- 投稿日:2020-02-28T23:17:22+09:00
COTOHA 構文解析APIについて
のテストをしていて気づいたのですが、APIデモ では
「嫁と娘は旅行に行った。」の解析結果について
のように出力されるので、これがてっきり正解をすべて表しているのかと思っていましたが、実際には
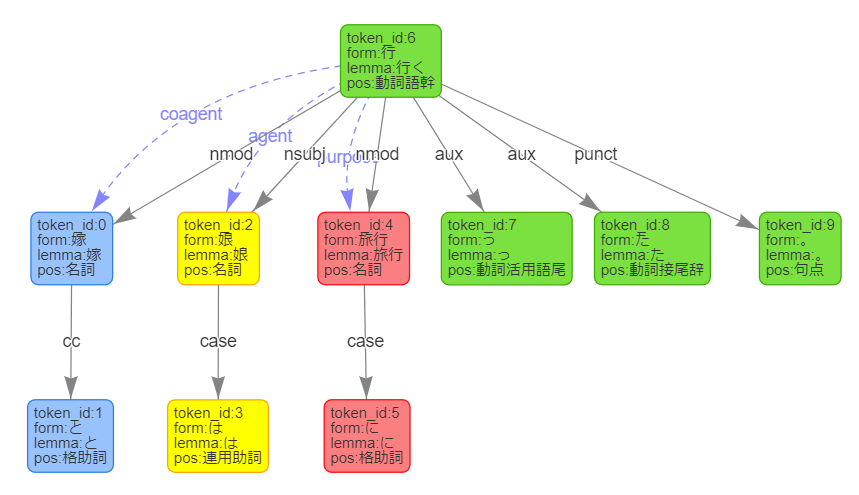
{ "id" : 2, "form" : "娘", "kana" : "ムスメ", "lemma" : "娘", "pos" : "名詞", "dependency_labels" : [ { "token_id" : 0, "label" : "conj" }, { "token_id" : 3, "label" : "case" } ], "attributes" : { } }として返ってきており、図にすると以下のようになります。
JSONの属性名が「dependency_labels」になっているので複数であるのはわかりやすいですが、デモだけを見ていると複数ではないようにも見えるので注意が必要だと思いました。
- 投稿日:2020-02-28T23:17:22+09:00
COTOHA 構文解析APIについてコメント
掛かりうけ元は複数
のテストをしていて気づいたのですが、APIデモ では
「嫁と娘は旅行に行った。」の解析結果について
のように出力されるので、これがてっきり正解をすべて表しているのかと思っていましたが、実際には
{ "id" : 2, "form" : "娘", "kana" : "ムスメ", "lemma" : "娘", "pos" : "名詞", "dependency_labels" : [ { "token_id" : 0, "label" : "conj" }, { "token_id" : 3, "label" : "case" } ], "attributes" : { } }として返ってきており、図にすると以下のようになります。
JSONの属性名が「dependency_labels」になっているので複数であるのはわかりやすいですが、デモだけを見ていると複数ではないようにも見えるので注意が必要だと思いました。
また、デモがAPIの魅力を伝えきれていないようにも見えました。送信できる文書は1つ
処理対象として指定できる「文書」(例:コールセンターの複数件のログ)は、1回のAPIコールで1つです。大量の文書を処理しようとするときは1つずつではなくて複数の文書をまとめて処理したくなるのでこの点も要注意かと思いました。(例:別々の顧客のコールログを連結して構文解析処理するのは不適切。)次のバージョンでは複数の文書を処理できることを期待します。
複数文を解析処理したときの挙動
「嫁と娘は旅行に行った。私と息子は焼き肉を食べた。」を送信すると以下のレスポンスが返ります。
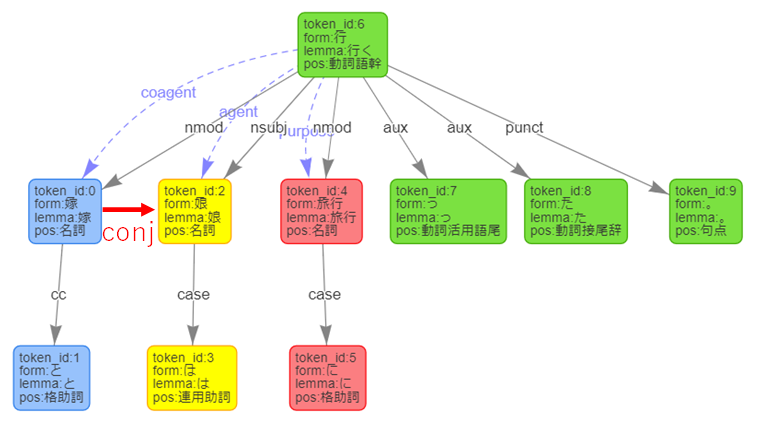
{ "result" : [ { "chunk_info" : { "id" : 0, "head" : 1, "dep" : "P", "chunk_head" : 0, "chunk_func" : 1, "links" : [ ] }, "tokens" : [ { "id" : 0, "form" : "嫁", "kana" : "ヨメ", "lemma" : "嫁", "pos" : "名詞", "features" : [ ], "common_noun_semantic" : [ 49, 76, 88 ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ ], "dependency_labels" : [ { "token_id" : 1, "label" : "cc" } ], "attributes" : { } }, { "id" : 1, "form" : "と", "kana" : "ト", "lemma" : "と", "pos" : "格助詞", "features" : [ "連用" ], "common_noun_semantic" : [ ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ ], "attributes" : { } } ] }, { "chunk_info" : { "id" : 1, "head" : 7, "dep" : "D", "chunk_head" : 0, "chunk_func" : 1, "links" : [ { "link" : 0, "label" : "other" } ] }, "tokens" : [ { "id" : 2, "form" : "娘", "kana" : "ムスメ", "lemma" : "娘", "pos" : "名詞", "features" : [ ], "common_noun_semantic" : [ 49, 59, 88 ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ ], "dependency_labels" : [ { "token_id" : 0, "label" : "conj" }, { "token_id" : 3, "label" : "case" } ], "attributes" : { } }, { "id" : 3, "form" : "は", "kana" : "ハ", "lemma" : "は", "pos" : "連用助詞", "features" : [ ], "common_noun_semantic" : [ ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ ], "attributes" : { } } ] }, { "chunk_info" : { "id" : 2, "head" : 3, "dep" : "D", "chunk_head" : 0, "chunk_func" : 1, "links" : [ ] }, "tokens" : [ { "id" : 4, "form" : "旅行", "kana" : "リョコウ", "lemma" : "旅行", "pos" : "名詞", "features" : [ "動作" ], "common_noun_semantic" : [ 1658, 1659, 1660 ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ 18 ], "dependency_labels" : [ { "token_id" : 5, "label" : "case" } ], "attributes" : { } }, { "id" : 5, "form" : "に", "kana" : "ニ", "lemma" : "に", "pos" : "格助詞", "features" : [ "連用" ], "common_noun_semantic" : [ ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ ], "attributes" : { } } ] }, { "chunk_info" : { "id" : 3, "head" : 7, "dep" : "P", "chunk_head" : 0, "chunk_func" : 2, "links" : [ { "link" : 2, "label" : "purpose" } ], "predicate" : [ "past" ] }, "tokens" : [ { "id" : 6, "form" : "行", "kana" : "イ", "lemma" : "行く", "pos" : "動詞語幹", "features" : [ "IKU" ], "common_noun_semantic" : [ 2053, 2132 ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ 15, 20, 29, 32, 5 ], "dependency_labels" : [ { "token_id" : 4, "label" : "nmod" }, { "token_id" : 7, "label" : "aux" }, { "token_id" : 8, "label" : "aux" }, { "token_id" : 9, "label" : "punct" } ], "attributes" : { } }, { "id" : 7, "form" : "っ", "kana" : "ッ", "lemma" : "っ", "pos" : "動詞活用語尾", "features" : [ ], "common_noun_semantic" : [ ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ ], "attributes" : { } }, { "id" : 8, "form" : "た", "kana" : "タ", "lemma" : "た", "pos" : "動詞接尾辞", "features" : [ "終止" ], "common_noun_semantic" : [ ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ ], "attributes" : { } }, { "id" : 9, "form" : "。", "kana" : "", "lemma" : "。", "pos" : "句点", "features" : [ ], "common_noun_semantic" : [ ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ ], "attributes" : { } } ] }, { "chunk_info" : { "id" : 4, "head" : 7, "dep" : "D", "chunk_head" : 0, "chunk_func" : 1, "links" : [ ] }, "tokens" : [ { "id" : 10, "form" : "私", "kana" : "ワタシ", "lemma" : "私", "pos" : "名詞", "features" : [ "代名詞" ], "common_noun_semantic" : [ 37, 8 ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ ], "dependency_labels" : [ { "token_id" : 11, "label" : "cc" } ], "attributes" : { } }, { "id" : 11, "form" : "と", "kana" : "ト", "lemma" : "と", "pos" : "格助詞", "features" : [ "連用" ], "common_noun_semantic" : [ ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ ], "attributes" : { } } ] }, { "chunk_info" : { "id" : 5, "head" : 7, "dep" : "D", "chunk_head" : 0, "chunk_func" : 1, "links" : [ ] }, "tokens" : [ { "id" : 12, "form" : "息子", "kana" : "ムスコ", "lemma" : "息子", "pos" : "名詞", "features" : [ ], "common_noun_semantic" : [ 48, 58, 87 ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ ], "dependency_labels" : [ { "token_id" : 13, "label" : "case" } ], "attributes" : { } }, { "id" : 13, "form" : "は", "kana" : "ハ", "lemma" : "は", "pos" : "連用助詞", "features" : [ ], "common_noun_semantic" : [ ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ ], "attributes" : { } } ] }, { "chunk_info" : { "id" : 6, "head" : 7, "dep" : "D", "chunk_head" : 0, "chunk_func" : 1, "links" : [ ] }, "tokens" : [ { "id" : 14, "form" : "焼き肉", "kana" : "ヤキニク", "lemma" : "焼き肉", "pos" : "名詞", "features" : [ ], "common_noun_semantic" : [ 843, 852 ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ ], "dependency_labels" : [ { "token_id" : 15, "label" : "case" } ], "attributes" : { } }, { "id" : 15, "form" : "を", "kana" : "ヲ", "lemma" : "を", "pos" : "格助詞", "features" : [ "連用" ], "common_noun_semantic" : [ ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ ], "attributes" : { } } ] }, { "chunk_info" : { "id" : 7, "head" : -1, "dep" : "O", "chunk_head" : 0, "chunk_func" : 1, "links" : [ { "link" : 1, "label" : "agent" }, { "link" : 3, "label" : "manner" }, { "link" : 4, "label" : "coagent" }, { "link" : 5, "label" : "agent" }, { "link" : 6, "label" : "object" } ], "predicate" : [ "past" ] }, "tokens" : [ { "id" : 16, "form" : "食べ", "kana" : "タベ", "lemma" : "食べる", "pos" : "動詞語幹", "features" : [ "A" ], "common_noun_semantic" : [ 1581, 1590 ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ 2, 23 ], "dependency_labels" : [ { "token_id" : 2, "label" : "nsubj" }, { "token_id" : 6, "label" : "advcl" }, { "token_id" : 10, "label" : "nmod" }, { "token_id" : 12, "label" : "nsubj" }, { "token_id" : 14, "label" : "dobj" }, { "token_id" : 17, "label" : "aux" }, { "token_id" : 18, "label" : "punct" } ], "attributes" : { } }, { "id" : 17, "form" : "た", "kana" : "タ", "lemma" : "た", "pos" : "動詞接尾辞", "features" : [ "終止" ], "common_noun_semantic" : [ ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ ], "attributes" : { } }, { "id" : 18, "form" : "。", "kana" : "", "lemma" : "。", "pos" : "句点", "features" : [ ], "common_noun_semantic" : [ ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ ], "attributes" : { } } ] } ], "status" : 0, "message" : "" }ここで「行く」を見ると、掛かり先は「4,7,8,9」の4つになっています。
実際には「0,2」を含む6つになるはずですが、APIが返すのは4つになります。期待する結果
単一の文で送信すると期待した結果になります。
「嫁と娘は旅行に行った。」のみを送信したときの「行く」の掛かり先
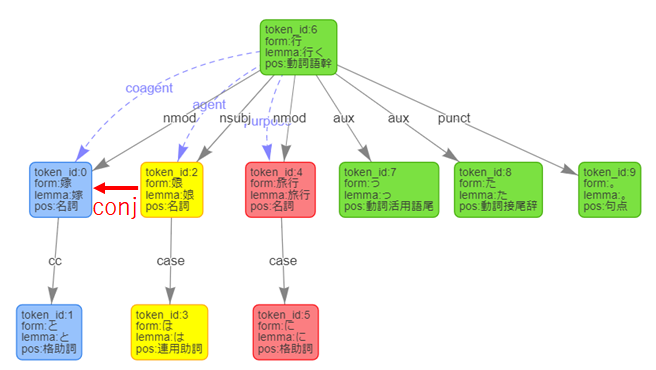
{ "id" : 6, "form" : "行", "kana" : "イ", "lemma" : "行く", "pos" : "動詞語幹", "features" : [ "IKU" ], "common_noun_semantic" : [ 2053, 2132 ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ 15, 20, 29, 32, 5 ], "dependency_labels" : [ { "token_id" : 0, "label" : "nmod" }, { "token_id" : 2, "label" : "nsubj" }, { "token_id" : 4, "label" : "nmod" }, { "token_id" : 7, "label" : "aux" }, { "token_id" : 8, "label" : "aux" }, { "token_id" : 9, "label" : "punct" } ], "attributes" : { } }複数文を送信すると構文解析がちょっと怪しいのか、それとも私の呼び方に問題があるのか。。要調査です。
「嫁と娘は旅行に行った。」の後ろに別の文を連結して送信したときの「行く」の掛かり先
{ "id" : 6, "form" : "行", "kana" : "イ", "lemma" : "行く", "pos" : "動詞語幹", "features" : [ "IKU" ], "common_noun_semantic" : [ 2053, 2132 ], "proper_noun_semantic" : [ ], "declinable_word_semantic" : [ 15, 20, 29, 32, 5 ], "dependency_labels" : [ { "token_id" : 4, "label" : "nmod" }, { "token_id" : 7, "label" : "aux" }, { "token_id" : 8, "label" : "aux" }, { "token_id" : 9, "label" : "punct" } ], "attributes" : { } }spec を見ると「sentence」「解析対象文」となっており、単一の文に限るとも読めますが、「文で区切る」も自然言語処理の一つですので、もし単一の文だけを対象としているのであればAPI仕様として課題になるかと思いました。アカデミックな世界と違って、単一の文だけを処理することはあまりないと思います。(たとえば「モーニング娘。のライブを見に行った」も正しく解析できないといけない)
例えば Stanford NLP は文の区切りもアノテーションとして返してきます。
仕事であればサポートに問い合わせます。^_^;;
リンク
以上


- 投稿日:2020-02-28T22:03:38+09:00
DBLINKを使用した Oracle Database で、DBLINK元と先のデータを取得して表示するJavaコードのサンプル
DBLINKを使用した Oracle Database で DBLINK元と先のデータを取得して表示するJavaコードのサンプルです。
某チャットの某質問で「ソース(情報源)はありますか?」と聞かれて「ぐぬぬ。」となったので、書いてみますた。彡(゚)(゚)1. 環境と構成
下記の構成で検証してみました。
Java → (JDBC) → User_A → (DBLINK) → User_B
環境は Virtualbox の下記環境を使ってます。初めから色々入ってて、セットアップもラクなんで。彡(゚)(゚)
OTN の VirtualBoxイメージ で Oracle DB 19c環境 を 楽々構築
https://qiita.com/ora_gonsuke777/items/b41f37637e59319796b42. User_A の作成とデータ挿入
まずは User_A を作成して、データを挿入します。
export ORACLE_HOME=/u01/app/oracle/product/version/db_1 export PATH=${PATH}:${ORACLE_HOME}/bin sqlplus /nolog CONNECT SYS/oracle@ORCL AS SYSDBA CREATE USER USER_A IDENTIFIED BY USER_A DEFAULT TABLESPACE USERS TEMPORARY TABLESPACE TEMP; GRANT CREATE SESSION TO USER_A; GRANT CREATE TABLE TO USER_A; ALTER USER USER_A QUOTA UNLIMITED ON USERS; CONNECT USER_A/xxxxxxxx@orcl; CREATE TABLE TBL_A( COL1 NUMBER ); INSERT INTO TBL_A VALUES(100); COMMIT; Connected. User created. Grant succeeded. Grant succeeded. User altered. Connected. Table created. 1 row created. Commit complete.3. User_B の作成とデータ挿入
続いて User_B を作成して、データを挿入します。やる事は User_A と一緒彡(゚)(゚)
export ORACLE_HOME=/u01/app/oracle/product/version/db_1 export PATH=${PATH}:${ORACLE_HOME}/bin sqlplus /nolog CONNECT SYS/oracle@ORCL AS SYSDBA CREATE USER USER_B IDENTIFIED BY USER_B DEFAULT TABLESPACE USERS TEMPORARY TABLESPACE TEMP; GRANT CREATE SESSION TO USER_B; GRANT CREATE TABLE TO USER_B; ALTER USER USER_B QUOTA UNLIMITED ON USERS; CONNECT USER_B/xxxxxxxx@orcl; CREATE TABLE TBL_B( COL1 NUMBER ); INSERT INTO TBL_B VALUES(200); COMMIT; Connected. User created. Grant succeeded. Grant succeeded. User altered. Connected. Table created. 1 row created. Commit complete.4. DBLINK作成と動作確認
User_A に DBLINK を作成して、動作確認をします。User_B に作成した TBL_B は、DBLINK経由でしか参照できないことが確認できます。
export ORACLE_HOME=/u01/app/oracle/product/version/db_1 export PATH=${PATH}:${ORACLE_HOME}/bin sqlplus /nolog CONNECT SYS/oracle@ORCL AS SYSDBA GRANT CREATE DATABASE LINK TO USER_A; CONNECT USER_A/xxxxxxxx@orcl; CREATE DATABASE LINK DBL_USER_B CONNECT TO USER_B IDENTIFIED BY xxxxxxxx USING 'ORCL'; SELECT * FROM TBL_A; SELECT * FROM TBL_B; SELECT * FROM USER_B.TBL_B; SELECT * FROM TBL_B@DBL_USER_B; Connected. Grant succeeded. Connected. Database link created. COL1 ---------- 100 * ERROR at line 1: ORA-00942: table or view does not exist * ERROR at line 1: ORA-00942: table or view does not exist COL1 ---------- 2005. Javaコードのサンプル
User_A で接続して、TBL_A と TBL_B(DBLINK経由) をそれぞれ SELECT して表示するサンプルです。
import java.sql.*; public class GetDblinkData { public static void main(String[] args) { final String path = "jdbc:oracle:thin:@localhost:1521/orcl"; final String id = "USER_A"; //ID final String pw = "xxxxxxxx"; //password try ( Connection conn = DriverManager.getConnection(path, id, pw); Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery("SELECT COL1 FROM TBL_A"); Statement stmt2 = conn.createStatement(); ResultSet rs2 = stmt2.executeQuery("SELECT COL1 FROM TBL_B@DBL_USER_B"); ) { while (rs.next()) { int i = rs.getInt("COL1"); System.out.println("TBL_A COL1 => " + i); } while (rs2.next()) { int j = rs2.getInt("COL1"); System.out.println("TBL_B COL1 => " + j); } } catch(SQLException ex) { ex.printStackTrace(); //Error } } }5. コンパイルと実行
さて、ようやくコンパイルと実行。下記コマンドを実行すると……彡(゚)(゚)
javac GetDblinkData.java java -classpath /u01/app/oracle/product/version/db_1/jdbc/lib/ojdbc8.jar:. GetDblinkData TBL_A COL1 => 100 TBL_B COL1 => 200DBLINK元のデータ(TBL_A) と DBLINK先のデータ(TBL_B) が取得&表示できたで!彡(^)(^)
6. まとめ
一本のDB接続で DBLINK元 と DBLINK先 のデータを取得する事を確認できました。
ただ DBLINK は諸刃の剣。密結合な仕組みではあるので、乱用は控えるんやで。彡(゚)(゚)
- 投稿日:2020-02-28T18:10:22+09:00
Selenideオプション一覧
まえがき
Selenideを利用した自動テストを作成する場合、コーディングせずにSelenideにパラメータを与えておくだけで動作を切り替えられるオプションがあります。
これらを知り、活用することで無駄なコーディングを避けられるので、Selenideをガッツリ利用する場合にはあらかじめ把握したほうが無難です。実際にオプションを読み込んでいる処理はSelenideConfig.javaにかかれているので、SelenideConfig上のコードとともに見ていきましょう。
ドキュメントの内容と自分が利用してきた経験を踏まえた簡単な説明と個人的な所感も記載しています。
間違ってたらごめんなさい。前提
今回の解説はselenideのバージョン5.7ベースに記載しており、公式ドキュメントによる解説は下記ページからも参照が可能です。
https://selenide.org/javadoc/current/com/codeborne/selenide/Configuration.htmlオプション一覧
selenide.browser
活用度★★★
どのブラウザを利用するか指定できます。
マルチブラウザでのテストを行う際にもコード上でブラウザを指定する必要がなく便利ですね。
chrome", "firefox", "legacy_firefox" (upto ESR 52), "ie", "opera", "edge"のいずれかから選択します。private String browser = System.getProperty("selenide.browser", CHROME);selenide.headless
活用度★
ヘッドレスモードでの実行もできます。
ただ、E2Eテストととしては避けたほうが無難だと思います。スクレイピングで利用が前提でしょうかね。Chrome(59+) and Firefox(56+)のみで動くそうです。private boolean headless = Boolean.parseBoolean(System.getProperty("selenide.headless", "false"));selenide.remote
活用度★
Selenium Gridを利用する場合などRemoteWebDriverを利用する際にはこの設定が必要だそうです。
複数端末でのテストはjenkinsのパイプラインで実現しているので使ったことはないですが。private String remote = System.getProperty("selenide.remote");selenide.browserSize
活用度★★★
ウインドウサイズの指定もできます。
ウインドウサイズを切り替えたテストもあるあるだと思うので、パラメータで変更できるので便利ですね。
保証解像度で動作するか、それよりも高解像度でも動作するか、等。
また、テスト実行端末に依存しない均質なテストを行うためにも重要。private String browserSize = System.getProperty("selenide.browserSize", "1366x768");selenide.browserVersion
活用度★★★
ブラウザのバージョン指定もできるようです。ドキュメントには(for Internet Explorer)と書かれています。private String browserVersion = System.getProperty("selenide.browserVersion");selenide.browserPosition
活用度★
起動時のブラウザポジションも指定できます。あまり用途は思いつかないですが。private String browserPosition = System.getProperty("selenide.browserPosition");selenide.startMaximized
活用度★★
ブラウザ起動時にブラウザサイズを最大化するかどうかを選べます。
最大化しておくと、可視領域が広がって操作対象の要素も表示されやすいのでテストが通りやすくなる傾向はあると思います。
ただ、ブラウザサイズがテストを実行する端末に依存してしまう点はテスト結果の信憑性という点でちょっと微妙ですね。private boolean startMaximized = Boolean.parseBoolean(System.getProperty("selenide.startMaximized", "false"));selenide.driverManagerEnabled
活用度★★
ドライバの自動ダウンロードを行うか否かを切り替えることができます。
基本Onで良いですが、ダウンロード不要としておくと一連のテスト実行時間は短縮できます。
タイトなスケジュールでテスト実行が必要な場合には活用するのもアリだとおもいます
詳細はSee https://github.com/bonigarcia/webdrivermanager for WebDriverManager configuration details.だそうです。private boolean driverManagerEnabled = Boolean.parseBoolean(System.getProperty("selenide.driverManagerEnabled", "true"));selenide.browserBinary
活用度★
使ったことはないですが、ドライバまでのパスを指定できるようです。
ドキュメント上はWorks only for Chrome, Firefox and Opera.と書かれていますが、コードを見るとIEやsafariでも動きそうな気が。private String browserBinary = System.getProperty("selenide.browserBinary", "");selenide.pageLoadStrategy
活用度★★
ページの読み込み完了、をどのように判断するかを指定できます。
normal: return after the load event fires on the new page (it's default in Selenium webdriver);
eager: return after DOMContentLoaded fires;
none: return immediately
normalの場合はload eventが発火するまで待機するので一番保守的。
これからテストを作成する場合にはDOMの読込完了までは待機してくれるeagerを選択しておくと安定性と速度が両立できて良いかも。
noneはまったく待機しないので実用的ではないでしょうね。private String pageLoadStrategy = System.getProperty("selenide.pageLoadStrategy", "normal");selenide.baseUrl
活用度★★★
Selenide.open()を利用してページを開くときにここで設定されたURLを開きます。
開発・ステージング等テスト対象となる環境が複数ある場合に活躍します。
通常はホスト、ドメイン、ポートまでを指定します。private String baseUrl = System.getProperty("selenide.baseUrl", "http://localhost:8080");selenide.timeout
活用度★★★
shouldメソッドなどを利用して要素に対するチェックを行う際に待機する時間を指定できます。
テスト対象の環境スペックが低く、レスポンスが悪い場合にはタイムアウト時間を変更することでテストを安定化させることができます。private long timeout = Long.parseLong(System.getProperty("selenide.timeout", "4000"));selenide.pollingInterval
活用度★
あえて指定する必要はないですね。要素のチェックをする際のチェック間隔です。private long pollingInterval = Long.parseLong(System.getProperty("selenide.pollingInterval", "200"));selenide.holdBrowserOpen
活用度★
テストが終わった際にウインドウを開いたままにすることができます。
テスト実行に失敗する際の調査に利用できます。ただ、ウインドウを閉じなければならなくなるので基本的にはキャプチャ取得で代用可能な場合には、このオプションは利用しないほうがベターだと思います。private boolean holdBrowserOpen = Boolean.getBoolean("selenide.holdBrowserOpen");selenide.reopenBrowserOnFail
活用度?
ドキュメントによるとhangs, broken, unexpectedly closedによってブラウザが閉じてしまった時に開きなおすか、というオプションのようですが、開き直してもその後うまく処理進むんですかね。private boolean reopenBrowserOnFail = Boolean.parseBoolean(System.getProperty("selenide.reopenBrowserOnFail", "true"));selenide.clickViaJs
活用度★
要素のクリックをwebdriverが行うか、jsを使って実現するかという選択ができるようです。
ATTENTION! Automatic WebDriver waiting after click isn't working in case of using this feature.
とも書かれているので、理由がなければあえて変更する必要はないと思います。private boolean clickViaJs = Boolean.parseBoolean(System.getProperty("selenide.clickViaJs", "false"));selenide.screenshots
活用度★★★
テスト失敗時にスクショを撮るかどうか。
テスト失敗時のエビデンスとして、またテストコードの問題調査をする場合にはキャプチャが取れると良いので、パラメータでキャプチャ保存要否を切り替えられるのは良いですね。。private boolean screenshots = Boolean.parseBoolean(System.getProperty("selenide.screenshots", "true"));selenide.savePageSource
活用度★★★
実行時のhtmlを取得できるので、こちらもテスト失敗時の調査に役立ちます。private boolean savePageSource = Boolean.parseBoolean(System.getProperty("selenide.savePageSource", "true"));selenide.reportsFolder
活用度★★
private String reportsFolder = System.getProperty("selenide.reportsFolder", "build/reports/tests");selenide.savePageSource
活用度★★
ファイルのダウンロード先を指定できます。private String downloadsFolder = System.getProperty("selenide.downloadsFolder", "build/downloads");selenide.reportsUrl
活用度★★
CIと組み合わせて実行するときには便利。
If it's given, names of screenshots are printed as "http://ci.mycompany.com/job/my-job/446/artifact/build/reports/tests/my_test.png" - it's useful to analyze test failures in CI server.
Optional: URL of CI server where reports are published to. In case of Jenkins, it is "BUILD_URL/artifact" by default.private String reportsUrl = new CiReportUrl().getReportsUrl(System.getProperty("selenide.reportsUrl"));selenide.fastSetValue
活用度★★
入力欄への値の入力処理をjavascriptで行うかSeleniumの"sendKey" functionを利用するかを選択できます。
javascriptを利用したほうが入力動作が速いようなので、速度が気になる場合には一考の価値がありです。private boolean fastSetValue = Boolean.parseBoolean(System.getProperty("selenide.fastSetValue", "false"));selenide.versatileSetValue
活用度★
'setValue'、'val'メソッドを実際の要素のタイプに応じて'selectOptionByValue', 'selectRadio'のように動作させられるようです。private boolean versatileSetValue = Boolean.parseBoolean(System.getProperty("selenide.versatileSetValue", "false"));selenide.fileDownload
活用度★
ファイルダウンロードをする際にproxy serverを経由するか設定できます。private FileDownloadMode fileDownload = FileDownloadMode.valueOf(System.getProperty("selenide.fileDownload", HTTPGET.name()));selenide.proxyEnabled
活用度★
proxy serverを経由してブラウザを動作させるか設定できます。private boolean proxyEnabled = Boolean.parseBoolean(System.getProperty("selenide.proxyEnabled", "false"));selenide.proxyHost
活用度★
proxy serverを経由してブラウザを動作させる場合のホストを設定できます。
proxyEnabled == trueとなっていることが前提。private String proxyHost = System.getProperty("selenide.proxyHost", "");selenide.proxyPort
活用度★
proxy serverを経由してブラウザを動作させる場合のポート番号を設定できます。
proxyEnabled == trueとなっていることが前提。private int proxyPort = Integer.parseInt(System.getProperty("selenide.proxyPort", "0"));あとがき
テストに役に立ちそうなオプションは見つかったでしょうか。
ライブラリのバージョンアップによってオプションも随時追加されているようなので、継続的なチェックがおすすめです。
- 投稿日:2020-02-28T15:16:53+09:00
51歳からの(現52)プログラミング 備忘 FileOutputStream android.content.Context.openFileOutput(java.lang.String, int)' on a null object reference
こんなコードがあったとする
SampleActivityContext context; @Override protected void onCreate(Bundle savedInstanceState){ super.onCreate(savedInstanceState); setContantView(R.layout.sample); context = getApplicationContext(); new AsyncTask().execute(); } public void fileWrite(){ try{ openFileOutput("fileName",Context.MODE_APPEND); } }AsyncTask@Override protected void onPostExecute(String s){ super.onPostExecute(s); SampleActivity sampleA = new SampleActivity(); sampleA.fileWrite(); }これだと
FileOutputStream android.content.Context.openFileOutput(java.lang.String, int)' on a null object reference
エラーが出る。コード上のインスタンス生成時に
contextが生成されてないので、NullPointerExeptionになる。回避するのなら>https://qiita.com/old_cat/items/ff4f2116192fd536fb59
に記載の通り、コールバックメソッドを実装してcontextを扱う。SampleActivityContext context; @Override protected void onCreate(Bundle savedInstanceState){ super.onCreate(savedInstanceState); setContantView(R.layout.sample); context = getApplicationContext(); AsyncTaskCallBack asyncTaskCallBack = new AsyncTaskCallBack(); AsyncTask asyncTask = new AsyncTask(asyncTaskCallBack); } public class AsyncTaskCallBack(){ // ここでfileOutputStreamを使ってもOK // でも他のメソッドを呼び出してみる public void one(){ fileWriter(); } } public void fileWrite(){ try{ openFileOutput("fileName",Context.MODE_APPEND); } }AsyncTaskSampleActivity.AsyncTaskCallBack asyncTaskCallBack; public AsyncTask(SampleActivity.AsyncTaskCallBack asyncTaskCallBack){ this.asyncTaskCallBack = asyncTaskCallBack; } @Override protected void onPostExecute(String s){ super.onPostExecute(s); asyncTaskCallBack.one(); }
- 投稿日:2020-02-28T14:59:44+09:00
メソッドの分割について(Java)
メソッドを分割する手順
冗長なコードを書いてしまい可読性が悪化しました。
以下の手順でメソッドを分割したいと思います。
- printDataメソッドとfullNameメソッドを作成
- fullNameメソッドの中身を記述
- printDataメソッドの中身を記述
- printDataメソッドの呼び出すための記述
Main.javaimport java.util.Scanner; class Main { public static void main(String[] args) { Scanner scanner = new Scanner(System.in); System.out.print("名前:"); String firstName = scanner.next(); System.out.print("名字:"); String lastName = scanner.next(); String name = firstName + " " + lastName; System.out.print("年齢:"); int age = scanner.nextInt(); System.out.print("身長(m):"); double height = scanner.nextDouble(); System.out.print("体重(kg):"); double weight = scanner.nextDouble(); System.out.println("名前は" + name + "です"); System.out.println("年齢は" + age + "歳です"); if (age >= 20) { System.out.println("成年者です"); } else { System.out.println("未成年者です"); } System.out.println("身長は"+ height + "mです"); System.out.println("体重は" + weight + "kgです"); } }printDataメソッドとfullNameメソッドを作成
まず、printDataメソッドとfullNameメソッドを作成します。
中身はまだ空でいいです。Main.javaimport java.util.Scanner; class Main { public static void main(String[] args) { //長いので省略 } public static void printData(String firstName, String lastName, int age, double height, double weight) { } public static String fullName(String firstName, String lastName) { } }fullNameメソッドの中身を記述
fullNameメソッドの戻り値を記述します。
firstName と lastName を連結し、fullNameメソッドの戻り値とします。Main.javaimport java.util.Scanner; class Main { public static void main(String[] args) { Scanner scanner = new Scanner(System.in); System.out.print("名前:"); String firstName = scanner.next(); System.out.print("名字:"); String lastName = scanner.next(); // 不要になったので削除です↓ //String name = firstName + " " + lastName; System.out.print("年齢:"); int age = scanner.nextInt(); System.out.print("身長(m):"); double height = scanner.nextDouble(); System.out.print("体重(kg):"); double weight = scanner.nextDouble(); System.out.println("名前は" + name + "です"); System.out.println("年齢は" + age + "歳です"); if (age >= 20) { System.out.println("成年者です"); } else { System.out.println("未成年者です"); } System.out.println("身長は"+ height + "mです"); System.out.println("体重は" + weight + "kgです"); } public static void printData(String firstName, String lastName, int age, double height, double weight) { } public static String fullName(String firstName, String lastName) { // firstName と lastName を連結し、fullNameメソッドの戻り値とします return firstName + " " + lastName; } }printDataメソッドの中身を記述
fullNameメソッドを利用してフルネームを出力します。
その他、年齢などの出力をmainメソッドからコピペします。Main.javaimport java.util.Scanner; class Main { public static void main(String[] args) { Scanner scanner = new Scanner(System.in); System.out.print("名前:"); String firstName = scanner.next(); System.out.print("名字:"); String lastName = scanner.next(); System.out.print("年齢:"); int age = scanner.nextInt(); System.out.print("身長(m):"); double height = scanner.nextDouble(); System.out.print("体重(kg):"); double weight = scanner.nextDouble(); // 不要になったので削除です↓ // System.out.println("名前は" + name + "です"); // System.out.println("年齢は" + age + "歳です"); // if (age >= 20) { // System.out.println("成年者です"); // } else { // System.out.println("未成年者です"); // } // System.out.println("身長は"+ height + "mです"); // System.out.println("体重は" + weight + "kgです"); } public static void printData(String firstName, String lastName, int age, double height, double weight) { // fullNameメソッドを呼び出し、出力 System.out.println("名前は" + fullName(firstName, lastName) + "です"); // 年齢を出力(mainメソッドからコピペ) System.out.println("年齢は" + age + "歳です"); // 未成年か否かの条件分岐(mainメソッドからコピペ) if (age >= 20) { System.out.println("成年者です"); } else { System.out.println("未成年者です"); } // 身長と体重を出力(mainメソッドからコピペ) System.out.println("身長は" + height + "mです"); System.out.println("体重は" + weight + "kgです"); } public static String fullName(String firstName, String lastName) { return firstName + " " + lastName; } }printDataメソッドの呼び出すための記述
最後にprintDataメソッドの呼び出すための記述をmainメソッドに追加します。
Main.javaimport java.util.Scanner; class Main { public static void main(String[] args) { Scanner scanner = new Scanner(System.in); System.out.print("名前:"); String firstName = scanner.next(); System.out.print("名字:"); String lastName = scanner.next(); System.out.print("年齢:"); int age = scanner.nextInt(); System.out.print("身長(m):"); double height = scanner.nextDouble(); System.out.print("体重(kg):"); double weight = scanner.nextDouble(); // printDataメソッドを呼び出します printData(firstName, lastName, age, height, weight); } public static void printData(String firstName, String lastName, int age, double height, double weight) { System.out.println("名前は" + fullName(firstName, lastName) + "です"); System.out.println("年齢は" + age + "歳です"); if (age >= 20) { System.out.println("成年者です"); } else { System.out.println("未成年者です"); } System.out.println("身長は" + height + "mです"); System.out.println("体重は" + weight + "kgです"); } public static String fullName(String firstName, String lastName) { return firstName + " " + lastName; } }これで、可読性については改善されたかと思います。
- 投稿日:2020-02-28T14:32:02+09:00
Spring DI関連アノテーションについて
Spring DI関連アノテーションの種類
Context Configuration Annotations
@Scope
@Autowired
@Resource
@Inject
@Required
@Named
@Order
@PostConstruct
@PreDestroy@Scope
一般的に @Component @Service @Repository などで自動的にスキャニングするBeanはシングルトンとして一つのみ生成されるが、これを変更するためには @Scope アノテーションを使えばよい。つまり、Beanの範囲を設定してあげる。
singleton -
IoC コンテナー当たり一つのBeanをリターン
prototype -リクエストがある度に新しいBeanを作成し、リターン
request -HTTP request オブジェクト当たり一つのBeanをリターン
session -HTTP session オブジェクト当たり一つのBeanをリターン
globalSession -全てのセッションに対する一つのBeanをリターン
Example@Component @Scope("prototype") Class Hoge { ... } <bean id="hoge" class="aaa.java.bbb.ccc.hoge" scope="prototype" />Beanを注入してもらった場合は、下記のアノテーションが使える。
@Autowired
Spring Frameworkに属するアノテーション
Beanのidかname、どっちか合ったら適用する。Type Driven Injection
いくつかのBeanが検索された場合は、@Qualifier(name="hoge")アノテーションで区別する。
基本的に @Autowiredになった属性はすべてBeanが注入される。
- 適用できるとこ:メンバー変数、setterメソッド、コンストラクト、一般メソッド@Resource
Spring 2.5 以上で使えて、Spring Frameworkに属しないアノテーション
Beanのnameで注入されるBeanを探す。使うためには、JSR.250ライブラリのjsr250-api.jarをクラスパスに追加する。
- 適用できるとこ:メンバー変数、setterメソッドMaven設定<dependency> <groupId>javax.annotation</groupId> <artifactId>jsr250-api</artifactId> <version>1.0</version> </dependency>@Inject
Spring 3.0 以上で使える。特定のFrameworkに属しないアプリーを構成するためには、@Injectを使うことがおすすめされている。使うためには、JSR.330ライブラリの
javax.inject-x.x.x.jarをクラスパスに追加する。
- 適用できるとこ:メンバー変数、setterメソッド、コンストラクト、一般メソッドMaven設定<dependency> <groupId>javax.inject</groupId> <artifactId>javax.inject</artifactId> <version>1</version> </dependency>@Required
Setterメソッドの上に記述し、必須プロパティーを設定する用途で使われる。使うためには、RequiredannotationBeanPostProcessorクラスをBeanとして登録するか、設定を追加すればいける。
Examplepackage day1; public class Emp { private String ename; @Requried public void setEname( String ename ) { this.ename = ename; } public String getName() { return this.ename; } }Beans.xml<bean id="emp" class="day1.Emp" > <!-- 以下のプロパティーを設定しないとエラー --> <!-- <property ename="ename" value="hoge" /> --> </bean>main()ApplicationContext ctx = new ClassPathXmlApplicationContext("Beans.xml"); Emp emp = (Student) ctx.getBean("emp"); System.out.println("Ename : " + emp.getEname());実行すると、下記のエラーが出る。
ErrorProperty 'ename' is required for bean 'emp'
少し疲れたので、@Named @Order @PostConstruct については明日・・・
- 投稿日:2020-02-28T14:08:31+09:00
Androidの用語を整理
Androidの基礎用語を整理
Context
・アプリケーションの環境情報とかをグローバル(Android OSの全域)で受け渡しするためのインターフェース
・アクティビティの起動とかブロードキャスト、インテントの受け取りといった他のアプリからの応答を行え、アンドロイド特有のリソース・クラスにアクセスすることも出来る。
アプリ全体の状態を持っていて、何から起動されたかどういう状態か、何にアクセスしようとしているか、といった情報を受け渡すために使っている。ということでいいのかも。(次のサイトから抜粋)
http://individualmemo.blog104.fc2.com/blog-entry-41.htmlActivity
アプリの画面を表示するためのコンポーネントであり、また、状態の保存・復帰のための仕組みや、他のコンポーネントを呼び出す機能がある。ライフサイクルは今後追加
Intent
各コンポーネントの要求をシステムに伝えて、意図にあった相手のコンポーネントとつながる。
Fragment
FragmentはActivity上で運用されるものの独立した機能をもつので,Fragment自身もViewを装備・使用できるが、UI画面としてのライフサイクルの根本をコントロールするのはActivity。紙芝居の土台が、Activityで、一つ一つの紙芝居のページがFragment。ライフサイクルは今後追加
- 投稿日:2020-02-28T14:04:22+09:00
【Java】lengthとlength()とsize()の違い
この記事の内容
Javaで配列や文字列の長さを取得するとき、lengthなのかlength()なのかsize()なのかごっちゃになるので、その辺りを勉強を兼ねてまとめました。
結論
length length() size() 配列の長さ 文字列の長さ コレクションの要素数 length、length()、size()の違い
length
lengthは配列の長さを取得するのに使われます。
int[] a = new int [100]; a.length; // 100 a.length(); // コンパイルエラー配列のメンバであるlengthフィールドを利用するため、()は不要となります。
length()
length()は文字列の長さを取得するのに使われます。
String str = "aiueo" str.length; // コンパイルエラー str.length(); // 5文字列では長さの取得にlengthメソッドを用いるため、()が必要となります。
全角の場合でも文字数を(人間的に)正しく数えてくれます。String zenkaku = "あいうえお" zenkaku.length(); // 5size()
size()でコレクション(ListやSetなど)の要素数を取得できます。
ArrayList<Integer> b = new ArrayList<>(); for(int i = 0; i < 100; i++){ b.add(i); } b.size() //100size()はCollectionクラスで定義されているメソッドだそうです。なので、コレクションなら全てsize()が使えます。
参考文献
http://www.kab-studio.biz/Programing/JavaA2Z/Word/00000290.html
- 投稿日:2020-02-28T13:14:54+09:00
環境変数でJavaとMySQLのPATH を通してみる【Windows版】
環境設定でPath を通す
環境変数で「Pathを通す」とは一体何をしているのか、また設定のやり方について説明していきます
今回の記事
- Pathとは?
- Pathを通す意味
- システム環境変数でのPathの通し方
- Pathが通ったかどうか確認
Pathとは?
まずPathとは何かについてです。
Pathとはそのアプリケーションの場所を示すアドレスみたいなものです。
例を見てみましょう。例:Java
そのPCのjdkをインストールした場所を示すのものがPathです。
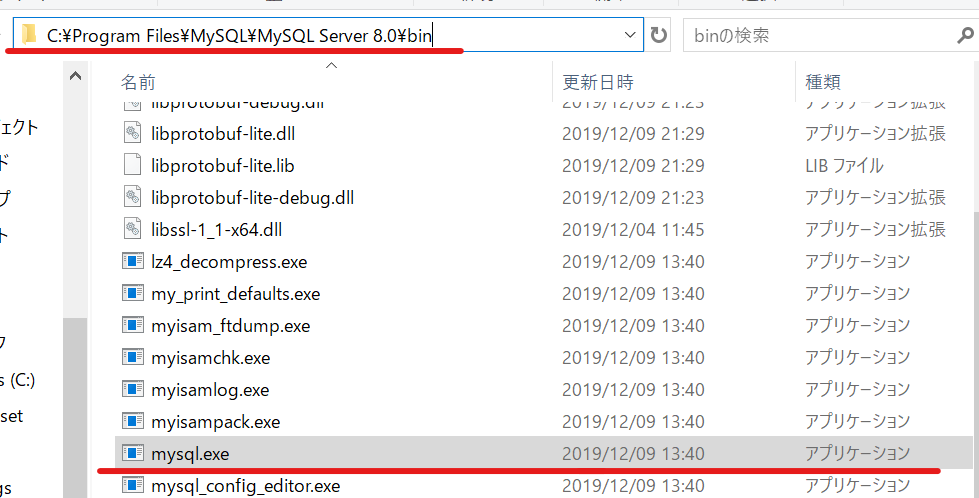
「C:\Program Files\Java\jdk1.X.X_XXX\bin」例:MySQL
「mysql.exe」というのがMySQLのアプリケーションなので、それの場所を指示している「C:\Program Files\MySQL\MySQL Server 8.0\bin」がPathになります。
Pathを通す意味
Pathとはアプリケーションの場所を示すものだとわかりました。
その「Pathを通す=Pathを設定する」ことによってパソコンに特定のプログラムを「プログラム名だけで実行できるようにして」と頼んでることになります。システム環境変数でのPathの通し方
早速システム環境変数でPathを通していきましょう!
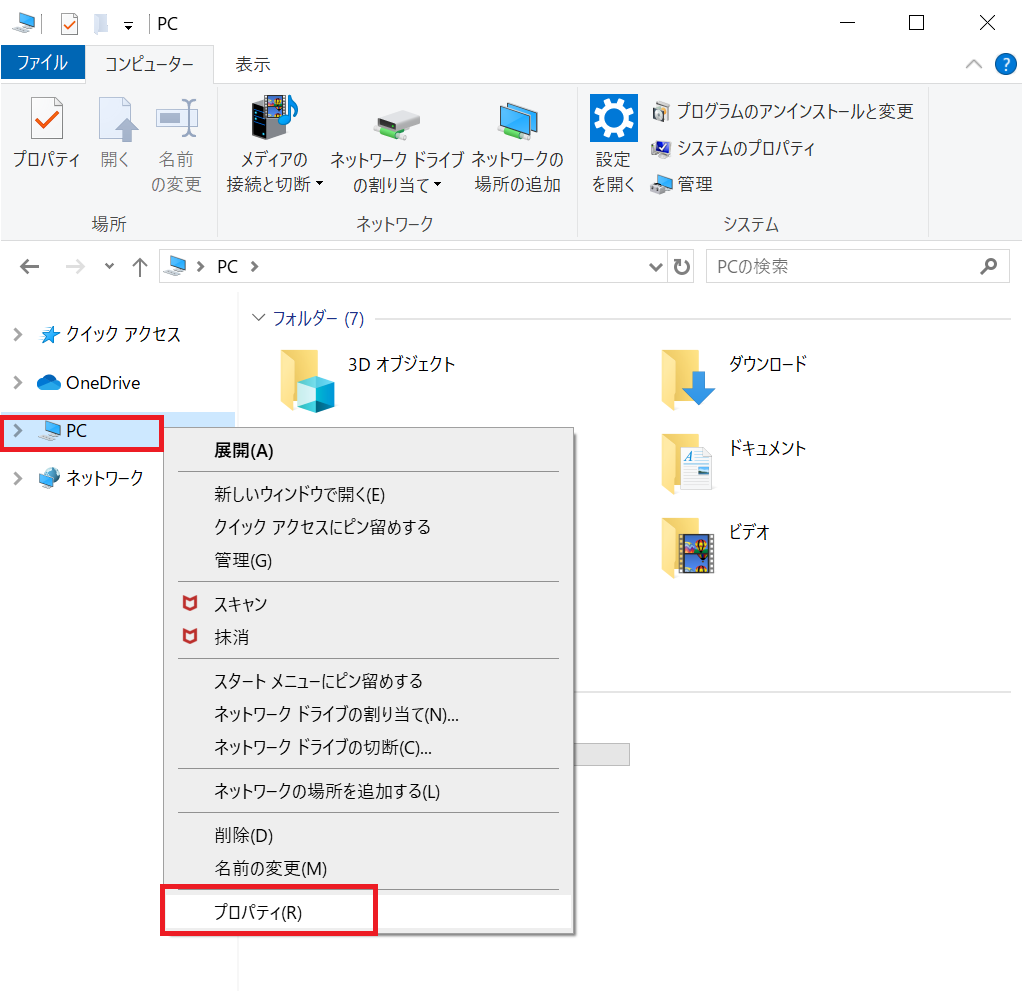
フォルダーのPCを右クリック→プロパティ(R)をクリック
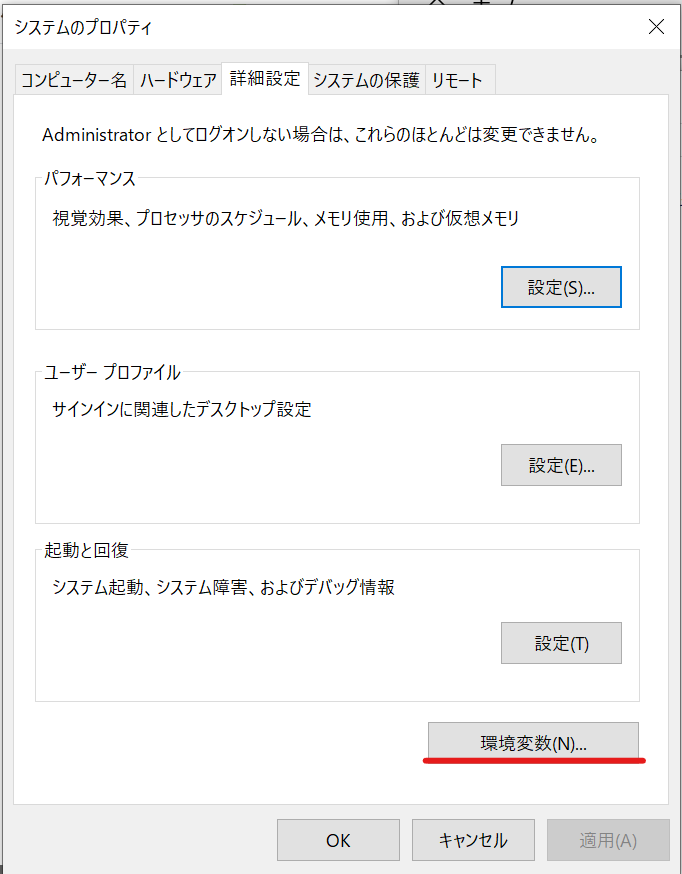
システムのページに行くのでシステム詳細設定を押します。
システムのプロパティが出てくるので、環境変数(N)をクリック
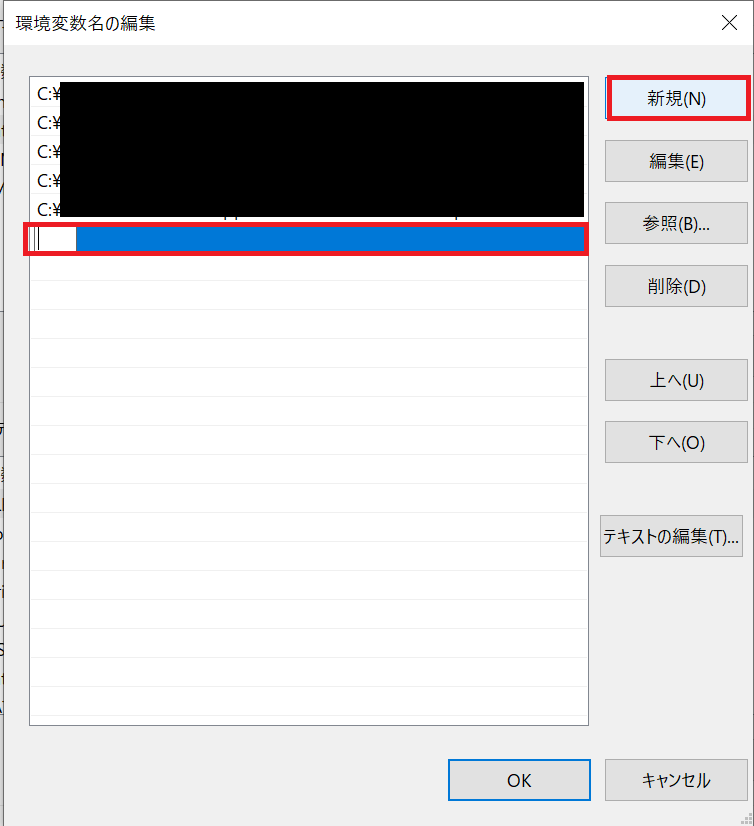
そこでPathを選択し→編集(E)
するとPathを入力する画面になります。
ここにPath(C:\Program Files\~)を入力しOKで完了です。
Pathが通ったかどうか確認
Pathが通ったかどうかの確認はコマンドプロンプトでできます。
例:Java
「javac -version」と打ってみましょう。
上記のように帰ってくれば成功です。
例:MySQL
「mysql --version」と打ってみましょう。
上記のように帰ってくれば成功です。
「'~' は、内部コマンドまたは外部コマンド、
操作可能なプログラムまたはバッチ ファイルとして認識されていません。」とでてきた場合はPathがしっかり通っていませんのでご注意ください




- 投稿日:2020-02-28T11:24:59+09:00
配列の奇数と偶数の和を出力するプログラム(Java)
手順について
配列の奇数の和と偶数の和をそれぞれ求め、その結果を表示するプログラムです。
以下の手順で記述していきます。
- 数字の配列を管理するための変数を定義
- 偶数と奇数を管理するための変数を定義
- for文で繰り返し処理を記述
- if文で奇数と偶数の条件分岐を記述
- 結果を出力ための記述
数字の配列を管理するための変数を定義
Main.javaclass Main { public static void main(String[] args) { // 変数numbersに、与えられた数字の配列を代入 int[] numbers = {1, 4, 6, 9, 13, 16}; } }偶数と奇数を管理するための変数を定義
Main.javaclass Main { public static void main(String[] args) { int[] numbers = {1, 4, 6, 9, 13, 16}; // 変数oddSumを定義し0を代入しておく(これが奇数) int oddSum = 0; // 変数evenSumを定義し0を代入しておく(これが偶数) int evenSum = 0; } }for文で繰り返し処理を記述
処理の手順としてfor文で配列をすべて出しつつ、if文で条件分岐させます。
以下のように記述することで変数numberに配列numbersの各要素が順に代入されます。Main.javaclass Main { public static void main(String[] args) { int[] numbers = {1, 4, 6, 9, 13, 16}; int oddSum = 0; int evenSum = 0; // for文を用いて、配列numbersを繰り返す for (int number : numbers) { } } }if文で奇数と偶数の条件分岐を記述
(number % 2 == 0)の記述で偶数であるかを判断させます。
Main.javaclass Main { public static void main(String[] args) { int[] numbers = {1, 4, 6, 9, 13, 16}; int oddSum = 0; int evenSum = 0; for (int number : numbers) { // if文で条件分岐を記述 if (number % 2 == 0) { evenSum += number; } else { oddSum += number; } } } }結果を出力ための記述
for文の外に記述します。
for文の中に書いてしまうとnumbersの各要素を呼び出す毎に出力されてしまいます。Main.javaclass Main { public static void main(String[] args) { int[] numbers = {1, 4, 6, 9, 13, 16}; int oddSum = 0; int evenSum = 0; for (int number : numbers) { // if文で条件分岐を記述 if (number % 2 == 0) { evenSum += number; } else { oddSum += number; } } // for文の外に記述 System.out.println("奇数の和は" + oddSum + "です"); System.out.println("偶数の和は" + evenSum + "です"); } }以上になります。