- 投稿日:2020-02-28T23:58:28+09:00
AWS EC2でMemoryErrorとNo space left on deviceで詰まった話
対処
MemoryError →
--no-cache-dirをつければ通る。
No space left on device → ファイル容量を減らせ!以下余談
MemoryErrorの対処
AWSのEC2でpipからtensorflowを入れようとしたところ。。。
pip install tensorflow ~ 真っ赤なエラー... ~ MemoryErrorMemoryErrorで入れることができない。。。
そんな時は--no-cache-dirを付けてキャッシュを無効化すればいい!ということで再度実行。pip install tensorflow --no-cache-dir ~ やっぱりエラー... ~ ERROR: Could not install packages due to an EnvironmentError: [Errno 28] No space left on deviceエラーが
[Errno 28] No space left on deviceに変わった。こいつの原因はなんだ?No space left on deviceの対処
容量を確認してみる
どうやら容量が足りないらしい。そこで
df -hで確認してみる。ファイルシス サイズ 使用 残り 使用% マウント位置 devtmpfs 475M 0 475M 0% /dev tmpfs 492M 0 492M 0% /dev/shm tmpfs 492M 412K 492M 1% /run tmpfs 492M 0 492M 0% /sys/fs/cgroup /dev/xvda1 8.0G 5.0G 3.1G 63% / tmpfs 99M 0 99M 0% /run/user/1000そんなに圧迫してるんか...?他に原因がないらしいのでとりあえず使用率30%くらいまで減らしてみる。
find . -xdev -type f | cut -d "/" -f 2 | sort | uniq -c | sort -nr
余談:このコマンド叩けば各ファイルの容量がわかる。
とりあえずcloneしたレポジトリと、pipの中身を消して容量を無理やり減らして再実行!したら通りました。めでたしめでたし
- 投稿日:2020-02-28T21:20:00+09:00
AWS CDK(Python)開発からAWSリソース構築までの手順※開発初心者向け
自分がほぼインフラ一本でやってきて、開発経験が乏しかったことから
開発初心者がCDKを使ってAWSリソースを構築するために行ったことや手順を纏めてみました。
※バージョンによってはこの通り動かないこともあると思いますのでご了承ください
私は2019年12月時点の最新版のバージョンを利用していますコーディング環境
環境用意は下記の記事を参照
WindowsにCDK環境構築する手順(Python)
https://qiita.com/toma_shohei/items/985916e1a95ec4c38121CDK(Python)コーディング
◾️まず概要をつかむ
https://pages.awscloud.com/rs/112-TZM-766/images/B-3.pdf◾️環境用意したらWorkShopやってみる
・Workshop(英語)
https://cdkworkshop.com/30-python.html・Workshop(日本語:ダウンロード版)
http://bit.ly/cdkworkshopjprequirements.txt編集(扱うリソースをinstall)
=======
aws-cdk.coreaws-cdk.aws-autoscaling
aws-cdk.aws-ec2
aws-cdk.aws-elasticloadbalancingv2
aws-cdk.aws-rds
aws-cdk.aws-ssm
aws-cdk.aws-route53aws-cdk.aws-autoscaling-common
====================
pip install -r requirements.txtフォルダ構成
cdk init した段階で以下のようなフォルダ構成が勝手に出来上がります。
https://cdkworkshop.com/30-python/20-create-project/300-structure.html自分はpyyaml導入してパラメータをコードから分離しています。
フォルダ構成は下記の様なイメージになります。・フォルダ構成イメージ
CDK-WORKSHOP
□┣config
□┃┣prd
□┃┃┣ec2.yaml
□┃┃┣vpc.yaml
□┃┃┣・・・
□┃┗stg
□┃□┣ec2.yaml
□┃□┣vpc.yaml
□┃□┣・・・
□┣cdk-workshop_stack.py
□┣・・・※CDKのTOP直下にconfigというフォルダを切っている。
その配下に環境別(prd、stgなど)のフォルダを切り、
その配下にリソース別(ec2やvpcなど)にパラメータを記述している。(cdk.jsonで読み込むディレクトリを切り替える)
cdk-workshop_stack.pyに全リソース構築するコードを記載(config配下のパラメータを読み取る)。
複数リージョンへの構築は同一フォルダではできなかったのでフォルダを分けること。下記のようなやり方はpyyamlを利用しているとできない(バグと思われるが必ず出力がJSONになってしまう)
https://dev.classmethod.jp/cloud/aws-cdk-multi-account-region/暫定対応(今後修正予定、現状では解決手段不明)
!Refをパラメータに書くときは「\!Ref」とし、
出力されたyamlを一括変換「\!Ref」⇒「!Ref」する。
※!GetAttも同様
※pyyamlでyaml.safe_loadを利用しているが「!」をエスケープする方法がわからない
yamlに書かずに.py上に"!Ref " + yamlから読み込んだ文字 とすると 文字列全体に" "がかかり、!Refまで文字列扱いされてしまうCloudFormation実行
・CloudFormationテンプレート出力
cdk synth --version-reporting false --path-metadata false > C:\Users\test\Desktop\test.txt・上記暫定対応実施
・CloudFormationデプロイコマンド(チェンジセット作成まで)
aws cloudformation deploy --stack-name testStack --template-file C:\Users\test\Desktop\test.txt --no-fail-on-empty-changeset --no-execute-changeset・変更セット確認⇒実行
マネジメントコンソールからCloudFormationを開くと
作成したスタックの変更セットを確認し、問題なければ実行を押すよく見るドキュメント
・AWS CDK Python Reference
https://docs.aws.amazon.com/cdk/api/latest/python/index.html・Python examples
https://github.com/aws-samples/aws-cdk-examples課題
・High-level constructsの利用
手動で構築済の既存のリソース上に新たに構築するリソースをコードで構築していく運用(?)のため
Low-level constructs(CfnXXXという名前のライブラリ)しか利用できていない
※本来ならコード量を少なくするため、High-level constructsを使いたいが、
High-level constructsで作ったリソース上にしか作れないようになっている?(⇒これは調査中)・テストコードがかけていない
そもそも何を確認すれば良いのかが未検討所感
・IaCでの構築について
品質は間違いなく上がります。(ある程度の規模の構築案件なら必ずミスする自分がミスしなかった)
検証環境作ったら本番環境はほぼコピペで作成できるので再現性はかなり高いです。・CDKの特徴
TerraformでもAWS構築経験はありますが、CDKの方がはまりポイントが少ない印象です。
後発のツールであるため、バージョンアップの間隔が短く(毎日のようにコミットされている)、
最新版が後方互換しない場合があるので、リスクはありますが現状はそれで悩まされたことは少ししかないです。
- 投稿日:2020-02-28T20:57:48+09:00
CloudFront + Lambda@Edgeでハマったことまとめ
概要
Lambda@Edgeとは、CloudFrontのエッジロケーションで実行できるLambda関数です。
コンテンツがオリジンから返されたときにキャッシュできるので、アプリケーション側のパフォーマンスを向上させることができます。
さらにLambda@Edgeの処理として、画像リサイズ機能を組み込むとリサイズされた画像をCloudFrontがキャッシュするので、ユーザはリサイズによるオーバーヘッドを受けない綺麗なアーキテクチャを作ることができます。
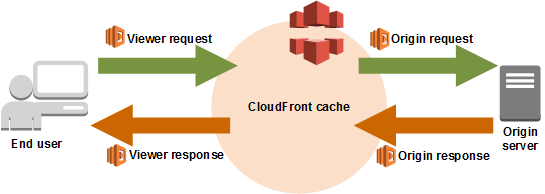
具体的には、下図で右下の「Origin response」に画像のリサイズ機能を持ったLambda@Edgeを配置します。
(下図はオフィシャルから拝借)
そんな一見便利そうに見えるLambda@Edgeですが、CloudFrontとLambda@Edgeを使って、画像リサイズのシステムを構築したときにLambda@Edgeの仕様でいくつかハマったのでまとめました。
Lambda@Edgeに東京リージョンはない
Lambda@Edgeに東京リージョン(ap-northeast-1)はありません。
バージニアリージョン(us-east-1)で作成しましょう。Lambda@Edgeでは環境変数は利用できない
Lambda@Edgeは環境変数を持てません。これ結構痛いですね。環境変数を使いたい時は別の方法を探す必要があります。
筆者はAWS System Managerのパラメータストアに事前にパラメータを設定しておき、Lambda関数内で読み込むようにしていました。
(CloudFormationのスタックにアウトプットしておく、DynamoDBに値を格納しておくなどやり方は様々だと思います)(現時点では)Lambda@EdgeはNode12.xをサポートしていない
(筆者はこれに気づくのになかなか時間がかかりました...)
サポートしているランタイムは、オフィシャルでチェックしましょう。
現時点では、Node8.10はサポート切れ、Node12.xは未サポートのため、Node.jsを使いたい場合はNode10.xを使うしかなさそうです。
LambdaがサポートしているからLambda@Edgeもサポートしている、わけではないので注意が必要です。CloudFrontにはバージョンつきのLambda関数のARNを設定する必要がある
CloudFront BehaviorにLambda関数のARNを設定する際、Lambda関数の名前のARNだけでは設定できません。
名前+バージョン入りのARNを設定する必要があります。
ちなみに、バージョンは$latestも設定できないので、バージョン番号を指定しないといけません。
lambda関数の更新したら、新しいバージョン番号を発行して、CloudFrontで更新する必要があります。つまり、lambda関数を更新する度にCloudFront Distributionを更新する、すなわちデプロイ(各エッジロケーションへの伝搬)に数十分かかります。
Lambda@Edgeの実行ログは実行地域のリージョンのCloudWatch Logsに出る
Lambda@Edgeをバージニアリージョン(us-east-1)に作成しましたが、バージニア側にはCloudWatchのログがありませんでした。
これは、Lambda@Edgeが実行されてないわけではなく、Lambda@Edgeが実行されたリージョンにログが出ています。(そりゃそうだって感じですね...)
日本でCloudFrontにアクセスしてLambda@Edgeを実行した場合は、東京リージョン付近のエッジロケーションで実行されるので、ログが出ないと思ったときはまず東京リージョンのCloudWatchのログを確認しましょう。オフィシャルにも書いてました。
Lambda 関数の CloudWatch メトリクスと CloudWatch LogsCloudFront イベントのトリガーを作成すると、Lambda から CloudWatch に自動的にメトリクスが送信されるようになります。メトリクスはすべての Lambda リージョンで使用できます。各メトリクスの名前は、/aws/lambda/us-east-1.function-name です。function-name は、関数を作成したときに割り当てた名前です。CloudWatch は、関数が実行される場所に最も近いリージョンにメトリクスを送信します。
Lambda@Edgeで設定した関数は削除に時間がかかる
lambda@Edgeで設定した関数は各リージョンにレプリカが作られて実行されるため、簡単には削除できません。
手順としては、
1. CloudFront Behaviorの設定からLambda@Edgeの連携を解除する
2. Lambda@Edgeを削除する(削除できない場合は時間が経ってから再度試してみる)
になります。Tips
CloudFrontのエンドポイントにアクセスすると、503エラーになる
Lambda@Edgeの問題の可能性があります。
- 同時実行数1,000に達している
- サポートされていないランタイムで実行している
- Lambda関数自体に誤りがある など。
原因の切り分けとして、簡単なLambda@Edgeをデプロイしてみましょう。また、Lambda@Edgeを入れずに、CloudFrontからS3にアクセスできるか、なども原因の切り分けになるかもしれません。
exports.handler = (event, context, callback) => { console.log("Hello"); callback(null, 'callback'); };
- 投稿日:2020-02-28T20:57:48+09:00
CloudFront+Lambda@Edgeの画像リサイズでハマったことまとめ
概要
Lambda@Edgeとは、CloudFrontのエッジロケーションで実行できるLambda関数です。
コンテンツがオリジンから返されたときにキャッシュできるので、アプリケーション側のパフォーマンスを向上させることができます。
さらにLambda@Edgeの処理として、画像リサイズ機能を組み込むとリサイズされた画像をCloudFrontがキャッシュするので、ユーザはリサイズによるオーバーヘッドを受けない綺麗なアーキテクチャを作ることができます。
具体的には、下図で右下の「Origin response」に画像のリサイズ機能を持ったLambda@Edgeを配置します。
(下図はオフィシャルから拝借)
そんな一見便利そうに見えるLambda@Edgeですが、CloudFrontとLambda@Edgeを使って、画像リサイズのシステムを構築したときにLambda@Edgeの仕様でいくつかハマったのでまとめました。
Lambda@Edgeに東京リージョンはない
Lambda@Edgeに東京リージョン(ap-northeast-1)はありません。
バージニアリージョン(us-east-1)で作成しましょう。Lambda@Edgeでは環境変数は利用できない
Lambda@Edgeは環境変数を持てません。これ結構痛いですね。環境変数を使いたい時は別の方法を探す必要があります。
筆者はAWS System Managerのパラメータストアに事前にパラメータを設定しておき、Lambda関数内で読み込むようにしていました。
(CloudFormationのスタックにアウトプットしておく、DynamoDBに値を格納しておくなどやり方は様々だと思います)(現時点では)Lambda@EdgeはNode12.xをサポートしていない
(筆者はこれに気づくのになかなか時間がかかりました...)
サポートしているランタイムは、オフィシャルでチェックしましょう。
現時点では、Node8.10はサポート切れ、Node12.xは未サポートのため、Node.jsを使いたい場合はNode10.xを使うしかなさそうです。
LambdaがサポートしているからLambda@Edgeもサポートしている、わけではないので注意が必要です。CloudFrontにはバージョンつきのLambda関数のARNを設定する必要がある
CloudFront BehaviorにLambda関数のARNを設定する際、Lambda関数の名前のARNだけでは設定できません。
名前+バージョン入りのARNを設定する必要があります。
ちなみに、バージョンは$latestも設定できないので、バージョン番号を指定しないといけません。
lambda関数の更新したら、新しいバージョン番号を発行して、CloudFrontで更新する必要があります。つまり、lambda関数を更新する度にCloudFront Distributionを更新する、すなわちデプロイ(各エッジロケーションへの伝搬)に数十分かかります。
Lambda@Edgeの実行ログは実行地域のリージョンのCloudWatch Logsに出る
Lambda@Edgeをバージニアリージョン(us-east-1)に作成しましたが、バージニア側にはCloudWatchのログがありませんでした。
これは、Lambda@Edgeが実行されてないわけではなく、Lambda@Edgeが実行されたリージョンにログが出ています。(そりゃそうだって感じですね...)
日本でCloudFrontにアクセスしてLambda@Edgeを実行した場合は、東京リージョン付近のエッジロケーションで実行されるので、ログが出ないと思ったときはまず東京リージョンのCloudWatchのログを確認しましょう。オフィシャルにも書いてました。
Lambda 関数の CloudWatch メトリクスと CloudWatch LogsCloudFront イベントのトリガーを作成すると、Lambda から CloudWatch に自動的にメトリクスが送信されるようになります。メトリクスはすべての Lambda リージョンで使用できます。各メトリクスの名前は、/aws/lambda/us-east-1.function-name です。function-name は、関数を作成したときに割り当てた名前です。CloudWatch は、関数が実行される場所に最も近いリージョンにメトリクスを送信します。
Lambda@Edgeで設定した関数は削除に時間がかかる
lambda@Edgeで設定した関数は各リージョンにレプリカが作られて実行されるため、簡単には削除できません。
手順としては、
1. CloudFront Behaviorの設定からLambda@Edgeの連携を解除する
2. Lambda@Edgeを削除する(削除できない場合は時間が経ってから再度試してみる)
になります。Tips
CloudFrontのエンドポイントにアクセスすると、503エラーになる
Lambda@Edgeの問題の可能性があります。
- 同時実行数1,000に達している
- サポートされていないランタイムで実行している
- Lambda関数自体に誤りがある など。
原因の切り分けとして、簡単なLambda@Edgeをデプロイしてみましょう。また、Lambda@Edgeを入れずに、CloudFrontからS3にアクセスできるか、なども原因の切り分けになるかもしれません。
exports.handler = (event, context, callback) => { console.log("Hello"); callback(null, 'callback'); };
- 投稿日:2020-02-28T19:27:46+09:00
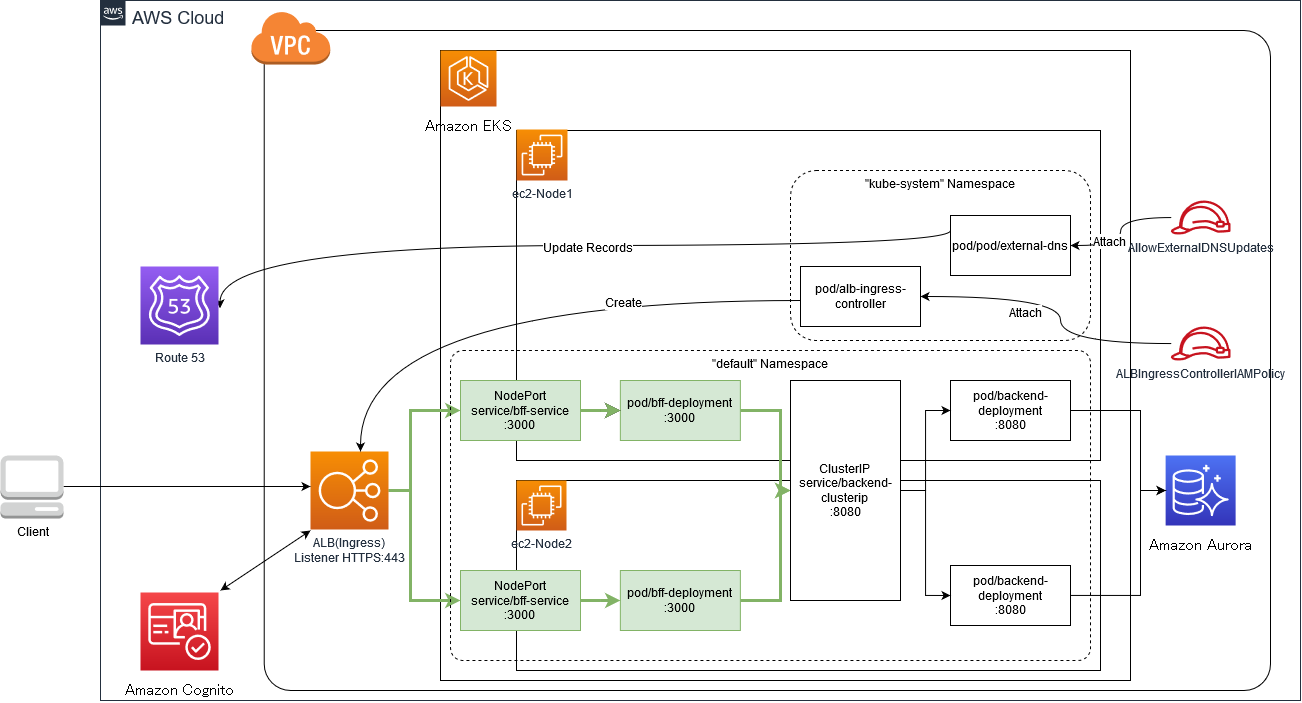
AWS ALB Ingress Controller を External DNS と Cognito と連携させる on EKS
以下の構成を作成し、Cognito 認証を終えたトラフィックのみ eks の世界に到達できるようにします。
EKS クラスター作成
- まずクラスターを作成
eksctl create cluster --name=k8s-clusterALB Ingress Controller のデプロイ
- Ingress リソースがデプロイされたタイミングで ALB を作成させる
IAM OIDC(OpenID Connect) プロバイダーを作成してクラスターに関連付ける
- k8s 内のリソース ServiceAccount と IAM の橋渡しをさせる
- 参考: [アップデート] EKS で IAM ロールを使った Pod 単位のアクセス制御が可能になりました!
$ eksctl utils associate-iam-oidc-provider --region=ap-northeast-1 --cluster=k8s-cluster --approveAWS IAM => ID プロバイダーを確認し、タイプ OpenIDConnect のプロバイダが作成されていることを確認
ALB Ingress Controller Pod にアタッチする IAM ポリシー作成
aws iam create-policy \ --policy-name ALBIngressControllerIAMPolicy \ --policy-document https://kubernetes-sigs.github.io/aws-alb-ingress-controller/examples/iam-policy.json返ってきたARNを控える
{ "Policy": { "PolicyName": "ALBIngressControllerIAMPolicy", "PermissionsBoundaryUsageCount": 0, "AttachmentCount": 0, "IsAttachable": true, "PolicyId": "POLICYID", "DefaultVersionId": "v1", "Path": "/", "Arn": "{ALBIngressControllerIAMPolicyのARN}" } }ALB Ingress Controller マニフェストを DL
wget https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.5/docs/examples/alb-ingress-controller.yamlクラスター名を作成したクラスター名に編集
- --cluster-name=k8s-clusterRBAC ロールマニフェストをデプロイする
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.5/docs/examples/rbac-role.yaml作成したサービスアカウントに IAM ポリシーをアタッチする
eksctl create iamserviceaccount \ --region ap-northeast-1 \ --name alb-ingress-controller \ --namespace kube-system \ --cluster k8s-cluster \ --attach-policy-arn {さっき控えたALBIngressControllerIAMPolicyのARN} \ --override-existing-serviceaccounts \ --approveALB Ingress Controller をデプロイする
kubectl apply -f alb-ingress-controller.yamlALB Ingress Controller の作成を確認
kubectl logs -n kube-system $(kubectl get po -n kube-system | egrep -o "alb-ingress[a-zA-Z0-9-]+")ExternalDNS のデプロイ
- ingress リソースのホスト情報に基づいて DNS レコードをプロビジョニングする
- alb-ingress-controller がデプロイした ALB を指す Route 53 のレコードを作成する
IAM ポリシー(AllowExternalDNSUpdates)を作成
- ExternalDNSPod に Route53 リソースレコードセットとホストゾーンを更新させるために IAM ポリシーを作成
- IAM ポリシーの元ネタを get
aws iam create-policy --policy-name AllowExternalDNSUpdates --policy-document file://AllowExternalDNSUpdates.json返ってきたARNを控える
{ "Policy": { "PolicyName": "AllowExternalDNSUpdates", "PermissionsBoundaryUsageCount": 0, "AttachmentCount": 0, "IsAttachable": true, "PolicyId": "POLICYID", "DefaultVersionId": "v1", "Path": "/", "Arn": "{AllowExternalDNSUpdatesのARN}" } }サービスアカウント(external-dns)と IAM ロールを作成
eksctl create iamserviceaccount \ --region ap-northeast-1 \ --name external-dns \ --namespace kube-system \ --cluster k8s-cluster \ --attach-policy-arn {AllowExternalDNSUpdatesのARN} \ --override-existing-serviceaccounts \ --approveIAM -> ポリシー AllowExternalDNSUpdates -> ポリシーの使用状況タブを見て、ロールが作成されていることを確認
Route 53 ホストゾーンを設定する
- public に レコードと SOA レコードを作成する
ExternalDNS を deploy する
- externaldns.yaml の元ネタを get する
- externaldns の ServiceAccount の annotaions に AllowExternalDNSUpdates ポリシーがアタッチされているロールの arn を記載する
$ kubectl apply -f externaldns.yamlExternalDNS の作成を確認
kubectl logs -n kube-system $(kubectl get po -n kube-system | egrep -o "external-dns[a-zA-Z0-9-]+")ExternalDNSPod にロールがアタッチされていることを確認
kubectl exec -n kube-system external-dns-576fb7578c-zmvlt env | grep AWS AWS_ROLE_ARN={ロールのarn}Cognito / ALB Ingress Controller のセットアップ
- Cognito ユーザープール作成
ベースはインフラエンジニアが一切コードを書かずにWebサーバーに認証機能を実装した話をみつつ作成する
- アプリクライアントのシークレットを生成するに
- ALLOW_USER_PASSWORD_AUTH にチェック
Certificate Manger (バージニア北部) にてドメインの証明書を発行する
- 証明書を Cognito でリクエストまたはインポートするには、ACM コンソールで AWS リージョンを米国東部 (バージニア北部) に変更する必要がある。
Route53 でサブドメイン無しの A レコードを適当に設定
- 1.1.1.1 とかでも よい
アプリケーション統合の構成
- Callback URL
https://<your-domain>/oauth2/idpresponse- 許可されている OAuth フロー
- Authorization code grant
- 許可されている OAuth スコープ
- openid
- ドメイン名
auth.<your-domain>- AWS マネージド証明書に CM(バージニア北部)で発行した証明書を指定
ドメインのステータスが 15 分程度かかって Active になったらドメイン名とエイリアスターゲットを Route53 に登録する
- タイプ CNAME
- 例) auth. → xxxxxxxxxxxxxx.cloudfront.net
Ingress をデプロイ
ingress.yamlapiVersion: networking.k8s.io/v1beta1 kind: Ingress metadata: name: "ingress" annotations: kubernetes.io/ingress.class: alb alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}, {"HTTPS": 443}]' # ドメインの証明書のarn alb.ingress.kubernetes.io/certificate-arn: {ドメインの証明書のarn} # http -> https のリダイレクト alb.ingress.kubernetes.io/actions.ssl-redirect: '{"Type": "redirect", "RedirectConfig": { "Protocol": "HTTPS", "Port": "443", "StatusCode": "HTTP_301"}}' # Authentication type must be cognito alb.ingress.kubernetes.io/auth-type: cognito # Required parameter for ALB/Cognito integration alb.ingress.kubernetes.io/auth-scope: openid # Session timeout on authentication credentials alb.ingress.kubernetes.io/auth-session-timeout: '3600' # Session cookie name alb.ingress.kubernetes.io/auth-session-cookie: AWSELBAuthSessionCookie # Action to take when a request is not authenticated alb.ingress.kubernetes.io/auth-on-unauthenticated-request: authenticate # Cognito parameters required for creation of authentication rules # The subdomain name only is sufficient for `UserPoolDomain` # e.g. if `FQDN=app.auth.ap-northeast-1.amazoncognito.com` then `UserPoolDomain=app` alb.ingress.kubernetes.io/auth-idp-cognito: '{"UserPoolArn": "arn:aws:cognito-idp:<region>:<account-id>:userpool/<region><cognito-id>","UserPoolClientId":"<user-pool-client-id>","UserPoolDomain":"<user-pool-authentication-domain>"}' labels: app: ingress spec: rules: - host: <your-domain> http: paths: - path: /* backend: serviceName: "bff-service" servicePort: 3000
ドメインの証明書の arn(alb.ingress.kubernetes.io/certificate-arn) を変更
- クラスターのあるリージョンで申請した SSL 証明書の ARN を設定しないとエラーがでた
Cognito 設定(alb.ingress.kubernetes.io/auth-idp-cognito)を変更
kubectl apply -f ingress.yaml確認(alb リソースなど完全にできるまで時間がかかる)
アプリをデプロイ
アプリは適当に好きなマニフェストでやってください
backend deploy
- kubectl apply -f backend.yaml
bff deploy
- kubectl apply -f bff.yaml
確認
- ALB が作成されていること
- Route 53 に ALB への A レコードと TXT レコードが作成されていること
でCognito認証 + ALB → EKS内への連携が出来ている筈
- 投稿日:2020-02-28T19:20:28+09:00
Capistranoでのデプロイを攻略する
今日の目標
デプロイ作業でよく使うコマンドを整理する
前提
Rails 5.0.7.2
レポジトリ名:freemarket
pemキー名:team_c.pem
ユーザー名:ec2-user
Elastic IP:@18.176.134.115SSH接続
$ cd .ssh/ $ ssh -i team_c.pem ec2-user@18.176.134.115 cd /var/www/freemarketpemキー確認
cd cd .ssh lsデプロイコマンド
bundle exec cap production deployAWSアクセスキー、キーID確認
env | grep AWS_SECRET_ACCESS_KEY env | grep AWS_ACCESS_KEY_IDMySQL
ターミナル(本番環境)状況確認 sudo service mysqld status 起動する sudo service mysqld start mysqlにアクセスする mysql -u root -p データベースを確認 show databases; データベースを選択 use freemarket; テーブルを確認 show tables; カラムを確認 show columns from テーブル名;本番環境のデータベースを作り変える(破壊系)場合はこちら
https://qiita.com/keitah/items/7b20fcae6ef13820d01funicorn
ターミナル(本番環境)状況確認 ps auxwww | grep unicorn ログ cat log/unicorn.stderr.log less /var/www/freemarket/current/log/unicorn.stderr.log または cat /var/www/freemarket/current/log/unicorn.stderr.lognginx
ターミナル(本番環境)再起動 sudo service nginx restart ログ ホームディレクトリで sudo less /var/log/nginx/error.logcapistrano
ターミナル(本番環境)ログ less log/capistrano.logvim
ローカルvimエディッタを起動 vim ~/.bash_profile insertモード i 環境変数を反映させる source ~/.bash_profile PCに設定されている環境変数を確認 $ printenv exportされている環境変数を確認 $ export -p insertモードを終了 esc :wq本番環境sudo vim /etc/environment 本番環境で env | grep SECRET_KEY_BASE (SECRET_KEY_BASEの値の確認) env | grep DATABASE_PASSWORD (DATABASE_PASSWORDの値の確認)おまけ
we're sorry, but something went wrongの内容を把握する方法
config/environments/production.rbconfig.consider_all_requests_local = true ← デフォルトはfalsehttps://qiita.com/keitah/items/2aa2ac968c76260e8750
デプロイ作業でよく使うコマンドを備忘録として整理しました。
今後気がついたらちょいちょい追記していきます。
- 投稿日:2020-02-28T18:38:32+09:00
amazon-qldb-driver-nodejsからQLDBを使う①(接続編)
QLDBとは
https://aws.amazon.com/jp/qldb/
Amazonが提供するフルマネージド型の台帳データベースです。
ブロックチェーンとは異なり中央集権で管理されます。データに対する変更は全て記録され、後から確認可能なようです。
また、変更履歴が正確であることを暗号的に検証する機能を提供しています。
https://docs.aws.amazon.com/qldb/latest/developerguide/verification.html中央集権からトランザクションの実行時にネットワーク参加者の合意を経る必要がないため、一般的なブロックチェーンベースのフレームワークより高いスループットが出るようです。
以上から、「データの信頼性やトレーサビリティを担保したいけど、分散型である必要はない」などの場合にとても魅力的な選択肢になりそうです。
amazon-qldb-driver-nodejsについて
プログラムからアクセスする場合は現状はJavaのdriverを使うのが主流なようです。
nodejs用のdriverも用意されており、今回はこちらを使ってQLDBにプログラムから接続してみます!
現在はまだpreviewで本番環境用途に使用するのは推奨していないようですので、ご注意下さい。
- https://docs.aws.amazon.com/ja_jp/qldb/latest/developerguide/getting-started.nodejs.html
- https://github.com/awslabs/amazon-qldb-driver-nodejs
前提
今回のサンプルはAWSのコンソールで台帳およびいくつかテーブルを作成してある状態を前提とします。
筆者の環境では以下のチュートリアルで登録したデータ使って動作確認しました。
https://docs.aws.amazon.com/ja_jp/qldb/latest/developerguide/getting-started.htmlチュートリアルは以下の記事が参考になりました。
https://qiita.com/yanyansk/items/586b7f1c86eca4352b44IAMユーザのアクセスキーの作成
実装する前にQLDBにアクセスするための認証情報を作成する必要があります。
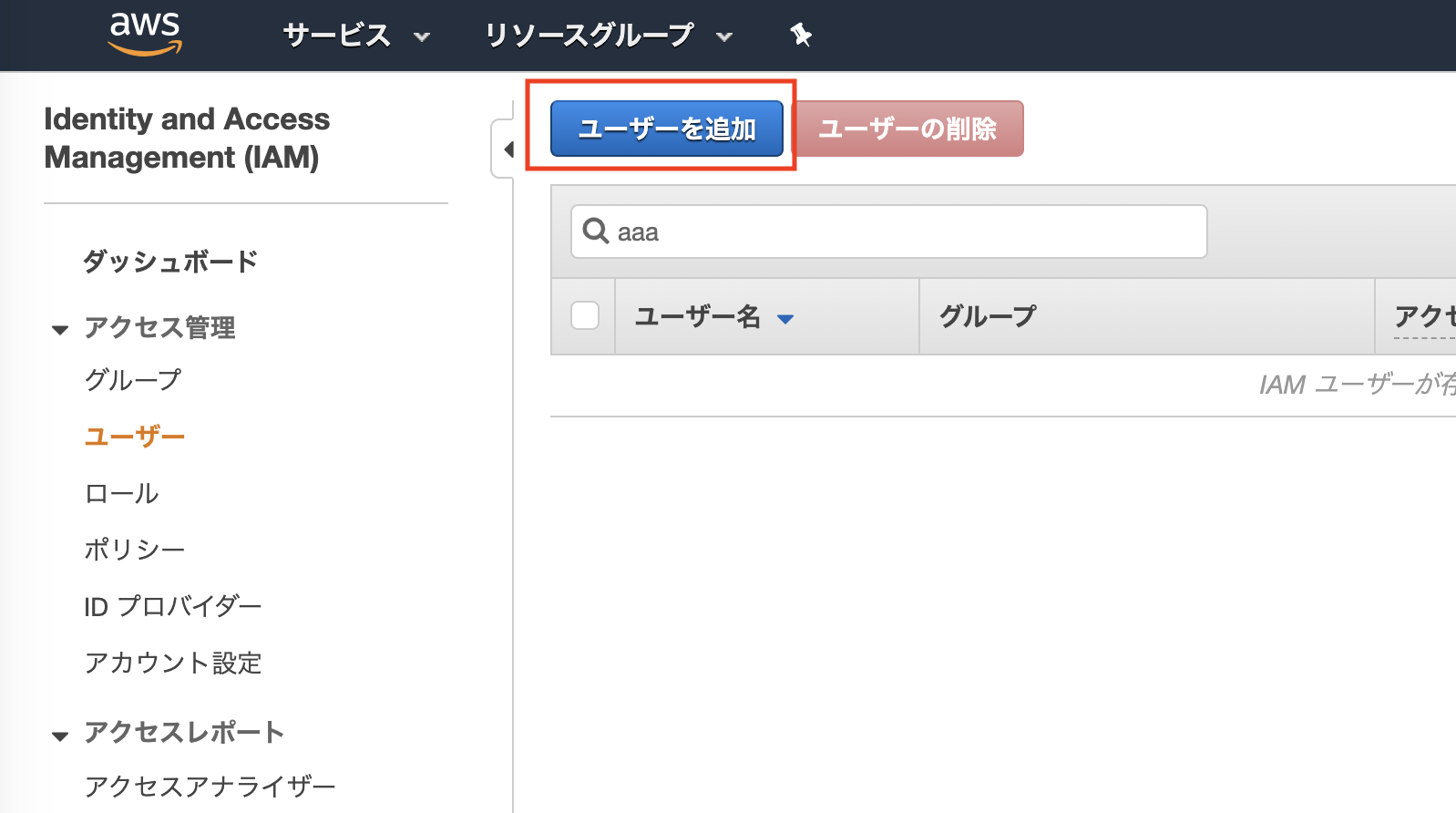
以下の手順でアクセスキーを発行して下さい。サービス > IAM > ユーザ からユーザの追加を選択して下さい。
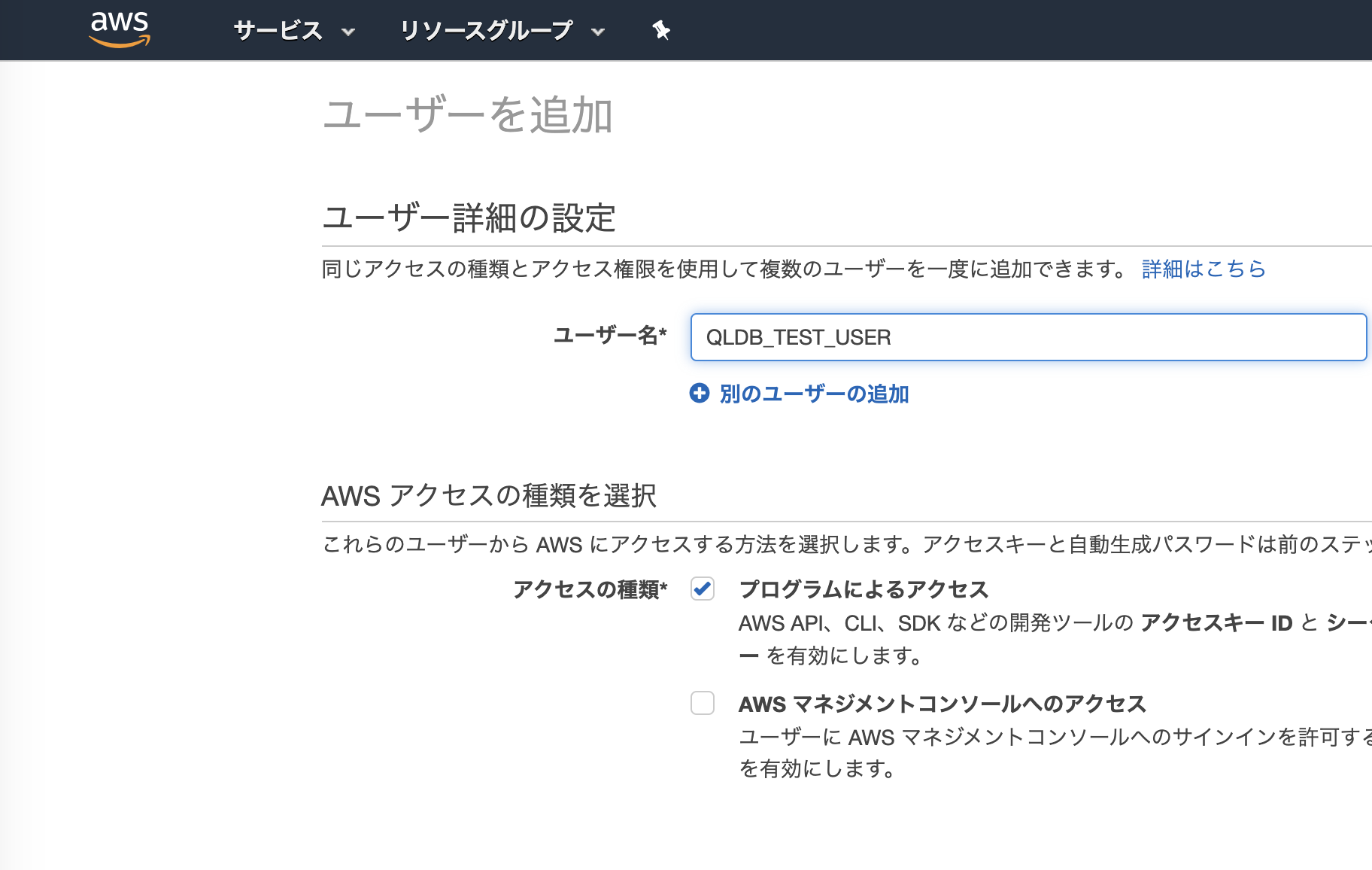
任意のユーザ名を入力して下さい。アクセスの種類は「プログラムによるアクセス」にチェックを入れて下さい。
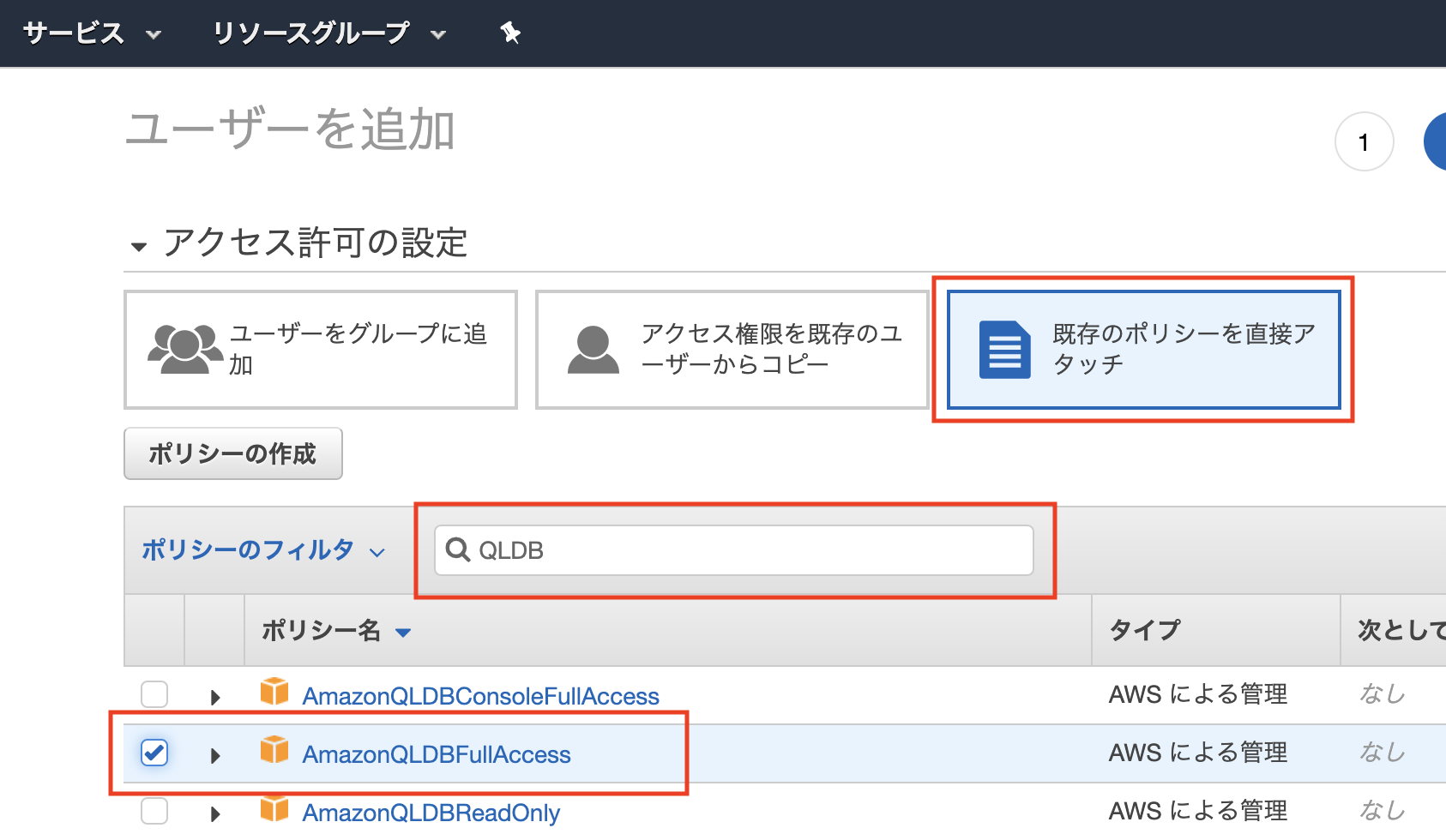
一旦はテストで使用するだけなので、ユーザグループなどは作成せず、ポリシーを直接アタッチします。
タグなどは特に必要がないので、ユーザーの作成まで完了して下さい。
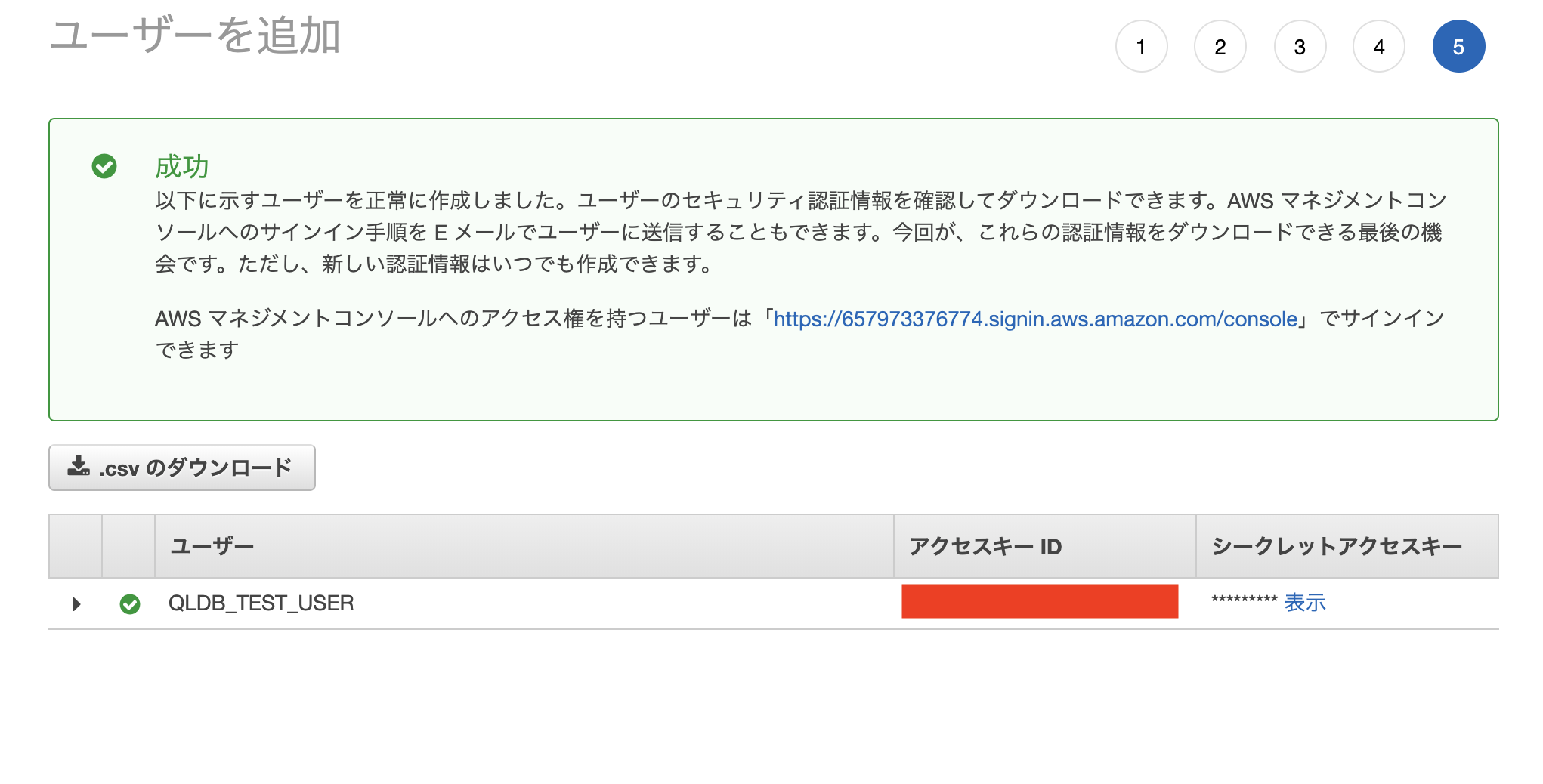
作成完了の画面で表示される「アクセスキーID」と「シークレットアクセスキー」を控えて下さい。
driverからQLDBにアクセスする際にこの情報を使って認証します。
実装
driverや必要なモジュールのinstall
npm i amazon-qldb-driver-nodejs aws-sdk ion-js typescriptcredential情報の編集
「credentials.json」などの名前で以下のファイルを作成してください。
{ "accessKeyId": "${作成したアクセスキーID}", "secretAccessKey": "${作成したシークレットアクセスキー}" }認証部分の実装
認証情報の設定
作成したcredentialのjsonを使って認証します。
const AWS = require("aws-sdk"); AWS.config.loadFromPath("./credentials.json");Credentialの確認
デバッグしやすいように、Credentialが正しく設定されているか確認するfunctionを追加します。
function checkCredential() { return new Promise((resolve, reject) => { AWS.config.getCredentials(function (err: Error) { if (err) { return reject(err); } console.log("Access key:", AWS.config.credentials.accessKeyId); console.log("Secret access key:", AWS.config.credentials.secretAccessKey); resolve(); }); }) }メインフローの実装
メインの部分を実装していきます。
セッションの作成
regionはQLDBを作成したリージョンを設定してください。
PooledQldbDriverの第一引数には作成した台帳の名前を指定して下さい。const testServiceConfigOptions = { region: "{QLDBを作成したリージョン}" }; const qldbDriver: PooledQldbDriver = new PooledQldbDriver("{作成した台帳の名前}", testServiceConfigOptions); const qldbSession: QldbSession = await qldbDriver.getSession();台帳上のテーブルの確認
for (const table of await qldbSession.getTableNames()) { console.log(table); }動作確認
実装したコードの全文は以下になります。
こちらを動作確認してみます。import { PooledQldbDriver, QldbSession } from "amazon-qldb-driver-nodejs"; const AWS = require("aws-sdk"); AWS.config.loadFromPath("./credentials.json"); (async () => { await checkCredential(); const testServiceConfigOptions = { region: "{QLDBを作成したリージョン}" }; const qldbDriver: PooledQldbDriver = new PooledQldbDriver("{作成した台帳の名前}", testServiceConfigOptions); const qldbSession: QldbSession = await qldbDriver.getSession(); for (const table of await qldbSession.getTableNames()) { console.log(table); } })().catch(err => { console.error(err); }); function checkCredential() { return new Promise((resolve, reject) => { AWS.config.getCredentials(function (err: Error) { if (err) { return reject(err); } console.log("Access key:", AWS.config.credentials.accessKeyId); console.log("Secret access key:", AWS.config.credentials.secretAccessKey); resolve(); }); }) }$ npx tsc main.ts $ node main.js Access key: xxxxxxxxxxxxxxxxxx Secret access key: xxxxxxxxxxxxxxxxxx VehicleRegistration DriversLicense Vehicle Person無事台帳上のテーブル名が表示されました!
次回は検索やデータの登録について書きたいと思います!さいごに
ZEROBILLBANKでは一緒に働く仲間を募集中です。
ZEROBILLBANK JAPAN Inc.
- 投稿日:2020-02-28T17:30:30+09:00
【AWS】IntelliJ(Jetbrains)からAWSを操作する設定方法まとめ。AWS作業が爆速はかどります!
はじめに
AWSに接続するのに、毎回、Terminalを立ち上げて、コマンドを打ってCLIで管理する。。
そんなことしなくても、
IntelliJの画面から、数クリックでGUIでAWSを操作できます。一度設定するだけで、AWSへの操作が劇的に楽になります。
さっそく設定方法をまとめてみました。
IntelliJに限らず、Jetbrains社のIDEなら共通で、
PyCharm,RubyMine,PhpStormなどでも利用できます。
以下、説明はintelliJの日本語版で進めさせていただきます。英語版の方は読み替えてください。何が楽になるか
IntelliJで設定するとこんな事が簡単に↓
- sshログイン→2clickでできます。
- DB接続,データ閲覧→3,4clickでできます。
- Deploy作業 → ["cmd" + S]でできます
- Deploy先と差分確認 →2,3clickでグラフィカルに差分表示できます。
リモートホスト
まずは、基本の設定です。
sshログイン、GUIでファイル管理、Deploy簡単にできるようになります。プロジェクトを開いたら、
ツール > デプロイ >リモートホストの参照をクリック。
もしくは、以下のサイドバーからクリック
・・・をクリックして、設定を開く接続先の設定
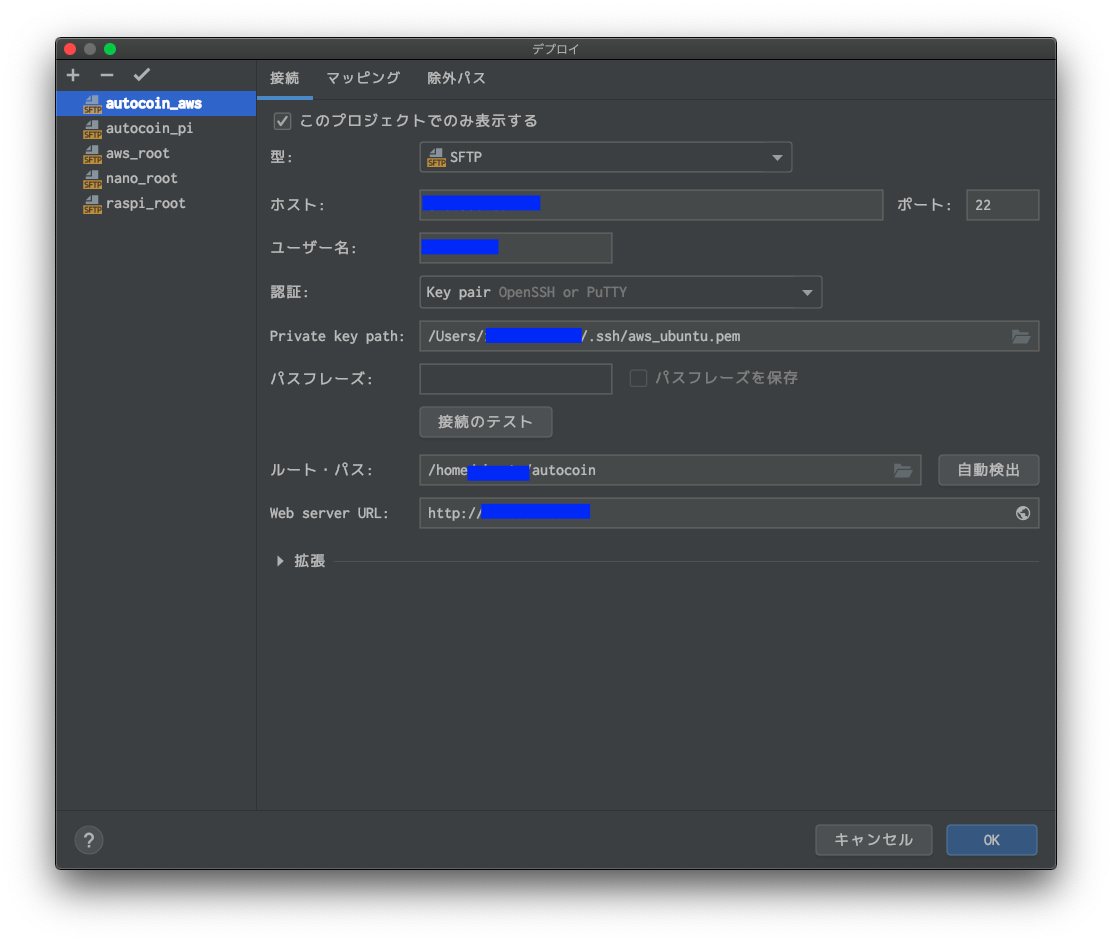
まずは、✓で新規作成して、接続タブを開きます。
- このプロジェクトでのみ表示する: 作った接続先がこのプロジェクトでしか表示されなくなります。
- 型:SFTPを選択
- ホスト:EC2の
IPv4 パブリック IPを入力- ユーザー名:AWS-EC2サーバーで設定したユーザー名
- 認証:
Key pair OpenSSHを選択- Private key path:localにある、AWS接続用pemファイルを設定
- パスフレーズ:認証でパスワードを選択した場合にパスワードを入れる
- 接続のテスト:接続の確認ボタン
- ルート・パス:接続後のリモート先のルートパスとなります。
- Web server URL:(任意) デプロイ先がWebサービスでサイトを閲覧したい際に利用
- 拡張:(任意) 文字Encordとか、接続limit時間とか。 デフォルトでOK
「このプロジェクトでのみ表示する」ですが、オススメは、
基本は✓しておいて、複数プロジェクトで共有して使用する接続先のみチェックしない
のがいいです。さもないと、接続先が複数で溢れてしまい邪魔です。
私の場合は、
aws_root: awsのルートへの接続先(AWS上で動かす複数のプロジェクトの共通利用として)
nano_root、raspi_root: エッジ端末の複数プロジェクトの共通利用としてチェックしない。
コレ以外は、基本チェックを入れて任意のプロジェクトに限定しています。それと、よくある失敗は、
EC2再起動した為にホスト先IPが変更されてしまいつながらないってのがあります。
これ意外と気が付きません(ノω・)テヘ
AWSのElasticIPで固定しておきましょう。sshで繋ぎたいだけなら、コレでOKですが、
Deployや、ファイル差分でも楽したいなら、次も設定しましょう。
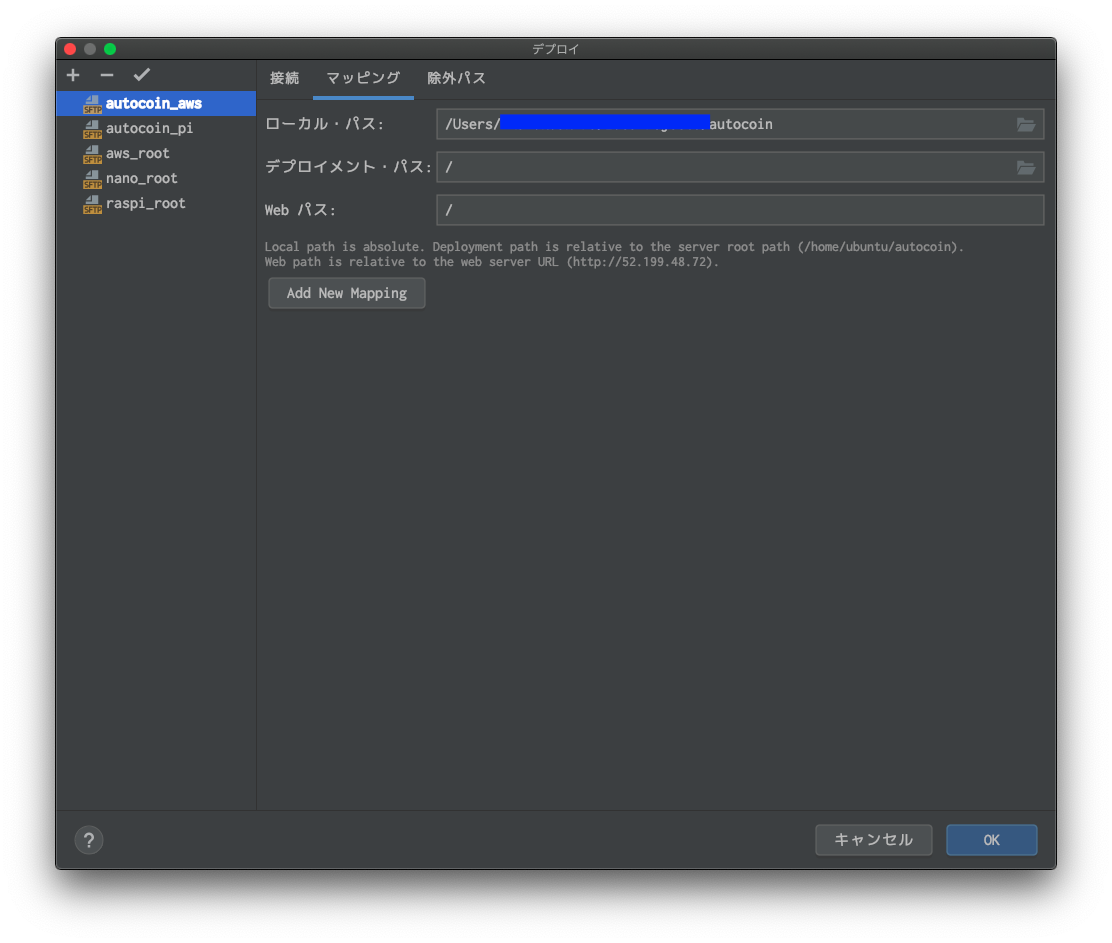
マッピングタブを開きます。
何をやってるかと言うと、
localと、リモート先のどのディレクトリとディレクトリを同じに(同期)させるかを設定しています。
- ローカル・パス: local環境で同期したいディレクトリを設定
- デプロイメント・パス: リモート先で同期したいディレクトリを設定
- Web パス:(すいません、使ったことないです)
- Add New Mapping:同期させるMappingを追加することができます。
「デプロイメント・パス」について、注意点です。
ここにフルパスを書くのではなく、
接続で入力したルートパスの続きのパスを書くことです。
私も使い始めの時、すこし混乱しました。
例:/home/hoge/project/launchに同期したいとします。
接続>ルートパスで、/home/hoge/projectと入力したら、デプロイメントパスは/launchと入力します。私のオススメは以下です。
・ルートパス:/home/hoge/project
・デプロイメントパス:/
理由ですが、
ssh接続機能を利用すると、ルートパスがその時の入り口となります。
余計に上位階層から入れてしまうと、結局cdでプロジェクトディレクトリに移動とかするので面倒です。
特に理由がない限り、ルートはプロジェクトパス、デプロイメントパスは/としています。「Add New Mapping」同期させるディレクトリが分散している場合、
ひとつひとつ追加でマッピングすることができます。
出番は少ないですが、何らかの理由で、
ローカルの開発内容が複数のディレクトリにバラバラに格納されている場合や、
ローカルと、リモートでのディレクトリ構成が違うなど、マッピングを追加することで一元管理できるようなります。
加えて、マッピングをignoreする除外パスを指定して組み合わせると、かなり自由度が高く設定できます。
すべて設定が終わったら、右下の「OK」をクリックして、設定を反映します。リモート接続先の管理
左カラムの説明してなかったですね。
複数の接続先の管理ができます。
- 接続先の新規作成: 左上
+から追加- 接続先削除: 左上
-で削除- プロジェクトのデフォルト接続先に指定: 左上
✓で指定デフォルト接続先に指定先が、Deploy先となりファイルの同期や、差分チェックが簡単になります。
そのプロジェクトのメインのリモート先だと思ってください。ここまでで、リモートホストに関して、GUIで簡単に操作ができるようなっています。
使ってみる: リモートホストのファイル操作
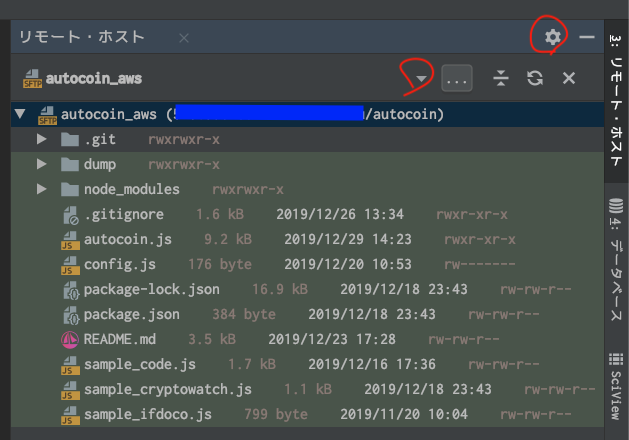
サイドバーから、リモート・ホストを表示
デフォルトホストに設定した接続先が、自動で接続され展開します。
例は、AWS上のautocoinってプロジェクトディレクトリ
接続先を変更したいときは▼から変更できます。
歯車アイコンから以下の表示内容をon/offできます。
- サイズの表示
- 日付の表示
- アクセス権の表示
- シンボリックリンクの強調表示
- マッピング対応のファイルに色をつける
(上記画像の場合、.git以外マッピング対象)ファイルをダブルクリックすると、リモートのファイルを直接開くことができ、そのまま編集することもできます。
右クリックで、localのファイルと同期、アップロード、ダウンロードや差分表示、ファイル名変更、アクセス権の変更など、
結構、色んなことができます。デプロイ用をより楽にする
デプロイを簡単にするために、追加設定します。
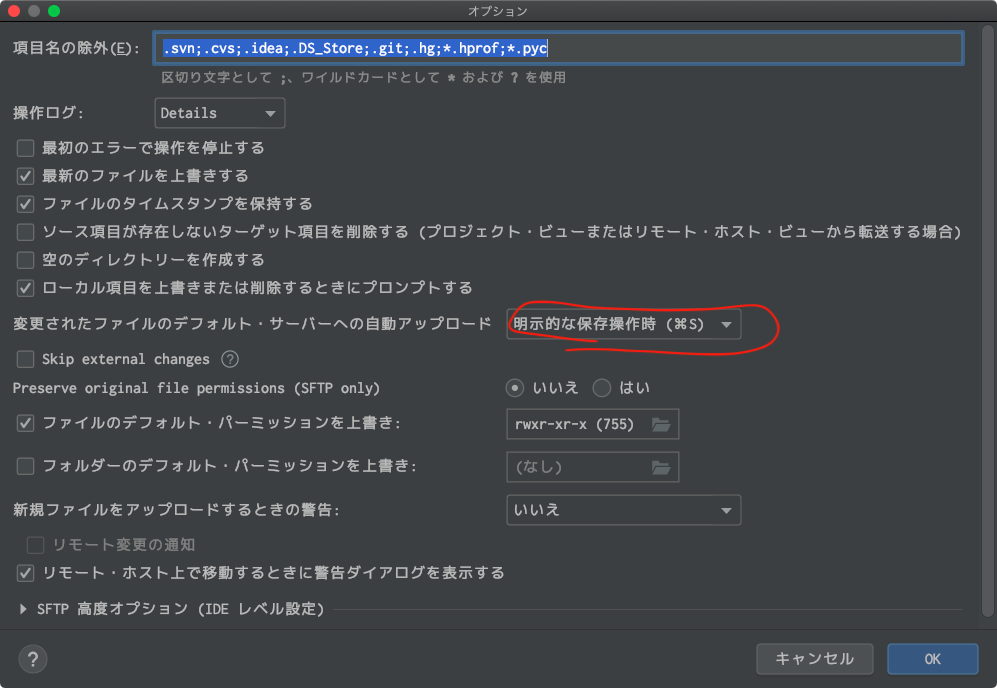
ツール > デプロイ > オプションから選択
ポイントだけ触れます。
- 変更されたファイルの〜自動アップデート: 明示的な保存操作時(⌘S)を選択。
他はお好みの設定でOKです。
これで、⌘S押すだけで、AWSにデプロイできるようなります。
この設定は、感覚的ですごく便利なのでぜひ設定しておくことをオススメします。
あたかも、リモートに保存するような感覚です。
ファイル単位だけでなくて、プロジェクトウィンドウから、ディレクトリを選択して⌘Sを押せばディレクトリ単位でリモートと同期できますし、複数ファイル選択して同期することもできます。
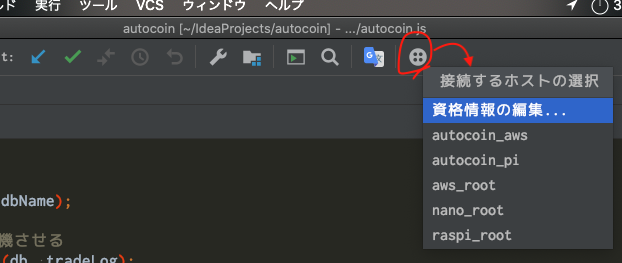
(逆に、仕事の本番運用では手軽にデプロイでき過ぎるので切っておいたほうが無難かもしれません。)ターミナルのssh接続を2クリックで。
AWSなどのリモート先にターミナルでssh接続する方法です。
ツール > SSHセッションの開始...の選択で、
接続先の選択ウィンドウが表示されて選ぶことができます。
しかし!
私は、コレすらも面倒くさかったので、ツールウィンドウにボタンを常駐させました。
ツールウィンドウを右クリックしてCustomize Menus and Toolbars...の選択からボタンを常駐させます。1度設定したら、
次回からは、、、
レンコン? アイコンを1clickするだけで、接続先候補がウインドウ表示されます。
接続先選択と合計2clickだけで、ターミナルが開き自動でssh接続されます。DBとの簡単接続
Jetbrains社のIDEは、様々なDBと簡単接続することが可能です。
今回は比較的簡単なsshトンネルを使用してDB接続する方法を紹介します。紹介する環境は以下となります。
- AWS:EC2 ubuntuAMIを使用
- ubuntuにMongoDBをインストール
- MongoDB: 「database→autocoin collection→btcfx」を構築
- AWS EC2上のMongoDBがdaemonで常駐稼働
Mongoのインストール方法や、設定方法は、別記事のコチラを参照ください↓
【MongoDB】APIログ取るのに手軽で最高だった件 (+intellijだとさらに手軽)また、AWS上でのDB構築方法は多種多様です。皆さんの環境に随時、読み替えてください。
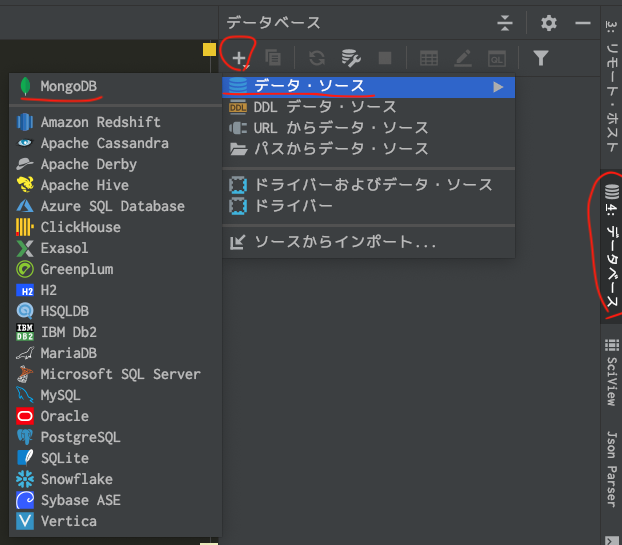
サイドバーからデータベースウィンドウを開く
+をクリックして接続先DBの新規作成します。
データ・ソースのインポートの方法や、対応しているDBも結構豊富にあります。今回は、
データ・ソース >MongoDBを選択します。
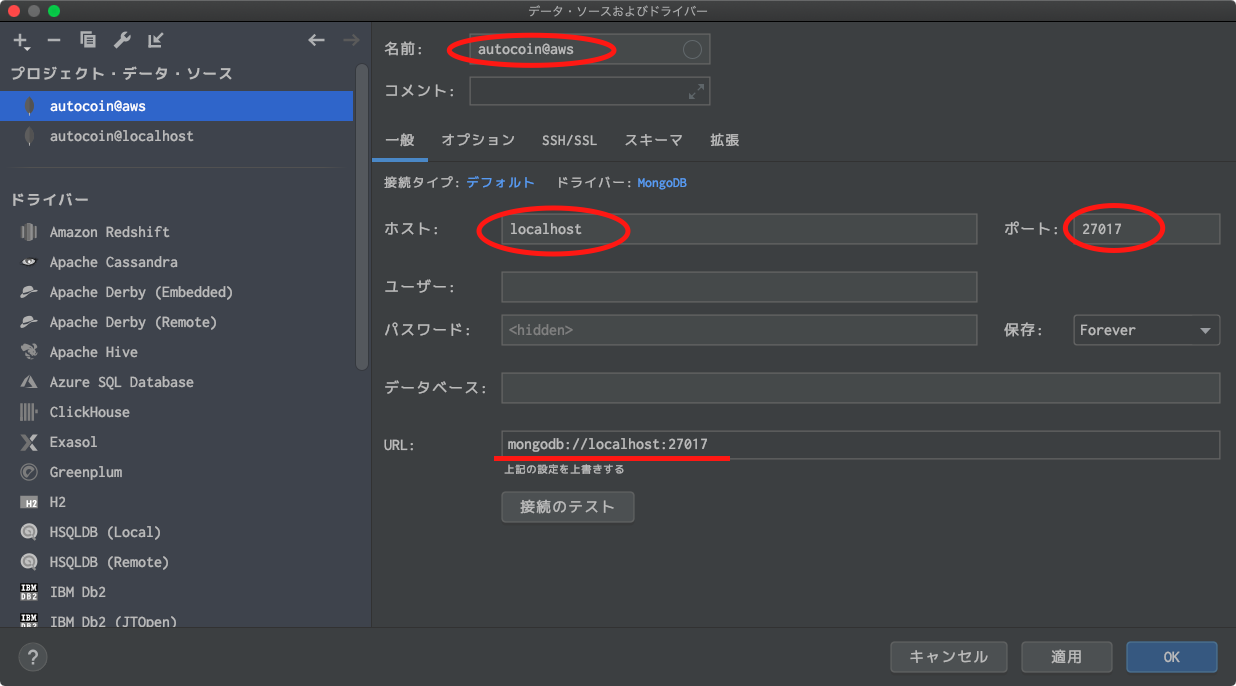
- 名前:任意の自分が分かりやすい名前でOKです。
- ホスト:DB接続先のIPアドレスを入力します。
今回は、sshトンネルを利用しますので、Mongoのデフォルトであるlocalhostとします。- ポート:DB接続先のポート番号を入力します。
こちらも、Mongoデフォルトの27017を指定します。- URL: DBの接続URL。スキーム名://ipアドレス:port番号です。
今回は、sshトンネルを使って、DB接続をしたいので、
SSH/SSLタブも設定します。
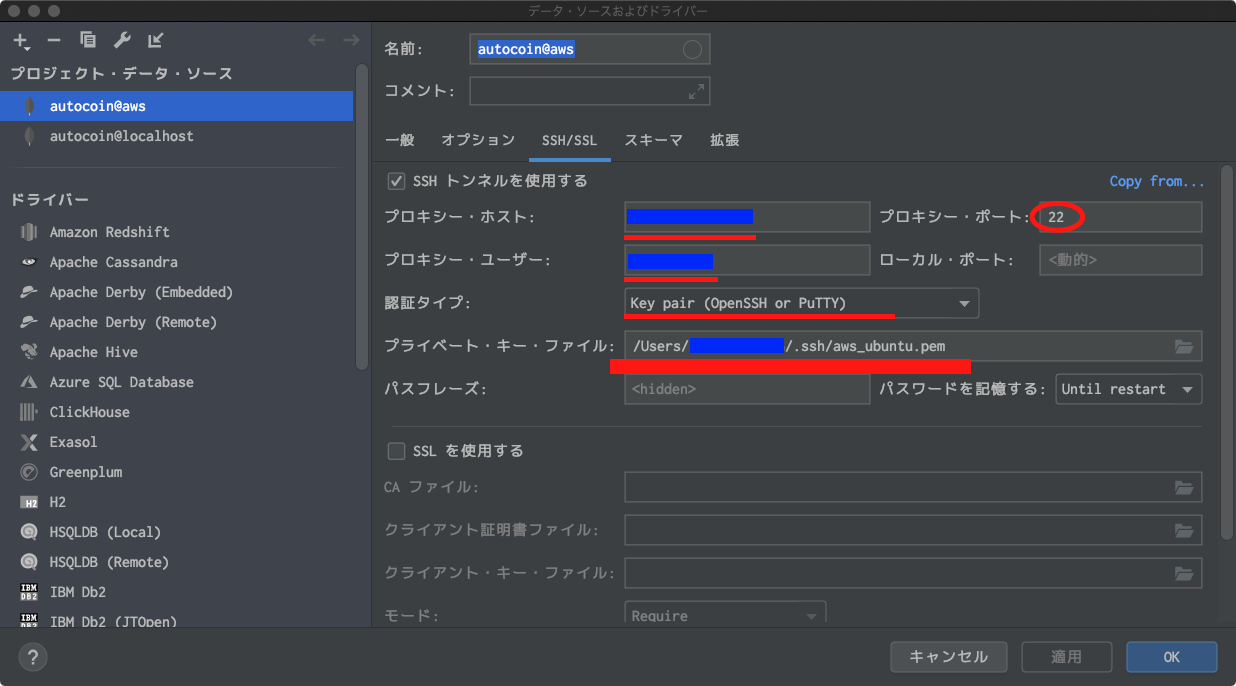
- SSHトンネルを使用する
- プロキシー・ホスト:AWS-EC2のパブリックIPアドレスを入力します。
- プロキシー・ポート:sshトンネルするため、sshデフォルトの22番を設定。
- プロキシー・ユーザー:AWS-EC2に接続するアカウント名を入力
- 認証タイプ:
Key pair(OpenSSH or PuTTy)を選択します。- プライベート・キー・ファイル:ローカルに保存したAWS-EC2接続用に保存したpemファイルを設定。
sshタブで設定した内容で、AWSにssh接続して、その接続をトンネルして
一般タブで設定した内容でDBに接続します。
ここまで設定できたら、適用 > OKで設定を反映させます。DB接続を使ってみる
さて、1度設定してしまえばコッチのものです!
AWS上のDBへの接続は、もはやキーボードも使わずに、今後4clickだけとなります。
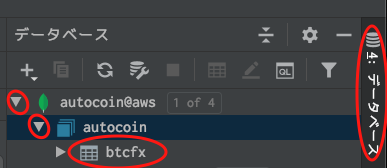
- サイドバーの
データベースをクリックデータソース名をクリック(例:autocoin@aws)データベース名をクリック(例:autocoin)テーブルorコレクションをダブルクリック(例:btcfx)問題なければ、たったこれだけDB接続されます。
もう一度言います、わずか4クリックです。
しかも、IntelliJではDBの閲覧・変更、エキスポートなどの操作が直感的にできる機能がたくさんあります。
AWS-EC2上のDBへのアレコレが劇的に楽になりますよ、オススメです!IntelliJでのDB接続画面に関しては、前述した記事をご参考ください。
【MongoDB】APIログ取るのに手軽で最高だった件 (+intellijだとさらに手軽)おわりに
私は、Jetbrains社のIDEを使用していますが、
他のIDEでも似たような機能があるかもしれません。
ご自分のIDEを調べてみると、作業効率が爆上がりするかもしれませんよ!ツールに頼れるところはできるだけ自分でやらずに、
自分のチカラがつくところ、人間しかやれないところに時間を割いていきたいですね。
最後まで、お読み頂きありがとうございました!!!
- 投稿日:2020-02-28T17:08:42+09:00
Lambda+API Gateway+CloudFrontとVueでOGP画像の自動生成をする
Lambda+API Gateway+CloudFrontとVueを使ってフロントエンドのみでOGP画像の自動生成をしてみたので備忘録。
構成
まずVueでSVGを返すページを用意しておく。
Lambda側はchrome-aws-lambdaでスクリーンショットを撮って、base64で返すようにする。よくあるLambda@Edgeを使ったダイナミックレンダリングを行いつつ、Edgeで返すMetaタグの
og:imageやtwitter:imageのURLへのアクセスがあったら、用意しておいたSVGページをLambdaでスクリーンショット撮ってAPI Gateway経由でpngにして返す、というちょっと面倒くさい構成。バックエンド側でLambdaを起動させてスクリーンショット撮ってS3に保存とかでもよかったのだけど、今回はあくまでもアクセスがあったらOGP画像を返すようにしたかったので、こんな感じの構成にした。
VueでSVG生成
VueでSVGを生成するのはこちらの記事を参考にさせていただいた。
Vue.jsとFirebaseでOGP画像生成系のサービスを爆速で作ろう<template> <div class="hello"> <svg ref="svgCard"> <text transform="translate(103.29 347.281)" fill="#e51f4e" font-size="29" font-family="HiraginoSans-W5, Hiragino Sans" letter-spacing="-0.002em"> <tspan x="0" y="26">{{ data.content }}</tspan> </text> </svg> </div> </template> <script> import { mapActions } from 'vuex' export default { name: 'Svg', data () { return { data: {} } }, beforeMount () { this.fetchData(response => { this.data = response }) }, methods: { ...mapActions([ 'fetchData', ]) }, } </script>svgタグの中にvueのデータを埋め込めるので、APIから持ってきたデータを表示できるようにする。
注意が必要なのが、svgタグではテキストを自動で折り返してくれないので、途中で切って配列にしてv-forで回すとかしないといけない。あとはこのページをrouterに登録する。
import Svg from '@/views/Svg.vue' Vue.use(VueRouter) const routes = [ ... { path: '/path/to/svg', name: 'Svg', component: Svg } ]Lambda+API Gateway
次にスクリーンショットを撮るLambdaを作る。ほんとはserverless frameworkで作りたかったのだけど、serverlessで作ると何故かchromeが動いてくれなかったのと、API Gateway側の設定がイマイチ把握しきれなかったので、今回はコンソールでポチポチした。
Lambda
const chromeLambda = require("chrome-aws-lambda"); const defaultViewport = { width: 1200, height: 630 }; exports.handler = async event => { const browser = await chromeLambda.puppeteer.launch({ args: chromeLambda.args, executablePath: await chromeLambda.executablePath, defaultViewport }); const sleep = (time) => { return new Promise((resolve, reject) => { setTimeout(() => { resolve(); }, time); }); } const page = await browser.newPage(); const url = "https://" + process.env.DOMAIN + "/path/to/svg"; await page.goto(url, { waitUntil: "networkidle0" }); sleep(1000) const buffer = await page.screenshot({ encoding: "base64", type: "png" }); return { "statusCode": 200, "headers": {"Content-Type": "image/png"}, "isBase64Encoded": true, "body": buffer }; };Lambda側のソースコードはこんな感じ。
chrome-aws-lambdaはLambda Layerを使わせてもらった。
https://github.com/shelfio/chrome-aws-lambda-layer#available-regionsAPI Gateway
API Gateway側は適当なリソースを作って、GETメソッドを用意する。
/path/to/svg - GET - 統合リクエストで上で作ったLambdaに繋いで、Lambda プロキシ統合の使用にチェックを入れる- HTTP リクエストヘッダーに
Acceptを追加する- メソッドレスポンスのコンテンツタイプに
image/pngを追加する- APIの設定で、バイナリメディアタイプに
image/pngを追加するAPIキーや使用量プランは必要に応じて設定して、ステージにデプロイする。ここでは仮に
prodステージにデプロイしたと仮定して進める。これでcurlコマンドでAPI Gatewayを叩くと画像が返ってくるようになる。
curl -H "Accept: image/png" --output test.png https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/prod/path/to/svgCloudFront
この状態でブラウザでアクセスすると、Acceptヘッダーがリクエストに含まれないのでjsonが返ってきてしまう。CloudFrontを経由させることで、Acceptヘッダーを付けつつ、一度アクセスのあった画像はキャッシュしてもらえる。
まずDistributionsの作成してOriginを追加する。
Origin Domain Name: xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com Origin Path: /prod Origin Custom Headers: Accept: image/pngBehavior側はOrigin or Origin Groupで先ほど追加したOriginを選択する。
CloudFrontのデプロイが完了したら、CloudFrontのURL経由でブラウザで画像が表示されるようになる。
Lambda@EdgeでOGPタグ
Lambda@Edgeを使ったOGPの生成はこのあたりを参考に。
Lambda@EdgeでSPAのOGPを動的に設定する
SSRをやめる。OGP対応はLambda@Edgeでダイナミックレンダリングする。今回は1個目の記事のような感じで、botからのアクセスだった場合はバックエンドのAPIにアクセスしてタイトルとかを整えつつ、上で用意した画像のURLを含んだOGPタグを生成して返すようにした。
botの種類はこのあたり。
const crawlers = [ "Googlebot", "facebookexternalhit", "Twitterbot", "bingbot", "msnbot", "Slackbot", "Discordbot" ];まとめ
とまあ、こんな具合でOGP用の画像を自動生成できた。あとは必要に応じてコールドスタート対策もしておきたいところ。
Serverless Frameworkで行うLambdaのコールドスタート対策いつもながら先人の知恵や知識に感謝。
参考URL
https://scottbartell.com/2019/03/25/automating-og-images-with-aws-lambda/
https://codissimo.sinumo.tech/2019/12/27/serverless-puppeteer-with-aws-lambda-layers-and-node-js/
https://qiita.com/junara/items/5563ad7ee133ce736ed0
https://qiita.com/kodai-saito/items/9051d2b30a29c7d64f7d
- 投稿日:2020-02-28T15:27:04+09:00
LambdaでCognito認証(ユーザー認可)
はじめに
SDKをローカルに持ってきてゴニョるサンプルは検索に引っかかるのですが、
クラウド側(Lambda関数内部)で完結するサンプルが見つからない...
よし、ならば投稿してしまえ。トップ
├ユーザー作成
├ユーザー確認
├ユーザー認証
└ユーザー認可 ←イマココ注意事項
本稿は、こちらの記事をLambda関数で実現することを目的としています。
兄弟記事とは毛色が違いますので、予めご了承ください。
- Decode and verify Amazon Cognito JWT tokens (Amazon Cognito JWT トークンを復号して検証する)を、JavaScriptで改変したプログラムを使用します。
- npmを使用してライブラリを入手し、Lambdaにアップロードする手順が含まれます。
- Lambda関数でAPI Gateway用のオーソライザーの作成方法を解説する記事ではありません。
- API Gatewayでオーソライザーの設定方法を解説する記事でもありません。→こちらをご覧ください。
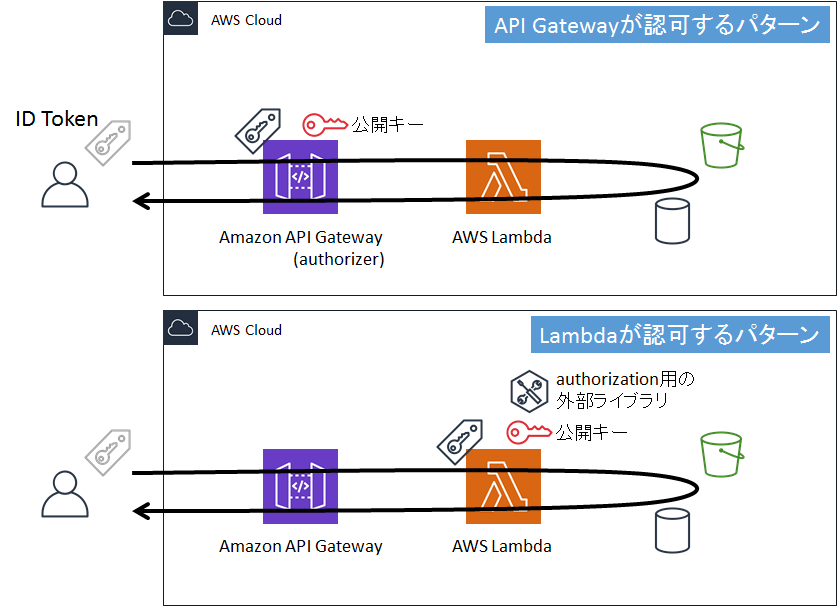
ユーザー認可 (Authorization)
通知されたIDトークンが有効かどうかを判断します。
通常、ユーザー認可はAPI Gatewayのオーソライザーに任せればいいのですが、諸事情によりAPI Gatewayに任せられない場合は、Lambdaに担当させる必要があります。本稿では、Lambda関数でユーザー認可する方法を解説します。
ドキュメント
AWSJavaScriptSDKは使用しません。
JSON ウェブトークンの検証npm
ユーザー認可に使用する外部ライブラリを入手します。
外部ライブラリ
npmで入手します。
入手した外部ライブラリはLambdaにアップロードします。npm i jwk-to-pem --save npm i jsonwebtoken --saveCognito
Cognitoのユーザープールから、ユーザー認可に使用する「公開キー」と「アプリクライアントID」を入手します。
公開キー
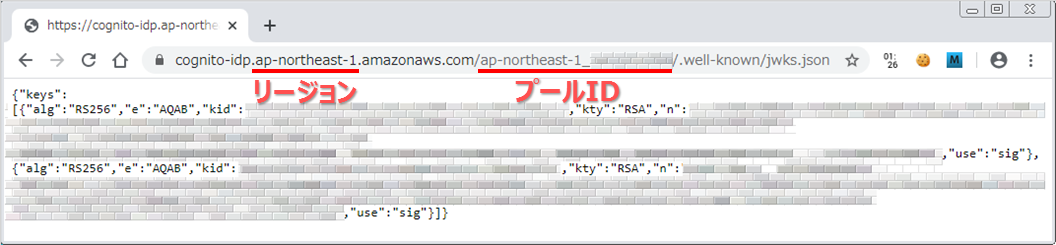
公開キーはこちらにあります。
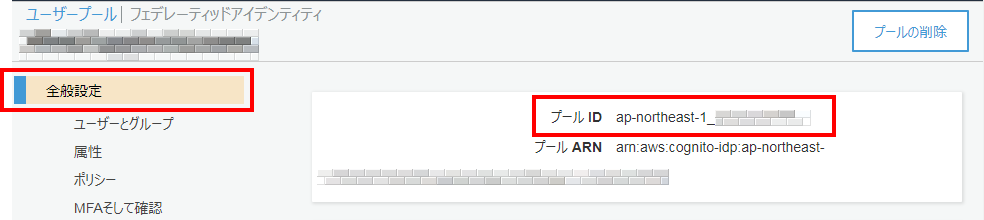
https://cognito-idp.{リージョン}.amazonaws.com/{プールID}/.well-known/jwks.json
プールIDは、Cognitoのユーザープールの「全般設定」のページから確認できます。
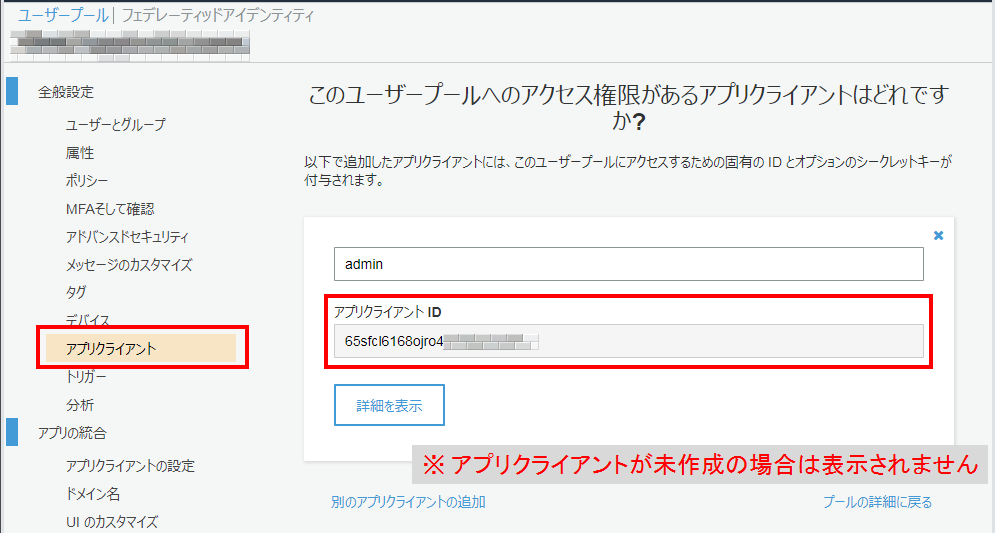
アプリクライアントID
アプリクライアントIDは、Cognitoのユーザープールの「全般設定>アプリクライアント」のページから確認できます。
Lambda
関数を一から作成します。
環境設定
最終的には次のような環境にします。
ソースコード
↓適当な例外をthrowしています。
アプリクライアントIDや発行者(issuer)の文字列は、Lambdaの環境変数に設定すると、プログラムの見通しが良くなると思います。authorizer.js'use strict'; // ライブラリ const jwkToPem = require('./node_modules/jwk-to-pem/src/jwk-to-pem.js'); const jsonwebtoken = require('./node_modules/jsonwebtoken'); // 公開キー。 https://cognito-idp.{リージョン}.amazonaws.com/{プールID}/.well-known/jwks.json と同じもの const jwks = require('./jwks.json'); // JWT形式判定用の正規表現 const jwtRe = /(?<header>.+)\.(?<payload>.+)\.(?<signature>.+)/; /** * オーソライザー (トークンを検証する) * @param {string} token IDトークン * @returns {Object} ペイロード */ module.exports = token => { // 入力はJWT形式の文字列か? const match = jwtRe.exec(token); if (!match) throw 'AuthError'; // ヘッダー情報を取得 const header = JSON.parse(Buffer.from(match.groups.header, 'base64').toString()); // 公開キーから使用するキーを選ぶ const jwk = jwks.keys.find(k => k.kid == header.kid); if (!jwk) throw 'AuthError'; // 外部ライブラリを使って署名を確認する const pem = jwkToPem(jwk); const claim = jsonwebtoken.verify(token, pem); // 有効期限の確認 const now = new Date() / 1000; if (now > claim.exp || now < claim.auth_time) throw 'AuthError'; // 利用者(audience)の確認 if (claim.aud !== '{アプリクライアントID}') throw 'AuthError'; // 発行者(issuer)の確認 if (claim.iss !== 'https://cognito-idp.{リージョン}.amazonaws.com/{プールID}') throw 'AuthError'; // トークン種別の確認 // IDトークンを使う場合の claim.token_use は 'id' // アクセストークンを使う場合の claim.token_use は 'access' if (claim.token_use !== 'id') throw 'AuthError'; // ハレて認可された return claim; };↓例外をcatchしていませんが、そのあたりを含めて適当に改変してください。
index.js'use strict'; // オーソライザー const authorizer = require('./authorizer.js'); /** * メイン * @param {Object} event プロキシ統合の情報 * @returns {Promise<HTTPResponse>} HTTPレスポンス */ exports.handler = async event => { // event情報からIDトークンを取得 const token = event.headers['Authorization']; // HTTPヘッダーのAuthorizationにIDトークンがある場合の例 // IDトークンをオーソライザーに投入 const claim = authorizer(token); // 例外が発生しなければ認可成功 // HTTPレスポンスを返して終了 return { statusCode: 200, body: 'Authorization succeeded.', }; };

- 投稿日:2020-02-28T14:10:56+09:00
S3とその管理 1
業務でS3を扱っているが、もう少し詳しく知りたい。
とりあえず公式を読む
「Amazon Simple Storage Service (Amazon S3) は、業界をリードするスケーラビリティ、データ可用性、セキュリティ、およびパフォーマンスを提供するオブジェクトストレージサービスです。つまり、あらゆる規模や業界のお客様が、ウェブサイト、モバイルアプリケーション、バックアップおよび復元、アーカイブ、エンタープライズアプリケーション、IoT デバイス、ビッグデータ分析など、広範にわたるユースケースのデータを容量に関係なく、保存して保護することができます。Amazon S3 では使いやすい管理機能を使用するため、データを整理して、細かく調整されたアクセス制御を設定することで、特定のビジネスや組織、コンプライアンスの要件を満たすことができます。Amazon S3 は 99.999999999% (9 x 11) の耐久性を実現するように設計されており、世界中の企業向けに何百万ものアプリケーションのデータを保存しています。」公式要は、
AWSのストレージサービス!
高い拡張性!
大規模なアプリケーションのデータを扱える!
99.99999999999(9*11)の高い可用性!「ストレージリソースをスケールアップ/ダウンして、変動する需要に対応します。先行投資やリソースの調達サイクルは不要です。Amazon S3 は、複数のシステムにまたがる S3 オブジェクトをすべて自動的に作成して保存しており、99.999999999% (9 x 11) のデータ耐久性を実現するように設計されています。つまり、必要に応じてデータを利用することができるため、障害やエラー、脅威から保護することができます。」公式
要は、
S3のおかげで先にリソースを確保しておく、という必要がなくなる!
高い可用性!
複数のシステムでオブジェクトを保存するので、障害耐久性も高い!「パフォーマンスを下げずにコストを節約するには、対応するレートでさまざまなデータアクセスレベルをサポートする S3 ストレージクラスにデータを保存します。S3 ストレージクラス分析を使用して、アクセスパターンに基づき、低コストのストレージクラスに移動する必要のあるデータを検出し、S3 ライフサイクルポリシーを設定して転送を実行できます。S3 Intelligent-Tiering では、アクセスパターンが変化するデータか、パターンが不明なデータを格納することもできます。これにより、オブジェクトはアクセスパターンの変化に応じて階層化されるため、コストは自動的に抑えられます。」
要は
あまりアクセスしないデータに関してはライフサイクルポリシーを設定してコストの低いストレージに移動することができる!
S3 Intelligent-Tieringはアクセスパターンが一定でないようなデータを格納することができる!
アクセスパターンに応じて、ストレージのタイプを変えることにより、コストの最適化を図ることができる!ちなみにS3ってどんな種類があるのだ??
「Amazon S3 では、各ユースケース向けに幅広いストレージクラスが提供されています。クラスの種類は、S3 標準 (高頻度アクセスの汎用ストレージ用)、S3 Intelligent-Tiering (未知のアクセスパターンのデータ、またはアクセスパターンが変化するデータ用)、S3 標準 – 低頻度アクセス (S3 標準 - IA)、S3 1 ゾーン - 低頻度アクセス (S3 1 ゾーン - IA) (長期間使用するが低頻度アクセスのデータ)、Amazon S3 Glacier (S3 Glacier)、Amazon S3 Glacier Deep Archive (S3 Glacier Deep Archive) (長期アーカイブおよびデジタル保存) があります。Amazon S3 には、ライフサイクルを通じてデータを管理する機能が搭載されています。S3 ライフサイクルポリシーを設定すると、データは別のストレージクラスに自動的に移行されます。アプリケーションに変更を加える必要はありません。 」
S3標準 – 高頻度アクセス用
S3 Intelligent-Tiering – アクセスパターンが一定でないもの用
S3 標準 – 低頻度アクセス - 長期間使用するがアクセスが少ないもの用
S3 1ゾーン - 長期間使用するがアクセスが少ないもの用
S3 Glacier – 長期アーカイブとデジタル保存用
S3 Glacier Deep Archive - 長期アーカイブとデジタル保存用
がある。
これらを使用するデータによって使い分けることで、パフォーマンス、コストの最適化が図れる!「データを Amazon S3 に保存し、暗号化機能とアクセス管理ツールを使用して不正なアクセスからデータを保護します。S3 は S3 Block Public Access を使用して、バケットレベルまたはアカウントレベルで、すべてのオブジェクトへのパブリックアクセスをブロックできる唯一のオブジェクトストレージサービスです。S3 は PCI-DSS、HIPAA/HITECH、FedRAMP、EU データ保護指令、および FISMA などのコンプライアンスプログラムを維持し、規制要件を満たしています。AWS では、S3 リソースへのアクセスリクエストをモニタリングするための監査機能も多数サポートしています。」
要は
A3では暗号化やアクセス管理ツールでデータを不正アクセスから保護できる!
S3 Block Public Accessですべてのオブジェクトへのパブリックアクセスをブロックすることができる!
セキュリティは様々な規制要件を満たしている!
オブジェクトへのアクセスを監視する機能もある!「S3 の堅牢な機能で、アクセス、コスト、レプリケーション、データ保護を管理できます。S3 Access Points では、共有データセットを使用するアプリケーションに個別のアクセス許可を付与できるため、データアクセスの管理が容易になります。S3 レプリケーション機能を利用すると、リージョン内やリージョン間のデータレプリケーションを管理できます。S3 バッチオペレーションでは、数十億にのぼるオブジェクトにわたる大規模な変更の管理が支援されます。S3 は AWS Lambda と連携しているため、追加のインフラストラクチャを管理することなく、アクティビティのログ記録、アラートの定義、ワークフローの自動化を行うことができます。」
要は
S3 Access Pointsで、アプリケーションの特定のデータへのアクセス権限を管理することができる。
レプリケーション機能でデータのレプリケーションもリージョンを選んで作成できる。
バッチオペレーションで、大規模なバッチ処理もできる。
あとはLambdaと連携しているので、Lambdaでそのまま使える。「すぐに活用できるクエリ (query-in-place) サービスを使用して、S3 オブジェクト (および AWS の他のデータセット) 全体で大きなデータ分析を実行します。Amazon Athena を使用して標準の SQL 式で S3 データを照会し、Amazon Redshift Spectrum を使用して AWS データウェアハウスおよび S3 リソースに格納されているデータを分析します。また、S3 Select を使用して、オブジェクト全体ではなくオブジェクトデータのサブセットを取得し、クエリのパフォーマンスを最大 400% 向上させることもできます。」公式
要は
クエリサービス(query-in-place)でデータ検索ができる。
Amazon AthenaとはS3のデータの分析ツール。
S3 Selectでデータをサブセット化してパフォーマンスを向上させる。「Amazon S3 のデータを保存し、保護するには、AWS Partner Network (APN) のパートナー (テクノロジーとコンサルティングのクラウドサービスプロバイダーの最大のコミュニティ) と提携します。APN は、Amazon S3 にデータを転送する移行パートナーと、プライマリストレージ、バックアップ、復元、アーカイブ、災害復旧用に S3 統合ソリューションを提供するストレージパートナーを認識します。また、AWS Marketplace から AWS 統合ソリューションを直接購入することもできます。ここでは、ストレージに関する 250 以上のサービスが表示されています。」公式
パートナーと提携していることでいろんな構築のソリューションが提供されている。
統合ソリューションも購入できる。
いろんなサービスが提供されている。S3はAWSのストレージサービスで、いろんなソリューションが提供されているのか…
まぁ知識マスターしてれば自分でストレージの最適化も図れるし、あんま良く分かってなくてもソリューション単位でいろんなサービスが受けれるのか…読み進める。
「 Amazon S3 Access Points により、S3 上の共有データセットを使用するアプリケーションの大規模なデータアクセスを簡単に管理できるようになります。S3 Access Points は、バケットあたり数百にのぼるアクセスポイントを簡単に作成できるため、共有データセットへのアクセスをプロビジョンする新たな手段となります。Access Points では、一意のホスト名とアクセスポリシーによって、アクセスポイント経由のあらゆるリクエストに対して固有のアクセス許可とネットワーク制御が適用されます。これにより、バケットへのカスタマイズされたパスを利用できます。」公式
要は
Access Point使えばバケットごとにアクセスポイントを設定できる。
アクセス権限を設定したパスも作れる。「Amazon S3 などの AWS のサービス (例: S3 Glacier、Amazon EFS、Amazon EBS) を使用して、スケーラブルで、耐久性、安全性に優れたバックアップと復元のソリューションを構築して、既存のオンプレミス機能を強化するか、リプレースすることができます。AWS と APN のパートナーは、目標復旧時間 (RTO)、目標復旧時点 (RPO)、およびコンプライアンス要件を満たすのに役立ちます。AWS では、AWS クラウドにある既存のデータをバックアップするか、AWS Storage Gateway (ハイブリッドなストレージサービス) を使用して、オンプレミスデータのバックアップを AWS に送信することができます。」公式
要は
S3は既存のオンプレ環境に適応してパワーアップも図れるし、
オンプレ環境をS3で全部管理するようにもできる。
APNパートナーはRTOやRPOやコンプライアンス要件を満たせる。
オンプレのデータのバックアップをS3に移動するには、AWS Storage Gatewayを使う。ん?もしかしたらAPNパートナーを完全に理解していないかもしれない…
APNパートナーの説明を読む
「AWS パートナーネットワーク (APN) は、アマゾン ウェブ サービスを活用して顧客向けのソリューションとサービスを構築しているテクノロジーおよびコンサルティング企業向けのグローバルパートナープログラムです。APN は、価値のあるビジネス、技術、マーケティングのサポートを提供することで、企業が AWS サービスを構築、マーケティング、販売するのを支援します。
世界中に数万にも及ぶ APN パートナーがいます。フォーチュン 100 企業のうち 90% 以上、そしてフォーチュン 500 企業の大多数が、APN パートナーソリューションとそのサービスを利用しています。」公式
要は
AWS使ってソリューション提供する企業のこと。なるほど。S3の説明に戻る。
「AWS クラウド、またはオンプレミス環境で実行されている重要なデータ、アプリケーション、および IT システムを保護します。予備の物理データセンターにコストをかける必要はありません。Amazon S3 ストレージや S3 クロスリージョンレプリケーション に加え、AWS のコンピューティング、ネットワーキング、データベースサービスでは、DR アーキテクチャを作成して、自然災害やシステム障害、人為的ミスによって発生する機能停止から簡単にすばやく復旧することができます。」公式
要は
S3にデータ入れておけば災害などに対する耐久を高められる。
DRアーキテクチャ?を作成して災害が起きた時に迅速に復旧させることが可能になる。DRアーキテクチャ?
「災害対策(Disaster Recovery:DR)の目的は、災害時にもサービスを継続して提供するためのITシステムおよびデータの保護です。」NEC
https://jpn.nec.com/techrep/journal/g06/n04/pdf/t060407.pdf
要は、ディザスタリカバリアーキテクチャ。バックアップを保存しておく設計とか。これをしておくことで、災害発生時にすぐに復旧することができる。詳細は割愛。S3に戻る。
「アーカイブ - 物理インフラストラクチャを廃止し、S3 Glacier と S3 Glacier Deep Archive でデータをアーカイブします。これらの S3 ストレージクラスでは、オブジェクトを長期間、低コストで保持することができます。ライフサイクル全体にわたってオブジェクトをアーカイブする S3 ライフサイクルポリシーを作成するか、オブジェクトをアーカイブのストレージクラスに直接アップロードします。S3 オブジェクトのロックでは、オブジェクトに保持日を適用してオブジェクトを削除から保護し、コンプライアンス要件を満たすことができます。テープライブラリとは異なり、S3 Glacier では、迅速取り出しの場合は 1 分、標準取り出しの場合は 3〜5 時間でアーカイブオブジェクトを復元できます。S3 Glacier からの一括データ復元と S3 Glacier Deep Archive を使用した復元はすべて 12 時間以内に完了します。」公式要は
GlacierとGlacier Deep Archiveは主にアーカイブ用。
Glacier群は長期ストレージ用で、コストは低い。
保存方法はライフサイクル設定かそのままアップロード。
オブジェクトのロックをすることで、自動的に削除されるのを防ぐことができる。
ただデータの取り出しには時間がかかる。1分~5時間。
一括データ復元は最大で12時間かかることもある。オブジェクトのロックがいまいちわからなかったので調べてみる。
つづく
- 投稿日:2020-02-28T14:05:11+09:00
ELB配下のEC2インスタンスのnginxの設定
ELBを使うと何が困るか
ELBを使ってEC2にアクセスする場合、nginxが認識する直近のアクセス元は全てELBとなります。
従って、アクセスログをみるとアクセスがすべてELBということになったり、IP制限をかけようにもクライアントのIPが取得できなくて困ることがあります。そういう時には
X-Forwarded-Forを使うといいと言うことがさらっと書いてあることが多いのですが、もう少し細かく記載しておきます。実際の設定
set_real_ip_from 172.32.10.0/20; # プライベートIPは実際のものを使ってください set_real_ip_from 172.32.18.0/20; # プライベートIPは実際のものを使ってください real_ip_header X-Forwarded-For; real_ip_recursive on;この設定を追加します。この設定を追加すると
set_real_ip_fromで設定したサブネットからのアクセスはX-Forwarded-Forを利用するようになります。real_ip_recursiveをonにしておくことで、その他のプロキシなどが噛んでいた場合も元々のクライアントのIPが取得できるようになります。recursiveなので再帰的に転送元をたどる設定かと。set_real_ip_fromにはELBの存在するサブネットを設定しておきます。基本的には複数あると思うので並べて記載すればOKです。
この設定を反映することでaccess.logの
$remote_addrにはELBではなく、実際のユーザーのIPアドレスが記録されるようになります。$http_x_forwarded_forを使わずともクライアントのIPが記録可能となります。limit_reqとlimit_con
同一IPからの集中アクセスがある場合も
# limit req limit_req_zone $binary_remote_addr zone=limit_req_by_ip:10m rate=10r/s; limit_req_log_level error; limit_req_status 503; # limit conn limit_conn_zone $binary_remote_addr zone=limit_per_ip:10m; limit_conn_log_level error; limit_conn_status 503;このように設定してlocationディレクティブで
location / { limit_req zone=limit_req_by_ip burst=10; limit_conn limit_per_ip 5; }このように設定します。こうすると同一IPから一秒間に10リクエスト以上、または同一IPから同時に5接続という制限がかかり、制限を超えると503エラーを返します。
これもreal_ip_headerの設定をしていないと、全てELBからのアクセスとなるため、間違ってしまうと不要にエラーを返してしまうことにあります。調べながら書いたので正しくない箇所もあると思うので指摘あったらいただけると助かります。
- 投稿日:2020-02-28T13:38:47+09:00
【Amazon Web Services 基礎からのネットワーク&サーバー構築 】に取り組む
Amazon Web Services 基礎からのネットワーク&サーバー構築この書籍ではWordPressでブログシステムを作りながら、サーバやネットワークの構築を学ぶ
初学者はネットワークやサーバに関する専門用語に不慣れなので、適宜用語の定義の確認も行う
また、AWSのユーザ設定など、AWSを始めるにあたっての必要事項についても、適宜参考URL等を貼るなどして補う
サーバーとは
サーバー用のOSをインストールしたコンピュータのこと
どのようなソフトウェアをインストールするかによってサーバーの役割が決まる
(例)
WebサーバーソフトをインストールするとwebサーバーになるDBサーバーソフトを入れるとDBサーバーとなる
※DBサーバー : データベースが置いてあるサーバーのこと
※データベース : 後で使いやすい形に整理されたデータの集まり
ネットワークとは
互いに接続されたコンピュータの集まりのこと
コンピュータなどの機器ごとにIPアドレス(住所)を割り当て、送受信が行えるようにしている
IPアドレス
ネットワーク上で重複しない唯一無二の番号
いわゆる「住所」に相当するもの
パブリックIPアドレス
インターネットで利用するアドレス
重複を避けるため、自由に値を決めることができない
ICANNという団体が一括管理している
プライベートIPアドレス
インターネットで使われないIPアドレス
誰にも申請することなく自由に使えるので個人でネットワークの実験を行うような場合に利用できる
表1:プライベートIPアドレス範囲
IPアドレス範囲 10.0.0.0 ~ 10.255.255.255 172.16.0.0 ~ 172.31.255.255 192.168.0.0 ~ 192.168.255.255 IPアドレス範囲と表記法
ホストに割り当てるIPアドレスの範囲は「2のn乗個で区切る」という決まりがある
一般に良く使われる区切りが「256個」と「65536個」
「256」は8ビット(2の8乗)
IPアドレスの「ピリオドで区切られた一つの数字」が256個。(例えば192.168.1.0 ~ 192.168.1.255)
「65536」は16ビット(2の16乗)
IPアドレスの「ピリオドで区切られた数字二つ分」が65536個である。例えば192.168.0.0 ~ 192.168.255.255)
IPアドレスの値が固定された部分をネットワーク部といい、値が変化する部分をホスト部と呼ぶ
ホスト(host)とは、コンピュータやルーターなどのネットワーク機器など、IPアドレスをもつ通信機器の総称のこと
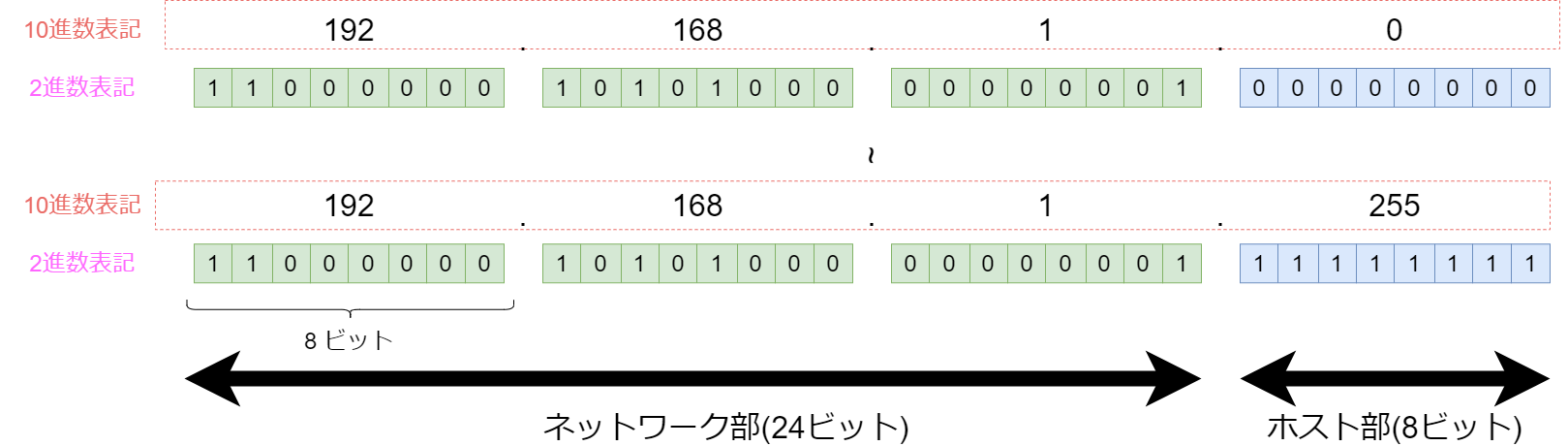
$$図1 : IPアドレス$$
CIDR(サイダー)表記とサブネットマスク表記
「192.168.1.0 ~192.168.1.255」という表現は長いので「CIDR表記」や「サブネットマスク表記」を用いてアドレスを表現する
CIDR表記
IPアドレスの「 ネットワーク部のビット長」を「 /ビット長」として末尾に表記する
例.
「192.168.1.0 ~ 192.168.1.255」 → 192.168.1.0/24「192.168.0.0 ~ 192.168.255.255」 → 192.168.0.0/16
CIDR : Classless Inter-Domain Routing
サブネットマスク表記
IPアドレスのネットワーク部をすべて255で埋めた表記を並べる
例.
「192.168.1.0 ~ 192.168.1.255」 → 192.168.1.0/255.255.255.0「192.168.0.0 ~ 192.168.255.255」 → 192.168.0.0/255.255.0.0
ネットワーク部のビット長を プレフィックス(prefix)と呼ぶ
サブネット
分割したネットワークのこと
言い換えると、全体のネットワーク領域から一部の領域を切り出したもの
パブリックサブネット
インターネットに繋がっているサブネット
WEBサーバーなどで用いる
プライベートサブネット
インターネットに繋がっていないサブネット
DBサーバーなどで用いる
ネットワークの構築
サーバーはネットワークに接続される
インターネットと接続可能なネットワークではTCP/IPというプロトコルを使う
※TCP/IP : Transmission Control Protocol/Internet Procotol
※プロトコル : 情報を相互に伝達できるようにするため、あらかじめ決められた約束や手順のこと
インターネットに接続する際にはルーターという機器を使う
各サーバーはルーターにデータが流れるように構成しないとインターネットに接続できない
インターネットでは。「
http://www.example.co.jp/」のようなドメイン名でアクセスするドメイン名とは数字とピリオドだけで表現されるわかりにくいIPアドレスに結びつけ、人が理解しやすい名前にしたもの
ドメイン名を使うにはDNSサーバーの設定が必要
NAT
片方向だけのインターネット接続を許す機能
サーバーからはインターネットに接続できるが、インターネット側からサーバーには接続できない
サーバーからリクエストした際の返事の通信は通してくれる
これによって、サーバーは外部からソフトウェアを安全にダウンロードできるようになる
AWSのアカウント作成と初期設定
AWSのアカウント作成については以下のURLが参考になった
AWSアカウント作成の流れ
https://aws.amazon.com/jp/register-flow/また、セキュリティやIAMユーザ作成などの初期設定を行う必要がある
以下の記事が参考になる
AWSアカウントを取得したら速攻でやっておくべき初期設定まとめ
https://qiita.com/tmknom/items/303db2d1d928db720888AWSアカウントでのIAMユーザの作成
https://qiita.com/kzykmyzw/items/ca0c3276dfebb401f7d8git-secretsがあれば、機密情報も怖くない
https://www.goriwaka.com/entry/2019/08/19/git-secrets%E3%81%8C%E3%81%82%E3%82%8C%E3%81%B0%E3%80%81%E6%A9%9F%E5%AF%86%E6%83%85%E5%A0%B1%E3%82%82%E6%80%96%E3%81%8F%E3%81%AA%E3%81%84CloudTrailでAWS Free Tier limit alert が届いた話
https://qiita.com/heyheyww/items/b67d2bab58ee1cf6057eAmazon VPC
VPCはVirtual Private Cloudの略で、アマゾンのクラウド上に仮想的にネットワークを作成することができる
ネットワークのIPアドレス範囲を決め、下図のようにVPCの全体の領域の中にパブリックのサブネットとプライベートのサブネットを作成できる
$$図2 : VPCのアドレス範囲$$
サブネットの分割
「10.0.0.0/16」のようなアドレス範囲のことをCIDRブロックと呼ぶ
実際のネットワークでは、割り当てられたCIDRブロックをさらに小さなCIDRブロックに分割して使う
このようにさらに細分化したCIDRブロックを サブネットと呼ぶ
例.
「10.0.0.0/16」を「/24」の大きさで切って256分割すると「10.0.1.0/24」,「10.0.2.0/24」,「10.0.3.0/24」…「10.0.255.0/24」
と分かれる
分けられたサブネットそれぞれに対して、異なるネットワーク設定が行える
(例)
10.0.1.0/24をインターネットからアクセスできる「パブリックサブネット」として使い、
10.0.2.0/24をインターネットから隔離した「プライベートサブネット」として利用するインターネット回線とルーティング
Amazon VPCにおいて、あるサブネットをインターネットに接続するにはインターネットゲートウェイ(Internet Gateway)を用いる
ネットワークにデータを流すためには、ルートテーブル(Route Table)と呼ばれる、ルーティング情報の設定が必要である
ルートテーブルは、データを送信する際、宛先のIPアドレスまでデータを流せるよう転送ルールを示す設定である
宛先アドレス 流すべきネットワークの入り口となるルーター $$図3: ルートテーブル$$
宛先アドレスのことをディスティネーション(destination)と呼ぶ
仮想サーバーの構築 : Amazon EC2の利用
Amazon EC2 インスタンス
Amazon EC2 : Amazon Elastic Compute Cloud の略
AWS内ではEC2を使ってVPC領域内にサーバーを作る
起動された各サーバーの個体はインスタンスと呼ばれるインスタンスにはプライベートIPアドレスとパブリックIPアドレスを設定する
※プライベートIPアドレス : パブリックサブネット内で利用可能だがインターネットとの接続はできない
※パブリックIPアドレス : インターネットで通信するためのIPアドレス
AMI
AMI(Amazon Machine Image) はインスタンスを起動する際に用いるイメージファイルのこと
OSがインストールされていて、初期アカウントの設定までが済んでいる
インスタンスタイプ
仮想マシンのスペックのこと
ストレージタイプ
インスタンスで使用する仮想ハードディスク(EBS:Elastic Block Store)を設定する
セキュリティグループ
インスタンスにセキュリティを設定する機能
キーペアの作成
キーペアは、インスタンスにログインする際に必要となる「鍵」である
SSH(Secure SHell)
SSHは、リモートコンピュータと通信するためのプロトコル
認証部分を含めネットワーク上の通信がすべて暗号化されるため、安全に通信することができる
作成したキーペアファイルを用いて接続する
windowsではTera Termを使ってSSH接続する
IPアドレスとポート番号
ルーティングプロトコル
インターネットでは、ルーター動詞が通信してルートテーブルの情報をやりとりし、必要に応じて自動的に更新するようにしている
これを実現するのがルーティングプロトコルであるルーティングプロトコルは大きく分けてEGPとIGPの2種類がある
EGP(Exterior Gateway Protocol)
ある程度大きなネットワーク(AWSやインターネットサービスプロバイダーISPなど)は、そのネットワークを管理するAS番号(Automous System)という番号を持っている
EGPでは、このAS番号をやりとりして「どのネットワークの先に、どのネットワークが接続されているか」を大まかにやりとりする
IGP(Interior Gateway Protocol)
EGP内部のルーター同士で、ルートテーブルの情報をやりとりするのに使われる
ポート番号
ポートとポート番号
TCP/IPで通信するサーバーなどの機器に用意された、ほかのコンピュータとデータを送受信するためのデータの出入り口のこと
ポートに対してポート番号が割り当てられる
ポート番号を使うことで一つのIPアドレスで同時に複数のアプリケーションが通信できる
ウェルノウンポート番号
ウェルノウンポート(Well-known Port: 良く知られているポート)は代表的なアプリケーションが使うポート番号のこと
SSH通信では「ポート22番」がウェルノウンポートである
ファイアウォール
通してよいデータだけを通して、それ以外を遮断する機能の総称
もっとも簡単な構造のファイアウォールがパケットフィルタリングである
パケットフィルタリング
流れるパケットを見て、通貨の可否を決める仕組みのこと
パケットには、「IPアドレス」のほか「ポート番号」も含まれている
パケットフィルタリングではパケットに付随するこれらの情報を見て通過の可否を決める
ドメイン名と名前解決
ドメイン名
一般に、IPアドレスは数字の羅列で覚えにくいため、一般にブラウザからのアクセスには「
http://www.exampke.co.jp」のようなドメイン名を用いる名前解決
ドメイン名を使って通信する場合、ドメイン名がどのパブリックIPアドレスなのかを知る必要がある
「ドメイン名とIPアドレス」との相互変換をすることを名前解決という
DNS
DNS(Domain Name System)は、名前解決を行う仕組みのこと
DNSサーバーが行う
HTTP
HTTP(Hyper Text Transfer Protocol)は、HTMLをはじめとするWebサービスに必要な情報を伝達するためのルール
WebサーバーとWebブラウザはHTTPを用いてデータをやりとりする
TCP/IPによる通信の仕組み
TCP/IPはネットワーク状況に合わせて適切なデータ送信サイズを決めたり、エラーがあったときに再送したりするなど、より詳細な通信方法を定義している
IPアドレス、ポート番号、DNS、HTTPといった一連の処理は、TCP/IPモデルという役割ごとに4つの階層に分かれたモデルで構成されている
$$表 : TCP/IPモデルの階層$$
層 役割 代表的なプロトコル アプリケーション層 ソフトウェア同士が会話をする HTTP,SSH,DNS,SMTP トランスポート層 データのやり取りの順番を制御したり、エラー訂正したりするなど、信頼性を高めたデータの転送を制御する TCP,UDP インターネット層 IPアドレスの割り当て、ルーティングをする IP,ICMP,ARP インターフェース層 ネットワーク上で接続されている機器同士で通信する Ethernet,PPP 上記のように階層化させることで、上位の階層は下位の階層が何でもよく、下位の階層は上位の階層の内容はわからなくてもよい、という階層ごとに独立した構造になっている
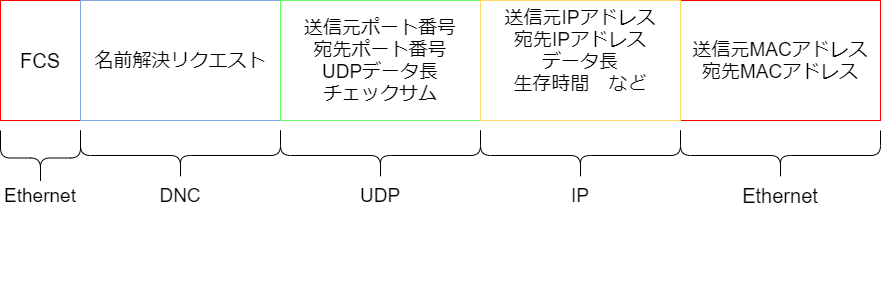
データのカプセル化
データに対して、下の階層で処理ができるようにデータを付与すること
一例として、DNSが名前解決する処理について考える
1.名前解決リクエストの作成
DNSサーバーに対して名前解決の処理を依頼するため、DNSプロトコルで定められたフォーマットに従い、名前解決のリクエストデータを作成する2.UDPでカプセル化(トランスポート層)
作成した名前解決のリクエストデータに対して、中身に手を加えずに、さらに下の階層で処理ができるようにデータを付与するトランスポート層のプロトコルはTCPかUDPであるが、DNSでは一般的にUDPを使うのでUDPに引き渡す
3. IPでカプセル化(インターネット層)
次にデータをインターネット層に渡す
IPでのカプセル化ではIPヘッダーが追加される
これによってIPアドレスが付き、実際にLANや電話回線などの配線上に流せるようになる
4.Ethernetでカプセル化(インターフェース層)
「それぞれの配線の規格」に準拠したヘッダーがいくつか付けられる
LANには「Ethernet」という規格がある
データの先頭と末尾にいくつかのデータが付与される
これをEthernetフレームという
UDP(User Datagram Protocol)
UDPは「ステートレスプロトコル」と呼ばれる、状態を持たないプロトコルのこと
データが送りっぱなしのプロトコルで、相手がパケットを受け取ったかどうかを確認する手段を持たない
UDPはやりとりが単純なので高速に送信できる
DNSサーバーへのリクエストのように、データが1パケットに収まる場合や、送信したパケットが前後しても良い場合、相手から返答がないときには再度処理すればよい場合などではUDPが適している
TCP(Transmission Control Protocol)
TCPは双方向の通信が可能
TCPでは、自分と通信相手との間に「コネクション」を確立する
Webブラウザで入力したデータをHTTP経由でWebサーバーに送り、データベースに格納するような場合など、高い信頼性を必要とする場合に用いる


- 投稿日:2020-02-28T11:47:37+09:00
aws cli でcloudwatch log group の保持期間をまとめて設定する
備忘録
- 1. ロググループ名を列挙する
# 保持期間(retentionInDays)が設定されていないロググループを列挙する # 数が多くて1回で取り切らない場合は --log-group-name-prefix で絞り込むとか aws logs describe-log-groups \ --query 'logGroups[?!(retentionInDays)].logGroupName' \ --output text
- 2. 保持期間を設定する
aws logs put-retention-policy \ --log-group-name <ロググループ名> \ --retention-in-days <保持日数>
- 1. と 2. の合わせ技
# 保持期間が設定されていないloggroupの保持期間を7日間に設定する for lg in `aws logs describe-log-groups --query 'logGroups[?!(retentionInDays)].logGroupName' --output text` do aws logs put-retention-policy --log-group-name $lg --retention-in-days 7 done
- 投稿日:2020-02-28T10:31:36+09:00
AWS CLIでパラメーターストアにパラメーターを保存する方法
- 投稿日:2020-02-28T08:51:44+09:00
AWS Lambda入門(Node編)
概要
- ServerlessFrameworkを使ってLambda関数を作り、ローカルで動作確認したあとにAWSにデプロイしてアクセスするところまでやってみます
Lambdaとは
- LambdaはAWSが提供するサービスの1つで以下のような特徴を持ちます
サーバーレス
- 通常のアプリケーションはサーバにデプロイし稼働させることでアクセスすることができますが、当然サーバが止まっていたら利用することはできません
- Lambdaはサーバーレスに分類されるサービスで、アクセスがあるとそのつど起動し処理が実行され終了すると停止します
- つまりLambdaはサーバの死活監視のようなことをする必要がなく、また課金も実行時間単位なので金銭面でもお得といった特徴があります
FaaS
- LambdaはいわゆるFaaS(Function as a Service)に分類されます
- つまり、Function(関数)をデプロイして、それを公開するサービスというわけですね
関数の作成
- 今回はServerlessFrameworkを使います
ServerlessFrameworkのインストール
- グローバルにインストール
npm i -g serverless
- 動作確認
sls -vServerlessFrameworkのコマンドが
slsとserverlessのどちらでも動きます
- 以下のような内容が表示されればOKです
Framework Core: 1.64.1 Plugin: 3.4.1 SDK: 2.3.0 Components Core: 1.1.2 Components CLI: 1.4.0雛形の生成
- ServerlessFrameworkの機能でLambda用の関数や設定ファイルの雛形を生成します
- 今回は
aws-nodejsというtemplateを指定します- 他にどんなtemplateがあるかは
serverless create --helpを実行すると見ることができますmkdir sls-sample cd sls-sample serverless create --template aws-nodejs
- 以下のようなファイルが生成されているはずです
% tree -a . ├── .gitignore ├── handler.js └── serverless.yml
handler.jsは今回のメインのファイルでLambdaで実行する処理を書きますserverless.ymlはServerlessFrameworkを使う上での設定ファイルです.gitignoreはgit管理する際にServerlessFrameworkが生成する一時ファイルを管理対象外にするための記載が追加されています関数をローカルで実行してみる
- AWSにデプロイする前にまずはローカルで動作確認します
関数の内容を確認
- 実行する前に
handler.jsの中身を確認しましょう'use strict'; module.exports.hello = async event => { return { statusCode: 200, body: JSON.stringify( { message: 'Go Serverless v1.0! Your function executed successfully!', input: event, }, null, 2 ), }; // Use this code if you don't use the http event with the LAMBDA-PROXY integration // return { message: 'Go Serverless v1.0! Your function executed successfully!', event }; };
- メインの処理である関数を
helloという名前でmodule.exportsによって外部からアクセス可能にしています- 関数の中を見てみると
return文しかありませんstatusCodeとbodyの2つのプロパティを持ったobjectを返却しています
statusCodeは実行結果を表現していて200は成功を意味しています(詳しくはググって)bodyは実行結果のメイン部分でメッセージを定義したmessageと入力値をそのまま返却するinputを返していますローカルで実行する
- それでは実行してみましょう
- ServerlessFrameworkを使うとAWSにデプロイせずともLocalマシン上で動作確認ができます
sls invoke local --function hello
sls invokeが関数を呼び出すためのコマンドです
- そのあとの
localはAWSにアクセスするのではなく手元のファイルにアクセスすることを意味しています- 最後の
--function helloは実行したい関数を指定していています
- 先程
helloという名前でexportしていることを確認しましたね- 実行結果はこんな感じです
{ "statusCode": 200, "body": "{\n \"message\": \"Go Serverless v1.0! Your function executed successfully!\",\n \"input\": \"\"\n}" }
inputが空っぽなので適当な値を渡してみます
--dataで値を渡すことができますsls invoke local --function hello --data Hello{ "statusCode": 200, "body": "{\n \"message\": \"Go Serverless v1.0! Your function executed successfully!\",\n \"input\": \"Hello\"\n}" }
- Helloも取得できることが確認できました
関数をAWSにデプロイして実行してみる
- AWSにデプロイしてアクセスしてみます
AWSにアクセスするための設定
- AWSにデプロイするためにはキー情報の設定が必要になります
- アクセスキーの発行についてはIAM ユーザーのアクセスキーの管理を参考に実施してください
- 以下のコマンドの
aws_access_key_idにAccess key IDを、aws_secret_access_keyにSecret access keyを入れて実行してください
~/.aws/credentialsがすでに作成されている場合は上書きされるか尋ねられるので問題ないかファイルの内容を確認し対応してくださいserverless config credentials --provider aws --key aws_access_key_id --secret aws_secret_access_key
- キー情報が漏洩し悪用されると多額の請求につながる危険性があるので取り扱いには十分気をつけてください
デプロイする
- デプロイもServerlessFrameworkの機能で簡単に実行できます
serverless deploy --region ap-northeast-1
--region ap-northeast-1はAWSの東京リージョンにデプロイすることを指定しています
serverless.ymlに記載しておけば毎回引数で設定する必要はなくなりますserverless.yml# 抜粋 provider: name: aws runtime: nodejs12.x region: ap-northeast-1 # これ
- デプロイが成功すると以下のような出力がされます
Service Information service: sls-sample stage: dev region: ap-northeast-1 stack: sls-sample-dev resources: 6 api keys: None endpoints: None functions: hello: sls-sample-dev-hello layers: None Serverless: Run the "serverless" command to setup monitoring, troubleshooting and testing.
- エラーが出た場合は出力されたログをよく確認して対処しましょう
デプロイした関数を実行する
- AWSにデプロイしたLambda関数もコマンドラインから実行することができます
sls invoke --function hello --data Hello --region ap-northeast-1
- ローカルで実行したときとの違いは
localを指定していないだけですね- ローカルのときと同じように以下のレスポンスを受け取れていれば成功です
{ "statusCode": 200, "body": "{\n \"message\": \"Go Serverless v1.0! Your function executed successfully!\",\n \"input\": \"Hello\"\n}" }まとめ
- Lambda関数の基本的な扱い方について紹介しました
- ServerlessFrameworkを使うと設定やデプロイ周りがとても簡単ですね!
- 投稿日:2020-02-28T00:13:46+09:00
Lambda入門#4 API Gatewayとの連携
昨日の続き、やってきます!
参考URL
今日も以下の記事を参考にしてやったことを記載しています。
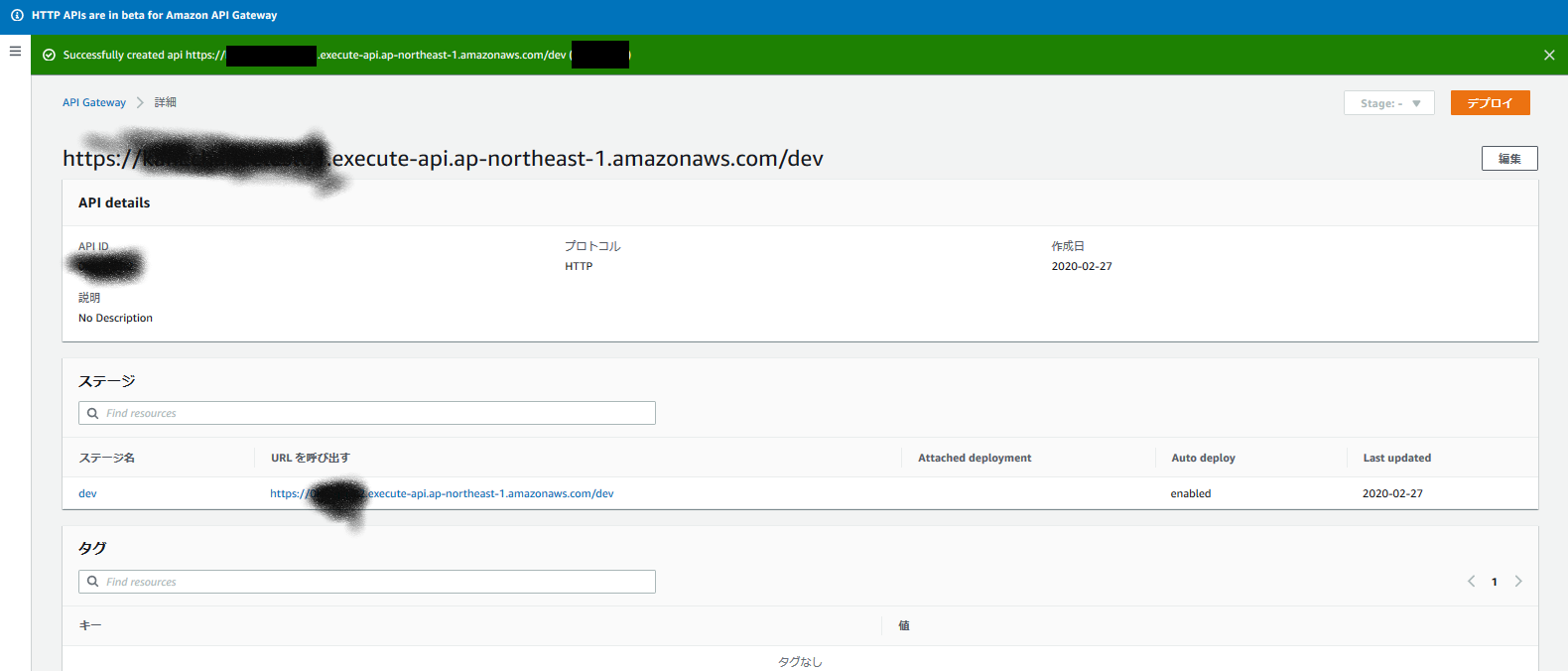
https://dev.classmethod.jp/cloud/aws/version-management-with-api-gateway-and-lambda/API Gatewayの設定
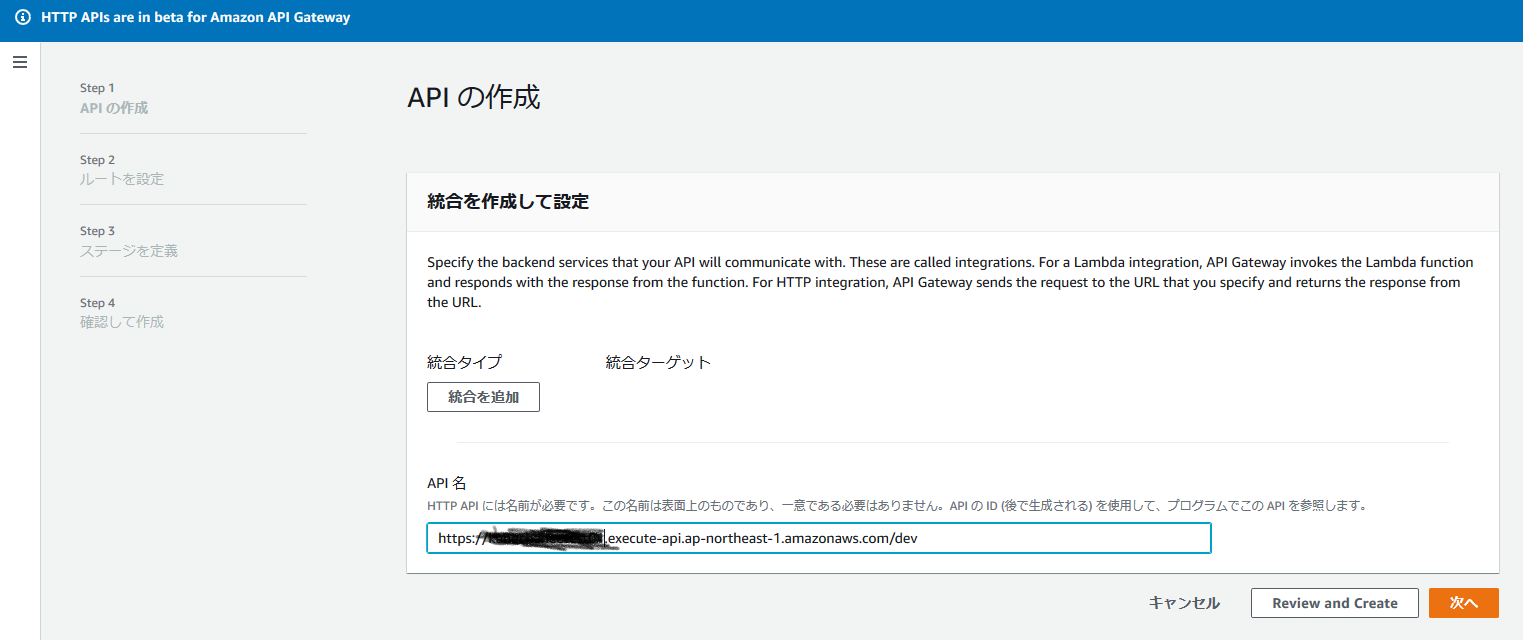
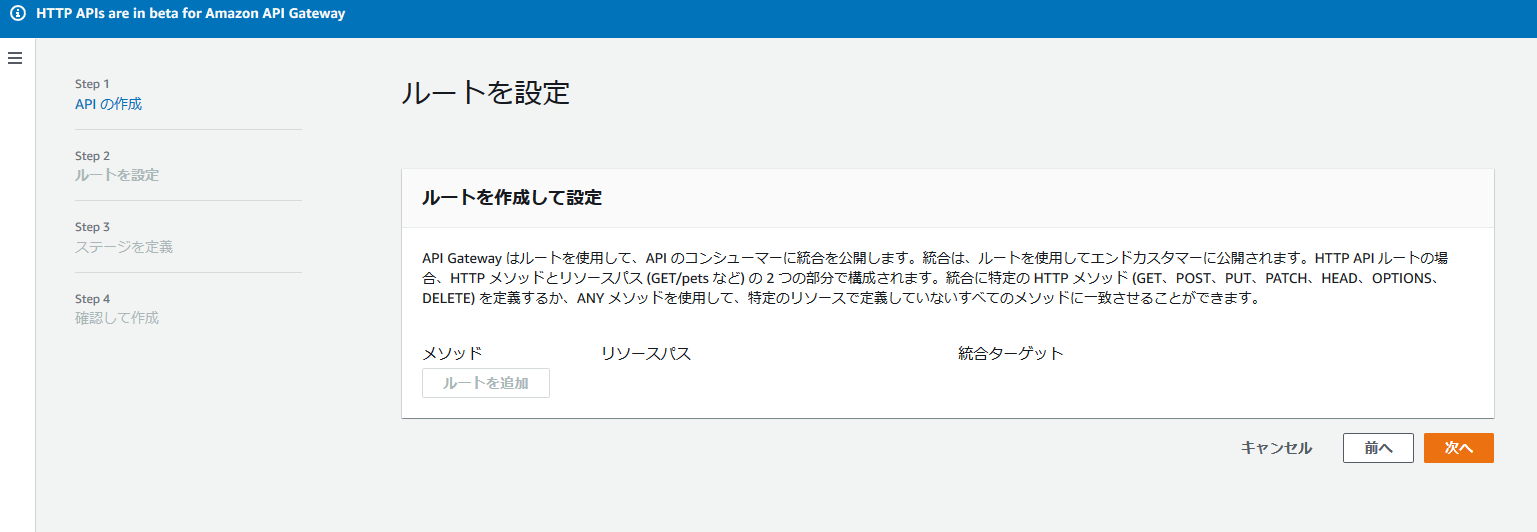
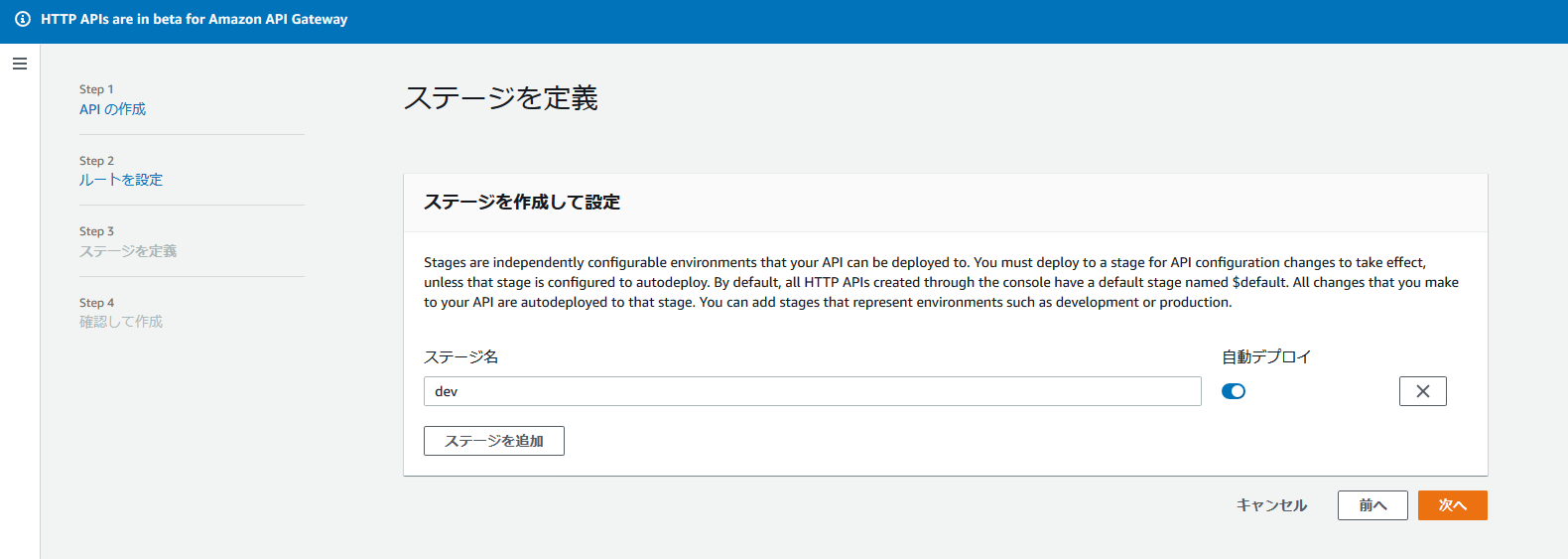
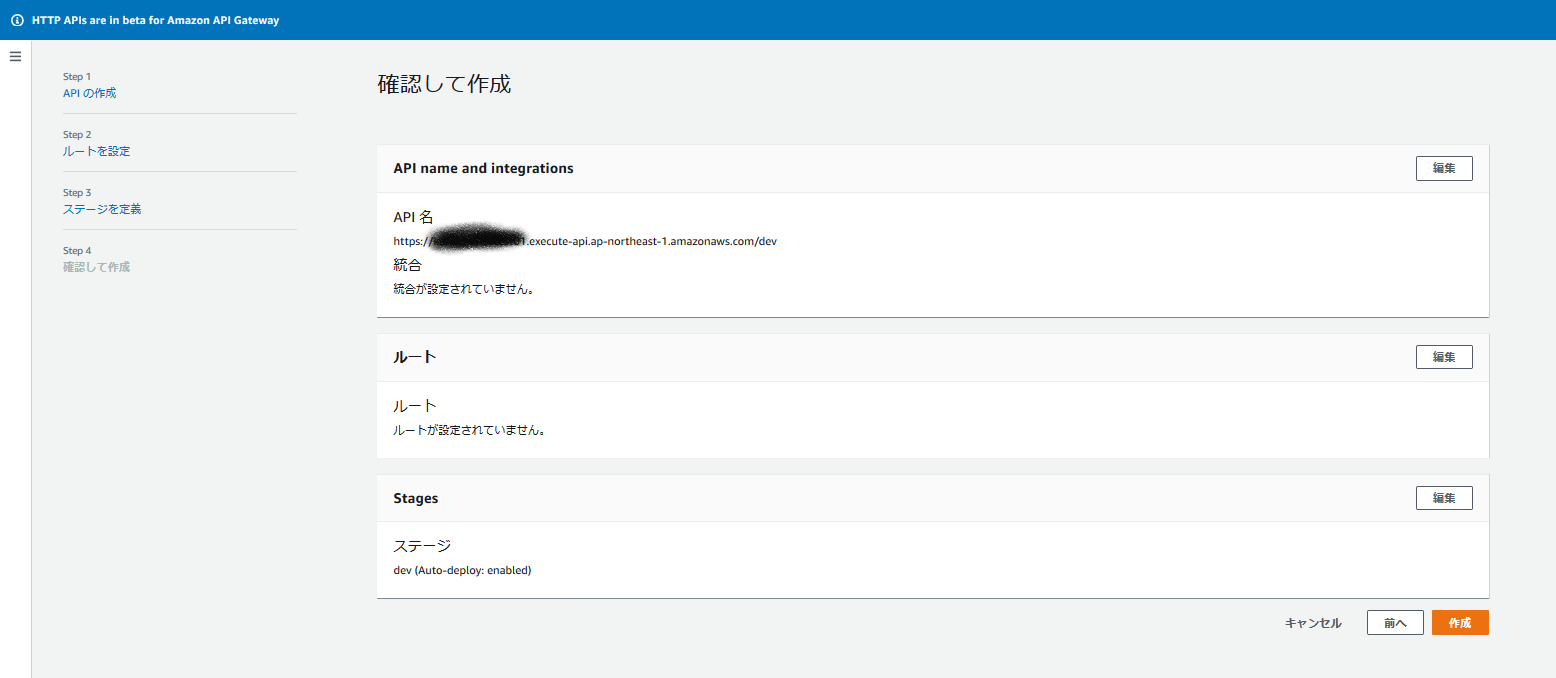
↓のような感じでエンドポイントを払い出します。
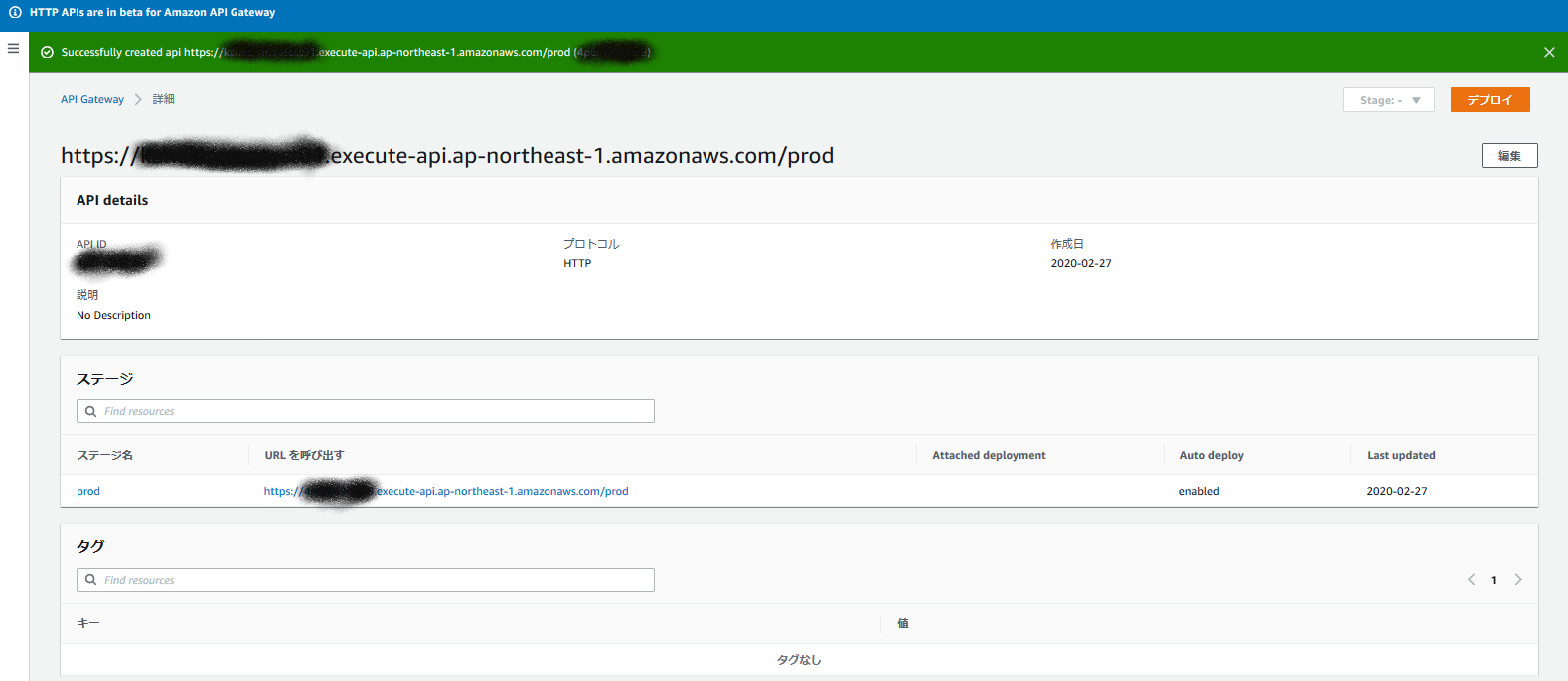
出来上がりました!
同じようにprodのエンドポイントも払い出します。