- 投稿日:2019-11-30T22:35:32+09:00
Find Maximum in Sliding Window
Find Maximum in Sliding Window
説明
整数の配列とサイズ w のWindow が与えられた場合、Window (配列の一部)が配列全体をスライドするときに Window中の 現在の最大値を見つけます。
例
Window の Sizeが 3 で、スライディングしていく中で、すべての最大値を見つけてみましょう。
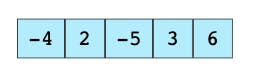
step1
Window の三つの要素の中の最大値が 2
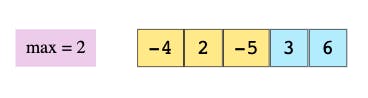
step2
一つずらして、Window の三つの要素の中の最大値が 3
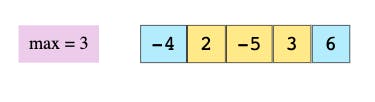
step3
一つずらして、Window の三つの要素の中の最大値が 6
最終的に 2 3 6 が入ったデータ構造を返せば良い。
Solution
Time Complexity: O(n)
すべての要素は、1回の走査で一度だけdequeからプッシュおよびポップされます。プッシュとポップはO(1)なので、
アルゴリズムはTime Complexity O(n)で機能します。Space Complexity: O(w)
Window のサイズ分のリストを使うのでSpace Complexity は O(w)です。
大まかなアルゴリズムの流れ
このアルゴリズムでは、dequeデータ構造を使用して、ウィンドウ内の最大値を見つけます。
このデータ構造を使用する目的は、両端に対して、データを追加、削除といったプッシュおよびポップ操作がほぼ、
O(1)で機能する両端キューだからです。これがウィンドウとして機能をします。ここでの注意が二つ。
1. dequeに入れるのは配列の要素ではなく、要素のIndex。
2. dequeの先頭に最大値のIndexを、末尾にそれ以外のIndexを入れていく。アルゴリズムの開始時には、dequeはかっらぽなので、最初のウィンドウサイズの分だけ要素のIndexを追加していく。
もし、追加する要素がdequeの後ろの要素よりも小さい場合、追加した要素は新しいdequeの末尾要素となります。
もし、追加する要素の方が大きい場合は、より大きい要素が見つかるまでdeque後ろ側から繰り返し要素をポップしていき、
新しく末尾として追加する要素をプッシュします。ご覧のとおり、dequeは要素を降順で格納します。
dequeの先頭には、その特定のウィンドウの最大値のインデックスが含まれます。ウィンドウが右に移動するたびに、次の手順を繰り返します。
- もし、dequeの後ろ側の要素が現在の追加する要素よりも小さいまたは等しい場合、追加する要素よりも大きい要素のインデックスが出てくるまで要素をdequeから削除します。
- 一つウィンドウをずらすと、値が現在のウィンドウに収まらなくなる場合に、先頭の要素インデックスを削除します。
- ウィンドウの後ろに現在の要素のインデックスをプッシュします。
Code



- 投稿日:2019-11-30T21:37:13+09:00
Java(set)
【set】
ArrayListの要素を書き換える際に使用するメソッドである。
以下のように変更したい場所と値を入れて使用する。
変数名.set(インデックス,書き換える値)Java(add)の回で使用したArrayList「array」に
setメソッドで指定した場所の要素を書き換える。ArrayList<String> array = new ArrayList<String>(); array.add("日本語"); array.add("英語"); array.add("フランス語"); array.add("中国語"); array.add("ドイツ語"); System.out.println(array); [日本語, 英語, フランス語, 中国語, ドイツ語]インデックス3の「中国語」を「韓国語」に変更する。
array.set(3,"韓国語"); System.out.println(array);リストの中を出力すると以下のようになる。
[日本語, 英語, フランス語, 韓国語, ドイツ語]指定した場所の値が書き換えられる。
addメソッド同様、存在しない場所を指定して値を書き換えようとすると
「IndexOutOfBoundsException」という例外が発生する。
- 投稿日:2019-11-30T21:17:31+09:00
Java(add2)
前回使用したArrayList「array」にaddメソッドで指定の場所へ要素を追加挿入する。
ArrayList<String> array = new ArrayList<String>(); array.add("日本語"); array.add("英語"); array.add("フランス語"); array.add("中国語"); array.add("ドイツ語"); System.out.println(array); [日本語, 英語, フランス語, 中国語, ドイツ語]インデックス1へ要素「イタリア語」を挿入する。
array.add(1,"イタリア語"); System.out.println(array);リストの中を出力すると以下のようになる。
[日本語, イタリア語, 英語, フランス語, 中国語, ドイツ語]指定した場所に要素が挿入され、それ以降の要素が後ろにズレる。
因みに、存在しない場所を指定して要素を挿入しようとすると
「IndexOutOfBoundsException」という例外が発生する。
- 投稿日:2019-11-30T19:50:53+09:00
Arrays.binarySearchは完全一致
// 注: アルゴリズムの性質上ソートされていないとうまく機能しない int[] array = {2, 3, 4, 7, 8, 9, 14, 23, 56, 67, 78, 89, 90}; // NOT FOUND int index = Arrays.binarySearch(array, 5);さて、これが何を返すだろうか?
答えは-4だ。
javadocによれば:戻り値:
配列内に検索キーがある場合は検索キーのインデックス。それ以外の場合は(-(挿入ポイント) - 1)。挿入時点は、そのキーが配列に挿入される時点として定義される。つまり、そのキーよりも大きな最初の要素のインデックス。こんな翻訳で分かるかっ!
参考:戻り値:
配列内に検索キーがある場合は検索キーのインデックス。それ以外の場合は(-(挿入添字) - 1)。ここで、「挿入添字」は、そのキーが配列に挿入される添字として定義される。つまり、そのキーよりも大きな最初の要素のインデックスである。―――とはいえ
-4がarray[2]とarray[3]の間なんて、誰が思うだろうか?
- 投稿日:2019-11-30T18:22:10+09:00
Algorithm Binary Search on Arrays
Binary Search
説明
ソートされた整数を保存するArrayと探してるキーが渡されて、もしそのキーがArrayの中にある場合はキーのIndexを返す。もし、そのキーが無ければ-1を返す。
例
キーが47で要素20個を保持するArray
Solution
Runtime Complexity: O(logn)
Memory Complexity: O(logn)
Binary Searchは、ソートされた配列内の要素のインデックスを見つけるために使用されます。 要素が存在しない場合もそれも同様に効率的に見つけることが出来ます。アルゴリズムは、各ステップで入力配列を半分に分割していきます。すべてのステップの後、探しているインデックスが見つかったかどうか、配列の半分を破棄できます。 したがって、解はO(logn)時間で計算できます。
大まかなアルゴリズムの流れ
- Arrayの調べる範囲である、一番小さいインデックスのlowと一番大きいインデックスのhighを決める。
- そのlowとhighから中間地点のmidの値を求める。
- もし、midのインデックスにある要素がキーと同じであればmidを返す。
- もし、midのインデックスにある要素よりも大きい場合はhigh = mid - 1。(lowはそのまま)
- もし、midのインデックスにある要素よりも小さい場合はlow = mid + 1。(highはそのまま)
- ただ、low が high よりも大きくなってしまったらキーは存在していないことになるので - 1を返す。
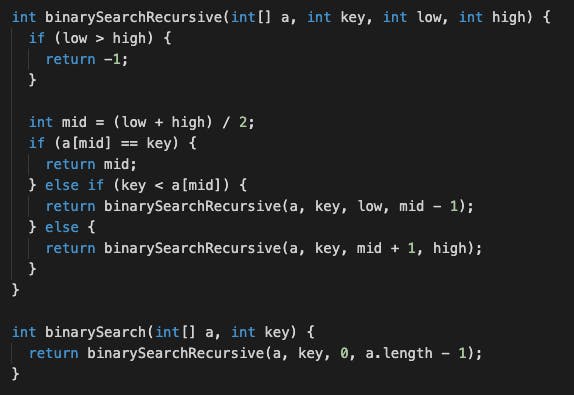
code
補足
Recursive ではなく、While loopを使うIterative の方法だと速度効率は同じですが、Space Complexity がO(1)と出来ます。

- 投稿日:2019-11-30T18:14:00+09:00
JavaでBoyer-Mooreの実装
アルゴリズムの勉強、Javaの文法を勉強するために、文字列検索アルゴリズムの一つであるBoyer-Moore法を実装しました!!
Boyer-Moore法とは?
ボイヤー・ムーア法(1976年)
R.S.Boyer と J.S.Moore が提案
単純検索アルゴリズムよりも高速なアルゴリズム
文字の比較結果によってずらす位置を変える
時間計算量は単純検索アルゴリズム以下他にも文字列検索のアルゴリズムは、単純検索法とかラビンカープ法等色々あります。
Skip表
検索する前にスキップ表というものを作ります。
検索パターン:ighi
だったとして、
パターン i g h i ずらし幅 3 2 1 0 となりますが、重複する文字列があった場合、小さい方を優先します。
したがって、
パターン g h i デフォルト ずらし幅 2 1 0 4 となります。
デフォルトは、文字比較が重複しないところまで、Skipするために、設けています。
パターンを自然数でカウントした時の値です。検索例
1回目
検索対象 a b c d e f g i g h i パターン i g h i 検索は先頭からはじめ、検索対象とパターンの末尾を比較します。
検索対象の文字列と検索対象の末尾は、「d」と「i」なので、デフォルトの「4」つ分Skipします。2回目
検索対象 a b c d e i g i g h i パターン i g h i 「i」と「i」で、Skip表は「0」なので、隣の文字を比較します。
「g」と「h」なので、異なっています。
Skip表を見ると、「g」の時、Skipは「1」です。
1個分だけSkipします。3回目
検索対象 a b c d e i g i g h i パターン i g h i 「g」と「i」で、Skip表は「2」なので、2個分Skipします。
4回目
検索対象 a b c d e i g i g h i パターン i g h i 「i」と「i」で、Skip表は「0」なので、隣の文字列を比較します。
「h」と「h」で一緒なので、隣の文字列を比較します。
「g」と「g」で一緒なので、隣の文字列を比較します。
「i」と「i」で一緒なので、検索終了です。イメージを掴めたところで、ここからコードで実装していきたいと思います。
変数定義
public final static int bmTableSize = 1_114_111; public final static String txt = "あいうえおっぱお"; //検索対象 public final static char[] txtChar = txt.toCharArray(); //char型にスプリット public final static String pattern = "おっぱお"; //パターン public final static char[] patternChar = pattern.toCharArray();ASCIIだけしか検索出来ないのは、少しつまらなかったので、日本語にも対応しようかと思います。
JavaのリファレンスCharacter型を見ると、
Java SE APIドキュメンテーションでは、U+0000 - U+10FFFFの範囲の文字値にUnicodeコード・ポイントを使用し、UTF-16エンコーディングのコード単位である16ビットchar値にUnicodeコード単位を使用します。Unicode用語の詳細は、「Unicode Glossary」を参照してください。
文字集合:Unicode
であり、
符号化方式:UTF-16
であることがわかりますなので、10FFFFを10進数に変換、テーブルサイズ(bmTableSize)を
1,114,111にしました。テーブル作成
BoyerMooreTableInitpublic static int[] BoyerMooreTableInit(int[] table, char[] patternChar, int ptnLen) { int count = 0; /* パターンに無い文字はパターン文字列長をずらし幅にする */ ・・・① for(count = 0; count < bmTableSize; count++){ table[count] = ptnLen; } /* パターンに含まれる文字のずらし幅を決定する */ ・・・② for(count = 0; count < ptnLen; count++){ table[(int)patternChar[count]] = ptnLen - count - 1; } /* デバッグ出力 */ System.out.printf("[table] : default: step=%d\n", ptnLen); for(count = 0; count < bmTableSize; count++){ if(table[count] != ptnLen) System.out.printf(" : char=%c: table[%03d]: step=%d\n", (char)count,count,(int)table[count]); } return table; }Skip表ですが、
パターン お っ ぱ お ずらし幅 3 2 1 0 重複する文字があった場合、小さい方を優先するため
パターン っ ぱ お デフォルト ずらし幅 2 1 0 4 最終的にこうなります。
①に関して、全てテーブルの中に、デフォルトの「4」を入れています。
②に関して、
table[(int)patternChar[count]] = ptnLen - count - 1;は、patternChar[count]には、[お,ぱ,っ,お]が入ってます。
これをint型にキャストしてあげると、UTF-16を10進数に変換した値が返ってきます。「っ」 ・・・ table[12387] = 2 「ぱ」 ・・・ table[12401] = 1 「お」 ・・・ table[12362] = 0 「デフォルト」 ・・・ table[上の3つ以外の場所] = 4検索実施
BoyerMooreSearchpublic static int BoyerMooreSearch(char[] txtChar, char[] patternChar) { int table[] = new int[bmTableSize]; int txtLen = 0; int ptnLen = 0; int i = 0; /* テキストの比較位置 */ int j = 0; /* パターンの比較位置 */ txtLen = txtChar.length; ptnLen = patternChar.length; /* ずらし表を作成する */ table = BoyerMooreTableInit(table, patternChar, ptnLen); /* 比較処理 */ i = j = ptnLen - 1; /* 比較位置をパターン末尾にする */ while((i < txtLen) && (j >= 0)){ PrintCompareProcess(txt, pattern, i, j); if(txtChar[i] != patternChar[j]){ /* ずらし表を参照して、次の比較位置を設定する */ i += next_step(table, txtChar[i], (ptnLen - j)); j = ptnLen - 1; /* 比較位置をパターン末尾にする */ }else{ /* 文字が一致したので、前の文字を照合していく */ j--; i--; } } if(j < 0) { return i + 2; }else { return 0; } } }・1回目比較
検索対象 あ い う え ぱ っ お っ ぱ お パターン お っ ぱ お 末尾「え」と「お」が異なっており、かつパターンにも存在しない文字列なので、
4文字スキップします。・2回目比較
検索対象 あ い う え ぱ っ お っ ぱ お パターン お っ ぱ お 末尾がパターンの中に存在する文字で、 「っ」 = 2なので、
2文字文スキップします。・3回目比較
検索対象 あ い う え ぱ っ お っ ぱ お パターン お っ ぱ お 末尾がパターンの中に存在する文字で、 「ぱ」 = 1なので、
1文字文スキップします。・4回目比較
検索対象 あ い う え ぱ っ お っ ぱ お パターン お っ ぱ お 末尾が 「お」 = 0 なので、隣の文字を検索します。
・・・以下繰り返し
最終的に、こんな感じです。
コード
Main.javaimport java.io.UnsupportedEncodingException; public class Main { public final static int bmTableSize = 1_114_111; public final static String txt = "あいうえぱっおっぱお"; public final static char[] txtChar = txt.toCharArray(); public final static String pattern = "おっぱお"; public final static char[] patternChar = pattern.toCharArray(); public static void main(String[] args) throws UnsupportedEncodingException { int result; System.out.printf("[text] :%s\n", txt); System.out.printf("[pattern]:%s\n", pattern); result = BoyerMooreSearch(txtChar, patternChar); if (0 < result) { System.out.println(result + "番目にあったよ!!"); }else { System.out.println("見つからなかったよ"); } } public static int[] BoyerMooreTableInit(int[] table, char[] patternChar, int ptnLen) { int count = 0; /* パターンに無い文字はパターン文字列長をずらし幅にする */ for(count = 0; count < bmTableSize; count++){ table[count] = ptnLen; } /* パターンに含まれる文字のずらし幅を決定する */ for(count = 0; count < ptnLen; count++){ table[(int)patternChar[count]] = ptnLen - count - 1; } /* デバッグ出力 */ System.out.printf("[table] : default: step=%d\n", ptnLen); for(count = 0; count < bmTableSize; count++){ if(table[count] != ptnLen) System.out.printf(" : char=%c: table[%03d]: step=%d\n", (char)count,count,(int)table[count]); } return table; } public static void PrintCompareProcess(String txt, String pattern, int i, int j) { int count = 0; System.out.printf("-----------------------------------\n"); System.out.printf("[compare]:(text i=%d)(pattern j=%d)\n", i+1, j+1); System.out.printf(" text :%s\n", txt); /* パターンを比較位置で重ねる */ System.out.printf(" pattern :"); for(count = 0; count < (i - j); count++) System.out.print(" "); //全角半角でずれる。 System.out.printf("%s\n", pattern); /* 比較点にマークする */ System.out.printf(" :"); for(count = 0; count < i; count++) System.out.printf(" "); System.out.printf("^\n"); } public static int next_step(int[] table, char target, int remain) { /* ループ防止のために確認する */ if(table[(int)target] > remain){ /* ずらし表から値を取得する */ return(table[(int)target]); }else{ /* 照合を開始した地点の次の文字に進める */ return(remain); } } public static int BoyerMooreSearch(char[] txtChar, char[] patternChar) { int table[] = new int[bmTableSize]; int txtLen = 0; int ptnLen = 0; int i = 0; /* テキストの比較位置 */ int j = 0; /* パターンの比較位置 */ txtLen = txtChar.length; ptnLen = patternChar.length; /* ずらし表を作成する */ table = BoyerMooreTableInit(table, patternChar, ptnLen); /* 比較処理 */ i = j = ptnLen - 1; /* 比較位置をパターン末尾にする */ while((i < txtLen) && (j >= 0)){ PrintCompareProcess(txt, pattern, i, j); if(txtChar[i] != patternChar[j]){ /* ずらし表を参照して、次の比較位置を設定する */ i += next_step(table, txtChar[i], (ptnLen - j)); j = ptnLen - 1; /* 比較位置をパターン末尾にする */ }else{ /* 文字が一致したので、前の文字を照合していく */ j--; i--; } } if(j < 0) { return i + 2; }else { return 0; } } }出力結果
[text] :あいうえぱっおっぱお [table] : default: step=4 : char=お: table[12362]: step=0 : char=っ: table[12387]: step=2 : char=ぱ: table[12401]: step=1 ----------------------------------- [compare]:(text i=4)(pattern j=4) text :あいうえぱっおっぱお pattern :おっぱお : ^ ----------------------------------- [compare]:(text i=8)(pattern j=4) text :あいうえぱっおっぱお pattern : おっぱお : ^ ----------------------------------- [compare]:(text i=10)(pattern j=4) text :あいうえぱっおっぱお pattern : おっぱお : ^ ----------------------------------- [compare]:(text i=9)(pattern j=3) text :あいうえぱっおっぱお pattern : おっぱお : ^ ----------------------------------- [compare]:(text i=8)(pattern j=2) text :あいうえぱっおっぱお pattern : おっぱお : ^ ----------------------------------- [compare]:(text i=7)(pattern j=1) text :あいうえぱっおっぱお pattern : おっぱお : ^ 7番目にあったよ!!参考になった方がいれば幸いです。
参考文献
・Java Character型 リファレンス
・C言語アルゴリズム-BM法
・Unicode対応 文字コード表
・【Java】char型はint型にキャストできる
- 投稿日:2019-11-30T18:08:31+09:00
初めてやるDDDでデジモンをモデリングする その1
アドベントカレンダー書くための考えた流れを残しておくメモです。
自社でDDDやってるけど、DDD実践したことがない。
個人でお試しでDDDやってみよう。
好きなことの方がモデリングしやすいのでは?
と思い、昔好きだったデジモンアドベンチャーをDDDで表して見ようと思い、
今に至る。経験ないので、
技術書店で買った
もくもくモデリングの森を旅するチビドラゴンの軌跡
https://taimen.jp/f/867
を参考に試行してみる題材
デジモンアドベンチャーといえば、
デジモンの進化も良し、
子どもたちの成長も良しと
色々ありますが、
広げすぎると何もできないので、
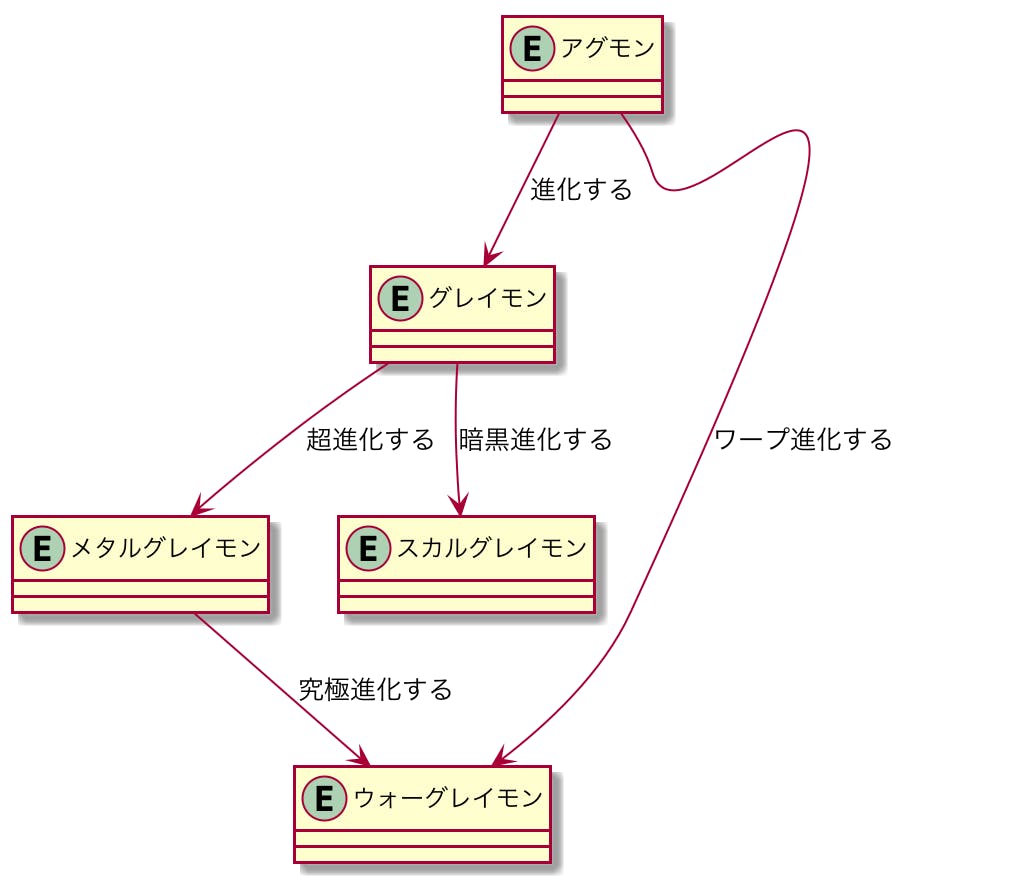
今回は「アグモン」を題材にやってみます。いざモデリング
ユースケース
本に「誰が何をするとこうなる」を書き出してみようとあるので書いてみた。
- アグモンが進化するとグレイモンになる
- グレイモンが超進化するメタルグレイモンになる
- グレイモンが暗黒進化するとスカルグレイモンになる
- メタルグレイモンが究極進化するとウォーグレイモンになる
- アグモンがワープ進化するとウォーグレイモンになる
悩んだところ
アグモンがワープ進化するとウォーグレイモンになるのか。
それとも、ワープ進化とは、アグモン、グレイモン、メタルグレイモン、ウォーグレイモンの順に進化していくことをワープ進化というのか。
アニメでは、メタルグレイモンに進化するときは必ずグレイモンへの進化シーン入るけど、
ウォーグレイモンに進化するときは、アグモンから進化のモーション入るよね?って考えると、
自分はアグモンがウォーグレイモンにワープ進化している。の定義に落ち着きました。
で、一応公式確認したところ、メタルグレイモンからウォーグレイモンへの進化は究極進化というそうだ。
http://digimon-adventure.net/tri/evolution/agumon.html
つまり、「究極進化」と「ワープ進化」は言葉として別だという整理になった。用語集
次に本では、ユースケースができたら、
ヒト、モノ、コトに当たる単語を抜き出そう。
って書いてあるので実践。
ここで思ったのは、「ヒト、モノ、コト」ってことは名詞を抜け
ということで「進化する」とかの動詞はここでは抜いてはいけないってことだ。
- アグモン
- グレイモン
- メタルグレイモン
- スカルグレイモン
- ウォーグレイモン
ドメインモデル
ここでドメインモデル。
用語集に上がったアグモンたちをドメインに。
ユースケースに合わせて関係するドメインに線を引いていく。
こんな感じになった。
次はこれでクラス図を書いています。
- 投稿日:2019-11-30T16:46:01+09:00
大文字小文字を区別しないという不幸な世界のワイルドカード(macOS)
この記事について
macOS のファイルシステムは、デフォルトでは殆どのディレクトリで大文字小文字を区別しない。
そのような世界で、ワイルドカードを用いると何がマッチするか、という話。大文字小文字を区別しないということ
例えばこんなスクリプトを実行すると
bash#!/bin/bash set -eu # ASCII の英数字 touch foo.txt FOO.txt ls *.txt && rm *.txt # 所謂全角文字 touch zen.txt ZEN.txt ls *.txt && rm *.txt # ギリシャ文字・キリル文字・ローマ数字 touch ωяⅶ.txt ΩЯⅦ.txt ls *.txt && rm *.txt # DZ, NJ touch dz.txt # U+01F3 Latin Small Letter DZ touch Dz.txt # U+01F2 Latin Capital Letter D with Small Letter z touch DZ.txt # U+01F1 Latin Capital Letter DZ touch nj.txt # U+01CC Latin Small Letter NJ touch Nj.txt # U+01CB Latin Capital Letter N with Small Letter J touch NJ.txt # U+01CA Latin Capital Letter NJ ls *.txt && rm *.txt # i witout dot, etc. touch ı.txt # U+0131 Small I without dot touch İ.txt # U+0130 Capital I with dot touch i.txt # U+0069 Small I touch I.txt # U+0049 Capital I ls *.txt && rm *.txt # 囲み文字 touch ⓐ.txt # U+24D0 touch Ⓐ.txt # U+24B6 ls *.txt && rm *.txtこんな結果になる
foo.txt zen.txt ωяⅶ.txt nj.txt dz.txt i.txt İ.txt ı.txt ⓐ.txt
FOOとfooは簡単。大文字小文字を区別しないのでどちらかしか生き残れない。
zen、ωяⅶやⓐのあたりを見て分かる通り、7bit-ASCII の範囲外の文字にも大文字小文字があり、それらは区別されない。
Dzは「Titlecase Letter」というカテゴリの文字で、大文字でも小文字でもない。
対応する小文字はdzで、対応する大文字はDZになる。
この文字も大文字小文字を区別しないので、touch dz.txt Dz.txt DZ.txtとしても、ひとつしか生き残れない。
ı,İ,i,Iの件は下表のとおり。
言語 Iの小文字iの大文字英語 iIトルコ語 ıİ
ı.txt,İ.txt,i.txt,I.txtを touch すると、
i.txt,İ.txt,ı.txtが生き残る。unicode.org を見ると、dot のない小文字
ıは、大文字にすると普通のIになる。
にも関わらず、APFS 上ではı.txtとI.txtは別の名前だとみなされる。様々な環境での対応
いくつかの環境で何が起こるのか試してみた。
shell script(bash) 他
以下の環境でこの結果になる:
- shell script(bash)
- C(POSIX glob)
- Go(filepath.Glob)
- Python3(glob.glob)
- PHP7(glob)
POSIX glob や bash と同じなのでこれが基本っぽいんだけど、わりと気持ち悪い動作になっている。
基本的には、
- ワイルドカードがない場合は大文字小文字を区別しない。
- ワイルドカードがある場合は大文字小文字を区別する。
となっている。
Foo.txtだと1件マッチしてF*.txtだと 0件マッチするというのはかなり意外だった。ワイルドカードがない部分については、(気付いた範囲では)ファイルシステムと同じ意見になっている。
F*/f*/Foo
wildcard foo.txt fred.txt F*.txt ❌ ❌ f*.txt ✅ ✅ Foo.txt ✅ ❌ i / I / ı / İ
wildcard i-lat-lo.txt I-lat-up.txt ı-tur-lo.txt İ-tur-up.txt i*.txt ✅ ❌ ❌ ❌ I*.txt ❌ ✅ ❌ ❌ ı*.txt ❌ ❌ ✅ ❌ İ*.txt ❌ ❌ ❌ ✅ İ-tur-lo.txt ❌ ❌ ❌ ❌ I-tur-lo.txt ❌ ❌ ❌ ❌ ı-lat-up.txt ❌ ❌ ❌ ❌ DZ / Dz / dz
wildcard DZ-uu.txt Dz-ul.txt dz-ll.txt DZ*.txt ✅ ❌ ❌ Dz*.txt ❌ ✅ ❌ dz*.txt ❌ ❌ ✅ dz-uu.txt ✅ ❌ ❌ dz-ul.txt ❌ ✅ ❌ Dz-uu.txt ✅ ❌ ❌ ruby(Dir.glob)
ruby の動作は POSIX glob とはだいぶ異なる。
基本的には「大文字と小文字を区別しない」という動作で一貫しているような感じ。
Foo.txtだとfoo.txtのみがマッチして、F*.txtだとfoo.txtとfred.txtがマッチする。わかりやすい。しかし、
rubyDir.glob("dz-u*.txt") #=> [] Dir.glob("dz-uu.txt") #=> ["files/DZ-uu.txt"]と、ワイルドカードを入れるとマッチする件数が減るというパターンもある。
バグ?F*/f*/Foo
wildcard foo.txt fred.txt F*.txt ✅ ✅ f*.txt ✅ ✅ Foo.txt ✅ ❌ i / I / ı / İ
wildcard i-lat-lo.txt I-lat-up.txt ı-tur-lo.txt İ-tur-up.txt i*.txt ✅ ✅ ❌ ❌ I*.txt ✅ ✅ ❌ ❌ ı*.txt ❌ ❌ ✅ ❌ İ*.txt ❌ ❌ ❌ ✅ İ-tur-lo.txt ❌ ❌ ❌ ❌ I-tur-lo.txt ❌ ❌ ❌ ❌ ı-lat-up.txt ❌ ❌ ❌ ❌ DZ / Dz / dz
wildcard DZ-uu.txt Dz-ul.txt dz-ll.txt DZ*.txt ✅ ❌ ❌ Dz*.txt ❌ ✅ ❌ dz*.txt ❌ ❌ ✅ dz-uu.txt ✅ ❌ ❌ dz-ul.txt ❌ ✅ ❌ Dz-uu.txt ✅ ❌ ❌ Java(PathMatcher)
java.nio.fileにPathMatcherという インターフェイスがあるので、それを使ってみた。
これも POSIX glob とはだいぶ異なる。
常に大文字小文字を区別するように見える。
ファイルシステムのファイル名とは異なる動作だが、一貫性はある。F*/f*/Foo
wildcard foo.txt fred.txt F*.txt ❌ ❌ f*.txt ✅ ✅ Foo.txt ❌ ❌ i / I / ı / İ
wildcard i-lat-lo.txt I-lat-up.txt ı-tur-lo.txt İ-tur-up.txt i*.txt ✅ ❌ ❌ ❌ I*.txt ❌ ✅ ❌ ❌ ı*.txt ❌ ❌ ✅ ❌ İ*.txt ❌ ❌ ❌ ✅ İ-tur-lo.txt ❌ ❌ ❌ ❌ I-tur-lo.txt ❌ ❌ ❌ ❌ ı-lat-up.txt ❌ ❌ ❌ ❌ DZ / Dz / dz
wildcard DZ-uu.txt Dz-ul.txt dz-ll.txt DZ*.txt ✅ ❌ ❌ Dz*.txt ❌ ✅ ❌ dz*.txt ❌ ❌ ✅ dz-uu.txt ❌ ❌ ❌ dz-ul.txt ❌ ❌ ❌ Dz-uu.txt ❌ ❌ ❌ C#(.NET Core / Directory.GetFiles)
ruby の動きと似ている。
ruby と異なり、DZ*.txtでdz-ll.txtにちゃんと(?)マッチする。
しかし逆に、dz-uu.txtではDZ-uu.txtが取れない。F*/f*/Foo
wildcard foo.txt fred.txt F*.txt ✅ ✅ f*.txt ✅ ✅ Foo.txt ✅ ❌ i / I / ı / İ
wildcard i-lat-lo.txt I-lat-up.txt ı-tur-lo.txt İ-tur-up.txt i*.txt ✅ ✅ ❌ ❌ I*.txt ✅ ✅ ❌ ❌ ı*.txt ❌ ❌ ✅ ❌ İ*.txt ❌ ❌ ❌ ✅ İ-tur-lo.txt ❌ ❌ ❌ ❌ I-tur-lo.txt ❌ ❌ ❌ ❌ ı-lat-up.txt ❌ ❌ ❌ ❌ DZ / Dz / dz
wildcard DZ-uu.txt Dz-ul.txt dz-ll.txt DZ*.txt ✅ ✅ ✅ Dz*.txt ✅ ✅ ✅ dz*.txt ✅ ✅ ✅ dz-uu.txt ❌ ❌ ❌ dz-ul.txt ❌ ❌ ❌ Dz-uu.txt ❌ ❌ ❌ C#(Mono / Directory.GetFiles)
意外にも、 .NET Core と Mono で動作が異なる。
大文字でも小文字でもないDzという文字に負けている感じがする。F*/f*/Foo
wildcard foo.txt fred.txt F*.txt ✅ ✅ f*.txt ✅ ✅ Foo.txt ✅ ❌ i / I / ı / İ
wildcard i-lat-lo.txt I-lat-up.txt ı-tur-lo.txt İ-tur-up.txt i*.txt ✅ ✅ ❌ ❌ I*.txt ✅ ✅ ❌ ❌ ı*.txt ❌ ❌ ✅ ❌ İ*.txt ❌ ❌ ❌ ✅ İ-tur-lo.txt ❌ ❌ ❌ ❌ I-tur-lo.txt ❌ ❌ ❌ ❌ ı-lat-up.txt ❌ ❌ ❌ ❌ DZ / Dz / dz
wildcard DZ-uu.txt Dz-ul.txt dz-ll.txt DZ*.txt ✅ ❌ ✅ Dz*.txt ❌ ✅ ❌ dz*.txt ✅ ❌ ✅ dz-uu.txt ✅ ❌ ❌ dz-ul.txt ❌ ❌ ❌ Dz-uu.txt ❌ ❌ ❌ Perl(glob)
POSIX glob とよく似た動作になっているが、ドットなしの小文字 i の扱いが異なる。
F*/f*/Foo
wildcard foo.txt fred.txt F*.txt ❌ ❌ f*.txt ✅ ✅ Foo.txt ✅ ❌ i / I / ı / İ
wildcard i-lat-lo.txt I-lat-up.txt ı-tur-lo.txt İ-tur-up.txt i*.txt ✅ ❌ ❌ ❌ I*.txt ❌ ✅ ❌ ❌ ı*.txt ❌ ❌ ✅ ❌ İ*.txt ❌ ❌ ❌ ✅ İ-tur-lo.txt ❌ ❌ ❌ ❌ I-tur-lo.txt ❌ ❌ ✅ ❌ ı-lat-up.txt ❌ ✅ ❌ ❌ DZ / Dz / dz
wildcard DZ-uu.txt Dz-ul.txt dz-ll.txt DZ*.txt ✅ ❌ ❌ Dz*.txt ❌ ✅ ❌ dz*.txt ❌ ❌ ✅ dz-uu.txt ✅ ❌ ❌ dz-ul.txt ❌ ✅ ❌ Dz-uu.txt ✅ ❌ ❌ まとめ
POSIX glob は、ワイルドカードがない部分についてはファイルシステムと同じ意見になっているものの、ワイルドカードが入ると大文字小文字を区別するようになるところがわかりにくい。
- Go(filepath.Glob)
- Python3(glob.glob)
- PHP7(glob)
は、POSIX glob と同じ意見になっている。
一方
- ruby(Dir.glob)
- Java(PathMatcher)
- C#(.NET Core GetFiles)
- C#(Mono Directory.GetFiles)
- Perl(glob)
は独自のアルゴリズムで処理しているらしく、POSIX glob とは異なる結果を返す。
「アルファベット2文字をセットにした文字で一文字目だけ大文字に出来るもの」や「小文字のiからドットを除いたもの」のあたりで不穏な動作になりやすい。
- 投稿日:2019-11-30T15:05:42+09:00
Java Tips
String
・文字列の操作は、StringBuilderを利用することでパフォーマンスが向上
→特にループ内で+での文字列結合を行わないことbad.javastatic String concat(String[] array) { String result = ""; for (String s : array) { result += s; // } return result; }↓
better.javastatic String concat(String[] array) { StringBuiler result = new StringBuiler(); for (String s : array) { result.append(s); } return result.toString(); }※StringBuiler 比較は、注意が必要
StringBuiler_equals.javaStringBuilder sb1 = new StringBuilder("ABC"); StringBuilder sb2 = new StringBuilder("ABC"); if(sb1 == sb2){ System.out.println("sb1 == sb2" + " is OK."); }else{ System.out.println("sb1 == sb2" + " is NG.");//FALSE } if(sb1.equals(sb2)){ System.out.println("sb1 equals sb2" + " is OK."); }else{ System.out.println("sb1 equals sb2" + " is NG.");//FALSE } if(sb1.toString().contentEquals(sb2)){ System.out.println("sb1 contentEquals sb2" + " is OK.");//TRUE }else{ System.out.println("sb1 contentEquals sb2" + " is NG."); }
- 投稿日:2019-11-30T12:52:20+09:00
Java Optional型
sample.javaimport java.util.Optional; public class Main { void exec(Optional<StringBuilder> pSb) { System.out.println("pSb-->" + pSb); StringBuilder sbEdit = pSb.orElseGet(() -> new StringBuilder("none")); // System.out.println("orElseGet-->" + sbEdit ); -- "none" // 引数の編集 Optional<String> os = pSb.map(sb -> { sb.insert(0, "["); sb.append("]"); return sb.toString(); }); } public static void main(String... args) { Main main = new Main(); // foo StringBuilder sb = new StringBuilder("Jack"); sb = null; main.exec(Optional.ofNullable(sb )); System.out.println("return-->" + sb ); -- "[none]" } }
- 投稿日:2019-11-30T10:35:43+09:00
Spring 案件ソルーション
Spring画面系をどう乗り切るか(技術面)
案件という単位でソリューションを探る。
設計書作成 + プログラミングがある場合。
・画面系のフレームワークを勉強する。
https://www.marineroad.com/staff-blog/17761.html
・簡単な例を作ってみる。
・ UMLを学ぶ
http://objectclub.jp/technicaldoc/uml/umlintro2
・設計書の例を探してみる。
http://warp.da.ndl.go.jp/info:ndljp/pid/9972728/ecom-plat.jp/fbox.php?eid=16496
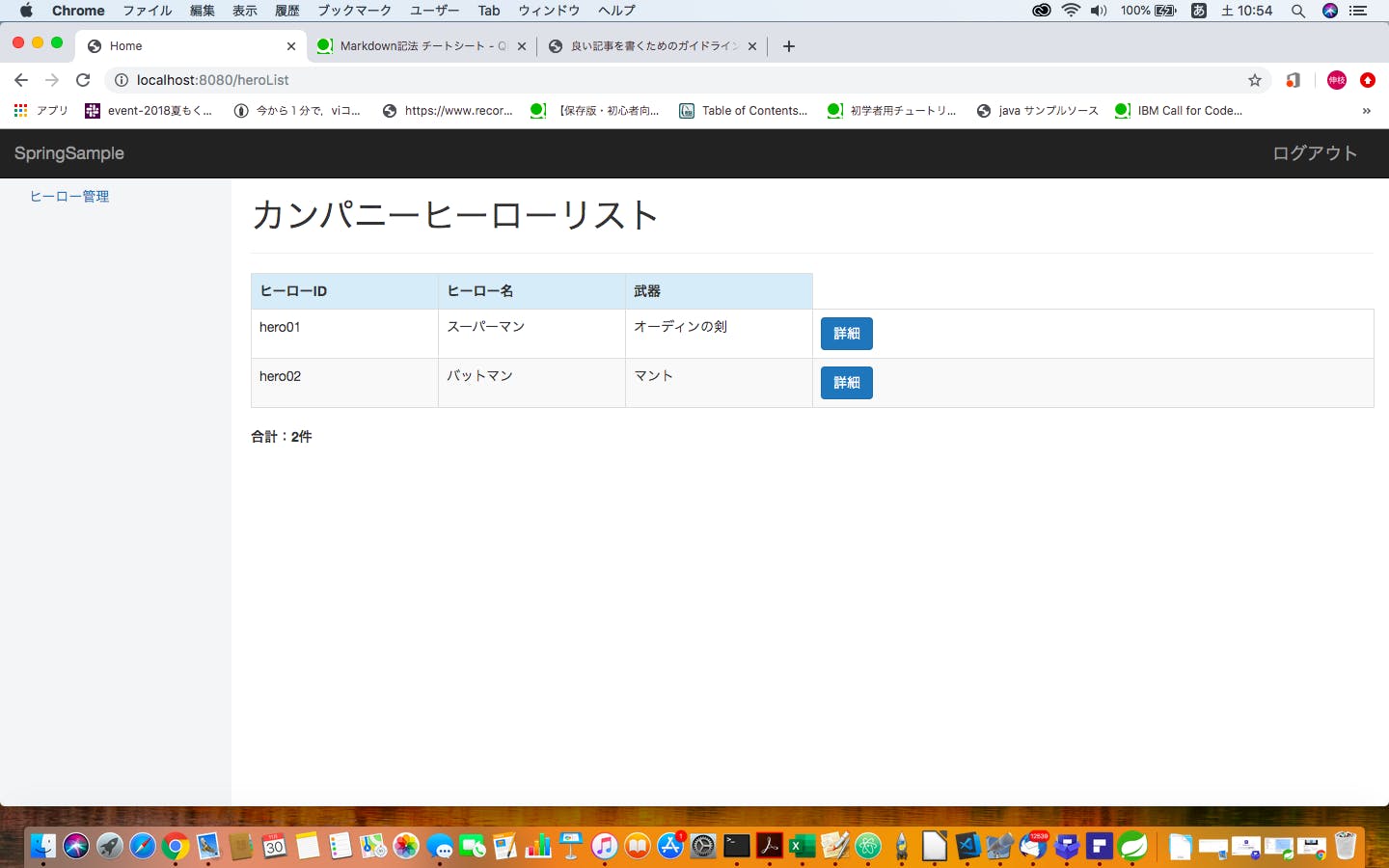
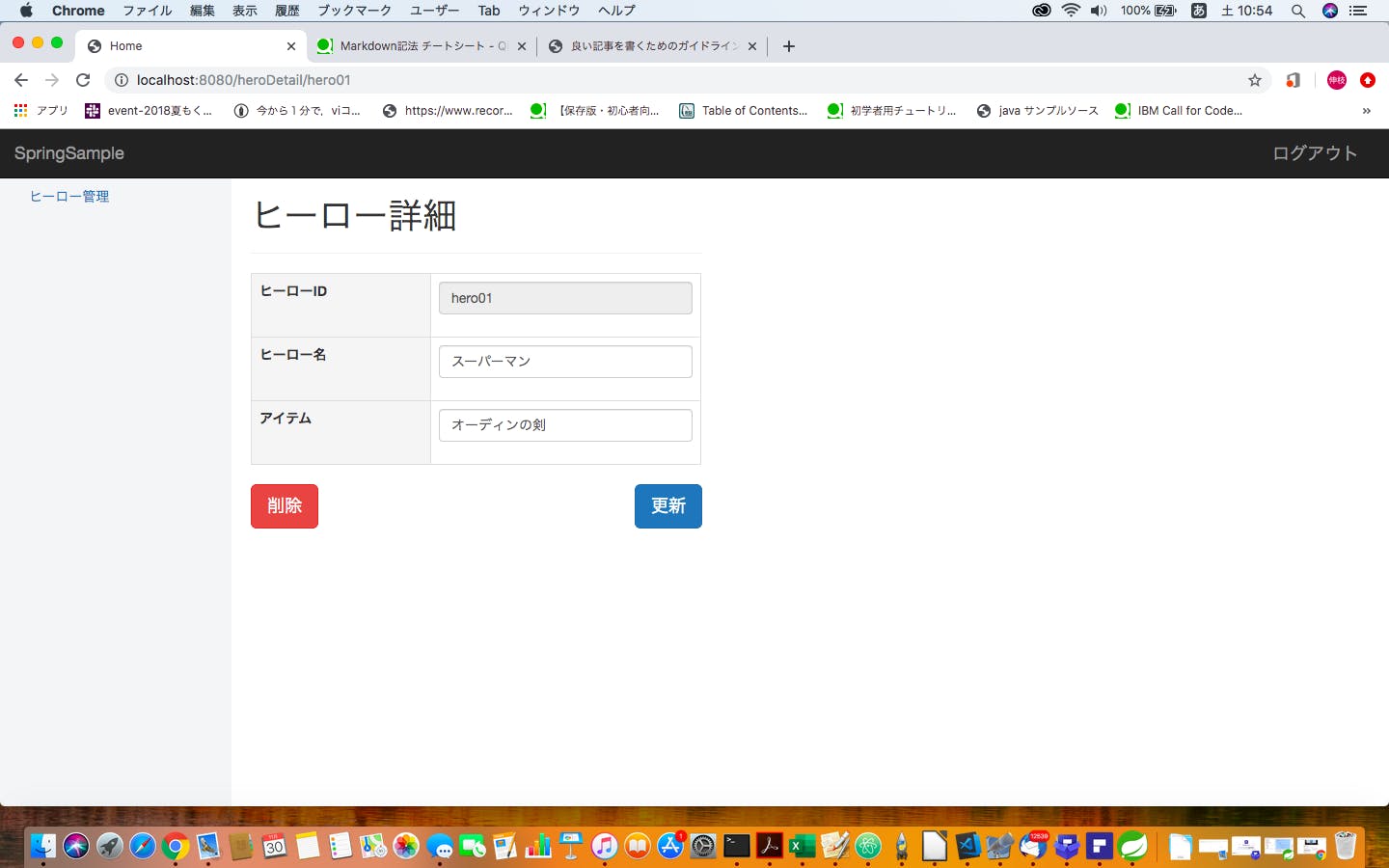
http://blog.nadia.bz/post/177/post-177簡単な例を作ってみる。
学習用アプリの画像貼り付け
学習用アプリのプログラム抜粋
@Controller public class HomeController { @Autowired HeroService heroService; /** * ヒーロー一覧画面のGETメソッド用処理. */ @GetMapping("/heroList") public String getHeroList(Model model) { // コンテンツ部分にヒーロー一覧を表示するための文字列を登録 model.addAttribute("contents", "login/heroList :: heroList_contents"); // ヒーロー一覧の生成 List<Hero> heroList = new ArrayList(); Hero hero1 = new Hero(); Hero hero2 = new Hero(); hero1.setHeroId("hero01"); hero1.setHeroName("スーパーマン"); hero1.setHeroItem("オーディンの剣"); heroList.add(hero1); hero2.setHeroId("hero02"); hero2.setHeroName("バットマン"); hero2.setHeroItem("マント"); heroList.add(hero2); // Modelにヒーローリストを登録 model.addAttribute("heroList", heroList); // データ件数を取得 int count = 2; model.addAttribute("heroListCount", count); return "login/homeLayout"; } /** * ヒーロー詳細画面のGETメソッド用処理. */ @GetMapping("/heroDetail/{id:.+}") public String getHeroDetail(@ModelAttribute SignupForm form, Model model, @PathVariable("id") String heroId) { // ヒーローID確認(デバッグ) System.out.println("heroId = " + heroId); // コンテンツ部分にヒーロー詳細を表示するための文字列を登録 model.addAttribute("contents", "login/heroDetail :: heroDetail_contents"); // ヒーローIDのチェック if (heroId != null && heroId.length() > 0) { // ヒーロー情報を取得 // Hero hero = heroService.selectOne(heroId); Hero hero1 = new Hero(); hero1.setHeroId("hero01"); hero1.setHeroName("スーパーマン"); hero1.setHeroItem("オーディンの剣"); // Heroクラスをフォームクラスに変換 form.setHeroId(hero1.getHeroId()); // ヒーローID form.setHeroName(hero1.getHeroName()); // ヒーロー名 form.setHeroItem(hero1.getHeroItem()); // アイテム // Modelに登録 model.addAttribute("signupForm", form); } return "login/homeLayout"; } /** * ヒーロー更新用処理. */ @PostMapping(value = "/heroDetail", params = "update") public String postHeroDetailUpdate(@ModelAttribute SignupForm form, Model model) { System.out.println("更新ボタンの処理"); // Heroインスタンスの生成 Hero hero = new Hero(); // フォームクラスをHeroクラスに変換 hero.setHeroId(form.getHeroId()); hero.setPassword(form.getPassword()); hero.setHeroName(form.getHeroName()); hero.setBirthday(form.getBirthday()); hero.setAge(form.getAge()); hero.setMarriage(form.isMarriage()); try { // 更新実行 boolean result = heroService.updateOne(hero); if (result == true) { model.addAttribute("result", "更新成功"); } else { model.addAttribute("result", "更新失敗"); } } catch (DataAccessException e) { model.addAttribute("result", "更新失敗(トランザクションテスト)"); } // ヒーロー一覧画面を表示 return getHeroList(model); } /** * ヒーロー削除用処理. */ @PostMapping(value = "/heroDetail", params = "delete") public String postHeroDetailDelete(@ModelAttribute SignupForm form, Model model) { System.out.println("削除ボタンの処理"); // 削除実行 boolean result = heroService.deleteOne(form.getHeroId()); if (result == true) { model.addAttribute("result", "削除成功"); } else { model.addAttribute("result", "削除失敗"); } // ヒーロー一覧画面を表示 return getHeroList(model); } }<!DOCTYPE html> <html xmlns:th="http://www.thymeleaf.org" xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"> <head> <meta charset="UTF-8"></meta> </head> <body> <!-- コンテンツ部分 --> <div th:fragment="heroList_contents"> <div class="page-header"> <h1>カンパニーヒーローリスト</h1> </div> <table class="table table-bordered table-hover table-striped"> <tr> <th class="info col-sm-2">ヒーローID</th> <th class="info col-sm-2">ヒーロー名</th> <th class="info col-sm-2">武器</th> </tr> <tr th:each="hero : ${heroList}"> <td th:text="${hero.heroId}"></td> <td th:text="${hero.heroName}"></td> <td th:text="${hero.heroItem}"></td> <td> <!-- ヒーロー詳細画面へのリンク --> <a class="btn btn-primary" th:href="@{'/heroDetail/' + ${hero.heroId}}">詳細</a> </td> </tr> </table> <!-- ユーザー一覧の件数 --> <label th:text=" '合計:' + ${heroListCount} + '件' "></label><br/> <!-- 更新・削除処理の結果表示用 --> <label class="text-info" th:text="${result}">結果表示</label><br/> </div> </body> </html> <!DOCTYPE html> <html xmlns:th="http://www.thymeleaf.org" xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"> <head> <meta charset="UTF-8"></meta> </head> <body> <div th:fragment="heroDetail_contents"> <div class="row"> <div class="col-sm-5"> <div class="page-header"> <h1>ヒーロー詳細</h1> </div> <form method="post" th:action="@{/heroDetail}" th:object="${signupForm}"> <table class="table table-bordered table-hover"> <tr> <!-- ヒーローID(入力不可) --> <th class="active col-sm-2">ヒーローID</th> <td class="col-sm-3"> <div class="form-group"> <input type="text" class="form-control" th:field="*{heroId}" readonly="readonly" /> </div> </td> </tr> <tr> <!-- ヒーロー名 --> <th class="active">ヒーロー名</th> <td> <div class="form-group" th:classappend="${#fields.hasErrors('heroName')} ? 'has-error'"> <input type="text" class="form-control" th:field="*{heroName}" /> <span class="text-danger" th:if="${#fields.hasErrors('heroName')}" th:errors="*{heroName}">heroName error</span> </div> </td> </tr> <tr> <!-- アイテム --> <th class="active">アイテム</th> <td> <div class="form-group" th:classappend="${#fields.hasErrors('heroItem')} ? 'has-error'"> <input type="text" class="form-control" th:field="*{heroItem}" /> <span class="text-danger" th:if="${#fields.hasErrors('heroItem')}" th:errors="*{heroItem}">heroItem error</span> </div> </td> </tr> </table> <!-- 更新ボタン --> <button class="btn btn-primary btn-lg pull-right" type="submit" name="update">更新</button> <!-- 削除ボタン --> <button class="btn btn-danger btn-lg" type="submit" name="delete">削除</button> </form> </div> </div> </div> </body> </html>
- 投稿日:2019-11-30T10:30:43+09:00
SpringのLocalTimeをMySQLのTimeでINSERTしたい(millisecondsも)
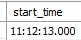
概要
String型で取得した
11:12:13.14(時間:分:秒.ミリ秒)を
MySQLにINSERTして
とミリ秒まで表示させる方法についてです。(日付情報はいらない)そんなの普通に実装すればできそうじゃない?
って思うじゃないですか。簡単そうに見えて面倒くさい処理を挟まないとうまくいきませんでした。。。
もっとスマートな方法をお存じの方がいましたら、教えていただけるととっても嬉しいです!!バージョン
Spring
build.gradleid 'org.springframework.boot' version '2.2.2.BUILD-SNAPSHOT' sourceCompatibility = '1.8' runtimeOnly('mysql:mysql-connector-java') implementation 'org.springframework.boot:spring-boot-starter' implementation('org.springframework.boot:spring-boot-starter-web') implementation('org.springframework.boot:spring-boot-starter-data-jpa')データベース
MySQL 8.0ステップその1 テーブル作成
小数点3桁まで対応
MySQL :: MySQL 5.6 リファレンスマニュアル :: 11.1.2 日付と時間型の概要create table timesample( ... start_time TIME(3) );ステップその2 AttributeConverterの作成
JPA がエンティティのフィールドの型としてjava.time.LocalDate、java.time.LocalTime、java.time.LocalDateTimeは対応していないため、次のようなAttributeConverterを作成する必要があります。
package app.entities.converter; import java.time.LocalTime; import javax.persistence.AttributeConverter; import javax.persistence.Converter; @Converter(autoApply = true) public class LocalTimeConverter implements AttributeConverter<LocalTime, java.sql.Time> { @Override public java.sql.Time convertToDatabaseColumn(LocalTime time) { return time == null ? null : java.sql.Time.valueOf(time); } @Override public LocalTime convertToEntityAttribute(java.sql.Time value) { return value == null ? null : value.toLocalTime(); } }Entity@Column(name = "start_time") private LocalTime startTime;entity.setStartTime(LocalTime.of(11, 12, 13, 14*10000000)); repository.save(entity);
ミリ秒が入ってないぞ!
ステップその3 ミリ秒を保有してjava.sql.Timeに変換する
先程作成したLocalTimeConverterのconvertToDatabaseColumnメソッドを変更
spring-ミリ秒のjava.time.LocalTimeをミリ秒のjava.sql.Timeにマッピングする方法LocalTimeConverter@Override public java.sql.Time convertToDatabaseColumn(LocalTime time) { // この日付はコンバートで捨てられるので何でもOK long epochMilli = time.atDate(LocalDate.of(2019, 1, 1)).atZone(java.time.ZoneId.systemDefault()) .toInstant().toEpochMilli(); java.sql.Time sqlTime = new java.sql.Time(epochMilli); return time == null ? null : sqlTime; }

- 投稿日:2019-11-30T02:02:24+09:00
AndroidStudioでFileInputStreamを使うときの文字化けについて
実機デバッグ時に文字列をメールアプリの本文に渡したら、文章の間に文字化け記号が挟まった。
AndroidStudioの基本的な設定
ここを見る。
http://k-hiura.cocolog-nifty.com/blog/2015/07/androidstudio-b.html
FileInputStreamで文字コードをUTF-8指定にする
文字化けするコード
public String readFile(String fileName){ try { FileInputStream stream = openFileInput(fileName); byte[] buf = new byte[1024]; stream.read(buf); return new String(buf); } catch (FileNotFoundException e) { e.printStackTrace(); return "readFile() is wrong"; } catch (IOException e){ e.printStackTrace(); return "readFile() is wrong"; } }文字化け解消コード
public String readFile(String fileName){ try { FileInputStream stream = openFileInput(fileName); InputStreamReader streamReader = new InputStreamReader(stream, "UTF-8"); BufferedReader bufferedReader = new BufferedReader(streamReader); String s; String col = ""; while ((s = bufferedReader.readLine()) != null){ byte[] b = s.getBytes(); s = new String(b, "UTF-8"); col += s; } return col; } catch (FileNotFoundException e) { e.printStackTrace(); return "readFile() is wrong"; } catch (IOException e){ e.printStackTrace(); return "readFile() is wrong"; } }FileInputStreamから文字列を取得するときに文字コードがUTF-8以外になって余計なものが付いてきたっぽい。
参考
https://www.sejuku.net/blog/20746
https://qiita.com/aaaanwz/items/1554afadc44cb5cf3a80