- 投稿日:2020-01-17T23:34:04+09:00
[Python3 入門 11日目]6章 オブジェクトとクラス(6.1〜6.2)
6.1 オブジェクトとは何か
- Pythonに含まれるオブジェクトは全てオブジェクト
- オブジェクトはデータ(変数、属性と呼ばれる)とコード(関数、メソッドと呼ばれる)の両方が含まれている。
- オブジェクトは何らかの具体的なものの一意なインスタンス(実体、実例)を表している。
- オブジェクトは名詞、オブジェクトのメソッドは動詞と考えることができる。オブジェクトは個別のものを、メソッドは他のものとどのようなやりとりをするかを定義する。
6.2 classによるクラスの定義
- オブジェクトはプラスチックのボックスに喩えたが、クラスはそのようなボックスを作るための鋳型のようなもの。
#Personクラスの定義 >>> class Person(): ... pass ... #オブジェクトはクラス名を関数のように呼び出して作る。 >>> someone=Person() >>> class Person(): ... def __init(self): ... pass ... #__init__()はクラス定義から個々のオブジェクトを作るときにそれを初期化するメソッドにつけられた特殊名である。また、クラス内で定義する場合、第一引数はselfでなければならない。 #self引数は作られたオブジェクト自体を参照する。 #新しく作ったオブジェクトをself、もう一つの引数("Elmer Fudd")をnameとして渡してオブジェクトの__init__()メソッドを呼び出す。 >>> class Person(): ... def __init__(self,name): ... self.name=name ... >>> hunter = Person("Elmer Fudd") >>> print("The mighty hunter:",hunter.name) The mighty hunter: Elmer Fudd
- Personクラスの内部では、name属性にはself.nameという形で、オブジェクト(hunter)の外部からはhunter.nameと呼ぶ。
感想
オブジェクトとクラスは概念はまずまず理解できたが文法が慣れるまで大変だ、、、
参考文献
「Bill Lubanovic著 『入門 Python3』(オライリージャパン発行)」
- 投稿日:2020-01-17T22:56:16+09:00
ナチュラルソート
以下の変数を並び替える状況があるとする。
sample = ["a_12", "a_2", "a_0", "a_10", "a_4"]例えば組み込み関数の
sortedを利用するとsorted(sample) # ['a_0', 'a_10', 'a_12', 'a_2', 'a_4']という結果が得られる。これは人間の直感には反する結果だろう。
['a_0', 'a_2', 'a_4', 'a_10', 'a_12']という結果が得られる方が自然な感じがする。
この自然な感じがする並びは、 Natural Sort Order と呼ばれ、そのソート方法はHuman Sortingとも呼ばれる。この並び順をpythonで再現する。
ライブラリを利用する場合
natsortを利用する。https://pypi.org/project/natsort/
$ pip install natsortsample = ["a_12", "a_2", "a_0", "a_10", "a_4"] print(sample) print(natsorted(sample, key=lambda y: y.lower())) # ['a_12', 'a_2', 'a_0', 'a_10', 'a_4'] # ['a_0', 'a_2', 'a_4', 'a_10', 'a_12']自分で関数を書く場合
組み込み関数の
sortedにkeyを指定すれば良い。def natural_sort(l): def alphanum_key(s): return [int(c) if c.isdecimal() else c for c in re.split('([0-9]+)', s) ] return sorted(l, key=alphanum_key) print(sample) print(natural_sort(sample)) # ['a_12', 'a_2', 'a_0', 'a_10', 'a_4'] # ['a_0', 'a_2', 'a_4', 'a_10', 'a_12']
- 投稿日:2020-01-17T22:20:31+09:00
Python の __init__.py とは何なのか
Python を使い始めると、ディレクトリの階層で分けてファイルを管理したくなります。
そこで出てくるのが__init__.pyファイル。これは一体何者なのか。
色々と情報がころがってはいるものの、なかなか納得行くように説明しているものが見当たりません。
Python のドキュメントでも、何を参照すれば正解なのかがわかりにくい1。ということで、
__init__.pyについてまとめてみました。(少し長いです)
読み物形式で書いていますので、結論(「__init__.pyの役割」)だけ見たい方はスクロールして最後の方を読んでください。
python コードの例は、主に 3.6/3.5 を使用しています2。
- 「モジュール」と「パッケージ」と「名前空間」
- モジュールと階層構造
- 単一ファイルのモジュール
- ディレクトリによる階層構造と名前空間
- ディレクトリと名前空間のマッピング
__init__.pyの役割- まとめ
「モジュール」と「パッケージ」と「名前空間」
本題に入る前に、「モジュール」と「パッケージ」、「名前空間」について簡単に。
- 「モジュール (Module)」は、ファイル単位で分けてプログラムを記載したもの。
わかりにくければ、一つの foo.py という Python プログラムファイルが一つの「モジュール」と考えればよいでしょう3(これを「pure Python モジュール」と呼ぶようです)。Glossary: module
An object that serves as an organizational unit of Python code. Modules have a namespace containing arbitrary Python objects. Modules are loaded into Python by the process of importing.参照: 「Python ドキュメント - チュートリアル- モジュール」
- 「パッケージ (Package)」は、複数のファイル、ディレクトリ構造からなり、ルールに従ってそれらをひと固まりにしたもの4。
Glossary: package
A Python module which can contain submodules or recursively, subpackages. Technically, a package is a Python module with an __path__ attribute.
- 「名前空間 (Namespace)」は、「モジュール」や「パッケージ」(およびその中)で 使用する「名前」が衝突しないように、使用する名前の空間を分けたもの。
階層構造で構成される。Glossary: namespace
The place where a variable is stored. Namespaces are implemented as dictionaries. There are the local, global and built-in namespaces as well as nested namespaces in objects (in methods). Namespaces support modularity by preventing naming conflicts. For instance, the functions builtins.open and os.open() are distinguished by their namespaces. Namespaces also aid readability and maintainability by making it clear which module implements a function. For instance, writing random.seed() or itertools.islice() makes it clear that those functions are implemented by the random and itertools modules, respectively.名前空間の例1import alpha.bravo.charlie alpha.bravo.charlie.delta()この例 (例1) では、
alpha→bravo→charlieという階層構造の名前空間になっており、そのcharlieの中で実装されたdelta()という手続き (関数) を呼び出しています。上位の名前空間が異なれば、下位の名前空間で名前が同じであっても、異なるアイテムである、ということは直感的にわかると思います。
名前空間の例2import os.path os.path.join('/home', 'user')こちら (例2) は、よく使われるパスの結合例で、
os→pathという名前空間のjoin()を呼び出しています。モジュールと階層構造
単一ファイルのモジュール
同じディレクトリに二つのファイルを用意します。
ファイル構成./ ├─ module01.py ..... モジュール └─ sample0010.py ... 実行ファイル (= メインモジュール)
- モジュール1
module01.py: "Hello, world!" を出力するだけの関数hello()を定義しています。module1.pydef hello(): print( "Hello, world!" )
- 実行ファイル
sample0010.py:importでmodule01を読み込み、module01.hello()を呼び出しています。sample0010.pyimport module01 module01.hello()
- 実行結果
sample0010.pyの実行$ python3 sample0010.py Hello, world! $ python2 sample0010.py Hello, world!単一ファイルのモジュールは、同じディレクトリに置くことで、
importすることができます。
ファイルを分けるだけであれば、ディレクトリを作る必要はありません。この時、
__init__.pyは不要です。
ファイル名はmodule01.pyですが、モジュール名はmodule01(ファイル名から .py を除いたもの)です。
名前空間は、module01です。ディレクトリによる階層構造と名前空間
次のようなディレクトリ、ファイル構成を考えます。
サンプル2 階層構造./ ├─ sample0020.py ..... 実行ファイル └─ dir/ └─ module02.py ... モジュールdir/module02.pydef hello(): print( "Hello, world! from module02" )この時、
module02を呼び出すためには、sample0020.pyでは、次のように記述する必要があります。sample0020.pyimport dir.module02 dir.module02.hello()実行結果$ python3 sample0020.py Hello, world! from module02 $ python2 sample0020.py Traceback (most recent call last): File "sample0020.py", line 1, in <module> import dir.module02 ImportError: No module named dir.module02python3 では期待通りに動きましたが、python2 ではエラーになってしまいました。
これは、Version 3.2 までは、dir下に__init__.pyが必要だったためです。v3.3 からは、呼び出すモジュールのあるディレクトリに
__init__.pyは必要なくなりました。What’s New In Python 3.3: PEP 420: Implicit Namespace Packages
Native support for package directories that don’t require __init__.py marker files and can automatically span multiple path segments (inspired by various third party approaches to namespace packages, as described in PEP 420)では、なぜ、3.2 までは
__init__.pyが必要だったのでしょうか。その話をする前に、少し寄り道をします。
ディレクトリと名前空間のマッピング
module02を呼び出すのに、dir/というディレクトリがあるために、dir.module02という名前空間で参照する必要がありました。
dirが邪魔ですね。実体がないのに、名前空間の階層として指定しなければなりません。そこで登場するのが、
__init__.py。
ディレクトリ階層にした上で、直接、module02という名前で呼び出す方法が__init__.pyです。
dir/の代わりにmodule02/というディレクトリ名にすればよいのですが、呼び出すファイルは、結局module02.なにがし.hello()とせざるを得ません。そこで、__init__.pyというファイルに特別な意味をもたせ、ディレクトリ名と同じ名前空間のモジュールとして扱えるようになっています。つまり、
dir/module02.pyの代わりにmodule02/__init__.pyの中にプログラムを書くことで、module02として呼び出せるようになります。サンプル3 __init__.pyを含む階層構造./ ├─ sample0030.py ..... 実行ファイル └─ module02/ └─ __init__.py ... "module02" の実体module02/__init__.pydef hello(): print( "Hello, world! from __init__.py" )sample0030.pyimport module02 module02.hello()実行結果$ python2 sample0030.py Hello, world! from __init__.py $ python3 sample0030.py Hello, world! from __init__.py歴史的な経緯はわかりません(調べてません)が、これが本来の
__init__.pyだったのではないかと思います。(筆者の憶測)そして、
__init__.pyが名前空間の存在を表すという位置づけから、__init__.pyがモジュールのマーカーとして使われていたのでしょう。
そのため、v3.2 までは、モジュールとして読み込むファイルがあるディレクトリには、__init__.pyがなければならない (=__init__.pyがあるディレクトリのみが名前空間の一部である)、という実装になっていたものと想像しています。上で引用したとおり、v3.3 からは、モジュールをディレクトリに
__init__.pyを置く必要はなくなりました。
__init__.pyを置いた場合には、ディレクトリ名と同じ名前空間の実体モジュールとして扱われています。
もう少し違う言い方をすれば、__init__.pyは、ディレクトリ名をモジュール名(あるいは「名前空間」)としてマッピングするためのファイル、と言えます。これが理解できると、今までなんだかよくわからなかった
__init__.pyが、少し身近になってくるのではないでしょうか。
__init__.pyの役割ここまでのことをわかった上で Python チュートリアルの「モジュール (module)」を読むと、
__init__.pyの役割がわかりやすいと思います。
__init__.pyは、それが存在するディレクトリ名を名前とする名前空間の初期化を行う。__init__.pyは、同、名前空間におけるワイルドカード import の対象を定義する (__all__の定義) 。__init__.pyは、同じディレクトリにある他のモジュールの名前空間を定義する。__init__.pyは、(バージョン3.3 より前のバージョンでは) モジュール検索のためのマーカーとなる。1. ~ 3. をひとまとめにして、「モジュールあるいはパッケージの初期化」ということもできますが、ここでは分けてみました。
1. 名前空間の初期化
既に見てきた通り、ディレクトリ名を名前空間とするモジュールとして扱う際に、
__init__.pyには一番最初に実行しておくべき内容を登録しておきます。下位のモジュールのimportであっても、上位名前空間としての初期化が行われた後に、下位モジュールが実行されます。2. ワイルドカード import の対象の定義 (
__all__の定義)「Python チュートリアル - パッケージから * を import する」に記載されていますが、
from my_module import *という呼び出し方をしたときに、import される対象を定義するのが__all__リストです。これは、
__init__.pyに限った話ではなく、すべてのモジュールで定義可能です。下のサンプル4を見てください。同じディレクトリに二つの Python スクリプトファイルを用意します。
サンプル4./ ├─ sample0040.py ... 実行ファイル └─ module04.py ..... モジュールsample0040.pyfrom module04 import * hello1() hello2() hello3()
sample0040.pyでは、from module04 import *というように、*を使用してimportしています。
import後、hello1()、hello2()、hello3()を順に呼び出すという簡単なプログラムです。module04.py__all__ = ['hello1', 'hello2'] def hello1(): print( "Hello, this is hello1" ) def hello2(): print( "Hello, this is hello2" ) def hello3(): print( "Hello, this is hello3" )
module04.pyの中では、hello1()、hello2()、hello3()を定義しています。
__all__リストには、'hello1'と'hello2'のみを含め、'hello3'は含まれていません。実行結果は下の通りです。
実行結果$ python sample0040.py Hello, this is hello1 Hello, this is hello2 Traceback (most recent call last): File "sample0040.py", line 5, in <module> hello3() NameError: name 'hello3' is not defined
hello3()の呼び出しは未定義として "NameError: name 'hello3' is not defined" というエラーになってしまいました。__all__のリストに無いためです。
これは、hello3()が隠蔽されているわけではなく、あくまでもimport *としたときの動作です。
試しに、*を使わずにimportし、module04を明示的に呼べば、hello3()も呼び出し可能です。sample0041.pyimport module04 module04.hello1() module04.hello2() module04.hello3()実行結果$ python sample0041.py Hello, this is hello1 Hello, this is hello2 Hello, this is hello3
__init__.pyの中で__all__を定義するのは、ディレクトリ名を名前空間とするモジュールを*でimportしたときに参照可能とするオブジェクトを定義しているにすぎません。3. 同じディレクトリにある他のモジュールの名前空間の定義
__init__.pyの中に関数などを定義することで、ディレクトリ名と同じ名前のモジュールとして呼び出しが可能なことは上で書きました。
__init__.pyが大きくなってくると、__init__.pyには初期化のみを記述して、ファイルを外に出したくなってきます。以下のようなディレクトリ、ファイル構成で試してみます。
サンプル5./ ├─ sample0050.py ...... 実行ファイル └─ module05 ├─ __init__.py .... "module05" の初期化ファイル ├─ _module05.py ... "module05" の実体 └─ module06.py .... "module05" の追加モジュール
module05/_module05.pyは、__init__.pyが膨れ上がったので、外に出した、あるいは、初めからmodule05として提供するために開発した、という想定です。
モジュール名の実体としてわかるように、アンダースコア (_) を付けて、ディレクトリと同じファイル名にしました。./module05/_module05.pyprint( "in _module05.py" ) def hello(caller=""): print( "Hello, world! in _module05 called by {}".format(caller) )
module05/module06.pyは、最初から__init__.pyの外部で開発を進めたファイル、という想定です。./module05/module06.pyprint( "in module06.py" ) def hello(caller=""): print( "Hello, world! in module06 called by {}".format(caller) )
_module05.pyのhello()も、module06.pyのhello()も、呼び出し側が分かるように、caller を引数に渡すようにしてあります。さて、
__init__.pyですが、同じディレクトリにあるモジュールを読み込むので、_module05とmodule06の頭に、カレントディレクトリ(同一名前空間)を表すドット (.) を付けてあります。
また、hello()の名前が衝突しているので、asを用いて、名前を変更しています。./module05/__init__.pyprint( "in __init__.py" ) # import _module05.hello() as hello05() in the same directory from ._module05 import hello as hello05 # import module06.hello() as hello06() in the same directory from .module06 import hello as hello06 __all__ = ['hello05', 'hello06'] # Do initialize something bellow hello05("__init__.py") hello06("__init__.py")
__all__で*呼び出し可能なオブジェクトの定義、# Do initialize something bellowの下は、何かしらの初期化を行っているという想定です。大元呼び出しの
sample0050.pyは以下の通り。
from module05 import *で、module05のモジュールのみを読み込んでいます。./sample0050.pyprint( "in {} 1".format( __file__ ) ) from module05 import * print( "in {} 2".format( __file__ ) ) hello05(__file__) hello06(__file__)実行結果は以下の通り。
実行結果$ python3 sample0050.py in sample0050.py 1 in __init__.py in _module05.py in module06.py Hello, world! in _module05 called by __init__.py Hello, world! in module06 called by __init__.py in sample0050.py 2 Hello, world! in _module05 called by sample0050.py Hello, world! in module06 called by sample0050.py
__init__.pyが介在することで、module05/_module05.pyとmodule05/module06.pyが、module05として呼び出される様子がわかったかと思います。ちなみに、
module05/module06.pyは、隠蔽されたわけではないので、直接呼び出すことも可能です。module05/module06.pyの直接呼出し$ python3 -c "import module05.module06; module05.module06.hello('shell')" in __init__.py in _module05.py in module06.py Hello, world! in _module05 called by __init__.py Hello, world! in module06 called by __init__.py Hello, world! in module06 called by shellここまでわかると、「パッケージ」として再利用可能なモジュール開発が進められるようになると思います。
4. モジュール検索のためのマーカー (バージョン3.3 より前のバージョン)
python2 と、バージョンが 3.3 より前の python3 では、
__init__.pyは、階層のモジュールを検索するためのマーカーとして利用されます。言い方を変えると、これらのバージョンの Python で、ディレクトリで階層化させたモジュールを読み込ませるためには、__init__.pyが存在している必要があります。バージョンが 3.3 以上の python3 では、階層モジュールを読み込むだけであれば、
__init__.pyは不要です。まとめ
__init__.pyの役割について、検証しながら確認しました。
- 階層化されたモジュールを import するためには
__init__.pyが必要。ただし、バージョン 3.3 以降では不要。__init__.pyにはモジュールの初期化処理を記載という役割があると書かれていることが多いのですが、ここでは、2番目の役割を 3つに分けて記述しました。
2-1. 名前空間の初期化
2-2. ワイルドカードimportの対象の定義 (__all__の定義)
2-3. 同じディレクトリにある他のモジュールの名前空間の定義3番目は、正しくは、同じディレクトリにはない他のモジュールを
importして定義することも可能ですが、まずは、同じディレクトリにあるモジュールということで、記述した次第です。なお、モジュールに記載された実行文については、「これらの実行文は、インポート文の中で 最初に モジュール名が見つかったときにだけ実行されます。」と記載されており5、何度
importを繰り返しても、1度しか実行されません。(importlibを用いてimportlib.reload()した場合には、明示的に実行されます)この投稿を読んでから、改めて 「Python チュートリアル - モジュール」を読み直すと、より理解が深まるのではないかと思います。
少しでもお役に立てば幸いです。
「Python チュートリアル - モジュール」を読むのが正解のようです(利用しているバージョンに合ったドキュメントを参照してください)。チュートリアルとして、最初に読んだときは、全然理解できず、記憶の彼方に飛んでいってしまいました。 ↩
雑音を少なくするために、
#!/usr/bin/env pythonなどの shebang や、文字コード指定の-*- coding: utf-8 -*-などを排除して、コア部分のみをシンプルに記述しています。 ↩「Python 一般の用語」には、「Python においてコードを再利用する際の基本単位: すなわち、他のコードから import されるひとかたまりのコード」と記載されています。 ↩
「Python ドキュメント - チュートリアル - パッケージ」では、「他のモジュールが入っているモジュール」と記載されています。 ↩
「モジュールについてもうすこし」参照 ↩
- 投稿日:2020-01-17T22:08:23+09:00
【Python】Poetry始めてみた & Pipenv から poetry へ移行した所感
動機
近頃pipenv のインストールがかなり遅いので poetry を試してみました。
一通り使ってみてわかったことをまとめます。Pipenvを使っているのでそことの比較も。
パッケージ関連のコマンド(build, publish...)に関してや、細かい機能に関しては記述しないので、公式 Docを参考にしてください。Poetryについて
Poetryは、Pythonのパッケージ管理ツールです。Pipenvと同様、依存関係を解決しパッケージのインストール、アンインストールを行ってくれ、
poetry.lockファイルによって、他のユーザーも適切なバージョン、依存関係でパッケージをインストールすることが出来ます。
仮想環境を利用でき、パッケージングも可能です。環境
- CentOS 7.6.1810
- pyenv 1.2.14-8-g0e7cfc3b
- poetry 1.0.2
Python は pyenv でインストールしたものを使う。
- Python 3.7.4 (pyenv global)
導入
$ curl -sSL https://raw.githubusercontent.com/python-poetry/poetry/master/get-poetry.py | python
~./bash_profileに PATH が記入され、poetry が立ち上がる。$ poetry -V Poetry version 1.0.2Poetry 設定
- PIPENV_VENV_IN_PROJECT
pipenv の場合、
.venvフォルダをプロジェクト内に設定するには環境変数を利用していた。Pipenv$ export PIPENV_VENV_IN_PROJECT=1 $ pipenv install...poetry の場合、
poetry configから設定を行う。
--listオプションで現在の設定を確認できる。デフォルトではvirtualenvs.in-project=false。poetry$ poetry config --list cache-dir = "/home/user/.cache/pypoetry" virtualenvs.create = true virtualenvs.in-project = false virtualenvs.path = "{cache-dir}/virtualenvs" # /home/user/.cache/pypoetry/virtualenvs設定を変更。
$ poetry config virtualenvs.in-project true$ poetry config --list cache-dir = "/home/user/.cache/pypoetry" virtualenvs.create = true virtualenvs.in-project = true virtualenvs.path = "{cache-dir}/virtualenvs" # /home/user/.cache/pypoetry/virtualenvsプロジェクトのスタート
ひな形の生成
poetry newでプロジェクトをスタート、ひな形が生成される。
以下は公式 Docの通り。$ poetry new my-package Created package my_package in my-package生成されたひな形my-package ├── pyproject.toml ├── README.rst ├── my_package │ └── __init__.py └── tests ├── __init__.py └── test_my_package.py生成される
pyproject.tomlは以下の通り。dev-dependencies に自動で pytest が入るようだ。pyproject.toml[tool.poetry] name = "my-package" version = "0.1.0" description = "" authors = ["Your Name <you@example.com>"] [tool.poetry.dependencies] python = "^3.7" [tool.poetry.dev-dependencies] pytest = "^5.2" [build-system] requires = ["poetry>=0.12"] build-backend = "poetry.masonry.api"ただどうも my-package の中に my_package ディレクトリが出来るのが使いにくい。
--nameオプションでパッケージ内のディレクトリ名を変更出来る。
--nameオプション$ poetry new my-package --name app Created package app in my-packageひな形my-package ├── pyproject.toml ├── README.rst ├── app │ └── __init__.py └── tests ├── __init__.py └── test_my_package.py
--srcオプション
--srcオプションというのもあるようだが、余計ややこしくなるので使わなそう。$ poetry new --src my-packageひな形├── pyproject.toml ├── README.rst ├── src │ └── my_package │ └── __init__.py └── tests ├── __init__.py └── test_my_package.py
pyproject.tomlの生成ひな形が必要ない場合、
poetry initでpyproject.tomlのみ作成出来る。
npm initのように対話式でpyproject.tomlの内容を決める。$ poetry init Package name [{folder_name}]: Version [0.1.0]: Description []: Author [None, n to skip]: n License []: Compatible Python versions [^3.7]: Would you like to define your main dependencies interactively? (yes/no) [yes] no Would you like to define your dev dependencies (require-dev) interactively (yes/no) [yes] no Generated file [tool.poetry] name = "new_ais" version = "0.1.0" description = "" authors = ["Your Name <you@example.com>"] [tool.poetry.dependencies] python = "^3.7" [tool.poetry.dev-dependencies] [build-system] requires = ["poetry>=0.12"] build-backend = "poetry.masonry.api" Do you confirm generation? (yes/no) [yes] yespackage name は何も入力しないとそこのフォルダ名になる。Author と dependencies のところは y/n を入力。これでカレントディレクトリに
pyproject.tomlが作成される。Pipenv と同じように使うなら init で始めたほうがわかりやすそう。
install
poetry installはpipenv installと同じく、上で作成したpyproject.tomlから、依存関係を解決し、必要なパッケージをインストールする。$ poetry new myapp $ cd myapp$ poetry install reating virtualenv myapp in /home/user/workspace/poetry/myapp/.venv Updating dependencies Resolving dependencies... (0.5s) Writing lock file Package operations: 11 installs, 0 updates, 0 removals - Installing more-itertools (8.1.0) - Installing zipp (1.0.0) - Installing importlib-metadata (1.4.0) - Installing pyparsing (2.4.6) - Installing six (1.14.0) - Installing attrs (19.3.0) - Installing packaging (20.0) - Installing pluggy (0.13.1) - Installing py (1.8.1) - Installing wcwidth (0.1.8) - Installing pytest (5.3.2) - Installing myapp (0.1.0)install を行うと、
poetry.lockファイルが作成され、依存関係を見ることが出来る。
--no-rootオプションpoetry はデフォルトで myapp をインストールする。これを回避するには、
--no-rootオプションを付けてインストール。$ poetry install --no-root
--no-devオプションdev-dependencies を install しない場合は、
--no-devオプションで OK。$ poetry install --no-devadd
パッケージをインストール。Pipenv とは異なり、add なので注意。
pipenv に比べて locking が早い。$ poetry add django==2.2.8dev-dependencies の場合、
--dev(-D)オプション。$ poetry add flake8 -D
--dry-runオプションを用いればインストールは行わず、インストールされる内容を見る事ができる。$ poetry add django --dry-run Using version ^3.0.2 for django Updating dependencies Resolving dependencies... (0.4s) Package operations: 4 installs, 0 updates, 0 removals, 13 skipped - Skipping more-itertools (8.1.0) Already installed - Skipping zipp (1.0.0) Already installed - Skipping importlib-metadata (1.4.0) Already installed - Skipping pyparsing (2.4.6) Already installed - ...update
プロジェクトにインストールしたパッケージをアップデートする場合
$ poetry update個別にアップデート
$ poetry update requests djangoadd と同じく、
--dry-runオプションでアップデートの内容を見る事ができる。$ poetry update --dry-run Updating dependencies Resolving dependencies... (0.4s) No dependencies to install or update - Skipping more-itertools (8.1.0) Already installed - Skipping zipp (1.0.0) Already installed - Skipping importlib-metadata (1.4.0) Already installed - Skipping pyparsing (2.4.6) Already installed - Skipping six (1.14.0) Already installed - Skipping atomicwrites (1.3.0) Not needed for the current environment - ...remove
インストールしたパッケージを削除。
$ poetry remove flaskdev-dependencies にインストールしたパッケージは
--dev(-D)オプションが必要なので注意。$ poetry add flake8 -D $ poetry remove flake8 # failed [ValueError] Package flake8 not found $ poetry remove flake8 -D # OKremove でも
--dry-runオプションが使用できる。show
利用可能なパッケージの一覧を表示する。
pip listの強化版のような機能。$ poetry show asgiref 3.2.3 ASGI specs, helper code, and ada... attrs 19.3.0 Classes Without Boilerplate django 3.0.2 A high-level Python Web framewor... entrypoints 0.3 Discover and load entry points f... flake8 3.7.9 the modular source code checker:... importlib-metadata 1.4.0 Read metadata from Python packages mccabe 0.6.1 McCabe checker, plugin for flake8 more-itertools 8.1.0 More routines for operating on i... packaging 20.0 Core utilities for Python packages pluggy 0.13.1 plugin and hook calling mechanis... ...パッケージに関する情報も表示出来る。
$ poetry show django name : django version : 3.0.2 description : A high-level Python Web framework that encourages rapid development and clean, pragmatic design. dependencies - asgiref >=3.2,<4.0 - pytz * - sqlparse >=0.2.2
--treeオプションツリー構造で依存関係を表示できる。
pipenv graphに近い機能。実際は色付き出力なので見やすい。$ poetry show --tree django 3.0.2 A high-level Python Web framework that encourages rapid development and clean, pragmatic design. ├── asgiref >=3.2,<4.0 ├── pytz * └── sqlparse >=0.2.2 flake8 3.7.9 the modular source code checker: pep8, pyflakes and co ├── entrypoints >=0.3.0,<0.4.0 ├── mccabe >=0.6.0,<0.7.0 ├── pycodestyle >=2.5.0,<2.6.0 └── pyflakes >=2.1.0,<2.2.0 ...
--latest(-l)オプション最新バージョンを表示。
$ poetry show --latest asgiref 3.2.3 3.2.3 ASGI specs, helper code, a... attrs 19.3.0 19.3.0 Classes Without Boilerplate django 3.0.2 3.0.2 A high-level Python Web fr... entrypoints 0.3 0.3 Discover and load entry po... flake8 3.7.9 3.7.9 the modular source code ch... importlib-metadata 1.4.0 1.4.0 Read metadata from Python ...
--outdated(-o)オプションバージョンが古いパッケージの表示。
$ poetry show -o django 2.2.4 3.0.2 A high-level Python Web framework that e...lock
pyproject.tomlで指定された依存関係をロックする。(インストールは行わない)
poetry.lockが生成される。$ poetry lockenv
仮想環境関連のコマンド。[python]の部分には 3.7.4 等を指定すればよい。
$ poetry env info # 現在の仮想環境の情報 $ poetry env list # 仮想環境一覧 $ poetry env remove <python> # 仮想環境の削除 $ poetry env use <python> # 仮想環境をアクティブまたは作成自分の環境だと、
virtualenvs.in-project=trueの場合、list にも表示されず remove も効かなかった。
.venv/を削除すればいい話だが。shell
仮想環境内でシェルを起動。
pipenv shellと同等。$ poetry shellscripts
pyproject.tomlに以下を記入し、スクリプトを実行することが出来る。pyproject.toml[tool.poetry.scripts] start = "script:main"script.pydef main(): print("Run script with poetry!")$ poetry run start Run script with poetry!仮想環境に入らずとも、スクリプトから実行すると仮想環境内で実行してくれる。
引数の扱い
poetry の scripts 実行コードを見る限り、引数は渡せないようだ。
poetry/console/commands/run.py# poetry script実行コード def run_script(self, script, args): if isinstance(script, dict): script = script["callable"] module, callable_ = script.split(":") src_in_sys_path = "sys.path.append('src'); " if self._module.is_in_src() else "" cmd = ["python", "-c"] cmd += [ "import sys; " "from importlib import import_module; " "sys.argv = {!r}; {}" "import_module('{}').{}()".format(args, src_in_sys_path, module, callable_) # 実行 ] return self.env.execute(*cmd)上のスクリプト設定であれば、
import_module('script').main()が実行されるので、そもそも引数を渡す部分がない。
Pipenv ではよくstart = "python manage.py runserver 0.0.0.0:8000"を登録していたので、困った。pyproject.toml[tool.poetry.scripts] start = "manage:main"とし、
poetry run start runserver 0.0.0.0:8000とすれば一応動くが。。。所感
(pipenv と比べ)良い
install、add、remove、lock が Pipenv より早く(重要)、コンソール上の表示が見やすいので良い。
pip listやpipenv graphに相当する機能もかなり見やすい。(pipenv と比べ)申し分ない
venv との連携。Pipenv と同様の使い心地で使える。
(venv in project の時の動作が気になるが)
pipenv から pyenv install できる機能はないようだが、そんな頻繁に使うものでもないので大丈夫。(pipenv と比べ)悪い
やはり script の部分。issue は多く出ていたので改善待ちかな。
オプションが多い気がする。覚えれば良い。以上の点を踏まえても、poetry を使っていくことになりそうだ。
贅沢を言うならpoetry showで dev かどうかわかればよかったな。参考
- Poetry - Python dependency management and packaging made easy https://python-poetry.org/docs/
- 投稿日:2020-01-17T21:39:00+09:00
学習記録 その23(27日目)
学習記録(27日目)
勉強開始:12/7(土)〜
教材等:
・大重美幸『詳細! Python3 入門ノート』(ソーテック社、2017年):12/7(土)〜12/19(木)読了
・Progate Python講座(全5コース):12/19(木)〜12/21(土)終了
・Andreas C. Müller、Sarah Guido『(邦題)Pythonではじめる機械学習』(オライリージャパン、2017年):12/21(土)〜12月23日(土)読了
・Kaggle : Real or Not? NLP with Disaster Tweets :12月28日(土)投稿〜1月3日(金)まで調整
・Wes Mckinney『(邦題)Pythonによるデータ分析入門』(オライリージャパン、2018年):1/4(水)〜1/13(月)読了
・斎藤康毅『ゼロから作るDeep Learning』(オライリージャパン、2016年):1/15(水)〜『ゼロから作るDeep Learning』
p.164 第5章 誤差逆伝播法 まで読み終わり。
5章 誤差逆伝播法
・誤差逆伝播法は要素の重要度である重みパラメータの勾配計算を効率良く行う手法
4章で実施した数値微分による勾配計算はシンプルであるが時間がかかるのに対し、こちらは高速に計算ができる。(ただし、複雑な部分がある。)
本書においては「計算グラフ」を用いて解説が実施されている。・順伝播(forward propagation):計算を左から右へ進める。
逆伝播(backward propagation):計算を右から左へ進める。・計算グラフでは局所的な計算、つまり自分に関係する小さな範囲のみを考えて次の結果を出力することができる。
局所的な計算は単純であるが、結果を伝播することで全体を構成する複雑な計算の結果が得られる。・順伝播では局所的な計算結果をアローダイアグラムのように左から右へ伝播するのに対し、逆伝播では「局所的な微分」の結果を右から左へ伝播させる。
この計算結果は最終的に最初の要素(値段であったり個数であったり)まで伝播され、ここに現れた数値が最終的な値段に与える影響の大きさを示している。・連鎖率(chain rule):合成関数の微分についての性質
"ある関数が合成関数で表される場合、その合成関数の微分は、合成関数を構成するそれぞれの関数の微分の積によって表すことができる。""\frac{\partial_z}{\partial_x} = \frac{\partial_z}{\partial_t}\frac{\partial_t}{\partial_x}この連鎖率の原則を用いて微分の逆伝播を進めていく。
ノードの入力信号に対して同じように後ろにくっつけていけばよいだけ。
入力信号が右から左にh、yと続くのであれば以下のようになる。\frac{\partial_z}{\partial_t}\frac{\partial_t}{\partial_x}\frac{\partial_x}{\partial_h}\frac{\partial_h}{\partial_y}・加算ノード:z = x + y という数式を考える。
どちらの偏微分も定数となるため、加算ノードにおける逆伝播はそのままの数値を次のノード(前のノード)に流す。・乗算ノード:z = x * y という数式を考える。
xに関する偏微分の解は y、yに関する偏微分の解は x
となるため、乗算ノードの逆伝播は入力信号をひっくり返した値を乗算して次のノード(前のノード)に流す。
つまり、xが流れてきた方にはyを乗算して、yが流れてきた方にはxを乗算して返す。・上記の考え方に活性化関数(ReLU, Sigmoid)を適用させることで、実際のニューラルネットワークの仕組みとなる。
・ReLUは回路における「スイッチ」のように機能する。
値が基準を満たさない場合は、ノードを通過する際に「0」を値として送る。
(つまり、その系統の伝播はそこで止まる。)・アフィン変換:ニューラルネットワークの順伝播で行う行列の積の計算
ニューロンの重み付き和は Y = np.dot(X, W) + B のように表すことができる。
この重み付き和を伝播させる際、アフィン変換を行う。・最後の処理である出力層における処理で、ソフトマックス関数もしくは恒等関数を用いる。
前回の学習のとおり、分類はソフトマックス関数(+交差エントロピー誤差)を、回帰は恒等関数(+2乗和誤差)を用いる。・勾配確認(gradient check):数値微分の結果と誤差逆伝播法で求めた勾配の結果を確認すること。
誤差逆伝播の値から数値微分の数値を引く。
正しい実装がされていれば、誤差は0に近い限りなく小さい値になる。
- 投稿日:2020-01-17T21:18:30+09:00
VS CodeでDocker開発コンテナを便利に使おう
はじめに
- ローカル環境で開発し、Linux環境にデプロイしてテストするのが面倒
- Dockerを使っていい感じに開発環境を作りたい
- しかし色々設定や構築が面倒
そんな方のためにDockerコンテナを用いた開発環境をVS Codeから便利に構築、運用できる拡張機能「Remote-Containers」の使い方のご紹介です。
この拡張機能の素晴らしさ
VS Codeの拡張機能「Remote-Containers」はコンテナ内でVS Codeを立ち上げ、ホストマシンのVS Codeと通信させることであたかもローカル環境で開発しているような操作感でコンテナ内開発が行えるというものです。
詳しい構成は公式ドキュメントに図があります。
(https://code.visualstudio.com/assets/docs/remote/containers/)また、複数の開発環境をVS Code上から管理して、ワンクリックでコンテナを立ち上げることが可能です。
(https://code.visualstudio.com/assets/docs/remote/containers/)そのために開発を始める際にコンテナをコマンドから立ち上げ、シェルをアタッチしてコンテナ内に入るなどの作業が必要なくなります。
ローカル環境でVS Codeを開いて開発を始めるのとほぼ同じ感覚でコンテナ内での開発が始められるのです。
システム要件は以下になります。
- Windows: Docker Desktop 2.0+ on Windows 10 Pro/Enterprise. (Docker Toolbox is not supported.)
- macOS: Docker Desktop 2.0+.
- Linux: Docker CE/EE 18.06+ and Docker Compose 1.21+. (The Ubuntu snap package is not supported.)
環境構築のための環境構築
Docker
まずDockerをインストールしますが、ここは省略します。
筆者はWindows環境にDocker Desktopをインストールしましたが、想像を絶する艱難辛苦を味わいました。
VS Code 拡張機能
VS Code上でctrl + shift + Xで拡張機能メニューを開き、「Remote-Containers」を検索してインストールします。
Microsoft公式なので安心(?)です。
Remote-Containers / Remote-SSH / Remote-WSLをひとつにしたRemote Developmentという拡張機能もあるのでそちらでも大丈夫です。
git
GithubのMicrosoft公式リポジトリに設定ファイルのサンプルがあるので、それをcloneしてくるとスムーズです。
なのでgitをインストールしましょう(手順省略)。
サンプルのリポジトリは以下です。
今回はPythonを使いますが、node.jsやjava、goなどもあります。
必要なのは.devcontainerディレクトリ配下のDockerfileとdevcontainer.jsonなので、そこだけ持ってきても構いません。
Remote-Containersの機能で「Try a Sample」というのがあり、cloneしなくてもこれらのリポジトリを使って試すことができますが突然docker imageのビルドが始まるのでやや面喰います。
開発環境構築
プロジェクト構成
例えばPythonのアプリケーションの開発環境を作るとします。
ディレクトリ構成を以下のようにしてVS Codeからprojectディレクトリを開きます。
project/ └ .devcontainer/ ├ Dockerfile └ devcontainer.json └ .git/ └ package/ ├ __init__.py ├ __main__.py └ module.py ├ requirements.txt └ .gitignoref1メニューまたは左下に現れる緑色のアイコンをクリックして「Remote-Containers: Open Folder in Container...」を選択します。
(https://code.visualstudio.com/assets/docs/remote/containers/)するとVS Codeが.devcontainer配下のDockerfileとdevcontainer.jsonを読み込み、その設定に従ってDockerコンテナを立ち上げてくれるという寸法です。
それでは、Dockerfileとdevcontainer.jsonの中身を見て具体的に何が起こっているのかを理解しましょう。
Dockerfile
ここは普通のDockerfileで、特別なことはありませんがユーザー権限回りの設定をいい感じにやってくれています。
#------------------------------------------------------------------------------------------------------------- # Copyright (c) Microsoft Corporation. All rights reserved. # Licensed under the MIT License. See https://go.microsoft.com/fwlink/?linkid=2090316 for license information. #------------------------------------------------------------------------------------------------------------- FROM python:3Docker imageをビルドするための元となるイメージを指定する項目です。
pythonのバージョンを詳しく指定したい場合はここをpython:3.7などにします。
ARG USERNAME=vscode ARG USER_UID=1000 ARG USER_GID=$USER_UID RUN apt-get update \ && apt-get -y install --no-install-recommends apt-utils dialog 2>&1 \ && apt-get -y install git iproute2 procps lsb-release \ ~~~ && groupadd --gid $USER_GID $USERNAME \ && useradd -s /bin/bash --uid $USER_UID --gid $USER_GID -m $USERNAME \ && apt-get install -y sudo \ && echo $USERNAME ALL=\(root\) NOPASSWD:ALL > /etc/sudoers.d/$USERNAME\ && chmod 0440 /etc/sudoers.d/$USERNAME \ここでapt-getの設定とユーザーの権限回りを設定しています。
要はsudoできる権限を持ったvscodeというユーザーでコンテナを扱えるようにしているようです。
devcontainer.json
こちらがこの拡張機能のミソです。
"name": "Python 3", "context": "..", "dockerFile": "Dockerfile", "settings": { "terminal.integrated.shell.linux": "/bin/bash", "python.pythonPath": "/usr/local/bin/python", "python.linting.enabled": true, "python.linting.pylintEnabled": true, "python.linting.pylintPath": "/usr/local/bin/pylint" }, "appPort": [ 9000 ], "postCreateCommand": "sudo pip install -r requirements.txt", "remoteUser": "vscode", "extensions": [ "ms-python.python" ] }ここにjson形式で書かれている項目がRemote-Containers拡張機能の設定となります。
- name
- Dev Containerの表示名を指定できます(Dockerコンテナ名とは別物です)。
- context
- プロジェクトのルートを指定します。
- この場合devcontainer.jsonがいる.devcontainerディレクトリの一つ上なので".."が指定されています。
- settings
- コンテナ側のVS Codeにおける各種設定を行う項目です。シェルやPythonのパスなど。
- appPort
- ホストマシンからアクセスできるコンテナのポート番号を指定します。
- docker runするときの-pオプションで9000:9000と指定するのと同じです。
- つまりホストマシンのブラウザでlocalhost:9000を叩くとコンテナのlocalhost:9000につながります。
- postCreateCommand
- イメージをビルドした後にコンテナ内で実行されるコマンドを書くことができます。
- この場合はプロジェクトのルートにあるrequirements.txtに書かれたパッケージがインストールされます。
- extensions
- コンテナ側のVS Codeにインストールされる拡張機能を指定できます。
公式ドキュメントによると、その他にも色々設定できる項目があります。
デフォルトではプロジェクトのルートディレクトリがコンテナの/workspaceにバインドされますが、
{ "workspaceFolder": "/home/vscode", "workspaceMount": "type=bind,source=${localWorkspaceFolder},target=/home/vscode/project" }のようにすれば、/home/vscodeにバインドされてVS Codeで開くデフォルトのディレクトリもそこになります。
{ "containerEnv": { "WORKSPACE": "/home/vscode" } }containerEnv項目を指定すると、コンテナ内で使える環境変数を設定できます。
{ "runArgs": [ "--name=project_dev_container" ] }runArgsの項目で、コンテナ立ち上げ時のオプションを直接指定することもできます。
実際にはVS Codeがこのdevcontainer.jsonを読み込んで各種オプションをつけてdocker runしてコンテナを立ち上げています。
その際にrunArgsの項目で指定した文字列のリストがスペース区切りで追加されるわけです。
さらに詳しくはこちら : Developing inside a Container - devcontainer.json reference
その他個別設定
git
コンテナにバインドするプロジェクトディレクトリに.git/が入っていると、そのままコンテナ内のVS Codeのバージョン管理機能が使えます。
VS Codeのバージョン管理機能は大変便利で、git addやgit commit、git pushなどがGUIで行えます。
しかしながらコンテナ内でモートリポジトリと通信しようとすると、毎回Githubの認証が必要になってしまいます。
ですがそこは我らがVS Code、gitの認証情報をホストマシンと共有できる機能が付いています。
Developing inside a Container - Sharing Git credentials with your container
まずホストマシンとでGithubのユーザー名やメールアドレスを.gitconfigファイルに保存しておきます。
$ git config --global user.name "Your Name" $ git config --global user.email "your.email@address"ユーザールートにある.gitconfigにこれらの設定が書き込まれていますが、これをVS Codeが自動でコンテナにコピーしてくれるようです。
次にパスワードなどの認証情報ですが、二通り設定方法があります。
https通信を使ってidとパスワードで認証している場合、gitのcredential helperにパスワードを保存しておけばその設定がコンテナと同期されます。
Caching your GitHub password in Git
$ git config --global credential.helper wincredsshでの認証では、ホストマシンでSSH agentにGithub用の公開鍵を登録しておくとその設定が同期されるようです。
PowerShellで
ssh-add $HOME/.ssh/github_rsaとするとSSH agentに鍵が登録されます。
しかしながらSSH agentが起動していない場合が多く、そのときは管理者権限でPowerShellに入って
Set-Service ssh-agent -StartupType Automatic Start-Service ssh-agent Get-Service ssh-agentするか、GUIでサービス > OpenSSH Authentication Agentのプロパティから設定できます。
詳しくはWindows 10のssh-agentをコマンド プロンプト、WSL、Git Bashで使ってみた#ssh-agent-の有効化など。
AWS Access Key
コンテナ内からAWS S3と通信しようとすると、アクセスキーの問題が発生します。
ホストマシンのユーザールートにある.awsディレクトリ内にアクセスキーの情報があり、それをコンテナ内でも読み込みたいものです。
しかしながらgitの場合とは異なりそこは自動的に読み込んではくれないようです。
それゆえに一度コンテナの外からdocker cpを使ってコンテナにコピーしてくる必要があります。
docker cp $HOME/.aws {コンテナ名}:home/vscodeここで、Remote-Containersで立ち上げるコンテナに名前がついてると便利です。
先ほどのdevcontainer.jsonのrunArgsの項目で、
{ "runArgs": [ "--name=project_dev_container" ] }のようにしてコンテナ名をつけるようにすると良いでしょう。
素晴らしい航海
実際に使ってみると、普通にVS Codeで開発するのとほぼ同じ感覚で開発コンテナを扱うことができます。
また、Pythonで開発する際には仮想環境を用意するのが普通ですがコンテナ内で環境を構築することでその必要がなくなります。
なぜなら、各プロジェクトごとに違うコンテナを使っているのでパッケージをグローバルにインストールしても環境を汚染しないからです。
そして、Pythonのバージョンごとにイメージが用意されているので本番環境に合わせてそれを指定することもできます。
(この辺りはRemote-Containersというよりdockerを使うことのメリットですが)
こうした開発環境をワンクリックで開いたり、切り替えたりできるわけです。
また、この拡張機能はポートのバインドも自動で行ってくれるため、フロントエンド開発でのローカルサーバーもストレスなく使うことができます。
ただし、例えばnode.jsなどは3000番ポート指定でローカルサーバーが立ち上がるのでそのポートをローカルマシンに公開しなければなりません。
その場合はdevcontainer.jsonで
{ "appPort": [ 3000 ] }のように設定しておきましょう。
参考
公式ドキュメント、長い
この記事を見てRemote-Containersを使い始めました。感謝!



- 投稿日:2020-01-17T19:24:07+09:00
【対決! 人力 vs Python】結局、センター試験の数学はPythonで解くのと、自力で解くのと、どっちが速いのか?
どこかで見たことあるネタだなと思ったら
やっぱり、先人がいました(ほかにもあるかも)。
素晴らしい!1. センター試験に持ち込めるもの
以下が持ち込めるようですが、現時点で、Pythonのインタプリタは持ち込めないようなので、注意が必要です。
開発者にとって、開発環境は鉛筆のようなものという主張も通じないと思います。
※許可されているもの以外を持ち込むのは絶対に絶対にやめましょう!* 黒鉛筆(H,F,HBに限る。和歌・格言等が印刷されているものは不可。)、鉛筆キャップ。 * シャープペンシル(メモや計算に使用する場合のみ可、黒い芯に限る。) * プラスチック製の消しゴム * 鉛筆削り(電動式・大型のもの・ナイフ類は不可。) * 時計(辞書、電卓、端末等の機能があるものや、それらの機能の有無が判別しづらいもの・秒針音のするもの・キッチンタイマー・大型のものは不可。) * 眼鏡、ハンカチ、目薬、ティッシュペーパー(袋又は箱から中身だけ取り出したもの。)2. 今回、勝負する問題
2017年 大学入試センター試験 数学Ⅱ・数学Bの第1問 [1]だけです。
この問題を選んだ理由: 「この問題ならPythonで勝てそうだから。」
第1問 (必答問題) (配点 30)
[1] 連立方程式
\left\{ \begin{array}{ll} cos \, 2\alpha + cos \, 2\beta = \frac{4}{15} \quad\quad\quad\,\,\,\,...(1) \\ cos \, \alpha \, \, cos \, \beta = -\frac{2\sqrt{15}}{15} \quad\quad\quad\,\,\,\,\,...(2) \end{array} \right.を考える。ただし、$0 \leqq \alpha \leqq \pi, \quad 0 \leqq \beta \leqq \pi$ であり, $\alpha < \beta$ かつ、
|cos \, \alpha| \geqq |cos \, \beta| \quad\quad\quad\quad\quad\quad...(3)とする。このとき, $cos \, \alpha$ と $cos \, \beta$ の値を求めよう。
2倍角の公式を用いると, (1)から
cos^2 \alpha + cos^2 \beta = \frac{[アイ]}{[ウエ]}が得られる。また, (2)から,
cos^2 \alpha \, \, cos^2 \beta = \frac{[オ]}{15}である。
したがって, 条件(3)を用いるとcos^2 \alpha = \frac{[カ]}{[キ]} \quad, \quad\quad cos^2 \beta = \frac{[ク]}{[ケ]}である。よって, (2)の条件 $0 \leqq \alpha \leqq \pi, \quad 0 \leqq \beta \leqq \pi, \quad \alpha < \beta$ から
cos \, \alpha = \frac{[コ]\sqrt{[サ]}}{[シ]} \quad, \quad\quad cos \, \beta = \frac{[ス]\sqrt{[セ]}}{[ソ]}である。
3. 「Python + 私」側の勝利条件
全体の問題量からして、この問題は、たぶん6分とか7分以内で解かないと厳しいと思います。
その辺を考慮して、「Python + 私」側の勝利条件は以下に設定します。
- コーディングに要する時間と、実行する時間の合計が5分以内。
- 完勝と言えるレベルに達するには、3分、いや、2分を切ることが必要。
- Pythonの開発環境(IDE含む)は事前インストール、起動しておいてよい。
参考までに準備した環境は、以下です。
- Windows 10 Pro
- Python 3.6
- Visual Studio Code + Python Extensionインストール済み
4. いざ尋常に勝負!
(完成したコード全体は、本記事一番最後に掲載します。)
4.1. 出題者の誘導など、はなっから無視します!
2倍角の公式とかわけわかんないこと言ってるので、
いきなり、最後の、$cos \alpha, cos \beta$ から求めます。
PythonとSymPy使えばできるはず。
まずは、SymPyインストール!pip install sympyでは、一気に解いちゃいましょう!
$f_1 = cos \, 2\alpha + cos \, 2\beta - \frac{4}{15}$
$f_2 = cos \, \alpha \, \, cos \, \beta + \frac{2\sqrt{15}}{15}$
として、$f_1 = 0$ と $f_2 = 0$の連立方程式を、
$cos \, \alpha$ と $cos \, \beta$ に関して解いていきます。from sympy import symbols, expand, cos, Rational, sqrt, solve # シンボルの定義。今回の問題ではαとβを、それぞれaとbのシンボルとして扱う。 a, b = symbols('a b') # (1)と(2)それぞれの式をf1 = 0, f2 = 0となるような関数f1, f2として定義。 # この後、cos(a)とcos(b)に関して連立方程式を解くので、(1)は展開(expand)しておく。 f1 = expand(cos(2*a) + cos(2*b) - Rational(4, 15), trig = True) f2 = cos(a) * cos(b) + 2 * sqrt(15) / 15 # f1とf2の連立方程式を、cos(a)とcos(b)に関して解きます(solve)。 answers = solve([f1, f2], [cos(a), cos(b)])4.2. 条件から目的の解に絞り込む。
この時点で、
answersにはいくつかの解が入っているはずですが、条件から目的のものを見つけます。$0 \leqq \alpha \leqq \pi, \quad 0 \leqq \beta \leqq \pi$ であり, $\alpha < \beta$ という条件ですが、
$0 \leqq \theta \leqq \pi$ の範囲では、$\theta$ が大きくなるにつれて、$cos \theta$ は小さくなっていくので、
$cos \alpha > cos \beta$ となる解を探します。
かつ、(3)の条件 $|cos \, \alpha| \geqq |cos \, \beta|$ も評価して目的の解を探します。絶対値出てきたので、
importに加えておきます。from sympy import symbols, expand, cos, Rational, sqrt, solve, Absあとは、
answersに入っている解の組のリストから条件に合う解の組を探していきます。
if文では、単に条件をそのまま、条件式にするだけです。# 0 <= a <= π, 0 <= b <= πでは、a, bが大きい方がcos(a), cos(b)の値は小さくなる。 # a < bなので、cos(a) > cos(b)になるものを探す。 # かつ、(3)の条件に合うものを探す。 for cos_a, cos_b in answers: if cos_a > cos_b and Abs(cos_a) >= Abs(cos_b): break4.3. [コ][サ][シ][ス][セ][ソ]の攻略完了!
これで、$cos \alpha, cos \beta$ が求まります。
# 目的のcos(a)とcos(b)が求まったので、表示します([コ][サ][シ][ス][セ][ソ]の答え)。 print("[コサシ] -> {}, [スセソ] -> {}".format(cos_a, cos_b))4.4. あとは簡単!
$ cos^2 \alpha, cos^2 \beta$ と $cos^2 \alpha + cos^2 \beta$、$cos^2 \alpha \, \, cos^2 \beta$ を求めるだけですが、
$cos \alpha, cos \beta$が既に求まっているので単に計算していくだけで求まります。# cos(a)とcos(b)それぞの2乗を求めます。 squared_cos_a = cos_a ** 2 squared_cos_b = cos_b ** 2 # cos(a)の2乗と、cos(b)の2乗を表示します([カ][キ][ク][ケ]の答え)。 print("[カキ] -> {}, [クケ] -> {}".format(squared_cos_a, squared_cos_b)) # cos(a)の2乗と、cos(b)の2乗の和と積もそれぞれ表示します([ア][イ][ウ][エ][オ]の答え)。 print("[アイウエ] -> {}".format(squared_cos_a + squared_cos_b)) print("[オ] -> {}".format(squared_cos_a * squared_cos_b))(完成したコード全体は、本記事一番最後に掲載します。)
5. 勝敗
完成したPythonコードの実行に要した時間(すべての解を求めるまでの時間)は、
私の手元の環境では、400ミリ秒未満 (あくまでも、コードが実行開始されてからの時間)でした。ただし、コーディングに要した時間が 14分41秒524 だったので、
Python側(というか、私)の完敗、圧倒的敗北でした。。。(この記事自体は、勝負決着後に書き始めているので、記事の執筆時間は含まれません。)
5.1. 敗因の分析
- 私のプログラミング能力の未熟さ。
- まじめに、コメントを書いてしまったこと。
- 連立方程式解いた後の解の絞り込みの実装で、デバッガ使いながら、多少手こずったこと。
- 思った以上に、SymPyのインストールに時間がかかったこと。
6. 完成したコード
from sympy import symbols, expand, cos, Rational, sqrt, solve, Abs import time # 解くのにかかった時間を出力したいので、最初の時刻を覚えておく。 offset = time.time() # シンボルの定義。今回の問題ではαとβを、それぞれaとbのシンボルとして扱う。 a, b = symbols('a b') # (1)と(2)それぞれの式をf1 = 0, f2 = 0となるような関数f1, f2として定義。 # この後、cos(a)とcos(b)に関して連立方程式を解くので、(1)は展開(expand)しておく。 f1 = expand(cos(2*a) + cos(2*b) - Rational(4, 15), trig = True) f2 = cos(a) * cos(b) + 2 * sqrt(15) / 15 # f1とf2の連立方程式を、cos(a)とcos(b)に関して解きます(solve)。 answers = solve([f1, f2], [cos(a), cos(b)]) # 0 <= a <= π, 0 <= b <= πでは、a, bが大きい方がcos(a), cos(b)の値は小さくなる。 # a < bなので、cos(a) > cos(b)になるものを探す。 # かつ、(3)の条件に合うものを探す。 for cos_a, cos_b in answers: if cos_a > cos_b and Abs(cos_a) >= Abs(cos_b): break # 目的のcos(a)とcos(b)が求まったので、表示します([コ][サ][シ][ス][セ][ソ]の答え)。 print("[コサシ] -> {}, [スセソ] -> {}".format(cos_a, cos_b)) # cos(a)とcos(b)それぞの2乗を求めます。 squared_cos_a = cos_a ** 2 squared_cos_b = cos_b ** 2 # cos(a)の2乗と、cos(b)の2乗を表示します([カ][キ][ク][ケ]の答え)。 print("[カキ] -> {}, [クケ] -> {}".format(squared_cos_a, squared_cos_b)) # cos(a)の2乗と、cos(b)の2乗の和と積もそれぞれ表示します([ア][イ][ウ][エ][オ]の答え)。 print("[アイウエ] -> {}".format(squared_cos_a + squared_cos_b)) print("[オ] -> {}".format(squared_cos_a * squared_cos_b)) # 解くのにかかった時間を表示します。 elapsed = time.time() - offset print('解くのにかかった時間: {0:.4f}ミリ秒'.format((elapsed * 1000)))
- 投稿日:2020-01-17T18:12:14+09:00
【Django】formでzipのバリデーションをしようとして沼にはまった話 【TDD】
Djangoさん「UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbb in position 10: invalid start byte」
formのFileFieldに複数ファイルをまとめたzipをアップロードして保存しようとするとこのエラーになった。
結論から言うと、テストの時に放り投げていたデータ形式が悪かったみたい。ただ、通るようになってエラーを再現しようとするとなぜかクリアするので、エラーの再現が困難なのが意味わからない。めっちゃ困ってたのに・・・
解決策
まずエラーが出てたときは、
tests.pyself.zip_error_test = File(open('tdd.zip')) file_data = {'upload_train_file': uploadedFile } form = DocumentForm(file_data) form.is_valid()端折りますがこんな感じでした。
こんなことするとdjangoさんが怒ります。
ちなみに1つのファイルを固めたZIPでも同じように怒られました。下のように変更すると解決しました。
tests.pywith open("tdd.zip", mode="rb") as f: uploadedFile = InMemoryUploadedFile(f, "field", "tdd.zip", "application/x-zip-compressed", 100, None, content_type_extra={}) file_data = {'field': uploadedFile } form = DocumentForm(request, data, file_data) self.assertFalse(form.is_valid(), f"error:{form.errors}/複数ファイル入ったZIPがバリデーションされませんでした")はい。
これで動きます。
やったね。原因は何だったのか。
いろいろ考えました。
そもそもforms.pyのカスタムバリデーションに書いていたので、それが原因なのかなと思ってみたり、
cleaned_dataを持ってきてるのがダメなのかなと思ってto_python()をいじってみたり。
forms.pyではファイルを保存できないのかな、とかもういろいろ考えてました。ふと思い立ってテストではなく、実際にHTMLのフォームからアップロードしたらどうなるんだろうとおもってやってみた結果
通りました。
これはformで受け取ってるデータ違うんじゃねと思って、viewsとtestsで受け取っているデータの型を見比べてみました。
するとforms.pydef clean_field(self): print(type(self.cleaned_data['field'])) # views > django.core.files.uploadedfile.InMemoryUploadedFile # tests > django.forms.widgets.ClearableFileInputわーお違ってるやーん
これのせいだったので、テストのほうのアップロードを先述のものに変更したわけです。
これにて一件落着です。
おかげでFormについて詳しくなれた気がします。
いわゆる完全に理解したってやつですね。かんぺきです。まとめ
解決したあとにこの記事書こうと思って、再度エラーになるであろうコードを書くとなぜかクリア。
マジで謎。
上記で通るって書いているけどtests.pywith open("tdd.zip", mode="rb") as f: file_data = {'field': f} form = DocumentForm(request, data, file_data) self.assertFalse(form.is_valid(), f"error:{form.errors}/複数ファイル入ったZIPがバリデーションされませんでした")これでも通ります。何でですかね。通らなかったんですよ?
何ならmode="rb"をなくしても通ります。なんでなんですかね。エラー出てたんですよ?本当です。しんじて。もしかすると再起動かけるとまた動かなくなっちゃうかもと思って上のほうのコードにしています。
明示的にクラスを変えればさすがに問題ないでしょう。ということでzipがなぜか保存できない現象の解決方法でした。
多分来週くらいの私が、この件で得たformの知識をまとめてくれます。
期待してます。
- 投稿日:2020-01-17T18:04:04+09:00
Pandasで特定の"文字列"を含む行を抽出
先日、基本的なPandasの条件抽出についてまとめた。
https://qiita.com/M_Faust/items/05a79e0372bf9c9003e5型が文字列のDataFrameに対して、ある特定の文字列を含む場合の条件抽出は下記。
特定の文字列を含む場合の条件抽出>>> df = pd.DataFrame ({"A":["hello","helloa","ahello","bye"]}) >>> df_extract = df.query ("A.str.contains ('hello')",engine="python") >>> df_extract A 0 hello 1 helloa 2 ahello環境美化活動がお金になるアプリを運営しています(PythonがBackendで使われているので載せます)。
https://play.google.com/store/apps/details?id=com.rainbowsv2.changetheworld&hl=ja
- 投稿日:2020-01-17T18:00:17+09:00
Pytorchのニューラルネットワーク(CNN)のチュートリアル1.3.1の解説
想定読者
Pytorchのニューラルネットワーク(CNN)のチュートリアル1.3.1についての解説です。
- CNNの仕組みはふんわり掴めている
- Pythonはなんとなく触ったことがある
- 初めてPytorchを勉強しようとしたものの公式チュートリアルよく分からない
という方向けの記事です。そのため、割と丁寧に書いています。必要なところだけサク読みしてください。
また、今回はあくまで公式チュートリアルの理解に焦点を当てており、チュートリアルに出てこない引数等については説明しません。
この記事が解説するのはPytorch Tutorial 1.3.1です。このチュートリアルでやること
このチュートリアルでは、「2次元の画像をニューラルネットワークに入れて目的関数まで出し(順伝播:forward propagation)、その後各パラメータ値を更新する(誤差逆伝播法:backpropagation)ところまでを、Pytorchではどのようにやるのか」ということを説明しています。
画像引用元:Pytorch Tutorial 1.3.1もう少しだけ詳しく概観すると、上の通り、画像の畳み込み→プーリング→畳み込み→プーリング→一次元配列に変換→全結合のネットワークで出力層(10のノード)まで持っていく、というイメージです(この後それぞれ解説してます)。
その後、上の画像には書かれていませんが、この出力結果と予め持っている答えを照らし合わせて目的関数(今回は平均二乗誤差)の値を出して、パラメータの値を更新します。(ちなみにこのモデルは、手書き文字のようなシンプルな物体認識に最適だとして1998年にCNNが最初に取り上げられた際に、Object Recognition with Gradient-Based Learningという論文で紹介された5層のLeNetです。)
さて、もっと細かいことはコードを書きながら見ていきましょう。
モデルを作る
qiita.pythonimport torch import torch.nn as nn import torch.nn.functional as Fまずは、torchをimportです。nnはパラメータを持つ層、Fはパラメータを持たない層がそれぞれ入っているモジュールです。
qiita.pythonclass Net(nn.Module): def __init__(self): super(Net, self).__init__() # 1 input image channel, 6 output channels, 3x3 square convolution # kernel self.conv1 = nn.Conv2d(1, 6, 3) self.conv2 = nn.Conv2d(6, 16, 3) # an affine operation: y = Wx + b self.fc1 = nn.Linear(16 * 6 * 6, 120) # 6*6 from image dimension self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): # Max pooling over a (2, 2) window x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) # If the size is a square you can only specify a single number x = F.max_pool2d(F.relu(self.conv2(x)), 2) x = x.view(-1, self.num_flat_features(x)) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x def num_flat_features(self, x): size = x.size()[1:] # all dimensions except the batch dimension num_features = 1 for s in size: num_features *= s return num_features net = Net() print(net)さて、ここではネットワークが定義されています。
Pytorchではnn.Moduleを継承するクラス(ここではNET)を作成し、ネットワークはこのクラスの中に定義します。
上にあげたコードを分割しながら、3つのメソッドについてそれぞれ説明していきます。パラメータを持つ層の入った
__init__def __init__(self): super(Net, self).__init__()1つ目はパラメータを持つ層での処理の仕方についてです。基本的にパラメータを持つ層はコンストラクタ
__init__の中に入れられます。
まずはsuper(Net, self).__init__()で親クラスのコンストラクタを継承しています。子クラスでコンストラクタを生成すると上書きされてしまうので、親クラスのコンストラクタを引き継ぎつつ今回追加が必要な部分をこれから書き足すようなイメージですね。ちなみにsuper(Net, self).__init__()はsuper().__init__()のように省略して書いてOKです。畳み込み層
self.conv1 = nn.Conv2d(1, 6, 3) self.conv2 = nn.Conv2d(6, 16, 3)
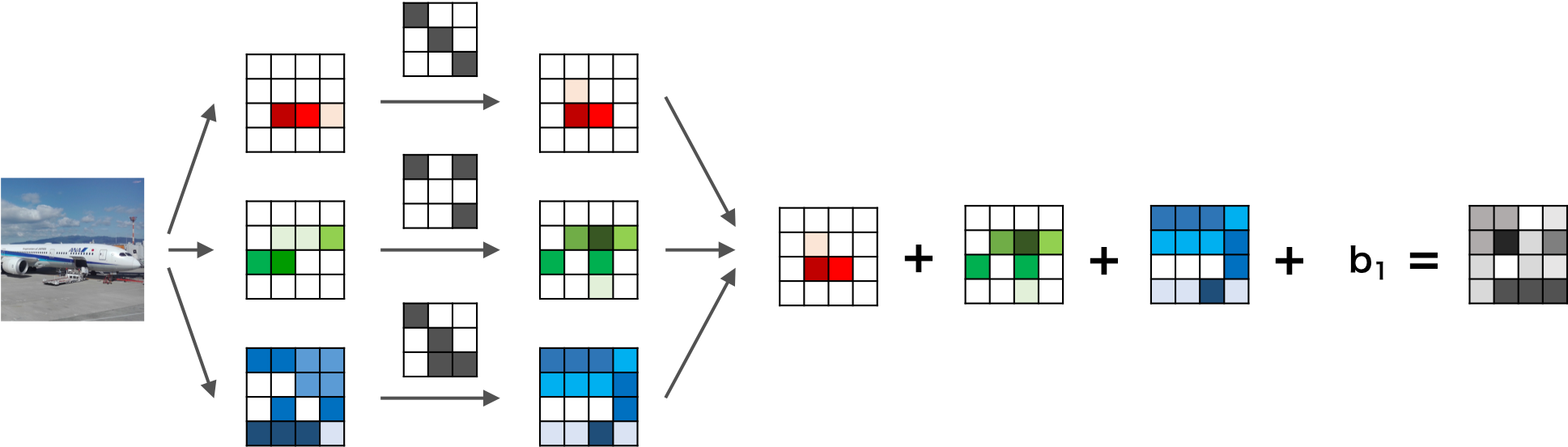
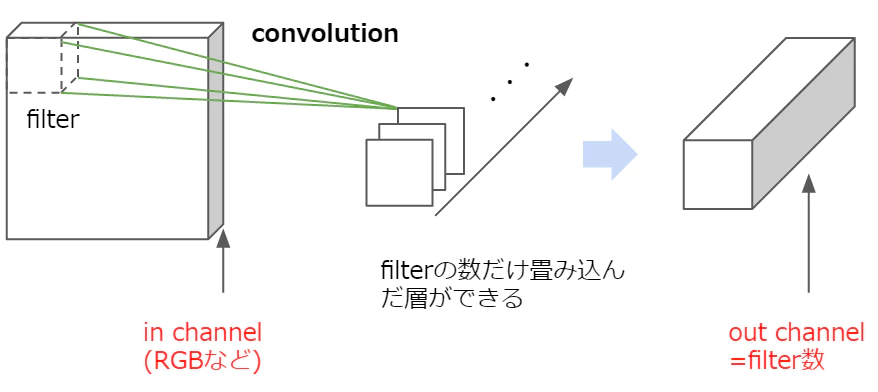
conv2Dは2次元の畳み込みをする際に使われるクラスです。つまりここでは、画像の縦横が圧縮されるようなイメージです。引数はそれぞれ(入力する画像の奥行き(インチャンネル),出力する画像の奥行き(アウトチャンネル),フィルタのサイズ)です。チャンネル(奥行き,深さ)って何?
画像には高さと幅以外にも奥行き(深さと訳されたりしてます)があり、この奥行きをチャンネルといいます。奥行きは画像の場合は色に対応しており、RGBだとチャンネル数は3、モノクロだと1です。これにフィルタを畳み込みますが、このフィルタは必ず入力層と同じチャンネル数を持つものとして自動的に設定されます。例えば入力のチャンネル数が3だったら、フィルタのチャンネル数も自動的に3です。
たとえば、
画像引用元:https://axa.biopapyrus.jp/deep-learning/cnn.htmlこのように、入力画像のチャンネル数が3だった場合はフィルタのチャンネル数も3になります。つまり、R,G,Bにフィルタの各チャンネルが畳み込まれ、その和として1つの特徴量マップができます。
そして、フィルタを何枚用意するかによって、出力の数が変わります。
画像引用元:https://qiita.com/icoxfog417/items/5aa1b3f87bb294f84bac最初の
conv1の引数を見てみると、入力データは1チャンネル=モノクロ、出力は6チャンネル、フィルタのサイズは3×3です。つまり、入力データと同じ奥行き1のフィルターを6つ用意して畳み込んだことによって6つの特徴マップが出力されたということです。
次のconv2は入力データは6チャンネル、出力は16チャンネルなので、奥行き6の16個のフィルターが畳み込まれたということです。出力の際の画像のチャネルは必ずフィルタの数になります。全結合層
次に、
nn.Linearは入力データに線形変換を適用するクラスで、引数は(インプットされたユニット数、アウトプットするユニット数)です。全ユニット(ノードとも言います)が結合されている全結合のネットワークです。self.fc1 = nn.Linear(16 * 6 * 6, 120) # 6*6 from image dimension self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10)さて、ここでいきなり16*6*6(=576)という数字が出てきていますが、これはその前までの3次元のデータを1次元にしたものです。
この全結合層に来る前の畳み込み層で画像データは16チャンネルになっていました。なので1つのデータは(チャンネル数,縦,横)=(16,縦,横)の3次元データです。このデータを全結合層に持ってくるためには、3次元のデータを1次元にする必要があります。今回のモデルでは縦・横が6の画像がここで入ってくると設定されており、16*6*6=576が全結合層の最初の入力層のノード数になっているわけです。
なので、もしこのモデルに入れる画像データが、全結合層の前に縦横6*6になっていない場合は、例えばこの層の前に6*6に変更する層が必要になってきます。順伝播を記述する
forward次に
forwardというメソッドについてです。ここでは、引数としてデータ(x)を受け取り、出力層の値を出すまでのネットワークを記述しています。def forward(self, x): # Max pooling over a (2, 2) window x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) # If the size is a square you can only specify a single number x = F.max_pool2d(F.relu(self.conv2(x)), 2) x = x.view(-1, self.num_flat_features(x)) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return xここでは、
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d
-> view -> linear -> relu -> linear -> relu -> linear
という順伝播の流れが記載されています。パラメータを持つ層についてはすでに説明をしたので、それ以外の層について説明をいていきます。
F.relu関数では畳み込まれたデータに対して非線形処理を行う活性化関数の1つである、ランプ関数です。ReLU(x)=max(x,0)であり、データが0より大きければその値を出力し、0より小さければ0を出力します。
max_pool2d関数は二次元の最大値プーリングを行うクラス?です。ここでは2*2の窓を使っています。図にすると以下のようなイメージです。
左上から順に窓の中の最大値を出力しています。プーリングはストライドの設定などなく、枠線がかぶらないように演算されていきます。今回は2*2なので、ここでサイズが縦横のサイズが2分の1に圧縮されていますね。
view関数については少し詳しく説明します。
viewは,入力データと同じ数字の羅列を、形状が異なる新しいテンソルにして返す関数です。これは全結合層の前に画像データを1次元データに変換するときに使います。
例えば、>>>x = torch.randn(2,2) >>>x tensor([[-0.2834, -0.3660], [-0.1678, -0.3034]]) >>>x.view(4) tensor([-0.2834, -0.3660, -0.1678, -0.3034])と言ったようにデータの形を変えることができます。
今回は引数の最初に-1があります。これは、その他(今回であれば2つ目)の引数に合わせて1つ目の次元のサイズを適切に調整してくれるものです。
例えば、>>>x = torch.randn(4,3) >>>x tensor([[-1.2163, 1.6905, 0.1850], [-0.2123, 0.5995, 0.7282], [-0.5564, -0.1090, -0.8454], [-0.5643, 1.2565, -0.5475]]) >>>x.view(-1,6) tensor([[-1.2163, 1.6905, 0.1850, -0.2123, 0.5995, 0.7282], [-0.5564, -0.1090, -0.8454, -0.5643, 1.2565, -0.5475]])こんな感じです。「4*3をx*6に変更して」、というと自動的に最適な2*6に変更してくれるということです。
今回の
x = x.view(-1, self.num_flat_features(x))について考えましょう。もとの画像データが(16,6,6)なら
x.view(576)で良さそうなのですが、実はもともとの入力テンソルは(サンプル数,チャネル数,縦,横)という4つの次元のテンソルです。
これまでは入力データを1つの画像と考えていたのでサンプル数について触れていませんでしたが、機械学習では基本的にミニバッチで複数の画像を処理したあとにパラメータを更新するため(Pytorchの'torch.nn'はミニバッチを利用する前提で作られています)、入力データにはサンプル数という情報も含まれているわけです。
そこで、ここではアウトプットの形状を(サンプル数、チャンネル数×縦×横))として、各サンプルごとの特徴量が一次元配列となるようにすることで、サンプルごとの特徴量を全結合層の開始ノードとしたいわけです。
x = x.view(-1, self.num_flat_features(x))とは、今回はx = x.view(-1, 576)です。このself.num_flat_features(x)は1サンプルあたりの特徴量の数を計算するメソッドとして作られているため、このメソッドで計算した結果をここに代入しているだけです。(self.num_flat_features(x)についてはこのあと触れます。)このforward関数で順伝播のモデルを作ることによって、backward関数も定義されたことになります。つまり、backward関数は順伝播で来た道を逆に戻り、目的関数についての勾配を求めていくだけなので、順伝播のネットワークが組まれれば、この計算式についても自動的に作られるとういことです。
特徴量の数を数えている
num_flat_features(x)ここでは、サンプル数以外の特徴量を一次元化するために、チャンネル数×縦×横をしているだけです。
def num_flat_features(self, x): size = x.size()[1:] # all dimensions except the batch dimension num_features = 1 for s in size: num_features *= s return num_features入力データの最初のサンプル数以外の次元を掛けているだけです。
[1:]は(0,16,6,・・・)の16以降(=インデックス[1]以降)を抽出する、ということです。
num_features *= s=num_features = num_features * sです。つまりここでは、(サンプル数,16,6,6)なので→(16,6,6)とした後に、16*6*6をして特徴量の数を出しているわけです。
さてこれでモデルの設計図は完成です。
インスタンス化しましょう。>>>net = Net() >>>print(net) Net( (conv1): Conv2d(1, 6, kernel_size=(3, 3), stride=(1, 1)) (conv2): Conv2d(6, 16, kernel_size=(3, 3), stride=(1, 1)) (fc1): Linear(in_features=576, out_features=120, bias=True) (fc2): Linear(in_features=120, out_features=84, bias=True) (fc3): Linear(in_features=84, out_features=10, bias=True) )機械学習の処理では自分が定義したクラス(ここではNet()クラス)をインスタンス化したオブジェクトを使って学習を行っていきます。
画像サイズの整理
念の為、このモデルはどの画像サイズを想定したものなのか、ここまでの画像サイズの変化について整理しましょう。
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d
-> view -> linear -> relu -> linear -> relu -> linear今回「LeNetの出力データは32*32が想定されていますよ」とpytorchの公式チュートリアルにも書いてあるんですが、今回のパラメータだと30が最適だと思います。
30×30のデータを入れる→畳込みのフィルタサイズが(3*3,1ストライド)なので28*28→プーリング(2*2)で14*14→畳み込み(3*3,1ストライド)なので12*12→プーリング(2*2)→6*6で全結合層へ投入、ですね。
もとの論文では、最初の畳み込み層は5*5のフィルタサイズを使っているので、その場合32*32が最適ですね。
(pytorchの'nn.MaxPool2d'プーリングは小数点以下は切り捨てられるので、一応今回のパラメータでも32*32を入れることは可能ではありますが)パラメータを確認
さて、ここでパラメータを確認しておきましょう。
学習されるパラメータはnet.parameter()で求めることができます。>>>params = list(net.parameters()) >>>print(len(params)) >>>print(params[0].size()) # conv1's .weight >>>print(params[1].size()) 10 torch.Size([6, 1, 3, 3]) torch.Size([6])今回パラメータは10個です。
最初の畳み込み層には[6, 1, 3, 3]と[6]のパラメータがあります。
畳み込み層でいうパラメータとはフィルタの値のことです。
このフィルタの値がパラメータであり、学習によって更新されていくものなので、6(出力チャネル数)×1(入力チャネル数)×3(縦)×3(横)+6(バイアス)です。
次の畳み込み層は、同じ理屈で[16,6,3,3]と[16]です。
ここまでわかればあとの全結合層の6つは分かりますね。
[120,576],[120],[84,120],[84],[10,84],[10]です。データを入力
それでは試しに先程のモデルに画像データを入力したこととして適当な数字を入れてみます。
>>>input = torch.randn(1, 1, 32, 32) >>>out = net(input) >>>print(out) tensor([[-0.0843, 0.0283, 0.0677, 0.0639, -0.0076, -0.0293, 0.1049, 0.2183, -0.1275, -0.1151]], grad_fn=<AddmmBackward>)しっかり10個出力されていますね。
ちなみにinputの際の4次元データの最初は1バッチあたりの画像の数です。損失の計算
目的関数は(出力値、ターゲット(答え))のペアを入力として受け取り、出力結果が出したかった答えからどれだけ離れているのかを推定する値を計算します。
nnパッケージには損失関数がいくつかありますが、今回は出力結果とターゲット間の平均二乗誤差を計算するnn.MSELossを利用します。>>>output = net(input) >>>target = torch.randn(10) # a dummy target, for example >>>target = target.view(1, -1) # make it the same shape as output >>>criterion = nn.MSELoss() >>>loss = criterion(output, target) >>>print(loss) tensor(0.6110, grad_fn=<MseLossBackward>)outputにモデルからの出力結果をいれ、targetにも今回は適当な数字を入れてモデルの出力結果と形を合わせています(モデルからの出力結果にはバッチ数も入っているので(1,10)です)。
損失関数はインスタンス化して使います。パラメータの更新
pytorchのoptimというモジュールには様々なパラメータの更新手法があり、簡単に誤差逆伝播法を行ないパラメータを更新していくことができます。
import torch.optim as optim # create your optimizer optimizer = optim.SGD(net.parameters(), lr=0.01) # in your training loop: optimizer.zero_grad() # zero the gradient buffers output = net(input) loss = criterion(output, target) loss.backward() optimizer.step() # Does the update
optim.SGD(net.parameters(), lr=0.01)は、確率的勾配降下法を使って、指定のパラメータ値(net.parameters())を学習率0.01で更新せよ、という意味です。
optimizer.zero_grad()
これは,目的関数の勾配を0にせよ、ということです。これは今までTransflowのようなdefine-and-runのフレームワークに馴染みがある人には、必要性が「?」かもしれませんが、Pytorchやchainerでは事前に逆伝播の計算処理について規定する必要がなく、勾配処理に必要になる計算履歴が全て記憶されていることによって柔軟にパラメータの更新ができるわけですが、逆に言えば、いつこの勾配の計算処理が終わるのか、ということについては規定されていません。そのため、必要な箇所でこれを0にしないと、その前の入力データから計算された勾配に対して,新しいデータの勾配が累積されていってしまうために、正しい勾配の計算ができなくなりす。
つまりこの勾配を初期化する処理は、誤差逆伝播するたび(=バッチを作成するたび)に行う必要があります。以上で、モデル作成→順伝播→損失関数を計算→誤差逆伝播でパラメータ更新までをPytorchで行う流れについて説明しました。
次は実際のデータを使ってモデルを動かしてみようというチュートリアルが待っているので、ぜひトライしてみてください。おわりに
今回私が理解するにあたって色々なURLを参考にさせてもらったのでご紹介です。
どれもオススメです。画像引用元
- Convolutional Neural Networkを実装する
https://qiita.com/icoxfog417/items/5aa1b3f87bb294f84bac- 畳み込みニューラルネットワーク(Convolutional neural network)
https://axa.biopapyrus.jp/deep-learning/cnn.html- Object Recognition with Gradient-Based Learning
http://yann.lecun.com/exdb/publis/pdf/lecun-99.pdf続いて参考URLです
- 畳み込みニューラルネットワーク_CNN(Vol.16)
https://products.sint.co.jp/aisia/blog/vol1-16#toc-3- 畳み込みニューラルネットワークの最新研究動向 (〜2017)
https://qiita.com/yu4u/items/7e93c454c9410c4b5427#fn3- メディカルAI専門コース オンライン講義資料
https://japan-medical-ai.github.io/medical-ai-course-materials/index.html- Convolutional Neural Networks (CNNs / ConvNets)
http://cs231n.github.io/convolutional-networks/- Why do we need to call zero_grad() in PyTorch?
https://discuss.pytorch.org/t/why-do-we-need-to-set-the-gradients-manually-to-zero-in-pytorch/4903

- 投稿日:2020-01-17T17:52:03+09:00
[Python]type関数から型名を文字列で取得してみた
Motive
paizaでRPGゲームとコード学習を融合したコードクロニクルが最近リリースされました。
それで試しに問題をといていったのですが、入門者向けなので基本的な構文についての問題が繰り返し出題される形式だったので難易度は難しくないですが、下記の問題が出題されました。(全く同一ではないです。)
#piの変数型を出力してください pi = 3.14 print("") #int, str, floatのどれかを入力してください。答えは
print("float")とすればいいのですがtype関数がせっかくあるので利用できないかと考えたとです。
Method
シンプルに
type関数を使うと、、、>> type(pi) #<class 'float'>の通りクラスの型が出力されます。
単純に
str()を使えばいいかなと思ったのですが、、、>> str(type(pi)) #"<class 'float'>"
"<class 'float'>"が文字列として出力されるので、期待しているfloatとは異なります。Python documentでtype関数について読んでみると、
name 文字列はクラス名で、
__name__属性になります。と書かれていたのでクラスの属性を取得すれば
floatが取得できます。>> type(pi).__name__ # `float`Digest
#変数型を出力してくださいの問題が出たときは整数・文字列・小数点のいずれかの型でも
type(pi).__name__
と書けば正解になる銀の弾です。Future
コードクロニクルなんすけど、来年度から政府がゴリ押し
で進めているプログラム学習に合わせたアプリゲームだと思うのですが、、、
ゲームバランスを考えつつ問題を作る、問題を作る仕組みを設計すると開発メンバーを揃えないと運用が厳しそうです。
入門者向けであればこの難易度でいいかもしれません。Reference

- 投稿日:2020-01-17T17:08:46+09:00
AWS CDKでVPC作ろうとしたら作れなかったとき
CloudFormationからAWS CDKに乗り換えようとして今日も元気にビルドを失敗したので解決方法をメモっておく。
やりたいこと
私はただAWSのサンプルをビルドしたかっただけなんだ…!!
https://github.com/aws-samples/aws-cdk-examples/tree/master/python/ecs/fargate-load-balanced-service無慈悲なCREATE_FAILED
CloudFormationと違って抽象化が激しいので、一行でVPCを作れるんですよ。
その代わり中身を全く知らない。VPCができる魔法の素晴らしいコード
vpc = ec2.Vpc( self, "MyVpc", max_azs=2 )無慈悲に幻想を打ち砕くCREATE_FAILED
$ cdk deploy ~略~ Do you wish to deploy these changes (y/n)? y ~略~ 9/36 | 7:11:35 AM | CREATE_COMPLETE | AWS::EC2::VPC | MyVpc (MyVpcF9F0CA6F) ~略~ 10/36 | 7:11:38 AM | CREATE_FAILED | AWS::EC2::Subnet | MyVpc/PublicSubnet1/Subnet (MyVpcPublicSubnet1SubnetF123456) Value (ap-northeast-1a) for parameter availabilityZone is invalid. Subnets can currently only be created in the following availability zones: ap-northeast-1d, ap-northeast-1c, ap-northeast-1b. (Service: AmazonEC2; Status Code: 400; Error Code: InvalidParameterValue; Request ID: xxxxx-xxxx-xxxx-xxxx-xxxxxxxxx)彼が私に伝えたかったこと
Subnets can currently only be created in the following availability zones: ap-northeast-1d, ap-northeast-1c, ap-northeast-1b.はい。Subnetを作る時にアベイラビリティーゾーンに振り回されるのはCloudFormationの頃から慣れてます。慣れてるなりにさっさと解決したいのにどうすればいいのか分からず途方に暮れる。
ap-northeast-1aに作ろうとして怒られたんだろうなという事くらいは分かる。逆に言うとなんでそこに作ろうとしたのかまったく知らないんですよこっちは。解決方法
cdk.context.json っていうファイルにavailability-zonesの指定があるので、
ap-northeast-1aがあったら消す。
指定がなかったら下記の内容を追記する。cdk.out/cdk.context.json"availability-zones:account=123456789999:region=ap-northeast-1": [ "ap-northeast-1b", "ap-northeast-1c", "ap-northeast-1d" ]おわり
3時間くらい悩んだ…。つらかった……。
まだまだCDKと仲良くなれない。ところでgitignoreを見るとcdk.outディレクトリがignoreされてるっぽいのですが、この設定って本当はどこに書いておくものなのかご存知の賢者様がいらっしゃれば教えていただけると嬉しいです。
- 投稿日:2020-01-17T15:39:56+09:00
あやまって/usr/local/bin/にあるpythonインタプリタを削除してしまったときの解決策。
https://www.python.org/downloads/source/
ここから削除したpythonインタプリタを見つけてGzipped source tarballからダウンロード。あとはREADME通りにインストールすれば良い。
インストール手順1. ターミナルを開く 2. ./configure 3. make 4. (make test) 5. sudo make install
- 投稿日:2020-01-17T15:39:56+09:00
間違って/usr/local/bin/にあるpythonインタプリタを削除してしまったときの解決策。
わたしの開発環境はLinux(Ubuntu)なのですが突然
aptコマンドが使えなくなり、エラーを確認したところpythonのライブラリに原因があることが判明しました。いくつかエラーが出ており、うろ覚えですが主な原因はpython3-aptだったと思います。30分ほど試行錯誤しましたが駄目だったので次のやり方で入れ直しました。やり方
https://www.python.org/downloads/source/
ここから削除したpythonインタプリタを見つけてGzipped source tarballからダウンロード。あとはREADME通りにインストールすれば良い。
インストール手順1. ターミナルを開く 2. ./configure 3. make 4. (make test) 5. sudo make install
- 投稿日:2020-01-17T15:38:17+09:00
Pythonでリストに含まれる各要素の出現回数を重み付きで数える方法
やりたいこと
以下のような2つのリストが与えられた時に、
aに含まれる各要素の出現回数をbの値で重み付けしてカウントしたい。
Pythonは3.7.5です。a = ["A", "B", "C", "A"] b = [ 1 , 1 , 2 , 2 ] c = hoge(a, b) print(c)出力{"A": 3, "B": 1, "C": 2} # こんな出力がほしい # keyとvalueは別々でもいいけど # (["A", "B", "C"], [3, 1, 2])やりたいことの具体例
書店で今までに売れた本の冊数を、各本ごとにカウントしたいとします。1
ただし、手元にあるのは既に月ごとに集計された複数のテーブルデータのみ。
簡単のために以下の二つのcsvファイルをイメージしてみます。■ 2020_01.csv
本の名前 売れた冊数 Book_A 1 Book_B 2 Book_C 3 ■ 2020_02.csv
本の名前 売れた冊数 Book_A 2 Book_C 1 Book_D 3 方法
以下の2つの手法で出来ました。
どっちが良いか、別の方法など教えていただけると嬉しいです2。
- 全テーブルを結合し、本の名前と一意に対応する
labelを作成し、numpy.bincountで重み付きカウントする。- 各テーブル毎に
collections.Counterオブジェクトを作成し、全テーブルのCounterオブジェクトを足す。1. numpy.bincount を使う
numpyのbincount関数を使うことで、入力に重み付けをしながらカウントすることができます。
参考:numpy.bincountのweightの意味ただし、
np.bincountは負でない整数しか扱えません。numpy.bincount(x, weights=None, minlength=0)
Count number of occurrences of each value in array of non-negative ints.x : array_like, 1 dimension, nonnegative ints
---- Input array.
weights : array_like, optional
---- Weights, array of the same shape as x.
minlength : int, optional
---- A minimum number of bins for the output array.
---- New in version 1.6.0.そこで、
np.bincountを使うために、本の名前と一意に対応するlabelを用意します。
labelの作成にはsklearnのLabelEncoderを使いました。コード
import pandas as pd import numpy as np from sklearn.preprocessing import LabelEncoder # データの準備 df_01 = pd.DataFrame([["Book_A", 1], ["Book_B", 2], ["Book_C", 3]], columns=["Name", "Count"]) df_02 = pd.DataFrame([["Book_A", 2], ["Book_C", 1], ["Book_D", 3]], columns=["Name", "Count"]) # テーブルの結合 df_all = pd.concat([df_01, df_02]) # 中身はこんな感じです。 # | | Name | Count | # |--:|:--|--:| # | 0 | Book_A | 1 | # | 1 | Book_B | 2 | # | 2 | Book_C | 3 | # | 0 | Book_A | 2 | # | 1 | Book_C | 1 | # | 2 | Book_D | 3 | # ラベルエンコーディング(LabelEncoder) from sklearn.preprocessing import LabelEncoder le = LabelEncoder() encoded = le.fit_transform(df_all['Name'].values) # Label列を新規に追加 df_all["Label"] = encoded # np.bincountで重み付きカウント # Label列に加えて、重みとしてCount列を入力します。結果が小数点付きなので、intに変換してます。 count_result = np.bincount(df_all["Label"], weights=df_all["Count"]).astype(int) # resultに対応するNameを取得 name_result = le.inverse_transform(range(len(result))) # 最終的に欲しい辞書を作成 result = dict(zip(name_result, count_result)) print(result)出力{'Book_A': 3, 'Book_B': 2, 'Book_C': 4, 'Book_D': 3}補足
labelの作成はnp.uniqueを使ってもできます。
np.uniqueの引数return_inverseをTrueに設定すると、LabelEncoderのfit_transformと同じ結果を得ることができます。
さらに、対応するName(上記でいうname_result)もまとめて取得できます。# np.uniqueを使ったラベルエンコーディング name_result, encoded = np.unique(df_all["Name"], return_inverse=True) print(encoded) print(name_result)出力[0 1 2 0 2 3] ['Book_A' 'Book_B' 'Book_C' 'Book_D']また、
np.bincountを使わなくてもfor文を回すことで重み付けカウントは可能です3。# 欲しい辞書と同じ長さのゼロ埋め配列を作成 unique_length = len(name_result) count_result = np.zeros(unique_length, dtype=int) # テーブル中で encoded が i に一致する行だけ抜き出し、Countの値の合計を求める。 for i in range(unique_length): count_result[i] = df_all.iloc[encoded==i]["Count"].sum().astype(int) result = dict(zip(name_result, count_result)) print(result)出力{'Book_A': 3, 'Book_B': 2, 'Book_C': 4, 'Book_D': 3}2. collections.Counter を使う
collections.Counterの概要
標準モジュールである
collectionsのCounterモジュールは、重み付けなしのカウントを行うために紹介されることが多いと思います。from collections import Counter a = ["A", "B", "C", "A"] # Counterにリストを与えて、重み付けなしのカウントを行う counter = Counter(a) print(counter) # 要素へのアクセスは辞書と同じ print("A:", counter["A"])出力Counter({'A': 2, 'B': 1, 'C': 1}) A: 2また、今回のように既に集計されている場合、一度辞書型に格納してから渡す事でオブジェクトの作成ができます。
counter = Counter(dict([["Book_A", 1], ["Book_B", 2], ["Book_C", 3]])) print(counter)出力Counter({'Book_A': 1, 'Book_B': 2, 'Book_C': 3})Counterを使った演算
ところで、この
Counterオブジェクトは演算が可能です。
参考:PythonのCounterで要素の出現回数を調べる様々な方法和の演算により、今回の目的が達成できそうです。
from collections import Counter a = ["A", "B", "C", "A"] b = ["C", "D"] counter_a = Counter(a) counter_b = Counter(b) # sum で足し合わせる事が可能 counter_ab = sum([counter_a, counter_b], Counter()) print(counter_ab)出力Counter({'A': 2, 'C': 2, 'B': 1, 'D': 1})コード
from collections import Counter # データの準備 df_01 = pd.DataFrame([["Book_A", 1], ["Book_B", 2], ["Book_C", 3]], columns=["Name", "Count"]) df_02 = pd.DataFrame([["Book_A", 2], ["Book_C", 1], ["Book_D", 3]], columns=["Name", "Count"]) # Counter の作成 counter_01 = Counter(dict(df_01[["Name", "Count"]].values)) counter_02 = Counter(dict(df_02[["Name", "Count"]].values)) # 和を計算 # *補足: sum の第二引数には初期値を設定する事ができます。 # 今回は初期値に空のCounterを設定しています。デフォルトは 0 (int)です。 result = sum([counter_01, counter_02], Counter()) print(result)出力Counter({'Book_C': 4, 'Book_A': 3, 'Book_D': 3, 'Book_B': 2})どうやらカウント数の降順に勝手にソートされるようです。
参考にしたページ
numpy.bincountのweightの意味
カテゴリ変数のエンコーディング【Python】リストの要素の数え上げ、collections.Counterの使い方
PythonのCounterで要素の出現回数を調べる様々な方法
- 投稿日:2020-01-17T13:56:59+09:00
AtCoder Beginner Contest 074 過去問復習
所要時間
感想
実際はバチャコン中に他の用事をしていたので、実際は15分くらい早く終わっています。
今回もDPとWFだったので早く解くことができました。A問題
白色のところを除く。
answerA.pyn=int(input()) print(n*n-int(input()))B問題
個人的にこのくらい長いと問題文を読む気が失せてしまう…。
近い方のロボットのみを順に考えれば良いです。answerB.pyn=int(input()) k=int(input()) x=[int(i) for i in input().split()] cnt=0 for i in range(n): cnt+=min(abs(k-x[i]),x[i]) print(2*cnt)C問題
少し違うタイプのDPだったので一瞬方針に迷ってしまいました。個人的には面白い問題だと思います。
できるだけ濃度を高くしたいのですが、高すぎると溶けきらないので、砂糖と水の量を調節しなければなりません。しかし、うまく量を調整して考えようとすると実装が面倒であると感じました。
ここで、まず、0~3000のうちの100の倍数もの(30通り)しか存在し得ないので水の量を先に決めてから残りの量を砂糖で埋めれば良いと考えました。ここで、水を足す操作がそれぞれ何回あるかを考えても良いのですが、最終的に知りたいのはどの水の量が作れるのかなのでDPでありうる水の量を全てチェックしました。また、水の量を除くと砂糖を入れることができる量がわかるので、水についても同様にDPをしてありうる量を全てチェックしました。
以上のDPにより水と砂糖のそれぞれについてありうる量が全てチェックできたので、それぞれの水の量に対して砂糖をどれだけ入れることができるのかを考えていきます。この際に、砂糖を最大限入れられる量はmin(溶けきる量、ビーカーの量から水の量を引いた量)であることには注意が必要です。
以上のことを実装して以下のコードになります。意外と高速なプログラムだったようなので嬉しいです。answerC.pya,b,c,d,e,f=map(int,input().split()) a=100*a b=100*b dp1=[0]*(f+1) dp2=[0]*(f+1) for i in range(f+1): if i%a==0: if i+a<=f: dp1[i+a]=1 for i in range(f+1): if i==0 or dp1[i]==1: if i+b<=f: dp1[i+b]=1 for i in range(f+1): if i%c==0: if i+c<=f: dp2[i+c]=1 for i in range(f+1): if i==0 or dp2[i]==1: if i+d<=f: dp2[i+d]=1 ans=[-1,-1,-1] for i in range(f+1): if dp1[i]==1: x=min(f-i,(i//100)*e) k=-1 for j in range(x,-1,-1): if dp2[j]==1 or j==0: k=j if ans[0]<100*k/(i+k): ans=[100*k/(i+k),i+k,k] break print(str(ans[1])+" "+str(ans[2]))D問題
昔の問題やたらグラフの問題が多い気がしませんか…。
まず、明らかに正の重み付き無向グラフであることは明らかなのでWF法やダイクストラ法を疑います(そして、だいたいダイクストラ法を使わなくても解けるのでWFを選びます。ダイクストラ法は書くのに時間がかかるので。)。
まず、一番考えやすい、出力が-1となる場合を考えます。この時は、$A_{u,v}$が都市uから都市vへの最短経路の長さではないようなものがu,v存在すると言えるので、WF法をして初めの$A_{u,v}$の状態から更新が起きるu,vが存在することを確かめれば良いです。
次に、出力が-1ではない場合は、任意のu,vについて$A_{u,v}$が都市uから都市vへの最短経路の長さになります。ここで、まずは全ての都市の間に最短経路の道が存在すると仮定してWF法を行います。この時に、都市iから都市jへ直接道を通って行く時と他の都市を経由して行く時の距離が同じである場合(下記のコードのa[i][j]==a[i][k]+a[k][j])を考えます。この時は他の都市を経由しても最短経路を実現できるのでその都市の間に道が存在する必要はないことがわかります。したがって、このような場合の道は削除していくことができます(僕はその道に1とマークをつけました。)。
このマークをつけておけば最後にマークがついてない部分の道のみを数え上げれば良いので以下のようなコードになります(求めるのは道の合計の距離であることと最後に2で割ることを忘れずに)。
ちなみに、C++を使ったのは普通にWF法をすると間に合わないからです。気が向いたらPythonでも気合いで通します。answerD.cc#include<iostream> #include<vector> #include<cmath> using namespace std; typedef long long ll; signed main(){ ll n;cin >> n; vector< vector<ll> > a(n,vector<ll>(n,0)); vector< vector<ll> > b(n,vector<ll>(n,0)); for(ll i=0;i<n;i++)for(ll j=0;j<n;j++) cin >> a[i][j]; bool f=false; for(ll k=0;k<n;k++){ for(ll i=0;i<n;i++){ for(ll j=0;j<n;j++){ if(a[i][j]>a[i][k]+a[k][j]){ f=true; }else if(i!=j and i!=k and j!=k and a[i][j]==a[i][k]+a[k][j]){ b[i][j]=1; } } } } if(f){ cout << -1 << endl; }else{ ll cnt=0; for(ll i=0;i<n;i++){ for(ll j=0;j<n;j++){ if(b[i][j]==0){ cnt+=a[i][j]; } } } cout << ll(cnt/2) << endl; } }

- 投稿日:2020-01-17T13:14:49+09:00
「統計」と「機械学習」の違いの整理で多くの事業会社で「機械学習」が使えない理由が視えてきた!
統計と機械学習って結局何が違うの?なんで今日から機械学習で予測して金儲けできないの?
機械学習を勉強し始めるとおそらく誰もが疑問に思う。そして、なんで事業会社の多くが日々の業務で今日から使えないの?っていう疑問も出てくる。いろいろな文献があるがいまいち理解に困ったので自分なりに整理しなおした資料。情報を組み合わせてかなり自論を入れています。
This article explains why many companies cannot use machine learning approaches to drive business starting today...まずは統計と機械学習の考え方や向き不向きの違いを表にまとめてみた
多くの人が言及しているが互いに関連しているとはいえ、最終目的が異なる。「機械学習」は予測や判断は行うもののなぜそうなったのかは一般的にはブラックボックスだ。「統計」で行う予測や判断は、なぜそういう結論になったのかの理由付けが重要になり(理由付けを行うための学問であり)、理由はホワイトボックスとなっている。
なぜ多くの事業会社が「機械学習のアプローチを使えない」のか?
要因の整理に力を入れることが目的の「統計」は社会科学の課題解決に向いており、「機械学習」は自然科学の予測やロボットでの自動処理に向いている。と、整理結果から私は考えるに至ったし現実はそうなっている。売上に変動する要因を洗い出せ、要因に対して売上アップの施策を考えろなんていうテーマがあればこれは影響度の整理を行う「統計」の話(社会科学の問題解決)で「機械学習」でどうこうなる話ではない。(なお、BIのAI機能として提供されている影響分析の機能があるが、これは影響しているであろう項目の指定を行うことが必要で、関連して行われる計算は「統計」のエリアだ。ECサイトのおすすめ商品表示も他の人が買ったことのある組み合わせを表示させているだけのことが多く、機械学習上の予測というよりシンプルなクエリーに近いことが多いはずだ。)一方で台風の進路予測や地震予測(まだ無理だと思うが)、画像認識や音声認識などのロボット処理は機械学習のアプローチになる。例えば台風の進路/強度予測は進路/強度さえ当たれば別に気温、海水温、ジェット気流など何が影響してようがしていまいがモデルが統計学的に綺麗であろうが嫌われようが(気温と海水温は多重共線性、multicollinearityにより相互連動するから統計モデルという意味では両方同時に使わない方が好ましいはずですが)結果さえ正しければ国民には関係ない、興味関心がない話だからだ。
多くの事業会社はセールス、マーケティング、ファイナンス、人事といったエリアの「社会科学」に興味があるのであって「自然科学」や「ロボット」に興味がないことが多い。
(※マーケティングオートメーションは自動化を考えるわけですから、この領域はロボットと言えるかも。限定的ですが。)さらに、なぜ多くの事業会社が「統計も機械学習も使えない」のか?
●データがない。これに尽きる。
Kaggleコンペであるような綺麗なデータセットは一般的な事業会社では持ち合わせていない。
(1)主要因であるはずの属性情報データがない。
例えば物やサービスを購入しているお客様の過去、最新、未来の属性情報がない。属性情報は変動しており過去の時は過去の属性、現在の時は現在の属性。例としてクレジットカード会社の例として顧客情報の最新情報が手に入る与信を自動化は比較的楽だが、10年後どうなっているかの予測はまずできない。学歴だの家族構成だの年収だの状況はコロコロ変わるが最新の属性情報をいつも正しく管理しているわけではないので、結果としてクレジットカードを利用している人が誰なのか(属性として誰なのか)クレジットカード会社は(大量に多くの属性の個人情報を持っている企業ですら)ほとんどわかっていない。一回入手したら変わらない性別、年齢といった変わらない情報の最新はいつも持っているけど顧客属性を考えるとあまりに限られた情報だ。こんな状態で過去、現在、未来の消費動向などをつなげようとするのは無理だ。(2)トランザクションデータとマスタデータが紐づいていない。
マスタデータ(品番など)がコロコロ変わり過去、現在、未来がつながらない。(3)社内情報ですら(全ての)戦略や施策を網羅的に統計用、機械学習用にデータ化できない。
企業戦略、施策によって(例として広告、キャンペーンなど)仕入や売上に影響するのはアタリマエの話であるのだが、統計や機械学習用にデータの受け渡しなどほぼできない。ピンポイントで施策が功を奏したか否かくらいの個別分析はできても企業全体でなんていう話は無理。でも経営者はそれを欲しがる。結論
●自然科学やロボット処理/処理自動化に興味関心がない人、会社は「機械学習」に入り込む多大なメリットはなさそう(各々がそちらの方面で潰しを利かすのなら別)
●分析に用いる適切なデータがなければ「統計」も「機械学習」も旗を振ったところで無意味、無駄な労力
●前提となる分析用データ整備がされていない場合は、データ入手/整備から入ることが必要
●根本、本質を理解していないデータサイエンティスト職の今後が危うい!成果出せずに結果...

- 投稿日:2020-01-17T12:31:48+09:00
Cygwinにpyenvをインストールした時の奮戦記
Cygwinに、pyenvをインストールしたときの記録。pythonのバージョンでインストールできたり、できなかったりした。
環境:Cygwin(Setup version 2.900(64 bit))
- Cygwinにpyenvをインストール
CygwinのSetupにはpyenvのパッケージが見つからなかったため、gitでインストールした。$ git clone https://github.com/pyenv/pyenv.git ~/.pyenv
- 環境変数の設定
$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_bashrc $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_bashrc $ echo 'eval "$(pyenv init -)"' >> ~/.bash_bashrc $ source ~/.bash_bashrc
- pyenvでインストールできるpythonの確認。
$ pyenv install --list Available versions: 2.1.3 2.2.3 2.3.7 以下略
- pythonのインストール
初めにpython 3.7.6をインストールした。$ pyenv install 3.7.6 Downloading Python-3.7.6.tar.xz... -> https://www.python.org/ftp/python/3.7.6/Python-3.7.6.tar.xz Installing Python-3.7.6... WARNING: The Python bz2 extension was not compiled. Missing the bzip2 lib? WARNING: The Python sqlite3 extension was not compiled. Missing the SQLite3 lib? Installed Python-3.7.6 to /home/xxxx/.pyenv/versions/3.7.6インストールは指定バージョンのpythonを自分のpyenv環境にインストールするため、時間がかかる。自分のPCで約10分かかった。
WARNINGが出たので次のように対応した。
WARNING: The Python bz2 extension was not compiled. Missing the bzip2 lib?の対応
CygwinのSetupで libbz2-devel というパッケージをインストールし、
pyenv uninstall -f 3.7.6
で、アンインストールしてから再度
pyenv install 3.7.6
を実行し解決。WARNING: The Python sqlite3 extension was not compiled. Missing the SQLite3 lib?の対応
CygwinのSetupでsqlite3関係のパッケージをインストール(最終的にはsqlite3関係の全てのパッケージをインストール)したが、WARNINGは解決されなかった。
そこでCygwinのSetupでsqlite3関係のパッケージを全てアンインストール、SQLiteダウンロードサイト(※1)からソース(sqlite-autoconf-3300100.tar.gz)をダウンロード。解凍、./configure、make、make install を実行してSQLite3をインストール(インストール先はデフォルトの/usr/local)して再度 pyenv install して解決。※1https://www.sqlite.org/download.html
- python 3.6.10のインストール
以下のようにエラーになった。$ pyenv install 3.6.10 Downloading Python-3.6.10.tar.xz... -> https://www.python.org/ftp/python/3.6.10/Python-3.6.10.tar.xz Installing Python-3.6.10... BUILD FAILED (CYGWIN_NT-6.1 3.1.2(0.340/5/3) using python-build 1.2.16-1-g4500a33c) Inspect or clean up the working tree at /tmp/python-build.20200114100336.19695 Results logged to /tmp/python-build.20200114100336.19695.log Last 10 log lines: PyStructSequence_SET_ITEM(result, 6, PyLong_FromLong(si->si_band)); ^ ./Include/tupleobject.h:62:75: 備考: in definition of macro ‘PyTuple_SET_ITEM’ #define PyTuple_SET_ITEM(op, i, v) (((PyTupleObject *)(op))->ob_item[i] = v) ^ ./Modules/signalmodule.c:979:5: 備考: in expansion of macro ‘PyStructSequence_SET_ITEM’ PyStructSequence_SET_ITEM(result, 6, PyLong_FromLong(si->si_band)); ^~~~~~~~~~~~~~~~~~~~~~~~~ make: *** [Makefile:1782: Modules/signalmodule.o] エラー 1 make: *** 未完了のジョブを待っています...../Modules/signalmodule.cでコンパイルエラーが発生している。そこでインストールが成功したPython-3.7.6とコンパイルエラーが発生したPython-3.6.10の./Modules/signalmodule.cソースを比べてみた。
◎python-3.6.10の./Modules/signalmodule.cでエラーになった箇所 PyStructSequence_SET_ITEM(result, 6, PyLong_FromLong(si->si_band)); ◎python-3.7.6の./Modules/signalmodule.cで同じ場所 #ifdef HAVE_SIGINFO_T_SI_BAND PyStructSequence_SET_ITEM(result, 6, PyLong_FromLong(si->si_band)); #else PyStructSequence_SET_ITEM(result, 6, PyLong_FromLong(0L)); #endif上を見ると、python-3.7.6ではHAVE_SIGINFO_T_SI_BANDスイッチで処理を切り分けているのがわかる。
python-3.7.6のインストールパッケージのconfigureを見ると、Cygwinのヘッダーを調べsiginfo_t構造体にsi_bandが存在すればHAVE_SIGINFO_T_SI_BANDスイッチを1に設定し、存在していなければなにも無処理であった(Issue #21085の対応である)。従って、python-3.7.6ではコンパイルエラーにならなかった。
実際には Cygwinのsiginfo_t 構造体に si_band は存在しない。
ということで python-3.6.10では無条件にsiginfo_tのsi_bandを参照しているのでエラーになった。
調べたら環境変数 PYTHON_BUILD_CACHE_PATH を設定し、キャッシュしたソースをインストールできるという記事(※2)を見つけたので、それを利用し python-3.6.10 の ./Modules/signalmodule.c を python-3.7.6 のように変更してそれをインストールすればよいのではと考えた。※2 https://github.com/pyenv/pyenv/tree/master/plugins/python-build
実際には以下のような手順を行ってみた。
$ pyenv install -k 3.6.10 *1 ⇒ エラーになるが、$PYENV_ROOT/sources/3.6.10 にダウンロードした Python-3.6.10.tar.xz が残る。 [手操作] Python-3.6.10.tar.xz を適当な場所で、解凍・展開。 エラーになった./Modules/signalmodule.cをpython-3.7.6のコードのように修正し、 新たなPython-3.6.10.tar.xzを作成する。 $ mkdir $PYENV_ROOT/cache *2 [手操作]先ほど新たに作成した Python-3.6.10.tar.xz を $PYENV_ROOT/cache にコピーする。 $ PYTHON_BUILD_CACHE_PATH=$PYENV_ROOT/cache pyenv install 3.6.10 *3*1 -kは、ソースを保存するオプション。
*2 キャッシュ用ディレクトリを作成
*3 キャッシュにあるソースをインストールする( python-build を参照)しかしそれでも
Downloading Python-3.6.10.tar.xz...
-> https://www.python.org/ftp/python/3.6.10/Python-3.6.10.tar.xz
と表示され、サーバーからダウンロードされる。
なお、pythonのサーバーからダウンロードしたパッケージをキャッシュに置いてキャッシュを用いる方法で install したら、Downloadはされなかった。
さらに調べたら、Join GitHub todayの記事(※3)で、インストールするパッケージは、pyenvで定義されている正しいSHA256 checksumでなければならないらしい。
もうこれ以上は、大変なのでこの方法によるPython-3.6.10のインストールは断念。※3 https://github.com/pyenv/pyenv/issues/563
インストールのコマンドは
$ pyenv help install Usage: pyenv install [-f] [-kvp] <version> pyenv install [-f] [-kvp] <definition-file> pyenv install -l|--list pyenv install --version -l/--list List all available versions -f/--force Install even if the version appears to be installed already -s/--skip-existing Skip if the version appears to be installed already python-build options: -k/--keep Keep source tree in $PYENV_BUILD_ROOT after installation (defaults to $PYENV_ROOT/sources) -p/--patch Apply a patch from stdin before building -v/--verbose Verbose mode: print compilation status to stdout --version Show version of python-build -g/--debug Build a debug versionで、他に<definition-file>を指定する方法と、--patchでパッチしてインストールする方法があるようだが、有用な情報を見つけることができずギブアップ。時間があれば pyenv のソースを見てみたいが!
本家に修正依頼をすればいいのだろうけど、英語駄目だし、やったこともないし流儀も分からないので無理。
他にpython 2.7.17とpython 3.5.9のインストールしたがエラー発生。深追いはしていない。
python 3.8.1のインストールは成功。
$ pyenv install 3.8.1 Downloading Python-3.8.1.tar.xz... -> https://www.python.org/ftp/python/3.8.1/Python-3.8.1.tar.xz Installing Python-3.8.1... Installed Python-3.8.1 to /home/xxxx/.pyenv/versions/3.8.1 $ pyenv versions * system (set by /home/xxxx/.pyenv/version) 3.7.6 3.8.1
- まとめ。
python 2.7.17 失敗
python 3.5.9 失敗
python 3.6.10 失敗
python 3.7.6 成功
python 3.8.1 成功Cygwinにパッケージを導入すのは難しい。
苦労している方々の参考になればうれしい。
また、こうすればインストールできるよという情報をいただければ幸いです。以上
- 投稿日:2020-01-17T11:43:39+09:00
indexのマージについて学んだので,復習します.
はじめに
現在,UdemyでPythonを使ったデータ分析について勉強しています.今回は,勉強をしていて難しいと感じた『indexのマージ』について復習がてらに投稿してみました.(Jupiter notebookを使用)
用いたライブラリ
import pandas as pd from pandas import Series,DataFrame import numpy as npDataFrameを2つ用意する
df_left = DataFrame({"key":["X","Y","Z","X","Y"], "data":range(5)}) df_right = DataFrame({"group_data":[10,20]},index=["X","Y"])結果
df_left
data key 0 0 x 1 1 Y 2 2 Z 3 3 X 4 4 Y df_right
group_data X 10 Y 20 pd.merge(df_left,df_right,left_on="key",right_index=True)
key group_data 0 x 10 3 x 10 1 y 20 4 y 20 結果の内容
pd.merge(df_left,df_right,left_on="key",right_index=True)
は,df_leftとdf_rightの2つのデータをマージし,left_on="key"は,df_leftのkeyを指し,right_index=Trueは,df_rightのインデックス部分を指す.おわりに
今回は,初めてのQiitaへの投稿ということもあり,見づらいかもしれません.今後は,Pythonの勉強をすすめながら,Qiitaへのアウトプットを増やしていこうと考えています.
それでは・・・
- 投稿日:2020-01-17T11:41:30+09:00
Qiita から Hugo 用の markdown を生成するやつ
- 投稿日:2020-01-17T09:41:06+09:00
PythonとC++の順列生成の方法
この記事で解説したAtCoder073のD問題においてn!(n<=8)通りの順列を生成してそのそれぞれについて操作を行うという問題がありました。順列生成はAtCoderで良く出ますが、書き方を忘れがちなのでここでまとめておきます。
[1]Pythonの場合
itertoolsモジュールにあるpermutationsを用います。
ここでは0~3が入った配列についてその順序を並べ替えた順列を全て生成させて考えます。>>> import itertools >>> t=[i for i in range(4)] >>> itertools.permutations(t) <itertools.permutations object at 0x104dc0af0> >>> list(itertools.permutations(t)) [(0, 1, 2, 3), (0, 1, 3, 2), (0, 2, 1, 3), (0, 2, 3, 1), (0, 3, 1, 2), (0, 3, 2, 1), (1, 0, 2, 3), (1, 0, 3, 2), (1, 2, 0, 3), (1, 2, 3, 0), (1, 3, 0, 2), (1, 3, 2, 0), (2, 0, 1, 3), (2, 0, 3, 1), (2, 1, 0, 3), (2, 1, 3, 0), (2, 3, 0, 1), (2, 3, 1, 0), (3, 0, 1, 2), (3, 0, 2, 1), (3, 1, 0, 2), (3, 1, 2, 0), (3, 2, 0, 1), (3, 2, 1, 0)] >>> list(itertools.permutations(t,2)) [(3, 2), (3, 1), (3, 0), (2, 3), (2, 1), (2, 0), (1, 3), (1, 2), (1, 0), (0, 3), (0, 2), (0, 1)]上記のようにイテラブルなオブジェクトである配列(permutationsの第一引数はイテラブルなオブジェクト)の順序を並べ替えてタプルに格納した順列の全通りが生成されているのが見てとれます。
また、permutationsの第二引数では$ _n P _r $の式におけるrを指定することができます(デフォルトではr=nで、ここではr=2より$ _n P _2 $が求まります。)。[2]C++の場合
algorithmライブラリにあるnext_permutationを使います。
ここでも0~3が入った配列についてその順序を並べ替えた順列を全て生成させて考えます。
Pythonでは順列を全て生成して考えていましたが、C++では昇順ソートしたものを初めの順列としてnext_permutation関数を適用することでその次の順列を生成するという方法をとります。そして、next_permutation関数を適用する順列が最後の順列(降順ソートしたもの)であった場合、初めの順列へと戻ります。また、このとき、next_permutation関数を適用する順列が最後の順列でない場合はfalseを最後の順列の場合はtrueを返すのでその返り値を利用してdo-while文を用いることで全ての順列に対してなんらかの操作をすることができます。
さらに、do-while文を用いる場合は最初の順列から始めないと全ての順列に対する操作ができませんが、順列が何通りあるかをあらかじめ計算しておけばその回数分だけnext_permutation関数を適用することで全ての順列に対してなんらかの操作をすることができます。#include <iostream> #include <algorithm> #include <vector> using namespace std; int main() { int n=4; vector<int> v(n); //1刻みで格納できる関数、便利 iota(v.begin(), v.end(), 0); do{ //vは次の順列になる for(int i=0;i<n;i++){ //なんらかの操作 } }while(next_permutation(v.begin(),v.end())); }[3]まとめ
PythonとC++それぞれの場合の順列生成について最後に重要な点をまとめておきます。
①Pythonの場合
・itertoolsモジュールのpermutationsを使う
・全通りの順列をタプルで生成する(非破壊的)
・それぞれの順列にはfor文でアクセスする②C++の場合
・algorithmライブラリのnext_permutationを使う
・次の順列に置き換える(破壊的)
・昇順ソートした順列から始めるときはdo_while文でアクセス
それ以外の順列から始めるときは順列の数を計算してfor分でアクセス
- 投稿日:2020-01-17T08:06:44+09:00
Pythonで、デザインパターン「Bridge」を学ぶ
GoFのデザインパターンを学習する素材として、書籍「増補改訂版Java言語で学ぶデザインパターン入門」が参考になるみたいですね。
ただ、取り上げられている実例は、JAVAベースのため、自分の理解を深めるためにも、Pythonで同等のプラクティスに挑んでみました。
■ Bridge(ブリッジ・パターン)
Bridgeパターン(ブリッジ・パターン)とは、GoF(Gang of Four; 4人のギャングたち)によって定義されたデザインパターンの1つである。 「橋渡し」のクラスを用意することによって、クラスを複数の方向に拡張させることを目的とする。
□ 備忘録
Bridgeパターンは、機能のクラス階層と実装のクラス階層を橋渡しするらしいです。
(1) 機能のクラス階層とは?
あるクラスに対して、新しい機能を追加したい場合、新しくサブクラスを定義した上で、メソッドを実装します。
既存のスーパークラスと、新たに定義したサブクラスの関係が、"機能のクラス階層"になります。
一般的には、以下のような関係を想定します。
- スーパークラスは基本的な機能を持っている
- サブクラスで新しい機能を追加する
(2) 実装のクラス階層とは?
新しい実装を追加したい場合、抽象クラスから派生した具体的なサブクラスを定義した上で、メソッドを実装します。
既存の抽象クラスと、新たに派生した具体的なサブクラスの関係が、"実装のクラス階層"になります。
一般的には、以下のような関係を想定します。
- 抽象クラスでは、抽象メソッドによってインタフェースを規定している
- 派生したサブクラスは具象メソッドによってそのインタフェースを実装する
■ "Bridge"のサンプルプログラム
実際に、Bridgeパターンを活用したサンプルプログラムを動かしてみて、次のような動作の様子を確認したいと思います。
機能のクラス階層と実装のクラス階層を橋渡しを想定したサンプルになります。
DisplayFuncと、DisplayStringImplの橋渡しを経て、文字列を表示するDisplayCountFuncと、DisplayStringImplの橋渡しを経て、文字列を表示するDisplayCountFuncと、DisplayStringImplの橋渡しを経て、文字列を表示するDisplayRandomFuncと、DisplayStringImplの橋渡しを経て、文字列を5回繰り返して表示するDisplayRandomFuncと、DisplayStringImplの橋渡しを経て、文字列をランダム回数繰り返して表示するDisplayFuncと、DisplayTextfileImplの橋渡しを経て、テキストファイルの内容を表示する$ python Main.py +-----------+ |Hello Japan| +-----------+ +-----------+ |Hello Japan| +-----------+ +--------------+ |Hello Universe| +--------------+ +--------------+ |Hello Universe| |Hello Universe| |Hello Universe| |Hello Universe| |Hello Universe| +--------------+ +--------------+ |Hello Universe| |Hello Universe| |Hello Universe| |Hello Universe| +--------------+ aaa bbb ccc ddd eee fff gggサンプルプログラムを動かしただけだと、いまいち、何がしたいのかよく分かりませんね。
つづいて、サンプルプログラムの詳細を確認していきます。■ サンプルプログラムの詳細
Gitリポジトリにも、同様のコードをアップしています。
https://github.com/ttsubo/study_of_design_pattern/tree/master/Bridge
- ディレクトリ構成
. ├── Main.py ├── bridge │ ├── __init__.py │ ├── function │ │ ├── __init__.py │ │ ├── display_count_func.py │ │ ├── display_func.py │ │ └── display_random_func.py │ └── implement │ ├── __init__.py │ ├── display_impl.py │ ├── display_string_impl.py │ └── display_textfile_impl.py └── test.txt(1) Abstraction(抽象化)の役
Implement役のメソッドを使って、基本的な機能だけが実装されているクラスです。
サンプルプログラムでは、DisplayFuncクラスが、この役を努めます。bridge/function/display_func.pyclass DisplayFunc(object): def __init__(self, impl): self.impl = impl def open(self): self.impl.rawOpen() def print_body(self): self.impl.rawPrint() def close(self): self.impl.rawClose() def display(self): self.open() self.print_body() self.close()(2) RefinedAbstraction(改善した抽象化)の役
Abstraction役に対して機能を追加した役です。
サンプルプログラムでは、DisplayCountFuncクラスと、DisplayRandomFuncクラスが、この役を努めます。bridge/function/display_count_func.pyfrom bridge.function.display_func import DisplayFunc class DisplayCountFunc(DisplayFunc): def __init__(self, impl): super(DisplayCountFunc, self).__init__(impl) def multiDisplay(self, times): self.open() for _ in range(times): self.print_body() self.close()bridge/function/display_random_func.pyimport random from bridge.function.display_func import DisplayFunc class DisplayRandomFunc(DisplayFunc): def __init__(self, impl): super(DisplayRandomFunc, self).__init__(impl) def randomDisplay(self, times): self.open() t = random.randint(0, times) for _ in range(t): self.print_body() self.close()(3) Implementor(実装者)の役
Abstraction役のインタフェースを実装するためのメソッドを規定する役です。
サンプルプログラムでは、DisplayImplクラスが、この役を努めます。bridge/implement/display_impl.pyfrom abc import ABCMeta, abstractmethod class DisplayImpl(metaclass=ABCMeta): @abstractmethod def rawOpen(self): pass @abstractmethod def rawPrint(self): pass @abstractmethod def rawClose(self): pass(4) ConcreteImplementor(具体的な実装者)の役
具体的に
Implement役のインタフェースを実装する役です。
サンプルプログラムでは、DisplayStringImplクラスと、DisplayTextfileImplが、この役を努めます。bridge/implement/display_string_impl.pyfrom bridge.implement.display_impl import DisplayImpl class DisplayStringImpl(DisplayImpl): def __init__(self, string): self.string = string self.width = len(string) def rawOpen(self): self.printLine() def rawPrint(self): print("|{0}|".format(self.string)) def rawClose(self): self.printLine() print("") def printLine(self): line = '-' * self.width print("+{0}+".format(line))bridge/implement/display_textfile_impl.pyfrom bridge.implement.display_impl import DisplayImpl class DisplayTextfileImpl(DisplayImpl): def __init__(self, filename): self.filename = filename def rawOpen(self): filename = self.filename self.f = open(filename, "r") def rawPrint(self): data = self.f.read() data = data.split('\n') for l in data: print(l) def rawClose(self): self.f.close()(5) Client(依頼人)の役
サンプルプログラムでは、
startMainメソッドが、この役を努めます。Main.pyfrom bridge.function.display_func import DisplayFunc from bridge.function.display_count_func import DisplayCountFunc from bridge.function.display_random_func import DisplayRandomFunc from bridge.implement.display_string_impl import DisplayStringImpl from bridge.implement.display_textfile_impl import DisplayTextfileImpl def startMain(): d1 = DisplayFunc(DisplayStringImpl("Hello Japan")) d2 = DisplayCountFunc(DisplayStringImpl("Hello Japan")) d3 = DisplayCountFunc(DisplayStringImpl("Hello Universe")) d4 = DisplayRandomFunc(DisplayStringImpl("Hello Universe")) d5 = DisplayFunc(DisplayTextfileImpl("test.txt")) d1.display() d2.display() d3.display() d3.multiDisplay(5) d4.randomDisplay(5) d5.display() if __name__ == '__main__': startMain()■ 参考URL


- 投稿日:2020-01-17T06:30:30+09:00
言語処理100本ノック-89:加法構成性によるアナロジー
言語処理100本ノック 2015の89本目「加法構成性によるアナロジー」の記録です。
「加法構成性」ということでベクトル演算をして結果を求めます。有名な「王 + 女性 - 男性 = 王女」の計算ですね。「上司 - 有能 = ?」のような計算で、世の中のいろいろなことで試してみたい演算です。参考リンク
リンク 備考 089.加法構成性によるアナロジー.ipynb 回答プログラムのGitHubリンク 素人の言語処理100本ノック:89 言語処理100本ノックで常にお世話になっています 環境
種類 バージョン 内容 OS Ubuntu18.04.01 LTS 仮想で動かしています pyenv 1.2.15 複数Python環境を使うことがあるのでpyenv使っています Python 3.6.9 pyenv上でpython3.6.9を使っています
3.7や3.8系を使っていないことに深い理由はありません
パッケージはvenvを使って管理しています上記環境で、以下のPython追加パッケージを使っています。通常のpipでインストールするだけです。
種類 バージョン numpy 1.17.4 pandas 0.25.3 課題
第9章: ベクトル空間法 (I)
enwiki-20150112-400-r10-105752.txt.bz2は,2015年1月12日時点の英語のWikipedia記事のうち,約400語以上で構成される記事の中から,ランダムに1/10サンプリングした105,752記事のテキストをbzip2形式で圧縮したものである.このテキストをコーパスとして,単語の意味を表すベクトル(分散表現)を学習したい.第9章の前半では,コーパスから作成した単語文脈共起行列に主成分分析を適用し,単語ベクトルを学習する過程を,いくつかの処理に分けて実装する.第9章の後半では,学習で得られた単語ベクトル(300次元)を用い,単語の類似度計算やアナロジー(類推)を行う.
なお,問題83を素直に実装すると,大量(約7GB)の主記憶が必要になる. メモリが不足する場合は,処理を工夫するか,1/100サンプリングのコーパスenwiki-20150112-400-r100-10576.txt.bz2を用いよ.
今回は「1/100サンプリングのコーパスenwiki-20150112-400-r100-10576.txt.bz2」を使っています。
89. 加法構成性によるアナロジー
85で得た単語の意味ベクトルを読み込み,vec("Spain") - vec("Madrid") + vec("Athens")を計算し,そのベクトルと類似度の高い10語とその類似度を出力せよ.
回答
回答プログラム 089.加法構成性によるアナロジー.ipynb
import numpy as np import pandas as pd # 保存時に引数を指定しなかったので'arr_0'に格納されている matrix_x300 = np.load('085.matrix_x300.npz')['arr_0'] print('matrix_x300 Shape:', matrix_x300.shape) group_t = pd.read_pickle('./083_group_t.zip') # 'vec("Spain") - vec("Madrid") + vec("Athens") のベクトル計算 vec = matrix_x300[group_t.index.get_loc('Spain')] \ - matrix_x300[group_t.index.get_loc('Madrid')] \ + matrix_x300[group_t.index.get_loc('Athens')] vec_norm = np.linalg.norm(vec) # コサイン類似度計算 def get_cos_similarity(v2): # ベクトルが全てゼロの場合は-1を返す if np.count_nonzero(v2) == 0: return -1 else: return np.dot(v1, v2) / (v1_norm * np.linalg.norm(v2)) cos_sim = [get_cos_similarity(matrix_x300[i]) for i in range(len(group_t))] print('Cosign Similarity result length:', len(cos_sim)) # インデックスを残してソート cos_sim_sorted = np.argsort(cos_sim) # 昇順でソートされた配列の1番最後から-10(-11)までを1件ずつ出力 for index in cos_sim_sorted[:-11:-1]: print('{}\t{}'.format(group_t.index[index], cos_sim[index]))回答解説
今回のメインの部分です。
ただ足し算、引き算をしているだけです。# 'vec("Spain") - vec("Madrid") + vec("Athens") のベクトル計算 vec = matrix_x300[group_t.index.get_loc('Spain')] \ - matrix_x300[group_t.index.get_loc('Madrid')] \ + matrix_x300[group_t.index.get_loc('Athens')]最後の出力結果です。
Spainから首都のマドリッドを引いて、アテネを足しているので、意味としてはギリシャが正解なのでしょうか。
ギリシャは12位でコサイン類似度は0.686でした。Spain 0.8178213952646727 Sweden 0.8071582503798717 Austria 0.7795030693787409 Italy 0.7466099164394225 Germany 0.7429125848677439 Belgium 0.729240312232219 Netherlands 0.7193045612969573 Télévisions 0.7067876635156688 Denmark 0.7062857691945504 France 0.7014078181006329
- 投稿日:2020-01-17T01:26:52+09:00
【Django×Plotly】Plotlyで作るグラフ等をDjangoで作るWEBアプリに使う
本記事について
Plotlyでガントチャートを作成する方法と、それをDjangoのテンプレートに配置して表示する方法を書きます。
現在作っているWEBアプリにガントチャートを導入しようと思ったのが経緯です。
スマホで扱いづらかったり、期待した効果を発揮しなかったのが理由で導入するのをやめようかな...と悩んでいますが、遊んでいて非常に面白かったため、記録しておきたいと思います。先に結論
plotly.figure_factory.create_gantt()を読み込むfig = ff.create_gantt(df)でガントチャートのオブジェクトを作成するplotly.offline.offline.plot()を読み込むgantt = plot(fig, output_type='div', include_plotlyjs=False)でグラフとグラフを描画するスクリプトを含むhtmlコードの文字列を取得するautoescapeとendautoescapeでエスケープ機能をoffにした上で、4.で取得した文字列をテンプレートにわたすPlotlyとは?
オンラインデータの分析や視覚化のツールを開発している会社で、JavaScriptやPython、Rで使えるグラフ作成ライブラリを提供しています。
Python用のライブラリを使えば、例えば以下のリンク先のようなグラフを描画することができます。
Plotly Python Open Source Graphing Libraryガントチャートの作成方法
以下のリンク先に例が記載されています。
Gantt Charts in Pythonsimpleなsampleimport plotly.figure_factory as ff # 日時のフォーマットは `2000-01-01 00:00:00` df = [dict(Task="Job A", Start='2009-01-01', Finish='2009-02-28'), dict(Task="Job B", Start='2009-03-05', Finish='2009-04-15'), dict(Task="Job C", Start='2009-02-20', Finish='2009-05-30')] fig = ff.create_gantt(df) fig.show()
データフレームもしくはリスト型のデータを使います。
キーが
Tast,Start,Finishの辞書型が、ガントチャートのバー1本分に相当し、それをリスト(変数figとする)に格納します
ff.create_gantt()の第一引数に変数figセットすることで、ガントチャートのオブジェクトが作成されます。
.show()はブラウザを起動して、引数に入れたオブジェクトのガントチャートを描画します。又、
create_gantt()には様々な引数があり、グラフをカスタマイズすることが可能です。
(カラーバーを表示したり、色を変えたり、太さを変えたりなどなど)
create_gantt(df, colors=None, index_col=None, show_colorbar=False, reverse_colors=False, title='Gantt Chart', bar_width=0.2, showgrid_x=False, showgrid_y=False, height=600, width=None, tasks=None, task_names=None, data=None, group_tasks=False, show_hover_fill=True)help(ff.create_gantt)で説明が見られます。
作成したグラフをHTMLとして取得する
上記の
.show()の代わりにplotly.offline.offline.plot()を使うことで、HTML形式のファイルを作成したり、divで囲まれたHTMLのコードを出力してくれます。Djangoのテンプレートに配置したい場合は、こちらの関数を使います。sample2from plotly.offline import plot df = [dict(Task="Job A", Start='2009-01-01', Finish='2009-02-28'), dict(Task="Job B", Start='2009-03-05', Finish='2009-04-15'), dict(Task="Job C", Start='2009-02-20', Finish='2009-05-30')] fig = ff.create_gantt(df) plot_fig = plot(fig, output_type='div', include_plotlyjs=False) print(plot_fig)↓
plot()にも様々な引数があります。
Chart StudiotというGUIでグラフをカスタマイズできるサービスへのリンクを表示するか否か・アニメーションを自動再生するかなどなど。
plot(figure_or_data, show_link=False, link_text='Export to plot.ly', validate=True, output_type='file', include_plotlyjs=True, filename='temp-plot.html', auto_open=True, image=None, image_filename='plot_image', image_width=800, image_height=600, config=None, include_mathjax=False, auto_play=True, animation_opts=None)Djangoでplotlyを使う際は、主に
include_plotlyjsとoutput_typeを設定しますoutput_type
グラフと、グラフを生成するスクリプトを含むHTMLを、どのように出力するかの設定。
output_type='div'
グラフとグラフを生成するスクリプトを含むHTMLのコード(divに囲まれている)が、文字列で出力される
output_type=file
グラフとグラフを生成するスクリプトを含むHTMLファイルが生成されるinclude_plotlyjs
plotly.jsライブラリのソースコードをどのように読み込むか設定できます。
include_plotlyjs=False
plotly.js CDNを参照するコードは含まれない
output_type = 'div'で出力したコードが、plotly.jsを読み込んでいるHTMLドキュメント内に配置されれば利用可能
include_plotlyjs=con
plotly.js CDNを参照するスクリプトタグが出力に含まれまれる。
include_plotlyjs=True
plotly.jsのソースコートが丸々含まれる。3MB程度になる。Djangoで使うときはどうする?
Djangoは
base.htmlなどの基盤となるテンプレートにcssやjavascriptの読み込みを記述し、他のテンプレートにおいて{% extends 'app/base.html' %}としてbase.htmlを引き継ぎます。そのため、基盤となるテンプレートにplotly.jsを読み込む旨記述し、include_plotlyjs=Falseとするのがよいかなと思います。base.html<script src="https://cdn.plot.ly/plotly-latest.min.js"></script>又、
output_type='div'で取得したHTMLコードの文字列をテンプレートに渡せば、そのテンプレート内でグラフを描画できます。
ただし、テンプレートタグの{% autoescape off %}と{% endautoescape %}を使い、エスケープ機能をoffにしないと正しく描画されません。グラフを描画するhtml{% extends 'blog/base.html' %} {% block content %} {% autoescape off %} {{ plot_gantt }} <!-- HTMLコードの文字列が格納されたコンテキスト --> {% endautoescape %}まとめ
plotly.figure_factory.create_gantt()を読み込むfig = ff.create_gantt(df)でガントチャートのオブジェクトを作成するplotly.offline.offline.plot()を読み込むgantt = plot(fig, output_type='div', include_plotlyjs=False)でグラフとグラフを描画するスクリプトを含むhtmlコードの文字列を取得するautoescapeとendautoescapeでエスケープ機能をoffにした上で、4.で取得した文字列をテンプレートにわたすおまけ : 製作中のアプリにplotlyのガントチャートを導入してみた結果
現在、タスク管理アプリを作っています。プロジェクトを立ち上げ、それに向けてタスクを作成・実施していくものです。
このアプリにガントチャートを起用したいと思った理由は、これまでクリアしてきたタスクの軌跡をグラフで見ることで自信やモチベUPにつながる思ったからです。本来のガントチャートの使い方ではありませんが、こういう使い方もアリかな?と...すでに完了したタスクのスケジュールを取得し、ガントチャートを作成、テンプレートに配置してみます。
models.py# Projectsと、その小モデルTasks class Projects(models.Model): # 略 class Tasks(models.Model): STATUS_LIST = ((0, '待機'), (1, '取組中'), (2, '完了')) project = models.ForeignKey(Projects, on_delete=models.CASCADE, related_name='project_task') taskName = models.CharField(max_length=100, verbose_name='タスク') status = models.IntegerField(choices=STATUS_LIST, verbose_name='状況') createdDate = models.DateTimeField(default=now, null=True, blank=True, verbose_name='開始日') deadline = DateTimeField(blank=True,null=True, verbose_name='締め切り') finishedDate = DateTimeField(blank=True,null=True, verbose_name='達成した日')views.pydef projects_detail_view(request, p_pk): project = Projects.objects.get(pk=p_pk) # 完了済のタスクを取得し、開始日の昇順でタスク一覧を取得 tasks = project.project_task.filter(status=2).order_by('createdDate') df = [] for task in tasks: df.append( dict(Task=task.taskName, # create_ganttのStartとFinishで使うため、フォーマットを整形 Start="{0:%Y-%m-%d %H:%M:%S}".format(task.createdDate), Finish="{0:%Y-%m-%d %H:%M:%S}".format(task.finishedDate),)) fig = ff.create_gantt(df, title='これまでの軌跡', bar_width=0.5, showgrid_x=True, showgrid_y=False,) plot_html = plot(fig, output_type='div', include_plotlyjs=False) context = { 'plot_html': plot_html, } return render(request, 'detail.html', context)detail.html<script src="https://cdn.plot.ly/plotly-latest.min.js"></script> {% autoescape off %} {{ plot_html }} {% endautoescape %}結果
タスク名が長いため、グラフを圧迫しています。バーにマウスをホバーすればタスク名は表示されるので、左側のタスク名はいらないのでは?とおもったのですが、どうにも消し方がわからず悩んでいるところです。
プロジェクト管理画面のTOPに描画して、かっこ良いページにしたかったのですが、タスク名の羅列がかっこ悪くて...

- 投稿日:2020-01-17T01:24:24+09:00
ゼロから始める Python 爆速環境構築(Mac)
- Python の環境構築は色々バリエーションがあって分かりづらいですが、今現在最も良いと感じている方法を提示します
- 具体的には
pyenv+PoetryPyenv
brew install pyenvでインストール。
まず環境変数の設定をします。
パス$HOME/.pyenvとしてPYENV_ROOTを登録し、$PYENV_ROOT/binをPATHに含め、シェル起動時にpyenv initさせます。例えば bash であれば
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile echo -e 'if command -v pyenv 1>/dev/null 2>&1; then\n eval "$(pyenv init -)"\nfi' >> ~/.bash_profile exec "$SHELL"となります。他のシェルの場合などはドキュメントを確認してください。
準備が整ったので、お好みのバージョンの Python を入れましょう。
pyenv install 3.7.2 pyenv global 3.7.2これで Python v3.7.2 が使えるようになりました。
python --versionと入力してPython 3.7.2と出力されることを確認しましょう。Poetry
Poetry は新進気鋭のパッケージ管理ツールです。
類似品として Pipenv がありますが、Pipenv に比べて断然速いのと、Pipenv は現在更新が滞ってしまっていることから、もし今から新しく Python を始めようという方であれば Poetry を使うべきです。インストールは
curl -sSL https://raw.githubusercontent.com/sdispater/poetry/master/get-poetry.py | pythonで完了します。
一つだけやっておくべき設定があります。それは
poetry config virtualenvs.in-project trueです。これで、
.venvディレクトリをローカル(pyproject.tomlと同じ階層)で作ってくれるようになるので、VSCode や IDE 等でディレクトリを開いた時に、自動で仮想環境を認識してくれるようになります。では、試しに動かしてみましょう。サンプルディレクトリを用意します。
mkdir example cd example
poetry initをすると、対話形式でpyproject.tomlに書く内容を決めていきます。Node.js ユーザーであればnpm initなどでお馴染みだと思います。面白いのは、この時点で既に入れたい依存パッケージが決まっている場合は
Would you like to define your main dependencies interactively?でyesと答えると順次モジュールを指定して入れていくことができる点です。
もちろん後で依存パッケージを入れることもできるのでご安心を。対話が終了すると
pyproject.tomlが書き出されます。それではプログラムを書いていきましょう。爆速つながりで、阿部 寛のホームページをスクレイピングしてみます。
まず、Python のスクレイピングではおなじみのrequestsを入れます。poetry add requestsこれで
requestsが入ると同時に、ディレクトリ内に.venvディレクトリが新しく作られると思います。
ちなみにこの状態で VSCode でディレクトリを開くと左下にPython 3.7.2 64-bit ('.venv': venv)みたいな表示が出て、ローカルの仮想環境を認識してくれているのが分かります。そうしたら、スクレイピングするプログラムを書きます。
abe.pyimport requests r = requests.get("http://abehiroshi.la.coocan.jp/") print(r.text)動かしてみましょう。
VSCode は賢いので、VSCode 内でターミナルを開くとシェルが自動で仮想環境に入ってくれます。なので普通にpython abe.pyだけでOKです。
もし、VSCode 内ではなくコンソールなどでコマンドを打ちたいのであれば
poetry run python abe.pyまたは
poetry shell python abe.pyとなります。
- 投稿日:2020-01-17T00:56:59+09:00
【Python】混合ガウスモデルを使ったクラスタリングの実装
機械学習プロフェッショナルシリーズ『ノンパラメトリックベイズ 点過程と統計的機械学習の数理』を読んで、本に書いてあるモデルをPythonで実装してみました。ノンパラメトリックベイズとは、混合ガウスモデルを拡張した手法です。本当はノンパラメトリックベイズを実装したいのですが、その準備として、混合ガウスモデルを実装します。
※Qiitaにて、同様のモデルや手法の説明、実装を説明されている記事がありましたので、紹介させていただきます。どちらも大変参考になりました。
環境
Python: 3.7.5
numpy: 1.18.1
pandas: 0.25.3
matplotlib: 3.1.2
seaborn: 0.9.0
混合ガウスモデルとは
混合ガウスモデル(Gaussian Mixture Model, GMM)とは、複数のガウス分布から生成されたデータが混在しているデータセットのモデルです。アヤメのデータセットを例に説明します。これはアヤメの特徴と種類のデータセットであり、3種類のアヤメ「setosa」「versicolor」「virginica」が混在しています。機械学習の分類の練習問題によく使われるのでご存知の方も多いと思います。
このデータセットの説明変数は4つですが、簡略化のため「petal_length」「petal_width」の2つを取り出し、「色分けなしバージョン」と「アヤメの種類ごとに色分けしたバージョン」の散布図を作成します。
ソースコード
import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4)) df = sns.load_dataset('iris') ax1.scatter(df['petal_length'], df['petal_width'], color='gray') ax1.set_title('without label') ax1.set_xlabel('petal_length') ax1.set_ylabel('petal_width') for sp in df['species'].unique(): x = df[df['species'] == sp]['petal_length'] y = df[df['species'] == sp]['petal_width'] ax2.scatter(x, y, label=sp) ax2.legend() ax2.set_title('with label') ax2.set_xlabel('petal_length') ax2.set_ylabel('petal_width') plt.show()右図を見ると、アヤメの種類ごとに平均が異なる多変量ガウス分布1に従って、各データが生成されていると解釈できます。これが混合ガウスモデルです。大雑把な平均を下の表に示しました。
種類 petal_length petal_width setosa 約1.5 約0.25 versicolor 約4.5 約1.3 virsinica 約6.0 約2.0 混合ガウスモデルを使うことで、ラベルのない左図のデータセットから複数のガウス分布の平均を推定し、データと各ガウス分布を紐付けてクラスタリングをすることができます。
数式的な説明
混合ガウスモデルは確率モデルとして記述されます。
データ$x_i$のクラスタを$z_i$、各クラスタ$1, \cdots, k$に対応する多変量ガウス分布を$N(\mu_k, \Sigma_k)$とします。つまり、$x_i$がクラスラ$k$に所属するとき、その生成確率は次のように書けます。$D$は$x_i$の次元で、$x^{\backslash i}, z^{\backslash i}$は、それぞれ$x_1, \cdots, x_N$、$z_1, \cdots, z_N$から$i$番目の変数$x_i, z_i$を抜いたものです。$N$はデータの数とします。\begin{align} P(x_i | z_i=k, x^{\backslash i}, z^{\backslash i}, \mu_k, \Sigma_k) &= N(x | \mu_k, \Sigma_k) \end{align}一方、$z_i$も確率的に表現します。$z_i$を$\pi := (\pi_1, \cdots, \pi_K)^T$をパラメータとするカテゴリカル分布から生成されているとします。$K$はクラスタの数です。
P(z_i = k | x_k, \pi) = \pi_k以上から、データ$x_i$のクラスタ$z_i$が$k$である確率は次のように書けます。2
P(z_i = k | x_1, \cdots, x_N, z^{\backslash i}, \mu_k, \Sigma_k, \pi) = \frac{\pi_k N(x_i| \mu_k, \Sigma_k)}{\sum_{l=1}^K \pi_l N(x_i| \mu_l, \Sigma_l)} \qquad\cdots (1)データセットからこの式を使って各$z_i$を推定することで、クラスタリングを行います。
クラスタの推定方法
数式$(1)$より、各データのクラスタ$z_1, \cdots, z_N$を推定するためには、各クラスタに対応する多変量ガウス分布のパラメータ$\mu_1, \Sigma_1, \cdots, \mu_K, \Sigma_K$とカテゴリカル分布のパラメータ$\pi$を知っておく必要があります。これらは陽に与えられるものではないため、データセットから推定するか適切な値に仮定することになります。
今回、多変量ガウス分布の平均$\mu_1, \cdots, \mu_K$をデータセットから推定し、残りのパラメータを次の値に仮定します。$I_D$は$D \times D$の単位行列で、$\sigma^2$はハイパパラメータです。3\Sigma_1 = \cdots = \Sigma_K = \sigma^2 I_D \\ \pi = (1 / K, \cdots, 1 / K)^Tそして、$\mu_1, \cdots, \mu_K$および$z_1, \cdots, z_N$を推定するため、これらをひとつずつ確率的にサンプリングしていく方法を採用します。この方法をギブスサンプリングといいます。45
$z_i$のサンプリングは数式$(1)$に従えばいいので、以下、$\mu_k$の確率分布を考えます。
確率分布を推定したいので、ベイズ推定が使えそうですね。$\mu_k$の共役事前分布の平均$\mu_{\rm pri}$と共分散行列$\Sigma_{\rm pri}$を次の通りに定めます。6これらは、全ての$k=1, \cdots, K$で共通とします。$\sigma_{\rm pri}^2$はハイパパラメータです。\begin{align} \mu_{\rm pri} &= (0, \cdots, 0)^T \\ \Sigma_{\rm pri} &= \sigma_{\rm pri}^2I_D \end{align}このとき、$\mu_k$の事後分布は次のようになります。$n_k$はクラスタ$k$に属するデータ$x_{1}, \cdots, x_{N}$の数、$\bar{x}_k$はそれらの平均です。
\begin{align} \mu_{k, {\rm pos}} &= \Sigma_{k, {\rm pos}}(n_k \Sigma_k^{-1} \overline{x}_k + \Sigma_{\rm pri}^{-1}\mu_{\rm pri}) \\ \Sigma_{k, {\rm pos}} &= (n_k \Sigma_{k}^{-1} + \Sigma_{\rm pri}^{-1})^{-1} \\ \mu_k &= N(\mu | \mu_{k, {\rm pos}}, \Sigma_{k, {\rm pos}}) \qquad\cdots (2) \end{align}今回は、$\Sigma_k$と$\Sigma_{\rm pri}^{-1}$がともに$I_D$の定数倍なので、$\mu_{k, {\rm pos}}$と$\Sigma_{k, {\rm pos}}$は次のように変形できます。
\begin{align} \mu_{k, {\rm pos}} &= \Sigma_{k, {\rm pos}}\left(\frac{n_k}{\sigma^2} \overline{x}_k + \frac{1}{\sigma_{\rm pri}^2}\mu_{\rm pri}\right) \\ \Sigma_{k, {\rm pos}} &= \left(\frac{n_k}{\sigma^2} + \frac{1}{\sigma_{\rm pri}^{2}}\right)^{-1} \end{align}以上より、$\mu_k$のサンプリングは数式(2)に従えばよいことが分かります。
実装
実装において重要なポイントをいくつかピックアップして説明します。
クラスタのデータ数をカウントできる配列の実装
数式$(2)$より、各クラスタが持っているデータの個数を計算する必要があります。そこで、その個数を返す
countメソッドが備わった配列クラスClusterArrayを実装します。7countメソッドの他、使いそうなメソッドをnumpy.ndarrayから委譲しています。import numpy as np from collections import Counter class ClusterArray(object): def __init__(self, array): # arrayは1次元のリスト、配列 self._array = np.array(array, dtype=np.int) self._counter = Counter(array) @property def array(self): return self._array.copy() def count(self, k): return self._counter[k] def __setitem__(self, i, k): # 実行されるとself._counterも更新される pre_value = self._array[i] if pre_value == k: return if self._counter[pre_value] > 0: self._counter[pre_value] -= 1 self._array[i] = k self._counter[k] += 1 def __getitem__(self, i): return self._array[i]余分な計算の削除
数式$(1)$において、確率密度関数を直接計算してもいいのですが、$k$と無関係な因子を削除することで計算量を減らすことができます。
\begin{align} P(z_i = k | x_1, \cdots, x_N, z^{\backslash i}, \mu_k, \Sigma_k, \pi) &= \frac{\pi_k \exp\{- \frac{1}{2}\log|\Sigma_k| - \frac{1}{2} (x_i - \mu_k)^T\Sigma_k(x_i - \mu_k)\}}{\sum_{l=1}^K \pi_l \exp\{- \frac{1}{2}\log|\Sigma_l|- \frac{1}{2} (x_i - \mu_l)^T\Sigma_l(x_i - \mu_l)\}} \\ &= \frac{\pi_k \exp\{- \frac{1}{2 \sigma^2}\ \| x_i - \mu_k \|_2^2\}}{\sum_{l=1}^{K}\pi_l \exp\{- \frac{1}{2 \sigma^2}\ \| x_i - \mu_l \|_2^2\}} \end{align}この式の$\exp$の中身を計算するメソッド
log_deformed_gaussianを実装し、計算に使います。def log_deformed_gaussian(x, mu, var): norm_squared = ((x - mu) * (x - mu)).sum(axis=1) return -norm_squared / (2 * var)logsumexpについて
$\log(\sum_{i=1} \exp f_i(x))$のような計算において、オーバーフローやアンダーフローを防ぐためのテクニックにlogsumexpがあります。しかし、これは$\log$や$\exp$を何度も使うため計算の効率は良くないと思います。そこで、今回はlogsumexpを使用しません。8
logsumexpについては、次の記事が大変参考になります。
混合ガウス分布とlogsumexp全体の実装
上記に留意しつつ実装してみました。
scikit-learnを意識して、fitメソッドでクラスタリングが実行できるようにしています。
ソースコードは、長いので折りたたみにしています。
ソースコード
import numpy as np from collections import Counter def log_deformed_gaussian(x, mu, var): norm_squared = ((x - mu) * (x - mu)).sum(axis=1) return -norm_squared / (2 * var) class ClusterArray(object): def __init__(self, array): # arrayは1次元のリスト、配列 self._array = np.array(array, dtype=np.int) self._counter = Counter(array) @property def array(self): return self._array.copy() def count(self, k): return self._counter[k] def __setitem__(self, i, k): # 実行されるとself._counterも更新される pre_value = self._array[i] if pre_value == k: return if self._counter[pre_value] > 0: self._counter[pre_value] -= 1 self._array[i] = k self._counter[k] += 1 def __getitem__(self, i): return self._array[i] class GaussianMixtureClustering(object): def __init__(self, K, D, var=1, var_pri=1, seed=None): self.K = K # クラスタ数 self.D = D # 説明変数の次元(実装しやすたのため、コンストラクタの時点で設定しておく) self.z = None # 確率分布のパラメータ設定 self.mu = np.zeros((self.K, self.D)) self.var = var # 固定、すべてのクラスタで共通 self.pi = np.full(self.K, 1 / self.K) # 固定、すべてのクラスタで共通 # 事前分布の設定 self.mu_pri = np.zeros(self.D) self.var_pri = var_pri self._random = np.random.RandomState(seed) def fit(self, X, n_iter): init_z = self._random.randint(0, self.K, X.shape[0]) self.z = ClusterArray(init_z) for _ in range(n_iter): for k in range(self.K): self.mu[k] = self._sample_mu_k(X, k) for i, x_i in enumerate(X): self.z[i] = self._sample_zi(x_i) def _sample_zi(self, x_i): log_probs_xi = log_deformed_gaussian(x_i, self.mu, self.var) probs_zi = np.exp(log_probs_xi) * self.pi probs_zi = probs_zi / probs_zi.sum() z_i = self._random.multinomial(1, probs_zi) z_i = np.where(z_i)[0][0] return z_i def _sample_mu_k(self, X, k): xk_bar = np.array([x for i, x in enumerate(X) if self.z[i] == k]).mean(axis=0) var_pos = 1 / (self.z.count(k) / self.var + 1 / self.var_pri) mu_pos = var_pos * (xk_bar * self.z.count(k) / self.var + self.mu_pri / self.var_pri) mu_k = self._random.multivariate_normal(mu_pos, var_pos * np.eye(self.D)) return mu_kクラスタリングを試してみる
実装した混合ガウスモデルを使って、冒頭のアヤメのデータセットをクラスタリングしてみます。ハイパパラメータは、$\sigma^2=0.1, \sigma_{\rm pri}^2=1$とし、ギブスサンプリングの反復回数は10回にしました。
実際のデータセットのラベルとクラスタリング結果を比較すると、次のようになりました。
ソースコード
import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline from gaussian_mixture_clustering import GMMClustering # データセットの読み込み df = sns.load_dataset('iris') X = df[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']].values # 混合ガウスモデルによるクラスタリング gmc = GMMClustering(K=3, D=4, var=0.1, seed=1) gmc.fit(X, n_iter=10) df['GMM_cluster'] = gmc.z.array # 結果の可視化 fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4)) for sp in df['species'].unique(): x = df[df['species'] == sp]['petal_length'] y = df[df['species'] == sp]['petal_width'] ax1.scatter(x, y, label=sp) ax1.legend() ax1.set_title('species') ax1.set_xlabel('petal_length') ax1.set_ylabel('petal_width') for k in range(gmc.K): x = df[df['GMM_cluster'] == k]['petal_length'] y = df[df['GMM_cluster'] == k]['petal_width'] ax2.scatter(x, y, label=k) ax2.legend() ax2.set_title('GMM cluster') ax2.set_xlabel('petal_length') ax2.set_ylabel('petal_width') plt.show()「versicolor」と「virginica」の境目が怪しいですが、ラベル通りのクラスタリングが概ねできています。
また、seabornのpairplotを使って、クラスタリング結果を可視化してみました。
ソースコード
sns.pairplot( df.drop(columns=['species']), vars=['sepal_length', 'sepal_width', 'petal_length', 'petal_width'], hue='GMM_cluster' )いい感じにクラスタリングできています。
pairplotの対角線上に並んでいる図を見ると、データセットが混合ガウスモデルで表現されていることが分かると思います。おわりに
機械学習プロフェッショナルシリーズ『ノンパラメトリックベイズ 点過程と統計的機械学習の数理』から混合ガウスモデルを実装し、簡単なデータセットでクラスタリングを試してみました。
今回は混合ガウスモデルを扱いましたが、「混合ベルヌーイモデル」や「混合ポアソンモデル」のようなモデルも考えることができ、クラスタリングに利用することができます。
次回は、周辺化ギブスサンプリングについて書く予定です。これは、ノンパラメトリックベイズを行う上で必要な技術です。
分散も異なりますが、簡略化のため平均のみ考えています。 ↩
ベイズの定理を使って導出することができます。 ↩
$\sigma^2$は分散です。共分散はすべて$0$とします。雑な仮定に見えますが、$\sigma^2$を適切に決めることでこれでも十分クラスタリングできますし、簡略化したことで計算量を減らすことができます。当然、これらもデータセットから推定することで、より正確なクラスタリングが可能になるはずです。 ↩
ギブスサンプリングは解析的な計算が困難な同時分布を近似するための手法です。今回は、$P(\mu_1, \cdots, \mu_K, z_1, \cdots, z_N | \cdots)$を近似しています。 ↩
混合ガウス分布の推定には他の手法も使えますが、ノンパラメトリックベイズに拡張するためにはギブスサンプリングが必要だと認識しています。正直ちゃんと理解できていないので、分かる方いたら教えて下さい。 ↩
$\mu_k$の共役事前分布は多変量ガウス分布です。 ↩
わざわざこのようなクラスを作らずに、
Counterインスタンスを外に保持してもいいと思います。私はこういうのをカプセル化してクラスを作るのが好きです。 ↩データセットに対して大きすぎず、小さすぎない$\sigma^2$を設定すればオーバーフローとアンダーフローを回避できるので、logsumexpを使わなくても問題ないと判断しました。 ↩


- 投稿日:2020-01-17T00:05:33+09:00
あえてseleniumを使わずにフォームに入力してみる
はじめに
「あえて」というほどでもないのですが、Pythonでフォームの編集を調べているとseleniumが良く出てくるのでRequests+BeautifulSoupで実装してみました。
以前投稿した記事の発展編としてちょうどいいのでQiitaのプロフィール文を編集してみました。
編集用関数
編集可能な多くの項目はtypeが['text', 'url', 'checkbox']のいずれかであることがソースから判明したため、ほとんど手打ちする必要なく取得できました。
取得もれである'user[desctiption]]'を追加するついでに編集すればpost用データの完成です。なぜかemail公開のチェックボックスがデフォルトでチェック済みになっていたため0に修正しています。データの作成ができたらログイン時のセッションを使ってPostすれば完成です。def edit_profile(session): profile_page_data = get_page_data(session, profile_url) bs_profile_page = BeautifulSoup(profile_page_data.text, 'html.parser') authenticity_token = str(bs_profile_page.find(attrs={'name':'authenticity_token'}).get('value')) post_data = { 'utf-8':'✓', '_method': 'put', 'authenticity_token':authenticity_token } response = bs_profile_page.find_all(attrs={'type':['text', 'url', 'checkbox']}) for i in response: value = i.get('value') post_data[i.get('name')] = value post_data['user[public_email]'] = 0 # なぜかデフォルトで1 post_data['user[description]'] = '編集したよ!!!!' print(post_data) response = session.post(profile_url, post_data) print(response)いざ実行
前回作成したプログラムに上で記載したedit_profile()を追加すればプログラムの完成です。
import requests import os from bs4 import BeautifulSoup import json user_name = 'user_name' user_password = 'user_password' login_url = 'https://qiita.com/login' profile_url = 'https://qiita.com/settings/profile' def get_authenticity_token(session, login_url): page_data = get_page_data(session, login_url) bs_page_data = BeautifulSoup(page_data.text, 'html.parser') authenticity_token = str(bs_login_page.find(attrs={'name':'authenticity_token'}).get('value')) return bs_page_data, authenticity_token def get_page_data(session, url): response = session.get(url) response.encoding = response.apparent_encoding return response def login(session): login_form = { 'utf-8':'✓', 'authenticity_token':'token', 'identity':user_name, 'password':user_password } bs_login_page, authenticity_token = get_authenticity_token(session, login_url) login_form['authenticity_token'] = authenticity_token session.post(login_url, login_form) def edit_profile(session): bs_profile_page, authenticity_token = get_authenticity_token(session, profile_url) post_data = { 'utf-8':'✓', '_method': 'put', 'authenticity_token':authenticity_token } response = bs_profile_page.find_all(attrs={'type':['text', 'url', 'checkbox', 'textarea']}) for i in response: value = i.get('value') post_data[i.get('name')] = value post_data['user[public_email]'] = 0 # なぜかデフォルトで1 post_data['user[description]'] = '編集したよ!!!!' print(post_data) response = session.post(profile_url, post_data) print(response) if __name__ == '__main__': session = requests.Session() login(session) edit_profile(session)実行してResponse [200]が返ってくれば成功です。
- 投稿日:2020-01-17T00:02:47+09:00
[Pythonアルゴリズム]深さ優先探索より、数独の答えを出力するプログラム
はじめに
皆さんこんにちは。今日は深さ優先探索という方法を使って、数独の答えを出力するプログラムの解説をしていく。例題の説明からして難しいので、記事の不備等は、コメントにてご連絡いただけると嬉しい。
例題
nは自然数、N=n^2を満たす自然数とする。このとき横N行縦N列の計N^2個のマス目からなる盤面をつくり、さらに太線でそれぞれn行n列からなるn^2個の区画に分ける。
このときそれぞれのマス目に1からNまでの数字を1つずつ書き込む。ただし、以下の3つの条件を全て満たすものとする。
- (A)各行には1,2,3,...,Nが1回ずつ現れる
- (B)各列には1,2,3,...,Nが1回ずつ現れる
- (C)各区画には1,2,3,...,Nが1回ずつ現れる
以下の[入力例1]や[入力例2]のように、途中まで数字が書き込まれた盤面(問題)がある。これらの盤面の空欄に1,2,3,...,Nの自然数を書き込み、上記の(A)~(C)の条件を満たす盤面(解答)を出力するプログラムを作成せよ。
制約
n=2(N=4)数独の盤面
入力例1
[[1,0,3,4],[3,0,0,2],[0,3,0,0],[2,0,0,3]] 未入力のマス目には0を入力する。
出力例1
[[1,2,3,4],[3,4,1,2],[4,3,2,1],[2,1,4,3]]
数独の盤面
入力例2
[[4,0,0,0],[0,0,0,0],[1,0,4,0],[0,0,0,2]] 未入力のマス目には0を入力する。
(出典:https://sudoku.tokyo/mini-sudoku.php 問題番号:6596750)
出力例2
[[4,3,2,1],[2,1,3,4],[1,2,4,3],[3,4,1,2]]プログラム作成の手順
数独の解答作成のプログラムの作り方は、大まかにまとめると以下の2段階に分けられる。
- 判定部分を作成:マス目(y,x)が、問題の(A)(B)(C)を満たすか判定するプログラムを作成。マス目の縦、横、ブロック毎に1〜Nの数字が1個ずつ使われているか確認する。
- マス目に数字を置く:空いているマス目に1〜Nの数字を置いていき、前項を満たすようならば次のマス目を調べる。このときマス目(0,0),(1,0),...,(N-1,0),(1,0),(1,1),...,(N-1,N-1)と横に調べていく。
上記1でマス目(y,x)のみを調べる理由は、再帰が進まなくなるからである。(自分の経験上、一つのマス目のみに数字が入力される)
1:マス目(y,x)を判定するプログラム
(A) マス目の縦の判定する部分
まず縦x列目に、1〜Nの数字が1つずつ使われているか調べるプログラムを作成する。
マス目(x,0),(x,1),...,(x,N-1)において、1~Nがいくつあるか配列にカウントしていく。このとき1が1つ、2が1つ・・・Nが1つというように各数字が1つずつ使われていればTrue,使われていなければFalseを返す。# 縦列に答えがあっているか調べる def checkQuestionRow(self,Row): # 1~Nの数字がいくつ含まれるかを格納する配列 num = [0 for m in range((self.N + 1))] # 縦0行目~縦(N-1)行目までを走査する for x in range(0,self.N): # 1~Nがいくつ含まれるか調べる for m in range(1,self.N+1): #(x,Row)のマス目の値がmのとき if m == self.question[x][Row]: # 数字がmの個数に+1する num[m] = num[m] + 1 # 列Row内で、数字が2つ以上使われて場合はFalseを返す for m in range(1,self.N+1): if num[m] > 1: return False return True(B) マス目の横の判定する部分
こちらは縦の場合と同様の判定を行えば良い。
def checkQuestionCol(self,Col): # 1~Nの数字がいくつ含まれるかを格納する配列 num = [0 for m in range((self.N + 1))] # 縦0列目~横(N-1)列目までを走査する for y in range(0,self.N): for m in range(1,self.N+1): if m == self.question[Col][y]: num[m] = num[m] + 1 # 列Col内で、数字が2つ以上使われて場合はFalseを返す for m in range(1,self.N+1): if num[m] > 1: return False return True(C) マス目のブロック部分の判定する部分
ブロックは縦colblock目、横rowblock目・・・というように判定していく。例えば4*4(n=2,N=4)の数独ならば0番目と2番目に太線が来る。太線は縦横とも1<=k<=nとして、(k*n-1)番目に来るため 、k * n番目に始点、k * (n+1)番目に終点が来る。
このkをcollock,rowlockに置き換えて、縦と横のブロックの始点から終点まで1〜Nの数字が1つずつ含まれるかどうか調べていく。
# 2*2,3*3のブロックごとに、1~Nの数字が1つずつ出現しているか調べる def checkQuestionBlock(self,rowBlock,colBlock): # ブロックの開始地点(colBlock* n ,rowBlock* n)を定義 startCol = colBlock * self.n startRow = rowBlock * self.n # ブロックの終了地点(colBlock* {n+1} ,rowBlock* {n+1})を定義 endCol = (colBlock + 1) * (self.n) endRow = (rowBlock + 1) * (self.n) # 1~Nの数字がいくつ含まれるかを格納する配列 num = [0 for m in range((self.N + 1))] # ブロック毎に走査を行う for y in range(startCol,endCol): for x in range(startRow,endRow): for m in range(1,self.N+1): if m == self.question[y][x]: num[m] = num[m] + 1 # ブロック内で、数字が2つ以上使われて場合はFalseを返す for m in range(1,self.N+1): if num[m] > 1: return False return True(A)〜(C)をとりまとめる
最後に(A)〜(C)全ての条件をとりまとめる。(A)〜(C)のひとつでも条件を満たさなければ、Falseを返す。
# 現在の(x,y)の解が合っているかどうか調べる def checkQuestion(self,x,y): # まず全てのRowに1~(half * half)までの数字が含まれているか調べる if self.checkQuestionRow(x) == False: return False # 次に全てのColに1~(half * half)までの数字が含まれているか調べる if self.checkQuestionCol(y) == False: return False # 最後にブロック毎に1~(half * half)までの数字が含まれているか調べる colBlock = x // self.n rowBlock = y // self.n if self.checkQuestionBlock(colBlock,rowBlock) == False: return False return True2:マス目に数字を置く(深さ優先探索 Depth-First Search)
数独のマス目への数字の置き方は、以下の手順で実装する。
- 再帰の終了条件を書く。主に縦列がNに差し掛かったら再帰を打ち切る。
- マス目(y,x)に既に数字が置かれている場合は、マス目(y,x+1)。すでに横の終端にいる時はマス目(0,y+1)に再帰させていく。
- マス目(y,x)に既に数字が置かれていない場合は、まずマス目(y,x)に1〜Nの数字を置いてみる。置いてみた結果、(A)〜(C)の条件を満たす時はTrueを返す。加え2.と同じようにマス目(y,x+1)又は(0,y+1)へと再帰させる。
- 3.でマス目(y,x)に1〜Nの全ての数字が条件を満たさないときは、マス目(y,x)の値を数字置く前{0}に戻す。
このように次へ次へと掘り進んで行って、条件を満たさない場合はひとつ前に戻って考え直す探索法を深さ優先探索(Depth-First Search)と言う。
# 深さ優先探索より、数独の解を探索する def solve(self,question,x=0,y=0): # 最終行の次の行に差し掛かったら、再帰を終了する if x == 0 and y == self.N: return True # マス目に既に数字が置かれているとき if self.question[y][x] != 0: # 最終行にたどり着いたら、次の列の最初を調べる if x == self.N-1: if self.solve(self.question,0,y+1): return True # 最終行以外の場合は、次の行を調べる else: if self.solve(self.question,x+1,y): return True # マス目に数字が置かれていないとき else: for m in range(1,self.N+1): # まず数字iをマス(x,y)に仮置きする self.question[y][x] = m # 判定が通ったら、マス(x,y)の値をmで確定する if self.checkQuestion(x,y) == True: self.question[y][x] = m # デバッグ用 # print("(x,y,i) = (" + str(x) + "," + str(y) + "," + str(m) + ")") # 最終行にたどり着いたら、次の列の最初を調べる if x == self.N-1: if self.solve(self.question,0,y+1): return True # 最終行以外の場合は、次の行を調べる else: if self.solve(self.question,x+1,y): return True # 判定が通らない場合は、マス目を元に戻す self.question[y][x] = 0 return False*尚、本部分のプログラム作成にあたり、@wsldenli氏の「Pythonで数独を解く -Qiita」を真似させていただいた。
プログラム全体
Sudoku.pyimport os import sys class Sudoku(): # データを初期化 def __init__(self): # 小枠の大きさ self.n = 2 # 大枠と数値の終端を定義 self.N = self.n * self.n # 問題の全ての配列を0で初期化する self.question = [[0 for i in range((self.N))] for j in range((self.N))] # 縦列に答えがあっているか調べる def checkQuestionRow(self,Row): # 1~Nの数字がいくつ含まれるかを格納する配列 num = [0 for m in range((self.N + 1))] # 横0行目~横(N-1)行目までを走査する for x in range(0,self.N): # 1~Nがいくつ含まれるか調べる for m in range(1,self.N+1): #(x,Row)のマス目の値がmのとき if m == self.question[x][Row]: # 数字がmの個数に+1する num[m] = num[m] + 1 # 列Row内で、数字が2つ以上使われて場合はFalseを返す for m in range(1,self.N+1): if num[m] > 1: return False return True # 横:行Colにおいて、1~Nの数字が1つずつ出現しているか調べる # 基本、checkQuestionRowと同じ動作 def checkQuestionCol(self,Col): # 1~Nの数字がいくつ含まれるかを格納する配列 num = [0 for m in range((self.N + 1))] # 縦0列目~横(N-1)列目までを走査する for y in range(0,self.N): for m in range(1,self.N+1): if m == self.question[Col][y]: num[m] = num[m] + 1 # 列Col内で、数字が2つ以上使われて場合はFalseを返す for m in range(1,self.N+1): if num[m] > 1: return False return True # 2*2,3*3のブロックごとに、1~Nの数字が1つずつ出現しているか調べる def checkQuestionBlock(self,rowBlock,colBlock): # ブロックの開始地点(colBlock* n ,rowBlock* n)を定義 startCol = colBlock * self.n startRow = rowBlock * self.n # ブロックの終了地点(colBlock* {n+1} ,rowBlock* {n+1})を定義 endCol = (colBlock + 1) * (self.n) endRow = (rowBlock + 1) * (self.n) # 1~Nの数字がいくつ含まれるかを格納する配列 num = [0 for m in range((self.N + 1))] # ブロック毎に走査を行う for y in range(startCol,endCol): for x in range(startRow,endRow): for m in range(1,self.N+1): if m == self.question[y][x]: num[m] = num[m] + 1 # ブロック内で、数字が2つ以上使われて場合はFalseを返す for m in range(1,self.N+1): if num[m] > 1: return False return True # 現在の(x,y)の解が合っているかどうか調べる def checkQuestion(self,x,y): # まず全てのRowに1~(half * half)までの数字が含まれているか調べる if self.checkQuestionRow(x) == False: return False # 次に全てのColに1~(half * half)までの数字が含まれているか調べる if self.checkQuestionCol(y) == False: return False # 最後にブロック毎に1~(half * half)までの数字が含まれているか調べる colBlock = x // self.n rowBlock = y // self.n if self.checkQuestionBlock(colBlock,rowBlock) == False: return False return True # 幅優先探索ないしは深さ優先探索より、数独の解を探索する def solve(self,question,x=0,y=0): # 最終行の次の行に差し掛かったら、再帰を終了する if x == 0 and y == self.N: return True # マス目に既に数字が置かれているとき if self.question[y][x] != 0: # 最終行にたどり着いたら、次の列の最初を調べる if x == self.N-1: if self.solve(self.question,0,y+1): return True # 最終行以外の場合は、次の行を調べる else: if self.solve(self.question,x+1,y): return True # マス目に数字が置かれていないとき else: for m in range(1,self.N+1): # まず数字iをマス(x,y)に仮置きする self.question[y][x] = m # デバッグ用 # print("(x,y,i) = (" + str(x) + "," + str(y) + "," + str(self.question[y][x]) + ")") # 判定が通ったら、マス(x,y)の値をmで確定する if self.checkQuestion(x,y) == True: self.question[y][x] = m # 最終行にたどり着いたら、次の列の最初を調べる if x == self.N-1: if self.solve(self.question,0,y+1): return True # 最終行以外の場合は、次の行を調べる else: if self.solve(self.question,x+1,y): return True # 判定が通らない場合は、マス目を元に戻す self.question[y][x] = 0 # デバッグ用 # print("(x,y,i) = (" + str(x) + "," + str(y) + "," + str(self.question[y][x]) + ")") return False # メイン関数 if __name__ == '__main__': # 問題データ Sudoku = Sudoku() Sudoku.question =[[1,0,3,4],[3,0,0,2],[0,3,0,0],[2,0,0,3]] # Sudoku.question =[[4,0,0,0],[0,0,0,0],[1,0,4,0],[0,0,0,2]] print("Question") print(Sudoku.question) Sudoku.solve(Sudoku.question,0,0) print("Answer") print(Sudoku.question)その他参考にしたサイト
○ 数独の数理(http://shochandas.xsrv.jp/number/sudoku.htm)
問題の説明は、2012年の慶応大学の入試問題を真似した。ちなみに4*4の数独の答えの盤面は全部で288通りあるらしい。バックナンバー
・Python3で配列をクイックソートする
・Pythonで最大部分配列問題(maximum subarray problem)を解く