- 投稿日:2020-01-16T23:35:07+09:00
Python#Snap7 Libray Import 問題
毎回も忘れ、毎回も時間かけて探し解決方法見つかる。
とりあえずメモしておく。Linux
https://stackoverflow.com/questions/24343557/cant-find-snap7-library-linux
- まずSNAP7ライブラリをダウンロードする(この例は1.2.1)
- 解凍する
- tar -zxvf snap7-full-1.2.1.tar.gz
- コンパイルする(arm_v6_linux.mk is used for RPI 1. For RPI 2 use arm_v7_linux.mk)
- cd snap7-full-1.2.1/build/unix && sudo make -f arm_v6_linux.mk all
- コンパイル後のライブラリをlib へ
- sudo cp ../bin/arm_v6-linux/libsnap7.so /usr/lib/libsnap7.so
- sudo cp ../bin/arm_v6-linux/libsnap7.so /usr/local/lib/libsnap7.so
- 一応pipをInstall
- sudo apt-get install python-pip
- python-snap7インストール
- sudo pip install python-snap7
それでもなぜかImportできなかった。そしてもう一度エラーをみたら。
多分common.pyの中になにかあるかも!Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/usr/local/lib/python2.7/dist-packages/snap7/client.py", line 29, in __init__ self.library = load_library() File "/usr/local/lib/python2.7/dist-packages/snap7/common.py", line 48, in load_library return Snap7Library(lib_location).cdll File "/usr/local/lib/python2.7/dist-packages/snap7/common.py", line 40, in __init__ raise Snap7Exception(msg) snap7.exceptions.Snap7Exception: can't find snap7 library. If installed, try running ldconfigこうしたら無事に行けました!
class Snap7Library(object): """ Snap7 loader and encapsulator. We make this a singleton to make sure the library is loaded only once. """ _instance = None def __new__(cls, *args, **kwargs): if not cls._instance: cls._instance = object.__new__(cls) cls._instance.lib_location = None cls._instance.cdll = None return cls._instance def __init__(self, lib_location=None): if self.cdll: return #Change here #self.lib_location = lib_location or self.lib_location or find_library('snap7') self.lib_location = 'your lib location' if not self.lib_location: msg = "can't find snap7 library. If installed, try running ldconfig" raise Snap7Exception(msg) self.cdll = cdll.LoadLibrary(self.lib_location)Window
これです。
The folder where the snap7.dll and .lib file are located must be present in the Enviroment variables of Windows.
https://stackoverflow.com/questions/33697263/python-snap7-windows-cant-find-snap7-library

- 投稿日:2020-01-16T23:20:13+09:00
学習記録 その22(26日目)
学習記録(26日目)
勉強開始:12/7(土)〜
教材等:
・大重美幸『詳細! Python3 入門ノート』(ソーテック社、2017年):12/7(土)〜12/19(木)読了
・Progate Python講座(全5コース):12/19(木)〜12/21(土)終了
・Andreas C. Müller、Sarah Guido『(邦題)Pythonではじめる機械学習』(オライリージャパン、2017年):12/21(土)〜12月23日(土)読了
・Kaggle : Real or Not? NLP with Disaster Tweets :12月28日(土)投稿〜1月3日(金)まで調整
・Wes Mckinney『(邦題)Pythonによるデータ分析入門』(オライリージャパン、2018年):1/4(水)〜1/13(月)読了
・斎藤康毅『ゼロから作るDeep Learning』(オライリージャパン、2016年):1/15(水)〜『ゼロから作るDeep Learning』
ニューラルネット、そしてAI研究のブレークスルーとなったディープラーニングについて理解を深めておきたかったため、昨日から読み始めました。
p.122 第4章 ニューラルネットの学習 まで読み終わり。1章 python入門
・基本的に今までやってたことのおさらい(Python概要、環境構築、算術平均 etc)
本書を読み進めていくための必要な知識概要を記した章
ちょっと理解が足りてなかった部分のみ記載・ブーリアン(bool):True or False のどちらかを取る型
and, or, notといった演算子を用いることができる。クラス定義class クラス名: def __init__(self, 引数, …): #コンストラクタ ... def メソッド名1(self, 引数, …): #メソッド1 ... def メソッド名2(self, 引数, …): #メソッド2 ... #コンストラクタは初期化用メソッドとも言う。2章 パーセプトロン
・パーセプトロンとは、60年程前からあるアルゴリズム(1957年に考案)
ニューラルネットワーク(ディープラーニング)の起源である。・パーセプトロンは複数の信号を入力として受け取り、一つの信号を出力する。
パーセプトロンの信号は「流すか流さないか」(1か0か)の2値の値
複数ある入力信号のそれぞれに固有の重みを持ち、大きいほど対応する信号の重要性が高くなる。入力信号の重要度をコントロールする値。・「入力」「重み」「出力」の他に、「バイアス」という要素がある。
バイアスは出力信号が1を出力する度合い(ニューロン発火)を調整するパラメータのこと。・パーセプトロンは線形であるがゆえに排他的論理和(XOR)のような分類は実現できない。(パーセプトロンの限界)
ただし、パーセプトロンは"層を重ねる"ことができるため、重ねることで非線形も表現ができるようになる。(なので上記を正確に言うと"単層"パーセプトロンの限界)3章 ニューラルネットワーク
・理論上パーセプトロンはコンピュータも表現できるほど可能性を秘めているものの、期待する入力と出力を満たすように適切な重みを決める作業は人の手で行わなければならない。
ただし、ニューラルネットワークはこの問題を解決するための手段の一つで、適切な重みパラメータをデータから自動学習できる性質がある。・ニューラルネットワーク(パーセプトロン)では、入力に重みをつけ、バイアスをかけて、これら入力信号の総和を活性化関数(activation function)にかけて変換し出力している。
・活性化関数とは閾値を境にして出力が切り替わる関数で、ステップ関数や階段関数と呼ばれている。パーセプトロンではステップ関数を用いている。
・ニューラルネットワークでは、活性化関数にシグモイド関数(sigmoid function)を用いている。
シグモイド関数はステップ関数と比較すると滑らかな曲線であり、入力に対して連続的に出力が変化する。
この滑らかさこそがニューラルネットワークの学習の元となっている。
重要であれば大きい値を、そうでなければ小さい値を、どんなに大きい値でも出力を0〜1の間に押し込めるという特性は共通している。・最近はシグモイド関数のほかにReLU(Rectified LinearUnit)というものも多く用いられている。
・一番最後の出力層で用いる活性化関数はタスクによって使い分ける必要がある。
一般的に、分類問題(どのクラスに属するか当てる)ではソフトマックス関数を、回帰問題(数字を当てる)では恒等関数を用いる。・恒等関数は出てきた値をそのまま流す。
ソフトマックス関数は問題に対して確率的(統計的)な対応ができるようになるのが特徴で、出力の総和は1になる。(つまり、a=0.2, b=0.5, c=0.3であれば、aの確率が20%、bの確率が50%、cの確率が30% という形でとらえることができる。)・クラス分類における出力層のニューロンの数は、分類したいクラスの数に設定するのが一般的。(0~9の数字のどの数字に属するか当てる問題であれば10に設定)
・まとまりのある入力データをバッチ(batch)と呼ぶ。束という意味がある。
バッチ単位で推論処理を行うことで、計算を高速化できる。4章 ニューラルネットワークの学習
・「学習」とは、訓練データから最適な重みパラメータの値を自動で獲得することを指す。
この学習を行えるようにするために、**「損失関数(loss function)」という指標を導入する。
損失関数を基準として、この値が最も小さくなる重みパラメータを探し出すことが学習の目的となる。・ニューラルネットワーク(ディープラーニング)は与えられたデータをただひたすらに学習し、パターンを発見することを試みる。
対象とする問題に関係なく、データをそのままの生データとして"end-to-end"で学習することができる。・2乗和誤差(mean squared error):最も有名な損失関数。
出力と正解となる教師データの各要素の差の2乗を計算し、その総和を求める。・交差エントロピー誤差(cross entropy error):上記に次いでよく用いられる損失関数。
出力と正解ラベルを乗じたものの総和を計算する。ただし正解ラベルはone-hot表現(0か1か)で表されているため、実質的には正解ラベルが1に対応する出力の自然対数を計算するのみとなっている。・すべてのデータを対象として損失関数を求めるのは時間がかかるため、ミニバッチと呼ばれる小さなかたまりを取り出し、このミニバッチごとに学習を行うのが基本。(統計の勉強中に似たような話を見た気がする。)
・重みパラメータを少し変化させたときに、損失関数がどのように変化するかを計算し、より小さな損失となる場所を探すのが学習の目的。
ここで微分(勾配)という考えが出てくる。
シグモイド関数の微分はどの場所であっても0にならないことが、この学習において重要な性質となる。・微分とはある瞬間の変化の量を示したもの。
微小な差分によって微分を求めることを数値微分(numerical differentiation)と呼び、こちらを主に用いる。
微小な差hは 1e-4(10の-4乗,0.0001) がよいと言われている。
一方、数式展開によって求めることは解析的(analystic)微分と呼ばれている。・すべての変数の偏微分をベクトルとしてまとめたものを勾配(gradient)と呼ぶ。
この勾配が示す方向こそが、各場所において関数の値を最も減らす方向であり、これをうまく利用して関数の最小値を探そうというのが勾配法と呼ばれている。・勾配法を数式で表す際、1回の学習でどれだけ学習するか、どれだけパラメータを更新するか、という量ηを定める。これを学習率(learning rate)という。
・学習率のようなパラメータをハイパーパラメータという。これはニューラルネットワークが自己学習できる重みやバイアスといったものと異なり、人の手によって設定する必要がある。
・ニューラルネットの学習4手順
1 ミニバッチを選び出し、損失関数を得る。
2 勾配を求め、損失関数を減らす方向を探る。
3 重みパラメータを勾配方向に更新する。
4 1~3を繰り返す。上記は確率的勾配降下法(SVD:stochastic gradient descent)と呼ばれる。
・損失関数とiteration(繰り返し回数)を図示することで、損失関数の推移(学習の経過)を可視化することができる。
・エポック(epoch):1エポックとは単位のことで、データを全て使い切った時の回数に対応する。10,000個のデータに対して100個のミニバッチで学習する場合、100回繰り返した時点で全ての訓練データを見たことになる。
つまり、100回 = 1エポックとなる。
- 投稿日:2020-01-16T23:12:50+09:00
[Python3 入門 10日目] 5章 Pyの化粧箱:モジュール、パッケージ、プログラム(5.4〜5.7)
5.5 Python標準ライブラリ
- Pythonには様々な」役に立つ仕事をしてくれるモジュールを集めた大規模な標準ライブラリがある。
5.5.1 setdefault()とdefaultdict()による存在しないキーの処理
- 存在しないキーで辞書にアクセスしようとすると例外が生成される。辞書のget()関数を使って、キーが存在しない場合はデフォルト値を返すようにすれば例外を避けられる。
- setdefault()関数はget()と似ているがキーがなければ更に辞書に要素を追加するところが異なる。
- defaultdict()関数は存在しない全てのキーに対してデフォルトの値を設定するところがget()と異なる。引数は関数である。また、存在しないキーを用いた場合、そのキーが自動で生成される。デフォルト値引数を省略するとデフォルト値はNoneになる。
>>> periodic_table={"Hydrogen":1,"Helium":2} >>> print(periodic_table) {'Hydrogen': 1, 'Helium': 2} #キーが辞書になければ新しい値と共に追加される。 >>> carbon=periodic_table.setdefault("Carbon",12) >>> carbon 12 #既存のキーに別のデフォルト値を代入しようとしても元の値が返され、辞書は変更されない。 >>> helium=periodic_table.setdefault("Helium",457) >>> helium 2 >>> print(periodic_table) {'Hydrogen': 1, 'Helium': 2, 'Carbon': 12}#モジュールcollectionsからdefaultdictをインポート。 >>> from collections import defaultdict #存在しないキーに対するデフォルトの値(int)が設定される。 >>> periodic_table=defaultdict(int) >>> periodic_table["Hydrogen"]=1 #存在しないキーに対してデフォルト値が返される。 >>> periodic_table["Lead"] 0 >>> periodic_table defaultdict(<class 'int'>, {'Hydrogen': 1, 'Lead': 0})#モジュールcollectionsからdefaultdictをインポート >>> from collections import defaultdict >>> >>> def no_idea(): ... return "Huh?" ... >>> bestiary = defaultdict(no_idea) >>> bestiary["a"]= "A" >>> bestiary["b"]= "B" >>> bestiary["a"] 'A' >>> bestiary["b"] 'B' #存在しないキーを入力するとdefaultdictの引数で指定された関数を呼び出し値を返す。 >>> bestiary["c"] 'Huh?' >>> bestiary["v"] 'Huh?' #defaultdict()呼び出しの中でデフォルト作成関数を定義 >>> bestiary=defaultdict(lambda:"Huh?") >>> bestiary["E"] 'Huh?' #intは独自カウンタを作るための手段になり得る。 >>> from collections import defaultdict >>> food_counter=defaultdict(int) >>> for food in ["spam","spam","eggs","spam"]: ... food_counter[food]+=1 ... >>> for food,count in food_counter.items(): ... print(food,count) ... spam 3 eggs 15.5.2 Counter()による要素数の計算
>>> breakfast=["spam","spam","eggs","spam"] >>> breakfast_counter=Counter(breakfast) >>> breakfast_counter Counter({'spam': 3, 'eggs': 1}) #most_common()関数は全ての要素を降順で返す。 >>> breakfast_counter.most_common() [('spam', 3), ('eggs', 1)] #most_common()関数は引数として整数を指定すると最上位から数えてその個数分だけ表示する。 >>> breakfast_counter.most_common(1) [('spam', 3)] >>> breakfast_counter Counter({'spam': 3, 'eggs': 1}) >>> lunch=["eggs","eggs","bacon"] >>> lunch_counter=Counter(lunch) >>> lunch_counter Counter({'eggs': 2, 'bacon': 1}) #カウンタの結合 >>> lunch_counter+breakfast_counter Counter({'eggs': 3, 'spam': 3, 'bacon': 1}) #カウンタの差 昼食では使われているが朝食では使われていないもの。 >>> lunch_counter-breakfast_counter Counter({'eggs': 1, 'bacon': 1}) #カウンタの差 朝食では使われているが昼食では使われていないもの。 >>> breakfast_counter-lunch_counter Counter({'spam': 3}) #積集合演算子 共通の個数は1。 >>> breakfast_counter & lunch_counter Counter({'eggs': 1}) #和集合演算子 大きい方ほカウンタ値を使う。 >>> breakfast_counter | lunch_counter Counter({'spam': 3, 'eggs': 2, 'bacon': 1})5.5.3 OrderdDict()によるキー順のソート
- OrderedDict()はイテレータから同じ順序でキーを返す。
>>> quotes={ ... "M":"A", ... "L":"O", ... "C":"N", ... } >>> for s in quotes: ... print(s) ... M L C >>> from collections import OrderedDict >>> quotes=OrderedDict([ ... ("M","A"), ... ("L","C"), ... ("C","N"), ... ]) >>>5.5.4 スタック+キュー=デック
- duque(デック)は両端キューのことでスタックとキューの両方の機能を持っており、シーケンスのどちらの端でも要素を追加、削除できる。
>>> def palindrome(word): ... from collections import deque ... dq=deque(word) ... while len(dq)>1: #popleft()は左端の要素を削除して返す、pop()は右端の要素を削除して返す関数。 ... if dq.popleft()!=dq.pop(): ... return False ... return True ... >>> palindrome("a") True >>> palindrome(" ") True >>> palindrome("racecar") True >>> palindrome("halibut") False #逆順の文字列を比較した方が簡単。 >>> def another_palindrome(word): ... return word==word[::-1] ... >>> another_palindrome("racecar") True >>> another_palindrome("halibut") False5.5.5 itertoolsによるコード構造の反復処理
- itertoolsには特別な目的を持つイテレータ関数が含まれている。
#chain()は、引数全体が一つのイテラブルであるかのように扱い、その中で反復処理を行う。 >>> import itertools >>> for item in itertools.chain([1,2],["a","b"]): ... print(item) ... 1 2 a b #cycle()は無限反復子で、引数から循環的に要素を返す。 >>> import itertools >>> for item in itertools.cycle([1,2]): ... print(item) ... 1 2 1 2 1 2 1 2 1 2 1 2 1 2 #accumulate()は要素を一つにまとめた値を計算する。デフォルトでは和を計算する。 >>> import itertools >>> for item in itertools.accumulate([1,2,3,4]): ... print(item) ... 1 3 6 10 ##accumulate()は第二引数として関数を受け付け、この引数が加算の代わりに使われる。 >>> import itertools >>> def multiply(a,b): ... return a*b ... >>> for item in itertools.accumulate([1,2,3,4],multiply): ... print(item) ... 1 2 6 245.5.6 pprint()による綺麗な表示
- print()は読みやすくするために要素の位置を揃えようとする。
>>> from pprint import pprint >>> q=OrderedDict([ ... ("Moe","A wise guy,huh?"), ... ("Larry","Ow!"), ... ("Curly","Nuyk nyuk!"), ... ]) >>> #続けて表示する。 >>> print(q) OrderedDict([('Moe', 'A wise guy,huh?'), ('Larry', 'Ow!'), ('Curly', 'Nuyk nyuk!')]) #要素の位置を揃えて表示する。 >>> pprint(q) OrderedDict([('Moe', 'A wise guy,huh?'), ('Larry', 'Ow!'), ('Curly', 'Nuyk nyuk!')])5.7 復習課題
5-1 zoo.pyというファイルを作り、その中にOpen 9-5 dailyという文字列を表示する。hours()関数を定義しよう。次に対話型インタープリタでzooモジュールをインポートし、そのhours()関数を呼び出そう。
zop.pydef hours(): print("Open 9-5 daily")結果>>> import zoo >>> zoo.hours() Open 9-5 daily5-2 対話型インタープリタの中でzooモジュールをmenagerieという名前でインポートし、そのhours()関数を呼び出そう。
#モジュールzooをmenagerieとしてインポート >>> import zoo as menagerie >>> menagerie.hours() Open 9-5 daily5-3 対話型インタープリタにそのまま残り、zooのhours()関数を直接インポートして呼び出そう。
>>> from zoo import hours >>> hours() Open 9-5 daily5-4 hours()関数をinfoという名前でインポートし、呼び出そう。
>>> from zoo import hours as info >>> info() Open 9-5 daily5-5 "a":1,"b":2,"c":3というキー/値ペアを使ってplainという辞書を作り、内容を表示しよう。
>>> plain={"a":1,"b":2,"c":3} >>> plain {'a': 1, 'b': 2, 'c': 3}5-6 上の5-5と同じペアからfancyという名前のOrderdDictを作り、内容を表示しよう。plainと同じ順序で表示されただろうか。
>>> from collections import OrderedDict >>> fancy=OrderedDict([("a",1),("b",2),("c",3)]) >>> fancy OrderedDict([('a', 1), ('b', 2), ('c', 3)])5-7 dict_of_listsという名前のdefaultdictを作り、list引数を渡そう。次に、一度の操作でdict_of_lists["a"]というリストを作り、"something for a"という値を追加しよう。最後に、dict_of_lists["a"]を表示しよう。
>>> from collections import defaultdict >>> dict_of_lists=defaultdict(list) >>> dict_of_lists["a"]=["something for a"] >>> dict_of_lists["a"] ['something for a']感想
遂に後半戦突入しました。6章やり始めたんですが、オブジェクトとクラスの概念が出てきました。
明日も引き続き頑張ります。参考文献
「Bill Lubanovic著 『入門 Python3』(オライリージャパン発行)」
- 投稿日:2020-01-16T23:08:41+09:00
python lru_cache
引数に対して戻り値をキャッシュしてくれるので重い処理をするときに役に立つ。
import functools class Sample(): def __init__(self): self.num = 5 @functools.lru_cache() def add(self, a, b): print("sample") return a + b @functools.lru_cache() def times(self, a): return self.num + a s = Sample() s.add(5, 5) s.add(5, 5) # 2回目はprint文が実行されない。 print(s.times(10)) # 戻り値は15 s.number = 3 print(s.times(10)) # numの値を変更しても戻り値は15結果
sample 15 15単純に引数と戻り値の組み合わせを保存して、以前に同じ引数で実行されていればその時の戻り値をいきなり返すよう。
なので何か値が変わったり副作用がある関数に対しては使わない方が良い?
(ニュースサイトで人気記事を1日ごとに取得するとかなら使える?articles.get_recommend(date.today))lru_cache(maxsize=数)
でキャッシュする量を決められる。maxsizeを決めないと無限らしい。おまけ
ちなみに何か副作用のあるものをコマンド、値を返すだけのものを照会関数という。
さらにコマンドは戻り値を持つべきでなく、照会関数は何かの副作用を持ってはいけない。
(clean codeより)
- 投稿日:2020-01-16T23:01:36+09:00
電子ペーパーモジュールをToDoリストとして使う
きっかけ
僕「電子ペーパーモジュール何かに使えないかな?」
僕「最近やること多くて忘れそうだからToDoリスト(メモ的な何か)として使おう」※電子ペーパーのセットアップ(接続や画像の表示等)はこっちに書いてあります。
Raspberry Piで電子ペーパーモジュールを動作させる
今回は文字を電子ペーパーモジュールに表示させます用意したもの
・Raspberry Pi 3 model B+
・電子ペーパーモジュール (4.2inch e-Paper Module)
・スペーサー (お好みで)手順
こんなものをイメージ
・適当なテキストファイル(text.txt)にやること(文字)を箇条書きして保存
・Pythonでテキストファイルを読み出し、e-Paperに書き込みpythonのソースコードを書く
write.py#!/usr/bin/python # -*- coding:utf-8 -*- import sys import os picdir = os.path.join(os.path.dirname(os.path.dirname(os.path.realpath(__file__))), 'pic') libdir = os.path.join(os.path.dirname(os.path.dirname(os.path.realpath(__file__))), 'lib') if os.path.exists(libdir): sys.path.append(libdir) import logging from waveshare_epd import epd4in2bc import time from PIL import Image,ImageDraw,ImageFont import traceback import RPi.GPIO as GPIO logging.basicConfig(level=logging.DEBUG) try: #erase e-paper logging.info("epd4in2bc Demo") epd = epd4in2bc.EPD() logging.info("init and Clear") epd.init() epd.Clear() time.sleep(1) #read text file f = open('text.txt', 'r') memo_text = [] for line in f: memo_text.append(line) f.close() #print(memo_text) #make text figure im = Image.new("RGB",(400,300),"white") draw = ImageDraw.Draw(im) fig1 = Image.open('fig.png').convert("RGBA") #いらすとやの画像を読み込み draw.rectangle((0, 0, 399, 299), fill=(255, 255, 255), outline=(0, 0, 0), width=3) #外枠の四角形 draw.rectangle((0, 0, 399, 50), fill=(0, 0, 0), outline=(0, 0, 0)) #To Doリストの部分の塗りつぶしの四角形 im.paste(fig1, (200, 150),fig1.split()[3]) font_path = ImageFont.truetype('/usr/share/fonts/opentype/noto/NotoSansCJK-Light.ttc',30) text1 = "To Doリスト\n" draw.text((10, 10), text1 , fill=(255, 255, 255), font=font_path) font_path = ImageFont.truetype('/usr/share/fonts/opentype/noto/NotoSansCJK-Light.ttc',24) i = 0 w = 0 while i in range(len(memo_text)): draw.text((10, 50 + w), "・" + memo_text[i] , fill=(0, 0, 0), font=font_path) w = w + 35 i = i + 1 im.save("./../pic/hoge.bmp") # Drawing on the image logging.info("3.read bmp file") HBlackimage = Image.open(os.path.join(picdir, 'hoge.bmp')) HRYimage = Image.open(os.path.join(picdir, 'hoge.bmp')) epd.display(epd.getbuffer(HBlackimage), epd.getbuffer(HRYimage)) time.sleep(2) logging.info("Goto Sleep...") epd.sleep() except IOError as e: logging.info(e) except KeyboardInterrupt: logging.info("ctrl + c:") epd4in2bc.epdconfig.module_exit() exit()テキストファイル内を以下のように編集し、
write.pyと同じディレクトリに配置text.txt修論 予稿 不動産屋に連絡 明日飲み会やってみた
いらすとやのイラストを入れるとシュールな感じになった
表示する項目を変えたい場合は、text.textを書き換えた後にもう一度Pythonのコードを走らせると変えた項目に更新される

- 投稿日:2020-01-16T22:28:29+09:00
python threading.Thread
新しいスレッドの作成方法。
Threadを継承したクラスのrunをオーバーライドして行いたい処理を書きます。
新しくインスタンスを作成しstartメソッドを呼べばrunメソッドの処理を新しいスレッドで行ってくれます。from threading import Thread import time class SampleThread(Thread): def run(self): # 通信処理や巨大なファイルの読み込みなど時間のかかる処理をする。 time.sleep(1) print("sub thread") time.sleep(1) thread = SampleThread() thread.start()
- 投稿日:2020-01-16T21:42:31+09:00
ジェネレーター内包表記 タプル内包表記
1def g(): for i in range(10): yield i g = g() print(next(g)) print(next(g)) print(next(g))1の実行結果0 1 2これを内包表記で書くと
ジェネレーター内包表記g = (i for i in range(10)) for j in range(3): print(next(g))ジェネレーター内包表記の実行結果0 1 2()で囲っているので一見、
タプルの様にも見えなくはない。
タプルの内包表記は下記の様になる。タプルの内包表記t = tuple(i for i in range(10)) print(t)タプルの内包表記実行結果(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)ジェネレーター内包表記2g = (i for i in range(10)) for j in g: print(j)ジェネレーター内包表記2の実行結果0 1 2 3 4 5 6 7 8 9ジェネレーター内包表記3g = (i for i in range(10) if i % 3 == 0) for j in g: print(j)ジェネレーター内包表記3の実行結果0 3 6 9
- 投稿日:2020-01-16T21:38:11+09:00
個人用メモ(python)
環境変数の確認をするには
対話型シェルの起動 >>>python manage.py shell >>> import sys >>> print('\n'.join(sys.path))
- 投稿日:2020-01-16T19:45:49+09:00
VScodeでインテリセンスが効かなくなったので復活させた
はじめに
プログラミング初心者です。
最近MacでDjangoの勉強を始めました。
VScodeでDjangoを書いていたらインテリセンスが効かなくなったのでその解決策を記載。
前提条件
・Visual Studio Code for mac 1.41.1
・Python 3.8.0
・Django 3.0.2
原因
仮想環境でDjangoをインストールしていたため、物理マシンではいらないと判断しDjangoをアンインストールしたせい(だと予想)。
対策
いろいろ試しましたが以下の手順で復活しました。
1.物理マシンにDjangoをインストール
2.Djangoの格納場所を確認
3.VScodeの設定ファイルを変更
手順
上の対策の1から3まで順に記載していきます。
1.物理マシンにDjangoをインストール
仮想環境からdeactivateした状態で、コンソールにて以下のコマンドを実施。
$ python >>> pip install django
2.Djangoの格納場所を確認
Djangoがどこに格納されているのかを以下のコマンドで表示。
>>> django.__path__ ['/Users/~/.pyenv/versions/3.8.0/lib/python3.8/site-packages/django']
3.VScodeの設定ファイルを変更
・VScodeのヘッダー > Code > 基本設定 > 設定 (またはcommand + 「、」キー)
・上部検索ウィンドウ右上の「設定(JSONを開く)」を押下してsettings.jsonを開く
・JSONファイルに以下を追記"python.autoComplete.extraPaths": [ "/Users/~/.pyenv/versions/3.8.0/lib/python3.8/site-packages/" ],
結果
Django特有のオブジェクトに対しても無事インテリセンスが効くようになりました。
今後もまたなにか問題が発生次第、記述していきます。
ちなみに
こちらにもっと詳しい記事があったので掲載させていただきます。
VSCode・インテリセンスが効かない?を解消

- 投稿日:2020-01-16T19:41:34+09:00
関数内で例外が発生した場合、呼び出し元へ伝わる2
1def test_exception(num): print(1) try: print(2) answer = 100 / num return answer print(3) except ZeroDivisionError as e: print(4) raise e print(5) print('start') try: test_exception(1) print(6) except ZeroDivisionError as e: print(7) raise e finally: print('end')1の実行結果start 1 2 6 endprint('start')を
最初に実行。次に、
tryブロックを実行する。
tryブロック1行目のtest_exception関数に引数1で入る。
なので、
print(1)を実行し、
test_exception関数内のtryブロック内を実行する。
print(2)を実行し、
answer = 100
となり100を返す。
retrunしているので、
その下のprint(3)は実行されない点に注意。
ZeroDivisionErrorは発生していないので、
test_exception関数内のexceptブロックは実行せず、とばす。tryブロックのtest_exception関数が終わったので、
その続きでprint(6)を実行。ZeroDivisionErrorは発生していないので、
exceptブロックは実行せず、とばす。最後にfinallyブロックを実行する。
test_exception関数の引数を0にすると、
2def test_exception(num): print(1) try: print(2) answer = 100 / num return answer print(3) except ZeroDivisionError as e: print(4) raise e print(5) print('start') try: test_exception(0) print(6) except ZeroDivisionError as e: print(7) raise e finally: print('end')2の実行結果start 1 2 4 7 end
- 投稿日:2020-01-16T19:35:42+09:00
Python3とFlaskのインストール[環境構築まとめ]
PythonのFlaskを最初から構築する機会があったので、環境構築のメモを残しておく。
pyenvを使ったPythonのインストールなどは以下で行なっていたので、最初にそれをやっていない人は以下をまずは行う。
Python 環境構築 mac windows
virtualenvのインストール
上記が終わったら
virtualenvをインストール。※Virtualenvとは
Virtualenvは、Shell上でプロジェクト毎に個別の環境が構築出来るナイスなツールです。pip install virtualenv上記で動かない人は
pip3で実行してみてください。自分はエイリアス設定をしているのでpipで動きます。alias pip=pip3flaskアプリケーションを作成する
適当なワーキングディレクトリに移動してから環境を作る。
コマンドは
virtualenv {app_name}cd /Work/flask_app/ $ virtualenv testapp Using base prefix '/usr/local/Cellar/python/3.7.6_1/Frameworks/Python.framework/Versions/3.7' New python executable in /Work/flask_app/testapp/bin/python3.7 Also creating executable in /Users/yoshi/Work/sample_python/testapp/bin/python Installing setuptools, pip, wheel... done.完了すると以下のように指定した
{app_name}でディレクトリ(プロジェクト?)が作成される。$ ll total 0 drwxr-xr-x 6 ys staff 192 1 16 11:02 testapp/中身はこんな感じ
$ ll testapp/ total 0 drwxr-xr-x 6 ys staff 192 1 16 11:02 ./ drwxr-xr-x 4 ys staff 128 1 16 11:02 ../ lrwxr-xr-x 1 ys staff 80 1 16 11:02 .Python@ -> /usr/local/Cellar/python/3.7.6_1/Frameworks/Python.framework/Versions/3.7/Python drwxr-xr-x 18 ys staff 576 1 16 11:02 bin/ drwxr-xr-x 3 ys staff 96 1 16 11:02 include/ drwxr-xr-x 3 ys staff 96 1 16 11:02 lib/この環境を使用するようにアクティブ化する必要があります。OS XとLinuxでは以下のコマンドを実行。
$ cd testapp $ . bin/activate # 上記で動かなかったら $ source bin/activate (testapp) adminnoMacBook-Pro-4:testapp ys$うまく起動できると(
{app_name})とターミナル上に出現して実行可能な状態になる。Flaskのインストール
$ pip install Flask Collecting Flask Downloading https://files.pythonhosted.org/packages/9b/93/628509b8d5dc749656a9641f4caf13540e2cdec85276964ff8f43bbb1d3b/Flask-1.1.1-py2.py3-none-any.whl (94kB) |████████████████████████████████| 102kB 1.8MB/s Collecting Werkzeug>=0.15 Downloading https://files.pythonhosted.org/packages/ce/42/3aeda98f96e85fd26180534d36570e4d18108d62ae36f87694b476b83d6f/Werkzeug-0.16.0-py2.py3-none-any.whl (327kB) |████████████████████████████████| 327kB 1.9MB/s Collecting itsdangerous>=0.24 Downloading https://files.pythonhosted.org/packages/76/ae/44b03b253d6fade317f32c24d100b3b35c2239807046a4c953c7b89fa49e/itsdangerous-1.1.0-py2.py3-none-any.whl Collecting click>=5.1 Downloading https://files.pythonhosted.org/packages/fa/37/45185cb5abbc30d7257104c434fe0b07e5a195a6847506c074527aa599ec/Click-7.0-py2.py3-none-any.whl (81kB) |████████████████████████████████| 81kB 2.4MB/s Collecting Jinja2>=2.10.1 Downloading https://files.pythonhosted.org/packages/65/e0/eb35e762802015cab1ccee04e8a277b03f1d8e53da3ec3106882ec42558b/Jinja2-2.10.3-py2.py3-none-any.whl (125kB) |████████████████████████████████| 133kB 3.4MB/s Collecting MarkupSafe>=0.23 Downloading https://files.pythonhosted.org/packages/ce/c6/f000f1af136ef74e4a95e33785921c73595c5390403f102e9b231b065b7a/MarkupSafe-1.1.1-cp37-cp37m-macosx_10_6_intel.whl Installing collected packages: Werkzeug, itsdangerous, click, MarkupSafe, Jinja2, Flask Successfully installed Flask-1.1.1 Jinja2-2.10.3 MarkupSafe-1.1.1 Werkzeug-0.16.0 click-7.0 itsdangerous-1.1.0無事に完了したか確認。
$ flask --version Python 3.7.6 Flask 1.1.1 Werkzeug 0.16.0Flask上で動作確認をしてみる
公式ドキュメントからサンプルプログラムを拝借。
クイックスタート¶
サンプルのPythonファイルは{app_name}の直下で大丈夫。sample_flask.pyfrom flask import Flask app = Flask(__name__) @app.route('/') def hello_world(): return "Hello Flask" if __name__ == '__main__': app.run()python sample_flask.py動くかな....
動いた!
$ python test_flask.py * Serving Flask app "test_flask" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: off * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) 127.0.0.1 - - [16/Jan/2020 11:33:03] "GET / HTTP/1.1" 200 - 127.0.0.1 - - [16/Jan/2020 11:33:03] "GET /favicon.ico HTTP/1.1" 404 -ちゃんとTOPページへのアクセスが
200になっている。ブラウザで確認してみてもちゃんと表示された。
ただ、なぜかコンソールをみると
* Environment: productionをみている。開発環境なんだからこのまま本番用に使うなよって以下のように警告が出ています。(現状は問題ないけど
WARNING: This is a development server. Do not use it in a production deployment.気になる人は以下のコマンドを実行。
$ export FLASK_APP=app_name $ export FLASK_ENV=development (testapp) ys $ flask runおわり。

- 投稿日:2020-01-16T19:19:25+09:00
Ubuntu18.04 開発環境作成メモ
how to use
cd ~ chmod +x setup.sh ./setup.shsetup.sh
setup.shsudo apt update sudo apt -y upgrade sudo apt -y install vim sudo apt -y install git sudo apt -y install guake sudo apt -y install curl sudo apt-get -y install xsel # pyenv sudo apt -y install build-essential libffi-dev libssl-dev zlib1g-dev liblzma-dev libbz2-dev libreadline-dev libsqlite3-dev git clone https://github.com/pyenv/pyenv.git ~/.pyenv echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile echo 'eval "$(pyenv init -)"' >> ~/.bash_profile source ~/.bash_profile pyenv install 3.7.6 pyenv global 3.7.6 # nodebrew curl -L git.io/nodebrew | perl - setup echo 'export PATH=$HOME/.nodebrew/current/bin:$PATH' >> ~/.bash_profile source ~/.bash_profile nodebrew install-binary latest nodebrew use latest # docker sudo apt install docker.io sudo groupadd docker sudo gpasswd -a $USER docker sudo systemctl restart docker # docker-compose sudo curl -L "https://github.com/docker/compose/releases/download/1.25.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose sudo chmod +x /usr/local/bin/docker-compose # ssh keygen ssh-keygen -t rsa cat .ssh/id_rsa.pub | xsel --clipboard --input # english directory LANG=C xdg-user-dirs-gtk-update # sudo reboot -h now
- 投稿日:2020-01-16T18:44:42+09:00
Pythonで始める音響信号処理 - 立体音響システムを作ろう
概要
昨今、VTuberなど3Dモデルを用いた配信者が増えてきている。多くの配信者はモノチャネルの音響情報を用いて配信しているが、より没入感のある配信を行うため、3Dioなどのマイクロホンアレイを用いることで、立体音響を生成している。複数の音源がある場合、このようなマイクロホンアレイを用いることをおすすめするが、例えばASMRなどのシチュエーションにおいて、単一音源(人物)を立体音響にする場合、信号処理により立体音響を生成できる。もちろん、複数音源でも可能であるが、、、
ここで重要になるのが、頭部伝達関数である、3DioなどASMRに使用されるマイクロホンアレイのマイク部分は耳の形をしている。これは、音源から、耳の鼓膜までの音の伝達を模倣しているからである。この伝達関数を頭部伝達関数(HRTF)と呼ぶ。
本記事では、この右, 左耳までのHRTFを用いた信号処理で立体音響を生成するシステムをPythonで実装する方法を記載する。注意点: HRTFは個人差があり、前後の音像位置推定が不一致になることが多々あります。実際、3Dio等を使用した場合も、標準的な耳の形を模倣しただけであり、個人差を解決できていません。
プログラムが長いため概要のみ説明していきます。詳細は以下のGitのプログラムを読んでみてください。
また、使用方法に関しても、gitに記載しています。
Git: k-washi/stereophonic-Sound-Systemプログラム中に記載しているloggingや設定ファイルの読み込み、位置情報取得のためのgRPC通信に関しては、以下のQiitaの記事を適宜参考にしてください。
立体音響例 (イヤホン必須です)
以下の画像をクリックしてみてください。
Youtubeのリンクで実際に作成した立体音響が聞けます。マイクがmac付属のもののため、もともとの音が悪いですが、立体音響になっていることはわかると思います。ライブラリのインストール
pip install PyAudio==0.2.11 pip install grpcio-tools pip install numpyHRTFの取得
ここでは、HRTFのデータベースを読み込み周波数領域に変換しpickleを用いて保存する。
HRTFは、名古屋大学 HRTFのHRTF data (2)を使用した。
※ 西野隆典, 梶田将司, 武田一哉, 板倉文忠, "水平方向及び仰角方向に関 する頭部伝達関数の補間," 日本音響学会誌, 57巻, 11号, pp.685-692, 2001.以下に、プログラムを記載する。細かい部分は、...として省略している。全プログラムを見る場合は、acoustic/spacialSound.pyを見てください。
acoustic/spacialSound.py... class HRTF(): def __init__(self): ... def checkModel(self): #モデルファイル名を取得 ... self.getModelNameList() ... def getModelNameList(self): #方位角、仰角ごとにHRTFファイル名を解析 ... def openData(self, path, dataType = np.int16): #H各方向,仰角のHRTF信号のサンプル数は512点であり、このデータを読み込んでnumpy形式に変換している with open(path, 'r') as rData: temp = rData.read().split("\n") data = [] for item in temp: if item != '': data.append(float(item)) return np.array(data) def convHRTF2Np(self): #各方位角、仰角のHRTFデータを読み込み、overlap Add methodに基づき 512点 + 0埋め(512点)をFFTしている。(FFTに関しては次章に記載) #上記のFFTを両耳に関して行い、全データをpickleで保存している。保存はsaveData関数を用いている。 #読み込みは、保存したpickleデータは、readDataで読み込むことができる。 for e, _ in enumerate(self.elev): LaziData = [] RaziData = [] for a, _ in enumerate(self.azimuth[e]): Lpath = self.Lpath[e][a] Rpath = self.Rpath[e][a] Ldata = spec.overlapAdderFFT(self.openData(Lpath)) Rdata = spec.overlapAdderFFT(self.openData(Rpath)) LaziData.append(Ldata) RaziData.append(Rdata) self.hrtf[self.left].append(LaziData) self.hrtf[self.right].append(RaziData) self.saveData(self.hrtf, Conf.HRTFpath) self.saveData(self.elev, Conf.Elevpath) self.saveData(self.azimuth, Conf.Azimuthpath) def saveData(self, data, path): #pickleデータ保存 try: with open(path, 'wb') as hrtf: pickle.dump(data, hrtf) except Exception as e: logger.critical(e) def readData(self, path): #pickleデータ読み込み try: with open(path, 'rb') as hrtf: data = pickle.load(hrtf) except Exception as e: logger.critical(e) return data高速フーリエ変換(FFT)
ここでは、FFTに関する実装について説明する。
詳細は、acoustic/acousticSignalProc.py
音響情報を処理する際、HRTFとマイク入力の畳み込み積分が必要となる。しかし、生の音響信号で処理した場合に、処理に時間がかかり、かつ、データも扱いづらい。そのため、信号を周波数領域の情報に変換するフーリエ変換が必要となる。そして、このフーリエ変換を高速に行うものがFFTである。
HRTFとマイク入力を畳み込むとき、OverLap Add method (OLA)がよく用いられる。
例えば、HRTFとマイク入力のサンプル数が512点の場合、各データに加えて、512点を0埋めする。つまり512 + 512(0)のデータを作成する。
その後、numpyのrfft関数でFFTの正の周波数を計算している。
numpyのfftの場合、512/2 = 256点の正の周波数成分と256点の負の周波数成分が計算される。しかし、多くの工学的な用途では正の周波数成分のみで十分な場合が多いためrfftを用いている。
また、numpyのrfftとfftの計算アルゴリズムが異なるが結果の誤差はかなり小さいため、今回はrfftを用いている。
そして、FFTの実行後、HRTFとマイク入力を各周波数ごとに掛け合わせる。このかけわせに関しては、次の章で説明する。以下のプログラムでは、overlapAdderFFTとspacializeFFTの2つのFFTを準備している。違いは。window(窓関数)をかけ合わせているかどうかである。
窓関数は、フーリエ変換が切り出した範囲の周期性を仮定しているため、端を小さくするような関数をデータにかけて端と端がつながるようにするものである。
ただし、HRTFは、1データ512点しかなく、窓関数をかけた場合、もとのデータを復元できないため、窓関数をかけずに使用している。
一方で、マイク入力は、窓関数をかけている。
次章で説明するが、窓関数をかけた場合、端の情報がなくなるため、各データを128点づつずらしながら使用している。acoustic/acousticSignalProc.pyimport pyaudio import numpy as np class SpectrogramProcessing(): def __init__(self, freq = Conf.SamplingRate): self.window = np.hamming(Conf.SysChunk) self.overlapFreq = np.fft.rfftfreq(Conf.SysChunk * 2, d=1./freq) self.overlapData = np.zeros((int(Conf.SysChunk * 2)), dtype = np.float32) def overlapAdderFFT(self, data): #0埋めしてFFT self.overlapData[:Conf.SysChunk] = data return np.fft.rfft(self.overlapData) def spacializeFFT(self, data): #0埋めかつ、hanning windowをかける。 self.overlapData[:Conf.SysChunk] = data * self.window return np.fft.rfft(self.overlapData) def ifft(self, data): #in: chanel_num x freq num (if 1.6kHz, 0,...,7984.375 Hz) #out: chanel_num x frame num(Conf.SysChunk = 512) return np.fft.irfft(data)マイク入力, 出力, 音響処理プログラム
次に、実際にマイク入力、出力、そして、立体音響への変換プログラムを背逸名する。
上記で説明した関数等を用いて、処理していく。また、設定やgRPCに関しては、最初に記載した通り、私の過去記事を参考にしてください。acoustic/audioStreamOverlapAdder.py... from acoustic.acousticSignalProc import AudioDevice, SpectrogramProcessing, WaveProcessing, convNp2pa, convPa2np from acoustic.spacialSound import spacialSound # ------------ import pyaudio import numpy as np import time class MicAudioStream(): def __init__(self): self.pAudio = pyaudio.PyAudio() self.micInfo = AudioDevice(Conf.MicID) self.outInfo = AudioDevice(Conf.OutpuID) #出力デバイスの制限処理 if self.outInfo.micOutChannelNum < 2: self.left = 0 self.right = 0 else: self.left = 0 self.right = 1 if self.outInfo.micOutChannelNum > 2: self.outInfo.micChannelNum = 2 logger.info("出力マイク数が過剰であるため2チャンネルに制限しました。") self.startTime = time.time() #現在は16bitのビット幅のみ対応している。(他の場合の動作を確認できていないため) if Conf.SysSampleWidth == 2: self.format = pyaudio.paInt16 self.dtype = np.int16 else: logger.critical("現在対応していない") exec(-1) self.fft = SpectrogramProcessing() #毎回numpyのarray形式のデータを作成し、メモリー確保を実行した場合、時間がかかるため、予め作成しておく。 self.data = np.zeros((int(Conf.StreamChunk * 2)), dtype=self.dtype) self.npData = np.zeros((int(Conf.StreamChunk * 2)) , dtype=self.dtype) self.overlapNum = int(Conf.StreamChunk / Conf.SysFFToverlap) self.freqData = np.zeros((self.overlapNum, self.outInfo.micOutChannelNum, self.fft.overlapFreq.shape[0]), dtype=np.complex) self.convFreqData = np.zeros((self.outInfo.micOutChannelNum, int(Conf.StreamChunk*3)) , dtype=self.dtype) self.outData = np.zeros((self.outInfo.micOutChannelNum * Conf.StreamChunk), dtype=self.dtype) self.Aweight = self.fft.Aweight() #A特性をかけているが、ほとんど変わらなかったため、気にする必要はない。(消しても良い) #位置情報の初期値 self.x = 0.2 self.y = 10 self.z = 0.2 #HRTFの読み込み(acoustic/spacialSound.py) #位置情報に対して、HRTFを返す処理を実行できる self.hrft = spacialSound() #立体音響を録音する場合、 if Conf.Record: #test/listOrNumpy.pyにて速度比較 # numpyのArray形式は、array形式を結合していくより、一旦、numpyをlistに変換してlistの拡張を行った方が早い self.recordList = [] def spacialSoundConvering(self, freqData): #位置に対して、HRTFを返している lhrtf, rhrtf = self.hrft.getHRTF(self.x, self.y, self.z) #以下のようにHRTFのマイクの入力データを畳み込み、立体音響を生成している。 freqData[self.left] = freqData[self.left] * lhrtf freqData[self.right] = freqData[self.right] * rhrtf return freqData * self.Aweight def callback(self, in_data, frame_count, time_info, status): #pyAudioのstream処理で、音データを処理する関数。 #in_dataが入力で、returnでout_dataとして、音データを出力している。 if time.time() - self.startTime > Conf.SysCutTime: #pyAudio形式の入力をnumpy形式に変換している。 self.npData[Conf.StreamChunk:] = convPa2np(np.fromstring(in_data, self.dtype), channelNum=self.micInfo.micChannelNum)[0, :] #ch1 input #以下でデータをオーバーラップ幅(128)づつずらしながら、立体音響を生成する。 for i in range(self.overlapNum): #512点(SysChunk)の幅でFFTをおこなっている。 self.freqData[i, :, :] = self.fft.spacializeFFT(self.npData[Conf.SysFFToverlap * i : Conf.SysChunk + Conf.SysFFToverlap * i]) #HRTFとマイク入力を畳み込んでいる。 self.freqData[i, :, :] = self.spacialSoundConvering(self.freqData[i]) #逆フーリエ変換で周波数領域から時間領域へ変換している。 self.convFreqData[:, Conf.SysFFToverlap * i : Conf.SysChunk * 2 + Conf.SysFFToverlap * i] += self.fft.ifft(self.freqData[i]).real.astype(self.dtype)#[:,:Conf.SysChunk] #numpy形式からpyAudioで出力する形式に変換している。 self.outData[:] = convNp2pa(self.convFreqData[:,:Conf.StreamChunk]) #音の距離減衰を計算している。また、音が大きすぎるので、SysAttenuationで割っている。 self.outData[:] = self.hrft.disanceAtenuation(self.outData[:], self.x, self.y, self.z) / Conf.SysAttenuation if Conf.Record: self.recordList += self.outData.tolist() #次のマイク入力に備えて初期化 self.npData[:Conf.StreamChunk] = self.npData[Conf.StreamChunk:] self.convFreqData[:, :Conf.StreamChunk*2] = self.convFreqData[:, Conf.StreamChunk:] self.convFreqData[:,Conf.StreamChunk*2:] = 0 #pyAudio形式であるデータを出力する形式に変換 out_data = self.outData.tostring() return (out_data, pyaudio.paContinue) def start(self): #以下の形式で、入出力のデバイスや形式を設定し、処理を開始する。 """ rate – Sampling rate channels – Number of channels format – Sampling size and format. See PortAudio Sample Format. input – Specifies whether this is an input stream. Defaults to False. output – Specifies whether this is an output stream. Defaults to False. input_device_index – Index of Input Device to use. Unspecified (or None) uses default device. Ignored if input is False. output_device_index – Index of Output Device to use. Unspecified (or None) uses the default device. Ignored if output is False. frames_per_buffer – Specifies the number of frames per buffer. start – Start the stream running immediately. Defaults to True. In general, there is no reason to set this to False. input_host_api_specific_stream_info – Specifies a host API specific stream information data structure for input. output_host_api_specific_stream_info – Specifies a host API specific stream information data structure for output. stream_callback –Specifies a callback function for non-blocking (callback) operation. Default is None, which indicates blocking operation (i.e., Stream.read() and Stream.write()). To use non-blocking operation, specify a callback that conforms to the following signature: callback(in_data, # recorded data if input=True; else None frame_count, # number of frames time_info, # dictionary status_flags) # PaCallbackFlags time_info is a dictionary with the following keys: input_buffer_adc_time, current_time, and output_buffer_dac_time; see the PortAudio documentation for their meanings. status_flags is one of PortAutio Callback Flag. The callback must return a tuple: (out_data, flag) out_data is a byte array whose length should be the (frame_count * channels * bytes-per-channel) if output=True or None if output=False. flag must be either paContinue, paComplete or paAbort (one of PortAudio Callback Return Code). When output=True and out_data does not contain at least frame_count frames, paComplete is assumed for flag. """ self.stream = self.pAudio.open( format = self.format, rate = Conf.SamplingRate,#self.micInfo.samplingRate, channels = self.micInfo.micChannelNum, input = True, output = True, input_device_index = Conf.MicID, output_device_index = Conf.OutpuID, stream_callback = self.callback, frames_per_buffer = Conf.StreamChunk ) self.stream.start_stream() def stop(self): #音響処理とは別に必要な処理を実行している。また、最終的に、システムの終了を実行する際のクローズ処理も実行している。 #ここでは、gRPCを使用して、音源位置の情報を更新している。 from proto.client import posClient grpcPosGetter = posClient() grpcPosGetter.open() while self.stream.is_active(): time.sleep(0.1) try: ok = grpcPosGetter.posRequest() if ok: self.x, self.y, self.z = grpcPosGetter.getPos() except Exception as e: logger.error("pos getter error {0}".format(e)) if time.time() - self.startTime > Conf.RecordTime + Conf.SysCutTime: break if Conf.Record: record = WaveProcessing() record.SaveFlatteData(self.recordList, channelNum=self.outInfo.micOutChannelNum) self.stream.start_stream() self.stream.close() self.close() grpcPosGetter.close() def close(self): self.pAudio.terminate() logger.debug("Close proc") exit(0) if __name__ == "__main__": st = MicAudioStream() st.start() try: pass finally: st.stop()入力、出力デバイスの確認
実際に音響処理を試すためには、入出力デバイスのIDを確認する必要がある。
デバイス情報例
2020-01-16 03:46:49,436 [acousticSignalProc.py:34] INFO Index: 0 | Name: Built-in Microphone | ChannelNum: in 2 out 0 | SampleRate: 44100.0 2020-01-16 03:46:49,436 [acousticSignalProc.py:34] INFO Index: 1 | Name: Built-in Output | ChannelNum: in 0 out 2 | SampleRate: 44100.0 2020-01-16 03:46:49,436 [acousticSignalProc.py:34] INFO Index: 2 | Name: DisplayPort | ChannelNum: in 0 out 2 | SampleRate: 48000.0 ...以下に、PyAudioを用いて入出力デバイスの情報を出力するプログラムを示す。
acoustic/acousticSignalProc.py... import pyaudio import numpy as np class AudioDevice(): def __init__(self, devId = Conf.MicID): self.pAudio = pyaudio.PyAudio() self.setAudioDeviceInfo(devId) self.samplingRate = Conf.SamplingRate def getAudioDeviceInfo(self): #PyAudioを用いてデバイス情報を出力する。 for i in range(self.pAudio.get_device_count()): tempDic = self.pAudio.get_device_info_by_index(i) text = 'Index: {0} | Name: {1} | ChannelNum: in {2} out {3} | SampleRate: {4}'.format(tempDic['index'], tempDic['name'], tempDic['maxInputChannels'], tempDic['maxOutputChannels'], tempDic['defaultSampleRate']) logger.info(text) def setAudioDeviceInfo(self, micId = 0): #設定したデバイスIDが存在するか確認し、そのIDの情報を保持する micInfoDic = {} for i in range(self.pAudio.get_device_count()): micInfoDic = self.pAudio.get_device_info_by_index(i) if micInfoDic['index'] == micId: self.micName = micInfoDic['name'] self.micChannelNum = micInfoDic['maxInputChannels'] self.micOutChannelNum = micInfoDic['maxOutputChannels'] self.micSamplingRate = int(micInfoDic['defaultSampleRate']) text = 'Set Audio Device Info || Index: {0} | Name: {1} | ChannelNum: {2}, {3} | SampleRate: {4}'.format(micId, self.micName, self.micChannelNum,self.micOutChannelNum, self.micSamplingRate) logger.info(text) if self.micChannelNum > 2: logger.critical("3個以上のマイクロホン入力に対応していません。") exit(-1) break if self.pAudio.get_device_count() == i + 1: logger.critical("対応するidのマイクロホンがありません。")まとめ
以上、Pythonを用いた立体音響システムに関する解説でした。
かなり省いた部分もあり、また、他の記事も参考にする必要があるため、複雑になっているかもしれませんが、参考になればと思います。
pythonは遅いと言われていますが、予めメモリを確保しておくなどし、numpyを効率的に使っていけば、十分な速度で実行可能なことが多いです。
他にも、いろいろ記事を書いているので参考にしてみてください。
- 投稿日:2020-01-16T17:44:52+09:00
拗ねる時に画像を偽暗号化する
なにこれ
予め決めた暗号に基づいてノイズを算出して、画像に入れるやつ。復号可能。
目次
1、暗号化
2、復号化
3、暗号を当ててもらう
4、後書き暗号化
文字列の暗号を決めて、asciiコードを算出します。画像の行毎に行数と暗号の長さの余りを計算して、ノイズの値にします。当該行の全ての画素にノイズを加算します。
例えば私の暗号は「ore mo waru katta」(俺も悪かった)です→_→。
asciiコードは[111, 114, 101, 95, 109, 111, 95, 119, 97, 114, 117, 95, 107, 97, 116, 116, 97]です。
↑これにノイズを入れるよencode.pydef encode(x,key): return ((255,x+key) if x+key<=255 else (0,x-255+key))↑これで、画素に入れるノイズの値を計算しますね。画素の値にノイズを加算して、255を超えたら255を引いて、0と計算の結果をreturnします。超えてない場合1と結果をreturnします。
単純すぎて申し訳ない。。。
で、画像全体に対してこうします。encode_img.pydef encode_image(img): ori_img = plt.imread(img) encode_img = np.array(ori_img,dtype='uint8') with open('{}_code.txt'.format(img[:-4]),'w') as f: for sub_array in encode_img[:,:,-1]: f.write(str(list(sub_array)).replace('[','').replace(']','')+',') f.close() for x in range(encode_img.shape[0]): for y in encode_img[x]: y[-1] == 255 key = password[x%len(password)] y[-1],y[1] = (encode(y[1],key)) img_name = 'encode_'+img[:-4]+'.png' plt.imshow(encode_img) print(img_name) plt.imsave(img_name,encode_img)画素の第二チャンネルにノイズを入れ、第四チャンネルは'255を引いたかのフラグ'として使っています。引いたら0、引いてなかったら1にすることで、復号するとき第四チャンネルの値に基づいて255を加算するかを決めますね。
(ちなみになんかこの方法アホみたい...)
(完璧に復号するため元の画像の第四チャンネルも知らないといけないから、txtに保存した...)
(さらにアホみたくなってきた...)
と!暗号化したら先の画像はこうなりました!↓
よし、使えなくなったでしょ!復号化
第二チャンネルに加算した値を減算して、第四チャンネルを直接オリジナル画像の第四チャンネルをコピーします...(ここ本当にアホらしい)ちなみにオリジナル画像の第四チャネルを'画像の名前_code.txt'に保存しました。
decode.pydef decode(x,flag,key): return (x-key if flag==255 else x+255-key)↑ちなみにこのflagは第四チャネルの数値です。
で、ここ、相手に暗号を入力してもらって、入力のasciiコードを復号キーに使います。
つまり正しい暗号を入力しない限り正しく復号できないってことですね。decode_img.pydef test(input_): for file in os.listdir(): if file.endswith('.png'): encode_img = plt.imread(file) encode_img = np.array(encode_img*255,dtype='uint8') img = copy.deepcopy(encode_img) with open (file[:-4]+'_code.txt','r') as f: txt = f.read() f.close() code_array = np.fromstring(txt, dtype=int, sep=',') code_array = code_array.reshape(encode_img.shape[:2]) input_password = [] for i in str(input_): input_password.append(ord(str(i))) print('password:',input_password) for x in range(img.shape[0]): for y in img[x]: key = input_password[x%len(input_password)] y[1] = decode(y[1],y[-1],key) img[:,:,-1] = code_array plt.imsave('result/{}.jpg'.format(file[:-4]+input_),img) print('result saved as /result/{}.jpg'.format(file[:-4]+input_)) if __name__=='__main__': test(input('please input the password:\n'))で、例えば「'onigunsou'」(鬼軍曹)を入力するとーー
こんなりましたーー!
「'ore mo waru katta'」を入力したら?
お見事。暗号を当ててもらう
あとは簡単ですね。
guess_password.pypassword = [111, 114, 101, 95, 109, 111, 95, 119, 97, 114, 117, 95, 107, 97, 116, 116, 97] init = '---_--_----_-----' def guess_password(ate): guess = input('please guess the password\n') for i in guess: if ord(i) in password and i not in ate: ate.append(i) print(ate) result = '' for j in range(len(password)): result +=(chr(password[j]) if chr(password[j]) in ate else init[j]) print(result) return result def start(): init = '---_--_----_-----' ate = ['_'] result = guess_password(ate) while not all(chr(k) in ate for k in password): result = guess_password(ate) print('おめでとう!暗証番号は{}ですよ。\n私も悪かった。'.format(result)) if __name__ == '__main__': start()と、暗号を当ててもらいます。
ちなみにこんな感じです。
暴力で英文字を全部入力しても解けますけど...
相手に優しい暗号システムですね笑。後書き
Sくんにグラフの作成を頼まれて、しかし翌日喧嘩になっちゃった。
もちろん自分も悪かったけど、相手もちょっと鬼軍曹だった。。。
正直自分もちょっと怒っていたし、送りたくなかった。けど!拗ねてると言ってもやるべき事はやるでしょ。そうしないと自分も責任感のない人になっちゃうじゃん。
と思って、作ったグラフの一枚を送って、自分の非を認めて、「私悪かった。ごめん。」て言った。
しかし相手の返信遅かったし、堂々と「もう一枚もちょうだい」って書いてた。
- _ -
-_-??
何かしら自分の責任感を示しながら、- _ -??の気持ちを伝える方法ないのかなぁって思って、こういう手を考えた。
と、相手に送って、丁寧に説明して、忙しかったら放置してもいいよ、夜12時までに必ずオリジナル画像を送信しますっと言ったら。
相手は(多分暴力で解けたと思いますけど)秒で解けた。。。流石に誰も使わないと思うので、コード適度に書きました。
まあ、プログラミングの練習になりましたし、楽しかった!
なんか人生全ての知恵を使ってしまった気がする...





- 投稿日:2020-01-16T17:25:24+09:00
Macでpyinstallerを使ってPythonコードから実行ファイルを生成した時の記録(OSError: Python library not found: libpython3.7m.dylib, .Python, libpython3.7.dylibの回避)
記事の内容
Macでpyinstallerを使ってPythonコードから実行ファイルを生成した時の記録です。
Pythonコード
print_sys_path.pyimport sys print(sys.path) print(f"__name__ = {__name__}") print(f"__file__ = {__file__}")pyinstaller実行とエラーメッセージ
pipでインストールしたpyinstallerを使用し、端末で以下を実行しました。
pyinstaller print_sys_path.py --onefile以下のようにPython library not foundエラーが出ました。
71 INFO: PyInstaller: 3.6 71 INFO: Python: 3.7.4 83 INFO: Platform: Darwin-19.2.0-x86_64-i386-64bit (中略) OSError: Python library not found: libpython3.7m.dylib, .Python, libpython3.7.dylib, Python This would mean your Python installation doesn't come with proper library files. This usually happens by missing development package, or unsuitable build parameters of Python installation. * On Debian/Ubuntu, you would need to install Python development packages * apt-get install python3-dev * apt-get install python-dev * If you're building Python by yourself, please rebuild your Python with `--enable-shared` (or, `--enable-framework` on Darwin)対処その1 (1回目の--enable-sharedで失敗)
pyenvでPythonをインストールするときのオプションに「--enable-shared」を使用。
端末で以下を実行しました。PYTHON_CONFIGURE_OPTS="--enable-shared" pyenv install 3.7.4以下のように表示されて、3.7.4が上書きインストールされました。
pyenv: /Users/username/.pyenv/versions/3.7.4 already exists continue with installation? (y/N) y python-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Downloading Python-3.7.4.tar.xz... -> https://www.python.org/ftp/python/3.7.4/Python-3.7.4.tar.xz Installing Python-3.7.4... python-build: use readline from homebrew python-build: use zlib from xcode sdk Installed Python-3.7.4 to /Users/username/.pyenv/versions/3.7.4使用されるPythonを確認します。
$ pyenv global 3.7.4pyinstallerを起動したら、以下のようにまだPython library not foundエラーが出ました。
$ pyinstaller print_sys_path.py --onefile (中略) OSError: Python library not found: Python, libpython3.7.dylib, .Python, libpython3.7m.dylib This would mean your Python installation doesn't come with proper library files. This usually happens by missing development package, or unsuitable build parameters of Python installation. * On Debian/Ubuntu, you would need to install Python development packages * apt-get install python3-dev * apt-get install python-dev * If you're building Python by yourself, please rebuild your Python with `--enable-shared` (or, `--enable-framework` on Darwin).dylibファイルが見つからないと叱られているので、以下のようにfindコマンドで場所を探して、
find $HOME -name 'libpython3*.dylib' 2> /dev/nullLD_LIBRARY_PATH環境変数にlibpython3.7m.dylibの場所を指定して実行してみましたが、以下のようにPython library not foundエラーのままでした。
$ LD_LIBRARY_PATH=/Users/username/.pyenv/versions/3.7.4/lib pyinstaller print_sys_path.py --onefile (中略) OSError: Python library not found: .Python, Python, libpython3.7m.dylib, libpython3.7.dylib This would mean your Python installation doesn't come with proper library files. This usually happens by missing development package, or unsuitable build parameters of Python installation. * On Debian/Ubuntu, you would need to install Python development packages * apt-get install python3-dev * apt-get install python-dev * If you're building Python by yourself, please rebuild your Python with `--enable-shared` (or, `--enable-framework` on Darwin)対処その2 (--enable-frameworkで成功)
pyenvでPythonをインストールするときのオプションに「--enable-framework」を使用。
端末で以下を実行しました。PYTHON_CONFIGURE_OPTS="--enable-framework" pyenv install 3.7.4以下のように表示されて、3.7.4が上書きインストールされました。
pyenv: /Users/username/.pyenv/versions/3.7.4 already exists continue with installation? (y/N) Y python-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Downloading Python-3.7.4.tar.xz... -> https://www.python.org/ftp/python/3.7.4/Python-3.7.4.tar.xz Installing Python-3.7.4... python-build: use readline from homebrew python-build: use zlib from xcode sdk Installed Python-3.7.4 to /Users/username/.pyenv/versions/3.7.4pyinstallerを起動したら、以下のように「pyinstallerがない」というエラーが出ました。
$ LD_LIBRARY_PATH=/Users/username/.pyenv/versions/3.7.4/lib pyinstaller print_sys_path.py --onefile -bash: /Users/username/.pyenv/shims/pyinstaller: No such file or directorypyinstallerの再インストールを試みたら、以下のように「既にある」と言われました。
$ pip install pyinstaller Requirement already satisfied: pyinstaller in /Users/username/.pyenv/versions/3.7.4/lib/python3.7/site-packages (3.6) Requirement already satisfied: altgraph in /Users/username/.pyenv/versions/3.7.4/lib/python3.7/site-packages (from pyinstaller) (0.17) Requirement already satisfied: setuptools in /Users/username/.pyenv/versions/3.7.4/Python.framework/Versions/3.7/lib/python3.7/site-packages (from pyinstaller) (40.8.0) Requirement already satisfied: macholib>=1.8 in /Users/username/.pyenv/versions/3.7.4/lib/python3.7/site-packages (from pyinstaller) (1.14)訳がわからなくなりました!
試行錯誤の結果、以下のようにアンインストール→インストールの手順で、pyinstallerを再インストールできました。$ pip uninstall pyinstaller Uninstalling PyInstaller-3.6: Would remove: /Users/username/.pyenv/versions/3.7.4/lib/python3.7/site-packages/PyInstaller-3.6.dist-info/* /Users/username/.pyenv/versions/3.7.4/lib/python3.7/site-packages/PyInstaller/* Proceed (y/n)? Y Successfully uninstalled PyInstaller-3.6$ pip install pyinstaller Processing /Users/username/Library/Caches/pip/wheels/62/fe/62/4c0f196d1e0dd689e097449bc81d7d585a7de7dd86b081b80b/PyInstaller-3.6-cp37-none-any.whl Requirement already satisfied: setuptools in /Users/username/.pyenv/versions/3.7.4/Python.framework/Versions/3.7/lib/python3.7/site-packages (from pyinstaller) (40.8.0) Requirement already satisfied: macholib>=1.8 in /Users/username/.pyenv/versions/3.7.4/lib/python3.7/site-packages (from pyinstaller) (1.14) Requirement already satisfied: altgraph in /Users/username/.pyenv/versions/3.7.4/lib/python3.7/site-packages (from pyinstaller) (0.17) Installing collected packages: pyinstaller Successfully installed pyinstaller-3.6以下のように再びpyinstallerを起動したら、distディレクトリの下に実行ファイルが生成されました。
LD_LIBRARY_PATHを指定しましたが、指定しなくても動くようです。LD_LIBRARY_PATH=/Users/username/.pyenv/versions/3.7.4/lib pyinstaller print_sys_path.py --onefile生成された実行ファイルを起動しました(成功)。
dist/print_sys_path ['/var/folders/kc/blch89657dv8zrzlxjljz6f40000gr/T/_MEInZMCQo/base_library.zip', '/var/folders/kc/blch89657dv8zrzlxjljz6f40000gr/T/_MEInZMCQo'] __name__ = __main__ __file__ = print_sys_path.py対処その3 (2回目の--enable-sharedで成功)
1回目の--enable-sharedは失敗しましたが、再び--enable-sharedでインストールしたら成功するようになっていたので、記録しておきます。
pyenvでPythonのインストール:
$ PYTHON_CONFIGURE_OPTS="--enable-shared" pyenv install 3.7.4 pyenv: /Users/username/.pyenv/versions/3.7.4 already exists continue with installation? (y/N) y python-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Downloading Python-3.7.4.tar.xz... -> https://www.python.org/ftp/python/3.7.4/Python-3.7.4.tar.xz Installing Python-3.7.4... python-build: use readline from homebrew python-build: use zlib from xcode sdk Installed Python-3.7.4 to /Users/username/.pyenv/versions/3.7.4pyinstaller起動:
pyinstaller print_sys_path.py --onefile生成された実行ファイルを起動:
$ dist/print_sys_path ['/var/folders/kc/blch89657dv8zrzlxjljz6f40000gr/T/_MEIf6CW7m/base_library.zip', '/var/folders/kc/blch89657dv8zrzlxjljz6f40000gr/T/_MEIf6CW7m'] __name__ = __main__ __file__ = print_sys_path.pypipenvでも試します。
pyinstaller起動:pipenv run pyinstaller print_sys_path.py --onefile生成された実行ファイルを起動:
$ dist/print_sys_path ['/var/folders/kc/blch89657dv8zrzlxjljz6f40000gr/T/_MEIPYS34b/base_library.zip', '/var/folders/kc/blch89657dv8zrzlxjljz6f40000gr/T/_MEIPYS34b'] __name__ = __main__ __file__ = print_sys_path.py対処その1でうまく動かなかった理由
たぶん、pyenvでPythonを上書きインストールしたら、pipでインストールされていたものも再インストール(uninstall → install)が必要なんだろうと思います。
対処その1でPythonを上書きインストールしたけど、pyinstallerは以前から入っていたものをそのまま使ったので、同じエラーが発生してしまったのでしょう。
- 投稿日:2020-01-16T16:49:42+09:00
AtCoder Beginner Contest 073 過去問復習
所要時間
感想
D問題はPythonだと若干難しめで2ペナになりましたが、WF法の10^7はきついということがわかりました。
後、DでC++で書き直すときにfor文が面倒だったりinclude書くのだるかったりしたのでそろそろテンプレートを作らなきゃなあと思いました。A問題
文字列のままの方が扱いやすい。
answerA.pyn=input() print("Yes" if "9" in n else "No")B問題
席が被ったら若干面倒なのと、いもす法とか使いそう??
この問題はそのまま数えればいいだけanswerB.pyn=int(input()) cnt=0 for i in range(n): l,r=map(int,input().split()) cnt+=(r-l+1) print(cnt)C問題
被ってるかどうかを繰り返し確かめるのでsetなどのaddやremoveがO(1)でできるset型を用いてシミュレートしていけば良いです。
Writer解はソートしてgroupby関数を適用し、それぞれの数字の個数で奇数個あるものの身をカウントしていっています。answerC.pyn=int(input()) s=set() for i in range(n): a=int(input()) if a in s: s.remove(a) else: s.add(a) print(len(s))answerC_writer.pyn=int(input()) s=[int(input()) for i in range(n)] s.sort() def groupby(a): a2=[[a[0],1]] for i in range(1,len(a)): if a2[-1][0]==a[i]: a2[-1][1]+=1 else: a2.append([a[i],1]) return a2 s=groupby(s) l=len(s) cnt=0 for i in range(l): cnt+=s[i][1]%2 print(cnt)D問題
この問題ではR個の街を順番を適当に定めて訪れた際の最短距離を求めるという問題です。
まず、最短距離を求める(+制約を見たら間に合いそうだった)のでWF法を思いつきました。
WF法で全点間最短路を求めた後は、R個の街を順番に訪れるのでその順番を考える必要がありますが、Rが高々8であり8!=40320であることからその順番を求めるのもそこまでの計算量になりません。
よって、この問題は解けたと言いたかったのですが、Pythonでナイーブに実装した場合この方法では通りませんでした(定数倍高速化をすれば通りそうですが、三重ループをどのようにしたら早くできるのかが全くわかりませんでした。)
そこで、Pythonで書いたコードをそのままC++に翻訳したところ余裕で間に合いました(Pythonよりも100倍くらい早かったです。Pythonのforループは本当に遅い気がします。体感ではありますが)。また、試しにPyPyでも試したところこちらも余裕で間に合いました(Pythonよりも5倍くらい早い)。
しかし、よく考えるとWF法では全点間最短路を求めていますが、結局知りたいのは、訪れるR(<=8)個の町についてのそれぞれの町の間の最短経路であるので、R個の街を始点とするような最短経路(重みつき無向グラフなので始点と終点を入れ替えてもその最短経路の距離は変わらない)を求めれば十分であることがわかります。従って、このR個の町からの最短経路をダイクストラ法で求めてやれば十分高速なプログラムを書くことができると考えられます(Pythonでダイクストラ法を書いたことがないのでここでは割愛します。気が向いたら書くかもしれません。)。
↓PythonのコードはTLEします
answerD.pyimport itertools n,m,r=map(int,input().split()) rx=[int(i) for i in input().split()] inf=100000000 wf=[[inf]*n for i in range(n)] for i in range(n): wf[i][i]=0 for i in range(m): a,b,c=map(int,input().split()) wf[a-1][b-1]=c wf[b-1][a-1]=c for k in range(n): for i in range(n): for j in range(n): if wf[i][j]>wf[i][k]+wf[k][j]: wf[i][j]=wf[i][k]+wf[k][j] cnt=0 l=list(itertools.permutations([i for i in range(r)])) cnt=inf for i in l: cnt_sub=0 for j in range(r-1): cnt_sub+=wf[rx[i[j]]-1][rx[i[j+1]]-1] cnt=min(cnt,cnt_sub) print(cnt)answerD.cc#include<iostream> #include<vector> #include<algorithm> using namespace std; typedef long long ll; #define INF 100000000000 signed main(){ ll n,m,r;cin >> n >> m >> r; vector<ll> rx(r);for(int i=0;i<r;i++)cin >> rx[i]; vector<vector<ll>> wf(n,vector<ll>(n,INF)); for(int i=0;i<n;i++) wf[i][i]=0; for(int i=0;i<m;i++){ ll a,b,c;cin >> a >> b >> c; wf[a-1][b-1]=c; wf[b-1][a-1]=c; } for(int k=0;k<n;k++){ for(int i=0;i<n;i++){ for(int j=0;j<n;j++){ wf[i][j]=min(wf[i][j],wf[i][k]+wf[k][j]); } } } ll cnt=INF; vector<ll> v(r);for(int i=0;i<r;i++) v[i]=i; do{ ll cnt_sub=0; for(int i=0;i<r-1;i++){ cnt_sub+=wf[rx[v[i]]-1][rx[v[i+1]]-1]; } cnt=min(cnt,cnt_sub); }while(next_permutation(v.begin(),v.end())); cout << cnt << endl; }


- 投稿日:2020-01-16T16:49:05+09:00
AtCoder Beginner Contest 073 過去問復習
所要時間
感想
D問題はPythonだと若干難しめで2ペナになりましたが、WF法の10^7はきついということがわかりました。
後、DでC++で書き直すときにfor文が面倒だったりinclude書くのだるかったりしたのでそろそろテンプレートを作らなきゃなあと思いました。A問題
文字列のままの方が扱いやすい。
answerA.pyn=input() print("Yes" if "9" in n else "No")B問題
席が被ったら若干面倒なのと、いもす法とか使いそう??
この問題はそのまま数えればいいだけanswerB.pyn=int(input()) cnt=0 for i in range(n): l,r=map(int,input().split()) cnt+=(r-l+1) print(cnt)C問題
被ってるかどうかを繰り返し確かめるのでsetなどのaddやremoveがO(1)でできるset型を用いてシミュレートしていけば良いです。
Writer解はソートしてgroupby関数を適用し、それぞれの数字の個数で奇数個あるものの身をカウントしていっています。answerC.pyn=int(input()) s=set() for i in range(n): a=int(input()) if a in s: s.remove(a) else: s.add(a) print(len(s))answerC_writer.pyn=int(input()) s=[int(input()) for i in range(n)] s.sort() def groupby(a): a2=[[a[0],1]] for i in range(1,len(a)): if a2[-1][0]==a[i]: a2[-1][1]+=1 else: a2.append([a[i],1]) return a2 s=groupby(s) l=len(s) cnt=0 for i in range(l): cnt+=s[i][1]%2 print(cnt)D問題
この問題ではR個の街を順番を適当に定めて訪れた際の最短距離を求めるという問題です。
まず、最短距離を求める(+制約を見たら間に合いそうだった)のでWF法を思いつきました。
WF法で全点間最短路を求めた後は、R個の街を順番に訪れるのでその順番を考える必要がありますが、Rが高々8であり8!=40320であることからその順番を求めるのもそこまでの計算量になりません。
よって、この問題は解けたと言いたかったのですが、Pythonでナイーブに実装した場合この方法では通りませんでした(定数倍高速化をすれば通りそうですが、三重ループをどのようにしたら早くできるのかが全くわかりませんでした。)
そこで、Pythonで書いたコードをそのままC++に翻訳したところ余裕で間に合いました(Pythonよりも100倍くらい早かったです。Pythonのforループは本当に遅い気がします。体感ではありますが)。また、試しにPyPyでも試したところこちらも余裕で間に合いました(Pythonよりも5倍くらい早い)。
しかし、よく考えるとWF法では全点間最短路を求めていますが、結局知りたいのは、訪れるR(<=8)個の町についてのそれぞれの町の間の最短経路であるので、R個の街を始点とするような最短経路(重みつき無向グラフなので始点と終点を入れ替えてもその最短経路の距離は変わらない)を求めれば十分であることがわかります。従って、このR個の町からの最短経路をダイクストラ法で求めてやれば十分高速なプログラムを書くことができると考えられます(Pythonでダイクストラ法を書いたことがないのでここでは割愛します。気が向いたら書くかもしれません。)。
↓PythonのコードはTLEします
answerD.pyimport itertools n,m,r=map(int,input().split()) rx=[int(i) for i in input().split()] inf=100000000 wf=[[inf]*n for i in range(n)] for i in range(n): wf[i][i]=0 for i in range(m): a,b,c=map(int,input().split()) wf[a-1][b-1]=c wf[b-1][a-1]=c for k in range(n): for i in range(n): for j in range(n): if wf[i][j]>wf[i][k]+wf[k][j]: wf[i][j]=wf[i][k]+wf[k][j] cnt=0 l=list(itertools.permutations([i for i in range(r)])) cnt=inf for i in l: cnt_sub=0 for j in range(r-1): cnt_sub+=wf[rx[i[j]]-1][rx[i[j+1]]-1] cnt=min(cnt,cnt_sub) print(cnt)answerD.cc#include<iostream> #include<vector> #include<algorithm> using namespace std; typedef long long ll; #define INF 100000000000 signed main(){ ll n,m,r;cin >> n >> m >> r; vector<ll> rx(r);for(int i=0;i<r;i++)cin >> rx[i]; vector<vector<ll>> wf(n,vector<ll>(n,INF)); for(int i=0;i<n;i++) wf[i][i]=0; for(int i=0;i<m;i++){ ll a,b,c;cin >> a >> b >> c; wf[a-1][b-1]=c; wf[b-1][a-1]=c; } for(int k=0;k<n;k++){ for(int i=0;i<n;i++){ for(int j=0;j<n;j++){ wf[i][j]=min(wf[i][j],wf[i][k]+wf[k][j]); } } } ll cnt=INF; vector<ll> v(r);for(int i=0;i<r;i++) v[i]=i; do{ ll cnt_sub=0; for(int i=0;i<r-1;i++){ cnt_sub+=wf[rx[v[i]]-1][rx[v[i+1]]-1]; } cnt=min(cnt,cnt_sub); }while(next_permutation(v.begin(),v.end())); cout << cnt << endl; }
- 投稿日:2020-01-16T16:38:55+09:00
機械学習超入門 確率モデルと最尤推定編
はじめに
このシリーズは、私個人の学習及びその備忘録として記述するものですが、せっかくですので学んだ内容を皆さんとシェアできればと思い投稿させていただいています。
主に機械学習やディープラーニングを勉強する中で出てくる用語の整理等を行います。
今回は機械学習のモデルで登場する確率モデルと最尤推定について、その概要をまとめていきます。確率モデル
確率モデルは、変数xがパラメータθを持つある確率分布
P(x|θ)から生成されていると仮定したモデルのことを指します。確率モデルx ~ P(x|\theta)例)正規分布
xが連続変数の場合は正規分布となります。
正規分布N(x|\mu, \sigma^2) = \frac{1}{\sqrt{2\pi \sigma^2}} exp \begin{bmatrix} - \frac{(x-\mu)^2}{2\sigma^2} \end{bmatrix}例)ベルヌーイ分布
離散変数、特に恋んトスなどのような0か1をとる場合はベルヌーイ分布と呼ばれます。
ベルヌーイ分布B(x|p) = p^x(1-p)^{1-x}尤度(ゆうど)
ある互いに独立なNこのデータX=(x0, x1, ...)が与えられたとき、以下のように各データの確率関数の値の積をθの関数とすると、これはシータの尤(もっと)もらしさとなり、尤度(ゆうど、Likelihood)と呼びます。
尤度L(\theta) = \prod_{n}P(x_n|\theta)尤度は確率モデルで最も重要な量であり、尤度を最大にするようなパラメータθを求めることを最尤推定(さいゆうすいてい、Maximum Likelihood Estimation, MLE)といいます。
通常は、計算のしやすさなどから下のような対数尤度の形で扱うそうです。対数尤度lnL(\theta) = \sum_nlnP(x_n|\theta)例)正規分布の期待値パラメータμの最尤推定
対数尤度をμについて偏微分し、値が0になる方程式を解くことで求められます(結果的に、期待値パラメータμの最尤推定はすべてのxの平均値となります)。
正規分布の期待値パラメータμの最尤推定lnL(\theta) = - \frac{N}{2}ln2\pi\sigma^2 - \frac{1}{2\sigma^2}\sum_n(x_n-\mu)^2\\ \frac{\delta}{\delta_p}lnL(\theta) = - \frac{1}{\sigma^2}\sum_n(x_n - \mu) = 0 \\ \mu = \frac{1}{N}\sum_nx_n = \bar{x}例)ベルヌーイ分布のpの最尤推定
同様にベルヌーイ分布についてもpの最尤推定を解くと次のようになります。ここで、x=1の個数をMとすると
ベルヌーイ分布の最尤推定\sum_nx_n = M \\ lnL(\theta) = \sum_nx_nlnp + (1 - x_n)ln (1 - p) \\ =Nlnp + (N - M)ln(1 - p) \\ \frac{\delta}{\delta_p}lnL(\theta) = - \frac{M}{p} + \frac{N -M}{1 -p} = 0 \\ p = \frac{M}{N}となり、pはx=1の回数の割合という結果になります。
おわりに
このシリーズはこのくらいのボリューム感で必要な部分だけをおさえていこうと思います。
次回は確率的勾配降下法についてまとめていこうと思いますので、ぜひそちらもご覧ください。
それでは最後までご閲覧頂き、ありがとうございました。
- 投稿日:2020-01-16T16:25:02+09:00
変数で見るRubyとPythonの違い
ローカル変数のスコープ
rubyではローカル変数の参照は定義されたスコープ内のみです。
rubya = 1 def func puts a end func #=> error (undefined local variable)pythonでは子孫スコープからも参照できます。
pythona = 1 def func(): print(a) func() #=> 1さらに、ローカル変数は定義されているスコープが消滅しても、子孫スコープなどから参照されている限り消去されません。この性質を応用してインスタンス変数を持つクラスのようなものを作ることもできます。このクラスもどきをクロージャーと言います。
pythondef cls(): x = {} # インスタンス変数的振る舞いをする def a(): x['a'] = 1 def b(): x['b'] = 1 def g(): return x return a, b, g # xのスコープは関数呼び出し終了とともに消滅する a, b, g = cls() a(); b(); print(g()) #=> {'a': 1, 'b': 1}ローカル変数に見えるインスタンスメソッド
定義が見当たらないローカル変数への参照は、実は引数なしのインスタンスメソッド呼び出しかもしれません。本当によく出会います。
rubyclass C def hoge # インスタンスメソッド return "hoge" end def show fuga = "fuga" puts hoge # インスタンスメソッド呼び出し puts fuga # ローカル変数参照 end endさらに、クラスマクロのattr_accessor、attr_reader、attr_writerを使えば、ローカル変数に見えるインスタンスメソッドを簡単に作れます。変数の実体は、引数のシンボルに@を前置した名前のインスタンス変数です。
rubyclass C attr_accessor :hoge # インスタンス変数@hogeが実体 def initialize self.hoge = "hoge" # インスタンスメソッドhoge=を呼び出し end def show fuga = "fuga" # ローカル変数fugaを定義&初期化 puts hoge # インスタンスメソッドhogeを呼び出し puts fuga # ローカル変数fugaを参照 end end C.new.methods.include?(:hoge) #=> true C.new.methods.include?(:hoge=) #=> truepythonの場合は、インスタンスメソッド呼び出しにselfが付いていたり、関数呼び出しの括弧が省略できなかったりするので、簡単に見分けられます。それよりも、インスタンスメソッド呼び出しとクラスメソッド呼び出しを区別するのが大変です。
pythonclass C: def hoge(self): return "hoge" @classmethod def piyo(cls): return "piyo" def show(self): fuga = "fuga" print(self.hoge()) # インスタンスメソッド呼び出し print(fuga) # ローカル変数参照 print(self.piyo()) # クラスメソッド呼び出しローカル変数による上書き
(scivola様のコメントを元に追加しました)
先ほどの例でインスタンスメソッドhoge=を呼び出す際、selfをレシーバーとして明示しました。
ruby(再掲)class C attr_accessor :hoge def initialize self.hoge = "hoge" # ここ end ...これは、selfを明示しないとローカル変数hogeの定義として扱われるからです。
rubyclass C attr_accessor :hoge def initialize hoge = "hoge" # ローカル変数hogeの定義 end def show puts hoge end end C.new.show #=> nil同じことが、pythonでも起こり得ます。例えば、先ほど紹介したクラスもどきの場合、インスタンス変数もどきは更新できません。
pythondef cls(): x = {} # インスタンス変数的振る舞いをする def u(): x = 'updated' # 実はローカル変数xの定義 def g(): return x return u, g # xのスコープは関数呼び出し終了とともに消滅する u, g = cls() u(); print(g()) #=> {}pythonではselfを省略できないので、インスタンス変数の更新の際に間違うことはないでしょう。
pythonclass C: def __init__(self): self.hoge = "not updated" def wrong(self): hoge = "updated" # 間違いに気付き易い def correct(self): self.hoge = "updated" def show(self): #print(hoge) #=> error (name 'hoge' is not defined) print(self.hoge) c = C() c.wrong(); c.show(); #=> not updated c.correct(); c.show(); #=> updatedinclude先のインスタンス変数を参照
rubymodule M def show puts @message end end class C include M def initialize @message = "accessible" end end C.new.show #=> accessiblepythonでも似たことが出来ます。
pythonclass S: def show(self): print(self.message) class C(S): def __init__(self): self.message = "accessible" C().show() #=> accessible関数を変数に代入
rubyでは関数呼び出しの括弧を省略できます。そのため、関数を変数に代入することは出来ません。
rubydef func return "called" end a = func # 関数funcの呼び出し puts a #=> calledObject#methodインスタンスメソッドを使って、関数をMethodオブジェクトに変換すると、変数に代入できます。
rubydef func return "called" end a = method(:func) # Methodオブジェクトの代入 puts a #=> #<Method: main.func> puts a.call #=> called一方、pythonでは関数を変数に代入できます。
pythondef func(): return "called" a = func # 関数funcの代入 print(func) #=> <function func at 0x...>
- 投稿日:2020-01-16T13:00:42+09:00
random.randint(a,b) と np.random.randint(a,b) を入れ替えると分析結果が正反対になってしまった!
実は違っていた!random.randint(a,b) と np.random.randint(a,b)
Pythonでよく使われているライブラリでこんなことがあるのかとハマってしまった件。
次のGoogle Collaboratory で実行可能な単純なコードを見てもらいたい。
広く使われている一般的なライブラリを呼び出しているだけだし
式的には全く同じように見えるのですが、
出力結果が似ていて実は異なる結果になっていることを。We need some caution when using randint whether this function is called from random library or numpy library. The result will be very different !!
import random import numpy as np for i in range (500): print (np.random.randint(0,37)) for j in range (500): print (random.randint(0,37))numpyをつけて呼び出したrandomの場合は0~36しか出力されない。
一方でnumpyをつけずにrandomを呼び出した場合は0~37になってしまうのだ!なぜ気づいたかというと
以前、カジノで儲けられないかを検証した記事を投稿したのですが、
ランダム結果が違うのではないかとの指摘があり、
調査したところ
np.random.randint(a,b) と random.randint(a,b)
の分析結果が全く違うことが判明!正反対の結果になり( ; ; )(T.T)
普段から使われていそうなこんな単純な式で
全く異なる分析結果が生まれることになってしまう紛らわしいことってあるんだ!
注意喚起資料をネットで見たことがなかったのだが。皆さんも普段から使われているコードで少し先頭に何かついただけで挙動が変わってしまうということがあるかもしれない。いや、ライブラリ使っていると絶対にあるはず!
良い勉強になりました!元の記事:
https://qiita.com/mnoda/items/3a0d1f6e21b52bbf79d0#comment-904693840460457f4ae3
- 投稿日:2020-01-16T12:49:52+09:00
【Selenium】【VBS】ワンクリックでchromedriverを更新するスクリプト
この記事は、windows10でSelenium + GoogleChromeでスクライピングしている方に向けた記事です。
chromedriverの更新が面倒
気づいたら「オートメーションエラー」になるchromedriver。
「はいはい、『chromedriver』と検索して……あのサイトに行って……このフォルダに上書きして……」
というの単純な作業はvbsにしてワンクリックでできるようにしましょう。コードをメモ帳に貼り付けて.vbsで保存
★マークのchromedriver.exeのディレクトリをあなたのローカル環境に合わせて書き換えて保存してください。
保存した.vbsを実行すれば、使っているGoogleChromeのバージョンと同じマイナーバージョンを持つchromedriver.exeを自動でダウンロード&上書きします。'----------------------------------------------------------------------- ' Seleniumのchromedriver.exeを自動で更新するスクリプト ' 更新日:2020-01-16 ' ★SeleniumBasicやPython環境など、複数のChromedriverを一度に更新できるようにしました。 ' ★外部アプリからの呼び出しに際してメッセージポップアップをオフにできるようにしました。 '----------------------------------------------------------------------- Set fso = CreateObject("Scripting.FileSystemObject") Set objShell = WScript.CreateObject("WScript.Shell") Set objFile = WScript.CreateObject("Scripting.FileSystemObject") 'Seleniumが%AppData%内に設置されている環境向けにパス生成 If destDir = "" Then appdata = objShell.ExpandEnvironmentStrings("%APPDATA%") 'C:\Users\TEST\AppData\Roaming appdata = fso.GetParentFolderName(appdata) 'C:\Users\TEST\AppData appdata = appdata & "\Local\SeleniumBasic" 'C:\Users\TEST\AppData\Local\SeleniumBasic End If '------------------------------------------------------------- 'USER SETTING chromeDir = "C:\Program Files (x86)\Google\Chrome\Application" 'chrome.exeのあるディレクトリ(GoogleChromeのフォルダ) seleniumDirs = Array(appdata, "C:\Program Files\SeleniumBasic") '★chromedriver.exeのディレクトリ。複数可(Seleniumのフォルダ) msgbox_is = True '★ポップアップのオン・オフ(True or False) '------------------------------------------------------------- For Each seleniumDir In seleniumDirs If Dir(seleniumDir) <> "" Then version = chkVersion(chromeDir, seleniumDir, msgbox_is) Call chromedriverDL(version, seleniumDir, msgbox_is) End If Next WScript.Quit 0 '======================================================================= 'chromedriverをダウンロードする関数 'version : ダウンロードしたいバージョン。例)「78.0.3904.105」 'destDir : 新しいchromedriverを置くディレクトリ。 Sub chromedriverDL(version, destDir, msgbox_is) '例)「78.0.3904.105」= [メジャー].[マイナー].[ビルド].[リビジョン]どこまで一致させるか dots = Split(version, ".") version = Left(version, Len(version) - Len(dots(UBound(dots))) - 1) '"ビルドまで一致"指定:(互換性高。入手性低) version = Left(version, Len(version) - Len(dots(UBound(dots))) - 1) '"マイナーまで一致"指定:(互換性低。入手性高)※この行をコメントアウトで"ビルドまで一致"に変更。 Set httpReq = CreateObject("MSXML2.XMLHTTP") Set objStream = WScript.CreateObject("ADODB.Stream") Set objShell = WScript.CreateObject("WScript.Shell") Set fso = WScript.CreateObject("Scripting.FileSystemObject") Const zipName = "chromedriver_win32.zip" workDir = objShell.CurrentDirectory & "\" & zipName 'このvbsの場所を作業フォルダに httpReq.Open "GET", "https://chromedriver.storage.googleapis.com" httpReq.Send Do While httpReq.readyState < 4 WScript.sleep 100 Loop txts = InStr(httpReq.responseText, version) txte = InStr(txts, httpReq.responseText, "/chromedriver_linux64.zip</Key>") version = Mid(httpReq.responseText, txts, txte - txts) Url = "https://chromedriver.storage.googleapis.com/" & version & "/chromedriver_win32.zip" httpReq.Open "GET", Url, False httpReq.Send objStream.Open objStream.Type = 1 objStream.Write httpReq.responseBody objStream.SaveToFile workDir, 2 objStream.Close Call unzip(workDir, destDir) fso.DeleteFile workDir Set objStream = Nothing Set htmlDoc = Nothing Set httpReq = Nothing '---------------------------------------------- '更新した履歴(バージョン)をテキストに記録する Filename = destDir & "\version.txt" Set tso = fso.OpenTextFile(Filename, 2, True) tso.Write (version) tso.Close '---------------------------------------------- If msgbox_is = True Then MsgBox "updated chromedriver : " & version End Sub '======================================================================= '.zipファイルを解凍する関数 'sourcePath : 解凍したいzipのファイルパス 'destPath : 展開したファイルを置くディレクトリ Sub unzip(sourcePath, destDir) Const FOF_SILENT = &H4 '進捗ダイアログを表示しない。 Const FOF_NOCONFIRMATION = &H10 '上書き確認ダイアログを表示しない([すべて上書き]と同じ)。 Set objShell = CreateObject("Shell.Application") Set FilesInZip = objShell.Namespace(sourcePath).items Set objFolder = objShell.Namespace(destDir) '解凍 If (Not objFolder Is Nothing) Then objFolder.CopyHere FilesInZip, FOF_NOCONFIRMATION + FOF_SILENT End If End Sub '======================================================================= 'インストールされているGoogleChromeのバージョンをチェックする 'chromeDir : chrome.exeのあるディレクトリ。(例)"C:\Program Files (x86)\Google\Chrome\Application" 'destDir : 新しいchromedriverを置くディレクトリ。 Function chkVersion(chromeDir, destDir, msgbox_is) '------------------------------------------------------------- Set fso = CreateObject("Scripting.FileSystemObject") Set folder = fso.getFolder(chromeDir) 'サブフォルダ一覧 version = "" For Each subfolder In folder.subfolders dots = Split(subfolder.Name, ".") If UBound(dots) > 2 Then version = subfolder.Name Exit For End If Next 'エラーチェック If version = "" Then MsgBox "現在のChromeのversionが取得できませんでした。" & vbCrLf & "終了します。" WScript.Quit -1 End If '------------------------------------------------------------- 'このvbsによって最近アップデートしたchromedriverのバージョンと 'このPCのGoogleChromeのバージョンを比較して、そもそもアップデートが必要なのか判断する Filename = destDir & "\version.txt" 'C:\Users\TEST\AppData\Local\SeleniumBasic\version.txt If objFile.FileExists(Filename) Then Set fp = fso.OpenTextFile(Filename, 1) curVersion = fp.ReadAll fp.Close 'メジャー.マイナー.ビルド.リビジョン dots = Split(curVersion, ".") If UBound(dots) > 2 Then buildver = Left(curVersion, Len(curVersion) - Len(dots(UBound(dots))) - 1) minorver = Left(buildver, Len(buildver) - Len(dots(UBound(dots) - 1)) - 1) If InStr(version, buildver) > 0 Then If msgbox_is = True Then MsgBox "ビルドバージョンまで同じです" & vbCrLf & "アップデートの必要はありません" WScript.Quit 0 ElseIf InStr(version, minorver) > 0 Then If msgbox_is = True Then MsgBox "マイナーバージョンまで同じです" & vbCrLf & "アップデートの必要はありません" WScript.Quit 0 Else If msgbox_is = True Then MsgBox "最適なChromedriverをダウンロードする必要があります:" & version End If End If Else Set tso = fso.OpenTextFile(Filename, 2, True) tso.Write ("0.0.0.0") tso.Close End If '------------------------------------------------------------- chkVersion = version End Function '======================================================================= 'DIR関数(パスの存在判定をする:VBAにあってVBSにない関数) 'path : 存在やファイル名をチェックしたいパス Function Dir(path) Dim fso Set fso = CreateObject("Scripting.FileSystemObject") If fso.FolderExists(path) Then Dir = path Else Dir = "" End If Set fso = Nothing End Function「ワンクリックでchromedriverを更新するスクリプト」の記事は以上です。
- 投稿日:2020-01-16T12:18:54+09:00
関数内で例外が発生した場合、呼び出し元へ伝わる1
1def test_exception(num): print(1) answer = 100 / num return answer print(2) print('start') try: test_exception(1) print(4) except ZeroDivisionError as e: print(3) print(e) finally: print('end')1の実行結果start 1 4 endprint('start')を
最初に実行。次に、
tryブロックを実行する。
tryブロック1行目のtest_exception関数に引数1で入る。
なので、
print(1)を実行し、
answer = 100
となり100を返す。
retrunしているので、
その下のprint(2)は実行されない点に注意。
tryブロックのtest_exception関数が終わったので、
その続きでprint(4)を実行。ZeroDivisionErrorは発生していないので、
exceptブロックは実行せず、とばす。最後にfinallyブロックを実行する。
test_exception関数の引数を0にすると、
2def test_exception(num): print(1) answer = 100 / num return answer print(2) print('start') try: test_exception(0) print(4) except ZeroDivisionError as e: print(3) print(e) finally: print('end')2の実行結果start 1 3 division by zero endprint('start')を
最初に実行。次に、
tryブロックを実行する。
tryブロック1行目のtest_exception関数に引数0で入る。
なので、
print(1)を実行し、
answerが100を0で割る事になりエラー発生。
この場合も、
retrunしているので、
その下のprint(2)は実行されない点に注意。
tryブロックのtest_exception関数でエラーが発生した為、
その続きは実行されない。ZeroDivisionErrorが発生しているので、
exceptブロックを実行する。最後にfinallyブロックを実行する。
- 投稿日:2020-01-16T12:17:04+09:00
【Python】MotoでモックしたAWSリソースをpytestフィクスチャ化する
motoとは AWSサービスをモック化できる非常に便利なツール。
これをpytestのフィクスチャと組み合わせれば
conftest.pyのsetUpで自動的にAWSサービスをモックできる。参考 - Issue with Moto and creating pytest fixture #620
SQSの例
- SQSのモックキューを作成
- モックキューにメッセージ送信
- モックキューのメッセージを検証
import boto3 import pytest from moto import mock_sqs import json @pytest.fixture() def mock_fixture(): """キューを作成してメッセージを1件送信する""" mock = mock_sqs() mock.start() # モックの開始 client = boto3.client('sqs') # モックキューを作成 response = client.create_queue(QueueName='example') queue_url = response['QueueUrl'] # メッセージを送信 client.send_message(QueueUrl=queue_url, MessageBody=json.dumps({'msg': 'hello'})) yield client, queue_url # ここでテストに遷移する mock.stop() # モックの終了 def test_moto_sqs(mock_fixture): """フィクスチャのテスト""" client, queue_url = mock_fixture messages = client.receive_message(QueueUrl=queue_url)['Messages'] assert messages[0]['Body'] == '{"msg": "hello"}'
mock.start()、mock.stop()そしてyieldによるフィクスチャ生成がポイント。
yieldではなくreturnを使用するとティアダウン処理(上記のmock.stop())は実行されない。
- 投稿日:2020-01-16T12:09:19+09:00
Python環境構築(Anaconda + VSCode) @ Windows10 【2020年1月版】
背景
Anaconda + VS Code でPython環境を作るときに、最新の設定方法が出てこなくて困ったので、今からやる方のために自分のメモを公開します。
2017年頃にVS Codeの仕様変更があったみたいですね。古い解説文を読むときには注意が必要です。参考にした記事:
@Atupon0302さん : Windows10環境にAnaconda+Visual Studio CodeでPython環境を構築【2017年9月】この記事で書くこと
この記事では、Windows10 パソコンにAnacondaとVS CodeでPython環境を構築し、簡単なプログラムのビルドとデバッグができるところまでの手順を書きます。
Python導入の目的は、機械学習で遊ぶことですので、機械学習用のPythonライブラリを一気に入れられるAnacondaを使います。
(以前、機械学習関連のライブラリを個別に入れたらものすごく苦労したの。。。)前提環境
- Windows10 Enterprise
- Anaconda 2019.10
- VS Code 1.41.1
- VS Code Python Extention 2020.1.58038
手順
Anacondaを入れる
本体のインストール
AnacondaページのDownloadリンクからWindows向けモジュールを入手します。Pythonバージョンは3.xを選択します。
インストーラの内容はすべてデフォルトで、Nextボタンを押すだけです。
私は「Anaconda 2019.10 for Windows Installer」でした。
動作確認
スタートメニューからAnaconda3>Anaconda Promptを起動します。
Anaconda Promptで以下を実行して、バージョン番号が返ってきたらOK。conda -V python -V仮想環境の作成
実行環境のライブラリ構成を保持するために、自分用の仮想環境を作っておきます。
デフォルトではbase環境があり、すでにnumpyなどの便利なライブラリが入っているので、baseをコピーして新しい環境を作成します。
--cloneオプションを使わない場合はまっさらな新環境が作れます。ここに自分で好きなライブラリを追加していきます。(後述)# py37環境を作成(baseを複製する場合) conda create -n py37 --clone base # py37環境を作成(pythonのみ入れて作成し、必要なライブラリはあとで追加する場合) conda create -n py37 python=3.7作成した環境を確認します。
# 環境一覧を表示 conda info -e有効になっている環境に * がついています。現在はデフォルトのbase環境が有効です。
(base) C:\Users\XXXX>conda info -e # conda environments: # py37 C:\Users\XXXX\.conda\envs\py37 base * C:\Users\XXXX\Anaconda3新しい環境にスイッチするには
conda activateコマンド。# py37環境を有効にする conda activate py37成功すると、プロンプトに環境名(py37)がつく
(base) C:\Users\XXXX>activate py37 (py37) C:\Users\XXXX>その環境に入っているライブラリの表示は
conda list# numpyライブラリのバージョンを見る conda list numpy(py37) C:\Users\XXXX>conda list numpy # packages in environment at C:\Users\XXXX\Anaconda3\envs\py37: # # Name Version Build Channel numpy 1.16.5 py37h19fb1c0_0 numpy-base 1.16.5 py37hc3f5095_0 numpydoc 0.9.1 py_0ライブラリの追加が必要な場合は、
conda searchconda installで追加する。# djangoライブラリを探す場合 conda search django # djangoライブラリを追加する場合 conda install django環境から抜けるには、
conda deactivateコマンド。
(コマンドがdeactivateとなっている説明もありますが、現在非推奨なのでconda deactivateにします。)# 環境から抜ける conda deactivatecondaコマンドは、Pythonで提供されているPIPコマンドみたいに使います。Anaconda環境では、
pipではなくcondaコマンドを使ってパッケージ管理を行います。Pythonのパス
上記のように、自分の作業に合わせて仮想環境を作って作業するので、WindowsのPATHの設定は行いません。(コントロールパネルから設定するアレ)
VS Codeを入れる
本体のインストール
vscodeページのDownloadリンクからWindows向けモジュールをとってきて入れます。
インストーラの内容はデフォルトで入れます。
動作確認
スタートメニューからVisual Studio Code を起動します。以下VS Codeと記述します。
セットアップ:Pythonをビルド&デバッグできるようにする
- Python拡張を入れる VS Codeのツールバーの拡張ボタンをクリックして、「Python」で検索し、Python拡張(Python extention for Visual Studio Code)をいれます。
※画像のバージョンでは問題がでたので、最終的にPython Extention 2020.1.58038をいれました。
- パス設定をする VS Codeの、File>Preferences>Settingsで設定画面を開く。
検索キーに「python.pythonpath」と入れて、Pythonのパスを設定。
値は、Anaconda上でconda info -eと入力した値を参考にします。
C:\Users\XXXX\Anaconda3\envs\py37\python.exe検索キーに「python.condapath」と入れて、Condaコマンドのパスも設定。
値はconda.exeがあるディレクトリ名を指定します。(Scripts)
C:\Users\XXXX\Anaconda3\Scripts\
- ビルド用のタスクを作成する
適当な作業用フォルダを作成し、test.pyを書きます。
このとき、作業用フォルダがAnacondaの仮想環境の下にあると、後述のデバッグ実行でブレークポイントが使えなくなります。
VS Codeで開発するときは、Anacondaの仮想環境とは別の開発フォルダが必要です(せっかく環境を分けたのに、ちょっと面倒、、、)参考:VS CodeでPython仮想環境のデバッグ実行時にブレークポイントで止まらない問題
以下は
c:\dev\pydevにて作業しています。test.pyprint("foo") print("bar") print("ふがふが")VS Codeでtest.pyを開いた状態で、「Ctrl + Shift + B」(ビルドタスクの実行コマンド)を実行すると、タスクがないという警告メッセージが表示されます。
メッセージをクリックすると、テンプレートからタスクを作成するというメッセージが表示されるのでさらにクリックし、テンプレート種別から「Others」を選択するとタスク設定ファイル(tasks.json)が作成されます。
tasks.jsonを以下のように編集し保存します。
ポイントは、commandに、settings.jsonで指定したPythonのパスを書くことです。tasks.json{ // See https://go.microsoft.com/fwlink/?LinkId=733558 // for the documentation about the tasks.json format "version": "2.0.0", "tasks": [ { "label": "python build", "type": "shell", "command": "${config:python.pythonPath}", "args": ["${file}"], "group": { "kind": "build", "isDefault": true } } ] }
- ビルドする
「Ctrl + Shift + B」
task.jsonを保存したのち、test.pyを開いた状態で、「Ctrl + Shift + B」(ビルドタスクの実行コマンド)を実行すると、コンソールに実行結果が表示されます。
- デバッグする
「F5」
VS Codeでtest.pyを開いた状態で、「F5」(ビルドタスクの実行コマンド)を実行するとデバッグモードで実行されます。
ブレークポイントを置くと、黄色くハイライトされ、ステップ実行が可能になります。
はまったところ
- condaのエラーがでる。
Python Extentionの最新(2020.1) を使っていたのに、PythonExtention 2019.12版を使うとcondaが見つからないエラーが出るので2020.1を使おうという問題が発生した。Python Extentionを2020.1.57204から2020.1.58038に更新したら消えたけどこれでいいのかな?
参考リンク








- 投稿日:2020-01-16T10:29:05+09:00
AtCoder Beginner Contest 051 過去問復習
所要時間
感想
今回は意外と早く解けました。
DPやグラフなどの典型問題は解けるようになってきましたが、実験して把握する問題とか数列の問題とかが苦手なのかもしれません。A問題
綺麗にかけたと思ったらreplaceで良いことに気づいた…
answerA.pyprint(" ".join(input().split(",")))answerA_better.pyprint(input().replace(',',' '))B問題
O($k^2$)でxとyを決めていけば良い。
answerB.pyk,s=map(int,input().split()) cnt=0 for i in range(k+1): for j in range(k+1): if 0<=s-i-j<=k: cnt+=1 print(cnt)C問題
最短でたどり着ける経路と少し遠回りする経路の二つを考えれば良いだけ。それぞれのPathは後からつないで出力する。
answerC.pysx,sy,tx,ty=map(int,input().split()) path1=(tx-sx)*"R"+(ty-sy)*"U" path2=(tx-sx)*"L"+(ty-sy)*"D" path3="D"+(tx-sx+1)*"R"+(ty-sy+1)*"U"+"L" path4="U"+(tx-sx+1)*"L"+(ty-sy+1)*"D"+"R" print(path1+path2+path3+path4)D問題
すぐに思いつけてよかったです。こういう典型問題を確実にしていきたいです。
以下、解説を簡略化した説明になります。詳しくは解説を参照してください。
まず、edge(i,j)を頂点iと頂点jを結ぶ辺のコスト、dist(i,j)を頂点iから頂点jへの最短距離であるとします。ここで、ある辺i→jが頂点sから頂点tまでの最短経路に含まれる場合を考えます。この時、以下のような等式が成り立つことがわかります。$$dist(s,t)=dist(s,i)+edge(i,j)+dist(j,t)$$つまり、この等式を満たすような最短経路が存在しない場合は辺i→jはどの最短経路にも含まれないと言えます。従って、最短経路をWF法またはダイクストラ法で求めた際に、dist(i,j)がedge(i,j)ではない場合は辺i→jはどの最短経路にも含まれないと言えます。
以上より、WF法で最短経路を求めた後にそれぞれの辺i→jについてedge(i,j)$\neq$dist(i,j)であるものをカウントしていくことで、以下のようなコードになります。answerD.pyn,m=map(int,input().split()) inf=100000000 wf=[[inf]*n for i in range(n)] wf_sub=[[inf]*n for i in range(n)] for i in range(n): wf[i][i]=0 wf_sub[i][i]=0 for i in range(m): a,b,c=map(int,input().split()) wf[a-1][b-1]=c wf_sub[a-1][b-1]=c wf[b-1][a-1]=c wf_sub[b-1][a-1]=c for k in range(n): for i in range(n): for j in range(n): wf[i][j]=min(wf[i][j],wf[i][k]+wf[k][j]) cnt=0 for i in range(n): for j in range(n): if wf_sub[i][j]!=0 and wf_sub[i][j]!=inf: if wf[i][j]!=wf_sub[i][j]: cnt+=1 print(cnt//2)

- 投稿日:2020-01-16T09:46:09+09:00
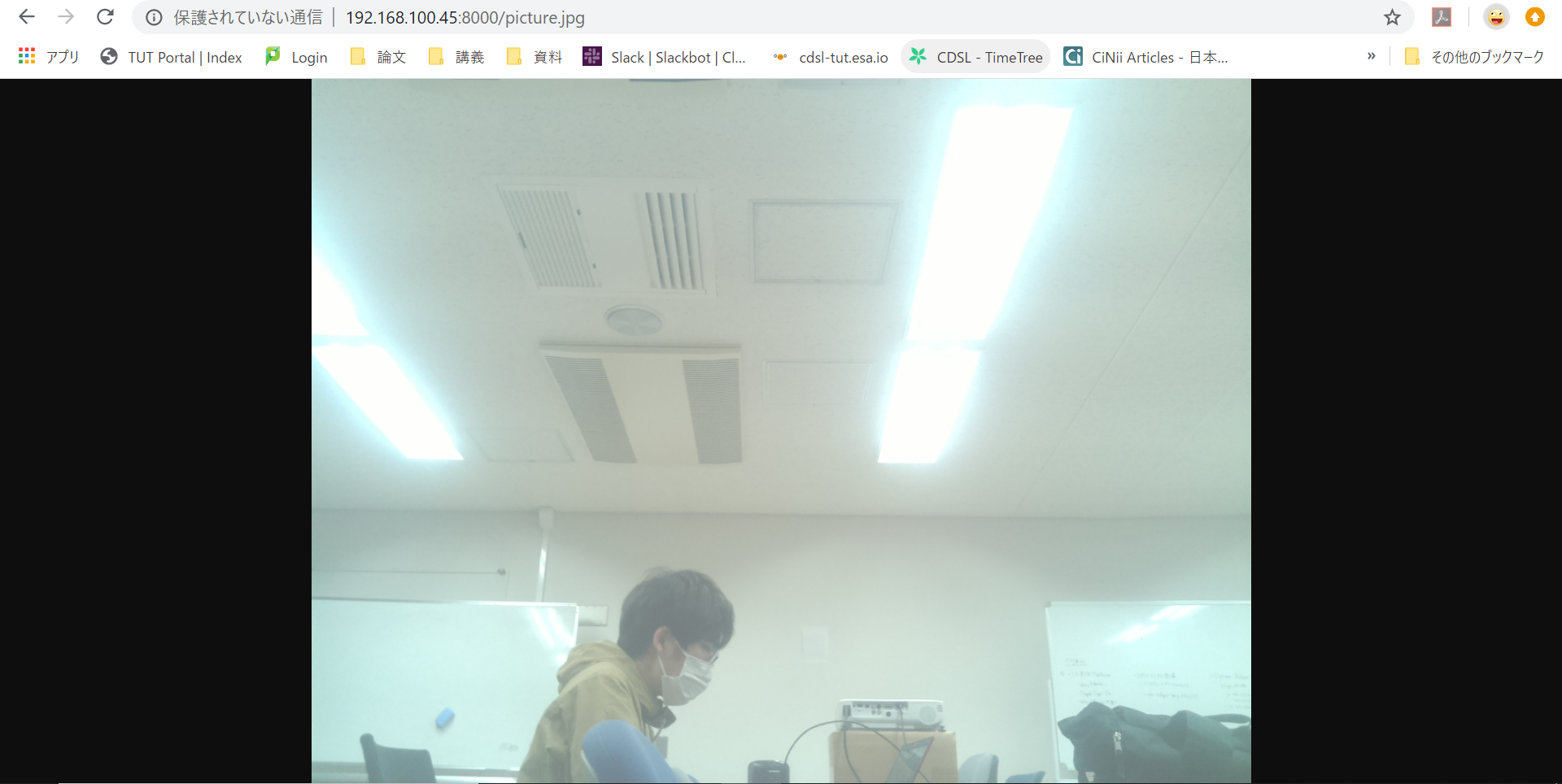
Raspberry Piを用いた室内監視
はじめに
Qiita初投稿です.よろしくお願いします.
提案
RaspberryPiとセンサで安価な監視システムを作りたいと思いました。具体的には、研究室内にRaspBerryPi Zero,RaspBerryPi camera,人感センサ(HC-SR501)を設置し、人を検知したらカメラで撮影し,その画像をSlackに送信する監視システムです(未完成).
使用した機材
・RaspberryPi zero
・RaspberryPi camera
・HC-SR501人体赤外線感応モジュール
・ジャンパーワイヤー(メス・メス) 3本
実装
人感センサが人を検知したら、RaspberryPi cameraで撮影するプログラムは下記の通りです。
monitoring.pyimport time import picamera import RPi.GPIO as GPIO INTERVAL = 5 SLEEPTIME = 1 GPIO_PIN = 18 GPIO.setmode(GPIO.BCM) GPIO.setup(GPIO_PIN,GPIO.IN) if __name__ == '__main__': try: print("処理キャンセルはCTRL+C") while True: if(GPIO.input(GPIO_PIN) == GPIO.HIGH): with picamera.PiCamera() as camera camera.resolution = (1024,768) camera.brightness = 70 camera.capture('picture.jpg') else: time.sleep(INTERVAL) except KeyboardInterrupt: print("全処理終了") finally: GPIO.cleanup()実行結果
ローカルのWebサーバーを建て、画像が取得できていることを確認できました。
おわりに
現状、このシステムはSlackにデータを送信する処理が実装できていない為、未完成です。実装後、他の監視システムと比較し、このシステムの有用性を追求していきたいです。

- 投稿日:2020-01-16T09:16:48+09:00
Pythonで、デザインパターン「Adapter」を学ぶ
GoFのデザインパターンを学習する素材として、書籍「増補改訂版Java言語で学ぶデザインパターン入門」が参考になるみたいですね。
ただ、取り上げられている実例は、JAVAベースのため、自分の理解を深めるためにも、Pythonで同等のプラクティスに挑んでみました。
■ Adapter(アダプター・パターン)
Adapterパターン(アダプター・パターン)とは、GoF (Gang of Four; 4人のギャングたち) によって定義されたデザインパターンの1つである。Adapterパターンを用いると、既存のクラスに対して修正を加えることなく、インタフェースを変更することができる。Adapterパターンを実現するための手法として"継承を利用した手法"と"委譲を利用した手法"が存在する。
□ 継承を利用したAdapter
継承を利用したAdapterは、利用したいクラスのサブクラスを作成し、そのサブクラスに対して必要なインタフェースを実装することで実現される。
□ 委譲を利用したAdapter
委譲を利用したAdapterは、利用したいクラスのインスタンスを生成し、そのインスタンスを他クラスから利用することで実現される。
(以上、ウィキペディア(Wikipedia)より引用)■ "Adapter"のサンプルプログラム
実際に、Adapterパターンを活用したサンプルプログラムを動かしてみて、次のような動作の様子を確認したいと思います。
- 文字列を、カッコでくくって表示する
- 文字列の前後に、*印をつけて表示する
$ python Main.py (Hello) *Hello*■ サンプルプログラムの詳細
Gitリポジトリにも、同様のコードをアップしています。
https://github.com/ttsubo/study_of_design_pattern/tree/master/Adapter
- ディレクトリ構成
. ├── Main.py └── adapter ├── __init__.py ├── banner.py ├── print.py └── print_banner.py(1) Target(対象)の役
Target役は、インスタンスの振る舞いに関わるインタフェースを定めます。
サンプルプログラムでは、adapter/print.pyfrom abc import ABCMeta, abstractmethod class Print(metaclass=ABCMeta): @abstractmethod def printWeak(self): pass @abstractmethod def printStrng(self): pass(2) Client(依頼者)の役
Target役のメソッドを使って、仕事をする役です。
サンプルプログラムでは、startMainメソッドが、この役を努めます。Main.pyfrom adapter.print_banner import PrintBanner def startMain(): p = PrintBanner("Hello") p.printWeak() p.printStrng() if __name__ == '__main__': startMain()(3) Adaptee(適合される側)の役
Adapter
役のなかで実際に動作するメソッドを、ここで実装します。Banner`クラスが、この役を努めます。
サンプルプログラムでは、adapter/banner.pyclass Banner(object): def __init__(self, string): self.__string = string def showWithParen(self): print("({0})".format(self.__string)) def showWithAster(self): print("*{0}*".format(self.__string))(4) Adapter(適合する側)の役
Adapter役は、Target役のインタフェースを実装しているクラスです。
サンプルプログラムでは、PrintBannerクラスが、この役を努めます。
Adapterパターンを実現するための手法として、次の二つの手法が存在します。
- 継承を利用した手法
- 委譲を利用した手法
□ 継承を利用したサンプルプログラム
adapter/print_banner.pyfrom adapter.banner import Banner from adapter.print import Print class PrintBanner(Banner, Print): def __init__(self, string): super(PrintBanner, self).__init__(string) def printWeak(self): self.showWithParen() def printStrng(self): self.showWithAster()□ 委譲を利用したサンプルプログラム
adapter/print_banner.pyfrom adapter.banner import Banner from adapter.print import Print class PrintBanner(Print): def __init__(self, string): self.__banner = Banner(string) def printWeak(self): self.__banner.showWithParen() def printStrng(self): self.__banner.showWithAster()■ 参考URL

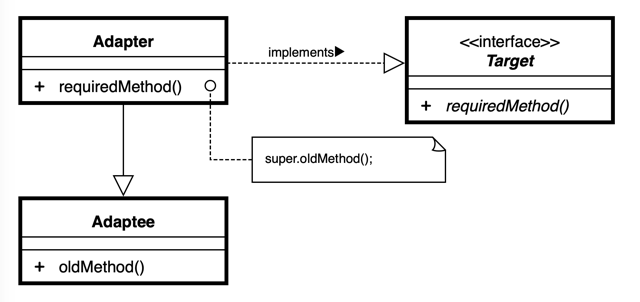
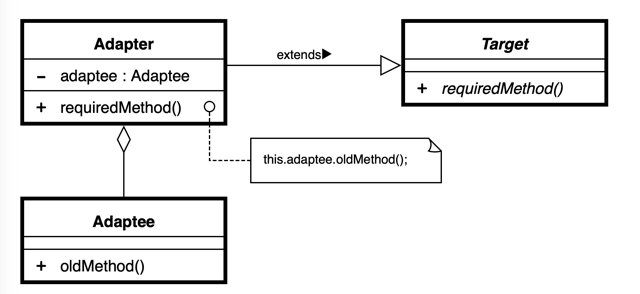
- 投稿日:2020-01-16T07:59:07+09:00
WEB API利用時のプロキシ対策
PythonのRequestsモジュールは環境変数のプロキシを使用しています。なので環境変数として設定してやりましょう。
※ここで設定するプロキシはプログラム内でのみ有効です。以下の関数をmainの最初に呼んでやることでrequestsでプロキシを抜けられるようになります。
import os # Proxy setting def proxy_setting(): proxy_user = 'proxy_user' proxy_pass = 'proxy_pass' proxy_url = '******:8080' os.environ["http_proxy"] = 'http://' + proxy_user + ':' + proxy_pass + '@' + proxy_url os.environ["https_proxy"] = 'http://' + proxy_user + ':' + proxy_pass + '@' + proxy_url
- 投稿日:2020-01-16T07:59:07+09:00
スクレイピング時のプロキシ対策
PythonのRequestsモジュールは環境変数のプロキシを使用しています。なので環境変数として設定してやりましょう。APIの利用時も同様です。
※ここで設定するプロキシはプログラム内でのみ有効です。以下の関数をmainの最初に呼んでやることでrequestsでプロキシを抜けられるようになります。
import os # Proxy setting def proxy_setting(): proxy_user = 'proxy_user' proxy_pass = 'proxy_pass' proxy_url = 'http://******:8080' os.environ["http_proxy"] = 'http://' + proxy_user + ':' + proxy_pass + proxy_url os.environ["https_proxy"] = 'http://' + proxy_user + ':' + proxy_pass + proxy_url
- 投稿日:2020-01-16T06:08:05+09:00
言語処理100本ノック-88:類似度の高い単語10件
言語処理100本ノック 2015の88本目「類似度の高い単語10件」の記録です。
すべての単語から似たやつを抜き出します。これまた、自分のメールボックスや議事録等からやってみたい処理ですね。
技術的には前回の内容とほぼ同じです。参考リンク
リンク 備考 088.類似度の高い単語10件.ipynb 回答プログラムのGitHubリンク 素人の言語処理100本ノック:88 言語処理100本ノックで常にお世話になっています 環境
種類 バージョン 内容 OS Ubuntu18.04.01 LTS 仮想で動かしています pyenv 1.2.15 複数Python環境を使うことがあるのでpyenv使っています Python 3.6.9 pyenv上でpython3.6.9を使っています
3.7や3.8系を使っていないことに深い理由はありません
パッケージはvenvを使って管理しています上記環境で、以下のPython追加パッケージを使っています。通常のpipでインストールするだけです。
種類 バージョン numpy 1.17.4 pandas 0.25.3 課題
第9章: ベクトル空間法 (I)
enwiki-20150112-400-r10-105752.txt.bz2は,2015年1月12日時点の英語のWikipedia記事のうち,約400語以上で構成される記事の中から,ランダムに1/10サンプリングした105,752記事のテキストをbzip2形式で圧縮したものである.このテキストをコーパスとして,単語の意味を表すベクトル(分散表現)を学習したい.第9章の前半では,コーパスから作成した単語文脈共起行列に主成分分析を適用し,単語ベクトルを学習する過程を,いくつかの処理に分けて実装する.第9章の後半では,学習で得られた単語ベクトル(300次元)を用い,単語の類似度計算やアナロジー(類推)を行う.
なお,問題83を素直に実装すると,大量(約7GB)の主記憶が必要になる. メモリが不足する場合は,処理を工夫するか,1/100サンプリングのコーパスenwiki-20150112-400-r100-10576.txt.bz2を用いよ.
今回は「1/100サンプリングのコーパスenwiki-20150112-400-r100-10576.txt.bz2」を使っています。
88. 類似度の高い単語10件
85で得た単語の意味ベクトルを読み込み,"England"とコサイン類似度が高い10語と,その類似度を出力せよ.
回答
回答プログラム 088.類似度の高い単語10件.ipynb
import numpy as np import pandas as pd # 保存時に引数を指定しなかったので'arr_0'に格納されている matrix_x300 = np.load('085.matrix_x300.npz')['arr_0'] print('matrix_x300 Shape:', matrix_x300.shape) # 'Englandの単語ベクトルを読み込み、ノルムも計算 v1 = matrix_x300[group_t.index.get_loc('England')] v1_norm = np.linalg.norm(v1) # コサイン類似度計算 def get_cos_similarity(v2): # ベクトルが全てゼロの場合は-1を返す if np.count_nonzero(v2) == 0: return -1 else: return np.dot(v1, v2) / (v1_norm * np.linalg.norm(v2)) cos_sim = [get_cos_similarity(matrix_x300[i]) for i in range(len(group_t))] print('Cosign Similarity result length:', len(cos_sim)) # インデックスを残してソート cos_sim_sorted = np.argsort(cos_sim) # 昇順でソートされた配列の1番最後から-11(-12)までを1件ずつ出力(トップはEngland自身) for index in cos_sim_sorted[:-12:-1]: print('{}\t{}'.format(group_t.index[index], cos_sim[index]))回答解説
コサイン類似度計算部分を関数にしました。
count_nonzero関数で判定して、ベクトルがすべてゼロの場合は-1を返すようにしています。# コサイン類似度計算 def get_cos_similarity(v2): # ベクトルが全てゼロの場合は-1を返す if np.count_nonzero(v2) == 0: return -1 else: return np.dot(v1, v2) / (v1_norm * np.linalg.norm(v2))配列に対して内包表記で一気に結果を出しています。
cos_sim = [get_cos_similarity(matrix_x300[i]) for i in range(len(group_t))]上記の計算に対して、numpyだとこっちの
apply_along_axisを使った方が速いかとも思いましたが、むしろ遅かったので非採用です。cos_sim = np.apply_along_axis(get_cos_similarity, 1, matrix_x300)最後の出力結果です。ScotlandやItalyなどが上位にいます。
Japanもいるのが意外です。島国だからなのでしょうか。England 1.0000000000000002 Scotland 0.6364961613062289 Italy 0.6033905306935802 Wales 0.5961887337227456 Australia 0.5953277272306978 Spain 0.5752511915429617 Japan 0.5611603300967408 France 0.5547284075334182 Germany 0.5539239745925412 United_Kingdom 0.5225684232409136 Cheshire 0.5125286144779688