- 投稿日:2019-11-30T23:33:47+09:00
[TensorFlow]勾配降下法(最急降下法)による最小2乗線形回帰
TensorFlow:最初のステップ
TensorFlowとは機械学習のアルゴリズムを実装して実行するための、スケーラブルなマルチプラットフォームのプログラミングインターフェースである........
簡単にまとめると計算グラフと呼ばれる処理フローを作成して、実行するPackageらしい。
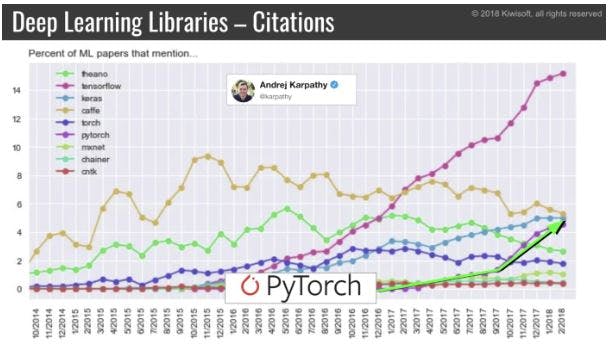
PyTorchとかKerasとかも追いついてきてるけど、依然としてTensorFlowの人気が高い。
Kerasに比べるとデバッグしずらいし、分かりずらい。
実際上記の指摘も多くあってか、シンプルにかけるTensorFlow2.0をリリースした模様。この記事では初期のTensorFlowの文法を使って記載していく。
TensorFlow2.0入れちゃったよという場合でも安心。以下のコードでコンバートできる....!import tensorflow.compat.v1 as tf tf.disable_v2_behavior()書き方はざっくり以下の構成になっている。
とりあえず実行してみよう。
なおTensorFlowのパッケージはインストールしていざ実行しようとすると意味不明なエラーが良く出てくるので、容赦なくアンインストール→インストールしよう。import os import numpy as np import tensorflow as tf g = tf.Graph() with g.as_default(): x = tf.placeholder(dtype=tf.float32, shape=(None), name='x') # 引数 w = tf.Variable(2.0, name='weight') # 変数① b = tf.Variable(0.7, name='bias') # 変数② z=w*x + b init=tf.global_variables_initializer() # 変数の初期化(tf.Session中で定義しても良いがここの方が扱いやすい) with tf.Session(graph=g) as sess: sess.run(init) # 変数の初期化の実行 for number in [1.0, 0.6, -1.8]: z = sess.run(z, feed_dict={x:number}) # z= w * x + bの実行 print(z) # 処理結果をprintz = sess.run(z, feed_dict={x:number})
ここの箇所だけ簡単に解説。
sess.run(アクセスしたい変数名, feed_dict={引数: 引数に渡したい値となる})どんどん行こう。次は配列(テンソル)を操作する。
TensorFlowでは計算グラフではエッジを流れる値をテンソルと呼ぶ。まさにテンソル流れだ。
テンソルはスカラ・ベクトル・行列として解釈できる。例えば以下の要領だ。
それでは早速TensorFlowでテンソルを操作してみよう。g = tf.Graph() with g.as_default(): x = tf.placeholder(dtype=tf.float32, shape=(None,2,3), name='input_x') # テンソルを受け取る引数 x2 = tf.reshape(x,shape=(-1,6),name='x2') # 受け取った引数xをreshapeメソッドで変形 print(x2) # 変数の定義を出力 xsum=tf.reduce_sum(x2,axis=0,name='col_sum') # 各列の合計 xmean=tf.reduce_mean(x2,axis=0,name='col_mean') # 各列の平均 with tf.Session(graph=g) as sess: x_array = np.arange(18).reshape(3,2,3) # 配列を作成 print('Column Sums:\n', sess.run(xsum, feed_dict={x:x_array})) # 各列の合計を出力 print('Column Means:\n', sess.run(xmean, feed_dict={x:x_array})) # 各列の平均を出力tf.reshape(x,shape=(-1,6),name='x2')
ここでのポイントはshapeに-1が指定されていること。これは型定義が未定でよしなに入力された配列にあわせて変換してくださいな、という意味。
TensorFlow:最小2乗線形回帰の実装
まずは最小2乗線形回帰ってなによってとこから。
①y = w * x + b の式を使って予測値を算出する
②(正解ラベル - 予測値)^2を求める
③②の平均値を求める
④③を使ってwとbを求める
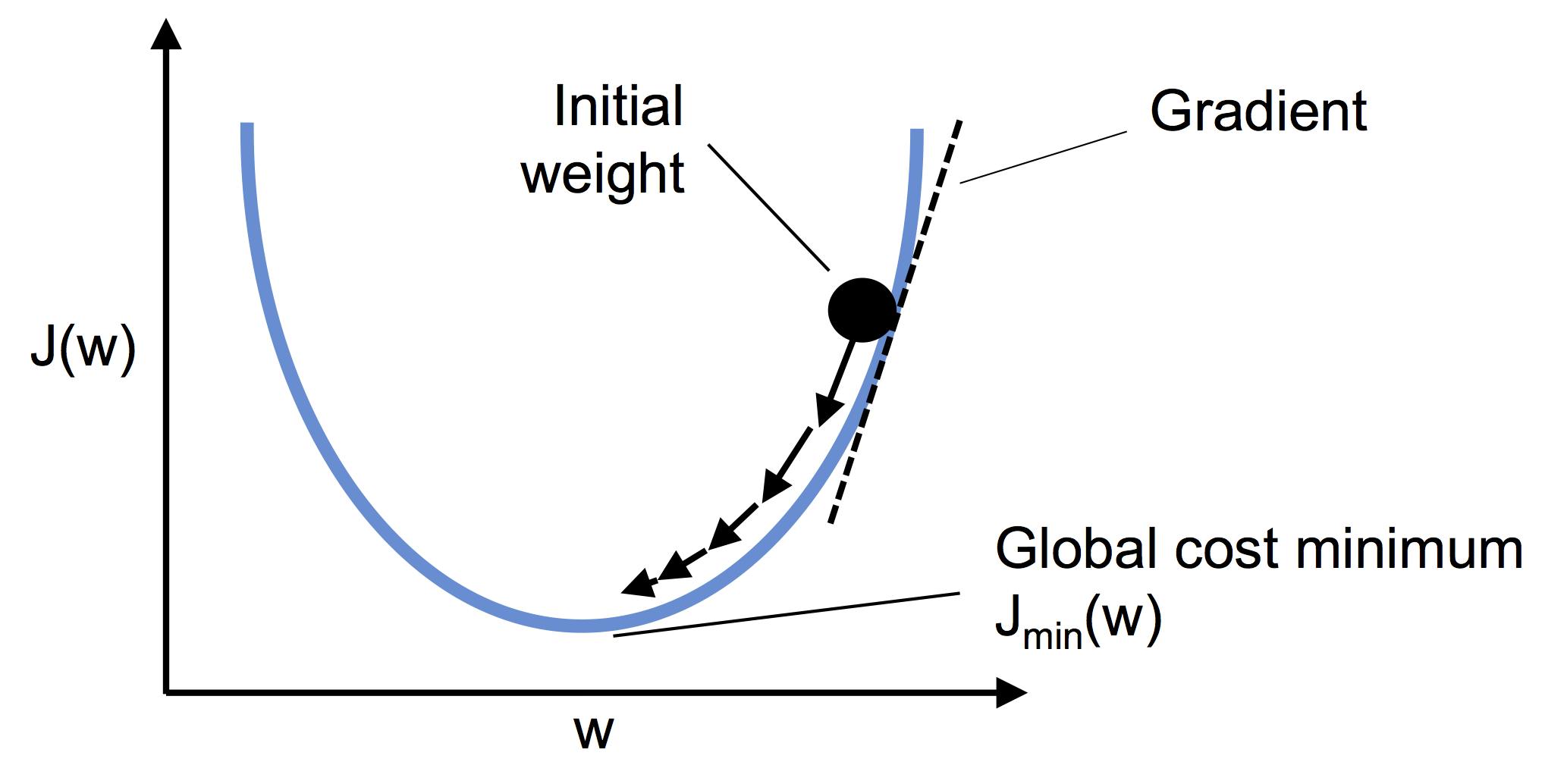
⑤これをエポック数分繰り返す結果、コスト値が大局的最小値に落ち着けば収束したといえる。
以下エクセルで手動で計算してみた様子。
そしてよくある図。
これはコスト値(エクセルの黄色い部分)をプロットして収束していく様子を表したもの。
線形関数のコスト関数は微分可能な凸関数になる。
それでは実際コードを見てみよう!!
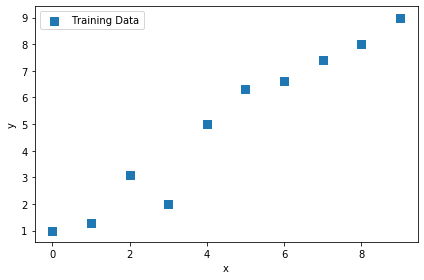
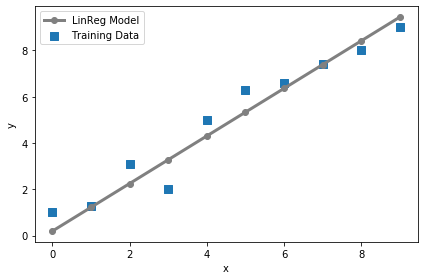
まずは訓練用のデータを用意する# 訓練データ X_train = np.arange(10).reshape((10, 1)) y_train = np.array([1.0, 1.3, 3.1,2.0, 5.0, 6.3, 6.6, 7.4, 8.0, 9.0]) # 線形回帰モデルのプロット plt.scatter(X_train, y_train, marker='s', s=50,label='Training Data') plt.xlabel('x') plt.ylabel('y') plt.legend() plt.tight_layout() plt.show()はい、matplotlibでプロットしてみましたー!
次にTfLinregクラスを用意する。
class TfLinreg(object): # コンストラクタ def __init__(self, x_dim, learning_rate=0.01, random_seed=None): self.x_dim = x_dim self.learning_rate = learning_rate self.g = tf.Graph() with self.g.as_default(): tf.set_random_seed(random_seed) self.build() # 変数のイニシャライザ self.init_op = tf.global_variables_initializer() def build(self): # プレースホルダ―を定義 self.X = tf.placeholder(dtype=tf.float32, shape=(None,self.x_dim), name='x_input') self.y = tf.placeholder(dtype=tf.float32, shape=(None), name='y_input') # tf.zeros:要素が全て0の行列 # 1×1のテンソル w = tf.Variable(tf.zeros(shape=(1)), name='weight') b = tf.Variable(tf.zeros(shape=(1)), name='bias') self.w = w self.b = b # 予測値を算出 # tf.squeeze:1の次元を削除し、テンソルを1つ下げる関数 self.test = w * self.X + b self.z_net = tf.squeeze(w * self.X + b, name='z_net') # 実績値-予測値 # tf.square:要素ごとに2乗をとる sqr_errors = tf.square(self.y - self.z_net, name='sqr_errors') self.sqr_errors = sqr_errors # コスト関数 # tf.reduce_mean:与えたリストに入っている数値の平均値を求める関数 self.mean_cost = tf.reduce_mean(sqr_errors, name='mean_cost') ## オプティマイザを作成 # GradientDescentOptimizer:最急降下法 optimizer = tf.train.GradientDescentOptimizer( learning_rate=self.learning_rate, name='GradientDescent' ) # 損失関数の勾配(重みと傾き)を計算 self.optimizer = optimizer.minimize(self.mean_cost)この時点ではクラスを定義しただけなので、何も具体的な数値は設定されていません。
ここでワンポイント。勾配降下法の中にはいくつか種類があります。・最急降下法(Gradient Descent)
・確率的勾配降下法(Stochastic Gradient Descent - SDG)
・ミニバッチ確率的勾配降下法(Minibatch SGD - MSGD)最急降下法は全ての誤差の合計をとってからパラメタ更新するのに対して
確率的勾配降下法はデータ1つごとに重みを更新していきます。
ミニバッチは2つの中間的な存在で膨大なデータをバッチ数ごとにぶった切って実行していくようなイメージ。それじゃあ続き。
まずはコンストラクタを呼んでインスタンスを作成します。# モデルのインスタンス化 lrmodel = TfLinreg(x_dim=X_train.shape[1], learning_rate=0.01)続いて学習を実施
### 学習 # self.optimizer def train_linreg(sess, model, X_train, y_train, num_epochs=10): # 変数の初期化 sess.run(model.init_op) training_costs=[] # 同じX_trainを10回繰り返す for i in range(num_epochs): """ model.optimizer:急速降下法を適用する model.X:学習データ(階数2) model.y:正解データ(階数1) model.z_net:予測値(w * self.X + bから計算) model.sqr_errors:実績値-予測値の2乗 model.mean_cost:2乗誤差の平均値 model.w:更新後の重み model.b:更新後のバイアス """ _,X,y,z_net,sql_errors,cost,w,b= sess.run([ model.optimizer, model.X, model.y, model.z_net, model.sqr_errors, model.mean_cost, model.w, model.b, ],feed_dict={model.X:X_train, model.y:y_train}) # 同じのを10回繰り返す print(' ') print(X) print(y) print(z_net) print(sql_errors) print(cost) print(w) print(b) training_costs.append(cost) return training_costsmodel.optimizer
で最急降下法が実行されます。結構迷ったとこがwとbには更新後の重みが設定されていること。
だから出力は、[0.60279995]
[0.09940001]
みたいになるけど初回の予測は[0][0]で実施されています。早速動かしてみる。
sess = tf.Session(graph=lrmodel.g) training_costs = train_linreg(sess, lrmodel, X_train, y_train)ほんでコスト値をプロットしてみる。
plt.plot(range(1,len(training_costs) + 1), training_costs) plt.tight_layout() plt.xlabel('Epoch') plt.ylabel('Training Cost') #plt.savefig('images/13_01.png', dpi=300) plt.show()
・・・!
やったね、収束したよ!!続いては予測をしよう。
予測は予測値(z_net)を呼び出すだけなので難しくない。
引数のx_testに2階数のテンソルをぶち込めば実行される。### 予測 # model.z_net def predict_linreg(sess, model, X_test): y_pred = sess.run(model.z_net, feed_dict={model.X:X_test}) return y_pred最後に訓練データで作成したモデルを可視化してみよう。
### 線形回帰モデルのプロット # 訓練データ plt.scatter(X_train, y_train, marker='s', s=50,label='Training Data') # 訓練データを使って出力した線形回帰モデル plt.plot(range(X_train.shape[0]), predict_linreg(sess, lrmodel, X_train),color='gray' , marker='o', markersize=6, linewidth=3,label='LinReg Model') plt.xlabel('x') plt.ylabel('y') plt.legend() plt.tight_layout() plt.show()
いい感じに線形が引かれている...........!
ということで今回はここまで。




- 投稿日:2019-11-30T22:59:14+09:00
JavaScriptのみで構築するディープラーニング with Jupyter and TensorFlow.js
はじめに
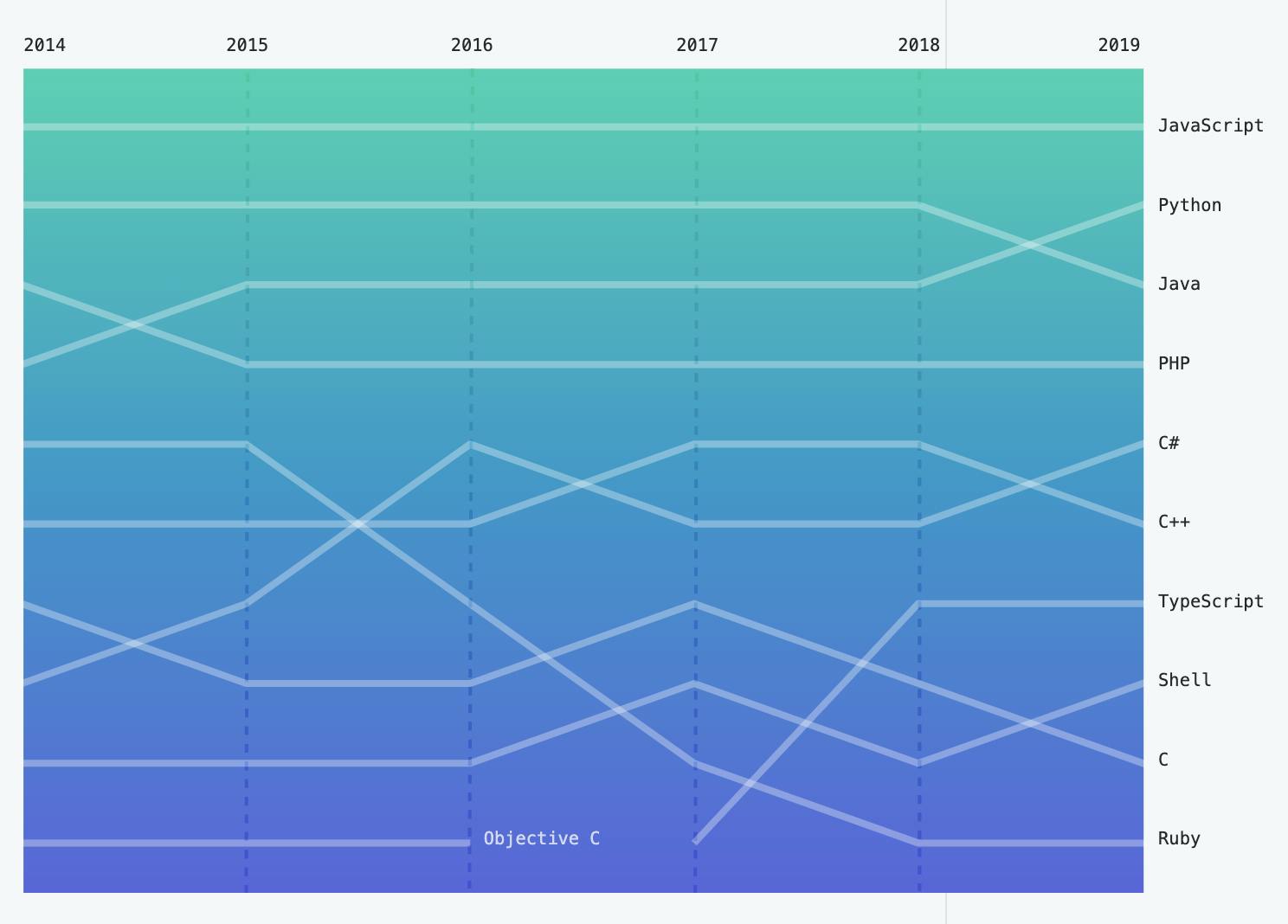
間も無く終了する2010年代はJavaScriptが大きく成長した十年でした。Reactなどの革新的なフレームワークが登場し、Node.js、React Naitive などブラウザ以外でのエコシステムも大きく成長しました。また言語自体もES2015以降日々進歩しており、JavaScriptは2010年代でもっとも多くの人に使われたプログラミング言語となりました。さらにJavaScriptに静的型付を導入したTypeScriptとそのエコシステムもここ数年で大きく成長しており、JavaScriptは大規模なソフトウェアの開発にも耐えうるようになってきています。
出典: https://octoverse.github.com/#top-languages一方で2010年代にJavaScript以上に大きく人気を伸ばしたプログラミング言語がありました。Pythonです。2010年代に大きく伸びた分野であるデータサイエンスと機械学習(AI)の分野ではPythonはその利便性で他のメジャーなプログラミング言語を圧倒しています。2010年代はPython2から下位互換性のないPython3への移行という混乱と困難があったにも関わらず、Pythonはデータ分析・機械学習分野の成長と歩みをともにして大きく人気を伸ばしました。2019年のGitHubの報告ではJavaを抜いて遂にユーザー数が2位となっています。JavaScriptはまだPythonにユーザー数では優っているもののデータ分析・機械学習の分野では大きく遅れをとっており、この分野の今後の伸び次第では近いうちにランキングが逆転するかもしれません。逆にユーザー数で優位にあるJavaScriptがこの分野でも人気を獲得し、その地位を不動のものとするかもしれません。
2020年代がJavaScript, Pythonにとってどのような時代になるのか楽しみです。この記事では2020年代におけるJavaScriptの機械学習、特にディープラーニングにおける成長の可能性を探るべく、JavaScriptのみを使ってディープニューラルネットワークモデルを構築することに挑戦してみます。
TensorFlow
TensorFlowはGoogleが公開しているディープラーニングのフレームワークです。FacebookのPyTorchと人気を二分するディープラーニングの二大フレームワークの1つです。学術分野では最近PyTorchに追い上げられているとの指摘もありますが、産業分野では一日の長があり2019年現在もっとも広く使用されているディープラーニングのフレームワークです。
TensorFlowのメインのターゲットはPythonですが、Python以外にもJavaScript, C++, Java, Go, Swiftなどが(実験的に)サポートされています。
TensorFlow.js
TensorFlow.js is a JavaScript Library for training and deploying machine learning models in the browser and in Node.js.
TensorFlow.jsはTensorFlowのJavaScript版のAPIです。TensorFlow.jsのもっとも重要な用途は他の環境で作成したTensorFlowのトレーニング済みモデルをウェブブラウザ上のアプリケーションに組み込めるようにすることです。ただしTensorFlow.jsはブラウザ上でのトレーニング済みモデルの実行だけでなく、Node.js上での実行やJavaScriptを使ったディープラーニングモデルのトレーニングもサポートしています。そのためTensorFlow.jsを使えばPythonを使うことなく、JavaScriptのみでディープラーニングモデルの構築からトレーニング、実際のアプリケーションとしての利用までエンドツーエンドで行うことが可能になっています。
Jupyter
Pythonをブラウザからインタラクティブに実行するための環境です。コードや実行結果が「ノート」として保存されるので非常に便利です。JavaScriptユーザーにはあまり知られてないツールかもしれませんが、Pythonを用いたデータ処理や機械学習、あるいは教育分野で非常に人気のあるツールであり、ここ数年で急激にユーザを増やしています。2019年のGitHub OctoverseでもJupyterの急激な成長が言及されています。Jupyter Notebook自体についてもっと知りたい人はGoogleでJupyterを検索して下さい。
Jupyterは「カーネル」を追加することでPython以外の言語もサポートすることが可能です。さまざまな言語のカーネルが存在しています。今回は僕が作っているJavaScript/TypeScript用のカーネルを使用してJupyter上で機械学習を行います。
出典: https://octoverse.github.com/#industry-spotlight-data-sciencetslab
Jupyter上でJavaScriptおよびTypeScriptをインタラクティブに実行するためのJupyterカーネルです。
yunabe/tslab - Interactive JavaScript and TypeScript programming with Jupyter (GitHub)
(気に入ったらぜひStarもして下さい
)
tslabはTypeScriptをベースに作られており、以下のような特徴があります:
- Jupyter上でのJavaScriptおよびTypeScriptのインタラクティブな実行
- TypeScript由来の静的型情報の活用
- JavaScriptでも静的型チェックが行われる。
- 静的型情報を利用した、コード補完やtipsの表示
- TypeScript 3.7のサポート
- Top-level await のサポート
またtslabはJavaScript/TypeScriptのリッチなREPLとして使用することもできます。
この記事ではtslabを使って、Jupyter上でインタラクティブにディープラーニングモデルを構築していきます。
環境構築
Node.js
Node.jsがインストールされていない場合はNode.jsを導入しましょう。現在の最新のLTSであるv12を前提に話を進めますが、v10, v13でも問題はないと思います。
Jupyter
Jupyterを使ってインタラクティブにディープラーニングモデルの構築を行いたいので、Jupyterもインストールしましょう。Pythonがよくわからない場合はAnacondaを使って導入するのが一番簡単だと思います。最新版のJupyterはPython2のサポートをすでに停止しています。特に理由がなければPython3版を使用して下さい。
tslab
tslabのREADME.mdに従ってインストールしてください。
npm install -g tslabインストールに成功したら、tslabをJupyterに登録します
tslab install
tslab installが成功したら、jupyter kernelspec listでカーネルがJupyterに登録されていることを確認しましょう。$ jupyter kernelspec list Available kernels: jslab /usr/local/google/home/yunabe/.local/share/jupyter/kernels/jslab tslab /usr/local/google/home/yunabe/.local/share/jupyter/kernels/tslabこれでJupyter上でJavaScript/TypeScriptを実行できる環境が整いました。
jupyter notebook [--port=8888]を実行して、JavaScript, TypeScriptの「ノートブック」がJupyterで作成でき、JavaScriptをインタラクティブにノートブック上で実行できることを確かめてください。
npmプロジェクトの作成
Node.js, Jupyter, tslab のセットアップができたら環境のセットアップは完了です。npmのプロジェクトを作ってTensorFlowをインストールし、ディープニューラルネットーワークをJavaScriptで行っていきましょう。今回は僕が作成したnpmプロジェクトとJupyterのノートがGitHubに置いてあるのでそれを取得してください。
git clone https://github.com/yunabe/qiita-20191202-jsml.git cd qiita-20191202-jsml npm install # or yarn一からプロジェクトを構築する場合は通常通り、
npm initやyarn initでプロジェクトを作ってください。TensorFlow.js のインストール
チュートリアルTensorFlow.js in Nodeに従って、TensorFlow.jsをプロジェクトにインストールしてください。
npm install @tensorflow/tfjs-nodeTensorFlow.jsはGPUによる高速化にも対応しています。
LinuxでGPU/CUDAが使用可能な環境であれば、tsjs-nodeではなく、@tensorflow/tfjs-node-gpuをインストールしてください。これでJupyter上でTensorFlow.jsを使ってディープラーニングを行う準備は完了です。Jupyterを起動してJavaScriptあるいはTypeScriptのノートブックを作成してください。ここから先のコードはJupyter上で実行していきます。
jupyter notebookここで使ったノートブックはGitHubにコミットしてあります。ここから先はGitHub上のノートブックを直接参照してもらっても構いません。この記事ではJavaScriptを使用していますが、ノートブックはTypeScript版も用意しています。TypeScriptが分かる人にはTypeScript版をお勧めします。
GitHub
nbviewer (GitHubよりノートブックがみやすいです)
JavaScriptと静的型チェック
今回使用するJavaScript/TypeScriptの実行環境 tslabはTypeScriptをベースに実装されており、JavaScriptに対してもある程度の静的型チェックを行います。
let x = 123; x += ' hello'; console.log(x);例えば上のコードは1行目では
xの型はnumberであることを意図しているようにみえるのに、2行目でstringを代入しています。tslabはこのようなケースに対してエラーを表示します。2:1 - Type 'string' is not assignable to type 'number'.ただし、上記のコードは
stringの代入が本当に意図的なのであれば正当なJavaScriptのコードです。そのような場合にはJSDocを使ってxが任意の型(any)をとりうることを明示する必要があります。/** @type {any} */ let x = 123; x += ' hello'; console.log(x);このノートブックでは
を利用しているので留意して下さい。型チェックの詳細についてはType Checking JavaScript Files
を参照して下さい。またtslabでは静的型情報を使っているので、強力なコードの補完(
Tab)と変数・関数定義情報の表示(Shift-Tab)が使用可能です。活用しながらコーディングして下さい。TensorFlow.jsがインストールされていることの確認
まず初めに、TensorFlow.jsが正しくimportでき実行できるかバージョンを表示して確かめてみましょう。ちなみにtslabでHTMLや画像を表示するには
tslab.displayを使用します。無事バージョン番号が表示されたでしょうか。ちなみにJupyter上では
Tabでコード補完、Shift-Tabで関数定義などの表示が行えます。活用しながらコードを書いてください。// const tf = require('@tensorflow/tfjs-node') も可能。 import * as tf from '@tensorflow/tfjs-node' import * as tslab from "tslab"; tslab.display.html('<h2>tf.version</h2>') console.log(tf.version); tslab.display.html('<h2>tslab.versions</h2>') console.log('tslab.versions:', tslab.versions);MNIST をダウンロードする
TensorFlowが無事にNodeにインストール出来たので、ニューラルネットワークモデルを実際に構築してJavaScriptでトレーニングを行ってみましょう。ここでは機械学習のチュートリアルで常に使わる手書き文字認識のデータセットMNIST databaseを使って、数字の文字認識の機械学習を行ってみましょう。
TensorFlow.jsのサンプルコードの中にMNISTをダウンロードしてTensorFlowの内部表現に変換するコードの例が存在するので今回はそれを利用します。このコードはすでに例のレポジトリにコピーしてあるのでここではそれを
importします。興味があればどのような実装になっているかのぞいてみてください。
loadData()はPromiseを返すのでタスクの終了まで待機するのを忘れないでください。tslabはtop-level awaitをサポートしているのでawaitをつけるだけでOKです。import mnist from '../lib/mnist'; await mnist.loadData();データの確認と可視化
WikipediaのMNISTの記事にも書かれているように、MNISTのデータは60,000の訓練用データ(training data)と10,000の評価用データ(test data)に事前に分けられています。実際にダウンロードされたデータの大きさを確認してみましょう。
訓練データに60,000個、評価データに10,000個の数字の画像(
images)と文字認識の正解データ(labels)が存在することが確認できたと思います。数字の画像データは28x28の白黒1チャンネル(グレースケール)であることも分かります。ちなみにデータの内部表現として使われている
TensorのAPIはここにドキュメントがあります。tslab.display.html('<h2>訓練データのサイズ</h2>') console.log(mnist.getTrainData()); tslab.display.html('<h2>評価データのサイズ</h2>') console.log(mnist.getTestData());// 訓練データのサイズ { images: Tensor { kept: false, isDisposedInternal: false, shape: [ 60000, 28, 28, 1 ], dtype: 'float32', size: 47040000, strides: [ 784, 28, 1 ], dataId: {}, id: 0, rankType: '4' }, labels: Tensor { kept: false, isDisposedInternal: false, shape: [ 60000, 10 ], dtype: 'float32', size: 600000, strides: [ 10 ], dataId: {}, id: 10, rankType: '2', scopeId: 6 } } // 評価データのサイズ { images: Tensor { kept: false, isDisposedInternal: false, shape: [ 10000, 28, 28, 1 ], dtype: 'float32', size: 7840000, strides: [ 784, 28, 1 ], dataId: {}, id: 11, rankType: '4' }, labels: Tensor { kept: false, isDisposedInternal: false, shape: [ 10000, 10 ], dtype: 'float32', size: 100000, strides: [ 10 ], dataId: {}, id: 21, rankType: '2', scopeId: 14 } }次にMNISTのデータの可視化もしてみましょう。MNISTの画像データは28x28の
0から1.0のグレースケールのデータの配列です。画像ライブラリjimpを使用してPNGに変換して可視化してみます。import Jimp from 'jimp'; import {promisify} from 'util'; /** * @param {tf.Tensor4D} images * @param {number} start * @param {number} size * @return {Promise<Buffer[]>} */ async function toPng(images, start, size) { // Note: mnist.getTrainData().images.slice([index], [1]) is slow. let arry = images.slice([start], [size]).flatten().arraySync(); let ret = []; for (let i = 0; i < size; i++) { let raw = []; for (const v of arry.slice(i * 28 * 28, (i+1)*28*28)) { raw.push(...[v*255, v*255, v*255, 255]) } let img = await promisify(cb => { new Jimp({ data: Buffer.from(raw), width: 28, height: 28 }, cb); })(); ret.push(await img.getBufferAsync(Jimp.MIME_PNG)); } return ret; } { const size = 8; const labels = await mnist.getTestData().labels.slice([0], [size]).argMax(1).array(); const pngs = await toPng(mnist.getTestData().images, 0, size); for (let i = 0; i < size; i++) { tslab.display.html(`<h3>label: ${labels[i]}</h3>`) tslab.display.png(pngs[i]); } }
ディープラーニングで文字認識を行う
MNISTのデータの素性が一通り分かったので、TensorFlow.jsを使って「ディープニューラルネットワーク」機械学習のモデルを設計、訓練し文字認識を行ってみます。
初めはPythonのTensorFlowチュートリアルでも利用されている、128ノードの中間層を一つ持つ単純なニューラルネットワークモデルを使って文字認識を行います。TensorFlow.jsは、PythonのTensorFlowでも使われているkerasをベースにしたAPIを提供しています。そのためこの程度のシンプルなディープニューラルネットワークはTensorFlow.jsでも非常に簡単に実装できます。Layer APIの詳細はTensorFlow.jsのドキュメントを参照してください。
const model = tf.sequential(); model.add(tf.layers.flatten({inputShape: [28, 28, 1]})); model.add(tf.layers.dense({units: 128, activation: 'relu'})); model.add(tf.layers.dropout({rate: 0.2})); model.add(tf.layers.dense({units: 10, activation: 'softmax'})); model.compile({ optimizer: 'adam', loss: 'categoricalCrossentropy', metrics: ['accuracy'], }); /** * @param {tf.Sequential} model * @param {number} epochs * @param {number} batchSize * @param {string} modelSavePath */ async function train(model, epochs, batchSize, modelSavePath) { // Hack to suppress the progress bar by TensorFlow.js process.stderr.isTTY = false; const {images: trainImages, labels: trainLabels} = mnist.getTrainData(); model.summary(); let epochBeginTime; let millisPerStep; const validationSplit = 0.15; const numTrainExamplesPerEpoch = trainImages.shape[0] * (1 - validationSplit); const numTrainBatchesPerEpoch = Math.ceil(numTrainExamplesPerEpoch / batchSize); const batchesPerEpoch = Math.floor(trainImages.shape[0]*(1-validationSplit)/batchSize); /** @type {tslab.Display} */ let display = null; await model.fit(trainImages, trainLabels, { callbacks: { onEpochBegin: (epoch) => { display = tslab.newDisplay(); }, onBatchBegin: (batch) => { display.text(`Progress: ${(100*batch/batchesPerEpoch).toFixed(1)}%`) }, }, epochs, batchSize, validationSplit, }); const {images: testImages, labels: testLabels} = mnist.getTestData(); const evalOutput = model.evaluate(testImages, testLabels); console.log( `\nEvaluation result:\n` + ` Loss = ${evalOutput[0].dataSync()[0].toFixed(3)}; `+ `Accuracy = ${evalOutput[1].dataSync()[0].toFixed(3)}`); if (modelSavePath != null) { await model.save(`file://${modelSavePath}`); console.log(`Saved model to path: ${modelSavePath}`); } } const epochs = 5; const batchSize = 32; const modelSavePath = 'mnist' await train(model, epochs, batchSize, modelSavePath);_________________________________________________________________ Layer (type) Output shape Param # ================================================================= flatten_Flatten1 (Flatten) [null,784] 0 _________________________________________________________________ dense_Dense1 (Dense) [null,128] 100480 _________________________________________________________________ dropout_Dropout1 (Dropout) [null,128] 0 _________________________________________________________________ dense_Dense2 (Dense) [null,10] 1290 ================================================================= Total params: 101770 Trainable params: 101770 Non-trainable params: 0 _________________________________________________________________ Epoch 1 / 5 Epoch 2 / 5 Epoch 3 / 5 Epoch 4 / 5 Epoch 5 / 5 14906ms 292us/step - acc=0.974 loss=0.0845 val_acc=0.975 val_loss=0.0796 Evaluation result: Loss = 0.083; Accuracy = 0.980 Saved model to path: mnistトレーニングしたモデルを実行する
98%とそこそこ精度のよい文字認識のモデルができたので実際にテストデータを使って文字認識を行ってみましょう。
const predicted = /** @type {number[]} */(tf.argMax(/** @type {tf.Tensor} */ (model.predict(mnist.getTestData().images)), 1).arraySync()); const labels = /** @type {number[]} */(tf.argMax(mnist.getTestData().labels, 1).arraySync()); console.log('predictions:', predicted.slice(0, 10)); console.log('labels:', labels.slice(0, 10));predictions: [ 7, 2, 1, 0, 4, 1, 4, 9, 5, 9 ] labels: [ 7, 2, 1, 0, 4, 1, 4, 9, 5, 9 ]正しく文字認識ができていますね。せっかくなので文字認識に失敗する例を可視化してみましょう。精度が98%程度あるとはいえ、人間であれば間違えないようなものが多いですね。
const predicted = /** @type {number[]} */(tf.argMax(/** @type {tf.Tensor} */ (model.predict(mnist.getTestData().images)), 1).arraySync()); const labels = /** @type {number[]} */(tf.argMax(mnist.getTestData().labels, 1).arraySync()); const numSamples = 32; let count = 0; for (let i = 0; i < predicted.length && labels.length; i++) { const pred = predicted[i]; const label = labels[i]; if (pred === label) { continue; } tslab.display.html(`<h3>予測: ${pred}, 正解: ${label}</h3>`) const pngs = await toPng(mnist.getTestData().images, i, 1); tslab.display.png(pngs[0]); count++; if (count >= numSamples) { break; } }
CNN (convolutional neural network) による画像認識
MNISTの文字列認識は典型的な画像を対象としたディープラーニングなので、CNNによるディープラーニングも試してみましょう。モデルの構造はTensorFlow.jsの例から拝借してきます。
const cnnModel = tf.sequential(); cnnModel.add(tf.layers.conv2d({ inputShape: [28, 28, 1], filters: 32, kernelSize: 3, activation: 'relu', })); cnnModel.add(tf.layers.conv2d({ filters: 32, kernelSize: 3, activation: 'relu', })); cnnModel.add(tf.layers.maxPooling2d({poolSize: [2, 2]})); cnnModel.add(tf.layers.conv2d({ filters: 64, kernelSize: 3, activation: 'relu', })); cnnModel.add(tf.layers.conv2d({ filters: 64, kernelSize: 3, activation: 'relu', })); cnnModel.add(tf.layers.maxPooling2d({poolSize: [2, 2]})); cnnModel.add(tf.layers.flatten()); cnnModel.add(tf.layers.dropout({rate: 0.25})); cnnModel.add(tf.layers.dense({units: 512, activation: 'relu'})); cnnModel.add(tf.layers.dropout({rate: 0.5})); cnnModel.add(tf.layers.dense({units: 10, activation: 'softmax'})); const optimizer = 'rmsprop'; cnnModel.compile({ optimizer: optimizer, loss: 'categoricalCrossentropy', metrics: ['accuracy'], });最初のモデルに比べると構造が複雑なのでトレーニングには時間がかかります。GPUが使える場合はGPUによる高速化の威力がよく実感できると思います。
const epochs = 20; const batchSize = 128; const modelSavePath = 'cnn_mnist' await train(cnnModel, epochs, batchSize, modelSavePath);Layer (type) Output shape Param # ================================================================= conv2d_Conv2D5 (Conv2D) [null,26,26,32] 320 _________________________________________________________________ conv2d_Conv2D6 (Conv2D) [null,24,24,32] 9248 _________________________________________________________________ max_pooling2d_MaxPooling2D3 [null,12,12,32] 0 _________________________________________________________________ conv2d_Conv2D7 (Conv2D) [null,10,10,64] 18496 _________________________________________________________________ conv2d_Conv2D8 (Conv2D) [null,8,8,64] 36928 _________________________________________________________________ max_pooling2d_MaxPooling2D4 [null,4,4,64] 0 _________________________________________________________________ flatten_Flatten3 (Flatten) [null,1024] 0 _________________________________________________________________ dropout_Dropout4 (Dropout) [null,1024] 0 _________________________________________________________________ dense_Dense5 (Dense) [null,512] 524800 _________________________________________________________________ dropout_Dropout5 (Dropout) [null,512] 0 _________________________________________________________________ dense_Dense6 (Dense) [null,10] 5130 ================================================================= Total params: 594922 Trainable params: 594922 Non-trainable params: 0 _________________________________________________________________ Epoch 1 / 20 ... Epoch 20 / 20 Evaluation result: Loss = 0.022; Accuracy = 0.994 Saved model to path: cnn_mnistテストデータに対する精度が99.4%まで上昇しました。先の精度98%の単純なモデルでやったように、CNNでも認識に失敗している画像を表示してみましょう。
最初の単純なモデルの失敗例に比べると、人間でも認識に失敗しそうな、あるいはラベルが間違っていると言いたくなるような例が多くなっており、文字認識の精度が大きく向上していることが体感できると思います。const predicted = /** @type {number[]} */(tf.argMax(/** @type {tf.Tensor} */ (cnnModel.predict(mnist.getTestData().images)), 1).arraySync()); const labels = /** @type {number[]} */(tf.argMax(mnist.getTestData().labels, 1).arraySync()); const numSamples = 32; let count = 0; for (let i = 0; i < predicted.length && labels.length; i++) { const pred = predicted[i]; const label = labels[i]; if (pred === label) { continue; } tslab.display.html(`<h3>予測: ${pred}, 正解: ${label}</h3>`) const pngs = await toPng(mnist.getTestData().images, i, 1); tslab.display.png(pngs[0]); count++; if (count >= numSamples) { break; } }
以上でJavaScriptのみで複雑なディープラーニングモデルを構築・訓練から実際にアプリケーション上で推論を行うところまでエンドツーエンドで行うことができました。TensorFlow.jsを使っているので、完成したモデルをブラウザ上で実行することも最小限の追加コードで実現できます。詳しくはTensorFlow.jsのドキュメントや他の人による解説記事を参照してください。
最後に
JavaScript (TypeScript) でもTensorFlowとJupyterを使用してディープラーニングのトレーニングが行えることを示しました。TensorFlow.jsを使えばPythonを使用しなくてもJavaScriptだけで最新のディープラーニングをモデルのトレーニングから実際のプロダクションでの利用までエンドツーエンドで行うことが可能です。
もちろん現状では機械学習の分野でのPythonの地位は圧倒的なものであり、TensorFlowがJavaScriptをサポートしているとはいえ、APIやドキュメントの充実度には同じTensorFlowの中でも天地ほどの差があります。また周辺のデータ分析関係のライブラリの充実度やエコシステムの規模も考えると機械学習のプロジェクトにJavaScript(というよりPython以外の言語)をメインで採用する合理的な理由は現時点ではほとんど存在しないと思います。
一方でPythonは2010年代に大きく成長したもう一つの分野であるモバイルアプリ開発やWebの分野ではそれほど成功していない現状や、Webフロントエンド開発でのJavaScriptの地位は当分の間は揺らぎそうにないこと、TypeScriptとそのエコシステムが大きく成長しているおり大規模開発にも耐えうるようになってきていることなどを踏まえるとデータ分析分野でのPythonの不動の地位と、それによるPythonの人気の上昇も必ずしも向こう10年間安泰ではないかもしれません。いずれにしてもプログラミング言語のある分野での人気と人気を裏付ける利便性は鶏と卵の関係にあるので誰かが初期投資をする必要があります。2019年末現在、この分野におけるJavaScriptのライブラリ、フレームワークは非常に貧弱であり、Pythonにおけるnumpy, pandas, sklearnなどのようなデファクトスタンダードは存在しません。JavaScriptユーザのみなさん、ブルー・オーシャンであるJavaScriptの機械学習分野での成長に賭けてみるのも面白いかもしれませんよ。





- 投稿日:2019-11-30T22:52:34+09:00
TensorFlow2.1をUbuntu18.04で動かす(その2)
その1からの続きです。
はじめに
Ubuntu18.04とCUDA10.2、cuDNN7.6.5でTensorFlow2.1を動かすことを想定してます。
自分の環境のGPUはRTX2080Tiですが様々なNVIDIA製GPUシリーズで共通になる解説をしています。この記事はその2です。
その1はこちら
CUDA10.2をまだ入れてない人はこの記事へ。準備
必要なパッケージをインストール
$ sudo apt install build-essential cmake git unzip zip $ sudo add-apt-repository ppa:deadsnakes/ppa $ sudo apt update $ sudo apt install python2.7-dev python3.5-dev python3.6-dev pylint $ sudo apt install python3-numpy python3-dev python3-pip python3-wheel $ sudo apt install libcupti-dev $ echo 'export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH' >> ~/.bashrcCompute Capabilityを確認
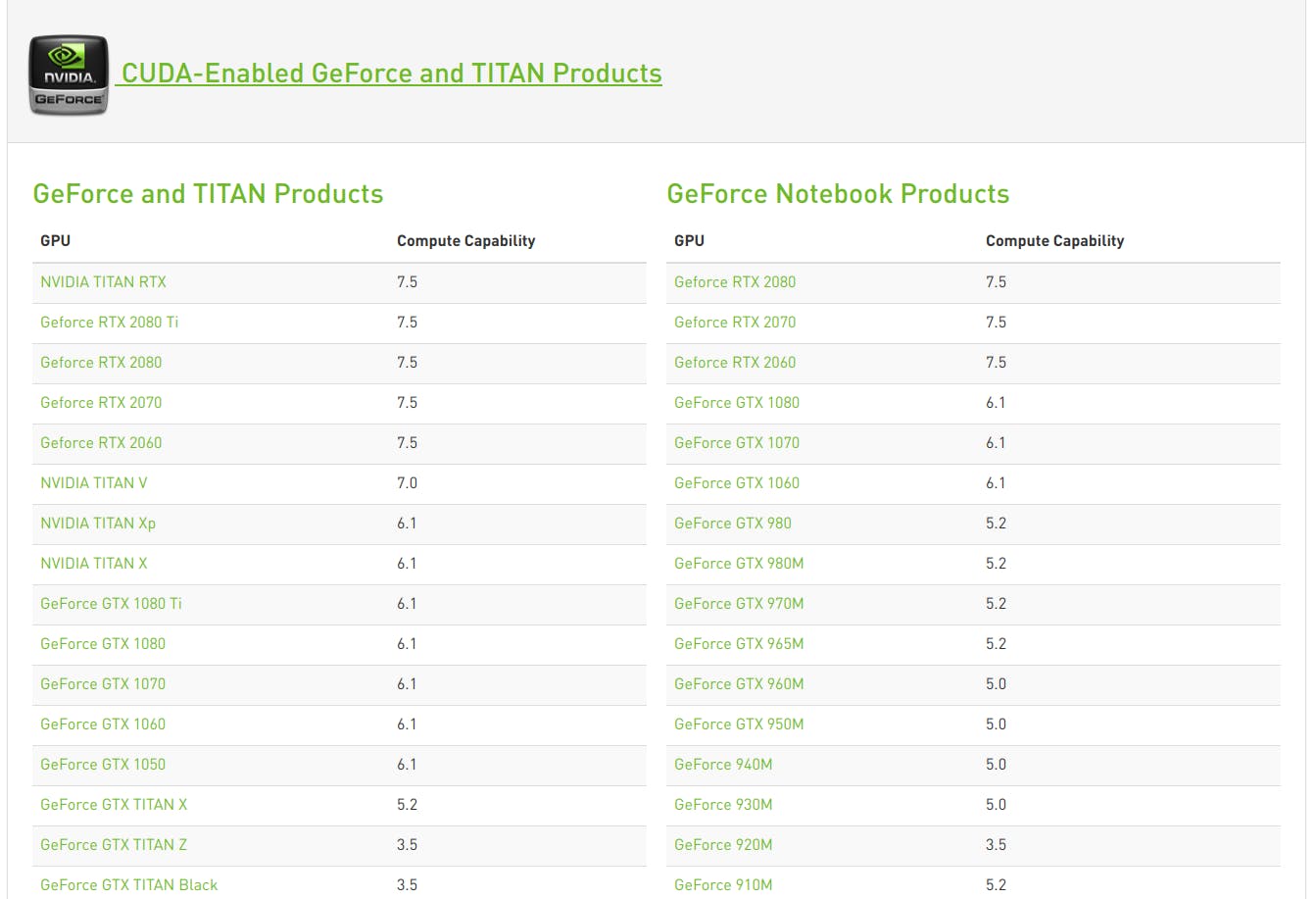
https://developer.nvidia.com/cuda-gpus にアクセスします。
自分の型番のGPUのCompute Capabilityを確認してメモしておいてください。自分のGeForce RTX 2080 Tiは7.5でした。
TensorFlowのビルド
bazelのダウンロードとインストール
bazelはTensorFlowをソースからビルドする際に必要なコンパイラです。bazelの最新バージョンは1.2.1ですが、0.29.1以下でないとTensorFlowをビルドできないため0.29.1にしています。
$ cd ~/ $ wget https://github.com/bazelbuild/bazel/releases/download/0.16.1/bazel-0.29.1-installer-linux-x86_64.sh $ chmod +x bazel-0.29.1-installer-linux-x86_64.sh $ ./bazel-0.29.1-installer-linux-x86_64.sh --user $ echo 'export PATH="$PATH:$HOME/bin"' >> ~/.bashrc $ source ~/.bashrc $ sudo ldconfigTensorFlowのソースをクローン
TensorFlowをクローンしてきて最新の2.1にブランチを切り替えます。
$ cd ~/ $ git clone https://github.com/tensorflow/tensorflow.git $ cd tensorflow $ git pull $ git checkout r2.1TensorFlowのビルド設定
$ ./configureこのコマンドを実行すると設定に入ります。
間違えた場合はCtrl + cで中断し、もう一度$ ./configureからやり直しましょう。WARNING: --batch mode is deprecated. Please instead explicitly shut down your Bazel server using the command "bazel shutdown".
You have bazel 0.29.1 installed.
Please specify the location of python. [Default is /usr/bin/python]:とpythonのパスを聞かれるので
/usr/bin/python3などと入力してENTERキーを押します。
ubuntuはデフォルトでは/usr/bin/python3です。仮想環境を使っていたり、いろいろ変更した覚えがある人は
別のターミナルで$ which python3と打てば確認できますFound possible Python library paths:
/usr/lib/python3/dist-packages
/usr/local/lib/python3.6/dist-packages
Please input the desired Python library path to use. Default is [/usr/lib/python3/dist-packages]と出てくるので
ENTERキー基本この設定で困ることはないですが、
自分のしたいことがはっきりわかる人は自分でオプションを調整してください。Do you wish to build TensorFlow with jemalloc as malloc support? [Y/n]: y
jemalloc as malloc support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Google Cloud Platform support? [Y/n]: y
Google Cloud Platform support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Hadoop File System support? [Y/n]: y
Hadoop File System support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Amazon AWS Platform support? [Y/n]: y
Amazon AWS Platform support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Apache Kafka Platform support? [Y/n]: y
Apache Kafka Platform support will be enabled for TensorFlow.
Do you wish to build TensorFlow with XLA JIT support? [y/N]: n
No XLA JIT support will be enabled for TensorFlow.
Do you wish to build TensorFlow with GDR support? [y/N]: n
No GDR support will be enabled for TensorFlow.
Do you wish to build TensorFlow with VERBS support? [y/N]: n
No VERBS support will be enabled for TensorFlow.
Do you wish to build TensorFlow with OpenCL SYCL support? [y/N]: n
No OpenCL SYCL support will be enabled for TensorFlow.
Do you wish to build TensorFlow with CUDA support? [y/N]: y
CUDA support will be enabled for TensorFlow.
Please specify the CUDA SDK version you want to use.
[Leave empty to default to CUDA 9.0]: 10.2
Please specify the location where CUDA 9.2 toolkit is installed.
Refer to README.md for more details.
[Default is /usr/local/cuda]: /usr/local/cuda-10.2
Please specify the cuDNN version you want to use.
[Leave empty to default to cuDNN 7.0]: 7.6.5
Please specify the location where cuDNN 7 library is installed. Refer to README.md for more details. [Default is /usr/local/cuda-9.2]:/usr/local/cuda-10.2
Do you wish to build TensorFlow with TensorRT support? [y/N]: n
No TensorRT support will be enabled for TensorFlow.
Please specify the NCCL version you want to use. If NCCL 2.2 is not installed, then you can use version 1.3 that can be fetched automatically but it may have worse performance with multiple GPUs. [Default is 2.2]: 2.5
Please specify the location where NCCL 2 library is installed.
Refer to README.md for more details.
[Default is /usr/local/cuda-9.2]:/usr/local/cuda-10.2/targets/x86_64-linux次にこのように表示されます。ここでメモしておいたCompute Capabilityを入力します。
自分はRTX2080Tiなので 7.5 を入力しました。Please specify a list of comma-separated Cuda compute capabilities you want to build with.
You can find the compute capability of your device at: https://developer.nvidia.com/cuda-gpus.
Please note that each additional compute capability significantly increases your build time and binary size. [Default is: 6.1]7.5Do you want to use clang as CUDA compiler? [y/N]: n
nvcc will be used as CUDA compiler.
Please specify which gcc should be used by nvcc as the host compiler. [Default is /usr/bin/gcc]: /usr/bin/gcc
Do you wish to build TensorFlow with MPI support? [y/N]: n
No MPI support will be enabled for TensorFlow.
Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -march=native]: -march=native
Would you like to interactively configure ./WORKSPACE for Android builds? [y/N]: n
Not configuring the WORKSPACE for Android builds.これで入力はおしまいです。
次で長かった作業も終わりです。ついにビルドします。TensorFlowをビルドする
$ bazel build --config=opt --config=cuda //tensorflow/tools/pip_package:build_pip_packageビルドに失敗してやり直す際は
./configureをもう一度$ bazel-bin/tensorflow/tools/pip_package/build_pip_package tensorflow_pkg $ cd tensorflow_pkg $ pip3 install tensorflow*.whl動作の確認
端末でpython3を起動します。
$ python3バージョンを確認し簡単なプログラムを実行します。
python3>>import tensorflow as tf >>tf.__version__ '2.1' >>hello = tf.constant('Hello, TensorFlow!') >>sess = tf.Session() >>sess.run(hello) b'Hello, TensorFlow!'このようになれば成功です。
お疲れ様でした。リンク集
- 投稿日:2019-11-30T20:03:07+09:00
TensorFlow2をUbuntu18.04で動かす(その1)
はじめに
Ubuntu18.04とCUDA10.2で動かすことを想定してます。
この記事はその1です。
その2へ続きます。
CUDA10.2をまだ入れてない人はこの記事へ。まずはTensorFlow2を動かすために必要なライブラリを入れていきましょう。
cuDNN 7.6.5のインストール
Deep Neural Networksを動かす際にGPUのパフォーマンスを向上させるためのライブラリです。
ダウンロードするためにはにはアカウントの登録(無料)が必要です。登録はすぐに終わります。アカウント登録とダウンロード
https://developer.nvidia.com/cudnn へ移動します。
右上のACCOUNTの部分をクリックしてアカウント登録します。
登録後、ログインして上記のリンクへもう一度行きます。
サイトにあるDownload cuDNNを選択します。
□ I Agree To the Terms of the cuDNN Software License Agreement にチェックします。
Download cuDNN v7.6.5 (November 18th, 2019), for CUDA 10.2
>cuDNN Library for Linux
の順に選択しファイルを保存します。
インストール
ダウンロードしたフォルダに移動します
$ cd <ダウンロードしたフォルダ>そして以下のコマンドを順に実行します。
1つめのコマンドで今ダウンロードしたcuDNNの.tgzファイルを展開しています。
ここは自分のダウンロードしたファイルの名前にしてください。(ls などで確認すると良いでしょう)$ tar -xf cudnn-10.2-linux-x64-v7.6.5.32.tgz $ sudo cp -R cuda/include/* /usr/local/cuda-10.2/include $ sudo cp -R cuda/lib64/* /usr/local/cuda-10.2/lib64NCCL 2.5.6のインストール
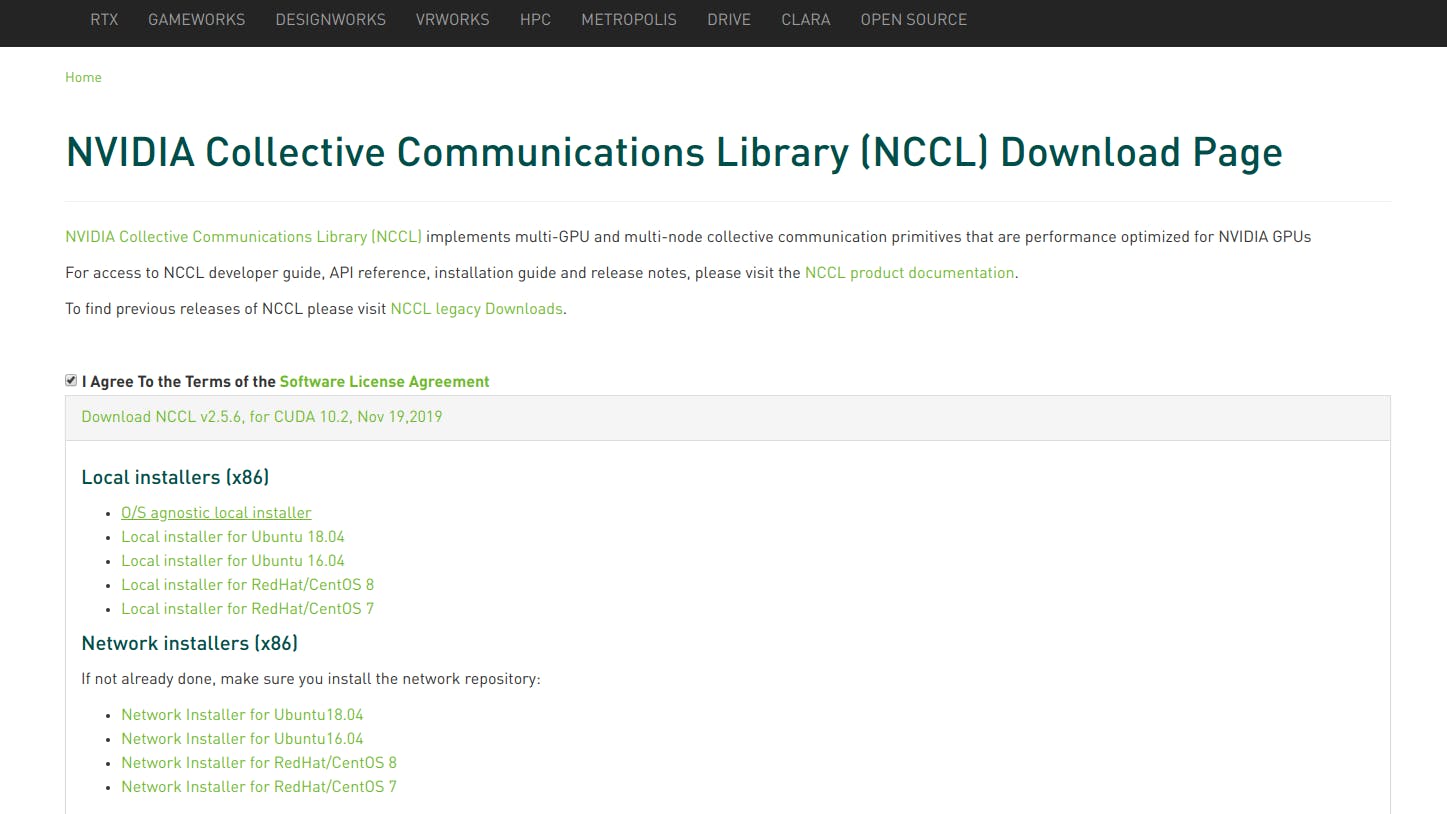
https://developer.nvidia.com/nccl へアクセスし
Download NCLLを選択します。
使用目的や使用方法のアンケートに答えるとダウンロードできるようになります。
アンケートで答えた内容はダウンロード内容には影響しないので適当で大丈夫です。
先程同様ソフトウェアライセンスへの同意を求められるので、
□ I Agree To the Terms of the Software License Agreement にチェックします。
Download NCCL v2.5.6, for CUDA 10.2, Nov 19,2019
>Local installers (x86)
>O/S agnostic local installer
の順に選択しファイルを保存します。
ダウンロードしたフォルダに移動します。
$ cd <ダウンロードしたフォルダ>そして以下のコマンドを実行します。
それぞれ自分のダウンロードしたファイルの名前にしてください。$ tar -xf nccl_2.5.6-2+cuda10.2_x86_64.txz $ cd nccl_2.5.6-2+cuda10.2_x86_64 $ sudo cp -R * /usr/local/cuda-10.2/targets/x86_64-linux/ $ sudo ldconfig
その2へ続きます。
次回はいよいよTensorFlow2をインストールします。

- 投稿日:2019-11-30T20:03:07+09:00
TensorFlow2.1をUbuntu18.04で動かす(その1)
はじめに
Ubuntu18.04とCUDA10.2、cuDNN7.6.5でTensorFlow2.1を動かすことを想定してます。
自分の環境のGPUはRTX2080Tiですが様々なNVIDIA製GPUシリーズで共通になる解説をしています。この記事はその1です。
その2へ続きます。
CUDA10.2をまだ入れてない人はCUDA10.2をUbuntu18.04にインストールまずはTensorFlow2を動かすために必要なライブラリを入れていきましょう。
cuDNN 7.6.5のインストール
Deep Neural Networksを動かす際にGPUのパフォーマンスを向上させるためのライブラリです。
ダウンロードするためにはにはアカウントの登録(無料)が必要です。登録はすぐに終わります。アカウント登録とダウンロード
https://developer.nvidia.com/cudnn へ移動します。
右上のACCOUNTの部分をクリックしてアカウント登録します。
登録後、ログインして上記のリンクへもう一度行きます。
サイトにあるDownload cuDNNを選択します。
□ I Agree To the Terms of the cuDNN Software License Agreement にチェックします。
Download cuDNN v7.6.5 (November 18th, 2019), for CUDA 10.2
>cuDNN Library for Linux
の順に選択しファイルを保存します。
インストール
ダウンロードしたフォルダに移動します
$ cd <ダウンロードしたフォルダ>そして以下のコマンドを順に実行します。
1つめのコマンドで今ダウンロードしたcuDNNの.tgzファイルを展開しています。
ここは自分のダウンロードしたファイルの名前にしてください。(ls などで確認すると良いでしょう)$ tar -xf cudnn-10.2-linux-x64-v7.6.5.32.tgz $ sudo cp -R cuda/include/* /usr/local/cuda-10.2/include $ sudo cp -R cuda/lib64/* /usr/local/cuda-10.2/lib64NCCL 2.5.6のインストール
https://developer.nvidia.com/nccl へアクセスし
Download NCLLを選択します。
使用目的や使用方法のアンケートに答えるとダウンロードできるようになります。
アンケートで答えた内容はダウンロード内容には影響しないので適当で大丈夫です。
先程同様ソフトウェアライセンスへの同意を求められるので、
□ I Agree To the Terms of the Software License Agreement にチェックします。
Download NCCL v2.5.6, for CUDA 10.2, Nov 19,2019
>Local installers (x86)
>O/S agnostic local installer
の順に選択しファイルを保存します。
ダウンロードしたフォルダに移動します。
$ cd <ダウンロードしたフォルダ>そして以下のコマンドを実行します。
それぞれ自分のダウンロードしたファイルの名前にしてください。$ tar -xf nccl_2.5.6-2+cuda10.2_x86_64.txz $ cd nccl_2.5.6-2+cuda10.2_x86_64 $ sudo cp -R * /usr/local/cuda-10.2/targets/x86_64-linux/ $ sudo ldconfig
その2へ続きます。
次回はいよいよTensorFlow2をインストールします。
- 投稿日:2019-11-30T14:33:37+09:00
【AI初心者向け】mnist_mlp.pyを1行ずつ解説していく(KerasでMNISTを学習させる)
はじめに
皆さんはじめまして。
この記事はmnist_mlp.pyを1行ずつ解説していくだけの記事です。
AIに興味があるけどまだ触ったことはない人などが対象です。これを読めばディープラーニングの基本的な学習の流れが理解できるはず、と思って書いていきます。(もともとは社内で研修用に使おうと思って作成していた内容です)全3回予定です。
1. 【AI初心者向け】mnist_mlp.pyを1行ずつ解説していく(KerasでMNISTを学習させる)
2. 【AI初心者向け】mnist_cnn.pyを1行ずつ解説していく(KerasでMNISTを学習させる)
3. 【AI初心者向け】mnist_transfer_cnn.pyを1行ずつ解説していく(KerasでMNISTを学習させる)動作確認方法について
MNISTは画像なので、このコードを動かすにはGPUがあったほうがいいです(CPUだとちょっと辛いです)。
おすすめの方法はGoogle Colaboratoryを使う方法です。
やることは2つだけ。
・Python3の新しいノートブックを開く
・ランタイムからGPUを有効にする
これでGPUが使えるようになりました。
セルにコードを貼り付けて実行(ショートカットはCTRL+ENTER)するだけで動きます。mnistについて
手書き文字画像のデータセットで、機械学習のチュートリアルでよく使用されます。
内容:0~9の手書き文字
画像サイズ:28pix*28pix
カラー:白黒
データサイズ:7万枚(訓練データ6万、テストデータ1万の画像とラベルが用意されています)mlpとは
Multilayer perceptron、多層パーセプトロンのことです。
mnistは画像データですが、画像データの形を(28, 28)から(784,)に変更することでmlpとして学習させることができます。(精度は第2回でやるCNNのほうが上です。)mnist_mlp.pyについて
mnistの手書き文字の判定を行うモデルをKerasとTensorFlowを使って作成するコードです。
0~9の10種類の手書き文字を入力として受け取り、0~9のいずれであるか10種類に分類するモデルを作成します。コードの解説
準備
'''Trains a simple deep NN on the MNIST dataset. Gets to 98.40% test accuracy after 20 epochs (there is *a lot* of margin for parameter tuning). 2 seconds per epoch on a K520 GPU. ''' # 特に必要ないコードです(Pythonのバージョンが3だが、コードがPython2で書かれている場合に必要になる) from __future__ import print_function # 必要なライブラリをインポートしていく import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout from keras.optimizers import RMSprop # 定数を最初にまとめて指定する batch_size = 128 # バッチサイズ。1度に学習するデータサイズ num_classes = 10 # 分類するラベル数。今回は手書き画像を0~9の10種類に分類する epochs = 20 # エポック数。全データを何回学習するかデータの前処理
# mnistのデータを読み込み、訓練データ(6万件)とテストデータ(1万件)に分割する (x_train, y_train), (x_test, y_test) = mnist.load_data() '''mlpでインプットデータとして使用できるようにするため、reshapeしてデータの形式を合わせる x_train:(60000, 28, 28) ->(60000, 784) 28pix*28pixの画像を1列にする x_test:(10000, 28, 28) ->(10000, 784) 28pix*28pixの画像を1列にする''' x_train = x_train.reshape(60000, 784) x_test = x_test.reshape(10000, 784) # 画像データは0~255の値をとるので255で割ることでデータを標準化する # .astype('float32')でデータ型を変換する。(しないと割ったときにエラーが出るはず) x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 # データの数を出力して確認 print(x_train.shape[0], 'train samples') print(x_test.shape[0], 'test samples') # ラベルデータをone-hot-vector化する '''one-hot-vectorのイメージはこんな感じ label 0 1 2 3 4 5 6 7 8 9 0: [1,0,0,0,0,0,0,0,0,0] 8: [0,0,0,0,0,,0,0,1,0]''' y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes)標準化について:画像の各ピクセルの値は0~255になっています。これを0~1に変換するイメージです。画像で機械学習するときは大体この255で割る処理をして、値を標準化します。
one-hot-vectorについて:今回、ラベルは0~9の10種類があり、それぞれ0~9の数字で表しています。しかし、10種類に分類したいだけなので、ラベルの数字自体には意味がありません。そこで、one-hot-vectorすることにより0と1のみでどのラベルなのかを表せるように変換します。
モデルの定義
# Sequentialクラスをインスタンス化 model = Sequential() # 中間層 # 全結合層(512ユニット、活性化関数:Relu、受け取る入力サイズ:784)を追加 model.add(Dense(512, activation='relu', input_shape=(784,))) # 0.2の確率でドロップアウト model.add(Dropout(0.2)) # 全結合層(512ユニット、活性化関数:Relu、受け取る入力サイズは自動で判断)を追加 model.add(Dense(512, activation='relu')) # 0.2の確率でドロップアウト model.add(Dropout(0.2)) # 出力層 # 全結合層(10ユニット、活性化関数:SoftMax、受け取る入力サイズは自動で判断)を追加 model.add(Dense(num_classes, activation='softmax')) # モデルの構造を可視化 model.summary()SequentialモデルはDNNの層を積み重ねて作るモデルです。一番最初の層にだけ、input_shapeを指定してやる必要があります。
出力層の活性化関数は、今回は多値分類するモデルなのでsoftmaxを使います。学習
# 学習プロセスを設定する model.compile( # 損失関数を設定。今回は分類なのでcategorical_crossentropy loss='categorical_crossentropy', # 最適化アルゴリズムを指定。学習率などをいじれる optimizer=RMSprop(), # 評価関数を指定 metrics=['accuracy']) # 学習させる history = model.fit( # 学習データ、ラベル x_train, y_train, # バッチサイズ(128) batch_size=batch_size, # エポック数(20) epochs=epochs, # 学習の進捗をリアルタムに棒グラフで表示(0で非表示) verbose=1, # テストデータ(エポックごとにテストを行い誤差を計算するため) validation_data=(x_test, y_test))モデルの定義が終わったら、損失関数や最適化アルゴリズムを指定してコンパイルします。その後、モデルにデータを渡して学習させます。より良いモデルを作るためには、最適化アルゴリズムやバッチサイズ、エポック数などをいろいろ変更して試してやる必要があります。
評価
# テストデータを渡す(verbose=0で進行状況メッセージを出さない) score = model.evaluate(x_test, y_test, verbose=0) # 汎化誤差を出力 print('Test loss:', score[0]) # 汎化性能を出力 print('Test accuracy:', score[1])学習が終わったら、テストデータを使ってどの程度の性能になったのかを評価します。lossが低く、accuracyが高いほど良いモデルといえます。

- 投稿日:2019-11-30T14:12:01+09:00
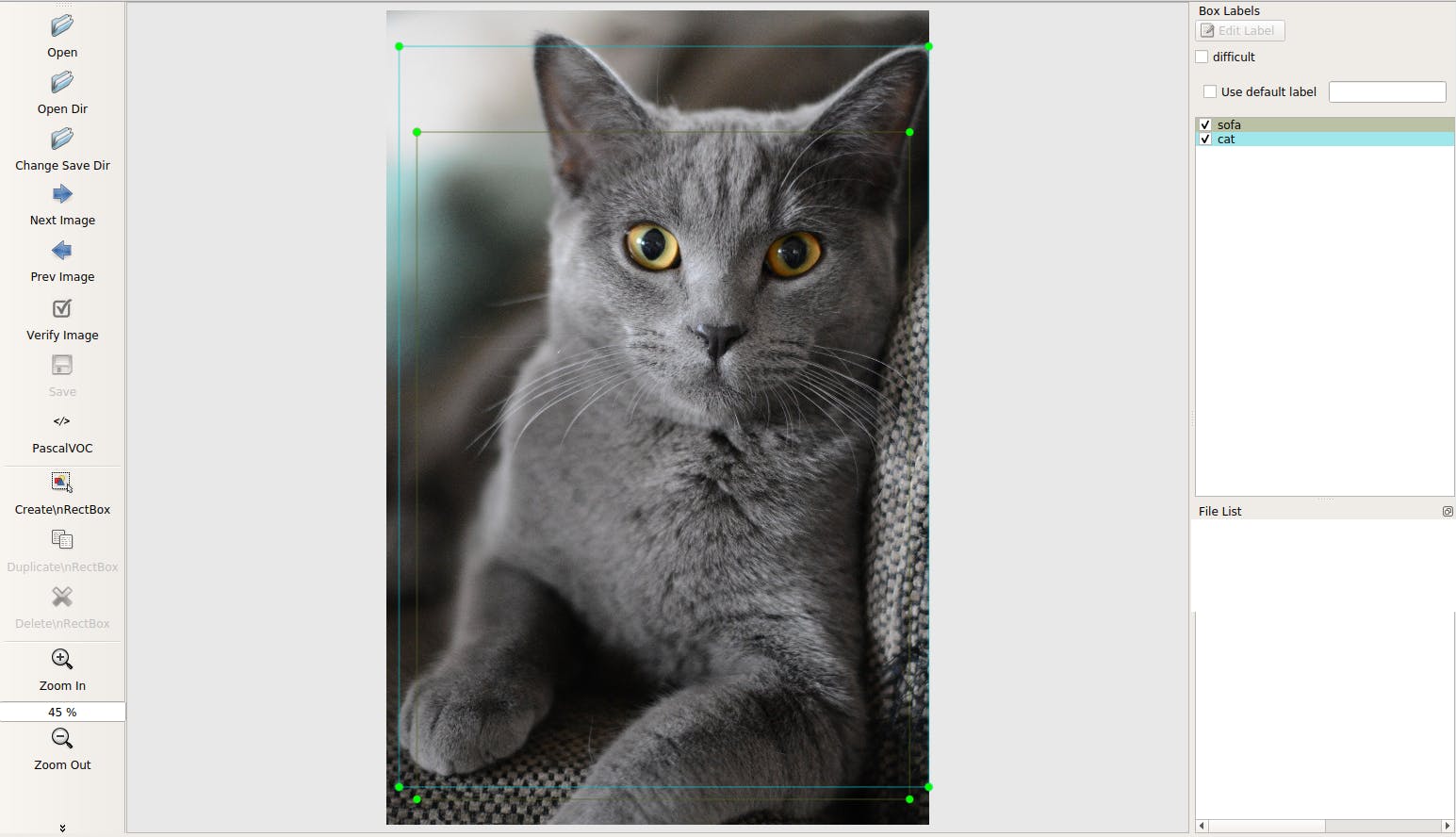
物体認識用データセット自動作成プログラム
目的
YOLOやSSDで自作のデータセットを用いて物体認識を行う際、大量な画像とラベリング処理が必要となる。
今回は、ラベリング処理にかかる時間を短縮するためのプログラムを作成した。※クラスを新たに追加して検出する際は、100枚程度を手作業でラベリングすることと、voc_annotation.pyの変更が必要。
使用したもの
物体認識アルゴリズム
[YOLO]https://github.com/qqwweee/keras-yolo3
[SSD]https://github.com/rykov8/ssd_kerasラベリング用ソフト
https://github.com/tzutalin/labelImg
処理の流れ
- 学習(python train.py)
- yolo_labeling.py の model_path を1で作成したものに変更
- 検出(python yolo_img.py)
- "Input filepath" のあとに検出画像があるディレクトリを入力
- 検出結果からAnnotationファイル作成
なお、デフォルトのクラス内に存在するものであれば1.2は省略可。
プログラムの詳細は最後に示す。結果
未学習画像に対して、自動的にラベリングができる。
これを使用することで学習データを増やす際のラベリング処理にかかる時間を短縮することができる。
結論
デフォルトのクラスにない新たなものを認識する場合は大量のデータセットが必要となる。実際YOLOでは、単純なものであれば100枚程度で認識することはできたが、似たものが存在する場合は認識できなかった。また、バウンディングボックスの位置にもずれがあった。
このプログラムを使用することで、100枚程度は手作業でラベリングする必要があるがその後の何百枚を短時間でラベリングすることができる。今回はラベリングソフトに合わせた形式で出力を行った。そのため、このプログラム実行後にvoc_annotation.pyを実行して、train.txtを作成する必要がある。今後はこの処理も短縮し、train.txtに自動的に追加する機能を持たせたい。
また、新しいものを物体認識するためには、voc_annotation.py の変更などを行う必要がある。今後はこれについて説明する記事も書きたい。プログラム
プログラムはgithub上に公開済 https://github.com/ptxyasu/keras-yolo3
ここでは、keras-yolo3に追加したプログラムの説明を行う。デフォルトのyolo.pyをラベリング作成用に修正したものがyolo_labeling.pyである。
ラベリング処理用に make_xml, make_xml_object を追加した。
make_xmlは主なタグの作成とファイル名やファイルパス、画像サイズをセットする。
make_xml_objectは検出されたオブジェクトごとにクラス名と位置をセットする。
※Annotationファイルの形式は参考にあるラベリングソフトに合わせてあることに注意yolo_labeling.pydef make_xml(self,image,img_name,img_path): #parent annotation = ET.Element('annotation') #child folder = ET.SubElement(annotation, 'folder') filename = ET.SubElement(annotation, 'filename') path = ET.SubElement(annotation, 'path') source = ET.SubElement(annotation, 'source') size = ET.SubElement(annotation, 'size') segmented = ET.SubElement(annotation, 'segmented') database = ET.SubElement(source, 'database') width = ET.SubElement(size,'width') height = ET.SubElement(size,'height') depth = ET.SubElement(size,'depth') #set folder.text = "JPEGImages" filename.text = img_name path.text = os.getcwd() +"/"+ img_path database.text = "Unknown" imgw,imgh = image.size width.text = str(imgw) height.text = str(imgh) depth.text = "3" segmented.text = "0" return annotation def make_xml_object(self,annotation,class_name,x1,y1,x2,y2): object = ET.SubElement(annotation, 'object') name = ET.SubElement(object,'name') pose = ET.SubElement(object,'pose') truncated = ET.SubElement(object,'truncated') difficult = ET.SubElement(object,'difficult') bndbox = ET.SubElement(object,'bndbox') xmin = ET.SubElement(bndbox,'xmin') ymin = ET.SubElement(bndbox,'ymin') xmax = ET.SubElement(bndbox,'xmax') ymax = ET.SubElement(bndbox,'ymax') name.text = class_name pose.text = "Unspecified" truncated.text = "0" difficult.text = "0" xmin.text = str(x1) ymin.text = str(y1) xmax.text = str(x2) ymax.text = str(y2) return annotationまた、上の二つのをプログラムに実装するためにdetect_image の変更を行った。
make_xmlは写真1枚につき1回、make_xml_objectは検出されたオブジェクトの数だけ実行される。yolo_labiling.pydef detect_image(self,image,img_name,img_path,annotation_path): start = timer() if self.model_image_size != (None, None): assert self.model_image_size[0]%32 == 0, 'Multiples of 32 required' assert self.model_image_size[1]%32 == 0, 'Multiples of 32 required' boxed_image = letterbox_image(image, tuple(reversed(self.model_image_size))) else: new_image_size = (image.width - (image.width % 32), image.height - (image.height % 32)) boxed_image = letterbox_image(image, new_image_size) image_data = np.array(boxed_image, dtype='float32') print(image_data.shape) image_data /= 255. image_data = np.expand_dims(image_data, 0) # Add batch dimension. out_boxes, out_scores, out_classes = self.sess.run( [self.boxes, self.scores, self.classes], feed_dict={ self.yolo_model.input: image_data, self.input_image_shape: [image.size[1], image.size[0]], K.learning_phase(): 0 }) print('Found {} boxes for {}'.format(len(out_boxes), 'img')) font = ImageFont.truetype(font='font/FiraMono-Medium.otf', size=np.floor(8e-3 * image.size[1] + 0.5).astype('int32')) thickness = (image.size[0] + image.size[1]) // 500 ann = self.make_xml(image,img_name,img_path) for i, c in reversed(list(enumerate(out_classes))): predicted_class = self.class_names[c] box = out_boxes[i] score = out_scores[i] label = '{} {:.2f}'.format(predicted_class, score) draw = ImageDraw.Draw(image) label_size = draw.textsize(label, font) top, left, bottom, right = box top = max(0, np.floor(top + 0.5).astype('int32')) left = max(0, np.floor(left + 0.5).astype('int32')) bottom = min(image.size[1], np.floor(bottom + 0.5).astype('int32')) right = min(image.size[0], np.floor(right + 0.5).astype('int32')) print(label, (left, top), (right, bottom)) ann = self.make_xml_object(ann,predicted_class,left,bottom,right,top) if top - label_size[1] >= 0: text_origin = np.array([left, top - label_size[1]]) else: text_origin = np.array([left, top + 1]) # My kingdom for a good redistributable image drawing library. for i in range(thickness): draw.rectangle( [left + i, top + i, right - i, bottom - i], outline=self.colors[c]) draw.rectangle( [tuple(text_origin), tuple(text_origin + label_size)], fill=self.colors[c]) draw.text(text_origin, label, fill=(0, 0, 0), font=font) del draw end = timer() print(end - start) tree = ET.ElementTree(ann) annotation_name,ext = img_name.split(".") annotation_name = "/" + annotation_name + ".xml" annotation = annotation_path + annotation_name tree.write(annotation,"utf-8",True) return imageまた、デフォルトではyolo_video.py にオプションimageをつけて実行することで、画像からの物体認識が行えるが、画像名を毎回手入力しなければならない。複数画像を一気に行うためにyolo_video.pyを変更したものがyolo_img.pyである。
”Input filepath”と表示されたら、対象画像があるディレクトリを入力する。そのディレクトリ内にある画像全てに物体認識が行われ、検出結果を表す画像とAnnotationファイルが出力される。yolo_img.pyimport sys import argparse import os #from yolo import YOLO, detect_video from yolo_labeling import YOLO, detect_video from PIL import Image def detect_img(yolo): while True: file_path = input('Input filepath:') img_list = os.listdir(file_path) if file_path[-1] != "/": file_path += "/" if os.path.exists(file_path+"result") != True: os.mkdir(file_path+"result") if os.path.exists(file_path+"Annotations") != True: annotation_path = file_path+"Annotations" os.mkdir(annotation_path) for i in range(len(img_list)): img_name = img_list[i] print(img_name) img_path = file_path + img_name try: image = Image.open(img_path) except: print('Open Error! Try again!') continue else: #r_image = yolo.detect_image(image) #r_image.show() r_image = yolo.detect_image(image,img_name,img_path,annotation_path) r_image.save(file_path+"result/"+img_name) yolo.close_session() FLAGS = None if __name__ == '__main__': # class YOLO defines the default value, so suppress any default here parser = argparse.ArgumentParser(argument_default=argparse.SUPPRESS) ''' Command line options ''' parser.add_argument( '--model', type=str, help='path to model weight file, default ' + YOLO.get_defaults("model_path") ) parser.add_argument( '--anchors', type=str, help='path to anchor definitions, default ' + YOLO.get_defaults("anchors_path") ) parser.add_argument( '--classes', type=str, help='path to class definitions, default ' + YOLO.get_defaults("classes_path") ) parser.add_argument( '--gpu_num', type=int, help='Number of GPU to use, default ' + str(YOLO.get_defaults("gpu_num")) ) FLAGS = parser.parse_args() print("Image detection mode") detect_img(YOLO(**vars(FLAGS)))