- 投稿日:2020-01-24T23:34:15+09:00
JAWS-UGコンテナ支部 #16に参加しました【備忘】
はじめに
1/23のJAWS-UGコンテナ支部#16に行ってきたので、その時に知らなかったり知っていたけど曖昧だったことをまとめようと思います。
ただ自分がコンテナ知らな過ぎるせいで、ほとんど用語集兼資料リンク集になっています。
どうでも良いですが、「kubectl」は人によって読み方が違うようです。
今回のイベントでは「きゅーぶしーてぃーえる」と読む人が多かったですが、今日(1/24)に参加したOpenshiftのハンズオンでは「きゅーびーこんとろーる」と言っていました。わけがわからないよ(QB違い)kubetnetesの設計思想
当日の発表資料より抜粋
- 宣言的に構成管理
- コントローラを中心とした高い拡張性
- コンテナを基とした軽量、柔軟、高速なスケーリング
用語集
KubernetesのIngressについて
平たく言うと、外部(インターネットなど)からのアクセスをクラスター内のServiceにルーティングしてくれるコンポーネント。
Serviceというのは複数のPodをひとまとめにした論理的な単位のこと。※参考
Amazon EKS の ALB Ingress Controllerコンテナネットワークインターフェース(CNI)
KubernetesがAWSのネットワーク(VPC)と繋ぐためのプラグインらしいです。
コンテナストレージインターフェース(CSI)
平たく言うとCNIのストレージ版。
Kubernetes Container Storage Interface(CSI)とは?
Introducing Container Storage Interface (CSI) Alpha for Kubernetes
学習用記事
イベントレポート
発表資料のリンクをまとめて下さっていました。Amazon EKS Advent Calendar 2019
その他雑感
もちろん他にも色々な話がありましたが、自分が理解していなさ過ぎて本当にただのWebページ貼り付けマンになりそうだったのである程度絞りました(それでもほぼリンク集ですが)
とりあえずeksctlは超便利らしいので今度使ってみようと思います。
- 投稿日:2020-01-24T22:12:29+09:00
AWS WorkspacesのAmazon Linux2からWindowsサーバにRDPするためのremminaインストール手順
AWS WorkspacesにはWindows10だけでなく、Amazon Linux2が用意されていてコストもお得です。
そんなAmazon Linux2からWindowsサーバを管理するためにRDPを利用できる状態にセットアップする手順です。作成時に選択したバンドルなどは以下。
- Value with Amazon Linux 2 (Standardとの差は性能だけの認識)
- Language 日本語
手順
とても簡単で、remmina という定番ツールをインストールするだけでした。
Terminalを開いて
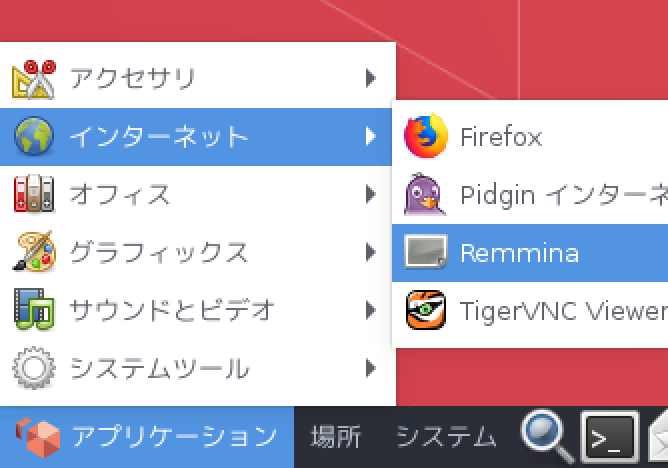
# rootになってしまい(ちょっと乱暴かも) sudo su - # epelを最初に入れる wget http://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm{ rpm -ivh epel-release-latest-7.noarch.rpm # remminaのインストール yum install remminaあとは、左下の [アプリケーション] -> [インターネット] -> [Remmina] を起動します。
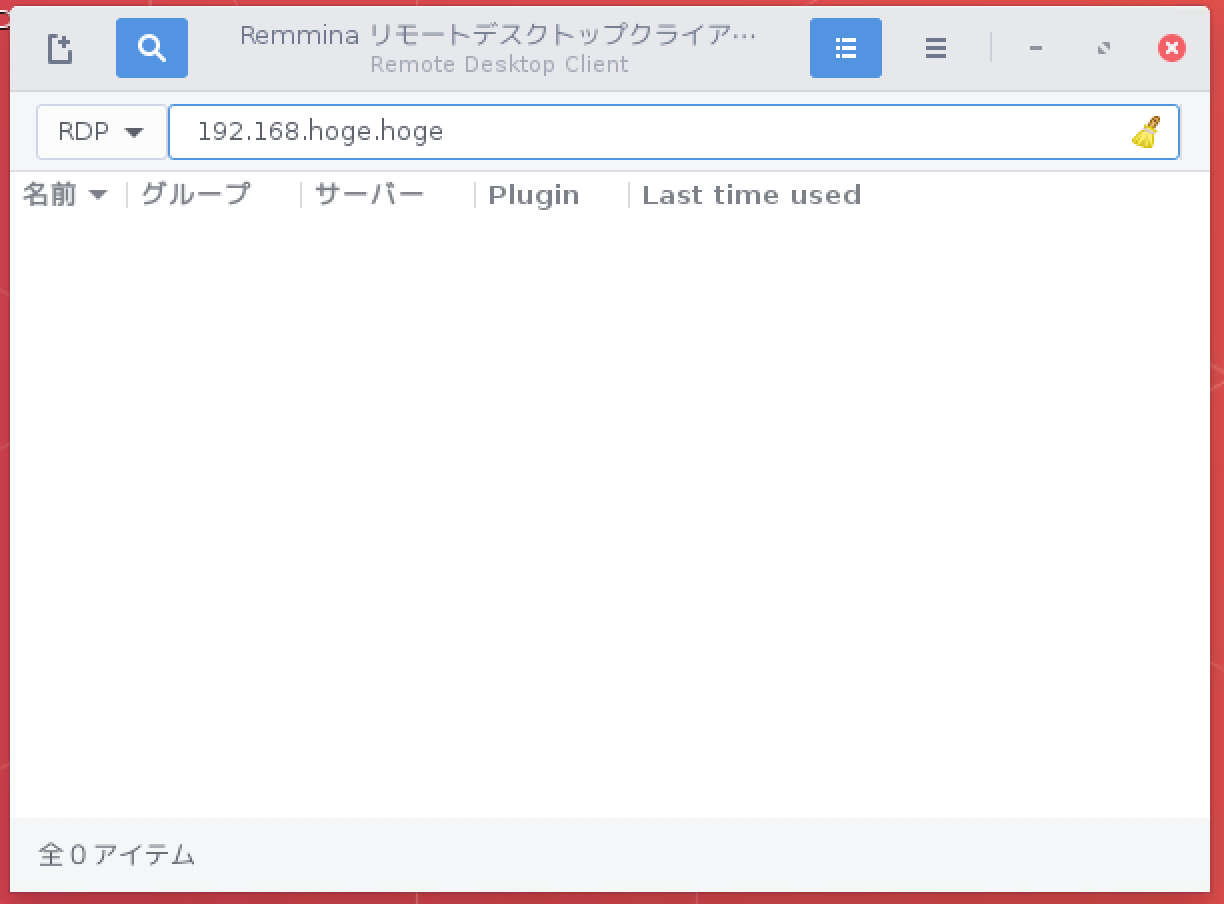
以下の様なremminaの画面が起動するので、IPやホスト名などの接続先を入力してログオンしましょう。
補足
- remminaのインストール手順は公式ドキュメントを参照しました
- この記事を書いておいてなんですが、Windows Bundleと比較してそこまでコストの差はないので、使いやすい方を選んでいいかと思います
- 東京, 2 vCPU, 4 GiB Memory で Root 80GB, Data 50 GBの場合(2020/01/24調べ)
- Linux Bundle:
固定 $43, 時間 $14/month + $0.36/hour- Windows Bundle:
固定 $47, 時間 $14/month + $0.40/hour- 一応コマンドのログも載せておきます
[root@a-1vo34nwckj3og ~]# [root@a-1vo34nwckj3og ~]# wget http://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm --2020-01-24 21:22:31-- http://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm dl.fedoraproject.org (dl.fedoraproject.org) をDNSに問いあわせています... 209.132.181.25, 209.132.181.24, 209.132.181.23 dl.fedoraproject.org (dl.fedoraproject.org)|209.132.181.25|:80 に接続しています... 接続しました。 HTTP による接続要求を送信しました、応答を待っています... 200 OK 長さ: 15264 (15K) [application/x-rpm] `epel-release-latest-7.noarch.rpm' に保存中 100%[======================================>] 15,264 --.-K/s 時間 0.1s 2020-01-24 21:22:31 (113 KB/s) - `epel-release-latest-7.noarch.rpm' へ保存完了 [15264/15264] [root@a-1vo34nwckj3og ~]# rpm -ivh epel-release-latest-7.noarch.rpm 警告: epel-release-latest-7.noarch.rpm: ヘッダー V3 RSA/SHA256 Signature、鍵 ID 352c64e5: NOKEY 準備しています... ################################# [100%] 更新中 / インストール中... 1:epel-release-7-12 ################################# [100%] [root@a-1vo34nwckj3og ~]# [root@a-1vo34nwckj3og ~]# [root@a-1vo34nwckj3og ~]# yum search remmina 読み込んだプラグイン:amzn_workspaces_filter_updates, halt_os_update_check, priorities, : update-motd パッケージの検索中: amzn2-core | 2.4 kB 00:00 epel/x86_64/metalink | 9.0 kB 00:00 epel | 5.3 kB 00:00 firefox | 2.2 kB 00:00 (1/3): epel/x86_64/group_gz | 90 kB 00:00 (2/3): epel/x86_64/updateinfo | 1.0 MB 00:00 (3/3): epel/x86_64/primary_db | 6.9 MB 00:00 363 packages excluded due to repository priority protections ============================= N/S matched: remmina ============================= remmina-devel.x86_64 : Development files for remmina remmina-gnome-session.x86_64 : Gnome Shell session for Remmina kiosk mode remmina-plugins-exec.x86_64 : External execution plugin for Remmina Remote : Desktop Client remmina-plugins-kwallet.x86_64 : KDE Wallet plugin for Remmina Remote Desktop : Client remmina-plugins-nx.x86_64 : NX plugin for Remmina Remote Desktop Client remmina-plugins-rdp.x86_64 : RDP plugin for Remmina Remote Desktop Client remmina-plugins-secret.x86_64 : Keyring integration for Remmina Remote Desktop : Client remmina-plugins-spice.x86_64 : SPICE plugin for Remmina Remote Desktop Client remmina-plugins-st.x86_64 : Simple Terminal plugin for Remmina Remote Desktop : Client remmina-plugins-vnc.x86_64 : VNC plugin for Remmina Remote Desktop Client remmina-plugins-www.x86_64 : WWW plugin for Remmina Remote Desktop Client remmina-plugins-xdmcp.x86_64 : XDMCP plugin for Remmina Remote Desktop Client remmina.x86_64 : Remote Desktop Client Name and summary matches only, use "search all" for everything. [root@a-1vo34nwckj3og ~]# [root@a-1vo34nwckj3og ~]# yum install remmina 読み込んだプラグイン:amzn_workspaces_filter_updates, halt_os_update_check, priorities, : update-motd [amzn_workspaces_filter_updates] 33 packages excluded as currently disabled by Amazon WorkSpaces 363 packages excluded due to repository priority protections 依存性の解決をしています --> トランザクションの確認を実行しています。 ---> パッケージ remmina.x86_64 0:1.3.6-1.el7 を インストール --> 依存性の処理をしています: remmina-plugins-exec のパッケージ: remmina-1.3.6-1.el7.x86_64 --> 依存性の処理をしています: remmina-plugins-nx のパッケージ: remmina-1.3.6-1.el7.x86_64 --> 依存性の処理をしています: remmina-plugins-rdp のパッケージ: remmina-1.3.6-1.el7.x86_64 --> 依存性の処理をしています: remmina-plugins-secret のパッケージ: remmina-1.3.6-1.el7.x86_64 --> 依存性の処理をしています: remmina-plugins-st のパッケージ: remmina-1.3.6-1.el7.x86_64 --> 依存性の処理をしています: remmina-plugins-vnc のパッケージ: remmina-1.3.6-1.el7.x86_64 --> 依存性の処理をしています: remmina-plugins-xdmcp のパッケージ: remmina-1.3.6-1.el7.x86_64 --> 依存性の処理をしています: libavahi-ui-gtk3.so.0()(64bit) のパッケージ: remmina-1.3.6-1.el7.x86_64 --> 依存性の処理をしています: libsodium.so.23()(64bit) のパッケージ: remmina-1.3.6-1.el7.x86_64 --> 依存性の処理をしています: libssh.so.4()(64bit) のパッケージ: remmina-1.3.6-1.el7.x86_64 --> 依存性の処理をしています: libssh_threads.so.4()(64bit) のパッケージ: remmina-1.3.6-1.el7.x86_64 --> トランザクションの確認を実行しています。 ---> パッケージ avahi-ui-gtk3.x86_64 0:0.6.31-19.amzn2 を インストール ---> パッケージ libsodium.x86_64 0:1.0.18-1.el7 を インストール ---> パッケージ libssh.x86_64 0:0.7.1-0.7.el7 を インストール ---> パッケージ remmina-plugins-exec.x86_64 0:1.3.6-1.el7 を インストール ---> パッケージ remmina-plugins-nx.x86_64 0:1.3.6-1.el7 を インストール --> 依存性の処理をしています: nxproxy のパッケージ: remmina-plugins-nx-1.3.6-1.el7.x86_64 ---> パッケージ remmina-plugins-rdp.x86_64 0:1.3.6-1.el7 を インストール --> 依存性の処理をしています: libfreerdp-client2.so.2()(64bit) のパッケージ: remmina-plugins-rdp-1.3.6-1.el7.x86_64 --> 依存性の処理をしています: libfreerdp2.so.2()(64bit) のパッケージ: remmina-plugins-rdp-1.3.6-1.el7.x86_64 --> 依存性の処理をしています: libwinpr2.so.2()(64bit) のパッケージ: remmina-plugins-rdp-1.3.6-1.el7.x86_64 ---> パッケージ remmina-plugins-secret.x86_64 0:1.3.6-1.el7 を インストール ---> パッケージ remmina-plugins-st.x86_64 0:1.3.6-1.el7 を インストール ---> パッケージ remmina-plugins-vnc.x86_64 0:1.3.6-1.el7 を インストール --> 依存性の処理をしています: libvncclient.so.0()(64bit) のパッケージ: remmina-plugins-vnc-1.3.6-1.el7.x86_64 ---> パッケージ remmina-plugins-xdmcp.x86_64 0:1.3.6-1.el7 を インストール --> 依存性の処理をしています: xorg-x11-server-Xephyr のパッケージ: remmina-plugins-xdmcp-1.3.6-1.el7.x86_64 --> トランザクションの確認を実行しています。 ---> パッケージ freerdp-libs.x86_64 0:2.0.0-1.rc4.amzn2 を インストール ---> パッケージ libvncserver.x86_64 0:0.9.9-13.amzn2 を インストール --> 依存性の処理をしています: libminilzo.so.0()(64bit) のパッケージ: libvncserver-0.9.9-13.amzn2.x86_64 ---> パッケージ libwinpr.x86_64 0:2.0.0-1.rc4.amzn2 を インストール ---> パッケージ nxproxy.x86_64 0:3.5.99.17-1.el7 を インストール --> 依存性の処理をしています: libXcomp.so.3()(64bit) のパッケージ: nxproxy-3.5.99.17-1.el7.x86_64 ---> パッケージ xorg-x11-server-Xephyr.x86_64 0:1.19.5-6.amzn2.0.2 を インストール --> 依存性の処理をしています: libxcb-render-util.so.0()(64bit) のパッケージ: xorg-x11-server-Xephyr-1.19.5-6.amzn2.0.2.x86_64 --> 依存性の処理をしています: libxcb-keysyms.so.1()(64bit) のパッケージ: xorg-x11-server-Xephyr-1.19.5-6.amzn2.0.2.x86_64 --> 依存性の処理をしています: libxcb-image.so.0()(64bit) のパッケージ: xorg-x11-server-Xephyr-1.19.5-6.amzn2.0.2.x86_64 --> 依存性の処理をしています: libxcb-icccm.so.4()(64bit) のパッケージ: xorg-x11-server-Xephyr-1.19.5-6.amzn2.0.2.x86_64 --> トランザクションの確認を実行しています。 ---> パッケージ libXcomp.x86_64 0:3.5.99.17-1.el7 を インストール --> 依存性の処理をしています: nx-libs(x86-64) = 3.5.99.17-1.el7 のパッケージ: libXcomp-3.5.99.17-1.el7.x86_64 ---> パッケージ lzo-minilzo.x86_64 0:2.06-8.amzn2.0.3 を インストール ---> パッケージ xcb-util-image.x86_64 0:0.4.0-2.amzn2.0.2 を インストール ---> パッケージ xcb-util-keysyms.x86_64 0:0.4.0-1.amzn2.0.2 を インストール ---> パッケージ xcb-util-renderutil.x86_64 0:0.3.9-3.amzn2.0.2 を インストール ---> パッケージ xcb-util-wm.x86_64 0:0.4.1-5.amzn2.0.2 を インストール --> トランザクションの確認を実行しています。 ---> パッケージ nx-libs.x86_64 0:3.5.99.17-1.el7 を インストール --> 依存性解決を終了しました。 依存性を解決しました ================================================================================ Package アーキテクチャー バージョン リポジトリー 容量 ================================================================================ インストール中: remmina x86_64 1.3.6-1.el7 epel 609 k 依存性関連でのインストールをします: avahi-ui-gtk3 x86_64 0.6.31-19.amzn2 amzn2-core 37 k freerdp-libs x86_64 2.0.0-1.rc4.amzn2 amzn2-core 806 k libXcomp x86_64 3.5.99.17-1.el7 epel 496 k libsodium x86_64 1.0.18-1.el7 epel 147 k libssh x86_64 0.7.1-0.7.el7 epel 195 k libvncserver x86_64 0.9.9-13.amzn2 amzn2-core 237 k libwinpr x86_64 2.0.0-1.rc4.amzn2 amzn2-core 327 k lzo-minilzo x86_64 2.06-8.amzn2.0.3 amzn2-core 16 k nx-libs x86_64 3.5.99.17-1.el7 epel 140 k nxproxy x86_64 3.5.99.17-1.el7 epel 18 k remmina-plugins-exec x86_64 1.3.6-1.el7 epel 16 k remmina-plugins-nx x86_64 1.3.6-1.el7 epel 29 k remmina-plugins-rdp x86_64 1.3.6-1.el7 epel 48 k remmina-plugins-secret x86_64 1.3.6-1.el7 epel 14 k remmina-plugins-st x86_64 1.3.6-1.el7 epel 17 k remmina-plugins-vnc x86_64 1.3.6-1.el7 epel 29 k remmina-plugins-xdmcp x86_64 1.3.6-1.el7 epel 19 k xcb-util-image x86_64 0.4.0-2.amzn2.0.2 amzn2-core 15 k xcb-util-keysyms x86_64 0.4.0-1.amzn2.0.2 amzn2-core 10 k xcb-util-renderutil x86_64 0.3.9-3.amzn2.0.2 amzn2-core 13 k xcb-util-wm x86_64 0.4.1-5.amzn2.0.2 amzn2-core 25 k xorg-x11-server-Xephyr x86_64 1.19.5-6.amzn2.0.2 amzn2-core 1.0 M トランザクションの要約 ================================================================================ インストール 1 パッケージ (+22 個の依存関係のパッケージ) 総ダウンロード容量: 4.2 M インストール容量: 12 M Is this ok [y/d/N]: y Downloading packages: (1/23): avahi-ui-gtk3-0.6.31-19.amzn2.x86_64.rpm | 37 kB 00:00 warning: /var/cache/yum/x86_64/2/epel/packages/libXcomp-3.5.99.17-1.el7.x86_64.rpm: Header V3 RSA/SHA256 Signature, key ID 352c64e5: NOKEY libXcomp-3.5.99.17-1.el7.x86_64.rpm の公開鍵がインストールされていません (2/23): libXcomp-3.5.99.17-1.el7.x86_64.rpm | 496 kB 00:00 (3/23): freerdp-libs-2.0.0-1.rc4.amzn2.x86_64.rpm | 806 kB 00:00 (4/23): libsodium-1.0.18-1.el7.x86_64.rpm | 147 kB 00:00 (5/23): libvncserver-0.9.9-13.amzn2.x86_64.rpm | 237 kB 00:00 (6/23): libssh-0.7.1-0.7.el7.x86_64.rpm | 195 kB 00:00 (7/23): lzo-minilzo-2.06-8.amzn2.0.3.x86_64.rpm | 16 kB 00:00 (8/23): nx-libs-3.5.99.17-1.el7.x86_64.rpm | 140 kB 00:00 (9/23): nxproxy-3.5.99.17-1.el7.x86_64.rpm | 18 kB 00:00 (10/23): libwinpr-2.0.0-1.rc4.amzn2.x86_64.rpm | 327 kB 00:00 (11/23): remmina-1.3.6-1.el7.x86_64.rpm | 609 kB 00:00 (12/23): remmina-plugins-exec-1.3.6-1.el7.x86_64.rpm | 16 kB 00:00 (13/23): remmina-plugins-nx-1.3.6-1.el7.x86_64.rpm | 29 kB 00:00 (14/23): remmina-plugins-rdp-1.3.6-1.el7.x86_64.rpm | 48 kB 00:00 (15/23): remmina-plugins-secret-1.3.6-1.el7.x86_64.rpm | 14 kB 00:00 (16/23): remmina-plugins-st-1.3.6-1.el7.x86_64.rpm | 17 kB 00:00 (17/23): remmina-plugins-vnc-1.3.6-1.el7.x86_64.rpm | 29 kB 00:00 (18/23): remmina-plugins-xdmcp-1.3.6-1.el7.x86_64.rpm | 19 kB 00:00 (19/23): xcb-util-image-0.4.0-2.amzn2.0.2.x86_64.rpm | 15 kB 00:00 (20/23): xcb-util-renderutil-0.3.9-3.amzn2.0.2.x86_64.rpm | 13 kB 00:00 (21/23): xcb-util-wm-0.4.1-5.amzn2.0.2.x86_64.rpm | 25 kB 00:00 (22/23): xcb-util-keysyms-0.4.0-1.amzn2.0.2.x86_64.rpm | 10 kB 00:00 (23/23): xorg-x11-server-Xephyr-1.19.5-6.amzn2.0.2.x86_64. | 1.0 MB 00:00 -------------------------------------------------------------------------------- 合計 4.2 MB/s | 4.2 MB 00:00 file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7 から鍵を取得中です。 上記の処理を行います。よろしいでしょうか? [y/N]y Running transaction check Running transaction test Transaction test succeeded Running transaction インストール中 : libwinpr-2.0.0-1.rc4.amzn2.x86_64 1/23 インストール中 : libssh-0.7.1-0.7.el7.x86_64 2/23 インストール中 : freerdp-libs-2.0.0-1.rc4.amzn2.x86_64 3/23 インストール中 : nx-libs-3.5.99.17-1.el7.x86_64 4/23 インストール中 : libXcomp-3.5.99.17-1.el7.x86_64 5/23 インストール中 : nxproxy-3.5.99.17-1.el7.x86_64 6/23 インストール中 : xcb-util-renderutil-0.3.9-3.amzn2.0.2.x86_6 7/23 インストール中 : xcb-util-keysyms-0.4.0-1.amzn2.0.2.x86_64 8/23 インストール中 : xcb-util-wm-0.4.1-5.amzn2.0.2.x86_64 9/23 インストール中 : libsodium-1.0.18-1.el7.x86_64 10/23 インストール中 : lzo-minilzo-2.06-8.amzn2.0.3.x86_64 11/23 インストール中 : libvncserver-0.9.9-13.amzn2.x86_64 12/23 インストール中 : avahi-ui-gtk3-0.6.31-19.amzn2.x86_64 13/23 インストール中 : xcb-util-image-0.4.0-2.amzn2.0.2.x86_64 14/23 インストール中 : xorg-x11-server-Xephyr-1.19.5-6.amzn2.0.2.x 15/23 インストール中 : remmina-plugins-exec-1.3.6-1.el7.x86_64 16/23 インストール中 : remmina-plugins-st-1.3.6-1.el7.x86_64 17/23 インストール中 : remmina-plugins-secret-1.3.6-1.el7.x86_64 18/23 インストール中 : remmina-plugins-rdp-1.3.6-1.el7.x86_64 19/23 インストール中 : remmina-plugins-nx-1.3.6-1.el7.x86_64 20/23 インストール中 : remmina-plugins-xdmcp-1.3.6-1.el7.x86_64 21/23 インストール中 : remmina-1.3.6-1.el7.x86_64 22/23 インストール中 : remmina-plugins-vnc-1.3.6-1.el7.x86_64 23/23 検証中 : remmina-plugins-vnc-1.3.6-1.el7.x86_64 1/23 検証中 : libXcomp-3.5.99.17-1.el7.x86_64 2/23 検証中 : xcb-util-image-0.4.0-2.amzn2.0.2.x86_64 3/23 検証中 : avahi-ui-gtk3-0.6.31-19.amzn2.x86_64 4/23 検証中 : lzo-minilzo-2.06-8.amzn2.0.3.x86_64 5/23 検証中 : libvncserver-0.9.9-13.amzn2.x86_64 6/23 検証中 : xorg-x11-server-Xephyr-1.19.5-6.amzn2.0.2.x 7/23 検証中 : remmina-plugins-exec-1.3.6-1.el7.x86_64 8/23 検証中 : nxproxy-3.5.99.17-1.el7.x86_64 9/23 検証中 : freerdp-libs-2.0.0-1.rc4.amzn2.x86_64 10/23 検証中 : remmina-plugins-st-1.3.6-1.el7.x86_64 11/23 検証中 : libsodium-1.0.18-1.el7.x86_64 12/23 検証中 : remmina-plugins-secret-1.3.6-1.el7.x86_64 13/23 検証中 : xcb-util-wm-0.4.1-5.amzn2.0.2.x86_64 14/23 検証中 : xcb-util-keysyms-0.4.0-1.amzn2.0.2.x86_64 15/23 検証中 : remmina-plugins-rdp-1.3.6-1.el7.x86_64 16/23 検証中 : libssh-0.7.1-0.7.el7.x86_64 17/23 検証中 : xcb-util-renderutil-0.3.9-3.amzn2.0.2.x86_6 18/23 検証中 : remmina-plugins-nx-1.3.6-1.el7.x86_64 19/23 検証中 : remmina-plugins-xdmcp-1.3.6-1.el7.x86_64 20/23 検証中 : libwinpr-2.0.0-1.rc4.amzn2.x86_64 21/23 検証中 : remmina-1.3.6-1.el7.x86_64 22/23 検証中 : nx-libs-3.5.99.17-1.el7.x86_64 23/23 インストール: remmina.x86_64 0:1.3.6-1.el7 依存性関連をインストールしました: avahi-ui-gtk3.x86_64 0:0.6.31-19.amzn2 freerdp-libs.x86_64 0:2.0.0-1.rc4.amzn2 libXcomp.x86_64 0:3.5.99.17-1.el7 libsodium.x86_64 0:1.0.18-1.el7 libssh.x86_64 0:0.7.1-0.7.el7 libvncserver.x86_64 0:0.9.9-13.amzn2 libwinpr.x86_64 0:2.0.0-1.rc4.amzn2 lzo-minilzo.x86_64 0:2.06-8.amzn2.0.3 nx-libs.x86_64 0:3.5.99.17-1.el7 nxproxy.x86_64 0:3.5.99.17-1.el7 remmina-plugins-exec.x86_64 0:1.3.6-1.el7 remmina-plugins-nx.x86_64 0:1.3.6-1.el7 remmina-plugins-rdp.x86_64 0:1.3.6-1.el7 remmina-plugins-secret.x86_64 0:1.3.6-1.el7 remmina-plugins-st.x86_64 0:1.3.6-1.el7 remmina-plugins-vnc.x86_64 0:1.3.6-1.el7 remmina-plugins-xdmcp.x86_64 0:1.3.6-1.el7 xcb-util-image.x86_64 0:0.4.0-2.amzn2.0.2 xcb-util-keysyms.x86_64 0:0.4.0-1.amzn2.0.2 xcb-util-renderutil.x86_64 0:0.3.9-3.amzn2.0.2 xcb-util-wm.x86_64 0:0.4.1-5.amzn2.0.2 xorg-x11-server-Xephyr.x86_64 0:1.19.5-6.amzn2.0.2 完了しました! [root@a-1vo34nwckj3og ~]# [root@a-1vo34nwckj3og ~]#
- 投稿日:2020-01-24T21:13:39+09:00
【AWS/Lambda】lambdaに固定IPをつける/VPCに所属させる
「困ったら大体lambda(とS3)」「lambda イズ 仙道」、AWSの基本ですね()
ただ彼は基本的に固定IPを持ちません。仙道同様、気まぐれです。
今回はそんな彼に固定IPを付与する方法をまとめます。
また、結果としてVPC&サブネットへ所属させる方法にもなります。どんな時に役立つか
例えば
- 申請式で特定IPからのアクセスしか認められないサービスとの連携
- インスタンス内で動くIP制限付きサイトの死活監視
- プライベートサブネット内のインスタンスと通信
※インスタンスそのものの監視はcloudwatchでどうぞ
構成図
以下の形です。
手順
手順的には大まかに以下の形です。
1. lambdaをVPC内のプライベートサブネットに設置
2. lambdaのロールにvpc、eniに関する権限を追加
3. パブリックサブネットにNATゲートウェイを設置
4. プライベートサブネットのルートテーブルを編集順番に見ていきましょう。
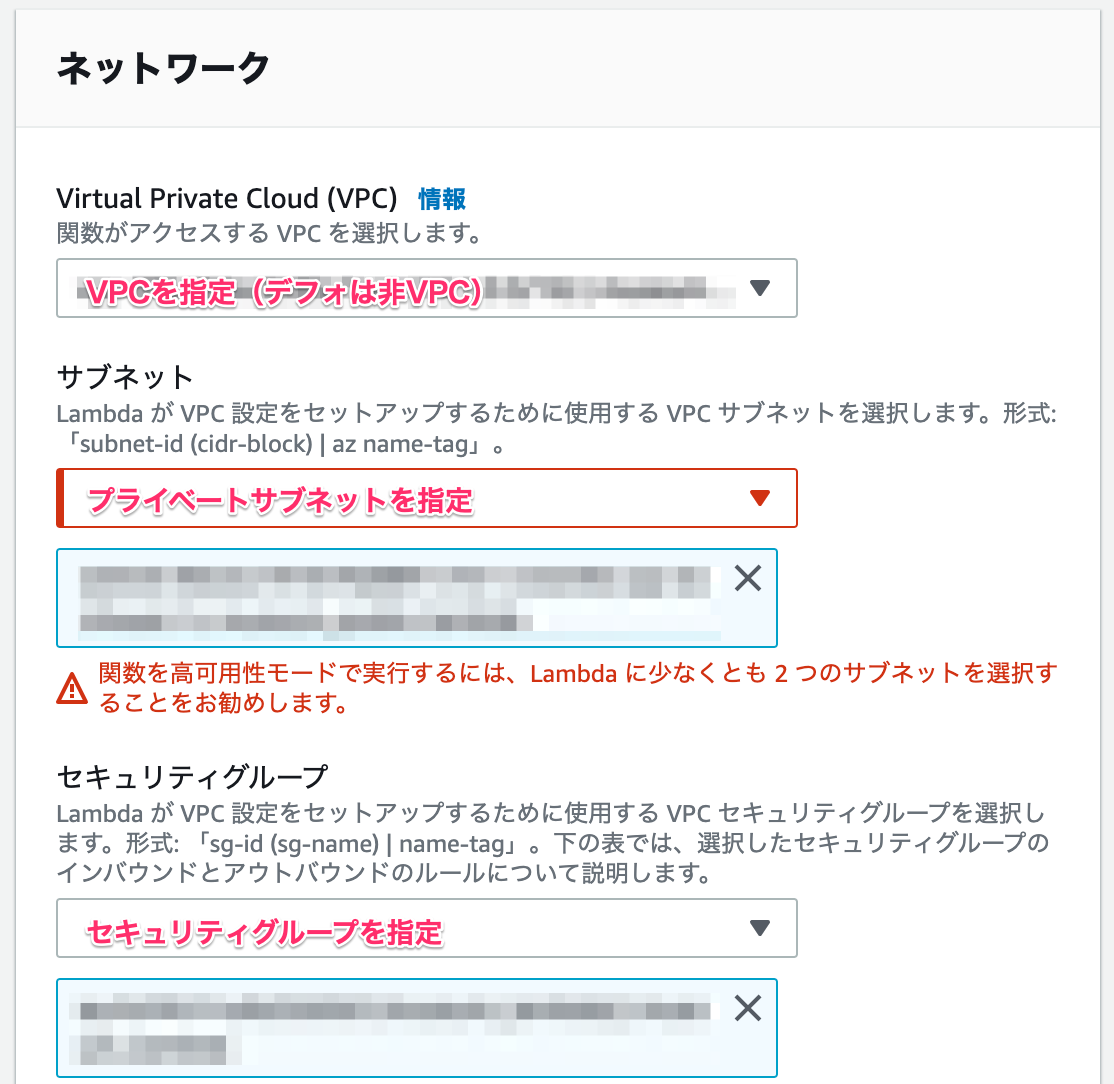
VPC内にプライベートサブネット(インターネットゲートウェイを持たない)、パブリックサブネットが一つずつある前提です。1. lambdaをVPC内のプライベートサブネットに設置
lambda関数の作成時、デフォルトでは非VPCとなっています。
普段はこれで問題ないですが、今回は既存のVPC、プライベートサブネット、セキュリティグループを設定して下さい。
ちなみにパブリックサブネットに設置するとVPC内はいけますが、外に出られません。
公式より2. lambdaのロールにvpc、eniに関する権限を追加
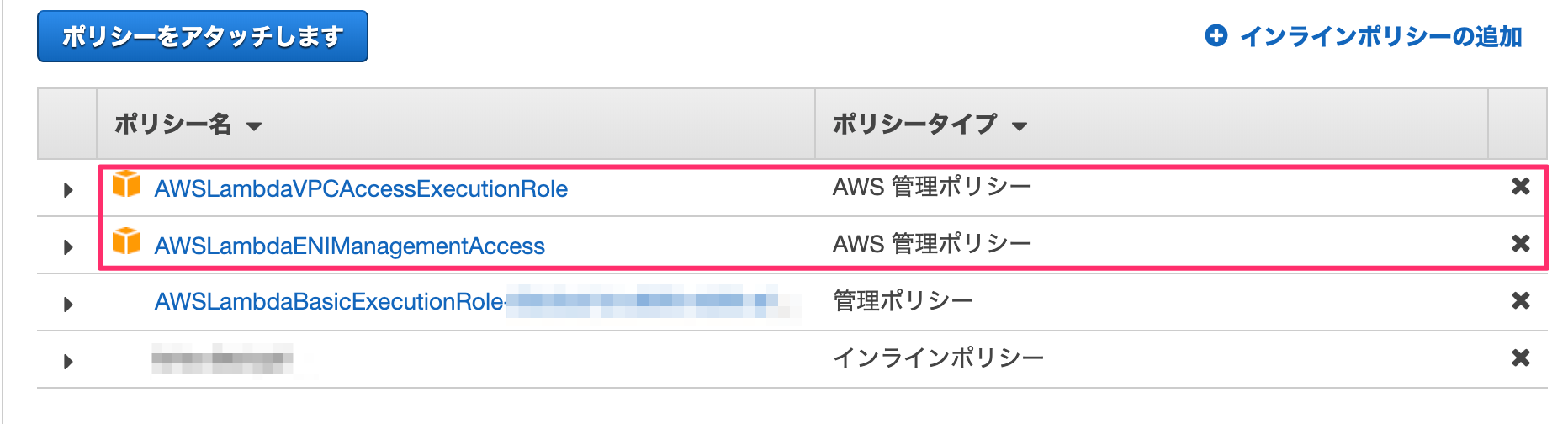
lambda関数作成時に指定したロールにVPCアクセス、eni作成、削除の権限が必要になります。
「IAM -> ロール」より当該ロールを選択し、AWSLambdaVPCAccessExecutionRole、AWSLambdaENIManagementAccessをアタッチしてください。
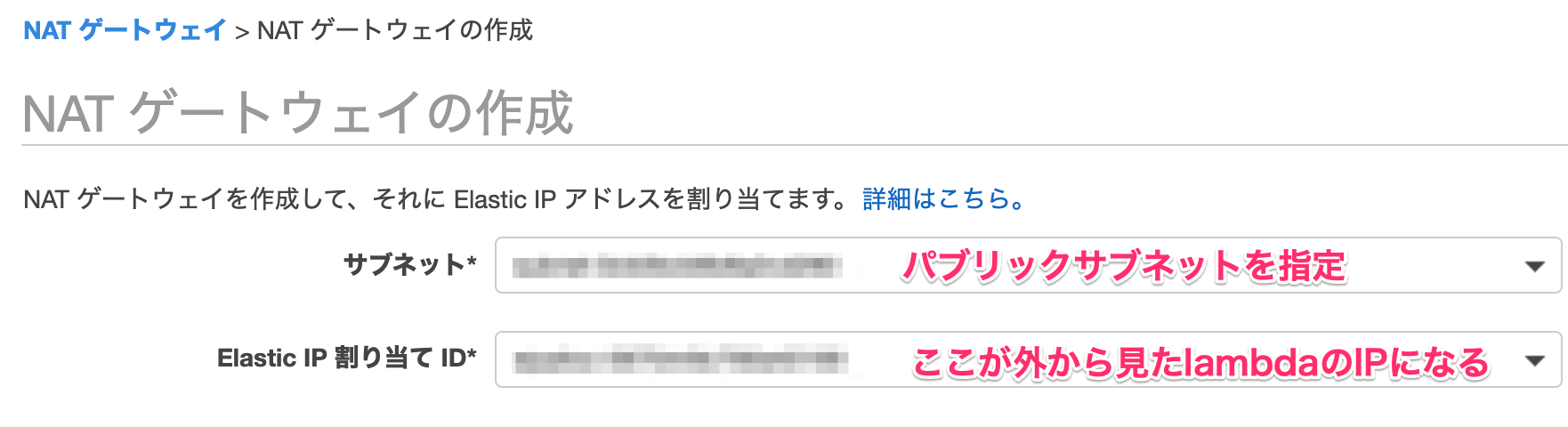
3. パブリックサブネットにNATゲートウェイを設置
「VPC -> NATゲートウェイ」よりNATゲートウェイを作成します。
サブネットにパブリックサブネットを指定する点に注意してください。
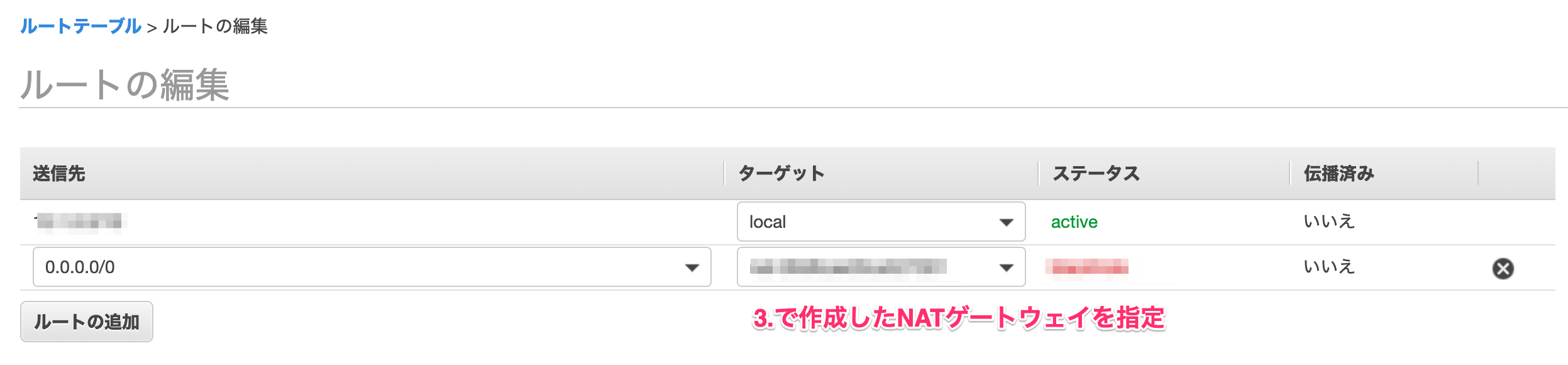
4. プライベートサブネットのルートテーブルを編集
最後の手順です。
「VPC -> ルートテーブル」よりプライベートサブネットに紐づくルートテーブルを選択し、ルートテーブルの編集より、以下のように送信先に0.0.0.0/0、ターゲットに3.で作成したNATゲートウェイを指定したルートを追加してください。
これにより、lambda関数から外に出る際に、パブリックサブネット内のNATゲートウェイを経由する形となります。ちなみにサブネットを作成した直後は、サブネットのルートテーブルにVPCのものが紐づいているので、間違ってそちらを編集しないように気をつけてください。
おしまい
あとはlambda関数内で外部アクセスするコードを記述、検証してOKなら問題なしです。
なにか抜けや間違いなどありましたらご指摘いただけると幸いです。

- 投稿日:2020-01-24T20:02:27+09:00
AWSアカウント作り直してみた
はじめに
- これからawsの勉強をする予定です。
- 2年前くらいに、railsチュートリアルをしました。その際に、一度AWSのアカウントを登録したのですが、途中で挫折して、ずっと放置されてたままになっていました....
- 今回、AWSアカウントを作り直そうか迷っていましたが、作り直すと
無料枠がリセットされることが判明したので、作り直そうと思います!!(メールアドレスは変える必要があるみたいです)目次
- awsのアカウントを削除
- awsのアカウントを再登録
- 初期設定
1.awsのアカウントを削除
rootアカウントでログイン
- サインインの画面でrootアカウントに紐づくメールアドレスを入力します。
2. パスワードと多要素認証が求めれるので、それぞれ入力します。
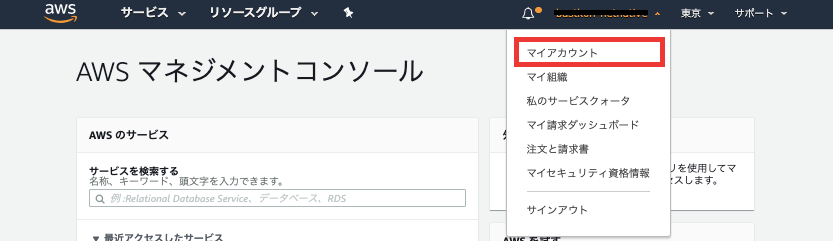
3. AWSマネジメントコンソール画面に入ることができます。アカウント解約へ
マネジメントコンソール画面から自分のアカウント管理画面へ
そのページをスクロールし、最下部へ
クリックすると、
これでアカウントの解約ができました!!
解約手続き完了メールが登録したメールアドレスに届いているはずです。2.awsアカウントの再登録
ここから基本情報を入力し、再度アカウントを作り直しました。
できました!!3.初期設定
- 以下の記事を参考に初期設定を行いました。
多少記事のUIと異なることはありましたが、特に詰まることなく、15分くらいで設定することができました!!
まとめ・感想
- 初めて作った時は、1時間くらいかかった気がしますが、特に迷うことなく作り直すことができました。調べてみると分かりやすい記事たくさんありますね。今後も勉強しやすそうです。
- やっと勉強する準備が整ったので、次回からは無料枠を使って何かしたいと思っています。アカウント作り直すことで
無料枠がリセットされるの本当にありがたいです...- そういえば、就活用にWordPressで作ったポートフォリオをサクラサーバに放置してあったはずなので、この機会にAWSに移行しようかなと思います。






- 投稿日:2020-01-24T19:57:48+09:00
インフラエンジニア、自由人として現状aws cloud9が最強だと思う理由
- 投稿日:2020-01-24T19:25:06+09:00
Jest実行時にserverless.ymlのfunctionsのenvironmentを読み込む
jest-environment-serverless を利用して
serverless.ymlから環境変数を読み込みます。
(.envを読み込む以外の方法を試してみたかった)手順
パッケージのインストール
必要なパッケージをインストールします。
$ npm install serverless jest jest-environment-serverlessプロジェクトの作成
$ npx serverless create --template aws-nodejs設定
serverless.ymlに読み込む環境変数の名称と値を記述します。serverless.ymlservice: sample provider: name: aws runtime: nodejs12.x functions: hello: handler: handler.hello environment: # これを読み込みます SAMPLE_VALUE: Sample
package.jsonにjestの設定を追加します。package.json{ : "jest": { "testEnvironment": "jest-environment-serverless", } }テストの作成
環境変数を console.log で出力する処理を記述します。
__test__/handler.spec.jsdescribe('Sample', () => { it('check env', () => { // 表示 console.log(process.env.SAMPLE_VALUE); expect(''); }); });テストの実行
$ npx jest PASS __test__/handler.spec.js (10.71s) Sample ✓ check env (67ms) console.log __test__/handler.spec.js:5 Sample Test Suites: 1 passed, 1 total Tests: 1 passed, 1 total Snapshots: 0 total Time: 16.159s Ran all test suites.環境変数の値(
Sample)を読み込むことができました。おまけ
環境変数の名称と値をAPIから取得することもできます。
__test__/handler.spec.jsdescribe('Sample', () => { it('check env', () => { // serverless.yml の functions.hello.environment の読み込み const envVars = ServerlessWrapper.getEnv('hello'); // 出力 console.log(envVars); expect(''); }); });$ npx jest PASS __test__/handler.spec.js (8.714s) Sample ✓ check env (68ms) console.log __test__/handler.spec.js:8 { SAMPLE_VALUE: 'Sample' } Test Suites: 1 passed, 1 total Tests: 1 passed, 1 total Snapshots: 0 total Time: 13.556s Ran all test suites.環境変数の名称と値(
{ SAMPLE_VALUE: 'Sample' })を出力することができました。
- 投稿日:2020-01-24T19:25:06+09:00
Jest実行時にserverless.ymlの環境変数を読み込む
jest-environment-serverless を利用して
serverless.ymlから環境変数を読み込みます。
(.envを読み込む以外の方法を試してみたかった)手順
パッケージのインストール
必要なパッケージをインストールします。
$ npm install serverless jest jest-environment-serverlessプロジェクトの作成
$ npx serverless create --template aws-nodejs設定
serverless.ymlに読み込む環境変数の名称と値を記述します。serverless.ymlservice: sample provider: name: aws runtime: nodejs12.x functions: hello: handler: handler.hello environment: # これを読み込みます SAMPLE_VALUE: Sample
package.jsonにjestの設定を追加します。package.json{ : "jest": { "testEnvironment": "jest-environment-serverless", } }テストの作成
環境変数を console.log で出力する処理を記述します。
__test__/handler.spec.jsdescribe('Sample', () => { it('check env', () => { // 表示 console.log(process.env.SAMPLE_VALUE); expect(''); }); });テストの実行
$ npx jest PASS __test__/handler.spec.js (10.71s) Sample ✓ check env (67ms) console.log __test__/handler.spec.js:5 Sample Test Suites: 1 passed, 1 total Tests: 1 passed, 1 total Snapshots: 0 total Time: 16.159s Ran all test suites.環境変数の値(
Sample)を読み込むことができました。おまけ
環境変数の名称と値をAPIから取得することもできます。
__test__/handler.spec.jsdescribe('Sample', () => { it('check env', () => { // serverless.yml の functions.hello.environment の読み込み const envVars = ServerlessWrapper.getEnv('hello'); // 出力 console.log(envVars); expect(''); }); });$ npx jest PASS __test__/handler.spec.js (8.714s) Sample ✓ check env (68ms) console.log __test__/handler.spec.js:8 { SAMPLE_VALUE: 'Sample' } Test Suites: 1 passed, 1 total Tests: 1 passed, 1 total Snapshots: 0 total Time: 13.556s Ran all test suites.環境変数の名称と値(
{ SAMPLE_VALUE: 'Sample' })を出力することができました。
- 投稿日:2020-01-24T19:10:54+09:00
YAMAHA vRXをDatadogのSNMPで監視しちゃおう
そもそもSNMPを活用した監視についてあまり記事がなかったので備忘録として。
経緯
YAMAHA vRXの検証環境に触れる機会があったので、運用の観点から利用方法だけでなく監視ができないかを調査。
ネットワーク機器ではお馴染みのSNMPの機能を用いて、vRXが出力する値を監視する手段の考察必要なもの
- datadog-agentを稼働させるためのvRXに通信可能な別インスタンス
- vRX用MIBファイル
- MIBファイルをpython化するための作業環境(一度きり)
- 気合い
諸々の概要
Datadogについて
説明する気はありませんので、気になる方は以下なりインターネッツでお調べください。
https://www.datadoghq.com/ja/
このDatadogのエージェントがもつ標準のsnmp監視インテグレーションを利用します。
https://docs.datadoghq.com/ja/integrations/snmp/DatadogのSNMPインテグレーションについて
非常に難解。
というのも、そもそもSNMPをそこまで詳しく知らないため、yaml見てもピンとこなかったのが原因。
OIDの指定だけでも取得はできるが、せっかくなのでカスタムMIB使っちゃおうとしたのが間違いの始まり。
Specify an additional folder for your custom mib files (python format).
pythonフォーマットのMIBファイルが必要です。
辛い。YAMAHA vRXについて
詳しい情報はこちら
https://network.yamaha.com/products/software_service/vrx/index
注目される強みはここかな、と。
IPsecのアグレッシブモードをサポートしており、固定IPアドレス環境を用意しなくても、動的IPアドレスを持つ端末やルーターからのVPN接続が可能です。検証の環境
- YAMAHA vRX Rev.19.00.01
- Amazon Linux 2 Linux version 4.14.154-128.181.amzn2.x86_64 < datadog-agentを導入しvRXを監視するインスタンス
- datadog-agent v7.16.1
下準備
面倒だったので作業はAmazonLinux2上で行なっています。
カスタムMIBファイルの取得
適当なディレクトリにて
$ mkdir yamahamib $ cd yamahamib $ wget http://www.rtpro.yamaha.co.jp/RT/docs/mib/yamaha-private-mib.zip $ unzip yamaha-private-mib.zip $ rm yamaha-private-mib.zip (ディレクトリに残ったzipは消すか移動させてください)MIBの参照先はこちら
http://www.rtpro.yamaha.co.jp/RT/FAQ/SNMP/private-mib.html作業環境作成
・pipインストール
$ sudo yum install python3-pip・pysnmp,pysnmp-mibsのインストール
$ sudo pip3 install pysnmp pysnmp-mibspythonファイルへのコンバート
MIBファイルを展開したディレクトリにて
$ mibdump.py ./*以下のディレクトリにpyファイルに変換されたMIBファイルが保管される(はず)
/hogeuser/.pysnmp/mibsこのファイルを
/etc/datadog-agent/mibs
など、適当なディレクトリを用意して移動させる
(datadog-agentで指定するので、アクセス権があればどこでも良い)私の環境では念の為chownコマンドにてディレクトリとファイルのオーナーをdd-agentに変えましたが、必要かどうかは知りません。
検証環境のディレクトリの中身はこんな感じです。-rw------- 1 dd-agent dd-agent 6007 Jan 23 09:30 YAMAHA-PRODUCTS-MIB.py -rw------- 1 dd-agent dd-agent 8053 Jan 23 09:30 YAMAHA-RT-FIRMWARE.py -rw------- 1 dd-agent dd-agent 14570 Jan 23 09:30 YAMAHA-RT-HARDWARE.py -rw------- 1 dd-agent dd-agent 62248 Jan 23 09:30 YAMAHA-RT-INTERFACES.py -rw------- 1 dd-agent dd-agent 7134 Jan 23 09:30 YAMAHA-RT-IP.py -rw------- 1 dd-agent dd-agent 2117 Jan 23 09:30 YAMAHA-RT.py -rw------- 1 dd-agent dd-agent 10571 Jan 23 09:30 YAMAHA-RT-SWITCH.py -rw------- 1 dd-agent dd-agent 1904 Jan 23 09:30 YAMAHA-SMI.py -rw------- 1 dd-agent dd-agent 4851 Jan 23 09:30 YAMAHA-SW-ERRDISABLE.py -rw------- 1 dd-agent dd-agent 4571 Jan 23 09:30 YAMAHA-SW-FIRMWARE.py -rw------- 1 dd-agent dd-agent 15584 Jan 23 09:30 YAMAHA-SW-HARDWARE.py -rw------- 1 dd-agent dd-agent 11757 Jan 23 09:30 YAMAHA-SW-L2MS.py -rw------- 1 dd-agent dd-agent 2214 Jan 23 09:30 YAMAHA-SW.py -rw------- 1 dd-agent dd-agent 2313 Jan 23 09:30 YAMAHA-SW-RMON.py -rw------- 1 dd-agent dd-agent 5595 Jan 23 09:30 YAMAHA-SW-TERMMON.pyYAMAHA vRX側の設定
ここで肝心のvRXの設定を忘れていたので、記載します。
SNMPを利用して取得を行いたいのが目的ですので、難しいことはしていません。
aws内部通信で完結するため、SNMP V3ほどの要件は想定せず、コミュニティ名で対応しています。なお、前提として初期設定や通信接続設定は完了していることとなります。
aws前提ですので、vRX側のSGのインバウンドをdatadogを入れてsnmpを叩かせるインスタンスからの通信も許可しておいてください。SNMPの設定
以下の設定を追記
snmp host any snmp community read-write hogecom snmp syscontact hoge snmp sysname VPC3_RT snmp syslocation aws snmp yriftunneldisplayatmib2 on反映、保存を忘れずに。
詳しい方は知識に合わせて変更ください。
細かい説明はできませんので省略します。
なお、host anyは検証でやってるだけなので、アクセス元の制限が必要であれば指定ください。datadog-agentの設定
通常設定はされている前提です。
snmp用yamlファイルの準備
datadog-agentのv7では以下の場所にyamlのサンプルファイルが保管されています。
/etc/datadog-agent/conf.d/snmp.d
コピーしてファイル名を変更し、読み込まれるように設定します。
記述が面倒なので、以下からはroot権限でやります。# cd /etc/datadog-agent/conf.d/snmp.d # cp conf.yaml.example conf.yaml拡張子をyamlにすることでdatadog-agentの次回起動時から読み込みされます。
snmpの取得設定
conf.yamlファイルをエディタなどで編集します。
とりあえずの設定箇所はinit_config: . . # mibs_folder: /path/to/your/mibs/folder ↓↓↓↓↓↓この検証だとこのディレクトリ。変更された方はそれに合わせて設定ください。 mibs_folder: /etc/datadog-agent/mibs . . instances: . . # ip_address: <IP_ADDRESS> ↓↓↓↓↓↓vRXのLAN側のIPアドレスを指定 ip_address: xxx.xxx.xxx.xxx . . # community_string: public ↓↓↓↓↓↓この検証だとこのコミュニティ名。環境に合わせて指定ください。 community_string: hogecom . . # snmp_version: 2 ↓↓↓↓↓↓今回v1で手を抜いたので。環境に合わせて指定ください。 snmp_version: 1 . .datadog-agentを再起動します。
その後、statusコマンドにてsnmpの取得がうまくいってることを確認します。# systemctl restart datadog-agent # datadog-agent status . . snmp (2.1.0) ------------ Instance ID: snmp:9a97f28adcb05e32 [OK] Configuration Source: file:/etc/datadog-agent/conf.d/snmp.d/conf.yaml Total Runs: 1 Metric Samples: Last Run: 4, Total: 4 Events: Last Run: 0, Total: 0 Service Checks: Last Run: 1, Total: 1 Average Execution Time : 191msうまく動けばsnmpの項目がOKで返って来ることがわかります。
少しおいてからDatadogのコンソールにて、Insfastructureを探すと「snmp」が表示されるようになります。
merticsのグラフが参照できるので、そこでグラフが表示されれば取得完了となります。画面は取っていませんが、おそらく黄色いsnmpマークとグラフは3つが出ていると思います。
これが初期設定で拾ってくる情報となります。MIBの設定から取得してみる
大詰めです。
せっかくプライベートMIBが使えるようになっているので、それを指定した取得も入れてみましょう。conf.yamlファイルをエディタなどで編集します。
instances: . . metrics: . . - MIB: YAMAHA-RT-HARDWARE symbol: yrhMemoryUtilこれでdatadog-agentを再起動すると、メモリの使用率が取得できるようになります。
なお、MIBとかsymbolって?って話ですが、指定する情報は以下の通りです。MIB=mibs_folder: /etc/datadog-agent/mibsに保管したpyのファイル名(.pyは不要) symbol=対象pythonファイル内の定義情報です。上記の設定では、YAMAHA-RT-HARDWARE.pyのyrhMemoryUtilの値を返してね。
ちなみにOIDは「1.3.6.1.4.1.1182.2.1.4」なので、このOID指定+nameでも同じ値は返ります。
が、せっかくなので。なお、vRXはRTのカテゴリ扱いなので、SWファイル(OID:1.3.6.1.4.1.1182.3)には対応していないようです。
詳しいことはmib.txtの内部に書かれているので、それを参照してください。例)YAMAHA-RT-HARDWARE
http://www.rtpro.yamaha.co.jp/RT/docs/mib/yamaha-rt-hardware.mib.txtyrhMemoryUtil OBJECT-TYPE SYNTAX Gauge (0..100) ACCESS read-only STATUS mandatory DESCRIPTION "The utilization in percentage of main memory." ::= { yamahaRTHardware 4 }あと、Datadog側のyamlに標準で書かれている以下の項目はエラーになって取得ができない可能性が高いので、いっそのこと消してしまいましょう。
(活用できる方はぜひ使っていただければ)- OID: 1.3.6.1.2.1.6.5 name: tcpPassiveOpens metric_tags: - TCPMIBでの取得情報追加、上記の設定削除後にdatadog-agentを再起動し、statusで問題がなければ、
以下のようにDatadogのコンソール側で「yrhMemoryUtil」が取れるようになったことが確認できます。
SNMPV2c情報が欲しい場合は、vRX側でV2cのコミュニティ、受け入れhost設定の追加、
Datadog側ではV1からV2利用の宣言に変更すれば取得可能でした。付録
トンネルのリンクupdownはOID「1.3.6.1.4.1.1182.2.3.16.1.2系」にて確認できるようです。
SNMP V2cが前提であることにご注意ください。どれがリンクするかは、configのtunnelの設定番号を確認し、snmpwalkでインターフェースのディスクリプション番号と関連を確認
$ snmpwalk -v 1 -c hogecom xxx.xxx.xxx.xxx | grep ifDescr IF-MIB::ifDescr.1 = STRING: LAN1 IF-MIB::ifDescr.2 = STRING: LAN2 IF-MIB::ifDescr.3 = STRING: LAN3 IF-MIB::ifDescr.4 = STRING: LAN4 IF-MIB::ifDescr.1195 = STRING: TUNNEL[1] IF-MIB::ifDescr.1196 = STRING: TUNNEL[2] . .tunnel 1が1195と確認できるので、
$ snmpwalk -v 1 -c hogecom xxx.xxx.xxx.xxx 1.3.6.1.4.1.1182.2.3.16.1.2.1195 SNMPv2-SMI::enterprises.1182.2.3.16.1.2.1195 = INTEGER: 1で値を取得。
1はUp、2はDownなので、2を取得した場合にアラートとすることで対応できそう。私の検証環境では
SNMPv2-SMI::enterprises.1182.2.3.16.1.2.1195 = INTEGER: 1 SNMPv2-SMI::enterprises.1182.2.3.16.1.2.1196 = INTEGER: 1 SNMPv2-SMI::enterprises.1182.2.3.16.1.2.1197 = INTEGER: 2 SNMPv2-SMI::enterprises.1182.2.3.16.1.2.1198 = INTEGER: 2となっており、tunnel1,2がup(1)、3以降は存在しないためdown(2) が取得されました。
まとめ
まとめというほどじゃないですが、python化とMIBの指定さえわかれば、なんとかなるかなという印象。
OID指定の方が楽な場合もあるので、そこは臨機応変にお願いします。
(取れると思って試してる値が取れずに悩んでますが、諦めも肝心です)
snmpwalkなどで取れるものは、普通に取れる印象です。

- 投稿日:2020-01-24T18:57:54+09:00
Elastic Beanstalk 指定時間だけインスタンスタイプを上げる
改善
12:00~13:00のみ負荷のかかるElastic Beanstalkの環境がある。
インスタンスタイプの調整で費用を抑える。
PMから指示がなくてもインフラはそうする。lambda_function.lambda_handler
python3.8import json import boto3 from datetime import datetime def lambda_handler(event, context): envName = str(event['env-name']) instanceType = '' currHour = datetime.now().hour + 9 if currHour > 24: currHour = currHour - 24 print(currHour) if(currHour == 11): #11時代に上げる instanceType = 'c5.xlarge' elif(currHour == 13): #13時代に下げる instanceType = 't3.micro' else: return 'NONE' client = boto3.client('elasticbeanstalk', region_name="ap-northeast-1") response = client.update_environment( EnvironmentName=envName, OptionSettings=[ { 'Namespace': 'aws:autoscaling:launchconfiguration', 'OptionName': 'InstanceType', 'Value': instanceType, } ], ) return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') }CloudWatch Events
例)cron(5 * ? * * *)
テストイベント
{ "env-name": "app-env" }参照
- https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/elasticbeanstalk.html
- https://docs.aws.amazon.com/ja_jp/elasticbeanstalk/latest/dg/environment-configuration-methods-after.html
- https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-beanstalk-environment.html
- 投稿日:2020-01-24T18:21:44+09:00
EC2 AutoScalingを使ったGraceful Shutdownを考える
はじめに
筆者がEC2 AutoScalingを含むAWS環境の運用を行う中で理解した内容を書き起こしています。
EC2のシャットダウンについて、AWSのサービスから各種ソフトウェアまで横断的に説明された記事があまり見つからなかったので、この記事が誰かの助けになればと思います。前提知識
EC2 AutoScalingとは?
EC2 AutoScalingはEC2のスケールイン/スケールアウトを担うサービスです。
設定したスケジュールベースのスケーリングや各種条件を踏まえた動的なスケーリングなど様々なタイプのスケーリングに対応しています。また、LifeCycleHookと呼ばれるEC2 AutoScalingの機能を利用してスケールイン/スケールアウト時の前処理をキックすることも可能です。
実装例はこの記事に記載しますが、LifeCycleHookに関する説明は下記のリンク先に記載されています。
https://docs.aws.amazon.com/ja_jp/autoscaling/ec2/userguide/lifecycle-hooks.htmlGraceful Shutdownとは?
サービスなどのシャットダウンにおいて「決められた手順に従って正常にサービス (当記事ではEC2インスタンス) を終了させること」を指しています。
Graceful Shutdownを実現するために、サービスによっては「特定のAPIリクエストを受け付けると新規リクエストの受付を停止する」などの補助機能を用意しているものもあります。なぜGraceful Shutdownが重要なのか?
ここからはクラウド環境(非コンテナ環境)においてサービスを運用している想定で話を進めていきます。
自分が運用に携わった環境では、サーバ(EC2)の運用にあたって元々下記のような要望がありました。
- ログ管理
- スケールインの際に、アプリやOS周りのログを退避させたい
- 監視
- スケールインで消えたサーバは監視の対象外にしたい
- DatadogのAutomuting のような削除されたインスタンスを自動的に監視対象外にすることができないので、スケールイン時に手動で監視対象から除外したい
- 構成管理
- 各種設定ファイルの変更時に、変更前の状態をバックアップとして保管したい
この環境ではEC2 AutoScalingを利用していましたが、「インスタンスがいつ消えてもいい」前提で上記のような運用設計を行う必要がありました。
つまり、スケールイン時にインスタンスをただ削除するのではなく、必要な事前処理を全て実行した上でEC2インスタンスを削除することが求められていました。構成管理に関しては、構成変更時にEC2 AutoScalingのベースとなるAMIを毎回取得することで対応できるため、ログ管理・監視について考える必要がありました。
ログ管理・監視について上記の要件を満たすために、この環境では下記のようなAWSサービスとソフトウェアを利用しました。
- AWSサービス
- EC2
- EC2 AutoScaling
- SQS
- Fluentd
- Zabbix
EC2 AutoScaling LifeCycleHookを利用した処理フロー
上記の内容を実現するために、EC2 AutoScalingのLifeCycleHookをメインで利用します。
まず、参考としてLifeCycleHook利用時のスケールアウトのフローを下記に記載します。
(https://docs.aws.amazon.com/ja_jp/autoscaling/ec2/userguide/lifecycle-hooks.html)
- (EC2 AutoScaling) スケールアウトのイベントが発生
- (EC2 AutoScaling LifeCycleHook) インスタンスを待機状態(
Terminating:Wait)にする
- SQS内のメッセージを確認する
- カスタムアクションの実行
- 通知ターゲットに対してメッセージの送信
- CloudWatchイベントを利用したLambda関数の呼び出し
- (EC2 AutoScaling LifeCycleHook) ライフサイクルアクションを完了させて待機状態を解除する
- (EC2 AutoScaling) インスタンスをスケールアウトする
これをベースに、スクリプトを用いて下記のような処理フローでの対応を試みました。
- (EC2 AutoScaling) スケールアウトのイベントが発生
- (EC2 AutoScaling LifeCycleHook) インスタンスを待機状態(
Terminating:Wait)にする- (EC2 AutoScaling) カスタムアクションの実行
- (EC2 AutoScaling) 通知ターゲット(SQS)に対してメッセージの送信
- (EC2) SQSにメッセージを見に行くスクリプト(A)をcronjobを用いて定期的に実行させる
- メッセージ内のホスト名が一致する場合のみ必要な事前処理を実施する
- (EC2 AutoScaling LifeCycleHook) ライフサイクルアクションを完了させて待機状態を解除する
- (EC2) ライフサイクルアクションを完了させるコマンドをスクリプト(A)内で実行する
- (EC2 AutoScaling) インスタンスをスケールアウトする
カスタムアクションの実行
上記の処理フローの具体的な内容を確認していきます。
上記のフローの前提として、EC2 AutoScalingにLifeCycleHookを作成する必要があります。
通知先のターゲットはGUIから設定できないため、AWS CLIを利用して作成します。(0)aws autoscaling put-lifecycle-hook \ --lifecycle-hook-name <LifecycleHookName> \ --auto-scaling-group-name <AutoScalingGroupName> \ --lifecycle-transition autoscaling:EC2_INSTANCE_TERMINATING \ --notification-target-arn arn:aws:sqs:<RegionName>:<AccountId>:<SqsName> \ --role-arn arn:aws:iam::<AccountId>:role/<RoleName>LifeCycleHookを設定した上で、上記フローの流れを確認していきます。
EC2 AutoScalingによってインスタンスのスケールアウトのイベントが発生する (1) と、LifeCycleHookによってインスタンスが待機状態(Terminating:Wait)になります。(2)
Terminating:Waitの状態になったタイミングで、(0)で指定した通知ターゲット(SQS)に対してメッセージを送信します。
メッセージの中には、下記のようなメタデータが含まれています。
EC2InstanceId:削除対象のEC2インスタンスのIDLifecycleTransition:ライフサイクルフックをアタッチするEC2インスタンスの状態AutoScalingGroupName:EC2 AutoScalingのグループ名{ "Messages": [ { "Body": "{\"LifecycleHookName\":\"<LifecycleHookName>\",\"AccountId\":\"<AccountId>\",\"RequestId\":\"8e5ccd3a-...2bbd\",\"LifecycleTransition\":\"autoscaling:EC2_INSTANCE_TERMINATING\",\"AutoScalingGroupName\":\"<AutoScalingGroupName>\",\"Service\":\"AWS Auto Scaling\",\"Time\":\"2020-01-21T05:02:07.003Z\",\"EC2InstanceId\":\"<EC2InstanceId>\",\"LifecycleActionToken\":\"<ActionToken>\"}", "ReceiptHandle": "AQEB/tVhFsV7fWVd7mxhPhruxGW7/QkDm/K13qJ1e7tB2pRGj2uxgsxsE2YH0l+NV/2L42S6yX0W7LPlnPdyV+vW8Fga4nc4XaSwO0ARtgmC53ej7NW3akQtvVTLy46CxYJfkJ/lovVlZyELLSiEz4IapDHlJLDv1iiIRoEXGyRITrcAwTPKiKtNcWJE3t/WhGwDIJr/4PdqfdA5+nWSw/ydOHxFGUxns8yJTF3Vs8IkSQP7vLQH4Ht2TfWDBRB9K2Kujq4gzn3JhKdwwOIQCapBguK+3mPwEtvCUL0V6FzF1tufwMXXGvkuAJYUEIyJtPh0vOzog/nDzY2Ajnjw0Vty2x4pWpVogg/cNhkJep5hvjYQXvlBT82W5+SItKj42tYjqqQ70lhmOUI5WzVIgSMcR3g3WXDE/0S7FTUaWR2Lir4=", "MD5OfBody": "5b1a33fd76a6d6a49415a84300c7b4d3", "MessageId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" } ] }一方、インスタンス側では、cronjobを用いて定期的にスクリプトを実行します。
最初に、SQSのキュー内のメッセージの有無を確認します。aws sqs receive-message \ --queue-url https://sqs.<RegionName>.amazonaws.com/<AccountId>/<LifecycleHookName> \ --region <RegionName>メッセージから各種メタデータを取り出して
EC2InstanceIdを確認し、自分自身が削除対象である場合に事前処理を実行します。
事前処理の中では下記のような内容を実行します。
- 各種エージェントの停止
- Fluentd:シグナル(
SIGUSR1)の送信によるエージェントの停止- Zabbix:
systemctlコマンドによるエージェントの停止- 監視用の設定の削除を行うスクリプト(B)を実行
# 各種エージェントの停止 kill -SIGUSR1 $(cat /var/run/td-agent/td-agent.pid) systemctl stop zabbix-agent # 監視設定の削除を行うスクリプト(B)を実行 /usr/local/bin/shell/delete_host_conf.shログ管理
Fluentdでは、各EC2インスタンスからログ保管用のサーバにログを送信するために、
out_forwardプラグインを利用しています。
(実際には、Input・Filterプラグインを利用していますが長くなるため省略しています。)## Output <match <tag_pattern> > type forward heartbeat_type tcp flush_at_shutdown true flush_interval 60s buffer_chunk_limit 256m <server> name logserver1 host 192.168.74.150 port 24224 </server> <server> name logserver2 host 192.168.74.151 port 24224 standby </server> </match>詳細な説明は省きますが、FluentdのSupervisor Processに対して
SIGUSR1のシグナルを送信することで、バッファ内のchunkを強制的にFlushし、転送先のサーバに送るようにします。
(参考:https://docs.fluentd.org/deployment/signals)監視
この環境では監視ツールとしてZabbixを利用しています。
/usr/local/bin/shell/delete_host_conf.shに関する詳細については割愛しますが、中身としてはZabbix APIを利用して下記のような流れでホスト定義を削除します。
- ホスト名でフィルターしてホストIDを取得する(
host.get)- ホストIDを指定してホスト定義削除のリクエストを送る(
host.delete)バージョンごとの差異は別として、公式ドキュメントを確認することで大まかなAPIの利用方法は理解できるかと思います。
https://www.zabbix.com/documentation/2.2/manual/apiLifeCycleHookのステータス更新
次に、メッセージから取得した
ReceiptHandleを変数$MSG_Receiptに詰めて、SQS内の指定したメッセージを削除します。メッセージIDではなく、メッセージハンドルを指定して削除する点は注意が必要です。
参考:https://docs.aws.amazon.com/AWSSimpleQueueService/latest/APIReference/API_DeleteMessage.htmlaws sqs delete-message \ --queue-url https://sqs.<RegionName>.amazonaws.com/<AccountId>/<LifecycleHookName> \ --region <RegionName> --receipt-handle $MSG_Receipt最後に、メッセージから取得したメタデータを基に、各種処理が完了したことをAutoScalingに知らせる
complete-lifecycle-actionコマンドを実行します。(4)aws autoscaling complete-lifecycle-action \ --lifecycle-hook-name $LH_Name \ --auto-scaling-group-name $ASG_Name \ --instance-id $InsId \ --lifecycle-action-token $MSG_LH_Token \ --lifecycle-action-result CONTINUEこれにより、インスタンスの待機状態が解除されて削除可能な状態(
Termination:Proceed)になり、インスタンスが削除されます。(5)最後に
EC2 AutoScalingと各種サービスを利用したシャットダウン処理についてまとめました。
個人的にはFluentdの機能やオプションの多さに感謝しつつ、まだまだ使いこなせていないと痛感しました。( 勉強せねば... )参考
EC2 AutoScaling - Lifecyclehook
- https://docs.aws.amazon.com/ja_jp/autoscaling/ec2/userguide/lifecycle-hooks.html
- https://dev.classmethod.jp/cloud/aws/autoscaling-lifecyclehook/
Fluentd
- 投稿日:2020-01-24T17:42:12+09:00
AWS Athenaで、WAFのcountログが絞り込めなくて苦戦した件
はじめに
- WAFでBLOCK設定するために、BLOCKしてほしくないアクセスを絞り込むためCOUNT設定
- WAFのログを、S3にJsonで保存
- COUNTになったアクセスを調査するために、ログに対して、Athenaでaction='COUNT' なクエリを書いたら、結果が0件
- COUNTが無いってことはBLOCKをONにできるーと思ってたら、actionにCOUNTは出てこない模様
- しかし、nonterminatingmatchingrulesカラムから取得できるとのことで、設定
- 取得はできるようになったが、Mysqlのノリだけでは理解が甘く、WHERE文が通らなかったことの解決
結論
取得SELECT timestamp, FROM_UNIXTIME(timestamp / 1000) as unixtime_to_timestamp, nonterminatingmatchingrules, FROM "default"."waflog2020" CROSS JOIN UNNEST(nonterminatingmatchingrules) AS t (nonterminatingmatchingrule) WHERE nonterminatingmatchingrule.action='COUNT' ORDER BY timestamp DESC limit 1詳細
取得対象のS3バケットを指定し、下記のようなテーブルを作る
テーブルCREATE EXTERNAL TABLE `waflog2020`( `timestamp` bigint COMMENT 'from deserializer', `formatversion` int COMMENT 'from deserializer', `webaclid` string COMMENT 'from deserializer', `terminatingruleid` string COMMENT 'from deserializer', `terminatingruletype` string COMMENT 'from deserializer', `action` string COMMENT 'from deserializer', `httpsourcename` string COMMENT 'from deserializer', `httpsourceid` string COMMENT 'from deserializer', `rulegrouplist` array<string> COMMENT 'from deserializer', `ratebasedrulelist` array<struct<ratebasedruleid:string,limitkey:string,maxrateallowed:int>> COMMENT 'from deserializer', `nonterminatingmatchingrules` array<struct<ruleid:string,action:string>> COMMENT 'from deserializer', `httprequest` struct<clientip:string,country:string,headers:array<struct<name:string,value:string>>,uri:string,args:string,httpversion:string,httpmethod:string,requestid:string> COMMENT 'from deserializer')bigint, int, stringなどのカラムの値は、Mysqlのノリでいけましたが、array型, struct型, それが入れ子になっていて詰みました
AthenaはFacebook社製のSQLエンジンPrestoを使っていて、Presto用の構文がよくわかりませんでした、、
struct型は、Key => Value形式で値を持てるみたいで、PrestoじゃなくてAthenaの機能っぽい・・・?CROSS JOIN UNNEST(nonterminatingmatchingrules) AS t (unnest) WHERE unnest.action='COUNT'UNNEST関数でnonterminatingmatchingrulesカラムをarrayじゃない状態にする
unnestカラムとstructのKeyをドットで繋いで、Valueを指定すればいけました。
※ AS t (unnest)の引数で、カラムにも別名を付けてるらしいおわりに
Prestoって結構前からあったみたいですね。アンテナ張っていかないと・・・
- 投稿日:2020-01-24T16:17:58+09:00
THIS BEHAVIOR MAY CHANGE IN A FUTURE VERSION OF CAPISTRANO. Please join the conversation here if this affects you. https://github.com/capistrano/capistrano/issues/1686のエラー解決例
1.エラーの様子
まず、自動デプロイを設定し、実行コマンドを行いました。すると下記のようになりました。
Neverland:chat-space-kai kontatomoya$ bundle exec cap production deploy #自動deployのコマンドを打ちました #ここまでまでエラーなし(省略) 00:51 unicorn:start unicorn is running... unicorn restarting... 01 kill -s USR2 `cat /var/www/chat-space-kai/shared/tmp/pids/unicorn.pid` ✔ 01 ec2-user@13.112.68.204 0.609s Skipping task `unicorn:restart'. Capistrano tasks may only be invoked once. Since task `unicorn:restart' was previously invoked, invoke("unicorn:restart") at config/deploy.rb:43 will be skipped. If you really meant to run this task again, use invoke!("unicorn:restart") THIS BEHAVIOR MAY CHANGE IN A FUTURE VERSION OF CAPISTRANO. Please join the conversation here if this affects you. https://github.com/capistrano/capistrano/issues/1686 #↑エラーの全文 #以下エラーなし(省略)黄色い文章(筆者の環境では赤文字でした)を読むとバージョン違うんじゃない?と書いてあって心当たりがなかったので
THIS BEHAVIOR MAY CHANGE IN A FUTURE VERSION OF CAPISTRANO. Please join the conversation here if this affects you.の部分で検索をかけたところ下記の記事を見つけました。
https://github.com/capistrano/capistrano/issues/1686
https://obel.hatenablog.jp/entry/20181030/1540880580
この中ではunicornのrestartができないのをどうにかすれば良い。とありましたが、restartコマンドは挿入した記憶があるため分からない。そしてgithubの更新を反映できないという状況になってました。2.原因と解決策
結論から言いますと下記のファイルにrestartの実行を2回重複して記載していたためエラーを起こしており、その部分を取り除けば解決しました。
app/config/deploy.rblock '3.11.2' set :application, 'chat-space-kai' set :repo_url, 'git@github.com:KONTA2019/chat-space-kai.git' set :linked_dirs, fetch(:linked_dirs, []).push('log', 'tmp/pids', 'tmp/cache', 'tmp/sockets', 'vendor/bundle', 'public/system', 'public/uploads') set :rbenv_type, :user set :rbenv_ruby, '2.5.1' set :ssh_options, auth_methods: ['publickey'], keys: ['~/.ssh/ChatSpace.pem'] set :unicorn_pid, -> { "#{shared_path}/tmp/pids/unicorn.pid" } set :unicorn_config_path, -> { "#{current_path}/config/unicorn.rb" } set :keep_releases, 5 after 'deploy:publishing', 'deploy:restart' namespace :deploy do task :restart do invoke 'unicorn:restart' end end #↑この部分が不要です set :linked_files, %w{ config/secrets.yml } after 'deploy:publishing', 'deploy:restart' namespace :deploy do task :restart do invoke 'unicorn:restart' end desc 'upload secrets.yml' task :upload do on roles(:app) do |host| if test "[ ! -d #{shared_path}/config ]" execute "mkdir -p #{shared_path}/config" end upload!('config/secrets.yml', "#{shared_path}/config/secrets.yml") end end before :starting, 'deploy:upload' after :finishing, 'deploy:cleanup' end3.この記事で伝えたかったこと
題名のエラーが目立つため、バージョンの間違いによる「互換性の問題に違いない」とドツボにはまってしまうことがあるかもしれませんが、もしかしたら筆者のように簡単なことで止まってるかもしれないので、'app/config/deploy.rb'を見直してみるとエラーが発見できるかもしれませんよ!ということを伝えたいと思ってこの記事を書きました。
何かのご参考になればと思います。
- 投稿日:2020-01-24T16:09:14+09:00
実践Terraformを読んでハマったこと
実践Terraform AWSにおけるシステム設計とベストプラクティスのコードを写経してみました。
今回はやってみてハマったことについてです。
変数と文字列を混同する
Terraformにも型はあるため、そのようなミスはplan実行時に検出してもらえます。ただ、型さえ合えばplanは正常終了するため、
文字列の受け渡しについてはapplyの実行をしてはじめてエラーが発生して間違いがわかることちょこちょことありました。
以下はvpcのidを変数aws_vpc.example.idで参照しようとしたけど、クォートでくくってしまったために変数名の文字列が渡されてエラーになったときです。Error: Error creating Security Group: InvalidVpcID.NotFound: The vpc ID 'aws_vpc.example.id' does not exist status code: 400, request id: 6f78b923-d690-42a6-b367-8fa4c71b3556 on security_group/main.tf line 23, in resource "aws_security_group" "default": 23: resource "aws_security_group" "default" {初歩的といえば初歩的なミスなのですが、以下の例のようにTerraformではAWSで定義されている値を文字列で参照するときがあります。
# AWSが管理しているポリシーを参照 data "aws_iam_policy" "ecs_task_execution_role_policy" { # ECSタスク実行IAMロールでの使用が想定されているポリシー arn = "arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy" }Terraformで定義されているのか、クラウドサービスで定義されているのか区別ができていないときは頻発しました。
S3の名前はユニーク
S3バケット名は全世界でユニークでなければなりません。本に載っているサンプルコードとおりのバケット名にするとエラーになります。
ユニークにしないといけないことは本で説明がしっかりとされています。
しかし、バケット名を設定するすべてのサンプルコードに「※注意ここはユニークな値に書き換えること」とは書かれていないため、うっかりしているとエラーになります。
まあなってもそんなに大事にはならないですが、バケット名はユニークになるようにサフィックスに年月日(-2019-01-24)とかつけるとよいと思います。FARGATEでヘルスチェックが行われるタイミング
9章「コンテナオーケストラレーション」ではまったところです。
1節から3節ではECS上でnginxコンテナを起動します。その後9章4節でヘルスチェックのログを確認できるようにします。
ヘルスチェックはコンテナ起動時にしかされないため、ログの設定をapplyで反映してもコンテナの再起動はされません。
したがってコンテナのヘルスチェックログを確認したい場合は一度destroyしてapplyし、作り直さないとヘルスチェックログを確認できません。RDSの削除保護設定について
13章「データストア」でRDSを削除保護して構築します。
ここはサンプルコード通りに書いたのですが、apply実行時に以下のエラーが出ました。
Error: DB Instance FinalSnapshotIdentifier is required when a final snapshot is required削除保護について、インスタンス削除時にスナップショットをとるならば、final_snapshot_identifierが必須のようです。
GitHubでもissueがあがっていたのと、公式ドキュメントでもskip_final_snapshotをtrueにするならば、final_snapshot_identifierは必須と書かれていました。
執筆時と仕様が変わったのかな?
(※2020/01/25追記 書籍の問い合わせの方に問い合わせてみました。結果がわかればまた更新します。)
あとこのIDは英数字とハイフンのみ使われた文字列ではないとだめらしいです。Error: only alphanumeric characters and hyphens allowed in "final_snapshot_identifier"ECSで実行するコンテナで常時起動していなくてもいいものは明示的に設定する
ECSで実行したいコンテナの定義はcontainer_definitions.jsonで定義できます。
これは9章のサンプルコードではwebサーバーとしてnginx1つしか定義していません。14章「デプロイメントパイプライン」でAWS CodePipelineを使い、CI/CD環境を構築したあと、
サンプルコードはなかったのですが、この環境でデプロイしたコンテナもECS上で実行させたくなってもう1つ定義したときにはまりました。追加したコンテナはよくサンプルで使われるhello-worldイメージのものです。
このコンテナは起動して標準出力で'hello world'と出力したら終了します。以下のように定義しました。[ { "name": "example_nginx", "image": "nginx:latest", "essential": true, "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "nginx", "awslogs-group": "/ecs/example" } }, "portMappings": [ { "protocol": "tcp", "containerPort": 80 } ] }, ***** 以下が追加したコンテナ ***** { "name": "example_container", "image": "[アカウント名].dkr.ecr.ap-northeast-1.amazonaws.com/example:latest", "essential": true, "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "example_container", "awslogs-group": "/ecs/example" } } } ]これでデプロイを行うと、ECSで定義した上記2つのコンテナを実行するタスクは失敗となりました。
理由は、essenntialをtrueにしていたからでした。コンテナの essential パラメータが true とマークされている場合、そのコンテナが何らかの理由で失敗または停止すると、タスクに含まれる他のすべてのコンテナは停止されます。
詳細コンテナ定義パラメータ 環境, https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/task_definition_parameters.html#container_definition_environment, (検索年月日:2019年1月24日
この値のデフォルトはtrueであるため、明示的にesselntial: falseと指定しないと標準出力をしたらすぐ停止してしまうhello-worldコンテナがいると、
nignxが正常に起動していたけどタスクは失敗となっていたというわけでした。
明示的に指定すると、タスクは成功しました。基本的なポリシーとして実行するコンテナは起動しっぱなしにする前提だからこういう設定になるのでしょうね。お試しでやっていたので、その前提が抜けていました。さいごに
写経をしてみてTerraformは使いこなすと便利そうなのはたしかでした。
- コード化しているため変更内容を管理しやすい
- コード化していると、あるモジュールはどんなサービスをどう使っているのかわかりやすい。
- たとえばCI/CD環境はECRとAWS CodePipeline, Code Buildを使って構築しているとか。
ただ、エラーがでたときにTerraformの使い方とAWSの使い方のどちらが悪いのかがわかりにくいというのは明らかでした。どちらの知識も中途半端だと、かえってデバッグの手間が多くなりそうです。
その手間が少なくなるようにどんどんコードを書いていこうと思います!!
- 投稿日:2020-01-24T15:50:29+09:00
Lambda Node.js8.10から10.xへの バージョンアップに伴うImageMagickの対応
はじめに
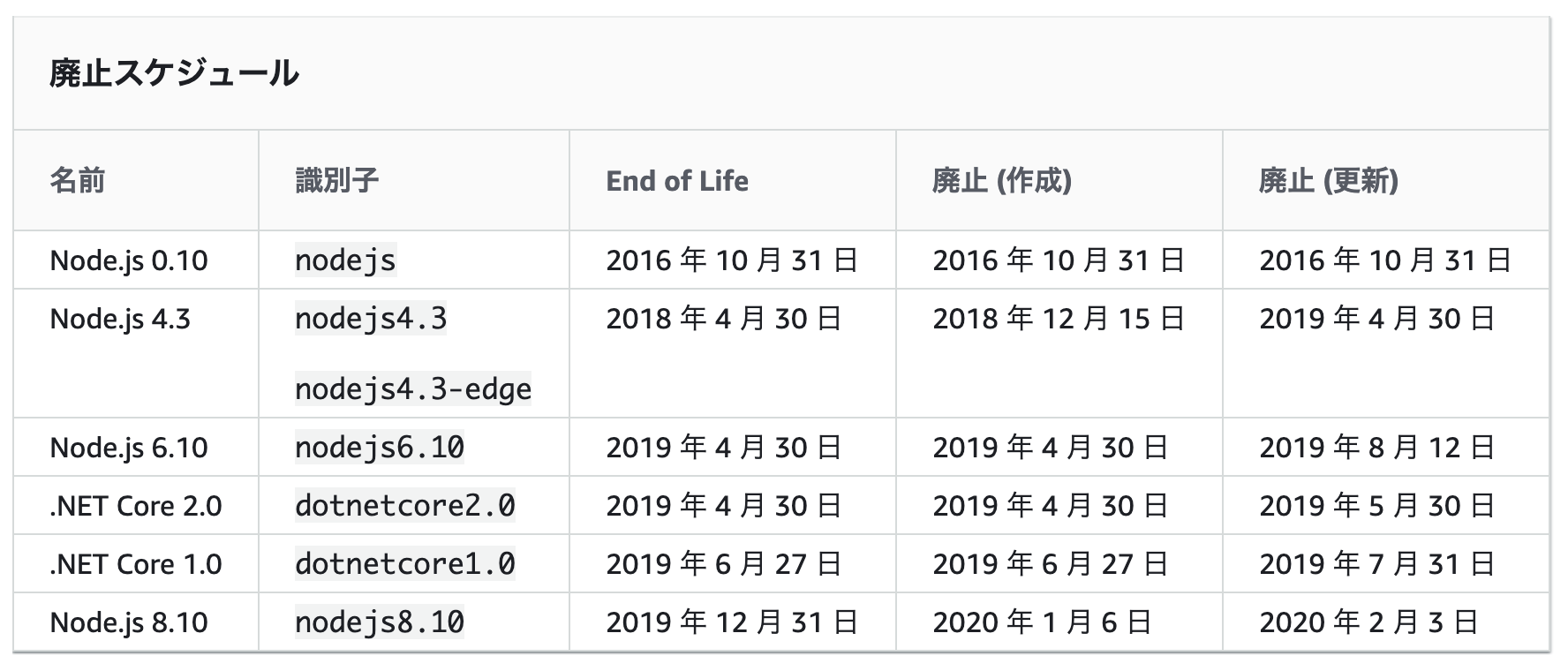
今回、LambdaランタイムNode.js8.10のサポート終了に伴い、Node.js10.xへアップデートを行いました。
結構詰まった部分などが合ったので、その備忘録として残します。LambdaランタイムNode.js8.10のサポート終了について
以下、AWS公式より
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/runtime-support-policy.html2020/2/3を持ってLambdaのランタイムNode.js8.10の更新が終了します。
これに伴い、Node.js8.10で実装しているLambdaのランタイムを10.xにバージョンアップをしました。Lambdaのランタイム変更による変更内容
大きな変更は、コンテナ内で起動するEC2のOSがAmazon LinuxからAmazon Linux2へ変わることです。
これにより、もともとデフォルトでOSにインストールされていた、graphicsmagick と imagemagickがAmazon Linux2ではインストールされていないという状態になります。こちらが参考記事です
https://note.com/mohya/n/n48692d8e4a57#jgl1s
つまり、Node.js10以上で、imagemagickなどを使いたい場合は、インストールしなければけません。本記事では、この点についての対応方法を紹介します。
手順
- 単純にランタイムを変更する
- Lambdaを実行させ、エラー内容を確認する
- graphicsmagickとimagemagickのレイヤーを追加する
- Lambdaを実行させ、成功を確認する
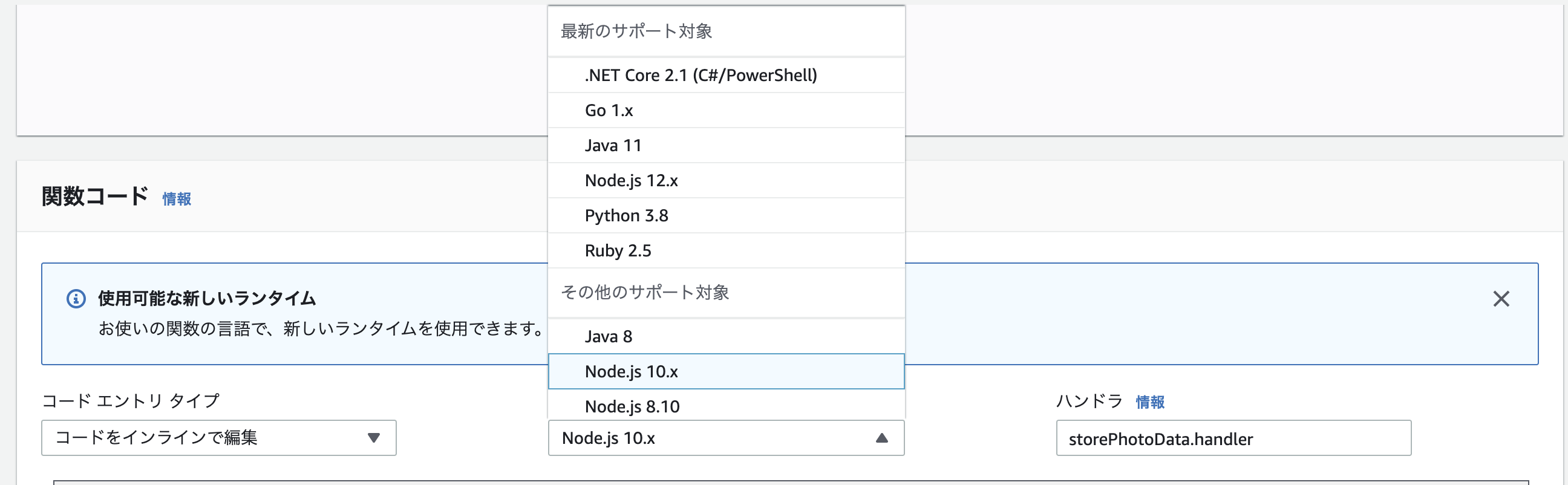
1. 単純にランタイムを変更する
まず、状況確認をするために単純にランタイムを変更します。
2. Lambdaを実行させ、エラー内容を確認する
以下のようなエラーが出ました。
2020-01-24T02:40:09.509Z c28c7e8b-b775-48ae-ac36-aec733c9b025 ERROR Invoke Error { "errorType": "Error", "errorMessage": "Could not execute GraphicsMagick/ImageMagick: identify \"-ping\" \"-format\" \"%wx%h\" \"-\" this most likely means the gm/convert binaries can't be found", "stack": [ "Error: Could not execute GraphicsMagick/ImageMagick: identify \"-ping\" \"-format\" \"%wx%h\" \"-\" this most likely means the gm/convert binaries can't be found", " at ChildProcess.<anonymous> (/opt/nodejs/node_modules/gm/lib/command.js:232:12)", " at ChildProcess.emit (events.js:198:13)", " at ChildProcess.EventEmitter.emit (domain.js:448:20)", " at Process.ChildProcess._handle.onexit (internal/child_process.js:246:12)", " at onErrorNT (internal/child_process.js:415:16)", " at process._tickCallback (internal/process/next_tick.js:63:19)" ] }ImageMagickが見つからず、実行できないと言われてしまっています。
3. graphicsmagickとimagemagickのレイヤーを追加する
ここがメインです。
Amazon Linux2ではImageMagickが存在しないので、インストールする必要があります。
こちらのissueが大変参考になりました。
https://github.com/ysugimoto/aws-lambda-image/issues/191Imagemagickレイヤーの設置
サーバーレスレポジトリにて提供されているので、こちらから作成します。
https://serverlessrepo.aws.amazon.com/applications/arn:aws:serverlessrepo:us-east-1:145266761615:applications~image-magick-lambda-layerGaphicsmagickレイヤーの設置
こちらは、誰か知らない人が作ってくれているので、使っちゃいます。
https://github.com/rpidanny/gm-lambda-layer
こちらは、Dockerになっていて、あれ???と思いましたが
LayerもそれぞれDockerを起動してくれ、起動時にDockerfileに記載してあるこの辺りでインストールしてくれます。RUN curl https://versaweb.dl.sourceforge.net/project/graphicsmagick/graphicsmagick/${GM_VERSION}/GraphicsMagick-${GM_VERSION}.tar.xz | tar -xJ && \ cd GraphicsMagick-${GM_VERSION} && \ ./configure --prefix=/opt --enable-shared=no --enable-static=yes --with-gs-font-dir=/opt/share/fonts/default/Type1 && \ make && \ make installこのレイヤーをLambdaに登録しておけば、いいらしいですね。便利です。
レイヤーの適応
今回はServerless Frameworkを使用しているため、ymlで記載します。
functions: storePhotoData: handler: storePhotoData.handler layers: - arn:aws:lambda:ap-northeast-1:579663348364:layer:image-magick:1 - arn:aws:lambda:ap-northeast-1:175033217214:layer:graphicsmagick:2 - { Ref: MyLayerLambdaLayer } tracing: Active description: create storePhotoData memorySize: 2048 timeout: 10 role: storePhotoDataLambdaFunctionRoleレイヤーには実行順序という概念もあるため、レイヤーの順番も気をつけなければなりません。
MyLayerLambdaLayer はカスタマイズして作ったレイヤーで、graphicsmagickとimagemagickがないと実行できないので、念の為後ろに持ってきました。
(あんまり意味ないかも...)4. Lambdaを実行させ、成功を確認する
ログが出せないのが申し訳ないですが、これで成功しました!!
Node.js 12.xの対応
この時どうせならと思ってランタイムをNode.js12.xにしてみたのですが、一応動きました。w
少しだけ気になる点もありましたが、恐らく大丈夫かなと思います。
一気に12へあげたい方はやってみてください。
- 投稿日:2020-01-24T15:35:18+09:00
【AWS】~/.ssh/configを使って、簡単にssh接続する
概要
AWSのサーバーにssh接続する際は、ご自身のディレクトリの配下に隠しファイル「.ssh」を作成し、その中にAWSの設定を書いておくと、毎回以下のようなものを書かなくて済みます。
Terminalssh -i /path/my-key-pair.pem ec2-user@ec2-198-51-100-1.compute-1.amazonaws.com.sshディレクトリの作成と下準備
Terminal# 作業したいディレクトリかどうかを確認してください [~@~ your_dir]$ pwd # ディレクトリを作成します [~@~ your_dir]$ mkdir .ssh # cd .ssh と同義。「!$」は、直前行った引数を指すので、今回は「.ssh」を指す [~@~ .ssh]$ cd !$ # aws.key, configファイルを作成します [~@~ .ssh]$ touch aws.key && touch configaws.keyとconfigファイルの作成と設定
①ディレクトリ構成を確認します
②aws.keyに、ご自身がssh接続で使用しているpemファイルをコピペします
③configファイルに設定を書き込みます①ディレクトリ構成を確認します
現状以下のようなファイル構成になっていると思います。
Terminal[~@~ .ssh]$ ls -la -rw------- 1 ~ ~ ~ ~月 ~ ~:~ aws.key -rwxr-xr-x 1 ~ ~ ~ ~月 ~ ~:~ config②aws.keyに、ご自身がssh接続で使用しているpemファイルをコピペします
ご自身がssh接続で使用しているpemファイルをコピーして、aws.keyに貼ってください。
「-----BEGIN RSA PRIVATE KEY-----」から「-----END RSA PRIVATE KEY-----」まで、すべて貼ってください。.ssh/aws.key-----BEGIN RSA PRIVATE KEY----- MIIEpAIBAAKCAQEAhioJPY7kJGHQ1m5dR+ ~~~~~~(中略)~~~~~~ -----END RSA PRIVATE KEY-----③configファイルに設定を書き込みます
.ssh/configStrictHostKeyChecking no UserKnownHostsFile /dev/null IdentityFile .ssh/aws.key User ec2-user Host <HOST名> Hostname <IPアドレス>以下、記述例を記載してます。
・Host名を使用して、ssh接続します。なので、ご自分の好きな名前を設定してください。
・複数ある場合は、同じように設定していきます。.ssh/configStrictHostKeyChecking no UserKnownHostsFile /dev/null IdentityFile .ssh/aws.key User ec2-user Host live-web01 Hostname 192.168.xxx.xx Host live-web02 Hostname 127.0.xxx.xx Host live-batch Hostname 52.168.xxx.xxssh接続する
設定したので、ssh接続しましょう。
Terminal# 作業ディレクトリにいることを確認してください。 [~@~ your_dir]$ pwd your_dir # ssh -F .ssh/config <Host名> で接続できます。上記で設定したlivew-web01に接続したい場合は、 [~@~ your_dir]$ ssh -F .ssh/config live-web01これで、ssh接続が簡単になりました!
- 投稿日:2020-01-24T15:15:29+09:00
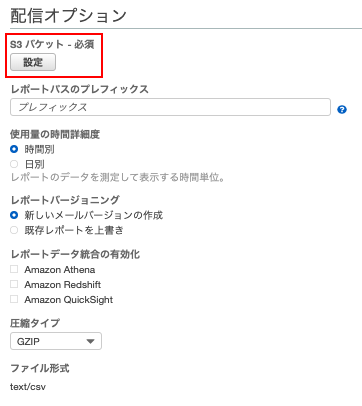
Amazon S3 へ Amazon RDS のスナップショットをエクスポートできるようになったので、 AWS CLI で実行してみました。
以下の記事で発表があったとおり、Amazon S3 へ Amazon RDS のスナップショットをエクスポートできるようになりました。
★Announcing Amazon Relational Database Service (RDS) Snapshot Export to S3
https://aws.amazon.com/jp/about-aws/whats-new/2020/01/announcing-amazon-relational-database-service-snapshot-export-to-s3/You can analyze the exported data with other AWS services such as Amazon Athena, Amazon EMR, and Amazon SageMaker.
エクスポートされたデータは、Amazon Athena、Amazon EMR、Amazon SageMakerなどの他のAWSサービスで分析できます。
ということは、例えば、分析用に ReadReplica を別途起動するといった運用をしなくてもよくなりそうです!
早速、AWS CLI で試してみました。
準備
- 手順や注意点などをユーザーズガイドで確認する。
- Amazon RDS のスナップショット
- 対象のエンジンバージョンに注意
- 最新の AWS CLI (バージョン1.17.8で確認しました)
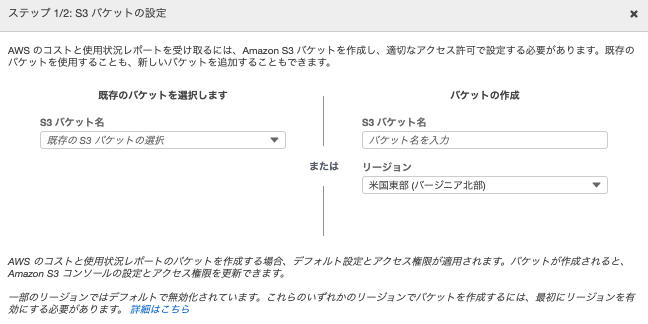
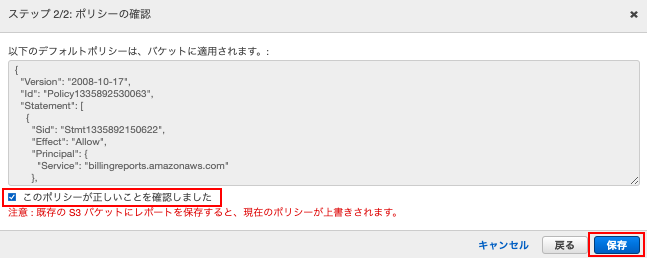
- IAM Role
- エクスポートする際に必要。
IAM Role の設定
IAM Role をサクッと作るため、以下の流れで実施します。
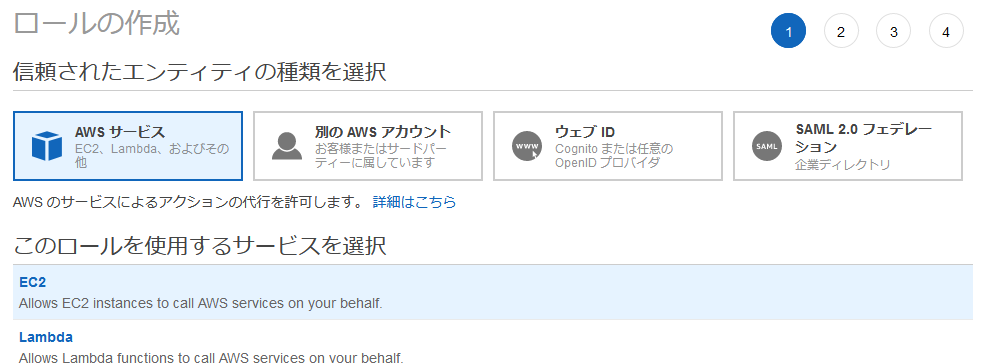
- ロールの作成ボタンをクリック
このロールを使用するサービスを選択」で EC2 を選択
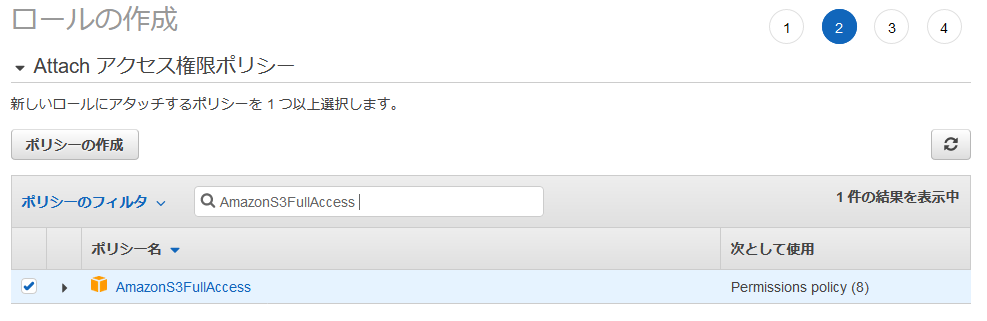
Attach アクセス権限ポリシーで AmazonS3FullAccess を選択(環境に応じてポリシーを作成・変更してください。例えば 認められたバケットのみにする・・・など)
タグの追加は任意で実施
ロール名は任意(例:exportRole)の名称で指定
ロールの作成 ボタンをクリック
Amazon RDS のスナップショットをエクスポートする際に、このロールを使えるようにするために以下の設定変更を行います。
- 作成した IAM Role の詳細画面を開く
- 信頼関係のタブを開く
- 信頼関係の編集ボタンをクリック
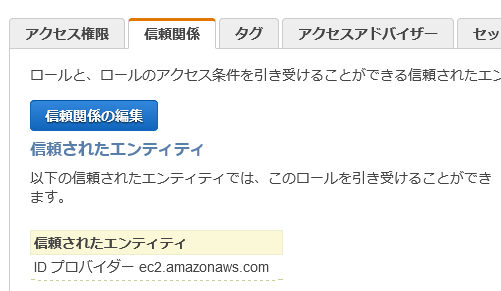
- ec2.amazonaws.com と書いてある場所を export.rds.amazonaws.com に変更する
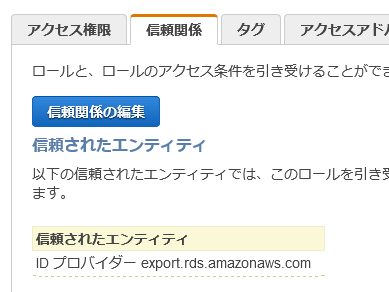
5.信頼ポリシーの更新ボタンをクリック。以下のようになっていればOK
AWS CLI で IAM Role を設定するなら・・・
以下を参考に実行するとよいです。
ポリシーの作成aws iam create-policy \ --policy-name ExportPolicy \ --policy-document '{ "Version": "2012-10-17", "Statement": [ { "Sid": ""ExportPolicy", "Effect": "Allow", "Action": [ "s3:PutObject*", "s3:ListBucket", "s3:GetObject*", "s3:DeleteObject*", "s3:GetBucketLocation" ], "Resource": [ "arn:aws:s3:::your-s3-bucket", "arn:aws:s3:::your-s3-bucket/*", ] } ] }'ロールの作成aws iam create-role \ --role-name rds-s3-export-role \ --assume-role-policy-document '{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "export.rds.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }'ポリシーとロールを関連付けるaws iam attach-role-policy \ --policy-arn your-policy-arn \ --role-name rds-s3-export-roleAWS CLI でスナップショットのエクスポートを実行
ユーザーズガイド記載の構文に従ってコマンド実行します。
環境に応じて適宜指定してください。aws rds start-export-task \ --export-task-identifier my_snapshot_export \ --source-arn arn:aws:rds:ap-northeast-1:*********:snapshot:snapshot_name \ --s3-bucket-name my_export_bucket \ --iam-role-arn arn:aws:iam::*********:role/exportRole \ --kms-key-id master_key注意点:
--kms-key-id に指定するIDは、カスタマー管理型のキー の ARN です。正常に実行できると以下のレスポンスが返ってきます。
{ "Status": "STARTING", "IamRoleArn": "arn:aws:iam::*********:role/exportRole", "ExportTime": "2020-01-24T03:40:42.823Z", "S3Bucket": "my_export_bucket", "PercentProgress": 0, "KmsKeyId": "master_key", "ExportTaskIdentifier": "my_snapshot_export", "TotalExtractedDataInGB": 0, "TaskStartTime": "2020-01-24T03:35:00.173Z", "SourceArn": "arn:aws:rds:AWS_Region:*********:snapshot:test-snapshot" }状況を確認する
以下のコマンドでエクスポートの状況が確認できます。
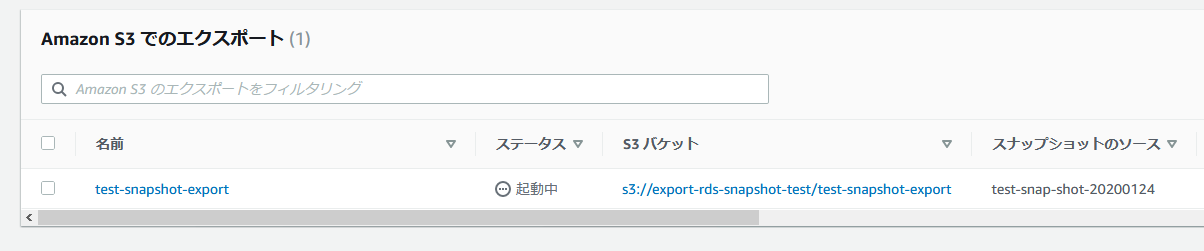
状況確認aws rds describe-export-tasks出力結果(実行中){ "ExportTasks": [ { "Status": "STARTING", "SnapshotTime": "2020-01-24T03:34:49.027Z", "S3Prefix": "", "S3Bucket": "export-rds-snapshot-test", "PercentProgress": 0, "KmsKeyId": "arn:aws:kms:ap-northeast-1:******:key/************", "ExportTaskIdentifier": "test-snapshot-export", "IamRoleArn": "arn:aws:iam::******:role/exportRole", "TotalExtractedDataInGB": 0, "TaskStartTime": "2020-01-24T03:35:00.173Z", "SourceArn": "arn:aws:rds:ap-northeast-1:************:snapshot:test-snap-shot-20200124" } ] }マネージメントコンソールではこのような出力がされています。
出力結果(進行中){ "ExportTasks": [ { "Status": "IN_PROGRESS", "SnapshotTime": "2020-01-24T03:34:49.027Z", "S3Prefix": "", "S3Bucket": "export-rds-snapshot-test", "PercentProgress": 100, "KmsKeyId": "arn:aws:kms:ap-northeast-1:******:key/************", "ExportTaskIdentifier": "test-snapshot-export", "IamRoleArn": "arn:aws:iam::******:role/exportRole", "TotalExtractedDataInGB": 0, "TaskStartTime": "2020-01-24T03:35:00.173Z", "SourceArn": "arn:aws:rds:ap-northeast-1:************:snapshot:test-snap-shot-20200124" } ] }・・・PercentProgress が 100 になっていますが、TotalExtractedDataInGB が 0 なのはなぜ......
・・・その後、改めて実施したところ、TotalExtractedDataInGB の値が増加していました。出力結果(出力完了){ "ExportTasks": [ { "Status": "COMPLETE", "TaskEndTime": "2020-01-24T04:03:47.428Z", "SnapshotTime": "2020-01-24T03:34:49.027Z", "S3Prefix": "", "S3Bucket": "export-rds-snapshot-test", "PercentProgress": 100, "KmsKeyId": "arn:aws:kms:ap-northeast-1:******:key/************", "ExportTaskIdentifier": "test-snapshot-export", "IamRoleArn": "arn:aws:iam::******:role/exportRole", "TotalExtractedDataInGB": 2, "TaskStartTime": "2020-01-24T03:35:00.173Z", "SourceArn": "arn:aws:rds:ap-northeast-1:************:snapshot:test-snap-shot-20200124" } ] }この環境は 20GiB のストレージで約 3GiB 程度使用している状態でのスナップショットでした。
所用時間は、およそ 30 分でした。出力されたファイルを確認する
Amazon S3 のバケットにエクスポートされたデータを確認してみます。
これらフォルダ・ファイルは以下のようになっています。
- testdatabase(実際には RDS 内のデータベース名のフォルダ)
- この中に Apache Parquet 形式のファイルが格納される
- export_info_test-snapshot-export.json(実際には太字の箇所がエクスポートタスク名になる)
- aws rds describe-export-tasksの結果と同等の内容が書き込まれている
- export_tables_info_test-snapshot-export_from_1_to_1.json(実際には太字の箇所がエクスポートタスク名になる)
- データベース内のスキーマ情報などが記録されている
まとめ
今回はマネジメントコンソールで実行できなかったため AWS CLI での試行としました。
2 GiB で 30 分近くかかっており、思いの外時間かかる印象でしたが、テーブル内の行数(今回は100万行くらいありました)などによっても変わってくるのではと考えています。

- 投稿日:2020-01-24T13:54:34+09:00
EC2で立ち上げたWordPressで.htaccessを使えるようにする方法
はじめに
EC2にて「WordPress Certified by Bitnami and Automattic」のAMIを使用して、WordPressを立ち上げた際、.htaccessが効かなかったので、対処法の備忘録を残します
結果
httpd-app.confの11行目を「AllowOverride All」に変更すればOKです
変更手順
- httpd-app.confをオープンする。見慣れない場所にあるので注意
$ sudo vi /opt/bitnami/apps/wordpress/conf/httpd-app.conf ・ ・ ・ <Directory "/opt/bitnami/apps/wordpress/htdocs"> Options +MultiViews +FollowSymLinks AllowOverride None ・ ・
- AllowOverride Allに書き換え、保存
・ ・ <Directory "/opt/bitnami/apps/wordpress/htdocs"> Options +MultiViews +FollowSymLinks AllowOverride All ・ ・
- Apache再起動
$ sudo /opt/bitnami/ctlscript.sh restart apache Unmonitored apache Syntax OK /opt/bitnami/apache2/scripts/ctl.sh : httpd stopped Syntax OK /opt/bitnami/apache2/scripts/ctl.sh : httpd started at port 80 Monitored apache上記のようなログが出力されれば、OKです
参考
- 投稿日:2020-01-24T13:26:01+09:00
AWSのストレージにフラッシュコピー的な機能があるか聞かれた時の回答
はじめに
以前、オンプレ(IBM)からクラウドへの移行を検討しているお客様との打ち合わせに参加した際、「AWSにもフラッシュコピー(ディスクのスナップショット)ってあるんだっけ?」と聞かれて、EBSのスナップショットがあるのは知っていたものの、それがフラッシュコピーと同じくオンラインで取れるかどうかが曖昧だったことを今になって急に思い出したので、備忘録がてら調べました。
結論としてはありました
Q: スナップショットをとるために、ボリュームをアンマウントする必要がありますか?
いいえ。スナップショットはボリュームがアタッチされ使用中の状態でもリアルタイムで実行できます。ただし、スナップショットは、お客様の Amazon EBS ボリュームに対して記述されたデータのみを捕捉します。
付帯事項はあるものの、要は「ディスクに書き込まれていないと保存されないよ」ということで、オンプレのストレージも同じですね。
- 投稿日:2020-01-24T12:33:43+09:00
【クラウド初心者向け】留守番電話4(録音した留守番電話を聴く)
概要
- Amazon Connectには留守番電話機能は無いため個別に作成する。
- 基本の考え方等は『[Amazon Connect]営業時間外に着信したビジネスチャンスを失わないように留守番電話機能をつけてみた』をもとにしています。
- S3でWebサイトをホスティングします。そこに留守番電話を聴くためのHTMLを配置します。
- Cognito(コグニート)を利用してkinesis Video StreamsデータをWAVに変換したデータが保存されているバケットへアクセス権を付与します。
- セキュリティには配慮していませんので、留守番電話を聴く画面にCoginito(コグニート)のキーを貼り付けて全世界に公開しています。
使用ユーザー
- IAMユーザー
手順
Cognito(コグニート)による権限設定
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にCognitoと入力し、検索結果から《Cognito》をクリックし、Amazon Cognito コンソール(https://console.aws.amazon.com/cognito/)を開きます。
Cognitoの画面が表示されるので《IDプールの管理》をクリックします。
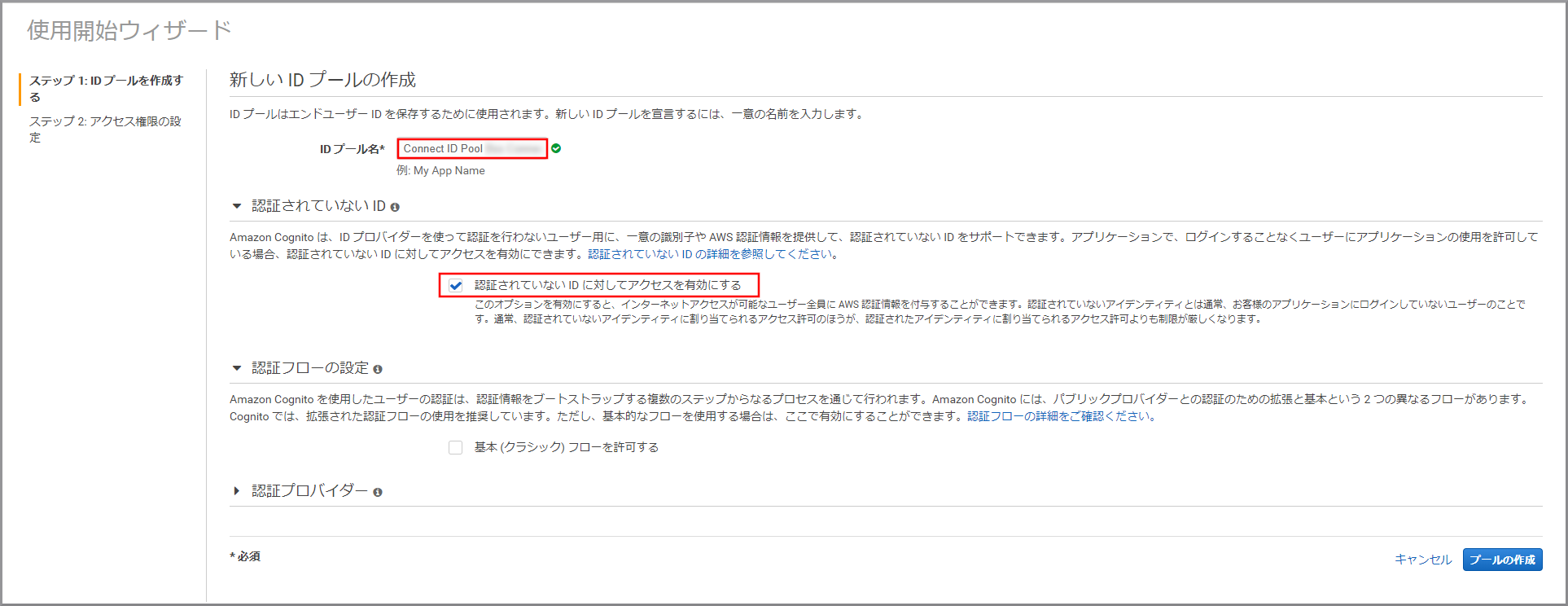
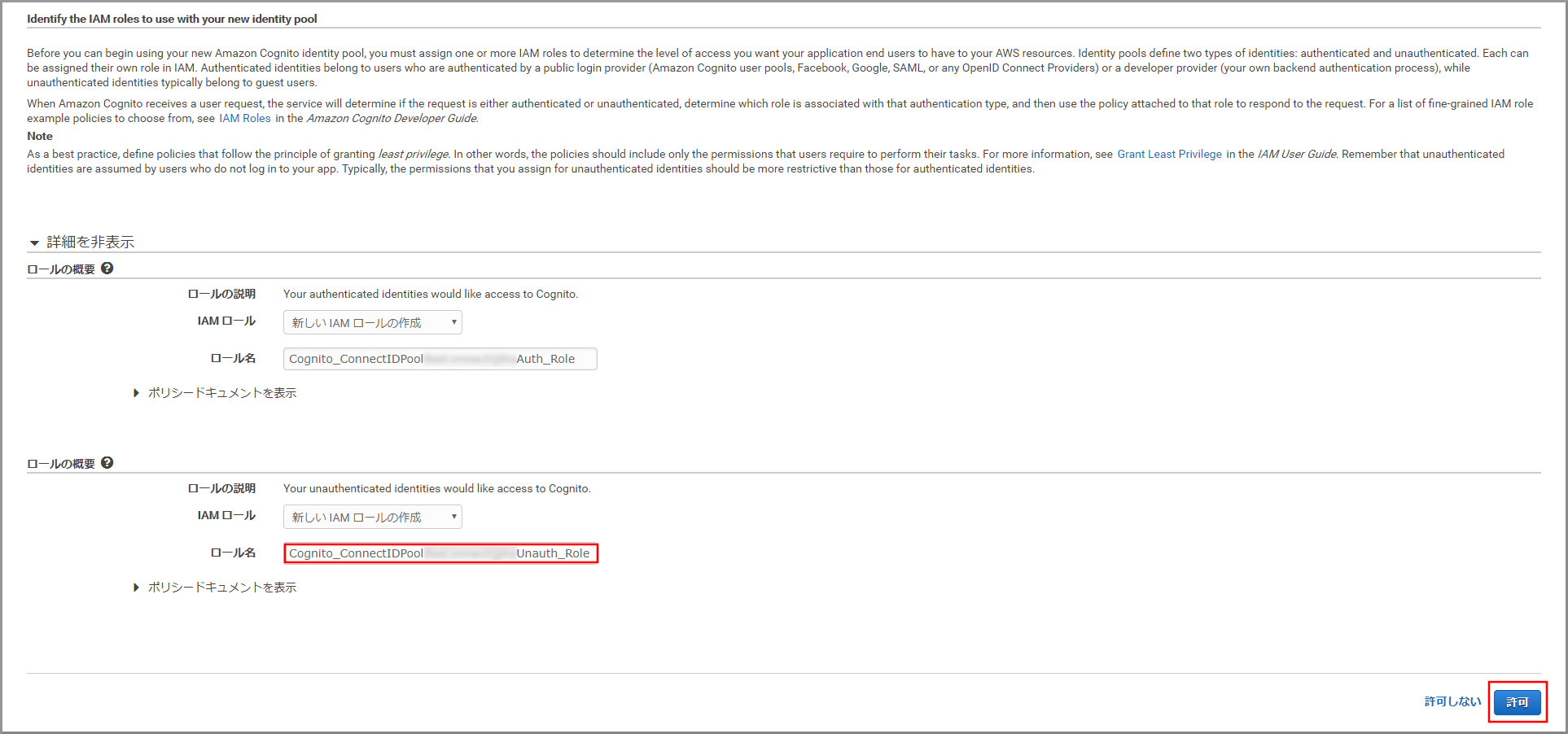
以下の項目を選択、入力して《プールの作成》をクリックします。
- IDプール名:適当な名前を入力します。
- 認証されていないIDに対してアクセスを有効にする:選択します。
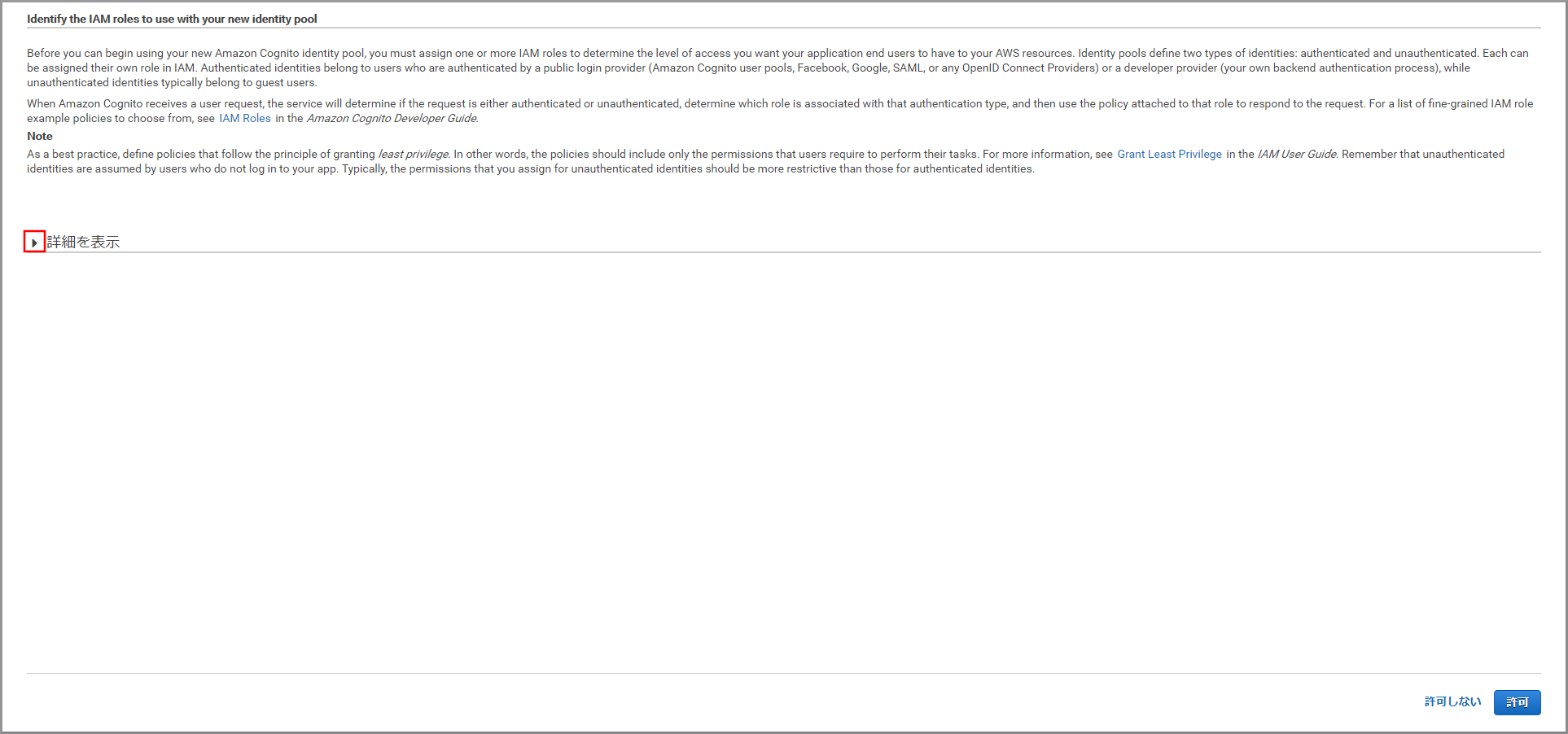
IAMロール作成確認画面が表示されるので《詳細を表示》をクリックします。
未承認のロールを使用しますので、ロール名をメモしてから《許可》をクリックします。
サンプルコードの画面が表示されるので、「プラットフォーム」からJavaScriptを選択します。
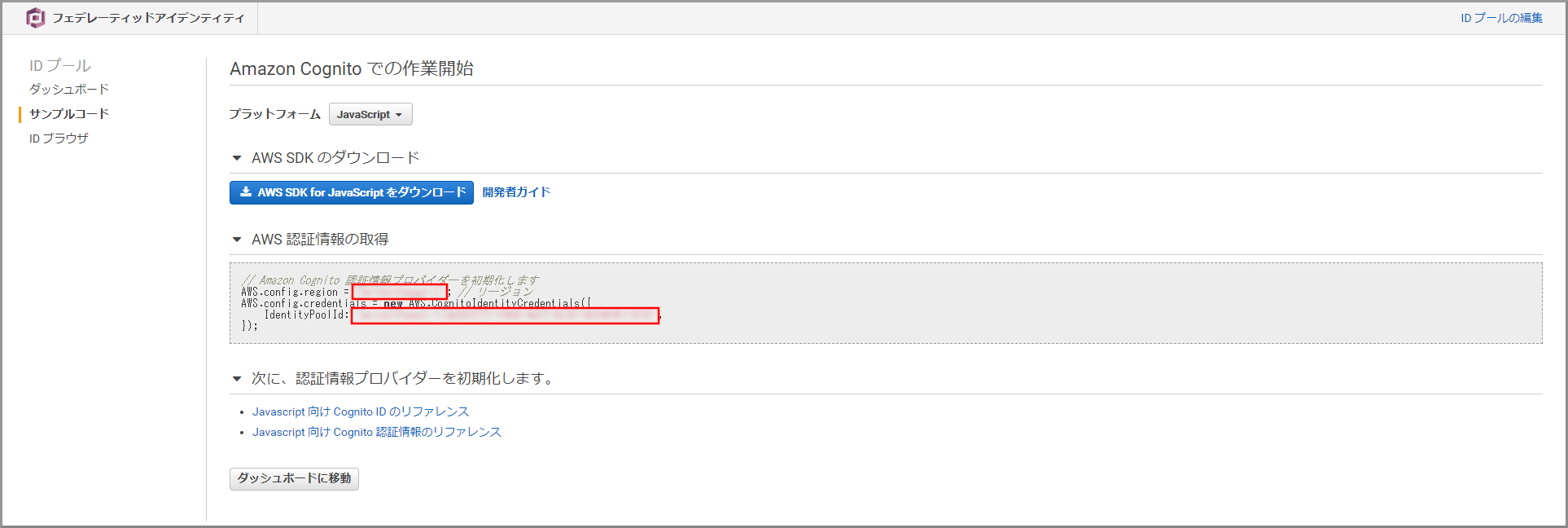
AWS認証情報の取得に表示されている「region」と「IdentityPoolId」をメモします。
作成したロールに必要な権限を付与するため、『AWSマネジメントコンソール』画面にある「サービスを検索」にIAMと入力し、検索結果から《IAM》をクリックし、IAM コンソール(https://console.aws.amazon.com/iam/)を開きます。
『IAMコンソール』画面のメニューから《ロール》をクリックします。
ロール一覧から先ほど作成したロールをクリックします。
- WAV変換後のデータをS3から取得するための権限
- Bucketに設定する権限
- ListBucket
- GetBucketTagging
- フォルダに設定する権限
- GetObject
- GetObjectTagging
選択したロールの概要が表示されるのでポリシー名の「▶」をクリックします。
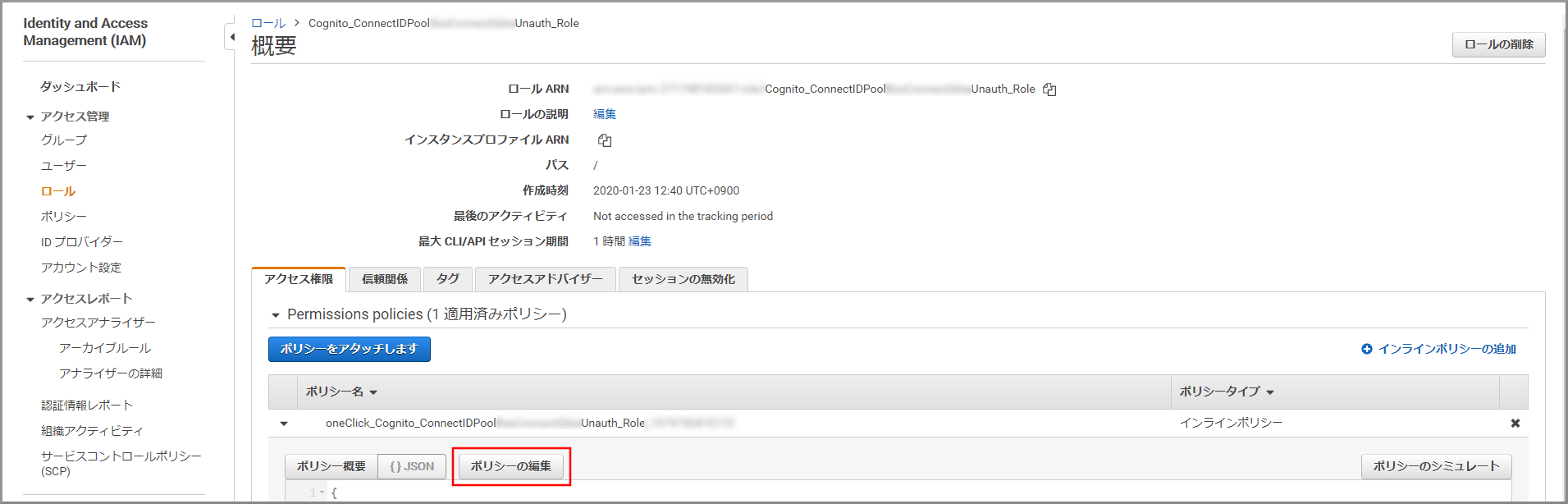
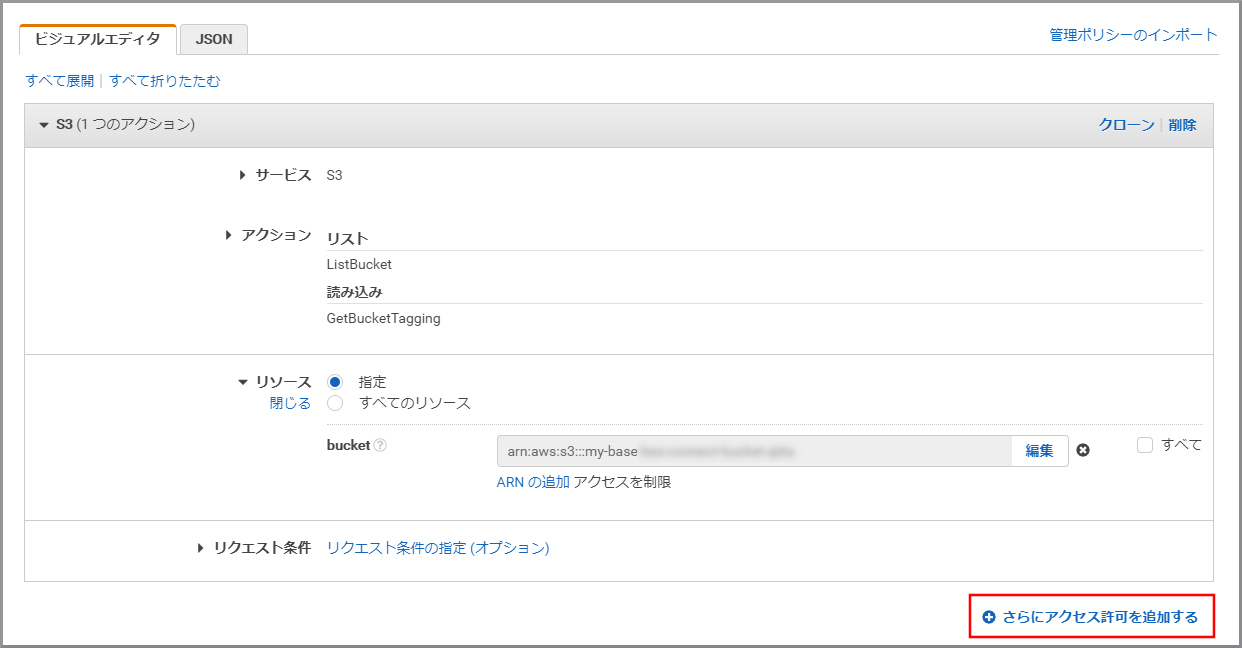
《ポリシーの編集》をクリックします。
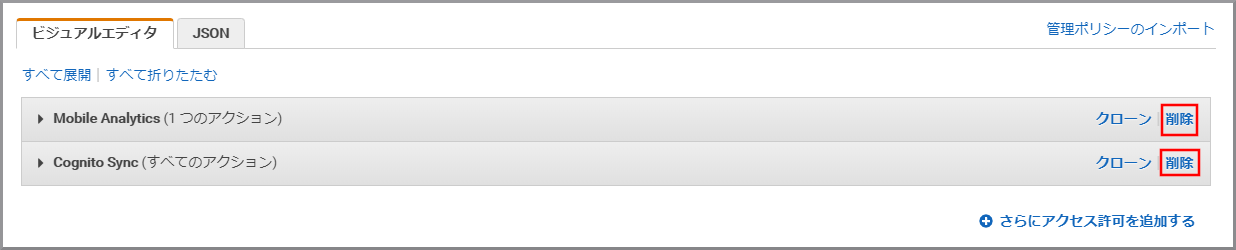
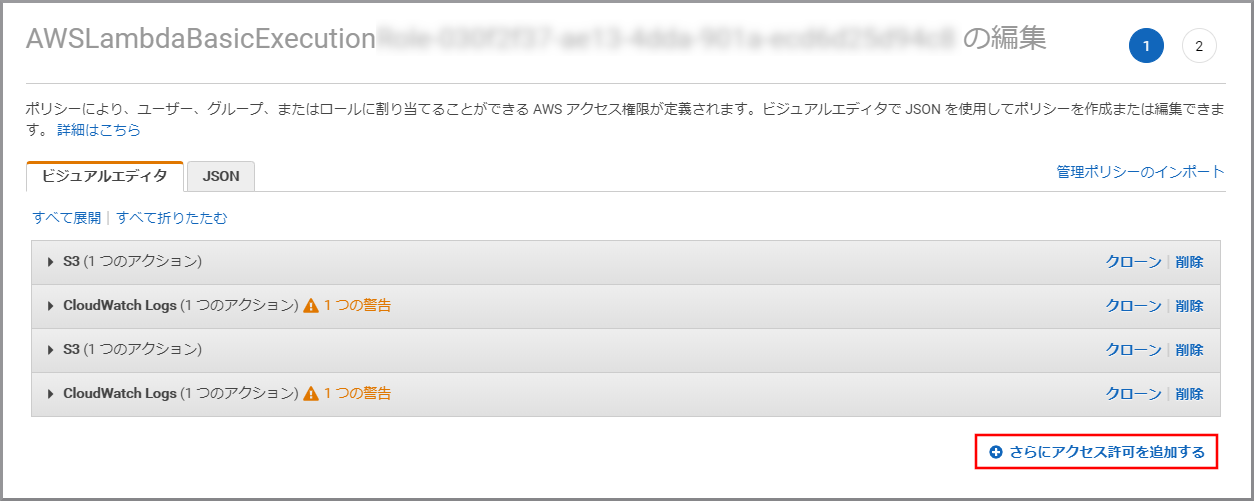
ビジュアルエディタが表示されるので、登録されている権限の《削除》をクリックします。(今回は利用しないため)
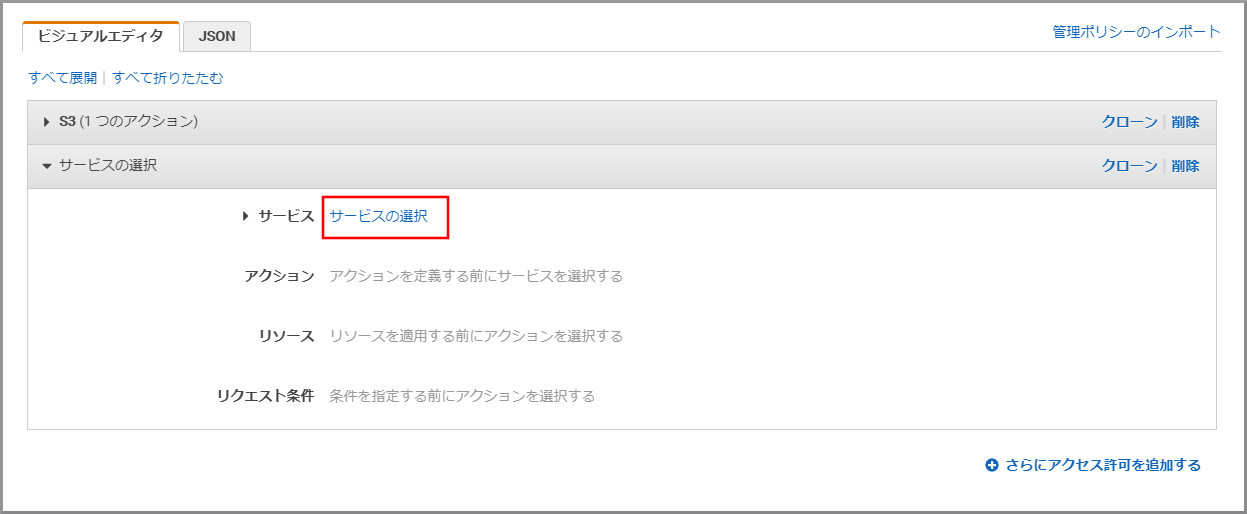
《さらにアクセス許可を追加する》をクリックします。
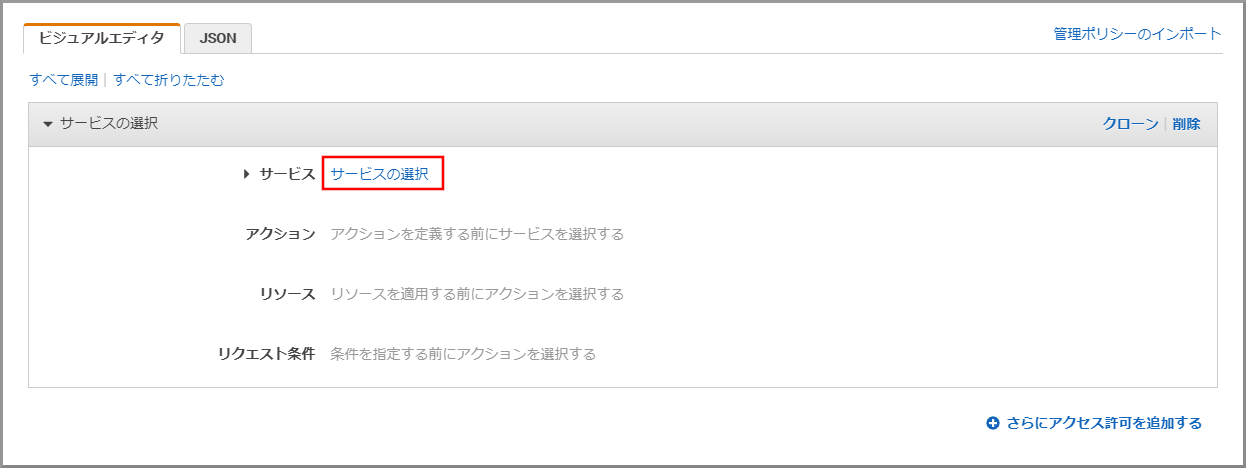
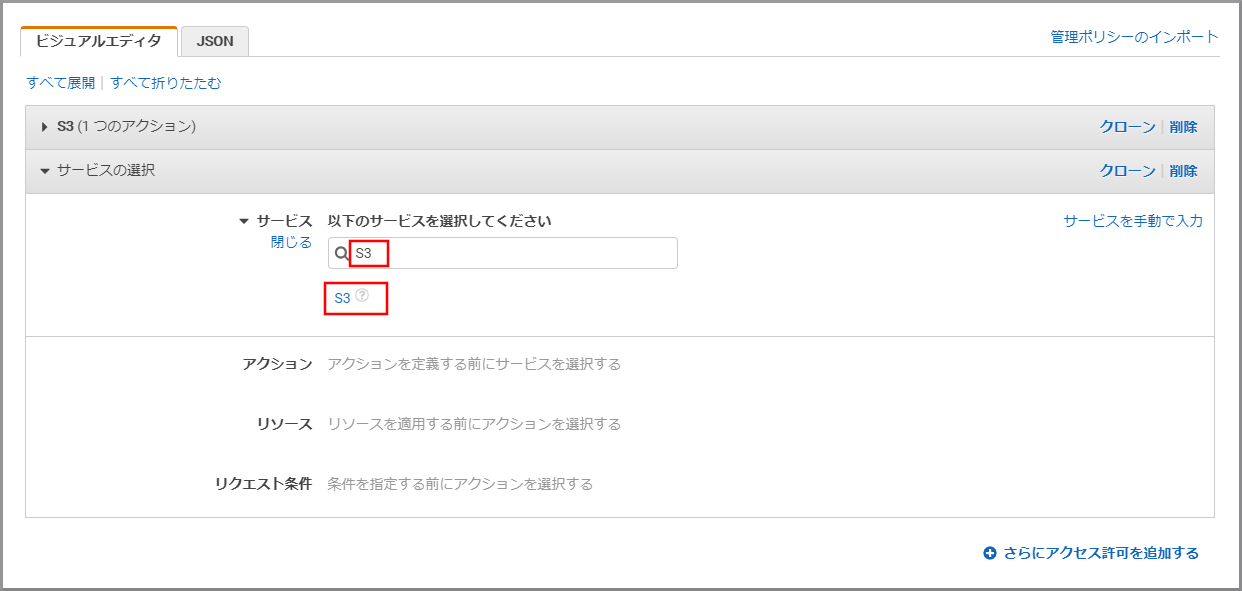
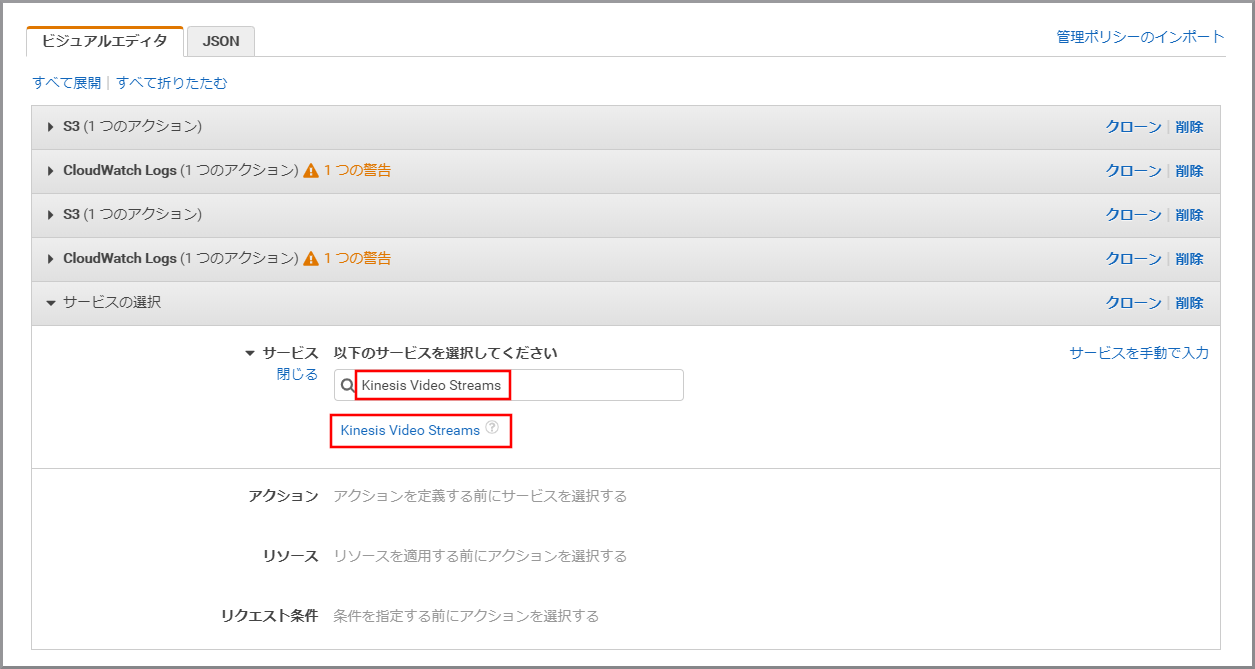
《サービスの選択》をクリックします。
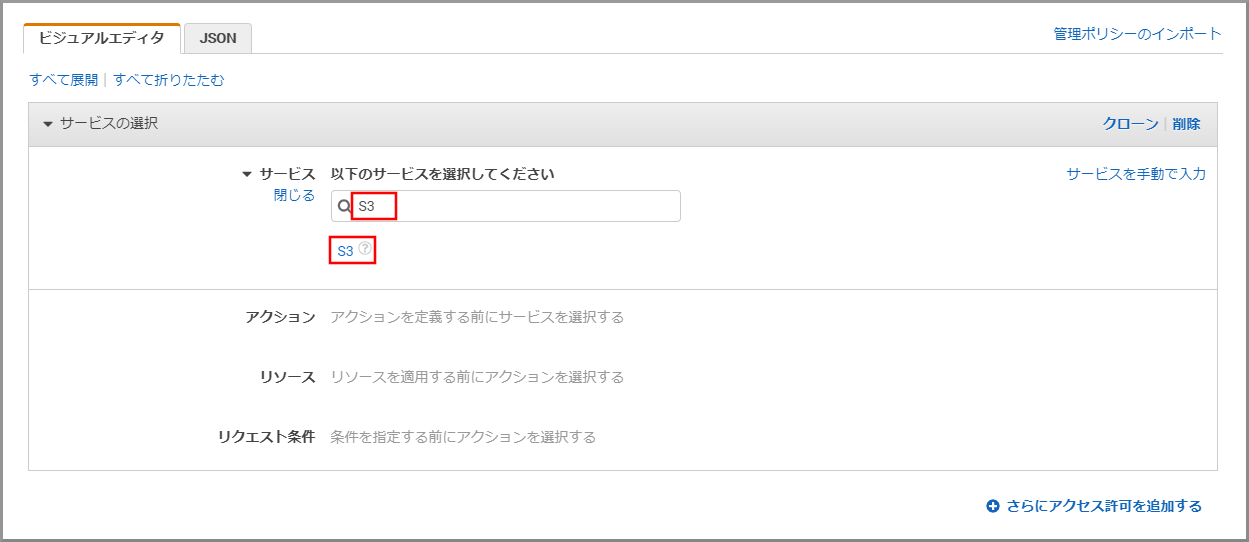
「サービス」にS3と入力し、検索結果から《S3》をクリックします。
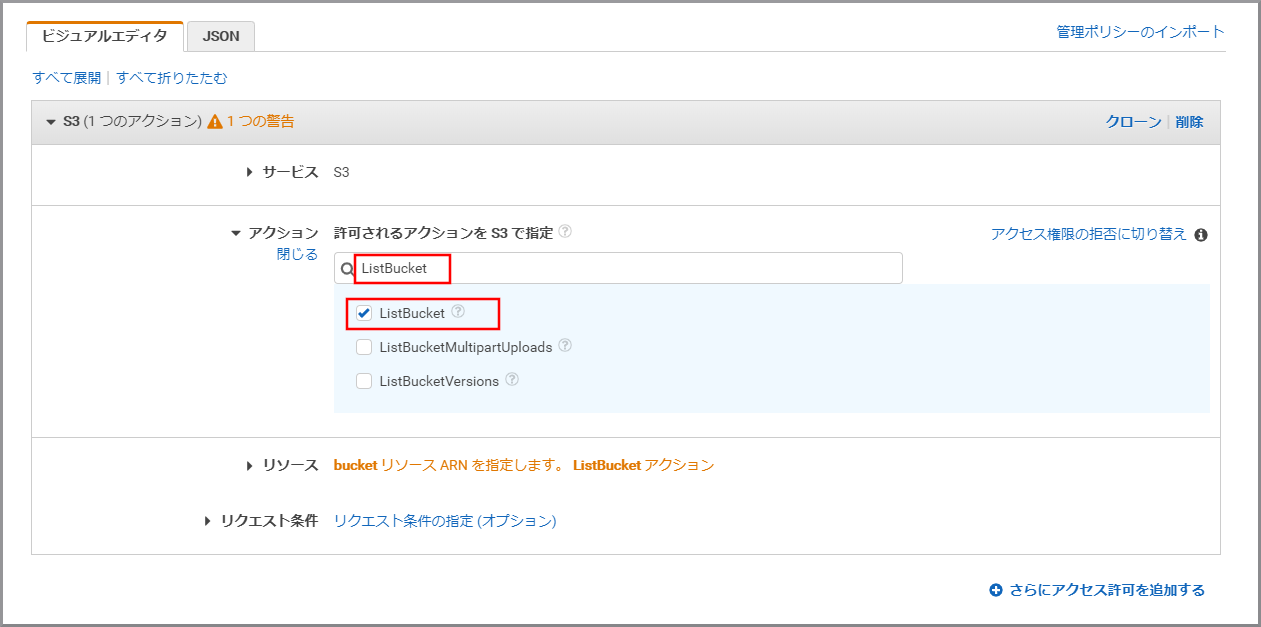
「アクション」に今回利用するListBucketを入力し、《ListBucket》をクリックし、選択状態にします。
「アクション」に今回利用するGetBucketTaggingを上書き入力し、《GetBucketTagging》をクリックし、選択状態にします。
《リソース》をクリックします。
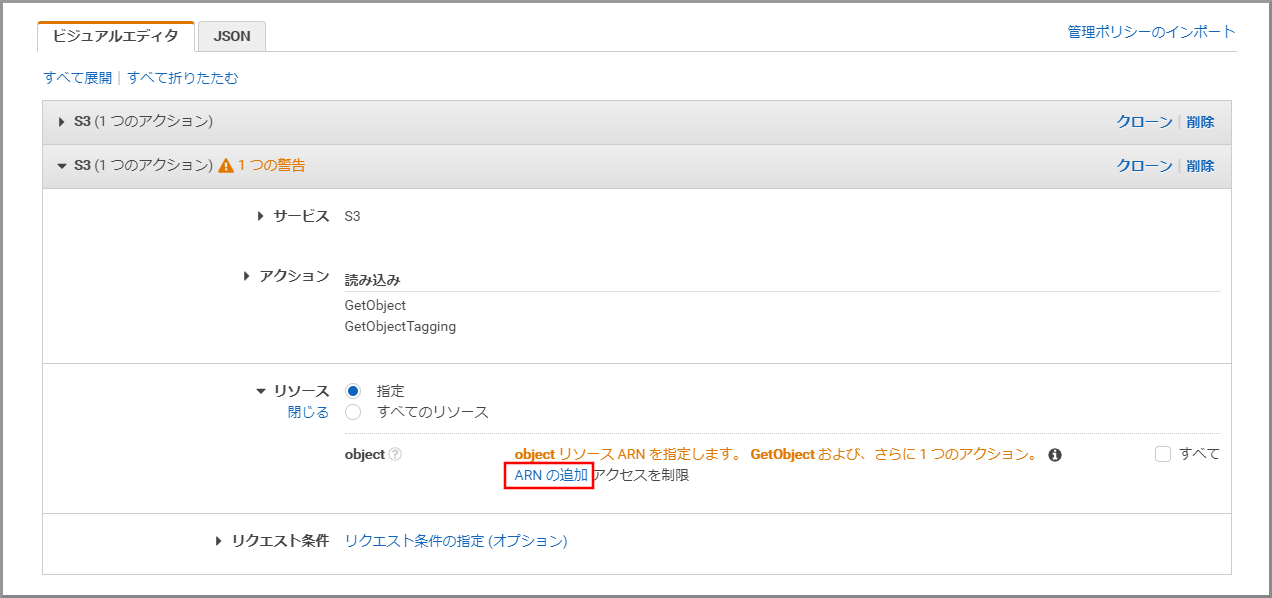
《ARNの追加》をクリックします。
以下の項目を選択、入力して《追加》をクリックします。
- Bucket name:kinesis Video StreamsデータをWAVに変換したデータが保存されているS3のバケット名
- Bucket name:my-baseXXXXXXXXX
《さらにアクセス許可を追加する》をクリックします。
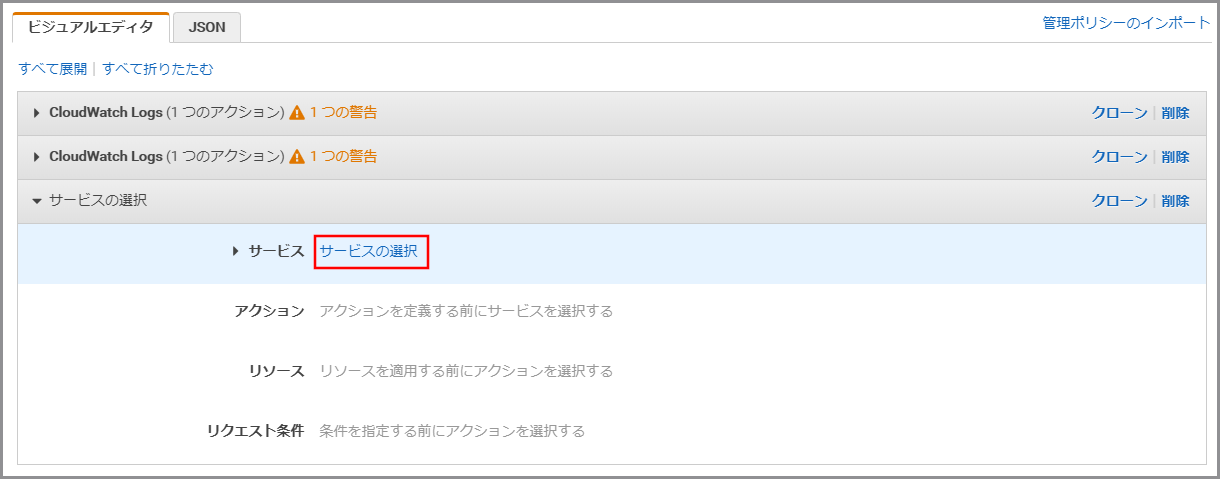
《サービスの選択》をクリックします。
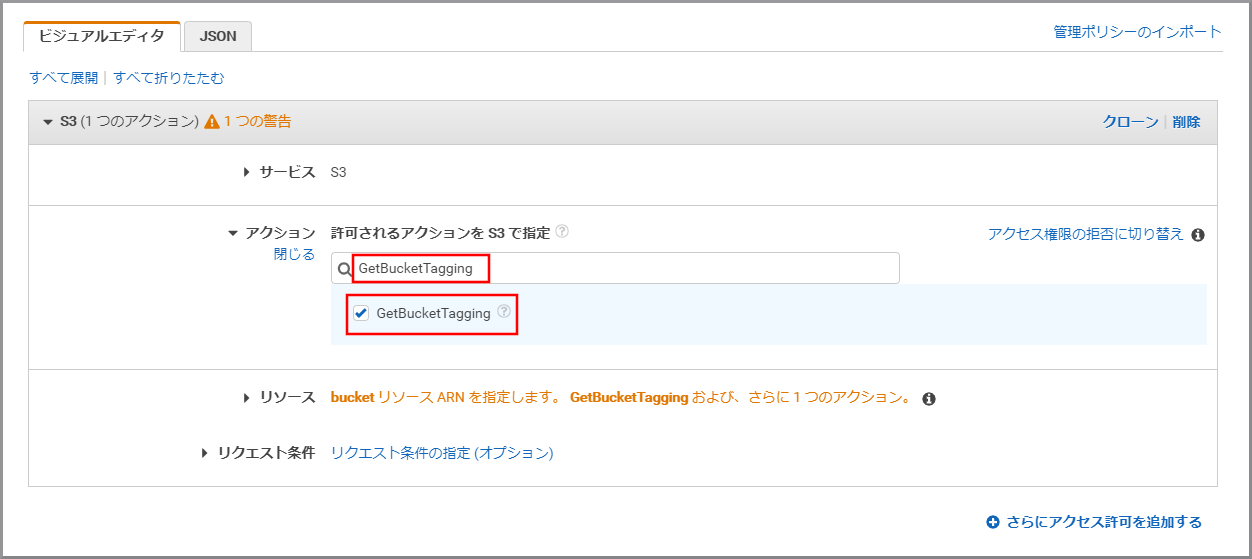
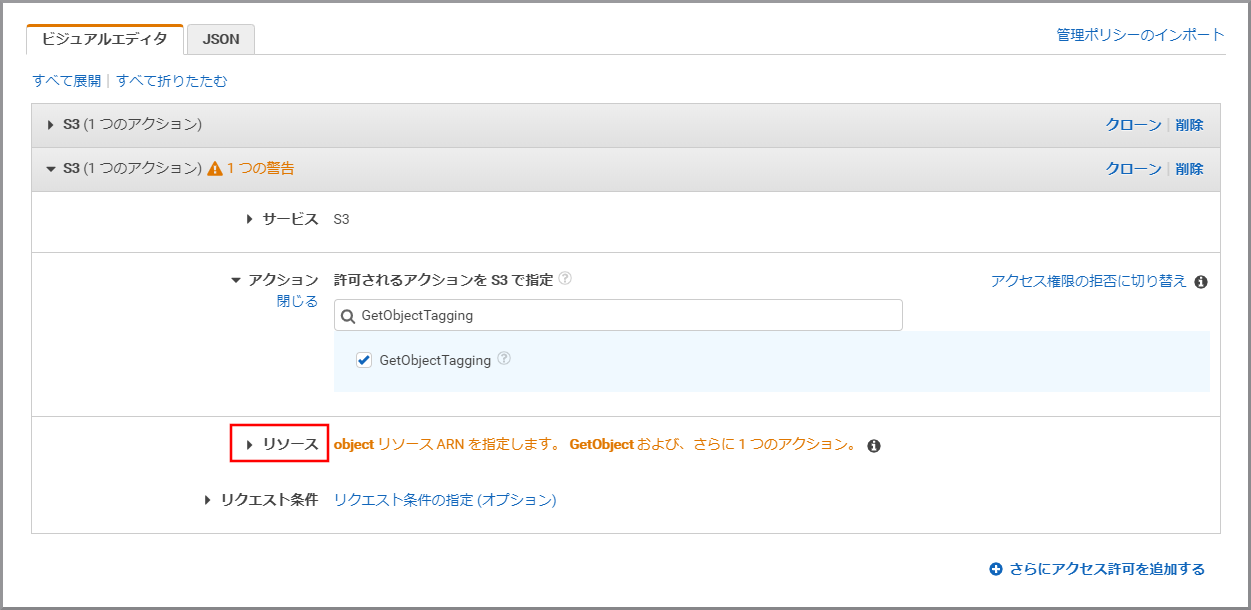
「サービス」にS3と入力し、検索結果から《S3》をクリックします。
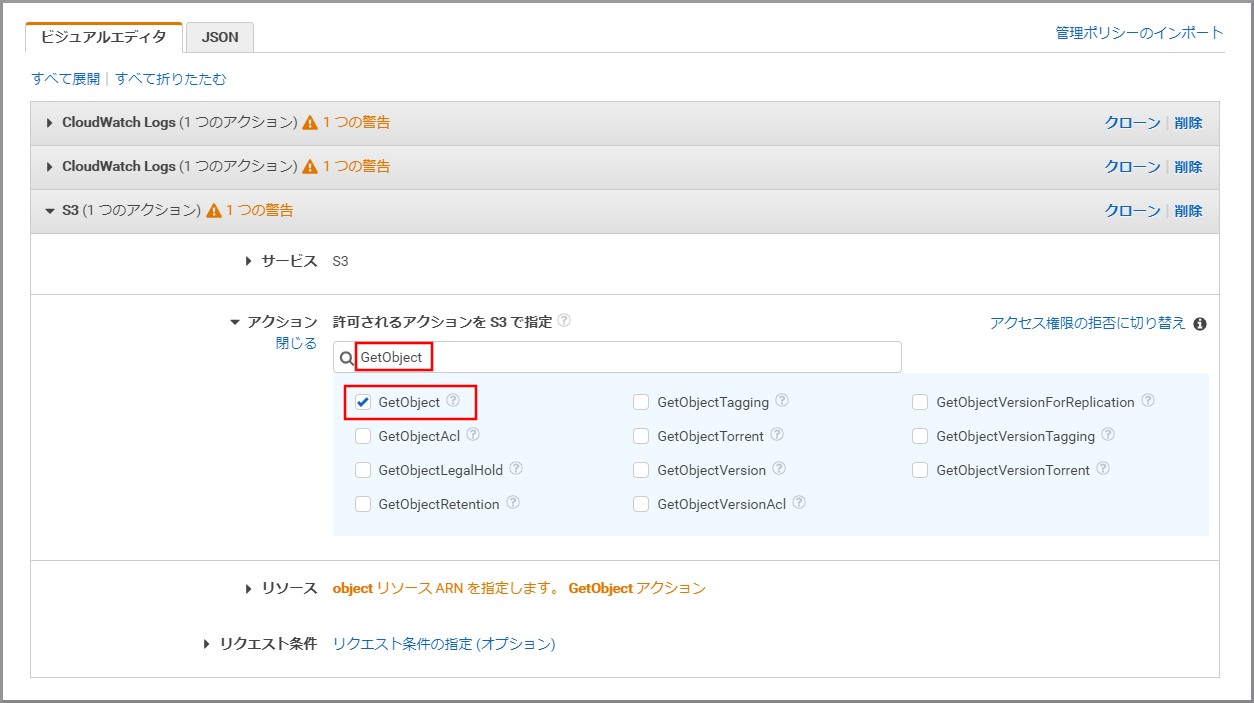
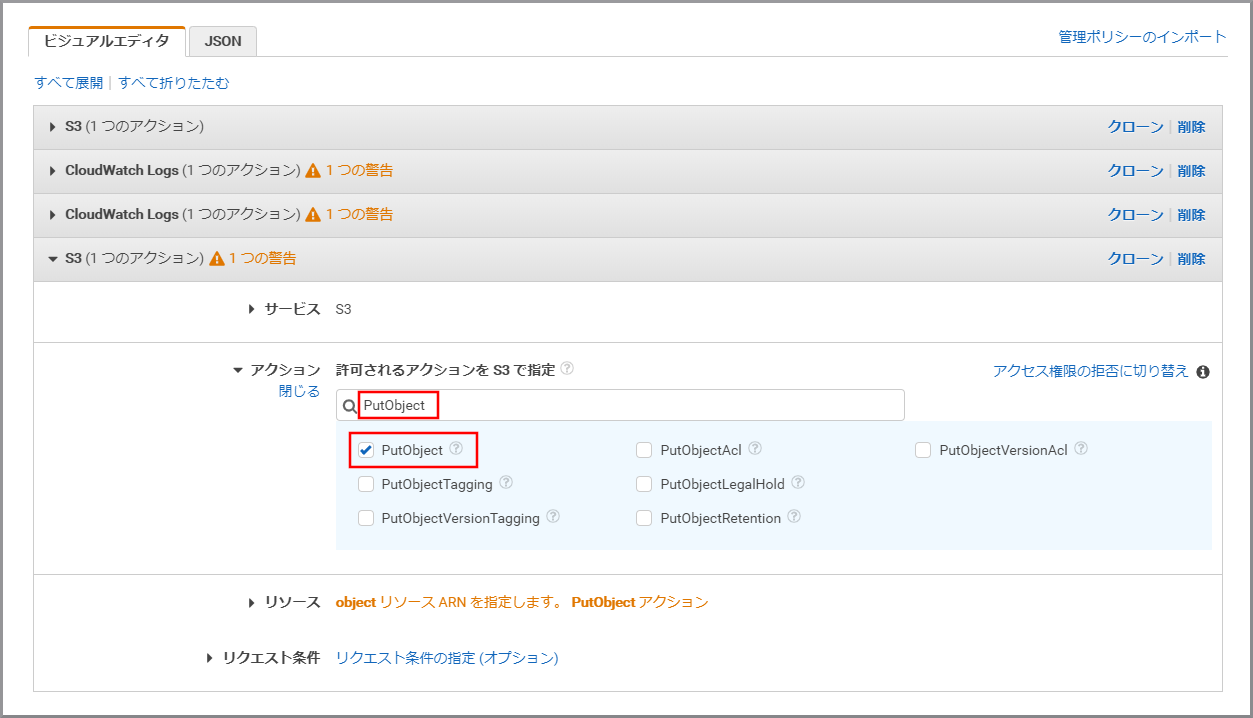
「アクション」に今回利用するGetObjectを入力し、《GetObject》をクリックし、選択状態にします。
「アクション」に今回利用するGetObjectTaggingを上書き入力し、《GetObjectTagging》をクリックし、選択状態にします。
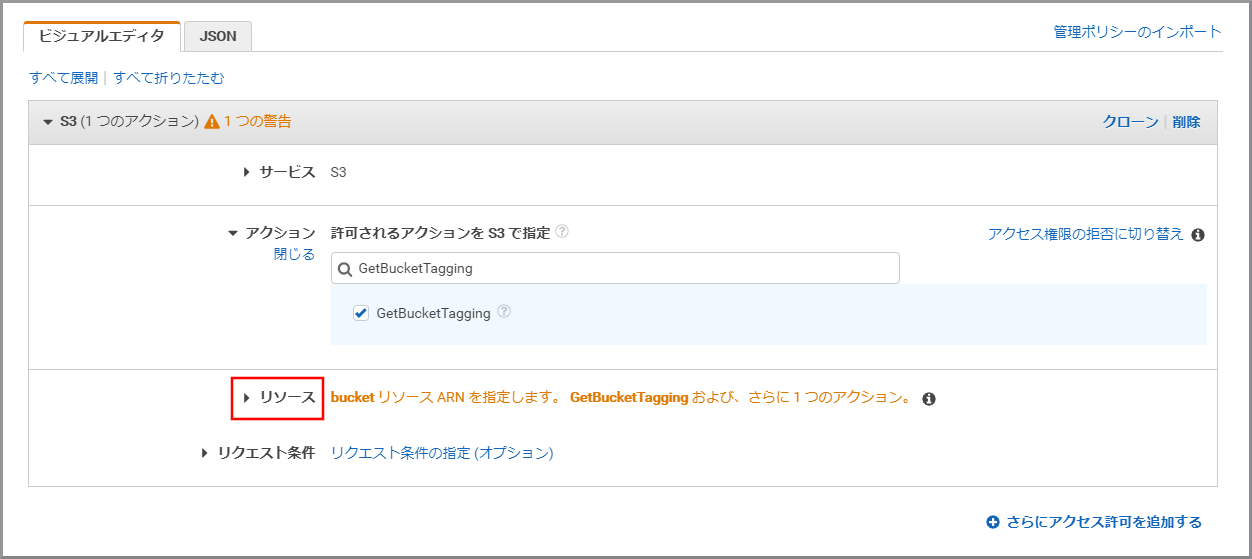
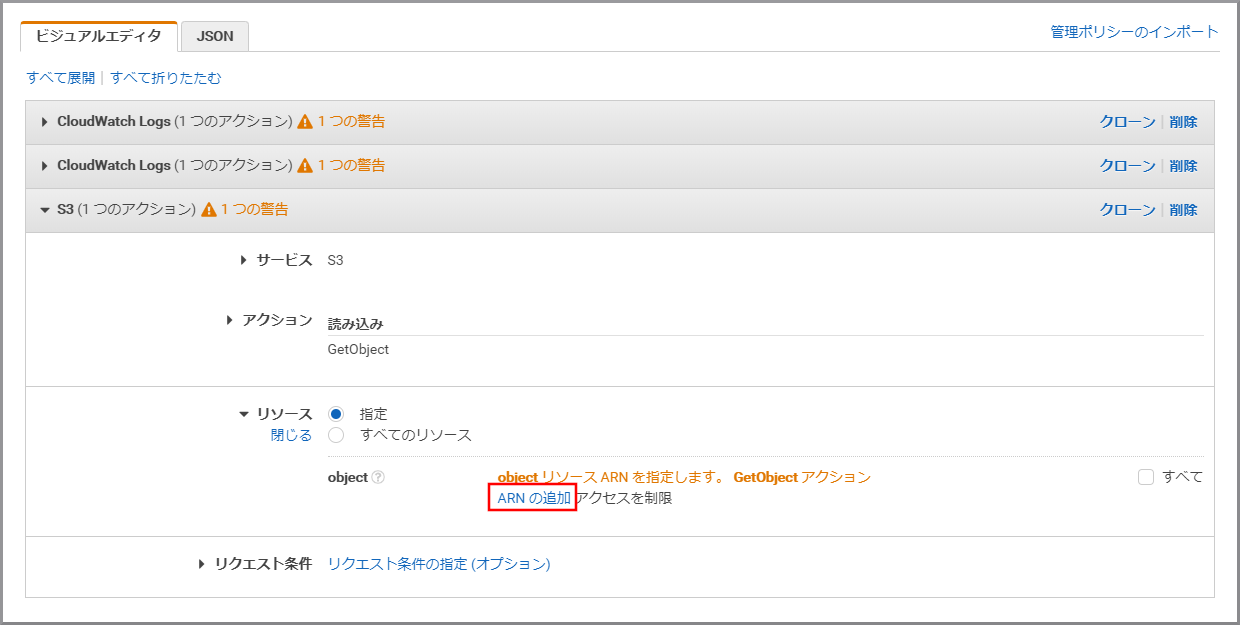
《リソース》をクリックします。
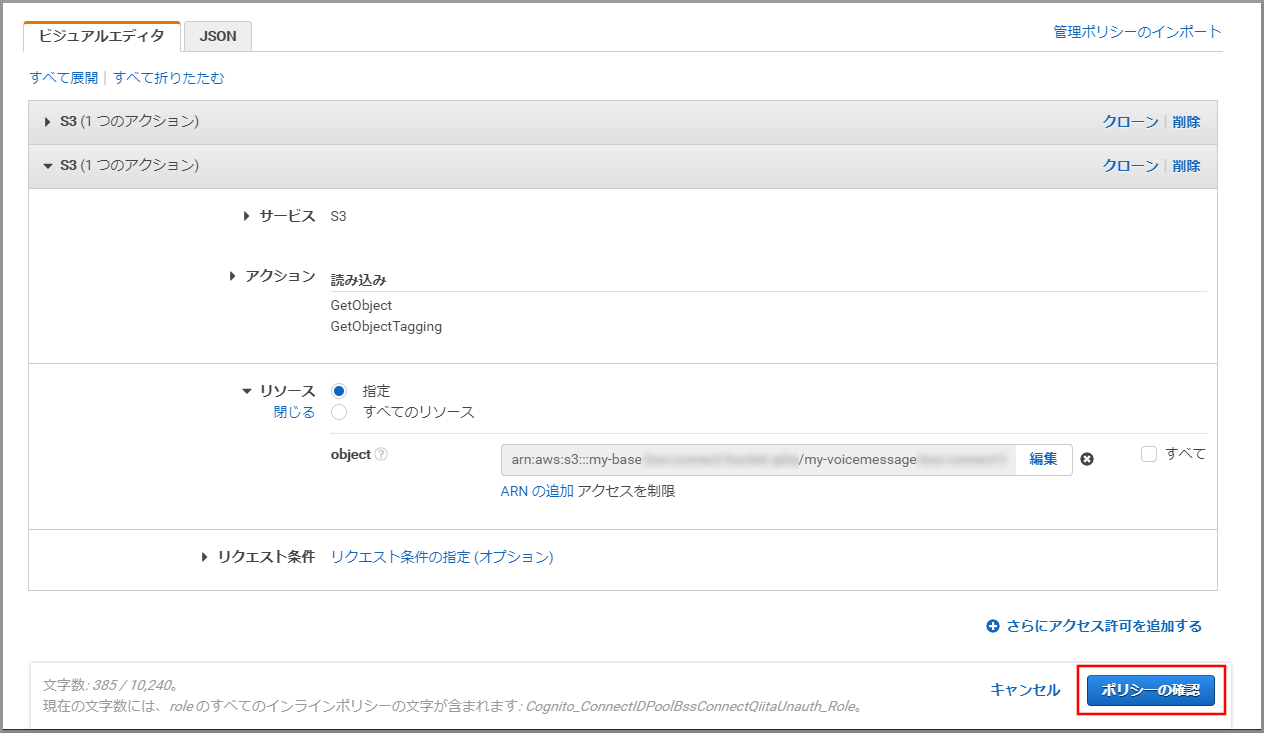
《ARNの追加》をクリックします。
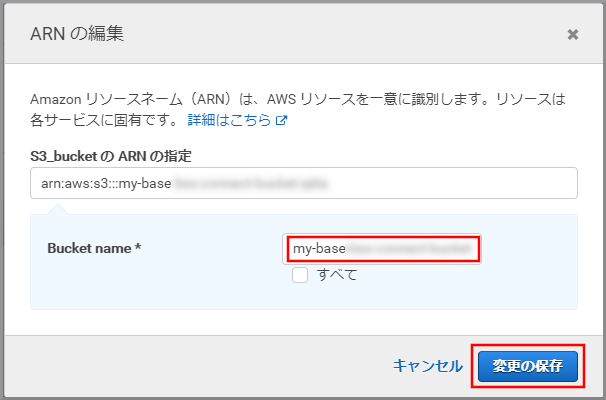
以下の項目を選択、入力して《追加》をクリックします。
- Bucket name:kinesis Video StreamsデータをWAVに変換したデータが保存してあるS3のバケット名
- Bucket name:my-baseXXXXXXXXX/my-voicemessageXXXXXXX/wav
- Object name:すべてにチェックを付ける(テキストボックスには*が入力される)
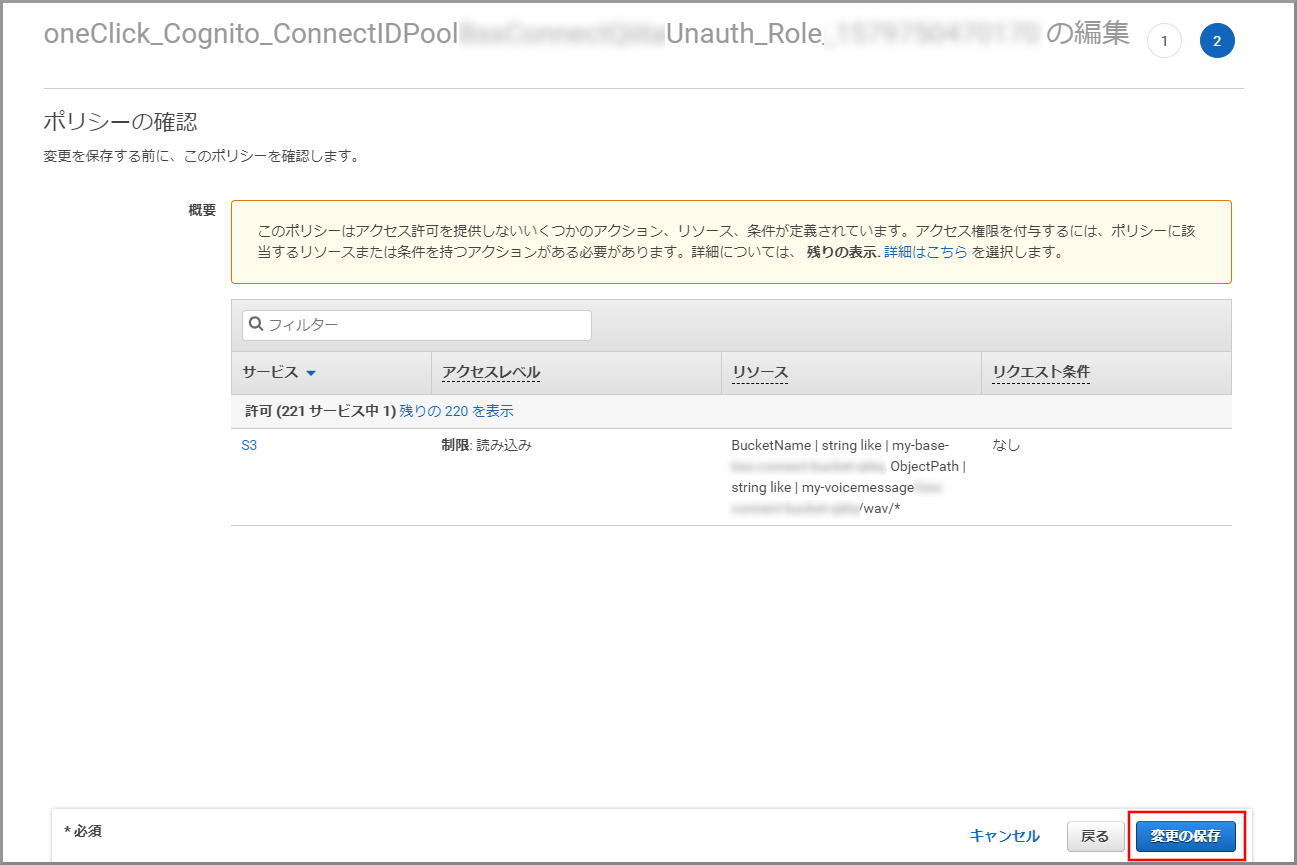
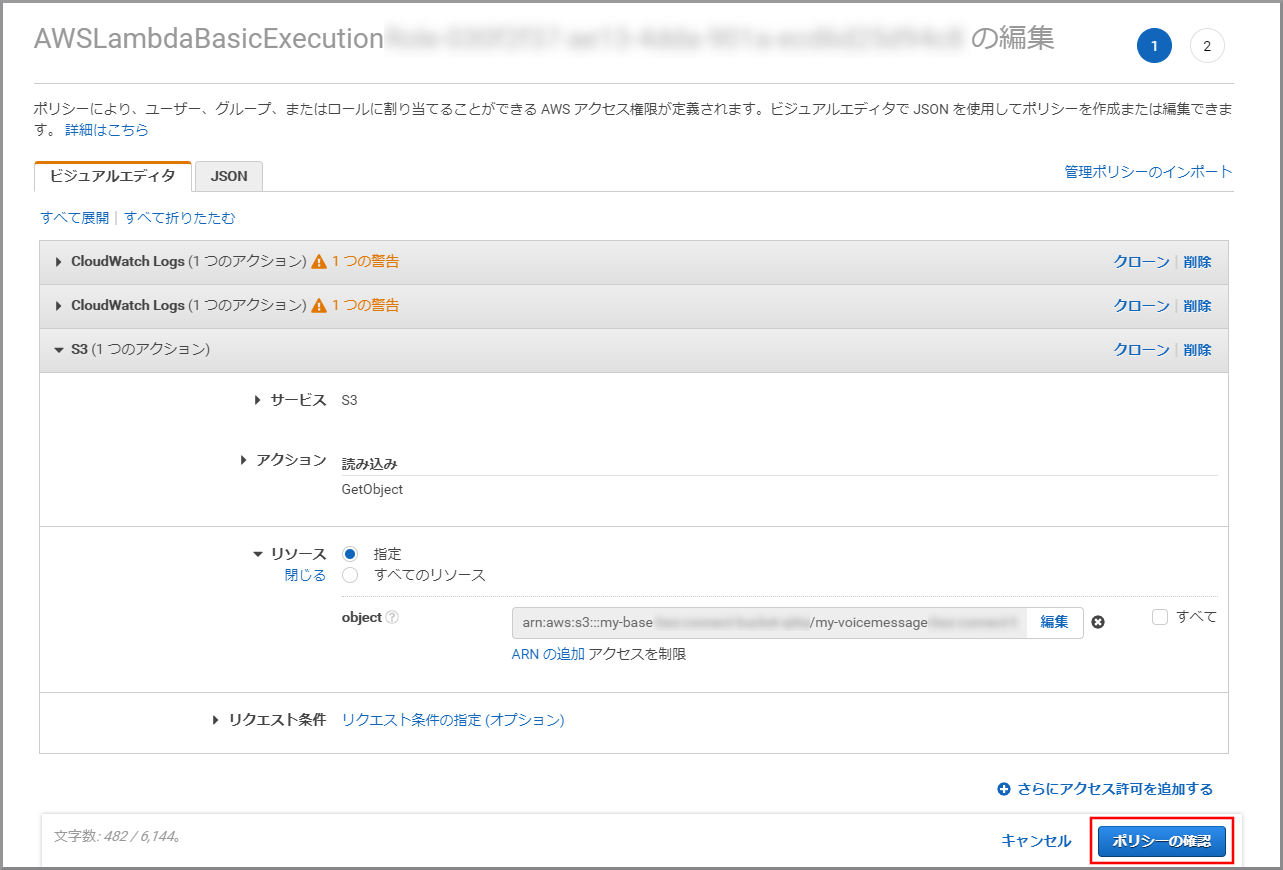
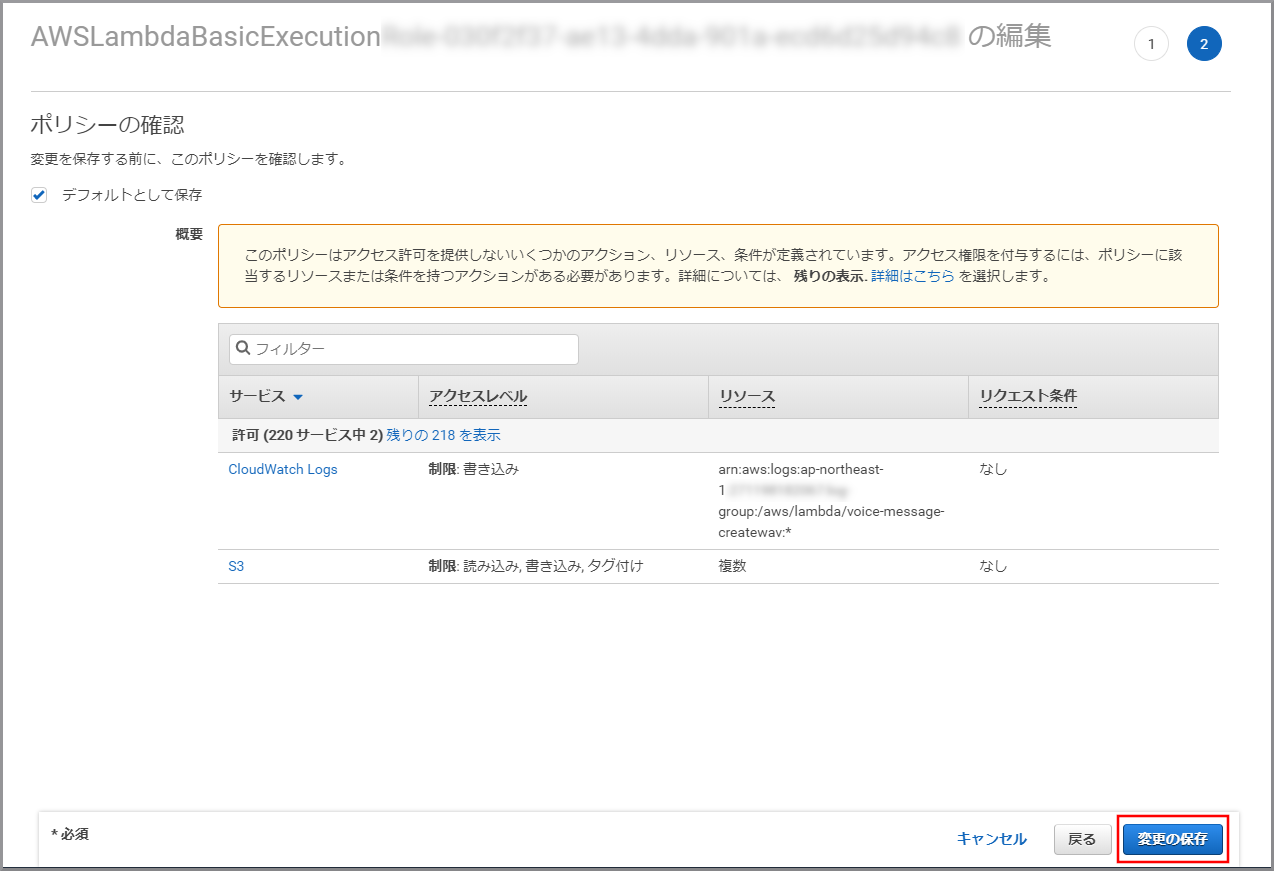
《ポリシーの確認》をクリックします。
内容を確認して、《変更の保存》をクリックします。
留守番電話を聴く画面の作成
- 以下のコードで各自で変える部分
- AWS.config.region変数、AWS.config.credentials変数:先ほどメモした、CognitoのreagionとIdentityPoolIdを設定する
- bucketName変数、prefix変数に指定する値:kinesis Video StreamsデータをWAVに変換したデータが保存されているS3のバケット名とフォルダ名
index.html<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Voice Mail Viewer</title> <script src="https://sdk.amazonaws.com/js/aws-sdk-2.283.1.min.js"></script> <script src="https://ajax.googleapis.com/ajax/libs/jquery/3.3.1/jquery.min.js"></script> <!-- <link rel="stylesheet" type="text/css" href="style.css"> --> </head> <body> <h1 id="time">留守番電話</h1> <audio id="sound" preload="auto"> </audio> <table id="contents"/ border=1> <script> AWS.config.region = 'XXXXXXXXX'; AWS.config.credentials = new AWS.CognitoIdentityCredentials({ IdentityPoolId: 'XXXXXXXXX:XXXXXXXXXXXXXXXXXXXXXXXXXXXX', }); const bucketName = 'my-baseXXXXXXXXX'; const prefix = 'my-voicemessageXXXXXXXXX/wav/' const s3 = new AWS.S3(); async function refresh(){ const list = await s3.listObjects({Bucket: bucketName, Prefix: prefix}).promise(); const keys = list.Contents.map(v => v.Key).filter( v => { if (v.indexOf('.wav') >= 0) { return true; } }); let items = await Promise.all(keys.map(async (key)=>{ // S3上のオブジェクトのタグ情報を取得する const tagging = await s3.getObjectTagging({Bucket: bucketName, Key: key }).promise(); const customerEndpoint = tagging.TagSet.find((v => { return v.Key == "customerEndpoint"}))["Value"]; const startTimestamp = Number(tagging.TagSet.find((v => { return v.Key == "startTimestamp"}))["Value"]); const item = { customerEndpoint: customerEndpoint, startTimestamp: dateString(new Date(startTimestamp)), // yyyy/mm/dd hh:mm key: key }; return item; })); // 録音時間でソートする items = items.sort((a, b) => b.startTimestamp - a.startTimestamp); const table = $("#contents"); const tr = table.append($("<tr></tr>")) tr.append("<th>着信時間</th>") tr.append("<th>発信番号</th>") tr.append("<th></th>") // 一覧の表示 items.forEach( item => { const customerEndpoint = $("<td></td>").text(item.customerEndpoint.replace("81","0")); const startTimestamp = $("<td></td>").text(item.startTimestamp); const listenButton = $("<td><img src=listen.png></td>").click(()=> {listen(listenButton,item.key)}); const tr = table.append($("<tr></tr>")) tr.append(startTimestamp) tr.append(customerEndpoint) tr.append(listenButton) }); } refresh(); // スピーカーのアイコンをクリックした際にWAVファイルを取得する async function listen(element, key) { var params = { Bucket: bucketName, Key: key }; const data = await s3.getObject(params).promise(); var blob = new Blob([data.Body], {type : 'audio/wav'}); element.html('<audio src=' + URL.createObjectURL(blob) + ' controls></audio>'); } function dateString(date) { const year = date.getFullYear(); const mon = (date.getMonth() + 1); const day = date.getDate(); const hour = date.getHours(); const min = date.getMinutes(); const space = (n) => { return ('0' + (n)).slice(-2) } let result = year + '/'; result += space(mon) + '/'; result += space(day) + ' '; result += space(hour) + ':'; result += space(min); return result; } </script> </body> </html>
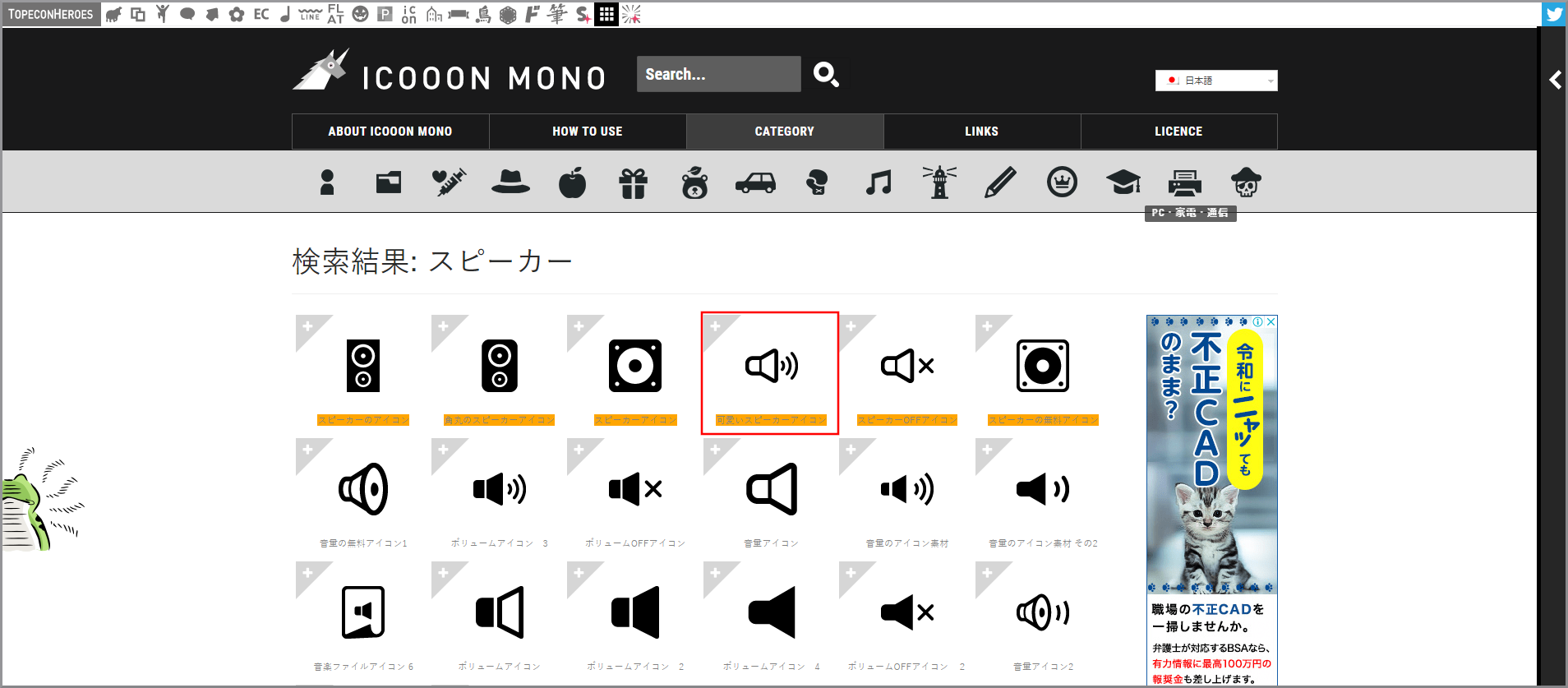
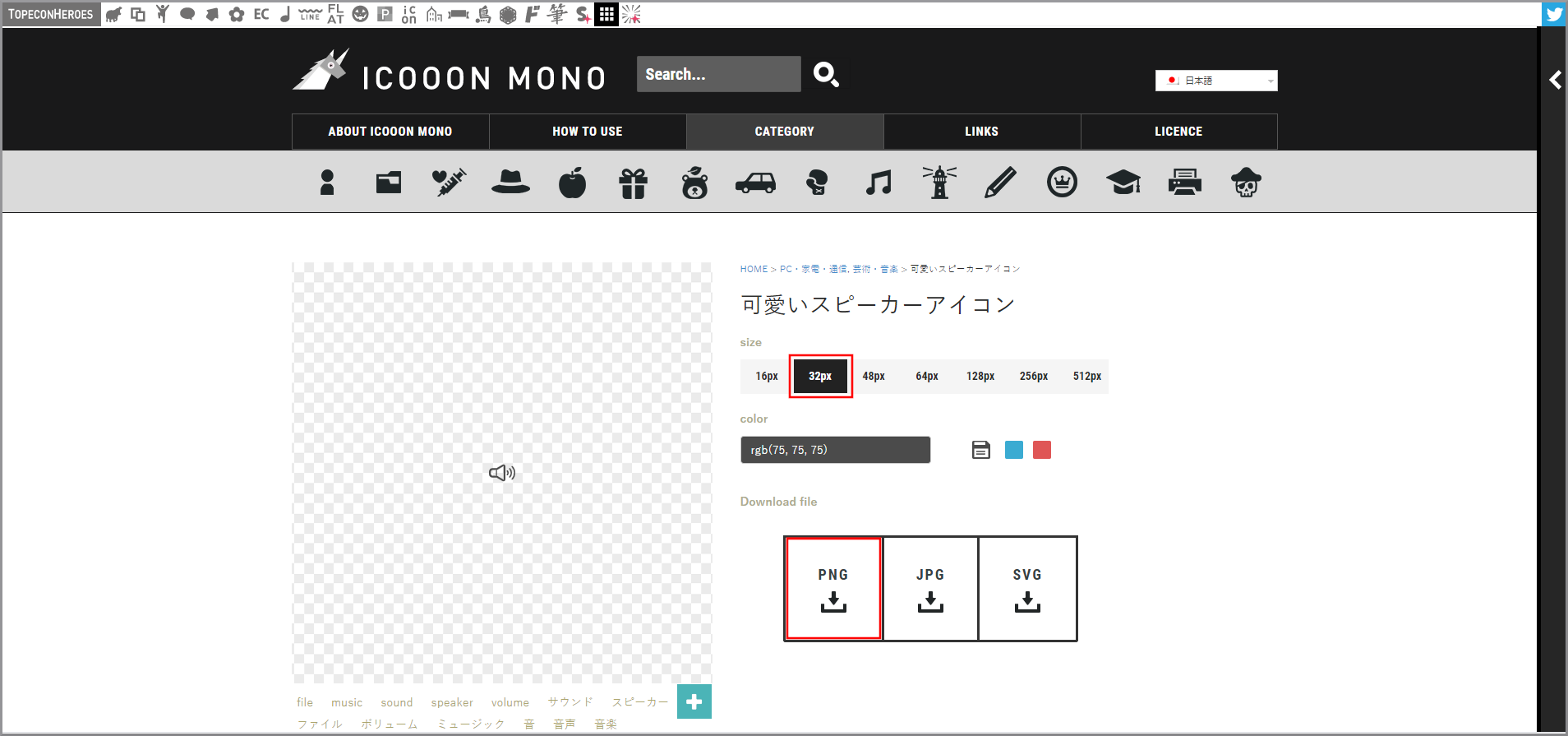
留守番電話一覧画面で利用するアイコンをダウンロードするのでICOON MONOを開きます。
アイコンを検索するので検索欄に以下の文言を入力して検索します。
- 検索文言:スピーカー
《可愛いスピーカーアイコン》をクリックします。
PNG形式のアイコンをダウンロードするので、サイズから《32px》を選択し、《PNG》をクリックします。
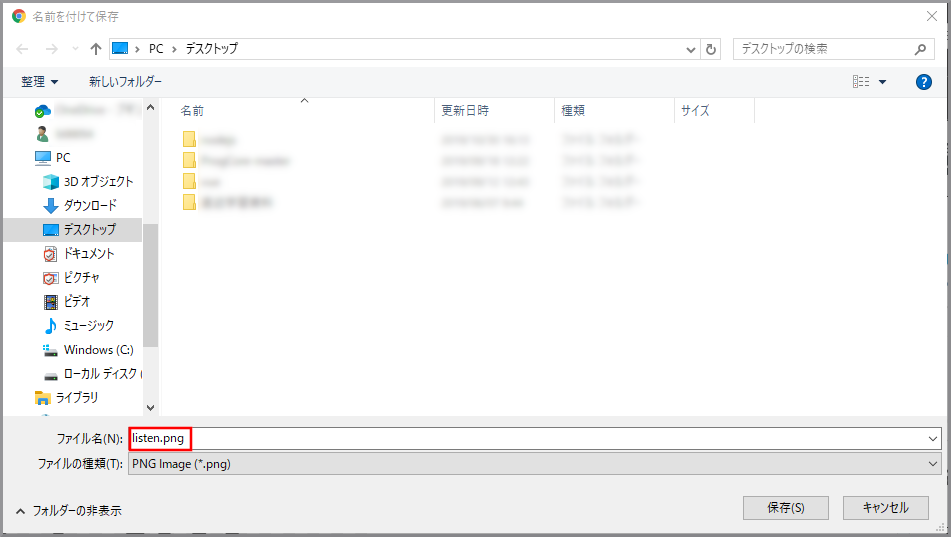
ファイル名を「listen.png」に変更して保存します。
アイコンを保存したフォルダにテキストファイルを作成し、開いて上記のindex.htmlをコピー&ペーストします。
保存してテキストファイルを閉じます。
テキストファイルの名前を「index.html」に変更します。
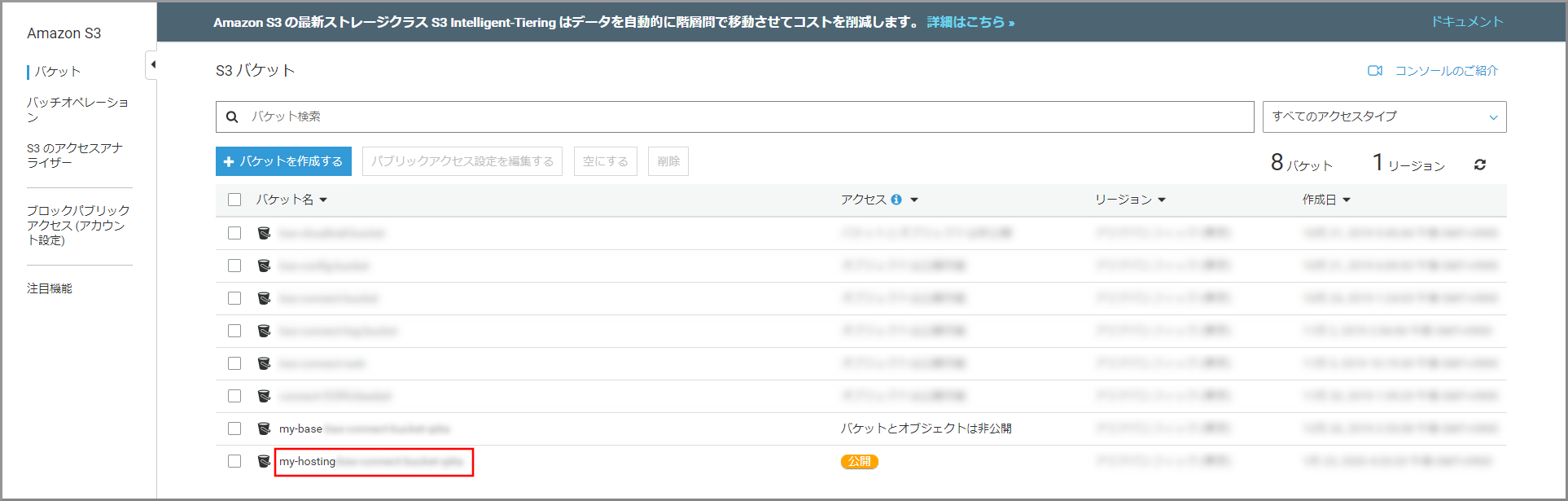
留守番電話を聴く画面をホスティングするS3を作成
- my-hostingXXXXXXXXX:作成したバケット名に変更してください。
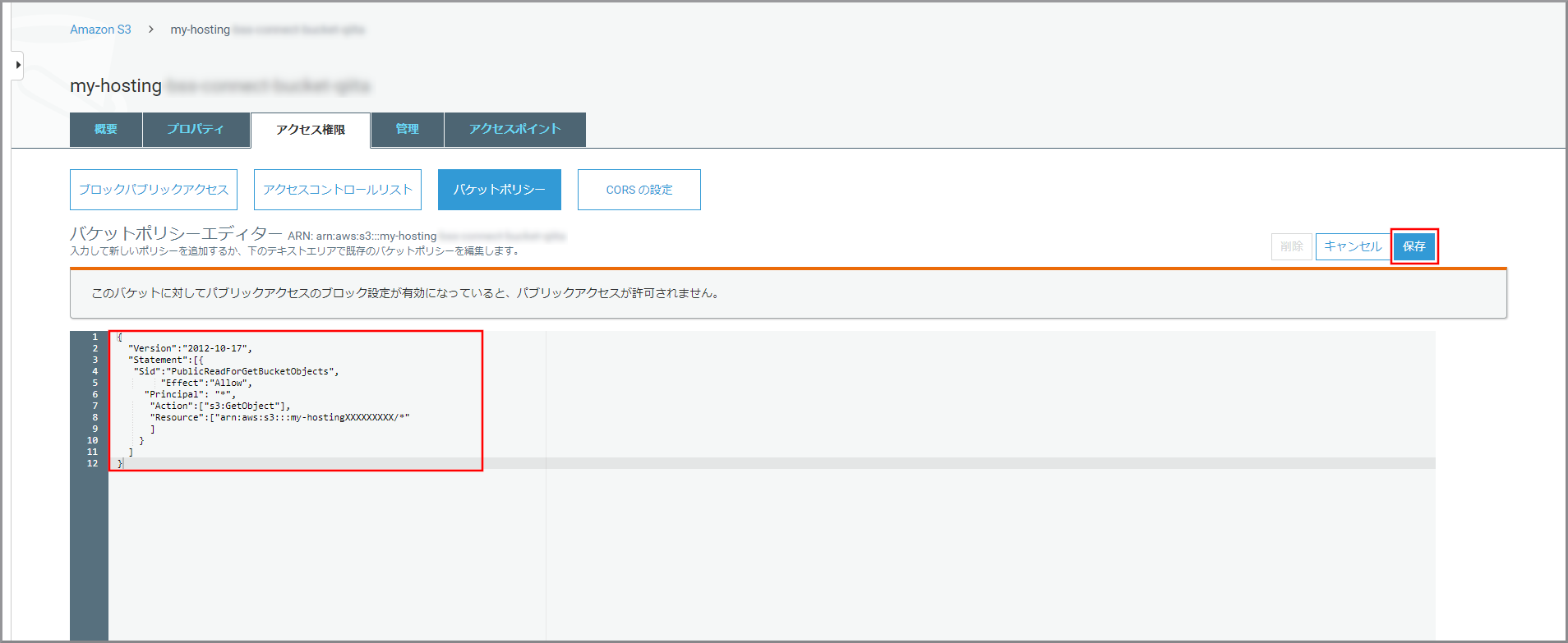
バケットポリシー{ "Version":"2012-10-17", "Statement":[{ "Sid":"PublicReadForGetBucketObjects", "Effect":"Allow", "Principal": "*", "Action":["s3:GetObject"], "Resource":["arn:aws:s3:::my-hostingXXXXXXXXX/*" ] } ] }
- my-hostingXXXXXXXXX:作成したバケット名に変更してください。
- reagionXXXXXX:作成したバケットのリージョン名に変更してください。
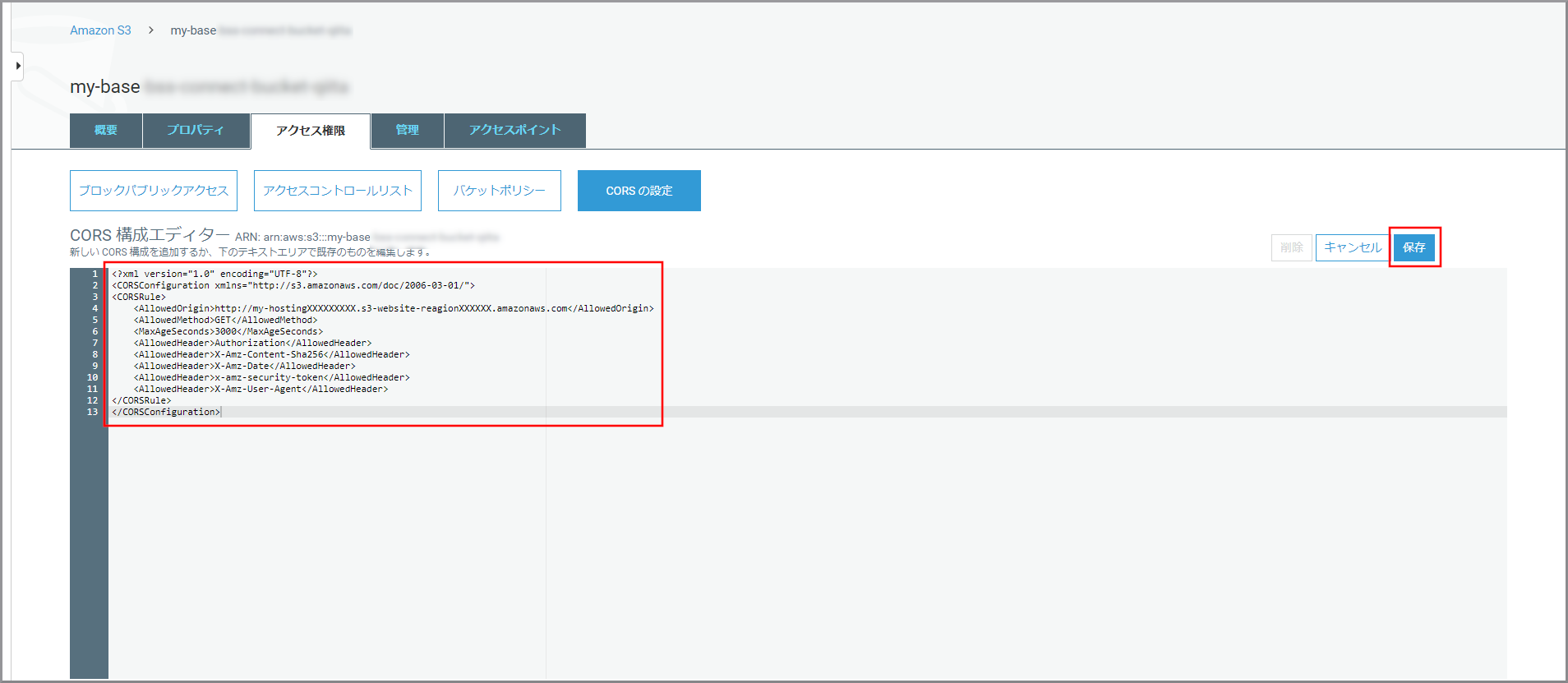
CORS構成<?xml version="1.0" encoding="UTF-8"?> <CORSConfiguration xmlns="http://s3.amazonaws.com/doc/2006-03-01/"> <CORSRule> <AllowedOrigin>http://my-hostingXXXXXXXXX.s3-website-reagionXXXXXX.amazonaws.com</AllowedOrigin> <AllowedMethod>GET</AllowedMethod> <MaxAgeSeconds>3000</MaxAgeSeconds> <AllowedHeader>Authorization</AllowedHeader> <AllowedHeader>X-Amz-Content-Sha256</AllowedHeader> <AllowedHeader>X-Amz-Date</AllowedHeader> <AllowedHeader>x-amz-security-token</AllowedHeader> <AllowedHeader>X-Amz-User-Agent</AllowedHeader> </CORSRule> </CORSConfiguration>
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
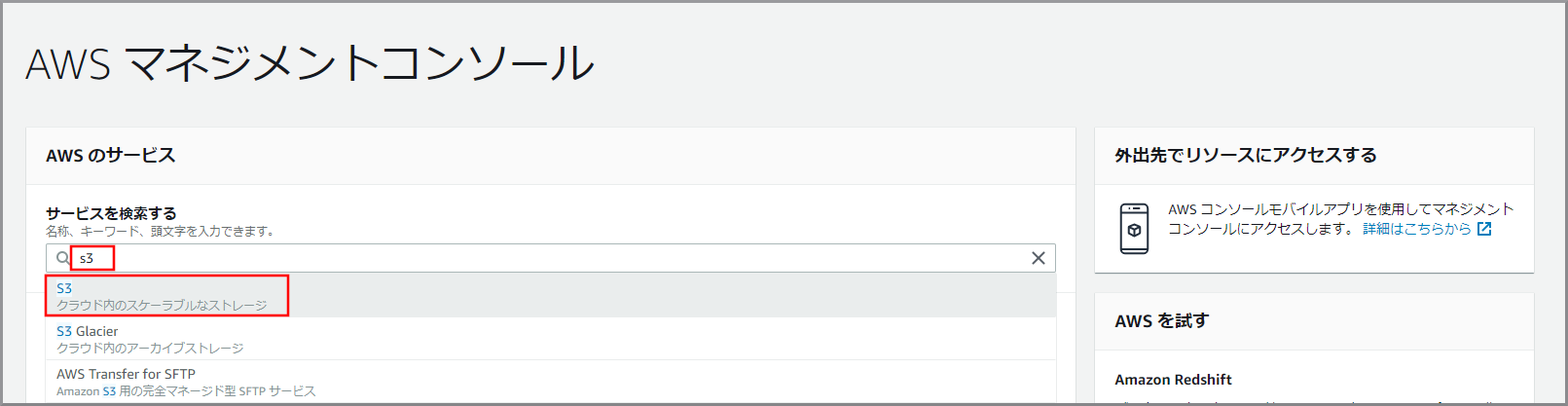
『AWSマネジメントコンソール』画面にある「サービスを検索」にS3と入力し、検索結果から《S3》をクリックし、Amazon S3 コンソール(https://console.aws.amazon.com/s3/)を開きます。
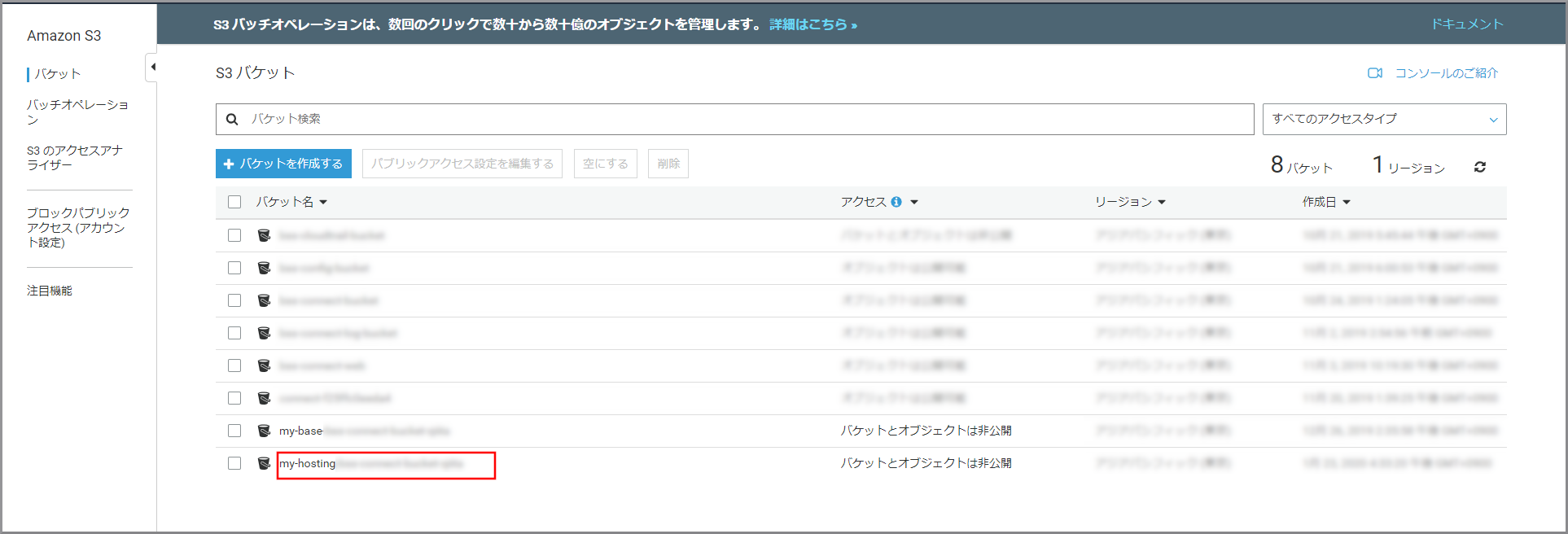
S3のバケット一覧が表示されるので、《バケットを作成する》をクリックします。
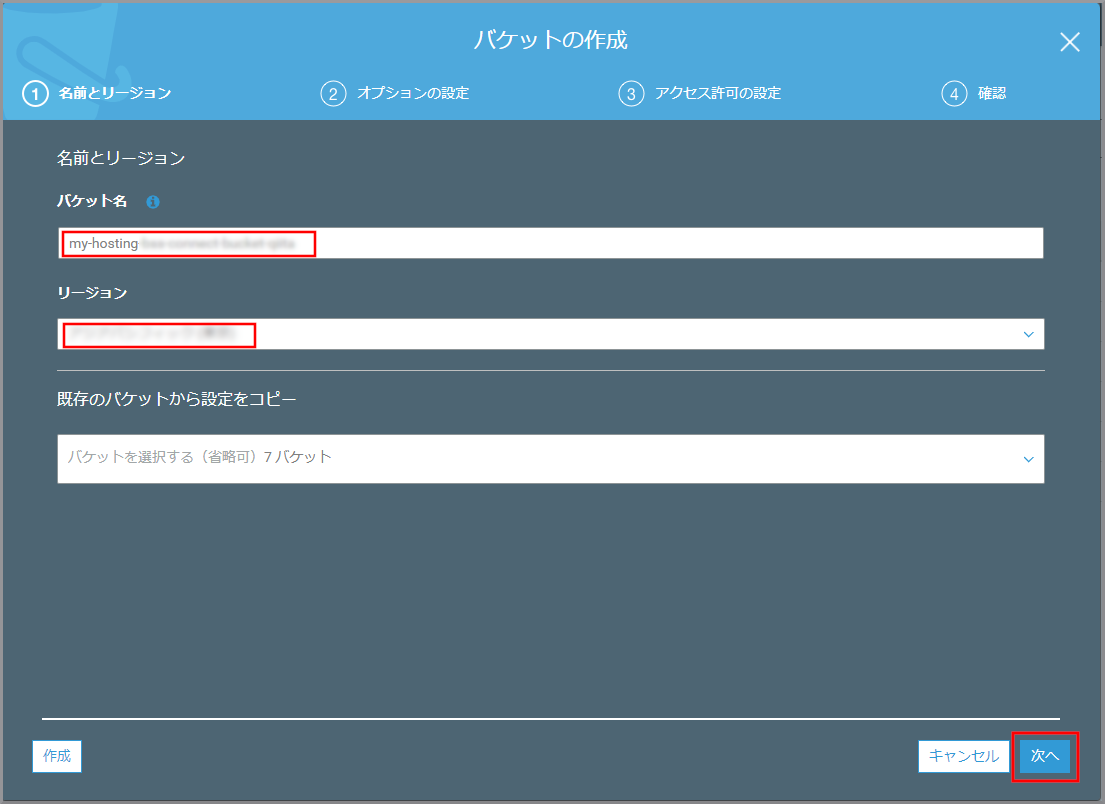
「バケット作成」画面が表示されるので、以下の項目を選択、入力して《次へ》をクリックします。
- バケット名:世界中で一意になる名前を付ける
- my-hostingXXXXXXXXX
- リージョン:作成するを選択します。
適宜必要な設定を行い《次へ》をクリックします。
- 今回はデフォルトのまま
適宜必要な設定を行い《次へ》をクリックします。
- 今回はデフォルトのまま
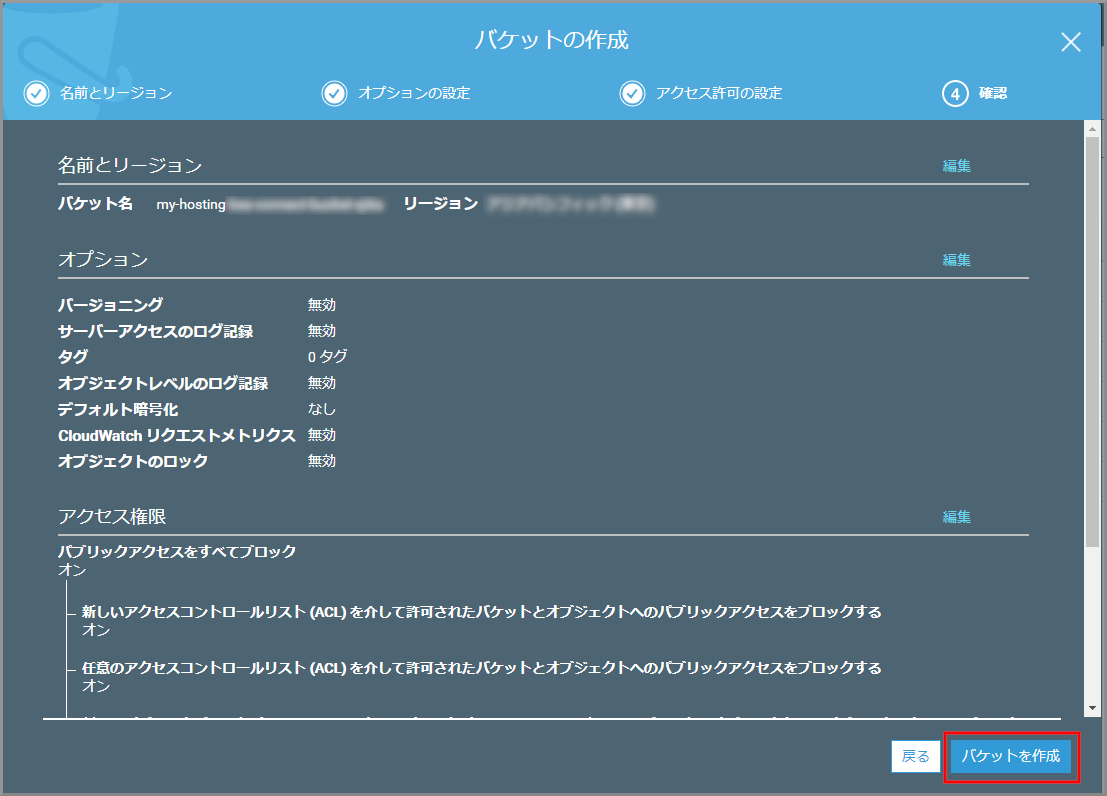
設定内容を確認して《バケットを作成》をクリックします。
S3のバケット一覧が表示されるので、作成したバケットをクリックします。
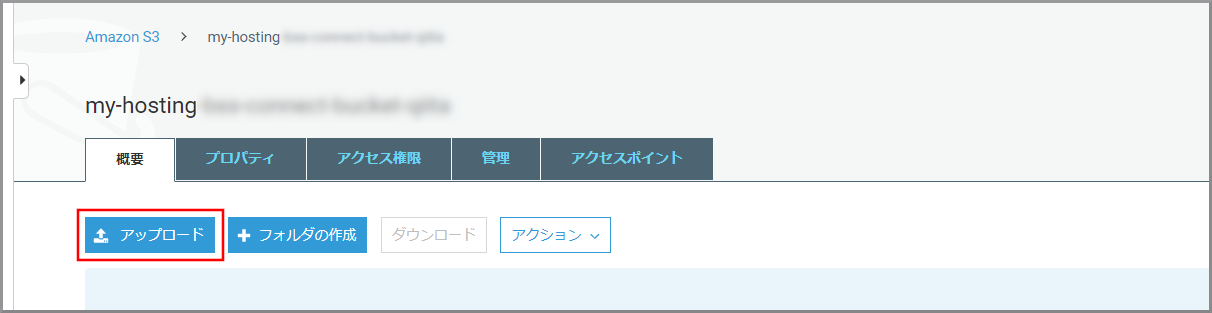
《アップロード》をクリックします。
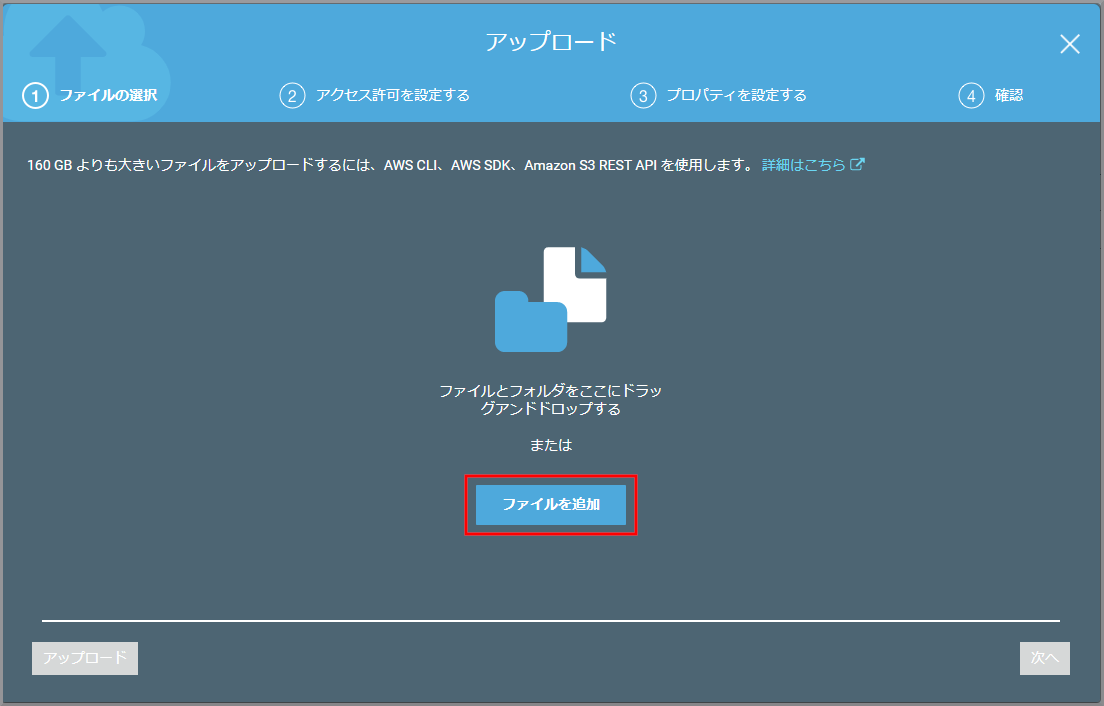
「アップロード」画面が表示されるので、ドラッグ&ドロップまたは、《ファイルを追加》ボタンを押してindex.htmlとlisten.pngをアップロードします。
指定したファイルを確認して、《次へ》をクリックします。
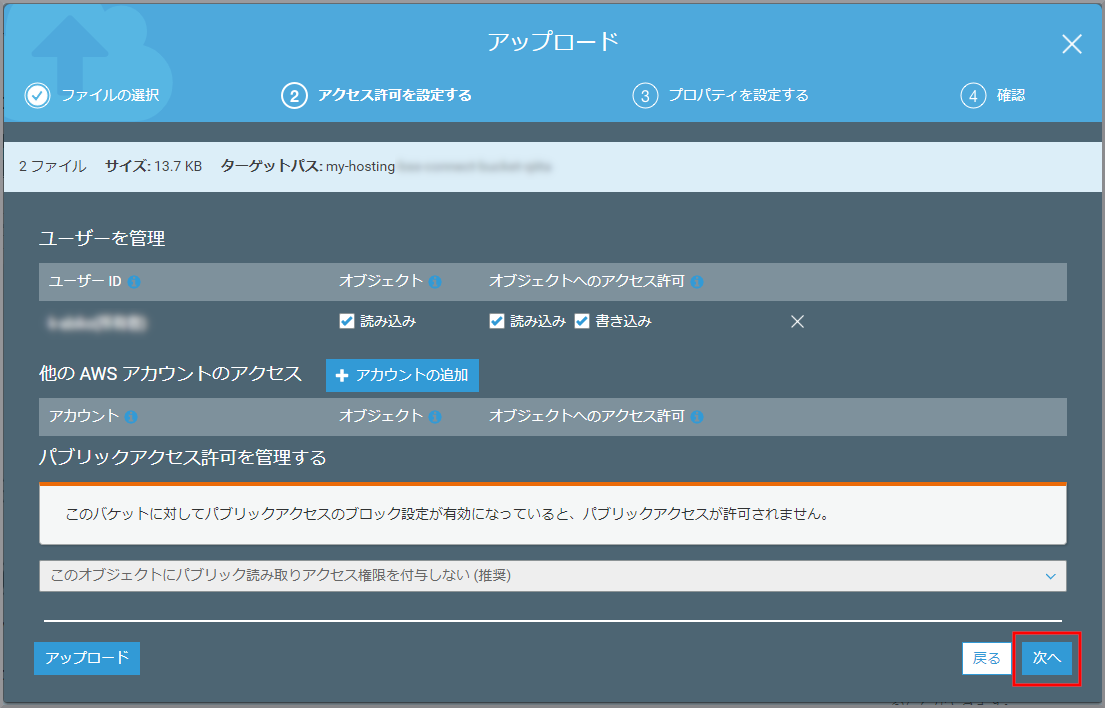
アクセス許可の設定を確認して、《次へ》をクリックします。
- 今回はデフォルトのまま
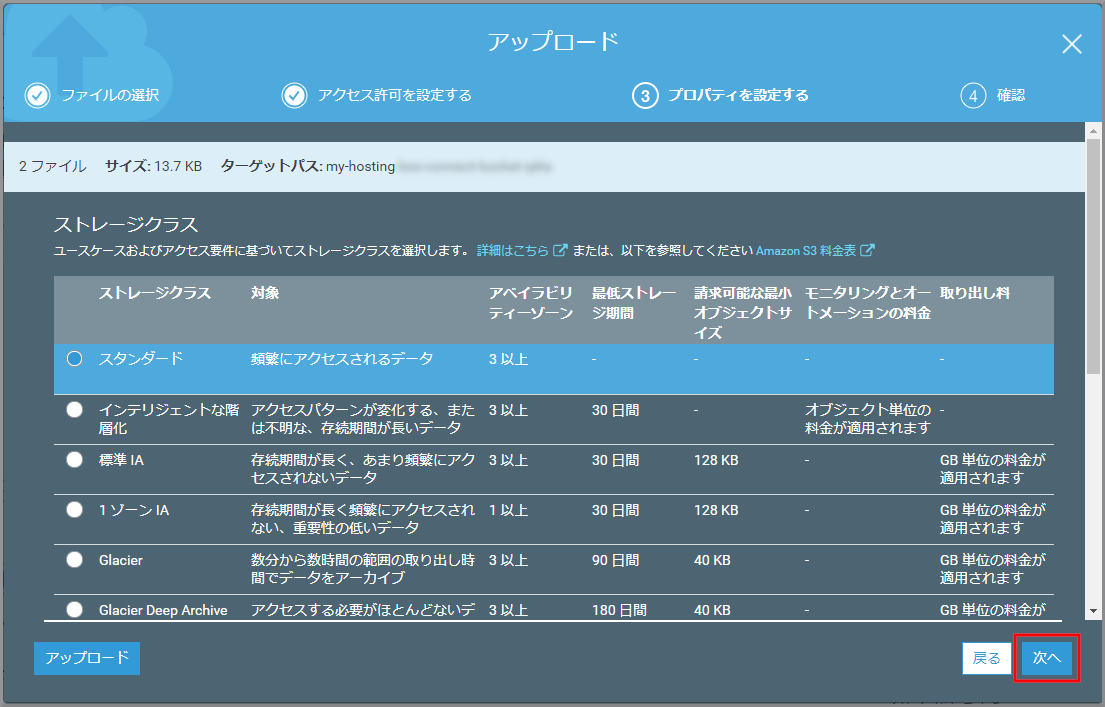
ストレージクラスの設定を確認して、《次へ》をクリックします。
- 今回はデフォルトのまま
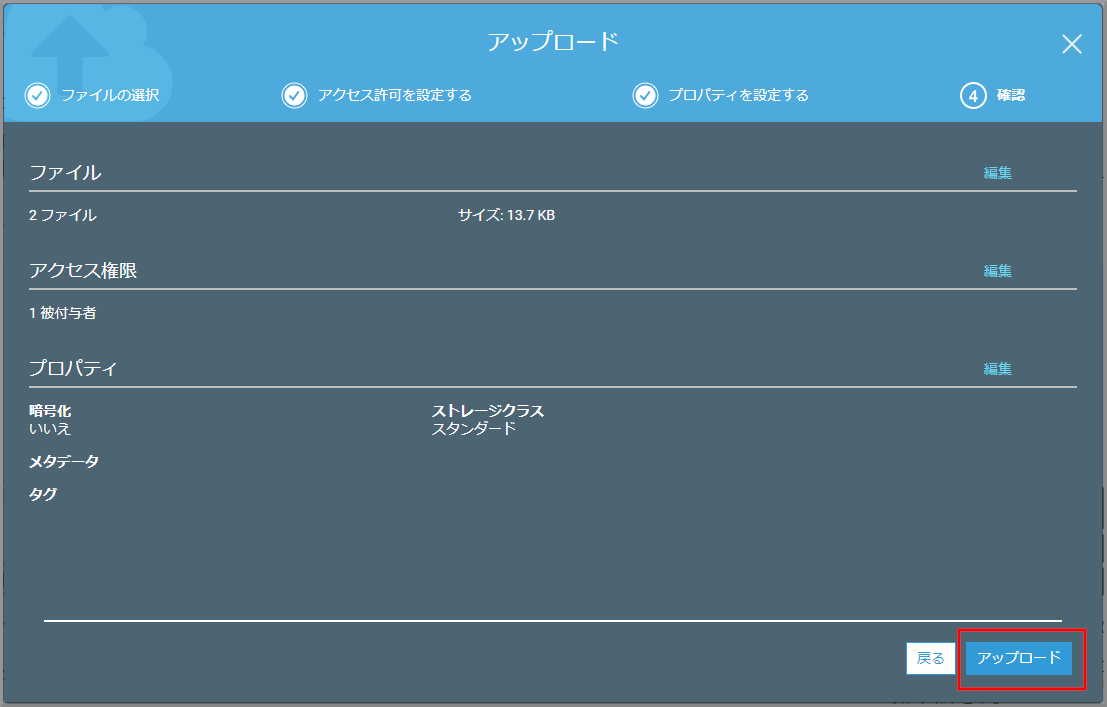
設定を確認して、《アップロード》をクリックします。
ファイルがアップロードされました。
S3にホスティングの設定を行うため《プロパティ》をクリックします。
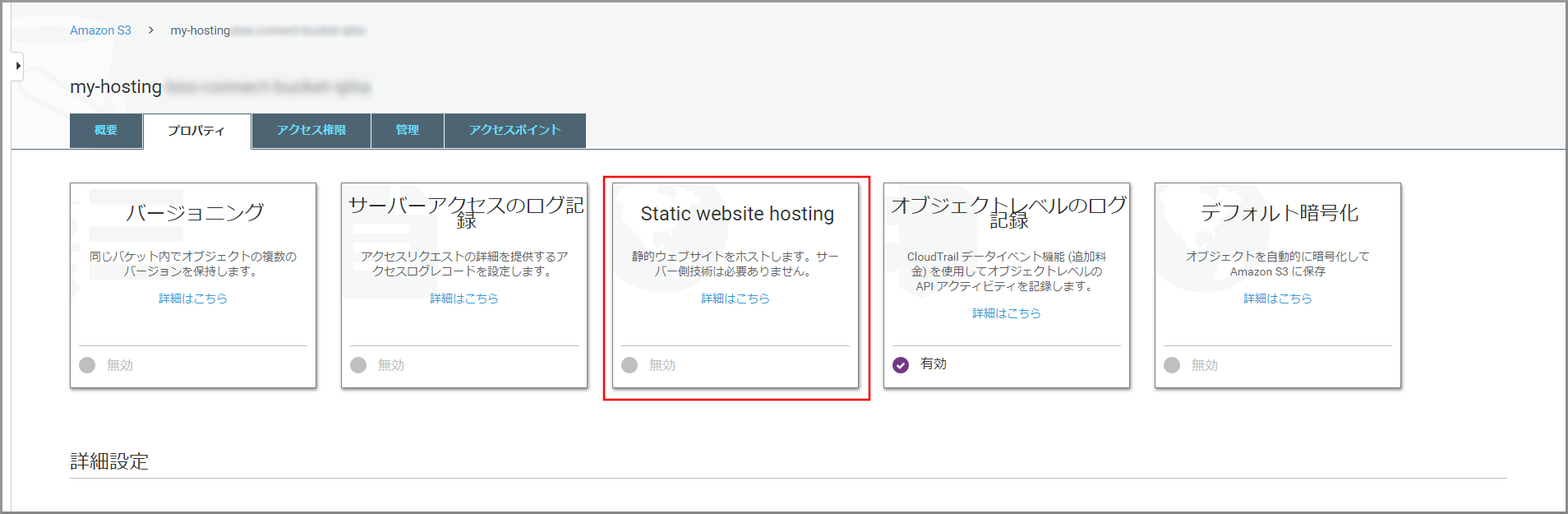
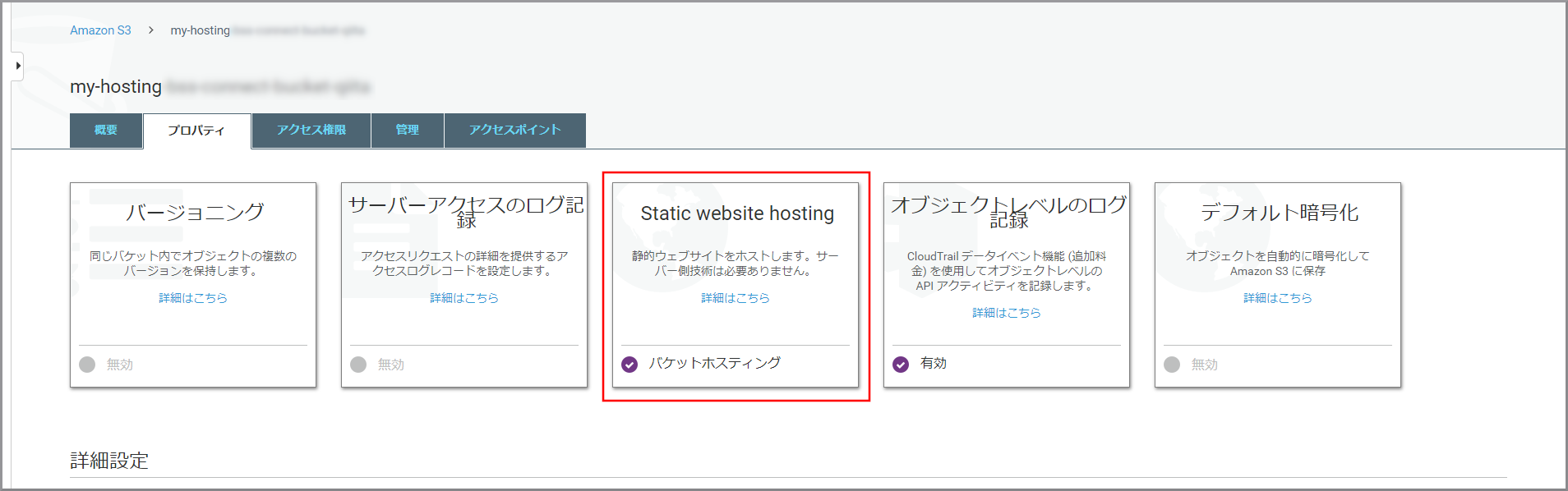
《Static website hosting》をクリックします。
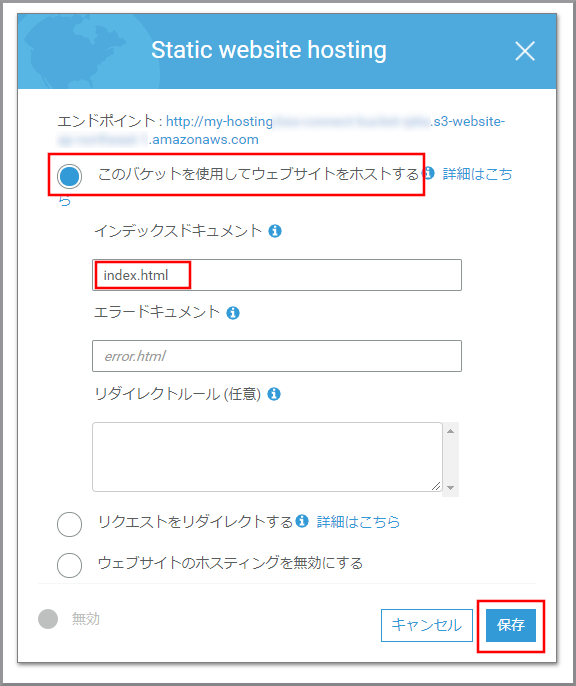
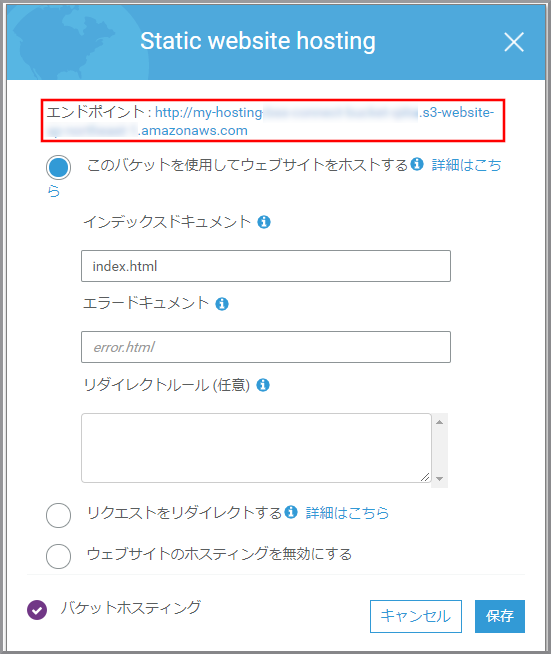
以下の項目を選択、入力して《保存》をクリックします。
- このバケットを使用してウェブサイトをホストする:選択します。
- インデックスドキュメント:index.html
このバケットをインターネットに公開するように設定するので《アクセス権限》をクリックします。
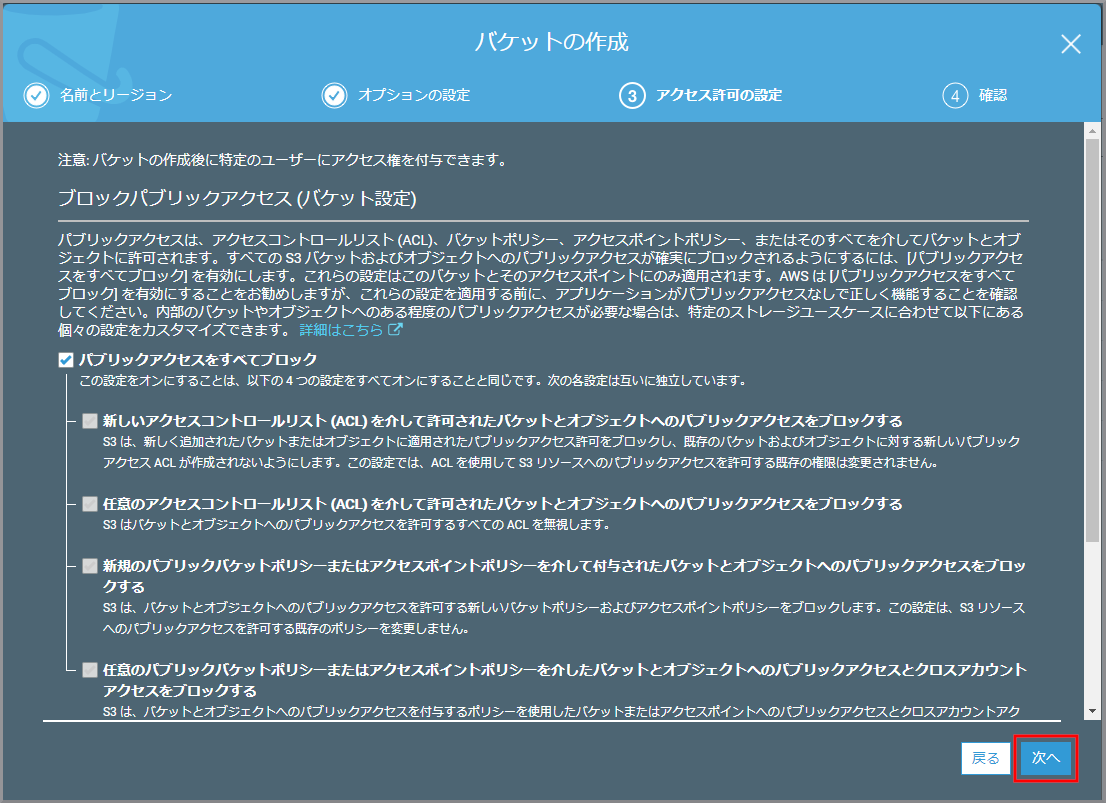
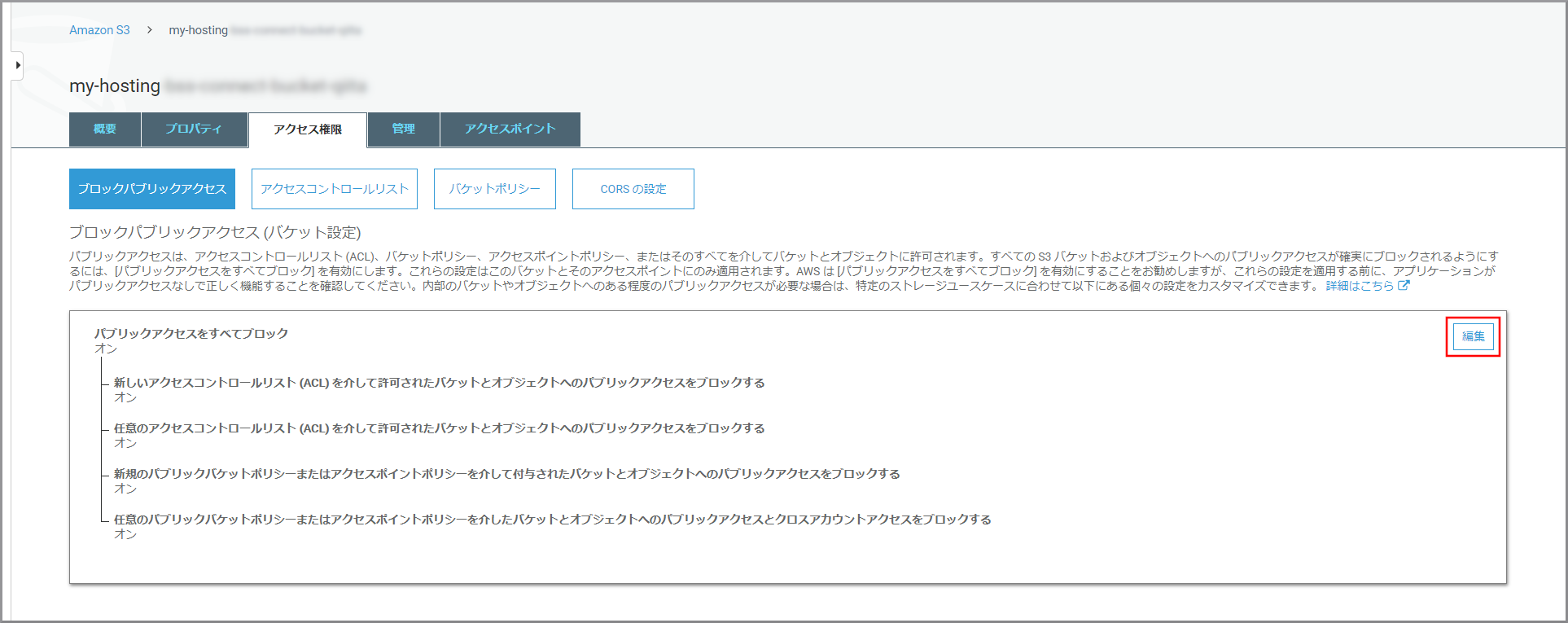
ブロックパブリックアクセスの設定を変更するので《編集》をクリックします。
以下の項目を選択して《保存》をクリックします。
- パブリックアクセスをすべてブロック
確認画面が表示されるので、以下の項目を入力して《確認》をクリックします。
- 確認フィールド:確認
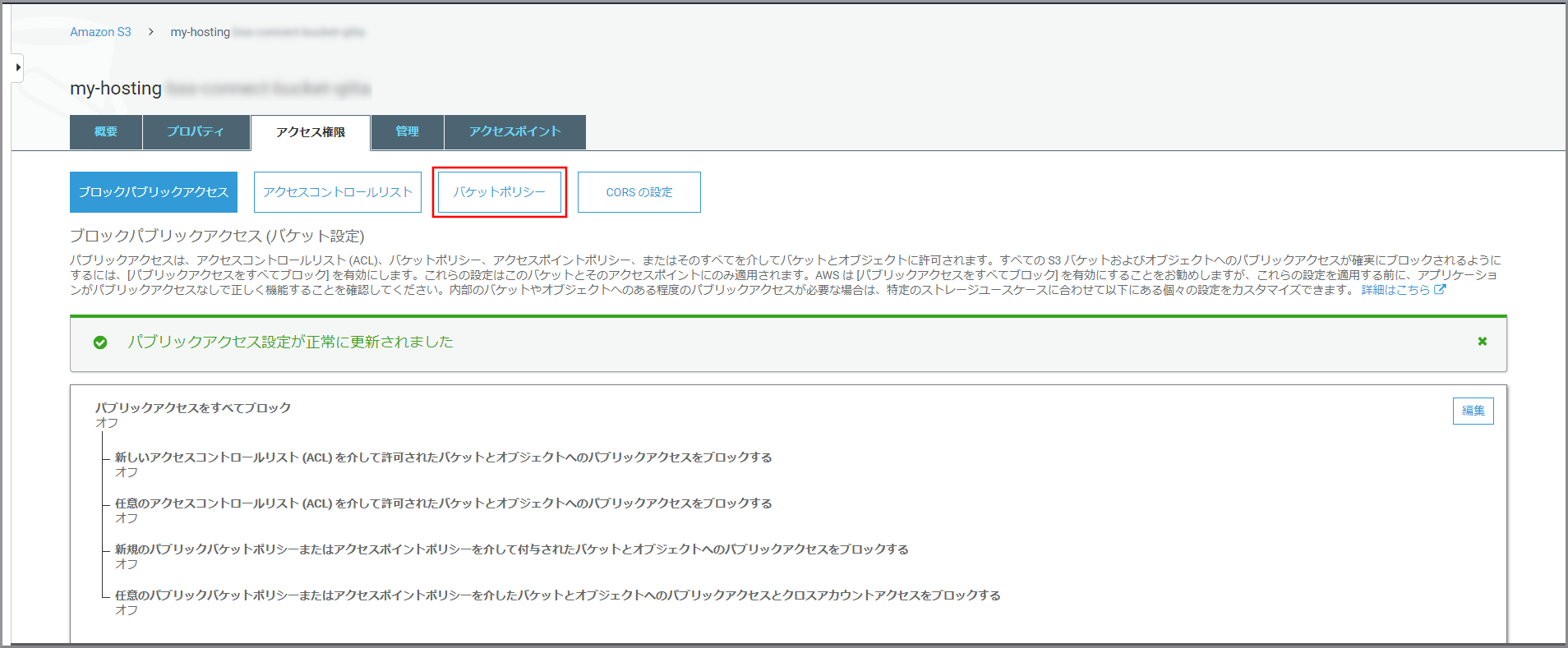
《バケットポリシー》をクリックします。
バケットポリシーエディターに上記のバケットポリシーを貼り付けて《保存》をクリックしてください。
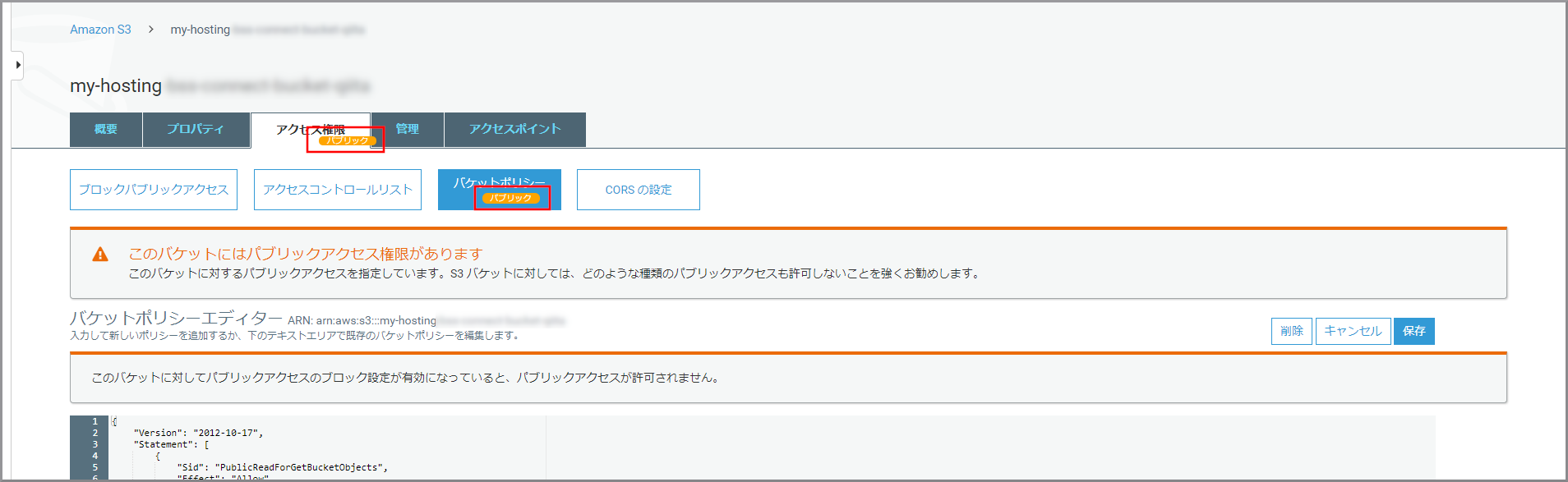
保存すると「パブリック」という表示がでます。これでインターネット上に公開されました。
kinesis Video StreamsデータをWAVに変換したデータが保存されているS3のバケットを開きます。
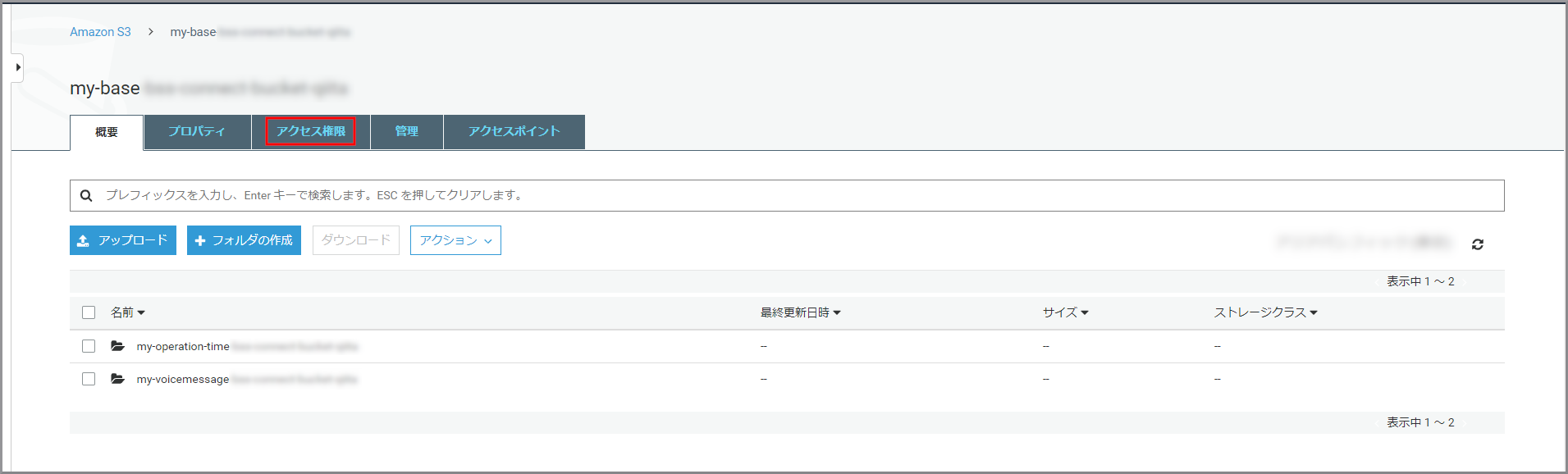
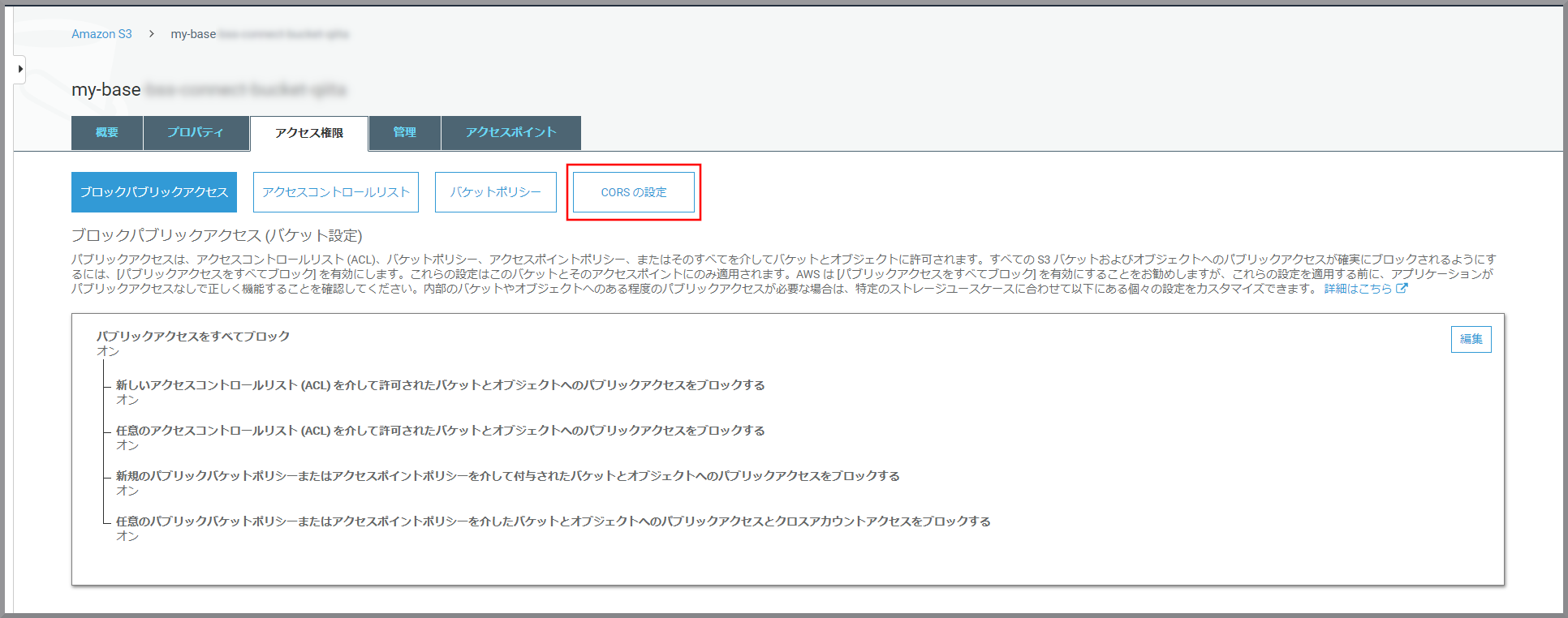
HTMLが保存されているバケットからJavaScriptでデータを取得できるようにするため《アクセス権限》をクリックします。
《CORSの設定》をクリックします。
CORS 構成エディターに上記のCORS構成を貼り付けて《保存》をクリックしてください。
留守番電話画面の動作を確認するため、パブリック設定にしたバケットを開きます。
《プロパティ》をクリックします。
《Static website hosting》をクリックします。
エンドポイントに表示されているURLをクリックします。
留守番電話画面が表示されます。リストから聞きたいものを選択して《スピーカー》アイコンをクリックします。
参考サイト
- [Amazon Connect]営業時間外に着信したビジネスチャンスを失わないように留守番電話機能をつけてみた
- 例: 静的ウェブサイトをセットアップする
- CloudFrontとS3のCORS対応
- CORS(Cross-Origin Resource Sharing)について整理してみた
目次に戻る















- 投稿日:2020-01-24T12:33:34+09:00
【クラウド初心者向け】留守番電話3(kinesis Video StreamsデータをWAV形式に変換してS3に保存)
概要
- Amazon Connectには留守番電話機能は無いため個別に作成する。
- 基本の考え方等は『[Amazon Connect]営業時間外に着信したビジネスチャンスを失わないように留守番電話機能をつけてみた』をもとにしています。
- ここまで作成すると、留守番電話で受け付けた音声がWAV形式でS3に保存されます。
使用ユーザー
- IAMユーザー
手順
WAVデータを保存するS3の作成
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にS3と入力し、検索結果から《S3》をクリックし、Amazon S3 コンソール(https://console.aws.amazon.com/s3/)を開きます。
S3のバケット一覧が表示されるので、営業時間の判断で作成したバケットをクリックします。
先ほど作成したフォルダをクリックします。
《フォルダの作成》をクリックします。
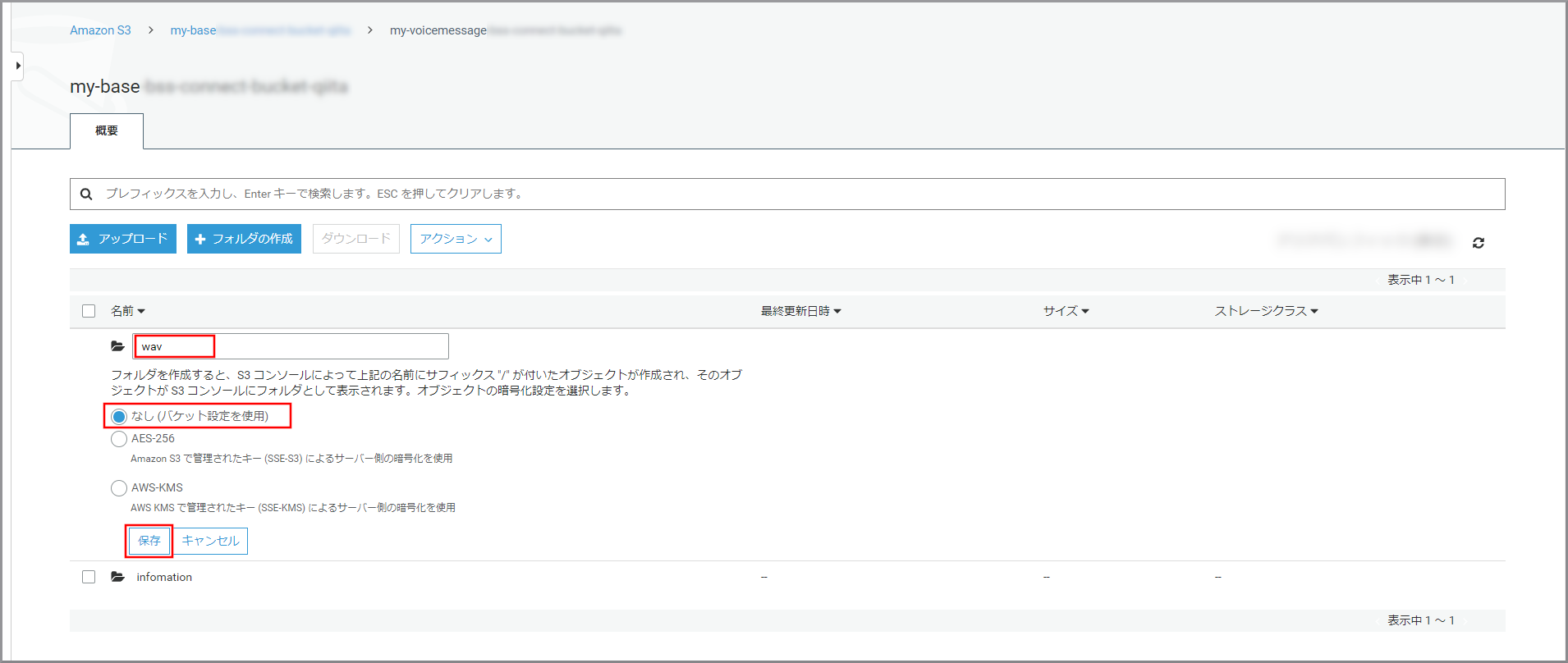
以下の項目を選択、入力して《保存》をクリックします。
- フォルダ名:フォルダの名前
- 暗号化:適宜必要な暗号化設定を選択
Lambdaでebmlを利用するための準備
Node.jsをインストールする
- 詳細は、Windows 10へNode.jsをインストールするを参照してください。
Windows PowerShellを起動します。
ebmlをダウンロードするため「nodejs」フォルダを作成するためコマンドを入力して実行します。
md nodejsnodejsフォルダに移動するためコマンドを入力して実行します。
cd nodejsebmlをダウンロードするためコマンドを入力して実行します。
npm install ebml作成したnodejsフォルダをZip形式で圧縮します。
- 作成したnodejsフォルダの中身ではなくフォルダ自体を圧縮します。
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にLambdaと入力し、検索結果から《Lambda》をクリックし、Amazon Lambda コンソール(https://console.aws.amazon.com/lambda/)を開きます。
Lambdaの関数一覧画面が表示されるので左側のメニューから《Layers》をクリックします。
《レイヤーの作成》をクリックします。
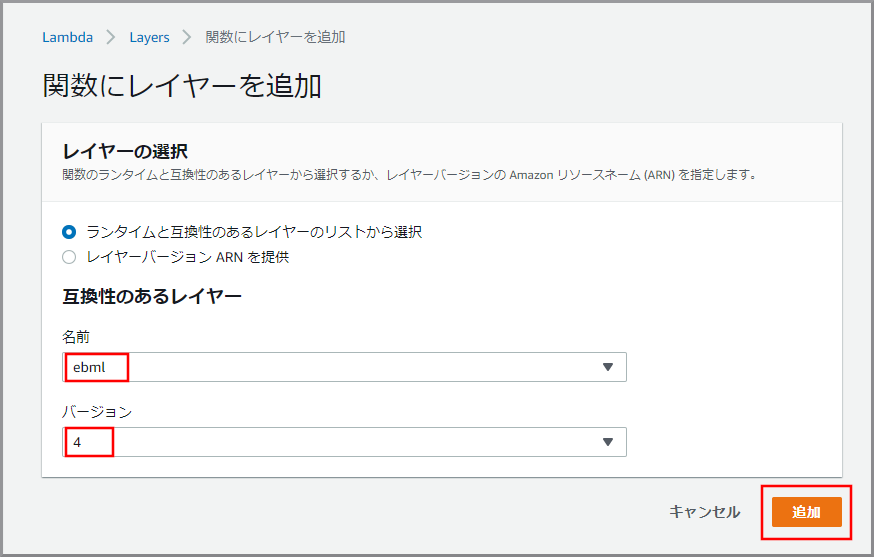
以下の項目を選択、入力して《作成》をクリックします。
- 名前:ebml
- アップロード:先ほど作成したZipファイル
- ランタイム:Node.js 12.x
WAV形式に変換してS3に保存するLambdaの作成
- 以下のコードで各自で変える部分
- region変数:バケットを作成したリージョン名
- bucketName変数:作成したバケット名
- putKey変数:作成したフォルダ名(終わりに『/』を入れる)
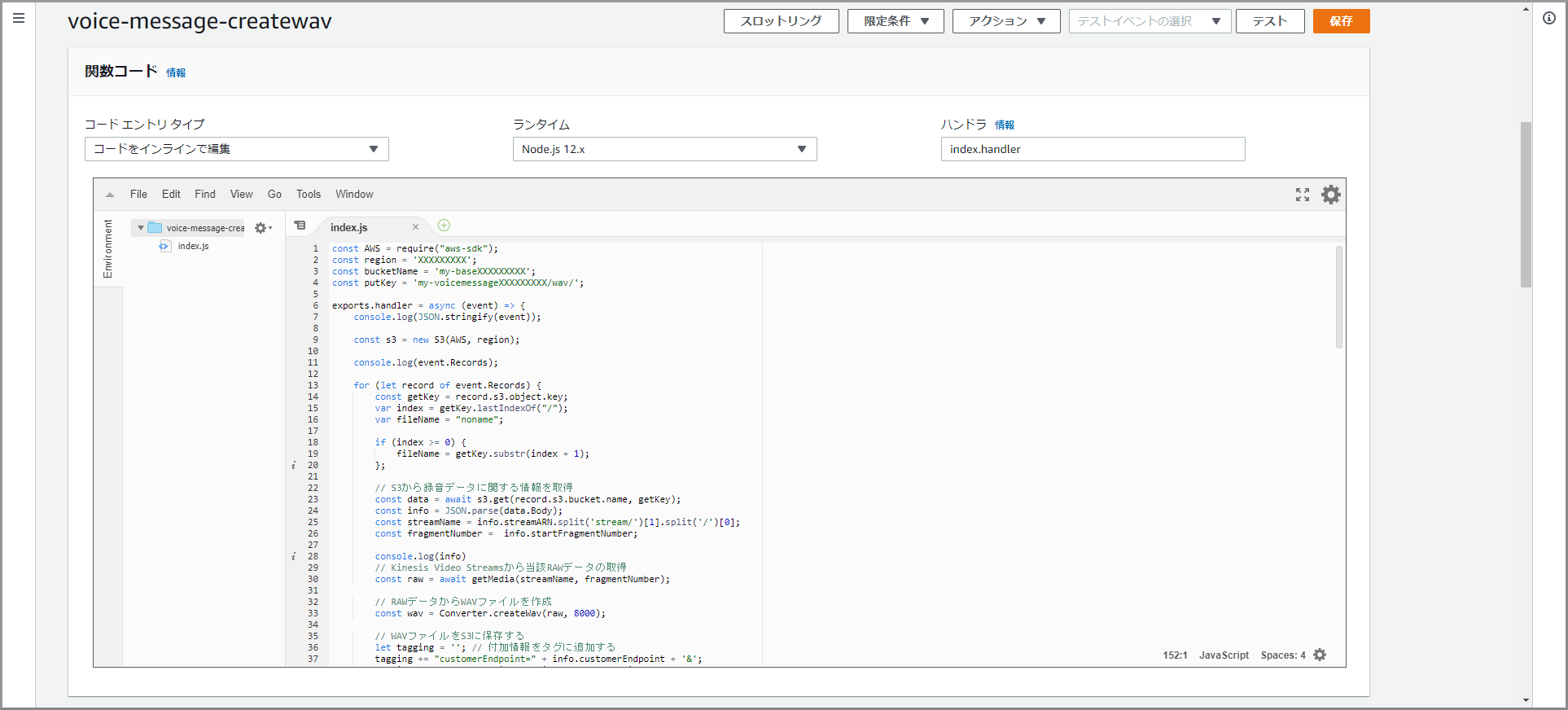
voice-message-createwavconst AWS = require("aws-sdk"); const region = 'XXXXXXXXX'; const bucketName = 'my-baseXXXXXXXXX'; const putKey = 'my-voicemessageXXXXXXXXX/wav/'; exports.handler = async (event) => { console.log(JSON.stringify(event)); const s3 = new S3(AWS, region); console.log(event.Records); for (let record of event.Records) { const getKey = record.s3.object.key; var index = getKey.lastIndexOf("/"); var fileName = "noname"; if (index >= 0) { fileName = getKey.substr(index + 1); }; // S3から録音データに関する情報を取得 const data = await s3.get(record.s3.bucket.name, getKey); const info = JSON.parse(data.Body); const streamName = info.streamARN.split('stream/')[1].split('/')[0]; const fragmentNumber = info.startFragmentNumber; console.log(info) // Kinesis Video Streamsから当該RAWデータの取得 const raw = await getMedia(streamName, fragmentNumber); // RAWデータからWAVファイルを作成 const wav = Converter.createWav(raw, 8000); // WAVファイルをS3に保存する let tagging = ''; // 付加情報をタグに追加する tagging += "customerEndpoint=" + info.customerEndpoint + '&'; tagging += "systemEndpoint=" + info.systemEndpoint + '&'; tagging += "startTimestamp=" + info.startTimestamp; await s3.put(bucketName, putKey + fileName + '.wav', Buffer.from(wav.buffer), tagging) } return {}; }; class S3 { constructor(AWS, region){ this._s3 = new AWS.S3({region:region}); } async get(bucketName, key){ const params = { Bucket: bucketName, Key: key }; return await this._s3.getObject(params).promise(); } async put(bucketName, key, body, tagging) { const params = { Bucket: bucketName, Key: key, Body: body, Tagging: tagging }; return await this._s3.putObject(params).promise(); } } const ebml = require('ebml'); async function getMedia(streamName, fragmentNumber) { // Endpointの取得 const kinesisvideo = new AWS.KinesisVideo({region: region}); var params = { APIName: "GET_MEDIA", StreamName: streamName }; const end = await kinesisvideo.getDataEndpoint(params).promise(); // RAWデータの取得 const kinesisvideomedia = new AWS.KinesisVideoMedia({endpoint: end.DataEndpoint, region:region}); var params = { StartSelector: { StartSelectorType: "FRAGMENT_NUMBER", AfterFragmentNumber:fragmentNumber, }, StreamName: streamName }; const data = await kinesisvideomedia.getMedia(params).promise(); const decoder = new ebml.Decoder(); let chunks = []; decoder.on('data', chunk => { if(chunk[1].name == 'SimpleBlock'){ chunks.push(chunk[1].data); } }); decoder.write(data["Payload"]); // chunksの結合 const margin = 4; // 各chunkの先頭4バイトを破棄する var sumLength = 0; chunks.forEach( chunk => { sumLength += chunk.byteLength - margin; }) var sample = new Uint8Array(sumLength); var pos = 0; chunks.forEach(chunk => { let tmp = new Uint8Array(chunk.byteLength - margin); for(var e = 0; e < chunk.byteLength - margin; e++){ tmp[e] = chunk[e + margin]; } sample.set(tmp, pos); pos += chunk.byteLength - margin; }) return sample.buffer; } class Converter { // WAVファイルの生成 static createWav(samples, sampleRate) { const len = samples.byteLength; const view = new DataView(new ArrayBuffer(44 + len)); this._writeString(view, 0, 'RIFF'); view.setUint32(4, 32 + len, true); this._writeString(view, 8, 'WAVE'); this._writeString(view, 12, 'fmt '); view.setUint32(16, 16, true); view.setUint16(20, 1, true); // リニアPCM view.setUint16(22, 1, true); // モノラル view.setUint32(24, sampleRate, true); view.setUint32(28, sampleRate * 2, true); view.setUint16(32, 2, true); view.setUint16(34, 16, true); this._writeString(view, 36, 'data'); view.setUint32(40, len, true); let offset = 44; const srcView = new DataView(samples); for (var i = 0; i < len; i+=4, offset+=4) { view.setInt32(offset, srcView.getUint32(i)); } return view; } static _writeString(view, offset, string) { for (var i = 0; i < string.length; i++) { view.setUint8(offset + i, string.charCodeAt(i)); } } }
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にLambdaと入力し、検索結果から《Lambda》をクリックし、Amazon Lambda コンソール(https://console.aws.amazon.com/lambda/)を開きます。
Lambdaの関数一覧画面が表示されるので《関数の作成》をクリックします。
「関数名」を入力して《関数の作成》をクリックします。
- voice-message-createwav
関数のベースが作成されました。関数コードを入力するため下にスクロールして「関数コード」を表示します。
「関数コード」に初期で登録されているコードを削除して、上記voice-message-createwavをコピー&ペーストします。
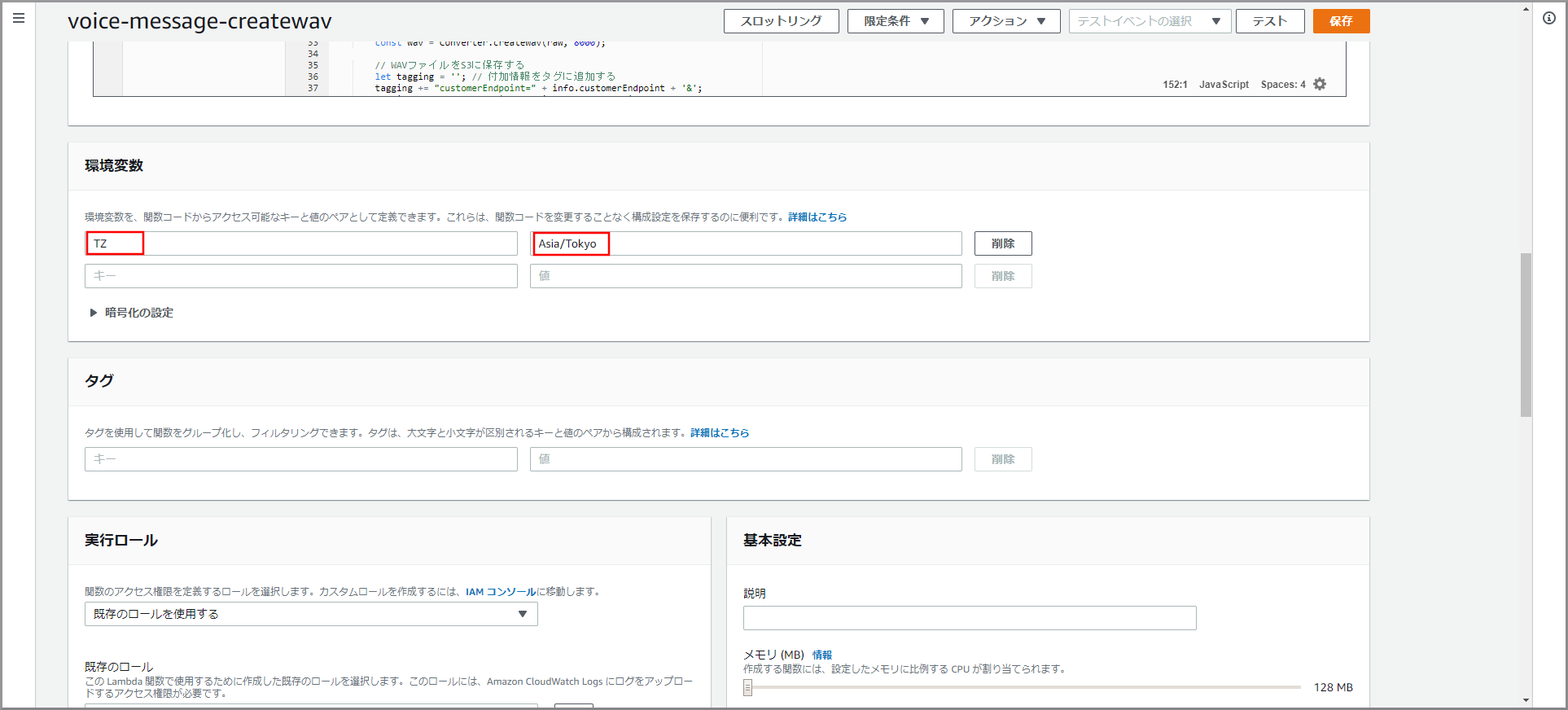
日本時間に対応させるため、画面を下にスクロールして「環境変数」に以下の値を入力し《保存》ボタンをクリックします。
- キー:TZ、値:Asia/Tokyo
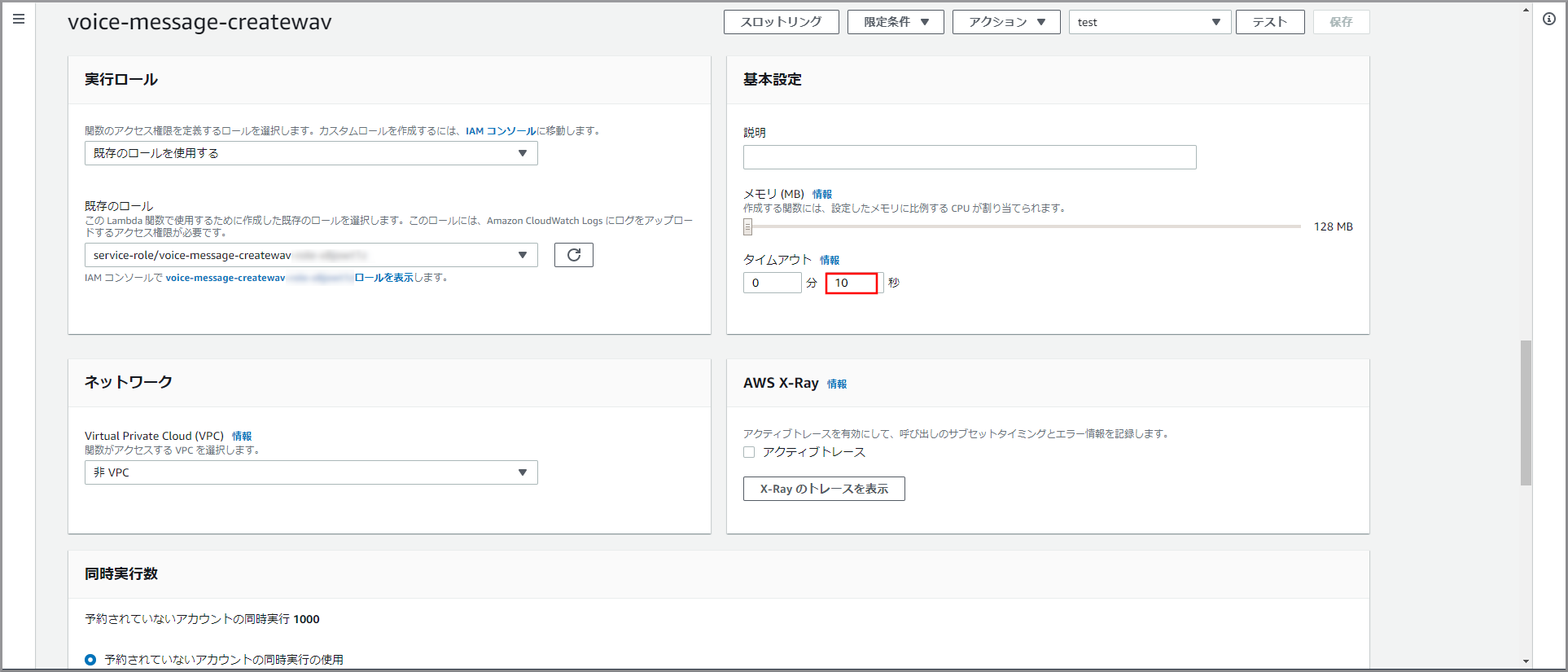
このLambdaは実行時間がかかるため、デフォルトの設定ではTimeOutエラー発生するためタイムアウトの設定を以下の内容に変更します。
- タイムアウト:10秒
Lambdaにサービスへのアクセス権を設定するため下にスクロールして「実行ロール」を表示し、《XXXXXXXXロールを表示》をクリックします。
- Lambdaを作成する毎に自動的にLambda名の付いたロールが一つ作成されます。
- Lambdaで利用しているAPIのアクセス権を付与します。
- kinesis Video Streamsデータ取得用情報(voice-message-infomationで作成したもの)をS3から取得するための権限
- GetObject
- kinesis Video Streamsからデータを読み込むための権限
- GetMedia
- GetDataEndpoint
- kinesis Video StreamsデータをWAV形式に変換したものをS3に保存するための権限
- PutObjectTagging
- PutObject
選択したロールの概要が表示されるのでポリシー名の「▶」をクリックします。
《ポリシーの編集》をクリックします。
ビジュアルエディタが表示されるので《さらにアクセス許可を追加する》をクリックします。
- Lambdaの実行ログを記録するため、デフォルトでCloudWatch Logsの権限が付与されます。
《サービスの選択》をクリックします。
「サービス」にS3と入力し、検索結果から《S3》をクリックします。
「アクション」に今回利用するGetObjectを入力し、《GetObject》をクリックし、選択状態にします。
《リソース》をクリックします。
《ARNの追加》をクリックします。
以下の項目を選択、入力して《追加》をクリックします。
- Bucket name:kinesis Video Streamsデータ取得用情報が保存されているS3のバケット名+フォルダ名(バケット名とフォルダ名やフォルダ名とフォルダ名の間は『/』で連結する)
- Bucket name:my-baseXXXXXXXXX/my-voicemessageXXXXXXX/infomation
- Object name:すべてにチェックを付ける(テキストボックスには*が入力される)
《ポリシーの確認》をクリックします。
内容を確認して、《変更の保存》をクリックします。
再度、ポリシー名の「▶」をクリックします。
《ポリシーの編集》をクリックします。
ビジュアルエディタが表示されるので《さらにアクセス許可を追加する》をクリックします。
《サービスの選択》をクリックします。
「サービス」にS3と入力し、検索結果から《S3》をクリックします。
「アクション」に今回利用するPutObjectを入力し、《PutObject》をクリックし、選択状態にします。
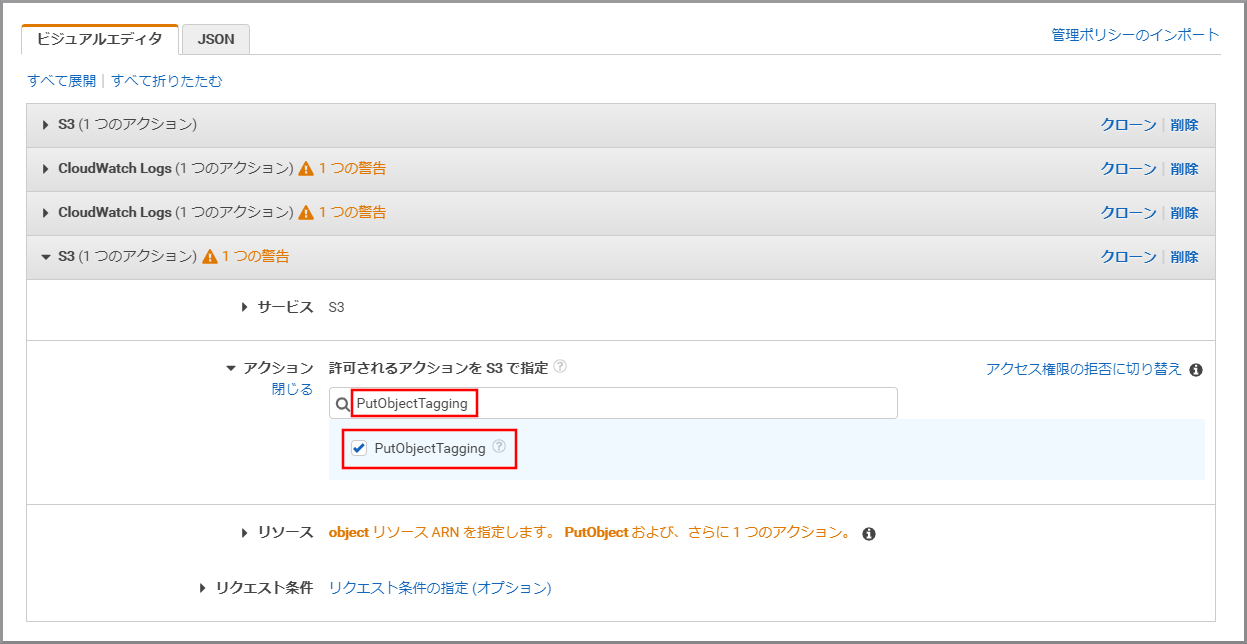
「アクション」に今回利用するPutObjectTaggingを上書き入力し、《PutObjectTagging》をクリックし、選択状態にします。
《リソース》をクリックします。
《ARNの追加》をクリックします。
以下の項目を選択、入力して《追加》をクリックします。
- Bucket name:kinesis Video StreamsデータをWAVに変換したデータを保存するS3のバケット名+フォルダ名(バケット名とフォルダ名やフォルダ名とフォルダ名の間は『/』で連結する)
- Bucket name:my-baseXXXXXXXXX/my-voicemessageXXXXXXX/wav
- Object name:すべてにチェックを付ける(テキストボックスには*が入力される)
《ポリシーの確認》をクリックします。
内容を確認して、《変更の保存》をクリックします。
再度、ポリシー名の「▶」をクリックします。
《ポリシーの編集》をクリックします。
ビジュアルエディタが表示されるので《さらにアクセス許可を追加する》をクリックします。
《サービスの選択》をクリックします。
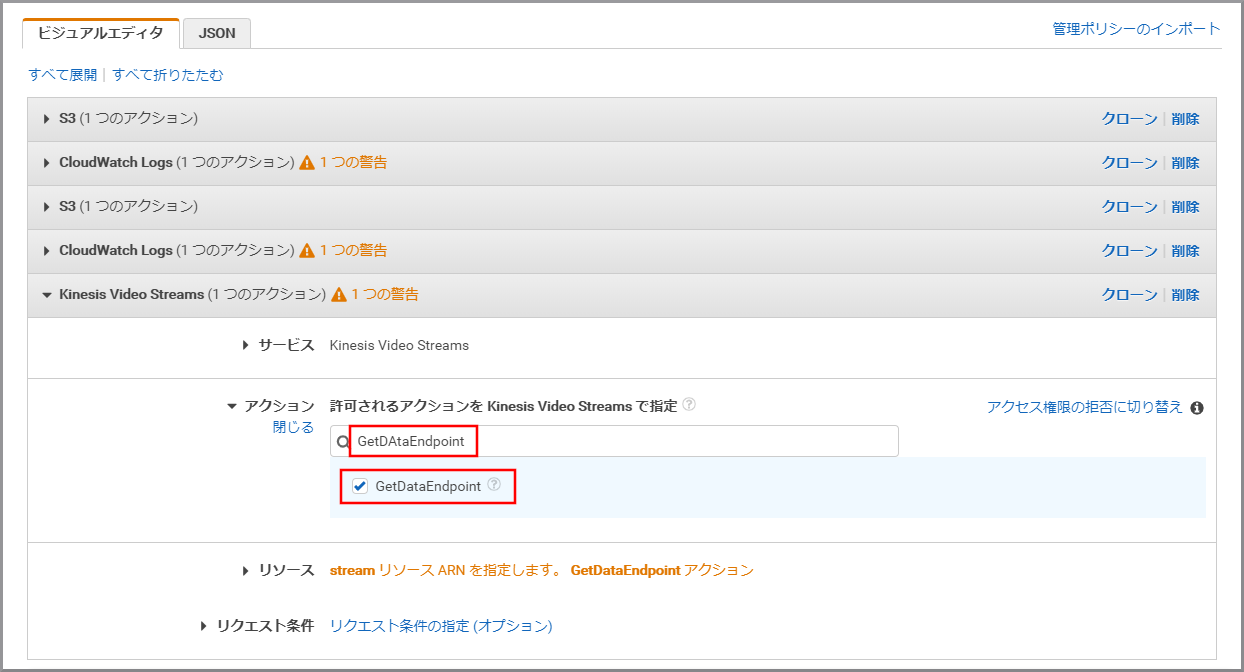
「サービス」にKinesis Video Streamsと入力し、検索結果から《Kinesis Video Streams》をクリックします。
「アクション」に今回利用するGetDAtaEndpointを入力し、《GetDAtaEndpoint》をクリックし、選択状態にします。
「アクション」に今回利用するGetMediaを上書き入力し、《GetMedia》をクリックし、選択状態にします。
《リソース》をクリックします。
《ARNの追加》をクリックします。
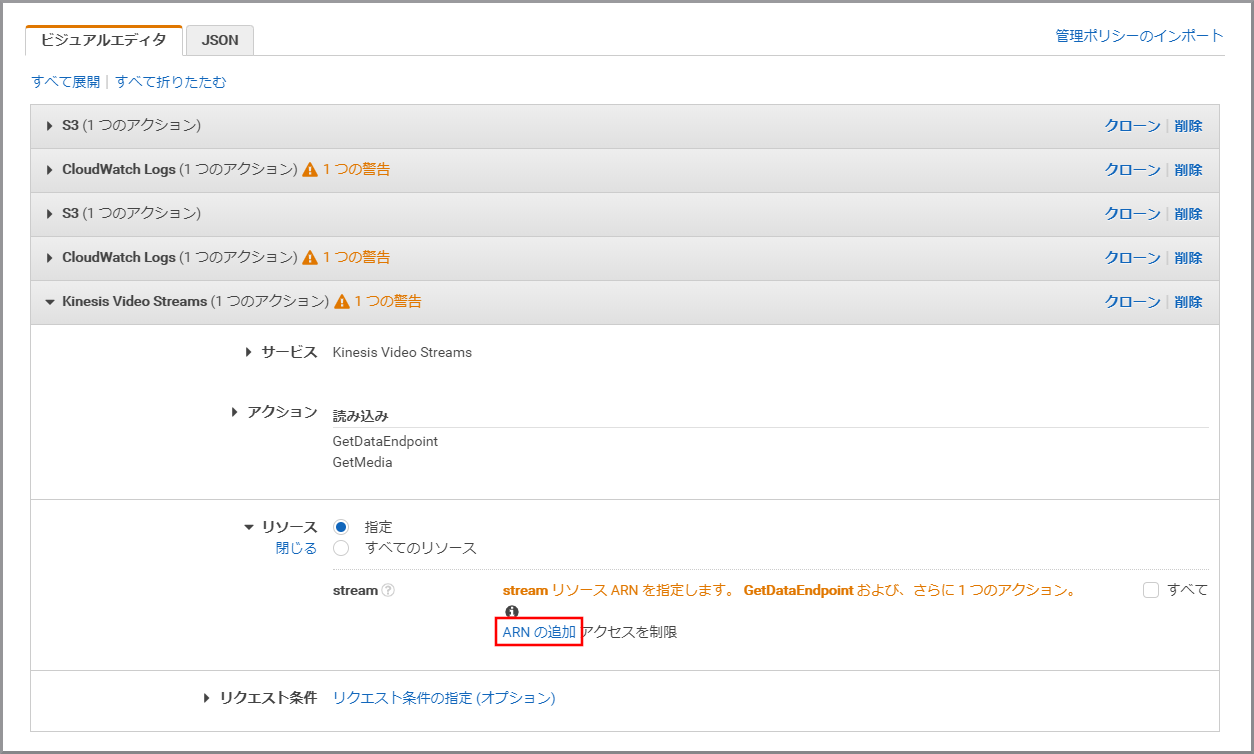
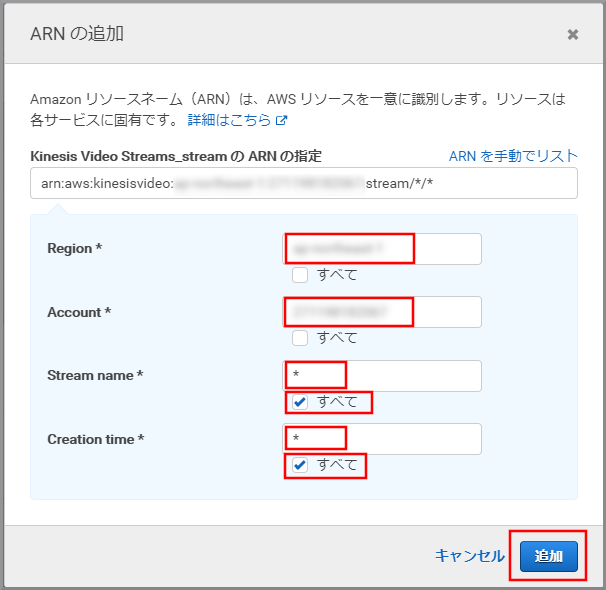
以下の項目を選択、入力して《追加》をクリックします。
- Reagion:kinesis Video Streamsを作成したリージョン名
- Reagion : aap-northeast-1(Kinesis Video Streamsを作成したリージョン)
- Account:自分のアカウント名(デフォルトで入力される)
- Stream name:すべて
- Creation time:すべて
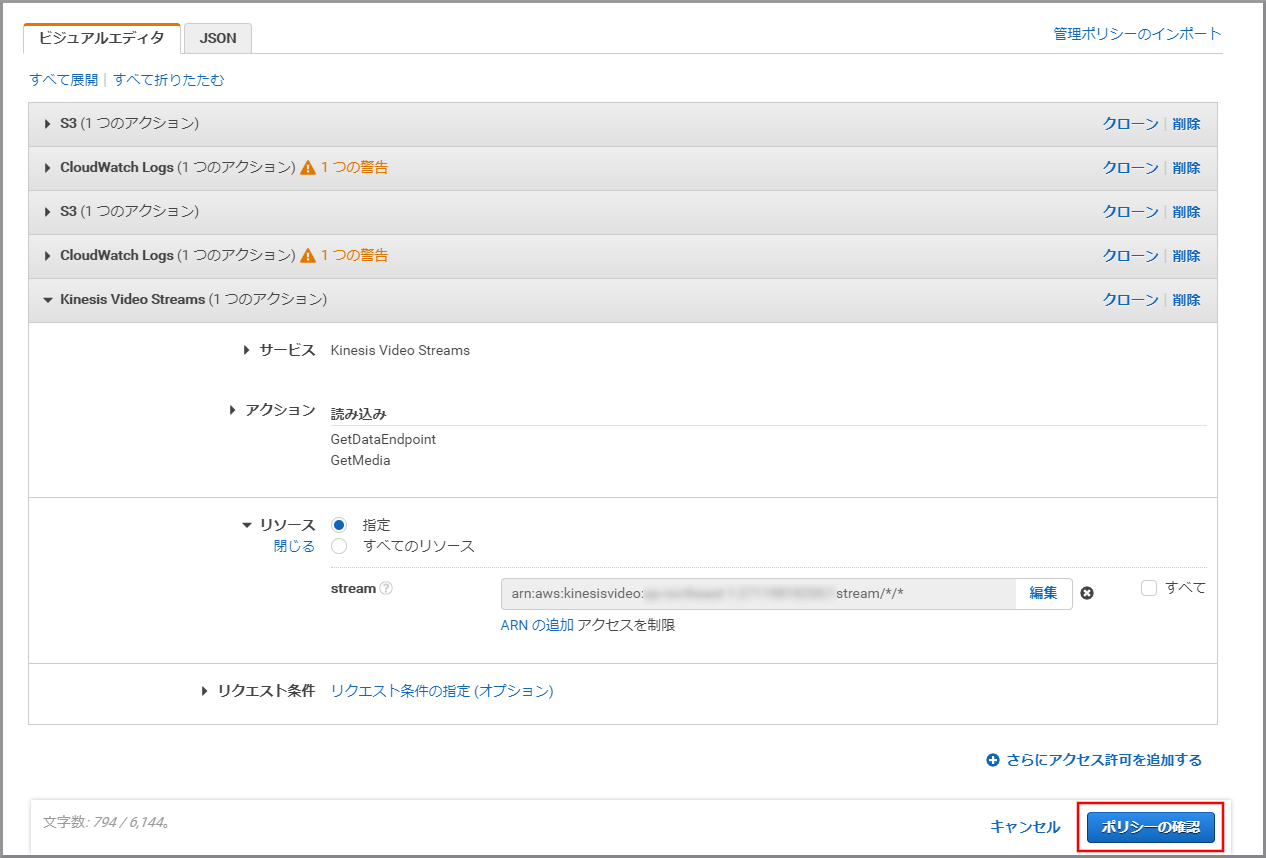
《ポリシーの確認》をクリックします。
内容を確認して、《変更の保存》をクリックします。
Lambdaでebmlを利用するため上にスクロールして《Layers》をクリックします。
《レイヤーの追加》をクリックします。
以下の項目を選択して《追加》をクリックします。
- 名前:ebml
- バージョン:先ほど作成したebmlで利用するバージョン番号
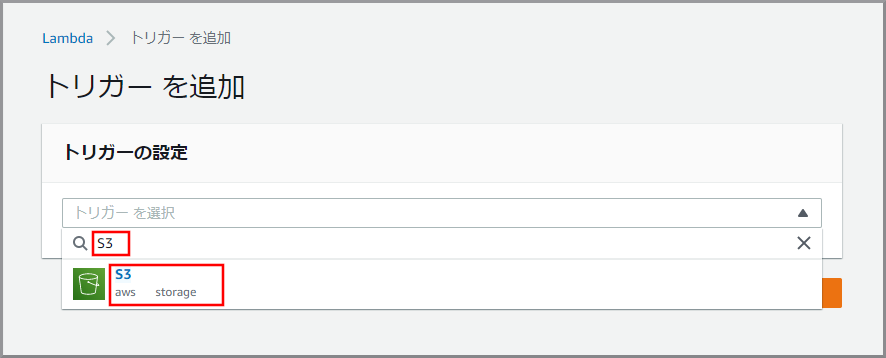
kinesis Video Streamsデータ取得用情報がS3に作成された場合に動かしたいので《トリガーを追加》をクリックします。
「トリガー」にS3と入力し、検索結果から《S3》をクリックします。
以下の項目を選択して《追加》をクリックします。
- バケット:kinesis Video Streamsデータ取得用情報を作成したバケット
- イベントタイプ:PUT
- プレフィックス:kinesis Video Streamsデータ取得用情報を作成したフォルダ
《保存》をクリックします。
参考サイト
- [Amazon Connect]営業時間外に着信したビジネスチャンスを失わないように留守番電話機能をつけてみた
- AWS Lambda Layersでnode_modulesを使う
- Kinesis ビデオストリーム API およびプロデューサーライブラリのサポート
- Kinesis ビデオストリーム データにアクセスする方法
- GitHub amazon-connect/amazon-connect-realtime-transcription
- サンプリング周波数とビットレート
- 音ファイル(拡張子:WAVファイル)のデータ構造について
- Windows 10へNode.jsをインストールする
目次に戻る





















- 投稿日:2020-01-24T12:33:26+09:00
【クラウド初心者向け】留守番電話2(Amazon Connect問い合わせフローに留守番電話機能を追加)
概要
- Amazon Connectには留守番電話機能は無いため個別に作成する。
- 基本の考え方等は『[Amazon Connect]営業時間外に着信したビジネスチャンスを失わないように留守番電話機能をつけてみた』をもとにしています。
- ここまで作成すると、kinesis Video Streamsデータ取得用情報がS3に作成されkinesis Video Streamsに留守番電話で受け付けた音声が録音されますが、まだ音声の再生はできません。
使用ユーザー
- IAMユーザー
手順
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にConnectと入力し、検索結果から《Amazon Connect》をクリックし、Amazon Connect コンソール(https://console.aws.amazon.com/connect/)を開きます。
Amazon Connectのインスタンス一覧が表示されるので、該当のインスタンスをクリックします。
インスタンスの概要が表示されるので左側のメニューから《問い合わせフロー》をクリックします。
画面を下にスクロールして「AWS Lambda」の《関数》をクリックし、先ほど作成したLambdaをクリックします。
《+Lambda関数の追加》をクリックします。
Lambda関数の一覧に登録されました。これで、Amazon Connectから操作できるようになりました。
インスタンスの概要に戻って、左側のメニューから《データストレージ》をクリックします。
「ライブメディアストリーミング」の《編集》をクリックします。
「ライブメディアストリーミング」設定項目が表示されるので、以下の項目を入力して《保存》をクリックします。
- ライブメディアストリーミングの有効化:選択する
- プレフィックス:プレフィックスの名前
- 名前でKMSキーを選択:選択する
- KMSマスターキー:aws/kinesisvideo
- データ保持期間:適宜必要な保持期限を設定する
インスタンスの概要に戻って《管理者としてログイン》をクリックします。
左側のメニューから《問い合わせフロー》をクリックします。
営業時間の判断で作成した問い合わせフローをクリックします。
《プロンプトの再生》から出ている矢印にカーソルを合わせて『×』ボタンをクリックして矢印を消し、タイトル部分をクリックします。
右側に「プロンプトの再生」画面が表示されるので、以下の項目を入力して《Save》をクリックします。
- テキストの入力:選択し、音声案内する文言を入力します。
左側メニューの「操作」から《プロンプトの再生》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続後に《プロンプトの再生》のタイトル部分をクリックします。
右側に「プロンプトの再生」画面が表示されるので、以下の項目を選択、入力して《Save》をクリックします。
- プロンプトライブラリ(音声)より選択します。:選択します。
- プロンプトの選択:選択します。
- オーディオプロンプト:Beep.wav
左側メニューの「操作」から《メディアストリーミングの開始》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続後に《メディアストリーミングの開始》のタイトル部分をクリックします。
右側に「メディアストリーミングの開始」画面が表示されるので、以下の項目を選択して《Save》をクリックします。
- 顧客へ:選択しない(留守番電話なのでこちらの声は保存しないため)
左側メニューの「統合」から《Lambda関数を呼び出す》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続後に《Lambda関数を呼び出す》のタイトル部分をクリックします。
右側に「Lambda関数を呼び出す」画面が表示されるので、以下の項目を選択、入力して《Save》をクリックします。
- 関数を選択する:先ほど作成したLambda関数を指定
- タイムアウト:8秒
左側メニューの「操作」から《プロンプトの再生》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続後に《プロンプトの再生》のタイトル部分をクリックします。
右側に「プロンプトの再生」画面が表示されるので、以下の項目を選択、入力して《Save》をクリックします。
- テキスト読み上げまたはチャットテキスト:選択します。
- テキストの入力:選択します。
- テキスト:
<speak> <break time="10s"/> メッセージをお預かりいたしました。</speak>- 解釈する:SSML
左側メニューの「操作」から《メディアストリーミングの停止》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続します。
左側メニューの「操作」から《切断/ハングアップ》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続します。
右上の《公開》をクリックします。
《公開》をクリックします。
参考サイト
目次に戻る
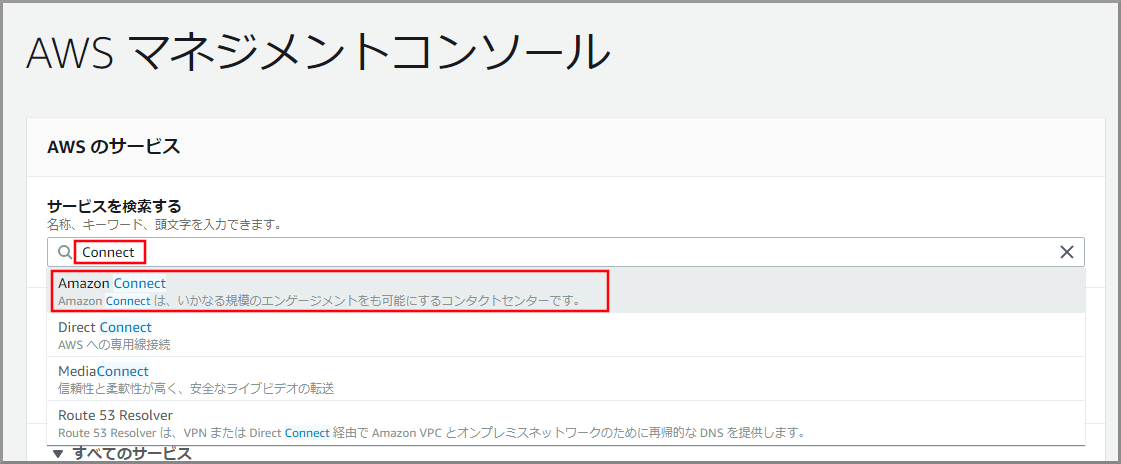
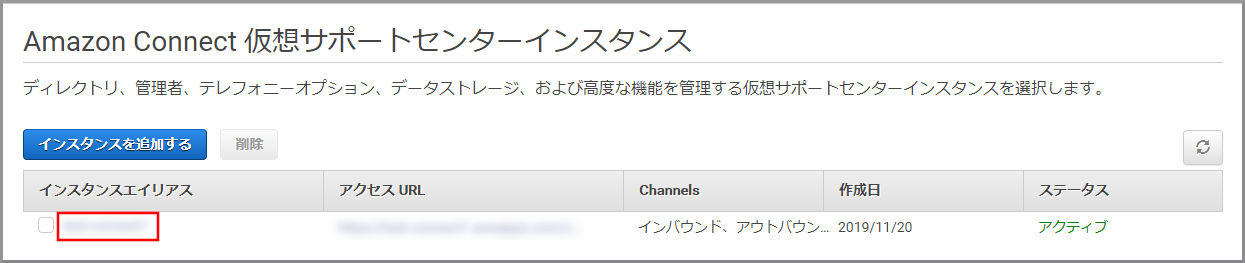
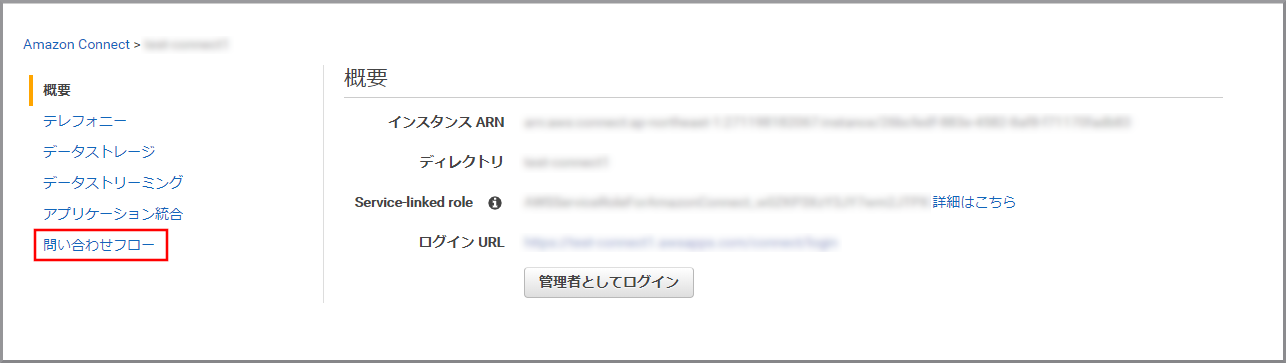
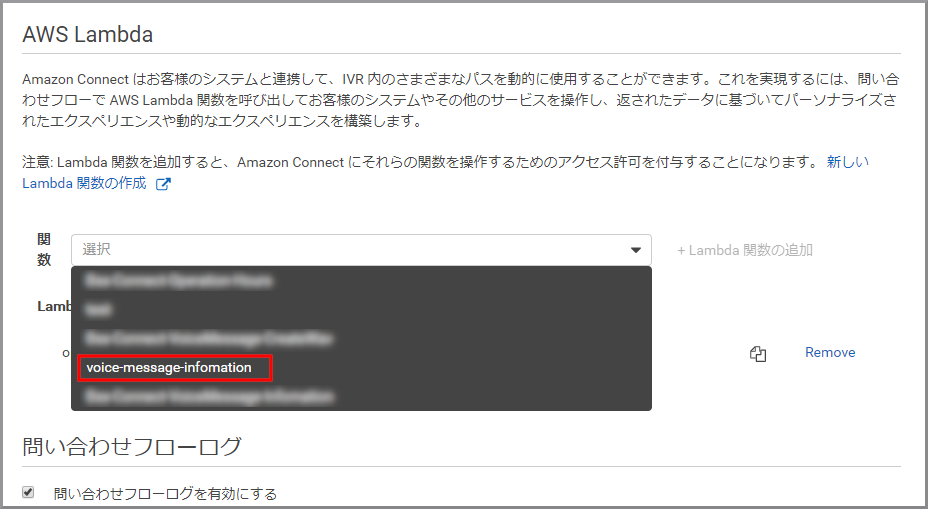

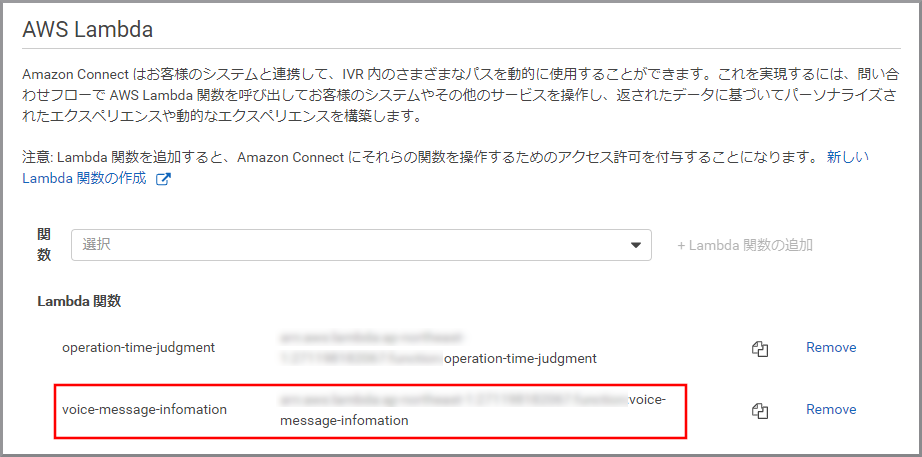

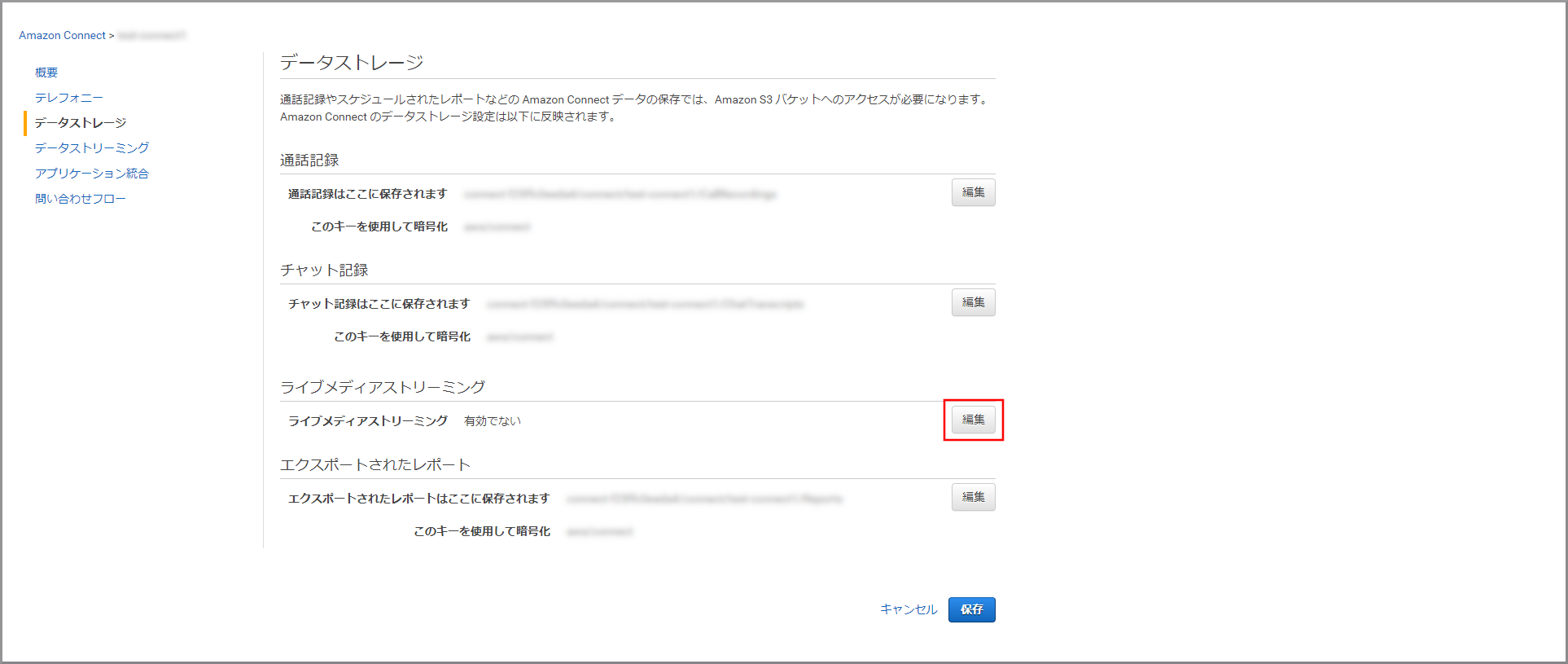
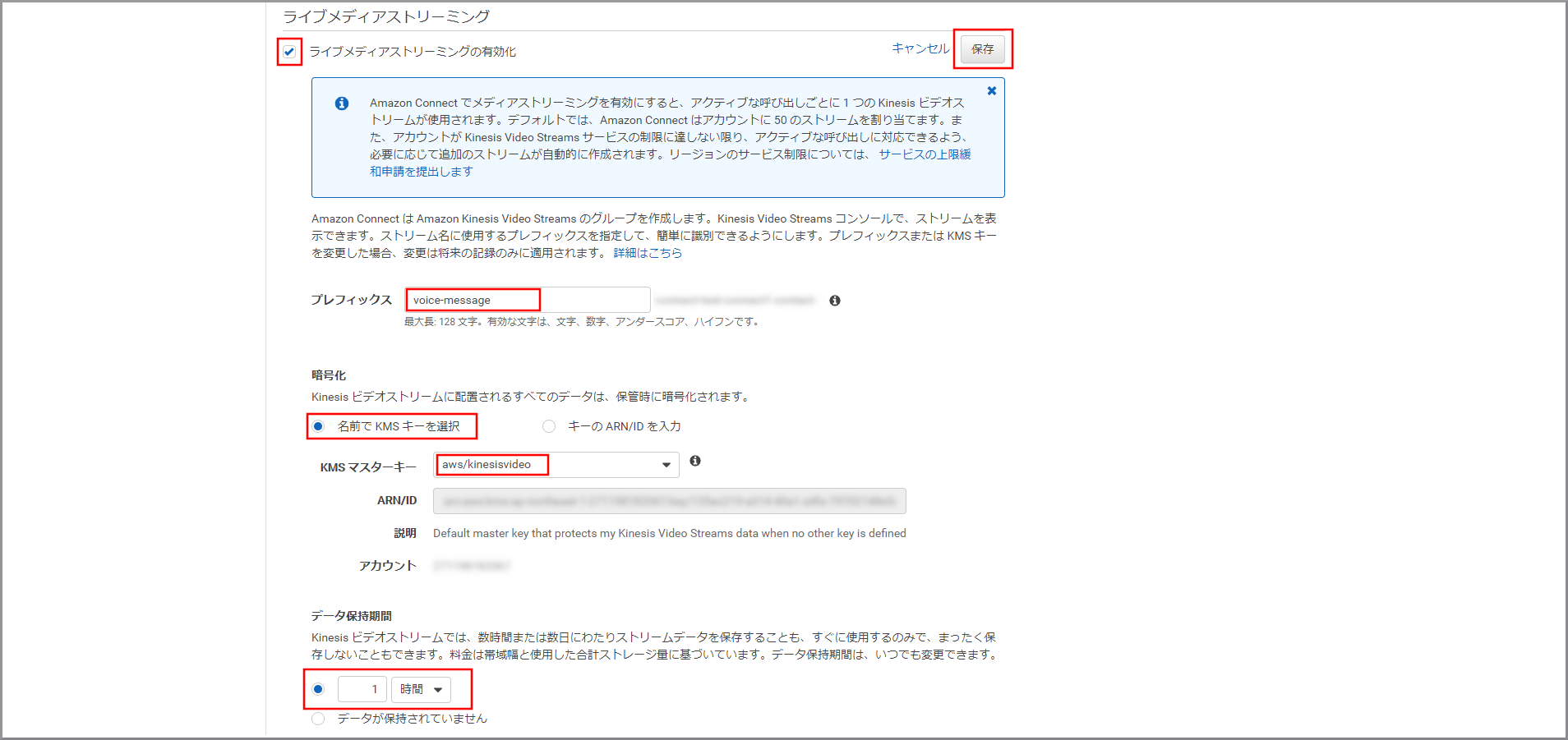
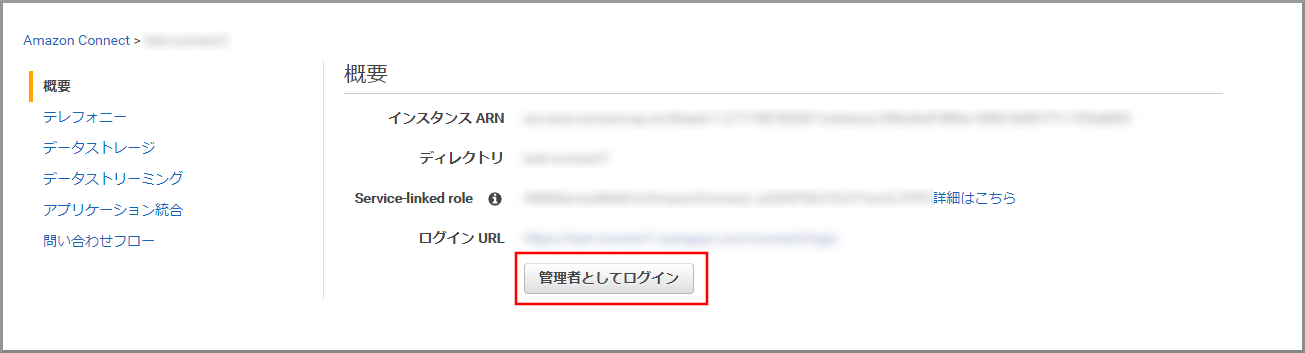
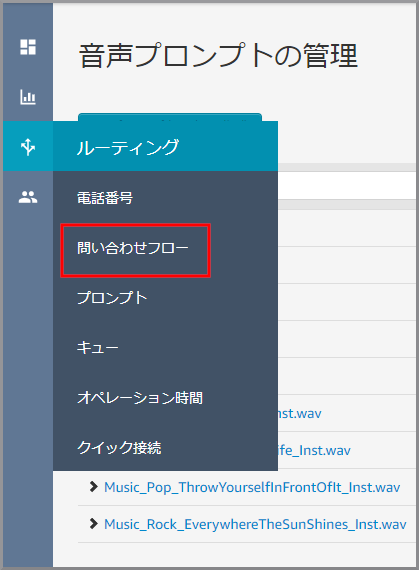
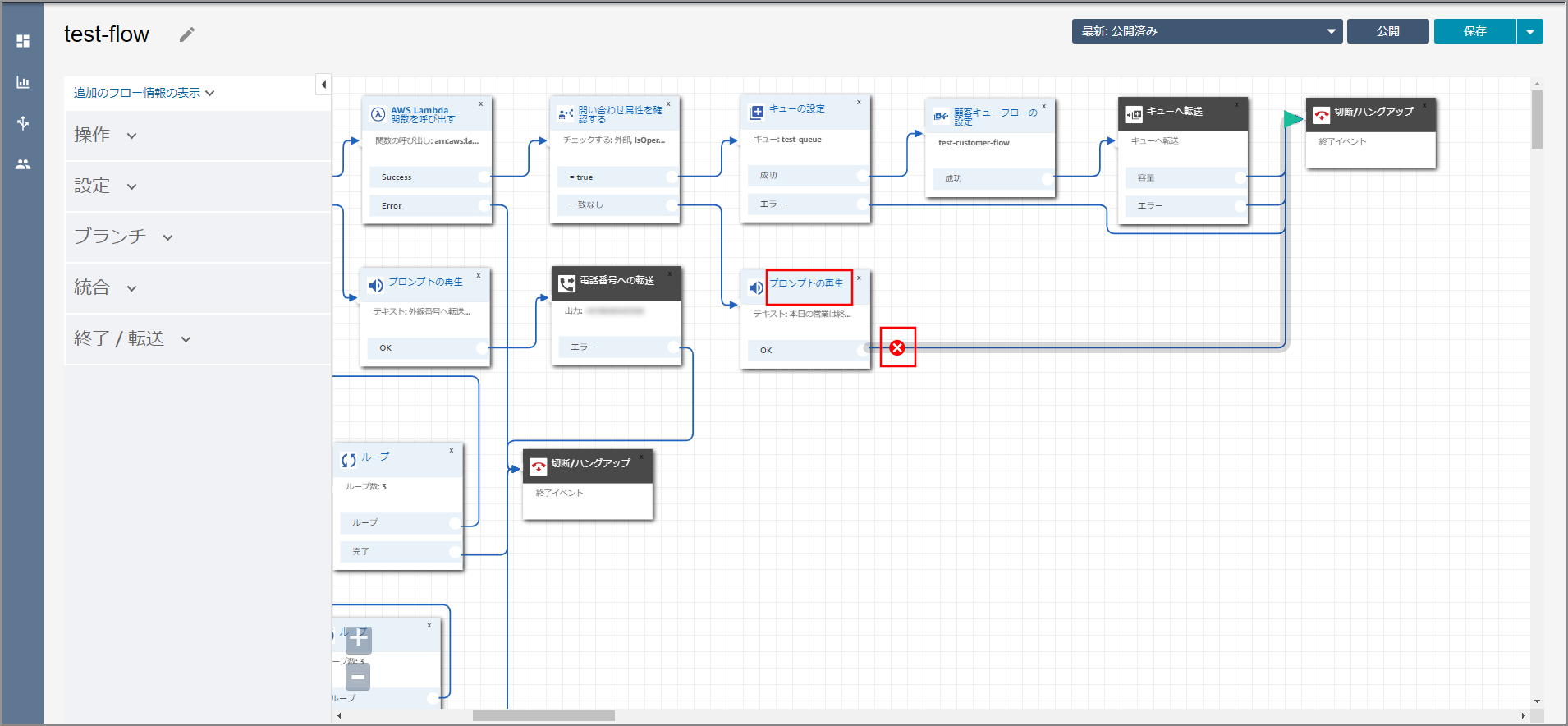


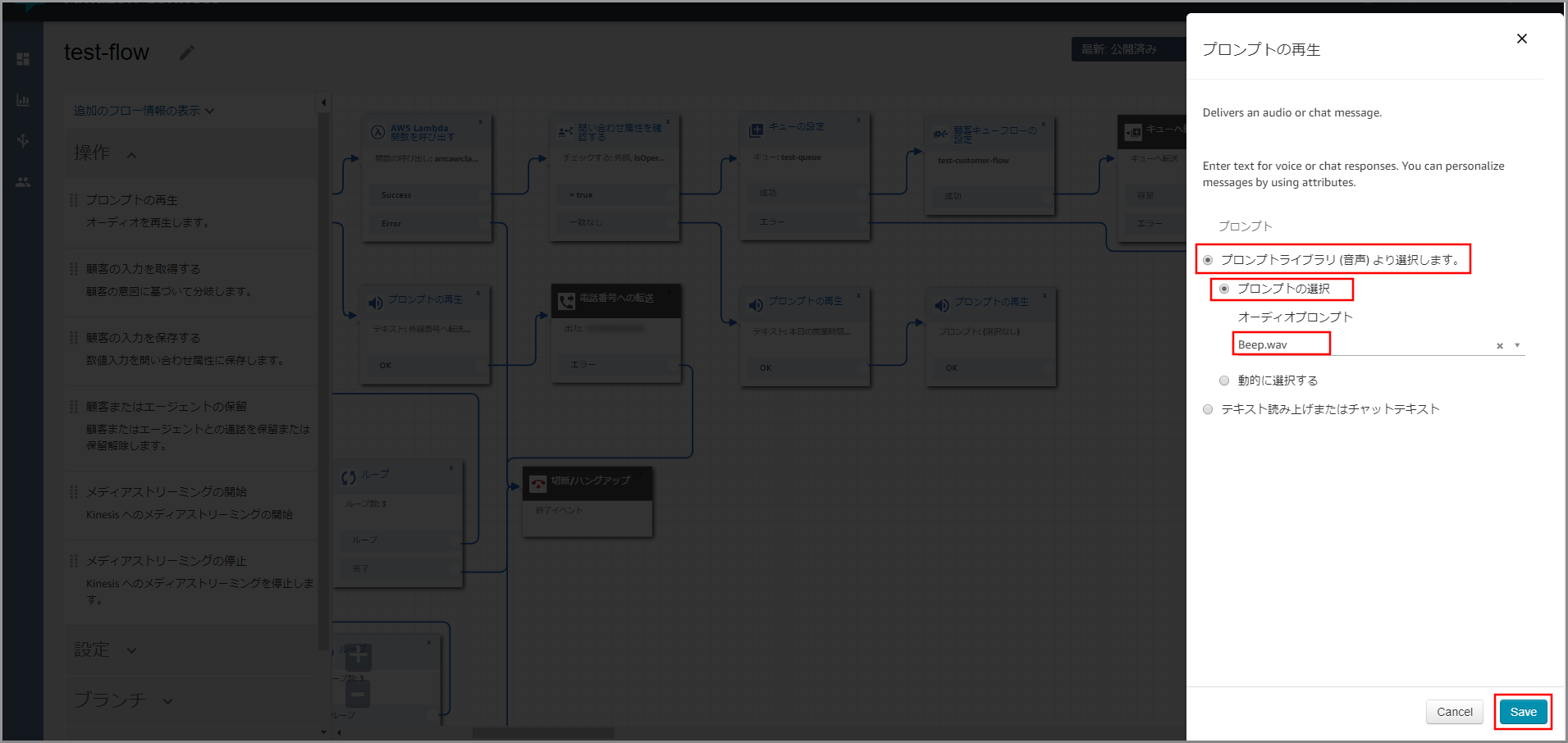
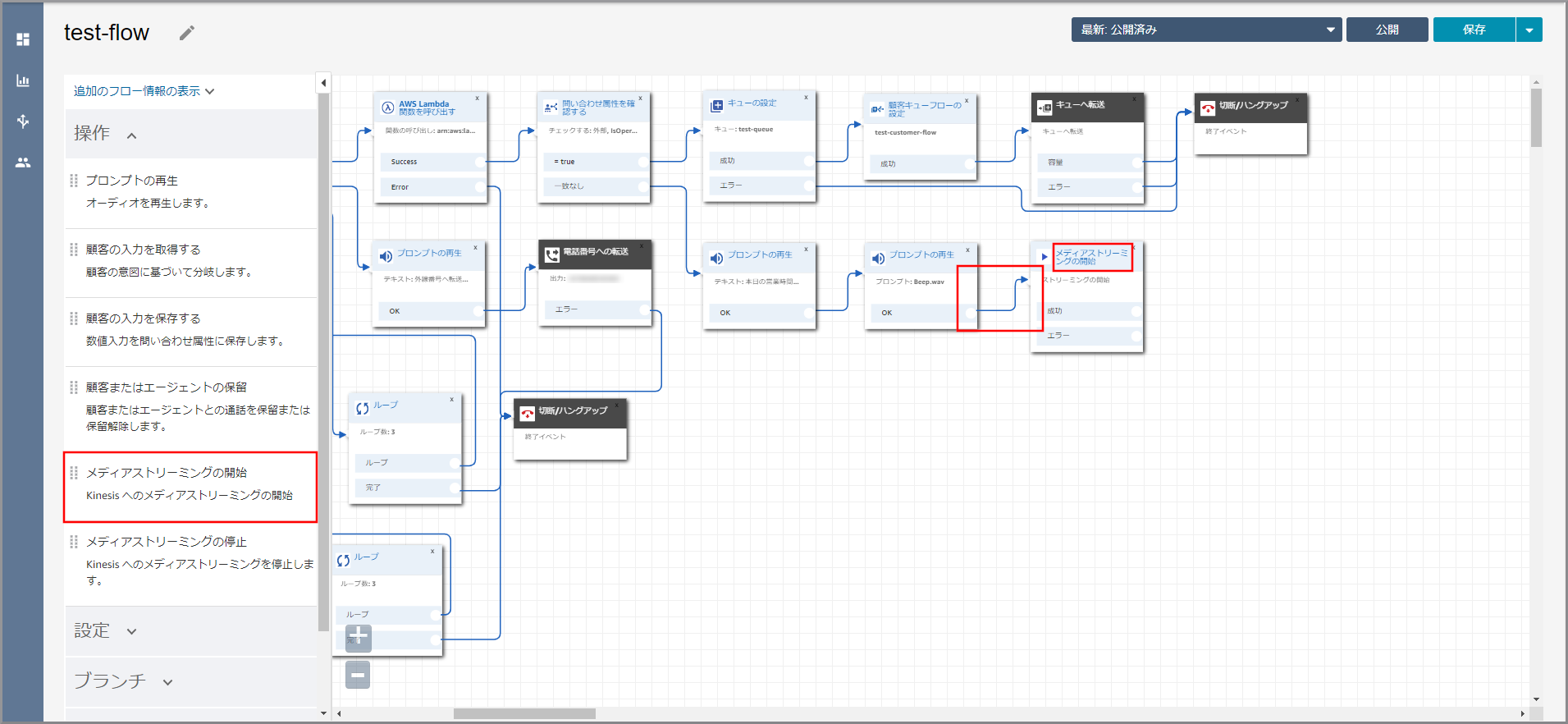
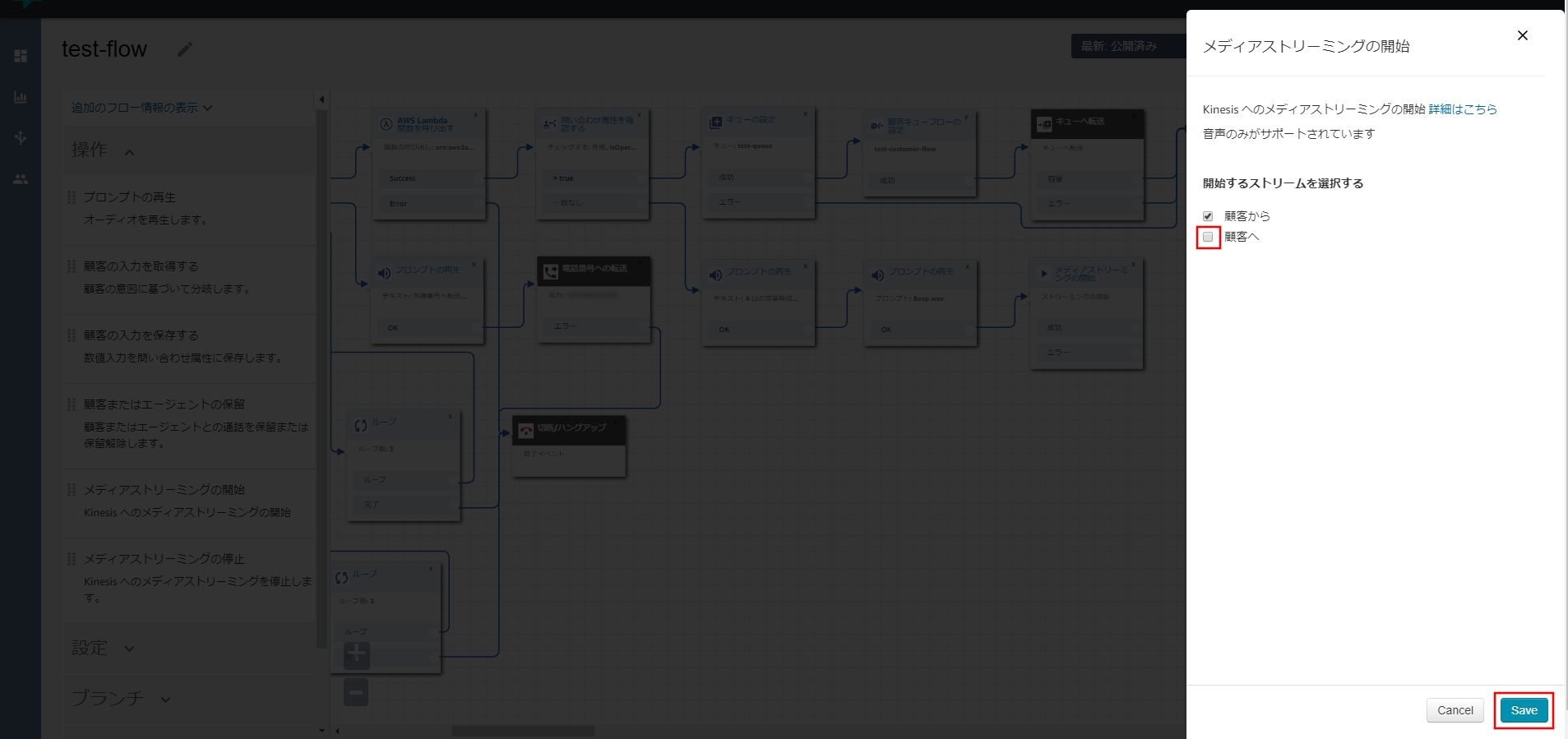
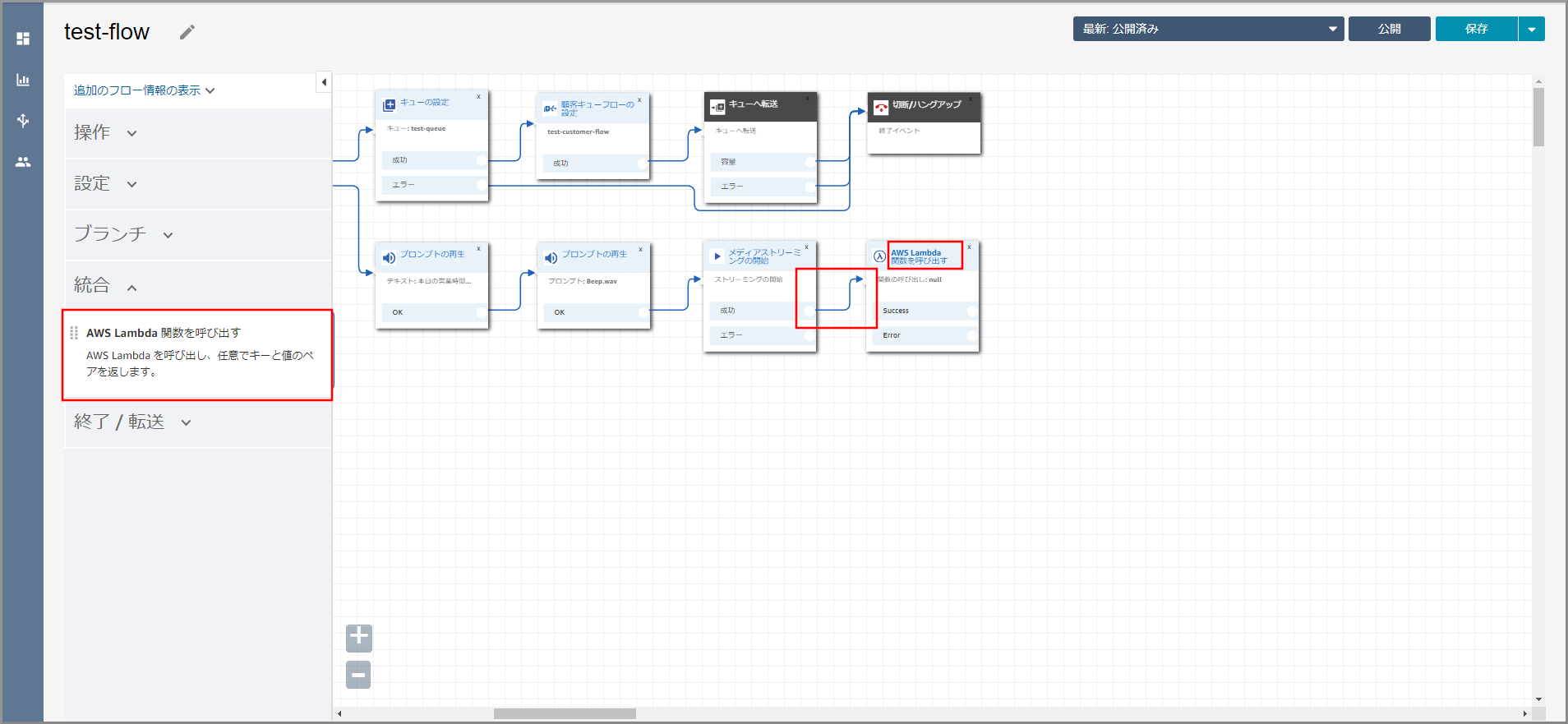
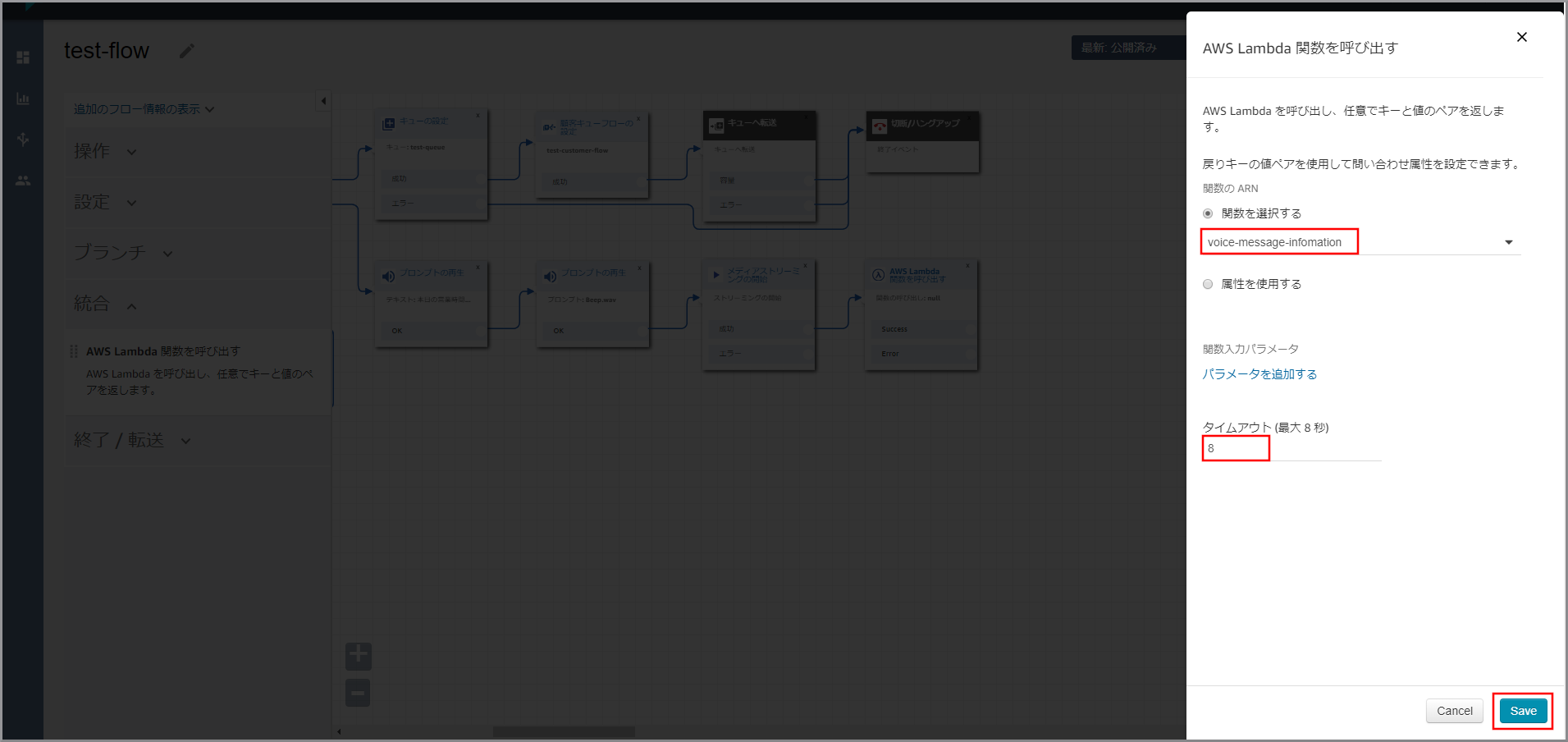
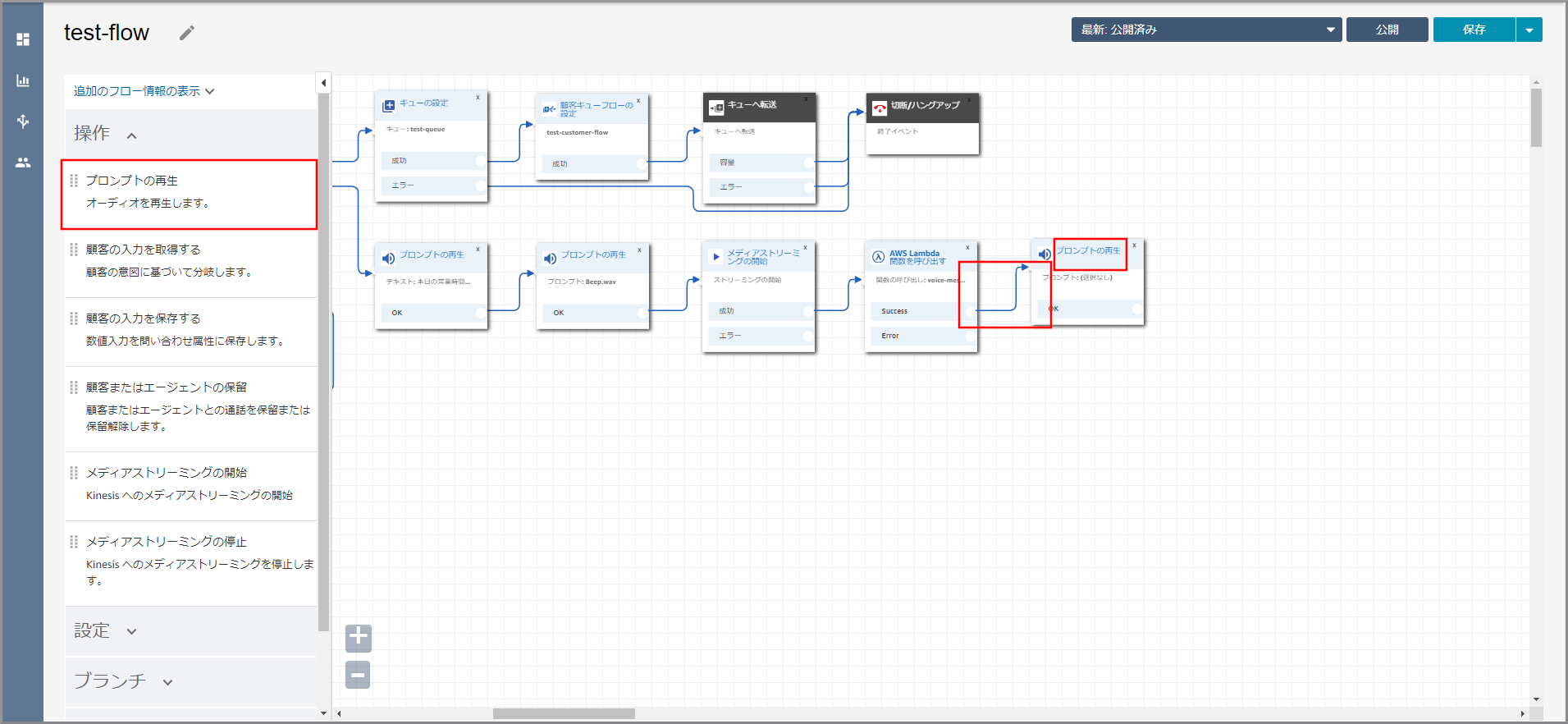

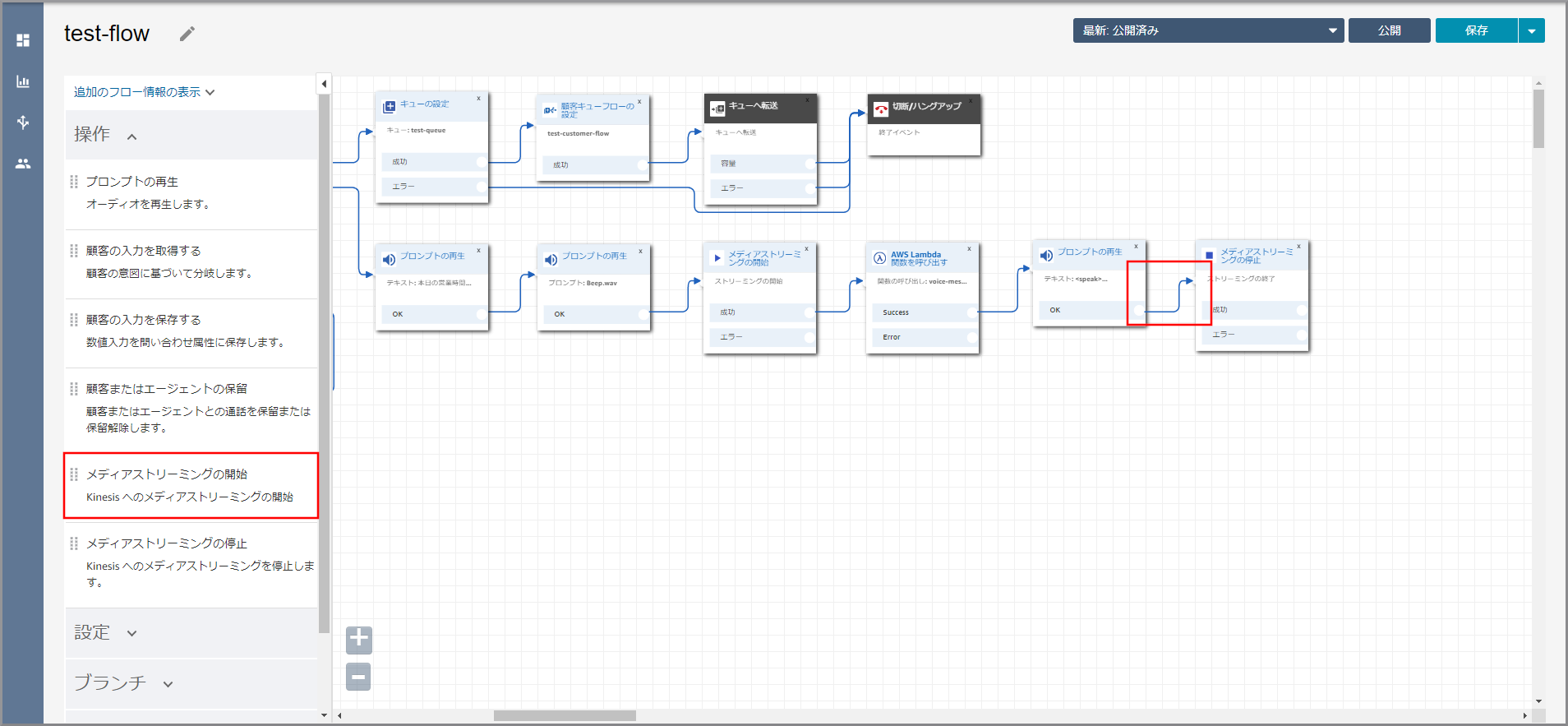
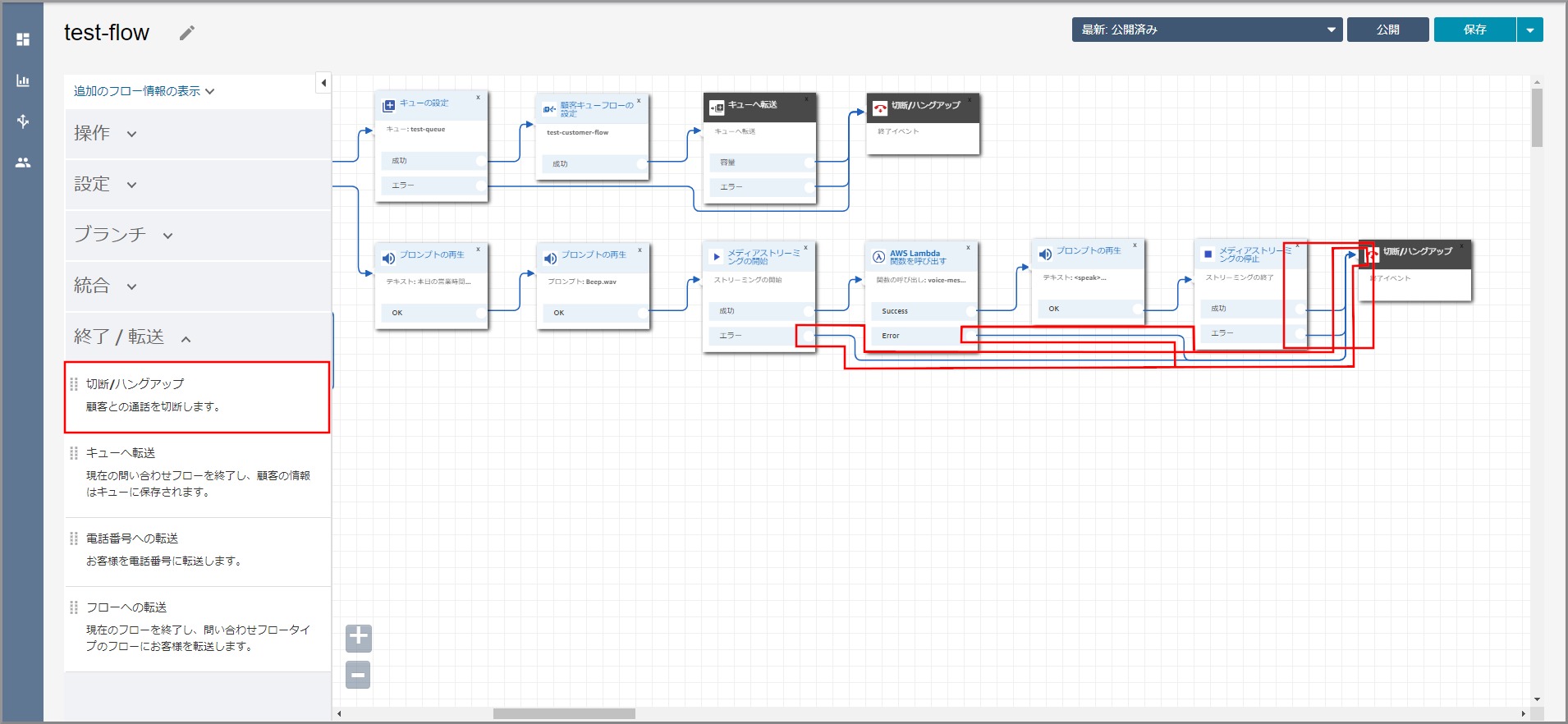
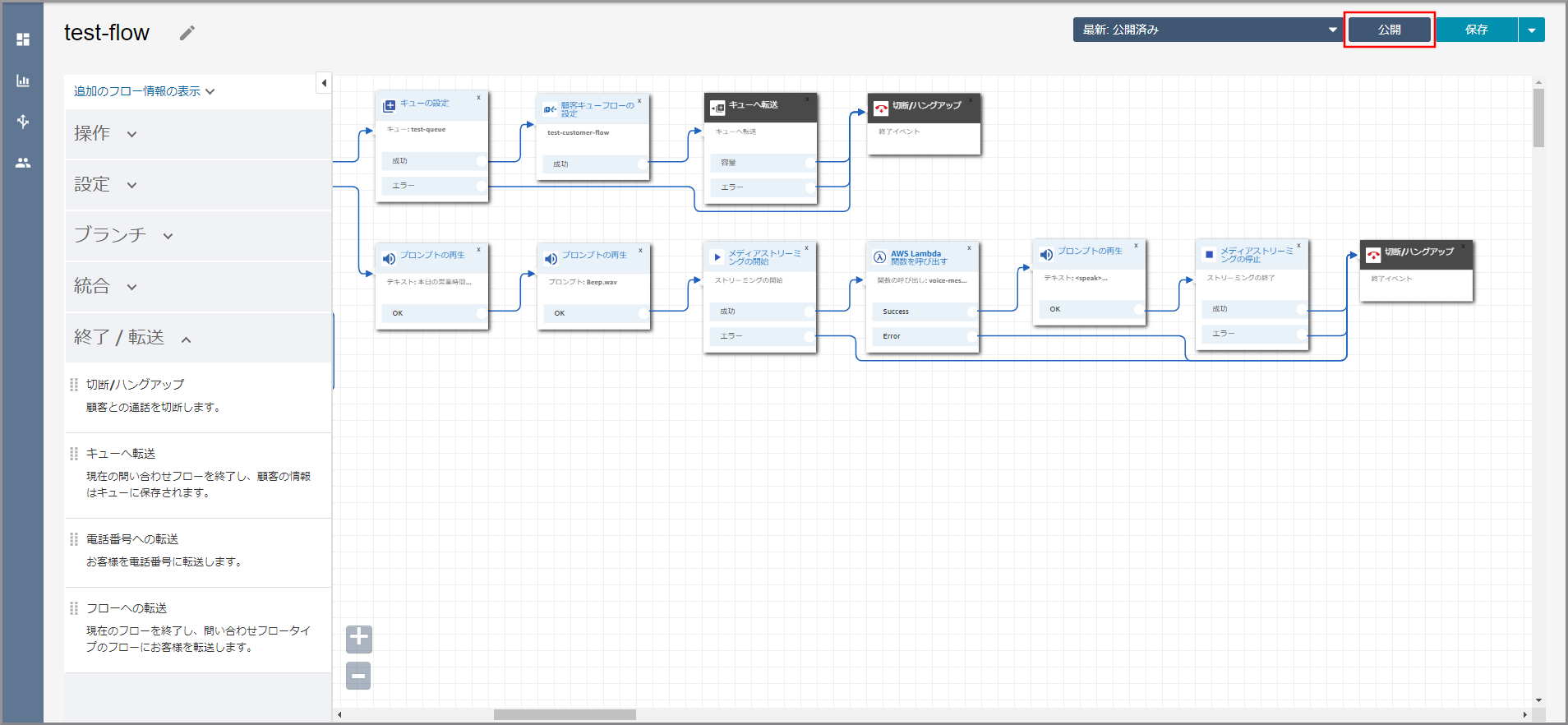

- 投稿日:2020-01-24T12:33:19+09:00
【クラウド初心者向け】留守番電話1(kinesis Video Streamsデータ取得用情報の作成環境の準備)
概要
- Amazon Connectには留守番電話機能は無いため個別に作成する。
- 基本の考え方等は『[Amazon Connect]営業時間外に着信したビジネスチャンスを失わないように留守番電話機能をつけてみた』をもとにしています。
使用ユーザー
- IAMユーザー
手順
kinesis Video Streamsデータ取得用情報を保存するS3の作成
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にS3と入力し、検索結果から《S3》をクリックし、Amazon S3 コンソール(https://console.aws.amazon.com/s3/)を開きます。
S3のバケット一覧が表示されるので、営業時間の判断で作成したバケットをクリックします。
《フォルダの作成》をクリックします。
以下の項目を選択、入力して《保存》をクリックします。
- フォルダ名:フォルダの名前
- 暗号化:適宜必要な暗号化設定を選択
作成したフォルダをクリックします。
《フォルダの作成》をクリックします。
以下の項目を選択、入力して《保存》をクリックします。
- フォルダ名:フォルダの名前
- 暗号化:適宜必要な暗号化設定を選択
kinesis Video Streamsデータ取得用情報を作成するLambdaの作成
- 以下のコードで各自で変える部分
- region変数:バケットを作成したリージョン名
- bucketName変数:作成したバケット名
- key変数:作成したフォルダ名(終わりに『/』を入れる)
voice-message-infomationconst AWS = require("aws-sdk"); const region = 'XXXXXXXXX'; const bucketName = 'my-baseXXXXXXXXX'; const key = 'my-voicemessageXXXXXXXXX/infomation/'; exports.handler = async (event) => { console.log(JSON.stringify(event)); // リクエストから必要データを取得する let streamInformation = {}; const contactData = event.Details.ContactData; streamInformation.contactId = contactData.ContactId; // コンタクトID streamInformation.customerEndpoint = contactData.CustomerEndpoint.Address; // 発信者番号 streamInformation.systemEndpoint = contactData.SystemEndpoint.Address; // 着信番号 const audio = contactData.MediaStreams.Customer.Audio; streamInformation.startFragmentNumber = audio.StartFragmentNumber; // 録音データの開始フラグメント番号 streamInformation.startTimestamp = audio.StartTimestamp; // 録音データの開始時間 streamInformation.stopFragmentNumber = audio.StopFragmentNumber;// 録音データの終了フラグメント番号 streamInformation.stopTimestamp = audio.StopTimestamp;// 録音データの終了時間 streamInformation.streamARN = audio.StreamARN; // ストリームのARN // S3に日付文字列をキーとして保存する const s3 = new AWS.S3({region:region}); const createKey = key + createKeyName(); const body = JSON.stringify(streamInformation); const params = { Bucket: bucketName, Key: createKey, Body: body }; await s3.putObject(params).promise(); return {}; }; function createKeyName() { const date = new Date(); const year = date.getFullYear(); const mon = (date.getMonth() + 1); const day = date.getDate(); const hour = date.getHours(); const min = date.getMinutes(); const sec = date.getSeconds(); const space = (n) => { console.log(n); return ('0' + (n)).slice(-2); }; let result = year + '_'; result += space(mon) + '_'; result += space(day) + '_'; result += space(hour) + '_'; result += space(min) + '_'; result += space(sec); return result; };
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にLambdaと入力し、検索結果から《Lambda》をクリックし、Amazon Lambda コンソール(https://console.aws.amazon.com/lambda/)を開きます。
Lambdaの関数一覧画面が表示されるので《関数の作成》をクリックします。
「関数名」を入力して《関数の作成》をクリックします。
- 関数名:voice-message-infomation
関数のベースが作成されました。関数コードを入力するため下にスクロールして「関数コード」を表示します。
「関数コード」に初期で登録されているコードを削除して、上記voice-message-infomationをコピー&ペーストします。
日本時間に対応させるため、画面を下にスクロールして「環境変数」に以下の値を入力し《保存》ボタンをクリックします。
- キー:TZ、値:Asia/Tokyo
LambdaにS3へのアクセス権を設定するため下にスクロールして「実行ロール」を表示し、《XXXXXXXXロールを表示》をクリックします。
- Lambdaを作成する毎に自動的にLambda名の付いたロールが一つ作成されます。
- Lambdaで利用しているAPIのアクセス権を付与します。
- 今回は、kinesis Video Streamsデータ取得用情報をS3に保存するための権限を付与します。
選択したロールの概要が表示されるのでポリシー名の「▶」をクリックします。
《ポリシーの編集》をクリックします。
ビジュアルエディタが表示されるので《さらにアクセス許可を追加する》をクリックします。
- Lambdaの実行ログを記録するため、デフォルトでCloudWatch Logsの権限が付与されます。
《サービスの選択》をクリックします。
「サービス」にS3と入力し、検索結果から《S3》をクリックします。
「アクション」に今回利用するPutObjectを入力し、《PutObject》をクリックし、選択状態にします。
《リソース》をクリックします。
《ARNの追加》をクリックします。
以下の項目を選択、入力して《追加》をクリックします。
- Bucket name:kinesis Video Streamsデータ取得用情報を保存するS3のバケット名+フォルダ名(バケット名とフォルダ名やフォルダ名とフォルダ名の間は『/』で連結する)
- Bucket name:my-baseXXXXXXXXX/my-voicemessageXXXXXXX/infomation
- Object name:すべてにチェックを付ける(テキストボックスには*が入力される)
《ポリシーの確認》をクリックします。
内容を確認して、《変更の保存》をクリックします。
参考サイト
目次に戻る
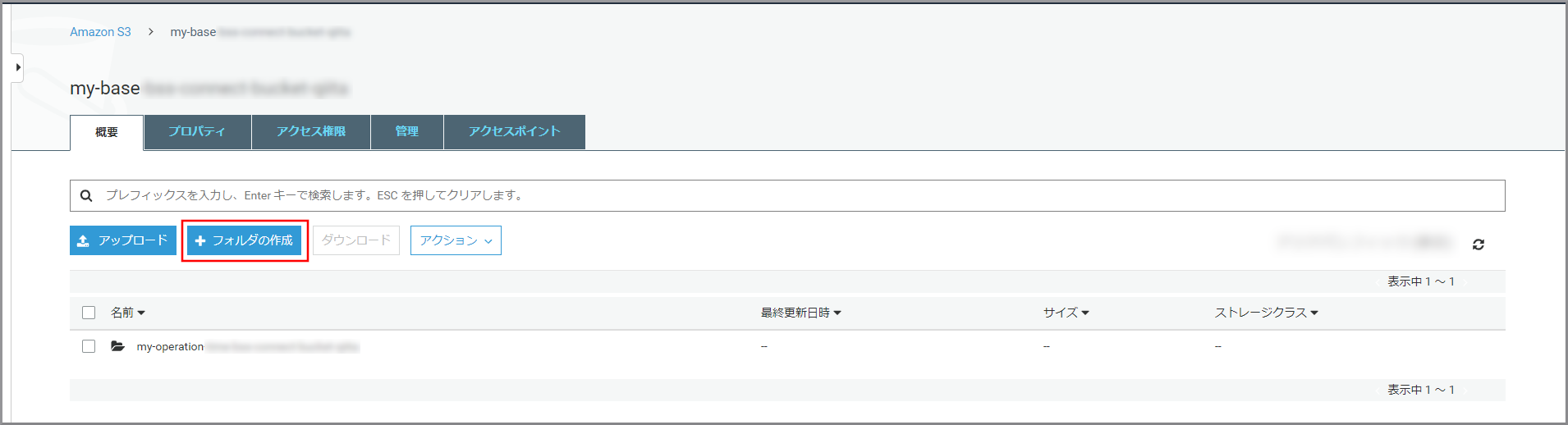
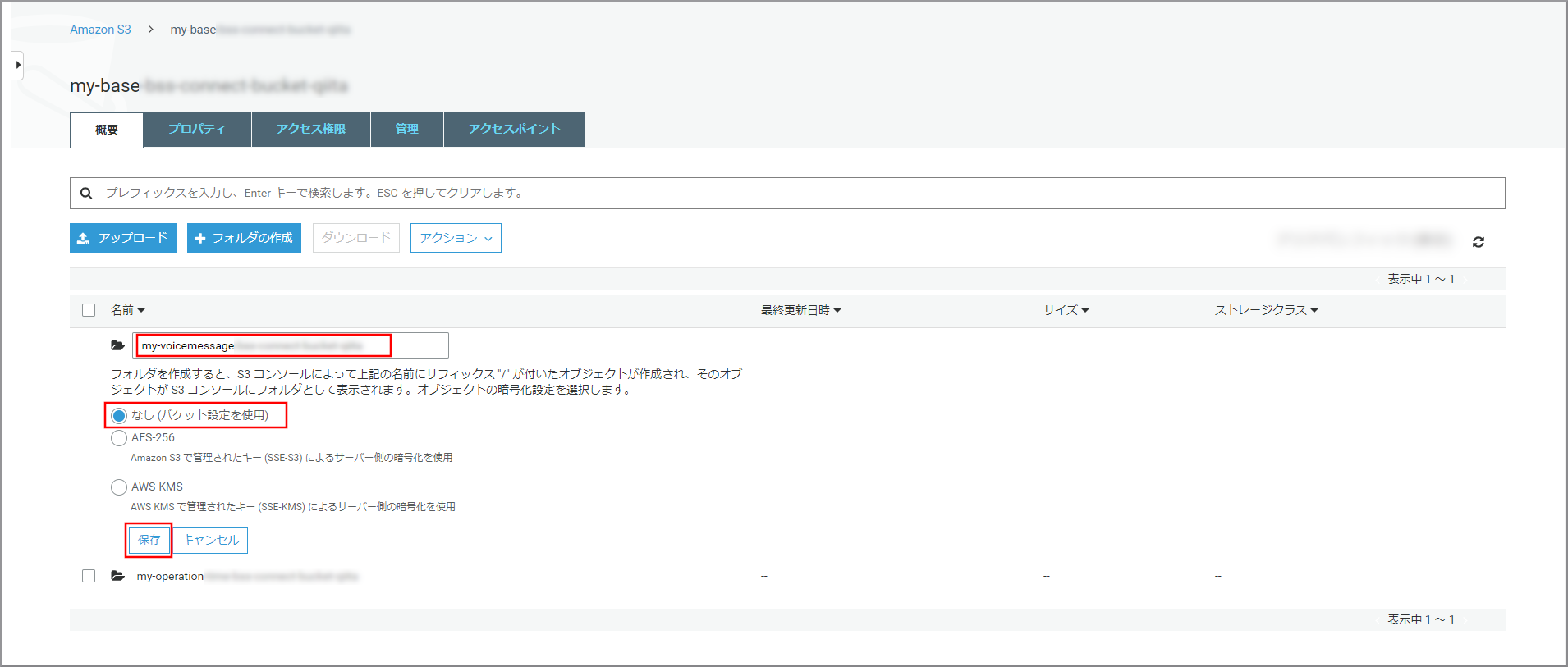
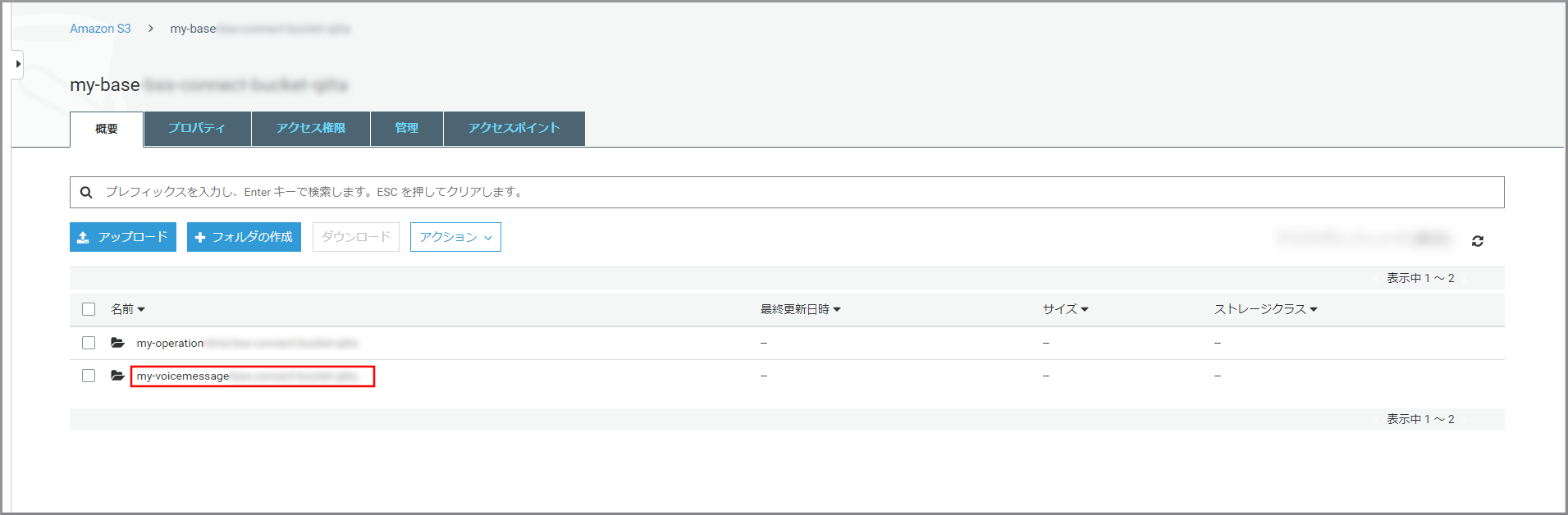
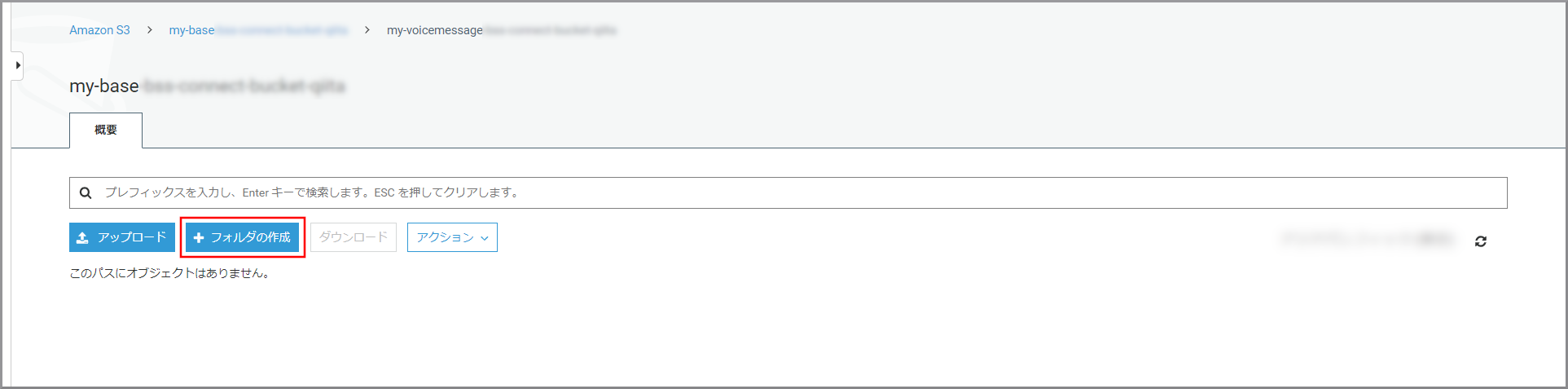
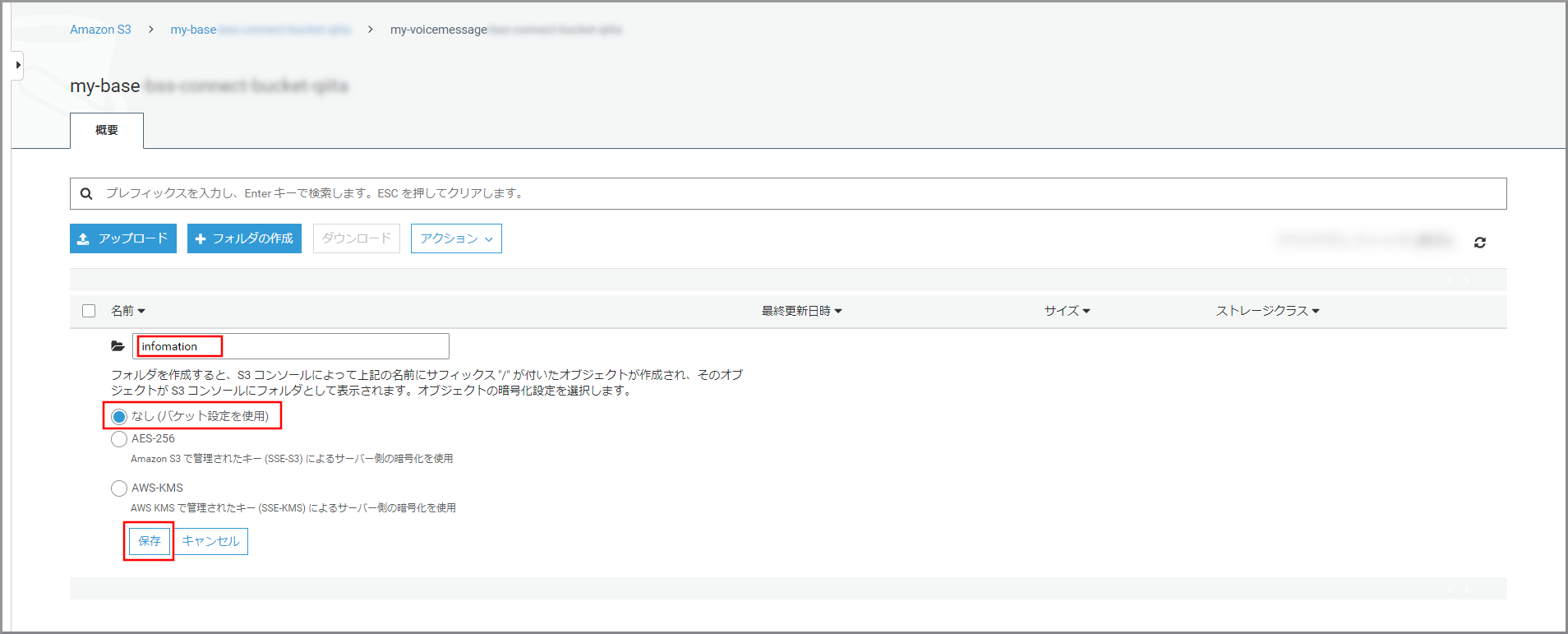
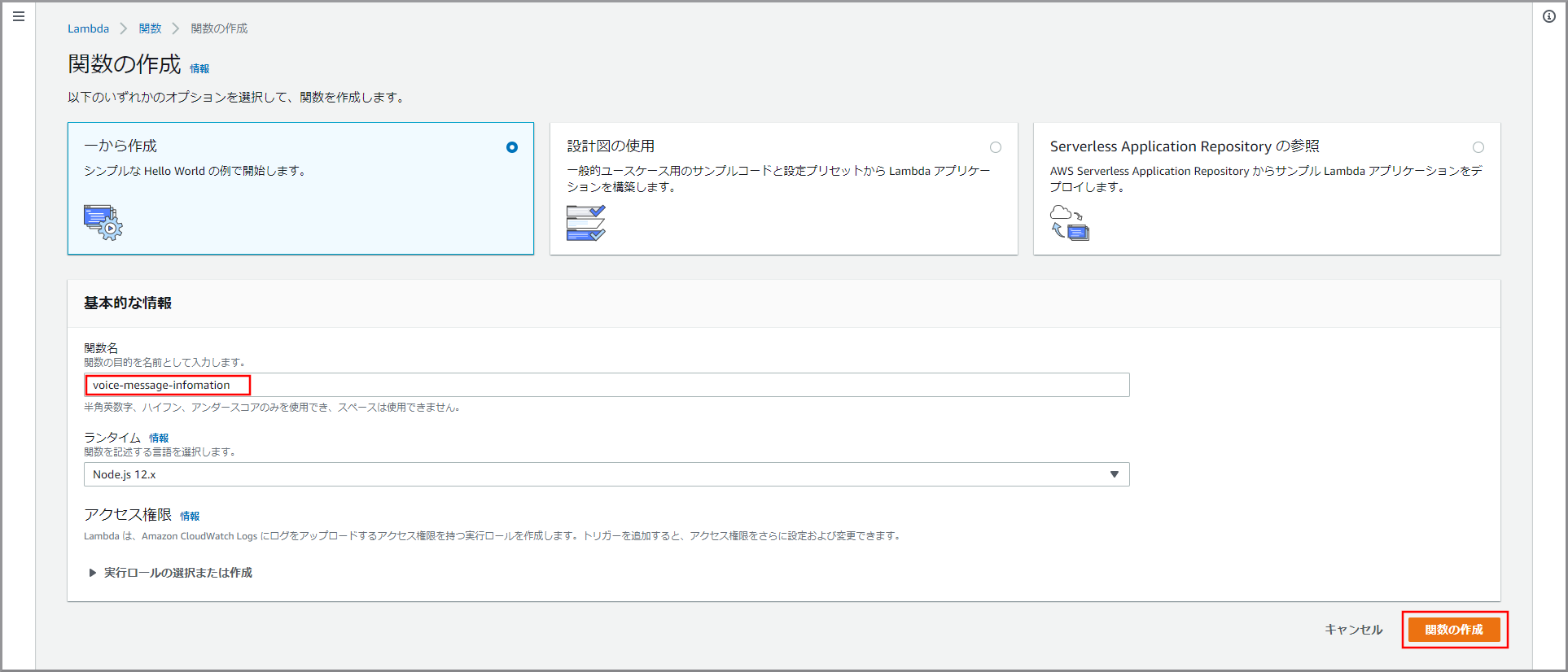

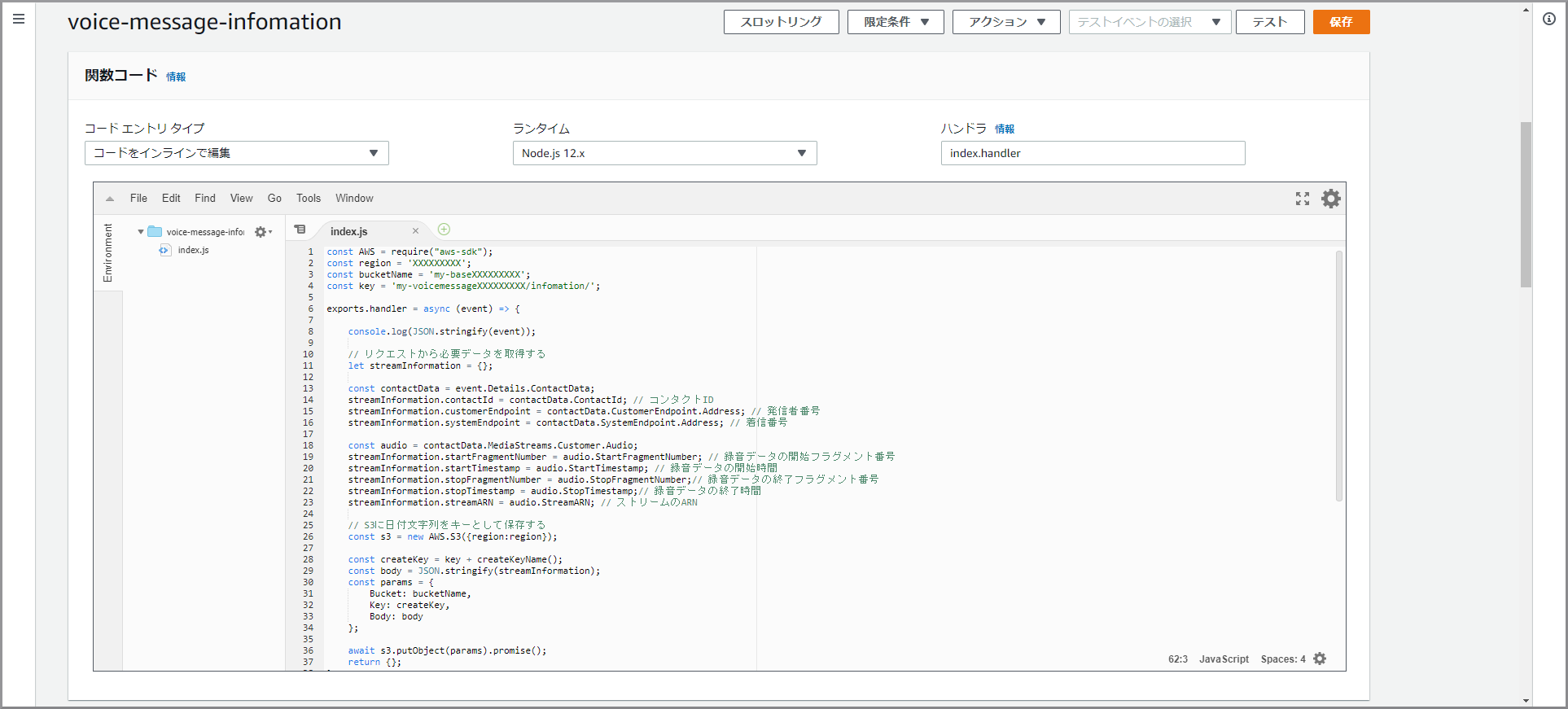
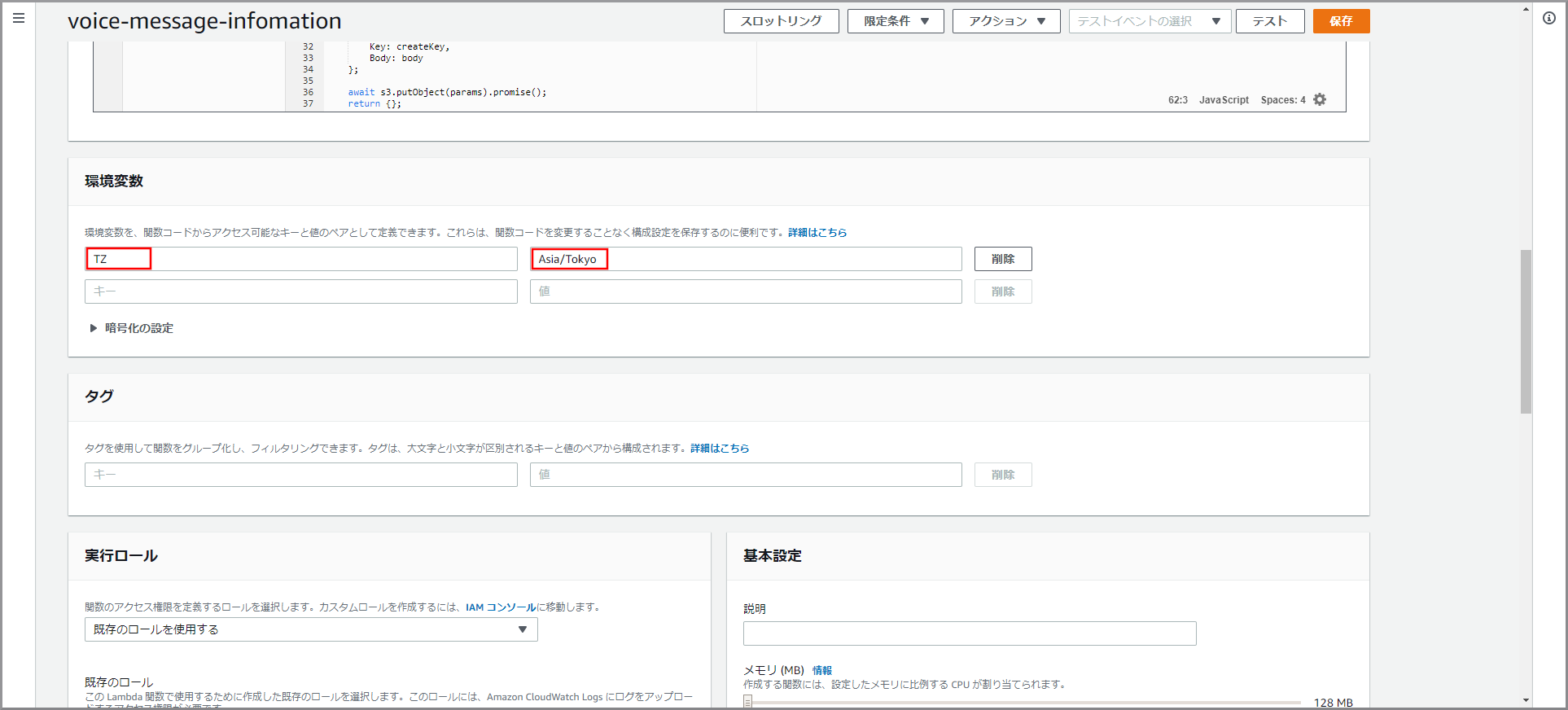
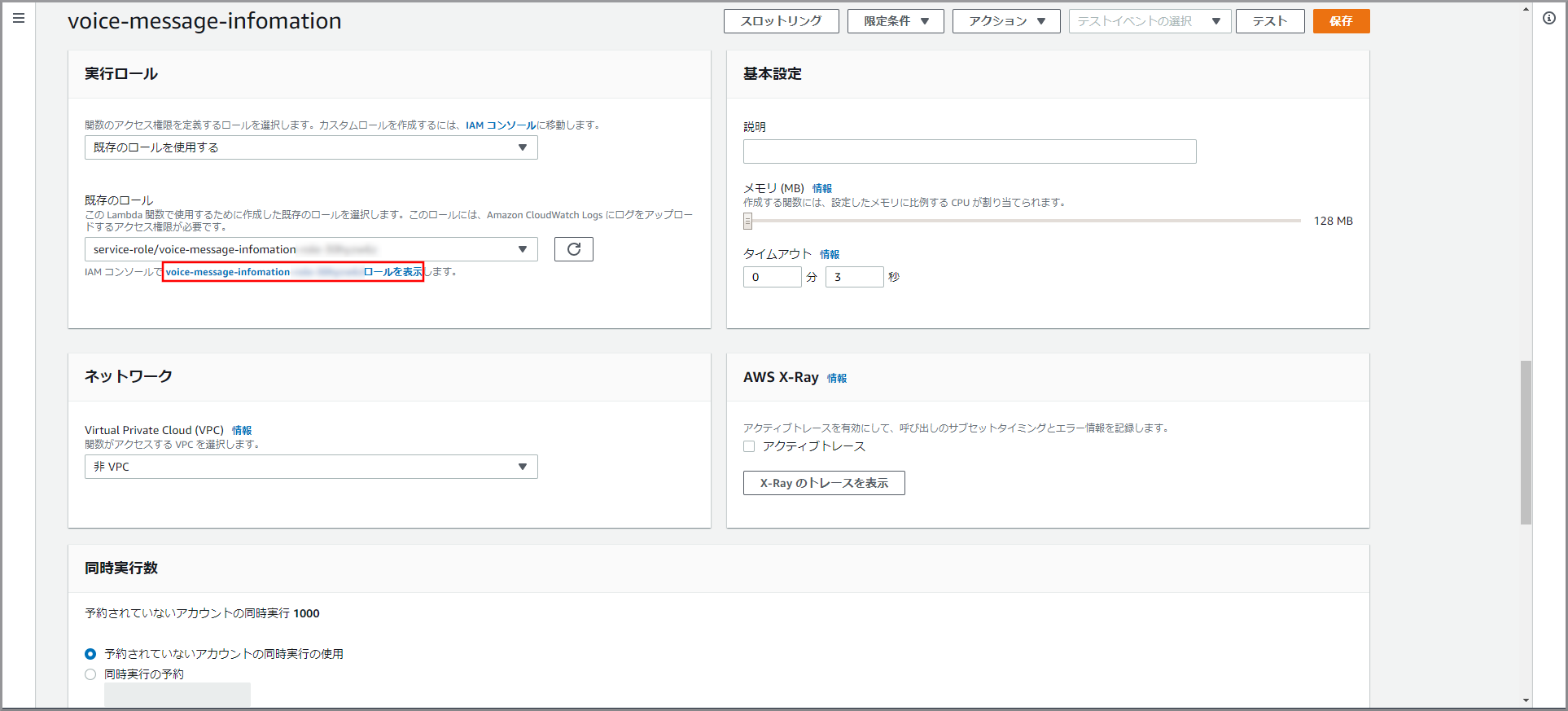

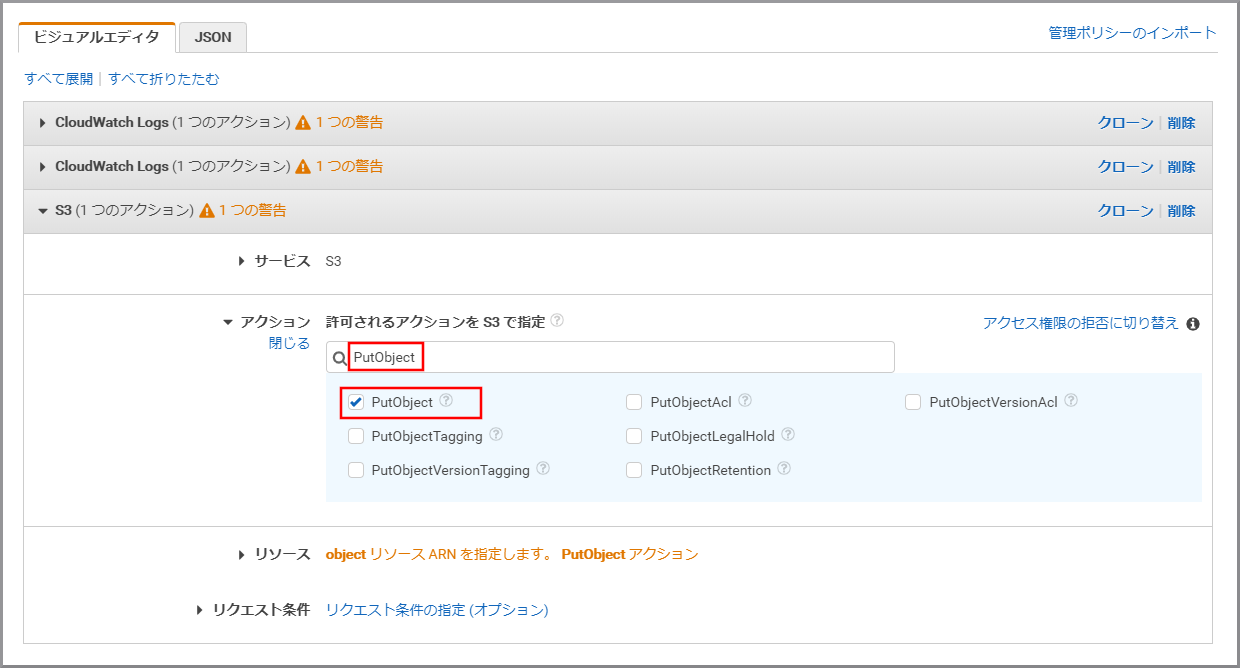
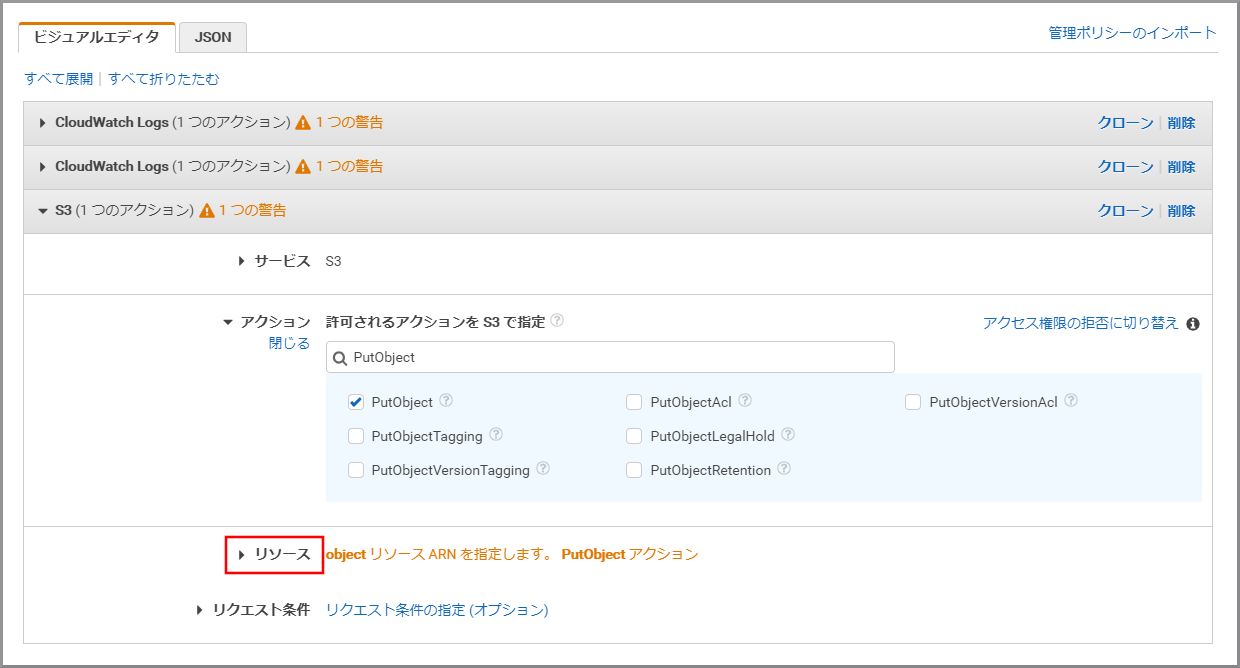
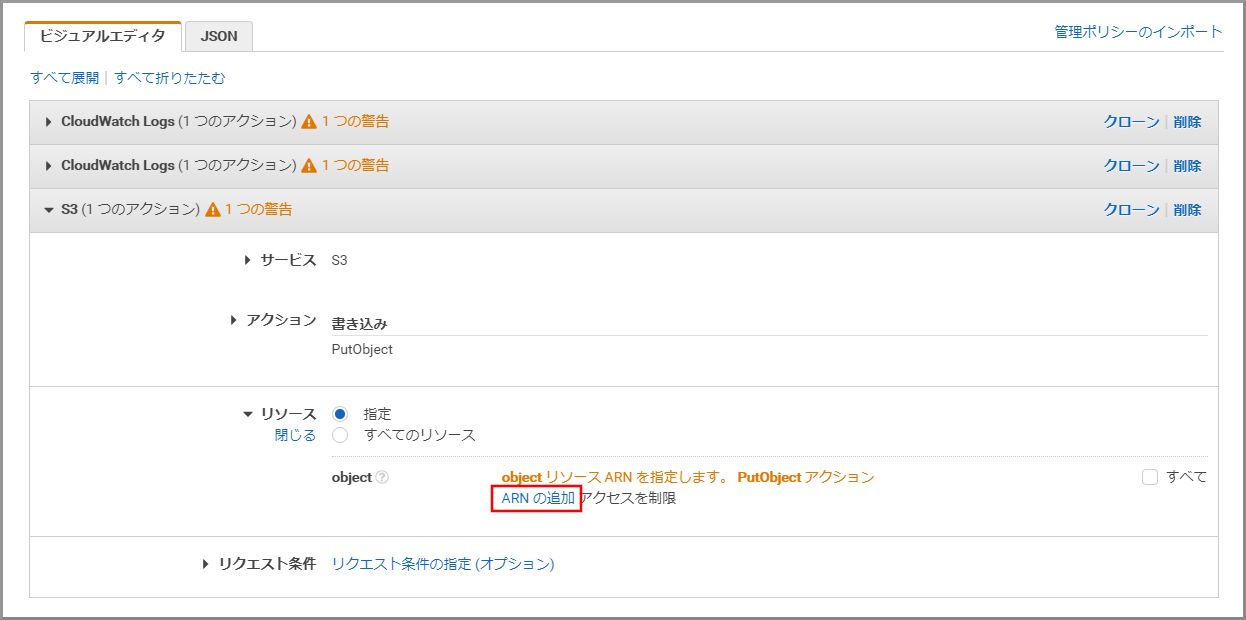


- 投稿日:2020-01-24T12:02:32+09:00
AWS CodePipeline (CodeCommit + Codedeploy → EC2へデプロイ)
AWS認定学習のためにチュートリアルをやってみたのでメモ。
実際にやってみた方がかなりイメージがわくと思います。1.CodeCommit リポジトリの作成
以下の手順どおりに、git をインストールして、クローンを作成する。
$ sudo yum install git -y $ git clone https://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/MyDemoRepo $ mkdir tmp $ cd tmp2.CodeCommit リポジトリにサンプルコードを追加する
サンプルコードの準備
$ curl -o https://s3.amazonaws.com/aws-codedeploy-us-east-1/samples/latest/SampleApp_Linux.zip $ unzip SampleApp_Linux.zip -d MyDemoRepo/ $ ls -la MyDemoRepo/ステージング→コミット→プッシュします。
$ git add -A $ git commit -m "test 1" $ git push3.デプロイするEC2インスタンスの準備
以下のとおりロールを作成する。
- サービス:EC2
- ロール名: EC2InstanceRole
- ポリシー名:AmazonEC2RoleforAWSCodeDeploy
タグは、MyCodePipelineDemo とし、ユーザデータは以下のとおりにし、EC2インスタンスを作成する。
#!/bin/bash yum -y update yum install -y ruby yum install -y aws-cli cd /home/ec2-user aws s3 cp s3://aws-codedeploy-us-east-2/latest/install . --region us-east-2 chmod +x ./install ./install auto4.CodeDeploy で EC2インスタンスにデプロイする
以下のとおりロールを作成する。
- サービス:CodeDeploy
- ロール名: CodeDeployRole
- ポリシー名:CodeDeploy
CodeDeploy アプリケーションを作成する。
CodeDeploy デプロイグループを作成する。
5.CodePipeline パイプラインを作成する
Step 1 パイプラインの設定を選択する
Step 2 ソースステージを追加する
Step 3 ビルドステージを追加する
今回ビルドはしないのでスキップします。
Step 4 デプロイステージを追加する
Step 5 レビュー
内容を確認し、「パイプラインの作成」をする。
成功した場合は、パブリック DNSにアクセスして表示されるか確認。
失敗した場合は、CodePipeline のトラブルシューティングをする。5.CodeCommit リポジトリのコードを編集
index.html のファイルを適当に編集して、変更されるか確認してみます。
$ git commit -am "test2" $ git push

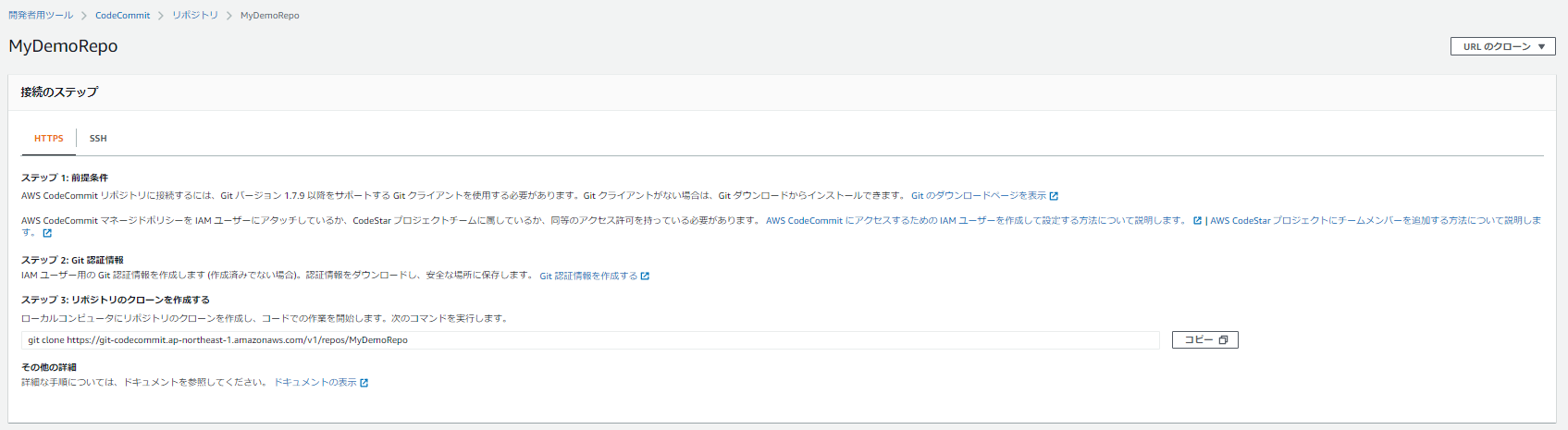

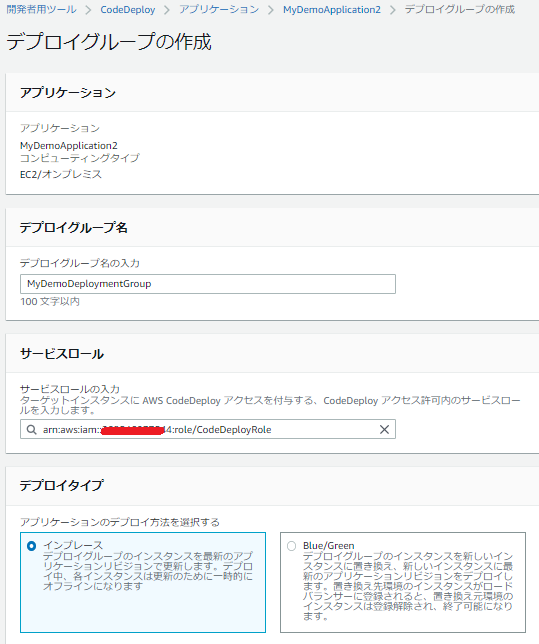
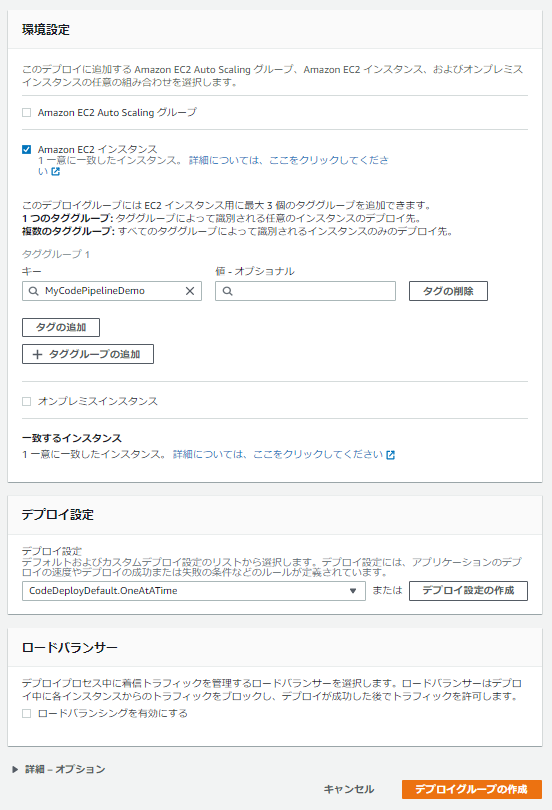
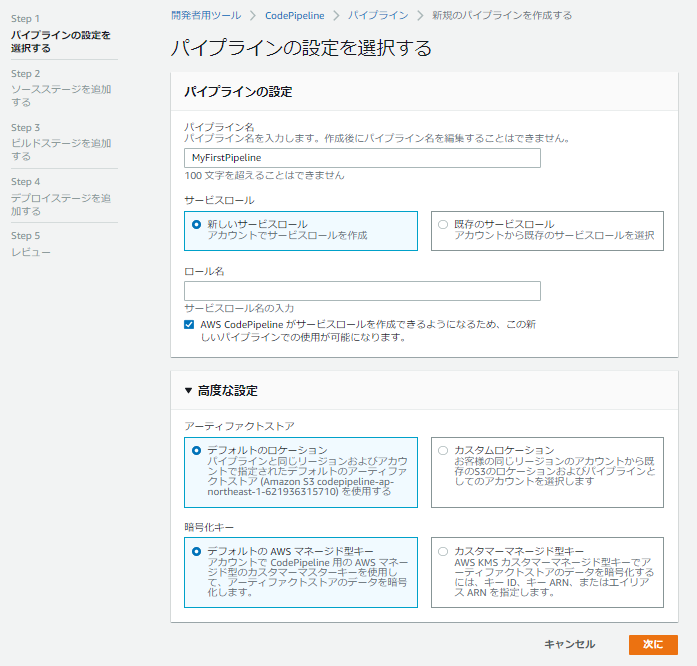
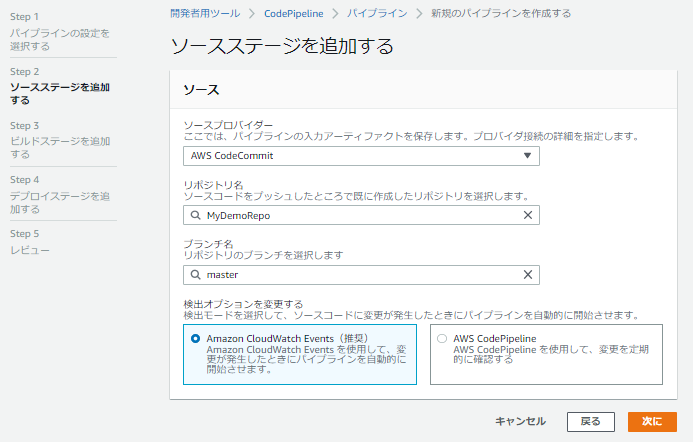
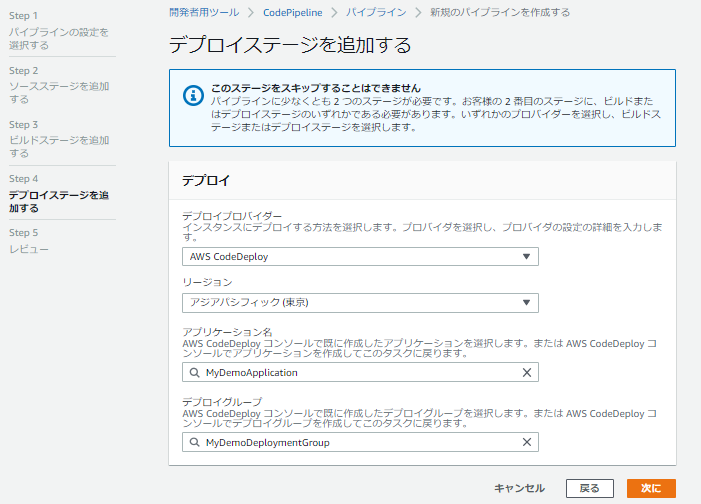
- 投稿日:2020-01-24T12:02:11+09:00
AWS EC2インスタンスにSSH接続する時のパーミッションエラー回避方法
EC2にSSH接続しようとするとこんなエラーが,,,
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @ WARNING: UNPROTECTED PRIVATE KEY FILE! @ @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@よくエラーを見ると、
Permissions 0755 for '/Users/user/Desktop/xxxxxxxxxxxx.pem' are too open.パーミッションが開きすぎ!とのこと。
ググるとパーミッションを600に変更すればOKだと。
chmod 600 /Desktop/xxxxxxxxxxxx.pem変更したのちに、
__| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/こうなれば成功です。
- 投稿日:2020-01-24T11:16:48+09:00
【クラウド初心者向け】営業時間の判断
概要
- Amazon Connectにあるオペレーション時間では休日判断等ができないためLambda(ラムダ)を利用して休日を判断できるようにします。
- 基本の考え方等は『[Amazon Connect] オペレーション時間の設定ファイルをS3に置くだけで制御する』をもとにしています。
使用ユーザー
- IAMユーザー
手順
営業時間テキストファイルの作成とバケットへのアップロード
- 営業時間と祝日を登録したテキストファイル(以下、operation-time.txt)を用意します。
operation-time.txt月,09:00,17:00 火,09:00,17:00 水,09:00,17:00 木,09:00,18:00 金,09:00,17:00 1/1 #元旦 1/2 #銀行休業日 1/3 #銀行休業日 1/14 #成人の日 2/11 #建国記念日 2/23 #天皇誕生日 3/21 #春分の日 4/29 #昭和の日 5/3 #憲法記念日 5/4 #みどりの日 5/5 #こどもの日 5/6 #振替休日 7/15 #海の日 8/12 #山の日 9/16 #敬老の日(9月第三月曜日) 9/23 #秋分の日 10/14 #体育の日 11/3 #文化の日 11/4 #振替休日 11/23 #勤労感謝の日
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にS3と入力し、検索結果から《S3》をクリックし、Amazon S3 コンソール(https://console.aws.amazon.com/s3/)を開きます。
S3のバケット一覧が表示されるので、《バケットを作成する》をクリックします。
「バケット作成」画面が表示されるので、以下の項目を選択、入力して《次へ》をクリックします。
- バケット名:世界中で一意になる名前を付ける
- リージョン:作成するを選択します。
適宜必要な設定を行い《次へ》をクリックします。
- 今回はデフォルトのまま
適宜必要な設定を行い《次へ》をクリックします。
- 今回はデフォルトのまま
設定内容を確認して《バケットを作成》をクリックします。
S3のバケット一覧が表示されるので、作成したバケットをクリックします。
《フォルダの作成》をクリックします。
以下の項目を選択、入力して《保存》をクリックします。
- フォルダ名:フォルダの名前
- バケット名:my-baseXXXXXXXXX
- 暗号化:適宜必要な暗号化設定を選択
作成したフォルダをクリックします。
《アップロード》をクリックします。
「アップロード」画面が表示されるので、ドラッグ&ドロップまたは、《ファイルを追加》ボタンを押してoperation-time.txtをアップロードします。
指定したファイルを確認して、《次へ》をクリックします。
アクセス許可の設定を確認して、《次へ》をクリックします。
- 今回はデフォルトのまま
ストレージクラスの設定を確認して、《次へ》をクリックします。
- 今回はデフォルトのまま
設定を確認して、《アップロード》をクリックします。
ファイルがアップロードされました。
営業時間判定用のLambda作成とテスト
Lambdaの作成
- 今回作成したLambdaのコードは以下の通りで、クラスメソッドさんのコードとは以下の部分を変えています。
- バケット直下ではなくフォルダにあるファイルを読み込む。
- 読み込むテキストファイルの名前はConnect側(問い合わせフロー)から受け取る。
- 営業時間が複数パターン有った場合に対応するため
- コメント削除及び、余分な空白削除が動作しなかったので修正
- 営業時間判定を9:00 ~ 17:00とした場合に17:00が営業時間だったのを営業時間外とした。
- 以下のコードで各自で変える部分
- bucket変数、key変数に指定する値
operation-time-judgment// AWSのSDKを使う宣言 const aws_sdk = require('aws-sdk'); // S3を使う宣言 const s3 = new aws_sdk.S3(); const bucket = 'my-baseXXXXXXXXX'; // フォルダが階層の場合は"/"で連結 例:folder1/folder2/folder3/ // 最後は"/"で終了する const key = 'my-operationXXXXXXX/'; exports.handler = async function(event, context) { console.log(JSON.stringify(event)) // オペレーション時間の取得 // objectNameはAmazon Connectで指定した値を受け取ります。 // 拡張子も含めて指定 例:operation-time.txt // s3にGetObject関数でアクセスするのでこの権限をLambdaに付与する必要がある。 const data = await s3.getObject({Bucket: bucket,Key: key + event.Details.Parameters.objectName}).promise(); const operationTime = data.Body.toString(); var lines = operationTime.split('\n'); // コメント削除及び、余分な空白削除 lines = lines.map( line => { return line.replace(/#[\s\S]*$/g, '').replace(/\s+$/g, ''); }); // 無効(空白)行の削除 lines = lines.filter( line => { return line != ''; }); // 時間内かどうかのチェック const IsOperationTime = CheckInTime(lines); return { IsOperationTime: IsOperationTime }; } function CheckInTime(lines) { // 現在時間 const now = new Date(); const month = now.getMonth() + 1; const day = now.getDate(); const week = now.getDay(); const hour = now.getHours(); const miniute = now.getMinutes(); var weekdays = ["日", "月", "火", "水", "木", "金", "土"]; // 曜日指定の抽出 const weeks = lines.filter(line => { return 0 < weekdays.indexOf(line.split(',')[0]); }); // 祝日指定の抽出 const holidays = lines.filter(line => { return line.split(',')[0].split('/').length == 2; }); // 曜日チェック let flg = false; // デフォルトで時間外(設定がない場合時間外となるため) weeks.forEach( line => { const tmp = line.split(','); const w = weekdays.indexOf(tmp[0]); if(week == w) { // 当該曜日の設定 // 始業時間以降かどうかのチェック let t = tmp[1].split(':'); if(t.length == 2) { if( Number(t[0]) * 60 + Number(t[1]) <= (hour * 60 + miniute )){ // 終業時間前かどうかのチェック t = tmp[2].split(':'); if(t.length == 2) { if((hour * 60 + miniute ) < (Number(t[0]) * 60 + Number(t[1]))){ flg = true; } } } } } }); // 曜日指定で時間外の場合は、祝日に関係なく時間外となる if(!flg){ return false; } // 祝日のチェック flg = true; // デフォルトで時間内(設定がない場合時間内となるため) holidays.forEach( line => { const tmp = line.split(','); const date = tmp[0].split('/'); if(date.length == 2){ if(month == date[0] && day == date[1]){ flg = false; } } }) return flg; }
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にLambdaと入力し、検索結果から《Lambda》をクリックし、Amazon Connect コンソール(https://console.aws.amazon.com/lambda/)を開きます。
Lambdaの関数一覧画面が表示されるので《関数の作成》をクリックします。
「関数名」を入力して《関数の作成》をクリックします。
関数のベースが作成されました。関数コードを入力するため下にスクロールして「関数コード」を表示します。
「関数コード」に初期で登録されているコードを削除して、上記operation-time-judgmentをコピー&ペーストします。
日本時間に対応させるため、画面を下にスクロールして「環境変数」に以下の値を入力し《保存》ボタンをクリックします。
- キー:TZ、値:Asia/Tokyo
LambdaにS3へのアクセス権を設定するため下にスクロールして「実行ロール」を表示し、《XXXXXXXXロールを表示》をクリックします。
- Lambdaを作成する毎に自動的にLambda名の付いたロールが一つ作成されます。
- Lambdaで利用しているAPIのアクセス権を付与します。
- 今回は、営業時間を判断するためS3に保存したoperation-time-judgmentテキストをLambdaから読み取る権限を付与します。
選択したロールの概要が表示されるのでポリシー名の「▶」をクリックします。
《ポリシーの編集》をクリックします。
ビジュアルエディタが表示されるので《さらにアクセス許可を追加する》をクリックします。
- Lambdaの実行ログを記録するため、デフォルトでCloudWatch Logsの権限が付与されます。
《サービスの選択》をクリックします。
「サービス」にS3と入力し、検索結果から《S3》をクリックします。
「アクション」に今回利用するGetObjectを入力し、《GetObject》をクリックし、選択状態にします。
《リソース》をクリックします。
《ARNの追加》をクリックします。
以下の項目を選択、入力して《追加》をクリックします。
- Bucket name:operation-time-judgmentテキストが保存されているS3のバケット名+フォルダ名(バケット名とフォルダ名やフォルダ名とフォルダ名の間は『/』で連結する)
- Bucket name:my-baseXXXXXXXXX/my-operationXXXXXXX
- Object name:すべてにチェックを付ける(テキストボックスには*が入力される)
《ポリシーの確認》をクリックします。
内容を確認して、《変更の保存》をクリックします。
Lambdaのテスト
Lambdaの画面に戻り、《テスト》をクリックします。
「テストイベントの設定」画面が表示されるので、以下の項目を選択、入力します。
- イベントテンプレート:Amazon Connect Contact Flow
- イベント名:OperationTimeJudgment
テストで使用するパラメータに今回Amazon Connectから渡す値を追加して《作成》をクリックします。
- パラメータ:"objectName": "operation-time.txt"
テストイベント選択欄に先ほど作成したテストが選択されている状態で《テスト》をクリックします。
テストの実行結果を確認するため、画面を上にスクロールして《詳細》ボタンをクリックします。
Lambdaから返す値やログなどが表示されます。
エラーの場合はエラーの理由などが出ているのでエラーを推測して関数コード等を修正します。
さらに詳細なログを見る場合は《ログ》ボタンをクリックします。
CloudWatchの画面が表示されるので、「最終のイベント時刻」から見たいログを判断して「ログストリーム」をクリックします。
ログが表示されます。さらに詳細を見たい場合は各行をクリックします。
- INFO:関数内に
console.log(JSON.stringify(event))(Nodeの場合)を入れる事によりその時点のevent変数をログに書き出します。- ERROR:実行時にエラーになったログが出力されます。
Amazon Connect問い合わせフローに営業時間判定を追加
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にConnectと入力し、検索結果から《Amazon Connect》をクリックし、Amazon Connect コンソール(https://console.aws.amazon.com/connect/)を開きます。
Amazon Connectのインスタンス一覧が表示されるので、該当のインスタンスをクリックします。
インスタンスの概要が表示されるので左側のメニューから《問い合わせフロー》をクリックします。
画面を下にスクロールして「AWS Lambda」の《関数》をクリックし、先ほど作成したLambdaをクリックします。
《+Lambda関数の追加》をクリックします。
Lambda関数の一覧に登録されました。これで、Amazon Connectから操作できるようになりました。
インスタンスの概要に戻って《管理者としてログイン》をクリックします。
左側のメニューから《問い合わせフロー》をクリックします。
お客様の選択による分岐と外線転送で作成した問い合わせフローをクリックします。
《顧客の入力を取得する》から《キューの設定》に出ている矢印にカーソルを合わせて『×』ボタンをクリックして矢印を消し、後ろのフローを右にずらします
左側メニューの「統合」から《AWS Lambda関数を呼び出す》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続後に《AWS Lambda関数を呼び出す》のタイトル部分をクリックします。
右側に「AWS Lambda 関数を呼び出す」画面が表示されるので、以下の項目を選択して《パラメータを追加する》をクリックします。
- 関数を選択する:作成したLambda
以下の項目を入力して《Save》をクリックします。
- 宛先キー:objectName(Lambda側で値を受け取る変数名)
- 値:operation-time.txt(S3に保存されているオブジェクト名)
- タイムアウト:5
左側メニューの「ブランチ」から《問い合わせ属性を確認する》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続後に《問い合わせ属性を確認する》のタイトル部分をクリックします。
右側に「問い合わせ属性を確認する」画面が表示されるので、以下の項目を選択、入力して《別の条件の追加》をクリックします。
- タイプ:外部(Lambdaからの引数)
- 属性:IsOperationTime(Lambdaでの処理結果を返す変数名)
以下の項目を入力して《Save》をクリックします。
- 条件:等しい、true(分岐の条件を指定する)
左側メニューの「操作」から《プロンプトの再生》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続後に《プロンプトの再生》のタイトル部分をクリックします。
右側に「プロンプトの再生」画面が表示されるので、以下の項目を選択、入力して《Save》をクリックします。
- テキスト読み上げまたはチャットテキスト:選択します。
- テキストの入力:選択し、音声案内する文言を入力します。
オブジェクト同志を矢印で接続します。
右上の《公開》をクリックします。
《公開》をクリックします。
参考サイト
- [Amazon Connect] オペレーション時間の設定ファイルをS3に置くだけで制御する
- [Amazon Connect] 超便利 Lambdaへのパーミッション追加がGUIからできるようになった(新機能)
目次に戻る
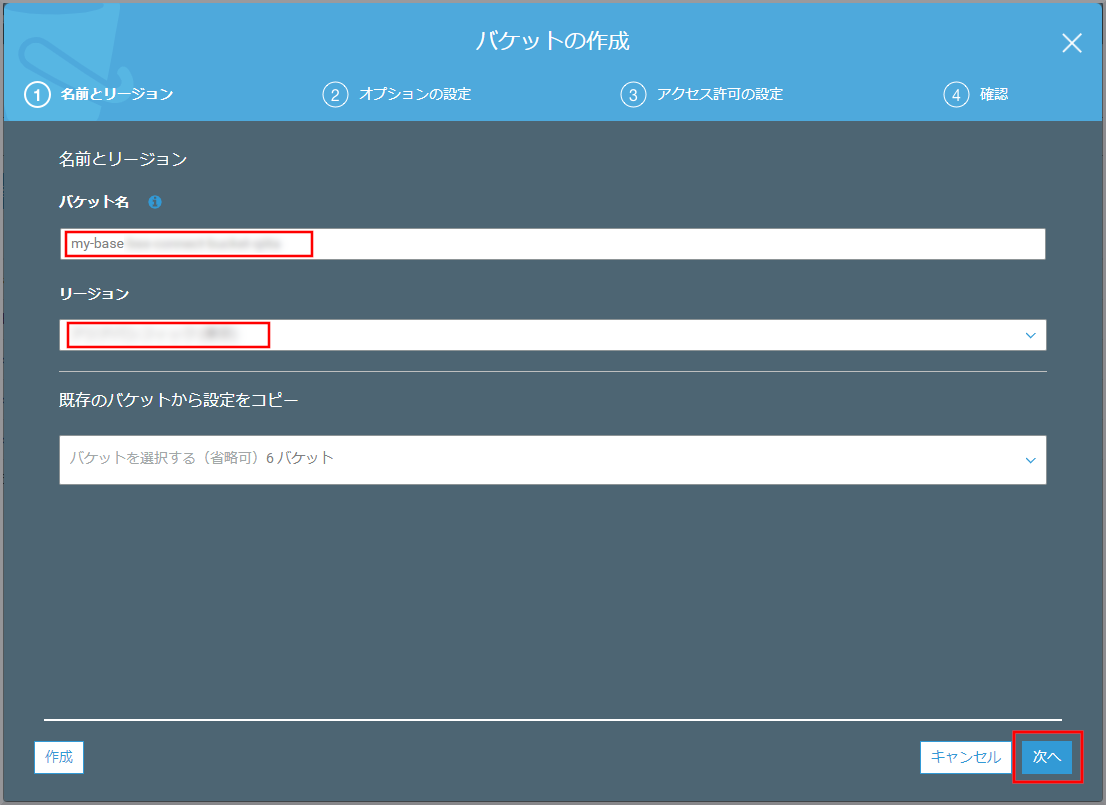



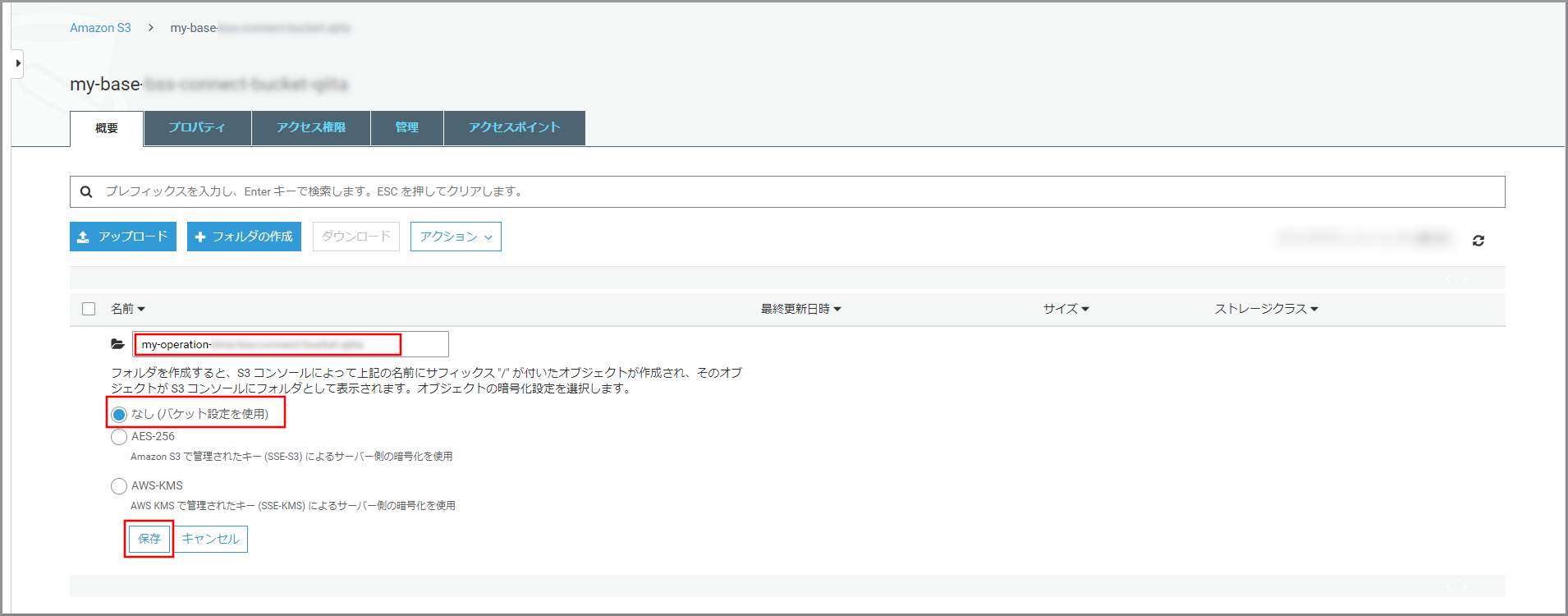
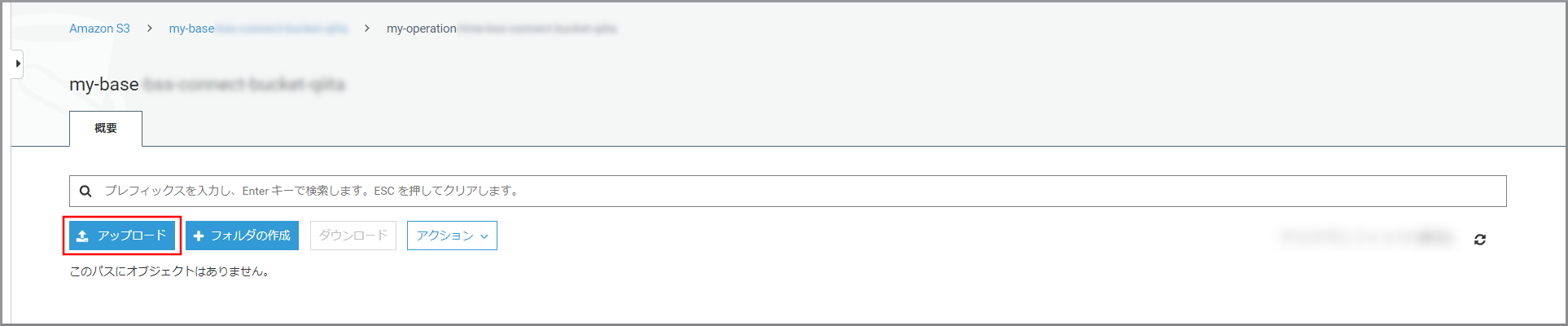
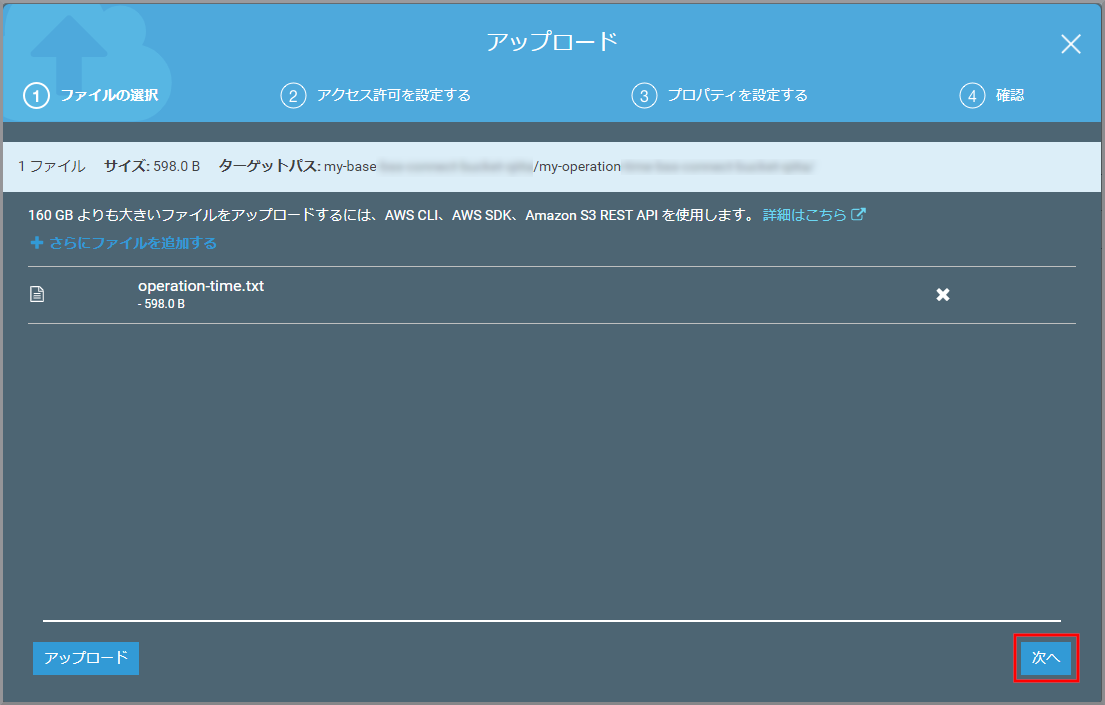

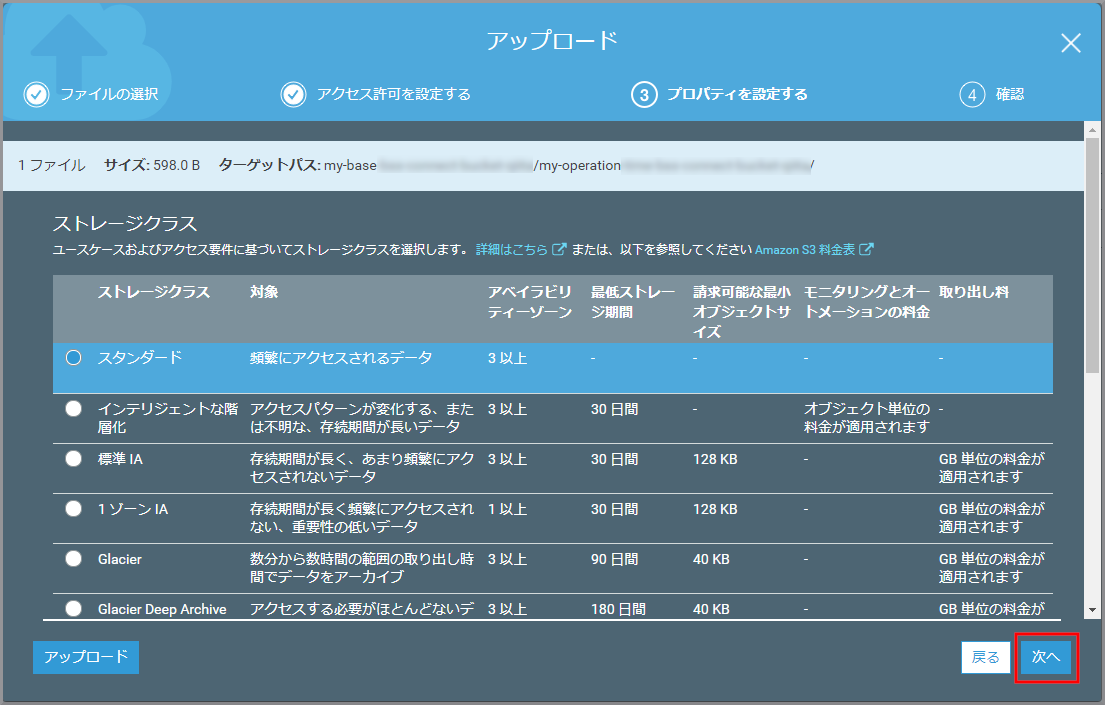
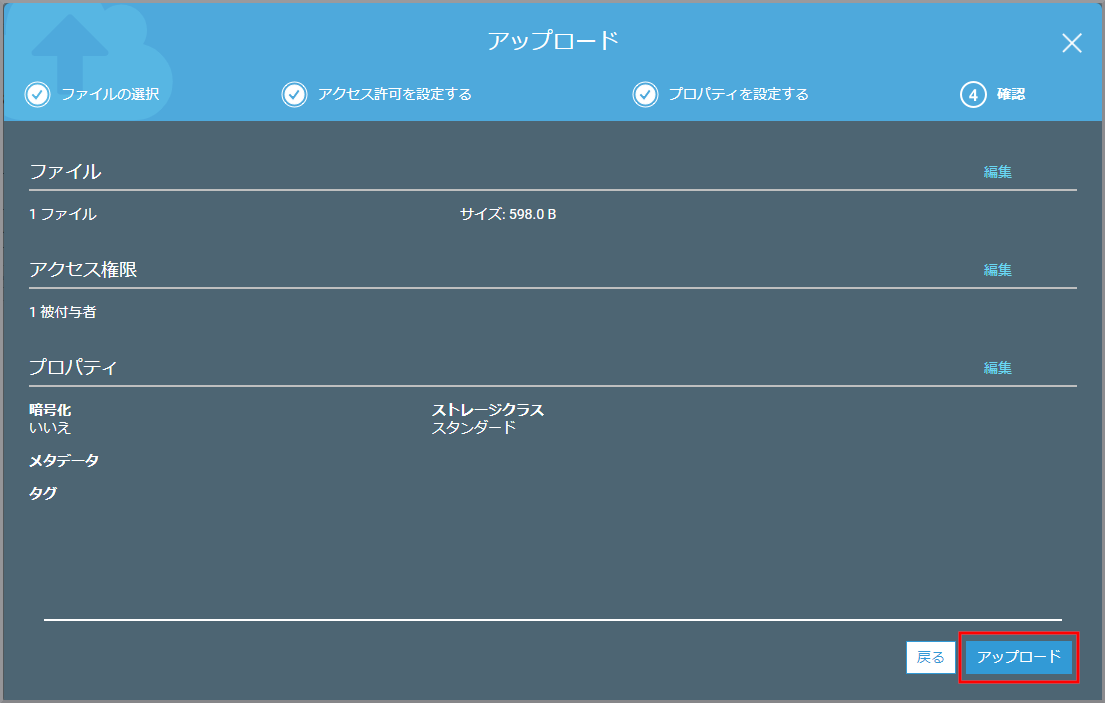
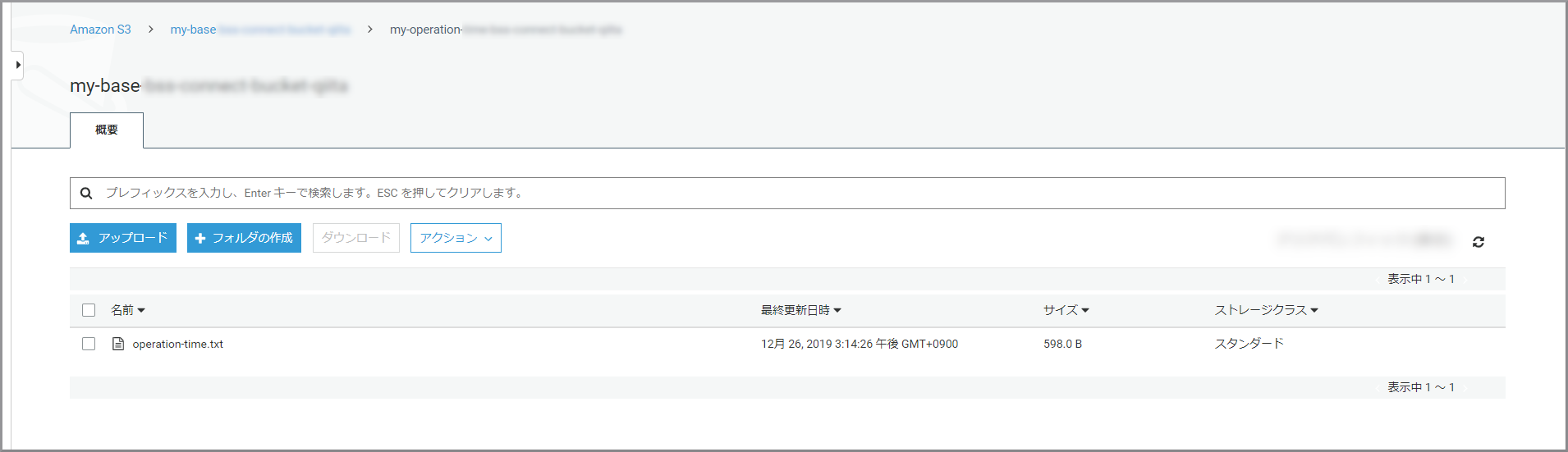
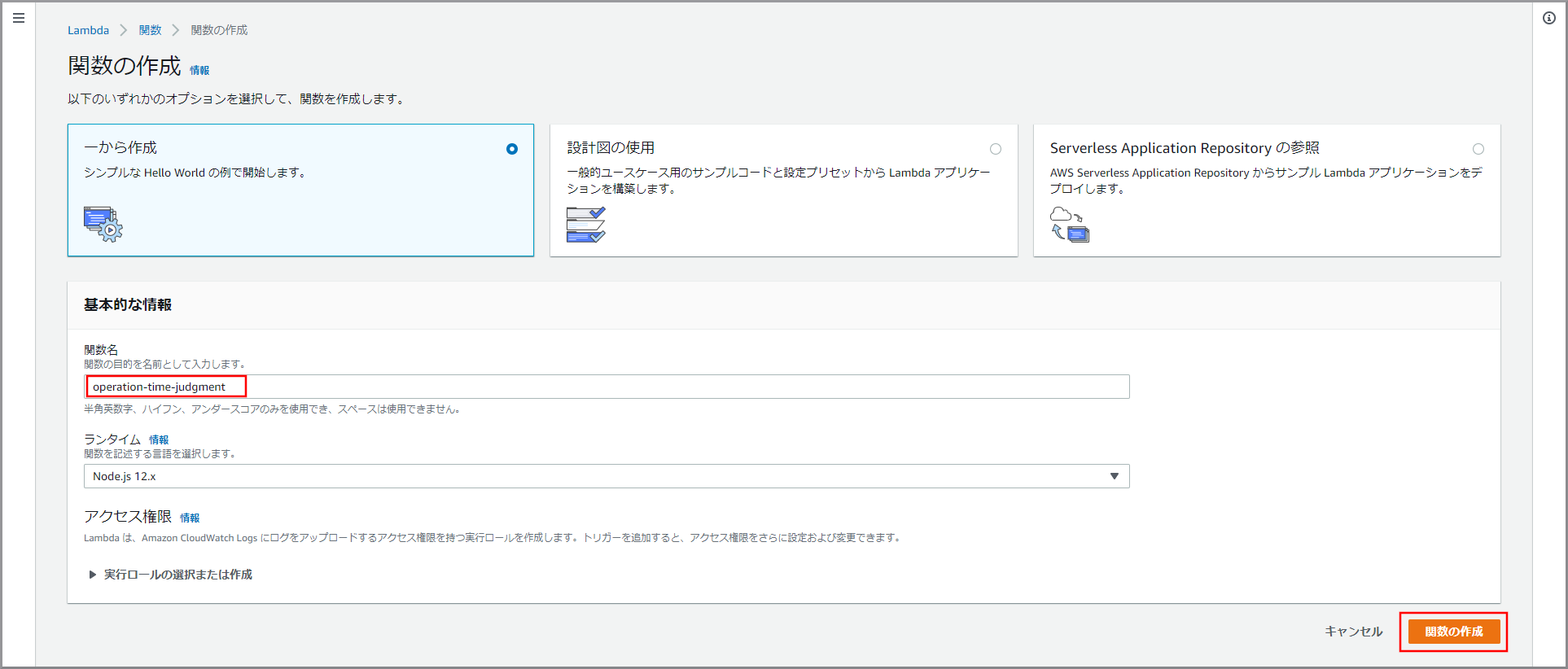
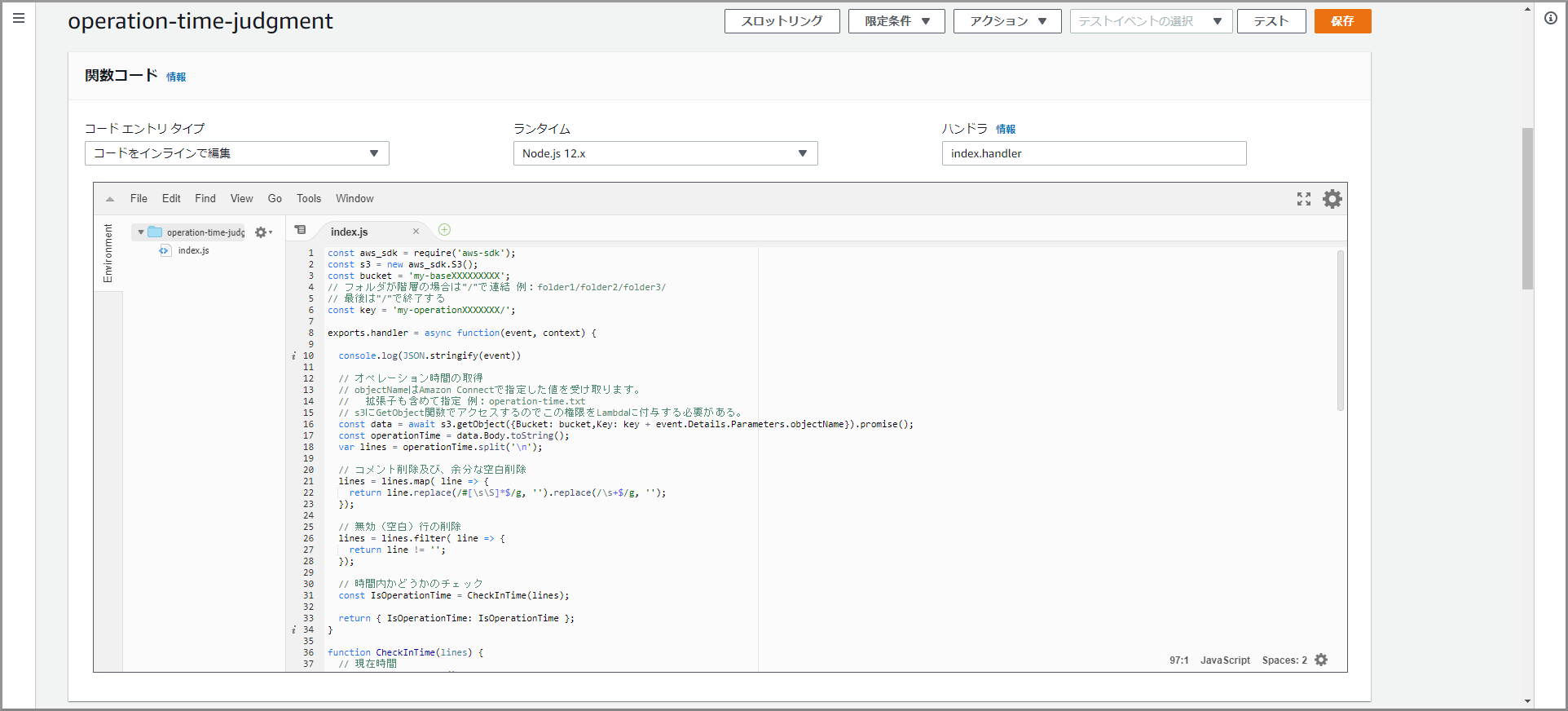
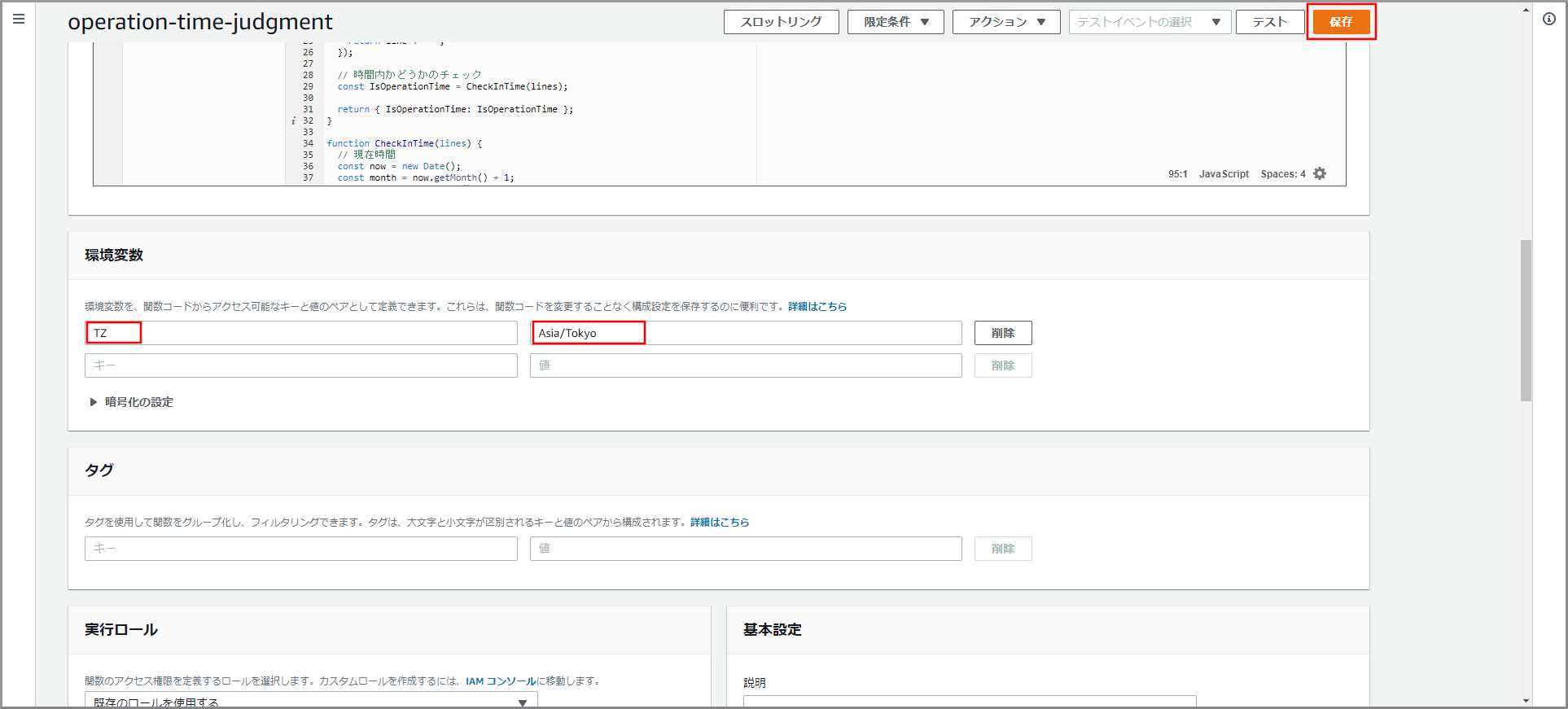
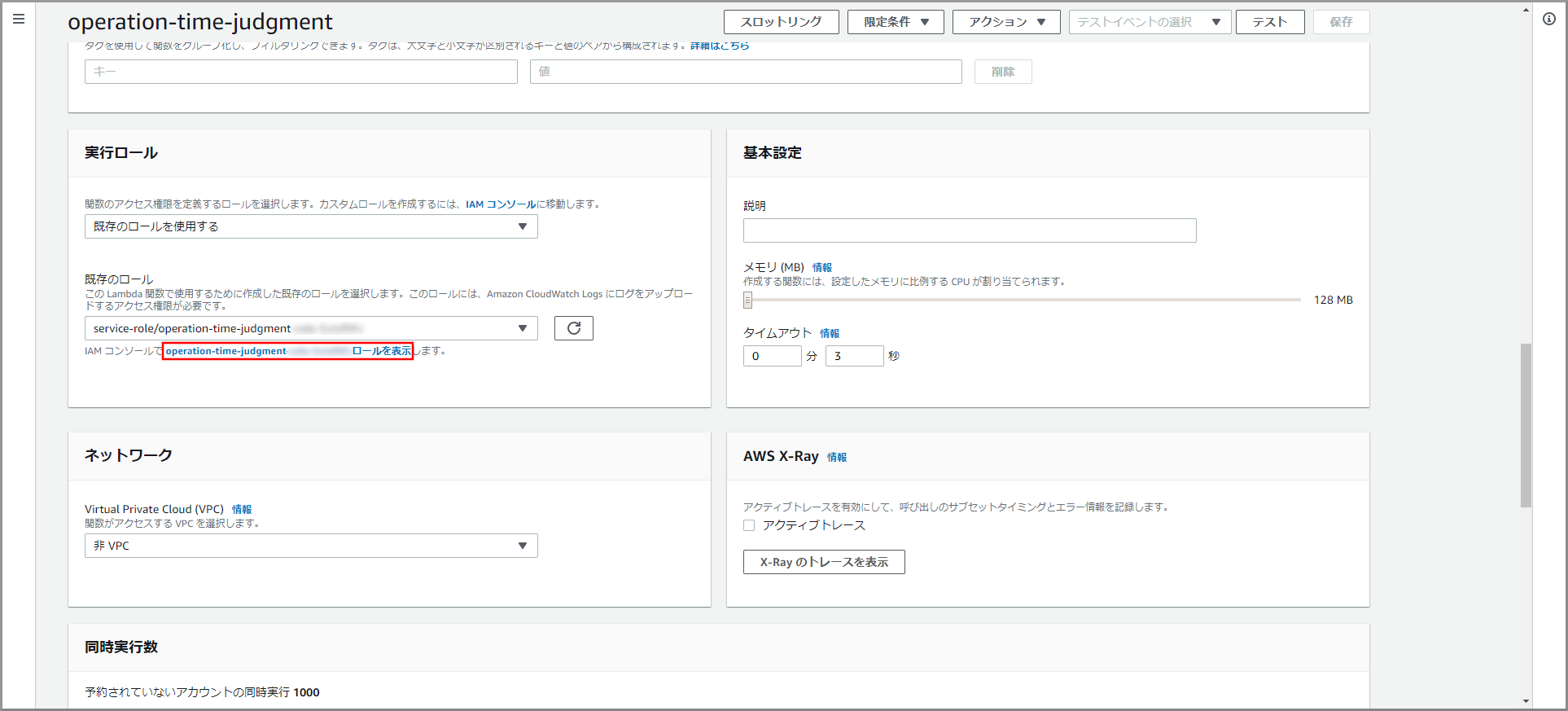
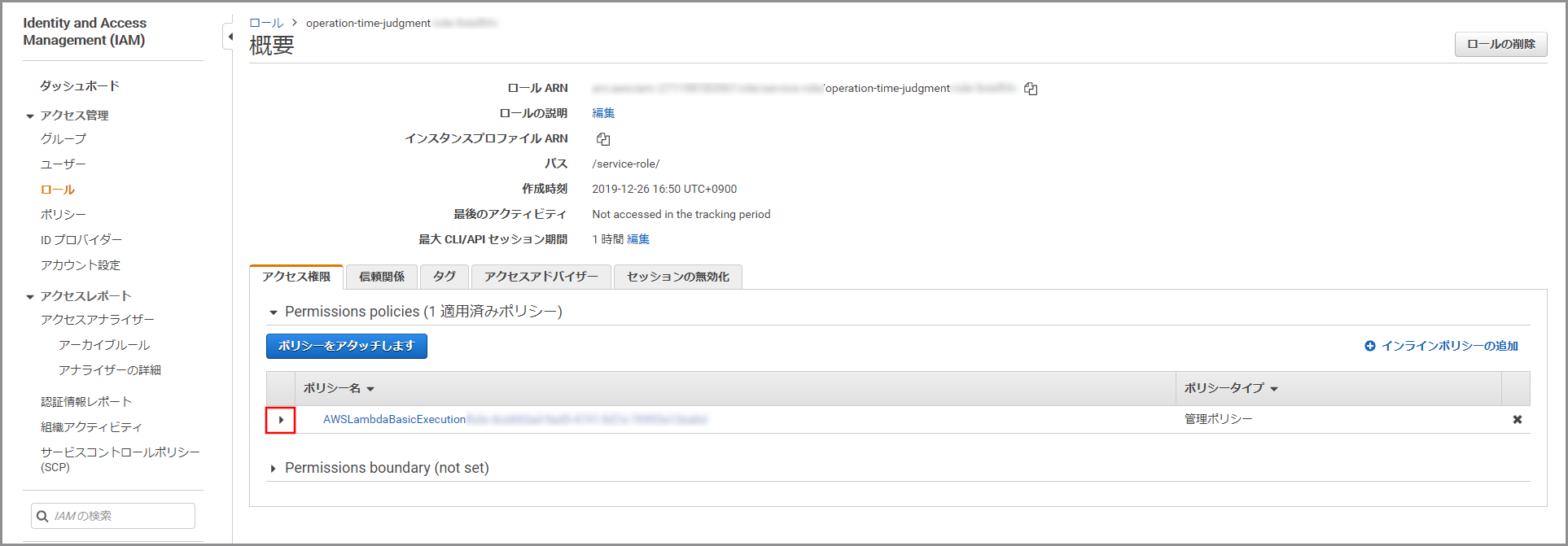
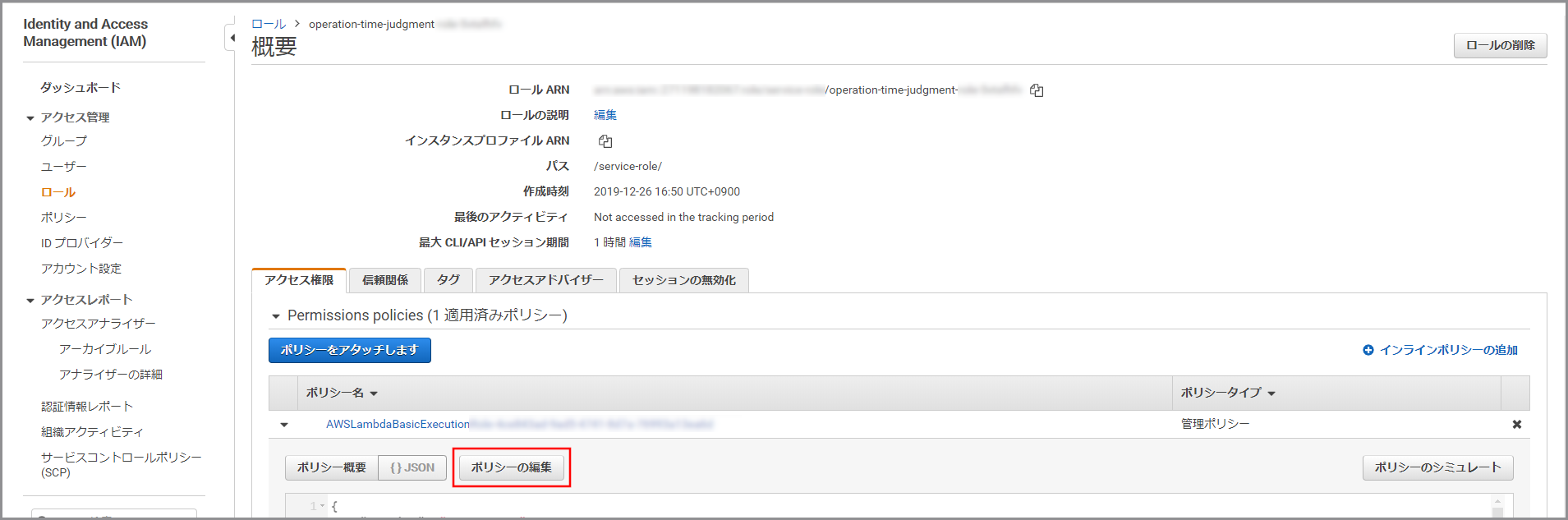


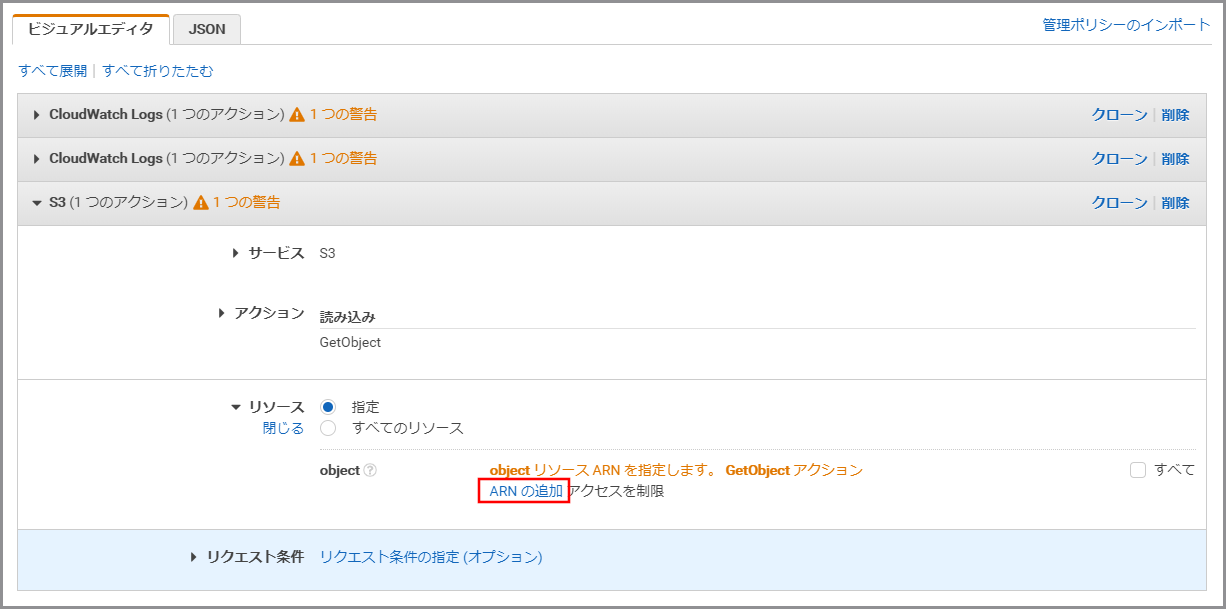
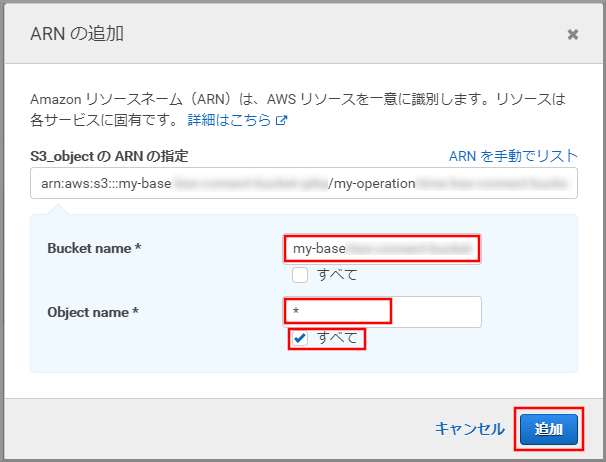
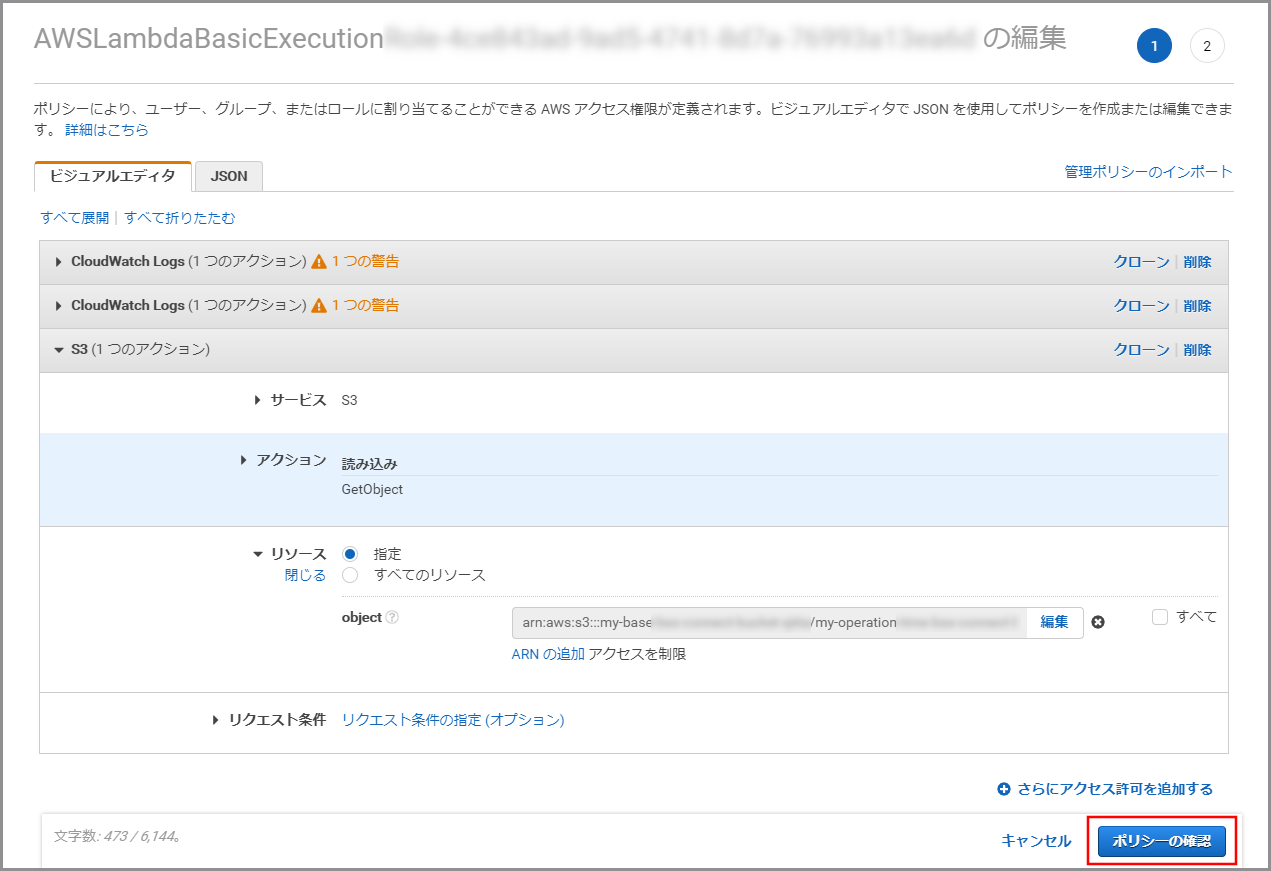
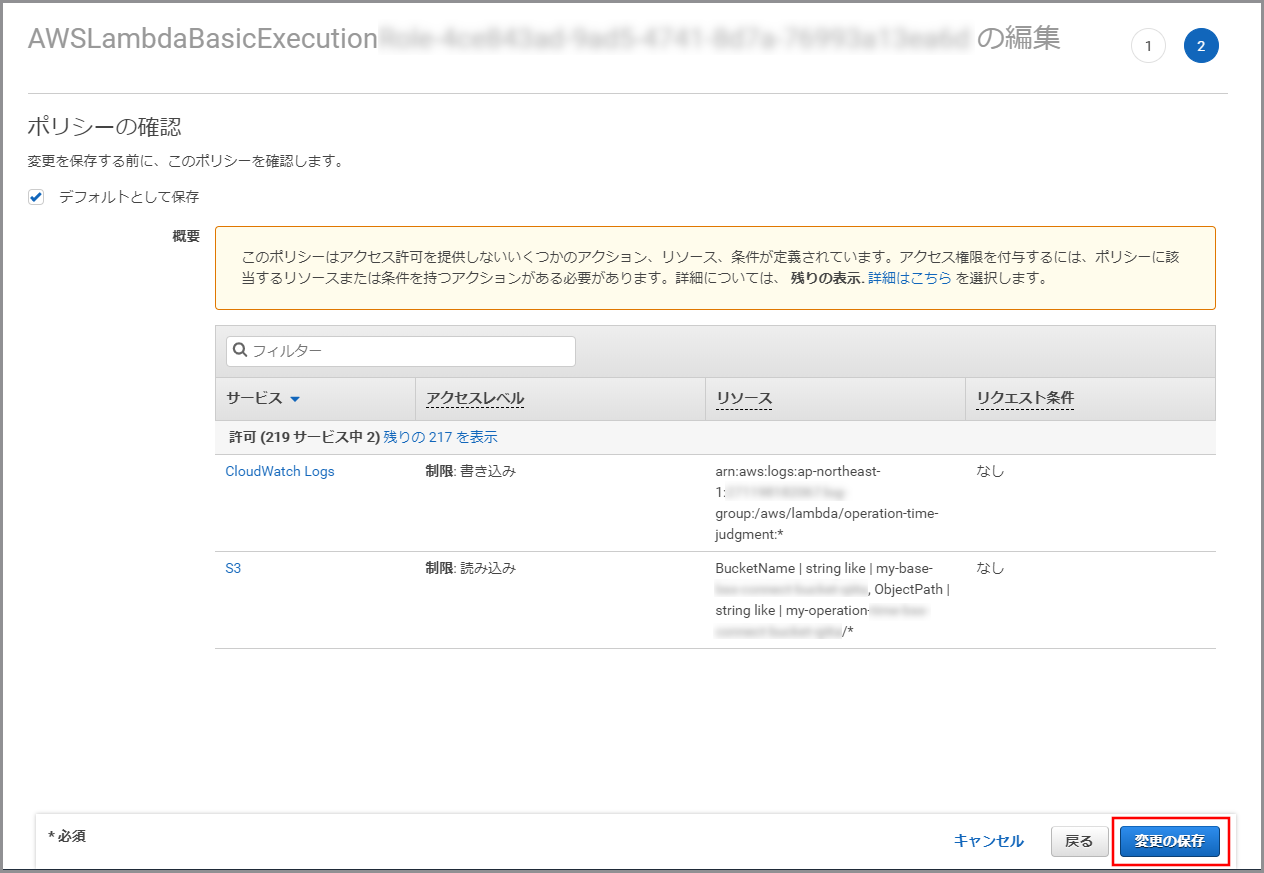
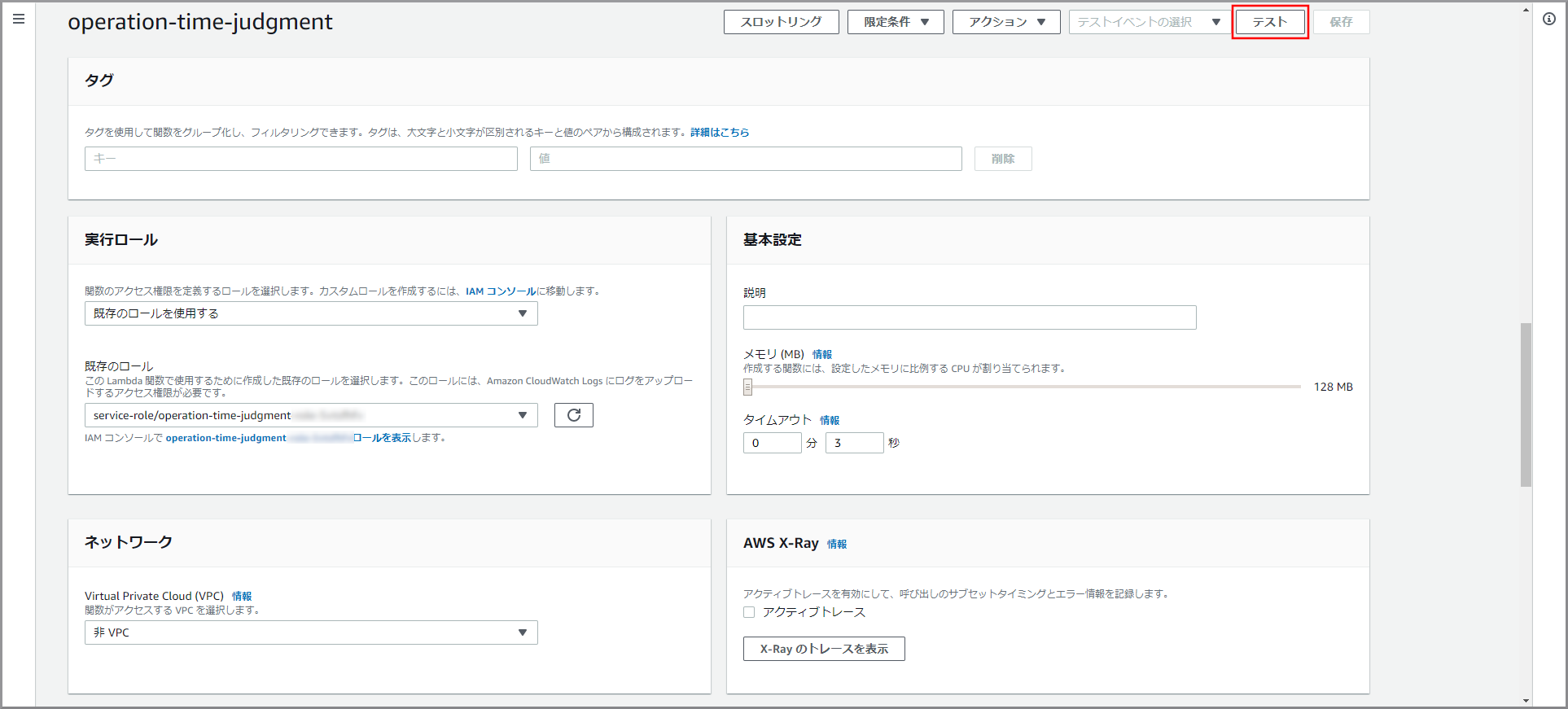
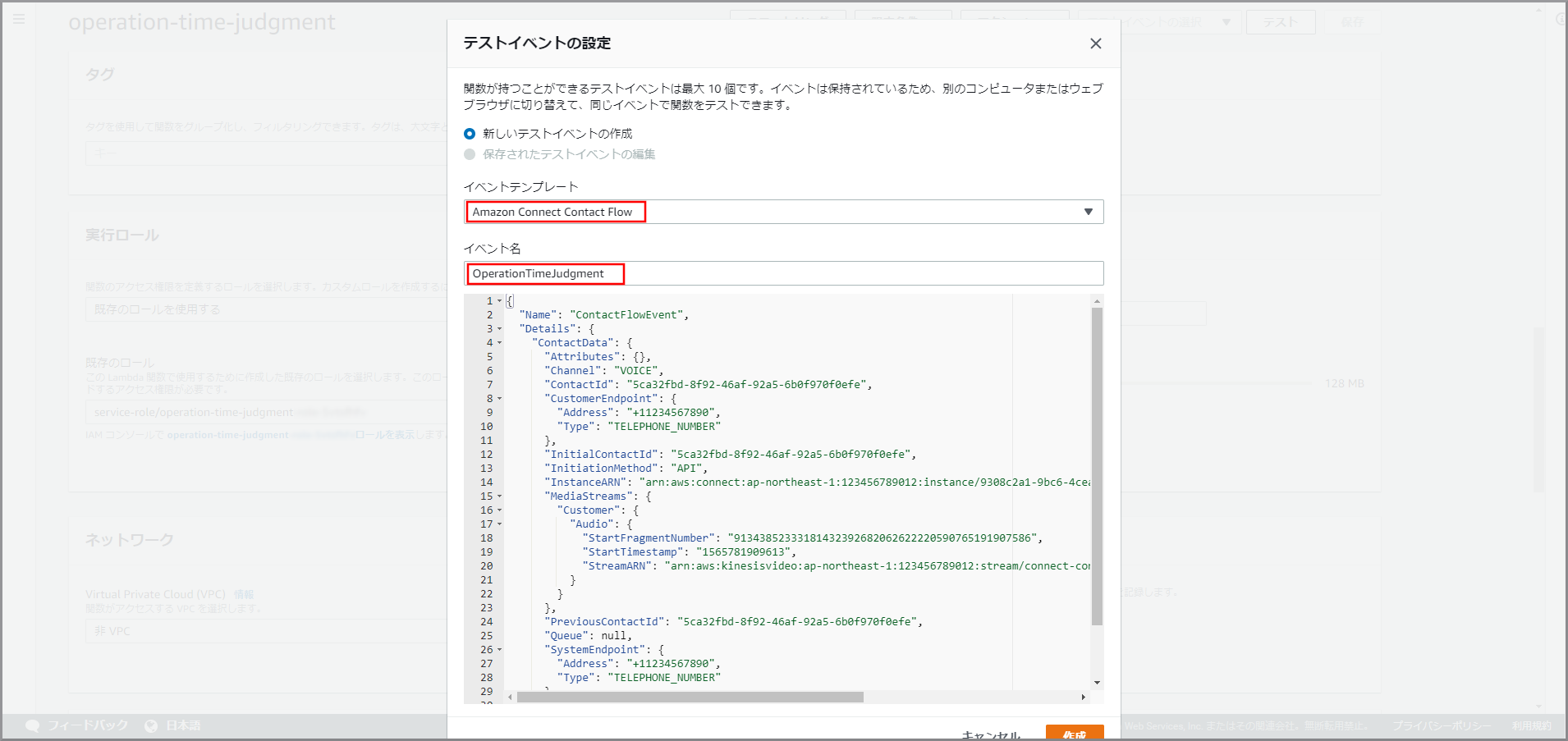
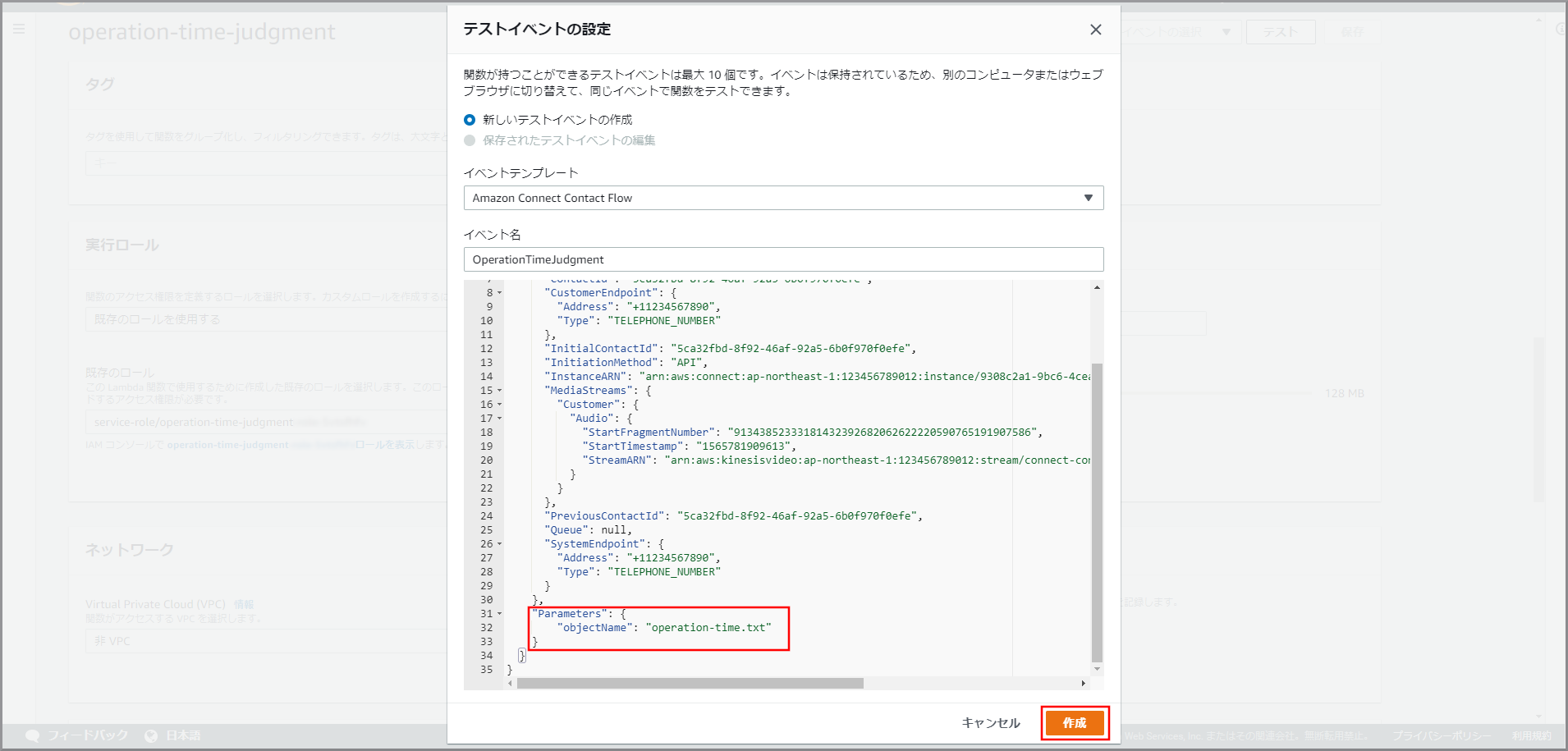
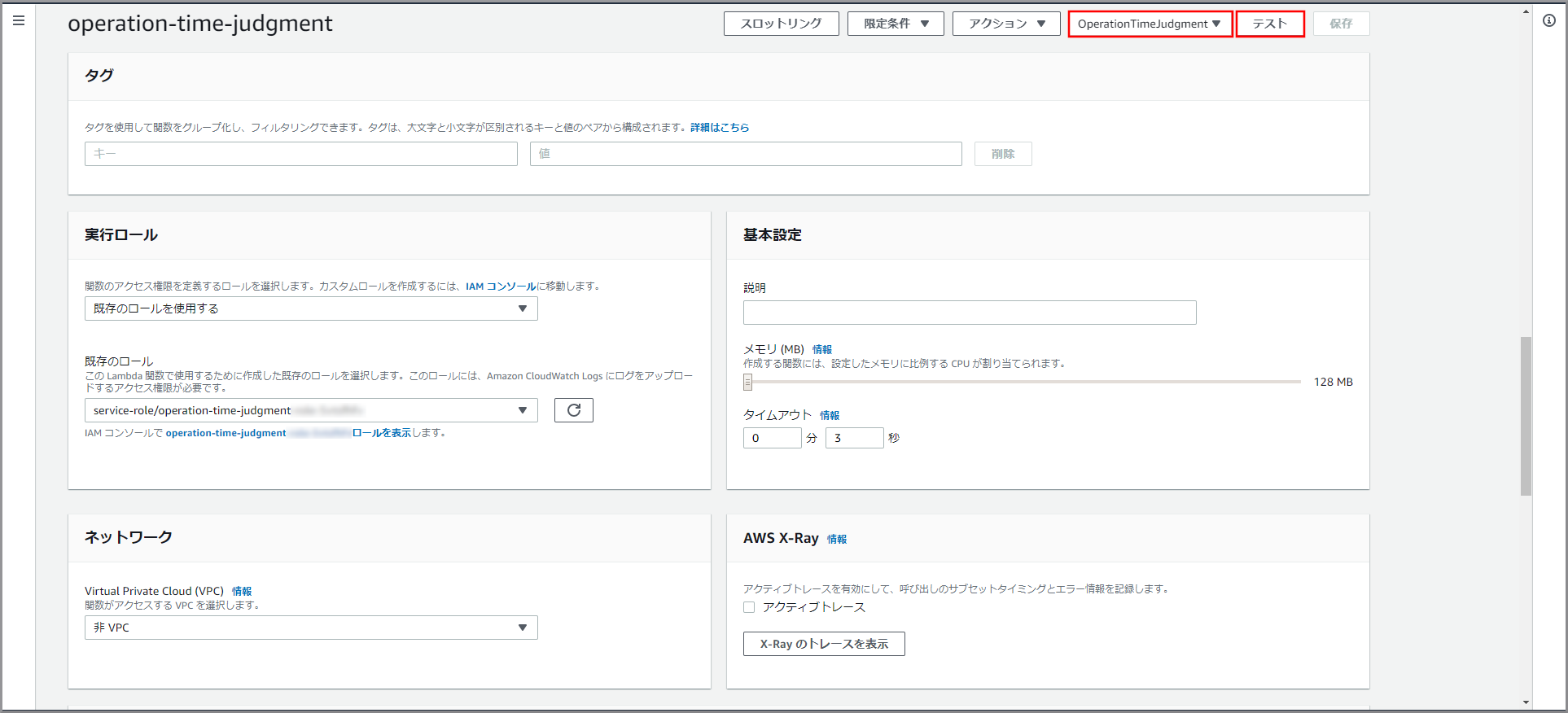
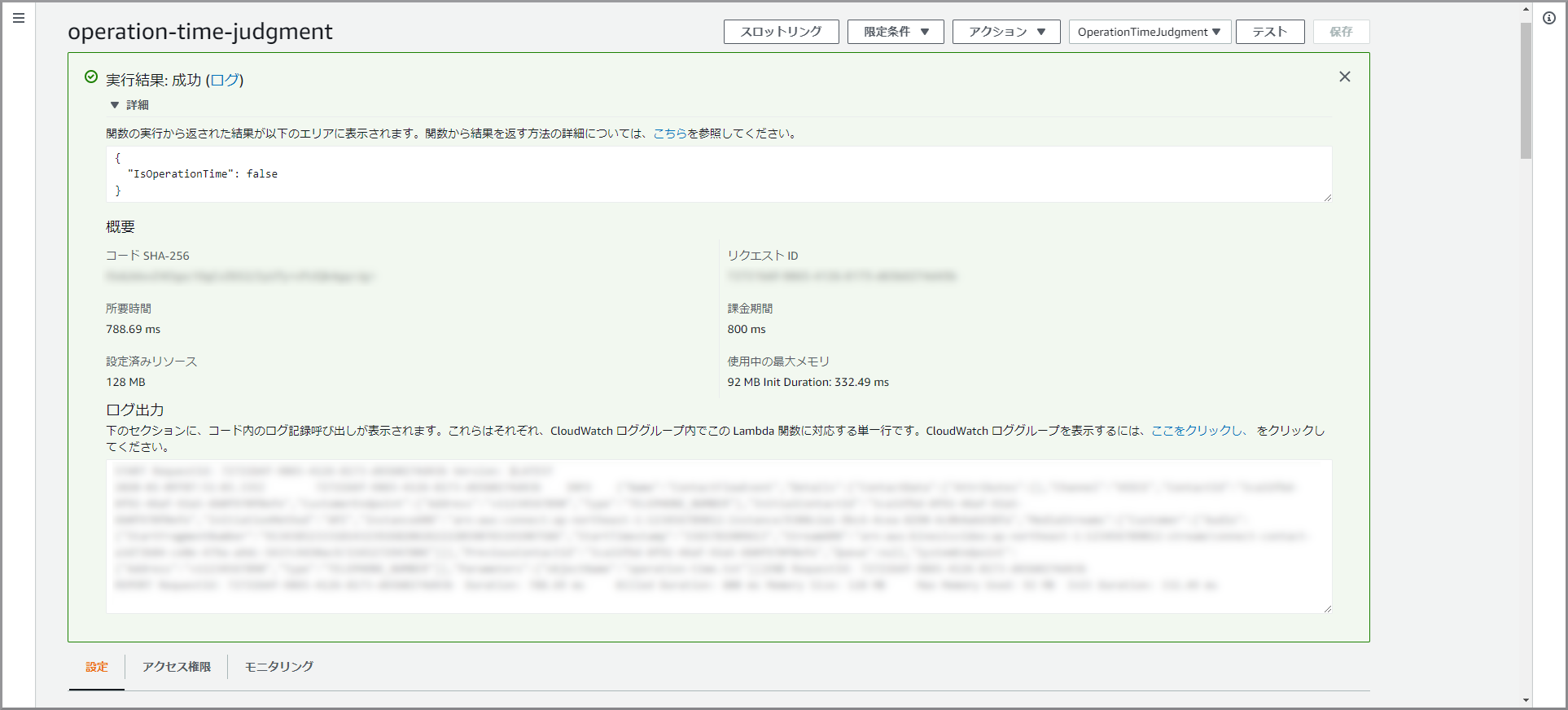
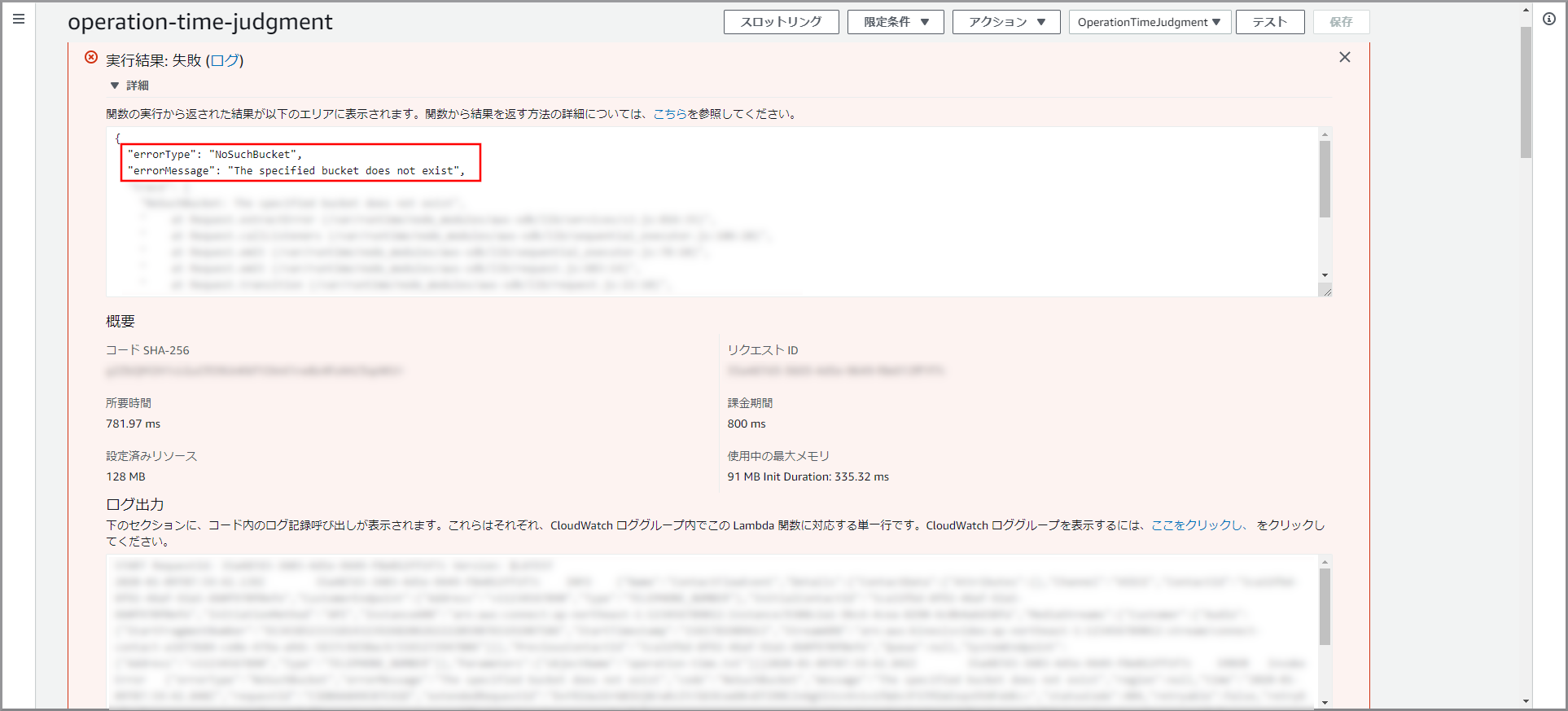
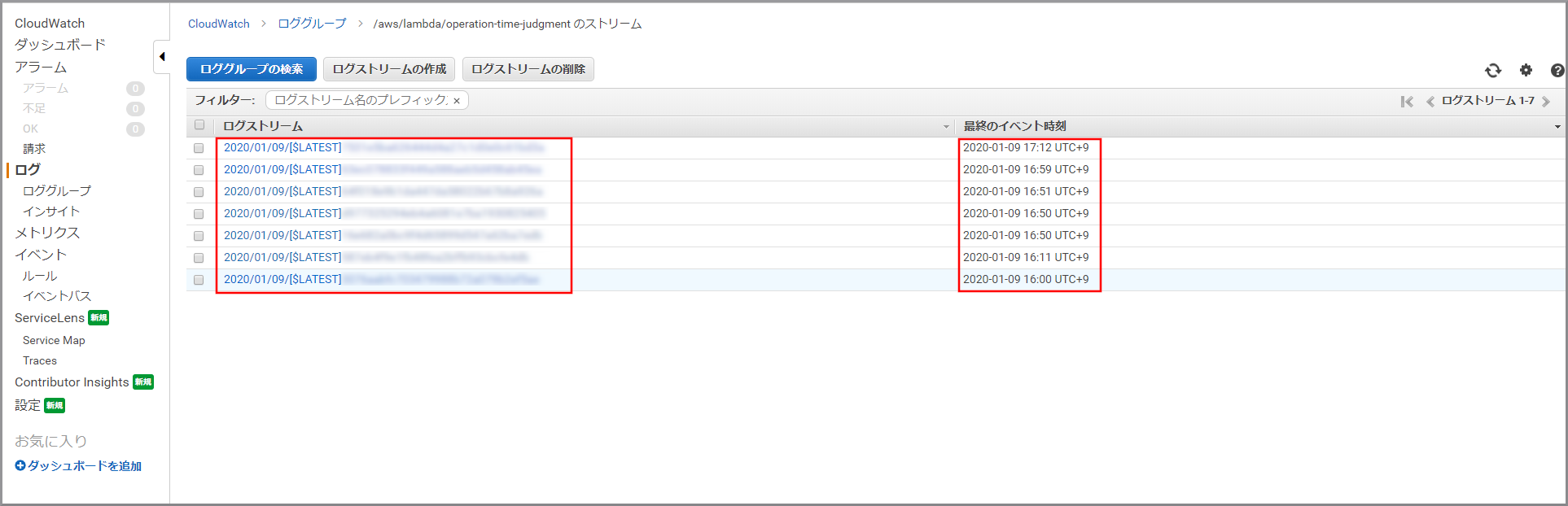
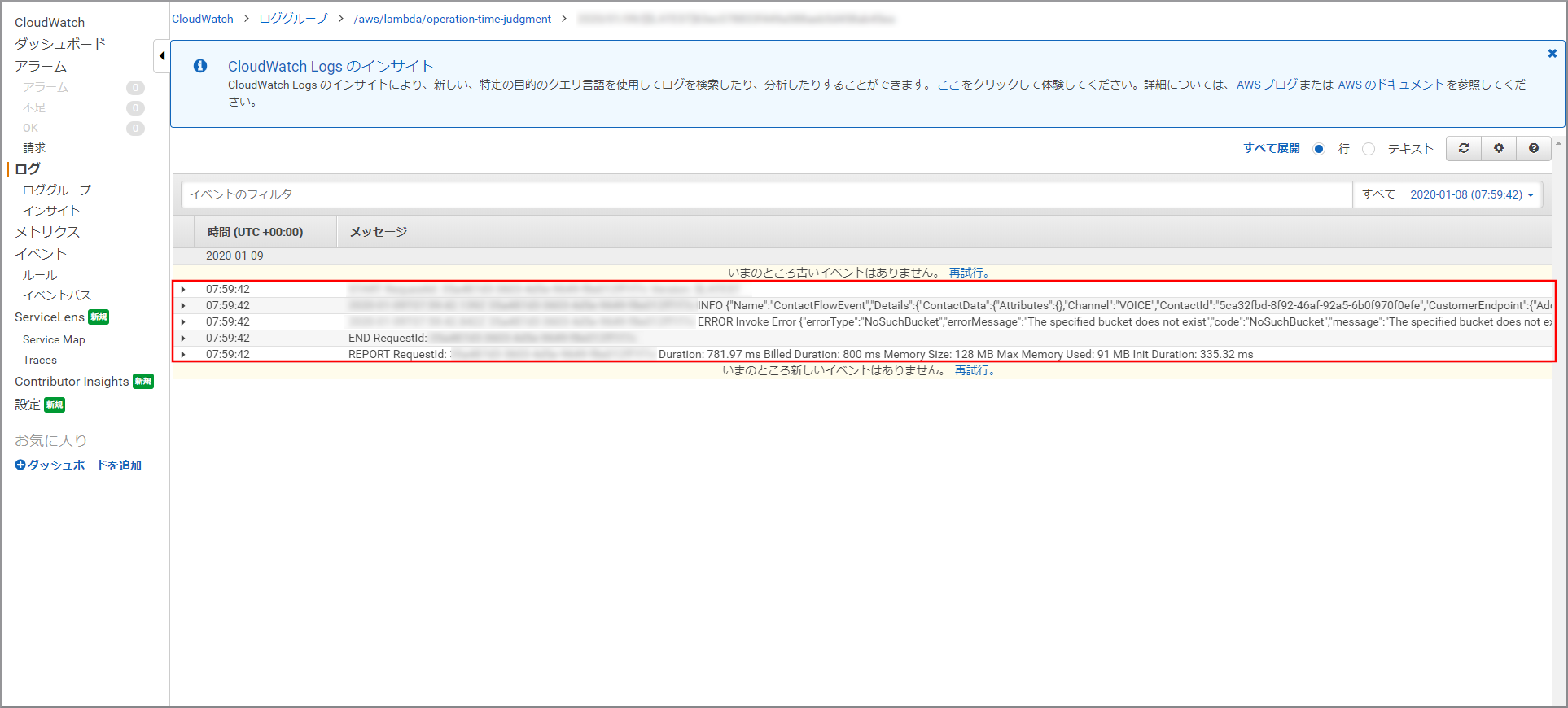

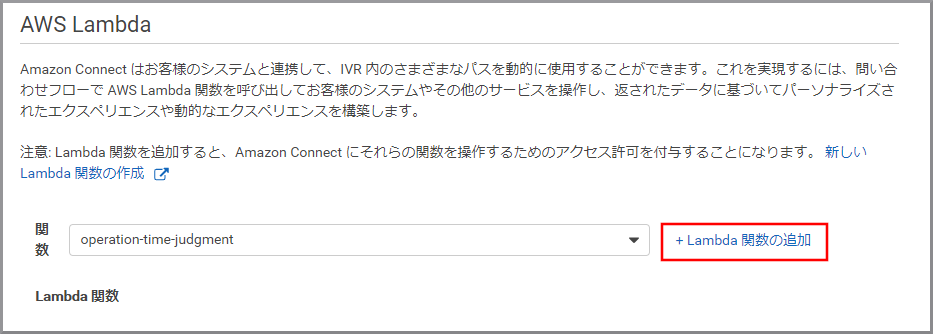
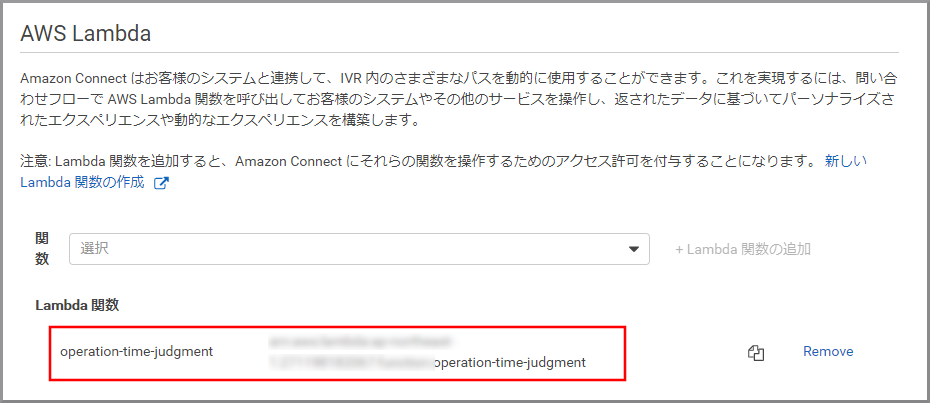


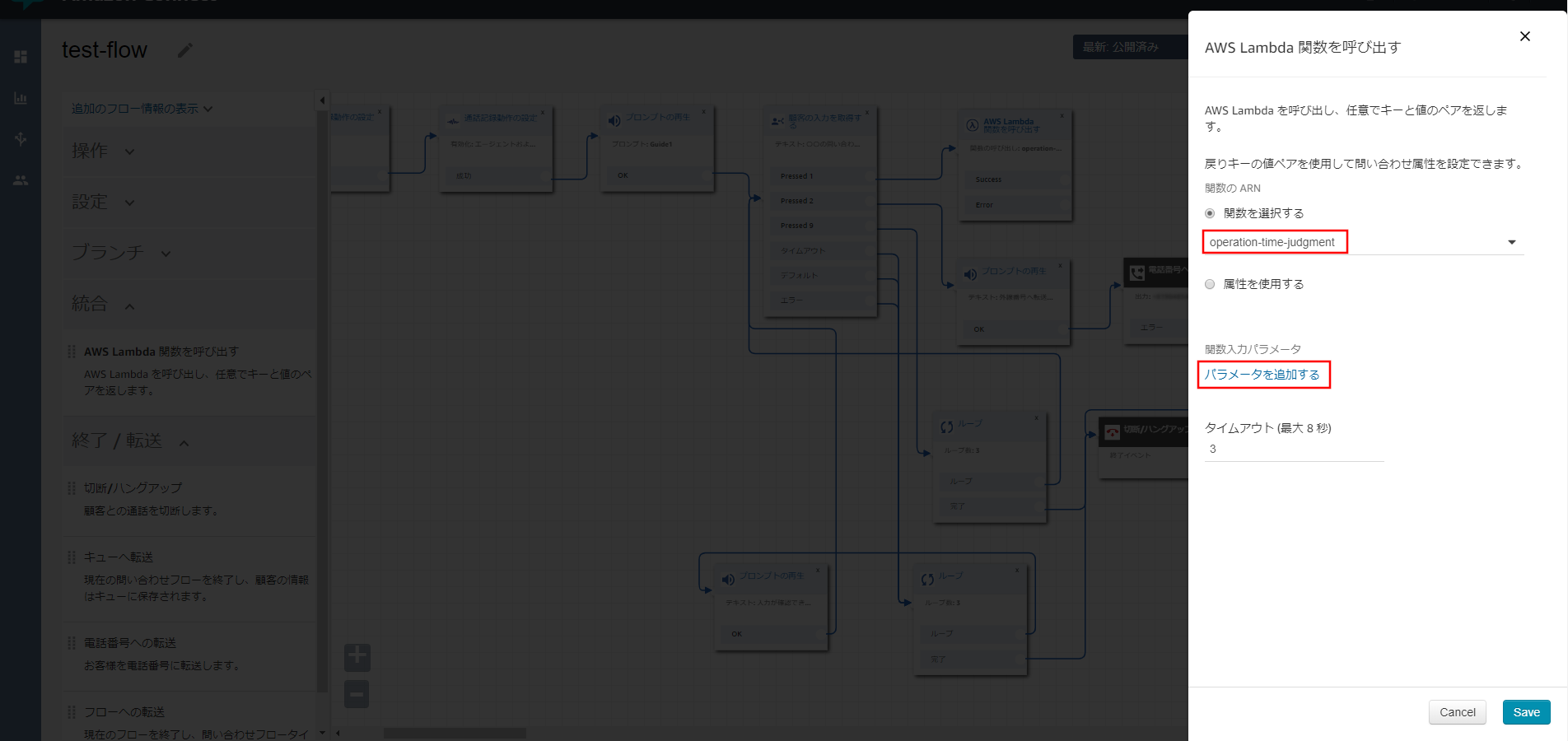
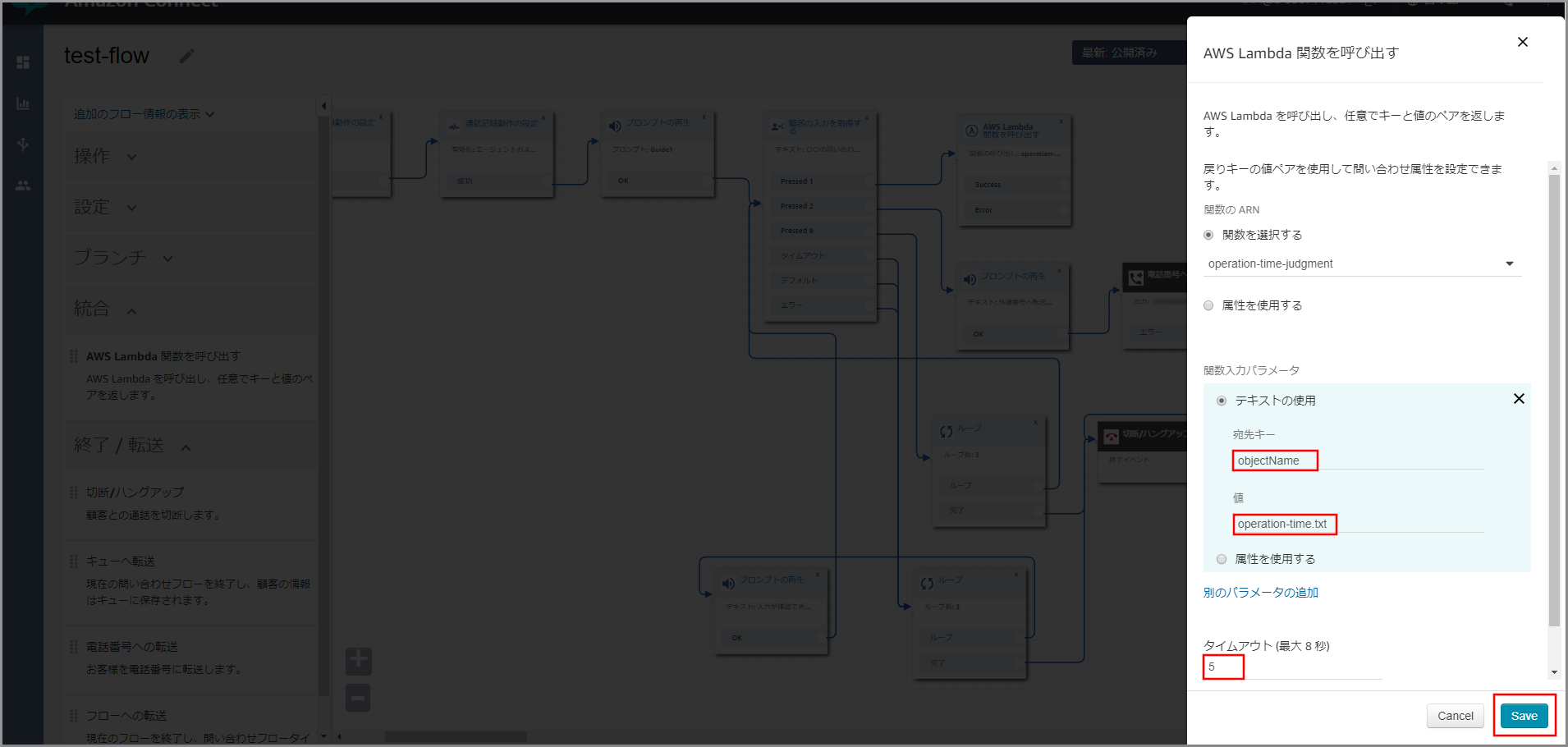

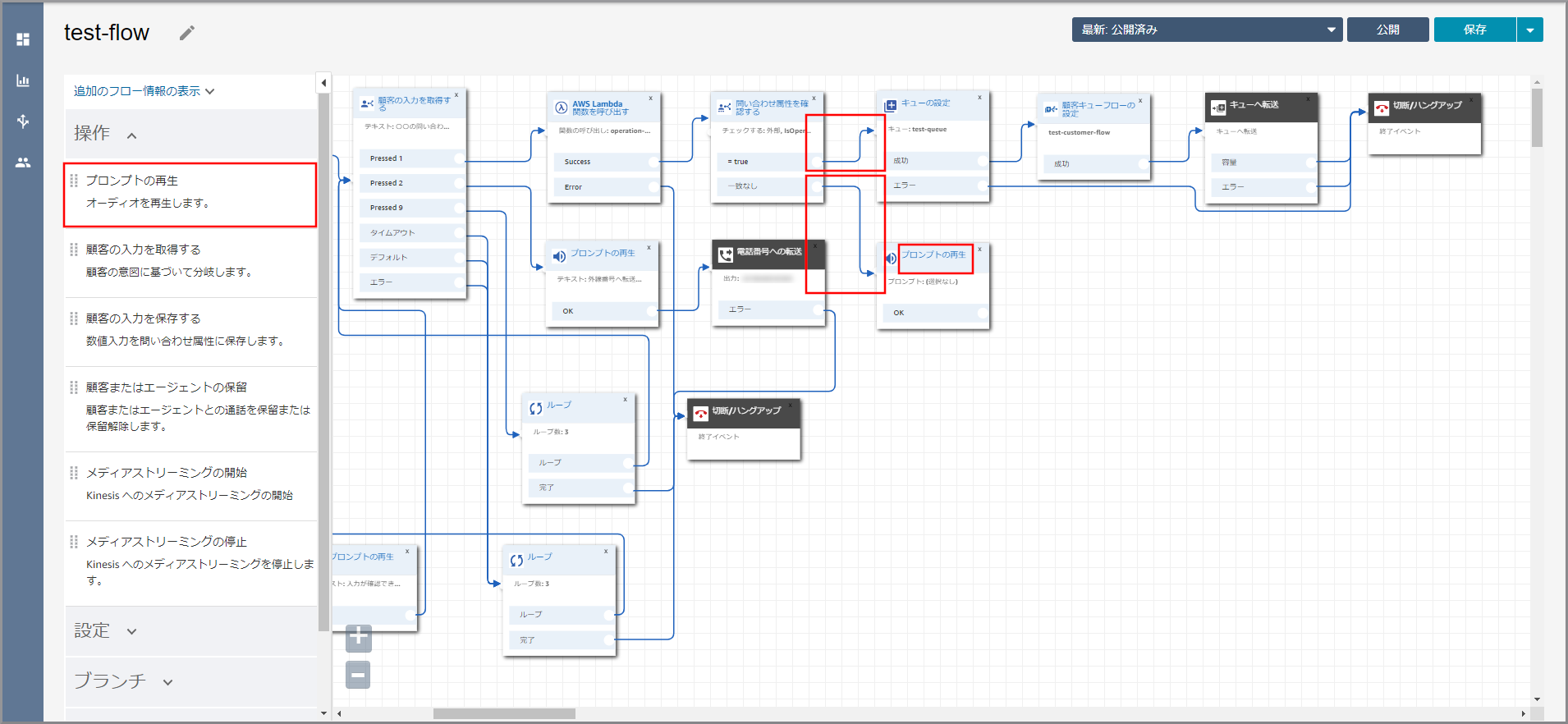
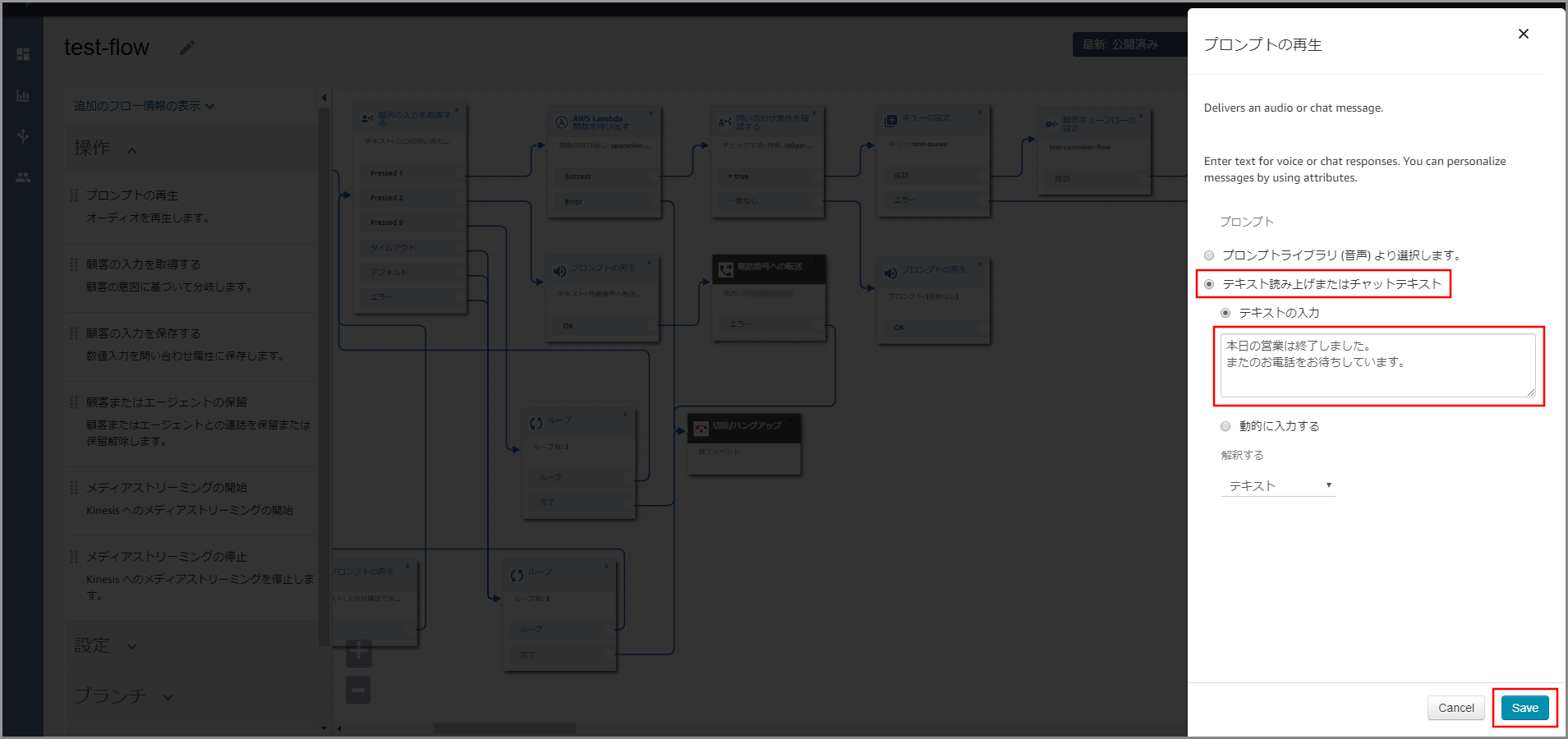
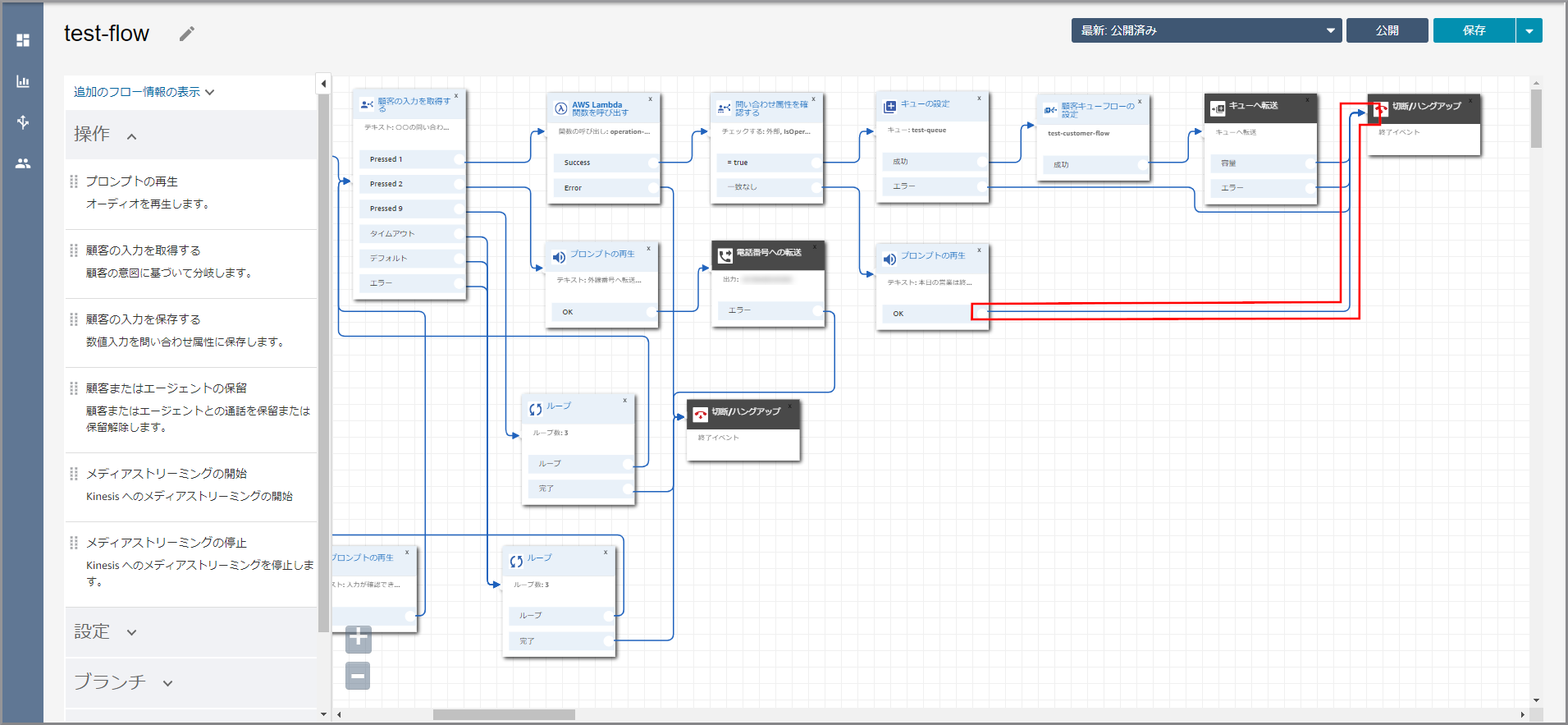

- 投稿日:2020-01-24T10:17:38+09:00
画像から人物の性別、年齢を推測するLine botを作ってみた
概要
lineを使って、送信した画像から
性別、年齢予想、表情分析を実施するbotを作成しました。こんな感じ
画像を送ると、分析した結果が返ってくる(3人まで同時に写っててOK)
ソースコードはこちら
(ほぼべた書きでとりあえず作ってみたら、満足してしまい
リファクタリングする気力がなくなってしまった)使用言語、技術
- Python3.6
- AWS API Gateway
- AWS Lambda
- AWS S3
- AWS DynamoDB
- AWS rekognition
構成
こんな感じの構成
引っかかったところ
s3の署名付きurlを使って画像を送ろうとしたら送れない
line botに画像を送る際には画像のurlが必要なので、
以下のようなコードで画像をリプライしようとしたらエラーになったs3_url = generate_presigned_url( ClientMethod='get_object', Params={ 'Bucket': BUCKET, 'Key': KEY }, ExpiresIn=60, HttpMethod='GET' ) line_bot_api.reply_message( reply_token=event.reply_token, messages=ImageSendMessage( original_content_url=s3_url, preview_image_url=s3_url ) )LineBotApiError: status_code=400, request_id=xxxxx-xxx-xxx-xxx-xxxxxxxxxx, error_response= { "details": [ { "message": "Length must be between 0 and 1000", "property": "messages[0].originalContentUrl" }, { "message": "Length must be between 0 and 1000", "property": "messages[0].previewImageUrl" } ], "message": "The request body has 2 error(s)" }url長すぎって怒られた・・・
s3の署名付きurlを発行するとurl長すぎて送れないので
新たにパブリックなs3バケットを作成し、
送信する画像をread-onlyでs3に入れてurlを取得することにした# アクセス権を付与してput client.put_object(ACL='public-read', Bucket=bucketname, Body=image, Key=key) # urlは文字列結合で作成 s3_pub_url = 'https://' + bucketname + '.s3-ap-northeast-1.amazonaws.com/' + key line_bot_api.reply_message( reply_token=event.reply_token, messages=ImageSendMessage( original_content_url=s3_pub_url, preview_image_url=s3_pub_url ) )s3のパブリックアクセスは使ったことがなく、
アクセス権限の云々を見よう見まねで色々いじっていたら時間がかかってしまったlambdaでPILモジュールが読み込めない
BoundingBoxを画像上に描画するために、
PILモジュールをインポートしようとしたらエラーになったUnable to import module 'lambda_function': cannot import name '_imaging'ローカルでは動くのに、lambdaだとPILモジュールがインポートできなくてエラーになる
Google先生に聞いてみると、どうもPillowのライブラリはosに依存する部分があるらしい
なので、lambdaが動く環境(= Amazon Linux) にインストールしたPillowライブラリが必要らしい参考サイト:
https://michimani.net/post/aws-use-pillow-in-lambda/上記の記事ではdockerを使ってライブラリを作成していますが、
なんか面倒くさそうだったので、cloud9を利用してライブラリを作成することにした
- cloud9の環境作成
- lambdaのインポート
- 対象のフォルダにPillowライブラリをインストール
python3 -m pip install Pillow -t ./- 対象のフォルダをダウンロードして、s3に上げてデプロイ
- cloud9環境は削除
お金をなるべくかけたくない精神なので、
cloud9の環境はPillowライブラリを作成するためのみに使用したcloud9からダウンロードするとzipで圧縮されているが、
フォルダごとの圧縮なので、そのままlambdaをデプロイすると関数が呼び出せなくてエラーになる(1敗)現状の課題、やりたいことなど
リファクタリング
- コードがほぼべた書きの状態。
せめてDBにアクセスする処理くらいは切り離したいAWSの権限回りの整理
色々考えるのが面倒くさく、lambdaのiamロールに必要のない権限がついてしまっている
必要のない権限は持たないように整理したいDynamoDBの設計
- 今までRDBしか触ったことがなかったので、イマイチ使い方、メリットなどがわかっていない。
使い方もRDBっぽくなってしまっているので、知識を増やして改めて設計を考えてみたい


- 投稿日:2020-01-24T09:00:15+09:00
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #24 (SDK とツールキット)
Amazon Web Services (AWS)のサービスで正式名称や略称はともかく、読み方がわからずに困ることがよくあるのでまとめてみました。
Amazon Web Services (AWS) - Cloud Computing Services
https://aws.amazon.com/全サービスを並べたチートシートもあるよ!
Amazon Web Services (AWS)サービスの正式名称・略称・読み方チートシート - Qiita
https://qiita.com/kai_kou/items/cb29d261c8acc49fd22aまとめルールについては下記を参考ください。
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #1 (コンピューティング) - Qiita
https://qiita.com/kai_kou/items/a6795dbab7e707b0d1a6間違いや、こんな呼び方あるよーなどありましたらコメントお願いします!
SDKs & Toolkits - SDK とツールキット
AWS Cloud Development Kit (AWS CDK)
- 正式名称: AWS Cloud Development Kit
- https://docs.aws.amazon.com/cdk/?id=docs_gateway
- 読み方: クラウド デベロップメント キット
- 略称: AWS CDK
- 俗称: なし
AWS Code Sample Catalog
- 正式名称: AWS Code Sample Catalog
- https://docs.aws.amazon.com/code-samples/latest/catalog/welcome.html
- 読み方: コード サンプル カタログ
- 略称: なし
- 俗称: なし
AWS Command Line Interface (AWS CLI)
- 正式名称: AWS Command Line Interface
- https://docs.aws.amazon.com/cli/?id=docs_gateway
- 読み方: コマンド ライン インターフェイス
- 略称: AWS CLI
- 俗称: なし
Amazon Corretto
- 正式名称: Amazon Corretto
- https://docs.aws.amazon.com/corretto/?id=docs_gateway
- 読み方: コレット
- 略称: なし
- 俗称: なし
AWS Crypto Tools
- 正式名称: AWS Crypto Tools
- https://docs.aws.amazon.com/aws-crypto-tools/?id=docs_gateway
- 読み方: クリプト ツール
- 略称: なし
- 俗称: なし
AWS Serverless Application Model (AWS SAM)
- 正式名称: AWS Serverless Application Model
- https://docs.aws.amazon.com/serverless-application-model/?id=docs_gateway
- 読み方: サーバレス アプリケーション モデル
- 略称: AWS SAM
- 俗称: なし
他のまとめ
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #1 (コンピューティング) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #2 (ストレージ) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #3 (データベース) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #4 (開発者用ツール) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #5 (セキュリティ、アイデンティティ、コンプライアンス) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #6 (暗号化と PKI) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #7 (機械学習) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #8 (マネジメントとガバナンス) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #9 (移行と転送) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #10 (モバイル) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #11 (ネットワーキングとコンテンツ配信) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #12 (メディアサービス) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #13 (エンドユーザーコンピューティング) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #14 (分析) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #15 (アプリケーション統合) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #16 (ビジネスアプリケーション) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #17 (サテライト) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #18 (ロボット工学) - Qiita
- 投稿日:2020-01-24T00:52:43+09:00
LocalStack で AWS CLI の練習をする
LocalStack とは、AWS のリソースのモックをローカルに作成するツール。
LocalStack は AWS CLI の練習をするのに最適なのではと思い立ち実験してみた。前提
- Docker がインストールされていること
- Python 3 がインストールされていること
- AWS CLI がインストールされていること(← awscli-local を使用するなら必要ないかもしれない)
LocalStack のコンテナ作成
LocalStack の Docker イメージを使用することでコマンド1発で LocalStack 環境が出来上がる。
docker run -itd --rm -p 4567-4597:4567-4597 -p 8080:8080 localstack/localstack:latest※ docker run のオプションの説明
-itd:-i -t -dの略。ざっくり言うと「バックグラウンド」で「起動しっぱなし」にする--rm: コンテナ停止時にコンテナを削除-p: ホストとコンテナとのポート疎通設定。4567-4597は 4567 から 4597 ポートを表す※ 8080 ポートについて
LocalStack にはダッシュボード機能がある。
ダッシュボードが 8080 ポートで起動されるため 8080 を開放している。
しかし、コンテナ起動後に http://localhost:8080 にアクセスすると下記のメッセージが表示される。This dashboard is outdated and may be removed in a future version. Please check out LocalStack Pro for a more up-to-date UI.
- 無料版 LocalStack のダッシュボードはいつか削除されるかも
- 最新のダッシュボード機能を使うには有料版の LocalStack Pro を使って
とのこと。
awscli-local をインストール(任意)
LocalStack に対して
awsコマンドを実行するとき、--endpoint-url=http://localhost:<各サービスに割り当てられたポート番号>を指定する必要がある。(AWS CLI を使用した例)
aws --endpoint-url=http://localhost:4568 kinesis list-streams毎回
--endpoint-urlを指定するのは面倒。。そこで awscli-local の出番。awscli-local のインストールは pip で行う。
pip install awscli-local(awscli-local を使用した例、LocalStack 使用時のオプションを省略できる!)
awslocal kinesis list-streams動作確認
awscli-local を使って動作確認する。
パラメータストア作成
awslocal ssm put-parameter \ --name sample-param \ --value sample-value \ --type Stringパラメータストア取得
awslocal ssm get-parameter --name sample-paramS3 バケット作成
awslocal s3 mb s3://sample-bucketS3 バケット一覧取得
awslocal s3 lsS3 ファイルアップロード
touch test.txt awslocal s3 cp test.txt s3://sample-bucket/ rm test.txtS3 バケット内のオブジェクト一覧取得
awslocal s3 ls s3://sample-bucketS3 バケット内のオブジェクト削除
awslocal s3 rm s3://sample-bucket/test.txtまとめ
- LocalStack を使えば AWS CLI を試す環境が簡単に作れることが分かった
- 一部 AWS サービスのモックは 有料版 LocalStack が必要になるが、主要サービスは無料版で十分まかなえる
- LocalStack で心置きなくコマンドを実行して AWS CLI に慣れていきたいと思う
参考ページ
docker runのリファレンス
https://docs.docker.com/engine/reference/commandline/run/LocalStack のリポジトリ
https://github.com/localstack/localstackawscli-local のリポジトリ
https://github.com/localstack/awscli-local
aws ssmのリファレンス
https://docs.aws.amazon.com/cli/latest/reference/ssm/index.html
aws s3のリファレンス
https://docs.aws.amazon.com/cli/latest/reference/s3/index.html
- 投稿日:2020-01-24T00:35:57+09:00
新しめの設定をいれた AWS Billing and Cost Management 総まとめ
1. はじめに
- 私が現在行っている AWS Billing and Cost Management 設定がかなりレガシーなものになっているので、新しめの設定へ移行する。
- AWS Billing and Cost Management 設定やること/やらないことリストをアップデートする。
- 設定を CloudFormation, Terraform 化できるところは作成する。
2. やること/やらないことリスト
2.1. やることリスト
アカウントの請求情報の表示を IAM ユーザーに許可
- 手動で設定する。(要ルートユーザー)
Cost Explorer 有効化と設定
- 手動で設定する。
コスト配分タグをアクティブ化
- 手動で設定する。
電子メールで PDF 版請求書を受け取る設定
- 手動で設定する。
Budgets 作成
- 従来の「請求書アラート」設定は止めて、こちらを使う。
- Terraform で設定する。
Cost & Usage Reports 作成
- 従来の「AWSの請求明細レポート(DetailedBillingReport)」を止めて、こちらを使う。
- Terraform で設定する。
Billing管理専用IAMユーザ作成
- CloudFormation で設定する。
2.2. やらないことリスト
AWS支払の円払いへの切り替え設定
- 現時点でこの機能を利用できるクレジットカードは、VISA と Master カード。
- 私が登録しているクレジットカードは JCB なので使えない。。ので、デフォルトの USD のままで。
- AWS支払の円払いへの切り替え方法について
Budgets Reports 作成
- いまのところ予算管理は行ってないので。
- 現時点 Terraform に Budgets Reports のリソースがない。
- AWS 予算レポートのご紹介
請求アラートを受け取る設定と、請求アラーム設定
- Budgets 設定へ移行したので。
- AWS の予想請求額をモニタリングする請求アラームの作成
有効期限が切れる予約(リザーブドインスタンス)のアラート通知設定
- 現時点では、メール通知のみ。
- Slackへ通知したいので、自作した監視設定を入れている。
- AWS Cost Explorer で予約の有効期限切れアラートを提供開始
3. やることリストの設定
3.1. アカウントの請求情報の表示を IAM ユーザーに許可
3.1.1. 目的
- AWSアカウント開通直後のデフォルト設定では、請求情報へアクセスすることができるのはルートユーザーのみとなっている。
- ルートユーザーはAWSアカウント開通時だけ使用するユーザーであり、IAMドキュメント では、日常の作業で AWS ルートユーザーを使用しないことを推奨している(サポートプラン変更など、ルートユーザーしか設定できない場合は除く)。
- IAMユーザーにも請求書情報へのアクセスを許可するために、この設定を行う。
- ただし、この設定だけでは IAMユーザーは請求書情報へアクセスすることはできない。請求書情報へアクセスしたい IAMユーザー(例えば、AWS管理者ユーザー、経理部門ユーザー、Terraformユーザーなど)に Billing ポリシーをアタッチする必要がある。
- Billing のすべての権限を許可したい場合は、IAMポリシーの「AWS管理のジョブ機能」の「Billing」ポリシーをアタッチする。
3.1.2. 設定
(1) ルートユーザーでサインインする
(2) マイアカウント
(3) IAM ユーザー/ロールによる請求情報へのアクセス の箇所までスクロール
(ルートユーザー以外がサインインしたときには表示されない)「IAM アクセスのアクティブ化」にチェックを入れて、更新
(4) 確認
「IAM ユーザー/ロールによる請求情報へのアクセスは有効になっています。」
と表示されていることを確認
(5) 設定が終わったら、速やかにルートユーザーをサインアウトする
3.2. Cost Explorer 有効と設定
3.2.1. 目的
Cost Explorer は、コストと使用状況を表示および分析するために使用できるツール。メイングラフ、Cost Explorer コストと使用状況レポート、または Cost Explorer RI レポートを使用して、使用状況とコストを確認できる。
コスト配分タグを利用することで、より効率的なコスト管理ができる。
EC2 リソース最適化推奨を確認し、できることがあれば対応する
リザーブドインスタンスの利用状況を確認する。
3.2.2. 設定
(1) 「Billing」ポリシーをアタッチしたIAMユーザーでサインインする
(2) 「請求情報とコスト管理ダッシュボード」(Billing) コンソールへ
(3) Cost Esplorer へ
(4) コストエクスプローラーを有効化 する
※ すでに有効化してあるので、画面キャプチャは取れず・・
※ Cost Explorer を有効にした後、コストと使用状況のデータが追加されるまで、最大 24 時間かかることがある。(5) コストエクスプローラーを起動 する
(6) 設定画面へ
(7) 「時間単位とリソースレベルのデータ」と「Amazon EC2 リソースの推奨事項を受け取る」にチェックを入れる
(8) リザーブドインスタンスの有効期限切れアラート設定を行う場合
※ 現時点では、メール通知のみ。私はSlackへ通知したいので、自作した監視設定を入れている。
3.3. コスト配分タグをアクティブ化
3.3.1. 目的
- Cost Explorer で効率的なコスト管理を行う。
3.3.2. 設定
(1) 「Billing」ポリシーをアタッチしたIAMユーザーでサインインする
(2) 「請求情報とコスト管理ダッシュボード」(Billing) コンソールへ
(3) コスト配分タグ へ
(4) 有効化 を押下で有効にする
(5) ユーザー定義のコスト配分タグ設定
コスト配分タグに設定したいタグにチェックを入れて、有効化 を押下する。
※ 設定したタグが Cost Explorer に表示されるまで最大 3 日かかることがある。
3.4. 電子メールで PDF 版請求書を受け取る設定
3.4.1. 目的
- 毎月3日か4日くらいに、前月分の請求書のPDFファイルを指定したメールアドレスへ送信する。
3.4.2. 設定
(1) 「Billing」ポリシーをアタッチしたIAMユーザーでサインインする
(2) 「請求情報とコスト管理ダッシュボード」(Billing) コンソールへ
(3) Billing の設定 へ
(4) 電子メールで PDF 版請求書を受け取る にチェックをいれて、設定を保存する
3.5. Budgets 設定
3.5.1. 目的
予算の管理を行う。
予算がアラートの閾値を超えた場合に通知(Eメール or SNSトピック)する。
実際のコストがアラートの閾値を超えた場合に通知(Eメール or SNSトピック)する。
従来の「請求書アラート」設定よりもきめ細かいアラート設定ができる。
3.5.2. Budgets 設定
※ ここでは、1ヶ月の実際のコストが閾値を超えた場合に通知する設定を行う。
※ 通知を SNS トピックで行う場合は、事前に SNS トピックを作成しておく。(1) 「Billing」ポリシーをアタッチしたIAMユーザーでサインインする
(2) 「請求情報とコスト管理ダッシュボード」(Billing) コンソールへ
(3) Budgets へ
(4) 「Create a budget」へ}
(5) 「コスト予算」へ
(6) 予算の設定
名前:〇〇〇
間隔:月別
定期予算
開始月:〇〇〇
予算額:〇〇〇※ 設定例
(7) アラートの設定
次に基づいてアラートを送信:実際のコスト
アラートの閾値:〇〇〇 金額
SNS トピックのARN:〇〇〇※ 設定例
3.5.3. 従来の「請求書アラート」設定は止める
(1) 「Billing」ポリシーをアタッチしたIAMユーザーでサインインする
(2) 「請求情報とコスト管理ダッシュボード」(Billing) コンソールへ
(3) Billing の設定 へ
(4) 請求書アラートは、一度オンにするとオフに戻すことはできない・・
(5) バージニア北部リージョンの CloudWatch にある 請求アラームを削除する
3.5.4. Terraform
- 3.5.2. で行った設定の Terraform(0.11, 0.12対応)例
resource "aws_budgets_budget" "cost" { budget_type = "COST" limit_amount = "1000.0" limit_unit = "USD" name = "〇〇〇" time_period_start = "2020-01-01_00:00" time_unit = "MONTHLY" cost_types { include_credit = false include_discount = true include_other_subscription = true include_recurring = true include_refund = false include_subscription = true include_support = true include_tax = true include_upfront = true use_amortized = false use_blended = false } notification { comparison_operator = "GREATER_THAN" notification_type = "ACTUAL" subscriber_email_addresses = [] subscriber_sns_topic_arns = [ "arn:aws:sns:us-east-1:〇〇〇:〇〇〇" ] threshold = 800 threshold_type = "ABSOLUTE_VALUE" } }3.6. Cost & Usage Reports 作成
3.6.1. 目的
※ 一般的な目的
AWS のコストと使用状況レポートは、AWS 請求に関する詳細なデータセットを提供し、選択した Amazon Simple Storage Service (Amazon S3) バケットに配信されます。次の 2 つの方法のいずれかでコストと使用状況レポートを表示できます。
- S3 バケットから .csv 形式のレポートファイルを表示またはダウンロードします。
- レポートを Amazon Athena、Amazon QuickSight、または Amazon Redshift に取り込みます。
AWS のコストと使用状況レポートには、アカウントとその IAM ユーザーが使用した各サービスカテゴリの AWS 使用状況が、時間単位または日単位の明細項目として一覧表示されているほか、コスト配分のためにアクティブ化されたタグも表示されます。また、AWS のコストと使用状況レポートをカスタマイズし、使用状況のデータを日単位または時間単位で集計することも可能です。
Amazon Athena に統合するように、コストと使用状況レポートを 設定することも可能です。Amazon Athena と、AWS のコストと使用状況レポートとの統合が有効化されると、ユーザーのデータは、圧縮された Apache Parquet ファイルとしてユーザーが指定した Amazon S3 バケットに配信されます。AWS のコストと使用状況レポートは、Amazon Redshift に直接取り込むか、または、Amazon QuickSight にアップロードすることも出来ます。
参考
※ 個人的な目的
- 従来の 請求明細レポート(DBR: Detailed Billing Report)設定をなんとなく入れていたけど、結局、S3バケットに配信されたレポートをダウンロードして開くことは、最初の設定時くらいだけだった。。
- そして、請求明細レポート(DBR)はレガシーな存在となって、コストと使用状況レポート(CUR: Cost and Usage Report)へ移行することを強く勧めている。
- コストと使用状況レポート(CUR)では、レポート活用手段が増え、今後もしかしたら活用する機会があるかもしれないので、請求明細レポート(DBR)からコストと使用状況レポート(CUR)へ移行しておくことにする。
- 参考
3.6.2. コストと使用状況レポート(CUR)設定
(1) 「Billing」ポリシーをアタッチしたIAMユーザーでサインインする
(2) 「請求情報とコスト管理ダッシュボード」(Billing) コンソールへ
(3) Cost & Usage Reports へ
(4) レポートの作成 へ
(5) レポートの明細項目
設定例
(6) 配信オプション
レポートを配信する S3 バケットを設定する
既存バケットを選択 あるいは 新規に作成する
ポリシーの確認にチェックを入れる
今回は、レポートデータ統合の有効化 はチェックしない
確認して完了
3.6.3. 請求明細レポート(DBR)を停止する
(1) 「Billing」ポリシーをアタッチしたIAMユーザーでサインインする
(2) 「請求情報とコスト管理ダッシュボード」(Billing) コンソールへ
(3) Billing の設定 へ
(4) 請求明細レポート(レガシー)設定を無効にする
「レガシー化した請求明細レポート機能を使って、AWS の料金に関する継続的なレポートを受け取る。」のチェックを外して、設定を保存する。
レポートを保存していたS3バケットは、消さずに残しておく。3.6.4. Terraform
3.6.2. で行った設定の Terraform(0.11, 0.12対応)例
コストと使用状況レポートは、バージニア北部(us-east-1)リージョンに作成する必要がある。
S3バケットは 東京(ap-northeast-1)リージョンに作成する。
なので、Multiple Providers 機能を使う。provider "aws" { shared_credentials_file = "credentials" profile = "terraform" region = "ap-northeast-1" } provider "aws" { shared_credentials_file = "credentials" profile = "terraform" alias = "virginia" region = "us-east-1" }アクセスキーID と シークレットアクセスキー を credentials ファイルに設定する。
[terraform] aws_access_key_id = ******************** aws_secret_access_key = ****************************************AWSアカウントIDを data "aws_caller_identity" "current" {} で取得している。
S3 バケット名は「cost-report-AWSアカウントID」としている。data "aws_caller_identity" "current" { } data "aws_iam_policy_document" "s3bucket-policy" { version = "2008-10-17" statement { sid = "Stmt1" effect = "Allow" principals { type = "Service" identifiers = ["billingreports.amazonaws.com"] } actions = [ "s3:GetBucketPolicy", "s3:GetBucketAcl" ] resources = [ "${aws_s3_bucket.cost-report.arn}" ] } statement { sid = "Stmt2" effect = "Allow" principals { type = "Service" identifiers = ["billingreports.amazonaws.com"] } actions = [ "s3:PutObject" ] resources = [ "${aws_s3_bucket.cost-report.arn}/*" ] } } resource "aws_s3_bucket" "cost-report" { bucket = "cost-report-${data.aws_caller_identity.current.account_id}" acl = "private" force_destroy = "false" region = "ap-northeast-1" } resource "aws_s3_bucket_policy" "cost-report" { bucket = "${aws_s3_bucket.cost-report.bucket}" policy = "${data.aws_iam_policy_document.s3bucket-policy.json}" } resource "aws_cur_report_definition" "cost-report" { provider = "aws.virginia" report_name = "〇〇〇" s3_bucket = aws_s3_bucket.cost-report.bucket s3_region = "ap-northeast-1" format = "textORcsv" compression = "GZIP" additional_schema_elements = ["RESOURCES"] time_unit = "DAILY" }3.7. Billing管理専用IAMユーザ作成
3.7.1. 目的
- 経理部門など、Billing設定以外は操作しない利用者用
3.7.2. CloudFormation
- 概要
- IAMグループ BillingUsers を作成
- IAMグループに IAMポリシーの「AWS管理のジョブ機能」の「Billing」ポリシーをアタッチする。
- IAMユーザ yamada-taro を作成して、IAMグループ BillingUsers へ所属させる
- 初期パスワードを適当に設定
- 初回ログイン時にパスワードを変更させる
※ MFA の設定忘れずに。
Resources: IAMGroupBillingUsers: Type: AWS::IAM::Group Properties: GroupName: BillingUsers ManagedPolicyArns: - "arn:aws:iam::aws:policy/job-function/Billing" Path: "/" IAMManagedPolicyIAMChangePassword: Type: AWS::IAM::ManagedPolicy Properties: Description: "IAM Change Password" Groups: - !Ref IAMGroupBillingUsers ManagedPolicyName: "IAMChangePassword" Path: "/" PolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Action: "iam:GetAccountPasswordPolicy" Resource: "*" - Effect: "Allow" Action: "iam:ChangePassword" Resource: "arn:aws:iam::397190037767:user/${aws:username}" IAMUserBilling: Type: AWS::IAM::User Properties: UserName: "yamada-taro" Groups: - !Ref IAMGroupBillingUsers LoginProfile: Password: "z2854jBW!M(%3%dpJT-f" PasswordResetRequired: true Path: "/"