- 投稿日:2020-01-16T23:57:06+09:00
【初心者】AWS Elemental MediaLive + MediaPackage を使ってみる(PCからのライブ配信)
目的
- 「3日間で使い捨て!イベント用有料ライブ配信サービスの構築」 (HTB三浦さんによる、商用ライブ配信環境を1カ月で作った話)を見てすごいなと思い、配信の部分だけでもどんなものか勉強したくなったため。
やったこと
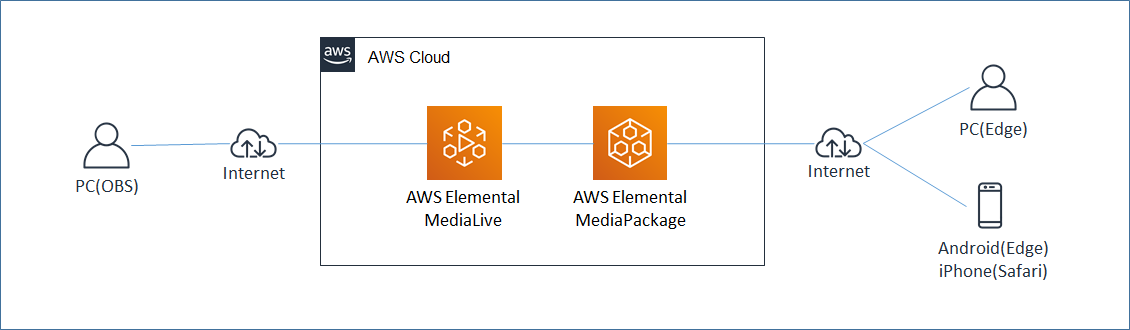
- PCのWEBカメラの動画を動画配信ソフト(OBS Studio)を使ってAWS Elemental MediaLive に送信する。
- AWS Elemental MediaLive から AWS Elemental MediaPackage へデータを連携し、MediaPackageからライブ動画を配信する。
- PC(Edge)、Android(Edge)、iPhone(Safari)でライブ動画を閲覧する。
- 何も設定をいじってない状態で、どのくらい配信時の遅延が発生するのか確認する。
構成図
作業手順
- Developers.IOのブログ「 OBSとAWS Elemental MediaLiveでライブ配信をしてみた 」にほとんど網羅されているが、気になった点等含め自分なりに整理する。
AWS Elemental MediaPackage の設定
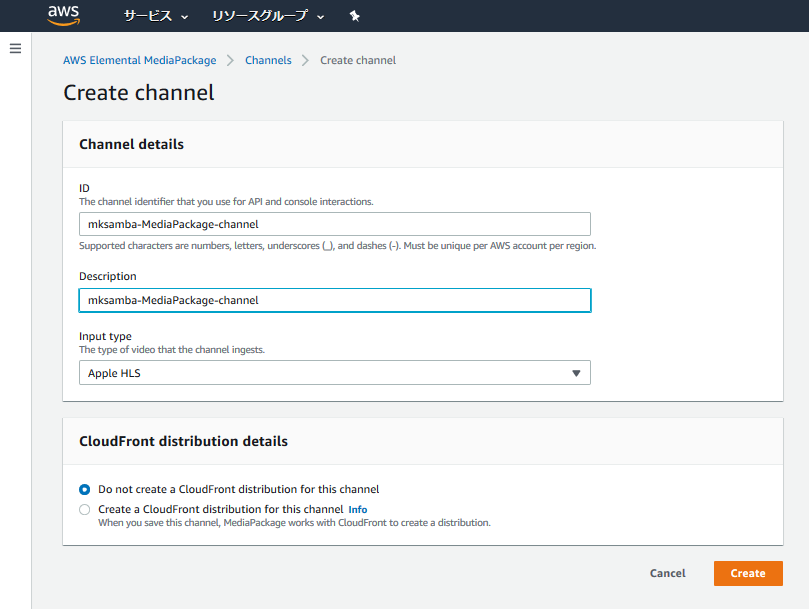
- Channelを作成する。InputTypeは、2020/1現在、「Apple HLS」固定になっている。今回はCloudFrontは作成しない。
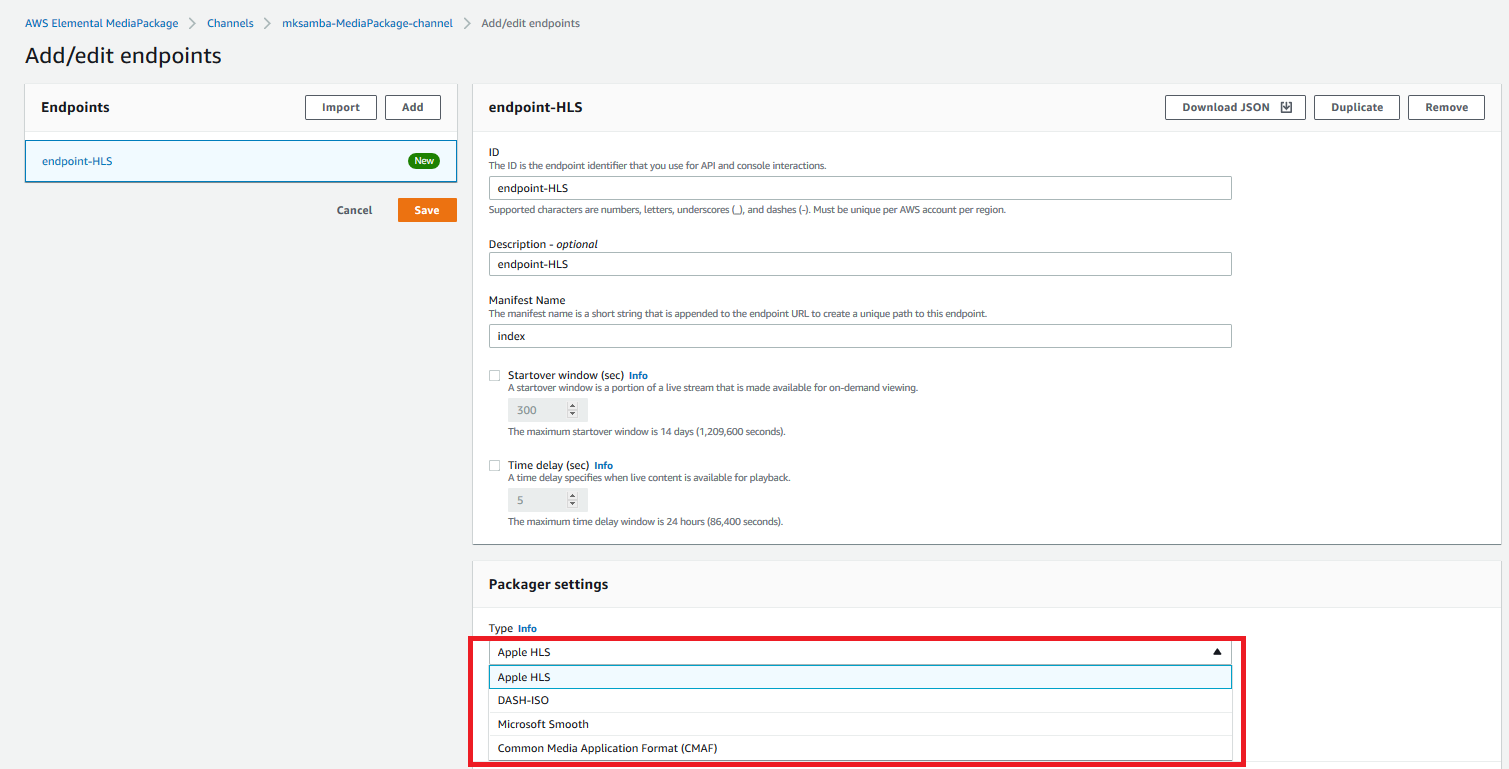
- Endpoint (動画を閲覧するためのEdgeやSafari等のPlayerの接続先)を追加する。2020/1現在、「Apple HLS」「DASH-ISO」「Microsoft Smooth」「Common Media Application Format(CMAF)」が選択可能。今回は「Apple HLS」と「DASH-ISO」のEndpointを作成しておく。
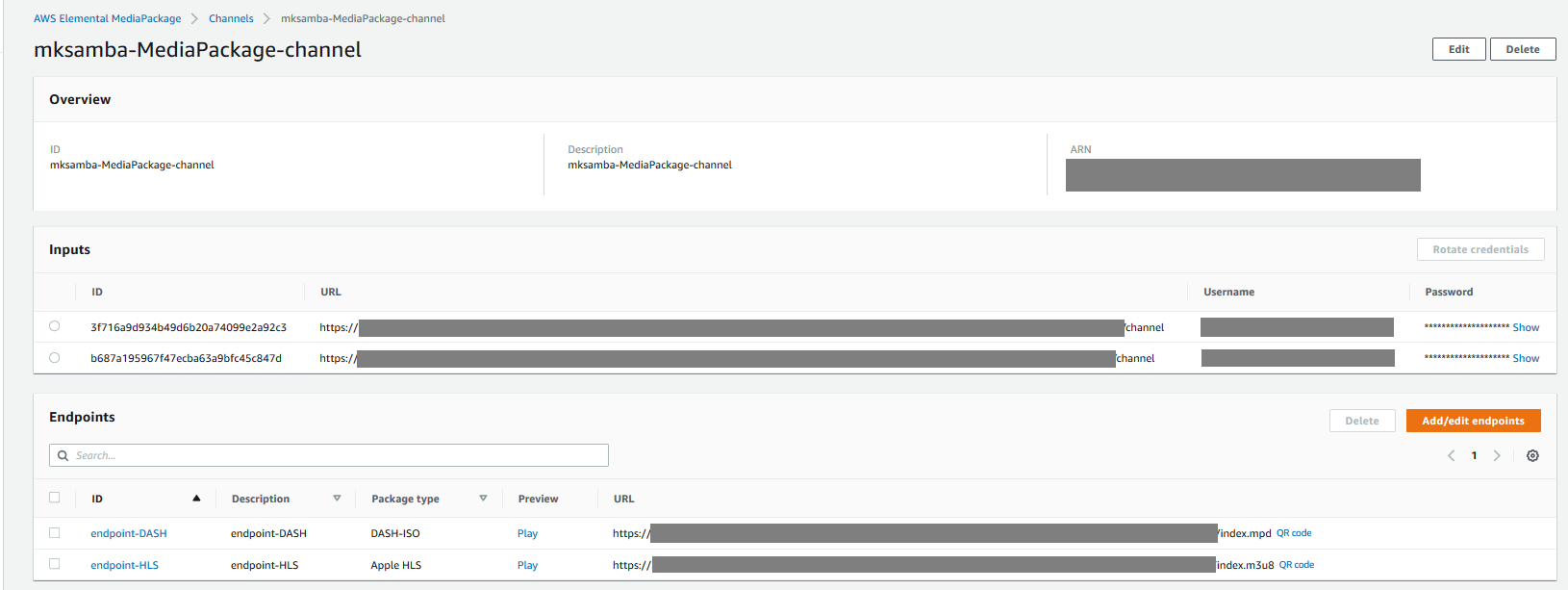
- Endpointを追加すると、接続用のURLが作成される。
AWS Elemental MediaLive の設定
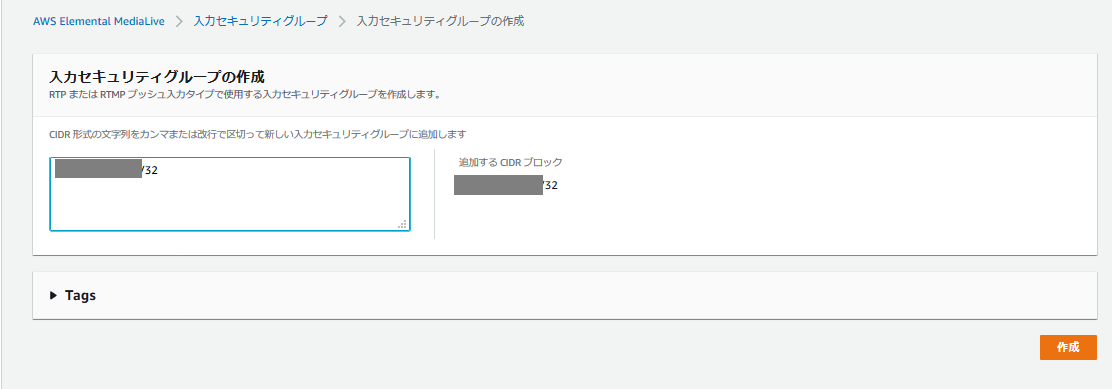
- 「入力セキュリティグループ」を作成する。ライブ動画の送信元として許可するIPアドレスを設定する。
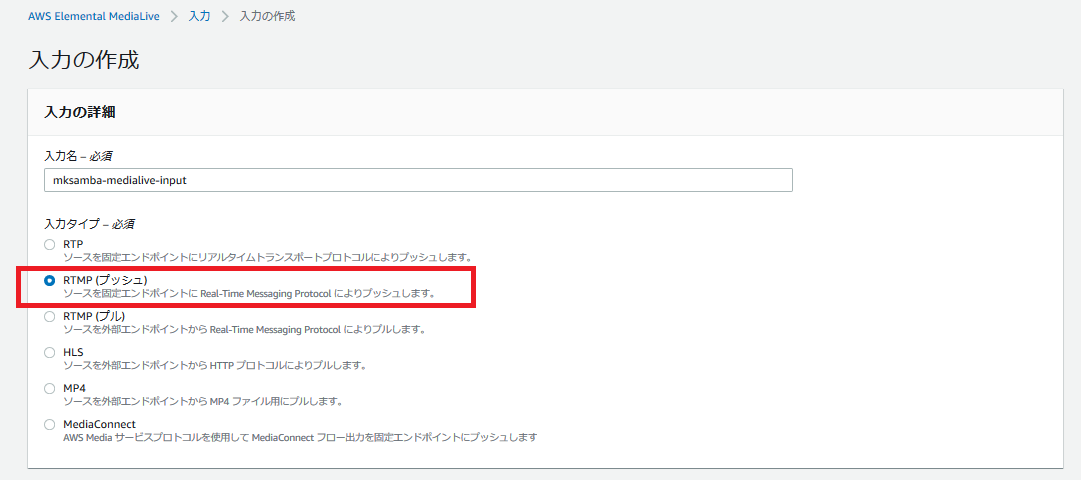
- 「入力」を作成する。入力タイプとして今回はRTMP(プッシュ)を指定する。(配信ソフトOBS Studioの出力方式とあわせる)
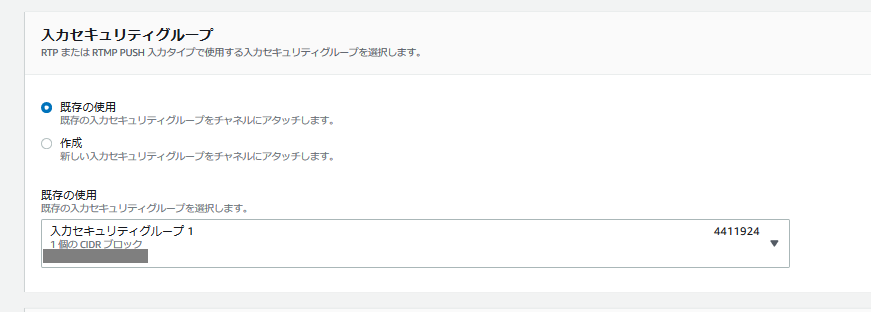
- 前段で設定しておいた「入力セキュリティグループ」を指定する。
- 「アプリケーション名」と「インスタンス」を設定する。それぞれが配信ソフト(OBS Studio)で送信先URLを指定する際の「パス」と「ストリームキー」に該当する。
- 「チャネル」を作成する。まずIAM Roleを設定する。「テンプレートからRoleを作成する」と、「MediaLiveAccessRole」という名前のRoleが作成されるので、それを設定する。
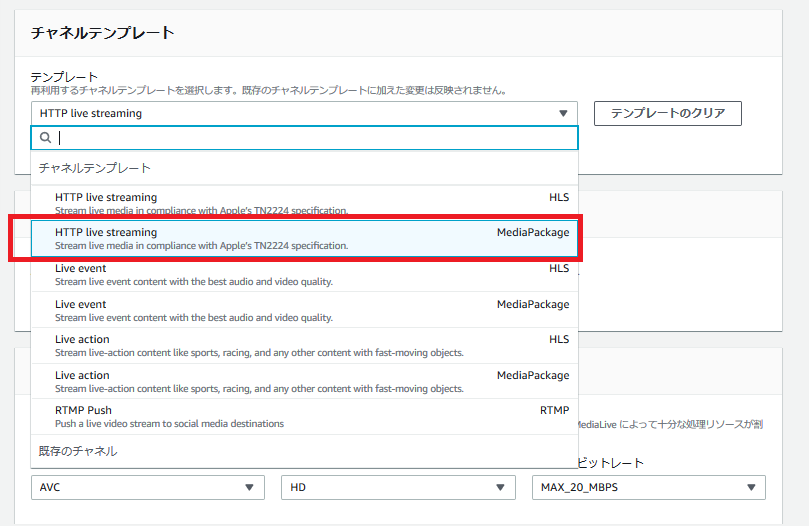
- 「チャネルテンプレート」で、「HTTP live streaming - MediaPackage」を選択する。(MediaPackageに送信するため、これを選択)
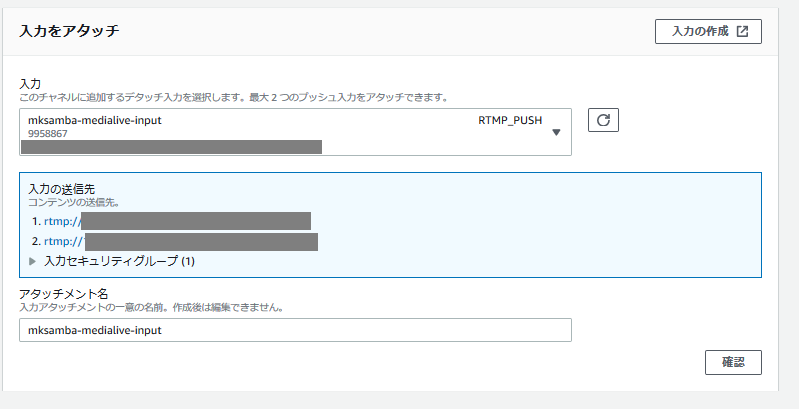
- 「入力をアタッチ」を行う。前段の手順で作成した「入力」を選択して設定する。
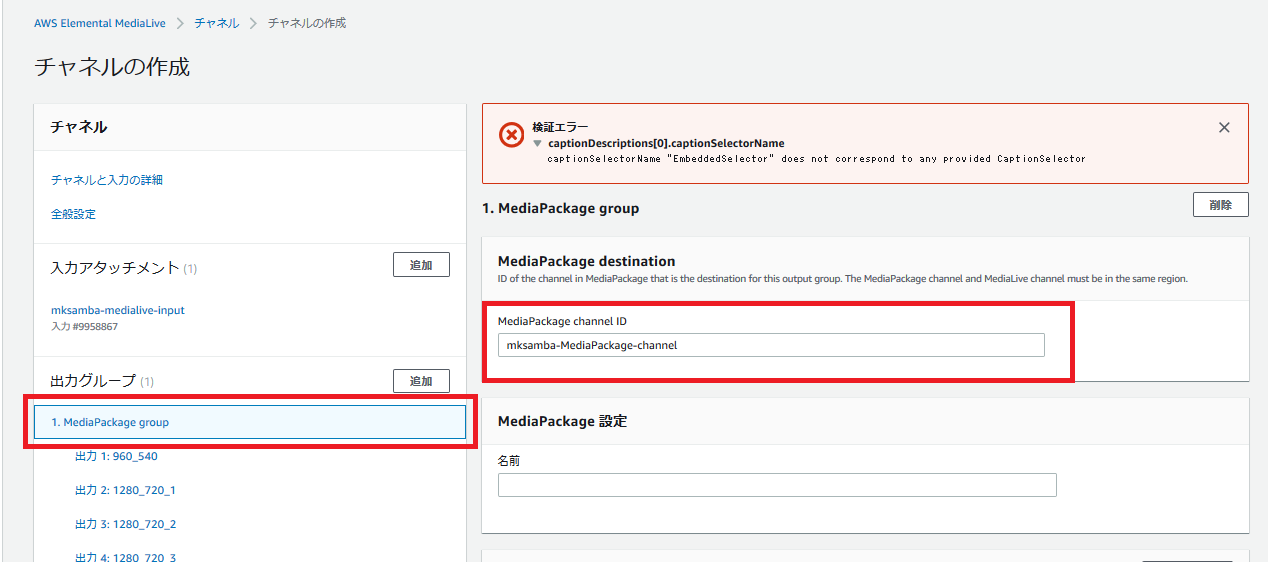
- 「出力グループ」の「MediaPackage group」を選択し、前段の手順で作成したMediaPackage の channel ID を入力する。これにより、MediaLiveとMediaPackageの紐づけが行われる。
- 「チャネルの作成」を実行すると、「検証エラー: captionDescription[0].captionSelectorName」が発生する。このエラーで検索すると、AWS Developer Forum のQAにて、WebVTTの出力を削除すべきとあるため、「出力10: WebVTT」を削除する。これによりチャネル作成が成功する。
OBS Studioの設定
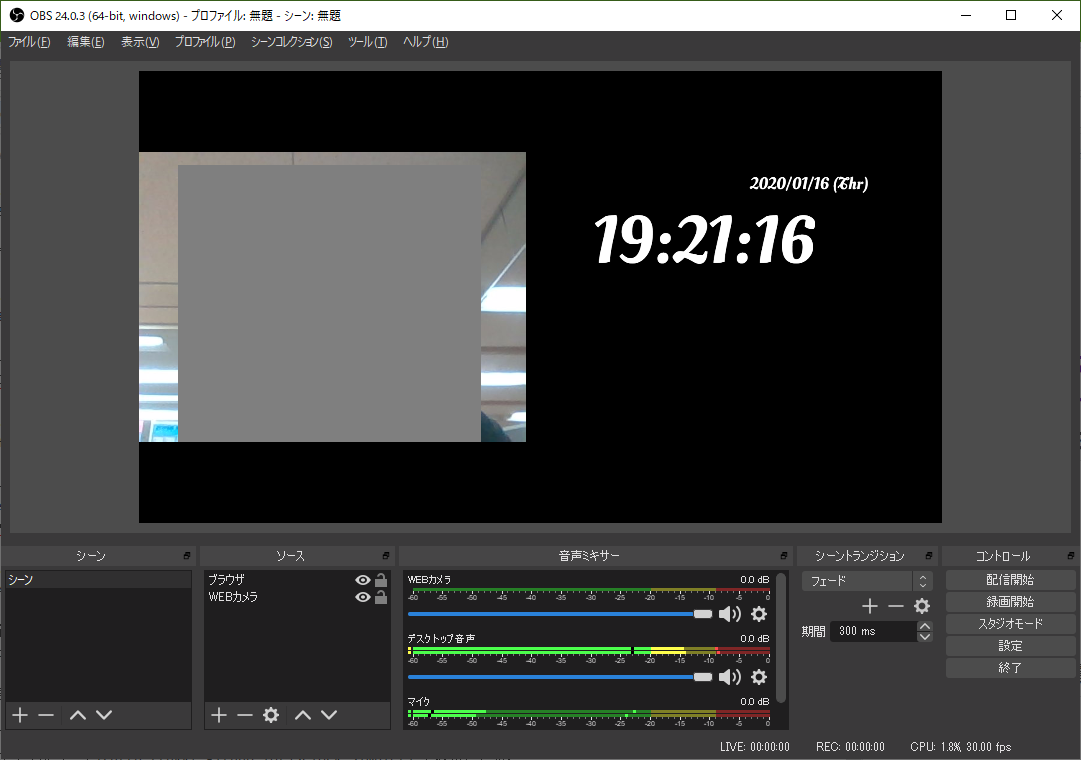
- 「OBS Studioの詳しい使い方・設定方法」を見て、OBSの設定を行う。
配信内容の設定
- PCのWebカメラと、デジタル時計(配信遅延測定のため)を左右に並べて表示させる。デジタル時計は「おてがる!JavaScriptでシンプルなデジタル時計をつくってみよう(Webフォント使用/サイズ自動調整)」の記事内にある、時刻表示のサンプルページ を表示させる。
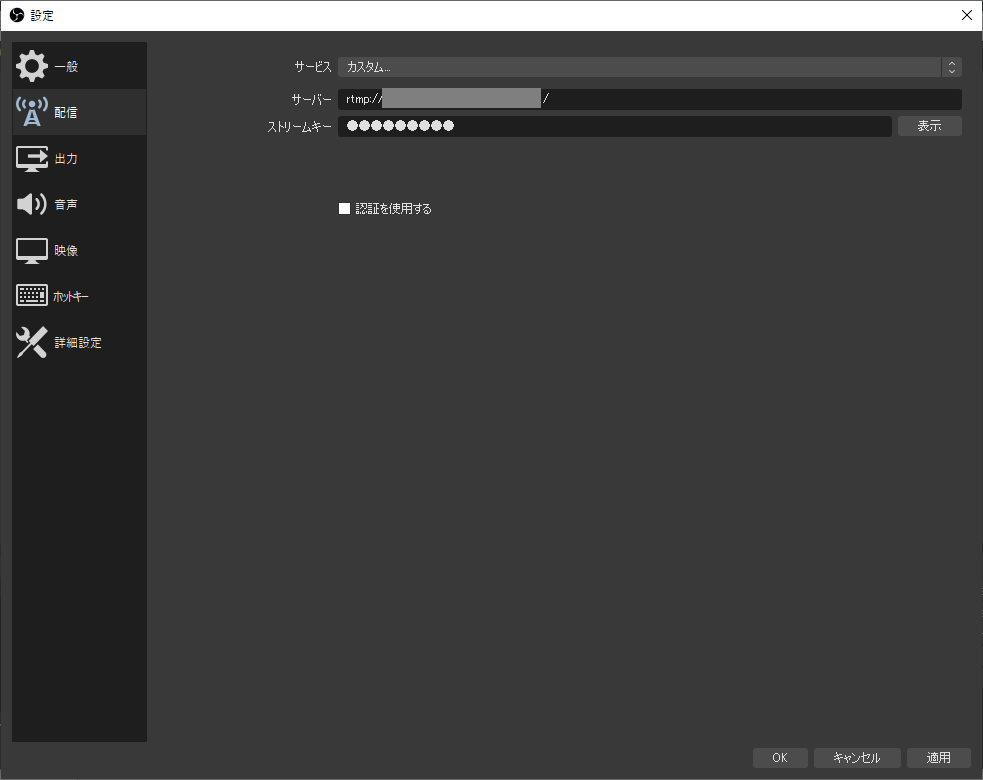
データ送信先の設定
- 「設定」-「配信」の画面にて、「カスタム」を選択し、サーバ(URL)とストリームキーを入力する。MediaLiveを設定した際の「アプリケーション名」までの値を「サーバ」に、「インスタンス」の値を「ストリームキー」に設定する。
PC/スマホでの閲覧
- 作成した MediaLive の チャネルを選択し、「開始」を実行する。これによりRTMPでのデータ受信ができるようになる。
配信ソフト(OBS)で、「配信開始」を押す。問題なければRTMPでのデータ送信が開始される。(画面割愛)
MediaPackageで作成した、HLSの接続URLにPCのEdgeでアクセスする(EdgeはHLSの再生に対応しているため、Edgeを利用)。左がPCのローカルの配信ソフト(OBS Studio)の表示、右がEdgeでAWS経由で配信されてきた動画の表示となる。配信されてから受信できるまで、このタイミングでは約38秒遅延が発生している。(現在時刻 19:41:38 時点で、クライアントに配信されているのは 19:41:00 時点の映像)
同様にスマホ(AndroidのEdge, iPhoneのSafari)でHLSのエンドポイントにアクセスして動画の表示が可能。(画面割愛)
EdgeはMPEG-DASHの再生もサポートしているため、左のEdgeはHLS、右のEdgeはMPEG-DASHのエンドポイントに同時に接続。このタイミングではHLSは約17秒、MPEG-DASHは約54秒の遅延が発生している。
所感
・単純に配信するだけであれば簡単なので、会社で勉強会の模様を別のオフィスに配信するとかに活かしてみたい。
・遅延を小さくするとかは奥が深そうなので、別の構成や設定も試してみたい。





- 投稿日:2020-01-16T23:36:02+09:00
ELBの設定とトラフィック検証
はじめに
AWS試験勉強の備忘録です。
ELB(Elastic Load Balancing)とは
マネージド型のロードバランシングサービスです。
複数のサーバーによる冗長化構成を構築し、それらのサーバーに対して負荷分散を行います。
マネージドサービスなのでELBが稼働しているサーバー自体の管理はいりません。特徴
- ヘルスチェック
- 負荷分散
- SSL/TLSサポート
- スティッキーセッション
- Connection Draining
- アクセスログの記録
ELBの種類
以下の3つのタイプが存在する。
CLB(Classic Load Balancer)
ALB(Application Load Balancer )
NLB(Network Load Balancer)
それぞれの違いについてはこちらを参考にしてください。
CLBとALBの違い
大きな違いはALBのみコンテントベースルーティングがあることです。
どんな機能かというとURLに含まれるURI文字列によって判定を行い、
事前に設定された振り分け先にルーティングします。ALBはパスルーティングによりCLBより容易にバランシング構成が可能ということです。
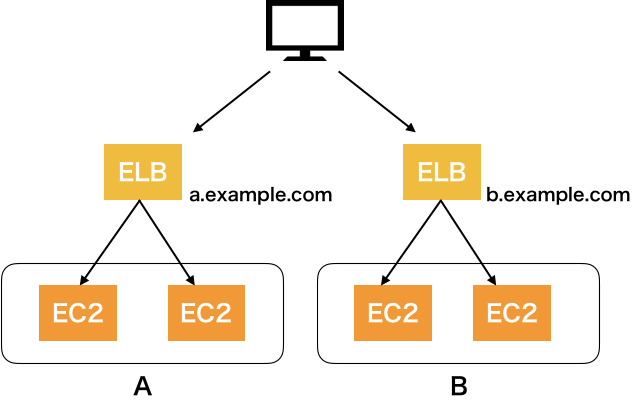
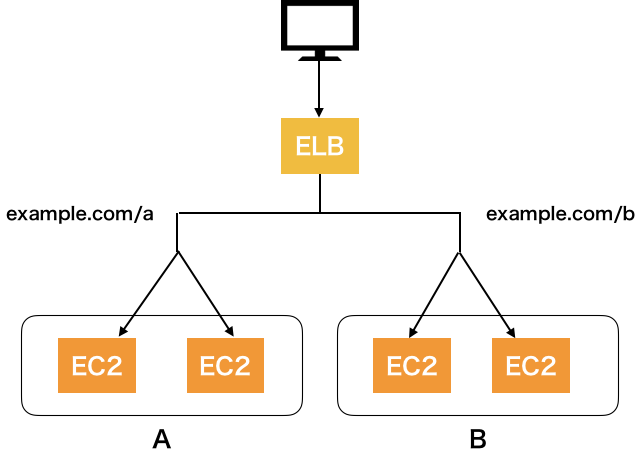
CLBだと
2つのURLにわけた場合にELBが2つ必要になリます。
ALBだと
パスルーティングにより1つのELBでバランシングが可能になります。
ELBの検証
マルチAZ構成で2つのwebサーバーにELBを使用して
実際にどのようなトラフィックになるのか検証してみたいと思います。
手順
1.VPC、パブリックサブネットの作成
VPCダッシュボード画面から[VPCの作成]をクリックします。
下記を選択します。
任意のVPC名を付けます。
AZはap-northeast-1aを選択しています。
これで[VPCの作成]をクリックします。完成するとパブリックサブネットが一つ作成されていることが確認できます。
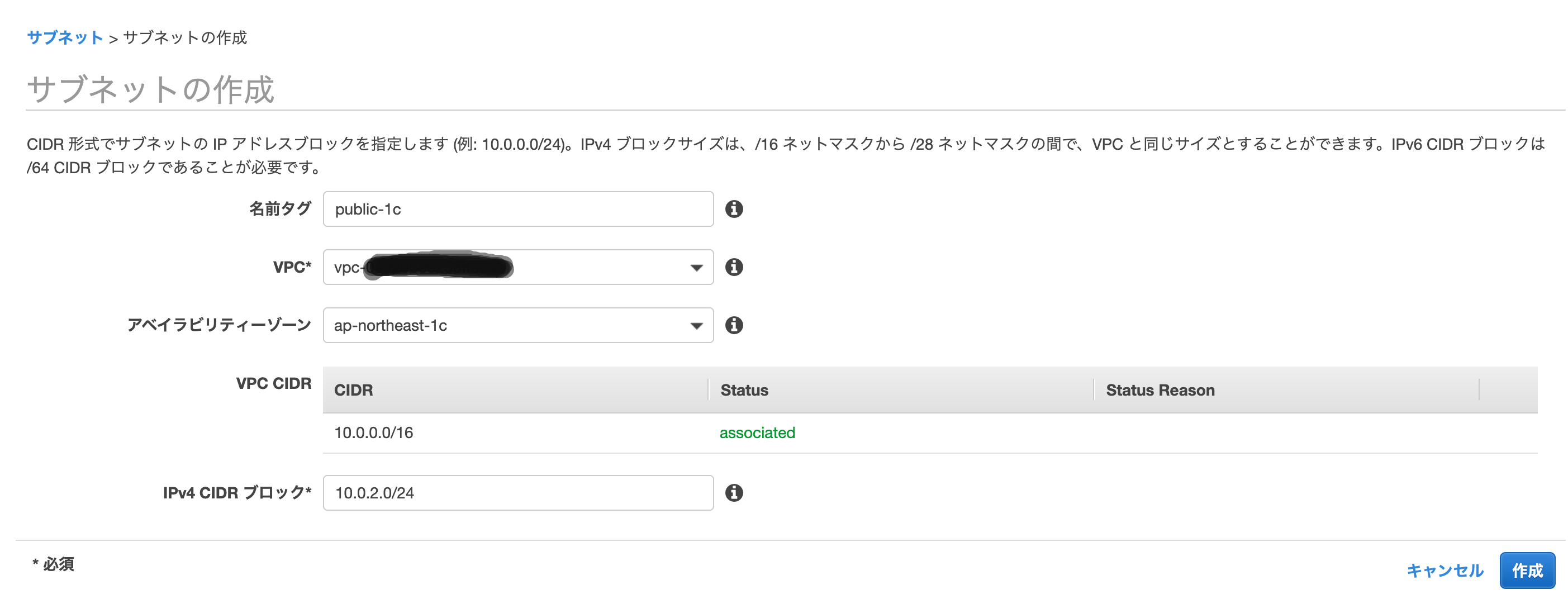
今度は先程とは違うAZにパブリックサブネットをもう1つ追加していきます。コンソールのサブネット画面から[サブネットの作成]をクリックします。
作成したVPCを選択して、
AZを今度はap-northeast-1cにします。
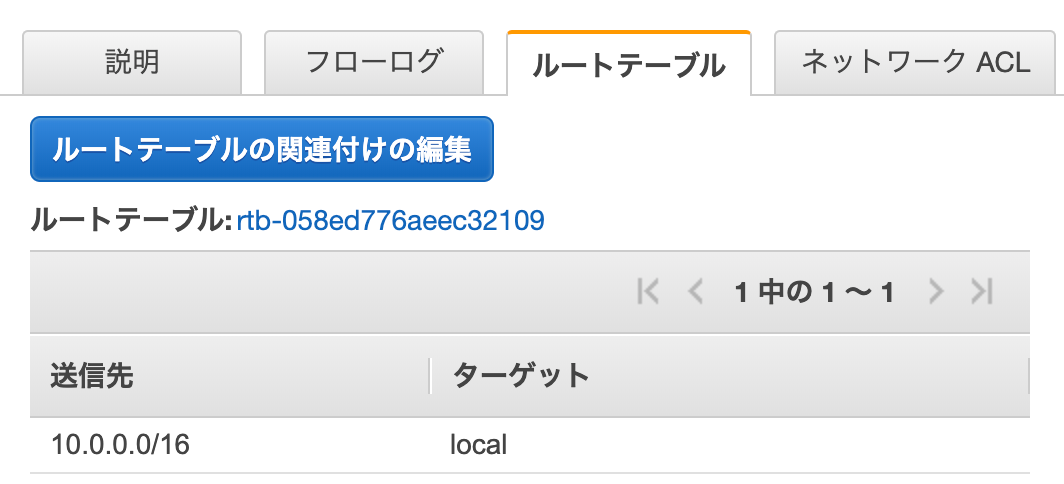
ルートテーブルにインターネットゲートウェイを付与していきます。
[ルートテーブルの関連付けの編集]をクリックして、
インターネットゲートウェイがあるルートテーブルIDにして保存します。
これで2つのパブリックサブネットが完成しました。
2.インスタンスの構築
それぞれのパブリックサブネットにEC2インスタンスを構築していきます。
インスタンスのコンソール画面から
[インスタンスの作成]ボタンをクリックします。
AMIは一番上のを選択します。
インスタンスタイプはデフォルトのままにします。
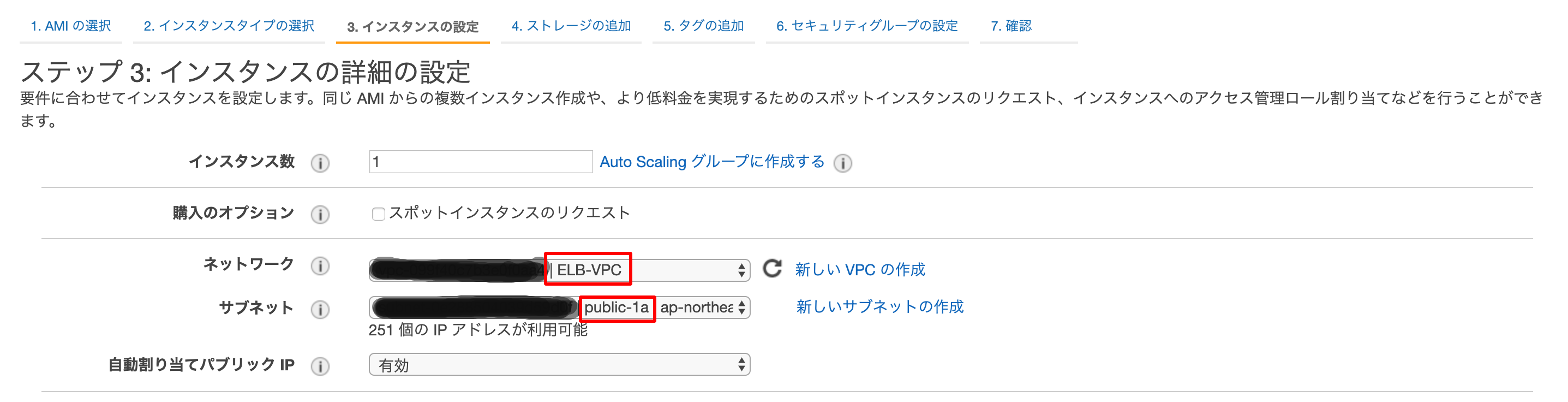
インスタンスの詳細の設定ではVPCは作成したものにし、
サブネットに関しては、最初にAZがap-northeast-1aのものを選択します。自動割り当てパブリックIPも有効にしておきます。
それ以外はデフォルトのまま次に進みます。
ストレージの追加はデフォルトのまま進み
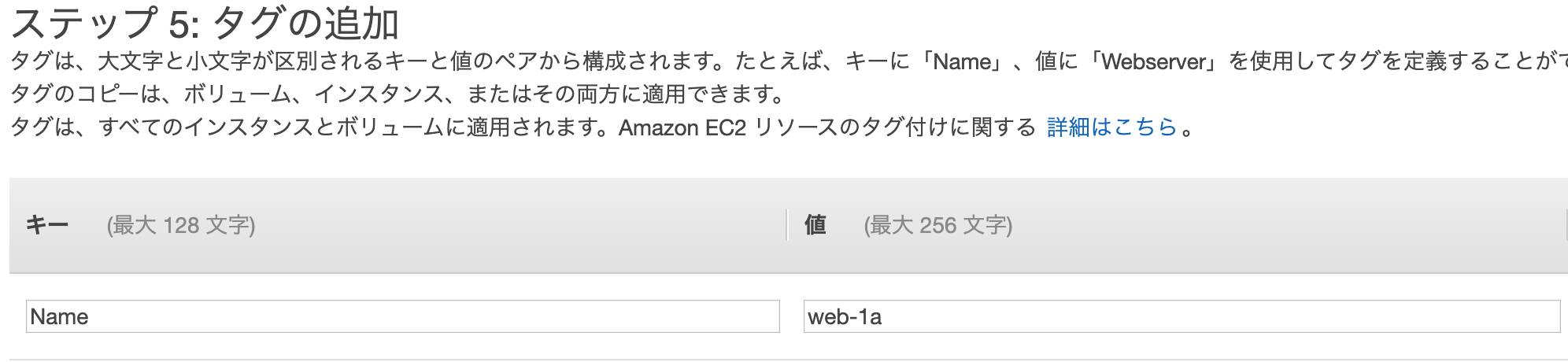
タグは任意でnameなどを付けてください。
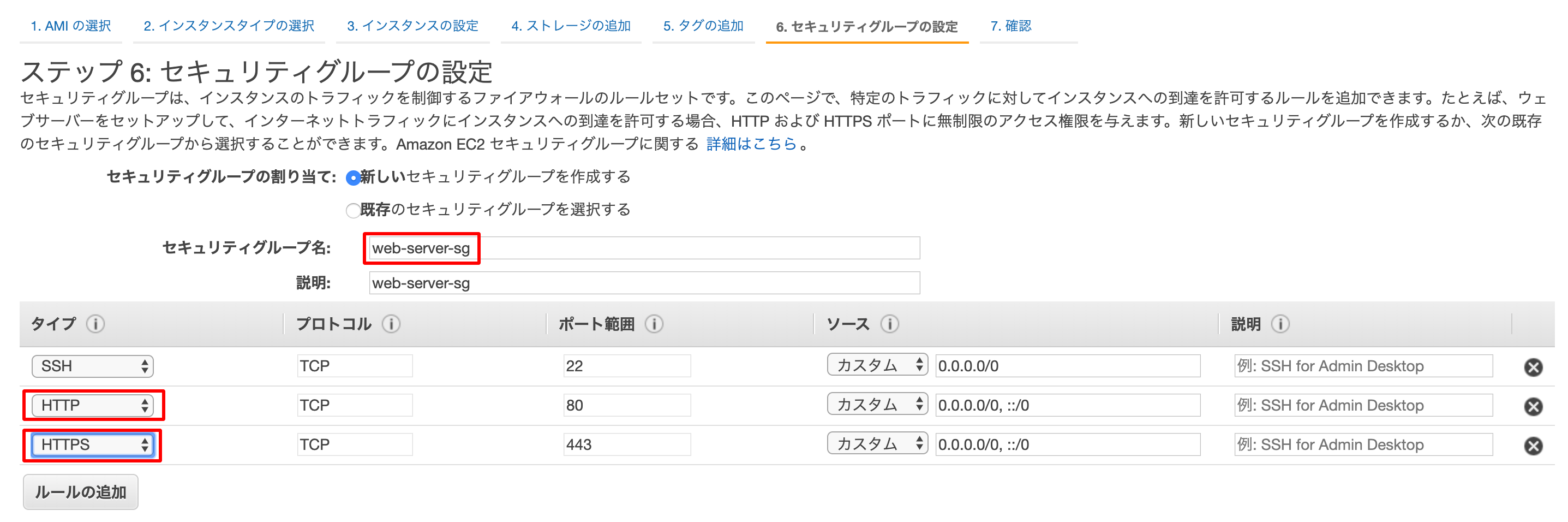
セキュリティグループの設定画面では
新しいセキュリティグループを作成してください。
タイプの方ではHTTPとHTTPSを選択しました。
この状態でインスタンスを作成します。
作成されたことを確認したら
今度はAZがap-northeast-1cの所に上記の流れでインスタンスを作成します。
変更箇所は以下になります。
- サブネットを
ap-northeast-1cで作成したものにすること- セキュリティグループは上で作成したものを使用すること
以上でそれぞれのAZに1つずつインスタンスが構築されました。
3.WEBサーバーに設定
作成したインスタンスをWEBサーバーに設定していきます。
まずは
web-1aにsshします。
インスタンスの説明からパブリックIPをコピーしていき、
macならターミナル、windowsならteratermを使用して接続してみて下さい。sshできたら
まず管理者権限に移動します$ sudo su -次にファイルのアップデート状況を確認します。
# yum update -yアパッチのソフトウェアをインストールして
WEBサーバーにしていきます。# yum install httpd -yインストールが完了したら
以下のコマンドでアパッチソフトウェアを起動します。# service httpd starthtmlファイルを作成していきます。
以下のディレクトリまで移動します。# cd /var/www/html
lsコマンドで中身を見てみると何もないことが確認できます。
ここにhtmlファイルを作成します。
今回はvimを使用します。vim index.htmlindex.html<html><h1>hello A!!</h1></html>入力が完了したら
:wqで保存します。
保存できたらリスタートさせます。# service httpd restartこれで完了しました。
確認のためインスタンスの画面から対象インスタンスのパブリックIPをコピーして
WEBのURLに貼り付けてみて下さい。
htmlで作成した文字が表示されました。これをもう一つのインスタンスにも同じ流れで、
作業してWEBサーバーとして設定していきます。一応違いを表すためにhtmlファイルを下記の内容にしておきます。
index.html<html><h1>hello C!!</h1></html>インスタンスのパブリックIPから
下記の内容で表示されました。
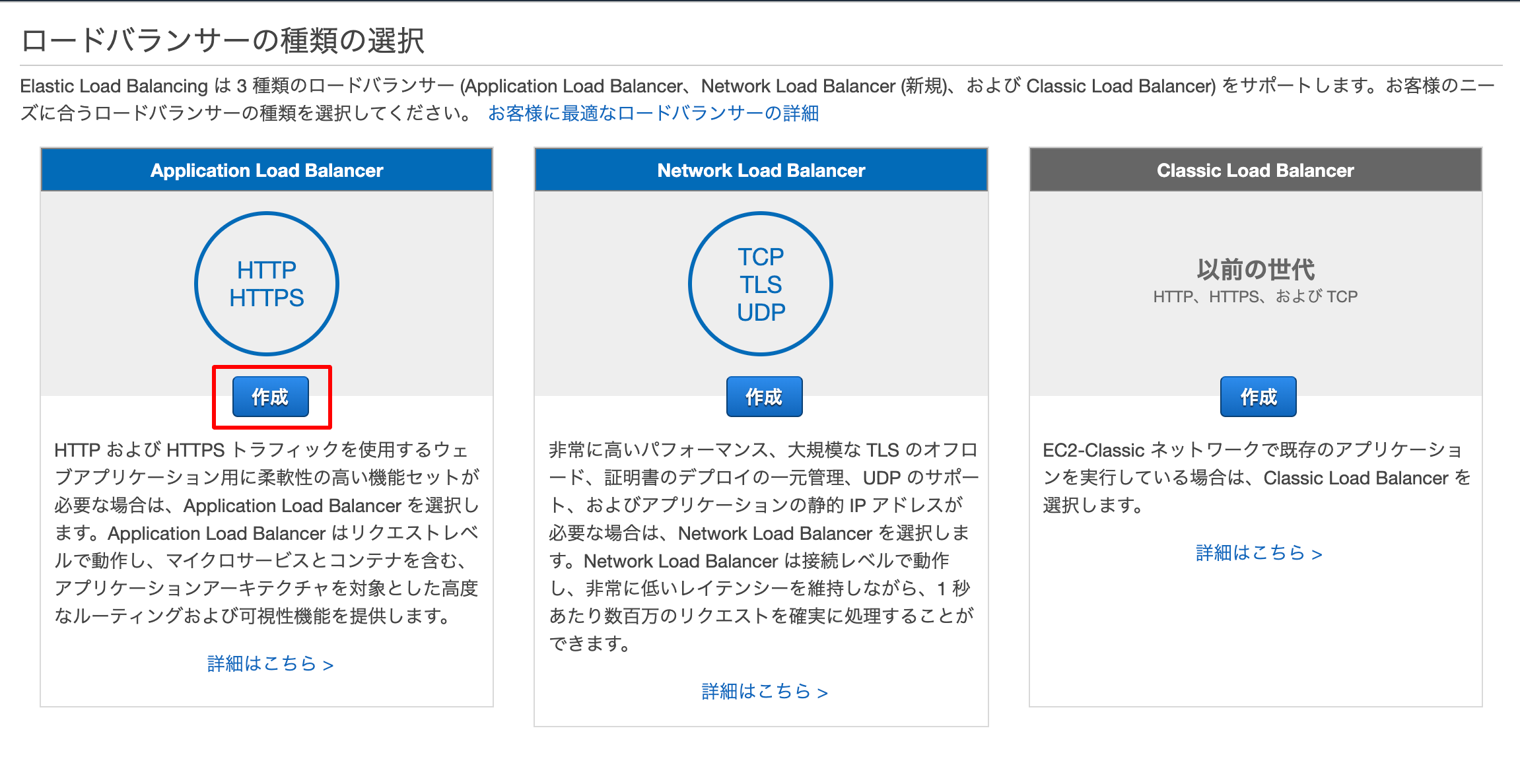
4.ELBの作成
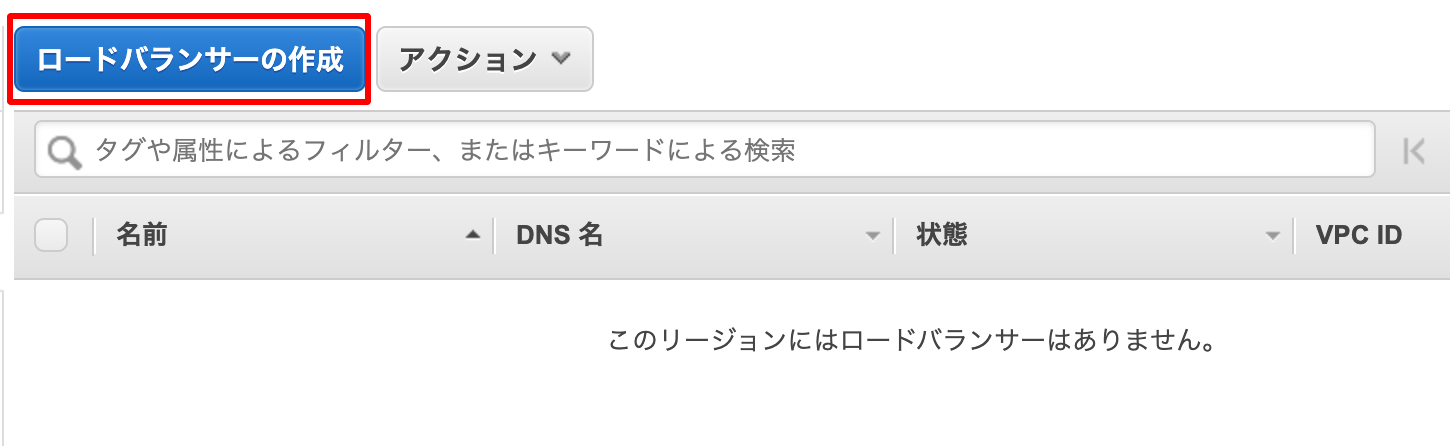
インスタンス画面の左にロードバランサーの項目があるので、
そこをクリックします。
[ロードバランサーの作成]をクリックします。
ALB、NLB、CLBの3つがあります。
今回はALBを選択します。
名前を入力します。
そのまま下のアベイラビリティーまで進みます。
作成したVPC、AZを選択します。
タグ任意で名前などを付けてください。
セキュリティグループの設定まで進み、セキュリティグループは
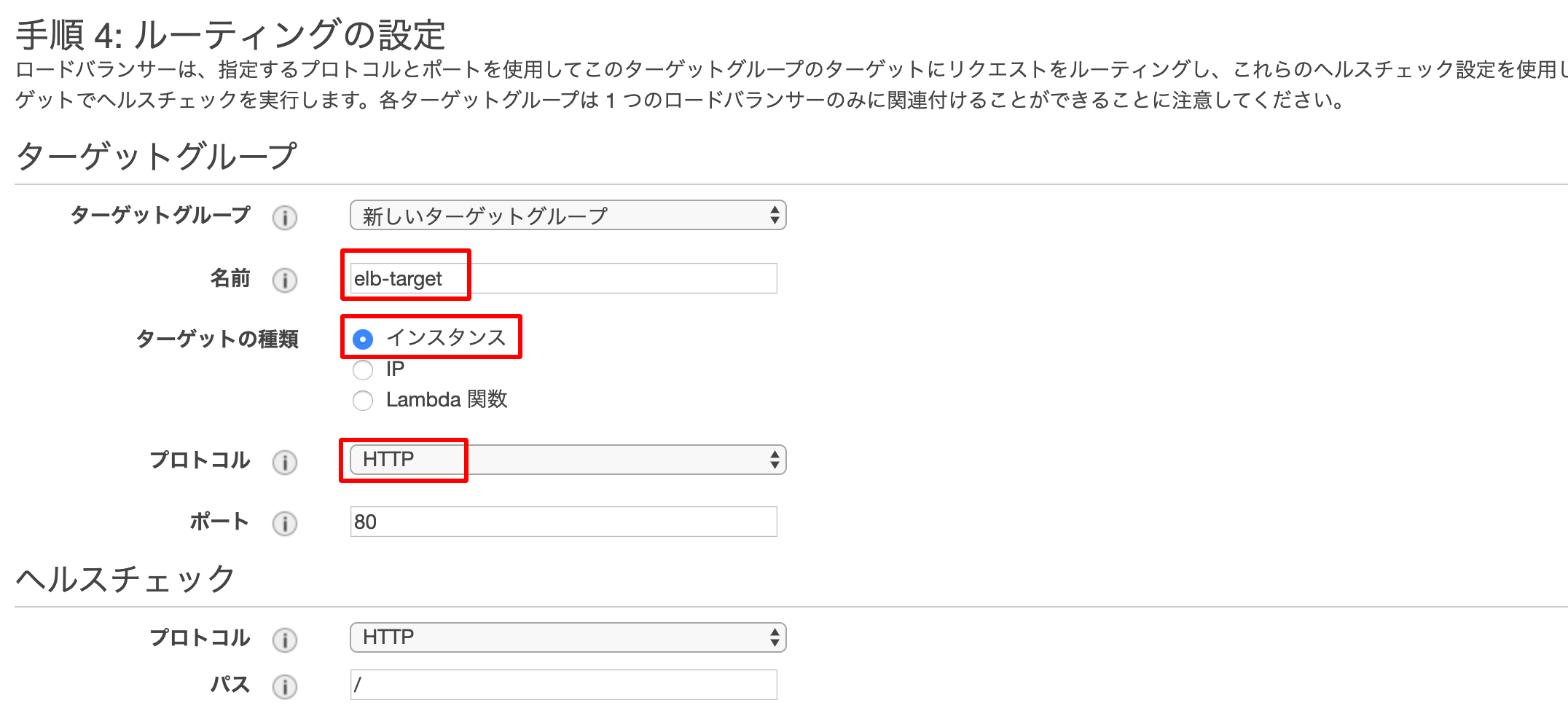
インスタンスの作成時に利用したものを選択してください。ルーティングの設定でターゲットをインスタンスにして、
プロトコルもHTTPにして作成します。
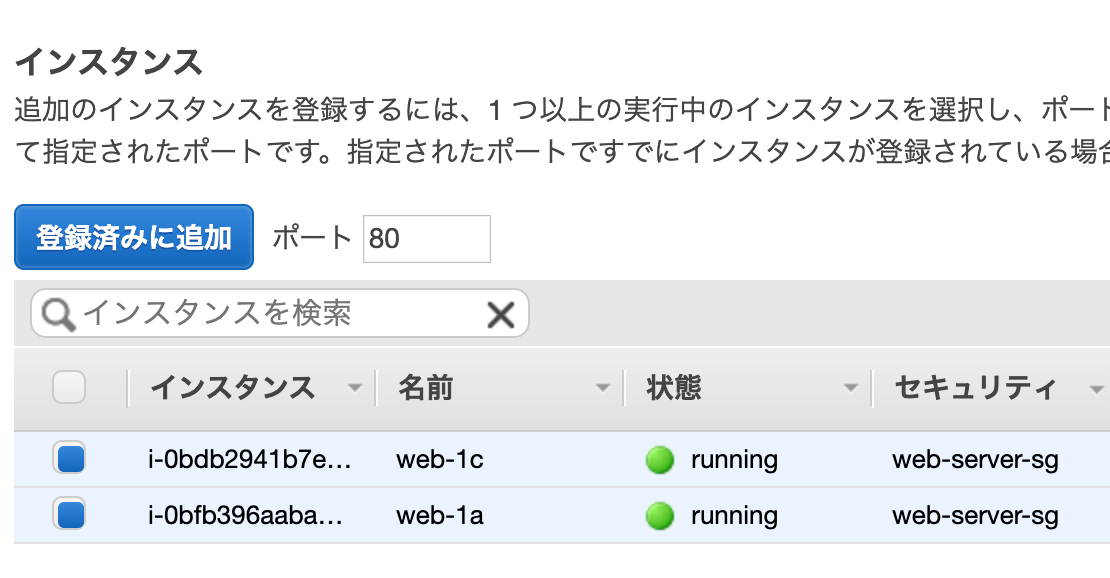
ターゲット登録画面で
作成した2つのインスタンスにチェックを付けて
[登録済みに追加]をクリックします。
これで作成します。5.トラフィック検証
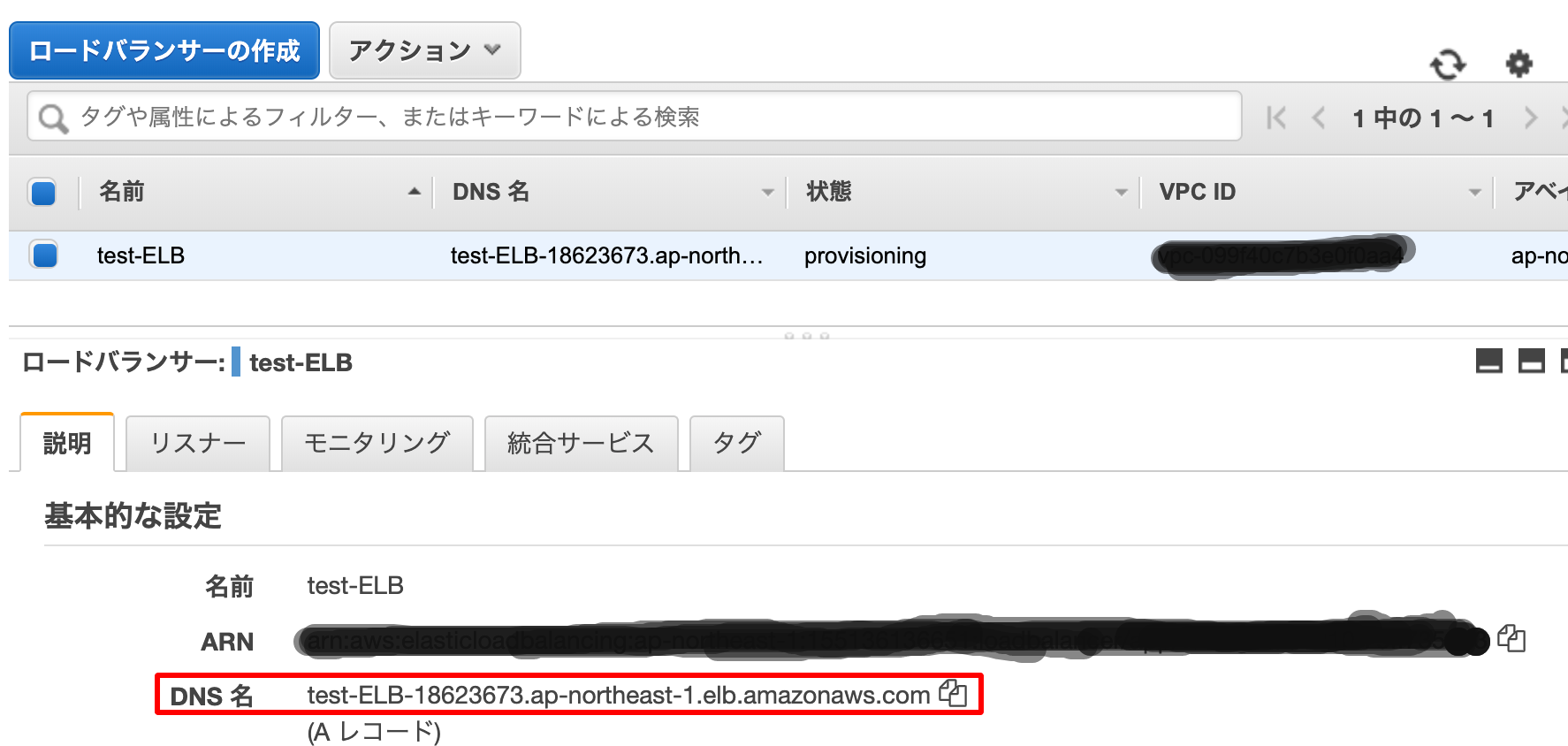
ELBの画面から
作成したELBのDNS名をコピーします。
それをURLに貼り付けると
WEBサーバーの設定で確認した画面が出てくると思います。
このサイトにアクセスできませんというエラーが出た場合は
少し時間を置いてから実行してみてください。
何回か更新すると表記が変わってくると思います。
今回だとhello A!!とhello C!!のようになります。試しに
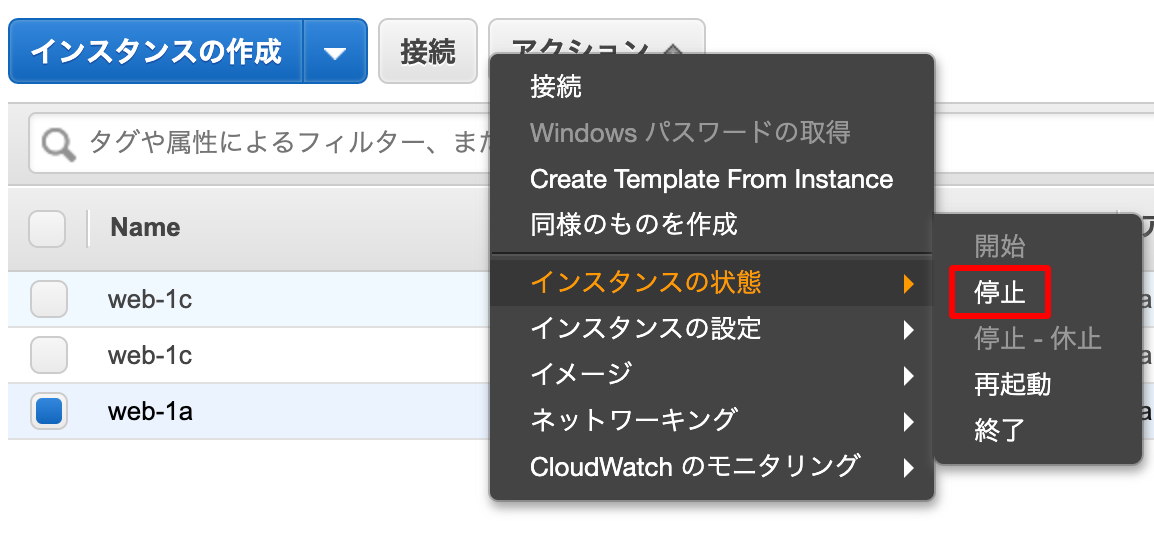
hello A!!を表示させるインスタンスを
停止させてみたいと思います。
この状態でELBのDNS名でアクセスすると
hello C!!しか表示されないことがわかりました。
まとめ
以上のことからELBがターゲット内のインスタンスの状況を
配慮してトラフィックの制御をしていることが確認できました。












- 投稿日:2020-01-16T22:57:47+09:00
Static website hosting な S3 バケットに SPA をアップロードしたが *.js の読み込みでエラーになった件
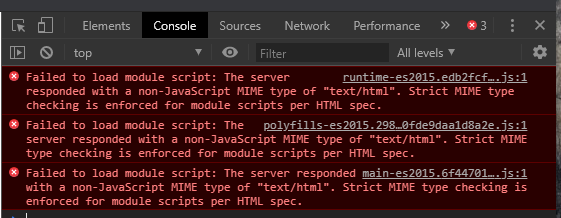
静的ホスティングを有効にした AWS S3 のバケット(その他諸々の権限も設定済)に、Angular で作成した SPA を aws cli でアップロードしたら、index.html の起動時に *.js が読み込めないというエラーが Chrome の Console に出力された。
Failed to load module script: The server responded with a non-JavaScript MIME type of "text/html".
Strict MIME type checking is enforced for module scripts per HTML spec.「Angular の tsconfig.json の設定か?」などいろいろ調べた 1 結果、アップロードされた
*.jsファイルの content-type がtext/htmlになっていた事が原因だった。なぜ発生したかというと、きっかけは aws cli の
s3 syncコマンドを使っていた事。
このコマンドは既定ではファイルの種類に応じて自動的に content-type を設定してくれるという事(実際*.icoファイルにはが設定されていた)だが、どういうわけか
image/x-icon*.jsファイルに期待するapplication/javascriptは設定されず、text/htmlが設定されていた。ちなみに動作環境は Windows10 Pro x64。macOS や Linux ではまた異なる結果なのかも知れない。
環境によって content-type が変わるのがいやだったので、
*.jsファイルについては任意の content-type を指定することにした。こちらの解決方法に習って、次のようなコマンドにした。
■Linux/macOS
aws s3 sync <アップロード元ディレクトリ 例: ./dist/ > \ s3://<バケット名> \ --acl public-read \ --exclude "*.js" \ --delete aws s3 sync <アップロード元ディレクトリ 例: ./dist/ > \ s3://<バケット名> \ --acl public-read \ --exclude "*" \ --include "*.js" --content-type application/javascript■Windows
call aws s3 sync <アップロード元ディレクトリ 例: .\dist\ > ^ s3://<バケット名> ^ --acl public-read ^ --exclude "*.js" ^ --delete call aws s3 sync <アップロード元ディレクトリ 例: .\dist\ > ^ s3://<バケット名> ^ --acl public-read ^ --exclude "*" ^ --include "*.js" --content-type application/javascript1つ目の
syncで*.js以外をアップロード、2つ目で*.jsのみをアップロードして content-type を明示的にapplication/javascriptに設定する。
--acl public-readは、バケット全体で公開にしてあれば不要と思われるのでお好みで。s3 sync は、変更があったものだけがアップロードされるので、正しくない content-type でアップロードされたファイル群は手動で削除してから(あるいは
s3 rmでバケット内を全削除してから)このスクリプトを実行した方が確実。
- 投稿日:2020-01-16T22:48:36+09:00
異なるAWSアカウント間でDNSを移行する手順
異なるAWSアカウント間でDNSを移行する必要があったため、手順を備忘録的に書いておきます。
- 使用しているドメイン登録サービスにログインし、対象ドメインのネームサーバーを確認する
- 1に移行元のRoute53のnsレコードが登録されていることを確認
- 移行先のRoute53で新規にホストゾーンを作成
- 作成したゾーンにレコードを移植
- 1のネームサーバーを移行先のnsレコードに変更して切り換え
ネームサーバーは以下のコマンドでも確認できます。
$ dig <対象ドメイン名> ns大丈夫だと思ってもちゃんと確認しよう。。
- 投稿日:2020-01-16T22:02:40+09:00
AWS Security Hubで特定のコンプライアンスチェック項目を無効化する
はじめに
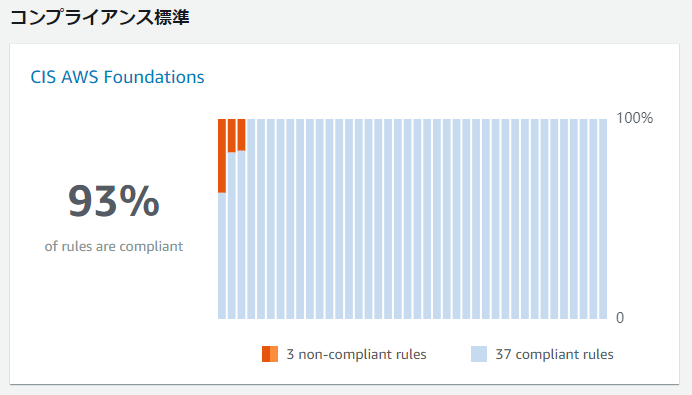
2020/1/15 の Updateにより AWS Secuirty Hub のコンプライアンス標準機能で
CIS AWS Foundations Benchmark の個別のチェック項目を無効化できるようになりました。AWS Security Hub releases the ability to disable specific compliance controls
https://aws.amazon.com/jp/about-aws/whats-new/2020/01/aws-security-hub-releases-ability-disable-specific-compliance-controls/個人的に待ち望んでいた機能であったため、こちらについてまとめます。
CIS AWS Foundations Benchmark とは
米国の非営利団体である CIS (Center for Internet Secuirty) が公開している
AWSアカウントの基本的なセキュリティを実装するための技術的なベストプラクティスです。
CISのベンチマークは PCI DSS などのコンプライアンス要件で業界標準のベストプラクティスとの
記載があった場合などに参照されます。CIS Amazon Web Services Foundations Benchmark v1.2.0 - 05-23-2018
https://d1.awsstatic.com/whitepapers/compliance/AWS_CIS_Foundations_Benchmark.pdfCIS AWS Foundations Benchmarkのv1.2.0では49項目の推奨事項があり、以下のような構成になっています。
- Identity and Access Management (22項目)
- アカウントやユーザーIDのアクセス管理に関する推奨事項
- 主にルートアカウントやIAMユーザーおよびそれらに紐づくアクセスキーを管理するための内容
- Logging (9項目)
- アカウント内のログの取得と管理方法に関する推奨事項
- 主にCloudTrailおよびConfigによるアクティビティの記録およびその保護に関する内容
- Monitoring (14項目)
- アカウントに関連するアクティビティのモニタリングに関する推奨事項
- 意図しないアクティビティをCloudTrailによって記録し、CloudWatchによってモニタリングする
- Networking (4項目)
- VPCのセキュリティに関する推奨事項
- VPCフローログの取得、セキュリティグループの設定、VPCピアリング時のルートテーブルの設定
AWS Security Hubによるコンプライアンスの自動チェック
AWS Security Hub は AWS環境全体のセキュリティとコンプライアンスの状況を確認可能なサービスです。
https://aws.amazon.com/jp/security-hub/
Security Hubのコンプライアンス標準機能を利用すると、CIS AWS Foundations に
定義されている各項目を自動的かつ継続的にチェック※することができます。
※以下の7項目は外部からチェックできないため、Security Hubではサポートされていません。
- 1.15 秘密の質問がAWSアカウントに登録されていることを確認する
- 1.17 現在の連絡先を最新の状態に維持する
- 1.18 セキュリティ連絡先情報が登録されていることを確認する
- 1.19 インスタンスからのAWSリソースアクセスにIAMインスタンスロールが使用されていることを確認する
- 1.20 AWSサポートでインシデントを管理するためのサポートロールが作成されていることを確認する
- 1.21 コンソールパスワードを持つIAMユーザーの初期セットアップ中にアクセスキーを設定しない
- 4.4 VPCピアリングのルーティングテーブルが「最小アクセス」であることを確認する
これらを除いた全42項目のチェックが行われるわけですが、今回のアップデートで
項目単位でチェックを無効化できるようになりました。個別に無効化できると何が嬉しいのか
CIS Benchmarkで提供されるベストプラクティスは推奨事項ですので
あらゆる環境で必ず全て準拠しなければならないというものではありません。
特に以下のような場面で活用が期待できます。1.Identity and Access Management に関わる項目
パスワードポリシーに関連する項目は組織やシステムレベルで既にルールが決まっているケースもあります。
例えば、
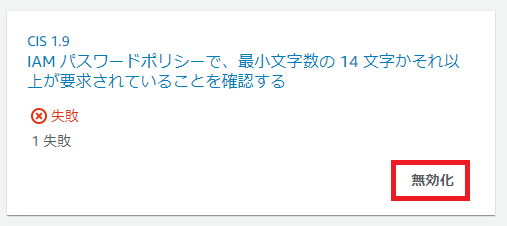
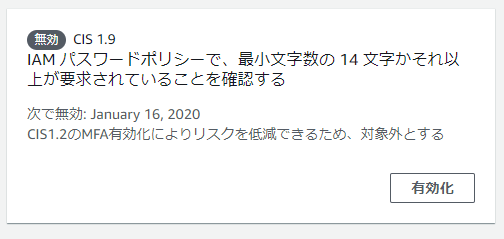
「1.9 IAM パスワードポリシーで 14 文字以上の長さが要求されていることを確認する」
という推奨事項があります。これはコンソールアクセス時のパスワードに対する総当たり攻撃への対策となりますが
一方で
「1.2 コンソールパスワードを持っているすべての IAM ユーザーについて多要素認証 (MFA) を有効にする」
ではコンソールパスワードの他に多要素認証(MFA)の使用を推奨しています。1.2を必須とし、安全対策が十分と判断できるのであれば、組織やシステム環境によっては
14桁以上のパスワードは必須ではないと考えることができる場合もあります。2. Loggingに関わる項目
AWS Security Hubはリージョナルサービスです。
つまり、AWSアカウント全体のコンプライアンスを可視化するには
リージョンごとにSecurity Hubを有効化する必要があります。
しかしながら、Loggingや後述するMonitoringに関する推奨事項は
実運用を考えると、全てのリージョンで完全な準拠を目指すことは難しくなります。例えば
「2.1 CloudTrail がすべてのリージョンで有効であることを確認する」という推奨項目と
これに関連して
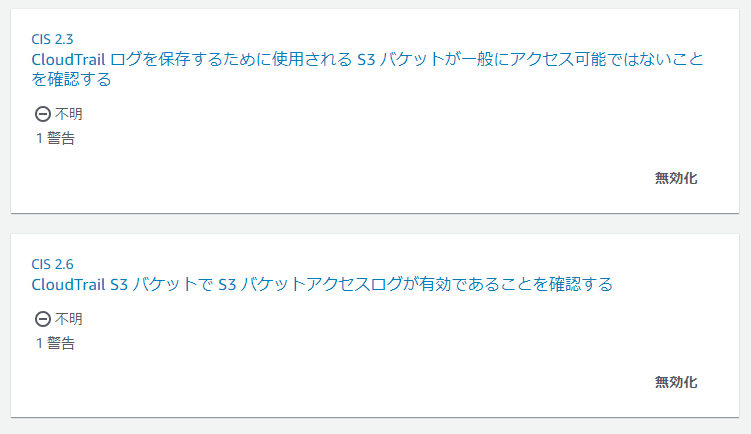
「2.3 CloudTrail ログを保存するために使用される S3 バケットが一般にアクセス可能ではないことを確認する」
「2.6 CloudTrail S3 バケットで S3 バケットアクセスログが有効であることを確認する」
という推奨項目があります。2.1 の推奨項目ではCloudTrailでマルチリージョンの証跡が有効化されているかどうかを確認します。
具体的には証跡設定の「証跡情報全てのリージョンに適用」という項目を はい に設定する必要があります。
東京リージョンでマルチリージョンの証跡を有効化する場合、ログを保存するS3バケットも
東京リージョン作成することになります。
一方、2.3および2.6を確認する際、Security Hubは自分と同じリージョンのバケットしか参照できません。
つまり東京リージョン以外のSecuirty Hubは証跡が保存されているS3バケットの設定を確認できません。この場合、東京リージョン以外のSecurity Hubは以下のように対象のリソースが見つからないという
「警告」という結果を返します。
複数アカウントのログを1つのバケットに集約しているような場合も同じような状況になります。
このような場合ではマルチリージョンの証跡を取得しているリージョンやアカウント以外では
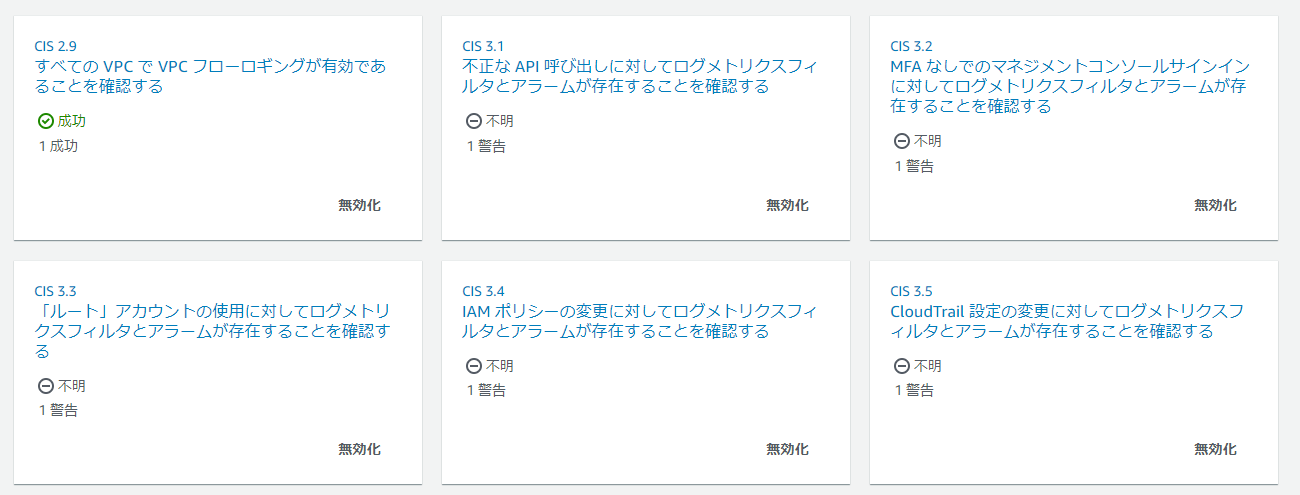
チェックを無効化することができるでしょう。3. Monitoringに関わる項目
Loggingと同様の理由です。
Monitoringの全14項目に準拠するにはCloudTrailのログをCloudWatchでモニタリングし
特定の操作が発生した場合に、SNSによってメール通知する設定が必要です。東京リージョンでマルチリージョン証跡を有効化している場合は
東京リージョンのCloudWatch/SNSにモニタリングの設定を行う必要があります。その他のリージョンのSecurity Hubは東京リージョンのモニタリングの設定を
確認することはできないので以下のように「警告」のステータスとなります。
全てのリージョンでCloudTrailを設定し、モニタリングの設定を行うこともできなくはないですが
- 同じ内容のログが複数のリージョンで取得される
- 1つのアラーム結果がリージョンの数だけ重複して通知される
などかなり冗長な設定となります。
コンプライアンス標準の準拠率をあげるために冗長なログを取得してコストをかけるというのは本末転倒です。
このような場合はモニタリングを行うリージョン以外では3.Monitoringの14項目を
全て無効化してしまうほうが運用しやすいはずです。また「1.1「ルート」アカウントの使用を避ける」に関しても、チェックの際は
「3.3 「ルート」アカウントの使用に対してログメトリクスフィルタとアラームが存在することを確認する」
の定義が適切に設定されていることを確認するため、
その他のリージョンでは同じく結果は「警告」となります。
実際に無効化してみる
コンソールから無効化
無効化を行う手順はとても簡単です。
各チェック項目に表示されている「無効化」を選択します。
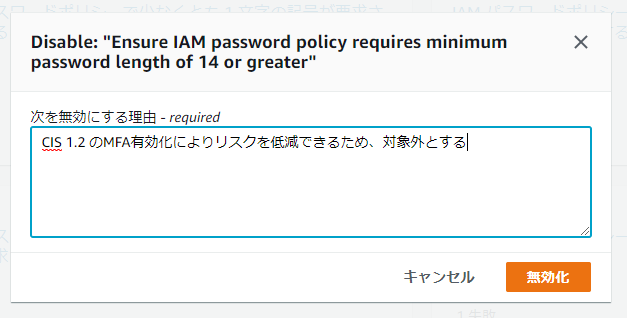
無効化時は必ずチェックを無効にする理由を入力する必要があります。
理由を入力後、無効化をクリックします。
この操作によりチェックの対象外となり、準拠率の計算からも外されるようになります。
誰でも簡単に無効化できないように、IAMユーザーに渡す権限には注意する必要があります。
CLIから無効化
コンソールから簡単に無効化できるとはいえ、全てのリージョンで無効化を行いたい場合
画面ポチポチでリージョンを切り替えて操作するのはとても辛いと思います。その場合、CLIやSDK経由で一括で無効化してしまうのがよいかと思います。
CLIの場合、以下のようなコマンドで無効化/有効化を切り替えることができます。
アカウントIDの箇所は読み替えてください。# 専用のAPIが追加されているため、AWSCLIの場合、Version 1.17.3 以降が必要 $ aws --version aws-cli/1.17.3 Python/3.6.0 Windows/10 botocore/1.14.3 # バージニア北部リージョンで、CIS 1.9 を無効化するコマンド例 $ aws securityhub update-standards-control --control-status DISABLED \ --disabled-reason "CIS1.2のMFA有効化によりリスクを低減できるため、対象外とする" \ --standards-control-arn "arn:aws:securityhub:us-east-1:0123456789012:subscription/cis-aws-foundations-benchmark/v/1.2.0/1.9" \ --region us-east-1 # 無効化→有効化に戻すパターン $ aws securityhub update-standards-control --control-status ENABLED \ --standards-control-arn "arn:aws:securityhub:us-east-1:0123456789012:subscription/cis-aws-foundations-benchmark/v/1.2.0/1.9" \ --region us-east-1本来であれば CloudFormation で必要な項目を一括設定できるのが理想なのですが、
残念ながら2020年1月時点ではコンプライアンス標準に関連する操作には対応していません。複数アカウントで結果を統合している場合の挙動
Security Hubは複数アカウント出力結果を1つのマスターアカウントにまとめることができます。
メンバーアカウントで項目を無効化した場合、マスターアカウントではどう見えるかなどについては
調査中のため、確認でき次第更新したいと思います。参考
Disabling Individual Compliance Controls - AWS Security Hub User Guide
https://docs.aws.amazon.com/securityhub/latest/userguide/securityhub-standards.html#securityhub-controls-disablesecurityhub update-standards-control - AWS CLI Command Reference
https://docs.aws.amazon.com/cli/latest/reference/securityhub/update-standards-control.html以上です。
参考になれば幸いです


- 投稿日:2020-01-16T21:46:41+09:00
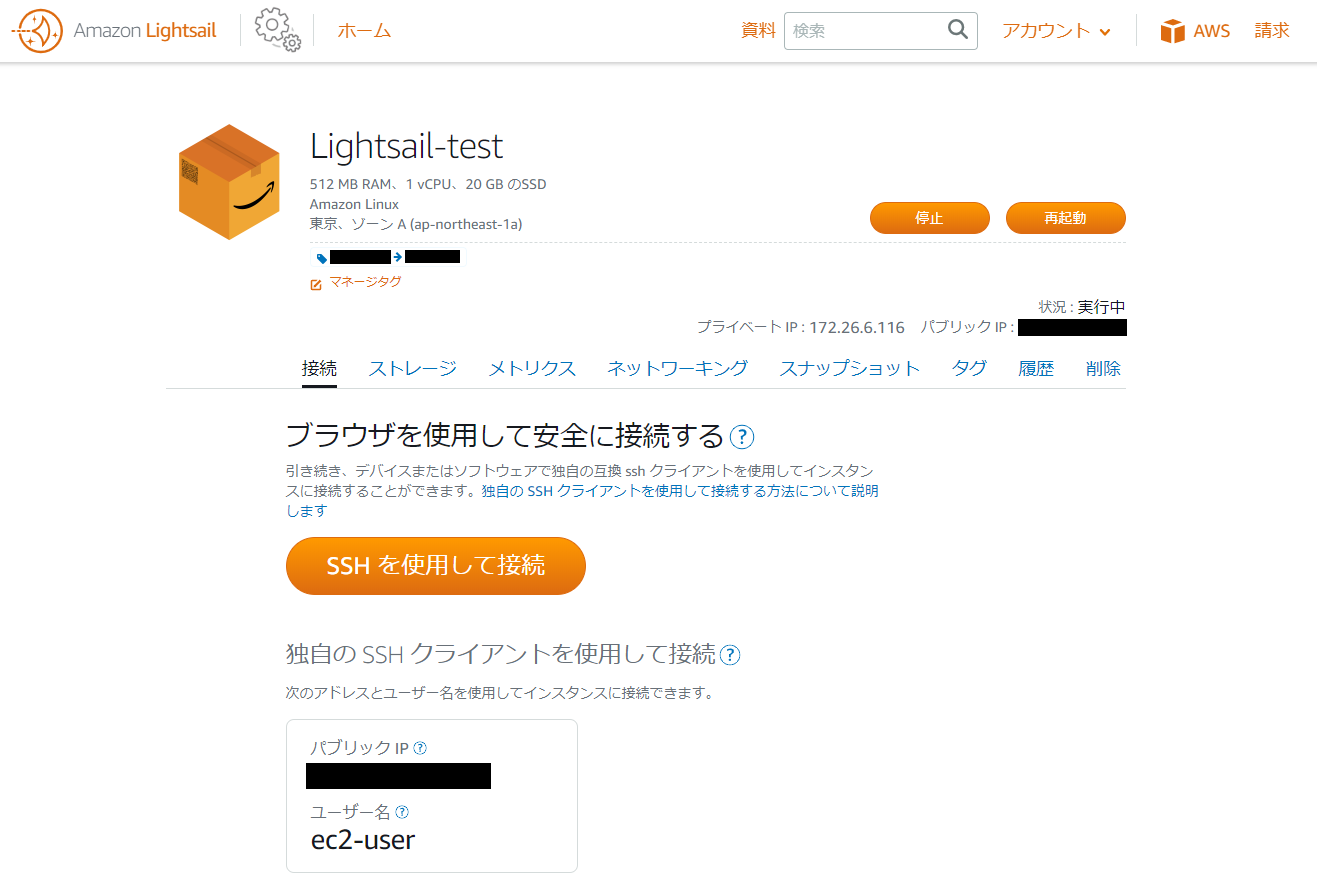
AWS Lightsailを使ってみた
はじめに
AWSのコンピューティングサービスの一つであるLightsailを試しに少しだけ触ってみたので、その記録を記事としてまとめてみました。
Lightsailの管理画面
[AWS マネジメントコンソール]にログインして、[サービス]>[コンピューティング]>[Lightsail]と進むと、Lightsailの管理画面が表示されます。
画面中央の[インスタンスの作成]をクリックすると、インスタンス作成のウィザードに入ります。
インスタンスの作成
ロケーションの選択
- 個人で利用するのであれば、低レイテンシーな東京リージョン(ap-northeast-1)を選択するのが良いと思います。
- 東京リージョンを選択した場合、A/B/DのAZの中から1つを選ぶことが出来ますが、AZによる違いはないと思うので、どれを選んでも良いと思います。
- 厳密にはAZによる違いがあるのかもしれませんが、特に記載されていませんでした。
インスタンスイメージの選択
- EC2のようにOS(プラットフォーム)の種類を選べるだけでなく、利用するアプリも含めてイメージ(設計図)を選択できます。
- 独自のSSHキーペアを使う場合は、ここでキーペアをアップロードしておきます。
OSのみ アプリ+OS Windows系 Windows Server 2016、
Windows Server 2012R2SQL Server 2016 Expressのみ
※OSはWindows Server 2016のみLinux系 Amazon LinuxやCentOS、
Ubuntuなど8種類のOSWordPressやNginxなど14種類のアプリから1つを選択
※OSは不明(選択不可)インスタンスプランの選択
- 必要とするリソース(CPU、メモリ、ストレージ容量、データ転送量)に応じて、インスタンスの種類を選ぶことができます。
- [並べ替え:]の右側にある項目名をクリックすると、リソースやコストの順にインスタンスを並べ替えて表示できます。
- [月次料金]をクリックすると「月額料金の安いインスタンス」の順に表示されます。
- [メモリ]などをクリックすると「メモリ量の多いインスタンス」の順に表示されます。
- [処理中]と書かれている部分は、「サーバーの処理能力(CPU)の高いインスタンス」の順に表示されるようです。
インスタンス名とタグの設定
- 一意なインスタンス名を指定する必要がありますが、どのレベルでの「一意」なのかは分かりませんでした。
- リージョン内で一意、AWSアカウント内で一意など色々と考えられますが...
- インスタンスを識別できるように、必要に応じてタグの設定をします。
- 全て設定が完了したら、[インスタンスの作成]をクリックします。
インスタンスの利用
サーバーコンソールで接続する
- Lightsailのトップ画面から、作成したインスタンスの名前をクリックしてインスタンスの管理画面へ遷移します。
- 所望のインスタンス名(※ここでは
Lightsail-test)をクリックして、インスタンスの設定画面へと遷移します。
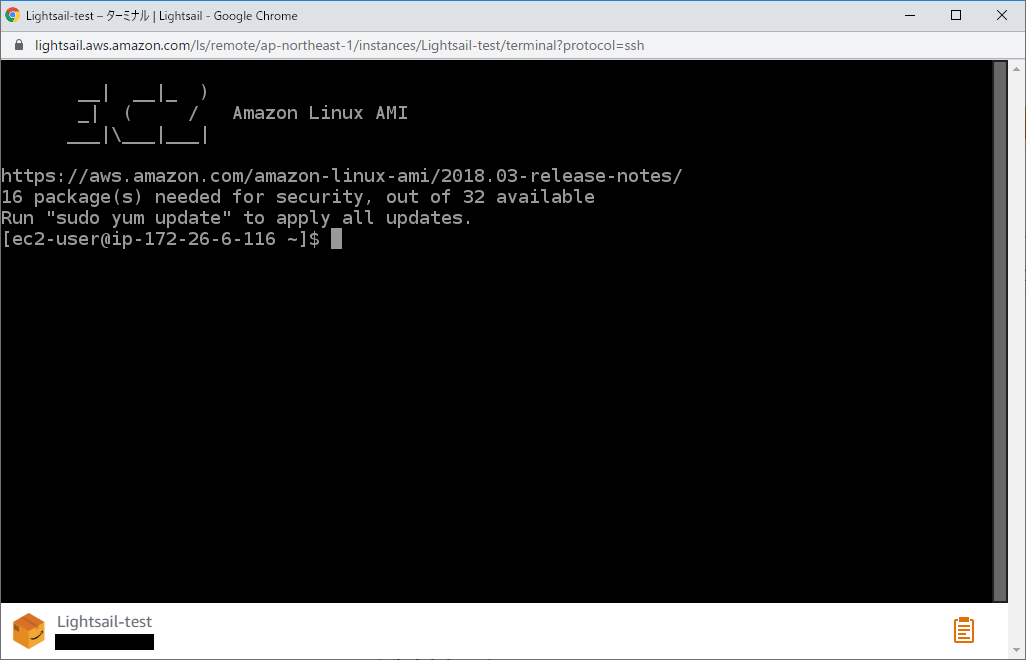
遷移先の設定画面で[SSHを使用して接続]をクリックすると、サーバーコンソールが起動してインスタンスに接続できます。
独自のSSHクライアントで接続する
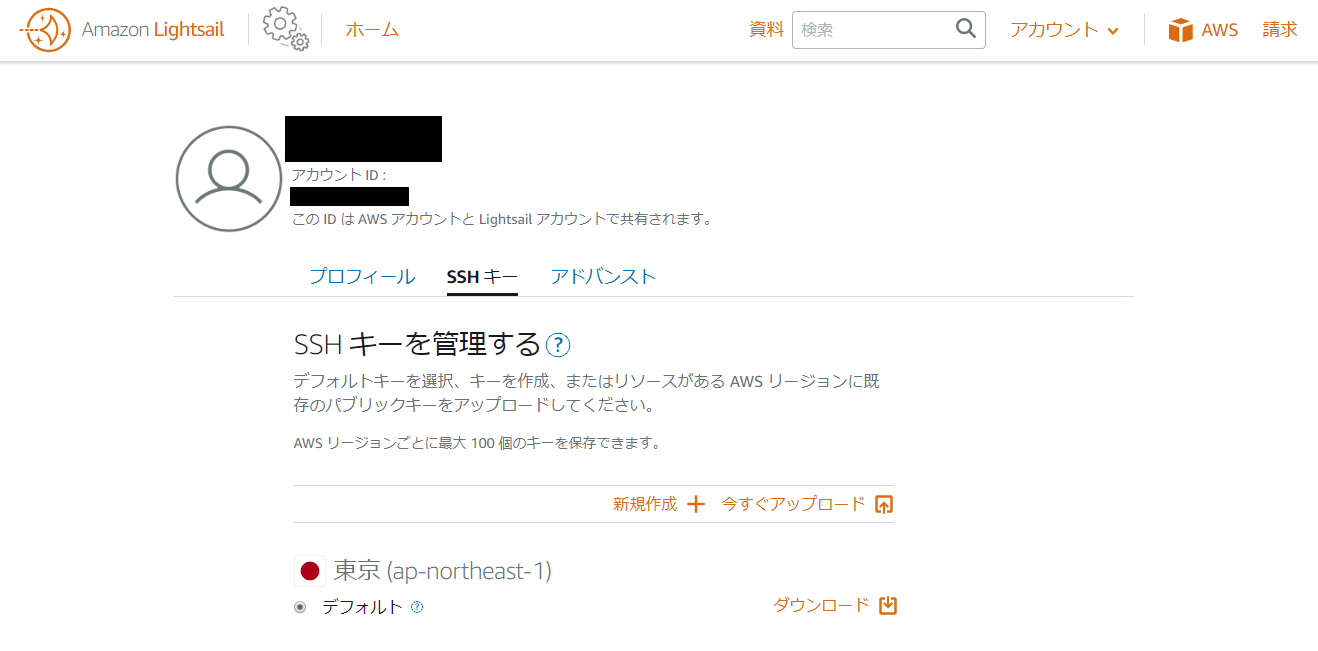
- Lightsailのトップ画面の右上にある[アカウント]ボタンをクリックして、[アカウント]画面へと遷移します。
- アカウント画面で[SSHキー]タブを開き、[デフォルトのキー]を選択して、pemファイルをダウンロードします。
- 独自のSSHキーを利用する場合は、仮想サーバーの作成時にSSHキーをアップロードしておく必要があります。
- あとは所望のSSHクライアントに「仮想サーバーのパブリックIP」「ユーザー名(ec2-user)」「pemファイル」の3つを設定すれば、仮想サーバーにログインすることができます。
- インスタンスのパブリックIP(もしくは静的IP)は、インスタンスの管理画面だけでなく、Lightsailのトップ画面でも確認できます。
利用上の注意点
- インスタンスを[停止]しても課金が継続されるため、課金を止めるにはインスタンスの[削除]が必要となります。
- インスタンスを削除しても、追加したストレージや静的IPは同時に削除されないため、[ストレージ]タブや[ネットワーキングタブ]から個別に削除する必要があります。
- インスタンスの設定画面で[ネットワーキング]タブを選択すると、ファイアウォールの設定を変更出来ますが、変更できるのはインバウンドのみとなります。


- 投稿日:2020-01-16T19:46:03+09:00
AWS EC2インスタンスの複製をしてみた。その7(備忘録)
前回の続きです。https://qiita.com/Bikeiken-IT/items/e1b80cc6cf2cbced5440
EC2インスタンスのEC2-test-2にSnapshotから生成したボリュームをアタッチします。
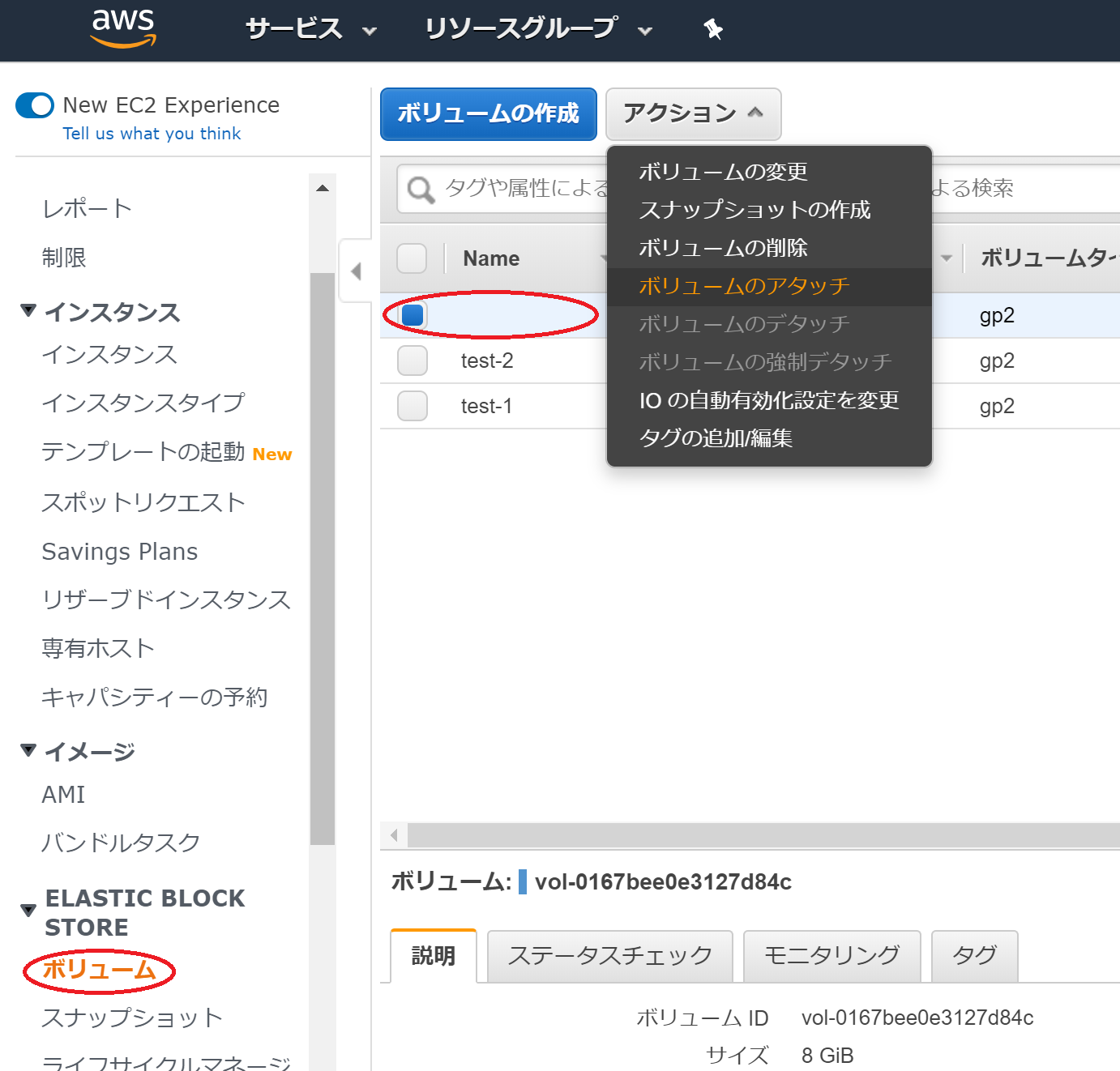
AWSサービスのEC2の画面の左側にスクロールがあります。スクロールのなかにボリュームという項目があるので、それを選択します。
次に、先ほどSnapshotから生成したボリュームを選択します。アクションからボリュームのアタッチを選択します。
ボリュームのアタッチには二つの入力項目があります。
一つは、ボリュームをアタッチするインスタンスの選択です。
もう一つは、その6でメモ帳等に保存してあるはずのEC2-test-2のボリュームを置くディレクトリです。
二つの項目の入力を確認して、アタッチのボタンを押してください。
これでEC2-test-2にSnapshotから生成したボリュームがアタッチされました。
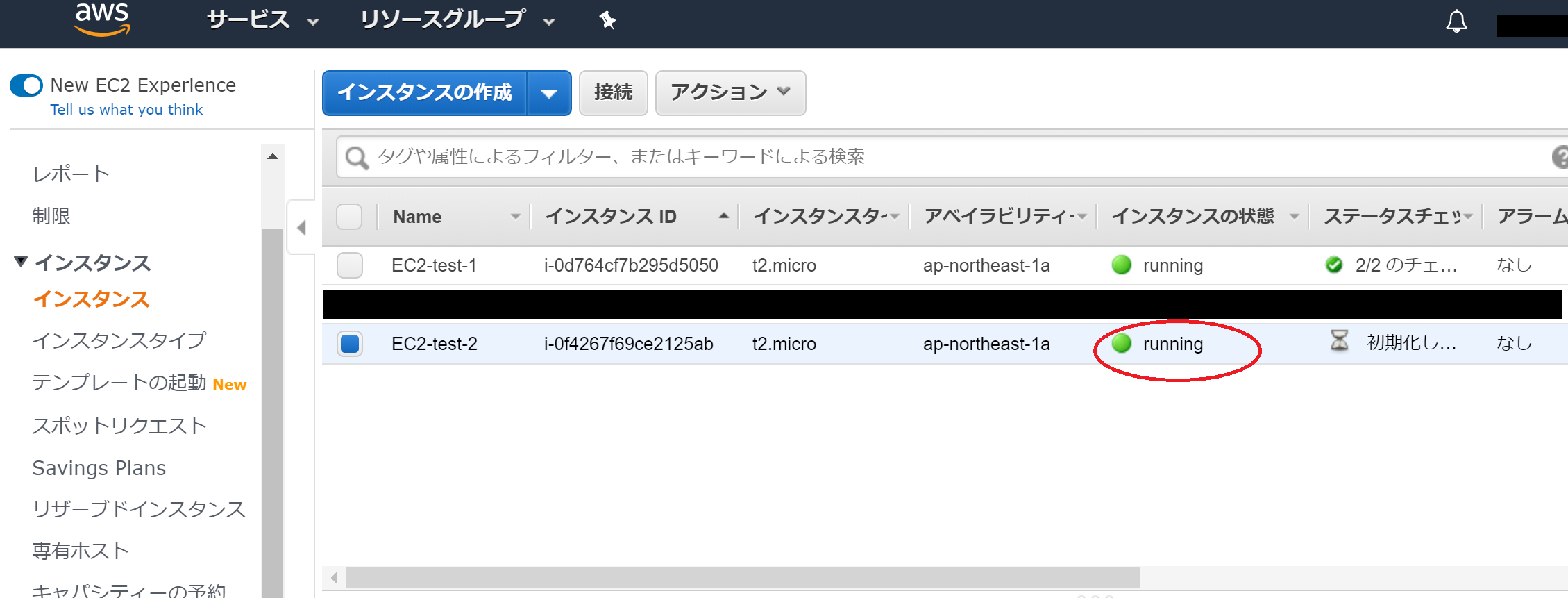
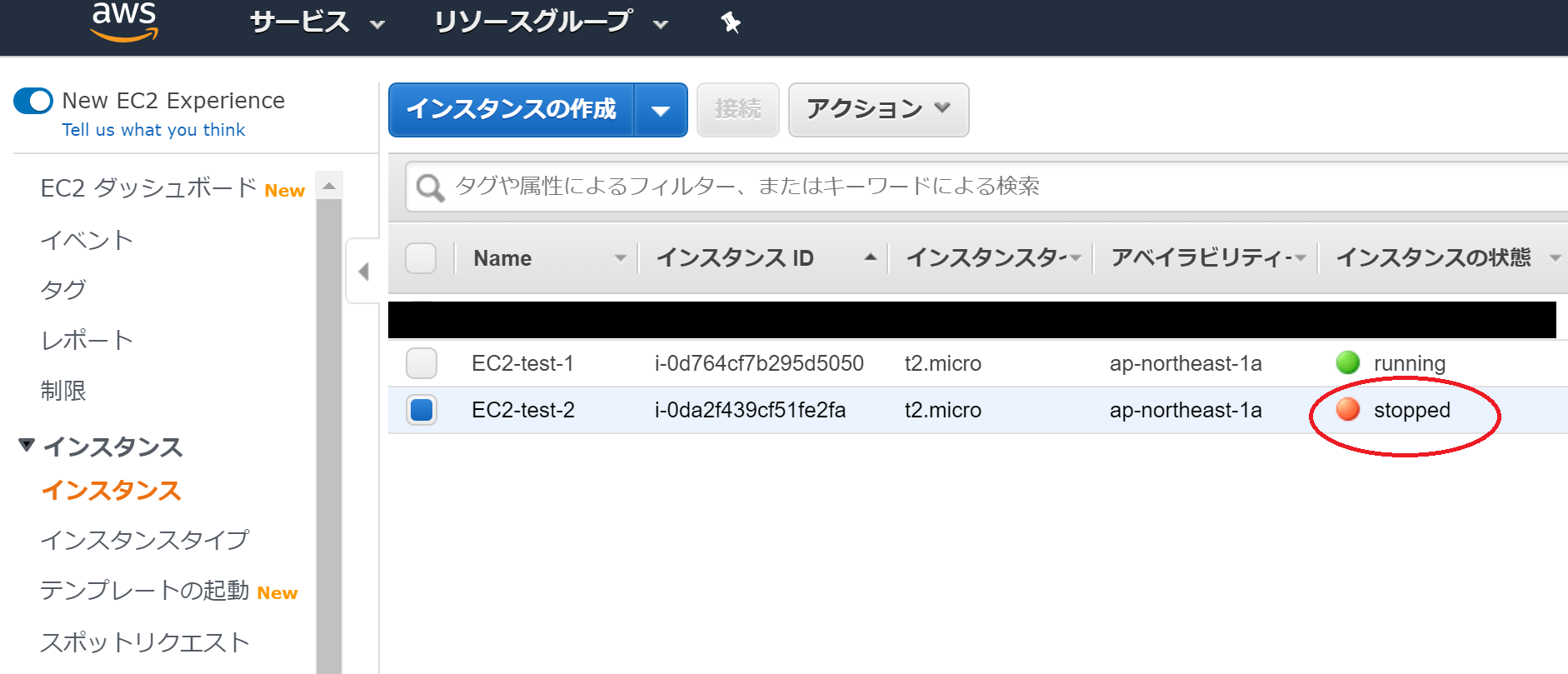
最後に、アタッチされたボリュームが反映されているかをブラウザで確認します。まず、停止してあるEC2-test-2を動作させます。
次に、TeraTermからEC2-test-2に接続します。
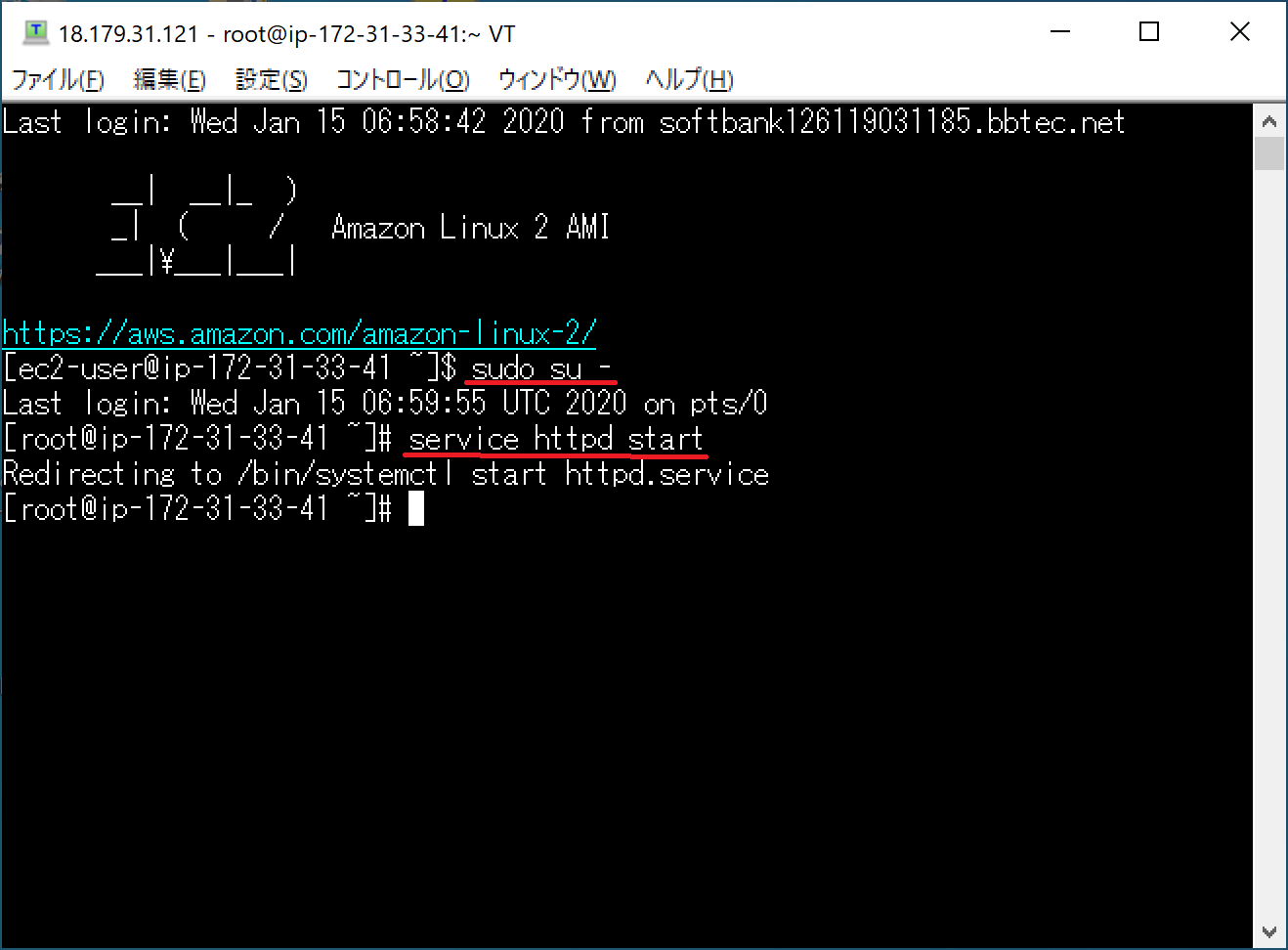
"sudo su -"コマンドで管理者権限に移行します。
そして、"service httpd start"コマンドでApacheサーバーを起動させます。
最後に、ブラウザにEC2-test-2のパブリックIPを入力して、出力を確認します。きちんと反映されていることが確認できました。
以上で”AWS EC2インスタンスの複製をしてみた編”を終わります。
最後まで読んでいただきまして、ありがとうございました!!!


- 投稿日:2020-01-16T19:45:41+09:00
iPadから新規にEC2サーバー立てて、Blink ShellからSSHでログインする手順
iPadから新規にEC2サーバー立てて、Blink ShellからSSHでログインする手順
Blink ShellはiOS上のターミナルソフト
このソフトとiPadだけでAWSのEC2立ててログインするところまでの手順をまとめました。
大枠の操作は一般的な手順と変わりませんが、
EC2で生成したキーペアのダウンロードがiPad上でうまくいかないので、
先にipad上でキーペアを作成しておく箇所だけがつまづきポイントです。今回使用した環境
- iPad Air2
- Blink Shell
- Google Chrome
暗号鍵のキーペアを事前に作成する
Blink Shell上で下記のコマンドを打てばOK
暗号鍵を生成するblink> ssh-keygen -t rsa -b 4096 -m PEM -f asw_rsa.pemEC2にキーペアをインポートする
まずBlink Shell上で下記のコマンドを実行し、公開鍵をテキスト表示する。
それをまるっと選択してコピーしておく。公開鍵の表示。これをコピーするblink> cat asw_rsa.pem.pub次にWEBブラウザからAWSにログインし、
下記の手順でキーペアをインポートする。
- EC2ダッシュボードの
キーペアを選択キーペアのインポートキーペア名は任意の名前- パブリックキーに先にコピーしておいた公開鍵をペーストする
インポートをクリックするEC2のインスタンスを作成する
- EC2ダッシュボードのインスタンスからインスタンスの作成を実行
- ステップ7までは普通に選択していく
- ステップ7「インスタンス作成の確認」で起動をクリック
- 「既存のキーペアを選択するか、新しいキーペアを〜〜」のダイアログが表示される
- 「既存のキーペアの選択」を選択、キーペアは先の手順でインポートしたものを指定
- 「インスタンスの作成」をクリック
動作確認
Blink Shellから下記のコマンドでSSH接続ができることを確認する。
sshでのログイン確認blink> ssh -i ./asw_rsa.pem ec2-user@ホストのIPアドレス
- 投稿日:2020-01-16T18:56:48+09:00
S3バケットのファイルをfindコマンド風に期間外分のみ出力する
S3バケットのファイルを指定した期間外分だけ出力
S3バケットに入れているファイルをライフサイクルルールにて改廃するときに、実際に改廃が発動しているのかどうかを確認するために、S3バケット上のログを指定した日数以前のものだけ出力したいケースがあった。標準のawscliだけだと、期間指定する方法が見当たらなかったため、Pythonスクリプトを組んでみた。
S3バケット全体に対して指定した日数以前のファイルを出力(第一引数でバケット名、第二引数で日数を指定)#!/usr/bin/python import boto3 import sys import datetime args = sys.argv bucket_name=args[1] expired_day=int(args[2]) timestamp_now=datetime.datetime.now() s3 = boto3.resource('s3') bucket = s3.Bucket(bucket_name) for obj_summary in bucket.objects.all(): dt=obj_summary.last_modified.strftime("%Y-%m-%d %H:%M:%S") dp=datetime.datetime.strptime(dt,"%Y-%m-%d %H:%M:%S") timestamp_put=dp + datetime.timedelta(hours=9) timestamp_del=timestamp_now - datetime.timedelta(days=expired_day) if timestamp_put < timestamp_del: print (str(timestamp_put),"s3://" + bucket_name + "/" + obj_summary.key)S3バケットの特定のプレフィックスに対して指定した日数以前のファイルを出力(第一引数でバケット名、第二引数でプレフィックス名、第三引数で日数を指定)#!/usr/bin/python import boto3 import sys import datetime args = sys.argv bucket_name=args[1] prefix=args[2] expired_day=int(args[3]) timestamp_now=datetime.datetime.now() s3 = boto3.resource('s3') bucket = s3.Bucket(bucket_name) for obj_summary in bucket.objects.filter(Prefix=prefix): dt=obj_summary.last_modified.strftime("%Y-%m-%d %H:%M:%S") dp=datetime.datetime.strptime(dt,"%Y-%m-%d %H:%M:%S") timestamp_put=dp + datetime.timedelta(hours=9) timestamp_del=timestamp_now - datetime.timedelta(days=expired_day) if timestamp_put < timestamp_del: print (str(timestamp_put),"s3://" + bucket_name + "/" + obj_summary.key)
- 投稿日:2020-01-16T18:56:48+09:00
S3バケットのファイルをfindコマンド風に指定日数外分のみ出力するscript
S3バケットのファイルを指定した期間外分だけ出力
S3バケットに入れているファイルをライフサイクルルールにて改廃するときに、実際に改廃が発動しているのかどうかを確認するために、S3バケット上のログを指定した日数以前のものだけ出力したいケースがあった。標準のawscliだけだと、期間指定する方法が見当たらなかったため、Pythonスクリプトを組んでみた。タイムスタンプはデフォルトのままだとUTC時間で出てきてしまうため、JST時間で出るように手を加えている。
S3バケット全体に対して指定した日数以前のファイルを出力(第一引数でバケット名、第二引数で日数を指定)#!/usr/bin/python import boto3 import sys import datetime args = sys.argv bucket_name=args[1] expired_day=int(args[2]) timestamp_now=datetime.datetime.now() s3 = boto3.resource('s3') bucket = s3.Bucket(bucket_name) for obj_summary in bucket.objects.all(): dt=obj_summary.last_modified.strftime("%Y-%m-%d %H:%M:%S") dp=datetime.datetime.strptime(dt,"%Y-%m-%d %H:%M:%S") timestamp_put=dp + datetime.timedelta(hours=9) timestamp_del=timestamp_now - datetime.timedelta(days=expired_day) if timestamp_put < timestamp_del: print (str(timestamp_put),"s3://" + bucket_name + "/" + obj_summary.key)S3バケットの特定のプレフィックスに対して指定した日数以前のファイルを出力(第一引数でバケット名、第二引数でプレフィックス名、第三引数で日数を指定)#!/usr/bin/python import boto3 import sys import datetime args = sys.argv bucket_name=args[1] prefix=args[2] expired_day=int(args[3]) timestamp_now=datetime.datetime.now() s3 = boto3.resource('s3') bucket = s3.Bucket(bucket_name) for obj_summary in bucket.objects.filter(Prefix=prefix): dt=obj_summary.last_modified.strftime("%Y-%m-%d %H:%M:%S") dp=datetime.datetime.strptime(dt,"%Y-%m-%d %H:%M:%S") timestamp_put=dp + datetime.timedelta(hours=9) timestamp_del=timestamp_now - datetime.timedelta(days=expired_day) if timestamp_put < timestamp_del: print (str(timestamp_put),"s3://" + bucket_name + "/" + obj_summary.key)S3ライフサイクルルールの発動タイミング
マニュアルによると下記のため、発動タイミングの算出基準は毎日UTC0時(日本時間9時)の模様。
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/intro-lifecycle-rules.htmlライフサイクルルール: オブジェクトの存在時間に基づく
Amazon S3 がアクションを実行できる期間を、そのオブジェクトの作成 (または変更) からの日数で指定できます。
日数をライフサイクル設定の Transition アクションおよび Expiration アクションで指定する場合は、以下の点に注意してください。
アクションが実行される、オブジェクト作成からの日数です。
Amazon S3 は、ルールに指定された日数をオブジェクトの作成時間に加算し、得られた日時を翌日の午前 00:00 UTC (協定世界時) に丸めることで、時間を算出します。たとえば、あるオブジェクトが 2014 年 1 月 15 日午前 10 時 30 分 (UTC) に作成され、移行ルールに 3 日と指定した場合、オブジェクトの移行日は 2014 年 1 月 19 日 0 時 0 分 (UTC) となります。
- 投稿日:2020-01-16T17:55:45+09:00
AWS RDSをオンプレのPostgreSQLデータベースのバックアップで使用する
背景
通常は初めからクラウド上に全て構築すると思いますが、オンプレミスのベアメタルサーバーで構築したデータベースのバックアップ先として、クラウドサービスのAWS RDSを利用すると言う話です。
以下のような利点に合致する場合を想定しています。
- 組織の施設内にオンプレミスのベアメタルサーバーを主として利用している。
- ベアメタルサーバーが物理故障した場合、新たに調達する為には予算や時間が必要。
- バックアップ用に別のベアメタルサーバーを用意するコストを抑えたい。
- 自然災害や、火災、事故などを想定して、施設外にバックアップを用意したい。
- オンプレミス側が停止した場合、一時的にクラウド側も利用可能
動作環境
オンプレミス側(メイン)
- OS:CentOS7
- データベース:PostgreSQL
クラウド側(バックアップ)
- AWS RDS
- データベース:PostgreSQL
AWS RDSの設定
データベースサービスに特化したコンソールが無いEC2という感じですので、基本的にはEC2に準拠した設定になります。
AWS RDSの料金
詳細は公式サイトを参照して下さい。
今回のバックアップに利用する場合、データ転送はデータ転送受信(イン)は無料なので、基本サービスの利用時間、ストレージ使用量が主な課金内容になると思います。データベースの作成
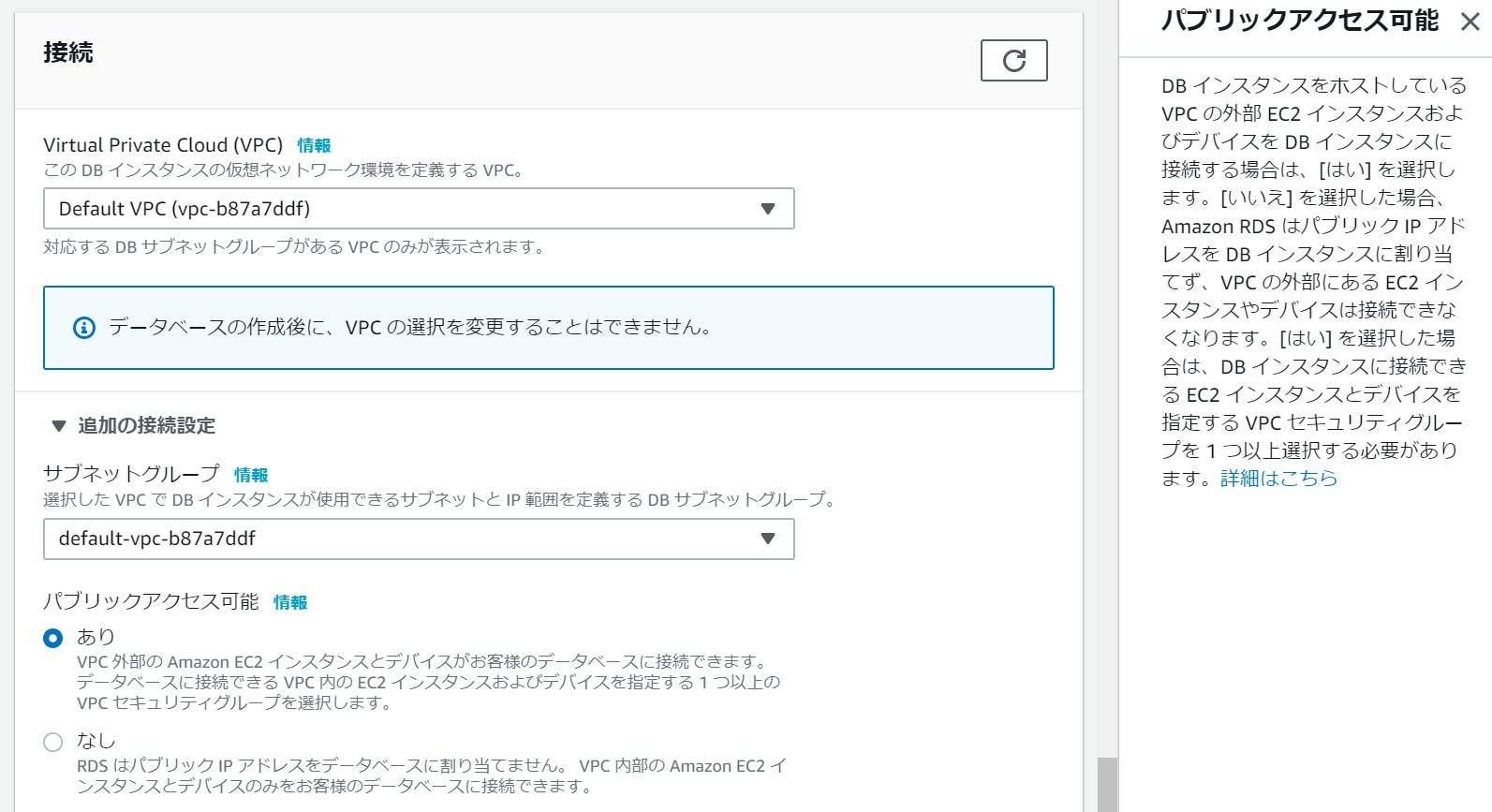
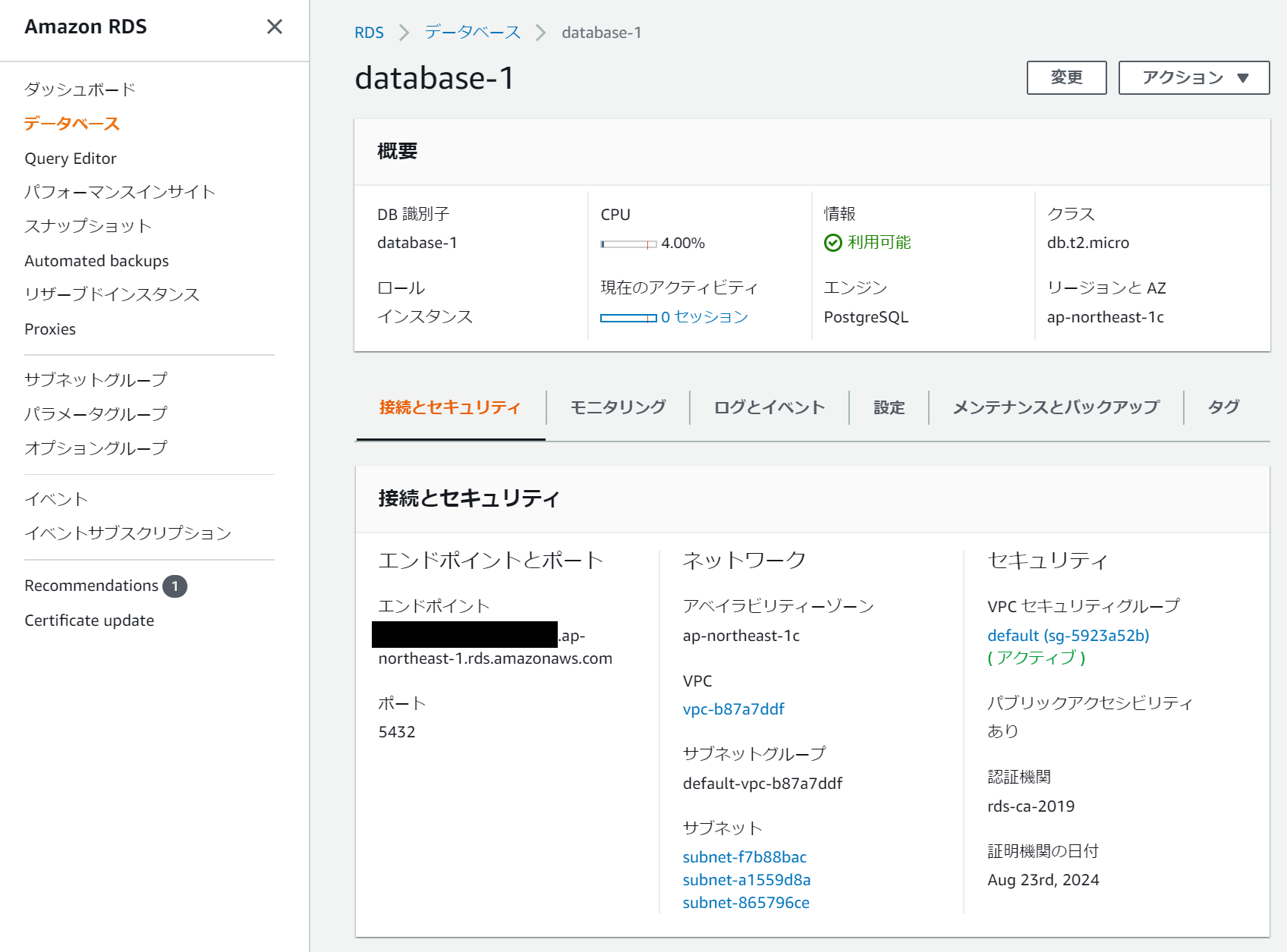
AWSのダッシュボードからRDSを選択して、データベースを作成します。
作成時の「接続」オプションで「パブリックアクセス可能」を「あり」に選択変更しておきます。
作成した後からでも変更は可能です。
データベース作成後のステータスに、エンドポイントとポート番号が表示されます。
これが外部からAWS RDSに接続する値になります。
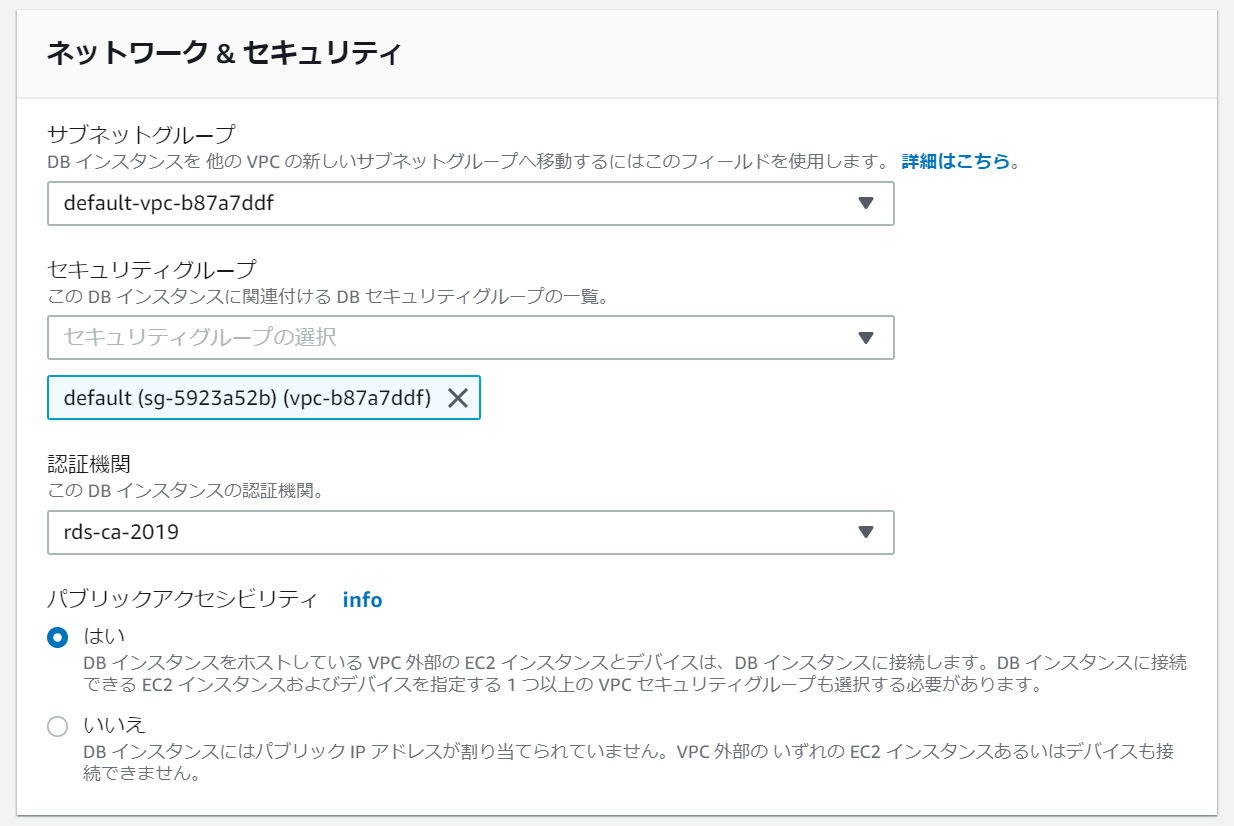
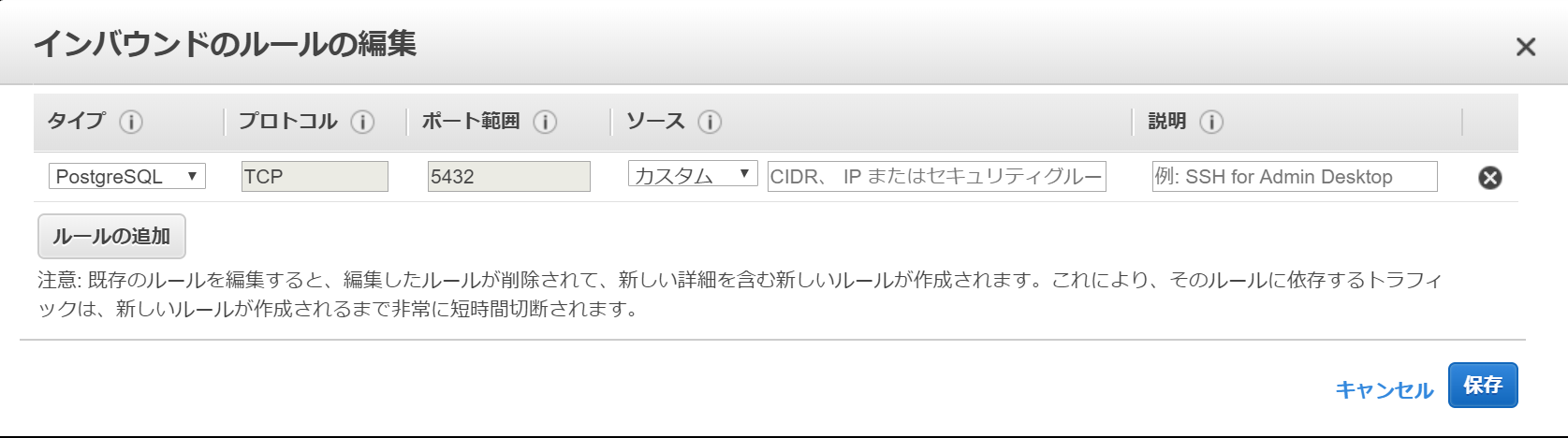
セキュリティグループの設定
EC2と同じ様に外部から接続出来るように設定します。
特定のIPアドレス番号だけ許可するように制限しましょう。
データベース接続確認
「pgAdmin」などのソフトでもAWS RDSデータベースに接続が可能ですので、事前確認してみましょう。
オンプレミス側PostgreSQLの設定
既存のPostgreSQLが稼働している事が前提です。
バックアップファイルを作成して、作成したバックアップファイルからAWS RDS側へリストアする事でバックアップします。
バックアップファイルが正しく復元リストアされる事の検証にもなって一石二鳥だったりします。ローカルバックアップ
PostgreSQLのデータをローカルにバックアップする為に、「pg_dump」コマンドを使用します。
バックアップ形式には2種類があります。
- スクリプト形式:SQLのプレーンテキスト。直接編集可能で他への移行がし易い。
- アーカイブ形式:バイナリで編集不可だが個別の復元が可能。またアーカイブ方法として「tar形式」とデフォルトで圧縮される「custom形式」がある。
それぞれにメリット・デメリットがありますが、ファイルサイズが小さく内容が見えない点がクラウド側へデータ転送するメリットなので、今回はアーカイブ(custom)形式を使用します。
また定期的にバックアップを実行する様にシェルスクリプトにしてcronで定期実行させます。形式
$ pg_dump -Fc -w --host=127.0.0.1 --dbname=[データベース名] --dbusername=[ユーザー名] > [出力ファイル名とPATH]例
backup.sh#/bin/bash pg_dump -Fc -w --host=127.0.0.1 --dbname=db1 --dbusername=postgres > ~/db1-backup.custom適当にcronの定期実行を設定
$ crontab -l 00 0 * * * /home/pg-user/backup.sh 2>&1AWS RDSへのリストアバックアップ
先に設定したAWS RDSのPostgreSQLデータベースに、ローカルバックアップしたファイルからリストアを実行します。
それに先立って、AWS RDS側への接続認証に関する設定ファイルを作成します。
シェルスクリプトで実行する際にパスワード入力待ちで停止してしまう事をこれで回避します。形式
~/.pgpass[AWS RDSのエンドポイント] : [ポート番号] : [データベース名] : [ユーザー名] : [パスワード]例
~/.pgpassxxx.yyy.ap-northeast-1.rds.amazonaws.com:5432:db1:postgres:passwordファイル属性をオーナー読み取りに制限しておきます。
$ chmod 600 ~/.pgpass復元するリストアのコマンド「gr_restore」を使用します。
また定期的にバックアップを実行する様にシェルスクリプトにしてcronで定期実行させます。形式
$ pg_restore --host=[AWS RDSのエンドポイント] --username=[ユーザー名] -c -Fc --dbname=[データベース名] [バックファイル名PATH]例
restore.sh#/bin/bash pg_restore --host=xxx.yyy.ap-northeast-1.rds.amazonaws.com --username=postgres -c -Fc --dbname=db1 ~/db1-backup.custom適当にcronの定期実行を設定
$ crontab -l 00 1 * * * /home/pg-user/restore.sh 2>&1
- 投稿日:2020-01-16T17:21:22+09:00
AWS EC2インスタンスの複製をしてみた。その6(備忘録)
前回の続きです。https://qiita.com/Bikeiken-IT/items/6c885d40fd92b1a6dee9
AMIからEC2インスタンスを複製しました。続きまして、Snapshot機能を用いて新しく作成したEC2インスタンスにストレージをアタッチします。
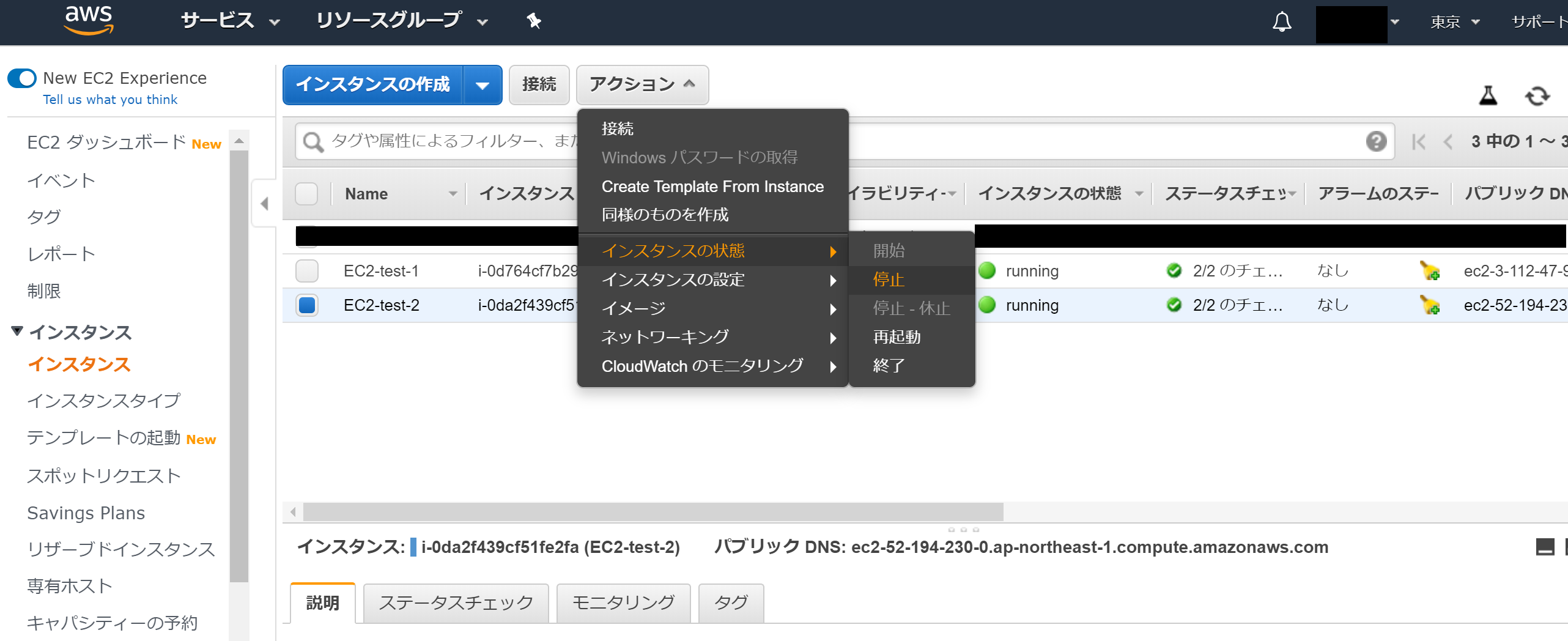
その前に、EC2-test-2のボリューム(ストレージに相当するもの)をデタッチしなければなりません。そのために、EC2-test-2を停止させます。
インスタンスの状態が"stopped"と表示されていれば、EC2インスタンスは停止しています。
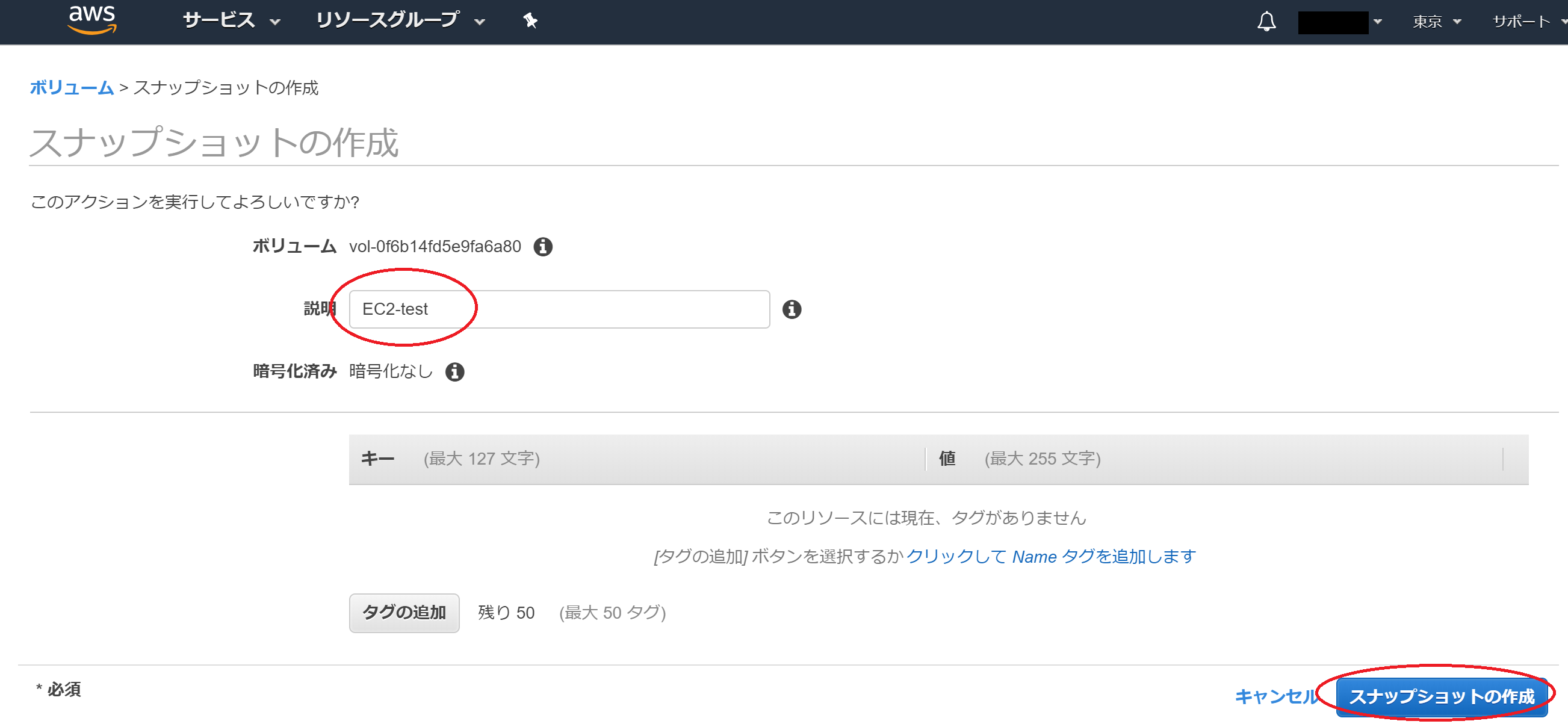
続いて、Snapshotを作成します。
画面左のスクロールからボリュームを選択してください。
そして、EC2-test-1のボリュームであるtest-1を本来は選択します。(画面上ではtest-2(EC2-test-2)となっています。こちらのミスです。しかし、目的は複製なのでtest-1を選択すべきでした。)
次に、アクションからスナップショットの作成を選択してください。
スナップショットの説明の入力を行い、スナップショットの作成のボタンを押してください。
これでEC2-test-1のボリュームのSnapshotは作成されます。
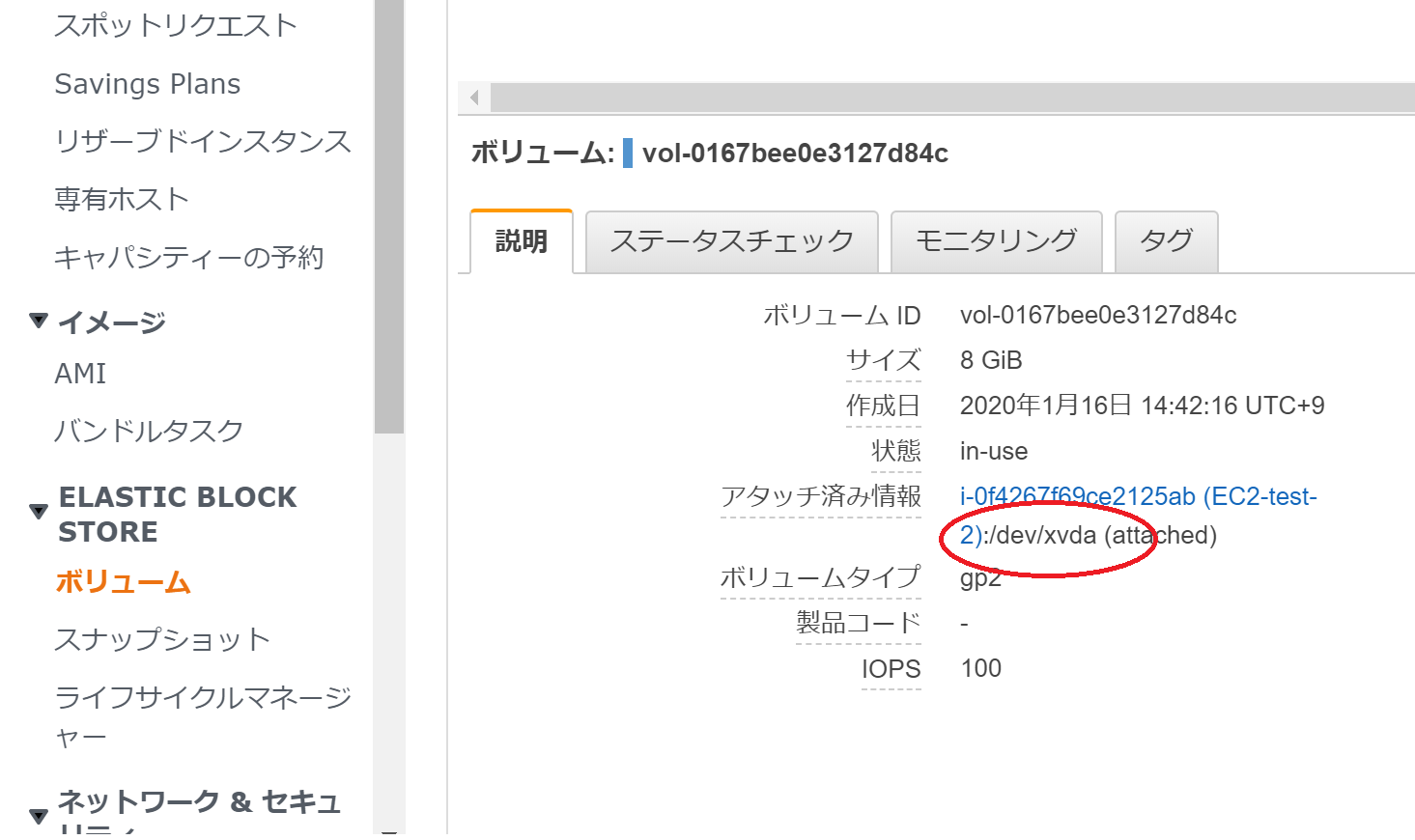
その前に、現在のtest-2のあるディレクトリを控えておく必要があります。
画面左のスクロールからボリュームを選択します。test-2を選択すると、説明欄に赤丸で囲った部分が表示されます。
今回の場合は/dev/xvdaです。
Snapshotから作られたボリュームをtest-2にアタッチする際に必要となります。メモ帳などに保存しておくことをおすすめします。
続いて、先ほどSnapshotから作成したEC2-test-1のボリュームをEC2-test-2にアタッチするために、現在EC2-test-2にアタッチされているボリュームをデタッチします。(表現が分かりづらくて申し訳ありません。)
デタッチするというボタンを押します。これでtest-2のボリュームをデタッチできます。
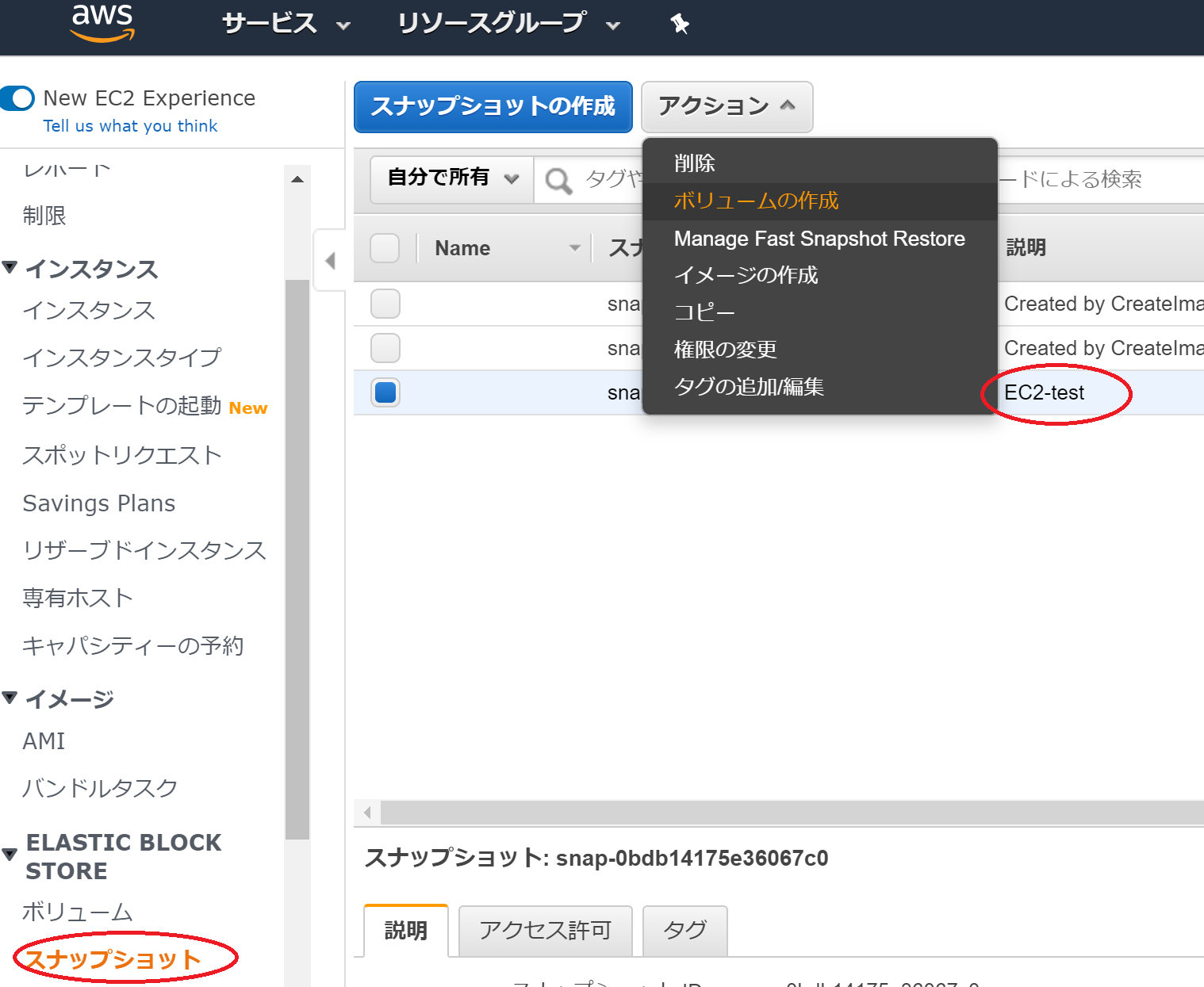
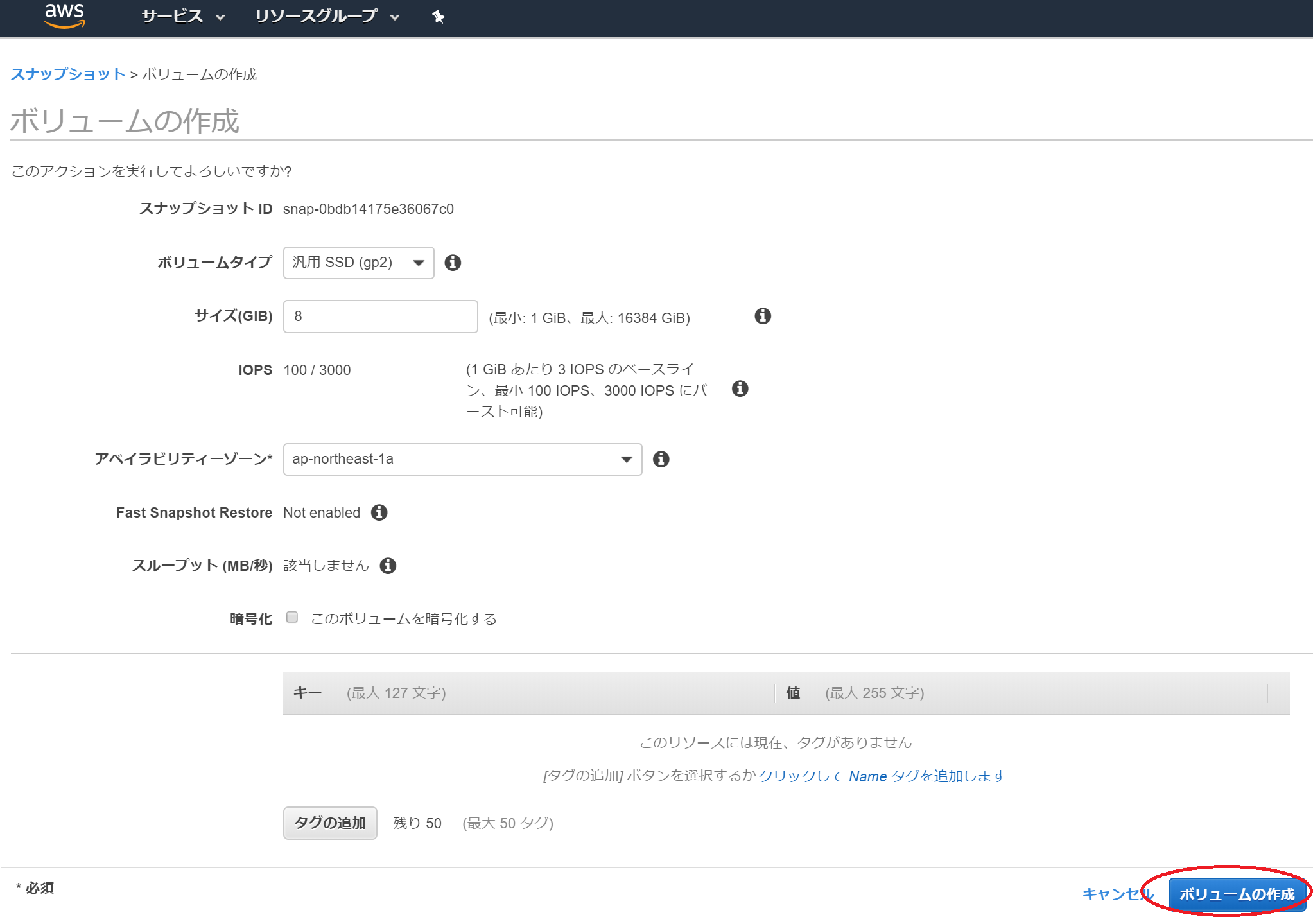
次に、先ほど作成したSnapshotからボリュームを作成します。
作成したSnapshotを選択して、アクションからボリュームの作成を選んでください。
デフォルトのままボリュームの作成のボタンを押します。これでEC2-test-1のスナップショットからボリュームを作成しました。
EC2-test-2のボリュームのデタッチも終えているため、後はスナップショットから作成したボリュームをEC2-test-2にアタッチする工程だけです。その7に続きます。https://qiita.com/Bikeiken-IT/items/baac8bd1e4cfdfe3af51



- 投稿日:2020-01-16T16:23:53+09:00
AWS EC2インスタンスの複製をしてみた。その5(備忘録)
前回の続きです。https://qiita.com/Bikeiken-IT/items/5b6d1e3ab5573c081ba8
本記事の本題であるEC2インスタンスの複製を行います。
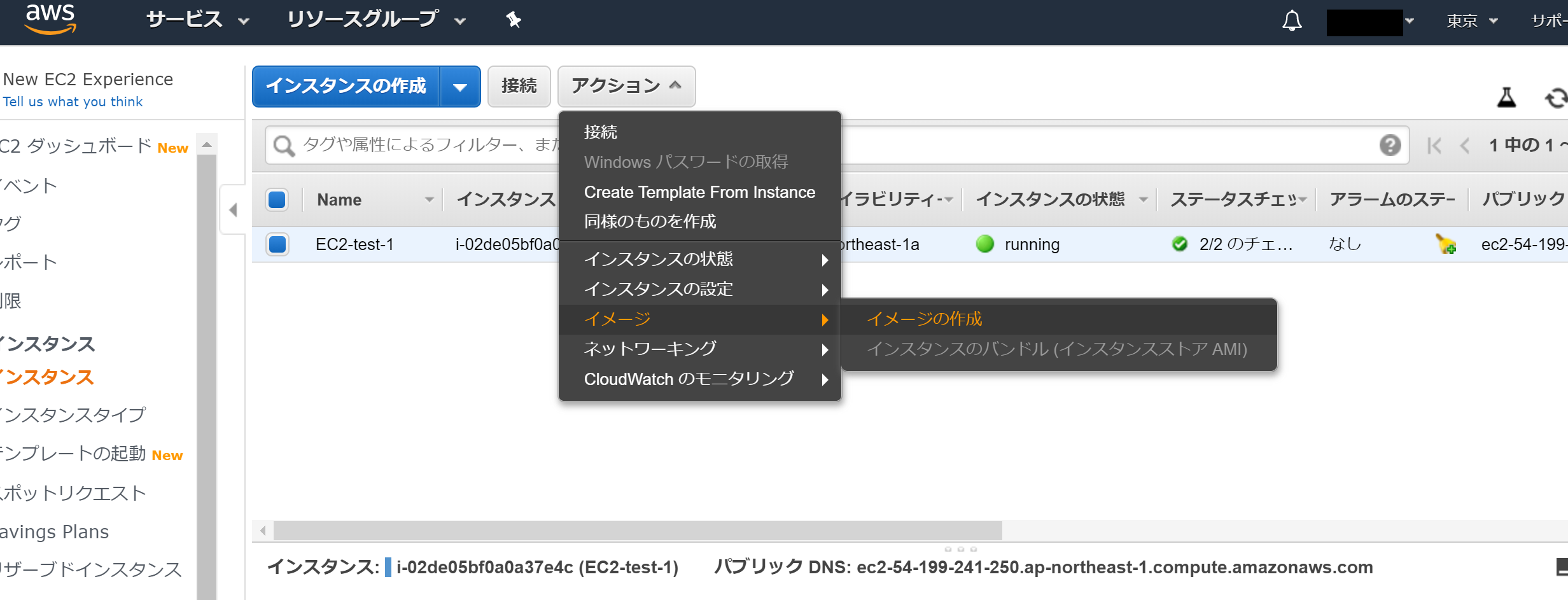
それではAWSサービスのEC2画面に戻りまして、作成したEC2インスタンスのEC2-test-1を選択します。
そして、アクションからイメージの作成を選択してください。
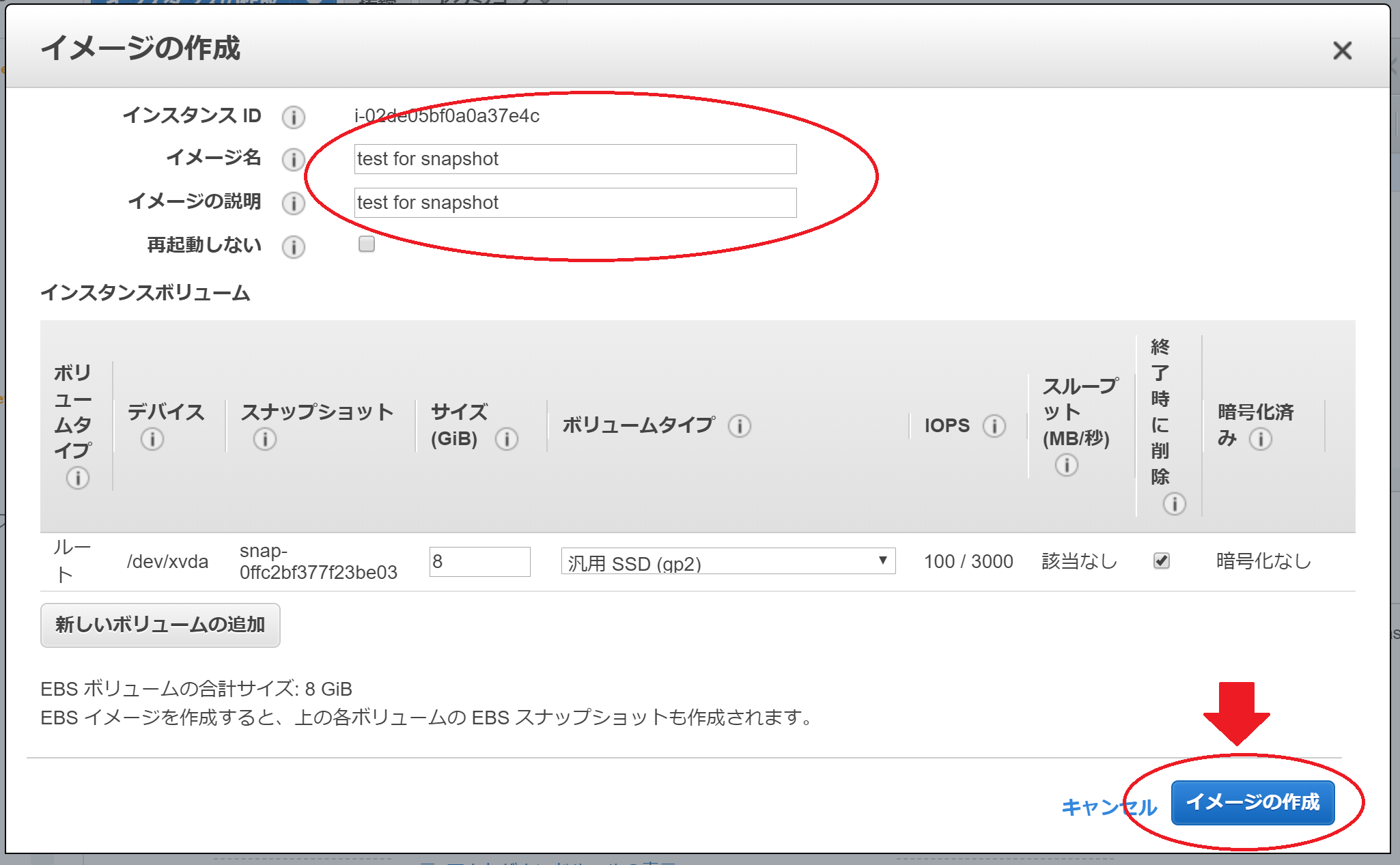
イメージの作成の画面が表示されます。イメージ名とイメージの説明を入力し、イメージの作成のボタンを押します。
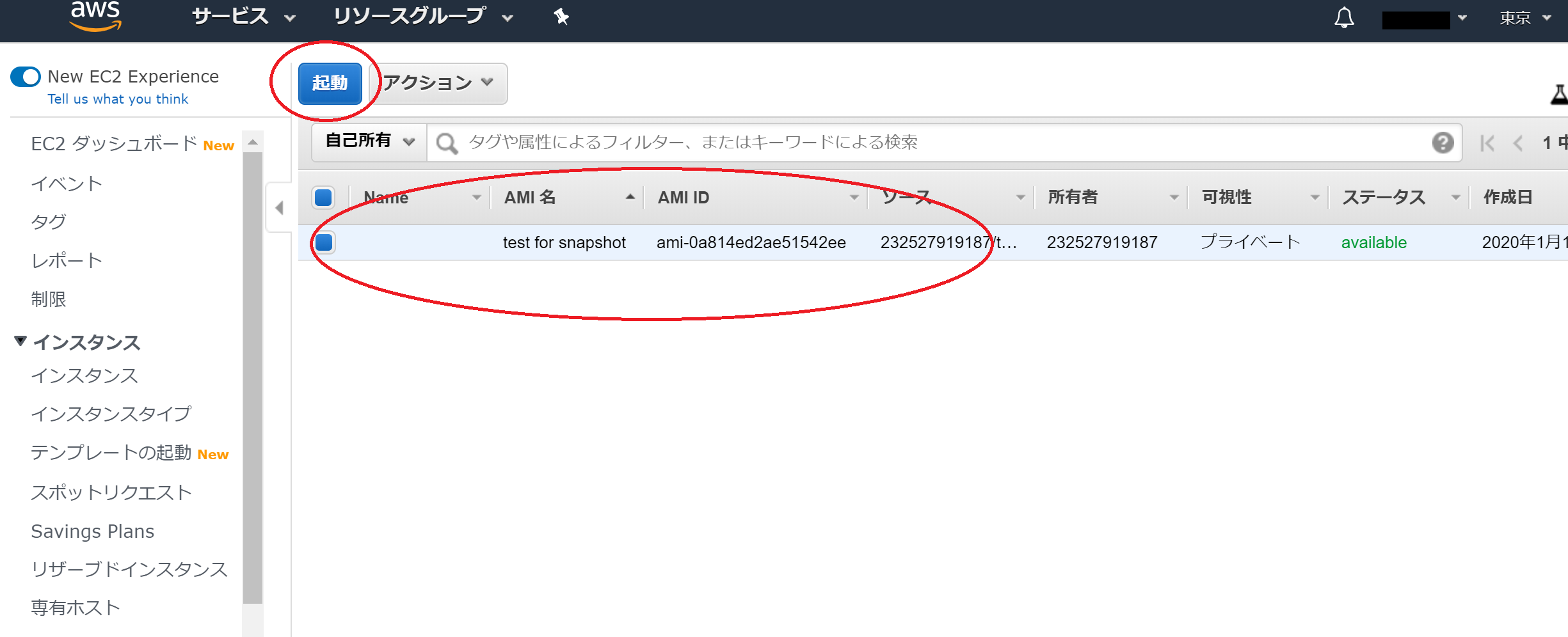
続いて、EC2の左のスクロールからAMIを選択して、先ほど作成したOSイメージを選択して、起動ボタンを押してください。
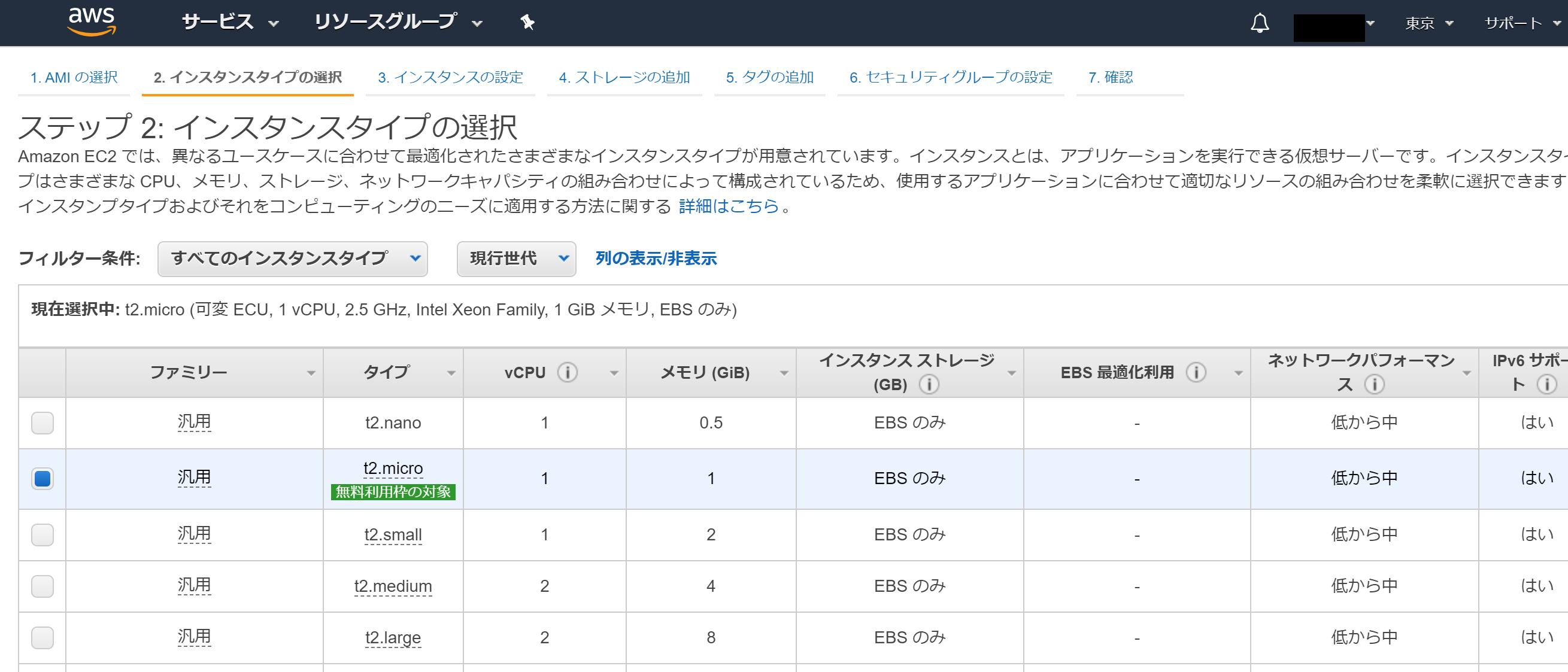
すると、EC2のインスタンスタイプの選択画面からとなります。これはAMIをEC2-test-1(EC2インスタンス)から作成したため、OSイメージが確定しているためです。
ここからはEC2-test-1を作成した時と同じ条件でEC2-test-2というEC2インスタンスを作成します。
EC2-test-2が作成されたことが確認できました。その6に続きます。https://qiita.com/Bikeiken-IT/items/e1b80cc6cf2cbced5440
- 投稿日:2020-01-16T16:02:20+09:00
Rails Tutorialの知識から【ポートフォリオ】を作って勉強する話 #17 VPC環境構築編
こんな人におすすめ
- プログラミング初心者でポートフォリオの作り方が分からない
- Rails Tutorialをやってみたが理解することが難しい
前回:#16 線グラフ, Chartkick編
次回:準備中今回の流れ
- AWS環境を再構築する理由を知る
- 完成のイメージを理解する
- VPC内を構築する
この記事は、動画を観た時間を記録するアプリのポートフォリオです。
今回は完成したRailsアプリの環境をAWS内で再構築します。
なお、ローカル開発環境にはMacを使います。AWS環境を再構築する理由を知る
これまでは、ポートフォリオのIDEにcloud9を使ってきました。
このcloud9によって開発環境をクラウド上で整えることができました。
しかし、それでは開発環境がどのように構築されたのかが分かりません。さらに、こんな動画と出会いました。
ポートフォリオにAWSとDockerとCircleCIを組み込むための学習順序と教材についてモダンな企業の書類選考を突破するポートフォリオには、
AWS、Docker、CircleCI(できたら)
以上を理解し、組み込むことが得策である。モダン企業が使うインフラや環境構築には、AWSを使います。
そんなわけでAWS(やDockerなど)を知るために、AWSで環境を再構築します。完成のイメージを理解する
完成したポートフォリオをAWSで動かすためには、2つの環境構築が必要です。
- VPC内の環境構築
- EC2内の環境構築
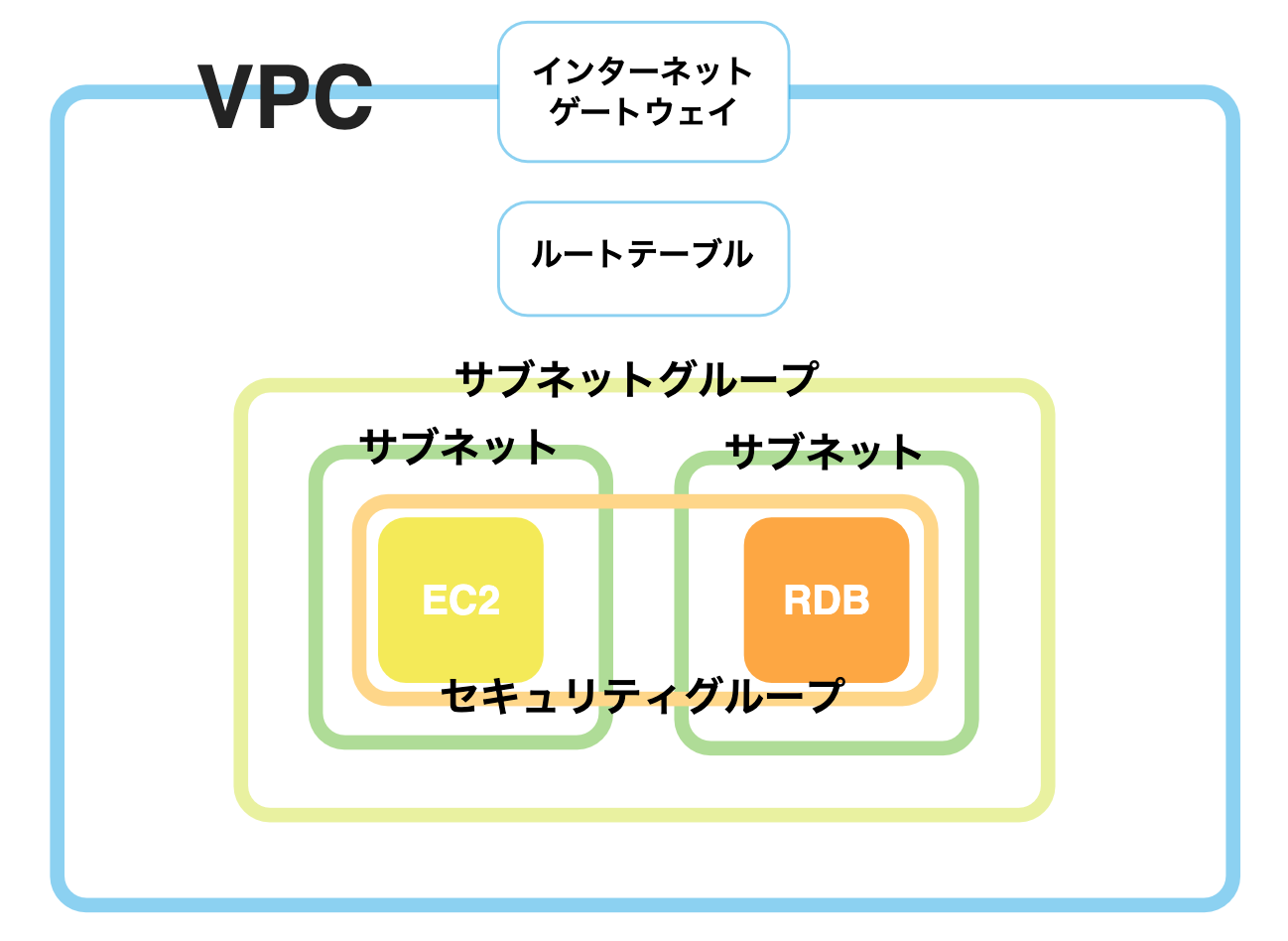
今回は、2つのうち「VPC内の環境構築」を行います。
VPC内は以下のように構築します。
今のところ理解できなくても問題ありません。
実際にVPC内を構築しながら理解しましょう。VPC内を構築する
それではVPC内を構築します。
これからAWSで環境を構築するのに、色々な言葉が出てきます。
- VPC
- サブネット
- インターネットゲートウェイ
- ルートテーブル
- セキュリティグループ
- サブネットグループ
- RDS
- EC2
- キーペア
- Elastic IP
これらすべてを設定する必要があります。
環境構築内で作業したい人を、パソコンで作業したいタロウくんと見立てると、それぞれこんなイメージです。
- VPC(=土地)
- サブネット(=家族それぞれの部屋)
- サブネットグループ(部屋の種類)
- インターネットゲートウェイ(=玄関)
- ルートテーブル(=家出ていくときのルール)
- セキュリティグループ(=部屋の鍵)
- RDS(部屋の物置)
- EC2(タロウの部屋のパソコン)
- キーペア(パソコンのパスワード)
- Elastic IP(パソコンを置いている詳しい位置)
1つずつ設定し、ローカルからEC2に接続できるかを確かめます。
VPC
まずは自分が作業する場所をインターネット上に確保します。
これがないと何も動かないので、早速設定していきます。AWSにログイン → AWSマネジメントコンソール『VPC』
画面左のダッシュボード『VPC』 → 『VPCの作成』名前タグ:VPC_for_Lantern(自分のアプリ名) IPv4 CIDR ブロック:10.0.0.0/16 IPv6 CIDR ブロック:なし テナンシー:デフォルト 『作成』サブネット
環境が動くために必要な部屋を用意します。
具体的には、EC2とDB用のサブネット(部屋)を用意します。画面左のダッシュボード『サブネット』 → 『サブネットの作成』
名前タグ:Lantern-Subnet1(自分のアプリ名) VPC:VPC_for_Lantern アベイラビリティーゾーン:ap-northeast-1a IPv4 CIDR ブロック:10.0.0.0/24 『作成』再び『サブネットの作成』
名前タグ:Lantern-Subnet2(自分のアプリ名) VPC:VPC_for_Lantern アベイラビリティーゾーン:ap-northeast-1c IPv4 CIDR ブロック:10.0.1.0/24 『作成』インターネットゲートウェイ
それぞれの通信がVPC内外を通るために、玄関を用意します。
すべての通信をここから通るようにするルールづけには、後述のルートテーブルを使います。画面左のダッシュボード『インターネットゲートウェイ』 → 『インターネットゲートウェイの作成』
名前タグ:Gateway_for_Lantern(自分のアプリ名) 『作成』作成したゲートウェイを選択 → 『アクション』 → 『VPCにアタッチ』
VPC:VPC_for_Lantern 『アタッチ』ルートテーブル
通信を通すルールを作ります。
今回はサブネットがインターネットゲートウェイを通るというルールを作ります。画面左のダッシュボード『ルートテーブル』 → 『ルートテーブルの作成』
名前タグ:Table_for_Lantern(自分のアプリ名) VPC:VPC_for_Lantern 『作成』作成したルートテーブルを選択 → 下部タブ『ルート』 → 『ルートの編集』
『ルートの追加』 送信先:0.0.0.0/0 ターゲット:igw-**(Gateway_for_Lantern) 『ルートの保存』セキュリティグループ
通信のセキュリティールールを作ります。
外から内を制限するインバウンドルールと、内から外を制限するアウトバウンドルールがあります。画面左のダッシュボード『セキュリティグループ』 → 『セキュリティグループの作成』
セキュリティグループ名:Lantern-SecurityGroup(自分のアプリ名) 説明:SecurityGroup_for_Lantern(自分のアプリ名) VPC:VPC_for_Lantern 『作成』作成したセキュリティグループを選択 → 下部タブ『インバウンドのルール』 → 『ルールの編集』
『ルールの追加』 タイプ:SSH ソース:カスタム、0.0.0.0/0 『ルールの追加』 タイプ:HTTP ソース:カスタム、0.0.0.0/0 『ルールの保存』サブネットグループ
サブネットをグループ化します。
RDS(データベース)作成時にサブネットグループが必要なので、作成します。AWSマネジメントコンソール『RDS』 → 画面左のダッシュボード『サブネットグループ』 → 『DBサブネットグループの作成』
名前:Lantern-DB-Subnet-Group(自分のアプリ名) 説明:DB Subnet Group for Lantern(自分のアプリ名) VPC:VPC_for_Lantern 『このVPCに関連するすべてのサブネットを追加します』 『作成』RDS
データベースを作成します。
環境の再構築に伴って、データベースをMySQLに変更します。画面左のダッシュボード『データベース』 → 『データベースの作成』
データベース作成方法を選択:標準作成 エンジンのオプション:MySQL テンプレート:無料利用枠 DBインスタンスの識別子:Lantern-mysql マスターユーザー名:任意 マスターパスワード:任意 DBインスタンスサイズ:db.t2.micro 接続;VPC:VPC_for_Lantern 追加の接続設定;サブネットグループ:Lantern-DB-Subnet-Group 追加の接続設定;VPCセキュリティグループ:既存の選択 追加の接続設定;既存のVPCセキュリティグループ:Lantern-SecurityGroup 追加設定;バックアップの保存期間:1日 他、デフォルトでOK 『データベースの作成』EC2
仮想のパソコンを作成します。
アプリを作成やデプロイはここで行います。AWSマネジメントコンソール『EC2』 → 画面左のダッシュボード『インスタンス』 → 『インスタンスの作成』
1. AMIの選択 Amazon Linux 2 AMI(記事公開時は一番上) 『選択』 2. インスタンスタイプの選択 デフォルトでOK 『次のステップ:インスタンスの詳細の設定』 3. インスタンスの詳細の設定 ネットワーク:VPC_for_Lantern サブネット:Lantern_Subnet1 自動割り当てパブリックIP:有効 終了保護の有効化:チェック 『次のステップ:ストレージの追加』 4. ストレージの追加 『次のステップ:タグの追加』 5. タグの追加 『タグの追加』 キー:Name 値:Lantern-instance(自分のアプリ名) 『次のステップ:セキュリティグループの設定』 6. セキュリティグループの設定 セキュリティグループの割り当て:既存のセキュリティグループを選択する Lantern-SecurityGroupにチェック 『確認と作成』 7. インスタンス作成の確認 『作成』キーペア
ローカルからサーバーのEC2に接続するための鍵です。
EC2インスタンスの作成を終えると、自動的に作成画面に移ります。新しいキーペアの作成 キーペア名:lantern-key-pair(自分のアプリ名) 『キーペアのダウンロード』 ※必須! 『インスタンスの作成』このキーペアは後で必ず使うので、無くさないようにします。
Elastic IP
このままだとサーバーが再起動するたびにパブリックIPが変わります。
それを固定するためにElastic IPを使います。画面左のダッシュボード『Elastic IP』 → 『インスタンスの作成』 → 『Elastic IPアドレスの割り当て』
『割り当て』作成したElastic IPを選択 → 『アクション』 → 『Elastic IPアドレスの関連付け』
インスタンス:Lantern-instance 『関連付ける』ローカルから接続
キーペアを使って、ローカルからEC2インスタンスに接続します。
以下は、Macのターミナルでの操作です。
local$ mv Downloads/lantern-key-pair.pem .ssh/ $ cd .ssh/ $ chmod 400 lantern-key-pair.pem $ ssh -i lantern-key-pair.pem ec2-user@100.100.100.100 (@以降はElastic IPを入れる)出てくる選択肢にyesと答えてenterします。
こういうのが出てくると成功です。server__| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___|補足:参考記事とAWS用語について
RailsアプリケーションをデプロイするまでのAWSに出てくる用語は、以下の記事がわかりやすいので、ぜひ参考にしてみてください。
(@naoki_mochizukiさん、素敵な記事をありがとうございます。)
(下準備編)世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで他、参考になりました↓
RailsアプリをAWSで公開する(Rails+Unicorn+Nginx)
RailsアプリをAWSにイチからデプロイするまでの手順メモ
RailsアプリをAWS EC2にデプロイする方法(つまづきそうなポイント)
初心者向け:AWS(EC2)にRailsのWebアプリをデプロイする方法 ④
ssh AWSデプロイ時のCloud9での公開鍵の見つけ方
前回:#16 線グラフ, Chartkick編
次回:準備中
- 投稿日:2020-01-16T15:59:34+09:00
AWS Support との思い出をいつまでもとっておけるようにしました。
AWS Support みなさん使っていますか?
わたしの好きなサービスのひとつが AWS Support なのは皆さんご存知だとは思います。
試験に出ますよ。さて。
この AWS Support を使って問い合わせたもの(起票したもの)は、起票後12か月間は使えるとのこと。
https://aws.amazon.com/jp/premiumsupport/faqs/Q: ケース履歴の保存期間はどれほどですか?
サポートケースの履歴は、作成後12ヵ月間ご利用いただけます。
ということは、起票から12か月経過すると、 AWS Support との思い出がなくなってしまう!?
軽微な質問や超重要な障害への問い合わせも全部なくなってしまうの!?それは、なんだか嫌だな、って。
と、弊社の複数のつよつよエンジニアーズから同じタイミングで話をもらったので、
ものは試しと、AWS Support との思い出を取っておけるようにしてみました。レシピ
登場人物
- AWS Support
AWS Support との思い出サポートケース- AWS Lambda
- Python 3.x で Lambda 関数を作ります
- IAM Roleは適宜つけてくださいね。
- Amazon CloudWatch Logs の書き込み系と Amazon DynamoDB の読み書き系を付与しています。
- Amazon DynamoDB
- 思い出を取っておく場所(SupportCasesテーブル)
- 育んでいる最中の思い出を取っておく場所(notResolvedCasesテーブル)
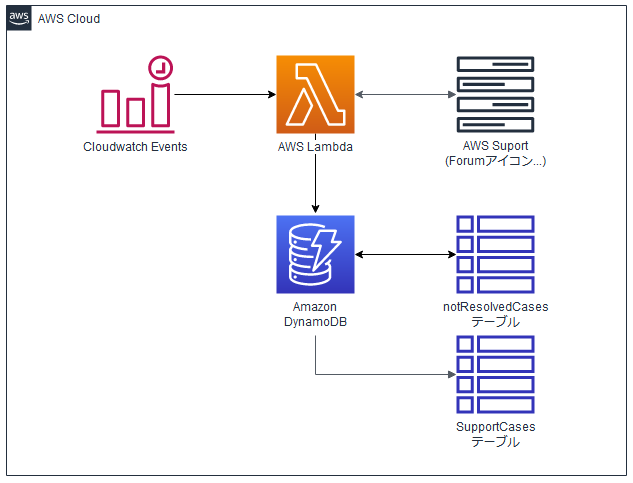
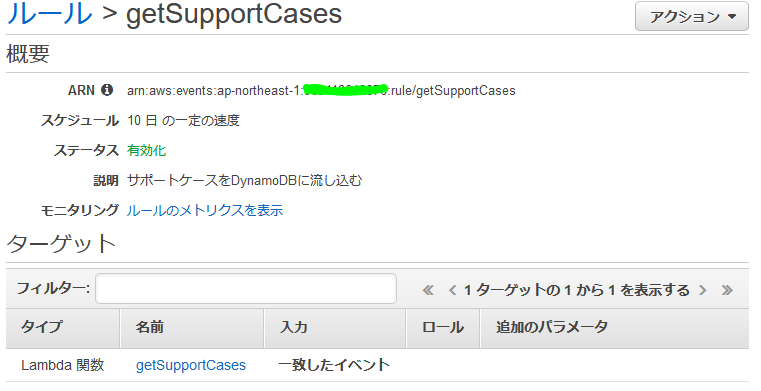
構成図
※ AWS Support のシンプルアイコンが見当たらなかったのでForumsアイコンで代用しています。Amazon CloudWatch Events
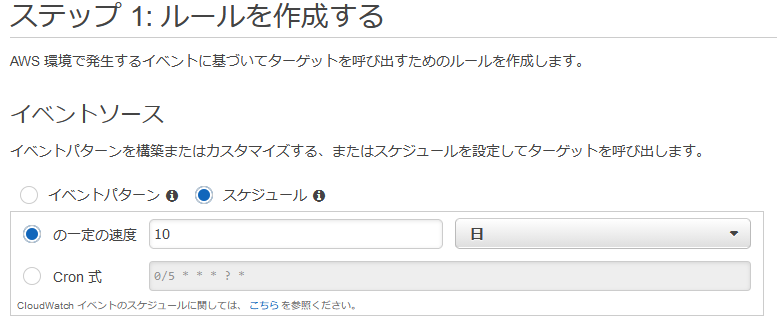
今回は10日に1度取り込むので以下のような設定にしました。
後述の Lambda 関数を作ってから設定してくださいね。
完成した Amazon CloudWatch Events はこんな感じです。
Amazon DynamoDB のテーブル
SupportCasesテーブル(思い出を取っておく場所=解決済状態のサポートケース)
キー名 設定 case_id プライマリキー timeCreated ソートキー notResolvedCasesテーブル(育んでいる最中の思い出を取っておく場所=未解決状態のサポートケース)
キー名 設定 case_id プライマリキー timeCreated ソートキー AWS Lambda の Lambda関数
エラーハンドリングはやっていないので、あくまでご参考・・・
lambda_function.pyimport json import boto3 import datetime dynamodb = boto3.resource('dynamodb') s_table = dynamodb.Table('SupportCases') n_table = dynamodb.Table('notResolvedCases') # AWS Support の エンドポイントは米国東部(us-east-1) support = boto3.client('support', 'us-east-1') # 10日に1度動くために実行時点から10日前の0時0分とする。 now = datetime.datetime.now() lastUpdate = '{0:%Y}-{0:%m}-{0:%d}T00:00:00.000Z'.format(now - datetime.timedelta(days=10)) def lambda_handler(event, context): # 前回見た際に、resolved になっていないものがあったかを確認 notResolvedIds = getNotResolvedIds() # resolved になっていなかったものがあれば更新する if len(notResolvedIds) >= 1: upDateNotReslvedIds(notResolvedIds) # 前回取得から今回までの間の追加・更新分を取得 supportCases = describeSupportCases() # あれば更新する if len(supportCases) >= 1: addSupportCases(supportCases) return def getNotResolvedIds(): # notResolvedCases テーブルから resolved になっていない # サポートケースの caseId を取得する case_ids=[] response = n_table.scan() for i in response['Items']: case_ids.append(i['case_id']) return case_ids def upDateNotReslvedIds(notResolvedIds): # case_idを指定して resolved にいなかったサポートケースを取得する response=support.describe_cases( caseIdList=notResolvedIds, includeResolvedCases=True, language='ja' ) for i in response['cases']: # resolved になっていなかったサポートケースの情報を更新する response = s_table.put_item( Item={ 'case_id': i['caseId'], 'display_id': i['displayId'], 'subject': i['subject'], 'serviceCode': i['serviceCode'], 'categoryCode': i['categoryCode'], 'severityCode': i['severityCode'], 'timeCreated': i['timeCreated'], 'status': i['status'], 'communications': i['recentCommunications']['communications'] } ) # 更新時に resolvedになっていたら、notResolvedCasesテーブルから情報を消す if i['status'] == "resolved": response = n_table.delete_item( Key={ 'case_id': i['caseId'], 'timeCreated': i['timeCreated'] } ) def describeSupportCases(): # 指定日(例:10日前)から実行時点までのサポートケースを取得する response = support.describe_cases( afterTime=lastUpdate, includeResolvedCases=True, language='ja' ) return response def addSupportCases(supportCases): # 取得したサポートケースを SupportCases テーブルに格納する for i in supportCases['cases']: response = s_table.put_item( Item={ 'case_id': i['caseId'], 'display_id': i['displayId'], 'subject': i['subject'], 'serviceCode': i['serviceCode'], 'categoryCode': i['categoryCode'], 'severityCode': i['severityCode'], 'timeCreated': i['timeCreated'], 'status': i['status'], 'communications': i['recentCommunications']['communications'] } ) # status が resolved 以外だったら notResolvedCases テーブルに記録する if i['status'] != "resolved": response = n_table.put_item( Item={ 'case_id': i['caseId'], 'timeCreated': i['timeCreated'], 'status': i['status'], } )これが動くとどうなるのか
かんたんにまとめると以下の通り。。
- Amazon CloudWatch Events が発火する
- AWS Lambda が動き出し、Lambda 関数を実行
- notResolvedCases テーブルに情報があるか確認
- ある場合は、そのサポートケースのIDをもとに情報を取得
- 取得した情報を SupportCases テーブルへ更新
- そのサポートケースのステータスが resolved(解決済み)になっていたら notResolvedCases テーブルから削除
- 実行時の10日前から実行時までの期間を指定して、 AWS Support からサポートケースの情報を取得する。
- 取得したサポートケースの情報を SupportCases テーブルに格納する
- その際、サポートケースのステータスが resolved(解決済み)になっていない場合には、notResolvedCases テーブルに情報を書き込む
おしまい。
まとめ
12か月程度しか記憶しておけない AWS Support との思い出をこのように保存しておくことで、
今後は、以下の例のような表示方法でいつまでも楽しむことができます。
- Amazon QuickSight
- Amazon CloudSearch
- Amazon API Gateway + AWS Lambda + Amazon S3 によるWebUIでの表示
- 投稿日:2020-01-16T14:40:20+09:00
ELBからALBに変更したら初回の接続が遅くなった(igwの設定を見直して解消)
事象
ELBでは遅くなかったのに、ALBを利用すると初回の接続が遅くなるケースに相対しました。
データ量が重いという感じではなく、接続までに時間がかかっている、という感触です。その後は、一定期間は遅さを感じなくなり、また一定時間後に遅くなる、という挙動でした。
原因と解決策
VPCのルーティングテーブルの関連付けに問題がありました。
ALBは最低二つのpublicなsubnetを指定する必要がありますが、両方ともigwを設定している必要があるようです。私の場合は、以下のルーティングになっていました。
- ap-northeast-1a:public
- デフォルトゲートウェイ: インターネットゲートウェイ
- ap-northeast-1c:public
- デフォルトゲートウェイ: なんとNATゲートウェイを指定
- ここを1aと同じインターネットゲートウェイを指定することで解消した。
- おそらく、新しくigwを作っても解消する。
もともとMulti AZ構成を取っていればこのようなことにはならなかったのでしょうが、Single AZ構成で運用していたため変なルーティングテーブルになっていたのに気づいていませんでした。
参考
- https://qiita.com/TakenoriHirao/items/a3ace404d785e6a4db22
- https://stackoverflow.com/questions/35523421/aws-elastic-load-balancing-seeing-extremely-long-initial-connection-time
- https://stackoverflow.com/questions/48287348/aws-application-load-balancing-seeing-extremely-long-initial-connection-time/48287350#48287350
- 投稿日:2020-01-16T12:50:33+09:00
ParallelizationFactorによる並列化でKinesisのレコードはLambdaにどう渡されるのか
Lambdaはこのアップデートで、
ParallelizationFactorがサポートされ、ストリームソースの1つのシャードを複数のLambda呼び出しで並列処理できるようになりました。並列化した場合に関数にはどのようにレコードが渡ってくるのか、気になる点を確認しました。
ParallelizationFactor の意義
Kinesis Data Streamsではシャード毎にレコードに振ったシーケンス番号でレコードの入力と出力の順序を保証しているため、コンシューマで、あるレコードの処理が完了せず停滞した場合、次以降のレコードはその分遅延します。
この遅延量は、Kinesisでは
GetRecords.IteratorAgeMillisecondsメトリクスで1、Lambda側ではIteratorAgeメトリクス2で監視でき、遅延測定のポイントが違いますが、Kinesisを使う時は両方のメトリクスの増加に気をつける必要があります。遅延はストリームのデータの供給速度より消費速度が遅ければ、徐々に蓄積していくことになります。
これまで、Kinesis Client LibraryでもLambdaでも、基本的に1つのシャードを1つのコンシューマが担当してシリアルに処理するため、シャード数を増やして遅延対策をする他ありませんでした。しかし、Lambdaに
ParallelizationFactorオプションが追加され、1つのシャードに対して、Lambda呼び出しを1〜10並列実行でき、消費側のスループットだけをスケールさせられるようになりました。
これは IteratorAge が高くなりがちなワークロードに対して非常に有効な対策となります。実験環境
下記のように、コンシューマ側で遅延を生じる環境を作成して、DynamoDBに記録された処理結果と、CloudWatchのメトリクスを見ていきます。
- Kinesis Data Streams
- シャード数: 1
- Producer
- producer/put_records.rb をPCで実行する
- put_records.rb
1〜5をパーティションキーとして、各パーティションキーごとに1始まりの整数をデータとするレコードを1秒毎に30回送信する- Consumer
- consumer/lambda_function.rb をトリガをKinesisとして、Lambdaで実行する
- lambda_function.rb
- 1呼び出しごとに、DynamoDBに受信したレコードと処理時刻を記録する
- 1レコードの処理ごとに3秒スリープする
環境構築はこちらのterraformで行いました。
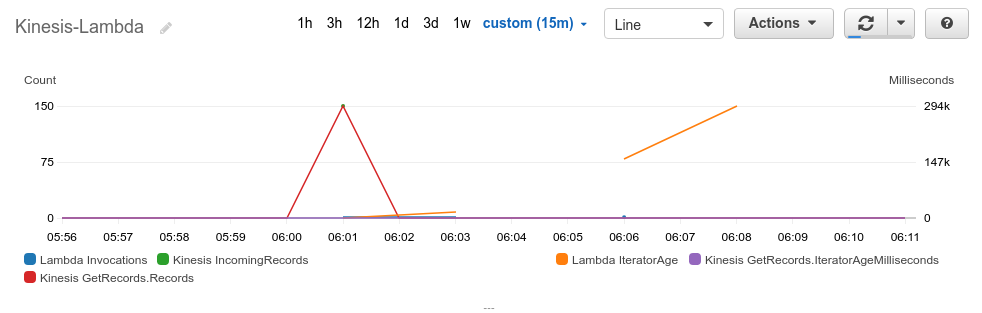
並列なし(ParallelizationFactor = 1)の場合
まず、並列なしで実行した結果です。
以下は関数から処理開始時刻、終了時刻、イベントで渡されたレコードの{パーティションキー}-{データ番号}をDynamoDBに記録したものと、CloudWatchのメトリクスです。
呼び出しは計4回シリアルに行われ、最後の呼び出し時点ではLambdaのIteratorAgeは300秒の遅延となり、トータル450秒かかりました。$ aws dynamodb scan --table-name $TABLENAME | jq '.Items | map({start: .start.S, end: .end.S, records: [.records.L[].S] | join(",")}) | sort_by(.start)' [ { "start": "2020-01-14 06:01:10 +0000", "end": "2020-01-14 06:01:25 +0000", "records": "1-1,2-1,3-1,4-1,5-1" }, { "start": "2020-01-14 06:01:25 +0000", "end": "2020-01-14 06:03:55 +0000", "records": "1-2,2-2,3-2,4-2,5-2,1-3,2-3,3-3,4-3,5-3,1-4,2-4,3-4,4-4,5-4,1-5,2-5,3-5,4-5,5-5,1-6,2-6,3-6,4-6,5-6,1-7,2-7,3-7,4-7,5-7,1-8,2-8,3-8,4-8,5-8,1-9,2-9,3-9,4-9,5-9,1-10,2-10,3-10,4-10,5-10,1-11,2-11,3-11,4-11,5-11" }, { "start": "2020-01-14 06:03:55 +0000", "end": "2020-01-14 06:06:25 +0000", "records": "1-12,2-12,3-12,4-12,5-12,1-13,2-13,3-13,4-13,5-13,1-14,2-14,3-14,4-14,5-14,1-15,2-15,3-15,4-15,5-15,1-16,2-16,3-16,4-16,5-16,1-17,2-17,3-17,4-17,5-17,1-18,2-18,3-18,4-18,5-18,1-19,2-19,3-19,4-19,5-19,1-20,2-20,3-20,4-20,5-20,1-21,2-21,3-21,4-21,5-21" }, { "start": "2020-01-14 06:06:25 +0000", "end": "2020-01-14 06:08:40 +0000", "records": "1-22,2-22,3-22,4-22,5-22,1-23,2-23,3-23,4-23,5-23,1-24,2-24,3-24,4-24,5-24,1-25,2-25,3-25,4-25,5-25,1-26,2-26,3-26,4-26,5-26,1-27,2-27,3-27,4-27,5-27,1-28,2-28,3-28,4-28,5-28,1-29,2-29,3-29,4-29,5-29,1-30,2-30,3-30,4-30,5-30" } ]
re:invent2019の A serverless journey: AWS Lambda under the hood (SVS405-R1)で説明されていますが、Lambdaのストリームソースの処理の内部では、
Stream Trackerが、Leasing Serviceを通じて、起動しているシャード数に従ってPollerをアレンジし、PollerがシャードをサブスクライブをしてGetRecordsを行っています。そしてLambdaの関数はPollerから呼び出されます。ここで、Kinesisの
GetRecords.IteratorAgeMilliSecondsに遅延がないのは、PollerのGetRecordsの実行には遅延がないためです。
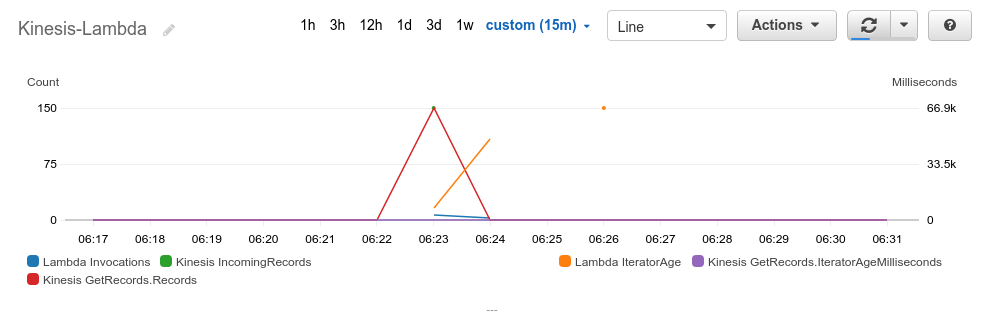
GetRecords.IteratorAgeMilliSecondsは、タイムアウトなどLambdaの呼び出しがエラーになったことで、GetRecordsが遡って行われる場合に増加します。ParallelizationFactor = 3の場合
次にParallelizationFactorを3にして実行します。変更はコンソールか、CLIで下記のように設定できます。
$ aws lambda update-event-source-mapping --uuid $TRIGGER_UUID --parallelization-factor 3結果はこのようになりました。
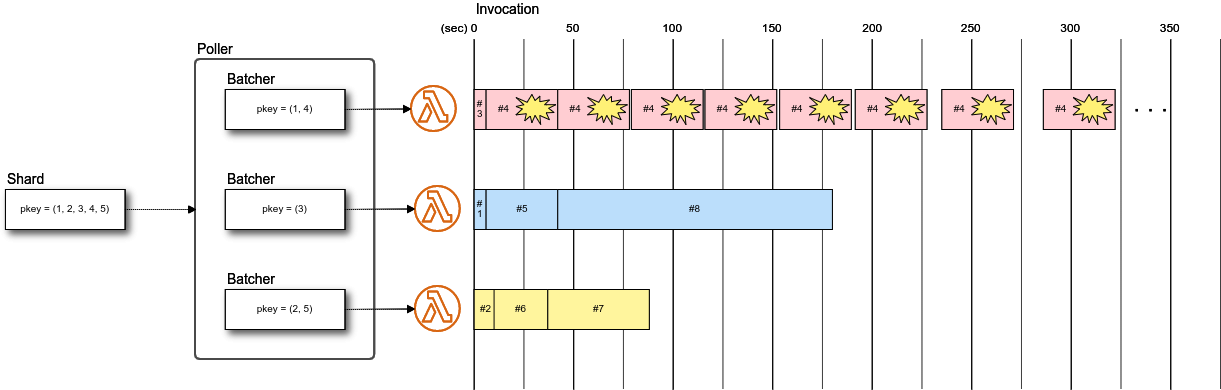
Lambdaの呼び出しは計10回で、トータルは180秒で完了しました。IteratorAgeの最大も67秒に短縮できています。各呼び出しで渡されたレコードを見ると、パーティションキー 1, 4 のレコード、3のレコード、2, 5のレコードのグループに分けられています。
そして呼び出しのタイムスタンプを見ると、各グループの処理は並列に呼び出されているけれども、グループごとにシリアルに実行されています。
つまり、並列化してもパーティションキー毎のレコード順序は保証されます。こちらでも説明されていますが、PollerはLambdaのParallelizationFactorの設定をみて、フロントエンドの起動数をスケールします。
このときスケールするのはBatcherで、パーティションキー毎に割り振られるBatcherは一意に決まることで順序を維持しているようです。[ { "start": "2020-01-14 06:23:05 +0000", "end": "2020-01-14 06:23:17 +0000", "records": "1-1,4-1,1-2,4-2" }, { "start": "2020-01-14 06:23:05 +0000", "end": "2020-01-14 06:23:11 +0000", "records": "3-1,3-2" }, { "start": "2020-01-14 06:23:05 +0000", "end": "2020-01-14 06:23:17 +0000", "records": "2-1,5-1,2-2,5-2" }, { "start": "2020-01-14 06:23:11 +0000", "end": "2020-01-14 06:23:29 +0000", "records": "3-3,3-4,3-5,3-6,3-7,3-8" }, { "start": "2020-01-14 06:23:17 +0000", "end": "2020-01-14 06:24:23 +0000", "records": "2-3,5-3,2-4,5-4,2-5,5-5,2-6,5-6,2-7,5-7,2-8,5-8,2-9,5-9,2-10,5-10,2-11,5-11,2-12,5-12,2-13,5-13" }, { "start": "2020-01-14 06:23:17 +0000", "end": "2020-01-14 06:24:23 +0000", "records": "1-3,4-3,1-4,4-4,1-5,4-5,1-6,4-6,1-7,4-7,1-8,4-8,1-9,4-9,1-10,4-10,1-11,4-11,1-12,4-12,1-13,4-13" }, { "start": "2020-01-14 06:23:29 +0000", "end": "2020-01-14 06:24:17 +0000", "records": "3-9,3-10,3-11,3-12,3-13,3-14,3-15,3-16,3-17,3-18,3-19,3-20,3-21,3-22,3-23,3-24" }, { "start": "2020-01-14 06:24:17 +0000", "end": "2020-01-14 06:24:35 +0000", "records": "3-25,3-26,3-27,3-28,3-29,3-30" }, { "start": "2020-01-14 06:24:23 +0000", "end": "2020-01-14 06:26:05 +0000", "records": "2-14,5-14,2-15,5-15,2-16,5-16,2-17,5-17,2-18,5-18,2-19,5-19,2-20,5-20,2-21,5-21,2-22,5-22,2-23,5-23,2-24,5-24,2-25,5-25,2-26,5-26,2-27,5-27,2-28,5-28,2-29,5-29,2-30,5-30" }, { "start": "2020-01-14 06:24:23 +0000", "end": "2020-01-14 06:26:05 +0000", "records": "1-14,4-14,1-15,4-15,1-16,4-16,1-17,4-17,1-18,4-18,1-19,4-19,1-20,4-20,1-21,4-21,1-22,4-22,1-23,4-23,1-24,4-24,1-25,4-25,1-26,4-26,1-27,4-27,1-28,4-28,1-29,4-29,1-30,4-30" } ]
呼び出しのタイミングのイメージです。
エラーハンドリング
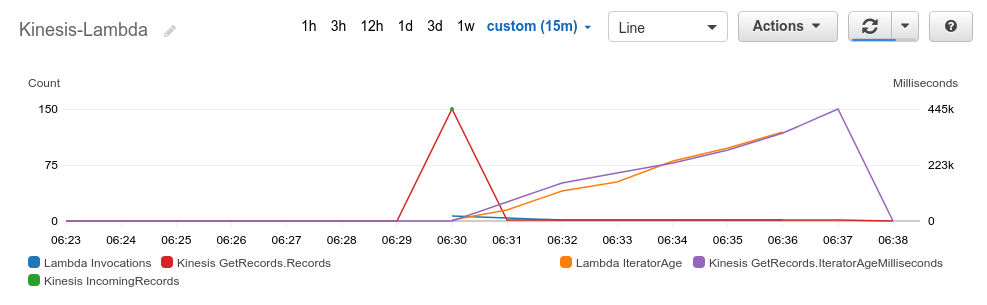
並列化した場合も、パーティションキー毎に担当されるBatcherは固定されていることがわかりました。では、あるレコードでエラーが発生した場合に、同じBatcherに割り振られた他のパーティションキーのレコードの処理はどうなるのでしょうか。
意図的にパーティションキー1のデータ5の処理でエラー終了するように関数を変更して実行しました。[ { "id": "dd0433d1-d3ea-45ad-b90f-38571fae3682@2020-01-15 06:30:21 +0000", "start": "2020-01-15 06:30:21 +0000", "end": "2020-01-15 06:30:27 +0000", "records": "2-1,5-1" }, { "id": "c50dd83a-6f7e-4bb0-99dd-373f3514d41a@2020-01-15 06:30:21 +0000", "start": "2020-01-15 06:30:21 +0000", "end": "2020-01-15 06:30:24 +0000", "records": "3-1" }, { "id": "22bbbc6c-393a-4cb4-9270-a32fab209970@2020-01-15 06:30:21 +0000", "start": "2020-01-15 06:30:21 +0000", "end": "2020-01-15 06:30:27 +0000", "records": "1-1,4-1" }, (略) { "aws_request_id": "1ec49225-cb26-444f-b2a4-a7c7bc2eb71f", "start": "2020-01-15 06:30:27 +0000", "end": "2020-01-15 06:31:03 +0000", "records": "1-2,4-2,1-3,4-3,1-4,4-4,1-5,4-5,1-6,4-6,1-7,4-7" }, (略) { "aws_request_id": "a966ff27-8569-4fbf-8594-adcf7947683f", "start": "2020-01-15 06:31:00 +0000", "end": "2020-01-15 06:31:51 +0000", "records": "3-14,3-15,3-16,3-17,3-18,3-19,3-20,3-21,3-22,3-23,3-24,3-25,3-26,3-27,3-28,3-29,3-30" }, { "aws_request_id": "1ec49225-cb26-444f-b2a4-a7c7bc2eb71f", "start": "2020-01-15 06:31:03 +0000", "end": "2020-01-15 06:31:39 +0000", "records": "1-2,4-2,1-3,4-3,1-4,4-4,1-5,4-5,1-6,4-6,1-7,4-7" }, { "aws_request_id": "c43dbc93-16b1-4666-b565-2df99f7f68eb", "start": "2020-01-15 06:31:03 +0000", "end": "2020-01-15 06:33:21 +0000", "records": "2-8,5-8,2-9,5-9,2-10,5-10,2-11,5-11,2-12,5-12,2-13,5-13,2-14,5-14,2-15,5-15,2-16,5-16,2-17,5-17,2-18,5-18,2-19,5-19,2-20,5-20,2-21,5-21,2-22,5-22,2-23,5-23,2-24,5-24,2-25,5-25,2-26,5-26,2-27,5-27,2-28,5-28,2-29,5-29,2-30,5-30" }, { "aws_request_id": "1ec49225-cb26-444f-b2a4-a7c7bc2eb71f", "start": "2020-01-15 06:31:40 +0000", "end": "2020-01-15 06:32:16 +0000", "records": "1-2,4-2,1-3,4-3,1-4,4-4,1-5,4-5,1-6,4-6,1-7,4-7" }, { "aws_request_id": "1ec49225-cb26-444f-b2a4-a7c7bc2eb71f", "start": "2020-01-15 06:32:17 +0000", "end": "2020-01-15 06:32:53 +0000", "records": "1-2,4-2,1-3,4-3,1-4,4-4,1-5,4-5,1-6,4-6,1-7,4-7" }, { "aws_request_id": "1ec49225-cb26-444f-b2a4-a7c7bc2eb71f", "start": "2020-01-15 06:32:55 +0000", "end": "2020-01-15 06:33:31 +0000", "records": "1-2,4-2,1-3,4-3,1-4,4-4,1-5,4-5,1-6,4-6,1-7,4-7" }, { "aws_request_id": "1ec49225-cb26-444f-b2a4-a7c7bc2eb71f", "start": "2020-01-15 06:33:34 +0000", "end": "2020-01-15 06:34:10 +0000", "records": "1-2,4-2,1-3,4-3,1-4,4-4,1-5,4-5,1-6,4-6,1-7,4-7" }, { "aws_request_id": "1ec49225-cb26-444f-b2a4-a7c7bc2eb71f", "start": "2020-01-15 06:34:17 +0000", "end": "2020-01-15 06:34:53 +0000", "records": "1-2,4-2,1-3,4-3,1-4,4-4,1-5,4-5,1-6,4-6,1-7,4-7" } ]
結果、
1-5レコードを含むLambdaの呼び出し1ec49225-cb26-444f-b2a4-a7c7bc2eb71fはエラーとなり、他のBatcherの呼び出しが完了した後もリトライを繰り返しています。
そして、パーティションキー1, 4のレコードはこのバッチ移行処理が進まなくなり、IteratorAgeはどんどん増加しています。これは一番避けるべき事態です。
対策として、Lambdaのイベントソースマッピングのストリームソースのオプションには、エラーのリカバリのためのサポートがあるので、これを利用すべきです。
BisectBatchOnFunctionError
今回のエラーは意図的に発生させているため回復の見込みがないですが、タイムアウトの場合、処理対象のデータを減らすことは有効です。
BisectBatchOnFunctionErrorを有効にすると、エラーになったバッチを2分割してLambdaの呼び出しが行われるので、制限時間内に処理を完了できる可能性が高められます。MaximumRecordAgeInSeconds, MaximumRetryAttempts と DestinationConfig
エラーによるリトライは
MaximumRecordAgeInSecondsまたはMaximumRetryAttemptsを満了するまで続きます。
1ec49225-cb26-444f-b2a4-a7c7bc2eb71fの呼び出し時刻を見ると、徐々に前回の終了時刻からのラグが増えていることがわかります。
これはエクスポネンシャルバックオフが採用されているためで、連続するエラーのリトライ回数を緩和するためです。
これらの係数を小さくすることは、リトライアウトを早めますが、ストリームのスループット維持の妨げにならない値に調整する必要があります。
そして仮にリトライアウトが発生しても、DestinationConfigでSQSのデッドレターキューを指定することができるので、リトライでリカバリ出来ないレコードは、ストリーム処理の枠外でエラーを確認し、場合によってはリトライすることができます。以上です。
これまでKinesisClientLibraryを使っていましたが、自前で頑張る必要があった部分が、Lambdaでほぼ機能としてサポートされているので、Kinesisの処理はLambda一択になりそうです。

- 投稿日:2020-01-16T12:02:23+09:00
LambdaからRedisのデータを取得したい
使用するもの
- Lambda
- Redis
私の環境
Node 12系
DockerでLamdaを用意しています。方法については、以下の記事を参考にしてください。
https://qiita.com/gdtypk/items/78b6a76dc9f212296c89Redisも同様にDockerで起動しています。
redis:4.0困ったこと
Node.jsは非同期で動作するので、そのあたりが苦労した。
コード
const redis = require("redis"); const Promise = require('bluebird'); // 接続情報 const config = { host: 'redis', port: 6379 }; let client = null; let value = ""; const key = "key"; exports.handler = async (event, context) => { try { //Redisに接続 client = await connectRedis(); // データの取得 value = await findValueOfKey(client, key); //Redisとの接続を切断 disconnectRedis(); //レスポンス返却 console.error('レスポンス:' + value); context.succeed({statusCode: 200, body: JSON.stringify(value)}); } catch (error) { console.error('エラー:', error); disconnectRedis(); } }; /** * Redisに接続する処理。 */ function connectRedis() { return new Promise(function (resolve, reject) { const client = redis.createClient(config); client.on('connect', () => { console.log('接続OK'); resolve(client); }); client.on('error', (error) => { console.log(`接続NG`); reject(error); }); }); } /** * Redisとの接続を切断する。 */ function disconnectRedis() { if (client) { console.log("切断します"); client.end(true); } } /** * Keyを使用し、Valueを取得する。 * @param client * @param key */ function findValueOfKey(client, key) { return new Promise(function (resolve) { client.get(key, (err, reply) => { resolve(reply); }); }); }おわり
もっといい書き方があったり、コードがおかしいとかあれば、教えて下さい。
- 投稿日:2020-01-16T11:49:49+09:00
Amazon Transcribeで日本語のカスタム語彙を作成してみた
Amazon Transcribeが日本語に対応しましたね!
これで日本語の音声をテキストに変換することができますが、一般的でない固有名詞などを認識させたい場合のためにカスタム語彙を試してみました。カスタム語彙とは
カスタム語彙を作成して、入力ファイルの音声を処理する方法について Amazon Transcribe により詳細な情報を与えることができます。
カスタム語彙は、オーディオ入力で Amazon Transcribe に認識させたい特別な語句のリストです。
これらは通常、Amazon Transcribe が認識しないドメイン固有の語句や適切な名詞です。https://docs.aws.amazon.com/ja_jp/transcribe/latest/dg/how-vocabulary.html
カスタム語彙ファイルを作る
カスタム語彙の作成方法はリストとテーブルの2種類がありますが、今回はテーブルを使用して作成してみました。
カスタム語彙に登録する語句は「奈良萬」です。奈良萬は日本酒の銘柄で、「ならまん」と読みます。とっても美味しいので、ぜひ飲んでみてください!以下の2行をファイルに記載し、custom-vocabulary.txtという名前で保存します。
※保存するときに文字コードをShift-JISにしたらCreate vocabularyが失敗したので、UTF-8で保存し直しました。Phrase[TAB]IPA[TAB]SoundsLike[TAB]DisplayAs ならまん[TAB][TAB][TAB]奈良萬カスタム語彙を登録する
マネジメントコンソールからカスタム語彙を登録します。
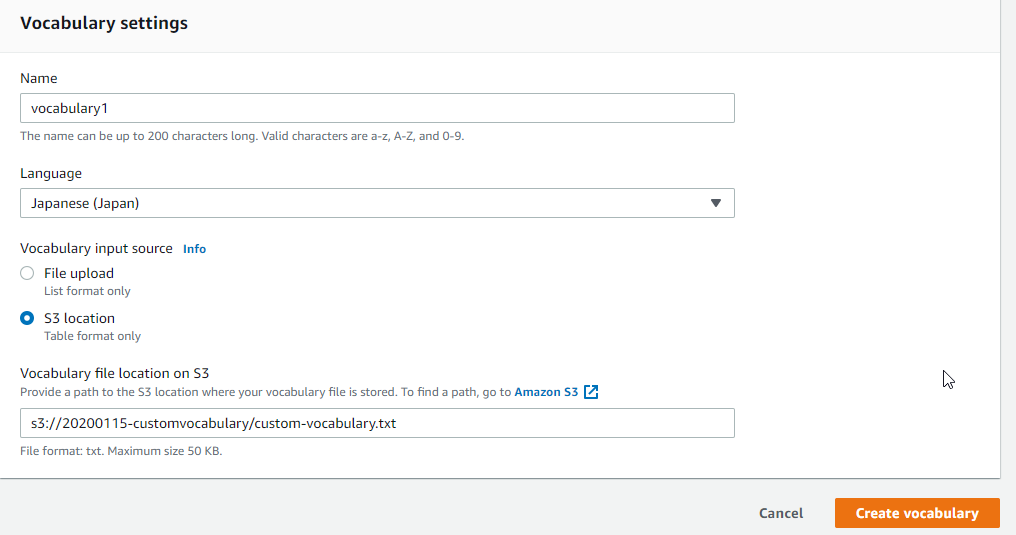
事前に上で作成したカスタム語彙のファイルを任意のS3バケットにアップロードしておきます。Amazon Transcribe>Custom vocabularyを選択し、Create vocabularyをクリックします。
Nameに任意の名前を入力し、Languageは「Japanese(Japan)」、Vocabulary input sourceは「S3 location」を選択し、Vocabulary file location on S3にはファイルのアップロード先を指定します。
その後、Create vocabularyをクリックします。
ステータスがReadyになったらカスタム語彙登録成功です。
Amazon Pollyでテスト用の音声ファイルを作る
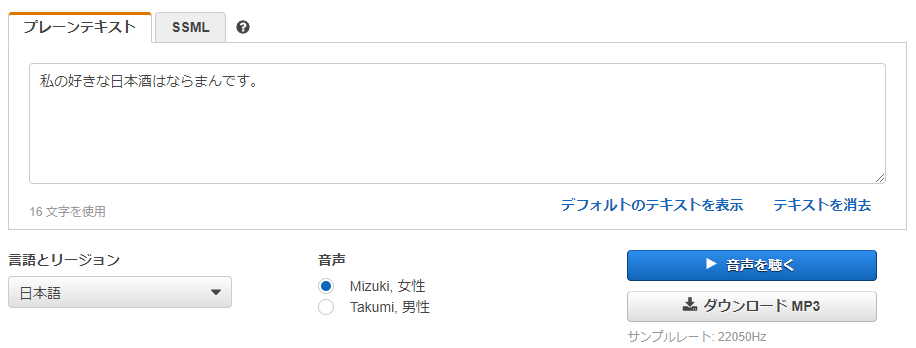
Amazon Pollyでプレーンファイルに「私の好きな日本酒はならまんです。」と入力し、音声ファイルをダウンロードします。
「私の好きな日本酒は奈良萬です。」と入力したところ、「奈良萬」を「ならいちまん」と読み上げてしまったので、銘柄名はひらがなで入力しました。
音声ファイルはカスタム語彙のファイルと同じく任意のS3バケットにアップロードしておきます。
カスタム語彙を使って音声認識させる
Amazon Pollyで作成した音声を認識させます。
ちなみにカスタム語彙を指定しない場合、認識結果は「私 の 好き な 日本 酒 は なら ま ん です」になりました。
Amazon Transcribe>Transcription jobsを選択し、Create jobsをクリックします。
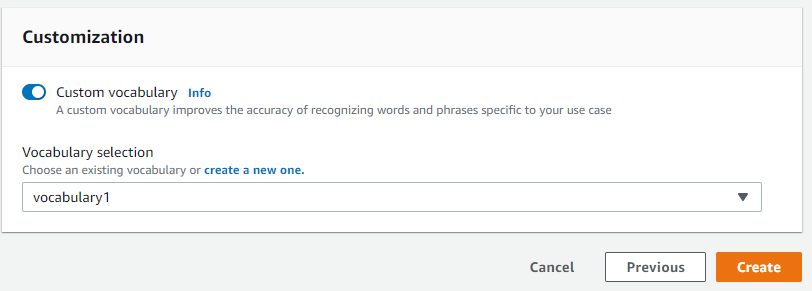
Nameに任意の名前を入力し、Languageは「Japanese(Japan)」を選択し、Input dataに音声ファイルのアップロード先を指定してNextをクリックします。
CustomizationのCustom vocabularyをクリックし、先程登録したカスタム語彙を選択してCreateをクリックします。
しばらくするとStatusがCompleteになりました。
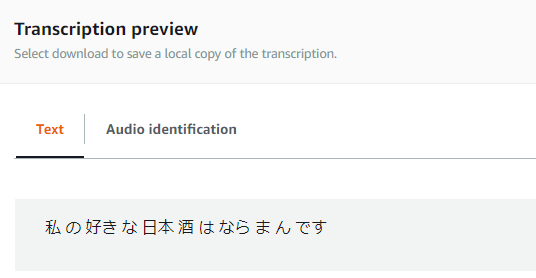
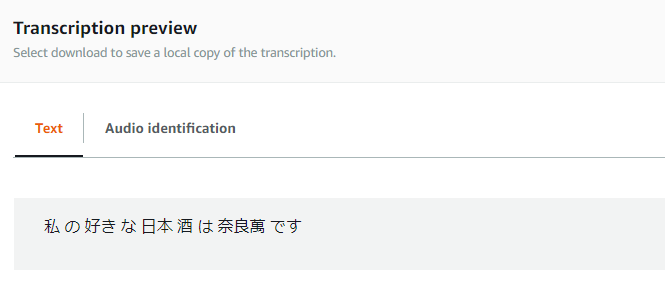
認識結果を見てみると…
期待通り認識結果が「私 の 好き な 日本 酒 は 奈良萬 です」になっていました!
以上、どなたかのお役に立てれば幸いです。





- 投稿日:2020-01-16T11:33:58+09:00
AWS CLIで複数アカウント(認証情報)を簡単に切り替える方法
はじめに
以下の状況を踏まえ、備忘録を兼ねてアカウント切替え方法をまとめます。
- 異なるアカウントで操作する機会が増えた
- aws configureで認証情報を毎回入力して切替えるのが煩わしい
Profileを作成する
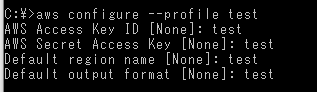
コマンドaws configure --profile [profile名]↓↓↓ 作成サンプル
↓↓↓ 作成先は以下の2ファイル
・C:\Users[ユーザー名].aws\credentialscredentials[test] aws_access_key_id = test aws_secret_access_key = test・C:\Users[ユーザー名].aws\config
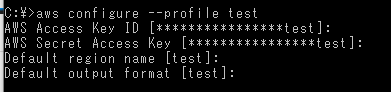
config[profile test] output = test region = testProfileを切り替える
以下のいずれかのコマンドで切り替える
awsconfigure`作成済みProfileの場合は認証情報セットとなる(セット結果が合わせて分かるのでオススメ)` aws configure --profile [Profile名]AWS_DEFAULT_PROFILEset AWS_DEFAULT_PROFILE=[Proflie名]↓↓↓ 実行サンプル
コマンド補足
コマンド`認証状況` aws configure list
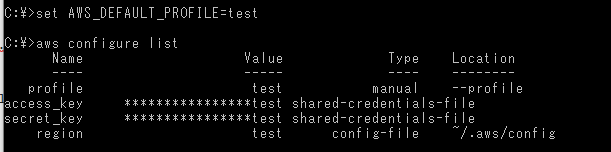
- 投稿日:2020-01-16T11:06:52+09:00
AWS EC2インスタンスの複製をしてみた。その4(備忘録)
前回の続きです。https://qiita.com/Bikeiken-IT/items/d8b1f731334c4f179447
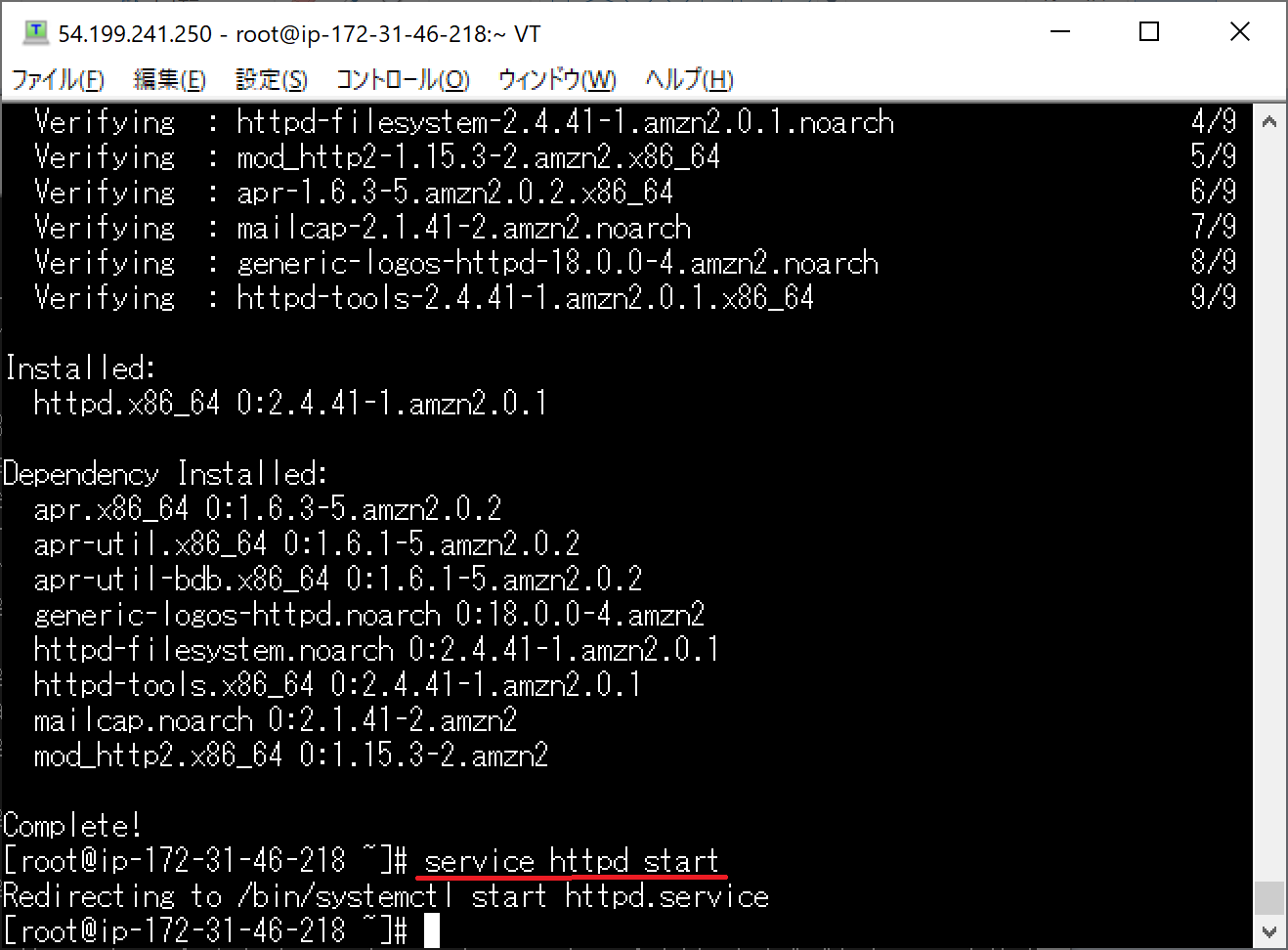
インストールしたApacheサーバーを起動します。
"service httpd start"と入力してください。
Apacheサーバーの起動を確認したら、ホストのEC2インスタンスのパブリックIPをブラウザに入力します。
上記の画面がブラウザに表示されることで、作成したEC2インスタンスのApacheサーバーの動作を確認することができます。
先ほどのTeraTermの画面に戻ります。
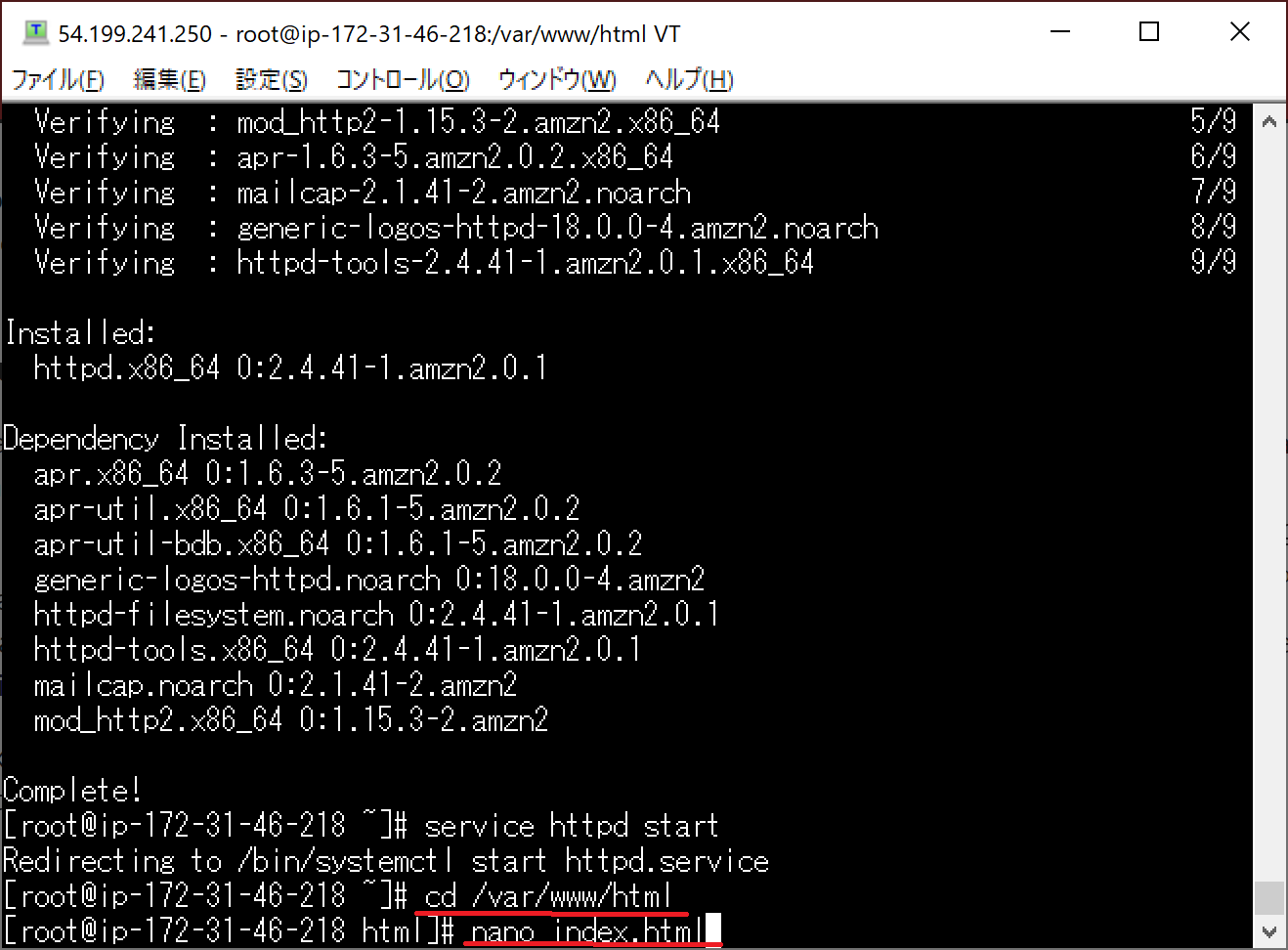
"cd /var/www/html"と入力して、htmlフォルダに移動してください。
htmlフォルダに移動したらHTMLファイルを作成します。
"nano index.html"と入力します。これでindex.htmlファイルが作成されます。
"nano index.html"と入力すると、index.htmlファイルの編集画面が表示されます。
index.htmlファイルの中身を書きました。
CtrlキーとXを同時に押すと、保存を選択することができます。
保存後にEnterキーを押すと、元の画面に戻ります。
そして、改めてApacheサーバーをリスタートします。
"service httpd restart"と入力してください。
もう一度、ブラウザに作成したEC2インスタンスのパブリックIPアドレスを入力してください。
先ほど編集したindex.htmlファイルの内容が反映されていることが確認できました。次回以降は、このEC2インスタンスをAMIとSnapshotを使って複製したいと思います。
その5に続きます。https://qiita.com/Bikeiken-IT/items/6c885d40fd92b1a6dee9


- 投稿日:2020-01-16T10:22:29+09:00
AWS EC2インスタンスの複製をしてみた。その3(備忘録)
前回の続きです。https://qiita.com/Bikeiken-IT/items/5cf4bb3203ce27faf567
TeraTermからEC2にアクセスします。
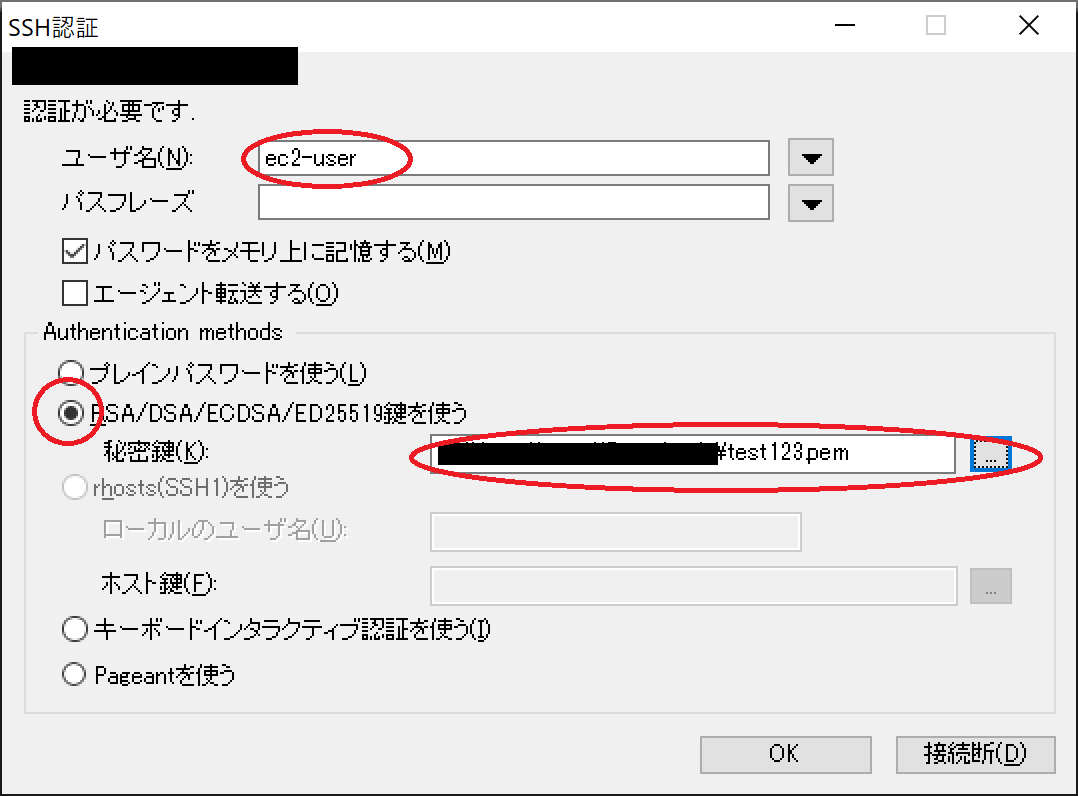
TeraTermの接続画面に、先ほど作成したEC2インスタンスのIPv4のパブリックIPをホストのIPアドレスとして入力します。
続いて、セキュリティ警告の画面が現れますが、無視して続行のボタンを押してください。
続いて、認証の為にユーザー名の入力とキーペアの指定(pemファイル)を行います。
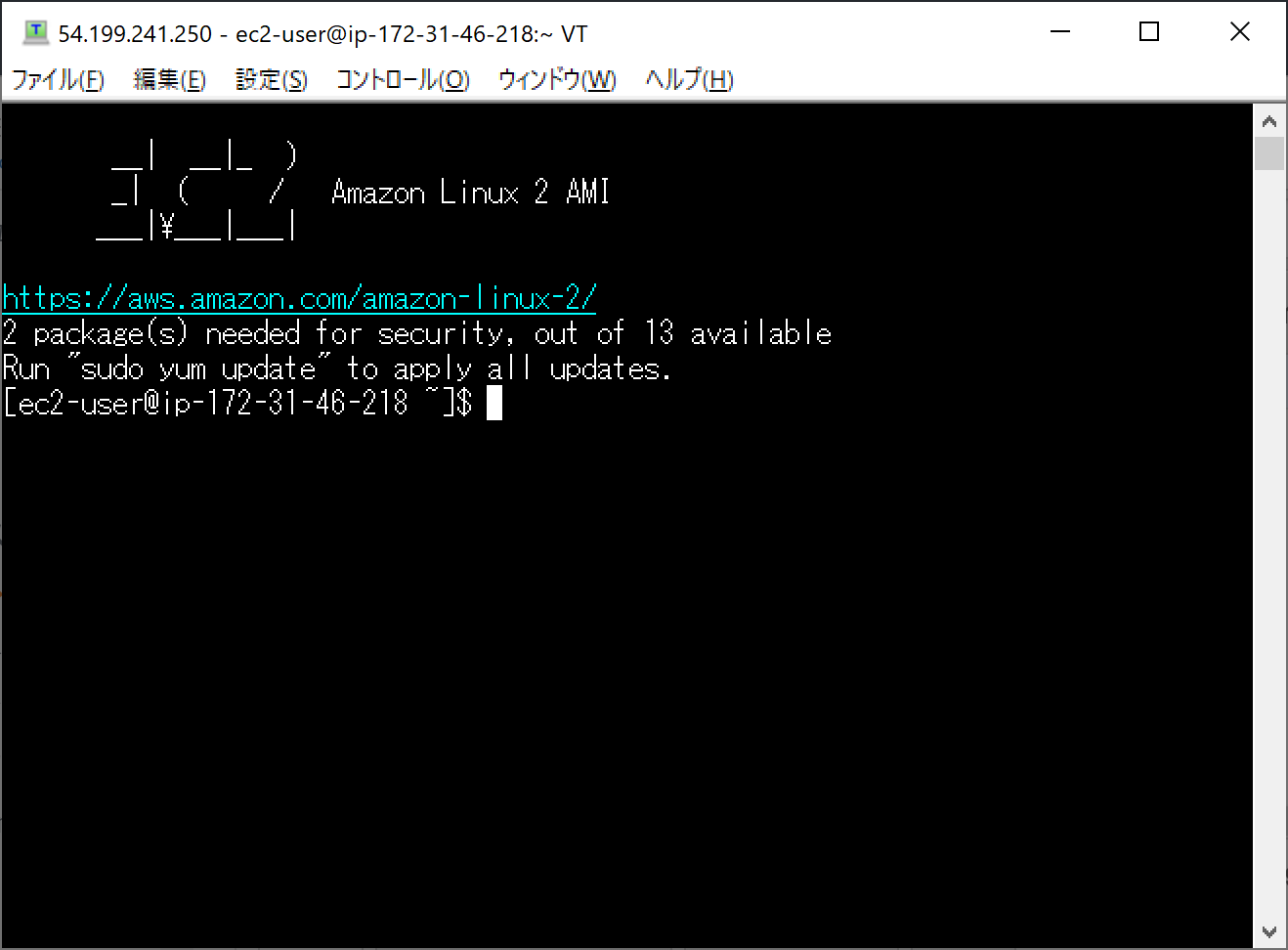
TeraTermからEC2への接続が出来ました。
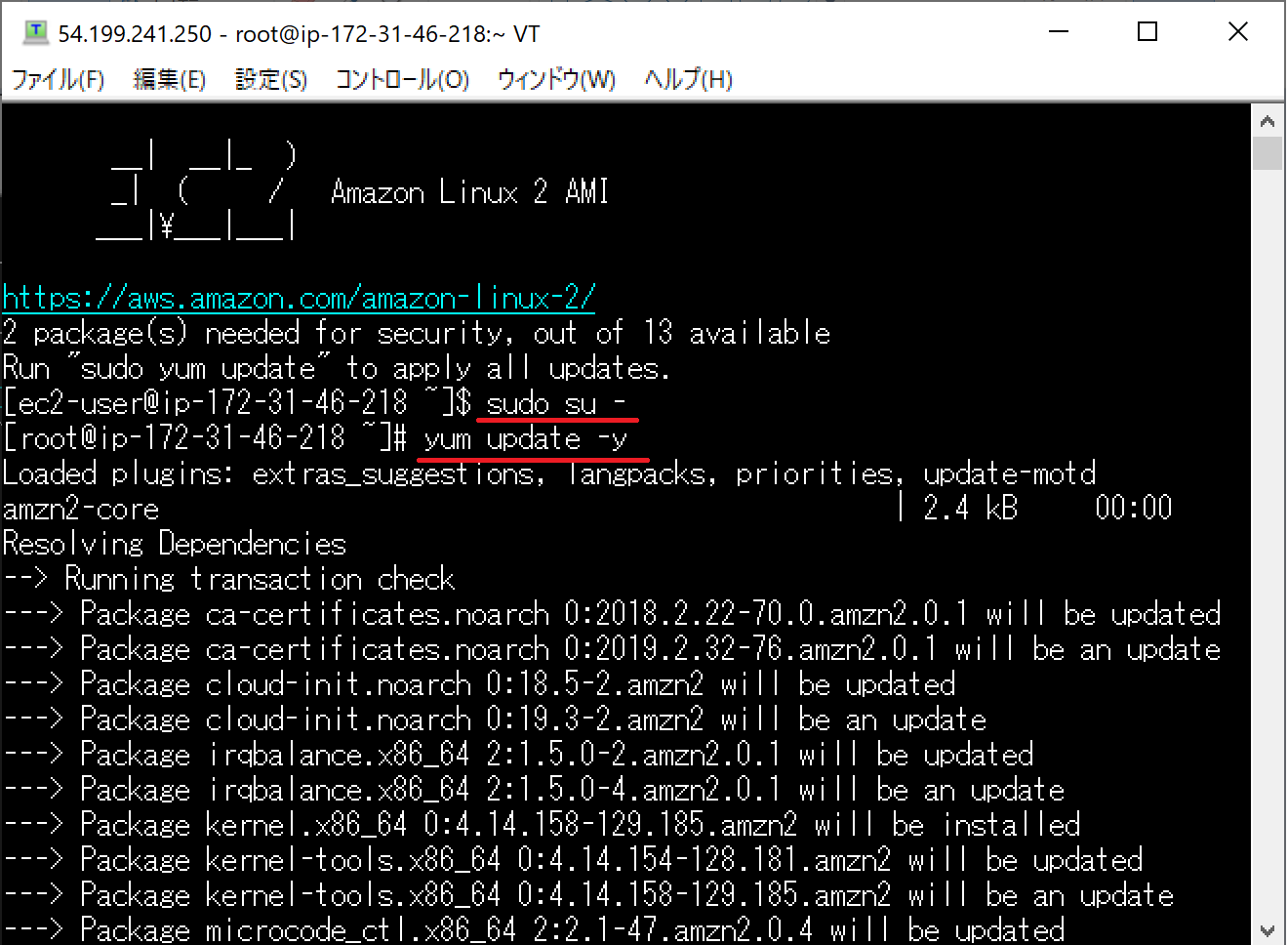
続いて、管理者権限に移行します。
Bashコマンドで"Sudo su -"と入力してください。続いて、ファイルのアップデートを行います。
"Yum update -y"と入力してください。
アップデートが完了したら、次にApacheサーバーをインストールします。その4に続きます。https://qiita.com/Bikeiken-IT/items/5b6d1e3ab5573c081ba8


- 投稿日:2020-01-16T10:02:19+09:00
Amazon EKS のチュートリアルで Kubernetes を理解する #04 セルフヒーリング
はじめに
本記事は、以下の内容の続きになります。
今回は、k8s自体の特長のひとつである 「セルフヒーリング(自己回復)」 の動作を確認してみたいと思います。
障害が発生してノードがダウンした場合に、どのように振る舞うかの検証を行います。セルフヒーリング時の動作
セルフヒーリングが実行される状況を、順を追って確認していきます。
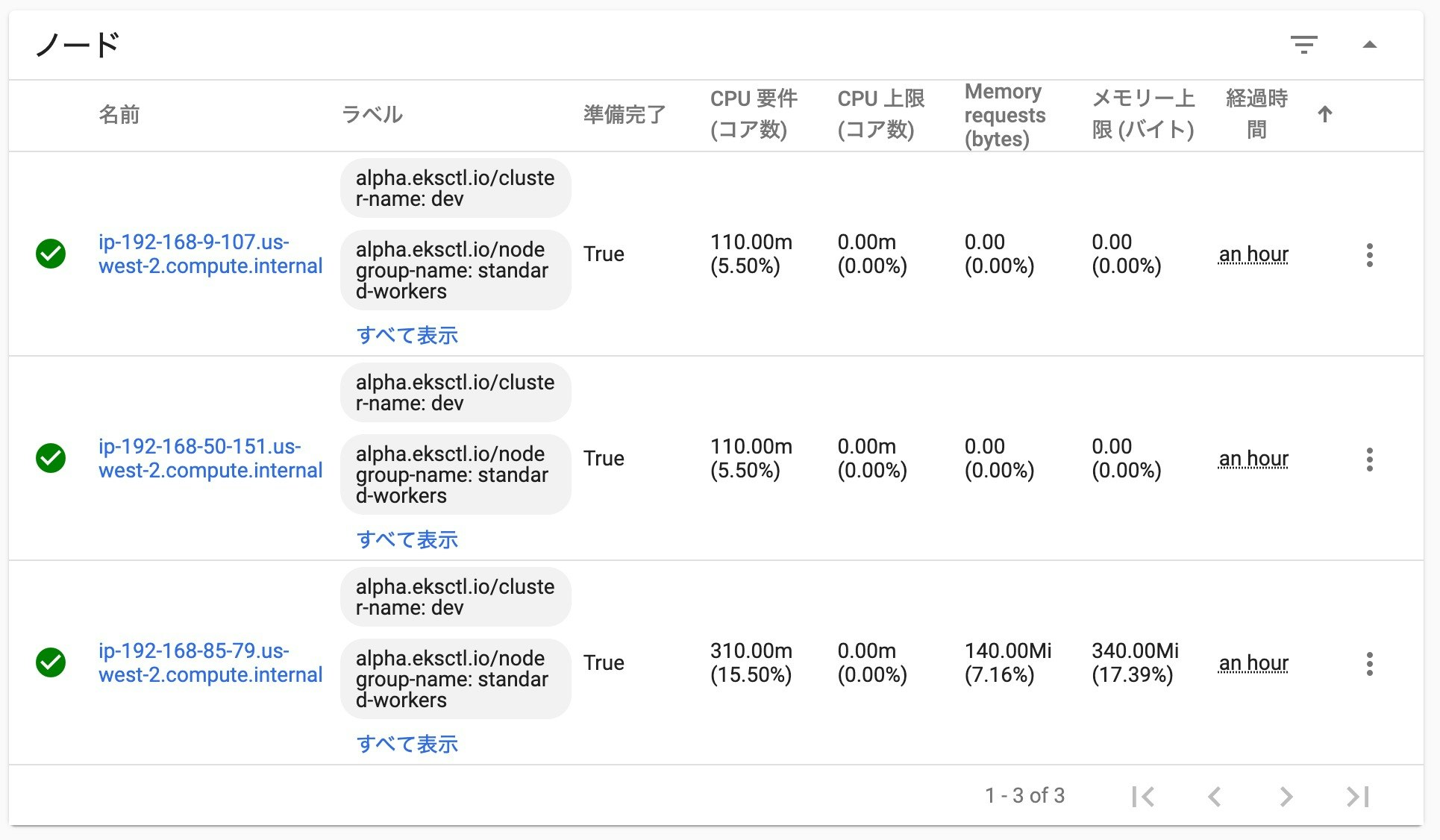
ここでは、3ノードでクラスタを構築しています。正常時の状況
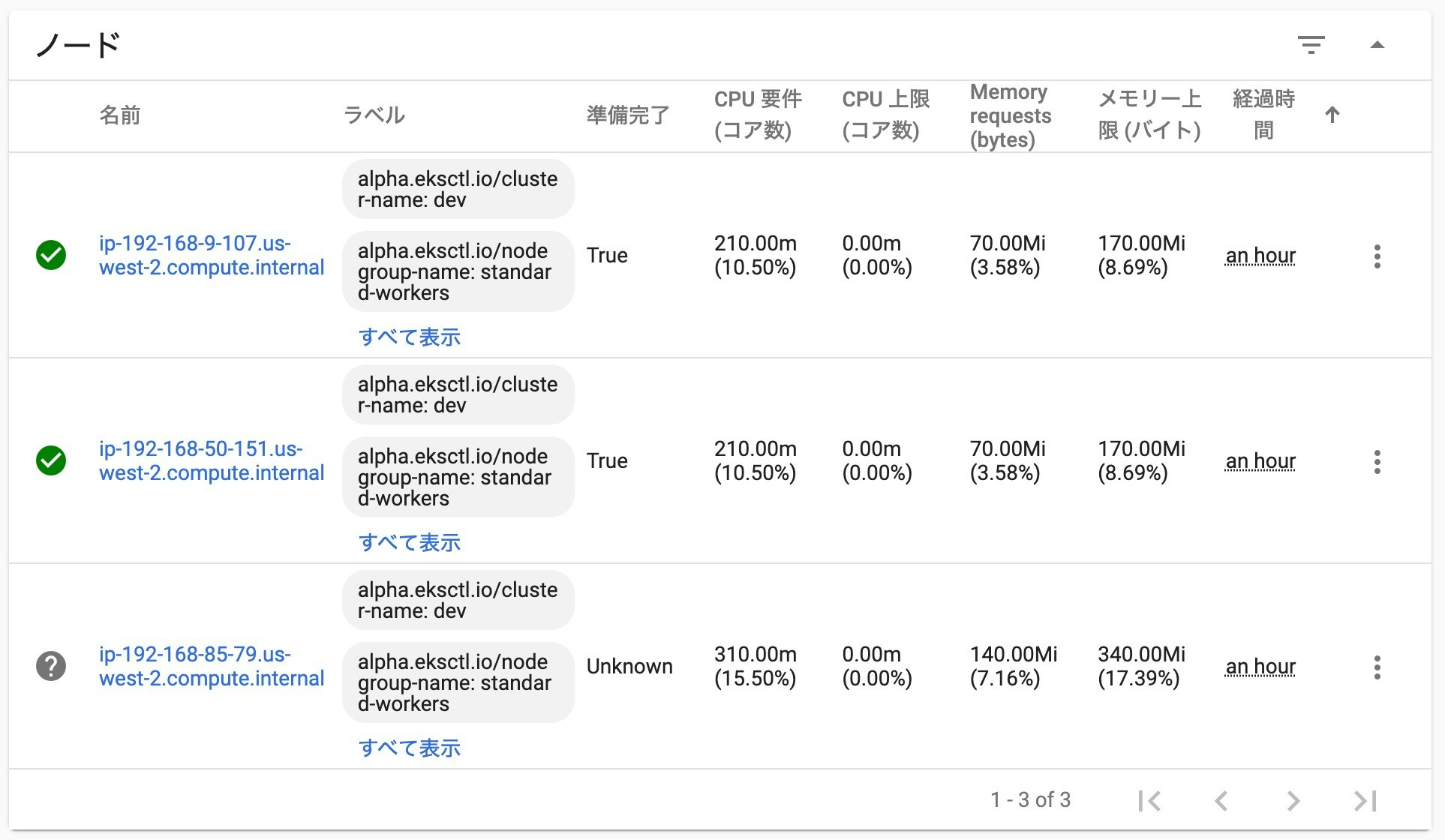
まず、障害発生前の状況です。
AWSコンソールで、k8sクラスタに登録されているノード(EC2インスタンス)の状況、
および、Kubernetes のダッシュボードの状況を確認します。
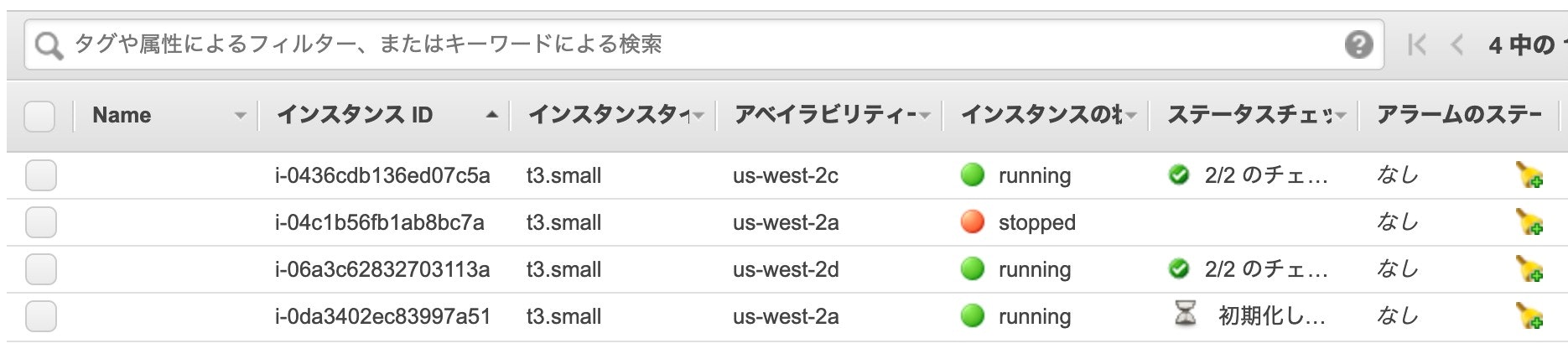
インスタンスIDと、ノード名が一致しないので、分かりにくいかもしれませんが、以下のノードが対応するモノになっています。
AWSコンソールで、2番目に表示されている 「i-04c1b56fb1ab8bc7a」
↓ ↑
Kubernetes ダッシュボードで、3番目に表示されている 「ip-192-168-85-79.us-west-2.compute.internal」障害の発生
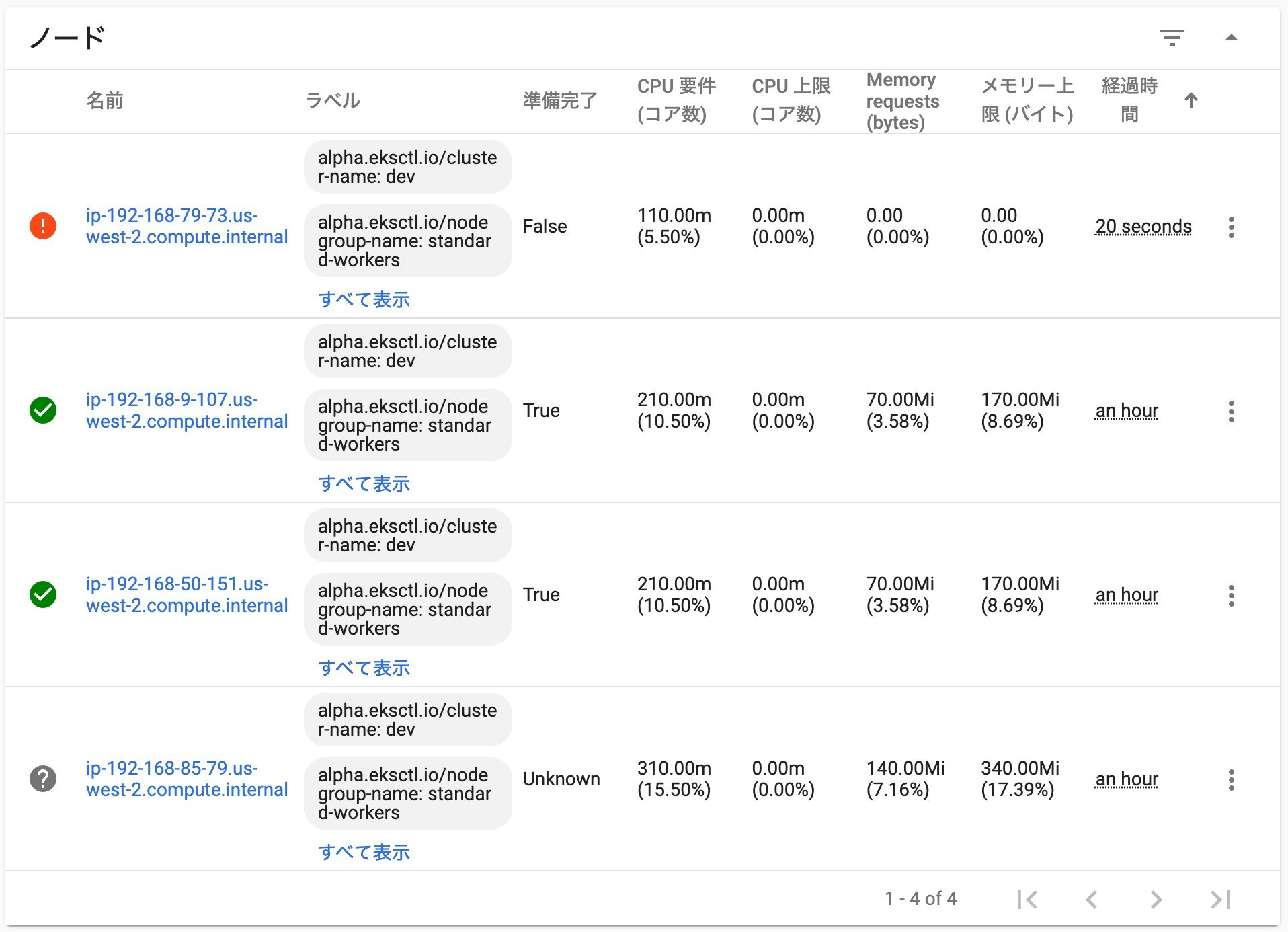
次に、障害を発生させるために、AWSコンソールから、ECインスタンスを強制的に停止させます。
少し待つと、Kubernetes ダッシュボードで、先程のノードのアイコンが、「?」マークに変わりました。
ノードからのヘルチェックの応答がなくなり、状態が不明(Unknown)となっています。セルフ・ヒーリングの開始
そのまま、何もしないで、待ってみます。
すると、新しく 「ip-192-168-79-73.us-west-2.compute.internal」 のノードが自動的に追加されました!
ただし、まだノードが起動している最中なので、状態は 「False」 になっています。
AWSコンソールから、EC2インスタンスの状況も確認してみると、
停止したインスタンスは 「stopped」 の状態になり、新しく 「i-0da3402ec83997a51」 のインスタンスが追加されています。セルフ・ヒーリング後
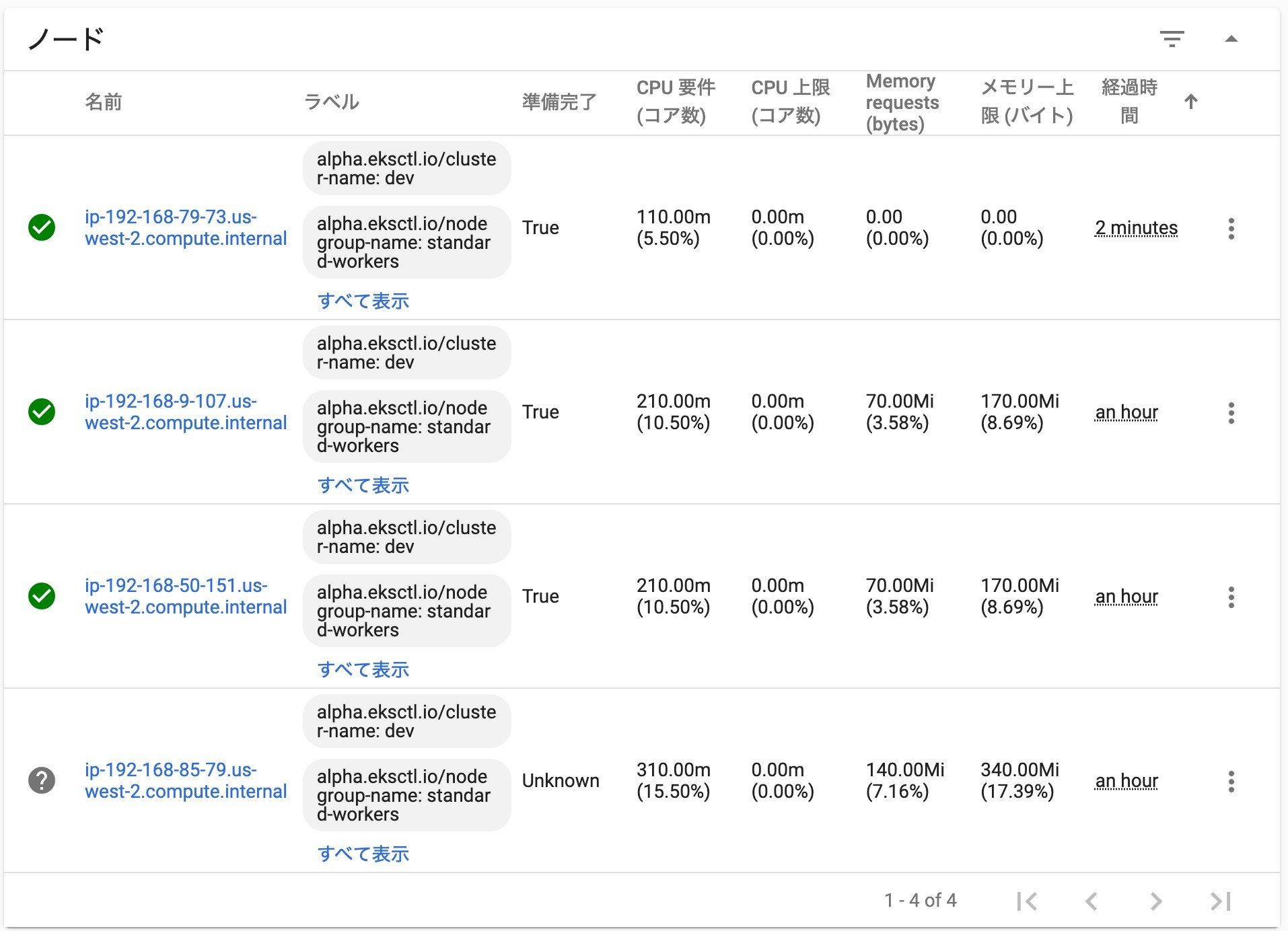
さらに、何もしないで、もう少し待ってみます。
すると、先程自動で追加された 「ip-192-168-79-73.us-west-2.compute.internal」 のノードが正常な状態になりました。
今回の場合は、およそ2分程度で、新しいノードに変わって動作する状態になりました!
障害が発生したノードで稼働していたコンテナも、新しく登録されたノードに、自動的にデプロイされたようです。ちなみに、強制的に停止し、状態不明となった 「ip-192-168-85-79.us-west-2.compute.internal」 のノードは、しばらくすると、Kubernetes ダッシュボード上からも無くなっていました。
まとめ
今回、セルフヒーリングの動作を確認してみましたが、障害が発生した後、
特に何をしなくても、自動でノードが追加され、元々の3ノード構成となって稼働していました。
このように、楽に回復性を向上させることができるのがk8sのメリットのひとつであり、ノードも自動で追加されるのがクラウド上でk8sを動作させるメリットだと思います。実際の運用では、完全にノードが停止せずに、ゾンビ状態やコンテナプロセスがダウンする等のことも考えられますが、
その辺りはどのように検知+セルフヒーリングできるのか、別途調べたいと思います。

- 投稿日:2020-01-16T09:36:24+09:00
AWS Client VPN 経由でグローバルIPを固定する
AWS Client VPN 経由でグローバルIPを固定する手順をまとめます。
グローバルIPを固定できれば、リモートワークなどで接続状況が変わっても、ホワイトリスト登録された状態でウェブサーバやAPIサーバを利用できます。
今回参考にさせてもらったのは次の記事です。事前知識のある方はそちらを見れば進められると思います。
- 『AWS Client VPNがTokyoに来た! | 概要と固定IPの設定方法を解説 - SMARTCAMP』
- 『[AWS Client VPN] VPC を経由して固定のIPでインターネットへアクセスする』
事前知識のない方は、より細かくまとめた以下の内容を参考にしてみてください
※ 後述のとおり、AWS の利用料金が発生するので自己責任でセットアップしてください。
登場サービス・用語のおさらい
今回登場する AWS のサービス・用語について整理します。概ね公式ドキュメントからの抜粋・引用です。
Amazon VPC
AWS リソースを起動できる仮想ネットワーク。用意されているリソースは、サブネット、Elastic IP、セキュリティグループ、ネットワークACL、ゲートウェイ、ルートテーブルなど。
サブネット
VPC の IP アドレスの範囲。例えば、VPC のアドレススペースが
10.0.0.0/16であれば、そのサブネットとして10.0.x.xで始まるIPアドレスを使える。Elastic IP
インスタンスまたはネットワークインターフェイスに関連付けられるパブリック IPv4 アドレス。
NATゲートウェイ
プライベートサブネットのインスタンスからのトラフィックをインターネットや他の AWS サービスに送信し、その応答をインスタンスに返送する。
トラフィックがインターネットに送信される場合、送信元の IPv4 アドレスは NAT デバイスのアドレスに置き換えられる。
Client VPN
AWS リソースや、オンプレミスネットワーク内のリソースに安全にアクセスできるようにする、クライアントベースのマネージド VPN サービス。
AWS Certificate Manager(ACM)
AWS の他サービスで利用する SSL/TLS 証明書のプロビジョニング、管理、デプロイをおこなう。
設計
Client VPN でプライベートサブネットにアクセスし、そこから固定IP(Elastic IP)が割り当てらた NAT ゲートウェイ(パブリックサブネット)経由でインターネットを利用します。
設計の全体像はこちらの記事でご確認ください。
グローバルIPを固定する手順
それでは本題に入り、AWS Client VPN 経由でグローバル IP を固定する手順を整理します。
1. VPC の設定(プライベートサブネット)
パブリックサブネットの作成
VPC のコンソールから、VPN 用のパブリックサブネットを作成します。
今回は、デフォルトの VPC(IPv4 CIDR:
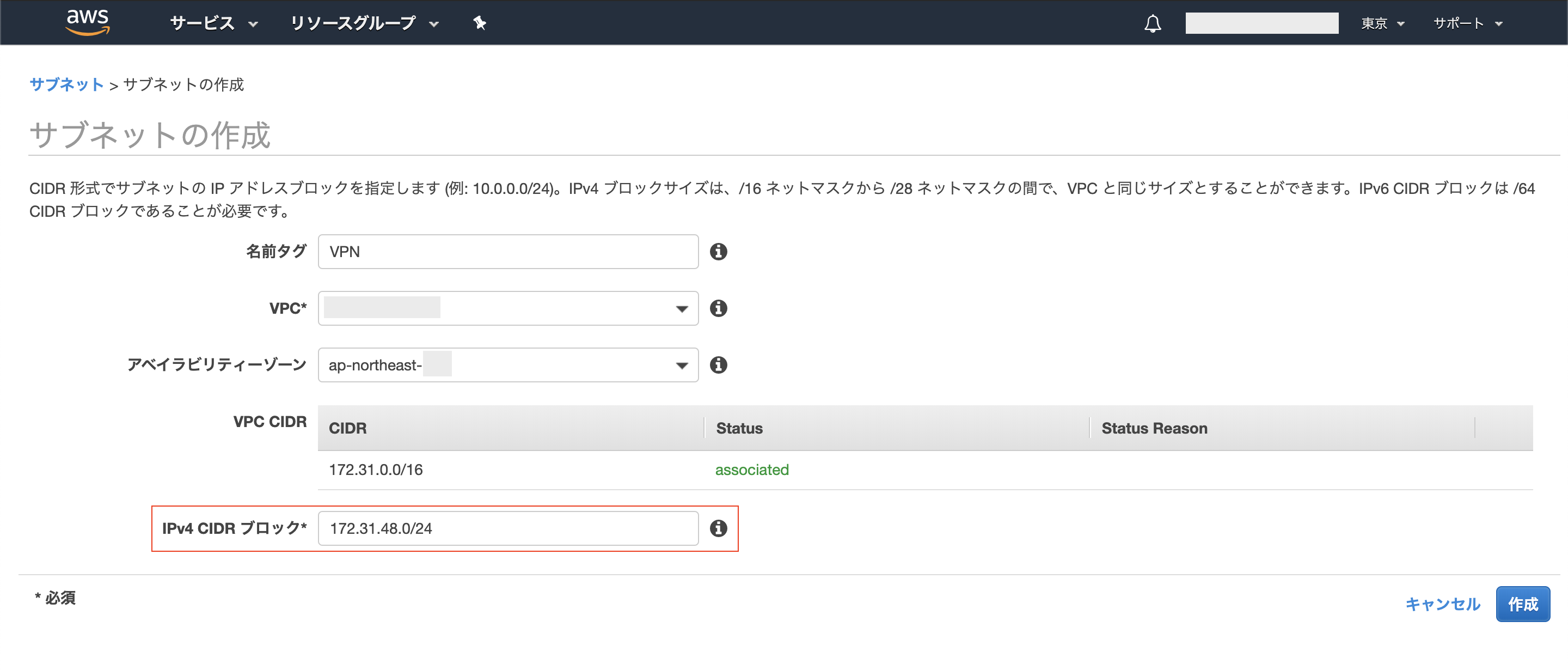
172.31.0.0/16)に新しいサブネットを追加しました。既存のサブネットと重複しないレンジの「IPv4 CIDR ブロック」を指定しましょう。(使用済みのIPアドレスのレンジは、こちらのサイトに既存サブネットの IPv4 CIDR を入力して確認できます。)
NATゲートウェイの作成
作成した パブリックサブネットに NAT ゲートウェイを追加し、Elastic IP も関連付けさせます。
※ この Elastic IP が固定されるグローバル IP です。
ルートテーブルの作成
送信先
0.0.0.0/0のターゲットが作成した NAT ゲートウェイとなるルートテーブルを新規作成します。
プライベートサブネットの作成
VPN 用のパブリックサブネットと同じアベイラビリティーゾーン内にプライベートサブネットを作成し、先ほど作ったルートテーブルを紐付けます。
2. ACM の設定(証明書・キーの生成)
今回は VPN の認証オプションとして「相互認証」を利用するので、それに必要な証明書・キーを OpenVPN Easy-RSA で生成し、それらを ACM に登録します。
OpenVPN Easy-RSA のインストール
git clone https://github.com/OpenVPN/easy-rsa.git cd easy-rsa/easyrsa3証明書の生成
./easyrsa init-pki ./easyrsa build-ca nopass ./easyrsa build-server-full server nopass ./easyrsa build-client-full client1.domain.tld nopassACM への登録
ACMコンソールの「証明書のインポート」より、作成した2ペアの証明書・キーを登録します。
証明書本文・証明書チェーン-----BEGIN CERTIFICATE----- ....== -----END CERTIFICATE-----証明書のプライベートキー-----BEGIN PRIVATE KEY----- .... -----END PRIVATE KEY-----サーバ証明書 (server)
- 証明書本文
~/easy-rsa/easyrsa3/pki/issued/server.crt- 証明書のプライベートキー
~/easy-rsa/easyrsa3/pki/private/server.key- 証明書チェーン
~/easy-rsa/easyrsa3/pki/ca.crtクライアント証明書 (client1.domain.tld)
- 証明書本文
~/easy-rsa/easyrsa3/pki/issued/client1.domain.tld.crt- 証明書のプライベートキー
~/easy-rsa/easyrsa3/pki/private/client1.domain.tld.key- 証明書チェーン
~/easy-rsa/easyrsa3/pki/ca.crt3. Client VPN エンドポイントの設定
Client VPN エンドポイントの作成
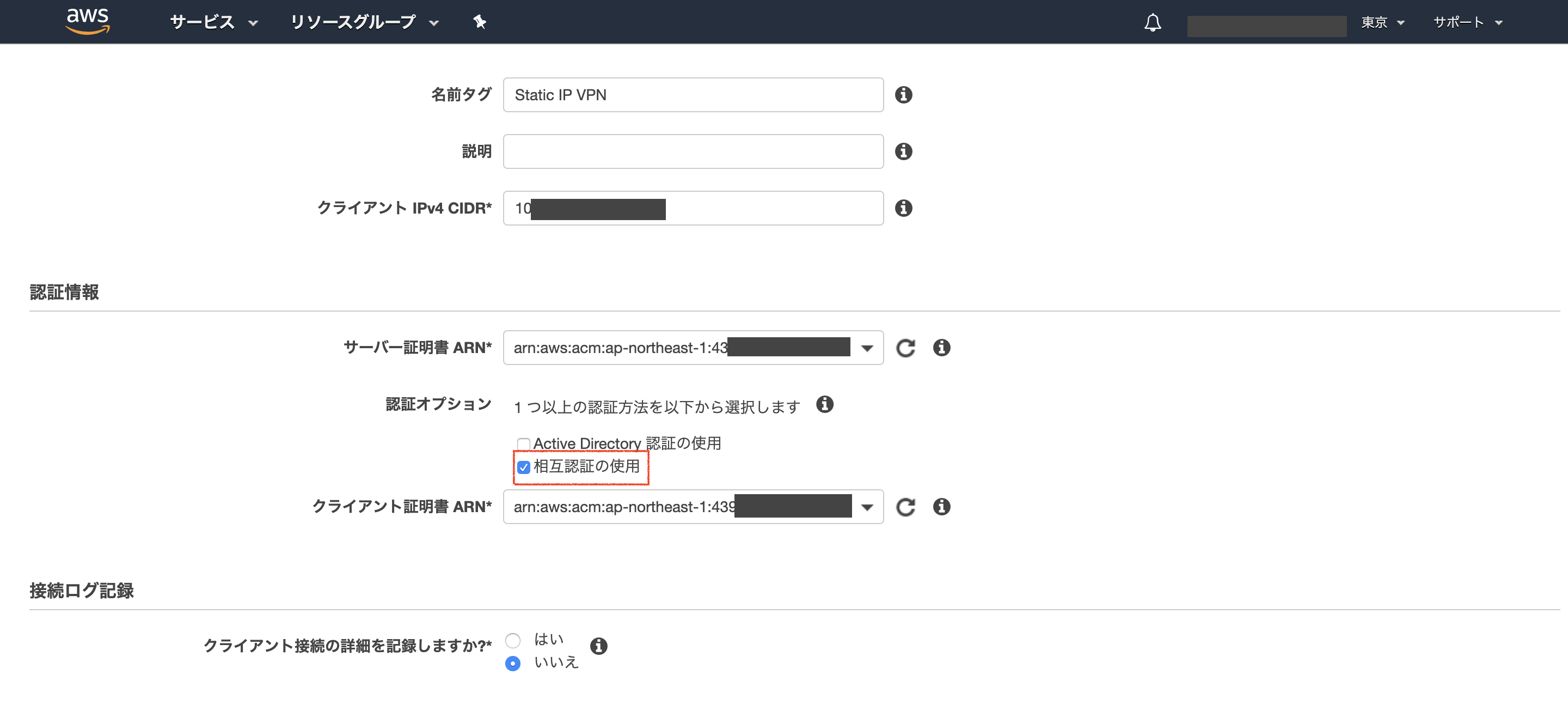
VPC コンソールから「クライアントVPNエンドポイント」を作成します。
- クライアント IPv4 CIDR:接続先のVPCのCIDRと被らない任意のアドレス
- サーバ証明書:ACMに登録したサーバ証明書
- 相互認証の使用:チェック
- クライアント証明書:ACMに登録したクライアント証明書
- DNSの設定は不要
NAT ゲートウェイへの関連付け
作成後、「Client VPN エンドポイント > 関連付け」から VPN 用に作成したプライベートサブネットに紐付けます。
ルートテーブルの追加
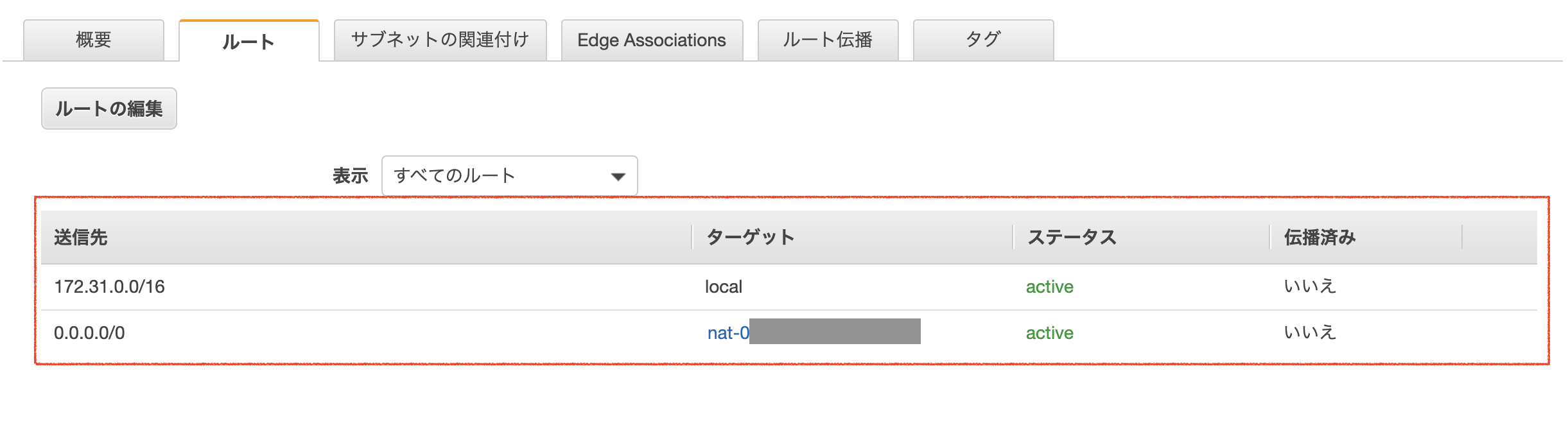
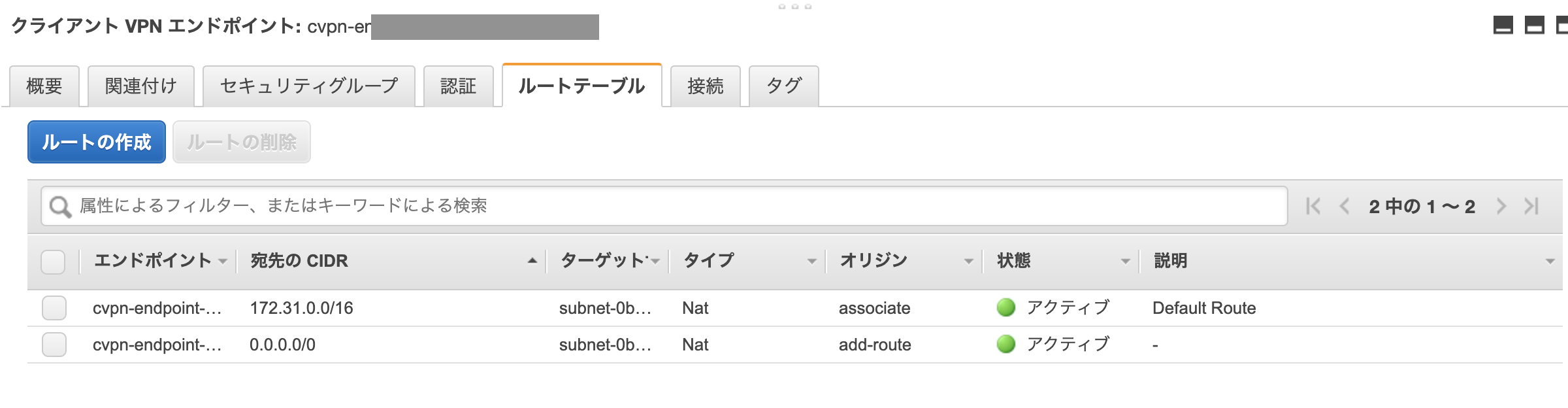
「Client VPN エンドポイント > ルートテーブル」から「宛先
0.0.0.0/0」を追加します。
- 宛先の CIDR
0.0.0.0/0- ターゲット VPC サブネット ID: VPN 用に作成したプライベートサブネット
追加後のルートテーブルは次のようになります。
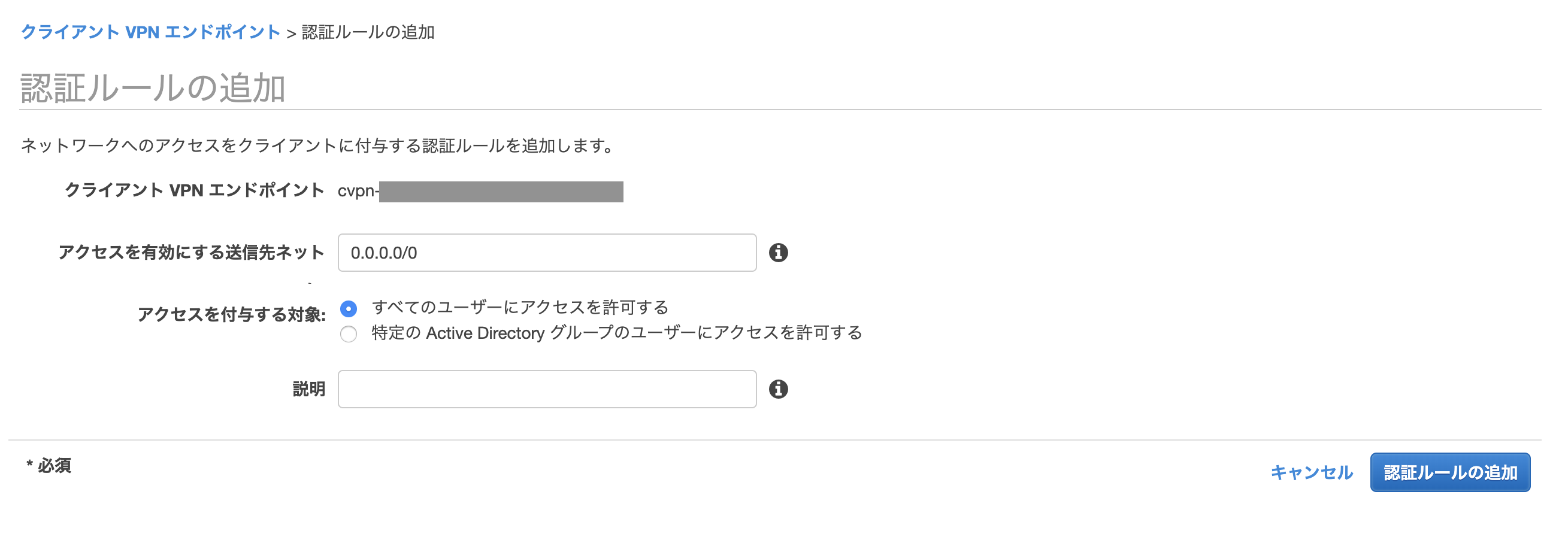
認証ルールの追加
「Client VPN エンドポイント > 認証」から認証ルールを追加します。
- アクセスを有効にする送信先ネット: 0.0.0.0/0
- アクセスを付与する対象: すべてのユーザーにアクセスを許可する
設定ファイルのダウンロード
「Client VPN エンドポイント > クライアント設定のダウンロード」から設定ファイルを落とします。
設定ファイルをエディタで開き、クライアント証明書とキーのパスを追記します。
downloaded-client-config.ovpn# 省略 cert /Users/[username]/easy-rsa/easyrsa3/pki/issued/client1.domain.tld.crt key /Users/[username]/easy-rsa/easyrsa3/pki/private/client1.domain.tld.key設定は以上です。
接続テスト(Tunnelblick)
VPNの接続には Tunnelblick を使います。
更新した設定ファイルを Tunnelblick に追加し、接続します。
接続完了後、CMAN で利用中のグローバルIPを確認し、割り当てた Elastic IP が表示されればOKです。
概算利用料金
同セットアップでグローバルIPを固定する場合の利用料金を考えてみます。
各サービス料金
(*) 利用可能になった時点から課金
(^)VPN 利用時に課金NAT ゲートウェイの料金
『Amazon VPC の料金』によると、東京リージョンでの利用料金は次のとおりです。
- 利用可能な NAT ゲートウェイの時間料金:0.062USD/時 (*)
- データ処理料金:0.062USD/GB (^)
Client VPN の料金
『AWS VPN の料金』によると、東京リージョンでの利用料金は次のとおりです。
- Client VPN エンドポイントの時間料金:0.15USD/時・サブネットとの関連付け (*)
- Client VPN 接続料金:0.05USD/時 (^)
セットアップした状態だと、維持費は月150ドル?!
上のとおり、NAT ゲートウェイと Client VPN には、「利用可能になった時点から課金」される金額があります。なので、利用可能な状態(active)を維持しておくと...
# 1日あたり (0.062 + 0.15) * 24時間 = 5.09ドル/日 # 1月あたり 5.09 * 30日 = 152.7ドル/月なんと、維持費だけで月152.7ドルも請求されてしまいます!
(実際に使った場合は、これに加えて、データ処理料金と VPN 接続料金も請求されます。)
維持費の抑えかた: 152ドル → 3.6ドル
この高額な維持費は、次の2つの方法で月3.6ドルまで抑えられます。
VPN を使用していない時は:
- NAT ゲートウェイを削除する
- Client VPN のサブネットとの関連付けを解除する
これで NAT ゲートウェイと Client VPN の維持費はなくなります。
一方、NAT ゲートウェイを削除したことにより、Elastic IP アドレスの関連付けがなくなります。これによって、Elastic IP アドレスの維持費が月3.6ドル発生します。
詳細はこちら → Elastic IP アドレス - Amazon EC2 料金表
# 1日あたり 0.005 * 24時間 = 0.12ドル/日 # 1月あたり 0.12 * 30日 = 3.6ドル/月VPN 利用時の再セットアップ
この場合、VPN を使用する時に次のセットアップが必要です:
- NAT ゲートウェイを再作成(Elastic IP を割り当てる)
- ルートテーブルの作成(
0.0.0.0/0を NAT ゲートウェイに向ける)- 作成したルートテーブルをプライベートサブネットに適用
- Client VPN とプライベートサブネットを関連付ける
- Client VPN 宛先の CIDR
0.0.0.0/0を追加めんどくさいですが、「維持費 152ドル → 3.6ドル」を考えると許容できる作業量だと思います。
結局の概算利用料金
上のように維持費を抑えた場合、結局利用料をどれぐらいになるでしょうか?
例えば、再セットアップして1日8時間 VPN 接続し、2GBのデータ処理をした時の概算利用料は、1日2ドルちょっとになります。
0.262 * 8時間 + 0.062 * 2GB = 2.22ドル/日VPN 接続しない時の Elastic IP 維持費は1日0.12ドルなので、差額コストはだいたい2ドル。
つまり、
3.6ドル/月 + 利用日数 * 2ドルが概算利用料金の目安になります。
なので、ヘビーに利用する場合はそれなりの料金がかかります。そういったケースでは、専用の有料サービスを利用した方が良さそうです。(日本のIPでも月額1,000円ぐらいで利用できそう)
利用するタイミングが限定的であれば、この方法でグローバルIPを固定するのもアリだと思います。あとは VPC 周りの勉強になったので、そういった観点でセットアップしてみるのもいいかもしれません。
References
- 投稿日:2020-01-16T08:30:27+09:00
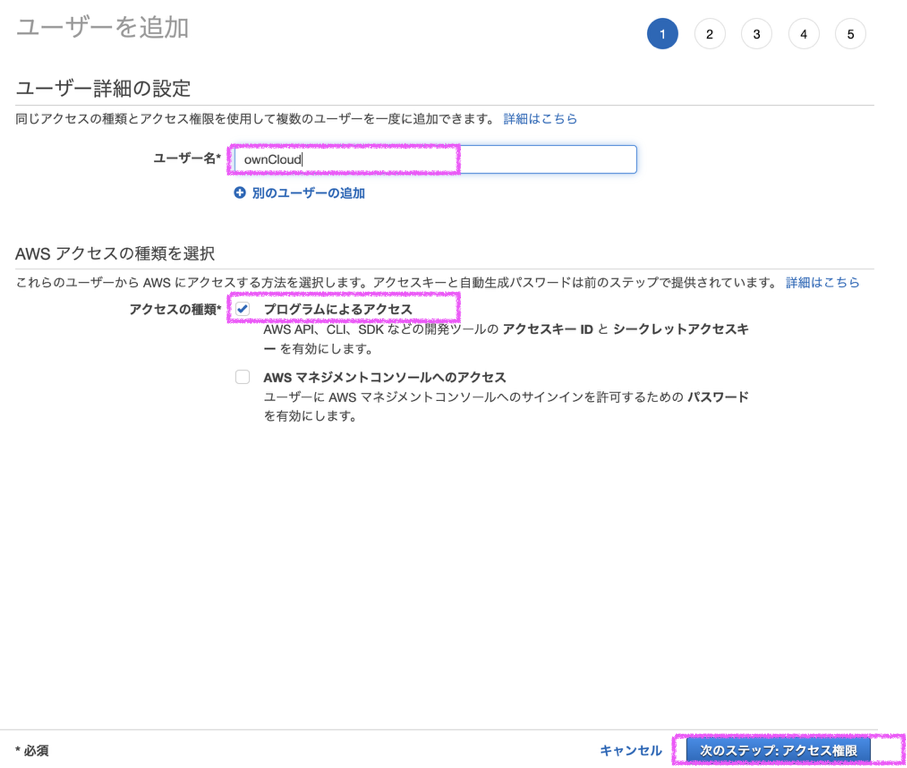
AWS IAMユーザー作成方法
はじめに
AWS IAMユーザーの作成方法をまとめました。
関連リンク
関連リンクを下記に載せておくので、必要であれば参考にしてください。。
- 誰でも作れるクラウドストレージサービス ownCloud + EC2(AMI)
IAMユーザーとは
AWS Identity and Access Management (IAM) では、AWS のサービスやリソースへのアクセスを安全に管理できる。
IAM を使用すると、AWS のユーザーとグループを作成および管理し、アクセス権を使用して AWS リソースへのアクセスを許可および拒否できる。IAM は追加料金なしで AWS アカウントに提供されている機能。
前提条件
- AWS アカウントが作成済みであること。
IAM作成
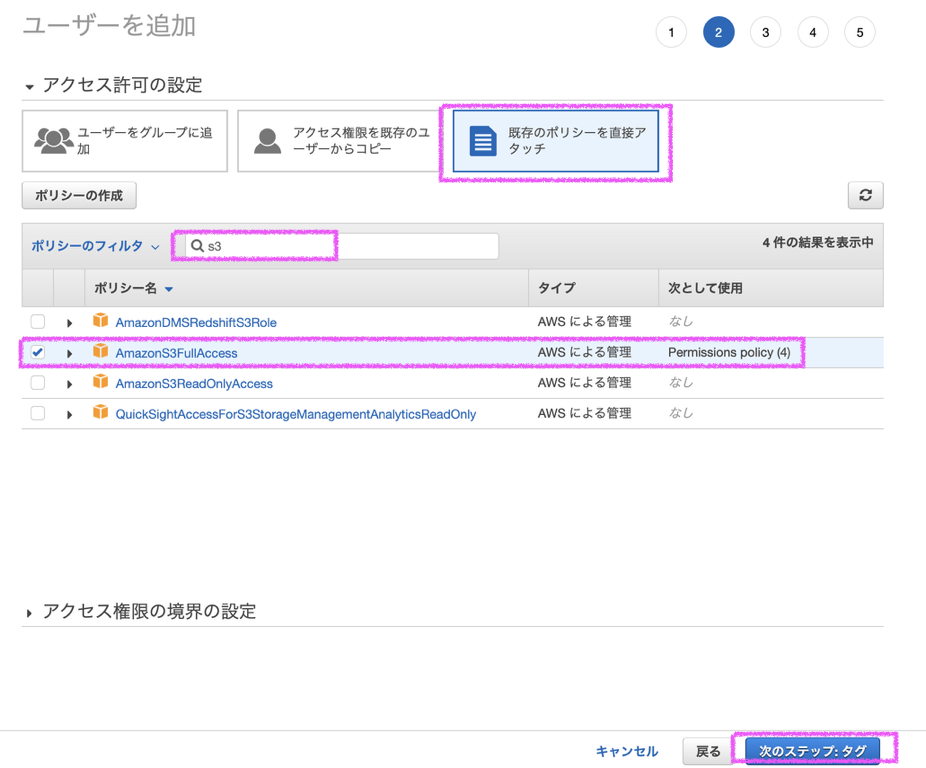
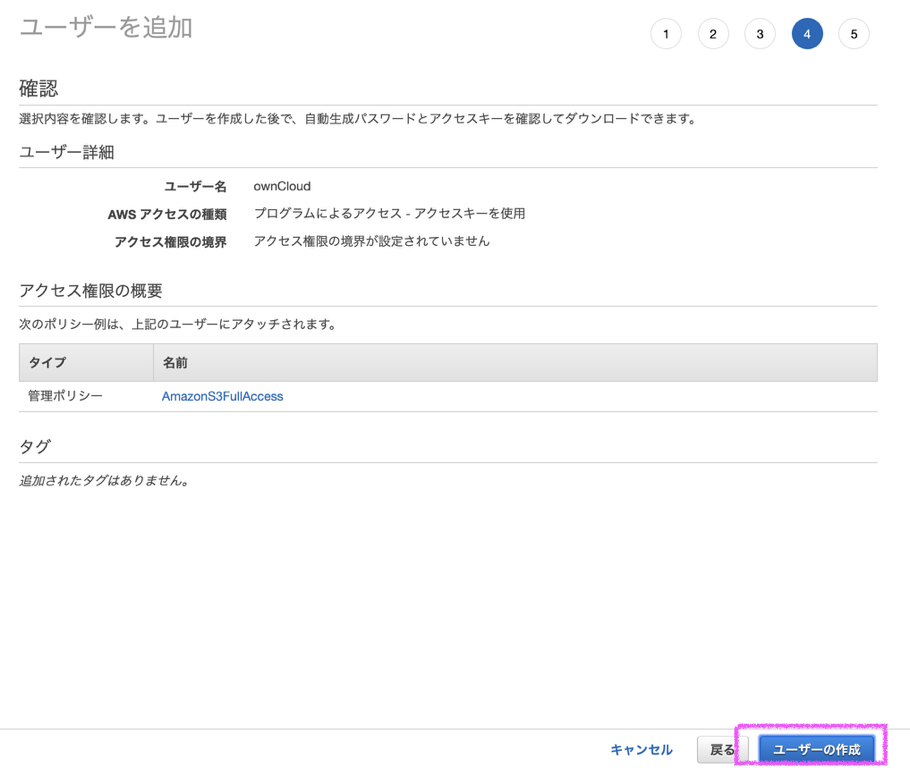
ポリシーについては、そのIAMユーザーに何をさせたいかによりますので、各自必要なポリシーをつけるようにしてください。
添付画像はS3にアクセスできるIAMユーザーを作成するときの例を示しています。
下記のアクセスキーIDとシークレットアクセスキーをメモしておく。





- 投稿日:2020-01-16T00:19:01+09:00
CodePipelineでS3にデプロイしてCloudFrontでコンテンツを配信する
CodeStarでさくさくCI/CD作りもいいのだが、とりあえず一旦はCodeCommitからDeployまでCodePipelineで連携する方法を理解しておこうと思ったので、軽く試してみた。
CloudFrontで配信するところまでやってみる。
やること
- CodePipelineを利用して、CodeCommit, CodeBuildを連携させ、ReactクライアントをS3にアップロードする(デプロイ)。
- S3に配置されたReactクライアントをCloudFrontで配信する。
やる順番
- CodeCommitでリポジトリを作成
- CodeBuildでビルドの設定(テストの設定とかはしない)
- CodePipelineでCommitからDeployまでを一貫して行う(S3へビルドファイルをアップロード)
- CloudFrontでコンテンツを配信(細かい設定はしない)
CodeCommitでリポジトリを作成
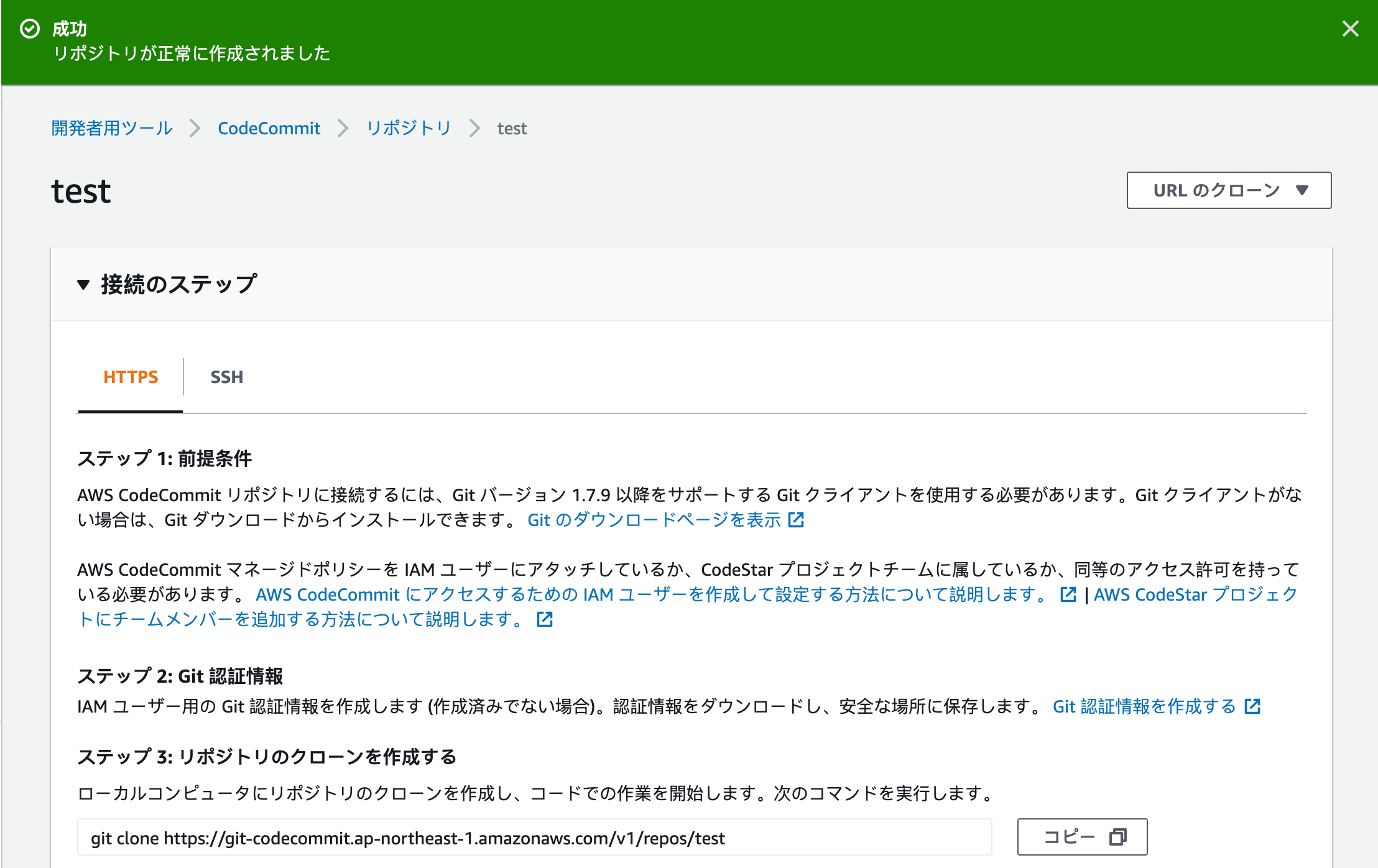
AWSコンソールのCodeCommitを開き、リポジトリを作成する。
仮にリポジトリ名testを作成すると以下のような「接続のステップ」が表示される。
ソースコードをプッシュするには、まずこのリポジトリをクローンする必要がある。
右上の「URLのクローン」から「HTTPSのクローン」を選択すると、URLがコピーされるのでローカルでgit cloneする。git cloneの際に尋ねられるユーザー名等はIAMの認証情報から取得する。
IAMのアクセス管理>ユーザーからアカウントを選択して、「AWS CodeCommit の HTTPS Git 認証情報」の「認証情報を生成」から証明書をダウンロードする。中のユーザー名とパスワードを使ってgit cloneできるようになる。
cloneしたディレクトリにソースコードを置いてプッシュすればCodeCommitにソースコードが表示される。
CodeBuildでビルドの設定
AWSコンソールのCodeBuildを開き、ビルドプロジェクトを作成する。
公式の解説ページも参考に。
CodeBuild でビルドプロジェクトを作成する「ビルドプロジェクトを作成」へ入ると、
- プロジェクトの設定
- 送信元
- 環境
- Buildspec
- アーティファクト
- ログ
の設定項目が目につくが、ここでは「送信元」、「環境」、「Buildspec」のみに触れる。
「アーティファクト」と「ログ」の設定は触れずにビルドプロジェクトを作成する。
CodeBuild 送信元設定
ここで指定するソースプロバイダは、CodeCommitの入力アーティファクトを出力するソースコードを指す。
CodePipeline(CodeCommit, CodeBuild, CodeDeployをCI/CD機能)では入力アーティファクトと出力アーティファクトが各フェイズで受け渡される。
アーティファクトとはそれぞれのフェイズの成果物のことで、CodeCommitの出力アーティファクトはコードそのものであり、CodeBuildはそれを入力アーティファクトとして受け取って、ビルドしたファイルを出力アーティファクトとしてCodeDeployへ渡す。CodeBuild 環境設定
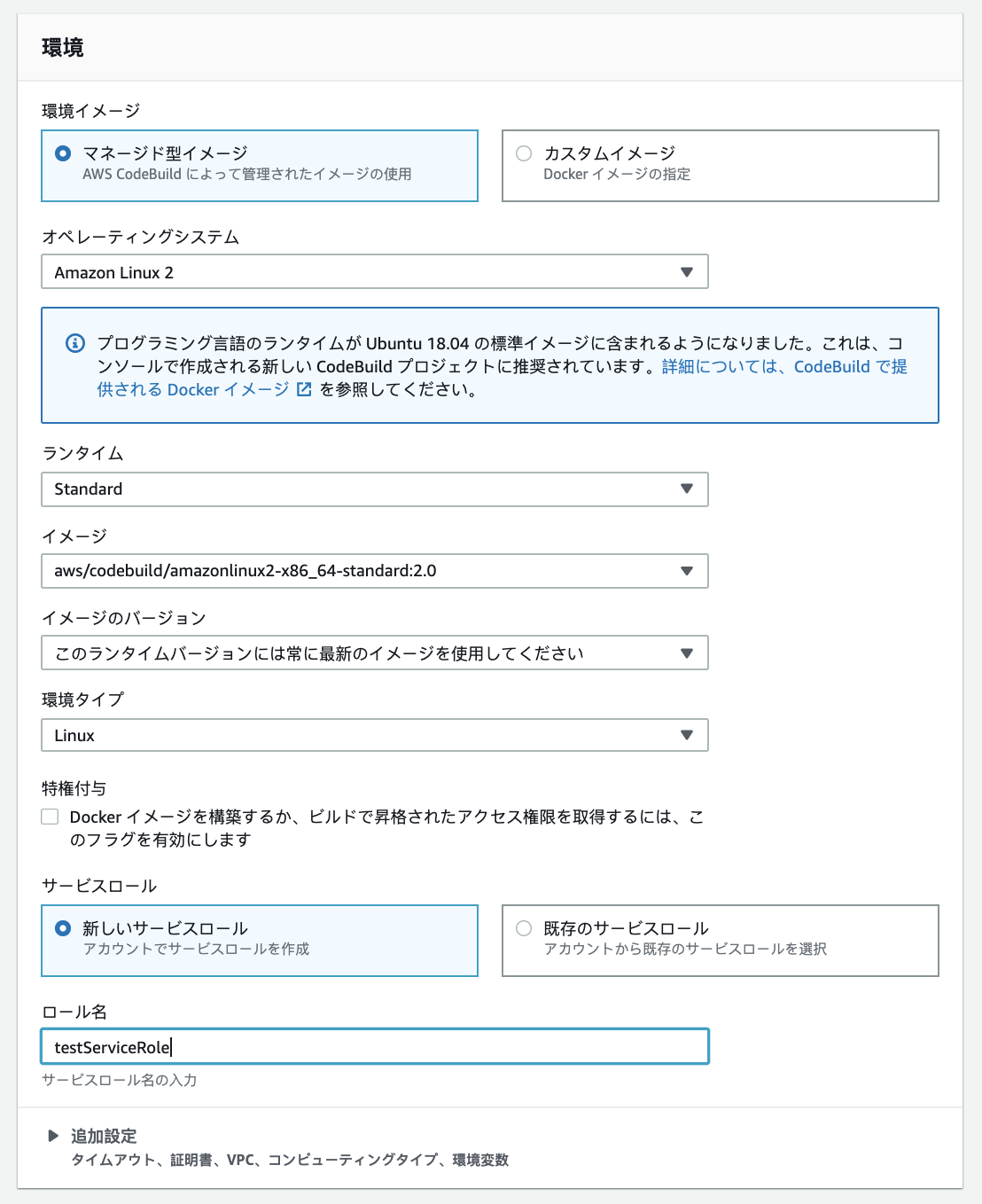
ビルド環境設定では、ビルドを実行するためにCodeBuildが使用するオペレーティングシステム、プログラミング言語ランタイム、およびツールの組み合わせを設定することができる。
特にこだわりがないのであれば、
OS、ランタイム、イメージ、イメージのバージョン、環境タイプは上記のように設定すればたいして困らないと思う。サービスロールではCodeBuildの実行に必要なポリシーが組まれたロールが作成される。
すでにある場合は既存のものを使える。CodeBuild のビルド環境リファレンス
CodeBuild に用意されている Docker イメージCodeBuild Buildspec設定
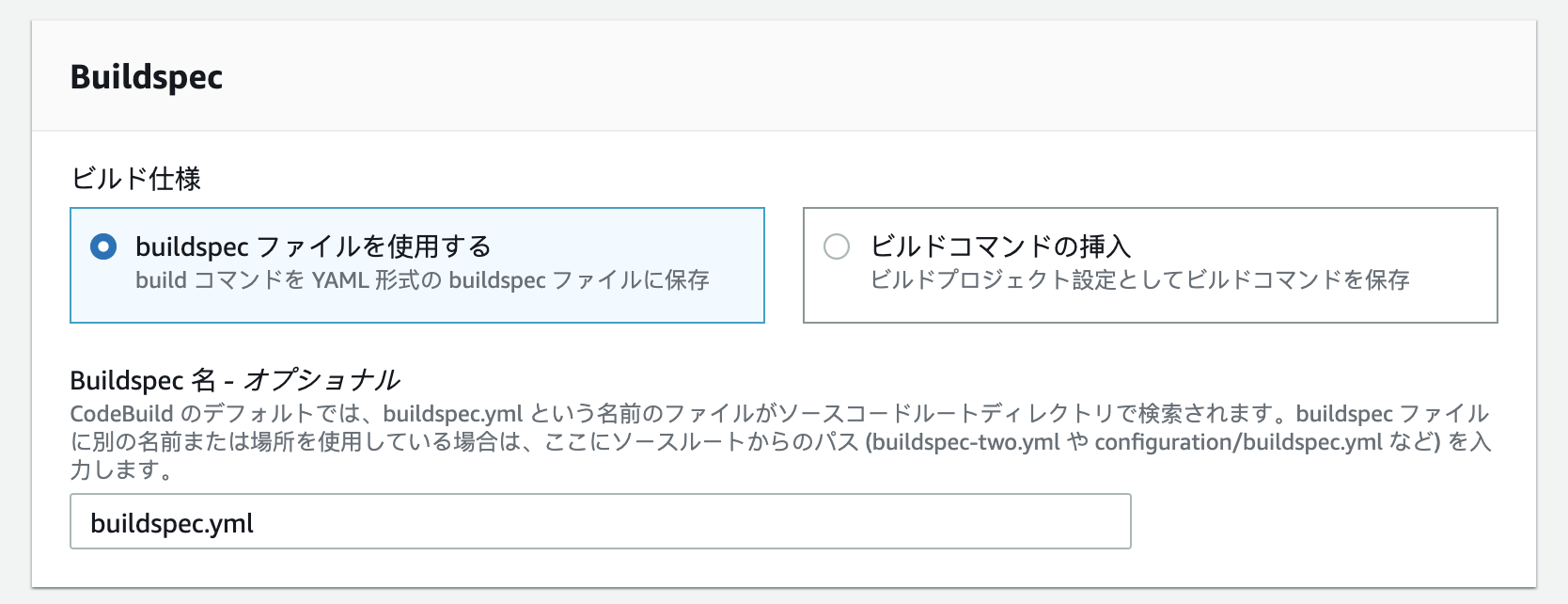
ビルドコマンドの挿入の選択肢もあるが、ここではbuildspecファイルを使ったビルド設定について触れる。
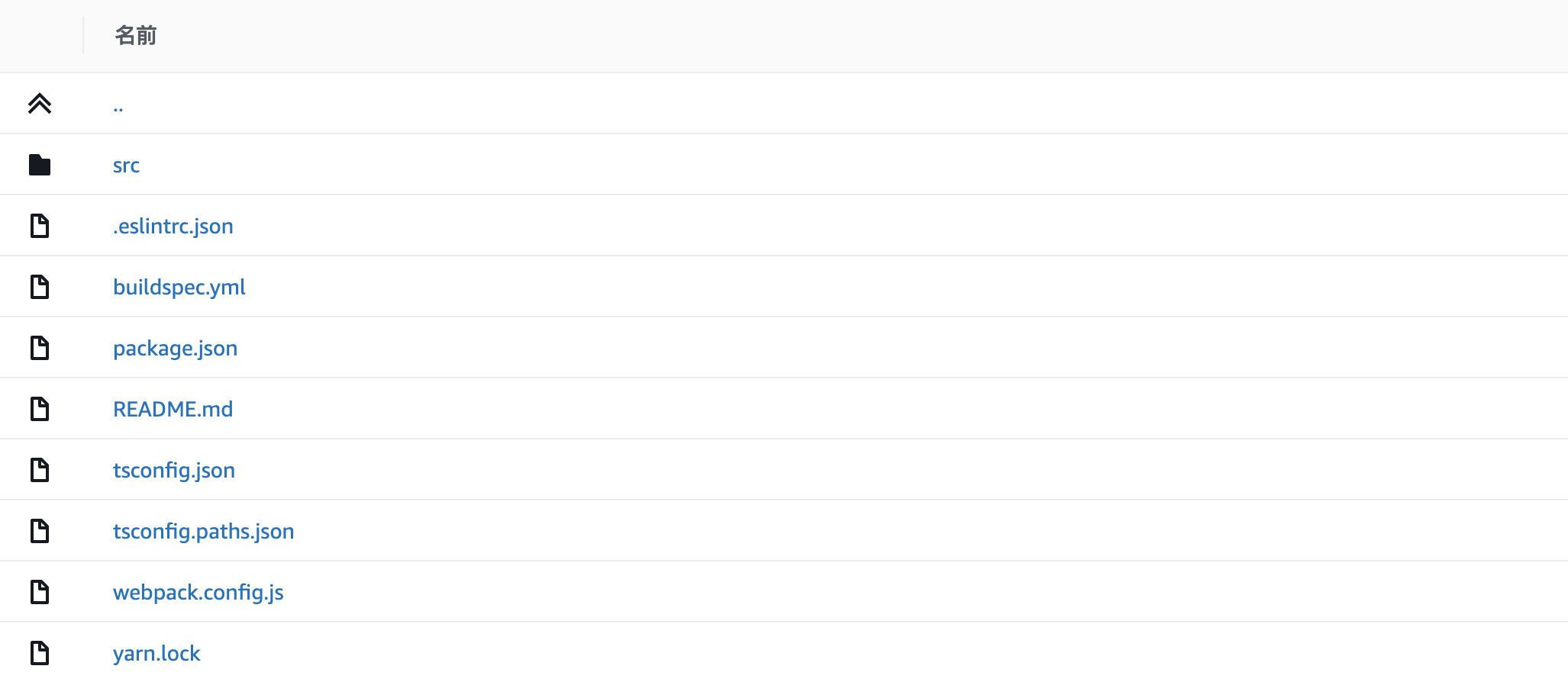
ここまでにCodeBuildがビルドを行うソースコードの設定と、ビルドを行う環境の設定について書いたが、Buildspecではビルドの実行時に実行する細かい処理についての設定を行うことができる。例えば、reactクライアントをCodeCommitへのプッシュをトリガーとしてビルドしたい場合は、以下のようにディレクトリ内にbuildspec.ymlを配置する。
これがこのリポジトリのルートディレクトリだとすると、Buildspecの項目におけるBuildspec名にはファイルそのものを指定すれば良い。
もしリポジトリ内の特定のディレクトリに存在するBuildspecファイルを指定したい場合は、そのパスを書く(client/buildspec.ymlのように)。また、このymlファイルの名前が
buildspecである必要はない(clientspec.ymlとかでも良い)。buildspec.ymlの例
例ではreactクライアントのビルドを念頭に置いているため、runtime-versionsはnodejs10.xを指定しており、 typescriptをインストールしている。version: 0.2 phases: install: runtime-versions: nodejs: 10 commands: - npm install -g typescript pre_build: # ビルド実行前に実行する処理等の設定 commands: - cd client - npm install build: # ビルド実行処理等の設定 commands: - npm run build # post_build: # commands: # - some command # - some command artifacts: files: - 'client/dist/*' # 出力するビルドファイル discard-paths: yes # 出力するビルドファイルからパスを省く(client/dist/などを省く)CodePipelineでCommitからDeployまでを一貫して行う
AWSコンソールのCodePipelineを開き、パイプラインを作成する。
パイプライン名とサービスロールを設定すると、
- ソースステージ
- ビルドステージ
- デプロイステージ
の設定に入る。
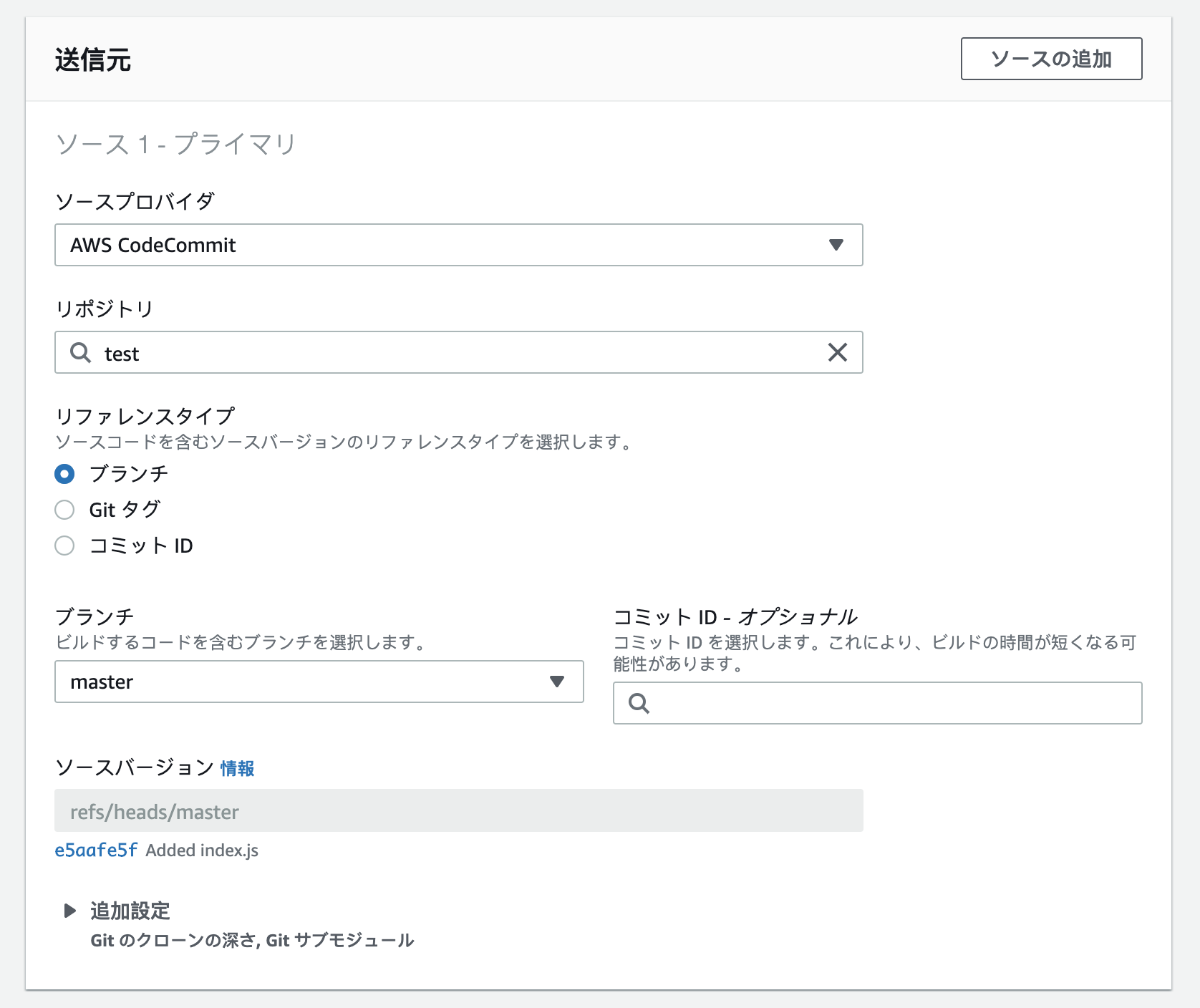
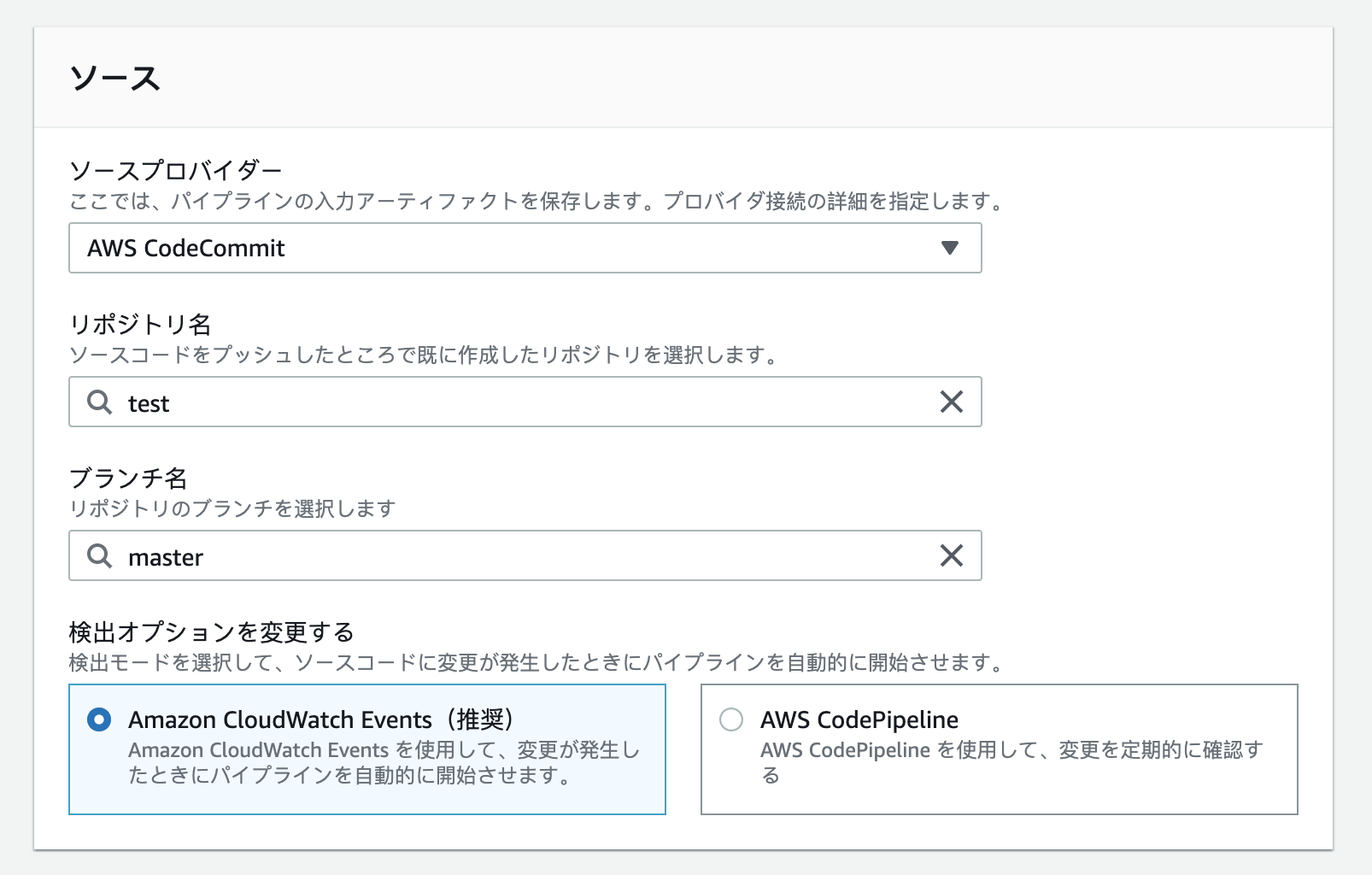
ソースステージの設定
CodeCommitのリポジトリ名とブランチ名を指定する。
これはビルドステージへの出力アーティファクトとなる。ビルドステージの設定
CodeBuildで設定したプロジェクトを指定する。
デプロイステージの設定
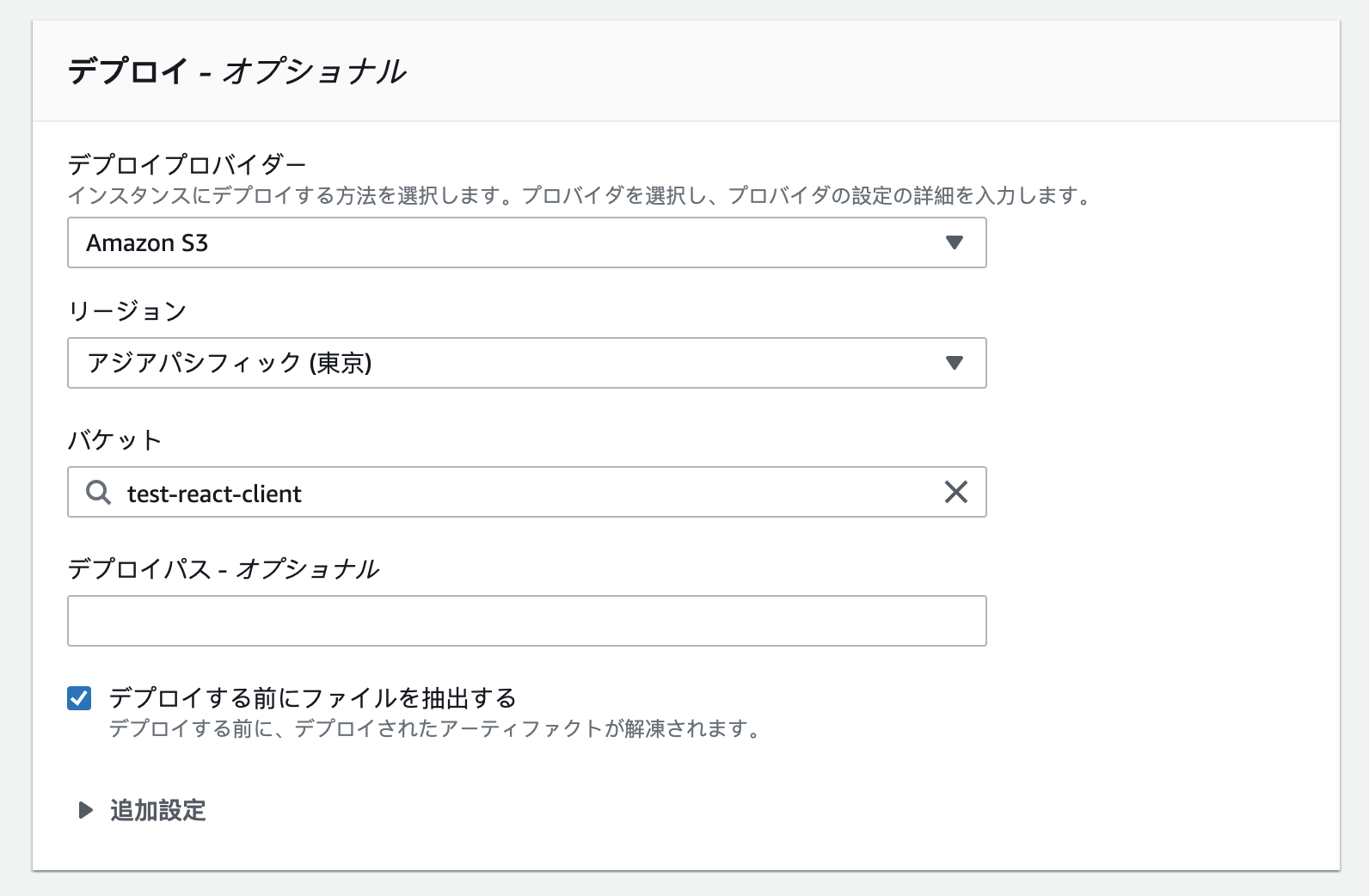
CodeDeployはS3のデプロイに対応していないため、S3デプロイを行うためにはCodePipelineを使う必要がある。
デプロイプロバイダーにS3を指定し、デプロイ先のバケットを選択する。
ここでは「デプロイする前にファイルを抽出する」にチェックを入れている(何もしないとzipがバケットに配置されるが、ここでは解凍された状態で配置したいため。デプロイパスはバケット内に展開されるディレクトリの構成を設定できる)。全ての設定を終えて確認画面から「パイプラインを作成する」と、パイプライン一覧に新規パイプラインが表示される。
ソースコードに変更を加え、CodeCommitへプッシュすると、自動的にCodeBuildが起動し、S3へのビルドファイルのデプロイが行われる。デプロイ設定で指定したバケット内にビルドしたファイルが表示されるはず。
CloudFrontでコンテンツを配信
CloudFrontとはオリジンサーバーが直接アクセスに対応する機会を減らし、キャッシュ化されたエッジロケーションのリソースに対してユーザをルーティングする機能のこと。
Amazon CloudFront とはAWSコンソールでCloudFrontを開き、CreateDistributionを選択する。
WebのGet Startedからディストリビューションの設定を行う。
Origin Settingでは以下の2点を設定する。
Origin Domain Name
CodePipelineでビルドファイルをデプロイしたS3バケットを選択する。Restrict Bucket Access
バケットのリソースへのアクセスを、S3のURLを使わずに常にCloudFrontのURLを利用したアクセスのみに絞りたい場合はこの項目をYesに設定する。Default Cache Behavior Settingsは飛ばして、
Distribution Settingsでは以下の項目だけを設定する。
- Default Root Object
index.htmlを指定する。 これはバケット内のインデックスドキュメントの設定。 設定しないと${URL}/index.htmlとしてアクセスしなければならない。Create Distributionをクリックして一覧に表示されるディストリビューションのStatusがDeployedになるまで待つ。
DeployedとなったらDomain Nameに表示されているURLにアクセスしてページが動いているかを確認する。
完。
まとめ
ここまででCodeCommitに新しい変更をコミットしていくと、S3バケットに自動的にビルドファイルがアップロードされるようになる。
厳密なデプロイはそのあとにCloudFrontのディストリビューションのInvalidate(CloudFrontのエッジロケーションのキャッシュを削除して更新されたコンテンツを再配布する)を行ったときに行われる。
InvalidateはCloudFrontのディストリビューションの一覧画面からディストリビューションを選び、Invalidationタブを選択した画面で行える。
Create InvalidationからInvalidateする項目を指定してInvalidateボタンをクリックするだけ。
バケット内の全てのファイルを指定してInvalidateする場合は*(アスタリスク)を指定すれば良い。今後デプロイの手順としては、
- CodeCommitへコードのプッシュ
- CloudFrontでInvalidateを実行
をするだけでよくなる。
おしまい。

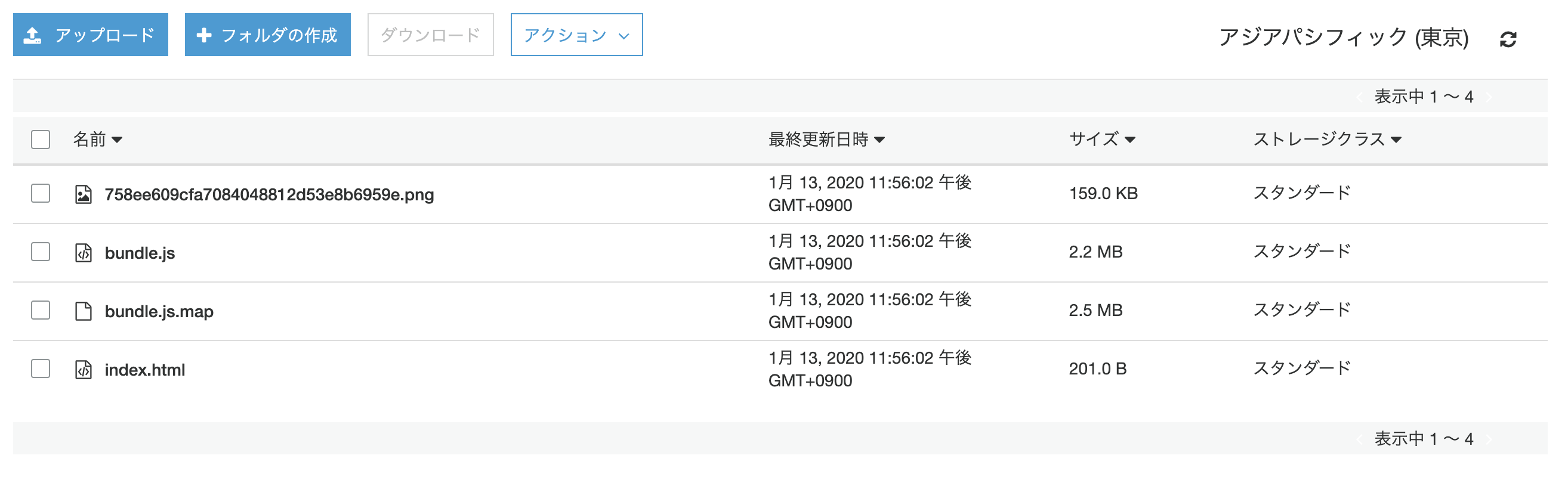


- 投稿日:2020-01-16T00:13:18+09:00
AWSのストレージサービス
出展:AWS認定資格試験テキスト AWS認定 クラウドプラクティショナー
EBS
・Amazon Elastic Block Storeの略
・EC2インスタンスにアタッチして使用するブロックストレージボリュームEBSの特徴
EC2インスタンスのボリュームとして使用
・EC2インスタンスのルートボリューム(ブートボリューム)または追加のボリュームとして使用
・不要になればいつでも削除することができるアベイラリティゾーン内でレプリケート
・同じアベイラリティゾーン内の複数サーバ間で自動的にレプリケートされる
・ハードウェア障害が発生してもデータが失われることを防ぐボリュームタイプの変更が可能
・使い始めた後に需要やニーズが変わった場合は、オンラインでボリュームを変更できる
・汎用SSD:
・最大でも16,000IOPS、かつ一定の性能を約束するものではない
・プロビジョンドIOPS SSD:
・持続的で一定のIOPSが必要な場合や、16,000を超えるIOPSが必要な場合に使用
・最小のIOPSを指定することができる
・IOPSの最大値は64,000
・スループット最適化HDD:
・SSDほどの性能を必要とせず、コストを節約したい場合に使用
・Cold HDD:
・アクセス頻度が低い場合に使用
・スループット最適化HDDとCold HDDはルートボリューム(ブートボリューム)としては使用できない容量の変更が可能
・使い始めた後にオンラインでストレージ容量を増やすことができる
高い耐久性のスナップショット
・スナップショットをS3に保存することで高い耐久性を実現できる(イレブンナイン:99.999999999%)
ボリュームの暗号化
・EBSの暗号化を有効にすればボリュームが暗号化される
・ボリュームを暗号化すると、そのボリュームから作成されたスナップショットも暗号化される
・EC2インスタンスからのデータの暗号化/複合化は透過的に行われるので、プログラムやユーザから追加の操作を行う必要はない永続的ストレージ
・EBSはインスタンスのホストとは異なるハードウェアで管理される
・EBSに保存したデータはインスタンスの状態に関係なく永続的に保存される
インスタンスストア:
・インスタンスのホストローカルのストレージを使用
・データを一時的に扱う⇒EC2のインスタンスが起動している間のみ、データを保持しているS3
・Amazon Simple Storage Serviceの略
・インターネット対応の完全マネージド型のオブジェクトストレージS3の特徴
無制限の外レージ容量
・S3では保存したいデータ容量を先に決めておく必要はない
・バケットというデータの入れものを作ればデータを保存し始めることができる
・データ容量は無制限
・ストレージ容量の確保/調達を気にすることなく開発に専念できる高い耐久性
・S3ではリージョンを選択してバケットを作成し、データをオブジェクトとしてアップロードする。そのオブジェクトは1つのリージョン内の複数のアベイラビリティゾーンにまたがって、自動的に冗長化して保存される
・これによりS3の耐久性はイレブンナイン(99.999999999%)となる
・冗長化やバックアップを意識することなく開発に専念できるインターネット経由でアクセス
・S3にはインターネット経由(HTTP/HTTPS)でアクセスするため、世界中のどこからでもアクセスできる
・アクセスとして使うことができる可用性は99.99%S3のセキュリティ
・S3バケットは作成した時点では、作成したアカウントから許可されたユーザやリソースからのアクセスのみ受け付ける(デフォルトでプライベート)
・必要に応じて特定のアカウント、IAMユーザ、AWSリソースにアクセス権限を設定するアクセス権限
アクセスコントロールリスト(ACL):
・主に以下のことが可能
・他の特定のAWSアカウントにオブジェクトの一覧を許可
・他の特定のAWSアカウントにオブジェクトの書き込みを許可
・他の特定のAWSアカウントにオブジェクトの読み取りを許可
・誰にでもオブジェクトの一覧を許可
・誰にでもオブジェクトの書き込みを許可
・誰にでもオブジェクトの読み取りを許可
バケットポリシー:
・アクセスコントロールリストよりも細かい設定が必要な場合に使用する
IAMポリシー:
・IAMユーザに対してアクセス権を設定する
・AWSサービスにS3へのアクセス権を設定する通信、保存データの暗号化
・通信中のデータの暗号化
・HTTPSでアクセスすることによって通信が暗号化される
・保存データの暗号化
・S3のキーを使用したサーバサイドの暗号化
・KMS(ユーザがAWS上に作成するマスターキー)を使用したサーバサイド暗号化
・ユーザ独自のキーを使用したサーバサイド、またはクライアントサイド暗号化S3の料金
ストレージ料金
・保存しているオブジェクトの容量に対しての料金
・1ヵ月全体をとおしての平均保存料で料金が算出される
・ストレージクラスによっても料金が異なる
・ストレージクラス
・標準:
・デフォルトのストレージクラス
・アプリケーションによって頻繁に利用されるオブジェクト、静的Webコンテンツの配信に使用
・低頻度アクセスストレージ(標準IA):
・アクセス頻度の少ないオブジェクトを格納する
・ストレージ料金は標準ストレージよりも安価になるが、リクエスト料金が標準ストレージよりもあがる
・バックアップデータなどに使用
・1ゾーン低頻度アクセスストレージ(1ゾーンIA):
・アクセスする頻度が少なく、かつ、複数のアベイラリティゾーンに冗長化される耐久性を必要としないオブジェクトを保存する場合に使用
・Amazon Glacier:
・単独のサービスとしても使用できるアーカイブサービス
・ほとんどアクセスしないものの保存はしておかなければならないような、アーカイブデータを格納する
・規約によって保存年数が定められているなど、アクセスすることはほとんどなくても削除はできないデータを保存
・ライフサイクルポリシー
・初回のアップロード時から各ストレージクラスを指定することができる
・アップロードした日から起算して自動でストレージクラスを変更するライフサイクルポリシーを設定することもできる
ex)当日:EC2(EBS)に保存
1日~30日間:標準ストレージに保存
31日~60日間:低頻度アクセスストレージに保存
61日~1年間:Amazon Glacierに保存
1年経過後:削除リクエスト料金
・データをアップロードしたり、ダウンロードするリクエストに対しての料金
データ転送料金
・リージョンの外にデータを転送した場合にのみ発生
・リージョンによって異なる
・インターネットに転送した場合とリージョンへ転送した場合でも異なるS3のユースケース
・アプリケーションデータの保存
・HTML、CSS、JavaScript、画像、動画ファイルなどの静的コンテンツの配信
・データバックアップの保存
・ログデータ、センサーデータなどの保存
・ビッグデータのステージング
・クロスリージョンレプリケーションによるDR(ディザスタリカバリ)対策