- 投稿日:2020-01-17T22:49:44+09:00
過去1世紀の間に日本で出回ったすべての本のデータベースを作ろう
0. 初めに(対象読者など)
釣りタイトルです。すみません。
本当は、過去1世紀の間に日本で出回ったすべての 「699 テレビ・ラジオ」に分類される本のデータベースを作ります。
また、 国会国立図書館のサーバへの自動アクセスを大量に行うこととなるので、くれぐれも自己責任でお願いします。対象読者
- 国会国立図書館サーチを(API使わずに)自動で行いたい人
- javaがある程度できる人
- privateメソッドで怒らない人
- 自己責任を理解できる、精神的に大人の方(極稀に、これに残念ながら該当しない社会ガク者の方がいます)
1. 実験
国会国立図書館サーチで詳細検索し、分類記号「699」だけを条件に検索すると、
1925年~2020年の、テレビやラジオに関する本をすべて検索することができる。
しかし、誠に残念ながら、一回の検索で見ることができるのは、上位500件の結果のみである。(501件目以降は、そもそも検索結果に表示されない)
また、出版年で絞り込み検索を行うことができるが、1925年~2020年のどの年においても、(1年で)結果が500件を超えることはなかった。
そこで、すべての年ごとに、検索をかけて、その結果をとってくれば、手間はかかるが、すべての結果を見ることを試みよう。1-1. 実験1 ndlクローラの設計
クローラとは、webから情報を集めてくるプログラムのことである。
国会国立図書館サーチから情報を集めてくるプログラムを「ndlクローラ」と呼ぶことにして、これを設計していこう。
次のような手順で設計できる。
1. ブラウザから国会国立図書館サーチを利用
2. 詳細検索における各項目をすべて英数字で入力し、検索を実行
3. getパラメータと比較することで、どの項目がどのパラメータに対応しているか確認
4. 3までで得られたヒントをもとに、プログラムを設計1-1-1. 手順1~3
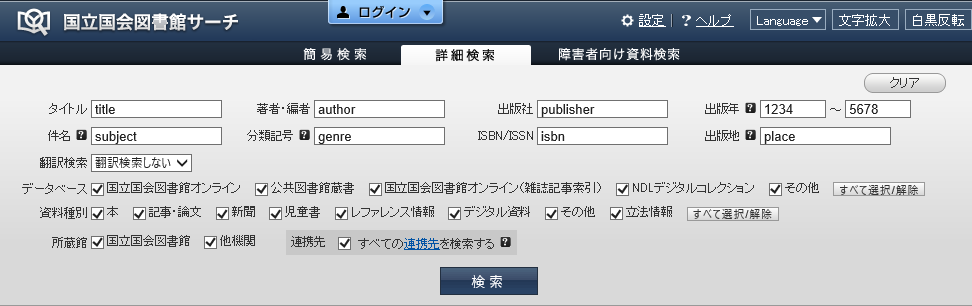
まず、図1.1.1.1 の条件で検索したところ、検索結果(サムネイル表示)のurlは次のようになった。
https://iss.ndl.go.jp/books?datefrom=1234&place=place&rft.isbn=isbn&rft.title=title&dateto=5678&rft.au=author&subject=subject&do_remote_search=true&rft.pub=publisher&display=thumbnail&ndc=genre&search_mode=advanced
図1.1.1.1 urlパラメータ観察用の検索条件比較すると、表1.1.1.1の通りのことが分かる。(但し、「結果のページ番号」だけは、別の試行で確認した。)
表1.1.1.1 国会国立図書館サーチのurlパラメータ
項目 パラメータ 値 タイトル rft.title 著者・編者 rft.au 出版社 rft.pub 出版年区間始点 datefrom 出版年区間終点 dateto 件名 subject 分類記号 ndc ISBN/ISSN rft.isbn 出版地 place 結果のページ番号 page 結果をサムネイル表示 display thumbnail そのほか一応つけておく1/2 do_remote_search true そのほか一応つけておく2/2 search_mode advance 1-1-2. 手順4(クローラの設計)
javaパッケージ
ndlを作り、その中に次のようなNDLCrawler.javaを作る。
(コード中に出てくるParserクラスについては1-1-3節で述べる。
簡潔に述べると、コンストラクタに渡された結果ページの内容をparse()メソッドでcsvに成型する。
has15()メソッドは、結果が15件であるかの真偽値を返す。)
(コード中に出てくるWebGetterクラスは、getメソッドでインターネット上からhtmlソースをとってくるだけのものである)NDLCrawler.javapackage ndl; import java.io.*; import java.net.*; public class NDLCrawler { private String url = "https://iss.ndl.go.jp/books?", title="", author="", publisher="", yearfrom="",yearto="", subject="", bunrui="", isbn_issn="", place=""; public void setTitle(String str){title=str;} public void setAuthor(String str){author=str;} public void setPublisher(String str){publisher=str;} public void setYearfrom(String str){yearfrom=str;} public void setYearto(String str){yearto=str;} public void setSubject(String str){subject=str;} public void setBunrui(String str){bunrui=str;} public void setIsbn_issn(String str){isbn_issn=str;} public void setPlace(String str){place=str;} public String crawle() { System.out.println(" クローラ起動"); String csv=""; String urlWithGet = url+ "rft.title=" + title + "&rft.au=" + author + "&rft.pub=" + publisher + "&datefrom=" + yearfrom + "&dateto=" + yearto + "&subject=" + subject + "&ndc=" + bunrui + "&rft.isbn=" + isbn_issn + "&place=" + place; urlWithGet = urlWithGet + "&do_remote_search=true&display=thumbnail&search_mode=advanced"; System.out.println(" url:"+urlWithGet+"&page=(ページ番号)"); WebGetter wg = new WebGetter(); try { for(int page=1; page<=34; page++) { System.out.println(" "+page+"ページ目"); String source = wg.get(urlWithGet+"&page="+page); Parser p = new Parser(source, false); csv = csv + p.parse().replaceFirst("^(\r\n|\r|\n)", ""); if(!p.has15()) break; } System.out.println(" クローラ終了"); return csv; } catch (IOException e) {e.printStackTrace();return null;} } }WebGetterクラスは次のようになる。(NDLCrawler.javaの後ろに追記する)
WebGetterクラス/** * * 参考サイト:https://www.javalife.jp/2018/04/25/java-%E3%82%A4%E3%83%B3%E3%82%BF%E3%83%BC%E3%83%8D%E3%83%83%E3%83%88%E3%81%AE%E3%82%B5%E3%82%A4%E3%83%88%E3%81%8B%E3%82%89html%E3%82%92%E5%8F%96%E5%BE%97%E3%81%99%E3%82%8B/ * */ class WebGetter { String get(String url) throws MalformedURLException, IOException { InputStream is = null; InputStreamReader isr = null; BufferedReader br = null; try { URLConnection conn = new URL(url).openConnection(); is = conn.getInputStream(); isr = new InputStreamReader(is); br = new BufferedReader(isr); String line, source=""; while((line = br.readLine()) != null) source=source+line+"\r\n"; return source; }finally {br.close();isr.close();is.close();} } }1-1-3. 手順4(結果ページのソース(html)からcsvを作る)
「国会国立図書館サーチ」における検索結果のhtmlソースについて、次のような法則を発見した。
<a href="https://iss.ndl.go.jp/books/(英数字とハイフンから成る書籍のID)">(文字列1)の直後には必ず書籍のタイトルが来る。逆も各書籍について最低1回は成立する。- 各書籍について最低一回は、タイトルの直後に
</a>(改行)(ホワイトスペース)+</h3>(改行)(ホワイトスペース)+<p>(改行)(ホワイトスペース)+が来る。これを文字列2と呼ぼう。- 「文字列1、書籍のタイトル、文字列2」の直後には必ず
(著者名)/.*(,(著者名)/.*)*(文字列3)が来る。- 「文字列1、書籍のタイトル、文字列2~3」の最終行の2行後に出版者名、3行後に発行年、4行後にシリーズ名が来る。欠損情報がある場合は空値が入り、行が飛ばされることはない。
この法則(および若干の例外)に則って書籍のタイトルを並べたcsvファイルを作るjavaプログラムを作ると次のようになる。
(htmlソースをcsvに変換する処理をParseと呼ぶことにしている。)Parser.javapackage ndl; public class Parser { private boolean has15; private String csv; Parser(String source, boolean needHeader) { this.csv=needHeader?"国立国会図書館リンク,タイトル,著者,出版者,年,シリーズ\n":"\n"; String[] books = divide(source);//「<a href="https://iss.ndl.go.jp/books/」で区切る books = remove0(books);//先頭だけ無意味なデータなので切り落とす has15 = books.length==15;//デフォルトで、検索結果の件数は1ページあたり15件 String link, title, publisher, year, series; String[] authors; for(String book : books)//それぞれの書籍について { book = book.replaceAll("((\r\n)|\r|\n)( |\t)*<span style=\"font-weight:normal;\">[^<]+</span>","");//シリーズもので番号が振られている場合、その情報をカットすることで「法則」に当てはめることができる。 link = getLink(book).replaceAll(",", "、"); title = getTitle(book).replaceAll(",", "、"); authors = getAuthors(book); publisher = getPublisher(book).replaceAll(",", "、"); year = getYear(book).replaceAll(",", "、"); series = getSeries(book).replaceAll(",", "、");//詳細情報を抽出して for(String author : authors)//csvに変換 csv = csv + link+","+title+","+author.replaceAll(",", "、")+","+publisher+","+year+","+series+"\n"; } } public boolean has15(){return has15;} public String parse() {return csv;} //本当はよくないprivateメソッドたち private String[] divide(String source){return source.split("<a href=\"https://iss\\.ndl\\.go\\.jp/books/", -1);} private String[] remove0(String[] before) { String[] after = new String[before.length-1]; for(int i=1; i<before.length; i++)after[i-1]=before[i]; return after; } private String getLink(String book){return "https://iss.ndl.go.jp/books/"+book.split("\"")[0];}//「"」で区切った0番目を返せばよい private String getTitle(String book){return book.split("<|>")[1];}//「<」または「>」で区切った1番目を返せばよい private String[] getAuthors(String book){return book.split("(\r\n)|\r|\n")[3].replaceFirst("( |\t)*", "").split("/([^,])+,?");} private String getPublisher(String book){return book.split("(\r\n)|\r|\n")[5].replaceFirst("( |\t)*", "");} private String getYear(String book){return book.split("(\r\n)|\r|\n")[6].replaceFirst("( |\t)*", "");} private String getSeries(String book){return book.split("(\r\n)|\r|\n")[7].replaceFirst("( |\t)*", "");} }1-1-4. 手順4(クローラの制御)
1-1-2節で国会国立図書館サーチへアクセスするクローラのクラスを設計し、
1-1-3節でクローラのとってきた情報をもとにcsvを生成するクラスを実装した。
1-1-4節では、これらのクラスを利用してクローラを実際に制御するクラスを設計しよう。制御内容としては、for文にて1925年~2020年それぞれを指定して、また分類番号は699を指定して、クローラを動作させ、出来上がったcsvをファイルに書き込めばよい。また、年数情報が分からないものについては「1900年」と扱われているようなので、これも考慮する。
Main.javapackage ndl; import java.io.*; public class Main { public static void main(String...args) { String header = "国立国会図書館リンク,タイトル,著者,出版者,年,シリーズ,図書館\n"; NDLCrawler c = new NDLCrawler(); c.setBunrui("699"); generateCsv(c); } private static void generateCsv(NDLCrawler c) { System.out.println(1900); c.setYearfrom("1900"); c.setYearto("1900"); output(c.crawle());//末尾追記で書き込み for(int year=1925; year<=2020; year++) { System.out.println(" "+year); c.setYearfrom(""+year); c.setYearto(""+year); output(c.crawle());//末尾追記で書き込み } } private static void output(String csv) { String path = "D:\\all699.csv";//パスは任意に変更のこと System.out.println("出力"+csv); try{ FileWriter fw = new FileWriter(path, true);//第2引数trueで末尾追記モード fw.write(csv); fw.close(); } catch (IOException e) {e.printStackTrace();} } }2.結果
実験環境および条件は表2-1の通り
表2-1. 実験環境および条件
項目 値 OS windows10 ソフト Eclipse IDE for Enterprise Java Developers(4.11.0) プロバイダおよび接続元 Jupiter Telecommunication Co. Ltd (210.194.32.203) プログラム起動日時(日本時間) 2020年1月17日20時44分00秒 プログラム停止時刻および動作期間,停止理由 2020年1月17日21時39分44秒
(約56分、正常終了)出力されたファイルall699.csv(githubへアップロードした)は12145行に及んだ。
また、実験後、ブラウザで国会国立図書館サーチへアクセスし、同じ条件で検索した結果における件数情報をみると12633件とあった。
件数に矛盾があるため、調べたところ、出版年情報として1900年及び、1925~2020年が与えられている書籍の合計は12030件であることが分かった。
これは12145件と比べて若干少ないが、「著者情報が複数ある時、行を分けて一人一行を割り当てる」としたParser.getAuthorsメソッドの仕様のためであると考えられる。3.今後の展望
国会国立図書館サーチでは、国会国立図書館以外にも幾つかの地方図書館等の蔵書を検索することができる。
これを利用して、「どこにでも置いてある本」と「そうでない本」を分類するような研究にも応用できるのではないか興味があるので、これをやってみたい。
- 投稿日:2020-01-17T17:15:11+09:00
Yellowfinのカスタムフォーマッターを作って数値のマイナスを△(三角)で表示する
経理関係の資料などでマイナスの数値を「△100,000」のように表記するケースがあります。
Yellowfinでは カスタムフォーマッター を使えばこのような表示を実現することができます。カスタムフォーマッター等の Yellowfinのプラグイン はJavaで開発します。
今回はEclipse(を日本語化した Pleiades)を用いています。なお、開発方法はYellowfinのオンラインマニュアルに記載があります。
プラグイン開発の基礎
カスタムフォーマッターの作成
本記事では端折りながら進めていきますので、適宜マニュアルを参照してください。Javaプロジェクトの作成
新規Javaプロジェクトを作成します。Javaのバージョンは7にせよとマニュアルに書かれているので、JREはjava7を選択しておきます。
「次へ」をクリックし、「デフォルト出力フォルダー」を <プロジェクト名>/ROOT/WEB-INF/classes に変更します。
プロジェクトを右クリックし、「インポート」を選択します。
「ファイル・システム」を選択し、「次へ」をクリックします。
<Yellowfinインストールディレクトリ>/appserver/webapps/ROOT に移動します。「ROOT」を選択し、「Open」をクリックします。
ROOT配下のすべてを選択し、「拡張」項目で「Create links in workspace(ワークスペース内にリンクを作成)」チェックボックスにチェックを入れます。
プロジェクトの構成
プロジェクトを右クリックし、メニューから「ビルド・パス」>「ビルド・パスの構成」を選択します。
「ライブラリー」をクリックします。
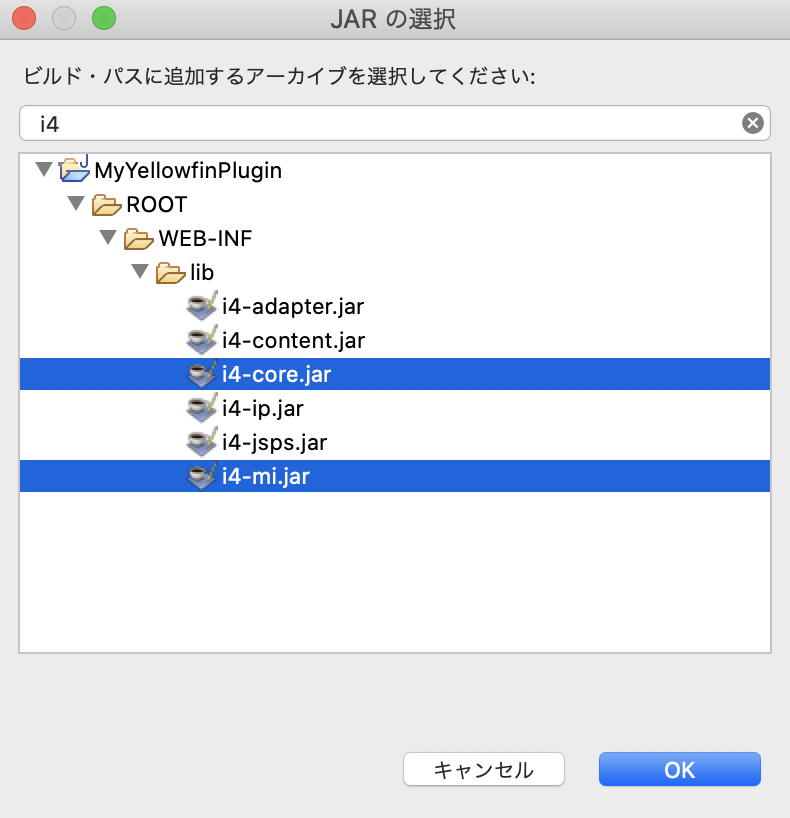
「JARの追加」ボタンをクリックし、検索バーに「i4」と入力します。検索結果から「i4-core.jar」と「i4-mi.jar」を選択します。
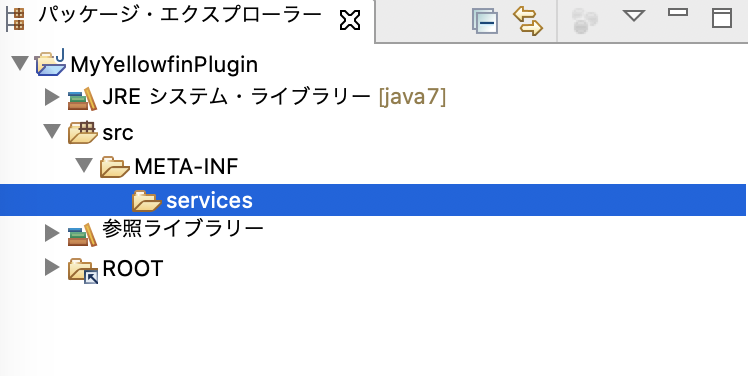
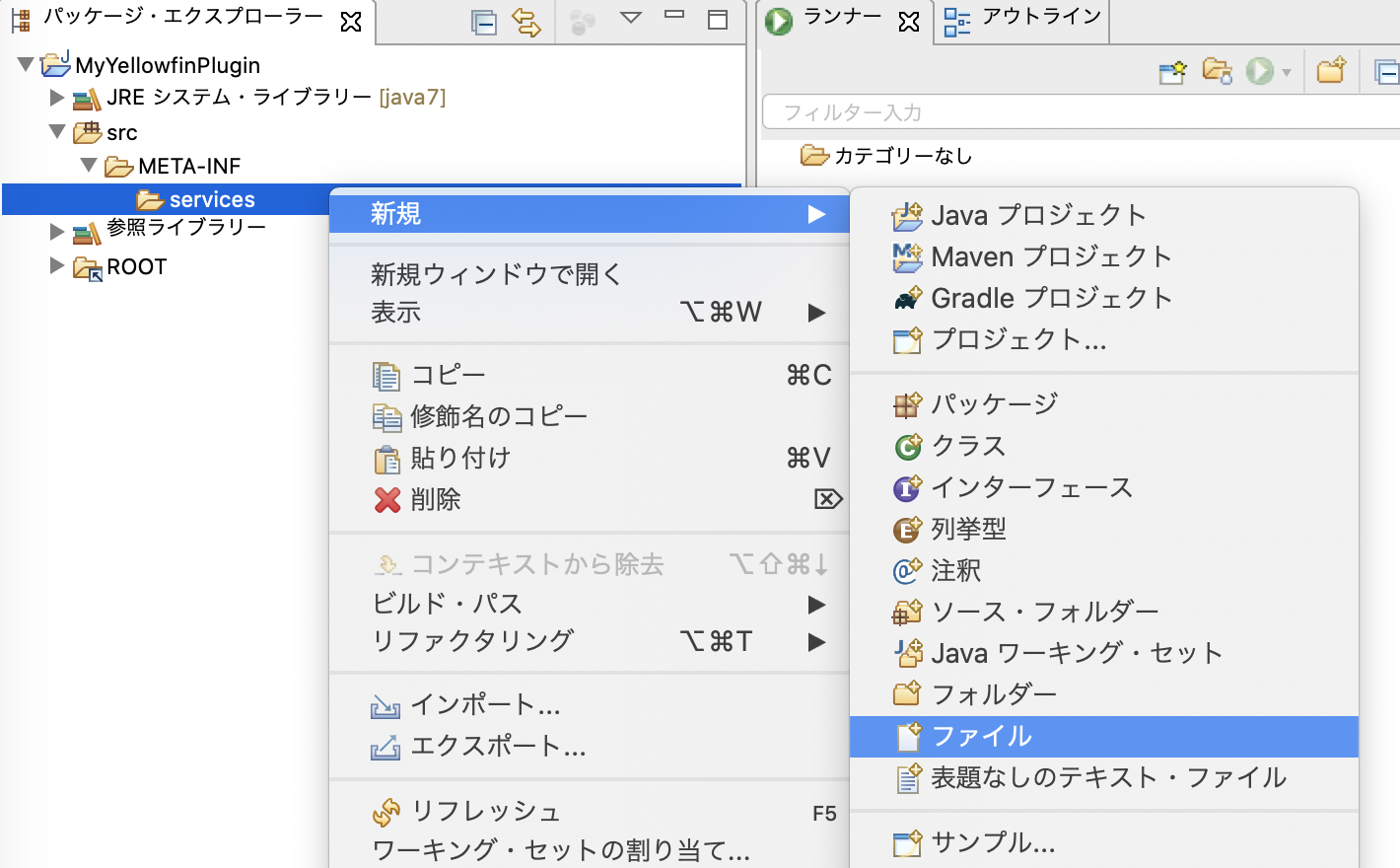
srcフォルダー配下に、META-INF という名前で新規フォルダーを作成します。そのフォルダー配下に services という名前の新規フォルダーを作成します。
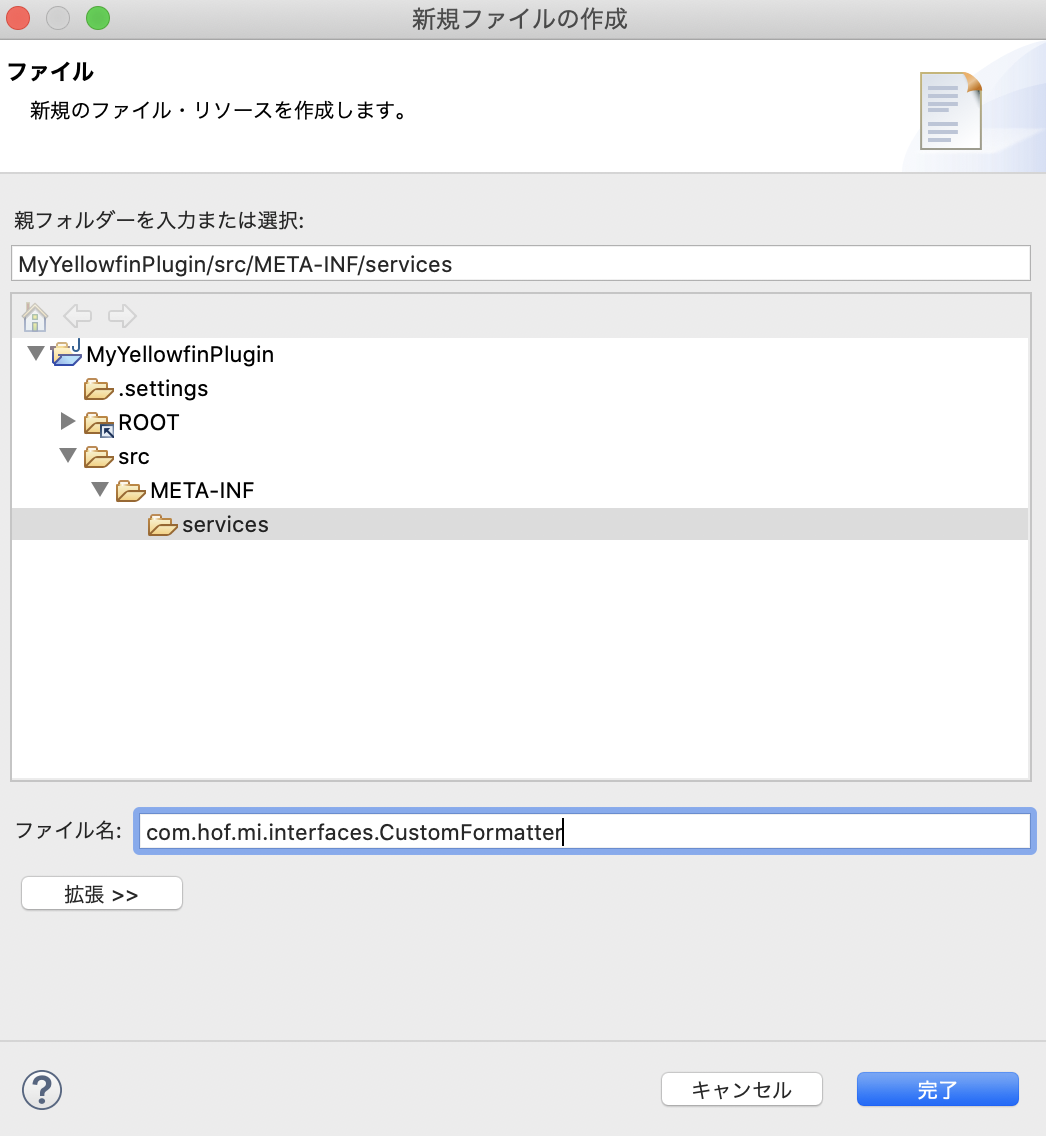
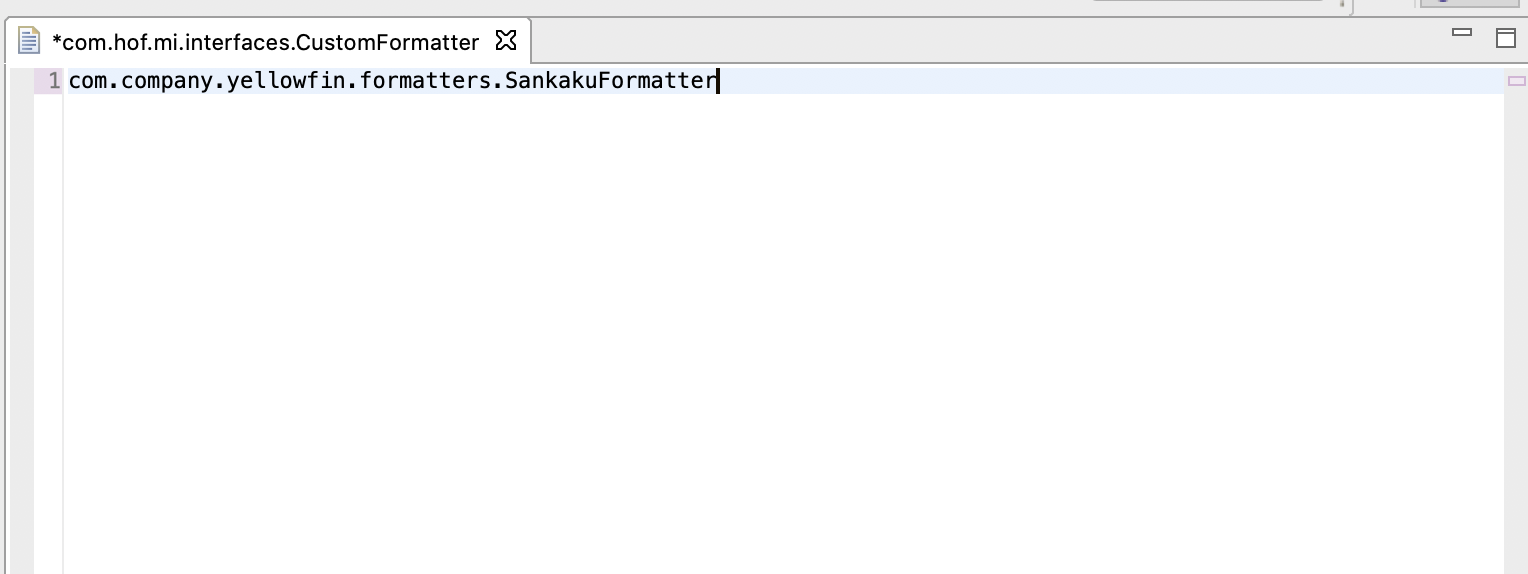
servicesフォルダー配下に、com.hof.mi.interfaces.CustomFormatter というファイルを作成します。
作成したファイルに
com.company.yellowfin.formatters.SankakuFormatterと記述します。これが作成するカスタムフォーマッターの完全修飾クラス名になります。
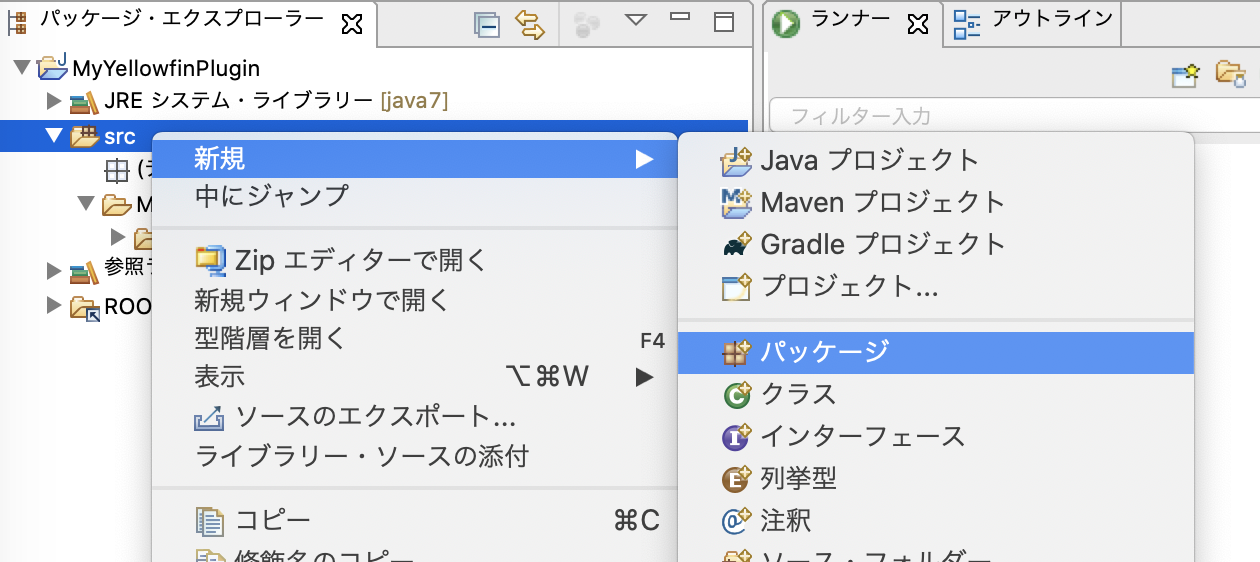
カスタムフォーマッターの作成
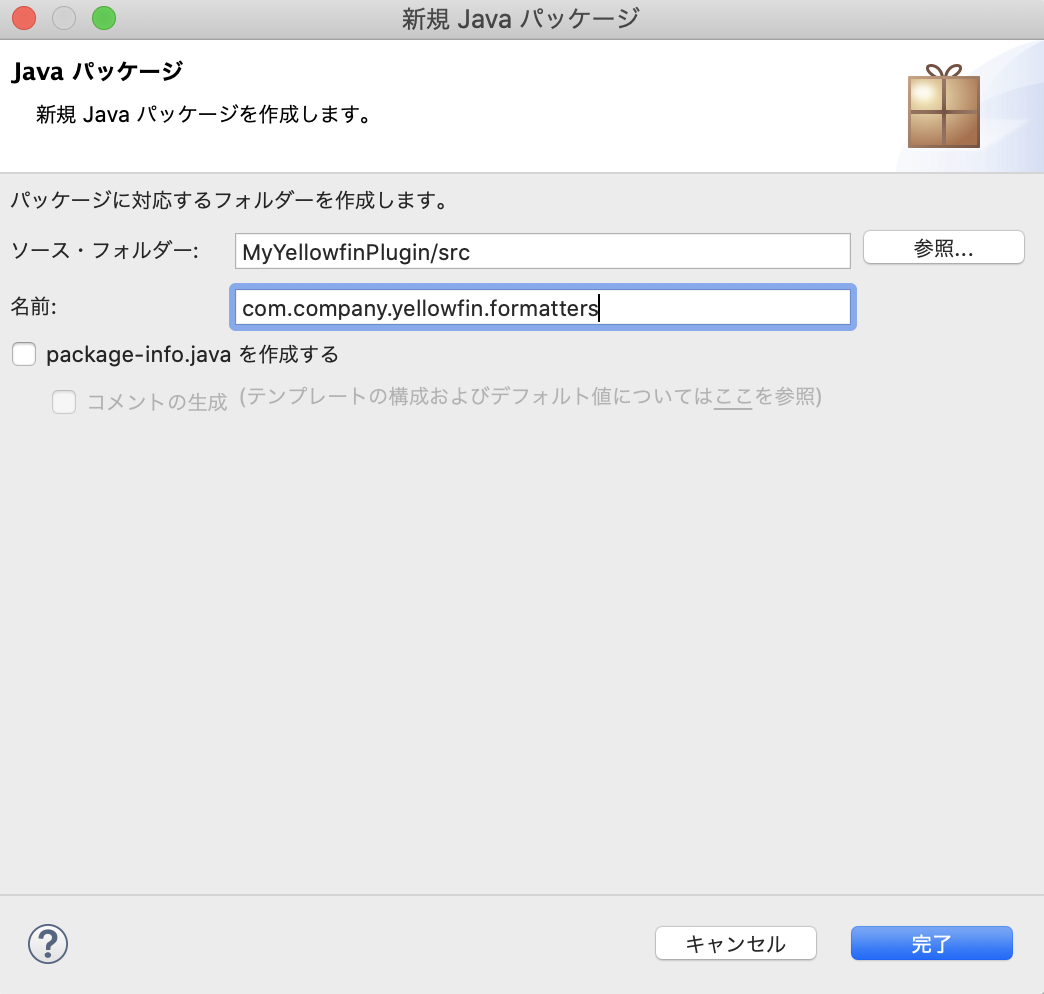
プロジェクトを右クリックし、「新規」>「パッケージ」を選択します。新規パッケージの名前は com.company.yellowfin.formatters とします。(先ほど設定した完全修飾クラス名と合わせます)
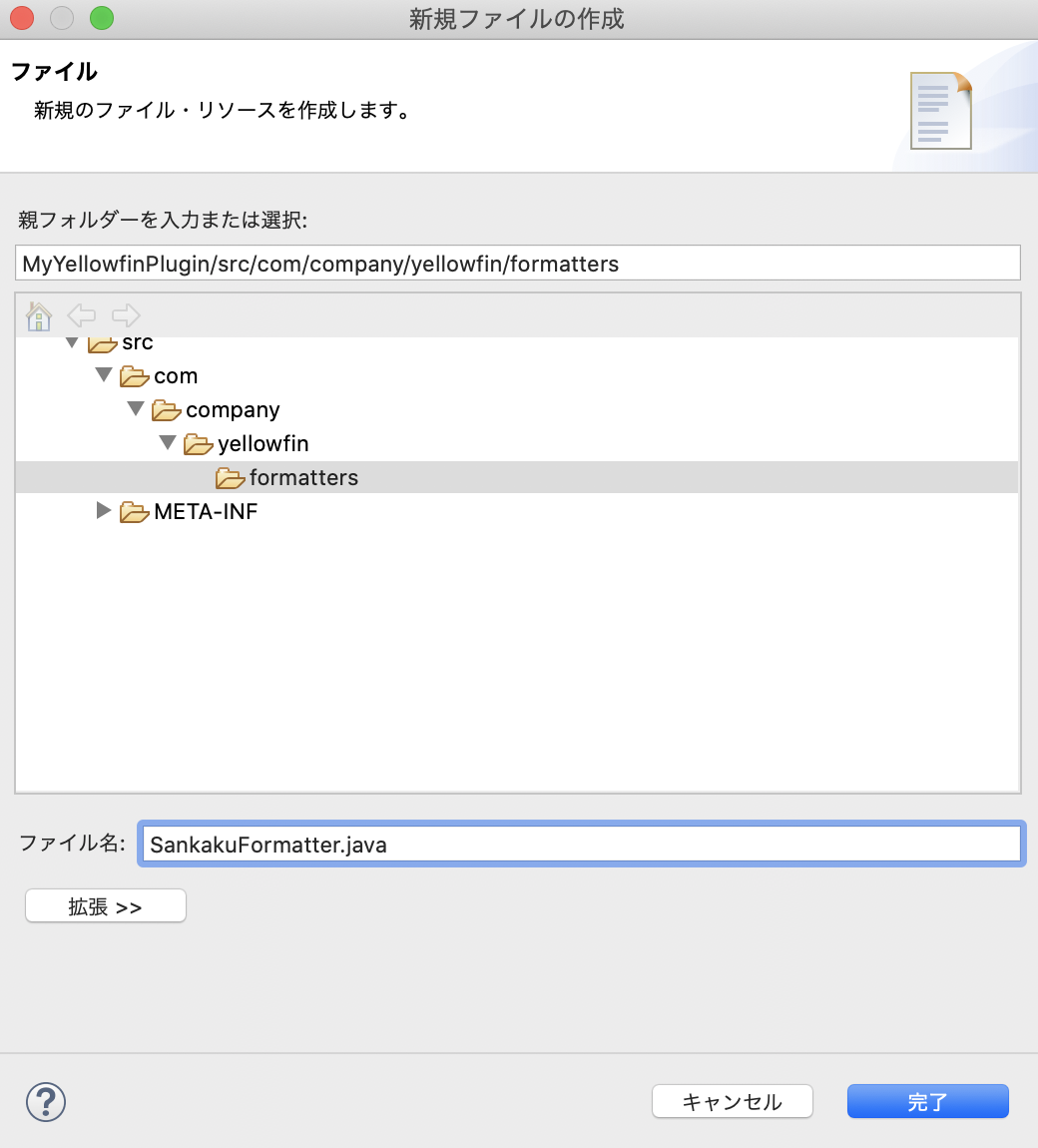
作成したパッケージを右クリックし、「新規」>「ファイル」を選択します。ファイル名は SankakuFormatter.java とします。(こちらも完全修飾クラス名と合わせておきます)
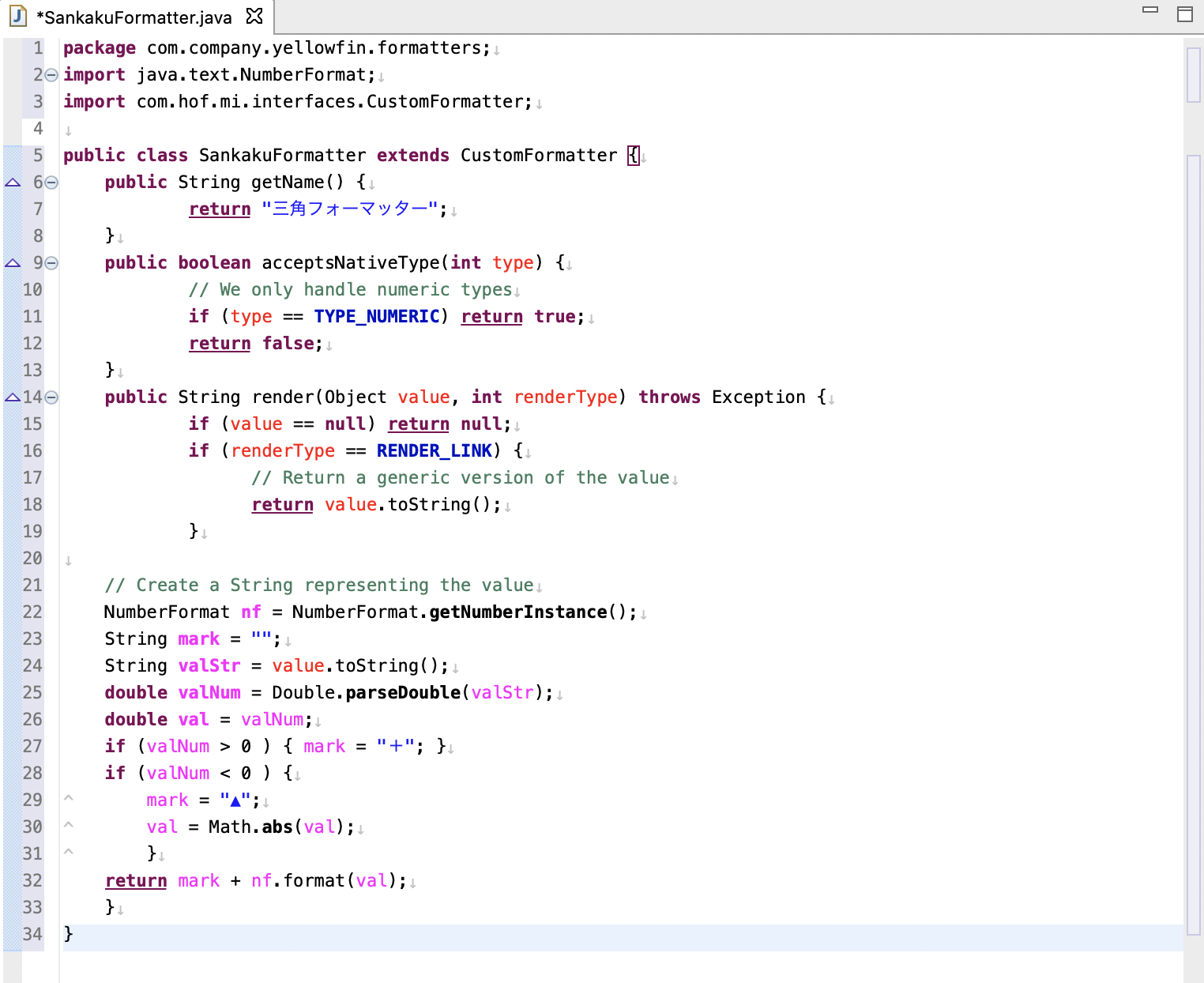
SankakuFormatter.javaに以下のコードを貼り付けます。
SankakuFormatter.javapackage com.company.yellowfin.formatters; import java.text.NumberFormat; import com.hof.mi.interfaces.CustomFormatter; public class SankakuFormatter extends CustomFormatter { public String getName() { return "三角フォーマッター"; } public boolean acceptsNativeType(int type) { // We only handle numeric types if (type == TYPE_NUMERIC) return true; return false; } public String render(Object value, int renderType) throws Exception { if (value == null) return null; if (renderType == RENDER_LINK) { // Return a generic version of the value return value.toString(); } // Create a String representing the value NumberFormat nf = NumberFormat.getNumberInstance(); String mark = ""; String valStr = value.toString(); double valNum = Double.parseDouble(valStr); double val = valNum; if (valNum < 0 ) { mark = "△"; val = Math.abs(val); } return mark + nf.format(val); } }
ちなみに、参考にしたコードの例がオンラインマニュアルにあります。
JARファイルの作成
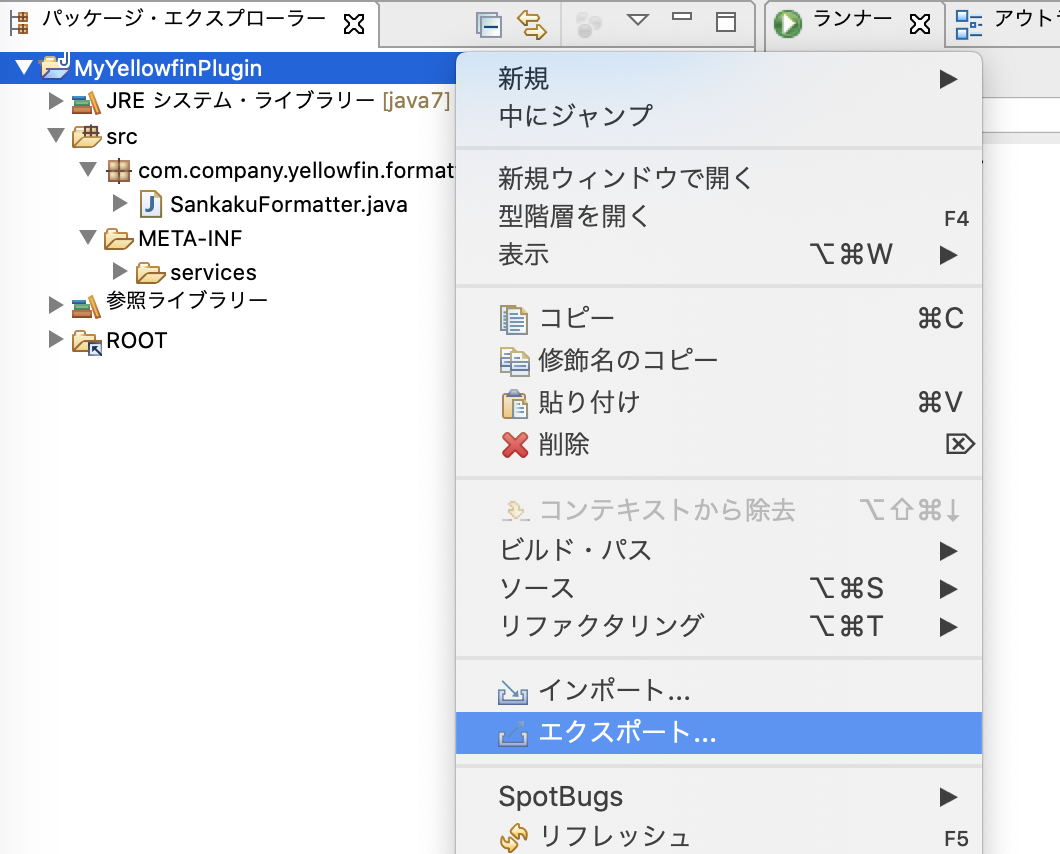
プロジェクトを右クリックし、「エクスポート」を選択します。
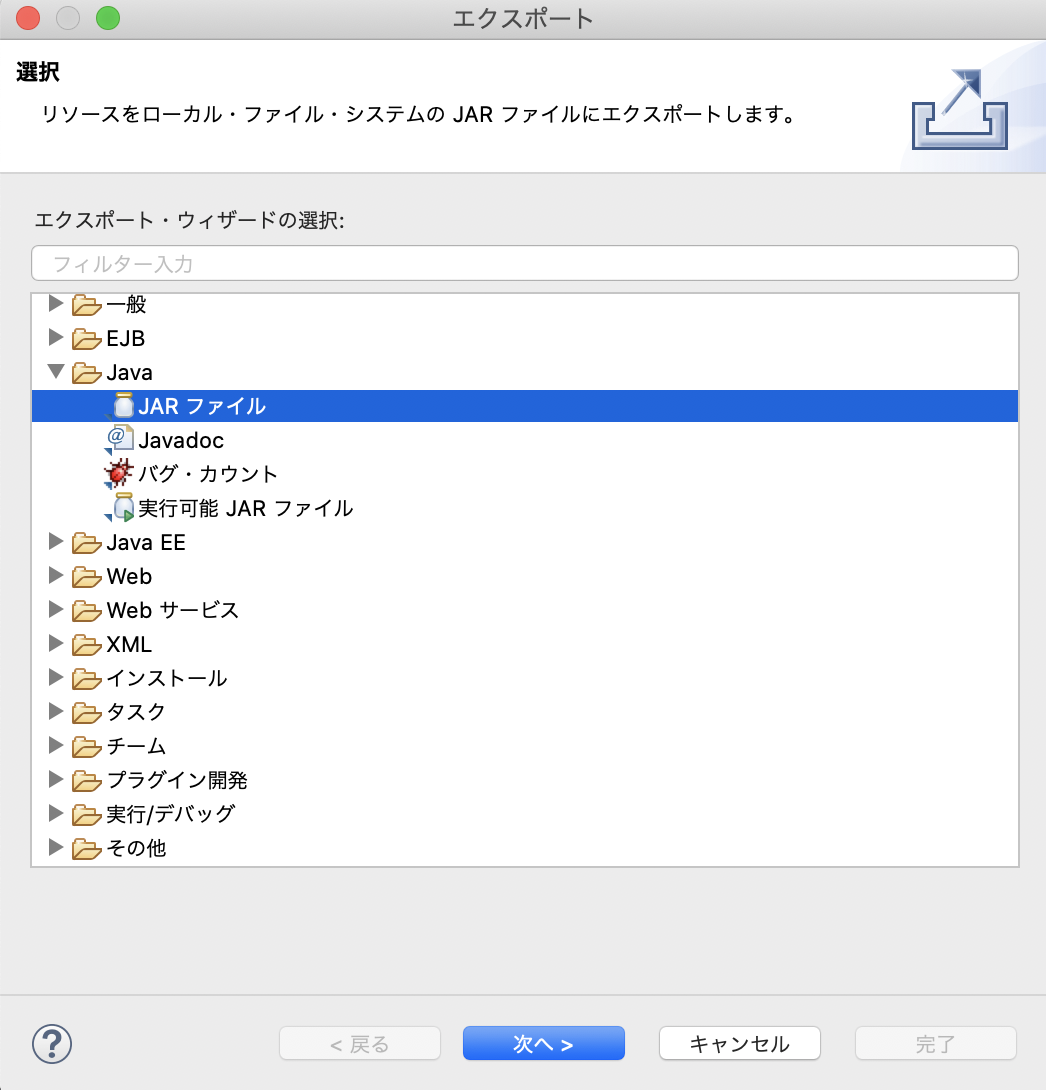
「JARファイル」を選択します。
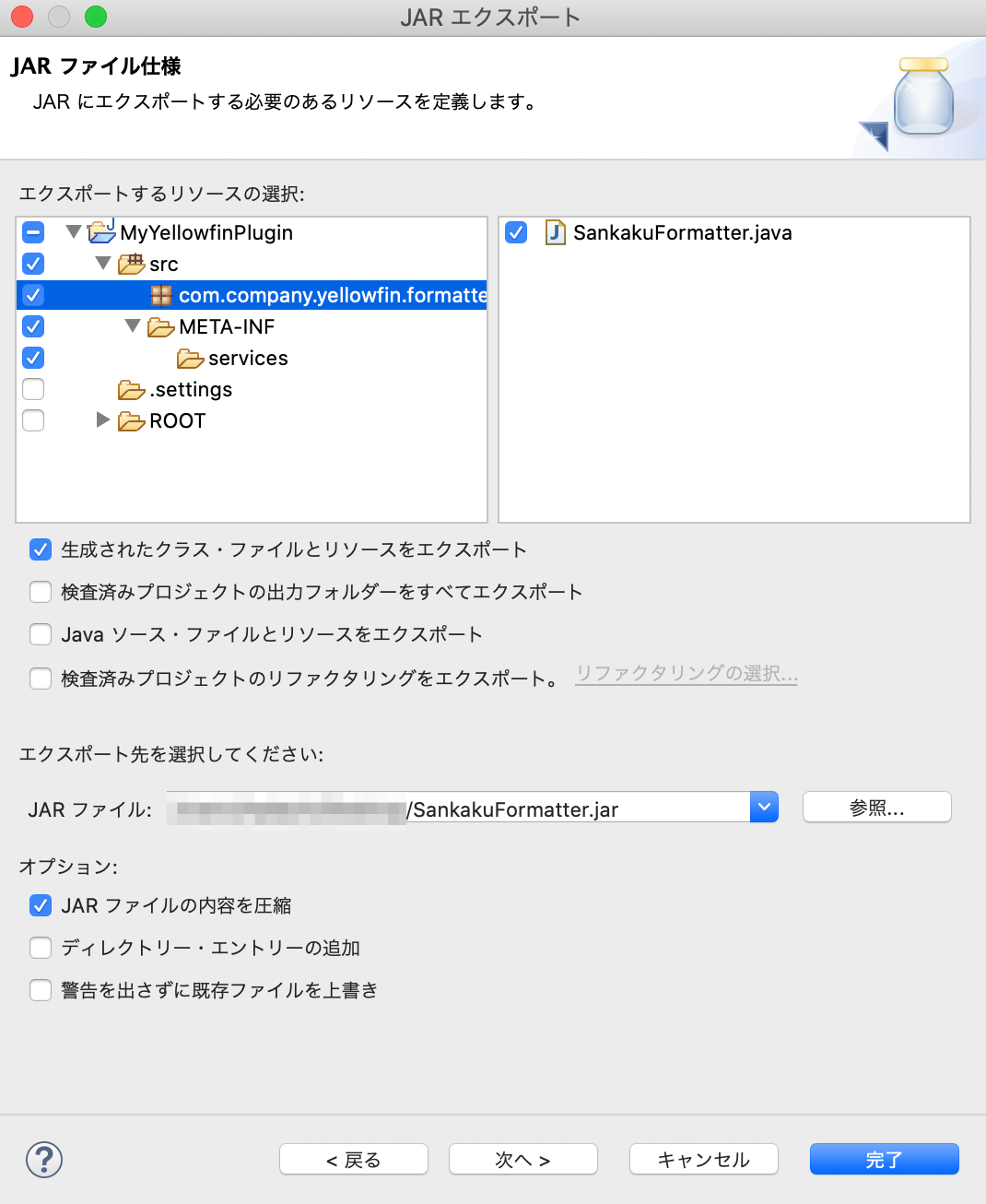
.settingsとROOT以外 をすべて選択し、JARファイル名(ここでは SankakuFormatter.jar としました)を指定してエクスポートします。
Yellowfinに新規プラグイン追加
Yellowfinのプラグイン管理画面から、作成したJARファイルを新規プラグインとして追加します。
Yellowfinレポートでの使用例
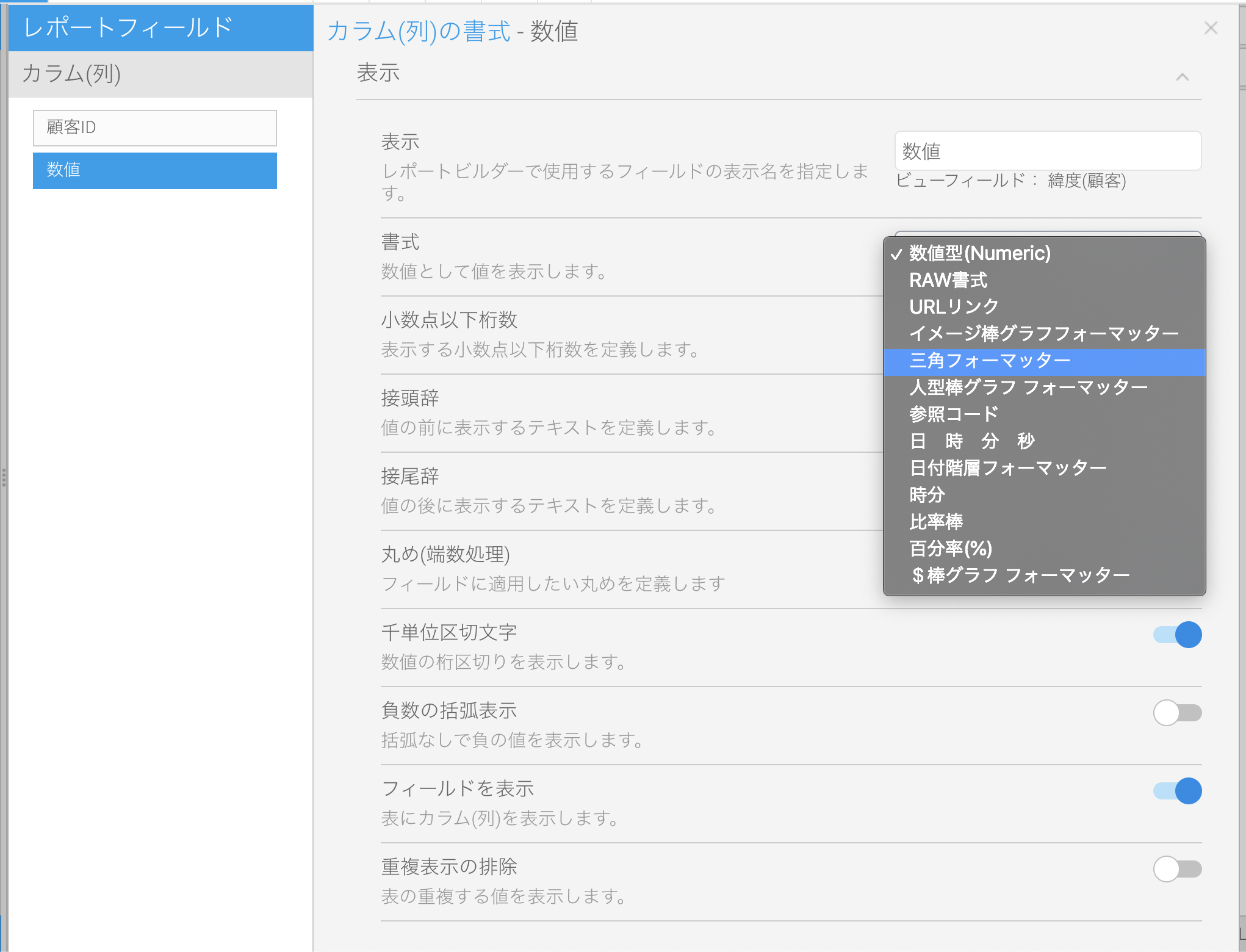
今回作成したカスタムフォーマッターは 三角フォーマッター という名前にしています。名前はSankakuFormatter.java内の getName() の箇所で指定しています。
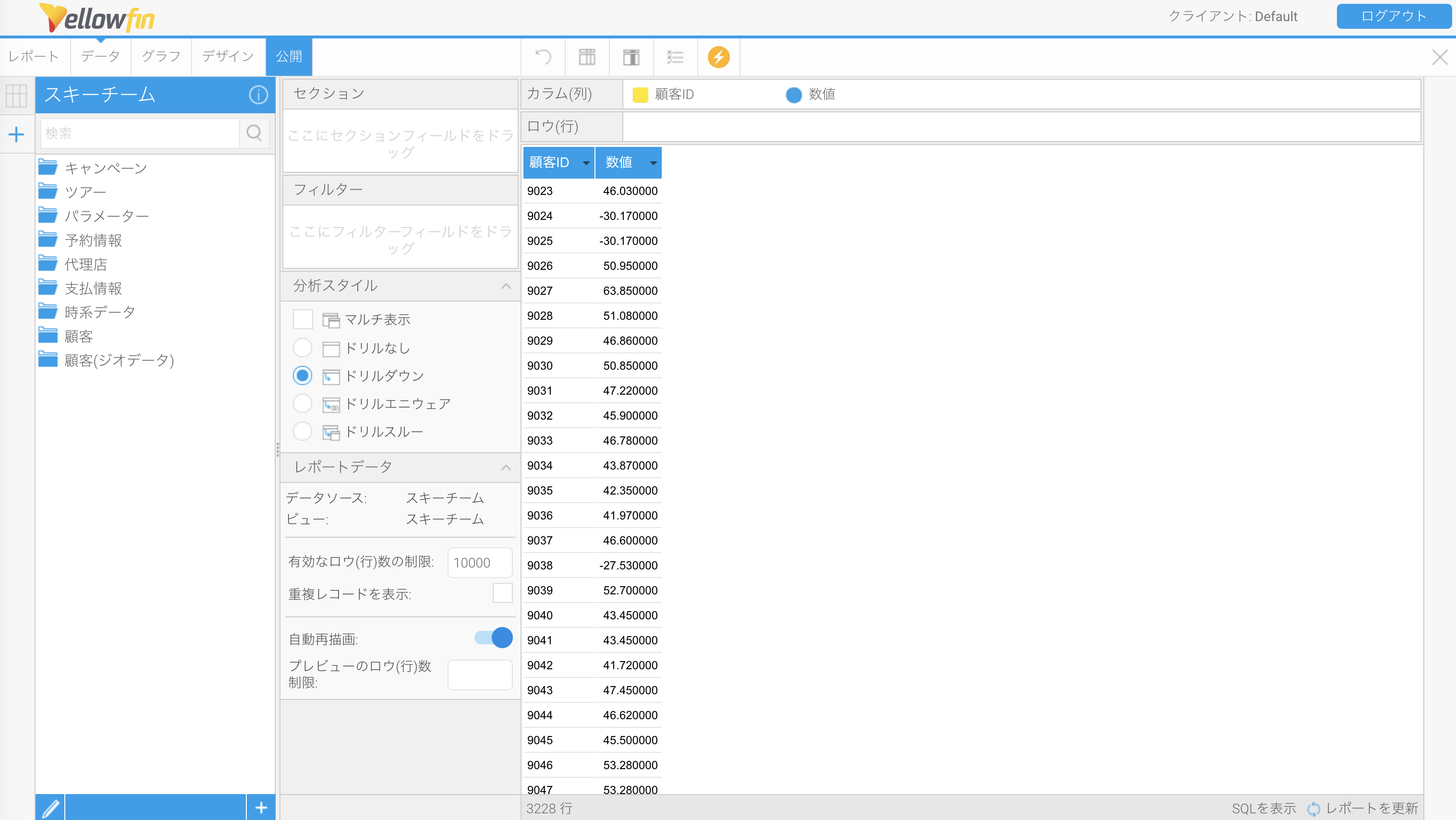
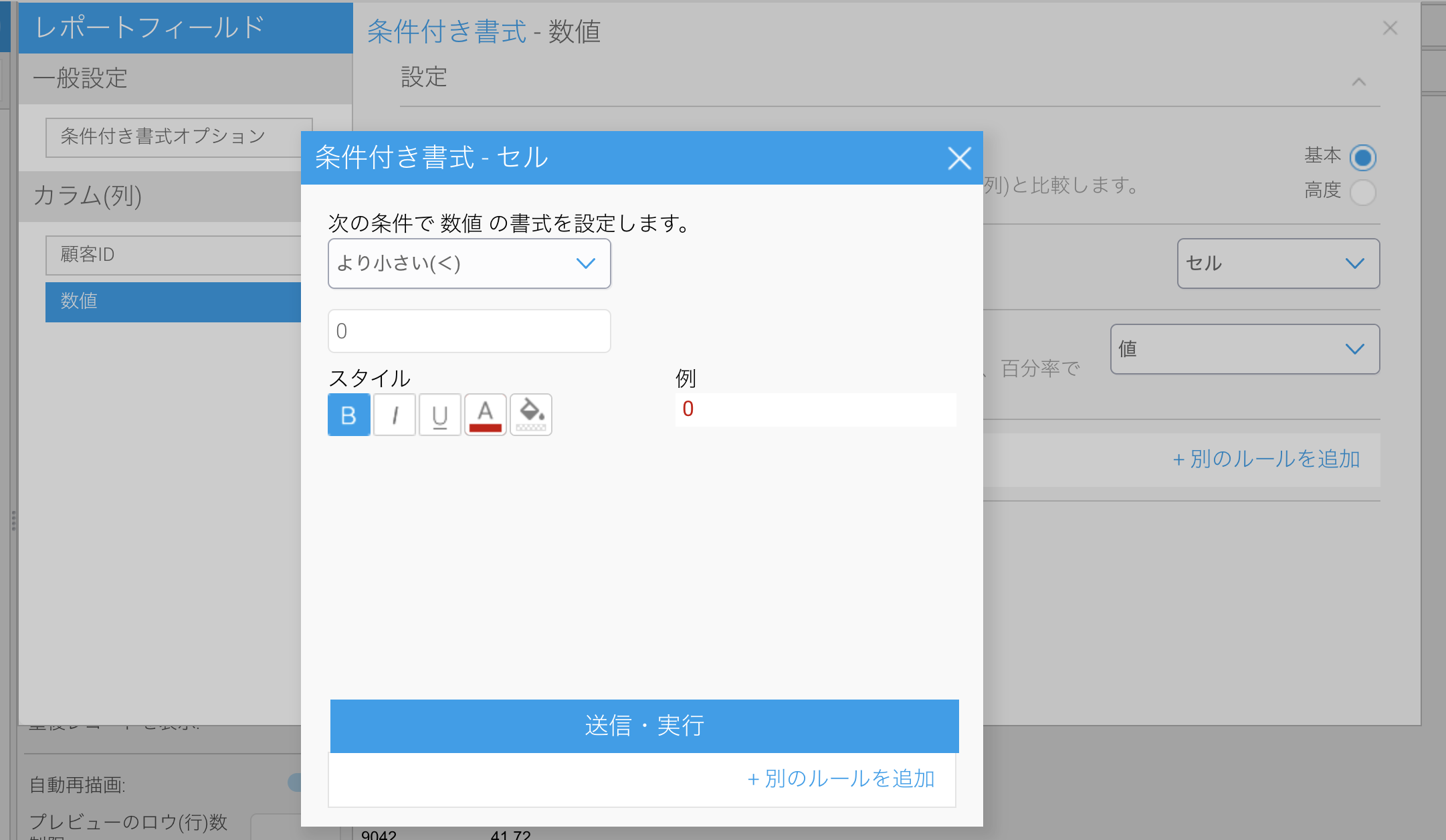
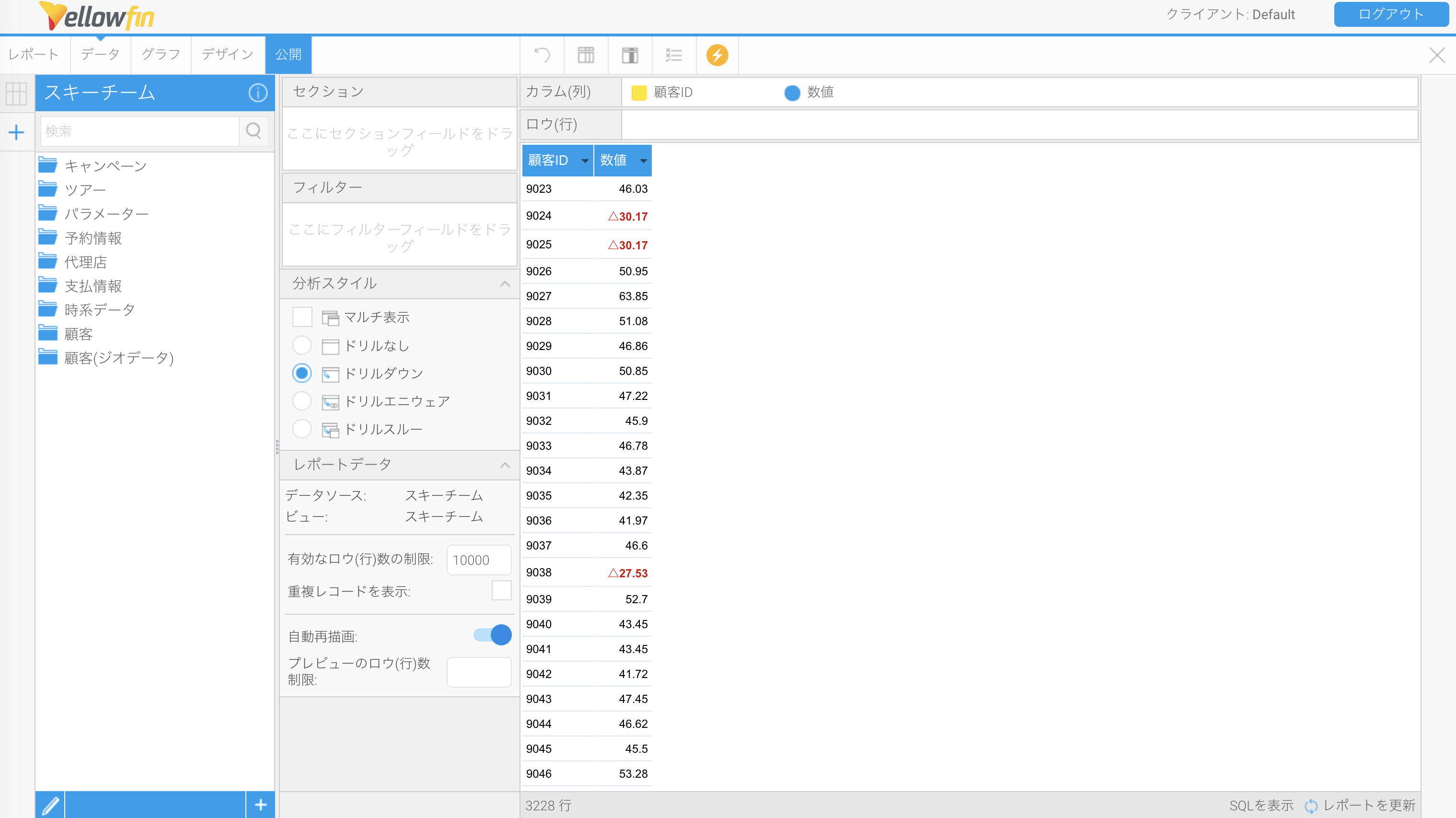
このフォーマッターを使うと、マイナスの数値を「△」の記号付きの書式にすることができます。例えば以下のような単純なデータがあったとします。
この数値に対して、書式で「三角フォーマッター」を指定します。
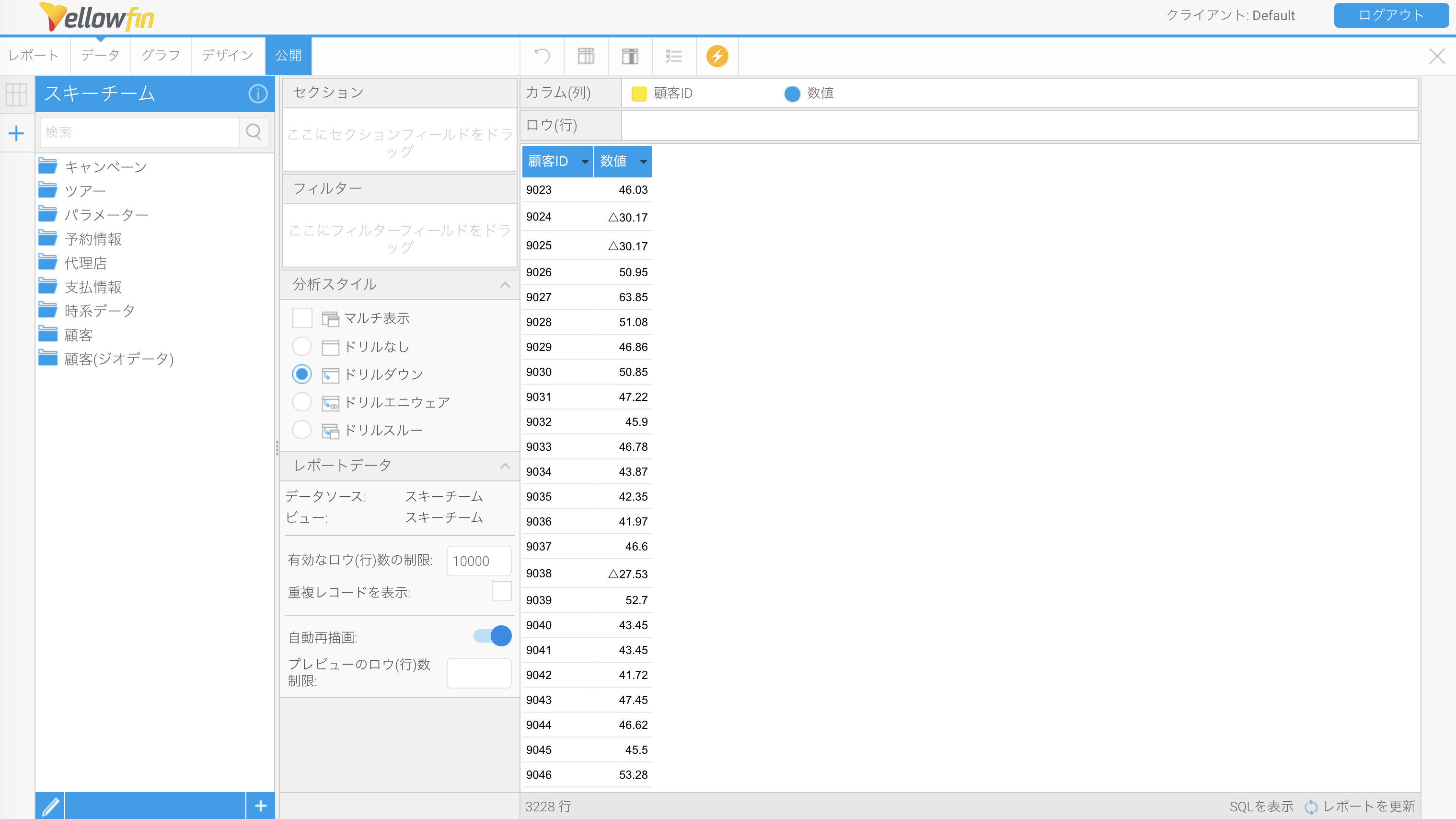
すると、マイナスの数値が三角記号で表示されるようになりました!
一見すると記号付きの文字列に改変されたように思えますが、実際は見かけの書式を変更しただけで、データ自体は数値型のままですので、条件付き書式を適用することも可能です。
おまけ:今回作ったJARファイル
作成したJARファイルをGithubに置いています。よろしければご利用ください!
https://github.com/hadatuna/SankakuFormatter







- 投稿日:2020-01-17T16:27:42+09:00
[MySQL][java]日時を受け取る
概要
MySQLに登録された日時をjavaで取得する方法、javaからMySQLへ日時を登録する方法を紹介する。
MySQLへ接続する方法はこちらを見て頂きたい。https://qiita.com/QiitaD/items/d605b07e849e3bec0722MySQLに定義する列
日時をtimestamp方で定義する。列名は"date_time"、フォーマットは"yyyy-MM-dd HH
ss"である。
MySQLからjavaでの取得
String mySql = "select * from table_name";//日時のあるデータを取得するSQL文 ResultSet rs = stmt.executeQuery(mySql); //SQL実行、データを取得 while (rs.next()) { rs.getTimestamp("date_time"); //取得データから日時情報を取得 }javaからMySQLへ日時を登録する
例として現在時刻を登録する。
String mySql = "insert into table (date_time) values ('" + getNowDateTime(){ + "')"; stmt.executeUpdate(mySql);/** * 現在日時をyyyy/MM/dd HH:mm:ss形式で取得する.<br> */ public static String getNowDateTime(){ final DateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); final Date date = new Date(System.currentTimeMillis()); return df.format(date); }現在時刻取得方法はこちらを参照した。https://qiita.com/zuccyi/items/d9c185588a5628837137
困ったところ
困ったというほどではないが、初心者の方に向けて注意点が2つある。
①SQLの実行文
selectでデータを取得するときはexecuteQueryだが、updateやinsert、deleteの時はexecuteUpdateである。②シングルクォーテーション
忘れやすいが、今回のサンプルでは日時を'(シングルクォーテーション)で囲まなければならない。上記2つは私が超初心者時代によく躓いていたので気を付けて頂きたい。
感想
本記事では日時の扱い方として一例を紹介したが、日時には方が様々なので他にも使い方がある。(DateやLocaleDateTimeなど)
型を変えると変換が面倒になったりするので、よく考えて使いたい。参考URL
日付と時刻型
https://www.dbonline.jp/mysql/type/index4.htmltimestampとdatetimeの違い
https://qiita.com/ykawakami/items/2449a24e3b82ff0cbab6timestampの例外
https://ts0818.hatenablog.com/entry/2017/08/11/155011
- 投稿日:2020-01-17T15:32:49+09:00
Java合併 & マージを解除Excelセル
本論文では、どのように使うかを紹介しますSpire.XLS for Java Excel Java合併 & マージを解除Excelセル
使用ツール: Free Spire.XLS for Java無料版
Jarファイルの取得と導入:
Method 1:ホームページを通じてjarファイルのカバンをダウンロードします。ダウンロード後、ファイルを解凍して、libフォルダの下のSpire.xls.jarファイルをJavaプログラムに導入します。
Method 2:maven倉庫設置による導入。
合併Excelセル
Spire.XLSにおいて, 私たちは通過できます worksheet. getRange().get().merge()方法でセルの行と列を結合します。
import com.spire.xls.FileFormat; import com.spire.xls.Workbook; import com.spire.xls.Worksheet; public class MergeCells { public static void main(String[] args){ // Workbookの作成例 Workbook workbook = new Workbook(); // Excelドキュメントを読み込む workbook.loadFromFile("Test1.xlsx"); //最初のシートを取得 Worksheet sheet = workbook.getWorksheets().get(0); //セル範囲A 1からC 1を結合 sheet.getRange().get("A1:C1").merge(); //結果ドキュメントを保存 workbook.saveToFile("MergeCells.xlsx", FileFormat.Version2013); } }
セルの結合を解除
Spire.XLS同時に提供しましたworksheet. getRange().get().UnMerge()方法でセルの結合を解除します。
import com.spire.xls.FileFormat; import com.spire.xls.Workbook; import com.spire.xls.Worksheet; public class UnmergeCells { public static void main(String[] args){ // Workbookの作成例 Workbook workbook = new Workbook(); // Excelドキュメントを読み込む workbook.loadFromFile("MergeCells.xlsx"); //最初のシートを取得 Worksheet sheet = workbook.getWorksheets().get(0); //セルの結合を解除する範囲A 1からC 1まで sheet.getRange().get("A1:C1").unMerge(); //結果ドキュメントを保存 workbook.saveToFile("UnMergeCells.xlsx", FileFormat.Version2013); } }

- 投稿日:2020-01-17T12:47:42+09:00
Java 11 (OpenJDK: AdoptOpenJDK) を Homebrew で macOS にインストールする
今回の環境
- macOS Catalina 10.15.2
インストール
公式資料通りにインストールする。
GitHub - AdoptOpenJDK/homebrew-openjdk: AdoptOpenJDK HomeBrew Tap$ brew tap AdoptOpenJDK/openjdk $ brew cask install adoptopenjdk11java_home コマンドでインストールされたディレクトリの場所を確認
$ /usr/libexec/java_home -v 11 /Library/Java/JavaVirtualMachines/adoptopenjdk-11.jdk/Contents/Home環境変数 JAVA_HOME と PATH を設定
必要に応じて .bash_profile や .bashrc などに記述する。
export JAVA_HOME=/Library/Java/JavaVirtualMachines/adoptopenjdk-11.jdk/Contents/Home PATH=${JAVA_HOME}/bin:${PATH}インストールされた AdoptOpenJDK を確認
$ java -version openjdk version "11.0.6" 2020-01-14 OpenJDK Runtime Environment AdoptOpenJDK (build 11.0.6+10) OpenJDK 64-Bit Server VM AdoptOpenJDK (build 11.0.6+10, mixed mode) $ javac -version javac 11.0.6 $ which java /Library/Java/JavaVirtualMachines/adoptopenjdk-11.jdk/Contents/Home/bin/java $ which javac /Library/Java/JavaVirtualMachines/adoptopenjdk-11.jdk/Contents/Home/bin/javac $ ls /Library/Java/JavaVirtualMachines/adoptopenjdk-11.jdk/Contents/Home/bin/ jaotc javap jfr jmap jstat rmiregistry jar jcmd jhsdb jmod jstatd serialver jarsigner jconsole jimage jps keytool unpack200 java jdb jinfo jrunscript pack200 javac jdeprscan jjs jshell rmic javadoc jdeps jlink jstack rmid
- 投稿日:2020-01-17T11:56:15+09:00
SpringSecurityで認証機能を実装③
前回の続きです。
※ここからたくさんのファイルを作成していきます。失敗した際に、途中で後戻りが出来なくなる可能性が高いので、ここまでプロジェクト情報をコピーまたはGithubなどに挙げておくといいでしょう。
私はこれをせず何度もプロジェクト作成してかなりの時間を要しました。5、SpringSecurityの認証機能の実装。
・ここからがメインディッシュになります。
前回までの実装がうまく行ってないとエラー対応が面倒なので、ここまでを完璧に実装しておきましょう。5-1,POMを編集。
・まずSpringSecurityを導入するためMavenの依存関係を記載してある、pom.xmlを書き換えます。またDBから受け取ったデータを格納するエンティティクラスを使用するためjavax.persistenceも導入します。
pom.xml<!-- SpringSecurity --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-security</artifactId> </dependency> <!-- Thyemeleaf拡張(セキュリティ) --> <dependency> <groupId>org.thymeleaf.extras</groupId> <artifactId>thymeleaf-extras-springsecurity5</artifactId> </dependency> <!-- https://mvnrepository.com/artifact/javax.persistence/javax.persistence-api --> <!-- Entityのアノテーションを使うため --> <dependency> <groupId>javax.persistence</groupId> <artifactId>javax.persistence-api</artifactId> <version>2.2</version> </dependency> <!-- JpaRepository--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency>・コードを書いただけだと反映されません。Mavenプロジェクト更新する必要があります。
「プロジェクト右クリック」→「Maven」→「プロジェクトの更新」でMavenファイルに更新をかけます。選択したファイルが正しければ「OK」で更新をかけましょう。
・アプリを実行した際にコンソール上にエラーが出なければOKです。
5-2,認証機能を実装する。
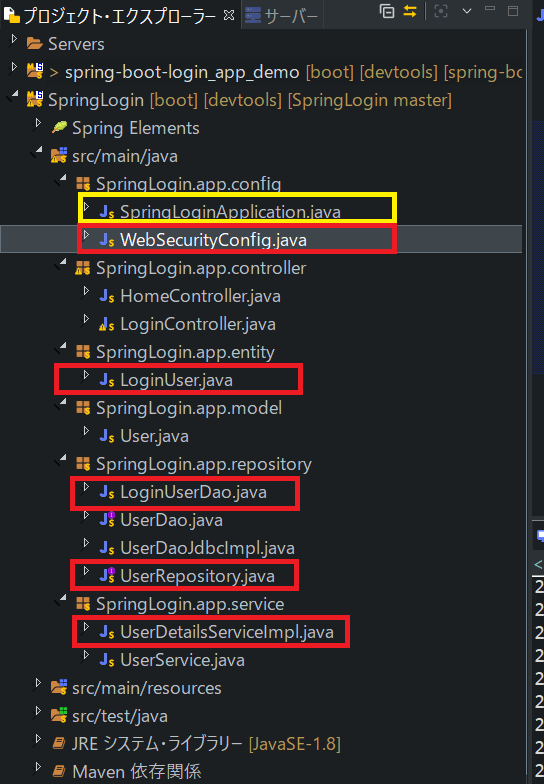
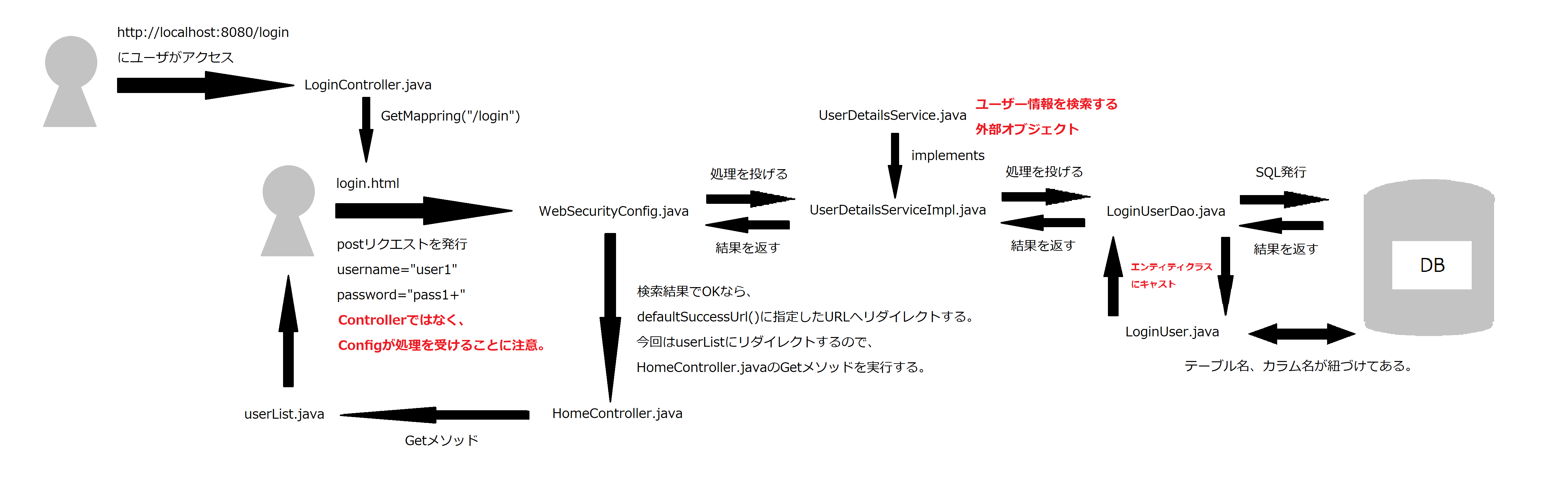
・最後です。最後にして、たくさんのファイルを作成していきます。ファイル構成イメージは以下になります。赤枠が新規作成、黄色枠が編集するファイルです。
・また処理の流れもイメージにしましたので、参考にして下さい。(非常に見づらくて申し訳ない・・・)
・コードを載せます。コメントをたくさん書いていますが、正直全てを理解するのが難しく間違っている可能性もあります。各自で調べて理解を深めて頂くと幸いです。
SpringLogin.app.config/WebSecurityConfig.javapackage SpringLogin.app.config; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.security.config.annotation.authentication.builders.AuthenticationManagerBuilder; import org.springframework.security.config.annotation.web.builders.HttpSecurity; import org.springframework.security.config.annotation.web.builders.WebSecurity; import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity; import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter; import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder; import SpringLogin.app.service.UserDetailsServiceImpl; /** * SpringSecurityを利用するための設定クラス * ログイン処理でのパラメータ、画面遷移や認証処理でのデータアクセス先を設定する * @author aoi * */ @Configuration @EnableWebSecurity public class WebSecurityConfig extends WebSecurityConfigurerAdapter { // UserDetailsServiceImplのメソッドを使えるようインスタンス化しておきます。 @Autowired private UserDetailsServiceImpl userDetailsService; //フォームの値と比較するDBから取得したパスワードは暗号化されているのでフォームの値も暗号化するために利用 @Bean public BCryptPasswordEncoder passwordEncoder() { BCryptPasswordEncoder bCryptPasswordEncoder = new BCryptPasswordEncoder(); return bCryptPasswordEncoder; } /** * 認可設定を無視するリクエストを設定 * 静的リソース(image,javascript,css)を認可処理の対象から除外する */ @Override public void configure(WebSecurity web) throws Exception { web.ignoring().antMatchers( "/images/**", "/css/**", "/javascript/**" ); } /** * 認証・認可の情報を設定する * 画面遷移のURL・パラメータを取得するname属性の値を設定 * SpringSecurityのconfigureメソッドをオーバーライドしています。 */ @Override protected void configure(HttpSecurity http) throws Exception { http .authorizeRequests() .anyRequest().authenticated() .and() .formLogin() .loginPage("/login") //ログインページはコントローラを経由しないのでViewNameとの紐付けが必要 .loginProcessingUrl("/login") //フォームのSubmitURL、このURLへリクエストが送られると認証処理が実行される .usernameParameter("username") //リクエストパラメータのname属性を明示 .passwordParameter("password") .defaultSuccessUrl("/userList", true) //認証が成功した際に遷移するURL .failureUrl("/login?error") //認証が失敗した際に遷移するURL .permitAll() //どのユーザでも接続できる。 .and() .logout() .logoutUrl("/logout") .logoutSuccessUrl("/login?logout") .permitAll(); } /** * 認証時に利用するデータソースを定義する設定メソッド * ここではDBから取得したユーザ情報をuserDetailsServiceへセットすることで認証時の比較情報としている * @param auth * @throws Exception * AuthenticationManagerBuilderは認証系の機能を有している。 * userDetailsServiceもその一つでフォームに入力されたユーザが使用可能か判断します。 * https://docs.spring.io/spring-security/site/docs/4.0.x/apidocs/org/springframework/security/config/annotation/authentication/builders/AuthenticationManagerBuilder.html */ @Autowired public void configure(AuthenticationManagerBuilder auth) throws Exception{ auth.userDetailsService(userDetailsService).passwordEncoder(passwordEncoder()); /* * インメモリの場合は以下を使います。 auth .inMemoryAuthentication() .withUser("user").password("{noop}password").roles("USER"); */ } }SpringLogin.app.servise/UserDetailsServiceImpl.javapackage SpringLogin.app.service; import java.util.ArrayList; import java.util.List; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.security.core.GrantedAuthority; import org.springframework.security.core.authority.SimpleGrantedAuthority; import org.springframework.security.core.userdetails.User; import org.springframework.security.core.userdetails.UserDetails; import org.springframework.security.core.userdetails.UserDetailsService; import org.springframework.security.core.userdetails.UsernameNotFoundException; import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder; import org.springframework.stereotype.Service; import SpringLogin.app.repository.LoginUserDao; import SpringLogin.app.entity.LoginUser; /** * Spring Securityのユーザ検索用のサービスの実装クラス * DataSourceの引数として指定することで認証にDBを利用できるようになる * @author aoi * */ @Service public class UserDetailsServiceImpl implements UserDetailsService{ //DBからユーザ情報を検索するメソッドを実装したクラス @Autowired private LoginUserDao userDao; /** * UserDetailsServiceインタフェースの実装メソッド * フォームから取得したユーザ名でDBを検索し、合致するものが存在したとき、 * パスワード、権限情報と共にUserDetailsオブジェクトを生成 * コンフィグクラスで上入力値とDBから取得したパスワードと比較し、ログイン判定を行う */ @Override public UserDetails loadUserByUsername(String userName) throws UsernameNotFoundException { LoginUser user = userDao.findUser(userName); if (user == null) { throw new UsernameNotFoundException("User" + userName + "was not found in the database"); } //権限のリスト //AdminやUserなどが存在するが、今回は利用しないのでUSERのみを仮で設定 //権限を利用する場合は、DB上で権限テーブル、ユーザ権限テーブルを作成し管理が必要 List<GrantedAuthority> grantList = new ArrayList<GrantedAuthority>(); GrantedAuthority authority = new SimpleGrantedAuthority("USER"); grantList.add(authority); //rawDataのパスワードは渡すことができないので、暗号化 BCryptPasswordEncoder encoder = new BCryptPasswordEncoder(); //UserDetailsはインタフェースなのでUserクラスのコンストラクタで生成したユーザオブジェクトをキャスト UserDetails userDetails = (UserDetails)new User(user.getUserName(), encoder.encode(user.getPassword()),grantList); return userDetails; } }SpringLogin.app.repository/LoginUserDao.javapackage SpringLogin.app.repository; import javax.persistence.EntityManager; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Repository; import SpringLogin.app.entity.LoginUser; /** * DBへのアクセスメソッドを呼び出すDao * @author aoi * */ @Repository public class LoginUserDao { /** * エンティティを管理するオブジェクト。 * 以下のメソッドでエンティティクラスであるLoginUserにキャストして戻り値を返すので必要なオブジェクト。 */ @Autowired EntityManager em; /** * フォームの入力値から該当するユーザを検索 合致するものが無い場合Nullが返される * @param userName * @return 一致するユーザが存在するとき:UserEntity、存在しないとき:Null */ public LoginUser findUser(String userName) { String query = ""; query += "SELECT * "; query += "FROM user "; query += "WHERE user_name = :userName "; //setParameterで引数の値を代入できるようにNamedParameterを利用 //EntityManagerで取得された結果はオブジェクトとなるので、LoginUser型へキャストが必要となる return (LoginUser)em.createNativeQuery(query, LoginUser.class).setParameter("userName", userName).getSingleResult(); } }SpringLogin.app.entity/LoginUser.javapackage SpringLogin.app.entity; import javax.persistence.Column; import javax.persistence.Entity; import javax.persistence.Id; import javax.persistence.Table; /** * ログインユーザのユーザ名、パスワードを格納するためのEntity * @author aoi * */ @Entity @Table(name = "user") public class LoginUser { @Column(name = "user_id") @Id private Long userId; @Column(name = "user_name") private String userName; @Column(name = "password") private String password; public String getUserName() { return userName; } public void setUserName(String userName) { this.userName = userName; } public String getPassword() { return password; } public void setPassword(String password) { this.password = password; } }SpringLogin.app.repository/UserRepository.javapackage SpringLogin.app.repository; import org.springframework.data.jpa.repository.JpaRepository; import org.springframework.stereotype.Repository; import SpringLogin.app.entity.LoginUser; /* * Spring Frameworkのデータ検索を行うための仕組み。 * DIに登録しておくことでデータ検索が可能になる。引数には<エンティティクラス, IDタイプとなる> * https://www.tuyano.com/index3?id=12626003 */ @Repository public interface UserRepository extends JpaRepository<LoginUser, Integer>{ }SpringLogin.app.config/SpringLoginApplication.javapackage SpringLogin.app.config; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.boot.autoconfigure.domain.EntityScan; import org.springframework.context.annotation.ComponentScan; import org.springframework.data.jpa.repository.config.EnableJpaRepositories; @SpringBootApplication //Spring Bootアプリケーションであることを示す @ComponentScan("SpringLogin.app") //BeanとしてDIに登録する。パッケージとして指定することができる。 @EntityScan("SpringLogin.app.entity") //上記同様BeanとしてDIに登録。 @EnableJpaRepositories("SpringLogin.app.repository") //JpaRepositoryをONにするためのもの。指定されたパッケージ内を検索し、@Repositoryを付けたクラスをBeanとして登録。 public class SpringLoginApplication { public static void main(String[] args) { SpringApplication.run(SpringLoginApplication.class, args); } }・お疲れ様です。だいぶ長いコードになりましたがあともう一踏ん張りです!では、ここまでコードが書けたら、ブラウザで確認しましょう。
5-3,動作確認。
まずここにアクセスします→http://localhost:8080/
するとURLが/loginの画面に遷移します。
これはSpringSecurityのが適用されている証拠で、WebSecurityConfig.javaのauthorizeRequestsメソッド内にはloginしていない状態でもアクセスできるURLを指定します。ですが今回は何も指定がないので、未ログイン状態ではログインページ以外アクセスが出来ません。なのでlocalhost:8080/にアクセスした際に/loginにリダイレクトされます。
・上のイメージの様に動いていたらOKです。
・次に認証機能を確認します。
まず間違ったパスとユーザでログインします。
そうするとログインできない&"/login?error"にリダイレクトされます。
これはWebSecurityConfig.jav内のfailureUrl()に影響されています。
・上のイメージの様に動いていたらOKです。
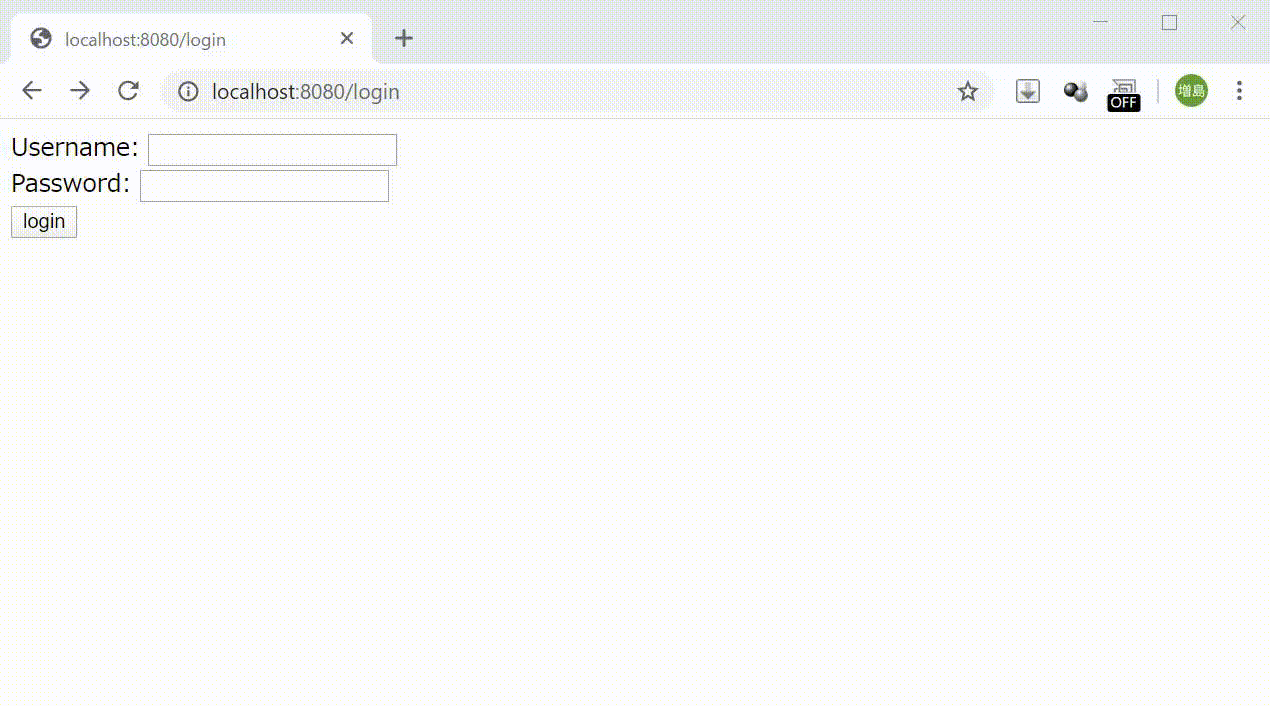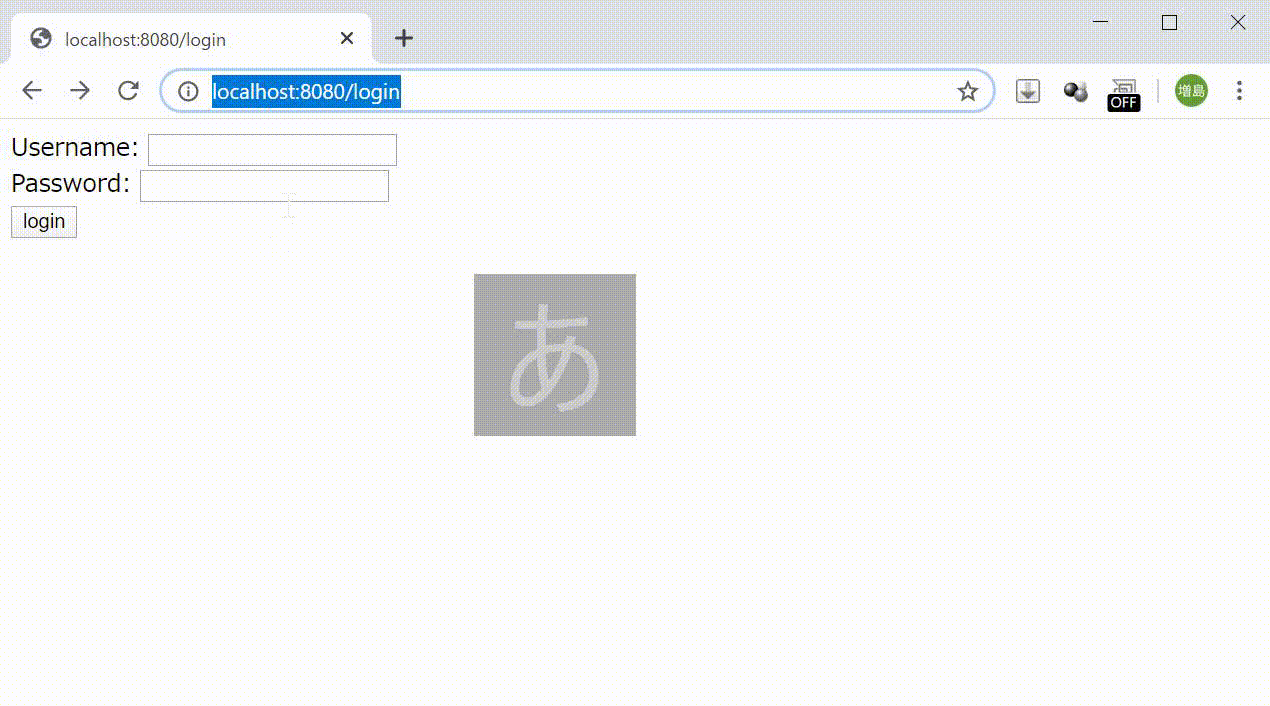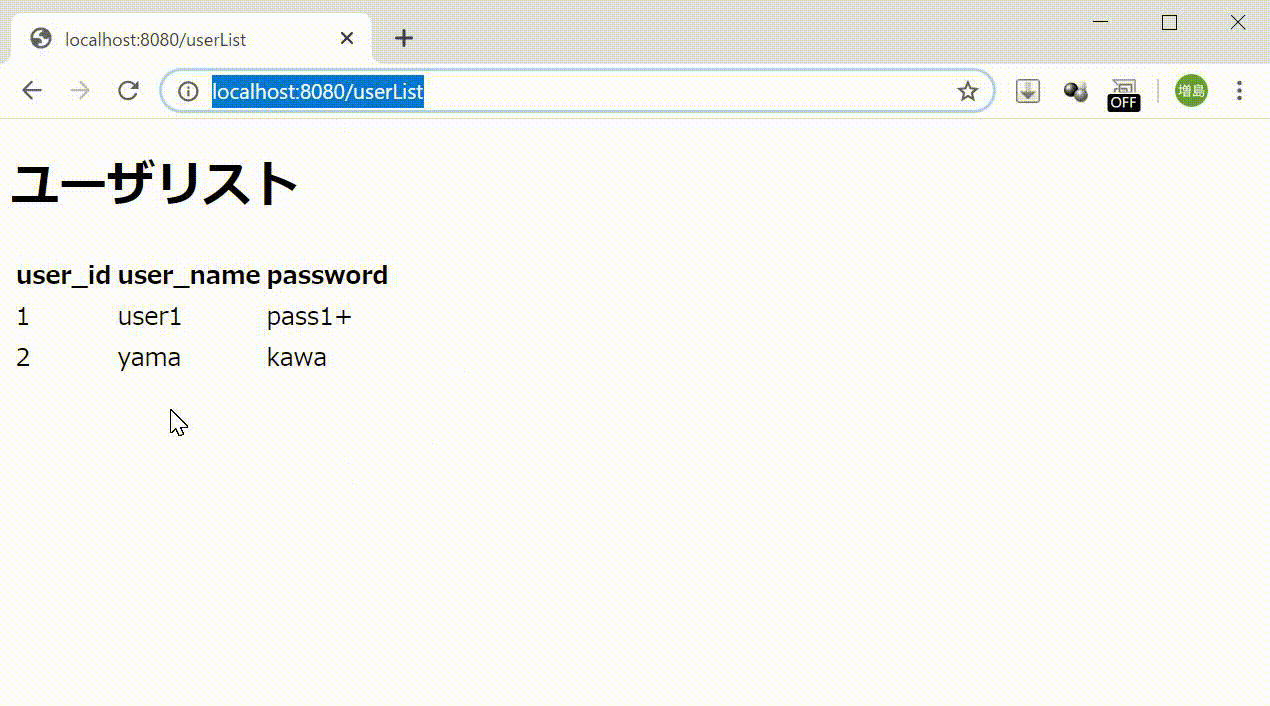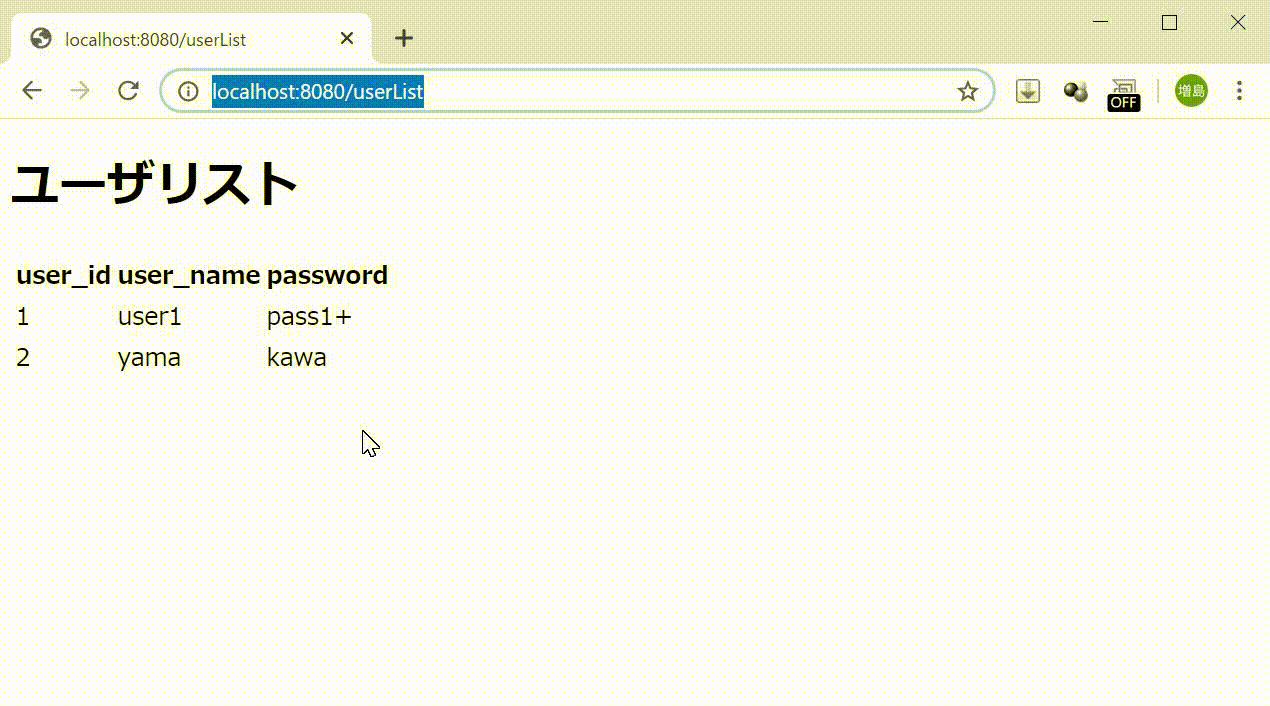
次に正規のユーザとパスでログインします。今回はユーザを2つ(user1, pass1+)(yama, kawa)作成してありますがどちらでもOKです。
・上のイメージの様に動いていたらOKです。
まとめ
これで以上になります。長らくお付き合いありがとうございました。認証機能、MySQLの使い方は何とか理解できたかと思います。私自身まだ理解しきれていないところもあるので間違っていたり、足りない記述がありましたら是非コメント下さい
感想として正直Rails上がりと言うのもあり、少しなめていました。と言うのもRailsにはdeviceがあったのでログイン機能の実装には苦労しなかったからです。SpringSecurityは桁違いに難しかったです...
いろいろ記事を探し回ったのですが、これ本当に理解できて、まとめている人いるのかなぁ?と感じています。
今回理解仕切れてない状態で投稿する事に迷いましたが、自分と同じ様に悩んでる人の為にも早く投稿したかったのでこのような状態で投稿させていただきました!
自分もまだまだなのでもっとスキル磨きたいと思います!ありがとうございました。



- 投稿日:2020-01-17T10:52:08+09:00
SpringSecurityで認証機能を実装②
前回の続きです。
4、ログイン画面の実装。
・今回はログイン画面と実装します。ただ認証機能は実装しないので、ログイン画面からボタンを押せばフォームの内容に限らず画面を遷移させます。
・ファイルの構成イメージは以下になります。コメントをズラーと書いてしまったので不要な場合は消して下さい。
・コードは以下になります。
SpringLogin.app.controller/LoginController.javapackage SpringLogin.app.controller; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Controller; import org.springframework.ui.Model; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.ModelAttribute; import org.springframework.web.bind.annotation.PostMapping; //import SpringLogin.app.service.UserService; @Controller public class LoginController { // @Autowired // UserService userService; @GetMapping("/login") public String getSignUp(Model model) { return "login"; } //FormのSubmitを押すとPostメソッドがリクエストされます。()に書かれたURLのリクエストを受け取るとこのメソッドが発動します。 @PostMapping("/login") public String postSignUp(Model model) { /* 今回はリダイレクトを使います。画面遷移などファイル間をまたぐ場合はリダイレクト使います。 イメージ的にはGetメソッドを呼び出していると考えていいでしょう。 試しにリダイレクトせず通常のフォワード(return "xxx";)とすると画面自体は表示されますがURLが変わりません。 こうすると、遷移先で受け取りたいデータなどが受け取れないことがあるので、リダイレクトを使用したほうが良いでしょう。 */ return "redirect:/userList"; } }:templates/login.html <!DOCTYPE html> <html xmlns:th="http://www.thymeleaf.org"> <head> <meta charset="UTF-8"></meta> </head> <body> <!-- コンテンツ部分 --> <div> <!-- method="post"にすることでpostリクエストを発行することができます。th:actionでPostを処理するメソッドをURLで指定します。 --> <form method="post" th:action="@{/login}"> <div> <label>Username:</label> <!-- 今回の実装では使いませんがname属性を指定してあります。後で認証の時に使います。 --> <input type="text" name="username" /> </div> <div> <label>Password:</label> <input type="password" name="password" /> </div> <button type="submit">login</button> </form> </div> </body> </html>・コードが書けたら、ブラウザでアプリを確認しましょう。
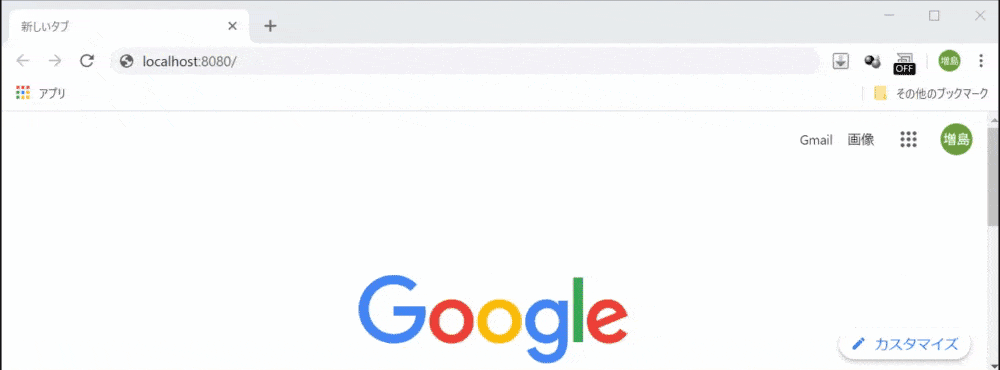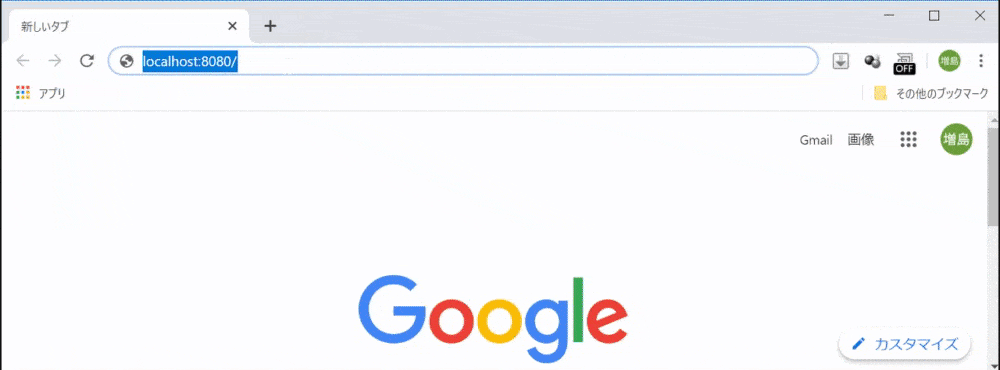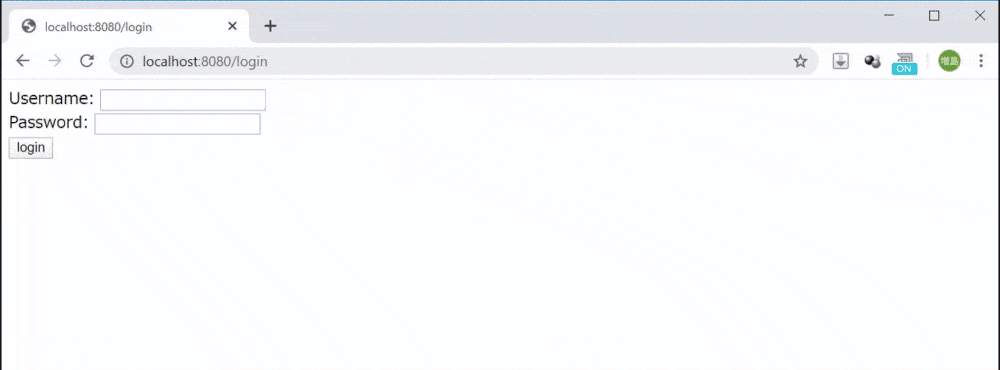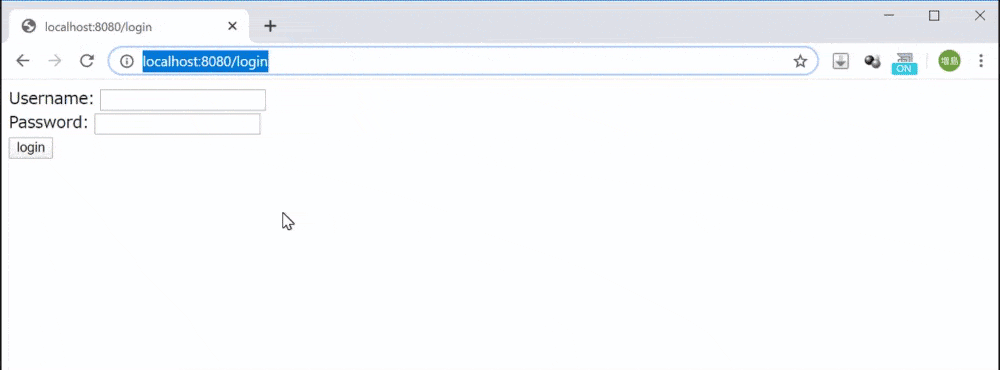
URLが変わります→http://localhost:8080/login
ページが表示されたら、Loginボタンを押下してuserListに遷移することを確認します。この時URLが変わっていることを確認しましょう。
・動画の様に遷移できていればOKです!
次からはこの記事のメインになります。ここもボリュームが大きくなりそうなのでいったん切ります。続きはこちら。
- 投稿日:2020-01-17T01:06:33+09:00
JDBCを利用する場合、NLSパラメータはJavaのロケールに影響される。
実行環境
本記事を書くにあたって、利用した主なソフトウェアのバージョンは次の通りです。なおOracle Databaseの構築にあたってはDockerおよびOracle公式のDocker Imageを利用しています。
software version, edition Oracle Database 12c Oracle Database 12c Standard Edition Release 12.2.0.1.0 - 64bit Production ojdbc8.jar (12c JDBC Driver) Oracle 12.2.0.1.0 JDBC 4.2 compiled with javac 1.8.0_91 on Tue_Dec_13_06:08:31_PST_2016 javac javac 11.0.4 java openjdk version "11.0.4" 2019-07-16 概要
Oracle DatabaseのNLSパラメータはさまざまな設定方法があるため、「どこの設定値がどう影響しているのかわからん!」ということが起きるのですが、Oracle Databaseとの接続にJDBCドライバを利用している場合、クライアントとなるJavaのロケールによりNLSパラメータが変わる場合があります。
「Databaseインストレーション・ガイドfor Linux - クライアント接続の言語およびロケール・プリファレンスの設定」より抜粋:
Oracle Databaseへの接続にOracle JDBCを使用するJavaアプリケーションでは、NLS_LANGを使用しません。かわりにOracle JDBCでは、アプリケーションを実行しているJava VMのデフォルトのロケールをOracle Databaseのlanguageとterritoryの設定にマップします。
実験
実験してみましょう。以下はJDBCを利用し、NLSパラメータの現在の設定値を格納している
V$NLS_PARAMETERSの内容をすべて出力するJavaアプリケーションです。Main1.javaimport java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; public class Main1 { public static void main(String[] args) { String url = "jdbc:oracle:thin:@//192.168.99.100:1521/ORCLPDB1"; String user = "dev1"; String password = "password"; try (Connection c = DriverManager.getConnection(url, user, password)) { Statement stmt = c.createStatement(); ResultSet rs = stmt.executeQuery("SELECT * FROM V$NLS_PARAMETERS ORDER BY PARAMETER"); while (rs.next()) { String parameter = rs.getString("PARAMETER"); String value = rs.getString("VALUE"); System.out.printf("%s = %s%n", parameter, value); } } catch (SQLException e) { e.printStackTrace(); } } }これをJavaのロケールを変更して実行してみましょう。まずは日本語。
$ java -Duser.language=ja -Duser.country=JP -cp .:../lib/ojdbc8.jar Main1 NLS_CALENDAR = GREGORIAN NLS_CHARACTERSET = AL32UTF8 NLS_COMP = BINARY NLS_CURRENCY = ¥ NLS_DATE_FORMAT = RR-MM-DD NLS_DATE_LANGUAGE = JAPANESE NLS_DUAL_CURRENCY = \ NLS_ISO_CURRENCY = JAPAN NLS_LANGUAGE = JAPANESE NLS_LENGTH_SEMANTICS = BYTE NLS_NCHAR_CHARACTERSET = AL16UTF16 NLS_NCHAR_CONV_EXCP = FALSE NLS_NUMERIC_CHARACTERS = ., NLS_SORT = BINARY NLS_TERRITORY = JAPAN NLS_TIMESTAMP_FORMAT = RR-MM-DD HH24:MI:SSXFF NLS_TIMESTAMP_TZ_FORMAT = RR-MM-DD HH24:MI:SSXFF TZR NLS_TIME_FORMAT = HH24:MI:SSXFF NLS_TIME_TZ_FORMAT = HH24:MI:SSXFF TZR次は英語。
$ java -Duser.language=en -Duser.country=US -cp .:../lib/ojdbc8.jar Main1 NLS_CALENDAR = GREGORIAN NLS_CHARACTERSET = AL32UTF8 NLS_COMP = BINARY NLS_CURRENCY = $ NLS_DATE_FORMAT = DD-MON-RR NLS_DATE_LANGUAGE = AMERICAN NLS_DUAL_CURRENCY = $ NLS_ISO_CURRENCY = AMERICA NLS_LANGUAGE = AMERICAN NLS_LENGTH_SEMANTICS = BYTE NLS_NCHAR_CHARACTERSET = AL16UTF16 NLS_NCHAR_CONV_EXCP = FALSE NLS_NUMERIC_CHARACTERS = ., NLS_SORT = BINARY NLS_TERRITORY = AMERICA NLS_TIMESTAMP_FORMAT = DD-MON-RR HH.MI.SSXFF AM NLS_TIMESTAMP_TZ_FORMAT = DD-MON-RR HH.MI.SSXFF AM TZR NLS_TIME_FORMAT = HH.MI.SSXFF AM NLS_TIME_TZ_FORMAT = HH.MI.SSXFF AM TZROracle Database側の設定をまったく変更していないにも関わらず、クライアント側のロケールによってNLSパラメータが変わってしまうことがわかりました。
何が恐ろしいのか
このふるまいの何が恐ろしいかというと、以下のようなことが起きかねないということにあります。
- Windows PCでは正常に稼働したモジュールがLinuxサーバでは正常に稼働しない。
- 開発機と本番機でアプリケーションサーバのロケール設定が違うため、NLSパラメータにも違いが生じて、結果として同じJavaモジュールが開発機と本番機で動作に違いが出る
要はJavaアプリケーションが環境によって、違う振る舞いを起こす可能性があるということです。経験値豊かなJavaプログラマであれば、DBMSやロケールに依存しないプログラミングを心掛けるとは思いますが、そうもいかない現実があるわけですね(´・ω・`)
具体例: 文字列型からTIMESTAMP型への暗黙の型変換
このふるまいにより、問題が発生するより具体的な例を示して終わりとします。
以下のような
usersというテーブルがあるとします。このテーブルはユーザの名前nameとレコードの更新時間updated_atをそれぞれ有しているとしましょう (よくある構成ですね)CREATE TABLE users ( name VARCHAR2(256 CHAR), updated_at TIMESTAMP )以下の
Main2.javaはこのusersテーブルにデータを挿入するJavaアプリケーションです。Main2.javaimport java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.SQLException; public class Main2 { public static void main(String[] args) { String url = "jdbc:oracle:thin:@//192.168.99.100:1521/ORCLPDB1"; String user = "dev1"; String password = "password"; try (Connection c = DriverManager.getConnection(url, user, password)) { PreparedStatement pstmt = c.prepareStatement("INSERT INTO users (name, updated_at) VALUES (?, ?)"); pstmt.setString(1, "nekoTheShadow"); pstmt.setString(2, "20200117"); int count = pstmt.executeUpdate(); System.out.printf("PreparedStatement::executeUpdate = %d%n", count); } catch (SQLException e) { e.printStackTrace(); } } }ここで着目してほしいのは、
TIMESTAMP型のカラムであるupdated_atに文字列型の値("20200117")を挿入しようとしていることです。この場合はOracle Databaseの「暗黙の型変換」機能によって、文字列型からTIMESTAMP型へ返還されます。そして、どのように「暗黙の型変換」されるのかについては、NLSパラメータに強く依存します。では、この
Main2.javaをロケールを変えて実行してみましょう。まずは日本語。$ java -Duser.language=ja -Duser.country=JP -cp .:../lib/ojdbc8.jar Main2 PreparedStatement::executeUpdate = 1ただしくデータが挿入されたようです。次に英語で実行します。
$ java -Duser.language=en -Duser.country=US -cp .:../lib/ojdbc8.jar Main2 java.sql.SQLDataException: ORA-01843: not a valid month at oracle.jdbc.driver.T4CTTIoer11.processError(T4CTTIoer11.java:494) at oracle.jdbc.driver.T4CTTIoer11.processError(T4CTTIoer11.java:446) at oracle.jdbc.driver.T4C8Oall.processError(T4C8Oall.java:1054) at oracle.jdbc.driver.T4CTTIfun.receive(T4CTTIfun.java:623) at oracle.jdbc.driver.T4CTTIfun.doRPC(T4CTTIfun.java:252) at oracle.jdbc.driver.T4C8Oall.doOALL(T4C8Oall.java:612) at oracle.jdbc.driver.T4CPreparedStatement.doOall8(T4CPreparedStatement.java:226) at oracle.jdbc.driver.T4CPreparedStatement.doOall8(T4CPreparedStatement.java:59) at oracle.jdbc.driver.T4CPreparedStatement.executeForRows(T4CPreparedStatement.java:910) at oracle.jdbc.driver.OracleStatement.doExecuteWithTimeout(OracleStatement.java:1119) at oracle.jdbc.driver.OraclePreparedStatement.executeInternal(OraclePreparedStatement.java:3780) at oracle.jdbc.driver.T4CPreparedStatement.executeInternal(T4CPreparedStatement.java:1343) at oracle.jdbc.driver.OraclePreparedStatement.executeLargeUpdate(OraclePreparedStatement.java:3865) at oracle.jdbc.driver.OraclePreparedStatement.executeUpdate(OraclePreparedStatement.java:3845) at oracle.jdbc.driver.OraclePreparedStatementWrapper.executeUpdate(OraclePreparedStatementWrapper.java:1061) at Main2.main(Main2.java:16) Caused by: Error : 1843, Position : 51, Sql = INSERT INTO users (name, updated_at) VALUES (:1 , :2 ), OriginalSql = INSERT INTO users (name, updated_at) VALUES (?, ?), Error Msg = ORA-01843: not a valid month at oracle.jdbc.driver.T4CTTIoer11.processError(T4CTTIoer11.java:498) ... 15 moreロケール=日本の場合は想定通り動作したにもかかわらず、ロケール=英語に変えたとたん、Exceptionを投げる結果になりました。しかも、Exception内容がかなりわかりにくいというか、少なくともロケールに端を発した問題であるとは一目ではわかりません。なお、解決策としては、暗黙の型変換をしないこと、もしくは、Javaの
Date型を利用することにつきます。