- 投稿日:2020-03-23T23:50:45+09:00
AtCoderの挑戦環境構築(Java8)
はじめに
AtCoderの挑戦環境が自分として満足できるところまで構築できたので
皆様のお役に立てるかはわかりませんが情報共有を兼ねて記事にまとめさせていただきました。モチベーション
- 自社風潮よりJavaを学習しておいたほうが良さそうに感じだしていた
- 3/1より本格的にJava学習を開始
- 習うより慣れよということでCodingBatにて問題を解きまくり
- 問題の易しさもあり飽きが来ていたので情報収集からAtCoderに到達
- 2020/3/14(土)開催のパナソニックプログラミングコンテスト2020にて初参加。
平方根の誤差調整ができずA,B2問のみという惨敗を喫した。- その後過去問題の演習に励むが、はじめに利用していたCodingBatとは違い、
テストケースの容易や提出が徐々に手間と感じるようになる。
(問題選択ミスや言語選択ミスでのWAを何回も・・・)- 各種情報を集めてローカル上から色々と操作できるように環境を構築。
問題に集中できるようになった。- 同じ悩みを持っている人がいるかも?と思った。(今ここ)
対象環境
Windows10での構築をしました。
WSLでも構築できましたが、特に優劣ない状態になったのでどちらでも良いと思います。
構築後は以下のような状態になります。
- Windows10
- Java(JDK)
- VSCode
- Java Extension Pack
- WSL(選択の自由)
- Python3(pip3)
- online-judge-tools
- Node.js(npm)
- atcoder-cli
1. Javaのインストール
AtCoderではOpenJDK1.7.0またはOpenJDK1.8.0が使用できます。
私はJava SE 8をローカル環境にインストールしました。
1. Java SE Downloadsからインストーラのダウンロード
2. インストーラに従いインストール。
3. インストール場所を変えてる人も変えてない人もバージョン管理も兼ねて環境変数を調整することを推奨
<新規> JAVA_HOME : [Javaをインストールした場所。Default:C:\Program Files\Java\jdk1.8.0_xxx]
<更新> PATHに追加: %JAVA_HOME%\bin2. VSCodeのインストール
省略。私の記事をリンクしておきます。
Visual Studio CodeをオフラインPCで使用する
拡張機能はJava Extension Packがあれば足りると思います。
Eclipse使ってるとか他のエディタ使ってる場合は入れる必要ありません。3. WSL
Microsoft Storeにて「WSL」で検索すればいくつかでてきます。
どれ入れたらいいかわからない方はUbuntu18.04で問題ないかと思います。(記事も多いです)
以降のPython3/Node.jsはWindowsに入れるか、WSLに入れるかで
参考とするページの内容も異なるかと思いますので、ここで決めておいたほうが良いでしょう。4. Python3/online-judge-toolsおよびNode.js/atcoder-cli
atcoder-cliのページでこの4点の導入について優しく書いてありますので、従いながらインストールしていきます。
5. Javaでの提出を簡単にする工夫
上記でatcoder-cli/online-judge-toolsを導入したことで以下が簡略化しています。
- 問題に合わせたフォルダ作成(contestID/A~Fフォルダ)
- テンプレート設定したファイルの配置
- サンプルテストケース取得
- サンプルテスト判定
何かが足りません。そう、提出です。
設定方法が不足しているのか、今は機能不足で未対応なのかわかりませんが、Javaソースの提出をatcoder-cliから行うと「バージョン選択してね!」って怒られちゃいます。
online-judge-toolsでは言語指定できるので実行できるのですが、こちらだと毎回URL入力しないといけません。
・・・ブラウザのほうが楽。
なので、カバーするためにバッチを作りました。
atcoder-cliの提出操作acc sを借用してaccs(空白なし)で作成しました。
(WSLの方はaliasやbashで対応できると思います。)accs.bat@echo off setlocal enabledelayedexpansion rem --- メインシーケンス setlocal rem コマンド実行位置取得 FOR /F %%i in ('cd') do set pwd=%%i rem コマンド実行位置に移動 cd %pwd% rem ローカルパスからコンテストID、タスクIDを取得 rem 例) C:\AtCoder\abc123\a set contest_id=%pwd:~-8,6% set task_id=%pwd:~-1% rem コンテストID、タスクIDをパラメータにして提出コール call :Submit %contest_id% %task_id% endlocal exit /b rem --- 提出シーケンス :Submit rem online-judge-toolsにて言語指定して提出 rem パラメータからURLを作成 oj submit -l Java8 --no-guess https://atcoder.jp/contests/%1/tasks/%1_%2 Main.java exit /bまとめ
提出も無事、ローカルから出来るようになったので
ブラウザで問題確認後はVSCodeかじりつきで提出までいけるようになりました。
環境構築できた後は、ブラウザのコードテストページでコーディングしていた状況にはもう戻れません。蛇足:なぜWSLでなくWindowsを選択したか
蛇足ではありますが、Windows/WSLの選択で、私がWindowsにした理由は
過去問題のテストケースファイルが名前バラバラなので、名前変更頻度が高く、
リネームコマンドの便宜性からWindowsにしています。
例1) inフォルダ内の01.txt, 02.txt, ... 20.txtを01.in, 02.in, ... 20.inにしたい
Windows:ren *.txt *.in
Linux:rename txt in *.txt例2) inフォルダ内の01, 02, ... 20を01.in, 02.in, ... 20.inにしたい
Windows:ren * *.in
Linux:rename 's/$/.in/' *
Windowsのコマンドのほうが私には直感的なのでWindowsで作業しています。
- 投稿日:2020-03-23T22:22:07+09:00
Java(jdk1.8以降)のファイル入出力のサンプルプログラム
Javaの(jdk1.8以降)のファイル入出力のサンプルプログラムのメモです。
1. バイナリファイルの読み込み
1.1. 一括読み込み
C:/dk/input.xlsxを一括で読み込み、16進数で標準出力に出力するサンプルプログラムです。
一括で読み込む場合、Outofmemoryにならないようサイズに注意する必要があります。BinaryFileInputNio.javapackage test.nio; import java.io.IOException; import java.nio.file.Files; import java.nio.file.Path; import java.nio.file.Paths; /** * バイナリーファイルを読み込む */ public class BinaryFileInputNio { /** * @param args */ public static void main(String[] args) { // 読み込みファイルの名前 Path path = Paths.get("C:/dk", "input.xlsx"); try { // バイナリファイル一括読み込み byte[] data = Files.readAllBytes(path); // 読み込んだバイナリデータを16進数で標準出力に出力 for (int i = 0; i < data.length; i++) { System.out.printf("%02x ", data[i]); } System.out.println(); } catch (IOException e) { e.printStackTrace(); } } }1.2. 分割読み込み
C:/dk/input.xlsxを1024バイト単位で読み込み、16進数で標準出力に出力するサンプルプログラムです。BinaryFileInputNioPart.javapackage test.nio; import java.io.IOException; import java.io.InputStream; import java.nio.file.Files; import java.nio.file.Path; import java.nio.file.Paths; /** * バイナリーファイルを読み込む */ public class BinaryFileInputNioPart { /** * @param args */ public static void main(String[] args) { // 読み込みファイルの名前 Path path = Paths.get("C:/dk", "input.xlsx"); // 入力ストリームの生成 try (InputStream inst = Files.newInputStream(path)) { // 読み込み用バイト配列 byte[] buf = new byte[1024]; int len = 0; // 入力ストリームからの読み込み(ファイルの読み込み) while ((len = inst.read(buf)) != -1) { // 読み込んだバイナリデータを16進数で標準出力に出力 for (int i = 0; i < len; i++) { System.out.printf("%02x ", buf[i]); } System.out.println(); } } catch (IOException e) { e.printStackTrace(); } } }2. バイナリファイルの書き込み
2.1. 一括書き込み
バイナリデータを
C:/dk/output.datに一括で書き込むサンプルプログラムです。BinaryFileOutputNio.javapackage test.nio; import java.io.IOException; import java.nio.file.Files; import java.nio.file.Path; import java.nio.file.Paths; /** * バイナリーファイルを書き込む */ public class BinaryFileOutputNio { /** * @param args */ public static void main(String[] args) { // 書き込みファイルの名前 Path path = Paths.get("C:/dk", "output.dat"); // バイナリデータ byte[] data = { (byte)0xe3, (byte)0x83, (byte)0x86, (byte)0xe3, (byte)0x82, (byte)0xad, (byte)0xe3, (byte)0x82, (byte)0xb9, (byte)0xe3, (byte)0x83, (byte)0x88, (byte)0xe3, (byte)0x83, (byte)0x95, (byte)0xe3, (byte)0x82, (byte)0xa1, (byte)0xe3, (byte)0x82, (byte)0xa4, (byte)0xe3, (byte)0x83, (byte)0xab, (byte)0xe5, (byte)0x87, (byte)0xba, (byte)0xe5, (byte)0x8a, (byte)0x9b, (byte)0x30, (byte)0x31, (byte)0x0d, (byte)0x0a, (byte)0xe3, (byte)0x83, (byte)0x86, (byte)0xe3, (byte)0x82, (byte)0xad, (byte)0xe3, (byte)0x82, (byte)0xb9, (byte)0xe3, (byte)0x83, (byte)0x88, (byte)0xe3, (byte)0x83, (byte)0x95, (byte)0xe3, (byte)0x82, (byte)0xa1, (byte)0xe3, (byte)0x82, (byte)0xa4, (byte)0xe3, (byte)0x83, (byte)0xab, (byte)0xe5, (byte)0x87, (byte)0xba, (byte)0xe5, (byte)0x8a, (byte)0x9b, (byte)0x30, (byte)0x32, (byte)0x0d, (byte)0x0a}; try { // バイナリデータ一括書き込み Files.write(path, data); } catch (IOException e) { e.printStackTrace(); } } }2.2. 分割書き込み
バイナリデータを
C:/dk/output.datに分割で書き込むサンプルプログラムです。BinaryFileOutputNioPart.javapackage test.nio; import java.io.IOException; import java.io.OutputStream; import java.nio.file.Files; import java.nio.file.Path; import java.nio.file.Paths; /** * バイナリーファイルを書き込む */ public class BinaryFileOutputNioPart { /** * @param args */ public static void main(String[] args) { // 書き込みファイルの名前 Path path = Paths.get("C:/dk", "output.dat"); // バイナリデータ byte[] data1 = { (byte)0xe3, (byte)0x83, (byte)0x86, (byte)0xe3, (byte)0x82, (byte)0xad, (byte)0xe3, (byte)0x82, (byte)0xb9, (byte)0xe3, (byte)0x83, (byte)0x88, (byte)0xe3, (byte)0x83, (byte)0x95, (byte)0xe3, (byte)0x82, (byte)0xa1, (byte)0xe3, (byte)0x82, (byte)0xa4, (byte)0xe3, (byte)0x83, (byte)0xab, (byte)0xe5, (byte)0x87, (byte)0xba, (byte)0xe5, (byte)0x8a, (byte)0x9b, (byte)0x30, (byte)0x31, (byte)0x0d, (byte)0x0a}; byte[] data2 = { (byte)0xe3, (byte)0x83, (byte)0x86, (byte)0xe3, (byte)0x82, (byte)0xad, (byte)0xe3, (byte)0x82, (byte)0xb9, (byte)0xe3, (byte)0x83, (byte)0x88, (byte)0xe3, (byte)0x83, (byte)0x95, (byte)0xe3, (byte)0x82, (byte)0xa1, (byte)0xe3, (byte)0x82, (byte)0xa4, (byte)0xe3, (byte)0x83, (byte)0xab, (byte)0xe5, (byte)0x87, (byte)0xba, (byte)0xe5, (byte)0x8a, (byte)0x9b, (byte)0x30, (byte)0x32, (byte)0x0d, (byte)0x0a}; // バイナリデータ書き込み try (OutputStream os = Files.newOutputStream(path)) { os.write(data1); os.write(data2); } catch (IOException e) { e.printStackTrace(); } } }3. テキストファイルの読み込み
3.1. 一括読み込み
C:/dk/input.txtを一括で読み込み、標準出力に出力するサンプルプログラムです。
一括で読み込む場合、Outofmemoryにならないようサイズに注意する必要があります。TextFileInputNio.javapackage test.nio; import java.io.IOException; import java.nio.charset.StandardCharsets; import java.nio.file.Files; import java.nio.file.Path; import java.nio.file.Paths; import java.util.List; /** * テキストファイルの読み込み */ public class TextFileInputNio { /** * @param args */ public static void main(String[] args) { // 読み込みファイルの名前 Path path = Paths.get("C:/dk", "input.txt"); try { // テキストファイルを一括読み込み List<String> lines = Files.readAllLines(path, StandardCharsets.UTF_8); // 読み込んだテキストファイルを標準出力に出力 lines.forEach(line -> System.out.println(line)); } catch (IOException e) { e.printStackTrace(); } } }3.2. 分割読み込み(BufferedReaderを使用)
C:/dk/input.txtをBufferedReaderで読み込み、標準出力に出力するサンプルプログラムです。TextFileInputNioPart1.javapackage test.nio; import java.io.BufferedReader; import java.io.IOException; import java.nio.charset.StandardCharsets; import java.nio.file.Files; import java.nio.file.Path; import java.nio.file.Paths; /** * テキストファイルの読み込み */ public class TextFileInputNioPart1 { /** * @param args */ public static void main(String[] args) { // 読み込みファイルの名前 Path path = Paths.get("C:/dk", "input.txt"); // BufferedReaderの生成 try (BufferedReader br = Files.newBufferedReader(path, StandardCharsets.UTF_8)) { String msg; // テキストファイルからの読み込み while ((msg = br.readLine()) != null) { // 標準出力に出力 System.out.println(msg); } } catch (IOException e) { e.printStackTrace(); } } }3.3. 分割読み込み(Streamを使用)
C:/dk/input.txtをStreamで読み込み、標準出力に出力するサンプルプログラムです。TextFileInputNioPart2.javapackage test.nio; import java.io.IOException; import java.nio.charset.StandardCharsets; import java.nio.file.Files; import java.nio.file.Path; import java.nio.file.Paths; import java.util.stream.Stream; /** * テキストファイルの読み込み */ public class TextFileInputNioPart2 { /** * @param args */ public static void main(String[] args) { // 読み込みファイルの名前 Path path = Paths.get("C:/dk", "input.txt"); // Streamの生成 try (Stream<String> lines = Files.lines(path, StandardCharsets.UTF_8)) { // 標準出力に出力 lines.forEach(line -> System.out.println(line)); } catch (IOException e) { e.printStackTrace(); } } }4. テキストファイルの書き込み
4.1. 書き込み(BufferedWriterを使用)
BufferedWriterを使用して、テキストデータを
C:/dk/output.txtに書き込むサンプルプログラムです。TextFileOutputNio1.javapackage test.nio; import java.io.BufferedWriter; import java.io.IOException; import java.nio.charset.StandardCharsets; import java.nio.file.Files; import java.nio.file.Path; import java.nio.file.Paths; /** * テキストファイルへの書き込み */ public class TextFileOutputNio1 { /** * @param args */ public static void main(String[] args) { // 書き込みファイルの名前 Path path = Paths.get("C:/dk", "output.txt"); // BufferedWriterの生成 try (BufferedWriter bw = Files.newBufferedWriter(path, StandardCharsets.UTF_8)) { // ファイルへの書き込み for (int i= 1; i <= 2; i++) { bw.write("テキストファイル出力" + String.format("%02d", i)); bw.newLine(); } } catch (IOException e) { e.printStackTrace(); } } }4.2. 書き込み(PrintWriterを使用)
PrintWriterを使用して、テキストデータを
C:/dk/output.txtに書き込むサンプルプログラムです。TextFileOutputNio2.javapackage test.nio; import java.io.BufferedWriter; import java.io.IOException; import java.io.PrintWriter; import java.nio.charset.StandardCharsets; import java.nio.file.Files; import java.nio.file.Path; import java.nio.file.Paths; /** * テキストファイルへの書き込み */ public class TextFileOutputNio2 { /** * @param args */ public static void main(String[] args) { // 書き込みファイルの名前 Path path = Paths.get("C:/dk", "output.txt"); try ( // PrintWriterの生成 BufferedWriter bw = Files.newBufferedWriter(path, StandardCharsets.UTF_8); PrintWriter pw = new PrintWriter(bw); ) { // ファイルへの書き込み for (int i= 1; i <= 2; i++) { pw.println("テキストファイル出力" + String.format("%02d", i)); } } catch (IOException e) { e.printStackTrace(); } } }
以上
- 投稿日:2020-03-23T17:45:20+09:00
spring-batchで複数DataSource定義時に使用する@BatchDataSource
spring-batchで複数のDataSourceを定義する場合、
@BatchDataSourceでspring-batchのauto-configurationで使用する方を指定できる。@BatchDataSourceのjavadocによると2.2.0で追加されたものらしい。その定義は以下のようになっており、実態は単なる
@Qualifier。javadocによると典型的な使い方としては、@Primaryを付与するメインのDataSourceと、このアノテーションを付与するspring-batch用のセカンドDataSource、というもの。メインとなるDBと、メタデータ格納先DBが分かれてる場合にこれを使う、といった感じだろう。/** * Qualifier annotation for a DataSource to be injected into Batch auto-configuration. Can * be used on a secondary data source, if there is another one marked as * {@link Primary @Primary}. * * @author Dmytro Nosan * @since 2.2.0 */ @Target({ ElementType.FIELD, ElementType.METHOD, ElementType.PARAMETER, ElementType.TYPE, ElementType.ANNOTATION_TYPE }) @Retention(RetentionPolicy.RUNTIME) @Documented @Qualifier public @interface BatchDataSource { }使用例。
@Bean @BatchDataSource public DataSource springBatchDs() { return DataSourceBuilder.create().url("jdbc:h2:~/test").username("sa").password("").build(); } @Bean @Primary public DataSource primaryDs() { return DataSourceBuilder.create().url("jdbc:oracle:thin:system/oracle@localhost:11521/XEPDB1").username("system").password("oracle").build(); }上記の例の場合、メインはOracle、メタデータ格納先をH2、としている。
従来もこういう設定が出来なかったわけではないが、専用アノテーションにより意図が明示しやすくなる、と思われる。
- 投稿日:2020-03-23T16:15:51+09:00
【Java】JavaでMethod/ConstructorからKFunctionを取得する【Kotlin】
やること
JavaのMethod/ConstructorからKFunctionを取り出します。やり方
下記の
Method.kotlinFunction/Constructor<T>.kotlinFunctionをJavaから呼び出せばできます。具体的には以下のようになります。
KFunction<?> function = ReflectJvmMapping.getKotlinFunction(Foo.class.getConstructors()[0]);注意点
ClassからのMethod/Constructor取得にはジェネリクスの型パラメータが設定されていない場合が多いため、型パラメータを入れたい場合はJava内でキャストする必要があります。KFunction<Foo> function = ReflectJvmMapping.getKotlinFunction((Constructor<Foo>) Foo.class.getConstructors()[0]);参考にさせて頂いた記事
- 投稿日:2020-03-23T16:10:42+09:00
[Java] UbuntuにJavaの開発環境を構築&実行確認
環境
Ubuntu
VSCodeやること
- Java, Maven, Intellij インストール
- vscodeの設定
- 実行確認
- エラー対処法
インストール
以下、aptアップデートとjavaインストールとjavaバージョン確認をまとめて行うので注意です。
Java
インストール
sudo apt update && sudo apt install default-jdk && java -versionopenjdk version "11.0.6" 2020-01-14 OpenJDK Runtime Environment (build 11.0.6+10-post-Ubuntu-1ubuntu118.04.1) OpenJDK 64-Bit Server VM (build 11.0.6+10-post-Ubuntu-1ubuntu118.04.1, mixed mode)JAVA_HOME 設定
jdkのインストール場所は/usr/lib/jvm/にあるのでこちらのパスを〇〇rcファイルへ追記する
~/.〇〇rcファイル# ------------------------------------------------------------------ # java # ------------------------------------------------------------------ export JAVA_HOME=/usr/lib/jvm/java-version-xxx-jdk export PATH="$PATH:$JAVA_HOME/bin"Maven
インストール
sudo apt update && apt install maven && mvn -versionApache Maven 3.6.0 Maven home: /usr/share/maven Java version: 11.0.6, vendor: Ubuntu, runtime: /usr/lib/jvm/java-11-openjdk-amd64 Default locale: ja_JP, platform encoding: UTF-8 OS name: "linux", version: "4.15.0-54-generic", arch: "amd64", family: "IntelliJ IDEA Community Edition
インストール
① PPAから
sudo add-apt-repository ppa:mmk2410/intellij-idea-community sudo apt update sudo apt install intellij-idea-community② ソフトウェアセンターから
intellijで検索してインストールをクリック
VSCode
インストール
wget -q https://packages.microsoft.com/keys/microsoft.asc -O- | sudo apt-key add -sudo add-apt-repository "deb [arch=amd64] https://packages.microsoft.com/repos/vscode stable main"sudo apt update && sudo apt install codeVSCodeの設定
拡張機能
Java Extension Pack
- 何も考えずにこれを入れる。
- Java開発に使うツールが必要最低限まとめてインストールされます。 https://marketplace.visualstudio.com/items?itemName=vscjava.vscode-java-pack
Code Runer
- 選択した範囲をデバッグできます。
- Ctrl + Alt + N でCode Runnerを実行できます。
https://marketplace.visualstudio.com/items?itemName=formulahendry.code-runner
settings.json
java.home
JAVAをVSCode上で実行できるようになります。maven.executable.path
MavenコマンドがVSCode上で実行できるようになります。code-runner.runInTerminal
terminalでCodeRunnerの入出力を可能にします。
code-runner.executorMap
code runner実行時のコマンドを設定します。
デフォルトの設定だと対象のファイルをfileNameWithoutExt拡張子なしと見なすため、デバッグの実行場所によってはエラー( java.lang.NoClassDefFoundError) となることがあります。これは$fileNameとすることで回避できますmavenの実行パスを調べるwhich mvn > /usr/bin/mvnsettings.json[ // Java "java.home":"/usr/lib/jvm/java-version-xxx-jdk", // Maven "maven.executable.path": "/usr/bin/mvn", // Code Runner "code-runner.runInTerminal": true, ]実行確認
- VSCodeを使います。
- 適当なディレクトリを作成してHelloWorld.javaファイルを作成する。
- メインメソッドがある箇所がデバックされます。
メインメソッド
public static void main(String[] args)
これを必ず記述します。~/java_lessons/hello_java/HelloWorld.javapublic class HelloWorld { public static void main(String[] args) { System.out.println("Hello World!"); } }実行
以下のどちらでも実行可能。コンパイル&実行されます。
- Code Runnerで実行する ( Ctrl + Alt + N)
- Run > Start Debugging ( F5 )
[Done] exited with code=1 in 1.227 seconds [Running] cd "/home/user/java_lessons/hello_java/" && javac HelloWorld.java && java HelloWorld Hello World!メインメソッドが無いと
次のようになります。エラー: メイン・メソッドがクラスHelloWorldで見つかりません。次のようにメイン・メソッドを定義してください。 public static void main(String[] argsエラー例
対処法など
The compiler compliance specified is x.x but a JRE x.y is used
.settings/org.eclipse.jdt.core.prefsの該当の数字をJREのバージョンに合わせるeclipse.preferences.version=1 org.eclipse.jdt.core.compiler.codegen.targetPlatform= x.y org.eclipse.jdt.core.compiler.compliance= x.y org.eclipse.jdt.core.compiler.problem.enablePreviewFeatures=disabled org.eclipse.jdt.core.compiler.problem.forbiddenReference=warning org.eclipse.jdt.core.compiler.problem.reportPreviewFeatures=ignore org.eclipse.jdt.core.compiler.processAnnotations=disabled org.eclipse.jdt.core.compiler.release=disabled org.eclipse.jdt.core.compiler.source= x.y
- 投稿日:2020-03-23T16:10:42+09:00
[Java] UbuntuにJavaの開発環境を構築メモ
環境
Ubuntu
インストール
以下、aptアップデートとjavaインストールとjavaバージョン確認をまとめて行うので注意です。
sudo apt update && sudo apt install default-jdk && java -version実行結果openjdk version "11.0.6" 2020-01-14 OpenJDK Runtime Environment (build 11.0.6+10-post-Ubuntu-1ubuntu118.04.1) OpenJDK 64-Bit Server VM (build 11.0.6+10-post-Ubuntu-1ubuntu118.04.1, mixed mode)JAVA_HOME設定
jdkのインストール場所は/usr/lib/jvm/にあるのでこちらのパスを〇〇rcファイルへ追記する
~/.〇〇rcファイル# ------------------------------------------------------------------ # java # ------------------------------------------------------------------ export JAVA_HOME=/usr/lib/jvm/java-version-xxx-jdk export PATH="$PATH:$JAVA_HOME/bin"VSCodeの設定
settings.jsonにjava.homeを設定してJAVAが実行できるようにします。パスは同上です。
settings.json// JAVA [ "java.home":"/usr/lib/jvm/java-version-xxx-jdk", ]
- 投稿日:2020-03-23T13:09:43+09:00
gh-ost実行履歴をflywayのバージョン管理下に置くにはどうするか
gh-ostとflywayについて
なぜgh-ostを使うのか/なぜflywayを使うのかは公式に任せる
解決したい問題
flywayでバージョン管理したいが、gh-ostを直接実行してスキーマ変更すると、その変更はflyway管理下に置けない
flyway migrateしたときにgh-ostコマンドが実行されて、成功/失敗がマークされるようにしたいどうするのか
flywayの Custom Migration resolvers & executors を使って
gh-ostコマンドを実行できるようにする
公式は使い方が全く書いてないので、以下使い方を解説する
なお、この記事では flyway-core 6.1.1を使用
OSコマンドを実行することになるので自己責任でCustom Migration resolvers & executors について
登場人物
- MigrationExecutor
- flyway migrateしたときの処理を定義するためのクラス
ResolvedMigrationに持たせることで、Flyway本体に実行させることができる- executeを実装すればよい
- ResolvedMigration
- 1つのmigrationのversionやdescription、
MigrationExecutorなどを定義するためのクラスgetVersionなど実装すべきメソッドは多いが、いちばん大事なのはgetExecutor- flyway infoしたときに表示される表の1行分の情報を持つと思えばいい。flyway infoの表ってのは↓みたいなやつ。
+-----------+---------+------------------------------------------+------+--------------+---------+ | Category | Version | Description | Type | Installed On | State | +-----------+---------+------------------------------------------+------+--------------+---------+ | Versioned | 1.0 | init | SQL | | Pending | | Versioned | 1.1 | add index for hoge | SQL | | Pending | | Versioned | 1.2 | renamed unnecessary tables | SQL | | Pending | | Versioned | 2.0 | drop unnecessary tables | SQL | | Pending | +-----------+---------+------------------------------------------+------+--------------+---------+
- MigrationResolver
- ファイルなどを解決して
Collection<ResolvedMigration>を返す- デフォではSQL-based MigrationsとJava-based Migrationsに必要なResolverが定義されている
resolveMigrationsを実装すればよい実装
src/main/resources/ghostに置いたファイルを読み込んでgh-ost使っていくケースを書いてみる概要
- Maven Plugin や Gradle Plugin あたりを使ってflywayを実行できるようにしておく
- MigrationExecutorを実装したクラスを作成
- ResolvedMigrationを実装したクラスを作成
- MigrationResolverを実装したクラスを作成
- Resolverをconfで指定する
1. Maven Plugin や Gradle Plugin あたりを使ってflywayを実行できるようにしておく
とりあえず、ここではMaven Pluginの例を。別にMavenじゃなくてもいいです。
pom.xml<project> ... <dependencies> <dependency> <groupId>org.flywaydb</groupId> <artifactId>flyway-core</artifactId> <version>6.1.1</version> </dependency> </dependencies> <build> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>11</source> <target>11</target> </configuration> </plugin> <plugin> <groupId>org.flywaydb</groupId> <artifactId>flyway-maven-plugin</artifactId> <version>6.1.1</version> <configuration> <locations> <location>classpath:db/migration</location> </locations> </configuration> <dependencies> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.18</version> </dependency> </dependencies> </plugin> </plugins> </build> </project>2. MigrationExecutorを実装したクラスを作成
class GhostMigrationExecutor implements MigrationExecutor { private final File file; GhostMigrationExecutor(File file) { this.file = file; } @Override public void execute(Context context) throws SQLException { // fileを読み込んで、ここで具体的なgh-ostのコマンドを実行する。ProcessBuilderなどを使うことになると思う。 } @Override public boolean canExecuteInTransaction() { return false; //gh-ostはALTER TABLEしか扱えなくて、それはオートコミットなのでトランザクションに入れたらダメ。 } }3. ResolvedMigrationを実装したクラスを作成
class ResolvedGhostMigration implements ResolvedMigration { private final File file; private final MigrationVersion version; private final String description; ResolvedGhostMigration(File file) { //この辺はFlywayオリジナルのBaseJavaMigrationがクラス名からversionとdescriptionを割り出すロジックを流用してる boolean repeatable = file.getName().startsWith("R"); if (!file.getName().startsWith("V") && !repeatable) { throw new FlywayException("Invalid file name: " + file.getName() + " => ensure it starts with V or R"); } else { String prefix = file.getName().substring(0, 1); Pair<MigrationVersion, String> info = MigrationInfoHelper.extractVersionAndDescription(file.getName(), prefix, "__", new String[]{".properties"}, repeatable); this.file = file; this.version = info.getLeft(); this.description = info.getRight(); } } @Override public MigrationVersion getVersion() { return this.version; } @Override public String getDescription() { return this.description; } @Override public String getScript() { return this.file.getName(); } @Override public Integer getChecksum() { // こいつがnullを返すのはオリジナルのResolvedJavaMigrationに準ずる。コンストラクタで渡されたfileから一意なchecksumを作ってnull以外を返してもよい。 // checksumを設定しておくと、すでにSuccessになったmigrationに利用したファイルをあとから編集したときにエラーを吐いてくれるようになる。 return null; } @Override public MigrationType getType() { // flyway infoしたときの `Type` カラムの値に使われる。Custom MigrationであることがわかるようにCUSTOMを返す return MigrationType.CUSTOM; } @Override public String getPhysicalLocation() { return this.file.getAbsolutePath(); } @Override public MigrationExecutor getExecutor() { return new GhostMigrationExecutor(this.file); //2で作成したExecutorを返すようにする } }4. MigrationResolverを実装したクラスを作成
public class GhostMigrationResolver implements MigrationResolver { @Override public Collection<ResolvedMigration> resolveMigrations(Context context) { try { return Files.walk(Paths.get(getClass().getResource("/ghost/").toURI())) //src/main/resources/ghostディレクトリを読み込み .map(Path::toFile) .filter((file) -> !file.isDirectory()) // ghostディレクトリ自身を除外 .map(file -> new ResolvedGhostMigration(file)) // 3で作ったResolvedMigrationのインスタンスを生成 .collect(Collectors.toList()); } catch (IOException | URISyntaxException e) { throw new FlywayException(e.getMessage(), e.getCause()); } } }5. Resolverをconfで指定する
Mavenで作ったので、pom.xmlで指定できる
pom.xml<project> ... <dependencies> <dependency> <groupId>org.flywaydb</groupId> <artifactId>flyway-core</artifactId> <version>6.1.1</version> </dependency> </dependencies> <build> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>11</source> <target>11</target> </configuration> </plugin> <plugin> <groupId>org.flywaydb</groupId> <artifactId>flyway-maven-plugin</artifactId> <version>6.1.1</version> <configuration> <locations> <location>classpath:db/migration</location> </locations> <!-- ここから --> <resolvers> <resolver>path.to.GhostMigrationResolver</resolver> </resolvers> <!-- ここまで追加 --> </configuration> <dependencies> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.18</version> </dependency> </dependencies> </plugin> </plugins> </build> </project>もしくは、flyway.confで指定してもよい
# ...その他の設定 flyway.resolvers=path.to.GhostMigrationResolver注意
gh-ostとflywayは別々にコネクションを獲得することになり、gh-ostの実行中にflywayのコネクションがタイムアウトする可能性がある
実行する際はautoReconnect=trueにするなどの対策をしておいたほうがいい
- 投稿日:2020-03-23T11:22:02+09:00
分子系統学演習をdockerで
分子系統学演習 データセットの作成から仮説検定まで 田辺晶史 2015/10/20
https://www.fifthdimension.jp/documents/molphytextbook/molphytextbook.ja.htmljava
最適な Java の Docker イメージを選びたい
https://k11i.biz/blog/2018/05/17/base-docker-images-for-java/Java 11 リリース後のオススメ Docker イメージを考える
https://k11i.biz/blog/2018/10/29/base-docker-images-for-java11/Javaのサポートについてのまとめ2018
https://qiita.com/nowokay/items/edb5c5df4dbfc4a99ffbJDKの公式Dockerイメージを使って手っ取り早くjshellを使うメモ
https://qiita.com/hi5san/items/d2f2fc77683530073267$ docker run -v /tmp/work:/tmp/work -it openjdk /bin/bash docker: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?. See 'docker run --help'.# apt update; apt -y upgrade bash: apt: command not foundopenjdk
https://hub.docker.com/_/openjdk
adoptopenjdk
https://hub.docker.com/_/adoptopenjdk
adoptopenjdk/openjdk11 - Docker Hub
https://hub.docker.com/r/adoptopenjdk/openjdk11/$ docker run -v /tmp/work:/tmp/work -it adoptopenjdk/openjdk11:alpine-slim /bin/bash Unable to find image 'adoptopenjdk/openjdk11:alpine-slim' locally alpine-slim: Pulling from adoptopenjdk/openjdk11 c9b1b535fdd9: Pull complete c27d8e400471: Pull complete deee333e69e3: Pull complete 951b04c9812e: Pull complete Digest: sha256:9f18e54372102ed0cd3cb782d49d147d03cc2f3a8f08f096ee95b84563685441 Status: Downloaded newer image for adoptopenjdk/openjdk11:alpine-slim docker: Error response from daemon: OCI runtime create failed: container_linux.go:346: starting container process caused "exec: \"/bin/bash\": stat /bin/bash: no such file or directory": unknown.参考資料(reference)
Dockerで色んなJDKを試す
https://qiita.com/kikutaro/items/d140f519253f276b94e0DockerコミュニティがメンテしているOpenJDKイメージを使って遭遇した問題
https://matsumana.info/blog/2018/10/13/openjdk11-docker/自己参考資料(self reference)
生物系統計資料
https://qiita.com/kaizen_nagoya/items/6ebfb7bae0495424061e
- 投稿日:2020-03-23T11:22:02+09:00
分子系統学演習をdockerで(作業中)
分子系統学演習 データセットの作成から仮説検定まで 田辺晶史 2015/10/20
https://www.fifthdimension.jp/documents/molphytextbook/molphytextbook.ja.htmlをdockerで動かそうと悪戦苦闘中(作業中)
java
最適な Java の Docker イメージを選びたい
https://k11i.biz/blog/2018/05/17/base-docker-images-for-java/Java 11 リリース後のオススメ Docker イメージを考える
https://k11i.biz/blog/2018/10/29/base-docker-images-for-java11/Javaのサポートについてのまとめ2018
https://qiita.com/nowokay/items/edb5c5df4dbfc4a99ffbJDKの公式Dockerイメージを使って手っ取り早くjshellを使うメモ
https://qiita.com/hi5san/items/d2f2fc77683530073267$ docker run -v /tmp/work:/tmp/work -it openjdk /bin/bash docker: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?. See 'docker run --help'.# apt update; apt -y upgrade bash: apt: command not foundopenjdk
https://hub.docker.com/_/openjdk
adoptopenjdk
https://hub.docker.com/_/adoptopenjdk
adoptopenjdk/openjdk11 - Docker Hub
https://hub.docker.com/r/adoptopenjdk/openjdk11/$ docker run -v /tmp/work:/tmp/work -it adoptopenjdk/openjdk11:alpine-slim /bin/bash Unable to find image 'adoptopenjdk/openjdk11:alpine-slim' locally alpine-slim: Pulling from adoptopenjdk/openjdk11 c9b1b535fdd9: Pull complete c27d8e400471: Pull complete deee333e69e3: Pull complete 951b04c9812e: Pull complete Digest: sha256:9f18e54372102ed0cd3cb782d49d147d03cc2f3a8f08f096ee95b84563685441 Status: Downloaded newer image for adoptopenjdk/openjdk11:alpine-slim docker: Error response from daemon: OCI runtime create failed: container_linux.go:346: starting container process caused "exec: \"/bin/bash\": stat /bin/bash: no such file or directory": unknown.参考資料(reference)
Dockerで色んなJDKを試す
https://qiita.com/kikutaro/items/d140f519253f276b94e0DockerコミュニティがメンテしているOpenJDKイメージを使って遭遇した問題
https://matsumana.info/blog/2018/10/13/openjdk11-docker/自己参考資料(self reference)
生物系統計資料
https://qiita.com/kaizen_nagoya/items/6ebfb7bae0495424061e
- 投稿日:2020-03-23T10:15:28+09:00
Effective Java 第3版 「ほぼ全章」を「読みやすい日本語」で説明してみました。
Effective Javaは「一人前」のJavaエンジニアになるために避けては通れない書籍だと思います。特に公開APIを作るような立場にいるエンジニアは、この書籍に書かれてあることを把握していないと、まともなものを作れません。
素晴らしい書籍だということは言うまでもありませんが、一方で「要するにこういうことだよね」という理解をしづらい書籍であるとも感じます。
その原因は、おそらく以下のとおりでしょう。
- 表現が回りくどいです。
- 全部で90の項目がありますが、項目内の構造が分かりづらいです。
- コード例が必要以上に複雑な場合があります。
内容の本質そのものはあまり難しくないのに、こういった理由でこの書籍の敷居が上がるのは、何と言うかもったいないと思います。
そこで、本記事では(ほぼ)全項目について、できるだけ「読みやすい日本語」で内容を説明してみたいと思います。
ただし、あまりにも当たり前の話だったり、読むのが簡単な項目などについては、解説を省略しました。また、私見も混ざっています。そういった前提でご覧いただければと思います。
なお、Effective Java 第3版はJava 9をターゲットに執筆されています。そこで、Java 9の公式ドキュメントのありかを念のため載せておきます(意外にたどり着きづらいですので)。
[Java 9] 公式ドキュメント トップ
https://docs.oracle.com/javase/jp/9/[Java 9] JDKのJavadoc(トップ画面から辿れます)
https://docs.oracle.com/javase/jp/9/docs/toc.htm[Java 9] Java言語仕様(トップ画面から辿れます)
https://docs.oracle.com/javase/specs/jls/se9/html/index.html第1章 はじめに
書籍で使う用語の定義などが書いてあるだけです。読まなくても良いでしょう。(おわり)
第2章 オブジェクトの生成と消滅
項目1 コンストラクタの代わりにstaticファクトリメソッドを検討する。
例えば、以下のような感じです。
- NG: BigInteger(int, int, Random) ← コンストラクタ。分かりづらい。
- OK: BigInteger.probablePrime(int, Random) ←staticファクトリメソッド。分かりやすい。
まずはstaticファクトリメソッドを検討し、それが微妙ならコンストラクタを選びましょう。
◆長所
①分かりやすい名前をつけることができる。
コンストラクタだと以下の不都合があります。
コンストラクタの名前は1つ(クラス名)に限定されてしまいます。
コンストラクタ同士を区別するのは引数の違いだけです。この結果、利用者はコンストラクタ間の違いを理解しづらいです。
staticファクトリメソッドには、このような不都合はありません。
②新たなオブジェクトを生成する必要がない。同じオブジェクトを使いまわせる。
③戻り値の型そのものではなく、そのサブタイプのオブジェクトを返せる。
例えば、java.util.Collectionsには
emptyList()というstaticなファクトリメソッドがあります。以下の特徴があります。
emptyList()は、内部クラスEmptyListのインスタンスを返却します。内部クラスEmptyListは、publicではありませんから、外部から隠蔽できます。emptyList()の戻り値の型は、Listインターフェースです。このおかげで、CollectionsのAPIはとても簡潔です。具体的には・・・
実装者にとっては、EmptyListの使い方(API)を利用者に説明する必要がありません。
利用者にとっては、EmptyListの存在を意識する必要はないですし、使い方(API)を理解する必要もありません。
Listインターフェースの使い方だけ知っておけば使えます。④ 状況に応じて、返却するサブタイプを切り替えることができる。
③では、常に同じサブタイプを返却する状況を想定して解説されています。
④で言いたいのは、「複数のサブタイプの中から、状況に応じたものを選んで返却できる」ということです。⑤ 返却するサブタイプは、実行時に決まってもOK。(staticファクトリメソッドの実装時点で決まっていなくてもOK。)
例えば、JDBCの
DriverManager.getConnection()がこれに該当します。結果、APIとしての柔軟性が高まります。
◆短所
①利用者は、戻り値の型のサブクラスを作れない。
例えば、java.util.Collectionsの
emptyList()ではEmptyListが返却されますが、EmptyListはprivateなクラスのため、利用者はEmptyListのサブクラスを作れません。この例に限らず、私にはサブクラスを作りたくなるようなケースを思いつけませんでした。
実務上は短所や制約には全く感じないと思います。②利用者は、staticファクトリメソッドを見つけづらい。
これは確かにそうですよね。Javadocではコンストラクタは別のセクションとなるため目立ちますが、staticファクトリメソッドはメソッドの一覧に埋もれてしまいます。
以下のような一般的な命名パターンに沿うことで、利用者にとって分かりやすいAPIとするよう、心がけましょう。
命名パターン 例 意味合い from Date d = Date.from(instant);型変換する。 of Set<Rank> faceCards = EnumSet.of(JACK, QUEEN, KING);集約する。 valueOf BigInteger prime = BigInteger.valueOf(Integer.MAX_VALUE);from、 ofと同じ意味で使われる。 instance / getInstance StackWalker luke = StackWalker.getInstance(options);パラメータに応じたインスタンスを返す。 create / newInstance Object newArray = Array.newInstance(classObject, arrayLen);呼び出しごとに新たなインスタンスを返す。 get型名 FileStore fs = Files.getFileStore(path);自身のクラスとは異なるクラスを返却する。 new型名 BufferedReader br = Files.newBufferedReader(path);自身のクラスとは異なるクラスを返却する。呼び出しごとに新たなインスタンスを返す。 型名 List<Complaint> litany = Collections.list(legacyLitany);get型名、new型名の短縮版。 参考
Collections Frameworkの概要
https://docs.oracle.com/javase/jp/9/docs/api/java/util/doc-files/coll-overview.html項目2 多くのコンストラクタパラメータに直面したときにはビルダーを検討する
【NG】テレスコーピング・パターン
public class NutritionFacts { // フィールド定義は省略 public NutritionFacts(int servingSize, int servings) { this(servingSize, servings, 0); } public NutritionFacts(int servingSize, int servings, int calories) { this(servingSize, servings, calories, 0); } // 上記のような流れが延々と続いていく・・・ }NGな点
- 利用者にとってどうでも良いパラメータであっても、設定を強制させてしまいます。
- 利用者は、何番目のパラメータが何かを気にする必要があり、とても大変です。(実務上は、IDEで多少軽減されます)
- コードの読み手は、各パラメータの意味を理解しづらいです。(実務上は、IDEで多少軽減されます)
- 型さえ合っていればコンパイルエラーにはならないので、同じ型のパラメータを誤った順番で指定しても、利用者は間違いに気づけません。
【NG】JavaBeansパターン
// 何の変哲もない、ふつうのJavaBeansです。 public class NutritionFacts { // フィールド定義は省略 public NutritionFats() {} public void setServingSize(int val) { //略 } public void setServings(int val) { //略 } public void setCalories(int val) { //略 } // まだまだsetterが続く・・・ }NGな点
- インスタンス化した後に、パラメータ間で不整合が起こるかもしれません。本来は、インスタンス化する前にそういった不整合を検知すべきです。
- setterから内部の状態を変更できるわけなので、クラスを不変にできません。
【Builderパターン】
// 利用者側のコード NutritionFacts cocaCola = new NutritionFacts.Builder(240, 8). calories(100).sodium(35).carbohydrate(27).build();長所
- 実装しやすいです。
- 読みやすいです。
build()でインスタンス化する前に、パラメータ間の不整合を検知できます。この長所はとっても重要です。なぜなら、不整合がここで検知されず、遠い場所で不整合を起因とするエラーが起きてしまうと、原因の特定が困難になってしまうからです。- クラスが階層構造になっている場合でも、このパターンを適用できます。
- APIが柔軟になります。例えば、1つのBuilder(のインスタンス)を使い回し、
build()内でシリアル番号を採番することで、一意なオブジェクトをどんどん生成できます。短所(些細なものです)
- Builderをインスタンス化する必要があり、性能要件がシビアな状況では気にする必要があります。しかし、実務上はそんな状況は稀だと思いますので、些細な短所です。
- テレスコーピングパターンより、利用者のコードが長くなってしまいます。なので、パラメータの数が多い時に使うのが良いかもしれません。ただ、パラメータの数は保守していくとどんどん増えていくこともありますし、途中からBuilderパターンに変更するのは非現実的なので、些細な短所です。
項目3 privateのコンストラクタかenum型でシングルトン特性を強制する
シングルトンを実現する方法は以下の3つです。状況に応じて最良のものを選びましょう。
- enum型でシングルトンを実装する。 ← 多くの場合これが最適
- privateコンストラクタでインスタンスを1つ作って・・・
- publicなフィールドに設定して公開する。
- staticファクトリメソッドで返却する。
enum型でシングルトンを実装すると、こんな感じになります。
enum型のシングルトンpublic enum Elvis { INSTANCE; public void someMethod(); }他の方法ではシングルトンでなくなるリスクがあり、それを回避する手間が発生してしまいますので、enumを使う方法がベストです。具体的には以下のとおりです。
- privateコンストラクタの場合では、利用者がリフレクションによって内部のprivateコンストラクタを呼び出せてしまいます。これを防ぐためのチェック処理を書かねばらなず、面倒です。
- シングルトンのクラスをシリアライズできるようにしたい場合、デシリアライズの度にインスタンスが生成されてしまう恐れがあります。これを防ぐための処理を書かねばらなず、面倒です。(シリアライズしたい状況は稀だと思いますが・・)
こういったリスクは、実務ではほぼ無視して良いのではと思ってしまいますが、きちんと考えるべきですね。
enum型を使う方法は、実務では見たことがありませんが、上記の点で合理的ですので積極的に使うべきでしょう。
なお、privateコンストラクタを使う2つの方法には、以下の長所があります。ただ、こういった長所を得たいケースは限られるような気がしますので、結局は多くの場合にenumが最適だと言えるでしょう。
方法 長所 publicなフィールドに設定して公開する ・シングルトンであることがAPIから明確に理解できる
・単純staticファクトリメソッドで返却する ・シングルトンにすべきかどうかを後から変更できる
・ジェネリックのシングルトンファクトリにできる
・メソッド参照を使える項目4 privateのコンストラクタでインスタンス化不可能を強制する
staticなメソッドとstaticなフィールドだけで構成されるクラスは、一般にユーティリティクラスと呼ばれます。
このようなクラスは、本来インスタンス化して使うべきではないですが、コンストラクタが使えてしまうと、誤ってインスタンス化されてしまう恐れがあります。実害はあまりないような気はしますが、そういった使われ方をすると非常に残念な気持ちになりますね・・。
そこで、以下のようにprivateなコンストラクタを実装しましょう。
public class UtilityClass { // インスタンス化できないように、デフォルトコンストラクタを抑制する。 // このようにコメントを残しておくことで、このコンストラクタの実装意図を後世に伝えましょう。 private UtilityClass() { throw new AssertionError(); } }こうしてけば、誤ってインスタンス化されたり、誤って継承されてサブクラスを作られるのを防げます。
項目5 資源を直接結びつけるよりも依存性注入を選ぶ
スペルチェッカーを例に説明します。
【NG】ユーティリティクラスとして実装
public class SpellChecker{ // スペクチェックに使う辞書 private static final Lexicon dictionary = ...; // 項目4の作法に従い、インスタンス化を抑止 private SpellChecker() {} public static boolean isValid(String word) { ... } }【NG】シングルトンとなるように実装
// SpellChecker.INSTANCE.isValid("some-word"); のように使います。 public class SpellChecker{ // スペクチェックに使う辞書 private final Lexicon dictionary = ...; // 項目4の作法に従い、インスタンス化を抑止 private SpellChecker() {} public static SpellChecker INSTANCE = new SpellChecker(...); public static boolean isValid(String word) { ... } }これらのNG例では1つの辞書しか使えないため、状況に応じて辞書を切り替えることができません。この難点は、本番のコードではもちろんのこと、テストの時にも当てはまります。
setDictionary(lexicon)のようなメソッドを用意して、後から変更できるようにする手段もありますが、利用者にとって分かりにくいです。スレッドセーフでもありません。そもそも、辞書が状況によって変わるということは、辞書は「状態」に当たります。ですので、インスタンス化して利用されるようなクラスとして、スペルチェッカーを実装すべきでしょう。
具体的には以下のとおりです。
【OK】依存性注入のスタイルで実装
public class SpellChecker{ // スペクチェックに使う辞書 private final Lexicon dictionary; // 辞書という「状態」を持つのでインスタンス化して利用してもらう。 // この時、辞書という依存性を注入する。 public SpellChecker(Lexicon dictionary) { this.dictionary = Objects.requireNonNull(dictionary); } public static boolean isValid(String word) { ... } }こうすれば、状況に応じて辞書を切り替えることができますし、スレッドセーフとなります。
項目6 不必要なオブジェクトの生成を避ける
オブジェクトを再利用すると、オブジェクトの生成コストを最小限にして、速度を高めることができます。
逆に、不要なオブジェクトを多数生成してしまうと、ものすごく遅くなります。
不変なオブジェクト(イミュータブルなオブジェクト)は常に安全に再利用できるため、イミュータブルである、という性質はとっても重要なのです。
【NG その1】
// new String()で、不要なオブジェクトを生成している。 // "bikini"で、不要なオブジェクトを生成している。 String s = new String("bikini");【OK】
// 生成されるオブジェクトは、"bikini"のStringインスタンスのみ。 // 同じJVM内であれば、文字列リテラル"bikini"のインスタンスは常に再利用される。 String s = "bikini";【NG その2】
// コンストラクタなので、常に新たなオブジェクトが生成されてしまう。 new Boolean(String);【OK】
// staticファクトリメソッドでは、新たなオブジェクトを生成する必要はない。 // trueあるいはfalseのBooleanオブジェクトが、再利用される。 Boolean.valueOf(String);【NG その3】
// matchesの内部でPatternオブジェクトが生成される。 // isRomanNumeral()が呼び出されるたび、Patternオブジェクトが生成されてしまう。 static boolean isRomanNumeral(String s){ return s.matches("正規表現。内容は省略します。"); }【OK】
public class RomanNumerals { // Patternオブジェクトを再利用している。 private static final Pattern ROMAN = Pattern.compile("正規表現。内容は省略します。"); static boolean isRomanNumeral(String s) { return ROMAN.matcher(s).matches(); } }【NG その4】
// オートボクシングでのNG例 private static long sum() { Long sum = 0L; for (long i = 0; i <= Integer.MAX_VALUE; i++) // Longはイミュータブルなので、加算の度に新たなインスタンスが生成されてしまう。 sum += i; return sum; }【OK】
private static long sum() { // プリミティブ型に変更(Long -> long) long sum = 0L; for (long i = 0; i <= Integer.MAX_VALUE; i++) sum += i; return sum; }ちなみに、例えばMap.keySet()はSetビュー(アダプター)を返しますが、何度keySet()を呼び出しても、同じSetインスタンスが返却されます。呼び出す度に新しいインスタンスが生成されていると思いがちですが、こういった所でも実はインスタンスが再利用され、効率化が図られています。自分たちがAPIを実装する場合も、「新たなインスタンスを生成する必要ってあるのかな?」という視点に立ち、最適な実装をすべきですね。
項目7 使われなくなったオブジェクト参照を取り除く
クラスの中で、ガベージコレクターの管理の及ばない独自のメモリを管理している場合、不要になったオブジェクトの参照をクリアする必要があります(変数に
nullを設定します)。管理が及ばない、というのは実質的に未使用のオブジェクトであっても、ガベージコレクタはそのことを認識できない、という意味です。
普通は、スコープから外れた変数はガベージコレクションの対象になります。一方、クラス内でオブジェクトを管理していると、スコープから外れないわけですから、ガベージコレクションの対象になりません。ガベージコレクタから見ると、そのオブジェクトは使用されている、と見なされるわけですね。
書籍では、シンプルなスタック実装を例に、上記を解説しています。詳しくは書籍を参照ください。
独自のキャッシュを実装するケース
独自のキャッシュを実装する場合も、先述の「クラスの中で独自のメモリ管理をするケース」に該当します。
例えばHashMapで画像データをキャッシュする場合、HashMapは何らかのオブジェクトAのフィールドとして管理されるはずですから、以下のように参照が連なります。
利用元 -> オブジェクトA -> HashMap -> keyおよびvalueHashMapで管理するデータ(keyおよびvalue)が実際には不要になったとしても、オブジェクトAやHashMapが参照され続ける限り、そのデータがガベージコレクションされることはありません。結果、メモリは膨れ上がっていきます。
この場合の対処方法は以下のとおりです。(自分でキャッシュを実装する機会は、あんまり無いと思いますが・・)
方法① WeakHashMapでキャッシュを実装します。
WeakHashMapは、キーがそのWeakHashMapオブジェクト以外から参照されなくなると、そのエントリー(キーと値のペア)が次のGCの対象になります。いわゆる弱参照という仕組みを利用しています。
「キーがそのWeakHashMapオブジェクト以外から参照されない」という状態をもって、キャッシュから削除したい場合に、採用を検討しましょう。
と、本書では説明されていますが、そんな簡単にキャッシュから削除されてしまっては、もはやキャッシュと呼べないですよね。詳しくは、後述します。
方法② ScheduledThreadPoolExecutorで、定期的にキャッシュ中の古いデータを削除します。
ScheduledThreadPoolExecutorの使い方をザッと理解するには、こちらの記事がおすすめです。
https://codechacha.com/ja/java-scheduled-thread-pool-executor/キャッシュに登録してからある程度時間が経ったものを削除したい、という場合に採用を検討しましょう。
方法③ キャッシュに新たなエントリを追加する時に、古いものを削除する。
シンプルですね。これも②と同様、キャッシュに登録してからある程度時間が経ったものを削除したい、という場合に採用を検討しましょう。
リスナーやコールバックをメモリに登録するケース
クライアントからリスナーやコールバックを登録できるAPIを作る場合、きちんと考えてつくらないと、登録されたリスナーやコールバックがGCの対象になりません。
WeakHashMapのキーとして保存するなど、弱参照の仕組みを使うと良いでしょう。WeakHashMap以外の誰からも使われなくなったら、GCの対象になります。
参考:弱参照とは?
ふつうは参照元に到達できないオブジェクト(誰からも使われていないオブジェクト)は、GCの対象となりメモリから削除されます。
しかし、そのようにすぐ削除されては困る場合があります。参照元に到達できないオブジェクトであっても、すぐにGCの対象とならないようにする仕組みがあります。それがjava.lang.refパッケージです。
このパッケージの世界では、通常の参照のことを「強参照」と呼び、以下の通り独自の「参照」が定義されています。
java.lang.refにおける参照の種類 GC対象へのなりにくさ(相対値) 説明 用途 弱参照 ★
あっさり消される自分(WeakReferenceオブジェクト)だけが、あるオブジェクトAを参照している場合、次のGCの対象になります。 オブジェクトAへの強参照が無くなったら、オブジェクトAをすぐにメモリから消したい場合に使います。WeakHashMapでは、正にこの用途でWeakReferenceが利用されています。本書ではキャッシュの用途で使えるみたいなことが書いてありますが、強参照が無くなったら消えてしまうなんて、それはもはやキャッシュではないと思いますので、使う機会はほぼないと思います。 ソフト参照 ★★
けっこうしぶとい自分(SoftReferenceオブジェクト)だけが、あるオブジェクトAを参照している場合、参照先のオブジェクトが最近 作成/参照されたなら、次のGCの対象になりません。そうでない場合は、次のGCの対象になります。 キャッシュの用途で使うならこれだと思いますが、JavaSEにはこれをサポートするMapはありません。実際に使う機会はほぼ無さそうです。 ファントム参照 ★★★
基本的に消えない自分(PhantomReferenceオブジェクト)だけが、あるオブジェクトAを参照している状態となっても、GCの対象になりません。 (不明) 項目8 ファイナライザとクリーナーを避ける
ここでいうファイナライザとは、java.lang.Object#finalize()、あるいはそれをサブクラスでオーバーライドしたメソッドのことです。
クリーナーとは、java.lang.ref.Cleanerのことです。
これがダメな理由が、書籍には色々と書いてありますが、中身を理解する必要はほぼ無いです。
とにかく危険なので絶対に使わない。それで良いでしょう。
項目9 try-finallyよりもtry-with-resourcesを選ぶ
try-finallyには以下の問題があります。
- クローズ漏れが起きやすい。
- 漏れなくクローズしようとすると、ネストが増える。結果、コードは読みづらく、修正しづらくなる。
- 発生する例外を握り潰しやすい。
- 例外を握り潰さないようにするには、catch節を書く必要がある。結果、コードは読みづらく、修正しづらくなる。
try-with-resourcesを使うと、これらの問題が解消されます。
なお、try中に例外が発生し、その後にcloseでも例外が発生した場合、前者の方を優先してthrowします。catfh節で、これをキャッチできます。
後者にアクセスするには、前者の例外オブジェクトにあるgetSuppressedメソッドを使います。ただ、多くの場合は前者を知りたい場合が多いはずなので、使う機会はあまりなさそうです。
第3章 すべてのオブジェクトに共通のメソッド
項目10 equalsをオーバーライドするときは一般契約に従う
そもそもequalsメソッドをオーバーライドする機会は限定的だと思います。
もしオーバーライドするのであれば、満たすべき要件があります。もしequalsメソッドをオーバーライドすべき状況となったら、その要件を守りましょう。要件とは、具体的には以下のとおりです。
- 反射性:x.equals(x)はtrueを返す。
- 対称性:y.equals(x)がtrueの場合のみ、x.equals(y)はtrueを返す。
- 推移性:x.equals(y)とy.equals(z)がtrueなら、x.equals(z)はtrueを返す。
- 整合性:x.equals(y)を複数回呼び出した場合、その結果は同じとなる。
非null性:x.equals(null)はfalseを返す。
※x, y, zはnullでないとする。
書籍では、それぞれの要件について気を付けるべきことが書いてありますが、そもそもequalsをオーバーライドする機会はあまりありませんので、必要性がない時点で詳しく学ぶのは、コスパが低いでしょう。
このため、私は必要になった時に書籍を参照するに留め、本記事でも詳しくは解説しません。
項目11 equalsをオーバーライドするときは、常にhashCodeをオーバーライドする
項目10の通り、equalsをオーバーライドする機会はあまり無さそうなので、この項目もあまり重要性は高くなさそうです。概要を解説するに留めます。
hashCodeメソッドをオーバーライドする場合の要件は、以下のとおりです。
- hashCodeメソッドが複数回呼び出された場合、同じ値を返す。
- 2つのオブジェクトがequalsメソッドで等しいなら、2つのオブジェクトのhashCodeメソッドは、同じ値を返す。
- 2つのオブジェクトがequalsメソッドで異なるからといって、2つのオブジェクトのhashCodeメソッドも、別々の値を返す必要は無い。しかし、別々の値を返した方が、ハッシュテーブルのパファーマンスが改善されやすい。
項目12 toStringを常にオーバーライドする
toStringメソッドをオーバーライドするメリットは、そのクラスの利用者がデバッグをしやすくなることです。
ただ、実務でつくるシステムは芸術作品ではなく、人的・期間的なリソースは限られています。ですので、必要に応じてオーバーライドの要否を決めれば良いと思います。
もしtoStringメソッドをオーバーライドするなら、以下に気をつけましょう。
- 利用者が知るべきと思われる、全ての情報を出力しましょう。toStringは利用者のために存在することを意識しましょう。
- 戻り値の形式(例えば電話番号なら090-1234-5678)を決めるかどうかは、状況に応じて判断しましょう。利用者にとっては形式が定まっている方が嬉しいかもしれませんが、一度定めると後から変更しづらいです。バランスをとりましょう。
項目13 cloneを注意してオーバーライドする
Object.clone()をオーバーライドするのは原則NGです。理由は以下の通りです。
- オーバーライドする時に満たすべき要件が、コンパイラで強制されないばかりか、Javadocに明記されてすらいません。
- その要件はかなり複雑です。詳細は書籍をご覧ください。
- オーバーライドしたメソッドでは、super.clone()という形でObject.clone()を呼び出す必要があります。その際、以下の煩雑さが生まれます。
- Object.clone()がthrowするかもしれない、CloneNotSupportedExceptionを処理する必要があります。
- Object.clone()の戻り型はObjectですが、実務上はこれを特定の型にキャストする必要があります。
- finalなフィールドは、変更が禁止されるためコピーできません。clone()をオーバーライドするため、という本質的でない理由でfinalを外す必要があります。
- 上記以外にも細々とした理由があります。詳細は書籍をご覧ください。
NGですので、既にObject.clone()をオーバーライドしたクラスが存在し、それを保守で修正せざるを得ない、などの特別な状況でもない限り、Object.clone()をオーバーライドするべきではありません。
代わりに、以下のような手段を採用しましょう。これらには、上記のような難点はありません。
// コピーコンストラクタ public Yum(Yum yum) { ... } // コピーファクトリ public static Yum newInstance(Yum yum) { ... }なお、コピーコンストラクタやコピーファクトリといった方法を採用する場合でも、Object.clone()を採用する場合でも、共通して以下の点に気をつけましょう。
フィールドをコピーする時は原則としてディープコピーとなるようにしましょう。
つまり、フィールドのコピーをする際は、コピー元のオブジェクト参照を、コピー先のフィールドに設定しただけではダメです。コピー元とコピー先で、同じオブジェクト参照を共有してしまうからです。これがいわゆるシャロー(浅い)コピーです。考え方としては当たり前ですが、実装するのはかなり面倒です。このルールには例外があり、不変なオブジェクトであれば参照のコピーでOKです。
コピー中にコピー元の状態が変わるのはもちろんNGですから、スレッドセーフに実装しましょう。
この項目を理解するには、以下について事前に把握しておくことをオススメします。
Object.clone()はnative修飾子がついているので、Java以外の言語で実装されています。つまり、処理の中身がある、ということです。
共変戻り値型
https://www.slideshare.net/ryotamurohoshi/ss-38240061項目14 Comparableの実装を検討する
開発するクラスにComparable.compareTo()を実装すると、そのクラスのオブジェクトをコレクションに格納して、コレクションの便利なAPIを使えるようになります。例えば、良い感じにソートできるようになります。
この利点を得たい場合は、Comparableインターフェースを実装しましょう。
その場合、equalsメソッドのオーバーライドと似たような要件を満たす必要があります。
- sgn(x.compareTo(y)) == -sgn(y.compareTo(x)) となる。つまり、順序を逆にして比較した場合、結果の符号も逆になる。
- (x.compareTo(y) > 0 && y.compareTo(z) > 0)なら、x.compareTo(z) > 0となる。つまり、推移的な関係になる。
- x.compareTo(y) == 0 なら、sgn(x.compareTo(z)) == sgn(y.compareTo(y)) となる。つまり、xとyの順序が等しいなら、他のオブジェクトzをx,yのそれぞれと比較した場合、結果は等しくなる。
- x.compareTo(y) == 0 なら、x.equals(y)はtrueになるし、その逆も成立するのが必須ではないが好ましい。
※sgn(expression)は、expressionが負、ゼロ、正の時にそれぞれ-1, 0, 1を返す関数です。
はじめの3つの要件については注意事項があります。Comparableを実装している既存のクラスがあったとして、それをextendsして新たなフィールドを追加する場合、これらの要件を満たすことは実質的に不可能です。無理に実現すると、もはやオブジェクト指向なコードではなくなるからです。このような場合は、extendsではなくコンポジションで実現しましょう(項目18)。
4つ目の要件については、仮に違反するとどうなるでしょうか?違反の例として、BigDecimalがあります。new BigDecimal("1.0")とnew BigDecimal("1.00")は、equalsメソッドでは等しくなく、compareToメソッドでは等しいです。
これらを新しいHashSetに入れると、equqlsメソッドで比較されるため、要素数は2となります。一方、新しいTreeSetに入れると、compareToメソッドで比較されるため、要素数は1となります。こういった挙動になることを頭の片隅に入れておかないと、万が一問題が発生した場合に、原因の見当がつかなくなります。
4つの要件以外に、以下の点に注意しましょう。
- Comparableインターフェースはパラメータ化されているので、引数の型のチェックやキャストは不要です。
- 引数がnullなら、NullPointerExceptionが送出されるべきです。何もしなくても普通はそうなるはずです。
- 比較対象のフィールドがオブジェクトなら、それらの参照を大小比較するのではなく、compareToによって比較しましょう。必要に応じて、自分でcompareToを実装しても良いですし、既存のComparatorを使っても良いです(例:String.CASE_INSENSITIVE_ORDER)。
- 大小比較するにあたって、関係演算子(>, <, ==)を使うのはやめましょう。分かりづらくなるだけです。代わりに、Integer.compare()といったcompareメソッドを使うようにしましょう。
- Java 8では、コンパレータ構築メソッドを使って、流れるように実装できます。
private static final Comparator<PhoneNumber> COMPARATOR = comparingInt((PhoneNumber pn) -> pn.areaCode) .thenComparingInt(pn -> pn.prefix) .thenComparingInt(pn -> pn.lineNum); public int compareTo(PhoneNumber pn) { return COMPARATOR.compare(this, pn); }
- 差に基づくコンパレータにしてしまうと、推移性の要件を満たせないばかりか、整数のオーバーフローなどが発生するリスクが生まれてしまいます。代わりに、先述のInteger.compare()などのstaticメソッドや、コンパレータ構築メソッドを使いましょう。
// NG例 static Comparator<Object> hashCodeOrder = new Comparator<>() { public int compare(Object o1, Object o2) { return o1.hashCode() - o2.hashCode(); } }第4章 クラスとインタフェース
項目15 クラスとメンバーへのアクセス可能性を最小限にする
情報隠蔽、カプセル化とは(what)
コンポーネントの外部からアクセスできる部分(公開API)を最小限に留めることです。それ以外の部分(内部データ、実装の詳細)を外部からアクセスできないようにします。
平たくいうと、publicやprotectedで宣言するものを、最小限に留めることです。そうなるように、注意深くクラスを設計します。
情報隠蔽、カプセル化をする理由(why)
情報隠蔽、カプセル化によって、コンポーネントを個別に開発でき、個別に最適化できます。つまり、他のコンポーネントに害を及ぼさないか、という心配を大きく減らせます。
それによって以下を狙うことが、情報隠蔽やカプセル化の目的です。
- 各コンポーネントを並列して開発できるようにして、開発のスピードを速めます。
- 影響調査の手間を減らして、保守の負荷を低くします。
- ボトルネックを局所的に解消できるようにして、パフォーマンスチューニングをしやすくします。
- コンポーネントを再利用できるようにします。
なお、こういった目的を達成できなければ、情報隠蔽やカプセル化を狙う意味はありません。実務で作るプログラムは芸術作品ではなく、ビジネスを成功させるための手段です。ですので、「キレイなものを作った」と満足しているようではいけないのです(私はそうやって満足してしまいやすいので、すごく注意しています)。
どうやれば良いか(how)
具体的には、以下の点を考慮しましょう。
- 何も考えずにpublicをつけるのではなく、アクセス可能性が最小限となるものを選びましょう。
- Serializableを実装すると、実質的に公開APIとなってしまいます。
- protectedで宣言されたものは、利用者(サブクラス)からアクセスできてしまうので公開APIになってしまいます。
- テストのためにパッケージプライベートにするのは、外部に公開していないという点で許容されます。
- 定数をpublic static finalで公開する場合は、その定数がコンポーネントの抽象化の方針に沿っているかを確認すべきです。
- 可変なオブジェクトは、利用者に中身を変更されてしまう恐れがあります。ですので、定数として公開するのはNGです。代わりに、不変なオブジェクトに変換して公開するか(Collections.unmodifiableListなど)、コピーを返すべきです。
- Java 9で追加されたモジュールシステムは、まだ広く使われておらず、有用性が確認されていませんので、現時点で積極的に使う必要はありません。
項目16 publicのクラスでは、publicのフィールドではなく、アクセッサーメソッドを使う
setter/getterをつけましょう、という当たり前の話です。
実務では「こうするのが常識でしょ」という感じで、何も考えずにsetter/getterをつけてしまいがちだと思います。ただ、理由を把握しておかないと、良いクラス設計になりません。改めて、setter/getterをつけるべき理由を把握しておきましょう。
setter/getterをつけるべき理由は、情報隠蔽、カプセル化の恩恵を得るためです。具体的には以下のとおりです。
- 内部データの表現形式(どんな型にするか、など)を、後から変更できるようにするためです。
- フィールド間の整合性などをチェックできるようにするためです。
- 後から補助処理を追加できるようにするためです。
公開APIをできるだけ減らすことが本質的なポイントですので、パッケージプライベートのクラスや、privateの内部クラスについては、そのフィールドにsetter/getterを用意する必要性は薄いです。不必要にsetter/getterを設けようとすると、実装の手間が増え、読みづらいコードになってしまいます。「何も考えずにとにかくsetter/getterをつけるんだ」という感じにならないようにしましょう。
項目17 可変性を最小限にする
不変オブジェクト(イミュータブルなオブジェクト)には、スレッドセーフに利用できる、といった点をはじめ、いくつかの利点があります。JDKでの代表例は、String, Integer等のボクシングされた基本データクラス, BigDecimal, BigIntegerです。
値を持つようなクラスを自作する場合は、可変にすべき正当な理由がない限り、不変に作りましょう。完璧に不変にするのが現実的でない場合でも、フィールドをできるだけfinalにするなど、できるだけ不変に近づけるのが良いです。とりうる状態が減ると、不具合が起こりづらいなどのメリットがあるからです。
不変オブジェクトの利点
- スレッドセーフ。複数のスレッドから、よってたかってアクセスされても問題が起きません。実務的にはこれが一番のメリットだと思います。
- 利用者は、オブジェクト内部の状態遷移を意識しなくて良いです。
- インスタンスを共有できます。結果、オブジェクトを生成するコスト、メモリ消費量を抑えられます。
- インスタンス間で、内部状態を共有できます。例えば、内部に配列を持つクラスであれば、あるインスタンスで保持する配列への参照を、新たなインスタンスに渡して再利用させることができます。
- そのインスタンスをフィールドに保持する他のオブジェクトが、内部的に何らかの状態を保たなければいけない場合があります(フィールド間の大小関係など)。フィールドで保持するインスタンスが可変だと、そのインスタンスの状態遷移を意識しなければならないため、望ましい状態を保つための処理は、すごく複雑になります。あるいは、そもそも実現は不可能です。逆に、フィールドで保持するインスタンスが不変な場合は、そういった問題が一切ありません。
- エラーアトミック性があります。エラーアトミック性とは、失敗する前の状態にオブジェクトが戻る性質です。不変オブジェクトはそもそも変化しませんので、この性質を持つのは当たり前です。可変オブジェクトにエラーアトミック性を持たせるためには、そのための手間がかかります。不変オブジェクトはそういった手間を必要としないが良いわけですね。
不変オブジェクトの欠点
異なる値を持つインスタンスそれぞれで、システム資源を消費します。結果、メモリをたくさん消費したり、パフォーマンスが悪くなる可能性があります。例えば、複数の計算ステップそれぞれで、その場限りのインスタンスを生成しては破棄する、といったことがあります。対処方法は以下のとおりです。
- 複数の処理ステップを、1つの公開APIにまとめる。
- Stringに対するStringBuilderのような、publicな可変コンパニオンクラスを提供する。
不変オブジェクトの作り方(満たすべき要件)
- setterのような、オブジェクトの状態を変更できるメソッドを提供してはいけません。
- extendsされないようにします。クラスをfinalにするか、コンストラクタをprivateにしつつstaticファクトリメソッドを提供するか、のどちらかで対応しましょう。
- 全てのフィールドをfinalにします。こうすることで、そのフィールドは変更不可となりますし、スレッド間でインスタンスの参照を安全に受け渡しできます。これには例外があります。内部でのみ利用する計算結果をフィールドでキャッシュしておきたい、といった場合もあります。その場合は、finalにしないという選択肢もアリです。
- 全てのフィールドをprivateにします。こうすることで、仮にフィールドに可変オブジェクトを持っていたとしても、利用者にオブジェクトの中身を変更させないようにできます。また、利用者に影響を及ぼさずに、後からフィールドの内部表現を変更できます。
- フィールドに可変オブジェクトを持つ場合、その可変オブジェクトにアクセスできるのは、不変クラス(自分自身)だけにします。利用者から渡されたオブジェクトを元に、不変クラスのオブジェクトを生成する場合、その参照をそのまま使うのではなく、防御的コピー(項目50)をしましょう。
項目18 継承よりもコンポジションを選ぶ
継承はカプセル化を破ります。つまり、サブクラスはスーパークラスの実装の詳細に依存してしまいます。結果、スーパークラスの実装の詳細が変更されると、サブクラスが意図通りに動かなくなったり、セキュリティホールが生まれかねません。
サブクラスがスーパークラスのメソッドをオーバーライドしなければ大丈夫、と思ってしまうかもしれませんが、そんなことはありません。スーパークラスが後で追加したメソッドのシグネチャが、サブクラスで実装されたメソッドと競合するかもしれないのです。
こういった不都合があるので、いきなり継承に飛びつくのはやめましょう。コンポジションには、同様の不都合はありません。
ただ、継承は100%悪で、コンポジションが100%正というわけでもありません。状況に応じてコンポジションと継承、どちらが最適なのかを選べるようになりましょう。
コンポジションとは
以下のように、既存のクラスを継承するのではなく、privateのフィールドに既存のクラスを保持します。
その既存クラスのメソッドを呼び出すことで、既存クラスを拡張します。// 転送クラスです。このクラスでコンポジションが適用されています。 // 再利用できるように、InstrumentedSetとは別にクラスを設けています。 public class ForwardingSet<E> implements Set<E> { // 拡張したい既存のクラスのオブジェクトを、フィールドで保持します。 private final Set<E> s; public ForwardingSet(Set<E> s) { this.s = s; } // 拡張したい既存のクラスのオブジェクトに、処理を丸投げします。 public void clear() { this.s.clear(); } // 以降は省略。 } /* 転送クラスを継承することで、独自のクラスを作ります。 「え?継承はダメなんでしょ?」と思うかもしれませんが、ここでの継承は、 ForwardingSetを他の用途で再利用できるようにするための妥当な判断です。 */ public class InstrumentedSet<E> extends FowardingSet<E> { // このクラスは、Setに累計で何回addされたかを管理する役割を持ちます。 private int addCount = 0; public InstrumentedSet(Set<E> s) { super(s); } @Override public boolean add(E e) { addCount++; return super.add(e); } // 以降は省略。 }ちなみに、上記コード例の技法は、厳密には「委譲(delegation)」とは異なります。ご注意ください。
継承しても良い場合とは
以下の場合は継承しても良いでしょう。
- 継承先のクラス(スーパークラスにしたいクラス)が、継承されることを前提に作られている場合です。クラスのJavadocに、その旨が記載されているはずです。
- 継承先のクラス(スーパークラスにしたいクラス)がパッケージ内にのみ公開されている場合です(パッケージプライベート)。この場合、スーパークラスを変更するときに、サブクラスに何らかの悪影響があったとしても、その悪影響はあくまでもパッケージ内に留まるからです。サブクラスを修正することで事なきを得られます。
なお、継承を採用する場合の大前提として、クラス間に「is-a」関係が成立している必要があります。つまり、クラスBがクラスAを継承する場合、「全てのBはAであるか」の答えはyesである必要があります。継承とは、そういった関係性をコードで実現するための技術だからです。
項目19 継承のために設計および文書化する、でなければ継承を禁止する
継承される前提のクラスを作るのは、実はものすごく大変で難しいことです。具体的には、以下の点を考慮する必要があります。
サブクラスでオーバーライド可能なメソッドが、スーパークラスでどのようなタイミングで呼び出されるのかを、利用者に示す必要があります。この情報は、正にスーパークラスの「実装の詳細」なので、情報隠蔽/カプセル化を破ってしまいます・・。
スーパークラスに、protectedのメソッド(場合によってはフィールド)を設けて、スーパークラスの内部動作に対するフックを、サブクラスに提供する必要に迫られるでしょう。多すぎると、情報隠蔽/カプセル化の恩恵から遠ざかります。一方、少なすぎると、サブクラスにとってスーパークラスは使いにくくなってしまいます。このバランスをとって設計する必要があり、ものすごく大変です。
スーパークラスのコンストラクタは、オーバーライド可能なメソッドを呼びしてはいけません。スーパークラスのコンストラクタは、サブクラスのコンストラクタの冒頭で呼び出されますので、サブクラスの準備が整っていない状態で、オーバーライド可能なメソッドを呼び出すことになるからです。
スーパークラスがCloneable, Serializableを実装する場合、注意しなければならないことがあります。ただ、そういった状況は稀だと思いますので、解説を省略します。詳細は書籍をご覧ください。
このように、ものすごく大変です。どうしても継承される前提のクラスを作る場合、上記の点を引き受ける覚悟をしてください。それがプロというものです。
継承される前提のクラスを作るケースより、そうでないケースが多いと思います。その場合は、作ったクラスが誤って継承されないように、クラスをfinalにするか、コンストラクタをprivateにしてstaticファクトリメソッドを用意するか、のどちらかの工夫を施しましょう。
項目20 抽象クラスよりもインタフェースを選ぶ
この項目は、読み解くのがものすごく難しいです。分かりやすさ優先で解説していきます。
ある「型」に対して、その実装は複数あります。例えば、Comparableという「型」の実装は複数あります。このような「複数の実装を許す」型というものを実現する仕組みとして、Javaでは以下の2つが提供されています。
- インタフェース(先ほどのComparableの例は、こちらですね。)
- 抽象クラス
「複数の実装を許す」ような独自の型を新たに作りたいなら、基本的にはインタフェースで実現しましょう。インタフェースは以下の点で、抽象クラスより優れているからです。利用者にとって使いやすいのです。
- 利用者は、複数のインタフェースを実装できます。Javaでは1つのクラスしか継承できませんので、抽象クラスを利用する場合はこういった利点を得られません。
- 既存のクラスがすでに何かを継承していたとしても、利用者は、そのクラスにインタフェースを導入できます。Javaでは1つのクラスしか継承できませんので、抽象クラスを利用する場合はこういった利点を得られません。
- 利用者は、既存のインタフェースを組み合わせて、新たなインタフェースを作り出せます。抽象クラスでも同様のことができますが、とんでもなく煩雑になります。具体的には、こちらの記事がとても参考になります。
- 利用者が既存の「複数の実装を許す」型を利用して、新たな機能をつくりたいとします。その型が抽象クラスなら、利用者は抽象クラスを継承するしかありません。インタフェースであれば、コンポジションを使えます(項目18)。
込み入ったインタフェースを作る時のテクニック「実装補助」「骨格実装」
単純なインタフェースを自作する場合は、気にしなくても良いテクニックです。必要な方だけご覧ください。
インタフェースを自作するとき、そのインタフェースに複数のメソッドを定義したとします。例えば、メソッドAとメソッドBを定義するとします。普通、メソッドAではメソッドBを呼び出すのが分かりきっているなら、典型的なメソッドAのロジックをインタフェースに実装した方が、利用者にとって使いやすくなります。利用者にとっては、自分が実装する部分が少ない方が楽ですもんね。
これを実現する方法には、以下の2パターンがあります。
- 実装補助:インタフェースのメソッドをdefaultで宣言し、インタフェース内にロジックを実装します。先ほどの例だと、メソッドAの宣言部にdefaultをつけて、ロジックを実装します。defaultはJava 8から使えます。これで済む場合は、先ほどのインタフェースの利点をフルに得られますので、次に示す骨格実装ではなく、まずはこちらの選択肢を検討しましょう。
- 骨格実装:実装補助を施したインタフェースを、抽象クラスで実装します。インタフェースのdefaultではequalsなどのObjectクラスのメソッドを実装できないなど、いくつか制約があります。抽象クラスでそれらの部分をカバーできます(実装できます)。このパターンの具体例は、AbstractListなどです。なお、継承されることを前提とするわけですから、項目19に従ってJavadocをしっかり書きましょう。
項目21 将来のためにインタフェースを設計する
インタフェースは一度公開したら最後。そう簡単に変更できません。公開前に、しっかりと検証しましょう。
後からインタフェースにメソッドを追加すると、そのインタフェースを実装していたクラスはコンパイルエラーになります。その問題を回避する「裏技」としてdefaultを使えますが、これは以下の点でNGです。defaultに頼らず、しっかりと設計するのが重要です。
- defaultは、そういった用途のために存在するわけではありません。
- defaultメソッドで、インタフェースの既存のメソッドを呼び出す場合、インタフェースを実装していたクラスの内部状態を壊す恐れがあります。現場の状況が理解されずに理不尽なルールを一方的に押しつけられ、現場が混乱するような感じですね。
項目22 型を定義するためだけにインタフェースを使う
インタフェースに定数を定義して、そのインタフェースを実装することでクラスに定数を利用させる、という手法があります。これはNGです。JDKにはそういったインタフェースが実際にありますが、真似してはいけません。
なぜなら、クラスが他のコンポーネントの定数を利用する、というのは実装の詳細だからです。インタフェースを実装するということは、その部分を公開APIにするということです。実装の詳細を公開APIにしてはいけません。そもそも、定数を公開するというのは、インタフェースの本質からかけ離れているので、論外なのです。
定数を外部に提供するなら、以下のいずれかにしましょう。
- 定数が特定のクラスに強く結びついているなら、そのクラスの中に定数を追加しましょう。例えば、Integer.MAX_VALUEなどです。
- 定数が列挙型のメンバーとして見なされるなら、enum型で定義しましょう。
- その他の場合、インスタンス化不可能なユーティリティクラスに定義しましょう。
// インスタンス化不可能なユーティリティクラス public class PhysicalConstatns(){ private PhysicalConstants() {} // インスタンス化を防ぐ public static final double AVOGADROS_NUMBER = 6.022_140_857e23; }なお、利用者では定数クラスをstaticインポートすることで、定数を利用するたびにクラス名を書かなくても済みます。と書籍では解説されていますが、そうすると後から見返したときに「この定数ってどこで定義してるやつだっけ?」ということになり、読みづらくなることもあります。staticインポートが適切かどうかは、バランスを考慮して判断しましょう。
項目23 タグ付きクラスよりもクラス階層を選ぶ
1つのクラスの中で、円か長方形かを表現するようなクラスがあったとします。その中には、円の場合に使われるコンストラクタ、フィールド、メソッドがあり、同様に長方形の場合に使われるものがあります。
このように、1つのクラスで複数の概念を表現しようとするクラスを、書籍では「タグ付きクラス」と呼んでいます。
複数の概念を表現したいなら、素直にクラスを分けましょう。具体的には、継承/サブタイプ化を利用して、階層構造に整理しましょう。当たり前ですね。
項目24 非staticのメンバークラスよりもstaticのメンバークラスを選ぶ
時に、クラスの内部で別のクラスを宣言したくなることがあります。こういった文脈では、前者のクラスは「エンクロージングクラス」、後者のクラスは「ネストしたクラス」と呼ばれます。
ネストしたクラスを実装する方法はいくつかあります。具体的には以下の4つです。
- staticのメンバークラス
- 非staticのメンバークラス
- 無名クラス
- ローカルクラス(メソッド内で名前付きで宣言するクラスです)
これらを適切に使い分けましょう。以下の流れで考えると、間違えることは無いはずです。
検討ステップ0
作ろうとしている「ネストしたクラス」は、エンクロージングクラスとは無関係に、他のクラスから利用される可能性があるでしょうか?
もしYESなら、そもそもネストしたクラスとして作るべきではありません。エンクロージングクラスとは独立した、単なる普通のクラスとして作成すべきです。
検討ステップ1
作ろうとしている「ネストしたクラス」が、以下の全てに該当する場合、無名クラスを使いましょう。
- エンクロージングクラスの特定のメソッドでしか使わない。
- ネストしたクラスの宣言部が短い。長いと、エンクロージングクラスのメソッドが読みづらいものになってしまいます。
- 一箇所でのみインスタンス化する。
なお、エンクロージングクラスの非staticメソッド内で、無名クラスが宣言されると、その無名クラスのインスタンスはエンクロージングクラスのインスタンスを自動的に参照します。場合によってはこれがメモリリークを引き起こします。その危険性を認識した上で、利用しましょう。
非staticメソッド内で宣言される場合は、こういったことは起きません。
検討ステップ2
作ろうとしている「ネストしたクラス」が、以下の全てに該当する場合、ローカルクラスを使いましょう。
- エンクロージングクラスの特定のメソッドでしか使わない。
- ネストしたクラスの宣言部が短い。
- そのメソッド内の複数箇所でインスタンス化する。複数箇所で使われるなら、名前付きで宣言しておく必要がおく必要があるわけです。
検討ステップ3
作ろうとしている「ネストしたクラス」が、以下の全てに該当する場合、非staticのメンバークラスを使いましょう。
- 以下のどちらかに該当する。
- ネストしたクラスの宣言部が長い。
- エンクロージングクラスの、複数のメソッドで利用される。
- エンクロージングクラスのインスタンスにアクセスする必要がある。非staticのメンバークラスがインスタンス化されると、そのインスタンスからエンクロージングクラスのインスタンスを、自動的に参照します。場合によってはこれがメモリリークを引き起こします。その危険性を認識した上で、利用しましょう。
検討ステップ4
作ろうとしている「ネストしたクラス」が、以下の全てに該当する場合、staticのメンバークラスを使いましょう。
- 以下のどちらかに該当する。
- ネストしたクラスの宣言部が長い。
- エンクロージングクラスの、複数のメソッドで利用される。
- エンクロージングクラスのインスタンスにアクセスする必要が無い。非staticのメンバークラスのような危険性がありませんので、できるだけこちらを選びましょう。
項目25 ソースファイルを単一のトップレベルのクラスに限定する
普通は、1つのソースファイルに複数のトップレベルのクラスを実装することなんて、無いですよね。この項目では、それがNGな理由が解説されていますが、そもそも実務ではそんなことをしないわけですから、理由を知る必要などありません。(おわり)
第5章 ジェネリックス
項目26 原型を使わない
原型というのは、
List<String>ではなくListのように、型パラメータを伴わない表現のことです。原型を使ってはいけない、というのはもはや常識ですね。その理由は、実行時にClassCastExceptionが起こる恐れがあるからです。型パラメータを指定して実装すると、そういったリスクをコンパイルエラーやコンパイル時の警告という形で気づくことができます。原型を使わないようにしましょう。
ただ、うっかり原型を使ってしまいそうになる局面があります。具体的には以下のとおりです。
【NG】
// Setの型パラメータが分からないからといって、こんな実装をしてはいけません。 static int numElementsInCommon(Set s1, Set s2) { int result = 0; for (Object o1 : s1) if(s2.contains(o1)) result++; return result; }以下のように実装しましょう。
【OK】
// こうすると、s1やs2に要素を追加しようとした時に、コンパイルエラーとなります。 // 実行時に気づくより断然良いですね。(ただし、nullは追加できます) static int numElementsInCommon(Set<?> s1, Set<?> s2) { // 略 }項目27 無検査警告を取り除く
ジェネリクスを使って実装すると、実行時のClassCastExceptionにつながるリスクを、コンパイルエラーやコンパイル時の警告によって気づくことができます。
警告は放っておいてもコンパイルできますが、原則として全ての警告に対応し、警告が出ないように修正しましょう。本当に問題がない場合のみ、
@SuppressWarning("unchecked")をつけて、警告を抑制しましょう。ちなみに、"unchecked"とは、「型をチェックしていないけど大丈夫?」という意味合いの警告です。本当に問題がない場合に警告を抑制しないと、本当に問題がある警告に気づくことができません。そこも手を抜かないようにしましょう。
項目28 配列よりもリストを選ぶ
歴史的経緯によって、配列とジェネリクスは異なる性質を持ちます。それが原因で、両者を組み合わせて使うと、問題が起きます。コードの簡潔さやパフォーマンスに関して顕著な問題がない限り、ジェネリクスに統一して実装しましょう。
組み合わせて使うと、どんな問題が起こるの?
両者を組み合わせて実装すると、コンパイラが出すエラーや警告の意味を理解できず、無駄に混乱してしまいます。場合によっては、十分な検討をせずにその警告を抑制してしまい、結果的にClassCastExceptionを発生させたり、保守メンバーに「何でここで
@SuppressWarningしてるんだろう・・?」と疑問を抱かせ、困惑させてしまうでしょう。例えば・・・
List<String>[]のような、ジェネリクスを要素に持つ配列、というものはコンパイルエラーになります。それを許してしまうと、ClassCastExceptionが起き得るからです。そんなことしないから関係ないよ、と思うかもしれませんが、そんなことはありません。例えば、可変長引数のメソッドでは可変長の引数を保持するために配列が生成されます。引数をジェネリクス型にすると、理解しづらい警告が出ます。舞台裏で何が起きているかを理解しないと、適切に解決できないでしょう。new E[]もダメです。コンパイルエラーや警告の意味を分からず、場当たり的に実装した結果、以下のようなNGなクラスが生まれます。
public class Chooserr<T> { private final T[] choiceArray; public Chooser(Collection<T> choices) { // choicesはTを保持する型かもしれないですが、 // 多くの場合、toArray()がT[]を返す保証など無いはずです。 // 実行時にClassCastExceptionが発生する恐れがあります。 // 意味も分からず@SuppressWarningsするのはNGです。 @SuppressWarning("unchecked") choiceArray = (T[]) choices.toArray(); } }なぜこんな問題が起こるのか?
両者には、以下の違いがあるためです。(と書籍では説明されていますが、これらの違いがなぜ上記の問題につながるのか、といったことについては説明されていません…。暇があれば後で解説を追加したいと思います。)
違い① 違い② 配列 例えば、 Object[] objectArray = new Long[1];では、Long[]はObject[]のサブタイプとして扱われます。なので、こういった代入が許可されます。こういった性質をcovariantと呼びます。「相手に応じて柔軟に変化する」といったニュアンスで覚えると良いでしょう。配列は、実行時に自身がどんな型を格納できるのか、ということを知っています。なので、不適切な型のオブジェクトを代入しようとすると、実行時に例外が起きます。こういった性質を、「具象化されている」と呼びます。 ジェネリクス 例えば、 List<Object> objectList = new ArrayList<Long>();では、ArrayList<Long>はList<Object>のサブタイプとして扱われません。なので、コンパイルエラーになります。こういった性質をinvariantと呼びます。covariantのような柔軟性がない、ということです。ジェネリクスはコンパイル時にのみ型制約を強制し、実行時には要素の型情報を廃棄(erase)します。こういったことを「イレイジャで実装されている」と表現します。これは、ジェネリクスが導入された時に、ジェネリクスを利用していない既存のコードと、利用する新しいコードが共存できるようにするための措置です。これが冒頭で触れた「歴史的経緯」です。 ※covariantは共変、invariantは不変と訳されていますが、こういった日本語訳は混乱につながるだけです。覚えない方が良いです。
項目29 ジェネリック型を使う
クラスを自作するときは、できるだけジェネリック化すべきです。そうすることで、利用者は以下の利点を得られます。
- 実行時にClassCastExceptionが起きる危険性を、排除できます。
- 利用者は、戻り値をいちいちキャストしなくても済みます。
場合によっては、自作するクラスの内部では配列を使った方がいいかもしれません。ArrayListのような基本的なジェネリック型を自作する場合や、パフォーマンス上の理由がある場合などです。
こういった場合、クラス内部ではコンパイル時の警告を抑制するため、
@SuppressWanings("unchecked")することになります。もちろん、抑制するのが本当に妥当なのか、十分に検討すべきなのは言うまでもありません。項目30 ジェネリックメソッドを使う
メソッドを自作するときも、できるだけジェネリック化すべきです。そうすることで、利用者は項目29と同じ利点を得られます。
まずは、ふつうのジェネリックメソッドを定義する場合について、解説します。
【NG】非ジェネリックなメソッド
// 保持するオブジェクトの型がs1とs2とで異なる場合、実行時にClassCastExceptionが発生します。 public static Set union(Set s1, Set s2) { Set reslut = new HashSet(s1); result.addAll(s2); return result; }【OK】ジェネリックなメソッド
// メソッドで利用する型パラメータ(のリスト)を、修飾子と戻り値型の間に宣言する必要があります。 // この例では、staticの直後にある<E>のことです。 public static <E> Set<E> union(Set<E> s1, Set<E> s2) { Set<E> reslut = new HashSet<>(s1); result.addAll(s2); return result; }次に、応用的なジェネリックなメソッドを実装する場合です。次の2つのテクニックを紹介します。
- ジェネリック・シングルトン・ファクトリ
- 再帰型境界
テクニックその1:ジェネリック・シングルトン・ファクトリ
利用者の指定する型で動作するオブジェクトを返す、という役割のAPIが必要になったとしましょう。生成するオブジェクトが状態を持たないのならば、利用者が指定する型が違うからといって毎回オブジェクトを生成するのは無駄です。
利用者の指定する型で動作しつつも、そのオブジェクトをシングルトンにできる(つまりインスタンスの生成コストやメモリ使用量を抑えられる)テクニックが、ジェネッリック・シングルトン・ファクトリです。
書籍では、この例として恒等関数が挙げられています。ちなみに、恒等関数とはパラメータをそのまま返す関数です。何の役に立つの?と思うかもしれませんが、機械学習の界隈では活性化関数の一つとして登場します。活性化関数としてAPIに何かしら指定しないといけないんだけど、何もしたくないから、実質的に何もしない関数を指定する、といった用途があります。
// このテクニックのポイント① private static UnaryOperator<Object> IDENTITY_FN = (t) -> t; // このテクニックのポイント② @SuppressWarnings("unchecked") public static <T> UnaryOperator<T> identityFunction() { return (UnaryOperator<T>) IDENTITY_FN; }このテクニックのポイント①
ジェネリクスがイレイジャで実装されているからこそ、利用者にどんな型を指定されたとしてもIDENTITY_FNという一つのインスタンスをひたすら返してもOKなのです。
一方、ジェネリクスが具象化されていたら、つまり実行時にもIDENTITY_FNが、利用者が指定した型パラメータを覚えていたら、IDENTITY_FNという一つのインスタンスだけでは対応できません。
例えば、利用者が型パラメータにStringを指定してidentityFunction()を呼び出したら、IDENTITY_FNは
UnaryOperator<String>とならざるを得ません(ジェネリクスが具象化される世界の話です)。これだと、型パラメータとしてLongを指定したい人に対応するには、IDENTITY_FNのLong版を用意しなければなりません。そのオブジェクトを返す、identityFunction()メソッドのLong版も必要でしょう。このテクニックのポイント②
ジェネリック・シングルトン・ファクトリを実装しようとすると、無検査でキャストしているけど大丈夫?という警告が出ます。ですが、多くの場合問題ないです。その理由を認識した上で、警告を抑制しましょう。
まず、この例の場合、無検査キャストの警告は何を意味するのでしょうか?
UnaryOperator<Object>は、Objectという「特定の型」で動作すると想定されています。なお、Objectは最も汎用的な型ですが、全ての型を表すTに含まれる一つの型という位置付けですので、「特定の型」と表現しました。一方、
UnaryOperator<T>のTは、全ての型を意味するわけですが、利用者が使う局面では一つの型に定まります。利用者が指定する型に定まるわけです。特定の型で動作することを想定したUnaryOperator<特定の型>を、利用者が指定する型のUnaryOperator<利用者が指定する型>として扱うと、内部で「利用者が指定する型」から「特定の型」にキャストできず、ClassCastExceptionが発生する可能性があります。事情を知らないコンパイラからすると、その可能性を否定しきれません。
警告には、こういったメッセージが込められているのです。
しかし、この場合、利用者から渡された引数を、何も変更せずそのまま返すだけです。正確には、実行時に内部で「利用者が指定する型」からObjectにキャストされますが、Objectというクラス階層の頂点に立つものにキャストするわけですので、ClassCastExceptionが起こる余地がありません。このため、「コンパイラさん、今回は大丈夫ですよ」という感じで、警告を抑制しても問題ありません。
参考:このキャストは何でコンパイルエラーにならないの?
return (UnaryOperator<T>) IDENTITY_FN;の部分で、無検査キャストの警告が出るわけですが、そもそもなぜUnaryOperator<Object>がUnaryOperator<T>にキャストできるのでしょうか?つまり、なぜコンパイルエラーが起きないのでしょうか?
List<Object> objectList = new ArrayList<Long>();がコンパイルエラーとなるように、ジェネリクスはinvariantです。ですから、一見こういったキャストはできなさそうです。しかし、一方がTのような総称型を型パラメータとする場合、両者が全く別の型とは言い切れない、とコンパイラが判断するため、キャストが許可されます。ちなみに、双方向のキャストが許可されます。
これは、参照型の縮小変換(narrowing reference conversion)と呼ばれており、Java言語規約で定められています。詳しくは、こちらがとても参考になります。
テクニックその2:再帰型境界
利用者が指定できる型パラメータに、何らかの制限を設けるテクニックです。なぜ「再帰型」と呼ぶのかは、例を見た方が分かりやすいでしょう。
public static <E extends Comparable<E>> E max(Collection<E> c);
<E extends Comparable<E>>の意味するところは、利用者が型パラメータに指定する型は、同じ型の他のオブジェクトと比較できるものでないとダメだよ。ということです。
もっと平たく言うと、利用者が引数で指定するコレクションは、その要素同士が相互に比較できるものじゃないとダメ、ということですね。
こういった感じで、利用者が指定できる型パラメータに制限を設けることができます。
項目31 APIの柔軟性向上のために境界ワイルドカードを使う
この項目もかなり読みづらいです。噛み砕いて説明します。
自作するAPIが、パラメータされた型を引数として受け取るとしましょう。例えば
List<E>やSet<E>、Iterable<E>、Collection<E>などですね。こういった場合、利用者にとって使いやすいAPIとするために、工夫すべきことがあります。
利用者にとっての「使いやすさ」とは?
まずは利用者の立場に立ってみましょう。誰かがStackというクラスをAPIとして公開し、あなたがそれを利用しているとします。
Stack<Number> numberStack = new Stack<>(); Iterable<Integer> integers = ... ; // IntegerはNumberのサブタイプなので、直感的にはこのように使えそうな気がしませんか? numberStack.pushAll(integers);利用者であるあなたは、暗黙的にこう考えているのです。「こちらがAPIにオブジェクトを提供する場合、より具体的な型のオブジェクトを渡しても、きっとうまく動くだろう」。
逆に、次の場合はどうでしょうか?
Stack<Number> numberStack = new Stack<>(); Collection<Object> objectsHolder = ... ; // ObjectはNumberのスーパータイプなので、直感的にはこのように使えそうな気がしませんか? numberStack.popAll(objectsHolder);利用者であるあなたは、暗黙的にこう考えているのです。「こちらがAPIからオブジェクトを受け取る側なら、より抽象的な型のオブジェクトとして受け取れるだろう」。
利用者にとっては、APIにこういった柔軟性があると助かるわけですね。
そのためには、どうすれば良いか?
APIを作る側の立場に戻りましょう。
まずは、先ほどの1つ目のケースです。
Stack<Number> numberStack = new Stack<>(); Iterable<Integer> integers = ... ; // IntegerはNumberのサブタイプなので、直感的にはこのように使えそうな気がしませんか? numberStack.pushAll(integers);このような柔軟性をAPIに持たせるには、APIを以下のように実装します。
// ポイントは、<? extends E> の部分です。ロジック部分は省略。 public <E> void pushAll(Iterable<? extends E> src) { ... }利用者は暗黙的にこう考えます。「こちらがAPIにオブジェクトを提供する場合、より具体的な型のオブジェクトを渡しても、きっとうまく動くだろう」。
利用者の気持ちをAPIで実現するならば、「EのIterable」ではなく、「Eそのもの、あるいはEのサブタイプのIterable」とすべきなのです。
このようにパラメータがAPIにオブジェクトを提供する場合、そのパラメータはproducerである、と言います。「producerの場合は、extends」というわけです。
なお、
<? extends E>という感じにパラメータされた型を「境界ワイルドカード型」と呼びます。次に、先ほどの2つ目のケースです。
Stack<Number> numberStack = new Stack<>(); Collection<Object> objectsHolder = ... ; // ObjectはNumberのスーパータイプなので、直感的にはこのように使えそうな気がしませんか? numberStack.popAll(objectsHolder);このような柔軟性をAPIに持たせるには、APIを以下のように実装します。
// ポイントは、<? super E> の部分です。ロジック部分は省略。 public <E> void popAll(Collection<? super E> dst) { ... }利用者は暗黙的にこう考えます。「こちらがAPIからオブジェクトを受け取る側なら、より抽象的な型のオブジェクトとして受け取れるだろう」。
利用者の気持ちをAPIで実現するならば、「EのCollection」ではなく、「Eそのもの、あるいはEのスーパータイプのCollection」とすべきなのです。
このようにパラメータがAPIからオブジェクトを受け取る場合、そのパラメータはconsumerである、と言います。「consumerの場合は、super」というわけです。
まとめると、以下の通りです。
- パラメータがproducerの場合は、<? extends E>
- パラメータがconsumerの場合は、<? super E>
頭文字をとって、「PECS」と覚えましょう。
その他のアドバイス
ここでは、比較的こまかめなアドバイスを紹介します。
APIの戻り値の型に、境界ワイルドカード型を適用するのはNGです。利用者に柔軟性を与えるどころか、制約を強制してしまいます。
利用者にワイルドカード型を何かしら意識させるようであれば、利用者にとって使いにくいAPIということです。API設計を見直しましょう。
APIの引数には
T extends Comparable<T>ではなく、T extends Comparable<? super T>を常に使いましょう。<? super T>は比較先であり、Tを受け取る側(consumer)ですのでsuperを付けます。「Tそのものか、Tのスーパータイプと比較できるT」という意味です。こうすることで、T自身ではComparableを実装していないけど、TのスーパータイプがComparableを実装していれば、APIに引数として渡せます。以下に例を示します。// APIの例(とっても複雑ですね・・。柔軟にするための代償です。) public static <T extends Comparable<? super T>> T max(List<? extends T> list) { ... } // APIの利用例 List<ScheduledFuture<?>> scheduledFutures = ...; ScheduledFuture<?> max = max(scheduledFutures);ScheduledFuture自身はComparableを実装していませんが、スーパータイプであるDelayedでは実装されています。スーパータイプであるDelayedの力を借りることができる、ということです。maxは、柔軟なAPIだと言えるでしょう。
項目32 ジェネリックスと可変長引数を注意して組み合わせる
List<String>[]といった、「ジェネリクスを要素に持つ配列」を生成しようとするとコンパイルエラーになります。そういった配列の存在を許すと、実行時にClassCastExceptionが起きる恐れがあるからです(項目28)。しかしこれには例外があります。可変長引数は配列によって実現されますが、可変長引数にジェネリクスを指定することで、ジェネリクスを要素に持つ配列が生まれてしまうのです。
static void dangerous(List<String>... stringLists) { // stringListsの正体は、List<String>を要素にもつ「配列」です。 // これが原因で、どこかでClassCastExceptionが起きてしまうかもしれません。 List<String>[] array = stringLists; ... }こういった事情がありますから、APIを作るときには以下の点を考慮しましょう。
パフォーマンスやコードの冗長さといった点で問題がなければ、可変長引数にジェネリクスを指定するのではなく、Listで可変長の引数を受け取るようにしましょう。可変長引数とジェネリクスという相性の悪いものを積極的に組み合わせる必要はないのです。「利用者が引数のListを生成するのが面倒では?」と思うかもしれませんが、利用者に
List.of()を使ってもらえば済む話です。どうしても可変長引数にジェネリクスを指定したい場合は、以下の全てに対応しましょう。
- 実行時にClassCastExceptionが起こる危険性を取り除きましょう。そのためには・・・
- ジェネリクスの配列に、要素を保存してはいけません(上書きしてはいけません)。
- ジェネリクスの配列(の参照)を、信頼できないコードに公開してはいけません。
- ClassCastExceptionの危険がないことを、
@SafeVarargsで示しましょう。メソッドにこのアノテーションを付けます。こうすることで、利用者があなたのAPIを呼び出すときに、不要なコンパイラ警告が表示されずに済みます。項目33 型安全な異種コンテナを検討する
個人的には、かなり発展的な内容と思います。
そもそも「異種コンテナ」とは何か?どんなときに嬉しいのか?
具体例で説明します。
アプリケーションFW(フレームワーク)を作ってそれを他のメンバーに使ってもらう立場ですと、アノテーションを利用して個々のアプリケーションを制御することがあります。私がアノテーションを作り、メンバーの皆さんは自作するクラスにそのアノテーションをつけます。私はそのアノテーションを目印に、メンバーの作ったアプリ(クラス)を制御をするわけですね。
FWでは、メンバーの作るクラスからアノテーションを取得して、どんな風にメンバーのクラスを制御すべきかを判断します。
メンバーの作るクラスにどんなアノテーションが付けられているか、という情報はそのクラスのClassオブジェクトに「異種コンテナ」として保持されています。
FWは、メンバーがクラスにつけた
@MyAnnotaion1に、どんな値が設定されているかを知りたいわけです。ですので、ClassCreatedByMember.class.getAnnotation(MyAnnotation1.class)を呼び出して、メンバーがそのクラスに付けた@MyAnnotation1(を表すオブジェクト)を取得します。同様に、
@MyAnnotation2の情報を知りたい場合は、FWはClassCreatedByMember.class.getAnnotation(MyAnnotation2.class)sを呼び出します。このように、特定のClassオブジェクト(この場合はMyAnnotation1.classや、MyAnnotation2.class)をキーにして、それに対応するオブジェクトを格納しておきたいことがあります。それが、この項目で紹介されている「異種コンテナ」です。
いつかそういった「異種コンテナ」を自作する機会が訪れるかもしれません。この項目の内容を、一つのテクニックとして覚えておきましょう。
優れた異種コンテナを作る方法
この項目では、優れた異種コンテナを作る方法が説明されています。具体的には、型安全に作る(ClassCastExceptionが起きないようにする)方法が説明されています。
ポイントは以下の通りです。
public class Favorites { // ・Mapのキーにワイルドカード「?」を使うことで、色々な型をキーにできる柔軟性が生まれます。 // ・Mapの値はObject型です。これで型安全なの?と思うかもしれませんが、他のところで型安全性を確保しています。 private Map<Class<?>, Object> favorites = new HashMap<>(); public <T> void putFavorite(Class<T> type, T instance) { // ・誤って原型を指定された時の対策として、type.cast()で型チェックします。 favorites.put(Objects.requireNonNull(type), type.cast(instance)); } public <T> T getFavorite(Class<T> type) { // ・引数typeで指定された型を、必ず返します。 // 例えば、String.classを指定したのにIntegerが返されて、 // ClassCastExceptionになる、といったことは起きません。 // ・favorites.get()の結果はObject型ですが、そのままで困るのでキャストしています。 return type.cast(favorites.get(type)); } }なお、Favoritesの例では、利用者は基本的にどんな型のオブジェクトでも格納できます。しかし、場合によっては格納できる型に何らかの制限を設けたい場合もあるでしょう。
例えば、Annotationのサブタイプじゃないとダメ、といった制限を設けたいなら
public <T extends Annotation> T getAnnotation(Class<T> annotationType);のように、
<T extends Annotation>で利用者に制限を課すことができます。第6章 enumとアノテーション
項目34 int定数の代わりにenumを使う
enumを使わずに定数を宣言する場合の「難点」
enumを使わずにintで定数を宣言すると・・・
- 型さえ合えば、本来の用途とはかけ離れた用途に使えてしまいます。そういった事態に、コンパイルエラーで気づくことができません。
- 独自の名前空間がないので、他の関係のない定数と重複しない名前にする必要があります。
- 定数の名前が、ログやデバッガに表示されません。値だけ表示されても調査の役には立たないでしょう。
- 定数をイテレートしたり、定数の数を数えられません。
Stringで定数を宣言すると・・・
- その定数フィールドの利用を強制できません。ハードコーディングされてミスタイプされたとしてもコンパイルエラーにならないので、そういった事態に気づけません。
enum型の仕組みと特徴
enum型という機能は、定数をはじめとする「列挙されるもの」に「独自の型」を持たせることが、その本質だと言えるでしょう。独自の型であるため、先述した「enumを使わない場合の難点」がありません。
enum型はつまるところクラスです。クラスの特殊な形なのです。
自分のインスタンスを、自分のpublic static finalフィールドに(暗黙的に)持っていて、独自のフィールドやメソッドを定義することができます。こういった性質は普通のクラスと同じですが、裏で色々な細工がなされるところが、普通のクラスと異なります。
例えば以下のような感じです。
- enumで宣言した型は、自動的にjava.lang.Enumを継承するようになります。なお、java.lang.Enumは抽象クラスで、以下のように、列挙型が共通して備えるべき機能がしっかりと実装されています。
- Objectクラスのequals(), hashCode()を適切にオーバーライドしています。
- Comparableを実装しています。
- Serializableを実装しています。enum型がどう実装されても対応できるようになっています。
- public static finalフィールドを設け、enum型をインスタンス化してそのフィールドに設定する、といったことを裏で自動的にやってくれます。
enumには以下の特徴があります。
- enum型の中に定義されている列挙定数1つに対して、public static finalフィールドの1インスタンスが割り当てられます。各列挙定数はシングルトンということです。
- enum型には外部からアクセスできるコンストラクタが無いので、以下のような「嬉しい制限」が備わっています。
- enum型そのものを外部からインスタンス化できません。
- enum型を外部から継承することはできません。
- enum型は独自の名前空間を持っています。定数名が衝突することを気にしなくても良いのです。
- toString()によって、調査の手掛かりになる情報をログやデバッガに表示できます。
- enum型には、メソッドやフィールドを定義できます。
- enum型は、任意のインタフェースを実装できます。
個人的には、enum型というのは世の中で考えられている以上に、その仕組みが分かりづらいと思います。Java言語仕様をしっかりと理解しておかないと、enumを効果的に使うのはちょっと難しいかなと思います。
Java言語仕様 8.9. Enum Types
https://docs.oracle.com/javase/specs/jls/se9/html/jls-8.html#jls-8.9Java言語仕様に書かれてあることで知っておくとよい点は、以下の通りかなと思います。
- 以下の結果、シングルトンであることが保証されます。
- enum型のcloneメソッドを呼び出しても、インスタンスは複製されません。
- リフレクションであっても、enum型のインスタンスを生成できません。
- enum型のインスタンスがデシリアライズされても、重複したインスタンスが生成されないようになっています。
- enum型には独自のコンストラクタを定義できますが、publicやprotectedをつけられません。アクセス修飾子をつけずに定義するわけですが、その場合は自動的にprivate扱いになります。
- enum型に独自のコンストラクタを定義しない場合、privateのデフォルトコンストラクタが自動的に設けられます。
- enumのstaticフィールドは、コンストラクタが実行された時点ではまだ初期化されていません。ですので、コンストラクタからstaticフィールドにはアクセスできません。
- enum型を定義すると、暗黙的に以下のメソッドが宣言されます。
public static E[] values();public static E valueOf(String name);enum型を作る時のポイント
独自のenum型を作る場合、以下の点を考慮しましょう。
enum型も普通のクラスと同じように、可視性を最小限にしましょう。
同じメソッド名だけど、定数ごとに異なる振る舞いをさせたい場合があります。ポリモーフィズムですね。enum型内部では自分自身を継承できます。具体的には、enum型の中で列挙定数を宣言するときに匿名クラスを定義できます。その匿名クラスからenum型自身を継承し、enum型自身に定義されているabstratメソッドをオーバーライドしたり、enum型がimplementsするインタフェースのメソッドを実装できます。
定数間でコードを共通化したい場合、定数ごとにabstractメソッドをオーバーライドさせ、共通部分をprivateメソッドにしても良いでしょう。書籍にあるように、戦略enumパターンを採用しても良いと思います。どちらにしても求められるのは「不適切な実装をしたときにコンパイルエラーで気付けるか」ということですし、どちらを選ぶかの判断基準は「簡潔さと柔軟性のバランスをどう取るか」ということです。
既存のenum型にswitch文をかますことで振る舞いを拡張することができます。以下のようなケースに役立ちます。
- 定数ごとに異なる振る舞いをする既存のenum型があるとしましょう。あなたは、そのenum型を修正できません。でもその既存のenum型の振る舞いを拡張しなければなりません。
- 既存のenum型にわざわざメソッドとして設けるほどではないけど、自分にとって何らかの拡張された振る舞いが必要です。
toString()をオーバーライドして独自の名前を返すようにした場合、valueOf(String)ではその独自の名前に対応できません。独自の名前に対応できるようなfromString(String)のようなメソッドを設けた方が良いです。
項目35 序数の代わりにインスタンスフィールドを使う
java.lang.Enumにはordinal()というメソッドがあります。enum定数のインスタンスに対してordinal()を呼び出すと、そのenum定数がenum型の中で何番目に宣言されているか、というintが返ります。
このメソッドを使って何かをしようとすると、多くの場合に破綻します。何番目に宣言されているかに依存するロジックは、いかにも変更に弱そうですよね。
なので、よほどの場合でない限り、ordinal()を使わないようにしましょう。
この項目はそういったレベルの理解をしておけば、実務上は問題ありません。
項目36 ビットフィールドの代わりにEnumSetを使う
定数の集合、というものを扱いたいときがあります。
例えば、書式という列挙型に「太字」「イタリック」「下線」といった要素があるとします。この場合、「太字」かつ「イタリック」といった、要素の組み合わせを表現できる必要があります。
enum型が登場する以前は、これをビットで表現していました。
// 現代ではNGです。 // 定数宣言 private static final int STYLE_BOLD = 1 << 0; // 0001 private static final int STYLE_ITALIC = 1 << 1; // 0010 private static final int STYLE_UNDERLINE = 1 << 2; // 0100 // 太字かつイタリック int styles = STYLE_BOLD | STYLE_ITALIC // 0011といった感じです。
この手法は、簡潔でパフォーマンスが良いという良さがある一方で、項目34に記載したint定数の欠点に加え、ビット数を初めの段階で確定させなければならない、という欠点があります。
現代では、こういった「定数の要素の組み合わせ」を良い感じに表現する方法があります。それがEnumSetです。
// 現代ではこちらが推奨されます。 // 定数宣言 enum Style {BOLD, ITALIC, UNDERLINE} // 太字かつイタリック Set<Style> styles = EnumSet.of(Style.BOLD, Style.ITALIC);こちらは明らかに簡潔です。EnumSetの内部ではビット演算がなされますので、パフォーマンスも良いです。当然ながら、int定数が持つ欠点もありません。
項目37 序数インデックスの代わりにEnumMapを使う
列挙定数(enum型のインスタンス)をキーにして、他の何らかのデータを値にして、Mapを作りたくなることがあります。
その場合は、EnumMapを使いましょう。
項目35と同様に、間違ってもjava.lang.Enum.ordinary()を使わないようにしましょう。
(おわり)
項目38 拡張可能なenumをインタフェースで模倣する
あなたが公開するenum型の列挙定数だけでは、利用者にとって不足があるかもしれません。
例えば、四則演算を表すenum型を公開したとして、利用者は「累乗の演算を表す列挙定数も欲しい」と思うかもしれません。
そういった類の柔軟性をAPIに持たせるために、公開するenum型にインタフェースを実装させましょう。利用者には、独自のenum型を作ってもらい、そのインターフェースを実装してもらいましょう。そして、あなたのAPIでは、四則演算を表すenum型という実装クラスに対してではなく、インタフェースに対してロジックを書きましょう。こうすることで、利用者が拡張したenum型を動作させることができます。
項目39 命名パターンよりもアノテーションを選ぶ
ページ数の多い項目ですが、それはコード例が長いだけであって、学び取るべきことは少ないです。具体的には以下の通りです。
メソッドなどのプログラム要素の名前に、何らかのルールを設けて、そのルールに応じて付けられた「目印」を手掛かりに、ツールやフレームワークがプログラムを制御する、ということが昔は行われていました。例えば、JUnitではテストメソッド名がtestで始まること、というルールを設けていました。こういった技法は命名パターンと呼ばれます。
そういった技法は明らかに脆弱です。
ツールやフレームワークからプログラムを制御したい場合は、「手掛かり」をアノテーションでつけるようにしましょう。命名パターンの持つ脆弱さとは無縁になれます。
JDKには既に有用なアノテーションがたくさんあります。それらをしっかり活用しましょう。
(おわり)
項目40 常にOverrideアノテーションを使う
スーパータイプのメソッドをオーバーライドする場合は、必ず
@Overrideをつけましょう。オーバーライドしているつもりが実はできていなかった、といった間違いをコンパイラが教えてくれます。(おわり)
項目41 型を定義するためにマーカーインタフェースを使う
この項目はかなり読みづらいです…。噛み砕いて説明していこうと思います。
例えばFWやツールを開発していて、それらを利用する個別のプログラムを制御したいとします。その場合、個別のプログラムのどんな部分をどんな風に制御するかを、FWやツールが判断するために、個別のプログラムに何らかの「目印」(マーカー)をつける必要があります。
こういったマーカーを実現する方法として、以下の2つがあります。
- マーカーインタフェース(Serializableなど)
- マーカーアノテーション(JUnitの
@Testなど)この項目では、これらをどう使い分けるべきか?ということが解説されています。
マーカーインタフェースの長所
マーカーインタフェースは、型を定義できます。このため、コンパイル時に誤りに気づくことができます。一方、マーカーアノテーションではそういったことはできません。
マーカーインタフェースには、適用するための条件を付けることができます。
例えば、あるインタフェースAがあって、そのインタフェースAを実装したクラスにだけ、マーカーインタフェースが適用されるようにしたいとします。その場合、マーカーインタフェースにインタフェースAをextendsさせます。すると、そのマーカーインタフェースを実装するクラスは、自動的にインタフェースAも実装することになります。
「このマーカーインタフェースをつけるには、インタフェースAを実装する必要があるんですよ」という条件を付けられるのです。(こういった状況の具体例は思いつきませんが・・)
一方、マーカーアノテーションではそういったことはできません。
マーカーアノテーションの長所
- クラスやインタフェース以外にも、適用できます。一方、マーカーインタフェースはクラスとインタフェースにしか適用できません。
使い分けの考え方
この項目のメッセージは、「できるだけマーカーインタフェースを使いましょう。なぜならコンパイル時に誤りに気付けるからです。」という感じです。それを念頭において、以下をご覧ください。
クラスやインタフェース以外に適用する必要があるなら、マーカーアノテーションを使うしかありません。
「マークしたオブジェクトを引数にとるメソッド」が必要になりそうなら、コンパイル時の型チェックができるのでマーカーインタフェースを使いましょう。そうでないなら、マーカーアノテーションを使えば良いでしょう。
アノテーションが多用されるフレームワークなら、一貫性を重視する目的でマーカーアノテーションを使った方がいいかもしれません。バランスを見て判断すべきでしょう。
第7章 ラムダとストリーム
項目42 無名クラスよりもラムダを選ぶ
昔は関数オブジェクトを表現するために、無名クラスが使われていました。
Java 8から、関数オブジェクトを表現しやすくするために、関数型インタフェースが導入されました。併せて、関数型インタフェースのインスタンスを簡潔に表現できる仕組みとして、ラムダ式(あるいは単に「ラムダ」)が導入されました。
ラムダについては、以下を理解した上で使いましょう。
- ラムダの良さは簡潔さにありますから、出来る限り型を省略してコードを書くのが良いです。
- 型を省略できるのは、ラムダが型推論をしてくれるからです。その型推論は、ジェネリクスを手掛かりにして行われますから、ジェネリクスを最大限に活用することがラムダの良さを引き出す重要ポイントとなります。
- ラムダには名前とドキュメンテーションがありませんから、自明なロジックでなかったり、数行を超えたロジックなら、ラムダで実装すべきではありません。
- ラムダよりも無名クラスの方が適切な場合があります。状況に応じて選択しましょう。
- ラムダは関数型インタフェースしか実装できません。無名クラスは抽象クラスを実装することができます。
- 無名クラスは、複数の抽象メソッドを持つインタフェースを実装できません。
- ラムダにおける
thisはエンクロージングインスタンスを表し、無名クラスにおけるthisは無名クラスのインスタンスを表します。項目43 ラムダよりもメソッド参照を選ぶ
ラムダよりもメソッド参照の方が簡潔に実装できる場合があります。メソッド参照も、選択肢の一つに入れておきましょう。
ただし、以下の点を考慮すべきです。
- ラムダの場合、パラメータ名を書きます。そのパラメータ名が読みやすさのために必要なら、ラムダを選ぶべきでしょう。
- ラムダの場合、ロジックを書きます。決まり切ったロジックであっても、そのロジックが書いてあることで、すごく読みやすくなるのなら、ラムダを選ぶべきでしょう。
- ラムダの処理をメソッドに抽出し、そのメソッド参照を使う、という選択肢もあります。その場合、抽出したメソッドにドキュメントを書けます。
- クラス名がすごく長かったりすると、メソッド参照の方が冗長になります。
なお、メソッド参照には5つの種類があります。書籍の表がとても分かりやすいのでそのまま引用します。はじめは慣れないかもしれませんが、頑張って覚える価値はあると思います。
メソッド参照の種類 例 同等のラムダ static Integer::parseIntstr -> Integer.parseInt(str)バウンド Instant.now()::isAfterInstant then = Instant.now();t -> then.isAfter(t)アンバウンド String::toLowerCasestr -> str.toLowerCase()クラスコンストラクタ TreeMap<K,V>::new() -> new TreeMap<K,V>()配列コンストラクタ int[]::newlen -> new int[len]項目44 標準の関数型インタフェースを使う
Javaに関数型インタフェースやラムダが備わったことで、APIを作る場合のベストプラクティスはかなり変わってきました。具体的には、関数オブジェクトを引数にとるコンストラクタやメソッドを作るのが当たり前になってきました。
例えば、このような感じです。
/** * 関数オブジェクトを利用するAPIの一例です。 * @param funcSpecifiedByUser 第1引数に主語、第2引数に目的語を取り、何らかの文章を返す関数です。この結果が標準出力に表示されます。 */ public static void apiUsingFuncObj(BinaryOperator<String> funcSpecifiedByUser) { System.out.println(funcSpecifiedByUser.apply("I", "you")); } // APIの利用例です。分かりやすさのために+で文字連結しています。 public static void main(String[] args) { apiUsingFuncObj((subjectWord, objectWord) -> subjectWord + " love " + objectWord + "."); // I love you. と表示されます。 }このように自作するAPIの引数として関数インタフェースを採用することができます。利用者はラムダを使って関数インタフェースを実装した関数オブジェクトをつくり、APIに渡すことができます。
この時、自作するAPIの引数の型には、何らかの関数インタフェースを指定するわけですが、多くの場合、Javaに標準で用意されている関数インタフェースで事足ります。APIの提供者としては、余計な関数インタフェースを定義する必要はないのです。
利用者からすると、APIが標準の関数インタフェースを採用してくれた方が楽です。独自の関数インタフェースが定義されていた場合、その仕様を理解しなければならないからです。標準の関数インタフェースなら「ああ、あれね」という感じで、既存の知識をそのまま使えるので楽なのです。
ということで、APIのパラメータとして関数インタフェースを採用する場合、まずはJava標準の関数インタフェースを使うことを考えましょう。
Java標準の関数インタフェースには、どんなものがあるか
Java標準の関数インタフェースを紹介する記事は、世の中にたくさんありますので、詳しくはそちらに譲ります。ここでは、基本の6個の関数インタフェースを紹介することで、全体像を把握してください。
基本の関数インタフェース
関数インタフェース シグニチャ 説明 メソッド参照の例 UnaryOperator<T>T apply(T t)引数の型と同じ型を返します。 String::toLowerCaseBinaryOperator<T>T apply(T t1, T t2)引数の型と同じ型を返します。2つの引数をとります。 BigInteger::addPredicate<T>boolean test(T t)引数を受け取ってbooleanを返します。 Collection::isEmptyFunction<T,R>R apply(T t)引数とは異なる型を返します。 Arrays::asListSupplier<T>T get()引数をとらずに値を返します。 Instant::nowConsumer<T>void accept(T t)引数を受け取りますが、何も返しません。 System.out::printlnそれぞれの機能は直交しているわけではありません。その辺りはあまり気にしない方が良いでしょう。
考慮すべき点
UnaryOperator<Integer>のように、基本の関数インタフェースの型パラメータに、ボクシングされた基本データクラスを指定するのはNGです。ボクシング、アンボクシングにはコストがかかるからです。代わりにIntUnaryOperatorのような、基本データ型に対応した関数インタフェースを使いましょう。場合によっては、独自の関数インタフェースを作った方が良いです。以下のどれかに当てはまるなら、自作した方が良いかもしれません。
- 広く使われて、説明的な名前から恩恵を得られる。
- インタフェースに関連付けられた強い契約を持っている。
- 特別なデフォルトメソッドから恩恵を得られる。
自作した関数インタフェースには
@FunctionalInterfaceを付けましょう。
- 関数インタフェースであり、ラムダに使えることを読み手に伝えることができます。
- 誤って抽象メソッドを複数定義した場合に、コンパイルエラーで気づかせてくれます。それは、関数インタフェースを自作するあなたにとっても、その面倒を見る他のメンバーにとっても有難いことです。
APIを自作する場合には、同じ引数の位置に異なる関数型インタフェースを受け取る、同じ名前のメソッドを設けてはいけません。利用者が困ります。例えば、ExecutorServiceのsubmitメソッドがこれに当てはまります。
項目45 ストリームを注意して使う
ストリームとは?ストリームAPIとは?
ストリームとは、データ要素の有限あるいは無限なシーケンスのことです。Java 8では、このストリームを扱いやすくするためにストリームAPIが追加されました。
ストリームAPIでは、「ストリームパイプライン」を利用することで、ストリームを操作できます。
ストリームパイプラインは以下から構成されます。
- ソースのストリーム
- 中間操作
- 終端操作
パイプラインは遅延評価されますので、無限なシーケンスを扱うことができます。
注意すべき点
ストリームAPIは「オシャレ」ですが、乱用すると可読性が下がります。ストリームAPIの目的は「コードを簡潔にすること」ですので、その目的が達成されないような使い方はNGです。
具体的には、以下の点を考慮しましょう。
極論すると、ストリームAPIとループのどちらを使って実装すべきかは、書いてみないと分かりません。チームメンバーがどれだけストリームAPIに慣れているか、にもよります。状況に応じて、どちらの方が読みやすいかを見極めましょう。
次のような場合には、ストリームAPIが適している可能性が高いです。
- 均一に要素のシーケンスを変換する
- 要素のシーケンスをフィルターする
- 単一操作(たとえば、加算する、結合する、最小値を計算する)を使って、シーケンス中の要素を一つにまとめる
- 共通の属性でグループ化するなどして、シーケンス中の要素をコレクションに蓄積する
- シーケンスの要素から、特定の上限に合致する要素を検索する
ストリームAPIに限った話ではありませんが、ラムダのパラメータ名は可読性に大きく影響します。注意深くパラメータ名を考えましょう。
ストリームAPIでは、ヘルパーメソッドが重要な役割を果たすことがあります。ストリームパイプラインの中で実行する処理をヘルパーメソッドに切り出すと、そのヘルパーメソッドに名前を付けられるわけです。ストリームパイプラインからヘルパーメソッドを呼び出すと、ヘルパーメソッドの名前を見ればそこで何をやっているのか分かりますから、可読性が上がります。
後の中間操作で、前の中間操作のスコープで有効だったデータにアクセスしたい時があります。その場合、そのデータを前の中間操作からずっと覚えておくために、中間操作間で引き回すような実装はやめましょう。読みづらいだけです。代わりに、後の中間操作のスコープでアクセスできるデータをもとに、お目当てのデータを逆算しましょう。
項目46 ストリームで副作用のない関数を選ぶ
この項目の趣旨は「コレクターAPIを使いましょう」ということです。
ストリームパイプラインから「外側」にアクセスするのはNG
ストリームAPIを使うことで、何を得るべきでしょうか?ストリームAPIで狙うものは「何となくのカッコ良さ」ではありません。
最も重要なものは「簡潔さ」です。その他、「効率性」(CPUやメモリ負荷を低くする)も大事です。場合によっては「並列性」(マルチスレッドで処理することで処理性能を高める)も狙うべきでしょう。ストリームAPIを使ったとしても、こういったものを得られないと意味がないのです。
適切にストリームAPIを使うためには、個々のステージでの変換では、前のステージの変換結果だけにアクセスできるべきです。
逆に、ストリームパイプラインの外にある変数などにアクセスしてはいけません。こういったことをしてしまうと、少なくとも「簡潔さ」が失われます。コードの読み手は、ストリームパイプラインの外にあるものまで気にしないと、処理内容を読み解けなくなるからです。不具合が混入されやすくもなるでしょう。
例えば、以下のようなコードはNGです。
Map<String, Long> freq = new HashMap<>(); try(Stream<String> words = new Scanner(file).tokens()) { words.forEach(word -> { freq.merge(word.toLowerCase(), 1L, Long::sum); }); } /* 【何がダメなのか?】 forEach終端操作は、最終的な変換結果をストリームパイプラインの外部に返せません。 それにも関わらず、forEach終端操作を使って、最終的な変換結果をストリームパイプラインの外側に連携しようとしています。 この結果、ストリームパイプラインの外にある変数freqにアクセスしてしまっており、「簡潔さ」が失われています。 平たく言うと、読みづらいのです。 */ストリームパイプラインは、全体として1つの変換処理を構成するわけですから、最終的な変換結果をストリームパイプラインの外部に返すのが本分と言えるでしょう。こういった意味では、forEach終端操作が役立つ機会は限定的です。デバッグ用途や、ログ出力くらいかなと思います。
どうすればいいのか?
では、各変換ステージを独立したものにしつつ、ストリームパイプラインの外側に最終的な変換結果を返すにはどうすれば良いのでしょうか?そのために、「コレクター」という役割が用意されています。
具体的には、終端処理として
Stream.collect(collector)を呼び出します。collectメソッドの引数にコレクターのオブジェクトを渡します。このコレクターが、ストリームの要素を集めてくれます。多くの場合、何らかのCollectionに要素を集めます。collectメソッドはコレクターが集めた結果を、ストリームパイプラインの外側に返します。標準で様々なコレクターが用意されています。これらのコレクターオブジェクトを取得するには、java.util.stream.Collectorsのファクトリメソッドを呼び出します。
以下に、標準で用意されているコレクターのうち、代表的なものを紹介します。
用途 用途 コレクターオブジェクトの取得方法 備考 ストリーム要素をListに集める - Collectors.toList() ストリーム要素をSetに集める - Collectors.toSet() ストリーム要素を任意のCollectionに集める - Collectors.toCollection(collectionFactory) ストリーム要素をMapに集める 単純に集める Collectors.toMap(keyMapper, valueMapper) 〃 キーが重複した場合に適切にマージしつつ集める Collectors.toMap(keyMapper, valueMapper, mergeFunction) 〃 ↑に加え、特定のMap実装を使うように指定する Collectors.toMap(keyMapper, valueMapper, mergeFunction, mapFactory) 〃 ストリーム要素をグループに分け、グループごとの要素リストをMapの値として格納する Collectors.groupingBy(classifier) 〃 ↑とほぼ同じだが、Mapの値としてリスト以外のコレクションを指定する Collectors.groupingBy(classifier, downstream) downstream(ダウンストリームコレクター)とは、サブストリーム(グループに属する要素の集合)を入力にして、コレクションを生成するコレクター(関数オブジェクト)です。例えば、Collectors.counting()で得られるダウンストリームコレクターを使い、グループごとの件数を集計できます。 〃 ↑に加え、特定のMap実装を使うように指定する Collectors.groupingBy(classifier, mapFactory, downstream) downstreamの順序が↑と異なります。注意しましょう。 ストリーム要素内の最大値要素を取得する - Collectors.maxBy(comparator) 比較ルールを示すコンパレータを引数にとります ストリーム要素内の最小値要素を取得する - Collectors.minBy(comparator) 〃 ストリーム要素の文字列を単純に連結する - Collectors.joining() ストリーム要素の文字列をデリミターで連結する - Collectors.joining(delimiter) もちろん上記以外にもあります。
なお、表では説明のためにCollectors.toList()などと書きましたが、実際に使うときはCollectorsに定義されている全てのメンバーをstaticインポートし、
Collectors.を省略できるようにしましょう。格段に読みやすくなります。項目47 戻り値型としてStreamよりもCollectionを選ぶ
自作するAPIが要素のシーケンスを返却する、ということはよくあると思います。その場合、利用者によっては、その返却値をStreamとして扱いたい場合もありますし、Iterableとして扱いたい場合もあるはずです。
ですので、両方に対応できる戻り値型がベストです。具体的には、Collectionかそのサブタイプが良いです。なぜなら、CollectionインタフェースはIterableのサブタイプであり、streamメソッドが備わっているからです。
戻り値型をCollectionかそのサブタイプにできる場合は、以下の点を考慮しましょう。
- 要素数がメモリに格納するのに十分に小さい場合、ArrayListなどのコレクションの標準的な実装で大丈夫です。
- そうでない場合、小さいメモリ領域で済む特殊なコレクションの実装が必要です。
戻り値型をCollectionかそのサブタイプにできできない場合は、以下の点を考慮しましょう。
- IterableかStreamのどちらか自然な方を選択するのが好ましいです。
- 時には実装のしやすさで、どちらを採用するかが決まってしまうこともあります。
- いずれにしても、一方から一方に変換するアダプターが必要になってしまいます。アダプターを使うと、実装が散らかってしまいますし、遅いです。
項目48 ストリームを並列化するときは注意を払う
ストリームパイプラインの中で
Stream.parallel()を呼び出すと、パイプラインの処理がマルチスレッドで実行されるわけですが、多くの場合、ひどい結果につながります。つまり、速くならないどころが、シングルスレッドで実行する場合よりも壊滅的に遅くなります。その理由を理解するのはかなり難しいですし、速くなるように実装するのも大変難しいことです。ですので、よほどの理由や確証がない限り、ストリームを並列化するのはやめましょう。
第8章 メソッド
項目49 パラメータの正当性を検査する
メソッドやコンストラクタで受け付けたパラメータについては、冒頭で正当性を検査しましょう。そうしないと、不正なパラメータが原因で訳のわからない例外が発生したり、コードと関係のないところで思わぬ異常事態が発生する恐れがあります。
以下の点を考慮しましょう。
- パラメータに何らかの制約がある場合、Javadocの
@throwsにそのことを書きましょう。- Java 7で追加されたObjects.requireNonNullメソッドは、Null検査に便利です。ぜひ使いましょう。
- Java 9から、リストと配列のインデックスを検査する用途に、ObjectsにcheckFromIndexSize, checkFromToIndex, checkIndexメソッドが追加されました。用途に合うなら便利です。
- 正当性検査の処理コストが高く、かつ処理の途中で正当性検査が暗黙的に行われる場合、明示的に正当性検査を設けるべきではありません。
項目50 必要な場合、防御的にコピーする
APIとして公開するクラスは、たとえ利用者に悪意がなくても、利用者からひどい扱いを受けると考えた方が良いです。具体的には、そのクラスの不変式が壊されるような使い方をされるもの、と考えましょう。
ですから、利用者がどんなに不適切な使い方をしようとも、クラスの不変式が崩されないような工夫をしておくべきです。それが防御的コピーです。具体的には以下の対処をしましょう。
- 利用者から可変オブジェクトを受け取り、それを状態として保存するのであれば、そのオブジェクトのコピーを作り、その参照を保存しておきましょう。その場合、受け取ったオブジェクトのcloneメソッドを使うのは危険です。そのサブクラスを信頼できないからです。
- クラスが状態として持つ可変オブジェクトや配列を利用者に返却する場合、そのオブジェクトのコピーを作り、それを返却しましょう。
- そもそも、できるだけ不変クラスを使うようにしましょう。上記のようなことを気にしなくてもよくなります。特に、Java 8からはjava.util.Dateではなく、java.time.Instant(と同じパッケージの他のクラス)といった不変クラスを使うようにしましょう。
ただし、防御的コピーをしない、という判断をするときもあります。それは以下のような場合です。そういった場合は、Javadocにその旨の記載をするといった対処が最低限必要です。
- 防御的コピーの処理コストが許容できない場合。
- 何らかの理由で利用者を信頼できる場合。
- 不変式が崩されても、困るのは利用者だけである場合。
項目51 メソッドのシグニチャを注意深く設計する
この項目はTIPS集です。これらを守ると、自作するAPIが学習しやすく、使いやすいものになります。そして、エラーにつながりづらくもなります。
- メソッド名を注意深く選びましょう。
- 理解可能であること。
- 同じパッケージ内の他の名前と矛盾がないこと。
- 存在する広範囲のコンセンサスと矛盾がないこと。
- 短いこと。
- 便利なメソッドを提供しすぎないようにしましょう。
- メソッドが多すぎると、保守する側も使う側も大変です。
- メソッドを複数組み合わせて行える処理を、さらに一つの便利なメソッドとして提供するのは、頻繁に使われることが明らかな場合だけにしましょう。
- パラメータ数は4個以下にしましょう。
- 利用者は多くのパラメータを覚えられません。
- 同一の型のパラメータが何個も続くのはNGです。うっかり順序を間違えてもコンパイラは教えてくれません。
- パラメータを減らす方法は以下の通りです。
- 複数のメソッドに分割すること。ListのsubList, indexOf, lastIndexOfがそのお手本です。
- パラメータの集まりを保持するヘルパークラスを作りましょう。staticのメンバークラスになるでしょう。
- Builderパターンをメソッド呼び出しに適用しましょう。最後にexecuteしますが、その時にパラメータの正当性チェックをすると良いでしょう。
- パラメータの型にはできる限りインタフェースを採用しましょう。
- 異なる実装に切り替えられる柔軟性が生まれます。
- booleanパラメータよりも二つの要素をもつenum型を使いましょう。
- 読みやすいですし、拡張性もあります。
項目52 オーバーロードを注意して使う
APIを自作するとき、同じパラメータ数の複数のオーバーロードされたメソッドやコンストラクタを提供するのはNGです。利用者の意図する通りに動作せず、利用者を混乱させる恐れがあります。
そこで、以下のように対応しましょう。
- メソッドであれば、メソッド名を変えましょう。
- コンストラクタであれば名前を変えられませんので、staticファクトリメソッドで実装しましょう。
- どうしてもオーバーロードせざるを得ず、それらに同じ振る舞いをさせたい場合、両者が同じ振る舞いになることを保証するために、限定的な方から一般的な方に転送しましょう。
項目53 可変長引数を注意して使う
可変長引数メソッドは便利です。ただし、以下の点に注意しましょう。
- 可変長引数に必須パラメータが含まれると、可変長引数を利用者が誤って指定しなかった場合にコンパイルエラーになってくれません。必須パラメータを可変長引数に含めず、可変長引数とは別に定義しましょう。
- 可変長引数は、メソッドが呼び出される度に配列を生成することで実現されています。そういった配列生成のコストがあることを認識して、APIを定義しましょう。そのコストが受け入れられない場合は、よく使われる引数の数を調べて、その引数のメソッドを個別に定義しましょう。
項目54 nullではなく、空コレクションか空配列を返す
データのシーケンスを返却するメソッドで、場合によってnullを返却するものがありますが、これはNGです。
理由は以下のとおりです。
- 利用者はnullを扱うコードを書く手間が生じます。そもそも、nullへの対応が漏れてしまうかもしれません。
- APIを実装する側にとって、nullを返却する処理によって不要にコードが散らかります。
【NG】
public List<Cheese> getCheeses() { return cheesesInStock.isEmpty() ? null : new ArrayList<>(cheesesInStock); }【OK】
public List<Cheese> getCheeses() { // わざわざ条件分岐させる必要はありません。 // これで空のリストを返せます。 return new ArrayList<>(cheesesInStock); }空のリストを毎回生成するコストは、無視できるほど小さい場合が多いです。万一それが問題になるのであれば、Collections.emptyList()などを使って、不変の空コレクションを返却するようにしましょう。ただし、そうすべき局面は滅多にありませんので無闇にそうしてはいけません。
項目55 オプショナルを注意して返す
Java 8より前では、値を返さないメソッドを書くために、以下の手段がとられていました。
- nullを返す。
- 例外をスローする。
これらの手段に問題があるのは明らかで、Java 8から良い手段が追加されました。それがOptionalです。
APIからOptionalを返すことで、利用者に戻り値が空である可能性を認識させ、空だった場合のハンドリングを利用者に強制させることができます。
Optionalオブジェクトを生成する方法は以下の通りです。
Optionalの生成方法 説明 Optional.empty() 空のオプショナルを返します。 Optional.of(value) nullでないvalueを含むオプショナルを返します。nullが渡されるとNullPointerExceptionがスローされます。 Optional.ofNullable(value) nullの可能性がある値を受け付けて、nullが渡されたら空オプショナルを返します。 APIの利用者は、次のようにOptionalをハンドリングします。
// 空だった場合、orElseで指定したデフォルト値を使うようにしています。 String lastWordInLexicon max(words).orElse("No words..."); // 空だった場合、orElseThrowで指定した例外ファクトリによって例外がスローさせるようにしています。 // 例外の生成コストが、実際に例外がスローされるときだけに発生するように、例外ファクトリを指定するようになっています。 Toy myToy = max(toys).orElseThrow(TemperTantrumException::new); // オプショナルが空でないと分かりきっている場合は、いきなり値を取得できます。 // 万が一オプショナルが空の場合は、NoSuchElementExceptionがスローされます。 Element lastNobleGas = max(Elements.NOBLE_GASES).get();Optionalには便利なメソッドが色々と定義されています。例えば、orElseGetメソッドは
Supplier<T>を受け取り、Optionalが空のときにそれを呼び出すことができます。このおうちisPresentメソッドは、他のメソッドでやりたいことができなかったために存在するものであって、これを積極的に使うべきではありません。Optionalを要素に持つStreamを扱う場合、空でないものだけにフィルターしたい場合はよくあります。その場合、以下のように実装すると良いでしょう。
// Java 8以前 // Optional.isPresent()が活躍する数少ない局面です。 streamOfOptional .filter(Optional::isPresent) .map(Optional::get) // Java 9以降 // Optionalに追加されたstream()メソッドでは、 // Optionalに値があればその要素を含み、値が無ければ何も含まないStreamを返します。 // この性質を利用して、以下のように実装できます。 streamOfOptional .flatMap(Optional::stream)Optionalについては、以下に注意しましょう。
- 当然ながら、コレクションなどをOptionalで包んで返却してはいけません。コレクションであれば、空のコレクションを返せば良いのです。
- ボクシングされた基本データ型のOptionalを返してはいけません。無駄な処理コストが発生し、それは無視できない場合が多いためです。
- メソッドの戻り値を返す以外の用途でOptionalを使うべきではありません。例えば、インスタンスフィールドにOptionalを保持するような使い方は、多くの場合で不適切です。他に手段があるはずです。
項目56 すべての公開API要素に対してドキュメントコメントを書く
ドキュメントコメント(Javadoc)はなぜ必要か?【why】
利用者に誤った使い方をさせないため、公開APIについてはJavadocを書くべきです。
更に、保守メンバーが誤った方向性で修正しないように、また、保守メンバーがもとの実装の意図や目的を理解できるようにして、APIを保守できるようにするために、公開されていないものについてもJavadocを書くべきです。
実務においては、こういった目的が果たせるような最小限の内容を書くべきでしょう。コードは芸術作品ではなく、利益を生み出す手段です。Javadocにかけるコストが実益に見合うか、という点も重要です。
どうすれば良いか?【how】
以下の通りです。
- APIと利用者で守るべき「契約」を明記しましょう。
- 事前条件:利用者がAPIを呼び出すために成立していなければならない事柄です。
- 事後条件:呼び出しが正常に完了した後に成立していなければならない事柄です。
- 副作用:システム状態の観察可能な変化です。バックグラウンドでスレッドを起動する、など。
- パラメータ:基本的には名詞句で書きましょう。
- 戻り値:基本的には名詞句で。APIの概要説明と同じなら省略可です。
- スローされる例外:チェック/非チェックに関わらず書きましょう。例外クラス名と、スローされる条件を書きましょう。
- コードは
{@code}で表現しましょう。- 例えば「this list」(このリスト)の「this(これ)」はメソッドが呼び出されたオブジェクトを表します。
- 継承して使ってもらうクラスの場合、自身の他のメソッドを呼び出していることを
@implSpecに書きましょう。そうしないと利用者が誤った利用をしてしまいます。少なくともJava 9ではこのタグはデフォルトでは有効にならないので、注意すべきです。< > &といった文字を表現したい場合は、{@literal}を使いましょう。- ドキュメントコメントの冒頭には概要説明を書きましょう。
- 異なるAPIが同じ概要説明であってはならなりません。
- 概要説明はピリオド(.)によって終了してしまうので要注意です。適切に
{@literal}などを使うべきです。- 概要説明では、簡潔さのために主語は多くの場合省略されます。英語の場合は三人称現在形を使うべきです。
- クラス、インタフェース、フィールドについては、名詞句を使うべきです。
- Java 9からは、Javadoc画面の右上にある検索ボックスで、キーワード検索をできます。このとき検索にHITするのは、クラス名やメソッド名だけでなく
{@index}で明示的に設定されたキーワードです。- ジェネリック型やメソッドについては全ての型パラメータを文書化しましょう。
- enum型の場合は、全ての定数それぞれに対してドキュメントコメントをつけましょう。
- アノテーションについては、全てのメンバーを文書化しましょう。
- パッケージレベルのドキュメントコメントはpackage-info.javaに記載しましょう。
- マルチスレッドで動作させても大丈夫なのか、について記載しましょう。
- シリアライズ可能なのか、どのような形式でシリアライズされるか、について記載しましょう。
{@inheritDoc}は利用しづらく、制約があると言われています。- 個々のクラスなどだけではなく、それらの関係性を説明するドキュメントが必要な場合もあります。
- 以上のルールは自動的に検査されるべきです。Java 8以降ではデフォルトで検査されます。checkstyleなどでは更にしっかりと検査されます。
第9章 プログラミング一般
この章で書かれていることは「当たり前」のことです。特筆すべきことだけ解説していきます。
項目57 ローカル変数のスコープを最小限にする
特筆すべきことはありません。
項目58 従来のforループよりもfor-eachループを選ぶ
細かいですが、以下の点だけ覚えておきましょう。
- Collection.removeIf(filter)を使えば、従来のforループに頼らなくても、走査しつつ特定の要素を削除できます。
項目59 ライブラリを知り、ライブラリを使う
java.lang, java.util, java.io, java.util.concurrentをはじめ、主要なサブパッケージにどんな機能が備わっているのかを、知っておきましょう。知らなければ、使うことができません。リリースで追加される新機能は必ずチェックしましょう。
たとえば、Java 7の時点では、RandomよりThreadLocalRandomを使うべきです。こちらの方が速いです。
項目60 正確な答えが必要ならば、floatとdoubleを避ける
floatとdoubleは、正確な結果に近似する計算を素早くおこなうために存在します。正確な計算結果を得るために存在していません。ですので、正確な計算結果が欲しい場合は、これらを使うべきではありません。
代わりにBigDecimalを使いましょう。
ただ、BigDecimalには「遅い」という欠点があります。BigDecimalの遅さが許容できない場合は、intやlongといった整数を使って計算しましょう(ドルをセントに換算して計算するなど)。9桁までならint、18桁までならlongが使えます。それを超える場合はBigDecimalを使うしかありません。
項目61 ボクシングされた基本データよりも基本データ型を選ぶ
特筆すべきことは特にありません。
項目62 他の型が適切な場所では、文字列を避ける
例えば本質的に数値を表す文字列ならintなどで扱いましょう、といった感じの当たり前の内容です。
細かいですが、以下の点だけ覚えておきましょう。
- Stringは不変なので、同じ文字列を表すものであればJVM全体で同じインスタンスが使用されます。ですので、スレッド間で同じ名前空間を共有している場合のキーとしては、使えません。
項目63 文字列結合のパフォーマンスに用心する
Stringは不変なので
+で連結されるたびに新たなインスタンスが生成されてしまいます。
+を何度も適用して文字列を結合するには、StringBuilderを使いましょう(スレッドセーフではないことに注意しましょう)。だからといって、
+での連結は全て悪か、というとそうでもありません。1個や2個の+であれば、簡潔でパフォーマンス上の問題は無いでしょう。項目64 インタフェースでオブジェクトを参照する
インタフェースや抽象クラスで参照した方が柔軟性は高いです。後で実装クラスを差し替えられるからです。
項目65 リフレクションよりもインタフェースを選ぶ
リフレクションを使うべき局面は極めて限定的です。無闇に使わないようにしましょう。
項目66 ネイティブメソッドを注意して使う
CやC++で実装されたメソッドを呼び出せる機能がJNIですが、これを自分で実装すべき局面はおそらくありません。万が一それをやる場合は注意しましょう、という内容です。本当にそんな局面に直面してから、この項目を読めばよいと思います。
PJで何らかの製品を使う必要になり、それを使う唯一の手段がJNIである、ということが稀にあります。 JNIで呼び出す処理はJVMの管理外で動きますから、メモリの破壊といったリスクが伴います。そういった危険性を認識し、徹底的にテストしましょう。
項目67 注意して最適化する
最適化とは極論すると、「速く」するために低レイヤーに着目したコードを書くことです。最適化というのは、それが必要になってはじめて実施するものであって、はじめからやるものではありません。なぜなら、最適化をするとコードが散らかりますし、そもそも効力が無い恐れがあるからです。
やるべきことは以下の通りです。
- アーキテクチャレベルで、パフォーマンスの問題がないようにすべきです。アーキテクチャを注意深く設計しましょう。特に注意すべき箇所は、公開API、外部との通信部、データ永続化部です。これらはパフォーマンスに大きく影響するとともに、後から差し替えることがほぼ不可能です。
- 注意深く公開APIを設計しましょう。
- 公開する型を可変にすると防御的コピーが必要になってしまいます。
- 不適切に継承を採用すると、スーパークラスがサブクラスの足かせになり、サブクラスをチューニングできなくなります。
- インタフェースに対して利用してもらわないと、後から効率的な実装に差し替えられなくなります。
- より良いパフォーマンスを狙ってAPI設計をねじ曲げると、そのAPIをサポートをし続ける苦労の方が大きくなります。
- 最適化が必要そうな場合、プロファイリングツールを使ってボトルネックを特定しましょう。例えば、jmhは可視性に優れたマイクロベンチマーク・フレームワークです。
- どうしても最適化する場合は、本当に良くなったかを確認するため測定しましょう。バイトコードが動作するハードウェアによって、実際にどのようにプログラムが処理されるかが変わってきます。今日では様々なハードウェアがあるわけですから、測定しない限り、最適化が功を奏したかどうかは判定できません。
項目68 一般的に受け入れられている命名規約を守る
特筆すべきことは特にありません。当たり前の話です。
第10章 例外
項目69 例外的状態にだけ例外を使う
タイトルの通りです。理由は説明するまでも無いでしょう。
項目70 回復可能な状態にはチェックされる例外を、プログラミングエラーには実行時例外を使う
異常事態を表すクラスは、以下の構造(継承関係)をとっています。それぞれの使い分けと注意事項についても記載しておきました。
説明 Throwable Errorとそのサブタイプ JVMが使うものです。自作するのはやめましょう。 Exception RuntimeExceptionとそのサブタイプ いわゆる「チェックされない例外」です。利用者が何らかの誤りを犯している状況であれば、これをスローすべきです。利用者にハンドリングされても害になるだけだからです。 RuntimeExceptionのサブタイプでないもの いわゆる「チェックされる例外」です。呼び出し元が適切に回復できるような状況であれば、これをスローすべきです。利用者に回復処理を強制させることができるからです。利用者が適切なハンドリングをできるように、例外クラスに情報取得用のメソッドを用意しましょう。ただし、項目71の通り、まずはOptionalを返すことを検討しましょう。 項目71 チェックされる例外を不必要に使うのを避ける
APIからチェックされる例外をスローするのであれば、それが本当に必要かどうかを吟味すべきです。その例外を利用者が受け取ったとしても、実質的には何もできないのであれば、スローしてはいけません。
利用者に何らかの回復処理を強制する必要性とその価値がある場合、チェックされる例外をスローするAPIは、利用者にとっては鬱陶しくも感じます。以下の難点があるからです。
- try-catchを書かないといけません。面倒ですし、コードが散らかります。
- ストリーム内でそのAPIを使えません。ストリームではチェックされる例外をハンドリングできないからです。
こういった難点を解消・軽減する手段として、Optionalを返す、というものがあります。例外をスローする代わりに、空Optionalを返すということです。ただし、Optionalには例外クラスのように付加情報を持たせることができません。バランスをみて判断しましょう。
項目72 標準的な例外を使う
タイトルの通りです。理由は説明するまでも無いでしょう。
項目73 抽象概念に適した例外をスローする。
Javaでは例外を伝播させることができます。下位レイヤーでスローされた例外が、複数層を経て上位レイヤーに伝播していくと、下位レイヤーのコードと上位レイヤーのコードが結合してしまいます。つまり、両者を独立して修正するのが難しくなってしまいます。
このため、以下を心がけましょう。
- そもそも例外を発生させないようにしましょう。つまり、上位レイヤーは下位レイヤーを呼び出すにあたり、下位レイヤーを呼び出すにあたっての事前条件が成立していることをチェックしましょう。それによって伝播をできるだけ回避しましょう。
- どうしても伝播させるべきであれば、上位レイヤーと下位レイヤーを分離するために、適切な抽象レベルのレイヤーで、適切な抽象レベルの例外を新たにスローしましょう。その際、元の例外をcauseとして設定すべきです。例外が起きたときの調査がしやすくなるからです。
項目74 各メソッドがスローするすべての例外を文書化する
項目56で説明されていることとかなり重複します。そちらをしっかり理解すれば大丈夫でしょう。
項目75 詳細メッセージにエラー記録情報を含める
例外発生時の調査のために、例外の詳細メッセージはとても重要な役割を果たします。
- 例外の原因となった、全てのパラメータとフィールドの値を含めましょう。
- ログは一般のプログラマ等も見ますので、当然ながらセキュアな情報を含めてはいけません。
- 詳細メッセージに、Javadocとソースコードから容易に読み取れることを含めるのは無駄です。
- 例外を自作するなら、調査に必要な情報を利用者に必ず設定してもらうために、例外クラスのコンストラクタ引数でそういった情報を受け取れるようにすべきです。
項目76 エラーアトミック性に務める
状態を持つオブジェクトのメソッドが呼び出され、メソッド内部で異常事態が発生したとします。その後、オブジェクトがメソッド呼び出しの前の状態に戻る、あるいはその状態と変わらないのが望ましいです。この性質のことを「エラーアトミック性」と呼びます。
この性質は、チェックされる例外をスローする場合に重要です。チェック例外がスローされる、ということは利用者が何らかの回復処理をできる、ということだからです。元の状態に戻らなければ、利用者が回復処理をすることは不可能でしょう。
エラーアトミック性を実現するために、以下の方法をとりましょう。
- そもそもクラスを不変なものとして作りましょう。不変であれば、何も考える必要はありません。
- 以下の処理が、「オブジェクトの状態を変更する処理」の前に実行されるようにしましょう。
- パラメータの正当性チェック
- 失敗するかもしれない処理
- オブジェクトの一時的コピーに対して操作を行い、操作が完了したらオブジェクトの内容を一時的コピーの内容で置き換えましょう。
エラーアトミック性は望ましいですが、必ず達成できるわけでもないですし、場合によっては実現にコストがかかりすぎることもあります。もしもエラーアトミック性が達成できない場合は、メソッドが失敗した場合にオブジェクトがどのような状態に置かれるか、とういことをJavadocに明記しましょう。
項目77 例外を無視しない
タイトルのとおりです。理由は説明するまでも無いでしょう。
稀ですが、例外を無視するのが適切な場合もあります。その場合は、必ずコメントにその理由を残しましょう。
第11章
項目78 共有された可変データへのアクセスを同期する
同期では「相互排他」と「スレッド間通信」が実現される
複数のスレッドで一つのオブジェクトのデータを読み書きする場合、以下の2点に注意を払う必要があります。
- 相互排他:あるスレッドがオブジェクトを変更している間に、他のスレッドからそのオブジェクトが不整合な状態に見えることを防ぐ必要があります。
- スレッド間通信:あるスレッドが行った変更が、他のスレッドから確実に見える必要があります。
後者は忘れられがちなので、注意が必要です。適切に実装しなければ、あるスレッドが行った変更が他のスレッドから永遠に見えないように、コンパイラが勝手に最適化したりします。その結果、タイミングによって発生したり発生しなかったりするような厄介な不具合につながります。
後者に着目したものにvolatile修飾子があります。これをフィールドにつけると、スレッドごとのキャッシュが利用されなくなるため、最後に書き込まれた値が読み込みをするスレッドから見える、ということが保証されます。ただし、volatileでは相互排他は行われません。複数スレッドでオブジェクトを共有する局面では、上記2点の両方を満たす必要があることがほとんどなので、volatileで済む局面は少ないでしょう。
上記2点の両方を満たすためには、同期を行う必要があります。具体的には、メソッドにsynchronized修飾子をつけましょう(syncronizedブロックだけでは、他スレッドでの値の可視性は保証されません)。場合によってはjava.util.concurrent.atomicパッケージが適切かもしれません(AtomicLongなど)。
おまけ:「アトミック性」とは何か?
マルチスレッドの文脈では「アトミック性」という用語がよく出てきますので、理解しておくことをオススメします。アトミック性とは、データに対する複数の操作が、他のスレッドから単一の操作のように見える性質のことです。
具体的なこととしては、以下の点を理解しておけば良いと思います。
- ふつうlongとdoubleの変数はアトミック性は保証されません。32bitずつの2つの書き込みが別々に行われる結果、別のスレッドから中途半端な状態が見えてしまいます。longとdoubleであっても、変数にvolatileをつけることで、他のスレッドからは64bitの1つの書き込みとして見えるようになります。
- インクリメント演算子
i++はアトミックではありません。変数の読み込みと書き込みという2つの操作が行われるわけですが、他のスレッドからはそれらの操作は別々の操作に見えます。その結果、あるスレッドでの読み込みと書き込みの間に、他のスレッドからの読み込みや書き込みが入り込めてしまいます。この問題に対応したライブラリがjava.util.concurrent.atomicパッケージです。項目79 過剰な同期は避ける
過剰に同期を利用すると、悪いことが起こります。
過剰に同期を利用する、というのはどういうことか?
過剰に同期を利用する、とは以下を指します。
- 同期すべきでないところで同期を利用する。
- 同期すべきだけど、同期のスコープが大きすぎる。
- 単純にスコープが大きすぎる。
- 同期のスコープで、利用者に制御を譲ってしまう(例:利用者がオーバーライドするメソッドや、利用者から渡された関数オブジェクトを、同期のスコープ内で呼び出す)。
過剰に同期を利用すると、どうなるのか?
過剰に同期を利用すると、以下の問題が起こります。
正確性の問題(書籍で紹介されているコード例が、とても参考になります)
- 1つのスレッドで重複してロックをとってしまい、そのスレッド自身でクラスの不変式を破ってしまいます。Javaのロックは再入可能です。つまり、ロックを取得した後に再度同じロックを取得しようとしても、エラーになりません。
- デッドロックが起こります。つまり、複数のスレッドが互いのロック解放を待ち合ってしまいます。
パフォーマンスの問題
- ロックを取得したスレッド以外のスレッドが、必要以上に待たされます。
- 全てのCPUコアに、メモリの一貫したビューを持たせるために遅延が発生します。マルチコアの時代には、このコストが非常に大きくなります。
- JVMがコード実行を十分に最適化できなくなります。
どうすればいいのか?
以下につきます。
- できるだけ同期をしないようにしましょう。
- 可変クラスを作る場合、以下の選択肢があります。できるだけ前者を採用しましょう。
- 利用者に同期してもらうようにします。できるだけこちらを採用しましょう。
- クラス内部で同期をします。こちらを採用すると、利用者に同期をする/しないの選択肢を提供できません。まずは利用者に同期してもらうことを検討し、それだと問題がある場合のみクラス内部での同期を採用しましょう。
- 同期するならスコープを最小限にしましょう。特に、同期のスコープ内で、利用者に制御を任せるような処理を呼び出さないようにしましょう。
項目80 スレッドよりもエグゼキュータ、タスク、ストリームを選ぶ
独自にThreadクラスを使うのではなく、java.util.concurrentパッケージにある
エグゼキュータフレームワークを使いましょう。というのが、本項目のメッセージです。この項目に書いてある内容は、何と言うか中途半端です。この項目で紹介されている「Java Concurrency in Practice(Java並行処理プログラミング ―その「基盤」と「最新API」を究める―)」を読んだ方が良いでしょう。
項目81 waitとnotifyよりも並行処理ユーティリティを選ぶ
以前にwaitとnotifyで実現していたことを、現在ではjava.util.concurrentパッケージの高レベルな並行処理ユーティリティで、簡単に実現できるようになっています。
高レベルな並行処理ユーティリティ
java.util.concurrentパッケージの高レベルな並行処理ユーティリティは、以下の3つに分類されます。
- エグゼキュータフレームワーク
- 項目81を参照ください。
- コンカレントコレクション
- List, Queue, Mapといった標準のインタフェースを実装しており、内部で適切な同期処理を行います。同期しつつも高パフォーマンスを実現してくれます。
- 外部から同期処理に介入することはできませんので、コンカレントコレクションに対する基本操作を複数組み合わせ、それらをアトミックにすることは、外部からはできません。これを実現するために、基本操作を複数組み合わせてアトミックな操作をするためのAPIが用意されています。(MapのputIfAbsentなど)。
- 基本操作を複数組み合わせた処理は、Mapなどのインタフェースにそのデフォルト実装として組み込まれていますが、アトミックになるのはコンカレントコレクションの実装のみです。Mapなどのインタフェースにデフォルト実装が組み込まれているのは、アトミックでなくても便利だからです。
- 同期されたコレクション(Collections.sysnchronizedMapなど)は過去の産物であり、遅いです。特段の理由がない限り、コンカレントコレクションを使いましょう。
- Queueなどの実装においては、操作が完了するまで待つ「ブロックする操作」をできるように拡張されています。例えばBlockingQueueのtakeメソッドでは、キューが空なら待ち、キューに登録されたら処理を行います。エグゼキュータフレームワークでは、この仕組みが利用されています。
- シンクロナイザ
- スレッド間の掲示板のような働きをして、スレッド間で足並みを揃えることを可能にします。
- よく使われるのはCountDownLatchです。たとえば親スレッドが
new CountDownLatch(3)のオブジェクトを生成し、子スレッドA, B, Cを起動させて、CountDownLatchオブジェクトのawait()を呼び出し、待ちに入ります。スレッドA, B, CがこのCountDownLatchオブジェクトのcountDown()を呼び出すと、親スレッドの待ちが解除され、親スレッドの後続処理が実行されます。一連の処理の裏側ではwait, notifyが実行されていますが、ややこしい部分をCountDownLatchが全て担当してくれています。※並行処理の文脈に限った話ではありませんが、時間間隔の測定には、System.currentTimeMillis()ではなく、System.nanoTime()を使いましょう。後者の方が正確かつ高精度で、システムのリアルタイムクロックの調整による影響を受けません。
waitとnotify
保守などでwaitとnotifyを使ったコードの面倒を見ることもあるでしょう。その場合は、waitとnotifyの定石を把握しておくべきです。
この部分はほぼ以下と同じですので、詳しい説明は省略します。
項目82 スレッド安全性を文書化する
書いてあること全てが重要です。この項目の内容を理解するのは簡単ですので、特に解説する必要は無いでしょう。
項目83 遅延初期化を注意して使う
稀に、フィールドの値が必要となるまで、そのフィールドの初期化を遅らせることがあります。これを遅延初期化と呼びます。
遅延初期化の目的は、以下のとおりです。
- 最適化のため(「速く」するため)
- 初期化に何らかの循環処理があり、その循環を断ち切るため
最適化を目的とする場合、「それをやって本当に意味があるのか?」ということを良く考えましょう。効果が極めて小さかったり、逆効果となる可能性もあります。そのためにコードを散らかすのは論外です。
通常の初期化で問題ない場合、以下のようにfinalをつけて初期化しましょう。
private final FieldType field = computeFieldValue();staticフィールドであっても同じです。
遅延初期化の方法
フィールドの型がオブジェクトの参照の場合を例に説明します。
なお、基本データでもほぼ同じです。本データの場合はnullではなく、デフォルト値0に対して検査する、という差異があるのみです。
①初期化循環を断ち切る場合
以下のように「同期されたアクセッサー」を使いましょう。単純かつ明快な方法です。
private FieldType field; // synchronizedメソッドにより、 // 「相互排他」と「スレッド間通信」の両方が実現されます。 private synchronized FieldType getField() { if (field == null) field = computeFieldValue(); return field; }staticフィールドであっても同じです。
②最適化のためにstaticフィールドを遅延初期化する場合
遅延初期化しない場合は以下のようにしますが・・・
private static final FieldType field = computeFieleValue();最適化のためにstaticフィールドを遅延初期化する場合は、以下のように「遅延初期化ホルダー・クラス・イディオム」を使いましょう。
private static class FieldHolder { // 遅延初期化したいフィールドを、staticなメンバークラスに持たせます。 static final FieldType field = computeFieleValue(); } private static FieldType getField() { // ・フィールドの値が必要になった時点で初めて、staticなメンバークラスをロードします。 // クラスがロードされた結果として、staticフィールドの初期化処理が実行されます。 // ・典型的なJVMでは、クラスを初期化する時にフィールドへのアクセスを同期するので、 // 明示的な同期処理を書く必要はありません。 return FieldHolder.field; }③最適化のためにインスタンスフィールドを遅延初期化する場合
以下のように、「二重チェックイディオム」を使いましょう。
// getFieldメソッド中のsyncronizedブロックだけでは、初期化されたフィールドが他スレッドから見えません。 // volatileをつけることで、初期化されたフィールドを他スレッドから即時に見えるようにします。 private volatile FieldType field; private FieldType getField() { // fieldの読み込みを1度だけにして性能を向上させるため // ローカル変数resultにfieldの値を代入しています。 FieldType result = field; // いったん初期化されたらロックは不要なので、 // 1回目の検査ではロックしません。 if (result != null) return result; // 2回目の検査のときに初めてロックします。 synchronized(this) { if (field == null) // ロックしないと、このタイミングで(ifの判定とcomputeFieldValueメソッドの呼び出しの間で) // 他スレッドがフィールドを初期化してしまう恐れがあります。 field = computeFieldValue(); return field; } }項目84 スレッドスケジューラに依存しない
スレッドスケジューラに依存するのはなぜNGか?
スレッドスケジューラとは、JVMの構成要素の一つで、その名の通りスレッドのスケジューリングをします。JVMの構成要素の一つということは、つまるところOSの機能を利用するわけで、その振る舞いはOSに強く依存します。
このため、私たちはスレッドスケジューラの振る舞いを正確に知ることはできませんし、制御することもできません。もしプログラムの正しさやパフォーマンスが、スレッドスケジューラに依存するものであれば、ある時はうまく動くけどある時はうまく動かない、ある時は速いけどある時は遅い、といった不安定な動きをするでしょう。また、違うOSのJVMに移植すると、移植前の環境と同じように動かないかもしれません。
こういった理由から、プログラムの正しさやパフォーマンスが、スレッドスケジューラに依存するものであってはいけません。
どうすればいいのか?
以下の点を考慮しましょう。
- 実行可能(RUNNABLE)なスレッドの平均数を少なく保ちましょう。具体的には、プロセッサの数よりはるかに大きくしないようにしましょう。実行可能(RUNNABLE)なスレッドの数が多いと、スケジューラに選択肢を与えることになり、結果、スケジューラに依存してしまいます。なお、スレッドの取り得る状態については、こちらの公式ドキュメントをご覧ください。実行可能(RUNNABLE)なスレッド数を少なく保つために、以下を考慮しましょう。
- スレッドの処理が終わったら、そのスレッドを待ちの状態(WAITING)にしましょう。
- エグゼキュータフレームワークでは
- スレッドプールを適切な大きさにしましょう。
- タスクの大きさを適度にしましょう。タスクの粒度が小さすぎると、タスクにスレッドをディスパッチするコストが大きくなり、遅くなります。
- while(true)の中で、ひたすら条件判定を繰り返し「待ち」を実現することを「ビジーウェイト」と呼びます。これをやってしまうと、以下の問題につながります。
- スレッドスケジューラの予想のつかない処理に対して、プログラムを脆弱にします。
- プロセッサへの負荷を増大させ、他のスレッドが処理されにくくなくなります。
- Thread.yieldを使うのはやめましょう。このメソッドは、「自スレッドに割り当てられているCPU使用量を、他のスレッドに譲っても良いよ」という意思をスケジューラに示すものです。これを受けたスケジューラがどのように振舞うのかは、予測がつきませんし不安定なので、Thread.yieldを使ってはいけません。
- スレッドの優先順位を調整するのはやめましょう。Thread.setPriority(int newPriority)でスレッドの優先順位を調整できるのですが、Thread.yieldと同様、これを受けたスケジューラがどう振舞るのかは、よく分かりません。
第12章 シリアライズ
項目85 Javaのシリアライズよりも代替手段を選ぶ
システム内で1箇所でもディシリアライズをしている場合、攻撃者によって作られた不正なオブジェクトをディシリアライズする危険性があります。ディシリアライズの過程で不正なコードが実行され、システムがハングする等、致命的な問題につながります。
こういったセキュリティ上の問題点があるので、シリアライズ/ディシリアライズを一切使うべきではありません。代わりに、JSONやprotobufといった技術を使いましょう。これらの技術を採用することで、先述のセキュリティ問題の多くを回避するとともに、クロスプラットフォームのサポート、高いパフォーマンス、ツールのエコシステム、コミュニティによるサポートといった利点を得られます。
既存システムの保守などで、どうしてもシリアライズ機構を利用せざるを得ない場合、以下のとおり対策しましょう。
- 信頼されないデータをディシリアライズしないようにしましょう。
- Java 9で追加されたjava.io.ObjectInputFilterを使って、ホワイトリストにあるクラスのみをディシリアライズするようにしましょう。ただし、これでは一般的なクラスだけで構成された攻撃コードには対応できません。
項目86 Serializableを最新の注意を払って実装する
どうしてもシリアライズ機構を採用する場合、それに伴う代償を認識しておくべきです。代償は以下のとおりです。
- いったんリリースされると、Serializableを実装したクラスの実装を変更する柔軟性が、ほぼ失われます。
- バグやセキュリティホールの可能性を増大させます。
- 新しいバージョンのクラスのリリースに関連したテストの負荷を増大させることです。
Serializableを実装する場合には、以下に注意しましょう。
- クラスにはシリアルバージョンUIDを明示的に設定しましょう。明示的に設定しないと、自動的にIDがふられ、互換性のある変更であるにも関わらず互換性が無いと判断されてしまいます。
- 継承のために設計されたクラスは、原則としてSerializableを実装すべきではありません。インタフェースは、原則としてSerializableを拡張すべきではありません。それらのクラスやインタフェースを利用する人が、Serializableを実装しなければならないからです。
- シリアライズ可能かつ拡張可能で、インスタンスフィールドを持つクラスを実装する場合、以下を考慮しましょう。
- サブクラスがfinalizeメソッドをオーバーライドできないようにすべきです。ファイナライザ攻撃を防ぎましょう。
- インスタンスフィールドがデフォルト値に初期化されると問題がある場合、readObjectNoDataメソッドを追加しましょう。
- staticのメンバークラスを除き、内部クラスはSerializableを実装すべきではありません。エンクロージングインスタンスへの参照など、シリアライズ形式が定まらない要素があるからです。
項目87〜90
ごめんなさい、記事を書く時間が無くなってしまったため、時間ができたら書きたいと思います。ただ、本当にSeirializableを実装する必要に迫られてから学び始めても、全く遅くは無い内容です、ということだけはお伝えしておきます。
おわりに
間違いなどありましたら、ぜひ教えてください!
- 投稿日:2020-03-23T01:27:32+09:00
Java 14で最低限押さえておきたい機能をEclipseで使ってみた
はじめに
2020/3/17にJava 14がリリースされました。
以下の機能がリリースされたようです。
下の表の「本記事の対象」列に〇がついているものを少し触ってみたので後で紹介します。
JEP(※1) 概要 本記事の対象 305 Pattern Matching for instanceof (Preview)(※2) 〇 343 Packaging Tool (Incubator)(※3) × 345 NUMA-Aware Memory Allocation for G1 × 349 JFR Event Streaming × 352 Non-Volatile Mapped Byte Buffers × 358 Helpful NullPointerExceptions 〇 359 Records (Preview) 〇 361 Switch Expressions (Standard) 〇 362 Deprecate the Solaris and SPARC Ports × 363 Remove the Concurrent Mark Sweep (CMS) Garbage Collector × 364 ZGC on macOS × 365 ZGC on Windows × 366 Deprecate the ParallelScavenge + SerialOld GC Combination × 367 Remove the Pack200 Tools and API × 368 Text Blocks (Second Preview) 〇 370 Foreign-Memory Access API (Incubator) × 公式はこちら
※1 JEP
JDK Enhancement Proposalsの略。
JDKに対する変更の提案を管理する番号。参考:https://www.slideshare.net/AyaEbata/jsrjepjbs
JEPの目次:https://openjdk.java.net/jeps/0※2 Preview
プレビュー版のこと。
機能としては保証されているが、どのように使うべきかは議論の余地があるもの。開発者が実際に使ってみて、フィードバックを受けて今後もJava SEの基本機能として提供し続けるかどうかが決まる。※3 Incubator
開発者からのフィードバックを得るために、Java SEに含めた実験的なAPI。参考:https://xtech.nikkei.com/it/atcl/column/15/120700278/080700044/
Java 14をEclipseで使えるようにするための設定
私はEclipse使いなので、JDK 14のインストールとEclipseの設定から始めます。
JDKダウンロード
以下のサイトからJDK14をダウンロードします。
https://www.oracle.com/java/technologies/javase-downloads.htmlEclipseインストール
Eclipseの最新版をインストールします。
https://www.eclipse.org/eclipseide/EclipseでJDK14を扱えるようにする
EclipseでJDK14を扱えるようにする手順は以下の通り。
①Eclipse Marketplaceを選択
②Java 14 Support for Eclipse をインストール
※こういったEclipse本体やプラグインのリリース情報は公式のtwitterからも流れてくるので興味ある方はフォローすることをお勧めします。
? Here is the new me! Eclipse IDE 2020-03! ?
— ? Eclipse Java IDE (@EclipseJavaIDE) March 18, 2020
Many improvements for users to leverage in many places
? https://t.co/tEp3O53CvA and https://t.co/lQsBQecjUb !
☕ Support for JDK 14 is also released today, at https://t.co/bqDu2awnjL
? Thanks to my contributors!
③Compiler compliance levelを14に設定
※Java 14 Support for Eclipse をインストールしないと14が選択肢に出ません。
④Installed JREに、インストールしたJDK14を設定
⑤Execution emvironmentにJDK14を設定
⑥今回はプレビューの機能も使うので、プレビューを有効化します。
これでJava 14を使ったJavaアプリケーションをEclipseで開発・実行できるようになります。
Java 14の新機能を触ってみる
早速触ってみました。
JEP 305:Pattern Matching for instanceof (Preview)
まずはJEP 305のPattern Matching for instanceofです。
instanceof と同時に変数を定義できるようになりました。
実際の書き方の例は以下の通りです。
前半がこれまでの書き方、後半がPattern Matching for instanceofを使用した書き方になっています。PatternMatchingTest.javapublic class PatternMatchingTest { public static void main(String... args) { patternMatch("literal"); patternMatch(1); } // previewなのでSuppressWarningsでワーニング抑止 @SuppressWarnings("preview") private static void patternMatch(Object obj) { // これまでの書き方 if (obj instanceof String) { String str = (String) obj; System.out.println("No Pattern Matching:" + str); } else if (obj instanceof Integer) { Integer inte = (Integer) obj; System.out.println("No Pattern Matching:" + inte); } // Pattern Matching for instanceof if (obj instanceof String str) { System.out.println("Pattern Matching:" + str); } else if (obj instanceof Integer inte) { System.out.println("Pattern Matching:" + inte); } } }switch文での使用はJava 15以降に持ち越しになっているようです。
http://openjdk.java.net/jeps/8213076JEP 358:Helpful NullPointerExceptions
NullPointerExceptionが発生した場合のメッセージが詳細になり、原因を特定しやすくなりました。
-XX:+ShowCodeDetailsInExceptionMessagesオプションをつけて実行することで、詳細なメッセージを得ることができます。
以下のサンプルコードで実験してみました。HelpfulNullPo.javapublic class HelpfulNullPo { public static void main(String... args) { String str = null; str.length(); } }
-XX:+ShowCodeDetailsInExceptionMessagesオプションを付けずに実行した結果がこちら。実行結果(オプションなし)Exception in thread "main" java.lang.NullPointerException at test.HelpfulNullPo.main(HelpfulNullPo.java:6)
-XX:+ShowCodeDetailsInExceptionMessagesオプションをつけて実行した結果がこちら。
実行結果(オプション有)Exception in thread "main" java.lang.NullPointerException: Cannot invoke "String.length()" because "str" is null at test.HelpfulNullPo.main(HelpfulNullPo.java:6)NullPointerExceptionの原因特定がしやすくなっています。
JEP 359:Records (Preview)
データ保持用のクラスとしてrecordという機能がpreviewとして入りました。
以下のように書くだけでデータ保持用のクラスを作ることができます。
(record Person(String name, int age) {}の部分)RecordTest.java@SuppressWarnings("preview") record Person(String name, int age) {} public class RecordTest { public static void main(String... args) { Person person = new Person("taumax", 13); System.out.println("name:" + person.name()); System.out.println("age:" + person.age()); System.out.println(person); } }実行結果name:taumax age:13 Person[name=taumax, age=13]インスタンス生成後に値を変更することはできないようです。
厳密には違いますが、イメージ的にはイミュータブルなJavaBeansを簡単に作ることができるようになったという感覚ですかね。JEP 361:Switch Expressions (Standard)
Switch文がアロー
->を使って書けるようになり、かなり読みやすくなりました。
Switch ExpressionsはJava 12でプレビューとして導入されたものですが、今回のJava 14で正式機能として導入されます。
実際の書き方の例は以下の通りです。
前半がこれまでの書き方、後半がSwitch Expressionsを使用した書き方になっています。SwitchExpressions1public class SwitchExpressions1 { public static void main(String... args) { for (Week day : Week.values()) { oldSwitch1(day); newSwitch1(day); } } // これまでのswitch文 private static void oldSwitch1(Week day) { System.out.print("old:"); switch (day) { case MONDAY, FRIDAY, SUNDAY: System.out.println(6); break; case TUESDAY: System.out.println(7); break; case THURSDAY, SATURDAY: System.out.println(8); break; case WEDNESDAY: System.out.println(9); break; } } // 新しいswitch文 private static void newSwitch1(Week day) { System.out.print("new:"); switch (day) { case MONDAY, FRIDAY, SUNDAY -> System.out.println(6); case TUESDAY -> System.out.println(7); case THURSDAY, SATURDAY -> System.out.println(8); case WEDNESDAY -> System.out.println(9); } } private enum Week { SUNDAY, MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY } }また、switch文の実行結果をそのまま変数に代入することができるようになりました。
実際の書き方の例は以下の通りです。
前半がこれまでの書き方、後半がSwitch Expressionsを使用した書き方になっています。SwitchExpressions2public class SwitchExpressions2 { public static void main(String... args) { for (Week day : Week.values()) { oldSwitch2(day); newSwitch2(day); } } // これまでのswitch文 private static void oldSwitch2(Week day) { System.out.print("old:"); int numLetters; switch (day) { case MONDAY, FRIDAY, SUNDAY: numLetters = 6; break; case TUESDAY: numLetters = 7; break; case THURSDAY, SATURDAY: numLetters = 8; break; case WEDNESDAY: numLetters = 9; break; default: throw new IllegalStateException("Wat: " + day); } System.out.println(numLetters); } // 新しいswitch文 private static void newSwitch2(Week day) { System.out.print("new:"); int numLetters = switch (day) { case MONDAY, FRIDAY, SUNDAY -> 6; case TUESDAY -> 7; case THURSDAY, SATURDAY -> 8; case WEDNESDAY -> 9; }; System.out.println(numLetters); } private enum Week { SUNDAY, MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY } }JEP 368:Text Blocks (Second Preview)
改行などを含んだ文字列を定義できるようになりました。
文字列を定義する場合の"ではなく"""で囲みます。
開始の"""のあとには文字列を続けることができません。TextBlockspublic class TextBlocks { @SuppressWarnings("preview") public static void main(String... args) { // これまでは改行をエスケープする必要があった。 String str1 = "I have a pen.\n" + "I don't have a pen."; System.out.println(str1); // エスケープしなくても改行してくれる。 String str2 = """ I have a pen. I don't have a pen. """; System.out.println(str2); // 改行したくない場合は「\」を付ける。 String str3 = """ I have a pen.\ I don't have a pen.\ """; System.out.println(str3); // 文字列に変数を埋め込む場合 String str4 = """ Hello %s. """.formatted("taumax"); System.out.println(str4); } }実行結果I have a pen. I don't have a pen. I have a pen. I don't have a pen. I have a pen.I don't have a pen. Hello taumax.以上。
参考
・Oracle、「Java 14」を発表 ~Recordクラスがプレビュー導入、switch式が正式機能に
・Java 14がリリース
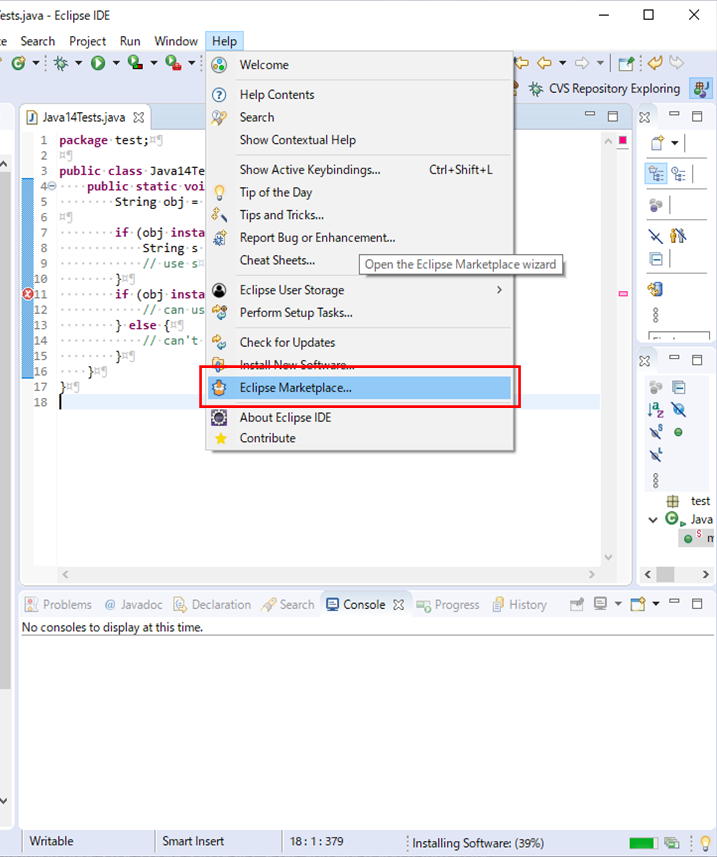
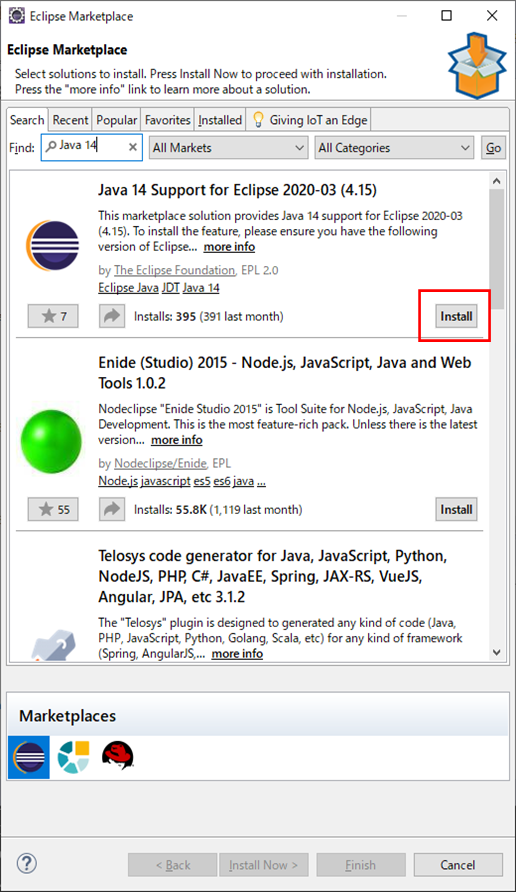
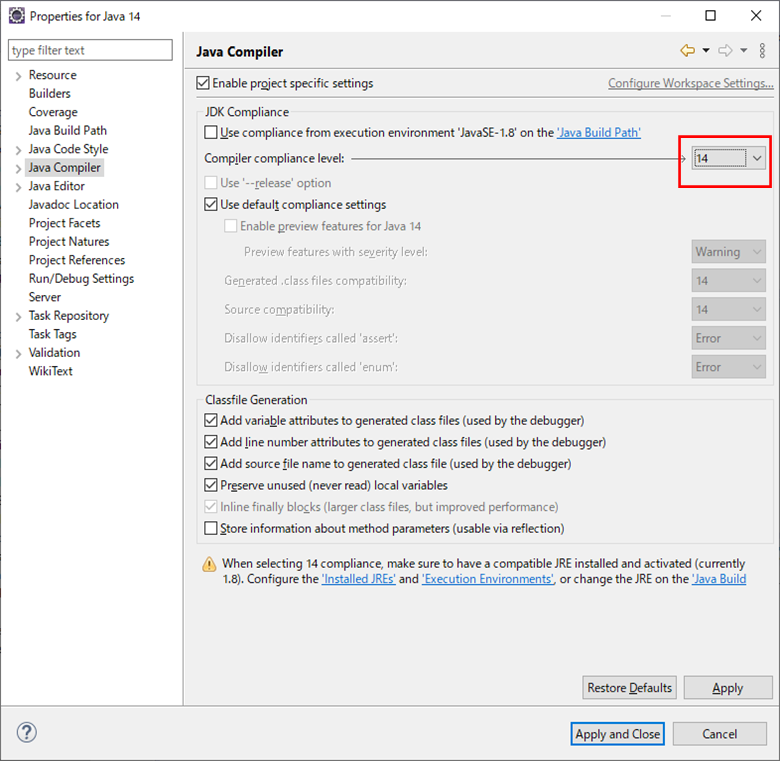
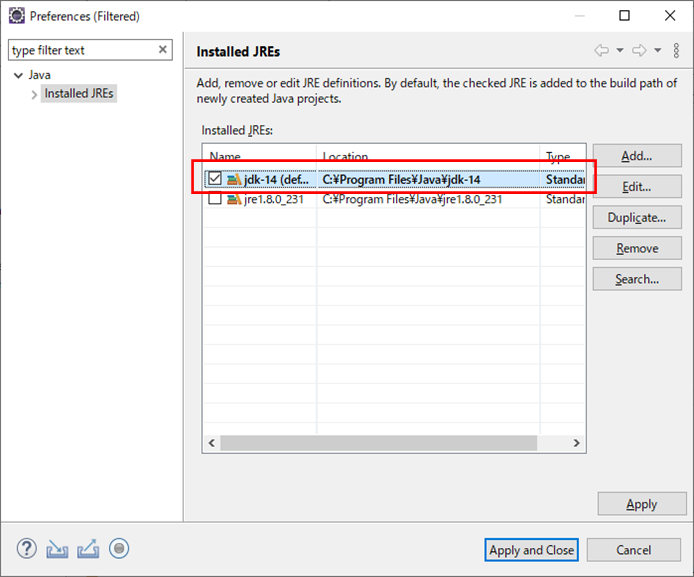


- 投稿日:2020-03-23T01:27:32+09:00
Java 14で個人的に気になる機能を使ってみた記事
はじめに
2020/3/17にJava 14がリリースされました。
以下の機能がリリースされたようです。
本記事の対象に〇がついているものについて少し触ってみたので後で紹介します。
JEP(※1) 概要 本記事の対象 305 Pattern Matching for instanceof (Preview)(※2) 〇 343 Packaging Tool (Incubator)(※3) × 345 NUMA-Aware Memory Allocation for G1 × 349 JFR Event Streaming × 352 Non-Volatile Mapped Byte Buffers × 358 Helpful NullPointerExceptions 〇 359 Records (Preview) 〇 361 Switch Expressions (Standard) 〇 362 Deprecate the Solaris and SPARC Ports × 363 Remove the Concurrent Mark Sweep (CMS) Garbage Collector × 364 ZGC on macOS × 365 ZGC on Windows × 366 Deprecate the ParallelScavenge + SerialOld GC Combination × 367 Remove the Pack200 Tools and API × 368 Text Blocks (Second Preview) 〇 370 Foreign-Memory Access API (Incubator) × 公式はこちら
※1 JEP
JDK Enhancement Proposalsの略。
JDKに対する変更の提案を管理する番号。参考:https://www.slideshare.net/AyaEbata/jsrjepjbs
JEPの目次:https://openjdk.java.net/jeps/0※2 Preview
プレビュー版のこと。
機能としては保証されているが、どのように使うべきかは議論の余地があるもの。開発者が実際に使ってみて、フィードバックを受けて今後もJava SEの基本機能として提供し続けるかどうかが決まる。※3 Incubator
開発者からのフィードバックを得るために、Java SEに含めた実験的なAPI。参考:https://xtech.nikkei.com/it/atcl/column/15/120700278/080700044/
Java 14をEclipseで使ってみる
私はEclipse使いなので、JDK 14のインストールとEclipseの設定から始めます。
JDKダウンロード
以下のサイトからJDK14をダウンロードします。
https://www.oracle.com/java/technologies/javase-downloads.htmlEclipseインストール
Eclipseの最新版をインストールします。
https://www.eclipse.org/eclipseide/EclipseでJDK14を扱えるようにする
EclipseでJDK14を扱えるようにするためには以下の設定が必要です。
Eclipse Marketplaceを開く
Java 14 Support for Eclipse をインストールする。
Compiler compliance levelを14に設定する。
※Java 14 Support for Eclipse をインストールしないと14が選択肢に出ません。
Installed JREの構成に、インストールしたJDK14を設定する。
Execution emvironmentの構成
今回はプレビューの機能も使うので、プレビューを有効化します。
これでJava 14をEclipseで開発・実行することができるようになります。
Java 14の新機能を触ってみる
早速触ってみました。
JEP 305:Pattern Matching for instanceof (Preview)
まずはJEP 305のPattern Matching for instanceofです。
instanceof と同時に変数を定義できるようになりました。
実際の書き方の例は以下の通りです。
前半がこれまでの書き方、後半がPattern Matching for instanceofを使用した書き方になっています。PatternMatchingTest.javapublic class PatternMatchingTest { public static void main(String... args) { patternMatch("literal"); patternMatch(1); } // previewなのでSuppressWarningsでワーニング抑止 @SuppressWarnings("preview") private static void patternMatch(Object obj) { // これまでの書き方 if (obj instanceof String) { String str = (String) obj; System.out.println("No Pattern Matching:" + str); } else if (obj instanceof Integer) { Integer inte = (Integer) obj; System.out.println("No Pattern Matching:" + inte); } // Pattern Matching for instanceof if (obj instanceof String str) { System.out.println("Pattern Matching:" + str); } else if (obj instanceof Integer inte) { System.out.println("Pattern Matching:" + inte); } } }実行結果No Pattern Matching:literal Pattern Matching:literal No Pattern Matching:1 Pattern Matching:1switch文での使用はJava 15以降に持ち越しになっているようです。
http://openjdk.java.net/jeps/8213076JEP 358:Helpful NullPointerExceptions
NullPointerExceptionが発生した場合のメッセージが詳細になり、原因を特定しやすくなりました。
これまでの実行結果はこちら。HelpfulNullPo.javapublic class HelpfulNullPo { public static void main(String... args) { String str = null; str.length(); } }実行結果(旧)Exception in thread "main" java.lang.NullPointerException at test.HelpfulNullPo.main(HelpfulNullPo.java:6)
-XX:+ShowCodeDetailsInExceptionMessagesオプションをつけて実行することで、詳細なメッセージを得ることができます。
実行結果(新)Exception in thread "main" java.lang.NullPointerException: Cannot invoke "String.length()" because "str" is null at test.HelpfulNullPo.main(HelpfulNullPo.java:6)NullPointerExceptionの原因特定がしやすくなっています。
JEP 359:Records (Preview)
データ保持用のクラスとしてrecordという機能がpreviewとして入りました。
以下のように書くだけでデータ保持用のクラスを作ることができます。
(record Person(String name, int age) {}の部分)RecordTest.java@SuppressWarnings("preview") record Person(String name, int age) {} public class RecordTest { public static void main(String... args) { Person foo = new Person("taumax", 13); System.out.println("name:" + foo.name()); System.out.println("age:" + foo.age()); System.out.println(foo); } }実行結果name:taumax age:13 Person[name=taumax, age=13]インスタンス生成後に値を変更することはできません。
イミュータブルなJava Beansクラスを簡単に作ることができるようになったというイメージですかね。JEP 361:Switch Expressions (Standard)
Switch文がアロー
->を使って書けるようになり、かなり読みやすくなりました。
Switch ExpressionsはJava 12でプレビューとして導入されたものですが、今回のJava 14で正式機能として導入されます。
実際の書き方の例は以下の通りです。
前半がこれまでの書き方、後半がSwitch Expressionsを使用した書き方になっています。SwitchExpressions1public class SwitchExpressions1 { public static void main(String... args) { for (Week day : Week.values()) { oldSwitch1(day); newSwitch1(day); } } // これまでのswitch文 private static void oldSwitch1(Week day) { System.out.print("old:"); switch (day) { case MONDAY, FRIDAY, SUNDAY: System.out.println(6); break; case TUESDAY: System.out.println(7); break; case THURSDAY, SATURDAY: System.out.println(8); break; case WEDNESDAY: System.out.println(9); break; } } // 新しいswitch文 private static void newSwitch1(Week day) { System.out.print("new:"); switch (day) { case MONDAY, FRIDAY, SUNDAY -> System.out.println(6); case TUESDAY -> System.out.println(7); case THURSDAY, SATURDAY -> System.out.println(8); case WEDNESDAY -> System.out.println(9); } } private enum Week { MONDAY, FRIDAY, SUNDAY, TUESDAY, THURSDAY, SATURDAY, WEDNESDAY } }実行結果old:6 new:6 old:6 new:6 old:6 new:6 old:7 new:7 old:8 new:8 old:8 new:8 old:9 new:9また、switch文の実行結果をそのまま変数に代入することができるようになりました。
実際の書き方の例は以下の通りです。
前半がこれまでの書き方、後半がSwitch Expressionsを使用した書き方になっています。SwitchExpressions2public class SwitchExpressions2 { public static void main(String... args) { for (Week day : Week.values()) { oldSwitch2(day); newSwitch2(day); } } // これまでのswitch文 private static void oldSwitch2(Week day) { System.out.print("old:"); int numLetters; switch (day) { case MONDAY, FRIDAY, SUNDAY: numLetters = 6; break; case TUESDAY: numLetters = 7; break; case THURSDAY, SATURDAY: numLetters = 8; break; case WEDNESDAY: numLetters = 9; break; default: throw new IllegalStateException("Wat: " + day); } System.out.println(numLetters); } // 新しいswitch文 private static void newSwitch2(Week day) { System.out.print("new:"); int numLetters = switch (day) { case MONDAY, FRIDAY, SUNDAY -> 6; case TUESDAY -> 7; case THURSDAY, SATURDAY -> 8; case WEDNESDAY -> 9; }; System.out.println(numLetters); } private enum Week { MONDAY, FRIDAY, SUNDAY, TUESDAY, THURSDAY, SATURDAY, WEDNESDAY } }実行結果old:6 new:6 old:6 new:6 old:6 new:6 old:7 new:7 old:8 new:8 old:8 new:8 old:9 new:9JEP 368:Text Blocks (Second Preview)
改行などを含んだ文字列を定義できるようになりました。
文字列を定義する場合の"ではなく"""で囲みます。
開始の"""のあとには文字列を続けることができません。TextBlockspublic class TextBlocks { @SuppressWarnings("preview") public static void main(String... args) { // これまでは改行をエスケープする必要があった。 String str1 = "I have a pen.\n" + "I don't have a pen."; System.out.println(str1); // エスケープしなくても改行してくれる。 String str2 = """ I have a pen. I don't have a pen. """; System.out.println(str2); // 改行したくない場合は「\」を付ける。 String str3 = """ I have a pen.\ I don't have a pen.\ """; System.out.println(str3); // 文字列に変数を埋め込む場合 String str4 = """ Hello %s. """.formatted("taumax"); System.out.println(str4); } }実行結果I have a pen. I don't have a pen. I have a pen. I don't have a pen. I have a pen.I don't have a pen. Hello taumax.以上。
参考
・Oracle、「Java 14」を発表 ~Recordクラスがプレビュー導入、switch式が正式機能に
・Java 14がリリース
- 投稿日:2020-03-23T01:27:32+09:00
Java 14で最低限押さえておきたい新機能をEclipseで使ってみた
はじめに
2020/3/17にJava 14がリリースされました。
以下の機能が追加されたようです。
下の表の「本記事の対象」列に〇がついているものを少し触ってみたので後で紹介します。
JEP(※1) 概要 本記事の対象 305 Pattern Matching for instanceof (Preview)(※2) 〇 343 Packaging Tool (Incubator)(※3) × 345 NUMA-Aware Memory Allocation for G1 × 349 JFR Event Streaming × 352 Non-Volatile Mapped Byte Buffers × 358 Helpful NullPointerExceptions 〇 359 Records (Preview) 〇 361 Switch Expressions (Standard) 〇 362 Deprecate the Solaris and SPARC Ports × 363 Remove the Concurrent Mark Sweep (CMS) Garbage Collector × 364 ZGC on macOS × 365 ZGC on Windows × 366 Deprecate the ParallelScavenge + SerialOld GC Combination × 367 Remove the Pack200 Tools and API × 368 Text Blocks (Second Preview) 〇 370 Foreign-Memory Access API (Incubator) × 公式はこちら
※1 JEP
JDK Enhancement Proposalsの略。
JDKに対する変更の提案を管理する番号。参考:https://www.slideshare.net/AyaEbata/jsrjepjbs
JEPの目次:https://openjdk.java.net/jeps/0※2 Preview
プレビュー版のこと。
機能としては保証されているが、どのように使うべきかは議論の余地があるもの。開発者が実際に使ってみて、フィードバックを受けて今後もJava SEの基本機能として提供し続けるかどうかが決まる。※3 Incubator
開発者からのフィードバックを得るために、Java SEに含めた実験的なAPI。参考:https://xtech.nikkei.com/it/atcl/column/15/120700278/080700044/
Java 14をEclipseで使えるようにするための設定
私はEclipse使いなので、JDK 14のインストールとEclipseの設定から始めます。
JDKダウンロード
以下のサイトからJDK14をダウンロードします。
https://www.oracle.com/java/technologies/javase-downloads.htmlEclipseインストール
Eclipseの最新版をインストールします。
https://www.eclipse.org/eclipseide/EclipseでJDK14を扱えるようにする
EclipseでJDK14を扱えるようにする手順は以下の通り。
①Eclipse Marketplaceを選択
②Java 14 Support for Eclipse をインストール
※こういったEclipse本体やプラグインのリリース情報は公式のtwitterからも流れてくるので興味ある方はフォローすることをお勧めします。
? Here is the new me! Eclipse IDE 2020-03! ?
— ? Eclipse Java IDE (@EclipseJavaIDE) March 18, 2020
Many improvements for users to leverage in many places
? https://t.co/tEp3O53CvA and https://t.co/lQsBQecjUb !
☕ Support for JDK 14 is also released today, at https://t.co/bqDu2awnjL
? Thanks to my contributors!
③Compiler compliance levelを14に設定
※Java 14 Support for Eclipse をインストールしないと14が選択肢に出ません。
④Installed JREに、インストールしたJDK14を設定
⑤Execution emvironmentにJDK14を設定
⑥今回はプレビューの機能も使うので、プレビューを有効化します。
これでJava 14を使ったJavaアプリケーションをEclipseで開発・実行できるようになります。
Java 14の新機能を触ってみる
早速触ってみました。
JEP 305:Pattern Matching for instanceof (Preview)
まずはJEP 305のPattern Matching for instanceofです。
instanceof と同時に変数を定義できるようになりました。
実際の書き方の例は以下の通りです。
前半がこれまでの書き方、後半がPattern Matching for instanceofを使用した書き方になっています。PatternMatchingTest.javapublic class PatternMatchingTest { public static void main(String... args) { patternMatch("literal"); patternMatch(1); } // previewなのでSuppressWarningsでワーニング抑止 @SuppressWarnings("preview") private static void patternMatch(Object obj) { // これまでの書き方 if (obj instanceof String) { String str = (String) obj; System.out.println("No Pattern Matching:" + str); } else if (obj instanceof Integer) { Integer inte = (Integer) obj; System.out.println("No Pattern Matching:" + inte); } // Pattern Matching for instanceof if (obj instanceof String str) { System.out.println("Pattern Matching:" + str); } else if (obj instanceof Integer inte) { System.out.println("Pattern Matching:" + inte); } } }switch文での使用はJava 15以降に持ち越しになっているようです。
http://openjdk.java.net/jeps/8213076JEP 358:Helpful NullPointerExceptions
NullPointerExceptionが発生した場合のメッセージが詳細になり、原因を特定しやすくなりました。
-XX:+ShowCodeDetailsInExceptionMessagesオプションをつけて実行することで、詳細なメッセージを得ることができます。
以下のサンプルコードで実験してみました。HelpfulNullPo.javapublic class HelpfulNullPo { public static void main(String... args) { String str = null; str.length(); } }
-XX:+ShowCodeDetailsInExceptionMessagesオプションを付けずに実行した結果がこちら。実行結果(オプションなし)Exception in thread "main" java.lang.NullPointerException at test.HelpfulNullPo.main(HelpfulNullPo.java:6)
-XX:+ShowCodeDetailsInExceptionMessagesオプションをつけて実行した結果がこちら。
実行結果(オプション有)Exception in thread "main" java.lang.NullPointerException: Cannot invoke "String.length()" because "str" is null at test.HelpfulNullPo.main(HelpfulNullPo.java:6)NullPointerExceptionの原因特定がしやすくなっています。
JEP 359:Records (Preview)
データ保持用のクラスとしてrecordという機能がpreviewとして入りました。
以下のように書くだけでデータ保持用のクラスを作ることができます。
(record Person(String name, int age) {}の部分)RecordTest.java@SuppressWarnings("preview") record Person(String name, int age) {} public class RecordTest { public static void main(String... args) { Person person = new Person("taumax", 13); System.out.println("name:" + person.name()); System.out.println("age:" + person.age()); System.out.println(person); } }実行結果name:taumax age:13 Person[name=taumax, age=13]インスタンス生成後に値を変更することはできないようです。
厳密には違いますが、イメージ的にはイミュータブルなJavaBeansを簡単に作ることができるようになったという感覚ですかね。JEP 361:Switch Expressions (Standard)
Switch文がアロー
->を使って書けるようになり、かなり読みやすくなりました。
Switch ExpressionsはJava 12でプレビューとして導入されたものですが、今回のJava 14で正式機能として導入されます。
実際の書き方の例は以下の通りです。
前半がこれまでの書き方、後半がSwitch Expressionsを使用した書き方になっています。SwitchExpressions1public class SwitchExpressions1 { public static void main(String... args) { for (Week day : Week.values()) { oldSwitch1(day); newSwitch1(day); } } // これまでのswitch文 private static void oldSwitch1(Week day) { System.out.print("old:"); switch (day) { case MONDAY, FRIDAY, SUNDAY: System.out.println(6); break; case TUESDAY: System.out.println(7); break; case THURSDAY, SATURDAY: System.out.println(8); break; case WEDNESDAY: System.out.println(9); break; } } // 新しいswitch文 private static void newSwitch1(Week day) { System.out.print("new:"); switch (day) { case MONDAY, FRIDAY, SUNDAY -> System.out.println(6); case TUESDAY -> System.out.println(7); case THURSDAY, SATURDAY -> System.out.println(8); case WEDNESDAY -> System.out.println(9); } } private enum Week { SUNDAY, MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY } }また、switch文の実行結果をそのまま変数に代入することができるようになりました。
実際の書き方の例は以下の通りです。
前半がこれまでの書き方、後半がSwitch Expressionsを使用した書き方になっています。SwitchExpressions2public class SwitchExpressions2 { public static void main(String... args) { for (Week day : Week.values()) { oldSwitch2(day); newSwitch2(day); } } // これまでのswitch文 private static void oldSwitch2(Week day) { System.out.print("old:"); int numLetters; switch (day) { case MONDAY, FRIDAY, SUNDAY: numLetters = 6; break; case TUESDAY: numLetters = 7; break; case THURSDAY, SATURDAY: numLetters = 8; break; case WEDNESDAY: numLetters = 9; break; default: throw new IllegalStateException("Wat: " + day); } System.out.println(numLetters); } // 新しいswitch文 private static void newSwitch2(Week day) { System.out.print("new:"); int numLetters = switch (day) { case MONDAY, FRIDAY, SUNDAY -> 6; case TUESDAY -> 7; case THURSDAY, SATURDAY -> 8; case WEDNESDAY -> 9; }; System.out.println(numLetters); } private enum Week { SUNDAY, MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY } }JEP 368:Text Blocks (Second Preview)
改行などを含んだ文字列を定義できるようになりました。
文字列を定義する場合の"ではなく"""で囲みます。
開始の"""のあとには文字列を続けることができません。TextBlockspublic class TextBlocks { @SuppressWarnings("preview") public static void main(String... args) { // これまでは改行をエスケープする必要があった。 String str1 = "I have a pen.\n" + "I don't have a pen."; System.out.println(str1); // エスケープしなくても改行してくれる。 String str2 = """ I have a pen. I don't have a pen. """; System.out.println(str2); // 改行したくない場合は「\」を付ける。 String str3 = """ I have a pen.\ I don't have a pen.\ """; System.out.println(str3); // 文字列に変数を埋め込む場合 String str4 = """ Hello %s. """.formatted("taumax"); System.out.println(str4); } }実行結果I have a pen. I don't have a pen. I have a pen. I don't have a pen. I have a pen.I don't have a pen. Hello taumax.以上。
参考
・Oracle、「Java 14」を発表 ~Recordクラスがプレビュー導入、switch式が正式機能に
・Java 14がリリース
- 投稿日:2020-03-23T00:08:47+09:00
エンジニア体験会での初心者への教え方(Java,Eclipse)
先日、自社で行っているプログラミング体験会で、未経験者に「プログラミングとは」を話す機会を頂いたので、次の機会の為に良かったことや改善していきたいことを自分用にまとめておきます。
--はじめに--
【体験会に来る人の経歴】
体験会には様々な経歴の人が来ます。
・大学の時にJava学んでました~
・接客業をしていてパソコンはあまり触ったことないです~
・転職を考えている中でIT業界に興味を持ちました~
など、他業種や未経験の人が多かったです。【体験会に来る人が求めていること(体験会後の交流会で多かった質問など)】
・完全未経験
→ プログラミングってなんか難しそう・・・
→ どうやって作るの?
・業務未経験だけどちょっと触ったことある(大学とか)
→ この会社で大丈夫か?(普通に企業説明会的な感じ)
→ エンジニアの仕事ってどんな感じ?レベルもまちまちなのでその人たち全てに同じようなレベル感で教えることはできない。
今回は完全未経験向けに教える方法をメモしていきたいと思います。
この会社で大丈夫かどうかは体験会が終わった後にでも答えてあげましょう。プログラムとは何か
まず初めにプログラム、プログラミング、プログラミング言語についてのイメージを話します。
初心者の多くはプログラムがどんなものか知らないことが多く、プログラミング言語って何?状態も珍しくないです。
そんな中話すわけなので、なるべくイメージをしてもらうことが大事だと思います。
そして、できるだけ難しい言葉は使わないようにします。
なんでもそうですが、苦手意識を持ってしまうとなかなか吸収しづらくなるため、わかりやすく説明します。
もちろん使わなければならない場面もあるので全く使わないのは無理ですが、使った場合にはその言葉の意味も伝えるようにすればたぶん大丈夫です。例)書いたプログラムはコンパイルしなければ実行できません。
→プログラムを実行するには、書いたコードをコンピュータ語に翻訳する「コンパイル」という処理をしなければなりません。というように、なるべくかみ砕いて教えていく方がよいと思います。
できるだけなじみの深い言葉で話すことによって、苦手意識を持たせないことが重要です。--講義の流れ--
1.プログラムとは
- プログラムが何をするものなのかをざっくりと(言語の種類などもここで)
2.プログラミング基礎知識
- プログラムの流れ(どういう流れで動いているか)
- 変数
- 簡単な構文をちょろっと(ifやfor)3.実践
- Eclipseで簡単なコードを書いて実行してもらう
--講義内容--
1.プログラムとは
プログラムとはコンピュータに向けた指示のことです。
普段私たちが人に何か指示をするとき、通常は言語を使いますよね。
日本人なら日本語、アメリカ人なら英語、中国人なら中国語といった言語を用いて指示するのですが、コンピュータに何かを支持するときも同様に言語を使用します。
それがプログラミング言語なのです。
プログラミング言語を用いて書かれた指示のことを「プログラム」といい、「プログラムを書く」ことを「プログラミング」というのです。「プログラミング」というと難しく感じる人も多いかもしれませんが、使用するのはプログラミング「言語」というくらいなのでルールがあります。ルールを覚えてしまえば、日本語のように読み書きが出来るので難しく考える必要はありません。
ところで、プログラミング言語は何種類くらい存在するのかご存じですか?
この記事でも紹介するJavaを含め、マイナーな言語も含めると約200種類以上と言われています。
しかし、これらすべてを日々の業務で使うかというとそんなことはありません。
言語によって実現しやすい機能や、実現しにくい機能があります。
詳しいことは調べてみてください。
ここではJavaの基礎を説明します。2.プログラミング基礎知識
2-1.プログラムの流れ
プログラミングが、【プログラムというコンピュータに指示を出すための指示】を書くことだと言うことが理解できたところで、プログラムを書いてから実行されるまでの流れを見ていきましょう。
プログラムはコンパイルしてから実行します。
(しかし、初心者にはコンパイルも実行もよく分からないと思います。日常で使わない言葉だし・・・
そこで、イメージしやすくするために
入力(プログラミング)→加工(コンパイル)→出力(実行)
という言葉で考えるとわかりやすいかもしれません。)mainメソッド内にコードを入力してコンパイル(コンピュータが分かる言葉に加工)、そしてコンソールに出力。
書いたものがどのように出力されるかの流れを言いながら実行すると良いでしょう。
コンソールの場所の説明も忘れずに(ここに表示されますよ~的なこと)Sample.javapackage sample; public class Sample { public static void main(String[] args) { System.out.println("Hello World!!"); } }出力内容Hello World!!※実際に実践してもらうときに注意すること
「Hello World!!」が出力できたら、自分の名前をコンソールに出力するプログラムを書いてもらいましょう。
その際に結構多いのが、System.out.println内の「Hello World!!」を書き変えるのではなく、packageから全部消してすべて書き直す人が多いのでSystem.out.println内だけを変えてもらうように注意しましょう。
また、全角のまま書いてエラーになっちゃう人が結構多いので教えてあげてください。
"とか{の出し方知らない人とかもいるので優しくしてあげてください。2-2.変数
(初心者が一番引っかかりやすいのが変数なのではないでしょうか)
変数は一言で言うと【値を入れておく(格納しておく)箱】のことです。
Javaにおいては変数に型が決まっており、決められた型の値しか格納することができません。
ここでは数値と文字列について簡単に説明します。
intとStringという型についてです。
この型というのはデータ型といい、値がどんな型なのかがわかるようになっています。
intが数値、Stringが文字列を表します。・int
ここでいう数値とは整数のことで、小数は含みません。
【1】や【10】や【100000】などです。
(小数は小数でほかのデータ型が存在しますがここでは割愛します。
また数値の中でも格納できる桁数によって使用するデータ型が決まっているのですがややこしくなるのでここでは割愛します。)
int型には数値のみを格納することができ、数値同士は計算することができます。・String
Stringには文字列を格納できます。
文字列とは【"あ"】や【"あいうえお"】【"こんにちは"】などの数値以外の文字のことです。
ですが実は数値も格納できます。【"1"】や【"10"】など。
しかしStringの中に数値をしまってしまうと、intのように計算ができなくなります。→文字列としての数値。(つかいかたで説明)・つかいかた
つかいかた【使用するデータ型】 【変数名】 = 【格納する値】;intでの計算int num1 = 10; int num2 = 15; // 式通りに計算される num1 + num2 = 25Stringでの計算String num1 = "10"; String num2 = "15" // 文字同士がつながって表示される num1 + num2 = "1015"2-3.簡単な構文(ifやforなど)
変数が理解できたら、簡単な構文について説明しましょう。
イメージが大事なので身の回りにあるものを例にして説明してあげると良いでしょう。
例えば条件分岐なら
コンビニでお酒やたばこを購入するときの年齢確認の「20歳以上ですか?はいorいいえ」などを説明の例にして実際に書いてもらう、など。if (条件分岐)
基本的な書き方
・if (もし○○なら△△する)if (条件1(○○)) {
条件1(○○)が満たされていたら実行する処理(△△)
}・else (もし○○なら△△、それ以外なら□□する)
if (条件1(○○)) {
条件1(○○)が満たされていたら実行する処理(△△)
} else {
条件1が満たされなかったら実行する処理(□□)
}・else if (もし○○なら△△、●●なら▲▲、それ以外なら□□する)
if (条件1(○○)) {
条件1(○○)が満たされていたら実行する処理(△△)
} else if (条件2(●●)) {
条件1(○○)は満たされていないが
条件2(●●)は満たしていたら実行する処理(▲▲)
} else {
条件1(○○)と条件2(●●)が満たされなかったら実行する処理(□□)
}※条件には算術演算子・比較演算子・条件演算子が使用できることを説明しましょう。
等しいか比較するときは「==」を使用する、などif練習問題※まずは簡単なプログラムを書いてもらい、動かす感覚を試してもらうことが大事だと思います。 変数ageの中身も各自で変更してもらい、100以外だとコンソールに出力されないことを確認してもらうと条件式の意味が分かりやすい。 // if // 年齢が100歳の場合、「1世紀生きています」と出力する。 // 変数 int age を使用すること // 解答 int age = 100; if (age == 100) { System.out.println("1世紀生きています。"); } // else // 年齢が20歳以上の場合「お酒が飲めます」、そうでない場合「お酒が飲めません」と出力する // 変数int age を使用すること int age = 20; if (age >= 20) { System.out.println("お酒が飲めます"); } else { System.out.println("お酒が飲めません"); } // ※ここもageの中身をいくつか変えて、出力内容の変化を試してもらう。 // else if // テストの点数が80点以上の人は「優」60点以上の人は「可」60点未満の人は不可と出力してください // 変数int score を使用すること(scoreは0~100のみが入ることとする) int score = 80; if (score >= 80) { System.out.println("優"); } else if (score >= 60) { System.out.println("可"); } else { System.out.println("不可"); } // ※ここもageの中身をいくつか変えて、出力内容の変化を試してもらう。for (繰り返し処理)
繰り返し処理の場合
「自分の名前をコンソールに5回出力するときはどのように書けばいいでしょうか?」
などと問いかけるとだいたいの方は5回出力System.out.println("自分の名前"); System.out.println("自分の名前"); System.out.println("自分の名前"); System.out.println("自分の名前"); System.out.println("自分の名前");と実装してくれます。
5回くらいなら楽に書けますが、100回出力してくださいとかになるとさすがにめんどくさいですよね。。。このような場合に繰り返し処理が利用できます。
という感じで進めます。・for構文
for (【初期値】;【繰り返し条件式】;【継続処理】;) {
// 繰り返し条件式が「true」の場合に行う処理内容
}練習問題// 自分の名前を5回出力してみましょう for (int i = 1; i<=5; i++) { System.out.println("山田太郎"); }forの中は「i」が「5」以下の場合に処理が実行されます。
「i」は1回の処理が終わるごとに「++」。すなわち1ずつ増加します。
わかりやすく処理を追ってみると1回目// iは1なので「山田太郎」が出力される。 for (1 <= 5) { System.out.println("山田太郎"); } // 出力結果:山田太郎2回目// i++でiは2なので「山田太郎」が出力される。 for (2 <= 5) { System.out.println("山田太郎"); } // 出力結果:山田太郎3回目// i++でiは3なので「山田太郎」が出力される。 for (3 <= 5) { System.out.println("山田太郎"); } // 出力結果:山田太郎4回目// i++でiは4なので「山田太郎」が出力される。 for (4 <= 5) { System.out.println("山田太郎"); } // 出力結果:山田太郎5回目// i++でiは5なので「山田太郎」が出力される。 for (5 <= 5) { System.out.println("山田太郎"); } // 出力結果:山田太郎6回目// i++でiは6なので「自分の名前」は出力されない。 for (6 <= 5) { System.out.println("山田太郎"); } // 出力結果:出力なしざっくりこんな感じで説明して、プログラミングって思ったより簡単で楽しい!から入ることが出れば吸収しやすくなると思います。
最後にロジックの練習問題をパズル感覚でやってあげるととっかかりやすくなると思うので、有名な問題だけ書いておきます。
fizzbuzz// 1~100まで順番に出力しながら // 3で割り切れる場合は「fizz」を // 5で割り切れる場合は「buzz」を // 3と5両方で割り切れる場合は「fizzbuzz」と出力してください // 例) 1,2,fizz,4,buzz,fizz,...,14,fizzbuzz,16,......,98,fizz,buzz // 解答 public class Sample { public static void main(String[] args) { for (int i = 1; i<=100; i++) { if (i % 3 == 0 && i % 5 == 0) { System.out.println("fizzbuzz"); } else if (i % 3 == 0) { System.out.println("fizz"); } else if (i % 5 == 0) { System.out.println("buzz"); } else { System.out.println(i); } } } }さいごに
苦手意識を持たせないように優しく教えてあげましょう!
読んでいただいてありがとうございました^^
ここ変だよとかこんな風に教えるとより良いよ!などあれば教えてください!
マークダウンの書き方とかでのアドバイスもうれしいです!