- 投稿日:2020-03-18T15:30:01+09:00
Python入門 〜B3に向けて〜 part3
part3では簡単な機械学習を行っていきます。
機械学習は3種類に分類されます。
種類 特徴 教師あり学習 データ:ラベル付けされている
目的:成果予測と未来予測
例:メールフィルタ,株価予測教師なし学習 データ:ラベル付けされていない
目的:データから隠れた構造を見つける
例:顧客のセグメント化,異常検知強化学習 データ:意思決定プロセス
目的:一連の動作などを学習
AlphaGo,ロボットのしつけ
機械学習の流れ
機械学習をするといっても学習モデルを作ってデータを入れただけではいい成果を得られることは少ないです。
具体的なワークフローを書くと以下のようになります。
- データの準備
モデルに学習させたいデータの内容を決め、収集します。- モデルの選択
データの形式や特徴から適したモデルを選択します。
すべてのデータに対して最適であるモデルは存在しない
(ノーフリーランチ定理)のでデータに適してモデルを探します。
評価指標は予測モデルだと正解率などです。- 前処理
生データでは学習がうまくいかないことがほとんどなのでデータの整形を行います。
欠損データの補完
・特徴量の抽出
・データに含まれている特徴量の尺度を同じくする
・無関係な特徴量(ノイズ)を圧縮するための次元削減
・学習,評価用にデータを分割する- モデルのトレーニング
選択したモデルでトレーニングを行っていきます。
ただし、モデルには手作業で調節しなければならないパラメータ(ハイパーパラメータ)が存在するためその調節も行います。- モデルの評価
評価用に残しておいたデータでモデルの評価(汎化性能の評価)を行います。このプロセスを繰り返すことにより適した学習モデルの生成を行っていきます。
今回のゼミでは3~5を行います。
と言っても3はほとんどpart2で行ったのでこれから紹介するモデルに対して4,5を中心に行っていきます。
ニューロン
機械学習とはいったい何でしょうか?
Warren McCullochさんとWalter Pittsさんは人工知能を設計するために人間の脳を模倣できないかと思案しました。
そこで人間の脳の最小単位であるニューロンを簡略化したものMcCulloch-Pittsニューロンとして発表しました。
ニューロンは脳内で化学信号や電気信号を受け取り、蓄積された信号が特定の閾値を超えたときに出力信号が生成されます。
彼らはそれを二値出力を行う論理ゲートとみなしMCPニューロンを設計しました。その数年後にFrank Rosenblattが最適な重み係数を自動的に学習した後、入力信号と掛け合わせ、ニューロンが発火(閾値を超える)するかを判断するアルゴリズムを考案しました。
これが「教師あり学習」の「分類問題」の最初です。人口ニューロンの定義は以下のようになっています。
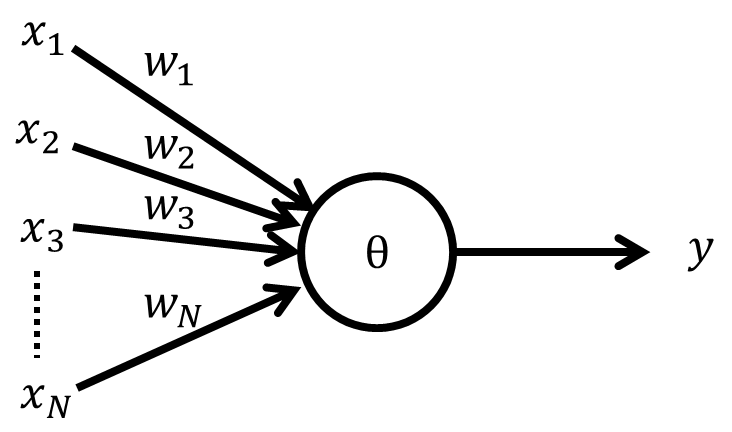
複数の入力信号 $\boldsymbol{x}$に対する重みベクトルを$\boldsymbol{w}$とします。
各入力$x_i$とそれに対する重み$w_i$の線形結合を総入力$z$と置きます。z = \Sigma_i^Nw_i x_i=\boldsymbol{w}^T\boldsymbol{x}二値分類の出力の値を
1(陽性クラス),-1(陰性クラス)に分けます。
総入力$z$が閾値$\theta$より大きい場合に陽性クラス、それ以外の場合は陰性クラスに分類する関数$\phi$(決定関数)を定義します。\phi(z) = \Biggl\{\begin{array}{l} 1 (z \geq\theta のとき) \\-1 (z < \thetaのとき)\end{array}ここで、話を単純にするために閾値$\theta$を左辺に移項し、$w_0=-\theta$,$x_0=1$と定義します。
このときの負の閾値である$-\theta$をバイアスユニットと呼びます。\phi(z) = \Biggl\{\begin{array}{l} 1 (z \geq0 のとき) \\-1 (z < 0のとき)\end{array}重みの更新(学習)
機械学習の学習とは重みの更新のことを指します。
学習の手順をまとめると以下のようになります。
- 重みを0か値の小さな乱数で初期化する。
- トレーニングサンプル毎に以下の手順を行う。
- ①出力値$\hat{y}$を計算
- ②重みの更新
ある入力$x_j$に対する重み$w_j$の更新は以下のように行います。
w_j = w_j + \Delta w_j\Delta w_j = \eta(y^{(i)}-\hat{y}^{(i)})x_jただし、$\eta$は学習率と言ってこの値が大きければ大きいほど
各トレーニングサンプルによる重みの更新への影響が大きくなります。
正解のクラスと出力ラベルの差$(y^{(i)}-\hat{y}^{(i)})$を誤差と呼びます。ではパーセプトロンを実装していきましょう。
class Perceptron(object): def __init__(self,eta=0.01,n_iter=50,random_state=1): #学習率の定義 self.eta=eta #トレーニング回数の定義 self.n_iter=n_iter #重みの初期化に使う乱数シード self.random_state=random_state def fit(self,X,y): #乱数の生成 rgen=np.random.RandomState(self.random_state) #step1 重みの初期化 self.w_=rgen.normal(loc = 0.0,scale=0.01,size=1+X.shape[1]) #誤差の宣言 self.errors_=[] #トレーニング回数分実行する for _ in range(self.n_iter): #誤差の初期化 errors=0 #step2 トレーニングサンプル毎に実行 for xi, target in zip(X,y): #出力値の計算およびdelta_wの計算 udelta_w = self.eta * (target - self.predict(xi)) #重みの更新 self.w_[1:] += delta_w * xi self.w_[0] += delta_w errors += int(delta_w != 0.0) self.errors_.append(errors) return self #総入力の定義 def net_input(self,X): return np.dot(X, self.w_[1:]) + self.w_[0] #決定関数の定義 def predict(self,X): return np.where(self.net_input(X) >= 0.0,1,-1)このパーセプトロンをつかってpart2で用いたIrisデータの予測をしていきましょう。
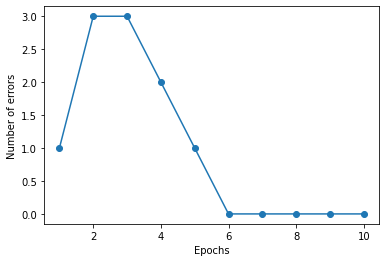
import pandas as pd df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',header=None) y = df.iloc[0:100,4].values y = np.where(y == 'Iris-setosa',-1,1) X = df.iloc[0:100,[0,2]].values ppn = Perceptron(eta=0.01,n_iter=10) ppn.fit(X,y) plt.plot(range(1,len(ppn.errors_)+1), ppn.errors_,marker='o') plt.xlabel('Epochs') plt.ylabel('Number of errors') plt.show()
このように10回のトレーニングを行うと誤分類が最終的になくなりました。
重みの更新をすることでデータセットをモデルが学習したわけですね。補足
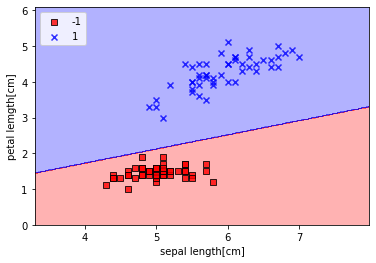
これを図示するとこのような決定領域になります。from matplotlib.colors import ListedColormap def plot_decision_regions(X,y,classifier,resolution=0.02): markers = ('s','x','o','^','v') colors = ('red','blue','lightgreen','gray','cyan') cmap = ListedColormap(colors[:len(np.unique(y))]) x1_min, x1_max = X[:,0].min() -1,X[:,0].max()+1 x2_min, x2_max = X[:,1].min() -1,X[:,1].max()+1 xx1,xx2 = np.meshgrid(np.arange(x1_min,x1_max,resolution),np.arange(x2_min,x2_max,resolution)) Z = classifier.predict(np.array([xx1.ravel(),xx2.ravel()]).T) Z = Z.reshape(xx1.shape) plt.contourf(xx1,xx2,Z,alpha=0.3,cmap = cmap) plt.xlim(xx1.min(),xx1.max()) plt.ylim(xx2.min(),xx2.max()) for idx, cl in enumerate(np.unique(y)): plt.scatter(x = X[y == cl,0],y = X[y == cl,1],alpha = 0.8, c = colors[idx],marker=markers[idx],label=cl,edgecolor='black') plot_decision_regions(X,y,classifier=ppn) plt.xlabel('sepal length[cm]') plt.ylabel('petal lemgth[cm]') plt.legend(loc='upper left') plt.show()
課題
学習率$\eta$ やトレーニング回数を変えることでモデルの学習がどのように変化するのか見てみよう
Scikit-learn
簡単な分類アルゴリズムが多数収録されているモジュールがscikit-learnです。
先ほど実装したパーセプトロンも入っています。
試しに使ってみましょう。from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.linear_model import Perceptron import numpy as np #irisデータの取得、使うデータ選択 iris = datasets.load_iris() X = iris.data[:,[2,3]] y = iris.target #テストデータとトレインデータに分割 X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=1,stratify=y) #パーセプトロンの呼び出し ppn = Perceptron(n_iter_no_change=500,eta0=0.1,random_state=1) #モデルにデータを学習させる ppn.fit(X_train,y_train) #学習したモデルの検証 y_predict = ppn.predict(X_test) #誤分類の個数の表示 print('Misclassified samples: %d' %(y_test != y_predict).sum()) #正解率の表示 print('Accuracy: %.2f' %ppn.score(X_test,y_test))Misclassified samples: 7 Accuracy: 0.84課題
上の補足で使った
plot_decision_regions関数を使って、今回の決定領域を図示しましょう。ロジスティック回帰
さて、どのような決定領域になったでしょうか。
パーセプトロンは線形分離を行うモデルなので、線形分離をすることができない
データセットに対しては不向きです。
そこでロジスティック回帰というアルゴリズムを見ていきます。
ロジスティック回帰ではオッズ比というものを用います。\frac{p}{(1-p)}オッズ比とは事象の起こりやすさをしめす比のことです。$p$は予測したい事象の確率を示します。
オッズ比に自然対数を掛けたものをロジット関数と呼びます。logit(p)=log{\frac{p}{1-p}}この関数を使うことによって、特徴量と対数オッズ比の間にはこのような関係が成り立ちます。
logit(p(y=1|x))=\boldsymbol{w}^T \boldsymbol{x}
p(y=1|x)は特徴量$x$が与えられた場合にサンプルがクラス1(y=1)に属する条件付確率です。
今回求めたいのはサンプルが特定のクラスに属している確率を予測することなので、p(y=1|x) = \phi(z) = logit^{-1}(\boldsymbol{w}^T \boldsymbol{x})=\frac{1}{1+e^{-z}}このように表せます。
つまり決定関数の前に一度ロジスティックシグモイド関数(通称シグモイド関数)をかませているわけです。
重みの更新もロジスティックシグモイドを掛けた後の出力値を予測データとして更新の材料にしていきます。
このように総入力と決定関数の間に入り込む関数のことを活性化関数と呼びます。
パーセプトロンでは決定関数の出力と真の値を比較することで重みの更新を行っていたので、
重みの更新の時に使われる差が離散値となっていました。
活性化関数を入れることにより重みの更新に使われる予測値$\hat{y}$が連続値となります。では実際にロジスティック回帰を使っていきましょう。
from sklearn.linear_model import LogisticRegression lr = LogisticRegression(C=100.0,random_state=1)課題
上のコードを実行してからロジスティック回帰でIrisデータを学習しよう
また学習後決定領域も図示してみようサポートベクトルマシン(SVM)
パーセプトロンでは誤分類率を最小化を目的としていました。
それに対して、サポートベクトルマシン(SVM)では
マージンというものの最大化を目的としています。
マージンというのは分類の決定境界と、決定境界から最も近い
トレーニングサンプルとの距離のことを言います。
上記のトレーニングサンプルのことをサポートベクトルと呼びます。
マージンを最大化するように決定境界を調節することで
分類器として強力な決定境界が生成されます。入力$\boldsymbol{x}$を2つのクラスに分類する分類関数を$y=f(\boldsymbol{x})$とします。
$n$個の学習サンプル$(\boldsymbol{x_1},y_1),(\boldsymbol{x_2},y_2),...,(\boldsymbol{x_m},y_m)$があったとします。
ここで、線形分類器$f(\boldsymbol{x})=sgn[\boldsymbol{w}\bullet\boldsymbol{x}+b]$を定義します。
これは $\boldsymbol{w}\bullet\boldsymbol{x}+b\geq0$のときに1を返し、$\boldsymbol{w}\bullet\boldsymbol{x}+b<0$のときに-1を返します。
このとき、$\boldsymbol{w}\bullet\boldsymbol{x}+b=0$を超曲面と呼びます。
超曲面と最も近いサンプル(サポートベクトル)との距離は\frac{|\boldsymbol{w}\bullet\boldsymbol{x_i}+b|}{||\boldsymbol{w}||}となります。
マージンの最大化を式で表すと以下のようになります。\max_{\boldsymbol{w},b}\min_{i}\{\frac{|\boldsymbol{w}\bullet\boldsymbol{x_i}|+b}{||\boldsymbol{w}||}\}超曲面は定数倍しても不変なのですべてのサンプルに対して
y_i(\boldsymbol{a}\bullet\boldsymbol{x_i}+b) \geq 1と仮定できます。
この時マージンは\min_{i}\{\frac{|\boldsymbol{w}\bullet\boldsymbol{x_i}|+b}{||\boldsymbol{w}||}\}=\frac{1}{||\boldsymbol{w}||}つまり$\frac{1}{||\boldsymbol{w}||}$を最大化すればいいわけです。
これは$||\boldsymbol{w}||^2$を最小化することと同義になります。
これは二次計画法により解くことができます。この最大マージン分類は線形分離が可能な場合のみ有効なので、
それ以外の場合の対処法としてスラック変数というものを導入します。線形規約の式
y_i(\boldsymbol{w}\bullet\boldsymbol{x_i}+b) \geq 1に対してスラック変数$\xi$を導入します。これによって制約を満たさないサンプルに対して許容するがコストを課すことが可能となり、非線形問題にも対処可能となります。
y_i(\boldsymbol{w}\bullet\boldsymbol{x_i}+b) \geq 1-\xiスラック変数を導入することにより最大マージン分類は以下のように記述することができます。
\frac{1}{2}||\boldsymbol{w}||^2+C(\Sigma_{i}{\xi^{(i)})}この変数$C$を使って誤分類のペナルティを制御していきます。
$C$が大きいほどペナルティが大きくマージンの幅も狭くなります。
このような最大マージン分類のことをソフトマージン分類(soft-margin classification)と呼びます。
また$\xi$導入以前の最大マージン分類のことをハードマージン分類と呼びます。今回はソフトマージン分類(SVC:Soft-Margin Classification)を使っていきます。
from sklearn.svm import SVC svm = SVC(kernel='linear',C = 1.0,random_state=1) svm.fit(X_train,y_train)課題
上のコードを実行してからSVCでIrisデータを学習しよう
また学習後決定領域も図示してみようカーネル化と呼ばれる非線形分類問題に対して有効な手段があります。
SVMは他の分類アルゴリズムよりカーネル化するのが簡単です。
そのことによりSVMは人気のある分類手法です。
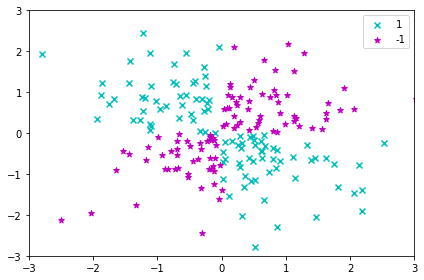
カーネル化が有効となる非線形データの例を見ていきましょう。import matplotlib.pyplot as plt import numpy as np np.random.seed(1) X_xor = np.random.randn(200, 2) y_xor = np.logical_xor(X_xor[:, 0] > 0, X_xor[:, 1] > 0) y_xor = np.where(y_xor, 1, -1) plt.scatter(X_xor[y_xor == 1, 0], X_xor[y_xor == 1, 1], c='c', marker='x', label='1') plt.scatter(X_xor[y_xor == -1, 0], X_xor[y_xor == -1, 1], c='m', marker='*', label='-1') plt.xlim([-3, 3]) plt.ylim([-3, 3]) plt.legend(loc='best') plt.tight_layout() plt.show()
このような場合は1本の直線で分離することは不可能です。
しかしこのデータを高次元に射影することでデータの見え方が変わってきます。射影関数$\phi(x_1,x_2)=(z_1,z_2,z_3)=(x_1,x_2,x_1*x_2)$
課題
$z=\phi(x,y)$として3次元にデータをプロットしてみましょう。
np.random.seed(1) X_xor = np.random.randn(200, 2) y_xor = np.logical_xor(X_xor[:, 0] > 0, X_xor[:, 1] > 0) y_xor = np.where(y_xor, 1, -1) svm = SVC(kernel='rbf', random_state=1, gamma=0.10, C=10.0) svm.fit(X_xor, y_xor) plot_decision_regions(X_xor, y_xor, classifier=svm) plt.legend(loc='upper left') plt.tight_layout() plt.show()
svm = SVC(kernel='rbf',random_state=1,gamma=0.20,C = 10.0) svm.fit(X_train,y_train) plot_decision_regions(X_combined,y_combined,classifier=svm) plt.xlabel('petal length') plt.ylabel('sepal length') plt.legend(loc = 'upper left') plt.tight_layout() plt.show()
課題
gammaの値を変化させることで決定領域がどのように変化するのか確認してみましょう
決定木学習
決定木分類器は意味解釈可能性に配慮する際に効力を発揮できるモデルです。
この分類器では一連の質問に基づいて決断を下し、データを分類していきます。
決定木分類器を説明するにあたって、情報利得という指標をまず説明していきます。
情報利得とはある集合を分割した時にそれぞれの集合の要素についてのばらつきの減少を示します。
決定木は情報利得がなくなるまで条件分岐をしていくことで多くの葉をもった木を形成します。
trainデータに対して完全に木が出来上がってしまうと過学習(trainデータにだけ適応しすぎたモデルになる)に陥りやすくなってしまうのである深さまでで枝を伸ばすのをストップします。
これを剪定と呼びます。決定木学習アルゴリズムの目的関数は以下のようになっています。
IG(D_p,f)=\boldsymbol{I}(D_p)-\Sigma^{m}_{j=1}\frac{N_j}{N_p}\boldsymbol{I}(D_j)ここで$f$は分割を行う特徴量で、$D_p$は親のデータセット、$N_p$は親のノードのサンプルの総数、
$D_j$はj番目の子のデータセット、 $N_j$はj番目の子のノードの総数、$\boldsymbol{I}$は不純度を表します。
つまり情報利得は親ノードの不純度と子ノードの不純度の合計との差になっており、異なるクラスのサンプルがノードにどの程度の割合で混ざっているのかを定量化する指標になってます。
不純度の指標でよく使われるものは
- ジニ不純度
- エントロピー
- 分類誤差
の3つです。
その中でもジニ不純度は$p(i|t)$が特例のノード$t$に対してクラス$i$に属するサンプルの割合を示します。
なのでジニ不純度は誤分類の確率を最小化する条件となっています。I_G(t)=\Sigma^c_{i=1}p(i|t)(1-p(i|t)) = 1-\Sigma^c_{i=1}p(i|t)^2決定木はサンプルのデータをどの値で分割することで誤分類の少ない条件分岐になるのかを学習していきます。
決定木の深さが4の決定木分類器でIrisデータを分類していきましょう。
from sklearn.tree import DecisionTreeClassifier tree = DecisionTreeClassifier(criterion='gini',max_depth=4,random_state=1)課題
上のコードを実行してから決定木でIrisデータを学習しよう
また学習後決定領域も図示してみよう
決定木の深さ(max_depth)を変えてみてどのように決定領域が変化するのかを見てみよう。ランダムフォレスト
ランダムフォレストアルゴリズムは複数の深い決定木を平均化することでより汎化性能の高い(どんなデータにも対応できる)モデルを作っていく考え方です。
このように複数のアルゴリズムを組み合わせることをアンサンブル学習と呼びます。違うモデルを組み合わせることが一般的です。ランダムフォレストは以下の手順で行われていきます。
1. トレーニングデータの中からnこのサンプルをランダムに選択する。
2. 選んだサンプルデータセットをもとに決定木を成長させる。
3. 2を繰り返す
4. 決定木ごとの予測ラベルをまとめて、多数決に基づいてクラスラベルを割り当てる。ではランダムフォレストでIrisデータを分類してみましょう。
from sklearn.ensemble import RandomForestClassifier forest = RandomForestClassifier(n_estimators=25,criterion='gini',random_state=1,n_jobs=2)課題
上のコードを実行してからランダムフォレストでIrisデータを学習しよう
また学習後決定領域も図示してみようk近傍法
k近傍法は怠惰学習とも呼ばれていて、トレーニングデータセットから学習せずデータセットを暗記して分類を行います。
k近傍法のアルゴリズムは以下の手順を取ります。
1. kの値と距離指標を選択
2. 分類したいサンプルからk個の最近傍データを探す。
3. 近傍データのクラスラベルから多数決でクラスラベルを割り当てる。この方法の利点は学習がいらないためすぐに分類段階に入れるところです。
ただし、トレーニングデータの量が多すぎると計算量が膨大になってしまうことには注意しなければいけません。実際にk近傍法を使って分類をしていきましょう。
from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors=5,p=2,metric='minkowski')課題
上のコードを実行してからk近傍法でIrisデータを学習しよう
また学習後決定領域も図示してみようまとめ
モデル メリット ロジスティック回帰 事象が生起する確率を予測できる SVM カーネルトリックで非線形問題にも対応できる 決定木 意味解釈可能性に配慮できる ランダムフォレスト パラメータの調整が多くない
過学習も決定木ほど起こらないk近傍法 トレーニングを必要としない 課題
titanicデータを使って生存の可否を予測してみよう!
使うカラムは今回は
'Passenderld','Age','Pclass','Sex','FamilySize'
とします。