で動く。 ALB の設定等で、時間を取らせたくないのだろう。
特に設定しなくても、ログが管理コンソール上で見れるのは嬉しい。
デプロイ
デプロイに若干はまった。
はまりどころとしては、イメージの更新がある。
まず、 ECR に新しい Docker Image をプッシュする。
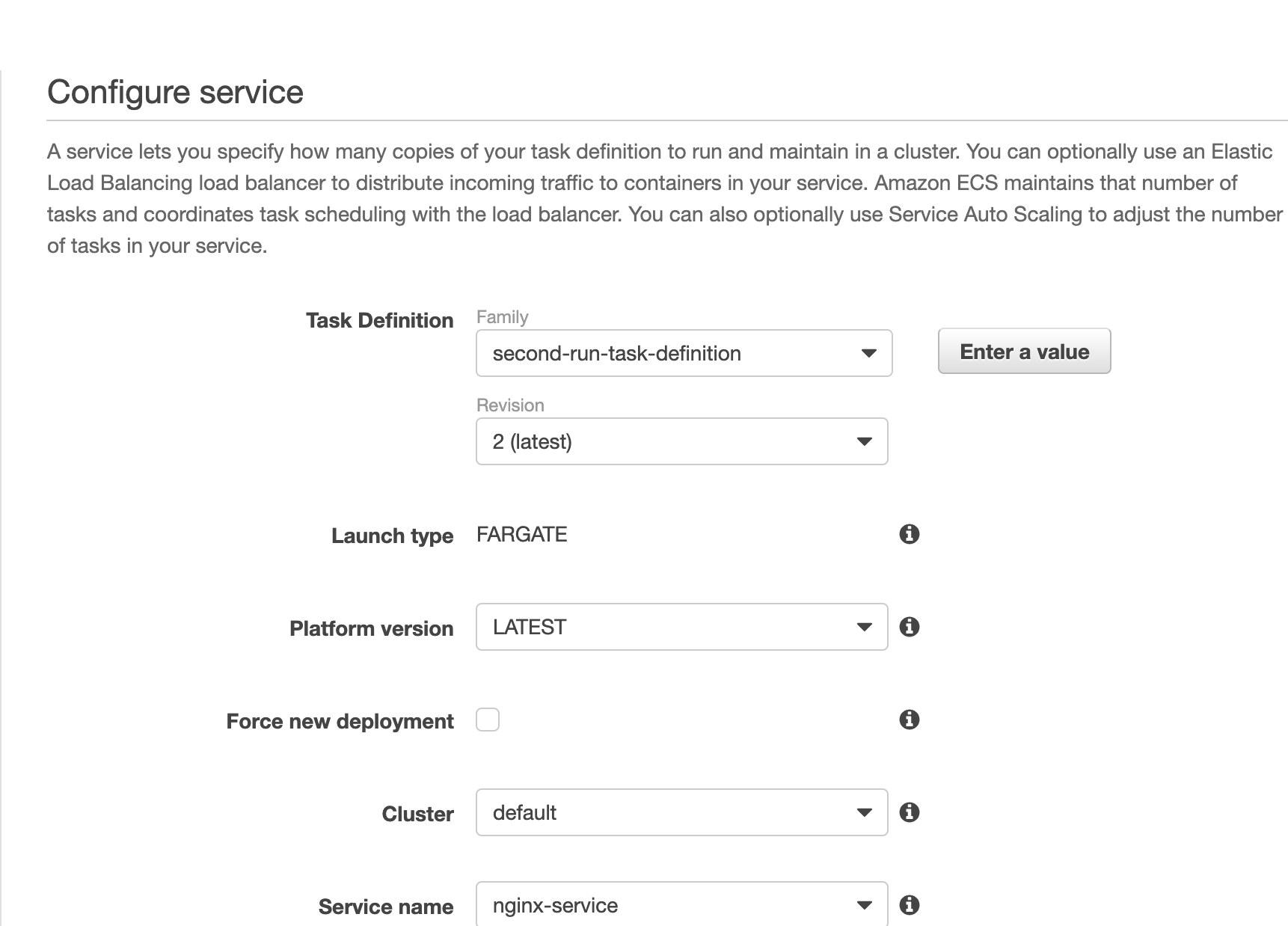
次に、 Task Definition を update して、 Docker Image を更新する。ここまでは良い。次に、単純に考えると、 Task を新しい Task Definition に Update と思うが、実際には Task ではなく Service をアップデートする 。多分、一度作成した Task は更新できないようになっているのだろう。 Immutable Infrastructure 的な。
管理コンソールでは、 Service を Update しようとすると下記のような画面が出てくるので、 Task Definition を最新にすれば良い。
これで Service を更新すると、自動的に新しい Task Definition を搭載した Task が作成され、デプロイされる。
今後
管理コンソールでサービス起動/更新するのは、割と簡単にできたが、以下の4点を調べる必要があるので、引き続き調査していく。
- 1. Terraform で、どこまで/どうやって管理するのか。 ecs-cli との棲み分けは?
- 2. 自動的なデプロイの仕組み。多分、上記で手動でやった
ECR にプッシュ → Task Definitionのバージョン作成 → Serviceの更新という流れは変わらないと思われるので、 ecs-cli でやればいけそう。- 3. Private IP Address が毎回変わるだが、これは固定する もしくは ALB Target Group に Fargate の Task を指定する方法はあるのだろうか・・・? Terraform なら設定できるのか、最悪 CLI で都度設定するか・・・