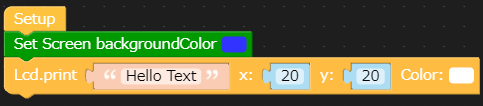
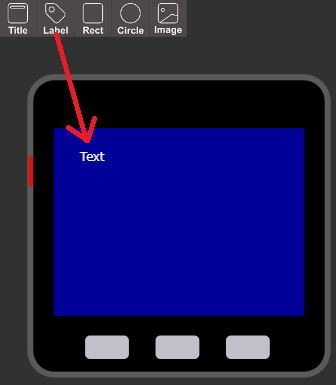
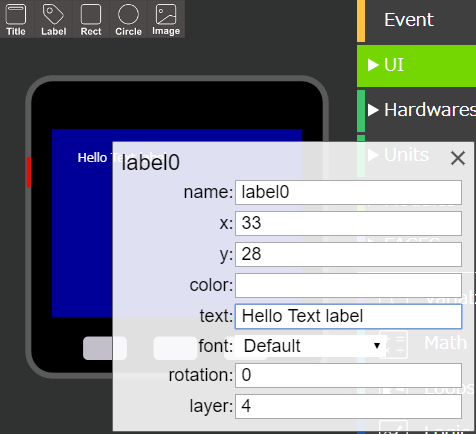
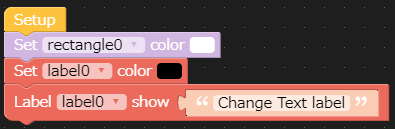
- 投稿日:2020-03-18T23:54:00+09:00
【python】datetimeモジュールのクラス種類と使い方
【備忘録】pythonのdatetimeモジュールのクラス種類と使い方
pythonのdatetimeモジュールで利用できるクラスの種類と違いを実例で確認する。
クラスの種類
6種類のクラス(データ型)が用意されている
datetime.date:日付(年、月、日)datetime.time:時刻(時、分、秒、マイクロ秒)datetime.datetime:日付+時刻datetime.timedelta:時間差分datetime.timezone:タイムゾーンの設定datetime.tzinfo:タイムゾーン情報各クラスの中身
0. 補足条件
datetimeモジュールはdtとして呼び出す。
datetimeモジュールの呼び出しimport datetime as dt▼実際の使用例
datetime.dateはdt.dateとして記述※datetime.datetime.dateはエラーになる
(name 'datetime' is not defined)1. datetime.date
dt.date.today()の実行結果
datetime.date(2020, 3, 18)
└ datetime.date型
└ (2020, 3, 18)=(年, 月, 日)⇒ 年、月、日の3つのデータが取得できる。
(属性:year, month, day)
2. datetime.time
dt.timeでメソッドは使えなさそう。。
dt.dateのように、現在時刻を取得しようと思ってもできない。
- dt.time.now(): エラー
- dt.time.today() :エラー
type object 'datetime.time' has no attribute 'today'
■使い方
時刻を自分で指定する。日付データが不要で、時刻データのみ呼び出したり、変更したい場合に有効。
- datetime.time型がもつ、hours, minute, second, microsecondを個別に指定。
- 指定したデータを呼び出す。(例:
.hour)- 指定したデータを変更する (例:
.replace(hour=1))指定した数値
時刻の指定と呼び出し(datetime.time)#時刻を設定 timeA = dt.time(10, 30, 45, 123456) #時刻を呼び出す timeA.hour #実行結果:10 timeA.minute #実行結果:30 timeA.second #実行結果:45 timeA.microsecond #実行結果:123456時刻の変更(replace())#時刻を設定 timeA = dt.time(10, 30, 45, 123456) #(1)個別に変更する timeA = timeA.replace(hour=5) timeA #実行結果 # → datetime.time(5, 30, 45, 123456) #(2)まとめて変更する timeA = timeA.replace(hour=1, minute=2, second=30, microsecond=400) timeA #出力結果 # → datetime.time(1, 2, 30, 400)
3. datetime.datetime
dt.datetime.today()の実行結果
datetime.datetime(2020, 3, 18, 7, 42, 54, 95450)
└ datetime.datetime型
└ (2020, 3, 18, 7, 42, 54, 95450)
(年, 月, 日,時,分,秒,マイクロ秒)⇒ 年、月、日、時、分、秒、マイクロ秒の7つのデータが取得できる。
(属性:year, month, day, hour, minute, microsecond)※裏側ではtzinfo(tz:タイムゾーン情報)も所持している。
▼tzinfo(tz:タイムゾーン情報)
カッコなしのnowなどでメソッドを実行した場合に情報が出力される。タイムゾーン情報を表示するdt.datetime.now <function datetime.now(tz=None)>
■now()とtoday()
datetime.datetimeでよく使うメソッド。
※どちらも同じよく使うメソッドnowとtoday#.now() dtNow = dt.datetime.now() dtNow #datetime.datetime(2020, 3, 18, 21, 28, 13, 409431) #.today() dtToday = dt.datetime.today() dtToday #datetime.datetime(2020, 3, 18, 22, 45, 10, 518281)
■combine(A, B)
日付の型と時刻の型を組み合わせることが可能。
datetime.datetime.combine(A, B)よく使うメソッドcombine#.combine(A, B) dateA = dt.date(2020,5,6) timeA = dt.time(10,20,0) dt.datetime.combine(dateA, timeA) #出力結果 # → datetime.datetime(2020, 5, 6, 10, 30, 0)※combine(A, B)は
A= datetime.date型、B= datetime.time型と決まっている。cobmbine(timeA, dateB)など、指定の型と異なる場合はエラーになる。
combine() argument 1 must be datetime.date, not datetime.time
■replace()
引数で指定した数値を変更できる(複数指定可能)replace#.replace() dtNow =dt.datetime.now() dtNow # datetime.datetime(2020, 3, 18, 22, 10, 15, 517216) dtNow = dtNow.replace(year=2018) dtNow = dtNow.replace(hour=5, minute=30, second=30) dtNow #出力結果 # → datetime.datetime(2018, 3, 18, 5, 30, 30, 474609)■曜日を出力する
weekday():0~6(月曜日0~日曜日6)
isoweekday():1~6(月曜日1~日曜日7)
出力 月 火 水 木 金 土 日 weekday() 0 1 2 3 4 5 6 isoweekday() 1 2 3 4 5 6 7 曜日の出力today = dt.datetime.today() #datetime.datetime(2020, 3, 18, 22, 30, 46, 646567) #.weekday() today.weekday() #出力:2 → 水曜日 #.isoweekday() today.weekday() #出力:3 → 水曜日■日付 or 時刻のみ出力する
date():year、month、day
time():hour、minute、second、microsecond日付・時刻の出力now = dt.datetime.now() #datetime.datetime(2020, 3, 18, 22, 35, 50, 177279) #.time() now.time() #出力:datetime.time(22, 38, 1, 997649) #.date() now.date() #datetime.date(2020, 3, 18)
4. datetime.timedelta
・日付や時間の足し算・引き算ができる。
・日付同士をひいた結果がtimedeltaで表示される。
- timedeltaは足し算・引き算処理をするものではい。
- ★どの項目をいくつ足すか・引くかの指定
- dt.timedelta(days=2) :2日足す
- dttimedelta(hours=-5) :5時間引く
- 指定できる引数(7種類。※複数形
- weeks (:7daysの倍数)
- days
- hours
- minutes
- seconds
- milliseconds
- microseconds
- 指定できない引数(年、月は不可)
- years
- months
- デフォルトの引数は0
指定できない引数や、間違った引数(単数形など)はエラーになる
'years' is an invalid keyword argument for __new__()
使い方
(1)2020年1月1日に2週間足す
+ dt.timedelta(weeks=2)timedeltaで足し算newyear = dt.datetime(2020, 1, 1) #datetime型で2020年1月1日を定義 newyear + dt.timedelta(weeks=2) #実行結果 #datetime.datetime(2020, 1, 15, 0, 0) # → 2020年1月15日
(2)2020年1月1日から25時間引く
+ dt.timedelta(hours=-25)timedeltaで引き算newyear = dt.datetime(2020, 1, 1) #datetime型で2020年1月1日を定義 newyear + dt.timedelta(hours=-25) #実行結果 datetime.datetime(2019, 12, 30, 23, 0) # → 2019年12月30日23時
補足
(3)所持していないデータ部分も計算される▼実例
・date型(時間データを持たない)に時間足してもエラーにならない。
・結果は計算されたものが表示される
└ 非表示部で計算している型が所持していないデータの取扱newyear2 = dt.date(2020, 1, 1) #datetime.date型(時間データを持たない) newyear2 + dt.timedelta(hours=100) #100時間足す #実行結果 #datetime.date(2020, 1, 5) # → 2020年1月5日
(3)日付の差分の結果
ある日付同士の間隔を算出する。
- 使える型は
datetime.datetimeとdatetime.date- datetime.timeは使えない
- 比較する方は同じ必要がある
- datetime.datetimeとdatetime.dateではエラーになる
- 足し算はできない(エラーになる)
2つの日付の間隔を求める(事例①)dateA = dt.date(2020,1,1) dateB = dt.date(2020,1,9) dateA - dateB #出力:datetime.timedelta(days=-8) dateB - dateA #出力:datetime.timedelta(days=8)2つの日付の間隔を求める(事例②)pastA = dt.datetime(2000, 1, 1) now = dt.datetime.now() #出力:datetime.datetime(2020, 3, 18, 22, 56, 50, 604259) now - pastA #出力結果 #datetime.timedelta(days=7382, seconds=82358, microseconds=594717)※datetime.timedeltaにyears, monthsはない
足し算はエラー(※「+」はサポートしてない)
unsupported operand type(s) for +
5. datetime.timezone
自分でタイムゾーンを設定する場合に使用。
dt.timezone(dt.timedelta(hours=AAA), 'BBB')設定する値は2つ。
- AAA:基準からどれだけズラすか
- +/-0~24 ※24以下
- 24はエラー
- BBB:設定したタイムゾーンにつける名称
- 呼び出すときに引数で使う
▼設定方法
①イギリス(UCT。基準:+0時間) [≒GMT]
datetime.timezone(datetime.timedelta(0), 'UCT')②トロント(EDT。-4)
datetime.timezone(datetime.timedelta(-4), 'EST')③日本(JST。+9)
dt.timezone(dt.timedelta(hours=+9), 'JST')▼実際の使い方の例
トロントの時刻(EDT)を設定し、現在時刻を呼び出す。timezoneの使い方(トロントの時刻)EDT = dt.timezone(dt.timedelta(hours=-4),'EDT') EDT #出力:datetime.timezone(datetime.timedelta(days=-1, seconds=72000), 'EDT') dt.datetime.now(EDT) #出力結果 # datetime.datetime(2020, 3, 18, 10, 34, 8, 685415, tzinfo=datetime.timezone(datetime.timedelta(days=-1, seconds=72000), 'EDT'))
■補足:UTCとGMTの違い①UTC:協定世界時間(Coordinated Universal Time)
└ 現在の世界標準時間
└ セシウム原子の振動数から算出②GMT:グリニッジ標準時間(Greenwich Mean Time)
└ 過去の標準時間
└ グリニッジ天文台の計測結果から算出
└ グリニッジはロンドンのすぐ南の都市
- どちらも大して変わらない(UTC≒GMT)
- イギリスの時間
- イギリスが基準:hours=±0
6. datetime.tzinfo
タイムゾーンや夏時間など、カスタマイズ可能な時刻修正の概念を提供する(とのこと)。
- 投稿日:2020-03-18T23:42:34+09:00
Spotify APIを使ってアプリケーションを作ろう
はじめに
サブスクリプションモデル系はデータが豊富になりやすい(使い放題だから使う)と思っています。
私の場合は最近、音楽をものすごく聞くため、Spotify APIを使用すると面白いかなと思いました。なので、今回はSpotify APIを使用して何かアプリケーションを作ってみます。
アプリケーションを登録しよう
https://developer.spotify.com/dashboard/
ここから登録可能です。
すでにアカウントがあればそれでログインすればすぐ使えるようになります。登録中に商用利用するかというのも聞かれますので、正確に答えましょう。
アプリケーションを作成したら、EDIT SETTINGSからOAuthの情報を入力可能となります。
Webだったりスマホだったり色々と選択肢があります。
自分に合ったものを登録しましょう。今回は後述しますが、厳密にWebサービスから叩くわけではないため、適当なURLを設定しています。
認証周りを作る
https://developer.spotify.com/documentation/general/guides/authorization-guide/
詳しくは上記に記載があります。
今回はWebアプリケーションとして作成しますが、実態としてはGoogle Cloud Functionsから実行するため、Refresh Tokenが必要となります。
Spotifyの仕様上、Access Tokenは1時間、Refresh Tokenは何かしら無効化するまで有効であり続けるとなっています。
なので、今回はアプリケーション作成前にRefresh Tokenを手で作って、コード上でAccess Tokenへ変換 -> SpotifyのAPIを叩くという手順を取ります。1. code取得
まずはcodeの取得を行うためのURLを生成します。
詳細は省きますが、最終的に以下のようなURLになります。
client_idとredirect_uriは環境に合わせてください。また、Spotify APIはscopeがとても細かく区切られています。
下記に記載されていますので、必要なscopeを指定するようにする必要があります。
https://developer.spotify.com/documentation/general/guides/scopes/https://accounts.spotify.com/authorize?client_id=${CLIENT_ID}&response_type=code&redirect_uri=${REDIRECT_URL}&scope=user-read-private%20user-read-email&state=34fFs29kd09出来上がったら適当なブラウザに貼り付けてEnter押すと設定したredirect_uriに帰ってきます。
ここでエラーになっていても特に問題はありません。
URL自体は変わっているため、そのURLからcodeの部分だけを次で使用します。2. Refresh Tokenの取得
次はPOSTを投げないといけません。
なので、curlで投げます。
具体的には下記コマンドを取れたcodeと環境に合わせたclient_id、client_secretを設定して投げます。
問題なければトークンが返ってきますので、Refresh Tokenを保持しておきます。curl --data "code=${CODE}" --data "client_id=${CLIENT_ID}" --data "client_secret=${CLIENT_SECRET}" --data "redirect_uri=http://localhost/callback" --data "grant_type=authorization_code" https://accounts.spotify.com/api/tokenfrom Refresh Token to Access Token
Refresh TokenからAccess Tokenへの変換はAPI叩けば一発です。
その際はHeaderにAuthorization: Basic <base64 encoded client_id:client_secret>を含めないといけなく、それを作るのが面倒くさいと思ったぐらいであとは簡単です。一応、自分が作ったpythonコードを貼っておきます。
from dotenv import load_dotenv import os import requests import base64 import json load_dotenv(verbose=True) client_id = os.environ.get("SPOTIFY_CLIENT_ID", default="") client_secret = os.environ.get("SPOTIFY_CLIENT_SECRET", default="") token = base64.b64encode((client_id + ":" + client_secret).encode("utf-8")).decode( "utf-8" ) headers = {"Authorization": "Basic " + token} data = { "refresh_token": os.environ.get("REFRESH_TOKEN"), "grant_type": "refresh_token", } response = requests.post( "https://accounts.spotify.com/api/token", data=data, headers=headers ) # noqa: E501 print(json.loads(response.text)["access_token"])APIコールする部分を作成する
APIコールは取れたAccess TokenをBearerに設定して投げるだけです。
下に自分が作ろうとしているランキングデータ生成についてのサンプルコードを載せます。header = {"Authorization": "Bearer " + access_token} data = { "limit": 50, "time_range": "short_term", } response = requests.get( "https://api.spotify.com/v1/me/top/tracks", params=data, headers=header )終わりに
ということでこれで無事Spotify API使ってアプリケーションが作れるようになりました。
Spotifyはどこに何があるかが分かりにくい反面、API仕様については細かく書かれています。
出来ることも意外と多いので、API作成の初歩としては中々良いサンプルとして使えるというのが感想です。ちなみに今作ってるのはTwitterに月に1回、前月の聞いてたランキングを投稿するというものです。
まだ投稿部分が出来ていないため、これから作ろうと思います。他のOAuthのAPIでも認証部分を手で作る手順は同じなので、応用効きます。
是非色んなAPIを叩いてみて色んなアプリケーションを作ってみてください。
ただし、公開するとAPI Limitをすぐ超えるので、その場合はきちんと認証部分をUIで出来るように作り込みましょう。
- 投稿日:2020-03-18T23:31:04+09:00
Click(Python) のサブコマンドをファイルを分割して実装する
Python の Click、結構便利で簡単に CLI ツールが作れて LGTM ですね(← 使い方あってる?)。
その Click を使ってサブコマンドを実装するときに、ファイルを分割して実装するのに少々苦戦したので、そのことについて適当な例を使って実装の流れを書いてみようと思う。
間違いの指摘や、ここもっとこうした方がいいよ等の助言がありましたら、コメント頂けると幸いです。ちなみに、サブコマンドを複数ファイルに分割して実装しようと思ったのは、「関心事は分離してそれぞれのファイルに分けた方が良いかなぁ」と思ったからである。
TL;DR
subcmd.py@click.command() def cmd(): passcmd.pyfrom subcmd import cmd as subcmd @click.group() def cmd(): pass cmd.add_command(subcmd)バージョン
- Python: 3.8.0
- Click: 7.0
サンプルとして実装するもの
良い例が思いつかなかったので、足し算と引き算ができる
calculateコマンドを作ってみようと思う。実行例$ calculate addition 4 3 7 $ calculate subtraction 4 3 1ディレクトリ構成
多少順番を変えたり省略したりしているが、下記のような感じである。
ご覧の様(?)に Pipenv を使っている(そろそろ Poetry か何かに乗り換えようかと思っているが、それはまた別のお話)。calculate ├─ calculate │ ├─ __init__.py │ ├─ __main__.py │ └─ cli │ ├─ __init__.py │ ├─ command.py │ ├─ addition │ │ ├─ __init__.py │ │ └─ command.py │ └─ subtraction │ ├─ __init__.py │ └─ command.py ├─ Pipfile ├─ Pipfile.lock └─ setup.py下準備
setup.py を書く
Pipenv を好んで使っている理由に、
pipenv install -de .を実行して仮想環境に開発中のツールを編集可能な状態でインストールすることができる点がある(他のパッケージ管理ツールでもできるのかな?)。
そうすることで、仮想環境をアクティベートしたときにコマンドを実行できる。コマンドを実行するためのエントリーポイントを setup.py に記述する。
下記の例では必要最低限しか記述していない。setup.pyfrom setuptools import find_packages, setup setup( name="calculate", version="0.0.1", # 適当 entry_points={ "console_scripts": ["calculate=calculate.__main__:main"], } )パッケージをインストールする
$ pipenv install click $ pipenv install -de .コマンドの実装
では、順番に実装を進めていこうと思う。
まずはエントリーポイントを用意する。__main__.pydef main(): # TODO: コマンドを呼び出す pass # `python -m calculate` という形で呼び出されたときのことを考慮 if __name__ == "__main__": main()これで、
calculateコマンドを実行したときに、__main__.pyにあるmain関数が呼び出される。
今はまだコマンドを実装していないので、main関数の中身は空っぽにしておく。次に
main関数で呼び出す最初のコマンドを実装する。cli.commnad.pyimport click @click.group() def cmd(): pass
@click.group()でデコレートすることで、cmdに対してサブコマンドを追加できるようになる。
calculateコマンドに相当する関数が実装できたので、先ほどの__main__.pyのmain関数から呼び出すようにする。__main__.pyfrom .cli.command import cmd def main(): cmd() # `python -m calculate` という形で呼び出されたときのことを考慮 if __name__ == "__main__": main()これで実行してみると、さも CLI ツールのような出力が得られる。
$ calculate Usage: calculate [OPTIONS] COMMAND [ARGS]... Options: --help Show this message and exit.やったね?
おっと、まだ目的は達成していなかった。サブコマンドの実装
CLI ツールとしての基盤(?)が出来上がったので、次に足し算サブコマンドを実装していく。
cli.addition.command.pyimport click @click.command(name="addition") @click.argument("augend", type=click.INT) @click.argument("addend", type=click.INT) def cmd(augend, addend): click.echo(augend + addend)
@click.commandにnameを渡しているが、こうすることでコマンドに任意の名前を付けることができる。
@click.argumentではtypeを渡すことで、バリデーションチェックを行ってくれるようになる。
click.echoで結果を出力している。
ちなみに、augend は足される数、 addend は足す数、という意味である(TDD 本で知った)。これで、足し算サブコマンドが実装できたので、
calculateコマンドに追加してみる。cli.command.pyimport click from .addition.command import cmd as addition_cmd @click.group() def cmd(): pass cmd.add_command(addition_cmd)グループにサブコマンドを追加するには、
add_commandメソッドを呼び出し、その引数にサブコマンドとして追加する関数を与えるだけである。
ここまで長々と書いてきたが、これだけである。
このメソッドを見つけるまでにとても時間がかかった。。。引き算サブコマンドの実装も同様である。
コマンドを実装して、cli.subtraction.command.pyimport click @click.command(name="subtraction") @click.argument("minuend", type=click.INT) @click.argument("subtrahend", type=click.INT) def cmd(minuend, subtrahend): click.echo(minuend - subtrahend)
add_commandで追加する。cli.command.pyimport click from .addition.command import cmd as addition_cmd from .subtraction.command import cmd as subtraction_cmd @click.group() def cmd(): pass cmd.add_command(addition_cmd) cmd.add_command(subtraction_cmd)これで実行してみると、足し算、引き算の結果が得られる。
$ calculate Usage: calculate [OPTIONS] COMMAND [ARGS]... Options: --help Show this message and exit. Commands: addition subtraction $ calculate addition 4 3 7 $ calculate subtraction 4 3 1今度こそ、やったね??
余談
@click.command(name=<another_name>)のnameには、記号も与えることができるみたい。
なので、四則演算を実装した場合、次のように書ける。$ calculate + 4 3 $ calculate - 4 3 $ calculate "*" 4 3 $ calculate / 4 3
*はワイルドカードと認識されるので、クォーテーションで囲まないといけないし、/は問題なく動くがシェルによってはルートと認識して色がつく。
需要があるかわからないけど、ちょっと面白いなと思ったので載せておきます。
試してないけど、他の記号も色々使えるはず。まとめ
順番に実装の流れを書いていったので長くなったが、求めていた結果を得るために必要なものは、
add_commandだった。間違いの指摘や、ここもっとこうした方がいいよ等の助言がありましたら、コメント頂けると幸いです。
- 投稿日:2020-03-18T23:24:17+09:00
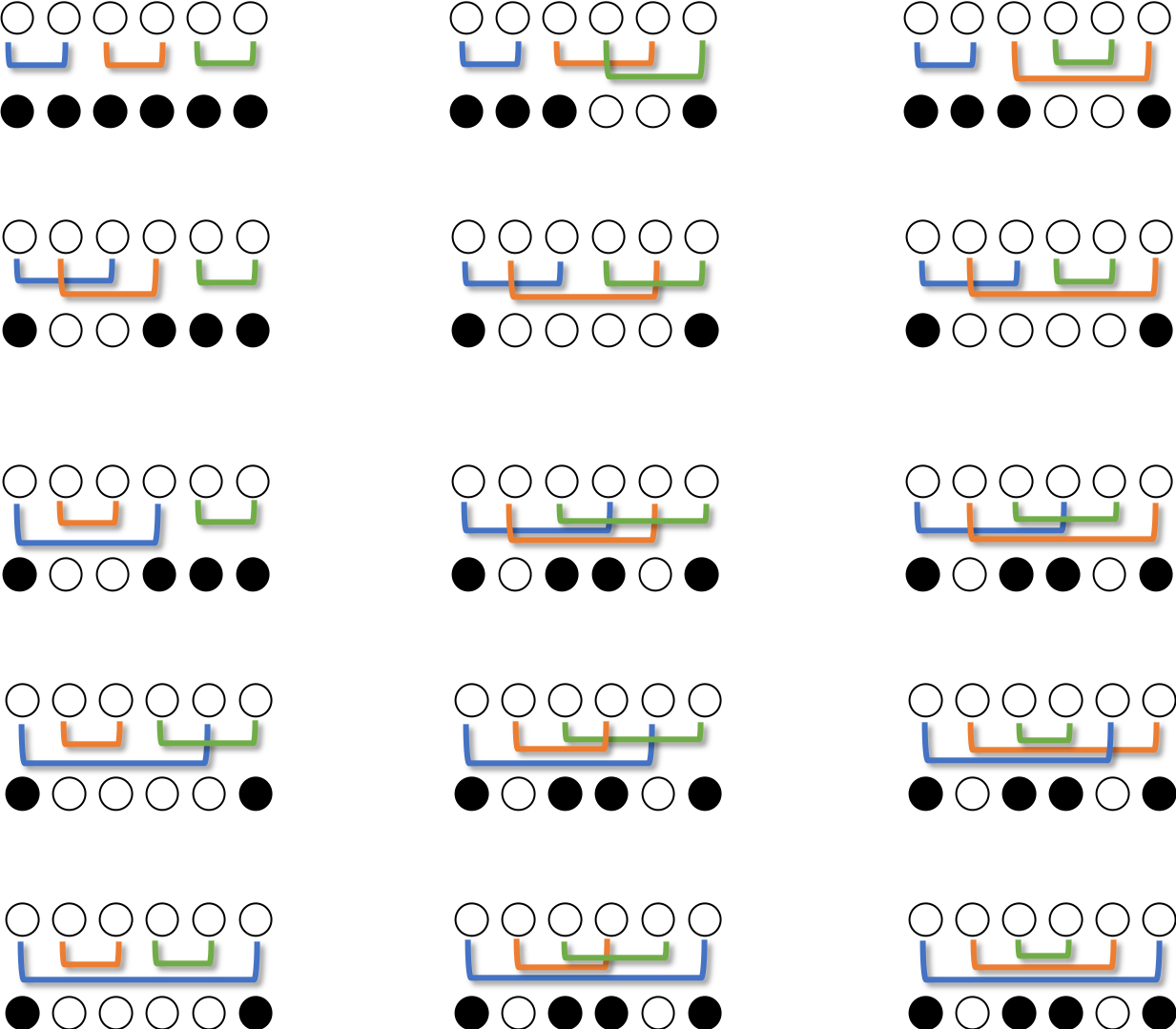
【競プロ】挟んだ部分をひっくり返して●○●●○○○●→○○○○○○○○にするアルゴリズム(JSC2019-C Cell Inversion)【図で解説】
もう数え上げも怖くない ~競プロ数え上げ問題35選~ - Qiitaの記事で紹介されていた問題のうち1つが面白そうだったので解いてみました。ちなみに問題を解きながら考えたことを含めて書いたため、最短で解にたどり着いていません。最短&最良の解を見たい場合は問題文のページから模範解答がリンクされていますのでそちらをご覧ください。
問題
$2N$ 個のマスが左右一列に並んでおり、各マスの色を表す長さ $2N$ の文字列 $S$ が与えられます。
左から $i$ 番目のマスの色は、 $S$ の $i$ 文字目が'B'のとき黒色で'W'のとき白色です。
あなたは異なる $2$ マスを選んで、それらのマスおよびそれらの間にあるマスの色を反転する操作をちょうど $N$ 回行います。 ここで、マスの色を反転するとは、そのマスの色が黒色なら白色に、白色なら黒色にすることです。
ただし、操作を通して同じマスを $2$ 回以上選ぶことはできません。 つまり、各マスがちょうど $1$ 回ずつ選ばれることになります。
$N$ 回の操作終了後に全てのマスを白色にする方法が何通りあるかを $10^9+7$ で割った余りを求めてください。
ここで、条件を満たす $2$ つの方法が異なるとは、$1$ つ目の方法で $i$ 番目に選んだ $2$ つのマスの組と
$2$ つ目の方法で $i$ 番目に選んだ $2$ つのマスの組が異なるような $i (1\leq i \leq N)$ が存在することをいいます。ちょっとさわってみよう
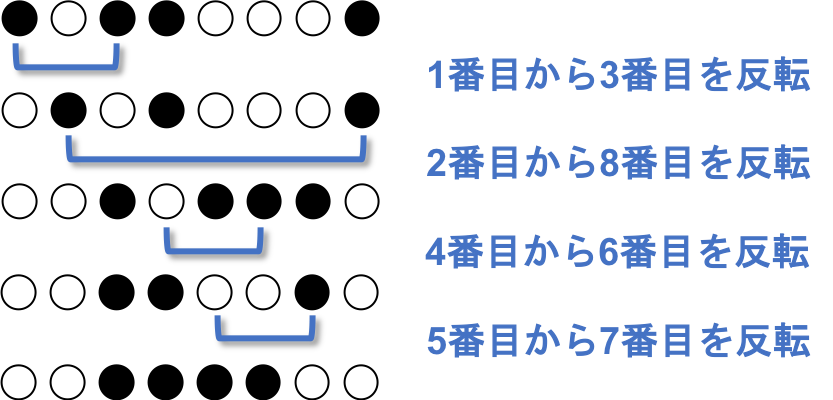
Bを●または黒、Wを○または白で表します。'反転'には'ひっくり返す'という言葉を使っています。オセロをイメージしてください。
問題文に、●○●●○○○● の例が載っているので、これを解いてみましょう。手始めに、手順にそってひっくり返してみましょう。
これは ○○○○○○○○ になりませんでした。
もう1回試してみましょう。
これは ○○○○○○○○ になりました。
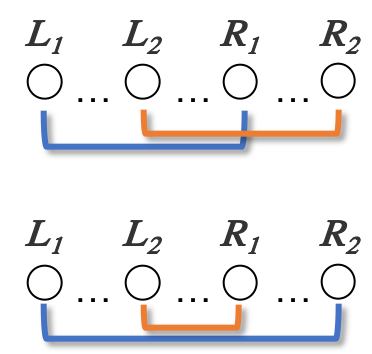
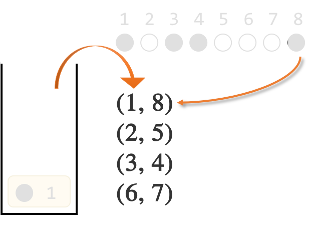
ひっくり返す手順を、ひっくり返す順に位置をペアにして記載しましょう。
上記の例では、$(2,8)(1,4)(6,7)(3,5)$ になります。このような、ひっくり返す順のペアを並べたものを反転列と呼びましょう。ひっくり返す順番は関係ない
いくつか試すと、ひっくり返すペアが同じであれば、ひっくり返す順番は最終的に出来上がるマスの模様に関係ないことがわかります。
例えば、$(2,8)(1,4)(6,7)(3,5)$ と $(1,4)(2,8)(3,5)(6,7)$ は同じ結果になります。
なお、以降マスの模様を白黒パターンと呼びます。
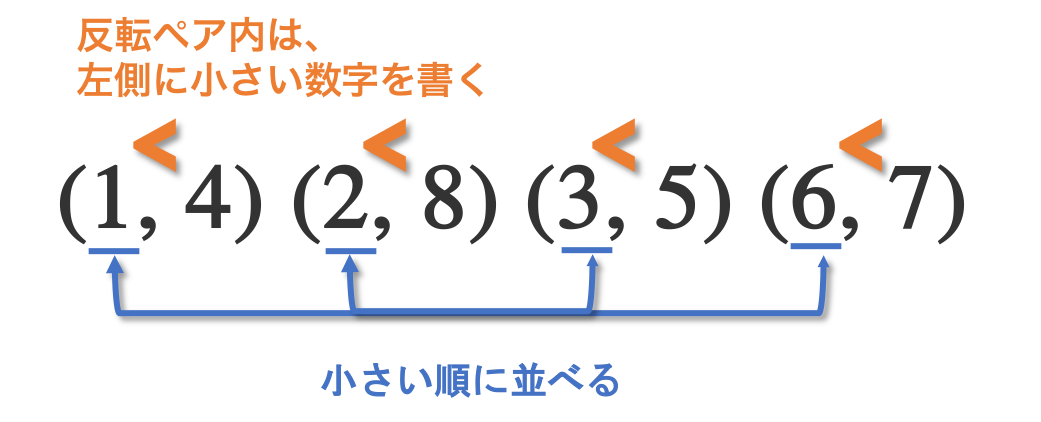
反転列を正規化する
反転列はペア同士を入れ替えても最終的に出来上がる模様(白黒パターン)は同じなので、規則を決めて一意に定まるようにします。この操作を反転列の正規化と呼びましょう。
- 小さい方の数字を左に書く
- 左側の数字が小さい順にペアを並べる
$(2,8)(1,4)(6,7)(3,5)$ を上記の規則に則って並べると、$(1,4)(2,8)(3,5)(6,7)$ です。
また、正規化された反転列の左側だけを抜き出したもの(今回だと $\{1,2,3,6\}$ )を左反転列と呼びましょう。
逆に考えてみる
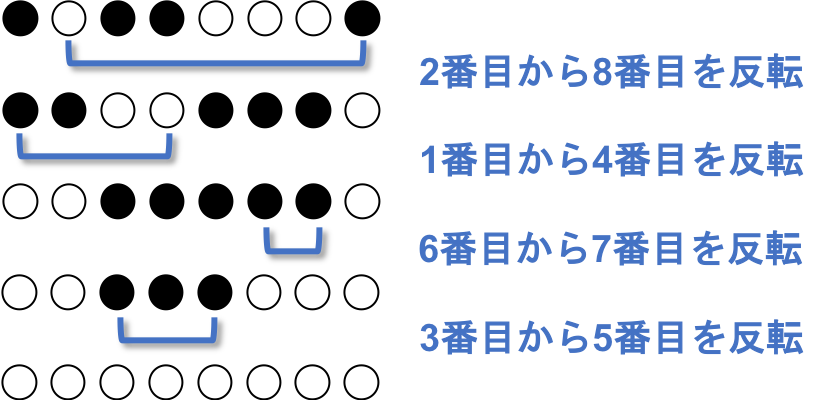
さて、まだどのようにひっくり返せば ●○●●○○○● を全て白にできるのか見当がつきません。
そこで、 全て白のマス( ○○○○○○○○ )を手順にそってひっくり返すとどのようになるのかを、$N$ が小さい範囲で確かめます。
●○●●○○○● を ○○○○○○○○ にすることと、 ○○○○○○○○ を ●○●●○○○● にするのは互いに逆の関係にあります。
○○○○○○○○ を ●○●●○○○● にした後、同じ反転列でひっくり返すと ○○○○○○○○ に戻るからです。N=1
$N=1$のとき、1通りのひっくり返し方があります。
N=2
$N=2$のときは、3通りのひっくり返し方がありますが、白黒パターンは2種類です。
N=3
$N=3$のときは、15通りのひっくり返し方があり、白黒パターンは5種類です。
規則の発見
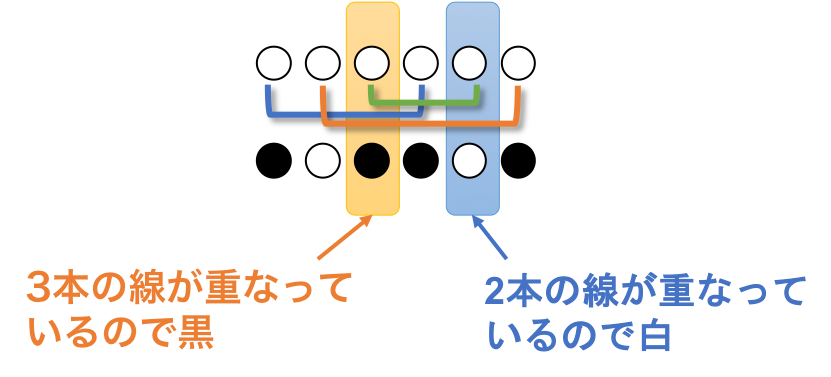
ここまででいくつか発見があるので、まとめてみましょう。
最終的に白か黒かは下に引かれている線の数によって決まる
マスの下にある(もしくは自分自身からのびている)線の回数ひっくり返されるので、線の数によって最終的にマスが白になるか黒になるか決まります。
線の数が偶数のとき白、奇数のとき黒になります。
白黒パターンの両端は黒
両端は自身を選択した際にひっくり返され、他のマスに挟まれないので黒です。
クラスタに分かれたとき、各クラスタの両端は黒
クラスタに分かれる、というのは、以下のように全くある区間内で反転が完了している状態です。
クラスタに分かれたとき、各クラスタの両端は黒です。
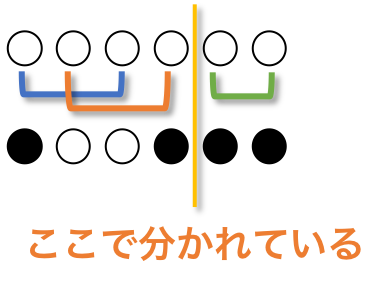
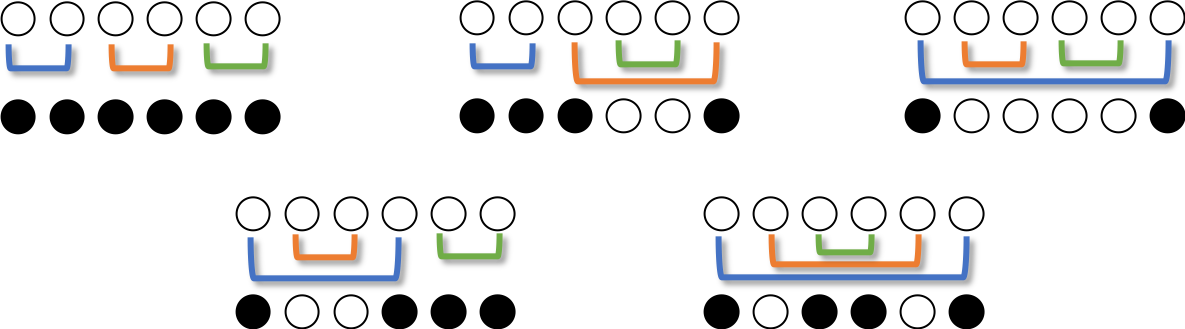
各パターンの反転列を見ると、左反転列の数字が共通
$N=3$ で、白黒パターンごとの入れ替え列をまとめます。
白黒パターンごとに反転列をまとめると、白黒パターンごとに反転列の左右が同じことに気づきます。例えば、○○○○○○ を ●○○○○● にする反転列には、ペアの左側に$\{1,2,4\}$が現れ、右側に$\{3,5,6\}$が現れます。
重なり合う(L1, R1)(L2, R2)を(L1, R2)(L2, R1)に入れ替えても結果は同じ
下の2つの反転列 $(L_1, R_1)(L_2, R_2)$ と $(L_1, R_2)(L_2, R_1)$ の白黒パターンは同じです。マスの下の線の数が変わらないためです。
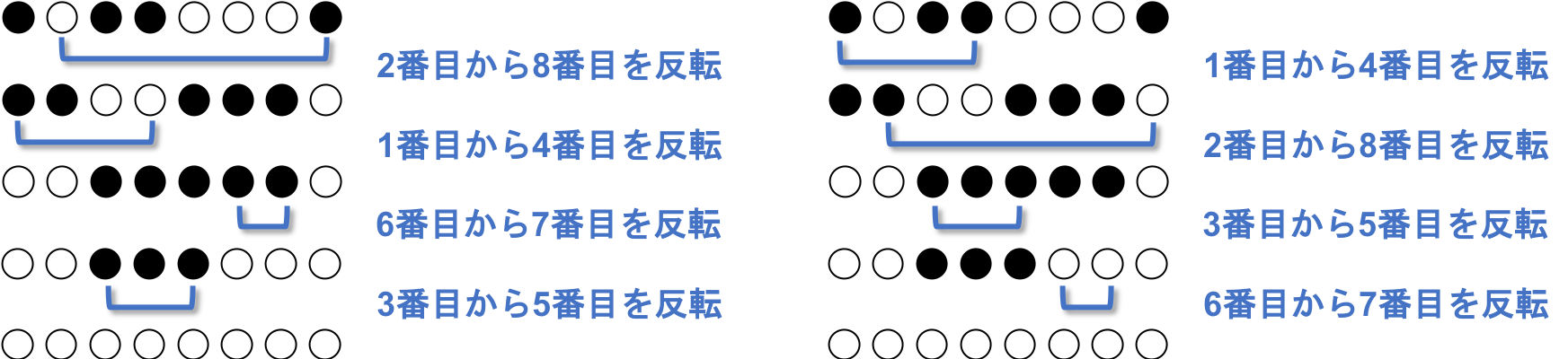
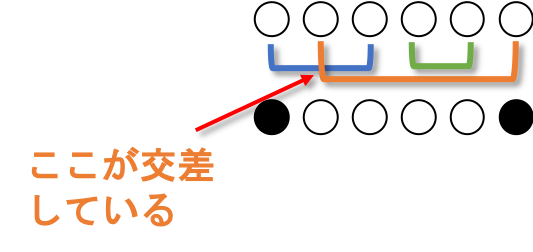
互いに線が交差しない反転列が各白黒パターンに1つだけ存在する
線が交差する、とは以下の状況を指します。
ひっくり返すペア同士を線で結んだ時、白黒パターンごとに1つだけ線が交差しない反転列があります。
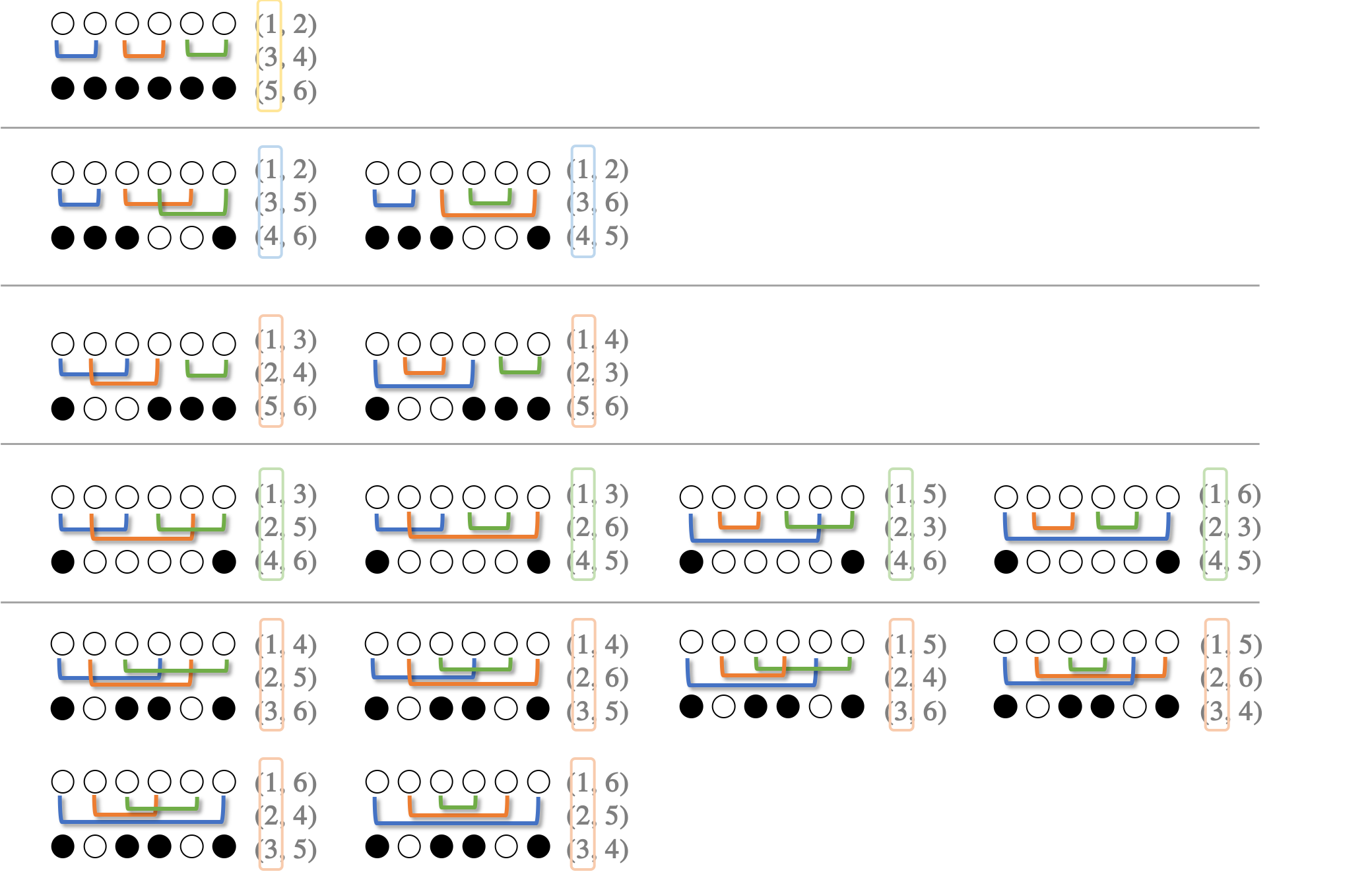
$N=3$ の場合はそれぞれこの反転列です。
互いに線が交差しない反転列を無交差反転列と呼びましょう。
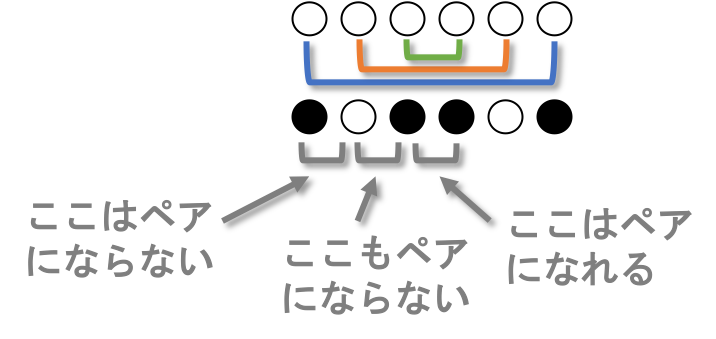
無交差反転列において、反転のペアは同じ色になる
無交差反転列において、線が繋がっているもの同士は操作終了後同じ色になります。互いに線が交差しない入れ替え列において、ひっくり返すペアは、それ以外のペアに囲まれているか、離れているかのどちらかなので、同時にひっくり返るか同時にひっくり返らないかのどちらかだからです。
隣同士のペアを見つける
無交差反転列では、値が隣同士のペアが少なくとも1つあります。そのペアは白黒パターンでは同じ色になっています。
マスを左から見ていくときに、色が違う場合は隣同士のペアではありません。
スタックに入れてペアを見つけよう
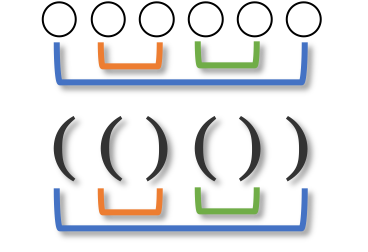
無交差反転列一覧をぼんやり眺めていると、数式のカッコの対応のように見えてきました。
このような対応関係を作成する場合はスタックを使います。
まずは隣同士のペアを見つけましょう。隣同士なので値が連続します。連続した色が見つかるまではスタックに積み上げていきましょう。
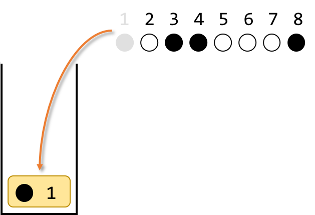
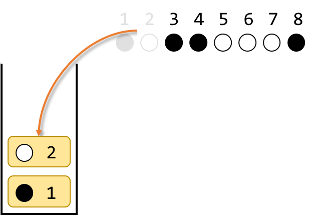
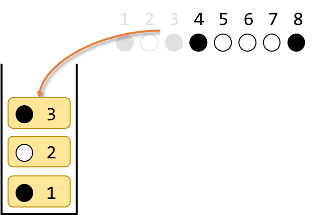
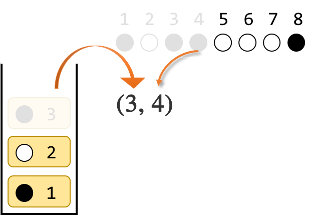
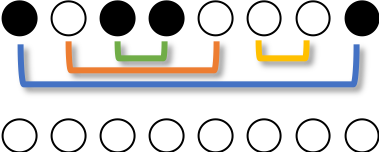
●○●●○○○● を例に考えます。
初期状態です。
1番目の●をスタックに入れます。
2番目の○は1番目と違う色なのでスタックに入れます。
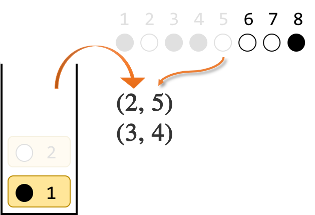
3番目の●は2番目と違う色なのでスタックに入れます。
4番目の●はスタックの一番上と同じ色なので、スタックの一番上を取り出し、4番目とペアにします。
5番目の○はスタックの一番上と同じ色なので、スタックの一番上を取り出し、5番目とペアにします。
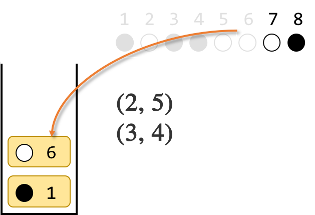
6番目の○はスタックの一番上と違う色なので、スタックに入れます。
7番目の○はスタックの一番上と同じ色なので、スタックの一番上を取り出し、7番目とペアにします。
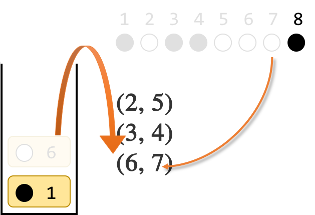
最後に、8番目の●はスタックの一番上と同じ色なので、スタックの一番上を取り出し、8番目とペアにします。
ここまでで ●○●●○○○● を ○○○○○○○○ にするには$(1,8)(2,5)(3,4)(6,7)$が1つの解であることがわかりました。実際に確かめて見ると、確かに全て白になります。
例外ケースの対応
上記は反転列が存在するケースですが、ここで例外もみておきます。
スタックの一番下が白
両端は黒でないと、全て白にすることができません。これを言い換えると、スタックに入れる時、一番下は黒でなければならない、となります。一番下に白が入るような入力が与えられた場合、全てのマスを白色にする方法は $0$ 通りです。
最後までマスを読んだときにスタックが空でない
最後までマスを読んだときにスタックが空でない場合は、与えられたパターンになる組み合わせは存在しません。この場合は全てのマスを白色にする方法は $0$ 通りです。
(L1, R1)(L2, R2)を(L1, R2)(L2, R1)に入れ替える場合の数
$(L_1, R_1)(L_2, R_2)$ を $(L_1, R_2)(L_2, R_1)$ に入れ替えても結果は同じです。$(1,8)(2,5)(3,4)(6,7)$ に対して、このような入れ替えが何パターンあるか考えます。
$(1, R_1)(2, R_2)(3,R_3 )(6, R_4)$
の $R_1$ から $R_4$ の部分に$\{4, 5, 7, 8\}$ を入れますが、 $L_i < R_i$ の制約があるので、$R_4$ から考えていきましょう。
$R_4$ : $7$ か $8$
$R_3$ : $4$, $5$, $7$, $8$ のうち1つ (ただし $R_4$ で使用した数字は含まない)
$R_2$ : $4$, $5$, $7$, $8$ (ただし $R_4$, $R_3$ で使用した数字は含まない)
$R_1$ : 残った数字1つこれを計算すると、$2 \times 3 \times 2 = 12 通り$ です。
ひっくり返す順番の数を掛ける
ここまで、反転列は正規化されていますが、ひっくり返す順番は区別するので、$N!$を掛けます。
$ 12 \times 4! = 288 $
10000000007で割る
最後に、求めた数を $10^9+7$ で割ります。実際のプログラミングでは上記の組み合わせを計算する過程で$10^9+7$で適宜割り、桁があふれないように工夫します。
参考 : 「1000000007 で割ったあまり」の求め方を総特集! 〜 逆元から離散対数まで 〜 - Qiita
$ 288 \bmod (10^9+7) = 288$
答えの 288 が導かれました。
スタックは無くても解ける
今回はスタックを使用しましたが、スタックが無くても解けます。詳しくは本家の解説をご覧ください。
ソースコード
上記アルゴリズム(を改善したもの)をPython(バージョン3.7)で実装しました。($10^9+7$で割る前まで実装してあります。なので$N$が小さい範囲しか扱えません)
さらなる課題
$N$ 毎に、現れる白黒パターンは、
$N=1$ で $1$種類
$N=2$ で $2$種類
$N=3$ で $5$種類
あることがわかりました。$N=6, 7, 8$と数を大きくしていくとどうなるでしょうか?あとがき
ざっと書いてみましたが、問題を本格的に考え始めてからアルゴリズムを思いつくまで3日かかりました。(最後ちょっとわからない部分があったので解説を見ました。)本家の解説よりだいぶ遠回りして解いていますが、そのぶん色んな発見があって楽しかったです。
コンテスト参加者はこんな問題をぱっと見で解いてるのかと思うと、末恐ろしいという浅い感想しか出てきません。




- 投稿日:2020-03-18T23:14:49+09:00
Python スクレピング 競馬サイトから出走馬の過去成績を取得
背景
現在、競馬×機械学習のために、
ウェブページから競馬情報をスクレイピングすることに取り組んでいます。入力内容に出走馬の過去の成績を組み込もうとしています。
そこで競馬のレース結果表から出走馬のページのURLを取得、アクセスし、
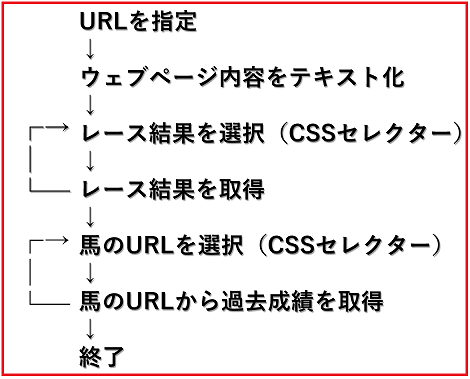
出走日の過去の成績を取得することにした。構想
サンプルコード
アイデアは以下の3点。
・取得方法をCSSセレクターで統一
・レース結果表から各馬のURLを取得し、そのURLに掲載されている過去成績を取得
・今回の出走馬は12頭だが、他の馬数でも取得できるように可変長変数を使用この記事の前に、Python スクレピング 競馬サイトからレース環境を抽出を紹介させていただきました。
こちらはレース環境をBeautifulSoupを使いました。
しかしcssセレクターで統一して処理したほうが気持ちがいいので書き換えました。scraping_of_race_and_past_horse_result.pyimport requests import lxml.html import csv rlt = [] #結果 horse_URL = []#馬の名前を取得する #スキャルピングでテキスト取得 def get_scarping_data(key_page,css_select_str,*URL): #取得したURLの個数分の情報を取得する for i in range(len(URL)): #URLから文字列を取得 r = requests.get(URL[i])#URLを指定 r.encoding = r.apparent_encoding #文字化けを防止 html = lxml.html.fromstring(r.text) #取得した文字列データ # 項目を取得 for css_id in html.cssselect(css_select_str): #レース結果サイトのレース環境 if key_page == "condition_in_race_page" : #Element番号のテキスト css_id = css_id.text_content() #内包表記 抽出する際に"天気"は不変であるので条件指定 css_id_ = [css_id for t in css_id if "天気" in css_id] css_id_ = css_id_[0].split('\xa0/\xa0') #リストに行のデータ(リストを追加) rlt.append(css_id_) #レース結果サイトのレース結果 if key_page == "result_in_race_page" : #Element番号のテキスト css_id = css_id.text_content() #改行("\n")をもとに分割する css_id = css_id.split("\n") #内包表記 空の要素を駆逐する 空文字を除く css_id_ = [tag for tag in css_id if tag != ''] #1位はタイム記録なし #強引に加える必要がある 8番目に0 if len(css_id_) != 13 : css_id_.insert(8,0) #リストに行のデータ(リストを追加) rlt.append(css_id_) #レースした馬の過去成績サイト if key_page == "horse_race_data" : #Element番号のテキスト css_id = css_id.text_content() #取得したElement番号の css_id = css_id.split("\n") #内包表記 空と"\xa0"と"映像"を除去 css_id_ = [tag for tag in css_id if tag != '' and tag != "\xa0" and tag != "映像" and tag != "厩舎コメント" and tag != "備考" ] #リストに行のデータ(リストを追加) rlt.append(css_id_) #抽出結果 return rlt #レースした馬のURLを取得 def get_scarping_past_horse_date(URL): response = requests.get(URL) root = lxml.html.fromstring(response.content) #1~12までの馬の情報を取得 for i in range(2,14):#2~13 13 - 2 + 1 = 12 css_select_str = "div#race_main tr:nth-child({}) > td:nth-child(4) > a".format(i) #レースした馬の情報を取得 for a in root.cssselect(css_select_str): horse_URL.append(a.get('href')) #抽出結果 return horse_URL #まず本家のレースサイトからレース環境を取得 URL = "https://nar.netkeiba.com/?pid=race&id=p201942100701" #レース環境を取得 rlt = get_scarping_data("condition_in_race_page","div#main span",URL) #レース結果を取得 rlt = get_scarping_data("result_in_race_page","#race_main > div > table > tr",URL) #レースした馬のURLを取得 horse_URL = get_scarping_past_horse_date(URL) print(len(horse_URL))#出走馬12に対し、出力結果は12 #取得した馬のURLから過去成績を取得 #項目(1行分)を取得 rlt = get_scarping_data("horse_race_data", "#contents > div.db_main_race.fc > div > table > thead > tr",horse_URL[0]) #項目以外の成績データ rlt = get_scarping_data("horse_race_data", "#contents > div.db_main_race.fc > div > table > tbody > tr",*horse_URL) #CSVファイルに保存 with open("scraping_of_race_and_past_horse_result.csv", 'w', newline='') as f: wrt = csv.writer(f) wrt.writerows(rlt) #抽出結果の書き込み実行結果
反省点
・レース結果から馬の情報が掲載されているURLを取得し、過去成績も取得できた。
・過去成績を取得できたが最新の情報も掲載されているので、レースした日を基準に遡った成績を取得する必要がある。
・取得できた情報をニューラルネットワークに入力できるレベルまで行っていない。
・レースした日を自動で取得する。毎回調べない
→方法として、レース情報数値(URLの末端の12桁)を規則性を考慮してインクリメント。CSSセレクタの調べ方
スクレイピングするうえで、以下のコード(文字列)を使いこなす必要がある。
(#contents > div.db_main_race.fc > div > table > tbody > tr')
↑ここの部分をどのようにして取得するのかをまとめる。how_to_search_css_sector.pyfor h in html.cssselect('#contents > div.db_main_race.fc > div > table > tbody > tr'):#スクレイピング箇所をCSSセレクタで指定初めはただコピペしたり、そっれっぽいコードを書いてトライしたが、うまく行かない。。。
調べてみるとCSSが絡んでいる。
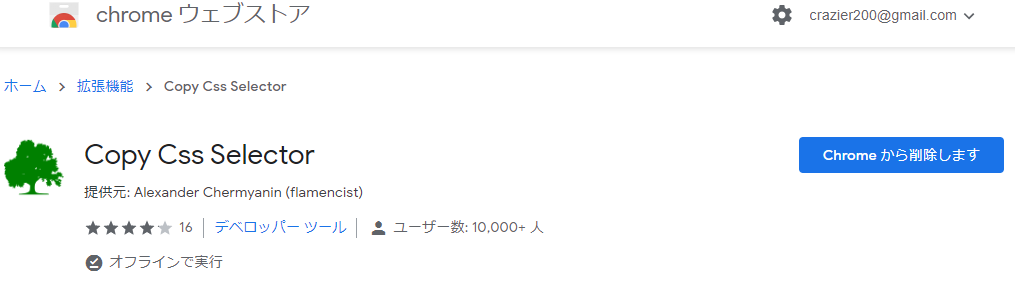
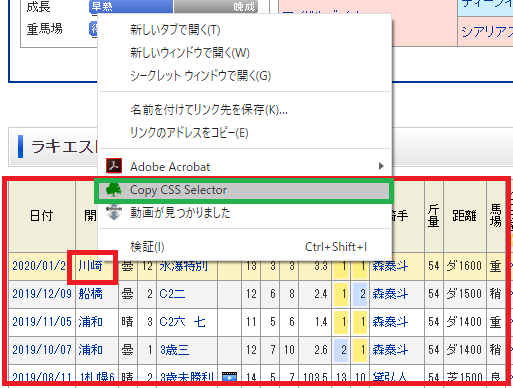
欲しい項目はどのCSSセレクターで構成されたいるかを知るために、
ChromeのCopy Css Selectorのツールを使う。
インストールすると右クリックでCopy Css Selectorの項目ができる。
欲しい項目でCopy Css Selectorを実行し、テキストに張り付けて確認するとCSSセレクターを知ることができる。
※うまくいかないこともあるかもしれない。
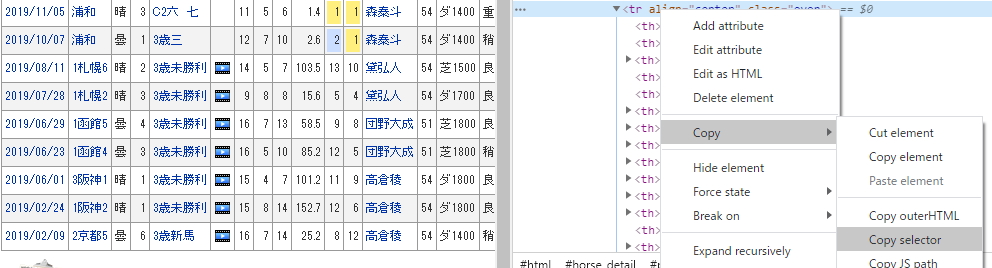
他にもディベロッパー ツールを用いて、
欲しい情報範囲で Copy → Copy Selector でCCSセクターをコピーできる。
たまにうまくいきます。
この2つを駆使すれば、SCCセレクターを取得できるはずです。

- 投稿日:2020-03-18T23:06:03+09:00
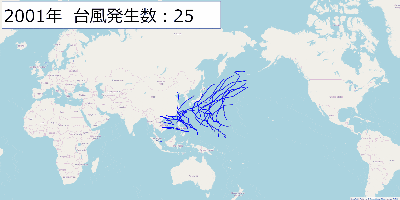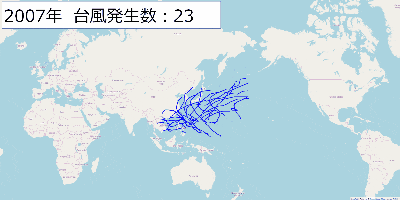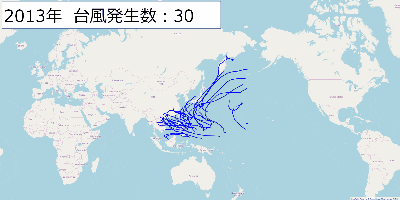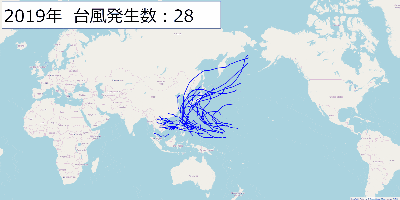
[Python]台風の経路をfoliumを使って地図上に書いてみた
記事の内容
子供の頃に台風ってこんなに頻繁に発生してたっけ?とか10月ぐらいに台風って日本に来てたっけ?という漠然とした疑問がありました。
気象庁が公開している台風に関するデータを使ってこのあたりの疑問を解決出来たらないいなと思い、色々やってみました。データ取得元
政府が運営しているデータカタログサイトから取得しました。
気象予報_天気予報・台風の資料
このページの「台風位置表のCSVデータ」を使用します。この記事ではリンク先に掲載されている2001年から2019年までのCSVデータを使用しました。
foliumを使って台風の経路を地図上に書いてみる
準備
CSVデータのヘッダーが日本語だったので英語に変えました。だいぶ適当です
year,month,day,hour(UTC),typhoon_no,typhoon_name,rank,latitude,longitude,central_pressure,max_wind_speed,50KT_LDD,50KT_LD,50KT_MA,30KT_LDD,30KT_LD,30KT_MA,landingコード
あまり、工夫したところはありません
typhoon_plot.pyimport folium import pandas as pd pd.options.display.precision = 3 # 開始と終了の年 start_year = 2001 end_year = 2019 # 1年単位で処理する for year in range(start_year, end_year+1): print('# ' + str(year) + ' year start') # データの読み込み df = pd.read_csv('./typhoon/table' + str(year) + '.csv',encoding="SHIFT-JIS") typhoon_names = list(df['typhoon_name']) latitude = list(df["latitude"]) longitude = list(df["longitude"]) landing = list(df["landing"]) map = folium.Map(location=[35.6611098,139.6953576], zoom_start=3) target_typhoon = typhoon_names[0] target_location = [] color = 'blue' typhoon_count = 0 # CSVデータを1行ずつ処理する for lt, lo, name, land in zip(latitude, longitude, typhoon_names, landing): # 台風の名前が変わったら処理中の台風の情報を地図に書く if name != target_typhoon: map.add_child(folium.PolyLine(locations=target_location, color=color)) target_location = [[float(lt), float(lo)]] target_typhoon = name typhoon_count += 1 else: target_location.append([float(lt), float(lo)]) map.add_child(folium.PolyLine(locations=target_location, color=color)) map.save('./output/' + str(year) + '_typhoon_location.html') print('# Number of typhoon : ' + str(typhoon_count)) print('# ' + str(year) + ' year end')出力結果
出力結果は年毎に「output」フォルダの配下に出力しています。
出力したHTMLを開くとこんな感じになります。
出力結果の画像を2001年から2019年まで表示するGIFを作ってみました。
日本に上陸した台風は線の色を変えてみる
やはり、日本に上陸した台風は目立たせたいですよね。
データの最終項目に「上陸」という項目がありました。上陸していたら1、していなかったら0です。
このデータを使って色分けをします。注意しないといけないのが、この「上陸」は「日本に」ではありません。
そのため、日本かどうかの判定を入れる必要がありました。コード
typhoon_plot.pyimport folium import pandas as pd pd.options.display.precision = 3 # 開始と終了の年 start_year = 2001 end_year = 2019 # 日本の東西南北の端の座標 east_end = 153.5911 west_end = 122.5601 north_end = 45.3326 south_end = 20.2531 def is_japan_randing(lt, lo, randing): if south_end <= lt and lt <= north_end and west_end <= lo and lo <= east_end and randing == 1: return True else: return False # 1年単位で処理する for year in range(start_year, end_year+1): print('# ' + str(year) + ' year start') # データの読み込み df = pd.read_csv('./typhoon/table' + str(year) + '.csv',encoding="SHIFT-JIS") typhoon_names = list(df['typhoon_name']) latitude = list(df["latitude"]) longitude = list(df["longitude"]) landing = list(df["landing"]) map = folium.Map(location=[35.6611098,139.6953576], zoom_start=3) target_typhoon = typhoon_names[0] target_location = [] typhoon_count = 0 color = 'blue' # CSVデータを1行ずつ処理する for lt, lo, name, land in zip(latitude, longitude, typhoon_names, landing): # 台風の名前が変わったら処理中の台風の情報を地図に書く if name != target_typhoon: map.add_child(folium.PolyLine(locations=target_location, color=color)) target_location = [[float(lt), float(lo)]] target_typhoon = name typhoon_count += 1 color = 'blue' else: target_location.append([float(lt), float(lo)]) if is_japan_randing(lt, lo, land): color = 'red' map.add_child(folium.PolyLine(locations=target_location, color=color)) map.save('./output/' + str(year) + '_typhoon_location.html') print('# Number of typhoon : ' + str(typhoon_count)) print('# ' + str(year) + ' year end')「is_japan_randing」の中で日本国内の判定をしています。
凄く雑な気がしますが、緯度が日本の最北端、最南端の範囲か?経度が最西端、最東端の範囲か?を判定しています。結果
日本上陸している線だけが赤くなりました。
九州や本州にかなり近づいている線がありますね。以下、お天気.comの引用です。台風の上陸とは台風の中心が北海道、本州、九州、四国の海岸に達した場合を言います。 (沖縄は台風の上陸とは言わず、通過と言う。) 台風の接近とは半径300km以内に入る事を言います。
こう考えると、この線は中心の座標なんだということが改めて分かりますね。
終わりに
近年こんなに台風って日本に上陸してたっけ?という疑問からこれをやってみましたが、上陸数とかは2001年以降だとあまり変わってないようですね。
次は台風の規模も可視化してみようと思います。

- 投稿日:2020-03-18T23:03:14+09:00
Databricks
Databricks とは、大量のデータを並列に処理するアプリを作るためのサービスだ。Apache Spark の開発者によって Apache Spark のマネージド・サービスとして開発された。ここ数日勉強しているが特に引っかかった点を書く。
一言でいうと Apache Spark とは、表形式のデータを加工するコードを自動的に並列処理に変換して並列で実行してくれるという物だ。開発者があたかも Jupyter 上の Pandas でコードを書いているような気分で巨大データを並列に加工出来る。機械学習関のライブラリも含まれているので、データの前処理から分析や予測まですべて Spark で行う事が出来る。
また、前身の(?) Hadoop との違いは、ストレージを切り離した所にある。Spark はデータ処理に特化してする事で様々な他のストレージと組み合わせて使えるようになった。
主な情報源
- Databricks ドキュメント: https://docs.databricks.com/
- 参考書: Spark: The Definitive Guide http://shop.oreilly.com/product/0636920034957.do
- Apache Spark についての本だが、勉強のお勧めは Databricks Community Edition を使う事とある
以下に Databricks で分かりにくい事があったので記録する。
CLI
分かりにくくは無いが CLI が無いとかなり面倒なのでインストールは必須。インストールには pip3 を使う。
databricks configureで接続情報を設定すると使えるようになる。# 設定 $ pip3 install databricks-cli $ databricks configure --token Databricks Host (should begin with https://): https://hogehoge.cloud.databricks.com/ Token: (GUI で作った token を入力) # 動作確認 $ databricks fs ls
databricksコマンドには様々なサブコマンドがあるが、databricks fsには最初から短縮形としてdbfsが用意されている。Secret
パスワードなどは scope ごとに Secret に保存する。
scope 作成
databricks secrets create-scope --scope astro_snowflakescope 表示
databricks secrets list-scopesscope に secrets 追加
databricks secrets put --scope hoge_scope --key User databricks secrets put --scope hoge_scope --key Passwordsecrets 表示
databricks secrets list --scope astro_snowflakeDBFS と Workspace の2つのファイル置き場
Databricks で利用するファイルは以下の二箇所がある。
- Databricks File System (DBFS)
- Python プログラムからは /dbfs にマウントされているように見える。
- プログラムで利用するファイルはここに置く。
- cli からは
databricks fsコマンドでアクセス出来る。- 特に、/FileStore/ 以下はファイルのアップロードなど UI からアクセスするのに使う。
- Workspace
- Notebook はここに置く。
- cli からは
databricks workspaceコマンドでアクセス出来る。なんと、プログラムから直接 Workspace にアクセスする事は出来ない!
SQL Table と DataFrame の関係
Databricks では、表にアクセスするのに Python や SQL を使う事が出来る。同じ表を別の言語で使うには表を SQL から見える所に Table として登録する必要がある。
Table にはどこからでもアクセス出来る global と、同じ Notebook からだけアクセス出来る local がある。
Python の DataFrame を "temp_table_name" という local table として登録する。これで SQL から参照出来る。
df.createOrReplaceTempView("temp_table_name")Python の DataFrame を "global_table_name" という global table として登録する。これで SQL から参照出来る。global table は Web UI の Data から参照出来る。
df.write.format("parquet").saveAsTable("global_table_name")"temp_table_name" という名前で登録されてある table を Python の DataFrame として読む。
temp_table = spark.table("temp_table_name")global table は DBFS 上に保存される。保存される場所は
DESCRIBE DETAILで出てくる location で確認出来る。DESCRIBE DETAIL `global_table_name`例えば
dbfs:/user/hive/warehouse/global_table_nameNotebook のマジックコマンド
https://docs.databricks.com/notebooks/notebooks-use.html
マジックコマンド
- %fs dbutils.fs を簡単に使う
- 例: %fs ls /databricks-datasets/structured-streaming/events/
- dbutils とは: https://docs.databricks.com/data/databricks-file-system.html#dbfs-dbutils
- %sh shell コマンド
- 例: %sh head -n 5 /dbfs/databricks-datasets/structured-streaming/events/file-0.json
- %md: Markdown
- 投稿日:2020-03-18T22:15:26+09:00
PDFファイルを画像解析してデータ抽出した話
はじめに
今話題のオープンデータですが、必ずしもCSVなどの生データではない事で、微妙に扱いにくいデータに仕上がっている事があります。
保有しているデータを新たに出している事自体は当然褒められるべき事で、「ほんとだったら生データ欲しいなァ〜」くらいの気持ちで期待している訳ですね。
そんな訳で、PDFで出したから悪いわけではありません、が、データの活用に際しては、PDFではなくより機械で読みやすい形式にする必要があります。
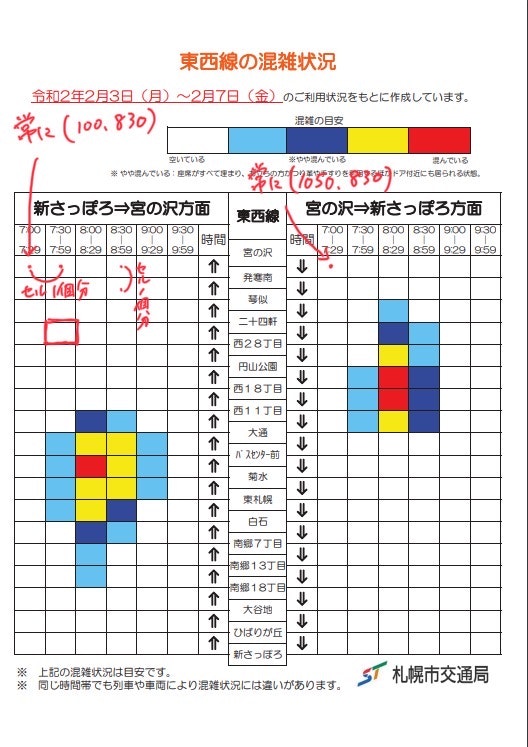
今回は、札幌市交通局が公開した朝ラッシュ時間帯の車内混雑状況についてのPDFデータを題材に、CSVデータを錬成する手順を紹介してみます。方針
上記ウェブサイトで得られるPDFファイルはこのような書式です
一応データは構造化されていて、エクセルをPDF出力した感じです。
なので「構造から解析路線」が思い浮かびます、が、表に格納されている日本語が解析時に化けてしまうなど手間がかかりそうでした。
そんな訳で次に、以下の画像のような手順を考案。
画像処理ソフト使うのが面倒だったのでiPadで手書きです。
要は、いくつかPDFを見ると、左表も右表も、左上のセルは常に同じ位置にあって、セルのサイズも全部同じという事がわかった訳です。
ならば、画像で言う赤点の箇所のRGB値(=色)を抽出・混雑度データに変換してやれば、望みのデータとなる訳ですね。結論
こんな風に実装できました
https://github.com/Kanahiro/sapporo_metro_analyze/こんな風にCSVを出力します
赤いとこは4、白は0で青は2になっている事がわかりますね。
では、PDF読み込み→画像に変換→指定ピクセルの色を取得→色から当該セルの混雑度データを生成→CSVファイルに、という手順を追ってみます。PDFから画像に変換
参考:PythonのPDF処理まとめ(結合・分割, 画像変換, パスワード解除)
pdf2imageを利用します。使い方は上記記事を参照。
なお、記事ではpip install popplerとありますが、現在はpipではインストール出来ません。
Linuxなら以下です。他のOSの説明は省略します。sudo apt install poppler-utils画像から指定ピクセルのRGB値を取得
pdf2imageで読み込んだデータは、numpyのarrayに変換する事が出来ます。
つまり、ピクセル構造と一致した2次元配列に、RGB配列を突っ込んで、3次元配列となります。#convert_from_pathはpdf2imageの関数 pdf_images = convert_from_path(pdffile) img_array = np.asarray(pdf_images[0]) ''' img_arrayのサンプル [[[255 255 255] [255 255 255] [255 255 255] ... [255 255 255] [255 255 255] [255 255 255]] [[255 255 255] [255 255 255] [255 255 255] ... [255 255 255] [255 255 255] [255 255 255]] [[255 255 255] [255 255 255] [255 255 255] ... [255 255 255] [255 255 255] [255 255 255]] (中略) ... [[255 255 255] [255 255 255] [255 255 255] ... [255 255 255] [255 255 255] [255 255 255]] [[255 255 255] [255 255 255] [255 255 255] ... [255 255 255] [255 255 255] [255 255 255]] [[255 255 255] [255 255 255] [255 255 255] ... [255 255 255] [255 255 255] [255 255 255]]]PDFの端っこは白いので当たり前ですが[255 255 255]すなわち白ばかりですね。
ピクセル単位に配列に格納出来ました。特定ピクセル(data_of_pixel)へのアクセスは
x = START_CELL[0] + c * CELL_SIZE[0] #x座標 y = START_CELL[1] + r * CELL_SIZE[1] #y座標 data_of_pixel = img_array[y][x]となります。これで、PDFを変換した画像の、特定の箇所のRGB値を取得出来ました。
混雑度の判定
上記の画像から、白、水色、青、黄色、赤の順で混雑度が高い事を示す事がわかります。
ところが、右上の凡例とデータエリアで、若干RGB値が異なるPDFに仕上がっていました。
幸い、段階ごとにそれなりに色の違いが大きいので、ここは凡例とデータエリアのセルとのRGB値の差の大きさで判定したいと思います。#混雑度凡例のRGB値 CROWD_RGBs = [ [255, 255, 255], [112, 200, 241], [57, 83, 164], [246, 235, 20], [237, 32, 36] ]def rgb_to_type(rgb_list)->int: #色差の閾値 threshold = 50 color_array = np.asarray(rgb_list) for i in range(len(CROWD_RGBs)): crowd_rgb_array = np.asarray(CROWD_RGBs[i]) color_dist = abs(color_array - crowd_rgb_array) sum_dist = color_dist.sum() if sum_dist < threshold: return i #0 - 4 混み具合この関数にRGB値のlistを渡すと、混雑度を0-4の整数値で返します。
何をしているかというと、先ほど取得したピクセルのRGB値と、混雑度凡例のRGB値を比較しています。
RGB値それぞれの差の絶対値の総和を色差と定義し、その差が50以内の場合、混雑度を確定しています。これで、すべてのセルの混雑度を判定し、CSVにすれば冒頭のCSVデータが完成します。
終わりに
こういった処理はオープンデータ界隈ならあるあるネタなんでしょう。「餅から米をつくる」とおっしゃっていた方もいましたが、これで私も錬米術師を名乗ってもよいでしょうか?ただやはり、一次データ(餅)がない限り米の錬成は出来ない訳なんで、そこには感謝しかない訳です、いつもありがとうございます。データの量は増えてきたので、次はそのデータの質の段階になっていくのかな…。

- 投稿日:2020-03-18T22:12:15+09:00
SympyでC言語を書く(メタプログラミング)
はじめに
メタプログラミングとは
メタプログラミング (metaprogramming) とはプログラミング技法の一種で、ロジックを直接コーディングするのではなく、あるパターンをもったロジックを生成する高位ロジックによってプログラミングを行う方法
出展 : wikipedia
要するに、コードを生成するコードを書いて複雑なコードを書いちゃいましょう!ってこと(だと私は解釈しています。間違っていたら教えてください)。
概要
Pythonの記号計算用ライブラリであるSympyを使って数式を生成し、C言語にコンバートします。SympyはMathematicaのように数式処理に使われることが多いようですが、数式を様々な言語にコンバートする機能も兼ね備えています。私はあまり使ったことがありませんが、ヘッダファイル付きで関数を出力する機能もあります。
この記事では入門的に、n×n行列の掛け算のコードをSympyでメタプログラミングしていきます。
Sympyの記法や使い方は以下にまとめられているので、興味のある方は読んでみてください。インストール
Sympyのインストールはpipでできます。
pip install sympyダウンロードの場合は以下から。
インポート
まずはSympyをインポートします。
from sympy import *今回は行列計算を実装したいので、Matrixもインポートしておきます。
from sympy import MatrixこれでMatrixも宣言できるようになりました。
シンボルの作成
数式に用いる変数はsymbolとして事前に宣言しておく必要があります。例えば、xとyをsymbolとして宣言する場合は
x = symbols('x') y = symbols('y')とすればOKです。今回は行列計算のために、n×nのMatrixの要素としてsymbolを定義していきます。
n = 3 A = Matrix([[symbols('a['+str(j)+']['+str(i)+']') for i in range(n)] for j in range(n)]) B = Matrix([[symbols('b['+str(j)+']['+str(i)+']') for i in range(n)] for j in range(n)])これで行列A,Bがそれぞれ以下のように宣言されました。ここではn=3としました。
⎡a[0][0] a[0][1] a[0][2]⎤ ⎢ ⎥ ⎢a[1][0] a[1][1] a[1][2]⎥ ⎢ ⎥ ⎣a[2][0] a[2][1] a[2][2]⎦ ⎡b[0][0] b[0][1] b[0][2]⎤ ⎢ ⎥ ⎢b[1][0] b[1][1] b[1][2]⎥ ⎢ ⎥ ⎣b[2][0] b[2][1] b[2][2]⎦行列の出力は
pprint(A)と記述するとこのように視覚的にわかりやすい形になります。行列の掛け算
先ほどの行列A,Bの積を行列Cとします。行列の掛け算は簡単に、以下でOKです。
C = A*B今度は
print(C)で中身を見てみるとMatrix([[a[0][0]*b[0][0] + a[0][1]*b[1][0] + a[0][2]*b[2][0], a[0][0]*b[0][1] + a[0][1]*b[1][1] + a[0][2]*b[2][1], a[0][0]*b[0][2] + a[0][1]*b[1][2] + a[0][2]*b[2][2]], [a[1][0]*b[0][0] + a[1][1]*b[1][0] + a[1][2]*b[2][0], a[1][0]*b[0][1] + a[1][1]*b[1][1] + a[1][2]*b[2][1], a[1][0]*b[0][2] + a[1][1]*b[1][2] + a[1][2]*b[2][2]], [a[2][0]*b[0][0] + a[2][1]*b[1][0] + a[2][2]*b[2][0], a[2][0]*b[0][1] + a[2][1]*b[1][1] + a[2][2]*b[2][1], a[2][0]*b[0][2] + a[2][1]*b[1][2] + a[2][2]*b[2][2]]])と、きちんと計算出来ていることがわかります。
C言語へのコンバート
C言語へのコンバートは
ccode(<数式>, <代入する変数>, standard='C99')と記述します。今回は行列Cの全要素をコンバート・出力したいので、
for i in range(n): for j in range(n): idx = i*n+j code = ccode(C[idx],assign_to=('c['+str(i)+']['+str(j)+']'), standard='C89') print(code)としました。
idx = i*n+jは、i, jを一次元に変換する式です。上記コードを実行すると以下が出力されます。c[0][0] = a[0][0]*b[0][0] + a[0][1]*b[1][0] + a[0][2]*b[2][0]; c[0][1] = a[0][0]*b[0][1] + a[0][1]*b[1][1] + a[0][2]*b[2][1]; c[0][2] = a[0][0]*b[0][2] + a[0][1]*b[1][2] + a[0][2]*b[2][2]; c[1][0] = a[1][0]*b[0][0] + a[1][1]*b[1][0] + a[1][2]*b[2][0]; c[1][1] = a[1][0]*b[0][1] + a[1][1]*b[1][1] + a[1][2]*b[2][1]; c[1][2] = a[1][0]*b[0][2] + a[1][1]*b[1][2] + a[1][2]*b[2][2]; c[2][0] = a[2][0]*b[0][0] + a[2][1]*b[1][0] + a[2][2]*b[2][0]; c[2][1] = a[2][0]*b[0][1] + a[2][1]*b[1][1] + a[2][2]*b[2][1]; c[2][2] = a[2][0]*b[0][2] + a[2][1]*b[1][2] + a[2][2]*b[2][2];行列Cの各要素が計算され、C言語の形で出力されました。ちゃんと ; も付いていますね。あとはこれを自分のコードに張り付ければOKです。
ソースコード
今回作成した行列計算コードです。
from sympy import * from sympy import Matrix from sympy.utilities.codegen import codegen n = 3 A = Matrix([[symbols('a['+str(j)+']['+str(i)+']') for i in range(n)] for j in range(n)]) B = Matrix([[symbols('b['+str(j)+']['+str(i)+']') for i in range(n)] for j in range(n)]) pprint(A) pprint(B) C = A*B print(C) for i in range(n): for j in range(n): idx = i*n+j code = ccode(C[idx],assign_to=('c['+str(i)+']['+str(j)+']'), standard='C89') print(code)まとめ
Sympyを使って行列の掛け算を計算するコードをメタプログラミングしました。このくらいの計算ならメタプログラミングするまでもなく書けますが、「元の式をtで何階偏微分して~」みたいな複雑な数式を実装する時には非常に有用です。(行列掛け算もfor文がなくなった分少し実行速度が上がるメリットはある?)
ご参考になれば幸いです!
- 投稿日:2020-03-18T22:11:57+09:00
ニューラルネットワークの最適化手法4つまとめてみた
どういう記事か?
- 最近「ゼロから作るニューラルネットワーク」という本を読んで学んだニューラルネットワークの4つの最適化手法についてまとめようと思います
- 基本的には本がベースになっていますが、どうイメージしたらわかりやすいか?ということに重点を置いて個人的な解釈をまとめた記事です。なので、厳密な数式や応用などは載せていません。
- ネットで調べるとこの記事よりももっと詳しい説明が腐るほど出てきますが、一方で本とほぼ同じ説明をそのまんまQiitaにまとめた記事も散見されたので、自分なりの解釈をまとめておく意味も少しはあるかなと思い、記事を書くに至りました
- Momentumという手法の説明にかなり偏ってしまいましたが、ご容赦ください。。
- 僕はニューラルネットワークについては初学者、初心者なので、間違っている箇所やアドバイスなどがあればコメントもらえると喜びます
ゼロから作るニューラルネットワーク
今や機械学習の専門でない一般の人でも名前だけは知っている「ニューラルネットワーク」「ディープラーニング」。
機械学習の1つで、画像認識などによく使われているやつですね(Google画像検索みたいなやつ)
このニューラルネットワークを勉強する際におそらく最も日本で読まれている本が「ゼロから作るDeep Learning」です。
よく読まれているだけあって、入門書としては非常に良書だと思います。(何様なんだ)機械学習における"学習"
ニューラルネットワークに限らず、機械学習の目的は学習データ(教師データ)をもとに学習し、未知のデータの予測を行う、というものです。
例えば画像認識で言えば猫の画像を大量に学習させて、新しく画像を見せた時に「その画像か猫かどうか?」を答えさせる、というものですね。
通常の機械学習であれば「特徴量を指定して学習しなければならない」 という制約がありますが、ディープラーニングの場合は学習する中で画像から勝手に特徴量を見つけてくれるという利点があります。最適化ってなーに?
学習とはいったい何をしているのか?というと、最適な重みパラメータを探す作業に当たります。
最適なパラメータが求まればそれを元に未知のデータから正解を予測できるようになります。
これを最適化(optimize)と言います。
最適化のためには損失関数(コスト関数)と呼ばれる関数を定義し、最小になるパラメータを探します。
損失関数としては最小二乗誤差やLogLoss (交差エントロピー誤差)などが用いられ、いずれも小さい値を取るほどうまく分類(or 回帰)できているということになります。
ではどうやって損失関数の最小の場所を探すか?を考えます。
この本では以下の4種類の最適化手法が紹介されています。
- SGD(勾配降下法)
- Momentum
- AdaGrad
- Adam
SGD
勾配降下法(Gradient Stochastic Descent)の略。
最適化手法の中で一番スタンダードなやつで、以下の式で重みを更新します\boldsymbol{W} \leftarrow \boldsymbol{W} - \eta\frac{\partial{L}}{\partial{\boldsymbol{W}}}損失関数の傾きを計算して損失関数が小さくなるように更新していきます。
「坂道を下に下っていけばいつかは一番低いところに辿りつけるだろう」という考えです。
$\eta$は学習率と呼ばれるやつで、小さすぎるとなかなかたどり着かず、大きすぎると一度に大きく動きすぎてとんでもない方向に飛んで行ってしまったりします。
なので、適切な値を最初に設定してあげる必要があります。
個人的にはゴルフのようなものだと思っていて、ちょこっとの力でしか打たないといつまでたってもホールにたどり着かないし、かといって力任せに打ちすぎるとホールを通り越してとんでもない方向にいってしまいます。
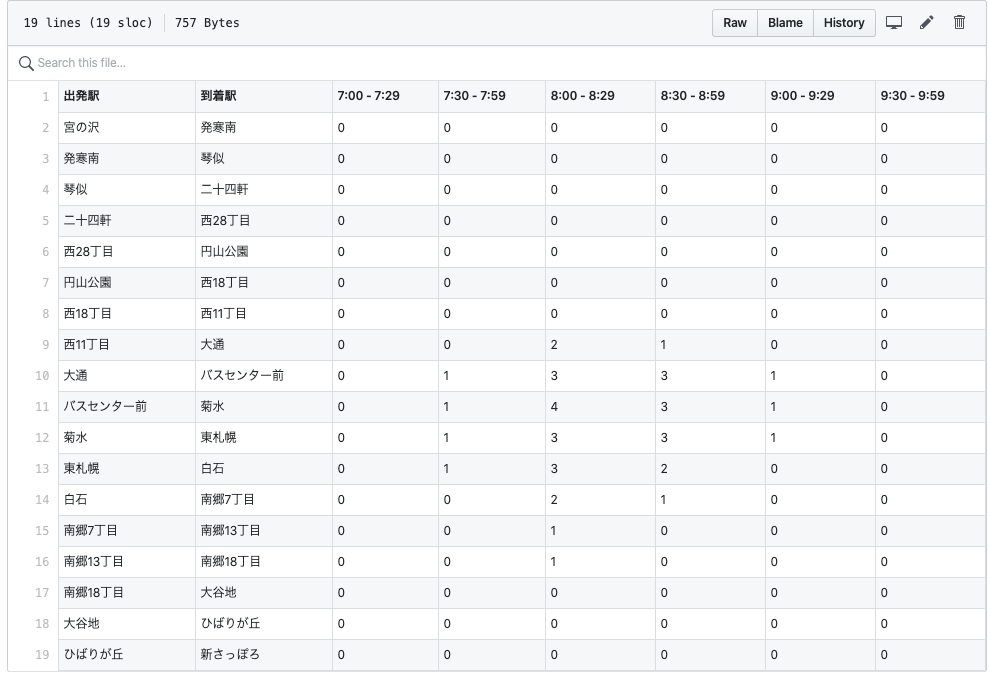
そんなSGDですが、常にうまくいくとは限りません。例えば$f(x,y)=\frac{1}{20}x^{2}+y^{2}$のような関数を考えます。お椀型をx軸方向にビヨっと引き伸ばしたような形ですね。
この関数でSGDをやってみた結果が以下です。
縦方向の勾配が急なので縦にギザギザしながら原点(損失関数が最小の点)に向かっていってるのがわかります。かなり効率の悪い動きをしていますね。これを改善したのが以下に出てくる3つの方法です。
Momentum
Momentumとは物理学で出てくる運動量のことです。まずは重みの更新式を見てみましょう。
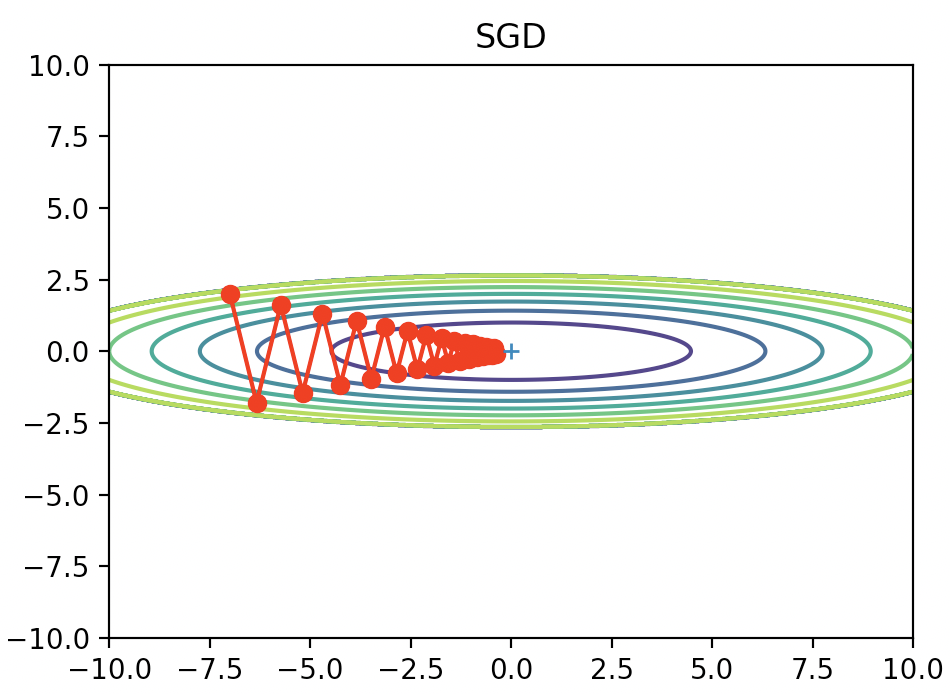
\boldsymbol{v} \leftarrow \alpha\boldsymbol{v} - \eta\frac{\partial{L}}{\partial{\boldsymbol{W}}}\\ \boldsymbol{W} \leftarrow \boldsymbol{W} +\boldsymbol{v}式を見ただけだとピンと来ないかもしれないので、まずは先ほどの関数に適用した結果を見てみましょう。
滑らかな動きになりましたね。なんとなくお椀の中をボールが転がったような軌跡を描いていて、自然です。
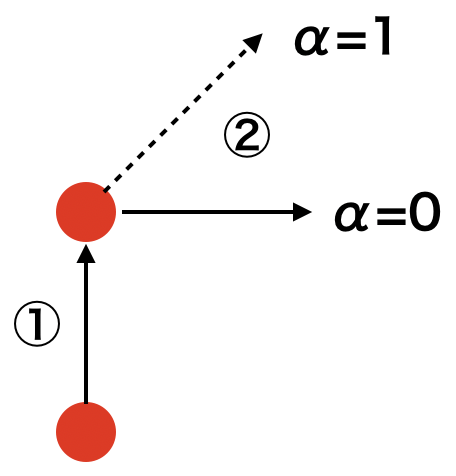
なぜ滑らかな動きになるのか?以下に簡単な概念図を書いてみました。
一つの例を考えてみましょう。①が最初の学習、②が2回目の学習を表すとします。
最初に$\frac{\partial{L}}{\partial{\boldsymbol{W}}}$を計算した結果、①のように上方向のベクトルとなったとします。その方向にしたがって$\eta$の大きさを掛けた分だけ移動したとします。
ここで②の重みを更新を考えます。再度Lの微分を計算した結果、今度は斜面の下り坂の方向が上ではなく右方向に変化していたとしましょう。SGDの場合だと①と同じように今度は②で右方向に進みます。
結果として直角に右に移動していますね。これがSGDのガタガタの原因で、不自然は軌道になってしまっています。
ここでMomentumの式を確認してみましょう。更新式の中に$\alpha{v}$の項がありますね。
これは①の時の$\frac{\partial{L}}{\partial{\boldsymbol{W}}}$にあたります。
簡単のため$\alpha=1$だったとしましょう。
すると$\alpha\boldsymbol{v}-\eta\frac{\partial{L}}{\partial{\boldsymbol{W}}}$の部分は①と②のベクトルの和になっていることがわかります。
すると②の方向は右ではなく斜め45度で右上に進むことになります。
このように、前回の重み更新時の傾きを次回の重み更新に反映させることで、動きが滑らかになります。
αは前回の更新時の傾きをどれくらい影響させるかというパラメータになります。
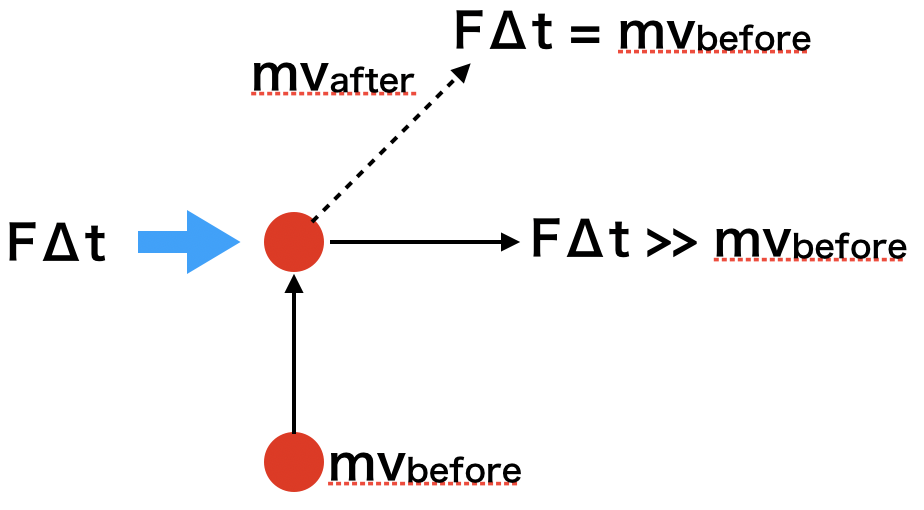
αが0なら前回の重み更新時の傾きは一切反映しないので右方向、つまりSGDと同じになります。次に、なぜこの手法がMomentumと呼ばれるのかを考えてみます。物理学(ニュートン力学)では運動量は質量(m)と速度のベクトル($\boldsymbol{v}$)の積になります。
運動量と力積($F\Delta{t}$)の関係という以下のような関係式が成り立ちます。m\boldsymbol{v_{before}}+F\Delta{t} = m\boldsymbol{v_{after}}これも図で考えてみましょう
上方向に運動量$m\boldsymbol{v_{before}}$で運動している物体が右方向に力積を受けた場合に物体の運動がどう変化するかを表します。
もし力積の大きさが最初の運動量と同じであれば斜め45度に右上に、力積の大きさがそれより大きくなると、より右側に物体は弾き飛ばされます。
これはさっきの概念図と非常に似ているということがわかると思います。
Momentumによって描かれた軌跡のことを先ほどお椀の中をボールが転がるようにと表現しましたが、実際の力学の物理法則と似たような式になっているためこのような軌跡になるということがわかると思います。
イメージ的には上に進んでいるところに急に右方向に力がかかっても急に直角には曲がれないよ!というのを重みの更新に適用したという感じですかね。AdaGrad
Momentumの説明が非常に長くなってしまいましたが、残りの方法についてもさらっと説明したいと思います。
SGDの説明の時に、重みの更新をゴルフに例えました。SGDでは毎回の学習で同じ学習率で更新します。つまりゴルフで言えば毎回同じ強さで球を打っていることになります。
しかし、ゴルフの場合、一打目は強く打って飛距離を伸ばし、ホールが近づいてきたらだんだん弱く打って微調整していきますよね?
同様のことがニューラルネットワークでも適用可能です。つまり最初の学習時は大きく重みを更新し、だんだんと更新する大きさを減らしていくという方法です。
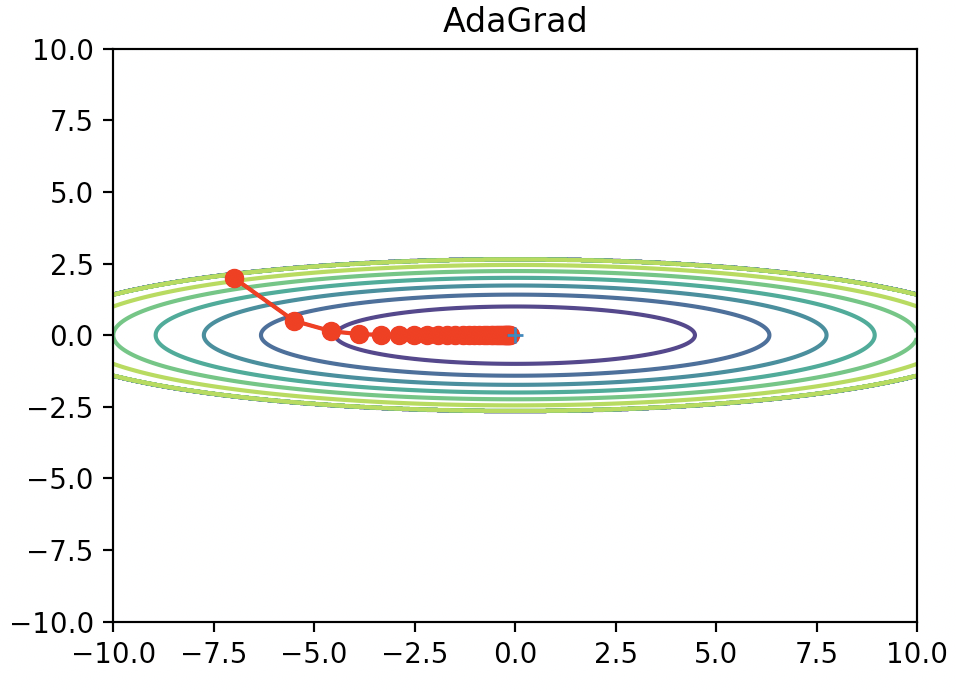
この手法をAdaGradといいます。
以下の式をみてみましょう。\boldsymbol{h} \leftarrow \boldsymbol{h} + \left(\frac{\partial{L}}{\partial{\boldsymbol{W}}}\right)^{2}\\ \boldsymbol{W} \leftarrow \boldsymbol{W} -\frac{1}{\sqrt{\boldsymbol{h}}}\eta\frac{\partial{L}}{\partial{\boldsymbol{W}}}下の式で$\sqrt{\boldsymbol{h}}$で割っていますね。これは毎回重みを更新するごとに更新する大きさが小さくなっていくことを意味します。
上の式の$\left(\frac{\partial{L}}{\partial{\boldsymbol{W}}}\right)^{2}$は行列の全要素を2乗したものを意味します。(内積ではないので、スカラーにはならない)
つまり、傾きが急であるほど大きく重みを更新し、だんだん小さくしていくということですね。
非常に理にかなっています。
これを実際に先ほどの関数に適用したのが以下になります。
今回の例だと非常にうまくいっているように見えますね。
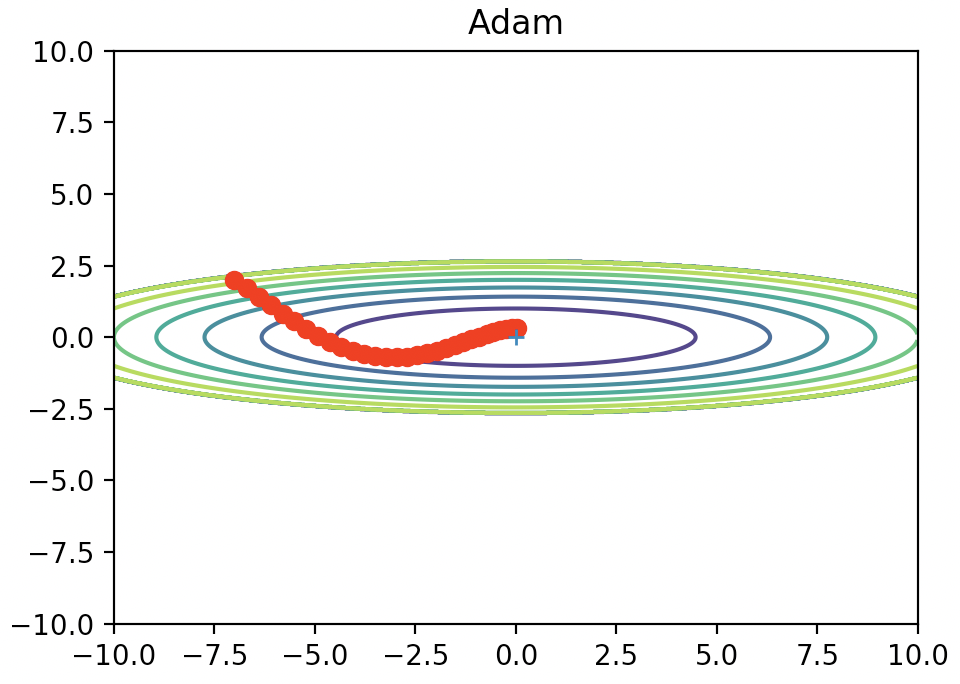
Adam
最後にAdamについて紹介します。
Adamは簡単に言えばMomentumとAdaGradのいいこと取りしたやつです。
数式含め、ここでは詳しく触れません。
例によって関数に当てはめると以下のような図になります。
これもSGDと比べるといい感じに最小値にたどり着けてますね。まとめ
- ニューラルネットワークで用いる4つの最適化手法を(かなりざっくり)紹介しました
- 「結局どれ使いばいいの?」という疑問ですが、万能な方法は存在しないので臨機応変に使い分ける必要がありそうです
- SGDは今でもよく用いられていますが、最近ではAdamが人気なようです
備考
- 今回図をplotするのに使ったコードは以下のgitで公開されています
- https://github.com/oreilly-japan/deep-learning-from-scratch
- 投稿日:2020-03-18T22:02:39+09:00
Python入門 〜B3に向けて〜 part1
Pythonとは?
- Pythonの特徴
動的な型付け 型宣言をプログラム実行前にしなくて良い ガベージコレクション 不要なメモリは自動的に解放 マルチパラダイム オブジェクト指向、命令型、手続き型、関数型など複数の特性を併せ持つプログラミング言語 外部ライブラリが豊富 機械学習用の「TensorFlow」「Chainer」や
Web開発用の「Django」「Flask」など様々読みやすい 簡単な短いコードによって書けて読みやすい 多くのプラットフォームに対応 Windows,Mac,Linux,ios,Android... C言語でのプログラム実行まで
たった1行の出力でもいろいろしなくちゃいけない...
*もちろんC言語も高速であったり自由度が高かったりと優れているところがたくさんあります。Hello.c//ライブラリの読み込み #include <stdio.h> //main関数の定義 int main(int argc, char *args[]) { printf("Hello, world!\n"); return 0; }$ gcc -o hello hello.c //コンパイル $ ./hello //実行 Hello, world! $Pythonでのプログラム実行まで
たったこれだけで動きます。
Pythonはインタプリタ言語といって
コンピュータがプログラミング言語を機械語に翻訳する作業を
プログラム実行時に同時作業で行ってくれます。
これにより、機械語への変換を一括で行うコンパイルという作業の指示をする必要がありません。Hello.pyprint("Hello, world!")$ python Hello Hello, world!
実際に書いてみよう!
Google Colaboratory
* ファイルをクリック
* ノートブックを新規作成をクリック
* 以下のコードを記入print("Hello, world!")
ボタンを押す
変数を使ってみよう
msg = "Hello, world!" num = 100 ADMIN_EMAIL = "hello@mail.com" squares = [1,4,9,16,25] print(msg) print(num) print(squares) print(ADMIN_EMAIL) msg = "I'm Pretender" num = num + 50 squares += [36, 49, 64, 81, 100] print(msg) print(num) print(squares)Hello, world! #numの出力 100 #squaresの出力 [1, 4, 9, 16, 25] #ADMIN_MAILの出力 hello@mail.com #更新後のmsgの出力 I'm Pretender #更新後のmsgの出力 150 #更新後のsquaresの出力 [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]数値の四則演算など
x = int(input("x=")) print(x+3) print(x-3) print(x*3) print(x/3) msg += "GoodBye!" print(msg)文字列に値を埋め込む
name = "Iwana" height = 173 #やり方1 文字列フォーマット指定 print("%s くんの身長は、 %d cmです。" %(name,height)) #やり方2 {}で指定 print("{1} くんの身長は、 {2} cmです。".format(name,height))
フォーマット指定子 型 %d 整数 %f 浮動小数 %s 文字列 %o 8進数 %x 16進数 課題
名前とBMIを計算して表示するプログラムを書いてみよう。
条件分岐をしてみよう
if文
score=int(input("score ? ")) if score >= 90: print("A+") elif score >= 80: print("A") elif score >= 70: print("B") elif score >= 60: print("C") else: print("You're failed.")Pythonに限らずプログラミング言語では基本的に
if 条件式:(;など)(改行) 実行文 else:(;など) 実行文のようにif文などを書いていきます。
if分では条件演算子を用いて数値や文字の比較をする式(条件式)を用いて、
その条件が真(True)だった時に配下に書いた実行文に移ります。
もし条件式が偽(False)だった時は次の文(elif,elseなど)に移ります。最初の条件式のときにifを用い、他に分岐させたい項目がある場合はelifを用います。
ifやelifの条件から外れた物への指示はelse文の配下に記述します。条件演算子には次のようなものがあります。
演算子 意味 > 左側の数が、右側の数よりも大きい < 左側の数が、右側の数よりも小さい == 両辺の数値の大きさが等しい != 等しくない >= 左側の数が、右側の数よりも大きいか、または両辺が等しい <= 左側の数が、右側の数よりも小さいか、または両辺が等しい また条件を掛け合わせる時にはビット演算子を使うと便利です。
演算子 意味 & 両方とも成り立つ。 | 少なくとも、どちらか一方は正しい。 if_sequence.pyday = int(input("What's the date today ? ")) week_of_day = input("What day is today ? ") if (day==13) & (week_of_day=="Friday") : print("Jason will come.") else: print("Jason will not come.")条件分岐は1行でも記述することができます。
score = int(input("score ?")) print ("Good Score!" if score >= 70 else "Not Good Score...")繰り返しをしてみよう
繰り返しにはfor文とwhile文の2種類があります。
for文
for文は以下のような文法で成り立っています。
ここでデータの集合とは1〜9の数字の集合であったり、配列であったり、
ファイルの集合であるフォルダであったりします。for 変数 in データの集合: 実行文実際にfor文を使ってみましょう。
今回はデータの集合に0~9の数字の集合を使うことで10回の操作を繰り返します。
0~9までの数字の集合には組み込み関数のrangeを用います。count.pyfor i in range(0,10): if i == 5: print("a") continue """if i == 9: break""" print(i)
i==5の時以外は0~9までの数字が出力されました。print(i)が動いてますね。
i==5の時だけaが出力されました。if文の中に入っていることがわかります。
if文の最後の行にcontinueと書いてあります。
coutinue文に当たると現在進行中の繰り返し処理一回分を終了させて
強制的につぎの繰り返し処理に入っていきます。
なのでi==5の処理時にはcontinue以降のprint(i)が実行されていません。この他にも
break文というのもあります。
これは繰り返し自体を終了させてしまいます。
i==9のコメントアウトを外して実行すると出力が8までになるはずです。while文
while文の文法は以下のようになっています。
while 条件式: 実行文while文では条件式が真(True)である限り実行式が繰り返し実行されます。
for文と同じプログラムを書いていきましょう。i = 0 while i < 10: if i == 5: print("a") elif i == 9: break print (i) i += 1関数
Pythonでは関数の定義も行うことができます。
f(x,y) = 2x + yを出力するような関数を作ってみます。
def function(x=0,y=0): print("2x+y = %f"%(2*x+y)) x = int(input("x = ")) y = int(input("y = ")) function(x,y)このように関数は
def 関数名(引数): 実行文のような文法で記述されます。引数は何個でも大丈夫です。
引数にはデフォルトの値を入れることができます。
関数を呼び出した時に引数の場所に値を入れていないとデフォルト値を入れた状態で実行されます。返り値がある場合
return文を使うことで関数の返り値を設定できます。def function(x,y): return 2 * x + y x = int(input("x = ")) y = int(input("y = ")) print("2x+y = %f"%(f(x,y)))課題
任意の値(n)までのフィボナッチ数列を出力する関数を作ってみましょう。
スコープ
プログラムの変数、(メソッド、クラス名)には有効範囲があります。これをスコープと呼びます。
スコープは対象を宣言した場所によって変わります。
スコープは3種類に分けられます。
スコープ名 意味 ビルドインスコープ Pythonプログラムの中に常に存在するスコープ グローバルスコープ 作成するPythonファイルやプロジェクト内で有効 ローカルスコープ 関数内でのみ有効 スコープの大きさは、
ローカルスコープ⊂グローバルスコープ⊂ビルドインスコープ
になっています。スコープの外側からは、その名前を参照できません。クラス
クラスの構造は次のようになっています。
クラスとはデータ構造を作る仕組みで、クラスを使うと新しいデータ型を作ることができます。class Personal_data(): def __init__(self, name, age, weight, height): #コンストラクタの定義 # インスタンス変数(属性の初期化) self.name = name self.age = age self.weight = weight self.height = height print("コンストラクタが呼ばれました") def hello(self): print("Hello, " + self.name) def BMI(self): print(self.weight/(self.height/100)**2) def __del__(self): #デストラクタの定義 print('デストラクタが呼ばれました') iwana = Personal_Data("Hiroki",23,65,170) # iwanaというインスタンスを生成しています。 iwana.hello() iwana.BMI() del iwanaこのようにクラスには変数や関数といった様々なものを入れることができます。
クラスの中に定義された関数をメソッド、クラスが内包しているデータを属性と呼びます。
クラスや関数は定義しただけでは何も行われません。
クラスや関数などを実際に使う状態にすることをインスタンスの作成と呼びます。
コンストラクタはクラスのインスタンスが作成される際に一度だけ呼ばれるメソッドです。
今回ではiwana = Personal_Data("Hiroki",23,65,175)のときにParsonal_Dataクラスのインスタンスが作成され、そのオブジェクトを変数iwanaに代入しています。
オブジェクトとは属性とメソッドを持ったもののことを指します。
コンストラクタとは別にクラスの特殊なメソッドとして、デストラクタがあります。デストラクタは呼び出された時にインスタンスを削除します。課題
自分で好きなクラスを作ってみよう!
- 投稿日:2020-03-18T22:02:39+09:00
Python入門:特徴、基本文法、関数、クラス (〜B3に向けて〜 part1)
Pythonとは?
- Pythonの特徴
動的な型付け 型宣言をプログラム実行前にしなくて良い ガベージコレクション 不要なメモリは自動的に解放 マルチパラダイム オブジェクト指向、命令型、手続き型、関数型など複数の特性を併せ持つプログラミング言語 外部ライブラリが豊富 機械学習用の「TensorFlow」「Chainer」や
Web開発用の「Django」「Flask」など様々読みやすい 簡単な短いコードによって書けて読みやすい 多くのプラットフォームに対応 Windows,Mac,Linux,ios,Android... C言語でのプログラム実行まで
たった1行の出力でもいろいろしなくちゃいけない...
*もちろんC言語も高速であったり自由度が高かったりと優れているところがたくさんあります。Hello.c//ライブラリの読み込み #include <stdio.h> //main関数の定義 int main(int argc, char *args[]){ printf("Hello, world!\n"); return 0; }$ gcc -o hello hello.c //コンパイル $ ./hello //実行 Hello, world! $Pythonでのプログラム実行まで
たったこれだけで動きます。
Pythonはインタプリタ言語といって
コンピュータがプログラミング言語を機械語に翻訳する作業を
プログラム実行時に同時作業で行ってくれます。
これにより、機械語への変換を一括で行うコンパイルという作業の指示をする必要がありません。Hello.pyprint("Hello, world!")$ python Hello Hello, world!
実際に書いてみよう!
Google Colaboratory
* ファイルをクリック
* ノートブックを新規作成をクリック
* 以下のコードを記入print("Hello, world!")
変数を使ってみよう
msg = "Hello, world!" num = 100 ADMIN_EMAIL = "hello@mail.com" squares = [1,4,9,16,25] print(msg) print(num) print(squares) print(ADMIN_EMAIL) msg = "I'm Pretender" num = num + 50 squares += [36, 49, 64, 81, 100] print(msg) print(num) print(squares)Hello, world! #numの出力 100 #squaresの出力 [1, 4, 9, 16, 25] #ADMIN_MAILの出力 hello@mail.com #更新後のmsgの出力 I'm Pretender #更新後のmsgの出力 150 #更新後のsquaresの出力 [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]数値の四則演算など
x = int(input("x=")) print(x+3) print(x-3) print(x*3) print(x/3) msg += "GoodBye!" print(msg)文字列に値を埋め込む
name = "Iwana" height = 173 #やり方1 文字列フォーマット指定 print("%sくんの身長は、%dcmです。"%(name,height)) #やり方2 {}で指定 print("{1}くんの身長は、{2}cmです。".format(name,height))
フォーマット指定子 型 %d 整数 %f 浮動小数 %s 文字列 %o 8進数 %x 16進数 課題
名前とBMIを計算して表示するプログラムを書いてみよう。
条件分岐をしてみよう
if文
score=int(input("score?")) if score >= 90: print("A+") elif score >= 80: print("A") elif score >= 70: print("B") elif score >= 60: print("C") else: print("You're failed.")Pythonに限らずプログラミング言語では基本的に
if 条件式: 実行文 else: 実行文のようにif文などを書いていきます。
if分では条件演算子を用いて数値や文字の比較をする式(条件式)を用いて、
その条件が真(True)だった時に配下に書いた実行文に移ります。
もし条件式が偽(False)だった時は次の文(elif,elseなど)に移ります。最初の条件式のときにifを用い、他に分岐させたい項目がある場合はelifを用います。
ifやelifの条件から外れた物への指示はelse文の配下に記述します。条件演算子には次のようなものがあります。
演算子 意味 > 左側の数が、右側の数よりも大きい < 左側の数が、右側の数よりも小さい == 両辺の数値の大きさが等しい != 等しくない >= 左側の数が、右側の数よりも大きいか、または両辺が等しい <= 左側の数が、右側の数よりも小さいか、または両辺が等しい また条件を掛け合わせる時にはブール演算子を使うと便利です。
演算子 意味 and 両方とも成り立つ。 or 少なくとも、どちらか一方は正しい。 if_sequence.pyday = int(input("What's the date today ? ")) week_of_day = input("What day is today ? ") if (day==13)and(week_of_day=="Friday") : print("Jason will come.") else: print("Jason will not come.")条件分岐は1行でも記述することができます。
score = int(input("score ?")) print ("Good Score!" if score >= 70 else "Not Good Score...")繰り返しをしてみよう
繰り返しにはfor文とwhile文の2種類があります。
for文
for文は以下のような文法で成り立っています。
ここでデータの集合とは1〜9の数字の集合であったり、配列であったり、
ファイルの集合であるフォルダであったりします。for 変数 in データの集合: 実行文実際にfor文を使ってみましょう。
今回はデータの集合に0~9の数字の集合を使うことで10回の操作を繰り返します。
0~9までの数字の集合には組み込み関数のrangeを用います。count.pyfor i in range(0,10): if i == 5: print("a") continue """if i == 9: break""" print(i)
i==5の時以外は0~9までの数字が出力されました。print(i)が動いてますね。
i==5の時だけaが出力されました。if文の中に入っていることがわかります。
if文の最後の行にcontinueと書いてあります。
coutinue文に当たると現在進行中の繰り返し処理一回分を終了させて
強制的につぎの繰り返し処理に入っていきます。
なのでi==5の処理時にはcontinue以降のprint(i)が実行されていません。この他にも
break文というのもあります。
これは繰り返し自体を終了させてしまいます。
i==9のコメントアウトを外して実行すると出力が8までになるはずです。while文
while文の文法は以下のようになっています。
while 条件式: 実行文while文では条件式が真(True)である限り実行式が繰り返し実行されます。
for文と同じプログラムを書いていきましょう。i = 0 while i < 10: if i == 5: print("a") elif i == 9: break print (i) i += 1関数
Pythonでは関数の定義も行うことができます。
f(x,y) = 2x + yを出力するような関数を作ってみます。
def function(x=0,y=0): print("2x+y=%f"%(2*x+y)) x = int(input("x=")) y = int(input("y=")) function(x,y)このように関数は
def 関数名(引数): 実行文のような文法で記述されます。引数は何個でも大丈夫です。
引数にはデフォルトの値を入れることができます。
関数を呼び出した時に引数の場所に値を入れていないとデフォルト値を入れた状態で実行されます。返り値がある場合
return文を使うことで関数の返り値を設定できます。def function(x,y): return 2*x + y x = int(input("x=")) y = int(input("y=")) print("2x+y=%f"%(f(x,y)))課題
任意の値(n)までのフィボナッチ数列を出力する関数を作ってみましょう。
スコープ
プログラムの変数、(メソッド、クラス名)には有効範囲があります。これをスコープと呼びます。
スコープは対象を宣言した場所によって変わります。
スコープは3種類に分けられます。
スコープ名 意味 ビルドインスコープ Pythonプログラムの中に常に存在するスコープ グローバルスコープ 作成するPythonファイルやプロジェクト内で有効 ローカルスコープ 関数内でのみ有効 スコープの大きさは、
ローカルスコープ⊂グローバルスコープ⊂ビルドインスコープ
になっています。スコープの外側からは、その名前を参照できません。クラス
クラスの構造は次のようになっています。
クラスとはデータ構造を作る仕組みで、クラスを使うと新しいデータ型を作ることができます。class Personal_data(): #コンストラクタの定義 def __init__(self, name, age, weight, height): # インスタンス変数(属性の初期化) self.name = name self.age = age self.weight = weight self.height = height print("コンストラクタが呼ばれました") def hello(self): print("Hello, " + self.name) def BMI(self): print(self.weight/(self.height/100)**2) #デストラクタの定義 def __del__(self): print('デストラクタが呼ばれました') # iwanaというインスタンスを生成しています。 iwana = Personal_Data("Hiroki",23,65,170) iwana.hello() iwana.BMI() del iwanaこのようにクラスには変数や関数といった様々なものを入れることができます。
クラスの中に定義された関数をメソッド、クラスが内包しているデータを属性と呼びます。
クラスや関数は定義しただけでは何も行われません。
クラスや関数などを実際に使う状態にすることをインスタンスの作成と呼びます。
コンストラクタはクラスのインスタンスが作成される際に一度だけ呼ばれるメソッドです。
今回ではiwana = Personal_Data("Hiroki",23,65,175)のときにParsonal_Dataクラスのインスタンスが作成され、そのオブジェクトを変数iwanaに代入しています。
オブジェクトとは属性とメソッドを持ったもののことを指します。
コンストラクタとは別にクラスの特殊なメソッドとして、デストラクタがあります。デストラクタは呼び出された時にインスタンスを削除します。課題
自分で好きなクラスを作ってみよう!
- 投稿日:2020-03-18T21:58:04+09:00
新型コロナウイルスの都道府県別の基本再生産数の推移を計算してみる
はじめに
新型コロナウイルス感染症(COVID-19)の感染の中心地はもはや中国本土から欧米に移行しつつあり、EU域内でも自由な国境の移動を制限したり、外出禁止令が発令されるなどの緊急事態になっています。日本において、新型コロナウイルスの脅威が認識されはじめたのは、2020年2月3日のダイヤモンド・プリンセス号の横浜港入港、2月25日の政府の基本方針表明、2月28日の北海道における緊急事態宣言、などが契機ですが、具体的な対策として2月26日から大規模なイベントの自粛要請、3月2日からの全国の小中高校の臨時休校などがなされて来ました。
それから約半月が経過しますが、その間、日経平均株価が22000円台から17000円台まで急落するなど、先行きに暗雲が立ち込めています。新型コロナウイルス感染症の影響は健康のみならず、社会経済に深刻な打撃を与えており、いつ収束するのかが極めて重大な関心を集めています。
そこで、本記事では、1月末から3月頭にかけて、日本における新型コロナウイルスの感染力の指標である、基本再生産数がどのように推移してきたか、計算で求める一つの方法を提示したいと思います。
計算式やコードは少し長いので、計算結果を先に見て頂いた方が良いかもしれません。基本再生産数とは?
基本再生産数は、実は非常に奥が深いようで、京大数理解析研究所講究録や日本数理生物学会レター等を見ると、世代間の変遷を考慮するなど単純ではないようですが、敢えて、一言でいうと、
- 人口集団の典型的な1人の感染者が、その全感染期間において再生産する2次感染者数の期待値
と定義されるようです。この数値をR0とすると、感染が拡大する条件は$R_0>1$、感染が収束する条件は$R_0 < 1$となります。
イギリスのボリス・ジョンソン首相が、3月16日の会見で、イギリス国民の約60%が集団免疫を獲得するまでピークをコントロールする趣旨の説明をしたようですが(ニューズウィークの記事)、これは、$R_0 = 2.6$と仮定して、ワクチンや自己免疫などでの集団免疫率$H$が、
(1-H)R_0 < 1を満たす条件から$H > 1-1/R_0=0.615$と想定されたようです。つまり、集団免疫によって、$R_0$の条件が緩和されるのですね。しかし、ワクチンの開発には臨床試験など1年以上かかる見込みですし、敢えて過剰に感染を抑えないことで集団免疫の獲得をしようという大胆な戦略です。
基本再生産数の計算モデル
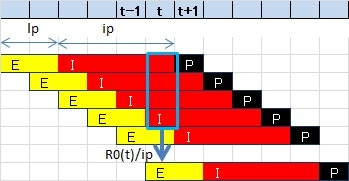
ここで、基本再生産数を計算するために、上記の定義とSEIRモデルをベースとした、簡易モデルを考えたいと思います。次の図を見てください。
上段は日付、下段の棒はある日の感染者集団を表しています。各記号の意味は、
- E:感染症が潜伏期間中の者(Exposed)
- I:発症者(Infectious)
- P:検査陽性者(Positive)
- lp:潜伏期間
- ip:感染期間
を表しています。つまり、ある日tにおけるIからEの生産は、t以前に感染し発症した状態にあるIの集団からの感染であり、その日tの再生産数は$R_0(t)/ip$である、というモデルです。
これを式で表すと、\frac{1}{ip} R_0(t) \times \sum_{s=t+1}^{t+ip} P(s) = P(t+lp+ip), \\ \therefore R_0(t) = \frac{ ip \times P(t+lp+ip)} {\sum_{s=t+1}^{t+ip} P(s)}となります。以下、この式を使って、公開されている検査陽性者のデータから、基本再生産数$R_0(t)$の時間推移を計算してみましょう。
元になるデータ
本記事では、都道府県別新型コロナウイルス感染者数マップ(ジャッグジャパン株式会社提供)において、公開されているcsvデータを使わせて頂きました。都道府県のデータが1つに集約されており、大変使いやすい形になっています。
Pythonで計算してみる
では、Pythonを使って、都道府県別の基本再生産数R0(t)を計算してみましょう。
前提条件
前提条件として、以下を用います。
- lp:潜伏期間 = 5[day]
- ip:感染期間 = 8[day]
- 上記の図のPは確定診断日とする。
なお、lpとipには諸説ありますが、一つの目安として設定しています。また、計算式の都合上、データの最新の日付から、lp+ip=13[day]以前の$R_0(t)$しか計算できません。グラフ上では、13日前~最新日の期間の値が0になっていても意味のない値ですので、ご注意ください。
コード
まず、ライブラリをインポートします。
# coding: utf-8 import numpy as np import matplotlib.pyplot as plt import pandas as pd import datetime import locale都道府県別新型コロナウイルス感染者数マップ(ジャッグジャパン株式会社提供)で提供されているcsvから、各都道府県別のデータを読み込み、データフレームに変換する関数です。
def readCsvOfJapanPref(pref : None): # 下記URLよりダウンロード # https://jag-japan.com/covid19map-readme/ fcsv = u'COVID-19.csv' df = pd.read_csv(fcsv, header=0, encoding='utf8', parse_dates=[u'確定日YYYYMMDD']) # 確定日, 受診都道府県のみ抽出 df1 = df.loc[:,[u'確定日YYYYMMDD',u'受診都道府県']] df1.columns = ['date','pref'] # 受診都道府県で抽出 if pref is not None: # Noneであれば日本全体 df1 = df1[df1.pref == pref] df1 = df1.loc[:,'date'] # 確定日でカウント df2 = pd.DataFrame( df1.value_counts() ).reset_index() df2.columns = ['date','P'] df2 = df2.sort_values('date') return df2計算用のデータフレームを定義する関数です。列のPpreは計算式の分母用、Patは計算式の分子用です。2020年1月24日を開始日として、days分だけ計算の枠を作ります。
def makeCalcFrame(days): t_1 = pd.Timestamp(2020,1,24) # 計算開始日 td = pd.Timedelta('1 days') # npd = [[t_1 + td * i, 0, 0, 0 ] for i in range(0,days)] df1 = pd.DataFrame(npd) df1.columns = ['date', 'Ppre','Pat', 'R0'] # return df1都道府県データと計算フレームを結合する関数です。
def mergeCalcFrame(df1, df2): return pd.merge(df1, df2, on='date', how='left').fillna(0)計算式に従って、$R_0$を計算する関数です。計算を簡単にするため、インデックスの範囲外にアクセスしたらNaNを返すラムダ式を作りました。
def calcR0(df, keys): lp = keys['lp'] ip = keys['ip'] nrow = len(df) getP = lambda s: df.loc[s, 'P'] if s < nrow else np.NaN for t in range(nrow): df.loc[t, 'Ppre'] = sum([ getP(s) for s in range(t+1, t + ip + 1)]) df.loc[t, 'Pat' ] = getP(t + lp + ip) if df.loc[t, 'Ppre'] > 0: df.loc[t, 'R0' ] = ip * df.loc[t, 'Pat'] / df.loc[t, 'Ppre'] else: df.loc[t, 'R0' ] = np.NaN return df結果をグラフ表示する関数です。
def showResult(df, title): # R0=1 : 収束のためのターゲット ptgt = pd.DataFrame([[df.iloc[0,0],1],[df.iloc[len(df)-1,0],1]]) ptgt.columns = ['date','target'] # show R0 plt.rcParams["font.size"] = 12 ax = df.plot(title=title,x='date',y='R0', figsize=(10,7)) ptgt.plot(x='date',y='target',style='r--',ax=ax) ax.grid(True) ax.set_ylim(0,) plt.show()各都道府県に対する計算を行う部分です。
def R0inJapanPref(pref, label): keys = {'lp':5, 'ip':8 } df1 = makeCalcFrame(60) # 60 days df2 = readCsvOfJapanPref(pref) df = mergeCalcFrame(df1, df2) df = calcR0(df, keys) showResult(df, 'COVID-19 R0 ({})'.format(label)) return df preflist = [[None, 'Japan'], [u'東京都', 'Tokyo'],\ [u'大阪府', 'Osaka'], [u'愛知県', 'Aichi'],\ [u'北海道', 'Hokkaido']] dflist = [[R0inJapanPref(pref, label), label] for pref, label in preflist]上の計算結果をまとめて表示する部分です。
def showResult2(ax, df, label): # show R0 plt.rcParams["font.size"] = 12 df1 = df.rename(columns={'R0':label}) df1.plot(x='date',y=label, ax=ax) # R0=1 ptgt = pd.DataFrame([[df_tko.iloc[0,0],1],[df_tko.iloc[len(df_tko)-1,0],1]]) ptgt.columns = ['date','target'] ax = ptgt.plot(title='COVID-19 R0', x='date',y='target',style='r--', figsize=(10,8)) # for df, label in dflist: showResult2(ax, df, label) # ax.grid(True) ax.set_ylim(0,10) plt.show()計算結果
それでは、いよいよ計算結果を見てみましょう。
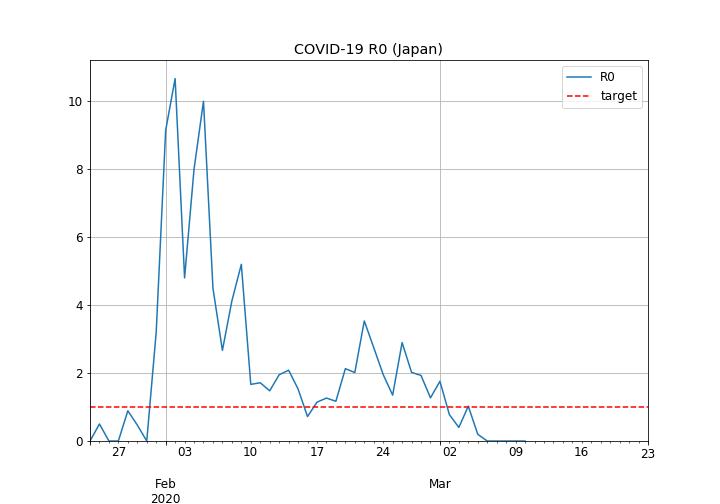
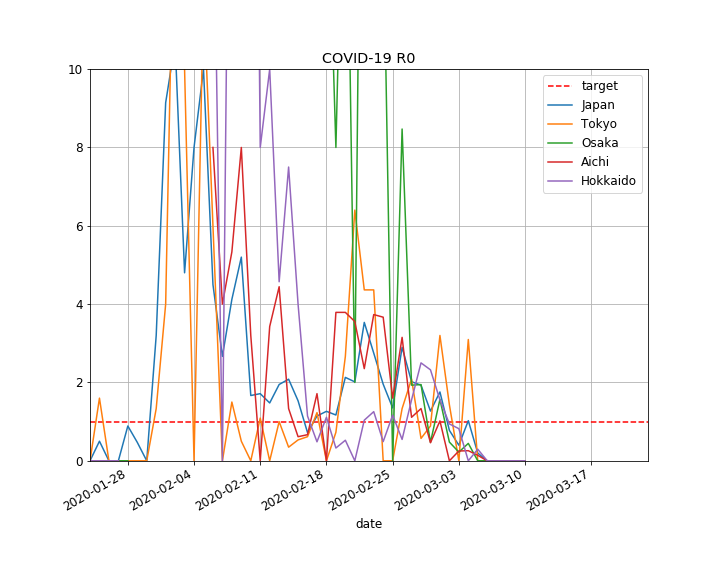
日本全体の基本再生産数の推移
- 2月10日までは最大10付近までの大きな流入があるようです。これは、恐らく、春節(1月24日~1月30日)に来日した中国旅行者の影響ではないでしょうか。
- その後は、一旦3付近まで上昇するものの、1を辛うじて超える付近(平均して1.5付近)で推移しているようです。
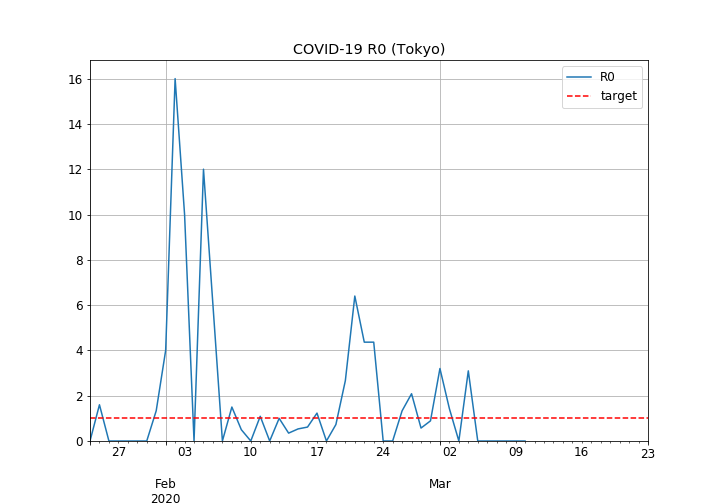
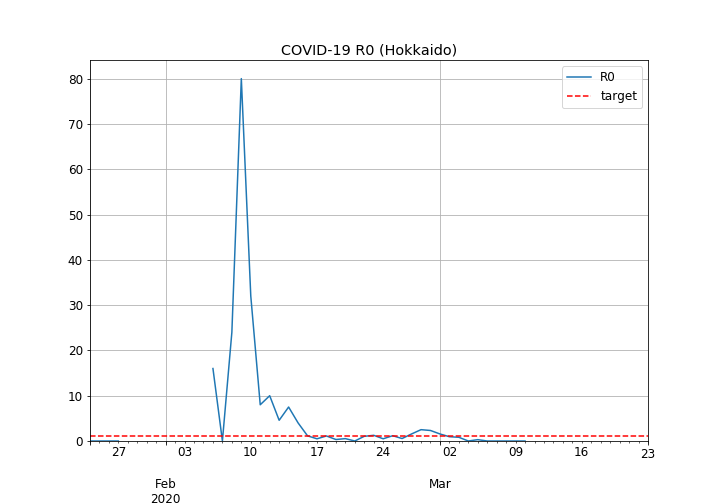
東京都の基本再生産数の推移
- 2月6日ごろまでは最大16の高い値でしたが、2月7日以降はおおむね落ち着いているようです。
- ただし、2月18日~2月23日や3月1日など、時折3を超える山があり、クラスターの発生や、海外からの流入があった可能性を示唆しています。
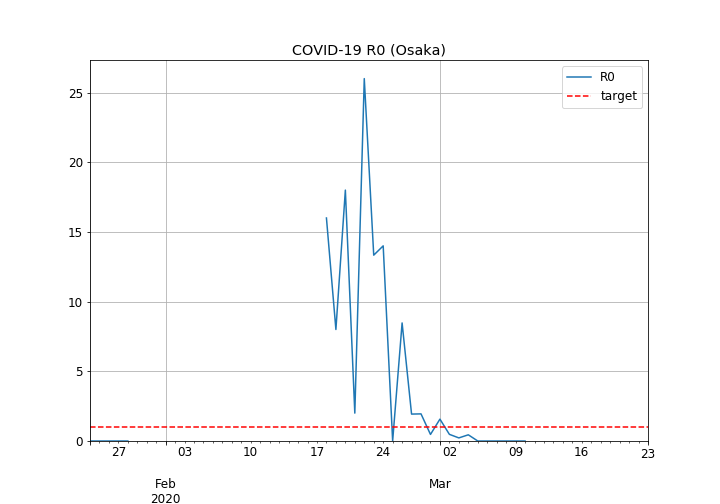
大阪府の基本再生産数の推移
- 2月17日~2月24日に最大26の大きなピークが見られます。これは恐らくクラスターの発生でしょう。
- 実際、高槻市のページによると、大阪市内の4つのライブハウスで2月15日から2月24日にかけて行われたライブの参加者から、感染クラスターの発生が確認されています。
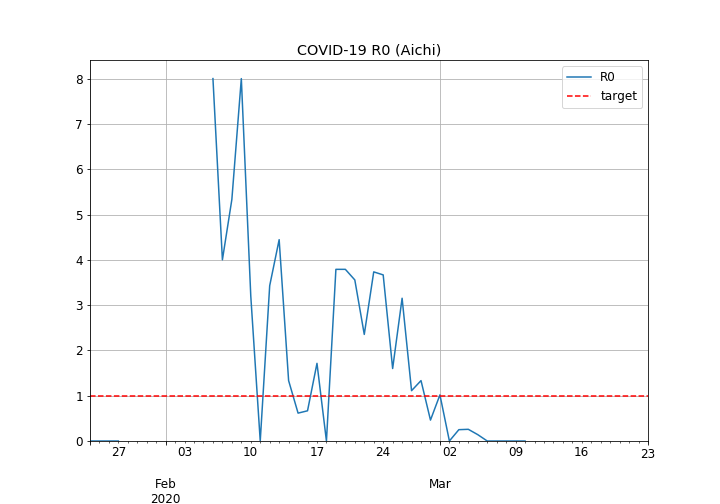
愛知県の基本再生産数の推移
- 2月12日までの、恐らく海外渡航者による感染が見られます。
- その後、2月18日から2月26日にかけておおむね3付近で推移する山が見られます。これは、報道されているように、ジムや福祉施設で起きたクラスターと思われます。
- クラスターの山と山が隣接してしまっているので、クラスター連鎖が心配されます。
北海道の基本再生産数の推移
- 2月8日から2月10日にかけて最大80もの鋭いピークが見られます。これは恐らく、さっぽろ雪祭り(2月4日~2月11日)で発生したクラスターではないかと思われます。
- 2月16日以降は、概ね1を下回る水準で推移しており、収束に向かっているものと思われます。
全体を比較
- 2月18日までに主に海外からの流入を主とした感染、3月1日までに国内でのクラスターの散発的な発生があったものと思われます。
- 3月1日以降は、全般的に落ち着いてきており、まだ1を超える水準であるものの、ギリギリ収束に向かっていると言えるのではないでしょうか。
考察
以上から、日本の各都道府県の感染者データに基づく、基本再生産数R0の推定に関して、次の傾向がシミュレーションから導けます。
- 2月中旬までの海外からの流入が最もR0が高く、その後国内でのクラスターと思われる影響で散発的に跳ね上がる傾向が見られる。
- それ以外の期間では、特に北海道では1を下回る期間をキープ出来ており、概ね良好な状態。
- 計算結果のクラスター疑惑日と、報道されているクラスター発生日(大阪のライブハウス、さっぽろ雪まつり)がよく一致しており、計算モデルからクラスター発生を当てられる可能性が高い。(もっとも、積極的疫学調査による発見の効果もあると思われます。)
さらに言えば・・・
- シミュレーション結果からは、基本再生産数$R_0$は一定ではなく、かなり変動しています。
- 基本再生産数$R_0$を上昇させる主要因は、海外からの流入と、クラスター発生であることが数値的にも裏付けられます。これらを抑制する対策は、やはり海外渡航制限と、クラスターの要因になりうるイベントや施設の自粛であると思われます。
- 全体的な傾向では、3月1日以降は収束傾向にあり、日本全体でR0が1に近づいているため、現状の対策が功を奏しているようにも見えます。
- $R_0$は陽性者数と陽性者数の比率なので、検査されていない隠れ感染者が検査陽性者の一定倍いたとしても影響は軽微でしょう。
参考リンク
下記のページを参考にさせて頂きました。
都道府県別新型コロナウイルス感染者数マップ(ジャッグジャパン株式会社提供)
京大数理解析研究所講究録
日本数理生物学会レター
ニューズウィークの記事
SEIRモデル
高槻市のページ直接引用してませんが、大変有用なリンクを追加しておきます。
COVID-19 reports
全国クラスターマップ
- 投稿日:2020-03-18T21:36:27+09:00
Django: 別 Middleware に依存している Middleware をテストする
概要
自作の Middleware を試験したいけど、別の Middleware に依存しているケースの対処法です。
どういうケース?
一般的に Middleware をテストする場合、Middleware のインスタンスを作成し、
process_requestメソッドを呼ぶのがメジャーなようです。
参照:Unit Testing Django Middleware - Adam Donaghy - Mediumしかし、別の Middleware で何かしらの処理を行っていることを前提にしている Middleware について、上記の方法では対応できません。
例えば、認証情報に係る処理を行う Middleware の場合、セッション関連のミドルウェアなどを経由していないとrequest.user参照時にuserattributeが存在せず例外が発生することなどが考えられます。対処
self.client.get()で実行します (View を試験するのと同じように)- Middleware が下の層を呼び出す
get_response()を適当なMockに差し替えます
- ※クラスインスタンスが持つ
get_response()は__init__で注入するものになっているので、__init__を適当なメソッドにすり替える必要があります。サンプル
Middleware
class SampleMiddleware(object): def __init__(self, get_response): self.get_response = get_response def __call__(self, request): # いろいろやる return self.get_response(request)テスト
def fake_init(self, _): def get_response(request): return HttpResponse() self.get_response = get_response class SampleMiddlewareTest(TestCase): def setUp(self): self.mock_init = mock.patch.object( AuthMiddleware, "__init__", fake_init ).start() self.addCleanup(mock.patch.stopall) def test_いろいろテスト(self): # リクエストする self.client.get("/") # assertする参照
- Mocking complicated
__init__in Python - George Shuklin - Medium
__init__を lambda で何もしない関数を注入しているサンプルを参考にしました。
- 投稿日:2020-03-18T21:14:37+09:00
兵庫県のCOVID19感染者状況のGraphQL APIを公開してみた。
どんなAPIにしたか
3分ごとに
↓↓↓よりエクセルファイルをダウンロードし
https://web.pref.hyogo.lg.jp/kk03/corona_kanjyajyokyo.html
読み込んだデータをDBに書き込みます。
別のコンテナにgraphQLサーバーを用意して配信します。コンテナ構成
- DB自動書き込み用コンテナ(pythonで実装)
- GraphQLサーバー(Goで実装)
ところが、残念ながら...
リリース後
定期実行される
pythonが読み込んでいる
エクセルファイルに想定外の変更が
before
after
画像の通りなんと空のセルで表現した二重線が追加されてしまいました。
ここに想定外のnullが発生してエラーが発生してしまい。
エクセルのデータをDBに書き込めないという状態になりました。
まぁ、担当の方が思いつくままに作っておられるであろうエクセルファイル仕方ありませんね。
なので、残念ながら3月16日までのデータしか提供できない状態となってしまいました。
残念!とはいえ、せっかくリリースしたのでリンク貼っておきます。
https://hyogo.covid19-api.ga
GraphQLのプレイグラウンドも公開しています。
https://hyogo.covid19-api.ga/playground
一応、ソースコードも
今回、残念な結果となったのでただ、アップしただけでドキュメントは書いてませんが...
https://github.com/inadati/hyogo-covid19-api.services


- 投稿日:2020-03-18T21:03:10+09:00
Python未経験者が言語処理100本ノックをやってみる07~ 今まさに書いている途中
これの続きでーす。
Python未経験者が言語処理100本ノックをやってみる00~04
https://qiita.com/earlgrey914/items/fe1d326880af83d37b22Python未経験者が言語処理100本ノックをやってみる05~06
https://qiita.com/earlgrey914/items/e772f1b7e5efea114e1d
07. テンプレートによる文生成
引数x, y, zを受け取り「x時のyはz」という文字列を返す関数を実装せよ.さらに,x=12, y="気温", z=22.4として,実行結果を確認せよ.
え。なにこれ?
なんか一気にすげー簡単になった・・・?iinoka.pyx=12 y="気温" z=22.4 def moziKetsugo(x, y, z): print(str(x) + "時の" + y + "は" + str(z)) moziKetsugo(x, y, z)12時の気温は22.4これでいいのか・・・?あまりにも簡単すぎないか・・・?
ちょっと穿った視点で考えてみよう。
この問題は引数が「x, y, z」という文字列だったら「x時のyはz」と返し、
x=12, y="気温", z=22.4 という変数だったら文字を当てはめて返す関数を作る問題ではないだろうか・・・?
(だとしたらもう少しわかりやすくそう書いてくれ)
だとしたら・・・Javaだと引数の有無で処理変えられたけど(何ていうのかわすれた)それと同じようなことをしろってことかしら。ググった。
デフォルト引数なるものがあるらしい。
<参考>
https://note.nkmk.me/python-argument-default/これでどうだ。
enshu07.pyx=12 y="気温" z=22.4 def moziKetsugo(x="x", y="y", z="z"): print(str(x) + "時の" + y + "は" + str(z)) #ただ出力 moziKetsugo() #引数を指定して出力 moziKetsugo(x, y, z)x時のyはz 12時の気温は22.4うーん、ちょっと出題意図がわからないので、もしわかる人がいたら教えて下さい。
流石にこんな簡単なのでいいのか怪しいゾ・・・08. 暗号文
与えられた文字列の各文字を,以下の仕様で変換する関数cipherを実装せよ.
・英小文字ならば(219 - 文字コード)の文字に置換
・その他の文字はそのまま出力
この関数を用い,英語のメッセージを暗号化・復号化せよ.(問題文を見出しにしてたけど、見出しの改行のやり方がわからなかったから変な感じになっちゃったゴメンね)
で、これはどういう問題なんだ。
日本語が難しいわ・・・ち、ちpはー(TOEIC340)まぁとりあえず構成を書く。
問題文に例となる暗号文・平文くらい書いといてほしいわね(プンプンpunpun.pygenbun = "the magic words are squeamish ossifrage To know is to know that you know nothing That is the true meaning of knowledge" def cipher(s): if s == 英小文字: (219 - 文字コード)の文字に置換 return 暗号後の文字列 else: return そのまま出力 #暗号化 angobun = cipher(genbun)) print(angobun) #復号化 fukugobun = decryption(genbun) print(fukugobun)で、文字コード変換はどうやるのかなっとググる。
てかこれ何にコード変換するの?UTF-8でいいの?UTF-8だと219-文字コードの部分が実装できないよ・・・?てことでググっていたら、pythonには文字のUnicodeコードポイントっていう整数を返してくれる関数
ord()ってのがあるらしい。たぶんコレを使えってことなんだろう。不親切ね!!!(プンプン試してみる。
tameshi.pyprint("a") print(ord("a"))a 97はー、なるほど。
じゃあ文字列は?moziha.pyprint("abc") print(ord("abc"))abc Traceback (most recent call last): File "/home/ec2-user/knock/enshu08.py", line 2, in <module> print(ord("abc")) TypeError: ord() expected a character, but string of length 3 foundなるほど。
ord()には1文字ずつ渡せと。OK。まずこのif文を書こう。
if.pyif s == 英小文字:「python 英小文字 判断」とかでテキトーにググったらソレ用の関数があるらしい。
小文字かどうかを判定(islower)
英数字であることを判定(isalnum)
英字かどうかを判定(isalpha)<参考URL>
https://hibiki-press.tech/learn_prog/python/isupper-islower/3728#islowerできたよー
dekitayo.pygenbun = "aBc0" def cipher(s): kaesubun = "" for i in s: #英字かどうか、かつ小文字かどうか判定 if i.isalpha() and i.islower(): kaesubun = kaesubun + chr(219-ord(i)) else: kaesubun = kaesubun + i return kaesubun angobun = cipher(genbun) print(angobun)zBx0上で書き忘れたけど文字→Unicodeコードポイントの変換は
ord()で、その逆はchr()でできるらしい。
今フツーにfor i in s:という書き方をしているが、この記法に演習03で気づいたのはデカい。
(個人的褒めポイント。みんな褒めて!!)
この記法に気づいていなかったら、わざわざstringを1文字ずつ分割して配列に入れて、取り出して処理・・・なんて書き方をしていたかもしれない。ていうかJava時代はそう書いていた。
- 投稿日:2020-03-18T21:03:10+09:00
Python未経験者が言語処理100本ノックをやってみる07~09
これの続きでーす。
Python未経験者が言語処理100本ノックをやってみる00~04
https://qiita.com/earlgrey914/items/fe1d326880af83d37b22Python未経験者が言語処理100本ノックをやってみる05~06
https://qiita.com/earlgrey914/items/e772f1b7e5efea114e1d
07. テンプレートによる文生成
引数x, y, zを受け取り「x時のyはz」という文字列を返す関数を実装せよ.さらに,x=12, y="気温", z=22.4として,実行結果を確認せよ.
え。なにこれ?
なんか一気にすげー簡単になった・・・?iinoka.pyx=12 y="気温" z=22.4 def moziKetsugo(x, y, z): print(str(x) + "時の" + y + "は" + str(z)) moziKetsugo(x, y, z)12時の気温は22.4これでいいのか・・・?あまりにも簡単すぎないか・・・?
ちょっと穿った視点で考えてみよう。
この問題は引数が「x, y, z」という文字列だったら「x時のyはz」と返し、
x=12, y="気温", z=22.4 という変数だったら文字を当てはめて返す関数を作る問題ではないだろうか・・・?
(だとしたらもう少しわかりやすくそう書いてくれ)
だとしたら・・・Javaだと引数の有無で処理変えられたけど(何ていうのかわすれた)それと同じようなことをしろってことかしら。ググった。
デフォルト引数なるものがあるらしい。
<参考>
https://note.nkmk.me/python-argument-default/これでどうだ。
enshu07.pyx=12 y="気温" z=22.4 def moziKetsugo(x="x", y="y", z="z"): print(str(x) + "時の" + y + "は" + str(z)) #ただ出力 moziKetsugo() #引数を指定して出力 moziKetsugo(x, y, z)x時のyはz 12時の気温は22.4うーん、ちょっと出題意図がわからないので、もしわかる人がいたら教えて下さい。
流石にこんな簡単なのでいいのか怪しいゾ・・・08. 暗号文
与えられた文字列の各文字を,以下の仕様で変換する関数cipherを実装せよ.
・英小文字ならば(219 - 文字コード)の文字に置換
・その他の文字はそのまま出力
この関数を用い,英語のメッセージを暗号化・復号化せよ.(問題文を見出しにしてたけど、見出しの改行のやり方がわからなかったから変な感じになっちゃったゴメンね)
cipherね、ハイハイ・・・ち、ちpはー(TOEIC340)
まぁとりあえず構成を書く。
問題文に例となる平文くらい書いといてほしいわね(プンプンpunpun.pygenbun = "the magic words are squeamish ossifrage To know is to know that you know nothing That is the true meaning of knowledge" def cipher(s): if s == 英小文字: (219 - 文字コード)の文字に置換 return 暗号後の文字列 else: return そのまま出力 #暗号化 angobun = cipher(genbun)) print(angobun) #復号化 fukugobun = decryption(genbun) print(fukugobun)で、文字コード変換はどうやるのかなっとググる。
てかこれ何にコード変換するの?UTF-8でいいの?UTF-8だと219-文字コードの部分が実装できないよ・・・?ググっていたら、pythonには文字のUnicodeコードポイントっていう整数を返してくれる関数
ord()ってのがあるらしい。たぶんコレを使えってことなんだろう。不親切ね!!!(プンプン試してみる。
tameshi.pyprint("a") print(ord("a"))a 97はー、なるほど。
aは97ですか。
じゃあ文字列は?moziha.pyprint("abc") print(ord("abc"))abc Traceback (most recent call last): File "/home/ec2-user/knock/enshu08.py", line 2, in <module> print(ord("abc")) TypeError: ord() expected a character, but string of length 3 foundなるほど。
ord()には1文字ずつ渡せと。OK。まずこのif文を書こう。
if.pyif s == 英小文字:「python 英小文字 判断」とかでテキトーにググったらソレ用の関数があるらしい。
小文字かどうかを判定(islower)
英数字であることを判定(isalnum)
英字かどうかを判定(isalpha)<参考URL>
https://hibiki-press.tech/learn_prog/python/isupper-islower/3728#islower暗号化できたよー
dekitayo.pygenbun = "aBc0" def cipher(s): kaesubun = "" for i in s: #英字かどうか、かつ小文字かどうか判定 if i.isalpha() and i.islower(): kaesubun = kaesubun + chr(219-ord(i)) else: kaesubun = kaesubun + i return kaesubun angobun = cipher(genbun) print(angobun)zBx0上で書き忘れたけど文字→Unicodeコードポイントの変換は
ord()で、その逆はchr()でできるらしい。
そして今フツーにfor i in s:という書き方をしているが、この記法に演習03で気づいたのはデカい。
(個人的褒めポイント。みんな褒めて!!)
この記法に気づいていなかったら、わざわざstringを1文字ずつ分割して配列に入れて、取り出して処理・・・なんて書き方をしていたかもしれない。ていうかJava時代はそう書いていた。次に復号化。これは簡単ね。
yoyu.pygenbun = "aBc0" #暗号化の関数 def cipher(s): kaesubun = "" for i in s: #英字かどうか、かつ小文字かどうか判定 if i.isalpha() and i.islower(): kaesubun = kaesubun + chr(219-ord(i)) else: kaesubun = kaesubun + i return kaesubun #復号化の関数 def decryption(s): kaesubun = "" for i in s: if i.isalpha() and i.islower(): kaesubun = kaesubun + chr(219+ord(i)) else: kaesubun = kaesubun + i return kaesubun print("原文") print(genbun) angobun = cipher(genbun) print("暗号文") print(angobun) fukugobun = decryption(angobun) print("復号文") print(fukugobun)原文 aBc0 暗号文 zBx0 復号文 ŕBœ0アルェーーーーーーーーーー!?!?!?
紙で算数してみたら
chr(219+ord(i))じゃなくchr(219-ord(i))でした。
簡単だと思っているところに落とし穴がある。教訓としてください()てことで完成↓。
enshu08.pygenbun = "aBcDeFghijKLM0123456789" #暗号化の関数 def cipher(s): kaesubun = "" for i in s: #英字かどうか、かつ小文字かどうか判定 if i.isalpha() and i.islower(): kaesubun = kaesubun + chr(219-ord(i)) else: kaesubun = kaesubun + i return kaesubun #復号化の関数 def decryption(s): kaesubun = "" for i in s: if i.isalpha() and i.islower(): kaesubun = kaesubun + chr(219-ord(i)) else: kaesubun = kaesubun + i return kaesubun print("原文") print(genbun) angobun = cipher(genbun) print("暗号文") print(angobun) fukugobun = decryption(angobun) print("復号文") print(fukugobun)原文 aBcDeFghijKLM0123456789 暗号文 zBxDvFtsrqKLM0123456789 復号文 aBcDeFghijKLM0123456789次つぎ!!
09. Typoglycemia
スペースで区切られた単語列に対して,各単語の先頭と末尾の文字は残し,それ以外の文字の順序をランダムに並び替えるプログラムを作成せよ.ただし,長さが4以下の単語は並び替えないこととする.適当な英語の文(例えば"I couldn't believe that I could actually understand what I was reading : the phenomenal power of the human mind .")を与え,その実行結果を確認せよ.
日本語難しい定期。
まずは全体像。
zenta.pys = "I couldn't believe that I could actually understand what I was reading : the phenomenal power of the human mind ." #原文を半角スペースで区切ったリストを作る list = s.split() kaesubun = [] for i in list: if リスト内の文字列の長さが4より大きい: 先頭と末尾の文字は残し,それ以外の文字の順序をランダムに並び替える kaesubun.append(入れ替えた後の文字) else: #入れ替えずそのまま kaesubun.append(i)うん、そんなに難しくなさそう。
「それ以外の文字の順序をランダムに並び替える」ってのはどうやるのかなっとググった。ランダムに複数の要素を選択(重複なし): random.sample()
<参考URL>
https://note.nkmk.me/python-random-choice-sample-choices/なるほど。
ここで初めてrandomを仕様するために標準ライブラリを使うことになるけどいいのかしら?まぁいいか。
randomを試してみる。rand.pyimport random s = ["a", "b", "c", "d","e"] print(random.sample(s, 5))['c', 'e', 'b', 'a', 'd']うん。いい感じ。5文字がランダムに取得できた。
「先頭と末尾は残し」ってのは演習02でやったのと同じようにスライスを使う。
「2文字目(1)から末尾の一つ前の文字まで(-1)」とも言えるので[1:-1]とonazi.pys = ["a", "b", "c", "d", "e"] print(s[1:-1])['b', 'c', 'd']「先頭」と「末尾」も同じくスライス
nokosi.pys = ["a", "b", "c", "d", "e"] print(s[0]) print(s[-1])['a'] ['e']よし。行けそう。
てかやっぱりスライスの記法、ちょっと面倒ね。
s[-1]は「末尾の1文字」なのに
s[1:-1]は「2文字目から末尾の一つ前の文字まで」なんだよ?
ちょっとわかりづらくない?↓こう書いたほうがいいかもね。(こんな書き方ができるのかは知らん)
「末尾の1文字」
s[-1: : ]
「2文字目から末尾の一つ前の文字まで」
s[1:-1: ]~20分後~
できました。enshu09.pyimport random s = "I couldn't believe that I could actually understand what I was reading : the phenomenal power of the human mind ." #原文を半角スペースで区切ったリストを作る kugitta_list = s.split() kaesubun = [] #原文の単語ごとに処理 for ichitango in kugitta_list: #単語が4文字より大きいなら if len(ichitango) > 4: kaesutango = [] #単語を1文字ずつ区切ってリスト化 ichitango_kugitta_list= list(ichitango) #先頭と末尾の文字を除いた文字のリストを作る sentou_matsubi_nozoita_list = ichitango_kugitta_list[1:-1] #先頭の文字を「返す単語」リストに入れる kaesutango.append(ichitango_kugitta_list[0]) #先頭と末尾の文字を除いた文字のリストからランダムで全文字を取得して「返す単語」リストに入れる kaesutango.extend(random.sample(sentou_matsubi_nozoita_list, len(sentou_matsubi_nozoita_list))) #末尾の文字を「返す単語」リストに入れる kaesutango.append(ichitango_kugitta_list[-1]) #返す単語」を「返す文」のリストに入れる kaesubun.append(''.join(kaesutango)) else: #入れ替えずそのまま「返す文」のリストに入れる kaesubun.append(ichitango) #返す文の配列を文字列に変換して出力(ついでに配列の要素の区切り文字に空白スペースを指定) print(' '.join(kaesubun))I c'ulnodt bvlieee that I could altluacy usraetdnnd what I was rdnieag : the paemonnhel pewor of the hmuan mind .初出の記法は
''.join(kaesubun)かな。1文字ずつに区切った文字列リストを文字列に変換しているよ。
["a", "b", "c"]というリストがあったなら
''.join(リスト)と書くことでabcと出力されるよ。
'あ'.join(リスト)と書くことでaあbあcと出力されるよ。(「あ」が区切り文字となる)うーん、我ながら良いぞ。
よし!!!これで言語処理第1章の10問がすべて完了しました!!!!
この記事だけで2時間かかりました!!!!!!!!(重要)
第1章にかかった時間は7時間です!!!!!!(重要)明日からは第2章でーす。
- 投稿日:2020-03-18T20:51:43+09:00
3層順伝搬型ニューラルネットワークを自作して、計算を深く理解しようとした
はじめに
機械学習や深層学習はライブラリが豊富なため、簡単なコピペにより予測が可能になっています。私自身も多くの先人が作ったプログラムを動かして概要は分かるようなレベルになってきました。
特に、深層学習(ニューラルネットワーク)に関してはGANや自然言語処理に応用されています。目まぐるしく新しい技術が生み出されているジャンルであり、社会・産業への応用が迅速に進んでいると思っています。従って、そのような変革の中心にある技術と認識しており、非常に興味深くこれら分野について深く理解したい!という動機があります。現在、ディープラーニングの教科書として有名なこちらで基礎から学び始めております。
https://www.oreilly.co.jp/books/9784873117584/
今回、ニューラルネットワークをほぼ一から構築することで(numpyは使用しますが)、そこで行われている計算を実感を持って理解したいと思います。要約としては下記です。
- パーセプトロンを理解する
- ニューラルネットワークに展開する
- 3層のニューラルネットワークを実装する
パーセプトロンを理解する
パーセプトロンとは、複数の信号を入力として受け取り、一つの信号を出力することを示します。機械学習の分野では、信号を出力しないことは0、信号を出力することを1として扱います。
この考えを簡単に図にしたものが上の図になります。xは入力信号、yが出力信号、wが重みを表します。この〇はニューロンと呼ばれます。ニューロンには、重みと入力の値を掛けた総和が送られます。この時、総和が閾値θを超えたときに出力1を出します。下記の式になります。
AND回路で確認してみる
それでは、実際にプログラムを作ります。上記の図で示している簡単なパターンを再現しました。
まず、閾値が0.4の時で計算してみましょう。NN.ipynbdef AND(x1,x2): w1,w2,theta = 0.5,0.5,0.4 tmp = x1*w1 + x2*w2 b = -0.5 if tmp <= theta: return 0 elif tmp > theta: return 1print(AND(0,0)) print(AND(1,0)) print(AND(0,1)) print(AND(1,1)) 0 1 1 1結果として、x1,x2どちらかが1であれば出力として1を吐き出すことが分かりました。一方、閾値を0.7とすると、下記のようになります。
print(AND(0,0)) print(AND(1,0)) print(AND(0,1)) print(AND(1,1)) 0 0 0 1x1,x2どちらかだけが1だと出力で1を吐き出さなくなりました。閾値の設定により得られる出力が変わることが確認できます。
ニューラルネットワークに展開する
多層パーセプトロンとは、入力層と出力層の間に中間層と呼ばれる層があるネットワークのことです。本によっても記載が異なる場合がありますが、下記図の場合入力層を0層、中間層を1層、出力層を2層と呼ぶことにしています。
ニューラルネットワークの層の数え方
ここで、〇層のニューラルネットワークと呼ぶ際の数え方には流儀(慣習?)があるようです。重み層を数えたり、あるいはニューロンの層を呼ぶ場合もあるようです。どちらが一般的かは私も経験があまりありませんが、オライリーの教科書に習って重み層ベースで名付けたいと思います。
バイアスを理解する
次に、バイアスbと呼ぶ値を導入します。先ほどの閾値θを―bとして先ほどの式を整理すると上式のように、0を基準にしてyの出力を0か1に決めることが可能になります。バイアスとは、小職の業界(製造業)では「下駄をはかせる」補正値の意味合いで、値を全体的にy軸に上下させることが可能となります。
活性化関数を理解する
yが0か1かを判別させる関数を活性化関数と呼びます。この活性化関数によって得られる値は0か1近辺の値とすることができるため、計算の発散を防ぐことができる機能もあります。
この活性化関数はいくつか種類があります。
- シグモイド関数
活性化関数でよく使われる関数の一つです。下記のような自然対数の底であるネイピア数eの関数の分数、になります。ぱっとこの関数の形は思い浮かびにくいのですが、描くくと下記のようになります。
NN.ipynbimport numpy as np def sigmoid(x): return 1/(1+np.exp(-x)) xxx = np.arange(-5.0,5.0,0.1)#sigmoid関数を表示 yyy = sigmoid(xxx) plt.plot(xxx,yyy) plt.ylim(-0.1,1.1) plt.show
x=0を境にx>0では徐々にy=1に漸近していくことが分かります。また、逆にx<0ではy=0に漸近していくことが分かります。入力した値を0~1の間で出力させることができる点が、活性化関数の役割を果たせているため、非常に便利であることが分かります。
- ステップ関数
次に、先ほどのシグモイド関数をさらに極端に0,1を出力させる関数としてステップ関数があります。
これは下記のように書くことになります。NN.ipynbdef step_function(x): return np.array(x > 0, dtype=np.int) x = np.arange(-5.0, 5.0, 0.1) y = step_function(x) plt.plot(xxx,yyy) plt.plot(x, y) plt.ylim(-0.1, 1.1) plt.show()
青がステップ関数で、オレンジがシグモイド関数になります。出力値を0か1しかとらないことが良く分かります。この関数の使い分けに関しては、私自身感覚が薄いところもあるため、今後の宿題とさせてください。
感覚としては、シグモイド関数のほうがより細やかに値を取ることが可能であるため、微妙な入力差でも違いを区別できる機能を有していると理解しています。一方で、多層で計算負荷が高い場合は、適宜ステップ関数を利用することで負荷を下げつつ判別させることができる使い分けをするのではないかと思います。
- 非線形関数(ReLU関数)
最後に、こちらもよく使われている印象があるReLU(Rectified Linear Unit)関数についてです。xが0を超えていれば、その値をそのままyとして出力し、0以下なれば0を出力する関数になります。
NN.ipynbdef relu(x): return np.maximum(0,x) xx = np.arange(-5.0,5.0,0.1) yy = relu(xx) plt.plot(xx,yy) plt.ylim(-0.1,5) plt.show
順伝搬型ってなに
今回、順伝搬型のニューラルネットワークを作ります。この順伝搬型とは、入力から出力に一方向に流れていくことを示しています。モデルの学習を考える際は、逆に出力から入力へ向かって計算を行います。これは逆伝搬法と呼びます。3層のニューラルネットワークを実装する
さて、実際に3層のニューラルネットワークを記述していきたいと思います。
上図で記されている3層のニューラルネットワークを作ることを考えます。
まずは、上図の太字で目立っている計算だけを下記に取り出してみます。NN.ipynbdef init_network(): network = {} network['W1'] = np.array([[0.1,0.3,0.5],[0.2,0.4,0.6]]) network['b1'] = np.array([0.1,0.2,0.3]) return network def forword(network,x): W1= network['W1'] b1= network['b1'] a1 = np.dot(x,W1)+b1 z1 = sigmoid(a1) return y network = init_network() x = np.array([2,1]) z1 = forword(network,x) print(z1)[0.40442364 0.59557636]init_network()関数に重みやバイアスを定義させ、forword()関数に実際に計算させる式を定義させました。後は、その関数を呼び出して初期値のxを代入させて答えを吐き出せるようにしています。ずらっと関数を定義せずに記述するよりも分かりやすいですね。
また、ここでnp.dotとして記載している行列の内積を表す関数にも注意が必要です。行列の積は、掛け算の順番で得られる行列の次元が変わることから、記述の際は注意しましょう。
3層のニューラルネットワーク
NN.ipynbdef init_network(): network = {} network['W1'] = np.array([[0.1,0.3,0.5],[0.2,0.4,0.6]]) network['b1'] = np.array([0.1,0.2,0.3]) network['W2'] = np.array([[0.1,0.4],[0.2,0.5],[0.3,0.6]]) network['b2'] = np.array([0.1,0.2]) network['W3'] = np.array([[0.1,0.3],[0.2,0.4]]) network['b3'] = np.array([0.1,0.2]) return network def forword(network,x): W1,W2,W3 = network['W1'],network['W2'],network['W3'] b1,b2,b3 = network['b1'],network['b2'],network['b3'] a1 = np.dot(x,W1)+b1 z1 = sigmoid(a1) a2 = np.dot(z1,W2)+b2 z2 = sigmoid(a2) a3 = np.dot(z2,W3)+b3 y = softmax(a3) return y二つの関数に最後まで記述させるとこのような書き方になります。さて、ここで先出ししましたがsoftmaxと書かれた記述が最後にあります。これについて次でまとめました。
恒等関数とソフトマックス関数
あとは、この二つの関数に層を付け加えていけば良いことが分かります。そして、最後に出力する値yについて考えます。
数字の0~9種類を当てる問題など分類を行う必要がある場合は、それぞれの種類に該当する確率を出力させ、一番確率が高いものを予測値とします。そのような確率として表すうえで便利な関数がソフトマックス関数です。
ある分類の項目すべてで取る値の総和を分母とし、個別の取る値を分子とすることで確率を表す値とすることができます。
このソフトマックス関数で終えることで分類問題を確率へ帰着させ、最も高い値を予測値としているのです。
実装上では、expの指数関数であるため、非常に値が発散しやすくなる課題があります。
従って、ある定数を分母、分子にかけてexpの指数に入れ込むことで発散しにくくなることを便宜上行っておくことがよくあるようです。NN.ipynbdef softmax(a): c = np.max(a) exp_a = np.exp(a-c) sum_exp_a = np.sum(exp_a) y = exp_a/sum_exp_a return y初期条件を入力し、答えを出力させる
NN.ipynbnetwork = init_network() x = np.array([2,1]) y = forword(network,x) print(y)[0.40442364 0.59557636]試しに、xへ適当な値を入れてみたところ、下記のように答えが返ってきました。
y1が40%、y2が60%の確率であることを示す値が出力されました。
後は入力の行列が大きくなったり、層が深くなる(≒増える)ことで複雑な分類を行えるようになっていくと理解しています。終わりに
今回、非常にベーシックなニューラルネットワークを手作りしました。手を動かしてみるだけでかなり理解が深まりました。
なんとなくコピペして動かしたGANアルゴリズムの基礎の基礎、をようやっと分かるようになりました。ここに、モデルの学習や畳み込みといった考えを入れることで畳み込みニューラルネットワークへ、さらにGANへ繋がっていくのでしょう。
最新の技術へたどり着くにはまだまだ序章かもしれませんが、このようにまとめて着実に理解を深めることで確実に自分の技術力アップにつなげていければと思います。プログラム全文はこちらです。関数で遊んだだけのファイルと3層ニューラルネットワークのファイルに分かれています。
https://github.com/Fumio-eisan/neuralnetwork_20200318
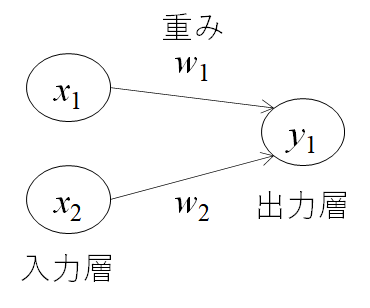
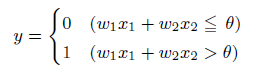
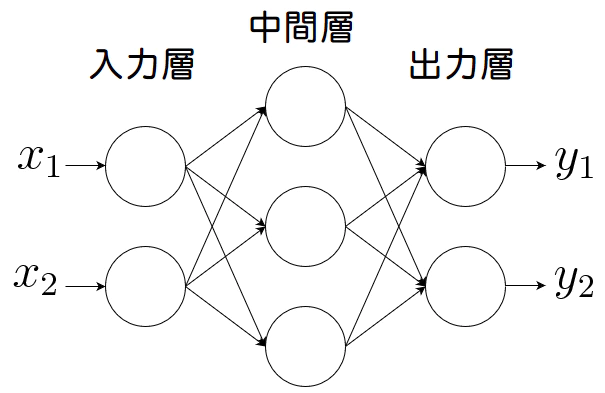
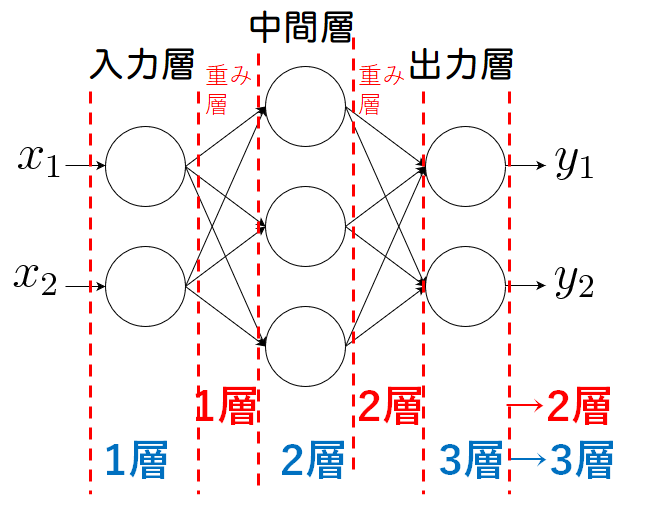
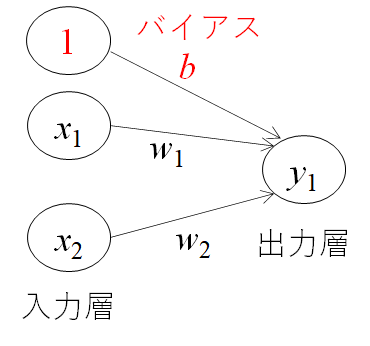
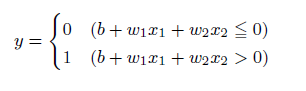
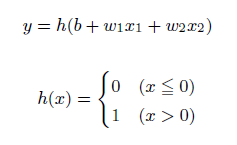
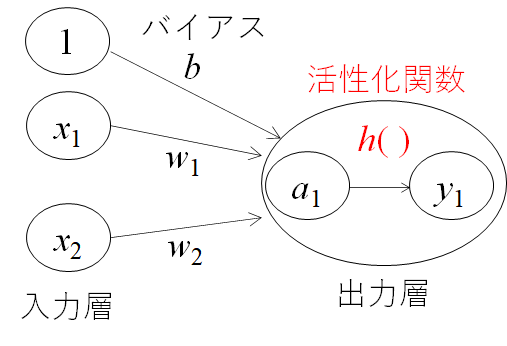
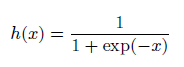
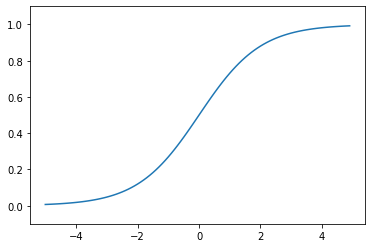
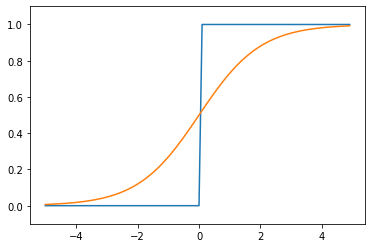

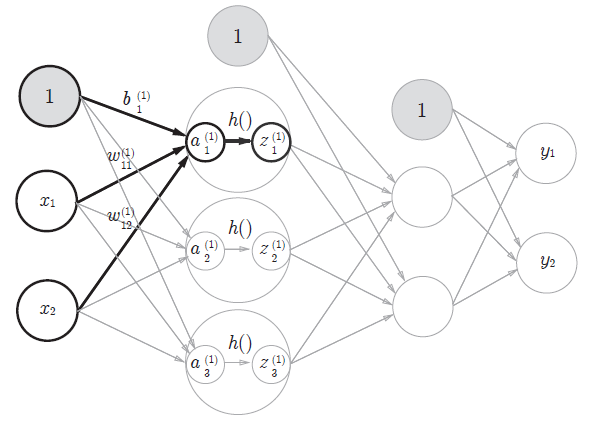
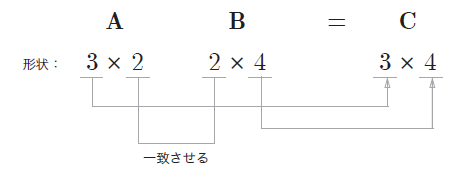
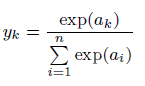
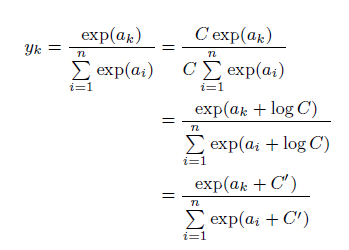
- 投稿日:2020-03-18T20:40:19+09:00
【Python】async/awaitで非同期リクエスト
Pythonでの非同期リクエストには、asyncioモジュールを用います。
requestsパッケージを用いて、APIを非同期で叩くコードを作成してみます。環境
- Python 3.7.4
API
time.sleep()を用いてもよかったのですが、今回はより実践よりにAPIを取得するパターンを想定してみます。
モックサーバーとして、JSONPlaceholderを使用しました。一覧を取得するAPI(以下の6つ)を同期・非同期でリクエストし、それぞれの結果を一つのリストにした結果を返すコードを書きます。
https://jsonplaceholder.typicode.com/posts
https://jsonplaceholder.typicode.com/comments
https://jsonplaceholder.typicode.com/albums
https://jsonplaceholder.typicode.com/photos
https://jsonplaceholder.typicode.com/todos
https://jsonplaceholder.typicode.com/users同期リクエスト
まずは同期処理でのリクエストを行ってみます。
普段のPythonコード通りに書くと、以下のようになります。import time import requests BASE_URL = "https://jsonplaceholder.typicode.com/" def calc_time(fn): """関数の実行時間を計測するデコレータ""" def wrapper(*args, **kwargs): start = time.time() fn(*args, **kwargs) end = time.time() print(f"[{fn.__name__}] elapsed time: {end - start}") return return wrapper def get_sync(path: str) -> dict: print(f"/{path} request") res = requests.get(BASE_URL + path) print(f"/{path} request done") return res.json() @calc_time def main_sync(): data_ls = [] paths = [ "posts", "comments", "albums", "photos", "todos", "users", ] for path in paths: data_ls.append(get_sync(path)) return data_ls if __name__ == "__main__": main_sync()実行すると、以下のような出力が得られます。
リクエスト1 -> リクエスト1完了
リクエスト2 -> リクエスト2完了
リクエスト3 -> リクエスト3完了...と実行されていることがわかります。
/posts request /posts request done /comments request /comments request done /albums request /albums request done /photos request /photos request done /todos request /todos request done /users request /users request done [main_sync] elapsed time: 1.157785415649414非同期リクエスト
次に非同期リクエストを行います。
非同期で行うタスクはイベントループ内で実行されます。
イベントループを取得するには、asyncio.get_event_loop()を用います。
loop.run_until_completeは、その名前の通りそれぞれのタスクが実行され終わるまでイベントループが実行されるメソッドです。
このメソッドの返り値は、それぞれの非同期実行タスクの返り値が入ったリストです。
実行される順番は保障されていないのですが、返り値は引数に渡した順番で返ってくるので、順番が重要な場合も利用できます。
async defで宣言されるget_asyncはコルーチン関数と呼ばれます。
コルーチン関数内でのawait式は、コルーチン関数の実行を返り値が戻るまで一時停止されます。import asyncio # コルーチン関数 async def get_async(path: str) -> dict: print(f"/{path} async request") url = BASE_URL + path loop = asyncio.get_event_loop() # イベントループで実行 res = await loop.run_in_executor(None, requests.get, url) print(f"/{path} async request done") return res.json() @calc_time def main_async(): # イベントループを取得 loop = asyncio.get_event_loop() # 非同期実行タスクを一つのFutureオブジェクトに tasks = asyncio.gather( get_async("posts"), get_async("comments"), get_async("albums"), get_async("photos"), get_async("todos"), get_async("users"), ) # 非同期実行、それぞれが終わるまで results = loop.run_until_complete(tasks) return results if __name__ == "__main__": main_async()出力は以下のようになります。
リクエスト1 リクエスト2 リクエスト3...
リクエスト1完了 リクエスト2完了 リクエスト3完了...と処理されていることがわかります。
また実行時間もかなり短縮されていることがわかります。/posts async request /comments async request /albums async request /photos async request /todos async request /users async request /users async request done /todos async request done /posts async request done /albums async request done /comments async request done /photos async request done [main_async] elapsed time: 0.17921733856201172
- 投稿日:2020-03-18T19:47:45+09:00
Kinx プレビュー版リリース
Kinx プレビュー版のリリース
はじめに
「見た目は JavaScript、頭脳(中身)は Ruby、(安定感は AC/DC)」でお送りするスクリプト言語 Kinx。まだまだ途中だがリリースするのも意味があるだろうとの想定から、実行可能な形でパッケージングし、まずはプレビュー・リリースすることにしました。Windows 版の実行ファイルはアイコンもつけていい感じ。Linux は /usr/bin にインストールしてしまうので、一応気にしておいてください。
本題
↓ここです。
もちろん、git clone して make もできます。
本題、おしまい。
振り返り
元々はこの記事での「プログラマに馴染むシンタックスってのは C 系だよね、でも何で Ruby も Python も全然違うのでしょう」というところから始まった今回のプロジェクト。プロジェクト自体は去年末くらいから実質スタートしてたので、約 5 ヶ月くらいか。
元々からしてほぼ JavaScript な文法なので、作りながらではあるものの、既にすっかり私の手には馴染んでます。
まだ初版にはできませんが(おっとさっき気づいたのだが標準入力がない...)、結構色々試せるとは思います。
ほんのちょっと興味があれば
何か試してみてフィードバック貰えると非常に嬉しい。まぁ、既存の何かを置き換えるようなたいそうなモノではないので、ちょっとした提案とかこんなんあるといいんじゃない、とか、そういうライトな感じのご意見ください。
すみません、見返りはあまり無いと思います…。そういうの楽しめる方か、面白そうだと思ってくださる方向け。
おわりに
最後はいつもの以下の定型フォーマットです。
- 最初の動機は スクリプト言語 KINX(ご紹介) を参照してください(もし宜しければ「
いいねLGTM」ボタンをポチっと)。- リポジトリは ここ(https://github.com/Kray-G/kinx) です。こちらももし宜しければ★をポチっと。
- 投稿日:2020-03-18T18:48:34+09:00
Python未経験者が言語処理100本ノックをやってみる05~
これの続きでーす。
Python未経験者が言語処理100本ノックをやってみる00~04
https://qiita.com/earlgrey914/items/fe1d326880af83d37b22
05. n-gram
与えられたシーケンス(文字列やリストなど)からn-gramを作る関数を作成せよ.この関数を用い,"I am an NLPer"という文から単語bi-gram,文字bi-gramを得よ.
n-gramって何だっけかなぁ・・・なんか聞いたことあるけど。
ってこの問題n-gramがなにか理解できてないと解けないじゃん!まずそこからかよ!!~2分ググった~
N-gramとは自然言語(テキスト)を連続するN個の文字、もしくはN個の単語単位で単語を切り出す手法のことです。
<参考>
https://www.pytry3g.com/entry/N-gram
なるほど。
じゃあ1が渡されたら1文字ずつ区切って、2が渡されたら2文字ずつ区切るような関数を作ればいのね。
単語bi-gramってのは単語単位で2文字区切り
文字bi-gramってのは文字単位で2文字区切りすばいいってことかしらね。
だから解答は
■単語bi-gram
["I", "am", "an", "NL", "Pe", "r"]
■文字bi-gram
["I ","ma","an","NL","Pe","r"]
って出力すればいいのかな?間違ってたらゴメンネ。この前提で解くよ。ふつーに間違っていたので解答の出力結果のみチラ見した。
[['I', 'am'], ['am', 'an'], ['an', 'NLPer']] ['I ', ' a', 'am', 'm ', ' a', 'an', 'n ', ' N', 'NL', 'LP', 'Pe', 'er']このように出力されればOKらしい。
なるほど。ウィ。とりあえず単語bigramができた。
enshu05.pys = "I am an NLPer" tango_bigram= [] def bigram(s): counter = 0 list = s.split() for i in list: if counter < len(list)-1: tango_bigram.extend([[list[counter],list[counter+1]]]) counter += 1 return tango_bigram print(bigram(s))[['I', 'am'], ['am', 'an'], ['an', 'NLPer']]ここらでそろそろお気づきだと思うが、コードを書いていく上で色々とよろしくない部分が見え始めた。
- 変数の命名が適当すぎる。英語と日本語が混ざってるし、
sやiといった1文字変数を使うところもあれば、counterなどの変数名を使っているところもある- ここではスネークケースである
tango_bigramという書き方をしているが、前(演習4)はキャメルケースでichimoziListと書いており、バラバラ。- 改行ルールが謎。半角スペースを入れるルールが謎。
今後直していきたいが、今はまだ目をつむっていく。一人で書いているだけなので。
まぁそのうち自分で書いたコードが自分で「見づれえええええ」ってなって直さざるをえなくなるんだけどね。前の演習ではリストへの追加は
append()を使ったが、ここではextend()を使った。
複数要素をいっきにリストに入れたい場合はextend()を使えばいいらしい。
l += [1, 2, 3]といった+=を使う記法もあるらしいが、extend()のほうがわかりやすいなぁという印象。<参考URL>
https://qiita.com/tag1216/items/416314cc75a099ad6149で、
似たような感じで文字bigramも書いた。enshu05.pys = "I am an NLPer" tango_bigram= [] moji_bigram = [] def bigram(s): tango_counter = 0 moji_counter = 0 #単語gram処理 list = s.split() for i in list: if tango_counter < len(list)-1: tango_bigram.extend([[list[tango_counter],list[tango_counter+1]]]) tango_counter += 1 #文字gram処理 for i in s: if moji_counter < len(s)-1: moji_bigram.append(s[moji_counter] + s[moji_counter+1]) moji_counter += 1 return tango_bigram,moji_bigram print(bigram(s))([['I', 'am'], ['am', 'an'], ['an', 'NLPer']], ['I ', ' a', 'am', 'm ', ' a', 'an', 'n ', ' N', 'NL', 'LP', 'Pe', 'er'])可読性がゴミだな!!!
まぁいいや。
Pythonの「関数は関数呼び出し処理より上に書かないといけない」っていう規約?慣れないなぁ・・・個人的な印象だが、Pythonは動的型付けである点と、インデントによるブロック区切りのおかけで、
「書くのは楽だが読むのは大変」という印象がある。
Javaみたいな静的型付け言語で{}を使ったブロック区切りに慣れているからかしら・・・
Javaもインデントが適当だと著しく可読性が落ちるけどね。ちょっと休憩
なんかいい変数名の付け方ないの?と思ってググったらこういう記事もあった。
<参考URL>
https://qiita.com/Ted-HM/items/7dde25dcffae4cdc792306. 集合
"paraparaparadise"と"paragraph"に含まれる文字bi-gramの集合を,それぞれ, XとYとして求め,XとYの和集合,積集合,差集合を求めよ.さらに,'se'というbi-gramがXおよびYに含まれるかどうかを調べよ.
なんかもうまず日本語が難しいんだが。
いや一応わかるけどさ。プログラム以前に日本語の解読が大変。この問題見た瞬間に「え?集合?もうそういうの計算できるライブラリをインポートして使っていい?」と思った。
さっきのN-gramもライブラリであるでしょ絶対・・・筆者は世の中において「自分で作らなければいけない」ものは「自分だけが思いついたもの」と思っているので、
誰かが作ってくれたものがあるならそれを活用したほうがいいと思っている。が、今回は目的が学習であるため、ちゃんと自分で作ります。
演習05のbigram関数をちょっといじれば2つの文字列bigramを取得するのは容易。
(bigram関数とmoji_bigramのスコープが無茶苦茶だったので修正してます)para.pystr_paradise = "paraparaparadise" str_paragraph = "paragraph" def bigram(s): moji_bigram = [] moji_counter = 0 #文字gram処理 #半角スペースを消す rep_str = s.replace(" ", "") for i in rep_str: if moji_counter < len(rep_str)-1: moji_bigram.append(rep_str[moji_counter]+rep_str[moji_counter+1]) moji_counter += 1 return moji_bigram print(bigram(str_paradise)) print(bigram(str_paragraph))['pa', 'ar', 'ra', 'ap', 'pa', 'ar', 'ra', 'ap', 'pa', 'ar', 'ra', 'ad', 'di', 'is', 'se'] ['pa', 'ar', 'ra', 'ag', 'gr', 'ra', 'ap', 'ph']
- 投稿日:2020-03-18T18:48:34+09:00
Python未経験者が言語処理100本ノックをやってみる05~06
これの続きでーす。
Python未経験者が言語処理100本ノックをやってみる00~04
https://qiita.com/earlgrey914/items/fe1d326880af83d37b22続きはこちら
Python未経験者が言語処理100本ノックをやってみる07~09
https://qiita.com/earlgrey914/items/a7b6781037bc0844744b
05. n-gram
与えられたシーケンス(文字列やリストなど)からn-gramを作る関数を作成せよ.この関数を用い,"I am an NLPer"という文から単語bi-gram,文字bi-gramを得よ.
n-gramって何だっけかなぁ・・・なんか聞いたことあるけど。
ってこの問題n-gramがなにか理解できてないと解けないじゃん!まずそこからかよ!!~2分ググった~
N-gramとは自然言語(テキスト)を連続するN個の文字、もしくはN個の単語単位で単語を切り出す手法のことです。
<参考>
https://www.pytry3g.com/entry/N-gram
なるほど。
じゃあ1が渡されたら1文字ずつ区切って、2が渡されたら2文字ずつ区切るような関数を作ればいのね。
単語bi-gramってのは単語単位で2文字区切り
文字bi-gramってのは文字単位で2文字区切りすばいいってことかしらね。
だから解答は
■単語bi-gram
["I", "am", "an", "NL", "Pe", "r"]
■文字bi-gram
["I ","ma","an","NL","Pe","r"]
って出力すればいいのかな?間違ってたらゴメンネ。この前提で解くよ。ふつーに間違っていたので解答の出力結果のみチラ見した。
[['I', 'am'], ['am', 'an'], ['an', 'NLPer']] ['I ', ' a', 'am', 'm ', ' a', 'an', 'n ', ' N', 'NL', 'LP', 'Pe', 'er']このように出力されればOKらしい。
なるほど。ウィ。とりあえず単語bigramができた。
enshu05.pys = "I am an NLPer" tango_bigram= [] def bigram(s): counter = 0 list = s.split() for i in list: if counter < len(list)-1: tango_bigram.extend([[list[counter],list[counter+1]]]) counter += 1 return tango_bigram print(bigram(s))[['I', 'am'], ['am', 'an'], ['an', 'NLPer']]ここらでそろそろお気づきだと思うが、コードを書いていく上で色々とよろしくない部分が見え始めた。
- 変数の命名が適当すぎる。英語と日本語が混ざってるし、
sやiといった1文字変数を使うところもあれば、counterなどの変数名を使っているところもある- ここではスネークケースである
tango_bigramという書き方をしているが、前(演習4)はキャメルケースでichimoziListと書いており、バラバラ。- 改行ルールが謎。半角スペースを入れるルールが謎。
今後直していきたいが、今はまだ目をつむっていく。一人で書いているだけなので。
まぁそのうち自分で書いたコードが自分で「見づれえええええ」ってなって直さざるをえなくなるんだけどね。前の演習ではリストへの追加は
append()を使ったが、ここではextend()を使った。
複数要素をいっきにリストに入れたい場合はextend()を使えばいいらしい。
l += [1, 2, 3]といった+=を使う記法もあるらしいが、extend()のほうがわかりやすいなぁという印象。<参考URL>
https://qiita.com/tag1216/items/416314cc75a099ad6149で、
似たような感じで文字bigramも書いた。enshu05.pys = "I am an NLPer" tango_bigram= [] moji_bigram = [] def bigram(s): tango_counter = 0 moji_counter = 0 #単語gram処理 list = s.split() for i in list: if tango_counter < len(list)-1: tango_bigram.extend([[list[tango_counter],list[tango_counter+1]]]) tango_counter += 1 #文字gram処理 for i in s: if moji_counter < len(s)-1: moji_bigram.append(s[moji_counter] + s[moji_counter+1]) moji_counter += 1 return tango_bigram,moji_bigram print(bigram(s))([['I', 'am'], ['am', 'an'], ['an', 'NLPer']], ['I ', ' a', 'am', 'm ', ' a', 'an', 'n ', ' N', 'NL', 'LP', 'Pe', 'er'])可読性がゴミだな!!!
まぁいいや。
Pythonの「関数は関数呼び出し処理より上に書かないといけない」っていう規約?慣れないなぁ・・・個人的な印象だが、Pythonは動的型付けである点と、インデントによるブロック区切りのおかけで、
「書くのは楽だが読むのは大変」という印象がある。
Javaみたいな静的型付け言語で{}を使ったブロック区切りに慣れているからかしら・・・
Javaもインデントが適当だと著しく可読性が落ちるけどね。ちょっと休憩
なんかいい変数名の付け方ないの?と思ってググったらこういう記事もあった。
<参考URL>
https://qiita.com/Ted-HM/items/7dde25dcffae4cdc792306. 集合
"paraparaparadise"と"paragraph"に含まれる文字bi-gramの集合を,それぞれ, XとYとして求め,XとYの和集合,積集合,差集合を求めよ.さらに,'se'というbi-gramがXおよびYに含まれるかどうかを調べよ.
なんかもうまず日本語が難しいんだが。
いや一応わかるけどさ。プログラム以前に日本語の解読が大変。この問題見た瞬間に「え?集合?もうそういうの計算できるライブラリをインポートして使っていい?」と思った。さっきのN-gramもライブラリであるでしょ絶対・・・
筆者は世の中において「自分で作らなければいけない」ものは「自分だけが思いついたもの」と思っているので、誰かが作ってくれたものがあるならそれを活用したほうがいいと思っている。
が、今回は目的が学習であるため、ちゃんと自分で作ります。
演習05のbigram関数をちょっといじれば2つの文字列bigramを取得するのは容易。
(bigram関数とmoji_bigramのスコープが無茶苦茶だったので修正してます)para.pystr_paradise = "paraparaparadise" str_paragraph = "paragraph" def bigram(s): moji_bigram = [] moji_counter = 0 #文字gram処理 for i in s: if moji_counter < len(s)-1: moji_bigram.append(s[moji_counter]+s[moji_counter+1]) moji_counter += 1 return moji_bigram print(bigram(str_paradise)) print(bigram(str_paragraph))['pa', 'ar', 'ra', 'ap', 'pa', 'ar', 'ra', 'ap', 'pa', 'ar', 'ra', 'ad', 'di', 'is', 'se'] ['pa', 'ar', 'ra', 'ag', 'gr', 'ra', 'ap', 'ph']で、集合を求めるにはどうすんのかなーと「Python 集合 計算」みたいな感じで適当にググったら
list型ではなくset型というものを使えばいいらしい。<参考URL>
https://note.nkmk.me/python-set/set型ってどんなもの?と思いググッたら、
・重複した要素がない
・要素に順番がないとのこと。パーフェクトじゃん。
<参考URL>
https://note.nkmk.me/python-set/てことでサクサクっと完成。
enshu06.pystr_paradise = "paraparaparadise" str_paragraph = "paragraph" #文字bigramのリストを返す関数 def bigram(s): moji_bigram = [] moji_counter = 0 for i in s: if moji_counter < len(s)-1: moji_bigram.append(s[moji_counter]+s[moji_counter+1]) moji_counter += 1 return moji_bigram #リストをsetに変換する関数 def listToSet(list): moji_bigram_set = {} moji_bigram_set = set(list) return moji_bigram_set #bigramのリストを作成 str_paradise_list = bigram(str_paradise) str_paragraph_list = bigram(str_paragraph) #bigramのリストをsetに変換し重複を削除 paradise_set_X = listToSet(str_paradise_list) paragraph_set_Y = listToSet(str_paragraph_list) print("paradise_set_X") print(paradise_set_X) print("paragraph_set_Y") print(paragraph_set_Y) print("和集合") print(paradise_set_X | paragraph_set_Y) print("積集合") print(paradise_set_X & paragraph_set_Y) print("差集合") print(paradise_set_X - paragraph_set_Y)paradise_set_X {'ap', 'ar', 'pa', 'di', 'is', 'ra', 'se', 'ad'} paragraph_set_Y {'ap', 'ar', 'pa', 'ph', 'ag', 'ra', 'gr'} 和集合 {'ap', 'ar', 'gr', 'pa', 'di', 'ph', 'is', 'ag', 'ra', 'se', 'ad'} 積集合 {'ra', 'pa', 'ap', 'ar'} 差集合 {'is', 'di', 'se', 'ad'}うん、簡単ですね。
答えがあってるのかチェックが大変だぜ・・・続きは明日!!!!
05~06でここまで2時間かかりました!!!!!!!!!!!!!!!(重要)
- 投稿日:2020-03-18T18:28:05+09:00
小売業に必要なデータサイエンティストの役割について考える④
はじめに
前回に引き続き、各役割別にどういうスキルセットが必要かを整理していきます。
データエンジニア
データエンジニアという専門の職というのは、あまり小売にはいないのではないでしょうか。(最大手とかは違うのでしょうか)
大体内部にいる人は、システムエンジニアまでだと思いますし、そこからデータ周りは外部にお願いしているというケースが多いのではないでしょうか。ただ、前述の様に、システムエンジニアや外部のデータエンジニアとパイプになっていく人材が必要ですね。
理想で言うと、システムエンジニアだけど、DWHにアクセスして簡単なデータであれば自身で取得することができる・取得したデータを見える化して必要な形にデータ加工ができる(外れ値・欠損値等の対応)というスキルを、エンジニアの方が取得されると、どんな小売りでも引っ張りだこだと思います。(当社比)
データストーリーテラー
この役割専用という人がいることはまず無いと思いますが、データアナリストがこの役割を強く担っているうちに、メインがストーリーテラーになったりするかなぁ(と妄想)。
前述しましたが、業態にもよると思いますが、小売業は店舗(店長等)から、店舗営業(企業によっては支社のケースも。スーパーバイザー当)、本社部署など様々な立場の人間が揃っています。
そして、データに対する理解度は、かなり異なっています。それもあって、現場を理解しながらも、データを語れる。できれば、BI等をつかってデータを”わかりやすく”見せられる。そして、話を聞いた相手が、そのデータをみながら、他の人に伝えられる。そんな資料がつくれる。
そんなスキルが必要になるかと思います。
おわりに
「小売業に必要なデータサイエンティストの役割について考える」というタイトルで、4回に渡って書かせていただきました。
途中でも書きましたが、そこまで「小売業」だから・・・と特別視しているつもりはありません。
ただ、やはり店舗まで含めて、如何に全体に広めていくのかというのは、他の業界よりも1つハードルが高いように思います。(そして、やはり店舗が強いですから)その仕事を理解しつつ、データを使っていける、そんなデータサイエンティストが小売業には必須かと思います。
- 投稿日:2020-03-18T18:05:23+09:00
現役理系院生が研究で使用したPythonの可視化ツール全部まとめてみた[基礎編]
はじめに
現在修士2年の大学院生です。
火星大気を数値シミュレーションを使って研究しています。
数値シミュレーションで得られた結果を主にPythonを使って解析していたので、その過程で使った関数などを全部まとめてみました。全てを網羅しているわけではありませんのでそこはご注意ください。。。
ただドキュメントを見て格闘して使ってきたので、これからもしPythonの可視化ツールを使う人いれば、その助けになればと思いまとめてみました!目標
基礎編なので、この記事では基礎的な関数しか扱いません。
この記事で以下のグラフを描く全ての要素を解説しています。
最終サンプルコードは記事の一番下の方にあります。(plotの方法を思い出したいくらいの人はこのサンプルだけ見れば十分だと思います)
使うライブラリー
この記事で使うライブラリーは以下になります。ひとまず以下のコードをコピペしてコードの上に貼っておけば問題ないです。
import matplotlib.pyplot as plt #実際にプロットする import numpy as np #データの整理実際にplotしてみる
基礎編なので、
1. データ1[x1,x2,x3,,,]とデータ2[y1,y2,y3,,,]を横軸縦軸にplotする
2. y=f(x)をplotする
3. plotの装飾オプションの解説(色、線の種類、etc)
1. [x,,,]と[y,,,]をplotする
これは他の記事でいくらでもあると思うのですが、一応基礎ということで残しておきます。これが一番の基本です。
データxを横軸とデータyを縦軸にplotします。import matplotlib.pyplot as plt #実際にプロットする import numpy as np #データの整理 X = np.linspace(1,10,num=10) #1から10までをnum=10等分した列を作る[1,2,3,,,,10] #X = [1,2,3,4,5,6,7,8,9,10]と同じ Y = np.random.rand(10) #乱数(0~1)から成るサイズが10の列を生成 plt.plot(X,Y)#plotする基本はplt.plot(データ1の列, データ2の列)です。
ただ乱数をplotしただけなので汚いですが、こんな感じのグラフができます。
2. y=f(x)をplotする
以下では、y=x^2をplotします
def fun(x): y = x**2 #ここに自分の関数を書く #ex) #y = np.sin(x) #y = np.log(x) return y X = np.linspace(1,10,num=10) #1から10までをnum=10等分した列を作る[1,2,3,,,,10] Y = fun(X) #データyの列を作成 plt.plot(X, Y)#plotする #plt.plot(xの列,yの列,options)でplotできるこんな感じになります。
3. plotオプション色々!(これがメイン笑)
- 色
- 凡例(位置調整、大きさ)
- 軸の調整(範囲、文字の大きさ、logスケール、目盛り)
- 線の種類
- ラベルに数式入れる
- グラフに直接文字を入れる
・ 線の色
線の色を変える時は、以下のオプションを追加します。
plt.plot(X,Y,color='k') #kは黒ですcolor='k'の部分を変えるだけです。
以下に基本的な色だけ載せておきます。
この公式ドキュメントにたくさんの色の一覧が載っているのでどうぞ。・凡例(ラベル)
以下でできます。
plt.legend(loc='lower right',prop={'size':15})import matplotlib.pyplot as plt #実際にプロットする import numpy as np #データの整理 def fun(x): y = 2*x #ここに自分の関数を書く return y X = np.linspace(1,10,num=100) #1から10までをnum=100等分した列を作る Y1 = fun(X) Y2 = 20*np.sin(X) #y=20sin(x) plt.plot(X,Y1,color='b',label='your original')#Y1をplotする plt.plot(X,Y2,color='r', label='sin')#Y2をplotする plt.legend(loc='lower right',prop={'size':15})#これが凡例サイズは、prop={'size':15}で変えることができます。
凡例の位置はloc='lower right'で変えられます。
以下のようにだいたいの位置に配置することができます。
詳しくはこちらにサンプルだとこんな感じになります。
plt.legend()で凡例をつけられます。
・軸ラベル追加 & 軸の調整(範囲、文字の大きさ、logスケール、目盛り)
軸ラベル追加
plt.xlabel('xaxis',size='10') #x軸にラベルを追加, size='好きな大きさに' plt.ylable('yaxis',size='10') #y軸にラベル追加軸調整(範囲、スケール、目盛りの大きさ)
#範囲 plt.xlim((0,10)) #xの範囲: 0-10 plt.ylim((0,20)) #yの範囲:0-20 #logスケール plt.xscale('log')#xをlogscale plt.yscale('log')#yをlogscale #目盛りの大きさ調整 plt.tick_params(labelsize=12) #labelsize=好きな大きさに色々追加したサンプルコードです。
import matplotlib.pyplot as plt #実際にプロットする import numpy as np #データの整理 def fun(x): y = 2**x #ここに自分の関数を書く return y X = np.linspace(1,10,num=100) #1から10までをnum=100等分した列を作る Y1 = fun(X) Y2 = np.exp(X) plt.plot(X,Y1,color='b',label=r'$y=2^x$')#plotする plt.plot(X,Y2,color='r', label=r'$y=e^x$') plt.legend(loc='lower right',prop={'size':18}) #凡例追加 plt.xlabel('xaxis',size='20') #x軸にラベルを追加, size='好きな大きさに' plt.ylabel('yaxis',size='20') #y軸にラベル追加 plt.xlim((0,10)) #xの範囲: 0-10 plt.ylim((0,100)) #yの範囲:0-20 plt.tick_params(labelsize=15) #labelsize=好きな大きさに以下のグラフのようになります。
・ラベルに数式入れる
実は、上のサンプルコードで文字ラベルに数式を追加していました。
plt.plot(X,Y1,color='b',label=r'$y=2^x$')#plotするラベルの文字に数式を入れるには,
label=r'$数式$'という風に書けば数式を挿入できます。
この数式はLatex形式になっています。・線の種類
ただの線ではなく、破線にしたり、データ点を表示したりするオプションです。
- linestyle='your style'
- marker='your marker style'
を使います。
例を示しておきます。#linestyle X = np.linspace(1,10,num=100) Y1=X Y2=2*X Y3=3*X Y4=4*X Y5=5*X plt.plot(X,Y1,linestyle=':',label=':')#plotする plt.plot(X,Y2,linestyle='-.',label='-.') plt.plot(X,Y3,linestyle='--',label='--') plt.plot(X,Y4,linestyle='-',label='-') plt.legend(prop={'size':18})
#Add marker X = np.linspace(1,10,num=10) Y1=X Y2=2*X Y3=3*X Y4=4*X Y5=5*X plt.plot(X,Y1,marker='.',markersize='10',label='.')#adding marker plt.plot(X,Y2,marker='v',markersize='12',label='v')#markersizeで大きさを変える plt.plot(X,Y3,marker='1',markersize='14',label='1') plt.plot(X,Y4,marker='*',markersize='16',label='*') plt.legend(prop={'size':18})
公式ドキュメントにたくさんのマーカー種類が載っています。
・グラフに直接文字を入れる
凡例ではなく、直接文字をグラフ上に書きたいときありますよね?
そんな時に活躍してくれるのが#座標(x,y)に'文字'を'好きなサイズ'の大きさで挿入する plt.text(x,y,'文字',size='好きなサイズ') #x:x座標 y:y座標です。
サンプルコードです。X = np.linspace(1,10,num=100) Y=X plt.plot(X,Y) plt.text(2,2,'(2,2)',size='10') plt.text(4,8,'(4,8)',size='15') plt.text(8,3,'(8,3)',size='20') plt.xlabel('xaxis') #x軸にラベルを追加, size='好きな大きさに' plt.ylabel('yaxis') #y軸にラベル追加
簡単ですね!最終サンプルコード
#最終サンプル import matplotlib.pyplot as plt #実際にプロットする import numpy as np #データの整理 def fun(x): y = 2**x #ここに自分の関数を書く return y plt.figure(dpi=100) #解像度(dpi)を変える X = np.linspace(1,10,num=50) #1から10までをnum=100等分した列を作る Y1 = fun(X)#データYを作成 Y2 = np.exp(X) plt.plot(X,Y1,color='g',label=r'$y=2^x$', linestyle='-.')#plotする plt.plot(X,Y2,color='r', label=r'$y=e^x$', marker='*',markersize='16')#plotする plt.legend(loc='lower right',prop={'size':18}) plt.xlabel('xaxis',size='20') #x軸にラベルを追加, size='好きな大きさに' plt.ylabel('yaxis',size='20') #y軸にラベル追加 plt.xlim((0,10)) #xの範囲: 0-10 plt.ylim((0,100)) #yの範囲:0-20 plt.tick_params(labelsize=15) #labelsize=好きな大きさに plt.text(6,50,r'$y=2^x$',size='15',color='g') #add text plt.text(1,20,r'$y=e^x$',size='15',color='r') #add text plt.text(1,80,'Good luck!',size='15',color='k')以下のようになります!
最後に
この記事では基礎編ということでアニメーションや軸2つのバージョンなどニッチなものを扱いませんでした。次の記事(応用編)では
- 軸2つ
- アニメーション(gifファイル作成)
- contourグラフ
- csvファイルの読み込み書き出し
- HDF5ファイルの読み込み、書き出し などをまとめたいと思います! では!





- 投稿日:2020-03-18T18:04:49+09:00
COTOHA APIを使用してメロスのネガティブな部分を消してみた
はじめに
先日COTOHA APIを触ってみたので、その流れでやったのがこちらになります。
COTOHA APIについてや、導入などについては先日投稿した記事を見てみてください。やること
流れとしては走れメロスを句読点ごと区切り、一文ごとに感情分析を行い、ネガティブと判定された文章を抹消して出力します。
1.青空文庫のgitをcloneして走れメロスを見つける
めっちゃおもい$ git clone git@github.com:aozorabunko/aozorabunko.git
- 走れメロスの本文をテキストファイルにコピー
2.走れメロスの文章を整形
- 句読点ごとに文章を分割
- 「」など不要な記号を除去
3.一文毎に感情分析を行い、ネガティブ判定されたものを除去
コードは長いので折りたたんであります
import requests import json import sys import time BASE_URL = "https://api.ce-cotoha.com/api/dev/nlp/" CLIENT_ID = "" # 発行されたIDを入力 CLIENT_SECRET = "" # 発行されたsecretを入力 # アクセストークンを取得 def auth(client_id, client_secret): token_url = "https://api.ce-cotoha.com/v1/oauth/accesstokens" headers = { "Content-Type": "application/json", "charset": "UTF-8" } data = { "grantType": "client_credentials", "clientId": client_id, "clientSecret": client_secret } r = requests.post(token_url, headers=headers, data=json.dumps(data)) return r.json()["access_token"] # 感情分析apiを呼び出し def sentiment(sentence, access_token): base_url = BASE_URL headers = { "Content-Type": "application/json", "charset": "UTF-8", "Authorization": "Bearer {}".format(access_token) } data = { "sentence": sentence } r = requests.post(base_url + "v1/sentiment", headers=headers, data=json.dumps(data)) return r.json() if __name__ == "__main__": document = "メロスは激怒した。" args = sys.argv if len(args) >= 2: document = str(args[1]) access_token = auth(CLIENT_ID, CLIENT_SECRET) # 解析可能な文に整形(句読点で切り分け、記号除去など) sentences = splitwords(document) f = open('opt.txt', 'w') for sentence in sentences: if not sentence: continue res = sentiment(sentence, access_token) print(res) if res['result']['sentiment'] == 'Negative': continue f.write(sentence + "\n") f.close() print("deleted negative melos")結果
メロスメロスは激怒した 必ず、かの邪智暴虐の王を除かなければならぬと決意した メロスには政治がわからぬ メロスは、村の牧人である 笛を吹き、羊と遊んで暮して来たネガティブじゃないメロス必ず、かの邪智暴虐の王を除かなければならぬと決意した メロスは、村の牧人である 笛を吹き、羊と遊んで暮して来たメロスが激怒しなくなっており、政治がわかるようになりました。
実行結果$ python melos.py melos.txt {'result': {'sentiment': 'Negative', 'score': 0.7040895800341446, 'emotional_phrase': [{'form': '激怒した', 'emotion': 'N'}]}, 'status': 0, 'message': 'OK'} {'result': {'sentiment': 'Neutral', 'score': 0.34207414196325664, 'emotional_phrase': []}, 'status': 0, 'message': 'OK'} {'result': {'sentiment': 'Negative', 'score': 0.33534926492915057, 'emotional_phrase': [{'form': 'わからぬ', 'emotion': 'N'}]}, 'status': 0, 'message': 'OK'} {'result': {'sentiment': 'Neutral', 'score': 0.4202261100237903, 'emotional_phrase': []}, 'status': 0, 'message': 'OK'} {'result': {'sentiment': 'Neutral', 'score': 0.38977432300637777, 'emotional_phrase': []}, 'status': 0, 'message': 'OK'} ...実行結果を見ると「激怒した」と「わからぬ」がNegativeの判定になっています。
全文の結果を比較すると元が464行に対して、粛清後は357行になったので107行消え去ったことになります。
粛清後のメロス全文
必ず、かの邪智暴虐の王を除かなければならぬと決意した メロスは、村の牧人である 笛を吹き、羊と遊んで暮して来た きょう未明メロスは村を出発し、野を越え山越え、十里はなれた此のシラクスの市にやって来た メロスには父も、母も無い 女房も無い 十六の、内気な妹と二人暮しだ この妹は、村の或る律気な一牧人を、近々、花婿として迎える事になっていた 結婚式も間近かなのである メロスは、それゆえ、花嫁の衣裳やら祝宴の御馳走やらを買いに、はるばる市にやって来たのだ 先ず、その品々を買い集め、それから都の大路をぶらぶら歩いた メロスには竹馬の友があった セリヌンティウスである 今は此のシラクスの市で、石工をしている その友を、これから訪ねてみるつもりなのだ 久しく逢わなかったのだから、訪ねて行くのが楽しみである 歩いているうちにメロスは、まちの様子を怪しく思った ひっそりしている 路で逢った若い衆をつかまえて、何かあったのか、二年まえに此の市に来たときは、夜でも皆が歌をうたって、まちは賑やかであった筈だが、と質問した 若い衆は、首を振って答えなかった しばらく歩いて老爺に逢い、こんどはもっと、語勢を強くして質問した 老爺は答えなかった メロスは両手で老爺のからだをゆすぶって質問を重ねた 王様は、人を殺します なぜ殺すのだ 悪心を抱いている、というのですが、誰もそんな、悪心を持っては居りませぬ たくさんの人を殺したのか はい、はじめは王様の妹婿さまを それから、御自身のお世嗣を それから、妹さまを それから、妹さまの御子さまを それから、皇后さまを それから、賢臣のアレキス様を おどろいた 国王は乱心か いいえ、乱心ではございませぬ 人を、信ずる事が出来ぬ、というのです このごろは、臣下の心をも、お疑いになり、少しく派手な暮しをしている者には、人質ひとりずつ差し出すことを命じて居ります きょうは、六人殺されました メロスは、単純な男であった 買い物を、背負ったままで、のそのそ王城にはいって行った たちまち彼は、巡邏の警吏に捕縛された 調べられて、メロスの懐中からは短剣が出て来たので、騒ぎが大きくなってしまった メロスは、王の前に引き出された この短刀で何をするつもりであったか 言え!暴君ディオニスは静かに、けれども威厳を以て問いつめた その王の顔は蒼白で、眉間の皺は、刻み込まれたように深かった 市を暴君の手から救うのだ おまえがか?王は、憫笑した 仕方の無いやつじゃ 言うな!とメロスは、いきり立って反駁した 疑うのが、正当の心構えなのだと、わしに教えてくれたのは、おまえたちだ 人間は、もともと私慾のかたまりさ 信じては、ならぬ 暴君は落着いて呟き、ほっと溜息をついた わしだって、平和を望んでいるのだが なんの為の平和だ 自分の地位を守る為か 罪の無い人を殺して、何が平和だ だまれ、下賤の者 王は、さっと顔を挙げて報いた 口では、どんな清らかな事でも言える わしには、人の腹綿の奥底が見え透いてならぬ おまえだって、いまに、磔になってから、泣いて詫びたって聞かぬぞ ああ、王は悧巧だ 私は、ちゃんと死ぬる覚悟で居るのに たった一人の妹に、亭主を持たせてやりたいのです 三日のうちに、私は村で結婚式を挙げさせ、必ず、ここへ帰って来ます ばかな と暴君は、嗄れた声で低く笑った とんでもない嘘を言うわい 逃がした小鳥が帰って来るというのか そうです 帰って来るのです 私は約束を守ります 私を、三日間だけ許して下さい 妹が、私の帰りを待っているのだ そんなに私を信じられないならば、よろしい、この市にセリヌンティウスという石工がいます 私の無二の友人だ あれを、人質としてここに置いて行こう 私が逃げてしまって、三日目の日暮まで、ここに帰って来なかったら、あの友人を絞め殺して下さい たのむ、そうして下さい それを聞いて王は、残虐な気持で、そっと北叟笑んだ どうせ帰って来ないにきまっている そうして身代りの男を、三日目に殺してやるのも気味がいい 世の中の、正直者とかいう奴輩にうんと見せつけてやりたいものさ 願いを、聞いた その身代りを呼ぶがよい 三日目には日没までに帰って来い おくれたら、その身代りを、きっと殺すぞ ちょっとおくれて来るがいい おまえの罪は、永遠にゆるしてやろうぞ なに、何をおっしゃる はは いのちが大事だったら、おくれて来い おまえの心は、わかっているぞ ものも言いたくなくなった 竹馬の友、セリヌンティウスは、深夜、王城に召された 暴君ディオニスの面前で、佳き友と佳き友は、二年ぶりで相逢うた メロスは、友に一切の事情を語った セリヌンティウスは無言で首肯き、メロスをひしと抱きしめた 友と友の間は、それでよかった セリヌンティウスは、縄打たれた メロスは、すぐに出発した 初夏、満天の星である メロスはその夜、一睡もせず十里の路を急ぎに急いで、村へ到着したのは、翌る日の午前、陽は既に高く昇って、村人たちは野に出て仕事をはじめていた メロスの十六の妹も、きょうは兄の代りに羊群の番をしていた よろめいて歩いて来る兄の、疲労困憊の姿を見つけて驚いた なんでも無い メロスは無理に笑おうと努めた 市に用事を残して来た またすぐ市に行かなければならぬ あす、おまえの結婚式を挙げる 早いほうがよかろう うれしいか 綺麗な衣裳も買って来た さあ、これから行って、村の人たちに知らせて来い 結婚式は、あすだと メロスは、また、よろよろと歩き出し、家へ帰って神々の祭壇を飾り、祝宴の席を調え、間もなく床に倒れ伏し、呼吸もせぬくらいの深い眠りに落ちてしまった 眼が覚めたのは夜だった メロスは起きてすぐ、花婿の家を訪れた そうして、少し事情があるから、結婚式を明日にしてくれ、と頼んだ メロスは、待つことは出来ぬ、どうか明日にしてくれ給え、と更に押してたのんだ 婿の牧人も頑強であった 結婚式は、真昼に行われた 新郎新婦の、神々への宣誓が済んだころ、黒雲が空を覆い、ぽつりぽつり雨が降り出し、やがて車軸を流すような大雨となった メロスも、満面に喜色を湛え、しばらくは、王とのあの約束をさえ忘れていた 祝宴は、夜に入っていよいよ乱れ華やかになり、人々は、外の豪雨を全く気にしなくなった メロスは、一生このままここにいたい、と思った この佳い人たちと生涯暮して行きたいと願ったが、いまは、自分のからだで、自分のものでは無い ままならぬ事である あすの日没までには、まだ十分の時が在る ちょっと一眠りして、それからすぐに出発しよう、と考えた その頃には、雨も小降りになっていよう 今宵呆然、歓喜に酔っているらしい花嫁に近寄り、 おめでとう 眼が覚めたら、すぐに市に出かける 大切な用事があるのだ 私がいなくても、もうおまえには優しい亭主があるのだから、決して寂しい事は無い おまえも、それは、知っているね 亭主との間に、どんな秘密でも作ってはならぬ おまえに言いたいのは、それだけだ おまえの兄は、たぶん偉い男なのだから、おまえもその誇りを持っていろ 花嫁は、夢見心地で首肯いた メロスは、それから花婿の肩をたたいて、 仕度の無いのはお互さまさ 私の家にも、宝といっては、妹と羊だけだ 他には、何も無い 全部あげよう もう一つ、メロスの弟になったことを誇ってくれ メロスは笑って村人たちにも会釈して、宴席から立ち去り、羊小屋にもぐり込んで、死んだように深く眠った 眼が覚めたのは翌る日の薄明の頃である メロスは跳ね起き、南無三、寝過したか、いや、まだまだ大丈夫、これからすぐに出発すれば、約束の刻限までには十分間に合う きょうは是非とも、あの王に、人の信実の存するところを見せてやろう そうして笑って磔の台に上ってやる メロスは、悠々と身仕度をはじめた 雨も、いくぶん小降りになっている様子である 身仕度は出来た さて、メロスは、ぶるんと両腕を大きく振って、雨中、矢の如く走り出た 私は、今宵、殺される 殺される為に走るのだ 身代りの友を救う為に走るのだ 王の奸佞邪智を打ち破る為に走るのだ 走らなければならぬ そうして、私は殺される 若い時から名誉を守れ さらば、ふるさと 幾度か、立ちどまりそうになった 村を出て、野を横切り、森をくぐり抜け、隣村に着いた頃には、雨も止み、日は高く昇って、そろそろ暑くなって来た 妹たちは、きっと佳い夫婦になるだろう 私には、いま、なんの気がかりも無い筈だ まっすぐに王城に行き着けば、それでよいのだ そんなに急ぐ必要も無い ゆっくり歩こう、と持ちまえの呑気さを取り返し、好きな小歌をいい声で歌い出した ぶらぶら歩いて二里行き三里行き、そろそろ全里程の半ばに到達した頃、降って湧いた災難、メロスの足は、はたと、とまった 見よ、前方の川を きのうの豪雨で山の水源地は氾濫し、濁流滔々と下流に集り、猛勢一挙に橋を破壊し、どうどうと響きをあげる激流が、木葉微塵に橋桁を跳ね飛ばしていた 流れはいよいよ、ふくれ上り、海のようになっている ああ、鎮めたまえ、荒れ狂う流れを! 時は刻々に過ぎて行きます 太陽も既に真昼時です あれが沈んでしまわぬうちに、王城に行き着くことが出来なかったら、あの佳い友達が、私のために死ぬのです 今はメロスも覚悟した 泳ぎ切るより他に無い ああ、神々も照覧あれ! 濁流にも負けぬ愛と誠の偉大な力を、いまこそ発揮して見せる 押し流されつつも、見事、対岸の樹木の幹に、すがりつく事が出来たのである ありがたい メロスは馬のように大きな胴震いを一つして、すぐにまた先きを急いだ 陽は既に西に傾きかけている 待て 何をするのだ 私は陽の沈まぬうちに王城へ行かなければならぬ 放せ どっこい放さぬ 持ちもの全部を置いて行け 私にはいのちの他には何も無い その、たった一つの命も、これから王にくれてやるのだ その、いのちが欲しいのだ さては、王の命令で、ここで私を待ち伏せしていたのだな 山賊たちは、ものも言わず一斉に棍棒を振り挙げた 立ち上る事が出来ぬのだ ああ、あ、濁流を泳ぎ切り、山賊を三人も撃ち倒し韋駄天、ここまで突破して来たメロスよ 真の勇者、メロスよ 愛する友は、おまえを信じたばかりに、やがて殺されなければならぬ 路傍の草原にごろりと寝ころがった 身体疲労すれば、精神も共にやられる 私は、これほど努力したのだ 約束を破る心は、みじんも無かった 神も照覧、私は精一ぱいに努めて来たのだ 動けなくなるまで走って来たのだ ああ、できる事なら私の胸を截ち割って、真紅の心臓をお目に掛けたい 愛と信実の血液だけで動いているこの心臓を見せてやりたい けれども私は、この大事な時に、精も根も尽きたのだ 私は、きっと笑われる 私の一家も笑われる 中途で倒れるのは、はじめから何もしないのと同じ事だ これが、私の定った運命なのかも知れない セリヌンティウスよ、ゆるしてくれ 君は、いつでも私を信じた 私も君を、欺かなかった 私たちは、本当に佳い友と友であったのだ いまだって、君は私を無心に待っているだろう ああ、待っているだろう ありがとう、セリヌンティウス よくも私を信じてくれた 友と友の間の信実は、この世で一ばん誇るべき宝なのだからな セリヌンティウス、私は走ったのだ 信じてくれ! 私は急ぎに急いでここまで来たのだ 濁流を突破した 山賊の囲みからも、するりと抜けて一気に峠を駈け降りて来たのだ 私だから、出来たのだよ ああ、この上、私に望み給うな 放って置いてくれ どうでも、いいのだ だらしが無い 笑ってくれ 王は私に、ちょっとおくれて来い、と耳打ちした おくれたら、身代りを殺して、私を助けてくれると約束した けれども、今になってみると、私は王の言うままになっている 私は、おくれて行くだろう 王は、ひとり合点して私を笑い、そうして事も無く私を放免するだろう 私は、永遠に裏切者だ セリヌンティウスよ、私も死ぬぞ 君だけは私を信じてくれるにちがい無い 村には私の家が在る 羊も居る 正義だの、信実だの、愛だの、考えてみれば、くだらない 人を殺して自分が生きる それが人間世界の定法ではなかったか やんぬる哉 ――四肢を投げ出して、うとうと、まどろんでしまった ふと耳に、潺々、水の流れる音が聞えた すぐ足もとで、水が流れているらしい よろよろ起き上って、見ると、岩の裂目から滾々と、何か小さく囁きながら清水が湧き出ているのである その泉に吸い込まれるようにメロスは身をかがめた 水を両手で掬って、一くち飲んだ 歩ける 行こう 肉体の疲労恢復と共に、わずかながら希望が生れた 義務遂行の希望である わが身を殺して、名誉を守る希望である 日没までには、まだ間がある 私を、待っている人があるのだ 少しも疑わず、静かに期待してくれている人があるのだ 私は、信じられている 私の命なぞは、問題ではない 死んでお詫び、などと気のいい事は言って居られぬ いまはただその一事だ 走れ! メロス 私は信頼されている 私は信頼されている 先刻の、あの悪魔の囁きは、あれは夢だ 忘れてしまえ メロス、おまえの恥ではない やはり、おまえは真の勇者だ 再び立って走れるようになったではないか ありがたい! 私は、正義の士として死ぬ事が出来るぞ 待ってくれ、ゼウスよ 私は生れた時から正直な男であった いまごろは、あの男も、磔にかかっているよ ああ、その男、その男のために私は、いまこんなに走っているのだ 急げ、メロス おくれてはならぬ 愛と誠の力を、いまこそ知らせてやるがよい メロスは、いまは、ほとんど全裸体であった 呼吸も出来ず、二度、三度、口から血が噴き出た 見える はるか向うに小さく、シラクスの市の塔楼が見える 塔楼は、夕陽を受けてきらきら光っている ああ、メロス様 誰だ メロスは走りながら尋ねた フィロストラトスでございます 貴方のお友達セリヌンティウス様の弟子でございます その若い石工も、メロスの後について走りながら叫んだ もう、駄目でございます 走るのは、やめて下さい もう、あの方をお助けになることは出来ません いや、まだ陽は沈まぬ ちょうど今、あの方が死刑になるところです ああ、あなたは遅かった ほんの少し、もうちょっとでも、早かったなら! いや、まだ陽は沈まぬ 走るより他は無い やめて下さい 走るのは、やめて下さい いまはご自分のお命が大事です あの方は、あなたを信じて居りました 刑場に引き出されても、平気でいました それだから、走るのだ 信じられているから走るのだ 間に合う、間に合わぬは問題でないのだ 人の命も問題でないのだ ついて来い! フィロストラトス ああ、あなたは気が狂ったか それでは、うんと走るがいい ひょっとしたら、間に合わぬものでもない 走るがいい 言うにや及ぶ まだ陽は沈まぬ 最後の死力を尽して、メロスは走った メロスの頭は、からっぽだ 間に合った 待て その人を殺してはならぬ メロスが帰って来た 約束のとおり、いま、帰って来た すでに磔の柱が高々と立てられ、縄を打たれたセリヌンティウスは、徐々に釣り上げられてゆく メロスはそれを目撃して最後の勇、先刻、濁流を泳いだように群衆を掻きわけ、掻きわけ、 私だ、刑吏! 殺されるのは、私だ メロスだ 彼を人質にした私は、ここにいる!と、かすれた声で精一ぱいに叫びながら、ついに磔台に昇り、釣り上げられてゆく友の両足に、齧りついた 群衆は、どよめいた あっぱれ ゆるせ、と口々にわめいた セリヌンティウスの縄は、ほどかれたのである セリヌンティウス 私を殴れ ちから一ぱいに頬を殴れ 君が若し私を殴ってくれなかったら、私は君と抱擁する資格さえ無いのだ 殴れ セリヌンティウスは、すべてを察した様子で首肯き、刑場一ぱいに鳴り響くほど音高くメロスの右頬を殴った 殴ってから優しく微笑み、 メロス、私を殴れ 同じくらい音高く私の頬を殴れ メロスは腕に唸りをつけてセリヌンティウスの頬を殴った ありがとう、友よ 群衆の中からも、歔欷の声が聞えた おまえらの望みは叶ったぞ おまえらは、わしの心に勝ったのだ どうか、わしをも仲間に入れてくれまいか どうか、わしの願いを聞き入れて、おまえらの仲間の一人にしてほしい どっと群衆の間に、歓声が起った 万歳、王様万歳 ひとりの少女が、緋のマントをメロスに捧げた 佳き友は、気をきかせて教えてやった メロス、君は、まっぱだかじゃないか 早くそのマントを着るがいい参考にさせていただいた記事
オレ プログラム ウゴカス オマエ ゲンシジン ナル
COTOHAを利用して、走れメロスの感情の経過に追走してみた。おわりに
PythonとCOTOHAを使用してなにかしたいと思いやってみましたが、ほぼAPIを呼ぶだけなのでさくっと作成できました。
粛清後のメロスも読んでみましたが、話の全容は掴めるくらいにまとまっているように感じました。(これはメロスの文体が味方してるかも)
感情分析以外にもCOTOHAには面白そうなAPIが用意されてるので、それも使って遊んでみたいです。
- 投稿日:2020-03-18T18:03:16+09:00
[テスト駆動開発(TDD)] 第21章 要約
概要
TDD本(※)の第21章を読んで要約したのでメモしておきます。
TDD本を読んで「ここで言ってることはどういうこと??」となっている方の参考になれば幸いです。
※https://www.amazon.co.jp/dp/B077D2L69C/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1第21章 要約
残りTODO
- [] テストメソッドが失敗したとしてもtearDownを呼び出す
- [] 複数のテストを走らせる
- [] 収集したテスト結果を出力する ◀︎ NEXT
次にやりたいこと
テストメソッドが失敗してもtearDownが呼ばれるようにしたい。
しかし、失敗したときに落ちずにtearDownが呼ばれるようにすると、落ちないので失敗した場所がわからない。
なので、失敗した場所の例外をキャッチする必要がある。テストを書く順番は重要で、筆者は次に書くテストを選ぶときは「何らかの気づきがある」か「動いたときに自信をもたらしてくれる」ものを選ぶ。
→「書こうとしているテストに少しでも不安があるときは、テストの対象を細分化して(TDD本的に言うと小さいステップに切り分けて)、目的や次のステップが明確なテストを先に書いて動かすべき」ということが言いたいのでは、と捉えたのですが、正直まだよく理解できていません。。読み進める中で理解できたら更新します。テストが動くようになっても、その次のテストを書く手が止まってしまうようであれば、2歩戻ろう。
(2歩前) テストを考えて、書く(1つ前に書いたテスト)
↑(1歩前) テストが動く(1つ前に書いたテスト)
↑(現在) 次のテストを考えて、書く →テストを書く手が止まっている2歩前の「1つ前に書いたテストを考える」ステップまで戻って考え直そう、ということだと思う。
TesyResult(テスト結果)のテストを追加する
まずは、「テストの実行数、失敗数、失敗の内容」という感じでテストツールっぽい実行結果を出したい。
ただ、いきなりフレームワーク自動的に全てのテスト結果(どのメソッドがどんな理由で落ちたかなど)をレポートさせるのは難しい(ステップが大きすぎる)。一歩目として、1つのテストを走らせたときに結果を記録したTestResultを返すようにするのがいいのでは?
これだと一つの結果しか扱えないが、まずはこれくらいの小さいステップで着手することが大事。[ソース更新]
TesyResultのテストメソッド、テスト実行コードを追加。仮実装
次に仮実装。
[ソース更新]
TestResultクラスを追加し、結果内容を返すsummaryメソッドを作成(仮実装なので返り値はベタがきの文字列)。
runメソッドがTestResult(テスト結果)を返すように更新。仮実装を本物に近づける①
テストが通ったので、仮実装してたTestResultクラスのsummaryメソッドを本物に近づける。
[ソース更新]
TestResultのコンストラクタでrunCount(テスト実行数)に1を代入するようにする。(まず小さいステップで進める。)
ベタがき文字列だった返り値の「テスト実行数」の表示部分にrunCountが表示されるようにする。ひとまず定数になっているrunCountは、本来、テスト実行ごとに増えるべきなので修正する。
[ソース更新]
runCountの初期値を0とし、テスト実行ごとにインクリメントするためのtestStartedメソッドを追加。runメソッドの中で作りたてのtestStartedメソッドを呼ぶ。
[ソース更新]
runメソッドの中で生成したTestResultインスタンスに対してtestStartedメソッドを実行し、runCountをインクリメントする。仮実装を本物に近づける②
もう1つのベタがき数字(失敗数のほう)を本物にしたい。
テストを書こう。[ソース更新]
テスト失敗時のテスト(testFailedResult)を追加。
↑でテストされるテスト失敗(例外を上げる)メソッド(testBrokenMethod)を追加。残りTODO
- [] テストメソッドが失敗したとしてもtearDownを呼び出す
- [] 複数のテストを走らせる
- 収集したテスト結果を出力する
- [] 失敗したテストを出力する ◀︎ TODO追加
小さいテストを足そう
テストを実行すると、"raise Exception"をキャッチしていないため、落ちてしまう。
Exceptionをキャッチして記録するようにしたいが、(ステップが大きいので)一旦棚に上げて、もっと小さいテストを足そう。第22章へ >>
- 投稿日:2020-03-18T17:39:02+09:00
pandasで任意の複数列(カラム)を抽出する
TL;DR
strアクセサを用いることで部分一致で簡単にカラム指定のマスクが作れる。(例:
df.columns.str.contains('任意の列名'))複数列をまとめて抽出する
ポイントは
- columnsを参照してその中に含まれる文字列を参照する。
- 最終的に出来上がるのは列を含むか否かのbooleanを含んだリストになる
なので、活用するなら
# この場合は任意の複数列を取り出す include_list = df.columns[df.columns.str.contains('hoge_') * df.columns.str.contains('fuga_')] df_prep = df[include_list]# この場合は任意の複数列以外を取り出す # Point: チルダ(~)を使うことでマスクを反転させている exclude_list = df.columns[~df.columns.str.contains('hoge_') * ~df.columns.str.contains('fuga_')] df_prep = df[exclude_list]またオプションには
case(大文字小文字の区別),regex(正規表現パターンの利用) があるので、柔軟につかえる。strアクセサの応用
今回はカラムに対して行ったが、たとえば特定の列内から任意の文字列を抽出したいときにも同様にできる。
df['user'].str.contains('Ruri')
- 投稿日:2020-03-18T17:39:02+09:00
pandasで特定の複数列(カラム)を抽出する
TL;DR
strアクセサを用いることで部分一致で簡単にカラム指定のマスクが作れる。(例:
df.columns.str.contains('任意の列名'))複数列をまとめて抽出する
ポイントは
- columnsを参照してその中に含まれる文字列を参照する。
- 最終的に出来上がるのは列を含むか否かのbooleanを含んだリストになる
なので、活用するなら
# この場合は任意の複数列を取り出す include_list = df.columns[df.columns.str.contains('hoge_') * df.columns.str.contains('fuga_')] df_prep = df[include_list]# この場合は任意の複数列以外を取り出す # Point: チルダ(~)を使うことでマスクを反転させている exclude_list = df.columns[~df.columns.str.contains('hoge_') * ~df.columns.str.contains('fuga_')] df_prep = df[exclude_list]またオプションには
case(大文字小文字の区別),regex(正規表現パターンの利用) があるので、柔軟につかえる。strアクセサの応用
今回はカラムに対して行ったが、たとえば特定の列内から任意の文字列を抽出したいときにも同様にできる。
df['user'].str.contains('Ruri')
- 投稿日:2020-03-18T17:31:02+09:00
[Python]Classの第一引数はなぜselfなの?
はじめに
Pythonでクラスを定義する際,第一引数の命名が
selfなのはなぜだろうとずっと疑問に思ったので,調べて書き残しときます.第一引数self以外ではダメ?
結論からするとダメです.PEP8(1)に
インスタンスメソッドのはじめの引数の名前は常に self を使ってください。
と定義されています.ただし,動作上ならself以外でもきちんと動きます.例はここ(2)を参考にしてます.class Hoge(): def __init__(self_inplace_hoge, string): self_inplace_hoge.string = string print('self_inplace_hoge: ', self_inplace_hoge.string) class Fuga(Hoge): def __init__(self_inplace_fuga, string): self_inplace_fuga.string = string print('self_inplace_fuga: ', self_inplace_fuga.string) hoge = Hoge('aaaa') fuga = Fuga('bbbb') print(hoge.string) print(fuga.string)self_inplace_hoge: aaaa self_inplace_fuga: bbbb aaaa bbbb動きはしますねルール違反なのでやったらだめですけど.
ちなみに
selfの役割として見てみるとちゃんと定義したクラスがメモリのどこにあるか返してくれます意外と見てみると楽しい?self_inplace_hoge: <__main__.Hoge object at 0x00000123D17C1CC8> self_inplace_fuga: <__main__.Fuga object at 0x00000123D17C12C8>さいごに
thisとかselfって誰でも好きな名前つけたらヤバイってなるからルールができたんだろうな~
ちょっとバズワードみたいですね.参考資料
(1) pep8-ja
(2) self in Python class
- 投稿日:2020-03-18T16:59:16+09:00
M5stack uiflow文字背景
M5stack uiflow文字背景のくせ
こんにちは、お疲れ様です。
M5stackを入手して使い勝手を試すため、ちょこちょこ触ってていますが、
その中でつまづいたことを自分なりの対処法をしたのでその備忘録。そのうちアップデートされてこういう問題も解消されるかもしれませんが、それまで有効なテクニック。
尚、私が試したのは、uiflow v1.4.5です。
ちなみに、micropythonでもblockyでも結果は同じなので、今回せっかくなのでblockyで説明してます。
(そんなに違いはないですが、M5stackらしくということで)文字の背景について
さて、M5stackのメインLCDに文字を表示させるには以下の方法があると思います。
・Graphic の lcd.print を使って表示
・UIの label を使って表示
これが手軽なところでしょうか。まずはgraphicで文字を表示
結論はUIの方を使うのですが、筋道立てるために
先に上手くいかない方(いかなかった方)の
まずGraphicで文字を表示します。
こうですね。
背景色を黒色にしていると気が付きませんが、背景色を変えると愕然とします。
Graphicでは、文字の背景が”黒”になります。
だ、ダサい・・・
このGraphicの文字背景(黒色)はUIの背景色との因果関係もなく、とにかく黒になるようです。
これ、同じくGraphicで塗りなおしたらそもそも表示したい文字も消えちゃうし、その上から文字表示したらまた黒くなる・・・
つまりprint.lcdの中身の問題なのでそこをいじらないとどうしようもないです。(正直ショボい・・・)UIの labelを使用して表示
次に、UIのlabelで文字を表示させると
とても簡単ですね。 マウスで配置するだけ。
ところが、下地に別の色を入れてこの文字を変更するとある事に気が付きます。
(※rectangle0は変更するlabelに被さる様にしています)残像が・・・
labelの文字を変更した時点でその変更する前の文字が残像のように残ります。
注目すべきは、この残像が背景色と同じということです。
この現象は、labelの置かれている場所が、「背景色では無い」時に起こります。
つまり、UIのlabelは以下の手順を踏んでいるということがわかります。① 現在の文字を背景色で上書き
↓
② 変更後の文字で描画色で上書きこの①②の工程が一つで、label showの処理だということがわかります。
ちなみに、「本当にそうか?」という検証がてら
・文字変更をする前に一度塗りつぶし
・変更を何回か行う
などやってみましたが結果は同じ。 上記の①②の処理が一つになっている以上、避けられません。では、どうやって対処するか
もちろん「pythonなんだしライブラリを修正する」とか、「uiflowを諦める」とか、「blockyなんた糞」なんていうことも有りかもしれませんが、やはりせっかくIOTなM5stackなんだし、blockyでやりたいじゃないですか!!
そこで私が考えた手順がこれです。①変更したいlabelを画面外に移動
↓
②元の場所をRectとかで塗りつぶす
↓
③画面の外でlabelを変更する
↓
④変更したlabelを元の場所に戻す
(※rectangle0は変更するlabelに被さる様にしています)labelの描画の原理が透過色ではなく、「上書き描画」っていうことを利用したやり方でした。
まとめ
本音をいうと、透過色が使えればそれでよいのだけど・・・pngとかの活用も広がるので至急対応を望む!!
EOL