- 投稿日:2020-03-18T23:14:49+09:00
Python スクレピング 競馬サイトから出走馬の過去成績を取得
背景
現在、競馬×機械学習のために、
ウェブページから競馬情報をスクレイピングすることに取り組んでいます。入力内容に出走馬の過去の成績を組み込もうとしています。
そこで競馬のレース結果表から出走馬のページのURLを取得、アクセスし、
出走日の過去の成績を取得することにした。構想
サンプルコード
アイデアは以下の3点。
・取得方法をCSSセレクターで統一
・レース結果表から各馬のURLを取得し、そのURLに掲載されている過去成績を取得
・今回の出走馬は12頭だが、他の馬数でも取得できるように可変長変数を使用この記事の前に、Python スクレピング 競馬サイトからレース環境を抽出を紹介させていただきました。
こちらはレース環境をBeautifulSoupを使いました。
しかしcssセレクターで統一して処理したほうが気持ちがいいので書き換えました。scraping_of_race_and_past_horse_result.pyimport requests import lxml.html import csv rlt = [] #結果 horse_URL = []#馬の名前を取得する #スキャルピングでテキスト取得 def get_scarping_data(key_page,css_select_str,*URL): #取得したURLの個数分の情報を取得する for i in range(len(URL)): #URLから文字列を取得 r = requests.get(URL[i])#URLを指定 r.encoding = r.apparent_encoding #文字化けを防止 html = lxml.html.fromstring(r.text) #取得した文字列データ # 項目を取得 for css_id in html.cssselect(css_select_str): #レース結果サイトのレース環境 if key_page == "condition_in_race_page" : #Element番号のテキスト css_id = css_id.text_content() #内包表記 抽出する際に"天気"は不変であるので条件指定 css_id_ = [css_id for t in css_id if "天気" in css_id] css_id_ = css_id_[0].split('\xa0/\xa0') #リストに行のデータ(リストを追加) rlt.append(css_id_) #レース結果サイトのレース結果 if key_page == "result_in_race_page" : #Element番号のテキスト css_id = css_id.text_content() #改行("\n")をもとに分割する css_id = css_id.split("\n") #内包表記 空の要素を駆逐する 空文字を除く css_id_ = [tag for tag in css_id if tag != ''] #1位はタイム記録なし #強引に加える必要がある 8番目に0 if len(css_id_) != 13 : css_id_.insert(8,0) #リストに行のデータ(リストを追加) rlt.append(css_id_) #レースした馬の過去成績サイト if key_page == "horse_race_data" : #Element番号のテキスト css_id = css_id.text_content() #取得したElement番号の css_id = css_id.split("\n") #内包表記 空と"\xa0"と"映像"を除去 css_id_ = [tag for tag in css_id if tag != '' and tag != "\xa0" and tag != "映像" and tag != "厩舎コメント" and tag != "備考" ] #リストに行のデータ(リストを追加) rlt.append(css_id_) #抽出結果 return rlt #レースした馬のURLを取得 def get_scarping_past_horse_date(URL): response = requests.get(URL) root = lxml.html.fromstring(response.content) #1~12までの馬の情報を取得 for i in range(2,14):#2~13 13 - 2 + 1 = 12 css_select_str = "div#race_main tr:nth-child({}) > td:nth-child(4) > a".format(i) #レースした馬の情報を取得 for a in root.cssselect(css_select_str): horse_URL.append(a.get('href')) #抽出結果 return horse_URL #まず本家のレースサイトからレース環境を取得 URL = "https://nar.netkeiba.com/?pid=race&id=p201942100701" #レース環境を取得 rlt = get_scarping_data("condition_in_race_page","div#main span",URL) #レース結果を取得 rlt = get_scarping_data("result_in_race_page","#race_main > div > table > tr",URL) #レースした馬のURLを取得 horse_URL = get_scarping_past_horse_date(URL) print(len(horse_URL))#出走馬12に対し、出力結果は12 #取得した馬のURLから過去成績を取得 #項目(1行分)を取得 rlt = get_scarping_data("horse_race_data", "#contents > div.db_main_race.fc > div > table > thead > tr",horse_URL[0]) #項目以外の成績データ rlt = get_scarping_data("horse_race_data", "#contents > div.db_main_race.fc > div > table > tbody > tr",*horse_URL) #CSVファイルに保存 with open("scraping_of_race_and_past_horse_result.csv", 'w', newline='') as f: wrt = csv.writer(f) wrt.writerows(rlt) #抽出結果の書き込み実行結果
反省点
・レース結果から馬の情報が掲載されているURLを取得し、過去成績も取得できた。
・過去成績を取得できたが最新の情報も掲載されているので、レースした日を基準に遡った成績を取得する必要がある。
・取得できた情報をニューラルネットワークに入力できるレベルまで行っていない。
・レースした日を自動で取得する。毎回調べない
→方法として、レース情報数値(URLの末端の12桁)を規則性を考慮してインクリメント。CSSセレクタの調べ方
スクレイピングするうえで、以下のコード(文字列)を使いこなす必要がある。
(#contents > div.db_main_race.fc > div > table > tbody > tr')
↑ここの部分をどのようにして取得するのかをまとめる。how_to_search_css_sector.pyfor h in html.cssselect('#contents > div.db_main_race.fc > div > table > tbody > tr'):#スクレイピング箇所をCSSセレクタで指定初めはただコピペしたり、そっれっぽいコードを書いてトライしたが、うまく行かない。。。
調べてみるとCSSが絡んでいる。
欲しい項目はどのCSSセレクターで構成されたいるかを知るために、
ChromeのCopy Css Selectorのツールを使う。
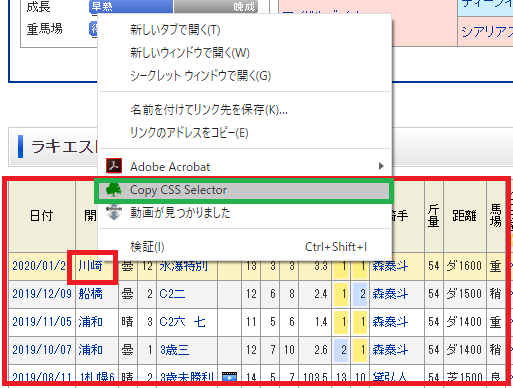
インストールすると右クリックでCopy Css Selectorの項目ができる。
欲しい項目でCopy Css Selectorを実行し、テキストに張り付けて確認するとCSSセレクターを知ることができる。
※うまくいかないこともあるかもしれない。
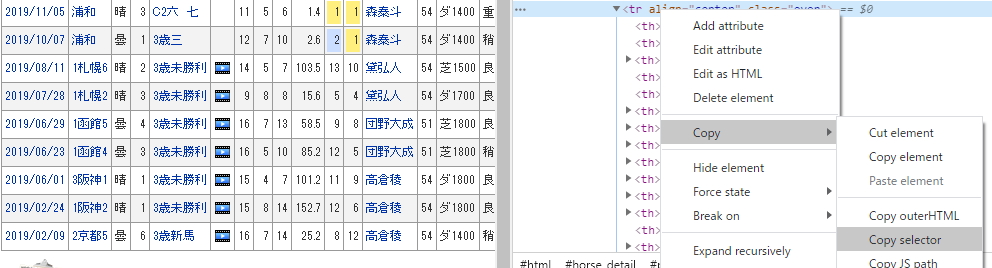
他にもディベロッパー ツールを用いて、
欲しい情報範囲で Copy → Copy Selector でCCSセクターをコピーできる。
たまにうまくいきます。
この2つを駆使すれば、SCCセレクターを取得できるはずです。

- 投稿日:2020-03-18T22:49:58+09:00
Vue.js 現在時刻の表示 ~時計~
Vue.jsとは
ユーザーインターフェイスを構築するためのプログレッシブフレームワークです。他の一枚板(モノリシック: monolithic)なフレームワークとは異なり、Vue は少しずつ適用していけるように設計されています。中核となるライブラリは view 層だけに焦点を当てています。そのため、使い始めるのも、他のライブラリや既存のプロジェクトに統合するのも、とても簡単です。また、モダンなツールやサポートライブラリと併用することで、洗練されたシングルページアプリケーションの開発も可能です。
Vue.jsを使用するメリット
- 気軽に使える: Vue.js はjQueryと同様に、scriptタグを1行書くだけで使い始めることができます。
DOM操作を自動的に行ってくれる:
HTMLドキュメント全体の要素の構成をDOM(Document Object Model)といいます。Vue.jsはHTML側の要素とJavaScript側の値やイベントとの対応付を自動で行ってくれます。これにより、jQueryよりも簡潔に分かりやすくコードを記載することができます。学習コストが低い:
AngularやReactと比較してフレームワークの規模が小さい分、覚えることも少なくて済みます。JavaScriptやjQueryの基礎知識があれば数時間の学習で開発を開始することができるでしょう。Vue.jsで現在時刻を取得して表示する
初めに全体像を掴んでもらうために、完成品を記述します。
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <div id="app"> <p>{{ now }}</p> <button v-on:click="time">現在時刻</button> <!-- v-on:event --> </div> <!-- Vue.jsをインストール --> <script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script> <!-- ここから記述していきます --> <script> let app = new Vue({ el: "#app", data:{ now: "00:00:00" }, methods: { time: function(e){ var date = new Date(); this.now = date.getHours() + ":" + date.getMinutes() + ":" + date.getSeconds(); } } }); </script> </body> </html>完成品
ここから要素ごとに説明していきます。ちなみにVue.jsは始めたばかりになるので、説明が至らぬところがあればコメントお願いします。
<div id="app"> <p>{{ now }}</p> <button v-on:click="time">現在時刻</button> <!-- v-on:event --> </div>まずはHTMLでのこちら。
{{ }}
こちらの記述がJavaScriptのメッセージに自動的に置換してくれます。
v-on
v-on ディレクティブを使うことで、DOM イベントの購読、イベント発火時の JavaScript の実行が可能になります。次に

- 投稿日:2020-03-18T17:34:43+09:00
ボタンを押すと開くナビ、非表示時フォーカスさせない!!
tabキーを連打しても何もフォーカスしない...はてな?
と思っていましたが、absoluteでマイナスをつけまくって端っこにやって見せないようにしていたナビにフォーカスしていました。機械は間違えない。非表示メニューはフォーカスが当たらないようにする。
最初は
display: none;やvisibility:hiddenなどで
フォーカスさせない作戦に出ました。しかし問題が....target { display: absolute; top: 50%; left: -600px; transition: .3s; } .is-active { left: 0; }
is-activeクラスをつけたり外したりすることでナビを出現するようにしています。
これにdisplay: none;やvisibility:hiddenで出し分けしてしまうと、
今まですっと出てきてすっと仕舞われるというアニメーションになっていた表示が パっと一瞬で消えたり出てきたりしてしまいます。当然ですね..JSでガチャガチャしたりCSSのアニメーションであれこれするのも
コードが増えてなんか嫌...と思っていましたが、もっと簡単な方法がありました。tabIndex
tabIndex="-1"要素につけるとフォーカスされなくなります。
これを出し分けする方針で行きます。
(ちなみにマイナスの値ならなんでもOKです)下記はreactでの例です。
<Link to="/" tabIndex={hamburgerToggle.get('flg') ? 'auto' : '-1'} > HOME </Link>スクリーンリーダーも対応させよう
tabIndexでフォーカスを無効にしても、スクリーンリーダで読まれてしまいます。
これを読まれないように調節しましょう。属性に`aria-hidden="true"をつけるとスクリーンリーダに読まれなくなります。非表示にしてもスクリーンリーダー利用者がアクセスしやすいように
非表示ナビへの不要なアクセスを封じ、一件落着!という風ですが、忘れてはいけないことがあると周囲の方に指摘いただきました。ありがたや...
ナビを開閉するボタンがスクリーンリーダーにとってわかりにくいものだったら、アクセスする手段が途絶えてしまいます。
開閉ボタンにaria-label属性をつけてナビをナビします。
こうすることで、aria-labelに指定したテキストがスクリーンリーダーに読み上げられます。<button type="button" onClick={clickhandler} aria-label="ナビ開閉ボタン" >× </button>もっと良い方法や意見等あればぜひコメントよろしくお願いします!
- 投稿日:2020-03-18T04:50:17+09:00
初心者によるプログラミング学習ログ 265日目
100日チャレンジの265日目
twitterの100日チャレンジ#タグ、#100DaysOfCode実施中です。
すでに100日超えましたが、継続。
100日チャレンジは、ぱぺまぺの中ではプログラミングに限らず継続学習のために使っています。
265日目は、おはようございます
— ぱぺまぺ@webエンジニアを目指したい社畜 (@yudapinokio) March 17, 2020
265日目
・webサイト模写 1.0h
・以前購入した模写教材のコンテンツ部分作成#早起きチャレンジ#駆け出しエンジニアと繋がりたい#100DaysOfCode