- 投稿日:2020-01-24T21:44:28+09:00
VQVAE2の実装
はじめに
Generating Diverse High-Fidelity Images with VQ-VAE-2で提案されているVQVAE2を実装しました。
VQVAEはNeural Discrete Representation Learningで提案されているモデルでVAEをアレンジしたものです。Auto-Encoding Variational Bayes(VAEが初めて提案された論文)やその派生モデルでは潜在表現として連続の確率分布(正規分布)を仮定していますが、VQVAEでは離散化された潜在表現を学習します。
ここでは画像のVQVAEについて記述しますが、VQVAEは音声にも適用できます。VQVAEや音声合成についてはhttps://www.monthly-hack.com/entry/2017/11/20/223457に詳しく書かれています。私もとても参考にさせて頂きました。実装にはtensorflow2.0を使用しました。
モデル解説(VQVAE)
VQVAEもVAEの名前がついているように、「入力を潜在表現にエンコード→潜在表現から入力を再構成」というモデル構造は同じです。VAEではエンコーダーの出力は確率分布のパラメータになっていました。そのパラメータから得た確率分布から潜在表現をサンプリングし、元の入力を再構成します。また、サンプリングを行うとバックプロパゲーションができないためreparameterization trickを用いて勾配計算を行いパラメータ更新を行います。これに対し、VQVAEでは特徴量の埋め込みを学習します。
Vector Quantization
入力画像を畳み込んだfeature mapのshapeは(height, width, channel)になっています(batchの次元は除く)。これに対して、(K, D)の埋め込み行列を用意します。Kは埋め込みベクトルの数、Dはベクトルの次元数になります。ここでchannel ≠ Dの場合は1x1の畳み込みを行ってchannel数を調整します。このfeature mapはD次元ベクトルがheight × width個の集合とみなします。このheight × width個のベクトルそれぞれとK個の埋め込み行列との差分のL2ノルムをとり、埋め込み行列から差が最小のベクトルをピックアップしそれに置き換えて出力します。
埋め込み行列の最適化
モデル全体のロス関数は以下のようになっています。
L = \log p(x|z_q(x)) + ||sg[z_e(x)] - e||_2^2 + β||z_e(x) - sg[e]||_2^2$z_e()$はエンコーダー、$e$はquantize後の潜在ベクトルを示します。$sg$はstop gradientでそこからは勾配を逆伝播させないことを示しています。
第1項は再構成誤差で実装の際には入力画像との2乗誤差にしています。第3項はエンコーダーの出力を制限するための項です。第2項が埋め込み行列に対する誤差になっており、$sg$で逆伝播を止めているため埋め込み行列の更新にのみ使われます。また、指数移動平均(Exponential Moving Average)を利用した埋め込み行列の更新方法も提案されています。これは以下のように更新を行います。N_i^{(t)} := N_i^{(t-1)}*γ + n_i^{(t)}*(1-γ)\\ m_i^{(t)} := m_i^{(t-1)}*γ + \sum_j^{n_i^{(t)}}z_e(x)_{i,j}^{(t)}*(1-γ)\\ e_i^{(t)} := \frac{m_i^{(t)}}{N_i^{(t)}}$n_i^{(t)}$は$i$番目の埋め込み行列がピックアップされた回数を示しています。$N_i^{(t)}$は0で、$m_i^{(t)}$は埋め込み行列と同じ値でそれぞれ初期化します。今回実装したのはこちらです。
実装&結果
kerasのLayerとして実装しました。コードは以下のようになります。
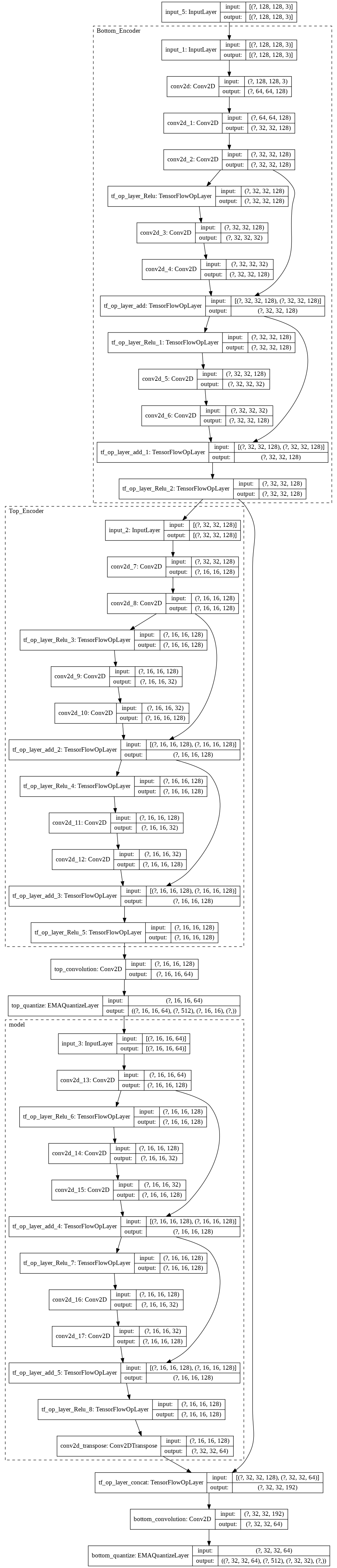
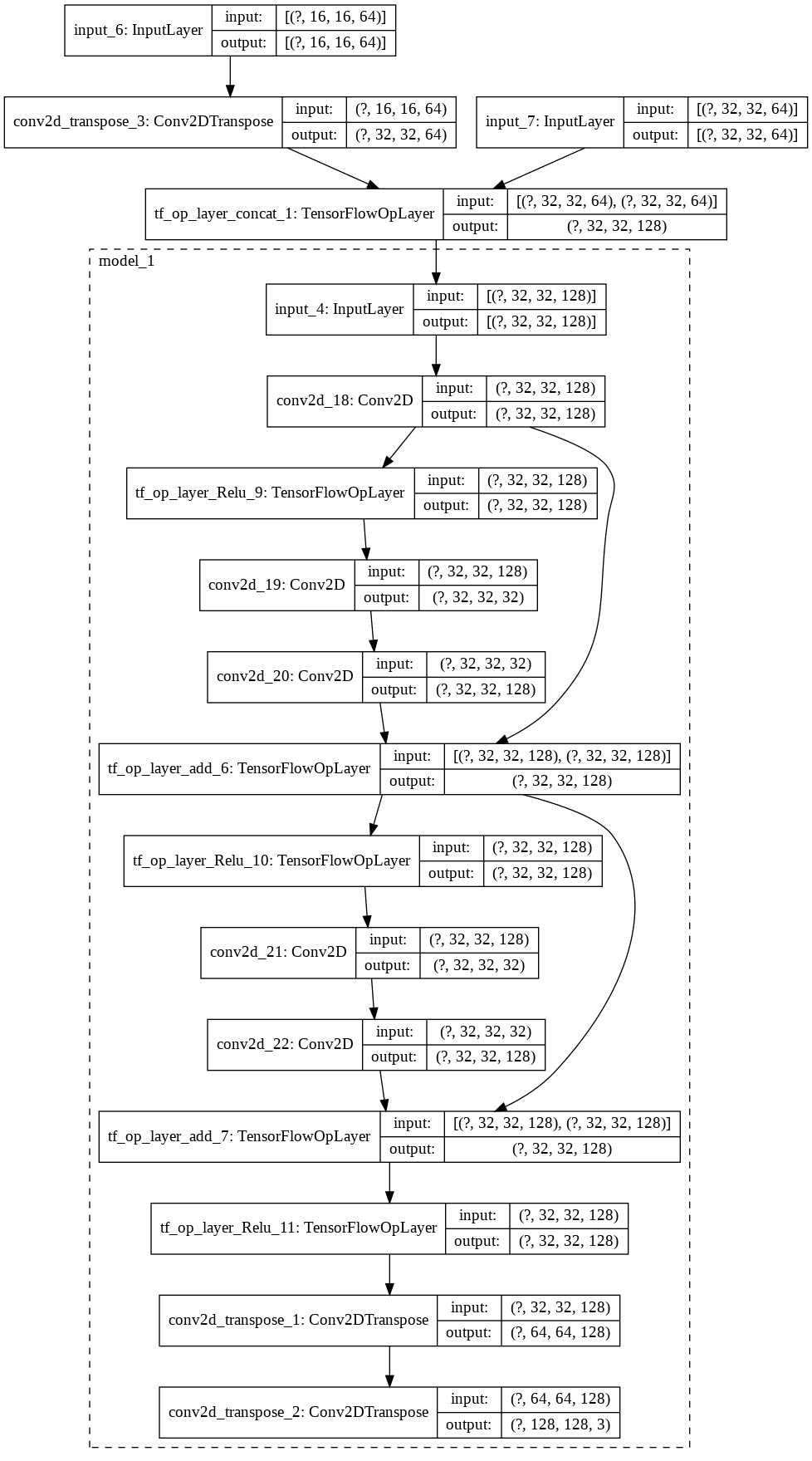
https://github.com/deepmind/sonnet/blob/master/sonnet/python/modules/nets/vqvae.pyを参考にしました。class EMAQuantizeLayer(tf.keras.layers.Layer): def __init__(self, num_embed, embed_dims, decay=0.99, epsilon=1e-5, loss_commitment=0.25, weight_initializer=tf.keras.initializers.RandomNormal(stddev=1.0), trainable=True, name=None, dtype=None, dynamic=False, **kwargs): super(EMAQuantizeLayer, self).__init__(trainable=trainable, name=name, dtype=dtype, dynamic=dynamic, **kwargs) self.num_embed = num_embed self.embed_dims = embed_dims self.decay = decay self.epsilon = epsilon self.loss_commitment = loss_commitment self.initializer = weight_initializer self.vectors = self.add_weight(name='embed_vector', shape=(self.embed_dims, self.num_embed), dtype=tf.float32, initializer=self.initializer, aggregation=tf.VariableAggregation.MEAN, trainable=False, use_resource=True) self.ema_size = self.add_weight(name='ema_size', shape=(self.num_embed), dtype=tf.float32, initializer=tf.keras.initializers.Constant(0.0), aggregation=tf.VariableAggregation.MEAN, trainable=False, use_resource=True) self.ema_w = self.add_weight(name='ema_w', shape=self.vectors.shape, dtype=tf.float32, initializer=tf.keras.initializers.Constant(self.vectors.numpy()), aggregation=tf.VariableAggregation.MEAN, trainable=False, use_resource=True) def call(self, inputs, training=None): flatten = tf.reshape(inputs, (-1, self.embed_dims)) d = (tf.reduce_sum(flatten**2, 1, keepdims=True) -2*tf.matmul(flatten, self.vectors)) + tf.reduce_sum(self.vectors**2, 0, keepdims=True) indices = tf.argsort(-d, axis=1, direction='DESCENDING')[:, 0] #indices = tf.argmax(-d, 1) one_hot_enc = tf.one_hot(indices, self.num_embed) indices = tf.reshape(indices, tf.shape(inputs)[:-1]) quantized = self.quantize(indices) latent_loss = tf.reduce_mean(tf.square(tf.stop_gradient(quantized) - inputs), axis=[1, 2, 3]) if training: self.ema_size.assign_sub((self.ema_size - tf.reduce_sum(one_hot_enc, 0))*self.decay) self.ema_w.assign_sub((self.ema_w - tf.matmul(flatten, one_hot_enc, transpose_a=True))*self.decay) n = tf.reduce_sum(self.ema_size) update_vector = (self.ema_size + self.epsilon) / (n + self.num_embed*self.epsilon) * n norm_vector = self.ema_w / (tf.reshape(update_vector, [1, self.num_embed])) self.vectors.assign(norm_vector) loss = self.loss_commitment*latent_loss else: loss = self.loss_commitment*latent_loss quantized = inputs + tf.stop_gradient(quantized - inputs) return quantized, one_hot_enc, indices, loss def quantize(self, indices): w = tf.transpose(self.vectors, [1, 0]) return tf.nn.embedding_lookup(w, indices) def get_config(self): config = { 'num_embed' : self.num_embed, 'embed_dims' : self.embed_dims, 'epsilon' : self.epsilon, 'decay' : self.decay, 'loss_commitment' : self.loss_commitment, 'weight_initializer' : tf.keras.initializers.serialize(self.initializer) } base_config = super(EMAQuantizeLayer, self).get_config() return dict(list(base_config.items())+list(config.items()))モデル全体の構造は以下のようになっています。VQVAE2はVQVAEを階層構造にすることで生成画像の質の向上に成功したモデルです。VQのパラメータはK=512, D=64です。今回は2層構造です。top featureとして16 x 16, bottom featureとして32 x 32の潜在表現を得ます。
エンコーダー
カーネルサイズ3,ストライド2の畳み込み+Resnetで(16, 16)にダウンサンプルしてそれをVQ。この出力を(32, 32)にアップサンプルして中間層の出力と合わせてVQを行い、2つの潜在表現を得ます。
モデル画像
デコーダー
エンコーダーの2つの出力をアップサンプルして元画像を再構成します。
モデル画像
学習はcolaboratoryのTPUを使って行いました。上記コードでargmaxをとる際にargsortを使っているのはTPUでの挙動がおかしかったのでこちらを使いました。
データセットはSafebooruからスクレイピングして顔部分を切り出したものを使いました。総数は12000枚くらい。バッチサイズは1024で30000イテレーション学習を行いました。学習時間は1時間30分くらいでした。学習結果
再構成画像 top featureとbottom featureをそれぞれ0にして生成してみた結果。なんとなくですが、top featureには色の情報が、bottom featureには細部の情報がエンコードされているように見えます。
top=0 bottom=0 GANでよく見るアナロジーもやってみました。潜在変数を動かして少しずつ画像が変化していく様子を可視化したものです。これは単に2つの画像を混ぜ合わせたようになっています。
アナロジー PixelCNN(未完成)
VQVAEは2段階で学習を行います。最初に上記にVQVAEで潜在表現を学習し、次にPixelCNNを用いて潜在表現の分布を学習させます。が、これがうまくいかずに苦戦しています。以下にPixelCNNのコードを載せておきます。なにか成果があったら記事を更新したいと思います。
def GatedResBlock(v_inp, h_inp, filter_size, p, condition=None, first_layer=False): assert filter_size % 2 == 1 v_k_size = [filter_size//2, filter_size] h_k_size = [1, filter_size//2 if first_layer else filter_size//2+1] v_pad = tf.pad(v_inp[:,:-1,:,:], [[0, 0],[v_k_size[0], 0], [filter_size//2, filter_size//2], [0, 0]]) v_stack = tf.keras.layers.Conv2D(p*2, v_k_size)(v_pad) v_stack_1 = tf.keras.layers.Conv2D(p*2, 1)(v_stack) h_pad = tf.pad(h_inp, [[0, 0], [0, 0], [h_k_size[1], 0], [0, 0]]) if first_layer: h_pad = h_pad[:, :, :-1, :] else: h_pad = h_pad[:, :, 1:, :] h_stack = tf.keras.layers.Conv2D(p*2, h_k_size)(h_pad) h_stack += v_stack_1 v_tanh, v_sig = tf.split(v_stack, 2, 3) h_tanh, h_sig = tf.split(h_stack, 2, 3) if condition is not None: upsacale = tf.keras.layers.Conv2DTranspose(condition.shape[-1], 3, strides=(2, 2), padding='SAME', activation='relu')(condition) vt_cond = tf.keras.layers.Conv2D(p, 1, use_bias=False)(upsacale) vs_cond = tf.keras.layers.Conv2D(p, 1, use_bias=False)(upsacale) ht_cond = tf.keras.layers.Conv2D(p, 1, use_bias=False)(upsacale) hs_cond = tf.keras.layers.Conv2D(p, 1, use_bias=False)(upsacale) v_tanh += vt_cond v_sig += vs_cond h_tanh += ht_cond h_sig += hs_cond v_stack = tf.tanh(v_tanh) * tf.sigmoid(v_sig) h_stack = tf.tanh(h_tanh) * tf.sigmoid(h_sig) if first_layer: return v_stack, h_stack else: h_res = tf.keras.layers.Conv2D(p, 1)(h_stack) h_res += h_inp return v_stack, h_res def pixelCNN(input, p, n_class, condition=None, n_gated_blocks=7): v_inp, h_inp = input, input v_stack, h_stack = GatedResBlock(v_inp, h_inp, 7, p, condition, True) for i in range(n_gated_blocks-1): v_stack, h_stack = GatedResBlock(v_stack, h_stack, 3, p, condition) out_conv = tf.keras.layers.Conv2D(n_class, 1, activation='relu')(tf.nn.relu(h_stack)) logit = tf.keras.layers.Conv2D(n_class, 1)(out_conv) return logit