- 投稿日:2020-01-22T22:55:37+09:00
[個人開発]大喜利サービスを5日でつくってわかったこと
サービスイメージ
ひとこと大喜利「ザブトン」
https://zabuton.co/
誰でもすぐに簡単に大喜利が投稿でき、
SNS主体で大喜利を楽しむことができる
そんな大喜利サービスを開発しました。はじめに
個人開発でサービスはいくつも作ってきましたが
こういった記事を書くのは初めてです。後半の方でコードもGithubにて公開していますが、
文章、コード共に拙い部分がありますが、何卒お目溢し頂ければと思います。筆者について
僕は元々はゲーム会社出身ですが、
メンタルやられて退職してからフリーランスとなり
サービス乱立したりしながら生計を立てている20代エンジニアです。ただ、エンジニアという職業は手段であって、
僕の目的はものづくり(サービスつくり)です。今までは外界との接触が苦手で
TwitterやGithub、QiitaやQrunchといったサービスなどを
利用して自分から発信することはなかったのですが
一人での活動に色々と限界を感じてきて
自分の活動内容やサービスを公開していこうという運びとなります。1月からTwitterも初めてみました。もしよろしければどうぞ。
つくったサービス詳細
ひとこと大喜利「ザブトン」
https://zabuton.co/最初にも記載しましたが、大喜利サービスをつくりました。
このサービスのポイントは3つあります。
・大喜利の"回答"のみに特化したサービスサイト
・回答はTwitterへシェアする前提の設計
・OGPでお題、回答が概観できることこのサービスは大喜利の回答(コンテンツ)をTwitterへのシェアありきで作った、というところがポイントです。
競合大手の大喜利サービスではプラットフォームとしてコミュニティを形成させています。
(サービス内で閲覧→回答→閲覧のフローを促し回遊させ、継続させている)
ただ、結局のところコンテンツがどういった経路を辿り人々の目に触れていくかといえば、
結局はSNSだったりの影響が大きいのかと感じています。そこで、コンテンツをサービスサイト内で流通させることなく、
Twitterでの流通に限定するようなサービスフローにしたらよいのではないか、という発想でこのサービスをつくりました。・大喜利の"回答"のみに特化したサービスサイト
・回答はTwitterへシェアする前提の設計
・OGPでお題、回答が概観できることはじめにあげた3点のうち、最初の2点については上記の発想からの理由で、
最後の1点については、このようなサービスフローにするということは、
Twitter上でもストレスなく1つのTwitter上のコンテンツとして閲覧できるような
設計にすべきだという理由からです。なぜ作った
僕の目的はサービスづくりであり、
多くの人に利用してもらい、売上を立てることです。それを前提とした上でザブトンを作った理由は、二つです。
- 市場が大きいこと
- 既存サービスへのUX不満一つめから説明します。
・市場が大きいこと
これはそのままの意です。
いまだに、某大手大喜利サービスにおけるコミュニティの活発性や
ニュースアプリ、まとめ系ブログなど様々な場所で取り上げられています。
日本のテレビ番組がお笑い一色なことからもわかるように
日本人の性質として"お笑い"に関して興味が高いことがわかります。基本的に僕がサービスを作るときには
ニッチゆえに競合がいないブルーオーシャンは避け
必ず、競合もいるが需要が確立されているレッドオーシャンを攻めます。ニッチな業界でのグロースハックはとんでもない根気と労力がかかります。
そもそも市場にユーザー数が少ないうえに、新しいサービス利用に対しての敷居の高さがあるからです。なのであれば、レッドオーシャンだが需要(ユーザー)が溢れている市場から0.01%を取りに行くだけの方が、僕としてははるかにやりやすい。
そういった理由があります。
・既存サービスへのUX不満
かくいう僕もお笑いは大好きです。
くすっと笑える小ネタも、腹を抱えて笑える漫才も、
人の心を暖かくする、とてもハッピーなものだと考えています。そこで、現在一強であるお笑い系サービス"bo●●te"さんですが、
実際に投稿者側として利用しようとするととんでもなく使いにくいです。例えば、「ちょっと面白いお題を思いついた!」という場合にboketeを検索します。
選択肢は2つ。
1:アプリ
2:Web
まずはアプリから試してみました。
アプリをインストールし、開いてみるとまず「ログイン画面」。
まず会員登録しないと進めません。この時点で断念。次にWebを試してみました。
TOP→お題一覧→お題詳細→このお題でボケる(おっ!)→ボケたりお題投稿するには、ログインするか新規登録が必要です。
そうです。お題を登録したりボケたりするには会員登録が必須なのです。
しかもSNSログインもなし、いまどきメールアドレスを登録させるという苦行。これには僕も膝から崩れ落ちました。
これではお笑いが廃れてしまう、と。ただ、b●ke●eさんのサービス性を否定するわけではありません。
なぜならば、サービス内におけるコミュニティはかなり強固なものになっているし、
そのコミュニティに所属する人たちによっては大きな心の拠り所だと感じるからです。
そもそもこういったネットにおける大喜利が普及したのは、このサービスのおかげでしょう。ただ現代のインターネット属性に合致しているかという部分で非常に疑念を抱いてしまったので
下記3点をポイントとして掲げ、サービス開発へと乗り出した経緯があります。・大喜利の回答のみに特化したサービスサイト
・回答はTwitterへシェアする前提の設計
・OGPでお題、回答が概観できること制作スケジュール
工程 工数 企画構想 3時間 ワイヤー作成 30分 デザイン 4時間 コーディング 5時間 インフラ&バックエンド 4日 TOTALで3日くらいで作りたかったのですが、
他作業もちょこちょこしたりして結局TOTAL工数としては一週間弱かかってしまいました。
あとは、OGP画像の自動生成ロジックになかなか手こずってしまいました。
企画〜コーディングについては慣れたものでトータル1日ちょっとでした。
ただ、かの有名なpeing(質問箱)を作ったせせりさんは、
peingを6時間で作ったとのことなのでまだまだ精進のしがいがあるなというところです。なお、僕の場合、とにかく早く作って出すということを大前提にしているため
こういったスケジュール感になりがちです。余談ですが、Facebookのマークザッカーバーグの言葉で好きなのがこちら。
「完璧を目指すよりまず終わらせろ」途中経過
ワイヤー
※ちなみにこれは違うサービスのワイヤーです。ザブトンのものはデザインで上書きしてしまって、残してありませんでした...すみません。ちなみに、チームワークの場合と個人開発の場合では「ワイヤーフレーム」の利用用途は異なるのを前提として
僕の場合は、ワイヤーはこんな感じで機能要素だけをドカッと置いて、画面概要の確認にとどめます。
これにより工数の詳細な算出、必要な技術の確認を改めてしていきます。デザイン
デザインは、そのままコーディング出来るレベルまで詰めます。
だいたい他サービスの同じコンテンツブロックを参考にさせていただきながら作っていきます。正直、僕くらいのデザインレベルだとこだわっても対してクオリティ変わらないので、速度重視で作っていきます。
コーディング
※左デザイン、右コーディングですデザインだけではわからなかった、要素を追加していきながらコーディングしていきます。
今回の場合、ヘッダーをTOPにつけるかというのはデザイン時点ではやめていたんですが、
実際に触ってみるとヘッダーがないとめちゃくちゃ不便だったため取り付けています。あとは、僕の場合XDを使ってワイヤーからデザインまで組みますが、
XDはカラーマネジメントしてくれずWebに乗せると色が変わってしまうので、
コーディングするときの感覚で色なんかも変えていっています。利用技術
ホスティングはAWS
Linux(Amazon Linux)
Apache
MySQL
PHP
フレームワークはcakephp3系
Html(css/js)今回は最低限しか利用していません。
サービスとしてログインや会員登録がなかったので、
サードパーティのAPIやライブラリもほとんど使ってません。
画像の合成にはImagineを利用しています。ソース
https://github.com/nsk-dev-gh/zabuton
こちらにまとめてあります。
Cakephp3系の
src配下とwebroot(img/css/js/font)配下をアップしておきます。
利用ライブラリは前述の通りImagineのみです。今回、Serviceを利用せずにController内でサービス処理を記載していたり
画像合成まわりの関数の可読性が最悪だったりするのですが
もしご参考になれば自由にご利用ください。ControllerはPagesのみを利用しています。
app.phpで下記記述をすることでURLからコントローラー名を排除しています。
$routes->connect('/', ['controller' => 'Pages', 'action' => 'index']);
$routes->connect('/:action', ['controller' => 'Pages']);
まとめ
今回はサービスリリースを目処として、この記事公開とさせていただきました。
ただ、広告を貼ってることからも収益が出始めた場合には、
アクセス数の情報や、売上なども公開していく予定です。他にもサービス作りを頻繁に発信していく予定ですので
改めてになりますが、よろしければTwitterフォローの方もよろしくお願いします。長々とした内容をここまでご拝読いただき
ありがとうございました!ひとこと大喜利「ザブトン」
https://zabuton.co/





- 投稿日:2020-01-22T22:51:15+09:00
AWS Amplify Android を試してみる(Mac)
はじめに
AWS Amplify Android をGetting StartedにしたがってMacで試してみる。
以降の各章はGetting Startedに合わせている。Prerequisites
以下の通り、Getting Started に記載されている手順は Mac でしか動作しない。Windows の場合、下の説明にあるリンク先の手順を実施する必要がある。
https://aws-amplify.github.io/docs/android/start#prerequisitesThese steps currently only work on Mac. If you have a Windows machine, follow the steps on one of our categories such as API here.node.js のインストール
バージョン 12.14.0をインストールした。
Android Studio のインストール
以下からインストール。バージョン 3.1 以上である必要がある。
現在最新のやつをインストールすれば問題なし。https://developer.android.com/studio/index.html#downloads
プロジェクトの作成
以下にしたがってプロジェクトを作成する。
https://developer.android.com/training/basics/firstapp/creating-projectMinimum API levelは15(Ice Cream Sandwich)以上を選択する必要がある。
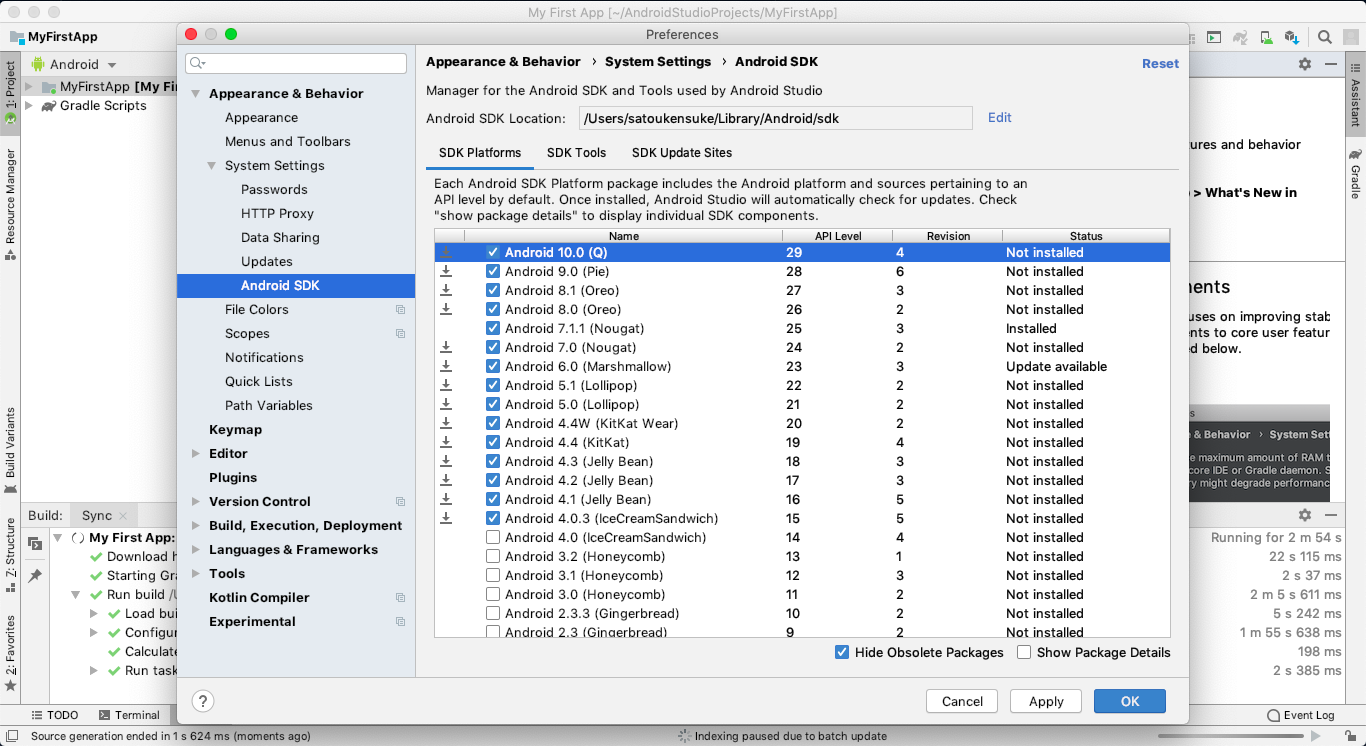
Android SDK のインストール
上で選択したAPI levelのSDKをイントールする。
Android Studio -> Preference をクリック
Appearance & Behavior -> System Settings -> Android SDK をクリックし、必要なSDKがインストールされていなければインストールする。
Amplify CLI のインストール
npm install -g @aws-amplify/cliStep 1: Configure your app
プロジェクト用build.gradleの修正
build.gradle(Project:My First App)を開き、いろいろ追加する。追加した箇所にコメントをした。build.gradle// Top-level build file where you can add configuration options common to all sub-projects/modules. buildscript { repositories { // mavenCentral()を追加 mavenCentral() google() jcenter() } dependencies { classpath 'com.android.tools.build:gradle:3.5.3' // amplify-tools-gradle-pluginを追加 classpath 'com.amplifyframework:amplify-tools-gradle-plugin:0.2.0' } } // amplifytoolsを追加 apply plugin: 'com.amplifyframework.amplifytools' allprojects { repositories { google() jcenter() } } task clean(type: Delete) { delete rootProject.buildDir }アプリ用のbuild.gradleの修正
build.gradle(Module:App)を開き、いろいろ追加する。追加した箇所にコメントをした。build.gradleapply plugin: 'com.android.application' android { // compileOptionsを追加 compileOptions { sourceCompatibility 1.8 targetCompatibility 1.8 } compileSdkVersion 28 buildToolsVersion "29.0.2" defaultConfig { applicationId "com.example.myfirstapp" minSdkVersion 15 targetSdkVersion 28 versionCode 1 versionName "1.0" testInstrumentationRunner "androidx.test.runner.AndroidJUnitRunner" } buildTypes { release { minifyEnabled false proguardFiles getDefaultProguardFile('proguard-android-optimize.txt'), 'proguard-rules.pro' } } } dependencies { implementation fileTree(dir: 'libs', include: ['*.jar']) implementation 'androidx.appcompat:appcompat:1.0.2' implementation 'androidx.constraintlayout:constraintlayout:1.1.3' testImplementation 'junit:junit:4.12' androidTestImplementation 'androidx.test.ext:junit:1.1.0' androidTestImplementation 'androidx.test.espresso:espresso-core:3.1.1' // amplifyframeworkを追加 implementation 'com.amplifyframework:core:0.9.0' implementation 'com.amplifyframework:aws-api:0.9.0' }Make Projectの実行
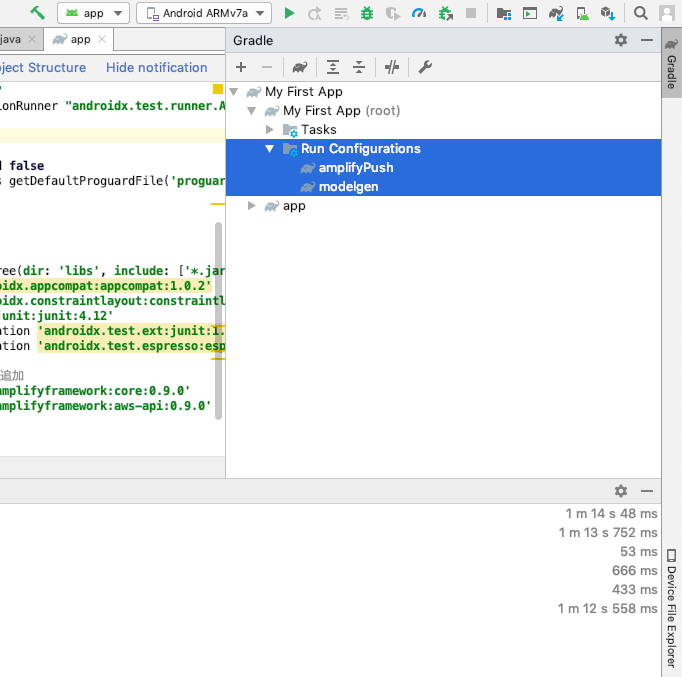
Build メニュー -> Make Project をクリック
Make Project に成功すると Gradle Task として
modelgenとamplifyPushが追加されます。
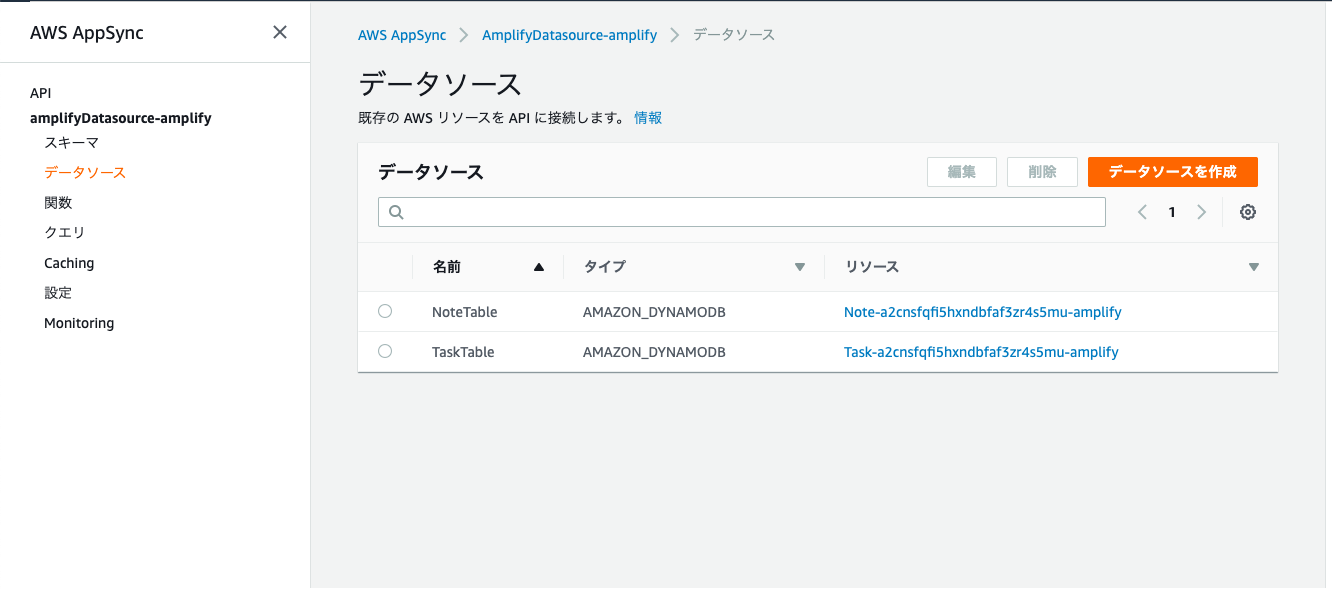
Step 2: Generate your Model files
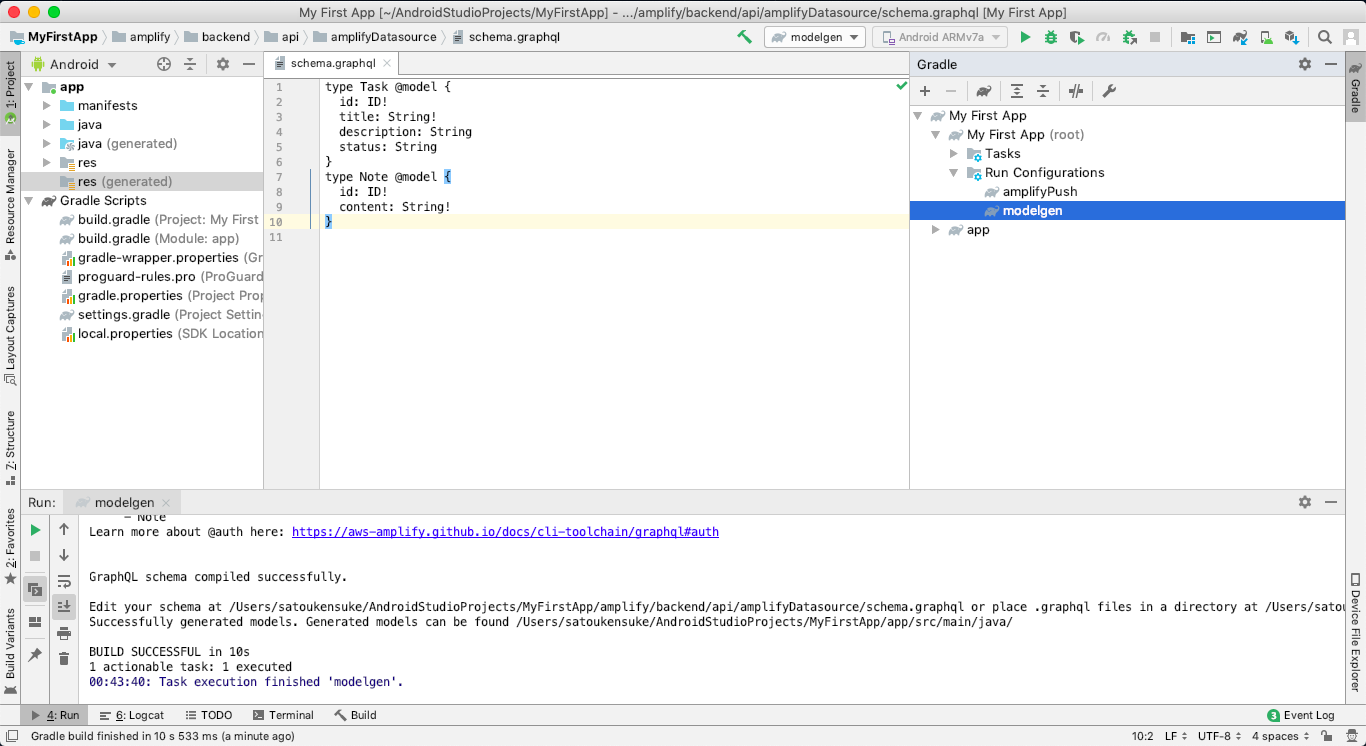
amplify/backend/api/amplifyDatasource/schema.graphqlを確認するamplify/backend/api/amplifyDatasource/schema.graphqltype Task @model { id: ID! title: String! description: String status: String } type Note @model { id: ID! content: String! }Gradle Task
modelgenを実行する
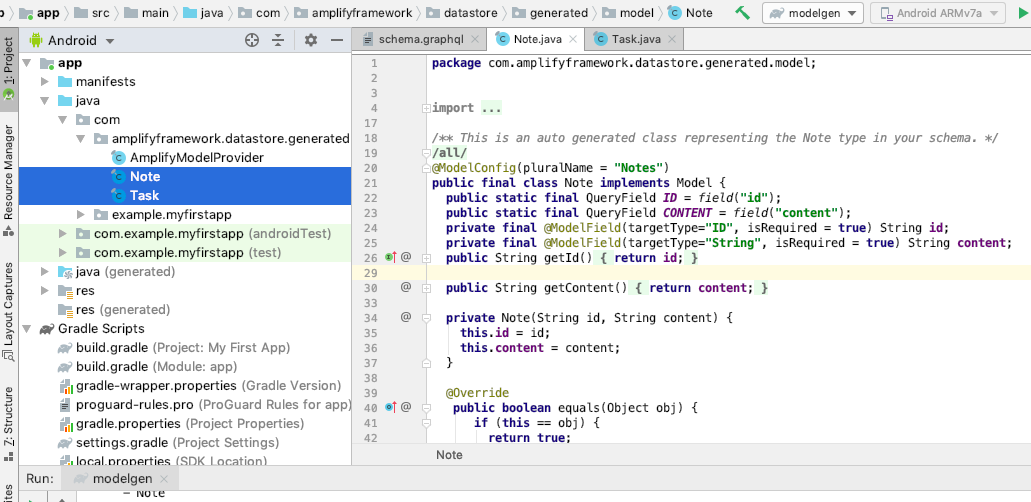
app/src/main/java/com/amplifyframework.datastore.generated.modelの下にschema.graphqlに記述したmodelクラスが生成されたことを確認する。
Step 3: Add API and Database
amplify configureの実行
コマンドプロンプトでプロジェクトのルートディレクトリに移動し、以下を実行する。
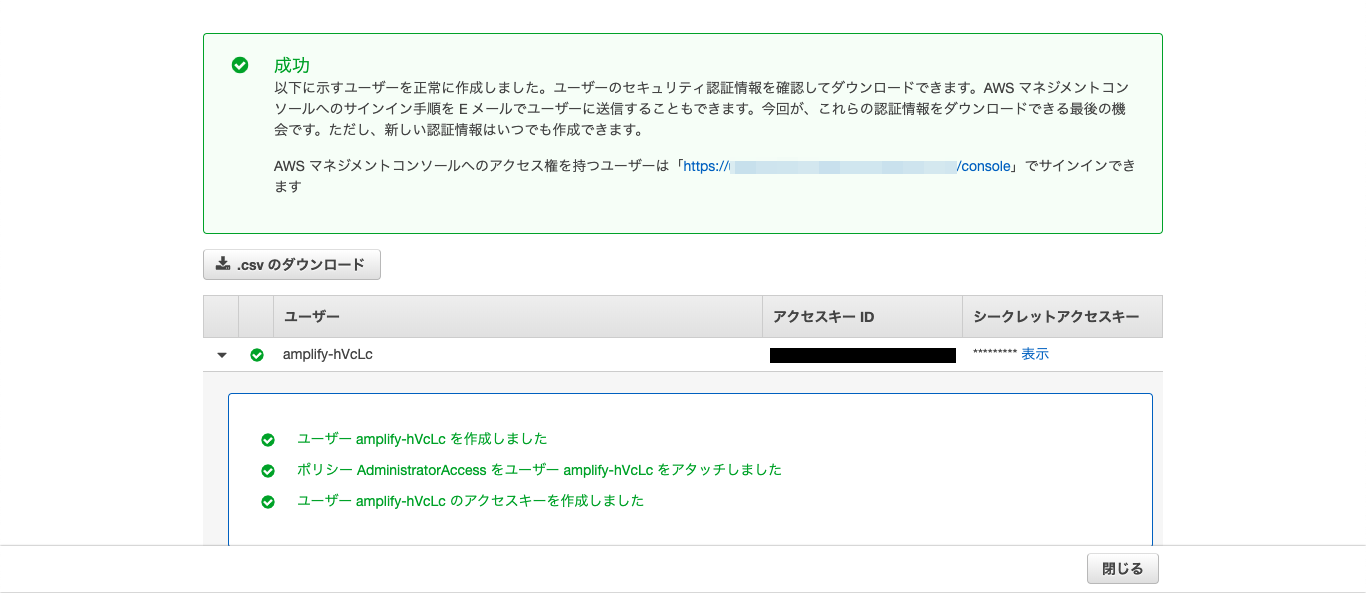
amplify configureAWSログイン画面が出るため、ログインしておく。
コマンドプロンプトに戻り、リージョンやら新規ユーザ名やらを入力すると、ブラウザにIAMユーザ登録画面が出るため、新規ユーザを登録する。
新規ユーザ登録後、アクセスキーIDとシークレットアクセスキーが発行される。
コマンドプロンプトでそれを聞かれるため、入力する。
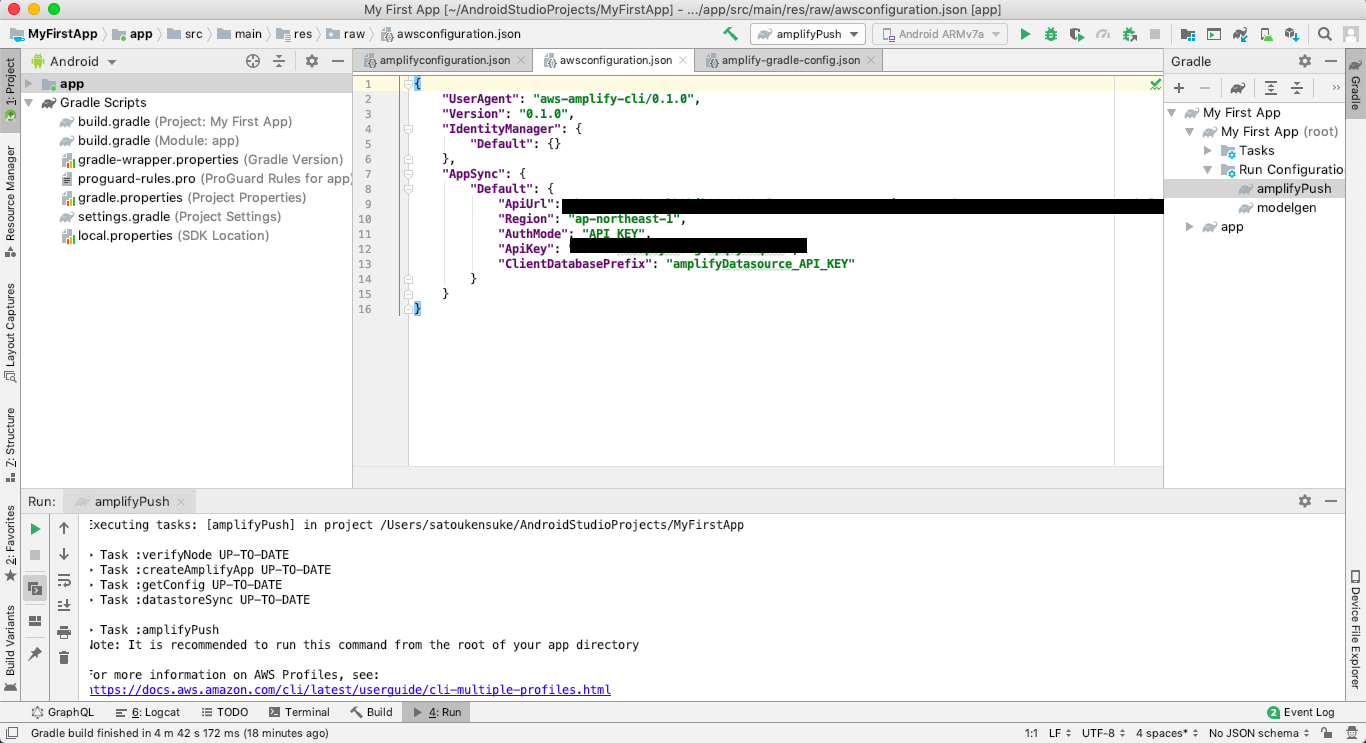
amplifyPushの実行
AndroidStudioに戻り、Gradle Task
amplifyPushを実行する
Task完了後、以下の2ファイルが生成されていることを確認する
src/main/res/raw/amplifyconfiguration.json
各サービスにアクセスするための情報を記載したファイル
src/main/res/raw/awsconfiguration.json
通信対象の全てのリージョンとエンドポイントを記載したファイル
Step 4: Integrate into your app
Amplifyの準備ができたので、Androidアプリに組み込んでいく、
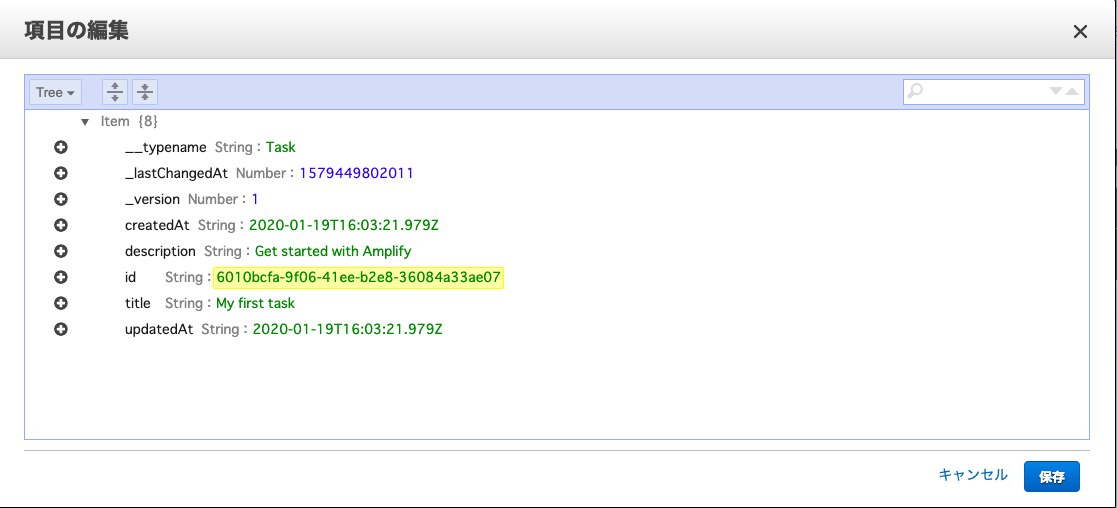
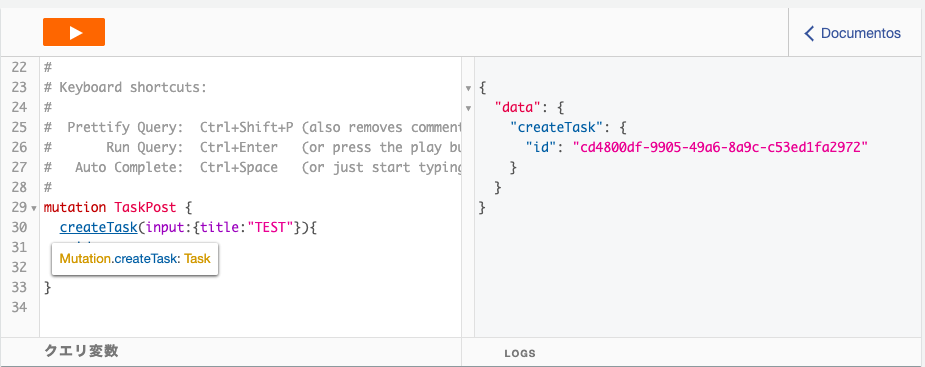
com.example.myfirstapp.MainActivity#onCreateを以下の通り修正するMainActivity.javapackage com.example.myfirstapp; import android.os.Bundle; import android.util.Log; import androidx.appcompat.app.AppCompatActivity; import com.amplifyframework.AmplifyException; import com.amplifyframework.api.aws.AWSApiPlugin; import com.amplifyframework.api.graphql.GraphQLResponse; import com.amplifyframework.api.graphql.MutationType; import com.amplifyframework.api.graphql.SubscriptionType; import com.amplifyframework.core.Amplify; import com.amplifyframework.core.ResultListener; import com.amplifyframework.core.StreamListener; import com.amplifyframework.datastore.generated.model.Task; public class MainActivity extends AppCompatActivity { @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); try { // Amplifyの初期化処理 Amplify.addPlugin(new AWSApiPlugin()); Amplify.configure(getApplicationContext()); Log.i("AmplifyGetStarted", "Amplify is all setup and ready to go!"); // テスト用Taskを生成し、mutate APIを実行。DynamoDBに登録 Task task = Task.builder().title("My first task").description("Get started with Amplify").build(); Amplify.API.mutate(task, MutationType.CREATE, new ResultListener<GraphQLResponse<Task>>() { @Override public void onResult(GraphQLResponse<Task> taskGraphQLResponse) { Log.i("AmplifyGetStarted", "Added task with id: " + taskGraphQLResponse.getData().getId()); } @Override public void onError(Throwable throwable) { Log.e("AmplifyGetStarted", throwable.toString()); } }); // 登録したTaskの取得。Dynamoはデフォルトでは「結果的に整合性のある読み込み」のため、 // 上記で登録したばかりのデータは取得できない場合がある。 Amplify.API.query(Task.class, new ResultListener<GraphQLResponse<Iterable<Task>>>() { @Override public void onResult(GraphQLResponse<Iterable<Task>> iterableGraphQLResponse) { for(Task task : iterableGraphQLResponse.getData()) { Log.i("AmplifyGetStarted", "Task : " + task.getTitle()); } } @Override public void onError(Throwable throwable) { Log.e("AmplifyGetStarted", throwable.toString()); } }); // Taskが登録された時に実行するメソッドをsubscribe Amplify.API.subscribe( Task.class, SubscriptionType.ON_CREATE, new StreamListener<GraphQLResponse<Task>>() { @Override public void onNext(GraphQLResponse<Task> taskGraphQLResponse) { Log.i("AmplifyGetStarted", "Subscription detected a create: " + taskGraphQLResponse.getData().getTitle()); } @Override public void onComplete() { // Whatever you want it to do on completing } @Override public void onError(Throwable throwable) { Log.e("AmplifyGetStarted", throwable.toString()); } } ); } catch (AmplifyException exception) { Log.e("AmplifyGetStarted", exception.getMessage()); } setContentView(R.layout.activity_main); } }AWS AppSync
以下のコマンドを実行し、
GraphQLを選択すると、ブラウザにAWS AppSyncが表示されるamplify console apiこの画面からこれまで生成したデータソースを確認したり、GraphQLクエリを発行して、APIのテストができる
クエリ画面で作成されたAPIの仕様が確認できる。
Java に記載されているソースが実行されると、GraphQL クエリが発行されるイメージ
アプリを起動してみる
作成したAndroidアプリをシミュレーターやら実機で起動してみる。
mutateの確認
Amplify.API.mutateでDynamoDBにtitleがMy first taskのレコードが登録されたことを確認できた。
queryの確認
登録後、
Amplify.API.queryで上記レコードを取得したいが、DynamoDBはデフォルトでは結果的に整合性のある読み込みのため、取得できない場合がある。
アプリを2回起動して、1回目のレコードを取得できるか確認する。
1回目
2回目
ログから1回目に登録したレコードの取得を確認できた。
subscribeの確認
Amplify.API.subscribeで指定したテーブルへの登録やレコードの削除などをトリガーにして、リスナーのメソッドを実行することができる。
試しに、アプリを実行した状態で、AWS AppSyncからTaskを登録してみる。
Taskの登録は成功しているが、
onError()が実行され、エラーログが出力されてしまった。
問題なくonNext()のログが表示された方がいたら教えていただきたい。
終わりに
最後の方、少し消化不良となってしまったが、チュートリアルにしたがって Amplify SDKを使用してAndroidアプリを作成することができた。
次はiosアプリの方を試してみたい。iosの場合、Prediction(予測機能)が使えるようだ。参考
https://aws-amplify.github.io/docs/android/start#step-1-configure-your-app
https://dev.classmethod.jp/cloud/aws/amplify-ios-identify-celebrities/
https://qiita.com/uenohara/items/44d2334c597dc631bc60










- 投稿日:2020-01-22T21:52:41+09:00
AWS DevOps Professional合格レポート
AWS DevOps Professional合格レポート
2020年1月18日にAWS 認定 DevOps エンジニア – プロフェッショナルに無事合格できたので、試験の振り返りも兼ねて勉強法などをまとめておこうと思います。これから受験される方の参考になれば幸いです。
私は英語が全くと言っていいほどできないので、なんとか日本語で勉強しました。
資格取得状況
- AWS Certified Solutions Architect - Associate (SAA)(2019-03-01)
- AWS Certified Developer - Associate (DVA)(2019-08-29)
- AWS Certified SysOps Administrator - Associate (SOA)(2019-09-28)
- AWS Certified DevOps Engineer - Professional (DOP)(2020-01-18)
AWSを触り始めて約一年くらいで、業務では構築はしていませんがAWSのサービスを評価するという少し変わったことをしています。DevOps系のサービス特に知見はありません。
試験結果
分野 セクション 達成度 分野 1 SDLC の自動化 22% 分野 2 構成管理およびInfrastructure as Code 19% 分野 3 監視およびロギング 15% 分野 4 ポリシーと標準の自動化 10% 分野 5 インシデントおよびイベントへの対応 18% 分野 6 高可用性、フォールトトレランス、およびディザスタリカバリ 16% 820点での合格なので、ギリギリではないけど余裕もないという感じでした。(分野1のSDLCの自動化のみ再学習の必要ありの評価)
印象としては何か通知したい時、Alerm使うの?Events使うの?、連携はLambdaかSNSどっちみたいな問題が多かった気がします。あとOpsWorks周りが全然わからなかった…
学習方法
以下の学習リソースを活用しました
* DevOps Engineering on AWS
* 公式E-ラーニング
* 模擬試験
* Blackbelt
* ユーザーガイド
* ホワイトペーパー
* Udemy問題集DevOps Engineering on AWS
AWS公式のトレーニングコースです。会社で受けさせてくれるとのことだったので、DevOpsを受けるきっかけになりました。正直なところ、他の学習リソースのみでも十分合格できるため必須はないです。大事なのは、3日間DevOpsの勉強時間を取れるところにあります。
個人で受けるには費用がかかるため、会社で受けさせてくれる場合のみ利用しましょう。
公式E-ラーニング
振り返ってみるとこれが一番大事でした。
何から初めていいかわからない人は、ここで説明している内容が理解できるよう何度も見ましょう。試験範囲をある程度網羅しており、重要なポイントがしっかりと説明されているにも関わらず無料という良コンテンツです。試験の傾向を掴むことができ、問題の解き方まで解説されています。模擬試験
前回Sysopsでもらったバウチャーを使って受験しました。結果は50%で不合格ラインでしたが、大事なのはすべての問題をBlackBeltやユーザーガイドを見て復習することです。
必ず試験中のスクリーンショットを撮ってメモしておきましょう。
ちなみに私はHackMDを使って保存しておき、復習して勉強した内容を問題ごとに追記していました。Blackbelt
プロフェッショナル資格を受ける人には説明不要のBlackbeltです。模擬試験や後から紹介するUdemy問題集でわからないことがあったら、真っ先にここを読みましょう。
私は以下のサービスを中心に読みました。(太字は絶対読むべき)
* AWS Elastic Beanstalk
* AWS CloudFormation
* Codeシリーズ
* AWS CloudTrail
* AWS Config
* AWS OpsWorks
* AWS Systems Manager
* Amazon CloudWatchユーザーガイド
これもBlackBeltと同様の使い方です。ただこちらは漠然と読んでても頭に入ってこないので、なるべく明確な要件に対してわからないことがあった場合に参照するようにしていました。
見たサービスはBlackBeltのサービスとほぼ同じです。ホワイトペーパー
必須かと言われればそうではないんですが、余裕があれば読んでおいたほうがいいものもいくつかあったので、紹介しておきます。全部英語なので、google翻訳でなんとか目を通してました。
Udemy問題集
私が最も力を入れたのが、Udemy問題集を解くことです。私はこちらを購入しました。
AWS Certified DevOps Engineer Professional [Practice Exam]
練習問題が10問、模擬問題が75問と他の問題集よりは少なく受験までは不安でしたが、問題なく試験に臨むことができました。
この75問をしっかりと理解することができれば、問題なく合格できるはずです。全く同じ問題はなくとも、考え方と問われる知識はほぼ同じ印象でした。
私は通勤中などの隙間時間にgoogle翻訳しながら解いていました。
まとめ
以下の流れでやれば、無駄なく学習できるはずです。
1. E-ラーニングを理解できるまで見る
2. 模擬試験を受ける
3. 模擬試験の復習
4. Udemy問題集を解く
5. 解けなかった問題の復習
6. 4と5を全問できるまで繰り返す復習は最初にBlackbelt、わからなかったらユーザーガイドを参照しましょう。
これからDevOps proを受験される方頑張ってください!
- 投稿日:2020-01-22T20:43:14+09:00
イベントレポート(AWS re:Invent 2019 re:cap for Startups)
参加してきたAWSイベントの概要を纏めます。
・アジェンダ
https://awsreinvent2019recapforstartup.splashthat.com/ML
遅刻で聞けず
コンテナ
遅刻で聞けず
Serverless
Lambda
LambdaからRDSへの接続数問題
RDS Proxy with AWS Lambda(プレビュー中)
データベースの接続プールの役割
パスワードなどの秘匿情報はSecretManager経由でLambdaに理解させるスパイキーなアクセス(Lambdaのコールドスタートがネックになりやすい)
Provisioned Concurrency for Lambda Functions
事前ウォームアップが可能に。
今まではJava ランタイムロードに数秒やENI作成に10秒などかかることがあった。Lambda Supports Amazon SQS FIFO
順序性をアプリ側で気にしなくてよくなったKinesis Datastream、DynamoDBイベントの並列化
今までシャードとLambda関数の実行数は1対1だったが1対Nの設定が可能になったAPI Gateway
- HTTP APIs for Amazon API Gateway HTTPSのエンドポイントとして利用。 REST API以外でも利用可能。シンプルに利用できて安くて速い。
Amplify
Amplifyとは
本質的な作業に注力
モバイルアプリを最速でリリースするための仕組み
AWSの理解が浅くてもシステム構築を可能にするAmplify CLI
AWSに詳しくなくてもBuildingBlockを構築することができる
下記のコマンドで対話形式でシステム構築可能
amplify add api
amplify pushAmplify Framework
ファイルアップロードにおけるセキュリティ対策などの機能を考えることなく実装可能Amplify Console
フロントエンドのCI/CD環境が瞬時に構築できるまとめ
Amplify CLIで作成した機能をAmplify Frameworkで呼び出したりできるAmplify Datastoreとは
デバイス側(iOS/Android)のストレージエンジン
GraphQLのスキーマを簡単にAmplify DataStore - Conflict Detection
コンフリクト解決手段も提供Big Data系
Athena
Federated Query
Lambda経由でクエリを投げることができる
データソースがAWSサービス(RedShift)などの場合はサーバレスアプリケーションリポジトリにAWSが用意したLambdaのコネクターが利用可能ユーザ定義関数(UDF)をサポート
機械学習モデルの呼び出しに対応
RedShift
第3世代Redshift
コンピュートとストレージの課金体系が分離した。
ストレージは利用分課金(S3のような)に変わった。
2倍の性能が同じ価格で利用可能になった。AQUA(Advanced Query Accelerator)
追加コストなしに10倍の速度を実現。プレビュー中。ElasticsearchService
- UltraWarm 例えば直近1か月のデータをHotDataとする Hotノード:SSD Warmノード:HDD
UltraWarmはWarmノードのストレージにS3が利用される。コスト、スケール、耐久性を実現
その他のサービスアップデート
SSO関連
IDソースとしてSAML対応の外部IDプロバイダをサポート
AD以外でも利用可能SCIMを使ったIDの同期機能をサポート
ユーザの2重管理を無くして、おおもとのIDプロバイダだけの管理をすればよくなった。AWS CLI v2がAWSSSOでの認証をサポート(ベータ版)
ログイン
aws2 sso login --profile ~Wavelength
現状利用不可。AWSのロードマップを知っておく
- リージョンまでの通信で大きな通信遅延が課題 通信先を近くのAGに指定できる
- 投稿日:2020-01-22T19:20:03+09:00
AWSで作ったLaravelアプリケーションをXserverにデプロイする
はじめに
タイトル通りですが、LaravelアプリケーションのデプロイをXserverで試してみました。
AWSでアプリケーションは作成したのですが、
XAMPPで作成した方も以下のやり方でできると思います。まとめ
さっそくですがやり方を以下にまとめました。
※XAMPPでアプリケーションを作成した方は⑥以降を参考にしていただければと思います。
①AWSでLaravelアプリケーションを作成。
②作成したアプリケーションのフォルダをダウンロードしてXAMPP環境下(htdocs内)に保存する。
③XAMPPでphpMyAdminを起動。アプリケーション用のDB(DB名:laravel)を作成する。
④.envをXAMPP環境下でDBが使えるようにに編集。
.envDB_DATABASE=laravel DB_USERNAME=root DB_PASSWORD=⑤コマンドプロンプトで同フォルダに移動してテーブル作成
$ cd 作成したアプリのフォルダ $ php artisan migrate//このコマンドでテーブルが作成されます。⑥FTP(FileZillaを使用しました)で転送したいドメイン内のpublic_htmlへ作成したアプリのpublic内のファイルをすべて転送
⑦publicフォルダ以外のファイルをまとめて新しく作ったフォルダに転送(public_htmlと同じ階層下)
フォルダ名はlaraveltestとしました。
⑧public_htmlに転送したindex.phpのrequire先を新しく作ったフォルダ先に変更
index.phprequire __DIR__.'/../laraveltest/vendor/autoload.php';//28行目 ~~ $app = require_once __DIR__.'/../laraveltest/bootstrap/app.php';//38行目⑨XAMPP環境下のphpMyAdminで同アプリ用に作ったテーブルをエクスポート(.sqlファイル)
⑩先ほどエクスポートしたsqlファイルをXserver環境下のphpMyAdminにインポートしてテーブル作成
⑪転送した.envを以下のように編集して保存
.envAPP_URL=http://独自ドメイン/ DB_connection=mysql DB_HOST=自身のサーバ名.xserver.jp DB_PORT=3306 DB_DATABASE=自身のデータベース名 DB_USERNAME=自身のユーザー名 DB_PASSWORD=自身で設定したパスワード⑫対象のドメインへアクセスして問題ないか確認。
参考
参考にさせていただいた記事は以下です。
https://qiita.com/hitotch/items/5c8c2858c883e69cd507最後に
完全に個人的備忘録です。
もしかしたらかなり遠回りな方法でデプロイしているかもしれませんので、
他にも良い方法がありましたら教えていただけますと幸いです。
また、初投稿で書き方もあまりわからなかったのでかなり雑な記事になってしまいました。。。

- 投稿日:2020-01-22T18:37:41+09:00
AWS S3のGUIツール
はじめに
AWSのS3はよく使うサービスです。
普段のS3のファイルのアップロード、ダウンロードはどういう感じで操作しますかね。
- AWS Console
- AWS CLI
- S3 Browser
- WinSCP
- そのた
AWSのコンソール画面から
こちらはAWSのコンソール画面にログインできるユーザーなら、ブラウザから直感的に操作できます。
AWS CLIを使ってコマンドで操作
コマンドラインが好きな方は良いですね。
aws s3 xxx使い方は
aws s3 helpで確認できます。S3 Browserを使ってGUI操作
S3 Browser: https://s3browser.com/download.aspx
使いやすいですね。
WinSCP
WinSCPはよく使うツールですが、SCP、FTPは昔からの機能ですが、
S3も使えます。WinSCP: https://winscp.net/eng/download.php
アクセスキーID、シークレットキーを設定すれば、SCPと同じ感じで、Bucket一覧は表示されて、
ファイルアップロード、ダウンロードは直感的に操作できます。ほかもいろいろがあると思いますが、自分の好みに応じて選びましょう。
以上

- 投稿日:2020-01-22T16:45:36+09:00
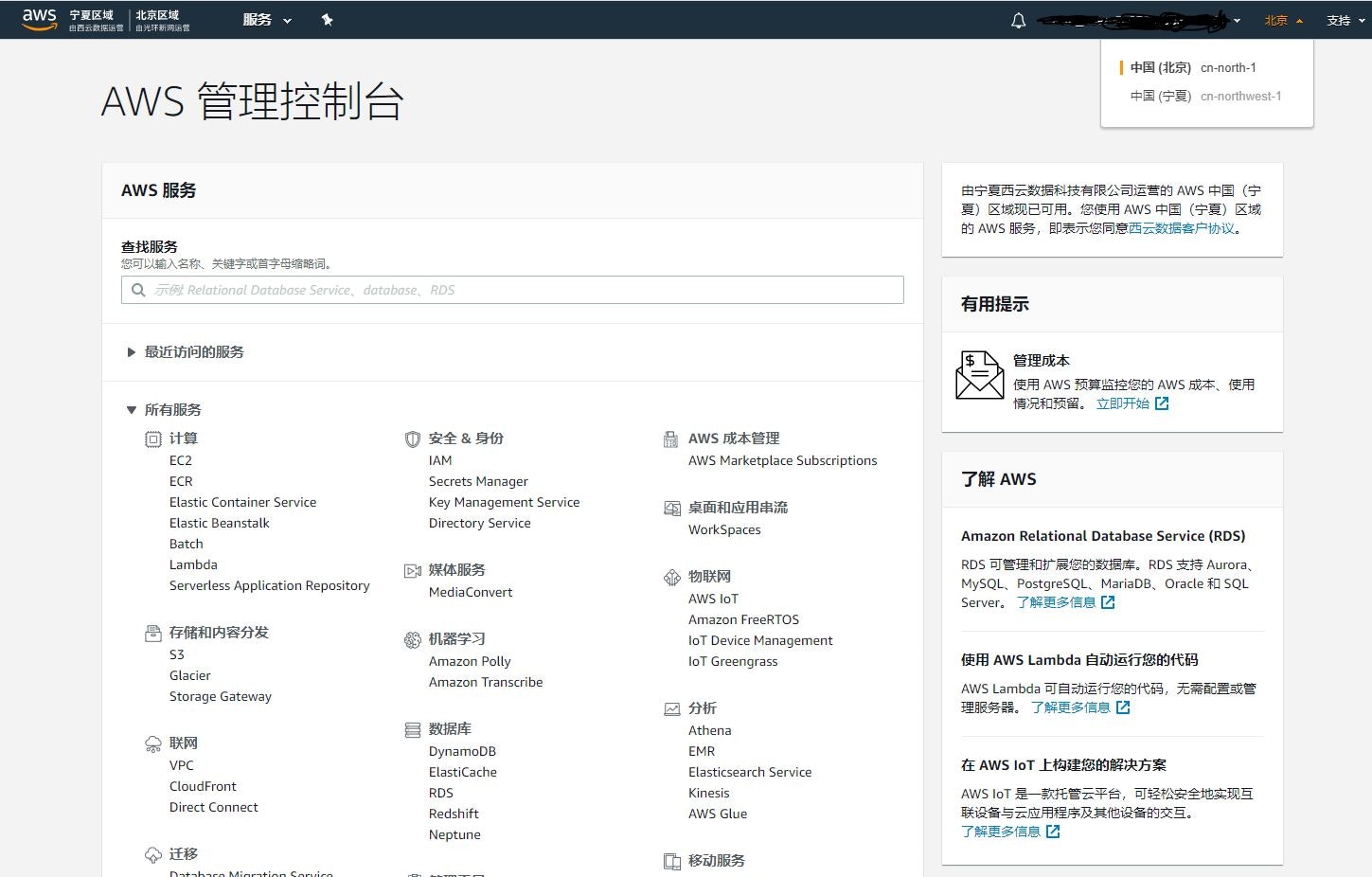
AWS中国コンソールとグローバルの違うところ
本日AWS中国のアカウントを入手したので、AWS中国コンソールとグローバルAWSの違うところを説明します。
1.右上のリージョンのListViewには、中国の二つリージョンしかいない。
北京リージョン 運用会社およびプロバイダーは、Beijing Sinnet Technology Co., Ltd. です(Sinnet)。
寧夏リージョン 運用会社およびプロバイダーは、Ningxia Western Cloud Data Technology Co., Ltd. です。(NWCD)。
2.右下の言語選択で中国語と英語しかない、日本語の選択肢がないです。
3.利用できるサービスは少ない、EFSやRoute53等はないです。
4.URLが違うです。
グローバルAWS https://console.aws.amazon.com/
中国AWS https://console.amazonaws.cn/

- 投稿日:2020-01-22T16:37:29+09:00
ECS-CLIを使用してFargateタスクのクラスターを作成する
前提条件
・AWSアカウントをセットアップしてある
・タスク実行IAMロールを作成してある (ECSコンテナエージェントはユーザに変わってAWS APIを呼び出すのでIAMポリシーとロールが必要
・Amazon ECS CLIのインストールしてある
・AWS CLIをインストールして設定してあるクラスター設定
ECS CLIで使用するクラスター名、リージョン、リソース作成プレフィックスを定義してクラスター設定を作成します。
ecs-cli configure --cluster クラスター名 --default-launch-type FARGATE --config-name チュートリアル --region ap-northeast-1クラスターとセキュリティを作成
1. ecs-cli up コマンドでECSクラスタを作成
このコマンドの出力に作成されたVPCとサブネットIDは後で使うのでメモっておく。
ecs-cli up --capability-iam --cluster-config クラスター名2. AWS CLIを使用してVPCのデフォルトのセキュリティグループIDを取得する
前の出力のVPC IDを使用する
このコマンドの出力には次のステップで使用するセキュリティグループIDが含まれるaws ec2 describe-security-groups --filters Name=vpc-id,Values=VPC_ID --region ap-northeast-13. AWS CLIを使ってセキュリティグループルールを追加し、ポート80でインバウンドアクセスを許可する
aws ec2 authorize-security-group-ingress --group-id SECURITY_GROUP_ID --protocol tcp --port 80 --cidr 0.0.0.0/0 --region ap-northeast-1構成ファイルを作る
デプロイ用の
docker-compose.ymlを作成
ここでは例としてWEBアプリケーションを作成するdocker-compose.ymlを作成します。
ECS CLIではバージョン1, 2, 3がサポートされています。ここでは3を使用する。docker-compose.ymlversion: '3' services: web: image: イメージ ports: - '80:80' logging: driver: awslogs options: awslogs-group: test awslogs-region: ap-northeast-1 awslogs-stream-prefix: webECS固有のパラメータを
ecs-params.ymlを作成するさっきメモったサブネット、セキュリティグループIDを書き込む
ecs-params.ymlversion: 1 task_definition: task_execution_role: ecsTaskExecutionRole ecs_network_mode: awsvpc task_size: mem_limit: 0.5GB cpu_limit: 256 run_params: network_configuration: awsvpc_configuration: subnets: - "subnet ID 1" - "subnet ID 2" security_groups: - "security group ID" assign_public_ip: ENABLEDクラスターに設定ファイルをデプロイする
ecs-cli compose service upでクラスターにデプロイする。デフォルトは現在ディレクトリで
docker-compose.ymlとecs-params.ymlを検索します。--fileオプションを使用して別構成ファイルを指定することや、--ecs-paramsオプションで別のECS Paramsファイルを指定することもできます。ecs-cli compose --project-name タスク名 service up --create-log-groups --cluster-config クラスター名
- 投稿日:2020-01-22T16:33:52+09:00
同じVPC内のEC2へホスト名でSSH接続する
やりたいこと
前回の記事ではローカル端末からAWS上のEC2へホスト名でSSH接続しましたが、
今回は同じVPC内のEC2からEC2へホスト名でSSH接続します。構成
AWSの設定
・test-bに対するインバウンド
- TCPの22番ポートを許可
- ソース:10.0.1.0/24現状確認
設定前は以下のように、[test-a]から[test-b]へホスト名でSSH接続ができない
ubuntu@test-a:~$ ssh test-b The authenticity of host 'test-b (10.0.2.100)' can't be established. ECDSA key fingerprint is SHA256:************************************. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'test-b' (ECDSA) to the list of known hosts. Permission denied (publickey).test-aの設定
[~/.ssh]配下に[test.pem]という名前のファイルを作成し、秘密鍵ファイルを保管する
ubuntu@test-a:~/.ssh$ sudo vim test.pem[~/.ssh]配下に[config]という名前のファイルを作成
ubuntu@test-a:~/.ssh$ sudo vim config[config]ファイルに以下を記載する
Host test-b HostName 10.0.2.100 User ubuntu Port 22 IdentityFile ~/.ssh/test.pem※[/etc/hosts]にtest-bのホスト名とIPアドレスが記載してあれば、「HostName」は記載不要
動作確認
ubuntu@test-a:~$ ssh test-b Welcome to Ubuntu 16.04.6 LTS (GNU/Linux 4.4.0-1100-aws x86_64) ubuntu@test-b:~$

- 投稿日:2020-01-22T15:57:23+09:00
AWS CLIを使ってDockerイメージをECRにpushする
Docker イメージを Amazon ECR リポジトリにプッシュするには
イメージのプッシュするになるAmazon ECRレジストリにDockerクライアント認証をする。
認証トークンは使用するレジストリごとに取得する必要があり、有効期限は12時間です。レジストリ認証
以下のコマンドを実行して出力されたコマンドをコピペしてそのまま実行
aws ecr get-login --no-include-email --region ap-northeast-1タグ付け
使用する ECR レジストリ、リポジトリ、オプションのイメージタグ名の組み合わせによってイメージをタグ付けします。レジストリ形式は aws_account_id.dkr.ecr.region.amazonaws.com です。
リポジトリ名は、イメージ用に作成したリポジトリ名と一致する必要があります。docker tag イメージID aws_account_id.dkr.ecr.region.amazonaws.com/my-web-appECRにpushする
docker push コマンドを使用してイメージをプッシュします。
docker push aws_account_id.dkr.ecr.region.amazonaws.com/my-web-appこれでおしまい
- 投稿日:2020-01-22T15:46:37+09:00
DynamoDBでPromiseが使えた(Lambda Node.js)
はじめに
Lambda(Node.js)でDynamoDBに接続し、値を取得したいときに、
非同期であるために、自分でPromiseで返す関数を作成していた。コード
/** * データの挿入を行う。 * @param ddb * @param params * @returns {Promise<any>} */ exports.addItem = function (ddb, params) { return new Promise(function (resolve) { ddb.putItem(params, function (err, data) { if (err) { console.log("PUT失敗", err, err.stack); } else { console.log("PUT成功"); resolve(data); } }); }); }; await this.addItem(ddb, putParams);改善後
なんと最後にpromise()を呼ぶことで、Promise型のものを返却してくれるようで、わざわざ自分でラップする必要がなかった。
await ddb.getItem(findParams, function (err, data) { if (err) { console.log("GET失敗"); } else { console.log("GET成功"); } }).promise();
- 投稿日:2020-01-22T14:52:34+09:00
IP制限しているインスタンスに対してCloudfrontからのアクセスを許可する
対象のSGに以下のIPを追加する
http://d7uri8nf7uskq.cloudfront.net/tools/list-cloudfront-ips
に書いてある
CLOUDFRONT_REGIONAL_EDGE_IP_LIST
を追加
- 投稿日:2020-01-22T14:45:23+09:00
AWSにおけるDataSunriseの導入及び初期設定
はじめに
こんにちは。
現在私は社内のデータ分析基盤の刷新に取り組んでいます。この記事は以下の要件を満たしてくれそうな製品であるDataSunriseを検証すべく、
まずは導入してみようという内容です。なお環境はAWSでEC2を用います。
- 要件
- DB内のセンシティブなデータはマスキングしたい
- リアルタイムに更新されるDBにアクセスしたい(※)
※現状マスキングは日次バッチ処理であり、データ分析担当はマスキング後のDBにしか触れられない状況にある
DataSunriseとは
- コーポレートサイト
公式ドキュメント
DataSunriseはDBに接続するユーザー/アプリの間のプロキシとして動作し、様々な機能を提供してくれるソフトウェアです(以下要約です)
- データ監査
- ユーザ/アプリのアクションやQuery、およびその結果を保存する機能(Export可)
- データ保護
- トラフィックを分析し、SQLインジェクション等の不正なQueryや認可されてQueryを防止する機能
- データマスキング
- 動的/静的なマスキングを提供し、センシティブなデータを保護する機能
データ検出
- DB内のセンシティブなデータを検出する機能
(公式ドキュメント1.1 ProductDescriptionより)
ちなみに
これまでそれとなくマスキングを扱っていましたが、動的/静的なる分類があることを今回初めて知りました。
- 静的なデータマスキング(Static Data Masking)
- オリジナルのDBからコピーを作成し、コピーしたDB内のデータ自体を書き換え、機密データを永続的に置き換えること
- 動的なデータマスキング(Dynamic Data Masking)
- 元データには手を加えず、送信中の機密データを一時的に非常時乃至は置換すること
当社の分析担当者が現状アクセス可能なのは静的マスキングされたDB(に近いもの)と言え、希望するのは動的マスキングされたDBと言えるでしょうか。
DataSunrise導入
この記事ではAWS環境を想定していますが、DataSunrise社はAzure等でもイメージを提供しているようです。
1.事前準備
- 接続先のDB
- DataSunrise初期設定時、hostやID/PW等の接続情報を入力することになります
- あとから別のDBを追加することも可能です
- 任意のVPC環境
- 対象DBへ接続できる環境を用意しておきましょう
2.EC2インスタンスの作成
AMIが提供されているのでこれを活用します(有料です)
- AMI選択にてDataSunriseのAMIを検索する
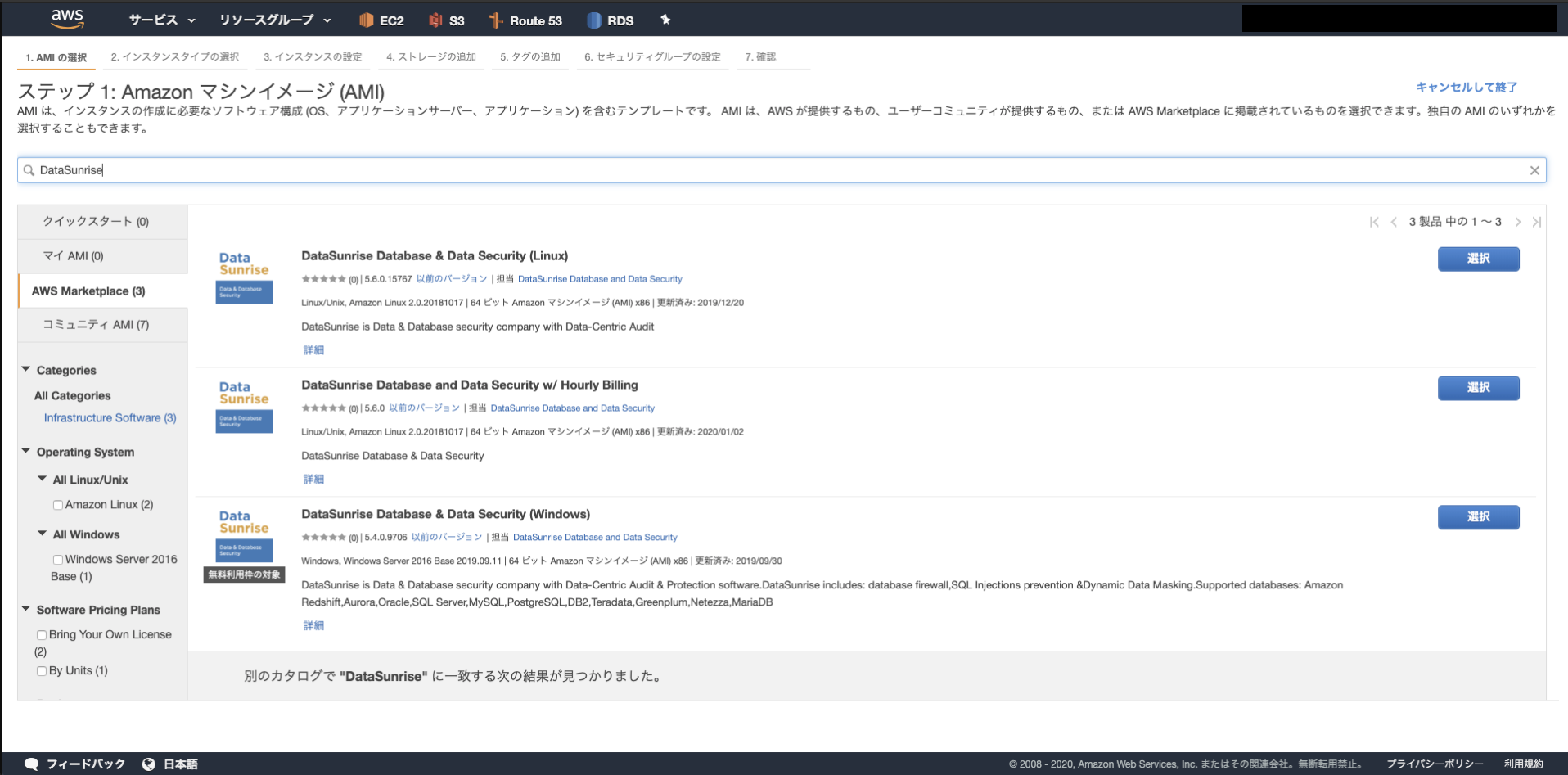
DataSunrise Database and Data Security w/ Hourly Billingがライセンス込みのAMIです
DataSunrise Database & Data Security (Linux)はBYOL制のAMIなので別途ライセンス購入する場合はこちらを選択- https://aws.amazon.com/marketplace/seller-profile?id=880a5857-74c1-44ea-a978-094093c08788
諸々設定しインスタンスを作成
- DataSunriseのMinimum hardware requirementsは次の通り
- CPU: 2core
- RAM: 4 GB
- Disk: インストールで1GB、ローカルのSQLiteをAuditストレージとして使う場合はもう1GB使用
- (公式ドキュメント1.4 System Requirementsより)
- EC2インスタンスの他の設定は環境に応じてよしなに
- DataSunriseのWebコンソールにアクセスする為パブリックなIPは付与(EIP等)
3.DataSunrise初期設定
- DataSunrise管理画面にアクセス
- https://[インスタンスのパブリックIP]:11000でアクセス
- インスタンス起動直後だとDataSunriseが立ち上がっていないためかアクセスできませんでした
- 初期設定のIDはadmin、PWはインスタンスIDです
- Step3: Static Masking Key
- ライセンス適用済みAMIの為Step3から開始されました
- Step3はグレーゾーンの中でマウスを任意に動かしていれば完了します
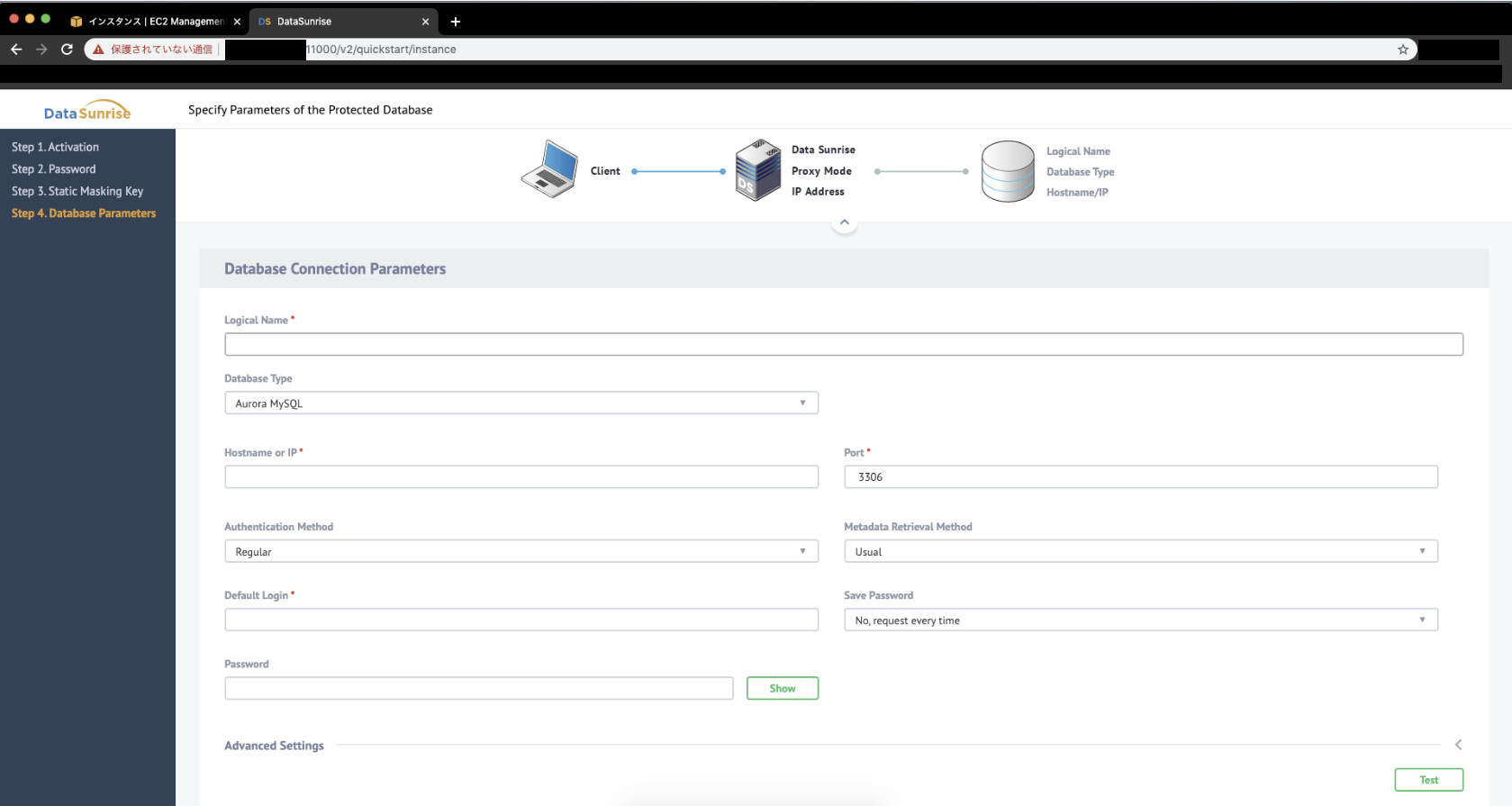
Step4: Database Parameters
- DBの接続情報入力です
- 接続情報を入力し、TESTを押下。接続できた場合は画面上部に結果が表示されます
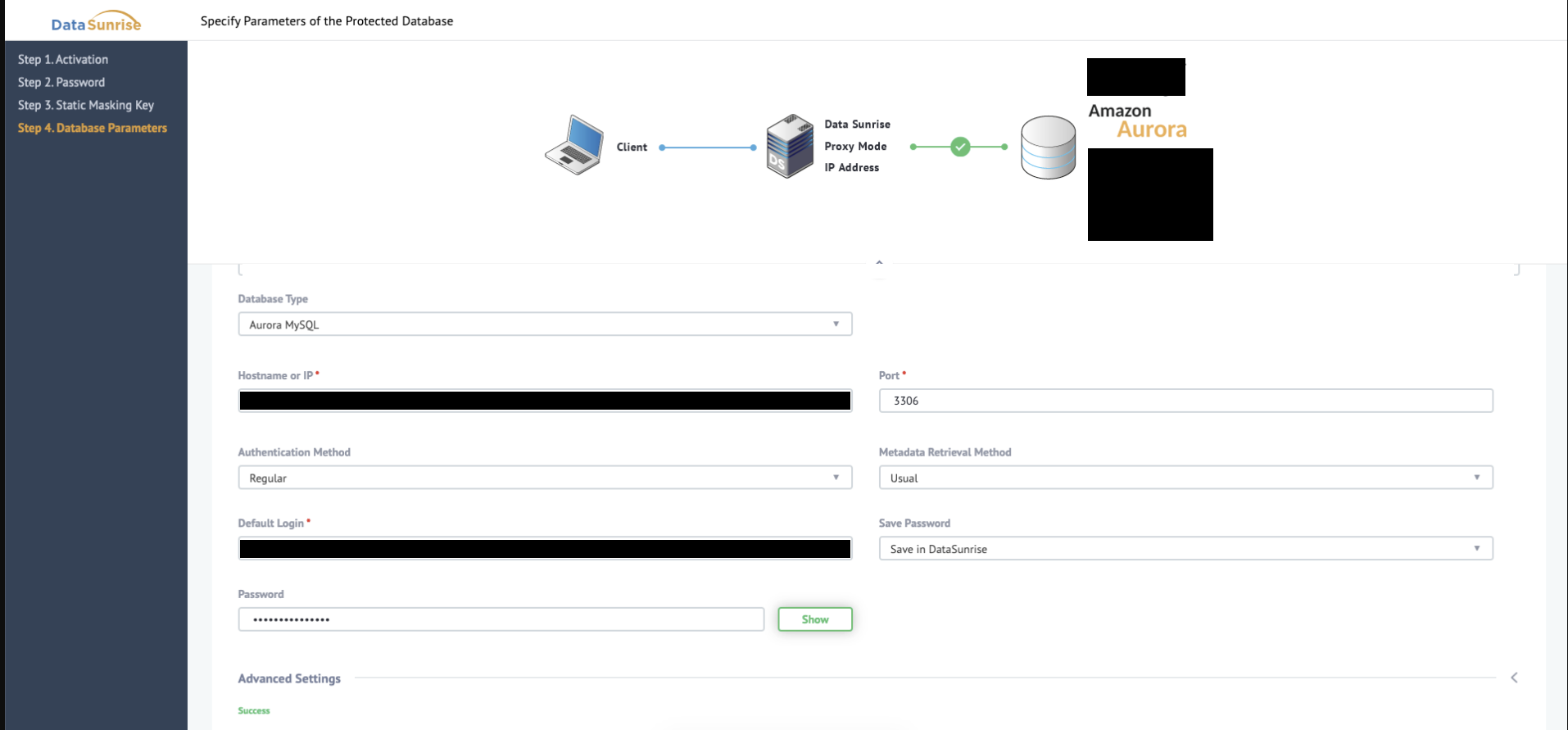
- mode設定はproxyとしました
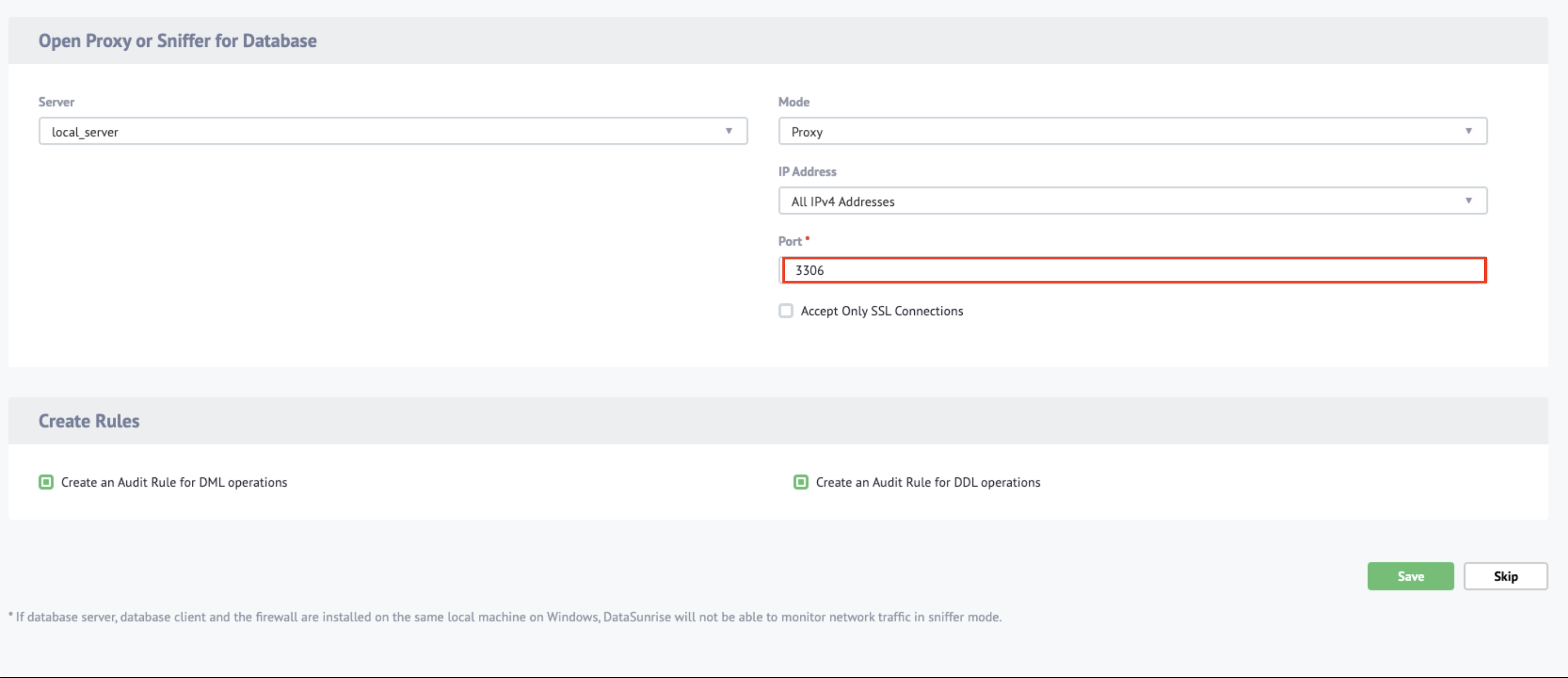
portの3306はデフォルトで入力されていたのですが、proxyのポート設定を接続したいDBのポートと一致させてはいけないとのことProxy's port number should differ from the database's port number(公式ドキュメント14.1.4より)
- DBに接続するのとは異なる任意の番号にしましょう
設定が完了するとダッシュボード画面が表示されます
4.SSL対応
- 今回は動作の検証がメインの為割愛します
- 実施する際はドキュメントの
3.3 SSL Certificatesに記載があります5.ハマったポイント
- 上述した、proxyのポート設定を接続したいDBのポートと一致させてはいけないルールでハマりました
- 当初3306としており接続できなくて焦った(一先ず33066とした)
- プロキシ経由でアクセスするには以下のようにする
mysql -h [DataSunriseインスタンスのhost名] -u [ユーザ名] -p -P [proxyのポート番号]- 例
mysql -h 127.0.0.1 -u root -p -P 33066設定変更手順は次の通り
- 1. ConfigrationからDatabasesを選択する
- 2. 対象のDB接続を選択する
- 3. 設定変更したいProxyの鉛筆マークを押す

- 4. Port番号を入力しSaveを押して完了
※33066はあくまで一例ですので環境に合わせて設定して下さい。
まとめ
admin以外のユーザ設定やSSL等、その他必要な設定は山積みですが、
DataSunriseを噛ませてのDBアクセスが可能になりました。また、今回はGUIベースでの設定を行いましたが、
CLIも準備されているうえにCloudFormation等での環境構築も可能なようなので、
中々幅広いニーズに対応してくれそうな印象です。
- 投稿日:2020-01-22T13:55:54+09:00
最新のAWS rDNS申請手順と確認方法
AWSのEC2やEKS、ECSでメールサーバを構築した場合、送信がうまく出来ないことが多いです。この問題を解決するためには、AWSが推奨するマネージドメール送信サービスのSESを使うか、またはメール送信制限解除申請(rDNS申請)を行う必要があります。ここでは、rDNS申請手順の最新版(2020年1月時点)を紹介します。
rDNS(reverse DNS)申請とは?
- 一般的なスパムフィルタは、逆引きできないIPアドレスからのメールは受け取らないことが多いです。そのため、メールサーバのドメイン(ホスト名)は逆引きレコートを設定する必要があります。
- AWSでメールサーバを構築する場合、この設定はユーザが直接行うことが出来ません。rDNS申請が必要になります。
注意点
- rDNS申請はルートアカウントでしかできません。
- ドメインの正引きのDNS(Aレコード)の登録が必須です。
- Aレコードとして登録したIPとメールサーバのリソース(EC2など)が紐付いていないといけません。
準備
- EIPを登録する
- 使いたいドメインと登録したEIPで正引きDNS(Aレコート)を登録する
- EC2などリソースに上記EIPをAssociateする
申請
- ルートアカウントでAWSコンソールにログイン
- 申請フォームにアクセス: https://aws.amazon.com/forms/ec2-email-limit-rdns-request
申請内容
- Use Case Description : 英語で申請理由を書きます。
- Elastic IP Address : 逆引き可能にしたいEIPを入れます。
- Reverse DNS Record for EIP : 逆引きの結果として設定したいドメイン名を書きます。(例: example.com)
- ここにEIPをAssociateしたEC2などリソースを書く項目は存在しません。しかし、リソースが実在しないと申請は承認されません。
申請が承認された後の確認
承認までは2営業日以上かかります。また、すんなり承認が通らない場合が多く、何回かメールでのやり取りが必要になることもあります。承認のメールが来たら、逆引きレコードを確認しましょう。
逆引き確認コマンド
# dig -x [申請したEIP]結果の例:
(省略) ;; ANSWER SECTION: [EIP].in-ddr.arpa. 17700 IN PTR [申請内容3のドメイン 例: example.com]これでOKです。
参考
ref. PTR レコードを持つ Route 53 で、逆引き DNS 機能を有効にするにはどうすればよいですか ? https://aws.amazon.com/jp/premiumsupport/knowledge-center/route-53-reverse-dns/
ref. AWSからのメール送信
https://www.slideshare.net/AmazonWebServicesJapan/aws-30934799
ref. AWS 逆引き申請手順(rDNS) https://qiita.com/tomozo6/items/5f3f4f674d3bcd924f17
- 投稿日:2020-01-22T12:55:24+09:00
Lambda + API GatewayでCORSを有効にしているのにCORSでエラーになる
Amazon Pinpoint を使用するために、チュートリアル: E メール設定管理システムの設定をやってみたら、ステップ 6: ウェブフォームを作成してデプロイするで引っかかったので。
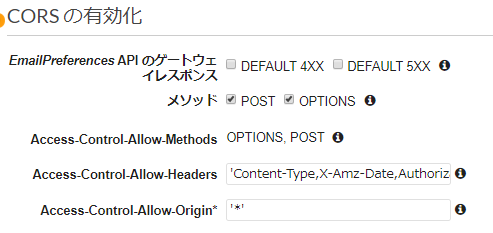
API GatewayでCORSは有効になっている
API Gatewayのメソッドレスポンスではこんな感じで設定済みなのに、いざ違うドメインから実行しようとするとブロックされてしまう。
対策:Lambda 関数側でもレスポンスヘッダーを設定する必要がある
チュートリアルの前ステップで作成したLambda関数のコードでは、レスポンスが特に設定されていない。
終了時にレスポンスを設定・返却する必要がある。
const response = { "statusCode": 200, "headers": { "Content-Type": 'application/json', "Access-Control-Allow-Headers": "Content-Type,X-Amz-Date,Authorization,X-Api-Key,X-Amz-Security-Token", "Access-Control-Allow-Methods": "POST", "Access-Control-Allow-Origin": "*" }, "body": JSON.stringify(event) }; callback(null, response);"body" の中身はJSON形式であれば空でもいい。設定しなかったりただの文字列だとAPI Gateway側のエラーで返される。
- 投稿日:2020-01-22T09:00:16+09:00
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #23 (AR とバーチャルリアリティ)
Amazon Web Services (AWS)のサービスで正式名称や略称はともかく、読み方がわからずに困ることがよくあるのでまとめてみました。
Amazon Web Services (AWS) - Cloud Computing Services
https://aws.amazon.com/全サービスを並べたチートシートもあるよ!
Amazon Web Services (AWS)サービスの正式名称・略称・読み方チートシート - Qiita
https://qiita.com/kai_kou/items/cb29d261c8acc49fd22aまとめルールについては下記を参考ください。
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #1 (コンピューティング) - Qiita
https://qiita.com/kai_kou/items/a6795dbab7e707b0d1a6間違いや、こんな呼び方あるよーなどありましたらコメントお願いします!
AR & VR - AR とバーチャルリアリティ
Amazon Sumerian
- 正式名称: Amazon Sumerian
- https://docs.aws.amazon.com/sumerian/?id=docs_gateway
- 読み方: シュメール
- 略称: なし
- 俗称: なし
他のまとめ
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #1 (コンピューティング) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #2 (ストレージ) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #3 (データベース) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #4 (開発者用ツール) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #5 (セキュリティ、アイデンティティ、コンプライアンス) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #6 (暗号化と PKI) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #7 (機械学習) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #8 (マネジメントとガバナンス) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #9 (移行と転送) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #10 (モバイル) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #11 (ネットワーキングとコンテンツ配信) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #12 (メディアサービス) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #13 (エンドユーザーコンピューティング) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #14 (分析) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #15 (アプリケーション統合) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #16 (ビジネスアプリケーション) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #17 (サテライト) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #18 (ロボット工学) - Qiita
- 投稿日:2020-01-22T08:00:59+09:00
AWS Solution Architect Associate メモ1
配点比率や試験の概要などは => 公式試験ガイド
ネットワーク
リージョン、アベイラビリティゾーン(AZ)
リージョン
- 各リージョンは、1つの地理的エリアにある複数のそれぞれが隔離され物理的にも分離されたAZによって構成される
- 複数のAZで実行するようにアプリケーションの設計をすることで、より強力な障害耐性を実現できる(高可用性)
- リージョン間の通信は低レイテンシー(高パフォーマンス)
- 国・拠点(北米、南米、欧州、中国、アジアパシフィック、中東)に地理的なリージョンを保持
AZ
- 1つのAWSリージョン内でそれぞれ独立
- 同一リージョンの複数のAZにシステムを構成すること(マルチAZ)で、高可用性と高い耐障害性と高いパフォーマンス効率を実現
- 各AZはそれぞれ他のAZから数キロメートル離れているが、すべて100km以内(互いに60マイル)に配置されている
リージョンの中に複数のAZ, ローカルゾーンはリージョン外
補足
ローカルゾーン(あんまり出ない)
- AWSサービスをエンドユーザから近い場所に配置する
- エンドユーザーに対するレイテンシーが10ミリ秒未満であることが要求される高性能なアプリケーション向け(メディア、エンタメコンテンツ、リアルタイムゲーミング、貯水池のシミュレーション、電子自動設計、機械学習など)
VPC
試験だけでなく、普段AWSを活用するうえでも超重要な項目だと思う。
VPCについては、不安なことを残すとそれを起点に混乱を起こすことが私は良くあるため、用語を整理して理解したい。
以下の資料が参考になりそう。圧倒的感謝。中でも下記の用語の違いなどはしっかり説明できるようにしておいた方が良さそう
- パブリックサブネット / プライベートサブネット
- セキュリティグループ / ネットワークACL
- CIDR表記
- ルートテーブル
- インターネットゲートウェイ(IGW)
- 仮装プライベートゲートウェイ(VPW)
- VPCピアリング
また、VPC関連の用語を把握するだけでなく、一緒に基本的なアーキテクト設計についても見ておくと良さそう。
例えば、DBインスタンスをパブリックな領域に置いてしまうのはセキュリティの観点でNGケース。
以下のように必ずプライベートな領域に設置し、やりとりするインスタンスに対してのみアクセスを許可するように設計する。
本番は紙とペンが渡されるようなので、これはしっかり図示して凡ミス回避と脳のリソースを割かないようにした方が良さそう。
出典: ナレコムAWSレシピSGとNACLの違いは、自分が出題者だったら絶対出すぞ~~~って印象
担任の先生が「ここ試験に出すからな」って言う確率99%
SG NACL ステートフルなFW ステートレスなFW ホワイトリスト方式で許可 ブラックリスト方式でブロック インスタンス単位で使用 サブネット単位で使用 IPか他のSGを指定可能 IP指定のみ ※ステートフルなFWってどゆこと?
=> 通信の状態(ステート)を保持するので、何の送信に対しての応答トラフィックなのを判断できる。ステートレスだといちいち応答トラフィックのことも考えて設計しないといけない。なのでステートフルの方が設定すること少なくて楽チン♪コンピューティングサービス
EC2
言わずと知れたEC2。
ここでは主にコスト最適化やユースケースなどの観点でインスタンスの利用オプションをまとめる。
- オンデマンド
- 初期利用なしで使用した分だけの従量課金
- 標準で適用される
- 開発・テスト環境などの決められた時間帯に使用するサーバ群や一時的なWebサイトでの使用が望ましい
- リザーブドインスタンス
- あらかじめ決められた利用期間(1〜3年)分を購入することで最大75%オフ
- あらかじめ最低限の台数が必要なサーバ用途
- 同様の考え方で、CloudFrontやDynamoDBなどにもリザーブドキャパシティがある
- StandardタイプとConvertibleタイプの2種類が提供されている
- Standardタイプ
- リージョンやAZを指定してインスタンスを購入できる
- 同じインスタンス構成であれば購入時に指定したリージョンまたはAZ内でインスタンスの配置変更が可能
- それ以外の場所に配置変更したい時は、手続きをすれば可能
- Convertibleタイプ
- あらかじめ指定したインスタンス構成に依らず、構成変更が可能
- 割引率はStandardより低い
- スポットインスタンス
- 最大で割引率が90%オフにもなるもっとも割引率が高い購入オプション
- (ちなみにスポット価格はオンデマンドよりも高くなることがあるので最高価格をしっかり設定した方が良いらしい)
- 変動制のEC2インスタンスのスポット価格に対して希望購入価格で入札する
- スポット価格が入札価格を上回るとインスタンスは強制終了される
- 処理が中断しても問題がない用途で使われる(何かのタスクのノードの一つなど)(メインではなくお助け的な数台に使われるイメージ)
- スポットブロックとスポットフリートのオプションがある
- スポットブロック
- あらかじめ決められた時間の起動を保証する(最大6時間)オプション
- 割引率は下がるが、予想外の強制終了を回避できる
- スポットフリート
- 指定した性能キャパシティを満たすようにスポットインスタンスを構成するオプション
- ユースケースに基づいてスポットフリートを最適化できる
ついでにインスタンスタイプ
「t2.xlarge」を例にとると、
「t」がインスタンスファミリー。色々特化型があるので下で書く
「2」がインスタンス世代。数字が大きい方が新しいのでより良いものであることが多い
「xlarge」がインスタンスサイズです。インスタンスファミリー
- 汎用
- T,M系
- 一般的な用途、バランス型
- コンピューティング最適化
- C系
- コストの高いCPU処理に特化
- メモリ最適化
- X,R系
- 大容量のメモリに特化
- 高速コンピューティング
- P,G,F系
- GPUやFGPAなど高速処理に特化
- ストレージ最適化
- H,I,D系
- ストレージ容量やI/Oスループット性能に特化
ついでにAMI(Amazon Machine Image)を取る際のルートデバイスについて
(これよくどっちだっけってなる・・?)
特徴 Amazon EBS-Backed AMI Amazon Instance Store-Backed AMI インスタンスの起動時間 1分以内 5分以内 データの永続性 インスタンスの終了後も保持される インスタンスの終了後は破棄される 停止状態[Stop] できる。ルートボリュームはEBSに保持 できない。実行か終了しかないロックな生き様 AMI保存先 EBS S3 EBS-backedインスタンスはデータを永続化できるが、Instance Store-Backedインスタンスは揮発性のためインスタンス停止時にはデータが削除される。
=> そのため、ブートボリュームは、EBS-backedインスタンスでなければならない!詳しくは、Amazon EC2 ルートデバイスボリューム参照のこと
ELB(+ Auto Scaling)
高可用性、高パフォーマンスの面で重要。
単一障害点をどうやって無くすかというプラクティス、EC2を複数台にしてELBをその前段に置きがち。
大事なこと、ELBはAWSのマネージドサービスなのでAWS内で十分冗長化されており単一障害点にはなり得ない。
AWSは以下3つのロードバランサーをマネージドサービスとして提供している
- Classic Load Balancer(CLB)
- Application Load Balancer(ALB)
- Network Load Balancer(NLB)
CLBとALBの比較
=> 基本的にALBの方が後発な分、安価で機能も優れている。NLBはHTTP(S)以外のプロトコル通信での負荷分散に用いる。
用途的に無理な話
=> Auto Scalingはスケールアウトに数分かかるため、スパイク的なアクセスは対応不可です。高可用性な話
=> 単一障害点を作らない意味で、作られるインスタンスは複数のAZに配置するべき。コスト最適化の大事な話
インスタンスの課金形態が時間性なので、利用時間を課金が発生する時間未満に収めることができれば安く済む。
AutoScalingの終了ポリシーを制するものはコスト最適化を制する
スケールインの際の終了ポリシーは開発者が定義できるが、デフォルトの終了ポリシーの動作は以下の通り。
- インスタンスが最も多く、スケールインから保護されていないインスタンスが 1 つ以上あるアベイラビリティーゾーンを決定
- 終了するオンデマンドまたはスポットインスタンスの配分戦略に残りのインスタンスが合うように、終了するインスタンスを決定する。このポリシーは、配分戦略を指定する Auto Scaling グループにのみ適用される。
- どのインスタンスが最も古い起動テンプレートまたは起動設定を使用しているかを判断する。
- 上記のすべての基準を適用した後で、終了する保護されていないインスタンスが複数ある場合は、どのインスタンスが次の課金時間に最も近いかを判断する。次の課金時間に最も近い保護されていないインスタンスが複数ある場合、これらのインスタンスのいずれかをランダムに終了する。
この配分戦略もしっかり抑えておきたい。AutoScalingの細かい挙動は結構問われるイメージ。
- リザーブドインスタンスはAutoScalingの対象外であること
- オンデマンドとスポットを混合したAutoScalingを設定できること
- あらかじめスケジュール設定されたAutoScalingも設定できること
も重要な点です。
スケジュールされたAutoScalingも設定できるので、例えば、夜間はほとんどアクセスが無いが、始業時間になるとアクセスが増える業務系のアプリケーションでもAutoScalingを活用することでコスト最適化できる。
また、開発者がカスタマイズできる終了ポリシーは以下の通り。
OldestInstance
- グループ内の最も古いインスタンスを削除します。
NewestInstance
- グループ内の最も新しいインスタンスを削除します。
OldestLaunchConfiguration
- 最も古い起動設定のインスタンスを削除します。
ClosestToNextInstanceHour
- 次の課金時間に最も近いインスタンスを削除します。 ← コスト最適化
Default
- デフォルトの終了のポリシーに従って、インスタンスを終了します。
OldestLaunchTemplate
- 最も古い起動テンプレートを使用するインスタンスを終了します。
AllocationStrategy
- Auto Scaling グループのインスタンスを終了して、残りのインスタンスを、終了するインスタンスのタイプ (スポットインスタンスまたはオンデマンドインスタンス) の配分戦略に合わせます。
チェックポイント
OldestInstanceも一見コスト最適化しそうだが、古いからと言って、次の課金時間に最も近いとは限らないのがポイント。
1番古いインスタンスが直前に課金時間の閾値を超えてしまったケースなどがそれ。小ネタ
AutoScalingは最小台数(min size)、最大台数(max size)に0を指定できる。(というか出来ないとAutoScalingグループを削除するにはインスタンスが停止されている必要があるので成り立たない)Lambda
AWS Lambdaは、サーバーレスアーキテクチャの中核を担う存在で、疎結合で高可用性に富んだアーキテクチャを導入できる。
ここでは試験対策(主にコスト最適化)として料金体系について以下2点がLambdaに対して課金される項目。
- Lambda関数の実行数
- Lambda関数の実行時間
使うほどにお金がかかる従属課金みたいな感じなので、
- 単位時間当たりに数回実行するバッチ処理
- どれくらいリクエストが来るか分からないAPI
に対して、コスト最適化 ?
ストレージサービス
そもそもAWSのストレージサービスは以下の3つに分類される
- ブロックストレージ
- 例)EBS
- ファイルストレージ
- 例)EFS
- オブジェクトストレージ
- 例)S3
EBS
ストレージのパフォーマンス ? 的には、
プロビジョンドIOPS SSD > 汎用SSD > スループット最適化HDD > コールドHDD
で、弱い方が安いです。ここでのコスト最適な設計に求められるのは、
「〇〇の用途ならコールドHDDで良いな」といったように如何にパフォーマンスを落とさず最も安いEBSタイプを選択していけるかだと思うそのためにはEBSボリュームそれぞれの特徴とユースケースを頭に入れる必要がある
- プロビジョンドIOPS SSD
- レイテンシーの影響が大きいトランザクションワークロード向け
- 極めてパフォーマンスの高いSSDボリューム
- I/O負荷の高いDB向け
- 汎用SSD
- 幅広いトランザクションワークロードに対応
- 価格とパフォーマンスのバランスが取れたSSDボリューム
- ブートボリュームやインタラクティブで低レイテンシーのアプリケーション向け
- スループット最適化HDD
- 高いスループットを必要とするアクセス頻度の高いワークロード向け
- 低コスト
- ビッグデータ、データウェアハウス、ログ処理向け
- コールドHDD
- アクセス頻度の低いワークロード向け
- 極めて低コスト
- アクセス頻度の少ないコールドデータ向け
また、EBSはデータボリューム、ブートボリューム、およびスナップショットがシームレスに暗号化される。
S3(+ Glacier)
イレブンナイン(99.999999999%)の堅牢性を誇るAWSの有名なストレージサービス
AWSのマネージドサービスのため単一障害点にはなり得ない(※他にもELBやSQSなど、マネージドサービスと呼ばれるものはAWS内部で冗長化されているため単一障害点にはなり得ない)
S3のデータはリージョンに配置されるので、同一リージョン間で同じパケット名は付けらない(はず)。
AWSのグローバルインフラストラクチャのリージョン表でもサービスの欄にS3が登場しているのでリージョンサービスで良いはず主なユースケースは以下の通り
- データバックアップ(高い堅牢性)
- データレイク(様々なデータ形式を保存できる)
- ログ転送先
- 静的コンテンツのホスティング
- 簡易的なkey-value型のDB用途
「大量・大容量」、「長期間」、「なくなると困る」といったデータの保存先には、まずS3を検討すると良い
次に、S3のストレージクラスと特徴は以下の通り
- S3 標準
- いわゆる普通の性能の良いS3
- アベイラビリティーゾーン3つ以上
- アクセス頻度の高いデータ向け
- クラウドアプリケーション、動的なウェブサイト、コンテンツ配信、モバイルやゲームのアプリケーション、ビッグデータ分析など、幅広いユースケース
- S3 Intelligent-Tiering
- 最もコスト効率の高いアクセス階層に自動的にデータを移動する
- コストを最小限に抑えるように設計されている
- S3 標準 – 低頻度アクセス
- アクセス頻度は低いが、必要に応じてすぐに取り出すことが必要なデータに適する
- 長期保存、バックアップ、災害対策ファイルのデータストアとして理想的
- S3 1 ゾーン – 低頻度アクセス
- アクセス頻度は低いが、必要に応じてすぐに取り出すことが必要なデータに適する
- 1つのAZのみに配置することでコストを20%ほど削減できる
- オンプレミスデータまたは容易に再作成可能なデータのセカンダリバックアップのコピーを保存するのに適する
- S3 Glacier(アーカイブ)
- セキュアで耐久性が高い、低コストのストレージクラスで、データのアーカイブに適する
- 数分から数時間まで、3種類の取り出しオプションを用意している
- S3 Glacier Deep Archive
- 最も低コストのストレージクラス
- 1年のうち1回か2回しかアクセスされないようなデータを対象とした長期保存やデジタル保存をサポート
- 金融サービス、ヘルスケア、パブリックセクターなどの規制が厳しい業界向け
- 7〜10年間保持されるデータの長期保存用
- 磁気テープの代替策として、費用効率が高く、管理が簡単
- 3つ以上のAZにレプリケート
- 12時間以内に復元可能
link: https://aws.amazon.com/jp/s3/storage-classes/
ちなみに、2018年にGlacierがS3の一部となりました。S3とClacierの使い分けので押さえておきたいポイントは、取り出しにかかる時間です
例えば、「次の日までに取得できれば良い」なら最もコストの低いS3 Glacier Deep Archiveで良かったり。
「即座」に欲しいならS3標準形
「即座ではない」ならGlacierが視野に入るはず。S3の整合性について
S3は結果整合性方式を採用しているため、同時にPUTとGETのアクセスなどをするとたまに整合性が合わない結果になることがある。
おそらくSolution Architect Associateの範疇外だが、この結果整合性に対しての操作は開発者が開発しているアプリケーションでケアする必要がある。
詳しくは、Amazon S3 のデータ整合性モデル小ネタ
S3はオブジェクトのキー(name)の先頭からインデックスをかけるため
その昔、S3のパフォーマンス向上テクニックとして、「ランダムなハッシュ値4桁を頭につける」ってのがあったのですが、現在は日付順の名前を使用できるようになったそうなので、不要なテクニックになったようです。Watch ?
最新のS3のパフォーマンス最適化に関する情報については、をウォッチしておくと良さそうです
Redshift
厳密には、ストレージサービスというよりは、DWH(データウェアハウス)と呼ばれるようなデータ分析するためのデータのため場所、データレイクに用いるサービスです。
Web系のアプリケーションエンジニアは普段業務などでRedshiftを使わない人が多いんじゃないかと思いますが、そこそこ問われるイメージ。
Redshiftは、フルマネージドサービスでデータウェアハウスやデータレイクにあるペタバイト規模の構造化データと半構造化データを、標準的なSQLを使用してクエリすることができます。JSONなどの半構造化データも扱えるのがポイント。
キーワードは「列指向型データベース」
Redshiftの最大の特徴でもあり、よく選択肢に絡んでくる印象。これによりデータの持ち方が異なるRDSにはできない手法でのデータ分析を高速化できる。データベースサービス
RDS(Aurora)
RDSにおいて、AWS SAAでよく問われるのは間違いなくAuroraについてだと思う。
(AWSが独自開発したこともあり、推していきたいのかな)
ここは特にAuroraに特化したことについてまず、AuroraはMySQLとPostgreSQLとの互換性があり、MySQLの最大5倍、PostgreSQLの最大3倍高速
パフォーマンスの問題であればだいたいAuroraに置き換える選択肢が入ってきそうまた、S3への継続的なバックアップ、3つのAZ間でのレプリケーションにより、優れたパフォーマンスと可用性を発揮することも抑えておきたい
Auroraはフェイルオーバー時間についても明記されており、普通30秒未満で完了するようです
DynamoDB
非リレーショナルデータベース(NoSQL)で問われやすいのはこちらもAWS独自のサービスであるDynamoDBだと思う。
主な特徴は以下の通り
- フルマネージドサービス
- データの格納と取得に特化(高度な最適化)されている
- 表結合など柔軟なクエリを発行するのは不得意
- Auto Scalling対応
- 保管時デフォルトで暗号化(KMS利用もできる)
- ポイントインタイムリカバリ(PITR)
- DynamoDB テーブルが誤って上書きされたり削除されたりしないようにできる
- 過去 35 日間の特定の時点に 2 つ目まで復元できる(連続バックアップ)
- DynamoDB テーブルのデータの完全なバックアップを作成して長期間の保存とアーカイブできる
- 「ドキュメントデータベース」でもある
- 半構造化データをJSONのようなドキュメントとして保存する
- 柔軟なインデックス作成、強力なアドホッククエリ、およびドキュメントのコレクション ?♀️
- ブログプラットフォームや動画プラットフォームなどのコンテンツ管理アプリケーションによく用いられる
- https://aws.amazon.com/jp/nosql/document/
- 1桁ミリ秒単位のレイテンシーを要求するアプリケーションにも対応
- 期限切れになった項目を自動的にテーブルから削除することも可能


- 投稿日:2020-01-22T00:21:07+09:00
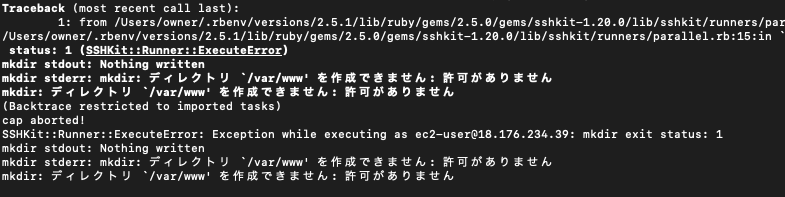
自動デプロイ(Capistrano)でエラー mkdir: ディレクトリ `/var/www' を作成できません: 許可がありません
Capistranoで自動デプロイをしていると、エラーが発生しました
テキストだと下記ですね
mkdir stdout: Nothing written mkdir stderr: mkdir: ディレクトリ `/var/www' を作成できません: 許可がありません mkdir: ディレクトリ `/var/www' を作成できません: 許可がありませんこのエラー"var/www/アプリ名"のディレクトリにしている場合は、パーミッションの問題等だと思いますが、、、
「 "var/www/アプリ名"使ってないんですけど!!!
なんでエラーが出るんだよ!!!
"www"が気に食わないから、別のフォルダ名にしてるんですけど!!!
他の記述も確認したけど、全部"var/www/アプリ名"書いてねええよ!!! 」という人向けに対処方法を解説します。
解決策
結論: Capistranoのデフォルト設定が"var/www/アプリ名"を読み込むので、オプション設定で変更する。
deploy.rb# 下記を挿入してください set :deploy_to, '/var/○○○(ディレクトリ名)/○○○(アプリ名)'これを挿入することで、EC2にあるアプリの保存場所を正しく認識され、Capistranoで読み込みが可能となります。
あとは自動デプロイを実行しましょう
# アプリケーションのディレクトリで実行する $ bundle exec cap production deploy今度はうまくいくはずです。
[参考](https://capistranorb.com/documentation/getting-started/configuration/)