- 投稿日:2020-01-22T23:29:44+09:00
docker-compose で Cloud Datastore Emulatorを立ち上げpythonアプリと連携する
背景
サービスでdatastoreを使う事になり、開発環境やCIでのテストをどうするか試行錯誤した。

AWSと比較して情報が少ないので、まとめた。
要点
- flaskアプリとCloud Datastore Emulatorをコンテナを作る
- docker-composeでサービス連携を行う
- datastoreの初期データ投入
- flaskアプリから、Cloud Datastore Emulatorを操作する
ディレクトリ構成
. ├── app │ ├── Dockerfile │ └── src │ ├── main.py │ └── requirements.txt ├── datastore │ ├── Dockerfile │ ├── entrypoint │ └── import │ ├── 2020-01-21.overall_export_metadata │ ├── default_namespace │ │ └── kind_test_data │ │ ├── default_namespace_kind_test_data.export_metadata │ │ └── output-0 │ └── run.sh └── docker-compose.yamlCloud Datastore Emulator コンテナ構築
datastore/Dockerfile
公式のSDKイメージから最小限で作成。
エミュレータ起動用shell、データ投入用shellに実行権限付与。FROM google/cloud-sdk:alpine RUN apk add --update --no-cache openjdk8-jre \ && gcloud components install cloud-datastore-emulator beta --quiet COPY . /datastore/ WORKDIR /datastore RUN chmod +x ./entrypoint RUN chmod +x ./import/run.sh ENTRYPOINT ["./entrypoint"]datastore/entrypoint
docker-compose downした際にも、データを維持するために、/datastore/.data/ディレクトリにデータをためる。オプションなしで起動すると、コンテナ内でしかアクセスできないので、
--host-port=0.0.0.0:8081として起動する。
環境変数から、プロジェクト名と一緒に流し込む。#!/usr/bin/env bash gcloud config set project ${DATASTORE_PROJECT_ID} gcloud beta emulators datastore start \ --data-dir=/datastore/.data \ --host-port=${DATASTORE_LISTEN_ADDRESS}データ投入のdatastore/import/run.sh
サーバー起動後、下記のエンドポイントにdump済みのデータの保存パスを投げるとデータがインポートできる。
export DATASTORE_PROJECT_ID curl -X POST localhost:8081/v1/projects/${DATASTORE_PROJECT_ID}:import \ -H 'Content-Type: application/json' \ -d '{"input_url":"/datastore/import/2020-01-21.overall_export_metadata"}'datastore/importのメタデータ
今回は、gcp のコンソールから、gcsにダンプしたデータをディレクトリ丸ごと
datastore/import配下に持ってきた。
sdkデータを直接生成してもよい。python アプリ コンテナ構築
サンプル用にペラペラのアプリ構築する。
app/Dockerfile
FROM python:3.7-slim-buster ENV HOME /api/ ADD ./ ${HOME} WORKDIR ${HOME} RUN pip install --upgrade pip \ && pip install --no-cache-dir -r ${HOME}src/requirements.txt ENTRYPOINT ["python", "src/main.py"]app/main.py
ちょっと適当すぎる気がするが、データを保存して取り出すだけのエンドポイントを作成。
認証情報は、ダミーの認証をかませる。
from flask import Flask, jsonify from google.auth.credentials import AnonymousCredentials from google.cloud import datastore from os import getenv client = datastore.Client( credentials=AnonymousCredentials(), project=getenv('PROJECT_ID') ) app = Flask(__name__) app.config['JSON_AS_ASCII'] = False @app.route('/') def index(): key = client.key('EntityKind', 1234) entity = datastore.Entity(key=key) entity.update({ 'foo': u'bar' }) client.put(entity) result = client.get(key) return jsonify(result) if __name__ == '__main__': app.run(host='0.0.0.0')app/requirements.txt
Flask==1.1.1 google-auth==1.6.2 google-cloud-datastore==1.8.0docker-compose.yaml
datastoreのポートは、ホスト側にも開けておくと、GUIツールで見ることができて便利
https://github.com/GabiAxel/google-cloud-gui
version: '3.7' x-custom: gcp: - &gcp_project_id "dummy" services: app: build: "./app/" volumes: - "./app/:/app/" environment: FLASK_APP: dev DATASTORE_HOST: "http://datastore:8081" DATASTORE_EMULATOR_HOST: "datastore:8081" PROJECT_ID: *gcp_project_id TZ: Asia/Tokyo ports: - "5000:5000" depends_on: - datastore datastore: build: "./datastore" volumes: - "./datastore/.data:/datastore/.data" environment: DATASTORE_PROJECT_ID: *gcp_project_id DATASTORE_LISTEN_ADDRESS: 0.0.0.0:8081 ports: - "18081:8081"起動
docker-compose upブラウザやcurlで、http://localhost:5000にアクセスすると{"foo": "bar"}と表示されるはず。
ログ
下記にデータが貯められてるのがわかる
/datastore/.data/WEB-INF/appengine-generated/local_db.bin
datastore_1 | Updated property [core/project]. datastore_1 | WARNING: Reusing existing data in [/datastore/.data]. datastore_1 | Executing: /google-cloud-sdk/platform/cloud-datastore-emulator/cloud_datastore_emulator start --host=0.0.0.0 --port=8081 --store_on_disk=True --consistency=0.9 --allow_remote_shutdown /datastore/.data app_1 | * Serving Flask app "main" (lazy loading) app_1 | * Environment: production app_1 | WARNING: This is a development server. Do not use it in a production deployment. app_1 | Use a production WSGI server instead. app_1 | * Debug mode: off app_1 | * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit) datastore_1 | [datastore] Jan 22, 2020 6:22:00 AM com.google.cloud.datastore.emulator.CloudDatastore$FakeDatastoreAction$9 apply datastore_1 | [datastore] INFO: Provided --allow_remote_shutdown to start command which is no longer necessary. datastore_1 | [datastore] Jan 22, 2020 6:22:01 AM com.google.cloud.datastore.emulator.impl.LocalDatastoreFileStub <init> datastore_1 | [datastore] INFO: Local Datastore initialized: datastore_1 | [datastore] Type: High Replication datastore_1 | [datastore] Storage: /datastore/.data/WEB-INF/appengine-generated/local_db.bin datastore_1 | [datastore] Jan 22, 2020 6:22:02 AM com.google.cloud.datastore.emulator.impl.LocalDatastoreFileStub load datastore_1 | [datastore] INFO: Time to load datastore: 218 ms datastore_1 | [datastore] API endpoint: http://0.0.0.0:8081 datastore_1 | [datastore] If you are using a library that supports the DATASTORE_EMULATOR_HOST environment variable, run: datastore_1 | [datastore] datastore_1 | [datastore] export DATASTORE_EMULATOR_HOST=0.0.0.0:8081 datastore_1 | [datastore] datastore_1 | [datastore] Dev App Server is now running. datastore_1 | [datastore] datastore_1 | [datastore] The previous line was printed for backwards compatibility only. datastore_1 | [datastore] If your tests rely on it to confirm emulator startup, datastore_1 | [datastore] please migrate to the emulator health check endpoint (/). Thank you! datastore_1 | [datastore] The health check endpoint for this emulator instance is http://0.0.0.0:8081/Jan 22, 2020 6:22:11 AM io.gapi.emulators.grpc.GrpcServer$3 operationComplete datastore_1 | [datastore] INFO: Adding handler(s) to newly registered Channel. datastore_1 | [datastore] Jan 22, 2020 6:22:11 AM io.gapi.emulators.netty.HttpVersionRoutingHandler channelRead datastore_1 | [datastore] INFO: Detected HTTP/2 connection.データ投入
エミュレータのエンドポイントに、リクエストを投げてあげれば、ダンプデータも取り込める
docker-compose exec datastore bash ./import/run.sh参考
下記のサイトを参考にさせていただきました。
- 投稿日:2020-01-22T23:09:55+09:00
学習記録 その26(30日目)
学習記録(30日目)
勉強開始:12/7(土)〜
教材等:
・大重美幸『詳細! Python3 入門ノート』(ソーテック社、2017年):12/7(土)〜12/19(木)読了
・Progate Python講座(全5コース):12/19(木)〜12/21(土)終了
・Andreas C. Müller、Sarah Guido『(邦題)Pythonではじめる機械学習』(オライリージャパン、2017年):12/21(土)〜12月23日(土)読了
・Kaggle : Real or Not? NLP with Disaster Tweets :12月28日(土)投稿〜1月3日(金)まで調整
・Wes Mckinney『(邦題)Pythonによるデータ分析入門』(オライリージャパン、2018年):1/4(水)〜1/13(月)読了
・斎藤康毅『ゼロから作るDeep Learning』(オライリージャパン、2016年):1/15(水)〜1/20(月)
・François Chollet『PythonとKerasによるディープラーニング』(クイープ、2018年):1/21(火)〜『PythonとKerasによるディープラーニング』
p.94 第3章 ニューラルネットワークまで読み終わり。
kerasによる回帰モデルfrom keras import models from keras import layers def build_model(): #addで層を追加できる。今回は2層で構成 model = models.Sequential() #入力(input_shape)に対し64個のユニットで隠れ層を作成、活性化関数はReLU model.add(layers.Dense(64, activation = 'relu', input_shape=(train_data.shape[1],))) #2層目 model.add(layers.Dense(64, activation = 'relu')) #最終層 スカラー回帰問題であることから活性化関数は適用しない。(数字幅が固定されてしまう。) model.add(layers.Dense(1)) #重み調整のオプティマイザーはrmsprop、損失関数はmse、指標はmae model.compile(optimizer='rmsprop', loss='mse', metrics=['mae']) return model第1層における第3引数input_shapeのshape[1]の後ろのカンマが何を意味しているのかさっぱりわからず、不要と思ってカンマを外したらエラーを吐くわで、色々と探しまわっていたところ以下のような記事を見つけた
What does TensorFlow shape (?,) mean? (stackoverflow)
どうやら、カンマは任意の次元をとるテンソルを取得するために使用するとのこと。
と、ここまでやった後、
train_data.shape[1] = 13 input_shape(13, )であることに気が付いた。
スライシングのような感じで、リスト[]の外にカンマを置く特別な処理なんだろうという意味のわからない勘違いをしてました。行き詰まったら、まずは慌てず構造を読み解いて、一つ一つ細分化し理解するのが大事ですね。
- 投稿日:2020-01-22T22:45:03+09:00
LiquidTap Python Clientを使う①
「Liquid by Quoine」の"Order Book"を取得する
(2020.01.22)
ライブラリをインストールしてBTC/JPYを取得してみる。ライブラリをインストール
$ pip3 install liquidtap本家のサンプルを参考にコードを書く
本家:https://github.com/QuoineFinancial/liquid-tap-python
price.pyimport liquidtap import time def update_callback_buy(data): print("buy:" + data) def update_callback_sell(data): print("sell:" + data) def on_connect(data): tap.pusher.subscribe("price_ladders_cash_btcjpy_buy").bind('updated', update_callback_buy) tap.pusher.subscribe("price_ladders_cash_btcjpy_sell").bind('updated', update_callback_sell) if __name__ == "__main__": tap = liquidtap.Client() tap.pusher.connection.bind('pusher:connection_established', on_connect) tap.pusher.connect() while True: # 無限ループ time.sleep(1)実行
実行してbuyとsellが(何行も)表示されれば成功。
$ python3 price.py sell:[["948886.00000","0.01419278"],["948922.00000","0.02100000"],["948934.00000","0.00191306"],["948944.94000","0.00100000"],["948946.00000","0.03242956"],["948947.00000","0.03242988"],["948954.00000","0.00850000"],["948955.94000","0.03243954"],["948956.94000","0.01621739"],["948959.94000","0.03243965"],["948962.94000","0.02800000"],["948975.00000","0.00100000"],["948987.00000","0.00900000"],["948987.93700","0.03705000"],["948991.65500","0.07000000"],["948996.00000","0.02100000"],["949000.00000","2.00000000"],["949018.00000","0.01000000"],["949046.89124","0.01000000"],["949087.99999","0.06000000"],["949101.61000","0.00100000"],["949103.00000","0.04900000"],["949143.43000","0.25140000"],["949158.06000","1.32366279"],["949183.00000","0.04000000"],["949206.50000","0.01000000"],["949219.97000","0.00100000"],["949249.50000","0.07000000"],["949265.27000","0.01220000"],["949283.00000","0.15000000"],["949307.69000","0.00860000"],["949354.00000","0.38919067"],["949355.00000","0.22500000"],["949357.00000","4.00000000"],["949371.00000","0.01000000"],["949384.00000","0.01100000"],["949390.11000","0.03999999"],["949399.00000","0.04000000"],["949421.11000","0.03999999"],["949427.00000","0.01710000"]] buy:[["948627.00000","0.03242956"],["948626.00000","0.03242988"],["948619.00000","0.04000000"],["948618.50000","0.00200000"],["948611.66000","0.03243954"],["948609.16000","0.03979000"],["948607.66000","0.01621955"],["948604.66000","0.01622010"],["948601.66000","0.00950000"],["948591.65500","0.07000000"],["948556.00000","0.03750000"],["948549.67000","0.01000000"],["948537.00001","0.01621739"],["948522.01000","0.01400000"],["948520.63000","0.00200000"],["948519.00001","0.03000000"],["948472.38000","0.01000000"],["948468.10000","0.10000000"],["948441.00000","0.02610000"],["948437.00000","0.04076885"],["948434.00000","0.00500000"],["948409.18000","0.00200000"],["948409.00000","0.06000000"],["948406.00000","0.03000000"],["948405.00000","0.01000000"],["948393.75000","0.02800000"],["948393.00000","0.02880000"],["948379.00000","0.02520000"],["948371.01000","0.13080000"],["948371.00000","0.03478991"],["948363.57077","0.00852120"],["948350.16098","0.00345380"],["948341.00000","0.50000013"],["948323.98000","0.17633721"],["948287.75000","0.00100000"],["948275.00000","0.09761507"],["948269.00000","0.01989854"],["948239.51000","0.01000000"],["948239.00000","0.20692222"],["948223.00000","0.15000000"]] buy:[["948627.00000","0.03242956"],["948626.00000","0.03242988"],["948619.00000","0.04000000"],["948618.50000","0.00200000"],["948611.66000","0.03243954"],["948609.16000","0.03979000"],["948607.66000","0.01621955"],["948604.66000","0.01622010"],["948601.66000","0.00950000"],["948591.65500","0.07000000"],["948556.00000","0.03750000"],["948549.67000","0.01000000"],["948537.00001","0.01621739"],["948522.01000","0.01400000"],["948520.63000","0.00200000"],["948472.38000","0.01000000"],["948468.10000","0.10000000"],["948441.00000","0.02610000"],["948437.00000","0.04076885"],["948434.00000","0.00500000"],["948409.18000","0.00200000"],["948409.00000","0.06000000"],["948406.00000","0.03000000"],["948405.00000","0.01000000"],["948393.75000","0.02800000"],["948393.00000","0.02880000"],["948379.00000","0.02520000"],["948371.01000","0.13080000"],["948371.00000","0.03478991"],["948363.57077","0.00852120"],["948350.16098","0.00345380"],["948341.00000","0.50000013"],["948323.98000","0.17633721"],["948287.75000","0.00100000"],["948275.00000","0.09761507"],["948269.00000","0.01989854"],["948239.51000","0.01000000"],["948239.00000","0.20692222"],["948223.00000","0.15000000"],["948184.00000","0.22500000"]] buy:[["948627.00000","0.03242956"],["948626.00000","0.03242988"],["948619.00000","0.04000000"],["948618.50000","0.00200000"],["948611.66000","0.03243954"],["948609.16000","0.03979000"],["948607.66000","0.01621955"],["948604.66000","0.01622010"],["948601.66000","0.00950000"],["948591.65500","0.07000000"],["948556.00000","0.03750000"],["948549.67000","0.01000000"],["948537.00001","0.01621739"],["948522.01000","0.01400000"],["948520.63000","0.00200000"],["948488.00001","0.03000000"],["948472.38000","0.01000000"],["948468.10000","0.10000000"],["948441.00000","0.02610000"],["948437.00000","0.04076885"],["948434.00000","0.00500000"],["948409.18000","0.00200000"],["948409.00000","0.06000000"],["948406.00000","0.03000000"],["948405.00000","0.01000000"],["948393.75000","0.02800000"],["948393.00000","0.02880000"],["948379.00000","0.02520000"],["948371.01000","0.13080000"],["948371.00000","0.03478991"],["948363.57077","0.00852120"],["948350.16098","0.00345380"],["948341.00000","0.50000013"],["948323.98000","0.17633721"],["948287.75000","0.00100000"],["948275.00000","0.09761507"],["948269.00000","0.01989854"],["948239.51000","0.01000000"],["948239.00000","0.20692222"],["948223.00000","0.15000000"]] buy:[["948627.00000","0.03242956"],["948626.00000","0.03242988"],["948619.00000","0.04000000"],["948618.50000","0.00200000"],["948611.66000","0.03243954"],["948609.16000","0.03979000"],["948607.66000","0.01621955"],["948604.66000","0.01622010"],["948601.66000","0.00950000"],["948591.65500","0.07000000"],["948556.00000","0.03750000"],["948549.67000","0.01000000"],["948537.00001","0.01621739"],["948522.01000","0.01400000"],["948520.63000","0.00200000"],["948488.00001","0.03000000"],["948472.38000","0.01000000"],["948468.10000","0.10000000"],["948441.00000","0.02610000"],["948434.00000","0.00500000"],["948411.00000","0.04076885"],["948409.18000","0.00200000"],["948409.00000","0.06000000"],["948406.00000","0.03000000"],["948405.00000","0.01000000"],["948393.75000","0.02800000"],["948393.00000","0.02880000"],["948379.00000","0.02520000"],["948371.01000","0.13080000"],["948371.00000","0.03478991"],["948363.57077","0.00852120"],["948350.16098","0.00345380"],["948341.00000","0.50000013"],["948323.98000","0.17633721"],["948287.75000","0.00100000"],["948275.00000","0.09761507"],["948269.00000","0.01989854"],["948239.51000","0.01000000"],["948239.00000","0.20692222"],["948223.00000","0.15000000"]]無限ループなので Ctrl+c で停止。
- 投稿日:2020-01-22T21:12:35+09:00
SciPy KDTree vs 総当たりベンチマーク
はじめに
k次元のユークリッド空間に点を空間分割で分類し、k次元領域の
点探索を効率的におこなうのがk-DTreeです。
SciPyにこんなのがあるとは知らなったので、どれくらい効率がいいか?
ベンチマークを行ってみたいと思います。
以降、2次元は2-D, 3次元は3-Dという風にk次元について
k-Dと表記します。比較条件
データ件数 100000件
検索回数 10000回
2-Dから8-Dデータまで行います。
各次元について4回ずつ探索を行います。
leafsizeは10固定。環境
Anaconda
Python 3.7.6
scipy.version.full_version 1.3.2
windows10プログラム
kdtbench.pydef search(S, pt): # 距離を求める distary = ss.distance.cdist([pt], S, metric='euclidean') # 最小のインデックスを求める idx = distary.argmin() return (distary[0, idx], idx) def benchmark(x, s, kdt, no, i): # k-DTree 探索 kdstart = time.time() for search_cond in s: dist, hitindex = kdtree.query(search_cond) kd_elapsed_time = time.time() - kdstart print('%d:%d-D K-DTree(秒) %.2f' % (i, no, kd_elapsed_time)) # 総あたり 探索 brstart = time.time() for search_cond in s: dist, hitindex = search(x, search_cond) br_elapsed_time = time.time() - brstart print('%d:%d-D 総当たり(秒) %.2f' % (i, no, br_elapsed_time)) return kd_elapsed_time, br_elapsed_time count_data = 100000 count_key = 10000 numturns = 4 np.random.seed(0) for n in range(2,9): #2-D...8-D X = np.random.rand(count_data, n) * 1000.0 S = np.random.rand(count_key, n) * 1000.0 kdtree = ss.KDTree(X, leafsize=10) total_k = 0 total_a = 0 for i in range(0,numturns): ktm, atm = benchmark(X,S, kdtree, n, i) total_k += ktm total_a += atm print('Avg k-DTree:%.2f秒 総当たり:%.2f秒' % (total_k/numturns, total_a/numturns)) print()ベンチマーク実施
プログラムを実行。
$ python kdtbench.py 0:2-D K-DTree(秒) 2.00 0:2-D 総当たり(秒) 6.61 1:2-D K-DTree(秒) 1.99 1:2-D 総当たり(秒) 6.62 2:2-D K-DTree(秒) 2.02 2:2-D 総当たり(秒) 6.78 3:2-D K-DTree(秒) 2.01 3:2-D 総当たり(秒) 7.33 Avg KDTree:2.00秒 総当たり:6.83秒 0:3-D K-DTree(秒) 2.71 0:3-D 総当たり(秒) 7.81 ~~~ 省略 ~~~ベンチマーク結果
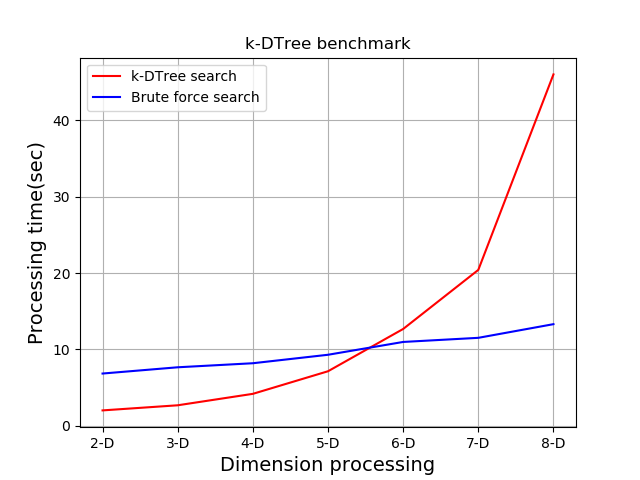
条件ごとの測定結果の平均時間(秒)が下記です。
総当たり(秒) K-DTree(秒) 2-D 6.83 2.00 3-D 7.65 2.67 4-D 8.18 4.17 5-D 9.29 7.13 6-D 10.97 12.67 7-D 11.51 20.41 8-D 13.30 46.03 各PC事に性能が異なるため時間うんぬんは意味が無く、比較で見て下さい。
測定値をグラフ化
K-DTree searchがK-DTreeによる探索処理の結果を示し、
Brute force searchが総当たり探索処理の結果です。5-D以降、性能が逆転することがわかりましたが、ここまで使うかは
今のところ分かりません。自分の場合は使ってもせいぜい3-Dくらいまで、
たぶんpythonではこういう使い方はしないかな。
ご清聴ありがとうございました。参考
- 投稿日:2020-01-22T20:24:15+09:00
MacOS Catalina(10.15.2) で、旧OSからアップデートした環境でpython pipがOpenSSLのエラーになる問題の解決法
TL;DR
/Library/Developer/CommandLineToolsをCommandLineTools.bakとかにmvして、xcode-select --installする。なぜそうするのか
Catalinaにupgradeする前から入れてあったCommandLineToolsがどうも古いのに新しいものと誤認識されているらしい。
なのでxcode-select --installしてもalready installedって言われてしまう。
それを強制的に入れ直すため。いろいろ修正方法が書いてあるけどどれも関係なかった
以下は無関係だった。
- brewを入れ直す
- OpenSSLをbrewで入れ直す
- MacOS10.14.pkgを入れる → そもそもファイルが無いのでできない。
問題のエラー文字列
$ pip install --upgrade pip pip is configured with locations that require TLS/SSL, however the ssl module in Python is not available. Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError("Can't connect to HTTPS URL because the SSL module is not avai lable.")': /simple/pip/ Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError("Can't connect to HTTPS URL because the SSL module is not avai lable.")': /simple/pip/ Retrying (Retry(total=2, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError("Can't connect to HTTPS URL because the SSL module is not avai lable.")': /simple/pip/ Retrying (Retry(total=1, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError("Can't connect to HTTPS URL because the SSL module is not avai lable.")': /simple/pip/ Retrying (Retry(total=0, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError("Can't connect to HTTPS URL because the SSL module is not avai lable.")': /simple/pip/ Could not fetch URL https://pypi.org/simple/pip/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='pypi.org', port=443): Max retries exceeded with ur l: /simple/pip/ (Caused by SSLError("Can't connect to HTTPS URL because the SSL module is not available.")) - skipping Requirement already up-to-date: pip in /usr/local/lib/python3.7/site-packages (18.1) pip is configured with locations that require TLS/SSL, however the ssl module in Python is not available. Could not fetch URL https://pypi.org/simple/pip/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='pypi.org', port=443): Max retries exceeded with ur l: /simple/pip/ (Caused by SSLError("Can't connect to HTTPS URL because the SSL module is not available.")) - skippingbrewが悪いのか、MacOSが悪いのか…。
もうCloud Shell(GCP)上でやったほうが楽そう。泣ける。
- 投稿日:2020-01-22T20:06:47+09:00
ビジネスで欠損値を扱うときの注意点(システム、機械学習予測モデル)
欠損値の意味合いは色々ある
このタイトルを見ると、「機械学習 欠損値」で検索すると出てきそうな、欠損値の補完の仕方をイメージすると思いますが、情報がありふれているため、ここでは言及しません。ここで言及したいのは、機械学習の予測モデルに入れるデータの欠損値をどう処理するかというテクニカルなことではなく、データが欠損している意味合いが異なる場合に機械学習モデル自身を見直す、モデルを使ったビジネス上の運用も慎重に考える必要があるということです。
欠損と未知は違う
いわゆる欠損値の種類といったときに、MCAR, MAR, MNARがありますが、これはデータを取得しようと試みた結果様々な理由でデータが欠損しているときの欠損の仕方の違いです。これには「データを取得しようとした」という前提があり、データを選択するバイアスになっています。一方そもそもデータの取得の試み自体まだ行っていない場合はデータを取得しようとした結果の「欠損」ではなく、「未知」なのです。
「欠損」と「未知」がなぜ重要か
ここまで見ると、当たり前じゃないかと思うでしょう。ただ、データ分析したり、データに関連した意思決定をしたり際に往々にしてデータベースやシステムから出力されたデータを使いますが、意識して「欠損」と「未知」を区別しない限り、データの持ち方上欠損値になってしまっていることが大いにあります。
例えば、ECサイトの会員ごとに再購買するか否かを予測する2値分類のタスクを行う予測モデルを作って、レコメンドに活用したいとします。そして、直近あるアンケートを順次会員に対して実施しており、週ごとに会員群を決めてアンケートを配信し、回答を得ます。アンケートの回答内容は各会員の嗜好や行動属性に関する情報があり、レコメンドのモデルを作成する人はその情報を活用してモデルの精度改善に生かそうとします。この時に、データベース上のアンケート結果が欠損ないし未知の違いを意識して設計されず、それを知らずにアンケート結果を用いて予測モデルを作成すると、おおいに実運用時で精度が悪化する可能性が高いです。
なぜなら、アンケートを取った会員群でアンケート結果が欠損している場合、そこには会員の何かしらの意図があり、回答しない結果欠損となっている一方、アンケートをまだ配信していない会員群のデータは、意図がなく単純に未知なので、これを欠損と同じように扱うと予測を誤るからです。ECサイトに愛着があって利用する会員ならアンケートを丁寧に回答して、欠損値は少ないので、欠損値があると再購買しない方向に機械学習モデルは学習するでしょう。一方このモデルを、単純にアンケートに未回答ゆえに未知な会員に適用すると、本来アンケートが配信されていれば丁寧に回答するリピーターも欠損値の影響で予測モデルで再購買しないと判定されてしまうのです。
どう対処すべきか
以上を踏まえて、欠損と未知の違いを意識しつつ、要件に応じて対応を変える必要があります。
欠損と未知が混在した情報でもビジネスに活用したい
このような場合は、下記のような対応が考えられるでしょう。
- システム設計時に、データが未知である事と、欠損している事を明示的に分けて定義する
- システム側で対応が困難な時には、データの前処理で欠損と未知の違いを欠損値補完の方法を変える、ないし欠損している予測対象群と未知である予測対象群で分けて予測モデルを作成し運用に使う
上記以外のプラスアルファで情報を生かしたい場合
特に、無理して欠損と未知が混在した情報を使用する必然性がなければ、以下のようにすればよいでしょう。
- そもそも情報として使わない
- 欠損と未知の違いがなくなるまで待つ(前述の例でいえば、全会員のアンケート取得が終わるまで待つ)
実際に検証してみた
(工事中)
まとめ
ここまで、実際にモデルも作って、「欠損」と「未知」が混在した状況があった時に、全て一様に欠損値として扱った予測モデルを適用するリスクと取りうる対応案を提示しました。言われれば当たり前ですが、概念としての違いがデータベースの設計時には思い及ばなかったり、データとしてだけ渡された場合に、大いに誤るリスクをはらんでいるため、記事にしました。また、機械学習モデルのみならず、データに欠損が関連し、それによるビジネス判断が必要な場合でも参考になる考え方ではないかと思います。
ご意見、フィードバック等あればぜひお願いいたします。
- 投稿日:2020-01-22T19:29:16+09:00
Flask + LINE Messaging APIでの人工知能LINEボットの作り方
Flask + LINE Messaging APIでの人工知能LINEボットの作り方
ナカノヒトシさんの書籍
Python + LINEで作る人工知能開発入門 - Flask + LINE Messaging APIでの人工知能LINEボットの作り方まあまあ面白かった。
この手のアプリはたくさんあるがLINEボットにすると使う方はラクかも。本の最後に宿題を出され、回答はないです自力でがんばりましょうと厳しいナカノさん。
少し苦労して宿題したので参考までに。
#app.py # ユーザの送った画像をGoogle Vison APIで顔検出しcat.pngで隠した合成写真をリプライ(顔複数対応) import io import base64 import json import requests from flask import Flask, request, abort from PIL import Image #Pillowをインストール pip3 install pillow from linebot import ( LineBotApi, WebhookHandler ) from linebot.exceptions import ( InvalidSignatureError ) from linebot.models import ( MessageEvent, TextMessage, TextSendMessage, ImageMessage, ImageSendMessage ) import os # LINEアクセストークンとアプリケーションシークレット ACCESS_TOKEN = '' SECRET = '' # Google Vision APIキー API_KEY = '' app = Flask(__name__) line_bot_api = LineBotApi(ACCESS_TOKEN) handler = WebhookHandler(SECRET) @app.route('/') def hello_world(): return 'Hello World!' @app.route('/callback',methods=['POST']) def callback(): signature = request.headers['X-Line-Signature'] body = request.get_data(as_text=True) app.logger.info("Request body: " + body) try: handler.handle(body, signature) except InvalidSignatureError: print("Invalid signature. Please check your channel access token/channel secret.") abort(400) return 'OK' @handler.add(MessageEvent,message=ImageMessage) def handle_message(event): message_content = line_bot_api.get_message_content(event.message.id) # event.message.idを指定することで画像本体データを読み出せる # message_content.content #取得した画像ファイル本体 image_base64 = base64.b64encode(message_content.content) #画像ファイルをbase64に変換 #リクエストボディを作成(json.dumps()でJSONに変換してる) req_body = json.dumps({ 'requests': [{ 'image': { 'content': image_base64.decode('utf-8') }, 'features': [{ 'type': 'FACE_DETECTION', 'maxResults': 20, }] }] }) # Vison APIのエンドポイント↓ res = requests.post("https://vision.googleapis.com/v1/images:annotate?key=" + API_KEY, data=req_body) #print('res内容は、' + res.text) result = res.json() vertices = result["responses"][0]["faceAnnotations"] #print('vertices内容は、' + json.dumps(vertices)) ## response内容は、レスポンス.jsonを参照. if vertices: print('取得できた') image_base = Image.open(io.BytesIO(message_content.content)) for face in vertices: corner = face["boundingPoly"]['vertices'][0] print('cornerは、' + json.dumps(corner)) print('face["boundingPoly"]["vertices"][1]["x"]は、' + json.dumps(face["boundingPoly"]['vertices'][1]["x"])) width = face["boundingPoly"]['vertices'][1]["x"] - face["boundingPoly"]['vertices'][0]["x"] height = face["boundingPoly"]['vertices'][2]["y"] - face["boundingPoly"]['vertices'][1]["y"] image_cover = Image.open('static/cat.png') # cat.pngはアルファチャンネル画像でないとダメ。ValueError: bad transparency maskエラー image_cover = image_cover.resize((width,height)) image_base.paste(image_cover, (corner['x'],corner['y']), image_cover) # Image.paste(im, box=None, mask=None) print('forループおわり') image_base.save('static/' + event.message.id + '.jpg') else: print('取得できない') line_bot_api.reply_message( event.reply_token, ImageSendMessage( original_content_url = "https://hidden-savannah-xxxxx.herokuapp.com/static/" + event.message.id + ".jpg", preview_image_url = "https://hidden-savannah-xxxxx.herokuapp.com/static/" + event.message.id + ".jpg" ) ) if __name__ == "__main__": app.run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000)))
- 念の為、78行目の
print('vertices内容は、' + json.dumps(vertices))のレスポンス内容[ { "boundingPoly": { "vertices": [ { "x": 917, "y": 318 }, { "x": 1174, "y": 318 }, { "x": 1174, "y": 616 }, { "x": 917, "y": 616 } ] }, "fdBoundingPoly": { "vertices": [ { "x": 971, "y": 396 }, { "x": 1163, "y": 396 }, { "x": 1163, "y": 588 }, { "x": 971, "y": 588 } ] }, "landmarks": [ { "type": "LEFT_EYE", "position": { "x": 1031.1968, "y": 456.0161, "z": 0.0003030986 } }, { "type": "RIGHT_EYE", "position": { "x": 1112.0862, "y": 460.92987, "z": 28.232975 } }, { "type": "LEFT_OF_LEFT_EYEBROW", "position": { "x": 1008.84607, "y": 436.544, "z": -1.8571037 } }, { "type": "RIGHT_OF_LEFT_EYEBROW", "position": { "x": 1060.1007, "y": 440.86813, "z": -7.585352 } }, { "type": "LEFT_OF_RIGHT_EYEBROW", "position": { "x": 1095.2485, "y": 442.76245, "z": 5.0468025 } }, { "type": "RIGHT_OF_RIGHT_EYEBROW", "position": { "x": 1131.141, "y": 444.30832, "z": 41.595203 } }, { "type": "MIDPOINT_BETWEEN_EYES", "position": { "x": 1075.8728, "y": 455.9283, "z": -1.5975293 } }, { "type": "NOSE_TIP", "position": { "x": 1080.8457, "y": 504.33997, "z": -20.247692 } }, { "type": "UPPER_LIP", "position": { "x": 1071.2343, "y": 531.5437, "z": -1.6211907 } }, { "type": "LOWER_LIP", "position": { "x": 1069.6505, "y": 551.9242, "z": 4.4038887 } }, { "type": "MOUTH_LEFT", "position": { "x": 1035.7985, "y": 538.815, "z": 8.222528 } }, { "type": "MOUTH_RIGHT", "position": { "x": 1101.0676, "y": 541.8905, "z": 30.981604 } }, { "type": "MOUTH_CENTER", "position": { "x": 1070.1655, "y": 541.40643, "z": 4.1978736 } }, { "type": "NOSE_BOTTOM_RIGHT", "position": { "x": 1092.8889, "y": 510.94235, "z": 16.238985 } }, { "type": "NOSE_BOTTOM_LEFT", "position": { "x": 1049.6199, "y": 507.50146, "z": 0.9902145 } }, { "type": "NOSE_BOTTOM_CENTER", "position": { "x": 1072.0765, "y": 515.82806, "z": -2.7877321 } }, { "type": "LEFT_EYE_TOP_BOUNDARY", "position": { "x": 1037.2472, "y": 452.2355, "z": -4.3320293 } }, { "type": "LEFT_EYE_RIGHT_CORNER", "position": { "x": 1047.4124, "y": 459.2465, "z": 6.317641 } }, { "type": "LEFT_EYE_BOTTOM_BOUNDARY", "position": { "x": 1030.3141, "y": 461.9699, "z": 0.34013578 } }, { "type": "LEFT_EYE_LEFT_CORNER", "position": { "x": 1018.07513, "y": 455.93164, "z": 2.3924496 } }, { "type": "LEFT_EYE_PUPIL", "position": { "x": 1034.6456, "y": 457.22366, "z": -1.4217875 } }, { "type": "RIGHT_EYE_TOP_BOUNDARY", "position": { "x": 1109.9236, "y": 456.6617, "z": 21.767094 } }, { "type": "RIGHT_EYE_RIGHT_CORNER", "position": { "x": 1119.8134, "y": 462.12448, "z": 38.996845 } }, { "type": "RIGHT_EYE_BOTTOM_BOUNDARY", "position": { "x": 1110.3936, "y": 466.81308, "z": 26.98832 } }, { "type": "RIGHT_EYE_LEFT_CORNER", "position": { "x": 1094.9646, "y": 462.28857, "z": 22.470396 } }, { "type": "RIGHT_EYE_PUPIL", "position": { "x": 1109.2263, "y": 461.79114, "z": 25.238665 } }, { "type": "LEFT_EYEBROW_UPPER_MIDPOINT", "position": { "x": 1037.4519, "y": 429.95596, "z": -10.386488 } }, { "type": "RIGHT_EYEBROW_UPPER_MIDPOINT", "position": { "x": 1116.0272, "y": 434.71762, "z": 18.003847 } }, { "type": "LEFT_EAR_TRAGION", "position": { "x": 954.1669, "y": 484.3548, "z": 76.21559 } }, { "type": "RIGHT_EAR_TRAGION", "position": { "x": 1119.6852, "y": 494.08078, "z": 135.9113 } }, { "type": "FOREHEAD_GLABELLA", "position": { "x": 1078.9543, "y": 441.30212, "z": -4.084726 } }, { "type": "CHIN_GNATHION", "position": { "x": 1062.5234, "y": 589.9864, "z": 16.94458 } }, { "type": "CHIN_LEFT_GONION", "position": { "x": 968.6994, "y": 536.28186, "z": 52.295383 } }, { "type": "CHIN_RIGHT_GONION", "position": { "x": 1117.5015, "y": 545.4246, "z": 105.74548 } } ], "rollAngle": 4.5907497, "panAngle": 19.758451, "tiltAngle": -3.1237326, "detectionConfidence": 0.91960925, "landmarkingConfidence": 0.5607769, "joyLikelihood": "VERY_UNLIKELY", "sorrowLikelihood": "VERY_UNLIKELY", "angerLikelihood": "VERY_UNLIKELY", "surpriseLikelihood": "VERY_UNLIKELY", "underExposedLikelihood": "VERY_UNLIKELY", "blurredLikelihood": "VERY_UNLIKELY", "headwearLikelihood": "LIKELY" }, ・・・・・・・・・・以上でひとり分・・・・・・・・・・・・ ]
書籍の中でうまく行かなかったところは以下の通り。
Flaskアプリをherokuにデプロイ(苦苦々)

- 投稿日:2020-01-22T19:24:22+09:00
自動でVtuberの配信予定を更新するカレンダーを作ってみた
はじめに
はじめまして。ほどよくエンジニアをがんばっているシュンといいます。
自動でVtuberの配信予定を更新するカレンダーを作ってみたので、その過程を書きたいと思います。
今回はYouTube Data APIを使ってYouTubeチャンネルの動画情報を取得します。環境
- Azure VM (Windows Server 2016)
- Python 3.7
用意するデータ
- YouTube チャンネルID
取得するデータ
- チャンネル情報
- 動画情報
方法
まずはじめに、YouTube Data APIを利用できるようにGoogleにアプリケーションを登録します。
詳しい方法はこちら。
(ちなみに、このページからAPIを試すこともできます。)
ここで手に入れたAPIキーを利用して、動画情報を取得していきます。取得の流れとしてはこんな感じになります。
- チャンネルIDからそのチャンネルの動画IDを取得
- 動画IDから動画情報を取得
1. チャンネルIDからそのチャンネルの動画IDを取得
チャンネルIDは知りたいチャンネルのホームを開いたときのURLから取得できます。
例えば僕のイチオシの湊あくあちゃんの場合は、
https://www.youtube.com/channel/UC1opHUrw8rvnsadT-iGp7Cg
これがYouTubeチャンネルのURLなので、チャンネルIDはUC1opHUrw8rvnsadT-iGp7Cgになります。このチャンネルIDを使って動画のリストを取得します。
import urllib.request import json import ssl context = ssl.SSLContext(ssl.PROTOCOL_TLSv1) def get_video_info(channel_id, page_token=None, published_after=None): url = 'https://www.googleapis.com/youtube/v3/search' params = { 'key': 'YOUTUBE_API_KEY', 'part': 'id', 'channelId': channel_id, 'maxResults': 50, 'order': 'date' } if page_token is not None: params['pageToken'] = page_token if published_after is not None: params['publishedAfter'] = published_after req = urllib.request.Request('{}?{}'.format(url, urllib.parse.urlencode(params))) with urllib.request.urlopen(req, context=context) as res: body = json.load(res) return bodyチャンネルID以外にもパラメータとして以下の値を指定します。
- key
- 最初に取得したAPIキー。
- part
- idとsnippetが指定できます。今回は動画IDが分かればいいのでidを指定。
- channelId
- チャンネルID。
- maxResults
- 返ってくるアイテムの最大数。最大で50なので50を指定。
- order
- いろいろ設定できます。日時順で欲しいのでdateを指定。
- pageToken
- 一度で指定した条件に当てはまる動画を取得しきれない場合、nextPageTokenとして次のページを示す値が得られるのでそれを指定することで続きを取得。
- publishedAfter
- 日時を指定して、その日時より後に作成された動画を取得。
- 日時形式例: 2020-01-01T00:00:00Z
2. 動画IDから動画情報を取得
取得した動画IDを使って今度は各動画の詳細情報を取得します。
def get_video_details(video_ids): url = 'https://www.googleapis.com/youtube/v3/videos' params = { 'key': 'YOUTUBE_API_KEY', 'part': 'snippet, liveStreamingDetails', 'id': video_ids } req = urllib.request.Request('{}?{}'.format(url, urllib.parse.urlencode(params))) with urllib.request.urlopen(req, context=context) as res: body = json.load(res) return bodyパラメータは新たにidとして動画IDを指定しているほか、partにsnippetとliveStreamingDetailsを指定しています。
これで動画の基本的な情報に加えてライブ配信時の情報も取得できます。def get_videos(items): video_ids = '' for item in items: if 'videoId' in item['id']: video_ids += item['id']['videoId'] video_ids += ', ' video_details = get_video_details(video_ids[:-2]) for video_detail in video_details['items']: print(video_detail)最初に取得した動画IDのリストの中には再生リストのIDも含まれているので、videoIdを持っているものだけを集めてから動画情報を取得しています。
これらを合わせて実行するコードが↓になります。
video_info = get_video_info(channel_id='CHANNEL_ID', published_after='DATETIME') get_videos(video_info['items']) while 'nextPageToken' in video_info: page_token = video_info['nextPageToken'] video_info = get_video_info(channel_id='CHANNEL_ID', page_token=page_token) get_videos(video_info['items'])最初に日時を指定して取得、その後はnextPageTokenがある限り、取得を続けます。
湊あくあチャンネルの場合、チャンネル設立が2018/7/31なので、これより古い日時で取得を始めれば全動画の情報を取得できます。実際はこのあとカレンダーの更新等を続けて行いますが、それはまたの機会に......。
- 投稿日:2020-01-22T19:02:14+09:00
JavaでNumer0nの対戦ゲームを作ってみた(AIも作ったよ)
JavaでNumer0nの対戦ゲームを作ってみた
はじめに
今回、大学の授業でJavaでサーバ・クライアント間の通信を介した何かを作るという課題が出たので、高校生の頃、授業中によくやっていたNumer0nのゲームを作ってみようと思った。
高校生の頃、Numer0nのゲームにはまりすぎて、1手目で〇EAT〇BITEになる確率を手計算で求めて楽しんでた気がする...この記事を読んでくださっている方は、Numer0nの基本的なルールは知っていると思うのでそこのところは割愛させていただきます。
ヌメロンWikipedia開発環境
Java:version 7
Eclipse: Juno 4.2
OS: windows10開発方針
今回のシステムで実装したいことは、
1. サーバ・クライアント間の通信を行い、複数のクライアントが同時にアクセスでき、ルームを作成し、対戦ができる
2. それなりに強いコンピュータ対戦もできるようにする(アルゴリズムの実装)
3. 入力ミスや数値の重複などに対応する
4. ターン制のゲームなので入力を交互に受け取るようにするコード
コードをすべて載せると長くなってしまうので、今回はサーバ側の送受信を担当するChannelクラスと、コンピュータのアルゴリズムを実装したNumer0nAIクラスのみ掲載します。すべてのクラスと発表資料(パワポ)はGitHubに載せてあるのでよかったら見ていってください!pythonのほうでもNumeronAIを実装しているのでpythonよく使う人はそちらもどうぞ!
Javaで作るNumer0n(GitHub)
pythonのNumer0nAI(GitHub)Channelクラスについて
クライアントからの入力を確認するとサーバがChannelを生成し、Channelとクライアントがやり取りをします。そのおかげでクライアントに意図しない例外が発生しても、おおもとのサーバはダウンしないので他のクライアントの接続は保たれます。
Channel.javapackage server; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.io.OutputStreamWriter; import java.net.Socket; import java.util.ArrayList; import java.util.List; import java.util.Random; public class Channel extends Thread { JUDGE judge = new JUDGE(); Server server; Socket socket = null; BufferedReader input; OutputStreamWriter output; String handle; String playertype; String roomnumber; String mynumber; String tekinumber; boolean turn; String ex = "926";//AIの最初の予測値 String ca ="0123456789";//candidate number 最初は0~9まで String ex_number; List<String> old_list = new ArrayList<>(); final char controlChar = (char)05; final char separateChar = (char)06; Channel(Socket s,Server cs){ this.server = cs; this.socket = s; this.start(); } synchronized void write(String s){ try{ output.write(s + "\r\n"); output.flush(); }catch(IOException e){ System.out.println("Write Err"); close(); } } public void run(){ List<String> s_list = new ArrayList<>();//クライアントからの入力を受け取り、ためておくリスト String s; String opponent = null; try{ input = new BufferedReader( new InputStreamReader(socket.getInputStream())); output = new OutputStreamWriter(socket.getOutputStream()); write("# Welcome to Numr0n Game"); write("# Please input your name"); handle = input.readLine(); System.out.println("new user: "+ handle); while(true){//HOST or GUEST入力待ち write("INPUT YOUR TYPE(HOST or GUEST or AI)"); playertype = input.readLine(); if(playertype.equals("HOST")){ Random rnd = new Random(); s = String.valueOf(rnd.nextInt(100)+100); write("[HOST]ルーム番号: "+s); break; }else if(playertype.equals("GUEST")){ write("[GUEST]ルーム番号を入力してください"); s = input.readLine(); write("[GUEST]ルーム番号: "+s); break; }else if(playertype.equals("AI")){ write("[vs AIモード]"); Random rnd = new Random(); s = String.valueOf(rnd.nextInt(100)+100); write("[HOST]ルーム番号: "+s); break; }else{ write("ルーム番号入力でエラー"); } } roomnumber = s; //roomnumberの決定 System.out.println(roomnumber); write("対戦相手待ち"); if(playertype.equals("AI")){ //AIとの対戦 write("自分の数字を決めてください(*3桁の数値*0~9まで*数字の被りなし)"); boolean firstnum = false; while(firstnum == false){//最初の自分の数字が上記の条件を満たしているか mynumber = input.readLine(); firstnum = judge.isNumber(mynumber); } write("自分の数字: "+ mynumber); write(handle + "からスタートです"); tekinumber="864"; NumeronAI numeron = new NumeronAI(); while(true){ //ゲームスタート boolean finish = false; s = input.readLine(); if(s == null){ close(); }else{ System.out.println(s); boolean numsuccess = judge.isNumber(s);//数字が定義内 if (numsuccess) { JUDGE eatbite = judge.EatBite(s, tekinumber); finish = judge.Finish(eatbite.eat);//3eatになったかどうか write("["+ s +"] eat: " +String.valueOf(eatbite.eat) +" bite: "+ String.valueOf(eatbite.bite)); //ここからAIのターン JUDGE AIeatbite = judge.EatBite(ex, mynumber); NumeronAI squeeze = numeron.Squeeze(AIeatbite.eat,AIeatbite.bite,ex,ca,old_list); if(squeeze.new_can_list.size()<300){ //System.out.println(Arrays.toString(squeeze.new_can_list.toArray())); //System.out.println(squeeze.can_num); ex_number = numeron.choice(squeeze.new_can_list,squeeze.can_num); }else{ Random rnd = new Random(); int index = rnd.nextInt(100); ex_number = squeeze.new_can_list.get(index); } old_list = new ArrayList<>(squeeze.new_can_list); //System.out.println("残り候補数: " + String.valueOf(old_list.size())); write("AIの予測値:" + ex + " [残り候補数: " + String.valueOf(old_list.size())+"個]"); //System.out.println("AIの予測値: "+ ex); if(mynumber.equals(ex)){ write("#################you lose#################"); } ex = ex_number; //ここまでがAIのターン } else { write(" did not send such a number"); } } if(finish){ write("#################you win#################"); } } }else{//vs人間 while(opponent == null){//対戦相手待ち opponent = server.findopponent(handle,roomnumber); } //write("対戦相手が決まりました"); write("自分の数字を決めてください(*3桁の数値*0~9まで*数字の被りなし)"); boolean firstnum = false; while(firstnum == false){//最初の自分の数字が上記の条件を満たしているか mynumber = input.readLine(); firstnum = judge.isNumber(mynumber); } write("自分の数字: "+ mynumber); while(tekinumber == null){//敵の数値を取得するまで待つ tekinumber = server.findopponentnumber(handle, roomnumber); } if(playertype.equals("HOST")){ turn = true; }else{ turn =false; } write("HOSTプレイヤーからスタートです"); while(true){ //ゲームスタート boolean finish = false; while(true){ //ターンの確認 s_list.add(input.readLine());//入力を入れておく turn = server.isTurn(handle);//turnの確認 if(turn == true){ break; } } s = s_list.get(s_list.size()-1); s_list.clear(); if(s == null){ close(); }else{ System.out.println(s); boolean numsuccess = judge.isNumber(s);//数字が定義内 if (numsuccess) { //write("judge ok"); boolean connectsuccess = server.singleSend(opponent,"[相手の予測] "+s);//相手がいる if(connectsuccess){ //write("相手が存在する"); JUDGE eatbite = judge.EatBite(s, tekinumber); finish = judge.Finish(eatbite.eat);//3eatになったかどうか write(" [自分の予測]"+ s +" eat: " +String.valueOf(eatbite.eat) +" bite: "+ String.valueOf(eatbite.bite)); server.ChangeTurn(handle, opponent);//ターンの切り替え }else{ write("did not find opponent"); } } else { write(" did not send such a number"); } } if(finish){ write("#################you win#################"); server.singleSend(opponent, "#################you lose#################"); } } } }catch(IOException e){ System.out.println("Exception occurs in Channel: "+handle); } } public void close(){ try{ input.close(); output.close(); socket.close(); socket = null; //server.broadcast("回線切断 : " + handle); }catch(IOException e){ System.out.println("Close Err"); } } }NumeronAIクラスについて
NumeronAIクラスはコンピュータの予測部分を実装したクラス。
予測には、得られたEAT-BITE情報から考えられる候補を絞るSqueezeメソッドと、その候補の中から、良さそうな手を選ぶChoiceメソッド、良さそうな手を計算するcount_candメソッドからなります。良さそうな手とは、ある手を選んだ時に、返ってくるすべてのEAT-BITEの組み合わせから期待正解候補数が最も少ないものとしています。詳しくはnumer0nの必勝法を考えるを見てみてください。この理論に近いものを実装してます!
ちなみに平均コール数は5か6ぐらいだと思います(体感)。NumeronAI.javapackage server; import java.util.ArrayList; import java.util.List; public class NumeronAI { List<String> new_can_list = new ArrayList<>();//candidate list String can_num;//candidate number //考えられる候補数に絞る public NumeronAI Squeeze(int eat,int bite,String pred_num,String ca_num,List<String> old_list){ NumeronAI squeeze = new NumeronAI(); List<String> can_list = new ArrayList<>(); List<String> li = new ArrayList<>(); if(eat == 0 && bite == 0){ //System.out.println("--------" + String.valueOf(ca_num.length())); for(int i = 0; i<ca_num.length();i++){ if(ca_num.charAt(i) != pred_num.charAt(0) && ca_num.charAt(i) != pred_num.charAt(1) && ca_num.charAt(i) != pred_num.charAt(2)){ li.add(String.valueOf(ca_num.charAt(i))); } } ca_num =""; StringBuilder builder = new StringBuilder(); for(String num : li){ builder.append(num); } ca_num = builder.substring(0,builder.length()); for(int i = 0;i<ca_num.length();i++){ for(int j = 0;j<ca_num.length();j++){ for(int k = 0;k<ca_num.length();k++){ if(ca_num.charAt(i)!=ca_num.charAt(j) && ca_num.charAt(i)!=ca_num.charAt(k) && ca_num.charAt(j)!=ca_num.charAt(k)){ can_list.add(String.valueOf(ca_num.charAt(i))+String.valueOf(ca_num.charAt(j))+String.valueOf(ca_num.charAt(k))); } } } } }else if(eat ==0 && bite ==1){ for(int i = 0;i<ca_num.length();i++){ for(int j = 0;j<ca_num.length();j++){ if(ca_num.charAt(i) != ca_num.charAt(j) && ca_num.charAt(i)!=pred_num.charAt(0) && ca_num.charAt(i)!=pred_num.charAt(1) && ca_num.charAt(i)!=pred_num.charAt(2)){ can_list.add(String.valueOf(ca_num.charAt(i))+String.valueOf(pred_num.charAt(0))+String.valueOf(ca_num.charAt(j))); can_list.add(String.valueOf(ca_num.charAt(i))+String.valueOf(ca_num.charAt(j))+String.valueOf(pred_num.charAt(0))); can_list.add(String.valueOf(pred_num.charAt(1))+String.valueOf(ca_num.charAt(i))+String.valueOf(ca_num.charAt(j))); can_list.add(String.valueOf(ca_num.charAt(i))+String.valueOf(ca_num.charAt(j))+String.valueOf(pred_num.charAt(1))); can_list.add(String.valueOf(pred_num.charAt(2))+String.valueOf(ca_num.charAt(i))+String.valueOf(ca_num.charAt(j))); can_list.add(String.valueOf(ca_num.charAt(i))+String.valueOf(pred_num.charAt(2))+String.valueOf(ca_num.charAt(j))); } } } }else if(eat ==0 && bite ==2){ for(int i = 0;i<ca_num.length();i++){ if(ca_num.charAt(i)!=pred_num.charAt(0) && ca_num.charAt(i)!=pred_num.charAt(1) && ca_num.charAt(i)!=pred_num.charAt(2)){ can_list.add(String.valueOf(ca_num.charAt(i))+String.valueOf(pred_num.charAt(0))+String.valueOf(pred_num.charAt(1))); can_list.add(String.valueOf(ca_num.charAt(i))+String.valueOf(pred_num.charAt(2))+String.valueOf(pred_num.charAt(0))); can_list.add(String.valueOf(ca_num.charAt(i))+String.valueOf(pred_num.charAt(2))+String.valueOf(pred_num.charAt(1))); can_list.add(String.valueOf(pred_num.charAt(1))+String.valueOf(pred_num.charAt(0))+String.valueOf(ca_num.charAt(i))); can_list.add(String.valueOf(pred_num.charAt(1))+String.valueOf(ca_num.charAt(i))+String.valueOf(pred_num.charAt(0))); can_list.add(String.valueOf(pred_num.charAt(1))+String.valueOf(pred_num.charAt(2))+String.valueOf(ca_num.charAt(i))); can_list.add(String.valueOf(pred_num.charAt(2))+String.valueOf(ca_num.charAt(i))+String.valueOf(pred_num.charAt(0))); can_list.add(String.valueOf(pred_num.charAt(2))+String.valueOf(ca_num.charAt(i))+String.valueOf(pred_num.charAt(1))); can_list.add(String.valueOf(pred_num.charAt(2))+String.valueOf(pred_num.charAt(0))+String.valueOf(ca_num.charAt(i))); } } }else if(eat == 0 && bite ==3){ can_list.add(String.valueOf(pred_num.charAt(1))+String.valueOf(pred_num.charAt(2))+String.valueOf(pred_num.charAt(0))); can_list.add(String.valueOf(pred_num.charAt(2))+String.valueOf(pred_num.charAt(0))+String.valueOf(pred_num.charAt(1))); }else if(eat == 1 && bite ==0){ for(int i = 0;i<ca_num.length();i++){ for(int j = 0;j<ca_num.length();j++){ if(ca_num.charAt(i)!=ca_num.charAt(j) && ca_num.charAt(i)!=pred_num.charAt(0) && ca_num.charAt(i)!=pred_num.charAt(1) && ca_num.charAt(i)!=pred_num.charAt(2) && ca_num.charAt(j)!=pred_num.charAt(0) && ca_num.charAt(j)!=pred_num.charAt(1) && ca_num.charAt(j)!=pred_num.charAt(2)){ can_list.add(String.valueOf(pred_num.charAt(0))+String.valueOf(ca_num.charAt(i))+String.valueOf(ca_num.charAt(j))); can_list.add(String.valueOf(ca_num.charAt(i))+String.valueOf(pred_num.charAt(1))+String.valueOf(ca_num.charAt(j))); can_list.add(String.valueOf(ca_num.charAt(i))+String.valueOf(ca_num.charAt(j))+String.valueOf(pred_num.charAt(2))); } } } }else if(eat ==1 && bite ==1){ for(int i = 0;i<ca_num.length();i++){ if(ca_num.charAt(i)!=pred_num.charAt(0) && ca_num.charAt(i)!=pred_num.charAt(1) && ca_num.charAt(i)!=pred_num.charAt(2)){ can_list.add(String.valueOf(pred_num.charAt(0))+String.valueOf(ca_num.charAt(i))+String.valueOf(pred_num.charAt(1))); can_list.add(String.valueOf(pred_num.charAt(0))+String.valueOf(pred_num.charAt(2))+String.valueOf(ca_num.charAt(i))); can_list.add(String.valueOf(ca_num.charAt(i))+String.valueOf(pred_num.charAt(1))+String.valueOf(pred_num.charAt(0))); can_list.add(String.valueOf(pred_num.charAt(2))+String.valueOf(pred_num.charAt(1))+String.valueOf(ca_num.charAt(i))); can_list.add(String.valueOf(pred_num.charAt(1))+String.valueOf(ca_num.charAt(i))+String.valueOf(pred_num.charAt(2))); can_list.add(String.valueOf(ca_num.charAt(i))+String.valueOf(pred_num.charAt(0))+String.valueOf(pred_num.charAt(2))); } } }else if(eat ==1 && bite ==2){ for(int i = 0;i<ca_num.length();i++){ can_list.add(String.valueOf(pred_num.charAt(0))+String.valueOf(pred_num.charAt(2))+String.valueOf(pred_num.charAt(1))); can_list.add(String.valueOf(pred_num.charAt(2))+String.valueOf(pred_num.charAt(1))+String.valueOf(pred_num.charAt(0))); can_list.add(String.valueOf(pred_num.charAt(1))+String.valueOf(pred_num.charAt(0))+String.valueOf(pred_num.charAt(2))); } }else if(eat ==2 && bite ==0){ for(int i = 0;i<ca_num.length();i++){ if(ca_num.charAt(i)!=pred_num.charAt(0) && ca_num.charAt(i)!=pred_num.charAt(1) && ca_num.charAt(i)!=pred_num.charAt(2)){ can_list.add(String.valueOf(pred_num.charAt(0))+String.valueOf(pred_num.charAt(1))+String.valueOf(ca_num.charAt(i))); can_list.add(String.valueOf(pred_num.charAt(0))+String.valueOf(ca_num.charAt(i))+String.valueOf(pred_num.charAt(2))); can_list.add(String.valueOf(ca_num.charAt(i))+String.valueOf(pred_num.charAt(1))+String.valueOf(pred_num.charAt(2))); } } }else if(eat ==3 && bite ==0){ can_list.add(pred_num); } if(old_list.size()!=0){ for(String num : can_list){ if(old_list.contains(num)){ squeeze.new_can_list.add(num); squeeze.can_num =ca_num; } } }else{ squeeze.new_can_list = can_list; squeeze.can_num = ca_num; } //System.out.println(can_num); return squeeze; } //期待候補数を計算する public double count_cand(String pred_num,String ca_num,List<String> ca_list){ double ave_ca = 0; int[][] info_list = {{0,0},{0,1},{0,2},{0,3},{1,0},{1,1},{1,2},{2,1},{3,0}}; int sum_ex = 0; int sum_ex2 = 0; List<String> old_count_list = new ArrayList<>(ca_list); String ca_count_num = ca_num; NumeronAI squeeze2 = new NumeronAI(); for(int[] info :info_list){ squeeze2 = Squeeze(info[0],info[1],pred_num,ca_count_num,old_count_list); sum_ex=sum_ex+squeeze2.new_can_list.size(); sum_ex2=sum_ex2+squeeze2.new_can_list.size()^2; } if(sum_ex!=0){ ave_ca=sum_ex2/sum_ex; } return ave_ca; } //期待候補数が最小の数値を選択する public String choice(List<String> ca_list,String ca_num){ List<Double> ave_list = new ArrayList<>(); int min_index =0; try{ for(String num :ca_list){ double ave_ca = count_cand(num,ca_num,ca_list); ave_list.add(ave_ca); } double min =ave_list.get(0); for(int i =0;i<ave_list.size();i++){ double val = ave_list.get(i); if(min > val){ min = val; min_index = i; } } return ca_list.get(min_index); }catch(Exception e){ System.out.println("チョイスミス:" + e); return "111"; } } }実行結果
今回だと、6ターンで当てられてしまいました。感想
Javaはあまり書いたことがなかったけど一応自分の作りたかったものはできたと思います。
しかしまだまだ、デザインパターンの知識を実践するレベルには至ってないので、勉強する必要があるなぁと実感しました。(デザインパターン難しい...)
Numer0nのAI(AIとあまり言いたくないけど)を自分の手で書いてみるのは、Numer0nを知っていて、なにか作ってみたいという方には、ルールも分かりやすいのでオススメです!あと、pythonでもNumeronAIの部分だけ作成したのでJavaは書いてないけどpythonならわかるよって方は良かったら参考にしてみてください。
Qiitaの投稿はこれが初めてなので、Qiitaの先輩方、この記事について改善点などありましたら是非コメントよろしくお願いします<(_ _)>
これから少しずつアウトプットしていけるよう頑張ります!
- 投稿日:2020-01-22T18:23:11+09:00
AI Gaming はじめてみた
TL;DR
https://www.aigaming.com がBitCoinを賭けて戦う、バトルフィールドだ!!
AIやpythonに興味があれば、一緒に参加しよう!!この記事は
pythonもAIも初学者なnoyaがAI Gamingというプラットフォームで学習をはじめたというお話
AI Gamingとは
AIgaming.com is a platform that allows computer programs (bots) to challenge each other in games, puzzles and competitions, with the added incentive of winning cryptocurrency (Bitcoin and Satoshi)
プレイヤーがお互いに対戦型ゲーム(○×ゲームとか、囲碁とか)をするBotを作成し、仮想通貨を賭けて競うためのプラットフォームです。とのこと。実際は、Oppoturnityについて入れたりする欄もあるので、AI人材を見つけるための基盤としての一面もあるのでしょうが、Oppoturnityに関しては無視することもできるので、気にせず登録してよいかと思います。
How to Start
登録作業はとても簡単。さすが洗練されてきていますね。
- https://www.aigaming.com にアクセス
- 右上のRegisterから登録

- 必要事項を入力後、ダッシュボードがアクティベートされます
どんなゲームがあるの?
簡単なゲームから難しいゲームまで20種類くらいのゲームがリリースされています。
Nought and Crosses
小学生の頃に熱中した○×ゲーム
Battle Ship
相手の船を見つけて、早く全滅させた方が勝ち。(お互いに船の位置は見えておらず、着弾時の情報から場所を推測しています)
Match game
2枚のパネルを開いて、同じならポイント獲得!な神経衰弱。パネルの裏も表も画像のURLが渡されるので、まずはそれぞれのパネルが何なのか(動物・言葉・場所)を判断し、無駄なオープンを減らすところからスタートか。
BitCoinの稼ぎ方
Missionをクリア
登録時にいくらかのSatoshiが配布され、ミッションを進めていくことでSatoshiを増やしていくことができます。現在で最大4万Satoshiまで獲得できる模様。
最初はあまり気にしなくても、○×ゲームをやっていれば、3000Satoshiくらいにはなっていました。中には練習用Botと100連戦して50%以上の勝率をマークせよ、なんていうのもあります。
Betして勝つ
Satoshiを賭けて戦うこともできます。ただ、賭けて戦うケースはまだ稀みたいです。将来、貯めたSatoshiを全額投入!みたいなバトルがみられたりもするのでしょうか。
引き出し方
調べ中。(あまり興味がない)
遊び方
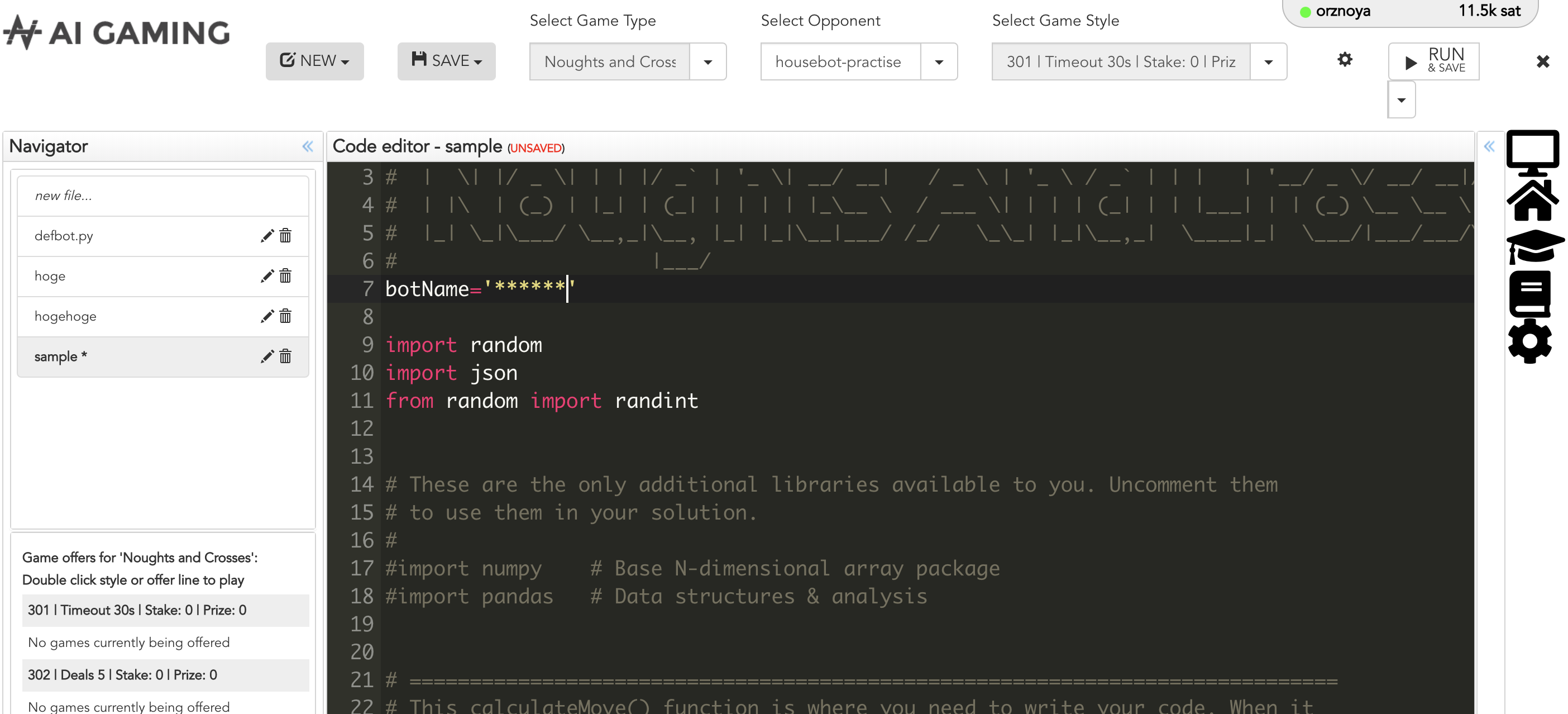
上部メニューの”EDITOR"からコーディング画面に入れます。
そのあと、Select Game Typeでゲームを選択すると、それぞれのゲームで「とりあえず動く」Botコードが記述されています。何もせずに右上のRunを押せば大抵の場合、ゲームが始まって、そして負けると思います。
Trouble
自分の場合は登録したあとに、ユーザアカウント名が気に入らなかったので変更したのですが、その場合botの名前が登録済みのBotの名前と一致せずゲームがはじめらませんでした。
デフォルトのBotの名前は(アカウント名)-defbotになっているのでMY ACCOUNT >> BOT MANAGEMENTで対応するBotを生成するか、旧アカウント名のBotを使うかなど、対応します。Coding
Sampleを参考にコーディングしましょう。
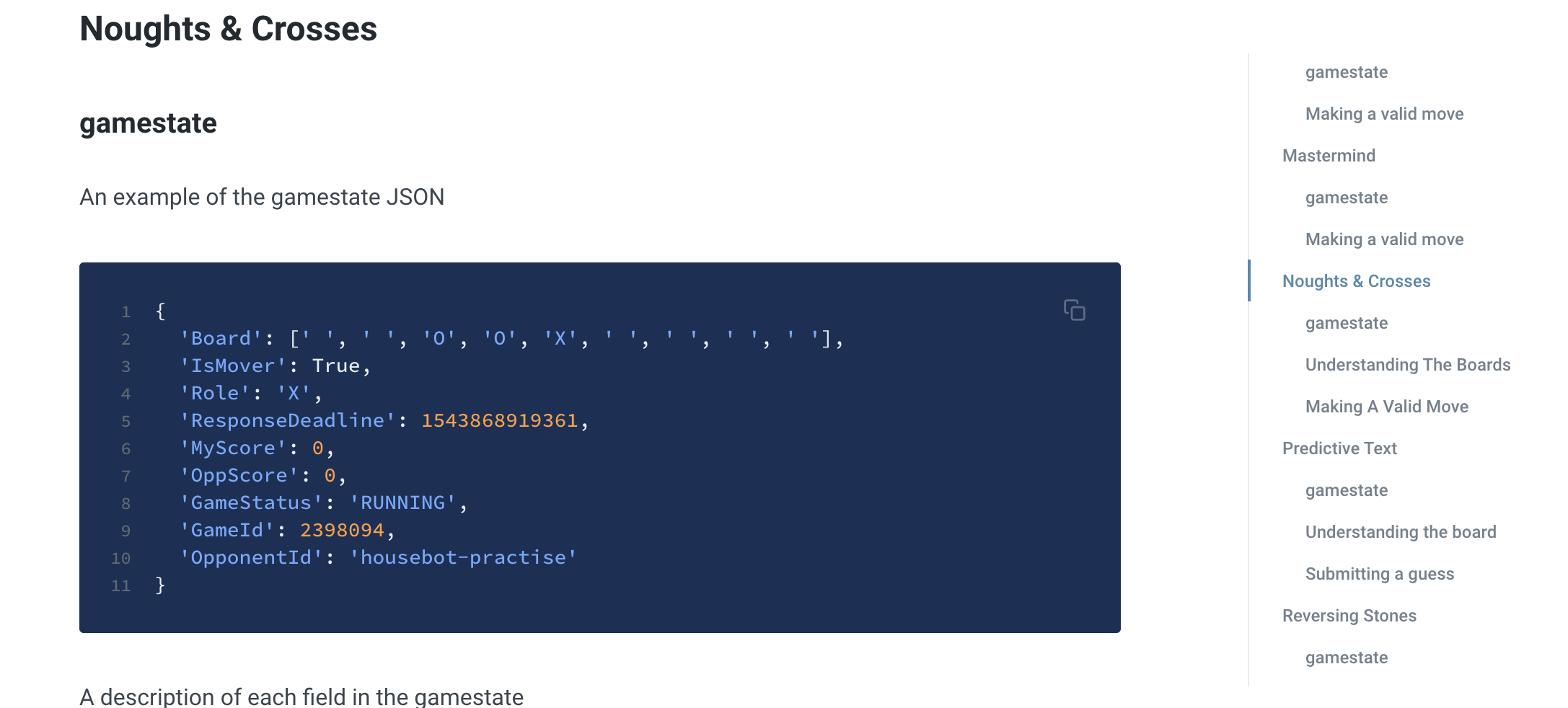
基本的にはゲームマスタが交代にとある関数にゲームの情報を引数として呼び出す(○×ゲームの場合はcalculateMove(gameState))ので、その中身を実装します。
gameStateの構造や返し値のフォーマットについては、https://www.aigaming.com/Help の各ゲームの説明かProgrammer’s Referenceにかなり丁寧に記載されています。
○×ゲームの場合は
gameState.Boardで一次元の配列としてボードの状態が引き渡されるので、これを理解して、自分のマークを置く位置nを{Positison: n}というJSONオブジェクトで返せばOKです。対戦を始める
Select Opponentのドロップダウンで対戦相手を選択可能です。
- housebot-practice : 弱いBot。まずはこいつに勝ちましょう。
- housebot-competition : 強いBot。筆者は現時点でまだ勝ててません。
対戦相手を指定する
ドロップダウンではなく、直接入力することで、対戦するBotを指名可能です。
面白いのは、自分自身とも対戦できるという点です。ブラウザを2面開いて、お互いに指名し合ってRunすれば、対戦可能です。(自分の作ったBot同士で対戦する、というミッションもあるので、是非とも試してみてください)
これからやってみようと思うこと
- competition Botに勝つ
- 画像認識や自然文解析のクラウド基盤と連携して、他のゲームに挑戦する
まとめ
以上、簡単にAI Gamingについてご紹介しました。ブラウザで完結し、気軽にpythonおよびAIについて、各自のレベルに合わせて学習できる、良い基盤だと思います。
それでは今回はこの辺で。



- 投稿日:2020-01-22T18:21:58+09:00
Django REST framework躓きどころ
Method Not Allowed:405
- requestsのメソッド
- postとputを間違えていた
401 Unauthorized
- 権限をなくす設定
- 'DEFAULT_PERMISSION_CLASSES': ['rest_framework.permissions.AllowAny']
URLの仕組み
- GET: api/book/
- POST: api/book/
- PUT: api/book/1/
Serializer
fields = '__all__'を駆使する'required': Falseを駆使するserializer.pyclass HistorySerializer(serializers.ModelSerializer): class Meta: model = History fields = '__all__' extra_kwargs = { 'id': {'required': False}, 'start_at': {'required': False}, }
- 投稿日:2020-01-22T18:16:55+09:00
精度をちょっぴり落としたら、重みパラメータが信じられない程減らせた 〜 CNNの驚きの結果 〜
1.はじめに
ニューラルネットワークの画像識別については、通常どこまで精度が上げられるかが注目されますが、私は天邪鬼なので、精度をちょっぴり落としたら、どれだけ重みパラメータが減らせるかに注目してみます。
ニューラルネットワークは精度の最後1〜2%を上げるために、リソースの大半が使われることが多いと思うので、精度を1〜2%程度犠牲にしただけでも、結構重みパラメーターを減らせるはずです。
今回実験に使うモデルは、kerasのチュートリアルに載っている、MNIST(0〜9の手書き数字)を識別するMLP(多層パーセプトロン)とCNN(畳み込みネットワーク)を使います。この2つのモデルの精度は98〜99%くらいなので、目標精度は97%台として、重みパラメータをどれだけ減らすことが出来るかを試してみます。
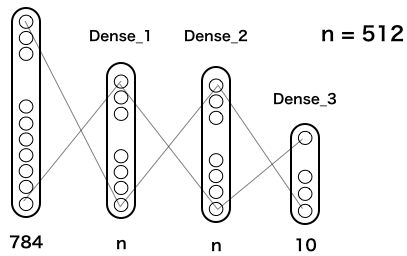
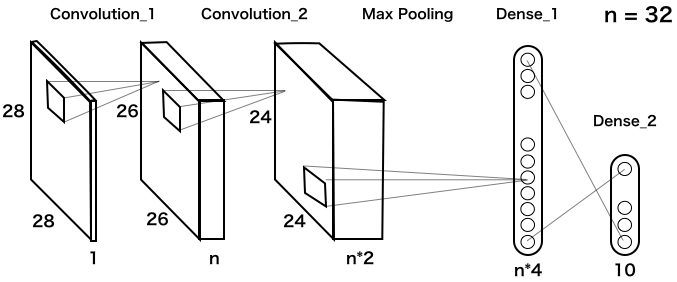
2.MLP(多層パーセプトロン)
これが、kerasチュートリアルに載っている、MLPの基本構造です(実際は、これに Dropout が2つ追加してありますが、単純化するために省略してあります)。
MNISTは28*28ピクセルなので、入力は28*28=784個。隠れ層は2層でいずれも n = 512個で全結合されています。この n を順次小さくしたら精度はどうなって行くのかをまず確認してみましょう。次のコードを実行します(実行時間は、google colab のGPUで3分半程度)。
from __future__ import print_function import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout from keras.optimizers import RMSprop batch_size = 128 num_classes = 10 epochs = 20 # load data (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train.reshape(60000, 784) x_test = x_test.reshape(10000, 784) x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) # multi Perceptoron_1 def mlp(n): model = Sequential() model.add(Dense(n, activation='relu', input_shape=(784,))) model.add(Dense(n, activation='relu')) model.add(Dense(num_classes, activation='softmax')) #model.summary() model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy']) model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=0, validation_data=(x_test, y_test)) score = model.evaluate(x_test, y_test, verbose=0) return score[1] # test list_n = [512, 256, 128, 64, 32, 16] x, y = [], [] for n in list_n: params = n*n + 796*n + 10 acc = mlp(n) x.append(params) y.append(acc) print ('n = ', n, ', ', 'params = ', params, ', ', 'accuracy = ', acc) # graph import matplotlib.pyplot as plt plt.scatter(x, y) plt.xscale('log') plt.show()
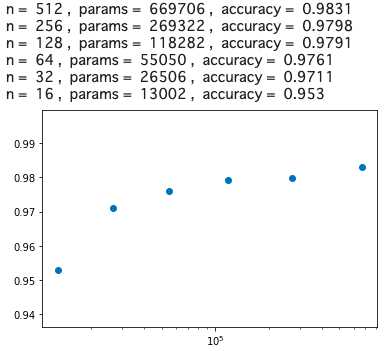
グラフの横軸は重みパラメータ数(log)、縦軸は精度です。精度97%を確保しようとすると、n = 32, params = 26506, accuracy = 0.9711 が分岐点でしょうか。そうすると、精度を若干犠牲にすることによって、669706/26506 = 25.26 なのでベースモデルの約1/25まで、重みパラメータを減らせるわけです。
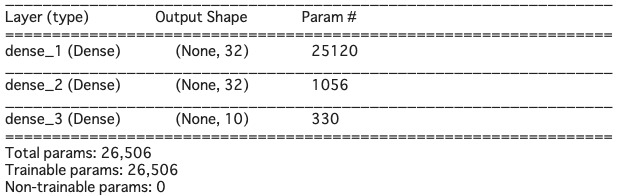
model.summary() でモデルの概要を見てみると(先頭の#を取って実行すると表示されます)、こんな感じ
これ以上重みパラメータを減らすことは無理でしょうか。いえ、まだ別の手があります。重みパラメータを一番消費するところはどこでしょうか。入力784個とdense_1のところで、(784+1)*32=25120 と全体の重みパラメータの95%はここで消費されているわけです。ちなみに、784+1となるのは、バイアス分が1あるからです。
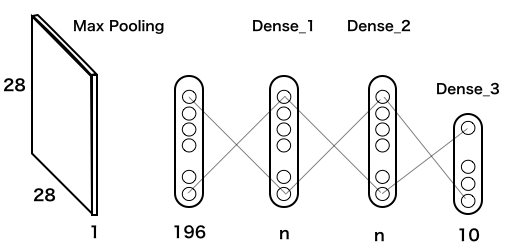
数字の解像度が悪くても、ある程度は識別出来るだろうと仮説を立て、28*28=784個の入力をフイルター(Max Pooling)を使って、1/4の14*14=196個にするモデルを考えます。
このモデルのコードを実行します(実行時間は、google colab のGPUで3分半程度)。from __future__ import print_function import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout from keras.optimizers import RMSprop from keras.layers import MaxPooling2D, Flatten # 追加 batch_size = 128 num_classes = 10 epochs = 20 # load data (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train.reshape(60000, 28, 28, 1) # 変更 x_test = x_test.reshape(10000, 28, 28, 1) # 変更 x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) # multi Perceptoron_2 def mlp(n): model = Sequential() model.add(MaxPooling2D(pool_size=(2, 2),input_shape=(28, 28, 1))) # 画像を14*14に縮小 model.add(Flatten()) # 全結合にする model.add(Dense(n, activation='relu')) model.add(Dense(n, activation='relu')) model.add(Dense(num_classes, activation='softmax')) #model.summary() model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy']) model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=0, validation_data=(x_test, y_test)) score = model.evaluate(x_test, y_test, verbose=0) return score[1] # test list_n = [512, 256, 128, 64, 32, 16] x, y = [], [] for n in list_n: params = n*n + 208*n + 10 # モデル変更 acc = mlp(n) x.append(params) y.append(acc) print ('n = ', n, ', ', 'params = ', params, ', ', 'accuracy = ', acc) # graph import matplotlib.pyplot as plt plt.scatter(x, y) plt.xscale('log') plt.show()
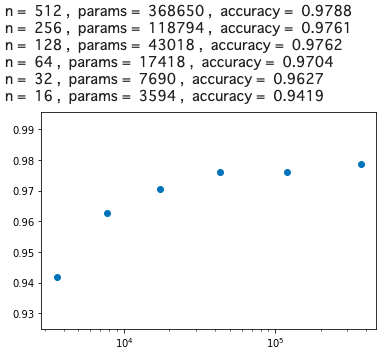
全体的に、若干精度の悪い方へスライドしましたが、n = 64, params = 17418, accuracy = 0.9704 が分岐点になりました。そうすると、精度を若干犠牲にすることによって、669706/17418=38.44 ということで、ベースモデルの約1/38まで重みパラメータを減らすことが出来ることが分かりました。結構減らせるものですね。
3.CNNの驚くべき結果
これが、kerasチュートリアルに載っている、CNNの基本構造です(実際は、これに Dropout が2つ追加してありますが、単純化するために省略してあります)。
2つある畳み込み層は、3*3=9のフィルターを使っています。その後、Max Poolingで縦横それぞれ1/2に縮小し、n*4の全結合層に繋げています。では、nを変化させた時の重みパラメータの数と精度を見てみましょう。次のコードを実行します(実行時間は、google colab のGPUで3分半程度)。
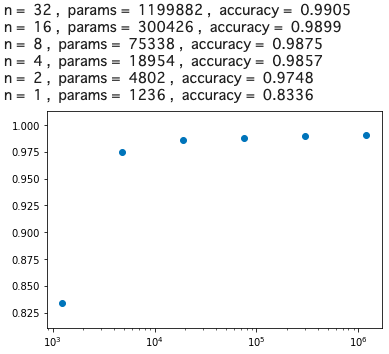
from __future__ import print_function import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D from keras import backend as K batch_size = 128 num_classes = 10 epochs = 12 img_rows, img_cols = 28, 28 # load data (x_train, y_train), (x_test, y_test) = mnist.load_data() if K.image_data_format() == 'channels_first': x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols) x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols) input_shape = (1, img_rows, img_cols) else: x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1) x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1) input_shape = (img_rows, img_cols, 1) x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) # CNN_1 def cnn(n): model = Sequential() model.add(Conv2D(n, kernel_size=(3, 3), activation='relu', input_shape=input_shape)) model.add(Conv2D(n*2, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) model.add(Dense(n*4, activation='relu')) model.add(Dense(num_classes, activation='softmax')) #model.summary() model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adadelta(), metrics=['accuracy']) model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=0, validation_data=(x_test, y_test)) score = model.evaluate(x_test, y_test, verbose=0) return score[1] # test list_n = [32, 16, 8, 4, 2, 1] x, y = [], [] for n in list_n: params = 1170*n*n + 56*n + 10 acc = cnn(n) x.append(params) y.append(acc) print ('n = ', n, ', ', 'params = ', params, ', ', 'accuracy = ', acc) # graph import matplotlib.pyplot as plt plt.scatter(x, y) plt.xscale('log') plt.show()
これは凄い! 分岐点は、n = 2, params = 4802, accuracy = 0.9748 です。そうすると、精度を若干犠牲にすることによって、1199882/4802=249.8 なのでベースモデルの約1/250まで重みパラメータの数を減らすことが出来たわけです。
さて、先程同様、model.summary()でモデルの概要を見てみると、
MLPとは逆で、入力と畳み込みの部分はパラメータの数は少ないです。畳み込み層のパラメータは、3*3=9個のフィルターが共通で使われるので、重みパラメータが少なくなります。その代わりに、最終の畳み込み層から全結合に入るところが、(12*12*4+1)*8=4616 で、全体の重みパラメータの96%を占めています。ここを何とか出来ないか。
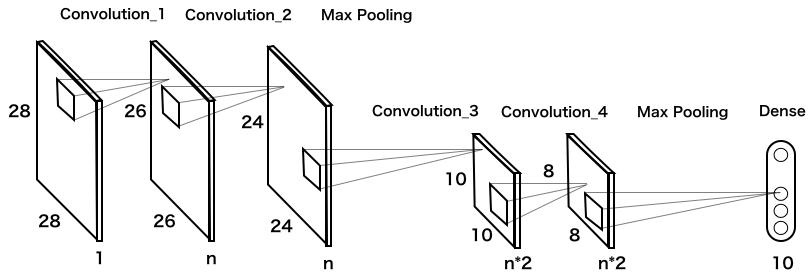
畳み込み層は、ほとんど重みパラメータを消費しないので、Max Poolingの後に再度畳み込み層を2つ入れて、さらにMax Poolingを掛けたらどうかというのが、以下のモデルです。
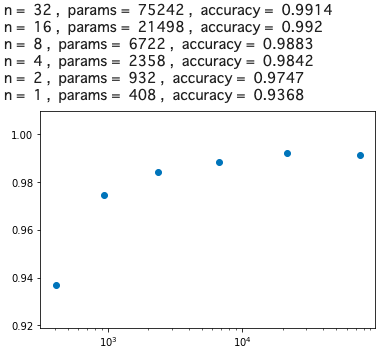
では、このモデルのコードを実行します(実行時間は、google colab のGPUで3分半程度)。from __future__ import print_function import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D from keras import backend as K batch_size = 128 num_classes = 10 epochs = 12 img_rows, img_cols = 28, 28 # load data (x_train, y_train), (x_test, y_test) = mnist.load_data() if K.image_data_format() == 'channels_first': x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols) x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols) input_shape = (1, img_rows, img_cols) else: x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1) x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1) input_shape = (img_rows, img_cols, 1) x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) # CNN_2 def cnn(n): model = Sequential() model.add(Conv2D(n, kernel_size=(3, 3), activation='relu', input_shape=input_shape)) model.add(Conv2D(n, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D(n*2, (3, 3), activation='relu')) model.add(Conv2D(n*2, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) model.add(Dense(num_classes, activation='softmax')) #model.summary() model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adadelta(), metrics=['accuracy']) model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=0, validation_data=(x_test, y_test)) score = model.evaluate(x_test, y_test, verbose=0) return score[1] # test list_n = [32, 16, 8, 4, 2, 1] x, y = [], [] for n in list_n: params = 63*n*n + 335*n + 10 acc = cnn(n) x.append(params) y.append(acc) print ('n = ', n, ', ', 'params = ', params, ', ', 'accuracy = ', acc) # graph import matplotlib.pyplot as plt plt.scatter(x, y) plt.xscale('log') plt.show()
驚いたことに、重みパラメータ数がたった932個で、精度97%が確保出来ました。この重みパラメータ数は、ベースモデルのなんと1/1000以下です!そして、MLPの17418個と比べると、17418/932=18.68 で、MLPの約1/18の重みパラメータで同等の精度が得られることが分かりました。
画像認識においては、CNNの畳み込み層が極めて有効に働くことが大変良く分かる結果ですね。CNN、恐るべしです!

- 投稿日:2020-01-22T18:15:05+09:00
字幕から文字抽出してみた(OpenCV:GoogleCloudVisionAPI編)
Motive
字幕から文字抽出してみた(OpenCV:tesseract-ocr編)の予告通りにGoogleCloudVisionAPIを使って字幕の文字を抽出してみたいと思います。
Method
まずGoogleCloudVisionAPIを使うにはgoogle cloud consoleにてアカウント登録してAPIキーを取得する必要があります。方法としては、Cloud Vision APIの使い方まとめ (サンプルコード付き)に書いてあるので参照してください。
import requests import json import base64 import cv2 import sys if __name__ == "__main__": KEY = "--- your api key ---" url = 'https://vision.googleapis.com/v1/images:annotate?key=' api_url = url + KEY # 画像読み込み img_file_path = sys.argv[1] mat = cv2.imread(img_file_path) # 字幕表示部分のみ roi = mat[435:600, :] # openCV -> base64 result, dst_data = cv2.imencode('.png', roi) img_content = base64.b64encode(dst_data) # リクエストBody作成 req_body = json.dumps({ 'requests': [{ 'image': { 'content': img_content.decode('utf-8') }, 'features': [{ 'type': 'DOCUMENT_TEXT_DETECTION' }] }] }) # リクエスト発行 res = requests.post(api_url, data=req_body) # リクエストから画像情報取得 res_json = res.json()['responses'] if 0 < len(res_json[0]): textobj = res_json[0]['textAnnotations'][0] print("".join(textobj["description"].strip().split("\n")))apiをリクエストするときは画像をbase64に文字列化してjsonを設計するのですが、
src = cv2.imread("image_path") result, dst_data = cv2.imencode('.png', src) img_content = base64.b64encode(dst_data)でopenCVからの変換ができます。
また、このまま最低限に逐次処理でAPIを呼び出しつつ文字抽出をすればいいのですが、
asyncioを使って並列処理をすれば処理スピードが上がります。asyncioを使う理由としてはmultiprocessing.Poolよりはコルーチン内でAPIのレスポンス処理をブロックしていて安定しているためです。async def main_image_process(src): #文字認識しやすいように加工 gray_frame = pre_process(src.content) #テロップが出そうなところだけトリミング roi = gray_frame[435:600, :] #テキストを抽出 text = await extractTelopText(roi) await asyncio.sleep(2) dst = await createFooterTelop(src.content) dst = await addJapaneseTelop(dst, text, 20, cap_height + telop_height - 30) dst = await addASCIITelop(dst, str(src.timestamp) + "[sec]", cap_width - 250, cap_height + telop_height - 10, color=(0,255,0)) return MovieFrame(src.id, dst, src.timestamp) if __name__ == "__main__": r = [] loop = asyncio.get_event_loop() try: r = loop.run_until_complete( asyncio.gather(*[main_image_process(f) for f in frames]) ) finally: loop.close()Python3.7以降だともっとシンプルに記述できるみたいですが、まだ安定しておらずcentOSのデフォルトパッケージがPython3.6だったので3.6ベースで書いています。
Development
コード全体です。
import sys import cv2 import io import os import numpy as np import base64 import json import requests import asyncio from PIL import Image, ImageDraw, ImageFont from collections import namedtuple import time MovieFrame = namedtuple("MovieFrame", ["id", "content", "timestamp"]) telop_height = 50 cap_width = 1 cap_height = 1 def pre_process(src): kernel = np.ones((3,3),np.uint8) gray = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY) o_ret, o_dst = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU) dst = cv2.morphologyEx(o_dst, cv2.MORPH_OPEN, kernel) dst = cv2.bitwise_not(dst) dst = cv2.cvtColor(dst, cv2.COLOR_GRAY2BGR) return dst async def extractTelopText(src): KEY = "--- your api key ---" url = 'https://vision.googleapis.com/v1/images:annotate?key=' api_url = url + KEY message = "" result, dst_data = cv2.imencode('.png', src) img_content = base64.b64encode(dst_data) # リクエストBody作成 req_body = json.dumps({ 'requests': [{ 'image': { 'content': img_content.decode('utf-8') }, 'features': [{ 'type': 'DOCUMENT_TEXT_DETECTION' }] }] }) # リクエスト発行 res = requests.post(api_url, data=req_body) # リクエストから画像情報取得 res_json = res.json()['responses'] if 0 < len(res_json[0]): textobj = res_json[0]["textAnnotations"][0] message = "".join(textobj["description"].strip().split("\n")) return message async def createFooterTelop(src): telop = np.zeros((telop_height, cap_width, 3), np.uint8) telop[:] = tuple((128,128,128)) images = [src, telop] dst = np.concatenate(images, axis=0) return dst async def main_image_process(src): #文字認識しやすいように加工 gray_frame = pre_process(src.content) #テロップが出そうなところだけトリミング roi = gray_frame[435:600, :] #テキストを抽出 text = await extractTelopText(roi) await asyncio.sleep(2) dst = await createFooterTelop(src.content) dst = await addJapaneseTelop(dst, text, 20, cap_height + telop_height - 30) dst = await addASCIITelop(dst, str(src.timestamp) + "[sec]", cap_width - 250, cap_height + telop_height - 10, color=(0,255,0)) return MovieFrame(src.id, dst, src.timestamp) async def addASCIITelop(src, sentence, px, py, color=(8,8,8), fsize=28): cv2.putText(src, sentence, (px, py), cv2.FONT_HERSHEY_SIMPLEX, 1, color, 2, cv2.LINE_AA) return src async def addJapaneseTelop(src, sentence, px, py, color=(8,8,8), fsize=28): rgbImg = cv2.cvtColor(src, cv2.COLOR_BGR2RGB) canvas = Image.fromarray(rgbImg).copy() draw = ImageDraw.Draw(canvas) font = ImageFont.truetype("./IPAfont00303/ipag.ttf", fsize) draw.text((px, py), sentence, fill=color, font=font) dst = cv2.cvtColor(np.array(canvas, dtype=np.uint8), cv2.COLOR_RGB2BGR) return dst if __name__ == '__main__': cap = cv2.VideoCapture('one_minutes.mp4') cap_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) cap_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) fps = cap.get(cv2.CAP_PROP_FPS) telop_height = 50 fourcc = cv2.VideoWriter_fourcc('m','p','4','v') writer = cv2.VideoWriter('extract_telop_async.mp4',fourcc, fps, (cap_width, cap_height + telop_height)) frames = [] start = time.time() idx = 0 #read frame try : while True: if not cap.isOpened(): break if cv2.waitKey(1) & 0xFF == ord('q'): break ret, frame = cap.read() if frame is None: break frames.append(MovieFrame(idx,frame, round(idx/fps, 4)) ) idx += 1 except cv2.error as e: print(e) cap.release() print("read movie file") #process r = [] loop = asyncio.get_event_loop() try: r = loop.run_until_complete( asyncio.gather(*[main_image_process(f) for f in frames]) ) finally: loop.close() #sort sorted_out = sorted(r, key=lambda x: x.id) #write frame try : for item in sorted_out: writer.write(item.content) except cv2.error as e: print(e) writer.release() print("write movie file") print("Done!!! {}[sec]".format(round(time.time() - start,4)))Result
tesseract-ocr
処理時間: 450sec ≒ 約7.5分GoogleCloudVisionAPI
処理時間:1315sec ≒ 21分
外部APIを使いつつ非同期処理をかけているので処理時間が結構かかりましたが、OCRの精度としてはGoogleCloudVisionAPIの方が良いのがわかると思います。
Future
次回は画像修復(inpaint)を使ってオブジェクト消去したった(OpenCV:C++)を動画編集しようかなと思っているのですが、今回使ったコードをもとにC++にしようかなと思っています。
となると、
- curlの使い方
- thread(そもそもあるのかasyncioと同等のライブラリがあるのか?)
を処理するにはどうすればいいか考えないといかんとです。
boostを使うしかないか。Reference


- 投稿日:2020-01-22T17:57:46+09:00
Shotgun APIを初めて使う方へ - データ操作編・後編 -
データ操作編・前編では、Shotgun APIを使用してProjectの作成、取得、更新を行う方法をご紹介しました
今回は、Projectに紐づくEntityのデータ操作方法をご紹介します
前回の記事で作成したフォルダやモジュールを使用して進めますので、
まだ前回の記事をご覧になっていない場合は、そちらから先にご覧頂ければ幸いですProjectに紐づくEntityの特徴
Shotgunにデフォルトで用意されているEntityの中で
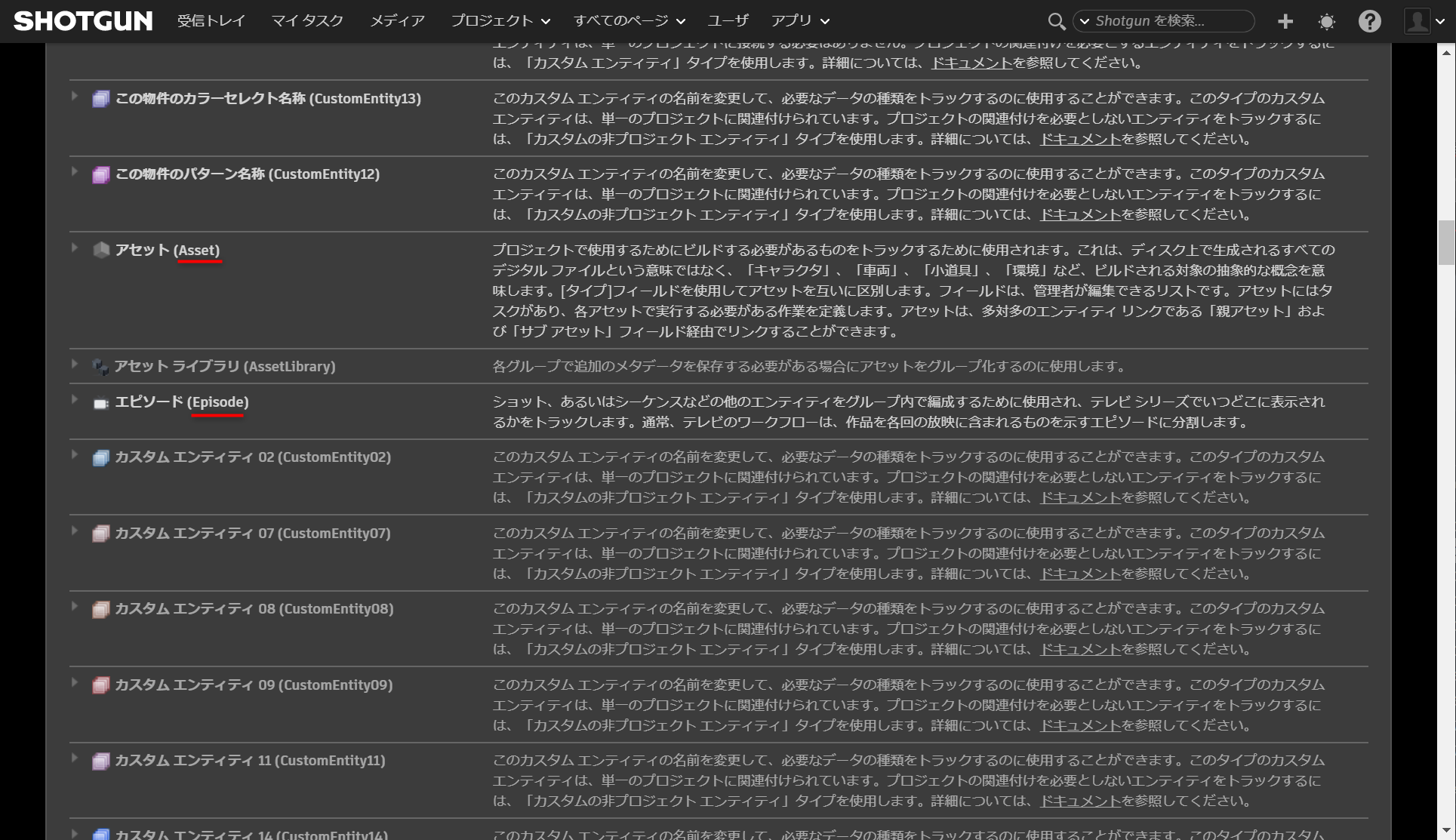
AssetやShot、TaskなどのEntityは、Projectと紐づける(リンクする)ことを前提に構成されていますそのため、APIで作成する際は、リンク先のProjectの情報も指定する必要があります
※指定しないで作成しようとするとエラーが出ますそれ以外は、前回の記事でProjectを操作した際の方法とほとんど同じ方法で操作出来ます
Shotgun APIでAssetを作成する
今回はAssetを作成してみます
※entity_typeを対応するものに変更すれば、ShotやTaskなどの他のEntityも作成出来ますリンク先のProjectは、前回の記事で作成したSHOTGUN_API_STARTUPとします
Asset作成用スクリプトを作成する
テキストエディタに下記のコードをコピー&ペーストし、shotgun_api_startupフォルダの中に
create_asset.pyという名前で保存しますcreate_asset.py# -*- coding: utf-8 -*- import sys from shotgun import create_shotgun_api from get_project import get_project # 作成するProjectの名称を指定します PROJECT_NAME = "SHOTGUN_API_STARTUP" # 作成するAssetの名称を指定します ASSET_NAME = "SAMPLE_ASSET" def create_asset(shotgun_api, project_info): # ShotgunにAssetを作成します data = {"code": ASSET_NAME, "description": u"このAssetは、Shotgun APIの学習用に作成されました", "project": {"id": project_info.get("id"), "type": project_info.get("type")}} return shotgun_api.create(entity_type="Asset", data=data) def main(): shotgun_api = create_shotgun_api() project_info = get_project(shotgun_api, PROJECT_NAME) print(create_asset(shotgun_api, project_info[0])) return 0 if __name__ == "__main__": sys.exit(main())解説
Shotgun APIを使用するためのオブジェクトの取得やProject情報の取得には、前回の記事(データ操作編・前編)で作成したスクリプトをインポートして使用します
from shotgun import create_shotgun_api from get_project import get_projectAssetの作成に関してもProjectの作成の際に使用した Shotgun APIのcreate 関数を使用します
- Projectを作成する際と異なる点
- create関数に指定しているentity_typeがAssetになっている
- dataにProjectとリンクするために必要な情報を指定している
Projectとリンクするためには、projectフィールドの値として、
対象のProjectのidとtype(entity_type)を指定することでリンクが作成されます# 作成するProjectの名称を指定します PROJECT_NAME = "SHOTGUN_API_STARTUP" # 作成するAssetの名称を指定します ASSET_NAME = "SAMPLE_ASSET" def create_asset(shotgun_api, project_info): # ShotgunにAssetを作成します data = {"code": ASSET_NAME, "description": u"このAssetは、Shotgun APIの学習用に作成されました", "project": {"id": project_info.get("id"), "type": project_info.get("type")}} return shotgun_api.create(entity_type="Asset", data=data)動作確認
動作確認をしている様子を動画にしたのでご覧頂ければと思います
ShotgunAPIでアセットを作成する方法 pic.twitter.com/tveYZQYfb9
— Tetsuya Nozawa (@lphing) January 29, 2020手順
コマンドプロンプトを開いて、下記のコマンドを入力して実行します
※D:\shotgun_api_startupの部分は、自分の環境に合わせて変更して頂ければと思いますcd /d D:\shotgun_api_startup python create_asset.py実行に成功した場合は、下記のような内容が出力されます
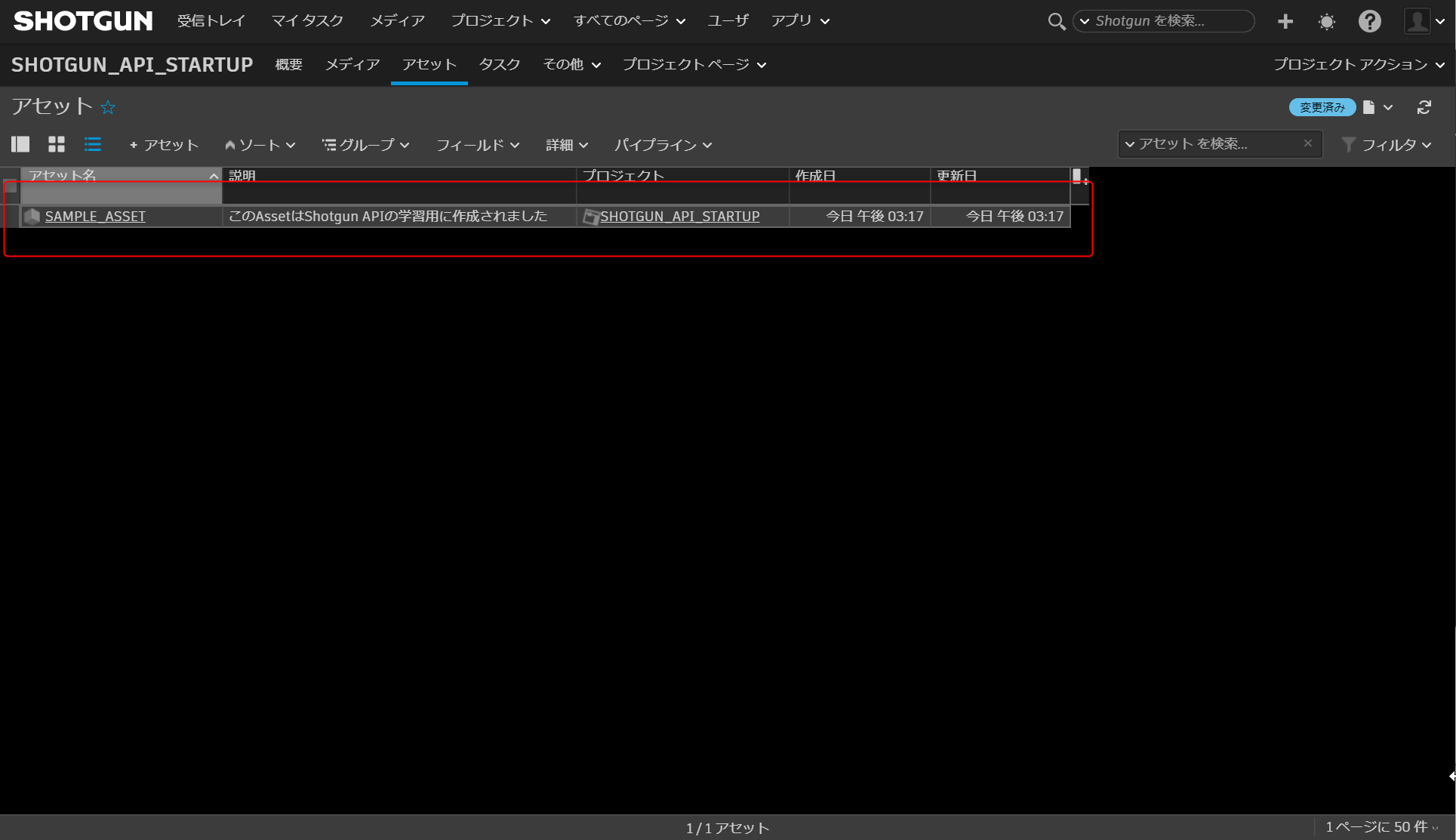
D:\shotgun_api_startup>python create_asset.py {'id': 2292, 'code': 'SAMPLE_ASSET', 'description': 'このAssetはShotgun APIの学習用に作成されました', 'project': {'id': 350, 'name': 'SHOTGUN_API_STARTUP', 'type': 'Project'}, 'type': 'Asset'}ShotgunでAssetテーブルを見てみると、SAMPLE_ASSETという名前のAssetが作成されていることが確認出来るかと思います
Shotgun APIでAssetの取得、更新に関して
Shotgun APIでAssetの取得と更新を行う方法に関しては、
前回の記事のProjectの取得と更新を行う際に作成したスクリプト内の
引数等を少し変更するだけで作成出来てしまいます下記にProjectの取得、更新時に作成したスクリプトをAsset用に変更を加えたものを載せましたので、それぞれテキストエディタにコピー&ペーストして、shotgun_api_startup フォルダに保存して下さい
Assetの取得用スクリプトの作成
下記の内容を get_asset.py という名前で保存します
get_asset.py# -*- coding: utf-8 -*- import sys from shotgun import create_shotgun_api # 取得するAssetの名称を指定します ASSET_NAME = "SAMPLE_ASSET" def get_asset(shotgun_api, asset_name): # codeがasset_nameの値に合致するものを取得対象に設定します filters = [["code", "is", asset_name]] # 取得したい情報が入っているフィールドのフィールドコードを指定します fields = ["code", "description"] # Shotgunからfiltersの条件に合致するAssetの情報を取得します return shotgun_api.find(entity_type="Asset", filters=filters, fields=fields) def main(): shotgun_api = create_shotgun_api() print(get_asset(shotgun_api, ASSET_NAME)) return 0 if __name__ == "__main__": sys.exit(main())
- Projectの取得用スクリプトからの主な変更点
- 取得対象の名称をSAMPLE_ASSETに変更
- entity_typeをAssetに変更
- filtersの値を[["code", "is", asset_name]]に変更
- Assetは名前を入れるためのフィールドがnameでは無くcodeになっているため
- fieldsの値を["code", "description"] に変更
- ProjectとAssetで対応するフィールドのフィールドコードが異なるため
Assetの更新用スクリプトの作成
下記の内容を update_asset.py という名前で保存します
update_asset.py# -*- coding: utf-8 -*- import sys import datetime from shotgun import create_shotgun_api from get_asset import get_asset # 更新対象のAssetの名称を指定します ASSET_NAME = "SAMPLE_ASSET" def update_asset(shotgun_api, asset_info): description = "このデータは、%s に更新されました" % datetime.datetime.now() # Shotgunから取得した情報を使ってdescriptionの内容を更新します return shotgun_api.update(entity_type=asset_info.get("type"), entity_id=asset_info.get("id"), data={"description": description}) def main(): shotgun_api = create_shotgun_api() # Asset情報取得用スクリプトを使って情報を取得します asset_info = get_asset(shotgun_api, ASSET_NAME) print(update_asset(shotgun_api=shotgun_api, asset_info=asset_info[0])) return 0 if __name__ == "__main__": sys.exit(main())
- Projectの更新用スクリプトからの主な変更点
- 更新対象の名称をSAMPLE_ASSETに変更
- update関数の引数dataの値を{"description": description}に変更
- Assetの場合は、説明内容を入れるフィールドのフィールドコードがsg_descriptionでは無くdescriptionとなっているため
取得用・更新用スクリプトの動作確認
動作確認の方法は、前回の記事の「作成したProjectの情報を取得する」と
「Projectの情報を更新(変更)する」を参考にして頂ければと思いますあとがき
今回は、Projectに紐づくEntityの中でAssetのデータ操作方法についてご紹介しました
Asset以外の別のEntityに関しても、今回作成したスクリプト内のentity_typeの値を
対応するものに変更することで別のEntityのデータ操作用スクリプトも作成出来るかと思いますちなみに各Entityのentity_typeを確認する方法に関しては、
確認方法を動画で撮影しましたので見て頂ければと思いますエンティティタイプの確認方法 pic.twitter.com/Sd2R51cvRR
— Tetsuya Nozawa (@lphing) January 29, 2020手順としては
1. Shotgun右上のプルダウンメニューから サイト基本設定 を選択します
2. エンティティのメニューを開きます
3. entity_typeを確認したいEntityを探します
4. 対象Entityの括弧内の文字がentity_typeです下記の画像の赤線を引いてある箇所がentity_typeです
このページ内で各Entityの詳細設定や新しいEntityの有効化なども出来るようになっています
次回は、ShotgunとSlackを連携して、Shotgunにデータが追加された際にSlackへ通知が飛ぶような仕組みを構築する方法について紹介したいと思います
- 投稿日:2020-01-22T17:56:40+09:00
Shotgun APIを初めて使う方へ - データ操作編・前編 -
前回は、Shotgun APIを使用するための導入部分についての説明を行いました
前回の記事
Shotgun APIを初めて使う方へ - 導入編 -今回は、Shotgun APIを実際に使用してShotgunにデータを登録し、取得や更新等を行っていきたいと思います
前回の記事で作成したフォルダやファイルを使用して進めますので、
まだ前回の記事をご覧になっていない場合は、そちらから先にご覧頂ければ幸いですShotgun APIでProjectを作成する
Shotgunでは、ProjectやAsset、Shotなどの各要素のことをEntityと呼びます
基本的に各Entityは、Project単位で管理が行われる仕組みとなっているため、まずはProjectの作成から入りたいと思いますProject作成用スクリプトの作成
テキストエディタに下記のコードをコピー&ペーストし、前回の記事で作成したshotgun_api_startupフォルダの中に
create_project.pyという名前で保存しますcreate_project.py# -*- coding: utf-8 -*- import sys from shotgun import create_shotgun_api # 作成するProjectの名前を指定します PROJECT_NAME = "SHOTGUN_API_STARTUP" def create_project(shotgun_api): # ShotgunにProjectを作成します data = {"name": PROJECT_NAME, "sg_description": u"このProjectはShotgun APIの学習用に作成しました"} return shotgun_api.create(entity_type="Project", data=data) def main(): shotgun_api = create_shotgun_api() print(create_project(shotgun_api)) return 0 if __name__ == "__main__": sys.exit(main())解説
Shotgunにデータを作成する際は、create 関数を使用します
- 引数
- entity_type
- 指定するentity_typeによってどのEntityを作成するのかが決まります
- data
- 指定した辞書データの内容がProjectの情報として追加されます
- 辞書データ内のnameは必須項目となっていて、作成したいProjectの名前を指定します。名前が重複する場合はエラーが出ます
- 辞書データ内のsg_descriptionは、Projectの説明を指定します
create関数の戻り値には、作成したProjectのidなどの情報が辞書データとして返ってきます
公式ドキュメントの方に詳しい情報が載っています# 作成するProjectの名前を指定します PROJECT_NAME = "SHOTGUN_API_STARTUP" def create_project(shotgun_api): # ShotgunにProjectを作成します data = {"name": PROJECT_NAME, "sg_description": u"このProjectはShotgun APIの学習用に作成しました"} return shotgun_api.create(entity_type="Project", data=data)動作確認
動作確認をしている様子を動画にしたのでご覧頂ければと思います
ShotgunAPIでプロジェクトを作る方法 pic.twitter.com/Ph6jqyYTa4
— Tetsuya Nozawa (@lphing) January 29, 2020手順
コマンドプロンプトを開いて、下記のコマンドを入力して実行します
※D:\shotgun_api_startupの部分は、shotgun_api_startupフォルダを作成した場所に応じて変更して下さいcd /d D:\shotgun_api_startup python create_project.pyProjectの作成に成功した場合は、下記のような内容がコマンドプロンプト上に出力されます
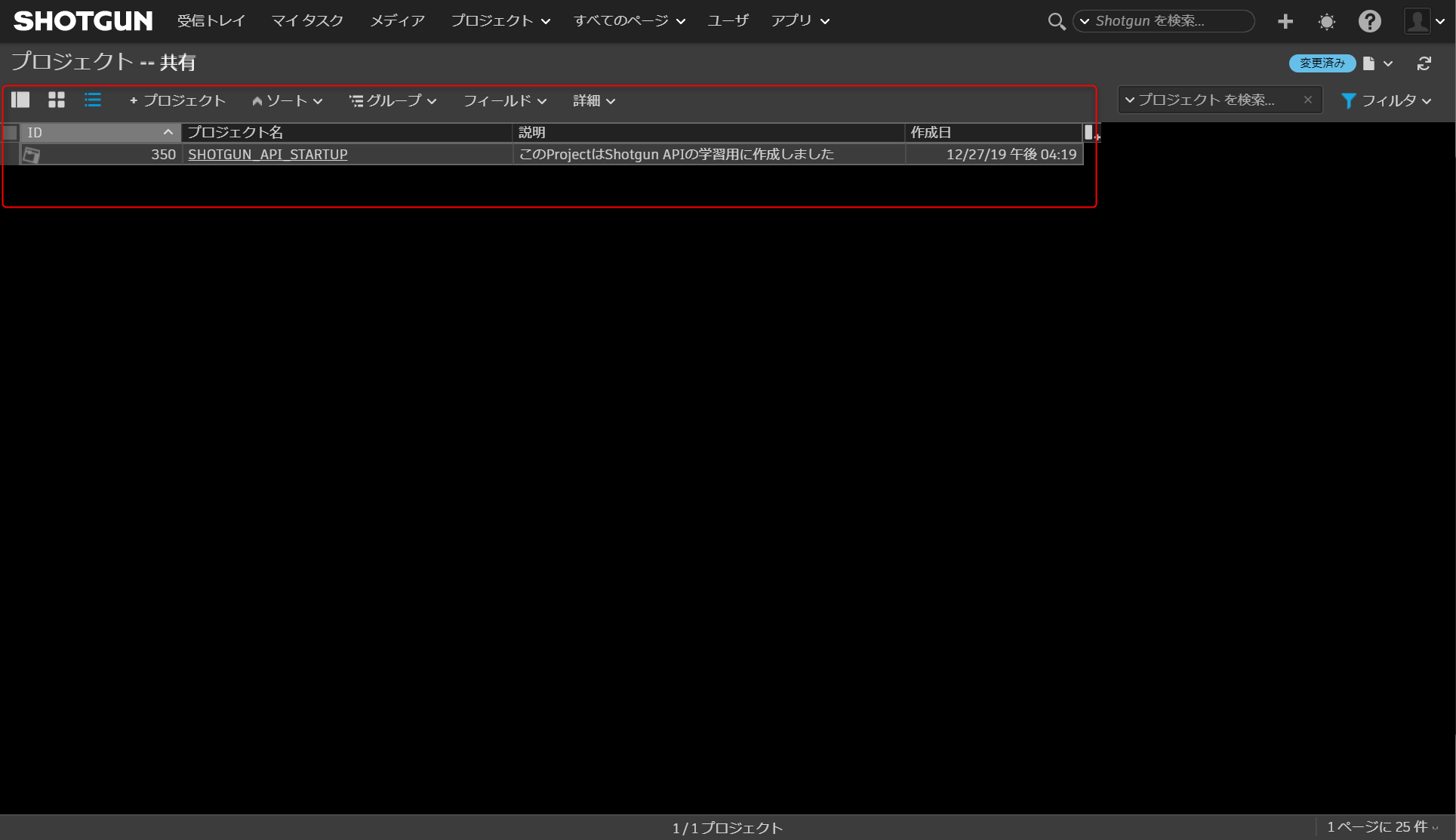
D:\shotgun_api_startup>python create_project.py {'id': 350, 'name': 'SHOTGUN_API_STARTUP', 'sg_description': 'このProjectはShotgun API の学習用に作成しました', 'type': 'Project'}ShotgunでProjectテーブルを見てみると、SHOTGUN_API_STARTUPという名前のProjectが作成されていることが確認出来るかと思います
作成したProjectの情報を取得する
先ほど作成したProjectの情報をAPIで取得してみます
Project取得用スクリプトの作成
テキストエディタに下記のコードをコピー&ペーストし shotgun_api_startupフォルダの中に
get_project.pyという名前で保存しますget_project.py# -*- coding: utf-8 -*- import sys from shotgun import create_shotgun_api # 取得するProjectの名称を指定します PROJECT_NAME = "SHOTGUN_API_STARTUP" def get_project(shotgun_api, project_name): # nameがproject_nameの値に合致するものを取得対象に設定します filters = [["name", "is", project_name]] # 取得したい情報が入っているフィールドのフィールドコードを指定します fields = ["name", "sg_description"] # Shotgunからfiltersの条件に合致するProjectの情報を取得します return shotgun_api.find(entity_type="Project", filters=filters, fields=fields) def main(): shotgun_api = create_shotgun_api() print(get_project(shotgun_api, PROJECT_NAME)) return 0 if __name__ == "__main__": sys.exit(main())解説
Shotgun APIでデータを取得する際は、find 関数を使用します
- 引数
- entity_type
- 指定するentity_typeによって取得するEntityを決めます
- filters
- 取得対象を絞り込むための条件を指定します
- 条件の指定方法に関しては、公式ドキュメントのFilter Syntaxページを参考にして下さい
- fields
- idとtypeに関しては、デフォルトで取得対象となっています
- idとtype以外のフィールドの値も取得する場合は、リストで対象のフィールドのフィールドコードを指定することで対象に含めることが出来ます
- フィールドコードの確認方法については、下記の記事が参考になります
findに関する詳しい情報は 公式ドキュメントに載っています
def get_project(shotgun_api, project_name): # nameがproject_nameの値に合致するものを取得対象に設定します filters = [["name", "is", project_name]] # 取得したい情報が入っているフィールドのフィールドコードを指定します fields = ["name", "sg_description"] # Shotgunからfiltersの条件に合致するProjectの情報を取得します return shotgun_api.find(entity_type="Project", filters=filters, fields=fields)動作確認
コマンドプロンプトを開いて、下記のコマンドを入力して実行します
※D:\shotgun_api_startupの部分は、shotgun_api_startupフォルダを作成した場所に応じて変更して下さいcd /d D:\shotgun_api_startup python get_project.py取得に成功した場合は、下記のような内容がコマンドプロンプト上に出力されます
D:\shotgun_api_startup>python get_project.py [{'type': 'Project', 'id': 350, 'name': 'SHOTGUN_API_STARTUP', 'sg_description': 'このProjectはShotgun APIの学習用に作成しました'}]Projectの情報を更新(変更)する
情報の取得が出来るようになったため、取得したIDを元にProjectの情報を更新したいと思います
※Shotgunに保存されている情報を更新するためには、対象のEntityのIDが必要になりますProject情報の更新用スクリプトを作成する
テキストエディタに下記のコードをコピー&ペーストし、shotgun_api_startupフォルダの中に
update_project.pyという名前で保存しますupdate_project.py# -*- coding: utf-8 -*- import sys import datetime from shotgun import create_shotgun_api from get_project import get_project # 更新対象のProjectの名称を指定します PROJECT_NAME = "SHOTGUN_API_STARTUP" def update_project(shotgun_api, project_info): description = "このデータは、%s に更新されました" % datetime.datetime.now() # Shotgunから取得した情報を使ってsg_descriptionの内容を更新します return shotgun_api.update(entity_type=project_info.get("type"), entity_id=project_info.get("id"), data={"sg_description": description}) def main(): shotgun_api = create_shotgun_api() # Project情報取得用スクリプトを使って情報を取得します project_info = get_project(shotgun_api, PROJECT_NAME) print(update_project(shotgun_api=shotgun_api, project_info=project_info[0])) return 0 if __name__ == "__main__": sys.exit(main())解説
Shotgun APIでデータを更新する場合は、update 関数を使用します
- 引数
- entity_type
- 更新対象のEntityのtypeを指定します
- entity_id
- 更新対象のEntityのIDを指定します
- data
- 更新する内容を辞書型で指定します
- 今回の場合は、sg_descriptionの値が更新されます
def update_project(shotgun_api, project_info): description = "このデータは、%s に更新されました" % datetime.datetime.now() # Shotgunから取得した情報を使ってsg_descriptionの内容を更新します return shotgun_api.update(entity_type=project_info.get("type"), entity_id=project_info.get("id"), data={"sg_description": description})動作確認
動作確認をしている様子を動画にしたのでご覧頂ければと思います
ShotgunAPIでプロジェクトの情報を取得・更する方法 pic.twitter.com/vwEI90oJcQ
— Tetsuya Nozawa (@lphing) January 29, 2020手順
コマンドプロンプトを開いて、下記のコマンドを入力して実行します
※D:\shotgun_api_startupの部分は、自分の環境に合わせて変更して頂ければと思いますcd /d D:\shotgun_api_startup python update_project.py実行に成功した場合は、下記のような内容が出力されます
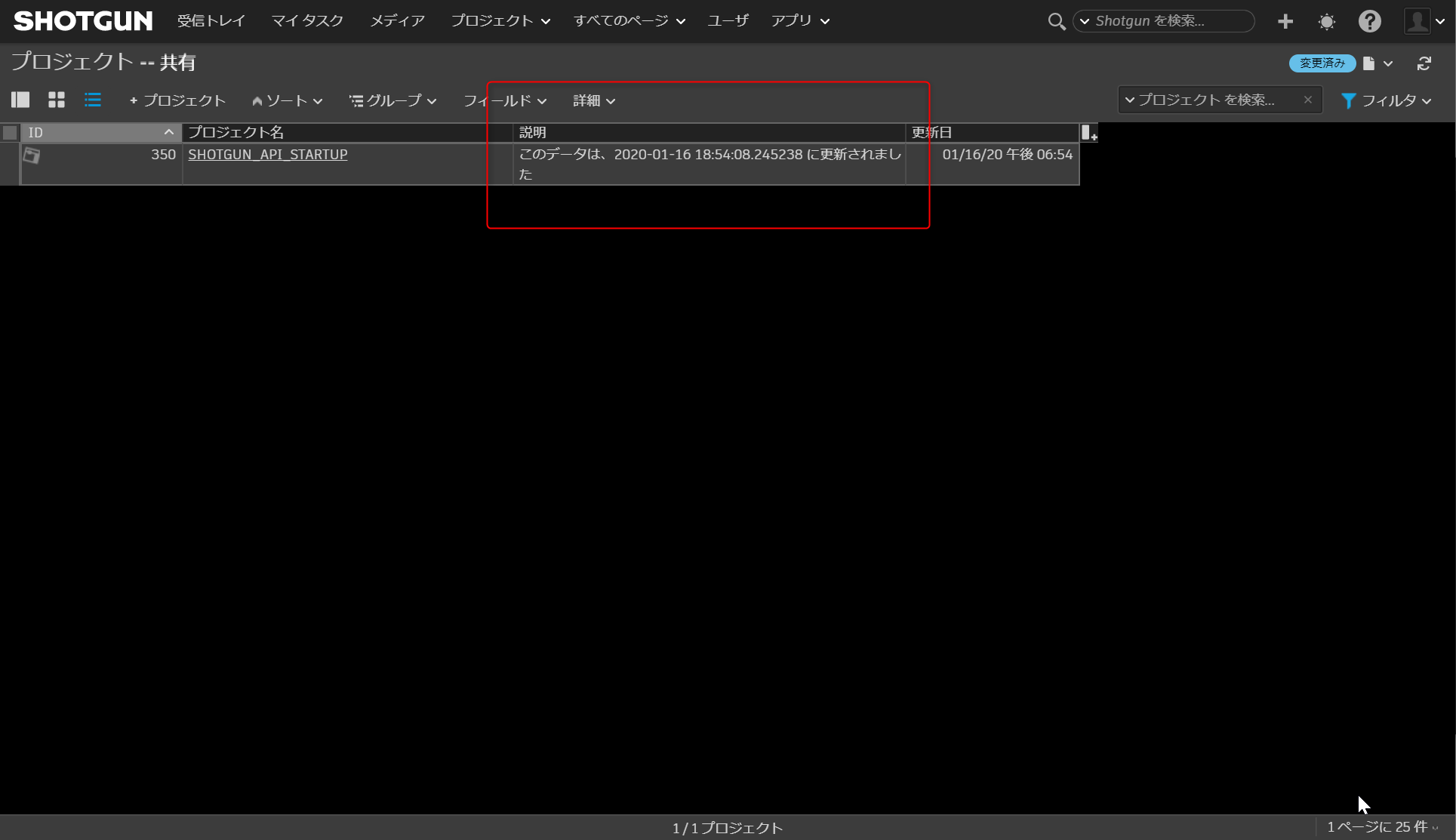
D:\shotgun_api_startup>python update_project.py {'type': 'Project', 'id': 350, 'sg_description': 'このデータは、2020-01-16 16:43:13.293248 に更新されました'}ShotgunでProjectテーブルを見てみると、SHOTGUN_API_STARTUPのdescriptionフィールドの値が更新
されていることが確認出来るかと思います
あとがき
ここまで紹介した内容で、Shotgun APIを使用した基本的なデータ操作が出来るようになったかと思います
次回の後編では、AssetやShot、TaskなどProjectに紐づくEntityの作成方法を紹介します
- 投稿日:2020-01-22T17:55:49+09:00
Shotgun APIを初めて使う方へ - 導入編 -
Shotgun APIを初めて使用する方に向けた記事をこれから書いていきたいと思っています
今回は、導入編ということでAPIを使うための導入手順について解説します
開発環境
- OS: Windows 10 Pro
- Python 3.6.8
- git 2.23.0
- テキストエディタ
- Visual Studio Code
Pythonをインストール
Python2 は2020年1月1日でサポート終了とのことですので
Python3をインストールして頂ければと思います下記のページが参考になります
Python3のインストールgitをインストール
Shotgun APIをインストールする際に必要なためインストールします
下記のページが参考になります
gitのインストールと起動方法Shotgun APIのインストール
Shotgun APIの公式ドキュメントの installation を見るといくつか方法が書かれています
pythonのpipコマンドを使用することでPYTHONPATHが通った場所にインストールすることが出来るため、
こちらを使用してインストールを行います下記のコマンドを実行します
pip install git+git://github.com/shotgunsoftware/python-api.gitインストールが完了すると下記のようなメッセージが表示されます
Successfully installed shotgun-api3-3.2.2下記のコマンドでインストールされているパッケージのリストを確認します
pip listshotgun_api3があれば問題無くインストールされています
Package Version ---------------- ---------- certifi 2019.9.11 pip 19.3.1 pipenv 2018.11.26 setuptools 40.6.2 shotgun-api3 3.2.2 virtualenv 16.7.8 virtualenv-clone 0.5.3Shotgunとの接続に必要な情報を取得する
Shotgun APIでShotgunと接続する際に下記の3つの情報が必要です
- 契約しているShotgunのページのURL
- スクリプトの名前
- アプリケーションキー
- ShotgunのサポートページなどでAPIキーやスクリプトキーとも表記されていますが全て同じものを指しています
上記の中で 契約しているShotgunのページのURL に関しては既に分かっているかと思いますが
スクリプトの名前とアプリケーションキーに関しては、ShotgunのWeb上でスクリプトユーザーを作成することで取得することが出来ますスクリプトユーザーの作成
スクリプトユーザーの作成手順に関しては、動画を作成しましたので、Shotgunにログイン後、動画に沿って進めて頂ければと思います
ShotgunAPIで使えるスクリプトユーザーを作り疎通させる方法#autodesk #shotgun pic.twitter.com/JwJEOK4pvQ
— Tetsuya Nozawa (@lphing) January 29, 2020解説
動画の途中で出てきた下記の画像の画面でスクリプト(スクリプトユーザー)の作成を行っていまして
この画面の中のスクリプト名に入力した内容が スクリプトの名前 で
アプリケーションキーの入力欄に入っている内容が アプリケーションキー となりますスクリプトの名前に関しては、ユーザー側で好きなものに変更することが出来ますが
アプリケーションキーに関しては、「スクリプトを作成」ボタンを押した後では、確認することが出来なくなってしまうので「クリップボードにコピー」ボタンを押した後にどこかにペーストしてメモっておく必要があります一応、この辺りの説明に関しては、Shtogunのサポートページの API スクリプトの作成と管理 にも載っています
アプリケーションキーが分らなくなってしまったら
もしも、スクリプトユーザーの作成後にアプリケーションキーが分らなくなってしまった場合は、
スクリプトユーザーのテーブル内で キーを変更 を押すことで専用の画面からアプリケーションキーを再度生成することが出来ます
Shotgunと接続が出来るか確認
Shotgun APIを使用して、Shotgunと接続出来るか確認してみます
Shotgunとの接続用スクリプトを作成する
任意の場所にshotgun_api_startupという名前でフォルダを作り、
下記のコードをコピーしてテキストエディタにペーストしたら、shotgun.pyという名前で
shotgun_api_startupフォルダの中に保存して下さいshotgun.py# -*- coding: utf-8 -*- import sys from shotgun_api3 import Shotgun # Shotgunに接続するために必要な情報を記述します SHOTGUN_URL = "ShotgunのURLを記述" SCRIPT_NAME = "shotgun_api_startup" API_KEY = "スクリプトユーザーのアプリケーションキーを記述" def create_shotgun_api(): # Shotgunクラスに接続に必要な情報を渡して、 # Shotgunとやりとりを行うためのオブジェクトを作成します return Shotgun(base_url=SHOTGUN_URL, script_name=SCRIPT_NAME, api_key=API_KEY) def main(): shotgun_api = create_shotgun_api() # 接続に問題が無いかテストするためにセッショントークンを取得します shotgun_api.get_session_token() print("Completed!!") return 0 if __name__ == "__main__": sys.exit(main())解説
変数のSHOTGUN_URLとAPI_KEYに関しては、自分の環境に合わせて適切なものを記述する必要があります
- "ShotgunのURLを記述"と書かれている箇所に契約しているShotgunのURLを記述して下さい
- "スクリプトユーザーのアプリケーションキーを記述"と書かれている箇所に先ほどスクリプトユーザーを作成した際に メモしておいたアプリケーションキーの内容を記述して下さい
# Shotgunに接続するために必要な情報を記述します SHOTGUN_URL = "ShotgunのURLを記述" SCRIPT_NAME = "shotgun_api_startup" API_KEY = "スクリプトユーザーのアプリケーションキーを記述"create_shotgun_api()の中でShotgunクラスに必要な情報を渡して、Shotgunとやりとりを行うためのオブジェクトを作成しています
Shotgunクラスに関しては、公式ドキュメントの下記のページに詳しく載っています
https://developer.shotgunsoftware.com/python-api/reference.html?highlight=user%20agent#shotgundef create_shotgun_api(): # Shotgunクラスに接続に必要な情報を渡して、 # Shotgunとやりとりを行うためのオブジェクトを作成します return Shotgun(base_url=SHOTGUN_URL, script_name=SCRIPT_NAME, api_key=API_KEY)shotgun.pyをimportでは無く直接実行された場合にmain関数が呼ばれます
shotgun_api.get_session_token()は、Shotgunに正常に接続出来た場合にのみセッショントークンが取得出来るため、接続テストのために使用しています
接続に問題がある場合は、shotgun_api3.shotgun.AuthenticationFault エラーが出ますdef main(): shotgun_api = create_shotgun_api() # 接続に問題が無いかテストするためにセッショントークンを取得します shotgun_api.get_session_token() print("Completed!!") return 0 if __name__ == "__main__": sys.exit(main())動作確認
コマンドプロンプトを開いて、下記のコマンドを入力して実行します
※D:\shotgun_api_startupの部分は、shotgun_api_startupフォルダを作成した場所に応じて変更して下さいcd /d D:\shotgun_api_startup python shotgun.py接続に成功した場合は、下記メッセージが表示されます
Completed!!ここまでの流れ
ShotgunのScriptユーザーの作成と疎通テスト pic.twitter.com/I4pEKP2gL2
— Tetsuya Nozawa (@lphing) January 31, 2020あとがき
ここまで出来ていれば、APIを使用するための準備が完了したことになります
次回は、APIを使用して実際にShotgunにデータを登録していきたいと思います
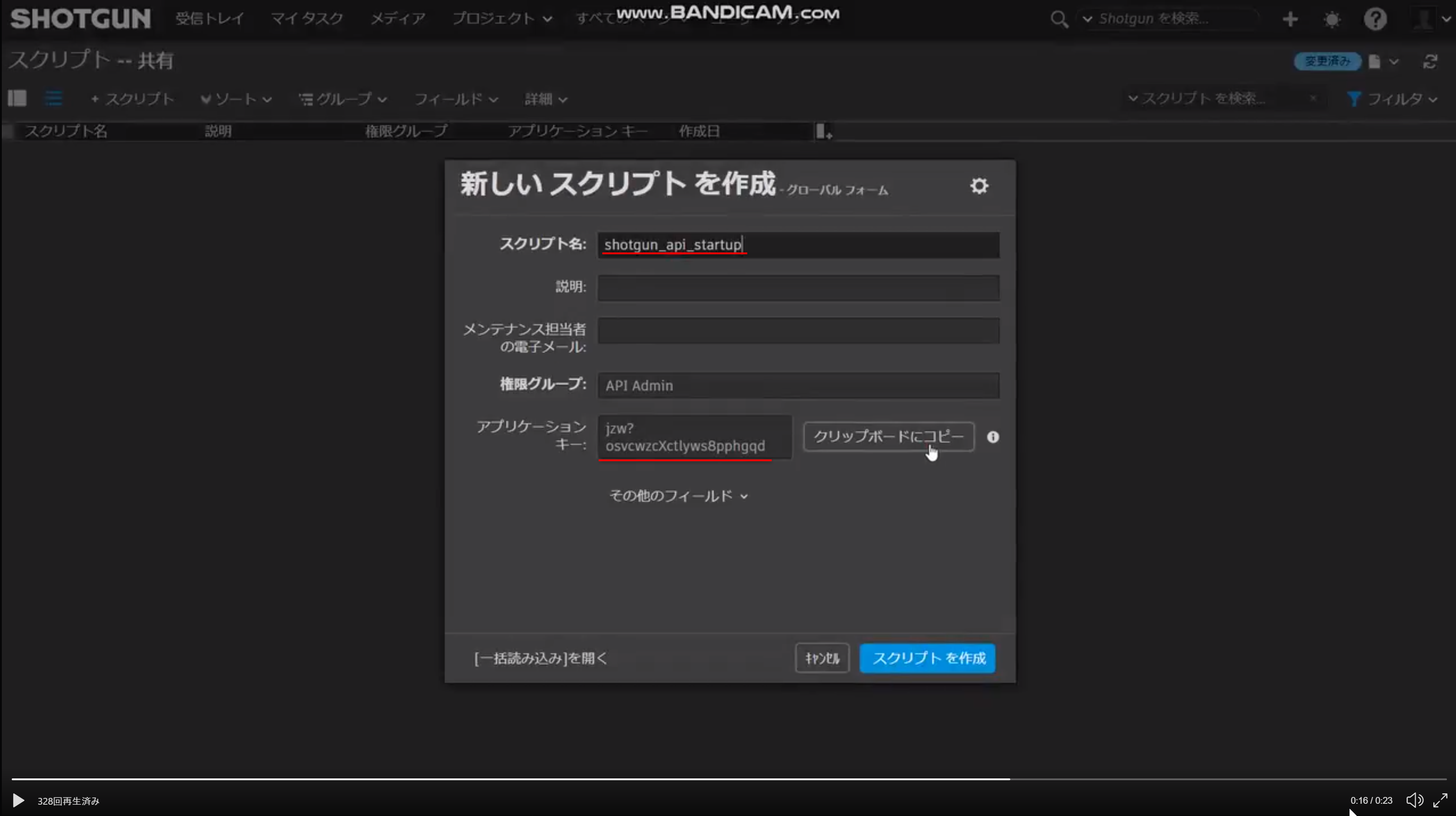
- 投稿日:2020-01-22T15:53:26+09:00
enable-sharedオプションで入れろと怒られた時に考えたこと
開発環境
Linux
あらすじ
vimのプラグインであるYouCompleteMeをいれようとしたときに「シェアードアブジェクトがねーぞ、enable-sharedでpyenvでインストールしろ」と丁寧なerror文で教えてくれた。
やり方
ターミナルで実行env PYTHON_CONFIGURE_OPTS="--enable-shared" pyenv install バージョンこちらを参照
https://github.com/pyenv/pyenv/wiki#how-to-build-cpython-with---enable-shared
- 投稿日:2020-01-22T15:53:26+09:00
enable-sharedオプションで入れろと怒られた時にやったこと
開発環境
Linux
あらすじ
vimのプラグインであるYouCompleteMeをいれようとしたときに「シェアードアブジェクトがねーぞ、pythonをenable-sharedオプションでインストールしろ」と丁寧なerror文で教えてくれた。
やり方
ターミナルで実行env PYTHON_CONFIGURE_OPTS="--enable-shared" pyenv install バージョンこちらを参照
https://github.com/pyenv/pyenv/wiki#how-to-build-cpython-with---enable-shared
- 投稿日:2020-01-22T15:34:33+09:00
【Azure】モデルを作成・デプロイ・再学習をしてみる【MLStudio classic】
わたし、公式ドキュメントわかんないです。
MLStudio classicでモデル作成やデプロイは何回かしてきてます。
今回、再学習させてみたいなと思って公式ドキュメントを読んでみたのですがよくわかんなくてあっちっこっち行ったり来たり。
どうにかできるようになったので忘れないように記事にします。
また、初めて使う人向けに書いてるつもりなので細かいことは省いているのでゆるしてください。大まかな流れ
- 学習実験を作る
- 予測実験を作る
- 予測実験のデプロイ
- 再学習をデプロイ
- 再学習を行う
- 再学習結果を予測実験に反映する
- 反映したかをテストする
です。
動作環境
途中でPythonを使うので環境とimportしたものを書いておきます。
- python3.7
- blobStorage
名前 urllib azure-storage-blob 利用するデータについて
それではまず今回使うデータです。
再学習できたのかどうかが知りたいので単調すぎるデータを使います。
下に学習用データ、テスト用データ、リモデル用データを書いておきます。train1.csvid,target 1,1 2,1 3,1 4,1 5,1remodel0.csvid,target 1,0 2,0 3,0 4,0 5,0作成したモデルではどんな数を入れても必ず1が返ってくるモデルを期待します。
なのでテストデータを入れてもすべて1で返ってくるはずです。
すべてが0であると学習することで0が返ってくることを期待します。モデルとしていいモデルでは全くないので、あくまでテスト用として使います。
学習実験を作成しましょう
それではモデルを作成します。
MLStudioにログインしたら、EXPERIMENTSを選択して画面下のNEWをクリックしましょう
そしたら
Blank Experimentをクリックしましょう。
これで予測モデルの作成準備ができました。では実際にモデルを作っていきます。
この検索窓から必要なブロックを検索して追加していくだけです。
今回は二項(一応)なのでtwo classで検索してできたたボックスを配置します。今回は
Two-Class Boosted Decision Treeを利用しました。
そのほかのブロックも同様に検索して画像のように配置しましょう。
次に各ブロックの設定をしていきます。ブロックをクリックすると
ページ右側に設定項目が出てきます。
アルゴリズムブロックではパラメータの設定ができます。今回はそのままでいいでしょう。続いてimport Dataです。ここでは学習に用いるデータの指定をします。
自身のblobユーザー名、Key、ファイルパスを記述しましょう。
今回のデータはフォーマットはcsvなのですが、ファイルにはヘッダーがあるため、File has header rowにチェックを入れましょう。最後にTrain Modelです。こちらでは学習するターゲットのカラム名を指定してあげます。
今回はtargetを学習したいので、Launch column selectorでtargetを記入してあげます。
ここまで終わったなら、ブロック同士を線でつないでみましょう。
Train Modelは左右反対には線でつなげないので気をつけましょう。
下のように配置できたら画面下部のRUNをクリックして実行してみましょう。
ボックスすべてにチェックマークがついたら完了です。
途中で止まってしまった場合、どこかに間違いがあるはずです。
blobのファイル名が違ったりするかもしれないですね(体験談)全部にチェックが付いたらモデルの完成です!
予測実験を作る
さてさて、では先ほど作ったモデルを使ってデータを投げると答えを返してくれるものを作りましょう。
先ほどのRUNの隣にあるSET UP WEB SERVICEからPredictiv web Serviceをクリックしましょう。
するとボックスがうようよ動いて下のようになります。
検索窓からExport Dataを持ってきて、blobのユーザー名などを書きます。
ここで書いたパスにテスト結果が出力されることになります。
もう一度
RUNしてみましょう。
先ほどのようにチェックが付いたのなら完了です。
完了したならDEPLOY WEB SERVICEをクリックしましょう。
しばらくすると画面が変わり、APIKEYなどが表示されます。
REQUEST/RESPONSEをクリックするとAPIが表示されるので、それを利用すると予測することができます。
このページで簡単なテストをすることもできます。
じっさにに青色のTESTボタンをクリックしてidに3、targetに1を入れて実験してみましょう。
しばらくするとページ下部に結果が返ってきます。
カラム名、カラムの型、値がリストで返ってきます。returnResult: {"Results":{"output1":{"type":"table","value":{"ColumnNames":["id","target","Scored Labels","Scored Probabilities"],"ColumnTypes":["Int32","Int32","Int32","Double"],"Values":[["3","1","1","0.142857149243355"]]}}}}
Scored Labelsが結果なので、この場合は1が返ってきてるので期待通りです。再学習をデプロイするよ
では
View latestをクリックして先ほどの画面に戻りましょう。
そしたら
Training expeprimentタブに移動して、Web service inputおよびWeb service outputを追加してRUNします。
そしたら下の
SET UP WEB SERVICEからDeploy Web Serviceをクリックしましょう。
これでデプロイは完了です。
APIKeyとAPIのURLは以降で必要になってきます。
APIKeyは画面に映っているものです。URLはBATCH EXECTIONをクリックすると出てきます。
利用するAPIのURLは?api-version…より前、つまりjobで終わるURLを使います。
私はここでつまずいた。
再学習してみよう!
それでは再学習してみます。
再学習自体はpythonで行いました。C#とかもサンプルであるのですが、ところどころ変えないと動かないかもしれないです。
(python3.7ではそうでした。)まず、実際に使うプログラムです。
retrain.py# python 3.7 なのでurllib2を変更 import urllib import urllib.request import json import time from azure.storage.blob import * def printHttpError(httpError): print(f"The request failed with status code: {str(httpError.code)}") print(json.loads(httpError.read())) return def processResults(result): results = result["Results"] for outputName in results: result_blob_location = results[outputName] sas_token = result_blob_location["SasBlobToken"] base_url = result_blob_location["BaseLocation"] relative_url = result_blob_location["RelativeLocation"] print(f"The results for {outputName} are available at the following Azure Storage location:") print(f"BaseLocation: {base_url}") print(f"RelativeLocation: {relative_url}") print(f"SasBlobToken: {sas_token}") return def uploadFileToBlob(input_file, input_blob_name, storage_container_name, storage_account_name, storage_account_key): #BlobServiceってのがないっぽいので変更 blob_service = BlockBlobService(account_name=storage_account_name, account_key=storage_account_key) print("Uploading the input to blob storage...") blob_service.create_blob_from_path(storage_container_name, input_blob_name, input_file) def invokeBatchExecutionService(): storage_account_name = "blobのユーザー名" storage_account_key = "blobのキー" storage_container_name = "blobのコンテナ名" connection_string = f"DefaultEndpointsProtocol=https;AccountName={storage_account_name};AccountKey={storage_account_key}" api_key = "再学習のAPIKey" url = "APIのURL" uploadFileToBlob("アップロードするファイルパス", "アップロードした後のファイルパス", storage_container_name, storage_account_name, storage_account_key) payload = { "Inputs": { "input1": { "ConnectionString": connection_string, "RelativeLocation": f"/{storage_container_name}/リモデル対象のblobのファイルパス" }, }, "Outputs": { "output1": { "ConnectionString": connection_string, "RelativeLocation": f"/{storage_container_name}/リモデル結果のblobのファイルパス.ilearner" }, }, "GlobalParameters": { } } body = str.encode(json.dumps(payload)) headers = { "Content-Type":"application/json", "Authorization":("Bearer " + api_key)} print("Submitting the job...") req = urllib.request.Request(url + "?api-version=2.0", body, headers) response = urllib.request.urlopen(req) result = response.read() job_id = result[1:-1] # job_idがstrじゃないよって怒られたので変換する job_id=job_id.decode('utf-8') print(f"Job ID: {job_id}") print("Starting the job...") headers = {"Authorization":("Bearer " + api_key)} req = urllib.request.Request(f"{url}/{job_id}/start?api-version=2.0", headers=headers, method="POST") response = urllib.request.urlopen(req) url2 = url + "/" + job_id + "?api-version=2.0" while True: print("Checking the job status...") req = urllib.request.Request(url2, headers = { "Authorization":("Bearer " + api_key) }) response = urllib.request.urlopen(req) result = json.loads(response.read()) status = result["StatusCode"] if (status == 0 or status == "NotStarted"): print(f"Job: {job_id} not yet started...") elif (status == 1 or status == "Running"): print(f"Job: {job_id} running...") elif (status == 2 or status == "Failed"): print(f"Job: {job_id} failed!") print("Error details: " + result["Details"]) break elif (status == 3 or status == "Cancelled"): print(f"Job: {job_id} cancelled!") break elif (status == 4 or status == "Finished"): print(f"Job: {job_id} finished!") processResults(result) break time.sleep(1) # wait one second return invokeBatchExecutionService()ほとんどサンプル通りなのですが、一部変更しています。(コメントで書いてます。)
URLやKey、PATHなどは各々の環境に合わせて書き換えてくださいね。
そしたらデータを用意して実行してみましょう。console>python remodel.py Uploading the input to blob storage... Submitting the job... Job ID: ID Starting the job... Checking the job status... JobID not yet started... Checking the job status... JobID running... Checking the job status... JobID running... Checking the job status... JobID running... Checking the job status... JobID running... Checking the job status... JobID running... Checking the job status... JobID running... Checking the job status... JobID running... Checking the job status... JobID finished! The results for output1 are available at the following Azure Storage location: BaseLocation: URL RelativeLocation: PATH SasBlobToken: KEY上記のように結果が返ってくるはずです。
下の三つは以降で利用します。再学習の反映
さて、リモデルの実行はしましたが、まだ反映はされていません。
この画面からNew Web Services Experienceを開いてください。
この時ページ上部のモデル名の後ろに[predictive exp.]がついていない場合はExperiment created on … [Predictive Exp.]をクリックして移動しましょう。
既存のものを上書きしてもいいと思いますがたいていは残しておくと思います。
なので新しいエンドポイントを作成します。
この画面から左ボタンを押して…
(矢印が雑になったのは気にたら負けです。)
+NEWをクリックしてエンドポイントに利用する名前を付けて保存します。
作成されたエンドポイント名をクリックすると先ほどのような画面に移動するので
Consumeタブを開きましょう。
開くといろんなKEYやらURLが出てきます。
今回利用するのはPrimary KeyとPatchです。これらを使って以下のコードを実行します。
update.pyimport urllib import urllib.request import json data = { "Resources": [ { "Name": "モデルの名前", "Location": { "BaseLocation": "結果のURL", "RelativeLocation": "結果のPATH", "SasBlobToken": "結果のKEY" } } ] } body = str.encode(json.dumps(data)) url = "Patchの値" api_key = "PrimaryKeyの値" # Replace this with the API key for the web service headers = {'Content-Type':'application/json', 'Authorization':('Bearer '+ api_key)} req = urllib.request.Request(url, body, headers) req.get_method = lambda: 'PATCH' response = urllib.request.urlopen(req) result = response.read() print(result)こんな感じです。
先ほどのページのPatchの下にあるAPIhelpを開くとサンプルがあるので、大体はその通りに書くといいと思います。
では、実行してみましょう。
b''が返ってきます。
なるほど?
でもこれでいいみたいです。
最後にこれをデプロイします。
デプロイ手順は再学習できたかな?
ページ上部の
Testタブを開いてテストしてみましょう。
もしかするとリロードが必要かもしれないです。
id=3,target=1です。
ちゃんと0になってるみたいです。
よかった…まとめ
どうにか再学習したモデルをデプロイすることができました。
皆さんも利用しているモデルの精度が下がってきたかな?と思ったら、再学習して、モデルを継続利用しましょう!
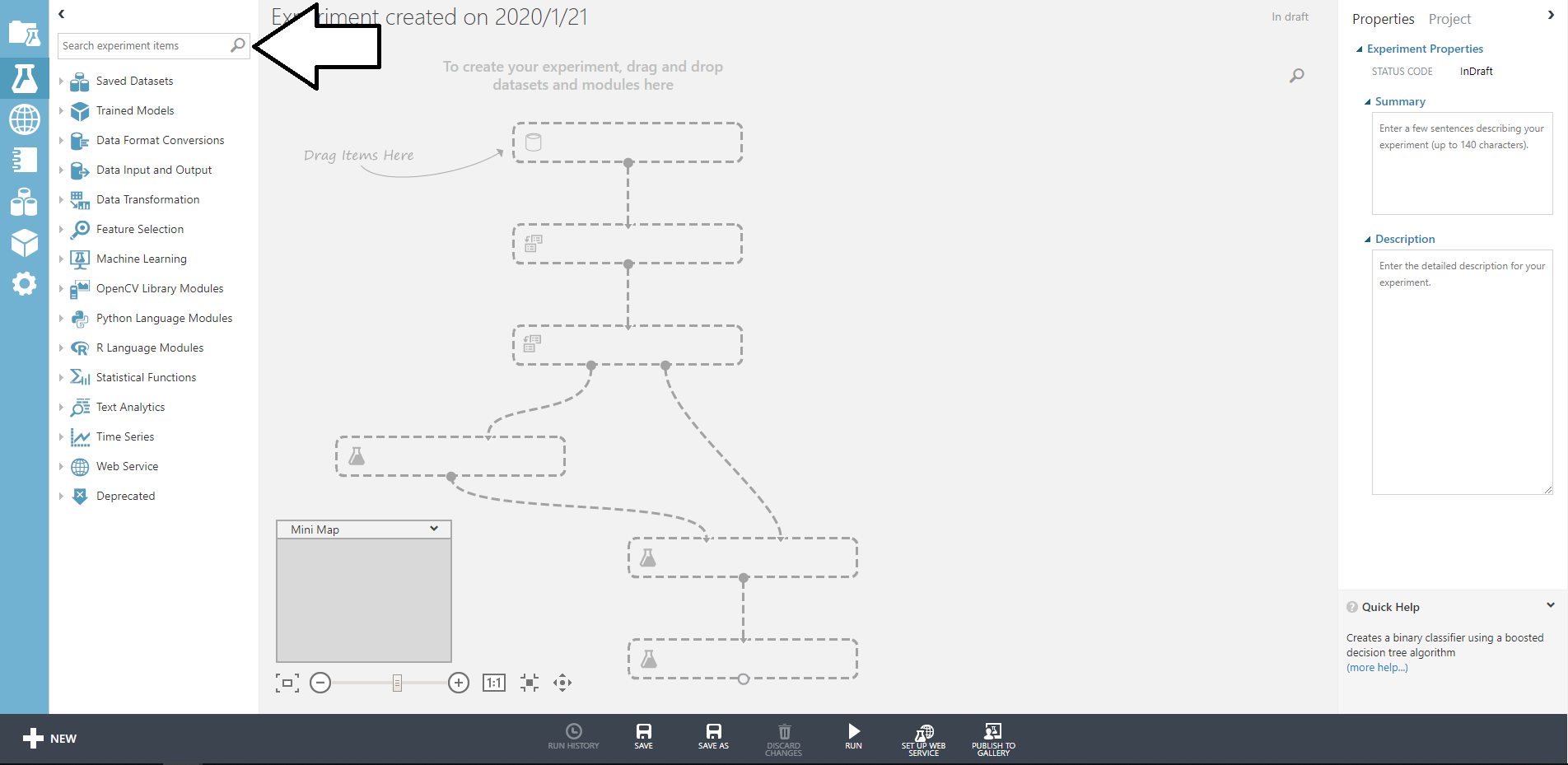
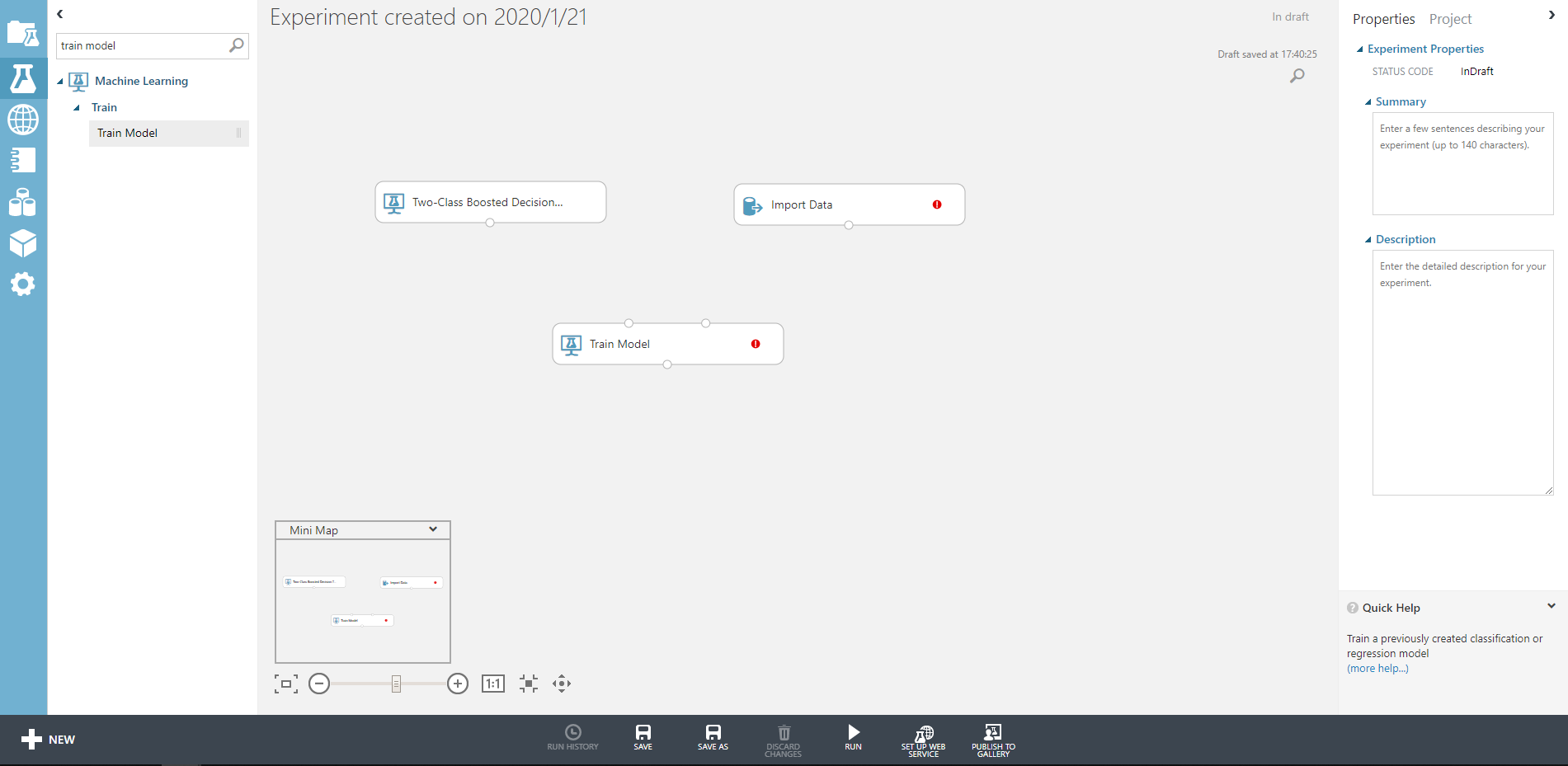
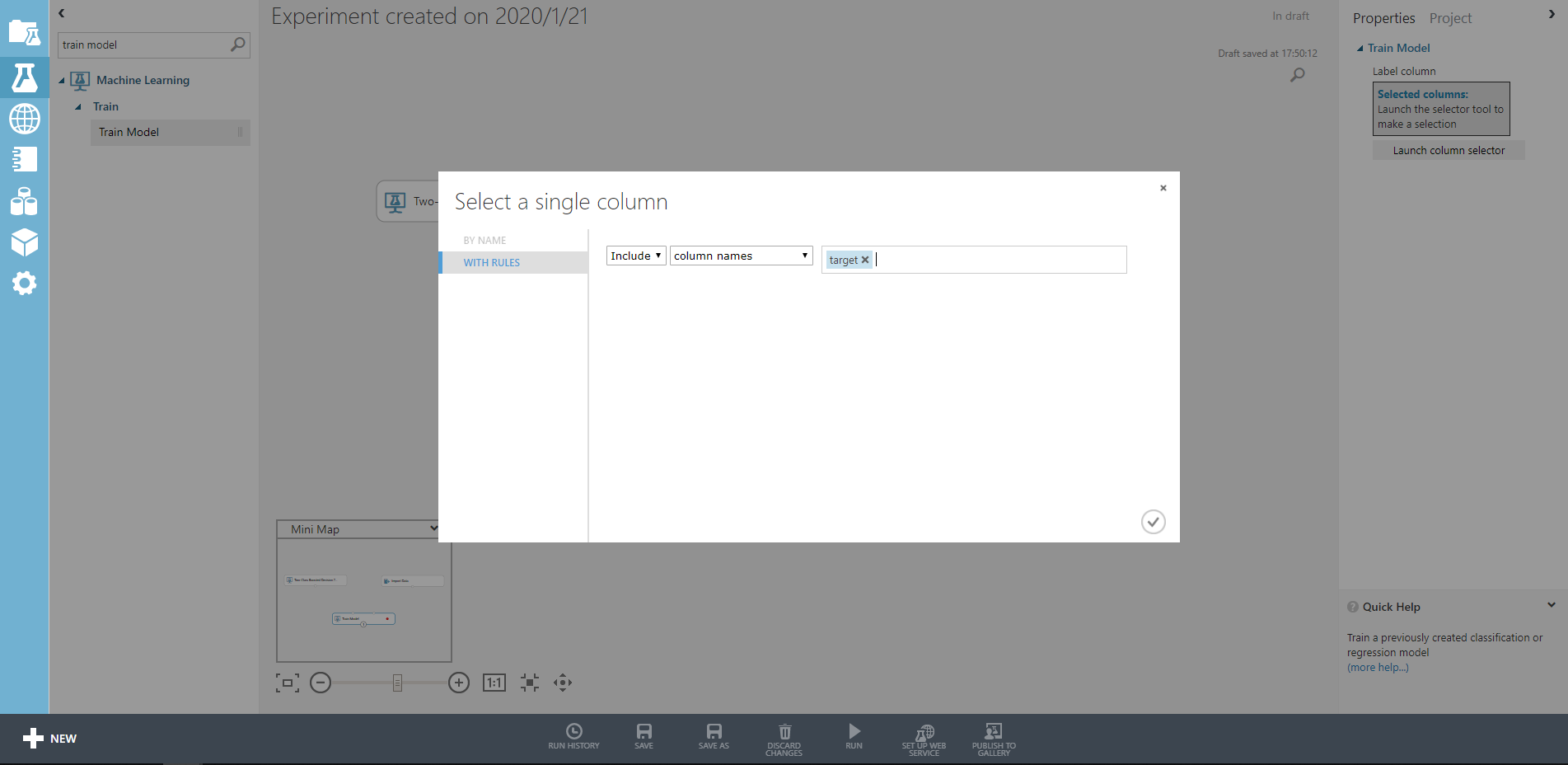
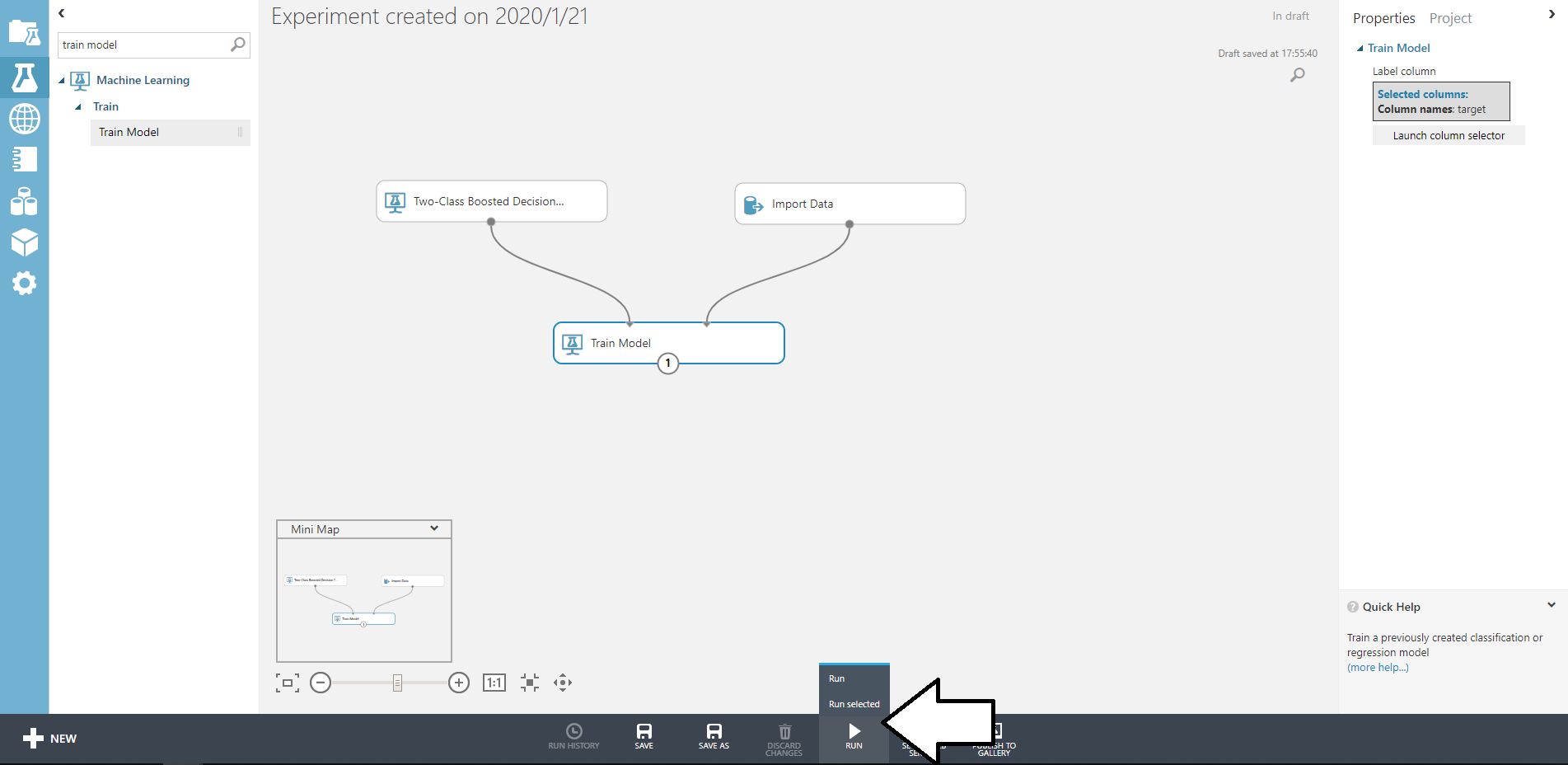
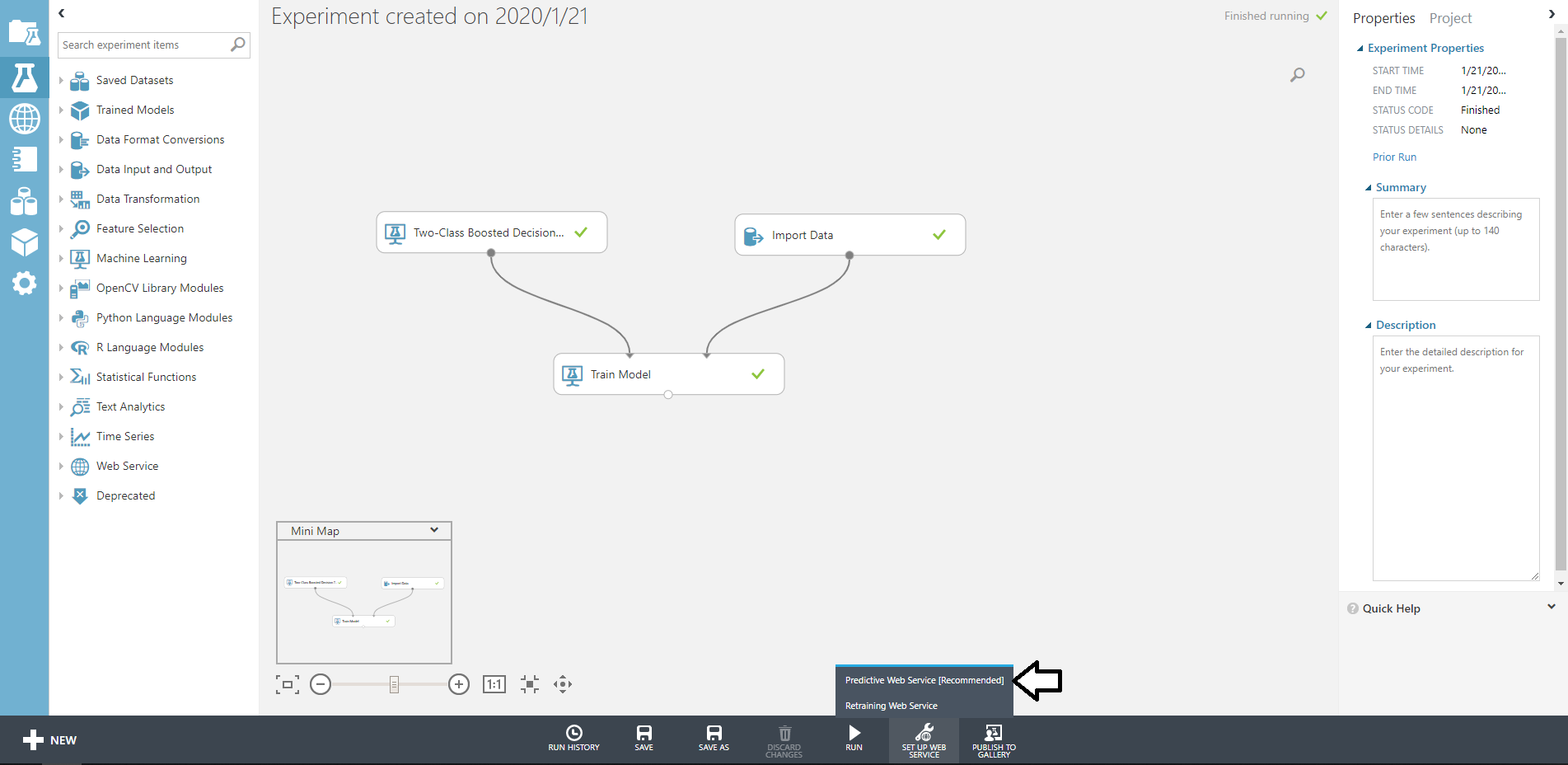
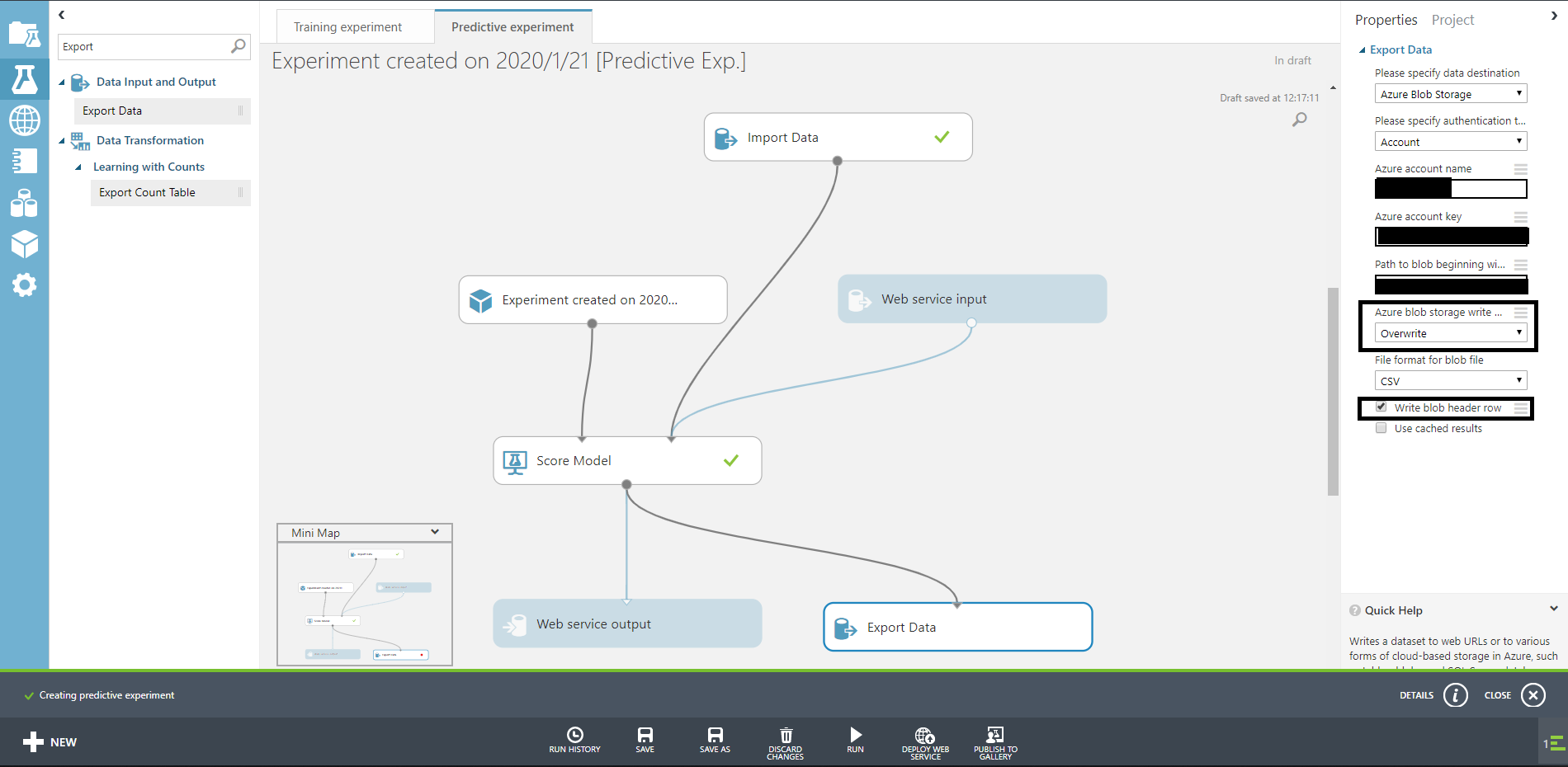
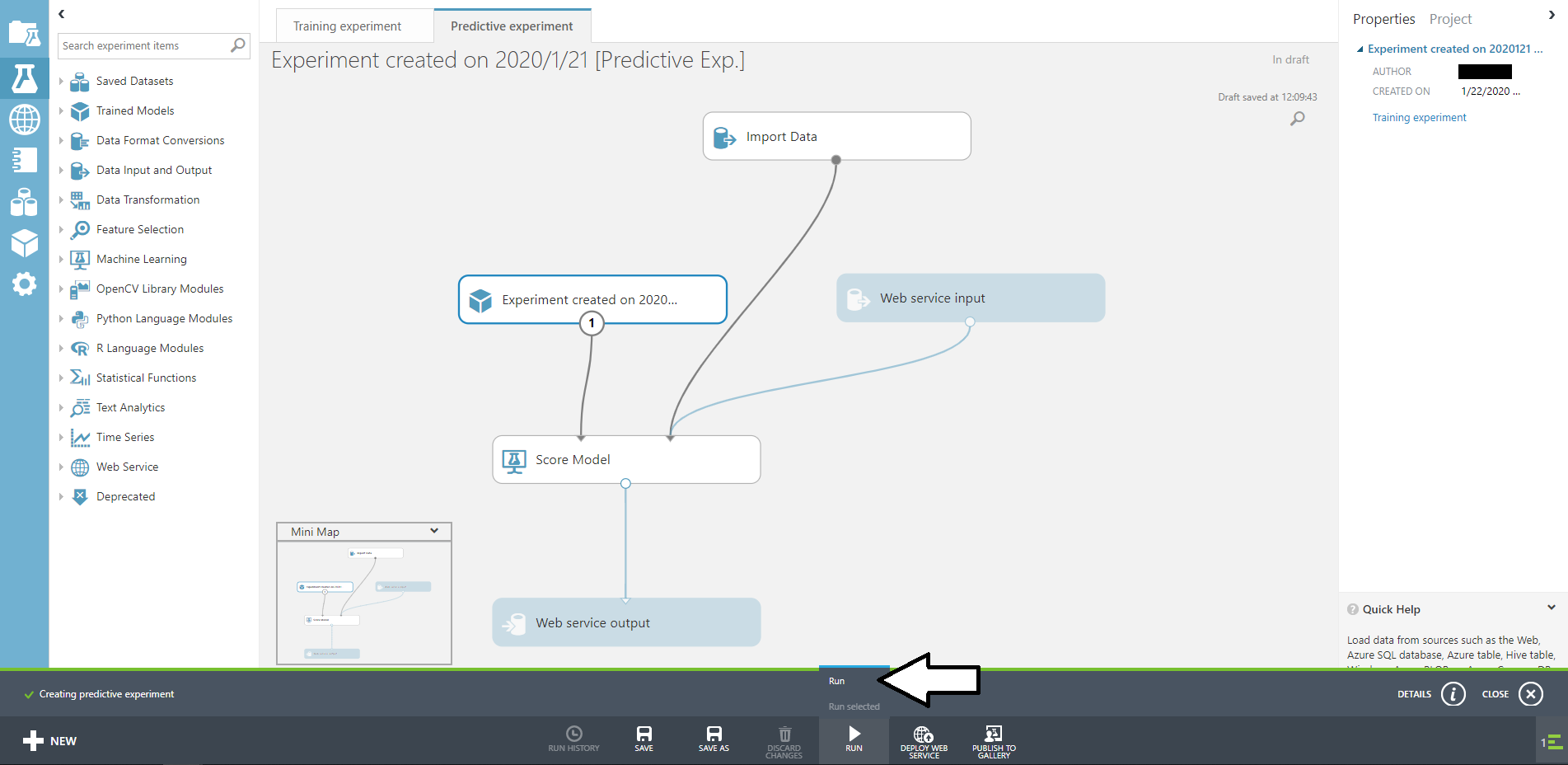
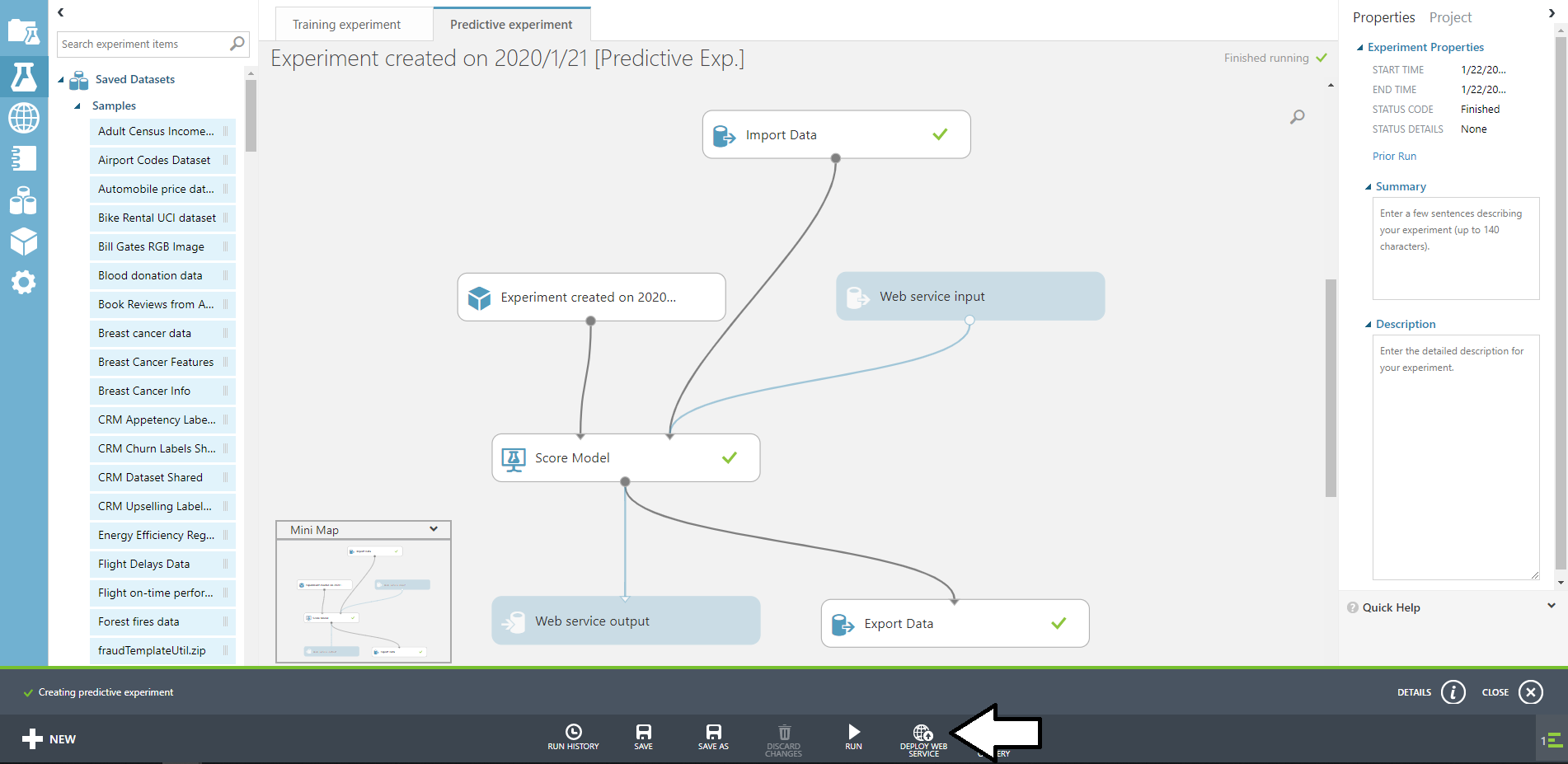
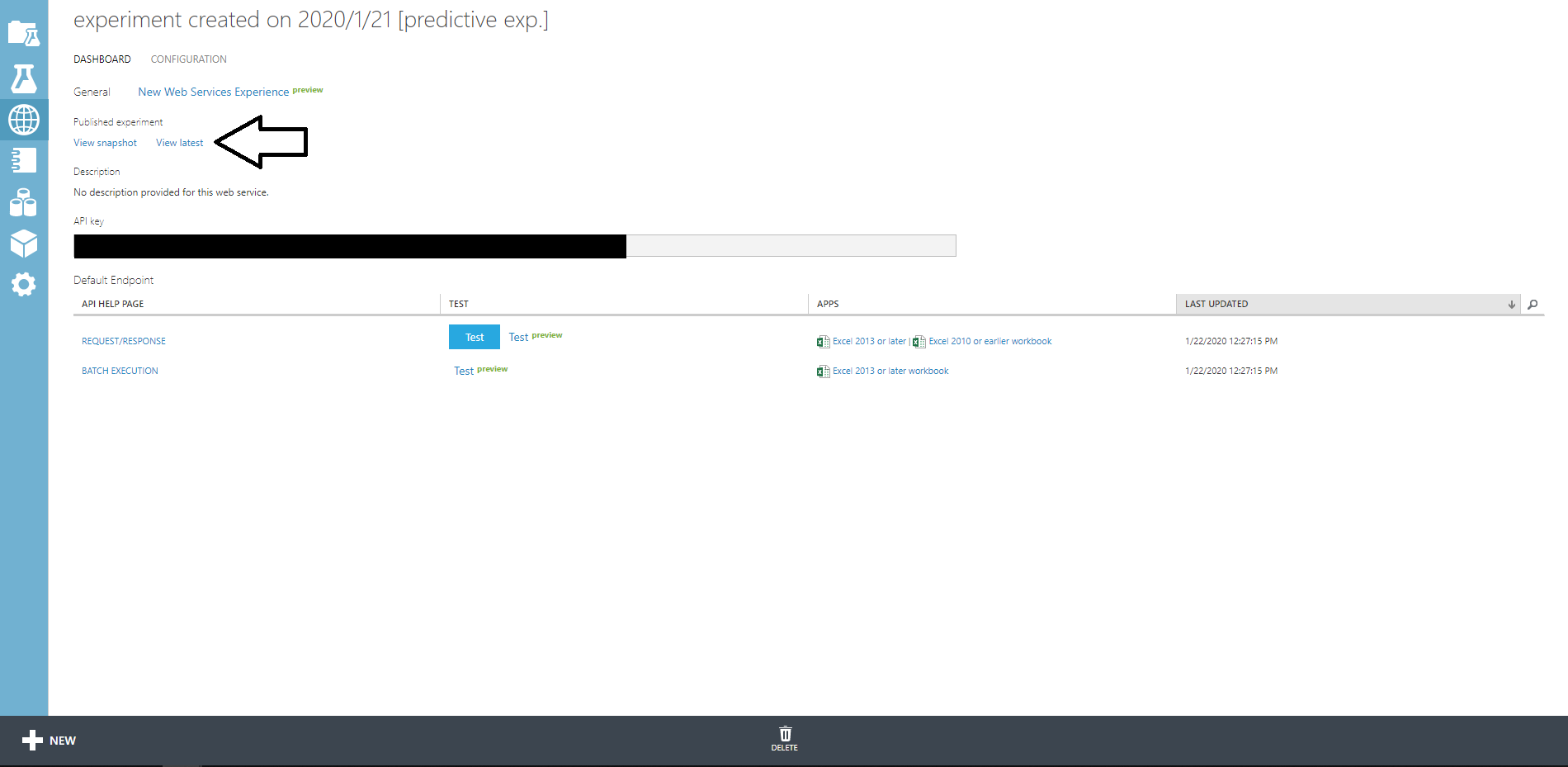
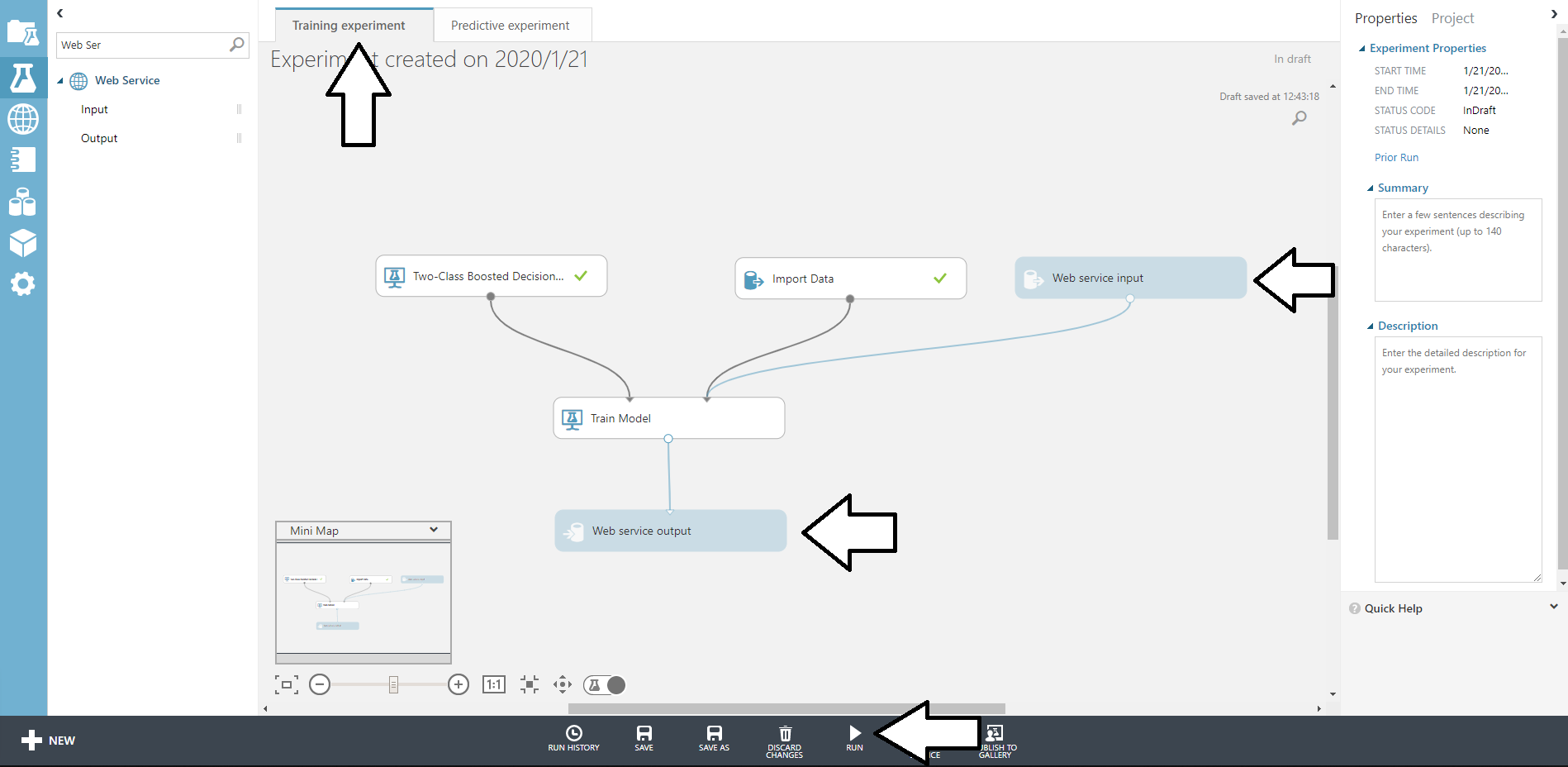
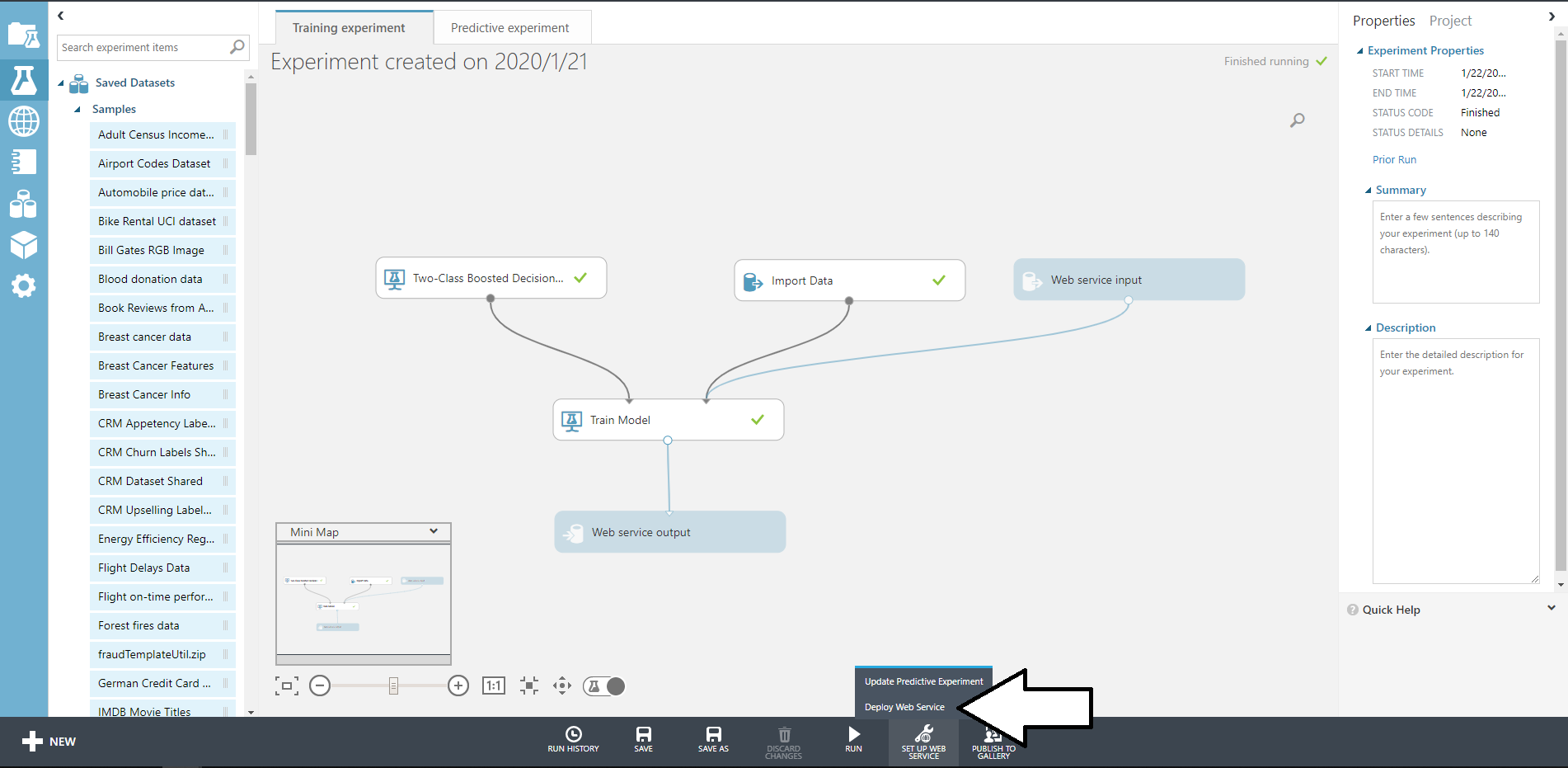
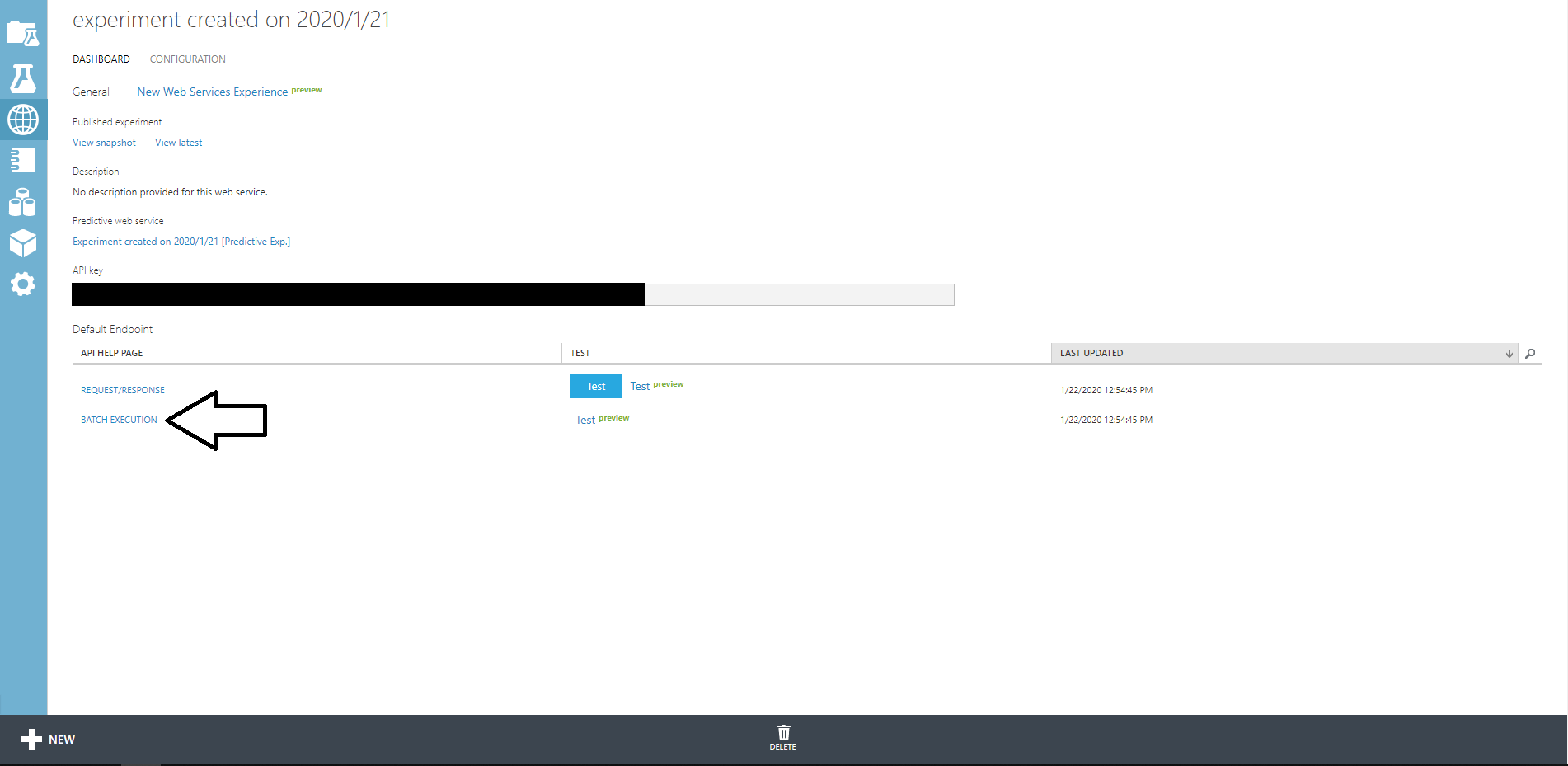
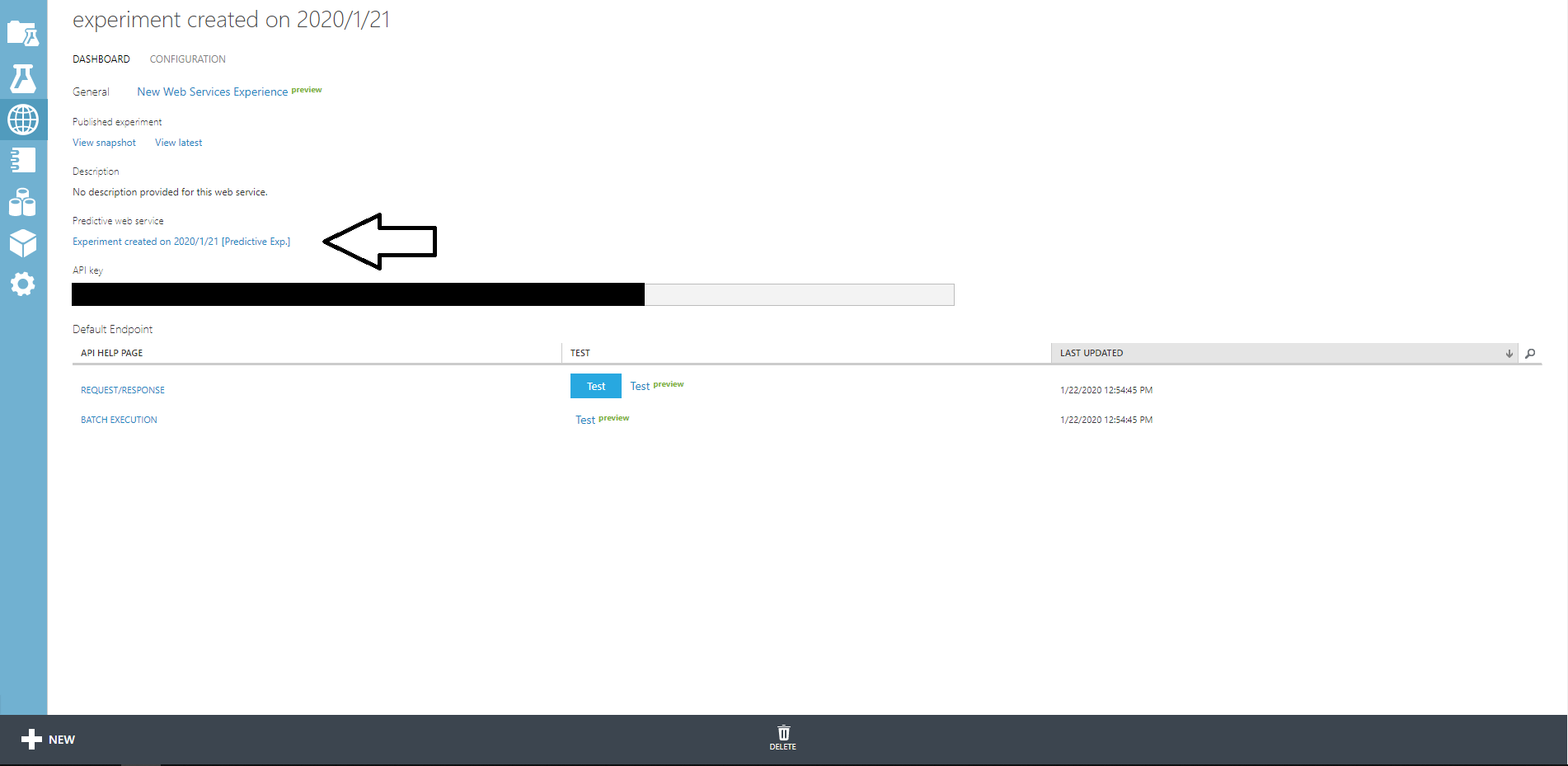
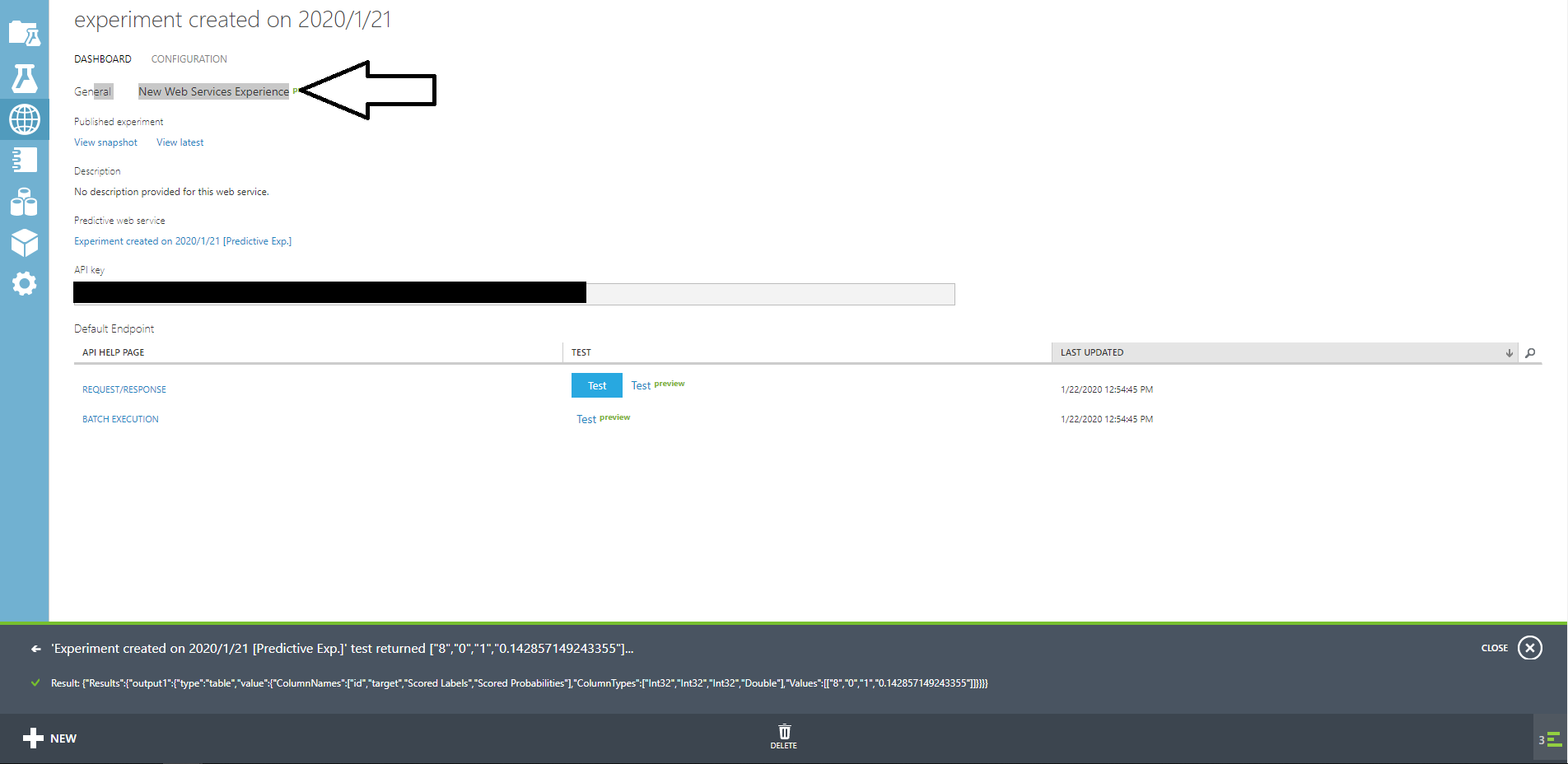
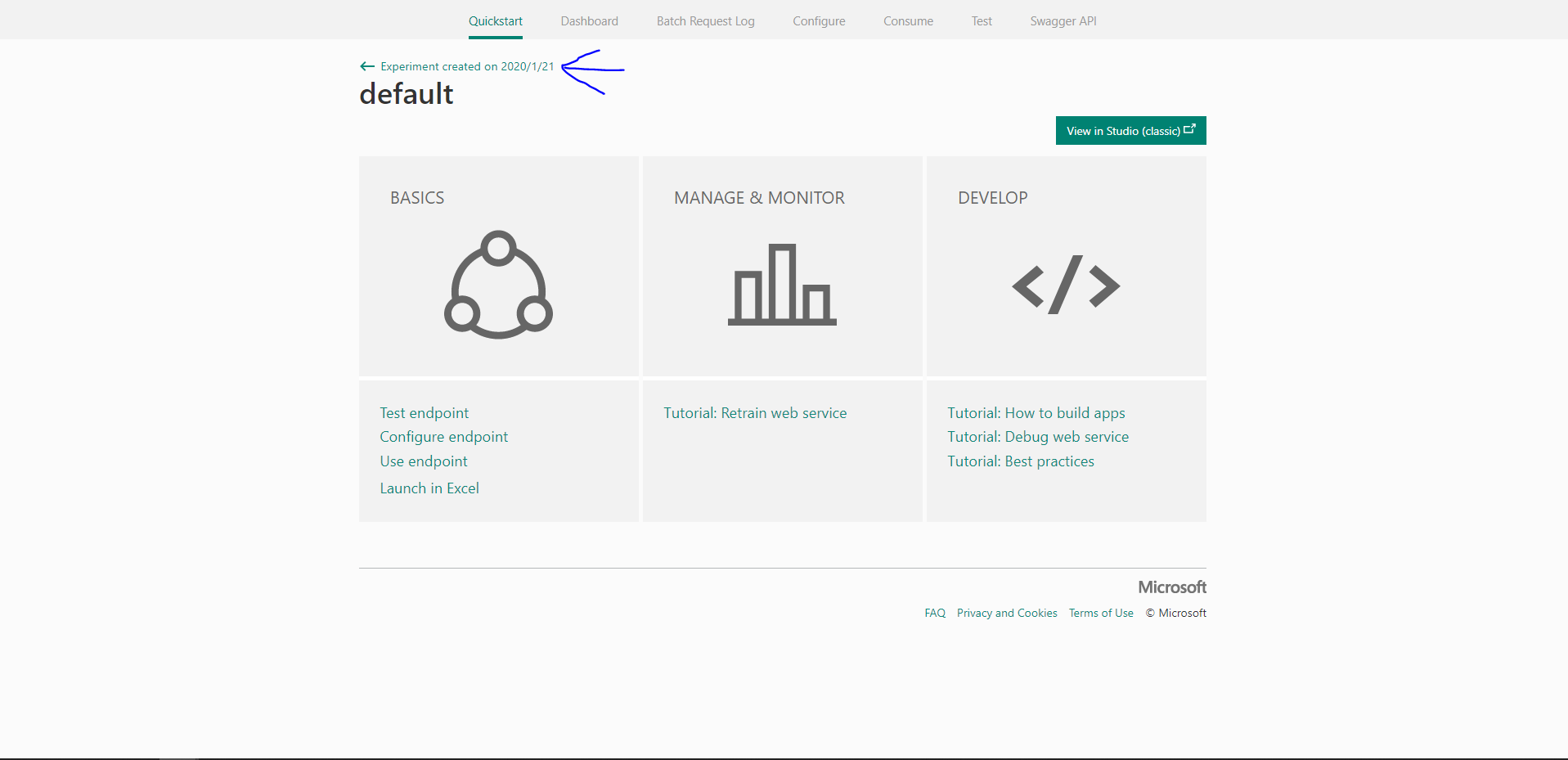
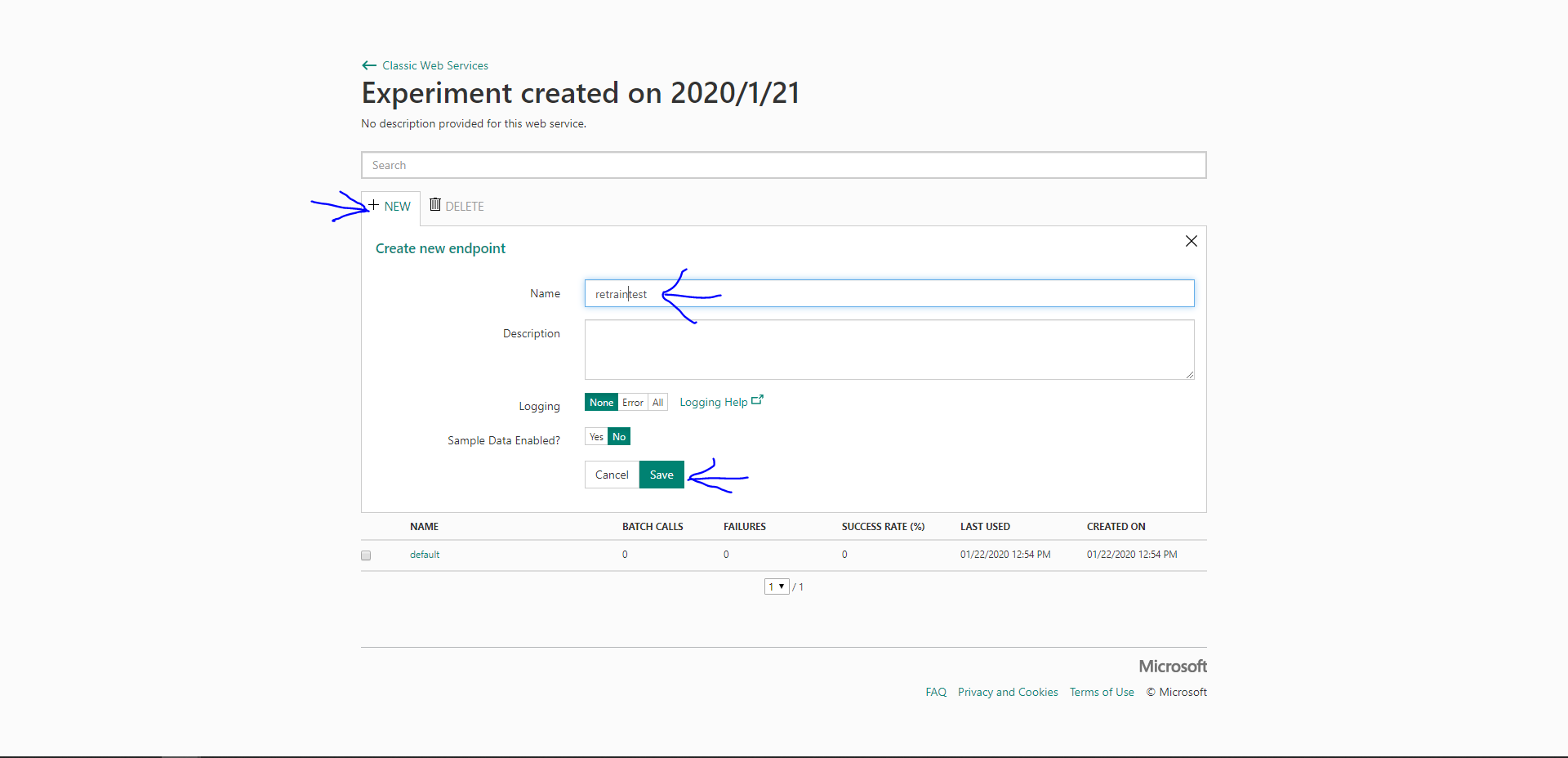
- 投稿日:2020-01-22T15:01:20+09:00
【Python3】Pythonを始めたときに参考にしたサイト一覧
Pythonを始めたときに参考にしたサイト一覧
- Pythonに初めて触る方
- とりあえずPythonを動かしてみたい方
上記の状態ではじめに参考にしたサイトの一覧です。
Pythonをインストールする(Mac版)
環境構築ガイド - python.jp(公式日本語版サイト)
上記の画面でmacOSなど、インストール先のOSのボタンをクリックすると、
インストール方法が詳しく書かれています。Pythonを試してみる
2. Python インタプリタを使う - python.jp(公式日本語版サイト)
インストールしたPythonでとりあえず何か動かしてみようと思ったときに参考にさせて頂きました。
Pythonについて
Python 3.8.1 ドキュメント(公式日本語版サイト)を見ると、詳しいPythonの使い方が載っています。
「チュートリアル」や「ライブラリーリファレンス」などを見ると、やりたいことを選んで確認できます。※バージョンが最新かについてはご自身でご確認ください。
参照URL
- 投稿日:2020-01-22T14:46:34+09:00
Reduced Rank Ridge Regression(縮小ランクリッジ回帰)とは?
参考リンク
- Mukherjee A, Zhu J. Reduced Rank Ridge Regression and Its Kernel Extensions. Stat Anal Data Min. 2011;4(6):612–622. doi:10.1002/sam.10138
- RRRR - Python implementation of Reduced Rank Ridge Regression
簡単に!

「縮小ランク回帰」と「リッジ回帰」を組み合わせて、説明変数の共線性と目的変数の低次元構造に同時に適合するようにした、線形モデル回帰の手法。
Reduced Rank Regression(縮小ランク回帰)とは?
一般化線形モデル
問題設定として、説明変数 $X_{N \times P}$により、目的変数 $Y_{N \times Q}$を予測する(回帰する)ことを考えます。
ここでよく用いられるのが、次の式で表される一般化線形モデルです。$$Y=XB+E$$ここで、$B_{P \times Q}$は係数行列であり、$E_{N \times Q}$はランダムな誤差行列を表しています。
この最小二乗法(OLS)による解は以下のようになります。$$\hat{B}_{OLS}=(X^TX)^{-1}X^TY$$
今回は、一般化線形モデルを最小二乗法で解くときの2つの問題点に着目することにします。
- 目的変数 $Y_{N \times Q}$の真の次元が $Q$ より小さいときに、性能が落ちる。($Y$のランク落ち)
- 説明変数 $X_{N \times P}$の行同士の相関が高いときに、性能が落ちる。($X$の共線性)
次元削減
このように、高次元のデータの中に潜在的な低次元の構造がある場合には、次元削減が有効です。有名なのでいえば、主成分分析(PCA)が挙げられるでしょう。主成分分析によって次元削減した後に回帰をするモデルを、主成分回帰(PCR)と呼んだりします。
主成分回帰のように、説明変数の中から低次元の因子(Factor)を選んで目的変数を回帰するようなモデルは、線形因子モデル(Linear Factor Model)と呼ばれています。例えば、独立成分回帰、偏最小二乗回帰、正準相関分析などがあります。
これとは別の次元削減の手法として、縮小ランク回帰(Reduced Rank Regression)があります。縮小ランク回帰では、係数行列 $B$ のランクを制限しながら誤差関数を最小化することで、潜在的な低次元の構造を仮定しつつ回帰することができます。
参考:縮小ランク回帰
正則化
2つめの問題点である説明変数 $X$ の共線性に対しては、正則化(regularization)がしばしば行われます。有名な手法に、リッジ回帰(Ridge Regression)やLASSO回帰(LASSO Regression)があります。LASSO回帰は、主にスパース性の推定に用いられ、特徴量選択の手法としても用いられています。リッジ回帰は、説明変数の共線性による不良設定問題に対応するために広く用いられています。
Reduced Rank Ridge Regression (縮小ランクリッジ回帰)への拡張
2つの制約を誤差関数に導入する
以上を踏まえて、2つの問題に対処するために、次の2つの制約を二乗誤差に追加することにします。
- リッジ回帰の正則化項
- $\hat{B}$ のランク制約
したがって、次のように誤差の最小化を行うことで、$\hat{B}(\lambda,r)$ を得ることができます。
$$\underset{ \lbrace B:rank(B) \leq r \rbrace}{argmin} \Vert Y-XB \Vert_F^2 + \lambda \Vert B \Vert_F^2$$
ただし、$r \leq \min \lbrace P, Q \rbrace$ とし、$\Vert \cdot \Vert_F^2$ はフロベニウスノルム(行列ノルム)とします。
これを縮小ランク回帰の枠組みで考えるために、
X_{(N+P)\times P}^* = \left( \begin{array}{c} X \\ \sqrt{\lambda}I \end{array}\right), \ Y_{(N+P)\times Q}^* = \left( \begin{array}{c} Y \\ 0 \end{array}\right)とすることで、誤差関数を次のように表現します。
$$\underset{ \lbrace B:rank(B) \leq r \rbrace}{argmin} \Vert Y^*-X^*B \Vert_F^2$$
また、リッジ回帰の推定値 $ \hat{Y_R}^* = X^* \hat{B_R}^*$ を用いて、正規直交性から、
\Vert Y^*-X^*B \Vert_F^2 = \Vert Y^*-\hat{Y}_R^* \Vert_F^2 + \Vert \hat{Y}_R^*-X^*B \Vert_F^2と変形できるので、第一項は $B$ に依存しないため、誤差関数は次のように表現できます。
\underset{ \lbrace B:rank(B) \leq r \rbrace}{argmin} \Vert \hat{Y}_R^*-X^*B \Vert_F^2線形問題による解を導出する
ここで、次のように特異値分解が与えられると仮定します。
\hat{Y}_R^* = \sum_{i=1}^{\tau} \sigma_i u_i v_i^Tここで、$\sigma_i$ は特異値、$u_i, v_i$ は左右の特異値ベクトルであり、$\tau$ は $\hat{Y}_R^*$ のランク(正則化により $Q$ となっている)となります。
これは、フロベニウスノルムにおけるエッカート・ヤングの定理(参考)として考えることができ、最適なランク $r$ による近似は次のようになります。
\hat{Y}_r^* = \sum_{i=1}^{r} \sigma_i u_i v_i^Tこれを用いて、最適な係数行列 $\hat{B}(\lambda,r)$ を表現しましょう。
\hat{Y}_r^* = \sum_{i=1}^{r} \sigma_i u_i v_i^T = \left(\sum_{i=1}^{\tau} \sigma_i u_i v_i^T\right) \left(\sum_{j=1}^{r} u_j v_j^T\right) = \hat{Y}_r^* P_r = X^* \hat{B}_R^* P_r = X^* \hat{B}(\lambda,r)とすることで、解として $\hat{B}(\lambda,r) = \hat{B}_R^* P_r $ が得られます。
さらに、リッジ回帰の最小二乗解を用いて以下のように表現することができます。
\hat{B}(\lambda,r) = \hat{B}_R^* P_r = (X^T X + \lambda I)^{-1}X^T Y P_r \\ \hat{Y}(\lambda,r) = X \hat{B}(\lambda,r) = X (X^T X + \lambda I)^{-1}X^T Y P_r = \hat{Y}_{\lambda} P_rここで、$\hat{Y}_{\lambda}$ は $\lambda$ におけるリッジ回帰の推定解となり、「リッジ回帰の推定解を$r$次元の空間に射影することで最適解を得ている」と解釈することができます。そのため、$r=Q$では、単純なリッジ回帰の解が最適解となることになります。
パラメータのチューニング
パラメータ $\lambda,r$ のチューニングが、縮小ランクリッジ回帰の性能を左右することになります。参照論文では、K-fold 交差検証 を行って、最適なパラメータを決定していました。
パッケージを試してみる
データ
用意されていたデモ用のデータを使用しましょう。
import numpy as np from sklearn.model_selection import GridSearchCV from sklearn.model_selection import PredefinedSplit import reduced_rank_regressor as RRR import matplotlib.pyplot as plt %matplotlib inline N_PARAMETERS_GRID_SEARCH = 20 Data_path = "data/" # Load Data trainX = np.loadtxt(Data_path+"trainX.txt") testX = np.loadtxt(Data_path+"testX.txt") validX = np.loadtxt(Data_path+"validX.txt") trainY = np.loadtxt(Data_path+"trainY.txt") testY = np.loadtxt(Data_path+"testY.txt") validY = np.loadtxt(Data_path+"validY.txt") # Inspection of Data f,ax = plt.subplots(1,2,figsize=(10,10)) ax[0].imshow(np.corrcoef(trainX), cmap='jet') ax[0].set_title('trainX') ax[1].imshow(np.corrcoef(trainY), cmap='jet') ax[1].set_title('trainY') plt.show()相関行列から、目的変数 $Y$ には低次元の構造があることがわかります。
交差検証
制約ランクと正則化の強さについてハイパーパラメータの交差検証を行い、最適化を行います。
# Cross-validation setup. Define search spaces rank_grid = np.linspace(1,min(min(trainX.shape),min(trainY.shape)), num=N_PARAMETERS_GRID_SEARCH) rank_grid = rank_grid.astype(int) reg_grid = np.power(10,np.linspace(-20,20, num=N_PARAMETERS_GRID_SEARCH+1)) parameters_grid_search = {'reg':reg_grid, 'rank':rank_grid} valid_test_fold = np.concatenate((np.zeros((trainX.shape[0],))-1,np.zeros((validX.shape[0],)))) ps_for_valid = PredefinedSplit(test_fold=valid_test_fold) # Model initialisation rrr = RRR.ReducedRankRegressor()#rank, reg) grid_search = GridSearchCV(rrr, parameters_grid_search, cv=ps_for_valid, scoring='neg_mean_squared_error') print("fitting...") grid_search.fit(np.concatenate((trainX,validX)), np.concatenate((trainY,validY))) # Display the best combination of values found print(grid_search.best_params_) means = grid_search.cv_results_['mean_test_score'] means = np.array(means).reshape(N_PARAMETERS_GRID_SEARCH, N_PARAMETERS_GRID_SEARCH+1) print(grid_search.best_score_)[output]
fitting... {'rank': 316, 'reg': 1e-20} -75126.47521541138交差検証の結果について視覚化しましょう。最適ランクの部分(316付近)でスコアの順位が高くなっていることがわかります。
# Show CV results scores = [x for x in grid_search.cv_results_['rank_test_score']] scores = np.array(scores).reshape(N_PARAMETERS_GRID_SEARCH, N_PARAMETERS_GRID_SEARCH+1) f,ax = plt.subplots(1,1,figsize=(10,10)) cbar = ax.imshow(scores, cmap='jet') ax.set_title('Test score Ranking') ax.set_xlabel('Regression') ax.set_ylabel('Rank') ax.set_xticks(list(range(len(reg_grid)))) ax.set_yticks(list(range(len(rank_grid)))) ax.set_xticklabels([str("%0.*e"%(0,x)) for x in reg_grid],rotation=30) ax.set_yticklabels([str(x) for x in rank_grid]) f.colorbar(cbar) plt.show()
推論
交差検証で求めた最適なハイパーパラメータを元に推論をします。
# Train a model with the best set of hyper-parameters found rrr.rank = int(grid_search.best_params_['rank']) rrr.reg = grid_search.best_params_['reg'] rrr.fit(trainX, trainY) # Testing Yhat = rrr.predict(testX).real MSE = (np.power((testY - Yhat),2)/np.prod(testY.shape)).mean() print("MSE =",MSE) f,ax = plt.subplots(1,2,figsize=(10,10)) ax[0].imshow(np.corrcoef(testY), cmap='jet') ax[0].set_title('testY') ax[1].imshow(np.corrcoef(Yhat), cmap='jet') ax[1].set_title('Yhat') plt.show()[output]
MSE = 0.1508996355795968
MSE(平均二乗誤差)は小さくなり、$\hat{Y}$ はよく予測できていると思われます。
まとめ
縮小ランクリッジ回帰は低次元である目的変数に適合する能力が高く、現実のデータ構造に広く適用できる可能性がありそうです。また、パッケージは、scikit-learn に準じて実装されているので、使い勝手がよさそうです。


- 投稿日:2020-01-22T14:10:06+09:00
VSCode の Python のデバッグで path が原因のエラーが出る場合の対処療法(Anaconda の場合)
Anaconda prompt の unittest では正常に完了するのに、VSCode ではエラーとなる場合、環境変数の path 設定が正しく行われていない可能性があります。
仮想環境を指定し直すことで正常に動くことがあるので試してみてください。
(Windows)
・コマンドパレットを開く(コントロール+シフトP)
・Python インタープリタを選択(Python select Interpreter)
・使用する環境を選択ほぼ、自分用のメモですが、ググっても見当たらなかったので参考まで。
- 投稿日:2020-01-22T14:10:06+09:00
VSCode の Python のデバッグで path が原因のエラーが出る場合の対症療法(Anaconda の場合)
表題の件、Anaconda prompt で実行すると正常に完了するのに、VSCode 上のデバッグやテスト等でエラーが発生する場合、環境変数の path 設定が正しく行われていない可能性があります。
ネットで検索すると、「path を登録しろ」系の記事に当たりますが、仮想環境を指定し直すことで正常に動くことがあるので試してみてください。
(Windows)
・コマンドパレットを開く(コントロール+シフトP)
・Python インタープリタを選択(Python select Interpreter)
・使用する環境を選択ほぼ、自分用のメモですが、ググっても見当たらなかったので参考まで。
- 投稿日:2020-01-22T14:05:02+09:00
画像位置合わせ:SIFTから深層学習まで
概要
画像位置合わせについて日本語記事がほとんど無い(2020/1/22 現在)ため、とても分かりやすいと思った Image Registration: From SIFT to Deep Learning という記事を翻訳というかまとめました。省略したり加筆した箇所もあるので、原典にあたりたい方は元記事の方を読んでください。
画像位置合わせ(image registration)とは?
画像位置合わせとは、2枚の画像の位置ずれを補正する処理のことです。画像位置合わせは、同じシーンの複数の画像を比較する時などに用います。例えば、衛星画像解析やオプティカルフロー、医用画像の分野でよく登場します。
具体例を見てみましょう。上の画像は私が新大久保で食べたマスカットボンボンの画像を位置合わせしたものです。とても美味しかったですが、甘党でない方にはおすすめしません。
この例では、左から2番目のマスカットボンボンの位置を、明るさなどはそのままに、左端のマスカットボンボンの位置に合わせているのがわかると思います。以下では、左端のような、変形されず参照される画像のことを参照画像、左から2番目のような、変形される画像を浮動画像とします。
本記事では、浮動画像と参照画像間で位置合わせを行なうためのいくつかの手法について述べます。なお、反復/信号強度に基づく方法はあまり一般的でないため、本記事では言及しません。特徴に基づくアプローチ
2000年代初期から、画像位置合わせに特徴に基づくアプローチが用いられてきました。このアプローチは、キーポイントの検出と特徴の記述、特徴のマッチング、画像の変形の3つのステップから成ります。簡単に言うと、両方の画像で関心のある点を選択し、参照画像の各関心のある点を浮動画像の対応点に関連付け、両方の画像の位置が合うように浮動画像を変形します。
キーポイントの検出と特徴の記述
キーポイントは画像において重要かつ特徴的なもの(角やエッジなど)を定義します。各キーポイントは、記述子で表されます。記述子は、キーポイントの本質的な特徴を含む特徴ベクトルです。記述子は、画像変形(ローカリゼーションやスケール、輝度など)に対して頑健でなければいけません。キーポイントの検出と特徴の記述を行なうアルゴリズムは多数存在します。
- SIFT (Scale-invariant feature transform) は、キーポイントの検出に使用される元のアルゴリズムですが、商用利用には有料です。SIFT特徴記述子は、均一なスケーリング、方向、輝度の変形に対して不変であり、アフィン歪に対して部分的に不変です。
- SURF (Speeded Up Robust Features) は、SIFTに影響を受けた検出器および記述子です。SIFTに比べ数倍高速です。また、特許も取得しています。
- ORB FAST Brief (Oriented FAST and Rotated BRIEF) は、FASTキーポイント検出器とBrief記述子の組み合わせに基づく高速バイナリ記述子です。回転に対して不変であり、ノイズに対して頑健です。OpenCV Labsで開発され、SIFTに代わる効率的で無料の代替手段です。
- AKAZE (Accelerated-KAZE) は、KAZEのスピードアップバージョンです。非線形スケール空間の高速マルチスケール特徴検出および記述アプローチを提供します。スケールと回転の両方に対して不変であり、無料です。
これらのアルゴリズムはOpenCVで簡単に使用できます。以下の例では、AKAZEのOpenCV実装を使用しました。アルゴリズムの名前を変更するだけで他のアルゴリズムを使用できます。
import cv2 as cv # キーポイントなどを見やすくするためにグレースケールで画像読み込み img = cv.imread('img/float.jpg') gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY) # キーポイントの検出と特徴の記述 akaze = cv.AKAZE_create() kp, descriptor = akaze.detectAndCompute(gray, None) keypoints_img = cv.drawKeypoints(gray, kp, img) cv.imwrite('keypoints.jpg', keypoints_img)
特徴検出と記述子の詳細については、OpenCVのチュートリアルをご覧ください。
特徴のマッチング
両方の画像でキーポイントを求めた後、対応するキーポイントを関連付けるか、「マッチング」する必要があります。そのためのメソッドの一つは、
BFMatcher.knnMatch()です。これは、キーポイント記述子の各ペア間の距離を測定し、各キーポイントに対して、最小距離でマッチングする最適なkを返します。
次に、比率フィルターを適用して、正しいマッチングのみを保持します。信頼性の高いマッチングを実現するには、マッチングしたキーポイントが最も近い誤ったマッチングより大幅に近い必要があります。import cv2 as cv float_img = cv.imread('img/float.jpg', cv.IMREAD_GRAYSCALE) ref_img = cv.imread('img/ref.jpg', cv.IMREAD_GRAYSCALE) akaze = cv.AKAZE_create() float_kp, float_des = akaze.detectAndCompute(float_img, None) ref_kp, ref_des = akaze.detectAndCompute(ref_img, None) # 特徴のマッチング bf = cv.BFMatcher() matches = bf.knnMatch(float_des, ref_des, k=2) # 正しいマッチングのみ保持 good_matches = [] for m, n in matches: if m.distance < 0.75 * n.distance: good_matches.append([m]) matches_img = cv.drawMatchesKnn( float_img, float_kp, ref_img, ref_kp, good_matches, None, flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS) cv.imwrite('matches.jpg', matches_img)
OpenCVに実装されている他の特徴マッチング方法については、ドキュメントをご覧ください。
画像の変形
少なくとも4組のキーポイントをマッチングした後、1つの画像を他の画像に相対的に変形します。これは、image warpingと呼ばれます。空間内の同じ平面上にある2つの画像は、ホモグラフィによって関連付けられます。ホモグラフィは、8つの自由なパラメータを持ち、3x3行列で表される幾何学的変形です。それらは、(局所的な変形とは対照的に、)画像全体に加えられた歪みを表します。したがって、変形された浮動画像を得るには、ホモグラフィ行列を計算し、それを浮動画像に適用します。
最適な変形を保証するために、RANSACアルゴリズムを用いて外れ値を検出し、それらを削除して最終的なホモグラフィを決定します。OpenCVのfindHomographyメソッドに直接組み込まれています。RANSACの代替としてLMEDS:最小メジアン法といったロバスト推定の手段もあります。import numpy as np import cv2 as cv float_img = cv.imread('img/float.jpg', cv.IMREAD_GRAYSCALE) ref_img = cv.imread('img/ref.jpg', cv.IMREAD_GRAYSCALE) akaze = cv.AKAZE_create() float_kp, float_des = akaze.detectAndCompute(float_img, None) ref_kp, ref_des = akaze.detectAndCompute(ref_img, None) bf = cv.BFMatcher() matches = bf.knnMatch(float_des, ref_des, k=2) good_matches = [] for m, n in matches: if m.distance < 0.75 * n.distance: good_matches.append([m]) # 適切なキーポイントを選択 ref_matched_kpts = np.float32( [float_kp[m[0].queryIdx].pt for m in good_matches]).reshape(-1, 1, 2) sensed_matched_kpts = np.float32( [ref_kp[m[0].trainIdx].pt for m in good_matches]).reshape(-1, 1, 2) # ホモグラフィを計算 H, status = cv.findHomography( ref_matched_kpts, sensed_matched_kpts, cv.RANSAC, 5.0) # 画像を変形 warped_image = cv.warpPerspective( float_img, H, (float_img.shape[1], float_img.shape[0])) cv.imwrite('warped.jpg', warped_image)
これらの3つのステップの詳細に関心がある場合、OpenCVは一連の便利なチュートリアルをまとめています。
深層学習アプローチ
最近の画像位置合わせのほとんどの研究は、深層学習の使用に関するものです。過去数年間で、深層学習により、分類、検出、セグメンテーションなどのコンピュータビジョンタスクの最先端のパフォーマンスが可能になりました。画像位置合わせに関しても例外ではありません。
特徴抽出
最初に深層学習が画像位置合わせに使用されたのは、特徴抽出のためでした。畳み込みニューラルネットワーク(CNN)の連続層は、ますます複雑な画像特徴をとらえ、タスク固有の特徴を学習します。2014年以来、研究者はこれらのネットワークをSIFTまたは同様のアルゴリズムではなく、特徴抽出ステップに適用しています。
- 2014年、Dosovitskiyらは、教師なしデータのみを用いてCNNを学習することを提案しました。これらの特徴の汎用性により、変形に対して頑健になりました。これらの特徴または記述子は、SIFT記述子よりも優れていました。
- 2018年、Yangらは、同じ考えに基づいた非剛体位置合わせ方法を開発しました。彼らは事前に学習されたVGGネットワークの層を用いて、畳み込み情報とローカリゼーション特徴の両方を保持する特徴記述子を生成しました。これらの記述子は、特にSIFTに多くの外れ値が含まれているか、十分な数の特徴点とマッチングできない場合に、SIFTのような検出器よりも優れているようです。 後者の論文のコードはここにあります。この位置合わせ方法は15分以内に手元の画像で試せますが、前半で実装したSIFTのような方法よりも約70倍遅いです。
ホモグラフィ学習
研究者たちは、深層学習の使用を特徴抽出に限定せず、ニューラルネットワークを用いて幾何学的変形を直接学習し、位置合わせを実現しようとしました。
教師あり学習
2016年、DeToneらは、2つの画像に関連するホモグラフィを学習するVGGスタイルモデルである回帰ホモグラフィネットを説明する深層画像ホモグラフィ推定を公開しました。このアルゴリズムには、ホモグラフィとCNNモデルのパラメータをエンドツーエンドで同時に学習するという利点があります。特徴抽出とマッチングのプロセスは不要です。
ネットワークは、出力として8つの実数値を生成します。出力とグランドトゥルースホモグラフィ間の損失によって教師あり学習を行います。
他の教師あり学習アプローチと同様に、このホモグラフィ推定法は教師データのペアが必要です。しかし、実際のデータでグランドトゥルースホモグラフィを得るのは簡単ではありません。
教師なし学習
Nguyenらは、深層画像ホモグラフィ推定への教師なし学習アプローチを提示しました。彼らは同じCNNを用いましたが、教師なしアプローチに適した損失関数を使用する必要がありました。そこで、グランドトゥルースラベルを必要としないフォトメトリック損失を選択しました。参照画像と変形した浮動画像の類似度を計算します。
$$
\mathbf{L}_{PW} = \frac{1}{|\mathbf{x} _i|}
\sum _{\mathbf{x} _i}|I^A(\mathscr{H}(\mathbf{x} _i))-I^B(\mathbf{x} _i)|
$$彼らのアプローチは、Tensor Direct Linear TransformとSpatial Transformation Layerという2つの新しいネットワーク構造を導入しています。
著者は、この教師なしの方法は、従来の特徴に基づく方法と比較して、より早い推論速度であり、同等以上の精度と照明変動に対して頑健性を持つと主張しています。さらに、教師あり手法と比較して、適応性とパフォーマンスに優れています。
その他のアプローチ
強化学習
深層強化学習は、医療アプリケーションの位置合わせ方法として注目されています。事前定義された最適化アルゴリズムとは対照的に、このアプローチでは、訓練されたエージェントを用いて位置合わせを実行します。
- 2016年、Liaoらは画像位置合わせに強化学習を最初に使用しました。彼らの方法は、エンドツーエンド学習のための貪欲な教師ありアルゴリズムに基づいています。その目標は、モーションアクションの最適なシーケンスを見つけることにより画像を位置合わせすることです。このアプローチはいくつかの最先端の方法より優れていましたが、剛体変形にのみ使用されました。
- 強化学習はより複雑な変形にも使用されています。Krebsらはエージェントに基づくアクション学習により頑健な非剛体位置合わせを行いました。変形モデルのパラメータを最適化するために人工エージェントを適用します。この方法は、前立腺MRIの被験者間位置合わせで評価され、2次元および3次元で有望な結果を示しました。
複雑な変形
かなりの割合の画像位置合わせにおける現在の研究が、医用画像の分野に関係しています。多くの場合、2つの医用画像間の変形は、被験者の局所的な変形(呼吸や解剖学的変化など)のために、ホモグラフィ行列によって単純に記述することはできません。変位ベクトル場で表現できる微分同相写像など、より複雑な変形モデルが必要です。
研究者は、ニューラルネットワークを用いて、多くのパラメータを持つこれらの大きな変形モデルを推定しようとしました。
- 最初の例は、上記のKrebsらの強化学習法です。
- 2017年、De VosらはDIRNetを提案しました。これは、CNNを用いてコントロールポイントのグリッドを予測するネットワークであり、このグリッドを用いて変位ベクトル場を生成し、参照画像に従って浮動画像をワープします。
- Quicksilver位置合わせは、同様の問題に対処します。Quicksilverは、深層符号化復号化ネットワークを用いて、画像の外観でパッチごとの変形を直接予測します。




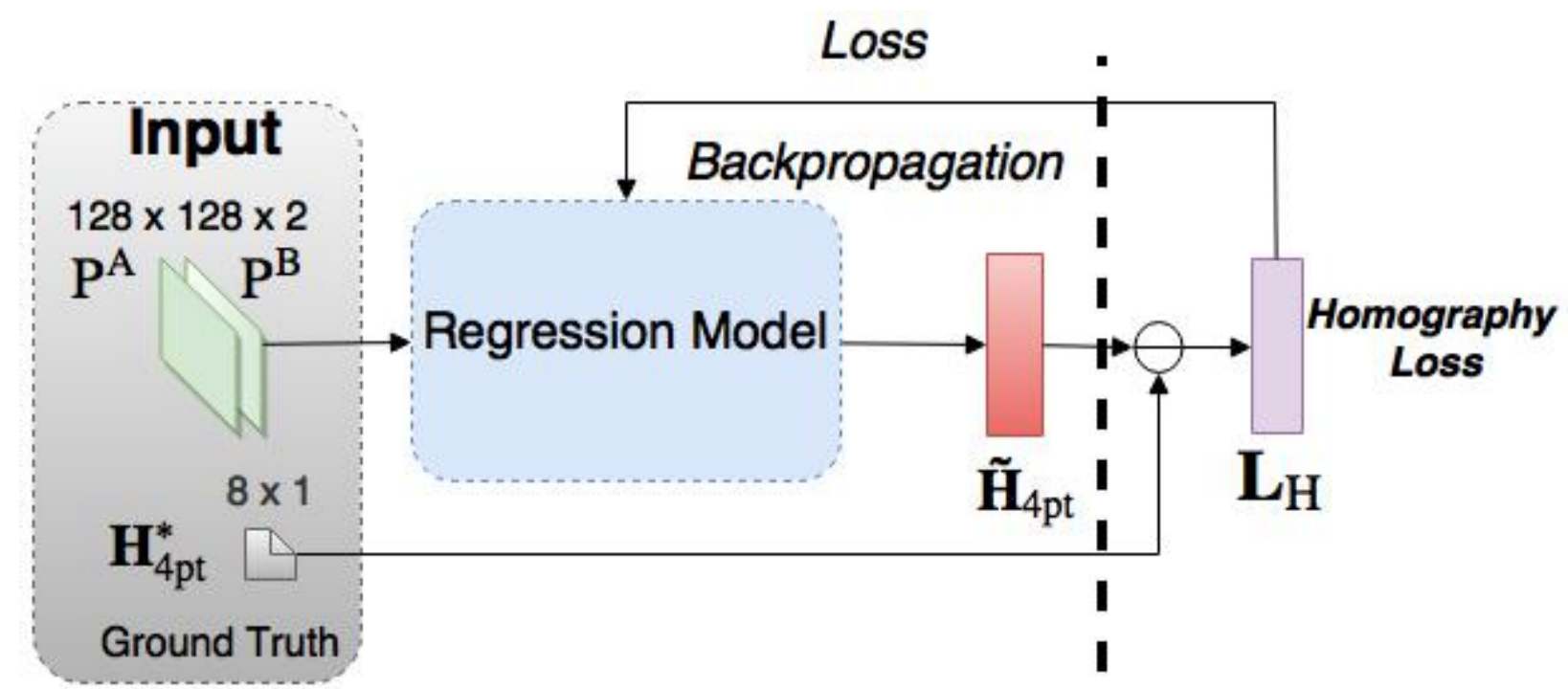
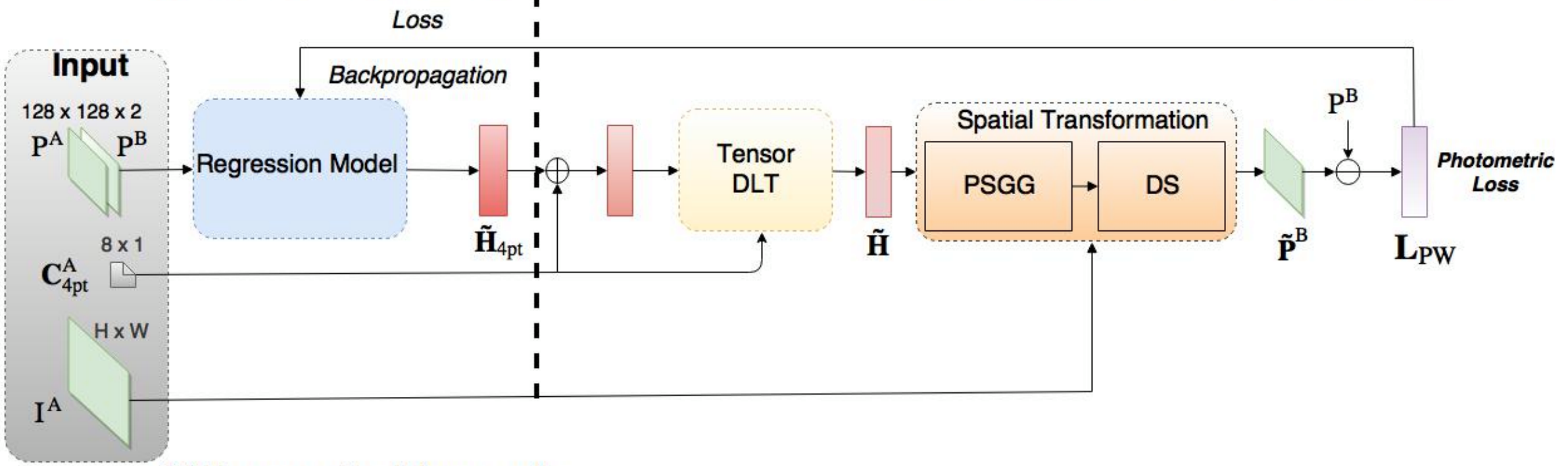
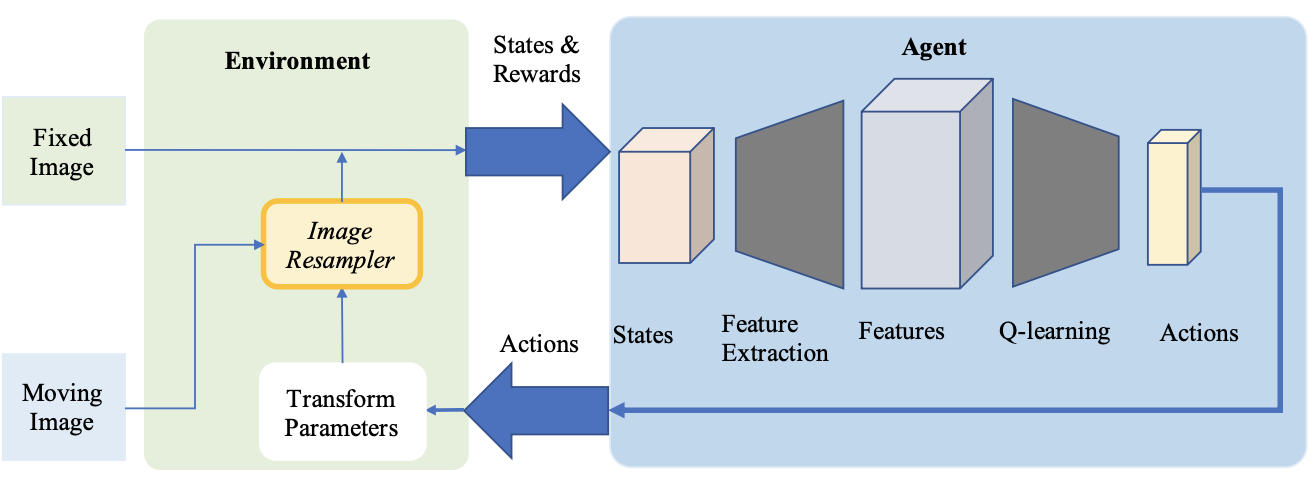

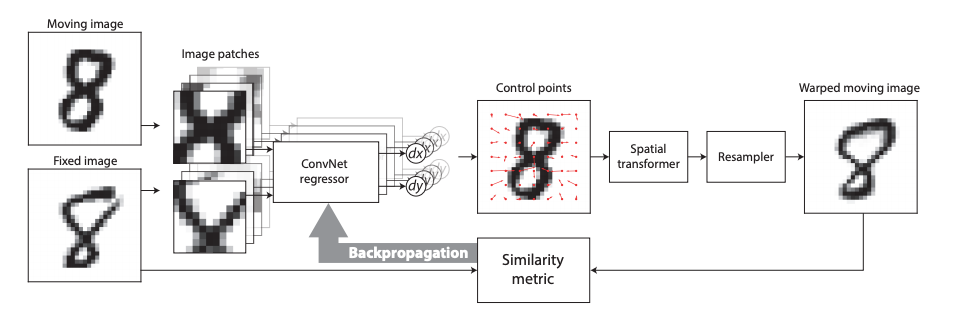
- 投稿日:2020-01-22T13:53:10+09:00
condaでインストールされるパッケージリスト
- 投稿日:2020-01-22T13:15:19+09:00
私的Python学習手順
概要
ここでは、個人的にPythonを学ぶ上での学習手順を示します。これは、私が人にPythonを教えた時の学習手順です。
学習手順は以下の通りです。期間は大体2週間から1か月です。
- 基本的なプログラミング文法は参考書を買い、その写経をする
- クラスを用いてプログラムを作成する
- GUI用ライブラリ:tkinterを用いて、デスクトップアプリを作成する
ここでの狙いは以下の通り。
- 参考書の写経を通じて基本的な文法をしっかり覚える
- デスクトップアプリの作成を通じて、オブジェクト指向(またはコンポーネント指向)の感覚を覚える
- GUIであると出来ているかどうか見て分かりやすいので、モチベーションを上げやすくする
私が思うに、本当に基礎の基礎の所は本を読めば誰かに教わる必要なんてないと考えています(実際、私が初めてプログラミングした際は独学でした)。基本的には独学に近い状態で勉強してもらい、調べても分からないところを都度誰かに聞くといった方が良いと思います。
開発環境
開発環境はAnacondaを使用させます。初学者の場合、環境構築で躓くことが多いと思います。Anacondaの場合であればインストールすればとりあえず使用できますし、AnacondaにあるSpyderというIDE(統合開発環境ソフト)を使用すれば特別何も考えなくてもプログラミングできるので、私はAnacondaを使用させています。
基本的なプログラミング文法は参考書を買い、その写経をする
私は「やさしいPython」を用いて勉強することを推奨しています。基本的なことが分かりやすく説明されていますし、簡単な練習問題も章末にあるので、勉強しやすいです。
クラスを用いてプログラムを作成する
次にクラスを用いてプログラミングしてもらいます。Pythonの講座などでは、あまりオブジェクト指向的なコードが見受けられないイメージがあります。個人的に最低限クラスを用いることが出来なければ、業務上使えるレベルにならないと思っています。
また、可能であれば、以下のAPIを用いたプログラムを作成してみると面白いと思います。Pythonは時折サーバサイドで使用したりするので、HTTP通信程度は知識として持つために、使用すると良いと思います。
- 個人でも使える!おすすめAPI一覧:https://qiita.com/mikan3rd/items/ba4737023f08bb2ca161
GUI用ライブラリ:tkinterを用いて、デスクトップアプリを作成する
最後に、2つめの項目で作成したプログラムを落ちいてデスクトップアプリを作成します。tkinterはPythonに標準で使用できるライブラリなので、初心者が躓きやすい環境構築の手間がなく、また見た目としても「出来上がっている感」があるので、モチベーションを上げやすいと思います。基本的にはgirdを多用するように作成します。私の頭の中では以下のような感じで組み立てていきます。
tk ├─frame1:ページ1用フレーム/自動で配置(pack) | ├─frame_component1:部品1/表的に配置(grid) | ├─frame_component2:部品2/表的に配置(grid) ├─frame2:ページ2用フレーム/自動で配置(pack) ├─frame_component3:部品3/表的に配置(grid) ├─frame_component4:部品4/表的に配置(grid)
- 投稿日:2020-01-22T13:07:50+09:00
【物体認識2020最前線】Windows10 に Pytorch をインストールして CornerNet-Lite を動かすまでのログ。
気が付けば1年以上ぶりの更新…(^^;;;
最近はJavaとか職業プログラミングばかりなので Python とか OpenCV とか触ってません。なので物体検出、物体認識の最新動向を追っかけてないけど、昨年より CornerNet-Lite が話題で、どうやらCornerNet-Squeeze は yolo v3 より速いらしいので環境構築してマックスくんを物体認識して実験してみる。動向の詳細は↓下記参照。
CornerNet の仕組みについて日本語でわかりやすい記事は↓参照。
https://engineer.dena.jp/2019/07/cv-papers-19-keypoint-object-detection.html
CornerNet は一言でいえば、ヒートマップを作製して、矩形の角(Corner)を推定して物体を検出して認識する仕組みのようです。で、以下にあるように、本当は、Anaconda 環境で構築されていたほうがいいのでしょうけど、pip3環境構築済だし、Anacondaとの競合(condaとpip:混ぜるな危険)とかめんどくさいので Anacondaは使わないで構築しましたので、そのログを残しておきます。
https://github.com/princeton-vl/CornerNet-Lite
pytorchのインストール
下記URL にアクセスし自分の環境に合わせてクリックするとコマンドが表示されます。
https://pytorch.org/QUICK START
LOCALLY
の部分ね!私の環境はWindows で パッケージマネージャは pip 、Python 3.7.4、cuda10.1 でインストールしてみます。
C:\>pip3 install torch===1.4.0 torchvision===0.5.0 -f https://download.pytorch.org/whl/torch_stable.html Looking in links: https://download.pytorch.org/whl/torch_stable.html Collecting torch===1.4.0 Downloading https://download.pytorch.org/whl/cu101/torch-1.4.0-cp37-cp37m-win_amd64.whl (796.8MB) |████████████████████████████████| 796.8MB 45kB/s Collecting torchvision===0.5.0 Using cached https://files.pythonhosted.org/packages/7d/3e/2b5ddf744226159dc90a52f0d044c0de7c5ca4f42d12a350a674ebb6fb2a/torchvision-0.5.0-cp37-cp37m-win_amd64.whl Requirement already satisfied: six in c:\python\python37\lib\site-packages (from torchvision===0.5.0) (1.12.0) Requirement already satisfied: pillow>=4.1.1 in c:\python\python37\lib\site-packages (from torchvision===0.5.0) (6.1.0) Requirement already satisfied: numpy in c:\python\python37\lib\site-packages (from torchvision===0.5.0) (1.17.2) Installing collected packages: torch, torchvision Found existing installation: torch 1.0.1 Uninstalling torch-1.0.1: Successfully uninstalled torch-1.0.1 Found existing installation: torchvision 0.4.0 Uninstalling torchvision-0.4.0: Successfully uninstalled torchvision-0.4.0 Successfully installed torch-1.4.0 torchvision-0.5.0 C:\>Successfully が表示されていれば完了です。
pytorch 版 CornerNet-Lite の取得
CornerNet-Lite の pytorch版を下記より取得して動かしてみましょう。
https://github.com/princeton-vl/CornerNet-Lite.git
C:\>cd github C:\github>git clone https://github.com/princeton-vl/CornerNet-Lite.git Cloning into 'CornerNet-Lite'... remote: Enumerating objects: 75, done. remote: Total 75 (delta 0), reused 0 (delta 0), pack-reused 75 Unpacking objects: 100% (75/75), done.make を実行しますが、前提として、mingw 環境が構築されていることとします。
C:\github\CornerNet-Lite\core\external>mingw32-make python setup.py build_ext --inplace Traceback (most recent call last): File "setup.py", line 4, in <module> from Cython.Build import cythonize ModuleNotFoundError: No module named 'Cython' Makefile:2: recipe for target 'all' failed mingw32-make: *** [all] Error 1No module named 'Cython' というエラーが出ているので、pip で Cython をインストールする。
構築済の環境によっては、その他のモジュールでも No module named というのが出るかもしれませんので、その場合は出てきたエラーメッセージを判断してモジュールをインストールしてください。Cythonとは?
Pythonを高速化するためのパッケージ。↓参照
https://qiita.com/pashango2/items/45cb85390193d97523caC:\>pip3 install cython Collecting cython Downloading https://files.pythonhosted.org/packages/1f/be/b14be5c3ad1ff73096b518be1538282f053ec34faaca60a8753d975d7e93/Cython-0.29.14-cp37-cp37m-win_amd64.whl (1.7MB) |████████████████████████████████| 1.7MB 6.4MB/s Installing collected packages: cython Successfully installed cython-0.29.14 C:\>気を取り直して…
C:\github\CornerNet-Lite\core\external>mingw32-make python setup.py build_ext --inplace Compiling bbox.pyx because it changed. Compiling nms.pyx because it changed. [1/2] Cythonizing bbox.pyx C:\Python\Python37\lib\site-packages\Cython\Compiler\Main.py:369: FutureWarning: Cython directive 'language_level' not set, using 2 for now (Py2). This will change in a later release! File: C:\github\CornerNet-Lite\core\external\bbox.pyx tree = Parsing.p_module(s, pxd, full_module_name) [2/2] Cythonizing nms.pyx C:\Python\Python37\lib\site-packages\Cython\Compiler\Main.py:369: FutureWarning: Cython directive 'language_level' not set, using 2 for now (Py2). This will change in a later release! File: C:\github\CornerNet-Lite\core\external\nms.pyx tree = Parsing.p_module(s, pxd, full_module_name) running build_ext building 'bbox' extension creating build creating build\temp.win-amd64-3.7 creating build\temp.win-amd64-3.7\Release C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Tools\MSVC\14.14.26428\bin\HostX86\x64\cl.exe /c /nologo /Ox /W3 /GL /DNDEBUG /MD -IC:\Python\Python37\lib\site-packages\numpy\core\include -IC:\Python\Python37\include -IC:\Python\Python37\include "-IC:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Tools\MSVC\14.14.26428\ATLMFC\include" "-IC:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Tools\MSVC\14.14.26428\include" "-IC:\Program Files (x86)\Windows Kits\NETFXSDK\4.6.1\include\um" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.17134.0\ucrt" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.17134.0\shared" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.17134.0\um" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.17134.0\winrt" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.17134.0\cppwinrt" "-IC:\Program Files (x86)\Windows Kits\10\Include\10.0.10240.0\ucrt" "-IC:\Program Files (x86)\Windows Kits\10\Include\10.0.10240.0\shared" -IC:\opencv3.4.0\sources\include\opencv2 -IC:\opencv3.4.0\sources\include -IC:\opencv3.4.0\build\include\opencv2 -IC:\opencv3.4.0\build\include -IC:\opencv\build\include /Tcbbox.c /Fobuild\temp.win-amd64-3.7\Release\bbox.obj -Wno-cpp -Wno-unused-function cl : コマンド ライン error D8021 : 数値型引数 '/Wno-cpp' は無効です。 error: command 'C:\\Program Files (x86)\\Microsoft Visual Studio\\2017\\Community\\VC\\Tools\\MSVC\\14.14.26428\\bin\\HostX86\\x64\\cl.exe' failed with exit status 2 Makefile:2: recipe for target 'all' failed mingw32-make: *** [all] Error 1 C:\github\CornerNet-Lite\core\external>まだ、エラーが出る。数値型引数 '/Wno-cpp' は無効です。なんて言われるので、
とりあえず、C:\github\CornerNet-Lite\core\external\setup.py のextra_compile_args=['-Wno-cpp', '-Wno-unused-function']コンパイルオプションが無効なんだからいらないよね?ってことで
extra_compile_args=[]として引数を無くしてしまい再実行する。
C:\github\CornerNet-Lite\core\external>mingw32-make ~~~~ 途中省略 ~~~~ md64.lib ライブラリ build\temp.win-amd64-3.7\Release\nms.cp37-win_amd64.lib とオブジェクト build\temp.win-amd64-3.7\Release\nms.cp37-win_amd64.exp を作成 中 コード生成しています。 コード生成が終了しました。 rm -rf buildで生成がうまくいく。
モデルファイルの取得
トレーニングデータは、MS COCOです。
https://github.com/princeton-vl/CornerNet-Lite#training-and-evaluationドキュメント にあるように作成済の3つのモデルファイルを取得して配置しています。
CornerNet-Saccade
CornerNet-Saccade model CornerNet_Saccade_500000.pkl(447M)
https://drive.google.com/file/d/1MQDyPRI0HgDHxHToudHqQ-2m8TVBciaa/view?usp=sharing
をダウンロードして下記に配置する。C:\github\CornerNet-Lite\cache\nnet\CornerNet_Saccade\CornerNet-Squeeze
CornerNet-Squeeze model CornerNet_Squeeze_500000.pkl(122M)
https://drive.google.com/file/d/1qM8BBYCLUBcZx_UmLT0qMXNTh-Yshp4X/view?usp=sharing
をダウンロードして下記に配置する。C:\github\CornerNet-Lite\cache\nnet\CornerNet_Squeeze\CornerNet
CornerNet model CornerNet_500000.pkl(768M)
https://drive.google.com/file/d/1e8At_iZWyXQgLlMwHkB83kN-AN85Uff1/view?usp=sharing
をダウンロードして下記に配置する。C:\github\CornerNet-Lite\cache\nnet\CornerNet\デモの実行
以下のコマンドを実行する。
C:\github\CornerNet-Lite>python demo.py Traceback (most recent call last): File "demo.py", line 7, in <module> detector = CornerNet_Saccade() File "C:\github\CornerNet-Lite\core\detectors.py", line 38, in __init__ from .test.cornernet_saccade import cornernet_saccade_inference File "C:\github\CornerNet-Lite\core\test\__init__.py", line 1, in <module> from .cornernet import cornernet File "C:\github\CornerNet-Lite\core\test\cornernet.py", line 7, in <module> from tqdm import tqdm ModuleNotFoundError: No module named 'tqdm' C:\github\CornerNet-Lite>ModuleNotFoundError: No module named 'tqdm' というエラーなので、pipでtqdmをインストールする。
C:\>pip3 install tqdm Collecting tqdm Downloading https://files.pythonhosted.org/packages/72/c9/7fc20feac72e79032a7c8138fd0d395dc6d8812b5b9edf53c3afd0b31017/tqdm-4.41.1-py2.py3-none-any.whl (56kB) |████████████████████████████████| 61kB 4.1MB/s Installing collected packages: tqdm Successfully installed tqdm-4.41.1 C:\>で、再実行してみる。
C:\github\CornerNet-Lite>python demo.py total parameters: 116969339 loading from C:\github\CornerNet-Lite\core\..\cache\nnet\CornerNet_Saccade\CornerNet_Saccade_500000.pkl C:\Python\Python37\lib\site-packages\torch\nn\functional.py:2506: UserWarning: Default upsampling behavior when mode=bilinear is changed to align_corners=False since 0.4.0. Please specify align_corners=True if the old behavior is desired. See the documentation of nn.Upsample for details. "See the documentation of nn.Upsample for details.".format(mode))C:\github\CornerNet-Lite に以下のファイルが作成される。
demo_out.jpg
こんな感じでちゃんとボルゾイは犬と認識して、SUPはサーフボード、人(オイラ)も認識している。ログを見ると
loading from C:\github\CornerNet-Lite\core\..\cache\nnet\CornerNet_Saccade\CornerNet_Saccade_500000.pklとなっている。
CornerNet-Saccade を使っていて yolo v3 より速いという話題の CornerNet-Squeeze ではないので、demo.py を変更してみる。demo.py#!/usr/bin/env python import cv2 from core.detectors import CornerNet_Squeeze from core.vis_utils import draw_bboxes detector = CornerNet_Squeeze() # image = cv2.imread("demo.jpg") image = cv2.imread("max_kun.jpg") bboxes = detector(image) image = draw_bboxes(image, bboxes) cv2.imwrite("demo_out_max_kun.jpg", image)で、実行する。
C:\github\CornerNet-Lite>python demo2.py total parameters: 31771852 loading from C:\github\CornerNet-Lite\core\..\cache\nnet\CornerNet_Squeeze\CornerNet_Squeeze_500000.pkl C:\github\CornerNet-Lite>結果はこんな感じ。
うむぅ。物体認識以前に物体検出ができていない。
しかも、キーラちゃんを鳥と認識している。精度はイマイチかも???AP (Average Precision、平均適合率)
ドキュメント のCOCOデータのAPを見ると、yolo v3 より高いんだけどな?
YOLOv3 39 msで33.0%
CornerNet-Squeezeは、30 msで34.4%
CornerNet-Saccadeは、190 msで43.2%って感じで精度が高くなっていってます。
yolo v3 で認識させたときの画像は↓こんな感じです。
yolo v3 を pytorch で動かしたときの記事はこちら↓参照。
https://qiita.com/goodboy_max/items/b75bb9eea52831fcdf15CornerNet-Squeeze は COCOデータと異なる画像を物体認識させ応用するとイマイチなんだろうか?
画像が荒かったから?
それともコンパイルオプション取っちゃったから???謎は深まるばかり・・・
参考情報
https://opencv.org/latest-trends-in-object-detection-from-cornernet-to-centernet-explained-part-ii-cornernet-lite/
https://engineer.dena.jp/2019/07/cv-papers-19-keypoint-object-detection.html
https://qiita.com/sounansu/items/9a6caf1ac5e78aefaeae
https://qiita.com/pashango2/items/45cb85390193d97523ca


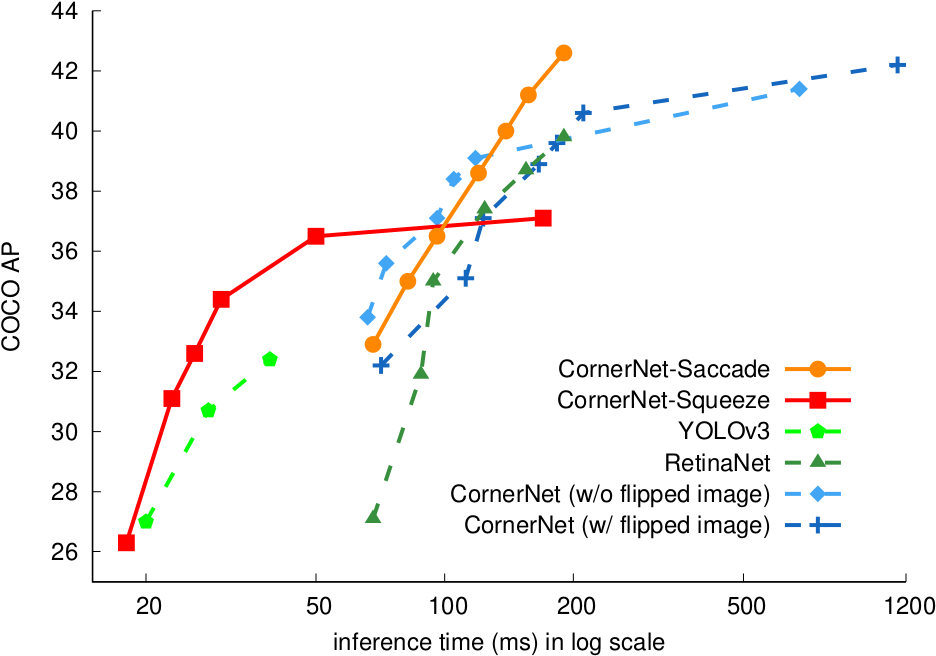
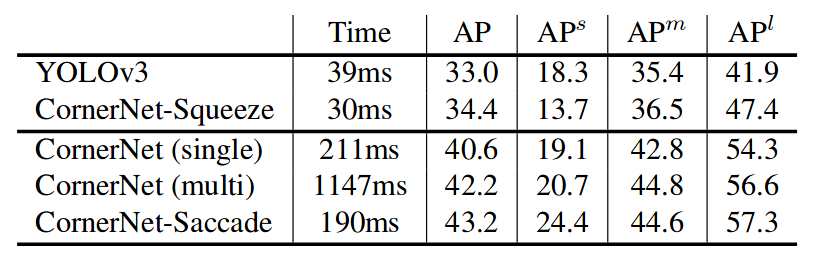
- 投稿日:2020-01-22T12:55:48+09:00
今日のpython error: killed
『フカシギの数え方』 おねえさんといっしょ:組み合わせ爆発の凄さ
https://qiita.com/kaizen_nagoya/items/f309b0c2bb015bbc71c3gra10.py# https://qiita.com/cabernet_rock/items/50f955afc16287244154 # https://qiita.com/kaizen_nagoya/items/f309b0c2bb015bbc71c3 # https://qiita.com/kaizen_nagoya/items/3a8d89f095489b6e1f56 # https://qiita.com/kaizen_nagoya/items/819f10124ec453b7ef27 # 必要なモジュールのインポート from graphillion import GraphSet import graphillion.tutorial as tl import time # 計算時間を調べる。 # グリッドのサイズを指定 universe = tl.grid(2, 2) GraphSet.set_universe(universe) tl.draw(universe) start = 1 # スタート位置 goal = 9 # ゴールの位置 paths = GraphSet.paths(start, goal) print (len(paths)) # key = 4 # 1箇所目 treasure = 2 # 2箇所目 paths_to_key = GraphSet.paths(start, key).excluding(treasure) treasure_paths = paths.including(paths_to_key).including(treasure) print (len(treasure_paths)) # universe = tl.grid(9, 9) # 9×9のグリッド GraphSet.set_universe(universe) start = 1 goal = 100 s = time.time() # 計算開始時刻 paths = GraphSet.paths(start, goal) print (time.time() - s )# 計算時間9X9が12時間たっても答えが出なかった。
graat.sh#!/bin/bash # https://qiita.com/kaizen_nagoya/items/f309b0c2bb015bbc71c3 date python3 gra10.py date仕事ができないので、別の機材をdocker 12G Bにして、上記script実行。
Wed Jan 22 02:44:58 UTC 2020 12 2 ./graat.sh: line 4: 22 Killed python3 gra10.py Wed Jan 22 02:47:29 UTC 202014G Bにして
Wed Jan 22 03:03:49 UTC 2020 12 2 ./graat.sh: line 4: 14 Killed python3 gra10.py Wed Jan 22 03:08:19 UTC 2020dockerの版が違うからかと思い、元の機材でやり直したら、昨日は12時間以上動いて停止してないのに、
今日は数分でkilled。理由不明。文書履歴(document history)
ver. 0.01 初稿 20200122午前
ver. 0.02 script 追記 20200122 昼
ver. 0.03 python 追記 20200122 午後
- 投稿日:2020-01-22T12:45:20+09:00
機械学習① パーセプトロンについて
はじめに
これから先どのようなことを勉強していくか悩んだとき、AI系の知識はつけておくべきだと思いました。学習の履歴をQiitaに残していこうと思います。
同じように、機械学習を学ぼうとしている方の手助けになると嬉しいです。環境
OS:windows 10
python3パーセプトロンについて
基本の形
パーセプトロンは複数の信号を入力値として受け取り、一つの信号に出力します。イメージは、信号の流れを作り、情報を出力先に伝達する感じです。パーセプトロンの信号は、流す/流さないの二択で要は「0」か「1」であるといえるでしょう。
下記の図に2入力1出力のパーセプトロンの例を示します。
x_1,x_2 = 入力信号\\ w_1,w_2 = 重み\\ y=出力信号入力信号は、ニューロンに送られるたびに固有の重みが乗算される。その総和がある限界値を超えた場合に1を出力します。これを、ニューロンが発火するといいます。この限界値を今後、閾値とします。(下式)
\theta = 閾値以上をまとめ、式に表すと下記になります。
f(x) = \left\{ \begin{array}{ll} 1 & (w1x1 + w2x2 \, > \, \theta) \\ 0 & (w1x1 + w2x2 \, \leqq \, \theta) \end{array} \right.パーセプトロンは複数ある入力信号のそれぞれに重みがあり、その重みが大きいものほど重要な情報という事がわかります。
バイアス
バイアスは、ニューロンの発火のしやすさを調整するパラメータです。(出力に「1」を出す度合いの調整)
以下に図と式を表示します。
\thetaをbに置き換える\\ f(x) = \left\{ \begin{array}{ll} 1 & (w1x1 + w2x2 \, > \, b) \\ 0 & (w1x1 + w2x2 \, \leqq \, b) \end{array} \right. \\ 移項\\ f(x) = \left\{ \begin{array}{ll} 1 & (b+w1x1 + w2x2 \, > \, 0) \\ 0 & (b+w1x1 + w2x2 \, \leqq \, 0) \end{array} \right.上記の式があらわすように、入力信号と重みを乗した値とバイアスの和が0を上回るか?という基準で出力値をコントロールできることがわかります。
実装してみる
適当に重みとバイアスを設定し、Pythonで実行しようと思います。
1-1perceptron_and_bias.py# coding: utf-8 import numpy as np # 入力値 x=np.array([0,1]) # 重み w = np.array([0.5, 0.5]) # 入力値 b = -0.7 print(x * w) print(np.sum(x * w)+b)実行結果[0. 0.5] -0.19999999999999996バイアスを用い、結果を0を下回るよう設定することができました。
まとめ
Pythonで実行しながら覚えていくと、良いアウトプットになるのではと思います。機械学習という領域においては、まだまだ氷山の一角ですらない為更新を続けていきます。
- 投稿日:2020-01-22T12:45:20+09:00
機械学習① パーセプトロン基礎の基礎
はじめに
これから先どのようなことを勉強していくか悩んだとき、AI系の知識はつけておくべきだと思いました。学習の履歴をQiitaに残していこうと思います。
同じように、機械学習を学ぼうとしている方の手助けになると嬉しいです。環境
OS:windows 10
python3パーセプトロンについて
基本の形
パーセプトロンは複数の信号を入力値として受け取り、一つの信号に出力します。イメージは、信号の流れを作り、情報を出力先に伝達する感じです。パーセプトロンの信号は、流す/流さないの二択で要は「0」か「1」であるといえるでしょう。
下記の図に2入力1出力のパーセプトロンの例を示します。
x_1,x_2 = 入力信号\\ w_1,w_2 = 重み\\ y=出力信号入力信号は、ニューロンに送られるたびに固有の重みが乗算される。その総和がある限界値を超えた場合に1を出力します。これを、ニューロンが発火するといいます。この限界値を今後、閾値とします。(下式)
\theta = 閾値以上をまとめ、式に表すと下記になります。
f(x) = \left\{ \begin{array}{ll} 1 & (w1x1 + w2x2 \, > \, \theta) \\ 0 & (w1x1 + w2x2 \, \leqq \, \theta) \end{array} \right.パーセプトロンは複数ある入力信号のそれぞれに重みがあり、その重みが大きいものほど重要な情報という事がわかります。
バイアス
バイアスは、ニューロンの発火のしやすさを調整するパラメータです。(出力に「1」を出す度合いの調整)
以下に図と式を表示します。
\thetaをbに置き換える\\ f(x) = \left\{ \begin{array}{ll} 1 & (w1x1 + w2x2 \, > \, b) \\ 0 & (w1x1 + w2x2 \, \leqq \, b) \end{array} \right. \\ 移項\\ f(x) = \left\{ \begin{array}{ll} 1 & (b+w1x1 + w2x2 \, > \, 0) \\ 0 & (b+w1x1 + w2x2 \, \leqq \, 0) \end{array} \right.上記の式があらわすように、入力信号と重みを乗した値とバイアスの和が0を上回るか?という基準で出力値をコントロールできることがわかります。
実装してみる
適当に重みとバイアスを設定し、Pythonで実行しようと思います。
1-1perceptron_and_bias.py# coding: utf-8 import numpy as np # 入力値 x=np.array([0,1]) # 重み w = np.array([0.5, 0.5]) # 入力値 b = -0.7 print(x * w) print(np.sum(x * w)+b)実行結果[0. 0.5] -0.19999999999999996バイアスを用い、結果を0を下回るよう設定することができました。
まとめ
Pythonで実行しながら覚えていくと、良いアウトプットになるのではと思います。機械学習という領域においては、まだまだ氷山の一角ですらない為更新を続けていきます。