- 投稿日:2020-01-24T23:45:53+09:00
Matplotlibでマウスオーバーすると対応する画像を表示させる
まとめ
こんなんできました。
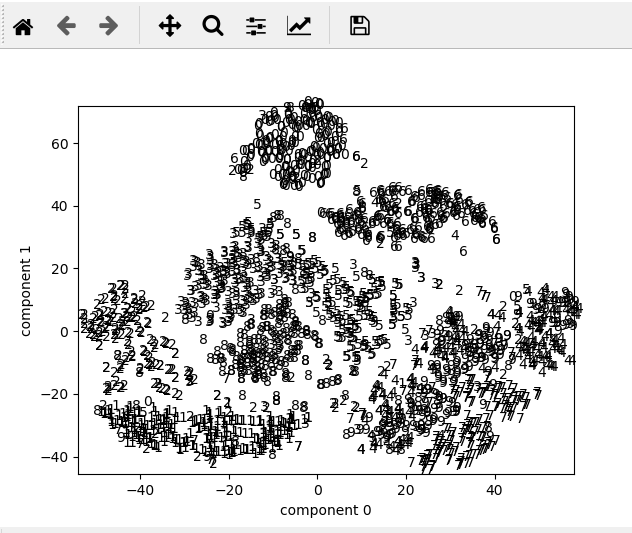
例はt-SNEで低次元化したMNISTの散布図です。プロット上にマウスカーソルを持ってくると、そのプロットに相当する図が表示されます。
環境
- python 3.7.3 anaconda
- matplotlib 3.1.0
- numpy 1.16.4
- sklearn 0.21.2
まずはt-SNE処理
今回の記事はmatplotlibの使い方をメインにします。MNISTとか、t-SNEとかの説明は省略します。
ただどんな変数名でどうやって作ったかなどはプログラム依存ですので、そちらのコードを掲載します。
import numpy as np from sklearn.datasets import fetch_openml from sklearn.manifold import TSNE width = 28 nskip = 35 mnist = fetch_openml("mnist_784", version=1) mnist_img = mnist["data"][::nskip, :] mnist_label = mnist["target"][::nskip] mnist_int = np.asarray(mnist_label, dtype=int) x_embedded = TSNE(n_components=2).fit_transform(mnist_img)
widthは画像の幅。nskipはサンプルの抽選確率(の逆数)です。このままではサンプルサイズが70000あってプロットとかには多すぎるので、1/35にして2000サンプルで行います。その他の配列の詳細は以下の通り。
mnist_img:(2000, 784)次元の倍精度浮動小数点の配列。画像の生データで、画素値が 0 ~ 255 で格納されています。mnist_label: (2000, )次元の配列。数字のラベルが文字列で格納。mnist_int: (2000,) 次元の配列。mnist_labelを整数型にしたもの。普通のプロット
多分2番目に素直なプロットです。
plt.xlim(x_embedded[:, 0].min(), x_embedded[:, 0].max()) plt.ylim(x_embedded[:, 1].min(), x_embedded[:, 1].max()) for x, label in zip(x_embedded, mnist_label): plt.text(x[0], x[1], label) plt.xlabel("component 0") plt.ylabel("component 1") plt.show()
数字をプロットしていくアイデアは
https://qiita.com/stfate/items/8988d01aad9596f9d586
に拠りました。素直に
scatterを使えば自動で調整してくれる x, y軸の範囲が、各点ごとにtextを置いていく方法のせいで、自分でxlim,ylimを調整しなければなりません。
ですが、まあ数字ごとにグループを形成し、たまにノイズのように別の数字が混ざっているのが一目で分かります。これをみて、
- やっぱり点はただの点にしたい。数字が重なると分かりにくくなる。
- だけど点の色、色と数字の対応を追いかけるのは面倒。
- なら気になる点にカーソルを持ってくれば詳細を表示するようにすればいいのでは
と考えました。ということで、まずはマウスオーバーでラベルを表示させてみましょう。
マウスオーバーでAnnotation表示
これはStackoverflowで答えを見つけました。
こちらのコードを今回のMNIST用に変更します。
fig, ax = plt.subplots() cmap = plt.cm.RdYlGn sc = plt.scatter(x_embedded[:, 0], x_embedded[:, 1], c=mnist_int/10.0, cmap=cmap, s=3) annot = ax.annotate("", xy=(0,0), xytext=(20,20),textcoords="offset points", bbox=dict(boxstyle="round", fc="w"), arrowprops=dict(arrowstyle="->")) annot.set_visible(False) def update_annot(ind): i = ind["ind"][0] pos = sc.get_offsets()[i] annot.xy = pos text = mnist_label[i] annot.set_text(text) annot.get_bbox_patch().set_facecolor(cmap(int(text)/10)) def hover(event): vis = annot.get_visible() if event.inaxes == ax: cont, ind = sc.contains(event) if cont: update_annot(ind) annot.set_visible(True) fig.canvas.draw_idle() else: if vis: annot.set_visible(False) fig.canvas.draw_idle() fig.canvas.mpl_connect("motion_notify_event", hover) plt.show()
まあGUIでよくあるイベントを利用したものです。
まず空白のAnnotationオブジェクトannotを作っておき、それの位置、内容などを更新する関数update_annotを作っておきます。
hover関数をfig.canvas.mpl_connect("motion_notify_event", hover)として登録、そのhoverの中でもしカーソルが何かしら点を指していたらannotを表示しつつupdate_annotを呼び出す、点を指していなければannotを非表示にするようにします。
scatterにおいて色をc=mnist_int/10.0とするために、わざわざラベルを整数にしたmnist_int配列を準備しました。これで上の動画のようなインタラクティブな散布図が描けます。
今回はさぼりましたが、どこかに色と数字の凡例を表示するとより親切だと思います。
ここまでやって、さらに不満点ができました。
「たとえば1のクラスタに入った7など、ノイズになっている点は果たしてどれくらい特殊な見た目なんだろう?もしかしたらアルゴリズムのせいで普通の点がノイズになっているかもしれない。なのでラベルだけでなく生データも確認したい。」
これの実現のためには、マウスオーバーで元の画像も表示させると良さそうです。
マウスオーバーで画像表示
アノテーションで画像を表示させるdemoが公式にありました。
https://matplotlib.org/3.1.0/gallery/text_labels_and_annotations/demo_annotation_box.html
こちらと先ほどのイベント登録を組み合わせます。
まず、先ほどはアノテーションはテキストだけだったので
Annotationでよかったのですが、画像になると少々厄介で、
- まず画像を
OffsetImageというクラスオブジェクトに持たせ、- それを
AnnotationBboxに持たせるという2段階の操作が必要になります。まず必要になるクラスをimportします。
from matplotlib.offsetbox import OffsetImage, AnnotationBbox必要なグラフオブジェクトの準備。
fig, ax = plt.subplots() cmap = plt.cm.RdYlGnその後、
OffsetImageを用意しますが、その際ダミー画像として0番目の画像を使います。img = mnist_img[0, :].reshape((width, width)) imagebox = OffsetImage(img, zoom=1.0) imagebox.image.axes = axそれをもとに
AnnotationBboxを作ります。annot = AnnotationBbox(imagebox, xy=(0,0), xybox=(width,width), xycoords="data", boxcoords="offset points", pad=0.5, arrowprops=dict( arrowstyle="->", connectionstyle="arc3,rad=-0.3")) annot.set_visible(False) ax.add_artist(annot)注意として、
xyboxはannotのサイズではなく、アノテーションを付加する点xyからの相対的な位置を示しています。つづいて、プロットと画像の更新です。
sc = plt.scatter(x_embedded[:, 0], x_embedded[:, 1], c=mnist_int/10.0, cmap=cmap, s=3) def update_annot(ind): i = ind["ind"][0] pos = sc.get_offsets()[i] annot.xy = (pos[0], pos[1]) img = mnist_img[i, :].reshape((width, width)) imagebox.set_data(img)新しい画像データを
imageboxに対しては更新していますが、annotについては更新処理は不要なようです。あと、別に実験した感じでは、
imgのサイズが変わっても動的に対応してくれていますので、様々なサイズがある場合でも別に追加する処理はないかと思います。あとのイベント登録などは同じです。
def hover(event): vis = annot.get_visible() if event.inaxes == ax: cont, ind = sc.contains(event) if cont: update_annot(ind) annot.set_visible(True) fig.canvas.draw_idle() else: if vis: annot.set_visible(False) fig.canvas.draw_idle() fig.canvas.mpl_connect("motion_notify_event", hover) plt.show()
一瞬しか表示されないので恐縮ですが、ノイズの点は確かに形が別の数字に近くて読み間違えそうな形であるのが分かりました。
終わり
まあ画像出力でやると意味のないテクニックですが、試行錯誤中は結構使えるんじゃないかなと。
今回の話で matplotlib においてオブジェクト描写を行う根源の抽象クラス
Artistの存在を知りました。おまけ コード全体
表示させたいプロット部分を、
if False:からif True:に変更してください。
複数をTrueにしたときの動作は確認していません。
ここをクリックして展開・折り畳み
import numpy as np from sklearn.datasets import fetch_openml from sklearn.manifold import TSNE import matplotlib.pyplot as plt from matplotlib.offsetbox import OffsetImage, AnnotationBbox width = 28 nskip = 35 mnist = fetch_openml("mnist_784", version=1) mnist_img = mnist["data"][::nskip, :] mnist_label = mnist["target"][::nskip] mnist_int = np.asarray(mnist_label, dtype=int) print(type(mnist_img)) print(mnist_img.max()) print(mnist_img.dtype) exit() x_embedded = TSNE(n_components=2).fit_transform(mnist_img) if True: plt.xlim(x_embedded[:, 0].min(), x_embedded[:, 0].max()) plt.ylim(x_embedded[:, 1].min(), x_embedded[:, 1].max()) for x, label in zip(x_embedded, mnist_label): plt.text(x[0], x[1], label) plt.xlabel("component 0") plt.ylabel("component 1") plt.show() exit() fig, ax = plt.subplots() cmap = plt.cm.RdYlGn if False: sc = plt.scatter(x_embedded[:, 0], x_embedded[:, 1], c=mnist_int/10.0, cmap=cmap, s=3) annot = ax.annotate("", xy=(0,0), xytext=(20,20),textcoords="offset points", bbox=dict(boxstyle="round", fc="w"), arrowprops=dict(arrowstyle="->")) annot.set_visible(False) def update_annot(ind): i = ind["ind"][0] pos = sc.get_offsets()[i] annot.xy = pos text = mnist_label[i] annot.set_text(text) annot.get_bbox_patch().set_facecolor(cmap(int(text)/10)) def hover(event): vis = annot.get_visible() if event.inaxes == ax: cont, ind = sc.contains(event) if cont: update_annot(ind) annot.set_visible(True) fig.canvas.draw_idle() else: if vis: annot.set_visible(False) fig.canvas.draw_idle() fig.canvas.mpl_connect("motion_notify_event", hover) plt.show() if False: img = mnist_img[0, :].reshape((width, width)) imagebox = OffsetImage(img, zoom=1.0) imagebox.image.axes = ax sc = plt.scatter(x_embedded[:, 0], x_embedded[:, 1], c=mnist_int/10.0, cmap=cmap, s=3) annot = AnnotationBbox(imagebox, xy=(0,0), xybox=(width,width), xycoords="data", boxcoords="offset points", pad=0.5, arrowprops=dict( arrowstyle="->", connectionstyle="arc3,rad=-0.3")) annot.set_visible(False) ax.add_artist(annot) def update_annot(ind): i = ind["ind"][0] pos = sc.get_offsets()[i] annot.xy = (pos[0], pos[1]) img = mnist_img[i, :].reshape((width, width)) imagebox.set_data(img) def hover(event): vis = annot.get_visible() if event.inaxes == ax: cont, ind = sc.contains(event) if cont: update_annot(ind) annot.set_visible(True) fig.canvas.draw_idle() else: if vis: annot.set_visible(False) fig.canvas.draw_idle() fig.canvas.mpl_connect("motion_notify_event", hover) plt.show()

- 投稿日:2020-01-24T23:27:55+09:00
カスタムUserモデルを作成した後にUserが上手く追加されない件
起きたこと
なにが起きたかというと、
- AbstractUserモデルを継承してカスタムUserモデルを作成。
- adminにadmin.register.site(CustomUser)のように普通に登録
- admin管理画面から新しくUserを登録!
- 何故かパスワードが生で表示される。
- ログインできない!!!
という問題が発生しました。。
結論から申しますと2の操作が原因です。ちなみにUserのカスタマイズについては以下の記事に詳しくあります。
okoppe8さんの記事解決方法
UserAdminをadmin.site.register()の第2引数に登録してあげる。
admin.pyfrom django.contrib import admin from . models import CustomUser from django.contrib.auth.admin import UserAdmin ) admin.site.register(CustomUser, UserAdmin)元のコード
管理画面をカスタマイズするためにUserAdminを自作してしまい、CustomUserモデルのadminとして登録してしまっていました。
これだと、パスワードが上手くハッシュされずに登録され、認証時にエラーとなってしまいます。admin.pyfrom django.contrib import admin from . models import CustomUser class UserAdmin(admin.ModelAdmin): list_display = ('username', 'id', ) admin.site.register(CustomUser, UserAdmin)参考
Stuck Overflow
Created User from django custom admin page can't login
- 投稿日:2020-01-24T22:26:02+09:00
[イメージ図付]Nginx+gunicorn+FlaskをDocker化[前編]
本記事の概要
PythonによるWebアプリケーション学習ロードマップのStep2として、Step1で作成したWebサーバおよびAppサーバをDockerコンテナにて起動するように設定する手順について記載していきます。
記事は前・後編の2編での構成となり、
前編:Docker化後編:docker-compose導入
についての記載となります。前提
MacOSをホストPCとして利用することを想定したコマンド表記となります。ホストPCとしての準備
本記事ではローカルPCをDockerのホストPCとして構築していきます。
これにあたりDockerを動かすための準備が必要です。
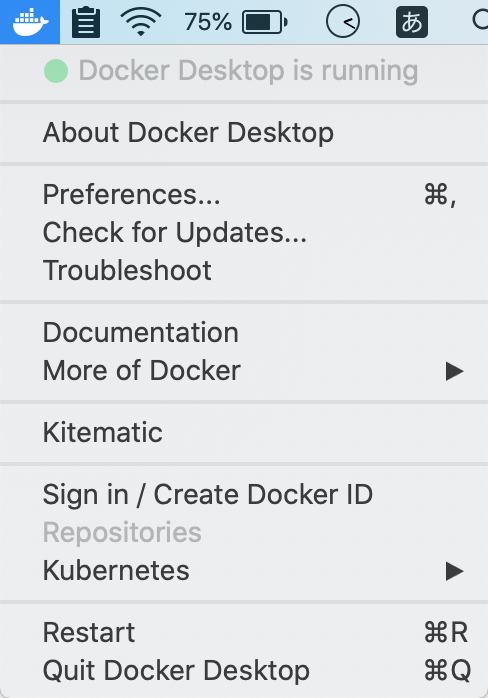
いくつかの方法がありますが、MacOSの場合はDocker for Macをbrewインストールするのが手っ取り早いと思います。Terminalbrew cask install dockerこれでアプリケーションがインストールされるので、ローカルで
Docker.appを起動します。右上にクジラのようなアイコンが出現して、下記のようにRunningになっていれば完了です。
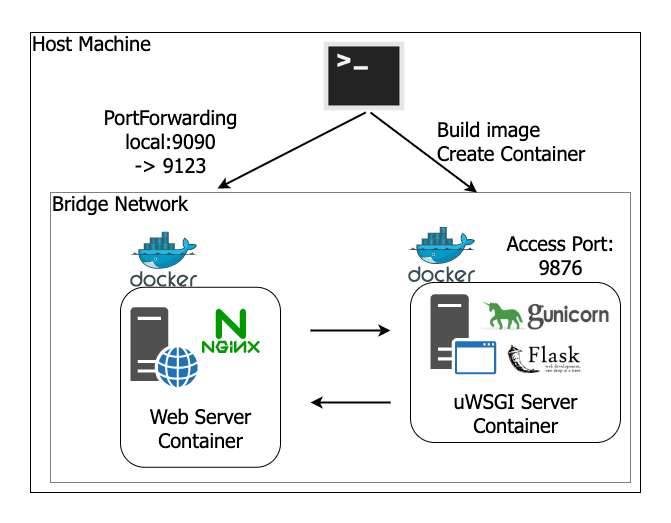
最終的な成果物
イメージ図
ソースコード
Githubリポジトリを参照ください。
ソースコード簡易解説
Dockerコンテナ化にあたって、Step1からの主な変更点は以下の2つです。
- Webサーバ、AppサーバそれぞれのDockerfileを新規作成
- 起動コマンドを記載したMakefileを新規作成
このうち、2つめのMakefileについては、dockerコマンドの入力を簡易的にするだけのものであり、本質的な追加は1つめのDockerfileになります。それぞれのDockerfileの内容について見ていきたいと思います。(Dockerfileそのものについては後述)
Webサーバ
Dockerfile# ベースとなるイメージを指定。この場合はバージョンまで特定のタグを指定している。 FROM nginx:1.17.6-alpine # ホストPCの設定ファイル(config/nginx.conf)を上で作成したディレクトリへコピーして送る RUN mkdir -p /etc/nginx COPY config/nginx.conf /etc/nginx/nginx.conf単にnginxを利用するのであれば、
Docker Hubに公開されているnginx Official ImageをpullするだけでOKです。今回は手元で作成したnginx設定ファイルを読んで起動させたいので、次のような作業を行っています。
- ベースとなるイメージを指示
- 自前の設定ファイルを送るパスを作成
- 自前の設定ファイルをホストPCから、このイメージへコピー
Appサーバ
Dockerfile# 今回はdebianベースのpythonイメージをベースとする FROM python:3.8-slim-buster # 設定ファイルの転送(適当な場所が思いつかないので/app直下) RUN mkdir -p /app/config COPY requirements.txt /app/requirements.txt COPY config/gunicorn_settings.py /app/config/gunicorn_settings.py COPY flask_app.py /app/flask_app.py # パッケージのインストール RUN pip install -r /app/requirements.txt EXPOSE 9876 WORKDIR /app # run実行時のコマンド # ENTRYPOINT->CMDでCMDはrunのときの引数で上書きすることが可能 ENTRYPOINT [ "gunicorn", "flask_app:app" ] CMD [ "-c", "/app/config/gunicorn_settings.py" ]osのみのベースイメージから始めて、python等をインストールするという手順でもいいのですが、せっかくpythonのOfficialイメージが公開されているので、今回はこれをベースとしてスタートします。
パッケージのインストールまではほぼWebサーバと同様ですが、それより下はWebサーバにはなかった記述ですね。次のようなことをしています。
- Appサーバのコンテナで、9876ポートをLISTEN状態とする
- コンテナ起動時のベースディレクトリを
/appに設定する- コンテナ起動時、
gunicorn flask_app:app -c /app/config/gunicorn_settings.pyコマンドを実行するAbout Docker
Docker化する理由
これに関してはいくつかあると思いますが、自分の感じる利点を2つ記載しておきます。
開発/実行環境の統一・準備の簡易化
チーム開発を行うにあたって、これまでは開発者がそれぞれのマシンで開発環境を準備してそのうえで開発を開始する必要がありました。手順を示したドキュメントはあるでしょうが、実際はドキュメント不備やツールのアップデートなどの事由によってうまく環境構築ができないなどコストがかかるかと思います。また、個人がそれぞれに言語のバージョンアップなどを行い微妙な違いが発生するというリスクも考えられます。
一方で、あらかじめ用意されたDockerコンテナを利用することにより、
- 少ないコマンド数(
docker run)で環境が構築できる- 開発環境の統一が容易
という恩恵を受けることができます。
本番環境にもコンテナをのせられる
クラウド上での運用が当たり前となった現在では、GKEなどを利用したコンテナオーケストレーションツールが数多く出回っています。コンテナオーケストレーションというくらいなので、実際に本番環境でもコンテナ上でアプリケーションが起動していることとなります。
もちろん開発、ステージング、本番とで環境変数やエンドポイントなどを変更することが必要ですが、オーケストレーション側でも吸収することはでき、いずれにせよ開発環境で動いたコンテナがほぼそのまま本番環境でも稼働することとなります。イメージとコンテナ
まずイメージを作成(=ビルド)して、そのイメージをもとにコンテナを作成・起動するといった順番です。
うまい例ではないですが、PCゲームで置き換えると
- Dockerイメージ = ディスク
- Dockerコンテナ = ゲーム起動中のウィンドウ
みたいな感じです。Docker Hubとは
自身が作成したコンテナイメージをアップロードして公開・共有できるサービス。要はGithubのDocker限定版みたいなものです。
公開されているイメージは自由にダウンロード、利用することが可能です。自身でカスタマイズしたイメージを作成する際にも、ベースとなるイメージはDocker Hubに登録されているものから選択します。イメージの信頼性
Docker Hubには有志によるイメージも数多く登録されています。その中でベースイメージとして選択するとよいものは
Docker Official Imagesというタグのついたものとなります。
理由を一言にすると、信頼性が高いからなのですが、いくつか箇条書きであげておきます。
- 適時セキュリティ・アップデートが行われる
- 明確なドキュメントが存在する
- Dockerfileのベストプラクティスを提供する
- 必要不可欠なベースイメージを提供する
Dockerfileとは
作成するコンテナのベースとなるイメージ、アプリケーションインストール、アプリケーション起動の準備などの一連の作業を一括で実施できる命令が記述されたファイルのことです。
なお、Dockerfileの記述に関する詳細はこちらを参照ください。
- 投稿日:2020-01-24T22:14:54+09:00
書籍「15Stepで踏破 自然言語処理アプリケーション開発入門」をやってみる - 2章Step05メモ
内容
15stepで踏破 自然言語処理アプリケーション入門 を読み進めていくにあたっての自分用のメモです。
今回は2章Step05で、自分なりのポイントをメモります。準備
- 個人用MacPC:MacOS Mojave バージョン10.14.6
- docker version:Client, Server共にバージョン19.03.2
章の概要
Step04では特徴抽出手法を学び、次のStep06では抽出した特徴ベクトルから学習して識別器を作成する。
Step05ではその間の処理で、特徴ベクトルを識別器にとって望ましい形へと加工する次元圧縮の手法について学ぶ。
- 潜在意味解析(LSA)
- 主成分分析(PCA)
05.1 特徴量の前処理
BoWは単語の出現頻度をベクトル化したもので、「特徴ベクトルの値の分布が非常に偏りがち」である。
- 特徴抽出で解決
- Step04のTF-IDFなど
- 抽出後に特徴ベクトルを加工して解決
- sklearn.preprocessing.QuantileTransformerで値を0以上1以下の範囲に収め、かつ値の分布を一様にする。
参考書の例がわかりづらかったので、自前で確認してみる。
test_quantileTransformer.pyimport numpy as np import MeCab import pprint from sklearn.preprocessing import QuantileTransformer from sklearn.feature_extraction.text import CountVectorizer def _tokenize(text): ~~ texts = [ '車は車は車は速く走る', 'バイクは速く走る', '自転車は自転車はゆっくり走る', '三輪車はゆっくり走る', 'プログラミングは楽しい', 'PythonはPythonはPythonはPythonはPythonは楽しい', ] vectorizer = CountVectorizer(tokenizer=_tokenize, max_features = 5) bow = vectorizer.fit_transform(texts) pprint.pprint(bow.toarray()) qt = QuantileTransformer() qtd = qt.fit_transform(bow) pprint.pprint(qtd.toarray())実行例array([[0, 3, 0, 1, 3], [0, 1, 0, 1, 0], [0, 2, 1, 1, 0], [0, 1, 1, 1, 0], [0, 1, 0, 0, 0], [5, 5, 0, 0, 0]], dtype=int64) array([[0.00000000e+00, 7.99911022e-01, 0.00000000e+00, 9.99999900e-01, 9.99999900e-01], [0.00000000e+00, 9.99999998e-08, 0.00000000e+00, 9.99999900e-01, 0.00000000e+00], [0.00000000e+00, 6.00000000e-01, 9.99999900e-01, 9.99999900e-01, 0.00000000e+00], [0.00000000e+00, 9.99999998e-08, 9.99999900e-01, 9.99999900e-01, 0.00000000e+00], [0.00000000e+00, 9.99999998e-08, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [9.99999900e-01, 9.99999900e-01, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]])
- (5,0)や(0,4)は出現回数が多いが、他の文には出現していないので、変換後の値はほぼ1になっている
- (2,:)や(3,:)は出現回数が1だが、他の文も多くて1なので、変換後の値はほぼ1になっている
- (1,:)は出現回数が1,2,3,5と様々あり、変換後の値もバラバラになっている
- 変換前1:変換後ほぼ0
- 変換前2:変換後ほぼ0.6
- 変換前3:変換後ほぼ0.8
- 変換前5:変換後ほぼ1
05.2 潜在意味解析(LSA) 05.3 主成分分析(PCA)
内容 LAS PCA 概要 BoWのような文書と単語の関係を表した特徴ベクトル群を元にして、「単語」の背後にある「意味」レベルで文書を表現するベクトルを得る手法 「データ点が広く散らばっている方向」を求める手法 数学的操作 SVD(特異値分解) EVD(固有値分解) 実装 svd = sklearn.decomposition.TruncatedSVD()
svd.fit_transform(<ベクトル>)evd = sklearn.decomposition.PCA()
evd.fit_transform(<ベクトル>)各次元の重要度 singular_values_を参照し、圧縮後の各次元の重要度がわかる。 explained_variance_ratio_を参照し、累積寄与率がわかる。 次元削減 インスタンス生成時に、n_componentsを指定 インスタンス生成時に、n_componentsを指定 両手法で考慮すべき点
- メリット
- 次元数減少による識別器の計算コスト低減
- 冗長な情報を削ることによる性能向上
- デメリット
- 必要な情報を削ってしまうと性能が下がってしまう
LSA - トピックモデル
明示的に学習データにクラスIDを与えるのではなく「ある文と別のある文が同じ意味を表しているか」という問題であるトピックモデルは、明示的に正解(クラスID)を与えないという点で「教師なし学習」の一種である。
PCA - 白色化
ベクトルの各成分を無相関化(対象ベクトルにPCAで得られた固有ベクトルを乗ずる)して平均0分散1にすることで、データが元々持っていた「各軸方向への広がり具合」を消し、識別性能の向上を期待できることがある。
PCA - 可視化手法
高次元ベクトルを低次元ベクトルに変換できるため、可視化の手法としても利用できる。
05.4 アプリケーションへの応用・実装
TruncatedSVDのところをPCAに書き換えるだけだと実行できなかった。(PCAへはsparseを入力できない)
実行例def train(self, texts, labels): vectorizer = TfidfVectorizer(tokenizer=self._tokenize, ngram_range=(1, 3)) bow = vectorizer.fit_transform(texts).toarray() pca = PCA(n_components = 500) pca_feat = pca.fit_transform(bow) classifier = SVC() classifier.fit(pca_feat, labels) self.vectorizer = vectorizer self.pca = pca self.classifier = classifier def predict(self, texts): bow = self.vectorizer.transform(texts).toarray() pca_feat = self.pca.transform(bow) return self.classifier.predict(pca_feat)pipeline表記をやめて、vectorizerの結果(sparse)をtoarray()してからPCAへ入力すれば実行できる。
- 投稿日:2020-01-24T21:51:18+09:00
Pipenvを用いた仮想環境上でDjangoを起動する
はじめに
Pipenvを用いた仮想環境上でDjangoを起動させます。
Pipenvを用いた仮想環境上にDjangoを配置することでDockerやチーム開発でのビルドが常に同じ結果となり、開発がスムーズになります。複数人やDockerを用いた開発でのベストプラクティスと考えています。
本記事はDjangoアプリをDocker上に構築しAWS Fargateにデプロイするプロジェクトの一部です。
pipenvのインストール
pipを用いてpipenvをインストールします。
$ pip install pipenv仮想環境上にDjangoをインストールする
pipenvをインストール後、デスクトップでhelloディレクトリを作成、helloディレクトリに移動します。
$ cd ~/Desktop $ mkdir hello && cd helloPipenvコマンドを使用して仮想環境上にDjangoをインストールします。
$ pipenv install django==2.2.3実行後、PipfileとPipfile.lockファイルが作成されます。
Pipfileにはインストールするライブラリ名とバージョンが記録されます。
Pipfile.lockには実際にインストールされたライブラリの情報が記録されます。$ ls Pipfile Pipfile.lock仮想環境に入り、startprojectコマンドを実行し新しいDjangoプロジェクトを作成します。ピリオドを忘れずに。
$ pipenv shell (hello)$ django-admin startproject hello_project .マイグレートを実施してデータベースの初期化を実行し、Django開発用サーバーを起動します。
(hello)$ python manage.py migrate (hello)$ python manage.py runserverhttp://127.0.0.1:8000/ にブラウザでアクセスするとDjangoのwelcomeページが表示されています。これにより仮想環境上でDjangoを立ち上がっていることが確認できました。

- 投稿日:2020-01-24T21:49:11+09:00
遺伝的アルゴリズムで特徴量選択
はじめに
へー遺伝的アルゴリズムってやつがあるのか〜。011101010...これって特徴量選択に使えるのでは?と思ったら当たり前のようにやっている人がいました。先駆者の方のコードを参考に自分なりにまとめ直しました。n番煎じです。
参考
- 遺伝的アルゴリズムで特徴量選択(https://horomary.hatenablog.com/entry/2019/03/10/190919)
- 遺伝的アルゴリズムに入門するときに参考になったスライドとOneMax問題の実装(https://tech.mof-mof.co.jp/blog/ga-one-max-problem.html)
- Azunyan1111 / OneMax(https://github.com/Azunyan1111/OneMax)
手順
遺伝的アルゴリズムの実装
遺伝的アルゴリズムの詳細はこちらが参考になります。この記事ではOneMax問題を例題にします。OneMax問題は、初期値として与えられた[0,1,0,1,1,1,0,...]という配列の要素をすべて1にする問題で、これを遺伝的アルゴリズムで解いてみます。
コードはこちらのgithubを参考にさせていただきました。遺伝的アルゴリズムに出てくる用語や変数の名前はこちらを参考にしました。簡単にまとめると、0または1をとるスカラー値を遺伝子(gene)、遺伝子を集めて配列[0,0,1,1,0,1,...]としたものを染色体(chromosome)、染色体を持った体?を個体(individual)としました。設計上は個体が属性として染色体を持つようにしています。個体の集合を集団(population)としました。アルゴリズムはエリート選択で、ルーレット選択はしていません。
遺伝的アルゴリズムに必要になる要素は下記です。
""" 著作 Azunyan https://github.com/Azunyan1111/OneMax """ """ 改変 Copyright 2020 ground0state All Rights Reserved. """ import random import time class Individual(): """個体. Parameters ---------- chromosome : list of {0 or 1} 染色体. evaluation : float 評価. """ chromosome = None evaluation = None def __init__(self, chromosome, evaluation): self.chromosome = chromosome self.evaluation = evaluation def create_individual(length): """引数で指定された桁のランダムな染色体を生成、格納した個体を返します. Parameters ---------- length : int 染色体の長さ. Returns ------- individual : Individual 個体. """ individual = Individual([random.randint(0, 1) for i in range(length)], 0) return individual def evaluate_individual(individual): """評価関数. Parameters ---------- individual : Individual 個体. Returns ------- eval : float 評価値. """ eval = sum(individual.chromosome)/len(individual.chromosome) return eval def extract_elites(population, num): """選択関数. Parameters ---------- population : list of Individual 集団. num : int 個体選択数. Returns ------- elites : list of Individual 選択処理をした集団. """ # 現行世代個体集団の評価を高い順番にソートする sort_result = sorted(population, reverse=True, key=lambda individual: individual.evaluation) # 一定の上位を抽出する elites = sort_result[:num] return elites def crossover(individual1, individual2, chromosome_length): """交叉関数. 二点交叉を行います. Parameters ---------- individual1 : Individual 交叉する個体1. individual2 : Individual 交叉する個体2. chromosome_length : int 染色体の長さ. Returns ------- offsprings : list of Individual 二つの孫. """ # 入れ替える二点の点を設定します cross_one = random.randint(0, chromosome_length) cross_second = random.randint(cross_one, chromosome_length) # 遺伝子を取り出します one = individual1.chromosome second = individual2.chromosome # 交叉させます progeny_one = one[:cross_one] + second[cross_one:cross_second] + one[cross_second:] progeny_second = second[:cross_one] + one[cross_one:cross_second] + second[cross_second:] # 子孫 offsprings = [Individual(progeny_one, 0), Individual(progeny_second, 0)] return offsprings def create_next_generation(population, elites, offsprings): """世代交代処理を行います. Parameters ---------- population : list of Individual 現行世代個体集団. elites : list of Individual 現行世代エリート集団. offsprings : list of Individual 現行世代子孫集団. Returns ------- next_generation_population : list of Individual 次世代個体集団. """ # 現行世代個体集団の評価を低い順番にソートする next_generation_population = sorted(population, reverse=False, key=lambda individual: individual.evaluation) # 追加するエリート集団と子孫集団の合計ぶんを取り除く next_generation_population = next_generation_population[len(elites)+len(offsprings):] # エリート集団と子孫集団を次世代集団を次世代へ追加します next_generation_population.extend(elites) next_generation_population.extend(offsprings) return next_generation_population def mutation(population, induvidual_mutation_probability, gene_mutation_probability): """突然変異関数. Parameters ---------- population : list of Individual 集団. induvidual_mutation_probability : float in [0, 1] 個体突然変異確率. gene_mutation_probability : float in [0, 1] 遺伝子突然変異確率. Returns ------- new_population : list of Individual 突然変異処理した集団. """ new_population = [] for individual in population: # 個体に対して一定の確率で突然変異が起きる if induvidual_mutation_probability > random.random(): new_chromosome = [] for gene in individual.chromosome: # 個体の遺伝子情報一つ一つに対して突然変異がおこる if gene_mutation_probability > random.random(): new_chromosome.append(random.randint(0, 1)) else: new_chromosome.append(gene) individual.chromosome = new_chromosome new_population.append(individual) else: new_population.append(individual) return new_populationこれらのクラスと関数を用いて、次のコードで実行します。
# 染色体の長さ CHROMOSOME_LENGTH = 13 # 集団の大きさ POPULATION_SIZE = 30 # エリート染色体選抜数 PICK_OUT_SIZE = 5 # 個体突然変異確率 INDIVIDUAL_MUTATION_PROBABILITY = 0.3 # 遺伝子突然変異確率 GENE_MUTATION_PROBABILITY = 0.1 # 繰り返す世代数 ITERATION = 10 # 現行世代の個体集団を初期化します current_generation_population = [create_individual(CHROMOSOME_LENGTH) for i in range(POPULATION_SIZE)] for count in range(ITERATION): # 各ループの開始時刻 start = time.time() # 現行世代個体集団の個体を評価 for individual in current_generation_population: individual.evaluation = evaluate_individual(individual) # エリート個体を選択します elites = extract_elites(current_generation_population, PICK_OUT_SIZE) # エリート遺伝子を交叉させ、リストに格納します offsprings = [] for i in range(0, PICK_OUT_SIZE-1): offsprings.extend(crossover(elites[i], elites[i+1], CHROMOSOME_LENGTH)) # 次世代個体集団を現行世代、エリート集団、子孫集団から作成します next_generation_population = create_next_generation(current_generation_population, elites, offsprings) # 次世代個体集団全ての個体に突然変異を施します。 next_generation_population = mutation(next_generation_population, INDIVIDUAL_MUTATION_PROBABILITY, GENE_MUTATION_PROBABILITY) # 1世代の進化的計算終了。評価に移ります # 各個体の評価値を配列化します。 fits = [individual.evaluation for individual in current_generation_population] # 進化結果を評価します min_val = min(fits) max_val = max(fits) avg_val = sum(fits) / len(fits) # 現行世代の進化結果を出力します print("-----第{}世代の結果-----".format(count+1)) print(" Min:{}".format(min_val)) print(" Max:{}".format(max_val)) print(" Avg:{}".format(avg_val)) # 現行世代と次世代を入れ替えます current_generation_population = next_generation_population # 時間計測 elapsed_time = time.time() - start print (" {}/{} elapsed_time:{:.2f}".format(count+1, ITERATION, elapsed_time) + "[sec]") # 最終結果出力 print("") # 改行 print("最も優れた個体は{}".format(elites[0].chromosome))出力はつぎのようになります。
-----第1世代の結果----- Min:0.23076923076923078 Max:0.8461538461538461 Avg:0.5384615384615384 1/10 elapsed_time:0.00[sec] -----第2世代の結果----- Min:0.46153846153846156 Max:0.8461538461538461 Avg:0.6692307692307694 2/10 elapsed_time:0.00[sec] -----第3世代の結果----- Min:0.6923076923076923 Max:0.9230769230769231 Avg:0.761538461538462 3/10 elapsed_time:0.00[sec] -----第4世代の結果----- Min:0.6923076923076923 Max:0.9230769230769231 Avg:0.8102564102564106 4/10 elapsed_time:0.00[sec] -----第5世代の結果----- Min:0.6923076923076923 Max:0.9230769230769231 Avg:0.8512820512820515 5/10 elapsed_time:0.00[sec] -----第6世代の結果----- Min:0.7692307692307693 Max:0.9230769230769231 Avg:0.848717948717949 6/10 elapsed_time:0.00[sec] -----第7世代の結果----- Min:0.7692307692307693 Max:0.9230769230769231 Avg:0.8948717948717951 7/10 elapsed_time:0.00[sec] -----第8世代の結果----- Min:0.6153846153846154 Max:0.9230769230769231 Avg:0.8974358974358977 8/10 elapsed_time:0.00[sec] -----第9世代の結果----- Min:0.7692307692307693 Max:0.9230769230769231 Avg:0.9000000000000002 9/10 elapsed_time:0.00[sec] -----第10世代の結果----- Min:0.8461538461538461 Max:1.0 Avg:0.9102564102564105 10/10 elapsed_time:0.00[sec] 最も優れた個体は[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]要素がすべて1の個体を得ることが出来ました。
遺伝的アルゴリズムで特徴量選択
こちらを参考にしてデータとモデルを準備しました。
データの準備は次のコードです。
import pandas as pd import numpy as np from sklearn.datasets import load_boston from sklearn.preprocessing import PolynomialFeatures from sklearn.preprocessing import StandardScaler # データセットのロード X = pd.DataFrame(load_boston().data, columns=load_boston().feature_names) y = load_boston().target # 多項式特徴量を追加 poly = PolynomialFeatures(2) poly.fit(X) X_poly = pd.DataFrame(poly.transform(X), columns=poly.get_feature_names(input_features=X.columns)) # 標準化 sc = StandardScaler() X_sc = pd.DataFrame(sc.fit_transform(X), columns=X.columns) X_poly_sc = pd.DataFrame(sc.fit_transform(X_poly), columns=X_poly.columns)特徴量が多いパターンを検証するために、
PolynomialFeaturesを使って特徴量を増やしたものがX_poly_scです。そのままのデータセットでのモデル。
from sklearn.linear_model import RidgeCV from sklearn.model_selection import train_test_split # そのままのデータセット scores = [] for _ in range(30): X_train, X_test, y_train, y_test = train_test_split(X_sc, y, test_size=0.4) model = RidgeCV() model.fit(X_train, y_train) scores.append(model.score(X_test, y_test)) print(np.array(scores).mean()) # 0.70多項式特徴量を追加したモデル。
from sklearn.linear_model import RidgeCV from sklearn.model_selection import train_test_split # 多項式特徴量を追加した場合 scores = [] for _ in range(30): X_train, X_test, y_train, y_test = train_test_split(X_poly_sc, y, test_size=0.4) model = RidgeCV() model.fit(X_train, y_train) scores.append(model.score(X_test, y_test)) print(np.array(scores).mean()) # 0.82さて、このモデルに対し遺伝的アルゴリズムで特徴量選択を行いましょう。改変するのは
evaluate_individualメソッドです。個体の染色体をインプットとしてブール値に変換し、使用する列の指定を行います。その後モデルを用いて学習、スコアを算出しています。スコアを個体の評価値としてreturnしています。def evaluate_individual(individual): """評価関数. Parameters ---------- individual : Individual 個体. Returns ------- eval : float 評価値. """ use_cols = [bool(gene) for gene in individual.chromosome] X_temp = X_sc.iloc[:, use_cols] scores = [] for _ in range(30): X_train, X_test, y_train, y_test = train_test_split(X_temp, y, test_size=0.4) model = RidgeCV() model.fit(X_train, y_train) scores.append(model.score(X_test, y_test)) eval = float(np.array(scores).mean()) return evalパラメータを下記のものに変えて実行してみました。
# 染色体の長さ CHROMOSOME_LENGTH = 13 # 集団の大きさ POPULATION_SIZE = 100 # エリート染色体選抜数 PICK_OUT_SIZE = 20 # 個体突然変異確率 INDIVIDUAL_MUTATION_PROBABILITY = 0.3 # 遺伝子突然変異確率 GENE_MUTATION_PROBABILITY = 0.1 # 繰り返す世代数 ITERATION = 10結果は次のようになりました。
-----第1世代の結果----- Min:0.245482696210891 Max:0.7062246093438559 Avg:0.5643638813331334 1/10 elapsed_time:13.21[sec] -----第2世代の結果----- Min:0.28765890628509017 Max:0.7175019664075553 Avg:0.6611343782899052 2/10 elapsed_time:14.07[sec] -----第3世代の結果----- Min:0.5958052127889627 Max:0.7343341487237112 Avg:0.6840346805288029 3/10 elapsed_time:14.39[sec] -----第4世代の結果----- Min:0.6011227398695212 Max:0.7265364514547696 Avg:0.694531099756538 4/10 elapsed_time:11.29[sec] -----第5世代の結果----- Min:0.6314510371602322 Max:0.7249977461594102 Avg:0.6938166370760438 5/10 elapsed_time:11.72[sec] -----第6世代の結果----- Min:0.6539907671434392 Max:0.7256998515926862 Avg:0.7042345770684423 6/10 elapsed_time:11.44[sec] -----第7世代の結果----- Min:0.6557998988298114 Max:0.7273580445493621 Avg:0.7009249865262361 7/10 elapsed_time:9.64[sec] -----第8世代の結果----- Min:0.6530159418050802 Max:0.7250968150681534 Avg:0.7044189020700958 8/10 elapsed_time:9.90[sec] -----第9世代の結果----- Min:0.6087336519329122 Max:0.7316442169584539 Avg:0.7008118423172378 9/10 elapsed_time:9.64[sec] -----第10世代の結果----- Min:0.6328245771251623 Max:0.7244970729879131 Avg:0.7034862249363725 10/10 elapsed_time:13.06[sec] 最も優れた個体は[1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]スコアが
0.72になっているので、より良い特徴量選択が出来ています。クラス化
使い回せるようにクラス化しました。抽象クラスとして作成し、継承して
evaluate_individualを実装します。""" 著作 Azunyan https://github.com/Azunyan1111/OneMax """ """ 改変 Copyright 2020 ground0state All Rights Reserved. """ import random import time from abc import ABCMeta, abstractmethod class Individual(): """個体. Parameters ---------- chromosome : list of {0 or 1} 染色体. evaluation : float 評価. """ chromosome = None evaluation = None def __init__(self, chromosome, evaluation): self.chromosome = chromosome self.evaluation = evaluation class GaSolver(metaclass=ABCMeta): """遺伝的アルゴリズムの抽象クラス. 染色体に対して、評価値を出力するメソッド「evaluate_individual」は要実装. Parameters ---------- chromosome_length : int 染色体の長さ. population_size : int 集団の大きさ. pick_out_size : int エリート染色体選抜数. individual_mutation_probability : float 個体突然変異確率. gene_mutation_probability : float 遺伝子突然変異確率. iteration : int 繰り返す世代数. """ def __init__(self, chromosome_length, population_size, pick_out_size, individual_mutation_probability=0.3, gene_mutation_probability=0.1, iteration=1, verbose=True): self.chromosome_length = chromosome_length self.population_size = population_size self.pick_out_size = pick_out_size self.individual_mutation_probability = individual_mutation_probability self.gene_mutation_probability = gene_mutation_probability self.iteration = iteration self.verbose = verbose self.history = None def _create_individual(self, length): """引数で指定された桁のランダムな染色体を生成、格納した個体を返します. Parameters ---------- length : int 染色体の長さ. Returns ------- individual : Individual 個体. """ individual = Individual([random.randint(0, 1) for i in range(length)], 0) return individual @abstractmethod def evaluate_individual(self, individual, X, y): """評価関数. Parameters ---------- individual : Individual 個体. X : pandas.DataFrame 説明変数. y : pandas.DataFrame 目的変数. Returns ------- eval : float 評価値. """ raise NotImplementedError() def _extract_elites(self, population, num): """選択関数. Parameters ---------- population : list of Individual 集団. num : int 個体選択数. Returns ------- elites : list of Individual 選択処理をした集団. """ # 現行世代個体集団の評価を高い順番にソートする sort_result = sorted(population, reverse=True, key=lambda individual: individual.evaluation) # 一定の上位を抽出する elites = sort_result[:num] return elites def _crossover(self, individual1, individual2, chromosome_length): """交叉関数. 二点交叉を行います. Parameters ---------- individual1 : Individual 交叉する個体1. individual2 : Individual 交叉する個体2. chromosome_length : int 染色体の長さ. Returns ------- offsprings : list of Individual 二つの孫. """ # 入れ替える二点の点を設定します cross_one = random.randint(0, chromosome_length) cross_second = random.randint(cross_one, chromosome_length) # 遺伝子を取り出します one = individual1.chromosome second = individual2.chromosome # 交叉させます progeny_one = one[:cross_one] + second[cross_one:cross_second] + one[cross_second:] progeny_second = second[:cross_one] + one[cross_one:cross_second] + second[cross_second:] # 子孫 offsprings = [Individual(progeny_one, 0), Individual(progeny_second, 0)] return offsprings def _create_next_generation(self, population, elites, offsprings): """世代交代処理を行います. Parameters ---------- population : list of Individual 現行世代個体集団. elites : list of Individual 現行世代エリート集団. offsprings : list of Individual 現行世代子孫集団. Returns ------- next_generation_population : list of Individual 次世代個体集団. """ # 現行世代個体集団の評価を低い順番にソートする next_generation_population = sorted(population, reverse=False, key=lambda individual: individual.evaluation) # 追加するエリート集団と子孫集団の合計ぶんを取り除く next_generation_population = next_generation_population[len(elites)+len(offsprings):] # エリート集団と子孫集団を次世代集団を次世代へ追加します next_generation_population.extend(elites) next_generation_population.extend(offsprings) return next_generation_population def _mutation(self, population, induvidual__mutation_probability, gene__mutation_probability): """突然変異関数. Parameters ---------- population : list of Individual 集団. induvidual__mutation_probability : float in [0, 1] 個体突然変異確率. gene__mutation_probability : float in [0, 1] 遺伝子突然変異確率. Returns ------- new_population : list of Individual 突然変異処理した集団. """ new_population = [] for individual in population: # 個体に対して一定の確率で突然変異が起きる if induvidual__mutation_probability > random.random(): new_chromosome = [] for gene in individual.chromosome: # 個体の遺伝子情報一つ一つに対して突然変異がおこる if gene__mutation_probability > random.random(): new_chromosome.append(random.randint(0, 1)) else: new_chromosome.append(gene) individual.chromosome = new_chromosome new_population.append(individual) else: new_population.append(individual) return new_population def solve(self, X, y): """遺伝的アルゴリズムのメインクラス. Returns ------- list of {0 or 1} 最も優れた個体の染色体. """ self.history = {"Min":[], "Max":[], "Avg":[], "BestChromosome":[]} # 現行世代の個体集団を初期化します current_generation_population = [self._create_individual(self.chromosome_length) for i in range(self.population_size)] # 現行世代個体集団の個体を評価 for individual in current_generation_population: individual.evaluation = self.evaluate_individual(individual, X, y) for count in range(self.iteration): # 各ループの開始時刻 start = time.time() # エリート個体を選択します elites = self._extract_elites(current_generation_population, self.pick_out_size) # エリート遺伝子を交叉させ、リストに格納します offsprings = [] for i in range(0, self.pick_out_size-1): offsprings.extend(self._crossover(elites[i], elites[i+1], self.chromosome_length)) # 次世代個体集団を現行世代、エリート集団、子孫集団から作成します next_generation_population = self._create_next_generation(current_generation_population, elites, offsprings) # 次世代個体集団全ての個体に突然変異を施します。 next_generation_population = self._mutation(next_generation_population, self.individual_mutation_probability, self.gene_mutation_probability) # 現行世代個体集団の個体を評価 for individual in current_generation_population: individual.evaluation = self.evaluate_individual(individual, X, y) # 1世代の進化的計算終了。評価に移ります # 各個体の評価値を配列化します。 fits = [individual.evaluation for individual in current_generation_population] # 最も評価値のよい個体を取り出します best_individual = self._extract_elites(current_generation_population, 1) best_chromosome = best_individual[0].chromosome # 進化結果を評価します min_val = min(fits) max_val = max(fits) avg_val = sum(fits) / len(fits) # 現行世代の進化結果を出力します if self.verbose: print("-----第{}世代の結果-----".format(count+1)) print(" Min:{}".format(min_val)) print(" Max:{}".format(max_val)) print(" Avg:{}".format(avg_val)) # history作成 self.history["Min"].append(min_val) self.history["Max"].append(max_val) self.history["Avg"].append(avg_val) self.history["BestChromosome"].append(best_chromosome) # 現行世代と次世代を入れ替えます current_generation_population = next_generation_population # 時間計測 elapsed_time = time.time() - start print (" {}/{} elapsed_time:{:.2f}".format(count+1, self.iteration, elapsed_time) + "[sec]") # 最終結果出力 if self.verbose: print("") # 改行 print("最も優れた個体は{}".format(elites[0].chromosome)) return self.history
evaluate_individualに評価したい機械学習モデルを実装します。from sklearn.linear_model import RidgeCV from sklearn.model_selection import train_test_split class GaSolverImpl(GaSolver): # override def evaluate_individual(self, individual, X, y): use_cols = [bool(gene) for gene in individual.chromosome] X_temp = X.iloc[:, use_cols] scores = [] for _ in range(30): X_train, X_test, y_train, y_test = train_test_split(X_temp, y, test_size=0.4) model = RidgeCV() model.fit(X_train, y_train) scores.append(model.score(X_test, y_test)) eval = float(np.array(scores).mean()) return eval実装クラスのインスタンスを生成して、データを渡して実行します。
solveメソッドは履歴であるhistoryを返却します。solver = GaSolverImpl( chromosome_length = X_poly_sc.shape[1], population_size = 50, pick_out_size = 10, individual_mutation_probability = 0.3, gene_mutation_probability = 0.1, iteration = 50, verbose = True ) history = solver.solve(X_poly_sc, y)実行結果は次のようになります。
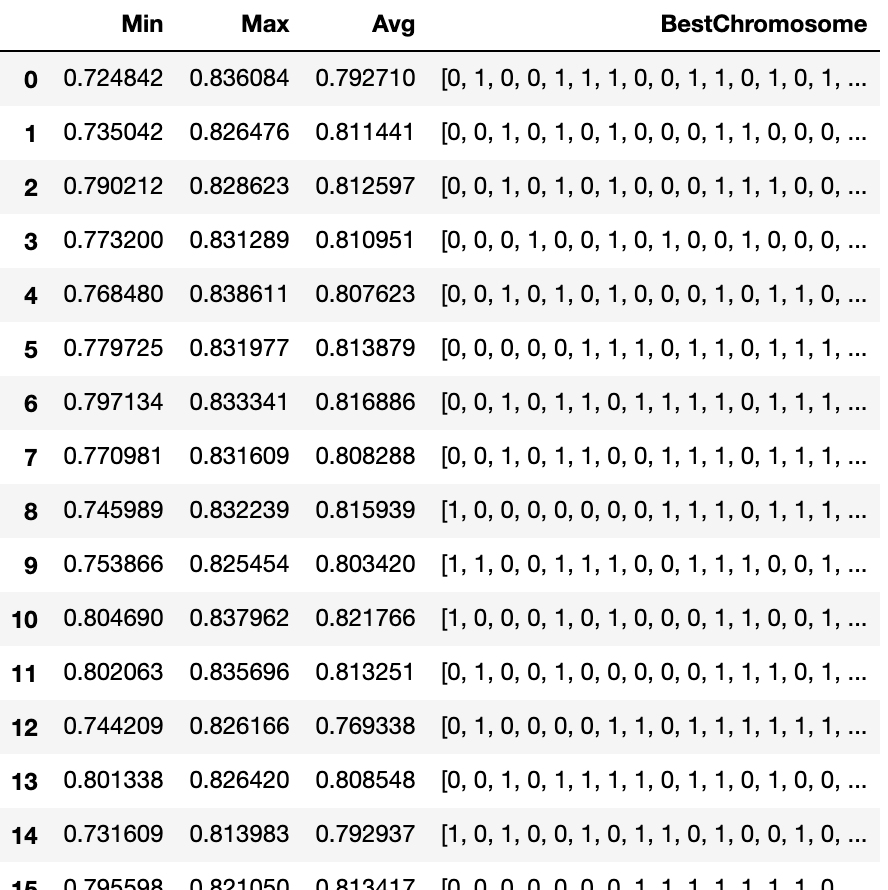
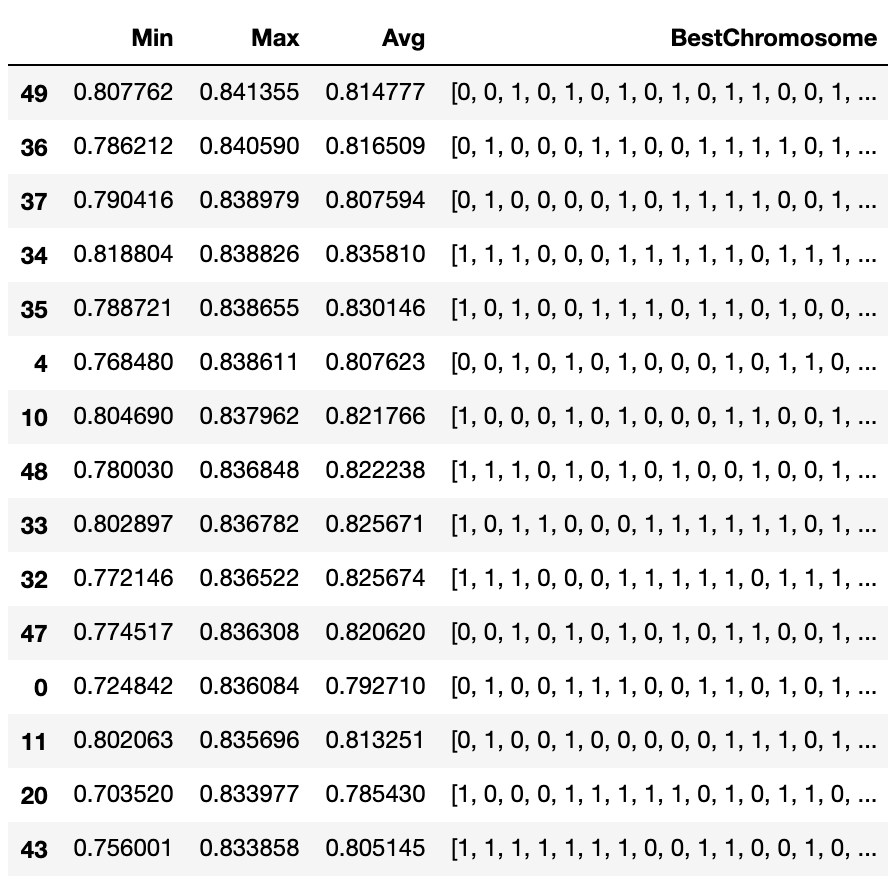
-----第1世代の結果----- Min:0.7248417700796147 Max:0.8360838319205105 Avg:0.7927103625892467 1/50 elapsed_time:6.13[sec] -----第2世代の結果----- Min:0.7350424889460248 Max:0.8264758137896353 Avg:0.8114411035733131 2/50 elapsed_time:10.81[sec] -----第3世代の結果----- Min:0.7902116792529935 Max:0.8286229243915363 Avg:0.8125974889978004 3/50 elapsed_time:8.20[sec] -----第4世代の結果----- Min:0.773199874021567 Max:0.8312887517624212 Avg:0.810950812639705 4/50 elapsed_time:7.56[sec] -----第5世代の結果----- Min:0.768479730905661 Max:0.8386114466226944 Avg:0.8076230726252596 5/50 elapsed_time:8.13[sec] -----第6世代の結果----- Min:0.7797249579245809 Max:0.8319768049107215 Avg:0.8138790949911054 6/50 elapsed_time:9.00[sec] -----第7世代の結果----- Min:0.7971344524880782 Max:0.8333411281001641 Avg:0.8168863897838727 7/50 elapsed_time:7.56[sec] -----第8世代の結果----- Min:0.7709812458007903 Max:0.8316092177782253 Avg:0.8082876757394714 8/50 elapsed_time:7.96[sec] -----第9世代の結果----- Min:0.7459891729563418 Max:0.8322393628831635 Avg:0.8159389943969992 9/50 elapsed_time:8.77[sec] -----第10世代の結果----- Min:0.7538656919599587 Max:0.8254541549046537 Avg:0.8034195187548075 10/50 elapsed_time:8.99[sec] -----第11世代の結果----- Min:0.8046900766607942 Max:0.8379618406470278 Avg:0.8217659811828382 11/50 elapsed_time:8.60[sec] -----第12世代の結果----- Min:0.8020625272756005 Max:0.8356958927515973 Avg:0.8132506462797608 12/50 elapsed_time:8.31[sec] -----第13世代の結果----- Min:0.7442093041785434 Max:0.826166208838109 Avg:0.7693376466706999 13/50 elapsed_time:9.22[sec] -----第14世代の結果----- Min:0.80133807286147 Max:0.8264198880246336 Avg:0.8085481113173225 14/50 elapsed_time:8.08[sec] -----第15世代の結果----- Min:0.7316094852550766 Max:0.8139831643344952 Avg:0.7929373870389733 15/50 elapsed_time:8.92[sec] -----第16世代の結果----- Min:0.7955982071682629 Max:0.8210496822695305 Avg:0.8134173712784526 16/50 elapsed_time:9.72[sec] -----第17世代の結果----- Min:0.758489267352653 Max:0.826441026953439 Avg:0.7773437348210647 17/50 elapsed_time:8.58[sec] -----第18世代の結果----- Min:0.7687388062022248 Max:0.8211801466346264 Avg:0.7826663042340634 18/50 elapsed_time:6.94[sec] -----第19世代の結果----- Min:0.7429453738843712 Max:0.794799782442768 Avg:0.7525262014670999 19/50 elapsed_time:8.35[sec] -----第20世代の結果----- Min:0.7059056866516289 Max:0.8115968792777923 Avg:0.7941420197838582 20/50 elapsed_time:7.01[sec] -----第21世代の結果----- Min:0.7035195424104084 Max:0.8339769569079513 Avg:0.785429874209423 21/50 elapsed_time:8.84[sec] -----第22世代の結果----- Min:0.7605334574905934 Max:0.8178769887665864 Avg:0.7764313614722025 22/50 elapsed_time:8.89[sec] -----第23世代の結果----- Min:0.7622888571603964 Max:0.8125955330567856 Avg:0.7761008854264979 23/50 elapsed_time:8.47[sec] -----第24世代の結果----- Min:0.7325862134323571 Max:0.7781021993458462 Avg:0.76629374412332 24/50 elapsed_time:6.80[sec] -----第25世代の結果----- Min:0.7155008056263605 Max:0.7770200781667415 Avg:0.7679494414264083 25/50 elapsed_time:6.34[sec] -----第26世代の結果----- Min:0.7435193687961383 Max:0.8178098302473983 Avg:0.8025839605868198 26/50 elapsed_time:7.55[sec] -----第27世代の結果----- Min:0.757023831644299 Max:0.8134233524435134 Avg:0.7987707913780304 27/50 elapsed_time:8.24[sec] -----第28世代の結果----- Min:0.7731968991993663 Max:0.8307874217208041 Avg:0.7886999734804412 28/50 elapsed_time:6.93[sec] -----第29世代の結果----- Min:0.7918044164374493 Max:0.8258234982562584 Avg:0.8092356291245499 29/50 elapsed_time:6.45[sec] -----第30世代の結果----- Min:0.7742914329017841 Max:0.8170916314535998 Avg:0.8057764064558626 30/50 elapsed_time:6.46[sec] -----第31世代の結果----- Min:0.7900272740547029 Max:0.8252185280503214 Avg:0.8121724282164997 31/50 elapsed_time:6.87[sec] -----第32世代の結果----- Min:0.7668694386968217 Max:0.8231354707898234 Avg:0.8170271080711664 32/50 elapsed_time:7.61[sec] -----第33世代の結果----- Min:0.7721459013264073 Max:0.8365223852672053 Avg:0.82567433930934 33/50 elapsed_time:8.28[sec] -----第34世代の結果----- Min:0.802896605790934 Max:0.8367820565860135 Avg:0.8256706142219095 34/50 elapsed_time:7.94[sec] -----第35世代の結果----- Min:0.8188038196577934 Max:0.8388260026966802 Avg:0.8358101024561487 35/50 elapsed_time:7.64[sec] -----第36世代の結果----- Min:0.7887209549961678 Max:0.8386551764887261 Avg:0.8301462683188676 36/50 elapsed_time:8.13[sec] -----第37世代の結果----- Min:0.7862123272076996 Max:0.8405895787926129 Avg:0.8165090312639174 37/50 elapsed_time:7.54[sec] -----第38世代の結果----- Min:0.79041640507099 Max:0.8389789987982965 Avg:0.8075935438809548 38/50 elapsed_time:8.58[sec] -----第39世代の結果----- Min:0.7632897869020304 Max:0.8249959874282974 Avg:0.7783194384843993 39/50 elapsed_time:8.18[sec] -----第40世代の結果----- Min:0.7391820233337305 Max:0.8140492870179213 Avg:0.7954486450055553 40/50 elapsed_time:6.36[sec] -----第41世代の結果----- Min:0.7085099265464342 Max:0.7981244256568432 Avg:0.7831723305042879 41/50 elapsed_time:7.90[sec] -----第42世代の結果----- Min:0.7826056505944214 Max:0.8327777219420097 Avg:0.8064707164336307 42/50 elapsed_time:7.53[sec] -----第43世代の結果----- Min:0.7799209160785368 Max:0.8183673115100479 Avg:0.7992172395182555 43/50 elapsed_time:6.74[sec] -----第44世代の結果----- Min:0.756001056689909 Max:0.8338583079593664 Avg:0.8051445406627477 44/50 elapsed_time:6.31[sec] -----第45世代の結果----- Min:0.7755735607344747 Max:0.8283597660188781 Avg:0.7882919431369523 45/50 elapsed_time:6.52[sec] -----第46世代の結果----- Min:0.7766070559704219 Max:0.8165316562327392 Avg:0.8106111873738964 46/50 elapsed_time:7.22[sec] -----第47世代の結果----- Min:0.7780606007516856 Max:0.8084622225234689 Avg:0.7942400594914705 47/50 elapsed_time:9.72[sec] -----第48世代の結果----- Min:0.7745173603676726 Max:0.8363078519583506 Avg:0.8206202750563127 48/50 elapsed_time:10.67[sec] -----第49世代の結果----- Min:0.7800301936781145 Max:0.8368475790583294 Avg:0.8222375502197947 49/50 elapsed_time:7.54[sec] -----第50世代の結果----- Min:0.8077617917763787 Max:0.841354566380394 Avg:0.8147771424682558 50/50 elapsed_time:6.78[sec] 最も優れた個体は[1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1]hisotryは次のようになります。
df = pd.DataFrame(history)
最終的に使用するカラムはMax列でソートして、上からいくつかを試してみて、ハイパーパラメータのサーチなども加味して採用すれば良いのではないでしょうか。
df.sort_values(["Max"], ascending=False)
おわりに
遺伝的アルゴリズムで特徴量選択をしてみました。遺伝的アルゴリズムにも種類があるようで、こちらのサイトで使用されているDEAPといったライブラリを使ってみるのもいいかもしれません。
- 投稿日:2020-01-24T20:36:29+09:00
Atcoder Beginner Contest152のきろく(python)
1
正答数と問題数が一致した時ACとする
N , M = map(int,input().split()) if N == M: print("Yes") else: print("No")2
辞書順で先に来るとは数が小さいことと同義である。
その為、smallの値をlargeの回数繰り返せば良いa, b = map(int,input().split()) ans = str(min(a, b)) * max(a, b) print(ans)3
chokudaiさんも解けてほしいと言っていた問題。
問題文が複雑であるが、問題文をあるiが任意のすべてのjのうち最小であるという問題に帰着できる。
その為、左から値を保持し、常に最小であるか判定すれば$O(N)$で解ける。N = int(input()) P = list(map(int, input().split())) now = P[0] ans = 1 for i in range(1, N): if now >= P[i]: now = P[i] ans += 1 print(ans)4
条件に適した二組の整数が何個あるかの問題。
制約より、$O(N)$で解けることがわかる。また、1〜20くらいまで書き出すと明確な法則がないように思える。
この問題のポイントは値を1〜9までしか使わない為、9*9の二次元配列を作る。それをforでカウントし、2数の組合せが答えとなる。
from pprint import pprint N = int(input()) digit_cnt = list([0] * 9 for _ in range(9)) now = 1 for i in range(1, N + 1): str_i = str(i) row = int(str_i[0]) column = int(str_i[-1]) if row != 0 and column != 0: digit_cnt[row - 1][column - 1] += 1 # pprint(digit_cnt) ans = 0 for i in range(9): for j in range(9): ans += digit_cnt[i][j] * digit_cnt[j][i] print(ans)
- 投稿日:2020-01-24T20:19:10+09:00
Djangoで区分値を管理する
Djangoで区分値を管理する
例でまとめました。
モデルに定義する
ポイント:
choices=manage.pyclass History(models.Model): STATUS = ( ('001', '実施前'), # BEFORE_EXECUTE ('011', 'ログイン中'), # DURING_LOGIN ('012', '取得中'), # WHILE_GETTING ('101', '完了'), # DONE ('401', '失敗') # fail ) start_at = models.DateTimeField() status = models.CharField(max_length=3, choices=STATUS)URL
url.pyurlpatterns = [ # リスト path(FR_URL + 'history_list', ex.HistoryListView.as_view(), name='history_list'), ]ListViewに定義
class HistoryListView(ListView): model = History template_name = 'history_list.html'Htmlの書き方
ポイント:
get_FIELD_diaplayexample.html<td> {{ history.get_status_display }} </td>
- 投稿日:2020-01-24T20:19:10+09:00
Djangoで区分値を定義し、簡単に画面へ反映する
Djangoで区分値を管理する
要件
model.pyで区分値を定義し、履歴のリストを表示するhtmlページへ反映します。1. モデルに定義する
HistoryテーブルにSTATUSという区分値を持たせます。
ポイント:choices=manage.pyclass History(models.Model): STATUS = ( ('001', '実施前'), # BEFORE_EXECUTE ('011', 'ログイン中'), # DURING_LOGIN ('012', '取得中'), # WHILE_GETTING ('101', '完了'), # DONE ('401', '失敗') # fail ) start_at = models.DateTimeField() status = models.CharField(max_length=3, choices=STATUS)2. URLを定義する
履歴のリストを表示するページへのURLを定義。
url.pyurlpatterns = [ # リスト path('history_list', views.HistoryListView.as_view(), name='history_list'), ]3. ListViewに定義する
履歴のリストを表示するページのhtmlへ渡すViewを定義。
class HistoryListView(ListView): model = History template_name = 'history_list.html'4. Htmlへ反映させる
ポイント:
get_FIELD_diaplayexample.html<td> {{ history.get_status_display }} </td>
- 投稿日:2020-01-24T20:07:34+09:00
たくさんインスタンス変数を使う場合の速度比較[Python]
速度比較
import timeit class checkTime(): def __init__(self): self.a = 0 self.b = 0 self.c = 0 def local(self): a = self.a b = self.b c = self.c for i in range(10000): a+b+c def self(self): for i in range(10000): self.a+self.b+self.c def getTime(self): def test1(): self.a = 1 self.b = 2 self.c = 3 self.self() self_elapsed_time = timeit.Timer(stmt=test1).repeat(number=100) def test2(): self.a = 1 self.b = 2 self.c = 3 self.local() local_elapsed_time = timeit.Timer(stmt=test2).repeat(number=100) print ("local_time:{0}".format(local_elapsed_time) + "[sec]") print ("self_time:{0}".format(self_elapsed_time) + "[sec]") checkTime = checkTime() checkTime.getTime()結果
local_time:[0.04716750000000003, 0.09638709999999995, 0.07357000000000002, 0.04696279999999997, 0.04360750000000002][sec] self_time:[0.09702539999999998, 0.111617, 0.07951390000000003, 0.08777400000000002, 0.099128][sec]いっぱい使う場合はローカル変数にしといた方がよい
自分用メモ
- 投稿日:2020-01-24T19:36:26+09:00
【Python】beautifulsoup4の備忘録
はじめに
beautifulsoup4による、htmlタグ検索の備忘録。環境
- python: 3.7
- beautifulsoup4: 4.8.2
基本の検索
# pタグ全部 find_all("p") # 一番初めに見つかったpタグのみ find("p") # aタグかつhrefがhogehogeから始まるもの import re find_all("a", href=re.compile("^hogehoge"))cssセレクタ使った検索
# 親子関係を指定、ゆるく select('body div p') # 親子関係その2、きびしく select('body > div > p') # クラス名 select('.myclass') # id名 select('#myid') # AND条件 select('.myclass1.myclass2')n番目のタグ
# 下記のhtmlの3番目の<li>タグを検索する # <html> # <body> # <ul> # <li>指定されない</li> # <li>指定されない</li> # <li>指定される</li> # <li>指定されない</li> # </ul> # </body> # </html> select('body > ul > li:nth-of-type(3)')nth-of-type()が効かないときなどの対処法
効かなかった原因は、スクレイピング元サイトのhtmlに、開始タグはあるが閉じタグがないものが存在していたこと。
解決策としては、その開始タグを削除すること。
(ちなみに、Chromeの開発者ツール上では閉じタグは存在していたため、ページのソースを表示してみるまで気づかなかった…)url = "http://hogehoge/" soup = BeautifulSoup(url.text, "lxml") # ddタグの閉じタグがないので、ddタグを除去 for tag in soup.find_all('dd'): tag.unwrap()全ての
<dd>タグを除去する。
ただし、.decompose()を使うと、<dd>より後ろにある要素も消えてしまうので、.unwrap()でタグのみを削除。参考文献
- 投稿日:2020-01-24T19:28:50+09:00
【#2】PythonでMinecraftを作る。~モデル描画とプレイヤー実装~
Part of pictures, articles, images on this page are copyrighted by Mojang AB.
概要
世界的に超有名なサンドボックスゲーム「Minecraft」をプログラミング言語「Python」で再現するプロジェクトです。
前回の記事: 「【#1】PythonでMinecraftを作る。~下調べと設計~」
前置き
大変おまたせしました。
第2弾です!今回やること
- ゲームエンジンの選定
- お試し実行
- モデルの描画
- プレイヤーの実装
ゲームエンジンの選定
流石に3Dゲームエンジンをイチから作るわけにもいかないので、Pythonにも対応している3Dゲームエンジン(ライブラリ)を探しました。
その中でも比較的利用しやすく、綺麗な描画ができそうなものを選定しました。
Panda3D Engine
「Panda3D」という3Dゲームエンジンです。
プラットフォームはPythonとC++。Panda3D使ってみた
実際に動かしてみます。
▼インストール
pip install --pre --extra-index-url https://archive.panda3d.org/ panda3d▼ソースコード
main.pyfrom Renderer import engine def main(): _render = engine.Renderer() _render.run() if __name__ == "__main__": main()engine.pyfrom direct.showbase.ShowBase import ShowBase from direct.gui.OnscreenText import OnscreenText from panda3d.core import TextNode from pandac.PandaModules import WindowProperties class Renderer(ShowBase): def __init__(self): ShowBase.__init__(self) props = WindowProperties() props.setTitle('PyCraft') props.setSize(1280, 720) self.win.requestProperties(props) OnscreenText(text="PyCraft ScreenText", parent=None, align=TextNode.ARight, fg=(1, 1, 1, 1), pos=(-0.1, 0.1), scale=.08, shadow=(0, 0, 0, 0.5))こんな感じに描画されました。
モデルを読み込んでみる
engine.pyfrom direct.showbase.ShowBase import ShowBase from direct.gui.OnscreenText import OnscreenText from panda3d.core import TextNode from pandac.PandaModules import WindowProperties from direct.showbase.Loader import Loader class Renderer(ShowBase): def __init__(self): ShowBase.__init__(self) props = WindowProperties() props.setTitle('PyCraft') props.setSize(1280, 720) self.win.requestProperties(props) OnscreenText(text="PyCraft ScreenText", parent=None, align=TextNode.ARight, fg=(1, 1, 1, 1), pos=(-0.1, 0.1), scale=.08, shadow=(0, 0, 0, 0.5)) self.scene = self.loader.loadModel("models/environment") self.scene.reparentTo(self.render) self.scene.setScale(1, 1, 1) self.scene.setPos(0, 0, 0) self.cube = self.loader.loadModel("models/misc/rgbCube") self.cube.reparentTo(self.render) self.cube.setScale(1, 1, 1) self.cube.setPos(0, 20, 0)こんな感じになりました。
マウスでくりくり操作できるみたいです。
キューブはこんな感じ。
3D描画してみる
▼ソースコード
長くなってしまうので、コア部分のみ記載します。engine.pyself.world = BulletWorld() self.world.setGravity(Vec3(0, 0, -9.81)) self.worldPath = self.render.attachNewNode("") debugNode = BulletDebugNode() nodePath = self.worldPath.attachNewNode(debugNode) nodePath.show() self.world.setDebugNode(debugNode) bodyGround = BulletRigidBodyNode() bodyGround.addShape(BulletBoxShape((3, 3, 0.001))) nodePath = self.worldPath.attachNewNode(bodyGround) nodePath.setPos(0, 0, -2) nodePath.setHpr(0, 12, 0) self.world.attachRigidBody(bodyGround) self.boxes = [] for i in range(30): bodyBox = BulletRigidBodyNode() bodyBox.setMass(1.0) bodyBox.addShape(BulletBoxShape((0.5, 0.5, 0.5))) nodePath = self.worldPath.attachNewNode(bodyBox) nodePath.setPos(0, 0, 2 + i * 2) self.boxes.append(nodePath) self.world.attachRigidBody(bodyBox)Ogre3D
「Ogre3D」 はハードウェアアクセラレーションを活用したゲームエンジンのひとつです。
C++はもちろん、Pythonや.NETにも対応している様子。
.NET上での3Dゲームの実現はかなり厳しいので、「C#でマインクラフト再現してみた!」の実現にはOgre.NETを使いたい。ショーケースを見てみる。
こちらは、「X-Morph: Defense」とうゲームらしい。
もちろん、Ogreエンジンが使われています。素晴らしいグラフィックですね。
色々考えた結果
上記以外のゲームエンジンも加えて、クロスプラットフォームである点も考慮に入れ、一番情報の多そうな「Pyglet」を使用することにしました。
他ライブラリに依存しないこと・マルチディスプレイやマルチモニタに対応している点も申し分無いです。Pyglet使ってみた
ここからは、実際にPygletを使用して簡単な描画を行ってみます。
環境構築
▼インストール
pip install pyglet▼インストール(PyCharmの場合)
メニューバー▶ファイル▶設定
動かしてみる
▼サンプルコード
main.py#モジュールをインポート from pyglet.gl import * #表示させるウィンドウ #widthは横幅、heightは縦幅です。 #captionはウィンドウタイトル、resizableはサイズ変更を許可するか、です。 pyglet.window.Window(width=700, height=400, caption='Hello Pyglet!', resizable=True) pyglet.app.run()こんな感じに表示されればOKです。
線を描画してみる
PygletではOpenGLが使われています。
▼サンプルコード
main.py#モジュールをインポート from pyglet.gl import * #ウィンドウ window = pyglet.window.Window(width=700, height=400, caption='Hello Pyglet!', resizable=True) #ウィンドウの描画イベント @window.event def on_draw(): #描画をクリア window.clear() glBegin(GL_LINES) # 線の描画を開始 glColor3f(1, 0, 0) # R,G,B ÷ 255 glVertex2f(0, 0) # x, y(0, 0)から glVertex2f(100, 100) # x, y(100, 100)まで glEnd() #線の描画を終わる pyglet.app.run()実行すると、このような感じに線が描画されます。
解説
上記ソースコードでは
windowの描画イベント関数を定義し、OpenGLを活用して線を描画しています。
OpenGLでは画面左下がゼロ座標と認識されるみたいですね。1.
glBegin(GL_LINES)で線の描画の開始を宣言2.
glColor3f(1, 0, 0)で色を宣言
ここでいう色はRGB(Red,Green,Blue)です。
それぞれ通常0~255ですが、ここでは3fとある通りFloatで宣言するので、255.fで割った数を引数として渡します。
3fは3つの数値をfloatで渡すという意味です。2.
glVertex2f(x, y)で線の開始地点を宣言
線の開始地点の座標を渡します。
2fは2次元の座標をfloatで渡す、という意味です。3.
glVertex2f(x, y)で線の終了地点を宣言
線の終了地点の座標を渡します。
ここではウィンドウサイズ以上の数値を渡しても問題ありませんが、画面外には描画されません。4.
glEnd()で線の描画の終了を宣言
Minecraftのブロックモデルを描画してみる
やっと本題です。
前置き
プロジェクトを実現するにあたって、最初から全てを一気に実装しようとするのは大きな間違いです。
機能Aと機能Bと機能Cを実装したいとします。
これらをいっぺんに実装してしまい、バグや不具合が発生した場合、どの機能(のどの部分)がバグや不具合を引き起こしているのか特定が困難であったり、通常よりも原因の発見までに時間を要してしまいます。正しい手順は、
機能Aの実装 ▶ 動作確認 ▶機能Bの実装 ▶ 動作確認 ▶機能Cの実装
です。万が一
機能Cの実装後に不具合が発生した場合、機能Bから機能Cの間で不具合が発生しているんだな。
と考えることができます。より効率的です。
※それぞれの機能の互換性による不具合を除く初めは、最小構成での実装で動作確認を行いましょう。
前置きが長い。テクスチャの用意
とりあえず試験的に運用するので、Minecraftでもお馴染みのこのテクスチャを用意しました。
▼テクスチャ
いざ実装
用意したテクスチャを使用して実際に描画してみます!
ソースコードは長くなるので、Gistに掲載しました。▼ソースコード
Gist: main.py実行すると、以下のように描画されます。
※正常な状態です。
とりあえず、1面だけではありますが描画できました。
解説
部分部分抜き出しながら解説します。
ワールドクラス
描画する
Vertexを保持するBatchと呼ばれるものを定義します。self.batch = pyglet.graphics.Batch()そして、肝となる3次元座標を定義します。
ここでは0としてしまうと、初期カメラの場所との兼ね合い上画面外に描画されてしまい確認することができませんので、微妙にずらして定義しています。#3次元ワールド座標を定義 x = 0.5 y = 0 z = -2テクスチャのロードは関数を用意。
pygletのネイティブローダーを使います。
pathにはイメージのパッチを指定して下さい。#テクスチャをロードする関数 def load_texture(self, path): texture = pyglet.image.load(path).get_texture()#pygletのテクスチャローダーを使います glTexParameterf(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST) glTexParameterf(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST) return pyglet.graphics.TextureGroup(texture)ウィンドウクラス
お次はウィンドウクラスです。
このクラスは、pyglet.window.Windowクラスを継承しています。初期化関数では先程定義した
Worldクラスのインスタンスの初期化を行っています。
superはJavaと似てますね。def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) #ワールドクラスの初期化 self.world = World()そして、肝心の描画を行う関数を定義。
def on_draw(self): #スクリーンをクリア self.clear() #ワールドは3次元なので、3D描画モードに設定 self.render_mode_3d() #ワールドを描画 self.world.draw()ここで
render_mode_3d()関数ですが、
3D描画を行う際と2D描画を行う際にはマトリクスモードの設定が必要です。
これには投影変換モード(Projection)や視野変換モード(Modelview)があり、デフォルトでは視野変換モードになっています。
これらのマトリクスモードについては、後ほど解説します。注: モード変換処理の累積の消去(初期化)は
glLoadIdentity()を使用します。
def render_mode_3d(self): self.render_mode_projection() #視野を設定 gluPerspective(70, self.width / self.height, 0.05, 1000) self.render_mode_modelview() def render_mode_2d(self): self.render_mode_projection() #描画領域 0からwindow_width、 0からwindow_height gluOrtho2D(0, self.width, 0, self.height) self.render_mode_modelview() def render_mode_projection(self): glMatrixMode(GL_PROJECTION)#投影変換モード glLoadIdentity()#変換処理の累積を消去 def render_mode_modelview(self): glMatrixMode(GL_MODELVIEW)#モデリング変換モード(視野変換) glLoadIdentity()#変換処理の累積を消去
gluOrtho2Dでは、2Dにおける並行投射である投射変換を行います。
gluOrtho2D(left, right, top, bottom)
そして、
gluPerspective()では視野の設定を行います。
gluPerspective(fovY, aspect, zNear, zFar)
それぞれY軸の視野角、アスペクト(横方向の視野角)、Zの最短距離、Zの最長距離です。
また、
zNearとzFarはスクリーン上の見た目に変化を及ぼしません。
これは、自分がスクリーンに1m近付こうが、スクリーンを1m近付けようが同じことであることと同様に考えることができます。番外編
ここからは専門的な内容になりますので、興味の無い方は飛ばして頂いて大丈夫です。
マトリクスモード
マトリクスモードには、
視界変換(GL_PROJECTION)とモデリング変換(GL_MODELVIEW)があります。
※正確には、GL_TEXTUREもありますが当ソースでは扱っていないので飛ばします。また、3次元▶2次元の変換のことを
ジオメトリ変換
拡大縮小・移動の際の変換のことをアフィン変換
と呼びます。超長くなりそう & 興味のある人は一部だと思うので、外部記事に投げます。
ごめんなさい。ジオメトリ変換については詳しく解説している日本語の記事を見つけられませんでした。
プレイヤーの実装
ブロックを全面描画したいところですが、このままでは視点移動ができず不便なので、とりあえずプレイヤーとは名ばかりの視点移動君を実装します。
また、デバッグ情報の表示には「PyImGui」を使いました。▼ソースコード
Gist: main.py▼こんな感じ
ブロックを全面描画してみよう
ようやく視点移動と座標移動を自由に行えるようになったところで、ブロックを全面描画してみましょう。
ソースコードは以下の通りです。
方角を間違えていましたらごめんなさい。怖いので予め謝っておきます。▼ソースコード
Gist: main.py#方向間違えてたらごめんなさい #前面 self.batch.add(4, GL_QUADS, self.loaded_texture, ('v3f', (x, y, z, x, y, z+1, x, y+1, z+1, x, y+1, z,)), texture_coordinates) #後方 self.batch.add(4, GL_QUADS, self.loaded_texture, ('v3f', (x+1, y, z+1, x+1, y, z, x+1, y+1, z, x+1, y+1, z+1,)), texture_coordinates) #下面 self.batch.add(4, GL_QUADS, self.loaded_texture, ('v3f', (x, y, z, x+1, y, z, x+1, y, z+1, x, y, z+1,)), texture_coordinates) #上面 self.batch.add(4, GL_QUADS, self.loaded_texture, ('v3f', (x, y+1, z+1, x+1, y+1, z+1, x+1, y+1, z, x, y+1, z,)), texture_coordinates) #右側 self.batch.add(4, GL_QUADS, self.loaded_texture, ('v3f', (x+1, y, z, x, y, z, x, y+1, z, x+1, y+1, z,)), texture_coordinates) #左側 self.batch.add(4, GL_QUADS, self.loaded_texture, ('v3f', (x, y, z+1, x+1, y, z+1, x+1, y+1, z+1, x, y+1, z+1,)), texture_coordinates)▼こんな感じになりました
さて、動画からわかります通り、一部描画に異常がみられます。
これは、通常見えていない部分(後面)等の余計な部分が描画されていることが原因です。
これを防ぐために、glEnable(GL_DEPTH_TEST)を設定します。
これは、OpenGL側で勝手にいらない面の描画を選定/排除してくれる便利なものです。▼設定後は綺麗に描画されました!
最後に
今回は、ゲームエンジンの選定からモデル描画、プレイヤーの実装を行いました。
次回はワールドの構築と当たり判定の実装を行えればいいかなと思ってます。今回も最後までご覧頂きありがとうございました。






















- 投稿日:2020-01-24T19:11:23+09:00
Pythonを使ってインストルメントとボーカルを分けてカラオケ音源をつくりたい
[Python]Pythonを使ってボーカルとインストルメントを分けてカラオケ音源をつくりたい
私はPython未経験ですが、 Pythonのツールを使って簡単にインストルメントとボーカルを分けることができたので共有します。
まずはPythonをインストール
下記記事を参考にPythonをインストール
$ brew install pyenv $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profile $ exec $SHELL -lプロジェクトはPython3を使ってるのでanaconda3をインストール
$ pyenv install anaconda3-2019.10 $ pyenv global anaconda3-2019.10https://qiita.com/aical/items/2d066801a7464a676994
spleeterをインストール
今回使用するツールはspleeter
https://github.com/deezer/spleeter
参考動画
https://www.youtube.com/watch?v=HqanOjPBRAQ$ git clone https://github.com/Deezer/spleeter $ conda install -c conda-forge spleeterこれで準備は終わりました。
インストルメントとボーカルを分けてみる
プロジェクトファイルのspleeterフォルダの中に分けたい音源を入れときます。
$ spleeter separate -i spleeter/(分けたい音源のファイル名).mp3 -p spleeter:2stems -o outputこのコマンドを打って処理が完了するとspleetrと同じディレクトリにoutputフォルダが生成されます。その中にインストルメントとボーカルのファイルが入っていれば成功です。
まとめ
男性ボーカルは少し分けにくかったです。女性ボーカルのほうがきれいに抜けていました。友人いわくこのソフトでインストルメントとボーカルを分ける前に作曲ソフトの方でイコライザーを使って低音を削ってあげると抜きやすいらしいです。
- 投稿日:2020-01-24T18:21:40+09:00
【Python】MeCab+TermExtractで抽出した重要語でMeCabの出力するテキストを置換する
初めに
termextractについて以下の記事を読ませてもらいました。
termextractを使って保持データから専門用語を抽出しmecabのユーザ辞書を作成する - Qiita形態素解析を行うにあたっては、その業界ならではの単語などをまとめた専門用語辞書を作っておくと分かち書きされる際に良い形となりやすいと言うことで、termextractを使ってmecabのユーザ辞書を作ることにした。
今の抽出結果を反映させて確認したいだけだったので、辞書を出力するほどではないな…と。
というわけで、MeCabの出力と同じ形式で文字列を吐き出せるようなクラスを作成しました。環境
Python 3.7.5
mecab-python 0.996.3
termextract 0.12b0使い方
`MeCab.parse()の結果を受けながらオブジェクトを作成し、getそれと同じ形式で文字列を返します。
mainimport MeCab text = "羅生門が、朱雀大路にある以上は、この男のほかにも、雨やみをする市女笠や揉烏帽子が、もう二三人はありそうなものである。" mecab = MeCab.Tagger() mecab_text = mecab.parse(text) # MeCabの結果を渡す TX = TermExtract(mecab_text) extracted = TX.get_extracted_words() # 重要な語を抽出 modified_text = TX.get_modified_mecab_text() # 重要な語を元に単語を連結したテキスト print(modified_text)実行結果羅生門 名詞,固有名詞,一般,*,*,*,羅生門,ラショウモン,ラショーモン が 助詞,格助詞,一般,*,*,*,が,ガ,ガ 、 記号,読点,*,*,*,*,、,、,、 朱雀大路 名詞,一般,*,*,*,*,朱雀大路,スザクオオジ,スザクオージ に 助詞,格助詞,一般,*,*,*,に,ニ,ニ ある 動詞,自立,*,*,五段・ラ行,基本形,ある,アル,アル 以上 名詞,非自立,副詞可能,*,*,*,以上,イジョウ,イジョー は 助詞,係助詞,*,*,*,*,は,ハ,ワ 、 記号,読点,*,*,*,*,、,、,、 ...
朱雀大路は、MeCabでは朱雀と大路に分けられるのですが、termextractで連続した語として抽出されるため、連結されます。ソースコード
全体はgithubに上げてあります。
自分好みにコーディングしたところについて書いておきます。形態素の連結について
複数の形態素を連結する時、[表層系, 原形, 読み, 発音] のみ文字列結合しています。
その他を文字列結合しない理由は、例えば「名詞名詞」のような新しい品詞ができてしまうのを避けるためです。
文字列結合しない場合、連結する最後の語の値を採用しています。my_termextract.pydef concat_morph(morphs): ''' 複数の形態素の結合を行う。 結合するのは [表層系, 原形, 読み, 発音] のみ。 その他はリストの最後の要素に合わせる。 Input: 形態素のリスト Output: 結合された形態素 ''' import copy new_morph = list(copy.deepcopy(morphs[-1])) # 表層系 new_morph[0] = "".join(x[0] for x in morphs) # 原形 new_morph[7] = "".join(x[7] for x in morphs if x[7]!="*") # 読み new_morph[8] = "".join(x[8] for x in morphs if x[8]!="*") # 発音 new_morph[9] = "".join(x[9] for x in morphs if x[9]!="*") return tuple(new_morph)例
朱雀 名詞,固有名詞,地域,一般,*,*,朱雀,スザク,スザク 大路 名詞,一般,*,*,*,*,大路,オオジ,オージ↓
朱雀大路 名詞,一般,*,*,*,*,朱雀大路,スザクオオジ,スザクオージ連結する単語の選定について
extracted_wordsに含まれる「2以上の語で構成される語」が対象となります。
基本的にはtermextractの結果を格納しているのですが、他に連結したい語がある場合や連結したくない語がある場合は、extracted_wordsを上書きすることで対応可能です。my_termextract.pyfor cmp_noun in self.extracted_words: # 表層系の取得 surfaces, *_ = zip(*self.morphs) # スペースで区切る cmp_list = cmp_noun.split(" ") len_cmp = len(cmp_list) # 連結語でない場合はcontinue if len_cmp < 2: continue # 連結語とマッチしたインデックス match_indeces = [i for i in range(len(surfaces)-len_cmp+1) if surfaces[i:i+len_cmp]==tuple(cmp_list)]termextractのパラメータについて
冒頭の記事を参考にしています。
termextractを使って保持データから専門用語を抽出しmecabのユーザ辞書を作成する - Qiitamy_termextract.py# 複合語を抽出し、重要度を算出 frequency = termextract.mecab.cmp_noun_dict(self.mecab_text) LR = termextract.core.score_lr(frequency, ignore_words=termextract.mecab.IGNORE_WORDS, lr_mode=1, average_rate=1 ) term_imp = termextract.core.term_importance(frequency, LR)最後に
MeCabの結果を受けてその後の処理を実装した場合に、差し込んで使えたら便利かなぁと思って作成しました。
とりあえずの確認には使えると思います。
※コードが汚いのでリファクタリング予定です。記事に書いた部分で変更した場合、書き換えるようにします。参考にしたページ
- 投稿日:2020-01-24T18:18:12+09:00
Numpyのブロードキャストについて
ブロードキャストとは
Numpyでは、次元の異なる行列同士の演算を行う際に自動で適切な形に変換してくれる機能が備わっており、これをブロードキャストと呼びます。
見たほうが早いと思うので以下に書きます。A = np.array([1, 2, 3, 4, 5]) print(f'{"="*20}A') print(A) print(f'{"="*20}A-1') # (1, 5)行列とスカラ値の演算 print(A - 1)====================A [1 2 3 4 5] ====================A-1 [0 1 2 3 4]内部の挙動
Numpyでは次元の異なる行列の演算を行う際に自動で次元を合わせてくれています。
例えば、$(m, n) + (1, n)$の演算では$(1, n)$を拡張して$(m, n)$に変換しています。$$
\begin{bmatrix}
1 & 2 & 3 & 4 & 5\\
6 & 7 & 8 &9 & 10
\end{bmatrix}
-
\begin{bmatrix}
1 & 2 & 3 & 4 & 5
\end{bmatrix}\\
=
\begin{bmatrix}
1 & 2 & 3 & 4 & 5\\
6 & 7 & 8 &9 & 10
\end{bmatrix}
-
\begin{bmatrix}
1 & 2 & 3 & 4 & 5\\
1 & 2 & 3 & 4 & 5
\end{bmatrix}
$$A = np.array([ [1, 2, 3, 4, 5], [6, 7, 8, 9, 10]]) B = np.array([1, 2, 3, 4, 5]) print(f'{"="*20}A') print(A) print(f'{"="*20}B') print(B) print(f'{"="*20}A - B') print(A - B)====================A [[ 1 2 3 4 5] [ 6 7 8 9 10]] ====================B [1 2 3 4 5] ====================A - B [[0 0 0 0 0] [5 5 5 5 5]]
- 投稿日:2020-01-24T17:49:37+09:00
文字列からそれぞれの文字がいくつあるか調べる。
1s = 'aeqwtwegwa' d = {} for c in s: if c not in d: d[c] = 0 d[c] += 1 print(d)1の実行結果{'a': 2, 'e': 2, 'q': 1, 'w': 3, 't': 1, 'g': 1}2s = 'aefqwdqfqwe' d = {} for c in s: d.setdefault(c, 0) d[c] += 1 print(d)2の実行結果{'a': 1, 'e': 2, 'f': 2, 'q': 3, 'w': 2, 'd': 1}標準ライブラリからdefaultdictを読み込んで書くと、
3from collections import defaultdict s = 'raegiowejgohg' d = defaultdict(int) for c in s: d[c] += 1 print(d) print(d['g'])3の実行結果defaultdict(<class 'int'>, {'r': 1, 'a': 1, 'e': 2, 'g': 3, 'i': 1, 'o': 2, 'w': 1, 'j': 1, 'h': 1}) 3
- 投稿日:2020-01-24T16:44:13+09:00
Pythonで読み込んだ画像にフィルタをかけるモジュールをC言語で作った
仕事で、Pythonを使って画像処理をする必要に迫られました。OpenCVなどでできる範囲ならそれでいいのですが、独自アルゴリズムのフィルタはC/C++でないと実用的な速度が出ません。そこで、Python用のモジュールをC言語で作ってみました。
早く試してみたい方は、私のリポジトリをご利用ください。
https://github.com/soramimi/pymodule-image-filterPython用自作モジュールの作り方
依存モジュールのインストール
最初のお試しは
helloworldなので不要ですが、後の画像処理編ではnumpy、pillow、matplotlibを使用していますので、これらのモジュールがインストールされている必要があります。Ubuntuで開発する想定です。Pythonの開発用パッケージが必要です。
sudo apt install python3-dev python3-matplotlib関数定義の構造体を書く
static PyMethodDef myMethods[] = { { "helloworld", helloworld, METH_NOARGS, "My helloworld function." }, { NULL } };定義の内容は {(関数名),(関数へのポインタ),(引数受け渡し方法),(説明文)} の順に記述します。
METH_NOARGSとなっているのは、引数がない関数の場合です。引数を利用するにはMETH_VARARGSとします。モジュール定義の構造体を書く
static struct PyModuleDef mymodule = { PyModuleDef_HEAD_INIT, "mymodule", "Python3 C API Module", -1, myMethods };モジュール名や説明などを書きます。
モジュールを初期化する関数を書く
PyMODINIT_FUNC PyInit_mymodule(void) { import_array(); return PyModule_Create(&mymodule); }
import_array()という関数呼び出しは、必要に応じて書きます。今回のテーマでは、画像処理で配列を扱うのでこれが必要です。配列を使わないなら不要です。配列APIを使用する全てのソースコードでimport_array()を実行する必要があります。関数本体を書く
static PyObject *helloworld(PyObject *self, PyObject *args) { fprintf(stderr, "Hello, world\n"); return Py_None; }最初のお試し関数なので
helloworldです。後ほど、画像処理を行うコードを実装していきます。ビルド用スクリプトを書く
setup.pyfrom distutils.core import setup, Extension setup(name = 'mymodule', version = '1.0.0', ext_modules = [Extension('mymodule', ['mymodule.c'])])ビルドする
python3 setup.py build_ext -i長い名前の
.soファイルができたら成功です。$ ls *.so mymodule.cpython-35m-x86_64-linux-gnu.so呼び出し(Python側)プログラムを書く
main.pyimport mymodule mymodule.helloworld()実行する
Pythonのプログラムとモジュールの
.soファイルを同じディレクトリに置いた状態で実行します。$ python3 main.py Hello, world画像処理フィルタを作る
例として、セピア調のフィルタをかける関数にします。関数名は
helloworldからsepiaに変更しています。Python側のプログラムは次のようになります。
main.pyfrom PIL import Image import numpy as np import matplotlib.pyplot as plt import mymodule im = np.array(Image.open('kamo.jpg')) im = mymodule.sepia(im) print(type(im)) print(im.dtype) print(im.shape) plt.imshow(im) plt.show()次のように動作します。
- 画像ファイルを読み込む
- フィルタをかける
- 配列の情報を表示する
- 画像を表示する
関数定義を以下のようにします。
{ "sepia", sepia, METH_VARARGS, "Sepia tone image filter" },C言語側ソースの抜粋です。
mymodule.cstatic PyObject *sepia(PyObject *self, PyObject *args) { PyArrayObject *srcarray; if (!PyArg_ParseTuple(args, "O", &srcarray)) { fprintf(stderr, "invalid argument\n"); return Py_None; }最初の(と言っても1個だけ)引数は配列です。オブジェクトとして取得します。
入力の配列は、(高さ)×(幅)×(チャンネル)の3次元配列ですので、そうでなければエラーとします。チャンネル数は3(RGB)に限定します。
if (srcarray->nd != 3) { fprintf(stderr, "invalid image\n"); return Py_None; } if (srcarray->dimensions[2] != 3) { fprintf(stderr, "invalid image\n"); return Py_None; }画像のサイズを取得します。
int h = srcarray->dimensions[0]; int w = srcarray->dimensions[1];フィルタ処理結果の画像を格納する配列を確保します。
npy_intp dims[] = { h, w, 3 }; PyObject *image = PyArray_SimpleNew(3, dims, NPY_UBYTE); if (!image) { fprintf(stderr, "failed to allocate array\n"); return Py_None; }(高さ)×(幅)×(チャンネル)の順番を間違えないでください。
配列として確保したオブジェクトは、そのまま配列構造体へのポインタにキャストできます。
PyArrayObject *dstarray = (PyArrayObject *)image;フィルタをかけます。
for (int y = 0; y < h; y++) { uint8_t const *src = (uint8_t const *)srcarray->data + y * w * 3; uint8_t *dst = (uint8_t *)dstarray->data + y * w * 3; for (int x = 0; x < w; x++) { uint8_t r = src[x * 3 + 0]; uint8_t g = src[x * 3 + 1]; uint8_t b = src[x * 3 + 2]; r = pow(r / 255.0, 0.62) * 205 + 19; g = pow(g / 255.0, 1.00) * 182 + 17; b = pow(b / 255.0, 1.16) * 156 + 21; dst[x * 3 + 0] = r; dst[x * 3 + 1] = g; dst[x * 3 + 2] = b; } }オブジェクトを返して終了です。
return image; }以上です。
エラー処理は省略しています。不正な画像ファイルを受け取った時など、関数が
None(Py_None)を返した場合のために、実用のプログラムでは適切なエラー処理を行ってください。冒頭にも書きましたが、全ソースコードはこちらで公開しています。

- 投稿日:2020-01-24T15:56:31+09:00
numpyをストレスなく使う!(エラー「AttributeError: 'float' object has no attribute 'sin'」の解釈(対処?))
目的
numpyをストレスなく使う!
Pythonで計算などをする場合には、numpyが頻繁に使われる。そのため、numpy関連のエラーに出会うことも少なくない。
エラーを早めに解決するためには、少しでも、理解のレベルを上げる必要あり。
なんでも、こだわって、、、、理解を深める。ここで、取り上げるエラーは、以下。
AttributeError: 'float' object has no attribute 'sin'どのような場面で出るかというと、例えば、以下。
>>> >>> import numpy as np >>> a = np.array([1.1, 2.2],dtype=object) >>> np.sin(a) Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'float' object has no attribute 'sin' >>>このエラーをとりあげる理由は、
エラーの意味がわからない
だろうと思うため。
'float'オブジェクトが、sinを持たない
と言われているが、そんな処理は、依頼してないし。。。。検討環境
Name: numpy
Version: 1.16.4エラーの説明
このエラーに対しては、以下の記事が参考になる。
https://github.com/numpy/numpy/issues/13666
ここでの報告者の方は、
Many NumPy methods fail if an array has dtype object, and produce a misleading error message.
他力で、日本語にすると(Google翻訳(ママ) )
配列にdtypeオブジェクトがある場合、多くのNumPyメソッドは失敗し、誤解を招くエラーメッセージが生成されます。
と主張されている。
⇒そのとおりだと思う。このサイトでのやり取りの結論は、よくわからないのですが、、、
とにかく、
numpy側も
エラーメッセージがあまり適切でない
ことは、認めているよう。
治しているようにも読めるが。。。。治ってない気がします。エラーの対処方法
エラーの対処方法は、そもそも、何がやりたいのかにもよるが、
経緯上、dtype=objectである必要があるのであれば、
sinの計算の前に、astypeでキャストする
などがいいと思う。>>> a = np.array([1.1, 2.2],dtype=object) >>> np.sin(a) Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'float' object has no attribute 'sin' >>> np.sin(a.astype(np.float64)) array([0.89120736, 0.8084964 ]) >>>まとめ
わずかに、numpyに詳しくなった。
numpyは、深いので、まだ、誤差の範囲だと思うが。関連(本人)
今後
numpy、学ぶぞーーーー。
コメントなどあれば、お願いします。
- 投稿日:2020-01-24T15:26:35+09:00
PythonでCSVから、insert文を生成する。
PythonでCSVから、insert文を生成する。
概要
一定のルールに従ったCSVを用意して、そこからinsert文を生成するスクリプト
Excelシートで同様のものを作っている事例も見かけるね一定のルールとは
1.ファイル名(拡張子を除く)がテーブル名
2.ヘッダありのcsvとし、カラム名はDBカラム名と一致しているものとする。課題があって、 CSVだけでは、テーブルに対する型の情報が無いので、''でくくるかどうかの判定ができない
この例では、一旦全て囲っている。
実務的には、後で正規表現で置換とかやればいいという考え利用環境
Python 3.7.2
Visual Studio Code 1.39.1ソースコード
CSV2insSQL.py#CSVから、insert文を生成する。 #ルール #ファイル名(拡張子を除く)がテーブル名 #ヘッダありのcsvとし、カラム名はDBカラム名と一致しているものとする。 #課題!! CSVだけでは、テーブルに対する型の情報が無いので、''でくくるかどうかの判定ができない # この例では、一旦全て囲っている (実用的には、後で正規表現で置換とか) import csv import os FROM_CSV = '.\\CSV\\' + "xxx_LIST.csv" def main(): #本体処理 #...マスタのinsert生成 with open(".\\CSV\\insertSQL.txt", "w", newline="",encoding="cp932") as wf: #ファイル名からテーブル名へ tablename = os.path.splitext(os.path.basename(FROM_CSV))[0] with open(FROM_CSV, encoding="cp932",) as f: reader = csv.DictReader(f) for row in reader: #insert文生成 insert_sql = "insert into " + tablename fields = ",".join(reader.fieldnames) insert_sql = insert_sql + "( " + fields + ") VALUES" valuelist = [] for fld in reader.fieldnames: #課題!! CSVだけでは、テーブルに対する型の情報が無いので、''でくくるかどうかの判定ができない # この例では、一旦全て囲っている valuelist.append("'" + row[fld] + "'") valustr = ",".join(valuelist) insert_sql = insert_sql + "( " + valustr + ");" wf.write(insert_sql+"\n") if __name__ == '__main__': main()
- 投稿日:2020-01-24T15:13:44+09:00
Python-peewee使用连接方式
方法1
To connect to a MySQL database, we will use MySQLDatabase. After the database name, you can specify arbitrary connection parameters that will be passed back to the driver (either MySQLdb or pymysql).
# http://docs.peewee-orm.com/en/latest/peewee/database.html#using-mysql from peewee import ( MySQLDatabase, Model, DateTimeField, ) # MySQL连接 db = MySQLDatabase('my_database') class BaseModel(Model): """ DB-Base """ class Meta: database = db created_at = DateTimeField(default=datetime.datetime.now) updated_at = DateTimeField(default=datetime.datetime.now) def save(self, *args, **kwargs): self.updated_at = datetime.datetime.now() return super(BaseModel, self).save(*args, **kwargs)参照
http://docs.peewee-orm.com/en/latest/index.html
方法2
Connection pooling is provided by the pool module, included in the playhouse extensions library.
The pool supports:
- Timeout after which connections will be recycled.
- Upper bound on the number of open connections.#http://docs.peewee-orm.com/en/latest/peewee/database.html#connection-pooling from playhouse.pool import PooledMySQLDatabase from peewee import ( Model, UUIDField, CharField, ) # MySQL连接 db = PooledMySQLDatabase('my_database', max_connections=my['max_connections'])参照
https://stackoverflow.com/questions/34764266/peewee-pooledmysqldatabase-has-cache-or-buffer
Q:peewee PooledMySQLDatabase has cache or buffer?
A:
No cache, no buffer. It has to do with transaction management. Just be sure that you're running your statements in transactions and you should be fine.Multi-threaded apps DO NOT REQUIRE A POOL with peewee. Peewee correctly manages per-thread connections even without a pool.
方法3
peewee-async is a library providing asynchronous interface powered by asyncio for peewee ORM.
#https://peewee-async.readthedocs.io/en/latest/ import peewee_async from peewee import ( Model, UUIDField, CharField, ) # 自定义连接类 class AsyncMySQLConnection(peewee_async.AsyncMySQLConnection): """ Asynchronous database connection pool. """ def __init__(self, *, database=None, loop=None, timeout=None, **kwargs): self.pool = None self.loop = loop self.database = database self.timeout = timeout kwargs.setdefault('pool_recycle', 3600) self.connect_params = kwargs # MySQL连接 db = peewee_async.PooledMySQLDatabase('my_database' max_connections=my['max_connections'], async_conn=AsyncMySQLConnection)参照
https://www.w3cschool.cn/hack_tutorial/hack_tutorial-qay32dz7.html
- 投稿日:2020-01-24T14:37:35+09:00
【Python】特定の文字列で始まる要素のみを配列に残す
はじめに
備忘録。
特定の文字列から始まる要素のみを配列に残したい。
['hogehoge.form', 'hugahuga.form', 'hogehoge.form2']という配列があり、hogehogeから始まる要素のみを残し、他の要素は削除したい。解決方法
文字列メソッド
startswith()を使う文字列の先頭を判別できるメソッド
moji = 'hogehoge' # trueを返す moji.startswith('hoge') # falseを返す moji.startswith('huga')サンプルコード
# 元の配列 moji_ary = ['hogehoge.form', 'hugahuga.form', 'hogehoge.form2'] # 新しい配列new_aryに、元の配列moji_aryの要素のうち`ho`から始まる要素のみを入れる new_ary = [hoge for hoge in moji_ary if hoge.startswith('ho')] # 出力結果['hogehoge.form', 'hogehoge.form2'] print(new_ary)さいごに
文字列の後尾(?)を判定するメソッド
endswith()もある。
「python 文字列操作」でググると他にも便利なものが見つかる。参考サイト
- 投稿日:2020-01-24T14:36:54+09:00
いらすとやの画像をドット絵にしたった。(part1)
Motive
ご存知の通りいらすとやは今トレンドのフリー素材をリリースし続けています。ふとこれらの画像をドット絵にしたらどうなるかが気になったので作成してみました。
Method
魔法使いの森に書いていたのですがファミコンの表示配色は52くらいだと言われています。(確定的でない。)
ここでは、ファミコンに似せるためにR,G,Bそれぞれの配色を4分割に減色して表示してみようと思います。それぞれの範囲は
0 ~ 255ですが単純に分割すると、[0, 85, 170, 255]となります。全ての色の組み合わせは
64パターンあるのですが実際に画像として出力すると下記の表示になります。import cv2 import numpy as np if __name__ == "__main__": height = 576 width = 1024 range_color = [0, 85, 170, 255] mono = np.zeros((height, width, 3), np.uint8) mono[:] = tuple((0,0,0)) for r in range(4): for g in range(4): for b in range(4): mono[144*b:144*(b+1), 64*(r+g*4):64*(r+(g*4+1))] = tuple((85*b,85*g,85*r)) cv2.imwrite("out.png", mono)
余談ですが、パッと見灰色がない、と思ったのですが2行6列
(85,85,85)、3行11列(170,170,170)にそれぞれ表示されています。それで、どのようにもとの色データの数字によって判定するかですが、 一つの例として
110の値を振り分けたい場合、85 ~ 170がどちらが近いかを判定します。ここでは85が一番近いので110 -> 85に変換して、全ての画素にこのアルゴリズムを適合させます。Develop
import cv2 import numpy as np import sys def resize(src): h,w = mat.shape[:-1] height = (h // 16) * 16 width = (w // 16)* 16 return cv2.resize(mat,(width,height)) def convertReduceColor(src): thresholds = [42,127,212] range_color = [0, 85, 170, 255] count = 0 for th in thresholds: if src <= th: break count += 1 return range_color[count] if __name__ == "__main__": __CELL_SIZE__ = 4 path = sys.argv[1] mat = cv2.imread(path,cv2.IMREAD_UNCHANGED) mat = resize(mat) height, width = mat.shape[:-1] for w in range(width//__CELL_SIZE__-1): for h in range(height//__CELL_SIZE__-1): c = np.mean( np.mean( mat[h*__CELL_SIZE__:(h+1)*__CELL_SIZE__, w*__CELL_SIZE__:(w+1)*__CELL_SIZE__], axis=0 ), axis=0 ) mat[ h*__CELL_SIZE__:(h+1)*__CELL_SIZE__, w*__CELL_SIZE__:(w+1)*__CELL_SIZE__ ] = tuple([convertReduceColor(c[0]), convertReduceColor(c[1]), convertReduceColor(c[2]), c[3]]) cv2.imwrite("output.png",mat)
np.mean(np.mean(mat[h*__CELL_SIZE__:(h+1)*__CELL_SIZE__, w*__CELL_SIZE__:(w+1)*__CELL_SIZE__], axis=0),axis=0)
ここでセルの大きさから画素の平均値を取得しています。
また、convertReduceColorでRGBそれぞれに対して近似判定しています。Result
ソース画像 画素の大きさ 処理後 4 8 16 4 8 16 4 8 16
- 一番成功したのはセルの大きさを16にした猫の画像です。右端は処理できていないですが全体的にそれっぽいドット絵になっていると思います。右端もドット調にするときはリサイズ処理を再考しないとダメっぽいです。
- ドット絵に変換するときは一枚のイラストの中に人物・物体が一つの方が処理が成功しやすいです。
- 基本的にいらすとやの画像ですが凸凹なフェルト調で区画を塗り潰しているのが特徴です。そのためあるオブジェクトに一色で塗り潰されておらずノイズが入っているように見えます。
- セルの大きさを4にしたペンギンの画像の目が(´・ω・`)としている。いらすとやのキャラクターは基本的に目が点になっていて小さいのでセルの大きさを高くすると消えてしまうため注意が必要です。
Future
- ノイズが気になるので変則的な二値化とモルフォロジー変換でなんとかなりそう
- 実際のファミコン色ですが今回使った配色と異なるので、使う50くらいの配色を固定値で埋め込んで近傍探索でマッチングさせた方が良さそうです
Reference














- 投稿日:2020-01-24T13:58:26+09:00
パーセプトロンを使って論理演算を実行する
はじめに
パーセプトロンとは何か、を理解することが目標です.
パーセプトロンとは
複数の信号を入力として受け取り、ひとつの信号を出力します. 出力信号は0または1の二値をとるものです.
x1,x2は入力信号、yは出力信号、w1,w2は重みを表します. ○はノード、またはニューロンと呼ばれます.
入力信号はそれぞれに固有の重みが乗算され、ニューロンに送られます. ニューロンでは、送られてきた信号の総和(x1w1 + x2w2)に対して出力を行います. その際、ある閾値(限界値)を超えると1を出力、閾値に満たない場合は0を出力します.入力と出力が直結し、単純化されたモデルを単純パーセプトロンといいます. 対して、入力と出力の間に層(中間層、隠れ層)があるモデルを多層パーセプトロンといいます.
パーセプトロンの動作原理を表す式
y = \left\{ \begin{array}{ll} 0 & (x_1 w_1 + x_2 w_2 \leq \phi) \\ 1 & (x_1 w_1 + x_2 w_2 \gt \phi) \end{array} \right.x : 入力信号, w : 重み, $ \phi $ : 閾値
閾値が扱いづらいのでマイナス値をつけて左辺に移項します. 移行したものを$b$ (バイアス)とします. バイアスは発火のしやすさ、しにくさを決めます. バイアスが大きい→発火しやすい(入力信号の総和が0を超えやすい).
y = \left\{ \begin{array}{ll} 0 & (b + x_1 w_1 + x_2 w_2 \leq 0) \\ 1 & (b + x_1 w_1 + x_2 w_2 \gt 0) \end{array} \right.
パラメータ(バイアスと重み)を発火条件に沿うように調節します.
AND演算
import numpy as np def AND(x1, x2): x1_x2 = np.array([x1, x2]) b = -0.8 w1_w2 = np.array([0.5, 0.5]) tmp = b + np.sum(x1_x2 * w1_w2) if tmp <= 0: return 0 elif tmp > 0: return 1
- 入力xは0または1
- ($x_1$, $x_2$)=(1, 1)のときのみ発火(計算結果が0を超える)
という条件に沿うようにパラメータを調節します.
($b$, $w_1$, $w_2$)に適当な値を代入します.
上のコードでは(-0.8, 0.5, 0.5)となっていますが、たとえば(-0.3, 0.2, 0.2)でも再現できます.NAND演算はAND演算のバイアスと重みの符号を反転します.
OR演算
import numpy as np def OR(x1, x2): x1_x2 = np.array([x1, x2]) b = -0.3 #変更 w1_w2 = np.array([0.5, 0.5]) tmp = b + np.sum(x1_x2 * w1_w2) if tmp <= 0: return 0 elif tmp > 0: return 1バイアス$b$が変わりました.
XOR演算
import numpy as np # NAND演算 def NAND(x1, x2): x1_x2 = np.array([x1, x2]) b = 0.8 w1_w2 = np.array([-0.5, -0.5]) tmp = b + np.sum(x1_x2 * w1_w2) if tmp <= 0: return 0 elif tmp > 0: return 1 # OR演算 def OR(x1, x2): x1_x2 = np.array([x1, x2]) b = -0.3 w1_w2 = np.array([0.5, 0.5]) tmp = b + np.sum(x1_x2 * w1_w2) if tmp <= 0: return 0 elif tmp > 0: return 1 # AND演算 def AND(x1, x2): x1_x2 = np.array([x1, x2]) b = -0.8 w1_w2 = np.array([0.5, 0.5]) tmp = b + np.sum(x1_x2 * w1_w2) if tmp <= 0: return 0 elif tmp > 0: return 1 # XOR演算 def XOR(x1, x2): nand_ = NAND(x1, x2) or_ = OR(x1, x2) xor_ = AND(nand_, or_) return xor_XOR演算は入力と出力を直結したモデル(単純パーセプトロン)では表現できないので、中に層をかませます. 多層パーセプトロンです. 今回はNANDとORした結果をANDしました.
単純パーセプトロンで表現できないということは、線形分離不可能ということです. グラフを書いて確認してみてください.さいごに
- パーセプトロンはある入力を与えたとき、発火するか否かによって決まった値が出力される
- パラメータとして重みとバイアスを持つ
- 単純パーセプトロンは線形分離可能なモデルに使用する
- 線形分離不可能なモデル場合、中間層をもった多層パーセプトロンを使用する
こんな感じでしょうか...


- 投稿日:2020-01-24T13:58:00+09:00
クマ...じゃなくて セマンティック・セグメンテーション
画像を扱うディープラーニング(深層学習)のうち、注目しているモノを抜き出す「セマンティック・セグメンテーション」について勉強してみました。
クマ画像の生成
セマンティック・セグメンテーションを学ぶにあたって、最初に困ったのが、画像の取得。いい感じのがなかなか見当たらなかったので、練習用の画像を自動生成するところから行いました。
コアラとクマの画像を自動生成する で作成した関数を用いて、セマンティック・セグメンテーションのための「画像データ」と「正解データ」を自作します。
from PIL import ImageFilter import numpy as np def getdata_for_semantic_segmentation(im): x_im = im.filter(ImageFilter.CONTOUR) # 輪郭をとったものを「画像データ」し入力に用いる a_im = np.asarray(im) # numpy に変換 # 黒クマさんを白クマさんにし、それ以外を黒にしたものを「正解データ」とする y_im = Image.fromarray(np.where(a_im == 1, 255, 0).astype(dtype='uint8')) return x_im, y_im次のようにして、2000個のデータセットを作成しました。
X_data = [] # 画像データ格納用 Y_data = [] # 正解データ格納用 for i in range(2000): # 画像を2000個生成する # クマの画像を生成 im = koala_or_bear(bear=True, rotate=True , resize=64, others=True) # セマンティック・セグメンテーション用に加工 x_im, y_im = getdata_for_semantic_segmentation(im) X_data.append(x_im) # 画像データ Y_data.append(y_im) # 正解データ作成した画像データ、正解データの最初の8件だけ図示して確認。
%matplotlib inline import matplotlib.pyplot as plt fig = plt.figure(figsize=(10,10)) for i in range(16): ax = fig.add_subplot(4, 4, i+1) ax.axis('off') if i < 8: # 画像データのトップ8を表示 ax.set_title('input_{}'.format(i)) ax.imshow(X_data[i],cmap=plt.cm.gray, interpolation='none') else: # 正解データのトップ8を表示 ax.set_title('answer_{}'.format(i - 8)) ax.imshow(Y_data[i - 8],cmap=plt.cm.gray, interpolation='none') plt.show()
セマンティック・セグメンテーションの目的は、上の「画像データ」から、クマさんに相当する部分を抜き出して「正解データ」を出力するようなモデルを構築することです。
クマンティック・セグメンテーションモデルの構築
データの整形
import torch from torch.utils.data import TensorDataset, DataLoader # 画像データと正解データを ndarray に変換 X_a = np.array([[np.asarray(x).transpose((2, 0, 1))[0]] for x in X_data]) Y_a = np.array([[np.asarray(y).transpose((2, 0, 1))[0]] for y in Y_data]) # ndarray の画像データと正解データを tensor に変換 X_t = torch.tensor(X_a, dtype = torch.float32) Y_t = torch.tensor(Y_a, dtype = torch.float32) # PyTorch で学習するためにデータローダーに格納 data_set = TensorDataset(X_t, Y_t) data_loader = DataLoader(data_set, batch_size = 100, shuffle = True)モデルの定義
セマンティック・セグメンテーションを行うモデルは、基本的には、畳み込みニューラルネットワーク (CNN)を使ったオートエンコーダーです。
from torch import nn, optim from torch.nn import functional as F class Kuma(nn.Module): def __init__(self): super(Kuma, self).__init__() # エンコーダー部分 self.encode1 = nn.Sequential( *[ nn.Conv2d( in_channels = 1, out_channels = 6, kernel_size = 3, padding = 1), nn.BatchNorm2d(6) ]) self.encode2 = nn.Sequential( *[ nn.Conv2d( in_channels = 6, out_channels = 16, kernel_size = 3, padding = 1), nn.BatchNorm2d(16) ]) self.encode3 = nn.Sequential( *[ nn.Conv2d( in_channels = 16, out_channels = 32, kernel_size = 3, padding = 1), nn.BatchNorm2d(32) ]) # デコーダー部分 self.decode3 = nn.Sequential( *[ nn.ConvTranspose2d( in_channels = 32, out_channels = 16, kernel_size = 3, padding = 1), nn.BatchNorm2d(16) ]) self.decode2 = nn.Sequential( *[ nn.ConvTranspose2d( in_channels = 16, out_channels = 6, kernel_size = 3, padding = 1), nn.BatchNorm2d(6) ]) self.decode1 = nn.Sequential( *[ nn.ConvTranspose2d( in_channels = 6, out_channels = 1, kernel_size = 3, padding = 1), ]) def forward(self, x): # エンコーダー部分 dim_0 = x.size() # デコーダー第1層でサイズを元に戻すとき用 x = F.relu(self.encode1(x)) # return_indices = True にして、デコーダーで max_pool の位置idxを用いる x, idx_1 = F.max_pool2d(x, kernel_size = 2, stride = 2, return_indices = True) dim_1 = x.size() # デコーダー第2層でサイズを元に戻すとき用 x = F.relu(self.encode2(x)) # return_indices = True にして、デコーダーで max_pool の位置idxを用いる x, idx_2 = F.max_pool2d(x, kernel_size = 2, stride = 2, return_indices = True) dim_2 = x.size() x = F.relu(self.encode3(x)) # デコーダー第3層でサイズを元に戻すとき用 # return_indices = True にして、デコーダーで max_pool の位置idxを用いる x, idx_3 = F.max_pool2d(x, kernel_size = 2, stride = 2, return_indices = True) # デコーダー部分 x = F.max_unpool2d(x, idx_3, kernel_size = 2, stride = 2, output_size = dim_2) x = F.relu(self.decode3(x)) x = F.max_unpool2d(x, idx_2, kernel_size = 2, stride = 2, output_size = dim_1) x = F.relu(self.decode2(x)) x = F.max_unpool2d(x, idx_1, kernel_size = 2, stride = 2, output_size = dim_0) x = F.relu(self.decode1(x)) x = torch.sigmoid(x) return x学習
%%time kuma = Kuma() loss_fn = nn.MSELoss() optimizer = optim.Adam(kuma.parameters(), lr = 0.01) total_loss_history = [] epoch_time = 50 for epoch in range(epoch_time): total_loss = 0.0 kuma.train() for i, (XX, yy) in enumerate(data_loader): optimizer.zero_grad() y_pred = kuma(XX) loss = loss_fn(y_pred, yy) loss.backward() optimizer.step() total_loss += loss.item() print("epoch:",epoch, " loss:", total_loss/(i + 1)) total_loss_history.append(total_loss/(i + 1)) plt.plot(total_loss_history) plt.ylabel("loss") plt.xlabel("epoch time") plt.savefig("total_loss_history") plt.show()epoch: 0 loss: 8388.166772460938 epoch: 2 loss: 8372.164868164062 epoch: 3 loss: 8372.035913085938 ... epoch: 48 loss: 8371.781372070312 epoch: 49 loss: 8371.78125損失関数の値がとんでもない数値になってますが、大丈夫でしょうか...
収束したようです。計算時間は次のとおり。
CPU times: user 6min 7s, sys: 8.1 s, total: 6min 16s Wall time: 6min 16s結果発表
テスト用のデータとして、新たにデータを生成します。
X_test = [] # テスト用の画像データを格納 Y_test = [] # テスト用の正解データを格納 Z_test = [] # テスト用の予測結果を格納 for i in range(100): # 学習に用いなかった新規データを100個生成 im = koala_or_bear(bear=True, rotate=True, resize=64, others=True) x_im, y_im = getdata_for_semantic_segmentation(im) X_test.append(x_im) Y_test.append(y_im)学習済みのモデルを用いて予測します。
# テスト用の画像データをPyTorch用に整形 X_test_a = np.array([[np.asarray(x).transpose((2, 0, 1))[0]] for x in X_test]) X_test_t = torch.tensor(X_test_a, dtype = torch.float32) # 学習済みのモデルを使って予測値を計算 Y_pred = kuma(X_test_t) # 予測値を ndarray として格納 for pred in Y_pred: Z_test.append(pred.detach().numpy())先頭10データの描画
どういう予測結果か、先頭10データだけ描画して見てみましょう。左から順に、入力画像データ、正解データ、予測データです。
# データの先頭10個に対して、画像データ、正解データ、予測値を描画 fig = plt.figure(figsize=(6,18)) for i in range(10): ax = fig.add_subplot(10, 3, (i * 3)+1) ax.axis('off') ax.set_title('input_{}'.format(i)) ax.imshow(X_test[i]) ax = fig.add_subplot(10, 3, (i * 3)+2) ax.axis('off') ax.set_title('answer_{}'.format(i)) ax.imshow(Y_test[i]) ax = fig.add_subplot(10, 3, (i * 3)+3) ax.axis('off') ax.set_title('predicted_{}'.format(i)) yp2 = Y_pred[i].detach().numpy()[0] * 255 z_im = Image.fromarray(np.array([yp2, yp2, yp2]).transpose((1, 2, 0)).astype(dtype='uint8')) ax.imshow(z_im) plt.show()
クマさんの部分を切り出せています。クマさんの大きさが変化しても、回転しても大丈夫です!
ですが、ちょっと大きめに切り出す傾向にあるようです。また、間違えている部分もけっこう見受けられます。
切り出し面積
正解データと予測データで、白く切り出した面積を比較してみましょう。
A_ans = [] A_pred = [] for yt, zt in zip(Y_test, Z_test): # 正解の白の面積(ベクトルが3色分あるので3で割る) A_ans.append(np.where(np.asarray(yt) > 0.5, 1, 0).sum() / 3) A_pred.append(np.where(np.asarray(zt) > 0.5, 1, 0).sum()) # 予測値の白の面積 plt.figure(figsize=(4, 4)) plt.scatter(A_ans, A_pred, alpha=0.5) plt.grid() plt.xlabel('Observed sizes of bears') plt.ylabel('Predicted sizes of bears') plt.xlim([0, 1700]) plt.ylim([0, 1700]) plt.show()
正解値と予測値がほぼ直線関係にあるのは良いですが、予測値は大きく出る傾向があるようです。
クマさんの大きさだけ知りたい場合は、この関係を元に補正を行うと良いでしょう。ですが、切り出しをより正確に行うためには、もっと複雑なモデルを構築する必要があることでしょう。



- 投稿日:2020-01-24T13:03:13+09:00
[Python] csvファイルの区切り文字をタブ区切りに変換
やりたいこと
- csvファイルの区切り文字をタブ区切りに変換したい
- ファイル中に住所等、カンマが含まれている場合にタブ区切りにした方が後続処理(例えばDBに取り込む等)がしやすくなる
ポイント
- csvモジュールをimportして使うと簡単
呼び出し側のプログラムの方でcsvモジュールをimport
- defのファイルの最初でcsvモジュールをimport
- with openで対象ファイルの読み書きを行う
- 対象ファイルをカンマ区切りで読み込んで、タブく区切りで書き出す → 対象ファイルに上書きされる
csv.readerを使って読み込んだら、行単位で配列に格納する- 書き込みは↑で読み込んだ配列を
writer.writerrows(配列名)で一気に書き出す 1行づつ書き込みたい時はwriter.writerrow(行列)で書き出せるconvertTav.pydef CsvToTsv(path): #読み込み用配列 line = [] #読み込み with open(path, "r", newline="") as f: #読み込みオブジェクト作成(カンマ区切り) reader = csv.reader(f, delimiter = ",") #読み込み line = [row for row in reader] #close f.close #書き込み with open(path, "w", newline="") as f: #書き込みオブジェクト作成(タブ区切り) writer = csv.writer(f, delimiter = "\t") #まとめて書き込み writer.writerows(line) #close f.close
- 投稿日:2020-01-24T11:34:41+09:00
【Django】Django+MySQL+Vue.jsな環境を作るメモ【Python】
システム構成
・Django
・Vue.js
・MySQLdjango-admin startproject config . python manage.py startapp accounts最初の設定
APPSに追加
config/setting.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', "accounts.apps.AccountsConfig", ]言語とタイムゾーンを日本仕様にする
config/setting.pyLANGUAGE_CODE = 'ja' TIME_ZONE = 'Asia/Tokyo'DjangoのデータベースにMySQLを設定する
pip install pymysql pip install python-dotenvmanage.pyの編集(MySQLの追加)
manage.pyimport pymysql pymysql.install_as_MySQLdb()configの中に.envファイルの作成
config/.envDB_NAME = XXXXX DB_PWD = XXXXX DB_USER = XXXXX DB_HOST = XXXXXsetting.pyの編集
config/setting.pyfrom os.path import join, dirname from dotenv import load_dotenvconfig/setting.pydotenv_path = join(dirname(__file__), '.env') load_dotenv(dotenv_path) DB_NAME = os.environ.get("DB_NAME") DB_PWD = os.environ.get("DB_PWD") DB_USER = os.environ.get("DB_USER") DB_HOST = os.environ.get("DB_HOST") DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': DB_NAME,#データベース名 'USER': DB_USER,#ユーザー名 'PASSWORD': DB_PWD,#パスワード 'HOST': DB_HOST,#ローカルホスト等 'PORT': '3306',#接続ポート } }ロガーの設定をする
config/settings.py#ロギング設定 LOGGING = { "version": 1, "disavle_existing_loggers": False, #ロガーの設定 "logger":{ "django": { "handlers": ["console"], "lebel": "INFO", } }, #accountsのアプリ利用するロガー "diary": { "handlers": ["console"], "level": "DEBUG", }, #ハンドラの設定 "handlers": { "console": { "level": "DEBUG", "class": "logging.StreamHandler", "formatter": "dev" }, }, #フォーマッターの設定 "formatters": { "dev": { "format": "\t".join([ "%(asctime)s", "[%(levelname)s]", "%(pathname)s(Line:%(lineno)d)", "%(message)s" ]) }, }, }ルーティングの設定し、index.htmlへアクセスさせる
config/urls.pyfrom django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path("", include("accounts.urls")) ]新規ファイル作成:accounts/urls.py
accounts/urls.pyfrom django.urls import path from . import views app_name = "accounts" urlpatterns = [ path("", views.IndexView.as_view(), name="index") ]新しいディレクトリ『templates』を作成
accounts/templatesに作成新規ファイルindex.htmlを作成
accouts/templates/index.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <title>トップページ</title> </head> <body> <h1>Hello World</h1> </body> </html>確認
python manage.py runserverBootstrapテンプレートを反映させる
staticフォルダの追加
Bootstrapをダウンロード
(https://startbootstrap.com/themes/one-page-wonder)プロジェクト直下にstaticフォルダを新規作成
ダウンロードしたBootStrapをstaticフォルダに入れる
├── accounts ├── config ├── static | ├── css | ├── img | └── vender ├── manage.py静的フォルダが配置されている場所を設定する
config/settings.pySTATICFILES_DIRS = ( os.path.join(BASE_DIR, "static"), )各ページで共通するbase.htmlを作る
accounts/templates/base.html{% load static %} <html lang="ja"> <head> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <meta name="description" content=""> <meta name="author" content=""> <title>{% block title %}{% endblock %}</title> <!-- Bootstrap core CSS --> <link href="{% static 'vendor/bootstrap/css/bootstrap.min.css' %}" rel="stylesheet"> <!-- Custom fonts for this template --> <link href="https://fonts.googleapis.com/css?family=Catamaran:100,200,300,400,500,600,700,800,900" rel="stylesheet"> <link href="https://fonts.googleapis.com/css?family=Lato:100,100i,300,300i,400,400i,700,700i,900,900i" rel="stylesheet"> <!-- Custom styles for this template --> <link href="{% static 'css/one-page-wonder.min.css' %}" rel="stylesheet"> <!-- My style --> <link rel="stylesheet" type="text/css" href="{% static 'css/mystyle.css' %}"> <script src="https://cdn.jsdelivr.net/npm/vue"></script> <script src="https://unpkg.com/vue"></script> {% block head %}{% endblock %} </head> <body> <div id="wrapper"> <!-- ナビヘッダー --> <nav class="navbar navbar-expand-lg navbar-dark navbar-custom fixed-top"> <div class="container"> <a class="navbar-brand" href="{% url 'accounts:index' %}">TITLE</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarResponsive" aria-controls="navbarResponsive" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarResponsive"> <ul class="navbar-nav mr-auto"> <li class="nav-item {% block active_inquiry %}{% endblock %}"> <a class="nav-link" href="#">INQUIRY</a> </li> </ul> <ul class="navbar-nav ml-auto"> <li class="nav-item"> <a class="nav-link" href="#">Sign Up</a> </li> <li class="nav-item"> <a class="nav-link" href="#">Log In</a> </li> </ul> </div> </div> </nav> {% block contents%}{% endblock %} <!-- Footer --> <footer class="py-5 bg-black"> <div class="container"> <p class="m-0 text-center text-white small">©Foa TemplatesCode 2020</p> </div> <!-- /.container --> </footer> <!-- Vue.js JavaScript --> {% block scripts%}{% endblock %} <!-- Bootstrap core JavaScript --> <script src="{% static 'vendor/jquery/jquery.min.js' %}"></script> <script src="{% static 'vendor/bootstrap/js/bootstrap.bundle.min.js' %}"></script> </div> </body> </html>合わせてindex.htmlもそれっぽく編集する
accounts/templates/index.html{% extends 'base.html' %} {% load static %} {% block title %}TITLE --Subtitle{% endblock %} {% block contents %} <div id="indexapp"> <header class="masthead text-center text-white"> <div class="masthead-content"> <div class="container"> <h1 class="masthead-heading mb-0">[[ title ]]</h1> <h2 class="masthead-subheading mb-0">SubTitle</h2> <a href="#" class="btn btn-primary btn-xl rounded-pill mt-5">LOG IN</a> </div> </div> <div class="bg-circle-1 bg-circle"></div> <div class="bg-circle-2 bg-circle"></div> <div class="bg-circle-3 bg-circle"></div> <div class="bg-circle-4 bg-circle"></div> </header> <div class="py-5 text-white" style="background-image: linear-gradient(to bottom, rgba(0, 0, 0, .75), rgba(0, 0, 0, .75)), url(https://static.pingendo.com/cover-bubble-dark.svg); background-position: center center, center center; background-size: cover, cover; background-repeat: repeat, repeat;"> <div class="container"> <div class="row"> <div class="p-3 col-md-8 col-lg-6 ml-auto text-right text-white"> <p class="lead">"I throw myself down among the tall grass by the trickling stream; and, as I lie close to the earth, a thousand unknown plants are noticed by me: when I hear the buzz of the little world among the stalks."</p> <p><b>Johann Goethe</b><br><small>CEO and founder</small></p> </div> </div> </div> </div> <div class="py-5" style="background-image: linear-gradient(to left bottom, rgba(189, 195, 199, .75), rgba(44, 62, 80, .75)); background-size: 100%;"> <div class="container"> <div class="row"> <div class="text-center mx-auto col-md-12"> <h1 class="text-white mb-4">Testimonials</h1> </div> </div> <div class="row"> <div class="col-lg-4 col-md-6 p-3"> <div class="card"> <div class="card-body p-4"> <div class="row"> <div class="col-md-4 col-3"> <img class="img-fluid d-block rounded-circle" src="https://static.pingendo.com/img-placeholder-2.svg"> </div> <div class="d-flex col-md-8 flex-column justify-content-center align-items-start col-9"> <p class="mb-0 lead"> <b>J. W. Goethe</b> </p> <p class="mb-0">Co-founder</p> </div> </div> <p class="mt-3 mb-0">I throw myself down among the tall grass by the trickling stream; and, as I lie close to the earth, a thousand unknown plants are noticed by me: when I hear the buzz of the little world.</p> </div> </div> </div> <div class="col-lg-4 col-md-6 p-3"> <div class="card"> <div class="card-body p-4"> <div class="row"> <div class="col-md-4 col-3"> <img class="img-fluid d-block rounded-circle" src="https://static.pingendo.com/img-placeholder-1.svg"> </div> <div class="d-flex col-md-8 flex-column justify-content-center align-items-start col-9"> <p class="mb-0 lead"> <b>G. W. John</b> </p> <p class="mb-0">CEO & founder</p> </div> </div> <p class="mt-3 mb-0" >I lie close to the earth, a thousand unknown plants are noticed by me: when I hear the buzz of the little world among the stalks, and grow familiar with the countless indescribable forms of the insects and flies.</p> </div> </div> </div> <div class="col-lg-4 p-3"> <div class="card"> <div class="card-body p-4"> <div class="row"> <div class="col-md-4 col-3"> <img class="img-fluid d-block rounded-circle" src="https://static.pingendo.com/img-placeholder-3.svg"> </div> <div class="d-flex col-md-8 flex-column justify-content-center align-items-start col-9"> <p class="mb-0 lead"> <b>J. G. Wolf</b> </p> <p class="mb-0">CFO</p> </div> </div> <p class="mt-3 mb-0">Oh, would I could describe these conceptions, could impress upon paper all that is living so full and warm within me, that it might be the mirror of my soul, as my soul is the mirror of the infinite God!</p> </div> </div> </div> </div> </div> </div> <div class="py-5 text-center"> <div class="container"> <div class="row"> <div class="mx-auto col-md-8"> <h1>{{ this.title }}</h1> <p class="mb-4"> Oh, would I could describe these conceptions, could impress upon paper all that is living so full and warm within me, that it might be the mirror of my soul, as my soul is the mirror of the infinite God! O my friend -- but it is too much for my strength -- I sink under the weight of the splendour of these visions!</p> <div class="row text-muted"> <div class="col-md-2 col-4 p-2"> <i class="d-block fa fa-angellist fa-3x"></i> </div> <div class="col-md-2 col-4 p-2"> <i class="d-block fa fa-cc-visa fa-3x"></i> </div> <div class="col-md-2 col-4 p-2"> <i class="d-block fa fa-empire fa-3x"></i> </div> <div class="col-md-2 col-4 p-2"> <i class="d-block fa fa-paypal fa-3x"></i> </div> <div class="col-md-2 col-4 p-2"> <i class="d-block fa fa-rebel fa-3x"></i> </div> <div class="col-md-2 col-4 p-2"> <i class="d-block fa fa-first-order fa-3x"></i> </div> </div> </div> </div> </div> </div> </div> {% endblock %} {% block scripts %} <script src="{% static 'js/index_vue.js' %}"></script> {% endblock %}Vue.jsを組み込む
ファイルを作成し、Titleを動的に変化させる
static内に新規フォルダ『js』に作成
js内にindex.jsを作成
Djangoのシステムと混同させないため、
delimiters: ['[[', ']]']が大事static/js/index.jsvar app = new Vue({ delimiters: ['[[', ']]'], el: '#indexapp', data: { title: "TestTitle" }, })実行
python manage.py runserver
- 投稿日:2020-01-24T11:24:53+09:00
VsCodeで自作モジュールをImportすると何故かNo name in module...と言われる
- 投稿日:2020-01-24T11:03:53+09:00
pythonのdataclassで後ろに継承したい
各dataclassで共通のフィールドがほしい、でもデフォルトの値を付けたいから普通に継承すると前にこれがついてtypeerror。つらいさんなのだ
だめ
from dataclasses import dataclass @dataclass class Base: base: int = 10 @dataclass class Extend(Base): extend: inttypeerrorです
あと、
@dataclassしていないclassを継承しても継承元のフィールドは(__init__には)継承しないみたい。正直読みにくいけどまあ解決
デコレータを書きます
from dataclasses import dataclass def add(c): @dataclass class wrap(c): added: int = 10 return wrap @add @dataclass class DataClass: field: str欠点としては、インタプリタで名前じゃなくて
<locals>.wrapになることですね>> DataClass <class '__main__.add.<locals>.wrap'>追記
どうやらclassの名前は
__qualname__にあるらしい。def add(c): @dataclass class wrap(c): added: int = 10 __qualname__ = c.__qualname__ return wrap>> DataClass <class '__main__.DataClass'>
- 投稿日:2020-01-24T10:47:49+09:00
リストの中身を繋げて文字列にする方法
- 投稿日:2020-01-24T10:40:55+09:00
dict list クラスをカスタマイズするときの覚え書き
memo
・カスタマイズ済みのlistに
memo.c=[1,2,3]
のように初期化すると普通のlistで初期化されるので memo_baseの__setattr__で回避するコードを書くコード
class memo_base(object): def __init__(self): self.prm=["PRM"] self.a="" self.b=self.dict_base(self.prm) self.c=self.list_base(self.prm,[1,2,3]) #__getattribute__(self, name, /) #Return getattr(self, name). def __getattribute__(self, name): print("memo_base.__getattribute__>",name) return super().__getattribute__( name) def __setattr__(self, name, value): print("memo_base.__setattr__>{}>{}".format(name, value)) #初期化の回避 if name=="b": print("dict_baseをset") value=self.dict_base(self.prm,value) if name=="c": print("list_baseをset") value=self.list_base(self.prm,value) return super().__setattr__( name, value) #dictのカスタマイズ class dict_base(dict): pass # __setitem__(self, key, value, /) # Set self[key] to value. def __setitem__(self, key, value): print("dict_base.__setitem__>{}>{}".format(key, value)) super().__setitem__(key, value) #object.__getitem__(self, key) def __getitem__(self, key): print("dict_base.__getitem__>{}".format(key)) return super().__getitem__(key) # __init__(self, /, *args, **kwargs) # Initialize self. See help(type(self)) for accurate signature. def __init__(self,prm , *args, **kwargs): super().__init__( *args, **kwargs) #listのカスタマイズ class list_base(list): pass def __setitem__(self, key, value): print("list_base.__setitem__>{}>{}".format(key, value)) super().__setitem__(key, value) #object.__getitem__(self, key) def __getitem__(self, key): print("list_base.__getitem__>{}".format(key)) return super().__getitem__(key) def __init__(self,prm , *args, **kwargs): super().__init__( *args, **kwargs) #append(self, object, /) #Append object to the end of the list. def append(self, object): print("list_base.append >{}".format(object)) print("list_base.self befor super().append >{}".format(self)) super().append(object) print("list_base.self after super().append > {}".format(self)) print("#インスタンス化 #インスタンス化 #インスタンス化 #インスタンス化 ") print("> memo=memo_base()") memo=memo_base() print() print("#管理対象外 #管理対象外 #管理対象外 #管理対象外 #管理対象外 #管理対象外 ") print() print("> memo.z=99 ") memo.z=99 print() print('> print( memo.z)') print(memo.z) print() print("#変数 #変数 #変数 #変数 #変数 #変数 #変数 #変数 #変数 ") print() print("> memo.a=5") memo.a=5 print() print('> print memo.a') print(memo.a) print() print("#dict #dict #dict #dict #dict #dict #dict #dict #dict #dict #dict #dict #dict ") print() print('> memo.b["b3"]="b33"') memo.b["b3"]="b33" print() print('> print(memo.b["b3"])') print(memo.b["b3"]) print() print("再設定") print('"> memo.b={"b1":"b11" ,"b2":"b22" }') memo.b={"b1":"b11" ,"b2":"b22" } print() print('> memo.b["b3"]="b33"') memo.b["b3"]="b33新規" print() print('> memo.b["b2"]="b222"') memo.b["b2"]="b222変更" print() print('> print() memo.b)') print(memo.b) print() print('> print( memo.b["b2"])') print(memo.b["b2"]) print() print("#list #list #list #list #list #list #list #list #list #list #list ") print() print("> memo.c[2]=22") memo.c[2]=22 print() print("> print(memo.c[2])") print(memo.c[2]) print() print("再設定") print("> memo.c=[1,2,3]") memo.c=[1,2,3] print() print("> memo.c[2]=22") memo.c[2]=22 print() print("> memo.c.append(4)") memo.c.append(4) print() print('> print( memo.c)') print(memo.c) print() print('> print (memo.c[2])') print(memo.c[2]) print()結果
#インスタンス化 #インスタンス化 #インスタンス化 #インスタンス化 > memo=memo_base() memo_base.__setattr__>prm>['PRM'] memo_base.__setattr__>a> memo_base.__getattribute__> dict_base memo_base.__getattribute__> prm memo_base.__setattr__>b>{} dict_baseをset memo_base.__getattribute__> dict_base memo_base.__getattribute__> prm memo_base.__getattribute__> list_base memo_base.__getattribute__> prm memo_base.__setattr__>c>[1, 2, 3] list_baseをset memo_base.__getattribute__> list_base memo_base.__getattribute__> prm #管理対象外 #管理対象外 #管理対象外 #管理対象外 #管理対象外 #管理対象外 > memo.z=99 memo_base.__setattr__>z>99 > print( memo.z) memo_base.__getattribute__> z 99 #変数 #変数 #変数 #変数 #変数 #変数 #変数 #変数 #変数 > memo.a=5 memo_base.__setattr__>a>5 > print memo.a memo_base.__getattribute__> a 5 #dict #dict #dict #dict #dict #dict #dict #dict #dict #dict #dict #dict #dict > memo.b["b3"]="b33" memo_base.__getattribute__> b dict_base.__setitem__>b3>b33 > print(memo.b["b3"]) memo_base.__getattribute__> b dict_base.__getitem__>b3 b33 再設定 "> memo.b={"b1":"b11" ,"b2":"b22" } memo_base.__setattr__>b>{'b1': 'b11', 'b2': 'b22'} dict_baseをset memo_base.__getattribute__> dict_base memo_base.__getattribute__> prm > memo.b["b3"]="b33" memo_base.__getattribute__> b dict_base.__setitem__>b3>b33新規 > memo.b["b2"]="b222" memo_base.__getattribute__> b dict_base.__setitem__>b2>b222変更 > print() memo.b) memo_base.__getattribute__> b {'b1': 'b11', 'b2': 'b222変更', 'b3': 'b33新規'} > print( memo.b["b2"]) memo_base.__getattribute__> b dict_base.__getitem__>b2 b222変更 #list #list #list #list #list #list #list #list #list #list #list > memo.c[2]=22 memo_base.__getattribute__> c list_base.__setitem__>2>22 > print(memo.c[2]) memo_base.__getattribute__> c list_base.__getitem__>2 22 再設定 > memo.c=[1,2,3] memo_base.__setattr__>c>[1, 2, 3] list_baseをset memo_base.__getattribute__> list_base memo_base.__getattribute__> prm > memo.c[2]=22 memo_base.__getattribute__> c list_base.__setitem__>2>22 > memo.c.append(4) memo_base.__getattribute__> c list_base.append >4 list_base.self befor super().append >[1, 2, 22] list_base.self after super().append > [1, 2, 22, 4] > print( memo.c) memo_base.__getattribute__> c [1, 2, 22, 4] > print (memo.c[2]) memo_base.__getattribute__> c list_base.__getitem__>2 22