- 投稿日:2020-03-18T23:58:46+09:00
Amplify apiで簡単バックエンド構築
今回は、Amplify-CLIを利用したGraphQLのバックエンドAPI構築を紹介します。
手順は公式を参考に。GraphQL/AWS AppSync
GraphQLはFacebookとコミュニティにより開発されたクエリ言語です。典型的なRESTでの大きく以下の3つの問題点を解消するために開発されました。
GraphQL公式を見ると他にもメリットが記載されているようですが。
- 過剰なデータ取得(クライアントにとって必要がないデータでも返却され不必要なリソース消費が起こる)
- 複数URLへのアクセス(単一の動作の実現でも複数エンドポイントへのアクセスが必要)
- フロントとバックエンドとの仕様不整合(仕様書などで規約を記載しても仕様変更に更新が追いつかない不整合がたびたび起こる)
AppSyncはそのGraphQLを使用したAWSのマネージド・サービスです。
今回は、apmlifyを利用したAppSyncのAPI構築方法をご紹介します。事前準備
amplify cliのインストール
npm install -g @aws-amplify/cli amplify configureamplifyの初期設定
amplify initamplify-cliがインタラクティブに設定情報を聞いてくるので、回答します。
過去記事と同じなので説明省略。API作成
amplify add apiこれまたインタラクティブに聞いてくるので回答。
? Please select from one of the below mentioned services GraphQL ? Provide API name: AmplifyFunction ? Choose an authorization type for the API Amazon Cognito User Pool Using service: Cognito, provided by: awscloudformation The current configured provider is Amazon Cognito. Do you want to use the default authentication and security configuration? Defau lt configuration Warning: you will not be able to edit these selections. How do you want users to be able to sign in when using your Cognito User Pool? Email Warning: you will not be able to edit these selections. What attributes are required for signing up? (Press <space> to select, <a> to t oggle all, <i> to invert selection)Email Successfully added auth resource ? Do you have an annotated GraphQL schema? No ? Do you want a guided schema creation? Yes ? What best describes your project: Single object with fields (e.g., “Todo” with ID, name, description) ? Do you want to edit the schema now? Yesここでエディタが起動されます。
schema.graphqlというファイルが自動生成されているので適宜スキーマ定義を変更します。以下はスキーマにtitleフィールドを追加した例
type Todo @model { id: ID! name: String! description: String title: String }typeに
@modelディレクティブをつけるとテーブルが作成されます。
スキーマ定義ではその他に様々なディレクティブ(@key,@auth,@connectionなど)が用意されいます。
詳細はこちらを参照。schema.qraphqlのスキーマ定義が終わったら保存した上でターミナルに戻ります。
? Press enter to continueと聞かれているはずなので、enterキーを押します。最後に以下のコマンドを実行してデプロイします。
amplify push以下のように新しく作成される認証とApiのリソースが表示されます。
| Category | Resource name | Operation | Provider plugin | | -------- | ----------------------- | --------- | ----------------- | | Auth | amplifyfunctiondxxxxxxx | Create | awscloudformation | | Api | AmplifyFunction | Create | awscloudformation |このあと、インタラクティブにいくつかの回答(基本全部Yes)していくとデプロイが実行されます。
? Do you want to generate code for your newly created GraphQL API Yes ? Choose the code generation language target typescript ? Enter the file name pattern of graphql queries, mutations and subscriptions sr c/graphql/**/*.ts ? Do you want to generate/update all possible GraphQL operations - queries, muta tions and subscriptions Yes ? Enter maximum statement depth [increase from default if your schema is deeply nested] 2 ? Enter the file name for the generated code src/API.ts正常にデプロイが完了したら、AWSコンソールにアクセスしてリソースが作成されていることを確認できます。
AmplifyでAPIを作成すると標準的なCRUD操作に必要なクエリが自動生成されます。
クエリは必要に応じて自分で定義すれば良いですが、簡単なアプリケーションであればこの自動生成されたクエリだけで十分でしょう。queries.tsexport const getTodo = `query GetTodo($id: ID!) { getTodo(id: $id) { id name description title } } `; export const listTodos = `query ListTodos( $filter: ModelTodoFilterInput $limit: Int $nextToken: String ) { listTodos(filter: $filter, limit: $limit, nextToken: $nextToken) { items { id name description title } nextToken } } `;mutation.tsexport const createTodo = `mutation CreateTodo($input: CreateTodoInput!) { createTodo(input: $input) { id name description title } } `; ...などなどsubscriptions.tsexport const onCreateTodo = `subscription OnCreateTodo { onCreateTodo { id name description title } } `; ...などなどAPIを使う
デプロイが完了するとsrcフォルダの直下に「aws-exports.js」ファイルが生成されます。
このファイルにバックエンドの接続先となるAppSyncエンドポイントやリージョン、認証方式などの情報が記録されています。アプリケーションに組み込んで利用する際にはこのファイルを読み込んで利用します。例えば、以下のような感じ
API.tsimport awsmobile from './aws-exports'; Amplify.configure(awsmobile) const App: React.FC = () => { return ( ...snip... ); }API呼び出しは以下のような感じ
Query
(listはデフォルトだと取得10件までなので適宜limitの値を変更)
ListTodoSample.tsimport { API, graphqlOperation } from 'aws-amplify' import { listTodos } from './graphql/queries' //Todoリスト取得する実装抜粋 const result = await API.graphql(graphqlOperation(listTodos, { limit: 1000 })) as GraphQLResult const query = result.data as ListTodosQuery if (query.listTodos) { const list = query.listTodos.items as Array<CreateTodoInput> return list }Mutations
MutationSample.tsimport { API, graphqlOperation } from 'aws-amplify' import { createTodo } from './graphql/mutations' //Todo追加する実装抜粋 const input: CreateTodoInput = { name: 'hoge', description: 'fuga', title: 'piyo', } const newTodo = await API.graphql(graphqlOperation(createTodo, { input }))Subscriptions
SubscriptionSample.tsimport { API, graphqlOperation } from "aws-amplify"; import { onUpdateTodo } from "../graphql/subscriptions"; //更新されたTodoをサブスクライブする実装抜粋 const subscription = API.graphql(graphqlOperation(onUpdateTodo)).subscribe({ next: (response: any) => { const todo = response.value.data.onUpdateTodo as UpdateTodoInput //do something } })まとめ
ざっくりとamplify add apiを利用したバックエンド構築を試してみました。ものすごく簡単な手順であっという間に作れてしまいますね。今回は単純なテーブル作成のケースをご紹介しましたが、amplifyではschema.graphqlに色々なカテゴリが用意されていて、複雑なシステム構成でも簡単に構築ができるようになっています。
機会があれば、ご紹介したいと思いますが、今回はここまで。
- 投稿日:2020-03-18T23:53:54+09:00
EC2インスタンスからAWS CLIを実行する際には
個人的メモになります
インターネットアクセスかエンドポイントが必要
対応策
- EC2インスタンスにパブリックIPを付与する
- NATゲートウェイを使用する
- エンドポイントを使用する
EC2インスタンスにパブリックIPを付与する
- 自動割り当てパブリック IPを利用
- ElasticIPを付与パブリックサブネット上に踏み台サーバを配置する構成は、最近は少ないのではないだろうか
NATゲートウェイを使用する
プライベートサブネット上のEC2インスタンスではこちらの構成
ただ、アウトバウンドを絞りたい為、簡単にインターネットに出れない場合もエンドポイントを使用する
CLIで実行するサービスのエンドポイントが必要
EC2の場合
インターフェースエンドポイント
com.amazonaws.ap-northeast-1.ec2S3の場合
ゲートウェイエンドポイント
com.amazonaws.ap-northeast-1.s3参考
- 投稿日:2020-03-18T23:34:26+09:00
AWS Well-Architected フレームワーク
概要
- AWS Well-Architected フレームワークに記載されているAWSが推奨するアーキテクチャフレームワークについてまとめました
- 対象読者はアーキテクチャ設計に興味のある方です
- 一読してなんとなく雰囲気を掴み、必要に応じて参照するのが良いかと考えています
はじめに
- フレームワークによって、現代のクラウドベースのシステムに期待する品質を評価するための一貫したアプローチと、その品質を達成するために必要な対応を提供することが目的
- AWS Well-Architected(WA) Toolは、AWS Well-Architectedフレームワークを使ってアーキテクチャをレビューし、測定するための一貫したプロセスを提供する
- AWS WA Tool は、ワークロードを信頼性が高く、よりセキュアかつ効率的で、コスト効率性に優れたものにするためのレコメンデーションを提供します
- ベストプラクティスの適用をサポートするためにAWS Well-Architected Labsが作成された
- このラボでは、コードとドキュメントのリポジトリを使用してベストプラクティスの実装を実践的に体験できる
用語解説
- コンポーネント
- 用件に対して提供されるコード、設定、AWSリソース
- ワークロード
- ビジネス価値を提供する一連のコンポーネントを識別するために使用
- マイルストーン
- アーキテクチャが設計、テスト、ゴーライブ、及び本番という製品ライフサイクル全体を通じて進化するにあたり、アーキテクチャにおける重要な変更を記録
- アーキテクチャ
- コンポーネントがワークロードで連携する方法。コンポーネントが通信や対話を行う方法は、アーキテクチャ図の中心となることがよくある
- テクノロジーポートフォリオ
- ビジネスの運営に必要なワークロードの集合体
AWS Well-Architected フレームワークの5本柱
ワークロードを設計するときには、ビジネスの状況に応じて5本の柱の間でトレードオフを行う
* 開発環境では新rな異性を犠牲にすることでコストを削減する
* ミッションクリティカルなソリューションでは、信頼性を最適化するためにコストをかける
* eコマースソリューションでは、パフォーマンスが収益と顧客の購買傾向に影響する
など
セキュリティと運用性は、通常、他の柱とトレードオフされることはない運用上の優秀性
ビジネス価値を提供し、サポートのプロセスと手順を継続的に向上させるためにシステムを稼働及びモニタリングする能力
セキュリティ
リスク評価とリスク軽減の戦略を通してビジネスに価値をもたらす、情報、システム、アセットのセキュリティ保護機能
信頼性
インフラストラクチャやサービスの中断から復旧し、需要に適したコンピューティングリソースを動的に獲得し、語設定や一時的なネットワークの問題といった中断の影響を緩和する能力
パフォーマンス効率
システムの要件を満たすためにコンピューティングリソースを効率的に使用し、要求の変化とテクノロジーの進化に対してもその効率性を維持する能力
コスト最適化
最も低い価格でシステムを運用してビジネス価値を実現する能力
一般的な設計の原則
クラウド上における適切な設計を可能にする一般的な設計の原則
* 必要キャパシティーの推測が不要になる
* クラウドコンピューティングでは、必要な分のみキャパシティーを使用し、自動的にスケールアップまたはスケールダウンできる
* 本稼働スケールでシステムをテストする
* クラウド上では、本稼働スケールのテスト環境をオンデマンドで作成し、テスト完了後にリソースを解放できる
* 自動化によってアーキテクチャでの実験を容易にする
* 自動化によって低コストでシステムを作成及びレプリケートして、手動作業の支出を回避できる
* 発展するアーキテクチャが可能になる
* クラウド上では、自動化し、オンデマンドでテストできるので、設計変更によって生じる影響のリスクを軽減できる
* その他め、イノベーションを標準プラクティスとしてビジネスで活用できるように、システムを時間と共に進化させることができる
* データに基づいてアーキテクチャを進化させる
* クラウドのインフラストラクチャはコードなので、そのデータに基づいてアーキテクチャに関する選択と改善を徐々に進めることができる
* ゲームでーを利用して改善する
* ゲームでーを定期的にスケジュールして、本稼働環境のイベントをシミュレートすることで、アーキテクチャとプロセスのパフォーマンスをテストする運用上の優秀性
運用上の優秀性
運用上の優秀性の柱には、ビジネス価値を提供し、サポートのプロセスと手順を継続的に向上させるためにシステムを稼働及びモニタリングする能力が含まれる設計原則
- 運用をコードとして実行する
- ドキュメントに注釈をつける
- 定期的に、小規模な、元に戻すことができる変更を適用する
- 運用手順を定期的に改善する
- 障害を予想する
- 運用上の全ての障害から学ぶ
3つのベストプラクティス
準備
- アプリケーション、プラットフォーム、インフラストラクチャのコンポーネント、およびカスタマーエクスペリエンスと顧客の行動をモニタリングし、インサイトを取得するメカニズムを使用してワークロードを設計する
- ワークロードまたは変更が本番環境に移行できる状態であり、運用上、サポートされていることを検証するためのメカニズムを作成する
- 運用準備状態はチェックリストを使用して検証し、ワークロードが規定の標準を満たしていることと、必要な手順がランブックとプレイブックに適切に記載されていることを確認する
- ワークロードを効果的にサポートするために、十分にトレーニングを受けた担当者がいることを確認する
- 移行前に、運用上のイベントと障害への応答をテストする
- 障害の投入やゲームデーイベントによって、サポートされる環境で応答を練習する
- 運用アクティビティをコードとして実装することに投資することにより、運用担当者の生産性を最大に引き上げ、エラーの発生を最小限に抑え、自動応答を可能にする
- クラウドの伸縮性を活用したデプロイ方法を導入し、システムの事前デプロイを促進して実装を高速化する
運用
- 予想される成果を定義し、成功を評価する方法を決定する
- また、運用が成功したかどうかを判断するための計算で使用するワークロードと運用のメトリクスを特定する
- ワークロードの状態と、そのワークロードで実行する運用の状態と成功 (デプロイとインシデント対応など) の両方を含めて、運用の状態を検討する
- 運用の向上または低下を特定するための基準を確立し、メトリクスを収集および分析する
- 次に、運用の成功に関する理解と、時間の経過とともにどのように変化するかについて検証する
- 収集したメトリクスを使用して、顧客とビジネスのニーズを満たしているかどうかを確認し、改善の余地がある分野を特定する
- 運用上の優秀性を実現するには、運用上のイベントを効率的かつ効果的に管理する必要がある
- これには、計画した運用上のイベントと計画外の運用上のイベントの両方が含まれる
- 十分に把握しているイベントには既定のランブックを使用し、その他のイベントの解決にはプレイブックを使用する
- ビジネスと顧客への影響に基づいてイベントへの応答に優先順位を付ける
- イベントへの応答でアラートが発生する場合、実行する関連プロセスがあり、所有者が具体的に指名されていることを確認する
- イベントを解決する担当者を事前に決めておき、影響 (期間、規模、範囲) に基づいて、必要に応じて他の担当者を関与させるためにエスカレーションするトリガーを含める
- 以前に処理したことがないイベント応答によってビジネスに影響が及ぶ場合は、アクションの方針を決定する権限を持つ担当者を特定し、関与させる
- 日常的な運用や計画外のイベントへの応答は自動化する必要がある
- デプロイ、リリース管理、変更、ロールバックについて、手作業のプロセスは避ける必要がある
- リリースは、低頻度で行われる大規模なバッチ処理にしないようにする
進化
- 継続的かつ段階的な改善を行うために専用の作業サイクルを作成する
- ワークロードと運用手順の両方について、改善の機会 (機能のリクエスト、問題の修正、コンプライアンス要件など) を定期的に評価し、優先順位を付ける
- 手順にフィードバックループを取り入れ、改善が必要な分野をすばやく特定し、実際に運用して教訓を学ぶ
- チーム間で学んだ教訓を共有し、その教訓の利点を活用する
- 学んだ教訓に見られる傾向を分析し、運用のメトリクスに関してチーム間で遡及的分析を行い、改善の機会とその方法を特定する
- 改善をもたらす変更を実施し、結果を評価して成功の判断を行う
- 運用の進化を成功させるためには、頻繁な小規模の改善、実験と開発およびテストの改善のための安全な環境と時間、失敗から学ぶことを推奨する環境が重要
主なAWSのサービス
運用上の優秀性に不可欠なAWS のサービスは AWS CloudFormation であり、ベストプラクティスに基づいたテンプレートを作成できる
これにより、開発環境から本番環境まで規則的で一貫した方法でリソースをプロビジョンできる
* 準備
* AWS Config と AWS Config のルールを使用して、ワークロードの標準を作成し、本番稼働の前に環境がその標準に準拠しているかどうかを確認できる
* 運用
* Amazon CloudWatch では、ワークロードの運用状態をモニタリングできる
* 進化
* Amazon Elasticsearch Service (Amazon ES) を使用すると、ログデータを分析し、実用的なインサイトをすばやく確実に取得できるリソース
Operational Excellence Pillar
DevOps - ユースケース別クラウドソリューション
AWS re:Invent 2015: DevOps at Amazon: A Look at Our Tools and Processes (DVO202) - YouTubeセキュリティ
セキュリティ
セキュリティの柱には、リスク評価とリスク軽減の戦略を通してビジネスに価値をもたらす、情報、システム、アセットのセキュリティ保護機能が含まれる設計原則
- 強力なアイデンティティ基盤の実装
- トレーサビリティの実現
- 全レイヤーへのセキュリティの適用
- セキュリティのベストプラクティスの自動化
- 伝送中および保管中のデータの保護
- データに人の手を入れない
- セキュリティイベントへの備え
5つのベストプラクティス
アイデンティティ管理とアクセス管理
- アイデンティティ管理とアクセス管理は情報セキュリティプログラムの重要な要素であり、これにより顧客が意図した仕方で、承認され認証されたユーザーのみがリソースにアクセスできる
- 例えば、プリンシパル (顧客のアカウントに対してアクションをとるユーザー、グループ、サービス、ロール) を定義し、これらのプリンシパルに合わせたポリシーを構築し、強力な認証情報管理を実装できる
- これらの権限管理機能は認証と承認の中枢となっている
- すべてのユーザーやシステムが認証情報を共有してはいけない
- ユーザーアクセス権は、パスワード要件や MFA の強制などのベストプラクティスを実践した上で、最小権限で与えられるべき
発見的統制
- 発見的統制により、セキュリティの潜在的な脅威やインシデントを特定できる
- これはガバナンスフレームワークの最重要機能であり、品質管理プロセス、法的義務またはコンプライアンス義務、脅威の特定とその対応のサポートのために、この機能を使用できる
- ログ管理は、セキュリティやフォレンジックから規制要件や法的要件まで十分に対応できる、優れたアーキテクチャを設計するために重要
- 潜在的なセキュリティインシデントを特定するために、ログの分析とそれに対する対応は特に重要
インフラストラクチャ保護
- インフラストラクチャ保護には、ベストプラクティスと組織の義務または規制上の義務に準拠するために必要な、深層防御などの制御手段が含まれている
- すべての環境で複数レイヤーを防御するのが賢明
- 境界保護の強制、イングレスおよびエグレスのモニタリングポイント、包括的なログ記録、モニタリング、アラートはすべて、効果的な情報セキュリティ計画には必須
データ保護
- システムを設計する前に、セキュリティに影響を与える基本的なプラクティスを実施する必要がある
- 例えば、データ分類は組織のデータを機密性レベルに基づいてカテゴリーに分類し、暗号化は認証されていないアクセスに対してデータが開示されてしまうことを防ぐ
- これらのツールやテクニックは、金銭的な損失の予防や規制遵守という目的を達成するためにも重要
インシデント対応
- 非常に優れた予防的、発見的統制が実装されていてもなお、組織はセキュリティインシデントの潜在的な影響に対応し、影響を緩和する手段を講じる必要がある
- ワークロードのアーキテクチャは、インシデントの際にチームが効果的に対応できるかどうか、システムを隔離するかどうか、運用を既知の正常な状態に復元できるかどうかに大きく影響する
- セキュリティインシデントが起きる前にツールとアクセスを実践し、本番を想定したインシデント対応を定期的に実施することで、タイムリーな調査と復旧を可能にするアーキテクチャを構築できる
主要なAWSのサービス
セキュリティに不可欠なAWS のサービスは AWS Identity and Access Management (IAM) であり、これにより、AWS のサービスとリソースへのユーザーアクセスを保護して管理できる
* アイデンティティ管理とアクセス管理
* IAM により、AWS のサービスとリソースへのアクセスを保護して管理できる
* MFA は、ユーザーアクセスに保護レイヤーを追加する
* AWS Organizations により、複数の AWS アカウントのポリシーを一元的に管理・強制できる
* 発見的統制
* AWS CloudTrail は AWS API コールを記録し、AWS Config は AWS のリソースと設定の詳細なインベントリを提供する
* Amazon GuardDuty は、悪意のある動作や不正な動作を継続的にモニタリングする、マネージド型の脅威検出サービス
* Amazon CloudWatch は、CloudWatch Events をトリガーしてセキュリティ対応を自動化できる、AWS リソースのモニタリングサービス
* インフラストラクチャ保護
* Amazon Virtual Private Cloud (Amazon VPC) を使用して、顧客が定義した仮想ネットワーク内で AWS リソースを起動できる
* Amazon CloudFront は、DDoS を緩和する AWS Shield に統合されたビューワーに対して、データ、動画、アプリケーション、API を安全に提供する、グローバルコンテンツ配信ネットワーク
* AWS WAF は、ウェブの一般的な脆弱性からウェブアプリケーションを保護するために役立つ、Amazon CloudFront または Application Load Balancer にデプロイされたウェブアプリケーションファイアウォール
* データ保護
* ELB、Amazon Elastic Block Store (Amazon EBS)、Amazon S3、Amazon Relational Database Service (Amazon RDS) などのサービスには、伝送中および保管中のデータを保護する暗号化機能が含まれている
* Amazon Macie は、機密性の高いデータを自動で発見し、分類し、保護する
* AWS Key Management Service (AWS KMS) は、暗号化に使用するキーの作成と管理を容易にする
* インシデント対応
* IAM は、インシデント対応チームと対応ツールに適切な承認を与えるために使用する
* AWS CloudFormation は、調査を実施する際の信頼できる環境やクリーンルームを作成するために使用できる
* Amazon CloudWatch Events を使用すれば、AWS Lambda などの自動化されたレスポンスをトリガーするルールを作成できるリソース
Security Pillar
クラウドセキュリティ
AWS クラウドコンプライアンス
AWS Security Blog
Overview of Security Processes
AWS Security Best Practices
Risk and Compliance
AWS re:Invent 2017: AWS Security State of the Union (SID326) - YouTube
AWS Compliance - The Shared Responsibility Model - YouTube信頼性
信頼性
信頼性の柱には、インフラストラクチャやサービスの中断から復旧し、需要に適したコンピューティングリソースを動的に獲得し、誤設定や一時的なネットワークの問題といった中断の影響を緩和する能力が含まれる設計原則
- 復旧手順をテストする
- 障害から自動的に復旧する
- 水平方向にスケールしてシステム全体の可溶性を高める
- キャパシティーを推測しない
- オートメーションで変更を管理する
3つのベストプラクティス
基盤
- システムを設計する前に、信頼性に影響を与える基本的な要件を満たしておく必要がある
- 例えば、データセンターへの十分なネットワーク帯域幅が必要
- このような要件は、単一のプロジェクトの範囲を超えているため、無視される場合がある
- この点を無視すると、システムの信頼性の達成に多大な影響が及ぶ
変更管理
- 変更がシステムに及ぼす影響に注意していれば、事前に計画できるようになる
- モニタリングによってキャパシティーの問題や SLA 違反につながりかねない傾向をすばやく識別できる
- 従来の環境では、変更管理プロセスはしばしば手動で行われ、誰がいつ変更するかを効果的に制御するには、監査との注意深い連携が必要
- 需要の変動に対応してリソースの追加や削除を自動で行うシステムを設計しておけば、信頼性が高まることに加え、ビジネスの成功が負担に変わってしまうことを避けられる
- モニタリングを実行しておけば、KPI が予測された基準から逸脱すると、アラートが自動的にチームに送られる
- 環境の変更は自動的にログに記録されるため、アクションを監査して、信頼性に影響を与える可能性のあるアクションを特定できる
- 変更管理をコントロールすることで、必要な信頼性を実現するためのルールに効力を持たせることができる
障害の管理
- どのようなシステムでも、ある程度複雑になると障害が発生することが予想される
- そのため、それらの障害をどのように検出して対応し、再発を防止するかが問題
- 定期的にデータをバックアップして、バックアップファイルをテストすることで、論理的および物理的なエラーから確実に復旧できるようになる
- 障害の管理で重要なのは、システムに対し自動化されたテストを頻繁に実施して障害を発生させ、どのように復旧するかを確認すること
- このようなテストは定期的なスケジュールでも大きなシステム変更後にトリガーされる
- KPI を積極的に追跡し、目標復旧時間 (RTO)、目標復旧時点 (RPO)、システムの回復力を評価する
- KPI の追跡は、単一障害点を特定して排除するのに役立る
- 目的は、システム復旧プロセスを徹底的にテストして、問題が持続する場合でも、すべてのデータを復旧し、サービスを顧客に提供し続けられることを確認すること
- 復旧プロセスも、通常の本番プロセスと同じように実施する必要がある
主要なAWSのサービス
信頼性に不可欠なAWS のサービスは Amazon CloudWatch であり、はランタイムメトリクスをモニタリングする
* 基盤
* AWS IAM により、AWS のサービスとリソースへのアクセスを保護して管理できる
* Amazon VPC では、AWS クラウドのプライベートで孤立したセクションをプロビジョニングできる
* ここでは、顧客が定義する仮想ネットワークで AWS リソースを起動できる
* サービスの制限は AWS Trusted Advisor で可視化できる
* AWS Shield はマネージド型分散サービス妨害攻撃 (DDoS) 防止サービスで、AWS で実行されるウェブアプリケーションを保護する
* 変更管理
* AWS CloudTrail ではアカウントの AWS API コールが記録され、監査のためにログファイルが送られる
* AWS Config は AWS のリソースと設定の詳細なインベントリを提供し、設定内容の変更を継続的に記録する
* Amazon Auto Scaling はデプロイされたワークロードに対して需要管理の自動化を実現する
* Amazon CloudWatch には、カスタムメトリクスなどのメトリクスに基づいてアラートを送る機能がある
* Amazon CloudWatch にはロギング機能があり、複数のリソースのログファイルを集約することができる
* 障害の管理
* AWS CloudFormation には、AWS リソースを作成し、予測可能な方法で順番にプロビジョニングするためのテンプレートが用意されている
* Amazon S3 はバックアップの保存先として耐久性の高いサービス
* Amazon Glacier には耐久性の高いアーカイブを保存できる
* AWS KMS は信頼性の高いキー管理システムで、AWS のサービスの多くと統合されているリソース
Reliability Pillar
AWS のサービスの制限を管理する
AWS re:Invent 2014 | (PFC305) Embracing Failure: Fault-Injection and Service Reliability - YouTube
AWS Limit Monitor
AWS Service Quotas
Amazon EC2 Service Limits Report Now Available
What Is Amazon VPC?
AWS Shield
What Is Amazon CloudWatch?
What is Amazon S3?
What is AWS Key Management Service?
Backup, Archive, and Restore Approaches Using AWS
Managing Your AWS Infrastructure at Scale
Amazon Virtual Private Cloud Connectivity Options
AWS サポート
Trusted Advisorパフォーマンス効率
パフォーマンス効率
パフォーマンス効率の柱には、システムの要件を満たすためにコンピューティングリソースを効率的に使用し、要求の変化とテクノロジーの進化に対してもその効率性を維持する能力が含まれる設計原則
- 最新テクノロジーの標準化
- 数分でグローバルに展開
- サーバーレスアーキテクチャを使用
- より頻繁に実験可能
- システムを深く理解
4つのベストプラクティス
選択
- システムにとって最適なソリューションは、顧客のワークロードの種類に応じて異なる
- 多くの場合、複数のアプローチを組み合わせて使用する
- 優れた設計のシステムでは複数のソリューションが使用され、さまざまな機能によってパフォーマンスが改善される
- アーキテクチャでは通常、アーキテクチャに関するさまざまなアプローチが組み合わされて使用される (イベント駆動型、ETL、パイプラインなど)
- アーキテクチャを実装する場合は、アーキテクチャのパフォーマンスを最適化するための AWS のサービスが使用される 顧客が検討すべき4つの主なリソースタイプ (コンピューティング、ストレージ、データベース、ネットワーク) は以下になる
コンピューティング
システムにとって最適なコンピューティングソリューションは、アプリケーションの設計、使用パターン、設定に応じて異なる
各アーキテクチャでは、コンポーネントごとに異なるコンピューティングソリューションが使用されることもあり、パフォーマンスを向上させるための機能も異なる
アーキテクチャに対して適切でないコンピューティングソリューションを選択すると、パフォーマンス効率が低下する場合があるストレージ
システムにとって最適なストレージソリューションは、アクセス方法 (ブロック、ファイル、オブジェクト)、アクセスパターン (ランダムまたはシーケンシャル)、必要なスループット、アクセス頻度 (オンライン、オフライン、アーカイブ)、更新頻度 (WORM、動的)、および可用性と耐久性に関する制約に応じて異なる
優れた設計のシステムでは複数のストレージソリューションが使用され、さまざまな機能によってパフォーマンスが改善されるデータベース
システムにとって最適なデータベースソリューションは、可用性、整合性、パーティション対応性、レイテンシー、耐久性、スケーラビリティ、クエリ機能などの要件に応じて異なる
多くのシステムでは、各種サブシステムに異なるデータベースソリューションを使用しているため、パフォーマンスを向上させるために活用する機能も異なる
システムに対して適切でないデータベースソリューションや機能を選択すると、パフォーマンス効率が低下する場合があるネットワーク
システムにとって最適なネットワークソリューションは、レイテンシーやスループットなどの要件によって異なる
場所のオプションはユーザーリソースやオンプレミスリソースなどの物理的制約の影響を受けるが、最新技術を使用することやリソースを置き換えることで、こうした影響を軽減できるレビュー
- ソリューションを設計するときは、選択できるオプションが限られていても、時間が経つにつれ、アーキテクチャのパフォーマンスを向上させることができる新しいテクノロジーやアプローチが利用できるようになる
- アーキテクチャのどの部分でパフォーマンスが制約されているかを把握することで、そうした制約を緩和できるリリースを見つけることができる
モニタリング
- アーキテクチャの実装後は、顧客が発見する前に問題を修正できるよう、アーキテクチャのパフォーマンスをモニタリングする必要がある
- モニタリングメトリクスを使用して、メトリクスがしきい値を超えたときにアラームを発生させるようにする
- アラームを使用すれば、正しく動作していないコンポーネントが見つかったときに、そのコンポーネントを回避するための自動アクションをトリガーできる
- 効果的にモニタリングするには、大量の誤検出を発生させたり、大量のデータに振り回されたりしないことが重要
- 自動化されたトリガーを使用すれば、ヒューマンエラーを防ぐことができ、問題解決までの時間を短縮できる
- アラームソリューションをテストするシミュレーションを本番環境で実行するゲームデーを計画し、そのソリューションが問題を正しく認識するか確認する
トレードオフ
- ソリューションのアーキテクチャを設計する場合は、トレードオフを考慮して最適なアプローチを選択する
- より高いパフォーマンスを実現できるように、整合性、耐久性、容量を重視するのか、時間またはレイテンシーを重視するのかを、顧客の状況に応じてトレードオフしなければならない
- トレードオフを行うことで、アーキテクチャが複雑になる可能性がある
- トレードオフを行った場合は、ロードテストを実施して、トレードオフによって目に見える効果が得られたか確認する必要がある
主要なAWSのサービス
パフォーマンス効率に不可欠なAWS のサービスは Amazon CloudWatch であり、リソースとシステムをモニタリングし、全体的なパフォーマンスと動作状況を可視化する
* 選択
* コンピューティング
* 需要に対応し、応答性を維持するための十分なインスタンスを確保するには、Auto Scaling が重要
* ストレージ
* Amazon EBS では、ユースケースを最適化できる幅広いストレージオプション (SSD、プロビジョニングされた 1 秒あたりの入力/出力オペレーション数 (PIOPS) など) 利用できる
* Amazon S3 では、サーバーレスのコンテンツ配信機能が用意されている
* Amazon S3 Transfer Acceleration を使用すれば、すばやく簡単かつセキュアにファイルを長距離転送できる
* データベース
* Amazon RDS では、ユースケースを最適化できる幅広いデータベース機能が用意されている (PIOPS やリードレプリカなど)
* Amazon DynamoDB は、あらゆる規模で 10 ミリ秒未満のレイテンシーを実現する
* ネットワーク
* Amazon Route 53 では、レイテンシーベースのルーティングが用意されている
* Amazon VPC エンドポイントおよび AWS Direct Connect を使用すれば、ネットワークの距離を縮めたり、ジッターを減らしたりできる
* レビュー
* AWS ブログと AWS ウェブサイトの「最新情報」セクションで、新たに利用できるようになった機能とサービスを確認できる
* モニタリング
* Amazon CloudWatch で提供されているメトリクスやアラーム、通知を顧客の既存のモニタリングソリューションに組み込んだり、AWS Lambda と組み合わせてアクションをトリガーしたりできる
* トレードオフ
* Amazon ElastiCache、Amazon CloudFront、AWS Snowball は、パフォーマンスの向上を可能にするサービス
* Amazon RDS でレプリカを読み込めば、読み込み負荷が高いワークロードをスケーリングできるリソース
Performance Efficiency Pillar
Best Practices Design Patterns
Amazon EBS Volume Performance on Linux Instances
AWS re:Invent 2016: Scaling Up to Your First 10 Million Users (ARC201) - YouTube
AWS re:Invent 2017: Deep Dive on Amazon EC2 Instances, Featuring Performance Optimiz (CMP301) - YouTubeコスト最適化
コスト最適化
コスト最適化の柱には、最も低い価格でシステムを運用してビジネス価値を実現する能力が含まれる設計原則
- 消費モデルを導入する
- 全体的な効率を測定する
- データセンター運用のための費用を排除する
- 費用を分析し、帰結させる
- アプリケーションレベルのマネージドサービスを使用して所有コストを削減する
4つのベストプラクティス
費用認識
- 多くのビジネスは、さまざまなチームが運用する複数のシステムによって構成されている
- リソースのコストをそれぞれの組織や製品オーナーに帰属させることができると、リソースを効率的に使用し、無駄を削減できる
- コストの帰属を明確にすることで、実際に利益率の高い製品を把握し、予算の配分先についてより多くの情報に基づいた決定ができるようになる
費用対効果の高いリソース
- ワークロードにとって適切なインスタンスとリソースを使用することが、コスト削減の鍵になる
- たとえば、レポート処理を小規模なサーバーで実行すると 5 時間かかるものの、費用が 2 倍の大規模なサーバーでは 1 時間で実行できるとすると、どちらのサーバーでも同じ結果が得らるが、長期的に見れば小規模なサーバーで発生するコストの方が大きくなる
- 優れた設計のワークロードでは最もコスト効率の良いリソースが使用されるため、大幅にプラスの経済的影響が生じる
- マネージドサービスを使用することで、コストを削減できる場合もある
- 例えば、E メールを配信するためにサーバーを保守することなく、メッセージ単位で料金が発生するサービスを使用できる
需要と供給を一致させる
- 需要と供給を最適に一致させることでワークロードのコストを最低限に抑えることができるが、プロビジョニングの時間と個々のリソースの障害に備えて十分に余裕を持った供給も必要
- 需要が一定の場合も変動する場合もあり、管理に多大なコストがかからないようにメトリクスと自動化が必要
長期的な最適化
- AWS では新しいサービスと機能がリリースされるため、既存のアーキテクチャの決定をレビューし、現在でもコスト効率が最も優れているかどうかを確認することがベストプラクティス
- 要件の変化に応じて、不要になったリソース、サービス全体、システムを積極的に廃止しなければならない
主要なAWSのサービス
コスト最適化に不可欠なツールは Cost Explorer であり、ワークロードと組織の全体にわたり、使用量を可視化して深く理解するのに役立つ
* 費用認識
* AWS Cost Explorer を使用すると、詳細な使用状況の確認と追跡が行える
* AWS Budgets では、使用量や費用が実際の、または事前の予算範囲を超えたときに通知が送付される
* 費用対効果の高いリソース
* リザーブドインスタンスのレコメンデーションに Cost Explorer を利用すると、これまでの AWS リソースに対する支払いパターンを確認できる
* Amazon CloudWatch と Trusted Advisor を使用して、リソースを適切にサイジングする
* RDS で Amazon Aurora を使用すると、データベースのライセンスコストを排除できる
* AWS Direct Connect と Amazon CloudFront を、データ転送の最適化に使用できる
* 需要と供給を一致させる
* Auto Scaling を使用すると、浪費することなく、需要に対応するようにリソースの追加や削除を行うことができる
* 長期的な最適化
* AWS ニュースブログと AWS ウェブサイトの最新情報セクションには、新しくリリースされた機能やサービスについて案内するリソースがある
* AWS Trusted Advisor で AWS 環境を検査すると、未使用のリソースやアイドル状態のリソースを削除することや、リザーブドインスタンスのキャパシティーを活用することで費用を節約する方法を見つけることができるリソース
Cost Optimization Pillar
Analyzing Your Costs with Cost Explorer
エコノミクスセンター
What Are AWS Cost and Usage Reports?
AWS 総所有コスト(TCO)計算ツール
AWS Simple Monthly Calculator
AWS re:Invent 2017: Running Lean Architectures: How to Optimize for Cost Efficiency (ARC303) - YouTubeレビュープロセス
- アーキテクチャの評価は非難せずに掘り下げることができる一貫した方法で実施される必要がある
- これは何日もかけずに数時間で終わる軽いプロセスである必要がある
- 話し合いであり、監査ではない
- アーキテクチャレビューの目的は、対策を必要とする重大な問題や改善可能な領域を特定すること
- レビュー結果は、ワークロードの扱いやすさを改善する対策
- 各チームメンバーがアーキテクチャの品質に責任を持つ必要がある
- レビューを継続することで、チームメンバーはアーキテクチャの変化に応じて回答を更新したり、機能を提供しながらアーキテクチャを改善したりすることができる
- 設計の初期段階におけるレビューを実施する
- 本番運用前にもレビューを行う
- 本稼働開始後に新しい機能を追加したり、テクノロジーの実装を変更したりするにつれて、ワークロードは変化し続け、ワークロードのアーキテクチャは時間とともに変わるので、その変化にともなってアーキテクチャの特性が劣化しないように適切な予防策を取る必要がある
- アーキテクチャを大幅に変更するときには、Well-Architected レビューを含めて、予防プロセスに従う必要がある
- 1 回限りのレビューまたは単独の測定として評価を活用するには、すべての適切な関係者をその話し合いに含める必要がある
- 別のチームのワークロードをレビューするときに有効な方法は、そのアーキテクチャについて何度か気軽に話し合うこと
- 会議を進行するために推奨されるアイテム
- ホワイトボードのある会議室
- 印刷した構成図や設計ノート
- 回答に別途調査が必要な質問のアクションリスト(例えば「暗号化を有効にしましたか?」など)
- レビューを完了すると、問題のリストが出来上がる
- ビジネスの状況に応じてその優先順位を決める
- 課題がチームの日常業務に及ぼす影響を考慮する必要もある
- 課題に早く対処することで、ビジネス価値の想像に費やす時間ができる
- 課題に対処しながらレビューを更新することで、アーキテクチャがどのように改善しているのかを知ることができる
- 組織内の他のチームと何度かレビューを実施すると、主題となる課題が見つかるかもしれない
- すべてのレビューを総合的に検討し、それらの主題に関する課題に対処するのに役立つメカニズム、トレーニング、またはプリンシパルエンジニアリングの説明を見つける必要がある
- 投稿日:2020-03-18T23:29:00+09:00
Windows10ProでAWS SAMでHelloWorld(サンプルはnode.js)
初めに
Windows10ProでAWS SAMを使ってHelloWorldしようと思ったら意外と大変だったので自分用メモ。
何も入っていない前提ですが、Dockerとかnodeとか入っている場合は飛ばしてください(特にこだわりがなければこの機会にすべて最新化をおススメします)執筆時の各バージョン
GitBash
v2.25.1
Docker
v2.2.0.4
node.js
v12.16.1
aws sam
v0.45.0
必要なものインストール/設定
Git for Windowsインストール
Git for Windows公式からダウンロードし、インストールする。
(特にチェック付けなくて大丈夫です)Dockerのインストール/設定
Docker公式からStableバージョンをダウンロードしてインストーラーをクリック。
インストールすると再起動を促されるので、再起動する。
再起動後にタスクバーのDockerアイコンを右クリック
-> Settings -> Resourses -> FILE SHARINGでCにチェックを付け、Aplly&Restertを押下する。(AWS SAMを実行するドライブ)
node.jsのインストール
nodejs公式で最新のLTSをダウンロードし、ライセンスに同意してインストールする。
(ライセンス以外はチェック付けなくて大丈夫です)AWS SAMのインストール
AWS SAMをクリックしてインストーラーをダウンロードし、ライセンスに同意してインストールする。
(ライセンス以外はチェック付けなくて大丈夫です)SAMサンプルアプリでHelloWorld
1.コマンドプロンプトで
sam initと入力する。
2.Choice: で1と入力する(サンプルアプリ作成)
3.Runtime:で1と入力する(nodejs12.xで作成)出力例
> sam init Which template source would you like to use? 1 - AWS Quick Start Templates 2 - Custom Template Location Choice: 1 Which runtime would you like to use? 1 - nodejs12.x 2 - python3.8 3 - ruby2.7 4 - go1.x 5 - java11 6 - dotnetcore2.1 7 - nodejs10.x 8 - python3.7 9 - python3.6 10 - python2.7 11 - ruby2.5 12 - java8 13 - dotnetcore2.0 14 - dotnetcore1.0 Runtime: 1 Project name [sam-app]: hello-world Cloning app templates from https://github.com/awslabs/aws-sam-cli-app-templates.git ----------------------- Generating application: ----------------------- Name: hello-world Runtime: nodejs12.x Dependency Manager: npm Application Template: hello-world Output Directory: . Next steps can be found in the README file at ./hello-world/README.md4.
cd hello-worldと入力する(作成したサンプルアプリルートへ移動)
5.sam local start-apiと入力する(ローカルでサンプルアプリを起動)サンプルアプリ起動出力例
>sam local start-api Mounting HelloWorldFunction at http://127.0.0.1:3000/hello [GET] You can now browse to the above endpoints to invoke your functions. You do not need to restart/reload SAM CLI while working on your functions, changes will be reflected instantly/automatically. You only need to restart SAM CLI if you update your AWS SAM template 2020-03-18 23:26:19 * Running on http://127.0.0.1:3000/ (Press CTRL+C to quit)6.http://127.0.0.1:3000/helloにアクセスする(hello world!!!!1)
参考リンク
終わりに
不明点/修正点あれば気軽にコメントください!
Twitterを細々とやっています_:(´ཀ`」 ∠):!?


- 投稿日:2020-03-18T23:29:00+09:00
Windows10ProでAWS SAMを使ってHelloWorld(サンプルはnode.js)
初めに
Windows10ProでAWS SAMを使ってHelloWorldしようと思ったら意外と大変だったので自分用メモ。
何も入っていない前提ですが、Dockerとかnodeとか入っている場合は飛ばしてください(特にこだわりがなければこの機会にすべて最新化をおススメします)執筆時の各バージョン
GitBash
v2.25.1
Docker
v2.2.0.4
node.js
v12.16.1
aws sam
v0.45.0
必要なものインストール/設定
Git for Windowsインストール
Git for Windows公式からダウンロードし、インストールする。
(特にチェック付けなくて大丈夫です)Dockerのインストール/設定
Docker公式からStableバージョンをダウンロードしてインストーラーをクリック。
インストールすると再起動を促されるので、再起動する。
再起動後にタスクバーのDockerアイコンを右クリック
-> Settings -> Resourses -> FILE SHARINGでCにチェックを付け、Aplly&Restertを押下する。(AWS SAMを実行するドライブ)
node.jsのインストール
nodejs公式で最新のLTSをダウンロードし、ライセンスに同意してインストールする。
(ライセンス以外はチェック付けなくて大丈夫です)AWS SAMのインストール
AWS SAMをクリックしてインストーラーをダウンロードし、ライセンスに同意してインストールする。
(ライセンス以外はチェック付けなくて大丈夫です)SAMサンプルアプリでHelloWorld
1.コマンドプロンプトで
sam initと入力する。
2.Choice: で1と入力する(サンプルアプリ作成)
3.Runtime:で1と入力する(nodejs12.xで作成)出力例
> sam init Which template source would you like to use? 1 - AWS Quick Start Templates 2 - Custom Template Location Choice: 1 Which runtime would you like to use? 1 - nodejs12.x 2 - python3.8 3 - ruby2.7 4 - go1.x 5 - java11 6 - dotnetcore2.1 7 - nodejs10.x 8 - python3.7 9 - python3.6 10 - python2.7 11 - ruby2.5 12 - java8 13 - dotnetcore2.0 14 - dotnetcore1.0 Runtime: 1 Project name [sam-app]: hello-world Cloning app templates from https://github.com/awslabs/aws-sam-cli-app-templates.git ----------------------- Generating application: ----------------------- Name: hello-world Runtime: nodejs12.x Dependency Manager: npm Application Template: hello-world Output Directory: . Next steps can be found in the README file at ./hello-world/README.md4.
cd hello-worldと入力する(作成したサンプルアプリルートへ移動)
5.sam local start-apiと入力する(ローカルでサンプルアプリを起動)サンプルアプリ起動出力例
>sam local start-api Mounting HelloWorldFunction at http://127.0.0.1:3000/hello [GET] You can now browse to the above endpoints to invoke your functions. You do not need to restart/reload SAM CLI while working on your functions, changes will be reflected instantly/automatically. You only need to restart SAM CLI if you update your AWS SAM template 2020-03-18 23:26:19 * Running on http://127.0.0.1:3000/ (Press CTRL+C to quit)6.http://127.0.0.1:3000/helloにアクセスする(hello world!!!!1)
参考リンク
終わりに
不明点/修正点あれば気軽にコメントください!
Twitterを細々とやっています_:(´ཀ`」 ∠):!?
- 投稿日:2020-03-18T23:29:00+09:00
Windows10ProでAWS SAMを使ってローカルでHelloWorld(サンプルはnode.js)
初めに
Windows10ProでAWS SAMを使ってHelloWorldしようと思ったら意外と大変だったので自分用メモ。
何も入っていない前提ですが、Dockerやnode等が入っている場合は飛ばしてください(特にこだわりがなければこの機会にすべて最新化をおススメします)この記事ですること
- node.jsを使ってローカルでHelloWorldする
この記事でしないこと
- AWS上にソースをアップロードする
- node.js以外を使ってHelloWorldする
執筆時の各バージョン
GitBash
v2.25.1
Docker
v2.2.0.4
node.js
v12.16.1
aws sam
v0.45.0
必要なものインストール/設定
Git for Windowsインストール
Git for Windows公式からダウンロードし、インストールする。
(特にチェック付けなくて大丈夫です)Dockerのインストール/設定
Docker公式からStableバージョンをダウンロードしてインストーラーをクリック。
インストールすると再起動を促されるので、再起動する。
再起動後にタスクバーのDockerアイコンを右クリック
-> Settings -> Resourses -> FILE SHARINGでCにチェックを付け、Aplly&Restertを押下する(AWS SAMを実行するドライブ)
node.jsのインストール
nodejs公式で最新のLTSをダウンロードし、ライセンスに同意してインストールする。
(ライセンス以外はチェック付けなくて大丈夫です)AWS SAMのインストール
AWS SAMをクリックしてインストーラーをダウンロードし、ライセンスに同意してインストールする。
(ライセンス以外はチェック付けなくて大丈夫です)SAMサンプルアプリでHelloWorld
1.コマンドプロンプトで
sam initと入力する。
2.Choice: で1と入力する(サンプルアプリ作成)
3.Runtime:で1と入力する(nodejs12.xで作成)出力例
> sam init Which template source would you like to use? 1 - AWS Quick Start Templates 2 - Custom Template Location Choice: 1 Which runtime would you like to use? 1 - nodejs12.x 2 - python3.8 3 - ruby2.7 4 - go1.x 5 - java11 6 - dotnetcore2.1 7 - nodejs10.x 8 - python3.7 9 - python3.6 10 - python2.7 11 - ruby2.5 12 - java8 13 - dotnetcore2.0 14 - dotnetcore1.0 Runtime: 1 Project name [sam-app]: hello-world Cloning app templates from https://github.com/awslabs/aws-sam-cli-app-templates.git ----------------------- Generating application: ----------------------- Name: hello-world Runtime: nodejs12.x Dependency Manager: npm Application Template: hello-world Output Directory: . Next steps can be found in the README file at ./hello-world/README.md4.
cd hello-worldと入力する(作成したサンプルアプリルートへ移動)
5.sam local start-apiと入力する(ローカルでサンプルアプリを起動)サンプルアプリ起動時出力例
>sam local start-api Mounting HelloWorldFunction at http://127.0.0.1:3000/hello [GET] You can now browse to the above endpoints to invoke your functions. You do not need to restart/reload SAM CLI while working on your functions, changes will be reflected instantly/automatically. You only need to restart SAM CLI if you update your AWS SAM template 2020-03-18 23:26:19 * Running on http://127.0.0.1:3000/ (Press CTRL+C to quit)6.http://127.0.0.1:3000/helloにアクセスする(hello world!!!!1)
参考リンク
終わりに
不明点/修正点あれば気軽にコメントください!
Twitterを細々とやっています_:(´ཀ`」 ∠):!?
- 投稿日:2020-03-18T21:24:54+09:00
Amplify auth は複数のコールバックURLに対応していない
Vueで作ったアプリケーションにAmplifyでFacebook認証機能をつけた。
ところが認証ボタンを押して見ると以下のアドレスにリダイレクトされ、「An error was encountered with the requested page.」というエラーが表示されてしまう。
https://vueamplify-facebook1e4b7722-1e4b7722-dev.auth.ap-northeast-1.amazoncognito.com/error?error=redirect_mismatch&client_id=2ekt6keenqpntdpftetaeeqlh5redirect_mismatch??
あれこれ試してみたところ、
amplify add authの際に、認証後のリダイレクト先のURLを複数指定していたのが原因の様子。
amplify add authで複数のコールバックURLを指定Amplify Consoleで
masterとdevelopmentブランチ用の環境が構築されているのと、あとは開発用にlocalhostの計3つのURLを指定していたのだった。? Do you want to add another redirect signin URI Yes Enter your redirect signin URI: https://master.d3bh1ri8gu6eyb.amplifyapp.com/ ? Do you want to add another redirect signin URI Yes Enter your redirect signin URI: https://development.d3bh1ri8gu6eyb.amplifyapp.com/ ? Do you want to add another redirect signin URI No Enter your redirect signout URI: http://localhost:8080/仕様です
Amplify CLIのリポジトリにissueがあがっていた。
どうやら仕様とのこと。Allowing multiple redirectSignIn/redirectSignOut urls breaks federated auth #2792
Sorry guys but in fact, this is a normal behavior.
There is no way for the react app. to know by default which URLs to use when you have two or more URLs. You must inform the app. to use one of these URLs
アプリケーション側からどのコールバックURLが有効なのか判定できないから、らしい。
対応方法
このissueでいくつか対応策が議論されている。
aws-exports.jsを読み込んだ後に改めて1つのコールバックURLを指定する感じ。基本的に
window.location.hostnameの値をみてどのリダイレクトURLを使うか判定する感じなのかな。
最後のほうにdjheru氏が投稿したコードを参考にするのが一番いいかもしれない。if (awsmobile.oauth.redirectSignIn.includes(',')) { const filterHost = url => new URL(url).host === host; awsmobile.oauth.redirectSignIn = awsmobile.oauth.redirectSignIn .split(',') .filter(filterHost) .shift(); awsmobile.oauth.redirectSignOut = awsmobile.oauth.redirectSignOut .split(',') .filter(filterHost) .shift(); }(https://github.com/aws-amplify/amplify-cli/issues/2792#issuecomment-575406663)
まとめ
仕様ですとのことだけど、CLIで対応してくれ的な意見も出ている。
feature-requestラベルが付けられているのでいつかは対応されるかも。
issueも閉じていないし。手元でざっくり試した感じ↑のコードでうまくいきそうなので、CLIが対応するまでは各自対応しておきましょうってことで〜。
- 投稿日:2020-03-18T18:34:46+09:00
[fondesk用bot]SlashCommandで表記ゆれに抗う
はじめに
皆さんリモートワークしていますか?慣れてきましたか?
前回の記事で弊社がfondeskを導入し、メンションをつけてくれるbotを開発しましたよというお話をしました。(無事にfondeskは正式採用されたようです。)今回は、メンションをつけるために必要になる、表記ゆれ対策用の辞書を更新するSlash Commandを開発した話です。
関連ツール&技術
今回紹介する機能の関連項目です。
- Slack
- AWS
- API Gateway
- Lambda
- S3
- Serverless Framework
- Python3.7
事の発端
前回紹介のbotを導入してから、良い感じにメンションがついているのを喜んでいたのですが、(見ないふりをしていた)事態が勃発しました。そう、表記ゆれです。。
田が「た」なのか「だ」なのか、漢字で投稿されるのかカタカナで投稿されるのか等々…少しずれた表記で投稿されたことで飛ぶ
@hereメンション...この段階では、Lambdaの中に直に辞書を持っており、修正後にはLambdaをデプロイし直さなければいけませんでした。なので発見したら辞書に追加してデプロイ!を都度やっていました。。。つらい
何度かはfondesk用チャンネルで
@hereが出ると飛んでいき、辞書を修正して、デプロイ!とやっていたのですが、、、
思ったより、揺れてました。主だった人はすでに登録してたのですが、全員分やるのだるい…(あと@hereが無闇に飛んでしまうのも心苦しい)ということで、辞書登録を各自に委ねることにしました。(自然言語処理と戦うという選択肢も有りましたが、今回は避けています。)公式を見てみると「なまえ辞書の使い方」なるものがあり、これである程度は防げているようでした。(漢字で来る投稿は登録済みということなのかな?)
要件
- slackから辞書の操作ができる。
- 各ユーザーがそれぞれ自分の辞書の[登録, 確認, 削除]ができる。
これでやるなら、Slash Command + API Gateway + Lambdaですな、ということで実装します。
設定&実装
設定
slack側
前回作成したAppsにcommandsを追加しておきます。
Features→Slash Commands→Create New Commandと進み、必要事項を埋めて保存します。
AWS側
今回もServerlessでズドンとやります。
ここで、timeoutを10秒に設定していますが、どのみちslack側は3000msしか待ってくれないので、あまり意味はありません。(将来的に3秒以上処理に時間がかかるようだと、Lambdaの非同期化を考えないといけないですね。)serverless.ymlslash-command: handler: slashcommand.handler name: fondesker-slashcommand-${self:provider.stage} timeout: 10 events: - http: path: fondesker/slashcommand method: post integration: lambda request: passThrough: WHEN_NO_TEMPLATES template: application/octet-stream: '{"headers":{ #foreach($key in $input.params().header.keySet()) "$key": "$input.params().header.get($key)"#if($foreach.hasNext),#end #end }, "body": "$util.base64Encode($input.json(''$''))" }' application/x-www-form-urlencoded: '{"body": $input.json(''$'')}' response: headers: Content-Type: "'application/json'" template: $input.path('$') statusCodes: 200: pattern: '' 401: pattern: '.*"statusCode": 401,.*' template: $input.path("$.errorMessage") headers: Content-Type: "'application/json'" environment: FONDESK_BOT_ID: ${env:FONDESK_BOT_ID} SLACK_TOKEN: ${self:custom.token.${self:provider.stage}} S3BUCKET: ${self:custom.S3Bucket.name} S3KEY: ${self:custom.S3Bucket.key}deploy成功後に表示されるAPI Gatewayのエンドポイントを控えておき、Slack側に記入しておきます。
実装
Slash Command側からは
application/x-www-form-urlencoded形式でリクエストが飛んできます。
parse_qsでDict形式に変換しておきます。slashcommand.pyimport os import json import re from typing import List, Dict, Any from urllib.parse import parse_qs import requests from utils.Commands import Commands HELP = """ このスラッシュコマンドは次の3つのコマンドが実行できます。\n 1. /fondesker list\n 2. /fondesker add <name> <NAME> (スペース区切りで複数指定可)\n 3. /fondesker remove <name> <NAME> (スペース区切りで複数指定可) """ def handler(event: Dict[str, str], context: Any) -> str: body = event["body"] params = parse_qs(body) user_id = params["user_id"][0] # 引数がなかった場合 if params.get("text") is None: return HELP args = re.split(r"\s", params["text"][0]) commands = Commands(bucket=os.environ["S3BUCKET"], key=os.environ["S3KEY"]) if args[0] == "add": res = commands.add_list(user_id, args[1:]) elif args[0] == "list": res = commands.get_list(user_id) elif args[0] == "remove": res = commands.remove_list(user_id, args[1:]) else: res = HELP if type(res) is list: res = list2str(res) return res def list2str(res: List[str]) -> str: if len(res) == 0: response_sentence = "現在登録されていません。" else: response_sentence = "現在名簿に登録されている名前は、\n" response_sentence += " ".join(res) response_sentence += "\nです。" return response_sentencetextキー以下に、/commandの後に打った文字列が格納されています。
今回のケースだと
1. add
2. list
3. remove
を待ち構えておき、実行する処理を切り替えていきます。実行する処理側の実装は↓のような感じです。基本的にはS3から読み込んで、JSONファイルの中身を変更し、その後S3にアップロードするという流れです。
Commands.pyimport os import json from io import BytesIO from typing import List from dataclasses import dataclass from utils.s3_bucket import S3Bucket @dataclass class Commands: """ Slash Commandで実行したい処理を書く。 名簿はS3に格納してある想定なので、随時S3へのアクセス権限は付与しておく。 params: bucket: 名簿が保存されているバケット名 key: 名簿へのS3 Key region: S3バケットのリージョン(default: ap-northeast-1) """ bucket: str key: str region: str = "ap-northeast-1" def __post_init__(self,): self.s3_bucket = S3Bucket(self.region, self.bucket) def _get_name_list(self,): return json.load(self.s3_bucket.get_object_body(self.key)) def get_list(self, user_id: str) -> List[str]: name_list = self._get_name_list() return name_list.get(user_id, []) def add_list(self, user_id: str, names: List[str]) -> List[str]: name_list = self._get_name_list() if user_id in name_list.keys(): name_list[user_id].extend(names) name_list[user_id] = list(set(name_list[user_id])) else: name_list[user_id] = names self.s3_bucket.put_object(key=self.key, body=json.dumps(name_list), content_type="text/json") return name_list[user_id] def remove_list(self, user_id: str, names: List[str]) -> List[str]: name_list = self._get_name_list() if user_id in name_list.keys(): name_list[user_id] = [synonym for synonym in name_list[user_id] if synonym not in names] self.s3_bucket.put_object(key=self.key, body=json.dumps(name_list), content_type="text/json") return name_list.get(user_id, [])結果
List
Add
Remove
まとめ
今回はSlash Commandを使って、fondeskメンション用の辞書の更新ができるようにしました。これで一人で表記ゆれと格闘する日々は終わり、作業が各自に委ねられることで安心してfondeskチャンネルを眺められるようになりました。めでたし、めでたし。







- 投稿日:2020-03-18T18:25:33+09:00
ソリューションアーキテクトの有効期限が切れるため受験しましたが不合格でした(2週間後に再受験し合格)
旧試験から新試験を受ける方は気をつけてください的な記事
合格ラインは720のため、あと2問くらい足らず...筆者のAWSスペック
- インフラの知識ほぼなし。Apache、ネットワークむずかしい...
- 昔はオンプレからAWSに移行する作業などしていました
- 今はフロントエンドしてます。たまに簡単なAWS構築(AWS/インフラ担当が他にいるため)
- 資格手当のためだけに受験
- AWSの知識が2015年くらい昔のまま
- 過去試験の成績
- 2015年 ギリギリ合格
- 2017年 再認定試験1回目不合格、2回目ギリギリ合格
試験前対策
- 1ヶ月間每日2〜3時間勉強
- 前回作成した試験対策メモで復習
- 前回利用した問題集550問で復習
- 最近発売された対策本を読んだ
- https://www.amazon.co.jp/この1冊で合格-AWS認定ソリューションアーキテクト-アソシエイト-テキスト-問題集/dp/4046042036/ref=asc_df_4046042036/
- 基本がわかりやすい
- 問題は旧バージョンの試験に近い
- Amazonのトップレビューにも記述されていますが、この1冊だけでは合格は無理だと思います
なぜ落ちたのか?
旧バージョンから新バージョンSAA-C01に変わった
- 2018年2月に新バージョン(SAA-C01)に変わった
- 問題数: 55問 → 65問
- 試験時間: 80分 → 130分
- ※2020年3月22日にさらに新バージョン(SAA-C02)に変わりますが、旧→新(SAA-001)ほど大きく変わらないそうです
- 問題数と制限時間が増え、長文問題になり、1単語見落としたら回答が変わるような問題も出題されるため集中力がもたなかった
- 30分くらい見直しの時間はありました
過去問で復習した意味がなかった
- 旧バージョンの問題はほぼ出題されなかった
- 今発売されている対策本などの問題は旧バージョンに近いため、あまり参考にならないと思います
- 公式のサンプル問題も模擬試験も旧バージョンに近いものなのであまり参考になりません
新旧バージョンの問題の違い
長文にするための無駄な文章が増えた
<例>...(略)...あなたはソリューションアーキテクトとして...(略)...
基礎を覚えていれば解ける短文のクイズ問題がなくなった
<旧例> S3ってな〜んだ?
<新例> ...(略)...S3でXXXする時にOOOするには?アーキテクトな問題が増えた
- 改善したい問題をAWSが推奨している解答を選ぶ
正解複数、AWSが推奨する答えを選ぶ問題ができたため消去法では解けなくなった
<旧例> 回答の選択肢は4つ。正解1つ、間違い3つから選ぶ
<新例> 回答の選択肢は4つ。4つどれも可能(選択肢が1つなら正解)。一番最適な(AWSが推奨する)回答を選ぶ試験範囲が広く深くなった
<旧例> Redshiftはビッグデータ解析に使うサービスくらいでOKだった(Redshiftってな〜んだ?みたいな問題だった)
<新例> RedshiftなどもS3と同様に使い方やナレッジを覚える必要がある新サービスがたくさん増えた
- S3 Transfer Acceleration、Athena、Dynamodb Accesrorator、Glacier迅速、CloudTrailなど
昔の問題なら間違いだが、新サービスにより正解になる
<旧例>「データをすぐに取り出す」場合は「Glacier」は選択肢にならなかった
<新例>「データを数分で取り出す」場合は「Glacier迅速」が問題によっては正解になる1番すごいもの以外も正解の選択肢になった
<旧例>処理スピードが1番速いのは?
<新例>XXXの処理スピードが必要です。最適なのは?1単語で回答が変わるひっかけ問題が増えた
<旧例> すごいDBは?
o Aurora
x Redshift
<新例> ...解析...(略)...すごいDBは?
x Aurora
o Redshift選択肢で別の呼び名を使って惑わしてくる(これは旧バージョンからですが)
- OAIを使って...
- オリジンアクセスアイデンティティを使って...
何を勉強した方がいいのか?
※公式の各サービスページや試験対策本などに書いてあるような基礎知識は大前提
ナレッジを読む
- https://aws.amazon.com/jp/premiumsupport/knowledge-center/
- 量が多いですが、試験の問題に1番近い内容だと思います
- とある状況のときの最適なパターンを覚える
各サービスのQ&Aを読む
- 特に新しく追加されたサービス
- 似たようなサービス「〇〇〇と何が違うのか?」の明確な違いを覚える
公式やクラスメソッドなどの最新サービス紹介記事を読む
- 最新サービスを使った問題が結構出題されます
Udemy 模擬試験5セット(325問)
- いまのところ本試験に1番近い雰囲気な問題集だと思います
- URL: https://www.udemy.com/course/aws-knan/
- ※初回5時間以内割引表示はシークレットウィンドウなどで開きなおすとまた表示されます
- もし基礎が必要な場合は、もう一つの21時間完全コースで「動画ハンズオン+模擬試験3セット」ができるようです
- 「この状況の時はどの答えが最適か?」のような問題が多く実際の試験と同じような難易度だと感じました
- 「この単語があるから今回はこっちが正解です」のような丁寧な解説があるのでひっかけ問題対策になります
- 公式の模擬試験を購入するより、同じくらいの値段で65問x5セットと解説付き、何度も繰り返しできるためこちらの方が10倍くらいお得だと思います
- 公式の模擬試験は25問
- 公式のサンプル問題の延長で旧バージョンに近い問題
- 正答率100%じゃないと正解かどうかわからない
- 解説がない
- もう1度テストするには再購入が必要
受験する際の注意点
- 試験方法に新しくPSIが増えましたが、ピアソンがいいようです(いままでと同じ)
- PSIだとほおづえなどで注意されるらしい
- アンケート終了後の次の画面にさりげなく試験結果が表示されるので、次へ連打で見逃さないように
- 点数などは数時間後のお知らせメールからログインするページで見れる
不合格から2週間後の再受験
- なんとか合格できました...
- 2週間ひたらすら勉強して合格しました
- Udemy 模擬試験を2巡
- 1巡目平均65%
- 2巡目平均90%
- 各サービスのQ&Aをざっくりと読んだ
- ナレッジを2割くらい読んだ
- 前回と同じ問題は3問くらいであとは新しい問題でした
- 10問くらいわからなくて、これは落ちたかもしれないと思いました?
- もっとナレッジとQ&Aをしっかり読んどけばよかったと後悔しました
期限が切れる3年後の自分へのメモ
新サービス
- S3 Transfer Acceleration
- Athena
- DBX (Dynamodb Accesrorator。マイクロ秒対応。高価)
- Bring Your Own Keys
- Pipe Line
- DLM
- Glue
- VPCフローログ
- VPNエンドポイント
- GuardDuty(連携できるサービスも)
- Shield
- Waf、セキリティグループ、ACLとの違い
- CloudTrail
- Config
- Batch
- Backup
S3
- Transfer Acceleration
- マルチパートアップロード
- クロスリージョンレプリケーション
- Intelligent-Tiering
- Standard
- Standard-IA
- One Zero-IA (↑より安い)
- Glacier
- 取り出し
- 標準: 3〜5時間
- 大容量 (Deep Archive) 5〜12時間
- 迅速 1〜5分
- 最低保存期間
- Vault Lock (ボールトロック)
EBS
- 暗号化
- タイプの違い(数字もちゃんと覚える)
Route53
- 位置
- Clound Frontの地域制限との違い(https://docs.aws.amazon.com/ja_jp/AmazonCloudFront/latest/DeveloperGuide/georestrictions.html)
- 加重
- 複数値回答(マルチバリュー)
- フェイルオーバー
- レイテンシー
Clound Front
- ディストリビューション
- OAI
- 署名付きURL
- 署名付きCookie
- TTL
ELB
- ALB、NLB、CLBの違い
- 暗号化方法
AutoScaling
- デフォルトのターミネーションポリシーでスケールインする順番
CloudWatch(違いと連携できるサービス)
- イベント
- メトリクス
- アラーム
- ログ
SQS、SNS、S3、Lambda、API Gateway、Cloud Watchなどの連携
暗号化/セキリティ
- ざっくりな違い(把握用): https://awsjp.com/AWS/hikaku/KMS-CloudHSM-compare.html
- ※公式ドキュメントで詳細な違いも把握すること
- CSE
- SSE-C
- SSE-S3
- SSE-KMS (AWS KMS)
- AES-256
- Inspector(使い方: https://docs.aws.amazon.com/ja_jp/inspector/latest/userguide/inspector_installing-uninstalling-agents.html)
- Trusted Advisor
- CloudHSM
- Cognito
- CloudTrail
自動化/簡単に構築(違いを明確に)
- OpsWorks
- Chef/Puppet
- ElasticBeanstalk
- Dockerも扱える
- SWF
- Step Functions
Dockeer/コンテナ
- ECS
- EKS
- 起動タイプ: EC2、Fargate
- S3、ELB、RDSなどをどう組み合わせるか。参考: https://qiita.com/hareku/items/6be1b71e58033b9739fd
- ECR
- Elastic Beanstalk
Dynamodb
- バックアップ方法: https://dev.classmethod.jp/cloud/aws/aws-backup-dynamodb/
- どういう状況の時に使われるか?
EFS
- バックアップ方法
- どういう状況の時に使われるか?
Redshift
- バックアップ方法
- 耐障害性をあげる方法
オンプレのストレージ
- https://dev.classmethod.jp/etc/storage-geteway-to-s3/
- キャッシュ型
- S3をプライマリー、よく使うのはローカル
- 保存型
- S3に保存、ローカルをプライマリー
- ファイルゲートウェイ
- キャッシュ型のS3オブジェクトとして保存版
- EC2上でStorage Gatewayインスタンスを起動できない
- オンプレ限定
- SnowBall
- SnowBall Edge
- Snowmobile
- Import/Export
- VM Import/Export
- DirectConnect
- Snowballとの使い分け
Kinesis
- Kinesis Data Streams (KDS)
- スループット上げる方法
- Kinesis Firehose
- シャード


- 投稿日:2020-03-18T17:00:58+09:00
インフラCI/CDを試してみる(AWS CloudDevelopmentKit + CircleCI)
概要
Infrastructure as Codeの勉強会にてAWS Cloud Development Kitを利用して、CircleCI上でCI/CDを行ってみた際の手順+所感メモです。
CDKについては、こちらの公式チュートリアルを参照ください。
環境:AWS_CDK==1.28.0 python==3.7.5 npm==5.8.0
詳しくはこちらのgithubで。
所感を3行でまとめると以下の通りです。
- 実際にCI/CDすることができた。インフラ部分のデプロイはジョブの実行コードはこれで大きく変わらないと思う。
- CI/CDといってもテストをしていないので、CDだけである。Python版はテストがまだできない。
- ブランチ戦略を適切に取れば、ステージングの環境も同時に作ることができそう。デプロイ戦略になりうる気がする。
作成するアーキテクチャ
図
今回はこのようなアーキテクチャを作ろうと思います。デフォルトでかなりの値が設定されています。
実際のコード
app.py#!/usr/bin/env python3 from aws_cdk import core from src.ec2_stack import EC2Stack app = core.App() EC2Stack(app, "cdk-ec2") app.synth()ec2_stack.pyfrom aws_cdk import ( core, aws_ec2 as ec2 ) class EC2Stack(core.Stack): def __init__(self, scope: core.Construct, id: str, **kwargs) -> None: super().__init__(scope, id, **kwargs) cidr = '10.0.0.0/16' vpc = ec2.Vpc( self, id = 'cdk-test-vpc', cidr=cidr, max_azs=1) security_group = ec2.SecurityGroup( self, id='cdk-sg', vpc=vpc, security_group_name='cdk-sg', ) # what is peer security_group.add_ingress_rule( peer=ec2.Peer.ipv4(cidr), connection=ec2.Port.tcp(22), ) security_group.add_ingress_rule( peer=ec2.Peer.ipv4('0.0.0.0/0'), connection=ec2.Port.tcp(80), ) image_id = ec2.AmazonLinuxImage(generation=ec2.AmazonLinuxGeneration.AMAZON_LINUX_2).get_image(self).image_id ec2.CfnInstance( self, id = 'cdk-instancd', availability_zone="ap-northeast-1a", image_id=image_id, instance_type="t2.micro", security_group_ids=[security_group.security_group_id], subnet_id=vpc.private_subnets[0].subnet_id, tags=[{ "key":"Name", "value":"cdk-instance" }] )circleCIの設定
circleCIで実行する環境を整えます。
Docker Image
DockerfileFROM python:3.7.5-slim # install npm RUN apt-get update \ && apt-get install -y --no-install-recommends \ npm=5.8.0+ds6-4 \ && apt-get -y clean \ && rm -rf /var/lib/apt/lists/* # install aws cdk RUN npm install -g aws-cdk@1.28.0Context
最初はworkflowのAWS Permissionを利用しようと思ったのですが、認証情報がコンテナの中の~/.aws/credentialsに記述されるみたいです。.circleci/config.ymlで
ls -la等実行してちゃんと書かれているかを確認したところ、自分のDocker Imageを利用している状況では~/.aws/というディレクトリは作られませんでした。なので、contextにAWSの認証情報を記述することにしました。config.yml
.circleci/config.ymlversion: 2.1 jobs: deploy: docker: - image: danish9966/aws-cdk:1.28.0 steps: - checkout - run: command: pip install -r requirements.txt working_directory: code - run: command: cdk deploy --require-approval never working_directory: code workflows: cdk-deploy: jobs: - deploy: context: AWS_CREDENTIALS filters: branches: only: - master - developやってみる
できた。大体3分くらいでdeploy完了。
AWSのEC2ダッシュボード上にも確認。ちゃんとできている。
CI/CDなので、ec2のインスタンスタイプをmicroからsmallに変更してみる。
所感
ちゃんとcircleCI上からAWSリソースをデプロイできて良かったです。
しかしこれでインフラのCI/CDできた!と思っても、CIは何もしてないと気付いてしまいました。。。そこでInfrastructure as Code のテストについて考えてみます。
Infrastructure as Code のテストについて
公式のブログによると、Snapshot tests,Fine-grained assertions,Validation testsの3種類のテストがあるようです。
Snapshot tests
生成されるCloudFormationのコードが変化ないかどうかを確認する。CDK自体のバージョンアップが早いため、その影響がないことを検証するのが目的。
Fine-grained assertions
作られるリソースが正しく設定されているかを確認する。Snapshot testsから変更が発生する場合に発動し、作られるリソースのパラメータと意図したものの比較が行われる。
Validation tests
作られるリソースが設定可能かどうかを確認する。例えば、SubnetMaskに33以上の値が入っていないかどうかをテストする。
Python版のCDKでは、対応してないようです。悲しい。
私としては他にテストの観点として、載せるアプリが要求通りにそのインフラ上で稼働するかをテストすることが必要だなと思っています。統合テストの自動化こそインフラCI/CDの妙味が仕込まれていると思います。またブランチ戦略を適切に取り、circleCI上の環境変数を設定することで1つのコードでステージング用と本番用のインフラを構築できると思いました。ステージング環境と本番環境が同じソースでgit管理されてれば、ステージングと本番のバージョンが違うというあるあるな問題も解決しそうで興味深いです。
まとめ
- 実際にCI/CDすることができた。インフラ部分のデプロイはジョブの実行コードはこれで大きく変わらないと思う。
- CI/CDといってもテストをしていないので、CDだけである。Python版はテストがまだできない。
- ブランチ戦略を適切に取れば、ステージングの環境も同時に作ることができそう。デプロイ戦略になりうる気がする。
ありがとうございました!
参考




- 投稿日:2020-03-18T15:49:02+09:00
<初心者向け>CloudWatch LogsのログをKinesis Data Streams経由でLambdaに連携 チュートリアル①
はじめに
この記事はAWSを勉強し始めた人を対象としたものです。
私自身は、IT未経験で今の会社に入社し、丁度1年が経とうとしています。
AWSは数ヶ月勉強しており、現在は『AWS 認定 デベロッパー - アソシエイト』の取得を目指しています。前提知識
・Amazon CloudWatch Logs
・ロググループ
・サブスクリプションフィルタ
・Amazon Kinesis Data Streams
・AWS Lambda
・AWS Lambda イベントソースマッピング実現したい構成
・サブスクリプションフィルタを使用して、CloudWatch LogsのログをKinesis Data Streamsに配信
・イベントソースマッピングでKinesis Data StreamsとLambdaを連携し、Kinesis Data Streams(イベントソース)からLambda関数を呼び出す構成図は以下の通りです。
手順
以下のコマンドをEC2上で実行します。
※サーバにはコマンドによってサービスを操作するためのIAM権限が必要になります。
今回はIAM Roleで以下のポリシーをアタッチしています。
- AWSLambdaFullAccess
- CloudWatchFullAccess
- AmazonKinesisFullAccess
- CloudWatchLogsFullAccess①Kinesis Data Streams作成(※シャード数はデフォルト1を使用)
$ aws kinesis create-stream --stream-name <ストリーム名> --shard-count <シャード数>②IAM Role作成(CloudWatch Logsに対しての一時的な権限付与を許可するための設定)
$ aws iam create-role --role-name <CloudWatch Logs用のIAM Role名> --assume-role-policy-document file://<IAM Role定義ファイルパス>※IAM Role定義ファイルを事前に作成する必要があります。以下はサンプルです。
{ "Version": "2008-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "logs.ap-northeast-1.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }③IAM Policy作成(①で作成したKinesis Data Streamsにデータを書き込むこと、②で作成したIAM Roleの付与対象をCloudWatchに制限することを許可するための設定)
$ aws iam create-policy --policy-name <②で作成したIAM RoleにアタッチするIAM Policy名> --policy-document file://<IAM Policy定義ファイルパス>※IAM Policy定義ファイルを事前に作成する必要があります。以下はサンプルです。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "kinesis:PutRecord", "Resource": "<①で作成したKinesis Data Streams ARN>" }, { "Effect": "Allow", "Action": "iam:PassRole", "Resource": "<②で作成したIAM Role ARN>" } ] }※①で作成したKinesis Data Streams ARN 確認コマンド
aws kinesis describe-stream --stream-name <①で作成したストリーム名>※②で作成したIAM Role ARN 確認コマンド
aws iam get-role --role-name <②で作成したIAM Role名>④IAM PolicyをIAM Roleにアタッチ
$ aws iam attach-role-policy --role-name <②で作成したIAM Role名> --policy-arn <③で作成したIAM Policy ARN>※③で作成したIAM Policy ARN 確認コマンド
aws iam list-policies | grep <③で作成したIAM Policy名>⑤サブスクリプションフィルタ設定
$ aws logs put-subscription-filter --log-group-name <連携させたいロググループ名> --filter-name <フィルタ名> --filter-pattern <フィルタパターン> --destination-arn <①で作成したKinesis Data Streams ARN> --role-arn <②で作成したIAM Role ARN>⑥IAM Role作成(Lambdaに対しての一時的な権限付与を許可するための設定)
$ aws iam create-role --role-name <Lambda用のIAM Role名> --assume-role-policy-document file://<IAM Role定義ファイルパス>※IAM Role定義ファイルを事前に作成する必要があります。以下はサンプルです。
{ "Version": "2008-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "lambda.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }⑦1つ目のIAM Policy作成(LambdaからKinesisへのポーリングを許可するための設定)
$ aws iam create-policy --policy-name <⑥で作成したIAM RoleにアタッチするIAM Policy名> --policy-document file://<IAM Policy定義ファイルパス>※IAM Policy定義ファイルを事前に作成する必要があります。以下はサンプルです。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "kinesis:DescribeStream", "kinesis:DescribeStreamSummary", "kinesis:GetRecords", "kinesis:GetShardIterator", "kinesis:ListShards", "kinesis:ListStreams", "kinesis:SubscribeToShard", "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*" } ] }⑧2つ目のIAM Policy作成(Lambda 関数の呼び出しを許可するための設定)
$ aws iam create-policy --policy-name <⑥で作成したIAM RoleにアタッチするIAM Policy名> --policy-document file://<IAM Policy定義ファイルパス>※IAM Policy定義ファイルを事前に作成する必要があります。以下はサンプルです。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "lambda:InvokeFunction", "Resource": "*" } ] }⑨3つ目のIAM Policy作成(Lambda自身がENIを作成/削除することを許可するための設定)
$ aws iam create-policy --policy-name <⑥で作成したIAM RoleにアタッチするIAM Policy名> --policy-document file://<IAM Policy定義ファイルパス>※IAM Policy定義ファイルを事前に作成する必要があります。以下はサンプルです。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:CreateNetworkInterface", "ec2:DescribeNetworkInterfaces", "ec2:DeleteNetworkInterface" ], "Resource": "*" } ] }⑩1つ目のIAM Policy(⑦で作成)をIAM Roleにアタッチ
$ aws iam attach-role-policy --role-name <⑥で作成したIAM Role名> --policy-arn <⑦で作成したIAM Policy ARN>※⑦で作成したIAM Policy ARN 確認コマンド
aws iam list-policies | grep <⑦で作成したIAM Policy名>⑪2つ目のIAM Policy(⑧で作成)をIAM Roleにアタッチ
$ aws iam attach-role-policy --role-name <⑥で作成したIAM Role名> --policy-arn <⑧で作成したIAM Policy ARN>※⑧で作成したIAM Policy ARN 確認コマンド
aws iam list-policies | grep <⑧で作成したIAM Policy名>⑫3つ目のIAM Policy(⑨で作成)をIAM Roleにアタッチ
$ aws iam attach-role-policy --role-name <⑥で作成したIAM Role名> --policy-arn <⑨で作成したIAM Policy ARN>※⑨で作成したIAM Policy ARN 確認コマンド
aws iam list-policies | grep <⑨で作成したIAM Policy名>⑬Lambda関数作成(※VPCに所属させている)
$ aws lambda create-function --function-name <ログの連携先となるLambda 関数名> --runtime <ランタイム> --role <⑥で作成したIAM Role ARN> --handler <handler名> --timeout <タイムアウト値> --memory-size <メモリサイズ> --no-publish --vpc-config SubnetIds=<サブネットID>,SecurityGroupIds=<セキュリティグループID> --zip-file <アップロードするコードのzipファイルへのパス>※⑥で作成したIAM Role ARN 確認コマンド
aws iam get-role --role-name <⑥で作成したIAM Role名>⑭イベントソースマッピング作成
$ aws lambda create-event-source-mapping --function-name <⑬で作成したLambda 関数名> --event-source <①で作成したKinesis Data Streams ARN> --batch-size <バッチサイズ> --starting-position <読み取りを開始するストリーム内の位置>※①で作成したKinesis Data Streams ARN 確認コマンド
aws kinesis describe-stream --stream-name <①で作成したストリーム名>ポイント
今回の作業を実施する上でのポイントを4つ挙げました。参考程度に読んでいただければと思います。
・特に記載はしませんでしたが、明記したコマンド(リソースの作成、確認)以外にも、不要なリソースを削除するコマンドを使用しました。実施したい作業を、どのAWS CLIコマンドで実現できるのか調べることで、自然とAWS CLIコマンドについて学べます。
・大体は「describe」、「get」、「list」の3つが結果を表示するコマンドだと思います。例えば、Kinesis Data Streamsの内容(設定)を確認するコマンドは、AWS CLIで「aws kinesis describe-stream --streams-name <ストリーム名>」であるのですが、もしコマンドが分からないのであれば、「get stream aws cli」や、「list stream aws cli」などの文字列で検索してみるとよいです。
・サブスクリプションフィルタとイベントソースマッピングの役割を理解することがポイントだと思います。それぞれの役割を理解してください。
・ポリシードキュメント(IAM Role定義ファイル、IAM Policy定義ファイル)では "Action" が定義されています。リソースに対して許可(拒否)する操作をActionに定義するのですが、その "Action" の内容を理解することだけでも、大分勉強になると思います。あとがき
今回はLambdaの中身までは説明しておりませんでした。
実はLogsから直接Lambdaと連携することもできます。
ただ、まれにLambdaが起動しない場合があるようで、Kinesisを挟むことで信頼性を向上したい意図です。
※CloudWatch Logsのログを確実に後続サービスで処理したい場合に有効な構成だと思っています。次回、Lambdaで処理をする部分について説明させていただければと思っています。

- 投稿日:2020-03-18T15:48:45+09:00
【AWS Elastic BeansTalk】Python アプリを秒速で展開
はじめに
前前回の記事に引き続き
AWS の自動化サービスである Elastic BeansTalk を、今度はコンソール画面のみで展開してみました。
びっくりするくらい簡単なのですぐにお試しできます!
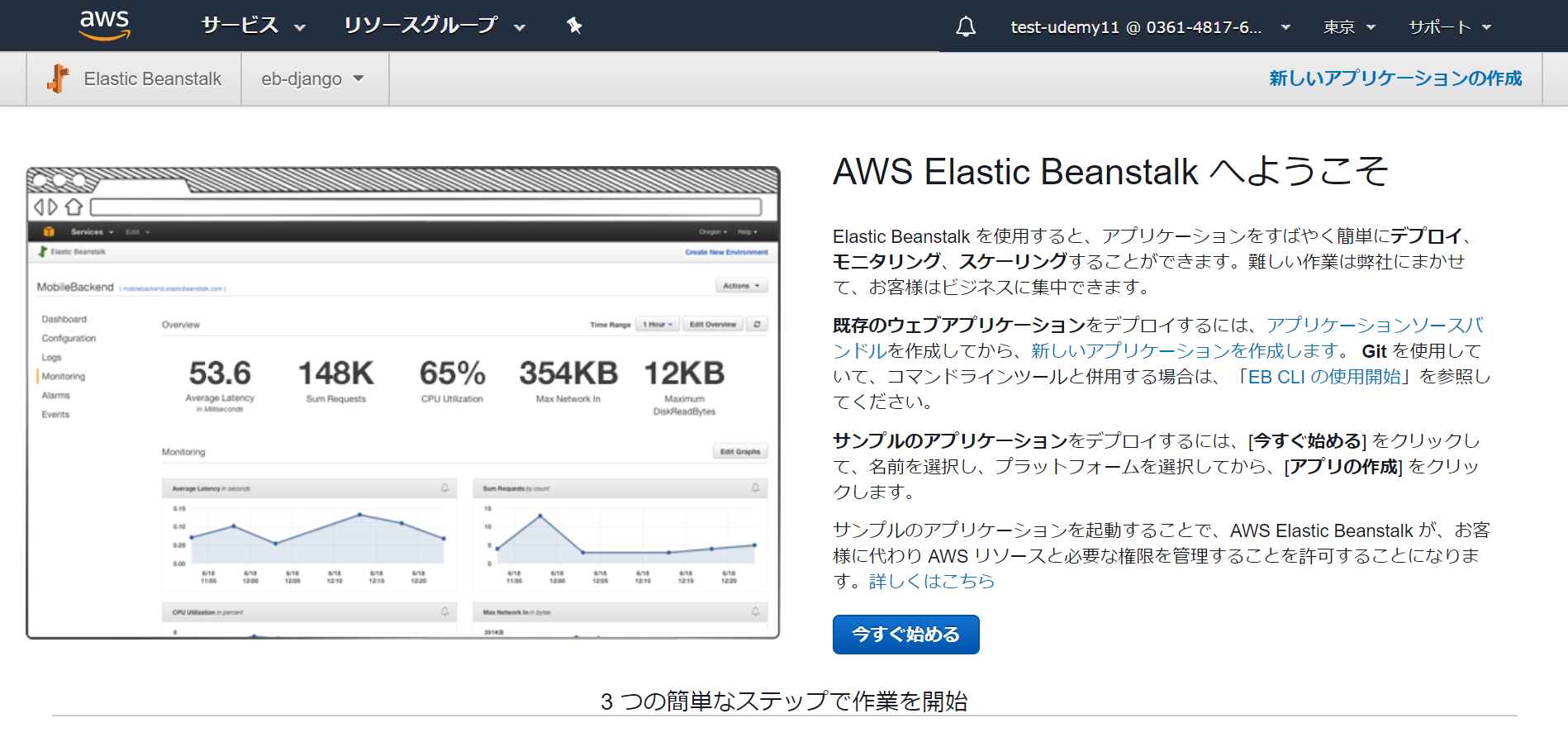
1. プラットフォームを決める
今すぐ始めるをクリック。名前を決めて、基本設定の「プラットフォーム」のプルダウンで「事前設定済み」の「Python」を選択。
「アプリケーションコード」は「サンプルアプリケーション」を選択。
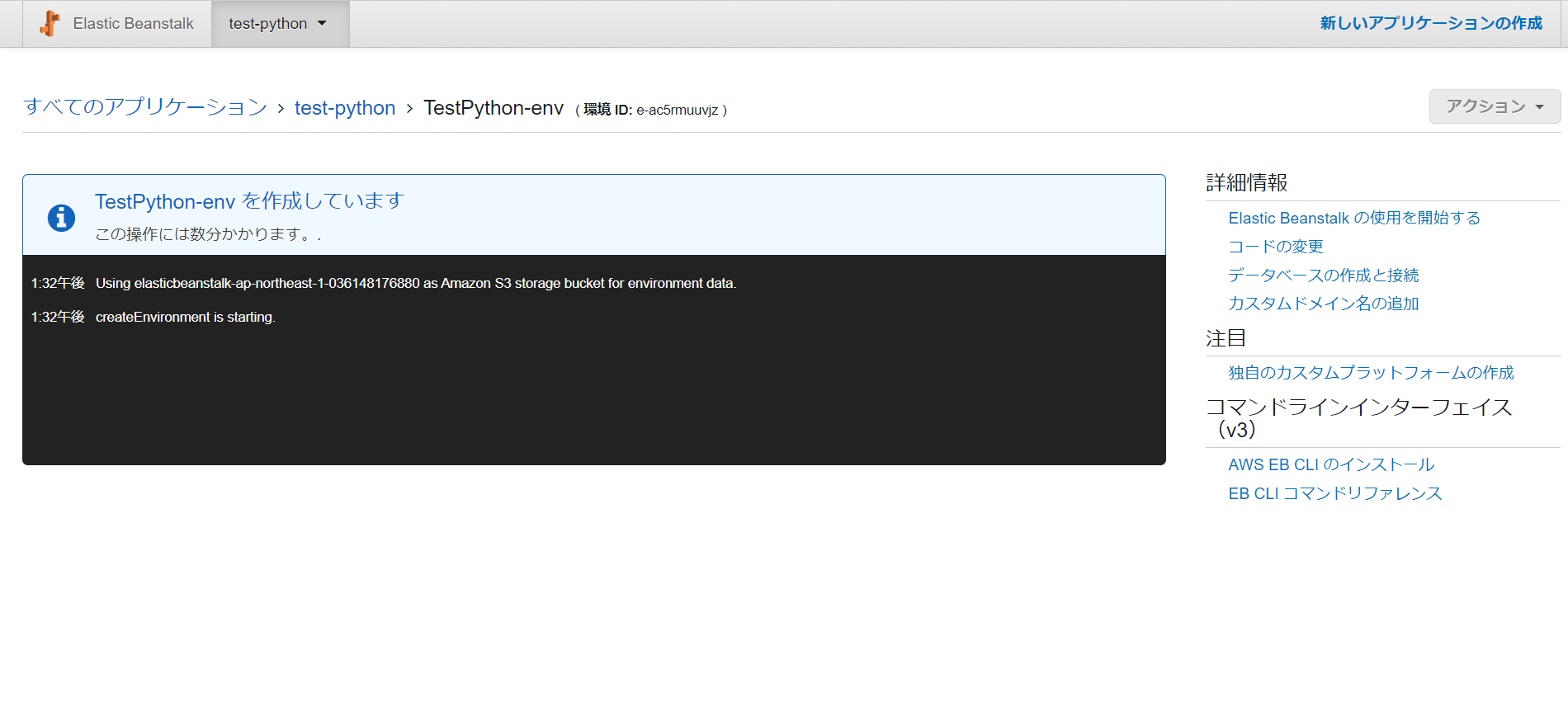
2. 待つ
とくになにもせず数分待ちます。
中では CloudFormation からスタックベースにアプリケーションのデプロイ環境がつくられており、VPC や EC2 インスタンス(セキュリティグループや Elastic IP)や データベース、S3 バケットがつくられ、後に設定をいじることもできます。
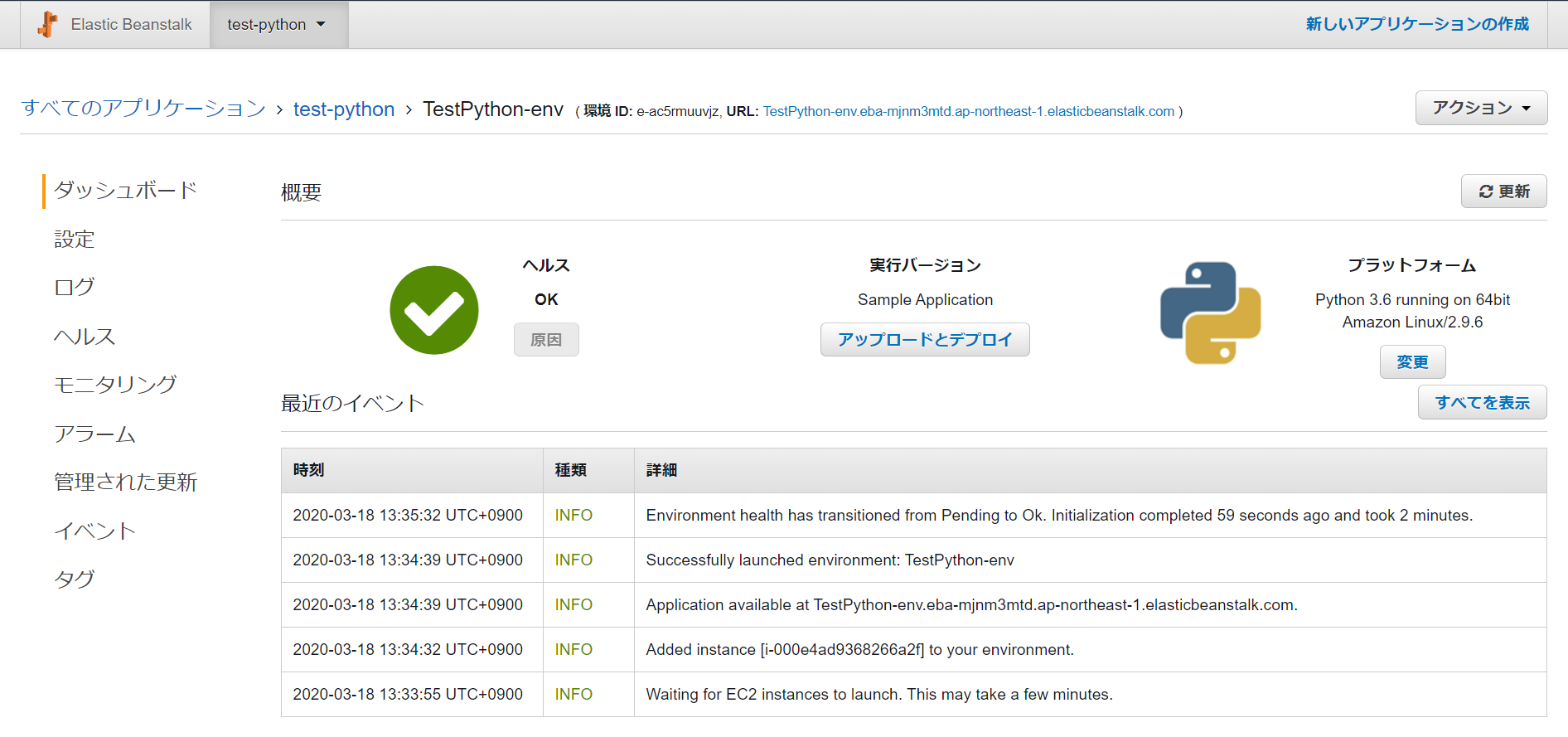
3. Pythonファイルをアップロードする
「最近のイベント」で更新状況が表示されます。モニタリングやアラームの設定を行うこともできます。
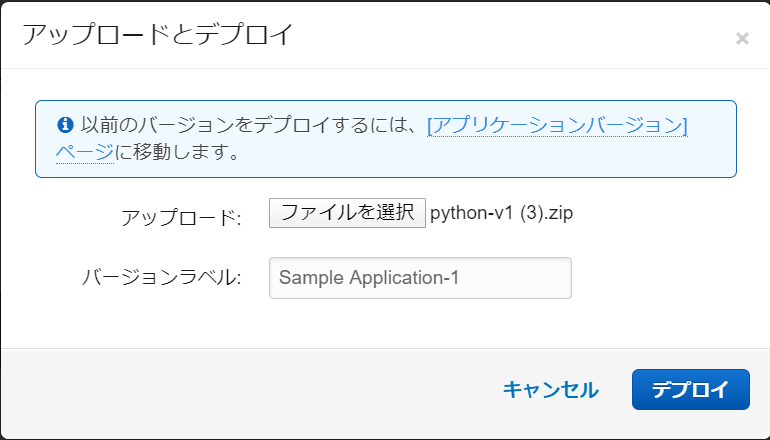
開発者ガイドのサンプルアプリを使ってアプリケーションをアップロードします。
「実行バージョン」の「アップロードとデプロイ」をクリック。
4. 確認する
数秒でアップロードされ、ヘルスチェックされて「最近のイベント」が更新されます。
URLをクリックして確認するとこんな画面がでてきます。
所感
とっても簡単で、秒でデプロイできました!
これならCLIやコマンドの知識がなくてもすぐにアプリケーションを展開できますし、一つの画面ですべてのリソースをらくらく組み立てられます!
まさに、インフラストラクチャを気にせずにアプリ開発に集中できるとはこのことですね!公式サイトリンク




- 投稿日:2020-03-18T15:48:45+09:00
【AWS Elastic BeansTalk】Python アプリを爆速で展開
はじめに
前前回の記事に引き続き
AWS の自動化サービスである Elastic BeansTalk を、今度はコンソール画面のみで展開してみました。
びっくりするくらい簡単なのですぐにお試しできます!
1. プラットフォームを決める
今すぐ始めるをクリック。名前を決めて、基本設定の「プラットフォーム」のプルダウンで「事前設定済み」の「Python」を選択。
「アプリケーションコード」は「サンプルアプリケーション」を選択。
2. 待つ
とくになにもせず数分待ちます。
中では CloudFormation からスタックベースにアプリケーションのデプロイ環境がつくられており、VPC や EC2 インスタンス(セキュリティグループや Elastic IP)や データベース、S3 バケットがつくられ、後に設定をいじることもできます。
3. Pythonファイルをアップロードする
「最近のイベント」で更新状況が表示されます。モニタリングやアラームの設定を行うこともできます。
開発者ガイドのサンプルアプリを使ってアプリケーションをアップロードします。
「実行バージョン」の「アップロードとデプロイ」をクリック。
4. 確認する
数秒でアップロードされ、ヘルスチェックされて「最近のイベント」が更新されます。
URLをクリックして確認するとこんな画面がでてきます。
所感
とっても簡単で、秒でデプロイできました!
これならCLIやコマンドの知識がなくてもすぐにアプリケーションを展開できますし、一つの画面ですべてのリソースをらくらく組み立てられます!
まさに、インフラストラクチャを気にせずにアプリ開発に集中できるとはこのことですね!公式サイトリンク
- 投稿日:2020-03-18T10:51:30+09:00
AuroraのActiveTransactionsをMetricsで取得する
はじめに
DBの監視目的に
CloudWatchのMetricsを取得してみたが、ActiveTransactionsがそのままでは取得できなかったので取得できるようにしてみた。ドキュメントを読む
Amazon Aurora メトリクス
メトリクス 説明 Applies to ActiveTransactions Aurora データベースインスタンスで実行されている現在のトランザクションの 1 秒あたりの平均数。 Aurora では、このメトリクスはデフォルトで有効になっていません。この値の計測を開始するには、特定の DB インスタンス用の DB パラメータグループに innodb_monitor_enable='all' を設定します。 Amazon Aurora DB クラスターメトリクスのモニタリング
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/Aurora.Monitoring.htmlどうやらDBの設定を有効にしないといけないことが分かりました。
DB設定の有効化(間違い)
Auroraに接続し設定を有効にします。
MuSQL 5.6.17のinnodb_metricsを有効にしてみる を参考に、実際にDBに接続して設定してみます。$ mysql -h hogehoge.ap-northeast-1.rds.amazonaws.com -P 3306 -u admin -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 34 Server version: 5.7.12 MySQL Community Server (GPL) Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> SET GLOBAL innodb_monitor_enable = 'all'; ERROR 1227 (42000): Access denied; you need (at least one of) the SUPER privilege(s) for this operationadminで実行しているのに権限がない…だと?
AWSコンソール上で有効化
どうやらAuroraはコンソール上でパラメータを設定しないといけないようです。(AWSCLIでもいける?)
パラメータグループの作成
RDS作成時のデフォルトのパラメータは変更できないと怒られたので新しくパラメータグループを作ります。
公式に 『DBパラメータグループに』 と指定があるので、タイプは
DB Parameter Groupにします。
作成したパラメータグループの編集ボタンを押すと、パラメータがたくさん表示されます。
検索項目に変更したいパラメータを入力すると絞り込めます。
パラメータの編集で値を入れて保存を押します。
RDSの設定変更
作ったパラメータグループをDBインスタンスのパラメータグループに変更します。
ActiveTransactionsを取得してみる
無事、
ActiveTransactionsを取得することができました。$ aws cloudwatch get-metric-statistics --region ap-northeast-1 --period 300 \ > --namespace "AWS/RDS" \ > --dimensions "Name=DBClusterIdentifier,Value=hogehoge-db-cluster" \ > --metric-name "ActiveTransactions" \ > --statistics "Average" \ > --start-time `date --iso-8601=seconds --date '5 minutes ago'` \ > --end-time `date --iso-8601=seconds --date '0 minutes ago'` \ > --endpoint-url "https://hogehoge.ap-northeast-1.amazonaws.com" { "Datapoints": [ { "Timestamp": "2020-03-18T01:41:00Z", "Average": 0.28497748183989613, "Unit": "Count/Second" } ], "Label": "ActiveTransactions" }





- 投稿日:2020-03-18T10:46:29+09:00
Amazon Workspaces / AWS Client VPN を多要素認証に対応させる方法
この時期、リモートワークの手段として、Aamzon Workspaces や AWS Client VPN を試そうとしてる方もいるんじゃないかと思います。
どちらも、多要素認証(MFA)が可能なので少しだけ書いておきます。
Workspaces の MFA について
公式の対応記事
Multi-Factor Authentication for Amazon WorkSpaces
https://aws.amazon.com/jp/blogs/aws/multi-factor-auth-for-workspaces/具体的な方法
多要素認証による Amazon WorkSpaces の利用
https://www.slideshare.net/AmazonWebServicesJapan/amazon-workspaces-86568155以前、こちらの記事でAWS Single Sign-On を 多要素認証(MFA) に対応させる方法を書きましたが、多要素認証に対応させる部分は流用できます。方法はほぼ同じで、こちらはAD Connector を使っています。
どちらも、別途RADIUSサーバーを用意してMFAを実現しています。
簡単な流れは次のようになります。
- 多要素認証用のRADIUSサーバーを用意する
- AWS Managed Microsoft AD の多要素認証を有効にするか、AD Connector の多要素認証を有効にして、RADIUSサーバを設定に追加する
- Workspaces で利用するディレクトリとして、多要素認証を有効にしたディレクトリを指定すると
MFAに対応させると、ログイン時にMFAコードを求められるようになります。
Client VPN の MFA について
公式の対応記事
AWS Client VPN が Active Directory 用の多要素認証をサポート
https://aws.amazon.com/jp/about-aws/whats-new/2019/09/aws-client-vpn-now-supports-multi-factor-authentication-for-active-directory/具体的な方法
Workspaces と同じ手順でAWS Managed Microsoft AD の多要素認証を有効にするか、AD Connector の多要素認証を有効にすればOKです。
AWSが提供しているClient VPN接続ツールを使うと、このような感じで接続時にMFAコードを求められるようになります。


- 投稿日:2020-03-18T07:43:47+09:00
爆速でLambda@edgeにNuxt.jsを構築できるテンプレートを作りました
注意事項
Lambda@Edgeに無料利用枠は無いので注意
詳細な利用料金はこちらある日の夜
はぁ・・・やる事無くて暇だしなんかサービス作りたい・・・
とりあえずNuxt.jsでなんか作るか
デプロイ先はどこにしようか、、、Lambda@Edgeにデプロイするの面白そうだなぁ・・・
いっちょやってみっか
Serverless Nuxt
ということで作っちゃいました。
成果物はこちら→ serverless-nuxt
不具合修正、機能追加のプルリク待ってます!
あと付けてくれたらめっちゃ喜びます。
誰向け?
- サーバー費用ケチりたいけど、ちゃんとしたサービス作りたい人
- とりあえずNuxt/Vue使ってみたい人
- 環境構築めんどくせぇ!!誰かやってくれって人
何が良いの?
- .envをちょろっと弄ってコマンド叩くだけで簡単デプロイ
- Nuxtやる時に大体使うModuleやらPluginやらが導入済み
- デプロイ時にS3に静的ファイルも自動でアップロード!!
- 静的ファイルはCloudFrontを通して取得するから爆速!!
導入済みModule/Plugin
- @nuxt/typescript-build
- @nuxt/typescript-runtime
- @nuxtjs/tailwindcss
- @nuxtjs/dotenv
- @nuxtjs/axios
- @nuxtjs/pwa
- @vue/composition-api
- nuxt-webfontloader
- Stylus
個人的に好きな奴全部ブチ込んでます。
Pugは嫌いなんで入れてないです、使いたい人は自分で入れてどうぞ。ネットワーク図
環境構築
.env編集
AWS_ACCESS_KEY_ID=EXAMPLE_ACCES_KEY AWS_SECRET_ACCESS_KEY=EXAMPLE_SECRET_ACCES_KEY適切な権限が割り振られたユーザーのACCES_KEYを指定する
AWS_DOMAIN=example.comRoute53に登録しているドメインを指定する
Docker構築
$ dcoker-compose build $ docker-compose up -d $ docker-compose exec node ashDockerは使わなくても大丈夫です。
使いたくない人は飛ばしてください。依存ライブラリのインストール
$ npm install
説明要らない気がする開発ビルド
$ npm run devNuxtのビルドを行います。
もちろん開発ビルドなのでファイル変更のWatch, 自動更新も行ってくれます。本番ビルド
$ npm run build $ npm run prod本番とほぼ同じ条件での動作テストが行えます。
ファイル変更のWatch, 自動更新は行いません。AWSへデプロイ
$ npm run build $ npm run deploy下記の処理を上記のコマンドで全て行います。
- CloudFrontのDistributionの設定、Route53との紐付け
- S3バケットの作成、静的ファイルアップロード
- Lambdaの登録、CloudFrontへの紐付け
初回デプロイ時はCloudFrontの設定に時間が掛かるので注意
- 投稿日:2020-03-18T00:30:55+09:00
RaspberryPiを使って洗濯乾燥タイマーを作る
RaspberryPiを使って洗濯乾燥タイマーを作る
はじめに(制作の目的)
- 会社勤めのため、日中、不在にしていることが多く、にわか雨が降ったときに洗濯物の取り込みができません。このため洗濯物については、基本的に室内干しで乾燥させています。
- ところが、物干し部屋の日当たりが悪く、冬場だとなかなか思うように乾燥が進まないため、取り込むタイミングを逸することがあり、洗濯物が雪ダルマ式に溜まるという悪循環に陥っています。
- この悪循環を断ち切る(?)ため、洗濯物の乾燥完了時間を計算し、スマートフォンに通知する仕組みを作りました。
用意するもの
①デバイス側の環境構築に必要なもの。秋月電子で購入可能です。
http://akizukidenshi.com/catalog/top.aspx②サーバ側の環境構築に必要なもの。AWSとSlackのアカウントが必要です。
AWS: https://aws.amazon.com/jp/
Slack: https://slack.com/intl/ja-jp/
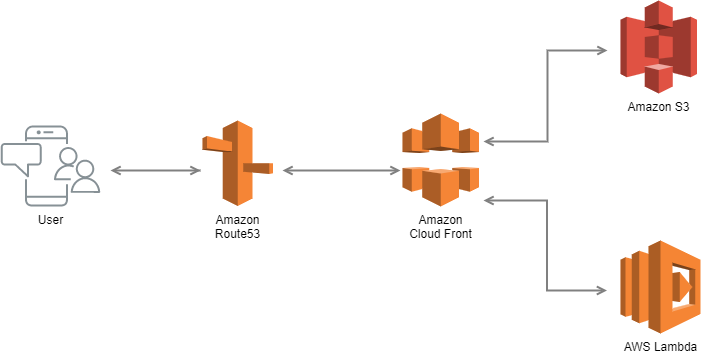
品名 数量 用途 ① RaspberryPi ZeroWH 1 制御用マイコン ① ブレッドボード 1 回路構築用 ① DHT11 1 温湿度センサー ① 抵抗(4.7kΩ) 2 ① 抵抗(1kΩ) 1 ① タクトスイッチ 1 起動・停止スイッチ ① LED 1 起動時に点灯(目視確認用) ② AWS IoT Core 端末との通信を終端。MQTTブローカーの役割。 ② AWS Lambda IoTCoreのバックエンド。Slackとの通信を仲介。 ② Slack スマートフォンへの通知に利用 システム概要
RaspberryPi --- AWS IoT Core --- AWS Lambda --- Slack --- スマホ
- RaspberryPi ~ AWS IoT Core
- MQTT over TLS。AWS IoT Device SDK for Pythonを使って接続します。
- AWS IoT Core ~ AWS Lambda
- AWS IoT Coreのアクション定義でMQTT topic受信時にLambdaをトリガーします。
- AWS Lambda ~ Slack
- Lambda関数でSlackのIncoming WebhookのAPIをキックします。
- Slack ~ スマホ
- スマホにSlackアプリをインストールして、Slackからの通知を受信します。
環境構築(サーバ)
AWS IoT Core
証明書の作成
AWS IoT Coreとの接続認証に必要なX.509証明書を作成します。作成手順として、まずポリシー(AWSリソースへの認可情報)を事前に作成してから、証明書に対してポリシーをアタッチしていきます。
AWSマネジメントコンソール上でAWS IoT Coreサービスを選択し、「安全性」→「ポリシー」からポリシーの作成を行います。ポリシー名は任意の値を設定します。アクションは「iot:*」、リソースARNは「*」として、任意の名前でポリシーを作成します。
「安全性」→「証明書」から証明書の作成を行います。1-Click 証明書作成メニューから証明書を作成し、「このモノの証明書」「プライベートキー」をPCにダウンロードします。この証明書とプライベートキーはAWS IoT SDKの設定で後ほど必要となります。また同じく必要なルートCA証明書については、こちらからRSA 2048 ビットキーの内容をテキストエディタに保存して作成します。
「有効化」を押して証明書を有効にしてから、「ポリシーをアタッチ」で先ほど作成したポリシーを証明書にアタッチします。
デバイス(モノ)の登録
AWS IoT Coreに接続するデバイスの登録を行います。
- AWSマネジメントコンソールからAWS IoT Coreサービスを選択し、「管理」→「モノ」→「作成」→「単一のモノを作成する」より、画面の指示に従って、デバイス(モノ)の登録を行います。証明書の新規作成を促されますが、先ほど作成した証明書を使うため、「証明書なしでモノを作成」を選びます。
- 「安全性」→「証明書」で先ほど作成した証明書のカード右上のサブメニューにある「モノをアタッチ」をクリックして、先ほど作成したデバイス(モノ)を証明書にアタッチします。
これでAWS IoT Coreへの接続に必要な設定は完了です。
ルールの作成
次にAWS IoT Coreで受信したデータをAWS Lambdaに転送するための設定を行います。
- AWSマネジメントコンソールからAWS IoT Coreサービスを選択し、「ACT」→「ルール」→「ルールの作成」より、画面の指示に従って、転送ルールを作成します。
- ルールクエリステートメントでは受信したMQTTメッセージに対して、アクションを適用する条件をSQLで指定します。今回のケースではtopic名="condition"、且つnotice=1の条件でLambda関数を呼び出すため、(SELECT * FROM 'condition' WHERE notice = 1)としています。
- Lambda関数を呼び出すための設定は、「1 つ以上のアクションを設定する」→「アクションの追加」から行います。
AWS Lambda
AWSマネジメントコンソールから、Lambdaサービスを選択し、AWS IoT Coreから呼び出されるLambda関数の定義を行います。Slackへの通知はIncoming Webhook URLに対して、"payload=" + json.dumps(send_data)の形式でテキストデータを作成しPOSTします。
import json import urllib.request def lambda_handler(event, context): d = json.dumps(event) post_slack(event) return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') } def post_slack(event): t = event["remaining_time"] # メッセージ作成 if t < 0: message = "洗濯物が乾きました!" else: message = "あと%-2i分で洗濯物が乾きます。" % t send_data = { "username" : "dry_notice", "text" : message, } send_text = "payload=" + json.dumps(send_data) # slackへの通知 request = urllib.request.Request( "SlackのIncomming WebhookのURL", data=send_text.encode('utf-8'), method="POST" ) with urllib.request.urlopen(request) as response: response_body = response.read().decode('utf-8')Slack
Slackでアカウントを作成し、任意のチャンネルを追加します。その後、追加したチャンネルに対してIncoming Webhookの登録を行います。
これでサーバ側の環境構築は完了です。
環境構築(デバイス)
ハードウェア設計
- ブレッドボードを使って、RaspberryPiと①の各パーツを配線します。RaspberryPiのピン配置はこちらがわかりやすく纏まっていて参考になるかと思います。
- 水色の四角い箱がDHT11になります。左から5V電源、DATA、NC(未使用)、GNDになります。DATAは任意のGPIO(下図では14Pin)に接続します。またDATAラインには4.7kΩの抵抗を接続し、5vでプルアップしておきます。
- そのほか、LEDとタクトスイッチは1kΩ、4.7kΩの抵抗で任意のGPIO(下図では23,24Pin)に接続します。
ソフトウェア設計
全体の処理の流れとしては以下のようになります。
- GPIO24のPull_UPイベントをトリガーとして、モニターを起動する。
- dht11から10秒毎に温度・湿度値を取得する。
- 洗濯物の重量と温度・湿度値から乾燥するまでの残り時間を計算する。
- (残り時間が10分以下になったら)AWS IoT Core経由で残り時間10分の通知を行う。
- (残り時間が0になったら)AWS IoT Core経由で乾燥完了の通知を行う。
- 乾燥完了もしくはGPIO24のPull_UPイベントによりモニターを停止する。
#!/usr/bin/python3 # coding: UTF-8 # Import SDK packages import RPi.GPIO as GPIO import dht11 #・・・1 import time import datetime from AWSIoTPythonSDK.MQTTLib import AWSIoTMQTTShadowClient,AWSIoTMQTTClient from AWSIoTPythonSDK.exception import AWSIoTExceptions import json import logging # Init logging logging.basicConfig(filename="ログファイルのパス",level=logging.INFO,format='%(asctime)s - %(name)s - %(levelname)s - %(message)s') # Init AWSIoTMQTTClient #・・・2 myAWSIoTMQTTClient = None myAWSIoTMQTTClient = AWSIoTMQTTClient("AWS IoT Coreのモノの名称") myAWSIoTMQTTClient.configureEndpoint("AWS IoT CoreのエンドポイントURL", 8883) myAWSIoTMQTTClient.configureCredentials("ルート証明書のパス", "秘密鍵のパス", "クライアント証明書のパス") # AWSIoTMQTTClient connection configuration myAWSIoTMQTTClient.configureAutoReconnectBackoffTime(1, 32, 20) myAWSIoTMQTTClient.configureOfflinePublishQueueing(-1) # Infinite offline Publish queueing myAWSIoTMQTTClient.configureDrainingFrequency(2) # Draining: 2 Hz myAWSIoTMQTTClient.configureConnectDisconnectTimeout(10) # 10 sec myAWSIoTMQTTClient.configureMQTTOperationTimeout(5) # 5 sec # Connect to AWS IoT myAWSIoTMQTTClient.connect() logging.info('connect to AWS IoT') # MQTT topic #・・・3 topic_1 = "condition" topic_2 = "monitermode" # Variable modeState = False # Operating state(True:ON False:OFF) v = 3000 # Laundry weight delta_v = 0 # Delta of Laundry weight notice = 0 # Notification to Slack flg_1 = True flg_2 = True starttime = datetime.datetime.now() lasttime = starttime # Init GPIO LED = 23 SWITCH = 24 GPIO.setwarnings(True) GPIO.setmode(GPIO.BCM) GPIO.setup(LED,GPIO.OUT) GPIO.setup(SWITCH,GPIO.IN) # Read data using pin 14 instance = dht11.DHT11(pin=14) # Action when switch is pressed def switch_on(self): # When it is running if modeState: GPIO.output(LED,0) modeState = False logging.info("Stop drying monitor") payload = { "mode": 0} # When stopped else: GPIO.output(LED,1) modeState = True v = 3000 delta_v = 0 notice = 0 flg_1 = True flg_2 = True starttime = datetime.datetime.now() lasttime = starttime logging.info("Start drying monitor") payload = { "mode": 1} myAWSIoTMQTTClient.publish(topic_2, json.dumps(payload), 1) # GPIO event setting #・・・4 GPIO.add_event_detect(SWITCH,GPIO.RISING,callback=switch_on,bouncetime=200) while True: try: # When it is running if modeState: result = instance.read() if result.is_valid(): logging.info("Temperature: %-3.1f C" % result.temperature) logging.info("Humidity: %-3.1f %%" % result.humidity) now = datetime.datetime.now() delta = now - lasttime logging.info("delta_time: %-2i sec" % delta.seconds) lasttime = now #・・・5 ps = 6.11 * 10 ** (7.5 * result.temperature / (result.temperature + 237.3)) delta_v += (-0.45 * ps * (1-result.humidity / 100) + 0.25) * delta.seconds / 60 logging.info("delta_v: %-3i g" % int(delta_v)) elapsed_time = lasttime - starttime estimate_time = elapsed_time.seconds * v / (-1 * delta_v) / 60 remaining_time = elapsed_time.seconds * (v / (-1 * delta_v) - 1) / 60 logging.info("estimate_time: %-3.1f minutes" % estimate_time) logging.info("remaining_time: %-3.1f minutes" % remaining_time) #・・・6 if remaining_time < 10: if flg_1: notice = 1 flg_1 = False else: notice = 0 if remaining_time < 0: if flg_2: notice = 1 flg_2 = False modeState = False else: notice = 0 payload = { "time":str(datetime.datetime.now()),\ "temperature":round(result.temperature,1),\ "humidity":round(result.humidity,1),\ "estimate_time":round(estimate_time,1),\ "remaining_time":round(remaining_time,1),\ "notice":notice} myAWSIoTMQTTClient.publish(topic_1, json.dumps(payload), 1) # When stopped else: GPIO.output(LED,0) time.sleep(6) except KeyboardInterrupt: break except: pass logging.warning("Exception detected. Finish application.") GPIO.cleanup() myAWSIoTMQTTClient.disconnect()
dht11はセンサーから温度・湿度の値を取得するライブラリです。GitHubから入手できます。
AWS IoT Coreに接続するMQTTクライアントの設定。いずれもAWS Iot Coreのメニューで参照した内容を設定します。
- モノの名前:「管理」→「モノ」に登録したデバイス名称
- エンドポイント:「設定」→「カスタムエンドポイント」に表示されるURL
- 各種証明書:「安全性」→「証明書」から「モノ」にアタッチした証明書をダウンロードして、RaspberryPiに格納しておきます。
MQTTのトピック名。topic_1(condition)は温度・湿度などのセンサー値、topic_2(monitermode)はモニター状態を投稿するためのトピック。
タクトスイッチの接続先であるGPIO24の監視設定。スイッチを押す(Lo→Hi)とswitch_on関数を起動します。switch_on関数ではLED制御とパラメータの初期化を行います。modeStateでモニター状態を保持しており、スイッチを押すたびに状態(OFF/ON)を遷移させています。
乾燥時間を計算する処理部です。乾燥時間の数式はこちらのサイトを参考にしています。vは洗濯カゴを洗濯物で一杯にした時の重量(乾燥前-乾燥後→水分重量)、delta_vはスイッチで起動開始してから乾燥した水分重量です。
残り時間(remaining_time)が①10分以下、②0分以下となった時点でtopic_1への投稿を行います。topic_1には以下のデータを投稿します。
項目名 内容 time 現在時刻 temperature 温度(℃) humidity 湿度(%) estimate_time 乾燥完了するまでの所要時間(分) remaining_time 残り時間(分) notice Slackへの通知フラグ(1:通知する 0:通知しない) おわりに
時間があれば、拡張機能として、扇風機を制御して乾燥時間を短縮する機能を追加したいと思っています。
